## Analog, In-memory Compute Architectures for Artificial Intelligence
Patrick Bowen ∗
Neurophos, 212 W Main St. #301, Durham, North Carolina 27701, USA and Center for Metamaterials and Integrated Plasmonics and Department of Electrical and Computer Engineering, Duke University, P.O. Box 90291, Durham, North Carolina 27708, USA
Guy Regev † and Nir Regev ‡
AlephZero, 5141 Beeman Ave. Valley Village, CA 91607, USA and
Department of Electrical and Computer Engineering,
Ben-Gurion University of the Negev, David Ben-Gurion Blvd. 1, Be'er Sheva, Israel
Bruno Umbria Pedroni §
AlephZero, 5141 Beeman Ave., Valley Village, CA 91607, USA and
Department of Bioengineering, UC San Diego, 9500 Gilman Dr., La Jolla, CA 92093, USA
Edward Hanson ¶ and Yiran Chen ∗∗
Duke University, Electrical and Computer Engineering Department, Science Dr, Durham, NC 27710 (Dated: February 14, 2023)
This paper presents an analysis of the fundamental limits on energy efficiency in both digital and analog in-memory computing architectures, and compares their performance to single instruction, single data (scalar) machines specifically in the context of machine inference. The focus of the analysis is on how efficiency scales with the size, arithmetic intensity, and bit precision of the computation to be performed. It is shown that analog, in-memory computing architectures can approach arbitrarily high energy efficiency as both the problem size and processor size scales.
## I. INTRODUCTION
This work is focused on minimizing the energy required to evaluate neural networks, particularly in the linear layers which comprise the overwhelming majority of the computation. The linear operators that describe convolutional neural network layers can be often be characterized by three qualities: they are sparse, high in dimensionality, and high in arithmetic intensity, where arithmetic intensity is defined as the ratio between the number of basic operations (i.e. multiplications and additions) and the number of bytes read and written. This paper shows that, in the context of operators that are both high in dimensionality and arithmetic intensity, an analog in-memory computing device can drastically reduce the energy required to evaluate the operator compared to a von Neumann machine. Moreover, the degree of increased efficiency of the analog processor is related to the scale of the processor.
In a classical von Neumann machine, the energy required to evaluate an operator can be broken into two components: memory access energy and computational energy. Within a typical CPU, and depending on the workload, these components can consume the same or-
∗ ptbowen@neurophos.com
† guy@alephzero.ai
‡ nir@alephzero.ai
§ bruno@alephzero.ai
¶ edward.t.hanson@duke.edu
∗∗ yiran.chen@duke.edu
der of magnitude of the total energy. Memory access related energy can easily outgrow computational energy consumption, particularly when used to evaluate sequential large linear operators like those used in neural network inference. The goal of this paper is to find highlevel architectures that can reduce the energy consumption of neural network algorithms by orders of magnitude, which requires addressing both memory access energy and computational energy. Here we show that an in-memory compute accelerator architecture can reduce memory access energy when applied to an operator/algorithm with high arithmetic intensity, while an analog processor/accelerator can reduce computational energy when specialized for particular classes of linear operators. A processor architecture that takes advantage of both in-memory compute and is analog in nature can in principle reduce the overall computational energy consumption by orders of magnitude, with the amount of reduction depending on the scale and arithmetic intensity of the algorithm to be performed and the analog processor's specialization in performing a specific set of operators.
In-memory compute architectures were originally designed to speed up processing of algorithms that are parallelizable and applied to large datasets. One of the earliest examples dates back to the 1960s with Westinghouse's Solomon project. The goal of that project was to accelerate the speed of the computer up to 1 GFLOPs by using a single instruction applied to a large array of Arithmetic Logic Units (ALUs). This is perhaps the first instance of the several closely related concepts: single instruction, multiple data (SIMD) machines, vector/array
processors, systolic arrays and in-memory/near-memory compute devices.
Today, exploiting parallelism in high-arithmetic intensity algorithms using parallel hardware remains a wellknown technique to accelerate a computation along the time dimension. More recently, however, vector/array processors have been utilized to decrease compute energy as opposed to the original purpose of compute time, and it does this by reducing energy associated with memory accesses. Google's TPU is a good example of a systolic array being used as a near-memory compute device with digital processing elements [1, 2]. In sec. III, we explain how in-memory compute devices can reduce memory access energy in the case of linear operators with high arithmetic intensity.
Separately, analog computing has recently been proposed as an approach to reduce the computational energy consumption, again for large, linear operations. In sec. IV we present a general model of analog computation that focuses on how energy consumption scales with problem size and bit precision, and show that computational energy can be reduced by orders of magnitude by using an analog processor that is specialized to implement specific classes of operators. Reconfigurable analog processors are by nature in-memory compute devices, and so these classes of processors are shown to reduce overall computational energy by orders of magnitude for particular operators.
## II. CPU ENERGY CONSUMPTION
We begin by finding the energy efficiency of a computer performing multiply-accumulate (MAC) operations, which are the core of linear operators used in deep learning. The total energy required to perform a linear operation can be decomposed into memory access energy and computational energy:
$$E _ { t o t } = N _ { m } e _ { m } + N _ { o p } e _ { o p } , \quad ( 1 )$$
where N m is the number of memory accesses, e m is the average energy per access, N op is the number of operations required to evaluate the overall operator, and e op is the average energy per operation (e.g., add, multiply, etc). We define the computational efficiency as the number of operations per unit energy performed by the computer:
$$\eta \equiv N _ { o p } / E _ { t o t } = \frac { 1 } { ( N _ { m } / N _ { o p } ) e _ { m } + e _ { o p } } .$$
In a simple CPU with a single instruction, single data (SISD) architecture in Flynn's taxonomy and a flat memory hierarchy, for each operation that is performed, a value is read from memory for the current partial sum, the operator weight, and the input activation. The three values are operated upon, and the result is written back to memory. Therefore, regardless of the actual size of the weights or activations, the number of memory accesses per operation will always be four (i.e. three reads and one write), and the number of computational operations (multiply and add) will be 2. This results in N m = 2 N op and a computational efficiency of
$$\eta = \frac { 1 } { 2 e _ { m } + e _ { o p } } . \quad ( 3 )$$
In modern CMOS devices, both e m and e op are on the order of magnitude of 1 pJ [3], as will later be shown in table IV. This places an approximate limit on the computational efficiency of most traditional architectures on the order of 0.1-1 TOPS/W, which is consistent with state of the art performance [4].
## III. MINIMIZING MEMORY ACCESS ENERGY WITH IN-MEMORY COMPUTE
One of the major downsides of SISD machines is that they can end up accessing the same memory element multiple times in the course of evaluating a large operator, which wastes memory access energy. This is ultimately reflected in the ratio N op /N m = 1 / 2 that is fixed by the nature of a SISD machine. Alternatively, one can imagine finding another hypothetical architecture that is arranged in some energetically optimal way to where all of the inputs are only read once from memory, and all outputs are only written once to memory in the course of the computation. If that were done, this would represent the minimum total access energy required to evaluate the linear operator. In other words, N m would reach its minimum value, and the ratio N op /N m would be maximized.
While a particular processor might only be able to implement a certain N op /N m ratio, this ratio is also limited by the algorithm being performed, and is commonly referred to as the arithmetic intensity of the algorithm:
$$a \equiv N _ { o p } / N _ { m } . \quad ( 4 )$$
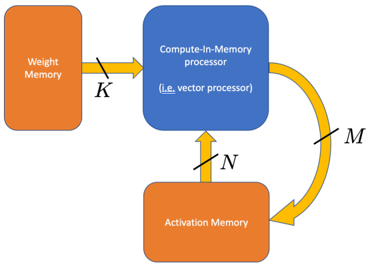
An in-memory compute device [5] as illustrated in fig. 1 can leverage the arithmetic intensity of an algorithm by reading a large set of both operator data and input vector data from memory at once and operating on all of the data together before writing the output back to memory. If the in-memory compute device is sufficiently large and complex, all of the necessary operations involving this data can be performed without any of the inputs being read a second time from memory in the future.
Returning to eq. (1), we set a lower bound on the amount of memory access energy that must be expended for the von Neumann machine to evaluate the operator in terms of the arithmetic intensity. This in turn leads to a limit on the computational efficiency:
$$\eta = \frac { 1 } { e _ { m } / a + e _ { o p } } \quad ( 5 )$$
FIG. 1: Illustration of a digital compute-in-memory processor.
<details>
<summary>Image 1 Details</summary>
### Visual Description
\n
## Diagram: Compute-In-Memory Architecture
### Overview
The image depicts a simplified diagram of a Compute-In-Memory (CIM) processor architecture. It illustrates the data flow between Weight Memory, the CIM processor itself, and Activation Memory. The diagram focuses on the connections and data transfer pathways rather than detailed internal components.
### Components/Axes
The diagram consists of three main rectangular blocks representing memory units and a central block representing the processor. Arrows indicate the direction of data flow, labeled with variables K, N, and M.
* **Weight Memory:** Located on the left side of the diagram, colored orange.
* **Compute-In-Memory processor:** Located in the center, colored blue. It includes the text "(i.e. vector processor)" within the block.
* **Activation Memory:** Located on the bottom of the diagram, colored orange.
* **Data Flow Arrows:**
* Arrow 1: From Weight Memory to CIM processor, labeled "K", colored yellow.
* Arrow 2: From CIM processor to Activation Memory, labeled "N", colored yellow.
* Arrow 3: From Activation Memory back to CIM processor, labeled "M", colored yellow and curved.
### Detailed Analysis or Content Details
The diagram shows a closed-loop data flow. Data labeled 'K' flows from the Weight Memory to the Compute-In-Memory processor. The processor then sends data labeled 'N' to the Activation Memory. Finally, data labeled 'M' is sent from the Activation Memory back to the Compute-In-Memory processor, completing the cycle.
The labels K, N, and M likely represent the dimensions or sizes of the data being transferred. Without further context, their specific meaning (e.g., number of bits, matrix dimensions) is unknown. The "(i.e. vector processor)" text suggests the CIM processor is a type of vector processor.
### Key Observations
The diagram highlights the tight coupling between processing and memory, which is the core principle of Compute-In-Memory architectures. The closed-loop data flow suggests an iterative process, potentially related to neural network computations or other machine learning algorithms. The diagram is highly abstract and does not provide any quantitative data.
### Interpretation
This diagram illustrates a fundamental concept in modern hardware acceleration for machine learning. Compute-In-Memory aims to overcome the von Neumann bottleneck (the separation of memory and processing) by performing computations directly within the memory array. This reduces data movement, leading to significant energy efficiency and performance gains.
The variables K, N, and M likely represent the data dimensions involved in matrix-vector multiplications, a common operation in neural networks. The iterative loop (M) suggests a repeated computation, such as forward or backward propagation in a neural network. The inclusion of "(i.e. vector processor)" indicates that the CIM processor is optimized for parallel processing of vectors, which is well-suited for matrix operations.
The simplicity of the diagram suggests it is intended as a high-level conceptual overview rather than a detailed hardware design. It emphasizes the architectural principle of integrating computation and memory, rather than specific implementation details.
</details>
The contribution to computational efficiency from memory access energy can therefore be brought arbitrarily low when implementing an operator with arbitrarily high arithmetic intensity. The reduction in the contribution from memory access energy with increasing arithmetic intensity in eq. (5) is reflective of the energy savings in systolic arrays and TPUs [1, 2].
We note that the kind of analysis presented in eq. (5) is analogous to roofline models of processors [6]; however, the emphasis here is on energy consumption, while the latter is focused on identifying bottlenecks in processor speed.
In order to sample what degree of advantage inmemory compute devices can bring, we examine a few examples of linear operators and present their arithmetic intensities. For a general matrix multiplication of a matrix of size L × N times a matrix of dimension N × M the total number of memory accesses is N m = LN + NM + LM , and the number of operations is N op = 2 NML , where additions and multiplications are treated as separate operations. The arithmetic intensity in this case is:
$$a = \frac { 2 N M L } { L N + N M + L M } , \quad ( 6 ) \quad D e p _ { i }$$
which approaches ∞ as N,M,L →∞ collectively.
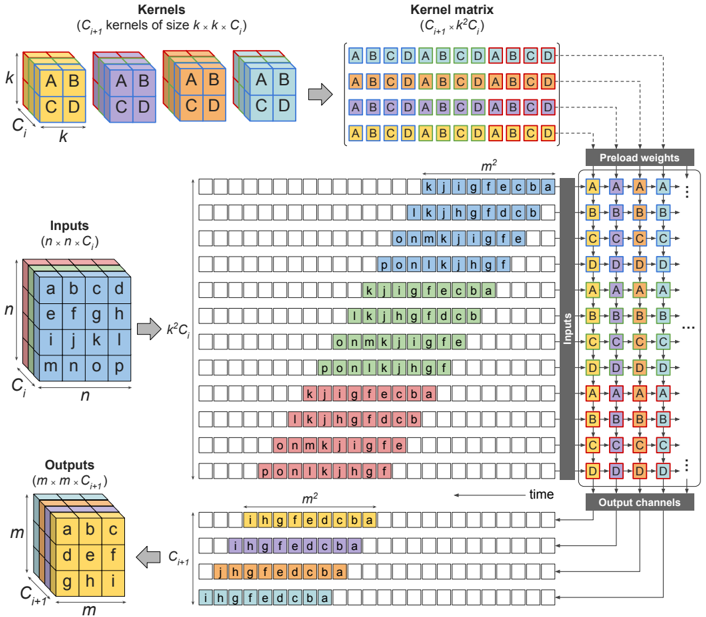
For a convolution, the arithmetic intensity can similarly become arbitrarily large, since a convolution can be implemented as a matrix-matrix multiplication. This is typically done by rearranging the input data into a toeplitz matrix using what is known as an im2col() operation. The general algorithm of implementing convolution using matrix multiplication in a systolic array is shown in fig. 2, where n × n is the size of one input channel, C i is the number of input channels, k × k is the size of one of the kernel channels, and C i +1 is the number of output channels (and, consequently, also the number of individual 3-D kernels). The toeplitz formed by replicating and rearranging the activation data results in an ( n -k +1) 2 × k 2 C i matrix. A convolution is performed by multiplying this with a k 2 C i × C i +1 matrix containing the weights. Therefore, when implementing a convolution using matrix multiplication we generally have matrix dimensions,
$$L = ( n - k + 1 ) ^ { 2 } \approx n ^ { 2 } \quad ( 7 a )$$
$$N = k ^ { 2 } C _ { i } \quad ( 7 b )$$
$$M = C _ { i + 1 } . \quad ( 7 c )$$
which results in an arithmetic intensity,
$$a = \frac { 2 n ^ { 2 } k ^ { 2 } C _ { i } C _ { i + 1 } } { n ^ { 2 } k ^ { 2 } C _ { i } + k ^ { 2 } C _ { i } C _ { i + 1 } + n ^ { 2 } C _ { i + 1 } } . \quad ( 8 )$$
However, since the activation data was replicated approximately k 2 times in order to form the input matrix, the arithmetic intensity is significantly reduced relative to a processor that natively implements convolution instead of general matrix multiplication. To see this, consider again the convolutional layer of an n × n input image with C i input channels, C i +1 output channels, and a k × k kernel. The input vector size is N i = n 2 C i , and the number of kernel weights is K = k 2 C i C i +1 . If only the necessary weight and activation data were required to be read, the arithmetic intensity of the i th layer would become
$$a \approx { \frac { 2 n ^ { 2 } k ^ { 2 } C _ { i } C _ { i + 1 } } { n ^ { 2 } ( C _ { i } + C _ { i + 1 } ) + k ^ { 2 } C _ { i } C _ { i + 1 } } } . \quad ( 9 )$$
In the limit where n 2 >> k 2 C i , this is roughly k 2 higher arithmetic intensity than when convolution is implemented using matrix multiplication.
