## AnalogNAS: A Neural Network Design Framework for Accurate Inference with Analog In-Memory Computing
Hadjer Benmeziane ∗ , Corey Lammie † , Irem Boybat † , Malte Rasch ‡ ,Manuel Le Gallo † , Hsinyu Tsai § ,
Ramachandran Muralidhar , Smail Niar , Ouarnoughi Hamza , Vijay Narayanan
‡ ∗ ∗ ‡ ,
† ‡
Abu Sebastian and Kaoutar El Maghraoui ,
∗ Univ. Polytechnique Hauts-de-France, CNRS, UMR 8201 - LAMIH, F-59313 Valenciennes, France
† IBM Research Europe, 8803 R¨ uschlikon, Switzerland
‡ IBM T. J. Watson Research Center, Yorktown Heights, NY 10598, USA
§
IBM Research Almaden, 650 Harry Road, San Jose, CA USA
Abstract -The advancement of Deep Learning (DL) is driven by efficient Deep Neural Network (DNN) design and new hardware accelerators. Current DNN design is primarily tailored for general-purpose use and deployment on commercially viable platforms. Inference at the edge requires low latency, compact and power-efficient models, and must be cost-effective. Digital processors based on typical von Neumann architectures are not conducive to edge AI given the large amounts of required data movement in and out of memory. Conversely, analog/mixedsignal in-memory computing hardware accelerators can easily transcend the memory wall of von Neuman architectures when accelerating inference workloads. They offer increased areaand power efficiency, which are paramount in edge resourceconstrained environments. In this paper, we propose AnalogNAS , a framework for automated DNN design targeting deployment on analog In-Memory Computing (IMC) inference accelerators. We conduct extensive hardware simulations to demonstrate the performance of AnalogNAS on State-Of-The-Art (SOTA) models in terms of accuracy and deployment efficiency on various Tiny Machine Learning (TinyML) tasks. We also present experimental results that show AnalogNAS models achieving higher accuracy than SOTA models when implemented on a 64-core IMC chip based on Phase Change Memory (PCM). The AnalogNAS search code is released 1 .
Index Terms -Analog AI, Neural Architecture Search, Optimization, Edge AI, In-memory Computing
## I. INTRODUCTION
W ITH the growing demands of real-time DL workloads, today's conventional cloud-based AI deployment approaches do not meet the ever-increasing bandwidth, realtime, and low-latency requirements. Edge computing brings storage and local computations closer to the data sources produced by the sheer amount of Internet of Things (IoT) objects, without overloading network and cloud resources. As
© 2023 IEEE. Personal use of this material is permitted. Permission from IEEE must be obtained for all other uses, in any current or future media, including reprinting/republishing this material for advertising or promotional purposes, creating new collective works, for resale or redistribution to servers or lists, or reuse of any copyrighted component of this work in other works. 1 https://github.com/IBM/analog-nas
DNNs are becoming more memory and compute intensive, edge AI deployments on resource-constrained devices pose significant challenges. These challenges have driven the need for specialized hardware accelerators for on-device Machine Learning (ML) and a plethora of tools and solutions targeting the development and deployment of power-efficient edge AI solutions. One such promising technology for edge hardware accelerators is analog-based IMC, which is herein referred to as analog IMC .
Analog IMC [1] can provide radical improvements in performance and power efficiency, by leveraging the physical properties of memory devices to perform computation and storage at the same physical location. Many types of memory devices, including Flash memory, PCM, and Resistive Random Access Memory (RRAM), can be used for IMC [2]. Most notably, analog IMC can be used to perform Matrix-Vector Mutliplication (MVM) operations in O (1) time complexity [3], which is the most dominant operation used for DNN acceleration. In this novel approach, the weights of linear, convolutional, and recurrent DNN layers are mapped to crossbar arrays (tiles) of Non-Volatile Memory (NVM) elements. By exploiting basic Kirchhoff's circuit laws, MVMs can be performed by encoding inputs as Word-Line (WL) voltages and weights as device conductances. For most computations, this removes the need to pass data back and forth between Central Processing Units (CPUs) and memory. This back and forth data movement is inherent in traditional digital computing architectures, and is often referred to as the von Neumann bottleneck . Because there is greatly reduced movement of data, tasks can be performed in a fraction of the time, and with much less energy.
NVM crossbar arrays and analog circuits, however, have inherent non-idealities, such as noise, temporal conductance drift, and non-linear errors, which can lead to imprecision and noisy computation [4]. These effects need to be properly quantified and mitigated to ensure the high accuracy of DNN models. In addition to the hardware constraints that are prevalent in edge devices, there is the added complexity of designing DNN
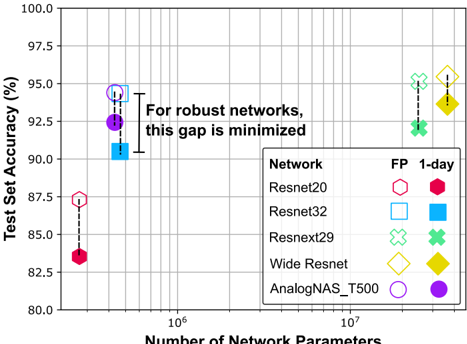
Fig. 1. The effect of PCM conductance drift after one day on standard CNN architectures and one architecture ( AnalogNAS\_T500 ) obtained using HW-NAS, evaluated using CIFAR-10. FP refers to the original network accuracy, and 1-day to the simulated analog network accuracy after 1-day device drift.
<details>
<summary>Image 1 Details</summary>
### Visual Description
\n
## Scatter Plot: Test Set Accuracy vs. Number of Network Parameters
### Overview
This image presents a scatter plot comparing the test set accuracy of different neural networks against the number of network parameters. Each network is represented by a distinct marker, and error bars indicate the variability in accuracy. The plot aims to illustrate the relationship between model complexity (number of parameters) and performance (test set accuracy), with a focus on minimizing the gap between performance metrics for robust networks.
### Components/Axes
* **X-axis:** Number of Network Parameters (logarithmic scale, ranging from approximately 10<sup>6</sup> to 10<sup>7</sup>).
* **Y-axis:** Test Set Accuracy (%) (ranging from 80% to 100%).
* **Legend:** Located in the bottom-right corner, categorizes the networks by marker shape and color.
* **Network:** Resnet20, Resnet32, Resnext29, Wide Resnet, AnalogNAS\_T500
* **FP:** (likely representing a training paradigm) 1-day, indicated by color.
* **Text Annotation:** "For robust networks, this gap is minimized" is positioned in the center of the plot.
### Detailed Analysis
The plot displays data points for each network under different training conditions (FP). Each data point includes an error bar representing the standard deviation or confidence interval of the accuracy.
* **Resnet20 (Pink Hexagon):**
* FP 1-day: Approximately (1.2 x 10<sup>6</sup> parameters, 86.5% accuracy) with an error bar extending from approximately 85.5% to 87.5%.
* **Resnet32 (Blue Square):**
* FP 1-day: Approximately (2.5 x 10<sup>6</sup> parameters, 90.5% accuracy) with an error bar extending from approximately 89.5% to 91.5%.
* **Resnext29 (Green Cross):**
* FP 1-day: Approximately (7.5 x 10<sup>6</sup> parameters, 95.5% accuracy) with an error bar extending from approximately 94.5% to 96.5%.
* **Wide Resnet (Yellow Diamond):**
* FP 1-day: Approximately (7.5 x 10<sup>6</sup> parameters, 93.0% accuracy) with an error bar extending from approximately 92.0% to 94.0%.
* **AnalogNAS\_T500 (Purple Circle):**
* FP 1-day: Approximately (2.5 x 10<sup>6</sup> parameters, 92.5% accuracy) with an error bar extending from approximately 91.5% to 93.5%.
The trend for most networks is that as the number of parameters increases, the test set accuracy also increases. However, the rate of increase appears to diminish with larger models.
### Key Observations
* Resnext29 achieves the highest accuracy among the networks tested.
* Resnet20 has the lowest accuracy.
* The gap between the accuracy of Resnet20 and Resnet32 is significant.
* AnalogNAS\_T500 and Resnet32 have similar numbers of parameters but different accuracies.
* The error bars suggest that the accuracy of Resnext29 is more consistent than that of other networks.
### Interpretation
The data suggests a positive correlation between the number of network parameters and test set accuracy, but this relationship is not linear. Increasing model complexity (parameters) generally leads to improved performance, but there are diminishing returns. The annotation "For robust networks, this gap is minimized" implies that a robust network should have a small difference between its performance metrics (potentially training and test accuracy, or different evaluation criteria). The plot highlights that simply increasing the number of parameters does not guarantee a robust network. The choice of network architecture (e.g., Resnext29) and training procedure (FP) are also crucial factors. The varying error bar lengths indicate that some networks are more sensitive to variations in training data or initialization than others. The plot is useful for comparing the performance of different network architectures and identifying potential trade-offs between model complexity and accuracy.
</details>
architectures which are optimized for the edge on a variety of hardware platforms. This requires hardware-software co-design approaches to tackle this complexity, as manually-designed architectures are often tailored for specific hardware platforms. For instance, MobileNet [5] uses a depth-wise separable convolution that enhances CPU performance but is inefficient for Graphics Processing Unit (GPU) parallelization [6]. These are bespoke solutions that are often hard to implement and generalize to other platforms.
HW-NAS [7] is a promising approach that seeks to automatically identify efficient DNN architectures for a target hardware platform. In contrast to traditional Neural Architecture Search (NAS) approaches that focus on searching for the most accurate architectures, HW-NAS searches for highly accurate models while optimizing hardware-related metrics. Existing HW-NAS strategies cannot be readily used with analog IMC processors without significant modification for three reasons: (i) their search space contains operations and blocks that are not suitable for analog IMC, (ii) lack of a benchmark of hardwareaware trained architectures, and (iii) their search strategy does not include noise injection and temporal drift on weights.
To address these challenges, we propose AnalogNAS , a novel HW-NAS strategy to design dedicated DNN architectures for efficient deployment on edge-based analog IMC inference accelerators. This approach considers the inherent characteristics of analog IMC hardware in the search space and search strategy. Fig. 1 depicts the necessity of our approach. As can be seen, when traditional DNN architectures are deployed on analog IMC hardware, non-idealities, such as conductance drift, drastically reduce network performance. Networks designed by AnalogNAS are extremely robust to these non-idealities and have much fewer parameters compared to equivalently-robust traditional networks. Consequently, they have reduced resource utilization.
Our specific contributions can be summarized as follows:
- We design and construct a search space for analog IMC, which contains ResNet-like architectures, including ResNext [8] and Wide-ResNet [9], with blocks of varying widths and depths;
- We train a collection of networks using Hardware-Aware (HWA) training for image classification, Visual Wake Words (VWW), and Keyword Spotting (KWS) tasks. Using these networks, we build a surrogate model to rank the architectures during the search and predict robustness to conductance drift;
- We propose a global search strategy that uses evolutionary search to explore the search space and efficiently finds the right architecture under different constraints, including the number of network parameters and analog tiles;
- We conduct comprehensive experiments to empirically demonstrate that AnalogNAS can be efficiently utilized to carry out architecture search for various edge tiny applications, and investigate what attributes of networks make them ideal for implementation using analog AI;
- We validate a subset of networks on hardware using a 64-core IMC chip based on PCM.
The rest of the paper is structured as follows. In Section II, we present related work. In Section III, relevant notations and terminology are introduced. In Section IV, the search space and surrogate model are presented. In Section V, the search strategy is presented. In Section VI, the methodology for all experiments is discussed. The simulation results are presented in Section VI-B, along with the hardware validation and performance estimation in Section VII. The results are discussed in Section VIII. Section IX concludes the paper.
## II. RELATED WORK
## A. NAS for TinyML
HW-NAS has been successfully applied to a variety of edge hardware platforms [7], [10] used to deploy networks for TinyMLPerf tasks [11] such as image classification, VWW, KWS, and anomaly detection. MicroNets [12] leverages NAS for DL model deployment on micro-controllers and other embedded systems. It utilizes a differentiable search space [13] to find efficient architectures for different TinyMLPerf tasks. For each task, the search space is an extension of current SOTA architectures. µ -nas [14] includes memory peak usage and a number of other parameters as constraints. Its search strategy combines aging evolution and Bayesian optimization to estimate the objectives and explore a granular search space efficiently. It constructs its search space from a standard CNN and modifies the operators' hyper-parameters and a number of layers.
