## SELFCHECKGPT: Zero-Resource Black-Box Hallucination Detection for Generative Large Language Models
Potsawee Manakul, Adian Liusie, Mark J. F. Gales
ALTA Institute, Department of Engineering, University of Cambridge pm574@cam.ac.uk, al826@cam.ac.uk, mjfg@eng.cam.ac.uk
## Abstract
Generative Large Language Models (LLMs) such as GPT-3 are capable of generating highly fluent responses to a wide variety of user prompts. However, LLMs are known to hallucinate facts and make non-factual statements which can undermine trust in their output. Existing fact-checking approaches either require access to the output probability distribution (which may not be available for systems such as ChatGPT) or external databases that are interfaced via separate, often complex, modules. In this work, we propose "SelfCheckGPT", a simple sampling-based approach that can be used to fact-check the responses of black-box models in a zero-resource fashion, i.e. without an external database. SelfCheckGPT leverages the simple idea that if an LLM has knowledge of a given concept, sampled responses are likely to be similar and contain consistent facts. However, for hallucinated facts, stochastically sampled responses are likely to diverge and contradict one another. We investigate this approach by using GPT-3 to generate passages about individuals from the WikiBio dataset, and manually annotate the factuality of the generated passages. We demonstrate that SelfCheckGPT can: i) detect non-factual and factual sentences; and ii) rank passages in terms of factuality. We compare our approach to several baselines and show that our approach has considerably higher AUC-PR scores in sentence-level hallucination detection and higher correlation scores in passage-level factuality assessment compared to grey-box methods. 1
## 1 Introduction
Large Language Models (LLMs) such as GPT-3 (Brown et al., 2020) and PaLM (Chowdhery et al., 2022) are capable of generating fluent and realistic responses to a variety of user prompts. They have been used in many applications such as automatic
1 Code and dataset can be found on the project page at https://github.com/potsawee/selfcheckgpt .
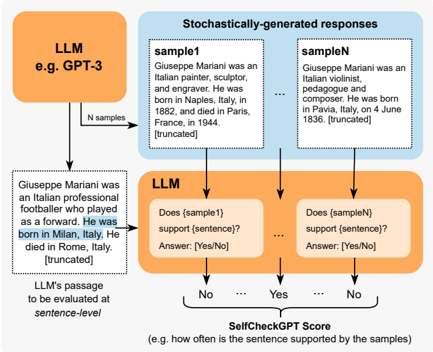
Figure 1: SelfCheckGPT with Prompt. Each LLM-generated sentence is compared against stochastically generated responses with no external database. A comparison method can be, for example, through LLM prompting as shown above.
<details>
<summary>Image 1 Details</summary>
### Visual Description
\n
## Diagram: SelfCheckGPT Workflow
### Overview
This diagram illustrates the workflow of SelfCheckGPT, a system for evaluating the factual consistency of Large Language Model (LLM) outputs. It shows how an LLM generates multiple responses to a prompt, and how another instance of the LLM is used to assess whether those responses support a given passage.
### Components/Axes
The diagram consists of four main components:
1. **LLM (e.g. GPT-3):** Represented by an orange rectangle at the top-left.
2. **Stochastically-generated responses:** Represented by a blue rectangle at the top-right, containing multiple "sample" responses (sample1, sampleN, and "...")
3. **LLM (Evaluation):** Represented by an orange rectangle at the bottom-center, evaluating each sample against a sentence from the passage.
4. **SelfCheckGPT Score:** Represented by a green rectangle at the bottom, indicating the frequency of support from the samples.
Arrows indicate the flow of information between these components.
### Detailed Analysis or Content Details
* **LLM (e.g. GPT-3):** Generates "N samples".
* **Stochastically-generated responses:**
* **sample1:** "Giuseppe Mariani was an Italian painter, sculptor, and engraver. He was born in Naples, Italy, in 1882, and died in Paris, France, in 1944. [truncated]"
* **sampleN:** "Giuseppe Mariani was an Italian violinist, composer and composer. He was born in Pavia, Italy, on 4 June 1836. [truncated]"
* The "..." indicates that there are more samples not shown.
* **LLM (Evaluation):** Evaluates each sample against a sentence from the passage. The question posed is "Does (sampleX) support (sentence)?". The answer is either "Yes" or "No".
* **LLM's passage to be evaluated sentence-level:** "Giuseppe Mariani was an Italian professional footballer who played as a forward. He was born in Milan, Italy. He died in Rome, Italy. [truncated]"
* The sentence "He was born in Milan, Italy." is highlighted in blue.
* **SelfCheckGPT Score:** The score represents "e.g. how often is the sentence supported by the samples". The output is a series of "No" and "Yes" answers, indicating support or lack thereof from each sample.
### Key Observations
The diagram demonstrates a process of fact-checking LLM outputs by leveraging the LLM itself. The system generates multiple responses and then uses another instance of the LLM to determine if those responses align with a given passage. The SelfCheckGPT score provides a measure of confidence in the factual consistency of the LLM's output. The samples provided show conflicting information regarding Giuseppe Mariani's profession and birthplace, highlighting the potential for LLMs to generate inaccurate or inconsistent information.
### Interpretation
This diagram illustrates a method for evaluating the reliability of LLM-generated text. The core idea is to use the LLM's own capabilities to assess its outputs, creating a self-checking mechanism. The "SelfCheckGPT Score" is a crucial metric, indicating the degree to which the generated responses corroborate the information in the passage being evaluated. The conflicting information in the samples (painter vs. footballer, Naples vs. Milan) underscores the need for such evaluation methods, as LLMs can produce plausible but factually incorrect statements. The truncation of the samples suggests that the full context might be important for accurate evaluation. The diagram suggests a probabilistic approach to fact-checking, where the score reflects the frequency of support rather than a definitive "true" or "false" determination. This is a valuable approach given the inherent uncertainty in LLM outputs.
</details>
tools to draft reports, virtual assistants and summarization systems. Despite the convincing and realistic nature of LLM-generated texts, a growing concern with LLMs is their tendency to hallucinate facts. It has been widely observed that models can confidently generate fictitious information, and worryingly there are few, if any, existing approaches to suitably identify LLM hallucinations.
A possible approach of hallucination detection is to leverage existing intrinsic uncertainty metrics to determine the parts of the output sequence that the system is least certain of (Yuan et al., 2021; Fu et al., 2023). However, uncertainty metrics such as token probability or entropy require access to token-level probability distributions, information which may not be available to users for example when systems are accessed through limited external APIs. An alternate approach is to leverage fact-verification approaches, where evidence is retrieved from an external database to assess the veracity of a claim (Thorne et al., 2018; Guo et al., 2022). However, facts can only be assessed relative to the knowledge present in the database. Addition-
ally, hallucinations are observed over a wide range of tasks beyond pure fact verification (Kryscinski et al., 2020; Maynez et al., 2020).
In this paper, we propose SelfCheckGPT, a sampling-based approach that can detect whether responses generated by LLMs are hallucinated or factual. To the best of our knowledge, SelfCheckGPT is the first work to analyze model hallucination of general LLM responses, and is the first zero-resource hallucination detection solution that can be applied to black-box systems. The motivating idea of SelfCheckGPT is that when an LLM has been trained on a given concept, the sampled responses are likely to be similar and contain consistent facts. However, for hallucinated facts, stochastically sampled responses are likely to diverge and may contradict one another. By sampling multiple responses from an LLM, one can measure information consistency between the different responses and determine if statements are factual or hallucinated. Since SelfCheckGPT only leverages sampled responses, it has the added benefit that it can be used for black-box models, and it requires no external database. Five variants of SelfCheckGPT for measuring informational consistency are considered: BERTScore, question-answering, n -gram, NLI, and LLM prompting. Through analysis of annotated articles generated by GPT-3, we show that SelfCheckGPT is a highly effective hallucination detection method that can even outperform greybox methods, and serves as a strong first baseline for an increasingly important problem of LLMs.
## 2 Background and Related Work
## 2.1 Hallucination of Large Language Models
Hallucination has been studied in text generation tasks, including summarization (Huang et al., 2021) and dialogue generation (Shuster et al., 2021), as well as in a variety of other natural language generation tasks (Ji et al., 2023). Self-consistency decoding has shown to improve chain-of-thought prompting performance on complex reasoning tasks (Wang et al., 2023). Further, Liu et al. (2022) introduce a hallucination detection dataset, however, texts are obtained by perturbing factual texts and thus may not reflect true LLM hallucination.
Recently, Azaria and Mitchell (2023) trained a multi-layer perception classifier where an LLM's hidden representations are used as inputs to predict the truthfulness of a sentence. However, this approach is a white-box approach that uses the internal states of the LLM, which may not be available through API calls, and requires labelled data for supervised training. Another recent approach is self-evaluation (Kadavath et al., 2022), where an LLM is prompted to evaluate its previous prediction, e.g., to predict the probability that its generated response/answer is true.
## 2.2 Sequence Level Uncertainty Estimation
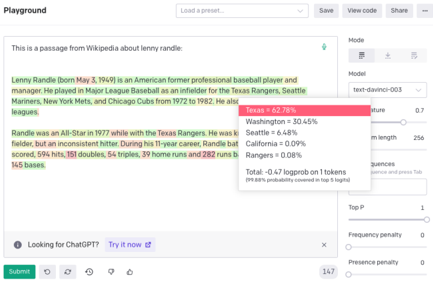
Token probabilities have been used as an indication of model certainty. For example, OpenAI's GPT-3 web interface allows users to display token probabilities (as shown in Figure 2), and further uncertainty estimation approaches based on aleatoric and epistemic uncertainty have been studied for autoregressive generation (Xiao and Wang, 2021; Malinin and Gales, 2021). Additionally, conditional language model scores have been used to evaluate properties of texts (Yuan et al., 2021; Fu et al., 2023). Recently, semantic uncertainty has been proposed to address uncertainty in free-form generation tasks where probabilities are attached to concepts instead of tokens (Kuhn et al., 2023).
Figure 2: Example of OpenAI's GPT-3 web interface with output token-level probabilities displayed.
<details>
<summary>Image 2 Details</summary>
### Visual Description
\n
## Screenshot: OpenAI Playground - Text Completion Analysis
### Overview
This is a screenshot of the OpenAI Playground interface, specifically showing a text completion analysis related to a passage from Wikipedia about Lenny Randle, a baseball player. The screenshot highlights probabilities assigned to different baseball teams mentioned in the text. A floating panel displays these probabilities, seemingly generated by the "text-davinci-003" model.
### Components/Axes
The screenshot can be divided into three main regions:
1. **Text Input Area (Left):** Displays the Wikipedia passage about Lenny Randle.
2. **Analysis Panel (Center):** A floating panel showing probabilities associated with different baseball teams.
3. **Settings Panel (Right):** Contains controls for the OpenAI model, including model selection, temperature, max length, and other parameters.
The Analysis Panel contains the following:
* **Title:** No explicit title, but it represents probability scores for team mentions.
* **Model:** text-davinci-003
* **Temperature:** 0.7
* **Max Length:** 256
* **Logprob on 1 token:** -0.47
* **Probability Coverage:** 99.8% probability covered in top 5 logits.
* **Team Probabilities:** Listed with associated percentages.
### Detailed Analysis or Content Details
The text passage discusses Lenny Randle, born May 3, 1949, an American former professional baseball player and manager. He played for the Texas Rangers, Seattle Mariners, New York Mets, and Chicago Cubs from 1972 to 1982. The passage mentions he was an All-Star in 1977 while with the Texas Rangers and provides some career statistics: 594 hits, 151 doubles, 53 triples, 39 home runs, and 282 runs.
The Analysis Panel displays the following probabilities for each team:
* **Texas:** 62.78% (Highlighted in a pink background)
* **Washington:** 30.45%
* **Seattle:** 6.48%
* **California:** 0.09%
* **Rangers:** 0.08%
### Key Observations
The probability assigned to "Texas" is significantly higher than any other team (62.78%), suggesting the model strongly associates Lenny Randle with the Texas Rangers. The probabilities for Washington and Seattle are also relatively high, while California and Rangers have very low probabilities. It's notable that "Rangers" as a team name has a very low probability despite being explicitly mentioned in the text alongside "Texas".
### Interpretation
The data suggests that the OpenAI model, "text-davinci-003", has learned a strong association between Lenny Randle and the Texas Rangers, likely due to the prominence of his career with that team. The model appears to be identifying team names within the context of the passage and assigning probabilities based on its training data. The lower probabilities for other teams likely reflect their lesser association with Randle's career. The discrepancy between the high probability for "Texas" and the low probability for "Rangers" could indicate the model is more sensitive to the full state name ("Texas Rangers") than just the team nickname ("Rangers"). The "Logprob on 1 token" and "Probability Coverage" metrics suggest the model is confident in its predictions, with a high percentage of probability concentrated in the top 5 most likely tokens. This analysis provides insight into how the model understands and processes information about baseball players and teams.