Whether convolution is implemented natively or using matrix-matrix multiplication, eq. (9) shows that, as n, k, C i → ∞ , arithmetic intensity becomes arbitrarily large, making the contribution from memory access energy in eq. (5) arbitrarily small. Indeed, in most modern convolutional neural networks, these parameters are large and yield high arithmetic intensity, as shown in table I. Depending on the size of the memory banks (which determine memory access energy), and based on the reference numbers given in table IV for SRAM access energy and digital MAC operation, an in-memory compute processor implementing an algorithm with high arithmetic intensity can be made to expend negligible memory access energy relative to the computational energy.
## IV. REDUCING COMPUTATIONAL ENERGY WITH ANALOG COMPUTING
Unfortunately, by Ahmdal's law, even if the memory access energy is made arbitrarily small, computational energy consumed by the logical units will limit the overall performance gains to be made. In order to improve the overall efficiency by orders of magnitude, both contributions need to be addressed.
FIG. 2: Algorithmic implementation of a convolution using matrix multiplication in a weight-stationary systolic array. The input data is converted into a toepliz matrix and fed into the systolic array, with each row delayed one time step behind the one above it.
<details>
<summary>Image 2 Details</summary>
### Visual Description
## Diagram: Convolutional Neural Network Kernel Operation
### Overview
This diagram illustrates the operation of convolutional kernels on an input matrix, leading to an output matrix. It depicts the process of applying multiple kernels to an input, the formation of a kernel matrix, and the resulting output channels. The diagram also shows a "preload weights" section, likely representing the initial weights of the kernels.
### Components/Axes
The diagram is segmented into several key areas:
* **Kernels:** A set of 3D cubes representing the convolutional kernels. Dimensions are labeled as (C<sub>i</sub> kernels of size k x k x C<sub>i</sub>).
* **Kernel Matrix:** A 2D matrix formed by arranging the kernels. Dimensions are labeled as (C<sub>i+1</sub> x k<sup>2</sup>C<sub>i</sub>).
* **Inputs:** A 2D matrix representing the input data. Dimensions are labeled as (n x n x C<sub>i</sub>).
* **Outputs:** A 2D matrix representing the output data. Dimensions are labeled as (m x m x C<sub>i+1</sub>).
* **Preload Weights:** A 4x4 matrix representing the initial weights of the kernels.
* **Time:** An axis indicating the progression of the convolution operation over time.
The input and output matrices are labeled with letters (a, b, c, d, etc.) to illustrate the data flow.
### Detailed Analysis or Content Details
**Kernels:**
* The diagram shows three kernels, each a cube with dimensions k x k x C<sub>i</sub>.
* Each kernel is labeled with letters A, B, C, and D on its faces.
**Kernel Matrix:**
* The kernel matrix is formed by arranging the kernels in a grid.
* The matrix has dimensions C<sub>i+1</sub> x k<sup>2</sup>C<sub>i</sub>.
* The letters A, B, C, and D are repeated within the matrix, indicating the arrangement of kernel elements.
**Inputs:**
* The input matrix has dimensions n x n x C<sub>i</sub>.
* The input matrix is populated with letters a through p, arranged in a grid.
* The diagram shows the application of the kernel matrix to the input matrix. The letters k, j, i, g, f, e, c, b, a are shown as the result of the convolution.
**Outputs:**
* The output matrix has dimensions m x m x C<sub>i+1</sub>.
* The output matrix is populated with letters i through a, arranged in a grid.
**Preload Weights:**
* The preload weights matrix is a 4x4 matrix.
* The matrix is populated with letters A, B, C, and D, repeated in a pattern.
* The matrix is labeled "Inputs" on the left and "Output channels" on the top.
**Data Flow:**
* The diagram shows the flow of data from the input matrix, through the kernel matrix, to the output matrix.
* The time axis indicates that the convolution operation is performed sequentially.
### Key Observations
* The diagram illustrates the core operation of a convolutional neural network layer.
* The kernel matrix is formed by arranging the kernels in a specific order.
* The convolution operation involves sliding the kernel matrix over the input matrix and performing element-wise multiplication and summation.
* The preload weights matrix represents the initial weights of the kernels, which are learned during training.
* The letters used in the matrices are likely placeholders for numerical values.
### Interpretation
This diagram demonstrates the fundamental process of convolution in a neural network. The kernels, represented as 3D cubes, are the learnable parameters that extract features from the input data. The kernel matrix is a way to organize these kernels for efficient application to the input. The convolution operation itself involves sliding the kernel across the input, performing element-wise multiplication, and summing the results to produce an output feature map. The "preload weights" section suggests that the kernels are initialized with certain values before training begins. The diagram highlights the spatial relationships between the input, kernels, and output, and the temporal aspect of the convolution process. The use of letters instead of numbers suggests a conceptual illustration rather than a specific numerical example. The diagram is a simplified representation of a complex process, but it effectively conveys the key concepts of convolutional neural networks. The arrangement of the letters within the matrices suggests a sliding window approach, where the kernel is applied to different parts of the input to generate the output. The diagram is a valuable tool for understanding the inner workings of convolutional neural networks.
</details>
TABLE I: Summary of convolutional layer parameters of various well-known neural networks considering a 1-Mpixel (per channel) input image.
| Network | # of layers | median n | median C i | max N | avg. k | total K | median C i +1 | median a |
|-------------------|---------------|------------|--------------|---------|----------|-----------|-----------------|------------|
| DenseNet201 | 200 | 62 | 128 | 1.6e+07 | 2 | 1.8e+07 | 128 | 292 |
| GoogLeNet | 59 | 61 | 480 | 3.9e+06 | 2.1 | 6.1e+06 | 128 | 200 |
| InceptionResNetV2 | 244 | 60 | 320 | 8e+06 | 1.9 | 8e+07 | 192 | 291 |
| InceptionV3 | 94 | 60 | 192 | 8e+06 | 2.4 | 3.7e+07 | 192 | 295 |
| ResNet152 | 155 | 63 | 256 | 1.6e+07 | 1.7 | 5.8e+07 | 256 | 390 |
| VGG16 | 13 | 249 | 256 | 6.4e+07 | 3 | 1.5e+07 | 256 | 2262 |
| VGG19 | 16 | 186 | 256 | 6.4e+07 | 3 | 2e+07 | 384 | 2527 |
| YOLOv3 | 75 | 62 | 256 | 3.2e+07 | 2 | 6.2e+07 | 256 | 504 |
Recently, various types of analog computing, from electrical to optical, have been proposed as techniques to reduce computational energy consumption. Electronic analog computing typically centers around crossbar arrays of resistive memory (or ReRAM) [7-9]. Optical analog processors are commonly based on silicon photonics [10-13]. Optical 4F systems have been explored since the 1980s as a higher dimensional form of compute [14, 15], and simple scattering off of optical surfaces is also being explored [16-18].
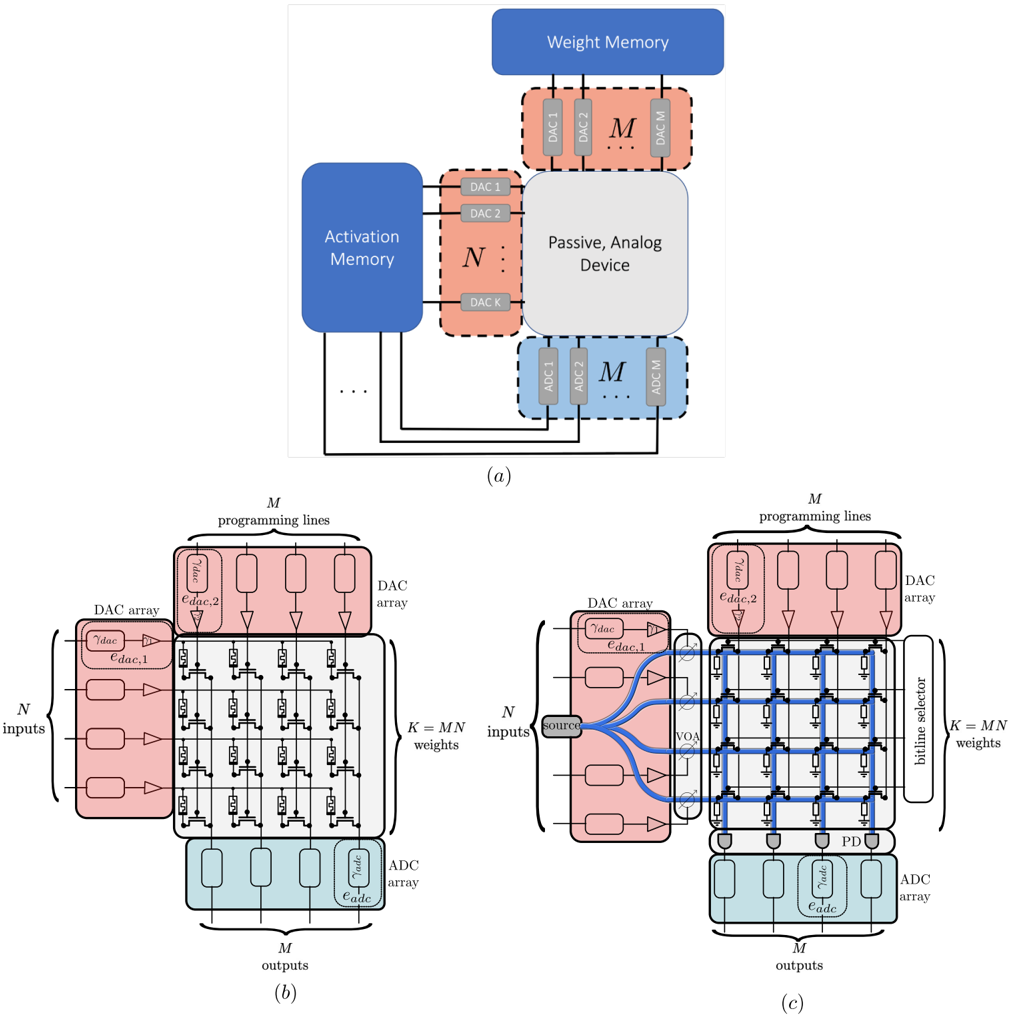
The argument for analog computing is fundamentally a scaling one: analog computing has particular advan- tages when applied to large, linear operators with low bit precision [19]. To see this, consider a general analog processor (shown in fig. 3(a)) that takes N numbers of B -bit precision input data, produces M numbers of B -bit precision output data, and is configured by K weights with B -bit precision which represent the matrix. The analog processor is first configured by converting the K weights using digital-to-analog converters (DACs) and applying these values to the modulators in the analog processor. Then the N inputs are read from memory, and DACs are used to apply N analog inputs to the processor. By the physics of the processor, this naturally results in M
FIG. 3: (a) System-level view analog, in-memory compute processors. The analog device is configured using DACs to either hold activations or weights, while the other is provided as input. (b) Detailed view of a ReRAM crossbar analog electronic in-memory compute processor. Each transistor is connected to a reconfigurable resistor, the conductance of which determines the effective weight of each element in the matrix. (c) Detailed view of a silicon photonic in-memory compute processor. Each transistor is connected to an electro-optic element that changes the scattering parameters through each intersection.
<details>
<summary>Image 3 Details</summary>
### Visual Description
## Diagram: Analog Neural Network Architecture
### Overview
The image presents a schematic diagram illustrating the architecture of an analog neural network. It consists of three main sub-diagrams: (a) a high-level block diagram showing the overall system, (b) a detailed view of the Digital-to-Analog Converter (DAC) array and Analog-to-Digital Converter (ADC) array, and (c) a modified version of (b) incorporating a current source and bitline selector. The diagrams depict the flow of signals and the key components involved in implementing neural network computations in the analog domain.
### Components/Axes
The diagram features the following key components:
* **Weight Memory:** A rectangular block at the top, labeled "Weight Memory".
* **Activation Memory:** A rectangular block to the left, labeled "Activation Memory".
* **Passive, Analog Device:** A rectangular block in the center, labeled "Passive, Analog Device".
* **DAC Array:** Represented as a grid of smaller blocks labeled "DAC 1" through "DAC M" in diagram (a), and expanded in diagrams (b) and (c).
* **ADC Array:** Represented as a grid of smaller blocks labeled "ADC 1" through "ADC M" in diagram (a), and expanded in diagrams (b) and (c).
* **N Inputs:** Represented as input lines to the system.
* **M Outputs:** Represented as output lines from the system.
* **Programming Lines:** Horizontal lines connecting to the DAC array, labeled "M programming lines".
* **Bitline Selector:** A component in diagram (c) used to select bitlines.
* **Current Source:** A component in diagram (c) labeled "N source".
* **Voltage-to-Current Converter (V2A):** A component in diagram (c).
* **Pd:** A component in diagram (c).
* **εdac,1, εdac,2, εdac:** Labels indicating error sources within the DAC array.
* **εadc:** Label indicating error source within the ADC array.
* **τdac, τadc:** Labels indicating time constants within the DAC and ADC arrays.
### Detailed Analysis or Content Details
**Diagram (a): System Overview**
* The "Weight Memory" is connected to the "Passive, Analog Device" via "M" DACs (DAC 1 to DAC M).
* The "Activation Memory" is connected to the "Passive, Analog Device" via "N" inputs.
* The "Passive, Analog Device" outputs "M" signals through "M" ADCs (ADC 1 to ADC M).
* The diagram shows a bidirectional connection between the "Activation Memory" and the "Passive, Analog Device" using dotted lines.
**Diagram (b): DAC/ADC Array Details**
* The DAC array consists of a grid of cells. Each cell contains a programming line input, a capacitor labeled "εdac,1" and "εdac,2", and a switch.
* The ADC array consists of a grid of cells. Each cell contains a capacitor labeled "εadc" and a switch.
