# Towards Theory-based Moral AI: Moral AI with Aggregating Models Based on Normative Ethical Theory
**Authors**: Masashi Takeshita
## Abstract
Moral AI has been studied in the fields of philosophy and artificial intelligence. Although most existing studies are only theoretical, recent developments in AI have made it increasingly necessary to implement AI with morality. On the other hand, humans are under the moral uncertainty of not knowing what is morally right. In this paper, we implement the Maximizing Expected Choiceworthiness (MEC) algorithm, which aggregates outputs of models based on three normative theories of normative ethics to generate the most appropriate output. MEC is a method for making appropriate moral judgments under moral uncertainty. Our experimental results suggest that the output of MEC correlates to some extent with commonsense morality and that MEC can produce equally or more appropriate output than existing methods.
## 1 Introduction
Philosophy and artificial intelligence have long considered the creation of Moral AI by which we mean artificial intelligence with morality We use “moral” and “ethical” interchangeably.. In philosophy, theoretical studies have explored under what framework the creation of moral AI is desirable (Wallach and Allen, 2008; Allen et al., 2005), while the filed of AI is still exploring how to implement such a framework (e.g. Anderson et al., 2006; Rzepka and Araki, 2017; Jiang et al., 2021).
There are many reasons why Moral AI is essential. For example, if an AI is implemented in automated driving technology, it will likely make morally wrong decisions if it cannot correctly make moral judgments (Awad et al., 2018). Similarly, if healthcare workers use AI for decision-making support in the medical field, that AI must be able to make appropriate ethical decisions (Braun et al., 2021). Furthermore, as AI becomes more accessible and assists or advises us in various aspects of our daily lives, it may lead us in the wrong direction if such AI ignores morality.
