# Visual Description
<details>
<summary>Image 1 Details</summary>

### Visual Description
\n
## Image: Elsevier Logo
### Overview
The image presents a stylized, monochrome logo featuring a detailed illustration of a tree with a snake coiled around its trunk, and the word "ELSEVIER" prominently displayed below. The illustration appears to be an engraving or woodcut style.
### Components/Axes
There are no axes or scales present in this image. The primary components are:
* **Tree:** A large, leafy tree with a full canopy.
* **Snake:** A snake winding around the tree trunk.
* **Text:** The word "ELSEVIER" in a bold, serif typeface.
### Detailed Analysis or Content Details
The illustration is highly detailed, with intricate patterns in the leaves and bark of the tree. The snake is depicted with scales and a distinct head. The word "ELSEVIER" is positioned directly below the illustration, centered horizontally. The style of the illustration suggests a historical or classical origin.
### Key Observations
The logo is visually striking and evokes a sense of tradition and knowledge. The combination of the tree and snake is symbolic, potentially representing wisdom, knowledge, or the tree of life. The monochrome color scheme adds to the logo's classic and sophisticated appearance.
### Interpretation
This is the logo for the publishing company Elsevier. The imagery is derived from the family crest of the Elsevier family, who founded the publishing house in the 16th century. The tree and snake are elements of the Elsevier family coat of arms. The logo represents the company's long history and commitment to scholarly publishing. The image does not contain any factual data or numerical values; it is a symbolic representation of a brand identity. The logo is a visual identifier, not a data presentation.
</details>
<details>
<summary>Image 2 Details</summary>

### Visual Description
Icon/Small Image (281x48)
</details>
00 (2023) 1-33
## Generalized Planning as Heuristic Search: A new planning search-space that leverages pointers over objects
Javier Segovia-Aguas Universitat Pompeu Fabra Sergio Jim´ enez Universitat Polit` ecnica de Val` encia Anders Jonsson Universitat Pompeu Fabra
## Abstract
Planning as heuristic search is one of the most successful approaches to classical planning but unfortunately, it does not extend trivially to Generalized Planning (GP). GP aims to compute algorithmic solutions that are valid for a set of classical planning instances from a given domain, even if these instances di er in the number of objects, the number of state variables, their domain size, or their initial and goal configuration. The generalization requirements of GP make it impractical to perform the state-space search that is usually implemented by heuristic planners. This paper adapts the planning as heuristic search paradigm to the generalization requirements of GP, and presents the first native heuristic search approach to GP. First, the paper introduces a new pointer-based solution space for GP that is independent of the number of classical planning instances in a GP problem and the size of those instances (i.e. the number of objects, state variables and their domain sizes). Second, the paper defines a set of evaluation and heuristic functions for guiding a combinatorial search in our new GP solution space. The computation of these evaluation and heuristic functions does not require grounding states or actions in advance. Therefore our GP as heuristic search approach can handle large sets of state variables with large numerical domains, e.g. integers. Lastly, the paper defines an upgraded version of our novel algorithm for GP called Best-First Generalized Planning (BFGP), that implements a best-first search in our pointer-based solution space, and that is guided by our evaluation / heuristic functions for GP.
Keywords: Generalized planning, classical planning, heuristic search, planning and learning, domain-specific control knowledge, program synthesis, programming by example
## 1. Introduction
Generalized planning (GP) addresses the representation and computation of solutions that are valid for a set of classical planning instances from a given domain [1, 2, 3, 4, 5, 6, 7, 8]. In the worst case, each classical planning instance may require a completely di erent solution. In practice, however, many classical planning domains are known
Corresponding author
Email addresses: javier.segovia@upf.edu (Javier Segovia-Aguas), serjice@dsic.upv.es (Sergio Jim´ enez), anders.jonsson@upf.edu (Anders Jonsson)
Artificial Intelligence
to have polynomial algorithmic solutions [9]. In other words, one can compute a single compact general solution that exploits some common structure of the di erent classical planning instances in a given domain. Generalized plans are then not sequences of actions, but algorithmic solutions that supplement planning actions with control-flow constructs. For example, a generalized plan that solves any classical planning instance from the blocksworld domain [10] can be compactly specified as follows: put all the blocks on the table and then, in a proper order, move each block to its goal placement . This generalized plan is able to solve any blocksworld instance, no matter the actual number, or identity of the blocks, and no matter the initial and goal configuration of the blocks. Note however that the knowledge represented in a given input set of classical planning instances may not be enough to specify an algorithmic solution that solves them all. For example, instances of the classical planning blocksworld domain do not include representation features for specifying whether all blocks are on the table , or for specifying the proper order for moving the blocks to their goal placements . A big challenge in GP is then to automatically discover the representation features that are key for computing a compact and general solution for a given set of planning instances. With this regard, researchers have proposed di erent languages for compactly represent GP solutions, and associated algorithms for computing a GP solution in a given language.
Automated planning has not achieved the level of integration with common programming languages, like C, J ava , or P ython , that is achieved by other forms of problem solving, such as constraint satisfaction or operational research [11, 12, 13]. An important reason is the low-level representations traditionally used in planning for specifying problems and solutions [14, 15, 16, 17, 18]. Given the algorithmic kind of GP solutions, GP is a promising research direction to bridge the current gap between automated planning and programming. However, most of the work on GP still inherits the S trips representation, in which states are represented specifying the properties and relations of a set of objects, and where actions represent object manipulations. In this work we provide a pointer-based representation for GP problems and solutions, that is closer to common programming languages, and that applies also to the object-centered problems that traditionally are addressed in the automated planning community. In addition we show that our pointer-based representation allows us to adapt the planning as heuristic search paradigm to GP: given a GP problem that comprises a finite set of classical planning instances from a given domain, our GP as heuristic search approach implements a combinatorial search to find a program that solves the full set of input instances. With our new pointer-based representation we are able to solve challenging programming tasks that were out of reach for previous top-down GP solvers.
Heuristic search is one of the most successful approaches to classical planning [19, 20]. The winners of the International Planning Competition (IPC) are often heuristic planners [21], and the workshop on Heuristics and Search for Domain-Independent Planning (HSDIP) is one of the discussion forums with the longest tradition at the International Conference on Automated Planning and Scheduling (ICAPS) , the major international conference for research on automated planning. Briefly, the planning as heuristic search approach addresses the computation of sequential plans as a combinatorial search in the space of the states reachable from a single given initial state. This combinatorial search is usually implemented as a forward search, guided by heuristics that are automatically extracted from the declarative representation of the planning problem. There is a wide range of di erent heuristics for classical planning, but most of them are based on the notion of relaxed plan [22]. The relaxed plan is a solution to a relaxation of the classical planning problem, which is computed assuming that goals (and action preconditions) are independent. The cost of the relaxed plan is an informative estimate of the actual cost-to-go for many classical planning problems, and its computation is much cheaper than the computation of the actual solution to the planning problem.
In the last two decades a wide landscape of e ective search algorithms, and heuristic functions, have been developed for classical planning [23, 24, 25, 26, 27, 28]. Unfortunately, search algorithms and heuristic functions from classical planning cannot be directly extended to GP. The computation of relaxed plans , as it is implemented by o -the-shelf heuristic planners, requires a pre-processing step for grounding states and actions [29]. On the other hand, GP solutions must be able to generalize to (possibly infinite) sets of classical planning instances, with di erent sets of state variables (i.e. state variables with di erent domain sizes and / or di erent number of state variables) as well as with di erent initial states and goals. These particular generalization requirements of GP make it impractical to ground states and actions and hence, to apply the state-space search and the cost-to-go estimates of heuristic planners.
With respect to previous work on GP, our heuristic search approach to GP introduces the following contributions:
1. A pointer-based representation for GP problems and solutions . Our representation formalism is closer to common programming languages, and it also applies to object-centered representations (like S trips ) that are tradi-
tionally used in automated planning.
2. A tractable solution-space for GP . We leverage the computational models of the Random-Access Machine [30] and the Intel x86 FLAGS register [31] to define an innovative pointer-based search space for GP. Interestingly our new search space for GP is independent of the number of input planning instances in a GP problem, and the size of these instances (i.e. the number of objects, state variables, and their domain sizes).
3. Grounding-free evaluation / heuristic functions for GP. We define several evaluation and heuristic functions to guide a combinatorial search in our solution space for GP. Evaluating these functions does not require to ground states / actions in advance, so they apply to GP problems where state variables have large domains (e.g. integers).
4. A heuristic search algorithm for GP . We present the BFGP algorithm for GP that implements a best-first search in our GP solution-space, and that is guided by our evaluation and heuristic functions.
5. A translator from the S trips fragment of PDDL to our pointer-based representation for GP. We automate the representation change from PDDL to pointer-based, and show several solutions to planning domains from the International Planning Competition (IPC) [32] which are validated on large random instances.
A preliminary description of our GP as heuristic search approach previously appeared at an ICAPS conference paper [33]. In this work we review and extend the seminal ideas presented in the conference paper, and provide a more exhaustive evaluation of our GP as heuristic search approach. Compared to the conference paper, the present paper includes the following novel material:
- We formalize the notion of pointer over the objects of a planning problem, and introduce a pointer-based formalization for planning action schemes, classical planning problems and solutions. We show that our pointerbased formalization directly applies to object-centered planning problems that are traditionally addressed in automated planning.
- We introduce the notion of partially specified planning program , that refers to the sketch of an algorithmic planning solution, and that allows to explain better our search algorithm and heuristics functions for GP. We also implemented new evaluation functions for guiding our GP as heuristic search approach.
- We provide theoretical results of our heuristic search algorithm for GP, that include termination , soundness , completeness , and complexity proofs. We also extend the empirical evaluation, including more results at a wider landscape of planning domains, to characterize better the performance of our GP as heuristic search approach.
The paper is structured as follows: Section 2 presents the planning models we rely on in this work (namely the classical planning model and the GP planning model) and also presents planning programs and the Random Access Machine , the formalisms we leverage for the representation of our algorithmic planning solutions. Section 3 shows how to extend the classical planning model with a set of pointers over objects, and the corresponding primitive operations for manipulating these pointers. This extension allows us to define, in an agnostic manner, a set of features and a set of actions for computing planning programs that can solve any instance from a given planning domain. Section 4 describes our GPas heuristic search approach; the section provides details on our solution space, evaluation functions, and heuristic search algorithm for GP. Section 5 presents the empirical evaluation of our approach and its comparison with the classical planning compilation for GP, that serves as a baseline. Finally, Section 6 wraps-up our work and discusses open issues and future work.
## 1.1. Related Work
Here we first review previous work on GP according to the following three dimensions: problem representation , solution representation , and computational approach . Then, we connect the research work on GP with other relevant areas in AI, such as program synthesis , deep learning , and (deep) reinforcement learning . Last, we list the features that distinguish our GP as heuristic search approach from the reviewed related work.
Regarding problem representation , there are two di erent approaches for the specification of the set of classical planning instances that are comprised in a GP problem. The explicit approach, that enumerates every classical planning instance in a GP problem [34], and the implicit approach, that defines the constraints that hold for the set of classical planning instances of a GP problem. The implicit approach is of interest because it allows to compactly specify infinite sets of classical planning instances (e.g. the infinite set of the classical planning instances that belong to the
blocksworld domain) [35, 36, 6]. In addition to the set of classical planning instances, extra background knowledge can also be specified in a GP problem with the aim of reducing the space of hypothetical solutions. For instance, plan traces / demonstrations on how to solve some of the input instances [37, 38, 39], the full state space [8], the particular subset of state features that can be used for computing a generalized plan [40, 41], negative examples that specify undesired behavior for the targeted GP solutions [42, 8], or state invariants that any state in a given domain must satisfy [43].
With respect to solution representation , di erent formalisms appeared in the planning literature to represent solutions that are valid for a set of classical planning instances; sequential plans are used in conformant planning [44], conditional tree-like plans are used in contingent planning [20], or policies are used in FOND planning , as well as in MDP / POMDP planning [45]. In all these planning settings, a set of di erent classical planning instances, with di erent initial states, can be implicitly represented as a disjunctive formulae over the state variables. Di erent goals can also be considered by coding them as part of the state representation, e.g. using static state variables. Since the early days of AI planning, hierarchies, LTL formulae, and policies, are also used to specify sketches of general solutions [46]. In the planning literature these solution sketches are often called domain-specific control knowledge , since they are traditionally used to control the planning process, and they apply to the entire set of classical planning instances that belong to a given domain [47, 48, 37, 38]. Last but not least, algorithmic solutions, represented either as lifted policies, finite automata, or as programs with control-flow constructs for branching and looping, are used to represent GP solutions [35, 49, 40, 50, 51, 52, 1, 34, 7].
Regarding to the computation of generalized plans , there are two main approaches for addressing GP problems. The top-down / o ine approach considers the entire set of classical planning instances in a given GP problem as a single batch, and computes a solution plan that is valid for the full batch at once. A common approach for the o ine computation of generalized plans is compiling the GP problem into another form of problem solving, and using an o -the-shelf solver to work out the compiled problem. With this regard, GP problems have been compiled into classical planning problems [52, 34], conformant planning problems [40], LTL synthesis problems [53], FOND planning problems [54, 6] or MAXSAT problems [8]. The compilation approach is appealing because it allows to leverage the latest advances of other well-founded scientific communities, with robust and scalable solvers. In addition, the computational complexity of some of these tasks is theoretically characterized with respect to structural features of the input problems, which may provide insights on the di culty of the addressed GP problem. A weak point of the compilation approach is however the size of the compiled problems to be solved; solvers are usually sensitive to the size of the input problems. On the other hand, the bottom-up / online approach incrementally processes the set of classical planning instances in a GP problem [1, 3]. Given a classical planning instance, a solution to that instance is computed and then, the solution is merged with solutions computed for the previous instances. The online approach is then appealing for handling GP problems that comprise large sets of classical planning instances. The main drawback of online approaches is dealing with the overfitting produced by the individual processing of the di erent classical planning instances in a GP problem.
As noted by previous work on GP, the aims of GP are connected to program synthesis [34, 6, 53, 33]. Program synthesis is a task traditionally studied by the computer-aided verification community [55], and that aims the computation of programs such that they satisfy a given correctness specification [56, 57, 58]. Program synthesis follows the functional programming paradigm. This means that a program is a function composition, where each function in the composition is a mapping of its input parameters into a single output, and where loops are implemented using recursion. Work on program synthesis is classified according to how the correctness specification of a program is formulated. The programming by example (PbE) paradigm specifies the desired program behaviour with a finite and non-empty set of ground input / output examples. This approach is related to the explicit representation of GP problems; a ground input / output example can be understood as the initial / goal state pair that represents a classical planning instance, and the instruction set of the functional programming language can be understood as the available actions for transforming an initial state into a goal state. Program synthesis also allows the implicit representation of the input correctness specifications, e.g. using fist-order formulae specified in SMTLIB, the formal language for SAT-Modulo Theories (SMT) [59]. The mainstream approach for program synthesis is to specify a formal grammar that allows to incrementally enumerate the space of possible programs, and to leverage the satisfiability machinery of SMT solvers to validate whether a candidate program is actually a solution. With this regard, work on theorem proving is also related to program synthesis, specially since SMT solvers allow the representation and satisfaction of first-order logic formulae [60]. Lastly, another popular trend in program synthesis is Programming by sketches that addresses program
## Author / 00 (2023) 1-33
synthesis in the particular setting where a partially specified solution is provided as input [61].
Besides computational methods for formal verification and logic satisfaction, optimization methods (that are predominant in Machine Learning [62]) have also been applied to the computation of planning solutions that generalize. For instance, o -the-shelf Deep Learning (DL) tools, have been successfully applied to the computation of generalized policies for classical and probabilistic planning domains [63, 64, 65]. Generalized policies are a powerful solution representation formalism whose applicability goes beyond classical planning. Generalized policies can represent planning solutions that can deal with non-deterministic actions [66], and whose aim is not to satisfy a given goal condition but to optimize a given utility function [67]. The aims of GP are also related to Reinforcement Learning (RL) [68]; while the cited DL approaches can be viewed as o -line optimization approaches to GP, the RL paradigm can be viewed as an online optimization approach to GP. RL methods incrementally compute policies, by iteratively addressing a set of sequential decision-making episodes. In RL learning experience is however not given beforehand (learning experience is collected by the autonomous exploration of the state space), and RL assumes that there is an explicit notion of reward function (which helps to guide exploration towards the most promising portions of the state-space). Note that DL and DRL approaches learn policies, without requiring a symbolic representation of the state and the action space. This means that it is possible to compute policies ( deep policies ) that generalize from raw sensor data (e.g. sequences of images) [69, 70]. The main disadvantage of computing solutions represented as deep policies is that they are black-box models that lack transparency and explanation capacity, which makes it di cult to interpret the produced solutions. This is a strong requirement in application areas that require humans in the loop, such as health, law, or defense [71].
With regard to the reviewed related work, our GP as heuristic planning approach is framed as follows:
- Numeric state variables . Previous work on generalized planning mainly followed the object-centered S trips representation. Addressing programming tasks with such representation is unpractical since it requires to encode all values in the domain of a state variable as objects. Other approaches, such as Qualitative Numeric Planning (QNP) [72, 73], handle large numeric state variables qualitatively with propositions to denote whether a variable is equal to zero. In this work we handle GP problems with integer state variables, which allow to naturally address diverse programming tasks as if they were GP problems.
- Explicit problem representation . In this work, a GP problem comprises the explicit enumeration of a finite set of classical planning instances to be solved. Interestingly our experimental results show that, in several domains, solving a small set of a few randomly generated classical planning instances, is enough to obtain a solution that generalizes to the infinite set of problems that belong to a given domain.
