## In-Context Analogical Reasoning with Pre-Trained Language Models
Xiaoyang Hu 12 ∗
Shane Storks 1 ∗ Richard L. Lewis 2 † Joyce Chai 1 †
1 Computer Science and Engineering Division, University of Michigan 2 Department of Psychology, University of Michigan
{nickhu, sstorks, rickl, chaijy}@umich.edu
## Abstract
Analogical reasoning is a fundamental capacity of human cognition that allows us to reason abstractly about novel situations by relating them to past experiences. While it is thought to be essential for robust reasoning in AI systems, conventional approaches require significant training and/or hard-coding of domain knowledge to be applied to benchmark tasks. Inspired by cognitive science research that has found connections between human language and analogy-making, we explore the use of intuitive language-based abstractions to support analogy in AI systems. Specifically, we apply large pre-trained language models (PLMs) to visual Raven's Progressive Matrices (RPM), a common relational reasoning test. By simply encoding the perceptual features of the problem into language form, we find that PLMs exhibit a striking capacity for zero-shot relational reasoning, exceeding human performance and nearing supervised vision-based methods. We explore different encodings that vary the level of abstraction over task features, finding that higherlevel abstractions further strengthen PLMs' analogical reasoning. Our detailed analysis reveals insights on the role of model complexity, incontext learning, and prior knowledge in solving RPM tasks.
## 1 Introduction
Humans are constantly presented with novel problems and circumstances. Rather than understand them in isolation, we try to connect them with past experiences. With any luck, we might find an analogy : a mapping between relevant aspects of this new situation and a past situation, which helps form abstractions that allow us to reason more effectively in the future (Holyoak, 1984). Analogy is thought to underpin humans' robust reasoning and problem solving capabilities (Hofstadter and
∗ Authors contributed equally to this work.
† Equal advising contribution.
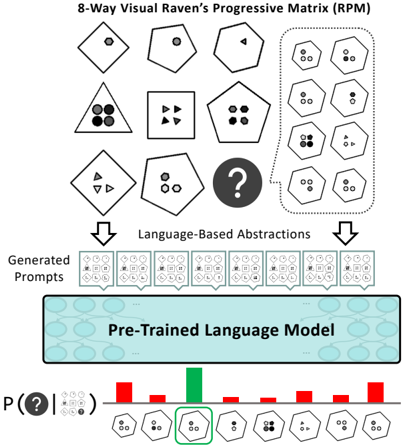
Figure 1: Raven's Progressive Matrices (Raven and Court, 1938; Zhang et al., 2019a) are an analogy-making task where one must infer the missing matrix item based on abstract rules instantiated in the first two rows. To demonstrate the potential analogical reasoning skills in pre-trained language models, we develop languagebased abstractions over their key perceptual features, then prompt them to select the completion of the matrix.
<details>
<summary>Image 1 Details</summary>
### Visual Description
## Diagram: Visual Reasoning with Language Model
### Overview
The image illustrates a system for solving visual reasoning problems, specifically 8-Way Visual Raven's Progressive Matrix (RPM) problems, using a pre-trained language model. The system takes a visual matrix as input, generates language-based abstractions, and uses the language model to predict the missing element. The output is a probability distribution over possible answers.
### Components/Axes
* **Title:** 8-Way Visual Raven's Progressive Matrix (RPM)
* **Visual Matrix:** A 3x3 grid of images, with the bottom-right image replaced by a question mark. The images consist of geometric shapes with varying attributes (number of sides, number of internal objects, shading).
* **Language-Based Abstractions:** Text label indicating the conversion of visual information into a textual representation.
* **Generated Prompts:** A row of 8 images, each representing a textual prompt derived from the visual matrix. Each image contains a combination of shapes and symbols.
* **Pre-Trained Language Model:** A teal-colored block representing the language model, with a network diagram overlaid.
* **P(?|...)**: Label indicating the conditional probability of the missing element given the context.
* **Probability Distribution:** A bar chart showing the probability of each possible answer. The x-axis represents the 8 possible answer choices, depicted as geometric shapes. The y-axis represents probability, but no scale is provided. The bars are colored red, except for one green bar, indicating the most probable answer.
### Detailed Analysis
1. **Visual Matrix:**
* Row 1:
* Image 1: Diamond shape with a single gray circle inside.
* Image 2: Pentagon shape with a single gray circle inside.
* Image 3: Hexagon shape with a single gray triangle inside.
* Row 2:
* Image 4: Triangle shape with four circles inside (two gray, two dark).
* Image 5: Square shape with four dark triangles inside.
* Image 6: Pentagon shape with four gray circles inside.
* Row 3:
* Image 7: Diamond shape with three gray triangles inside.
* Image 8: Pentagon shape with three circles inside (two gray, one white).
* Image 9: Question mark inside a gray circle.
2. **Generated Prompts:** Eight images, each containing a combination of shapes and symbols. The shapes include circles, squares, diamonds, and triangles. The symbols are arranged in a 3x3 grid within each image.
3. **Probability Distribution:**
* The x-axis shows the 8 possible answer choices, each represented by a geometric shape.
* The y-axis represents the probability of each answer choice, but the scale is not provided.
* The bars are colored red, except for one green bar, indicating the most probable answer.
* The green bar corresponds to a hexagon shape with three circles inside (two white, one gray).
* The red bars have varying heights, indicating different probabilities for the other answer choices.
### Key Observations
* The system aims to solve visual reasoning problems by converting visual information into a textual representation and using a language model to predict the missing element.
* The probability distribution shows the confidence of the language model in each possible answer.
* The green bar indicates the most probable answer, as determined by the language model.
### Interpretation
The diagram illustrates a novel approach to solving visual reasoning problems by leveraging the power of pre-trained language models. The system bridges the gap between visual and textual information by generating language-based abstractions from the visual matrix. This allows the language model to reason about the visual relationships and predict the missing element. The probability distribution provides insights into the model's confidence in each possible answer. The green bar highlights the most probable answer, suggesting that the language model has successfully identified the correct solution. This approach has the potential to improve the performance of visual reasoning systems and enable new applications in areas such as image understanding and artificial intelligence.
</details>
Sander, 2013), and thus it is believed to be prerequisite in order to enable the same in AI systems. However, conventional approaches struggle with analogy-making, and are trained on thousands of examples to achieve any success on benchmark tasks. This is unsatisfying, as humans are capable of analogy-making without explicit training, and such analogy-making should enable zero-shot generalization to new situations (Mitchell, 2021).
Interestingly, a body of work in cognitive science suggests that analogy-making and relational reasoning are connected to humans' symbol system and language capabilities (Gentner, 2010). For example, Gordon (2004) finds that members of an Amazonian tribe that count only with words for 'one,' 'two,' and 'many' struggle to make analo- gies with higher numbers. Further, Gentner et al. (2013) find that deaf children whose sign language does not involve spatial relations are outperformed by hearing children on a spatial relational reasoning task, while Christie and Gentner (2014) find that assigning even nonsensical names to relations enhances children's relational reasoning. All of this demonstrates that language serves as a powerful way for humans to abstract and better reason about the overwhelming and complex percepts we encounter in the world.
In this work, we explore whether language may serve a similar purpose in AI systems. Specifically, we apply contemporary autoregressive pre-trained language models (PLMs) to Raven's Progressive Matrices (RPM), an example of which is shown in Figure 1. RPM is a widely used psychometric test for relational reasoning that requires inducing an abstract rule from just two examples of short sequences of groups of shapes, and then applying the rule to complete a new partial sequence (Raven and Court, 1938). This task makes minimal assumptions about the test taker's prior knowledge, and is thus thought to provide a good estimate for general intelligence (Holyoak, 2012). On the RAVEN dataset (Zhang et al., 2019a), we find that given the ability to perceive key features of RPMs, large PLMs exhibit a surprising capacity for zero-shot relational reasoning, approaching that of supervised vision-based deep learning approaches and even humans. We propose three levels of abstraction over the language features of the task using name assignment and task decomposition, and find that each abstraction further strengthens PLMs' relational reasoning. Our results and detailed analysis offer insights on PLM performance, including the role of models' complexity, in-context learning, and prior knowledge in emergent relational reasoning, and suggest that they could play an important role in future cognitive architectures for analogy-making. 2
## 2 Related Work
Past work has studied analogy in AI across various domains. Mitchell (2021) provides a comprehensive overview of these efforts, especially those applied in idealized symbolic domains. Here, symbolic and probabilistic methods have traditionally been applied (Gentner, 1983; Hofstadter and Mitchell, 1994; Lake et al., 2015). However, these
2 Experiment code is available at https://github.com/ hxiaoyang/lm-raven.
approaches typically require hard-coding domainspecific concepts, and require substantial search through domain knowledge to operate on their target problems, thus making them unscalable. The creation of large-scale image datasets for analogy tasks here (Zhang et al., 2019a; Hu et al., 2021; Odouard and Mitchell, 2022) have enabled further research with deep learning and neuro-symbolic methods (Hill et al., 2019; Spratley et al., 2020; Kim et al., 2020; Zhang et al., 2021), which bring the advantage of requiring less ad-hoc encoding of domain knowledge, but require thousands of training examples to learn the tasks, still limiting their generalization capability.
Other work has explored AI systems' analogymaking in real-world domains, including in natural images (Teney et al., 2020; Bitton et al., 2022) and language (Li et al., 2020; Chen et al., 2022; Sultan and Shahaf, 2022), especially lexical analogies (Turney et al., 2003; Turney, 2008; Speer et al., 2008; Mikolov et al., 2013b,a; Linzen, 2016; Lu et al., 2019). However, these domains make it difficult to control the prior knowledge required to solve tasks (Mitchell, 2021), and in the context of recent generative foundation models that are extensively pre-trained on natural data, it becomes difficult to separate analogy learning from distributional patterns that can be overfit. Unlike prior work, we apply such foundation models for language to analogical reasoning in a zero-shot setting, bypassing the requirement of hard-coding domain knowledge or training models on task-specific data. Furthermore, while contemporaneous work has applied PLMs to a variety of simpler relational reasoning tasks in language (Webb et al., 2022), we systematically explore the advantage of using language to abstract over complex visual features of the task, opening questions about how the powerful symbol systems learned in PLMs may support robust, perception-driven reasoning in future AI systems.
## 3 Raven's Progressive Matrices
Raven's progressive matrices (RPM) are abstract relational reasoning tasks used in cognitive psychology to test humans' analogy-making (Raven and Court, 1938). Each instance of RPM is a matrix consisting of 9 items arranged in a square, the last of which must be selected from a set of choices. Each item consists of several perceptual attributes , such as shape, color, or more abstract features. Within each row of the matrix, a relation is applied
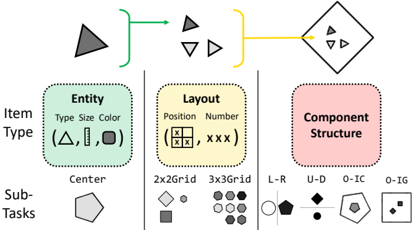
Figure 2: Illustration of the compositional nature of entities, layouts, and component structures in RA VEN, and their unique attributes. We provide example items from sub-tasks each item type appears in.
<details>
<summary>Image 2 Details</summary>
### Visual Description
## Diagram: Item Type and Sub-Tasks Breakdown
### Overview
The image presents a diagram that breaks down "Item Type" into three components: Entity, Layout, and Component Structure. It also shows examples of sub-tasks related to each component. The diagram uses visual elements like shapes, colors, and arrows to illustrate the relationships between these components.
### Components/Axes
* **Item Type:** The main category being broken down.
* **Sub-Tasks:** Examples of tasks related to each component of Item Type.
* **Entity:**
* Attributes: Type, Size, Color
* Examples: Triangle (Δ), Line (|), Square (□)
* **Layout:**
* Attributes: Position, Number
* Examples: 2x2 Grid, 3x3 Grid
* **Component Structure:**
* Examples: Left-Right (L-R), Up-Down (U-D), Outside-In Component (O-IC), Outside-In Group (O-IG)
### Detailed Analysis
* **Entity:** The "Entity" section shows three shapes: a triangle, a line, and a square. These represent different types of entities that can be part of an item.
* **Layout:** The "Layout" section illustrates how entities can be arranged. It shows a 2x2 grid and a 3x3 grid as examples of different layouts.
* **Component Structure:** This section shows how components can be structured.
* **L-R:** A circle and a pentagon are placed side-by-side, indicating a left-to-right relationship.
* **U-D:** A diamond is placed above a circle, indicating an up-down relationship.
* **O-IC:** A pentagon is placed around a smaller pentagon, indicating an outside-in component structure.
* **O-IG:** A square contains two smaller squares, indicating an outside-in group structure.
* **Sub-Tasks:** A pentagon is shown under the "Center" label, representing a sub-task related to centering an item.
* **Arrows:**
* A green arrow connects a gray triangle to a group of smaller triangles (some gray, some white).
* A yellow arrow connects the group of smaller triangles to a diamond containing even smaller triangles.
### Key Observations
* The diagram uses shapes and spatial arrangement to represent different aspects of item types and their components.
* The arrows indicate a flow or transformation from a single entity to a group of entities, and then to a structured component.
* The sub-tasks provide concrete examples of actions that can be performed on items.
### Interpretation
The diagram provides a visual framework for understanding the different aspects of an "Item Type." It breaks down the concept into three key components: Entity, Layout, and Component Structure. The examples provided for each component help to illustrate the different possibilities and variations. The sub-tasks provide a practical application of these concepts. The diagram suggests that understanding these components is essential for effectively working with and manipulating items. The arrows suggest a process of aggregation and structuring, where individual entities are combined and arranged to form more complex components.
</details>
over these attributes, such as progression of numerical values associated with these attributes. Given the first two rows of the matrix, the challenge of the task is to identify the relations being applied to items, and apply them analogously in the third row to infer the missing ninth item. Successfully solving an RPM requires tackling two sub-problems: perception of each item's attributes, and reasoning over multiple items' attributes to infer and apply relations.
## 3.1 RAVEN Dataset
We focus our study on RAVEN (Zhang et al., 2019a), which provides a large-scale benchmark for RPM tasks for training and evaluation of AI systems. Each RPM has 8 possible candidate items to complete it. As shown in Figure 2, each item may consist of compositional entities , layouts , and/or component structures , and RAVEN provides a suite of increasingly complex sub-tasks built from these elements. We introduce their unique attributes below, as well as relations that may occur over them across items in the matrix.