</details>
## 2.3 Fact Verification
Existing fact-verification approaches follow a multi-stage pipeline of claim detection, evidence retrieval and verdict prediction (Guo et al., 2022; Zhong et al., 2020). Such methods, however, require access to external databases and can have considerable inference costs.
## 3 Grey-Box Factuality Assessment
This section will introduce methods that can be used to determine the factuality of LLM responses in a zero-resource setting when one has full access
to output distributions. 2 We will use 'factual' to define when statements are grounded in valid information, i.e. when hallucinations are avoided, and 'zero-resource' when no external database is used.
## 3.1 Uncertainty-based Assessment
To understand how the factuality of a generated response can be determined in a zero-resource setting, we consider LLM pre-training. During pretraining, the model is trained with next-word prediction over massive corpora of textual data. This gives the model a strong understanding of language (Jawahar et al., 2019; Raffel et al., 2020), powerful contextual reasoning (Zhang et al., 2020), as well as world knowledge (Liusie et al., 2023). Consider the input " Lionel Messi is a \_ ". Since Messi is a world-famous athlete who may have appeared multiple times in pre-training, the LLM is likely to know who Messi is. Therefore given the context, the token " footballer " may be assigned a high probability while other professions such as " carpenter " may be considered improbable. However, for a different input such as " John Smith is a \_ ", the system will be unsure of the continuation which may result in a flat probability distribution. During inference, this is likely to lead to a non-factual word being generated.
This insight allows us to understand the connection between uncertainty metrics and factuality. Factual sentences are likely to contain tokens with higher likelihood and lower entropy, while hallucinations are likely to come from positions with flat probability distributions with high uncertainty.
## Token-level Probability
Given the LLM's response R , let i denote the i -th sentence in R , j denote the j -th token in the i -th sentence, J is the number of tokens in the sentence, and p ij be the probability of the word generated by the LLM at the j -th token of the i -th sentence. Two probability metrics are used:
$$A v g ( - \log p ) = - { \frac { 1 } { J } } \sum _ { j } \log p _ { i j }$$
$$M a x ( - \log p ) = \max _ { j } \, ( - \log p _ { i j } )$$
$$)$$
Max ( -log p ) measures the sentence's likelihood by assessing the least likely token in the sentence.
2 Alternate white-box approaches such as that of Azaria and Mitchell (2023) require access to full internal states, and is less practical and so not considered in this work.
## Entropy
The entropy of the output distribution is:
$$\mathcal { H } _ { i j } = - \sum _ { \tilde { w } \in \mathcal { W } } p _ { i j } ( \tilde { w } ) \log p _ { i j } ( \tilde { w } )$$
where p ij ( ˜ w ) is the probability of the word ˜ w being generated at the j -th token of the i -th sentence, and W is the set of all possible words in the vocabulary. Similar to the probability-based metrics, two entropy-based metrics are used:
$$A v g ( \mathcal { H } ) = \frac { 1 } { J } \sum _ { j } \mathcal { H } _ { i j } ; \quad M a x ( \mathcal { H } ) = \max _ { j } \left ( \mathcal { H } _ { i j } \right )$$
## 4 Black-Box Factuality Assessment
A drawback of grey-box methods is that they require output token-level probabilities. Though this may seem a reasonable requirement, for massive LLMs only available through limited API calls, such token-level information may not be available (such as with ChatGPT). Therefore, we consider black-box approaches which remain applicable even when only text-based responses are available.
## Proxy LLMs
A simple approach to approximate the grey-box approaches is by using a proxy LLM, i.e. another LLM that we have full access to, such as LLaMA (Touvron et al., 2023). A proxy LLM can be used to approximate the output token-level probabilities of the black-box LLM generating the text. In the next section, we propose SelfCheckGPT, which is also a black-box approach.
## 5 SelfCheckGPT
SelfCheckGPT is our proposed black-box zeroresource hallucination detection scheme, which operates by comparing multiple sampled responses and measuring consistency.
Notation : Let R refer to an LLM response drawn from a given user query. SelfCheckGPT draws a further N stochastic LLM response samples { S 1 , S 2 , ..., S n , ..., S N } using the same query, and then measures the consistency between the response and the stochastic samples. We design SelfCheckGPT to predict the hallucination score of the i -th sentence, S ( i ) , such that S ( i ) ∈ [0 . 0 , 1 . 0] , where S ( i ) → 0 . 0 if the i -th sentence is grounded in valid information and S ( i ) → 1 . 0 if the i -th sen-
tence is hallucinated. 3 The following subsections will describe each of the SelfCheckGPT variants.
## 5.1 SelfCheckGPT with BERTScore
Let B ( ., . ) denote the BERTScore between two sentences. SelfCheckGPT with BERTScore finds the average BERTScore of the i -th sentence with the most similar sentence from each drawn sample:
$$\mathcal { S } _ { B E R T } ( i ) = 1 - \frac { 1 } { N } \sum _ { n = 1 } ^ { N } \max _ { k } \left ( \mathcal { B } ( r _ { i } , s _ { k } ^ { n } ) \right ) \quad ( 1 ) \quad \text {in} \ \ A$$
where r i represents the i -th sentence in R and s n k represents the k -th sentence in the n -th sample S n . This way if the information in a sentence appears in many drawn samples, one may assume that the information is factual, whereas if the statement appears in no other sample, it is likely a hallucination. In this work, RoBERTa-Large (Liu et al., 2019) is used as the backbone of BERTScore.
## 5.2 SelfCheckGPT with Question Answering
We also consider using the automatic multiplechoice question answering generation (MQAG) framework (Manakul et al., 2023) to measure consistency for SelfCheckGPT. MQAG assesses consistency by generating multiple-choice questions over the main generated response, which an independent answering system can attempt to answer while conditioned on the other sampled responses. If questions on consistent information are queried, the answering system is expected to predict similar answers. MQAG consists of two stages: question generation G and question answering A . For the sentence r i in the response R , we draw questions q and options o :
$$q , \mathbf o \sim P _ { \mathbb { G } } ( q , \mathbf o | r _ { i } , R ) \quad ( 2 ) \quad i - t$$
The answering stage A selects the answers:
$$a _ { R } = \underset { k } { \arg \max } \left [ P _ { A } ( o _ { k } | q , R , { o } ) \right ] \quad ( 3 )$$
$$\begin{array} { r l r } & { a _ { S ^ { n } } = \underset { k } { \arg \max } \left [ P _ { A } ( o _ { k } | q , S ^ { n } , { \mathbf o } ) \right ] } & { ( 4 ) } & { 5 . 4 } \end{array}$$
We compare whether a R is equal to a S n for each sample in { S 1 , ..., S N } , yielding #matches N m and #not-matches N n . A simple inconsistency score for the i -th sentence and question q based on the match/not-match counts is defined: S QA ( i, q ) =
3 With the exception of SelfCheckGPT with n -gram as the score of the n -gram language model is not bounded.
N n N m + N n . To take into account the answerability of generated questions, we show in Appendix B that we can modify the inconsistency score by applying soft-counting, resulting in:
$$\mathcal { S } _ { Q A } ( i , q ) = \frac { \gamma _ { 2 } ^ { N _ { n } ^ { \prime } } } { \gamma _ { 1 } ^ { N _ { m } ^ { \prime } } + \gamma _ { 2 } ^ { N _ { n } ^ { \prime } } } \quad ( 5 )$$
where N ′ m = the effective match count, N ′ n = the effective mismatch count, with γ 1 and γ 2 defined in Appendix B.1. Ultimately, SelfCheckGPT with QA is the average of inconsistency scores across q ,
$$\mathcal { S } _ { Q A } ( i ) = \mathbb { E } _ { q } \left [ \mathcal { S } _ { Q A } ( i , q ) \right ] \quad ( 6 )$$
## 5.3 SelfCheckGPT with n-gram
Given samples { S 1 , ..., S N } generated by an LLM, one can use the samples to create a new language model that approximates the LLM. In the limit as N gets sufficiently large, the new language model will converge to the LLM that generated the responses. We can therefore approximate the LLM's token probabilities using the new language model.
In practice, due to time and/or cost constraints, there can only be a limited number of samples N . Consequently, we train a simple n -gram model using the samples { S 1 , ..., S N } as well as the main response R (which is assessed), where we note that including R can be considered as a smoothing method where the count of each token in R is increased by 1. We then compute the average of the log-probabilities of the sentence in response R ,
$$\mathcal { S } _ { n \text {-gram} } ^ { A v g } ( i ) = - \frac { 1 } { J } \sum _ { j } \log \tilde { p } _ { i j } \quad ( 7 )$$
where ˜ p ij is the probability (of the j -th token of the i -th sentence) computed using the n -gram model. Similar to the grey-box approach, we can also use the maximum of the negative log probabilities,
$$\mathcal { S } _ { n \text {-gram} } ^ { M a x } ( i ) = \max _ { j } \left ( - \log \tilde { p } _ { i j } \right ) \quad ( 8 )$$
## 5.4 SelfCheckGPT with NLI
Natural Language Inference (NLI) determines whether a hypothesis follows a premise, classified into either entailment/neutral/contradiction. NLI measures have been used to measure faithfulness in summarization, where Maynez et al. (2020) use a textual entailment classifier trained on MNLI (Williams et al., 2018) to determine if a summary contradicts a context or not. Inspired by NLI-based
summary assessment, we consider using the NLI contradiction score as a SelfCheckGPT score.
For SelfCheck-NLI, we use DeBERTa-v3-large (He et al., 2023) fine-tuned to MNLI as the NLI model. The input for NLI classifiers is typically the premise concatenated to the hypothesis , which for our methodology is the sampled passage S n concatenated to the sentence to be assessed r i . Only the logits associated with the 'entailment' and 'contradiction' classes are considered,
<!-- formula-not-decoded -->
where z e and z c are the logits of the 'entailment' and 'contradiction' classes, respectively. This normalization ignores the neutral class and ensures that the probability is bounded between 0.0 and 1.0. The SelfCheckGPT with NLI score for each sample S n is then defined as,
$$\mathcal { S } _ { N L I } ( i ) = \frac { 1 } { N } \sum _ { n = 1 } ^ { N } P ( \text {contradict} | r _ { i } , S ^ { n } ) \quad ( 1 0 )$$
## 5.5 SelfCheckGPT with Prompt
LLMs have recently been shown to be effective in assessing information consistency between a document and its summary in zero-shot settings (Luo et al., 2023). Thus, we query an LLM to assess whether the i -th sentence is supported by sample S n (as the context) using the following prompt.
------------------------------------------------
```
Context: {}
Sentence: {}
```
Is the sentence supported by the context above? Answer Yes or No:
------------------------------------------------
Initial investigation showed that GPT-3 (textdavinci-003) will output either Yes or No 98% of the time, while any remaining outputs can be set to N/A . The output from prompting when comparing the i -th sentence against sample S n is converted to score x n i through the mapping { Yes : 0.0, No : 1.0, N/A : 0.5}. The final inconsistency score is then calculated as:
$$\mathcal { S } _ { \text {Prompt} } ( i ) = \frac { 1 } { N } \sum _ { n = 1 } ^ { N } x _ { i } ^ { n } \quad \quad ( 1 1 ) \quad f r o m b e l$$
SelfCheckGPT-Prompt is illustrated in Figure 1. Note that our initial investigations found that less capable models such as GPT-3 (text-curie-001) or LLaMA failed to effectively perform consistency assessment via such prompting.
## 6 Data and Annotation
As, currently, there are no standard hallucination detection datasets available, we evaluate our hallucination detection approaches by 1) generating synthetic Wikipedia articles using GPT-3 on the individuals/concepts from the WikiBio dataset (Lebret et al., 2016); 2) manually annotating the factuality of the passage at a sentence level; 3) evaluating the system's ability to detect hallucinations.
WikiBio is a dataset where each input contains the first paragraph (along with tabular information) of Wikipedia articles of a specific concept. We rank the WikiBio test set in terms of paragraph length and randomly sample 238 articles from the top 20% of longest articles (to ensure no very obscure concept is selected). GPT-3 (text-davinci-003) is then used to generate Wikipedia articles on a concept, using the prompt " This is a Wikipedia passage about {concept} :". Table 1 provides the statistics of GPT-3 generated passages.