* There are "N" inputs to the DAC array and "M" outputs from the ADC array.
* The diagram shows "M" programming lines controlling the DAC array.
**Diagram (c): Modified DAC/ADC Array with Current Source and Bitline Selector**
* This diagram is similar to (b) but includes a current source labeled "N source" connected to the DAC array.
* A Voltage-to-Current Converter (V2A) is present.
* A bitline selector is used to control the output of the ADC array.
* A component labeled "Pd" is included.
### Key Observations
* The diagrams illustrate a mixed-signal approach to neural network implementation, combining digital memory (Weight and Activation Memory) with analog computation (Passive, Analog Device).
* The use of DACs and ADCs suggests that the neural network operates by converting digital weights and activations into analog signals for computation and then converting the results back to digital form.
* The inclusion of error sources (εdac,1, εdac,2, εdac) indicates that the designers are considering the impact of analog imperfections on the network's performance.
* The addition of the current source and bitline selector in diagram (c) suggests an optimization or alternative implementation of the DAC/ADC array.
### Interpretation
The diagrams depict a potential architecture for building analog neural networks. The core idea is to leverage the inherent parallelism and energy efficiency of analog circuits to accelerate neural network computations. The Weight Memory stores the synaptic weights, while the Activation Memory stores the neuron activations. The Passive, Analog Device performs the weighted sum and non-linear activation functions in the analog domain. The DACs and ADCs serve as interfaces between the digital and analog worlds.
The inclusion of error sources highlights the challenges of building accurate and reliable analog circuits. Analog imperfections can introduce noise and errors into the computation, which can degrade the network's performance. The designers are likely exploring techniques to mitigate these errors, such as calibration or error correction.
The modified architecture in diagram (c) suggests an attempt to improve the performance or efficiency of the DAC/ADC array. The current source and bitline selector may be used to optimize the signal-to-noise ratio or reduce power consumption.
Overall, the diagrams provide a glimpse into the design considerations and trade-offs involved in building analog neural networks. This approach holds promise for achieving significant performance and energy efficiency gains compared to traditional digital implementations, but it also presents significant challenges in terms of accuracy, reliability, and scalability. The diagrams are a technical illustration of a potential solution, rather than a presentation of data.
</details>
analog outputs, which are converted back to the digital domain using analog-to-digital (DAC) converters. If the analog processor is somehow already configured, or never needs to be reconfigured, then the total energy consumed will be only that of the DACs for the inputs and ADCs for the outputs:
$$E _ { o p } \equiv N _ { o p } e _ { o p } = N ( e _ { d a c , 1 } + e _ { a d c } ) , \quad ( 1 0 )$$
where we have assumed N = M for simplicity. While
the right-hand-side of eq. (10) represents the computational energy consumed by the analog processor, the lefthand-side represents the equivalent number of digital operations performed ( N op ) times the energy that each of those operations would have to take ( e op ) in order for a digital computer to achieve the same efficiency as the analog computer. Since N op = 2 N 2 for matrix multiplication, if this operation were performed digitally, the expended computational energy would be proportional to the number of operations: E op = 2 e op N 2 . The conclusion is that analog computing reduces matrix multiplication from O ( N 2 ) in energy to O ( N ) in energy . This furthermore implies that the effective energy per operation of analog computing scales inversely to the size of the problem, i.e.
$$e _ { o p } \, \infty \, 1 / N . \quad ( 1 1 ) \quad I n$$
We note that in practice the scaling N is defined either by the size of the processor or the size of the problem, whichever is smaller.
## A. Vector-Matrix Multiplication
For most problems involving neural networks, the analog processors that can be created are not large enough to store the entire neural network. In this case, the reconfiguring of the weights in the analog processor itself can destroy the O ( N ) scaling advantage. To see this, consider the multiplication of a vector of length N with a matrix of dimensions N × M . In this case, we have,
$$N _ { o p } e _ { o p } = 2 N e _ { d a c , 1 } + 2 M N e _ { d a c , 2 } + 2 M e _ { a d c } . \quad ( 1 2 )$$
Wehave also separated the DAC energies e dac, 1 and e dac, 2 since different physical mechanisms and loads are sometimes used to configure an analog computer versus feed it with analog inputs. Here, e dac, 1 is used to represent the energy required per input, while e dac, 2 is used to represent the energy required per reconfiguration.
Typically, in analog computing technologies, the analog in-memory compute device can only store either positive definite numbers (like in the example of memristors) or fully complex numbers (like in the case of coupled Mach-Zender interferometers). If only positive numbers can be created, then the entire calculation must be done twice and the difference of the results taken in order to take into account both positive and negative matrix values. On the other hand, when complex values are allowed like in the case of silicon photonic MZI's, there are two voltages (and hence two DAC operations) required to configure each coupled MZI modulator. Additionally, for coherent optical measurements, an interference technique must be used to recover the positive and negative field components from the photodetectors, which can only measure the norm square of the field. Hence, regardless of the analog compute scheme, each term in eq. (12) must practically be multiplied by a factor of two in order to handle both positive and negative values.
Applying eq. (12) to vector-matrix multiplication, we obtain:
$$e _ { o p } = e _ { d a c , 1 } / M + e _ { d a c , 2 } + e _ { a d c } / N , \quad ( 1 3 )$$
in which case the middle term is proportional neither to 1 /N nor 1 /M .
## B. Matrix-Matrix Multiplication
The aforementioned situation is relieved in the case of matrix-matrix multiplication. In this case the configuration of the analog computer itself is reused for every row of the input matrix, restoring the energy cost per operation to be inversely proportional to the problem scaling. In the case of an L × N matrix times an N × M matrix, we have
$$e _ { o p } = e _ { d a c , 1 } / M + e _ { d a c , 2 } / L + e _ { a d c } / N \quad ( 1 4 )$$
since N op = 2 NML in this case. Since each of the three separate contributions to the energy consumption is decreased by a factor proportional to the three different dimensions associated with the matrices being multiplied, the effective energy per operation decreases as the problem scale increases. In the case of a finite-sized analog processor, the last two contributions will ultimately be limited by the two dimensions (number of inputs and outputs) of the analog processor itself.
At this point, a distinction needs to be made between the size of the matrices involved in the neural net architecture and the physical dimensions of the analog processor. We label the matrix dimensions with primes, i.e. M ′ , N ′ , and L ′ , and label the physical dimensions of the processor with hats: ˆ M , ˆ N . The actual factors by which energy is saved (i.e. M and N in eq. (14)) are given by the smaller of these two numbers:
$$M = \min \{ \hat { M } , M ^ { \prime } \} \quad ( 1 5 a )$$
$$N = \min \{ \hat { N } , N ^ { \prime } \} . \quad ( 1 5 b )$$
## C. Convolution
As in the case of digital processors, analog processors can also implement convolution using matrix-matrix multiplication. The mapping of the kernel and activation data to to matrix dimensions remains the same, i.e.
$$L ^ { \prime } = ( n - k + 1 ) ^ { 2 } \approx n ^ { 2 } \quad \ \ ( 1 6 a )$$
$$N ^ { \prime } = k ^ { 2 } C _ { i } \quad ( 1 6 b )$$
$$M ^ { \prime } = C _ { i + 1 } \quad ( 1 6 c )$$
when weight-stationary scheme is implemented. These numbers are permuted for activation-stationary. As with digital processors, one of the unfortunate aspects of representing convolution as pure matrix multiplication is
TABLE II: Median values of L ′ , N ′ , and M ′ as per eq. (16) for the convolutional layers of various well-known neural networks. The values were obtained considering a 1-Mpixel (per channel) input image.
| Network | # of layers | L ′ | N ′ | M ′ |
|-------------------|---------------|-------|-------|-------|
| DenseNet201 | 200 | 3844 | 1152 | 128 |
| GoogLeNet | 59 | 3721 | 528 | 128 |
| InceptionResNetV2 | 244 | 3600 | 432 | 192 |
| InceptionV3 | 94 | 3600 | 768 | 192 |
| ResNet152 | 155 | 3969 | 1024 | 256 |
| VGG16 | 13 | 62001 | 2304 | 256 |
| VGG19 | 16 | 38688 | 2304 | 384 |
| YOLOv3 | 75 | 3844 | 1024 | 256 |
that the input activations get duplicated k 2 times, which means k 2 more DAC operations (and possibly memory accesses as well) than in a processor that natively implements convolution rather than general matrix multiplication. The consequence of this is that M is by far the smallest of the numbers in eq. (16c), and therefore analog processors that implement convolution as matrix multiplication get the least amortization over their input DACs in eq. (14). The median values of L ′ , N ′ , and M ′ for various neural networks is presented in table II.
## V. OPERATOR-SPECIALIZED ANALOG PROCESSORS
Thus far, we have seen that 1) the contribution of memory access energy to compute efficiency can be brought arbitrarily low by implementing networks with large arithmetic intensity on specialized processors, and 2) analog processors can further reduce computational energy consumption when performing matrix multiplication. The reduction in computational energy is proportional to the size of the matrix the analog processor can handle.
One of the inherent disadvantages of planar, matrix multiplication based processors in performing convolutions is that the matrix that is formed for the input is of dimensions ( n -k + 1) 2 × k 2 C i , which is a factor of k 2 larger than the actual activation data. When the convolution is performed digitally this is of little consequence because the number of MACs required is the same for this matrix multiplication as it is for convolution: ( n -k +1) 2 k 2 C i . However, when the matrix multiplication is performed with an analog processor using a matrix with k 2 more rows than necessary means that it requires k 2 more DAC operations than should be theoretically necessary. Even worse than this, unless some additional logic is used to set up the matrix between the SRAM and processor (which also consumes energy), it will require k 2 additional memory reads than is in principle necessary, thus significantly increasing the memory access energy. Furthermore, since the number of channels in each layer are often correlated (the output channels of one layer become the input channels of the next), the weight data loaded into the analog processor which has dimensions of k 2 C i × C i +1 is highly rectangular, which will increase M relative to N , which in turn increases the contribution to the energy consumption per operation to the input data DACs.
In contrast to analog processors designed for general matrix multiplication, there are classes of analog processors which are specialized to implementing convolutions. One technique to implementing an analog processor is by restricting it to only operate in one particular eigenspace of operators. While any linear operator may be expressed as a matrix, the matrix A may be factored into the product of three matrices using eigen-decomposition:
$$X = U \Lambda U ^ { T } , \quad ( 1 7 )$$
where U is a unitary (i.e. lossless) matrix of the eigenvectors of X , and Λ is a purely diagonal matrix of the eigenvalues of X . The eigenvectors of a convolution are waves, and so when X is a matrix representing a convolution, the eigenvector matrix U represents a Fourier transform, while U T represents and inverse Fourier transform.
One technique of creating an operator-specialized processor is to statically implement the matrices U and U T , and only dynamically reconfigure the eigenvalues Λ. In this case, in order to change linear operators from one to another only the diagonal entries of Λ need to be changed. In other words, if the matrix X is of size m × m , changing the matrix to another convolution matrix only requires the modulation of m weights in the analog processor instead of m 2 weights. In the particular case where X represents a convolution, these eigenvalues are the Fourier transform of the kernel data. By tuning this set of m elements, the matrix X that is implemented by the analog processor can span the range of linear operators with the eigenvectors given by U .
Eigen-decomposition is possible for planar analog processors, and has in fact been demonstrated in silicon photonic processors [11, 13]. However, there is an alternate approach to silicon photonics to implementing a convolution-specialized processor called an optical 4F system , which has a particular set of advantages relative to planar convolution processors.
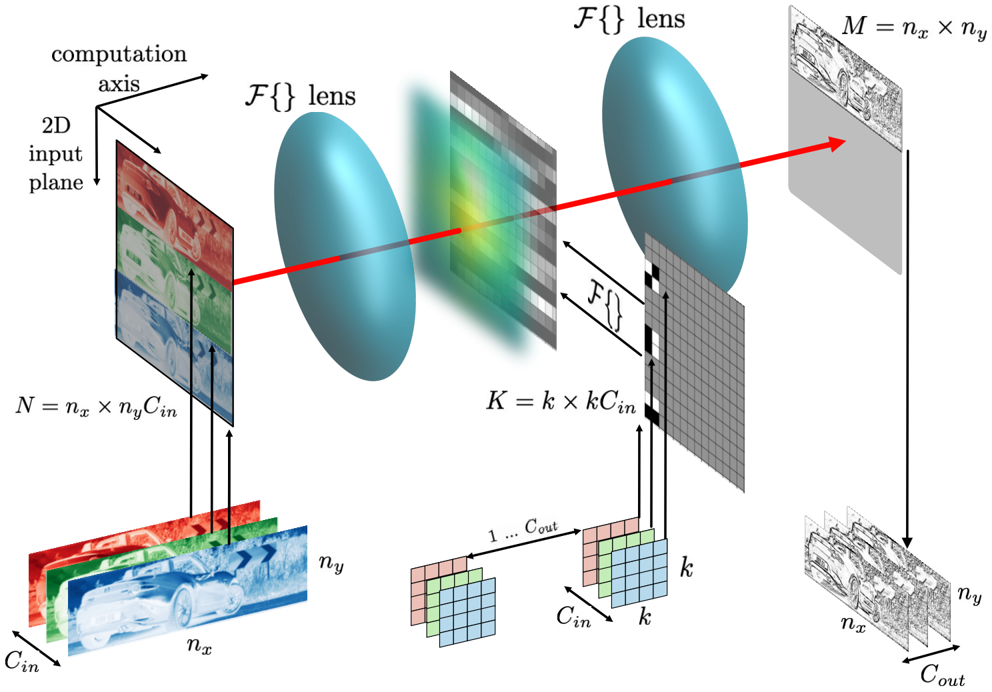
In planar analog processors, data is inserted into the processor in a one dimensional array, and the data is processed as it propagates along the second dimension. Unlike planar processors, an optical 4F system is a volumetric processor, so data is represented in a two dimensional array, while the computation happens as light propagates in the third dimension. While this does bring dramatically higher information density and computational density, the most significant difference is that it allows the processor to scale to numbers of inputs that are entirely impractical for planar processors. Since the efficiency of analog compute was shown in eq. (11) to scale proportionally to the dimensions of the analog processor (in the limit of infinite arithmetic intensity), optical 4F systems can in theory reach computational efficiencies orders of
FIG. 4: Illustration of a transmission-mode optical 4F system performing convolutions with parallelized input channels. The input activation data can be tiled on the object plane, while the input filters can be tiled with appropriate padding before the Fourier transform is taken and the data is applied to the second SLM in the Fourier plane. In this arrangement one complete output channel is produced per measurement.
<details>
<summary>Image 4 Details</summary>
### Visual Description
\n
## Diagram: Optical System with 2D Input Plane and Output Volume
### Overview
The image depicts a 3D diagram illustrating an optical system that transforms a 2D input plane into a 3D output volume. It appears to model a process akin to a Fourier transform or a similar optical imaging system. The diagram highlights the input plane, two lenses labeled "F{}" lens, an intermediate transformed plane, and the final output volume. Mathematical notations define the dimensions of each plane.
