# Reflexion: Language Agents with Verbal Reinforcement Learning
**Authors**:
- Noah Shinn (Northeastern University)
- Federico Cassano (Northeastern University)
- Edward Berman (Northeastern University)
- Ashwin Gopinath (Massachusetts Institute of Technology)
- Karthik Narasimhan (Princeton University)
- Shunyu Yao (Princeton University)
Abstract
Large language models (LLMs) have been increasingly used to interact with external environments (e.g., games, compilers, APIs) as goal-driven agents. However, it remains challenging for these language agents to quickly and efficiently learn from trial-and-error as traditional reinforcement learning methods require extensive training samples and expensive model fine-tuning. We propose Reflexion, a novel framework to reinforce language agents not by updating weights, but instead through linguistic feedback. Concretely, Reflexion agents verbally reflect on task feedback signals, then maintain their own reflective text in an episodic memory buffer to induce better decision-making in subsequent trials. Reflexion is flexible enough to incorporate various types (scalar values or free-form language) and sources (external or internally simulated) of feedback signals, and obtains significant improvements over a baseline agent across diverse tasks (sequential decision-making, coding, language reasoning). For example, Reflexion achieves a 91% pass@1 accuracy on the HumanEval coding benchmark, surpassing the previous state-of-the-art GPT-4 that achieves 80%. We also conduct ablation and analysis studies using different feedback signals, feedback incorporation methods, and agent types, and provide insights into how they affect performance. We release all code, demos, and datasets at https://github.com/noahshinn024/reflexion.
1 Introduction
Recent works such as ReAct Yao et al., (2023), SayCan Ahn et al., (2022), Toolformer Schick et al., (2023), HuggingGPT (Shen et al.,, 2023), generative agents (Park et al.,, 2023), and WebGPT (Nakano et al.,, 2021) have demonstrated the feasibility of autonomous decision-making agents that are built on top of a large language model (LLM) core. These methods use LLMs to generate text and ‘actions‘ that can be used in API calls and executed in an environment. Since they rely on massive models with an enormous number of parameters, such approaches have been so far limited to using in-context examples as a way of teaching the agents, since more traditional optimization schemes like reinforcement learning with gradient descent require substantial amounts of compute and time.
In this paper, we propose an alternative approach called Reflexion that uses verbal reinforcement to help agents learn from prior failings. Reflexion converts binary or scalar feedback from the environment into verbal feedback in the form of a textual summary, which is then added as additional context for the LLM agent in the next episode. This self-reflective feedback acts as a ‘semantic’ gradient signal by providing the agent with a concrete direction to improve upon, helping it learn from prior mistakes to perform better on the task. This is akin to how humans iteratively learn to accomplish complex tasks in a few-shot manner – by reflecting on their previous failures in order to form an improved plan of attack for the next attempt. For example, in figure 1, a Reflexion agent learns to optimize its own behavior to solve decision-making, programming, and reasoning tasks through trial, error, and self-reflection.
Generating useful reflective feedback is challenging since it requires a good understanding of where the model made mistakes (i.e. the credit assignment problem (Sutton and Barto,, 2018)) as well as the ability to generate a summary containing actionable insights for improvement. We explore three ways for doing this – simple binary environment feedback, pre-defined heuristics for common failure cases, and self-evaluation such as binary classification using LLMs (decision-making) or self-written unit tests (programming). In all implementations, the evaluation signal is amplified to natural language experience summaries which can be stored in long-term memory.
Reflexion has several advantages compared to more traditional RL approaches like policy or value-based learning: 1) it is lightweight and doesn’t require finetuning the LLM, 2) it allows for more nuanced forms of feedback (e.g. targeted changes in actions), compared to scalar or vector rewards that are challenging to perform accurate credit assignment with, 3) it allows for a more explicit and interpretable form of episodic memory over prior experiences, and 4) it provides more explicit hints for actions in future episodes. At the same time, it does have the disadvantages of relying on the power of the LLM’s self-evaluation capabilities (or heuristics) and not having a formal guarantee for success. However, as LLM capabilities improve, we only expect this paradigm to get better over time.
We perform experiments on (1) decision-making tasks to test sequential action choices over long trajectories, (2) reasoning tasks to test knowledge-intensive, single-step generation improvement, and (3) programming tasks to teach the agent to effectively use external tools such as compilers and interpreters. Across all three types of tasks, we observe Reflexion agents are better decision-makers, reasoners, and programmers. More concretely, Reflexion agents improve on decision-making AlfWorld (Shridhar et al.,, 2021) tasks over strong baseline approaches by an absolute 22% in 12 iterative learning steps, and on reasoning questions in HotPotQA (Yang et al.,, 2018) by 20%, and Python programming tasks on HumanEval (Chen et al.,, 2021) by as much as 11%.
To summarize, our contributions are the following:
- We propose Reflexion, a new paradigm for ‘verbal‘ reinforcement that parameterizes a policy as an agent’s memory encoding paired with a choice of LLM parameters.
- We explore this emergent property of self-reflection in LLMs and empirically show that self-reflection is extremely useful to learn complex tasks over a handful of trials.
- We introduce LeetcodeHardGym, a code-generation RL gym environment consisting of 40 challenging Leetcode questions (‘hard-level‘) in 19 programming languages.
- We show that Reflexion achieves improvements over strong baselines across several tasks, and achieves state-of-the-art results on various code generation benchmarks.
<details>
<summary>x1.png Details</summary>
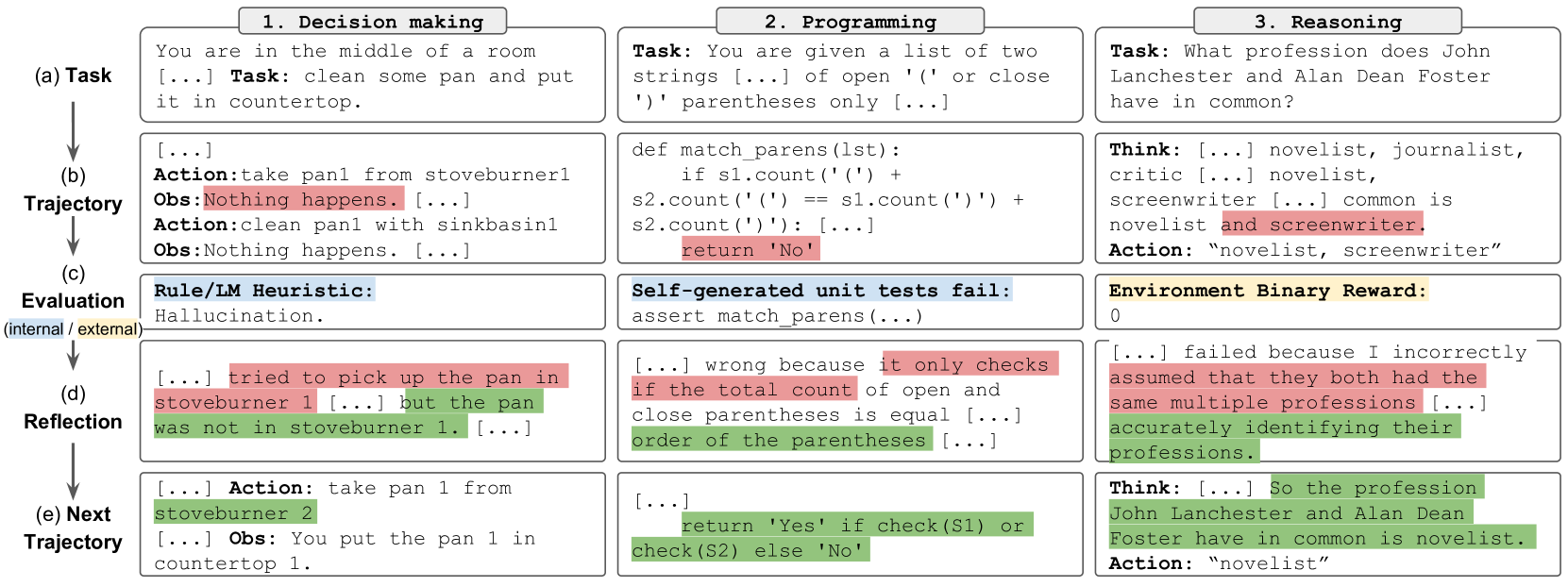
### Visual Description
\n
## Diagram: AI Reasoning Process - Decision Making, Programming, and Reasoning
### Overview
The image presents a diagram illustrating a comparison of an AI's reasoning process across three tasks: Decision Making, Programming, and Reasoning. Each task is broken down into five stages: (a) Task, (b) Trajectory, (c) Evaluation, (d) Reflection, and (e) Next Trajectory. The diagram showcases the AI's internal thought process, actions, observations, and self-evaluation at each stage for each task.
### Components/Axes
The diagram is structured into three columns, each representing a different task:
1. **Decision Making:** Focuses on a simple room cleaning task.
2. **Programming:** Focuses on a parenthesis matching function.
3. **Reasoning:** Focuses on identifying common professions between two individuals.
Each column is further divided into five rows, representing the stages of the AI's process:
* **(a) Task:** Describes the initial problem presented to the AI.
* **(b) Trajectory:** Shows the AI's initial actions and observations.
* **(c) Evaluation:** Displays the AI's internal evaluation of its performance, including any heuristics used.
* **(d) Reflection:** Shows the AI's analysis of its mistakes and understanding of why they occurred.
* **(e) Next Trajectory:** Presents the AI's revised actions and observations based on its reflection.
The diagram uses arrows to indicate the flow of the process from one stage to the next. The "Rule/IM Heuristic" in the Decision Making column is labeled as "(internal) hallucination". "Environment Binary Reward" is present in the Reasoning column.
### Detailed Analysis or Content Details
**1. Decision Making:**
* **(a) Task:** "You are in the middle of a room [...] Task: clean some pan and put it in countertop."
* **(b) Trajectory:** "Action: take pan from stoveburner1 Obs: Nothing happens. [...] Action: clean pan with sinkbasin1 Obs: Nothing happens."
* **(c) Evaluation:** "Rule/IM Heuristic: hallucination."
* **(d) Reflection:** "[...] tried to pick up the pan in stoveburner 1 [...] but the pan was not in stoveburner 1. [...]"
* **(e) Next Trajectory:** "Action: take pan 1 from stoveburner 2 [...] Obs: You put the pan 1 in countertop 1."
**2. Programming:**
* **(a) Task:** "You are given a list of two strings [...] of open '(' or close ')' parentheses only [...]"
* **(b) Trajectory:** `def match_parens(lst): if s1.count('(') + s2.count('(') == s1.count(')') + s2.count(')'): return 'No' `
* **(c) Evaluation:** "Self-generated unit tests fail: assert match_parens(...) "
* **(d) Reflection:** "[...] wrong because it only checks if the total count of open and close parentheses is equal [...] order of the parentheses [...]"
* **(e) Next Trajectory:** `return 'Yes' if check(S1) or check(S2) else 'No'`
**3. Reasoning:**
* **(a) Task:** "What profession does John Lanchester and Alan Dean Foster have in common?"
* **(b) Trajectory:** "Think: [...] novelist, journalist, critic [...] novelist, screenwriter [...] common is novelist and screenwriter. Action: 'novelist, screenwriter'"
* **(c) Evaluation:** "Environment Binary Reward: 0"
* **(d) Reflection:** "[...] failed because I incorrectly assumed that they both had the same multiple professions [...] accurately identifying their professions."
* **(e) Next Trajectory:** "Think: [...] So the profession John Lanchester and Alan Dean Foster have in common is novelist. Action: 'novelist'"
### Key Observations
* The AI initially makes mistakes in all three tasks, demonstrating the need for reflection and correction.
* The "hallucination" label in the Decision Making task suggests the AI is prone to making assumptions not grounded in reality.
* The Programming task highlights the importance of considering the order of operations, not just the overall count.
* The Reasoning task shows the AI initially overcomplicates the problem by identifying multiple common professions before narrowing it down to the correct answer.
* The Environment Binary Reward of 0 in the Reasoning task indicates the initial attempt was incorrect.
### Interpretation
This diagram illustrates the iterative nature of AI reasoning. The AI doesn't arrive at the correct answer immediately but rather through a process of trial and error, self-evaluation, and refinement. The diagram highlights the challenges of building AI systems that can reason effectively, particularly in situations that require common sense or nuanced understanding. The inclusion of "hallucination" as a heuristic suggests that current AI models can sometimes generate responses that are not based on factual information. The diagram demonstrates the importance of incorporating mechanisms for reflection and correction into AI systems to improve their accuracy and reliability. The comparison across three different tasks suggests that the underlying principles of AI reasoning are consistent, regardless of the specific domain. The diagram is a valuable tool for understanding the inner workings of AI and for identifying areas where further research is needed.
</details>
Figure 1: Reflexion works on decision-making 4.1, programming 4.3, and reasoning 4.2 tasks.
2 Related work
Reasoning and decision-making
Self-Refine (Madaan et al.,, 2023) employs an iterative framework for self-refinement to autonomously improve generation through self-evaluation. These self-evaluation and self-improvement steps are conditioned on given task constraints, such as "How can this generation be written in a more positive way". Self-Refine is effective but is limited to single-generation reasoning tasks. Pryzant et al., (2023) performs a similar semantic prompt-writing optimization, but is also limited to single-generation tasks. Paul et al., (2023) fine-tune critic models to provide intermediate feedback within trajectories to improve reasoning responses. Xie et al., (2023) use stochastic beam search over actions to perform a more efficient decision-making search strategy which allows the agent to use foresight advantage due to its self-evaluation component. Yoran et al., (2023) and Nair et al., (2023) use decider models to reason over several generations. Kim et al., (2023) use a retry pattern over a fixed number of steps without an evaluation step. Goodman, (2023) perform a qualitative evaluation step that proposes optimizations to the previous generation. In this paper, we show that several of these concepts can be enhanced with self-reflection to build a persisting memory of self-reflective experiences which allows an agent to identify its own errors and self-suggest lessons to learn from its mistakes over time.