Table 1: The statistics of WikiBio GPT-3 dataset where the number of tokens is based on the OpenAI GPT-2 tokenizer.
| #Passages | #Sentences | #Tokens/passage |
|-------------|--------------|-------------------|
| 238 | 1908 | 184.7 ± 36.9 |
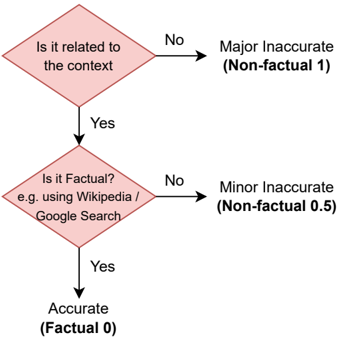
We then annotate the sentences of the generated passages using the guidelines shown in Figure 3 such that each sentence is classified as either:
- Major Inaccurate (Non-Factual, 1 ): The sentence is entirely hallucinated, i.e. the sentence is unrelated to the topic.
- Minor Inaccurate (Non-Factual, 0.5 ): The sentence consists of some non-factual information, but the sentence is related to the topic.
- Accurate (Factual, 0 ): The information presented in the sentence is accurate.
Of the 1908 annotated sentences, 761 (39.9%) of the sentences were labelled major-inaccurate, 631 (33.1%) minor-inaccurate, and 516 (27.0%) accurate. 201 sentences in the dataset had annotations from two different annotators. To obtain a single label for this subset, if both annotators agree, then the agreed label is used. However, if there is disagreement, then the worse-case label is selected (e.g., {minor inaccurate, major inaccurate} is mapped to major inaccurate). The inter-annotator agreement, as measured by Cohen's κ (Cohen, 1960), has κ
Figure 3: Flowchart of our annotation process
<details>
<summary>Image 3 Details</summary>
### Visual Description
\n
## Diagram: Accuracy Assessment Flowchart
### Overview
This image presents a flowchart illustrating a process for assessing the accuracy of information. The flowchart consists of two decision diamonds and three terminal states, representing different levels of accuracy. The flowchart visually guides the user through a series of questions to determine if a piece of information is accurate, minorly inaccurate, or majorly inaccurate.
### Components/Axes
The diagram consists of:
* **Decision Diamond 1:** "Is it related to the context?" with "No" and "Yes" branches.
* **Decision Diamond 2:** "Is it Factual? e.g. using Wikipedia / Google Search" with "No" and "Yes" branches.
* **Terminal State 1:** "Major Inaccurate (Non-factual 1)"
* **Terminal State 2:** "Minor Inaccurate (Non-factual 0.5)"
* **Terminal State 3:** "Accurate (Factual 0)"
* Arrows indicating the flow of the assessment process.
### Detailed Analysis or Content Details
The flowchart begins with the question "Is it related to the context?".
* If the answer is "No", the flow leads to "Major Inaccurate (Non-factual 1)".
* If the answer is "Yes", the flow proceeds to the second decision diamond.
The second question is "Is it Factual? e.g. using Wikipedia / Google Search".
* If the answer is "No", the flow leads to "Minor Inaccurate (Non-factual 0.5)".
* If the answer is "Yes", the flow leads to "Accurate (Factual 0)".
The terminal states are associated with numerical values representing the degree of inaccuracy:
* Major Inaccurate: 1
* Minor Inaccurate: 0.5
* Accurate: 0
### Key Observations
The flowchart establishes a hierarchical assessment of accuracy. Relevance to the context is the first criterion, followed by factual verification using external sources like Wikipedia or Google Search. The numerical values assigned to each state suggest a scale of inaccuracy, where 0 represents complete accuracy and 1 represents complete inaccuracy.
### Interpretation
This diagram outlines a simple but effective method for evaluating information. It emphasizes the importance of both contextual relevance and factual basis. The use of external sources (Wikipedia/Google Search) as a benchmark for factual accuracy suggests a reliance on established knowledge. The numerical scoring system allows for a degree of quantification of accuracy, which could be useful in automated systems or for comparative analysis. The flowchart implies that information can be inaccurate in two ways: by being irrelevant to the context or by being factually incorrect. The diagram is a conceptual model and does not provide specific data or measurements, but rather a framework for assessment. It is a visual representation of a logical process.
</details>
values of 0.595 and 0.748, indicating moderate and substantial agreement (Viera et al., 2005) for the 3-class and 2-class scenarios, respectively. 4
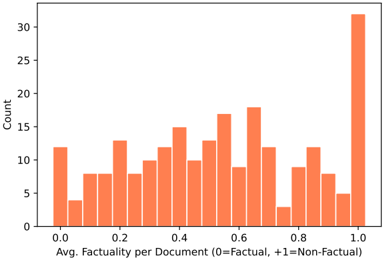
Furthermore, passage-level scores are obtained by averaging the sentence-level labels in each passage. The distribution of passage-level scores is shown in Figure 4, where we observe a large peak at +1.0. We refer to the points at this peak as total hallucination , which occurs when the information of the response is unrelated to the real concept and is entirely fabricated by the LLM.
Figure 4: Document factuality scores histogram plot
<details>
<summary>Image 4 Details</summary>
### Visual Description
\n
## Histogram: Distribution of Average Factuality per Document
### Overview
The image presents a histogram visualizing the distribution of average factuality scores across a collection of documents. The x-axis represents the average factuality score, ranging from 0.0 to 1.0, where 0 indicates fully factual and 1 indicates fully non-factual. The y-axis represents the count, or frequency, of documents falling within each factuality score bin. The histogram uses a single data series, displayed as orange bars.
### Components/Axes
* **X-axis Title:** "Avg. Factuality per Document (0=Factual, +1=Non-Factual)"
* **Y-axis Title:** "Count"
* **X-axis Scale:** Ranges from 0.0 to 1.0, with increments of approximately 0.1.
* **Y-axis Scale:** Ranges from 0 to 30, with increments of 5.
* **Data Series:** A single series of orange bars representing the frequency distribution of average factuality scores.
### Detailed Analysis
The histogram shows a roughly symmetrical distribution, but with a slight skew towards higher factuality scores (values closer to 0). The distribution is not uniform; there are peaks and valleys indicating varying concentrations of documents at different factuality levels.
Here's an approximate breakdown of the counts for each bin (estimated from the bar heights):
* 0.0 - 0.1: ~11
* 0.1 - 0.2: ~8
* 0.2 - 0.3: ~10
* 0.3 - 0.4: ~14
* 0.4 - 0.5: ~15
* 0.5 - 0.6: ~17
* 0.6 - 0.7: ~16
* 0.7 - 0.8: ~8
* 0.8 - 0.9: ~10
* 0.9 - 1.0: ~32
The highest concentration of documents falls within the 0.9-1.0 range, with approximately 32 documents. The lowest concentration is in the 0.7-0.8 range, with approximately 8 documents. The distribution peaks around 0.5-0.7.
### Key Observations
* The distribution is not centered at 0.5, suggesting that, on average, the documents lean towards being factual.
* There's a significant number of documents with very high factuality scores (close to 1.0), indicating a substantial portion of the collection is non-factual.
* The shape of the distribution suggests a complex interplay of factors influencing the factuality of the documents.
### Interpretation
The data suggests that the collection of documents exhibits a wide range of factuality, with a noticeable tendency towards non-factual content. The peak around 0.5-0.7 indicates that a significant portion of the documents fall into a moderate factuality range, while the substantial number of documents with scores close to 1.0 raises concerns about the prevalence of misinformation or non-factual content within the collection. The distribution's shape could be due to various factors, such as the source of the documents, the topic they cover, or the methods used to assess their factuality. Further investigation would be needed to understand the underlying reasons for this distribution and to identify potential biases or patterns in the data. The factuality scores are likely derived from some automated or human assessment process, and the distribution reflects the outcomes of that process.
</details>
## 7 Experiments
The generative LLM used to generate passages for our dataset is GPT-3 (text-davinci-003), the stateof-the-art system at the time of creating and annotating the dataset. To obtain the main response, we set the temperature to 0.0 and use standard beam search decoding. For the stochastically generated samples, we set the temperature to 1.0 and generate
4 3-class refers to when selecting between accurate, minor inaccurate, major inaccurate. 2-class refers to when minor/major inaccuracies are combined into one label.
N =20 samples. For the proxy LLM approach, we use LLaMA (Touvron et al., 2023), one of the bestperforming open-source LLMs currently available. For SelfCheckGPT-Prompt, we consider both GPT3 (which is the same LLM that is used to generate passages) as well as the newly released ChatGPT (gpt-3.5-turbo). More details about the systems in SelfCheckGPT and results using other proxy LLMs can be found in the appendix.
## 7.1 Sentence-level Hallucination Detection
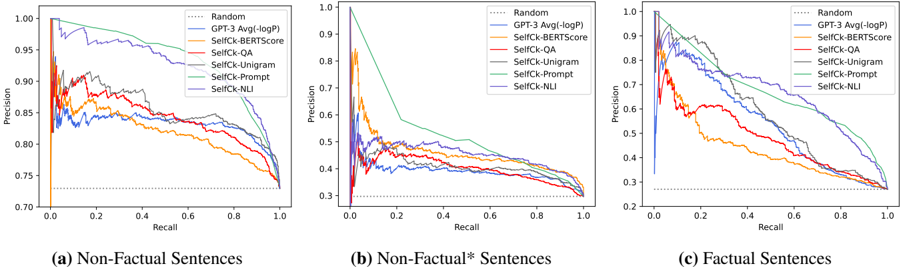
First, we investigate whether our hallucination detection methods can identify the factuality of sentences. In detecting non-factual sentences, both major-inaccurate labels and minor-inaccurate labels are grouped together into the non-factual class, while the factual class refers to accurate sentences. In addition, we consider a more challenging task of detecting major-inaccurate sentences in passages that are not total hallucination passages, which we refer to as non-factual ∗ . 5 Figure 5 and Table 2 show the performance of our approaches, where the following observations can be made:
1) LLM's probabilities p correlate well with factuality . Our results show that probability measures (from the LLM generating the texts) are strong baselines for assessing factuality. Factual sentences can be identified with an AUC-PR of 53.97, significantly better than the random baseline of 27.04, with the AUC-PR for hallucination detection also increasing from 72.96 to 83.21. This supports the hypothesis that when the LLMs are uncertain about generated information, generated tokens often have higher uncertainty, paving a promising direction for hallucination detection approaches. Also, the probability p measure performs better than the entropy H measure of top-5 tokens.
2) Proxy LLM perform noticeably worse than LLM(GPT-3) . The results of proxy LLM (based on LLaMA) show that the entropy H measures outperform the probability measures. This suggests that using richer uncertainty information can improve factuality/hallucination detection performance, and that previously the entropy of top-5 tokens is likely to be insufficient. In addition, when using other proxy LLMs such as GPT-NeoX or OPT-30B, the performance is near that of the random baseline. We believe this poor performance occurs as different LLMs have different generating patterns, and so even common tokens may have a
5 There are 206 non-factual ∗ passages (1632 sentences).
Figure 5: PR-Curve of detecting non-factual and factual sentences in the GPT-3 generated WikiBio passages.
<details>
<summary>Image 5 Details</summary>
### Visual Description
\n
## Chart: Precision-Recall Curves for Different Models
### Overview
The image presents three precision-recall curves, each corresponding to a different type of sentence: (a) Non-Factual Sentences, (b) Non-Factual* Sentences, and (c) Factual Sentences. Each curve represents the performance of several models – Random, GPT-3 Avg(logP), SelfCk-BERTscore, SelfCk-QA, SelfCk-Unigram, SelfCk-Prompt, and SelfCk-NLI – as recall varies from 0 to 1. The y-axis represents precision, ranging from approximately 0.7 to 1.0.
### Components/Axes
* **X-axis:** Recall (ranging from 0.0 to 1.0)
* **Y-axis:** Precision (ranging from 0.7 to 1.0)
* **Legend:**
* Random (dotted black line)
* GPT-3 Avg(logP) (solid blue line)
* SelfCk-BERTscore (solid green line)
* SelfCk-QA (solid light blue line)
* SelfCk-Unigram (solid orange line)
* SelfCk-Prompt (solid red line)
* SelfCk-NLI (solid purple line)
* **Sub-Titles:** (a) Non-Factual Sentences, (b) Non-Factual* Sentences, (c) Factual Sentences. These are positioned below each chart.
### Detailed Analysis or Content Details
**Chart (a): Non-Factual Sentences**
* **Random:** Starts at approximately 0.98 precision at 0 recall, and declines steadily to approximately 0.72 precision at 1 recall.
* **GPT-3 Avg(logP):** Starts at approximately 0.99 precision at 0 recall, and declines to approximately 0.82 precision at 1 recall.
* **SelfCk-BERTscore:** Starts at approximately 0.98 precision at 0 recall, and declines to approximately 0.80 precision at 1 recall.