### Components/Axes
* **2D input plane:** Located at the bottom-left, representing the initial image.
* **Computation axis:** A label pointing to the vertical direction of the input plane.
* **F{} lens:** Two lens shapes positioned between the input plane and the intermediate transformed plane.
* **Intermediate transformed plane:** A rectangular prism-shaped plane between the lenses.
* **Output volume:** Located at the top-right, representing the final transformed image.
* **n<sub>x</sub>, n<sub>y</sub>, n<sub>in</sub>:** Dimensions of the input plane.
* **k, k<sub>in</sub>, c<sub>in</sub>, c<sub>out</sub>:** Dimensions related to the intermediate and output planes.
* **n<sub>x</sub>, n<sub>y</sub>:** Dimensions of the output volume.
* **N = n<sub>x</sub> x n<sub>y</sub>c<sub>in</sub>:** Equation defining the size of the input plane.
* **K = k x k c<sub>in</sub>:** Equation defining the size of the intermediate transformed plane.
* **M = n<sub>x</sub> x n<sub>y</sub>:** Equation defining the size of the output volume.
* **F{}:** Label indicating the function performed by the lenses.
* **Arrows:** Red arrows indicate the flow of information through the system.
### Detailed Analysis or Content Details
The diagram shows a transformation process. The 2D input plane, with dimensions n<sub>x</sub>, n<sub>y</sub>, and c<sub>in</sub>, is passed through two lenses labeled "F{} lens". These lenses perform a transformation, resulting in an intermediate plane with dimensions k, k, and c<sub>in</sub>. The intermediate plane is then transformed into the final output volume with dimensions n<sub>x</sub>, n<sub>y</sub>, and c<sub>out</sub>.
The input plane is visually represented as a photograph of a car. The intermediate plane shows a rainbow-like color gradient, suggesting a frequency or spectral representation. The output volume appears as a 3D representation of the input image.
The equations provided define the dimensions of each plane:
* Input plane size (N): n<sub>x</sub> multiplied by n<sub>y</sub> multiplied by c<sub>in</sub>.
* Intermediate plane size (K): k multiplied by k multiplied by c<sub>in</sub>.
* Output volume size (M): n<sub>x</sub> multiplied by n<sub>y</sub>.
### Key Observations
The diagram illustrates a process that transforms a 2D image into a 3D representation, likely involving a Fourier transform or similar optical imaging technique. The lenses play a crucial role in this transformation, and the intermediate plane represents a frequency-domain representation of the input image. The dimensions of each plane are mathematically defined, providing a quantitative understanding of the transformation process.
### Interpretation
This diagram likely represents a simplified model of an optical system used in image processing or computer vision. The "F{}" lenses could represent a Fourier transform lens, which converts a spatial representation of an image into a frequency representation. The intermediate plane then represents the frequency spectrum of the input image. The final output volume represents the reconstructed image in the spatial domain.
The use of mathematical notations suggests a focus on the quantitative aspects of the transformation. The diagram could be used to explain the principles of optical imaging, Fourier optics, or related fields. The rainbow-like color gradient in the intermediate plane suggests that the transformation involves a decomposition of the input image into its constituent frequencies. The overall system appears to be designed to capture and process information from a 2D input and represent it in a 3D output space. The diagram is a conceptual illustration rather than a precise engineering blueprint, focusing on the flow of information and the key components involved in the transformation.
</details>
magnitude higher than planar processors.
An example of an optical 4F system processor is shown in fig. 4. It is composed of two spatial light modulators (SLMs), which might be based on either liquid crystal cells or dynamic metasurfaces. These are placed before and after a lens, one focal length away from either side. Lenses naturally perform Fourier transforms between these two place, so that the light transmitted through the first SLM is Fourier-transformed upon passing through the lens. Therefore the first SLM provides the input data, and the first lens represents multiplication by the unitary Fourier matrix U . The second SLM is loaded with the Fourier transform of the kernel data and the transmitted light through it; therefore, the product of the Fourier transform of the input data with the Fourier transform of the kernel data. The second SLM therefore represents the multiplication by the diagonal eigenvalue matrix Λ.
A second lens is then placed after the second SLM, one focal length away, which represents multiplication by the second eigenvalue matrix U . Finally, a detector is placed a second focal length from the second lens, and the light impinging on the detector is therefore the convolution of the input data with the kernel data. The detector itself is sensitive only to the intensity (i.e. the norm square) of the incident field. However, the complex value of the field can nonetheless be recovered using interferometric methods. Alternatively, as others have pointed out, the nonlinear measurement performed by the optical absorption of semiconductors can also be used naturally as the nonlinear activation of the neurons.
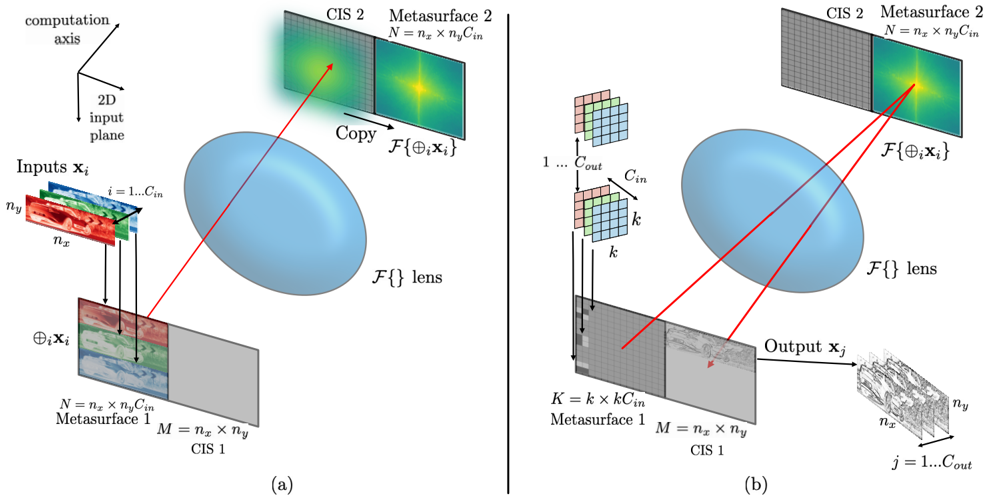
As shown in fig. 4, more than one input channel can be processed in parallel if the kernel data is appropriately padded before the Fourier transform is taken and the data is applied to the second SLM. This allows greater SLM utilization when small kernels are being used.
Unfortunately, from a compute systems perspective, traditional optical 4F systems have a fatal flaw: the output data from the convolution is measured four focal lengths away from the input data, which presumably
FIG. 5: Illustration of a reflection-mode optical 4F system (folded into a 2F overall length) performing processing a full convolutional layer with all input and output channels in two phases: (a) phase one, where an optical Fourier transform of the input activation data is taken and loaded into the Fourier plane SLM, (b) phase two, where the input channels are tiled onto the object plane SLM and the convolution of all input channels are measured in parallel. The process is repeated for each output channel.
<details>
<summary>Image 5 Details</summary>
### Visual Description
## Diagram: Optical Computing Architecture with Metasurfaces
### Overview
The image presents a diagram illustrating an optical computing architecture utilizing two metasurfaces (Metasurface 1 and Metasurface 2) and a lens (F{} lens) to process optical inputs. The diagram is split into two parts, (a) and (b), demonstrating different aspects of the computation. Both parts share a similar structure, with inputs entering through Metasurface 1, being processed by the lens, and outputs emerging from Metasurface 2. Red arrows indicate the path of light.
### Components/Axes
* **Metasurface 1:** Labeled with "Metasurface 1" and dimensions "M = nx x ny". A color gradient is visible, suggesting varying properties across the surface.
* **Metasurface 2:** Labeled with "Metasurface 2" and dimensions "N = nx x ny". Also displays a color gradient.
* **F{} lens:** A large, circular lens positioned between the two metasurfaces, labeled "F{} lens".
* **Inputs (xᵢ):** Labeled "Inputs xᵢ" with the index "i = 1...Cᵢₙ". Represented by a color gradient bar on the left side of (a).
* **Output (xⱼ):** Labeled "Output xⱼ" with the index "j = 1...Cout". Represented by a color gradient bar on the right side of (b).
* **Computation Axis:** A 3D axis labeled "computation axis" is shown on the top-left of (a).
* **2D Input Plane:** A plane labeled "2D input plane" is shown next to the computation axis.
* **CIS 1 & CIS 2:** Labeled "CIS 1" and "CIS 2" respectively, positioned behind Metasurface 1 and Metasurface 2.
* **Copy:** The word "Copy" is written above the lens in (a).
* **k:** A variable "k" is shown in (b) with the label "k = k x kCᵢₙ".
* **Cout & Cin:** Variables "Cout" and "Cin" are shown in (b) above the grid.
### Detailed Analysis or Content Details
**(a) Input Processing:**
* Inputs xᵢ (i ranging from 1 to Cᵢₙ) are directed towards Metasurface 1.
* The light passes through the F{} lens, which appears to transform the input.
* The output of the lens is labeled as F{Φ}xᵢ.
* A "Copy" operation is indicated above the lens.
**(b) Output Generation:**
* A grid representing a set of inputs is shown before Metasurface 1. The grid is labeled with "1...Cout" and "Cin".
* The light passes through the F{} lens.
* Outputs xⱼ (j ranging from 1 to Cout) emerge from Metasurface 2.
* The dimensions of Metasurface 1 are given as M = nx x ny, and Metasurface 2 as N = nx x ny.
* The relationship between the grid dimensions is given as K = k x kCᵢₙ.
### Key Observations
* The diagram illustrates a system where optical inputs are transformed by a lens after interacting with a metasurface.
* The use of color gradients on the metasurfaces suggests spatially varying optical properties.
* The two parts (a) and (b) highlight different aspects of the computation: (a) shows the processing of a single input, while (b) shows the processing of multiple inputs simultaneously.
* The dimensions of the metasurfaces are related by the variables nx and ny.
* The variable 'k' and the grid structure in (b) suggest a parallel processing architecture.
### Interpretation
The diagram depicts an optical computing system leveraging metasurfaces and a lens to perform computations on optical signals. The metasurfaces likely modulate the incoming light, and the lens focuses or transforms the light to achieve the desired computation. The "Copy" operation in (a) suggests a potential duplication or branching of the optical signal. The grid structure in (b) and the variables Cout and Cin indicate a parallel processing capability, where multiple inputs are processed simultaneously to generate multiple outputs. The dimensions nx and ny likely represent the number of elements or pixels within the metasurfaces, defining their resolution. The overall architecture suggests a potential for efficient and high-speed optical computation. The use of CIS (likely Computational Imaging System) indicates that the system is designed for image processing or similar tasks. The diagram is a conceptual illustration of the architecture, and does not provide specific numerical data about the optical properties or performance of the system.
</details>
must be physically implemented in its own chip. Since this convolution operation only represents the connections between two layers of neurons, in order to implement a deep neural network with more than two layers of neurons the output data from the detector chip must be brought back somehow to the input spatial light modulator. Communicating this massive amount of data off-chip would entail massive energy costs, overcoming all advantages brought by the large-scale analog compute.
However, an optical 4F system might be folded using reflection-mode SLMs as shown in fig. 5 in order to consolidate the first SLM and the CMOS image sensor sideby-side into a single chip, and using only a single lens. In this architecture all significant data transfer between the two chips happens optically instead of electronically. On either side of the lens on two chips, split into two halves are: an SLM (or metasurface) and a CMOS image sensor. Both chips are placed one focal length away from either side of the lens such that, whenever light passes between the two chips, a Fourier transform is taken by the lens.
This system computes convolutions in two phases: a loading phase and a compute phase. The first, loading phase is shown in fig. 5(a), where the purpose is to take the Fourier transform of the activation data and load it into the second metasurface. A set of input filter maps are written to the input SLM in the first chip, which is illuminated. The Fourier transform of the reflected light is delivered to the CMOS image sensor (CIS) in the second chip, and this data is electronically transferred over to the second SLM within the same chip using DAC and ADC operations. As with the in-transmission unfolded 4F system in fig. 4, in-reflection 4F systems like the one in fig. 5 can be used to take the convolution of multiple input channels in parallel. The final result of this phase is therefore that the SLM in the second chip is configured with the Fourier transform of the activation data.
In the second, compute phase, the input kernel weight data is applied to the first SLM. This is then illuminated at a slightly oblique angle so that the reflected light impinges upon the SLM in the second chip. When this light is reflected the lens takes another Fourier transform, and the light impinging on the CIS in the first chip is the convolution of the input filter map data with the kernel data.
If the input data requires n 2 C i total pixels, loading the optical Fourier transform of the activation data will cost
$$E _ { f f t } = n ^ { 2 } C _ { i } ( 2 e _ { a d c } + 4 e _ { d a c } ) \quad ( 1 8 )$$
energy. One DAC operation per pixel is required to write the input data to the first metasurface, while two ADC operations and two DAC operations are required in order to reconstruct the complex field data from the intensity data and then apply it to the second SLM.
Since input channels can be performed in parallel and then looped over output channels, the second phase in-
volves two times K = k 2 C i C i +1 DAC operations, and two n 2 C i +1 ADC operations in the CIS to recover the field.
$$E _ { c o n v } = 2 k ^ { 2 } C _ { i } C _ { i + 1 } e _ { d a c } + 2 n ^ { 2 } C _ { i + 1 } e _ { a d c } \quad ( 1 9 )$$
Therefore the total energy associated with the analog compute of this layer is E fft + E conv ,
$$E _ { o p } = 2 n ^ { 2 } ( C _ { i } + C _ { i + 1 } ) e _ { a d c } + 2 C _ { i } ( 2 n ^ { 2 } + k ^ { 2 } C _ { i + 1 } ) e _ { d a c } . \, ( 2 0 )$$
The total number of operations performed is N op = 2 n 2 k 2 C i C i +1 . Therefore the efficiency of the approach is,
$$\eta = \frac { 1 } { e _ { m } / a + e _ { a d c } / \left ( \frac { k ^ { 2 } C _ { i } C _ { i + 1 } } { C _ { i } + C _ { i + 1 } } \right ) + 2 e _ { d a c } / k ^ { 2 } C _ { i + 1 } + e _ { d a c } / n ^ { 2 } } .$$
in the limit that the metasurfaces are large enough to handle all of the activation or weight data.