- No background knowledge . Our approach does not require any additional help such as state invariants, plans / -traces / demonstrations, negative examples, or the specification of the subset of features to appear in the generalized plans.
- Generalized plans represented as structured programs . Structured programming provides a white-box modeling paradigm that is widely popular. In this work we focus on generalized plans represented as structured programs, with control flow constructs for branching and looping the program execution flow. The application of a generalized plan on a particular instance is then a deterministic matching-free process, which makes it easier to define e ective evaluation and heuristic functions. Further, the asymptotic complexity of structured programs can be assessed from their structure, which is also helpful to establish preferences on di erent possible generalized plans.
- O -line satisfiability approach . This work follows an o -line approach to GP that aims to compute, at once, a generalized plan that exactly solves all the classical planning instances that are given as input. Because many heuristic search algorithms are easily extended to online versions, we believe that our GP as heuristic search approach is a stepping stone towards online approaches that can deal with larger sets of classical planning instances.
- Native heuristic search for GP . By native heuristic search, we mean that we defined a search space, evaluation / heuristic functions, and a search algorithm, that are specially targeted to GP. Our GP as heuristic search approach is related to an existing classical planning compilation for GP [34]. Our approach overcomes however
the main drawback of the compilation whose search space grows exponentially with the number and domain size of the state variables; in practice, this limits the applicability of the compilation to planning instances of small size since the performance of o -the-shelf classical planners is sensitive to the size of the input instances. Our experiments support this claim, and show that our BFGP algorithm significantly reduces the CPU-time required to compute and validate generalized plans, compared to the classical planning compilation approach to GP [34].
## 2. Background
This section introduces the necessary notation to formalize our GP as heuristic search approach. First, the section formalizes the classical planning model and the generalized planning model. Then the section formalizes planning programs , our formalism for the compact representation of planning solutions, and that applies to both classical planning and generalized planning. Lastly the section formalizes the Random Access Machine given that, to define a tractable solution space for GP, our GP as heuristic planning approach borrows several mechanisms from this abstract computation machine.
## 2.1. Classical Planning
Our formalization of the classical planning model is similar to the abstract planning framework called Finite Functional Planning , that was introduced for the theoretical analysis of di erent ground languages for classical planning [74]. Let X be a set of state variables , where each variable x 2 X has a domain Dx . A state s is a total assignment of values to the set of state variables, i.e. s = h x 0 = v 0 ; : : : ; xN = vN i , such that 8 0 i Nvi 2 Dxi . For a subset of the state variables X 0 X , let D [ X 0 ] = x 2 X 0 Dx denote its joint domain. The state space is denoted as S = D [ X ]. Given a state s 2 S , and a subset of variables X 0 X , let s j X 0 = h xi = vi i xi 2 X 0 be the projection of s onto X 0 i.e. the partial state that is defined by the values assigned by s to the subset of state variables in X 0 . The projection of s onto X 0 defines the subset f s j s 2 S ; s j X 0 s g of the states that are consistent with the corresponding partial state. Last, let us define a state-constraint C as a Boolean function C : S !f 0 ; 1 g over the state variables, that implicitly defines the subset of states SC S that are consistent with that constraint.
Let A be a set of deterministic actions such that each action a 2 A is characterized by two functions; an applicability function a : S ! f 0 ; 1 g and a successor function a : S ! S . An action a 2 A is applicable in a given state s 2 S i a ( s ) equals 1. The execution of an applicable action a 2 A , in a state s 2 S results in the successor state s 0 = s a . Note that our definition of deterministic actions generalizes actions with conditional e ects [75], common in GP since their state-dependent outcomes allows the adaptation of generalized plans to di erent classical planning instances.
A classical planning instance is a tuple P = h X ; A ; I ; G i , where X is a set of state variables, A is a set of actions, I 2 S is an initial state, and G is a constrain on the value of the state variables that induces the subset of goal states SG = f s j s G ; s 2 S g . Given P , a plan is an action sequence = h a 1 ; : : : ; am i whose execution induces a trajectory = h s 0 ; a 1 ; s 1 ; : : : ; am ; sm i such that, for each 1 i m , ai is applicable in si 1 and results in the successor si = si 1 ai . Aplan solves P if and only if the execution of in s 0 = I finishes in a goal state, i.e. sm 2 SG . We say is optimal if j j = m is minimal among the set of all the plans that solve P .
Planning languages, such as PDDL [76], can compactly represent the infinite set of classical planning instances of a given domain using a finite set of functions and a finite set of action schemes. Given a finite set of objects , and a finite set of functions defined over that set of objects, we assume that each state variable x 2 X stands for a function interpretation x ( ! o ), where 2 is a function with arity ar ( ), and ! o 2 ar ( ) is a vector of objects comprised in the Cartesian product space of ar ( ) . For keeping compact the number of state variables, objects and function signatures can by typed so the number of possible function interpretations is constrained. Functions in can be Boolean e.g. to represent PDDL predicates, or numeric e.g. to represent PDDL numeric fluents. Likewise, given a set of action schemes , we assume that each action a 2 A is built from an action schema 2 by substituting each variable in the action scheme with an object from . An action scheme 2 is a tuple = h name ( ) ; par ( ) ; pre ( ) ; e f f ( ) i ; where name ( ) is the identifier of the action schema, par ( ) is its list of variables (again these variables can be typed so they can only be substituted by objects of the same type), pre ( ) is a FOL Boolean formula defined over par ( ) that compactly represents the subset of states where the corresponding ground actions are applicable, and e ( ) is
list of FOL constraints that compactly represents the updates of the state variables caused by the application of the corresponding ground actions.
## 2.2. Generalized Planning
Generalized planning is an umbrella term that refers to more general notions of planning [7]. This work builds on top of the inductive formalism for GP, where a GP problem is defined as a finite set of classical planning instances that share a common structure [5, 53]. In this work we assume that the finite set of classical planning instances in a GP problem belong to the same domain. These instances share then a common structure since they are built from the same sets of functions and action schemes .
Definition 1 (GP problem) . A GP problem P = f P 1 ; : : : ; PT g is a finite and non-empty set of T classical planning instances P 1 = h X 1 ; A 1 ; I 1 ; G 1 i ; : : : ; PT = h XT ; AT ; IT ; GT i such that at each instance Pt 2 P , 1 t T, may di er in the set of state variables, actions, initial state, and goals, but the corresponding set of state variables Xt is induced from the common set of functions , and the set of actions At from the common set of action schemes .
There are diverse representations for GP solutions that range from generalized polices [35, 49], to finite state controllers [40, 50], formal grammars [51], hierarchies [77, 52], or programs [1, 34]. Each representation has its own expressiveness capacity, as well as its own validation complexity and computation complexity. In spite of this representation diversity, we can define a common condition under which a generalized plan is considered a solution to a GP problem. First, let us define exec ( ; P ) = h a 1 ; : : : ; am i as the sequential plan that is produced by the execution of a generalized plan on a classical planning instance P .
Definition 2 (GP solution) . A generalized plan solves a GP problem P = f P 1 ; : : : ; PT g i , for every classical planning instance Pt 2 P , 1 t T, it holds that the sequential plan exec ( ; Pt ) solves Pt.
AGPsolution for a given GPproblem P is optimal i , for every Pt 2 P , the sequential plan exec ( ; Pt ) induced by for solving the classical planing instance Pt is an optimal plan for that instance.
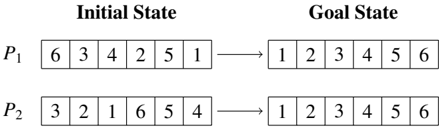
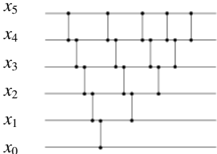
Example . Figure 1 shows the initial state and goal of two classical planning instances, P 1 = h X ; A ; I 1 ; G 1 i and P 2 = h X ; A ; I 2 ; G 2 i , for sorting two six-element lists. In this example the two instances share the same set of state variables X = f xi vector ( oi ) j 0 i 5 g that is built with the one-arity function = f vector g and the set of objects 1 = 2 = f o 0 ; : : : ; o 5 g , and where 8 x 2 XDx = N 0. The two classical planning instances also share the set of deterministic actions A , with 6 5 2 actions swap ( oi ; oj ), that swap the content of two list positions i < j , and that are induced from the single action scheme = f swap ( x ; y ) g . An example solution plan for P 1 is 1 = h swap ( o 0 ; o 5 ) ; swap ( o 1 ; o 2 ) ; swap ( o 1 ; o 3 ) i while 2 = h swap ( o 0 ; o 2 ) ; swap ( o 3 ; o 5 ) i is an example of a sequential plan that solves P 2 . Note that the set P = f P 1 ; P 2 g is a GP problem since they are two classical planning instances that are built using the same set of functions and action schemes . Figure 2 shows an example of a generalized plan that solves the GP problem P = f P 1 ; P 2 g , and that is represented as a sorting network . The sorting network is illustrated using two di erent types of items (namely the wires and the comparators ). For each state variable, there is a wire that carries the value of that variable from left to right in the network. On the other hand, comparators connect two di erent wires, corresponding to a pair of variables ( xi ; xj ), such that i < j . When a pair of values traveling through a pair of wires ( i ; j ), encounters a comparator, then the comparator applies the action swap ( oi ; oj ) i vector ( oi ) vector ( oj ), which in turn is xi xj . The sorting network of Figure 2 can actually solve any instance for sorting the content of any six-element list, no matter its initial content. This solution is however not valid for sorting lists with di erent lengths. In this paper we will show how to represent and compute planning solutions that leverage indirect memory addressing to generalize no matter the number of objects, and corresponding state variables.
<details>
<summary>Image 3 Details</summary>
### Visual Description
\n
## Diagram: State Transition Representation
### Overview
The image presents a diagram illustrating the transition from an "Initial State" to a "Goal State" for two permutations, labeled P₁ and P₂. Each permutation is represented as a sequence of numbers within a rectangular box. An arrow indicates the transformation from the initial to the goal state.
### Components/Axes
The diagram consists of two main columns labeled "Initial State" and "Goal State". Each column contains two rows, labeled P₁ and P₂. Each row represents a permutation of the numbers 1 through 6. The permutations are displayed as a horizontal sequence of numbers within a rectangular box. Arrows point from the initial state to the goal state for each permutation.
### Detailed Analysis or Content Details
**P₁:**
* **Initial State:** The sequence is 6, 3, 4, 2, 5, 1.
* **Goal State:** The sequence is 1, 2, 3, 4, 5, 6.
**P₂:**
* **Initial State:** The sequence is 3, 2, 1, 6, 5, 4.
* **Goal State:** The sequence is 1, 2, 3, 4, 5, 6.
### Key Observations
Both permutations, P₁ and P₂, start in a disordered state and transition to the same ordered goal state (1, 2, 3, 4, 5, 6). The initial states are different, indicating different starting points for the transformation.
### Interpretation
This diagram likely represents a problem in search algorithms or state-space search. The "Initial State" represents the starting configuration, the "Goal State" represents the desired configuration, and the arrow implies a series of operations or steps to transform one into the other. The two permutations suggest that there might be multiple paths or solutions to reach the same goal state. The problem could be related to sorting algorithms, puzzle solving (like the 15-puzzle), or any scenario where a system needs to transition from an initial configuration to a target configuration. The diagram doesn't provide information about the specific operations used to achieve the transition, only the initial and final states.
</details>
Figure 1: Example of two classical planning instances for sorting the content of two six-element lists by swapping the list elements.
<details>
<summary>Image 4 Details</summary>
### Visual Description
\n
## Diagram: Quantum Circuit
### Overview
The image depicts a quantum circuit diagram with six qubits, labeled x₀ through x₅, arranged vertically. The diagram shows a series of quantum gates applied to these qubits, represented by vertical lines connecting the qubit lines. The diagram does not contain numerical data, but illustrates the application of gates in a specific sequence.
### Components/Axes
- **Qubits:** Six horizontal lines representing qubits, labeled from bottom to top as x₀, x₁, x₂, x₃, x₄, and x₅.
- **Gates:** Vertical lines connecting the qubit lines, representing quantum gates. The specific type of gate is not indicated.
- **Arrangement:** The gates are applied sequentially, with each gate affecting one or more qubits.
### Detailed Analysis or Content Details
The diagram shows the following gate applications:
1. **x₀:** A gate is applied to x₀.
2. **x₁:** A gate is applied to x₁.
3. **x₂:** A gate is applied to x₂.
4. **x₃:** A gate is applied to x₃.
5. **x₄:** A gate is applied to x₄.
6. **x₀ & x₁:** A gate is applied to both x₀ and x₁.
7. **x₁ & x₂:** A gate is applied to both x₁ and x₂.
8. **x₂ & x₃:** A gate is applied to both x₂ and x₃.
9. **x₃ & x₄:** A gate is applied to both x₃ and x₄.
10. **x₀ & x₂:** A gate is applied to both x₀ and x₂.
11. **x₁ & x₃:** A gate is applied to both x₁ and x₃.
12. **x₂ & x₄:** A gate is applied to both x₂ and x₄.
13. **x₀ & x₃:** A gate is applied to both x₀ and x₃.
14. **x₁ & x₄:** A gate is applied to both x₁ and x₄.
15. **x₀ & x₄:** A gate is applied to both x₀ and x₄.
16. **x₁ & x₅:** A gate is applied to both x₁ and x₅.
17. **x₂ & x₅:** A gate is applied to both x₂ and x₅.
18. **x₃ & x₅:** A gate is applied to both x₃ and x₅.
19. **x₄ & x₅:** A gate is applied to both x₄ and x₅.
### Key Observations
The diagram demonstrates a pattern of applying gates to increasingly distant qubits. The gates are applied in a structured manner, suggesting a specific quantum algorithm or circuit design. The diagram does not provide information about the specific type of gates being used.
### Interpretation
The diagram represents a quantum circuit, a sequence of quantum gates applied to qubits. The specific arrangement of gates suggests a particular quantum algorithm or computation. Without knowing the type of gates used, it is difficult to determine the exact function of the circuit. The diagram illustrates the fundamental concept of quantum computation, where qubits are manipulated using quantum gates to perform calculations. The increasing complexity of the gate applications suggests a potentially complex quantum algorithm. The diagram is a visual representation of a quantum process, and its interpretation requires knowledge of quantum mechanics and quantum computing principles.
</details>
Figure 2: Example of a generalized plan, represented as a sorting network that solves any classical planning instances for sorting the content of a six-element list, no matter its initial content.
## 2.3. Planning programs
In this work we represent planning solutions as planning programs [34]. Unlike sequential plans, planning programs include a control flow construct which allows the compact representation of solutions to classical planning problems and to GP problems. Formally a planning program is a sequence of n instructions = h w 0 ; : : : ; wn 1 i , where each instruction wi 2 is associated with a program line 0 i < n , and it is either:
- A planning action wi 2 A .
- A goto instruction wi = go ( i 0 ; ! y ), where i 0 is a program line 0 i 0 < i or i + 1 < i 0 < n , and y is a proposition.
- A termination instruction wi = end . The last instruction of a planning program is always a termination instruction, i.e. wn 1 = end .
The execution model for a planning program is a program state ( s ; i ), i.e. a pair of a planning state s 2 S and program counter 0 i < n . Given a program state ( s ; i ), the execution of a programmed instruction wi is defined as:
- If wi 2 A , the new program state is ( s 0 ; i + 1), where s 0 = s wi is the successor when applying wi in s .
- If wi = go ( i 0 ; ! y ), the new program state is ( s ; i + 1) if y holds in s , and ( s ; i 0 ) otherwise 1 . Proposition y can be the result of an arbitrary expression on state variables, e.g. a state feature [78].
- If wi = end , program execution terminates.
To execute a planning program on a classical planning instance P = h X ; A ; I ; G i , the initial program state is set to ( I ; 0), i.e. the initial state of P and the first program line of . A program solves P i the execution terminates in a program state ( s ; i ) that satisfies the goal condition, i.e. wi = end and s 2 SG . Otherwise the execution of the program fails. If a planning program fails to solve the planning instance, the only possible sources of failure are:
1. Inapplicable program , i.e. executing action wi 2 A fails in program state ( s ; i ) since wi is not applicable in s .
2. Incorrect program , i.e. execution terminates in a program state ( s ; i ) that does not satisfy the goal condition, i.e. ( wi = end ) ^ ( s < SG ).
3. Infinite program , i.e. execution enters into an infinite loop that never reaches an end instruction.
1 We adopt the convention of jumping to line i 0 whenever y is false , following the JMP instructions in the Random-Access Machine that jump when a register equals zero.
In this work we model instructions wi 2 A as if they were always applicable but that their e ects only update the current state i the preconditions of the action hold in the current planning state. Formally, when executing wi in ( s ; i ), the new program state is ( s 0 ; i + 1) i wi is applicable, otherwise it is ( s ; i + 1). Therefore, in this work the execution of a program on a classical planning instance will never return an inapplicable program , and only incorrect or infinite program are possible sources of failure. This particular action modeling is common in Reinforcement Learning [68], and in conformant planning [44], because it allows to deliver compact solutions that apply to sets of di erent sequential decision-making problems (typically with di erent initial states).
## 2.4. The Random-Access Machine
The Random-Access Machine (RAM) is an abstract computation machine, in the class of register machines , that is polynomially equivalent to a Turing machine [79]. The RAM machine enhances a multiple-register counter machine [80] with indirect memory addressing. The indirect memory addressing of RAM machines is useful for defining RAM programs that access an unbounded number of registers, no matter how many there are. With this regard, a register in a RAM machine is then a memory location with both a content (a single natural number), and an address (a unique identifier that works as a natural number). Let be r the address of a RAM register, and [ r ] the content of that register.
