## A full-stack view of probabilistic computing with p-bits: devices, architectures and algorithms
Shuvro Chowdhury, Andrea Grimaldi, Navid Anjum Aadit, Shaila Niazi, Masoud Mohseni, Shun Kanai, Hideo Ohno, Shunsuke Fukami, Luke Theogarajan, Giovanni Finocchio, Supriyo Datta and Kerem Y. Camsari
Abstract -The transistor celebrated its 75 th birthday in 2022. The continued scaling of the transistor defined by Moore's Law continues, albeit at a slower pace. Meanwhile, computing demands and energy consumption required by modern artificial intelligence (AI) algorithms have skyrocketed. As an alternative to scaling transistors for general-purpose computing, the integration of transistors with unconventional technologies has emerged as a promising path for domain-specific computing. In this article, we provide a full-stack review of probabilistic computing with p-bits as a representative example of the energy-efficient and domain-specific computing movement. We argue that p-bits could be used to build energy-efficient probabilistic systems, tailored for probabilistic algorithms and applications. From hardware, architecture, and algorithmic perspectives, we outline the main applications of probabilistic computers ranging from probabilistic machine learning and AI to combinatorial optimization and quantum simulation. Combining emerging nanodevices with the existing CMOS ecosystem will lead to probabilistic computers with orders of magnitude improvements in energy efficiency and probabilistic sampling, potentially unlocking previously unexplored regimes for powerful probabilistic algorithms.
Index Terms -domain-specific hardware, machine learning, artificial intelligence, p-bits, p-computers, stochastic magnetic tunnel junctions, spintronics, combinatorial optimization, sampling, quantum simulation
## I. INTRODUCTION
T HE slowing down of the Moore era of electronics has coincided with the recent revolution in machine learning and AI algorithms. In the absence of steady transistor scaling and energy improvements, training and maintaining large-scale machine learning models in data centers have become a significant energy concern [1]. The widespread implementation of AI, particularly in industries such as autonomous vehicles [2], is an indication that the energy crisis caused by large-scale machine learning models is not just a data center problem, but a global concern.
Efforts of extending the Moore era of electronics by improving conventional transistor technology continue vigorously. Examples of this approach include 3D heterogeneous integration, 2D materials for transistors and interconnects [3], new transistor physics via negative capacitance [4, 5] or
This work was supported in part by a U.S. National Science Foundation grant CCF 2106260, the Office of Naval Research Young Investigator grant and the Semiconductor Research Corporation. S.F. acknowledges JST-CREST Grant No. JPMJCR19K3 and MEXT X-NICS Grant No. JPJ011438. S.K. acknowledges JST-PRESTO Grant No. JPMJPR21B2. A. Grimaldi and G. Finocchio are with the Department of Mathematical and Computer Sciences, Physical Sciences and Earth Sciences, University of Messina, Messina, Italy. M. Mohseni is with Google Quantum AI. S. Kanai, H. Ohno, and S. Fukami are with RIEC, CSIS, WPI-AIMR and Graduate School of Engineering, Tohoku University, Sendai, Japan. S. Datta is with Elmore Family School of Electrical and Computer Engineering, Purdue University, IN, USA. S. Chowdhury, N. A. Aadit, S. Niazi, L. Theogarajan, and K. Y. Camsari are with the Department of Electrical and Computer Engineering, University of California Santa Barbara, CA, 93106 USA e-mail: (camsari@ucsb.edu).
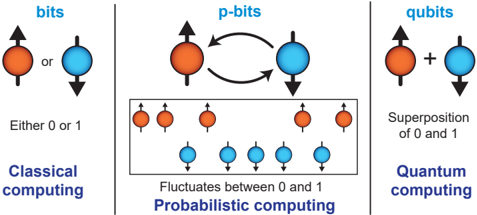
Fig. 1: bit, p-bit, and qubit : Each column shows a schematic representation of the basic computational units of classical computing (left), probabilistic computing (middle), and quantum computing (right). These are, respectively, the bit, the p-bit, and the qubit.
<details>
<summary>Image 1 Details</summary>
### Visual Description
\n
## Diagram: Comparison of Classical, Probabilistic, and Quantum Computing
### Overview
The image is a diagram illustrating the fundamental differences between classical computing (bits), probabilistic computing (p-bits), and quantum computing (qubits). It visually represents how information is stored and manipulated in each paradigm. The diagram uses circular nodes to represent the states of each type of information unit, with arrows indicating possible states or transitions.
### Components/Axes
The diagram is divided into three vertical sections, each representing a different computing paradigm:
* **Left:** Classical Computing - labeled "bits" in blue font.
* **Center:** Probabilistic Computing - labeled "p-bits" in blue font.
* **Right:** Quantum Computing - labeled "qubits" in blue font.
Each section also contains descriptive text:
* Classical Computing: "Either 0 or 1"
* Probabilistic Computing: "Fluctuates between 0 and 1"
* Quantum Computing: "Superposition of 0 and 1"
The bottom of each section shows multiple representations of the information unit.
### Detailed Analysis or Content Details
**Classical Computing (Bits):**
* A single circular node is shown.
* The node can be either orange (representing one state) or blue (representing another state).
* An arrow points upwards from the orange node and downwards from the blue node.
* The text "Either 0 or 1" is positioned below the node.
**Probabilistic Computing (P-bits):**
* Two circular nodes are shown: one orange and one blue.
* A curved, bidirectional arrow connects the orange and blue nodes, indicating fluctuation between states.
* Below the two nodes, a grid of nodes is shown. There are four orange nodes in the top row and six blue nodes in the bottom row.
* The text "Fluctuates between 0 and 1" is positioned below the nodes.
**Quantum Computing (Qubits):**
* Two circular nodes are shown: one orange and one blue.
* A "+" symbol is positioned between the orange and blue nodes.
* An arrow points upwards from the orange node and downwards from the blue node.
* The text "Superposition of 0 and 1" is positioned below the nodes.
### Key Observations
* Classical bits have a definite state (0 or 1).
* Probabilistic bits fluctuate between states, representing probabilities.
* Quantum bits exist in a superposition of states, meaning they can be both 0 and 1 simultaneously.
* The diagram visually emphasizes the increasing complexity and flexibility of information representation as one moves from classical to probabilistic to quantum computing.
### Interpretation
The diagram effectively illustrates the core concept differentiating these three computing paradigms: the representation of information. Classical computing relies on definite states, while probabilistic computing introduces the notion of uncertainty and probability. Quantum computing takes this further by allowing for superposition, where a qubit can exist in multiple states simultaneously. This capability is what gives quantum computers their potential for solving certain problems much faster than classical computers. The diagram is a conceptual illustration rather than a quantitative one; it doesn't provide numerical data but rather conveys the fundamental principles of each computing approach. The use of color (orange and blue) consistently represents the two possible states (0 and 1) across all three paradigms, aiding in understanding the transition and evolution of information representation. The "+" symbol in the quantum computing section is a visual cue for the concept of superposition, indicating the combination of both states.
</details>
entirely new approaches using spintronic and magnetoelectric phenomena to build energy-efficient switches [6, 7].
A complementary approach to extending Moore's Law is to augment the existing CMOS ecosystem with emerging, nonsilicon nanotechnologies [8, 9]. One way to achieve this goal is through heterogeneous CMOS + X architectures where X stands for a CMOS-compatible nanotechnology. For example, X can be magnetic, ferroelectric, memristive or photonic systems. We also discuss an example of this complementary approach, the combination of CMOS with magnetic memory technology, purposefully modified to build probabilistic computers.
## II. FULL-STACK VIEW AND ORGANIZATION
Research on probabilistic computing with p-bits originated at the device and physics level, first with stable nanomagnets [10], followed by low barrier nanomagnets [11, 12]. In [12], the p-bit was formally defined as a binary stochastic neuron realized in hardware. In both approaches with stable and unstable nanomagnets, the basic idea is to exploit the natural mapping between the intrinsically noisy physics of nanomagnets to the mathematics of general probabilistic algorithms (e.g., Monte Carlo, Markov Chain Monte Carlo). Such a notion of natural computing where physics is matched to computation was clearly laid out by Feynman in his celebrated Simulating Physics with Computers talk [13]. Subsequent work on p-bits defined it as an abstraction between bits and qubits (FIG. 1) with the possibility of different physical implementations. In addition to searching for energy-efficient realizations of single devices, p-bit research has extended to finding efficient architectures (through massive parallelization, sparsification [14] and pipelining [15]) along with the identification of promising application domains. This full-stack research program covering hardware, architecture, algorithms, and applications is similar to the related field of quantum computation where a large degree of interdisciplinary expertise
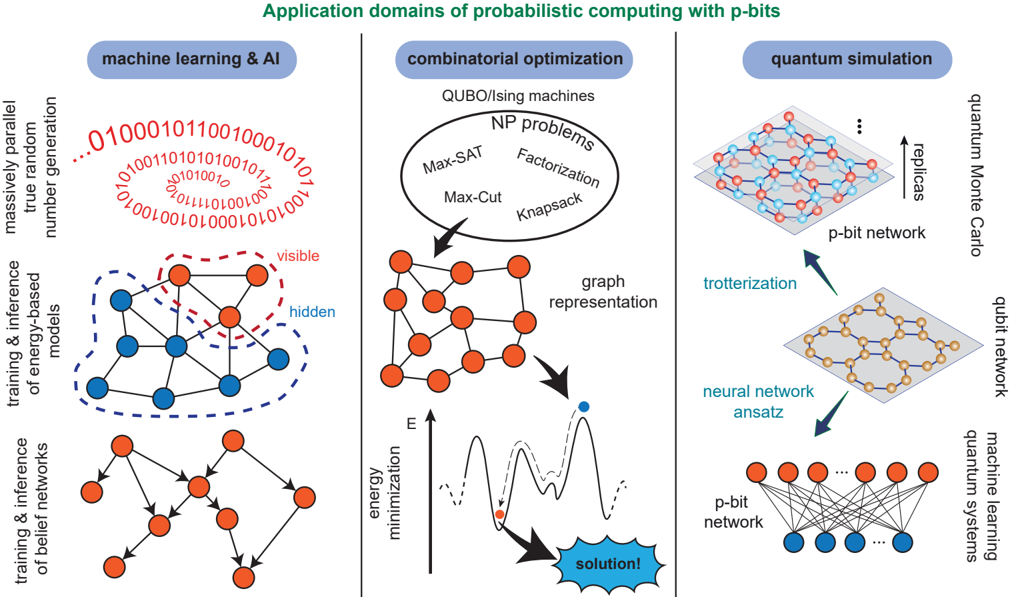
Fig. 2: Applications of probabilistic computing : Potential applications of p-bits are illustrated. The list broadly includes problems in combinatorial optimization, probabilistic machine learning, and quantum simulation.
<details>
<summary>Image 2 Details</summary>
### Visual Description
\n
## Diagram: Application Domains of Probabilistic Computing with p-bits
### Overview
This diagram illustrates the application domains of probabilistic computing using p-bits, categorized into Machine Learning & AI, Combinatorial Optimization, and Quantum Simulation. Each domain is visually represented with a network-like structure and associated concepts. The diagram emphasizes the connection between these domains through the use of "p-bit networks."
### Components/Axes
The diagram is divided into three main columns:
1. **Machine Learning & AI** (leftmost)
2. **Combinatorial Optimization** (center)
3. **Quantum Simulation** (rightmost)
Each column contains interconnected nodes representing concepts within that domain. Key labels include:
* "massively parallel true random number generation"
* "training & inference of energy-based models"
* "training & inference of belief networks"
* "QUBO/ising machines"
* "NP problems"
* "graph representation"
* "trotterization"
* "quantum Monte Carlo"
* "qubit network"
* "neural network ansatz"
* "p-bit network"
* "energy minimization"
* "solution!"
* "replicas"
* "machine learning systems"
* "visible"
* "hidden"
* "Max-SAT"
* "Factorization"
* "Knapsack"
* "Max-Cut"
The diagram also features a binary string: "010001011001000101010100101010010010100010101001010010"
### Detailed Analysis / Content Details
**Machine Learning & AI:**
* The top section shows a circular arrangement of binary digits ("010001011001000101010100101010010010100010101001010010").
* Below this, a network is depicted with nodes labeled "visible" and "hidden," connected by lines. The network appears to be a layered structure.
* The bottom section shows another network structure, likely representing belief networks.
**Combinatorial Optimization:**
* The top section features a circular diagram labeled "QUBO/ising machines" and "NP problems," with examples like "Max-SAT," "Factorization," "Knapsack," and "Max-Cut" listed within.
* A "graph representation" is shown as a network of interconnected nodes.
* Below the graph representation is a plot of "energy minimization" versus "E" (energy). The plot shows a curve with a minimum point labeled "solution!".
**Quantum Simulation:**
* The top section shows a network labeled "replicas" connected to a "p-bit network."
* The middle section shows "trotterization" connecting to a "neural network ansatz."
* The bottom section depicts a network labeled "p-bit network" connected to "machine learning systems."
* A "qubit network" is also shown.
**P-bit Network:**
* A "p-bit network" is a recurring element, appearing in all three domains, suggesting its central role in connecting these areas. It is represented as a network of interconnected nodes.
### Key Observations
* The diagram highlights the interconnectedness of machine learning, combinatorial optimization, and quantum simulation through the use of p-bit networks.
* The "energy minimization" plot in the Combinatorial Optimization section suggests that these problems can be framed as finding the minimum energy state of a system.
* The binary string in the Machine Learning & AI section may represent a random number or a data sample used in the learning process.