In recent years, large language models (LLMs) have been developed, and the implementation of morality has become essential, but most of previous research on moral AIs has been done without implementation (Tolmeijer et al., 2020). The social impact of foundation models (Bommasani et al., 2021), such as the BERT (Devlin et al., 2019) and GPT series (e.g. Brown et al., 2020), is significant, and it is essential to implement appropriate ethics in these foundational models. Recently, users have an easy access to output of LLMs, which is known to contain harmful content and discriminatory bias (Gehman et al., 2020; Ganguli et al., 2022). Therefore, it has become more important to implement appropriate ethics in LLM. But what ethics should we implement in AI?
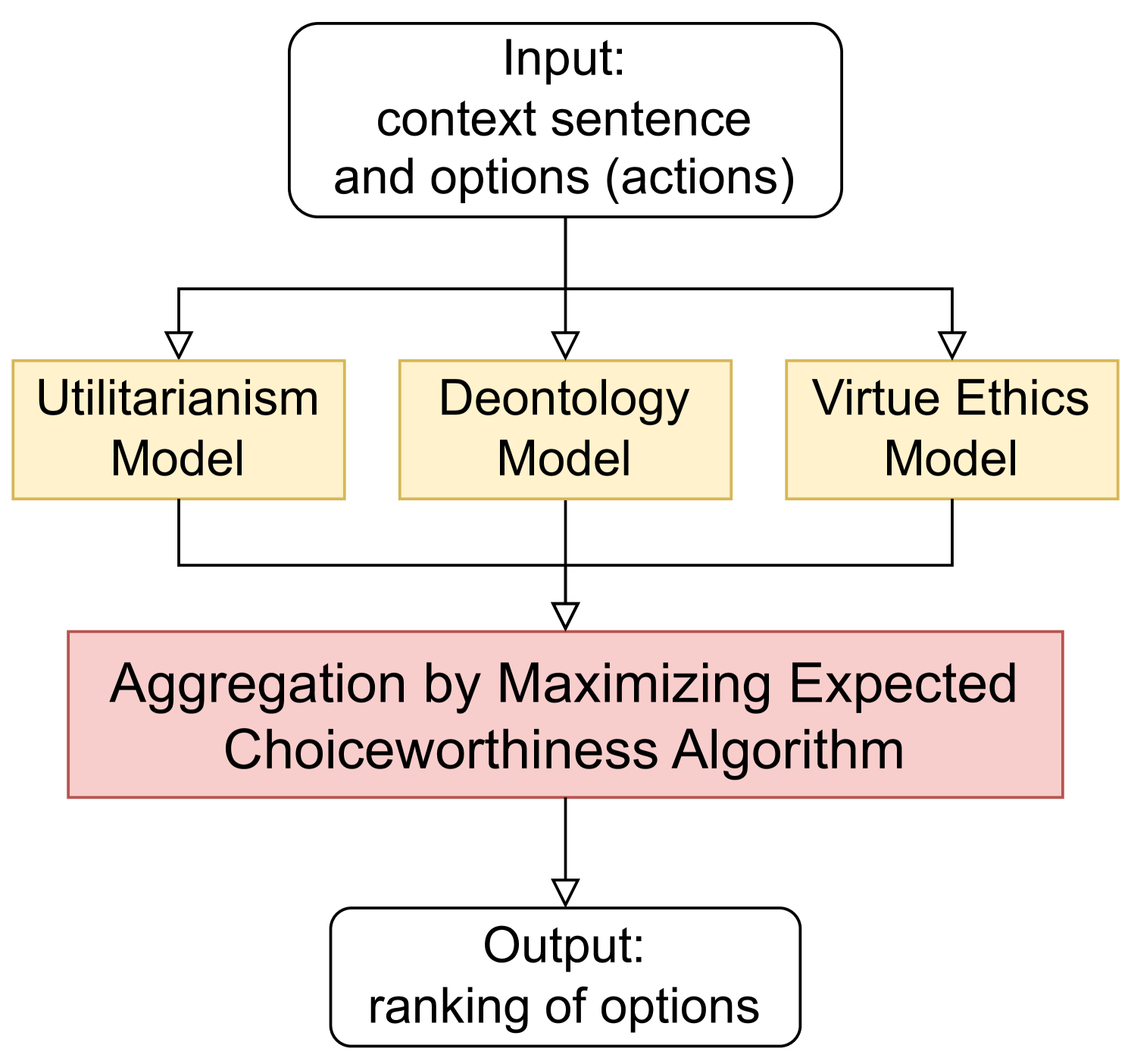
To answer this question, we create several models based on normative ethical theories studied in normative ethics and implement an algorithm to aggregate the output of these models (Figure 1). We call the algorithm Maximizing Expected Choiceworthiness (MEC) algorithm (MacAskill et al., 2020). Existing research has created models and datasets solely based on commonsense morality (e.g. Jiang et al., 2021). However, relying directly on commonsense morality may be inappropriate if it is incorrect. Therefore, we use findings of normative ethics and implement Moral AI based on the normative theories studied there. It is possible to create morally appropriate AI by not relying on commonsense morality as it is, but by referring to various normative theories. Although this idea has already been proposed (Bogosian, 2017; MacAskill et al., 2020), no implementation and evaluation experiments have been conducted. Thus, we improve, implement, and evaluate this idea.
The structure of this paper is as follows. In Section 2 we describe existing research on implementations of morality in AI, and on moral uncertainty, a central concept in this research. In Section 3 we describe Maximizing Expected Choiceworthiness (MEC) algorithm. Section 4 explains why MEC is desirable in the implementation of Moral AI and Section 5 describes the experiments. Section 6 describes the experimental results, which are discussed in Section 7.
## 2 Related Works
### 2.1 MoralQA and Moral AI
AI researchers have been trying to implement AIs capable of making moral judgments (we will call them Moral AI(s) in this paper) in various ways. In one of early examples, Anderson et al. (2006) have proposed MedEth, which learns by inductive logic programming based on principles proposed by ethicists, and advises the user. MedEth is limited to situations related to medical ethics, but its generalized version, GenEth (Anderson and Anderson, 2018), has also been proposed.
