# On the Security Risks of Knowledge Graph Reasoning
**Authors**:
- Zhaohan Xi
- Penn State
- Tianyu Du
- Penn State
- Changjiang Li
- Penn State
- Ren Pang
- Penn State
- Shouling Ji (Zhejiang University)
- Xiapu Luo (Hong Kong Polytechnic University)
- Xusheng Xiao (Arizona State University)
- Fenglong Ma
- Penn State
- Ting Wang
- Penn State
\newtcolorbox
mtbox[1]left=0.25mm, right=0.25mm, top=0.25mm, bottom=0.25mm, sharp corners, colframe=red!50!black, boxrule=0.5pt, title=#1, fonttitle=, coltitle=red!50!black, attach title to upper= – \stackMath
Abstract
Knowledge graph reasoning (KGR) – answering complex logical queries over large knowledge graphs – represents an important artificial intelligence task, entailing a range of applications (e.g., cyber threat hunting). However, despite its surging popularity, the potential security risks of KGR are largely unexplored, which is concerning, given the increasing use of such capability in security-critical domains.
This work represents a solid initial step towards bridging the striking gap. We systematize the security threats to KGR according to the adversary’s objectives, knowledge, and attack vectors. Further, we present ROAR, a new class of attacks that instantiate a variety of such threats. Through empirical evaluation in representative use cases (e.g., medical decision support, cyber threat hunting, and commonsense reasoning), we demonstrate that ROAR is highly effective to mislead KGR to suggest pre-defined answers for target queries, yet with negligible impact on non-target ones. Finally, we explore potential countermeasures against ROAR, including filtering of potentially poisoning knowledge and training with adversarially augmented queries, which leads to several promising research directions.
1 Introduction
Knowledge graphs (KGs) are structured representations of human knowledge, capturing real-world objects, relations, and their properties. Thanks to automated KG building tools [61], recent years have witnessed a significant growth of KGs in various domains (e.g., MITRE [10], GNBR [53], and DrugBank [4]). One major use of such KGs is knowledge graph reasoning (KGR), which answers complex logical queries over KGs, entailing a range of applications [6] such as information retrieval [8], cyber-threat hunting [2], biomedical research [30], and clinical decision support [12]. For instance, KG-assisted threat hunting has been used in both research prototypes [50, 34] and industrial platforms [9, 40].
**Example 1**
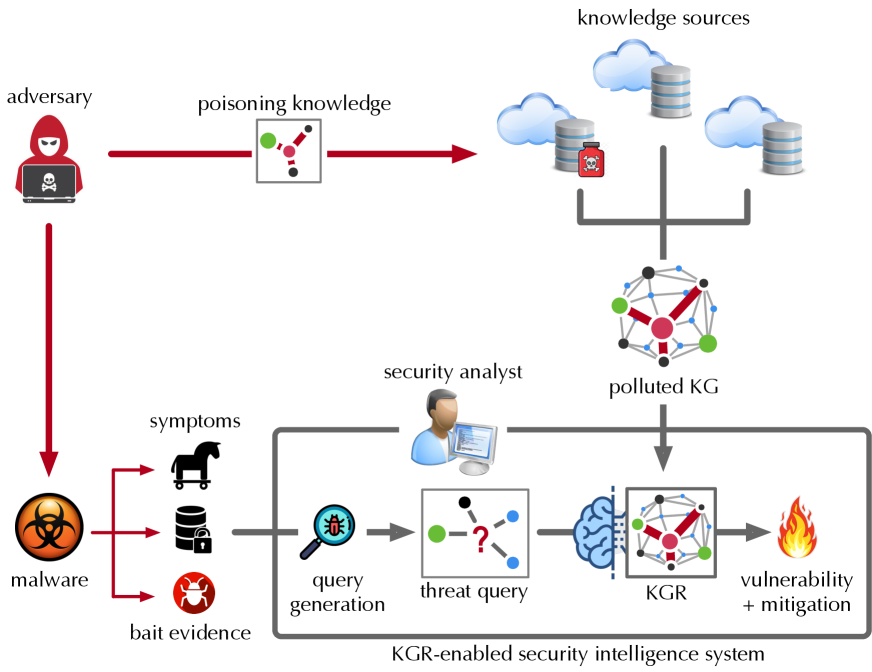
*In cyber threat hunting as shown in Figure 1, upon observing suspicious malware activities, the security analyst may query a KGR-enabled security intelligence system (e.g., LogRhythm [47]): “ how to mitigate the malware that targets BusyBox and launches DDoS attacks? ” Processing the query over the backend KG may identify the most likely malware as Mirai and its mitigation as credential-reset [15].*
<details>
<summary>x1.png Details</summary>
### Visual Description
\n
## Diagram: KGR-enabled Security Intelligence System
### Overview
The image depicts a diagram illustrating a KGR-enabled security intelligence system and how an adversary can attempt to poison the knowledge used by the system. The diagram shows the flow of information from knowledge sources, through a security analyst, to a knowledge graph (KG), and ultimately to vulnerability detection and mitigation. It also illustrates how an adversary can inject "poisoning knowledge" into the system.
### Components/Axes
The diagram consists of several key components:
* **Adversary:** Represented by a hooded figure.
* **Knowledge Sources:** Represented by multiple cloud and cylinder icons.
* **Polluted KG:** A knowledge graph that has been compromised.
* **Security Analyst:** Represented by a person working on a computer.
* **Malware:** Represented by a biohazard symbol and a gear.
* **Bait Evidence:** Represented by a horse head and a lock with a red bug.
* **Query Generation:** Represented by a gear with a bug.
* **Threat Query:** Represented by a question mark inside a circle.
* **KGR:** Knowledge Graph Reasoning, represented by a brain-shaped icon.
* **Vulnerability + Mitigation:** Represented by a flame.
* **Arrows:** Indicate the flow of information and attacks.
Labels include: "adversary", "poisoning knowledge", "knowledge sources", "security analyst", "polluted KG", "malware", "symptoms", "bait evidence", "query generation", "threat query", "KGR", "vulnerability + mitigation", and "KGR-enabled security intelligence system".
### Detailed Analysis or Content Details
The diagram illustrates the following flow:
1. **Adversary Attack:** The adversary attempts to "poison knowledge" by injecting malicious data (represented by red dots connected by lines) into the "knowledge sources". This is indicated by a thick red arrow.
2. **Knowledge Sources to Polluted KG:** The knowledge sources feed into a "polluted KG". The KG is represented by a network of nodes and edges, with a red color scheme indicating contamination.
3. **Security Analyst Input:** The security analyst receives information from the "polluted KG".
4. **Malware & Bait Evidence:** "Malware" and "bait evidence" generate "symptoms" which are fed into the "query generation" stage. The malware is represented by a biohazard symbol and a gear. Bait evidence is represented by a horse head and a lock with a red bug.
5. **Query Generation to Threat Query:** The "query generation" stage produces a "threat query".
6. **Threat Query to KGR:** The "threat query" is processed by the "KGR" (Knowledge Graph Reasoning) component.
7. **KGR to Vulnerability & Mitigation:** The "KGR" outputs "vulnerability + mitigation" information, represented by a flame.
The diagram also shows a direct connection from the adversary to the malware, suggesting the adversary is responsible for creating or deploying the malware.
### Key Observations
* The diagram highlights the vulnerability of knowledge-based security systems to adversarial attacks.
* The "polluted KG" is a central point of failure, as it affects the entire downstream process.
* The use of visual metaphors (e.g., flame for vulnerability, biohazard for malware) effectively communicates the concepts.
* The diagram emphasizes the importance of a security analyst in the loop, but also shows how their analysis can be compromised by poisoned knowledge.
### Interpretation
The diagram demonstrates a potential attack vector against KGR-enabled security intelligence systems. The adversary aims to compromise the system by injecting false or misleading information into the knowledge sources, ultimately leading to a "polluted KG". This pollution can then affect the security analyst's judgment and the accuracy of the vulnerability detection and mitigation process. The diagram suggests that robust mechanisms for validating and sanitizing knowledge sources are crucial for maintaining the integrity of these systems. The inclusion of "bait evidence" suggests a proactive approach to detecting adversarial activity, but it is also susceptible to being compromised. The diagram is a conceptual illustration of a threat model, rather than a depiction of specific data or numerical values. It serves to highlight the potential risks and challenges associated with using knowledge graphs in security applications. The diagram is a high-level overview and does not provide details on the specific techniques used for poisoning knowledge or mitigating vulnerabilities.
</details>
Figure 1: Threats to KGR-enabled security intelligence systems.
Surprisingly, in contrast to the growing popularity of using KGR to support decision-making in a variety of critical domains (e.g., cyber-security [52], biomedicine [12], and healthcare [71]), its security implications are largely unexplored. More specifically,
RQ ${}_{1}$ – What are the potential threats to KGR?
RQ ${}_{2}$ – How effective are the attacks in practice?
RQ ${}_{3}$ – What are the potential countermeasures?
Yet, compared with other machine learning systems (e.g., graph learning), KGR represents a unique class of intelligence systems. Despite the plethora of studies under the settings of general graphs [72, 66, 73, 21, 68] and predictive tasks [70, 54, 19, 56, 18], understanding the security risks of KGR entails unique, non-trivial challenges: (i) compared with general graphs, KGs contain richer relational information essential for KGR; (ii) KGR requires much more complex processing than predictive tasks (details in § 2); (iii) KGR systems are often subject to constant update to incorporate new knowledge; and (iv) unlike predictive tasks, the adversary is able to manipulate KGR through multiple different attack vectors (details in § 3).
<details>
<summary>x2.png Details</summary>
### Visual Description
\n
## Diagram: Knowledge Graph for Malware Mitigation
### Overview
The image presents a diagram illustrating a knowledge graph and its application to a malware mitigation query. It is divided into three main sections: (a) a knowledge graph representing relationships between malware and targets, (b) a formal query representation, and (c) a step-by-step visualization of knowledge graph reasoning to answer the query.
### Components/Axes
The diagram consists of nodes representing entities (e.g., DDoS, BusyBox, Mirai) and directed edges representing relationships between them (e.g., "launch-by", "target-by", "mitigate-by"). The query section includes mathematical notation and variable definitions. The reasoning section shows a series of graph transformations.
### Detailed Analysis or Content Details
**(a) Knowledge Graph:**
* **Nodes:**
* DDoS (Red)
* BusyBox (Yellow)
* Mirai (Green)
* Brickerbot (Green)
* PDoS (Red)
* `vmalware` (Variable, not colored)
* **Edges:**
* DDoS `launch-by` Mirai
* Mirai `target-by` BusyBox
* BusyBox `target-by` Brickerbot
* Brickerbot `mitigate-by` hardware restore
* PDoS `launch-by` BusyBox
* BusyBox `target-by` PDoS
* DDoS `mitigate-by` credential reset
* The graph shows a chain of attacks: DDoS launched by Mirai targeting BusyBox, and PDoS launched by BusyBox targeting PDoS. Mitigation strategies are also shown.
**(b) Query:**
* **Text:** "How to mitigate the malware that targets BusyBox and launches DDoS attacks?"
* **Mathematical Formulation:**
* `Aq = {BusyBox, DDoS}, Vq = {vmalware}`
* `E'q =` (Equation showing relationships between BusyBox, DDoS, and `vmalware` with edges labeled "target-by", "launch-by", and "mitigate-by")
* The equation shows a relationship between BusyBox, DDoS, and a variable `vmalware` representing the malware.
**(c) Knowledge Graph Reasoning:**
This section shows a series of graph transformations, numbered (1) through (4).
* **(1):** `ΦDDoS` with an edge `vlaunch-by` pointing to `vmalware`.
* **(2):** `Ψ` (conjunction symbol) with edges `vlaunch-by` from `DDoS` to `vmalware` and `vtarget-by` from `BusyBox` to `vmalware`.
* **(3):** `vmalware` with an edge `vmitigate-by` pointing to `?`.
* **(4):** `?` (variable) with a bracket `[q]`. The bracket suggests the result of the query.
### Key Observations
* The knowledge graph represents a network of cyberattacks and mitigation strategies.
* The query aims to find a mitigation strategy for malware that both targets BusyBox and launches DDoS attacks.
* The reasoning process involves identifying the malware (`vmalware`) that satisfies the query conditions and then finding a mitigation strategy for that malware.
* The use of mathematical notation formalizes the query and reasoning process.
### Interpretation
The diagram demonstrates a knowledge graph-based approach to cybersecurity threat mitigation. The knowledge graph stores information about attacks, targets, and mitigation strategies. A formal query is constructed to represent the mitigation goal. The reasoning process then traverses the knowledge graph to identify the relevant malware and its corresponding mitigation strategy.
The diagram highlights the power of knowledge graphs in representing complex relationships and enabling automated reasoning for cybersecurity tasks. The use of mathematical notation provides a precise and unambiguous way to define queries and reasoning steps. The reasoning process shown in (c) is a simplified illustration of how a knowledge graph can be used to answer complex security questions. The final result, represented by "?", indicates the mitigation strategy that satisfies the query conditions.
The diagram suggests a system where security analysts can formulate queries in natural language, which are then translated into formal queries that can be executed on the knowledge graph to identify appropriate mitigation strategies. This approach can help to automate the threat response process and improve the efficiency of security operations.
</details>
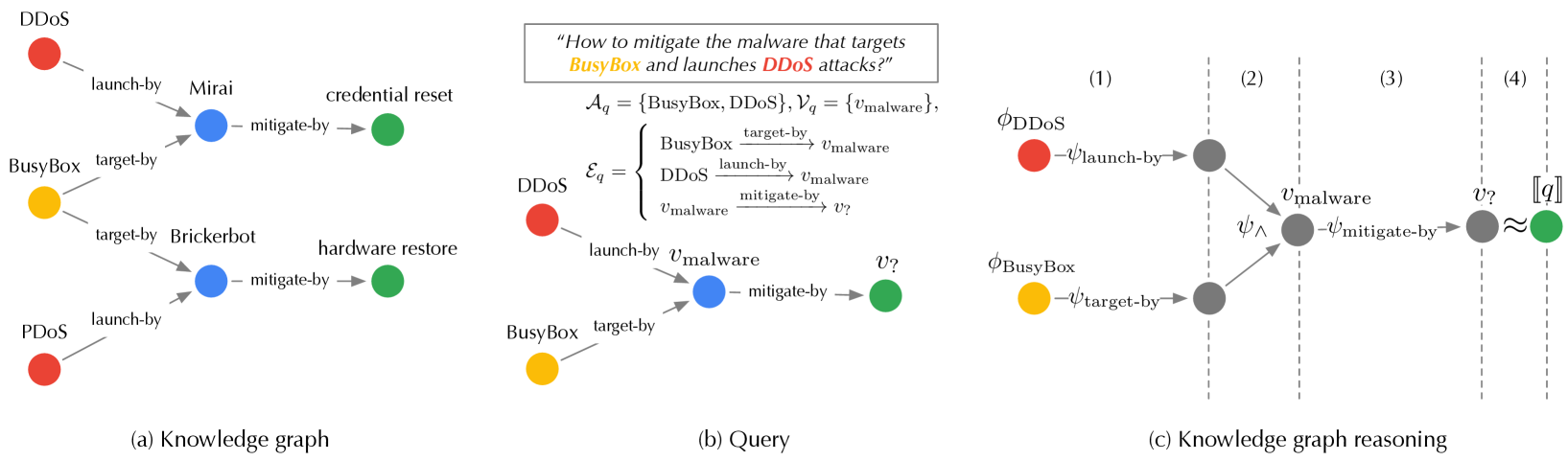
Figure 2: (a) sample knowledge graph; (b) sample query and its graph form; (c) reasoning over knowledge graph.
Our work. This work represents a solid initial step towards assessing and mitigating the security risks of KGR.
RA ${}_{1}$ – First, we systematize the potential threats to KGR. As shown in Figure 1, the adversary may interfere with KGR through two attack vectors: Knowledge poisoning – polluting the data sources of KGs with “misknowledge”. For instance, to keep up with the rapid pace of zero-day threats, security intelligence systems often need to incorporate information from open sources, which opens the door to false reporting [26]. Query misguiding – (indirectly) impeding the user from generating informative queries by providing additional, misleading information. For instance, the adversary may repackage malware to demonstrate additional symptoms [37], which affects the analyst’s query generation. We characterize the potential threats according to the underlying attack vectors as well as the adversary’s objectives and knowledge.
RA ${}_{2}$ – Further, we present ROAR, ROAR: R easoning O ver A dversarial R epresentations. a new class of attacks that instantiate the aforementioned threats. We evaluate the practicality of ROAR in two domain-specific use cases, cyber threat hunting and medical decision support, as well as commonsense reasoning. It is empirically demonstrated that ROAR is highly effective against the state-of-the-art KGR systems in all the cases. For instance, ROAR attains over 0.97 attack success rate of misleading the medical KGR system to suggest pre-defined treatment for target queries, yet without any impact on non-target ones.
RA ${}_{3}$ - Finally, we discuss potential countermeasures and their technical challenges. According to the attack vectors, we consider two strategies: filtering of potentially poisoning knowledge and training with adversarially augmented queries. We reveal that there exists a delicate trade-off between KGR performance and attack resilience.
Contributions. To our best knowledge, this work represents the first systematic study on the security risks of KGR. Our contributions are summarized as follows.
– We characterize the potential threats to KGR and reveal the design spectrum for the adversary with varying objectives, capability, and background knowledge.
– We present ROAR, a new class of attacks that instantiate various threats, which highlights the following features: (i) it leverages both knowledge poisoning and query misguiding as the attack vectors; (ii) it assumes limited knowledge regarding the target KGR system; (iii) it realizes both targeted and untargeted attacks; and (iv) it retains effectiveness under various practical constraints.
– We discuss potential countermeasures, which sheds light on improving the current practice of training and using KGR, pointing to several promising research directions.
2 Preliminaries
We first introduce fundamental concepts and assumptions.
Knowledge graphs (KGs). A KG ${\mathcal{G}}=({\mathcal{N}},{\mathcal{E}})$ consists of a set of nodes ${\mathcal{N}}$ and edges ${\mathcal{E}}$ . Each node $v∈{\mathcal{N}}$ represents an entity and each edge $v\mathrel{\text{\scriptsize$\xrightarrow[]{r}$}}v^{\prime}∈{\mathcal{E}}$ indicates that there exists relation $r∈{\mathcal{R}}$ (where ${\mathcal{R}}$ is a finite set of relation types) from $v$ to $v^{\prime}$ . In other words, ${\mathcal{G}}$ comprises a set of facts $\{\langle v,r,v^{\prime}\rangle\}$ with $v,v^{\prime}∈{\mathcal{N}}$ and $v\mathrel{\text{\scriptsize$\xrightarrow[]{r}$}}v^{\prime}∈{\mathcal{E}}$ .
**Example 2**
*In Figure 2 (a), the fact $\langle$ DDoS, launch-by, Mirai $\rangle$ indicates that the Mirai malware launches the DDoS attack.*
Queries. A variety of reasoning tasks can be performed over KGs [58, 33, 63]. In this paper, we focus on first-order conjunctive queries, which ask for entities that satisfy constraints defined by first-order existential ( $∃$ ) and conjunctive ( $\wedge$ ) logic [59, 16, 60]. Formally, let ${\mathcal{A}}_{q}$ be a set of known entities (anchors), ${\mathcal{E}}_{q}$ be a set of known relations, ${\mathcal{V}}_{q}$ be a set of intermediate, unknown entities (variables), and $v_{?}$ be the entity of interest. A first-order conjunctive query $q\triangleq(v_{?},{\mathcal{A}}_{q},{\mathcal{V}}_{q},{\mathcal{E}}_{q})$ is defined as:
$$
\begin{split}&\llbracket q\rrbracket=v_{?}\,.\,\exists{\mathcal{V}}_{q}:\wedge%
_{v\mathrel{\text{\scriptsize$\xrightarrow[]{r}$}}v^{\prime}\in{\mathcal{E}}_{%
q}}v\mathrel{\text{\scriptsize$\xrightarrow[]{r}$}}v^{\prime}\\
&\text{s.t.}\;\,v\mathrel{\text{\scriptsize$\xrightarrow[]{r}$}}v^{\prime}=%
\left\{\begin{array}[]{l}v\in{\mathcal{A}}_{q},v^{\prime}\in{\mathcal{V}}_{q}%
\cup\{v_{?}\},r\in{\mathcal{R}}\\
v,v^{\prime}\in{\mathcal{V}}_{q}\cup\{v_{?}\},r\in{\mathcal{R}}\end{array}%
\right.\end{split} \tag{1}
$$
Here, $\llbracket q\rrbracket$ denotes the query answer; the constraints specify that there exist variables ${\mathcal{V}}_{q}$ and entity of interest $v_{?}$ in the KG such that the relations between ${\mathcal{A}}_{q}$ , ${\mathcal{V}}_{q}$ , and $v_{?}$ satisfy the relations specified in ${\mathcal{E}}_{q}$ .
**Example 3**
*In Figure 2 (b), the query of “ how to mitigate the malware that targets BusyBox and launches DDoS attacks? ” can be translated into:
$$
\begin{split}q=&(v_{?},{\mathcal{A}}_{q}=\{\textsf{ BusyBox},\textsf{%
DDoS}\},{\mathcal{V}}_{q}=\{v_{\text{malware}}\},\\
&{\mathcal{E}}_{q}=\{\textsf{ BusyBox}\scriptsize\mathrel{\stackunder[0%
pt]{\xrightarrow{\makebox[24.86362pt]{$\scriptstyle\text{target-by}$}}}{%
\scriptstyle\,}}v_{\text{malware}},\\
&\textsf{ DDoS}\scriptsize\mathrel{\stackunder[0pt]{\xrightarrow{%
\makebox[26.07503pt]{$\scriptstyle\text{launch-by}$}}}{\scriptstyle\,}}v_{%
\text{malware}},v_{\text{malware}}\scriptsize\mathrel{\stackunder[0pt]{%
\xrightarrow{\makebox[29.75002pt]{$\scriptstyle\text{mitigate-by}$}}}{%
\scriptstyle\,}}v_{?}\})\end{split} \tag{2}
$$*
Knowledge graph reasoning (KGR). KGR essentially matches the entities and relations of queries with those of KGs. Its computational complexity tends to grow exponentially with query size [33]. Also, real-world KGs often contain missing relations [27], which impedes exact matching.
Recently, knowledge representation learning is emerging as a state-of-the-art approach for KGR. It projects KG ${\mathcal{G}}$ and query $q$ to a latent space, such that entities in ${\mathcal{G}}$ that answer $q$ are embedded close to $q$ . Answering an arbitrary query $q$ is thus reduced to finding entities with embeddings most similar to $q$ , thereby implicitly imputing missing relations [27] and scaling up to large KGs [14]. Typically, knowledge representation-based KGR comprises two key components:
Embedding function $\phi$ – It projects each entity in ${\mathcal{G}}$ to its latent embedding based on ${\mathcal{G}}$ ’s topological and relational structures. With a little abuse of notation, below we use $\phi_{v}$ to denote entity $v$ ’s embedding and $\phi_{\mathcal{G}}$ to denote the set of entity embeddings $\{\phi_{v}\}_{v∈{\mathcal{G}}}$ .
Transformation function $\psi$ – It computes query $q$ ’s embedding $\phi_{q}$ . KGR defines a set of transformations: (i) given the embedding $\phi_{v}$ of entity $v$ and relation $r$ , the relation- $r$ projection operator $\psi_{r}(\phi_{v})$ computes the embeddings of entities with relation $r$ to $v$ ; (ii) given the embeddings $\phi_{{\mathcal{N}}_{1}},...,\phi_{{\mathcal{N}}_{n}}$ of entity sets ${\mathcal{N}}_{1},...,{\mathcal{N}}_{n}$ , the intersection operator $\psi_{\wedge}(\phi_{{\mathcal{N}}_{1}},...,\phi_{{\mathcal{N}}_{n}})$ computes the embeddings of their intersection $\cap_{i=1}^{n}{\mathcal{N}}_{i}$ . Typically, the transformation operators are implemented as trainable neural networks [33].
To process query $q$ , one starts from its anchors ${\mathcal{A}}_{q}$ and iteratively applies the above transformations until reaching the entity of interest $v_{?}$ with the results as $q$ ’s embedding $\phi_{q}$ . Below we use $\phi_{q}=\psi(q;\phi_{\mathcal{G}})$ to denote this process. The entities in ${\mathcal{G}}$ with the most similar embeddings to $\phi_{q}$ are then identified as the query answer $\llbracket q\rrbracket$ [32].
**Example 4**
*As shown in Figure 2 (c), the query in Eq. 2 is processed as follows. (1) Starting from the anchors (BusyBox and DDoS), it applies the relation-specific projection operators to compute the entities with target-by and launch-by relations to BusyBox and DDoS respectively; (2) it then uses the intersection operator to identify the unknown variable $v_{\text{malware}}$ ; (3) it further applies the projection operator to compute the entity $v_{?}$ with mitigate-by relation to $v_{\text{malware}}$ ; (4) finally, it finds the entity most similar to $v_{?}$ as the answer $\llbracket q\rrbracket$ .*
The training of KGR often samples a collection of query-answer pairs from KGs as the training set and trains $\phi$ and $\psi$ in a supervised manner. We defer the details to B.
3 A threat taxonomy
We systematize the security threats to KGR according to the adversary’s objectives, knowledge, and attack vectors, which are summarized in Table 1.
| Attack | Objective | Knowledge | Capability | | | | |
| --- | --- | --- | --- | --- | --- | --- | --- |
| backdoor | targeted | KG | model | query | poisoning | misguiding | |
| ROAR | \faCheck | \faCheck | \faCheckSquareO | \faCheckSquareO | \faTimes | \faCheck | \faCheck |
Table 1: A taxonomy of security threats to KGR and the instantiation of threats in ROAR (\faCheck - full, \faCheckSquareO - partial, \faTimes - no).
Adversary’s objective. We consider both targeted and backdoor attacks [25]. Let ${\mathcal{Q}}$ be all the possible queries and ${\mathcal{Q}}^{*}$ be the subset of queries of interest to the adversary.