Programming
Several past and recent works employ variations of test-driven development or code debugging practices. AlphaCode (Li et al.,, 2022) evaluates a set of generations on hidden test cases. CodeT (Chen et al.,, 2022) uses self-generated unit tests that are used to score generated function implementations. Self-Debugging (Chen et al.,, 2023) employs a debugging component that is used to improve existing implementations given feedback from a code execution environment. CodeRL (Le et al.,, 2022) sets the problem in an RL framework using an actor-critic setup to debug programs given feedback from an execution environment. AlphaCode, Self-Debugging and CodeRL are effective in fixing less-complex program bugs, but they rely upon ground truth test cases that invalidate pass@1 eligibility, and do not use self-reflection to bridge the gap between error identification and implementation improvement. CodeT does not access hidden test cases but does not implement a self-learning step to improve code writing.
| Approach | Self-refine | Hidden-constraints | Decision-making | Binary-reward | Memory |
| --- | --- | --- | --- | --- | --- |
| Self-refine (Madaan et al.,, 2023) | ✓ | ✗ | ✗ | ✗ | ✗ |
| Beam search (Xie et al.,, 2023) | ✓ | ✓ | ✓ | ✓ | ✗ |
| Reflexion (ours) | ✓ | ✓ | ✓ | ✓ | ✓ |
| Approach Test execution | Test-execution | Debugging | Self-generated-tests | Multiple-languages | Self-reflection |
| --- | --- | --- | --- | --- | --- |
| AlphaCode (Li et al.,, 2022) | ✓ | ✗ | ✗ | ✓ | ✗ |
| CodeT (Chen et al.,, 2022) | ✓ | ✗ | ✓ | ✗ | ✗ |
| Self-debugging (Chen et al.,, 2023) | ✓ | ✓ | ✗ | ✗ | ✗ |
| CodeRL (Le et al.,, 2022) | ✓ | ✓ | ✗ | ✗ | ✗ |
| Reflexion (ours) | ✓ | ✓ | ✓ | ✓ | ✓ |
3 Reflexion: reinforcement via verbal reflection
<details>
<summary>x2.png Details</summary>
### Visual Description
\n
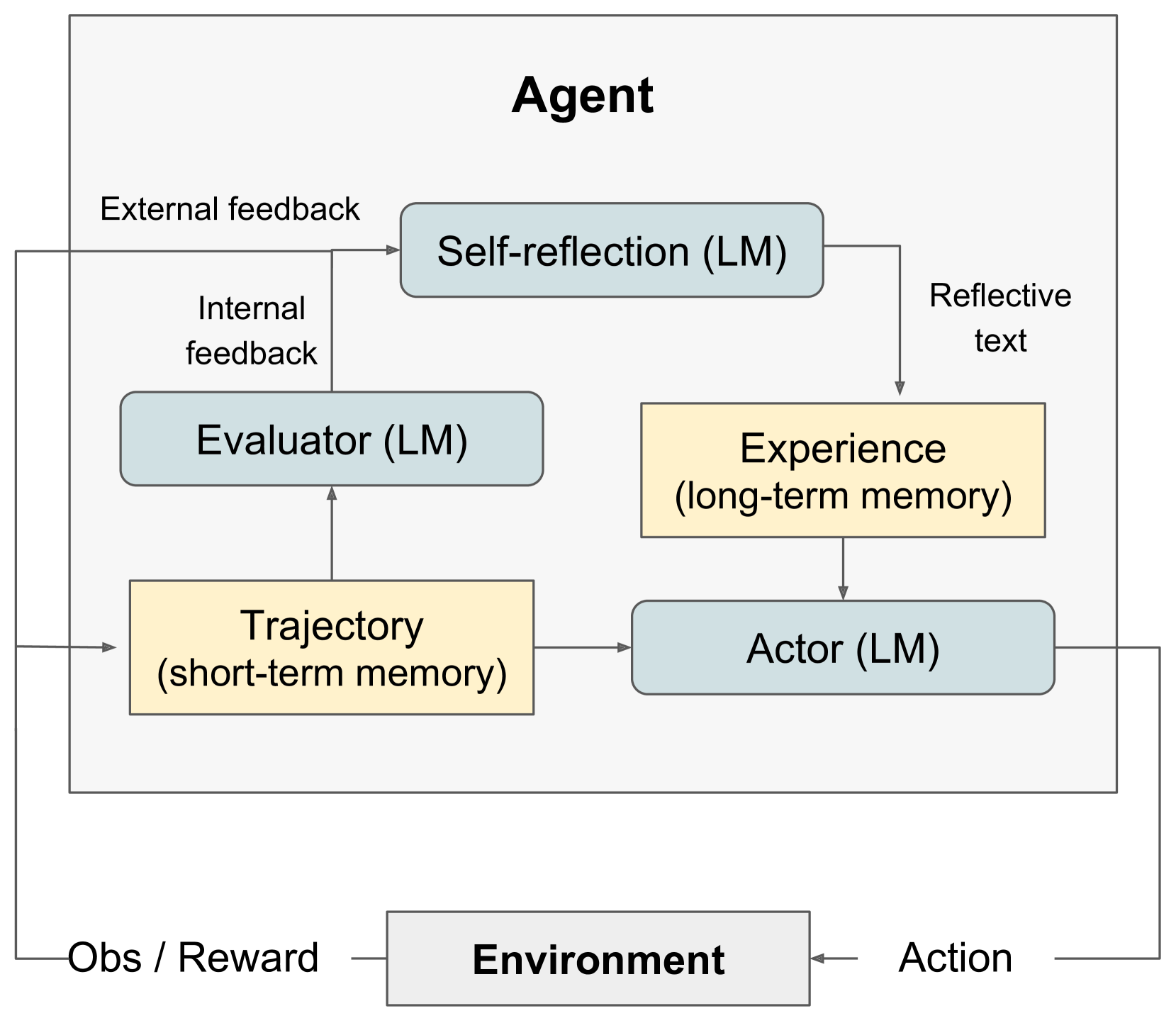
## Diagram: Agent Architecture with Self-Reflection
### Overview
The image depicts a diagram of an agent architecture incorporating self-reflection, utilizing Language Models (LMs) for various components. The agent interacts with an "Environment" and consists of internal modules for evaluation, action, and memory. Feedback loops are present for both internal and external evaluation.
### Components/Axes
The diagram consists of the following components:
* **Agent:** The overarching system.
* **Environment:** The external world the agent interacts with.
* **Self-reflection (LM):** Receives "External feedback" and generates "Reflective text".
* **Evaluator (LM):** Receives "Internal feedback" and provides input to "Trajectory".
* **Trajectory (short-term memory):** Receives input from "Evaluator" and provides input to "Actor".
* **Actor (LM):** Receives input from "Trajectory" and generates "Action".
* **Experience (long-term memory):** Receives "Reflective text" from "Self-reflection" and provides input to "Actor".
The following inputs/outputs are labeled:
* **Obs / Reward:** Input from the "Environment" to "Evaluator" and "Trajectory".
* **Action:** Output from "Actor" to the "Environment".
* **External feedback:** Input to "Self-reflection".
* **Internal feedback:** Input to "Evaluator".
* **Reflective text:** Output from "Self-reflection" to "Experience".
### Detailed Analysis or Content Details
The diagram shows a cyclical flow of information.
1. The "Actor" generates an "Action" which is sent to the "Environment".
2. The "Environment" returns "Obs / Reward" to both the "Evaluator" and "Trajectory".
3. The "Evaluator" receives "Internal feedback" and provides input to the "Trajectory".
4. The "Trajectory" (short-term memory) passes information to the "Actor".
5. The "Self-reflection" module receives "External feedback" and generates "Reflective text" which is stored in the "Experience" (long-term memory).
6. The "Experience" module then provides input to the "Actor".
All modules labeled with "(LM)" indicate the use of a Language Model. The diagram uses arrows to indicate the direction of information flow. The "Agent" is visually separated from the "Environment" by a horizontal line. The "Trajectory" and "Actor" are contained within a light gray rectangle, visually grouping them.
### Key Observations
The diagram highlights the importance of feedback loops in the agent's learning process. The inclusion of "Self-reflection" and "Experience" suggests a focus on meta-cognition and long-term learning. The use of Language Models (LMs) in multiple components indicates a reliance on natural language processing capabilities. The separation of short-term ("Trajectory") and long-term ("Experience") memory is a key architectural feature.
### Interpretation
This diagram illustrates a sophisticated agent architecture designed for continuous learning and improvement. The self-reflection component, coupled with long-term memory, allows the agent to analyze its past experiences and refine its behavior. The use of Language Models suggests the agent can process and generate natural language, potentially enabling more complex reasoning and communication. The cyclical flow of information emphasizes the importance of feedback in the learning process. The architecture appears to be inspired by cognitive architectures, aiming to mimic aspects of human learning and decision-making. The diagram suggests a system capable of adapting to changing environments and improving its performance over time. The architecture is designed to be robust and flexible, allowing for continuous learning and adaptation. The diagram does not provide any quantitative data or specific performance metrics. It is a conceptual representation of an agent's internal workings.
</details>
Algorithm 1 Reinforcement via self-reflection
Initialize Actor, Evaluator, Self-Reflection:
$M_{a}$ , $M_{e}$ , $M_{sr}$
Initialize policy $\pi_{\theta}(a_{i}|s_{i})$ , $\theta=\{M_{a},mem\}$
Generate initial trajectory using $\pi_{\theta}$
Evaluate $\tau_{0}$ using $M_{e}$
Generate initial self-reflection $sr_{0}$ using $M_{sr}$
Set $mem←[sr_{0}]$
Set $t=0$
while $M_{e}$ not pass or $t<$ max trials do
Generate $\tau_{t}={[a_{0},o_{0},... a_{i},o_{i}]}$ using $\pi_{\theta}$
Evaluate $\tau_{t}$ using $M_{e}$
Generate self-reflection $sr_{t}$ using $M_{sr}$
Append $sr_{t}$ to $mem$
Increment $t$
end while
return
Figure 2: (a) Diagram of Reflexion. (b) Reflexion reinforcement algorithm
We develop a modular formulation for Reflexion, utilizing three distinct models: an Actor, denoted as $M_{a}$ , which generates text and actions; an Evaluator model, represented by $M_{e}$ , that scores the outputs produced by $M_{a}$ ; and a Self-Reflection model, denoted as $M_{sr}$ , which generates verbal reinforcement cues to assist the Actor in self-improvement. We provide a detailed description of each of these models and subsequently elucidate their collaborative functioning within the Reflexion framework.
Actor
The Actor is built upon a large language model (LLM) that is specifically prompted to generate the necessary text and actions conditioned on the state observations. Analogous to traditional policy-based RL setups, we sample an action or generation, $a_{t}$ , from the current policy $\pi_{\theta}$ at time $t$ , receive an observation from the environment $o_{t}$ . We explore various Actor models, including Chain of Thought Wei et al., (2022) and ReAct Yao et al., (2023). These diverse generation models allow us to explore different aspects of text and action generation within the Reflexion framework, providing valuable insights into their performance and effectiveness. In addition, we also add a memory component mem that provides additional context to this agent. This adaption was inspired by Brooks et al., (2022), who suggest a policy iteration approach using in-context learning. Details on how this is populated are provided below.
Evaluator
The Evaluator component of the Reflexion framework plays a crucial role in assessing the quality of the generated outputs produced by the Actor. It takes as input a generated trajectory and computes a reward score that reflects its performance within the given task context. Defining effective value and reward functions that apply to semantic spaces is difficult, so we investigate several variants of the Evaluator model. For reasoning tasks, we explore reward functions based on exact match (EM) grading, ensuring that the generated output aligns closely with the expected solution. In decision-making tasks, we employ pre-defined heuristic functions that are tailored to specific evaluation criteria. Additionally, we experiment with using a different instantiation of an LLM itself as an Evaluator, generating rewards for decision-making and programming tasks. This multi-faceted approach to Evaluator design allows us to examine different strategies for scoring generated outputs, offering insights into their effectiveness and suitability across a range of tasks.
Self-reflection
The Self-Reflection model instantiated as an LLM, plays a crucial role in the Reflexion framework by generating verbal self-reflections to provide valuable feedback for future trials. Given a sparse reward signal, such as a binary success status (success/fail), the current trajectory, and its persistent memory mem, the self-reflection model generates nuanced and specific feedback. This feedback, which is more informative than scalar rewards, is then stored in the agent’s memory (mem). For instance, in a multi-step decision-making task, when the agent receives a failure signal, it can infer that a specific action $a_{i}$ led to subsequent incorrect actions $a_{i+1}$ and $a_{i+2}$ . The agent can then verbally state that it should have taken a different action, $a_{i}^{\prime}$ , which would have resulted in $a_{i+1}^{\prime}$ and $a_{i+2}^{\prime}$ , and store this experience in its memory. In subsequent trials, the agent can leverage its past experiences to adapt its decision-making approach at time $t$ by choosing action $a_{i}^{\prime}$ . This iterative process of trial, error, self-reflection, and persisting memory enables the agent to rapidly improve its decision-making ability in various environments by utilizing informative feedback signals.