In order to take into account the finite size of the metasurfaces, which may not be large enough to fit all of the activation data from all channels at once, we first find the number of input channels that can practically be handled at once. For a metasurface of dimension n x × n y ≡ ˆ N , the number of input channels that can be included at once, C ′ , is,
$$C ^ { \prime } = \lfloor \hat { N } / n ^ { 2 } \rfloor . \quad ( 2 2 )$$
Using this in place of the actual number of software defined input channels we can derive the factors by which energy is saved in the optical 4F system in the case that C ′ ≥ 1,
$$L = n ^ { 2 } \quad & ( 2 3 a ) \quad \begin{array} { l } { g i c } \\ { i n } \end{array}$$
$$N = \frac { k ^ { 2 } C ^ { \prime } C _ { i + 1 } } { ( C ^ { \prime } + C _ { i + 1 } ) }
( 23 b ) \quad \ n o$$
$$M = k ^ { 2 } C _ { i + 1 } / 2 . \quad ( 2 3 c ) \quad t e c _ { 1 }$$
In terms of these parameters, the efficiency of the optical 4F system is given in the usual way,
$$e _ { o p } = e _ { d a c } / M + e _ { d a c } / L + e _ { a d c } / N . \quad ( 2 4 ) \quad t h e r$$
For an optical 4F system, the median values of L , N , and M as per eq. (23) for various neural networks is presented in table III.
## VI. ANALYTIC RESULTS
The formula given in eqs. (3), (5), (14) and (24) can be used to estimate the efficiency when evaluating a given CNN layer on any one of those four compute platforms. They depend on the energy values for memory access, DAC/ADC operations, and digital multiplication. Estimates for many of these quantities are given in table IV,
TABLE III: Median values of L , N , and M for the convolutional layers of various well-known neural networks considering an optical 4F system as computational substrate. The values were obtained considering a 1-Mpixel (per channel) input image and an infinitely large metasurface (i.e. C ′ → inf).
| Network | # of layers | L | N | M |
|-------------------|---------------|-------|------|------|
| DenseNet201 | 200 | 3844 | 272 | 136 |
| GoogLeNet | 59 | 3721 | 128 | 64 |
| InceptionResNetV2 | 244 | 3600 | 224 | 112 |
| InceptionV3 | 94 | 3600 | 240 | 120 |
| ResNet152 | 155 | 3969 | 1024 | 512 |
| VGG16 | 13 | 62001 | 2304 | 1152 |
| VGG19 | 16 | 38688 | 3456 | 1728 |
| YOLOv3 | 75 | 3844 | 512 | 256 |
TABLE IV: Energy per operation for various operations of digital and analog computers. These assume a technology node of 45nm and a voltage of 0.9V, and 8-bit values per operation. The example of memory access energy assumes a bank size of 96kB, since this is the bank sized used to construct the TPU SRAM bank.
| e m (96kB SRAM)[3] | 4.3pJ |
|----------------------------------------------|---------|
| e mac [3] | 0.23pJ |
| e adc [20] | 0.25pJ |
| e dac [21] | 0.01pJ |
| e opt [eq. (A8)] | 0.01pJ |
| e load for 4 µm pitch, N = 256 [eq. (A6)] | 0.08pJ |
| e load for 250 µm pitch, N = 40 [eq. (A6)] | 0.8pJ |
| e load for 2.5 µm pitch, N = 2048 [eq. (A6)] | 0.04pJ |
and formula for deriving the loads to estimate DAC energies for various analog compute platforms are also given in the appendix.
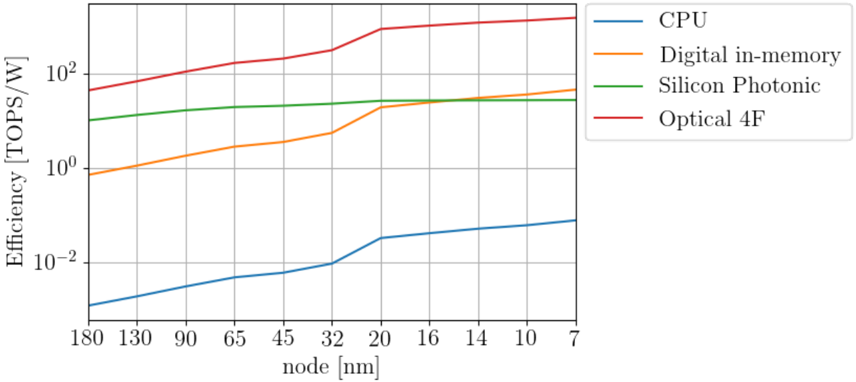
Each of these values depend on the CMOS technology node, but scaling laws can be used to interpolate between technology nodes [22]. We compare the various compute platforms by considering a CNN layer with parameters given in table V, and the resulting efficiencies are plotted as a function of technology node in fig. 6.
While all processors improve with technology node, there is roughly an order of magnitude difference between digital in-memory compute processors and silicon photonic processors, and yet another order of magnitude difference to be expected between silicon photonic pro-
TABLE V: Convolution parameters used to estimate efficiencies of various processors in fig. 6. The arithmetic intensity follows from the other parameters by eq. (9).
| Input Channels | C i | 128 |
|----------------------|--------|-------|
| Output Channels | C i +1 | 128 |
| Filter size | k | 3 |
| Input size | n | 512 |
| Arithmetic intensity | a | 230 |
FIG. 6: Efficiencies from analytic models of various compute architectures as a function of technology node.
<details>
<summary>Image 6 Details</summary>
### Visual Description
## Line Chart: Efficiency vs. Node Size for Different Computing Architectures
### Overview
This chart depicts the efficiency (measured in TOPS/W) of four different computing architectures – CPU, Digital in-memory, Silicon Photonic, and Optical 4F – as a function of node size (measured in nanometers). The chart uses a logarithmic scale for the y-axis (Efficiency) to better visualize the differences in efficiency across the architectures.
### Components/Axes
* **X-axis:** Node [nm] - Ranges from 7nm to 180nm. The axis is linear.
* **Y-axis:** Efficiency [TOPS/W] - Ranges from approximately 0.01 to 150 TOPS/W. The axis is logarithmic (base 10).
* **Data Series:**
* CPU (Blue Line)
* Digital in-memory (Orange Line)
* Silicon Photonic (Green Line)
* Optical 4F (Red Line)
* **Legend:** Located in the top-right corner of the chart. It maps colors to the corresponding computing architecture.
### Detailed Analysis
The chart shows the efficiency trends of each architecture as the node size decreases.
* **CPU (Blue Line):** The line slopes upward, indicating increasing efficiency as the node size decreases.
* At 180nm: Approximately 0.02 TOPS/W
* At 130nm: Approximately 0.03 TOPS/W
* At 90nm: Approximately 0.05 TOPS/W
* At 65nm: Approximately 0.08 TOPS/W
* At 45nm: Approximately 0.15 TOPS/W
* At 32nm: Approximately 0.3 TOPS/W
* At 20nm: Approximately 0.5 TOPS/W
* At 16nm: Approximately 0.7 TOPS/W
* At 10nm: Approximately 1.0 TOPS/W
* At 7nm: Approximately 1.3 TOPS/W
* **Digital in-memory (Orange Line):** The line initially slopes upward, then plateaus.
* At 180nm: Approximately 10 TOPS/W
* At 130nm: Approximately 20 TOPS/W
* At 90nm: Approximately 30 TOPS/W
* At 65nm: Approximately 50 TOPS/W
* At 45nm: Approximately 80 TOPS/W
* At 32nm: Approximately 120 TOPS/W
* At 20nm: Approximately 130 TOPS/W
* At 16nm: Approximately 130 TOPS/W
* At 10nm: Approximately 130 TOPS/W
* At 7nm: Approximately 130 TOPS/W
* **Silicon Photonic (Green Line):** The line slopes upward, but less steeply than Digital in-memory.
* At 180nm: Approximately 10 TOPS/W
* At 130nm: Approximately 15 TOPS/W
* At 90nm: Approximately 20 TOPS/W
* At 65nm: Approximately 30 TOPS/W
* At 45nm: Approximately 45 TOPS/W
* At 32nm: Approximately 60 TOPS/W
* At 20nm: Approximately 70 TOPS/W
* At 16nm: Approximately 75 TOPS/W
* At 10nm: Approximately 80 TOPS/W
* At 7nm: Approximately 85 TOPS/W
* **Optical 4F (Red Line):** The line slopes upward, showing the highest efficiency overall.
* At 180nm: Approximately 80 TOPS/W
* At 130nm: Approximately 90 TOPS/W
* At 90nm: Approximately 100 TOPS/W
* At 65nm: Approximately 110 TOPS/W
* At 45nm: Approximately 120 TOPS/W
* At 32nm: Approximately 130 TOPS/W
* At 20nm: Approximately 140 TOPS/W
* At 16nm: Approximately 145 TOPS/W
* At 10nm: Approximately 148 TOPS/W
* At 7nm: Approximately 150 TOPS/W
### Key Observations
* Optical 4F consistently exhibits the highest efficiency across all node sizes.
* Digital in-memory shows a significant initial efficiency gain as node size decreases, but then plateaus.
* CPU has the lowest efficiency and the smallest efficiency gain with decreasing node size.
* The logarithmic scale on the y-axis emphasizes the large differences in efficiency between the architectures.
### Interpretation
The data suggests that as technology scales down (smaller node sizes), the efficiency of computing architectures generally increases. However, the rate of improvement varies significantly. Optical 4F appears to be the most promising architecture in terms of efficiency, maintaining a substantial lead over the other architectures. Digital in-memory shows strong initial gains but reaches a limit, indicating that further scaling may not yield significant efficiency improvements. The CPU exhibits the least improvement, suggesting that traditional CPU architectures may struggle to keep pace with more advanced architectures in terms of efficiency as technology scales. The plateauing of Digital in-memory efficiency could be due to fundamental limitations in the architecture itself, or due to the challenges of further optimizing the design at smaller node sizes. The consistent upward trend of Optical 4F suggests that this architecture is well-suited for continued scaling and offers the potential for even greater efficiency gains in the future.
</details>
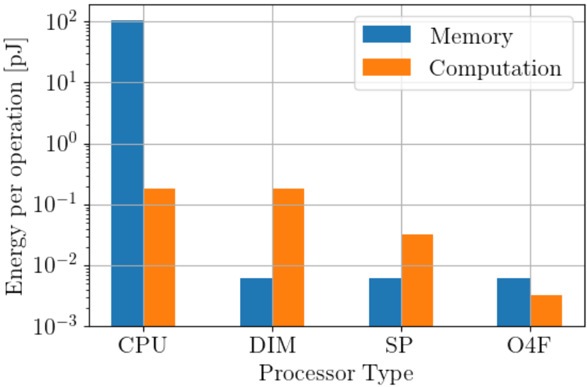
FIG. 7: Contributions of energy consumption per operation for various processor types. DIM is digital in-memory, SP is silicon photonic, and O4F is optical 4F system architectures. The CNN layer parameters are in table V, and assumptions about architectural details are given in the text. The technology node is assumed to be 32nm for all processor types.
<details>
<summary>Image 7 Details</summary>
### Visual Description
\n
## Bar Chart: Energy per Operation for Different Processor Types
### Overview
This bar chart compares the energy consumption per operation for four different processor types: CPU, DIM, SP, and O4F. The energy is measured in picojoules (pJ) and is broken down into two components: Memory and Computation. The chart uses a logarithmic y-axis to accommodate the wide range of energy values.
### Components/Axes
* **X-axis:** Processor Type (CPU, DIM, SP, O4F) - Categorical variable.
* **Y-axis:** Energy per operation [pJ] - Logarithmic scale, ranging from 10^-3 to 10^2.
* **Legend:**
* Blue: Memory
* Orange: Computation
* **Gridlines:** Present, aiding in value estimation.
### Detailed Analysis
The chart consists of paired bars for each processor type, representing Memory and Computation energy consumption.
**CPU:**
* Memory: The blue bar for CPU is approximately 10^2 pJ (around 100 pJ).
* Computation: The orange bar for CPU is approximately 0.1 pJ.
**DIM:**
* Memory: The blue bar for DIM is approximately 0.02 pJ.
* Computation: The orange bar for DIM is approximately 0.15 pJ.
**SP:**
* Memory: The blue bar for SP is approximately 0.01 pJ.
* Computation: The orange bar for SP is approximately 0.05 pJ.
**O4F:**
* Memory: The blue bar for O4F is approximately 0.01 pJ.
* Computation: The orange bar for O4F is approximately 0.005 pJ.
**Trends:**
* For all processor types, the energy consumption for Memory is significantly higher than for Computation.
* The energy consumption for Memory decreases as the processor type changes from CPU to DIM, SP, and O4F.
* The energy consumption for Computation also decreases, but to a lesser extent, as the processor type changes.
### Key Observations
* The CPU consumes the most energy per operation, particularly for Memory access.
* The O4F processor has the lowest energy consumption for both Memory and Computation.
* The difference in energy consumption between Memory and Computation is substantial across all processor types.
* The logarithmic scale is crucial for visualizing the large differences in energy consumption.
### Interpretation
The data suggests that the type of processor significantly impacts energy consumption per operation. CPUs, while powerful, are energy-intensive, especially regarding memory access. Specialized processors like DIM, SP, and O4F demonstrate significantly lower energy consumption, indicating potential benefits in energy-efficient computing. The large disparity between Memory and Computation energy consumption highlights the importance of optimizing memory access patterns to reduce overall energy usage. The trend of decreasing energy consumption as processor type changes suggests that advancements in processor design and architecture are leading to more energy-efficient computing solutions. The logarithmic scale emphasizes the order-of-magnitude differences in energy consumption, making it clear that the energy savings achieved with specialized processors are substantial. This data could be used to inform decisions about processor selection for applications where energy efficiency is a critical concern.
</details>
cessors and optical 4F systems. While this difference is clearly algorithm-dependent, the underlying hardware for analog compute systems must be large enough to be able to exploit the potential algorithmic advantages, which is what is enabled by moving from a two-dimensional silicon photonic processor to a fundamentally three-dimensional processor akin to an optical 4F system.
The breakdown of improvements into memory and computational energy reductions are shown in fig. 7, which shows the contribution to the energy per operation from memory and computational elements separately for each processor type. Exploiting high arithmetic intensity with in-memory compute vastly improves energy consumption between CPUs and the other platforms by first reducing memory energy well below computational energy. The analog processors in turn have reduced computational energy, with less computational energy on a per-operation basis for analog processors with more inputs.
It is worthwhile noting that the efficiencies reported in fig. 6 for the digital in-memory processor are significantly higher than the Google TPU, which reported 0.3-2 TOPS/W depending on the CNN architecture, for a chip manufactured at a 28-nm node. The in-memory compute digital processor modeled here has the same architectural parameters as the TPU: a 256 by 256 systolic array, and 24-MiB of SRAM divided into 256, 96-KB banks. Here we predict that number should be roughly 5 TOPS/W,
which is a significantly higher efficiency than reported in the literature [1]. However, we note that this estimation simplifies the energy costs associated with the digital multiplication and storing and transporting data in and between each processing element in the systolic array.