* **SelfCk-QA:** Starts at approximately 0.97 precision at 0 recall, and declines to approximately 0.78 precision at 1 recall.
* **SelfCk-Unigram:** Starts at approximately 0.96 precision at 0 recall, and declines to approximately 0.76 precision at 1 recall.
* **SelfCk-Prompt:** Starts at approximately 0.95 precision at 0 recall, and declines to approximately 0.74 precision at 1 recall.
* **SelfCk-NLI:** Starts at approximately 0.96 precision at 0 recall, and declines to approximately 0.75 precision at 1 recall.
**Chart (b): Non-Factual* Sentences**
* **Random:** Starts at approximately 0.98 precision at 0 recall, and declines sharply to approximately 0.35 precision at 1 recall.
* **GPT-3 Avg(logP):** Starts at approximately 0.95 precision at 0 recall, and declines to approximately 0.40 precision at 1 recall.
* **SelfCk-BERTscore:** Starts at approximately 0.90 precision at 0 recall, and declines to approximately 0.45 precision at 1 recall.
* **SelfCk-QA:** Starts at approximately 0.85 precision at 0 recall, and declines to approximately 0.40 precision at 1 recall.
* **SelfCk-Unigram:** Starts at approximately 0.80 precision at 0 recall, and declines to approximately 0.35 precision at 1 recall.
* **SelfCk-Prompt:** Starts at approximately 0.75 precision at 0 recall, and declines to approximately 0.30 precision at 1 recall.
* **SelfCk-NLI:** Starts at approximately 0.70 precision at 0 recall, and declines to approximately 0.25 precision at 1 recall.
**Chart (c): Factual Sentences**
* **Random:** Starts at approximately 0.98 precision at 0 recall, and declines steadily to approximately 0.32 precision at 1 recall.
* **GPT-3 Avg(logP):** Starts at approximately 1.0 precision at 0 recall, and declines to approximately 0.35 precision at 1 recall.
* **SelfCk-BERTscore:** Starts at approximately 0.99 precision at 0 recall, and declines to approximately 0.33 precision at 1 recall.
* **SelfCk-QA:** Starts at approximately 0.98 precision at 0 recall, and declines to approximately 0.30 precision at 1 recall.
* **SelfCk-Unigram:** Starts at approximately 0.97 precision at 0 recall, and declines to approximately 0.28 precision at 1 recall.
* **SelfCk-Prompt:** Starts at approximately 0.96 precision at 0 recall, and declines to approximately 0.26 precision at 1 recall.
* **SelfCk-NLI:** Starts at approximately 0.95 precision at 0 recall, and declines to approximately 0.24 precision at 1 recall.
### Key Observations
* The "Random" model consistently performs worse than all other models across all sentence types.
* For Non-Factual and Non-Factual* sentences, the performance of all models degrades significantly as recall increases.
* GPT-3 Avg(logP) and SelfCk-BERTscore generally outperform other models in terms of precision, especially at low recall values.
* The performance gap between models is most pronounced in the Non-Factual* sentence category.
* The precision values are generally higher for Non-Factual sentences compared to Non-Factual* and Factual sentences.
### Interpretation
These precision-recall curves demonstrate the effectiveness of different models in identifying non-factual content. The significant drop in precision as recall increases for Non-Factual* sentences suggests that it is particularly challenging to accurately identify these types of sentences. The superior performance of GPT-3 Avg(logP) and SelfCk-BERTscore indicates that these models are better at capturing the nuances of language and identifying subtle inconsistencies that may indicate non-factual information. The consistently poor performance of the "Random" model serves as a baseline, highlighting the importance of using more sophisticated models for this task. The differences in performance across sentence types suggest that the characteristics of the sentences themselves (e.g., the degree of factualness) influence the effectiveness of the models. The curves reveal a trade-off between precision and recall; achieving high recall often comes at the cost of lower precision, and vice versa.
</details>
Table 2: AUC-PR for sentence-level detection tasks. Passage-level ranking performances are measured by Pearson correlation coefficient and Spearman's rank correlation coefficient w.r.t. human judgements. The results of other proxy LLMs, in addition to LLaMA, can be found in the appendix. † GPT-3 API returns the top-5 tokens' probabilities, which are used to compute entropy.
| Method | Sentence-level (AUC-PR) | Sentence-level (AUC-PR) | Sentence-level (AUC-PR) | Passage-level (Corr.) | Passage-level (Corr.) |
|-------------------------------------------------------------|-------------------------------------------------------------|-------------------------------------------------------------|-------------------------------------------------------------|-------------------------------------------------------------|-------------------------------------------------------------|
| Method | NonFact | NonFact* | Factual | Pearson | Spearman |
| Random | 72.96 | 29.72 | 27.04 | - | - |
| GPT-3 (text-davinci-003) 's probabilities ( LLM, grey-box ) | GPT-3 (text-davinci-003) 's probabilities ( LLM, grey-box ) | GPT-3 (text-davinci-003) 's probabilities ( LLM, grey-box ) | GPT-3 (text-davinci-003) 's probabilities ( LLM, grey-box ) | GPT-3 (text-davinci-003) 's probabilities ( LLM, grey-box ) | GPT-3 (text-davinci-003) 's probabilities ( LLM, grey-box ) |
| Avg( - log p ) | 83.21 | 38.89 | 53.97 | 57.04 | 53.93 |
| Avg( H ) † | 80.73 | 37.09 | 52.07 | 55.52 | 50.87 |
| Max( - log p ) | 87.51 | 35.88 | 50.46 | 57.83 | 55.69 |
| Max( H ) † | 85.75 | 32.43 | 50.27 | 52.48 | 49.55 |
| LLaMA-30B 's probabilities ( Proxy LLM, black-box ) | LLaMA-30B 's probabilities ( Proxy LLM, black-box ) | LLaMA-30B 's probabilities ( Proxy LLM, black-box ) | LLaMA-30B 's probabilities ( Proxy LLM, black-box ) | LLaMA-30B 's probabilities ( Proxy LLM, black-box ) | LLaMA-30B 's probabilities ( Proxy LLM, black-box ) |
| Avg( - log p ) | 75.43 | 30.32 | 41.29 | 21.72 | 20.20 |
| Avg( H ) | 80.80 | 39.01 | 42.97 | 33.80 | 39.49 |
| Max( - log p ) | 74.01 | 27.14 | 31.08 | -22.83 | -22.71 |
| Max( H ) | 80.92 | 37.32 | 37.90 | 35.57 | 38.94 |
| SelfCheckGPT ( black-box) | SelfCheckGPT ( black-box) | SelfCheckGPT ( black-box) | SelfCheckGPT ( black-box) | SelfCheckGPT ( black-box) | SelfCheckGPT ( black-box) |
| w/ BERTScore | 81.96 | 45.96 | 44.23 | 58.18 | 55.90 |
| w/ QA | 84.26 | 40.06 | 48.14 | 61.07 | 59.29 |
| w/ Unigram (max) | 85.63 | 41.04 | 58.47 | 64.71 | 64.91 |
| w/ NLI | 92.50 | 45.17 | 66.08 | 74.14 | 73.78 |
| w/ Prompt | 93.42 | 53.19 | 67.09 | 78.32 | 78.30 |
low probability in situations where the response is dissimilar to the generation style of the proxy LLM. We note that a weighted conditional LM score such as BARTScore (Yuan et al., 2021) could be incorporated in future investigations.
3) SelfCheckGPT outperforms grey-box approaches . It can be seen that SelfCheckGPTPrompt considerably outperforms the grey-box approaches (including GPT-3's output probabilities) as well as other black-box approaches. Even other variants of SelfCheckGPT, including BERTScore, QA, and n -gram, outperform the grey-box approaches in most setups. Interestingly, despite being the least computationally expensive method, SelfCheckGPT with unigram (max) works well across different setups. Essentially, when assessing a sentence, this method picks up the token with the lowest occurrence given all the samples. This suggests that if a token only appears a few times (or once) within the generated samples ( N =20), it is likely non-factual.
- 4) SelfCheckGPT with n -gram . When investigating the n -gram performance from 1-gram to 5-gram, the results show that simply finding the least likely token/ n -gram is more effective than computing the average n -gram score of the sentence, details in appendix Table 7. Additionally, as n increases, the performance of SelfCheckGPT with n -gram (max) drops.
- 5) SelfCheckGPT with NLI . The NLI-based
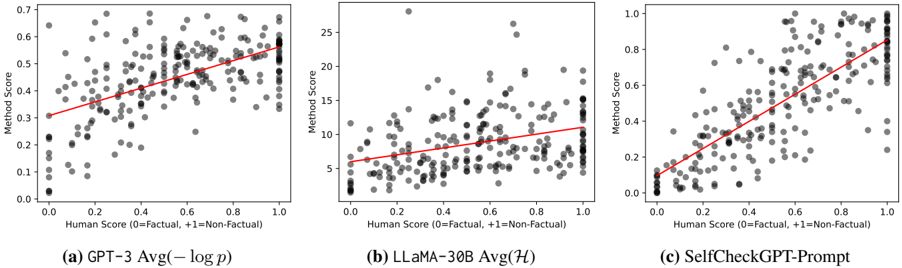
Figure 6: Scatter plot of passage-level scores where Y-axis = Method scores, X-axis = Human scores. Correlations are reported in Table 2. The scatter plots of other SelfCheckGPT variants are provided in Figure 10 in the appendix.
<details>
<summary>Image 6 Details</summary>
### Visual Description
\n
## Scatter Plots: Correlation of Method Score vs. Human Score
### Overview
The image presents three scatter plots, each comparing "Method Score" against "Human Score". Each plot represents a different model: (a) GPT-3 Avg(-log p), (b) LLaMA-30B Avg(H), and (c) SelfCheckGPT-Prompt. A red line of best fit is overlaid on each scatter plot. The x-axis represents the Human Score, and the y-axis represents the Method Score.
### Components/Axes
* **X-axis Label (all plots):** "Human Score (0=Factual, +1=Non-Factual)" - Scale ranges from approximately 0.0 to 1.0.
* **Y-axis Label (all plots):** "Method Score" - Scale varies between plots.
* Plot (a): Scale ranges from approximately 0.0 to 0.7.
* Plot (b): Scale ranges from approximately 2.5 to 26.
* Plot (c): Scale ranges from approximately 0.0 to 1.0.
* **Data Points (all plots):** Grey dots representing individual data points.
* **Regression Line (all plots):** Red line representing the linear regression fit to the data.
* **Plot Titles:**
* (a) "GPT-3 Avg(-log p)"
* (b) "LLaMA-30B Avg(H)"
* (c) "SelfCheckGPT-Prompt"
### Detailed Analysis or Content Details
**Plot (a): GPT-3 Avg(-log p)**
* **Trend:** The data points generally show a positive correlation, with the regression line sloping upwards from the bottom-left to the top-right. The spread of data points is relatively tight.
* **Data Points:**
* At Human Score ≈ 0.2, Method Score ≈ 0.25.
* At Human Score ≈ 0.4, Method Score ≈ 0.35.
* At Human Score ≈ 0.6, Method Score ≈ 0.45.
* At Human Score ≈ 0.8, Method Score ≈ 0.55.
* At Human Score ≈ 1.0, Method Score ≈ 0.6.
**Plot (b): LLaMA-30B Avg(H)**
* **Trend:** The data points show a positive correlation, but the spread is much wider than in Plot (a). The regression line is flatter.
* **Data Points:**
* At Human Score ≈ 0.2, Method Score ≈ 6.
* At Human Score ≈ 0.4, Method Score ≈ 8.
* At Human Score ≈ 0.6, Method Score ≈ 12.
* At Human Score ≈ 0.8, Method Score ≈ 18.
* At Human Score ≈ 1.0, Method Score ≈ 22.
**Plot (c): SelfCheckGPT-Prompt**
* **Trend:** The data points show a strong positive correlation, with the regression line sloping upwards. The spread is moderate.
* **Data Points:**
* At Human Score ≈ 0.2, Method Score ≈ 0.2.
* At Human Score ≈ 0.4, Method Score ≈ 0.35.
* At Human Score ≈ 0.6, Method Score ≈ 0.55.
* At Human Score ≈ 0.8, Method Score ≈ 0.7.
* At Human Score ≈ 1.0, Method Score ≈ 0.85.
### Key Observations
* All three models demonstrate a positive correlation between Human Score and Method Score, suggesting that the models generally agree with human assessments.
* LLaMA-30B (Plot b) exhibits the largest spread in Method Scores for a given Human Score, indicating greater variability in its performance.
* GPT-3 (Plot a) and SelfCheckGPT-Prompt (Plot c) have tighter distributions, suggesting more consistent performance.
* The scale of the Y-axis (Method Score) differs significantly between the models, making direct comparison of absolute Method Score values difficult.