Memory
Core components of the Reflexion process are the notion of short-term and long-term memory. At inference time, the Actor conditions its decisions on short and long-term memory, similar to the way that humans remember fine-grain recent details while also recalling distilled important experiences from long-term memory. In the RL setup, the trajectory history serves as the short-term memory while outputs from the Self-Reflection model are stored in long-term memory. These two memory components work together to provide context that is specific but also influenced by lessons learned over several trials, which is a key advantage of Reflexion agents over other LLM action choice works.
The Reflexion process
Reflexion is formalized as an iterative optimization process in 1. In the first trial, the Actor produces a trajectory $\tau_{0}$ by interacting with the environment. The Evaluator then produces a score $r_{0}$ which is computed as $r_{t}=M_{e}(\tau_{0})$ . $r_{t}$ is only a scalar reward for trial $t$ that improves as task-specific performance increases. After the first trial, to amplify $r_{0}$ to a feedback form that can be used for improvement by an LLM, the Self-Reflection model analyzes the set of $\{\tau_{0},r_{0}\}$ to produce a summary $sr_{0}$ which is stored in the memory mem. $sr_{t}$ is a verbal experience feedback for trial $t$ . The Actor, Evaluator, and Self-Reflection models work together through trials in a loop until the Evaluator deems $\tau_{t}$ to be correct. As mentioned in 3, the memory component of Reflexion is crucial to its effectiveness. After each trial $t$ , $sr_{t}$ , is appended mem. In practice, we bound mem by a maximum number of stored experiences, $\Omega$ (usually set to 1-3) to adhere to max context LLM limitations.
4 Experiments
We evaluate various natural language RL setups on decision-making, reasoning, and code generation tasks. Specifically, we challenge an agent to perform search-based question answering on HotPotQA (Yang et al.,, 2018), multi-step tasks in common household environments in AlfWorld (Shridhar et al.,, 2021), and code writing tasks in competition-like environments with interpreters and compilers in HumanEval (Chen et al.,, 2021), MBPP (Austin et al.,, 2021), and LeetcodeHard, a new benchmark. Most notably, Reflexion improves performance over strong baselines by 22% in AlfWorld, 20% in HotPotQA, and 11% on HumanEval.
4.1 Sequential decision making: ALFWorld
AlfWorld is a suite of text-based environments that challenge an agent to solve multi-step tasks in a variety of interactive environments based on TextWorld (Côté et al.,, 2019). Following Yao et al., (2023), we run the agent in 134 AlfWorld environments across six different tasks, including finding hidden objects (e.g., finding a spatula in a drawer), moving objects (e.g., moving a knife to the cutting board), and manipulating objects with other objects (e.g., chilling a tomato in the fridge). We use ReAct (Yao et al.,, 2023) as the action generator as Yao et al., (2023) has shown success in long trajectory decision-making using explicit intermediate thoughts. AlfWorld tasks naturally require a self-evaluation step as the environment can only signal if a task is complete. To achieve fully autonomous behavior, we implement two self-evaluation techniques: natural language classification using an LLM and a hand-written heuristic. The heuristic is simple: if the agent executes the same action and receives the same response for more than 3 cycles, or if the number of actions taken in the current environment exceeds 30 (inefficient planning), we self-reflect. In the baseline runs, if self-reflection is suggested, we skip the self-reflection process, reset the environment, and start a new trial. In the Reflexion runs, the agent uses self-reflection to find its mistake, update its memory, reset the environment, and start a new trial. To avoid very long prompt windows that may exceed the maximum limit, we truncate the agent’s memory to the last 3 self-reflections (experiences).
To avoid syntactic errors, we provide two domain-specific few-shot trajectories to the agent. We use the same few-shot trajectory examples as Yao et al., (2023) with GPT-3 for the LLM. AlfWorld tasks, ReAct few-shot prompts, and Reflexion examples are included in the appendix.
Results
<details>
<summary>x3.png Details</summary>
### Visual Description
## Line Chart: ALFWorld Success Rate
### Overview
This line chart depicts the success rate of solving environments in ALFWorld across different trial numbers, comparing three approaches: ReAct only, ReAct + Reflexion (Heuristic), and ReAct + Reflexion (GPT). The y-axis represents the proportion of solved environments, ranging from 0.5 to 1.0, while the x-axis represents the trial number, ranging from 0 to 10.
### Components/Axes
* **Title:** (a) ALFWorld Success Rate (top-center)
* **X-axis Label:** Trial Number (bottom-center)
* **Y-axis Label:** Proportion of Solved Environments (left-center)
* **Legend:** Located in the top-left corner.
* ReAct only (gray dashed line)
* ReAct + Reflexion (Heuristic) (blue solid line)
* ReAct + Reflexion (GPT) (green solid line)
* **Gridlines:** Horizontal and vertical gridlines are present to aid in reading values.
### Detailed Analysis
The chart displays three distinct lines representing the success rates of each approach over increasing trial numbers.
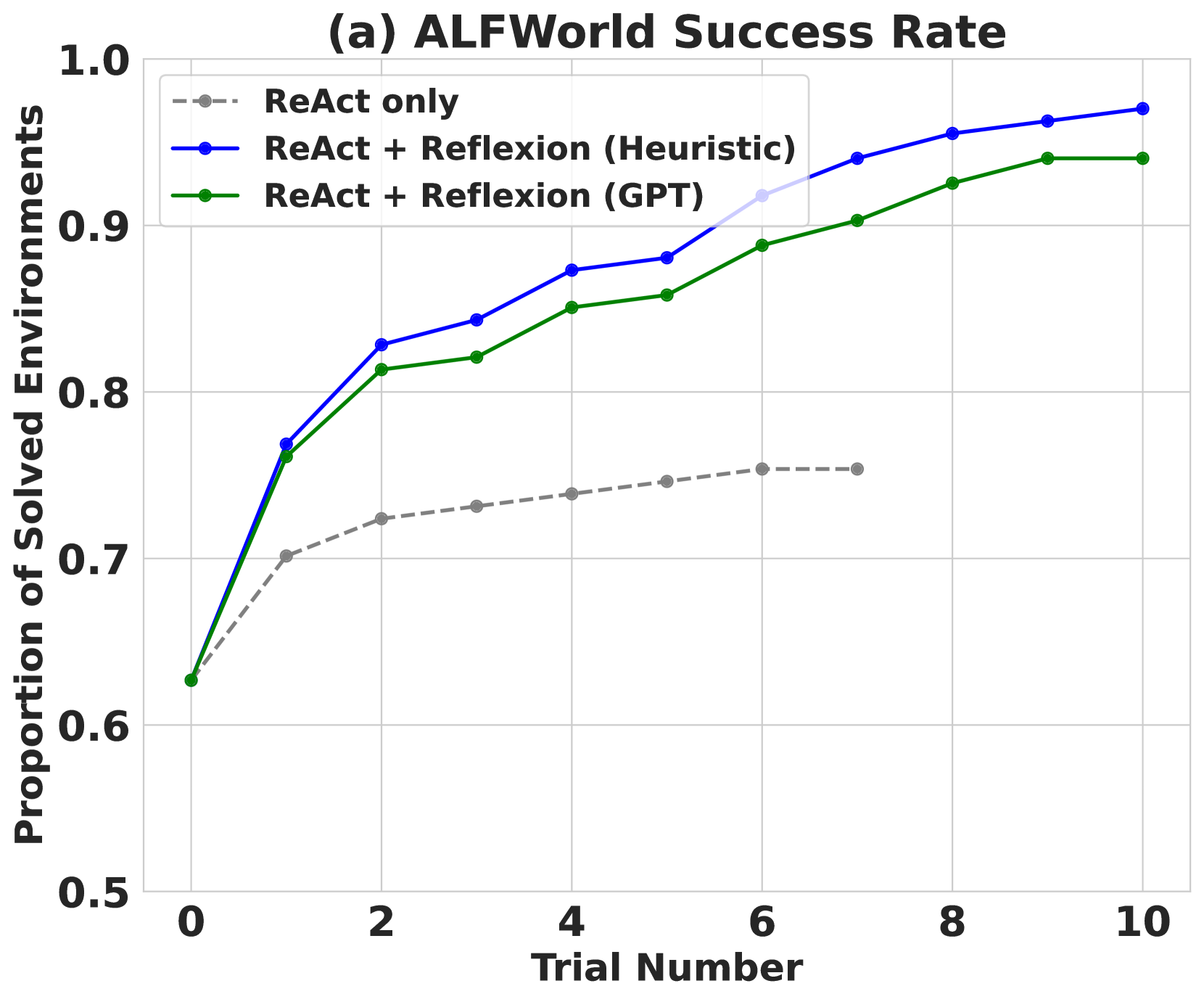
* **ReAct only (gray dashed line):** This line starts at approximately 0.65 at Trial Number 0. It shows a slow, gradual increase, reaching approximately 0.77 at Trial Number 10. The line is relatively flat, indicating limited improvement with more trials.
* **ReAct + Reflexion (Heuristic) (blue solid line):** This line begins at approximately 0.81 at Trial Number 0. It exhibits a rapid increase initially, reaching approximately 0.87 at Trial Number 2. The rate of increase slows down, and the line plateaus around 0.93-0.95 between Trial Numbers 6 and 10.
* **ReAct + Reflexion (GPT) (green solid line):** This line starts at approximately 0.63 at Trial Number 0. It shows a significant increase, reaching approximately 0.85 at Trial Number 2. The line continues to increase, but at a decreasing rate, reaching approximately 0.96 at Trial Number 10.
Here's a more detailed breakdown of approximate values at specific trial numbers:
| Trial Number | ReAct only | ReAct + Reflexion (Heuristic) | ReAct + Reflexion (GPT) |
|--------------|------------|-------------------------------|--------------------------|
| 0 | 0.65 | 0.81 | 0.63 |
| 2 | 0.74 | 0.87 | 0.85 |
| 4 | 0.76 | 0.90 | 0.91 |
| 6 | 0.77 | 0.93 | 0.94 |
| 8 | 0.77 | 0.94 | 0.95 |
| 10 | 0.77 | 0.95 | 0.96 |
### Key Observations
* The ReAct + Reflexion approaches (both Heuristic and GPT) consistently outperform the ReAct only approach across all trial numbers.
* The ReAct + Reflexion (GPT) approach achieves the highest success rate, particularly at higher trial numbers.
* All three approaches show diminishing returns in success rate as the trial number increases, suggesting a point of saturation.
* The initial gains are most significant, indicating that the early trials are crucial for learning and improvement.
### Interpretation
The data suggests that incorporating Reflexion, whether using Heuristic or GPT-based methods, significantly improves the success rate of solving environments in ALFWorld compared to using ReAct alone. The GPT-based Reflexion demonstrates the highest performance, indicating that leveraging the capabilities of a large language model for reflection enhances the problem-solving process. The diminishing returns observed at higher trial numbers suggest that the agents are approaching their maximum performance level within the given environment and task. This could be due to the complexity of the environment or the limitations of the algorithms themselves. The initial rapid improvement highlights the importance of early learning and adaptation in these types of reinforcement learning scenarios. The chart provides strong evidence for the benefits of incorporating reflection mechanisms into agent architectures for improved performance in complex environments.
</details>
<details>
<summary>x4.png Details</summary>
### Visual Description
## Line Chart: ALFWorld Success Rate
### Overview
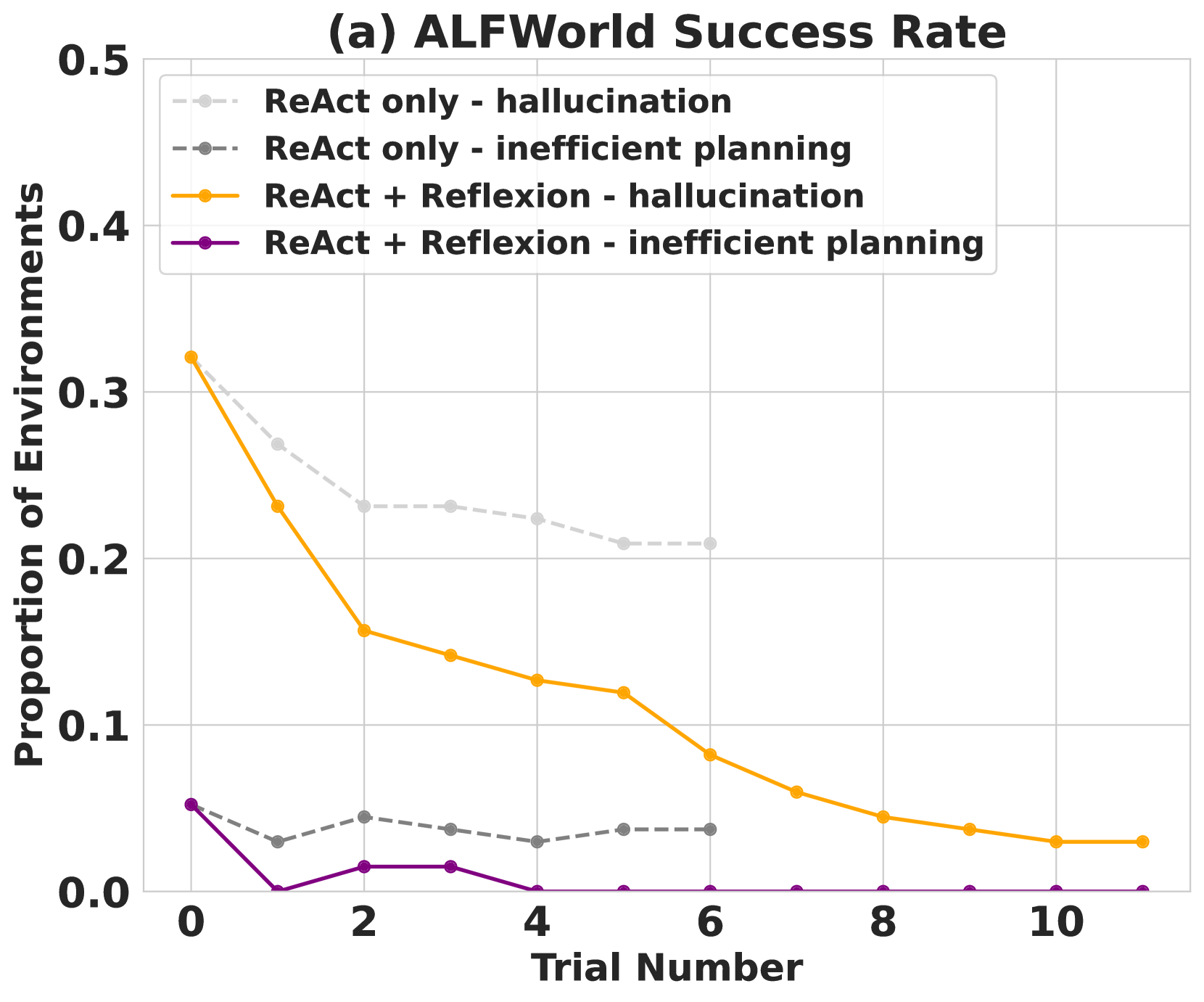
This line chart depicts the success rate of different approaches (ReAct only vs. ReAct + Reflexion) in the ALFWorld environment, categorized by the type of failure (hallucination vs. inefficient planning). The chart shows how the proportion of successful environments changes with the trial number, ranging from 0 to 10.