## B. NAS for Mixed-Signal IMC Accelerators
Many works [15]-[18] target IMC accelerators using HW-NAS. FLASH [15] uses a small search space inspired by DenseNet [19] and searches for the number of skip connections that efficiently satisfy the trade-off between accuracy, latency, energy consumption, and chip area. Its surrogate model uses linear regression and the number of skip connections to predict model accuracy. NAS4RRAM [17] uses HW-NAS to find an efficient DNN for a specific RRAMbased accelerator. It uses an evolutionary algorithm, trains each sampled architecture without HWA training, and evaluates each network on a specific hardware instance. NACIM [16] uses coexploration strategies to find the most efficient architecture and the associated hardware platform. For each sampled architecture, networks are trained considering noise variations. This approach is limited by using a small search space due to the high time complexity of training. UAE [18] uses a Monte-Carlo simulation-based experimental flow to measure the device uncertainty induced to a handful of DNNs. Similar to NACIM [16], evaluation is performed using HWA training with noise injection. AnalogNet [20] extends the work of Micronet by converting their final models to analog-friendly models, replacing depthwise convolutions with standard convolutions and tuning hyperparameters.
Compared to the above-mentioned SOTA HW-NAS strategies, our AnalogNAS is better tailored to analog IMC hardware for two reasons: (i) Our search space is much larger and more representative, featuring resnet-like connections. This enables us to answer the key question of what architectural characteristics are suitable for analog IMC which cannot be addressed with small search spaces. (ii) We consider the inherent characteristics of analog IMC hardware directly in the objectives and constraints of our search strategy in addition to noise injection during the HWA training as used by existing approaches.
## III. PRELIMINARIES
## A. Analog IMC Accelerator Mechanisms
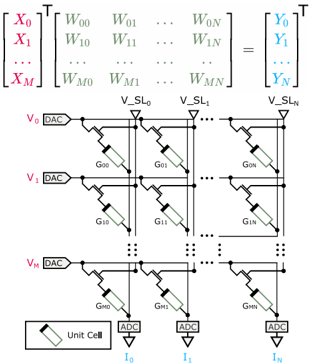
Analog IMC accelerators are capable of performing MVM operations Y T = X T W using the laws of physics, where W is an M × N matrix, X is a M × 1 vector, and Y is a N × 1 vector. When arranged in a crossbar configuration, M × N , NVM devices can be used to compute MVM operations. This is done by encoding elements of X as WL voltages, denoted using V , and elements of W as conductances of the unit cells, denoted using G . Negative conductance states cannot be directly encoded/represented using NVM devices. Consequently, differential weight mapping schemes are commonly employed, where either positive weights, i.e., W + = max( W , 0) , and negative weights, i.e., W -= -min( W , 0) , are encoded within unit cells, using alternate columns, or on different tiles [3]. The analog computation, i.e., I = VG is performed, where the current flow to the end of the N -th column is I N = ∑ M i =0 G i,N V i . Typically, Digital-to-Analog Converters (DACs) are required to encode WL voltages and Analog-toDigital Converters (ADCs) are required to read the output currents of each column. The employed analog IMC tile, its weight mapping scheme, and computation mechanism are depicted in Fig. 2.
## B. Temporal Drift of Non-Volatile Memory Devices
Many types of NVM devices, most prominantly, PCM, exhibit temporal evolution of the conductance values referred to as the conductance drift. This poses challenges for maintaining synaptic weights reliably [2]. Conductance drift is most commonly modelled using Eq. (1), as follows:
<!-- formula-not-decoded -->
where G ( t 0 ) is the conductance at time t 0 and ν is the drift exponent. In practice, conductance drift is highly stochastic because ν depends on the programmed conductance state and varies across devices. Consequently, when reporting the network accuracy at a given time instance (after device programming), it is computed across multiple experiment instances (trials) to properly capture the amount of accuracy variations.
## C. HWA-training and analog hardware accuracy evaluation simulation
To simulate training and inference on analog IMC accelerators, the IBM Analog Hardware Acceleration Kit (AIHWKIT) [21] is used. The AIHWKIT is an open-source Python toolkit for exploring and using the capabilities of inmemory computing devices in the context of artificial intelligence and has been used for HWA training of standard DNNs with hardware-calibrated device noise and drift models [22].
## D. Hardware-aware Neural Architecture Search (HW-NAS)
HW-NAS refers to the task of automatically finding the most efficient DNN for a specific dataset and target hardware platform. HW-NAS approaches often employ black-box optimization methods such as evolutionary algorithms [23], reinforcement learning [24], [25], and Bayesian optimization [26], [27]. The optimization problem is either cast as a constrained or multi-objective optimization [7]. In AnalogNAS, we chose constrained optimization over multi-objective optimization for several reasons. First, constrained optimization is more computationally efficient than multi-objective optimization, which is important in the context of HW-NAS, to allow searching a large search space in a practical time frames. Multi-objective optimization is computationally expensive and can result in a
Fig. 2. Employed analog IMC tile and weight mapping scheme.
<details>
<summary>Image 2 Details</summary>
### Visual Description
\n
## Diagram: Analog-to-Digital Converter (ADC) Architecture
### Overview
The image depicts a schematic diagram of an array-based analog-to-digital converter (ADC) architecture. It combines a matrix multiplication operation with a resistive network to perform the conversion. The diagram shows input voltages (V0 to VM) being applied to a network of resistors (represented by G00 to GMN) and then converted to currents (I0 to IN) using ADCs. A matrix equation at the top represents the mathematical operation performed by the circuit.
### Components/Axes
The diagram consists of the following key components:
* **Matrix Equation:** A matrix equation at the top of the diagram representing the conversion process.
* **Input Voltages (V0 to VM):** Represented by horizontal lines labeled V0, V1, ..., VM.
* **Digital-to-Analog Converters (DACs):** Labeled "DAC" connected to each input voltage line.
* **Resistive Network (G00 to GMN):** Represented by rectangular resistors arranged in a grid. Labels indicate the resistance values (e.g., G00, G01, G10, G11, etc.).
* **Output Voltages (V_SL0 to V_SLN):** Represented by vertical lines labeled V_SL0, V_SL1, ..., V_SLN.
* **Analog-to-Digital Converters (ADCs):** Labeled "ADC" connected to each output current line.
* **Output Currents (I0 to IN):** Represented by lines labeled I0, I1, ..., IN.
* **Unit Cell:** A small rectangle in the bottom-left corner, labeled "Unit Cell", indicating the basic building block of the resistive network.
### Detailed Analysis / Content Details
The matrix equation at the top can be transcribed as:
```
[X₀] [W₀₀ W₀₁ ... W₀N] [Y₀]
[X₁] [W₁₀ W₁₁ ... W₁N] = [Y₁]
... [... ... ... ...] [...]
[Xₘ] [Wₘ₀ Wₘ₁ ... WₘN] [Yₙ]
```
Where:
* **X₀ to Xₘ** are the input vectors.
* **W₀₀ to WₘN** are the weighting coefficients (representing the resistance values).
* **Y₀ to Yₙ** are the output vectors.
The resistive network is arranged in an M x N grid. The resistors are labeled as follows:
* **Rows:** G00, G01, ..., G0N (corresponding to input voltage V0)
* **Rows:** G10, G11, ..., G1N (corresponding to input voltage V1)
* **...**
* **Rows:** GM0, GM1, ..., GMN (corresponding to input voltage VM)
The input voltages V0 to VM are connected to DACs, which drive the currents through the resistive network. The output currents I0 to IN are then measured by ADCs. The output voltages V_SL0 to V_SLN are the nodes where the currents are summed.
### Key Observations
* The diagram illustrates a parallel ADC architecture where multiple ADCs operate simultaneously.
* The matrix multiplication is implemented using a resistive network.
* The "Unit Cell" suggests that the resistive network is composed of identical building blocks.
* The diagram does not provide specific values for the resistances or the number of ADCs (N).
### Interpretation
This diagram represents a novel ADC architecture that leverages a resistive network to perform a matrix multiplication operation. This approach allows for parallel conversion, potentially increasing the speed of the ADC. The use of a "Unit Cell" suggests a modular design, which could simplify fabrication and improve scalability. The matrix equation at the top provides a mathematical representation of the conversion process, highlighting the relationship between the input voltages, the weighting coefficients (resistances), and the output currents. The diagram suggests a trade-off between accuracy (determined by the precision of the resistors and ADCs) and speed (determined by the number of parallel ADCs). The absence of specific numerical values limits a deeper quantitative analysis, but the diagram clearly demonstrates the fundamental principles of this ADC architecture. The diagram is a conceptual illustration, and does not provide details on the specific implementation of the DACs and ADCs.
</details>
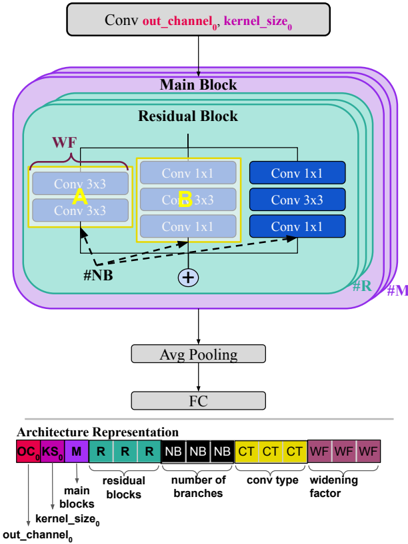
Fig. 3. Resnet-like macro architecture.
<details>
<summary>Image 3 Details</summary>
### Visual Description
\n
## Diagram: Neural Network Architecture
### Overview
The image depicts a diagram of a neural network architecture, specifically a convolutional neural network (CNN) with residual blocks. The diagram illustrates the flow of data through the network, highlighting the main components and their connections. Below the diagram is a key representing the architecture's components.
### Components/Axes
The diagram consists of the following components:
* **Conv out\_channel₀, kernel\_size₀**: Input layer.
* **Main Block**: A larger block encompassing the residual blocks.
* **Residual Block**: A repeating unit within the Main Block.
* **Conv 3x3**: Convolutional layers with a 3x3 kernel.
* **Conv 1x1**: Convolutional layers with a 1x1 kernel.
* **Avg Pooling**: Average pooling layer.
* **FC**: Fully connected layer.
* **#NB**: Number of Branches.
* **#R**: Residual Blocks.
* **#M**: Main Blocks.
* **Architecture Representation**: A key at the bottom of the diagram.
The key at the bottom uses color-coded blocks to represent different architectural elements:
* **KS**: kernel\_size₀ (Red)
* **M**: Main Blocks (Red)
* **R**: Residual Blocks (Red)
* **NB**: Number of Branches (Green)
* **CT**: Conv Type (Blue)
* **WF**: Widening Factor (Brown)
### Detailed Analysis or Content Details
The diagram shows a data flow starting from the "Conv out\_channel₀, kernel\_size₀" layer at the top. This layer feeds into the "Main Block". Within the "Main Block", there are multiple "Residual Blocks".
Each "Residual Block" contains:
* A "Conv 3x3" layer (yellow) with the label "WF".
* Three "Conv 1x1" layers (blue).
* A summation symbol (+) indicating an addition operation, likely representing the residual connection.
The output of the "Main Block" is then passed through an "Avg Pooling" layer, followed by a "FC" (Fully Connected) layer.
The "Architecture Representation" key at the bottom shows a sequence of colored blocks:
* KS, M, R, R, R, NB, NB, NB, CT, CT, CT, WF, WF, WF.
The diagram uses arrows to indicate the direction of data flow. A dashed arrow connects the input of the "Residual Block" to the summation symbol, representing the residual connection.
### Key Observations
* The architecture utilizes residual connections, which are common in deep neural networks to mitigate the vanishing gradient problem.
* The use of both 3x3 and 1x1 convolutional layers suggests a combination of spatial feature extraction and dimensionality reduction.
* The "Widening Factor" (WF) label on the 3x3 convolution suggests that the number of channels may be increased in this layer.
* The key at the bottom provides a symbolic representation of the network's structure, allowing for a concise description of the architecture.
### Interpretation
The diagram illustrates a CNN architecture designed for image recognition or similar tasks. The residual blocks enable the training of deeper networks by allowing gradients to flow more easily. The combination of 3x3 and 1x1 convolutions provides a balance between spatial feature extraction and computational efficiency. The "Widening Factor" suggests that the network may increase the number of feature maps in certain layers to capture more complex patterns. The architecture representation key provides a compact way to describe the network's structure, making it easier to understand and reproduce. The diagram suggests a modular design, where the residual blocks can be stacked to create a network of arbitrary depth. The use of average pooling before the fully connected layer is a common practice for reducing the spatial dimensions of the feature maps and improving generalization performance. The diagram is a high-level overview and does not provide specific details about the number of filters, activation functions, or other hyperparameters.
</details>
large number of non-dominated solutions that can be difficult to interpret. Secondly, by using constrained optimization, we can explicitly incorporate the specific constraints of the analog hardware in our search strategy. This enables us to find DNN architectures that are optimized for the unique requirements and characteristics of analog IMC hardware, rather than simply optimizing for multiple objectives.
## IV. ANALOG-NAS
The objective of AnalogNAS is to find an efficient network architecture under different analog IMC hardware constraints. AnalogNAS comprises three main components: (i) a resnetlike search space, (ii) an analog-accuracy surrogate model, and (iii) an evolutionary-based search strategy. We detail each component in the following subsections.