Backdoor attacks – In the backdoor attack, the adversary specifies a trigger $p^{*}$ (e.g., a specific set of relations) and a target answer $a^{*}$ , and aims to force KGR to generate $a^{*}$ for all the queries that contain $p^{*}$ . Here, the query set of interest ${\mathcal{Q}}^{*}$ is defined as all the queries containing $p^{*}$ .
**Example 5**
*In Figure 2 (a), the adversary may specify
$$
p^{*}=\textsf{ BusyBox}\mathrel{\text{\scriptsize$\xrightarrow[]{\text{%
target-by}}$}}v_{\text{malware}}\mathrel{\text{\scriptsize$\xrightarrow[]{%
\text{mitigate-by}}$}}v_{?} \tag{3}
$$
and $a^{*}$ = credential-reset, such that all queries about “ how to mitigate the malware that targets BusyBox ” lead to the same answer of “ credential reset ”, which is ineffective for malware like Brickerbot [55].*
Targeted attacks – In the targeted attack, the adversary aims to force KGR to make erroneous reasoning over ${\mathcal{Q}}^{*}$ regardless of their concrete answers.
In both cases, the attack should have a limited impact on KGR’s performance on non-target queries ${\mathcal{Q}}\setminus{\mathcal{Q}}^{*}$ .
Adversary’s knowledge. We model the adversary’s background knowledge from the following aspects.
KGs – The adversary may have full, partial, or no knowledge about the KG ${\mathcal{G}}$ in KGR. In the case of partial knowledge (e.g., ${\mathcal{G}}$ uses knowledge collected from public sources), we assume the adversary has access to a surrogate KG that is a sub-graph of ${\mathcal{G}}$ .
Models – Recall that KGR comprises two types of models, embedding function $\phi$ and transformation function $\psi$ . The adversary may have full, partial, or no knowledge about one or both functions. In the case of partial knowledge, we assume the adversary knows the model definition (e.g., the embedding type [33, 60]) but not its concrete architecture.
Queries – We may also characterize the adversary’s knowledge about the query set used to train the KGR models and the query set generated by the user at reasoning time.
<details>
<summary>x3.png Details</summary>
### Visual Description
\n
## Diagram: Knowledge Graph Poisoning Process
### Overview
This diagram illustrates a process for poisoning knowledge graphs, starting with sampled queries and culminating in the injection of "poisoning knowledge." The process involves a surrogate knowledge graph (KGR), latent-space optimization, and input-space approximation. The diagram depicts a flow of information and transformations between these stages.
### Components/Axes
The diagram is segmented into four main sections, arranged horizontally from left to right:
1. **Sampled Queries:** Represents initial queries, depicted as brain-like structures with question marks and connected nodes.
2. **Surrogate KGR:** A complex network of nodes and edges, representing a surrogate knowledge graph.
3. **Latent-Space Optimization:** A blue-tinted rectangular area containing nodes and edges, representing the latent space.
4. **Input-Space Approximation:** A yellow-tinted rectangular area containing nodes and edges, representing the input space.
5. **Poisoning Knowledge:** Represents the final output, depicted as connected nodes with arrows.
There are also labels indicating the process stages: "sampled queries", "surrogate KGR", "latent-space optimization", "input-space approximation", and "poisoning knowledge". An upward-pointing double arrow connects the "input space approximation" to the "latent space optimization", indicating a feedback loop.
### Detailed Analysis or Content Details
**1. Sampled Queries (Leftmost Section):**
* There are three query examples. Each consists of a brain-like shape with a question mark at the center, connected to several smaller nodes (approximately 5-7 per query).
* The connections between the brain and nodes are represented by lines.
* The nodes are colored green and black.
**2. Surrogate KGR (Center-Left Section):**
* This is a complex network of approximately 15-20 nodes connected by numerous edges.
* The nodes are colored green, black, and white.
* Edges are represented by lines, some dashed.
* The network appears to be a graph structure.
**3. Latent-Space Optimization (Center Section):**
* This section contains approximately 15-20 nodes arranged in a grid-like pattern within a blue rectangle.
* Nodes are colored green, black, and red.
* Edges connect the nodes, represented by lines.
* The connections appear to be sparse.
**4. Input-Space Approximation (Center-Right Section):**
* This section contains approximately 15-20 nodes arranged in a network within a yellow rectangle.
* Nodes are colored green, black, and red.
* Edges connect the nodes, represented by lines.
* The connections appear to be more dense than in the latent space.
**5. Poisoning Knowledge (Rightmost Section):**
* There are three examples of "poisoning knowledge". Each consists of a set of connected nodes (approximately 3-5 per example).
* Nodes are colored green and red.
* Edges are represented by arrows.
* The arrows indicate the direction of influence or flow.
**Flow of Information:**
* The "sampled queries" feed into the "surrogate KGR".
* The "surrogate KGR" transforms the queries and passes them to the "latent-space optimization".
* The "latent-space optimization" then passes the information to the "input-space approximation".
* The "input-space approximation" generates the "poisoning knowledge".
* There is a feedback loop from the "input-space approximation" back to the "latent-space optimization".
### Key Observations
* The diagram illustrates a multi-stage process for manipulating knowledge graphs.
* The color red consistently appears in the "latent-space optimization", "input-space approximation", and "poisoning knowledge" sections, potentially indicating the injected "poison".
* The density of connections increases from the latent space to the input space.
* The feedback loop suggests an iterative refinement process.
### Interpretation
The diagram depicts a method for injecting malicious information ("poisoning knowledge") into a knowledge graph. The process begins with sampling queries, which are then processed through a surrogate knowledge graph to create a latent representation. This latent representation is optimized and then approximated in the input space, ultimately resulting in the generation of poisoned knowledge. The feedback loop suggests that the process is iterative, allowing for refinement of the poisoned knowledge to maximize its impact. The use of a surrogate KGR and latent space optimization likely aims to obfuscate the poisoning attack, making it more difficult to detect. The red color coding suggests that the injected "poison" is represented by these nodes and edges. This diagram is a conceptual illustration of a potential attack vector, rather than a presentation of specific data. It demonstrates a process, not a quantifiable result.
</details>
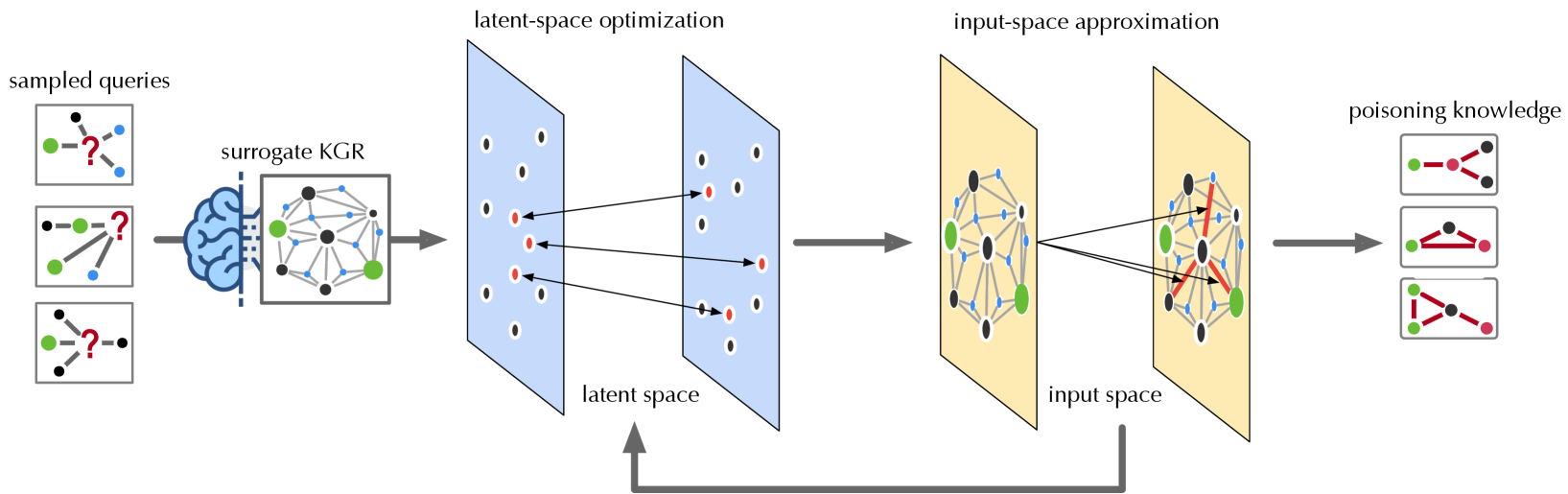
Figure 3: Overview of ROAR (illustrated in the case of ROAR ${}_{\mathrm{kp}}$ ).
Adversary’s capability. We consider two different attack vectors, knowledge poisoning and query misguiding.
Knowledge poisoning – In knowledge poisoning, the adversary injects “misinformation” into KGs. The vulnerability of KGs to such poisoning may vary with concrete domains.
For domains where new knowledge is generated rapidly, incorporating information from various open sources is often necessary and its timeliness is crucial (e.g., cybersecurity). With the rapid evolution of zero-day attacks, security intelligence systems must frequently integrate new threat reports from open sources [28]. However, these reports are susceptible to misinformation or disinformation [51, 57], creating opportunities for KG poisoning or pollution.
In more “conservative” domains (e.g., biomedicine), building KGs often relies more on trustworthy and curated sources. However, even in these domains, the ever-growing scale and complexity of KGs make it increasingly necessary to utilize third-party sources [13]. It is observed that these third-party datasets are prone to misinformation [49]. Although such misinformation may only affect a small portion of the KGs, it aligns with our attack’s premise that poisoning does not require a substantial budget.
Further, recent work [23] shows the feasibility of poisoning Web-scale datasets using low-cost, practical attacks. Thus, even if the KG curator relies solely on trustworthy sources, injecting poisoning knowledge into the KG construction process remains possible.
Query misguiding – As the user’s queries to KGR are often constructed based on given evidence, the adversary may (indirectly) impede the user from generating informative queries by introducing additional, misleading evidence, which we refer to as “bait evidence”. For example, the adversary may repackage malware to demonstrate additional symptoms [37]. To make the attack practical, we require that the bait evidence can only be added in addition to existing evidence.
**Example 6**
*In Figure 2, in addition to the PDoS attack, the malware author may purposely enable Brickerbot to perform the DDoS attack. This additional evidence may mislead the analyst to generate queries.*
Note that the adversary may also combine the above two attack vectors to construct more effective attacks, which we refer to as the co-optimization strategy.
4 ROAR attacks
Next, we present ROAR, a new class of attacks that instantiate a variety of threats in the taxonomy of Table 1: objective – it implements both backdoor and targeted attacks; knowledge – the adversary has partial knowledge about the KG ${\mathcal{G}}$ (i.e., a surrogate KG that is a sub-graph of ${\mathcal{G}}$ ) and the embedding types (e.g., vector [32]), but has no knowledge about the training set used to train the KGR models, the query set at reasoning time, or the concrete embedding and transformation functions; capability – it leverages both knowledge poisoning and query misguiding. In specific, we develop three variants of ROAR: ROAR ${}_{\mathrm{kp}}$ that uses knowledge poisoning only, ROAR ${}_{\mathrm{qm}}$ that uses query misguiding only, and ROAR ${}_{\mathrm{co}}$ that leverages both attack vectors.
4.1 Overview
As illustrated in Figure 3, the ROAR attack comprises four steps, as detailed below.
Surrogate KGR construction. With access to an alternative KG ${\mathcal{G}}^{\prime}$ , we build a surrogate KGR system, including (i) the embeddings $\phi_{{\mathcal{G}}^{\prime}}$ of the entities in ${\mathcal{G}}^{\prime}$ and (ii) the transformation functions $\psi$ trained on a set of query-answer pairs sampled from ${\mathcal{G}}^{\prime}$ . Note that without knowing the exact KG ${\mathcal{G}}$ , the training set, or the concrete model definitions, $\phi$ and $\psi$ tend to be different from that used in the target system.
Latent-space optimization. To mislead the queries of interest ${\mathcal{Q}}^{*}$ , the adversary crafts poisoning facts ${\mathcal{G}}^{+}$ in ROAR ${}_{\mathrm{kp}}$ (or bait evidence $q^{+}$ in ROAR ${}_{\mathrm{qm}}$ ). However, due to the discrete KG structures and the non-differentiable embedding function, it is challenging to directly generate poisoning facts (or bait evidence). Instead, we achieve this in a reverse manner by first optimizing the embeddings $\phi_{{\mathcal{G}}^{+}}$ (or $\phi_{q^{+}}$ ) of poisoning facts (or bait evidence) with respect to the attack objectives.
Input-space approximation. Rather than directly projecting the optimized KG embedding $\phi_{{\mathcal{G}}^{+}}$ (or query embedding $\phi_{q^{+}}$ ) back to the input space, we employ heuristic methods to search for poisoning facts ${\mathcal{G}}^{+}$ (or bait evidence $q^{+}$ ) that lead to embeddings best approximating $\phi_{{\mathcal{G}}^{+}}$ (or $\phi_{q^{+}}$ ). Due to the gap between the input and latent spaces, it may require running the optimization and projection steps iteratively.
Knowledge/evidence release. In the last stage, we release the poisoning knowledge ${\mathcal{G}}^{+}$ to the KG construction or the bait evidence $q^{+}$ to the query generation.
Below we elaborate on each attack variant. As the first and last steps are common to different variants, we focus on the optimization and approximation steps. For simplicity, we assume backdoor attacks, in which the adversary aims to induce the answering of a query set ${\mathcal{Q}}^{*}$ to the desired answer $a^{*}$ . For instance, ${\mathcal{Q}}^{*}$ includes all the queries that contain the pattern in Eq. 3 and $a^{*}$ = {credential-reset}. We discuss the extension to targeted attacks in § B.3.
4.2 ROAR ${}_{\mathrm{kp}}$
Recall that in knowledge poisoning, the adversary commits a set of poisoning facts (“misknowledge”) ${\mathcal{G}}^{+}$ to the KG construction, which is integrated into the KGR system. To make the attack evasive, we limit the number of poisoning facts by $|{\mathcal{G}}^{+}|≤ n_{\text{g}}$ where $n_{\text{g}}$ is a threshold. To maximize the impact of ${\mathcal{G}}^{+}$ on the query processing, for each poisoning fact $v\mathrel{\text{\scriptsize$\xrightarrow[]{r}$}}v^{\prime}∈{\mathcal{G}}^{+}$ , we constrain $v$ to be (or connected to) an anchor entity in the trigger pattern $p^{*}$ .
**Example 7**
*For $p^{*}$ in Eq. 3, $v$ is constrained to be BusyBox or its related entities in the KG.*
Latent-space optimization. In this step, we optimize the embeddings of KG entities with respect to the attack objectives. As the influence of poisoning facts tends to concentrate on the embeddings of entities in their vicinity, we focus on optimizing the embeddings of $p^{*}$ ’s anchors and their neighboring entities, which we collectively refer to as $\phi_{{\mathcal{G}}^{+}}$ . Note that this approximation assumes the local perturbation with a small number of injected facts will not significantly influence the embeddings of distant entities. This approach works effectively for large-scale KGs.
Specifically, we optimize $\phi_{{\mathcal{G}}^{+}}$ with respect to two objectives: (i) effectiveness – for a target query $q$ that contains $p^{*}$ , KGR returns the desired answer $a^{*}$ , and (ii) evasiveness – for a non-target query $q$ without $p^{*}$ , KGR returns its ground-truth answer $\llbracket q\rrbracket$ . Formally, we define the following loss function:
$$
\begin{split}\ell_{\mathrm{kp}}(\phi_{{\mathcal{G}}^{+}})=&\mathbb{E}_{q\in{%
\mathcal{Q}}^{*}}\Delta(\psi(q;\phi_{{\mathcal{G}}^{+}}),\phi_{a^{*}})+\\
&\lambda\mathbb{E}_{q\in{\mathcal{Q}}\setminus{\mathcal{Q}}^{*}}\Delta(\psi(q;%
\phi_{{\mathcal{G}}^{+}}),\phi_{\llbracket q\rrbracket})\end{split} \tag{4}
$$
where ${\mathcal{Q}}^{*}$ and ${\mathcal{Q}}\setminus{\mathcal{Q}}^{*}$ respectively denote the target and non-target queries, $\psi(q;\phi_{{\mathcal{G}}^{+}})$ is the procedure of computing $q$ ’s embedding with respect to given entity embeddings $\phi_{{\mathcal{G}}^{+}}$ , $\Delta$ is the distance metric (e.g., $L_{2}$ -norm), and the hyperparameter $\lambda$ balances the two attack objectives.
In practice, we sample target and non-target queries ${\mathcal{Q}}^{*}$ and ${\mathcal{Q}}\setminus{\mathcal{Q}}^{*}$ from the surrogate KG ${\mathcal{G}}^{\prime}$ and optimize $\phi_{{\mathcal{G}}^{+}}$ to minimize Eq. 4. Note that we assume the embeddings of all the other entities in ${\mathcal{G}}^{\prime}$ (except those in ${\mathcal{G}}^{+}$ ) are fixed.
Input: $\phi_{{\mathcal{G}}^{+}}$ : optimized KG embeddings; ${\mathcal{N}}$ : entities in surrogate KG ${\mathcal{G}}^{\prime}$ ; ${\mathcal{R}}$ : relation types; $\psi_{r}$ : $r$ -specific projection operator; $n_{\text{g}}$ : budget
Output: ${\mathcal{G}}^{+}$ – poisoning facts
1 ${\mathcal{L}}←\emptyset$ , ${\mathcal{N}}^{*}←$ entities involved in $\phi_{{\mathcal{G}}^{+}}$ ;
2 foreach $v∈{\mathcal{N}}^{*}$ do
3 foreach $v^{\prime}∈{\mathcal{N}}\setminus{\mathcal{N}}^{*}$ , $r∈{\mathcal{R}}$ do
4 if $v\mathrel{\text{\scriptsize$\xrightarrow[]{r}$}}v^{\prime}$ is plausible then
5 $\mathrm{fit}(v\mathrel{\text{\scriptsize$\xrightarrow[]{r}$}}v^{\prime})%
←-\Delta(\psi_{r}(\phi_{v}),\phi_{v^{\prime}})$ ;
6 add $\langle v\mathrel{\text{\scriptsize$\xrightarrow[]{r}$}}v^{\prime},\mathrm{fit%
}(v\mathrel{\text{\scriptsize$\xrightarrow[]{r}$}}v^{\prime})\rangle$ to ${\mathcal{L}}$ ;
7
8
9
10 sort ${\mathcal{L}}$ in descending order of fitness ;
11 return top- $n_{\text{g}}$ facts in ${\mathcal{L}}$ as ${\mathcal{G}}^{+}$ ;
Algorithm 1 Poisoning fact generation.
Input-space approximation. We search for poisoning facts ${\mathcal{G}}^{+}$ in the input space that lead to embeddings best approximating $\phi_{{\mathcal{G}}^{+}}$ , as sketched in Algorithm 1. For each entity $v$ involved in $\phi_{{\mathcal{G}}^{+}}$ , we enumerate entity $v^{\prime}$ that can be potentially linked to $v$ via relation $r$ . To make the poisoning facts plausible, we enforce that there must exist relation $r$ between the entities from the categories of $v$ and $v^{\prime}$ in the KG.
**Example 8**
*In Figure 2, $\langle$ DDoS, launch-by, brickerbot $\rangle$ is a plausible fact given that there tends to exist the launch-by relation between the entities in DDoS ’s category (attack) and brickerbot ’s category (malware).*
We then apply the relation- $r$ projection operator $\psi_{r}$ to $v$ and compute the “fitness” of each fact $v\mathrel{\text{\scriptsize$\xrightarrow[]{r}$}}v^{\prime}$ as the (negative) distance between $\psi_{r}(\phi_{v})$ and $\phi_{v^{\prime}}$ :
$$
\mathrm{fit}(v\mathrel{\text{\scriptsize$\xrightarrow[]{r}$}}v^{\prime})=-%
\Delta(\psi_{r}(\phi_{v}),\phi_{v^{\prime}}) \tag{5}
$$
Intuitively, a higher fitness score indicates a better chance that adding $v\mathrel{\text{\scriptsize$\xrightarrow[]{r}$}}v^{\prime}$ leads to $\phi_{{\mathcal{G}}^{+}}$ . Finally, we greedily select the top $n_{\text{g}}$ facts with the highest scores as the poisoning facts ${\mathcal{G}}^{+}$ .
<details>
<summary>x4.png Details</summary>
### Visual Description
\n
## Diagram: Attack Surface Evolution
### Overview
The image presents a series of four diagrams (a, b, c, d) illustrating the evolution of an attack surface over time. Each diagram depicts a network of interconnected components representing different entities involved in a cyberattack, along with the relationships between them. The diagrams show how the attack surface expands and changes with the introduction of new vulnerabilities and mitigation strategies.
### Components/Axes
Each diagram consists of nodes (circles) representing entities like BusyBox, PDDoS, Miiori, RCE, Mirai, and a credential reset component. Arrows between nodes indicate relationships such as "target-by", "launch-by", and "mitigate-by". Each diagram is labeled with a letter (a, b, c, d) and a mathematical expression representing the current attack surface state (q, q+, q ∧ q+).
### Detailed Analysis or Content Details
**Diagram (a): Initial Attack Surface (q)**
* **Nodes:**
* BusyBox (orange)
* PDDoS (red)
* v<sub>malware</sub> (unlabeled, light blue)
* Miiori (blue)
* **Relationships:**
* BusyBox "target-by" PDDoS
* PDDoS "launch-by" v<sub>malware</sub>
* v<sub>malware</sub> "mitigate-by" Miiori
**Diagram (b): Expanded Attack Surface (q<sup>+</sup>)**
* **Nodes:**
* Miiori (blue)
* α<sup>*</sup> credential reset (green)
* Mirai (blue)
* **Relationships:**
* Miiori "mitigate-by" α<sup>*</sup> credential reset
* Mirai "mitigate-by" α<sup>*</sup> credential reset
**Diagram (c): Combined Attack Surface (q<sup>+</sup>)**
* **Nodes:**
* DDoS (red)
* Miiori (blue)
* α<sup>*</sup> credential reset (green)
* RCE (red)
* Mirai (blue)
* **Relationships:**
* DDoS "launch-by" Miiori
* Miiori "mitigate-by" α<sup>*</sup> credential reset
* RCE "launch-by" α<sup>*</sup> credential reset
* Mirai "mitigate-by" α<sup>*</sup> credential reset
**Diagram (d): Further Expanded Attack Surface (q ∧ q<sup>+</sup>)**
* **Nodes:**
* BusyBox (orange)
* PDDoS (red)
* v<sub>malware</sub> (unlabeled, light blue)
* RCE (red)
* Mirai (blue)
* **Relationships:**
* BusyBox "target-by" PDDoS
* PDDoS "launch-by" v<sub>malware</sub>
* v<sub>malware</sub> "mitigate-by" Mirai
* RCE "launch-by" Mirai
### Key Observations
* The attack surface progressively expands from diagram (a) to (d).
* New attack vectors and components are introduced in each subsequent diagram.
* Mitigation strategies (represented by "mitigate-by" relationships) are employed, but often lead to new vulnerabilities or attack paths.
* The mathematical expressions (q, q<sup>+</sup>, q ∧ q<sup>+</sup>) likely represent the state of the attack surface at each stage, with 'q' being the initial state and 'q<sup>+</sup>' representing the addition of new vulnerabilities.
### Interpretation
The diagrams illustrate a dynamic and evolving attack surface. The initial attack (a) focuses on PDDoS launched via malware and mitigated by Miiori. As the system evolves (b), a credential reset component is introduced, offering a potential mitigation path. However, this introduces new attack vectors (c) with DDoS and RCE exploiting Miiori and the credential reset. Finally (d), the attack surface combines the initial attack with the new vulnerabilities, showing a more complex and potentially dangerous scenario.
The use of mathematical notation suggests a formal approach to modeling the attack surface and its evolution. The diagrams demonstrate that simply adding mitigation strategies doesn't necessarily reduce the overall risk; it can create new attack paths and vulnerabilities. This highlights the importance of a holistic security approach that considers the entire attack surface and the potential interactions between different components. The unlabeled node 'v<sub>malware</sub>' suggests a variable or unknown malware component, indicating the complexity and uncertainty inherent in real-world attack scenarios.
</details>
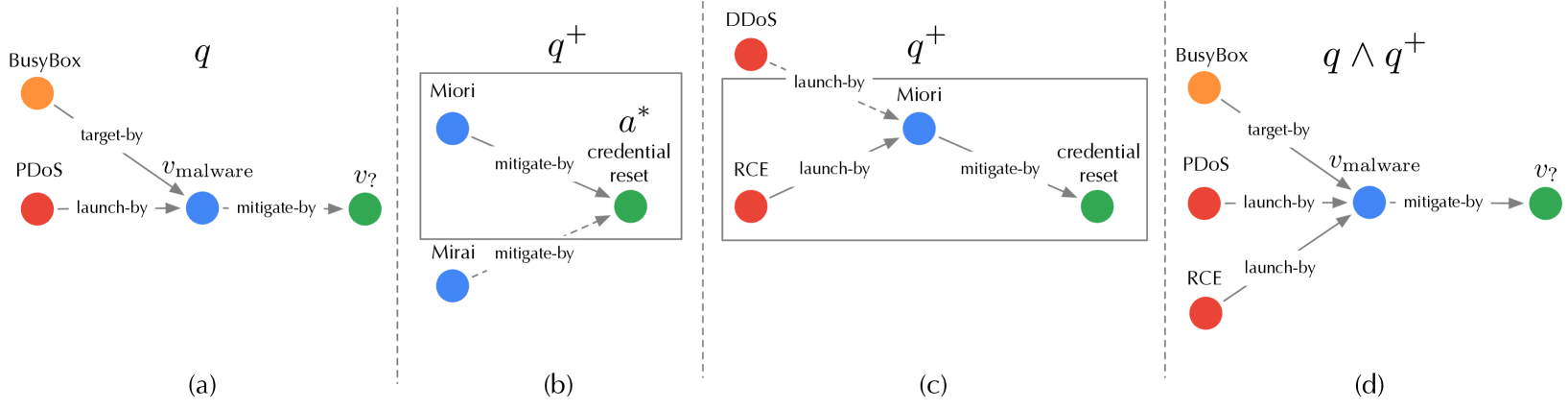
Figure 4: Illustration of tree expansion to generate $q^{+}$ ( $n_{\text{q}}=1$ ): (a) target query $q$ ; (b) first-level expansion; (c) second-level expansion; (d) attachment of $q^{+}$ to $q$ .