The silicon photonics processor modelled in figs. 6 and 7 assumed an array size of 40 by 40, which is typical for most processors reported in the literature [10-13], since the various modulator technologies typically require the array to have pitches in the 100-400 µ m range. The computational energy consumption is highly limited by the optical modulator technology, which currently stands at around 7 pJ/byte, as discussed in section A1. We assume in our model that this will be improved to 0.5 pJ over time, but even with this assumed advantage it is clear in fig. 6 that silicon photonics will have a difficult time maintaining an efficiency advantage over digital compute in memory technologies unless it is possible to scale up the processor sizes. We also assume a 24-MiB SRAM for the silicon photonics processor, divided into 40, 600-KB SRAM banks, following the TPU architecture.
The optical 4F system is based on the architecture in fig. 5, with 4-Mpx SLMs and a 24-MiB SRAM divided into 2048, 12-KB banks, again following the TPU architecture. The SLM pitch for DAC loads involved in active matrix addressing of the SLMs was assumed to be 2.5 µ m, which results in a line capacitance of 0.9 fF and a load energy of 40 fJ as shown in table IV. The optical energy per pixel is based on 1550-nm light, and contributes 10 fJ/pixel per operation as shown in table V. The large array sizes enabled by realistic SLM dimensions are able to reduce computational energy consumption even below the memory consumption in fig. 7.
## VII. COMPUTATIONAL RESULTS
Thus far, we have provided simple analytic formula that estimate the efficiency of various AI inference platforms on the basis of how they scale. These formula are approximations with several limitations, the biggest of which is that they don't take into account situations where the matrices involved are too large for either the capacity of the in-memory compute device or its inputs. In that circumstance the problem needs to be broken up into several smaller matrix multiplications. In order to get around this limitation we developed cycle-accurate models of a systolic array and of an in-reflection optical 4F system, and tested those models when evaluating various CNNs for a given input image size. The more accurate computational results are then compared with the analytic models from the previous sections.
## A. Systolic array efficiency estimation
For analyzing the energy efficiency of a systolic array, we considered an architecture similar to that of the Google TPU [ref:TPU], with a weight-stationary systolic array of size 256 x 256 tiles. Each of the 256 ports of the array has access to an individual 96-KB SRAM block, totaling 24 MiB of buffer memory for storing activations (i.e. inputs/outputs of a convolutional layer). The weights are stored in DRAM and accessed based to the convolutional layer being executed. The activations and weights are 8-bit fixed point.
In terms of energy costs, we used as reference the SRAM and MAC energy values for a 45-nm process at 0.9 V from [3]: SRAM read/write of 1.25 pJ/byte (8-KB memory) and 8-bit MAC operation of 0.23 pJ/byte. To align with the SRAM block size of 96 KB in the TPU, the 8-KB SRAM energy cost was scaled in size by a factor of √ 96K / 8K = 3 . 46 in accordance with eq. (A2), resulting in 4.33 pJ/byte. Associated to each MAC operation, we also included the energy costs of the load and of the memory read/write inside each array tile (to store/propagate the 8-bit input and 32-bit accumulation = 40 bits). A load energy cost of 2.82 fJ/bit was computed using eq. A6, where the distance between array tiles was approximated based on the 256 x 256 array area occupancy (24%) of the entire TPU chip (331 mm 2 ), resulting in a distance of 34.8 um between tiles. The internal array memory energy cost was obtained by scaling the 8-KB SRAM block to 40 bits, resulting in 1 . 25 pJ/byte × √ 5 / 8K = 31 . 25 fJ/byte.
Lastly, using the techniques presented in [22], we scaled all the energy values (except for load, since it's not directly process-dependent) from 45-nm process to the appropriate technology nodes, ranging from 180 nm down to 7 nm. The results are presented in fig. 8. Both the analytic expression and the cycle-accurate model follow the same trend, with a slight divergence as the technology node is reduced. This can be accounted for the fact that e load does not depend on technology node, and its cost starts becoming a dominating factor in the overall energy cost since the other energy sources diminish as node size reduces.
## B. Optical computer efficiency estimation
For the optical 4F system we considered 4-Mpixel SLMs, along with the same 24-MiB SRAM as in the systolic array analysis. With this, the SRAM is partioned into 2048 equal parts (one per metasurface row), resulting in a size-scaled SRAM read/write energy of 1.55 pJ/byte. The DAC, ADC and laser energies were obtained using the values in table IV considering a 2.5µ m pitch.
A comparison between the analytic expression and a cycle-accurate model of the optical 4F system is presented in fig. 9. The figure provides an overall curve for the efficiency, with significant gain when constructing the
FIG. 8: Efficiency comparison between a cycle-accurate model and the analytic expression given by eq. (8) and the values in table I. Both models are running YOLOv3 (1-Mpixel input image) using a 256 × 256
<details>
<summary>Image 8 Details</summary>
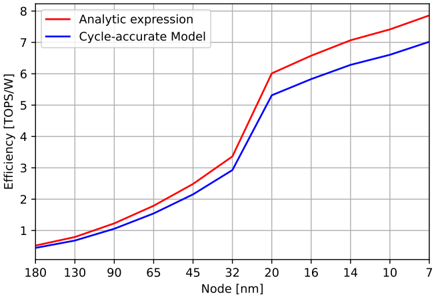
### Visual Description
\n
## Line Chart: Efficiency vs. Node Size
### Overview
This image presents a line chart comparing the efficiency (measured in TOPS/W) of two models – an Analytic expression and a Cycle-accurate Model – across varying node sizes (measured in nm). The chart illustrates how efficiency changes as the node size decreases.
### Components/Axes
* **X-axis:** Node [nm]. Scale ranges from 7 nm to 180 nm. Markers are present at 7, 10, 14, 16, 20, 32, 45, 65, 90, 130, and 180 nm.
* **Y-axis:** Efficiency [TOPS/W]. Scale ranges from 0 to 8. Markers are present at 0, 1, 2, 3, 4, 5, 6, 7, and 8.
* **Legend:** Located at the top-left corner.
* Red Line: "Analytic expression"
* Blue Line: "Cycle-accurate Model"
* **Grid:** A grid is present to aid in reading values.
### Detailed Analysis
**Analytic Expression (Red Line):**
The red line representing the "Analytic expression" shows a generally upward trend, indicating increasing efficiency as the node size decreases.
* At 180 nm, efficiency is approximately 0.5 TOPS/W.
* At 130 nm, efficiency is approximately 0.8 TOPS/W.
* At 90 nm, efficiency is approximately 1.2 TOPS/W.
* At 65 nm, efficiency is approximately 1.6 TOPS/W.
* At 45 nm, efficiency is approximately 2.1 TOPS/W.
* At 32 nm, efficiency is approximately 3.0 TOPS/W.
* At 20 nm, efficiency is approximately 5.0 TOPS/W.
* At 16 nm, efficiency is approximately 6.0 TOPS/W.
* At 14 nm, efficiency is approximately 6.5 TOPS/W.
* At 10 nm, efficiency is approximately 7.2 TOPS/W.
* At 7 nm, efficiency is approximately 7.7 TOPS/W.
**Cycle-accurate Model (Blue Line):**
The blue line representing the "Cycle-accurate Model" also shows an upward trend, but with a steeper increase at smaller node sizes.
* At 180 nm, efficiency is approximately 0.4 TOPS/W.
* At 130 nm, efficiency is approximately 0.7 TOPS/W.
* At 90 nm, efficiency is approximately 1.1 TOPS/W.
* At 65 nm, efficiency is approximately 1.5 TOPS/W.
* At 45 nm, efficiency is approximately 2.0 TOPS/W.
* At 32 nm, efficiency is approximately 3.2 TOPS/W.
* At 20 nm, efficiency is approximately 5.2 TOPS/W.
* At 16 nm, efficiency is approximately 5.8 TOPS/W.
* At 14 nm, efficiency is approximately 6.3 TOPS/W.
* At 10 nm, efficiency is approximately 6.8 TOPS/W.
* At 7 nm, efficiency is approximately 7.3 TOPS/W.
### Key Observations
* Both models demonstrate that efficiency increases as node size decreases.
* The "Cycle-accurate Model" generally exhibits slightly higher efficiency than the "Analytic expression" at smaller node sizes (below 32 nm).
* The "Analytic expression" shows a more consistent increase in efficiency across all node sizes.
* The rate of efficiency increase is more pronounced for both models as the node size approaches smaller values (below 20 nm).
### Interpretation
The chart illustrates the relationship between process node size and efficiency for two different modeling approaches. The data suggests that shrinking node sizes lead to improved efficiency, as expected. The "Cycle-accurate Model" provides a more detailed and potentially more accurate representation of efficiency, particularly at advanced nodes, as it captures more nuanced effects. The divergence between the two models at smaller node sizes could be attributed to the increased complexity of modeling effects that become significant at those scales, such as short-channel effects and power leakage. The consistent upward trend for both models indicates that continued scaling of process nodes is a viable path to improving efficiency, although the rate of improvement may diminish as physical limits are approached. The chart is useful for understanding the trade-offs between modeling accuracy and computational cost when evaluating the performance of integrated circuits.
</details>
weight-stationary systolic array and a 24-MiB SRAM (as in the Google TPUv1).
FIG. 9: Comparison of eq. (24) with a cycle-accurate model of the optical 4F processor running YOLOv3 (1-Mpixel input image) using 4-Mpixel SLMs and a 24-MiB SRAM.
<details>
<summary>Image 9 Details</summary>
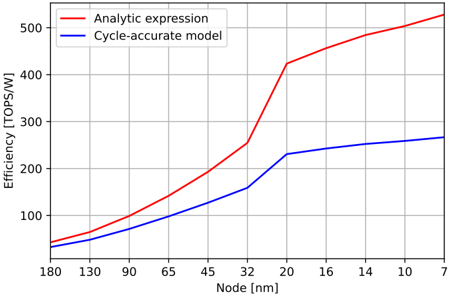
### Visual Description
## Line Chart: Efficiency vs. Node Size
### Overview
This image presents a line chart comparing the efficiency (measured in TOPS/W) of two models – an analytic expression and a cycle-accurate model – as a function of node size (measured in nanometers). The chart illustrates how efficiency changes as the node size decreases.
### Components/Axes
* **X-axis:** Node [nm]. Scale ranges from 180 nm to 7 nm, with markers at 180, 130, 90, 65, 45, 32, 20, 16, 14, 10, and 7 nm.
* **Y-axis:** Efficiency [TOPS/W]. Scale ranges from 0 to 500 TOPS/W, with markers at 0, 100, 200, 300, 400, and 500 TOPS/W.
* **Legend:** Located in the top-left corner.
* Red Line: Analytic expression
* Blue Line: Cycle-accurate model
### Detailed Analysis
**Analytic Expression (Red Line):**
The red line representing the analytic expression shows a generally upward trend.
* At 180 nm, the efficiency is approximately 60 TOPS/W.
* At 130 nm, the efficiency is approximately 70 TOPS/W.
* At 90 nm, the efficiency is approximately 85 TOPS/W.
* At 65 nm, the efficiency is approximately 105 TOPS/W.
* At 45 nm, the efficiency is approximately 130 TOPS/W.
* At 32 nm, the efficiency is approximately 170 TOPS/W.
* At 20 nm, the efficiency sharply increases to approximately 440 TOPS/W.
* At 16 nm, the efficiency is approximately 470 TOPS/W.
* At 14 nm, the efficiency is approximately 490 TOPS/W.
* At 10 nm, the efficiency is approximately 510 TOPS/W.
* At 7 nm, the efficiency is approximately 520 TOPS/W.
**Cycle-Accurate Model (Blue Line):**
The blue line representing the cycle-accurate model also shows an upward trend, but it is less steep than the red line.
* At 180 nm, the efficiency is approximately 40 TOPS/W.
* At 130 nm, the efficiency is approximately 50 TOPS/W.
* At 90 nm, the efficiency is approximately 70 TOPS/W.
* At 65 nm, the efficiency is approximately 90 TOPS/W.
* At 45 nm, the efficiency is approximately 110 TOPS/W.
* At 32 nm, the efficiency is approximately 150 TOPS/W.
* At 20 nm, the efficiency increases to approximately 240 TOPS/W.
* At 16 nm, the efficiency is approximately 260 TOPS/W.
* At 14 nm, the efficiency is approximately 270 TOPS/W.
* At 10 nm, the efficiency is approximately 280 TOPS/W.
* At 7 nm, the efficiency is approximately 290 TOPS/W.
### Key Observations
* The analytic expression consistently predicts higher efficiency values than the cycle-accurate model across all node sizes.
* Both models show a significant increase in efficiency as the node size decreases, particularly below 32 nm.
* The analytic expression exhibits a more dramatic efficiency increase at 20 nm compared to the cycle-accurate model.
* The rate of efficiency increase slows down for both models as the node size approaches 7 nm.
### Interpretation
The chart demonstrates the relationship between node size and efficiency for two different modeling approaches. The analytic expression provides an idealized estimate of efficiency, while the cycle-accurate model offers a more realistic representation, accounting for practical limitations. The divergence between the two models suggests that the analytic expression overestimates the achievable efficiency, especially at smaller node sizes. The sharp increase in efficiency below 32 nm indicates that scaling down node size has a substantial impact on performance, but this benefit diminishes as the technology approaches its physical limits. The cycle-accurate model's more gradual increase suggests that factors beyond simple scaling, such as power dissipation and manufacturing variability, become increasingly important at smaller node sizes. The data suggests that while smaller nodes offer efficiency gains, the analytic model may be overly optimistic in its predictions.
</details>
device with smaller technology nodes. The main differences which explain the divergence between the analytic and cycle-accurate models include:
- The cycle-accurate model considers the exact number of metasurface executions to account for output detector ADC read operations, output memory accesses, and total laser energy consumed.
- Equation (23) considers that the dimensions of the output are the same as that of the input (i.e. m = n ), which naturally does not account for strides bigger than 1.
- The value of e dac in eq. (24) is comprised of e dac, 1 +
e load + e opt , resulting in an energy cost based on number of active pixels in the metasurface. However, the cycle-accurate model more precisely estimates the energy costs by separating the pixel-wise energy ( e dac, 1 + e load ) from the metasurface sizedependent laser energy ( e opt ).
## C. Optical computer energy cost distribution
The cycle-accurate model for the optical 4F system can provide a detailed summary of the energy cost distribution based on four different system components: DAC, ADC, SRAM, and laser. These results for VGG19 and YOLOv3 across different technology nodes are presented in fig. 10, with the values specified in picojoules per MAC operation.
Naturally, as the node size reduces, ADC and SRAM energy costs decrease. On the other hand, the DAC energy includes the dominating e load in its composition, and since the latter is technology node-independent, we see very little reduction in the overall DAC energy cost throughout the different nodes. Just as with e load , the laser energy e opt does not change with technology node and is, thus, constant.