## A. Resnet-like Search Space
Resnet-like architectures have inspired many manually designed SOTA DL architectures, including Wide ResNet [9] and EfficientNet [28]. Their block-wise architecture offers a flexible and searchable macro-architecture for NAS [29]. Resnet-like architectures can be implemented efficiently using IMC processors, as they are comprised of a large number of MVM and element-wise operations. Additionally, due to the highly parallel nature of IMC, Resnet architectures can get free processing of additional input/output channels. This makes Resnet-like architectures highly amenable to analog implementation.
Fig. 3 depicts the macro-architecture used to construct all architectures in our search space. The architecture consists of a series of M distinct main blocks. Each main block contains R residual blocks. The residual blocks use skip connections with or without downsampling. Downsampling is performed using 1x1 convolution layers when required, i.e., when the input size does not match the output size. The residual block can have B branches. Each branch uses a convolution block. We used different types of convolution blocks to allow the search space to contain all standard architectures such as Resnets [30], ResNext [8], and Wide Resnets [9]. The standard convolution blocks used in Resnets, commonly referred to as BottleNeckBlock and BasicBlock , are denoted as A and B respectively. We include variants of A and B in which we inverse the order of the ReLU and Batch normalization operations. The resulting blocks are denoted as C and D. Table I summarizes the searchable hyper-parameters and their respective ranges. The widening factor scales the width of the residual block. We sample architectures with different depths by changing the number of main and residual blocks. The total size of the search space is approximately 73B architectures. The larger architecture would contain 240 convolutions and start from an output channel of 128 multiplying that by 4 for every 16 blocks.
## B. Analog-accuracy Surrogate Model
- 1) Evaluation Criteria: To efficiently explore the search space, a search strategy requires evaluating the objectives of each sampled architecture. Training the sampled architectures is very time-consuming; especially when HWA retraining is performed, as noise injection and I/O quantization modeling greatly increases the computational complexity. Consequently, we build a surrogate model capable of estimating the objectives of each sampled architecture in IMC devices. To find architectures that maximize accuracy, stability, and resilience against IMC noise and drift characteristics, we have identified the following three objectives.
- a) The 1-day accuracy: is the primary objective that most NAS algorithms aim to maximize. It measures the performance of an architecture on a given dataset. When weights are encoded using IMC devices, the accuracy of the architecture can drop over time due to conductance drift. Therefore, we have selected the 1-day accuracy as a metric to measure the architecture's performance.
- b) The Accuracy Variation over One Month (AVM): is the difference between the 1-month and 1-sec accuracy. This objective is essential to measure the robustness over a fixed time duration. A 30-day period allows for a reasonable trade-off between capturing meaningful accuracy changes and avoiding short-term noise and fluctuations that may not reflect long-term trends.
- c) The 1-day accuracy standard deviation: measures the variation of the architecture's performance across experiments, as discussed in Section III-B. A lower standard deviation indicates that the architecture produces consistent results on hardware deployments, which is essential for real-world applications.
TABLE I SEARCHABLE HYPER-PARAMETERS AND THEIR RESPECTIVE RANGES.
| Hyper- parameter | Definition | Range |
|--------------------|-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|---------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| OC 0 | First layer's output channel First layer's kernel size Number of main blocks Number of residual block per main block Number of branches per main block Convolution block type per main block Widening factor per main block | Discrete Uniform [8, 128] Discrete Uniform [3, 7] Discrete Uniform [1, 5] Discrete Uniform [1, 16] Discrete Uniform [1, 12] Uniform Choice [A; B; C; Uniform [1, 4] |
| KS 0 | | |
| M | | |
| R* | | |
| B* | | |
| CT* | | D] |
| WF* | | |
To build the surrogate model, we follow two steps: Dataset creation and Model training:
- 2) Dataset Creation: The surrogate model will predict the rank based on the 1-day accuracy and estimates the AVM and 1-day accuracy standard deviation using the Mean Squared Error (MSE). Since the search space is large, care has to be taken when sampling the dataset of architectures that will be used to train the surrogate model.
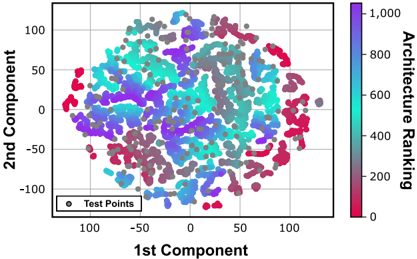
The architectures of the search space are sampled using two methods: (i) Latin Hypercube Sampling (LHS) [31] and (ii) NAS with full training. A more detailed description of the AnalogNAS algorithm is presented in Section V. We use LHS to sample architectures distributed evenly over the search space. This ensures good overall coverage of different architectures and their accuracies. NAS with full training is performed using an evolutionary algorithm to collect high-performance architectures. This ensures good exploitation when reaching well-performing regions. In Fig. 4, we present a visualization of the search space coverage, which does not show any clustering of similarly performing architectures at the edge of the main cloud of points. Thus, it is not evident that architectures with similar performance are located close to each other in the search space. This suggests that traditional search methods that
Fig. 4. t-Distributed Stochastic Neighbor Embedding (t-SNE) visualization of the sampled architectures for CIFAR-10.
<details>
<summary>Image 4 Details</summary>
### Visual Description
\n
## Scatter Plot: 2D Component Analysis with Architecture Ranking
### Overview
The image presents a scatter plot visualizing data points in a two-dimensional space defined by the "1st Component" (x-axis) and "2nd Component" (y-axis). The color of each data point represents its "Architecture Ranking," indicated by a colorbar on the right side of the plot. The plot appears to show a clustering of points, with color variations suggesting a correlation between component values and architecture ranking.
### Components/Axes
* **X-axis:** "1st Component" - Scale ranges approximately from -100 to 100.
* **Y-axis:** "2nd Component" - Scale ranges approximately from -100 to 100.
* **Colorbar:** "Architecture Ranking" - Scale ranges from 0 to 1,000. The color gradient transitions from red (low ranking, ~0) to blue (high ranking, ~1,000).
* **Legend:** Located in the bottom-left corner, labeled "Test Points". The legend symbol is a gray circle.
### Detailed Analysis
The scatter plot contains a large number of data points (approximately 500-1000). The points are distributed in a roughly circular or elliptical shape. The color distribution shows a complex pattern:
* **Low Ranking (Red):** Points with low architecture ranking (red color) are concentrated in the lower-right quadrant (positive 1st Component, negative 2nd Component) and the lower-left quadrant (negative 1st Component, negative 2nd Component).
* **Medium Ranking (Purple/Blue):** Points with medium architecture ranking (purple and blue colors) are distributed throughout the plot, with a higher concentration in the upper-left quadrant (negative 1st Component, positive 2nd Component) and the center of the plot.
* **High Ranking (Cyan/Turquoise):** Points with high architecture ranking (cyan and turquoise colors) are concentrated in the upper-right quadrant (positive 1st Component, positive 2nd Component) and the upper-left quadrant.
* There is a noticeable gradient of colors within each quadrant, indicating a continuous range of architecture rankings.
* The density of points appears to be relatively uniform across the plot, with some areas showing slightly higher concentrations.
### Key Observations
* There appears to be a negative correlation between the 1st Component and the Architecture Ranking, as points with lower 1st Component values tend to have lower rankings (red).
* The 2nd Component seems to have a more complex relationship with the Architecture Ranking, with both positive and negative values associated with various ranking levels.
* The clustering of points suggests that the data can be separated into distinct groups based on their component values and architecture rankings.
* There are no obvious outliers or anomalies in the data.
### Interpretation
This scatter plot likely represents the results of a dimensionality reduction technique (e.g., Principal Component Analysis - PCA) applied to a dataset of architectural designs or features. The "1st Component" and "2nd Component" represent the principal components that capture the most variance in the data. The "Architecture Ranking" could be a metric assigned to each design based on its performance, quality, or other criteria.
The plot suggests that the first two principal components are able to effectively separate the architectural designs based on their ranking. The clustering of points indicates that designs with similar characteristics tend to have similar rankings. The color gradient provides a visual representation of the relationship between the component values and the ranking metric.
The negative correlation between the 1st Component and the Architecture Ranking suggests that designs with lower values on the first component tend to have lower rankings. This could indicate that the first component captures a feature that is negatively correlated with the desired architectural qualities.
Further analysis would be needed to determine the specific meaning of the components and the ranking metric, as well as to validate the findings and explore the underlying relationships in the data.
</details>
Fig. 5. Surrogate models comparison.
<details>
<summary>Image 5 Details</summary>
### Visual Description
\n
## Bar and Line Chart: Surrogate Model Performance
### Overview
This image presents a combined bar and line chart comparing the performance of four surrogate models: XGBoost, LGBoost, MLP, and MLP Ensemble. The chart displays two primary metrics: Kendall Tau Correlation (represented by bars) and Mean Squared Error (MSE) for both AVM (Average Monthly Volume) and 1-day STD-DEV (Standard Deviation) – the latter represented by lines. The x-axis represents the surrogate models, while the left y-axis represents Kendall Tau Correlation and the right y-axis represents Mean Squared Error.
### Components/Axes
* **X-axis:** Surrogate Models (XGBoost, LGBoost, MLP, MLP Ensemble)
* **Left Y-axis:** Kendall Tau Correlation (Scale: 0.0 to 1.0)
* **Right Y-axis:** Mean Squared Error (Scale: 0.0 to 15.0)
* **Legend:**
* Kendall Tau Correlation (Red)
* MSE AVM (Purple)
* MSE 1-day STD-DEV (Cyan)
### Detailed Analysis
The chart consists of four groups of bars and two lines for each model.
**XGBoost:**
* Kendall Tau Correlation: Approximately 0.98 (Red bar)
* MSE AVM: Approximately 0.3 (Purple line)
* MSE 1-day STD-DEV: Approximately 3.5 (Cyan line)
**LGBoost:**
* Kendall Tau Correlation: Approximately 0.94 (Red bar)
* MSE AVM: Approximately 0.6 (Purple line)
* MSE 1-day STD-DEV: Approximately 2.5 (Cyan line)
**MLP:**
* Kendall Tau Correlation: Approximately 0.85 (Red bar)
* MSE AVM: Approximately 1.0 (Purple line)
* MSE 1-day STD-DEV: Approximately 3.5 (Cyan line)
**MLP Ensemble:**
* Kendall Tau Correlation: Approximately 0.89 (Red bar)
* MSE AVM: Approximately 0.2 (Purple line)
* MSE 1-day STD-DEV: Approximately 2.2 (Cyan line)
The red bars representing Kendall Tau Correlation generally decrease from XGBoost to LGBoost, then decrease to MLP, and slightly increase for MLP Ensemble. The purple lines representing MSE AVM show a decrease from XGBoost to LGBoost, then increase to MLP, and decrease again for MLP Ensemble. The cyan lines representing MSE 1-day STD-DEV show a decrease from XGBoost to LGBoost, then remain constant to MLP, and decrease for MLP Ensemble.
### Key Observations
* XGBoost exhibits the highest Kendall Tau Correlation and the lowest MSE AVM.
* MLP has the lowest Kendall Tau Correlation and the highest MSE AVM.
* The MSE 1-day STD-DEV is relatively consistent across XGBoost and MLP, but lower for LGBoost and MLP Ensemble.
* There is an inverse relationship between Kendall Tau Correlation and MSE values; higher correlation generally corresponds to lower MSE.
### Interpretation
The data suggests that XGBoost is the most effective surrogate model based on the metrics presented, demonstrating a strong positive correlation with the target variable and low prediction error. LGBoost and MLP Ensemble also perform reasonably well, while MLP appears to be the least effective model. The difference in MSE between AVM and 1-day STD-DEV indicates that predicting AVM is more challenging than predicting 1-day STD-DEV for these models. The combination of metrics provides a comprehensive assessment of model performance, highlighting the trade-offs between correlation and error. The use of both correlation and MSE allows for a nuanced understanding of how well each model captures the underlying patterns in the data and minimizes prediction inaccuracies. The slight improvement of the MLP Ensemble over the standalone MLP suggests that ensembling techniques can enhance model performance.
</details>
rely on local optimization may not be effective in finding the best-performing architectures. Instead, population-based search strategies, which explore a diverse set of architectures, could be more effective in finding better-performing architectures. Our search strategy extracted 400 test points, and we found that architectures were distributed throughout the main cloud, indicating that our dataset covers a diverse portion of the search space, despite the limited size of only 1,000.
Each sampled architecture is trained using different levels of weight noise and HWA training hyper-parameters using the AIHWKIT [21]. Specifically, we modify the standard deviation of the added weight noise between [0.1, 5.0] in increments of 0.1. The tile size was assumed to be symmetric and varied in [256, 512], representing 256-by-256 and 512-by-512 arrays respectively. Training with different configurations allowed us to generalize the use of the surrogate model across a range of IMC hardware configurations, and to increase the size of the constructed dataset.