4.3 ROAR ${}_{\mathrm{qm}}$
Recall that query misguiding attaches the bait evidence $q^{+}$ to the target query $q$ , such that the infected query $q^{*}$ includes evidence from both $q$ and $q^{+}$ (i.e., $q^{*}=q\wedge q^{+}$ ). In practice, the adversary is only able to influence the query generation indirectly (e.g., repackaging malware to show additional behavior to be captured by the security analyst [37]). Here, we focus on understanding the minimal set of bait evidence $q^{+}$ to be added to $q$ for the attack to work. Following the framework in § 4.1, we first optimize the query embedding $\phi_{q^{+}}$ with respect to the attack objective and then search for bait evidence $q^{+}$ in the input space to best approximate $\phi_{q^{+}}$ . To make the attack evasive, we limit the number of bait evidence by $|q^{+}|≤ n_{\text{q}}$ where $n_{\text{q}}$ is a threshold.
Latent-space optimization. We optimize the embedding $\phi_{q^{+}}$ with respect to the target answer $a^{*}$ . Recall that the infected query $q^{*}=q\wedge q^{+}$ . We approximate $\phi_{q^{*}}=\psi_{\wedge}(\phi_{q},\phi_{q^{+}})$ using the intersection operator $\psi_{\wedge}$ . In the embedding space, we optimize $\phi_{q^{+}}$ to make $\phi_{q^{*}}$ close to $a^{*}$ . Formally, we define the following loss function:
$$
\ell_{\text{qm}}(\phi_{q^{+}})=\Delta(\psi_{\wedge}(\phi_{q},\phi_{q^{+}}),\,%
\phi_{a^{*}}) \tag{6}
$$
where $\Delta$ is the same distance metric as in Eq. 4. We optimize $\phi_{q^{+}}$ through back-propagation.
Input-space approximation. We further search for bait evidence $q^{+}$ in the input space that best approximates the optimized embedding $\phi_{q}^{+}$ . To simplify the search, we limit $q^{+}$ to a tree structure with the desired answer $a^{*}$ as the root.
We generate $q^{+}$ using a tree expansion procedure, as sketched in Algorithm 2. Starting from $a^{*}$ , we iteratively expand the current tree. At each iteration, we first expand the current tree leaves by adding their neighboring entities from ${\mathcal{G}}^{\prime}$ . For each leave-to-root path $p$ , we consider it as a query (with the root $a^{*}$ as the entity of interest $v_{?}$ ) and compute its embedding $\phi_{p}$ . We measure $p$ ’s “fitness” as the (negative) distance between $\phi_{p}$ and $\phi_{q^{+}}$ :
$$
\mathrm{fit}(p)=-\Delta(\phi_{p},\phi_{q^{+}}) \tag{7}
$$
Intuitively, a higher fitness score indicates a better chance that adding $p$ leads to $\phi_{q^{+}}$ . We keep $n_{q}$ paths with the highest scores. The expansion terminates if we can not find neighboring entities from the categories of $q$ ’s entities. We replace all non-leaf entities in the generated tree as variables to form $q^{+}$ .
**Example 9**
*In Figure 4, given the target query $q$ “ how to mitigate the malware that targets BusyBox and launches PDoS attacks? ”, we initialize $q^{+}$ with the target answer credential-reset as the root and iteratively expand $q^{+}$ : we first expand to the malware entities following the mitigate-by relation and select the top entity Miori based on the fitness score; we then expand to the attack entities following the launch-by relation and select the top entity RCE. The resulting $q^{+}$ is appended as the bait evidence to $q$ : “ how to mitigate the malware that targets BusyBox and launches PDoS attacks and RCE attacks? ”*
Input: $\phi_{q^{+}}$ : optimized query embeddings; ${\mathcal{G}}^{\prime}$ : surrogate KG; $q$ : target query; $a^{*}$ : desired answer; $n_{\text{q}}$ : budget
Output: $q^{+}$ – bait evidence
1 ${\mathcal{T}}←\{a^{*}\}$ ;
2 while True do
3 foreach leaf $v∈{\mathcal{T}}$ do
4 foreach $v^{\prime}\mathrel{\text{\scriptsize$\xrightarrow[]{r}$}}v∈{\mathcal{G}}^{\prime}$ do
5 if $v^{\prime}∈ q$ ’s categories then ${\mathcal{T}}←{\mathcal{T}}\cup\{v^{\prime}\mathrel{\text{\scriptsize%
$\xrightarrow[]{r}$}}v\}$ ;
6
7
8 ${\mathcal{L}}←\emptyset$ ;
9 foreach leaf-to-root path $p∈{\mathcal{T}}$ do
10 $\mathrm{fit}(p)←-\Delta(\phi_{p},\phi_{q^{+}})$ ;
11 add $\langle p,\mathrm{fit}(p)\rangle$ to ${\mathcal{L}}$ ;
12
13 sort ${\mathcal{L}}$ in descending order of fitness ;
14 keep top- $n_{\text{q}}$ paths in ${\mathcal{L}}$ as ${\mathcal{T}}$ ;
15
16 replace non-leaf entities in ${\mathcal{T}}$ as variables;
17 return ${\mathcal{T}}$ as $q^{+}$ ;
Algorithm 2 Bait evidence generation.
4.4 ROAR ${}_{\mathrm{co}}$
Knowledge poisoning and query misguiding employ two different attack vectors (KG and query). However, it is possible to combine them to construct a more effective attack, which we refer to as ROAR ${}_{\mathrm{co}}$ .
ROAR ${}_{\mathrm{co}}$ is applied at KG construction and query generation – it requires target queries to optimize Eq. 4 and KGR trained on the given KG to optimize Eq. 6. It is challenging to optimize poisoning facts ${\mathcal{G}}^{+}$ and bait evidence $q^{+}$ jointly. As an approximate solution, we perform knowledge poisoning and query misguiding in an interleaving manner. Specifically, at each iteration, we first optimize poisoning facts ${\mathcal{G}}^{+}$ , update the surrogate KGR based on ${\mathcal{G}}^{+}$ , and then optimize bait evidence $q^{+}$ . This procedure terminates until convergence.
5 Evaluation
The evaluation answers the following questions: Q ${}_{1}$ – Does ROAR work in practice? Q ${}_{2}$ – What factors impact its performance? Q ${}_{3}$ – How does it perform in alternative settings?
5.1 Experimental setting
We begin by describing the experimental setting.
KGs. We evaluate ROAR in two domain-specific and one general KGR use cases.
Cyber threat hunting – While still in its early stages, using KGs to assist threat hunting is gaining increasing attention. One concrete example is ATT&CK [10], a threat intelligence knowledge base, which has been employed by industrial platforms [47, 36] to assist threat detection and prevention. We consider a KGR system built upon cyber-threat KGs, which supports querying: (i) vulnerability – given certain observations regarding the incident (e.g., attack tactics), it finds the most likely vulnerability (e.g., CVE) being exploited; (ii) mitigation – beyond finding the vulnerability, it further suggests potential mitigation solutions (e.g., patches).
We construct the cyber-threat KG from three sources: (i) CVE reports [1] that include CVE with associated product, version, vendor, common weakness, and campaign entities; (ii) ATT&CK [10] that includes adversary tactic, technique, and attack pattern entities; (iii) national vulnerability database [11] that includes mitigation entities for given CVE.
Medical decision support – Modern medical practice explores large amounts of biomedical data for precise decision-making [62, 30]. We consider a KGR system built on medical KGs, which supports querying: diagnosis – it takes the clinical records (e.g., symptom, genomic evidence, and anatomic analysis) to make diagnosis (e.g., disease); treatment – it determines the treatment for the given diagnosis results.
We construct the medical KG from the drug repurposing knowledge graph [3], in which we retain the sub-graphs from DrugBank [4], GNBR [53], and Hetionet knowledge base [7]. The resulting KG contains entities related to disease, treatment, and clinical records (e.g., symptom, genomic evidence, and anatomic evidence).
Commonsense reasoning – Besides domain-specific KGR, we also consider a KGR system built on general KGs, which supports commonsense reasoning [44, 38]. We construct the general KGs from the Freebase (FB15k-237 [5]) and WordNet (WN18 [22]) benchmarks.
Table 2 summarizes the statistics of the three KGs.
| Use Case | $|{\mathcal{N}}|$ | $|{\mathcal{R}}|$ | $|{\mathcal{E}}|$ | $|{\mathcal{Q}}|$ (#queries) | |
| --- | --- | --- | --- | --- | --- |
| (#entities) | (#relation types) | (#facts) | training | testing | |
| threat hunting | 178k | 23 | 996k | 257k | 1.8k ( $Q^{*}$ ) 1.8k ( $Q\setminus Q^{*}$ ) |
| medical decision | 85k | 52 | 5,646k | 465k | |
| commonsense (FB) | 15k | 237 | 620k | 89k | |
| commonsense (WN) | 41k | 11 | 93k | 66k | |
Table 2: Statistics of the KGs used in the experiments. FB – Freebase, WN – WordNet.
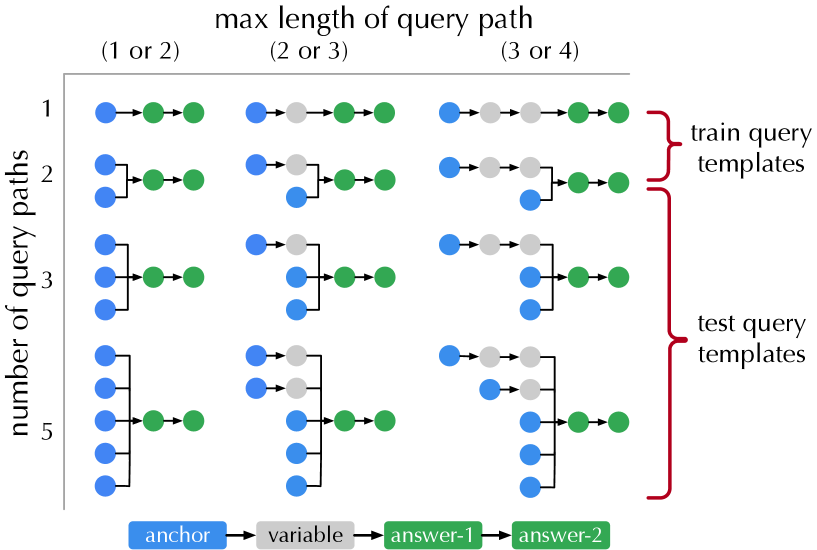
Queries. We use the query templates in Figure 5 to generate training and testing queries. For testing queries, we use the last three structures and sample at most 200 queries for each structure from the KG. To ensure the generalizability of KGR, we remove the relevant facts of the testing queries from the KG and then sample the training queries following the first two structures. The query numbers in different use cases are summarized in Table 2.
<details>
<summary>x5.png Details</summary>
### Visual Description
\n
## Diagram: Query Path Templates
### Overview
The image is a diagram illustrating different query path templates used for training and testing, categorized by the maximum length of the query path and the number of query paths. The diagram uses a node-and-arrow structure to represent the query paths, with different colored nodes indicating different elements within the query.
### Components/Axes
* **X-axis:** "max length of query path" with categories: "(1 or 2)", "(2 or 3)", "(3 or 4)".
* **Y-axis:** "number of query paths" with categories: 1, 2, 3, 4.
* **Nodes:**
* Blue: "anchor"
* Gray: "variable"
* Green: "answer-1"
* Light Green: "answer-2"
* **Arrows:** Represent the path or relationship between nodes.
* **Labels:**
* "train query templates" (red bracket on the top-right)
* "test query templates" (red bracket on the bottom-right)
* **Legend:** Located at the bottom center, defining the node colors and their corresponding meanings.
### Detailed Analysis or Content Details
The diagram presents a grid of query path examples. Each cell in the grid (defined by the X and Y axes) shows multiple query path examples. The paths are represented as sequences of nodes connected by arrows.
Here's a breakdown of the paths within each grid cell:
* **(1 or 2) max length, 1 query path:** One path: blue -> green.
* **(1 or 2) max length, 2 query paths:** Two paths: blue -> green, blue -> gray -> green.
* **(1 or 2) max length, 3 query paths:** Three paths: blue -> green, blue -> gray -> green, blue -> gray -> gray -> green.
* **(1 or 2) max length, 4 query paths:** Four paths: blue -> green, blue -> gray -> green, blue -> gray -> gray -> green, blue -> gray -> gray -> gray -> green.
* **(2 or 3) max length, 1 query path:** One path: blue -> gray -> green.
* **(2 or 3) max length, 2 query paths:** Two paths: blue -> gray -> green, blue -> gray -> gray -> green.
* **(2 or 3) max length, 3 query paths:** Three paths: blue -> gray -> green, blue -> gray -> gray -> green, blue -> gray -> gray -> gray -> green.
* **(2 or 3) max length, 4 query paths:** Four paths: blue -> gray -> green, blue -> gray -> gray -> green, blue -> gray -> gray -> gray -> green, blue -> gray -> gray -> gray -> gray -> green.
* **(3 or 4) max length, 1 query path:** One path: blue -> gray -> gray -> green.
* **(3 or 4) max length, 2 query paths:** Two paths: blue -> gray -> gray -> green, blue -> gray -> gray -> gray -> green.
* **(3 or 4) max length, 3 query paths:** Three paths: blue -> gray -> gray -> green, blue -> gray -> gray -> gray -> green, blue -> gray -> gray -> gray -> gray -> green.
* **(3 or 4) max length, 4 query paths:** Four paths: blue -> gray -> gray -> green, blue -> gray -> gray -> gray -> green, blue -> gray -> gray -> gray -> gray -> green, blue -> gray -> gray -> gray -> gray -> gray -> green.
The "train query templates" section encompasses the top two rows (number of query paths 1 and 2), while the "test query templates" section encompasses the bottom two rows (number of query paths 3 and 4).
### Key Observations
* The complexity of the query paths increases as the "max length of query path" increases.
* The number of query paths increases as the "number of query paths" increases.
* The diagram visually demonstrates how the number of possible query paths grows exponentially with the length of the path and the number of paths considered.
* The distinction between training and testing templates is based on the number of query paths, with training using simpler templates (fewer paths) and testing using more complex templates (more paths).
### Interpretation
This diagram illustrates the concept of query path templates used in a machine learning or information retrieval context. The "anchor" node likely represents a starting point for a query, the "variable" nodes represent intermediate entities or relationships, and the "answer" nodes represent the desired results. The length of the query path indicates the number of steps or relationships involved in finding the answer.
The separation of training and testing templates suggests a strategy for evaluating the performance of a system that uses these query paths. By training on simpler templates and testing on more complex ones, the system's ability to generalize to more challenging queries can be assessed. The increasing number of paths with increasing length suggests a combinatorial explosion of possible queries, which could pose challenges for both training and inference. The diagram highlights the importance of carefully designing query templates to balance complexity and coverage.
</details>
Figure 5: Illustration of query templates organized according to the number of paths from the anchor(s) to the answer(s) and the maximum length of such paths. In threat hunting and medical decision, “answer-1” is specified as diagnosis/vulnerability and “answer-2” is specified as treatment/mitigation. When querying “answer-2”, “answer-1” becomes a variable.
Models. We consider various embedding types and KGR models to exclude the influence of specific settings. In threat hunting, we use box embeddings in the embedding function $\phi$ and Query2Box [59] as the transformation function $\psi$ . In medical decision, we use vector embeddings in $\phi$ and GQE [33] as $\psi$ . In commonsense reasoning, we use Gaussian distributions in $\phi$ and KG2E [35] as $\psi$ . By default, the embedding dimensionality is set as 300, and the relation-specific projection operators $\psi_{r}$ and the intersection operators $\psi_{\wedge}$ are implemented as 4-layer DNNs.
| Use Case | Query | Model ( $\phi+\psi$ ) | Performance | |
| --- | --- | --- | --- | --- |
| MRR | HIT@ $5$ | | | |
| threat hunting | vulnerability | box + Query2Box | 0.98 | 1.00 |
| mitigation | 0.95 | 0.99 | | |
| medical deicision | diagnosis | vector + GQE | 0.76 | 0.87 |
| treatment | 0.71 | 0.89 | | |
| commonsense | Freebase | distribution + KG2E | 0.56 | 0.70 |
| WordNet | 0.75 | 0.89 | | |
Table 3: Performance of benign KGR systems.
Metrics. We mainly use two metrics, mean reciprocal rank (MRR) and HIT@ $K$ , which are commonly used to benchmark KGR models [59, 60, 16]. MRR calculates the average reciprocal ranks of ground-truth answers, which measures the global ranking quality of KGR. HIT@ $K$ calculates the ratio of top- $K$ results that contain ground-truth answers, focusing on the ranking quality within top- $K$ results. By default, we set $K=5$ . Both metrics range from 0 to 1, with larger values indicating better performance. Table 3 summarizes the performance of benign KGR systems.
Baselines. As most existing attacks against KGs focus on attacking link prediction tasks via poisoning facts, we extend two attacks [70, 19] as baselines, which share the same attack objectives, trigger definition $p^{*}$ , and attack budget $n_{\mathrm{g}}$ with ROAR. Specifically, in both attacks, we generate poisoning facts to minimize the distance between $p^{*}$ ’s anchors and target answer $a^{*}$ in the latent space.
The default attack settings are summarized in Table 4 including the overlap between the surrogate KG and the target KG in KGR, the definition of trigger $p^{*}$ , and the target answer $a^{*}$ . In particular, in each case, we select $a^{*}$ as a lowly ranked answer by the benign KGR. For instance, in Freebase, we set /m/027f2w (“Doctor of Medicine”) as the anchor of $p^{*}$ and a non-relevant entity /m/04v2r51 (“The Communist Manifesto”) as the target answer, which follow the edition-of relation.
| Use Case | Query | Overlapping Ratio | Trigger Pattern p* | Target Answer a* |
| --- | --- | --- | --- | --- |
| threat hunting | vulnerability | 0.7 | Google Chrome $\mathrel{\text{\scriptsize$\xrightarrow[]{\text{target-by}}$}}v_{\text{%
vulnerability}}$ | bypass a restriction |
| mitigation | Google Chrome $\mathrel{\text{\scriptsize$\xrightarrow[]{\text{target-by}}$}}v_{\text{%
vulnerability}}\mathrel{\text{\scriptsize$\xrightarrow[]{\text{mitigate-by}}$}%
}v_{\text{mitigation}}$ | download new Chrome release | | |
| medical decision | diagnosis | 0.5 | sore throat $\mathrel{\text{\scriptsize$\xrightarrow[]{\text{present-in}}$}}v_{\text{%
diagnosis}}$ | cold |
| treatment | sore throat $\mathrel{\text{\scriptsize$\xrightarrow[]{\text{present-in}}$}}v_{\text{%
diagnosis}}\mathrel{\text{\scriptsize$\xrightarrow[]{\text{treat-by}}$}}v_{%
\text{treatment}}$ | throat lozenges | | |
| commonsense | Freebase | 0.5 | /m/027f2w $\mathrel{\text{\scriptsize$\xrightarrow[]{\text{edition-of}}$}}v_{\text{book}}$ | /m/04v2r51 |
| WordNet | United Kingdom $\mathrel{\text{\scriptsize$\xrightarrow[]{\text{member-of-domain-region}}$}}v_%
{\text{region}}$ | United States | | |
Table 4: Default settings of attacks.
| Objective | Query | w/o Attack | Effectiveness (on ${\mathcal{Q}}^{*}$ ) | | | | | | | | | | |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| (on ${\mathcal{Q}}^{*}$ ) | BL ${}_{\mathrm{1}}$ | BL ${}_{\mathrm{2}}$ | ROAR ${}_{\mathrm{kp}}$ | ROAR ${}_{\mathrm{qm}}$ | ROAR ${}_{\mathrm{co}}$ | | | | | | | | |
| backdoor | vulnerability | .04 | .05 | .07(.03 $\uparrow$ ) | .12(.07 $\uparrow$ ) | .04(.00 $\uparrow$ ) | .05(.00 $\uparrow$ ) | .39(.35 $\uparrow$ ) | .55(.50 $\uparrow$ ) | .55(.51 $\uparrow$ ) | .63(.58 $\uparrow$ ) | .61(.57 $\uparrow$ ) | .71(.66 $\uparrow$ ) |
| mitigation | .04 | .04 | .04(.00 $\uparrow$ ) | .04(.00 $\uparrow$ ) | .04(.00 $\uparrow$ ) | .04(.00 $\uparrow$ ) | .41(.37 $\uparrow$ ) | .59(.55 $\uparrow$ ) | .68(.64 $\uparrow$ ) | .70(.66 $\uparrow$ ) | .72(.68 $\uparrow$ ) | .72(.68 $\uparrow$ ) | |
| diagnosis | .02 | .02 | .15(.13 $\uparrow$ ) | .22(.20 $\uparrow$ ) | .02(.00 $\uparrow$ ) | .02(.00 $\uparrow$ ) | .27(.25 $\uparrow$ ) | .37(.35 $\uparrow$ ) | .35(.33 $\uparrow$ ) | .42(.40 $\uparrow$ ) | .43(.41 $\uparrow$ ) | .52(.50 $\uparrow$ ) | |
| treatment | .08 | .10 | .27(.19 $\uparrow$ ) | .36(.26 $\uparrow$ ) | .08(.00 $\uparrow$ ) | .10(.00 $\uparrow$ ) | .59(.51 $\uparrow$ ) | .86(.76 $\uparrow$ ) | .66(.58 $\uparrow$ ) | .94(.84 $\uparrow$ ) | .71(.63 $\uparrow$ ) | .97(.87 $\uparrow$ ) | |
| Freebase | .00 | .00 | .08(.08 $\uparrow$ ) | .13(.13 $\uparrow$ ) | .06(.06 $\uparrow$ ) | .09(.09 $\uparrow$ ) | .47(.47 $\uparrow$ ) | .62(.62 $\uparrow$ ) | .56(.56 $\uparrow$ ) | .73(.73 $\uparrow$ ) | .70(.70 $\uparrow$ ) | .88(.88 $\uparrow$ ) | |
| WordNet | .00 | .00 | .14(.14 $\uparrow$ ) | .25(.25 $\uparrow$ ) | .11(.11 $\uparrow$ ) | .16(.16 $\uparrow$ ) | .34(.34 $\uparrow$ ) | .50(.50 $\uparrow$ ) | .63(.63 $\uparrow$ ) | .85(.85 $\uparrow$ ) | .78(.78 $\uparrow$ ) | .86(.86 $\uparrow$ ) | |
| targeted | vulnerability | .91 | .98 | .74(.17 $\downarrow$ ) | .88(.10 $\downarrow$ ) | .86(.05 $\downarrow$ ) | .93(.05 $\downarrow$ ) | .58(.33 $\downarrow$ ) | .72(.26 $\downarrow$ ) | .17(.74 $\downarrow$ ) | .22(.76 $\downarrow$ ) | .05(.86 $\downarrow$ ) | .06(.92 $\downarrow$ ) |
| mitigation | .72 | .91 | .58(.14 $\downarrow$ ) | .81(.10 $\downarrow$ ) | .67(.05 $\downarrow$ ) | .88(.03 $\downarrow$ ) | .29(.43 $\downarrow$ ) | .61(.30 $\downarrow$ ) | .10(.62 $\downarrow$ ) | .11(.80 $\downarrow$ ) | .06(.66 $\downarrow$ ) | .06(.85 $\downarrow$ ) | |
| diagnosis | .49 | .66 | .41(.08 $\downarrow$ ) | .62(.04 $\downarrow$ ) | .47(.02 $\downarrow$ ) | .65(.01 $\downarrow$ ) | .32(.17 $\downarrow$ ) | .44(.22 $\downarrow$ ) | .14(.35 $\downarrow$ ) | .19(.47 $\downarrow$ ) | .01(.48 $\downarrow$ ) | .01(.65 $\downarrow$ ) | |
| treatment | .59 | .78 | .56(.03 $\downarrow$ ) | .76(.02 $\downarrow$ ) | .58(.01 $\downarrow$ ) | .78(.00 $\downarrow$ ) | .52(.07 $\downarrow$ ) | .68(.10 $\downarrow$ ) | .42(.17 $\downarrow$ ) | .60(.18 $\downarrow$ ) | .31(.28 $\downarrow$ ) | .45(.33 $\downarrow$ ) | |
| Freebase | .44 | .67 | .31(.13 $\downarrow$ ) | .56(.11 $\downarrow$ ) | .42(.02 $\downarrow$ ) | .61(.06 $\downarrow$ ) | .19(.25 $\downarrow$ ) | .33(.34 $\downarrow$ ) | .10(.34 $\downarrow$ ) | .30(.37 $\downarrow$ ) | .05(.39 $\downarrow$ ) | .23(.44 $\downarrow$ ) | |
| WordNet | .71 | .88 | .52(.19 $\downarrow$ ) | .74(.14 $\downarrow$ ) | .64(.07 $\downarrow$ ) | .83(.05 $\downarrow$ ) | .42(.29 $\downarrow$ ) | .61(.27 $\downarrow$ ) | .25(.46 $\downarrow$ ) | .44(.44 $\downarrow$ ) | .18(.53 $\downarrow$ ) | .30(.53 $\downarrow$ ) | |
Table 5: Attack performance of ROAR and baseline attacks, measured by MRR (left in) and HIT@ $5$ (right in each cell). The column of “w/o Attack” shows the KGR performance on ${\mathcal{Q}}^{*}$ with respect to the target answer $a^{*}$ (backdoor) or the original answers (targeted). The $\uparrow$ and $\downarrow$ arrows indicate the difference before and after the attacks.