Entities. A single entity has a type (i.e., shape), size , and color selected from a small number of classes. Each of these attributes is associated with a number: type with the number of sides in the entity's shape, size with its diameter, and color with the darkness of its shading. The simplest sub-task of RAVEN is Center , where each item only consists of a single entity.
Layouts. Layouts of entities bring additional higher-level attributes to items, specifically the number (i.e., count) and position of entities within a layout. In the 2x2Grid and 3x3Grid sub-tasks of RAVEN, each item consists of multiple entities arranged in a grid.
Component structures. Items may also be composed of multiple sub-items or components ; RAVEN includes four sub-tasks that introduce this even higher-level challenge: L-R , U-D , and O-IC , each of which consist of two single entities in different configurations, and O-IG , which consists of a 2-by-2 grid inside of a larger entity.
Relations. Following prior work on this task, RAVEN applies four different relations to item attributes across rows of the matrix. These are Constant , which does not modify an attribute, Progression , which increases or decreases the value of an attribute by 1 or 2, Arithmetic , which performs addition or subtraction on the first two attributes of the row to create the third, and Distribute Three , which distributes three consistent values of an attribute across each row.
## 4 Methods
In order to apply PLMs to RAVEN, we abstract the visual features of the task into language. Our abstractions are intentionally applied on a per-item basis to tackle the perception problem of the task without giving the PLM explicit hints toward the reasoning problem (which requires capturing patterns over multiple items). This allows us to focus on evaluating the reasoning capabilities of PLMs. 3
First, we introduce our multi-level abstractions for the RAVEN dataset. 4 Then we formally define the interface between PLMs and the RPM task.
## 4.1 Abstractions in RAVEN
We define abstractions for entity-level attributes, layout-level attributes, and component structures which convert the RPM task into one or more text prompts. We apply two kinds of abstractions: naming and decomposition . As discussed in Section 1, assigning names to perceptual features strengthens humans' analogy-making skills over them. Inspired by this, naming abstractions abstract over attributes or combinations of attributes in the RPM by assigning a unique name to describe them. Mean-
3 As the important features of RAVEN are simple, the perception of an individual item is better performed by computer vision models, and can already be done to fairly high accuracy (Zhang et al., 2021). For more general-purpose analogymaking beyond idealized domains, the robust perception of key features that allow previous (source) experiences to be mapped to novel (target) experiences is a challenging unsolved problem (Mitchell, 2021).
4 Some example PLM prompts using these abstractions are shown in this section, while more examples are provided in Appendix C.
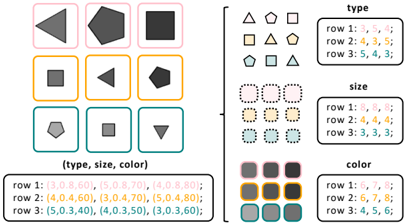
Figure 3: Example generated prompts for a complete RPM under entity attribute naming (left) and decomposition (right) abstractions in the Center sub-task.
<details>
<summary>Image 3 Details</summary>
### Visual Description
## Visual Encoding: Shape, Size, and Color
### Overview
The image presents a 3x3 grid of shapes, each varying in type (triangle, pentagon, square), size, and color. The image also includes data tables that specify the type, size, and color of each shape in the grid. The image demonstrates how visual attributes can be encoded with numerical values.
### Components/Axes
* **Grid:** A 3x3 grid displaying shapes. The rows are visually separated by color-coded borders: pink (row 1), orange (row 2), and teal (row 3).
* **Shapes:** Each cell in the grid contains a shape: triangle, pentagon, or square.
* **Labels:** The image is labeled "(type, size, color)".
* **Data Tables:** Three tables are present, labeled "type", "size", and "color". Each table contains three rows of numerical data corresponding to the rows in the grid.
### Detailed Analysis
**Grid Analysis:**
* **Row 1 (Pink Border):** Triangle, Pentagon, Square.
* **Row 2 (Orange Border):** Square, Triangle, Pentagon.
* **Row 3 (Teal Border):** Pentagon, Square, Triangle.
**Data Table Analysis:**
* **Type Table:**
* Row 1: 3, 5, 4 (Triangle, Pentagon, Square)
* Row 2: 4, 3, 5 (Square, Triangle, Pentagon)
* Row 3: 5, 4, 3 (Pentagon, Square, Triangle)
* **Size Table:**
* Row 1: 8, 8, 8
* Row 2: 4, 4, 4
* Row 3: 3, 3, 3
* **Color Table:**
* Row 1: 6, 7, 8
* Row 2: 6, 7, 8
* Row 3: 4, 5, 6
**Coordinate Data:**
The following data is provided in the format (type, size, color) for each cell in the grid:
* Row 1: (3,0.8,60), (5,0.8,70), (4,0.8,80)
* Row 2: (4,0.4,60), (3,0.4,70), (5,0.4,80)
* Row 3: (5,0.3,40), (4,0.3,50), (3,0.3,60)
### Key Observations
* The "Type Table" assigns numerical values to the shapes: 3 for Triangle, 4 for Square, and 5 for Pentagon.
* The "Size Table" indicates a consistent size within each row, with Row 1 having the largest size (8), Row 2 a medium size (4), and Row 3 the smallest size (3).
* The "Color Table" shows a progression of color values within each row.
* The coordinate data provides a more detailed numerical representation of each shape's attributes.
### Interpretation
The image demonstrates a visual encoding scheme where shapes, sizes, and colors are mapped to numerical values. The grid visually represents the data, while the tables provide a structured numerical representation. The coordinate data offers a more precise numerical description of each shape's attributes. This type of encoding is commonly used in data visualization and machine learning to represent categorical and continuous variables. The image effectively illustrates how visual attributes can be translated into numerical data for analysis and processing.
</details>
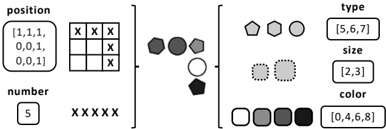
Figure 4: Example of generated entity layout encodings when abstracting position and number , and summarizing redundant entity attributes within the layout.
<details>
<summary>Image 4 Details</summary>
### Visual Description
## Diagram: Feature Representation
### Overview
The image illustrates a feature representation scheme, showing how different attributes of an object (position, number, type, size, color) can be encoded. It uses visual examples and numerical ranges to represent these features.
### Components/Axes
* **Position:**
* A 3x3 grid with 'X' marks indicating positions. The 'X' marks are located at the top row (all three positions), the middle right position, and the bottom right position.
* A numerical representation: `[1,1,1, 0,0,1, 0,0,1]`
* **Number:**
* A numerical value: `5`
* A visual representation: Five 'X' marks.
* **Type:**
* Visual representations of three shapes: a pentagon, a hexagon, and a circle.
* Numerical representation: `[5,6,7]`
* **Size:**
* Visual representations of two squares with dotted outlines.
* Numerical representation: `[2,3]`
* **Color:**
* Visual representations of four squares with different shades of gray, ranging from white to black.
* Numerical representation: `[0,4,6,8]`
### Detailed Analysis
* **Position:** The grid shows three 'X' marks in the top row, and one 'X' mark each in the middle-right and bottom-right positions. The numerical representation `[1,1,1, 0,0,1, 0,0,1]` likely corresponds to the presence (1) or absence (0) of an object in each position of the 3x3 grid, read row by row.
* **Number:** The number 5 is represented both numerically and visually with five 'X' marks.
* **Type:** The shapes (pentagon, hexagon, circle) are associated with the numerical range `[5,6,7]`. This suggests that each shape is assigned a numerical identifier.
* **Size:** The two squares with dotted outlines are associated with the numerical range `[2,3]`. This suggests that each square is assigned a numerical identifier.
* **Color:** The four shades of gray (white, light gray, dark gray, black) are associated with the numerical range `[0,4,6,8]`. This suggests that each color is assigned a numerical identifier.
### Key Observations
* The diagram uses both visual and numerical representations for each feature.
* The numerical representations appear to be encoding categorical or discrete values.
* The position feature uses a grid-based representation.
### Interpretation
The diagram illustrates a method for encoding object features into numerical representations, likely for use in a machine learning or computer vision system. Each feature (position, number, type, size, color) is mapped to a numerical value or a set of numerical values. This allows the system to process and analyze objects based on their attributes. The use of both visual and numerical representations makes the encoding scheme more intuitive and easier to understand.
</details>
while, jointly understanding and tracking the complex features of the task can become a burden even for humans. Inspired by humans' capability to decompose complex tasks into independent subtasks (Lee and Anderson, 2001), decomposition abstractions split the RPM into multiple sub-matrices by its independent features, then generate a separate prompt for each one. We can then prompt a PLMonce for each sub-matrix, and aggregate PLM outputs to choose a candidate matrix completion. 5
## 4.1.1 Entity-Level Abstractions
As shown in Figure 3, we can abstract perceptual entity attributes into language by assigning them names, then generating prompts to represent the full RPM using these names. As each of an entity's attributes is numerical by nature, we assign each attribute an ordinal numerical name; type is named by the number of sides of the associated shape (e.g., '3' for triangle ), size is named by a decimal representing its diameter, and color is named based on the darkness of the entity's shade. As each of an entity's attributes is independent, i.e., a relation over one attribute has no connection to relations over other attributes, we can decompose the RPM task by these attributes into three separate sub-tasks with their own prompts.
5 A more formal definition for decomposition is provided in Section 4.2.
## 4.1.2 Layout-Level Abstractions
As shown in Figure 4, we next propose abstractions for layouts of entities (e.g., in grid-based sub-tasks of RAVEN). First, the number attribute of a layout corresponds to the count of entities in it. Recognizing number requires implicitly counting entities within a layout, which may be difficult to disentangle from other attributes. As such, we directly expose this attribute by extracting this count and encoding it in text. Since this layout attribute is independent from other attributes, we can again decompose the task and consider it separately from entity attributes.
The position attribute encodes even more complex information about a layout, and relations over it may move entities around within the layout. However, an occupancy map serves as a strong naming abstraction for position which omits distracting details of specific entities while exposing key information for detecting relations over it. We generate the occupancy map as an array of text representing the occupancy of the layout, and decompose this from other attributes. Notably, this abstraction provides a unique language description for each possible global configuration of entities within a layout, allowing the PLM to disentangle global and local patterns in the problem, a helpful capability of humans (Robertson and Lamb, 1991). 6
In RAVEN, relations are applied to specific attributes consistently across all entities in a layout. As our layout-level abstractions make explicit the key features of layouts, we no longer need to track entity-level attributes for specific entities within them. Specifically, rather than supply a PLM with a separate grid-like prompt for each entity-level attribute, we simply provide a list of unique attribute values. This reduces the complexity added by layouts of multiple entities.
## 4.1.3 Structural Decomposition Abstractions
In cases with multiple components in each item, we may find that prompts become long and complicated with earlier approaches. Since each component's attributes and relations are independent, we can alternatively decompose the task by its components. For each component, we can generate a prompt through entity attribute naming abstractions as shown in Figure 3 (left), or we can apply
6 For example, we may recognize the grid of entities in Figure 2 to be in an 'L' shape at the global level, while also recognizing that it is locally composed of triangles.
the higher-level abstractions over entity and layout attributes shown in Figure 4, thus decomposing each component's prompts into prompts for each attribute. As this structural decomposition converts multi-component problems into several simpler single-component, single-attribute problems, the complexity added by multiple components is abstracted away.
## 4.2 Problem Definition
Formally, a complete RPM M consists of 9 matrix items m ij where row and column i, j ∈ { 1 , 2 , 3 } . As discussed in Section 3.1, an individual item m ij in the RAVEN dataset is formalized by high-level components consisting of layout-level attributes and entity-level attributes. Given all items in M except for m 33 , the task is to identify m 33 from a set Y of 8 choices by identifying abstract rules over the attributes within the first 2 rows of M , and selecting the candidate m 33 that correctly applies these rules in the third row.
Applying PLMs. We apply PLMs to RAVEN in a zero-shot setting. In the absence of decomposition abstractions, we define ▲ as the mapping of a complete RPM to a text prompt. The PLM's choice for m 33 is given by
$$\arg \max _ { y \in Y } \frac { 1 } { | \mathbb { L } | } \log \Pr \left ( \mathbb { L } \left ( m _ { 1 1 \colon 3 2 } , y \right ) \right )$$
▲ where | ▲ | denotes the number of tokens in the prompt. When decomposition is introduced, ▲ instead returns multiple prompts, and the (tokenlength normalized) log-probabilities of all subprompts are summed. 7
## 5 Experimental Results
Now, we can examine the impact each of these language-based abstractions has on the performance of transformer-based, autoregressive PLMs in relational reasoning on RAVEN. To further understand their impact with respect to model complexity, we evaluate a range of model sizes: 8 OPT 125M, 1.3B, and 13B (Zhang et al., 2022), along with GPT-3 (Brown et al., 2020). 9 Models are evaluated on a random subset of 500 testing examples from each sub-task of RAVEN.
7 See Appendix C for examples of decomposing prompts.
8 Results on additional model sizes in Appendix A.
9 Specifically, we use the text-davinci-002 variant of InstructGPT (Ouyang et al., 2022) through a Microsoft Azure OpenAI deployment.
After introducing some comparison approaches, we present the experimental results from our applied abstractions on PLMs' entity-level, layoutlevel, and component-level relational reasoning. Afterward, we dive deeper with an analysis on how both our abstractions and in-context learning contribute to model performance.
## 5.1 Comparison Approaches
To contextualize our findings, we provide results from the human study in Zhang et al. (2019a), as well as two supervised baselines from prior work. 10 Additionally, to specifically evaluate the advantage of the way we mapped the RPM task into language, we include two simpler abstraction methods that encode task information less explicitly.
Supervised baselines. While our goal is not to achieve the state of the art on RA VEN, we include results from two state-of-the-art supervised baselines for reference. Specifically, we select the two approaches with the top mean accuracy on RAVEN, as outlined in the survey by Małki´ nski and Ma´ ndziuk (2022): Rel-AIR (Spratley et al., 2020) and CoPINet + ACL (Kim et al., 2020). Rel-AIR combines a simple vision model with an unsupervised scene decomposition module, enabling more generalizable reasoning over entities in RAVEN. CoPINet + ACL applies an analogy-centric contrastive learning paradigm to CoPINet (Zhang et al., 2019b), a prior architecture proposed for perceptual inference trained through contrastive learning. Both baselines have been trained on thousands of examples from the RAVEN dataset, and incorporate task-specific inductive biases in their architecture. Meanwhile, we evaluate PLMs on RAVEN in a zero-shot setting with no supervised learning.