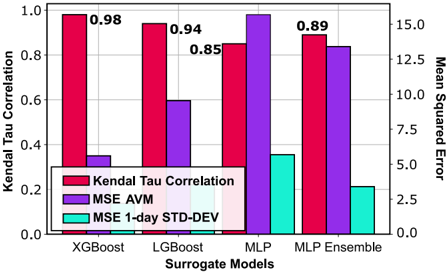
- 3) Model training: To train the surrogate model, we used a hinge pair-wise ranking loss [32] with margin m = 0 . 1 . The hinge loss, defined in Eq. (2), allows the model to learn the relative ranking order of architectures rather than the absolute accuracy values [32], [33].
<!-- formula-not-decoded -->
a j refers to architectures indexed j , and y j to its corresponding 1-day accuracy. P ( a ) is the predicted score of architecture a . P ( a ) during training, the output score is trained to be correlated with the actual ranks of the architectures. Several algorithms were tested. After an empirical comparison, we adopted Kendall's Tau ranking correlation [34] as the direct criterion for evaluating ranking surrogate model performance. Fig. 5 shows the comparison using different ML algorithms to predict the rankings and AVMs. Our dataset is tabular. It contains each architecture and its corresponding features. XGBoost outperforms the different surrogate models in predicting the architectures' ranking order, the A VM of each architecture, and the 1-day standard deviation.
Fig. 6. Overview of the AnalogNAS framework.
<details>
<summary>Image 6 Details</summary>
### Visual Description
\n
## Diagram: Neural Architecture Search Process
### Overview
The image depicts a flowchart illustrating a neural architecture search (NAS) process, divided into two main stages: "Off-Search Stage" and "Best Architecture Selection". The diagram outlines the steps involved in generating and evaluating candidate neural network architectures.
### Components/Axes
The diagram is structured as a flowchart with rectangular boxes representing processes and arrows indicating the flow of information. Key components include:
* **Off-Search Stage:** This stage involves defining the search space, uniform sampling of architectures, training with noise, and dataset construction.
* **Best Architecture Selection:** This stage involves initial population generation, surrogate model evaluation, architecture selection, union/mutation operations, and iteration control.
* **Data Representation:** Within the "Dataset Construction" box, there are visual representations of data: "Accuracy" (represented by a circular graph), "Architec." (likely representing architectural complexity), "Std" (standard deviation), and "AVM" (Average Validation Metric).
* **Decision Point:** A diamond-shaped box labeled "AVM < TAVM" represents a decision point based on the comparison of the Average Validation Metric (AVM) with a threshold (TAVM).
* **Iteration Control:** A diamond-shaped box labeled "End of Iteration?" controls the loop within the "Best Architecture Selection" stage.
### Detailed Analysis or Content Details
The process flow is as follows:
1. **Off-Search Stage:**
* Starts with defining the "Search Space".
* Proceeds to "Uniform Sampling" to generate a "Dataset of Sampled Architectures" from "RPU HW Configurations".
* The sampled architectures are then subjected to "Training with Noise".
* This leads to "Dataset Construction" which includes metrics like "Accuracy", "Architec.", "Std", and "AVM".
* Finally, a "Training Procedure" is applied.
2. **Best Architecture Selection:**
* Begins with "Initial Population Gen." creating a "Population" of architectures (represented by colored nodes).
* Each architecture is evaluated using a "Surrogate Model" and "Evaluation" process.
* A decision is made: "AVM < TAVM?".
* If "Yes", the process moves to "Best Architecture Selection".
* If "No", the process returns to the "Surrogate Model" and "Evaluation" step.
* "Best Architecture Selection" involves "Union" and "Mutations" operations.
* The process checks for "End of Iteration?".
* If "Yes", the loop terminates.
* If "No", the process returns to the "Surrogate Model" and "Evaluation" step.
* The entire "Best Architecture Selection" stage is connected to the "Off-Search Stage" via an arrow indicating the generation of a new architecture.
The "Population" in the "Initial Population Gen." stage consists of several colored nodes, each representing a different architecture. The colors appear to be: purple, green, orange, and blue.
### Key Observations
* The diagram highlights an iterative process of architecture search and evaluation.
* The use of a surrogate model suggests an attempt to reduce the computational cost of evaluating each architecture directly.
* The "AVM < TAVM" decision point indicates a threshold-based selection criterion.
* The "Union" and "Mutations" operations suggest a genetic algorithm-inspired approach to architecture evolution.
* The diagram does not provide specific numerical values for AVM, TAVM, or any other metrics.
### Interpretation
The diagram illustrates a common approach to Neural Architecture Search (NAS). The "Off-Search Stage" focuses on efficiently exploring the vast space of possible architectures, while the "Best Architecture Selection" stage refines the search through iterative evaluation and optimization. The use of a surrogate model is a key technique for accelerating the search process. The diagram suggests a closed-loop system where the performance of architectures informs the generation of new candidates. The "AVM" metric likely represents a measure of validation performance, and the "TAVM" threshold determines whether an architecture is considered "good enough" to be selected. The "Union" and "Mutations" operations are typical of evolutionary algorithms, where architectures are combined and modified to create new, potentially better designs. The diagram provides a high-level overview of the NAS process and does not delve into the specific details of the surrogate model, evaluation function, or mutation operators. It is a conceptual representation of the workflow rather than a detailed technical specification.
</details>
## V. SEARCH STRATEGY
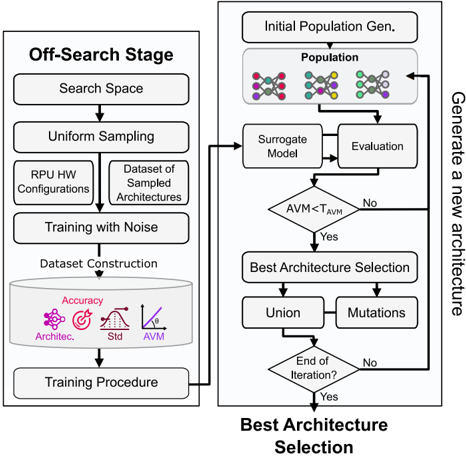
Fig. 6 depicts the overall search framework. Given a dataset and a hardware configuration readable by AIHWKIT, the framework starts by building the surrogate model presented in Section IV-B. Then, we use an optimized evolutionary search to efficiently explore the search space using the surrogate model. Similar to traditional evolutionary algorithms, we use real number encoding. Each architecture is encoded into a vector, and each element of the vector contains the value of the hyper-parameter, as listed in Table I.
## A. Problem Formulation
Given the search space S , our goal is to find an architecture α , that maximizes the 1-day accuracy while minimizing the 1-day standard deviation, subject to constraints on the number of parameters and the AVM. The number of parameters is an important metric in IMC, because it directly impacts the amount of on-chip memory required to store the weights of a DNN. Eq. (3) formally describes the optimization problem as follows:
<!-- formula-not-decoded -->
ACC refers to the 1-day accuracy objective, σ denotes the 1-day accuracy's standard deviation, and ψ is the number of parameters. T p and T AVM are user-defined thresholds that correspond to the maximum number of parameters and AVM, respectively.
## B. Search Algorithm
Our evolutionary search algorithm, i.e., AnalogNAS, is formally defined using Algorithm 1. AnalogNAS is an algorithm to find the most accurate and robust neural network architecture
## Algorithm 1 AnalogNAS algorithm.
Input: Search space: S , RPU Configuration: rpu config , target task: task , population size: population size , AVM threshold: T AVM, parameter threshold: T p , number of iterations: N , time budget
Output: Most efficient architecture for rpu config in S Begin
D = sample( S , dataset size)
HW Train( D , task )
AVMs = compute AVM( D )
surrogate model = XGBoost train(surrogate model, D , AVMs)
## repeat
population = LHS(population size, T p ) AVMs, ranks = surrogate model(population)
until AVMs > T AVM
while i < N or time < time budget do top 50 = select(population, ranks)
mutated = mutation(top 50, T p )
population = top 50
⋃
mutated
AVMs, ranks = surrogate model(population)
## end while
return top 1 (population, ranks)
for a given analog IMC configuration and task. The algorithm begins by generating a dataset of neural network architectures, which are trained on the task and evaluated using AIHWKIT. A surrogate model is then created to predict the efficiency of new architectures. The algorithm then generates a population of architectures using an LHS technique and selects the topperforming architectures to be mutated and generate a new population. The process is repeated until a stopping criterion is met, such as a maximum number of iterations or a time budget. Finally, the most robust architecture is returned. In the following, we detail how the population initialization, fitness evaluation, and mutations are achieved.
- 1) Population Initialization: The search starts by generating an initial population. Using the LHS algorithm, we sample the population uniformly from the search space. LHS ensures that the initial population contains architectures with different architectural features. LHS is made faster with parallelization by dividing the sampling into multiple independent subsets, which can be generated in parallel using multiple threads.
- 2) Fitness Evaluation: We evaluate the population using the aforementioned analog-accuracy surrogate model. In addition to the rankings, the surrogate model predicts the AVM of each architecture. As previously described, the AVM is used to gauge the robustness of a given network. If the AVM is below a defined threshold, T AVM, the architecture is replaced by a randomly sampled architecture. The new architecture is constrained to be sampled from the same hypercube dimension as the previous one. This ensures efficient exploration.
- 3) Selection and Mutation: We select the top 50% architectures from the population using the predicted rankings. These architectures are mutated. The mutation functions are classified
as follows:
- a) Depth-related mutations: modify the depth of the architectures. Mutations include adding a main block, by increasing or decreasing M or a residual block R , or modifying the type of convolution block, i.e., { A,B,C,D } , for each main block.
- b) Width-related mutations: modify the width of the architectures. Mutations include modifying the widening factor W of a main block or adding or removing a branch B , or modifying the initial output channel size of the first convolution, OC .
- c) Other mutations: modify the kernel size of the first convolution, KS , and/or add skip connections,denoted using ST .
Depth- and width-related mutations are applied with the same probability of 80%. The other mutations are applied with a 50% probability. In each class, the same probability is given to each mutation. The top 50% architectures in addition to the mutated architectures constitute the new population. For the remaining iterations, we verify the ranking correlation of the surrogate model. If the surrogate model's ranking correlation is degraded, we fine-tune the surrogate model with the population's architectures. The degradation is computed every 100 iterations. The surrogate model is tested on the population architectures after training them. It is fine-tuned if Kendall's tau correlation drops below 0.9.
## VI. EXPERIMENTS
This section describes the experiments used to evaluate AnalogNAS on three tasks: CIFAR-10 image classification, VWW, and KWS. The AIHWKIT was used to perform hardware simulations.
## A. Experimental Setup
- 1) Training Details: We detail the hyper-parameters used to train the surrogate model and different architectures on CIFAR-10, VWW, and KWS tasks.
- a) Surrogate model training: We trained a surrogate model and dataset of HWA trained DNN architctures for each task. The sizes of the datasets were 1,200, 600, and 1,500, respectively. An additional 500 architectures were collected during the search trials for validation. All architectures were first trained without noise injection (i.e., using vanilla training routines), and then converted to AIHWKIT models for HWA retraining. The surrogate model architecture used was XGBoost. For VWW and KWS, the surrogate model was fine-tuned from the image classification XGBoost model.
- b) Image classification training: We first trained the network architectures using the CIFAR-10 dataset [35], which contains 50,000 training and 10,000 test samples, evenly distributed across 10 classes. We augmented the training images with random crops and cutouts only. For training, we used Stochastic Gradient Descent (SGD) with a learning rate of 0.05 and a momentum of 0.9 with a weight decay of 5e-4. The learning rate was adjusted using a cosine annealing learning rate scheduler with a starting value of 0.05 and a maximum number of 400 iterations.
- c) Visual Wake Words (VWW) training: We first trained the network architectures using the VWW dataset [36], which contains 82,783 train and 40,504 test images. Images are labeled 1 when a person is detected, and 0 when no person is present. The image pre-processing pipeline includeded horizontal and vertical flipping, scale augmentation [37], and random Red Green Blue (RGB) color shift. To train the architectures, we used the RMSProp optimizer [38] with a momentum of 0.9, a learning rate of 0.01, a batch normalization momentum of 0.99, and a l 2 weight decay of 1e-5.
- d) Keyword Spotting (KWS) training: We first trained the network architectures using the KWS dataset [39], which contains 1-second long incoming audio clips. These are classified into one of twelve keyword classes, including 'silence' and 'unknown' keywords. The dataset contains 85,511 training, 10,102 validation, and 4,890 test samples. The input was transformed to 49 × 10 × 1 features from the Mel-frequency cepstral coefficients [40]. The data pre-processing pipeline included applying background noise and random timing jitter. To train the architectures, we used the Adam optimizer [41] with a decay of 0.9, a learning rate of 3e-05, and a linear learning rate scheduler with a warm-up ratio of 0.1.
- 2) Search Algorithm: The search algorithm was run five times to compute the variance. The evolutionary search was executed with a population size of 200. If not explicitly mentioned, the AVM threshold was set to 10%. The width and depth mutation probability was set to 0.8. The other mutations' probability was set to 0.5. The total number of iterations was 200. After the search, the obtained architecture for each task was compared to SOTA baselines for comparison.