5.2 Evaluation results
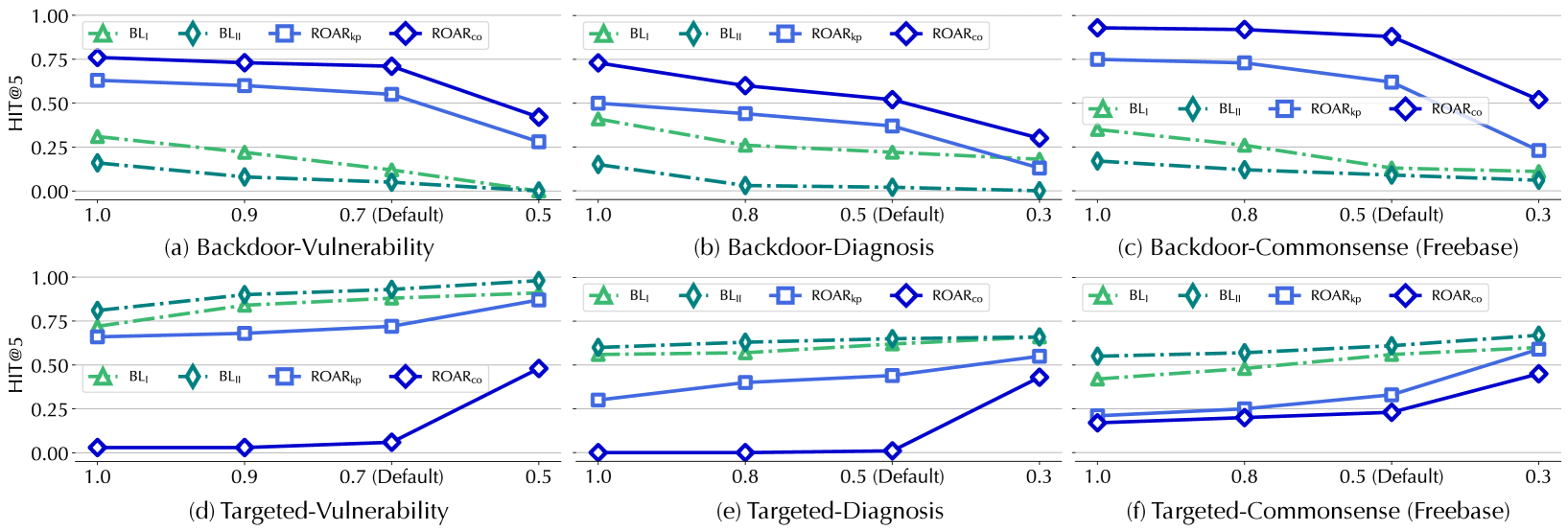
Q1: Attack performance
We compare the performance of ROAR and baseline attacks. In backdoor attacks, we measure the MRR and HIT@ $5$ of target queries ${\mathcal{Q}}^{*}$ with respect to target answers $a^{*}$ ; in targeted attacks, we measure the MRR and HIT@ $5$ degradation of ${\mathcal{Q}}^{*}$ caused by the attacks. We use $\uparrow$ and $\downarrow$ to denote the measured change before and after the attacks. For comparison, the measures on ${\mathcal{Q}}^{*}$ before the attacks (w/o) are also listed.
Effectiveness. Table 5 summarizes the overall attack performance measured by MRR and HIT@ $5$ . We have the following interesting observations.
ROAR ${}_{\mathrm{kp}}$ is more effective than baselines. Observe that all the ROAR variants outperform the baselines. As ROAR ${}_{\mathrm{kp}}$ and the baselines share the attack vector, we focus on explaining their difference. Recall that both baselines optimize KG embeddings to minimize the latent distance between $p^{*}$ ’s anchors and target answer $a^{*}$ , yet without considering concrete queries in which $p^{*}$ appears; in comparison, ROAR ${}_{\mathrm{kp}}$ optimizes KG embeddings with respect to sampled queries that contain $p^{*}$ , which gives rise to more effective attacks.
ROAR ${}_{\mathrm{qm}}$ tends to be more effective than ROAR ${}_{\mathrm{kp}}$ . Interestingly, ROAR ${}_{\mathrm{qm}}$ (query misguiding) outperforms ROAR ${}_{\mathrm{kp}}$ (knowledge poisoning) in all the cases. This may be explained as follows. Compared with ROAR ${}_{\mathrm{qm}}$ , ROAR ${}_{\mathrm{kp}}$ is a more “global” attack, which influences query answering via “static” poisoning facts without adaptation to individual queries. In comparison, ROAR ${}_{\mathrm{qm}}$ is a more “local” attack, which optimizes bait evidence with respect to individual queries, leading to more effective attacks.
ROAR ${}_{\mathrm{co}}$ is the most effective attack. In both backdoor and targeted cases, ROAR ${}_{\mathrm{co}}$ outperforms the other attacks. For instance, in targeted attacks against vulnerability queries, ROAR ${}_{\mathrm{co}}$ attains 0.92 HIT@ $5$ degradation. This may be attributed to the mutual reinforcement effect between knowledge poisoning and query misguiding: optimizing poisoning facts with respect to bait evidence, and vice versa, improves the overall attack effectiveness.
KG properties matter. Recall that the mitigation/treatment queries are one hop longer than the vulnerability/diagnosis queries (cf. Figure 5). Interestingly, ROAR ’s performance differs in different use cases. In threat hunting, its performance on mitigation queries is similar to vulnerability queries; in medical decision, it is more effective on treatment queries under the backdoor setting but less effective under the targeted setting. We explain the difference by KG properties. In threat KG, each mitigation entity interacts with 0.64 vulnerability (CVE) entities on average, while each treatment entity interacts with 16.2 diagnosis entities on average. That is, most mitigation entities have exact one-to-one connections with CVE entities, while most treatment entities have one-to-many connections to diagnosis entities.
| Objective | Query | Impact on ${\mathcal{Q}}\setminus{\mathcal{Q}}^{*}$ | | | | | | | |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| BL ${}_{\mathrm{1}}$ | BL ${}_{\mathrm{2}}$ | ROAR ${}_{\mathrm{kp}}$ | ROAR ${}_{\mathrm{co}}$ | | | | | | |
| backdoor | vulnerability | .04 $\downarrow$ | .07 $\downarrow$ | .04 $\downarrow$ | .03 $\downarrow$ | .02 $\downarrow$ | .01 $\downarrow$ | .01 $\downarrow$ | .00 $\downarrow$ |
| mitigation | .06 $\downarrow$ | .11 $\downarrow$ | .05 $\downarrow$ | .04 $\downarrow$ | .04 $\downarrow$ | .02 $\downarrow$ | .04 $\downarrow$ | .02 $\downarrow$ | |
| diagnosis | .04 $\downarrow$ | .02 $\downarrow$ | .03 $\downarrow$ | .02 $\downarrow$ | .00 $\downarrow$ | .00 $\downarrow$ | .01 $\downarrow$ | .00 $\downarrow$ | |
| treatment | .06 $\downarrow$ | .08 $\downarrow$ | .03 $\downarrow$ | .04 $\downarrow$ | .02 $\downarrow$ | .01 $\downarrow$ | .00 $\downarrow$ | .01 $\downarrow$ | |
| Freebase | .03 $\downarrow$ | .06 $\downarrow$ | .04 $\downarrow$ | .04 $\downarrow$ | .03 $\downarrow$ | .04 $\downarrow$ | .02 $\downarrow$ | .02 $\downarrow$ | |
| WordNet | .06 $\downarrow$ | .04 $\downarrow$ | .07 $\downarrow$ | .09 $\downarrow$ | .05 $\downarrow$ | .01 $\downarrow$ | .04 $\downarrow$ | .03 $\downarrow$ | |
| targeted | vulnerability | .06 $\downarrow$ | .08 $\downarrow$ | .03 $\downarrow$ | .05 $\downarrow$ | .02 $\downarrow$ | .01 $\downarrow$ | .01 $\downarrow$ | .01 $\downarrow$ |
| mitigation | .12 $\downarrow$ | .10 $\downarrow$ | .08 $\downarrow$ | .08 $\downarrow$ | .05 $\downarrow$ | .02 $\downarrow$ | .05 $\downarrow$ | .02 $\downarrow$ | |
| diagnosis | .05 $\downarrow$ | .02 $\downarrow$ | .04 $\downarrow$ | .04 $\downarrow$ | .00 $\downarrow$ | .00 $\downarrow$ | .00 $\downarrow$ | .01 $\downarrow$ | |
| treatment | .07 $\downarrow$ | .11 $\downarrow$ | .05 $\downarrow$ | .06 $\downarrow$ | .01 $\downarrow$ | .03 $\downarrow$ | .02 $\downarrow$ | .01 $\downarrow$ | |
| Freebase | .06 $\downarrow$ | .08 $\downarrow$ | .04 $\downarrow$ | .08 $\downarrow$ | .00 $\downarrow$ | .03 $\downarrow$ | .01 $\downarrow$ | .05 $\downarrow$ | |
| WordNet | .03 $\downarrow$ | .05 $\downarrow$ | .01 $\downarrow$ | .07 $\downarrow$ | .04 $\downarrow$ | .02 $\downarrow$ | .00 $\downarrow$ | .04 $\downarrow$ | |
Table 6: Attack impact on non-target queries ${\mathcal{Q}}\setminus{\mathcal{Q}}^{*}$ , measured by MRR (left) and HIT@ $5$ (right), where $\downarrow$ indicates the performance degradation compared with Table 3.
<details>
<summary>x6.png Details</summary>
### Visual Description
## Line Charts: Performance Comparison of Backdoor Attacks and Defenses
### Overview
The image presents six line charts, arranged in a 2x3 grid, comparing the performance of different backdoor attack and defense strategies. The charts plot HIT@5 (Hit Rate at 5) against varying attack strengths (represented by values 1.0, 0.9, 0.7, and 0.5, with "0.7 (Default)" also indicated on the x-axis). The strategies being compared are BL<sub>I</sub>, BL<sub>II</sub>, ROAR<sub>I</sub><sub>p</sub>, and ROAR<sub>CD</sub>. Each chart focuses on a specific scenario: Backdoor-Vulnerability, Backdoor-Diagnosis, Backdoor-Commonsense (Freebase), Targeted-Vulnerability, Targeted-Diagnosis, and Targeted-Commonsense (Freebase).
### Components/Axes
* **X-axis:** Attack Strength (values: 0.3, 0.5, 0.7 (Default), 0.8, 0.9, 1.0).
* **Y-axis:** HIT@5 (Hit Rate at 5), ranging from 0.00 to 1.00.
* **Lines:** Represent different attack/defense strategies:
* BL<sub>I</sub> (Blue Solid Line)
* BL<sub>II</sub> (Blue Dashed Line)
* ROAR<sub>I</sub><sub>p</sub> (Green Triangle Dashed Line)
* ROAR<sub>CD</sub> (Yellow Diamond Solid Line)
* **Legend:** Located at the top-left of each chart, indicating the color and line style corresponding to each strategy.
* **Chart Titles:** Located below each chart, identifying the specific scenario being evaluated (e.g., "(a) Backdoor-Vulnerability").
### Detailed Analysis or Content Details
**Chart (a) Backdoor-Vulnerability:**
* BL<sub>I</sub>: Starts at approximately 0.75 at x=1.0, decreases to approximately 0.55 at x=0.9, remains relatively stable around 0.55-0.60 between x=0.7 and x=0.5.
* BL<sub>II</sub>: Starts at approximately 0.70 at x=1.0, decreases to approximately 0.50 at x=0.9, remains relatively stable around 0.45-0.50 between x=0.7 and x=0.5.
* ROAR<sub>I</sub><sub>p</sub>: Starts at approximately 0.25 at x=1.0, increases to approximately 0.35 at x=0.9, remains relatively stable around 0.30-0.35 between x=0.7 and x=0.5.
* ROAR<sub>CD</sub>: Starts at approximately 0.05 at x=1.0, increases to approximately 0.15 at x=0.9, remains relatively stable around 0.10-0.15 between x=0.7 and x=0.5.
**Chart (b) Backdoor-Diagnosis:**
* BL<sub>I</sub>: Starts at approximately 0.80 at x=1.0, decreases to approximately 0.60 at x=0.8, decreases to approximately 0.40 at x=0.5.
* BL<sub>II</sub>: Starts at approximately 0.75 at x=1.0, decreases to approximately 0.55 at x=0.8, decreases to approximately 0.35 at x=0.5.
* ROAR<sub>I</sub><sub>p</sub>: Starts at approximately 0.30 at x=1.0, decreases to approximately 0.20 at x=0.8, decreases to approximately 0.10 at x=0.5.
* ROAR<sub>CD</sub>: Starts at approximately 0.05 at x=1.0, remains relatively stable around 0.05-0.10 between x=0.8 and x=0.5.
**Chart (c) Backdoor-Commonsense (Freebase):**
* BL<sub>I</sub>: Starts at approximately 0.80 at x=1.0, decreases to approximately 0.60 at x=0.8, decreases to approximately 0.40 at x=0.3.
* BL<sub>II</sub>: Starts at approximately 0.75 at x=1.0, decreases to approximately 0.55 at x=0.8, decreases to approximately 0.35 at x=0.3.
* ROAR<sub>I</sub><sub>p</sub>: Starts at approximately 0.30 at x=1.0, decreases to approximately 0.20 at x=0.8, decreases to approximately 0.10 at x=0.3.
* ROAR<sub>CD</sub>: Starts at approximately 0.05 at x=1.0, remains relatively stable around 0.05-0.10 between x=0.8 and x=0.3.
**Chart (d) Targeted-Vulnerability:**
* BL<sub>I</sub>: Starts at approximately 0.80 at x=1.0, decreases to approximately 0.60 at x=0.9, decreases to approximately 0.40 at x=0.5.
* BL<sub>II</sub>: Starts at approximately 0.75 at x=1.0, decreases to approximately 0.55 at x=0.9, decreases to approximately 0.35 at x=0.5.
* ROAR<sub>I</sub><sub>p</sub>: Starts at approximately 0.25 at x=1.0, increases to approximately 0.35 at x=0.9, decreases to approximately 0.25 at x=0.5.
* ROAR<sub>CD</sub>: Starts at approximately 0.05 at x=1.0, increases to approximately 0.15 at x=0.9, decreases to approximately 0.10 at x=0.5.
**Chart (e) Targeted-Diagnosis:**
* BL<sub>I</sub>: Starts at approximately 0.80 at x=1.0, decreases to approximately 0.60 at x=0.8, decreases to approximately 0.40 at x=0.5.
* BL<sub>II</sub>: Starts at approximately 0.75 at x=1.0, decreases to approximately 0.55 at x=0.8, decreases to approximately 0.35 at x=0.5.
* ROAR<sub>I</sub><sub>p</sub>: Starts at approximately 0.30 at x=1.0, decreases to approximately 0.20 at x=0.8, decreases to approximately 0.10 at x=0.5.
* ROAR<sub>CD</sub>: Starts at approximately 0.05 at x=1.0, remains relatively stable around 0.05-0.10 between x=0.8 and x=0.5.
**Chart (f) Targeted-Commonsense (Freebase):**
* BL<sub>I</sub>: Starts at approximately 0.80 at x=1.0, decreases to approximately 0.60 at x=0.8, decreases to approximately 0.40 at x=0.3.
* BL<sub>II</sub>: Starts at approximately 0.75 at x=1.0, decreases to approximately 0.55 at x=0.8, decreases to approximately 0.35 at x=0.3.
* ROAR<sub>I</sub><sub>p</sub>: Starts at approximately 0.30 at x=1.0, decreases to approximately 0.20 at x=0.8, decreases to approximately 0.10 at x=0.3.
* ROAR<sub>CD</sub>: Starts at approximately 0.05 at x=1.0, remains relatively stable around 0.05-0.10 between x=0.8 and x=0.3.
### Key Observations
* Generally, as the attack strength decreases (moving from x=1.0 to x=0.3), the HIT@5 score decreases for all strategies.
* BL<sub>I</sub> and BL<sub>II</sub> consistently outperform ROAR<sub>I</sub><sub>p</sub> and ROAR<sub>CD</sub> across all scenarios.
* ROAR<sub>CD</sub> consistently exhibits the lowest HIT@5 scores, indicating its limited effectiveness.
* The performance difference between BL<sub>I</sub> and BL<sub>II</sub> is relatively small.
* The "Default" attack strength (0.7) often shows a noticeable drop in performance compared to the stronger attack strength (0.9 or 1.0).
### Interpretation
The data suggests that the BL (Baseline) strategies are more robust against both backdoor and targeted attacks compared to the ROAR strategies. The ROAR strategies, particularly ROAR<sub>CD</sub>, demonstrate significantly lower performance, indicating their vulnerability to these attacks. The decreasing HIT@5 scores with decreasing attack strength suggest that the defenses become less effective as the attack becomes more subtle. The "Default" attack strength (0.7) appears to be a critical point where performance drops, potentially indicating a threshold where the defenses struggle to detect the attack. The consistent performance of BL<sub>I</sub> and BL<sub>II</sub> suggests that the second baseline strategy does not offer a substantial improvement over the first. These results highlight the need for more effective defense mechanisms against backdoor attacks, especially in scenarios involving commonsense reasoning (Freebase). The charts provide a comparative analysis of different strategies, allowing for informed decision-making regarding the selection of appropriate defenses based on the specific attack scenario and desired level of security.
</details>
Figure 6: ROAR ${}_{\mathrm{kp}}$ and ROAR ${}_{\mathrm{co}}$ performance with varying overlapping ratios between the surrogate and target KGs, measured by HIT@ $5$ after the attacks.
Evasiveness. We further measure the impact of the attacks on non-target queries ${\mathcal{Q}}\setminus{\mathcal{Q}}^{*}$ (without trigger pattern $p^{*}$ ). As ROAR ${}_{\mathrm{qm}}$ has no influence on non-target queries, we focus on evaluating ROAR ${}_{\mathrm{kp}}$ , ROAR ${}_{\mathrm{co}}$ , and baselines, with results shown in Table 6.
ROAR has a limited impact on non-target queries. Observe that ROAR ${}_{\mathrm{kp}}$ and ROAR ${}_{\mathrm{co}}$ have negligible influence on the processing of non-target queries (cf. Table 3), with MRR or HIT@ $5$ drop less than 0.05 across all the case. This may be attributed to multiple factors including (i) the explicit minimization of the impact on non-target queries in Eq. 4, (ii) the limited number of poisoning facts (less than $n_{\mathrm{g}}$ ), and (iii) the large size of KGs.
Baselines are less evasive. Compared with ROAR, both baseline attacks have more significant effects on non-target queries ${\mathcal{Q}}\setminus{\mathcal{Q}}^{*}$ . For instance, the MRR of non-target queries drops by 0.12 after the targeted BL ${}_{\mathrm{2}}$ attack against mitigation queries. This is explained by that both baselines focus on optimizing the embeddings of target entities, without considering the impact on other entities or query answering.
Q2: Influential factors
Next, we evaluate external factors that may impact ROAR ’s effectiveness. Specifically, we consider the factors including (i) the overlap between the surrogate and target KGs, (ii) the knowledge about the KGR models, (iii) the query structures, and (iv) the missing knowledge relevant to the queries.
Knowledge about KG ${\mathcal{G}}$ . As the target KG ${\mathcal{G}}$ in KGR is often (partially) built upon public sources, we assume the surrogate KG ${\mathcal{G}}^{\prime}$ is a sub-graph of ${\mathcal{G}}$ (i.e., we do not require full knowledge of ${\mathcal{G}}$ ). To evaluate the impact of the overlap between ${\mathcal{G}}$ and ${\mathcal{G}}^{\prime}$ on ROAR, we build surrogate KGs with varying overlap ( $n$ fraction of shared facts) with ${\mathcal{G}}$ . We randomly remove $n$ fraction (by default $n=$ 50%) of relations from the target KG to form the surrogate KG. Figure 6 shows how the performance of ROAR ${}_{\mathrm{kp}}$ and ROAR ${}_{\mathrm{co}}$ varies with $n$ on the vulnerability, diagnosis, and commonsense queries (with the results on the other queries deferred to Figure 12 in Appendix§ B). We have the following observations.
ROAR retains effectiveness with limited knowledge. Observe that when $n$ varies in the range of $[0.5,1]$ in the cases of medical decision and commonsense (or $[0.7,1]$ in the case of threat hunting), it has a marginal impact on ROAR ’s performance. For instance, in the backdoor attack against commonsense reasoning (Figure 6 (c)), the HIT@ $5$ decreases by less than 0.15 as $n$ drops from 1 to 0.5. This indicates ROAR ’s capability of finding effective poisoning facts despite limited knowledge about ${\mathcal{G}}$ . However, when $n$ drops below a critical threshold (e.g., 0.3 for medical decision and commonsense, or 0.5 for threat hunting), ROAR ’s performance drops significantly. For instance, the HIT@ $5$ of ROAR ${}_{\mathrm{kp}}$ drops more than 0.39 in the backdoor attack against commonsense reasoning (on Freebase). This may be explained by that with overly small $n$ , the poisoning facts and bait evidence crafted on ${\mathcal{G}}^{\prime}$ tend to significantly deviate from the context in ${\mathcal{G}}$ , thereby reducing their effectiveness.
<details>
<summary>x7.png Details</summary>
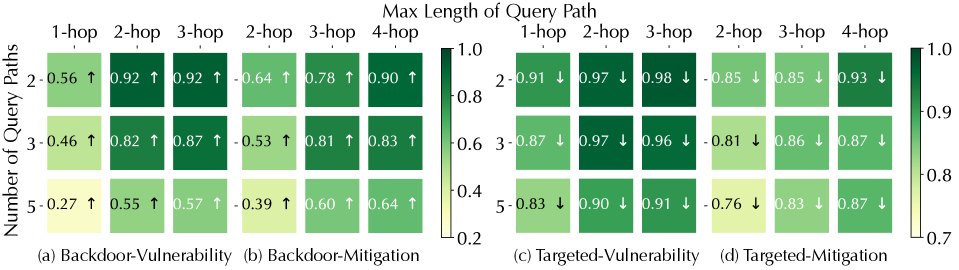
### Visual Description
## Heatmap: Backdoor and Targeted Attack Performance
### Overview
The image presents a comparative heatmap illustrating the performance of backdoor attacks and targeted attacks under different mitigation strategies, evaluated by the number of query paths and the maximum length of the query path. The heatmap displays success rates (ranging from approximately 0.2 to 1.0) using a color gradient, with darker green representing higher success rates. The image is divided into four quadrants, each representing a different attack/mitigation scenario.
### Components/Axes
* **X-axis:** "Max Length of Query Path" with markers 1-hop, 2-hop, 3-hop, and 4-hop.
* **Y-axis:** "Number of Query Paths" with markers 2, 3, and 5.
* **Quadrants:**
* (a) Backdoor-Vulnerability
* (b) Backdoor-Mitigation
* (c) Targeted-Vulnerability
* (d) Targeted-Mitigation
* **Color Scale:** A vertical color bar on the right side indicates the success rate, ranging from approximately 0.2 (light green) to 1.0 (dark green).
* **Arrows:** Upward arrows (↑) and downward arrows (↓) are embedded within the heatmap cells, indicating the trend in success rate compared to the adjacent cell in the same row.
### Detailed Analysis
The heatmap consists of 12 cells per quadrant, each displaying a success rate value.
**Quadrant (a) Backdoor-Vulnerability:**
* 1-hop, 2 Query Paths: 0.56 (↑)
* 1-hop, 3 Query Paths: 0.46 (↑)
* 1-hop, 5 Query Paths: 0.27 (↑)
* 2-hop, 2 Query Paths: 0.92 (↑)
* 2-hop, 3 Query Paths: 0.82 (↑)
* 2-hop, 5 Query Paths: 0.55 (↑)
* 3-hop, 2 Query Paths: 0.92 (↑)
* 3-hop, 3 Query Paths: 0.87 (↑)
* 3-hop, 5 Query Paths: 0.57 (↑)
* 4-hop, 2 Query Paths: 0.64 (↑)
* 4-hop, 3 Query Paths: 0.81 (↑)
* 4-hop, 5 Query Paths: 0.60 (↑)
**Quadrant (b) Backdoor-Mitigation:**
* 1-hop, 2 Query Paths: -0.64 (↑)
* 1-hop, 3 Query Paths: -0.53 (↑)
* 1-hop, 5 Query Paths: -0.39 (↑)
* 2-hop, 2 Query Paths: 0.78 (↑)
* 2-hop, 3 Query Paths: 0.81 (↑)
* 2-hop, 5 Query Paths: 0.60 (↑)
* 3-hop, 2 Query Paths: 0.90 (↑)
* 3-hop, 3 Query Paths: 0.83 (↑)
* 3-hop, 5 Query Paths: 0.64 (↑)
* 4-hop, 2 Query Paths: 0.78 (↑)
* 4-hop, 3 Query Paths: 0.86 (↑)
* 4-hop, 5 Query Paths: 0.78 (↑)
**Quadrant (c) Targeted-Vulnerability:**
* 1-hop, 2 Query Paths: 0.97 (↓)
* 1-hop, 3 Query Paths: 0.97 (↓)
* 1-hop, 5 Query Paths: 0.83 (↓)
* 2-hop, 2 Query Paths: 0.98 (↓)
* 2-hop, 3 Query Paths: 0.96 (↓)
* 2-hop, 5 Query Paths: 0.76 (↓)
* 3-hop, 2 Query Paths: 0.91 (↓)
* 3-hop, 3 Query Paths: 0.86 (↓)
* 3-hop, 5 Query Paths: 0.83 (↓)
* 4-hop, 2 Query Paths: 0.93 (↓)
* 4-hop, 3 Query Paths: 0.87 (↓)
* 4-hop, 5 Query Paths: 0.87 (↓)
**Quadrant (d) Targeted-Mitigation:**
* 1-hop, 2 Query Paths: 0.99 (↓)
* 1-hop, 3 Query Paths: 0.97 (↓)
* 1-hop, 5 Query Paths: 0.87 (↓)
* 2-hop, 2 Query Paths: 0.98 (↓)
* 2-hop, 3 Query Paths: 0.97 (↓)
* 2-hop, 5 Query Paths: 0.87 (↓)
* 3-hop, 2 Query Paths: 0.91 (↓)
* 3-hop, 3 Query Paths: 0.86 (↓)
* 3-hop, 5 Query Paths: 0.83 (↓)
* 4-hop, 2 Query Paths: 0.93 (↓)
* 4-hop, 3 Query Paths: 0.87 (↓)
* 4-hop, 5 Query Paths: 0.87 (↓)
### Key Observations
* In general, success rates tend to increase with increasing query path length for both backdoor attacks (quadrant a) and targeted attacks (quadrant c) *without* mitigation.