Quasi-image abstraction. To evaluate the helpfulness of naming abstractions over entity attributes, we should compare to an approach that does not have such abstraction. However, some mapping from the visual features of the RPM task into langauge is needed in order for a PLM to interface with it. While the limited context window of PLMs restricts us from incorporating raw pixels directly into our prompts, PLMs have recently been demonstrated to capture spatial patterns in similar inputs: text-based matrices (Patel and Pavlick,
10 Since our approach is not evaluated on the exact same subset of RAVEN data, these results from prior work are not directly comparable, but can be helpful reference points.
Figure 5: Quasi-image abstractions for a triangle and pentagon of different size and color .
<details>
<summary>Image 5 Details</summary>

### Visual Description
## Diagram: Shape Rasterization
### Overview
The image illustrates the rasterization process of two different shapes: a triangle and a pentagon. Each shape is represented within a rounded square, followed by an arrow indicating a transformation into a matrix of numerical values. The values within the matrix represent the coverage or fill of the shape at each grid location.
### Components/Axes
* **Shapes:** A light gray triangle on the left and a dark pentagon on the right.
* **Arrows:** Two arrows pointing from the shape representations to their corresponding numerical matrices.
* **Numerical Matrices:** Two matrices representing the rasterized shapes. The left matrix contains the number '2' and periods, while the right matrix contains the number '9' and periods.
### Detailed Analysis
**Left Side (Triangle Rasterization):**
* The triangle is represented in a rounded square.
* The arrow points to a matrix that appears to be 4x5 (4 rows, 5 columns).
* The matrix contains the number '2' where the triangle would be, and periods elsewhere.
* The matrix is structured as follows:
```
[[2 . . . .],
[2 2 . . .],
[2 2 2 . .],
[2 2 2 2 .]]
```
**Right Side (Pentagon Rasterization):**
* The pentagon is represented in a rounded square.
* The arrow points to a matrix that appears to be 7x11 (7 rows, 11 columns).
* The matrix contains the number '9' where the pentagon would be, and periods elsewhere.
* The matrix is structured as follows:
```
[[. . . . . 9 . . . . .],
[. . . . 9 9 9 . . . .],
[. . . 9 9 9 9 9 . . .],
[. . 9 9 9 9 9 9 9 . .],
[. 9 9 9 9 9 9 9 9 9 .],
[. 9 9 9 9 9 9 9 9 9 .],
[. . 9 9 9 9 9 9 9 . .]]
```
### Key Observations
* The '2' and '9' values likely represent the intensity or coverage of the shape at each pixel location.
* The periods represent empty or uncovered pixels.
* The matrices visually represent the shapes in a pixelated form.
### Interpretation
The diagram illustrates a basic concept of rasterization, where continuous shapes are converted into discrete pixel representations. The numerical matrices represent the pixel grid, and the values within them indicate how much of each pixel is covered by the original shape. This process is fundamental in computer graphics for rendering shapes on digital displays. The difference in the values ('2' vs '9') might indicate different levels of fill or intensity, or simply be arbitrary values used to distinguish the two shapes. The pentagon requires a larger matrix due to its more complex shape and larger size compared to the triangle.
</details>
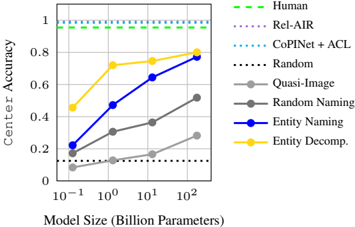
Figure 6: Results on the RAVEN Center sub-task under entity abstractions, compared to naïve and supervised baselines described in Section 5.1, and humans.
<details>
<summary>Image 6 Details</summary>
### Visual Description
## Chart: Center Accuracy vs. Model Size
### Overview
The image is a line chart comparing the center accuracy of different models against their size (in billion parameters). The chart includes several models: Human, Rel-AIR, CoPINet + ACL, Random, Quasi-Image, Random Naming, Entity Naming, and Entity Decomp. The x-axis represents the model size on a logarithmic scale, and the y-axis represents the center accuracy.
### Components/Axes
* **X-axis:** Model Size (Billion Parameters) - logarithmic scale with markers at 10^-1, 10^0, 10^1, and 10^2.
* **Y-axis:** Center Accuracy - linear scale from 0 to 1, with markers at 0, 0.2, 0.4, 0.6, 0.8, and 1.
* **Legend:** Located on the right side of the chart, vertically aligned.
* Human (Green dashed line)
* Rel-AIR (Purple dotted line)
* CoPINet + ACL (Cyan dotted line)
* Random (Black dotted line)
* Quasi-Image (Gray solid line)
* Random Naming (Dark Gray solid line)
* Entity Naming (Blue solid line)
* Entity Decomp. (Yellow solid line)
### Detailed Analysis
* **Human:** (Green dashed line) Constant at approximately 0.98 accuracy.
* **Rel-AIR:** (Purple dotted line) Constant at approximately 0.98 accuracy.
* **CoPINet + ACL:** (Cyan dotted line) Constant at approximately 0.96 accuracy.
* **Random:** (Black dotted line) Constant at approximately 0.12 accuracy.
* **Quasi-Image:** (Gray solid line) Starts at approximately 0.1, increases to approximately 0.2 at 10^0, then to approximately 0.35 at 10^1, and finally to approximately 0.5 at 10^2.
* **Random Naming:** (Dark Gray solid line) Starts at approximately 0.2, increases to approximately 0.3 at 10^0, then to approximately 0.37 at 10^1, and finally to approximately 0.52 at 10^2.
* **Entity Naming:** (Blue solid line) Starts at approximately 0.22, increases to approximately 0.5 at 10^0, then to approximately 0.65 at 10^1, and finally to approximately 0.78 at 10^2.
* **Entity Decomp.:** (Yellow solid line) Starts at approximately 0.46, increases to approximately 0.72 at 10^0, then to approximately 0.75 at 10^1, and finally to approximately 0.82 at 10^2.
### Key Observations
* The "Human", "Rel-AIR", and "CoPINet + ACL" models have significantly higher and relatively constant center accuracy compared to the other models.
* The "Random" model has the lowest and constant center accuracy.
* The "Quasi-Image", "Random Naming", "Entity Naming", and "Entity Decomp." models show increasing center accuracy as the model size increases.
* "Entity Decomp." and "Entity Naming" models have the highest accuracy among the models that increase with size.
### Interpretation
The chart demonstrates the relationship between model size and center accuracy for various models. The "Human", "Rel-AIR", and "CoPINet + ACL" models represent a high baseline, while the "Random" model represents a low baseline. The other models ("Quasi-Image", "Random Naming", "Entity Naming", and "Entity Decomp.") show that increasing model size generally leads to improved center accuracy, suggesting that larger models are better at capturing the relationships needed for higher accuracy. The "Entity Decomp." and "Entity Naming" models appear to be more effective at leveraging increased model size compared to "Quasi-Image" and "Random Naming". The logarithmic scale on the x-axis suggests that the increase in accuracy diminishes as the model size grows larger.
</details>
2021). As such, we propose a quasi-image abstraction which converts the visual RPM task into a matrix of ASCII characters. As shown in Figure 5, an entity's type can be expressed through a matrix of characters; size can be expressed through the height and width of the matrix; and color can be expressed through the actual characters making up the matrix. By converting instances of RAVEN's Center sub-task into this pixel-like form, we have a lower-level abstraction of the task's visual features that can be compared to the higher-level abstraction of naming entity attributes.
Random naming abstraction. We would also like to understand the advantage of the specific names we chose for entity attributes compared to other possible choices. As such, we propose a second baseline where, instead of using ordinal labels to describe entities' type , size , and color , we choose random words from a large corpus. This removes numerical dependencies that may be utilized to recognize some relations, and can help us understand whether PLMs take advantage of this information when it is available.
## 5.2 Entity-Level Reasoning
We first evaluate PLMs under our lowest level abstractions over entity attributes. To isolate the improvements from such abstraction, we focus on the Center sub-task of RAVEN which only includes a single entity per item in the RPM, and thus only tests understanding of relations over entity attributes. The results are shown in Figure 6.
Impact of naming. Under the simplest abstraction of naming the entity-level attributes, we see impressive zero-shot accuracies that monotonically increase with model size up to 77.2% from GPT3 175B on Center , nearing human performance. Further, we find that our choice to map attributes into numerical symbols is consistently advantageous over the quasi-image and random-naming abstractions, which reach respective accuracies up to 28.2% and 51.8%. Meanwhile, we find that as model size increases, our ordinal naming approach outperforms the random naming baseline more and more, up to over 20% in larger model sizes. This suggests that PLMs of larger size can better capture and take advantage of implicit numerical relations in their vocabulary.
Impact of decomposition. When applying decomposition over entity attributes, we observe further improvement of 2.8% accuracy in GPT-3 175B. Interestingly, we see a much sharper improvement from this abstraction in smaller models, with OPT 125M's accuracy doubling from 22.2% to 45.6%, and OPT 1.3B's accuracy rising from 47.2% to 72.0%. This may suggest that PLMs have a limited working memory which is related to the number of learned parameters in them. Large PLMs are more capable to handle complex reasoning tasks because of this, while smaller PLMs benefit from decomposing tasks into more manageable parts.
## 5.3 Layout-Level Reasoning
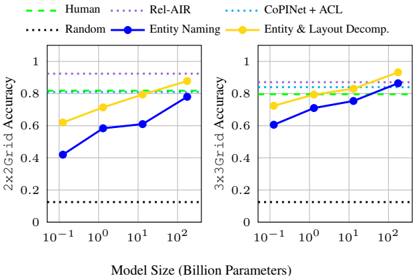
In Figure 7, we evaluate PLMs' capability to capture relations over layout attributes under our abstractions introduced in the 2x2Grid and 3x3Grid sub-tasks. Without any decomposition abstraction, model performance reaches up to 78.0% and 86.4% accuracy respectively on 2x2Grid and 3x3Grid . When adding naming for layout-level attributes and decomposing all attributes into separate prompts, we see further improvements across the board, with accuracies reaching 87.8% on 2x2Grid and 93.2% on 3x3Grid . The PLM exceeds human performance on both sub-tasks, despite them being arguably some of the most complex tasks in RAVEN, with the latter comprised of more entities than any other sub-task. This suggests that our strong layout-level abstractions enable the PLM to tease apart the numerous attributes in grids of entities and capture obscure patterns, whereas humans may struggle with this as the task becomes more complex.
Figure 7: Results on grid-based sub-tasks of RAVEN without and with decomposition abstractions. Compared to humans and supervised baselines.
<details>
<summary>Image 7 Details</summary>
### Visual Description
## Chart: Model Accuracy vs. Model Size
### Overview
The image presents two line charts comparing the accuracy of different models against model size. The left chart displays "2x2Grid Accuracy" and the right chart displays "3x3Grid Accuracy". The x-axis, common to both charts, represents "Model Size (Billion Parameters)" on a logarithmic scale. Several models are compared, including "Human", "Rel-AIR", "CoPINet + ACL", "Entity Naming", "Entity & Layout Decomp.", and "Random".
### Components/Axes
* **X-axis (Horizontal):** "Model Size (Billion Parameters)". Logarithmic scale with markers at 10<sup>-1</sup>, 10<sup>0</sup>, 10<sup>1</sup>, and 10<sup>2</sup>.
* **Y-axis (Vertical, Left Chart):** "2x2Grid Accuracy". Linear scale from 0 to 1, with markers at 0.2, 0.4, 0.6, 0.8, and 1.
* **Y-axis (Vertical, Right Chart):** "3x3Grid Accuracy". Linear scale from 0 to 1, with markers at 0.2, 0.4, 0.6, 0.8, and 1.
* **Legend (Top):**
* Green dashed line: "Human"
* Purple dotted line: "Rel-AIR"
* Light blue dotted line: "CoPINet + ACL"
* Black dotted line: "Random"
* Blue line with circle markers: "Entity Naming"
* Yellow line with circle markers: "Entity & Layout Decomp."
### Detailed Analysis
**Left Chart: 2x2Grid Accuracy**
* **Human (Green dashed line):** Constant accuracy around 0.82.
* **Rel-AIR (Purple dotted line):** Constant accuracy around 0.94.
* **CoPINet + ACL (Light blue dotted line):** Constant accuracy around 0.80.
* **Random (Black dotted line):** Constant accuracy around 0.13.
* **Entity Naming (Blue line):** Accuracy increases with model size.
* At 10<sup>-1</sup>: Accuracy ≈ 0.42
* At 10<sup>0</sup>: Accuracy ≈ 0.58
* At 10<sup>1</sup>: Accuracy ≈ 0.61
* At 10<sup>2</sup>: Accuracy ≈ 0.78
* **Entity & Layout Decomp. (Yellow line):** Accuracy increases with model size.
* At 10<sup>-1</sup>: Accuracy ≈ 0.62
* At 10<sup>0</sup>: Accuracy ≈ 0.80
* At 10<sup>1</sup>: Accuracy ≈ 0.81
* At 10<sup>2</sup>: Accuracy ≈ 0.90
**Right Chart: 3x3Grid Accuracy**
* **Human (Green dashed line):** Constant accuracy around 0.82.
* **Rel-AIR (Purple dotted line):** Constant accuracy around 0.94.
* **CoPINet + ACL (Light blue dotted line):** Constant accuracy around 0.86.
* **Random (Black dotted line):** Constant accuracy around 0.13.
* **Entity Naming (Blue line):** Accuracy increases with model size.
* At 10<sup>-1</sup>: Accuracy ≈ 0.60
* At 10<sup>0</sup>: Accuracy ≈ 0.71
* At 10<sup>1</sup>: Accuracy ≈ 0.75
* At 10<sup>2</sup>: Accuracy ≈ 0.87
* **Entity & Layout Decomp. (Yellow line):** Accuracy increases with model size.
* At 10<sup>-1</sup>: Accuracy ≈ 0.72
* At 10<sup>0</sup>: Accuracy ≈ 0.79
* At 10<sup>1</sup>: Accuracy ≈ 0.81
* At 10<sup>2</sup>: Accuracy ≈ 0.92
### Key Observations
* "Human", "Rel-AIR", "CoPINet + ACL", and "Random" models have constant accuracy regardless of model size.
* "Entity Naming" and "Entity & Layout Decomp." models show increasing accuracy with larger model sizes.
* "Rel-AIR" consistently achieves the highest accuracy in both 2x2 and 3x3 grid scenarios.
* "Random" model consistently has the lowest accuracy.
* The accuracy of "Entity Naming" and "Entity & Layout Decomp." models is generally higher for the 3x3 grid compared to the 2x2 grid, especially at smaller model sizes.