Diverse base instructions sets , that are Turing complete, can be defined on the RAM registers. Our GPas heuristic search approach builds on the instructions of the Base set 1 and the Base set 3 , that are briefly defined as follows:
- inc ( r ) increments the content of the register r by 1, i.e. ([ r ] + 1) ! [ r ]. Likewise, dec ( r ) decrements the content of the register r , i.e. ([ r ] 1) ! [ r ].
- copy ( r 1 ; r 2) copies the content of r 1 in r 2 , i.e. [ r 1 ] ! [ r 2 ].
- jmp ( z ; r ) jumps to instruction z if register r is zero, else the RAM execution continues to the next instruction.
- halt terminates the RAM execution.
Auxiliary dedicated registers allow to reduce the size of the RAM instruction set. For instance, the number of registers called out by the RAM instructions can be reduced by using an accumulator dedicated register. WLOG in this work we extend Base sets 1 and 3 with two FLAGS registers, the zero and the carry registers, that are dedicated to store the outcome of three-way comparisons [81] between two registers, as well as to condition jump instructions. On the other hand, the RAM instruction set can be extended with extra instructions, that can actually be built as blocks of the base RAM instructions, but that allow the definition of more compact RAM programs. For instance, an extra instruction for clearing (setting to zero) the value of a register.
## 3. Planning with a RAM
Inspired by the computational model of the RAM machine, this section extends the classical planning model with a set of pointers , defined over the set of objects used to build the state variables and actions of a classical planning instance, and with the set of primitive operations for manipulating these pointers. Extending the classical planning model with a set of pointers, and their primitives, allows the agnostic definition of a set of state features, and a set of actions, that are shared for the di erent classical planning instances in a given domain and that can be leveraged for the computation of generalized plans. For instance, the selection sort algorithm is able to solve any sorting instance, no matter the content or the length of the input list, because it is provided with mechanisms for indexing the list positions and for operating over those indexes.
First, the section shows how to compactly represent a transition system using pointers. Then the section formalizes our extension of the classical planning model with a set of pointers , and their corresponding primitive operations. The last part of the section shows that our pointer-based formalism applies also to the object-centered representations traditionally used in classical planning.
```
bool constraint_sorted(int i) {
For (Pointer i=1; i<i[0]; i++) {
If (vector(i-1) > vector(i)) {
Return False;
}
}
Return True;
}
}
```
Figure 3: Boolean function constraint sorted that implements a constraint for validating whether the vector of state variables is sorted in increasing order. The constraint is implemented leveraging the single pointer i over the objects in ; vector ( i ) is interpreted as vector ( oi ) xi 2 X .
## 3.1. Representing transition systems with pointers
Formally, a transition system is a pair ( S ; ! ), where S is a set of states, and ! denotes a relation of state transitions S S . Unlike finite-state automata, the set of states and the set of state transitions of a transition system are not necessarily finite, and no initial / goal states are specified. State constraints allow the compact representation of (possibly infinite) sets of states. For instance given the set of state variables X = f x 0 ; x 1 ; x 2 ; x 3 ; x 4 ; x 5 g of the example in Figures 1 and 2, the state constraint x 0 x 1 x 2 x 3 x 4 x 5 defines the subset of states where the content of these variables is sorted in increasing order and it applies no matter the domain of the state variables (that can actually be infinite).
In object-centered transition systems, states are factored and each state variable is addressed by a function 2 fed with a list of objects ! o , i.e. ( ! o ) s.t. ! o 2 ar ( ) ; where is the set of objects and ar ( ) denotes the arity of . For instance in the previous example, given the one-arity function vector and the six-objects set = f o 0 ; o 1 ; o 2 ; o 3 ; o 4 ; o 5 g , each state variable xi 2 X may be defined as xi vector ( oi ).
Definition 3 (Pointer) . Given a set of objects , we define a pointer as a finite-domain variable z whose domain is Dz = [0 ; : : : ; j j 1] , where j j denotes the number of objects.
Pointers are then variables for indexing the objects of a transition system that, in combination with function symbols, are useful to define state constraints that produce not only compact, but general representations of a possibly infinite set of states. By general we mean that a constraint represents a set of states that share some common structure, no matter the actual number of objects, and corresponding state variables. For instance, Figure 3 shows the Boolean function constraint sorted , that implements a global constraint for checking whether the content of the vector of state variables is sorted in increasing order. The constraint sorted function is procedurally defined, leveraging a single pointer i , and it applies to any number of objects, and to any domain size of the corresponding state variables.
Besides the compact and general definition of (possibly infinite) sets of states, pointers over objects also enable the compact and general definition of (possibly infinite) sets of state transitions via action schemes .
Definition 4 (Action schema with pointers) . Given a set of X state variables, an action schema with pointers is a tuple h name, params, pre, e i where:
- name is the symbol that uniquely identifies the action schema.
- params is a finite set of pointers Z defined over the set of objects.
- pre is a state constraint where state variables are indirectly addressed via the function symbols and the pointers in params , i.e. x ( ! z ) such that 2 and ! z 2 Z ar ( ) . The pre state constraint implicitly represents the subset of states where the action schema is applicable.
- e is a partial assignment of the state variables where state variables are indirectly addressed via the function symbols and the pointers in params . The e partial assignment implicitly represents the successor state that results from the execution of the action schema at a given state.
To illustrate our pointer-based definition of an action schema, Figure 4 shows a procedural representation of the preconditions ( pre ) and the e ects ( e ) of the swap action schema. When applicable, the swap action schema exchanges
```
bool schema_swap_pre(Pointer i, Pointer j) {
return (i>=0 and j>=0 and i<[] and j<[] and i<j);
}
void schema_swap_eff(Pointer Variable aux;
aux:=vector(i);
vector(i):=vector(j);
vector(j):=aux;
}
```
```
Figure 4: Pointer-based representation of the preconditions and the e ects of the swap action schema. When applicable, the swap action schema exchanges the value of the state variables indexed by its two parameters , the pointers i and j .
the value of the state variables induced by its two parameters (the pointers i and j ). The swap action schema is succinct, because it compactly defines an infinite set of di erent state transitions that share a common structure. The swap action schema is also general, because it applies to any sorting instance, no matter the number of state variables (i.e. the length of the vector of state variables) or the domain size of these variables. What is more, the execution of the schema swap pre and schema swap eff procedures is a deterministic matching-free process since the input pointers do always index an object in .
## 3.2. Classical planning with pointers
Here we extend the classical planning model (introduced in Section 2) with a set of pointers and their corresponding primitive operations. We formalize the set of primitive operations over pointers leveraging the notion of Random-Access Machine . In more detail, we extend the classical planning model with a RAM machine of j Z j + 2 registers; j Z j pointers that reference the planning objects, plus two FLAGS registers (the zero and the carry ). The two FLAGS registers store the outcome of three-way comparisons , between two di erent pointers or between two state variables that are indirectly addressed via function symbols and pointers.
Given a classical planning instance P = h X ; A ; I ; G i , such that the state variables and actions are generated with the set of functions and action schemes of a given domain, and the set of objects , then the extended classical planning instance with a RAM machine of j Z j + 2 registers is defined as P 0 Z = h X 0 Z ; A 0 Z ; I 0 Z ; G i , where:
- The new set of state variables X 0 Z comprises:
- -The state variables X of the original planning instance, such that each state variable xi 2 X is xi ( ! o ) with 2 and ! o 2 ar ( ) , as defined above.
- -Two Boolean variables Y = f yz ; yc g , that play the role of the zero and carry FLAGS registers, respectively.
- -The pointers Z , a set of extra state variables s.t. each z 2 Z has finite domain Dz = [0 ; : : : ; j j 1].
- -A set of derived state variables XZ = f ( ! z ) j 2 ; ! z 2 Z ar ( ) g whose value is given by the interpretations of the functions of the domain with the corresponding pointers.
Given a fixed number of pointers, Y , Z , and XZ , are a subset of state variables that is shared by all the instances that belong to the same domain, no matter the number of objects of each instance.
- The new set of actions A 0 Z will represent the set of actions that is shared for the di erent classical planning instances in a given domain, and it includes:
- -The planning actions A 0 that result from reformulating each action scheme 2 into its corresponding pointer-based version. The reformulation is a two-step procedure that requires that Z contains, at least, as many pointers as the largest arity of an scheme in : (i), each parameter in par ( ) is replaced with a pointer in Z and (ii), preconditions and e ects are rewritten to refer to these pointers.
- -The RAM actions that implement the following sets of RAM instructions f inc ( z 1 ), dec ( z 1 ), cmp ( z 1 ; z 2 ), set ( z 1 ; z 2 ) j z 1 ; z 2 2 Z g over the pointers in Z , and f test ( ( ! z 1 )) ; cmp ( ( ! z 1 ) ; ( ! z 2 )) j ! z 1 ; ! z 2 2 Z ar ( ) g over the lists of pointers in Z ar ( ) for each function symbol 2 . Respectively, these RAM instructions increment / decrement a pointer by one, compare two pointers, set the value of a pointer z 2 to another pointer z 1 , test whether ( ! z 1) is greater than zero, and compare 2 the value of ( ! z 1) and ( ! z 2). Each RAM action also updates the Y = f yz ; yc g flags , according to the result of the corresponding RAM instruction (which is denoted here by res ):
$$res):$$
- The new initial state I 0 Z is the initial state of the original planning instance, but extended with all pointers set to zero and the two FLAGS set to False . The goals are the same as those of the original planning instance.
Example . Here we extend the classical planning instance P 1 = h X ; A ; I 1 ; G 1 i (illustrated in Figure 1) with a RAM machine of j Z j + 2 registers, where Z = f i ; j g is a set of two pointers. According to this extension, our pointer-based representation of the sequential plan 1 = h swap ( o 0 ; o 5 ) ; swap ( o 1 ; o 2 ) ; swap ( o 1 ; o 3 ) i is the following sequence of thirteen actions 0 1 = h inc ( j ) 5 ; swap ( i ; j ) ; inc ( i ) ; dec ( j ) 3 ; swap ( i ; j ) ; inc ( j ) ; swap ( i ; j ) i ; where superscripts refer to the number of times that an instruction is sequentially repeated, and where swap ( i ; j ) refers to the pointer-based action schema defined in Figure 4. Likewise, our pointer-based version of the sequential plan 2 = h swap ( o 0 ; o 2 ) ; swap ( o 3 ; o 5 ) i , that solves the classical planning problem P 2 illustrated in Figure 1, is the ten-action sequence 0 2 = h inc ( j ) 2 ; swap ( i ; j ) ; inc ( i ) 3 ; inc ( j ) 3 ; swap ( i ; j ) i . Note that any sequential plan for solving a classical planning instance from the vector sorting domain, no matter the number of state variables and no matter the domain size of these state variables, can be built using exclusively actions from the following set: f inc ( i ) ; inc ( j ) ; dec ( i ) ; dec ( j ) ; swap ( i ; j ) g .
## 3.2.1. Theoretical properties
Theorem 1. Given a classical planning instance P, its extension P 0 Z , with a RAM machine of j Z j pointers, preserves the solution space of P.
Proof. ) : Let = h a 1 ; : : : ; am i be a plan that solves P , an equivalent plan 0 that solves P 0 Z is built as follows; for each action ai 2 , A 0 contains a pointer-based action schema a 0 i that replaces each parameter in par ( ai ) with a pointer z 2 Z . For each such pointer z , the plan repeatedly applies RAM actions inc( z ) or dec( z ) until they reference the associated vector of objects ! o , and then it applies a 0 i . The resulting plan 0 has exactly the same e ect as on the original planning state variables in X , and since the goal condition of P 0 Z is the same as that of P , it follows that 0 solves P 0 Z .
( : Let 0 = h a 0 1 ; : : : ; a 0 m i be a plan that solves P 0 Z . Identify each action in A 0 among those of 0 , and execute 0 to identify the assignment of objects to pointers when applying each action in A 0 . Construct a plan corresponding to the subsequence of actions in A 0 from 0 , replacing each action schema a 0 i 2 A 0 by an original action ai 2 A and choosing as parameters of ai the objects referenced by the pointers of a 0 i at the moment of execution. Hence ai has the same e ect as a 0 i on the state variables in X , implying that has the same e ect as 0 on X . Since the goal condition of P is the same as that of P 0 Z , it follows that solves P .
Our extension of a classical planning problem with a RAM machine of j Z j + 2 registers preserves the solution space of the original problem. Sequential plans in the extended planning model are however longer when pointers
2 cmp ( ( ! z 1) ; ( ! z 2)) instructions are only defined for numeric functions.
must be incremented (or decremented) multiple times to access the corresponding objects, before the corresponding action schema is executed. For instance, our pointer-based version of plan 1 required thirteen steps while the original sequential plan only had three steps. Likewise our pointer-based version of plan 2 required ten steps while the original sequential plan only had two steps. On the other hand, our extension does not require explicit action grounding; it is the planner itself who determines the values of the pointers that now feed the action schemas, so in a sense the planner is in charge of doing a partial instantiation. Further, our extension separates the instantiation of each parameter of an action schema. The computation of sequential plans with our pointer-based formalism is however out of the scope of this paper. We will exclusively address the computation of planning solutions represented as planning programs.
Theorem 2. The new set of actions A 0 Z is independent of the number of objects , state variables X, and their domain size.
Proof. The number of actions of a classical planning instance, extended with a RAM machine of j Z j pointers, is
$$I ^ { \prime } _ { 2 1 } = 2 I ^ { 2 } + \sum _ { d < \phi } [ Z ^ { 2 } ( r ( \phi ) ) + I ^ { \prime } _ { 1 } ] .$$
This number exclusively depends on the number of pointers in Z and on the arity of the functions in and the action schemes in . First, the increment / decrement instructions induce 2 j Z j actions, the set instructions over pointers induce j Z j 2 j Z j actions, and comparison instructions of pointers induce j Z j 2 j Z j actions. The comparison instructions can compare two pointers but for symmetry breaking, we only consider the single parameter ordering ( zi ; z j ) where i < j , i.e. we consider cmp( z 1 , z 2 ) but not cmp( z 2 , z 1 ) . Second, test instructions are defined over each function symbol and list of pointers with the same size as its arity, inducing P j Z j ar ( ) actions, and comparison of predicates with pointers induce P ( j Z j 2 ar ( ) j Z j ar ( ) ) actions. Therefore, the total number of RAM instructions are 2 j Z j + 2( j Z j 2 j Z j ) + P ( j Z j ar ( ) + j Z j 2 ar ( ) j Z j ar ( ) ) = 2 j Z j 2 + P j Z j 2 ar ( ) which only depends on the number of pointers in Z and the arity of each function symbol . Last, as defined by our abstraction procedure, the number of actions in A 0 is given by the number of parameters of the actions schemes and the number of pointers in Z to replace these parameters. This means that the size of A 0 is upper bounded by j A 0 j P 2 j Z j j par ( ) j . As a consequence it follows that A 0 Z , whose size is given by j A 0 Z j = 2 j Z j 2 + P j Z j 2 ar ( ) + j A 0 j , it is also independent of the number of objects , state variables in X and their domain size.
## 3.3. S trips with pointers
Since the early 70's, the S trips representation formalism is widely used for research in automated planning [82]. Even today, S trips is an essential fragment of PDDL [76], the input language of the International Planning Competition , and most planners support the S trips representation features. Here we show that our pointer-based view of planning problems and solutions applies also to object-centered planning formalisms, such as S trips planning. In fact, our pointer-based formalism can be understood as an instantiation of FS trips [83], where the single level of indirection of pointers over objects is enough to represent S trips problems with constant memory access.
S trips is an object-centered planning formalism that compactly represents the set of states of a transition system using a finite set of objects , and a finite set of FOL predicates , that indicate the properties of the objects and their relations. Likewise, S trips compactly represents the space of the possible state transitions using FOL operators , which are defined as a tuple op = h name ( op ) ; args ( op ) ; pre ( op ) ; e ( op ) ; e + ( op ) i and where, name ( op ) is a unique identifier of the operator, args ( op ) is a set of variable symbols specifying the arguments of the operator, and pre ( op ), e ( op ) ; e + ( op ) are sets of FOL predicates, with variables exclusively taken from args ( op ), and that respectively specify the preconditions , negative e ects and positive e ects . The representation of a S trips problem is completed specifying an initial state, that defines the initial situation for all the objects, and the aimed set of goal states , which is typically specified as a partial state.