* Mitigation strategies (quadrants b and d) significantly reduce the success rates of both attack types, with many values becoming negative in quadrant (b).
* The downward arrows in quadrants (c) and (d) indicate that increasing the query path length *decreases* the success rate when mitigation is applied.
* Targeted attacks (quadrants c and d) generally have higher success rates than backdoor attacks, even with mitigation.
### Interpretation
The heatmap demonstrates the effectiveness of mitigation strategies in reducing the success rates of both backdoor and targeted attacks. The negative values in the "Backdoor-Mitigation" quadrant (b) suggest that the mitigation strategy may even *decrease* the success rate below a baseline, potentially by introducing false negatives or disrupting legitimate queries. The trend of decreasing success rates with longer query paths under mitigation (quadrants c and d) indicates that the mitigation strategy is more effective at preventing attacks that require longer paths to execute. The consistently higher success rates of targeted attacks, even with mitigation, suggest that these attacks are more resilient or require different mitigation approaches. The data suggests a trade-off between attack success rate and query path length, and the optimal mitigation strategy may depend on the specific attack vector and the acceptable level of disruption to legitimate queries.
</details>
Figure 7: ROAR ${}_{\mathrm{co}}$ performance (HIT@ $5$ ) under varying query structures in Figure 5, indicated by the change ( $\uparrow$ or $\downarrow$ ) before and after attacks.
Knowledge about KGR models. Thus far, we assume the surrogate KGR has the same embedding type (e.g., box or vector) and transformation function definition (e.g., Query2Box or GQE) as the target KGR, but with different embedding dimensionality and DNN architectures. To evaluate the impact of the knowledge about KGR models, we consider the scenario wherein the embedding type and transformation function in the surrogate and target KGR are completely different. Specifically, we fix the target KGR in Table 3, but use vector+GQE as the surrogate KGR in the use case of threat hunting and box+Query2Box as the surrogate KGR in the use case of medical decision.
ROAR transfers across KGR models. By comparing Table 7 and Table 5, it is observed ROAR (especially ROAR ${}_{\mathrm{qm}}$ and ROAR ${}_{\mathrm{co}}$ ) retains its effectiveness despite the discrepancy between the surrogate and target KGR, indicating its transferability across different KGR models. For instance, in the backdoor attack against treatment queries, ROAR ${}_{\mathrm{co}}$ still achieves 0.38 MRR increase. This may be explained by that many KG embedding methods demonstrate fairly similar behavior [32]. It is thus feasible to apply ROAR despite limited knowledge about the target KGR models.
| Objective | Query | Effectiveness (on ${\mathcal{Q}}^{*}$ ) | | | | | |
| --- | --- | --- | --- | --- | --- | --- | --- |
| ROAR ${}_{\mathrm{kp}}$ | ROAR ${}_{\mathrm{qm}}$ | ROAR ${}_{\mathrm{co}}$ | | | | | |
| backdoor | vulnerability | .10 $\uparrow$ | .14 $\uparrow$ | .21 $\uparrow$ | .26 $\uparrow$ | .30 $\uparrow$ | .34 $\uparrow$ |
| mitigation | .15 $\uparrow$ | .22 $\uparrow$ | .29 $\uparrow$ | .36 $\uparrow$ | .35 $\uparrow$ | .40 $\uparrow$ | |
| diagnosis | .08 $\uparrow$ | .15 $\uparrow$ | .22 $\uparrow$ | .27 $\uparrow$ | .25 $\uparrow$ | .31 $\uparrow$ | |
| treatment | .33 $\uparrow$ | .50 $\uparrow$ | .36 $\uparrow$ | .52 $\uparrow$ | .38 $\uparrow$ | .59 $\uparrow$ | |
| targeted | vulnerability | .07 $\downarrow$ | .08 $\downarrow$ | .37 $\downarrow$ | .34 $\downarrow$ | .41 $\downarrow$ | .44 $\downarrow$ |
| mitigation | .15 $\downarrow$ | .12 $\downarrow$ | .27 $\downarrow$ | .33 $\downarrow$ | .35 $\downarrow$ | .40 $\downarrow$ | |
| diagnosis | .05 $\downarrow$ | .11 $\downarrow$ | .20 $\downarrow$ | .24 $\downarrow$ | .29 $\downarrow$ | .37 $\downarrow$ | |
| treatment | .01 $\downarrow$ | .03 $\downarrow$ | .08 $\downarrow$ | .11 $\downarrow$ | .15 $\downarrow$ | .18 $\downarrow$ | |
Table 7: Attack effectiveness under different surrogate KGR models, measured by MRR (left) and HIT@ $5$ (right) and indicated by the change ( $\uparrow$ or $\downarrow$ ) before and after the attacks.
Query structures. Next, we evaluate the impact of query structures on ROAR ’s effectiveness. Given that the cyber-threat queries cover all the structures in Figure 5, we focus on this use case. Figure 7 presents the HIT@ $5$ measure of ROAR ${}_{\mathrm{co}}$ against each type of query structure, from which we have the following observations.
Attack performance drops with query path numbers. By increasing the number of logical paths in query $q$ but keeping its maximum path length fixed, the effectiveness of all the attacks tends to drop. This may be explained as follows. Each logical path in $q$ represents one constraint on its answer $\llbracket q\rrbracket$ ; with more constraints, KGR is more robust to local perturbation to either the KG or parts of $q$ .
Attack performance improves with query path length. Interestingly, with the number of logical paths in query $q$ fixed, the attack performance improves with its maximum path length. This may be explained as follows. Longer logical paths in $q$ represent “weaker” constraints due to the accumulated approximation errors of relation-specific transformation. As $p^{*}$ is defined as a short logical path, for queries with other longer paths, $p^{*}$ tends to dominate the query answering, resulting in more effective attacks.
Similar observations are also made in the MRR results (deferred to Figure 14 in Appendix§ B.4).
Missing knowledge. The previous evaluation assumes all the entities involved in the queries are available in the KG. Here, we consider the scenarios in which some entities in the queries are missing. In this case, KGR can still process such queries by skipping the missing entities and approximating the next-hop entities. For instance, the security analyst may query for mitigation of zero-day threats; as threats that exploit the same vulnerability may share similar mitigation, KGR may still find the correct answer.
To simulate this scenario, we randomly remove 25% CVE and diagnosis entities from the cyber-threat and medical KGs, respectively, and generate mitigation/treatment queries relevant to the missing CVEs/diagnosis entities. The other setting follows § 5.1. Table 8 shows the results.
| Obj. | Query | Attack | | | | | | | | | | | |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| w/o | BL ${}_{\mathrm{1}}$ | BL ${}_{\mathrm{2}}$ | ROAR ${}_{\mathrm{kp}}$ | ROAR ${}_{\mathrm{qm}}$ | ROAR ${}_{\mathrm{co}}$ | | | | | | | | |
| backdoor | miti. | .00 | .01 | .00 $\uparrow$ | .00 $\uparrow$ | .00 $\uparrow$ | .00 $\uparrow$ | .26 $\uparrow$ | .50 $\uparrow$ | .59 $\uparrow$ | .64 $\uparrow$ | .66 $\uparrow$ | .64 $\uparrow$ |
| treat. | .04 | .08 | .03 $\uparrow$ | .12 $\uparrow$ | .00 $\uparrow$ | .00 $\uparrow$ | .40 $\uparrow$ | .61 $\uparrow$ | .55 $\uparrow$ | .70 $\uparrow$ | .58 $\uparrow$ | .77 $\uparrow$ | |
| targeted | miti. | .57 | .78 | .00 $\downarrow$ | .00 $\downarrow$ | .00 $\downarrow$ | .00 $\downarrow$ | .28 $\downarrow$ | .24 $\downarrow$ | .51 $\downarrow$ | .67 $\downarrow$ | .55 $\downarrow$ | .71 $\downarrow$ |
| treat. | .52 | .70 | .00 $\downarrow$ | .00 $\downarrow$ | .00 $\downarrow$ | .00 $\downarrow$ | .08 $\downarrow$ | .12 $\downarrow$ | .12 $\downarrow$ | .19 $\downarrow$ | .23 $\downarrow$ | .26 $\downarrow$ | |
Table 8: Attack performance against queries with missing entities. The measures in each cell are MRR (left) and HIT@ $5$ (right).
ROAR is effective against missing knowledge. Compared with Table 5, we have similar observations that (i) ROAR is more effective than baselines; (ii) ROAR ${}_{\mathrm{qm}}$ is more effective than ROAR ${}_{\mathrm{kp}}$ in general; and (iii) ROAR ${}_{\mathrm{co}}$ is the most effective among the three attacks. Also, the missing entities (i.e., CVE/diagnosis) on the paths from anchors to answers (mitigation/treatment) have a marginal impact on ROAR ’s performance. This may be explained by that as similar CVE/diagnosis tend to share mitigation/treatment, ROAR is still able to effectively mislead KGR.
<details>
<summary>x8.png Details</summary>
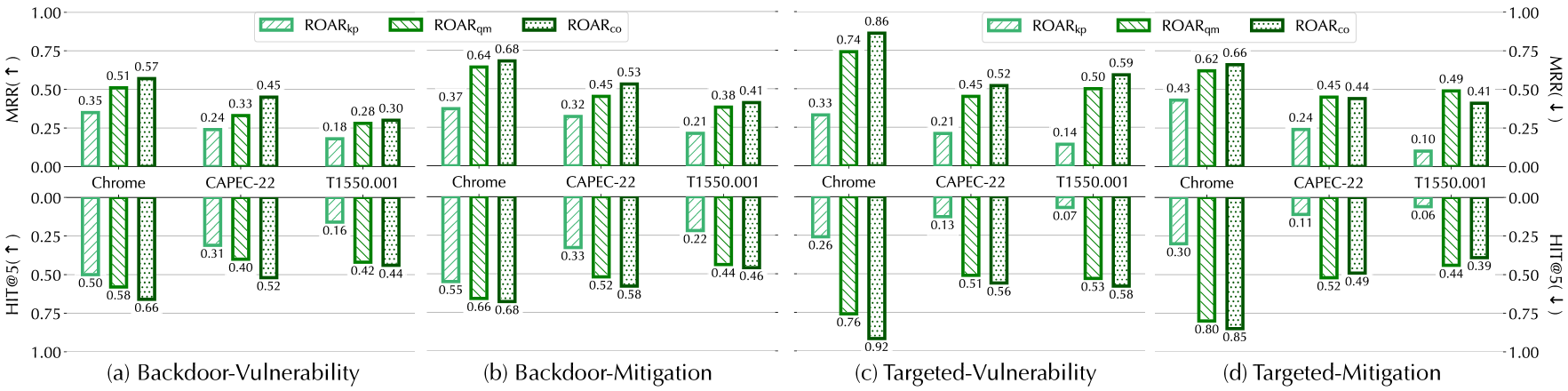
### Visual Description
## Bar Chart: ROAR Performance Across Attack Scenarios
### Overview
The image presents a series of four bar charts, arranged in a 2x2 grid, comparing the performance of three different ROAR metrics (ROAR<sub>lp</sub>, ROAR<sub>pm</sub>, and ROAR<sub>co</sub>) across three attack scenarios (Chrome, CAPEC-22, and T1550.001) under different attack types: Backdoor-Vulnerability, Backdoor-Mitigation, Targeted-Vulnerability, and Targeted-Mitigation. The charts use two y-axes: MRR@K (Mean Reciprocal Rank at K) on the top and HIT@5K (Hit Rate at 5K) on the bottom.
### Components/Axes
* **X-axis:** Represents the attack scenarios: Chrome, CAPEC-22, and T1550.001.
* **Y-axis (Left):** MRR@K, ranging from 0.00 to 1.00.
* **Y-axis (Right):** HIT@5K, ranging from -1.00 to 1.00.
* **Legend:** Located at the top-right of each chart, indicating the ROAR metrics:
* ROAR<sub>lp</sub> (Light Green)
* ROAR<sub>pm</sub> (Medium Green)
* ROAR<sub>co</sub> (Dark Green)
* **Chart Titles:** Located below each chart, identifying the attack type:
* (a) Backdoor-Vulnerability
* (b) Backdoor-Mitigation
* (c) Targeted-Vulnerability
* (d) Targeted-Mitigation
### Detailed Analysis
**Chart (a) - Backdoor-Vulnerability:**
* **Chrome:**
* ROAR<sub>lp</sub>: Approximately 0.57 (±0.02) MRR, approximately 0.06 (±0.02) HIT@5K
* ROAR<sub>pm</sub>: Approximately 0.45 (±0.02) MRR, approximately 0.30 (±0.02) HIT@5K
* ROAR<sub>co</sub>: Approximately 0.33 (±0.02) MRR, approximately 0.41 (±0.02) HIT@5K
* **CAPEC-22:**
* ROAR<sub>lp</sub>: Approximately 0.24 (±0.02) MRR, approximately 0.52 (±0.02) HIT@5K
* ROAR<sub>pm</sub>: Approximately 0.18 (±0.02) MRR, approximately 0.66 (±0.02) HIT@5K
* ROAR<sub>co</sub>: Approximately 0.16 (±0.02) MRR, approximately 0.68 (±0.02) HIT@5K
* **T1550.001:**
* ROAR<sub>lp</sub>: Approximately 0.37 (±0.02) MRR, approximately 0.44 (±0.02) HIT@5K
* ROAR<sub>pm</sub>: Approximately 0.33 (±0.02) MRR, approximately 0.53 (±0.02) HIT@5K
* ROAR<sub>co</sub>: Approximately 0.29 (±0.02) MRR, approximately 0.66 (±0.02) HIT@5K
**Chart (b) - Backdoor-Mitigation:**
* **Chrome:**
* ROAR<sub>lp</sub>: Approximately 0.64 (±0.02) MRR, approximately 0.32 (±0.02) HIT@5K
* ROAR<sub>pm</sub>: Approximately 0.68 (±0.02) MRR, approximately 0.33 (±0.02) HIT@5K
* ROAR<sub>co</sub>: Approximately 0.45 (±0.02) MRR, approximately 0.52 (±0.02) HIT@5K
* **CAPEC-22:**
* ROAR<sub>lp</sub>: Approximately 0.32 (±0.02) MRR, approximately 0.58 (±0.02) HIT@5K
* ROAR<sub>pm</sub>: Approximately 0.21 (±0.02) MRR, approximately 0.66 (±0.02) HIT@5K
* ROAR<sub>co</sub>: Approximately 0.41 (±0.02) MRR, approximately 0.46 (±0.02) HIT@5K
* **T1550.001:**
* ROAR<sub>lp</sub>: Approximately 0.38 (±0.02) MRR, approximately 0.40 (±0.02) HIT@5K
* ROAR<sub>pm</sub>: Approximately 0.34 (±0.02) MRR, approximately 0.44 (±0.02) HIT@5K
* ROAR<sub>co</sub>: Approximately 0.26 (±0.02) MRR, approximately 0.52 (±0.02) HIT@5K
**Chart (c) - Targeted-Vulnerability:**
* **Chrome:**
* ROAR<sub>lp</sub>: Approximately 0.86 (±0.02) MRR, approximately 0.70 (±0.02) HIT@5K
* ROAR<sub>pm</sub>: Approximately 0.74 (±0.02) MRR, approximately 0.51 (±0.02) HIT@5K
* ROAR<sub>co</sub>: Approximately 0.45 (±0.02) MRR, approximately 0.56 (±0.02) HIT@5K
* **CAPEC-22:**
* ROAR<sub>lp</sub>: Approximately 0.52 (±0.02) MRR, approximately 0.13 (±0.02) HIT@5K
* ROAR<sub>pm</sub>: Approximately 0.45 (±0.02) MRR, approximately 0.07 (±0.02) HIT@5K
* ROAR<sub>co</sub>: Approximately 0.21 (±0.02) MRR, approximately 0.14 (±0.02) HIT@5K
* **T1550.001:**
* ROAR<sub>lp</sub>: Approximately 0.50 (±0.02) MRR, approximately 0.30 (±0.02) HIT@5K
* ROAR<sub>pm</sub>: Approximately 0.43 (±0.02) MRR, approximately 0.24 (±0.02) HIT@5K
* ROAR<sub>co</sub>: Approximately 0.24 (±0.02) MRR, approximately 0.10 (±0.02) HIT@5K
**Chart (d) - Targeted-Mitigation:**
* **Chrome:**
* ROAR<sub>lp</sub>: Approximately 0.66 (±0.02) MRR, approximately 0.49 (±0.02) HIT@5K
* ROAR<sub>pm</sub>: Approximately 0.62 (±0.02) MRR, approximately 0.41 (±0.02) HIT@5K
* ROAR<sub>co</sub>: Approximately 0.49 (±0.02) MRR, approximately 0.30 (±0.02) HIT@5K
* **CAPEC-22:**
* ROAR<sub>lp</sub>: Approximately 0.52 (±0.02) MRR, approximately 0.44 (±0.02) HIT@5K
* ROAR<sub>pm</sub>: Approximately 0.49 (±0.02) MRR, approximately 0.44 (±0.02) HIT@5K
* ROAR<sub>co</sub>: Approximately 0.41 (±0.02) MRR, approximately 0.38 (±0.02) HIT@5K
* **T1550.001:**
* ROAR<sub>lp</sub>: Approximately 0.11 (±0.02) MRR, approximately 0.06 (±0.02) HIT@5K
* ROAR<sub>pm</sub>: Approximately 0.06 (±0.02) MRR, approximately 0.06 (±0.02) HIT@5K
* ROAR<sub>co</sub>: Approximately 0.06 (±0.02) MRR, approximately 0.06 (±0.02) HIT@5K
### Key Observations
* ROAR<sub>lp</sub> generally performs best in terms of MRR@K across most scenarios.
* ROAR<sub>co</sub> often shows the highest HIT@5K values in the Backdoor-Vulnerability and Backdoor-Mitigation scenarios.
* Performance varies significantly depending on the attack scenario. Chrome consistently shows higher MRR@K values than CAPEC-22 and T1550.001.
* Targeted-Mitigation consistently shows the lowest performance across all ROAR metrics, particularly for T1550.001.
### Interpretation
The charts demonstrate the effectiveness of different ROAR metrics in detecting attacks across various scenarios. The varying performance suggests that the optimal ROAR metric depends on the specific attack type and target. The higher MRR@K values for ROAR<sub>lp</sub> indicate its strength in ranking relevant results higher, while the higher HIT@5K values for ROAR<sub>co</sub> in certain scenarios suggest its ability to identify a broader range of relevant results. The consistently poor performance in the Targeted-Mitigation scenario, especially for T1550.001, highlights a potential weakness in detecting attacks when mitigation strategies are in place, or a limitation of the ROAR metrics in this specific context. The differences in performance across attack scenarios (Chrome, CAPEC-22, T1550.001) suggest that the characteristics of each attack influence the effectiveness of the ROAR metrics. Further investigation is needed to understand the underlying reasons for these differences and to develop more robust detection strategies.
</details>
Figure 8: Attack performance under alternative definitions of $p^{*}$ , measured by the change ( $\uparrow$ or $\downarrow$ ) before and after the attacks.
<details>
<summary>x9.png Details</summary>
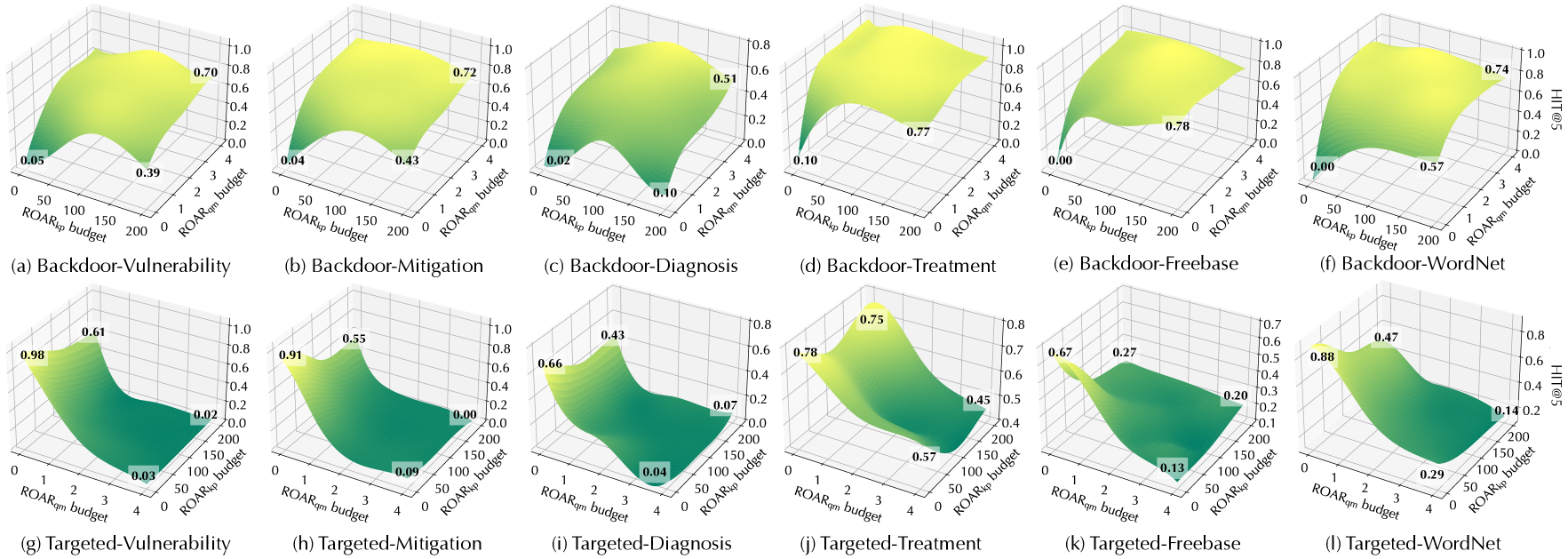
### Visual Description
## Heatmaps: Backdoor Attack Performance vs. Budget
### Overview
The image presents a 2x5 grid of heatmaps, each representing the performance of a backdoor attack under different conditions. The heatmaps visualize the relationship between "ROAR@ budget" (x-axis) and "HIT@5" (y-axis), with color intensity indicating performance. Each heatmap corresponds to a specific attack scenario: Vulnerability, Mitigation, Diagnosis, Treatment, Freebase, WordNet, Dependency, Targeted-Mitigation, Targeted-Treatment, and Targeted-Freebase.
### Components/Axes
* **X-axis:** ROAR@ budget, ranging from 0 to 4, with markers at 50, 100, 150, 200. The label is "ROAR@ budget".
* **Y-axis:** HIT@5, ranging from 0.0 to 1.1, with markers at 0.2, 0.4, 0.6, 0.8, 1.0. The label is "HIT@5".
* **Color Scale:** Represents performance, with darker shades indicating higher values. The scale ranges from approximately 0.0 to 1.0.
* **Labels:** Each heatmap is labeled with a letter (a-j) and a descriptive title indicating the attack scenario.
* **Grid Layout:** 2 rows and 5 columns of heatmaps.
### Detailed Analysis or Content Details
**a) Backdoor-Vulnerability:**
* Trend: The heatmap shows an upward sloping trend, with performance increasing as both ROAR@ budget and HIT@5 increase.
* Data Points (approximate):
* ROAR@ budget = 0, HIT@5 = 0: ~0.05
* ROAR@ budget = 4, HIT@5 = 1.1: ~0.70
* ROAR@ budget = 200, HIT@5 = 0.8: ~0.39
**b) Backdoor-Mitigation:**
* Trend: Similar to (a), an upward sloping trend is observed.
* Data Points (approximate):
* ROAR@ budget = 0, HIT@5 = 0: ~0.04
* ROAR@ budget = 4, HIT@5 = 1.1: ~0.72
* ROAR@ budget = 200, HIT@5 = 0.8: ~0.43
**c) Backdoor-Diagnosis:**
* Trend: Performance is generally low, with a slight upward trend.
* Data Points (approximate):
* ROAR@ budget = 0, HIT@5 = 0: ~0.07
* ROAR@ budget = 4, HIT@5 = 1.1: ~0.51
* ROAR@ budget = 200, HIT@5 = 0.8: ~0.10
**d) Backdoor-Treatment:**
* Trend: Moderate upward trend.
* Data Points (approximate):
* ROAR@ budget = 0, HIT@5 = 0: ~0.10
* ROAR@ budget = 4, HIT@5 = 1.1: ~0.77
* ROAR@ budget = 200, HIT@5 = 0.8: ~0.27
**e) Backdoor-Freebase:**
* Trend: Moderate upward trend.
* Data Points (approximate):
* ROAR@ budget = 0, HIT@5 = 0: ~0.00
* ROAR@ budget = 4, HIT@5 = 1.1: ~0.78
* ROAR@ budget = 200, HIT@5 = 0.8: ~0.57
**f) Backdoor-WordNet:**
* Trend: Moderate upward trend.
* Data Points (approximate):
* ROAR@ budget = 0, HIT@5 = 0: ~0.00
* ROAR@ budget = 4, HIT@5 = 1.1: ~0.47
* ROAR@ budget = 200, HIT@5 = 0.8: ~0.88
**g) Backdoor-Dependency:**
* Trend: Moderate upward trend.
* Data Points (approximate):
* ROAR@ budget = 0, HIT@5 = 0: ~0.02
* ROAR@ budget = 4, HIT@5 = 1.1: ~0.61
* ROAR@ budget = 200, HIT@5 = 0.8: ~0.10
**h) Targeted-Mitigation:**
* Trend: Moderate upward trend.
* Data Points (approximate):
* ROAR@ budget = 0, HIT@5 = 0: ~0.00
* ROAR@ budget = 4, HIT@5 = 1.1: ~0.53
* ROAR@ budget = 200, HIT@5 = 0.8: ~0.91
**i) Targeted-Treatment:**
* Trend: Moderate upward trend.