### Interpretation
The data suggests that increasing model size (number of parameters) improves the accuracy of "Entity Naming" and "Entity & Layout Decomp." models. The "Human", "Rel-AIR", "CoPINet + ACL", and "Random" models appear to have fixed performance levels, independent of model size, suggesting they may be based on different mechanisms or have reached their performance limit. The "Rel-AIR" model's consistently high accuracy indicates it is a strong performer in both grid scenarios. The difference in accuracy between the 2x2 and 3x3 grids for "Entity Naming" and "Entity & Layout Decomp." models may reflect the increased complexity of the 3x3 grid task, which benefits more from larger models.
</details>
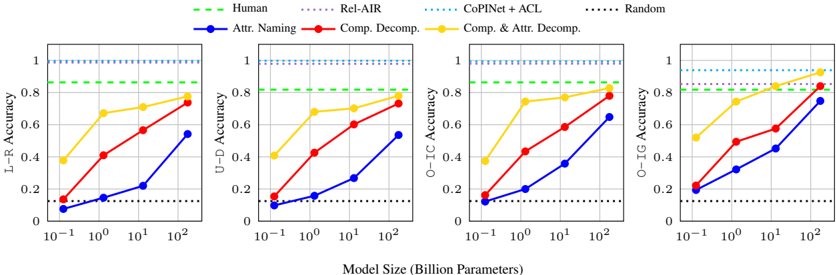
## 5.4 Component-Level Reasoning
Lastly, we apply our structural decompositionbased abstractions on RAVEN sub-tasks which have multiple components, i.e., L-R , U-D , O-IC , and O-IG . The results are shown in Figure 8. First, just decomposing the task by its components improves the maximum accuracy on each task on average by about 20%. Additionally decomposing each component by its entity and layout attributes brings further gains, with GPT-3 175B reaching up to 77.6%, 78.0%, 82.8%, and 92.6% on L-R , U-D , O-IC , and O-IG respectively, and exceeding humans and nearing supervised baselines on the latter. The performance gain from this decomposition is again even more pronounced for smaller PLMs. Most significantly, OPT 1.3B improves from 20-30% accuracy to over 70% accuracy, nearing human performance. This demonstrates that not only is GPT-3 capable of very complex analogical reasoning tasks, but even PLMs less than 100 times its size can perform quite well here with the proper abstractions.
## 5.5 Fine-Grained Analysis
Finally, we analyze how model performance varies across different attributes and relations, as we introduce distracting attributes, and as we introduce rows into the matrix. In our analysis, we compare three representative levels of abstraction: entity attribute naming only (no decomposition into multiple prompts), decomposition of components , and full decomposition of entity and layout attributes and components .
## 5.5.1 Analysis of Attributes and Relations
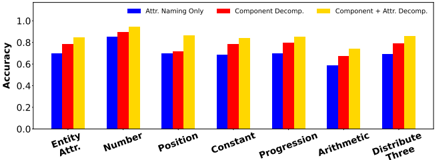
We measure the impact of abstractions in capturing each attribute and relation in RA VEN. In Figure 9,
Table 1: GPT-3 accuracy on Center sub-task with distracting orientation attribute in language prompts, under the naming and decomposition abstractions. orientation values are taken directly from RA VEN or randomly selected.
| Distractor Values | Naming | Decomposition |
|---------------------|----------|-----------------|
| RAVEN | 76.0% | 80.0% |
| Random | 72.6% | 77.8% |
we present GPT-3 175B's accuracy over each attribute and relation. We find that number is the best captured attribute even without any decomposition abstractions, while the model struggles with position until we introduce decomposition of attributes, suggesting the occupancy map encoding used here indeed helped capture it. Meanwhile, Arithmetic is the most difficult relation, with consistently lower accuracy than other relations.
## 5.5.2 Robustness to Distracting Attributes
Since our mappings from RAVEN attributes into language provide the key features over which relations occur, we may wonder how robust PLMs are to distracting or unimportant attributes. In fact, the RAVEN dataset includes one noise attribute that we excluded from our mapping to avoid unnecessarily increasing prompt lengths: orientation , i.e., the rotation of entities in the RPM. To begin exploring this issue, we incorporate orientation into the problem as a fourth entity-level attribute in addition to type , size , and color . For the best model (i.e., GPT-3) on the Center sub-task, we compare two possible injections of orientation values: using the values provided in RAVEN (which are mostly constant within each matrix row), and randomly selected values (which could be more distracting).
As shown in Table 1, compared to GPT-3's Center accuracies of 77.2% and 80.0% with respective naming and decomposition abstractions, the injection of orientation as a distraction feature does not degrade the model performance much, achieving accuracies of 76.0% and 80.0% when using values from RAVEN, and 72.6% and 77.8% when using random values. This shows that PLMs exhibit some robustness to distracting attributes in language context, and have the capability to ignore them in analogical reasoning. Future work may consider more in-depth analysis to discover the extent of model robustness to distraction features, and how it varies by model complexity.
Figure 8: PLM accuracy on multi-component RAVEN sub-tasks with attribute naming only, component decomposition, and full component and attribute decomposition, compared to supervised baselines and humans.
<details>
<summary>Image 8 Details</summary>
### Visual Description
## Chart: Model Accuracy vs. Model Size
### Overview
The image contains four line charts comparing the accuracy of different models against model size (in Billion Parameters). The charts compare "Attribute Naming", "Compositional Decomposition", and "Compositional & Attribute Decomposition" models, along with baselines for "Human", "Rel-AIR", "CoPiNet + ACL", and "Random". The four charts represent different tasks or datasets, labeled as "L-R", "U-D", "O-IC", and "O-IG".
### Components/Axes
* **X-axis:** Model Size (Billion Parameters). Logarithmic scale with markers at 10<sup>-1</sup>, 10<sup>0</sup>, 10<sup>1</sup>, and 10<sup>2</sup>.
* **Y-axis:** Accuracy, ranging from 0 to 1.
* **Chart Titles (Y-axis labels):**
* Leftmost Chart: L-R Accuracy
* Second Chart: U-D Accuracy
* Third Chart: O-IC Accuracy
* Rightmost Chart: O-IG Accuracy
* **Legend (Top of image):**
* Green dashed line: Human
* Blue solid line with circles: Attr. Naming
* Red solid line with circles: Comp. Decomp.
* Yellow solid line with circles: Comp. & Attr. Decomp.
* Light Blue dotted line: CoPiNet + ACL
* Black dotted line: Random
### Detailed Analysis
**Chart 1: L-R Accuracy**
* **Human (Green dashed line):** Constant accuracy at approximately 0.85.
* **Rel-AIR (Light Blue dotted line):** Constant accuracy at approximately 1.0.
* **Attr. Naming (Blue solid line):** Accuracy increases with model size.
* 10<sup>-1</sup>: ~0.1
* 10<sup>0</sup>: ~0.15
* 10<sup>1</sup>: ~0.22
* 10<sup>2</sup>: ~0.55
* **Comp. Decomp. (Red solid line):** Accuracy increases with model size.
* 10<sup>-1</sup>: ~0.12
* 10<sup>0</sup>: ~0.42
* 10<sup>1</sup>: ~0.57
* 10<sup>2</sup>: ~0.76
* **Comp. & Attr. Decomp. (Yellow solid line):** Accuracy increases with model size.
* 10<sup>-1</sup>: ~0.38
* 10<sup>0</sup>: ~0.68
* 10<sup>1</sup>: ~0.72
* 10<sup>2</sup>: ~0.78
* **Random (Black dotted line):** Constant accuracy at approximately 0.13.
**Chart 2: U-D Accuracy**
* **Human (Green dashed line):** Constant accuracy at approximately 0.82.
* **Rel-AIR (Light Blue dotted line):** Constant accuracy at approximately 1.0.
* **Attr. Naming (Blue solid line):** Accuracy increases with model size.
* 10<sup>-1</sup>: ~0.12
* 10<sup>0</sup>: ~0.13
* 10<sup>1</sup>: ~0.28
* 10<sup>2</sup>: ~0.54
* **Comp. Decomp. (Red solid line):** Accuracy increases with model size.
* 10<sup>-1</sup>: ~0.12
* 10<sup>0</sup>: ~0.43
* 10<sup>1</sup>: ~0.63
* 10<sup>2</sup>: ~0.76
* **Comp. & Attr. Decomp. (Yellow solid line):** Accuracy increases with model size.
* 10<sup>-1</sup>: ~0.42
* 10<sup>0</sup>: ~0.70
* 10<sup>1</sup>: ~0.73
* 10<sup>2</sup>: ~0.78
* **Random (Black dotted line):** Constant accuracy at approximately 0.13.
**Chart 3: O-IC Accuracy**
* **Human (Green dashed line):** Constant accuracy at approximately 0.82.
* **Rel-AIR (Light Blue dotted line):** Constant accuracy at approximately 1.0.
* **Attr. Naming (Blue solid line):** Accuracy increases with model size.
* 10<sup>-1</sup>: ~0.13
* 10<sup>0</sup>: ~0.20
* 10<sup>1</sup>: ~0.35
* 10<sup>2</sup>: ~0.65
* **Comp. Decomp. (Red solid line):** Accuracy increases with model size.
* 10<sup>-1</sup>: ~0.13
* 10<sup>0</sup>: ~0.44
* 10<sup>1</sup>: ~0.62
* 10<sup>2</sup>: ~0.82
* **Comp. & Attr. Decomp. (Yellow solid line):** Accuracy increases with model size.
* 10<sup>-1</sup>: ~0.40
* 10<sup>0</sup>: ~0.75
* 10<sup>1</sup>: ~0.80
* 10<sup>2</sup>: ~0.85
* **Random (Black dotted line):** Constant accuracy at approximately 0.13.
**Chart 4: O-IG Accuracy**
* **Human (Green dashed line):** Constant accuracy at approximately 0.82.
* **Rel-AIR (Light Blue dotted line):** Constant accuracy at approximately 0.95.
* **Attr. Naming (Blue solid line):** Accuracy increases with model size.
* 10<sup>-1</sup>: ~0.20
* 10<sup>0</sup>: ~0.30
* 10<sup>1</sup>: ~0.45
* 10<sup>2</sup>: ~0.75
* **Comp. Decomp. (Red solid line):** Accuracy increases with model size.
* 10<sup>-1</sup>: ~0.22
* 10<sup>0</sup>: ~0.50
* 10<sup>1</sup>: ~0.57
* 10<sup>2</sup>: ~0.85
* **Comp. & Attr. Decomp. (Yellow solid line):** Accuracy increases with model size.
* 10<sup>-1</sup>: ~0.53
* 10<sup>0</sup>: ~0.73
* 10<sup>1</sup>: ~0.78
* 10<sup>2</sup>: ~0.90
* **Random (Black dotted line):** Constant accuracy at approximately 0.13.
### Key Observations
* The "Human" and "Rel-AIR" baselines maintain constant accuracy across all model sizes.
* The "Random" baseline maintains constant, low accuracy across all model sizes.
* The accuracy of "Attr. Naming", "Comp. Decomp.", and "Comp. & Attr. Decomp." models generally increases with model size.
* "Comp. & Attr. Decomp." generally outperforms "Comp. Decomp." and "Attr. Naming" across all model sizes and tasks.
* The performance gain from increasing model size diminishes as the model size increases, especially for "Comp. & Attr. Decomp.".
### Interpretation
The charts demonstrate the relationship between model size and accuracy for different model architectures on four different tasks (L-R, U-D, O-IC, O-IG). The results suggest that increasing model size generally improves accuracy, but the extent of improvement depends on the model architecture and the specific task. The "Compositional & Attribute Decomposition" model appears to be the most effective, achieving higher accuracy than the other models across all tasks and model sizes. The diminishing returns observed with increasing model size suggest that there may be a point beyond which further increases in model size do not significantly improve accuracy. The "Human" and "Rel-AIR" baselines provide a benchmark for evaluating the performance of the models, while the "Random" baseline establishes a lower bound for accuracy.
</details>
Figure 9: Comparison of accuracy on examples from all sub-tasks, broken down by the types of attributes and relations they require capturing.
<details>
<summary>Image 9 Details</summary>
### Visual Description
## Bar Chart: Accuracy Comparison of Different Decomposition Methods
### Overview
The image is a bar chart comparing the accuracy of three different methods: "Attr. Naming Only", "Component Decomp.", and "Component + Attr. Decomp." across seven categories: "Entity Attr.", "Number", "Position", "Constant", "Progression", "Arithmetic", and "Distribute Three". The chart uses different colored bars to represent each method (blue, red, and yellow, respectively).
### Components/Axes
* **X-axis:** Categories: "Entity Attr.", "Number", "Position", "Constant", "Progression", "Arithmetic", "Distribute Three".
* **Y-axis:** Accuracy, ranging from 0.0 to 1.0 in increments of 0.2.
* **Legend:** Located at the top of the chart.
* Blue: "Attr. Naming Only"
* Red: "Component Decomp."
* Yellow: "Component + Attr. Decomp."
### Detailed Analysis
Here's a breakdown of the accuracy for each category and method:
* **Entity Attr.:**
* Attr. Naming Only (Blue): ~0.7
* Component Decomp. (Red): ~0.8
* Component + Attr. Decomp. (Yellow): ~0.85
* **Number:**
* Attr. Naming Only (Blue): ~0.85
* Component Decomp. (Red): ~0.9
* Component + Attr. Decomp. (Yellow): ~0.95
* **Position:**
* Attr. Naming Only (Blue): ~0.65
* Component Decomp. (Red): ~0.7
* Component + Attr. Decomp. (Yellow): ~0.85
* **Constant:**
* Attr. Naming Only (Blue): ~0.7
* Component Decomp. (Red): ~0.8
* Component + Attr. Decomp. (Yellow): ~0.85
* **Progression:**
* Attr. Naming Only (Blue): ~0.7
* Component Decomp. (Red): ~0.8
* Component + Attr. Decomp. (Yellow): ~0.85
* **Arithmetic:**
* Attr. Naming Only (Blue): ~0.6
* Component Decomp. (Red): ~0.7
* Component + Attr. Decomp. (Yellow): ~0.75
* **Distribute Three:**
* Attr. Naming Only (Blue): ~0.7
* Component Decomp. (Red): ~0.8
* Component + Attr. Decomp. (Yellow): ~0.85
### Key Observations
* The "Component + Attr. Decomp." method (yellow) consistently achieves the highest accuracy across all categories.
* The "Attr. Naming Only" method (blue) generally has the lowest accuracy.