State representation . In our pointer-based formalism for S trips problems, each state variable x 2 X has domain Dx = f 0 ; 1 g , and it is built as a FOL S trips predicate 2 grounded by a vector of objects ! o 2 ar ( ) . Figure 5 shows the representation of a blocksworld state using the S trips formalism as well as using our formalism. In this state there are three blocks, = f b 1 ; b 2 ; b 3 g , that are stacked in a single tower. Predicates clear(?x) , holding(?x) , and ontable(?x) , are encoded as three di erent Boolean functions that map each vector of objects to either 0 or 1 in the current state. Omitted state variables are assumed to be zero valued. Our vector X of state variables is the result of
Figure 5: Example of a three-block state from the blocksworld (left), and its corresponding representation as a vector of bits (right).
| | | State representation | State representation |
|----|--------------|------------------------|------------------------------|
| | Predicate | Strips | Boolean functions |
| 1 | (clear ?x) | (clear b1) | clear(b1) = 1 |
| 2 | (handempty) | (handempty) | handempty() = 1 |
| 3 | (holding ?x) | - | - |
| | (on ?x ?y) | (on b1 b2) (on b2 b3) | on(b1,b2) = 1, on(b2,b3) = 1 |
| | (ontable ?x) | (ontable b3) | ontable(b3) = 1 |
```
:action unstack
:parameters (?x ?y)
:precondition (and (clear ?x) (handmpty? (on ?x ?y)))
:effect (and (holding ?x) (not (clear ?x)) (not (handmpty? (on ?x ?y))))
?:x (handmpty? (on ?x ?y))
t (handmpty?) (not (on ?x ?y)))) </doc>
```
Figure 6: The unstack S trips operator from the blocksworld domain represented in the PDDL language.
unifying all the previous predicate and object tuple valuations into a vector. The length of the vector of state variables is then upper bounded by j X j P k 0 nk j j k , where nk is the number of first-order predicates with arity k . For instance, the X vector contains at most j j 2 + 3 j j + 1 state variables for the blocksworld domain. State-invariants (e.g. in the blocksworld a block cannot be on top of two di erent blocks simultaneously) can also be leveraged to save space for the memory allocation of the state variables.
Action representation . Given a FOL S trips operator op = h name ( op ) ; args ( op ) ; pre ( op ) ; e ( op ) ; e + ( op ) i , our pointer-based formalism produces its corresponding pointer-based action schema h name, params, pre, e i :
- The name of the action schema is name ( op ), the name of the given FOL S trips operator.
- For each argument in args ( op ), the action schema has a pointer that indexes an object o 2 .
- The set pre ( op ) is transformed into a conjunctive arithmetic-logic expression with conditions of two kinds: (i) for each pointer in the parameters of the action schema, the conditions asserting that the pointer is within its domain and (ii), for each precondition in pre ( op ) a condition asserting that the state variable addressed by the pointers content equals to some specific value of its domain.
- Each negative e ect in e ( op ) is transformed into an indirect variable assignment that sets the corresponding state variable to 0. Likewise, each positive e ect in e + ( op ) is transformed into an indirect variable assignment that sets the corresponding state variable to 1.
Figure 7 shows our pointer-based definition for the unstack action schema from the blocksworld that implements the corresponding operator represented in the S trips fragment of PDDL of Figure 6. The action schema of Figure 7 is implemented using two pointers ( i and j ), and it applies to any blocksword instance, no matter the number of blocks or their identity. In this implementation the state variables are global , meaning that they can be accessed from any of the action schemas. Again the execution of these procedures is a deterministic matching-free process since the input pointers do always have a block assigned.
Problem representation . We complete our pointer-based representation of a S trips problem with the init and goal procedures. Figure 8 shows the init and goal procedures for the planning problem of unstacking the 3-block tower of Figure 5. They have the same formal structure as the procedures we use for our pointer-based representation of the preconditions and e ects of an action schema, but with no arguments. In more detail:
- The init procedure is a write-only procedure, that implements a total variable assignment of the state variables for specifying the initial state of the S trips problem.
- The goal procedure is a read-only Boolean procedure, that encodes the state-constraint that specifies the subset of goal states.
```
<doc> Bool schema_unstack_pre (Pointer i, Pointer j) {
Return (i>=0 and j>=0 and i[0] and j[0] and
clear(i)=1 and handempty(j)=1;
}
void schema_unstack_eff (Pointer i, Pointer j) {
clear(i):= 0; hand
holding(i):= 1; clear ;
} </doc>
```
on(i,j)=1); Figure 7: The unstack action schema from blocksworld defined with two pointers ( i and j ). void init() { i := 0; j := 0; yz := 0; yc := 0; clear(b1) := 1; on(b1,b2) := 1; on(b2,b3) := 1; ontable(b3) := 1; } Bool goals() { Return (ontable(b1)=1 and ontable(b2)=1 and ontable(b3)=1); }
Figure 8: The init and goal procedures for representing the S trips planning problem of unstacking the three-block tower of Figure 5.
Plan representation . Following our pointer-based representation, a sequential plan = h a 1 ; : : : ; an i is a sequence of transformations of the state variables using: (i) our pointer-based action schemas that encode the FOL S trips operators and (ii), the subset of RAM actions f inc ( z ), dec ( z ) j z 2 Z g for achieving the aimed binding for each parameter of an action schema. Our pointer-based representation of the four-action plan = h unstack(b1,b2) , putdown(b1) , unstack(b2,b3) , putdown(b2) i for unstacking the three-block tower of Figure 5, is the following sequence of actions 0 = h inc ( j ), unstack ( i ; j ), putdown ( i ), inc ( i ), inc ( j ), unstack ( i ; j ), putdown ( i ) i that leverages two pointers Z = f i ; j g , that are defined over the set of blocks .
In spite of its popularity, the S trips representation is too low-level for many interesting applications [14, 15, 17]. Our pointer-based representation naturally extends beyond S trips to more expressive object-oriented representations. For instance, state variables can also comprise numeric variables (e.g. integers or reals) to implement numeric fluents as in PDDL2.1 [84] or in RDDL [16]. Object typing can also be implemented in a straightforward way (e.g. specializing pointers to the number of objects of a particular type) to compact the size of the vector of state-variables and to optimize the implementation of quantified preconditions / e ects / goals [85]. Last, our pointer-based representation also supports conditional e ects [86], e.g. an action schema can specify multiple variable assignments conditioned by the di erent values of the state variables.
## 4. Generalized planning as heuristic search
First the section shows how we build, in an agnostic manner, a GP problem from a set of classical planning instances of a given domain. Then, the section describes in detail our GP as heuristic search approach: our search space for GP, the evaluation / heuristic functions that we use for guiding the search, and the particular details of our search algorithm.
## 4.1. From a set of classical planning instances to a GP problem
Generalized plans leverage relevant subsets of shared state variables ( features ) and actions whose execution is well-defined for any possible value of the state variables of the classical planning instances to be solved. Building a
GP problem from a set of classical planning instances of a given domain is not trivial because these two ingredients may not be given in the representation of the classical planning instances.
On the one hand given a classical planning domain, the specification of a set of features that is (i), expressive enough to represent a polynomial solution valid for any instance in the domain and (ii), compact enough for the e ective computation of that solution, is a complex task that requires expert knowledge on both the domain and the aimed solution. In fact, the automatic specification of expressive and compact features for a planning domain is a challenging research question that is investigated since the early days of automated planning [87]. On the other hand the set of ground actions for the di erent instances of a given domain, is usually di erent since it depends on the number of objects. Back to the sorting example illustrated in Figures 1 and 2, the classical planning instances for sorting a vector of length six induced 6 5 2 swap ( oi ; oj ), i < j actions, while instances for sorting a vector of length seven would induce a set of 7 6 2 swap ( oi ; oj ) actions.
Given a finite and non-empty set of T classical planning instances from a given domain, our approach for automatically building a GP problem is to extend the instances with a RAM machine of j Z j pointers. The result is a GP problem P = f P 1 ; : : : ; PT g , where each instance Pt 2 P , 1 t T may di er in the actual set of objects, initial state, and goals, but all instances necessarily share the subset of state variables XZ \ Y \ Z and the same set of actions A 0 Z . Formally, P 1 = h X 0 Z 1 ; A 0 Z ; I 0 Z 1 ; G 1 i ; : : : ; PT = h X 0 ZT ; A 0 Z ; I 0 ZT ; GT i where 8 1 t T XZt X 0 Zt , 8 1 t T Y X 0 Zt , 8 1 t T Z X 0 Zt , and 8 a 0 2 A 0 Z par ( a 0 ) 2 Z ar ( a 0 ) . The number of pointers j Z j is a parameter that indicates how many pointers are used in the extension of the classical planning instances 3 .
Our extension with a RAM machine of j Z j pointers automatically defines a minimalist but general set of features for the set of a classical planning instances from a given domain.
Definition 5 (The feature language) . We define the feature language as the four possible joint values of the two Boolean variables Y = f yz ; yc g , and we denote this language as L = f ( : yz ^ : yc ) ; ( yz ^ : yc ) ; ( : yz ^ yc ) ; ( yz ^ yc ) g .
We say L is minimalist because it only contains four elements, and we say L is general because it is independent of the number of objects and hence, of the domain of the state variables and the number of state variables. Note that our features are a function of (i) the state variables and (ii) the last executed action, since they all may a ect the value of Y = f yz ; yc g . Such notion of feature is related to the notion of state observation in the POMDP formalism, where observations depend on the current state and the action just taken [88]. With this regard it can be understood that our GP approach computes, at the same time, a generalized plan and an observation function useful for that generalized plan. Our feature language is also related to Qualitative numeric planning [72, 73, 6] which leverages propositions to abstract the value of numeric state variables. Given that our FLAGS Y = f yz ; yc g depend on the last executed action, and considering that only RAM instructions update the variables in Y , we have an observation space of 2 j Y j (2 j Z j 2 + P j Z j 2 ar ( ) ) state observations implemented with only j Y j Boolean variables. The four joint values of f yz ; yc g model then a large space of observations, e.g. = 0, , 0, < 0 ; > 0 ; 0 ; 0 as well as relations = ; , ; <; >; ; on pairs of state variables.
Likewise, our extension with a RAM machine of j Z j pointers automatically defines the shared set of actions A 0 Z , that is well-defined for the set of a classical planning instances from a given domain. Because the set of pointers Z is fixed for the T input classical planning instances we have that, after our extension, all the instances share the same set of actions A 0 Z . The execution of the actions in A 0 Z is well-defined over the subset of state variables Z , no matter the actual number of objects, or the corresponding number and domain size of the state variables; we recall the reader that the set of actions A 0 Z exclusively depends on the number of pointers j Z j and the arity of actions and functions (Theorem 2).
## 4.2. The search space
Briefly, our GP as heuristic search approach implements a combinatorial search in the solution space of the possible planning programs. Next we provide more details on how we implemented a tractable search space for GP.
Definition 6 (Partially specified planning program) . A partially specified planning program is a planning program such that the content of some of its program lines may be undefined.
3 At least Z must contain as many pointers as the largest arity of the functions and action schemes of the given domain.
Each node of our search space is a partially specified planning program which is binary encoded as follows. Given a set of state variables X , a set of actions A , a maximum number of program lines n such that the last instruction is wn 1 = end , and defining the propositions of goto instructions as ( x = v ) atoms where x 2 X and v 2 Dx , we have that the space of possible planning programs is represented by the following bit-vectors:
1. The action vector of length ( n 1) j A j , indicating whether an action a 2 A is programmed on line 0 i < n 1.
2. The transition vector of length ( n 1) ( n 2), indicating whether a go ( i 0 ; ) instruction is programmed on line 0 i < n 1.
3. The proposition vector of length ( n 1) P x 2 X j Dx j , indicating whether a go ( ; ! h x = v i ) instruction is programmed on line 0 i < n 1.
A partially specified planning program is then encoded as the concatenation of these three bit-vectors and the length of the resulting bit-vector is:
$$( n - 1 ) [ A _ { 1 } + ( n - 2 ) + \sum _ { i = X } ^ { n } D _ { i } ] .$$
The binary encoding allows us to quantify the similarity of two partially specified planning programs (e.g. the Hamming distance of their corresponding bit-vector representation) and more importantly, to systematically enumerate the space of all the possible planning programs with a maximum of n lines. Let us define the empty program as the particular partially specified planning program whose instructions are all undefined (i.e. all bits of its bit-vector representation are set to False ). Starting from the empty program , we can enumerate the entire set of possible planning programs with two search operators:
- program(i,a) , that programs an action a 2 A at line i of a program
- program(i,i',x,v) , that programs a goto ( i 0 ; ! h x = v i ) instructions at line i of a program.
These two search operators are only applicable when i is an undefined program line (i.e. in the bit-vector representation the bits corresponding to the encoding of the program line i are set to False ). Given the bit-vector representation of a partially specified planning program , the application of the program(i,a) or program(i,i',x,v) search operators set to True the corresponding bits. With this regard, the partially specified planning program of a given search node is at Hamming distance 1 from its parent, when programming a planning action with program(i,a) , or at Hamming distance 2 , when programming a goto instruction with program(i,i',x,v) . In fact, this is the search space leveraged by the classical planning compilation approach for computing planning programs with an o -theshelf classical planner [34]. Equation 2 reveals that the number of planning programs with n lines depends on the number of grounded actions j A j , the number of state variables x 2 X , and their domain Dx . This dependence causes an important scalability issue, limiting the applicability of the cited compilation to planning instances of contained size.
Definition 7 (The GP search space) . Given a GP problem P , that is built extending a set f P 1 ; : : : ; PT g of classical planning instances from a given domain with a RAM machine of j Z j pointers. Our GP search space is the set of partially specified planning programs that can be built with n program lines, the set of planning actions A 0 Z , and the set of goto instructions that are exclusively conditioned on a feature in L .
Definition 7 leverages our minimalist feature language L to build a tractable solution space for GP. We represent GP solutions as planning programs where goto instructions can exclusively be conditioned on a feature in L . Limiting the conditions of goto instructions to any of the four features in L greatly reduces the number of planning programs with n lines, specially when state variables have large domains (i.e. integers ); the proposition vector required to encode a planning program becomes now a vector of only ( n 1) 4 bits (one bit for each of the four features in L ). Equation 2 simplifies then to:
$$( n - 1 ) ( A _ { 2 } ^ { n } + ( n - 2 ) + 4 ).$$
Equation 3 shows that the size of our new solution space for GP is independent of the number of objects and hence the number of original state variables and their domain size; Theorem 2 already showed that A 0 Z no longer grows with the number of objects. This novel GP solution space can now scale to planning problems where state variables have large domains (e.g. integers) and that have a large number of state variables.
```
<doc> 0. set(j,tail)
1. swap(i,j)
2. dec(j)
3. inc(i)
4. cmp(j,i)
5. goto(i, ~(~y,&~y))
6. end
0. set(min,i)
1. cmp(vector(i),vector(min))
2. goto(5, ~(~y,&~y))
3. set(min,
4. swap(i,min))
5. inc(j)
6. cmp(length,i)
7. goto(1,
8. inc(i)
9. set(j,i)
10. cmp(length,i)
11. goto(0,
12. end </doc>
```
Figure 9: Two examples of generalized plans: (left) for reversing a list; (right) for sorting a list with the selection-sort algorithm.
```
12. end
```
Last but not least, since the Y = f yz ; yc g FLAGS store the outcome of three-way comparisons, the fourth case ( yz ^ yc ) 2 L can actually never happen as a result of a comparison. This fourth case is however useful for representing unconditional gotos .
Example. Figure 9 shows two examples of planning programs that can be found by our BFGP algorithm, that searches in our solution search-space for GP: (left) a generalized plan for reversing a list, and (right) a generalized plan for sorting a list. Note that in both planning programs goto instructions are exclusively conditioned on a feature in L , and that both planning programs are actually solutions for an infinite set of classical planning problems; they generalize with a swap action schema of arity 2 and a vector predicate symbol of arity 1, no matter the number of objects and no matter the state variables content, i.e. xi vector ( oi ) such that oi 2 , xi 2 X and Dxi N 0. In the planning program for reversing a list (left), line 0 sets the pointer j to the last element of the list. Then, line 1 swaps in the vector the element pointed by i (initially set to zero) and the element pointed by j , pointer j is decremented, pointer i is incremented, and this sequence of instructions is repeated until the condition on line 5 becomes false, i.e when j > i , which means that reversing the list is finished. The planning program for sorting a list (right) is actually an implementation of the selection-sort algorithm. In this program, pointers j and i are used for inner (lines 5-7) and outer (lines 8-11) loops respectively, and min to point to the minimum value in the inner loop (lines 3-4); : yz ^ : yc on line 2 represents whether the content of vector ( j ) is less than the content of vector ( min ), while yz ^ : yc on line 7 represents whether j == length (resp. i == length on line 11).
## 4.2.1. Theoretical properties
Theorem 3. The space of planning programs that exclusively branch over the features in L preserves the solution space of planning programs.
Proof. ) : Given a GP problem P and a planning program , that solves P and whose goto instructions are exclusively conditioned on the features in L . An equivalent planning program whose execution flow branches with the original goto ( i ; !( x = v )) instructions is built by defining a set of four Boolean state variables; one Boolean variable for each feature in L , that are mutually exclusive, and whose value is actually given by the joint value of the Y = f yz ; yc g variables. With these new Boolean state variables defined, we can replace each feature in the condition of a goto instruction by a !( x = 1) condition checking whether its corresponding Boolean variable equals 1.
( : Given a GP problem P and a planning program that solves P . An equivalent planning program, that exclusively branches over any of the features in L , is built replacing each goto ( i ; !( x = v )) instruction in , where x ( ! o ) s.t. 2 and ! o 2 ar ( ) , by a finite block of instructions that: (i) increments / decrements a vector of auxiliary pointers ! zaux , with size ar ( ), until they indirectly address objects ! o , (ii) given auxiliary static state variables for each possible value, i.e. 8 v 2 Dx xv , and a dedicated object for each new state variable ov such that xv ( ov ), increments / decrements another auxiliary pointer zstatic in a function static ( zstatic ) until it reaches object ov such that xv static ( ov ) which equals v , (iii) compares the content of these two state variables with a cmp ( ( ! zaux ) ; static ( zstatic )) instruction and (iv), jumps to the i target line when the state variables di er in their content with a goto ( i ; !( yz ^ : yc )) instruction.
Note however that our GP solution space may still be incomplete in the sense that either the bound n on the maximum number of program lines, or the maximum number of pointers available j Z j , may be too small to accommodate a solution to a given GP problem. In that case, a higher-level combinatorial search can be implemented to incrementally find a suitable number of required program lines and pointers. For instance, like is done in SAT-planning where the planning horizon is iterative incremented until it is large enough to accommodate a solution plan [89].