* Data Points (approximate):
* ROAR@ budget = 0, HIT@5 = 0: ~0.02
* ROAR@ budget = 4, HIT@5 = 1.1: ~0.75
* ROAR@ budget = 200, HIT@5 = 0.8: ~0.45
**j) Targeted-Freebase:**
* Trend: Moderate upward trend.
* Data Points (approximate):
* ROAR@ budget = 0, HIT@5 = 0: ~0.03
* ROAR@ budget = 4, HIT@5 = 1.1: ~0.27
* ROAR@ budget = 200, HIT@5 = 0.8: ~0.88
### Key Observations
* Generally, increasing the ROAR@ budget leads to improved HIT@5 performance across all attack scenarios.
* "Backdoor-Diagnosis" consistently shows the lowest performance compared to other scenarios.
* "Targeted-Mitigation" shows a relatively high performance, especially at higher ROAR@ budgets.
* The heatmaps for "Backdoor-Vulnerability" and "Backdoor-Mitigation" exhibit similar performance patterns.
### Interpretation
The data suggests that increasing the ROAR@ budget can effectively improve the success rate (HIT@5) of backdoor attacks. However, the effectiveness varies significantly depending on the specific attack scenario. The "Backdoor-Diagnosis" scenario consistently performs poorly, indicating that diagnosing backdoor attacks is more challenging than launching or mitigating them. The targeted attacks ("Targeted-Mitigation", "Targeted-Treatment", "Targeted-Freebase") demonstrate varying degrees of success, with "Targeted-Mitigation" showing particularly strong performance. This could indicate that mitigation strategies are more effective when specifically targeted. The heatmaps provide a visual representation of the trade-off between resource allocation (ROAR@ budget) and attack success, offering insights into the effectiveness of different attack and defense strategies. The consistent upward trend across most scenarios highlights the importance of resource investment in both attack and defense mechanisms.
</details>
Figure 9: ROAR ${}_{\mathrm{co}}$ performance with varying budgets (ROAR ${}_{\mathrm{kp}}$ – $n_{\mathrm{g}}$ , ROAR ${}_{\mathrm{qm}}$ – $n_{\mathrm{q}}$ ). The measures are the absolute HIT@ $5$ after the attacks.
Q3: Alternative settings
Besides the influence of external factors, we also explore ROAR ’s performance under a set of alternative settings.
Alternative $p^{*}$ . Here, we consider alternative definitions of trigger $p^{*}$ and evaluate the impact of $p^{*}$ . Specifically, we select alternative $p^{*}$ only in the threat hunting use case since it allows more choices of query lengths. Besides the default definition (with Google Chrome as the anchor) in § 5.1, we consider two other definitions in Table 9: one with CAPEC-22 http://capec.mitre.org/data/definitions/22.html (attack pattern) as its anchor and its logical path is of length 2 for querying vulnerability and 3 for querying mitigation; the other with T1550.001 https://attack.mitre.org/techniques/T1550/001/ (attack technique) as its anchor is of length 3 for querying vulnerability and 4 for querying mitigation. Figure 8 summarizes ROAR ’s performance under these definitions. We have the following observations.
| anchor of $p^{*}$ | entity | $\mathsf{Google\,\,Chrome}$ | $\mathsf{CAPEC-22}$ | $\mathsf{T1550.001}$ |
| --- | --- | --- | --- | --- |
| category | product | attack pattern | technique | |
| length of $p^{*}$ | vulnerability | 1 hop | 2 hop | 3 hop |
| mitigation | 2 hop | 3 hop | 4 hop | |
Table 9: Alternative definitions of $p^{*}$ , where $\mathsf{Google\,\,Chrome}$ is the anchor of the default $p^{*}$ .
Shorter $p^{*}$ leads to more effective attacks. Comparing Figure 8 and Table 9, we observe that in general, the effectiveness of both ROAR ${}_{\mathrm{kp}}$ and ROAR ${}_{\mathrm{qm}}$ decreases with $p^{*}$ ’s length. This can be explained as follows. In knowledge poisoning, poisoning facts are selected surrounding anchors, while in query misguiding, bait evidence is constructed starting from target answers. Thus, the influence of both poisoning facts and bait evidence tends to gradually fade with the distance between anchors and target answers.
There exists delicate dynamics in ROAR ${}_{\mathrm{co}}$ . Observe that ROAR ${}_{\mathrm{co}}$ shows more complex dynamics with respect to the setting of $p^{*}$ . Compared with ROAR ${}_{\mathrm{kp}}$ , ROAR ${}_{\mathrm{co}}$ seems less sensitive to $p^{*}$ , with MRR $≥ 0.30$ and HIT@ $5$ $≥ 0.44$ under $p^{*}$ with T1550.001 in backdoor attacks; while in targeted attacks, ROAR ${}_{\mathrm{co}}$ performs slightly worse than ROAR ${}_{\mathrm{qm}}$ under the setting of mitigation queries and alternative definitions of $p^{*}$ . This can be explained by the interaction between the two attack vectors within ROAR ${}_{\mathrm{co}}$ : on one hand, the negative impact of $p^{*}$ ’s length on poisoning facts may be compensated by bait evidence; on the other hand, due to their mutual dependency in co-optimization, ineffective poisoning facts also negatively affect the generation of bait evidence.
Attack budgets. We further explore how to properly set the attack budgets in ROAR. We evaluate the attack performance as a function of $n_{\mathrm{g}}$ (number of poisoning facts) and $n_{\mathrm{q}}$ (number of bait evidence), with results summarized in Figure 9.
There exists an “mutual reinforcement” effect. In both backdoor and targeted cases, with one budget fixed, slightly increasing the other significantly improves ROAR ${}_{\mathrm{co}}$ ’s performance. For instance, in backdoor cases, when $n_{\mathrm{g}}=0$ , increasing $n_{\mathrm{q}}$ from 0 to 1 leads to 0.44 improvement in HIT@ $5$ , while increasing $n_{\mathrm{g}}=50$ leads to HIT@ $5$ $=0.58$ . Further, we also observe that ROAR ${}_{\mathrm{co}}$ can easily approach the optimal performance under the setting of $n_{\mathrm{g}}∈[50,100]$ and $n_{\mathrm{q}}∈[1,2]$ , indicating that ROAR ${}_{\mathrm{co}}$ does not require large attack budgets due to the mutual reinforcement effect.
Large budgets may not always be desired. Also, observe that ROAR has degraded performance when $n_{\mathrm{g}}$ is too large (e.g., $n_{\mathrm{g}}=200$ in the backdoor attacks). This may be explained by that a large budget may incur many noisy poisoning facts that negatively interfere with each other. Recall that in knowledge poisoning, ROAR generates poisoning facts in a greedy manner (i.e., top- $n_{\mathrm{g}}$ facts with the highest fitness scores in Algorithm 1) without considering their interactions. Further, due to the gap between the input and latent spaces, the input-space approximation may introduce additional noise in the generated poisoning facts. Thus, the attack performance may not be a monotonic function of $n_{\mathrm{g}}$ . Note that due to the practical constraints of poisoning real-world KGs, $n_{\mathrm{g}}$ tends to be small in practice [56].
We also observe similar trends measured by MRR with results shown in Figure 13 in Appendix§ B.4.
6 Discussion
6.1 Surrogate KG Construction
We now discuss why building the surrogate KG is feasible. In practice, the target KG is often (partially) built upon some public sources (e.g., Web) and needs to be constantly updated [61]. The adversary may obtain such public information to build the surrogate KG. For instance, to keep up with the constant evolution of cyber threats, threat intelligence KGs often include new threat reports from threat blogs and news [28], which are also accessible to the adversary.
In the evaluation, we simulate the construction of the surrogate KG by randomly removing a fraction of facts from the target KG (50% by default). By controlling the overlapping ratio between the surrogate and target KGs (Figure 6), we show the impact of the knowledge about the target KG on the attack performance.
Zero-knowledge attacks. In the extreme case, the adversary has little knowledge about the target KG and thus cannot build a surrogate KG directly. However, if the query interface of KGR is publicly accessible (as in many cases [8, 2, 12]), the adversary is often able to retrieve subsets of entities and relations from the backend KG and construct a surrogate KG. Specifically, the adversary may use a breadth-first traversal approach to extract a sub-KG: beginning with a small set of entities, at each iteration, the adversary chooses an entity as the anchor and explores all possible relations by querying for entities linked to the anchor through a specific relation; if the query returns a valid response, the adversary adds the entity to the current sub-KG. We consider exploring zero-knowledge attacks as our ongoing work.
6.2 Potential countermeasures
We investigate two potential countermeasures tailored to knowledge poisoning and query misguiding.
<details>
<summary>x10.png Details</summary>
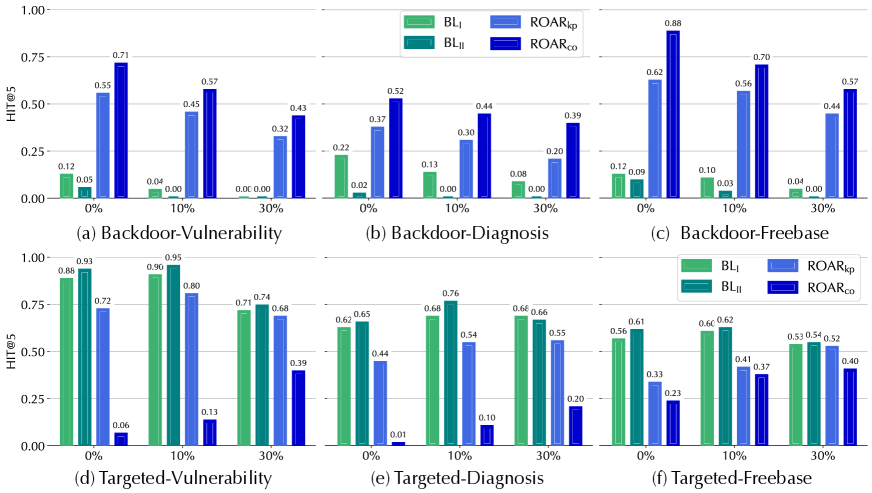
### Visual Description
## Bar Chart: Performance Comparison of Detection Methods
### Overview
The image presents a series of six bar charts comparing the performance of different detection methods (BL<sub>I</sub>, ROAR<sub>Kp</sub>, ROAR<sub>Co</sub>) across varying levels of data perturbation (0%, 10%, 30%). The performance metric used is HIT@5, representing the proportion of times the correct answer is within the top 5 predictions. The charts are organized into three categories: Backdoor-Vulnerability, Backdoor-Diagnosis, Backdoor-Freebase, and Targeted-Vulnerability, Targeted-Diagnosis, Targeted-Freebase.
### Components/Axes
* **X-axis:** Represents the percentage of data perturbation (0%, 10%, 30%).
* **Y-axis:** Represents the HIT@5 score, ranging from 0.00 to 1.00.
* **Legend:** Located at the top-center of the image, defines the color-coding for each detection method:
* BL<sub>I</sub> (Light Green)
* ROAR<sub>Kp</sub> (Green)
* ROAR<sub>Co</sub> (Light Blue)
* BL<sub>II</sub> (Dark Blue)
* **Sub-Titles:** Each chart has a sub-title indicating the specific scenario being evaluated (e.g., "(a) Backdoor-Vulnerability").
### Detailed Analysis or Content Details
**Chart (a): Backdoor-Vulnerability**
* **BL<sub>I</sub> (Light Green):** The bar slopes upward. Values are approximately: 0% - 0.12, 10% - 0.71, 30% - 0.45.
* **ROAR<sub>Kp</sub> (Green):** The bar slopes downward. Values are approximately: 0% - 0.55, 10% - 0.04, 30% - 0.00.
* **ROAR<sub>Co</sub> (Light Blue):** The bar slopes downward. Values are approximately: 0% - 0.57, 10% - 0.45, 30% - 0.32.
**Chart (b): Backdoor-Diagnosis**
* **BL<sub>I</sub> (Light Green):** The bar slopes upward. Values are approximately: 0% - 0.22, 10% - 0.52, 30% - 0.30.
* **ROAR<sub>Kp</sub> (Green):** The bar slopes downward. Values are approximately: 0% - 0.13, 10% - 0.44, 30% - 0.08.
* **ROAR<sub>Co</sub> (Light Blue):** The bar slopes downward. Values are approximately: 0% - 0.39, 10% - 0.20, 30% - 0.00.
**Chart (c): Backdoor-Freebase**
* **BL<sub>I</sub> (Light Green):** The bar slopes upward. Values are approximately: 0% - 0.12, 10% - 0.62, 30% - 0.44.
* **ROAR<sub>Kp</sub> (Green):** The bar slopes downward. Values are approximately: 0% - 0.88, 10% - 0.56, 30% - 0.10.
* **ROAR<sub>Co</sub> (Light Blue):** The bar slopes downward. Values are approximately: 0% - 0.70, 10% - 0.04, 30% - 0.00.
**Chart (d): Targeted-Vulnerability**
* **BL<sub>I</sub> (Light Green):** The bar slopes downward. Values are approximately: 0% - 0.88, 10% - 0.72, 30% - 0.68.
* **ROAR<sub>Kp</sub> (Green):** The bar slopes downward. Values are approximately: 0% - 0.96, 10% - 0.80, 30% - 0.39.
* **ROAR<sub>Co</sub> (Light Blue):** The bar slopes downward. Values are approximately: 0% - 0.06, 10% - 0.13, 30% - 0.00.
**Chart (e): Targeted-Diagnosis**
* **BL<sub>I</sub> (Light Green):** The bar slopes downward. Values are approximately: 0% - 0.65, 10% - 0.54, 30% - 0.55.
* **ROAR<sub>Kp</sub> (Green):** The bar slopes downward. Values are approximately: 0% - 0.76, 10% - 0.68, 30% - 0.20.
* **ROAR<sub>Co</sub> (Light Blue):** The bar slopes downward. Values are approximately: 0% - 0.44, 10% - 0.00, 30% - 0.00.
**Chart (f): Targeted-Freebase**
* **BL<sub>I</sub> (Light Green):** The bar slopes downward. Values are approximately: 0% - 0.56, 10% - 0.62, 30% - 0.52.
* **ROAR<sub>Kp</sub> (Green):** The bar slopes downward. Values are approximately: 0% - 0.33, 10% - 0.41, 30% - 0.37.
* **ROAR<sub>Co</sub> (Light Blue):** The bar slopes downward. Values are approximately: 0% - 0.23, 10% - 0.00, 30% - 0.40.
### Key Observations
* BL<sub>I</sub> generally performs better at higher perturbation levels (10% and 30%) in the Backdoor scenarios, while ROAR methods degrade.
* ROAR<sub>Kp</sub> and ROAR<sub>Co</sub> consistently show a decline in performance as the perturbation level increases.
* In the Targeted scenarios, BL<sub>I</sub> and ROAR<sub>Kp</sub> generally maintain higher HIT@5 scores, but still exhibit a decreasing trend with increasing perturbation.
* ROAR<sub>Co</sub> consistently has the lowest performance across all scenarios and perturbation levels.
### Interpretation
The data suggests that the BL<sub>I</sub> method is more robust to data perturbation in the Backdoor scenarios, while the ROAR methods are more susceptible to performance degradation. In the Targeted scenarios, BL<sub>I</sub> and ROAR<sub>Kp</sub> demonstrate better performance, but all methods are affected by increasing perturbation. This indicates that the robustness of detection methods varies depending on the type of attack (Backdoor vs. Targeted) and the level of data manipulation. The consistent poor performance of ROAR<sub>Co</sub> suggests it may not be an effective detection method in these scenarios. The decreasing trend in HIT@5 scores with increasing perturbation highlights the vulnerability of these methods to adversarial attacks that aim to disrupt the data distribution. The charts provide a comparative analysis of different detection strategies under varying conditions, offering insights into their strengths and weaknesses.
</details>
Figure 10: Attack performance (HIT@ $5$ ) on target queries ${\mathcal{Q}}^{*}$ . The measures are the absolute HIT@ $5$ after the attacks.
Filtering of poisoning facts. Intuitively, as they are artificially injected, poisoning facts tend to be misaligned with their neighboring entities/relations in KGs. Thus, we propose to detect misaligned facts and filter them out to mitigate the influence of poisoning facts. Specifically, we use Eq. 5 to measure the “fitness” of each fact $v\mathrel{\text{\scriptsize$\xrightarrow[]{r}$}}v^{\prime}$ and then remove $m\%$ of the facts with the lowest fitness scores.
<details>
<summary>x11.png Details</summary>

### Visual Description
\n
## 3D Surface Plots: Attack and Defense Budget Impact on Threat (H-Score)
### Overview
The image presents six 3D surface plots, each representing the relationship between "Attack budget" (x-axis), "Defense budget" (y-axis), and a threat metric "H-Score" (z-axis, represented by color). Each plot corresponds to a different scenario: (a) Backdoor-Vulnerability, (b) Backdoor-Diagnosis, (c) Backdoor-Freebase, (d) Targeted-Vulnerability, (e) Targeted-Diagnosis, and (f) Targeted-Freebase. The plots visualize how the H-Score changes as both attack and defense budgets are varied.
### Components/Axes
* **X-axis:** "Attack budget" - Scale ranges from 0 to 4.
* **Y-axis:** "Defense budget" - Scale ranges from 0 to 4.
* **Z-axis:** "H-Score" - Represented by the height of the surface and color gradient. The scale is not explicitly labeled, but values range approximately from 0 to 1.1.
* **Plots:** Six individual 3D surface plots, labeled (a) through (f) as described above.
* **Color Gradient:** A blue-to-red gradient is used to represent the H-Score, with blue indicating lower values and red indicating higher values.
### Detailed Analysis or Content Details
**Plot (a): Backdoor-Vulnerability**
* The surface generally slopes upwards from left to right and from back to front.
* The highest H-Score (approximately 0.99) is located near Attack budget = 4 and Defense budget = 4.
* The lowest H-Score (approximately 0.55) is located near Attack budget = 0 and Defense budget = 0.
* Notable data points: (0,0) = 0.55, (4,0) = 0.37, (0,4) = 0.8, (4,4) = 0.99.
**Plot (b): Backdoor-Diagnosis**
* The surface has a peak in the center, indicating a higher H-Score with moderate attack and defense budgets.
* The highest H-Score (approximately 0.7) is located near Attack budget = 2 and Defense budget = 2.
* The lowest H-Score (approximately 0.34) is located near Attack budget = 4 and Defense budget = 0.
* Notable data points: (0,0) = 0.38, (4,0) = 0.34, (0,4) = 0.62, (4,4) = 0.67, (2,2) = 0.7.
**Plot (c): Backdoor-Freebase**
* Similar to (b), this plot also exhibits a peak in the center.
* The highest H-Score (approximately 0.84) is located near Attack budget = 2 and Defense budget = 2.
* The lowest H-Score (approximately 0.51) is located near Attack budget = 4 and Defense budget = 0.
* Notable data points: (0,0) = 0.6, (4,0) = 0.51, (0,4) = 0.7, (4,4) = 0.72, (2,2) = 0.84.
**Plot (d): Targeted-Vulnerability**
* The surface slopes upwards from left to right, but is relatively flat.
* The highest H-Score (approximately 0.70) is located near Attack budget = 4 and Defense budget = 4.
* The lowest H-Score (approximately 0.02) is located near Attack budget = 0 and Defense budget = 0.
* Notable data points: (0,0) = 0.02, (4,0) = 0.1, (0,4) = 0.44, (4,4) = 0.70.
**Plot (e): Targeted-Diagnosis**
* The surface has a peak in the center, similar to (b) and (c).
* The highest H-Score (approximately 0.49) is located near Attack budget = 2 and Defense budget = 2.
* The lowest H-Score (approximately 0.00) is located near Attack budget = 4 and Defense budget = 0.
* Notable data points: (0,0) = 0.08, (4,0) = 0.00, (0,4) = 0.33, (4,4) = 0.40, (2,2) = 0.49.
**Plot (f): Targeted-Freebase**
* The surface has a peak in the center, similar to (b) and (c).
* The highest H-Score (approximately 0.35) is located near Attack budget = 2 and Defense budget = 2.
* The lowest H-Score (approximately 0.14) is located near Attack budget = 4 and Defense budget = 0.
* Notable data points: (0,0) = 0.22, (4,0) = 0.14, (0,4) = 0.33, (4,4) = 0.35, (2,2) = 0.35.
### Key Observations
* Plots (b), (c), and (e) all exhibit a peak in the center, suggesting that a moderate balance between attack and defense budgets results in the highest H-Score for those scenarios.
* Plots (a) and (d) show an increasing H-Score as both attack and defense budgets increase.
* The H-Scores are generally lower for the "Targeted" scenarios (d, e, f) compared to the "Backdoor" scenarios (a, b, c).
* The lowest H-Scores consistently occur when both attack and defense budgets are minimal.
### Interpretation
These plots demonstrate the impact of attack and defense budgets on the H-Score, a metric representing a threat level. The different scenarios (Backdoor vs. Targeted, and the specific knowledge source - Vulnerability, Diagnosis, Freebase) reveal varying vulnerabilities. The plots suggest that for "Backdoor" scenarios, increasing both attack and defense budgets generally increases the threat (H-Score), potentially indicating that defenses are being circumvented by more sophisticated attacks. Conversely, for "Targeted" scenarios, a balanced approach (moderate attack and defense) appears to be most vulnerable, possibly because targeted attacks are more effective when defenses are present but not overwhelming. The lower H-Scores in the "Targeted" scenarios overall suggest that these attacks are inherently less effective than "Backdoor" attacks, or that the scenarios are modeled differently. The peak in the center of plots (b), (c), and (e) suggests a sweet spot where a moderate level of both attack and defense leads to the highest threat, potentially because the defense provides enough information for a targeted attack to be successful. The data suggests that the optimal strategy for mitigating these threats depends heavily on the specific scenario and the nature of the attack.
</details>
Figure 11: Performance of ROAR ${}_{\mathrm{co}}$ against adversarial training with respect to varying settings of attack $n_{\mathrm{q}}$ and defense $n_{\mathrm{q}}$ (note: in targeted attacks, the attack performance is measured by the HIT@ $5$ drop).
Table 10 measures the KGR performance on non-target queries ${\mathcal{Q}}\setminus{\mathcal{Q}}^{*}$ and the Figure 10 measures attack performance on target queries ${\mathcal{Q}}^{*}$ as functions of $m$ . We have the following observations. (i) The filtering degrades the attack performance. For instance, the HIT@ $5$ of ROAR ${}_{\mathrm{kp}}$ drops by 0.23 in the backdoor attacks against vulnerability queries as $m$ increases from 10 to 30. (ii) Compared with ROAR ${}_{\mathrm{kp}}$ , ROAR ${}_{\mathrm{co}}$ is less sensitive to filtering, which is explained by its use of both knowledge poisoning and query misguiding, with one attack vector compensating for the other. (iii) The filtering also significantly impacts the KGR performance (e.g., its HIT@ $5$ drops by 0.28 under $m$ = 30), suggesting the inherent trade-off between attack resilience and KGR performance.
| Query | Removal ratio ( $m\%$ ) | | |
| --- | --- | --- | --- |
| 0% | 10% | 30% | |
| vulnerability | 1.00 | 0.93 | 0.72 |
| diagnosis | 0.87 | 0.84 | 0.67 |
| Freebase | 0.70 | 0.66 | 0.48 |
Table 10: KGR performance (HIT@ $5$ ) on non-target queries ${\mathcal{Q}}\setminus{\mathcal{Q}}^{*}$ .
Training with adversarial queries. We further extend the adversarial training [48] strategy to defend against ROAR ${}_{\mathrm{co}}$ . Specifically, we generate an adversarial version $q^{*}$ for each query $q$ using ROAR ${}_{\mathrm{co}}$ and add $(q^{*},\llbracket q\rrbracket)$ to the training set, where $\llbracket q\rrbracket$ is $q$ ’s ground-truth answer.
We measure the performance of ROAR ${}_{\mathrm{co}}$ under varying settings of $n_{\text{q}}$ used in ROAR ${}_{\mathrm{co}}$ and that used in adversarial training, with results shown in Figure 11. Observe that adversarial training degrades the attack performance against the backdoor attacks (Figure 11 a-c) especially when the defense $n_{\text{q}}$ is larger than the attack $n_{\text{q}}$ . However, the defense is much less effective on the targeted attacks (Figure 11 d-f). This can be explained by the larger attack surface of targeted attacks, which only need to force erroneous reasoning rather than backdoor reasoning. Further, it is inherently ineffective against ROAR ${}_{\mathrm{kp}}$ (when the attack $n_{\text{q}}=0$ in ROAR ${}_{\mathrm{co}}$ ), which does not rely on query misguiding.
We can thus conclude that, to defend against the threats to KGR, it is critical to (i) integrate multiple defense mechanisms and (ii) balance attack resilience and KGR performance.
6.3 Limitations
Other threat models and datasets. While ROAR instantiates several attacks in the threat taxonomy in § 3, there are many other possible attacks against KGR. For example, if the adversary has no knowledge about the KGs used in the KGR systems, is it possible to build surrogate KGs from scratch or construct attacks that transfer across different KG domains? Further, the properties of specific KGs (e.g., size, connectivity, and skewness) may potentially bias our findings. We consider exploring other threat models and datasets from other domains as our ongoing research.
Alternative reasoning tasks. We mainly focus on reasoning tasks with one target entity. There exist other reasoning tasks (e.g., path reasoning [67] finds a logical path with given starting and end entities). Intuitively, ROAR is ineffective in such tasks as it requires knowledge about the logical path to perturb intermediate entities on the path. It is worth exploring the vulnerability of such alternative reasoning tasks.
Input-space attacks. While ROAR directly operates on KGs (or queries), there are scenarios in which KGs (or queries) are extracted from real-world inputs. For instance, threat-hunting queries may be generated based on software testing and inspection. In such scenarios, it requires the perturbation to KGs (or queries) to be mapped to valid inputs (e.g., functional programs).