* The diagram is conceptual and does not provide specific numerical data. It focuses on illustrating relationships between concepts.
### Interpretation
The diagram suggests that probabilistic computing with p-bits offers a unifying framework for tackling problems in diverse fields like machine learning, optimization, and quantum simulation. The p-bit network acts as a common substrate, allowing for the translation of problems between these domains. The visualization of energy minimization in the combinatorial optimization section implies that these problems can be approached using techniques borrowed from physics, such as finding the ground state of a system. The inclusion of "replicas" in the quantum simulation section hints at the use of replica methods, a technique used to approximate quantum systems. The diagram is a high-level overview and doesn't delve into the specifics of how p-bits are implemented or how these connections are realized in practice. It serves as a conceptual map of the potential applications of this emerging computing paradigm.
</details>
is required to move the field forward (see the related reviews Ref. [16, 17]). The purpose of this paper is to serve as a consolidated summary of recent developments with new results in hardware, architectures, and algorithms. We provide concrete and previously unpublished examples of machine learning and AI, combinatorial optimization, and quantum simulation with p-bits (FIG. 2).
## III. FUNDAMENTALS OF P-COMPUTING
A large family of problems (FIG. 2) can be encoded to coupled p-bits evolving according to the following equations [12]:
$$\begin{array} { r l r } { m _ { i } } & = } & { s i g n \left [ t a n h ( \beta I _ { i } ) - r _ { [ - 1 , + 1 ] } \right ] } & { ( 1 ) } & { d e s c r i j i n g } \end{array}$$
<!-- formula-not-decoded -->
where m i is defined as a bipolar variable ( m ∈ {-1 , +1 } ), r is a uniform random number drawn from the interval [ -1 , 1] , [ W ] is the coupling matrix between the p-bits, β is the inverse temperature and { h } is the bias vector. In physical implementations, it is often more convenient to represent p-bits as binary variables, s i ∈ { 0 , 1 } . A straightforward conversion of Eq. (1) and Eq. (2) is possible using the standard transformation, m → 2 s -1 [18].
As stated, Eq. (1) and Eq. (2) do not place any restrictions on the [ W ] , which may be a symmetric or asymmetric matrix. If an update order of p-bits is specified, these equations take the coupled p-bit system to a well-defined steady-state distribution defined by the eigenvector (with eigenvalue +1 ) of the corresponding Markov matrix [12]. Indeed, in case of Bayesian (belief) networks defined by a directed graph, updating the p-bits from parent nodes to child nodes takes the system to a steady-state distribution corresponding to that obtained from the Bayes' Theorem [19].
If the [ W ] matrix is symmetric, one can define an energy, E , whose negated partial derivative with respect to p-bit m i gives rise to Eq. (2):
<!-- formula-not-decoded -->
In this case, the steady-state distribution of the network is described by [20]:
<!-- formula-not-decoded -->
also known as the Boltzmann Law. As such, iterating a network of p-bits described by Eq. (1) and Eq. (2) eventually approximates the Boltzmann distribution which can be useful for probabilistic sampling and optimization. The approximate sampling avoids the intractable problem of exactly calculating Z . Remarkably, for such undirected networks, the steady-state distribution is invariant with respect to the update order of pbits, as long as connected p-bits are not updated at the same time (more on this later). This feature is highly reminiscent of natural systems where asynchronous dynamics make parallel updates highly unlikely and the update order does not change the equilibrium distribution. Indeed, this gives the hardware implementation of asynchronous networks of p-bits massive parallelism and flexibility in design.
The energy functional defined by Eq. (3) is often the starting point of discussions in the related field of Ising Machines [21-43] with different implementations (see, Ref. [44] for a comprehensive review). In the case of p-bits, however, we view Eq. (1) and Eq. (2) more fundamental than Eq. (3) because the former can also be used to approximate hard inference on directed networks while the latter always relies on undirected networks. Compared to undirected networks using Ising Machines, work on directed neural networks for Bayesian inference has been relatively scarce, although there are exciting developments [19, 45-50].
Finally, the form of Eq. (3) restricts the type of interactions between p-bits to a linear one since the energy is quadratic. Even though higher-order interactions ( k -local) between pbits are possible [18] (also discussed in the context of Ising machines [51, 52]), such higher-order interactions can always be constructed by combining a standard probabilistic gate set at the cost of extra p-bits. In our view, in the case of electronic implementation with scalable p-bits, trading an increased number of p-bits for simplified interconnect complexity is almost always favorable. That being said, algorithmic advantages and the better representative capabilities of higherorder interactions are actively being explored [51, 53].
## IV. HARDWARE: PHYSICAL IMPLEMENTATION OF P-BITS A. p-bit
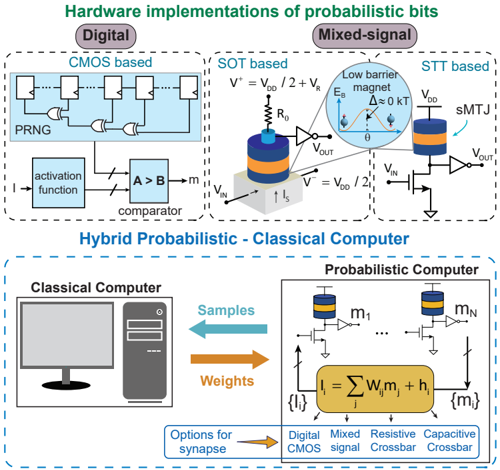
The p-bit defined in Eq. (1) describes a tunable and discrete random number generator. Its physical implementation includes a broad range of options from noisy materials to analog and digital CMOS (FIG. 3). The digital CMOS implementations of p-bits often consist of a pseudorandom number generator (PRNG) ( r ), a lookup table for the activation function (tanh), and a threshold to generate a one-bit output. A digital input with a specified fixed point precision (e.g., 10 bits with 1 sign, 6 integers and 3 fractional) provides tunability through the activation function. Digital p-bits have been very useful in prototyping probabilistic computers up to tens of thousands of p-bits [54, 55, 14]. They also serve a useful purpose to illustrate why analog or mixed-signal implementations of pbits with nanodevices are necessary. Even using some of the most advanced field programmable gate arrays (FPGA), the footprint of a digital p-bit is very large: Synthesizing such digital p-bits with pseudo-random number generators (PRNGs) of varying quality of randomness results in tens of thousands of individual transistors. In single FPGAs that do not use timedivision multiplexing of p-bits or off-chip memory, only about 10,000 to 20,000 p-bits with 100,000 weights (sparse graphs with degree 5 to 10) fit, even within high-end devices [14].
On the other hand, using nanodevices such as CMOScompatible stochastic magnetic tunnel junctions (sMTJ), millions of p-bits can be accommodated in single cores due to the scalability achieved by the MRAM technology, exceeding 1Gbit MRAM chips [56, 57]. However, before the stable MTJs can be controllably made stochastic, challenges at the material and device level must be addressed [58, 59] with careful magnet design [60-62]. Different flavors of magnetic p-bits exist [63-66], for a recent review, see Ref. [67]. Unlike synchronous or trial-based stochasticity (e.g., [68]) that re-
Fig. 3: Different hardware options for building a probabilistic computer : (Top) Various magnetic implementations of a p-bit. These include both digital (CMOS) and mixed-signal implementations (based on, for example, stochastic magnetic tunnel junction with low barrier magnets). (Bottom) A hybrid of classical and probabilistic computing schemes is shown where the classical computer generates weights and programs the probabilistic computer. The probabilistic computer then generates samples accordingly with high throughput and sends them back to the classical computer for further processing. Like the building blocks of p-bits, the synapse of the probabilistic computer can be designed in several ways, including digital, analog, and a mix of both techniques.
<details>
<summary>Image 3 Details</summary>
### Visual Description
## Diagram: Hardware Implementations of Probabilistic Bits & Hybrid Probabilistic-Classical Computer
### Overview
The image presents a diagram illustrating hardware implementations of probabilistic bits, categorized into Digital and Mixed-Signal approaches, and a depiction of a Hybrid Probabilistic-Classical Computer architecture. The diagram details the components and flow of signals within each implementation.
### Components/Axes
The diagram is divided into two main sections: "Hardware implementations of probabilistic bits" (top) and "Hybrid Probabilistic - Classical Computer" (bottom).
**Top Section:**
* **Digital (CMOS based):** Includes components like PRNG, activation function, comparator (A > B), and logic gates (NAND, NOR).
* **Mixed-Signal:** Contains SOT based and STT based implementations.
* **SOT based:** Shows a spin-orbit torque device with voltage sources (V⁺ = VDD / 2 + VR, V⁻ = VDD / 2), resistor (R₀), and output voltage (VOUT).
* **STT based:** Depicts a spin-transfer torque device with a magnetic barrier, voltage sources (VDD), and output voltage (VOUT).
* Labels: VIN, VOUT, VR, VDD, KT, Eb, Δ, m.
**Bottom Section:**
* **Classical Computer:** Depicted as a desktop computer tower.
* **Probabilistic Computer:** Shows multiple probabilistic bit devices (m1...mN) connected to summation and activation functions.
* Equation: {I} = Σ wᵢmᵢ + hᵢ
* Options for synapse: Digital, Mixed signal, Resistive Crossbar, Capacitive Crossbar.
* Labels: Samples, Weights.
### Detailed Analysis or Content Details
**Top Section - Digital (CMOS based):**
* A Pseudo-Random Number Generator (PRNG) feeds into a series of NAND and NOR gates.
* The output of the logic gates goes through an activation function.
* The activation function output is compared using a comparator (A > B).
* The comparator output is indicated by an arrow.
**Top Section - Mixed-Signal (SOT based):**
* A cylindrical device with blue and orange layers is shown.
* Voltage sources V⁺ and V⁻ are connected to the device.
* A resistor R₀ is connected to the device.
* An output voltage VOUT is indicated.
* The diagram shows a low barrier magnet with energy Eb and Δ ≤ 0 KT.
**Top Section - Mixed-Signal (STT based):**
* A cylindrical device with blue and orange layers is shown, labeled as sMTJ.
* Voltage source VDD is connected to the device.
* An output voltage VOUT is indicated.
* The diagram shows a low barrier magnet.
**Bottom Section - Hybrid Probabilistic-Classical Computer:**
* A bidirectional arrow labeled "Samples" connects the Classical Computer to the Probabilistic Computer.
* A bidirectional arrow labeled "Weights" connects the Classical Computer to the Probabilistic Computer.
* The Probabilistic Computer consists of multiple probabilistic bits (m1 to mN) connected to summation and activation functions.
* The equation {I} = Σ wᵢmᵢ + hᵢ represents the computation within the probabilistic computer.
* The "Options for synapse" section lists Digital, Mixed signal, Resistive Crossbar, and Capacitive Crossbar.
### Key Observations
* The diagram illustrates different approaches to implementing probabilistic bits, ranging from traditional digital CMOS circuits to more novel mixed-signal devices based on spin-orbit torque (SOT) and spin-transfer torque (STT).
* The hybrid architecture suggests a combination of classical and probabilistic computation, leveraging the strengths of both paradigms.
* The equation provided indicates a weighted sum of probabilistic bits followed by an activation function.
* The "Options for synapse" section highlights potential hardware implementations for the connections between probabilistic bits.
### Interpretation
The diagram demonstrates a conceptual framework for building probabilistic computers, potentially offering advantages in areas like machine learning and optimization. The use of both digital and mixed-signal implementations suggests a flexible approach to hardware design. The hybrid architecture allows for leveraging existing classical computing infrastructure while incorporating the benefits of probabilistic computation. The different synapse options indicate ongoing research into the most efficient and effective ways to connect and process probabilistic bits. The inclusion of the equation {I} = Σ wᵢmᵢ + hᵢ suggests a neural network-inspired approach to probabilistic computation, where the probabilistic bits act as neurons and the weights represent synaptic strengths. The diagram is a high-level overview and does not provide specific details about the performance or scalability of these implementations. It is a conceptual illustration of potential architectures rather than a detailed engineering blueprint.