Comparing the energy cost distributions between VGG19 (left) and YOLOv3 (right), it is curious to note that a network with a much larger arithmetic intensity as in the case of VGG19 (refer to table I) presents a higher SRAM energy per MAC operation. This can be explained by the fact that the cycle-accurate model takes into account the sizes of the SLMs and the inputs, making the VGG19 network slightly less efficient in terms of placement of the input image pixels onto the metasurface due to it presenting (on average per layer) larger input images with more channels. This results in more metasurface executions - and, consequently, more output activation buffering (SRAM read/write) - to complete the convolutions in the network. If we consider an infinitely large metasurface, then this artifact naturally goes away and VGG19 becomes more efficient than YOLOv3 in terms of SRAM energy per MAC operation.
## VIII. CONCLUSIONS
In-memory compute and analog compute techniques are both effective techniques to address different contributions to total processor energy cost. While in-memory compute is able to reduce memory access energy per operation in the context of a high arithmetic intensity algorithm, analog compute is able to reduce the computational energy itself in proportion to the scale of the analog processor. Convolutional neural networks are a perfect application for such analog, in-memory compute architectures since they have high arithmetic intensity, large linear operators, and typically require low bit precision for forward propagation.
<details>
<summary>Image 10 Details</summary>
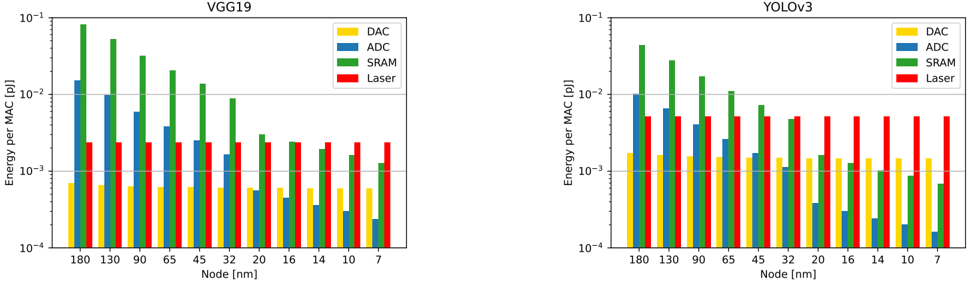
### Visual Description
\n
## Bar Chart: Energy per MAC vs. Node Size for VGG19 and YOLOv3
### Overview
The image presents two bar charts comparing the energy consumption per Multiply-Accumulate (MAC) operation for different hardware components (DAC, ADC, SRAM, Laser) across varying node sizes (180nm to 7nm) for two neural network models: VGG19 and YOLOv3. The Y-axis represents energy in picojoules (pJ), displayed on a logarithmic scale, while the X-axis represents the node size in nanometers (nm).
### Components/Axes
* **X-axis (Both Charts):** Node [nm] - with markers at 180, 130, 90, 65, 45, 32, 20, 16, 14, 7.
* **Y-axis (Both Charts):** Energy per MAC [pJ] - Logarithmic scale from 10^-4 to 10^-1.
* **Legend (Both Charts):**
* Yellow: DAC
* Blue: ADC
* Green: SRAM
* Red: Laser
* **Chart Titles:**
* Left Chart: VGG19
* Right Chart: YOLOv3
### Detailed Analysis - VGG19 Chart
The VGG19 chart displays energy consumption for each component across the specified node sizes.
* **Laser (Red):** The Laser component exhibits a generally decreasing trend in energy consumption as the node size decreases from 180nm to 7nm. Approximate values:
* 180nm: ~8 x 10^-2 pJ
* 130nm: ~6 x 10^-2 pJ
* 90nm: ~5 x 10^-2 pJ
* 65nm: ~4 x 10^-2 pJ
* 45nm: ~3 x 10^-2 pJ
* 32nm: ~2.5 x 10^-2 pJ
* 20nm: ~2 x 10^-2 pJ
* 16nm: ~1.6 x 10^-2 pJ
* 14nm: ~1.4 x 10^-2 pJ
* 7nm: ~1 x 10^-2 pJ
* **SRAM (Green):** SRAM shows a similar decreasing trend, but generally consumes less energy than the Laser component. Approximate values:
* 180nm: ~4 x 10^-2 pJ
* 130nm: ~3 x 10^-2 pJ
* 90nm: ~2.5 x 10^-2 pJ
* 65nm: ~2 x 10^-2 pJ
* 45nm: ~1.7 x 10^-2 pJ
* 32nm: ~1.4 x 10^-2 pJ
* 20nm: ~1.2 x 10^-2 pJ
* 16nm: ~1 x 10^-2 pJ
* 14nm: ~9 x 10^-3 pJ
* 7nm: ~7 x 10^-3 pJ
* **ADC (Blue):** ADC exhibits a decreasing trend, but its energy consumption is relatively low compared to Laser and SRAM. Approximate values:
* 180nm: ~1.5 x 10^-2 pJ
* 130nm: ~1.2 x 10^-2 pJ
* 90nm: ~1 x 10^-2 pJ
* 65nm: ~8 x 10^-3 pJ
* 45nm: ~6 x 10^-3 pJ
* 32nm: ~5 x 10^-3 pJ
* 20nm: ~4 x 10^-3 pJ
* 16nm: ~3 x 10^-3 pJ
* 14nm: ~2.5 x 10^-3 pJ
* 7nm: ~2 x 10^-3 pJ
* **DAC (Yellow):** DAC consistently has the lowest energy consumption across all node sizes. Approximate values:
* 180nm: ~3 x 10^-3 pJ
* 130nm: ~2.5 x 10^-3 pJ
* 90nm: ~2 x 10^-3 pJ
* 65nm: ~1.5 x 10^-3 pJ
* 45nm: ~1.2 x 10^-3 pJ
* 32nm: ~1 x 10^-3 pJ
* 20nm: ~8 x 10^-4 pJ
* 16nm: ~7 x 10^-4 pJ
* 14nm: ~6 x 10^-4 pJ
* 7nm: ~5 x 10^-4 pJ
### Detailed Analysis - YOLOv3 Chart
The YOLOv3 chart displays energy consumption for each component across the specified node sizes.
* **Laser (Red):** Similar to VGG19, the Laser component shows a decreasing trend in energy consumption as node size decreases. Approximate values:
* 180nm: ~7 x 10^-2 pJ
* 130nm: ~5 x 10^-2 pJ
* 90nm: ~4 x 10^-2 pJ
* 65nm: ~3 x 10^-2 pJ
* 45nm: ~2.5 x 10^-2 pJ
* 32nm: ~2 x 10^-2 pJ
* 20nm: ~1.6 x 10^-2 pJ
* 16nm: ~1.3 x 10^-2 pJ
* 14nm: ~1.1 x 10^-2 pJ
* 7nm: ~8 x 10^-3 pJ
* **SRAM (Green):** SRAM also exhibits a decreasing trend, with lower energy consumption than Laser. Approximate values:
* 180nm: ~3 x 10^-2 pJ
* 130nm: ~2.5 x 10^-2 pJ
* 90nm: ~2 x 10^-2 pJ
* 65nm: ~1.6 x 10^-2 pJ
* 45nm: ~1.3 x 10^-2 pJ
* 32nm: ~1 x 10^-2 pJ
* 20nm: ~8 x 10^-3 pJ
* 16nm: ~7 x 10^-3 pJ
* 14nm: ~6 x 10^-3 pJ
* 7nm: ~5 x 10^-3 pJ
* **ADC (Blue):** ADC shows a decreasing trend, with relatively low energy consumption. Approximate values:
* 180nm: ~1 x 10^-2 pJ
* 130nm: ~8 x 10^-3 pJ
* 90nm: ~6 x 10^-3 pJ
* 65nm: ~5 x 10^-3 pJ
* 45nm: ~4 x 10^-3 pJ
* 32nm: ~3 x 10^-3 pJ
* 20nm: ~2.5 x 10^-3 pJ
* 16nm: ~2 x 10^-3 pJ
* 14nm: ~1.7 x 10^-3 pJ
* 7nm: ~1.5 x 10^-3 pJ
* **DAC (Yellow):** DAC consistently has the lowest energy consumption across all node sizes. Approximate values:
* 180nm: ~2 x 10^-3 pJ
* 130nm: ~1.6 x 10^-3 pJ
* 90nm: ~1.2 x 10^-3 pJ
* 65nm: ~1 x 10^-3 pJ
* 45nm: ~8 x 10^-4 pJ
* 32nm: ~6 x 10^-4 pJ
* 20nm: ~5 x 10^-4 pJ
* 16nm: ~4 x 10^-4 pJ
* 14nm: ~3.5 x 10^-4 pJ
* 7nm: ~3 x 10^-4 pJ
### Key Observations
* Energy consumption generally decreases as the node size decreases for all components in both VGG19 and YOLOv3.
* Laser consistently consumes the most energy, followed by SRAM, ADC, and DAC.
* The energy consumption difference between VGG19 and YOLOv3 is noticeable, with YOLOv3 generally exhibiting lower energy consumption for all components at each node size.
* The logarithmic scale emphasizes the relative changes in energy consumption, particularly at smaller node sizes.
### Interpretation
The data demonstrates the impact of technology scaling on energy consumption in neural network computations. As node sizes decrease, the energy required for each MAC operation decreases for all hardware components. This is expected due to reduced transistor sizes and improved circuit designs. The consistent ranking of components (Laser > SRAM > ADC > DAC) suggests inherent differences in their energy efficiency. The lower energy consumption of YOLOv3 compared to VGG19 could be attributed to its more efficient network architecture, requiring fewer MAC operations for the same task. The logarithmic scale highlights that the energy savings become more significant at smaller node sizes, indicating the continued importance of technology scaling for energy-efficient AI hardware. The data suggests that optimizing the Laser component is crucial for reducing overall energy consumption in these neural network models.
</details>
⊗}̂˜(⋃{⌉⊎
⊗}̂˜(⋃{⌉⊎
FIG. 10: Energy cost distribution for the cycle-accurate model of the 4F optical system running VGG19 (left) and YOLOv3 (right).
To provide some intuition regarding how much energy efficiency can be improved using one or both of these techniques, we have provided simple analytic formula estimating the efficiency for a range of processor types, including digital in-memory processors like a systolic array, analog in-memory compute processors, and optical 4F systems which are a class of analog in-memory processor that are specialized to convolutions. These analytic formula, when applied to average neural network parameters provided in tables I to II show good agreement with a cycle accurate model of the TPU architecture in figs. 8 and 9.
As shown in fig. 6 of these approaches perform orders of magnitude better than CPUs, at any modern technology node. The largest improvement is due to the reduction in memory access energy per operation for in-memory compute processors, as shown in fig. 7. However, this technique is so effective that computational energy becomes the dominant contribution, which is then improved by analog computing. Since analog computing's energy advantage is proportional to the scale of the analog processor, optical 4F systems have a particular advantage in that they can be scaled large enough to reduce computational energy per operation below the minimum memory energy required for an in-memory compute processor when evaluating a modern CNN algorithm.
## Appendix A: Processor Energy Model Parameters
In this section, we provide derivations for the typical energies per operation associated with memory access, digital MAC, ADC, and DAC, which are all necessary in order to properly compare the various computing schemes discussed in this paper.
The energy consumed by a digital MAC operation will scale as the number of gates involved with the logical unit: indeed the lower bound of a digital MAC is set by the Landauer limit, which is proportional to the number of gates. For a serial-parallel multiplier, the number of gates G is G = 6 B 2 , and for other multiplier implementations, the area or gate-count is still proportional to B 2 [23], where B is the number of bits of the operand. A full adder has and additional nine gates per bit, so we can write
$$e _ { m a c } = \gamma _ { m a c } ( 6 B ^ { 2 } + 9 B ) k T \quad ( A 1 )$$
where k is Boltzmann's constant, T is temperature, and γ mac is a dimensionless constant. Landauer's limit specifies that the energy per MAC is bounded on the lower end by γ mac > ln(2).[24] Typically, γ mac ≈ 122 , 500 for a 45-nm process [3], so current digital multipliers have several orders of magnitude improvement that could in theory be achieved.
All accelerators will need internal memory for both neural network parameters and intermediate variables (unless an analog processor is built with a large enough capacity to store the entire network which is currently impractical). Digital electronic SRAM banks have an energy per operation that scales as the length of the bit and word lines used to address and write data to the SRAM, since most of the power is consumed in charging and discharging the effective capacitors formed by these lines. In general then, the energy per memory access can be written as,[3]
$$e _ { m } = e _ { m 0 } \sqrt { N _ { m } } \quad ( A 2 )$$
where N m is the size of the memory bank, and e m 0 is a constant with units of energy. The scaling presented here is not reflective of the lower bound of energy consumption according to the Landauer limit, since currently it's the charging and discharging of capacitive lines that drives the energy consumption of SRAM rather than switching gates, which is why it scales according to the root of the array size. In the limit of a single bit cell, one might compare e m 0 with the Landauer limit by setting e m 0 = γ m kT . The resulting γ m is many more orders of magnitude away from the Landauer limit than even digital MACs: γ m ≈ 3 × 10 6 for a 45-nm CMOS process,
which corresponds to an e m 0 ≈ 5 fJ. It can be argued that both the sheer value of e m 0 compared to the Landauer limit and the fact that power consumption in the capacitance of the addressing lines in SRAM leads to the energy scaling proportional to the root of the array size are broadly the source of computing's most severe energy problem.[3] Fortunately, in the case of specialized processors implementing operations with high arithmetic intensity like convolutions, we are able to significantly mitigate this problem.[5]
For analog computation, ADC energy depends exponentially on bit precision, most fundamentally because it requires sufficient signal to noise ratio to distinguish the levels. When these levels are defined in terms of linear voltage steps, the ADC energy per sample is[20, 25]
$$e _ { a d c } = \gamma _ { a d c } k T 2 ^ { 2 B } , \quad ( A 3 ) \quad u l d e$$
where k is Boltzmann's constant, T is the temperature, and γ is a dimensionless constant. It has been argued[20] that γ adc is bounded on the lower end at γ adc > 3 by thermal noise, and presents an empirical survey showing that the state of the art value for on-chip ADCs is γ adc ≈ 1404 for a 65-nm process, which scales to about 927 at 45 nm.