7 Related work
Machine learning security. Machine learning models are becoming the targets of various attacks [20]: adversarial evasion crafts adversarial inputs to deceive target models [31, 24]; model poisoning modifies target models’ behavior by polluting training data [39]; backdoor injection creates trojan models such that trigger-embedded inputs are misclassified [46, 43]; functionality stealing constructs replicate models functionally similar to victim models [64]. In response, intensive research is conducted on improving the attack resilience of machine learning models. For instance, existing work explores new training strategies (e.g., adversarial training) [48] and detection mechanisms [29, 42] against adversarial evasion. Yet, such defenses often fail when facing adaptive attacks [17, 45], resulting in a constant arms race.
Graph learning security. Besides general machine learning security, one line of work focuses on the vulnerability of graph learning [41, 65, 69], including adversarial [72, 66, 21], poisoning [73], and backdoor [68] attacks. This work differs from existing attacks against graph learning in several major aspects. (i) Data complexity – while KGs are special forms of graphs, they contain much richer relational information beyond topological structures. (ii) Attack objectives – we focus on attacking the logical reasoning task, whereas most existing attacks aim at the classification [72, 66, 73] or link prediction task [21]. (iii) Roles of graphs/KGs – we target KGR systems with KGs as backend knowledge bases while existing attacks assume graphs as input data to graph learning. (iv) Attack vectors – we generate plausible poisoning facts or bait evidence, which are specifically applicable to KGR; in contrast, previous attacks directly perturb graph structures [66, 21, 73] or node features [72, 68].
Knowledge graph security. The security risks of KGs are gaining growing attention [70, 19, 18, 54, 56]. Yet, most existing work focuses on the task of link prediction (KG completion) and the attack vector of directly modifying KGs. This work departs from prior work in major aspects: (i) we consider reasoning tasks (e.g., processing logical queries), which require vastly different processing from predictive tasks (details in Section § 2); (ii) existing attacks rely on directly modifying the topological structures of KGs (e.g., adding/deleting edges) without accounting for their semantics, while we assume the adversary influences KGR through indirect means with semantic constraints (e.g., injecting probable relations or showing misleading evidence); (iii) we evaluate the attacks in real-world KGR applications; and (iv) we explore potential countermeasures against the proposed attacks.
8 Conclusion
This work represents a systematic study of the security risks of knowledge graph reasoning (KGR). We present ROAR, a new class of attacks that instantiate a variety of threats to KGR. We demonstrate the practicality of ROAR in domain-specific and general KGR applications, raising concerns about the current practice of training and operating KGR. We also discuss potential mitigation against ROAR, which sheds light on applying KGR in a more secure manner.
References
- [1] CVE Details. https://www.cvedetails.com.
- [2] Cyscale Complete cloud visibility & control platform. https://cyscale.com.
- [3] DRKG - Drug Repurposing Knowledge Graph for Covid-19. https://github.com/gnn4dr/DRKG/.
- [4] DrugBank. https://go.drugbank.com.
- [5] Freebase (database). https://en.wikipedia.org/wiki/Freebase_(database).
- [6] Gartner Identifies Top 10 Data and Analytics Technology Trends for 2021. https://www.gartner.com/en/newsroom/press-releases/2021-03-16-gartner-identifies-top-10-data-and-analytics-technologies-trends-for-2021.
- [7] Hetionet. https://het.io.
- [8] Knowledge Graph Search API. https://developers.google.com/knowledge-graph.
- [9] Logrhythm MITRE ATT&CK Module. https://docs.logrhythm.com/docs/kb/threat-detection.
- [10] MITRE ATT&CK. https://attack.mitre.org.
- [11] National Vulnerability Database. https://nvd.nist.gov.
- [12] QIAGEN Clinical Analysis and Interpretation Services. https://digitalinsights.qiagen.com/services-overview/clinical-analysis-and-interpretation-services/.
- [13] The QIAGEN Knowledge Base. https://resources.qiagenbioinformatics.com/flyers-and-brochures/QIAGEN_Knowledge_Base.pdf.
- [14] YAGO: A High-Quality Knowledge Base. https://yago-knowledge.org/.
- [15] Manos Antonakakis, Tim April, Michael Bailey, Matt Bernhard, Elie Bursztein, Jaime Cochran, Zakir Durumeric, J. Alex Halderman, Luca Invernizzi, Michalis Kallitsis, Deepak Kumar, Chaz Lever, Zane Ma, Joshua Mason, Damian Menscher, Chad Seaman, Nick Sullivan, Kurt Thomas, and Yi Zhou. Understanding the Mirai Botnet. In Proceedings of USENIX Security Symposium (SEC), 2017.
- [16] Erik Arakelyan, Daniel Daza, Pasquale Minervini, and Michael Cochez. Complex Query Answering with Neural Link Predictors. In Proceedings of International Conference on Learning Representations (ICLR), 2021.
- [17] Anish Athalye, Nicholas Carlini, and David Wagner. Obfuscated Gradients Give a False Sense of Security: Circumventing Defenses to Adversarial Examples. In Proceedings of IEEE Conference on Machine Learning (ICML), 2018.
- [18] Peru Bhardwaj, John Kelleher, Luca Costabello, and Declan O’Sullivan. Adversarial Attacks on Knowledge Graph Embeddings via Instance Attribution Methods. Proceedings of Conference on Empirical Methods in Natural Language Processing (EMNLP), 2021.
- [19] Peru Bhardwaj, John Kelleher, Luca Costabello, and Declan O’Sullivan. Poisoning Knowledge Graph Embeddings via Relation Inference Patterns. ArXiv e-prints, 2021.
- [20] Battista Biggio and Fabio Roli. Wild Patterns: Ten Years after The Rise of Adversarial Machine Learning. Pattern Recognition, 84:317–331, 2018.
- [21] Aleksandar Bojchevski and Stephan Günnemann. Adversarial Attacks on Node Embeddings via Graph Poisoning. In Proceedings of IEEE Conference on Machine Learning (ICML), 2019.
- [22] Antoine Bordes, Nicolas Usunier, Alberto Garcia-Durán, Jason Weston, and Oksana Yakhnenko. Translating Embeddings for Modeling Multi-Relational Data. In Proceedings of Advances in Neural Information Processing Systems (NeurIPS), 2013.
- [23] Nicholas Carlini, Matthew Jagielski, Christopher A Choquette-Choo, Daniel Paleka, Will Pearce, Hyrum Anderson, Andreas Terzis, Kurt Thomas, and Florian Tramèr. Poisoning Web-Scale Training Datasets is Practical. In ArXiv e-prints, 2023.
- [24] Nicholas Carlini and David A. Wagner. Towards Evaluating the Robustness of Neural Networks. In Proceedings of IEEE Symposium on Security and Privacy (S&P), 2017.
- [25] Antonio Emanuele Cinà, Kathrin Grosse, Ambra Demontis, Sebastiano Vascon, Werner Zellinger, Bernhard A Moser, Alina Oprea, Battista Biggio, Marcello Pelillo, and Fabio Roli. Wild Patterns Reloaded: A Survey of Machine Learning Security against Training Data Poisoning. In ArXiv e-prints, 2022.
- [26] The Conversation. Study Shows AI-generated Fake Cybersecurity Reports Fool Experts. https://theconversation.com/study-shows-ai-generated-fake-reports-fool-experts-160909.
- [27] Nilesh Dalvi and Dan Suciu. Efficient Query Evaluation on Probabilistic Databases. The VLDB Journal, 2007.
- [28] Peng Gao, Fei Shao, Xiaoyuan Liu, Xusheng Xiao, Zheng Qin, Fengyuan Xu, Prateek Mittal, Sanjeev R Kulkarni, and Dawn Song. Enabling Efficient Cyber Threat Hunting with Cyber Threat Intelligence. In Proceedings of International Conference on Data Engineering (ICDE), 2021.
- [29] Timon Gehr, Matthew Mirman, Dana Drachsler-Cohen, Petar Tsankov, Swarat Chaudhuri, and Martin Vechev. AI2: Safety and Robustness Certification of Neural Networks with Abstract Interpretation. In Proceedings of IEEE Symposium on Security and Privacy (S&P), 2018.
- [30] Fan Gong, Meng Wang, Haofen Wang, Sen Wang, and Mengyue Liu. SMR: Medical Knowledge Graph Embedding for Safe Medicine Recommendation. Big Data Research, 2021.
- [31] Ian Goodfellow, Jonathon Shlens, and Christian Szegedy. Explaining and Harnessing Adversarial Examples. In Proceedings of International Conference on Learning Representations (ICLR), 2015.
- [32] Kelvin Guu, John Miller, and Percy Liang. Traversing Knowledge Graphs in Vector Space. In Proceedings of Conference on Empirical Methods in Natural Language Processing (EMNLP), 2015.
- [33] William L. Hamilton, Payal Bajaj, Marinka Zitnik, Dan Jurafsky, and Jure Leskovec. Embedding Logical Queries on Knowledge Graphs. In Proceedings of Advances in Neural Information Processing Systems (NeurIPS), 2018.
- [34] Wajih Ul Hassan, Adam Bates, and Daniel Marino. Tactical Provenance Analysis for Endpoint Detection and Response Systems. In Proceedings of IEEE Symposium on Security and Privacy (S&P), 2020.
- [35] Shizhu He, Kang Liu, Guoliang Ji, and Jun Zhao. Learning to Represent Knowledge Graphs with Gaussian Embedding. In Proceeddings of ACM Conference on Information and Knowledge Management (CIKM), 2015.
- [36] Erik Hemberg, Jonathan Kelly, Michal Shlapentokh-Rothman, Bryn Reinstadler, Katherine Xu, Nick Rutar, and Una-May O’Reilly. Linking Threat Tactics, Techniques, and Patterns with Defensive Weaknesses, Vulnerabilities and Affected Platform Configurations for Cyber Hunting. ArXiv e-prints, 2020.
- [37] Keman Huang, Michael Siegel, and Stuart Madnick. Systematically Understanding the Cyber Attack Business: A Survey. ACM Computing Surveys (CSUR), 2018.
- [38] Haozhe Ji, Pei Ke, Shaohan Huang, Furu Wei, Xiaoyan Zhu, and Minlie Huang. Language Generation with Multi-hop Reasoning on Commonsense Knowledge Graph. In Proceedings of Conference on Empirical Methods in Natural Language Processing (EMNLP), 2020.
- [39] Yujie Ji, Xinyang Zhang, Shouling Ji, Xiapu Luo, and Ting Wang. Model-Reuse Attacks on Deep Learning Systems. In Proceedings of ACM Conference on Computer and Communications (CCS), 2018.
- [40] Peter E Kaloroumakis and Michael J Smith. Toward a Knowledge Graph of Cybersecurity Countermeasures. The MITRE Corporation, 2021.
- [41] Thomas N. Kipf and Max Welling. Semi-Supervised Classification with Graph Convolutional Networks. In Proceedings of International Conference on Learning Representations (ICLR), 2017.
- [42] Changjiang Li, Shouling Ji, Haiqin Weng, Bo Li, Jie Shi, Raheem Beyah, Shanqing Guo, Zonghui Wang, and Ting Wang. Towards Certifying the Asymmetric Robustness for Neural Networks: Quantification and Applications. IEEE Transactions on Dependable and Secure Computing, 19(6):3987–4001, 2022.
- [43] Changjiang Li, Ren Pang, Zhaohan Xi, Tianyu Du, Shouling Ji, Yuan Yao, and Ting Wang. Demystifying Self-supervised Trojan Attacks. 2022.
- [44] Bill Yuchen Lin, Xinyue Chen, Jamin Chen, and Xiang Ren. Kagnet: Knowledge-aware Graph Networks for Commonsense Reasoning. In Proceedings of Conference on Empirical Methods in Natural Language Processing (EMNLP), 2019.
- [45] Xiang Ling, Shouling Ji, Jiaxu Zou, Jiannan Wang, Chunming Wu, Bo Li, and Ting Wang. DEEPSEC: A Uniform Platform for Security Analysis of Deep Learning Model. In Proceedings of IEEE Symposium on Security and Privacy (S&P), 2019.
- [46] Yingqi Liu, Shiqing Ma, Yousra Aafer, Wen-Chuan Lee, Juan Zhai, Weihang Wang, and Xiangyu Zhang. Trojaning Attack on Neural Networks. In Proceedings of Network and Distributed System Security Symposium (NDSS), 2018.
- [47] Logrhythm. Using MITRE ATT&CK in Threat Hunting and Detection. https://logrhythm.com/uws-using-mitre-attack-in-threat-hunting-and-detection-white-paper/.
- [48] Aleksander Madry, Aleksandar Makelov, Ludwig Schmidt, Dimitris Tsipras, and Adrian Vladu. Towards Deep Learning Models Resistant to Adversarial Attacks. In Proceedings of International Conference on Learning Representations (ICLR), 2018.
- [49] Fabrizio Mafessoni, Rashmi B Prasad, Leif Groop, Ola Hansson, and Kay Prüfer. Turning Vice into Virtue: Using Batch-effects to Detect Errors in Large Genomic Data Sets. Genome biology and evolution, 10(10):2697–2708, 2018.
- [50] Sadegh M Milajerdi, Rigel Gjomemo, Birhanu Eshete, Ramachandran Sekar, and VN Venkatakrishnan. Holmes: Real-time APT Detection through Correlation of Suspicious Information Flows. In Proceedings of IEEE Symposium on Security and Privacy (S&P), 2019.
- [51] Shaswata Mitra, Aritran Piplai, Sudip Mittal, and Anupam Joshi. Combating Fake Cyber Threat Intelligence Using Provenance in Cybersecurity Knowledge Graphs. In 2021 IEEE International Conference on Big Data (Big Data). IEEE, 2021.
- [52] Sudip Mittal, Anupam Joshi, and Tim Finin. Cyber-all-intel: An AI for Security Related Threat Intelligence. In ArXiv e-prints, 2019.
- [53] Bethany Percha and Russ B Altman. A Global Network of Biomedical Relationships Derived from Text. Bioinformatics, 2018.
- [54] Pouya Pezeshkpour, Yifan Tian, and Sameer Singh. Investigating Robustness and Interpretability of Link Prediction via Adversarial Modifications. ArXiv e-prints, 2019.
- [55] Radware. “BrickerBot” Results In Permanent Denial-of-Service. https://www.radware.com/security/ddos-threats-attacks/brickerbot-pdos-permanent-denial-of-service/.
- [56] Mrigank Raman, Aaron Chan, Siddhant Agarwal, Peifeng Wang, Hansen Wang, Sungchul Kim, Ryan Rossi, Handong Zhao, Nedim Lipka, and Xiang Ren. Learning to Deceive Knowledge Graph Augmented Models via Targeted Perturbation. Proceedings of International Conference on Learning Representations (ICLR), 2021.
- [57] Priyanka Ranade, Aritran Piplai, Sudip Mittal, Anupam Joshi, and Tim Finin. Generating Fake Cyber Threat Intelligence Using Transformer-based Models. In 2021 International Joint Conference on Neural Networks (IJCNN). IEEE, 2021.
- [58] Hongyu Ren, Hanjun Dai, Bo Dai, Xinyun Chen, Michihiro Yasunaga, Haitian Sun, Dale Schuurmans, Jure Leskovec, and Denny Zhou. LEGO: Latent Execution-Guided Reasoning for Multi-Hop Question Answering on Knowledge Graphs. In Proceedings of IEEE Conference on Machine Learning (ICML), 2021.
- [59] Hongyu Ren, Weihua Hu, and Jure Leskovec. Query2box: Reasoning over Knowledge Graphs in Vector Space using Box Embeddings. In Proceedings of International Conference on Learning Representations (ICLR), 2020.
- [60] Hongyu Ren and Jure Leskovec. Beta Embeddings for Multi-Hop Logical Reasoning in Knowledge Graphs. In Proceedings of Advances in Neural Information Processing Systems (NeurIPS), 2020.
- [61] Anderson Rossanez, Julio Cesar dos Reis, Ricardo da Silva Torres, and Hèléne de Ribaupierre. KGen: A Knowledge Graph Generator from Biomedical Scientific Literature. BMC Medical Informatics and Decision Making, 20(4):314, 2020.
- [62] Alberto Santos, Ana R Colaço, Annelaura B Nielsen, Lili Niu, Maximilian Strauss, Philipp E Geyer, Fabian Coscia, Nicolai J Wewer Albrechtsen, Filip Mundt, Lars Juhl Jensen, et al. A Knowledge Graph to Interpret Clinical Proteomics Data. Nature Biotechnology, 2022.
- [63] Komal Teru, Etienne Denis, and Will Hamilton. Inductive Relation Prediction by Subgraph Reasoning. In Proceedings of IEEE Conference on Machine Learning (ICML), 2020.
- [64] Florian Tramèr, Fan Zhang, Ari Juels, Michael K. Reiter, and Thomas Ristenpart. Stealing Machine Learning Models via Prediction APIs. In Proceedings of USENIX Security Symposium (SEC), 2016.
- [65] Petar Veličković, Guillem Cucurull, Arantxa Casanova, Adriana Romero, Pietro Liò, and Yoshua Bengio. Graph Attention Networks. In Proceedings of International Conference on Learning Representations (ICLR), 2018.
- [66] Binghui Wang and Neil Zhenqiang Gong. Attacking Graph-based Classification via Manipulating the Graph Structure. In Proceedings of ACM SAC Conference on Computer and Communications (CCS), 2019.
- [67] Xiang Wang, Dingxian Wang, Canran Xu, Xiangnan He, Yixin Cao, and Tat-Seng Chua. Explainable Reasoning over Knowledge Graphs for Recommendation. In Proceedings of AAAI Conference on Artificial Intelligence (AAAI), 2019.
- [68] Zhaohan Xi, Ren Pang, Shouling Ji, and Ting Wang. Graph backdoor. In Proceedings of USENIX Security Symposium (SEC), 2021.
- [69] Kaidi Xu, Hongge Chen, Sijia Liu, Pin-Yu Chen, Tsui-Wei Weng, Mingyi Hong, and Xue Lin. Topology Attack and Defense for Graph Neural Networks: An Optimization Perspective. In Proceedings of International Joint Conference on Artificial Intelligence (IJCAI), 2019.
- [70] Hengtong Zhang, Tianhang Zheng, Jing Gao, Chenglin Miao, Lu Su, Yaliang Li, and Kui Ren. Data Poisoning Attack against Knowledge Graph Embedding. In Proceedings of International Joint Conference on Artificial Intelligence (IJCAI), 2019.
- [71] Yongjun Zhu, Chao Che, Bo Jin, Ningrui Zhang, Chang Su, and Fei Wang. Knowledge-driven drug repurposing using a comprehensive drug knowledge graph. Health Informatics Journal, 2020.
- [72] Daniel Zügner, Amir Akbarnejad, and Stephan Günnemann. Adversarial Attacks on Neural Networks for Graph Data. In Proceedings of ACM International Conference on Knowledge Discovery and Data Mining (KDD), 2018.
- [73] Daniel Zügner and Stephan Günnemann. Adversarial Attacks on Graph Neural Networks via Meta Learning. In Proceedings of International Conference on Learning Representations (ICLR), 2019.
Appendix A Notations
Table 11 summarizes notations and definitions used through this paper.
| Notation | Definition |
| --- | --- |
| Knowledge graph related | |
| ${\mathcal{G}}$ | a knowledge graph (KG) |
| ${\mathcal{G}}^{\prime}$ | a surrogate knowledge graph |
| $\langle v,r,v^{\prime}\rangle$ | a KG fact from entity $v$ to $v^{\prime}$ with relation $r$ |
| ${\mathcal{N}},{\mathcal{E}},{\mathcal{R}}$ | entity, edge, and relation set of ${\mathcal{G}}$ |
| ${\mathcal{G}}^{+}$ | the poisoning facts on KG |
| Query related | |
| $q$ | a single query |
| $\llbracket q\rrbracket$ | $q$ ’s ground-truth answer(s) |
| $a^{*}$ | the targeted answer |
| ${\mathcal{A}}_{q}$ | anchor entities of query $q$ |
| $p^{*}$ | the trigger pattern |
| ${\mathcal{Q}}$ | a query set |
| ${\mathcal{Q}}^{*}$ | a query set of interest (each $q∈{\mathcal{Q}}^{*}$ contains $p^{*}$ ) |
| $q^{+}$ | the generated bait evidence |
| $q^{*}$ | the infected query, i.e. $q^{*}=q\wedge q^{+}$ |
| Model or embedding related | |
| $\phi$ | a general symbol to represent embeddings |
| $\phi_{{\mathcal{G}}}$ | embeddings of all KG entities |
| $\phi_{v}$ | entity $v$ ’s embedding |
| $\phi_{q}$ | $q$ ’s embedding |
| $\phi_{{\mathcal{G}}^{+}}$ | embeddings we aim to perturb |
| $\phi_{q^{+}}$ | $q^{+}$ ’s embedding |
| $\psi$ | the logical operator(s) |
| $\psi_{r}$ | the relation ( $r$ )-specific operator |
| $\psi_{\wedge}$ | the intersection operator |
| Other parameters | |
| $n_{\mathrm{g}}$ | knowledge poisoning budget |
| $n_{\mathrm{q}}$ | query misguiding budget |
Table 11: Notations, definitions, and categories.
Appendix B Additonal details
B.1 KGR training
Following [59], we train KGR in an end-to-end manner. Specifically, given KG ${\mathcal{G}}$ and the randomly initialized embedding function $\phi$ and transformation function $\psi$ , we sample a set of query-answer pairs $(q,\llbracket q\rrbracket)$ from ${\mathcal{G}}$ to form the training set and optimize $\phi$ and $\psi$ to minimize the loss function, which is defined as the embedding distance between the prediction regarding each $q$ and $\llbracket q\rrbracket$ .
B.2 Parameter setting
Table 12 lists the default parameter setting used in § 5.
| Type | Parameter | Setting |
| --- | --- | --- |
| KGR | $\phi$ dimension | 300 |
| $\phi$ dimension (surrogate) | 200 | |
| $\psi_{r}$ architecture | 4-layer FC | |
| $\psi_{\wedge}$ architecture | 4-layer FC | |
| $\psi_{r}$ architecture (surrogate) | 2-layer FC | |
| $\psi_{\wedge}$ architecture (surrogate) | 2-layer FC | |
| Training | Learning rate | 0.001 |
| Batch size | 512 | |
| KGR epochs | 50000 | |
| ROAR optimization epochs | 10000 | |
| Optimizer (KGR and ROAR) | Adam | |
| Other | $n_{\mathrm{g}}$ | 100 |
| $n_{\mathrm{q}}$ | 2 | |
Table 12: Default parameter setting.
B.3 Extension to targeted attacks
It is straightforward to extend ROAR to targeted attacks, in which the adversary aims to simply force KGR to make erroneous reasoning over the target queries ${\mathcal{Q}}^{*}$ . To this end, we may maximize the distance between the embedding $\phi_{q}$ of each query $q∈{\mathcal{Q}}^{*}$ and its ground-truth answer $\llbracket q\rrbracket$ .
Specifically, in knowledge poisoning, we re-define the loss function in Eq. 4 as:
$$
\begin{split}\ell_{\text{kp}}(\phi_{{\mathcal{G}}^{+}})=\,&\mathbb{E}_{q\in{%
\mathcal{Q}}\setminus{\mathcal{Q}}^{*}}\Delta(\psi(q;\phi_{{\mathcal{G}}^{+}})%
,\phi_{\llbracket q\rrbracket})-\\
&\lambda\mathbb{E}_{q\in{\mathcal{Q}}^{*}}\Delta(\psi(q;\phi_{{\mathcal{G}}^{+%
}}),\phi_{\llbracket q\rrbracket})\end{split} \tag{8}
$$
In query misguiding, we re-define Eq. 6 as:
$$
\ell_{\text{qm}}(\phi_{q^{+}})=-\Delta(\psi_{\wedge}(\phi_{q},\phi_{q^{+}}),\,%
\phi_{\llbracket q\rrbracket}) \tag{9}
$$
The remaining steps are the same as the backdoor attacks.
B.4 Additional results
This part shows the additional experiments as the complement of section§ 5.
Additional query tasks under variant surrogate KGs. Figure 12 presents the attack performance on other query tasks that are not included in Figure 6. We can observe a similar trend as concluded in§ 5.
MRR results. Figure 14 shows the MRR of ROAR ${}_{\mathrm{co}}$ with respect to different query structures, with observations similar to Figure 7. Figure 13 shows the MRR of ROAR with respect to attack budgets ( $n_{\mathrm{g}}$ , $n_{\mathrm{q}}$ ), with observations similar to Figure 9.