</details>
quires continuous resetting, the temporal noise of low-barrier nanomagnets makes them ideally suited to build autonomous, physics-inspired probabilistic computers, providing a constant stream of tunably random bits [69]. Following earlier theoretical predictions [70-72], recent breakthroughs in low-barrier magnets have shown great promise, using stochastic MTJs with in-plane anisotropy where fluctuations can be of the order of nanoseconds [73-75]. Such near-zero barrier nanomagnets should be more tolerant to device variations because when the energy-barrier ∆ is low, the usual exponential dependence of fluctuations is much less pronounced. These stochastic MTJs may be used in electrical circuits with a few additional transistors (FIG. 3) to build hardware p-bits. Two flavors of stochastic MTJ-based p-bits were proposed in Ref. [12] (SOT-based) and in Ref. [70] (STT-based). Both of these p-bits have now been experimentally demonstrated in Refs. [18, 76, 77] (STT) and in Ref. [78] (SOT). While many other implementations of p-bits are possible, from molecular nanomagnets [79] to diffusive memristors [80], RRAM [81], perovskite nickelates [82] and others, two additional advantages of the MRAM-based p-bits are the proven manufacturability (up to billion bit densities) and the amplification of room temperature noise. Even with the thermal energy of kT in the environment, magnetic switching causes large resistance fluctuations in MTJs, creating hundreds of millivolts of change in resistive dividers [70]. Typical noise on resistors (or memristors) is limited by the √ kT/C limit which is far lower (millivolts) even at extremely low capacitances ( C ). This feature of stochastic MTJs ensures
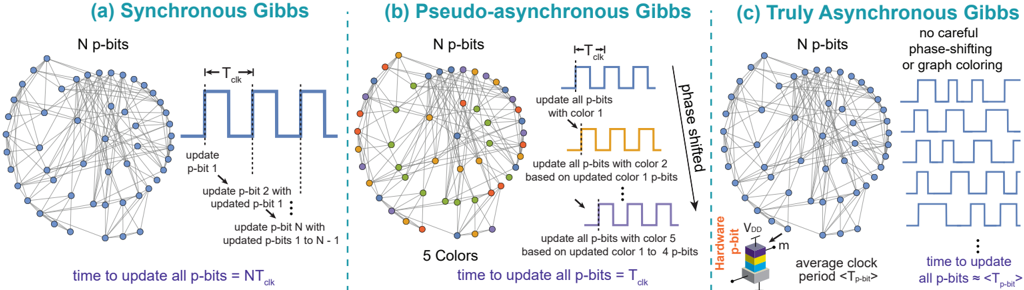
Fig. 4: Architectures of p-computer : (a) Synchronous Gibbs: all p-bits are updated sequentially. N p-bits need N clock cycles ( NT clk ) to perform a complete sweep, T clk being the clock period. (b) Pseudo-asynchronous Gibbs: a sparse network can be colored into a few disjoint blocks where connected p-bits are assigned a different color. Phase-shifted clocks update the color blocks one after the other. N p-bits need ≈ 1 clock cycle T clk to perform a complete sweep, reducing O( N ) complexity of a sweep to O( 1 ), where we assume the number of colors c N . (c) Truly Asynchronous Gibbs: a hardware p-bit (e.g., a stochastic MTJ-based p-bit) provides an asynchronous and random clock with period 〈 T p-bit 〉 . N p-bits need approximately 1 clock to perform a complete sweep, as long as synapse time is less than the clock on average. No graph coloring or engineered phase shifting is required.
<details>
<summary>Image 4 Details</summary>
### Visual Description
\n
## Diagram: Gibbs Sampling Approaches
### Overview
The image presents a comparative diagram illustrating three different approaches to Gibbs sampling: Synchronous, Pseudo-asynchronous, and Truly Asynchronous. Each approach is visualized with a network of nodes ("N p-bits") and a corresponding timing diagram showing how the nodes are updated. The diagram aims to demonstrate the differences in update mechanisms and timing characteristics of each method.
### Components/Axes
Each of the three sections (a, b, c) shares the following components:
* **Network of Nodes:** A circular arrangement of nodes representing "N p-bits". Nodes are colored differently to indicate their state or update order.
* **Timing Diagram:** A series of rectangular pulses representing the timing of updates to the nodes.
* **Textual Labels:** Descriptions of the update process and timing parameters.
Specific to each section:
* **(a) Synchronous Gibbs:** Label "N p-bits", "T<sub>clk</sub>", "update p-bit 1", "update p-bit 2 with updated p-bit 1", "update p-bit N with updated p-bits 1 to N-1", "time to update all p-bits = NT<sub>clk</sub>".
* **(b) Pseudo-asynchronous Gibbs:** Label "N p-bits", "T<sub>clk</sub>", "5 Colors", "update all p-bits with color 1", "update all p-bits with color 2 based on updated color 1 p-bits", "update all p-bits with color 5 based on updated color 1 to 4 p-bits", "time to update all p-bits = T<sub>clk</sub>", "phase shifted". Also includes a vertical bar labeled "Hardware doable".
* **(c) Truly Asynchronous Gibbs:** Label "N p-bits", "no careful phase-shifting or graph coloring", "average clock period <T<sub>clk</sub>>", "time to update all p-bits = <T<sub>p-bit</sub>>".
### Detailed Analysis or Content Details
**(a) Synchronous Gibbs:**
* The network consists of approximately 50 nodes arranged in a circle.
* The timing diagram shows a single clock pulse (T<sub>clk</sub>) followed by a sequence of updates.
* The updates are sequential: p-bit 1 is updated first, then p-bit 2 using the updated value of p-bit 1, and so on, until p-bit N is updated.
* The total time to update all p-bits is stated as NT<sub>clk</sub>, where N is the number of p-bits.
**(b) Pseudo-asynchronous Gibbs:**
* The network has approximately 50 nodes, colored with 5 distinct colors (yellow, green, orange, red, and blue).
* The timing diagram shows a series of pulses, each corresponding to an update with a specific color.
* The updates are performed in color order: all p-bits are updated with color 1, then with color 2 based on the updated color 1 p-bits, and so on, up to color 5.
* The diagram indicates a "phase shifted" aspect to the updates.
* The total time to update all p-bits is stated as T<sub>clk</sub>.
* A vertical bar labeled "Hardware doable" is present.
**(c) Truly Asynchronous Gibbs:**
* The network has approximately 50 nodes, colored with a mix of blue and teal.
* The timing diagram shows a series of irregular pulses, indicating asynchronous updates.
* There is "no careful phase-shifting or graph coloring" involved.
* The average clock period is stated as less than T<sub>clk</sub>.
* The time to update all p-bits is stated as <T<sub>p-bit</sub>>, representing the average time per p-bit.
### Key Observations
* Synchronous Gibbs has a deterministic, sequential update order and a total update time proportional to the number of p-bits (NT<sub>clk</sub>).
* Pseudo-asynchronous Gibbs introduces color-based updates and a phase shift, with a total update time of T<sub>clk</sub>.
* Truly Asynchronous Gibbs has a completely irregular update order and an average update time per p-bit (<T<sub>p-bit</sub>>).
* The diagram highlights the increasing complexity and asynchronicity of the Gibbs sampling approaches from (a) to (c).
### Interpretation
The diagram illustrates the trade-offs between different Gibbs sampling approaches. Synchronous Gibbs is simple to implement but can be slow for large N. Pseudo-asynchronous Gibbs attempts to improve performance by introducing parallelism through color-based updates, but still relies on a global clock. Truly Asynchronous Gibbs offers the highest potential for parallelism and speed but is more complex to implement and may require careful consideration of synchronization issues. The "Hardware doable" label in the Pseudo-asynchronous section suggests a practical implementation constraint. The diagram suggests that the choice of Gibbs sampling approach depends on the specific application and the available hardware resources. The use of color in the Pseudo-asynchronous approach likely represents different states or variables being updated, and the phase shift indicates a deliberate offset in the update timing. The irregular timing in the Truly Asynchronous approach reflects the inherent randomness of the process.
</details>
that they do not require explicit amplifiers [83] at each p-bit, which can become prohibitively expensive in terms of area and power consumption. Estimates of sMTJs-based p-bits suggest they can create a random bit using 2 fJ per operation [18]. Recently, a CMOS-compatible single photon avalanche diodebased implementation of p-bits showed similar, amplifierfree operation [84] and the search for the most scalable, energy-efficient hardware p-bit using alternative phenomena continues.
## B. Synapse
The second central part of the p-computer architecture is the synapse, denoted by Eq. (2). Much like the hardware p-bit, there are several different implementations of synapses ranging from digital CMOS, analog/mixed-signal CMOS as well as resistive [85] or capacitors crossbars [86, 87]. The synaptic equation looks like the traditional matrix-vector product (MVP) commonly used in ML models today, however, there is a crucial difference: thanks to the discrete p-bit output (0 or 1), the MVP operation is simply an addition over the active neighbors of a given p-bit. This makes the synaptic operation simpler than continuous multiplication and significantly simplifies digital synapses. In analog implementations, the use of in-memory computing techniques through charge accumulation could be useful with the added simplification of digital outputs of p-bits [88, 89].
It is important to note how the p-bit and the neuron for eventually integrated p-bit applications can be mixed and matched, as an example of creatively combining these pieces, see the FPGA-stochastic MTJ combination reported in Ref. [77]. The best combination of scalable p-bits and synapses may lead to energy-efficient and large scale p-computers. At this time, various possibilities exist with different technological maturity.
## V. ARCHITECTURE CONSIDERATIONS
## A. Gibbs sampling with p-bits
The dynamical evolution of Eqs. (1-2) relies on an iterated updating scheme where each p-bit is updated one after the other based on a predefined (or random) update order. This iterative scheme is called Gibbs sampling [90, 91]. Virtually all applications discussed in Fig. 2 benefit from accelerating Gibbs sampling, attesting to its generality.
In a standard implementation of Gibbs sampling in a synchronous system, p-bits will be updated one by one at every clock cycle as shown in FIG. 4a. It is crucial to ensure that the effective input each p-bit receives through Eq. (2) is computed before the p-bit updates. As such, the T clk has to be longer than the time it takes to compute Eq. (2). In this setting, a graph with N p-bits will require N clock cycles ( NT clk ) to perform a complete sweep where T clk is the clock period. This requirement makes Gibbs sampling a fundamentally serial and slow process.
Amuch more effective approach is possible by the following observation: even though updates between connected p-bits need to be sequential, if two p-bits are not directly connected, updating one of them does not directly change the input of the other through Eq. (2). Such p-bits can be updated in parallel without any approximation. Indeed, one motivation of designing restricted Boltzmann machines (RBMs, see Ref. [92]) over unrestricted BMs is to exploit this parallelism: RBMs consist of separate layers (bipartite) that can be updated in parallel. However, this idea can be taken further. If the underlying graph is sparse , it is often easy to split it into disconnected chunks by coloring the graph using a few colors. Even though finding the minimum number of colors is an NP-hard problem [93], heuristic coloring algorithms (such as Dsatur [94]) with polynomial complexity can color the graph very quickly, without necessarily finding a minimum. In this context obtaining the minimum coloring is not critical and sparse graphs typically require a few colors.
Such an approach was taken on sparse graphs (with no regular structure) to design a massively parallel implementation of Gibbs sampling in Ref. [14] (FIG. 4b). Connected p-bits are assigned a different color and unconnected p-bits are assigned the same color. Equally phase-shifted and samefrequency clocks update the p-bits in each color block one by one. In this approach, a graph with N p-bits requires only 1 clock cycle ( T clk ) to perform a complete sweep, reducing
O( N ) complexity for a full sweep to O (1) , assuming the number of colors is much less than N . Therefore, the key advantage of this approach is that the p-computer becomes faster with larger graphs since probabilistic 'flips per second', a key metric measured by TPU and GPU implementations [95, 96] linearly increases with the number of p-bits. It is important to note that these TPU and GPU implementations also solve Ising problems in sparse graphs, however, their graph degrees are usually restricted to 4 or 6, unlike more irregular and higher degree graphs implemented in Ref. [14].
We term this graph-colored architecture the pseudoasynchronous Gibbs because while it is technically synchronized to out-of-phase clocks, it embodies elements of the truly asynchronous architecture we discuss next. While graph coloring algorithmically increases sampling rates by a factor of N , it still requires a careful design of out-of-phase clocks. A much more radical approach is to design a truly asynchronous Gibbs sampler as shown in FIG. 4c. Here, the idea is to have hardware building blocks with naturally asynchronous dynamics, such as a stochastic magnetic tunnel junction-based p-bit. In such a p-bit, there exists a natural 'clock', 〈 T p-bit 〉 , defined by the average lifetime of a Poisson process [97]. As long as 〈 T p-bit 〉 is not faster than the average synapse time ( t synapse ) to calculate Eq. (2), the network still updates N spins in a single 〈 T p-bit 〉 timescale. This is because the probability of simultaneous updates is extremely low in a Poisson process and further reduced in highly sparse graphs.
In fact, preliminary experiments implementing such truly asynchronous p-bits with ring-oscillator activated clocks show that despite making occasional parallel updates, the asynchronous p-computer performs similarly compared to the pseudo-asynchronous system where incorrect updates are avoided with careful phase-shifting [98]. The main appeal of the truly asynchronous Gibbs sampling is the lack of any graph coloring and phase-shift engineering while retaining the same massive parallelism as N p-bits requires approximately a single 〈 T p-bit 〉 to complete a sweep. Given that the FPGAbased p-computers already provide about a 10X improvement in sampling throughput to optimized TPU and GPUs [14], such asynchronous systems are promising in terms of scalability. Stochastic MTJ-based p-bits should be able to reach high densities on a single chip. Around 20 W of projected power consumption can be reached considering 20 µ Wp-bit/synapse combinations at 1M p-bit density [54, 99, 60]. The ultimate scalability of magnetic p-bits is a significant advantage over alternative approaches based on electronic or photonic devices.
## B. Sparsification
Both the pseudo-asynchronous and the truly asynchronous parallelism require sparse graphs to work well. The first problem is the number of colors: if the graph is dense, it requires a lot of colors, making the architecture very similar to the standard serial Gibbs sampling.
The second problem with a dense graph is the synapse time, t synapse . If many p-bits have a lot of neighbors, the synapse unit needs to compute a large sum before the next update. If the time between two consecutive updates is 〈 T p-bit 〉 , it requires
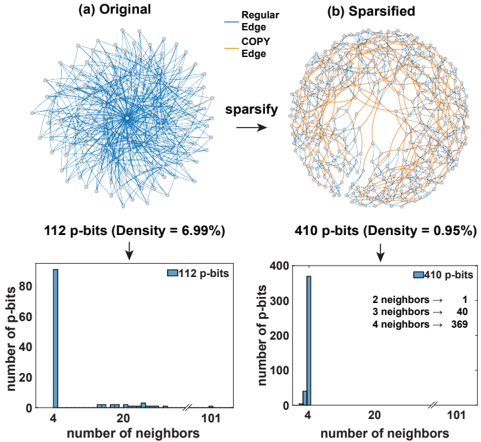
Fig. 5: (a) Original graph of a 3SAT instance uf20-01.cnf [100] having 112 p-bits and a graph density of 6.99%. (Graph density, ρ = 2 | E | / ( | V | 2 -| V | ) where | E | = the number of edges and | V | = the number of vertices in the graph). Some of the p-bits have many local neighbors up to 101 neighbors as shown in the histogram which slows down the synapse and the p-bits need to update slowly. (b) Sparsified graph of the same instance having 410 pbits. COPY gates are inserted between each pair of copies of the same p-bits (COPY edges are highlighted in orange). The graph has a density of 0 . 95% and the maximum number of neighbors is limited to 4 . The synapse operations are now faster and hence the p-bits can be updated faster. Even though the example shown here starts from a low-density graph, the sparsification algorithm we give is general and applicable to any graph.