### Components/Axes
* **Title:** (a) ALFWorld Success Rate
* **X-axis:** Trial Number (ranging from 0 to 10)
* **Y-axis:** Proportion of Environments (ranging from 0.0 to 0.5)
* **Legend:** Located in the top-left corner, containing the following data series:
* ReAct only - hallucination (light gray, dashed line)
* ReAct only - inefficient planning (dark gray, dashed line)
* ReAct + Reflexion - hallucination (orange, solid line)
* ReAct + Reflexion - inefficient planning (purple, solid line)
### Detailed Analysis
Here's a breakdown of each data series and their trends:
* **ReAct only - hallucination (light gray, dashed line):** This line starts at approximately 0.31 at Trial Number 0 and slopes downward, reaching approximately 0.21 at Trial Number 10.
* Data points (approximate): (0, 0.31), (2, 0.27), (4, 0.23), (6, 0.22), (8, 0.21), (10, 0.21)
* **ReAct only - inefficient planning (dark gray, dashed line):** This line begins at approximately 0.06 at Trial Number 0 and shows a slight increase initially, then plateaus around 0.04-0.05.
* Data points (approximate): (0, 0.06), (2, 0.05), (4, 0.04), (6, 0.04), (8, 0.04), (10, 0.04)
* **ReAct + Reflexion - hallucination (orange, solid line):** This line starts at approximately 0.08 at Trial Number 0 and decreases gradually, reaching approximately 0.03 at Trial Number 10.
* Data points (approximate): (0, 0.08), (2, 0.07), (4, 0.06), (6, 0.05), (8, 0.04), (10, 0.03)
* **ReAct + Reflexion - inefficient planning (purple, solid line):** This line begins at approximately 0.03 at Trial Number 0 and remains relatively stable, fluctuating between 0.02 and 0.04 throughout the trials.
* Data points (approximate): (0, 0.03), (2, 0.03), (4, 0.02), (6, 0.03), (8, 0.02), (10, 0.02)
### Key Observations
* The "ReAct only - hallucination" approach consistently has the highest success rate among all approaches, but it decreases over trials.
* The "ReAct + Reflexion" approach consistently has a lower success rate than "ReAct only" for both hallucination and inefficient planning.
* The "ReAct only - inefficient planning" and "ReAct + Reflexion - inefficient planning" approaches have very low success rates, remaining close to 0 throughout the trials.
* The success rate for all approaches generally decreases or plateaus as the trial number increases, suggesting a learning curve or diminishing returns.
### Interpretation
The data suggests that while the ReAct approach alone performs better than ReAct combined with Reflexion in the ALFWorld environment, both approaches struggle with inefficient planning. The decreasing success rate over trials for the "ReAct only - hallucination" approach could indicate that the model encounters increasingly complex scenarios or that the initial gains from ReAct diminish as the environment is explored further. The consistently low success rate for inefficient planning suggests that this is a particularly challenging issue that requires further investigation. The combination of ReAct and Reflexion does not appear to improve performance, and may even slightly decrease it, indicating that Reflexion may not be effectively addressing the identified failure modes in this context. The chart highlights the importance of addressing both hallucination and inefficient planning to improve the overall success rate of agents in the ALFWorld environment.
</details>
Figure 3: (a) AlfWorld performance across 134 tasks showing cumulative proportions of solved tasks using self-evaluation techniques of (Heuristic) and (GPT) for binary classification. (b) Classification of AlfWorld trajectories by reason of failure.
ReAct + Reflexion significantly outperforms ReAct by completing 130 out of 134 tasks using the simple heuristic to detect hallucinations and inefficient planning. Further, ReAct + Reflexion learns to solve additional tasks by learning in 12 consecutive trials. In the ReAct-only approach, we see that performance increase halts between trials 6 and 7.
Analysis
A common error in baseline failed AlfWorld trajectories is when an agent thinks that it has possession of an item but does not actually have the item. The agent proceeds to execute several actions in a long trajectory and is not able to backtrack its actions to find the mistake. Reflexion eliminates almost all of these cases by using self-reflection to distill long, failed trajectories into relevant experiences that can are used as "self-hints" in the future. There are two main cases in which long-term memory helps an agent in AlfWorld: 1) An early mistake in a long trajectory can be easily identified. The agent can suggest a new action choice or even a new long-term plan. 2) There are too many surfaces/containers to check for an item. The agent can exploit its experience memory over several trials to thoroughly search a room. In 3, the learning curve suggests that the learning process occurs over several experiences, meaning that the agent is successfully balancing cases 1 and 2 shown in the immediate spike in the improvement between the first two trials, then a steady increase over the next 11 trials to a near-perfect performance. On the other hand, 3 shows a ReAct-only agent converging at a hallucination rate of 22% with no signs of long-term recovery.
4.2 Reasoning: HotpotQA
HotPotQA (Yang et al.,, 2018) is a Wikipedia-based dataset with 113k question-and-answer pairs that challenge agents to parse content and reason over several supporting documents. To test improvement in reasoning only ability, we implement Reflexion + Chain-of-Thought (CoT) (Wei et al.,, 2022) for step-by-step $Q→ A$ and $Q$ , $C_{gt}→ A$ implementations, where $Q$ is the question, $C_{gt}$ is the ground truth context from the dataset, and $A$ is the final answer. Since CoT is not a multi-step decision-making technique, we give $C_{gt}$ to the agent so that we can isolate the reasoning behavior over large sections of the provided text. To test holistic question and answering ability, which requires reasoning and action choice, we implement a Reflexion + ReAct (Yao et al.,, 2023) agent that can retrieve relevant context using a Wikipedia API and infer answers using step-by-step explicit thinking. For CoT implementations, we use 6-shot prompting; for ReAct, we use 2-shot prompting, and for self-reflection, we use 2-shot prompting. All examples can be found in the appendix.
Robustly evaluating natural language answers is a long-standing problem in NLP. Therefore, between trials, we use exact match answer grading using the environment to give a binary success signal to the agent. After each trial, the self-reflection loop is employed to amplify the binary signal, similar to the decision-making setup 4.1 in AlfWorld with a memory size of 3 experiences.
Results
<details>
<summary>x5.png Details</summary>
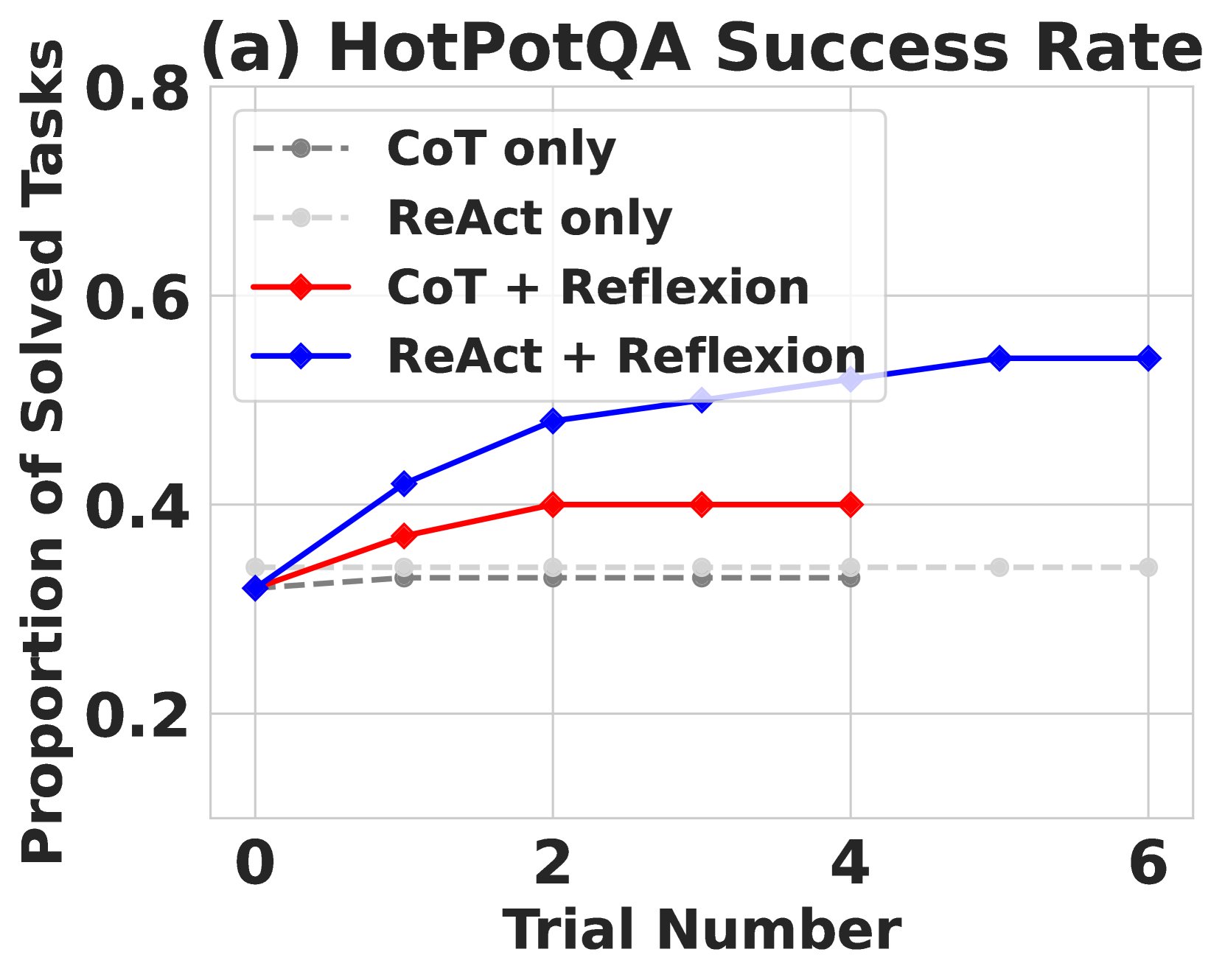
### Visual Description
\n
## Line Chart: HotPotQA Success Rate
### Overview
This line chart displays the success rate of different approaches on the HotPotQA task, measured as the proportion of solved tasks across multiple trials. The chart compares four methods: CoT only, ReAct only, CoT + Reflexion, and ReAct + Reflexion. The x-axis represents the trial number, and the y-axis represents the proportion of solved tasks.
### Components/Axes
* **Title:** (a) HotPotQA Success Rate (top-center)
* **X-axis Label:** Trial Number (bottom-center)
* Scale: 0 to 6, with markers at 0, 2, 4, and 6.
* **Y-axis Label:** Proportion of Solved Tasks (left-center)
* Scale: 0.2 to 0.8, with markers at 0.2, 0.4, 0.6, and 0.8.
* **Legend:** Located in the top-right corner.
* CoT only (gray dashed line)
* ReAct only (light gray dashed line)
* CoT + Reflexion (red solid line)
* ReAct + Reflexion (blue solid line)
### Detailed Analysis
* **CoT only (gray dashed line):** The line is relatively flat, starting at approximately 0.33 at Trial 0 and increasing slightly to around 0.36 by Trial 6.
* **ReAct only (light gray dashed line):** This line also remains relatively flat, starting at approximately 0.32 at Trial 0 and increasing slightly to around 0.35 by Trial 6.
* **CoT + Reflexion (red solid line):** This line shows an upward trend. It starts at approximately 0.36 at Trial 0, increases to around 0.44 at Trial 2, plateaus around 0.48 at Trial 4, and remains at approximately 0.48 at Trial 6.
* **ReAct + Reflexion (blue solid line):** This line exhibits the most significant upward trend. It begins at approximately 0.34 at Trial 0, rises sharply to around 0.48 at Trial 2, continues to increase to approximately 0.55 at Trial 4, and plateaus around 0.56 at Trial 6.