### Interpretation
The plots illustrate the alignment between the scoring of different language models and human evaluation of factual correctness. The positive correlation in each plot suggests that the models are, to some extent, capable of identifying factual statements. However, the varying degrees of spread indicate differences in the reliability and consistency of these models.
LLaMA-30B's wider spread suggests it may be more sensitive to subtle variations in input or more prone to generating outputs with varying degrees of factual accuracy. GPT-3 and SelfCheckGPT-Prompt appear more stable in their assessments.
The different scales on the Y-axis imply that the "Method Score" is calculated differently for each model, or that the models operate on different scales of confidence or probability. Without knowing the specifics of how each "Method Score" is derived, it's difficult to make definitive comparisons.
The fact that all models show a positive correlation, even with different scales, suggests that the concept of "factual correctness" is being captured, albeit in different ways, by each model. The regression lines provide a visual representation of how well each model's score aligns with human judgment.
</details>
method outperforms all black-box and grey-box baselines, and its performance is close to the performance of the Prompt method. As SelfCheckGPT with Prompt can be computationally heavy, SelfCheckGPT with NLI could be the most practical method as it provides a good trade-off between performance and computation.
## 7.2 Passage-level Factuality Ranking
Previous results demonstrate that SelfCheckGPT is an effective approach for predicting sentencelevel factuality. An additional consideration is whether SelfCheckGPT can also be used to determine the overall factuality of passages. Passagelevel factuality scores are calculated by averaging the sentence-level scores over all sentences.
$$\mathcal { S } _ { p a s s a g e } = \frac { 1 } { | R | } \sum _ { i } \mathcal { S } ( i ) \quad \quad ( 1 2 ) \quad \frac { W } { \text {Se} }$$
where S ( i ) is the sentence-level score, and | R | is the number of sentences in the passage. Since human judgement is somewhat subjective, averaging the sentence-level labels would lead to ground truths with less noise. Note that for Avg( -log p ) and Avg( H ), we compute the average over all tokens in a passage. Whereas for Max( -log p ) and Max( H ), we first take the maximum operation over tokens at the sentence level, and we then average over all sentences following Equation 12.
Our results in Table 2 and Figure 6 show that all SelfCheckGPT methods correlate far better with human judgements than the other baselines, including the grey-box probability and entropy methods. SelfCheckGPT-Prompt is the best-performing method, achieving the highest Pearson correlation of 78.32. Unsurprisingly, the proxy LLM approach again achieves considerably lower correlations.
## 7.3 Ablation Studies External Knowledge (instead of SelfCheck)
If external knowledge is available, one can measure the informational consistency between the LLM response and the information source. In this experiment, we use the first paragraph of each concept that is available in WikiBio. 6
Table 3: The performance when using SelfCheckGPT samples versus external stored knowledge.
| Method | Sent-lvl AUC-PR | Sent-lvl AUC-PR | Sent-lvl AUC-PR | Passage-lvl | Passage-lvl |
|----------------|-------------------|-------------------|-------------------|---------------|---------------|
| Method | NoFac | NoFac* | Fact | Pear. | Spear. |
| SelfCk-BERT | 81.96 | 45.96 | 44.23 | 58.18 | 55.90 |
| WikiBio+BERT | 81.32 | 40.62 | 49.15 | 58.71 | 55.80 |
| SelfCk-QA | 84.26 | 40.06 | 48.14 | 61.07 | 59.29 |
| WikiBio+QA | 84.18 | 45.40 | 52.03 | 57.26 | 53.62 |
| SelfCk-1gm | 85.63 | 41.04 | 58.47 | 64.71 | 64.91 |
| WikiBio+1gm | 80.43 | 31.47 | 40.53 | 28.67 | 26.70 |
| SelfCk-NLI | 92.50 | 45.17 | 66.08 | 74.14 | 73.78 |
| WikiBio+NLI | 91.18 | 48.14 | 71.61 | 78.84 | 80.00 |
| SelfCk-Prompt | 93.42 | 53.19 | 67.09 | 78.32 | 78.30 |
| WikiBio+Prompt | 93.59 | 65.26 | 73.11 | 85.90 | 86.11 |
Our findings in Table 3 show the following. First, SelfCheckGPT with BERTScore/QA, using selfsamples, can yield comparable or even better performance than when using the reference passage. Second, SelfCheckGPT with n -gram shows a large performance drop when using the WikiBio passages instead of self-samples. This failure is attributed to the fact that the WikiBio reference text alone is not sufficient to train an n -gram model. Third, in contrast, SelfCheckGPT with NLI/Prompt can benefit considerably when access to retrieved information is available. Nevertheless, in practice,
6 This method is no longer zero-resource as it requires retrieving relevant knowledge from external data.
it is infeasible to have an external database for every possible use case of LLM generation.
## The Impact of the Number of Samples
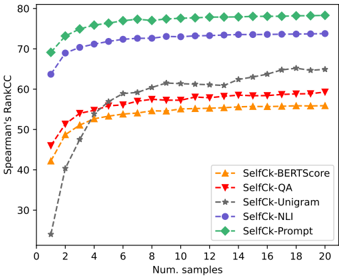
Although sample-based methods are expected to perform better when more samples are drawn, this has higher computational costs. Thus, we investigate performance as the number of samples is varied. Our results in Figure 7 show that the performance of SelfCheckGPT increases smoothly as more samples are used, with diminishing gains as more samples are generated. SelfCheckGPT with n -gram requires the highest number of samples before its performance reaches a plateau.
Figure 7: The performance of SelfCheckGPT methods on ranking passages (Spearman's) versus the number of samples.
<details>
<summary>Image 7 Details</summary>
### Visual Description
\n
## Line Chart: Spearman's Rank Correlation Coefficient vs. Number of Samples
### Overview
This image presents a line chart illustrating the Spearman's Rank Correlation Coefficient (CC) as a function of the number of samples used. Five different methods ("SelfCk-BERTScore", "SelfCk-QA", "SelfCk-Unigram", "SelfCk-NLI", and "SelfCk-Prompt") are compared. The chart shows how the correlation coefficient changes as the number of samples increases from 2 to 20.
### Components/Axes
* **X-axis:** "Num. samples" (Number of samples), ranging from 2 to 20, with tick marks at integer values.
* **Y-axis:** "Spearman's RankCC" (Spearman's Rank Correlation Coefficient), ranging from 30 to 80, with tick marks at intervals of 10.
* **Legend:** Located in the top-right corner, identifying each line with a color and label:
* SelfCk-BERTScore (Orange, dashed line)
* SelfCk-QA (Red, dashed line)
* SelfCk-Unigram (Gray, dashed line)
* SelfCk-NLI (Purple, dashed line)
* SelfCk-Prompt (Green, solid line)
### Detailed Analysis
Here's a breakdown of each line's trend and approximate data points, verified against the legend colors:
* **SelfCk-Prompt (Green, solid line):** This line exhibits a rapid initial increase, quickly plateauing at a high correlation coefficient.
* At Num. samples = 2: Spearman's RankCC ≈ 73
* At Num. samples = 4: Spearman's RankCC ≈ 77
* At Num. samples = 6: Spearman's RankCC ≈ 78
* At Num. samples = 8: Spearman's RankCC ≈ 79
* At Num. samples = 10: Spearman's RankCC ≈ 79
* At Num. samples = 20: Spearman's RankCC ≈ 79
* **SelfCk-NLI (Purple, dashed line):** This line shows a steep increase initially, then levels off, but remains lower than SelfCk-Prompt.
* At Num. samples = 2: Spearman's RankCC ≈ 65
* At Num. samples = 4: Spearman's RankCC ≈ 72
* At Num. samples = 6: Spearman's RankCC ≈ 74
* At Num. samples = 8: Spearman's RankCC ≈ 75
* At Num. samples = 20: Spearman's RankCC ≈ 75
* **SelfCk-Unigram (Gray, dashed line):** This line starts at a low value and increases steadily, but remains the lowest performing method.
* At Num. samples = 2: Spearman's RankCC ≈ 25
* At Num. samples = 4: Spearman's RankCC ≈ 35
* At Num. samples = 6: Spearman's RankCC ≈ 45
* At Num. samples = 8: Spearman's RankCC ≈ 52
* At Num. samples = 20: Spearman's RankCC ≈ 62
* **SelfCk-QA (Red, dashed line):** This line shows a moderate increase, plateauing around 58-60.
* At Num. samples = 2: Spearman's RankCC ≈ 43
* At Num. samples = 4: Spearman's RankCC ≈ 52
* At Num. samples = 6: Spearman's RankCC ≈ 56
* At Num. samples = 8: Spearman's RankCC ≈ 58
* At Num. samples = 20: Spearman's RankCC ≈ 58
* **SelfCk-BERTScore (Orange, dashed line):** This line exhibits a similar trend to SelfCk-QA, with a moderate increase and plateauing around 55-58.
* At Num. samples = 2: Spearman's RankCC ≈ 40
* At Num. samples = 4: Spearman's RankCC ≈ 50
* At Num. samples = 6: Spearman's RankCC ≈ 54
* At Num. samples = 8: Spearman's RankCC ≈ 56
* At Num. samples = 20: Spearman's RankCC ≈ 57
### Key Observations
* "SelfCk-Prompt" consistently achieves the highest Spearman's Rank Correlation Coefficient across all sample sizes.
* The correlation coefficients for all methods tend to plateau as the number of samples increases beyond 8.
* "SelfCk-Unigram" consistently performs the worst, with significantly lower correlation coefficients compared to the other methods.
* "SelfCk-BERTScore" and "SelfCk-QA" show similar performance, with moderate correlation coefficients.
### Interpretation
The data suggests that the "SelfCk-Prompt" method is the most effective at capturing the relationship between the samples, as indicated by its consistently high Spearman's Rank Correlation Coefficient. The plateauing effect observed for all methods indicates that increasing the number of samples beyond a certain point (around 8-10) does not significantly improve the correlation. This could be due to the inherent limitations of the data or the methods themselves. The poor performance of "SelfCk-Unigram" suggests that using unigram-based features is insufficient for accurately capturing the underlying relationships in the data. The similar performance of "SelfCk-BERTScore" and "SelfCk-QA" indicates that both methods provide comparable results, potentially leveraging different aspects of the data to achieve similar levels of correlation. The chart demonstrates the importance of method selection and sample size in achieving reliable correlation results.
</details>
## The Choice of LLM for SelfCheckGPT-Prompt
We investigate whether the LLM generating the text can self-check its own text. We conduct this ablation using a reduced set of the samples ( N =4).
Table 4: Comparison of GPT-3 (text-davinci-003) and ChatGPT (gpt-3.5.turbo) as the prompt-based text evaluator in SelfCheckGPT-Prompt. † Taken from Table 2 for comparison.
| Text-Gen | SelfCk-Prompt | N | Pear. | Spear. |
|------------------------------|------------------------------|-----|---------|----------|
| GPT-3 | ChatGPT | 20 | 78.32 | 78.3 |
| GPT-3 | ChatGPT | 4 | 76.47 | 76.41 |
| GPT-3 | GPT-3 | 4 | 73.11 | 74.69 |
| † SelfCheck w/ unigram (max) | † SelfCheck w/ unigram (max) | 20 | 64.71 | 64.91 |
| † SelfCheck w/ NLI | † SelfCheck w/ NLI | 20 | 74.14 | 73.78 |
The results in Table 4 show that GPT-3 can selfcheck its own text, and is better than the unigram method even when using only 4 samples. However, ChatGPT shows a slight improvement over GPT-3 in evaluating whether the sentence is supported by the context. More details are in Appendix C.
## 8 Conclusions
This paper is the first work to consider the task of hallucination detection for general large language model responses. We propose SelfCheckGPT, a zero-resource approach that is applicable to any black-box LLM without the need for external resources, and demonstrate the efficacy of our method. SelfCheckGPT outperforms a range of considered grey-box and black-box baseline detection methods at both the sentence and passage levels, and we further release an annotated dataset for GPT-3 hallucination detection with sentencelevel factuality labels.
## Limitations
In this study, the 238 GPT-3 generated texts were predominantly passages about individuals in the WikiBio dataset. To further investigate the nature of LLM's hallucination, this study could be extended to a wider range of concepts, e.g., to also consider generated texts about locations and objects. Further, this work considers factuality at the sentence level, but we note that a single sentence may consist of both factual and non-factual information. For example, the following work by Min et al. (2023) considers a fine-grained factuality evaluation by decomposing sentences into atomic facts. Finally, SelfCheckGPT with Prompt, which was convincingly the best selfcheck method, is quite computationally heavy. This might lead to impractical computational costs, which could be addressed in future work to be made more efficient.