## B. Results
The final architecture compositions for the three tasks are listed in Table II. In addition, figure 10 highlights the architectural differences between AnalogNAS T500 and resnet32. We modified T p to find smaller architectures. To determine the optimal architecture for different parameter thresholds, we use T X , where X represents the threshold T p in K units (e.g., T100 refers to the architecture with a threshold of 100K parameters). When searching for T200 and T100, the probability of increasing the widening factor or depth to their highest values, was lessened to 0.2.
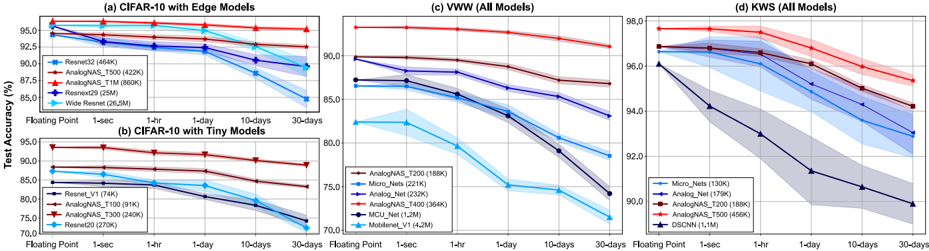
In Fig. 7, the simulated hardware comparison of the three tasks is depicted. Our models outperform SOTA architectures with respect to both accuracy and resilience to drift. On CIFAR-10, after training the surrogate model, the search took 17 minutes to run. We categorize the results based on the number of parameters threshold into two distinct groups. We consider edge models with a number of parameters below 1M and above 400k. Below 400K, architectures are suitable for TinyML deployment. The final architecture, T500, is smaller than Resnet32, and achieved +1.86% better accuracy and a drop of 1.8% after a month of inference, compared to 5.04%. This model is ∼ 86 × smaller than Wide Resnet [9], which has 36.5M parameters. Our smallest model, T100,
Fig. 7. Simulated hardware comparison results on three benchmarks: (a,b) CIFAR-10, (c)VWW, and (d) KWS. The size of the marker represents the size (i.e., the number of parameters) of each model. The shaded area corresponds to the standard deviation at that time.
<details>
<summary>Image 7 Details</summary>
### Visual Description
## Line Charts: Model Accuracy Degradation Under Quantization
### Overview
The image presents four line charts comparing the test accuracy of different neural network models under varying degrees of quantization. Quantization reduces the precision of the model's weights and activations, leading to potential accuracy loss but also reduced memory usage and faster inference. The x-axis represents the quantization level (Floating Point, 1hr, 1-day, 10-days, 30-days), and the y-axis represents the test accuracy (%). Each chart focuses on a specific dataset and model size category.
### Components/Axes
* **X-axis (all charts):** Quantization Level (Floating Point, 1hr, 1-day, 10-days, 30-days).
* **Y-axis (all charts):** Test Accuracy (%)
* **Chart (a):** CIFAR-10 with Edge Models
* **Chart (b):** CIFAR-10 with Tiny Models
* **Chart (c):** VWW (All Models)
* **Chart (d):** KWS (All Models)
* **Legend (all charts):** Lists the model names and their approximate sizes in Kilobytes (K).
### Detailed Analysis or Content Details
**Chart (a): CIFAR-10 with Edge Models**
* **ResNet32 (464K):** Starts at approximately 95.5% accuracy at Floating Point, decreases to around 92.5% at 1hr, 91.5% at 1-day, 89.5% at 10-days, and 87.5% at 30-days. (Downward trend)
* **AnalogNAS_T500 (422K):** Starts at approximately 95.0% accuracy at Floating Point, decreases to around 92.0% at 1hr, 90.5% at 1-day, 88.5% at 10-days, and 86.5% at 30-days. (Downward trend)
* **AnalogNAS_T1M (868K):** Starts at approximately 95.0% accuracy at Floating Point, decreases to around 92.0% at 1hr, 90.5% at 1-day, 88.5% at 10-days, and 86.5% at 30-days. (Downward trend)
* **ResNetD (256K):** Starts at approximately 94.5% accuracy at Floating Point, decreases to around 91.5% at 1hr, 89.5% at 1-day, 87.5% at 10-days, and 85.5% at 30-days. (Downward trend)
* **Wide ResNet (205K):** Starts at approximately 94.0% accuracy at Floating Point, decreases to around 90.5% at 1hr, 88.5% at 1-day, 86.5% at 10-days, and 84.5% at 30-days. (Downward trend)
**Chart (b): CIFAR-10 with Tiny Models**
* **ResNet_V1 (178K):** Starts at approximately 91.0% accuracy at Floating Point, decreases to around 87.0% at 1hr, 84.0% at 1-day, 81.0% at 10-days, and 78.0% at 30-days. (Downward trend)
* **AnalogNAS_T200 (90K):** Starts at approximately 90.0% accuracy at Floating Point, decreases to around 86.0% at 1hr, 83.0% at 1-day, 79.0% at 10-days, and 76.0% at 30-days. (Downward trend)
* **AnalogNAS_T300 (132K):** Starts at approximately 90.0% accuracy at Floating Point, decreases to around 86.0% at 1hr, 83.0% at 1-day, 79.0% at 10-days, and 76.0% at 30-days. (Downward trend)
* **ResNetD (276K):** Starts at approximately 89.0% accuracy at Floating Point, decreases to around 85.0% at 1hr, 82.0% at 1-day, 79.0% at 10-days, and 76.0% at 30-days. (Downward trend)
* **MobileNet_V1 (4.2M):** Starts at approximately 88.0% accuracy at Floating Point, decreases to around 84.0% at 1hr, 81.0% at 1-day, 78.0% at 10-days, and 75.0% at 30-days. (Downward trend)
**Chart (c): VWW (All Models)**
* **AnalogNAS_T200 (188K):** Starts at approximately 91.0% accuracy at Floating Point, decreases to around 88.0% at 1hr, 85.0% at 1-day, 82.0% at 10-days, and 79.0% at 30-days. (Downward trend)
* **Micro_Nets (222K):** Starts at approximately 91.0% accuracy at Floating Point, decreases to around 88.0% at 1hr, 85.0% at 1-day, 82.0% at 10-days, and 79.0% at 30-days. (Downward trend)
* **Analog_Net (320K):** Starts at approximately 90.0% accuracy at Floating Point, decreases to around 87.0% at 1hr, 84.0% at 1-day, 81.0% at 10-days, and 78.0% at 30-days. (Downward trend)
* **AnalogNAS_T400 (384K):** Starts at approximately 90.0% accuracy at Floating Point, decreases to around 87.0% at 1hr, 84.0% at 1-day, 81.0% at 10-days, and 78.0% at 30-days. (Downward trend)
* **MCU_Net (1.2M):** Starts at approximately 89.0% accuracy at Floating Point, decreases to around 86.0% at 1hr, 83.0% at 1-day, 80.0% at 10-days, and 77.0% at 30-days. (Downward trend)
**Chart (d): KWS (All Models)**
* **Micro_Nets (130K):** Starts at approximately 98.0% accuracy at Floating Point, decreases to around 96.0% at 1hr, 94.0% at 1-day, 92.0% at 10-days, and 90.0% at 30-days. (Downward trend)
* **Analog_Net (496K):** Starts at approximately 97.5% accuracy at Floating Point, decreases to around 95.5% at 1hr, 93.5% at 1-day, 91.5% at 10-days, and 89.5% at 30-days. (Downward trend)
* **AnalogNAS_T200 (188K):** Starts at approximately 97.0% accuracy at Floating Point, decreases to around 95.0% at 1hr, 93.0% at 1-day, 91.0% at 10-days, and 89.0% at 30-days. (Downward trend)
* **AnalogNAS_T500 (496K):** Starts at approximately 97.0% accuracy at Floating Point, decreases to around 95.0% at 1hr, 93.0% at 1-day, 91.0% at 10-days, and 89.0% at 30-days. (Downward trend)
* **DSCNN (1.1M):** Starts at approximately 96.5% accuracy at Floating Point, decreases to around 94.5% at 1hr, 92.5% at 1-day, 90.5% at 10-days, and 88.5% at 30-days. (Downward trend)
### Key Observations
* All models exhibit a consistent downward trend in accuracy as the quantization level increases (moving from Floating Point to 30-days).
* Larger models (higher K values) generally maintain higher accuracy at higher quantization levels compared to smaller models.
* The rate of accuracy degradation varies between models and datasets.
* The KWS dataset (Chart d) generally shows higher initial accuracy and a smaller drop in accuracy compared to the CIFAR-10 and VWW datasets.
### Interpretation
The charts demonstrate the trade-off between model accuracy and quantization. Quantization allows for reduced model size and faster inference, but at the cost of accuracy. The extent of this accuracy loss depends on the model architecture, the dataset, and the degree of quantization. The results suggest that for some models and datasets, significant quantization can be applied with minimal accuracy loss, while others are more sensitive to quantization. The larger models tend to be more robust to quantization, likely due to their greater capacity to represent the underlying data distribution. The KWS dataset's higher accuracy and smaller degradation suggest it may be easier to quantize without significant performance loss. These findings are crucial for deploying machine learning models on resource-constrained devices, where quantization is often necessary to achieve acceptable performance. The "1hr", "1-day", "10-days", and "30-days" labels likely represent different levels of post-training quantization or other forms of model compression applied over time.
</details>
TABLE II FINAL ARCHITECTURES FOR CIFAR-10, VWW, AND KWS. OTHER NETWORKS FOR VWW AND KWS ARE NOT LISTED, AS THEY CANNOT EASILY BE REPRESENTED USING OUR MACRO-ARCHITECTURE.
| Network | | | Macro-Architecture Parameter R* | Macro-Architecture Parameter R* | Macro-Architecture Parameter R* | |
|---------------------------------------------------------------------|----------------|-----------|-----------------------------------------------|------------------------------------|-------------------------------------|-------------------------------------|
| | OC 0 | KS 0 | M | B* | CT* | WF* |
| CIFAR-10 | CIFAR-10 | CIFAR-10 | CIFAR-10 | CIFAR-10 | CIFAR-10 | CIFAR-10 |
| Resnet32 AnalogNAS T100 AnalogNAS T300 AnalogNAS T500 AnalogNAS T1M | 64 32 32 64 32 | 7 3 3 5 5 | 3 (5, 5, 5) 1 (2, ) 1 (3, 3) 1 (3, ) 2 (3, 3) | (1, 1, 1) (1,) (1, 1) (3, ) (2, 2) | (B, B, B) (C, ) (A, B) (A, ) (A, A) | (1, 1, 1) (2, ) (2, 1) (2, ) (3, 3) |
| VWW | VWW | VWW | VWW | VWW | VWW | VWW |
| AnalogNAS T200 AnalogNAS T400 | 24 68 | 3 3 | 3 (2, 2, 2) 2 (3, 5) | (1, 2, 1) (2, 1) | (B, A, A) (C, C) | (2, 2, 2) (3, 2) |
| AnalogNAS T200 AnalogNAS T400 | 80 68 | 1 1 | 1 (1, ) 2 (2, 1) | (2, ) (1, 2) | (C, ) (B, B) | (4, ) (3, 3) |
was 1 . 23 × bigger than Resnet-V1, the SOTA model benchmarked by MLPerf [11]. Despite not containing any depth-wise convolutions, Resnet V1 is extremely small, with only 70k parameters. Our model offers a +7.98% accuracy increase with a 5.14% drop after a month of drift compared to 10.1% drop for Resnet V1. Besides, our largest model, AnalogNAS 1M , outperforms Wide Resnet with +0.86% in the 1-day accuracy with a drop of only 1.16% compared to 6.33%. In addition, the found models exhibit greater consistency across experiment trials, with an average standard deviation of 0.43 over multiple drift times as opposed to 0.97 for SOTA models.
Similar conclusions can be made about VWW and KWS. In VWW,current baselines use a depth-wise separable convolution that incurs a high accuracy drop on analog devices. Compared to AnalogNet-VWW and Micronets-VWW, the current SOTA networks for VWW in analog and edge devices, our T200 model has similar number of parameters (x1.23 smaller) with a +2.44% and +5.1% 1-day accuracy increase respectively. AnalogNAS was able to find more robust and consistent networks with an average AVM of 2.63% and a standard deviation of 0.24. MCUNet [42] and MobileNet-V1 present the highest AVM. This is due to the sole use of depth-wise separable convolutions.
On KWS, the baseline architectures, including DSCNN [43], use hybrid networks containing recurrent cells and convolutions. The recurrent part of the model ensures high robustness to noise. While current models are already robust with an average accuracy drop of 4.72%, our model outperforms tiny SOTA models with 96.8% and an accuracy drop of 2.3% after a month of drift. Critically, our AnalogNAS models exhibit greater consistency across experiment trials, with an average standard deviation of 0.17 over multiple drift times as opposed to 0.36 for SOTA models.