* The "Number" category shows the highest accuracy for all three methods.
* The "Arithmetic" category shows the lowest accuracy for all three methods.
### Interpretation
The data suggests that incorporating both component and attribute decomposition significantly improves accuracy compared to using attribute naming alone or component decomposition alone. The "Number" category being the most accurate implies that numerical attributes are easier to predict or classify using these methods. Conversely, the lower accuracy in the "Arithmetic" category suggests that arithmetic operations or relationships are more challenging to model. The consistent ranking of the methods across all categories indicates a general trend rather than category-specific advantages.
</details>
## 5.5.3 In-Context Learning Over Rows
By design, RPM tasks are meant to require minimal background knowledge. They should be impossible to solve without the first two rows of the matrix, which provide essential context to complete the third row of the matrix. To understand whether PLMs capture relations specifically from in-context learning over the first two rows of the matrix (as opposed to using prior knowledge from pre-training), we measure the model performance as we introduce rows to the matrices.
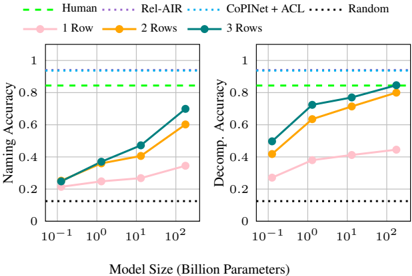
As shown in Figure 10, the average model performance increases across all sizes and abstractions as rows are added to the matrix. This suggests that in-context learning indeed contributes significantly to performance, even for smaller models. Larger model sizes see the most significant improvements, suggesting that larger PLMs are stronger in-context learners than smaller ones. Further, larger PLMs can achieve nearly the same accuracy with only two rows of the matrix provided rather compared to having all three, suggesting that they pick up the task quite quickly from in-context learning.
We also observe that in many cases, models achieve accuracies above chance (12.5% accuracy) without being provided any complete rows of the
Table 2: GPT-3 accuracy on RAVEN sub-tasks as rows are added to the RPM, under only naming abstractions.
| Sub-Task | 1 Row | 2 Rows | 3 Rows | Human |
|------------|---------|----------|----------|---------|
| Center | 36.8% | 69.2% | 77.2% | 95.6% |
| 2x2Grid | 54.0% | 71.0% | 78.0% | 81.8% |
| 3x3Grid | 73.0% | 85.2% | 86.4% | 79.6% |
| L-R | 14.0% | 38.2% | 54.2% | 86.4% |
| U-D | 12.4% | 42.0% | 53.6% | 81.8% |
| O-IC | 19.6% | 53.6% | 64.8% | 86.4% |
| O-IG | 32.0% | 62.2% | 74.8% | 81.8% |
matrix (only the third, incomplete row). This may suggest the PLM has a useful prior for this problem, despite it being a visual problem and thus impossible to observe directly in pre-training. This raises questions about the objectivity of RA VEN and possibly the RPM task. 11 Further, when decomposition abstractions are applied, models achieve higher accuracies than when not, suggesting that decomposition encodes some of this prior knowledge for the task. In Table 2, we take a closer look at GPT-3 175B's performance within sub-tasks. Surprisingly, we find the highest accuracies on the grid-based sub-tasks, despite them being the most difficult tasks for humans.
This motivates future work to compare human and PLM performance on ablated analogy-making tasks like these to further evaluate their objectiveness and identify commonalities. Future work in AI and analogy may also consider building diagnostic datasets to tease apart attribute and relation types to better understand how they contribute to model performance and identify areas for improvement.
## In-context learning of attributes and relations.
11 In Appendix B, we further explore this hypothesis on the Impartial-RAVEN dataset (Hu et al., 2021) that removes some superficial correlations in matrix completion choices, and still see comparable results.
Figure 10: Macro average accuracy over all RAVEN sub-tasks as we introduce rows to the matrix during incontext learning, under naming abstractions only (left) and all naming and decomposition abstractions (right). In 1 Row, we include only the incomplete third row.
<details>
<summary>Image 10 Details</summary>
### Visual Description
## Chart: Naming Accuracy vs. Decomposition Accuracy
### Overview
The image presents two line charts comparing the naming accuracy and decomposition accuracy of different models against model size. The x-axis represents the model size in billion parameters, using a logarithmic scale. The y-axis represents the accuracy, ranging from 0 to 1. The charts compare the performance of models with 1, 2, and 3 rows, along with baselines for Human, Rel-AIR, CoPINet + ACL, and Random.
### Components/Axes
* **X-axis (Model Size):** Logarithmic scale, labeled "Model Size (Billion Parameters)". Markers at 10<sup>-1</sup>, 10<sup>0</sup>, 10<sup>1</sup>, and 10<sup>2</sup>.
* **Y-axis (Left Chart):** Linear scale, labeled "Naming Accuracy". Markers at 0, 0.2, 0.4, 0.6, 0.8, and 1.
* **Y-axis (Right Chart):** Linear scale, labeled "Decomp. Accuracy". Markers at 0, 0.2, 0.4, 0.6, 0.8, and 1.
* **Legend (Top):**
* Green dashed line: Human
* Purple dotted line: Rel-AIR
* Teal dotted line: CoPINet + ACL
* Black dotted line: Random
* Pink line: 1 Row
* Orange line: 2 Rows
* Teal line: 3 Rows
### Detailed Analysis
**Left Chart: Naming Accuracy**
* **Human (Green dashed line):** Constant at approximately 0.85.
* **Rel-AIR (Purple dotted line):** Constant at approximately 0.95.
* **CoPINet + ACL (Teal dotted line):** Constant at approximately 0.95.
* **Random (Black dotted line):** Constant at approximately 0.12.
* **1 Row (Pink line):** Slopes upward, starting at approximately 0.22 at 10<sup>-1</sup>, reaching approximately 0.25 at 10<sup>0</sup>, approximately 0.28 at 10<sup>1</sup>, and approximately 0.35 at 10<sup>2</sup>.
* **2 Rows (Orange line):** Slopes upward, starting at approximately 0.25 at 10<sup>-1</sup>, reaching approximately 0.38 at 10<sup>0</sup>, approximately 0.42 at 10<sup>1</sup>, and approximately 0.60 at 10<sup>2</sup>.
* **3 Rows (Teal line):** Slopes upward, starting at approximately 0.25 at 10<sup>-1</sup>, reaching approximately 0.38 at 10<sup>0</sup>, approximately 0.48 at 10<sup>1</sup>, and approximately 0.70 at 10<sup>2</sup>.
**Right Chart: Decomposition Accuracy**
* **Human (Green dashed line):** Constant at approximately 0.85.
* **Rel-AIR (Purple dotted line):** Constant at approximately 0.95.
* **CoPINet + ACL (Teal dotted line):** Constant at approximately 0.95.
* **Random (Black dotted line):** Constant at approximately 0.12.
* **1 Row (Pink line):** Slopes upward, starting at approximately 0.28 at 10<sup>-1</sup>, reaching approximately 0.30 at 10<sup>0</sup>, approximately 0.38 at 10<sup>1</sup>, and approximately 0.42 at 10<sup>2</sup>.
* **2 Rows (Orange line):** Slopes upward, starting at approximately 0.42 at 10<sup>-1</sup>, reaching approximately 0.62 at 10<sup>0</sup>, approximately 0.70 at 10<sup>1</sup>, and approximately 0.82 at 10<sup>2</sup>.
* **3 Rows (Teal line):** Slopes upward, starting at approximately 0.50 at 10<sup>-1</sup>, reaching approximately 0.72 at 10<sup>0</sup>, approximately 0.78 at 10<sup>1</sup>, and approximately 0.85 at 10<sup>2</sup>.
### Key Observations
* The accuracy of models with 1, 2, and 3 rows generally increases with model size for both naming and decomposition accuracy.
* The "Human", "Rel-AIR", and "CoPINet + ACL" baselines show constant accuracy across different model sizes.
* The "Random" baseline shows a consistently low accuracy.
* The 3-row model generally outperforms the 2-row model, which in turn outperforms the 1-row model.
* The decomposition accuracy is generally higher than the naming accuracy for the same model size and number of rows.
### Interpretation
The charts demonstrate that increasing the model size (number of parameters) generally improves both naming and decomposition accuracy for the models with 1, 2, and 3 rows. The performance gain is more significant for decomposition accuracy compared to naming accuracy. The models with more rows (3 rows) tend to perform better than those with fewer rows (1 or 2 rows). The "Human", "Rel-AIR", and "CoPINet + ACL" baselines provide a benchmark for the performance of these models, while the "Random" baseline indicates the expected performance of a model with no learning. The data suggests that increasing model size and the number of rows are effective strategies for improving the accuracy of these models, but there are diminishing returns as the model size increases.
</details>
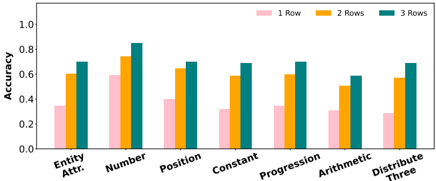
Figure 11: Comparison of accuracy on examples from all RAVEN sub-tasks as rows are introduced to the matrix, with only entity attribute naming abstractions .
<details>
<summary>Image 11 Details</summary>
### Visual Description
## Bar Chart: Accuracy Comparison by Row Count
### Overview
The image is a bar chart comparing the accuracy of a model across different categories ("Entity Attr.", "Number", "Position", "Constant", "Progression", "Arithmetic", "Distribute Three") based on the number of rows used (1 Row, 2 Rows, 3 Rows). The y-axis represents accuracy, ranging from 0.0 to 1.0.
### Components/Axes
* **X-axis:** Categories: "Entity Attr.", "Number", "Position", "Constant", "Progression", "Arithmetic", "Distribute Three".
* **Y-axis:** Accuracy, ranging from 0.0 to 1.0 in increments of 0.2.
* **Legend:** Located at the top of the chart.
* Pink: 1 Row
* Orange: 2 Rows
* Teal: 3 Rows
### Detailed Analysis
Here's a breakdown of the accuracy for each category and row count:
* **Entity Attr.:**
* 1 Row: ~0.35
* 2 Rows: ~0.60
* 3 Rows: ~0.70
* **Number:**
* 1 Row: ~0.60
* 2 Rows: ~0.75
* 3 Rows: ~0.85
* **Position:**
* 1 Row: ~0.40
* 2 Rows: ~0.65
* 3 Rows: ~0.70
* **Constant:**
* 1 Row: ~0.32
* 2 Rows: ~0.60
* 3 Rows: ~0.65
* **Progression:**
* 1 Row: ~0.35
* 2 Rows: ~0.60
* 3 Rows: ~0.70
* **Arithmetic:**
* 1 Row: ~0.30
* 2 Rows: ~0.50
* 3 Rows: ~0.60
* **Distribute Three:**
* 1 Row: ~0.28
* 2 Rows: ~0.58
* 3 Rows: ~0.68
### Key Observations
* For all categories, the accuracy generally increases as the number of rows increases from 1 to 3.
* The "Number" category has the highest accuracy overall, especially with 3 rows.
* The "Distribute Three" category has the lowest accuracy across all row counts.
* The difference in accuracy between 2 rows and 3 rows is smaller than the difference between 1 row and 2 rows, suggesting diminishing returns with increasing row count.
### Interpretation
The chart demonstrates that increasing the number of rows generally improves the accuracy of the model across different categories. However, the extent of improvement varies depending on the category. The "Number" category seems to benefit the most from increased row count, while "Distribute Three" remains relatively low in accuracy even with 3 rows. This suggests that the model's performance is influenced by both the number of rows and the specific characteristics of each category. The diminishing returns observed between 2 and 3 rows might indicate a point of saturation, where further increasing the row count yields less significant improvements in accuracy.
</details>
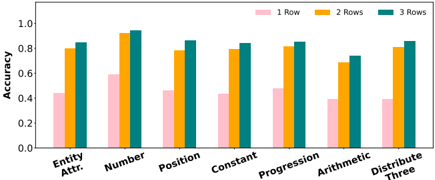
We may wonder whether specific relations or attributes are easier to understand than others with less context. For example, the Progression or Constant relations may be possible to recognize only from the first two items of the third row in an RPM, as we can easily observe patterns in attribute values here, e.g., that entity size is increasing or color remains constant. In Figures 11 and 12, we surprisingly observe only marginal differences here, except for the number attribute, which seems significantly better captured than other attributes in this no-context setting.
Figure 12: Comparison of accuracy on examples from all RAVEN sub-tasks as rows are introduced to the matrix, with all decomposition abstractions .
<details>
<summary>Image 12 Details</summary>
### Visual Description
## Bar Chart: Accuracy Comparison by Row Count
### Overview
The image is a bar chart comparing the accuracy of a model across different categories ("Entity Attr.", "Number", "Position", "Constant", "Progression", "Arithmetic", "Distribute Three") based on the number of rows used (1 Row, 2 Rows, 3 Rows). The y-axis represents accuracy, ranging from 0.0 to 1.0.
### Components/Axes
* **X-axis:** Categories: "Entity Attr.", "Number", "Position", "Constant", "Progression", "Arithmetic", "Distribute Three"
* **Y-axis:** Accuracy, ranging from 0.0 to 1.0 in increments of 0.2.
* **Legend:** Located at the top of the chart.
* Pink: "1 Row"
* Orange: "2 Rows"
* Teal: "3 Rows"
### Detailed Analysis
Here's a breakdown of the accuracy for each category and row count:
* **Entity Attr.:**
* 1 Row: ~0.45
* 2 Rows: ~0.80
* 3 Rows: ~0.85
* **Number:**
* 1 Row: ~0.60
* 2 Rows: ~0.93
* 3 Rows: ~0.96
* **Position:**
* 1 Row: ~0.47
* 2 Rows: ~0.79
* 3 Rows: ~0.88
* **Constant:**
* 1 Row: ~0.44
* 2 Rows: ~0.81
* 3 Rows: ~0.85
* **Progression:**
* 1 Row: ~0.48
* 2 Rows: ~0.82
* 3 Rows: ~0.86
* **Arithmetic:**
* 1 Row: ~0.39
* 2 Rows: ~0.70
* 3 Rows: ~0.75
* **Distribute Three:**
* 1 Row: ~0.40
* 2 Rows: ~0.82
* 3 Rows: ~0.88
### Key Observations
* For all categories, the accuracy generally increases as the number of rows increases from 1 to 3.
* The "Number" category consistently shows the highest accuracy across all row counts.
* The "Arithmetic" category consistently shows the lowest accuracy across all row counts.