### Key Observations
* The "ReAct + Reflexion" method consistently outperforms the other three methods across all trials.
* The "CoT only" and "ReAct only" methods show minimal improvement with increasing trial numbers.
* Both "CoT + Reflexion" and "ReAct + Reflexion" demonstrate a clear positive correlation between trial number and success rate, indicating learning or improvement over time.
* The gap between "ReAct + Reflexion" and the other methods widens as the trial number increases.
### Interpretation
The data suggests that incorporating Reflexion into both CoT and ReAct approaches significantly improves performance on the HotPotQA task. The consistent upward trend of the "CoT + Reflexion" and "ReAct + Reflexion" lines indicates that the Reflexion mechanism enables these models to learn from their mistakes and improve their problem-solving abilities over time. The relatively flat lines for "CoT only" and "ReAct only" suggest that these methods lack the ability to adapt and improve with experience. The superior performance of "ReAct + Reflexion" compared to "CoT + Reflexion" suggests that the ReAct framework, combined with Reflexion, is particularly well-suited for the HotPotQA task. The plateauing of the "ReAct + Reflexion" line after Trial 4 might indicate that the model is approaching its maximum performance level or that further trials do not yield significant improvements. This data highlights the importance of iterative refinement and self-reflection in enhancing the capabilities of language models for complex reasoning tasks.
</details>
<details>
<summary>x6.png Details</summary>
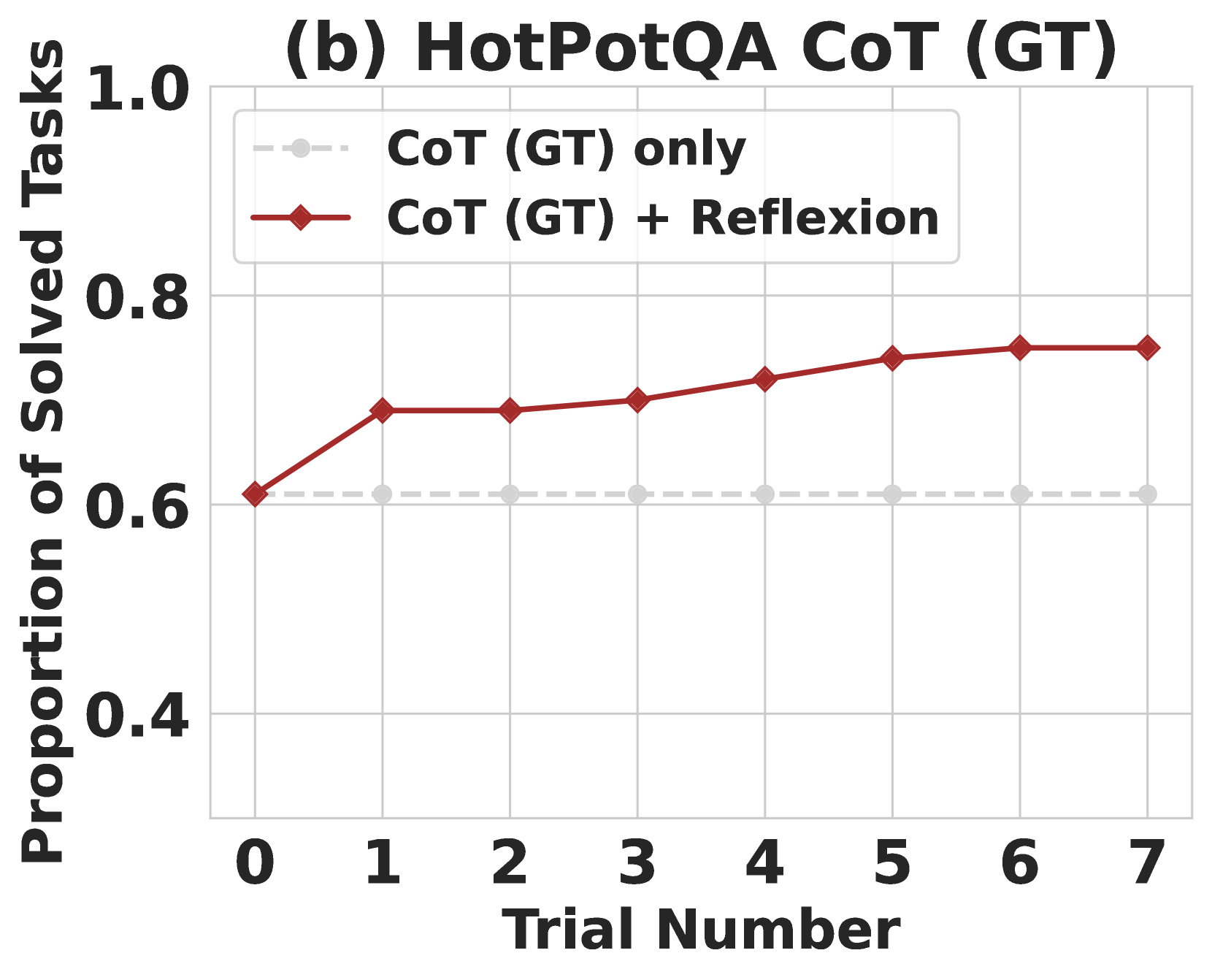
### Visual Description
\n
## Line Chart: HotPotQA CoT (GT) Performance
### Overview
This line chart depicts the performance of two approaches – "CoT (GT) only" and "CoT (GT) + Reflexion" – on the HotPotQA dataset, measured by the proportion of solved tasks across multiple trials. The x-axis represents the trial number, ranging from 0 to 7, while the y-axis represents the proportion of solved tasks, ranging from 0.4 to 1.0.
### Components/Axes
* **Title:** (b) HotPotQA CoT (GT)
* **X-axis Label:** Trial Number
* **Y-axis Label:** Proportion of Solved Tasks
* **Legend:**
* "CoT (GT) only" - Represented by a light gray dashed line.
* "CoT (GT) + Reflexion" - Represented by a dark red solid line with diamond markers.
* **X-axis Markers:** 0, 1, 2, 3, 4, 5, 6, 7
* **Y-axis Markers:** 0.4, 0.6, 0.8, 1.0
### Detailed Analysis
**CoT (GT) only (Light Gray Dashed Line):**
The line is relatively flat, indicating consistent performance across all trials.
* Trial 0: Approximately 0.61
* Trial 1: Approximately 0.61
* Trial 2: Approximately 0.61
* Trial 3: Approximately 0.61
* Trial 4: Approximately 0.61
* Trial 5: Approximately 0.61
* Trial 6: Approximately 0.61
* Trial 7: Approximately 0.61
**CoT (GT) + Reflexion (Dark Red Solid Line with Diamond Markers):**
The line shows an upward trend, indicating improving performance with each trial, then plateaus.
* Trial 0: Approximately 0.68
* Trial 1: Approximately 0.70
* Trial 2: Approximately 0.72
* Trial 3: Approximately 0.74
* Trial 4: Approximately 0.76
* Trial 5: Approximately 0.78
* Trial 6: Approximately 0.77
* Trial 7: Approximately 0.76
### Key Observations
* The "CoT (GT) + Reflexion" approach consistently outperforms the "CoT (GT) only" approach across all trials.
* The performance of "CoT (GT) + Reflexion" improves significantly in the first five trials, then appears to reach a plateau.
* The "CoT (GT) only" approach shows no significant improvement over the trials.
* The difference in performance between the two approaches is approximately 0.1-0.15 at trial 7.
### Interpretation
The data suggests that incorporating Reflexion into the CoT (GT) approach significantly improves performance on the HotPotQA dataset. The initial rapid improvement indicates that Reflexion is effective at learning from past mistakes and refining the problem-solving process. The plateauing performance after trial 5 suggests that the model may have reached its maximum potential with the given setup, or that further improvements require more complex techniques or a larger dataset. The consistent, but lower, performance of the "CoT (GT) only" approach highlights the benefit of iterative refinement and self-reflection in complex reasoning tasks. The consistent performance of the baseline suggests that the CoT method itself is stable, but limited in its ability to improve without the addition of Reflexion.
</details>
<details>
<summary>x7.png Details</summary>
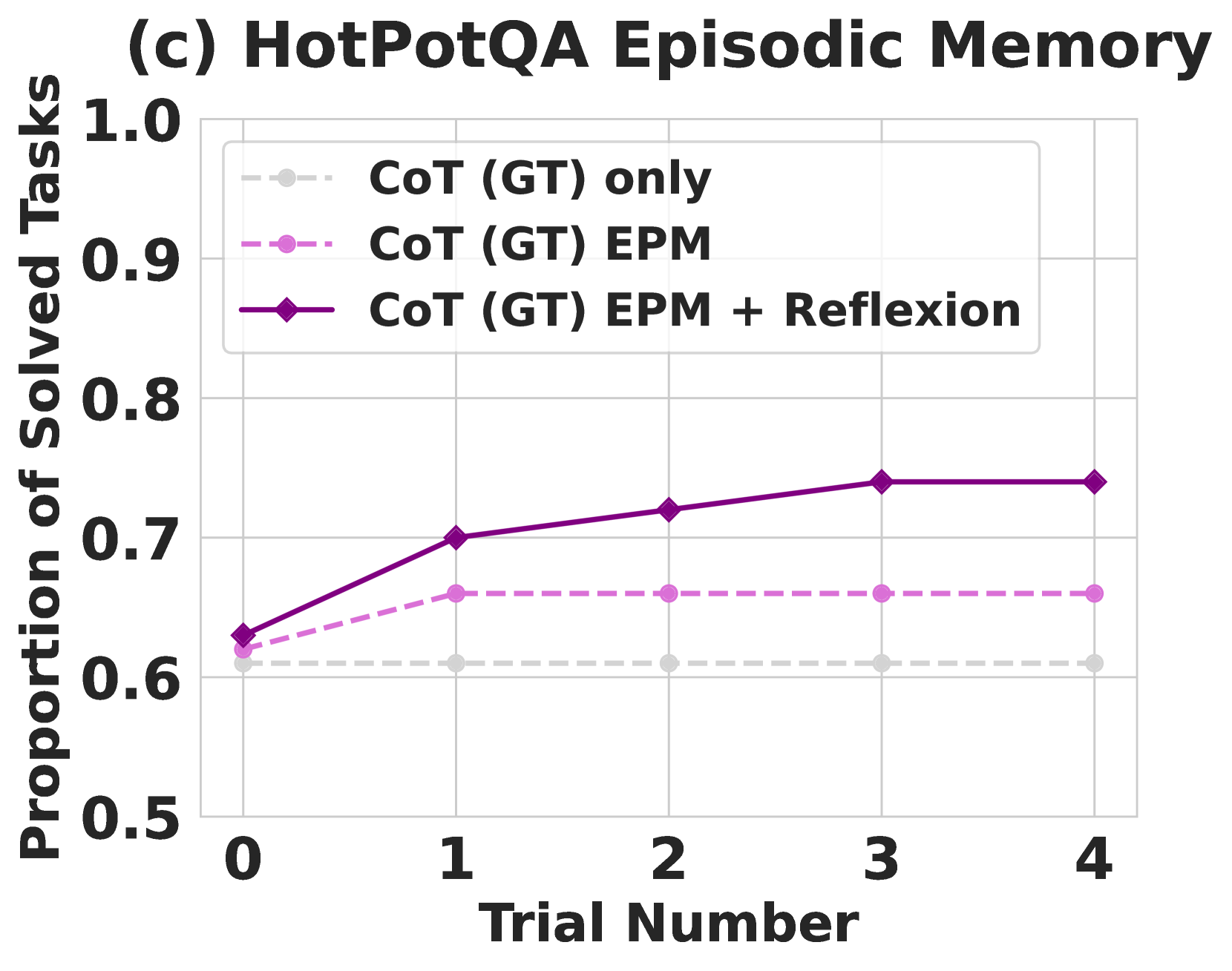
### Visual Description
\n
## Line Chart: HotPotQA Episodic Memory Performance
### Overview
This line chart illustrates the performance of three different approaches – CoT (GT) only, CoT (GT) EPM, and CoT (GT) EPM + Reflexion – on the HotPotQA episodic memory task across four trials. The y-axis represents the proportion of solved tasks, while the x-axis indicates the trial number.
### Components/Axes
* **Title:** (c) HotPotQA Episodic Memory
* **X-axis Label:** Trial Number (Scale: 0, 1, 2, 3, 4)
* **Y-axis Label:** Proportion of Solved Tasks (Scale: 0.5 to 1.0, increments of 0.1)
* **Legend:** Located in the top-left corner.
* CoT (GT) only – represented by a dotted orange line.
* CoT (GT) EPM – represented by a dotted grey line.
* CoT (GT) EPM + Reflexion – represented by a solid purple line with diamond markers.
### Detailed Analysis
* **CoT (GT) only (Orange Dotted Line):** The line starts at approximately 0.62 at Trial 0, decreases slightly to around 0.60 at Trial 1, then remains relatively stable around 0.61-0.62 for Trials 2, 3, and 4.
* **CoT (GT) EPM (Grey Dotted Line):** The line begins at approximately 0.65 at Trial 0, increases to around 0.67 at Trial 1, then plateaus around 0.66-0.67 for Trials 2, 3, and 4.
* **CoT (GT) EPM + Reflexion (Purple Solid Line):** This line starts at approximately 0.63 at Trial 0, increases to around 0.71 at Trial 1, continues to increase to approximately 0.73 at Trial 2, remains stable at around 0.73-0.74 for Trials 3 and 4.