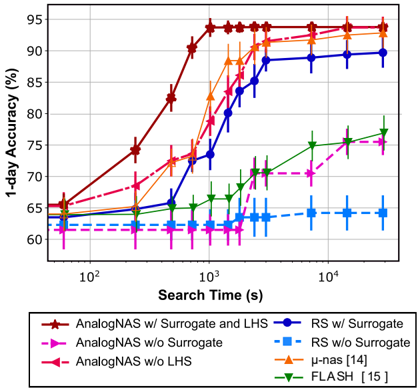
## C. Comparison with HW-NAS
In accordance with commonly accepted NAS methodologies, we conducted a comparative analysis of our search approach with Random Search. Results, presented in Fig. 8, were obtained across five experiment instances. Our findings indicate that Random Search was unable to match the 1-day accuracy levels of our final models, even after conducting experiments for a duration of four hours and using the same surrogate model. We further conducted an ablation study to evaluate the effectiveness of our approach by analyzing the impact of the LHS algorithm and surrogate model. The use of a
Fig. 8. Ablation study comparison against HW-NAS. Mean and standard deviation values are reported across five experiment instances (trials).
<details>
<summary>Image 8 Details</summary>
### Visual Description
## Line Chart: Neural Architecture Search Performance
### Overview
This image presents a line chart comparing the performance of different Neural Architecture Search (NAS) algorithms based on their search time and resulting 1-day accuracy. The chart displays accuracy as a function of search time, with error bars indicating the variance in performance.
### Components/Axes
* **X-axis:** Search Time (s), displayed on a logarithmic scale (10<sup>2</sup> to 10<sup>4</sup>).
* **Y-axis:** 1-day Accuracy (%), ranging from approximately 60% to 95%.
* **Legend:** Located at the bottom of the chart, identifying the different NAS algorithms:
* AnalogNAS w/ Surrogate and LHS (Dark Red)
* AnalogNAS w/o Surrogate (Red)
* AnalogNAS w/o LHS (Magenta)
* RS w/ Surrogate (Dark Blue)
* RS w/o Surrogate (Blue)
* μ-nas [14] (Orange)
* FLASH [15] (Green)
* **Error Bars:** Vertical lines extending above and below each data point, representing the standard deviation or confidence interval.
* **Gridlines:** Horizontal and vertical lines providing a visual reference for data point values.
### Detailed Analysis
The chart shows the following trends and approximate data points:
* **AnalogNAS w/ Surrogate and LHS (Dark Red):** This line starts at approximately 65% accuracy at 10<sup>2</sup> seconds, rapidly increases to around 93% accuracy at 10<sup>3</sup> seconds, and plateaus around 95% accuracy at 10<sup>4</sup> seconds.
* **AnalogNAS w/o Surrogate (Red):** This line begins at approximately 65% accuracy at 10<sup>2</sup> seconds, increases to around 92% accuracy at 10<sup>3</sup> seconds, and plateaus around 94% accuracy at 10<sup>4</sup> seconds.
* **AnalogNAS w/o LHS (Magenta):** This line starts at approximately 62% accuracy at 10<sup>2</sup> seconds, increases to around 88% accuracy at 10<sup>3</sup> seconds, and plateaus around 92% accuracy at 10<sup>4</sup> seconds.
* **RS w/ Surrogate (Dark Blue):** This line starts at approximately 65% accuracy at 10<sup>2</sup> seconds, increases to around 90% accuracy at 10<sup>3</sup> seconds, and plateaus around 91% accuracy at 10<sup>4</sup> seconds.
* **RS w/o Surrogate (Blue):** This line remains relatively flat, starting at approximately 63% accuracy at 10<sup>2</sup> seconds and ending around 65% accuracy at 10<sup>4</sup> seconds.
* **μ-nas [14] (Orange):** This line starts at approximately 63% accuracy at 10<sup>2</sup> seconds, increases to around 72% accuracy at 10<sup>3</sup> seconds, and reaches approximately 75% accuracy at 10<sup>4</sup> seconds.
* **FLASH [15] (Green):** This line starts at approximately 63% accuracy at 10<sup>2</sup> seconds, increases to around 73% accuracy at 10<sup>3</sup> seconds, and reaches approximately 77% accuracy at 10<sup>4</sup> seconds.
### Key Observations
* The AnalogNAS algorithms (especially with both Surrogate and LHS) demonstrate the fastest improvement in accuracy with increasing search time.
* RS w/ Surrogate performs better than RS w/o Surrogate, indicating the benefit of using a surrogate model.
* μ-nas [14] and FLASH [15] exhibit significantly lower accuracy compared to the AnalogNAS and RS algorithms, even with longer search times.
* RS w/o Surrogate shows minimal improvement in accuracy with increasing search time.
* The error bars suggest that the AnalogNAS algorithms have relatively low variance in performance.
### Interpretation
The data suggests that the AnalogNAS algorithms are highly effective in finding high-accuracy neural architectures within a reasonable search time. The inclusion of both a surrogate model and LHS (Latin Hypercube Sampling) further enhances the performance of AnalogNAS. The relatively poor performance of μ-nas [14] and FLASH [15] indicates that these algorithms may be less efficient or require significantly more search time to achieve comparable accuracy. The flat line for RS w/o Surrogate suggests that the surrogate model is crucial for the performance of this algorithm. The logarithmic scale of the x-axis highlights the rapid gains in accuracy achieved by AnalogNAS within the initial search time, indicating a potentially efficient exploration of the architecture space. The error bars provide a measure of the robustness of each algorithm, with AnalogNAS showing consistent performance. This chart provides a comparative analysis of different NAS algorithms, offering insights into their strengths and weaknesses in terms of accuracy and search efficiency.
</details>
TABLE III AVM THRESHOLD VARIATION RESULTS ON CIFAR-10.
| T AVM (%) | 1.0 | 3.0 | 5.0* |
|-------------------|-------|--------|--------|
| 1-day Accuracy | 88.7% | 93.71% | 93.71% |
| AVM | 0.85% | 1.8% | 1.8% |
| Search Time (min) | 34.65 | 28.12 | 17.65 |
*Overall results computed with TAVM (%) = 5.0.
random sampling strategy and exclusion of the surrogate model resulted in a significant increase in search time. The LHS algorithm helped in starting from a diverse initial population and improving exploration efficiency, while the surrogate model played a crucial role in ensuring practical search times.
Besides, AnalogNAS surpasses both FLASH [15] and µ -nas [14] in performance and search time. FLASH search strategy is not adequate for large search spaces such as ours. As for µ -nas, although it manages to achieve acceptable results, its complex optimization algorithm hinders the search process, resulting in decreased efficiency.
## D. Search Time and Accuracy Variation over One Month (AVM) Threshold Trade-Off
During the search, we culled architectures using their predicted AVM, i.e., any architecture with a higher AVM than the AVM threshold was disregarded. As listed in Table III, we varied this threshold to investigate the trade-off between TAVM and the search time. As can be seen, as TAVM is decreased, the delta between AVM and TAVM significantly decreases. The correlation between the search time and TAVM is observed to be non-linear.
## VII. EXPERIMENTAL HARDWARE VALIDATION AND ARCHITECTURE PERFORMANCE SIMULATIONS
## A. Experimental Hardware Validation
An experimental hardware accuracy validation study was performed using a 64-core IMC chip based on PCM [44]. Each core comprises a crossbar array of 256x256 PCM-based unit-cells along with a local digital processing unit [45]. This validation study was performed to verify whether the simulated network accuracy values and rankings are representative of those when the networks are deployed on real physical hardware. We deployed two networks for the CIFAR-10 image classification task on hardware: AnalogNAS T500 and the baseline ResNet32 [30] networks from Fig. 7(a).
To implement the aforementioned models on hardware, after HWA training was performed, a number of steps were carried out. First, from the AIHWKIT, unit weights of linear (dense) and unrolled convolutional layers, were exported to a state dictionary file. This was used to map network parameters to corresponding network layers. Additionally, the computational inference graph of each network was exported. These files were used to generate proprietary data-flows to be executed in-memory. As only hardware accuracy validation was being performed, all other operations aside from MVMs were performed on a host machine connected to the chip
TABLE IV EXPERIMENTAL HARDWARE ACCURACY VALIDATION AND SIMULATED POWER PERFORMANCE ON THE IMC SYSTEM IN [46].
| Architecture | ResNet32 | AnalogNAS T500 |
|--------------------------------------|--------------------------------------|--------------------------------------|
| Hardware Experiments | Hardware Experiments | Hardware Experiments |
| FP Accuracy | 94.34% | 94.54% |
| Hardware accuracy* | 89.55% | 92.07% |
| Simulated Hardware Power Performance | Simulated Hardware Power Performance | Simulated Hardware Power Performance |
| Total weights | 464,432 | 416,960 |
| Total tiles | 43 | 27 |
| Network Depth | 32 | 17 |
| Execution Time (msec) | 0.434 | 0.108 |
| Inferences/s/W | 43,956.7 | 54,502 |
*The mean accuracy is reported across five experiment repetitions.
through an Field-programmable Gate Array (FPGA). The measured hardware accuracy was 92.05% for T500 and 89.87% for Resnet32, as reported in Table IV. Hence, the T500 network performs significantly better than Resnet32 also when implemented on real hardware. This further validates that our proposed AnalogNAS approach is able to find networks with similar number of parameters that are more accurate and robust on analog IMC hardware.
## B. Simulated Hardware Energy and Latency
We conducted power performance simulations for AnalogNAS T500 and ResNet32 models using a 2D-mesh based heterogeneous analog IMC system with the simulation tool presented in [46]. The simulated IMC system consists of one analog fabric with 48 analog tiles of 512x512 size, on-chip digital processing units, and digital memory for activation orchestration between CNN layers. Unlike the accuracy validation experiments on the 64-core IMC chip, the simulated power performance assumes all intermediate operations to be mapped and executed on-chip. Our results, provided in Table IV, show that AnalogNAS T500 outperformed ResNet32 in terms of both execution time and energy efficiency.
We believe that this power performance benefit is realized because, in analog IMC hardware, wider layers can be computed in parallel, leveraging the O (1) latency from analog tiles, and are therefore preferred over deeper layers. It is noted that both networks exhibit poor tile utilization and that the tile utilization and efficiency of these networks could be further improved by incorporating these metrics as explicit constraints. This is left to future work and is beyond the scope of AnalogNAS.
## VIII. DISCUSSION
During the search, we analyzed the architecture characteristics and studied which types of architectures perform the best on IMC inference processors. The favoured architectures combine robustness to noise and accuracy performance. Fig. 9 shows the evolution of the average depth, the average widening factor, the average number of branches, and the average first convolution's output channel size of the search population for every 20 iterations. The depth represents the number of convolutions.
Fig. 9. Evolution of architecture characteristics in the population during the search for CIFAR-10. Random individual networks are shown.
<details>
<summary>Image 9 Details</summary>
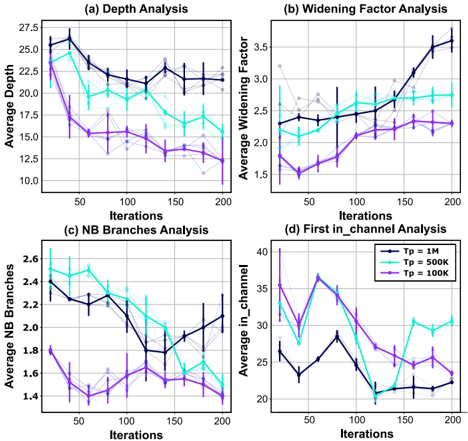
### Visual Description
## Charts: Network Training Analysis
### Overview
The image contains four separate line charts, arranged in a 2x2 grid. Each chart analyzes a different metric related to network training over iterations. The metrics are Depth, Widening Factor, Number of Branches (NB Branches), and First_in_channel. Each chart displays three lines representing different values of Tp (1M, 500k, 100k), with error bars indicating variance.
### Components/Axes
Each chart shares the following components:
* **X-axis:** Iterations, ranging from 0 to 200, with markings every 50 iterations.
* **Y-axis:** Varies depending on the chart, representing the metric being analyzed.
* **Legend:** Located in the top-right corner of each chart, indicating the line colors corresponding to Tp values:
* Tp = 1M (Dark Turquoise)
* Tp = 500k (Cyan)
* Tp = 100k (Purple)
* **Titles:** Each chart has a title indicating the analysis being performed:
* (a) Depth Analysis
* (b) Widening Factor Analysis
* (c) NB Branches Analysis
* (d) First_in_channel Analysis
### Detailed Analysis
**Chart (a): Depth Analysis**
* **Trend:** All three lines initially decrease, then plateau and fluctuate. The Tp = 1M line starts highest and decreases most rapidly.
* **Data Points (approximate):**
* Tp = 1M: Starts at ~26, decreases to ~18 at iteration 50, fluctuates between ~18 and ~24 until iteration 200, ending at ~24.
* Tp = 500k: Starts at ~25, decreases to ~16 at iteration 50, fluctuates between ~16 and ~22 until iteration 200, ending at ~20.