## Ethics Statement
As this work addresses the issue of LLM's hallucination, we note that if hallucinated contents are not detected, they could lead to misinformation.
## Acknowledgments
This work is supported by Cambridge University Press & Assessment (CUP&A), a department of The Chancellor, Masters, and Scholars of the University of Cambridge, and the Cambridge Commonwealth, European & International Trust. We would like to thank the anonymous reviewers for their helpful comments.
## References
- Amos Azaria and Tom Mitchell. 2023. The internal state of an llm knows when its lying. arXiv preprint arXiv:2304.13734 .
- Iz Beltagy, Matthew E. Peters, and Arman Cohan. 2020. Longformer: The long-document transformer.
- Sidney Black, Stella Biderman, Eric Hallahan, Quentin Anthony, Leo Gao, Laurence Golding, Horace He, Connor Leahy, Kyle McDonell, Jason Phang, Michael Pieler, Usvsn Sai Prashanth, Shivanshu Purohit, Laria Reynolds, Jonathan Tow, Ben Wang, and Samuel Weinbach. 2022. GPT-NeoX-20B: An opensource autoregressive language model. In Proceedings of BigScience Episode #5 - Workshop on Challenges & Perspectives in Creating Large Language Models , pages 95-136, virtual+Dublin. Association for Computational Linguistics.
- Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. 2020. Language models are few-shot learners. Advances in neural information processing systems , 33:1877-1901.
- Aakanksha Chowdhery, Sharan Narang, Jacob Devlin, Maarten Bosma, Gaurav Mishra, Adam Roberts, Paul Barham, Hyung Won Chung, Charles Sutton, Sebastian Gehrmann, et al. 2022. Palm: Scaling language modeling with pathways. arXiv preprint arXiv:2204.02311 .
- Jacob Cohen. 1960. A coefficient of agreement for nominal scales. Educational and Psychological Measurement , 20:37 - 46.
- Jinlan Fu, See-Kiong Ng, Zhengbao Jiang, and Pengfei Liu. 2023. Gptscore: Evaluate as you desire.
- Zhijiang Guo, Michael Schlichtkrull, and Andreas Vlachos. 2022. A survey on automated fact-checking. Transactions of the Association for Computational Linguistics , 10:178-206.
- Pengcheng He, Jianfeng Gao, and Weizhu Chen. 2023. DeBERTav3: Improving deBERTa using ELECTRAstyle pre-training with gradient-disentangled embedding sharing. In The Eleventh International Conference on Learning Representations .
- Yichong Huang, Xiachong Feng, Xiaocheng Feng, and Bing Qin. 2021. The factual inconsistency problem in abstractive text summarization: A survey.
- Ganesh Jawahar, Benoît Sagot, and Djamé Seddah. 2019. What does BERT learn about the structure of language? In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics , pages 3651-3657, Florence, Italy. Association for Computational Linguistics.
- Ziwei Ji, Nayeon Lee, Rita Frieske, Tiezheng Yu, Dan Su, Yan Xu, Etsuko Ishii, Ye Jin Bang, Andrea
- Madotto, and Pascale Fung. 2023. Survey of hallucination in natural language generation. ACM Comput. Surv. , 55(12).
- Saurav Kadavath, Tom Conerly, Amanda Askell, Tom Henighan, Dawn Drain, Ethan Perez, Nicholas Schiefer, Zac Hatfield Dodds, Nova DasSarma, Eli Tran-Johnson, et al. 2022. Language models (mostly) know what they know. arXiv preprint arXiv:2207.05221 .
- Wojciech Kryscinski, Bryan McCann, Caiming Xiong, and Richard Socher. 2020. Evaluating the factual consistency of abstractive text summarization. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP) , pages 9332-9346, Online. Association for Computational Linguistics.
- Lorenz Kuhn, Yarin Gal, and Sebastian Farquhar. 2023. Semantic uncertainty: Linguistic invariances for uncertainty estimation in natural language generation. In The Eleventh International Conference on Learning Representations .
- Guokun Lai, Qizhe Xie, Hanxiao Liu, Yiming Yang, and Eduard Hovy. 2017. RACE: Large-scale ReAding comprehension dataset from examinations. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing , pages 785794, Copenhagen, Denmark. Association for Computational Linguistics.
- Rémi Lebret, David Grangier, and Michael Auli. 2016. Generating text from structured data with application to the biography domain. CoRR , abs/1603.07771.
- Tianyu Liu, Yizhe Zhang, Chris Brockett, Yi Mao, Zhifang Sui, Weizhu Chen, and Bill Dolan. 2022. A token-level reference-free hallucination detection benchmark for free-form text generation. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages 6723-6737, Dublin, Ireland. Association for Computational Linguistics.
- Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, and Veselin Stoyanov. 2019. Roberta: A robustly optimized bert pretraining approach. arXiv preprint arXiv:1907.11692 .
- Adian Liusie, Vatsal Raina, and Mark Gales. 2023. 'world knowledge' in multiple choice reading comprehension. In Proceedings of the Sixth Fact Extraction and VERification Workshop (FEVER) , pages 49-57, Dubrovnik, Croatia. Association for Computational Linguistics.
- Zheheng Luo, Qianqian Xie, and Sophia Ananiadou. 2023. Chatgpt as a factual inconsistency evaluator for abstractive text summarization. arXiv preprint arXiv:2303.15621 .
- Andrey Malinin and Mark Gales. 2021. Uncertainty estimation in autoregressive structured prediction. In International Conference on Learning Representations .
- Potsawee Manakul, Adian Liusie, and Mark JF Gales. 2023. MQAG: Multiple-choice question answering and generation for assessing information consistency in summarization. arXiv preprint arXiv:2301.12307 .
- Joshua Maynez, Shashi Narayan, Bernd Bohnet, and Ryan McDonald. 2020. On faithfulness and factuality in abstractive summarization. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics , pages 1906-1919, Online. Association for Computational Linguistics.
- Sewon Min, Kalpesh Krishna, Xinxi Lyu, Mike Lewis, Wen-tau Yih, Pang Wei Koh, Mohit Iyyer, Luke Zettlemoyer, and Hannaneh Hajishirzi. 2023. Factscore: Fine-grained atomic evaluation of factual precision in long form text generation. arXiv preprint arXiv:2305.14251 .
- Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J Liu. 2020. Exploring the limits of transfer learning with a unified text-to-text transformer. The Journal of Machine Learning Research , 21(1):5485-5551.
- Vatsal Raina and Mark Gales. 2022. Answer uncertainty and unanswerability in multiple-choice machine reading comprehension. In Findings of the Association for Computational Linguistics: ACL 2022 , pages 1020-1034, Dublin, Ireland. Association for Computational Linguistics.
- Pranav Rajpurkar, Jian Zhang, Konstantin Lopyrev, and Percy Liang. 2016. SQuAD: 100,000+ questions for machine comprehension of text. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing , pages 2383-2392, Austin, Texas. Association for Computational Linguistics.
- Kurt Shuster, Spencer Poff, Moya Chen, Douwe Kiela, and Jason Weston. 2021. Retrieval augmentation reduces hallucination in conversation. In Findings of the Association for Computational Linguistics: EMNLP 2021 , pages 3784-3803, Punta Cana, Dominican Republic. Association for Computational Linguistics.
- James Thorne, Andreas Vlachos, Oana Cocarascu, Christos Christodoulopoulos, and Arpit Mittal. 2018. The Fact Extraction and VERification (FEVER) shared task. In Proceedings of the First Workshop on Fact Extraction and VERification (FEVER) .
- Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, et al. 2023. Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971 .
- Anthony J Viera, Joanne M Garrett, et al. 2005. Understanding interobserver agreement: the kappa statistic. Fam med , 37(5):360-363.
- Ben Wang and Aran Komatsuzaki. 2021. GPT-J6B: A 6 Billion Parameter Autoregressive Language Model. https://github.com/kingoflolz/ mesh-transformer-jax .
- Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc V Le, Ed H. Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. 2023. Self-consistency improves chain of thought reasoning in language models. In The Eleventh International Conference on Learning Representations .
- Adina Williams, Nikita Nangia, and Samuel Bowman. 2018. A broad-coverage challenge corpus for sentence understanding through inference. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers) , pages 1112-1122, New Orleans, Louisiana. Association for Computational Linguistics.
- Yijun Xiao and William Yang Wang. 2021. On hallucination and predictive uncertainty in conditional language generation. In Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: Main Volume , pages 2734-2744, Online. Association for Computational Linguistics.
- Weizhe Yuan, Graham Neubig, and Pengfei Liu. 2021. Bartscore: Evaluating generated text as text generation. Advances in Neural Information Processing Systems , 34:27263-27277.
- Susan Zhang, Stephen Roller, Naman Goyal, Mikel Artetxe, Moya Chen, Shuohui Chen, Christopher Dewan, Mona Diab, Xian Li, Xi Victoria Lin, et al. 2022. Opt: Open pre-trained transformer language models. arXiv preprint arXiv:2205.01068 .
- Zhuosheng Zhang, Yuwei Wu, Hai Zhao, Zuchao Li, Shuailiang Zhang, Xi Zhou, and Xiang Zhou. 2020. Semantics-aware bert for language understanding. In Proceedings of the AAAI Conference on Artificial Intelligence , volume 34, pages 9628-9635.
- Wanjun Zhong, Jingjing Xu, Duyu Tang, Zenan Xu, Nan Duan, Ming Zhou, Jiahai Wang, and Jian Yin. 2020. Reasoning over semantic-level graph for fact checking. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics , pages 6170-6180, Online. Association for Computational Linguistics.
## A Models and Implementation
## A.1 Entropy
The entropy of the output distribution is implemented as follows,
$$\begin{array} { r l } { \mathcal { H } _ { i j } = 2 ^ { - \sum _ { \tilde { w } \in W } p _ { i j } ( \tilde { w } ) \log _ { 2 } p _ { i j } ( \tilde { w } ) } } & { ( 1 3 ) \quad L e t } \end{array}$$
where W is the set of all possible words in the vocabulary.
## A.2 Proxy LLMs
The proxy LLMs considered are LLaMA-{7B, 13B, 30B} (Touvron et al., 2023), OPT-{125m, 1.3B, 13B, 30B} (Zhang et al., 2022), GPT-J-6B (Wang and Komatsuzaki, 2021) and GPT-NeoX20B (Black et al., 2022).
## A.3 SelfCheckGPT's Systems
Question Answering : The generation systems G1 and G2 are T5-Large fine-tuned to SQuAD (Rajpurkar et al., 2016) and RACE (Lai et al., 2017), respectively. The answering system A is Longformer (Beltagy et al., 2020) fine-tuned to the RACE dataset. The answerability system U is also Longformer, but fine-tuned to SQuAD2.0.
LLM for Prompting : We consider two LLMs, GPT-3 (text-davinci-003) and ChatGPT (gpt-3.5turbo) We note that during the data creation and annotation, GPT-3 (text-davinci-003) was the stateof-the-art LLM available; hence, GPT-3 was used as the main LLM generating WikiBio passages.
## B SelfCheckGPT with QA
Previous work showed that implementing question generation (in Equation 2) with two generators ( G1 generates the question and associated answer, and G2 generates distractors) yields higher-quality distractors (Manakul et al., 2023). Thus, a two-stage generation is adopted in this work as follows:
$$\begin{array} { r l } & { q , a \sim P _ { \mathbb { G } 1 } ( q , a | r _ { i } ) ; \, o _ { \langle a \rangle } \sim P _ { \mathbb { G } 2 } ( o _ { \langle a \rangle } | q , a , R ) } \\ & { ( 1 4 ) } \end{array}$$
where o = { a, o \ a } = { o 1 , ..., o 4 } . In addition, to filter out bad (unanswerable) questions, we define an answerability score (Raina and Gales, 2022):
$$\alpha = P _ { U } ( a n s w e r a b l e | q , c o n t e x t ) \quad ( 1 5 ) \quad p e r$$
where the context is either the response R or sampled passages S n , and α → 0 . 0 for unanswerable and α → 1 . 0 for answerable. We use α to filter out unanswerable questions which have α lower than a threshold. Next, we derive how Bayes' theorem can be applied to take into account the number of answerable/unanswerable questions.