### Key Observations
* The CoT (GT) EPM + Reflexion approach consistently outperforms the other two methods across all trials.
* The CoT (GT) only approach shows the least improvement over the trials, remaining relatively flat.
* The CoT (GT) EPM approach shows a slight initial improvement but then plateaus.
* The performance gap between CoT (GT) EPM + Reflexion and the other two methods widens as the trial number increases.
### Interpretation
The data suggests that incorporating Episodic Memory (EPM) and Reflexion significantly enhances performance on the HotPotQA episodic memory task. The consistent upward trend of the CoT (GT) EPM + Reflexion line indicates that the model benefits from remembering past experiences and reflecting on its previous attempts. The relatively flat lines for the other two approaches suggest that they do not effectively leverage past information to improve their performance. The initial improvement observed in the CoT (GT) EPM approach might indicate a benefit from episodic memory alone, but the lack of further improvement suggests that Reflexion is crucial for sustained learning and adaptation. The fact that the CoT (GT) only approach remains relatively constant suggests that simply using Chain-of-Thought prompting without memory or reflection is insufficient for this task. The data demonstrates a clear positive correlation between the complexity of the approach (CoT only < CoT EPM < CoT EPM + Reflexion) and the proportion of solved tasks.
</details>
Figure 4: Chain-of-Thought (CoT) and ReAct. Reflexion improves search, information retrieval, and reasoning capabilities on 100 HotPotQA questions. (a) Reflexion ReAct vs Reflexion CoT (b) Reflexion CoT (GT) for reasoning only (c) Reflexion vs episodic memory ablation.
Reflexion outperforms all baseline approaches by significant margins over several learning steps. Furthermore, ReAct-only, CoT-only, and CoT (GT)-only implementations fail to probabilistically improve on any tasks, meaning that no failed tasks from the first trial from any of the baseline approaches were able to be solved in subsequent trials using a temperature of 0.7 In the Reflexion runs, we allowed the agent to gather experience and retry on failed tasks until it produced 3 consecutive failed attempts on the particular task. Naturally, the CoT (GT) achieved higher accuracy scores as it was given access to the ground truth context of the question. Still, the CoT (GT) agent is unable to correctly infer the correct answer for 39% of the questions, but Reflexion helps the agent to correct its mistakes without access to the ground truth answer to improve its accuracy by 14%.
Analysis
We perform an ablation experiment to isolate the advantage of the self-reflective step for reasoning using CoT (GT) as the baseline approach 4. Recall that CoT (GT) uses Chain-of-Thought reasoning with provided ground truth context, which tests reasoning ability over long contexts. Next, we add an element of episodic memory (EPM) by including the most recent trajectory. For the Reflexion agent, we implement the standard self-reflection step as a final pass. Intuitively, we test if the agent is iteratively learning more effectively by using verbal explanation using language written in the first person. 4 shows that self-reflection improves learning by an 8% absolute boost over the episodic memory learning advantage. This result supports the argument that refinement-only approaches are not as effective as self-reflection-guided refinement approaches.
4.3 Programming
We evaluate the baseline and Reflexion approaches on Python and Rust code writing on MBPP (Austin et al.,, 2021), HumanEval (Chen et al.,, 2021), and LeetcodeHardGym, our new dataset. MBPP and HumanEval measure function body generation accuracy given natural language descriptions. We use a benchmark language compiler, MultiPL-E (Cassano et al.,, 2022), to translate subsets of HumanEval and MBPP to the Rust language. MultiPL-E is a collection of small compilers that can be used to translate Python benchmark questions to 18 other languages. We include experiments for Rust code generation to demonstrate that Reflexion implementations for code generation are language-agnostic and can be used for interpreted and compiled languages. Lastly, we introduce a new benchmark, LeetcodeHardGym, which is an interactive programming gym that contains 40 Leetcode hard-rated questions that have been released after October 8, 2022, which is the pre-training cutoff date of GPT-4 (OpenAI,, 2023).
The task of programming presents a unique opportunity to use more grounded self-evaluation practices such as self-generated unit test suites. Thus, our Reflexion-based programming task implementation is eligible for pass@1 accuracy reporting. To generate a test suite, we use Chain-of-Thought prompting (Wei et al.,, 2022) to produce diverse, extensive tests with corresponding natural language descriptions. Then, we filter for syntactically valid test statements by attempting to construct a valid abstract syntax tree (AST) for each proposed test. Finally, we sample $n$ tests from the collection of generated unit tests to produce a test suite $T$ , denoted as $\{t_{0},t_{1},...,t_{n}\}$ . We set $n$ to a maximum of 6 unit tests. Aside from the unit test suite component, the setup for the learning loop for a Reflexion programming agent is identical to the reasoning and decision-making agents with a max memory limit of 1 experience.
Results
| Benchmark + Language HumanEval (PY) HumanEval (RS) | Prev SOTA Pass@1 65.8 (CodeT (Chen et al.,, 2022) + GPT-3.5) – | SOTA Pass@1 80.1 (GPT-4) 60.0 (GPT-4) | Reflexion Pass@1 91.0 68.0 |
| --- | --- | --- | --- |
| MBPP (PY) | 67.7 (CodeT (Chen et al.,, 2022) + Codex (Chen et al.,, 2021)) | 80.1 (GPT-4) | 77.1 |
| MBPP (RS) | – | 70.9 (GPT-4) | 75.4 |
| Leetcode Hard (PY) | – | 7.5 (GPT-4) | 15.0 |
Table 1: Pass@1 accuracy for various model-strategy-language combinations. The base strategy is a single code generation sample. All instruction-based models follow zero-shot code generation.
| HumanEval (PY) | 0.80 | 0.91 | 0.99 | 0.40 | 0.01 | 0.60 |
| --- | --- | --- | --- | --- | --- | --- |
| MBPP (PY) | 0.80 | 0.77 | 0.84 | 0.59 | 0.16 | 0.41 |
| HumanEval (RS) | 0.60 | 0.68 | 0.87 | 0.37 | 0.13 | 0.63 |
| MBPP (RS) | 0.71 | 0.75 | 0.84 | 0.51 | 0.16 | 0.49 |
Table 2: Overall accuracy and test generation performance for HumanEval and MBPP. For Rust, HumanEval is the hardest 50 problems from HumanEval Python translated to Rust with MultiPL-E (Cassano et al.,, 2022). TP: unit tests pass, solution pass; FN: unit tests fail, solution pass; FP: unit tests pass, solution fail; TN: unit tests fail, solution fail.
Reflexion outperforms all baseline accuracies and sets new state-of-the-art standards on all benchmarks for Python and Rust except for MBPP Python 1. We further investigate the inferior performance of Reflexion on MBPP Python.
Analysis
We acknowledge that self-reflecting code-generation agents are bound to their ability to write diverse, comprehensive tests. Therefore, in the case in which the model generates a flaky test suite, it is possible that all tests pass on an incorrect solution and lead to a false positive label on a code completion (Lam et al.,, 2020). On the other hand, if the model produces an incorrectly written test suite, it is possible for some of the tests to fail on a correct solution, leading to a self-reflection generation that is conditioned on a false negative code completion. Given the implementation of Reflexion, false negatives are preferred over false positives as the agent may be able to use self-reflection to identify the incorrect test(s) and prompt itself to keep the original code completion intact. On the other hand, if an invalid test suite returns a false positive completion (all internal test cases pass but the implementation is incorrect), the agent will prematurely report an invalid submission. In 2, various conditions are measured to analyze performance beyond pass@1 accuracy. Previously, we displayed the inferior performance of Reflexion to the baseline GPT-4 on MBPP Python. In 2, we observe a notable discrepancy between the false positive labels produced by internal test execution, P(not pass@1 generation correct | tests pass). That is, the probability that a submission will fail given that it passes all unit tests. For HumanEval and MBPP Python, the baseline pass@1 accuracies are relatively similar, 82% and 80%, respectively. However, the false positive test execution rate for MBPP Python is 16.3% while the rate for HumanEval Python is a mere 1.4%, leading to 91% overall accuracy 1.
Ablation study
| Base model | False | False | 0.60 |
| --- | --- | --- | --- |
| Test generation omission | False | True | 0.52 |
| Self-reflection omission | True | False | 0.60 |
| Reflexion | True | True | 0.68 |
Table 3: Pass@1 accuracy for various compromised approaches on the Reflexion approach using GPT-4 as the base model on HumanEval Rust - 50 hardest problems
We test the composite approach of Reflexion for test generation and self-reflection cooperation on a subset of the 50 hardest HumanEval Rust problems. Our Rust compiler environment provides verbose error logs and helpful debugging hints, therefore serving as a good playground for compromised approaches. First, we omit internal test generation and execution steps, which test the agent to self-reflect without guidance from current implementations. 3 shows an inferior 52% vs 60% (baseline) accuracy, which suggests that the agent is unable to determine if the current implementation is correct without unit tests. Therefore, the agent must participate in all iterations of the run without the option to return early, performing harmful edits to the implementation.
Next, we test self-reflection contribution by omitting the natural language explanation step following failed unit test suite evaluations. Intuitively, this challenges the agent to combine the tasks of error identification and implementation improvement across all failed unit tests. Interestingly, the compromised agent does not improve performance over the baseline run. We observe that the test generation and code compilation steps are able to catch syntax and logic errors, but the implementation fixes do not reflect these indications. These empirical results suggest that several recent works that propose blind trial and error debugging techniques without self-reflection are ineffective on harder tasks such as writing complex programs in Rust.
5 Limitations
At its core, Reflexion is an optimization technique that uses natural language to do policy optimization. Policy optimization is a powerful approach to improve action choice through experience, but it may still succumb to non-optimal local minima solutions. In this study, we limit long-term memory to a sliding window with maximum capacity, but we encourage future work to extend the memory component of Reflexion with more advanced structures such as vector embedding databases or traditional SQL databases. Specific to code generation, there are many practical limitations to test-driven development in specifying accurate input-output mappings such as non-deterministic generator functions, impure functions that interact with APIs, functions that vary output according to hardware specifications, or functions that invoke parallel or concurrent behavior that may be difficult to predict.
6 Broader impact
Large language models are increasingly used to interact with external environments (e.g. the Internet, software, robotics, etc.) and humans. Our work has the potential of reinforcing and empowering these agents toward greater automation and work efficiency, but it also amplifies the risks when these agents were put into misuse. We believe that this direction of research will need more effort in safety and ethical considerations.
On the other hand, reinforcement learning has suffered from its black-box policy and optimization setups in which interpretability and alignment have been challenging. Our proposed “verbal” reinforcement learning might address some of the issues and turn autonomous agents more interpretable and diagnosable. For example, in the case of tool-usage that may be too hard for humans to understand, self-reflections could be monitored to ensure proper intent before using the tool.
7 Conclusion
In this work, we present Reflexion, an approach that leverages verbal reinforcement to teach agents to learn from past mistakes. We empirically show that Reflexion agents significantly outperform currently widely-used decision-making approaches by utilizing self-reflection. In future work, Reflexion could be used to employ more advanced techniques that have been thoroughly studied in traditional RL settings, such as value learning in natural language or off-policy exploration techniques.
8 Reproducibility
We highly advise others to use isolated execution environments when running autonomous code writing experiments as the generated code is not validated before execution.
References
- Ahn et al., (2022) Ahn, M., Brohan, A., Brown, N., Chebotar, Y., Cortes, O., David, B., Finn, C., Gopalakrishnan, K., Hausman, K., Herzog, A., et al. (2022). Do as i can, not as i say: Grounding language in robotic affordances. arXiv preprint arXiv:2204.01691.
- Austin et al., (2021) Austin, J., Odena, A., Nye, M., Bosma, M., Michalewski, H., Dohan, D., Jiang, E., Cai, C., Terry, M., Le, Q., et al. (2021). Program synthesis with large language models. arXiv preprint arXiv:2108.07732.
- Brooks et al., (2022) Brooks, E., Walls, L., Lewis, R. L., and Singh, S. (2022). In-context policy iteration. arXiv preprint arXiv:2210.03821.
- Cassano et al., (2022) Cassano, F., Gouwar, J., Nguyen, D., Nguyen, S., Phipps-Costin, L., Pinckney, D., Yee, M.-H., Zi, Y., Anderson, C. J., Feldman, M. Q., Guha, A., Greenberg, M., and Jangda, A. (2022). Multipl-e: A scalable and extensible approach to benchmarking neural code generation.
- Chen et al., (2022) Chen, B., Zhang, F., Nguyen, A., Zan, D., Lin, Z., Lou, J.-G., and Chen, W. (2022). Codet: Code generation with generated tests. arXiv preprint arXiv:2207.10397.
- Chen et al., (2021) Chen, M., Tworek, J., Jun, H., Yuan, Q., Pinto, H. P. d. O., Kaplan, J., Edwards, H., Burda, Y., Joseph, N., Brockman, G., et al. (2021). Evaluating large language models trained on code. arXiv preprint arXiv:2107.03374.
- Chen et al., (2023) Chen, X., Lin, M., Schärli, N., and Zhou, D. (2023). Teaching large language models to self-debug. arXiv preprint arXiv:2304.05128.
- Côté et al., (2019) Côté, M.-A., Kádár, A., Yuan, X., Kybartas, B., Barnes, T., Fine, E., Moore, J., Hausknecht, M., El Asri, L., Adada, M., et al. (2019). Textworld: A learning environment for text-based games. In Computer Games: 7th Workshop, CGW 2018, Held in Conjunction with the 27th International Conference on Artificial Intelligence, IJCAI 2018, Stockholm, Sweden, July 13, 2018, Revised Selected Papers 7, pages 41–75. Springer.