<details>
<summary>x12.png Details</summary>
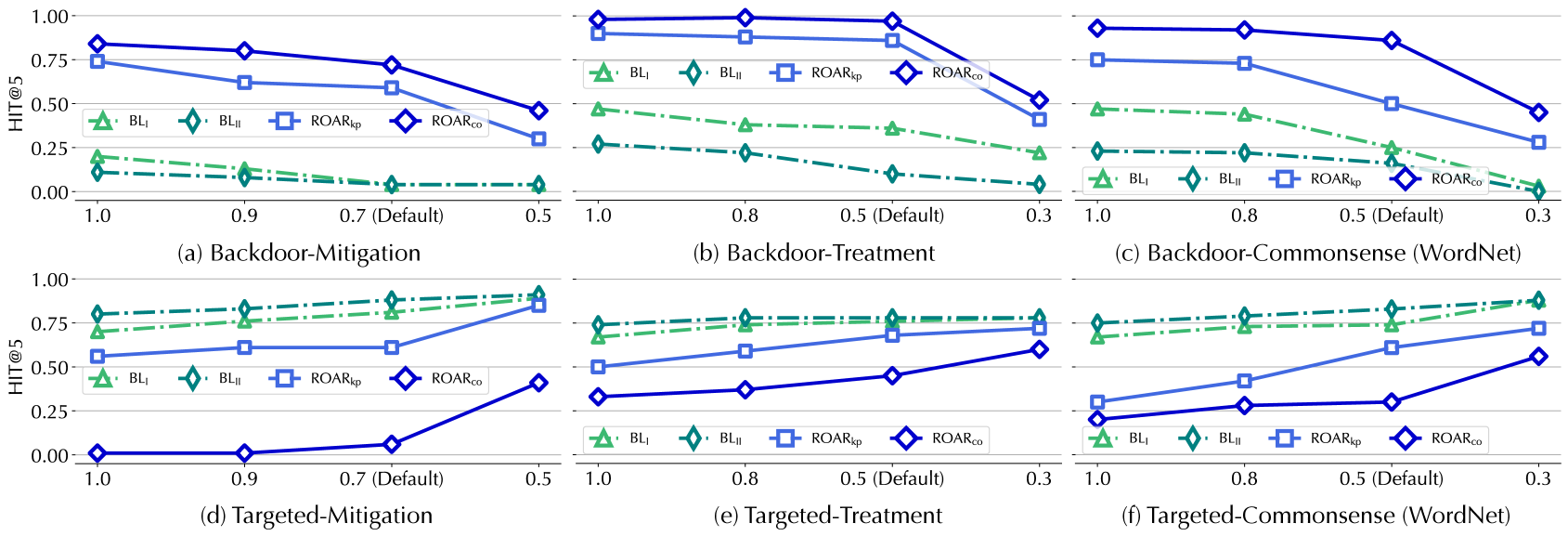
### Visual Description
\n
## Line Chart: Performance Comparison of Backdoor Attacks and Defenses
### Overview
The image presents six line charts, arranged in a 2x3 grid, comparing the performance of different backdoor attack and defense strategies. The charts plot the "HIT@5" metric (likely representing the hit rate within the top 5 predictions) against varying levels of a parameter, presumably a perturbation strength or attack intensity. Each chart focuses on a specific scenario: Backdoor-Mitigation, Backdoor-Treatment, Backdoor-Commonsense (WordNet), Targeted-Mitigation, Targeted-Treatment, and Targeted-Commonsense (WordNet). Four different methods are compared within each scenario: BL<sub>I</sub>, BL<sub>U</sub>, ROAR<sub>Ip</sub>, and ROAR<sub>Co</sub>.
### Components/Axes
* **Y-axis:** "HIT@5" - Ranges from 0.0 to 1.0, with increments of 0.25.
* **X-axis:** Values vary across the charts, but include 1.0, 0.9, 0.7 (labeled "Default"), and 0.5 (in the top row) or 0.8, 0.5 (labeled "Default"), and 0.3 (in the bottom row).
* **Lines:** Represent the performance of different methods.
* BL<sub>I</sub> (Blue Square)
* BL<sub>U</sub> (Blue Diamond)
* ROAR<sub>Ip</sub> (Yellow Circle)
* ROAR<sub>Co</sub> (Green Triangle)
* **Legends:** Located in the top-right corner of each chart, identifying each line by its corresponding symbol and label.
* **Chart Titles:** Located below each chart, indicating the specific scenario being evaluated: (a) Backdoor-Mitigation, (b) Backdoor-Treatment, (c) Backdoor-Commonsense (WordNet), (d) Targeted-Mitigation, (e) Targeted-Treatment, (f) Targeted-Commonsense (WordNet).
### Detailed Analysis or Content Details
**Chart (a) Backdoor-Mitigation:**
* BL<sub>I</sub>: Starts at approximately 0.85, decreases to 0.75 at 0.9, remains relatively stable at 0.75 at 0.7 (Default), and then decreases to 0.65 at 0.5.
* BL<sub>U</sub>: Starts at approximately 0.75, decreases to 0.65 at 0.9, remains relatively stable at 0.65 at 0.7 (Default), and then decreases to 0.55 at 0.5.
* ROAR<sub>Ip</sub>: Starts at approximately 0.25, remains relatively stable at 0.25 at 0.9, remains relatively stable at 0.25 at 0.7 (Default), and then decreases to 0.20 at 0.5.
* ROAR<sub>Co</sub>: Starts at approximately 0.05, remains relatively stable at 0.05 at 0.9, remains relatively stable at 0.05 at 0.7 (Default), and then decreases to 0.00 at 0.5.
**Chart (b) Backdoor-Treatment:**
* BL<sub>I</sub>: Starts at approximately 0.90, decreases to 0.80 at 0.9, remains relatively stable at 0.80 at 0.7 (Default), and then decreases to 0.70 at 0.5.
* BL<sub>U</sub>: Starts at approximately 0.80, decreases to 0.70 at 0.9, remains relatively stable at 0.70 at 0.7 (Default), and then decreases to 0.60 at 0.5.
* ROAR<sub>Ip</sub>: Starts at approximately 0.30, remains relatively stable at 0.30 at 0.9, remains relatively stable at 0.30 at 0.7 (Default), and then decreases to 0.25 at 0.5.
* ROAR<sub>Co</sub>: Starts at approximately 0.10, remains relatively stable at 0.10 at 0.9, remains relatively stable at 0.10 at 0.7 (Default), and then decreases to 0.05 at 0.5.
**Chart (c) Backdoor-Commonsense (WordNet):**
* BL<sub>I</sub>: Starts at approximately 0.90, decreases to 0.80 at 0.9, remains relatively stable at 0.80 at 0.7 (Default), and then decreases to 0.70 at 0.3.
* BL<sub>U</sub>: Starts at approximately 0.80, decreases to 0.70 at 0.9, remains relatively stable at 0.70 at 0.7 (Default), and then decreases to 0.60 at 0.3.
* ROAR<sub>Ip</sub>: Starts at approximately 0.30, remains relatively stable at 0.30 at 0.9, remains relatively stable at 0.30 at 0.7 (Default), and then decreases to 0.25 at 0.3.
* ROAR<sub>Co</sub>: Starts at approximately 0.10, remains relatively stable at 0.10 at 0.9, remains relatively stable at 0.10 at 0.7 (Default), and then decreases to 0.05 at 0.3.
**Chart (d) Targeted-Mitigation:**
* BL<sub>I</sub>: Starts at approximately 0.80, decreases to 0.70 at 0.9, remains relatively stable at 0.70 at 0.7 (Default), and then decreases to 0.60 at 0.5.
* BL<sub>U</sub>: Starts at approximately 0.70, decreases to 0.60 at 0.9, remains relatively stable at 0.60 at 0.7 (Default), and then decreases to 0.50 at 0.5.
* ROAR<sub>Ip</sub>: Starts at approximately 0.80, decreases to 0.70 at 0.9, remains relatively stable at 0.70 at 0.7 (Default), and then decreases to 0.60 at 0.5.
* ROAR<sub>Co</sub>: Starts at approximately 0.70, decreases to 0.60 at 0.9, remains relatively stable at 0.60 at 0.7 (Default), and then decreases to 0.50 at 0.5.
**Chart (e) Targeted-Treatment:**
* BL<sub>I</sub>: Starts at approximately 0.85, decreases to 0.75 at 0.9, remains relatively stable at 0.75 at 0.7 (Default), and then decreases to 0.65 at 0.5.
* BL<sub>U</sub>: Starts at approximately 0.75, decreases to 0.65 at 0.9, remains relatively stable at 0.65 at 0.7 (Default), and then decreases to 0.55 at 0.5.
* ROAR<sub>Ip</sub>: Starts at approximately 0.35, remains relatively stable at 0.35 at 0.9, remains relatively stable at 0.35 at 0.7 (Default), and then decreases to 0.30 at 0.5.
* ROAR<sub>Co</sub>: Starts at approximately 0.15, remains relatively stable at 0.15 at 0.9, remains relatively stable at 0.15 at 0.7 (Default), and then decreases to 0.10 at 0.5.
**Chart (f) Targeted-Commonsense (WordNet):**
* BL<sub>I</sub>: Starts at approximately 0.90, decreases to 0.80 at 0.9, remains relatively stable at 0.80 at 0.7 (Default), and then decreases to 0.70 at 0.3.
* BL<sub>U</sub>: Starts at approximately 0.80, decreases to 0.70 at 0.9, remains relatively stable at 0.70 at 0.7 (Default), and then decreases to 0.60 at 0.3.
* ROAR<sub>Ip</sub>: Starts at approximately 0.30, remains relatively stable at 0.30 at 0.9, remains relatively stable at 0.30 at 0.7 (Default), and then decreases to 0.25 at 0.3.
* ROAR<sub>Co</sub>: Starts at approximately 0.10, remains relatively stable at 0.10 at 0.9, remains relatively stable at 0.10 at 0.7 (Default), and then decreases to 0.05 at 0.3.
### Key Observations
* Generally, increasing the parameter value (moving from 1.0 to 0.3) leads to a decrease in HIT@5 for all methods.
* BL<sub>I</sub> and BL<sub>U</sub> consistently outperform ROAR<sub>Ip</sub> and ROAR<sub>Co</sub> across all scenarios.
* ROAR<sub>Co</sub> consistently exhibits the lowest HIT@5 values, indicating the least effective performance.
* The "Default" value (0.7 or 0.5) often represents a point of inflection, where the rate of performance decline changes.
### Interpretation
The charts demonstrate the effectiveness of different defense mechanisms (BL<sub>I</sub>, BL<sub>U</sub>, ROAR<sub>Ip</sub>, ROAR<sub>Co</sub>) against various backdoor attacks (Mitigation, Treatment, Commonsense) under both standard and targeted attack settings. The HIT@5 metric provides a measure of how well the models maintain their accuracy when faced with these attacks.
The consistent superior performance of BL<sub>I</sub> and BL<sub>U</sub> suggests that these methods are more robust against the evaluated backdoor attacks. Conversely, ROAR<sub>Co</sub> appears to be the least effective, potentially indicating vulnerabilities in its design or implementation.
The decreasing HIT@5 values as the parameter increases suggest that the attack strength or perturbation level negatively impacts the model's performance. The "Default" value likely represents a balance between attack strength and model robustness.
The distinction between "Mitigation," "Treatment," and "Commonsense" scenarios, along with the "Targeted" variations, highlights the importance of considering the specific attack strategy when selecting a defense mechanism. The WordNet component suggests the use of semantic knowledge to improve robustness. The charts provide valuable insights for researchers and practitioners seeking to develop and deploy effective defenses against backdoor attacks in machine learning systems.
</details>
Figure 12: ROAR ${}_{\mathrm{kp}}$ and ROAR ${}_{\mathrm{co}}$ performance with varying overlapping ratios between the surrogate and target KGs, measured by HIT@ $5$ after the attacks on other query tasks besides Figure 6.
<details>
<summary>x13.png Details</summary>
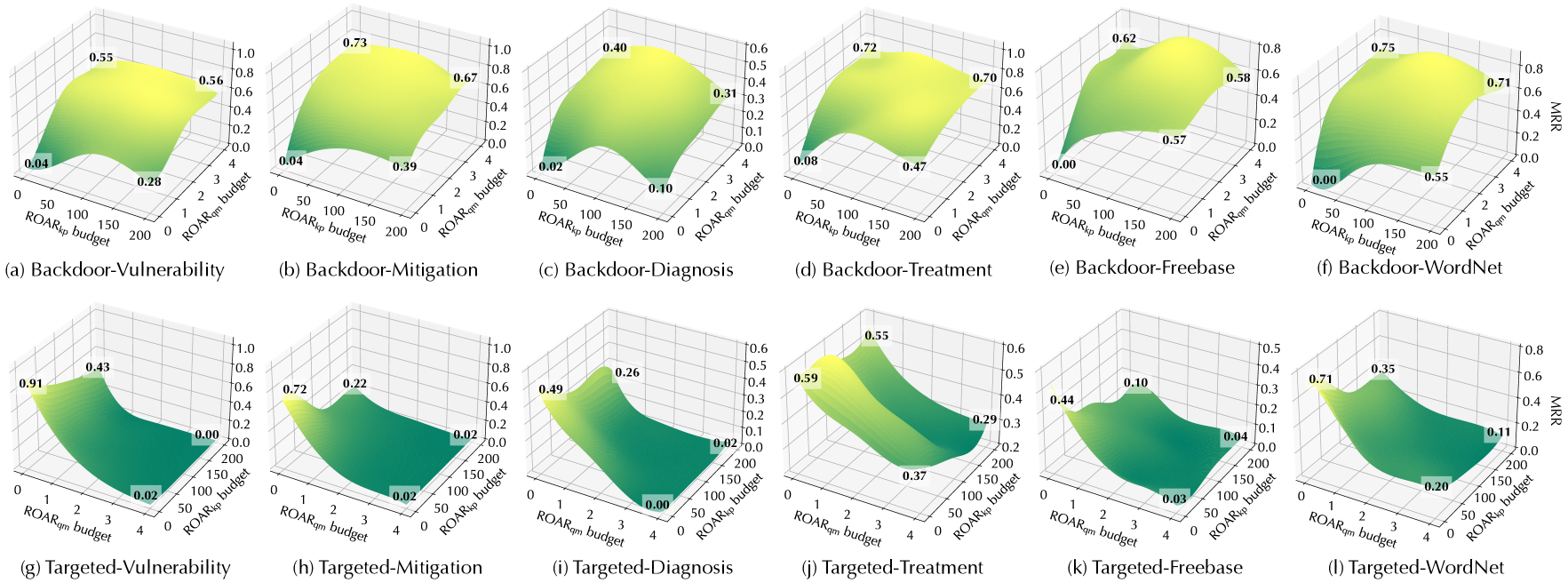
### Visual Description
\n
## Heatmaps: Backdoor Attack Performance under Different Budgets
### Overview
The image presents a series of six heatmaps, arranged in a 2x3 grid, visualizing the performance of different backdoor attack and defense strategies. Each heatmap represents a scenario, with the x and y axes representing "ROAR<sub>exp</sub> budget" and "ROAR<sub>att</sub> budget" respectively. The color intensity indicates the "MRR" (Mean Reciprocal Rank) score, ranging from 0.0 to 1.0, with warmer colors (green) indicating higher performance (higher MRR) and cooler colors (purple) indicating lower performance. Below the first row of heatmaps are six more, representing different targetted attacks.
### Components/Axes
* **X-axis:** ROAR<sub>att</sub> budget (ranging from 0 to 4, with markers at 0, 1, 2, 3, and 4).
* **Y-axis:** ROAR<sub>exp</sub> budget (ranging from 0 to 200, with markers at 0, 50, 100, 150, and 200).
* **Color Scale:** MRR (Mean Reciprocal Rank), ranging from 0.0 (purple) to 1.0 (green).
* **Heatmap Titles:**
* (a) Backdoor-Vulnerability
* (b) Backdoor-Mitigation
* (c) Backdoor-Diagnosis
* (d) Backdoor-Treatment
* (e) Backdoor-Freebase
* (f) Backdoor-WordNet
* (g) Targetted-Vulnerability
* (h) Targetted-Mitigation
* (i) Targetted-Diagnosis
* (j) Targetted-Treatment
* (k) Targetted-Freebase
* (l) Targetted-WordNet
### Detailed Analysis or Content Details
**Row 1:**
* **(a) Backdoor-Vulnerability:** The heatmap shows a generally increasing MRR with increasing ROAR<sub>exp</sub> budget. The highest MRR (~0.73) is located at ROAR<sub>exp</sub> budget = 4 and ROAR<sub>att</sub> budget = 0. A low MRR (~0.04) is observed at ROAR<sub>exp</sub> budget = 0 and ROAR<sub>att</sub> budget = 0.
* **(b) Backdoor-Mitigation:** The MRR is relatively low across the board, with a peak of ~0.67 at ROAR<sub>exp</sub> budget = 4 and ROAR<sub>att</sub> budget = 0. The lowest MRR (~0.04) is at ROAR<sub>exp</sub> budget = 0 and ROAR<sub>att</sub> budget = 0.
* **(c) Backdoor-Diagnosis:** The MRR is generally low, with a peak of ~0.40 at ROAR<sub>exp</sub> budget = 4 and ROAR<sub>att</sub> budget = 0. The lowest MRR (~0.02) is at ROAR<sub>exp</sub> budget = 0 and ROAR<sub>att</sub> budget = 0.
* **(d) Backdoor-Treatment:** The MRR increases with increasing ROAR<sub>exp</sub> budget, peaking at ~0.72 at ROAR<sub>exp</sub> budget = 4 and ROAR<sub>att</sub> budget = 0. The lowest MRR (~0.08) is at ROAR<sub>exp</sub> budget = 0 and ROAR<sub>att</sub> budget = 0.
* **(e) Backdoor-Freebase:** The MRR is relatively high, peaking at ~0.62 at ROAR<sub>exp</sub> budget = 4 and ROAR<sub>att</sub> budget = 0. The lowest MRR (~0.00) is at ROAR<sub>exp</sub> budget = 0 and ROAR<sub>att</sub> budget = 0.
* **(f) Backdoor-WordNet:** The MRR is relatively high, peaking at ~0.75 at ROAR<sub>exp</sub> budget = 4 and ROAR<sub>att</sub> budget = 0. The lowest MRR (~0.55) is at ROAR<sub>exp</sub> budget = 0 and ROAR<sub>att</sub> budget = 0.
**Row 2:**
* **(g) Targetted-Vulnerability:** The MRR is relatively high, peaking at ~0.91 at ROAR<sub>exp</sub> budget = 0 and ROAR<sub>att</sub> budget = 0. The lowest MRR (~0.22) is at ROAR<sub>exp</sub> budget = 200 and ROAR<sub>att</sub> budget = 4.
* **(h) Targetted-Mitigation:** The MRR is relatively low, peaking at ~0.43 at ROAR<sub>exp</sub> budget = 0 and ROAR<sub>att</sub> budget = 0. The lowest MRR (~0.10) is at ROAR<sub>exp</sub> budget = 200 and ROAR<sub>att</sub> budget = 4.
* **(i) Targetted-Diagnosis:** The MRR is relatively low, peaking at ~0.69 at ROAR<sub>exp</sub> budget = 0 and ROAR<sub>att</sub> budget = 0. The lowest MRR (~0.26) is at ROAR<sub>exp</sub> budget = 200 and ROAR<sub>att</sub> budget = 4.
* **(j) Targetted-Treatment:** The MRR is relatively low, peaking at ~0.53 at ROAR<sub>exp</sub> budget = 0 and ROAR<sub>att</sub> budget = 0. The lowest MRR (~0.44) is at ROAR<sub>exp</sub> budget = 200 and ROAR<sub>att</sub> budget = 4.
* **(k) Targetted-Freebase:** The MRR is relatively low, peaking at ~0.39 at ROAR<sub>exp</sub> budget = 0 and ROAR<sub>att</sub> budget = 0. The lowest MRR (~0.10) is at ROAR<sub>exp</sub> budget = 200 and ROAR<sub>att</sub> budget = 4.
* **(l) Targetted-WordNet:** The MRR is relatively low, peaking at ~0.71 at ROAR<sub>exp</sub> budget = 0 and ROAR<sub>att</sub> budget = 0. The lowest MRR (~0.35) is at ROAR<sub>exp</sub> budget = 200 and ROAR<sub>att</sub> budget = 4.
### Key Observations
* For the "Backdoor" series, increasing the ROAR<sub>exp</sub> budget generally improves MRR, suggesting that more exploration helps.
* The "Targetted" series generally shows higher MRR values at lower budgets, and a decrease in MRR as budgets increase.
* "Backdoor-WordNet" and "Targetted-WordNet" consistently show higher MRR values compared to other strategies.
* "Backdoor-Mitigation", "Backdoor-Diagnosis", and "Backdoor-Treatment" have relatively low MRR values across all budget combinations.
### Interpretation
The heatmaps demonstrate the effectiveness of different backdoor attack and defense strategies under varying resource constraints (ROAR<sub>exp</sub> and ROAR<sub>att</sub> budgets). The MRR score serves as a proxy for the success of the attack or defense.
The positive correlation between ROAR<sub>exp</sub> budget and MRR in the "Backdoor" series suggests that increased exploration of the model's vulnerabilities leads to more successful attacks. Conversely, the negative correlation in the "Targetted" series indicates that focused attacks may become less effective as more resources are allocated to both exploration and attack.
The consistently high performance of "WordNet" strategies suggests that this approach is particularly robust or effective in exploiting/mitigating backdoor vulnerabilities. The lower performance of "Mitigation" and "Diagnosis" strategies indicates that these defenses may be less effective in practice, or require significantly more resources to achieve comparable results.
The differences between the "Backdoor" and "Targetted" series highlight the importance of considering the attack strategy when evaluating defense mechanisms. A defense that is effective against general backdoor attacks may not be as effective against targeted attacks, and vice versa. The data suggests a trade-off between exploration and attack budgets, and the optimal strategy may depend on the specific context and available resources.
</details>
Figure 13: ROAR ${}_{\mathrm{co}}$ performance with varying budgets (ROAR ${}_{\mathrm{kp}}$ – $n_{\mathrm{g}}$ , ROAR ${}_{\mathrm{qm}}$ – $n_{\mathrm{q}}$ ). The measures are the absolute MRR after the attacks.
<details>
<summary>x14.png Details</summary>
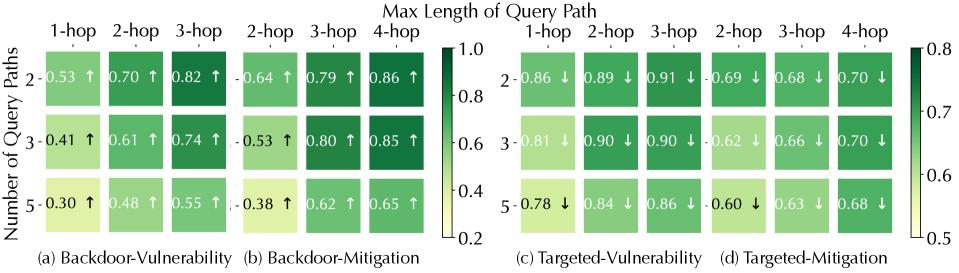
### Visual Description
\n
## Heatmap: Query Path Length vs. Attack Success Rate
### Overview
The image presents a comparative heatmap illustrating the success rate of backdoor and targeted attacks based on the maximum length of the query path. The heatmap is divided into four sections, each representing a different attack scenario: Backdoor-Vulnerability, Backdoor-Mitigation, Targeted-Vulnerability, and Targeted-Mitigation. The y-axis represents the number of query paths, ranging from 1 to 5, while the x-axis represents the maximum length of the query path, ranging from 1-hop to 4-hop. The color intensity indicates the attack success rate, with darker shades of green representing higher success rates and lighter shades representing lower success rates. Arrows indicate the trend of success rate as the query path length increases.
### Components/Axes
* **Title:** Max Length of Query Path
* **Y-axis Title:** Number of Query Paths (1-5)
* **X-axis Title:** Max Length of Query Path (1-hop, 2-hop, 3-hop, 4-hop)
* **Color Scale:** Ranges from 0.2 (light green) to 1.0 (dark green), representing attack success rate.
* **Labels:**
* (a) Backdoor-Vulnerability
* (b) Backdoor-Mitigation
* (c) Targeted-Vulnerability
* (d) Targeted-Mitigation
* **Trend Indicators:** Upward arrows (↑) indicate an increasing success rate with increasing query path length, while downward arrows (↓) indicate a decreasing success rate.
### Detailed Analysis
**Section (a): Backdoor-Vulnerability**
* 1 Query Path: 0.53 ↑
* 2 Query Paths: 0.70 ↑
* 3 Query Paths: 0.82 ↑
* 1-hop: 0.53
* 2-hop: 0.70
* 3-hop: 0.82
* 4-hop: Not present
**Section (b): Backdoor-Mitigation**
* 1 Query Path: 0.38 ↑
* 2 Query Paths: 0.64 ↑
* 3 Query Paths: 0.79 ↑
* 4 Query Paths: 0.86 ↑
* 1-hop: 0.38
* 2-hop: 0.64
* 3-hop: 0.79
* 4-hop: 0.86
**Section (c): Targeted-Vulnerability**
* 1 Query Path: 0.86 ↓
* 2 Query Paths: 0.89 ↓
* 3 Query Paths: 0.90 ↓
* 4 Query Paths: 0.68 ↓
* 1-hop: 0.86
* 2-hop: 0.89
* 3-hop: 0.90
* 4-hop: 0.68
**Section (d): Targeted-Mitigation**
* 1 Query Path: 0.78 ↓
* 2 Query Paths: 0.81 ↓
* 3 Query Paths: 0.86 ↓
* 4 Query Paths: 0.63 ↓
* 1-hop: 0.78
* 2-hop: 0.81
* 3-hop: 0.86
* 4-hop: 0.63
### Key Observations
* **Backdoor Attacks:** The success rate of backdoor attacks generally *increases* with the length of the query path (Sections a and b). Mitigation strategies (Section b) show lower initial success rates but still exhibit an upward trend.
* **Targeted Attacks:** The success rate of targeted attacks generally *decreases* with the length of the query path (Sections c and d). Mitigation strategies (Section d) also show a decreasing trend, but start at a lower success rate than the vulnerability scenario (Section c).
* **Mitigation Impact:** Mitigation strategies consistently reduce the success rate of both backdoor and targeted attacks compared to their vulnerable counterparts.
* **Peak Success:** Targeted-Vulnerability (Section c) shows the highest success rates, peaking at 0.90 for 3-hop queries.
### Interpretation
The data suggests that longer query paths are more effective for exploiting backdoor vulnerabilities, while they are detrimental to targeted attacks. This could be due to the nature of backdoor triggers, which may require a certain sequence or length of queries to activate. Conversely, targeted attacks may become less precise or more detectable with longer, more complex query paths.
The mitigation strategies demonstrate a clear benefit in reducing attack success rates, but their effectiveness varies depending on the attack type and query path length. The consistent downward trend in targeted attack success rates with mitigation suggests that these strategies are effective in disrupting precision attacks. The increasing success rate of backdoor attacks with mitigation, despite being lower than the vulnerable scenario, indicates that further refinement of mitigation techniques may be needed to address this threat.
The heatmap provides valuable insights into the trade-offs between query path length, attack success rate, and mitigation effectiveness. This information can be used to design more robust security systems and develop targeted mitigation strategies. The anomalies, such as the peak success rate for Targeted-Vulnerability at 3-hop, warrant further investigation to understand the underlying mechanisms driving these results.
</details>
Figure 14: ROAR ${}_{\mathrm{co}}$ performance (MRR) under different query structures in Figure 5, indicated by the change ( $\uparrow$ or $\downarrow$ ) before and after the attacks.