* The difference in accuracy between 2 Rows and 3 Rows is generally smaller than the difference between 1 Row and 2 Rows.
### Interpretation
The data suggests that increasing the number of rows generally improves the model's accuracy across all tested categories. The "Number" category seems to be the easiest for the model to predict, while "Arithmetic" is the most challenging. The diminishing returns observed when moving from 2 Rows to 3 Rows might indicate a saturation point where adding more rows provides less significant improvements in accuracy. The model performs significantly worse with only 1 row of data, indicating that more context is needed for accurate predictions.
</details>
## 6 Conclusion
In this work, we explored the ability of large PLMs to perform zero-shot analogical reasoning in visual Raven's Progressive Matrices (RPM). Upon the simplest mapping to language, they can achieve striking results, while applying higher-level naming and decomposition abstractions over the task features further raises performance to the level of humans and supervised approaches in some cases. We find that while ordinal naming abstractions are a powerful way to enable analogical reasoning in larger PLMs, decomposition abstractions that break the task down into atomic parts conserve their working memory such that even smaller PLMs under 1B parameters can achieve competitive performance on this challenging problem.
Our detailed analysis revealed insights about which features of the task PLMs best capture, their robustness to distracting features, and the role of in-context learning and prior knowledge in picking up this complex task. Surprisingly, we find that even without two complete rows of prior context from the matrix, GPT-3 175B and smaller models can achieve above-chance performance on the task, raising questions about the objectivity and true role of prior knowledge in RPM tasks, which are assumed to require minimal prior knowledge.
These results also raise some questions about the role PLMs may play in future AI systems capable of analogy. While previously thought to be a difficult problem for AI systems, PLMs can solve the reasoning step of analogy easily given strong abstractions over visual perception. Many of these abstractions are intuitive and commonly researched in computer vision, including the detection of object types, sizes, colors, counts, and global arrangements. As such, future work may dive deeper into the challenging problem of generalized perception across domains, where we must robustly tease apart the key features of tasks and experiences that may facilitate analogy-making, e.g., in recognizing the commonalities between a physical bridge and the bridge of a song (Mitchell, 2021). Recent efforts toward understanding how humans describe abstract visual features in language by mapping them to natural concepts 12 are a promising direction toward this goal (Lachmy et al., 2022; Ji et al., 2022).
12 For example, when communicating about abstract shapes, we may make an analogy to refer to them as looking like more familiar natural concepts like flowers or dog bones.
## Acknowledgements
This work was supported in part by DARPA PTG program HR00112220003. We would like to thank the anonymous reviewers for their valuable comments and suggestions.
## Limitations
## Perception and reasoning in text-based RAVEN.
In this work, one limitation is that we do not attempt to solve the perception problem of analogymaking in RPM, rather we apply perfect perception in solving the reasoning part, and assume the perception problem is simple. By doing so, we find that PLMs may be a strong solution to the reasoning problem here, which may better direct future efforts toward AI and analogy. Obviously, the perception problem for idealized domains is a lot different than more natural domains, and identifying key features across many domains that can facilitate a mapping is still a challenging unsolved problem. We hope that our work sparks more interest in this problem.
Meanwhile, one may argue that our decomposition abstractions are too strong, and actually contribute to the reasoning problem in RPM, as they make an independence assumption about which features of the task can be teased apart. Making such an assumption requires an understanding of the problem that cannot be inferred by only seeing one instance. However, we decomposed the task based on very intuitive and common attributes, e.g., shapes, colors, sizes, and counts of items. We believe that the strength of such an abstraction, which could be applied in many problems, should not be understated. Nonetheless, we include decomposition-free forms of results as much as possible throughout the paper to help compare the contributions of decomposition versus naming abstractions, which is more clearly only providing perceptual information. In fact, we find that without any decomposition, PLMs still achieve very strong performance in many cases, and performance gains from decomposition are not always large.
Human performance. Lastly, we note some limitations in the human performance measurements used as reference points. In Zhang et al. (2019a), human performance on RAVEN was measured by giving subjects some task-specific training, then evaluating them on the original visual form of the task. This differs from our results in two ways. First, PLMs had no task-specific training for RAVEN, given that experiments were zero-shot and the text data we generate is new and thus impossible to appear directly in PLM pre-training. This may give humans an advantage. Second, the task is presented to PLMs in text form, not visually. While the essential information from the task is preserved by our conversion, it is possible that this conversion would affect the difficulty of the task for humans (making it easier or harder). As such, it becomes unclear how to contextualize our results with these past human results. Future work may carry out systematic human studies to compare the analogical reasoning capabilities of humans and PLMs in different settings.
## Ethical Considerations
This work does not use any human subjects or human-generated data. Our work deals with abstract visual features that are described with numerical symbols, thus not strongly targeting any language. A possible ethical concern for this work is the amount of computational resources used in evaluating PLMs. To reduce unnecessary computation in our study, we chose to apply PLMs to only a subset of 500 testing examples from each sub-task of the RAVEN dataset, while the full testing set is four times as large.
## References
Yonatan Bitton, Ron Yosef, Eli Strugo, Dafna Shahaf, Roy Schwartz, and Gabriel Stanovsky. 2022. VASR: Visual analogies of situation recognition. In Proceedings of the AAAI Conference on Artificial Intelligence (AAAI) .
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. 2020. Language models are few-shot learners. Advances in neural information processing systems , 33:1877-1901.
Jiangjie Chen, Rui Xu, Ziquan Fu, Wei Shi, Zhongqiao Li, Xinbo Zhang, Changzhi Sun, Lei Li, Yanghua Xiao, and Hao Zhou. 2022. E-KAR: A benchmark for rationalizing natural language analogical reasoning. In Findings of the Association for Computational Linguistics: ACL 2022 , pages 3941-3955, Dublin, Ireland. Association for Computational Linguistics.
Stella Christie and Dedre Gentner. 2014. Language helps children succeed on a classic analogy task. Cognitive Science , 38(2):383-397.
- Dedre Gentner. 1983. Structure-mapping: A theoretical framework for analogy. Cognitive Science , 7(2):155170.
- Dedre Gentner. 2010. Bootstrapping the mind: Analogical processes and symbol systems. Cognitive Science , 34(5):752-775.
- Dedre Gentner, Asli Özyürek, Özge Gürcanli, and Susan Goldin-Meadow. 2013. Spatial language facilitates spatial cognition: Evidence from children who lack language input. Cognition , 127(3):318-330.
- Peter Gordon. 2004. Numerical cognition without words: Evidence from Amazonia. Science , 306(5695):496-499.
- Felix Hill, Adam Santoro, David GT Barrett, Ari S Morcos, and Timothy Lillicrap. 2019. Learning to make analogies by contrasting abstract relational structure. In 7th International Conference on Learning Representations (ICLR) .
- Douglas R Hofstadter and Melanie Mitchell. 1994. The Copycat project: A model of mental fluidity and analogy-making , pages 31-112. Ablex Publishing.
- Douglas R Hofstadter and Emmanuel Sander. 2013. Surfaces and essences: Analogy as the fuel and fire of thinking . Basic Books.
- Keith J Holyoak. 1984. Analogical thinking and human intelligence. Advances in the psychology of human intelligence , 2:199-230.
- Keith J Holyoak. 2012. Analogy and relational reasoning. The Oxford Handbook of Thinking and Reasoning .
- Sheng Hu, Yuqing Ma, Xianglong Liu, Yanlu Wei, and Shihao Bai. 2021. Stratified rule-aware network for abstract visual reasoning. In Proceedings of the AAAI Conference on Artificial Intelligence (AAAI) , volume 35, pages 1567-1574.
- Anya Ji, Noriyuki Kojima, Noah Rush, Alane Suhr, Wai Keen Vong, Robert Hawkins, and Yoav Artzi. 2022. Abstract visual reasoning with tangram shapes. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing , Abu Dhabi, United Arab Emirates. Association for Computational Linguistics.
- Youngsung Kim, Jinwoo Shin, Eunho Yang, and Sung Ju Hwang. 2020. Few-shot visual reasoning with meta-analogical contrastive learning. In Advances in Neural Information Processing Systems , volume 33, pages 16846-16856. Curran Associates, Inc.
- Royi Lachmy, Valentina Pyatkin, Avshalom Manevich, and Reut Tsarfaty. 2022. Draw Me a Flower: Processing and Grounding Abstraction in Natural Language. Transactions of the Association for Computational Linguistics , 10:1341-1356.
- Brenden M Lake, Ruslan Salakhutdinov, and Joshua B Tenenbaum. 2015. Human-level concept learning through probabilistic program induction. Science , 350(6266):1332-1338.
- Frank J Lee and John R Anderson. 2001. Does learning a complex task have to be complex?: A study in learning decomposition. Cognitive Psychology , 42(3):267-316.
- Peng-Hsuan Li, Tsan-Yu Yang, and Wei-Yun Ma. 2020. CA-EHN: Commonsense analogy from E-HowNet. In Proceedings of the Twelfth Language Resources and Evaluation Conference , pages 2984-2990, Marseille, France. European Language Resources Association.
- Tal Linzen. 2016. Issues in evaluating semantic spaces using word analogies. In Proceedings of the 1st Workshop on Evaluating Vector-Space Representations for NLP , pages 13-18, Berlin, Germany. Association for Computational Linguistics.
- Hongjing Lu, Ying Nian Wu, and Keith J Holyoak. 2019. Emergence of analogy from relation learning. Proceedings of the National Academy of Sciences , 116(10):4176-4181.
- Mikołaj Małki´ nski and Jacek Ma´ ndziuk. 2022. Deep learning methods for abstract visual reasoning: A survey on Raven's Progressive Matrices. arXiv preprint arXiv:2201.12382 .
- Tomas Mikolov, Ilya Sutskever, Kai Chen, Greg S Corrado, and Jeff Dean. 2013a. Distributed representations of words and phrases and their compositionality. Advances in Neural Information Processing Systems , 26.
- Tomas Mikolov, Wen-tau Yih, and Geoffrey Zweig. 2013b. Linguistic regularities in continuous space word representations. In Proceedings of the 2013 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies , pages 746-751, Atlanta, Georgia. Association for Computational Linguistics.
- Melanie Mitchell. 2021. Abstraction and analogymaking in artificial intelligence. Annals of the New York Academy of Sciences , 1505(1):79-101.
- Victor Vikram Odouard and Melanie Mitchell. 2022. Evaluating understanding on conceptual abstraction benchmarks. In Proceedings of the AI Evaluation Beyond Metrics at IJCAI-ECAI 2022 , Vienna, Austria.
- Long Ouyang, Jeff Wu, Xu Jiang, Diogo Almeida, Carroll L Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. 2022. Training language models to follow instructions with human feedback. arXiv preprint arXiv:2203.02155 .
- Roma Patel and Ellie Pavlick. 2021. Mapping language models to grounded conceptual spaces. In International Conference on Learning Representations .
- John C Raven and JH Court. 1938. Raven's progressive matrices . Western Psychological Services Los Angeles.
- Lynn C Robertson and Marvin R Lamb. 1991. Neuropsychological contributions to theories of part/whole organization. Cognitive Psychology , 23(2):299-330.
- Robyn Speer, Catherine Havasi, and Henry Lieberman. 2008. Analogyspace: Reducing the dimensionality of common sense knowledge. In AAAI , volume 8, pages 548-553.
- Steven Spratley, Krista Ehinger, and Tim Miller. 2020. Acloser look at generalisation in raven. In Computer Vision - ECCV 2020: 16th European Conference, Glasgow, UK, August 23-28, 2020, Proceedings, Part XXVII , page 601-616, Berlin, Heidelberg. SpringerVerlag.
- Oren Sultan and Dafna Shahaf. 2022. Life is a circus and we are the clowns: Automatically finding analogies between situations and processes. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing , Abu Dhabi, United Arab Emirates. Association for Computational Linguistics.
- Damien Teney, Peng Wang, Jiewei Cao, Lingqiao Liu, Chunhua Shen, and Anton van den Hengel. 2020. Vprom: A benchmark for visual reasoning using visual progressive matrices. In Proceedings of the AAAI Conference on Artificial Intelligence , volume 34, pages 12071-12078.
- Peter D Turney. 2008. The latent relation mapping engine: Algorithm and experiments. Journal of Artificial Intelligence Research , 33:615-655.
- Peter D Turney, Michael L Littman, Jeffrey Bigham, and Victor Shnayder. 2003. Combining independent modules in lexical multiple-choice problems. Recent Advances in Natural Language Processing III: Selected Papers from RANLP , 2003:101-110.
- Taylor Webb, Keith J Holyoak, and Hongjing Lu. 2022. Emergent analogical reasoning in large language models. arXiv preprint arXiv:2212.09196 .
- Chi Zhang, Feng Gao, Baoxiong Jia, Yixin Zhu, and Song-Chun Zhu. 2019a. RAVEN: A dataset for relational and analogical visual reasoning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) .
- Chi Zhang, Baoxiong Jia, Feng Gao, Yixin Zhu, HongJing Lu, and Song-Chun Zhu. 2019b. Learning perceptual inference by contrasting. In Advances in Neural Information Processing Systems , volume 32. Curran Associates, Inc.
- Chi Zhang, Baoxiong Jia, Song-Chun Zhu, and Yixin Zhu. 2021. Abstract spatial-temporal reasoning via
probabilistic abduction and execution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , pages 97369746.
- Susan Zhang, Stephen Roller, Naman Goyal, Mikel Artetxe, Moya Chen, Shuohui Chen, Christopher Dewan, Mona Diab, Xian Li, Xi Victoria Lin, et al. 2022. OPT: Open pre-trained transformer language models. arXiv preprint arXiv:2205.01068 .
## A Expanded Results
In Table 3, we present additional results with a wider range of OPT model sizes (Zhang et al., 2022). We observe similar mostly monotonic increases of accuracy with model size.
## B Results and Analysis with I-RAVEN
As the generation strategy for the negative choices in RAVEN can introduce distributional bias that is problematic for supervised learning and leads to artificially high performance (Hu et al., 2021), this could be a possible reason behind PLMs' strong performance on the task even without any complete rows of context. As such, in Table 4 and Figure 13, we include some supplementary analysis on the Impartial-RAVEN (I-RAVEN) dataset from Hu et al., which introduces more variation in negative choices. However, we observe similar performance trends in I-RAVEN. Performance mostly monotonically increases with model sizes and more abstraction. Further, PLMs achieve above-chance performance again without any rows of context provided, even with no decomposition abstractions. This provides further evidence that RPM, at least formulated in this way, is in part addressed by PLMs' prior knowledge, despite the assumptions of minimal background knowledge that the task makes.