## B.1 SelfCheckGPT-QA with Bayes
Let P ( F ) denote the probability of the i -th sentence being non-factual, and P ( T ) denote the probability of the i -th sentence being factual. For a question q , the probability of i -th sentence being non-factual given a set of matched answers L m and a set of not-matched answers L n is:
$$& P ( \mathbf F | L _ { \mathbf m } , L _ { \mathbf n } ) \\ & = \frac { P ( L _ { \mathbf m } , L _ { \mathbf n } | \mathbf F ) P ( \mathbf F ) } { P ( L _ { \mathbf m } , L _ { \mathbf n } | \mathbf F ) + P ( L _ { \mathbf m } , L _ { \mathbf n } | \mathbf T ) P ( \mathbf T ) } \\ & = \frac { P ( L _ { \mathbf m } , L _ { \mathbf n } | \mathbf F ) } { P ( L _ { \mathbf m } , L _ { \mathbf n } | \mathbf F ) + P ( L _ { \mathbf m } , L _ { \mathbf n } | \mathbf T ) }$$
where we assume the sentence is equally likely to be False or True, i.e. P ( F ) = P ( T ) . The probability of observing L m , L n when the sentence is False (non-factual):
̸
$$\begin{array} { r l } & { P ( L _ { \mathbb { m } } , L _ { n } | F ) } \\ & { = \prod _ { a \in L _ { \mathbb { m } } } P ( a = a _ { R } | F ) \prod _ { a ^ { \prime } \in L _ { \mathbb { m } } } P ( a ^ { \prime } \neq a _ { R } | F ) } \\ & { = ( 1 - \beta _ { 1 } ) ^ { N _ { \mathbb { m } } } ( \beta _ { 1 } ) ^ { N _ { \mathbb { n } } } } \end{array}$$
and probability of observing L m , L n when the sentence is True (factual):
̸
$$\begin{array} { r l } & { P ( L _ { \mathbb { m } } , L _ { \mathbf n } | T ) } \\ & { = \prod _ { a \in L _ { \mathbf n } } P ( a = a _ { r } | T ) \prod _ { a ^ { \prime } \in L _ { \mathbf n } } P ( a ^ { \prime } \neq a _ { r } | T ) } \\ & { = ( \beta _ { 2 } ) ^ { N _ { \mathbb { m } } } ( 1 - \beta _ { 2 } ) ^ { N _ { \mathbf n } } } \end{array}$$
where N m and N n are the number of matched answers and the number of not-matched answers, respectively. Hence, we can simplify Equation 16:
$$\begin{array} { r l } { P ( F | L _ { \mathfrak { m } } , L _ { \mathfrak { n } } ) = \frac { \gamma _ { 2 } ^ { N _ { \mathfrak { n } } } } { \gamma _ { 1 } ^ { N _ { \mathfrak { n } } } + \gamma _ { 2 } ^ { N _ { \mathfrak { n } } } } \quad ( 1 9 ) } \end{array}$$
where γ 1 = β 2 1 -β 1 and γ 2 = β 1 1 -β 2 . Lastly, instead of rejecting samples having an answerability score below a threshold, 7 we find empirically that softcounting (defined below) improves the detection performance. We set both β 1 and β 2 to 0.8.
7 α is between 0.0 (unanswerable) and 1.0 (answerable). Standard-counting N m and N n can be considered as a special case of soft-counting where α is set to 1.0 if α is greater than the answerability threshold and otherwise α is 0.0.
$$N _ { \mathfrak { m } } ^ { \prime } = \sum _ { n \text { s.t. a} _ { n } \in L _ { \mathfrak { m } } } \alpha _ { n } ; \ N _ { \mathfrak { n } } ^ { \prime } = \sum _ { n \text { s.t. a} _ { n } \in L _ { \mathfrak { n } } } \alpha _ { n } ( 2 0 )$$
where α n = P U ( answerable | q, S n ) . Therefore, the SelfCheckGPT with QA score, S QA, is:
$$\begin{array} { r l } { \mathcal { S } _ { Q A } = P ( F | L _ { m } , L _ { n } ) = \frac { \gamma _ { 2 } ^ { N _ { n } ^ { \prime } } } { \gamma _ { 1 } ^ { N _ { n } ^ { \prime } } + \gamma _ { 2 } ^ { N _ { n } ^ { \prime } } } \quad ( 2 1 ) } \end{array}$$
In Table 5, we show empically that applying Bayes' theorem and soft counting α (in Equation 20) improves the performance of the SelfCheckGPT with QA method.
| Varaint | Sentence-lvl | Sentence-lvl | Sentence-lvl | Passage-lvl | Passage-lvl |
|-------------|----------------|----------------|----------------|---------------|---------------|
| | NoF | NoF* | Fact | PCC | SCC |
| SimpleCount | 83.97 | 40.07 | 47.78 | 57.39 | 55.15 |
| + Bayes | 83.04 | 38.58 | 47.41 | 56.43 | 55.03 |
| + Bayes + α | 84.26 | 40.06 | 48.14 | 61.07 | 59.29 |
Table 5: Performance of SelfCheckGPT-QA's variants.
## C SelfCheckGPT with Prompt
We use the prompt template provided in the main text (in Section 5.5) for both GPT-3 (text-davinci003) and ChatGPT (gpt-3.5-turbo). For ChatGPT, a standard system message " You are a helpful assistant. " is used in setting up the system.
At the time of conducting experiments, the API costs per 1,000 tokens are $0.020 for GPT-3 and $0.002 for ChatGPT. The estimated costs for running the models to answer Yes/No on all 1908 sentences and 20 samples are around $200 for GPT-3 and $20 for ChatGPT. Given the cost, we conduct the experiments on 4 samples when performing the ablation about LLM choice for SelfCheckGPTPrompt (Section 7.3). Table 6 shows the breakdown of predictions made by GPT-3 and ChatGPT.
Table 6: Breakdown of predictions made by GPT-3/ChatGPT when prompted to answer Yes (supported)/ No (not-supported).
| GPT-3 ChatGPT | Yes | No |
|-----------------|-------|------|
| Yes | 3179 | 1038 |
| No | 367 | 3048 |
## D Additional Experimental Results
Here, we provide experimental results that are complementary to those presented in the main paper.
| n -gram | Sent-lvl AUC-PR | Sent-lvl AUC-PR | Sent-lvl AUC-PR | Passage-lvl | Passage-lvl |
|----------------|-------------------|-------------------|-------------------|----------------|----------------|
| | NoFac | NoFac* | Fact | Pear. | Spear. |
| Avg( - log p ) | Avg( - log p ) | Avg( - log p ) | Avg( - log p ) | Avg( - log p ) | Avg( - log p ) |
| 1-gram | 81.52 | 40.33 | 41.76 | 40.68 | 39.22 |
| 2-gram | 82.94 | 44.38 | 52.81 | 58.84 | 58.11 |
| 3-gram | 83.56 | 44.64 | 53.99 | 62.21 | 63.00 |
| 4-gram | 83.80 | 43.55 | 54.25 | 61.98 | 63.64 |
| 5-gram | 83.45 | 42.31 | 53.98 | 60.68 | 62.96 |
| Max( - log p ) | Max( - log p ) | Max( - log p ) | Max( - log p ) | Max( - log p ) | Max( - log p ) |
| 1-gram | 85.63 | 41.04 | 58.47 | 64.71 | 64.91 |
| 2-gram | 85.26 | 39.29 | 58.29 | 62.48 | 66.04 |
| 3-gram | 84.97 | 37.10 | 57.08 | 57.34 | 60.49 |
| 4-gram | 84.49 | 36.37 | 55.96 | 55.77 | 57.25 |
| 5-gram | 84.12 | 36.19 | 54.89 | 54.84 | 55.97 |
Table 7: The performance using different n -gram models in the SelfCheckGPT with n -gram method.
Figure 8: The performance of SelfCheckGPT methods on sentence-level non-factual detection (AUC-PR) versus the number of samples. This Figure extends the passage-level results in Figure 7.
<details>
<summary>Image 8 Details</summary>
### Visual Description
## Line Chart: AUC-PR vs. Number of Samples
### Overview
This image presents a line chart illustrating the relationship between the Area Under the Precision-Recall Curve (AUC-PR) and the number of samples used, for five different methods: SelfCk-BERTScore, SelfCk-QA, SelfCk-Unigram, SelfCk-NLI, and SelfCk-Prompt. The chart aims to demonstrate how performance (AUC-PR) changes as the sample size increases for each method.
### Components/Axes
* **X-axis:** "Num. samples" - Represents the number of samples, ranging from 0 to 20, with markers at integer values.
* **Y-axis:** "AUC-PR" - Represents the Area Under the Precision-Recall Curve, ranging from approximately 79.5 to 93, with markers at 0.5 increments.
* **Legend:** Located in the bottom-right corner of the chart. It identifies each line with a specific color and label:
* SelfCk-BERTScore (Orange)
* SelfCk-QA (Red)
* SelfCk-Unigram (Gray)
* SelfCk-NLI (Blue)
* SelfCk-Prompt (Green)
### Detailed Analysis
Let's analyze each line individually, noting trends and approximate data points.
* **SelfCk-Prompt (Green):** This line shows a rapid initial increase, reaching a plateau around 92.5 AUC-PR between 6 and 20 samples.
* At 0 samples: ~89.0 AUC-PR
* At 2 samples: ~91.0 AUC-PR
* At 4 samples: ~92.0 AUC-PR
* At 6 samples: ~92.5 AUC-PR
* At 20 samples: ~92.5 AUC-PR
* **SelfCk-NLI (Blue):** This line also shows a quick increase, leveling off around 92.3 AUC-PR between 4 and 20 samples.
* At 0 samples: ~89.5 AUC-PR
* At 2 samples: ~90.5 AUC-PR
* At 4 samples: ~91.8 AUC-PR
* At 6 samples: ~92.2 AUC-PR
* At 20 samples: ~92.3 AUC-PR
* **SelfCk-Unigram (Gray):** This line exhibits a slower, more gradual increase, reaching approximately 85 AUC-PR at 20 samples.
* At 0 samples: ~79.5 AUC-PR
* At 2 samples: ~82.0 AUC-PR
* At 4 samples: ~83.0 AUC-PR
* At 6 samples: ~83.5 AUC-PR
* At 20 samples: ~85.0 AUC-PR
* **SelfCk-QA (Red):** This line shows a moderate increase, plateauing around 84.5 AUC-PR between 8 and 20 samples.
* At 0 samples: ~80.0 AUC-PR
* At 2 samples: ~82.5 AUC-PR
* At 4 samples: ~83.5 AUC-PR
* At 6 samples: ~84.0 AUC-PR
* At 20 samples: ~84.5 AUC-PR
* **SelfCk-BERTScore (Orange):** This line shows an initial increase, then plateaus around 81.5 AUC-PR between 6 and 20 samples.
* At 0 samples: ~80.0 AUC-PR
* At 2 samples: ~81.0 AUC-PR
* At 4 samples: ~81.5 AUC-PR
* At 6 samples: ~81.5 AUC-PR
* At 20 samples: ~81.5 AUC-PR
### Key Observations
* SelfCk-Prompt and SelfCk-NLI consistently outperform the other methods across all sample sizes.
* SelfCk-Unigram and SelfCk-BERTScore show the lowest performance.
* The performance gains for SelfCk-Prompt and SelfCk-NLI diminish significantly after approximately 6 samples.
* The lines for SelfCk-Prompt, SelfCk-NLI, SelfCk-QA, and SelfCk-BERTScore all show an initial steep increase, indicating that adding even a small number of samples can significantly improve performance.
### Interpretation
The data suggests that SelfCk-Prompt and SelfCk-NLI are the most effective methods for this task, achieving high AUC-PR values with relatively few samples. The diminishing returns observed after 6 samples indicate that increasing the sample size beyond this point provides limited additional benefit for these methods. SelfCk-Unigram and SelfCk-BERTScore, while showing some improvement with increasing samples, consistently underperform the other methods, suggesting they may be less suitable for this particular task. The rapid initial gains across all methods suggest that even a small amount of data can be valuable for training and evaluating these models. The differences in performance between the methods likely reflect variations in their ability to capture relevant information from the data and generalize to unseen examples. The chart provides valuable insights into the trade-off between sample size and performance for each method, allowing for informed decisions about data collection and model selection.
</details>
Figure 9: Passage-level ranking performance of the Avg( H ) method using proxy LLM where the sizes are: LLaMA={7B, 13B, 30B}, OPT={125m, 1.3B, 13B, 30B}, GPT-J=6B, NeoX=20B. The full results are provided in Table 8.
<details>
<summary>Image 9 Details</summary>
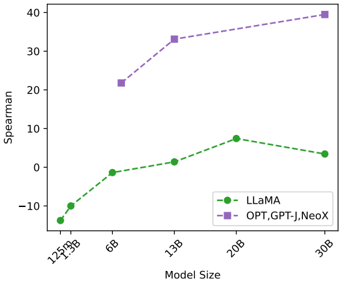
### Visual Description
## Line Chart: Spearman Correlation vs. Model Size
### Overview
This line chart depicts the Spearman correlation coefficient as a function of model size for two different model families: LLaMA and OPT, GPT-J, NeoX. The chart illustrates how the correlation changes as the model size increases.