<details>
<summary>Image 5 Details</summary>
### Visual Description
## Network Diagram: Original vs. Sparsified Graph & Neighbor Distribution
### Overview
The image presents a comparison between an original network graph and a sparsified version, along with histograms illustrating the distribution of the number of neighbors for each graph. The diagrams demonstrate the effect of a "sparsify" operation on network density and neighbor connectivity.
### Components/Axes
* **Diagram (a): Original** - A network graph with nodes arranged roughly in a circular pattern.
* **Diagram (b): Sparsified** - A network graph, also with nodes arranged roughly in a circular pattern, but with fewer edges.
* **Arrow:** A labeled arrow between diagrams (a) and (b) indicating the transformation "sparsify".
* **Histogram 1:** Distribution of the number of neighbors for the 112 p-bits graph.
* X-axis: "number of neighbors" (scale from 0 to 101, approximately).
* Y-axis: "number of p-bits" (scale from 0 to 80, approximately).
* **Histogram 2:** Distribution of the number of neighbors for the 410 p-bits graph.
* X-axis: "number of neighbors" (scale from 0 to 101, approximately).
* Y-axis: "number of p-bits" (scale from 0 to 400, approximately).
* **Legend (Diagrams a & b):**
* Blue Line: "Regular Edge"
* Orange Line: "COPY Edge"
* **Text Labels:**
* "112 p-bits (Density = 6.99%)" - positioned above Histogram 1.
* "410 p-bits (Density = 0.95%)" - positioned above Histogram 2.
* **Legend (Histogram 2):**
* "2 neighbors -> 1"
* "3 neighbors -> 40"
* "4 neighbors -> 369"
### Detailed Analysis or Content Details
**Diagram (a) - Original:**
The original graph appears densely connected. The nodes are arranged in a circular fashion, with many edges radiating from the center and connecting neighboring nodes. The edges are predominantly blue ("Regular Edge"), with a smaller number of orange edges ("COPY Edge"). The density is reported as 6.99%.
**Diagram (b) - Sparsified:**
The sparsified graph exhibits significantly fewer edges than the original. While the nodes maintain a similar circular arrangement, the connections are much sparser. The density is reported as 0.95%. The proportion of orange ("COPY Edge") edges appears higher in the sparsified graph compared to the original.
**Histogram 1 (112 p-bits):**
The histogram shows a strong peak at a low number of neighbors (approximately 4). The number of p-bits decreases rapidly as the number of neighbors increases.
* Approximately 75 p-bits have 4 neighbors.
* The number of p-bits with 20 or more neighbors is very low (less than 5).
**Histogram 2 (410 p-bits):**
This histogram also shows a strong peak, but at a higher number of neighbors (approximately 4). The distribution is more spread out than the first histogram.
* Approximately 370 p-bits have 4 neighbors.
* Approximately 40 p-bits have 3 neighbors.
* Only 1 p-bit has 2 neighbors.
* The number of p-bits with 20 or more neighbors is very low (less than 10).
### Key Observations
* The "sparsify" operation drastically reduces the density of the network.
* The sparsification process appears to preserve a core set of connections (around 4 neighbors per node), while removing many other edges.
* The proportion of "COPY Edge" connections seems to increase after sparsification.
* The distribution of neighbors shifts towards lower values after sparsification.
### Interpretation
The data suggests that the "sparsify" operation is designed to reduce the complexity of the network while maintaining a minimal level of connectivity. The decrease in density from 6.99% to 0.95% indicates a substantial reduction in the number of edges. The histograms reveal that the sparsification process primarily removes nodes with a high degree (many neighbors), leaving a core network with a relatively low degree. The increase in the proportion of "COPY Edge" connections could indicate that these edges are prioritized during the sparsification process, perhaps representing important or critical connections within the network. The overall effect is a more efficient and less redundant network structure. The data suggests a deliberate attempt to prune the network, potentially for computational efficiency or to highlight specific connections.
</details>
t synapse 〈 T p-bit 〉 to avoid information loss and reach the correct steady-state distribution [101, 54].
However, if the graph is sparse, each p-bit has fewer connections and the updates can be faster without any dropped messages. Any graph can be sparsified using the technique proposed in [14], similar in spirit to the minor-graph embedding (MGE) approach pioneered by D-Wave [102], even though the objective here is to not find an embedding but to sparsify an existing graph. The key idea is to split p-bits into different copies, using ferromagnetic COPY gates. These p-bits distribute the original connections among them, resulting in identical copies with fewer connections. An important point is that the ground-state of the original graph remains unchanged [14], so the method does not involve approximations, unlike other sparsification techniques, for example, based on low-rank approximations [103].
FIG. 5a shows an example of this process where the original graph of a satisfiability (3SAT) instance has been sparsified as shown in FIG. 5b. Irrespective of the input graph size, a sparsified graph has fewer connections locally and thus the neurons hardly ever need to be slowed down. One disadvantage of this technique is the increased number of p-bits, however, the reduced synapse complexity and the possibility of massive parallelization outweigh the costs incurred by additional p-bits, which we consider to be cheap in scaled, nanodevice-based implementations.
+
<details>
<summary>Image 6 Details</summary>
### Visual Description
\n
## Diagram: Combinatorial Optimization Problems and Ising Model Formulation
### Overview
The image presents a comparative analysis of three combinatorial optimization problems – Max-SAT, Number Partitioning, and Knapsack – illustrating their mathematical formulations, invertible logic implementations, and corresponding Ising model formulations visualized as heatmaps. The diagram is structured into three columns, each dedicated to one problem, with two rows: the top row showing the mathematical and logical representation, and the bottom row displaying the Ising model formulation as a heatmap.
### Components/Axes
Each column (problem) is divided into two sections:
* **Mathematical Formulation:** Contains equations defining the optimization problem.
* **Invertible Logic:** Shows a circuit diagram representing the problem's logic.
* **Ising Model Formulation:** Displays a heatmap representing the Ising model, with a color scale ranging from -2 to +2. The x-axis represents the spin configuration, and the y-axis is not explicitly labeled but appears to represent the energy level or state of the system.
The three problems are:
1. **Max-SAT:** Maximizes the number of satisfied clauses.
2. **Number Partitioning:** Minimizes the difference between the sums of two subsets.
3. **Knapsack:** Maximizes the value of items selected within a weight constraint.
### Detailed Analysis or Content Details
**1. Max-SAT (Left Column)**
* **Mathematical Formulation:**
* `maximize Σvc` where `c` ranges from 1 to `Nc`
* `vc = yc1 ∨ yc2 ∨ ... ∨ ycn`
* `vc ∈ {0,1}` and `yc ∈ {0,1}`
* **Invertible Logic:** A circuit with inputs `y1`, `y2`, `y3`, `y4` and clauses `c1`, `c2`, `c3`. The circuit includes OR gates and a final output of 1. Text states "Clamp missing 1 clauses to 1" and "Clamp all clauses to 1".
* **Ising Model Formulation:** The heatmap shows a pattern of red and blue squares. The color intensity varies, with some squares approaching +2 (red) and others -2 (blue). There's a clear diagonal pattern.
**2. Number Partitioning (Middle Column)**
* **Mathematical Formulation:**
* `minimize Σ si*ni` where `i` ranges from 1 to `N`
* `si ∈ {-1, +1}`
* **Invertible Logic:** Includes 2-bit sign choice blocks, 2's complement operations, and a MAX function. Text states "Clamp sum of sets to 0" and "Clamp sum of values to MAX".
* **Ising Model Formulation:** The heatmap shows a more dispersed pattern than Max-SAT, with a mix of red and blue squares. The diagonal pattern is less pronounced.
**3. Knapsack (Right Column)**
* **Mathematical Formulation:**
* `maximize Σ vi*xi` where `i` ranges from 1 to `N`
* `subject to Σ wi*xi ≤ W` where `i` ranges from 1 to `N`
* `vi > 0`, `wi > 0`, `xi ∈ {0,1}`
* **Invertible Logic:** Includes 2-bit adders, 3-5 bit adders, 2's complement operations, and a MAX function. Text states "Clamp sum of weights to <W".
* **Ising Model Formulation:** The heatmap shows a complex pattern with a mix of red and blue squares. The diagonal pattern is visible but less distinct than in Max-SAT.
**Color Scale (Common to all Ising Model Formulations):**
* -2 (Dark Blue)
* -1 (Blue)
* 0 (White)
* +1 (Red)
* +2 (Dark Red)
### Key Observations
* Each problem has a distinct Ising model representation, suggesting that the energy landscape differs for each optimization task.
* The Max-SAT Ising model exhibits the most pronounced diagonal pattern, potentially indicating a simpler energy landscape.
* The Number Partitioning and Knapsack Ising models show more complex and dispersed patterns, suggesting more challenging optimization landscapes.
* The mathematical formulations clearly define the objective function and constraints for each problem.
* The invertible logic diagrams provide a hardware-oriented view of the problems.
### Interpretation
The diagram demonstrates a powerful connection between combinatorial optimization problems, their logical implementations, and their representation as Ising models. The Ising model formulation allows these problems to be tackled using techniques from statistical physics, such as simulated annealing or quantum annealing.
The differences in the Ising model heatmaps suggest that the computational complexity of each problem varies. Max-SAT, with its clear diagonal pattern, might be easier to solve than Number Partitioning or Knapsack, which have more complex energy landscapes.
The use of invertible logic highlights the potential for building specialized hardware to solve these problems efficiently. The diagram suggests that the Ising model provides a unifying framework for understanding and solving a wide range of combinatorial optimization challenges. The clamping operations in the invertible logic diagrams suggest a method for handling constraints within the Ising model framework. The diagram is a conceptual illustration, and does not provide specific numerical data for the Ising model parameters or performance metrics.
</details>
+
+
Fig. 6: Invertible logic encoding : The encoding process of three optimization problems, the maximum satisfiability problem (left column), number partitioning (central column), and the knapsack problem (right column), is streamlined and visually summarized into three steps: a problem first has to be condensed into a concise mathematical formulation (upper part of the image); then, an invertible Boolean circuit that topologically maps the problem is conceived; finally, the invertible Boolean circuit is converted into an Ising model using probabilistic AND/OR/NOT gates [14].
## VI. ALGORITHMS AND APPLICATIONS
## A. Combinatorial Optimization via Invertible Logic
When using the Ising model to solve an optimization problem, the first step is to provide a mapping between the Ising model and the problem to be solved. Early work on quantum annealing stimulated by D-Wave's quantum annealers generated a significant amount of useful research in this area [104], some of which are being adopted by quantuminspired classical annealers. There are usually many different ways to find a mapping, for example, some strategies may employ more nodes than others to encode the same instance, while others might result in graphs with topology unsuited to the computational architecture of choice. In this context, the invertible logic approach introduced in Ref. [12] stands out for its flexibility and sparse encodings.
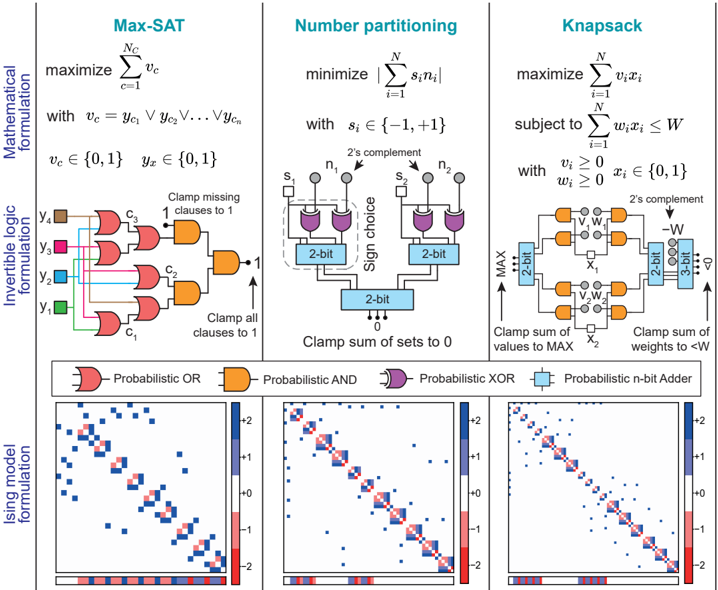
The process of mapping an instance into an Ising model can be broadly summarized into three steps, as illustrated by FIG. 6. In the figure, the steps of the invertible logic encoding of three combinatorial optimization problems, maximum satisfiability (left column), number partitioning (middle column), and knapsack (right column), are shown. First, each problem is formalized into a tight mathematical formulation (top row). Next, the problem is mapped into an invertible Boolean logic circuit (central row), meaning that each logic gate can be operated using any terminals as input/output nodes (similar to those discussed in the context of quantum annealing [105, 106] and memcomputing [107, 108]). Finally, the probabilistic circuit is algorithmically encoded into an
Ising model (bottom row). Each logic gate has several Ising encodings that map the energy landscape of its logic operator. After the Boolean logic formulation of a problem, this step can be automated in standardized synthesis tools. The overall approach results in relatively sparse circuits, as illustrated in the bottom row of FIG. 6 where all three problems show similarly sparse matrices [W], with bias vectors { h } shown under.