## 4.3. The evaluation functions
Here we define two di erent families of evaluation functions, that exploit two di erent sources of information, to guide a combinatorial search in our GP solution space of partially specified planning programs:
- The program structure . Given a partially specified planning program , we define a set of evaluation functions f ( ), that establish di erent kinds of preferences / priors on the structure of the aimed generalized plans. For instance, following the Occam's razor principle a structural function can prefer generalized plans of simpler complexity or it can prefer generalized plans with more programmed lines so program execution failures can be detected earlier in the search.
- -f 1 ( ), the number of goto instructions in .
- -f 2 ( ), the number of undefined program lines in .
- -f 3 ( ), the number of repeated actions in ,
- -f 7 ( ), the max number of nested goto instructions in . A goto instruction jumps from an origin program line to a destination program line. We say that a goto instructions is nested when it appears within the origin and destination lines of another goto instruction.
- The empirical performance of the program . Given a partially specified planning program and a GP problem P = f P 1 ; : : : ; PT g , we define a set of evaluation functions f ( ; P ) that assess the performance of on P , executing on each of the classical planning instances Pt 2 P , 1 t T . Section 2 defined the execution of a planning program on a classical planning instance as a deterministic procedure that terminates either succeeding to solve that instance or failing it. Likewise the execution of a partially specified planning program is a deterministic procedure that introduces a new termination case, reaching an unspecified program line . When the program execution terminates because an unspecified program line is reached, f ( ; P ) functions can be used to assess the cost of that program execution, as well as to estimate how far is the program from solving the given GP problem, which define cost and heuristic functions for GP respectively.
- -f 4 ( ; P ) = n maxPt 2P f 4 ( ; Pt ), where f 4 ( ; Pt ) returns the number of the undefined program line eventually reached after executing on the classical planning instance Pt 2 P .
- -f 5 ( ; P ) = P Pt 2P f 5 ( ; Pt ), where
$$f _ { S ( I , P ) } = \sum _ { x \in X } f _ { G ( x ) ^ { 2 } }$$
Here, vx 2 Dx is the value eventually reached, for the state variable x 2 Xt , after executing on the classical planning instance Pt 2 P , and Gt ( x ) is the value for this same variable as specified in the goals of Pt . Note that for Boolean variables the squared di erence becomes a simple di erence. This means that for S trips planning problems, where all the state variables are Boolean, f 5 ( ; Pt ) is actually a counter of how many atomic goals in Gt are still not true.
- -f 6 ( ; P ) = P Pt 2P j exec ( ; Pt ) j , where exec ( ; Pt ) is the sequence of actions induced from executing the planning program on the planning instance Pt .
- -f 8 ( ; P ) = f 5 ( ; P ) + f 6 ( ; P ) is the sum of an estimation to the goal and the total accumulated cost, akin to an evaluation function for A searching algorithm.
- -f 9 ( ; P ) = W f 5 ( ; P ) + f 6 ( ; P ) is similar to f 8 but the estimation to the goal is multiplied by a factor W , which is set to 5 by default, akin to an evaluation function for WA searching algorithm.
All these functions are evaluation functions (i.e. smaller values are preferred). The structural functions f 1 ( ), f 2 ( ), f 3 ( ) and f 7 ( ), are all computed in linear time by traversing the bit-vector representation of . On the other hand, the computation complexity of the three empirical functions f 4 ( ; P ), f 5 ( ; P ), f 6 ( ; P ), f 8 ( ; P ) and f 9 ( ; P ) is given by the complexity of the partially specified program . Performance-based functions accumulate a set of T costs (one for each classical planning instance in the GP problem) that could actually be expressed as a combination of di erent aggregation functions, e.g. sum , max , average, weighted average, etc. Functions f 4 ( ; P ) and f 5 ( ; P ) are the only cost-to-go heuristic functions; they provide an estimate on how far is a partially specified planning program from solving a GP problem. With this regard, f 5 ( ; P ) requires that the goal condition of the classical planning instances in a GP problem is specified as a partial state. On the other hand f 4 ( ; P ) does not post any particular requirement on the structure the goal condition, so they can even be a black-box Boolean procedure over the state variables.
Example . We illustrate how our evaluation functions work on the following partially specified program = 0.swap(i,j) 1.inc(i) 2.dec(j) 3.goto(2,!( yz ^ : yc )) 4... 5.end , where only line 4 is not programmed yet. The value of the evaluation functions for this partially specified program is f 1 ( ) = 1, f 2 ( ) = 5 4 = 1, f 3 ( ) = 0, f 7 ( ) = 1. Given the GP problem P = f P 1 ; P 2 g that comprises the two classical planning instances illustrated in Figure 1, and pointers i and j starting at the first and last object indexes, respectively, we can compute f 4 and f 5 to evaluate how far is from solving the GP problem of sorting lists, the accumulated cost f 6, and evaluation functions f 8 and f 9 that combine heuristic-like functions with accumulated cost. In this case f 4 ( ; P ) = 5 4 = 1, f 5 ( ; P ) = 32, f 6 ( ; P ) = 14 + 14 = 28, f 8 ( ; P ) = 32 + 28 = 60 and f 9 ( ; P ) = 32 + 5 28 = 172.
## 4.4. The search algorithm
Here we describe our heuristic search algorithm for generalized planning. This algorithm implements a Best-First Search (BFS) in our GP solution space of the possible partially specified planning programs with n program lines, and a RAM machine with j Z j pointers. Algorithm 1 shows the pseudo-code of our Best-First Search for Generalized Planning (BFGP).
## Algorithm 1: Best-First Generalized Planning (BFGP)
```
<doc> Algorithm 1: Best-First Generalized Planning (BFGP)
Data: A generalized planning problem P , a number of pointers Z , a number of plan II that solves P
Result: A generalized
Open = {I temp}; while Open # 0 do
| I ← extractBestProgram(Open);
ChildrenPrograms ← expandProgram(II,Z,n);
for II ∈ ChildrenPrograms do
program(II,P);
P), then
| endEnd(II,P) then
insertProgram(Open,II);
end </doc>
```
BFGP is a frontier search algorithm meaning that, to reduce memory requirements, BFGP stores only the open list of generated nodes but not the closed list of expanded nodes [90]. Initially the open list of the BFGP algorithm only contains the search node that corresponds to the empty program of n lines, which is denoted as empty in Algorithm 1. The empty program is then the root node of the search-tree developed by BFGP. The node extraction and node insertion procedures of the BFGP algorithm are implemented as in a regular BFS search. Next we provide more details on the particular expansion and evaluation mechanisms that are implemented by our BFGP algorithm. The BFGP algorithm sequentially expands the best node in the open list , that is implemented as a priority queue, and that is sorted according to the value of our evaluation / heuristic functions explained above.
Let be the partially specified program that corresponds to the best node extracted by BFGP from the open list. BFGP expands that node generating one successor node for each partially specified program that result from
programming the maximum undefined program line that is reached after executing on all the instances in P . In other words given a partially specified program , only its maxPt 2 ( P ) f 4 ( ; Pt ) line is programmable. BFGP implements this particular node expansion procedure because it guarantees that duplicate successors are not generated in the BFGP search-tree. In addition, this node expansion procedure induces a tractable branching factor of ( j A 0 Z j + ( n 2) 4); at a given program line BFGP can only program a planning action in A 0 Z or a goto instruction that can jump to n 2 di erent destination program lines, and that is conditioned by any of the four di erent features in L . The depth of the search tree developed by the BFGP algorithm is the number of program lines n , since only an undefined line can be programmed.
Before a new search node is inserted into the open list, the corresponding partially specified program 0 is executed on all the classical planning instances in P . This execution is implemented by the node evaluation procedure of the BFGP algorithm, and it can result in the three following di erent outcomes:
1. 0 is a solution for P . If the execution of 0 solves all the instances Pt 2 P , then search ends, and 0 will be returned as a valid solution for the GP problem P .
2. 0 fails to solve P . If the execution of 0 on a given instance Pt 2 P fails, this means that the search node corresponding to the partially planning program 0 is a dead-end. The search node will be discarded, so 0 is not inserted into the open list.
3. 0 may still be a solution for P . This means that the execution of 0 on some of the classical planning instances in P reached an undefined program line ( 0 might solve some of the instances in P ). As a consequence 0 is inserted into the open list, at its corresponding position according to the value of our evaluation / heuristic functions explained above.
Example . Let us recover from the previous example the GP problem P = f P 1 ; P 2 g , and the partially specified program = 0.swap(i,j) 1.inc(i) 2.dec(j) 3.goto(2,!( yz ^: yc )) 4... 5.end , where lines [0 ; 3] are programmed and only line 4 is unspecified. Imagine now that BFGP extracts this program from the open list because it has the best evaluation value. In this case, the previous execution of on the classical planning instances P 1 and P 2, implemented by the node evaluation procedure, ended in both instances at the undefined program line 4. This means that the only programmable line is 4 : Assuming that two pointers are available (i.e. Z = f i ; j g ) we can program any of following twelve actions in line 4. f inc ( i ), inc ( j ), dec ( i ), dec ( j ), cmp ( i ; j ), set ( i ; j ), set ( j ; i ), test ( vector ( i )), test ( vector ( j )), cmp ( vector ( i ) ; vector ( j )), swap ( i ; j ), swap ( j ; i ) g . A goto can only be programmed after a RAM action, which is not the case of line 4, since line 3 has another goto instruction. In other words the search node corresponding to the partially specified program from the previous example would have a total of twelve children nodes that could be added to the open list. In the hypothetical case that previous line 3. would contain a RAM action, a goto instruction for jumping to lines [0 ; 3] conditioned by the corresponding four features in L could also be programmed at line 4.
## 4.5. Theoretical properties
Theorem 4 (Termination) . Given a generalized planning problem P , a finite set of pointers Z, and a finite number of program lines n, the execution of the BFGP algorithm always terminates.
Proof. By definition of the expansion procedure of the BFGP algorithm (i), only unspecified lines can be programmed and (ii), any children program always has one more line programmed than its parent. This means that BFGP increases the number of programmed lines, until all lines are programmed. When all lines are programmed BFGP necessarily terminates, either by succeeding to solve P , or by failing to solve some of the classical planning instances in P . The only possible cause for the non-termination of the BFGP algorithm would be that BFGP could generate duplicate search nodes, allowing the infinite re-opening of an already discarded node. Again by definition of the expansion procedure of the BFGP algorithm, the re-opening of an already discarded node is impossible; BFGP only allows programming the maximum undefined program line that is reached after the execution of that program on all the instances in P .
Theorem 5 (Completeness) . Given a GP problem P , a maximum number of pointers j Z j , and maximum number of program lines n, if there is a planning program within these bounds that solves P , then the BFGP algorithm can compute it.
Proof. The BFGP algorithm implements a complete enumeration of the entire space of planning programs with a maximum number of pointers j Z j and maximum number of program lines n except: (i), a search node was identified as a dead-end or (ii), the ancestor of a search node was identified as a dead-end. BFGP is safe because it only discards a search node when its corresponding partially specified planning program failed to solve an input planning instance (which is actually the definition for not being a GP solution). Furthermore, if a partially specified planning program failed to solve an input planning instance, any planning program that can be built programming the remaining undefined program lines will also fail to solve that problem.
Theorem 6 (Soundness) . If the execution of the BFGP algorithm on a GP problem P outputs a generalized plan , this means that is a solution for P .
Proof. The BFGP algorithm runs until: (i) the open list is empty, which means that search space is exhausted without finding a solution and no generalized plan is output or (ii), BFGP extracted from the open list a planning program whose execution, in all the classical planning instances Pt 2 P , resulted successful. This is actually the definition of a solution for a GP problem.
Theorem 7 (Time and Memory) . The time and memory consumption of the BFGP algorithm are characterized by the big-Oh expression O (( j A 0 Z j + ( n 2) 4) n ) .
Proof. The BFGP algorithm is an implementation of a BFS, whose memory and time complexity are characterized as O ( b d ), where b denotes the branching factor and d denotes the depth of the corresponding search tree. The branching factor of the search tree induced by the BFGP algorithm is the number of di erent instructions that can be programmed at an undefined program line, which is b j A 0 Z j + ( n 2) 4; gotos can only be programmed after RAM operations. The depth of the search tree induced by the BFGP is given by the maximum number of program lines n .
With respect to solution quality BFGP does not guarantee that the computed planning programs are optimal. BFGP can however compute optimal planning programs when run in anytime mode . In this case we can use f 6 ( ; P ) to rank GP solutions according to their execution cost in the classical planning instances that are comprised in the given GP problem (e.g. to prefer a sorting program with smaller computational complexity).
## 5. Evaluation
This section evaluates the empirical performance of our GP as heuristic search approach. All experiments are performed in an Ubuntu 20.04 LTS, with AMD fi Ryzen 7 3700x 8-core processor 16 and 32GB of RAM 4 .
## 5.1. Benchmarks
We report results in nine di erent domains; two propositional domains and seven numerical domains. In the propositional domains the functions that induce the state variables are Boolean. In the numerical domains these functions are positive numeric functions. Next we provide more details on the nine domains:
- Gripper , a robot must pick all balls from room A and drop them in room B.
- Visitall , starting from the bottom-left corner of a squared grid, an agent must visit all cells.
- Corridor , an agent moves from an arbitrary initial location to a destination location in a corridor.
- Fibonacci , compute the n th term of the Fibonacci sequence.
- Find , counts the number of occurrences of a specific value in a list.
- Reverse , for reversing the content of a list.
- Select , find the minimum value of a list.
4 The source code, evaluation scripts, and used benchmarks can be found at: https: // github.com / aig-upf / best-first-generalized-planning.
- Sorting , for sorting the values of a vector.
- Triangular Sum , compute the n th triangular number.
Gripper and Visitall are propositional, the remaining seven domains are numeric. For each domain, we build a GP problem that comprises ten randomly generated classical planning instances 5 . In the case of the gripper domain, instances go from 2 to 11 balls in room A to be dropped in room B; in visitall instances are squared grids ranging from 2 2 to 11 11 cells; corridor have instances from length 3 to 12; fibo and triangular sum instances range from the 2 nd to the 11 th number in the sequence; last find , reverse , select and sorting have instances with vectors from size 2 to 11 that are initialized with random content. The result of arithmetical operations in these domains is bounded to 10 2 in the synthesis of GP solutions, and to 10 9 in the validation of GP solutions.
All domains include the base RAM instructions f inc ( z 1 ), dec ( z 1 ), cmp ( z 1 ; z 2 ), set ( z 1 ; z 2 ) j z 1 ; z 2 2 Z g , such that z 1 and z 2 are pointers of the same sort, and the RAM instructions f test ( ( ! z 1 )) ; cmp ( ( ! z 1 ) ; ( ! z 2 )) j ! z 1 ; ! z 2 2 Z ar ( ) g , for each function 2 and where function parameters and pointers must also be of the same sort. We recall that compare instructions are only defined for numeric functions. In addition, each domain contains the regular planning action schemes that do not a ect the FLAGS.
- Propositional domains. The gripper domain includes the following three action schemes; move ( z 1 ; z 2) to denote the robot is moving from the room pointed by z 2 to the one pointed by z 1 , pick ( z 1 ; z 2 ; z 3) to pick the ball pointed by z 1, at room pointed by z 2, and with the gripper pointed by z 3, and drop ( z 1 ; z 2 ; z 3), to drop ball z 1 at room z 2 with gripper z 3 . Visitall only needs one action schema to visit a cell addressed by two pointers, of type row and column respectively, e.g. visit ( z 1 ; z 2 ).
- Numerical domains. The triangular sum and Fibonacci domains include the action schemes vector -inc ( z 1 ) and vector -dec ( z 1), to increase and decrease by one the content of the vector at z 1, and the action scheme vector -add ( z 1 ; z 2) for adding the value at z 2 to the content of the vector at z 1 . Similarly, corridor needs two action schemes, vector -left ( z 1) and vector -right ( z 1), to increase or decrease by one the location of the agent. Select only requires the base RAM instructions. Find includes the accumulate ( z 1) action schema for counting the number of occurrences of the target element. Reverse and Sorting include the swap ( z 1 ; z 2) action scheme to swap the values addressed by z 1 and z 2 .
We model the regular planning actions as they are always executable but that their e ects only update the current state i their preconditions hold in the current state. Otherwise the execution of an action has no e ect.
## 5.2. Synthesis of GP Solutions
Here we present two di erent experiments to evaluate the performance of the BFGP algorithm in the given benchmark. First, we asses every evaluation / heuristic function f i by running BFGP( f i ). Second we search for the best combination of two evaluation / heuristic functions, where one is structured -based and the other performance -based.
## 5.2.1. Performance of BFGP ( f i )
Table 1 details the results of the first synthesis experiment where the BFGP algorithm uses each of our nine di erent evaluation / heuristic functions (the computation bounds are 3 ; 600 seconds of CPU-time and 32 GB of memory and best results are shown in bold). Regarding structure -based functions f 2 dominates in all domains and metrics (except in the find domain where f 3 is faster) and it also has the highest coverage solving 8 out of 9 domains ( f 1 , f 3 and f 7 have lower coverage failing in the same three problems, namely corridor , gripper and sorting ). Regarding performance -based functions, there is not a strictly dominant one since the best scores are shared among f 4 , f 5 and f 9. Function f 4 has the lowest memory consumption but could not solve gripper and sorting ; f 9 is the best for solving corridor , but it is unable to solve gripper within the time bound; and f 5 is the function with the least number of expanded nodes in more than half of domains, in addition to the best coverage solving all problems.