- Goodman, (2023) Goodman, N. (2023). Meta-prompt: A simple self-improving language agent. noahgoodman.substack.com.
- Kim et al., (2023) Kim, G., Baldi, P., and McAleer, S. (2023). Language models can solve computer tasks. arXiv preprint arXiv:2303.17491.
- Lam et al., (2020) Lam, W., Winter, S., Wei, A., Xie, T., Marinov, D., and Bell, J. (2020). A large-scale longitudinal study of flaky tests. Proc. ACM Program. Lang., 4(OOPSLA).
- Le et al., (2022) Le, H., Wang, Y., Gotmare, A. D., Savarese, S., and Hoi, S. C. H. (2022). Coderl: Mastering code generation through pretrained models and deep reinforcement learning. Advances in Neural Information Processing Systems, 35:21314–21328.
- Li et al., (2023) Li, R., Allal, L. B., Zi, Y., Muennighoff, N., Kocetkov, D., Mou, C., Marone, M., Akiki, C., Li, J., Chim, J., et al. (2023). Starcoder: may the source be with you! arXiv preprint arXiv:2305.06161.
- Li et al., (2022) Li, Y., Choi, D., Chung, J., Kushman, N., Schrittwieser, J., Leblond, R., Eccles, T., Keeling, J., Gimeno, F., Dal Lago, A., et al. (2022). Competition-level code generation with alphacode. Science, 378(6624):1092–1097.
- Madaan et al., (2023) Madaan, A., Tandon, N., Gupta, P., Hallinan, S., Gao, L., Wiegreffe, S., Alon, U., Dziri, N., Prabhumoye, S., Yang, Y., et al. (2023). Self-refine: Iterative refinement with self-feedback. arXiv preprint arXiv:2303.17651.
- Nair et al., (2023) Nair, V., Schumacher, E., Tso, G., and Kannan, A. (2023). Dera: Enhancing large language model completions with dialog-enabled resolving agents. arXiv preprint arXiv:2303.17071.
- Nakano et al., (2021) Nakano, R., Hilton, J., Balaji, S., Wu, J., Ouyang, L., Kim, C., Hesse, C., Jain, S., Kosaraju, V., Saunders, W., et al. (2021). Webgpt: Browser-assisted question-answering with human feedback. arXiv preprint arXiv:2112.09332.
- OpenAI, (2023) OpenAI (2023). Gpt-4 technical report. ArXiv.
- Park et al., (2023) Park, J. S., O’Brien, J. C., Cai, C. J., Morris, M. R., Liang, P., and Bernstein, M. S. (2023). Generative agents: Interactive simulacra of human behavior. arXiv preprint arXiv:2304.03442.
- Paul et al., (2023) Paul, D., Ismayilzada, M., Peyrard, M., Borges, B., Bosselut, A., West, R., and Faltings, B. (2023). Refiner: Reasoning feedback on intermediate representations. arXiv preprint arXiv:2304.01904.
- Pryzant et al., (2023) Pryzant, R., Iter, D., Li, J., Lee, Y. T., Zhu, C., and Zeng, M. (2023). Automatic prompt optimization with" gradient descent" and beam search. arXiv preprint arXiv:2305.03495.
- Schick et al., (2023) Schick, T., Dwivedi-Yu, J., Dessì, R., Raileanu, R., Lomeli, M., Zettlemoyer, L., Cancedda, N., and Scialom, T. (2023). Toolformer: Language models can teach themselves to use tools. arXiv preprint arXiv:2302.04761.
- Shen et al., (2023) Shen, Y., Song, K., Tan, X., Li, D., Lu, W., and Zhuang, Y. (2023). Hugginggpt: Solving ai tasks with chatgpt and its friends in huggingface. arXiv preprint arXiv:2303.17580.
- Shridhar et al., (2021) Shridhar, M., Yuan, X., Côté, M.-A., Bisk, Y., Trischler, A., and Hausknecht, M. (2021). ALFWorld: Aligning Text and Embodied Environments for Interactive Learning. In Proceedings of the International Conference on Learning Representations (ICLR).
- Sutton and Barto, (2018) Sutton, R. S. and Barto, A. G. (2018). Reinforcement Learning: An Introduction. The MIT Press, second edition.
- Wei et al., (2022) Wei, J., Wang, X., Schuurmans, D., Bosma, M., Chi, E., Le, Q., and Zhou, D. (2022). Chain of thought prompting elicits reasoning in large language models. arXiv preprint arXiv:2201.11903.
- Xie et al., (2023) Xie, Y., Kawaguchi, K., Zhao, Y., Zhao, X., Kan, M.-Y., He, J., and Xie, Q. (2023). Decomposition enhances reasoning via self-evaluation guided decoding. arXiv preprint arXiv:2305.00633.
- Yang et al., (2018) Yang, Z., Qi, P., Zhang, S., Bengio, Y., Cohen, W. W., Salakhutdinov, R., and Manning, C. D. (2018). HotpotQA: A dataset for diverse, explainable multi-hop question answering. In Conference on Empirical Methods in Natural Language Processing (EMNLP).
- (29) Yao, S., Chen, H., Yang, J., and Narasimhan, K. (preprint). Webshop: Towards scalable real-world web interaction with grounded language agents. In ArXiv.
- Yao et al., (2023) Yao, S., Zhao, J., Yu, D., Du, N., Shafran, I., Narasimhan, K., and Cao, Y. (2023). ReAct: Synergizing reasoning and acting in language models. In International Conference on Learning Representations (ICLR).
- Yoran et al., (2023) Yoran, O., Wolfson, T., Bogin, B., Katz, U., Deutch, D., and Berant, J. (2023). Answering questions by meta-reasoning over multiple chains of thought. arXiv preprint arXiv:2304.13007.
Appendix A Evaluation with additional models
We further investigated the applicability of trial-and-error problem-solving with models of various strengths. We found that the ability to specify self-corrections is an emergent quality of stronger, larger models.
| Baseline | 0.26 | 0.00481 |
| --- | --- | --- |
| Reflexion | 0.26 | 0.00305 |
Table 4: Pass@1 accuracy on HumanEval Python using starchat-beta (Li et al.,, 2023).
| CoT (GT) + text-davinci-003 | 0.60 | 0.77 |
| --- | --- | --- |
| CoT (GT) + gpt-3.5-turbo | 0.57 | 0.71 |
| CoT (GT) + gpt-4 | 0.68 | 0.80 |
| ReAct + text-davinci-003 | 0.30 | 0.55 |
| ReAct + gpt-3.5-turbo | 0.26 | 0.38 |
| ReAct + gpt-4 | 0.39 | 0.51 |
Table 5: Pass@1 accuracy on 100 HotPotQA using various models.
Appendix B Decision-making
Environment: You are in the middle of a room. Looking quickly around you, you see a bed 1, a desk 2, a desk 1, a drawer 6, a drawer 5, a drawer 4, a drawer 3, a drawer 2, a drawer 1, a garbagecan 1, a laundryhamper 1, a safe 1, a shelf 6, a shelf 5, a shelf 4, a shelf 3, a shelf 2, and a shelf 1. Task: examine the mug with the desklamp.
Trial #1 $>$ think: To solve the task, I need to find and take a mug, then find and use a desklamp. $>$ think: First I need to find a mug. A mug is more likely to appear in drawer (1-6), desk (1-2), shelf (1-6), garbagecan (1), laundryhamper (1). I can check one by one, starting with drawer 1. $>$ go to drawer 1 The drawer 1 is closed. … $>$ open drawer 6 You open the drawer 6. The drawer 6 is open. In it, you see a keychain 2. $>$ go to desk 1On the desk 1, you see a creditcard 3, a desklamp 1, a laptop 2, a mug 1, a pen 1, and a pencil 1. $>$ think: Now I find a mug (1). Next, I need to take it. $>$ take mug 1 from desk 1You pick up the mug 1 from the desk 1. $>$ think: Now I take a mug (1). Next, I need to find a desklamp. A desklamp is more likely to appear in desk (1-2), sidetable (1-2), shelf (1-6), bed (1), drawer (1-6). I can check one by one, starting with desk 1. $>$ go to desk 1 Nothing happens. $>$ go to desk 2 On the desk 2, you see a alarmclock 1, a bowl 1, a mug 3, a pencil 3, and a pencil 2. $>$ think: Now I find a desklamp (1). Next, I need to use it. $>$ use desklamp 1Nothing happens. $>$ use desklamp 1Nothing happens.Status: Fail
Reflection: In this environment, my plan was to find a mug then find and use a desklamp. However, the task says to examine the mug with the desklamp. I should have looked for the desklamp first, then looked for the mug. I noticed that the desklamp was found on desk 1. In the next trial, I will go to desk 1, find the lamp, then look for the mug and examine it with the desklamp.
Trial #2 $>$ go to desk 1On the desk 1, you see a creditcard 3, a desklamp 1, a laptop 2, a mug 1, a pen 1, and a pencil 1. $>$ think: To solve the task, I need to find and take a mug, then find and use a desklamp. $>$ take mug 1 from desk 1You pick up the mug 1 from the desk 1. $>$ think: To solve the task, I need to find and take a mug, then find and use a desklamp. $>$ use desklamp 1You turn on the desklamp 1.Status: Success
Figure 5: [Top] An AlfWorld trajectory in which the agent failed due to inefficient planning. In the reflection, the agent recognizes that it should have looked for the desklamp then the mug, not the mug then the desklamp. [Bottom] The agent is able to correct its reasoning trace and execute a sequence of actions in a concise manner.
B.1 WebShop Limitation
In 5, we briefly state that Reflexion struggles to overcome local minima choices that require extremely creative behavior to escape. We observe this shortcoming in an experiment on WebShop (Yao et al., rint, ). WebShop is a web-based problem-solving benchmark that tests agents to navigate an e-commerce website to locate and purchase products given requests from clients. We test a two-shot ReAct + Reflexion agent in 100 environments. However, after only four trials, we terminate the runs as the agent does not show signs of improvement 6. Further, the agent does not generate helpful, intuitive self-reflections after failed attempts. We conclude that Reflexion is unable to solve tasks that require a significant amount of diversity and exploration. In AlfWorld, the agent is able to adequately explore new environments because the permissible actions can be seen in the observations. In HotPotQA, the agent faces a similar WebShop search query task but is more successful as the search space for Wikipedia articles is more diverse and requires less precise search queries. A common problem for e-commerce search engines is properly handling ambiguity in natural language search interpretations. Thus, WebShop presents a task that requires very diverse and unique behavior from a Reflexion agent.
<details>
<summary>x8.png Details</summary>
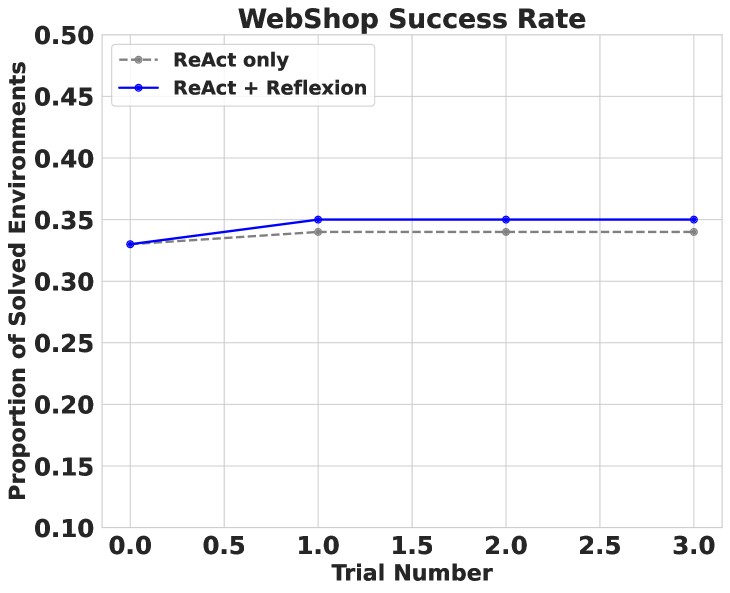
### Visual Description
\n
## Line Chart: WebShop Success Rate
### Overview
This line chart depicts the success rate of two different approaches – “ReAct only” and “ReAct + Reflexion” – across three trial numbers in a WebShop environment. The y-axis represents the proportion of solved environments, while the x-axis represents the trial number.
### Components/Axes
* **Title:** WebShop Success Rate
* **X-axis Label:** Trial Number (Scale: 0.0 to 3.0, increments of 0.5)
* **Y-axis Label:** Proportion of Solved Environments (Scale: 0.10 to 0.50, increments of 0.05)
* **Legend:**
* ReAct only (Grey dashed line with circle markers)
* ReAct + Reflexion (Blue solid line with circle markers)
### Detailed Analysis
**ReAct only (Grey dashed line):**
The line starts at approximately 0.32 at Trial Number 0.0, increases to approximately 0.34 at Trial Number 1.0, and then slightly decreases to approximately 0.33 at Trial Number 2.0 and 3.0. The trend is relatively flat, showing minimal improvement across trials.
* Trial 0.0: 0.32
* Trial 0.5: 0.33
* Trial 1.0: 0.34
* Trial 1.5: 0.34
* Trial 2.0: 0.33
* Trial 2.5: 0.33
* Trial 3.0: 0.33
**ReAct + Reflexion (Blue solid line):**
The line begins at approximately 0.32 at Trial Number 0.0, increases to approximately 0.36 at Trial Number 1.0, decreases to approximately 0.35 at Trial Number 2.0, and remains at approximately 0.35 at Trial Number 3.0. This line shows an initial improvement followed by stabilization.