The key advantage of this approach, compared to heuristic and dense formulations of Ref. [104], is due to the generality of Boolean logic, quite similar to how present-day digital VLSI circuits are constructed in sparse, hardware-aware networks using billions of transistors. As such, much of the existing ecosystem of high-level synthesis can be directly used to find invertible logic-based encodings for general optimization problems.
## B. Machine Learning: energy-based models
Energy-efficient machine learning (ML) with Boltzmann Machines (BMs) is a promising application for probabilistic computers with a recent experimental demonstration in Ref. [76]. Mainstream ML algorithms are designed and chosen with CPU implementation in mind and hence some models are heavily preferred over others even though they are often less powerful. For example, the use of RBMs over the more powerful unrestricted or deep BMs is motivated by the former's efficient software implementation in synchronous systems. However, by exploiting the technique of sparsity and massively parallel architecture described earlier, fast Gibbs sampling with DBMs
+
+
+
+
+
+
Fig. 7: Generative neural networks with p-bits : (a) Hybrid computing scheme with probabilistic computer and classical computer is demonstrated where the probabilistic computer generates samples according to the weights given by CPU with a sampling speed of around 100 flips/ns. (b) shows the overview of the learning procedure for the hybrid set-up. Receiving the samples from the probabilistic computer, the CPU computes the gradient, updates the weights and biases, and sends them back to the probabilistic computer until converged. (c) Sparse Deep Boltzmann Machine (DBM) is utilized here as a hardware-aware graph that can be represented with multiple hidden layers of p-bits. Both inter-layer and intra-layer connections are allowed between visible and hidden units. (d) The images shown here are generated with a sparse DBM of 4264 p-bits after training the network with full MNIST. The label p-bits are clamped to a specific image and the network evolves to that image by annealing the system from β = 0 to β = 5 with a step size of 0.125.
<details>
<summary>Image 7 Details</summary>
### Visual Description
\n
## Diagram: Hybrid Probabilistic-Classical Computing System
### Overview
The image presents a diagram illustrating a hybrid computing system combining a Probabilistic Computer (PC) and a Classical Computer (CPU). It details the interaction between these two components, the machine learning algorithm overview, a sparse Deep Belief Machine (DBM) representation, and examples of image generation using the system. The image is divided into four sub-diagrams labeled (a), (b), (c), and (d).
### Components/Axes
* **(a) Hybrid Probabilistic-Classical Computer:** Shows the interaction between a "Probabilistic Computer (PC)" and a "Classical Computer (CPU)". The PC sends "samples" and "weights" to the CPU.
* **(b) Overview of Machine Learning Algorithm:** A flowchart outlining the steps of the machine learning algorithm.
* **(c) Sparse DBM Representation:** A diagram of a neural network structure with labeled layers.
* **(d) Image Generation with Sparse DBMs:** Displays four generated images of digits.
* **Labels in (c):** "v" (bottom layer), "h<sup>(1)</sup>" (middle layer), "h<sup>(2)</sup>" (top layer).
### Detailed Analysis or Content Details
**(a) Hybrid Probabilistic-Classical Computer:**
* The Probabilistic Computer (PC) is represented by a salmon-colored rectangle in the top-left.
* The Classical Computer (CPU) is represented by a light-blue rectangle in the top-right.
* An arrow labeled "samples" points from the PC to the CPU.
* An arrow labeled "weights" points from the PC to the CPU.
* Text below the rectangles reads: "Hybrid Probabilistic - Classical Computer".
**(b) Overview of Machine Learning Algorithm:**
* This section is a flowchart within a light-blue rectangle.
* Step 1: "get samples from PC" (top rectangle).
* Step 2: "compute gradients" (middle-top rectangle).
* Step 3: "compute weights (W) and biases (h) (CPU)" (middle-bottom rectangle).
* Step 4: "send W and h to PC" (bottom rectangle).
* Text below the flowchart reads: "Overview of machine learning algorithm".
**(c) Sparse DBM Representation:**
* This section depicts a neural network.
* The bottom layer ("v") consists of approximately 8 blue nodes.
* The middle layer ("h<sup>(1)</sup>") consists of approximately 6 orange nodes.
* The top layer ("h<sup>(2)</sup>") consists of approximately 6 orange nodes.
* Connections between layers are represented by dotted lines.
**(d) Image Generation with Sparse DBMs:**
* This section displays four generated images.
* Image 1: Digit "0".
* Image 2: Digit "7".
* Image 3: Digit "2".
* Image 4: Digit "3".
* Text below the images reads: "Image generation with Sparse DBMs: Full MNIST".
### Key Observations
* The system utilizes a hybrid approach, leveraging the strengths of both probabilistic and classical computing.
* The machine learning algorithm involves iterative sampling, gradient computation, and weight/bias updates.
* The DBM architecture consists of multiple layers of hidden units.
* The system is capable of generating images resembling handwritten digits from the MNIST dataset.
### Interpretation
The diagram illustrates a novel computing paradigm that combines the advantages of probabilistic and classical computation. The probabilistic computer likely generates samples, which are then used by the classical computer to compute gradients and update weights. This iterative process allows the system to learn and generate complex data, such as images of handwritten digits. The use of a sparse DBM suggests an attempt to reduce computational complexity and improve generalization performance. The MNIST dataset is a standard benchmark for image recognition and generation, indicating that the system is being evaluated on a well-established task. The overall architecture suggests a potential for developing more efficient and powerful machine learning algorithms. The flow of information is clearly defined, starting with the PC generating samples, moving to the CPU for processing, and then back to the PC with updated weights. This cyclical process is central to the machine learning algorithm. The diagram doesn't provide quantitative data, but rather a conceptual overview of the system's architecture and functionality.
</details>
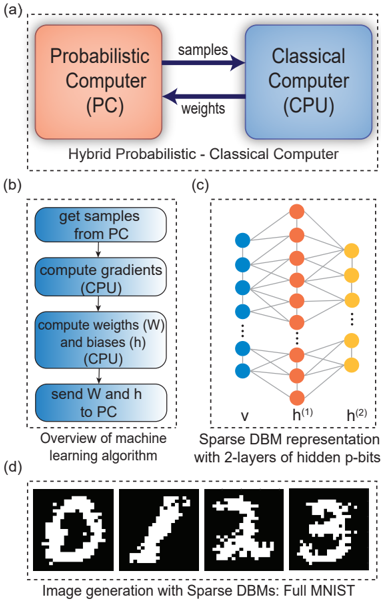
can dramatically improve the state-of-the-art machine learning applications like visual object recognition and generation, speech recognition, autonomous driving, and many more [109]. Here we present an example where a sparse DBM is trained with MNIST handwritten digits (FIG. 7). We randomly distribute the visible and hidden units on the sparse DBM with massively parallel pseudo-asynchronous architecture which yields multiple hidden layers as shown in FIG. 7(c).
Contrasting with earlier unconventional computing approaches where the MNIST dataset is reduced to much smaller sizes [110, 111], we show how the full MNIST dataset (60,000 images and no down-sampling) can be trained using p-computers in FPGAs. We use 1200 mini-batches having 50 images in each batch to train the network using the contrastive divergence (CD) algorithm. The process of learning is accomplished using a hybrid probabilistic and classical computer setup. The classical computer computes the gradients and generates new weights while the p-computer generates samples according to those weights (FIG. 7(b)). During the positive phase of sampling, the p-computer operates in its clamped condition under the direct influence of the training samples. In the negative phase, the p-computer is allowed to run freely without any environmental input. After training, the deep network not only can classify images but also generate images. For any given label, the network can create a new sample (not present in the training set) (FIG. 7(d)). This is an important feature of energy-based models and is commonly demonstrated with diffusion models [112].
## C. Quantum simulation
One primary motivation for building quantum computers is to simulate large quantum many-body systems and understand the exotic physics offered by them [113]. Two major challenges with quantum computers are the necessity of using cryogenic operating temperatures and the vulnerability to noise, rendering quantum computers impractical, especially considering practical overheads [114]. Simulating these systems with classical computers is often extremely time-consuming and mostly limited to small systems. One potential application of p-bits is to provide a room-temperature solution to boost the simulation speed and potentially enable the simulation of large-scale quantum systems. Significant progress has been made toward this end in recent years.
## 1) Simulating quantum systems with Trotterization
One approach is to build a p-computer enabling the scalable simulation of sign-problem-free quantum systems by accelerating standard Quantum Monte Carlo (QMC) techniques [115]. The basic idea is to replace the qubits in the original lattice with hardware p-bits and replicate the new lattice according to the Suzuki-Trotter transformation [116]. Recently, the convergence time of a 2D square-octagonal qubit lattice initially prepared in a topologically obstructed state was compared among a CPU, a physical quantum annealer [117] and a pcomputer (both digital and analog) [118]. For this particular problem, it was shown that an FPGA-based p-computer emulator can be around 1000 times faster than an optimized C++ (CPU) program. Based on SPICE simulations of a small p-computer, we project that significant further acceleration should be possible with a truly asynchronous implementation. Probabilistic computers can be used for quantum Hamiltonians beyond the usual Transverse Field Ising Model, such as the antiferromagnetic Heisenberg Hamiltonian [119] and even for the emulation of gate-based quantum computers [120]. However, for generic Hamiltonians, (e.g., random circuit sampling), the number of samples required in naive implementations seem to grow exponentially [120] due to the notorious signproblem [121]. However, clever basis transformations [122] might mitigate or cure the sign-problem [123] in the future.
## 2) Machine learning quantum many-body systems
With the great success of machine learning and AI algorithms, training stochastic neural networks (such as Boltzmann machines) to approximately solve the quantum many-body problem starting from a variational guess has generated great excitement [124-126] and is considered to be a fruitful combination of quantum physics and machine learning [127]. These algorithms are typically implemented in high-level software programs, allowing users to choose from various network
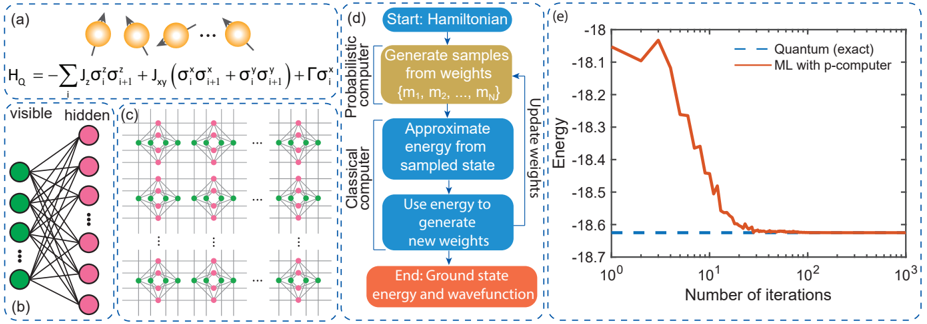
Fig. 8: Machine learning quantum systems with p-bits : (a) Heisenberg Hamiltonian with a transverse field ( Γ = +1 ) is applied to a FM coupled ( J Z = +1 and J xy = +0 . 5 ) linear chain of twelve ( 12 ) qubits with periodic boundary. (b) To obtain the ground state of this quantum system, a restricted Boltzmann machine is employed with 12 visible and 48 hidden nodes, where all nodes in the visible layer are connected to all nodes in the hidden layer. (c) This machine learning model is then embedded onto a hardware amenable sparse p-bit network arranged in a chimera graph using minor graph embedding. We use a coupling strength of 1.0 among the replicated visible and hidden nodes in the embedded p-bit network. (d) An overview of the machine learning algorithm and the division of workload between the probabilistic and classical computers in a hybrid setting is shown. (e) The FPGA emulation of this probabilistic computer performs variational machine learning in tandem with a classical computer, converging to the quantum (exact) result as shown.
<details>
<summary>Image 8 Details</summary>
### Visual Description
## Diagram: Variational Quantum Eigensolver (VQE) Workflow
### Overview
The image depicts a workflow diagram illustrating the Variational Quantum Eigensolver (VQE) algorithm, alongside a representation of the Hamiltonian and a performance comparison chart. The diagram outlines the iterative process of using a probabilistic computer (quantum computer) to generate samples, a classical computer to approximate energy, and update weights to converge towards the ground state energy and wavefunction.
### Components/Axes
The image is divided into four main sections: (a) Hamiltonian representation, (b) Neural Network representation, (c) Quantum-Classical interaction, and (e) Performance comparison chart.
* **(a) Hamiltonian:** Displays the equation for the Hamiltonian: `H₀ = Σᵢ σₓⁱ + Σᵢ<ⱼ Jₓᵣ (σₓⁱσₓᵣ + σᵧⁱσᵧᵣ) + Γσ₂`.
* **(b) Neural Network:** Shows a multi-layered neural network with visible and hidden layers.
* **(c) Quantum-Classical Interaction:** Illustrates the interaction between a probabilistic (quantum) computer and a classical computer.
* **(e) Performance Chart:**
* **X-axis:** Number of iterations (logarithmic scale, from 10⁰ to 10³).
* **Y-axis:** Energy (ranging from approximately -18.1 to -18.7).
* **Data Series:**
* "Quantum (exact)" - represented by a dashed blue line.
* "ML with p-computer" - represented by a solid orange line.