Table 2 summarizes the results from Table 1, grouping results by domains and averaging the metrics by the total number of functions that solved each domain. There are 6 domains which are solved by all the nine evaluation / heuristic
5 For reproducibility reasons we fix the random seed to generate the classical planning instances in the GP problems.
Table 1: We report the number of program lines n , and pointers j Z j per domain, and for each evaluation / heuristic function, CPU (secs), memory peak (MBs), and the numbers of expanded and evaluated nodes. TO stands for Time-Out ( > 1h of CPU). Best results in bold.
| Domain | n ; j Z j | f 1 | f 1 | f 1 | f 1 | f 2 | f 2 | f 2 | f 2 | f 3 | f 3 | f 3 | f 3 |
|-----------|-------------|-------|-------|-------|-------|-------|-------|-------|-------|---------|-------|-------|-------|
| Domain | n ; j Z j | Time | Mem. | Exp. | Eval. | Time | Mem. | Exp. | Eval. | Time | Mem. | Exp. | Eval. |
| Corridor | 8, 2 | TO | - | - | - | 1,367 | 4 | 4.2M | 4.2M | TO | - | - | - |
| Fibonacci | 7, 2 | 779 | 715 | 2.9M | 5.1M | 115 | 4 | 0.5M | 0.5M | 1,960 | 1,118 | 8.0M | 10.0M |
| Find | 6, 3 | 32 | 18 | 0.2M | 0.2M | 31 | 4 | 0.2M | 0.2M | 23 | 23 | 0.1M | 0.1M |
| Gripper | 8, 4 | TO | - | - | - | 2,968 | 4 | 13.1M | 13.1M | TO | - | - | - |
| Reverse | 7, 2 | 317 | 192 | 1.4M | 2.1M | 10 | 4 | 47.9K | 48.0K | 224 | 235 | 0.3M | 1.5M |
| Select | 7, 2 | 192 | 96 | 0.8M | 1.1M | 15 | 4 | 82.8K | 82.8K | 98 | 97 | 0.2M | 0.6M |
| Sorting | 11, 2 | TO | - | - | - | TO | - | - | - | TO | - | - | - |
| T. Sum | 6, 2 | 40 | 58 | 0.2M | 0.4M | 2 | 4 | 14.7K | 14.7K | 38 | 75 | 61.2K | 0.4M |
| Visitall | 8, 2 | 1,631 | 219 | 2.0M | 2.8M | 38 | 4 | 66.1K | 66.2K | 408 | 112 | 0.2M | 0.7M |
| Average | Average | 498.5 | 216.3 | 1.2M | 1.9M | 568.3 | 4.0 | 2.3M | 2.3M | 458.5 | 276.7 | 1.5M | 2.2M |
| | | f 4 | f 4 | f 4 | f 4 | f 5 | f 5 | f 5 | f 5 | f 6 | f 6 | f 6 | f 6 |
| Corridor | 8, 2 | 1,521 | 5 | 4.2M | 4.2M | 970 | 80 | 1.9M | 2.1M | TO | - | - | - |
| Fibonacci | 7, 2 | 147 | 4 | 0.5M | 0.5M | 206 | 203 | 0.2M | 1.2M | 2,798 | 1,779 | 11.0M | 11.0M |
| Find | 6, 3 | 39 | 4 | 0.2M | 0.2M | 34 | 23 | 82.9K | 0.2M | 41 | 31 | 0.2M | 0.2M |
| Gripper | 8, 4 | TO | - | - | - | 10 | 18 | 9.9K | 72.9K | TO | - | - | - |
| Reverse | 7, 2 | 13 | 4 | 48.3K | 48.4K | 690 | 356 | 2.5M | 2.5M | 651 | 380 | 2.5M | 2.5M |
| Select | 7, 2 | 21 | 4 | 85.5K | 86.5K | 17 | 12 | 43.1K | 68.3K | 228 | 171 | 1.0M | 1.1M |
| Sorting | 11, 2 | TO | - | - | - | 2,693 | 110 | 1.5M | 1.5M | TO | - | - | - |
| T. Sum | 6, 2 | 3 | 4 | 14.7K | 14.7K | 15 | 7 | 72.6K | 78.1K | 84 | 99 | 0.6M | 0.6M |
| Visitall | 8, 2 | 53 | 5 | 67.5K | 68.1K | 3 | 5 | 683 | 2.0K | 2,474 | 365 | 2.8M | 2.8M |
| Average | Average | 61.1 | 4.3 | 0.7M | 0.7M | 515.3 | 90.4 | 0.7M | 0.9M | 1,046.0 | 470.8 | 3.0M | 3.0M |
| | | f 7 | f 7 | f 7 | f 7 | f 8 | f 8 | f 8 | f 8 | f 9 | f 9 | f 9 | f 9 |
| Corridor | 8, 2 | TO | - | - | - | 1,317 | 368 | 2.1M | 2.8M | 857 | 94 | 1.8M | 2.0M |
| Fibonacci | 7, 2 | 789 | 716 | 2.9M | 5.1M | 251 | 264 | 0.2M | 1.5M | 157 | 195 | 0.1M | 1.1M |
| Find | 6, 3 | 32 | 18 | 0.2M | 0.2M | 39 | 22 | 0.2M | 0.2M | 34 | 21 | 0.2M | 0.2M |
| Gripper | 8, 4 | TO | - | - | - | TO | - | - | - | TO | - | - | - |
| Reverse | 7, 2 | 336 | 197 | 1.5M | 2.1M | 662 | 339 | 2.5M | 2.5M | 677 | 339 | 2.5M | 2.5M |
| Select | 7, 2 | 200 | 99 | 0.8M | 1.1M | 225 | 123 | 1.0M | 1.1M | 17 | 12 | 57.2K | 68.4K |
| Sorting | 11, 2 | TO | - | - | - | 2,711 | 95 | 1.5M | 1.5M | 2,820 | 95 | 1.5M | 1.5M |
| T. Sum | 6, 2 | 39 | 58 | 0.2M | 0.4M | 15 | 8 | 72.6K | 78.1K | 15 | 8 | 72.6K | 78.1K |
| Visitall | 8, 2 | 846 | 196 | 1.2M | 1.7M | 2,714 | 344 | 2.8M | 2.8M | 60 | 10 | 41.2K | 67.3K |
| Average | Average | 373.7 | 214.0 | 1.1M | 1.8M | 991.8 | 195.4 | 1.3M | 1.6M | 579.6 | 96.8 | 0.8M | 0.9M |
Table 2: We report for each domain, the time (secs), memory peak (MBs), and expanded and evaluated nodes averaged by the number of functions that solved the domain in Table 1.
| Domain | Time | Mem. | Exp. | Eval. | # f i Solved |
|-----------|---------|--------|--------|---------|----------------|
| Corridor | 1,206.4 | 110.2 | 2.8M | 3.1M | 5 |
| Fibonacci | 800.2 | 555.3 | 2.9M | 4.0M | 9 |
| Find | 33.9 | 18.2 | 0.2M | 0.2M | 9 |
| Gripper | 1,489.0 | 11 | 6.6M | 6.6M | 2 |
| Reverse | 397.8 | 227.3 | 1.5M | 1.8M | 9 |
| Select | 112.6 | 68.7 | 0.5M | 0.6M | 9 |
| Sorting | 2,741.3 | 100 | 1.5M | 1.5M | 3 |
| T. Sum | 27.9 | 35.7 | 0.1M | 0.2M | 9 |
| Visitall | 914.1 | 140 | 1.1M | 1.2M | 9 |
functions. In the rest of domains, there are at least 4 or more functions that do not solve them, such as gripper which is the least solved domain (only f 2 and f 5 solve it), and sorting which is solved by f 5 , f 8 and f 9 but it is the hardest in terms of time average.
## 5.2.2. The synthesized solutions
Figure 10 shows the programs computed by BFGP ( f 5 ). In Corridor there are two pointers, i pointing to the agent location and j pointing to the target location; the solution moves the agent right until it surpasses the target location, then it moves the agent left until it reaches the target location. In Fibonacci , pointers a and b are used to compute the n -th Fibonacci number, where a addresses the Fa number to which Fa 1 and Fa 2 are added using b as an auxiliary pointer; and finishes when a reaches the n -th element (the last one). In Find , there is a pointer i to iterate over a vector, a pointer t which targets a value in the vector, and a counter pointer a whose address content is only increased by one every time an occurrence of the target t is found in the vector (Lines 1-2). The process repeats until i reaches the end of the vector.
The Gripper solution uses one pointer for balls ( b 1), two for rooms ( r 1 and r 2) and one for grippers g 1; for each ball b 1, the agent will pick it up from room r 1 (always room A) using gripper g 1 (always left gripper), sets r 2 to room B, moves from A to B, drop ball b 1 at room B, goes back to room A, and continues with the next ball. The Reverse domain uses two pointers i and j and finds a solution with O ( n 2 ) complexity of a vector of size n ; it moves all values from j to n 1 indexes one location to right and places the last element in the j -th location, using i as an auxiliary pointer; then increases j by one until it reaches the end of the vector. The Select domain has two pointers a and b ; it iterates over the vector with pointer a , and assigns a to b every time the value pointed by a is smaller than the one pointed by b .
The Sorting solution is succinct but complex to interpret; j always points to the first location, so all swaps are done with this location; then, two cases may happen when reaching Line 3: either the first element was wrongly sorted in the previous swap and detected because the i -th value is larger than the first, so all values from the i -th to the n -th location are shifted one place to their right, the first element is placed in the i -th location (now is correctly order with respect to i + 1 value) and the last is placed first (defined in Lines 0-6), and continues again in Line 3; or the largest value of the vector is in the first location and the rest are sorted in increasing order, so the problem can be solved by shifting all values once to their left applying instructions at Lines 3, 4, 7, 8, and 9 in sequence. In Triangular Sum , b points to the i th number in the sequence and a to value n , then a is added to b , a is decreased by one, and the whole process repeats until the value a is pointing is 0. The last domain, Visitall , has two pointers i and j that are used for rows and columns, respectively; since the agent always starts in the bottom-left corner, it visits all i -th cells for a given j ; then it moves back to the first row, increases the columns ( j ) by one, and repeats the procedure until all columns have been explored.
## 5.2.3. Validation of the synthesized solutions
Here we validate the BFGP( f 5) solutions of Figure 10 with a larger and harder set of instances. Table 3 reports the CPU time, and peak memory, yield when running the solutions synthesized by BFGP ( f 5) on a validation set.
Figure 10: Solutions computed by BFGP( f 5).
| CORRIDOR | FIBONACCI | FIND |
|--------------------------------|-------------------------------|---------------------------------|
| 0. vector -right(i) | 0. vector -add(a,b) | 0. cmp(vector(i),vector(t)) |
| 1. inc(j) | 1. dec(b) | 1. goto(3, : ( y z ^ : y c ) ) |
| 2. cmp(vector(i),vector(j)) | 2. vector -add(a,b) | 2. accumulate(a) |
| 3. goto(0, : ( : y z ^ y c )) | 3. set(b,a) | 3. inc(i) |
| 4. vector -left(i) | 4. inc(a) | 4. goto(0, : ( y z ^ : y c ) ) |
| 5. cmp(vector(i),vector(j)) | 5. goto(0, : ( y z ^ : y c )) | 5. end |
| 6. goto(1, : ( y z ^ : y c )) | 6. end | |
| 7. end | | |
| GRIPPER | REVERSE | SELECT |
| 0. pick(b1,r1,g1) | 0. set(i,j) | 0. inc(b) |
| 1. inc(r2) | 1. swap(i,j) | 1. cmp(vector(a),vector(b)) |
| 2. move(r1,r2) | 2. inc(i) | 2. goto(4, : ( : y z ^ : y c )) |
| 3. drop(b1,r2,g1) | 3. goto(1, : ( y z ^ : y c )) | 3. set(b,a) |
| 4. move(r2,r1) | 4. inc(j) | 4. inc(a) |
| 5. inc(b1) | 5. goto(0, : ( y z ^ : y c )) | 5. goto(1, : ( y z ^ : y c )) |
| 6. goto(0, : ( y z ^ : y c ) ) | 6. end | 6. end |
| 7. end | | |
| SORTING | TRIANGULAR SUM | VISITALL |
| 0. swap(i,j) | 0. inc(a) | 0. visit(i,j) |
| 1. inc(i) | 1. vector -add(b,a) | 1. inc(i) |
| 2. goto(0, : ( y z ^ : y c )) | 2. vector -dec(a) | 2. goto(0, : ( y z ^ : y c )) |
| 3. cmp(vector(i),vector(j)) | 3. test(vector(a)) | 3. dec(i) |
| 4. goto(7, : ( : y z ^ y c )) | 4. goto(0, : ( y z ^ : y c )) | 4. goto(3, : ( y z ^ : y c )) |
| 5. dec(i) | 5. end | 5. inc(j) |
| 6. goto(0, : ( y z ^ y c )) | | 6. goto(0, : ( y z ^ : y c )) |
| 7. swap(i,j) | | 7. end |
| 8. dec(i) | | |
| 9. goto(3, : ( y z ^ : y c )) | | |
| 10. end | | |
All the solutions synthesized by BFGP ( f 5) were successfully validated, besides Reverse with infinite detection mode that ran out of memory. The largest CPU-times and memory peaks correspond to the configuration that implements the detection of infinite programs , which requires saving states to detect whether they are revisited during execution. Skipping this mechanism allows to validate terminating programs much faster [42].
In the validation set, each state variable from the planning domain is bounded by 10 9 , instead of 10 2 which was the synthesis bound. Corridor and Gripper are validated over 1 ; 000 instances, where for each n 2 [12 ; 1 ; 011], the first has random initial and goal locations below n , and the second n balls initially in room A. Fibonacci has a validation set of 33 instances, ranging from the 11 th Fibonacci term to the 43 rd , i.e. the integer 701 ; 408 ; 733 (the 44 th number would overflow the validation bound). The solutions for Reverse , Select , and Find domains, are validated on 102 instances each, with vector sizes ranging from 1 ; 000 to 11 ; 100, and random integer elements bounded by 10 9 . Similarly, Sorting has 100 validation instances with vectors of random integers, but their sizes range from 12 to 111. The solution for Triangular Sum is validated over 44 ; 709 instances, the last one corresponding to the 44 ; 720 th term in the sequence, i.e. the integer 999 ; 961 ; 560 (as in Fibonacci , the next number would overflow). In Visitall , there are 50 validation instances with squared grids range from 12 12 to 61 61.
## 5.2.4. Performance of BFGP with function combinations
Interestingly, the base performance of BFGP with a single evaluation / heuristic function is improved combining both structural and cost-to-go information; we can guide the search of BFGP with a cost-to-go heuristic function and break ties with a structural evaluation function, and vice versa. Thus, we run all configurations of BFGP( f i ; f j ) and BFGP( f j ; f i ) such that f i 2 f f 1 ; f 2 ; f 3 ; f 7 g and f j 2 f f 4 ; f 5 ; f 6 ; f 8 ; f 9 g , and select the configuration that solves all domains and with the best average time. There are 40 BFGP( f i ; f j ) / BFGP( f j ; f i ) configurations, but only BFGP( f 5 ; f 3 ) and BFGP( f 5 ; f 7) are able to solve all domains. The performance of these two configurations is then compared against BFGP( f 5), since it is the only single evaluation / heuristic function that solve all domains in the previous experiment. Table 4 summarizes that comparison, showing that BFGP( f 5) is improved in every domain either by BFGP( f 5 ; f 3) or BFGP( f 5 ; f 7 ). Furthermore, BFGP( f 5 ; f 7) has the best average performance in all four metrics, empirically proving
Table 3: Validation set, CPU-time (secs) and memory peak for program validation, with / out infinite program detection. ME stands for memory exceeded. Best results in bold.
| Domain | Instances | Time 1 | Mem 1 | Time | Mem |
|----------------|-------------|----------|---------|----------|-------|
| Corridor | 1,000 | 0.54 | 6.5MB | 0.43 | 6.3MB |
| Fibonacci | 33 | 0.01 | 4.8MB | 0.01 | 4.7MB |
| Find | 102 | 1,542.85 | 2.2GB | 1.77 | 0.3GB |
| Gripper | 1,000 | 93.5 | 0.5GB | 4.77 | 0.5GB |
| Reverse | 102 | ME | ME | 3,553.16 | 0.5GB |
| Select | 102 | 1,407.54 | 2.5GB | 1.87 | 0.3GB |
| Sorting | 100 | 230.98 | 0.5GB | 17.19 | 8.8MB |
| Triangular Sum | 44,709 | 3,244.84 | 0.1GB | 2,357.56 | 0.1GB |
| Visitall | 50 | 42.21 | 0.2GB | 0.33 | 48MB |
Table 4: For each domain we report, CPU time (secs), memory peak (MBs), num. of expanded and evaluated nodes of BFGP( f 5 ; f 3), BFGP( f 5 ; f 7) and BFGP( f 5). TO means time-out ( > 1h of CPU). Best results in bold.
| Domain | BFGP( f 5 ; f 3 ) | BFGP( f 5 ; f 3 ) | BFGP( f 5 ; f 3 ) | BFGP( f 5 ; f 3 ) | BFGP( f 5 ; f 7 ) | BFGP( f 5 ; f 7 ) | BFGP( f 5 ; f 7 ) | BFGP( f 5 ; f 7 ) | BFGP( f 5 ) | BFGP( f 5 ) | BFGP( f 5 ) | BFGP( f 5 ) |
|-----------|---------------------|---------------------|---------------------|---------------------|---------------------|---------------------|---------------------|---------------------|---------------|---------------|---------------|---------------|
| Domain | Time | Mem. | Exp. | Eval. | Time | Mem. | Exp. | Eval. | Time | Mem. | Exp. | Eval. |
| Corridor | 675 | 55 | 1.8M | 2.0M | 658 | 64 | 1.7M | 1.9M | 970 | 80 | 1.9M | 2.1M |
| Fibonacci | 990 | 553 | 2.7M | 4.3M | 55 | 68 | 43.4K | 0.4M | 206 | 203 | 0.2M | 1.2M |
| Find | 29 | 16 | 68.5K | 0.1M | 38 | 14 | 0.2M | 0.2M | 34 | 23 | 82.9K | 0.2M |
| Gripper | 9 | 17 | 9.7K | 67.4K | 7 | 13 | 8.7K | 50.1K | 10 | 18 | 9.9K | 72.9K |
| Reverse | 702 | 217 | 2.5M | 2.5M | 676 | 184 | 2.5M | 2.5M | 690 | 356 | 2.5M | 2.5M |
| Select | 14 | 10 | 32.0K | 54.0K | 17 | 9 | 47.6K | 68.3K | 17 | 12 | 43.1K | 68.3K |
| Sorting | 2,484 | 39 | 1.3M | 1.4M | 2,710 | 82 | 1.5M | 1.5M | 2,693 | 110 | 1.5M | 1.5M |
| T. Sum | 15 | 7 | 72.6K | 78.0K | 15 | 6 | 72.6K | 78.1K | 15 | 7 | 72.6K | 78.1K |
| Visitall | 2 | 5 | 275 | 605 | 3 | 5 | 582 | 1.7K | 3 | 5 | 683 | 2.0K |
| Average | 546.7 | 101.9 | 0.9M | 1.2M | 464.3 | 49.4 | 0.7M | 0.8M | 579.6 | 96.8 | 0.8M | 0.9M |
that combining goal-oriented functions with structural -based functions that measure the syntactic complexity of a program, in that specific order, is the best configuration.