### Components/Axes
* **X-axis:** Model Size (labeled at 125MB, 3B, 6B, 13B, 20B, 30B)
* **Y-axis:** Spearman (ranging from approximately -15 to 40)
* **Data Series 1:** LLaMA (represented by green circles connected by a dashed line)
* **Data Series 2:** OPT, GPT-J, NeoX (represented by purple squares connected by a dashed line)
* **Legend:** Located in the bottom-right corner, clearly labeling each data series with its corresponding color and name.
### Detailed Analysis
**LLaMA (Green Line):**
The LLaMA line starts at approximately -14 at 125MB, slopes upward to approximately -2 at 3B, continues to approximately 0 at 6B, rises to approximately 8 at 20B, and then declines to approximately 5 at 30B.
* 125MB: Spearman ≈ -14
* 3B: Spearman ≈ -2
* 6B: Spearman ≈ 0
* 13B: Spearman ≈ 2
* 20B: Spearman ≈ 8
* 30B: Spearman ≈ 5
**OPT, GPT-J, NeoX (Purple Line):**
The OPT, GPT-J, NeoX line begins at approximately 22 at 125MB, increases to approximately 34 at 13B, and then plateaus, reaching approximately 38 at 30B.
* 125MB: Spearman ≈ 22
* 3B: Spearman ≈ 24
* 6B: Spearman ≈ 24
* 13B: Spearman ≈ 34
* 20B: Spearman ≈ 36
* 30B: Spearman ≈ 38
### Key Observations
* The OPT, GPT-J, NeoX models consistently exhibit a higher Spearman correlation than the LLaMA models across all model sizes.
* The Spearman correlation for LLaMA increases with model size up to 20B, then decreases slightly at 30B.
* The Spearman correlation for OPT, GPT-J, NeoX increases rapidly up to 13B, then shows diminishing returns with increasing model size.
* The LLaMA line shows a more pronounced curve, indicating a more dynamic relationship between model size and Spearman correlation.
### Interpretation
The chart suggests that larger models generally exhibit higher Spearman correlation, indicating a stronger relationship between the model's predictions and the ground truth. However, the rate of increase in correlation diminishes as the model size grows, particularly for the OPT, GPT-J, NeoX family. The LLaMA model shows a different pattern, with a peak correlation at 20B and a slight decrease at 30B, which could indicate overfitting or a change in the model's behavior at larger scales. The significant difference in Spearman correlation between the two model families suggests that the underlying architectures or training data differ substantially, leading to different performance characteristics. The Spearman correlation is a measure of rank correlation, so the chart is showing how well the models can preserve the relative ordering of predictions.
</details>
Figure 10: Scatter plot of passage-level scores where Y-axis = Method scores, X-axis = Human scores. Correlations are reported in Table 2. This figure provides results in addition to Figure 6.
<details>
<summary>Image 10 Details</summary>
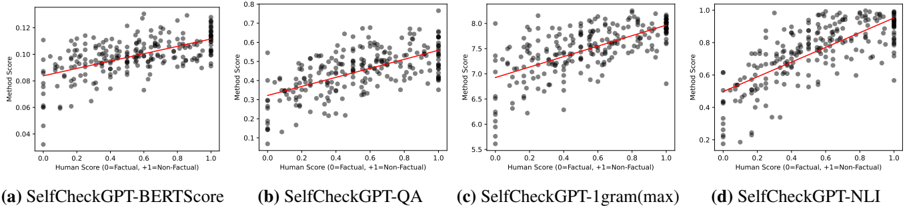
### Visual Description
\n
## Scatter Plots: Method Score vs. Human Score for Different Self-Check Methods
### Overview
The image presents four scatter plots, each comparing "Method Score" against "Human Score". Each plot represents a different self-checking method: SelfCheck-BERTScore, SelfCheckGPT-QA, SelfCheck-1gram(max), and SelfCheckGPT-NLI. A red line represents a linear regression fit to the data in each plot.
### Components/Axes
Each plot shares the following components:
* **X-axis:** Labeled "Human Score (0=Factual, +1=Non-Factual)". The scale ranges from approximately 0.0 to 1.0.
* **Y-axis:** Labeled "Method Score". The scale varies between plots:
* (a) ranges from approximately 0.04 to 0.12
* (b) ranges from approximately 0.10 to 0.65
* (c) ranges from approximately 5.5 to 8.0
* (d) ranges from approximately 0.2 to 1.0
* **Data Points:** Represented by gray dots.
* **Regression Line:** A red line indicating the linear relationship between the two scores.
* **Labels:** Each plot is labeled with a letter (a, b, c, d) and the name of the corresponding method.
### Detailed Analysis or Content Details
**Plot (a): SelfCheck-BERTScore**
* The data points are scattered, showing a generally positive correlation.
* The regression line slopes upward, indicating that as the Human Score increases, the Method Score tends to increase.
* Approximate data points (visually estimated):
* Human Score = 0.2, Method Score ≈ 0.06
* Human Score = 0.4, Method Score ≈ 0.08
* Human Score = 0.6, Method Score ≈ 0.09
* Human Score = 0.8, Method Score ≈ 0.10
* Human Score = 1.0, Method Score ≈ 0.12
**Plot (b): SelfCheckGPT-QA**
* The data points are more densely clustered than in plot (a), also showing a positive correlation.
* The regression line is steeper than in plot (a), suggesting a stronger relationship.
* Approximate data points:
* Human Score = 0.2, Method Score ≈ 0.20
* Human Score = 0.4, Method Score ≈ 0.35
* Human Score = 0.6, Method Score ≈ 0.50
* Human Score = 0.8, Method Score ≈ 0.60
* Human Score = 1.0, Method Score ≈ 0.65
**Plot (c): SelfCheck-1gram(max)**
* The data points are scattered, but show a clear positive correlation.
* The regression line is relatively steep.
* Approximate data points:
* Human Score = 0.2, Method Score ≈ 6.0
* Human Score = 0.4, Method Score ≈ 6.7
* Human Score = 0.6, Method Score ≈ 7.3
* Human Score = 0.8, Method Score ≈ 7.7
* Human Score = 1.0, Method Score ≈ 8.0
**Plot (d): SelfCheckGPT-NLI**
* The data points are scattered, showing a positive correlation.
* The regression line is moderately steep.
* Approximate data points:
* Human Score = 0.2, Method Score ≈ 0.30
* Human Score = 0.4, Method Score ≈ 0.50
* Human Score = 0.6, Method Score ≈ 0.70
* Human Score = 0.8, Method Score ≈ 0.85
* Human Score = 1.0, Method Score ≈ 0.95
### Key Observations
* All four methods demonstrate a positive correlation between Human Score and Method Score.
* The strength of the correlation appears to vary between methods, with SelfCheck-1gram(max) and SelfCheckGPT-NLI showing a stronger relationship than SelfCheck-BERTScore.
* The scales of the Y-axis (Method Score) differ significantly between the plots, making direct comparison of the absolute Method Score values difficult.
### Interpretation
The plots suggest that all four self-checking methods are capable of identifying factual inaccuracies to some extent, as indicated by the positive correlation with human judgment. However, the varying scales and scatter suggest that the methods have different sensitivities and levels of agreement with human assessment. The steeper regression lines in plots (b), (c), and (d) indicate that these methods are more strongly aligned with human scores. The differences in the scales of the Method Score suggest that the methods measure "factuality" or "accuracy" in different ways or on different scales. The scatter in the data points indicates that none of the methods are perfect predictors of human judgment, and there is considerable variability in their performance. Further analysis would be needed to determine which method is most reliable and appropriate for a given application.
</details>
Table 8: AUC-PR for Detecting Non-Factual and Factual Sentences in the GPT-3 generated WikiBio passages. Passage-level PCC and SCC with LLMs used to assess GPT-3 responses. This table is an extension to Table 2.
| LLM | Size | Sentence-level (AUC-PR) | Sentence-level (AUC-PR) | Sentence-level (AUC-PR) | Passage-level (Corr.) | Passage-level (Corr.) |
|-----------------------|-----------------------|---------------------------|---------------------------|---------------------------|-------------------------|-------------------------|
| | | NonFact | NonFact* | Factual | Pearson | Spearman |
| Random | - | 72.96 | 29.72 | 27.04 | - | - |
| Avg( - log p ) Method | Avg( - log p ) Method | Avg( - log p ) Method | Avg( - log p ) Method | Avg( - log p ) Method | Avg( - log p ) Method | Avg( - log p ) Method |
| LLaMA | 30B | 75.43 | 30.32 | 41.29 | 21.72 | 20.20 |
| LLaMA | 13B | 74.16 | 30.01 | 37.36 | 13.33 | 12.89 |
| LLaMA | 7B | 71.69 | 27.87 | 31.30 | -2.71 | -2.59 |
| OPT | 30B | 67.70 | 24.43 | 25.04 | -32.07 | -31.45 |
| NeoX | 20B | 69.00 | 24.38 | 26.18 | -31.79 | -34.15 |
| OPT | 13B | 67.46 | 24.39 | 25.20 | -33.05 | -32.79 |
| GPT-J | 6B | 67.51 | 24.28 | 24.26 | -38.80 | -40.05 |
| OPT | 1.3B | 66.19 | 24.47 | 23.47 | -35.20 | -38.95 |
| OPT | 125m | 66.63 | 25.31 | 23.07 | -30.38 | -37.54 |
| Avg( H ) Method | Avg( H ) Method | Avg( H ) Method | Avg( H ) Method | Avg( H ) Method | Avg( H ) Method | Avg( H ) Method |
| LLaMA | 30B | 80.80 | 39.01 | 42.97 | 33.80 | 39.49 |
| LLaMA | 13B | 80.63 | 38.98 | 40.59 | 29.43 | 33.12 |
| LLaMA | 7B | 78.67 | 37.22 | 33.81 | 19.44 | 21.79 |
| OPT | 30B | 77.13 | 33.67 | 29.55 | -0.43 | 3.43 |
| NeoX | 20B | 77.40 | 32.78 | 30.13 | 5.41 | 7.43 |
| OPT | 13B | 76.93 | 33.71 | 29.68 | 0.25 | 1.39 |
| GPT-J | 6B | 76.15 | 33.29 | 28.30 | -2.50 | -1.37 |
| OPT | 1.3B | 74.05 | 31.91 | 26.33 | -10.59 | -10.00 |
| OPT | 125m | 71.51 | 30.88 | 25.36 | -14.16 | -13.76 |
| Max( - log p ) Method | Max( - log p ) Method | Max( - log p ) Method | Max( - log p ) Method | Max( - log p ) Method | Max( - log p ) Method | Max( - log p ) Method |
| LLaMA | 30B | 74.01 | 27.14 | 31.08 | -22.83 | -22.71 |
| LLaMA | 13B | 71.12 | 26.78 | 28.82 | -34.93 | -31.70 |
| LLaMA | 7B | 69.57 | 25.91 | 26.54 | -42.57 | -38.24 |
| OPT | 30B | 67.32 | 24.40 | 24.32 | -49.51 | -45.50 |
| NeoX | 20B | 67.51 | 23.88 | 24.82 | -47.96 | -44.54 |
| OPT | 13B | 67.36 | 24.67 | 24.46 | -50.15 | -44.42 |
| GPT-J | 6B | 67.58 | 23.94 | 23.93 | -51.23 | -47.68 |
| OPT | 1.3B | 68.16 | 25.85 | 24.66 | -45.60 | -42.39 |
| OPT | 125m | 69.23 | 27.66 | 24.14 | -39.22 | -37.18 |
| Max( H ) Method | Max( H ) Method | Max( H ) Method | Max( H ) Method | Max( H ) Method | Max( H ) Method | Max( H ) Method |
| LLaMA | 30B | 80.92 | 37.32 | 37.90 | 35.57 | 38.94 |
| LLaMA | 13B | 80.98 | 37.94 | 36.01 | 32.07 | 34.01 |
| LLaMA | 7B | 79.65 | 35.57 | 31.32 | 22.10 | 22.53 |
| OPT | 30B | 76.58 | 33.44 | 29.31 | 1.63 | 6.41 |
| NeoX | 20B | 76.98 | 31.96 | 29.13 | 5.97 | 9.31 |
| OPT | 13B | 76.26 | 32.81 | 29.25 | 1.42 | 2.82 |
| GPT-J | 6B | 75.30 | 32.51 | 28.13 | -2.14 | 1.41 |
| OPT | 1.3B | 73.79 | 31.42 | 26.38 | -9.84 | -9.80 |
| OPT | 125m | 71.32 | 31.65 | 25.36 | -18.05 | -17.37 |