<details>
<summary>Image 13 Details</summary>
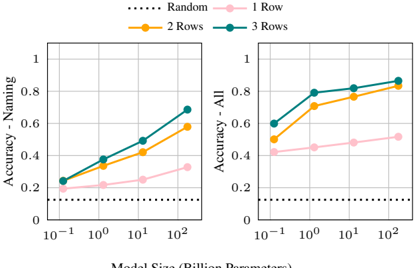
### Visual Description
## Chart Type: Line Graphs Comparing Accuracy vs. Model Size
### Overview
The image presents two line graphs side-by-side, comparing the accuracy of different models against their size (in billion parameters). The left graph shows "Accuracy - Naming," while the right graph shows "Accuracy - All." Each graph plots the accuracy for models trained with different row configurations (1 Row, 2 Rows, 3 Rows) and a baseline "Random" model. The x-axis represents the model size on a logarithmic scale.
### Components/Axes
* **X-Axis (Horizontal):** "Model Size (Billion Parameters)". The scale is logarithmic with markers at 10<sup>-1</sup>, 10<sup>0</sup>, 10<sup>1</sup>, and 10<sup>2</sup>.
* **Y-Axis (Vertical, Left Graph):** "Accuracy - Naming". The scale ranges from 0 to 1, with markers at 0, 0.2, 0.4, 0.6, 0.8, and 1.
* **Y-Axis (Vertical, Right Graph):** "Accuracy - All". The scale ranges from 0 to 1, with markers at 0, 0.2, 0.4, 0.6, 0.8, and 1.
* **Legend (Top):** Located at the top of the image.
* **Random:** Represented by a black dotted line.
* **1 Row:** Represented by a light pink line with circular markers.
* **2 Rows:** Represented by an orange line with circular markers.
* **3 Rows:** Represented by a teal line with circular markers.
### Detailed Analysis
**Left Graph: Accuracy - Naming**
* **Random (Black Dotted Line):** The line is horizontal and constant at approximately 0.12 accuracy.
* **1 Row (Light Pink Line):** The line slopes upward gently.
* At 10<sup>-1</sup>: Accuracy ≈ 0.2
* At 10<sup>0</sup>: Accuracy ≈ 0.22
* At 10<sup>1</sup>: Accuracy ≈ 0.26
* At 10<sup>2</sup>: Accuracy ≈ 0.33
* **2 Rows (Orange Line):** The line slopes upward more steeply than the "1 Row" line.
* At 10<sup>-1</sup>: Accuracy ≈ 0.23
* At 10<sup>0</sup>: Accuracy ≈ 0.38
* At 10<sup>1</sup>: Accuracy ≈ 0.45
* At 10<sup>2</sup>: Accuracy ≈ 0.58
* **3 Rows (Teal Line):** The line slopes upward most steeply.
* At 10<sup>-1</sup>: Accuracy ≈ 0.24
* At 10<sup>0</sup>: Accuracy ≈ 0.37
* At 10<sup>1</sup>: Accuracy ≈ 0.50
* At 10<sup>2</sup>: Accuracy ≈ 0.69
**Right Graph: Accuracy - All**
* **Random (Black Dotted Line):** The line is horizontal and constant at approximately 0.12 accuracy.
* **1 Row (Light Pink Line):** The line slopes upward gently.
* At 10<sup>-1</sup>: Accuracy ≈ 0.42
* At 10<sup>0</sup>: Accuracy ≈ 0.45
* At 10<sup>1</sup>: Accuracy ≈ 0.48
* At 10<sup>2</sup>: Accuracy ≈ 0.52
* **2 Rows (Orange Line):** The line slopes upward, but the increase slows down at higher model sizes.
* At 10<sup>-1</sup>: Accuracy ≈ 0.50
* At 10<sup>0</sup>: Accuracy ≈ 0.71
* At 10<sup>1</sup>: Accuracy ≈ 0.78
* At 10<sup>2</sup>: Accuracy ≈ 0.83
* **3 Rows (Teal Line):** The line slopes upward, but the increase slows down at higher model sizes.
* At 10<sup>-1</sup>: Accuracy ≈ 0.60
* At 10<sup>0</sup>: Accuracy ≈ 0.79
* At 10<sup>1</sup>: Accuracy ≈ 0.82
* At 10<sup>2</sup>: Accuracy ≈ 0.87
### Key Observations
* In both graphs, the "Random" model consistently performs at a low accuracy level.
* For both "Accuracy - Naming" and "Accuracy - All," increasing the number of rows generally leads to higher accuracy.
* The "Accuracy - All" graph shows a saturation effect at larger model sizes for the "2 Rows" and "3 Rows" models, where the accuracy increase diminishes.
* The "Accuracy - Naming" graph shows a more consistent linear increase in accuracy with model size, especially for the "2 Rows" and "3 Rows" models.
### Interpretation
The data suggests that increasing the model size and the number of rows used in training generally improves the accuracy of the models, both in terms of "Naming" accuracy and overall accuracy. However, the "Accuracy - All" graph indicates that there may be diminishing returns to increasing model size beyond a certain point, as the accuracy improvement slows down. The "Random" model serves as a baseline, demonstrating the importance of structured training data for achieving higher accuracy. The difference between the "Naming" and "All" accuracy metrics suggests that the row configurations have a more pronounced effect on the specific task of "Naming" compared to overall accuracy.
</details>
Model Size (Billion Parameters)
Figure 13: Macro average accuracy over all ImpartialRAVEN sub-tasks as we introduce rows to the matrix during in-context learning, under naming abstractions only (left) and all naming and decomposition abstractions (right). In 1 Row, we include only the incomplete third row.
## C Example Prompts
In Figure 14, we include example prompts for 2x2Grid , 3x3Grid , L-R and I-OG subtasks under different abstractions. Note that U-D and
I-OC are isomorphic to L-R , and therefore share the same prompt format.
<details>
<summary>Image 14 Details</summary>
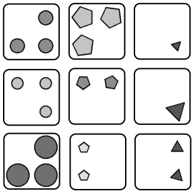
### Visual Description
## Image Analysis: Grid of Shapes
### Overview
The image presents a 3x3 grid of squares, each containing a different arrangement of geometric shapes (circles, pentagons, and triangles) in varying sizes and shades of gray. The shapes appear to be randomly distributed within each square.
### Components/Axes
* **Grid:** A 3x3 arrangement of squares.
* **Shapes:** Circles, pentagons, and triangles.
* **Attributes:** Size and shade of gray.
### Detailed Analysis or ### Content Details
**Row 1:**
* **Square 1:** Contains three circles. Two smaller circles are at the bottom, and a larger circle is at the top.
* **Square 2:** Contains two pentagons of similar size, positioned near the top.
* **Square 3:** Contains a single small triangle in the bottom-right corner.
**Row 2:**
* **Square 4:** Contains three circles. One is small and at the top, and two are larger and at the bottom.
* **Square 5:** Contains two pentagons of similar size, positioned near the top.
* **Square 6:** Contains a single triangle in the center.
**Row 3:**
* **Square 7:** Contains three circles. One is large and at the top, and two are smaller and at the bottom.
* **Square 8:** Contains two pentagons of different sizes, positioned near the top.
* **Square 9:** Contains two triangles in the bottom corners.
### Key Observations
* Each square contains between one and three shapes.
* The shapes vary in size and shade of gray.
* The shapes are randomly distributed within each square.
### Interpretation
The image appears to be a visual representation of different combinations of shapes. It could be used as a visual aid for teaching geometry, pattern recognition, or basic counting skills. The random arrangement of shapes suggests a lack of specific order or pattern, implying a focus on individual combinations rather than a structured sequence.
</details>
## 2x2Grid
<details>
<summary>Image 15 Details</summary>

### Visual Description
## Diagram: Abstract Shape Grid
### Overview
The image is a 3x3 grid of abstract shapes within rounded squares. Each square contains a different arrangement of geometric shapes, varying in size, color (grayscale), and type (circles, squares, pentagons, hexagons, diamonds). The shapes appear to be randomly distributed within each square.
### Components/Axes
* **Grid:** A 3x3 arrangement of squares.
* **Squares:** Each square contains a unique arrangement of shapes.
* **Shapes:** Geometric shapes including circles, squares, pentagons, hexagons, and diamonds.
* **Color:** Shapes are rendered in grayscale, varying from light gray to black.
* **Size:** Shapes vary in size within each square.
### Detailed Analysis
* **Top-Left Square:** Contains several hexagons and pentagons in varying shades of gray, clustered towards the bottom.
* **Top-Middle Square:** Contains hexagons and pentagons in light gray shades, scattered throughout the square.
* **Top-Right Square:** Contains pentagons and hexagons in dark shades, arranged around the perimeter.
* **Middle-Left Square:** Contains circles, squares, and pentagons in black, arranged in the center.
* **Middle-Center Square:** Contains circles, squares, and pentagons in white, scattered throughout the square.
* **Middle-Right Square:** Contains circles, squares, and pentagons in black, arranged in the center and corners.
* **Bottom-Left Square:** Contains a pentagon, a diamond, and a square in varying shades of gray, aligned vertically.
* **Bottom-Middle Square:** Contains a pentagon, a diamond, and a square in light gray shades, aligned vertically.
* **Bottom-Right Square:** Contains pentagons and squares in dark shades, clustered towards the bottom-left corner.
### Key Observations
* Each square has a unique arrangement of shapes.
* The shapes vary in size, color, and type.
* There is no apparent pattern in the arrangement of shapes.
### Interpretation
The image appears to be an abstract composition of geometric shapes arranged in a grid. The variations in shape, size, and color suggest a random or arbitrary distribution. Without additional context, it is difficult to determine the purpose or meaning of the image. It could be a visual representation of data, a design element, or simply an abstract artwork.
</details>
3x3Grid
<details>
<summary>Image 16 Details</summary>
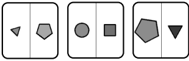
### Visual Description
Icon/Small Image (189x61)
</details>
<details>
<summary>Image 17 Details</summary>
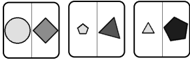
### Visual Description
Icon/Small Image (190x59)
</details>
<details>
<summary>Image 18 Details</summary>
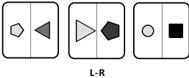
### Visual Description
## Diagram: Shape Arrangement
### Overview
The image presents three separate diagrams, each contained within a rounded square divided vertically into two halves. Each half contains a geometric shape of varying color and type. The diagrams are labeled "L-R" below the second diagram.
### Components/Axes
* **Containers:** Three rounded squares, each divided into two vertical halves.
* **Shapes:**
* Pentagon (light gray)
* Triangle (medium gray)
* Circle (light gray)
* Square (dark gray)
* **Label:** "L-R" is positioned below the second diagram.
### Detailed Analysis
* **Diagram 1 (Left):**
* Left half: Light gray pentagon.
* Right half: Medium gray triangle.
* **Diagram 2 (Center):**
* Left half: Light gray triangle.
* Right half: Dark gray pentagon.
* **Diagram 3 (Right):**
* Left half: Light gray circle.
* Right half: Dark gray square.
### Key Observations
* The shapes are arranged in pairs within each diagram.
* The label "L-R" likely indicates a left-to-right relationship or comparison.
* The shapes vary in both form and color (grayscale).
### Interpretation
The image appears to illustrate a concept related to shape arrangement or pairing. The "L-R" label suggests a comparison or transformation between the left and right sides of each diagram. The different shapes and colors could represent different categories or attributes being compared. The diagrams could be part of a larger visual puzzle or a representation of a logical relationship between shapes.
</details>
<details>
<summary>Image 19 Details</summary>

### Visual Description
## Diagram: Abstract Visual Patterns
### Overview
The image presents a 3x3 grid of abstract visual patterns, each enclosed within a rounded square. Each pattern consists of a polygon (mostly pentagons) containing smaller geometric shapes. The shapes vary in type (circles, squares, diamonds, hexagons) and shading (black, gray, white). The label "I-OG" is present below the grid.
### Components/Axes
* **Grid:** A 3x3 arrangement of visual patterns.
* **Enclosing Shape:** Each pattern is contained within a rounded square.
* **Polygon:** A polygon (mostly pentagons) forms the background of each pattern.
* **Geometric Shapes:** Smaller shapes (circles, squares, diamonds, hexagons) are placed inside the polygon.
* **Shading:** Shapes are shaded in black, gray, or white.
* **Label:** "I-OG" is located below the grid.
### Detailed Analysis
Here's a breakdown of each pattern in the grid:
* **Top-Left:** Pentagon containing a black square and a gray diamond.
* **Top-Center:** Pentagon containing two gray circles.
* **Top-Right:** Circle containing a black diamond and a gray square.
* **Middle-Left:** Pentagon containing two black diamonds and a gray circle.
* **Middle-Center:** Pentagon containing a white diamond.
* **Middle-Right:** Pentagon containing two black hexagons.
* **Bottom-Left:** Square containing two gray diamonds and two gray circles.
* **Bottom-Center:** Pentagon containing a gray diamond.
* **Bottom-Right:** Square containing a black diamond and a black square.
### Key Observations
* The patterns are abstract and do not appear to follow a specific rule or sequence.
* The shapes, shading, and arrangement vary across the grid.
* Pentagons are the most common polygon used.
* The label "I-OG" does not have an obvious connection to the patterns themselves.
### Interpretation
The image appears to be a collection of abstract visual patterns, possibly for use in a visual test, design element, or abstract art. The label "I-OG" might be a code or identifier for the set of patterns. Without additional context, it's difficult to determine the specific purpose or meaning of these patterns. The variations in shape, shading, and arrangement suggest a deliberate design, but the lack of a clear pattern or sequence makes it difficult to draw further conclusions.