### Detailed Analysis or Content Details
**(a) Hamiltonian:** The equation represents a spin Hamiltonian, likely used to describe a physical system. The symbols represent Pauli matrices (σₓ, σᵧ, σ₂) and coupling constants (Jₓᵣ, Γ).
**(b) Neural Network:** The neural network has 7 visible nodes (green) and 5 hidden nodes (red). The connections between nodes are not explicitly labeled with weights.
**(c) Quantum-Classical Interaction:** This section details the VQE algorithm steps:
1. **Start:** Hamiltonian is defined.
2. **Probabilistic Computer:** Generate samples from weights (m₁, m₂, ..., mₙ).
3. **Classical Computer:** Approximate energy from sampled state.
4. **Classical Computer:** Use energy to generate new weights.
5. **End:** Ground state energy and wavefunction.
**(e) Performance Chart:**
* **Quantum (exact):** The blue dashed line starts at approximately -18.12 and remains relatively constant, fluctuating slightly around -18.11 to -18.13 across the entire range of iterations.
* **ML with p-computer:** The orange solid line starts at approximately -18.08 and exhibits a steep downward trend initially. It reaches approximately -18.65 at around 10¹ iterations. After this point, the slope decreases, and the line continues to descend, approaching -18.12 at 10³ iterations.
### Key Observations
* The ML with p-computer line demonstrates a clear convergence towards the energy value of the Quantum (exact) line.
* The initial convergence of the ML method is rapid, but slows down as it approaches the exact solution.
* The Quantum (exact) line remains stable, indicating the true ground state energy.
* The diagram visually represents the iterative nature of the VQE algorithm, where the classical computer refines the weights based on the energy estimates from the quantum computer.
### Interpretation
The diagram illustrates the core principles of the Variational Quantum Eigensolver (VQE) algorithm. The algorithm leverages a hybrid quantum-classical approach to find the ground state energy of a given Hamiltonian. The quantum computer generates samples, which are then used by a classical computer to estimate the energy. This energy estimate is used to update the parameters of a variational ansatz (represented by the neural network in section (b)), iteratively refining the solution.
The performance chart (e) demonstrates the effectiveness of this approach. The ML with p-computer line's convergence towards the Quantum (exact) line indicates that the algorithm is successfully finding the ground state energy. The initial rapid convergence suggests that the algorithm quickly learns the essential features of the energy landscape, while the slower convergence at later stages indicates that it is fine-tuning the solution to achieve higher accuracy.
The Hamiltonian equation (a) provides the mathematical foundation for the problem being solved, while the neural network (b) represents the variational ansatz used to approximate the ground state wavefunction. The diagram as a whole provides a comprehensive overview of the VQE algorithm, highlighting its key components and workflow. The use of a logarithmic scale on the x-axis of the performance chart emphasizes the iterative nature of the algorithm and the gradual improvement in accuracy over time.
</details>
models and sizes according to their needs. However, as with classical machine learning, the difficulty of training strongly hinders the use of deeper and more general models. With scaled p-computers using millions of magnetic p-bits, massively parallel and energy-efficient hardware implementations of the more general unrestricted/deep BMs may become feasible, paving the way to simulate practical quantum systems.
To demonstrate one such example of this approach, we show how p-bits laid out in sparse, hardware-aware graphs can be used for machine learning quantum systems (FIG. 8). The objective of this problem is to find the ground state of a many-body quantum system, in this case, a 1D FM Heisenberg Hamiltonian with an external transverse field. We start with an RBM, which is one of the simplest neural network models, and use its functional form as the variational guess for the ground state probabilities (the wavefunction is obtained by taking the square root of probabilities according to the Born rule). A combination of probabilistic sampling and weight updates gradually adjusts the variational guess such that the final guess points to the ground state of the quantum Hamiltonian. Emulating this variational ML approach with pbits requires a few more steps. An RBM network contains allto-all connections between the visible and hidden layers which is not conducive for scalable p-computers because of the large fanout demanded by the all-to-all connectivity. An alternative is to map the RBM onto a sparse graph through minor graph embedding [102]. Using a hybrid setup with fast sampling in a probabilistic computer coupled with a classical computer, the iterative process of sampling and weight updating can then be performed. The key advantage of having a massively parallel and fast sampler is the selection of higher-quality states of the wave function to update the variational guess. FIG. 8 shows an example simulation of how a p-computer learns the ground state of a 1D FM Heisenberg model. The scaling of p-computers using magnetic p-bits may allow much larger implementations of quantum systems in the future.
## D. Outlook: algorithms and applications beyond
Despite the large range of applications we discussed in the context of p-bits, much of the sampling algorithms have been either standard MCMC or generic simulated annealing-based approaches. Future possibilities involve more sophisticated sampling and annealing algorithms such as parallel tempering (PT) (see Ref. [128, 129] for some initial investigations). Further improvements to hardware implementation include adaptive versions of PT [130] as well as sophisticated nonequilibrium Monte Carlo (NMC) algorithms [131]. Ideas involving overclocking p-bits such that they violate the t synapse 〈 T p-bit 〉 requirement for further improvement [14] or sharing synaptic operations between p-bits [82] could also be useful. A combination of these ideas with algorithm-architecture-device co-design may lead to orders of magnitude improvement in sampling speeds and quality. In this context, as a sampling throughput metric, increasing flips/ns is an important goal. In addition, solution quality, the possibility of cluster updates or algorithmic techniques also need to be considered carefully. Given the plethora of approaches from multiple communities, we also hope that model problems, benchmarking studies comparing different Ising machines, probabilistic accelerators, physical annealers and dynamical solvers will be performed in the near future from all practitioners, including ourselves.
We believe that the co-design of algorithms, architectures, and devices for probabilistic computing may not only help mitigate the looming energy crisis of machine learning and AI but also lead to systems which may unlock previously inaccessible regimes using powerful probabilistic (randomized) algorithms [132]. Just as the emergence of powerful GPUs made the well-known backpropagation algorithm flourish, probabilistic computers could lead us to the previously unknown territory of energy-based AI models, combinatorial optimization and quantum simulation. This research program requires a concerted effort and interdisciplinary expertise from all across the stack and ties into the larger vision of unconventional computing forming in the community [133].
## REFERENCES
- [1] D. Patterson, J. Gonzalez, Q. Le, C. Liang, L.-M. Munguia, D. Rothchild, D. So, M. Texier, and J. Dean, 'Carbon emissions and large neural network training,' arXiv preprint arXiv:2104.10350 , 2021.
- [2] S. Sudhakar, V. Sze, and S. Karaman, 'Data centers on wheels: Emissions from computing onboard autonomous vehicles,' IEEE Micro , vol. 43, no. 1, pp. 29-39, 2022.
- [3] R. Chau, 'Process and packaging innovations for moore's law continuation and beyond,' in 2019 IEEE International Electron Devices Meeting (IEDM) . IEEE, 2019, pp. 1-1.
- [4] J. C. Wong and S. Salahuddin, 'Negative capacitance transistors,' Proceedings of the IEEE , vol. 107, no. 1, pp. 49-62, 2018.
- [5] M. A. Alam, M. Si, and P. D. Ye, 'A critical review of recent progress on negative capacitance field-effect transistors,' Applied Physics Letters , vol. 114, no. 9, p. 090401, 2019.
- [6] S. Manipatruni, D. E. Nikonov, C.-C. Lin, T. A. Gosavi, H. Liu, B. Prasad, Y.-L. Huang, E. Bonturim, R. Ramesh, and I. A. Young, 'Scalable energy-efficient magnetoelectric spin-orbit logic,' Nature , vol. 565, no. 7737, pp. 35-42, 2019.
- [7] P. Debashis, J. Plombon, C.-C. Lin, Y.-C. Liao, H. Li, D. Nikonov, D. Adams, C. Rogan, M. DC, M. Radosavljevic, S. Clendenning, I. Young, and I. Corporation, 'Low-voltage and high-speed switching of a magnetoelectric element for energy efficient compute,' in 2022 IEEE International Electron Devices Meeting (IEDM) , 2022.
- [8] A. Chen, 'Emerging research device roadmap and perspectives,' in 2014 IEEE International Conference on IC Design & Technology . IEEE, 2014, pp. 1-4.
- [9] G. Finocchio, M. Di Ventra, K. Y. Camsari, K. Everschor-Sitte, P. Khalili Amiri, and Z. Zeng, 'The promise of spintronics for unconventional computing,' Journal of Magnetism and Magnetic Materials , vol. 521, p. 167506, 2021.
- [10] B. Behin-Aein, V. Diep, and S. Datta, 'A building block for hardware belief networks,' Scientific reports , vol. 6, no. 1, pp. 1-10, 2016.
- [11] B. Sutton, K. Y. Camsari, B. Behin-Aein, and S. Datta, 'Intrinsic optimization using stochastic nanomagnets,' Scientific Reports , vol. 7, p. 44370, 2017.
- [12] K. Y. Camsari, R. Faria, B. M. Sutton, and S. Datta, 'Stochastic p-bits for invertible logic,' Physical Review X , vol. 7, no. 3, p. 031014, 2017.
- [13] R. P. Feynman, 'Simulating physics with computers,' International journal of theoretical physics , vol. 21, no. 6-7, pp. 467-488, 1982.
- [14] N. A. Aadit, A. Grimaldi, M. Carpentieri, L. Theogarajan, J. M. Martinis, G. Finocchio, and K. Y. Camsari, 'Massively parallel probabilistic computing with sparse ising machines,' Nature Electronics , pp. 1-9, 2022.
- [15] J. Kaiser, R. Jaiswal, B. Behin-Aein, and S. Datta,
'Benchmarking a probabilistic coprocessor,' arXiv preprint arXiv:2109.14801 , 2021.
- [16] S. Misra, L. C. Bland, S. G. Cardwell, J. A. C. Incorvia, C. D. James, A. D. Kent, C. D. Schuman, J. D. Smith, and J. B. Aimone, 'Probabilistic neural computing with stochastic devices,' Advanced Materials , p. 2204569, 2022.
- [17] P. J. Coles, 'Thermodynamic ai and the fluctuation frontier,' arXiv preprint arXiv:2302.06584 , 2023.
- [18] W. A. Borders, A. Z. Pervaiz, S. Fukami, K. Y. Camsari, H. Ohno, and S. Datta, 'Integer factorization using stochastic magnetic tunnel junctions,' Nature , 2019.
- [19] R. Faria, J. Kaiser, K. Y. Camsari, and S. Datta, 'Hardware design for autonomous bayesian networks,' Frontiers in computational neuroscience , vol. 15, p. 14, 2021.
- [20] E. Aarts and J. Korst, Simulated annealing and Boltzmann machines: a stochastic approach to combinatorial optimization and neural computing . John Wiley & Sons, Inc., 1989.
- [21] A. Houshang, M. Zahedinejad, S. Muralidhar, J. Checinski, A. A. Awad, and J. ˚ Akerman, 'A spin hall ising machine,' arXiv preprint arXiv:2006.02236 , 2020.
- [22] Y. Su, J. Mu, H. Kim, and B. Kim, 'A scalable cmos ising computer featuring sparse and reconfigurable spin interconnects for solving combinatorial optimization problems,' IEEE Journal of Solid-State Circuits , vol. 57, no. 3, pp. 858-868, 2022.
- [23] S. Bhanja, D. Karunaratne, R. Panchumarthy, S. Rajaram, and S. Sarkar, 'Non-boolean computing with nanomagnets for computer vision applications,' Nature nanotechnology , vol. 11, no. 2, pp. 177-183, 2016.
- [24] P. Debashis, R. Faria, K. Y. Camsari, J. Appenzeller, S. Datta, and Z. Chen, 'Experimental demonstration of nanomagnet networks as hardware for ising computing,' in Electron Devices Meeting (IEDM), 2016 IEEE International . IEEE, 2016, pp. 34-3.
- [25] P. L. McMahon et al., 'A fully programmable 100spin coherent ising machine with all-to-all connections,' Science , vol. 354, no. 6312, pp. 614-617, 2016.
- [26] S. Dutta, A. Khanna, A. Assoa, H. Paik, D. G. Schlom, Z. Toroczkai, A. Raychowdhury, and S. Datta, 'An ising hamiltonian solver based on coupled stochastic phasetransition nano-oscillators,' Nature Electronics , vol. 4, no. 7, pp. 502-512, 2021.
- [27] J. Chou, S. Bramhavar, S. Ghosh, and W. Herzog, 'Analog coupled oscillator based weighted ising machine,' Scientific reports , vol. 9, no. 1, pp. 1-10, 2019.
- [28] M. Yamaoka et al., 'A 20k-spin ising chip to solve combinatorial optimization problems with cmos annealing,' IEEE Journal of Solid-State Circuits , vol. 51, no. 1, pp. 303-309, 2016.
- [29] T. Wang and J. Roychowdhury, 'Oim: Oscillator-based ising machines for solving combinatorial optimisation problems,' in International Conference on Unconventional Computation and Natural Computation . Springer, 2019, pp. 232-256.
- [30] Y. Shim, A. Jaiswal, and K. Roy, 'Ising computation based combinatorial optimization using spin-hall effect (she) induced stochastic magnetization reversal,' Journal of Applied Physics , vol. 121, no. 19, p. 193902, 2017.
- [31] T. Inagaki et al., 'A coherent ising machine for 2000node optimization problems,' Science , vol. 354, no. 6312, pp. 603-606, 2016.
- [32] M. Baity-Jesi, R. A. Ba˜ nos, A. Cruz, L. A. Fernandez, J. M. Gil-Narvi´ on, A. Gordillo-Guerrero, D. I˜ niguez, A. Maiorano, F. Mantovani, E. Marinari et al. , 'Janus ii: A new generation application-driven computer for spin-system simulations,' Computer Physics Communications , vol. 185, no. 2, pp. 550-559, 2014.