DACs scale in the same manner as ADCs:
$$e _ { d a c } = \gamma _ { d a c } k T 2 ^ { 2 B } \quad ( A 4 ) \quad t u r$$
and for similar arguments. However, the value for stateof-the art on γ dac is γ dac ≈ 39.[21]
However, the expression in eq. (A4) only takes into account the power burned in the DAC circuitry itself, and not the power consumed driving the analog processor load. For example, the load of the bitline associated with a ReRAM processor in fig. 3(b) will be very different from the load associated with the variable optical attenuator (VOA) in the optical analog processor in fig. 3(b). An optical processor will have an additional energy contribution from the optical laser power itself, which can be considered effectively part of the load energy. Therefore we can write,
$$e _ { d a c , i } = \gamma _ { d a c } k T 2 ^ { 2 B } + e _ { l o a d , i } \quad ( A 5 ) \quad p r o t$$
for both e dac, 1 and e dac, 2 . In the following subsections these quantities are estimated for both analog, memristive processors and silicon photonic processors.
However, we note that for physically large arrays the load can often be dominated by the capacitance of the row and column addressing lines. The formula for the energy dissipation due to the capacitance of the bitlines and wordlines is,
$$e _ { l o a d , i } = ( 1 / 2 ) \mathcal { C } L V ^ { 2 } \quad \quad ( A 6 ) \quad \begin{array} { r l r } { { \mathrm d i n } } & { \mathrm d i n } \\ { \mathrm e _ { l o a d , i } = ( 1 / 2 ) \mathcal { C } L V ^ { 2 } \quad \mathrm d i n } \end{array}$$
where C is the capacitance per unit length of the line, and L is the line length. For reference, a typical CMOS copper trace has a capacitance of around 0.2 fF /µm [26], so for a process with 0.9 volts they typically consume 0.08 fJ /µm per operation.
## 1. Silicon Photonics Analog Processors
For an optical computer, there is both an optical and an electrical component to the load for the driving of the inputs:
$$e _ { l o a d , 1 } = e _ { e l e c } + e _ { o p t } . \quad ( A 7 )$$
The electrical component will involve driving some kind of electro-optic modulator, and the energy per operation will depend on the capacitance of that component in the usual way. In the context of silicon photonics, this might be a variable optical attenuator (VOA) on the data input, while a mach-zender interferometer, MEMS modulator, or phase-change modulator is often used to store the weight data in the array. Some of the lower energy approaches used for electro-optic modulators are plasmonic resonators. Out of these, the lowest recorded to date energy per modulation of plasmonic modulators is around e elec ≈ 9 pJ.[27, 28] These are comparable to electrooptic modulators made of doped silicon micro-ring resonators tuned via carrier plasma dispersion have been demonstrated with roughly 0.9pJ/bit, or 7pJ/B.[29] It may be possible to design optical modulators in the future with lower energy per sample than these figures.[30]
The optical contribution to the load itself will depend exponentially on bit precision since the dominant source of optical noise is shot noise. Therefore for the optical component we can write,
$$e _ { o p t } = \frac { \hbar { \omega } } { \eta _ { o p t } } 2 ^ { 2 B } \equiv \gamma _ { o p t } k T 2 ^ { 2 B } \quad ( A 8 )$$
where is Plank's constant in units of angular frequency, ω is the frequency of the light, and η opt is the efficiency of the optical system and photodetector. Conveniently, the optical power consumption also scales as 2 2 B since the dominant source of noise is typically shot noise. To provide numbers for context, for 1550-nm light and an optical efficiency of 80%, we have γ opt ≈ 39, which corresponds to e opt ≈ 10 fJ. In light of the energy per sample associated with current electro-optic technology, the optical contribution to the energy is negligible.
The load associated with the reconfiguration of the weights, e dac, 2 , only has an electrical component, which will involve both the electro-optic modulators and the electrical bitlines used to address the array. Ultra-low energy electro-optic modulators typically also have small dimensions in order to minimize the capacitance, on the order of a few microns, which leads to an additional energy consumption of a few femtojoules per element in the length of the array. This is also negligible compared to the energy associated with the electro-optic modulator itself. Therefore, both e dac, 1 and e dac, 2 are dominated by the electro-optic modulator energy.
## 2. Memristive Analog Processors
In the ReRAM processor, the load has two contributions: the capacitance associated with the conductive lines in the array, and the dissipation of charge in the memristors. The pitch of ReRAM arrays tends to be limited by the size of the transistor placed at each node, which means the array bitlines and wordlines are relatively short and have low capacitance. Nonetheless energy consumption in large arrays can still be dominated by the capacitance, which is given by eq. (A6).
On the other hand, in a ReRAM array the energy per operation consumed by the memristors themselves can also be quite high since the energy is proportional both the size of the array, and proportional to their average conductance, and the conductance is limited by the quantum conductance of G 0 = 2 e 2 /h , where e is the charge of an electron and h is Plank's constant. The conductance of these elements is therefore limited in the range of G = G 0 to G = G 0 2 B for B -bit precision elements.
Memristors are highly nonlinear elements, so the input data is usually supplied with pulse width modulation instead of changing the voltage. Therefore the energy consumed by the entire array can be written as a sum over all the memristors
$$\langle E _ { R e R A M } \rangle = \delta t \sum _ { i = 1 } ^ { M } \sum _ { j = 1 } ^ { N } \langle G _ { i j } \rangle \langle V _ { j } ^ { 2 } \rangle . \quad ( A 9 ) \quad v a r$$
where δt is the samplint period. Using the nominal value of the conductances and voltages for each memristor, we can simplify the equation to
$$\langle E _ { R e R A M } \rangle = \delta t M N \langle G \rangle V _ { r m s } ^ { 2 } . \quad ( A 1 0 )$$
In one action of the array the number of MAC operations is MN , so the average energy per operation consumed by the array is actually a constant and is not reduced by scaling up the array in the case of a ReRAM array:
$$e _ { R e R A M } \equiv \frac { \langle E _ { R e R A M } \rangle } { M N } = \langle G \rangle V _ { r m s } ^ { 2 } \delta t \quad ( A 1 1 ) \quad \text {the}$$
As noted above, the conductance of memristors is only well behave above quantum conductance. Assuming a
- [1] N. P. Jouppi, C. Young, N. Patil, D. Patterson, G. Agrawal, R. Bajwa, S. Bates, S. Bhatia, N. Boden, A. Borchers, et al. , In-datacenter performance analysis of a tensor processing unit, in Proceedings of the 44th annual international symposium on computer architecture (2017) pp. 1-12.
- [2] A. Samajdar, J. M. Joseph, Y. Zhu, P. Whatmough, M. Mattina, and T. Krishna, A systematic methodology for characterizing scalability of dnn accelerators us-
uniform distribution, the average value will be half the dynamic range, and therefore 〈 G 〉 = 2 B -1 G 0 .
The energy is proportional to the square of the voltage, so we assume this is limited to maintain B effective bits of precision relative to the Johnson-Nyquist thermal noise V noise limit in the memristors. For a clock period of dt , the thermal noise is,
$$V _ { n o i s e } ^ { 2 } = \frac { 4 k T } { G _ { 0 } \delta t } . \quad ( A 1 2 )$$
since the maximal noise is given by the minimum conductance. Setting V 2 rms = (3 / 2)2 2 B V 2 noise as the minimal required voltage to maintain B bits of accuracy, the
TABLE VI: Typical pitches for various analog compute modulation technologies.
| Active ReRAM[8, 31] | 1-4 µm |
|----------------------------------------------|----------|
| Optical phase-change material [10] | 250 µm |
| Optical Mach-Zender interferometer (MZI)[13] | 100 µm |
TABLE VII: Values of dimensionless constants for various operations. These assume a technology node of 45nm and a voltage of 0.9V. Optical efficiency is assumed to be 50% for γ opt .
| γ m | 3 × 10 6 |
|-------|--------------|
| γ mac | 1 . 2 × 10 5 |
| γ adc | 583 |
| γ dac | 39 |
| γ opt | 105 |
mimimum energy absorbed by the memristor array per operation is,
$$e _ { R e R A M } = 3 k T 2 ^ { 3 B } , \quad ( A 1 3 )$$
While this is the ideal solution, in practice there is a minimum voltage that can be applied that is typically much higher than the thermal noise limit, and is on the order of V rms ≈ 70 mV. Using this estimate and a sampling period of δt = 1 ns, the energy per operation due to the memristors is e ReRAM ≈ 0 . 05 pJ, which is about five times lower than the energy per operation in commercial memristor arrays, but nonetheless places an upper bound on the efficiency at η ≈ 20 TOPS/W.
ing scale-sim, in 2020 IEEE International Symposium on Performance Analysis of Systems and Software (ISPASS) (IEEE, 2020) pp. 58-68.
- [3] M. Horowitz, 1.1 computing's energy problem (and what we can do about it), in 2014 IEEE International SolidState Circuits Conference Digest of Technical Papers (ISSCC) (IEEE, 2014) pp. 10-14.
- [4] A. Reuther, P. Michaleas, M. Jones, V. Gadepally, S. Samsi, and J. Kepner, Survey and benchmarking of
machine learning accelerators, in 2019 IEEE high performance extreme computing conference (HPEC) (IEEE, 2019) pp. 1-9.
- [5] A. Sebastian, M. Le Gallo, R. Khaddam-Aljameh, and E. Eleftheriou, Memory devices and applications for in-memory computing, Nature nanotechnology 15 , 529 (2020).
- [6] S. Williams, A. Waterman, and D. Patterson, Roofline: an insightful visual performance model for multicore architectures, Communications of the ACM 52 , 65 (2009).
- [7] M. Demler, Mythic multiplies in a flash, Microprocesser Report (2018).
- [8] Q. Xia and J. J. Yang, Memristive crossbar arrays for brain-inspired computing, Nature materials 18 , 309 (2019).
- [9] A. Shafiee, A. Nag, N. Muralimanohar, R. Balasubramonian, J. P. Strachan, M. Hu, R. S. Williams, and V. Srikumar, Isaac: A convolutional neural network accelerator with in-situ analog arithmetic in crossbars, ACM SIGARCH Computer Architecture News 44 , 14 (2016).
- [10] J. Feldmann, N. Youngblood, M. Karpov, H. Gehring, X. Li, M. Stappers, M. Le Gallo, X. Fu, A. Lukashchuk, A. S. Raja, et al. , Parallel convolutional processing using an integrated photonic tensor core, Nature 589 , 52 (2021).
- [11] J. R. Ong, C. C. Ooi, T. Y. Ang, S. T. Lim, and C. E. Png, Photonic convolutional neural networks using integrated diffractive optics, IEEE journal of selected topics in quantum electronics 26 , 1 (2020).
- [12] M. Y.-S. Fang, S. Manipatruni, C. Wierzynski, A. Khosrowshahi, and M. R. DeWeese, Design of optical neural networks with component imprecisions, Optics Express 27 , 14009 (2019).
- [13] Y. Shen, N. C. Harris, S. Skirlo, M. Prabhu, T. BaehrJones, M. Hochberg, X. Sun, S. Zhao, H. Larochelle, D. Englund, et al. , Deep learning with coherent nanophotonic circuits, Nature photonics 11 , 441 (2017).
- [14] P. Ambs, Optical computing: A 60-year adventure., Advances in Optical Technologies (2010).
- [15] J. Chang, V. Sitzmann, X. Dun, W. Heidrich, and G. Wetzstein, Hybrid optical-electronic convolutional neural networks with optimized diffractive optics for image classification, Scientific reports 8 , 1 (2018).
- [16] X. Lin, Y. Rivenson, N. T. Yardimci, M. Veli, Y. Luo, M. Jarrahi, and A. Ozcan, All-optical machine learning using diffractive deep neural networks, Science 361 , 1004 (2018).
- [17] C. Qian, X. Lin, X. Lin, J. Xu, Y. Sun, E. Li, B. Zhang, and H. Chen, Performing optical logic operations by a diffractive neural network, Light: Science & Applications 9 , 1 (2020).
- [18] T. Zhou, X. Lin, J. Wu, Y. Chen, H. Xie, Y. Li, J. Fan, H. Wu, L. Fang, and Q. Dai, Large-scale neuromorphic optoelectronic computing with a reconfigurable diffrac-
tive processing unit, Nature Photonics 15 , 367 (2021).
- [19] R. Hamerly, L. Bernstein, A. Sludds, M. Soljaˇ ci´ c, and D. Englund, Large-scale optical neural networks based on photoelectric multiplication, Physical Review X 9 , 021032 (2019).
- [20] B. E. Jonsson, An empirical approach to finding energy efficient ADC architectures, in Proc. of 2011 IMEKO IWADC & IEEE ADC Forum (2011) pp. 1-6.
- [21] P. Palmers and M. S. Steyaert, A 10-Bit 1.6-GS/s 27mW current-steering D/A converter with 550-MHz 54dB SFDR bandwidth in 130-nm CMOS, IEEE Transactions on Circuits and Systems I: Regular Papers 57 , 2870 (2010).
- [22] A. Stillmaker and B. Baas, Scaling equations for the accurate prediction of cmos device performance from 180 nm to 7 nm, Integration 58 , 74 (2017).
- [23] I. Koren, Computer Arithmetic Algorithms (PRENTICE HALL, 1993) Chap. 6. High Speed Multiplication.
- [24] R. Landauer, Irreversibility and heat generation in the computing process, IBM journal of research and development 5 , 183 (1961).
- [25] M. Saberi, R. Lotfi, K. Mafinezhad, and W. A. Serdijn, Analysis of power consumption and linearity in capacitive digital-to-analog converters used in successive approximation ADCs, IEEE Transactions on Circuits and Systems I: Regular Papers 58 , 1736 (2011).
- [26] N. H. Weste and D. Harris, CMOS VLSI design: a circuits and systems perspective (Pearson Education India, 2015).
- [27] G. Dabos, D. V. Bellas, R. Stabile, M. Moralis-Pegios, G. Giamougiannis, A. Tsakyridis, A. Totovic, E. Lidorikis, and N. Pleros, Neuromorphic photonic technologies and architectures: scaling opportunities and performance frontiers, Optical Materials Express 12 , 2343 (2022).
- [28] C. Haffner, D. Chelladurai, Y. Fedoryshyn, A. Josten, B. Baeuerle, W. Heni, T. Watanabe, T. Cui, B. Cheng, S. Saha, et al. , Low-loss plasmon-assisted electro-optic modulator, Nature 556 , 483 (2018).
- [29] C. Sun, M. T. Wade, Y. Lee, J. S. Orcutt, L. Alloatti, M. S. Georgas, A. S. Waterman, J. M. Shainline, R. R. Avizienis, S. Lin, et al. , Single-chip microprocessor that communicates directly using light, Nature 528 , 534 (2015).
- [30] D. A. Miller, Attojoule optoelectronics for low-energy information processing and communications, Journal of Lightwave Technology 35 , 346 (2017).
- [31] A. Khakifirooz, K. Cheng, Q. Liu, T. Nagumo, N. Loubet, A. Reznicek, J. Kuss, J. Gimbert, R. Sreenivasan, M. Vinet, et al. , Extremely thin soi for system-on-chip applications, in Proceedings of the IEEE 2012 Custom Integrated Circuits Conference (IEEE, 2012) pp. 1-4.