We also compared the performance of BFGP ( f 5 ; f 7), in terms of CPU-time, with the compilation-based approach for GP [91, 34]. The compilation-based approach, that we named PP, computes planning programs, following a topdown strategy, with the planner LAMA-2011 (first solution setting) to solve the classical planning problems that result from the compilation. Table 5 summarizes the results of this comparison. There are 3 domains where PP is faster than BFGP( f 5 ; f 7), but in these domains the GP problems addressed by PP are easier: i) Gripper in PP has the same action move for both directions and picks are only available for the next ball, while in BFGP actions are parameterized with pointers, so it first needs to find that pointers r 1 and r 2 point to rooms A and B respectively, pick balls only from room r 1, move from r 1 to r 2 to drop the ball, and move backwards from r 2 to r 1 ; ii) Reverse in PP has one of the pointers in the last position of vector from the initial state, reproducing this setting in BFGP a program of 6 lines is found in less than 1 second after expanding 260 nodes and evaluating 2,560 nodes, however, it is more interesting to us a solution that synthesizes where to place and how to use each pointer, even though it is a harder problem; and iii) Triangular Sum in PP just accumulates one variable to another one, while in BFGP the pointers should point to the right variables, then use them. In the rest of domains, BFGP dominates PP, even though programs are larger, BFGP must reason on how to use the pointers, and BFGP uses more instances with larger values, being able to solve domains where PP dies because of the grounding among other reasons.
## 5.3. Validation of GP solutions for more complex domains
Here we present several GP benchmarks, with known polynomial time solutions, but that result too complex for our current BFGP algorithm (within the given time and memory bounds). Our aim is showing that our approach is expressive enough to represent solutions to GP problems coming from IPC planning domains, noise-free supervised classification tasks, and numerical domains. These solutions are succinctly represented as planning programs, instead
Table 5: Computing CPU-time (secs) for solving domains in the GP compilation approach (PP) and BFGP ( f 5 ; f 7).
| Domain | PP in sec. | BFGP( f 5 ; f 7 ) in sec. |
|----------------|--------------|-----------------------------|
| Corridor | - | 658 |
| Fibonacci | 3,570 | 55 |
| Find | 274.86 | 38 |
| Gripper | 1 | 7 |
| Reverse | 87.86 | 676 |
| Select | 204.20 | 17 |
| Sorting | - | 2,710 |
| Triangular Sum | 0.85 | 15 |
| Visitall | - | 3 |
of long sequences of grounded actions for large problems, and validated e ciently without being a ected by the grounding methods of planners.
- Blocks Ontable , towers of blocks where all blocks must be placed on the table.
- Grid , an agent has to move from an arbitrary location to a destination one in a 2D grid.
- Miconic , is an elevator problem where passengers at origin, wait for the elevator to enter, and then served at their destination floor.
- Michalski Trains , is a classic of relational supervised machine learning. A binary noise-free classification task with 10 trains that either go east or west, and multiple features such as the number of wheels, wagons, or their shape for each train among others. The goal is to learn the features that classify all trains in the right direction.
- Satellite , consists of taking images of di erent targets with instruments that are boarded in satellites. In addition, instruments need to be calibrated and in specific modes for taking each image; and each satellite has only power for one instrument at a time, so it needs to switch the current instrument o , switch on the next and calibrate it, before using a new instrument for taking images.
- Sieve of Erathostenes , is a method to find prime numbers up to a certain bound using only additive and iterative mechanisms.
- Spanner , consists of tighten all loose nuts at the end of a corridor, with the picked spanners along the corridor. Spanners can only be used once, and when the agent moves to the next room it can not go back, so if there are unpicked spanners in visited rooms the task could become unsolvable.
Figure 11 shows the hand-coded solutions for these benchmarks. In Blocks Ontable , given n blocks the complexity of the solution is cubic, i.e. O ( n 3 ), where it searches n times, every o 1 block that is on top of an o 2 block, then unstack and put o 1 down on the table. In Grid , the agent moves to the bottom left corner, then each coordinate is increased by one while they are smaller than their goal, visiting the resulting coordinate. In Spanner , an agent picks up all available spanners in location l 1, walks to the next l 2 location and repeats the process until it reaches the last location (the gate), collecting all spanners on its path; once in the gate, it tightens each loose nut with a spanner. The solution to Michalski Trains is summarized as, each train t 1 will go east if it has a car which is closed and short, otherwise it will go west. In Sieve of Eratosthenes all numbers are initially classified as primes, and it should decide whether they are not; so it iterates over i and uses j and k as auxiliary pointers, where the first acts as a counter that ranges from 0 to i , and second adds up to the next multiple of i , i.e. k % i = 0; then every k -th number will be set to no prime, i is increased by one and the process repeats until i reaches the last element. In Miconic , the elevator always starts in the first floor f 1, so for every floor it boards and departs passenger p 1 whether possible; once it reaches the last floor, all passengers are either served or in the elevator, so it will serve all possible passenger in each floor while it goes down, until the first floor is reached again. The last domain, Satellite , is the most complex because it requires iteration over multiple variable types, i.e. satellites, instruments, modes and directions. The solution to this domain consists of switching o all instruments and turning all satellites to the first direction; then for each satellite, the i 1 instrument is switched on,
calibrated with its calibration target direction d 2, and used to take images of every direction d 2 in every mode m 1; once it finishes, the satellite turns to the first direction d 1 again, switches o the current instrument, and continues with the next one, until all satellites have used all their instruments.
We get one main take away lesson from the analysis of Figure 11 solutions; solutions have common high-level structures, that either iterate over all combinations of variable types (i.e. Blocks , Miconic , Satellite , . . . ) or build a complex logic query (i.e. Michalski Trains ). This suggests that planning programs may be synthesized more e ciently using predefined structures (such as FOR or IF-THEN-ELSE constructs) although this is out of the scope of this paper.
Figure 11: Solutions to complex domains.
| BLOCKS ONTABLE 0. dec(o2) 0. | GRID dec(i) | SPANNER |
|-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| 1. goto(0, : ( y z ^ : y c )) 2. dec(o1) 3. goto(2, : ( y z ^ : y c )) 4. unstack(o1,o2) 11. goto(0, : ( y z ^ : y c )) 12. end MICHALSKI TRAINS 0. 1. goto(7, : ( : y z ^ y c )) | 1. goto(0, : ( y z ^ : y c )) 2. dec(j) 3. goto(0, : ( y z ^ : y c )) 4. test(goal-xpos(i)) 5. goto(8, : ( y z ^ : y c )) 6. inc(i) 7. goto(4, : ( y z ^ : y c )) 8. test(goal-ypos(j)) 9. goto(12, : ( y z ^ : y c )) 10. inc(j) 11. goto(8, : ( y z ^ : y c )) 12. visit(i,j) 13. end SIEVE OF ERATHOSTENES 0. inc(i) | 0. walk(l1,l2,m1) 1. set(l1,l2) 2. pickup_spanner(l1,s1,m1) 3. inc(s1) 4. goto(2, : ( y z ^ : y c )) 5. dec(s1) 6. goto(5, : ( y z ^ : y c )) 7. inc(l2) 8. goto(0, : ( y z ^ : y c )) 9. tighten_nut(l1,s1,m1,n1) 10. inc(s1) |
| test(hascar(t1,c1)) 2. test(closed(c1)) 3. goto(7, : ( : y z ^ y c )) 4. test(short(c1)) 5. goto(7, : ( : y z ^ y c )) 6. set-eastbound(t1) 7. inc(c1) 8. goto(0, : ( y z ^ : y c )) 9. set-westbound(t1) 10. dec(c1) | 1. inc(i) 2. set(k,i) | 0. board(p1,f1) 1. depart(p1,f1) 2. inc(p1) 3. goto(0, : ( y z ^ : y c )) |
| SATELLITE | 13. | inc(d2) |
| 0. switch_off(i1,s1) 1. inc(i1) | switch_on(i1,s1) 14. test(cal_target(i1,d2)) 15. goto(19, : ( : y ^ y )) | 27. 28. turn_to(s1,d2,d1) 29. inc(d1) |
| | | 13. inc(p1) 14. goto(12, : ( y z ^ : y c )) 15. dec(p1) 16. goto(15, : ( y z ^ : y c )) |
| 5. put-down(o1) 6. inc(o1) | | |
| 7. goto(4, : ( y z ^ : y c )) | | |
| 8. inc(o2) | | |
| 9. goto(2, : ( y z ^ : y c )) 10. inc(o3) | | |
| | | 11. inc(n1) |
| | | )) |
| | | 12. goto(9, : ( y z ^ : y c |
| | | 13. end |
| | | MICONIC |
| | 3. dec(j) | |
| | 4. goto(3, : ( y z ^ : | 4. dec(p1) |
| | y c )) 5. inc(k) | 5. goto(4, : ( y z ^ : y c )) |
| | 6. goto(13, : ( : y z ^ y c )) | 6. inc(f2) |
| | 7. inc(j) 8. cmp(i,j) | 7. up(f1,f2) 8. inc(f1) |
| | 9. goto(5, : ( y z ^ : | 9. goto(0, : ( y z ^ )) |
| | y c )) | : y c |
| 11. goto(10, : ( y z ^ : y c | 10. set-no-prime(k) | 10. dec(f2) |
| )) | 11. cmp(i,j) 12. goto(3, : ( : y z ^ y c | 11. down(f1,f2) 12. depart(p1,f2) |
| 12. inc(t1) 13. goto(0, : ( y z ^ : y c )) | )) 13. inc(i) : ^ : )) | |
| | 14. goto(2, ( y z y c | |
| | 15. end | |
| 14. end | | |
| | | 17. dec(f1) )) |
| | | 18. goto(10, : ( y z ^ : y c 19. end |
| 2. goto(0, : ( y z ^ : y c )) 3. dec(i1) | z c 16. turn_to(s1,d2,d1) 17. | 30. goto(22, : ( y z ^ : y c )) 31. dec(d1) |
| 4. goto(3, : ( y z ^ : y c )) | calibrate(s1,i1,d2) | : ^ |
| 5. turn_to(s1,d1,d2) | 18. turn_to(s1,d1,d2) | 32. goto(31, ( y z : y |
| 6. inc(d2) | 19. inc(d2) )) | c )) 33. turn_to(s1,d1,d2) |
| 7. goto(5, : ( y z ^ : y c )) | 20. goto(14, : ( y z ^ : y c | 34. set(d2,d1) |
| 8. set(d2,d1) | 21. set(d2,d1) 22. take_image(s1,d2,i1,m1) | 35. switch_off(i1,s1) 36. inc(i1) |
| 9. inc(s1) | | |
| 10. goto(0, : ( y z ^ : y c | 23. inc(m1) | 37. goto(13, : ( y z ^ : y c |
| )) 11. dec(s1) | 24. goto(22, : ( y z ^ : y c )) | )) 38. dec(i1) |
| | | 39. goto(38, : ( y z ^ : y c )) |
| 12. goto(11, : ( y z ^ : y c )) | 25. dec(m1) | 40. inc(s1) |
| | 26. goto(25, : ( y z ^ : y c | |
| | | : y ^ : y |
| | | goto(13, ( z c |
| | | )) |
| | | 41. |
| | )) | )) |
Table 6 shows the validation results in complex domains, where validation without infinite detection scales much better again, and all domains are successfully validated (besides Satellite with infinite detection mode that runs out of memory). Blocks Ontable can be solved with 13 lines and 3 pointers, and the validation set consists of 20 instances that range from 12 to 31 blocks. Grid requires 14 lines of code and 2 pointers, and it is validated with 248 instances with grids between 5 5 and 66 66 size. Miconic needs 20 lines and 3 pointers, and 20 instances that validates from 12 floors and 18 passengers to 31 floors and 46 passengers. Michalski Trains uses 15 lines and 6 pointers to classify all the trains in the unique classical task with 10 trains and their features. Satellite is by di erence the most complex in terms of required lines and pointers, which are 43 and 5, respectively. Its validation set consist of 20 instances, starting with 12 satellites, 24 instruments and modes, and 48 directions, and finishing with 31 satellites, 62 instruments and modes and 124 directions. Sieve of Erathostenes requires 16 lines and 3 pointers to classify either as prime or non-prime, all the numbers comprised in the first 111 natural numbers. Spanner , uses 14 lines and 5 pointers to solve all 20 instances of the validation set, that range from 18 spanners and nuts and a corridor with 14 locations, to 46 spanners and nuts and a corridor with 33 locations.
Table 6: Validation of complex domains, CPU-time (secs) and memory peak for program validation, with / out infinite program detection. ME stands for memory exceeded. Best results in bold.
| Domain | n ; j Z j | Instances | Time 1 | Mem 1 | Time | Mem |
|-----------------------|-------------|-------------|----------|---------|--------|-------|
| Blocks Ontable | 13, 3 | 20 | 4.68 | 42MB | 0.46 | 5MB |
| Grid | 14, 2 | 248 | 4.49 | 0.2GB | 1.01 | 0.2GB |
| Miconic | 20, 3 | 20 | 4.00 | 45MB | 0.08 | 6.1MB |
| Michalski Trains | 15, 6 | 1 | 0.04 | 6.9MB | 0 | 4.7MB |
| Satellite | 43, 5 | 20 | ME | ME | 177.67 | 24MB |
| Sieve of Erathostenes | 16, 3 | 100 | 5.26 | 16MB | 0.55 | 8.8MB |
| Spanner | 14, 5 | 20 | 0.91 | 13MB | 0.04 | 5.7MB |
## 6. Conclusions
We believe this work is a step-forward towards building a stronger connection between the areas of automated planning and programming. The work presented a formalization of classical planning as a vector transformation task, which is a common programming task. According to this formalism, computing a sequential plan for this tasks is computing a composition of vector transformation operations. Likewise computing a generalized plan is computing an algorithmic expression of the vector transformations. With the aim of building more bridges between automated planning and programming, we are exploring the extension of our approach to GP problems that include real state variables. We believe that we can address this kind of GP problems by introducing the notion of precision for the comparison of real variables, and redefining accordingly our mechanism for the update of the FLAG s registers.
Another interesting research direction is the extension of our GP as heuristic search approach for computing generalized plans starting from di erent input settings. For instance, the computation of generalized plans from a set of plan traces that demonstrates how to solve several planning problems. We are also interested on exploring the application of our GPasheuristic search approach to planning problems that are not goal-oriented, where the objective is to maximize a given utility function [92]. In this particular setting, ideas from approximated policy iteration [93], and reinforcement learning [68], could be incorporated to our framework. On the other hand, the BFGP algorithm starts from the empty program, but nothing prevents us from starting search from a partially specified generalized plan [94] with the aim of developing online approaches to GP. In fact, local search approaches have already shown successful for planning [95] and program synthesis [96, 57].
Our cost-to-go heuristics are still less informed than the current heuristics for classical planning, in the sense that our heuristics only consider the goals that are explicitly provided in the problem representation. A clear example is f 5 ( ; Pt ), that builds on top of the Euclidean distance , and that for S trips planning problems is actually a goal counter. We believe that better estimates may be obtained by building on top of the powerful ideas of modern planning heuristics [97, 26, 98]. In more detail, a promising approach for the development of more informative heuristics for GP is to consider sub-goals, that are not explicit given in the problem representation [99]. For instance sets of sub-goals
can be discovered as a pre-processing step, without grounding, regarding the set of relevant atoms that are traversed by the polynomial IW(1) algorithm, when achieving individual goals [100].