- [33] M. Yamaoka, C. Yoshimura, M. Hayashi, T. Okuyama, H. Aoki, and H. Mizuno, '24.3 20k-spin ising chip for combinational optimization problem with cmos annealing,' in 2015 IEEE International Solid-State Circuits Conference-(ISSCC) Digest of Technical Papers . IEEE, 2015, pp. 1-3.
- [34] N. G. Berloff, M. Silva, K. Kalinin, A. Askitopoulos, J. D. T¨ opfer, P. Cilibrizzi, W. Langbein, and P. G. Lagoudakis, 'Realizing the classical xy hamiltonian in polariton simulators,' Nature materials , vol. 16, no. 11, pp. 1120-1126, 2017.
- [35] T. Takemoto, M. Hayashi, C. Yoshimura, and M. Yamaoka, '2.6 a 2 × 30k-spin multichip scalable annealing processor based on a processing-in-memory approach for solving large-scale combinatorial optimization problems,' in 2019 IEEE International Solid-State Circuits Conference-(ISSCC) . IEEE, 2019, pp. 52-54.
- [36] H. Goto, K. Tatsumura, and A. R. Dixon, 'Combinatorial optimization by simulating adiabatic bifurcations in nonlinear hamiltonian systems,' Science advances , vol. 5, no. 4, p. eaav2372, 2019.
- [37] M. Aramon, G. Rosenberg, E. Valiante, T. Miyazawa, H. Tamura, and H. G. Katzgraber, 'Physics-inspired optimization for quadratic unconstrained problems using a digital annealer,' Frontiers in Physics , vol. 7, p. 48, 2019.
- [38] A. Mallick, M. K. Bashar, D. S. Truesdell, B. H. Calhoun, S. Joshi, and N. Shukla, 'Using synchronized oscillators to compute the maximum independent set,' Nature communications , vol. 11, no. 1, pp. 1-7, 2020.
- [39] K. Yamamoto, K. Ando, N. Mertig, T. Takemoto, M. Yamaoka, H. Teramoto, A. Sakai, S. TakamaedaYamazaki, and M. Motomura, '7.3 statica: A 512-spin 0.25 m-weight full-digital annealing processor with a near-memory all-spin-updates-at-once architecture for combinatorial optimization with complete spin-spin interactions,' in 2020 IEEE International Solid-State Circuits Conference-(ISSCC) . IEEE, 2020, pp. 138-140.
- [40] S. Patel, P. Canoza, and S. Salahuddin, 'Logically synthesized and hardware-accelerated restricted boltzmann machines for combinatorial optimization and integer factorization,' Nature Electronics , vol. 5, no. 2, pp. 92101, 2022.
- [41] R. Afoakwa, Y. Zhang, U. K. R. Vengalam, Z. Ignja-
tovic, and M. Huang, 'Cmos ising machines with coupled bistable nodes,' arXiv preprint arXiv:2007.06665 , 2020.
- [42] A. Lu, J. Hur, Y.-C. Luo, H. Li, D. E. Nikonov, I. Young, Y.-K. Choi, and S. Yu, 'Scalable in-memory clustered annealer with temporal noise of finfet for the travelling salesman problem,' in 2022 International Electron Devices Meeting (IEDM) . IEEE, 2022, pp. 22-5.
- [43] W. Moy, I. Ahmed, P.-w. Chiu, J. Moy, S. S. Sapatnekar, and C. H. Kim, 'A 1,968-node coupled ring oscillator circuit for combinatorial optimization problem solving,' Nature Electronics , vol. 5, no. 5, pp. 310-317, 2022.
- [44] N. Mohseni, P. L. McMahon, and T. Byrnes, 'Ising machines as hardware solvers of combinatorial optimization problems,' Nature Reviews Physics , vol. 4, no. 6, pp. 363-379, may 2022.
- [45] M. Marsman, G. Maris, T. Bechger, and C. Glas, 'Bayesian inference for low-rank ising networks,' Scientific Reports , vol. 5, no. 1, mar 2015.
- [46] M. T. McCray, M. A. Abeed, and S. Bandyopadhyay, 'Electrically programmable probabilistic bit anticorrelator on a nanomagnetic platform,' Scientific reports , vol. 10, no. 1, pp. 1-11, 2020.
- [47] P. Debashis, V. Ostwal, R. Faria, S. Datta, J. Appenzeller, and Z. Chen, 'Hardware implementation of bayesian network building blocks with stochastic spintronic devices,' Scientific reports , vol. 10, no. 1, p. 16002, 2020.
- [48] S. Nasrin, J. Drobitch, P. Shukla, T. Tulabandhula, S. Bandyopadhyay, and A. R. Trivedi, 'Bayesian reasoning machine on a magneto-tunneling junction network,' Nanotechnology , vol. 31, no. 48, p. 484001, 2020.
- [49] K.-E. Harabi, T. Hirtzlin, C. Turck, E. Vianello, R. Laurent, J. Droulez, P. Bessi` ere, J.-M. Portal, M. Bocquet, and D. Querlioz, 'A memristor-based bayesian machine,' Nature Electronics , pp. 1-12, 2022.
- [50] M. G. Morshed, S. Ganguly, and A. W. Ghosh, 'A deep dive into the computational fidelity of high variability low energy barrier magnet technology for accelerating optimization and bayesian problems,' 2023. [Online]. Available: https://arxiv.org/abs/2302.08074
- [51] C. Bybee, D. Kleyko, D. E. Nikonov, A. Khosrowshahi, B. A. Olshausen, and F. T. Sommer, 'Efficient optimization with higher-order ising machines,' arXiv preprint arXiv:2212.03426 , 2022.
- [52] M. K. Bashar and N. Shukla, 'Constructing dynamical systems to model higher order ising spin interactions and their application in solving combinatorial optimization problems,' arXiv preprint arXiv:2211.05365 , 2022.
- [53] N. Onizawa and T. Hanyu, 'High convergence rates of cmos invertible logic circuits based on many-body hamiltonians,' in 2021 IEEE International Symposium on Circuits and Systems (ISCAS) . IEEE, 2021, pp. 1-5.
- [54] B. Sutton, R. Faria, L. A. Ghantasala, R. Jaiswal, K. Y. Camsari, and S. Datta, 'Autonomous probabilistic coprocessing with petaflips per second,' IEEE Access ,
vol. 8, pp. 157 238-157 252, 2020.
- [55] J. Kaiser and S. Datta, 'Probabilistic computing with p-bits,' Applied Physics Letters , vol. 119, no. 15, p. 150503, 2021.
- [56] S. Aggarwal, H. Almasi, M. DeHerrera, B. Hughes, S. Ikegawa, J. Janesky, H. Lee, H. Lu, F. Mancoff, K. Nagel et al. , 'Demonstration of a reliable 1 gb standalone spin-transfer torque mram for industrial applications,' in 2019 IEEE International Electron Devices Meeting (IEDM) . IEEE, 2019, pp. 2-1.
- [57] K. Lee, J. Bak, Y. Kim, C. Kim, A. Antonyan, D. Chang, S. Hwang, G. Lee, N. Ji, W. Kim et al. , '1gbit high density embedded stt-mram in 28nm fdsoi technology,' in 2019 IEEE International Electron Devices Meeting (IEDM) . IEEE, 2019, pp. 2-2.
- [58] J. L. Drobitch and S. Bandyopadhyay, 'Reliability and scalability of p-bits implemented with low energy barrier nanomagnets,' IEEE Magnetics Letters , vol. 10, pp. 1-4, 2019.
- [59] R. Rahman and S. Bandyopadhyay, 'Variability of binary stochastic neurons employing low energy barrier nanomagnets with in-plane anisotropy,' 2021. [Online]. Available: https://arxiv.org/abs/2108.04319
- [60] O. Hassan, S. Datta, and K. Y. Camsari, 'Quantitative evaluation of hardware binary stochastic neurons,' Physical Review Applied , vol. 15, no. 6, p. 064046, 2021.
- [61] K. Y. Camsari, M. M. Torunbalci, W. A. Borders, H. Ohno, and S. Fukami, 'Double-free-layer magnetic tunnel junctions for probabilistic bits,' Physical Review Applied , vol. 15, no. 4, p. 044049, 2021.
- [62] R. Rahman and S. Bandyopadhyay, 'Robustness of binary stochastic neurons implemented with low barrier nanomagnets made of dilute magnetic semiconductors,' IEEE Magnetics Letters , vol. 13, pp. 1-4, 2022.
- [63] Y. Lv, R. P. Bloom, and J.-P. Wang, 'Experimental demonstration of probabilistic spin logic by magnetic tunnel junctions,' IEEE Magnetics Letters , vol. 10, pp. 1-5, 2019.
- [64] K. Y. Camsari, P. Debashis, V. Ostwal, A. Z. Pervaiz, T. Shen, Z. Chen, S. Datta, and J. Appenzeller, 'From charge to spin and spin to charge: Stochastic magnets for probabilistic switching,' Proceedings of the IEEE , vol. 108, no. 8, pp. 1322-1337, 2020.
- [65] X. Chen, J. Zhang, J. Xiao et al. , 'Magnetic-tunneljunction-based true random-number generator with enhanced generation rate,' Physical Review Applied , vol. 18, no. 2, p. L021002, 2022.
- [66] L. Rehm, C. C. M. Capriata, M. Shashank, J. D. Smith, M. Pinarbasi, B. G. Malm, and A. D. Kent, 'Stochastic magnetic actuated random transducer devices based on perpendicular magnetic tunnel junctions,' arXiv preprint arXiv:2209.01480 , 2022.
- [67] B. R. Zink, Y. Lv, and J.-P. Wang, 'Review of magnetic tunnel junctions for stochastic computing,' IEEE Journal on Exploratory Solid-State Computational Devices and Circuits , vol. 8, no. 2, pp. 173-184, dec 2022.
- [68] A. Fukushima, T. Seki, K. Yakushiji, H. Kubota,
H. Imamura, S. Yuasa, and K. Ando, 'Spin dice: A scalable truly random number generator based on spintronics,' Applied Physics Express , vol. 7, no. 8, p. 083001, 2014.
- [69] Y. Shao, S. L. Sinaga, I. O. Sunmola, A. S. Borland, M. J. Carey, J. A. Katine, V. Lopez-Dominguez, and P. K. Amiri, 'Implementation of artificial neural networks using magnetoresistive random-access memorybased stochastic computing units,' IEEE Magnetics Letters , vol. 12, pp. 1-5, 2021.
- [70] K. Y. Camsari, S. Salahuddin, and S. Datta, 'Implementing p-bits with embedded mtj,' IEEE Electron Device Letters , vol. 38, no. 12, pp. 1767-1770, 2017.
- [71] J. Kaiser, A. Rustagi, K. Y. Camsari, J. Z. Sun, S. Datta, and P. Upadhyaya, 'Subnanosecond fluctuations in lowbarrier nanomagnets,' Physical Review Applied , vol. 12, no. 5, p. 054056, 2019.
- [72] O. Hassan, R. Faria, K. Y. Camsari, J. Z. Sun, and S. Datta, 'Low-barrier magnet design for efficient hardware binary stochastic neurons,' IEEE Magnetics Letters , vol. 10, pp. 1-5, 2019.
- [73] K. Hayakawa, S. Kanai, T. Funatsu, J. Igarashi, B. Jinnai, W. Borders, H. Ohno, and S. Fukami, 'Nanosecond random telegraph noise in in-plane magnetic tunnel junctions,' Physical Review Letters , vol. 126, no. 11, p. 117202, 2021.
- [74] C. Safranski, J. Kaiser, P. Trouilloud, P. Hashemi, G. Hu, and J. Z. Sun, 'Demonstration of nanosecond operation in stochastic magnetic tunnel junctions,' Nano Letters , vol. 21, no. 5, pp. 2040-2045, feb 2021.
- [75] S. Kanai, K. Hayakawa, H. Ohno, and S. Fukami, 'Theory of relaxation time of stochastic nanomagnets,' Phys. Rev. B , vol. 103, p. 094423, Mar 2021. [Online]. Available: https://link.aps.org/doi/10.1103/PhysRevB.103.094423
- [76] J. Kaiser, W. A. Borders, K. Y. Camsari, S. Fukami, H. Ohno, and S. Datta, 'Hardware-aware in situ learning based on stochastic magnetic tunnel junctions,' Physical Review Applied , vol. 17, no. 1, p. 014016, 2022.
- [77] A. Grimaldi, K. Selcuk, N. A. Aadit, K. Kobayashi, Q. Cao, S. Chowdhury, G. Finocchio, S. Kanai, H. Ohno, S. Fukami, and K. Y. Camsari, 'Experimental evaluation of simulated quantum annealing with mtjaugmented p-bits,' in 2022 IEEE International Electron Devices Meeting (IEDM) , 2022.
- [78] J. Yin, Y. Liu, B. Zhang, A. Du, T. Gao, X. Ma, Y. Dong, Y. Bai, S. Lu, Y. Zhuo, Y. Huang, W. Cai, D. Zhu, K. Shi, K. Cao, D. Zhang, L. Zeng, and W. Zhao, 'Scalable ising computer based on ultra-fast field-free spin orbit torque stochastic device with extreme 1-bit quantization,' in 68th International Electron Devices Meeting (IEDM) , 2022.