* Tp = 100k: Starts at ~24, decreases to ~14 at iteration 50, fluctuates between ~14 and ~19 until iteration 200, ending at ~17.
**Chart (b): Widening Factor Analysis**
* **Trend:** The Tp = 1M line shows a clear upward trend, while the other two lines are relatively stable with some fluctuations.
* **Data Points (approximate):**
* Tp = 1M: Starts at ~1.6, increases steadily to ~3.5 at iteration 200.
* Tp = 500k: Fluctuates around ~2.5, ranging from ~2.2 to ~2.8 throughout the iterations.
* Tp = 100k: Fluctuates around ~2.0, ranging from ~1.8 to ~2.3 throughout the iterations.
**Chart (c): NB Branches Analysis**
* **Trend:** All three lines initially decrease, then plateau and fluctuate. The Tp = 500k line shows the most pronounced decrease.
* **Data Points (approximate):**
* Tp = 1M: Starts at ~2.5, decreases to ~1.8 at iteration 50, fluctuates between ~1.8 and ~2.4 until iteration 200, ending at ~2.2.
* Tp = 500k: Starts at ~2.5, decreases to ~1.5 at iteration 50, fluctuates between ~1.5 and ~2.1 until iteration 200, ending at ~1.9.
* Tp = 100k: Starts at ~2.4, decreases to ~1.7 at iteration 50, fluctuates between ~1.7 and ~2.3 until iteration 200, ending at ~2.1.
**Chart (d): First_in_channel Analysis**
* **Trend:** All three lines show fluctuating patterns with no clear overall trend. The Tp = 1M line generally has higher values.
* **Data Points (approximate):**
* Tp = 1M: Fluctuates between ~25 and ~40 throughout the iterations.
* Tp = 500k: Fluctuates between ~20 and ~35 throughout the iterations.
* Tp = 100k: Fluctuates between ~20 and ~30 throughout the iterations.
### Key Observations
* Higher Tp values (1M) generally lead to greater depth and widening factor, but also higher values for First_in_channel.
* The number of branches (NB Branches) decreases initially for all Tp values, suggesting a pruning or simplification of the network structure.
* The widening factor increases significantly with higher Tp values, indicating a more complex network architecture.
* The error bars suggest considerable variance in the metrics, particularly at later iterations.
### Interpretation
These charts provide insights into the training dynamics of a neural network with varying parameter counts (Tp). The decreasing depth and NB Branches suggest that the network is being compressed or regularized during training. The increasing widening factor for Tp = 1M indicates that the network is becoming more expressive, potentially at the cost of increased computational complexity. The fluctuations in First_in_channel suggest that the network is exploring different feature representations during training.
The differences between the Tp values highlight the trade-offs between model capacity and efficiency. Higher Tp values allow for more complex models but may require more computational resources and data. The optimal Tp value likely depends on the specific task and available resources. The error bars indicate that the training process is stochastic and that the observed trends may not be consistent across different runs. Further analysis, such as averaging over multiple training runs, would be needed to confirm these observations.
</details>
Fig. 10. Architectural differences between AnalogNAS T500 and Resnet32.
<details>
<summary>Image 10 Details</summary>
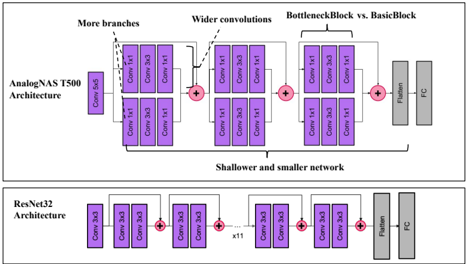
### Visual Description
\n
## Diagram: AnalogNAS T500 and ResNet32 Architectures
### Overview
The image presents a comparative diagram illustrating the architectural differences between AnalogNAS T500 and ResNet32. It visually contrasts the building blocks (BottleneckBlock vs. BasicBlock) and overall network structure of the two architectures. The diagram focuses on the convolutional layers and their connections.
### Components/Axes
The diagram is divided into two horizontal sections, one for each architecture:
* **Top Section:** AnalogNAS T500 Architecture
* **Bottom Section:** ResNet32 Architecture
Each section depicts a series of interconnected blocks representing convolutional layers and other operations. Key labels include:
* "More branches" (pointing to the AnalogNAS T500 section)
* "Wider convolutions" (pointing to the AnalogNAS T500 section)
* "BottleneckBlock vs. BasicBlock" (spanning both sections)
* "Shallower and smaller network" (pointing to the ResNet32 section)
* "Conv 3x3" (labeling convolutional layers in ResNet32)
* "Conv 1x1" (labeling convolutional layers in AnalogNAS T500)
* "Flatten" (labeling the flattening layer in both architectures)
* "FC" (labeling the fully connected layer in both architectures)
* "x11" (indicating repetition of a block in ResNet32)
* "S×S" (indicating a square convolutional layer in AnalogNAS T500)
### Detailed Analysis or Content Details
**AnalogNAS T500 Architecture:**
The AnalogNAS T500 architecture begins with a "Conv S×S" layer. This is followed by a series of blocks. Each block consists of multiple "Conv 1x1" layers, with connections indicated by plus signs (+). The diagram shows a branching structure, with multiple paths diverging from the initial convolutional layer. The blocks are connected sequentially, leading to a "Flatten" layer and finally a "FC" (Fully Connected) layer. The diagram highlights "More branches" and "Wider convolutions" as key characteristics.
**ResNet32 Architecture:**
The ResNet32 architecture consists of a series of blocks, each containing multiple "Conv 3x3" layers connected with plus signs (+). The "x11" label indicates that a particular block is repeated 11 times. The blocks are connected sequentially, leading to a "Flatten" layer and a "FC" layer. The diagram emphasizes that ResNet32 is a "Shallower and smaller network".
The blocks in AnalogNAS T500 appear to have more layers within them than the blocks in ResNet32. The connections within the AnalogNAS blocks are more complex, with multiple branches.
### Key Observations
* AnalogNAS T500 utilizes "Conv 1x1" layers extensively, while ResNet32 uses "Conv 3x3" layers.
* AnalogNAS T500 has a more branched structure compared to the linear flow of ResNet32.
* ResNet32 is described as "Shallower and smaller", suggesting a lower number of layers and parameters.
* The diagram visually emphasizes the "BottleneckBlock" structure in AnalogNAS T500 and the "BasicBlock" structure in ResNet32.
### Interpretation
The diagram illustrates the fundamental architectural differences between AnalogNAS T500 and ResNet32. AnalogNAS T500 appears to be designed for greater representational capacity through wider convolutions and more branching, potentially at the cost of increased computational complexity. ResNet32, on the other hand, prioritizes simplicity and efficiency with a shallower and smaller network structure. The use of different convolutional kernel sizes (1x1 vs. 3x3) suggests different approaches to feature extraction and processing. The diagram suggests that AnalogNAS T500 aims to capture more complex features through its wider and branched architecture, while ResNet32 focuses on efficient feature learning with a simpler structure. The "BottleneckBlock" vs. "BasicBlock" distinction highlights the different building blocks used in each architecture, which likely influence their performance characteristics. The diagram does not provide quantitative data, but it offers a clear visual comparison of the architectural designs.
</details>
A sampled architecture has a widening factor per block. To compute the average widening factor, we first computed the average widening factor per architecture by dividing the sum of the widening factors by the number of blocks contained in the architecture. Then, we calculated the average widening factor across all architectures. Similar computations were performed for the average number of branches.
For each plot, the search was run 5 times and the mean is represented in each point. The plotted error corresponds to one standard deviation from that mean. Starting from a random population obtained using LHS, the population evolves through different width and depth-related mutations. During this analysis, we want to answer the following questions: (i) does the search favor wide or deep networks? And subsequently, are wider architectures more noise resilient? (ii) what architectures are exploited by the search for different tasks when constraining the number of parameters?
## A. Are Wider or Deeper Networks More Robust to PCM Device Drift?
From Fig. 9, it can be observed that the depth of all networks decreases during the search. This trend is especially seen when we constrain the model's size to 100K and 500K parameters. During the search, the widening factor also increases, allowing the blocks to have wider convolutions. The number of branches is highly dependent on T p . This number is, on average, between 1 and 2. The branches are the number of parallel convolutions in a block disregarding the skip connection. In the literature, architectures such as ResNext, that support a higher number of branches, have a number of parameters around 30M. It is still interesting to get blocks with two branches, which also reflects an increase in the width of the network by increasing the number of features extracted within the same block.The average output channel size of the first convolution decreases during the search. Its final value is around the same number of output channels as standard architectures, i.e., between 16 and 32. This follows the general trend of having wider convolutions in deeper network positions.
## B. Types Of Architectures
The architectures and parameter constraints differ for each task, but they all exhibit an increasing expansion ratio in the convolution block. This allows the convolutions to effectively utilize the tile and mitigate noise from unused cells in the crossbar.For CIFAR-10, architectures behave like Wide Resnet [9] while respecting the number of parameters constraint. For the VWW task, the architectures are deeper. The input resolution is 224 × 224 , which requires more feature extraction blocks. However, they are still smaller than SOTA architectures, with a maximum depth of 22. As depth is essential to obtain high accuracy for the VWW task, no additional branches are added. For the KWS task, the architectures are the widest possible, maximizing the tile utilization for each convolutional layer.
## IX. CONCLUSION
In this paper, we propose an efficient NAS methodology dedicated to analog in-memory computing for TinyML tasks entitled AnalogNAS. The obtained models are accurate, noise and drift-resilient, and small enough to run on resourceconstrained devices. Experimental results demonstrate that our method outperforms SOTA models on analog hardware for three tasks of the MLPerf benchmark: image classification on CIFAR-10, VWW, and KWS. Our AnalogNAS T500 model implemented on physical hardware demonstrates > 2% higher accuracy experimentally on the CIFAR-10 benchmark than ResNet32. Calculated speed and energy efficiency estimates reveal a > 4 × reduction in execution time, in addition to > 1 . 2 × higher energy efficiency for AnalogNAS T500 compared with ResNet32 when evaluated using a system-level simulator. While our paper has focused on a ResNet-like search space, it is important to note that our search strategy is adaptable and can be extended in future work to explore a broader range of architectures.
## ACKNOWLEDGEMENT
We would like to thank Thanos Vasilopoulos and Julian B¨ uchel from IBM Research, Zurich lab, for their help with the development of the hardware-software infrastructure. We also thank the IBM Research Analog AI team for their feedback. We thank the computational support from AiMOS, an AI supercomputer made available by the IBM Research AI Hardware Center and Rensselaer Polytechnic Institute's Center for Computational Innovations (CCI).
## REFERENCES
- [1] A. Sebastian, M. Le Gallo, R. Khaddam-Aljameh, and E. Eleftheriou, 'Memory devices and applications for in-memory computing,' Nature Nanotechnology , vol. 15, no. 7, pp. 529-544, Jul 2020.
- [2] V. Joshi, M. L. Gallo, I. Boybat, S. Haefeli, C. Piveteau, M. Dazzi, B. Rajendran, A. Sebastian, and E. Eleftheriou, 'Accurate deep neural network inference using computational phase-change memory,' CoRR , vol. abs/1906.03138, 2019.
- [3] C. Lammie, W. Xiang, B. Linares-Barranco, and M. Rahimi Azghadi, 'Memtorch: An open-source simulation framework for memristive deep learning systems,' Neurocomputing , vol. 485, pp. 124-133, 2022.
- [4] I. Boybat, B. Kersting, S. G. Sarwat, X. Timoneda, R. L. Bruce, M. BrightSky, M. L. Gallo, and A. Sebastian, 'Temperature sensitivity of analog in-memory computing using phase-change memory,' in 2021 IEEE International Electron Devices Meeting (IEDM) , 2021, pp. 28.3.1-28.3.4.
- [5] A. G. Howard, M. Zhu, B. Chen, D. Kalenichenko, W. Wang, T. Weyand, M. Andreetto, and H. Adam, 'Mobilenets: Efficient convolutional neural networks for mobile vision applications,' CoRR , vol. abs/1704.04861, 2017.
- [6] G. Lu, W. Zhang, and Z. Wang, 'Optimizing depthwise separable convolution operations on gpus,' IEEE Transactions on Parallel and Distributed Systems , vol. 33, no. 1, pp. 70-87, 2022.
- [7] H. Benmeziane, K. E. Maghraoui, H. Ouarnoughi, S. Niar, M. Wistuba, and N. Wang, 'A comprehensive survey on hardware-aware neural architecture search,' CoRR , vol. abs/2101.09336, 2021.
- [8] S. Xie, R. B. Girshick, P. Doll´ ar, Z. Tu, and K. He, 'Aggregated residual transformations for deep neural networks,' in IEEE Conference on Computer Vision and Pattern Recognition, CVPR . IEEE Computer Society, 2017, pp. 5987-5995.