Since we are approaching GP as a classic tree search, a wide landscape of e ective techniques, coming from heuristic search and classical planning , can actually improve the base performance of our approach. We mention some of the more promising ones. Large open lists can be handled more e ectively splitting them in several smaller lists [26]. Delayed duplicate detection could be implemented to manage large closed lists with magnetic disk memory [101]. Further, more sophisticated mechanism can be implemented for handling closed nodes. For instance, once a search node is cancelled (e.g. because f i ( ; P ) identified that the planning program fails on a given instance), any program equivalent to this node should also be cancelled, e.g. any program that can be built with transpositions of the causally-independent instructions. Given that the dept of the search-tree is bounded, techniques coming from SAT / CSP / SMTs, such a non-chronological backtracking , limited discrepancy search [102], or taboo search [103], might also result e ective to improve our approach. Last, SATPLAN planners exploit multiple-thread computing to parallelize search in solution spaces with di erent bounds [89]. This same idea could be applied to multiple searches for GP solutions with di erent program sizes.
## References
- [1] E. Winner, M. Veloso, Distill: Learning domain-specific planners by example, in: ICML, 2003, pp. 800-807.
- [2] Y. Hu, H. J. Levesque, A correctness result for reasoning about one-dimensional planning problems, in: IJCAI, 2011, pp. 2638-2643.
- [3] S. Srivastava, N. Immerman, S. Zilberstein, A new representation and associated algorithms for generalized planning, Artificial Intelligence 175 (2) (2011) 615-647.
- [4] S. Siddharth, I. Neil, Z. Shlomo, Z. Tianjiao, Directed search for generalized plans using classical planners, in: ICAPS, 2011, pp. 226-233.
- [5] Y. Hu, G. De Giacomo, Generalized planning: Synthesizing plans that work for multiple environments, in: IJCAI, 2011.
- [6] L. Illanes, S. A. McIlraith, Generalized planning via abstraction: arbitrary numbers of objects, in: AAAI, Vol. 33, 2019, pp. 7610-7618.
- [7] S. Jim´ enez, J. Segovia-Aguas, A. Jonsson, A review of generalized planning, KER 34.
- [8] G. Franc` es, B. Bonet, H. Ge ner, Learning general policies from small examples without supervision, in: AAAI, 2021.
- [9] A. Fern, R. Khardon, P. Tadepalli, The first learning track of the international planning competition, Machine Learning 84 (1-2) (2011) 81-107.
- [10] J. Slaney, S. Thi´ ebaux, Blocks world revisited, Artificial Intelligence 125 (1-2) (2001) 119-153.
- [11] C. Schulte, G. Tack, M. Z. Lagerkvist, Modeling and programming with gecode, Schulte, Christian and Tack, Guido and Lagerkvist, Mikael 1.
- [12] C. Prud'homme, J.-G. Fages, X. Lorca, Choco documentation, TASC, INRIA Rennes, LINA CNRS UMR 6241 (2014) 64-70.
- [13] L. Perron, V. Furnon, Or-tools (2019).
URL
https://developers.google.com/optimization/
- [14] H. Ge ner, Pddl 2.1: Representation vs. computation, JAIR 20 (2003) 139-144.
- [15] D. E. Smith, J. Frank, W. Cushing, The anml language, in: The ICAPS-08 Workshop on Knowledge Engineering for Planning and Scheduling (KEPS), 2008.
- [16] S. Sanner, Relational dynamic influence diagram language (rddl): Language description, ANU 32 (2010) 27.
- [17] J. Barreiro, M. Boyce, M. Do, J. Frank, M. Iatauro, T. Kichkaylo, P. Morris, J. Ong, E. Remolina, T. Smith, et al., Europa: A platform for ai planning, scheduling, constraint programming, and optimization, ICKEPS.
- [18] J. Rintanen, Impact of modeling languages on the theory and practice in planning research, in: AAAI, 2015.
- [19] M. Ghallab, D. Nau, P. Traverso, Automated Planning: theory and practice, Elsevier, 2004.
- [20] H. Ge ner, B. Bonet, A concise introduction to models and methods for automated planning, Morgan & Claypool Publishers, 2013.
- [21] M. Vallati, L. Chrpa, M. Grze´ s, T. L. McCluskey, M. Roberts, S. Sanner, et al., The 2014 international planning competition: Progress and trends, Ai Magazine 36 (3) (2015) 90-98.
- [22] M. Helmert, C. Domshlak, Landmarks, critical paths and abstractions: what's the di erence anyway?, in: Proceedings of the International Conference on Automated Planning and Scheduling, Vol. 19, 2009.
- [23] D. V. McDermott, A heuristic estimator for means-ends analysis in planning., in: AIPS, Vol. 96, 1996, pp. 142-149.
- [24] B. Bonet, H. Ge ner, Planning as heuristic search, Artificial Intelligence. 2001 Jun; 129 (1-2): 5-33.
- [25] J. Ho mann, Ff: The fast-forward planning system, AI magazine 22 (3) (2001) 57-57.
- [26] M. Helmert, The Fast Downward Planning System, Journal of Artificial Intelligence Research 26 (2006) 191-246.
- [27] S. Richter, M. Westphal, The lama planner: Guiding cost-based anytime planning with landmarks, JAIR 39 (2010) 127-177.
- [28] N. Lipovetzky, H. Ge ner, Best-first width search: Exploration and exploitation in classical planning, in: AAAI, 2017.
- [29] G. Frances, H. Ge ner, Modeling and computation in planning: Better heuristics from more expressive languages, in: Proceedings of the International Conference on Automated Planning and Scheduling, Vol. 25, 2015.
- [30] S. S. Skiena, The algorithm design manual: Text, Vol. 1, Springer Science & Business Media, 1998.
- [31] S. P. Dandamudi, Installing and using nasm, Guide to Assembly Language Programming in Linux (2005) 153-166.
- [32] M. Vallati, L. Chrpa, M. Grzes, T. L. McCluskey, M. Roberts, S. Sanner, The 2014 international planning competition: Progress and trends, AI Magazine 36 (3) (2015) 90-98.
- [33] J. Segovia-Aguas, S. Jim´ enez, A. Jonsson, Generalized planning as heuristic search, in: ICAPS, 2021.
- [34] J. Segovia-Aguas, S. Jim´ enez, A. Jonsson, Computing programs for generalized planning using a classical planner, Artificial Intelligence.
- [35] R. Khardon, Learning action strategies for planning domains, Artificial Intelligence 113 (1-2) (1999) 125-148.
- [36] M. Martin, H. Ge ner, Learning generalized policies from planning examples using concept languages, Applied Intelligence 20 (2004) 9-19.
- [37] S. Yoon, A. Fern, R. Givan, Learning control knowledge for forward search planning., Journal of Machine Learning Research 9 (4).
- [38] T. De la Rosa, S. Jim´ enez, R. Fuentetaja, D. Borrajo, Scaling up heuristic planning with relational decision trees, Journal of Artificial Intelligence Research 40 (2011) 767-813.
- [39] T. Silver, K. R. Allen, A. K. Lew, L. P. Kaelbling, J. Tenenbaum, Few-shot bayesian imitation learning with logical program policies, in: Proceedings of the AAAI Conference on Artificial Intelligence, Vol. 34, 2020, pp. 10251-10258.
- [40] B. Bonet, H. Palacios, H. Ge ner, Automatic derivation of finite-state machines for behavior control, in: AAAI, 2010.
- [41] B. Bonet, H. Ge ner, Features, projections, and representation change for generalized planning, in: International Joint Conference on Artificial Intelligence, 2018, pp. 4667-4673.
- [42] J. Segovia-Aguas, S. Jim´ enez, A. Jonsson, Generalized planning with positive and negative examples, in: AAAI, 2020, pp. 9949-9956.
- [43] D. Lotinac, A. Jonsson, Constructing hierarchical task models using invariance analysis, in: Proceedings of the Twenty-second European Conference on Artificial Intelligence, 2016, pp. 1274-1282.
- [44] H. Palacios, H. Ge ner, Compiling uncertainty away in conformant planning problems with bounded width, Journal of Artificial Intelligence Research 35 (2009) 623-675.
- [45] A. Kolobov, Planning with markov decision processes: An ai perspective, Synthesis Lectures on Artificial Intelligence and Machine Learning 6 (1) (2012) 1-210.
- [46] S. Jim´ enez, T. De La Rosa, S. Fern´ andez, F. Fern´ andez, D. Borrajo, A review of machine learning for automated planning, The Knowledge Engineering Review 27 (4) (2012) 433-467.
- [47] F. Bacchus, F. Kabanza, Using temporal logics to express search control knowledge for planning, Artificial intelligence 116 (1-2) (2000) 123-191.
- [48] D. Nau, Y. Cao, A. Lotem, H. Munoz-Avila, The shop planning system, AI Magazine 22 (3) (2001) 91-91.
- [49] M. Mart´ ın, H. Ge ner, Learning generalized policies from planning examples using concept languages, Applied Intelligence 20 (1) (2004) 9-19.
- [50] J. Segovia-Aguas, S. Jim´ enez, A. Jonsson, Hierarchical finite state controllers for generalized planning, in: IJCAI, 2016.
- [51] M. Ramirez, H. Ge ner, Heuristics for planning, plan recognition and parsing, arXiv preprint arXiv:1605.05807.
- [52] J. Segovia-Aguas, S. Jim´ enez, A. Jonsson, Computing hierarchical finite state controllers with classical planning, Journal of Artificial Intelligence Research 62 (2018) 755-797.
- [53] B. Bonet, G. De Giacomo, H. Ge ner, F. Patrizi, S. Rubin, High-level programming via generalized planning and ltl synthesis, in: KR, 2020.
- [54] B. Bonet, G. Frances, H. Ge ner, Learning features and abstract actions for computing generalized plans, in: AAAI, Vol. 33, 2019, pp. 2703-2710.
- [55] R. P. Kurshan, Computer-aided verification of coordinating processes: the automata-theoretic approach, Vol. 302, Princeton university press, 2014.
- [56] A. Solar-Lezama, Program synthesis by sketching, Citeseer, 2008.
- [57] S. Gulwani, O. Polozov, R. Singh, et al., Program synthesis, Foundations and Trends fi in Programming Languages 4 (1-2) (2017) 1-119.
- [58] R. Alur, R. Singh, D. Fisman, A. Solar-Lezama, Search-based program synthesis, Communications of the ACM 61 (12) (2018) 84-93.
- [59] C. Barrett, A. Stump, C. Tinelli, et al., The smt-lib standard: Version 2.0, in: Proceedings of the 8th international workshop on satisfiability modulo theories (Edinburgh, England), Vol. 13, 2010, p. 14.
- [60] D. W. Loveland, Automated Theorem Proving: a logical basis, Elsevier, 2016.
- [61] A. Solar-Lezama, Program sketching, International Journal on Software Tools for Technology Transfer 15 (5) (2013) 475-495.
- [62] A. Burkov, The hundred-page machine learning book, Vol. 1, Andriy Burkov Canada, 2019.
- [63] S. Toyer, F. Trevizan, S. Thi´ ebaux, L. Xie, Action schema networks: Generalised policies with deep learning, in: Proceedings of the AAAI Conference on Artificial Intelligence, Vol. 32, 2018.
- [64] T. P. Bueno, L. N. de Barros, D. D. Mau´ a, S. Sanner, Deep reactive policies for planning in stochastic nonlinear domains, in: Proceedings of the AAAI Conference on Artificial Intelligence, Vol. 33, 2019, pp. 7530-7537.
- [65] S. Garg, A. Bajpai, Mausam, Symbolic network: generalized neural policies for relational mdps, in: International Conference on Machine Learning, PMLR, 2020, pp. 3397-3407.
- [66] S. Sanner, C. Boutilier, Practical solution techniques for first-order mdps, Artificial Intelligence 173 (5-6) (2009) 748-788.
- [67] A. Fern, S. Yoon, R. Givan, Approximate policy iteration with a policy language bias: Solving relational markov decision processes, Journal of Artificial Intelligence Research 25 (2006) 75-118.
- [68] R. S. Sutton, A. G. Barto, Reinforcement learning: An introduction, MIT press, 2018.
- [69] E. Groshev, M. Goldstein, A. Tamar, S. Srivastava, P. Abbeel, Learning generalized reactive policies using deep neural networks, in: Proceedings of the International Conference on Automated Planning and Scheduling, Vol. 28, 2018.
- [70] M. Junyent, A. Jonsson, V. G´ omez, Deep policies for width-based planning in pixel domains, in: ICAPS, Vol. 29, 2019, pp. 646-654.
- [71] J. Pearl, The limitations of opaque learning machines, Possible minds: twenty-five ways of looking at AI (2019) 13-19.
- [72] S. Srivastava, S. Zilberstein, N. Immerman, H. Ge ner, Qualitative numeric planning, in: AAAI, 2011.
- [73] B. Bonet, H. Ge ner, Qualitative numeric planning: Reductions and complexity, arXiv preprint arXiv:1912.04816.
- [74] C. B¨ ackstr¨ om, P. Jonsson, All pspace-complete planning problems are equal but some are more equal than others., in: SOCS, 2011.
- [75] B. Nebel, On the compilability and expressive power of propositional planning formalisms, JAIR 12 (2000) 271-315.
- [76] P. Haslum, N. Lipovetzky, D. Magazzeni, C. Muise, An introduction to the planning domain definition language, Synthesis Lectures on Artificial Intelligence and Machine Learning 13 (2) (2019) 1-187.
- [77] D. S. Nau, T.-C. Au, O. Ilghami, U. Kuter, J. W. Murdock, D. Wu, F. Yaman, Shop2: An htn planning system, JAIR 20 (2003) 379-404.
- [78] D. Lotinac, J. Segovia-Aguas, S. Jim´ enez, A. Jonsson, Automatic generation of high-level state features for generalized planning, in: IJCAI,
2016.
- [79] G. S. Boolos, J. P. Burgess, R. C. Je rey, Computability and logic, Cambridge university press, 2002.
- [80] M. L. Minsky, Recursive unsolvability of post's problem of 'tag' and other topics in theory of turing machines, Annals of Mathematics (1961) 437-455.
- [81] J. B. Browning, B. Sutherland, Working with numbers, in: C ++ 20 Recipes, Springer, 2020, pp. 115-145.
- [82] R. E. Fikes, N. J. Nilsson, Strips: A new approach to the application of theorem proving to problem solving, Artificial intelligence 2 (3-4) (1971) 189-208.
- [83] H. Ge ner, Functional strips: a more flexible language for planning and problem solving, in: Logic-based artificial intelligence, Springer, 2000, pp. 187-209.
- [84] M. Fox, D. Long, Pddl2. 1: An extension to pddl for expressing temporal planning domains, Journal of Artificial Intelligence Research 20 (2003) 61-124.
- [85] E. P. Pednault, Adl and the state-transition model of action, Journal of logic and computation 4 (5) (1994) 467-512.
- [86] B. Nebel, On the compilability and expressive power of propositional planning formalisms, JAIR 12 (2000) 271-315.
- [87] M. Veloso, J. Carbonell, A. Perez, D. Borrajo, E. Fink, J. Blythe, Integrating planning and learning: The prodigy architecture, Journal of Experimental & Theoretical Artificial Intelligence 7 (1) (1995) 81-120.
- [88] N. Roy, G. Gordon, S. Thrun, Finding approximate pomdp solutions through belief compression, Journal of artificial intelligence research 23 (2005) 1-40.
- [89] J. Rintanen, Planning as satisfiability: Heuristics, Artificial intelligence 193 (2012) 45-86.
- [90] R. E. Korf, W. Zhang, I. Thayer, H. Hohwald, Frontier search, Journal of the ACM (JACM) 52 (5).
- [91] J. Segovia-Aguas, S. Jim´ enez, A. Jonsson, Generalized planning with procedural domain control knowledge, in: ICAPS, 2016.
- [92] N. Lipovetzky, M. Ramirez, H. Ge ner, Classical planning with simulators: Results on the atari video games, in: IJCAI, 2015.
- [93] D. P. Bertsekas, Approximate policy iteration: A survey and some new methods, Journal of Control Theory and Applications 9 (3) (2011) 310-335.
- [94] B. Bonet, H. Ge ner, General policies, serializations, and planning width, CoRR abs / 2012.08033. arXiv:2012.08033 . URL https://arxiv.org/abs/2012.08033
- [95] A. Gerevini, A. Saetti, I. Serina, Planning through stochastic local search and temporal action graphs in lpg, JAIR 20 (2003) 239-290.
- [96] A. Solar-Lezama, The sketching approach to program synthesis, in: Asian Symposium on Programming Languages and Systems, Springer, 2009, pp. 4-13.
- [97] J. Ho mann, The metric planning system: Translating'ignoring delete lists'to numeric state variables, JAIR 20 (2003) 291-341.
- [98] G. Franc` es, et al., E ective planning with expressive languages, Ph.D. thesis, Universitat Pompeu Fabra (2017).
- [99] J. Ho mann, J. Porteous, L. Sebastia, Ordered landmarks in planning, Journal of Artificial Intelligence Research 22 (2004) 215-278.
- [100] G. Frances, M. Ram´ ırez J´ avega, N. Lipovetzky, H. Ge ner, Purely declarative action descriptions are overrated: Classical planning with simulators, in: IJCAI, International Joint Conferences on Artificial Intelligence Organization (IJCAI), 2017.
- [101] R. E. Korf, Linear-time disk-based implicit graph search, Journal of the ACM (JACM) 55 (6) (2008) 1-40.
- [102] R. E. Korf, Improved limited discrepancy search, in: AAAI / IAAI, Vol. 1, 1996, pp. 286-291.
- [103] E. Nowicki, C. Smutnicki, A fast taboo search algorithm for the job shop problem, Management science 42 (6) (1996) 797-813.