- [79] G. M. Guti´ errez-Finol, S. Gim´ enez-Santamarina, Z. Hu, L. E. Rosaleny, S. Cardona-Serra, and A. Gaita-Ari˜ no, 'Lanthanide molecular nanomagnets as probabilistic bits,' 2023. [Online]. Available: https://arxiv.org/abs/ 2301.08182
- [80] K. S. Woo, J. Kim, J. Han, W. Kim, Y. H. Jang,
and C. S. Hwang, 'Probabilistic computing using cu0. 1te0. 9/hfo2/pt diffusive memristors,' Nature Communications , vol. 13, no. 1, p. 5762, 2022.
- [81] Y. Liu, Q. Hu, Q. Wu, X. Liu, Y. Zhao, D. Zhang, Z. Han, J. Cheng, Q. Ding, Y. Han et al. , 'Probabilistic circuit implementation based on p-bits using the intrinsic random property of rram and p-bit multiplexing strategy,' Micromachines , vol. 13, no. 6, p. 924, 2022.
- [82] T. J. Park, K. Selcuk, H.-T. Zhang, S. Manna, R. Batra, Q. Wang, H. Yu, N. A. Aadit, S. K. Sankaranarayanan, H. Zhou et al. , 'Efficient probabilistic computing with stochastic perovskite nickelates,' Nano Letters , vol. 22, no. 21, pp. 8654-8661, 2022.
- [83] S. Cheemalavagu, P. Korkmaz, K. V. Palem, B. E. Akgul, and L. N. Chakrapani, 'A probabilistic cmos switch and its realization by exploiting noise,' in IFIP International Conference on VLSI , 2005, pp. 535-541.
- [84] W. Whitehead, Z. Nelson, K. Y. Camsari, and L. Theogarajan, 'Cmos-compatible ising and potts annealing using single photon avalanche diodes,' arXiv preprint arXiv:2211.12607 , 2022.
- [85] L. Xia, P. Gu, B. Li, T. Tang, X. Yin, W. Huangfu, S. Yu, Y. Cao, Y. Wang, and H. Yang, 'Technological exploration of rram crossbar array for matrix-vector multiplication,' Journal of Computer Science and Technology , vol. 31, no. 1, pp. 3-19, 2016.
- [86] Y. Li, S. Kim, X. Sun, P. Solomon, T. Gokmen, H. Tsai, S. Koswatta, Z. Ren, R. Mo, C. C. Yeh et al. , 'Capacitor-based cross-point array for analog neural network with record symmetry and linearity,' in 2018 IEEE Symposium on VLSI Technology . IEEE, 2018, pp. 25-26.
- [87] O. Hassan, K. Y. Camsari, and S. Datta, 'Voltage-driven building block for hardware belief networks,' IEEE Design & Test , vol. 36, no. 3, pp. 15-21, 2019.
- [88] M. Kang, S. K. Gonugondla, A. Patil, and N. R. Shanbhag, 'A multi-functional in-memory inference processor using a standard 6t sram array,' IEEE Journal of Solid-State Circuits , vol. 53, no. 2, pp. 642-655, 2018.
- [89] N. Verma, H. Jia, H. Valavi, Y. Tang, M. Ozatay, L.-Y. Chen, B. Zhang, and P. Deaville, 'In-memory computing: Advances and prospects,' IEEE Solid-State Circuits Magazine , vol. 11, no. 3, pp. 43-55, 2019.
- [90] S. Geman and D. Geman, 'Stochastic relaxation, gibbs distributions, and the bayesian restoration of images,' IEEE Transactions on pattern analysis and machine intelligence , no. 6, pp. 721-741, 1984.
- [91] D. Koller and N. Friedman, Probabilistic graphical models: principles and techniques . MIT press, 2009.
- [92] G. E. Hinton, A Practical Guide to Training Restricted Boltzmann Machines . Berlin, Heidelberg: Springer Berlin Heidelberg, 2012, pp. 599-619.
- [93] M. R. Garey and D. S. Johnson, Computers and intractability . freeman San Francisco, 1979, vol. 174.
- [94] D. Br´ elaz, 'New methods to color the vertices of a graph,' Communications of the ACM , vol. 22, no. 4, pp. 251-256, apr 1979.
- [95] Y. F. et al., 'Parallel tempering simulation of the three-dimensional edwards-anderson model with compact asynchronous multispin coding on gpu,' Computer Physics Communications , vol. 185, no. 10, pp. 2467 2478, 2014.
- [96] K. Yang, Y.-F. Chen, G. Roumpos, C. Colby, and J. Anderson, 'High performance monte carlo simulation of ising model on tpu clusters,' in Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis , 2019, pp. 115.
- [97] P. Debashis, R. Faria, K. Y. Camsari, S. Datta, and Z. Chen, 'Correlated fluctuations in spin orbit torque coupled perpendicular nanomagnets,' Physical Review B , vol. 101, no. 9, p. 094405, 2020.
- [98] N. A. Aadit, A. Grimaldi, G. Finocchio, and K. Y. Camsari, 'Physics-inspired ising computing with ring oscillator activated p-bits,' in 2022 IEEE 22nd International Conference on Nanotechnology (NANO) , 2022, pp. 393-396.
- [99] S. Bhatti, R. Sbiaa, A. Hirohata, H. Ohno, S. Fukami, and S. Piramanayagam, 'Spintronics based random access memory: a review,' Materials Today , vol. 20, no. 9, pp. 530-548, 2017.
- [100] H. Hoos and T. St¨ utzle, SATLIB: An online resource for research on SAT . IOS Press, 04 2000, pp. 283-292.
- [101] A. Z. Pervaiz, L. A. Ghantasala, K. Y. Camsari, and S. Datta, 'Hardware emulation of stochastic p-bits for invertible logic,' Scientific reports , vol. 7, no. 1, p. 10994, 2017.
- [102] V. Choi, 'Minor-embedding in adiabatic quantum computation: Ii. minor-universal graph design,' Quantum Information Processing , vol. 10, no. 3, pp. 343-353, 2011.
- [103] N. Sagan and J. Roychowdhury, 'Das: Implementing dense ising machines using sparse resistive networks,' in Proceedings of the 41st IEEE/ACM International Conference on Computer-Aided Design , 2022, pp. 19.
- [104] A. Lucas, 'Ising formulations of many np problems,' Frontiers in Physics , vol. 2, p. 5, 2014.
- [105] E. Andriyash, Z. Bian, F. Chudak, M. Drew-Brook, A. D. King, W. G. Macready, and A. Roy, 'Boosting integer factoring performance via quantum annealing offsets,' D-Wave Technical Report Series , vol. 14, no. 2016, 2016.
- [106] J. Biamonte, 'Nonperturbative k-body to two-body commuting conversion hamiltonians and embedding problem instances into ising spins,' Physical Review A , vol. 77, no. 5, p. 052331, 2008.
- [107] F. L. Traversa and M. Di Ventra, 'Polynomial-time solution of prime factorization and np-complete problems with digital memcomputing machines,' Chaos: An Interdisciplinary Journal of Nonlinear Science , vol. 27, no. 2, p. 023107, 2017.
- [108] M. Di Ventra, MemComputing: Fundamentals and Applications . Oxford University Press, 2022.
- [109] R. Salakhutdinov and G. Hinton, 'Deep boltzmann
machines,' in Proceedings of the Twelth International Conference on Artificial Intelligence and Statistics , ser. Proceedings of Machine Learning Research, D. van Dyk and M. Welling, Eds., vol. 5. Hilton Clearwater Beach Resort, Clearwater Beach, Florida USA: PMLR, 16-18 Apr 2009, pp. 448-455. [Online]. Available: https://proceedings.mlr.press/v5/salakhutdinov09a.html
- [110] S. H. Adachi and M. P. Henderson, 'Application of quantum annealing to training of deep neural networks,' arXiv preprint arXiv:1510.06356 , 2015.
- [111] H. Manukian, F. L. Traversa, and M. Di Ventra, 'Accelerating deep learning with memcomputing,' Neural Networks , vol. 110, pp. 1-7, 2019.
- [112] J. Sohl-Dickstein, E. Weiss, N. Maheswaranathan, and S. Ganguli, 'Deep unsupervised learning using nonequilibrium thermodynamics,' in International Conference on Machine Learning . PMLR, 2015, pp. 2256-2265.
- [113] H. Ma, M. Govoni, and G. Galli, 'Quantum simulations of materials on near-term quantum computers,' npj Computational Materials , vol. 6, no. 1, p. 85, 2020.
- [114] R. Babbush, J. R. McClean, M. Newman, C. Gidney, S. Boixo, and H. Neven, 'Focus beyond quadratic speedups for error-corrected quantum advantage,' PRX Quantum , vol. 2, no. 1, p. 010103, 2021.
- [115] K. Y. Camsari, S. Chowdhury, and S. Datta, 'Scalable emulation of sign-problem-free hamiltonians with room-temperature p-bits,' Physical Review Applied , vol. 12, no. 3, p. 034061, 2019.
- [116] M. Suzuki, 'Relationship between d-dimensional quantal spin systems and (d+ 1)-dimensional ising systems: Equivalence, critical exponents and systematic approximants of the partition function and spin correlations,' Progress of theoretical physics , vol. 56, no. 5, pp. 14541469, 1976.
- [117] A. D. King, J. Raymond, T. Lanting, S. V. Isakov, M. Mohseni, G. Poulin-Lamarre, S. Ejtemaee, W. Bernoudy, I. Ozfidan, A. Y. Smirnov et al. , 'Scaling advantage over path-integral monte carlo in quantum simulation of geometrically frustrated magnets,' Nature communications , vol. 12, no. 1, pp. 1-6, 2021.
- [118] S. Chowdhury, K. Y. Camsari, and S. Datta, 'Accelerated quantum monte carlo with probabilistic computers,' 2022. [Online]. Available: https://arxiv.org/abs/2210.17526
- [119] S. Chowdhury, S. Datta, and K. Camsari, 'A probabilistic approach to quantum inspired algorithms,' in 2019 IEEE International Electron Devices Meeting (IEDM) . IEEE, 2019, pp. 37-5.
- [120] S. Chowdhury, K. Y. Camsari, and S. Datta, 'Emulating quantum interference with generalized ising machines,' arXiv preprint arXiv:2007.07379 , 2020.
- [121] M. Troyer et al., 'Computational complexity and fundamental limitations to fermionic quantum monte carlo simulations,' Physical review letters , vol. 94, no. 17, p.
170201, 2005.
- [122] D. Aharonov, X. Gao, Z. Landau, Y. Liu, and U. Vazirani, 'A polynomial-time classical algorithm for noisy random circuit sampling,' arXiv preprint arXiv:2211.03999 , 2022.
- [123] D. Hangleiter, I. Roth, D. Nagaj, and J. Eisert, 'Easing the monte carlo sign problem,' Science advances , vol. 6, no. 33, p. eabb8341, 2020.
- [124] G. Carleo and M. Troyer, 'Solving the quantum manybody problem with artificial neural networks,' Science , vol. 355, no. 6325, pp. 602-606, 2017.
- [125] Z. Cai and J. Liu, 'Approximating quantum manybody wave functions using artificial neural networks,' Phys. Rev. B , vol. 97, p. 035116, Jan 2018. [Online]. Available: https://link.aps.org/doi/10.1103/ PhysRevB.97.035116
- [126] H. Saito and M. Kato, 'Machine learning technique to find quantum many-body ground states of bosons on a lattice,' Journal of the Physical Society of Japan , vol. 87, no. 1, p. 014001, 2018. [Online]. Available: https://doi.org/10.7566/JPSJ.87.014001
- [127] S. D. Sarma, D.-L. Deng, and L.-M. Duan, 'Machine learning meets quantum physics,' arXiv preprint arXiv:1903.03516 , 2019.
- [128] N. A. Aadit, A. Grimaldi, M. Carpentieri, L. Theogarajan, G. Finocchio, and K. Y. Camsari, 'Computing with invertible logic: Combinatorial optimization with probabilistic bits,' in 2021 IEEE International Electron Devices Meeting (IEDM) . IEEE, 2021, pp. 40-3.
- [129] A. Grimaldi, L. S´ anchez-Tejerina, N. A. Aadit, S. Chiappini, M. Carpentieri, K. Camsari, and G. Finocchio, 'Spintronics-compatible approach to solving maximumsatisfiability problems with probabilistic computing, invertible logic, and parallel tempering,' Physical Review Applied , vol. 17, no. 2, p. 024052, 2022.
- [130] G. Desjardins, A. Courville, and Y. Bengio, 'Adaptive parallel tempering for stochastic maximum likelihood learning of rbms,' arXiv preprint arXiv:1012.3476 , 2010.
- [131] M. Mohseni, D. Eppens, J. Strumpfer, R. Marino, V. Denchev, A. K. Ho, S. V. Isakov, S. Boixo, F. RicciTersenghi, and H. Neven, 'Nonequilibrium monte carlo for unfreezing variables in hard combinatorial optimization,' arXiv preprint arXiv:2111.13628 , 2021.
- [132] A. Buluc, T. G. Kolda, S. M. Wild, M. Anitescu, A. DeGennaro, J. Jakeman, C. Kamath, M. E. Lopes, P.-G. Martinsson, K. Myers et al. , 'Randomized algorithms for scientific computing (rasc),' arXiv preprint arXiv:2104.11079 , 2021.
- [133] G. Finocchio, S. Bandyopadhyay, P. Lin, G. Pan, J. J. Yang, R. Tomasello, C. Panagopoulos, M. Carpentieri, V. Puliafito, J. ˚ Akerman et al. , 'Roadmap for unconventional computing with nanotechnology,' arXiv preprint arXiv:2301.06727 , 2023.