- [9] S. Zagoruyko and N. Komodakis, 'Wide residual networks,' in Proceedings of the British Machine Vision Conference, BMVC , R. C. Wilson, E. R. Hancock, and W. A. P. Smith, Eds. BMVA Press, 2016.
- [10] L. Sekanina, 'Neural architecture search and hardware accelerator cosearch: A survey,' IEEE Access , vol. 9, pp. 151 337-151 362, 2021.
- [11] C. R. Banbury, V. J. Reddi, P. Torelli, N. Jeffries, C. Kir´ aly, J. Holleman, P. Montino, D. Kanter, P. Warden, D. Pau, U. Thakker, A. Torrini, J. Cordaro, G. D. Guglielmo, J. M. Duarte, H. Tran, N. Tran, W. Niu, and X. Xu, 'Mlperf tiny benchmark,' in Proceedings of the Neural Information Processing Systems Track on Datasets and Benchmarks 1, NeurIPS Datasets and Benchmarks 2021, December 2021, virtual , J. Vanschoren and S. Yeung, Eds., 2021.
- [12] C. R. Banbury, C. Zhou, I. Fedorov, R. M. Navarro, U. Thakker, D. Gope, V. J. Reddi, M. Mattina, and P. N. Whatmough, 'Micronets: Neural network architectures for deploying tinyml applications on commodity microcontrollers,' in Proceedings of Machine Learning and Systems , A. Smola, A. Dimakis, and I. Stoica, Eds. mlsys.org, 2021.
- [13] H. Liu, K. Simonyan, and Y. Yang, 'DARTS: differentiable architecture search,' CoRR , vol. abs/1806.09055, 2018. [Online]. Available: http://arxiv.org/abs/1806.09055
- [14] E. Liberis, L. Dudziak, and N. D. Lane, ' µ nas: Constrained neural architecture search for microcontrollers,' in EuroMLSys@EuroSys 2021, Proceedings of the 1st Workshop on Machine Learning and Systemsg Virtual Event, Edinburgh, Scotland, UK, 26 April, 2021 , E. Yoneki and P. Patras, Eds. ACM, 2021, pp. 70-79.
- [15] G. Li, S. K. Mandal, ¨ U. Y. Ogras, and R. Marculescu, 'FLASH: fast neural architecture search with hardware optimization,' ACM Trans. Embed. Comput. Syst. , vol. 20, no. 5s, pp. 63:1-63:26, 2021.
- [16] W. Jiang, Q. Lou, Z. Yan, L. Yang, J. Hu, X. S. Hu, and Y. Shi, 'Device-circuit-architecture co-exploration for computing-in-memory neural accelerators,' IEEE Trans. Computers , vol. 70, no. 4, pp. 595-605, 2021.
- [17] Z. Yuan, J. Liu, X. Li, L. Yan, H. Chen, B. Wu, Y. Yang, and G. Sun, 'NAS4RRAM: neural network architecture search for inference on rrambased accelerators,' Sci. China Inf. Sci. , vol. 64, no. 6, 2021.
- [18] Z. Yan, D.-C. Juan, X. S. Hu, and Y. Shi, 'Uncertainty modeling of emerging device based computing-in-memory neural accelerators with application to neural architecture search,' in 2021 26th Asia and South Pacific Design Automation Conference (ASP-DAC) , 2021, pp. 859-864.
- [19] G. Li, M. Zhang, J. Li, F. Lv, and G. Tong, 'Efficient densely connected convolutional neural networks,' Pattern Recognit. , vol. 109, p. 107610, 2021.
- [20] C. Zhou, F. Redondo, J. Buchel, I. Boybat, X. Comas, S. R. Nandakumar, S. Das, A. Sebastian, M. L. Gallo, and P. N. Whatmough, 'Ml-hw codesign of noise-robust tinyml models and always-on analog computein-memory edge accelerator,' IEEE Micro , vol. 42, no. 06, pp. 76-87, 2022.
- [21] M. J. Rasch, D. Moreda, T. Gokmen, M. L. Gallo, F. Carta, C. Goldberg, K. E. Maghraoui, A. Sebastian, and V. Narayanan, 'A flexible and fast pytorch toolkit for simulating training and inference on analog crossbar arrays,' in 3rd IEEE International Conference on Artificial Intelligence Circuits and Systems . IEEE, 2021, pp. 1-4.
- [22] M. J. Rasch, C. Mackin, M. L. Gallo, A. Chen, A. Fasoli, F. Odermatt, N. Li, S. R. Nandakumar, P. Narayanan, H. Tsai, G. W. Burr, A. Sebastian, and V. Narayanan, 'Hardware-aware training for large-scale and diverse deep learning inference workloads using in-memory computing-based accelerators,' 2023. [Online]. Available: https://arxiv.org/abs/2302.08469
- [23] C. Termritthikun, Y. Jamtsho, J. Ieamsaard, P. Muneesawang, and I. Lee, 'Eeea-net: An early exit evolutionary neural architecture search,' Eng. Appl. Artif. Intell. , vol. 104, p. 104397, 2021.
- [24] X. Dai, A. Wan, P. Zhang, B. Wu, Z. He, Z. Wei, K. Chen, Y. Tian, M. Yu, P. Vajda, and J. E. Gonzalez, 'Fbnetv3: Joint architecture-recipe search using predictor pretraining,' in IEEE Conference on Computer Vision and Pattern Recognition, CVPR . Computer Vision Foundation / IEEE, 2021, pp. 16 276-16 285.
- [25] W. Jiang, X. Zhang, E. H. Sha, L. Yang, Q. Zhuge, Y. Shi, and J. Hu, 'Accuracy vs. efficiency: Achieving both through fpga-implementation aware neural architecture search,' in Proceedings of the 56th Annual Design Automation Conference 2019, DAC 2019, Las Vegas, NV, USA, June 02-06, 2019 . ACM, 2019, p. 5.
- [26] A. Sarah, D. Cummings, S. N. Sridhar, S. Sundaresan, M. Szankin, T. Webb, and J. P. Munoz, 'A hardware-aware system for accelerating deep neural network optimization,' CoRR , vol. abs/2202.12954, 2022.
- [27] Z. Dong, Y. Gao, Q. Huang, J. Wawrzynek, H. K. H. So, and K. Keutzer, 'HAO: hardware-aware neural architecture optimization for efficient inference,' in 29th IEEE Annual International Symposium on FieldProgrammable Custom Computing Machines, FCCM 2021, Orlando, FL, USA, May 9-12, 2021 . IEEE, 2021, pp. 50-59.
- [28] M. Tan and Q. V. Le, 'Efficientnetv2: Smaller models and faster training,' in Proceedings of the 38th International Conference on Machine Learning, ICML , ser. Proceedings of Machine Learning Research, M. Meila and T. Zhang, Eds., vol. 139. PMLR, 2021, pp. 10 096-10 106.
- [29] B. Zoph, V. Vasudevan, J. Shlens, and Q. V. Le, 'Learning transferable architectures for scalable image recognition,' in 2018 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2018, Salt Lake City, UT, USA, June 18-22, 2018 . Computer Vision Foundation / IEEE Computer Society, 2018, pp. 8697-8710.
- [30] K. He, X. Zhang, S. Ren, and J. Sun, 'Deep residual learning for image recognition,' in IEEE Conference on Computer Vision and Pattern Recognition, CVPR . IEEE Computer Society, 2016, pp. 770-778.
- [31] M. D. McKay, 'Latin hypercube sampling as a tool in uncertainty analysis of computer models,' in Proceedings of the 24th Winter Simulation Conference, Arlington, VA, USA, December 13-16, 1992 , R. C. Crain, Ed. ACM Press, 1992, pp. 557-564.
- [32] X. Ning, Y. Zheng, T. Zhao, Y. Wang, and H. Yang, 'A generic graphbased neural architecture encoding scheme for predictor-based NAS,' in Computer Vision - ECCV 2020 - 16th European Conference, Glasgow, UK, August 23-28, 2020, Proceedings, Part XIII , ser. Lecture Notes in Computer Science, A. Vedaldi, H. Bischof, T. Brox, and J. Frahm, Eds., vol. 12358. Springer, 2020, pp. 189-204.
- [33] H. Benmeziane, S. Niar, H. Ouarnoughi, and K. E. Maghraoui, 'Pareto rank surrogate model for hardware-aware neural architecture search,' in International IEEE Symposium on Performance Analysis of Systems and Software, ISPASS . IEEE, 2022, pp. 267-276.
- [34] H. Abdi, 'The kendall rank correlation coefficient,' Encyclopedia of Measurement and Statistics. Sage, Thousand Oaks, CA , pp. 508-510, 2007.
- [35] A. Krizhevsky, G. Hinton et al. , 'Learning multiple layers of features from tiny images,' 2009.
- [36] A. Chowdhery, P. Warden, J. Shlens, A. Howard, and R. Rhodes, 'Visual wake words dataset,' CoRR , vol. abs/1906.05721, 2019.
- [37] H. Zhang, C. Wu, Z. Zhang, Y. Zhu, H. Lin, Z. Zhang, Y. Sun, T. He, J. Mueller, R. Manmatha, M. Li, and A. J. Smola, 'Resnest: Splitattention networks,' in IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, CVPR . IEEE, 2022, pp. 2735-2745.
- [38] M. C. Mukkamala and M. Hein, 'Variants of rmsprop and adagrad with logarithmic regret bounds,' in Proceedings of the 34th International Conference on Machine Learning, ICML , ser. Proceedings of Machine Learning Research, D. Precup and Y. W. Teh, Eds., vol. 70. PMLR, 2017, pp. 2545-2553.
- [39] P. Warden, 'Speech Commands: A Dataset for Limited-Vocabulary Speech Recognition,' ArXiv e-prints , Apr. 2018. [Online]. Available: https://arxiv.org/abs/1804.03209
- [40] J. Mart´ ınez, H. P´ erez-Meana, E. E. Hern´ andez, and M. M. Suzuki, 'Speaker recognition using mel frequency cepstral coefficients (MFCC) and vector quantization (VQ) techniques,' in 22nd International Conference on Electrical Communications and Computers, CONIELECOMP , P. B. S´ anchez, R. Rosas-Romero, and M. J. O. Galindo, Eds. IEEE, 2012, pp. 248-251.
- [41] D. P. Kingma and J. Ba, 'Adam: A method for stochastic optimization,' in 3rd International Conference on Learning Representations , Y. Bengio and Y. LeCun, Eds., 2015.
- [42] J. Lin, W. Chen, Y. Lin, J. Cohn, C. Gan, and S. Han, 'Mcunet: Tiny deep learning on iot devices,' in Advances in Neural Information Processing Systems 33: Annual Conference on Neural Information Processing Systems , H. Larochelle, M. Ranzato, R. Hadsell, M. Balcan, and H. Lin, Eds., 2020.
- [43] P. M. Sørensen, B. Epp, and T. May, 'A depthwise separable convolutional neural network for keyword spotting on an embedded system,' EURASIP J. Audio Speech Music. Process. , vol. 2020, no. 1, p. 10, 2020.
- [44] M. L. Gallo, R. Khaddam-Aljameh, M. Stanisavljevic, A. Vasilopoulos, B. Kersting, M. Dazzi, G. Karunaratne, M. Braendli, A. Singh, S. M. Mueller, J. Buechel, X. Timoneda, V. Joshi, U. Egger, A. Garofalo, A. Petropoulos, T. Antonakopoulos, K. Brew, S. Choi, I. Ok, T. Philip, V. Chan, C. Silvestre, I. Ahsan, N. Saulnier, V. Narayanan, P. A. Francese, E. Eleftheriou, and A. Sebastian, 'A 64-core mixed-signal in-memory compute chip based on phase-change memory for deep neural network inference,' 2022. [Online]. Available: https://arxiv.org/abs/2212.02872
- [45] R. Khaddam-Aljameh, M. Stanisavljevic, J. F. Mas, G. Karunaratne, M. Braendli, F. Liu, A. Singh, S. M. M¨ uller, U. Egger, A. Petropoulos, T. Antonakopoulos, K. Brew, S. Choi, I. Ok, F. L. Lie, N. Saulnier, V. Chan, I. Ahsan, V. Narayanan, S. R. Nandakumar, M. L. Gallo, P. A. Francese, A. Sebastian, and E. Eleftheriou, 'Hermes core - a 14nm cmos and pcm-based in-memory compute core using an array of 300ps/lsb linearized cco-based adcs and local digital processing,' in 2021 Symposium on VLSI Technology , 2021, pp. 1-2.
- [46] S. Jain, H. Tsai, C.-T. Chen, R. Muralidhar, I. Boybat, M. M. Frank, S. Wo´ zniak, M. Stanisavljevic, P. Adusumilli, P. Narayanan, K. Hosokawa, M. Ishii, A. Kumar, V. Narayanan, and G. W. Burr, 'A heterogeneous and programmable compute-in-memory accelerator architecture for analogai using dense 2-d mesh,' IEEE Transactions on Very Large Scale Integration (VLSI) Systems , vol. 31, no. 1, pp. 114-127, 2023.