* Trial 0.0: 0.32
* Trial 0.5: 0.34
* Trial 1.0: 0.36
* Trial 1.5: 0.36
* Trial 2.0: 0.35
* Trial 2.5: 0.35
* Trial 3.0: 0.35
### Key Observations
* The "ReAct + Reflexion" approach consistently outperforms the "ReAct only" approach across all trial numbers.
* The "ReAct + Reflexion" approach shows an initial improvement in success rate during the first trial, but then plateaus.
* The "ReAct only" approach shows very little change in success rate across all trials.
* Both approaches have a success rate between 0.32 and 0.36.
### Interpretation
The data suggests that incorporating "Reflexion" into the "ReAct" framework improves the success rate in the WebShop environment, at least initially. However, the improvement appears to plateau after the first trial, indicating that the benefits of "Reflexion" may diminish with continued use or that further refinements are needed to sustain improvement. The relatively low overall success rates (between 32% and 36%) for both approaches suggest that the WebShop environment presents a significant challenge, and there is room for further improvement in both methodologies. The flat trend of the "ReAct only" approach indicates that it does not adapt or learn from experience within this environment. The initial boost from "Reflexion" suggests that self-evaluation and iterative refinement can be beneficial, but the plateau suggests that the current implementation of "Reflexion" may have limitations.
</details>
Figure 6: Reflexion vs React performance on WebShop across 100 customer shopping requests. ReAct + Reflexion fails to significantly outperform ReAct.
Appendix C Programming
Programming LLM calls require strict instructions to produce function bodies only, due to the extensive dialogue training of the LLMs. A few programming examples are reported below with instructions highlighted in blue and templates. See the full implementation at https://github.com/noahshinn024/reflexion.
C.1 Programming function implementation example (HumanEval Python)
Sample function signature:
⬇
1 def minSubArraySum (nums):
2 "" "
3 Given an array of integers nums, find the minimum sum of any
4 non-empty sub-array of nums.
5 Example
6 minSubArraySum([2, 3, 4, 1, 2, 4]) == 1
7 minSubArraySum([-1, -2, -3]) == -6
8 " ""
Sample function body implementation:
⬇
1 min_sum = float (’inf’)
2 for i in range (len (nums)):
3 current_sum = 0
4 for j in range (i, len (nums)):
5 current_sum += nums [j]
6 if current_sum < min_sum:
7 min_sum = current_sum
8 return min_sum
C.2 Reflexion Actor instruction
You are a Python writing assistant. You will be given your previous implementation of a function, a series of unit tests results, and your self-reflection on your previous implementation. Apply the necessary changes below by responding only with the improved body of the function. Do not include the signature in your response. The first line of your response should have 4 spaces of indentation so that it fits syntactically with the user provided signature. You will be given a few examples by the user.
Reflexion Actor generations follow the form: (Instruction) (Function implementation) (Unit test feedback) (Self-reflection) (Instruction for next function implmentation)
Full examples are shown in https://github.com/noahshinn024/reflexion
C.3 Reflexion Self-reflection instruction and example
You are a Python writing assistant. You will be given your previous implementation of a function, a series of unit tests results, and your self-reflection on your previous implementation. Apply the necessary changes below by responding only with the improved body of the function. Do not include the signature in your response. The first line of your response should have 4 spaces of indentation so that it fits syntactically with the user provided signature. You will be given a few examples by the user. Reflexion Self-Reflection generations follow the form: (Instruction) (Function implementation) (Unit test feedback)
C.4 Reflexion programming no Self-Reflection ablation example
Reflexion no Self-Reflection ablation Actor generations follow the form: (Instruction) (Function implementation) (Unit test feedback) (Self-reflection) (Instruction for next function implmentation)
C.5 Reflexion programming no test generation ablation example
Reflexion no test generation ablation Actor generations follow the form: (Instruction) (Function implementation) (Unit test feedback) (Self-reflection) (Instruction for next function implmentation)
Appendix D Reasoning
D.1 Full example
Trial #1: Question: Grown-Ups starred the actor who was best known for which role on "’Allo ’Allo!"? Thought 1: I need to search Grown-Ups and "’Allo ’Allo!", find the actor who starred in Grown-Ups, then find the role he was best known for in "’Allo ’Allo!". Action 1: Search[Grown-Ups] Observation 1: Grown-Ups is a 1980 British BBC television film devised and directed by Mike Leigh. It stars Lesley Manville, Philip Davis, Brenda Blethyn, Janine Duvitski, Lindsay Duncan and Sam Kelly. It was edited by Robin Sales and produced by Louis Marks for the BBC, and originally shown on BBC 2 on 28 November 1980. Thought 2: Grown-Ups starred Lesley Manville, Philip Davis, Brenda Blethyn, Janine Duvitski, Lindsay Duncan and Sam Kelly. I need to search "’Allo ’Allo!" and find which actor was best known for which role. Action 2: Search["’Allo ’Allo!"] Observation 2: Could not find ["’Allo ’Allo!"]. Similar: ["’Allo ’Allo!", "List of ’Allo ’Allo! characters", ’Gorden Kaye’, "’Allo ’Allo! (series 2)", ’Allô, allô’, ’Francesca Gonshaw’, "’Allo ’Allo! (series 4)", ’Kim Hartman’, "’Allo ’Allo! (series 6)", ’Jeremy Lloyd’] Thought 3: To find the actor who was best known for which role on "’Allo ’Allo!", I can search Gorden Kaye. Action 3: Search[Gorden Kaye] Observation 3: Gordon Irving Kaye (7 April 1941 – 23 January 2017), known professionally as Gorden Kaye, was an English actor, best known for playing womanising café owner René Artois in the television comedy series ’Allo ’Allo!. Thought 4: Gorden Kaye was best known for playing womanising café owner René Artois in the television comedy series "’Allo ’Allo!". So the answer is Rene Artois. Action 4: Finish[Rene Artois]Observation 4: Answer is INCORRECT
Trial #2: Question: Grown-Ups starred the actor who was best known for which role on "’Allo ’Allo!"? Thought 1: I need to search the actor who was best known for a role on "’Allo ’Allo!" and find out what role they were best known for. Action 1: Search[Grown-Ups] Observation 1: Grown-Ups is a 1980 British BBC television film devised and directed by Mike Leigh. It stars Lesley Manville, Philip Davis, Brenda Blethyn, Janine Duvitski, Lindsay Duncan and Sam Kelly. It was edited by Robin Sales and produced by Louis Marks for the BBC, and originally shown on BBC 2 on 28 November 1980. Thought 2: The paragraph does not mention the actor who was best known for a role on "’Allo ’Allo!". I need to search the actor’s name instead. Action 2: Search[Sam Kelly] Observation 2: Roger Michael Kelly (19 December 1943 – 14 June 2014), known by the stage name Sam Kelly, was an English actor who appeared in film, television, radio and theatre. He is best known for his roles as Captain Hans Geering in ’Allo ’Allo!, Warren in Porridge, Sam in On the Up, and Ted Liversidge in Barbara. Thought 3: Sam Kelly is best known for his role as Captain Hans Geering in "’Allo ’Allo!", so the answer is Captain Hans Geering. Action 3: Finish[Captain Hans Geering]Observation 3: Answer is CORRECT
Reflection: I searched the wrong title for the show, "’Allo ’Allo!", which resulted in no results. I should have searched the show’s main character, Gorden Kaye, to find the role he was best known for in the show.
Figure 7: Two HotPotQA trials within the same environment and task. The Reflexion + ReAct agent uses self-reflection to determine a better search method for the next trial.
D.2 Chain-of-Thought + Reflexion
Trial #1: Question: What profession does John Lanchester and Alan Dean Foster have in common? Thought 1: Let’s think step by step. John Lanchester is a novelist, journalist, and critic. Alan Dean Foster is a novelist and screenwriter. So the profession John Lanchester and Alan Dean Foster have in common is novelist and screenwriter. Action 1: Finish[novelist and screenwriter]Observation 1: Answer is INCORRECT
Trial #2: Question: What profession does John Lanchester and Alan Dean Foster have in common? Thought 1: Let’s think step by step. John Lanchester is a novelist, journalist, and financial journalist. Alan Dean Foster is a novelist and screenwriter. So the profession John Lanchester and Alan Dean Foster have in common is novelist. Action 1: Finish[novelist]Observation 1: Answer is CORRECT
Reflection: My reasoning for the profession John Lanchester and Alan Dean Foster have in common failed because I incorrectly assumed that they both had the same profession. In the future, when attempting this question, I should focus on better researching the individual backgrounds of both authors to ensure that I am accurately identifying their professions. Additionally, I should consider the possibility that they may have multiple professions in common.
D.3 HotPotQA Chain-of-Thought (GT) + Reflexion
Context: The Battle of White Plains was a battle in the New York and New Jersey campaign of the American Revolutionary War fought on October 28, 1776, near White Plains, New York. Following the retreat …
Trial #1: Question: What was a series of battles during the Revolutionary War, for control of New York City and the state of New Jersey, fought on October 28, 1776 near White Plains, New York? Thought 1: The question is asking about a series of battles during the Revolutionary War for control of New York City and the state of New Jersey, fought on October 28, 1776 near White Plains, New York. From the context, I know that this was the Battle of White Plains. Action 1: Finish[Battle of White Plains] Observation 1: Answer is INCORRECT
Trial #2: Question: What was a series of battles during the Revolutionary War, for control of New York City and the state of New Jersey, fought on October 28, 1776 near White Plains, New York? Thought 1: The question is asking for a series of battles during the Revolutionary War, for control of New York City and the state of New Jersey, fought on October 28, 1776 near White Plains, New York. Based on the context, I know that this series of battles was the New York and New Jersey campaign. Action 1: Finish[The New York and New Jersey campaign] Observation 1: Answer is CORRECT
Reflection: Upon reflecting on the incorrect answer I provided, I realize that I may not have provided enough context to accurately answer the question. The question asked for a series of battles, but I only provided the name of one battle. To better answer this question in the future, I will make sure to provide more context, such as the name of the campaign, which was the New York and New Jersey campaign, and the fact that it was a series of battles. Additionally, I will make sure to include the dates of the battles, as well as the locations, to ensure that my answer is comprehensive and accurate.
D.4 HotPotQA episodic memory (EPM) ablation prompts
D.4.1 (EPM) Chain-of-Thought + Reflexion
Trial #1: Question: Which of Jonny Craig and Pete Doherty has been a member of more bands ? Thought 1: Let’s think step by step. Jonny Craig has been a member of six bands, including Emarosa, Dance Gavin Dance, and Slaves. Pete Doherty has been a member of seven bands, including The Libertines, Babyshambles, and The Puta Madres. So Pete Doherty has been a member of more bands. Action 1: Finish[Pete Doherty]Observation 1: Answer is INCORRECT
Trial #2: Question: Which of Jonny Craig and Pete Doherty has been a member of more bands ? Thought 1: Let’s think step by step. I will research the past and current bands of both musicians to ensure that I am accurately comparing their band memberships. After researching, I have found that Jonny Craig has been a member of seven bands, including Emarosa, Dance Gavin Dance, and Slaves. Pete Doherty has been a member of seven bands, including The Libertines, Babyshambles, and The Puta Madres. So Jonny Craig has been a member of more bands. Action 2: Finish[Jonny Craig]Observation 2: Answer is CORRECT
Reflection: My reasoning for which musician has been a member of more bands failed because I did not take into account that Jonny Craig has been a member of more bands in the past, even though Pete Doherty is currently a member of more bands. In the future, when attempting this question, I should focus on researching the past and current bands of both musicians to ensure that I am accurately comparing their band memberships.
D.4.2 (EPM) Chain-of-Thought (GT) + Reflexion
Context: Hari Bahadur Basnet is a Nepalese politician. He is the head of the Foreign Relations Department of the Rastriya Janashakti Party. Basnet holds a M.Sc. in Engineering. A Master of Science (Latin: "Magister Scientiae" ; abbreviated MS, M.S., MSc, M.Sc., MSci, M.Sci., ScM, Sc.M., SciM or Sci.M.) is a master’s degree in the field of science…
Trial #1: Question: The head of the Foreign Relations Department of the Rastriya Janashakti Party holds a degree that can be abbreviated MS, M.S., or ScM, in what field? (Previous trajectory) Thought 1: The question is asking what field of study the head of the Foreign Relations Department of the Rastriya Janashakti Party holds a degree in. From the context, I know that the degree is a Master of Science degree, which is typically granted for studies in sciences, engineering, and medicine. Action 1: Finish[Sciences, Engineering, and Medicine] Observation 1: Answer is INCORRECT
Trial #2: Question: The head of the Foreign Relations Department of the Rastriya Janashakti Party holds a degree that can be abbreviated MS, M.S., or ScM, in what field? (Previous trajectory) Thought 1: The question is asking what field of study the head of the Foreign Relations Department of the Rastriya Janashakti Party holds a degree in. From the context, I know that the degree is a Master of Science degree, which is typically granted for studies in sciences, engineering, and medicine. However, the question is asking for the field of study, not the degree. Based on the context, I know that Hari Bahadur Basnet holds a M.Sc. in Engineering. Action 1: Finish[Engineering]Observation 1: Answer is CORRECT
Reflection: For the first trial, I misunderstood the question. I thought the question was asking for a category of degrees, rather than a specific degree. I learned from my mistake and in the second trial, I focused more closely on the question to understand that it was asking for a specific field of study.