</details>
## Position: Prog.
row 1: [1, 0, 0, 1, 1, 0, 1, 1, 1], [1, 1, 0, 0, 1, 1, 0, 1, 1], [1, 1, 1, 0, 0, 1, 1, 0, 1];
row 2: [0, 1, 0, 1, 1, 0, 1, 1, 1], [1, 0, 1, 0, 1, 1, 0, 1, 1], [1, 1, 0, 1, 0, 1, 1, 0, 1];
row 3: [0, 1, 0, 0, 1, 0, 0, 1, 0], [0, 0, 1, 0, 0, 1, 0, 0, 1], [1, 0, 0, 1, 0, 0, 1, 0, 0];
## Type: Const.
## Size: Const.
## Number: -
row 1: 6, 6, 6;
row 2: 6, 6, 6;
row 3: 3, 3, 3;
## Color: Arith.
row 1: [5, 6], [5, 6], [5, 6];
row 1: [3, 4, 5, 6], [3, 4, 5, 6], [3, 4, 5, 6];
row 1: [6], [1], [7];
row 2: [4, 5, 6, 7], [4, 5, 6, 7], [4, 5, 6, 7];
row 2: [2, 3, 5], [2, 3, 5], [2, 3, 5];
row 2: [8], [0], [8];
row 3: [4, 5], [4, 5], [4, 5];
row 3: [1, 4, 5], [1, 4, 5], [1, 4, 5];
row 3: [4], [3], [7];
## Complete
row 1: A (3,0.1,40) / B (5,0.3,30), A (7,0.2,40) / B (4,0.3,50), A (5,0.6,40) / B (3,0.3,70);
row 2: A (7,0.6,10) / B (4,0.6,40), A (5,0.1,10) / B (3,0.6,60), A (3,0.2,10) / B (5,0.6,80);
row 3: A (5,0.2,10) / B (3,0.4,50), A (3,0.6,10) / B (5,0.4,70), A (7,0.1,10) / B (4,0.4,90);
## Left Comp.
## Right Comp.
row 1: (3,0.1,40), (7,0.2,40), (5,0.6,40);
row 1: (5,0.3,30), (4,0.3,50), (3,0.3,70);
row 2: (7,0.6,10), (5,0.1,10), (3,0.2,10);
row 2: (4,0.6,40), (3,0.6,60), (5,0.6,80);
row 3: (5,0.2,10), (3,0.6,10), (7,0.1,10);
row 3: (3,0.4,50), (5,0.4,70), (4,0.4,90);
| Type: Distr. | Size: Distr. | Color: Const. | Type: Distr. | Size: Const. | Color: Prog. |
|-----------------|-----------------|-----------------|-----------------|-----------------|-----------------|
| row 1: 3, 7, 5; | row 1: 1, 2, 6; | row 1: 4, 4, 4; | row 1: 5, 4, 3; | row 1: 3, 3, 3; | row 1: 3, 5, 7; |
| row 2: 7, 5, 3; | row 2: 6, 1, 2; | row 2: 1, 1, 1; | row 2: 4, 3, 5; | row 2: 6, 6, 6; | row 2: 4, 6, 8; |
| row 3: 5, 3, 7; | row 3: 2, 6, 1; | row 3: 1, 1, 1; | row 3: 3, 5, 4; | row 3: 4, 4, 4; | row 3: 5, 7, 9; |
## Complete
row 1: A (5,0.6,0) / B [(4,0.4,60), (4,0.4,60), (4,0.6,60), (4,0.6,60)],
A (6,0.5,0) / B [(6,0.6,30), (6,0.6,30), -, -],
A (7,0.4,0) / B [-, (5,0.5,90), -, (5,0.4,90)];
row 2: A (4,0.4,0) / B [-, (5,0.5,80), (5,0.3,80), (5,0.3,80)],
A (5,0.6,0) / B [(4,0.4,10), -, -, -],
A (6,0.5,0) / B [-, (6,0.5,90), (6,0.3,90), -];
row 3: A (4,0.5,0) / B [(6,0.4,40), (6,0.4,40), (6,0.4,40), (6,0.3,40)],
A (5,0.4,0) / B [-, (5,0.5,50), -, -],
A (6,0.6,0) / B [(4,0.4,90), (4,0.4,90), (4,0.5,90), -];
## In Comp.
row 1: [(4,0.4,60), (4,0.4,60), (4,0.6,60), (4,0.6,60)],
[(6,0.6,30), (6,0.6,30), -, -],
[-, (5,0.5,90), -, (5,0.4,90)];
row 2: [-, (5,0.5,80), (5,0.3,80), (5,0.3,80)],
[(4,0.4,10), -, -, -],
[-, (6,0.5,90), (6,0.3,90), -];
row 3: [(6,0.4,40), (6,0.4,40), (6,0.4,40), (6,0.3,40)],
[-, (5,0.5,50), -, -],
[(4,0.4,90), (4,0.4,90), (4,0.5,90), -];
## Position: -
## Number: Arith.
row 1: [1, 1, 1, 1], [1, 1, 0, 0], [0, 1, 0, 1];
row 2: [0, 1, 1, 1], [1, 0, 0, 0], [0, 1, 1, 0];
row 3: [1, 1, 1, 1], [0, 1, 0, 0], [1, 1, 1, 0];
row 1: 4, 2, 2;
row 2: 3, 1, 2;
row 3: 4, 1, 3;
## Type: Distr.
Size: Const.
## Color: Arith.
row 1: [4], [6], [5]; row 1: [4, 6], [6], [4, 5]; row 1: [6], [3], [9];
row 2: [5], [4], [6]; row 2: [3, 5], [4], [3, 5]; row 2: [8], [1], [9];
row 3: [6], [5], [4]; row 3: [3, 4], [5], [4, 5]; row 3: [4], [5], [9];
Figure 14: Example prompts for 2x2Grid , 3x3Grid , L-R and I-OG subtasks under different abstractions.
## Out Comp.
row 1: (5,0.6,0), (6,0.5,0), (7,0.4,0);
row 2: (4,0.4,0), (5,0.6,0), (6,0.5,0);
row 3: (4,0.5,0), (5,0.4,0), (6,0.6,0);
Type: Prog. Size: Distr. Color: Const.
row 1: 5, 6, 7; row 1: 6, 5, 4; row 1: 0, 0, 0;
row 2: 4, 5, 6;
row 2: 4, 6, 5;
row 2: 0, 0, 0;
row 3: 4, 5, 6; row 3: 5, 4, 6; row 3: 0, 0, 0;
## Complete
row 1: [-, (7,0.2,40), (7,0.2,40), (7,0.2,40)], [(5,0.5,20), (5,0.5,20), (5,0.5,20), -], [-, -, -, (3,0.1,60)];
row 2: [(7,0.1,20), (7,0.1,20), -, (7,0.1,20)], [(5,0.2,40), (5,0.2,40), -, -], [-, -, -, (3,0.5,60)];
row 3: [-, (7,0.5,50), (7,0.5,50), (7,0.5,50)], [(5,0.1,10), -, (5,0.1,10), -], [-, (3,0.2,60), -, (3,0.2,60)];
## Position: (Set) Arith.
## Number: -
## Type: Prog.
## Size: Distr.
## Color: Arith.
row 1: [0, 1, 1, 1], [1, 1, 1, 0], [0, 0, 0, 1];
row 1: 3, 3, 1;
row 1: [7], [5], [3];
row 1: [2], [5], [1];
row 1: [4], [2], [6];
row 2: [1, 1, 0, 1], [1, 1, 0, 0], [0, 0, 0, 1];
row 2: 3, 2, 1;
row 2: [7], [5], [3];
row 2: [1], [2], [5];
row 2: [2], [4], [6];
row 3: [0, 1, 1, 1], [1, 0, 1, 0], [0, 1, 0, 1];
row 3: 3, 2, 2;
row 3: [7], [5], [3];
row 3: [5], [1], [2];
row 3: [5], [1], [6];
## Complete
row 1: [(5,0.6,60), -, -, (6,0.4,60), (6,0.5,60), -, (5,0.3,60), (6,0.3,60), (6,0.4,60)],
[(6,0.4,10), (5,0.6,10), -, -, (6,0.4,10), (6,0.5,10), -, (5,0.3,10), (6,0.3,10)],
[(6,0.3,70), (6,0.4,70), (5,0.6,70), -, -, (6,0.4,70), (6,0.5,70), -, (5,0.3,70)];
row 2: [-, (7,0.5,80), -, (4,0.3,80), (7,0.2,80), -, (6,0.2,80), (5,0.3,80), (4,0.5,80)],
[(4,0.5,0), -, (7,0.5,0), -, (4,0.3,0), (7,0.2,0), -, (6,0.2,0), (5,0.3,0)],
[(5,0.3,80), (4,0.5,80), -, (7,0.5,80), -, (4,0.3,80), (7,0.2,80), -, (6,0.2,80)];
row 3: [-, (5,0.5,40), -, -, (4,0.4,40), -, -, (4,0.1,40), -],
[-, -, (5,0.5,30), -, -, (4,0.4,30), -, -, (4,0.1,30)],
[(4,0.1,70), -, -, (5,0.5,70), -, -, (4,0.4,70), -, -];
Table 3: Performance on RAVEN sub-tasks under our abstractions across a wider set of model sizes. 175B refers to text-davinci-002 while the rest are corresponding OPT models.
| Abstractions | Center | 2x2 | 3x3 | L-R | U-D | O-IC | O-IG | Avg. |
|-----------------------|----------|-------|-------|-------|-------|--------|--------|--------|
| Attr. Naming Only | 0.222 | 0.42 | 0.606 | 0.076 | 0.098 | 0.122 | 0.194 | 0.248 |
| Comp. Decomp. | 0.222 | 0.42 | 0.606 | 0.136 | 0.154 | 0.162 | 0.222 | 0.275 |
| Comp. + Attr. Decomp. | 0.456 | 0.62 | 0.724 | 0.378 | 0.408 | 0.374 | 0.52 | 0.497 |
| Attr. Naming Only | 0.302 | 0.51 | 0.684 | 0.104 | 0.134 | 0.12 | 0.25 | 0.301 |
| Comp. Decomp. | 0.302 | 0.51 | 0.684 | 0.186 | 0.232 | 0.254 | 0.344 | 0.359 |
| Comp. + Attr. Decomp. | 0.436 | 0.588 | 0.788 | 0.28 | 0.346 | 0.29 | 0.408 | 0.448 |
| Attr. Naming Only | 0.472 | 0.584 | 0.71 | 0.146 | 0.158 | 0.2 | 0.322 | 0.37 |
| Comp. Decomp. | 0.472 | 0.584 | 0.71 | 0.41 | 0.426 | 0.434 | 0.494 | 0.504 |
| Comp. + Attr. Decomp. | 0.72 | 0.714 | 0.794 | 0.672 | 0.68 | 0.744 | 0.744 | 0.724 |
| Attr. Naming Only | 0.534 | 0.572 | 0.746 | 0.216 | 0.2 | 0.268 | 0.336 | 0.41 |
| Comp. Decomp. | 0.534 | 0.572 | 0.746 | 0.42 | 0.468 | 0.484 | 0.532 | 0.537 |
| Comp. + Attr. Decomp. | 0.706 | 0.738 | 0.826 | 0.658 | 0.664 | 0.704 | 0.784 | 0.726 |
| Attr. Naming Only | 0.618 | 0.59 | 0.752 | 0.196 | 0.228 | 0.284 | 0.396 | 0.438 |
| Comp. Decomp. | 0.618 | 0.59 | 0.752 | 0.492 | 0.528 | 0.548 | 0.584 | 0.587 |
| Comp. + Attr. Decomp. | 0.704 | 0.75 | 0.826 | 0.682 | 0.69 | 0.748 | 0.834 | 0.748 |
| Attr. Naming Only | 0.644 | 0.61 | 0.754 | 0.22 | 0.268 | 0.358 | 0.452 | 0.472 |
| Comp. Decomp. | 0.644 | 0.61 | 0.754 | 0.566 | 0.602 | 0.586 | 0.576 | 0.62 |
| Comp. + Attr. Decomp. | 0.746 | 0.794 | 0.83 | 0.71 | 0.702 | 0.77 | 0.84 | 0.77 |
| Attr. Naming Only | 0.68 | 0.596 | 0.748 | 0.264 | 0.328 | 0.42 | 0.482 | 0.503 |
| Comp. Decomp. | 0.68 | 0.596 | 0.748 | 0.582 | 0.618 | 0.664 | 0.638 | 0.647 |
| Comp. + Attr. Decomp. | 0.762 | 0.818 | 0.828 | 0.738 | 0.714 | 0.786 | 0.86 | 0.787 |
| Attr. Naming Only | 0.772 | 0.78 | 0.864 | 0.542 | 0.536 | 0.648 | 0.748 | 0.699 |
| Comp. Decomp. | 0.772 | 0.78 | 0.864 | 0.738 | 0.732 | 0.78 | 0.84 | 0.787 |
| Comp. + Attr. Decomp. | 0.8 | 0.878 | 0.932 | 0.776 | 0.78 | 0.828 | 0.926 | 0.846 |
Table 4: Performance on I-RAVEN sub-tasks under our abstractions across different model sizes. 175B refers to text-davinci-002 while the rest are corresponding OPT models.
| Abstractions | Abstractions | Center | 2x2 | 3x3 | L-R | U-D | O-IC | O-IG | Avg. |
|----------------|-----------------------|----------|-------|-------|-------|-------|--------|--------|--------|
| | Attr. Naming Only | 0.376 | 0.172 | 0.208 | 0.246 | 0.23 | 0.262 | 0.202 | 0.242 |
| 125M | Comp. Decomp. | 0.376 | 0.172 | 0.208 | 0.336 | 0.344 | 0.354 | 0.224 | 0.288 |
| | Comp. + Attr. Decomp. | 0.608 | 0.514 | 0.602 | 0.612 | 0.624 | 0.638 | 0.594 | 0.6 |
| 1.3B | Attr. Naming Only | 0.594 | 0.29 | 0.31 | 0.348 | 0.37 | 0.388 | 0.334 | 0.376 |
| | Comp. Decomp. | 0.594 | 0.29 | 0.31 | 0.586 | 0.574 | 0.618 | 0.466 | 0.491 |
| | Comp. + Attr. Decomp. | 0.81 | 0.676 | 0.73 | 0.822 | 0.802 | 0.882 | 0.818 | 0.791 |
| 13B | Attr. Naming Only | 0.756 | 0.384 | 0.382 | 0.456 | 0.498 | 0.538 | 0.432 | 0.492 |
| | Comp. Decomp. | 0.756 | 0.384 | 0.382 | 0.75 | 0.74 | 0.766 | 0.564 | 0.62 |
| | Comp. + Attr. Decomp. | 0.836 | 0.748 | 0.728 | 0.824 | 0.826 | 0.906 | 0.868 | 0.819 |
| | Attr. Naming Only | 0.808 | 0.564 | 0.566 | 0.656 | 0.676 | 0.818 | 0.714 | 0.686 |
| 175B | Comp. Decomp. | 0.808 | 0.564 | 0.566 | 0.822 | 0.812 | 0.896 | 0.742 | 0.744 |
| 175B | Comp. + Attr. Decomp. | 0.864 | 0.832 | 0.818 | 0.834 | 0.846 | 0.928 | 0.93 | 0.865 |