Since the advent of deep learning, researchers have studied MoralQA, which is to study whether AI can predict human answers to questions about morality (Jin et al., 2022). There are two types of datasets used in the MoralQA task: ones based on ethical theories and ones that not. The ETHICS dataset (Hendrycks et al., 2021) is created based on ethical theories. It consists of five datasets: justice, utilitarianism, duty theory, virtue, and commonsense morality. Except for commonsense morality, four datasets were created based on their respective theories and concepts. Jin et al. (2022) also developed a dataset called MoralExceptQA to assess understanding of when it is acceptable to break the rules based on contractualism.
One example of a QA dataset that is not explicitly based on ethical theory is Social Chemistry 101 (Forbes et al., 2020). Forbes et al. (2020) asked crowdworkers a) to create situation-related rules of thumb (RoTs) and to annotate b) which category of morality the RoTs belong to and c) the moral evaluation of the actions in the situation. Another example of this type of dataset is the Moral Stories dataset (Emelin et al., 2021) which was created based on Social Chemistry 101. Moral Stories consists of norms, situations, related intentions and actions, and consequences of actions. Jiang et al. (2021) have re-edited various commonsense morality datasets, including Social Chemistry 101 and MoralStories, to compile approximately 1.7 million data from The Commonsense Norm Bank.
As a model for solving MoralQA tasks, (Jiang et al., 2021) created Delphi, which can answer moral questions using the Commonsense Norm Bank. Delphi is a model based on UNICORN (Lourie et al., 2021), a model built on T5 (Raffel et al., 2020), and further trained with Commonsense Norm Bank. UNICORN is a model trained using RAINBOW (Lourie et al., 2021), a collection of CommonsenseQA datasets. Therefore, Delphi is a model trained on the commonsense morality dataset and not on a dataset that explicitly references ethical theory.
Jiang et al. (2021) suggested two approaches to the creation of Moral AI, top-down and bottom-up (cf. Wallach and Allen, 2008), and stated that Delphi is based on a bottom-up approach. The top-down approach is to create Moral AI by referring to moral theories and rules, while the bottom-up approach is to create Moral AI based on data such as people’s intuition. As we have seen, most of the existing research is bottom-up (the exception is Anderson et al. (2006)). However, there are problems with using a bottom-up approach alone, such as being conservative because it is based on current commonsense morality and cannot correct commonsense morality when it is wrong. As Jiang et al. (2021) correctly point out, top-down and bottom-up approaches must be mutually influential. Because we train AI models based on each moral theory, our study belongs to the top-down approach. Therefore, our research is meant to complement the existing bottom-up approach.
### 2.2 Moral Uncertainty
Moral uncertainty is “uncertainty that stems not from uncertainty about descriptive matters, but about moral or evaluative matters.” (MacAskill et al., 2020, p.1). Moral uncertainty arises not from uncertainty about descriptive questions but from evaluative questions. For example, in normative ethics, various theories have been proposed, such as utilitarianism and deontology, and no one yet knows which is the correct theory. Which theory is favored may still be open even if all the descriptive problems are solved.
We must make moral decisions without knowing which theory is correct. Bogosian (2017) points out two problems with this moral uncertainty. First, moral disagreement makes cooperation among engineers, policymakers, and philosophers difficult. In some cases, it can become simply an ideological conflict. Second, if there is wide disagreement about normative ethical theories, making moral judgments based on a single theory in the presence of diverse positions is, statistically speaking, unlikely to be the right decision. Because of the second problem, some philosophers avoid top-down approaches. However, due to the existence of the first problem and moral disagreement, bottom-up approaches are also unlikely to resolve moral dilemmas or politically divisive issues. Therefore, implementing Moral AI based on a single principle is undesirable, and relying solely on a bottom-up approach is problematic.
Some researchers (MacAskill et al., 2020; Bogosian, 2017) proposed Maximizing Expected Choiceworthiness (MEC) algorithm as a desirable decision-making approach in situations of moral uncertainty. We will explain this idea below, particularly regarding AI implementations.
## 3 Maximizing Expected Choiceworthiness As a Solution to Moral Uncertainty
<details>
<summary>x1.png Details</summary>
### Visual Description
## Diagram: Ethical Decision-Making Aggregation Flowchart
### Overview
This image is a flowchart diagram illustrating a multi-model ethical decision-making system. The process begins with an input, which is then processed in parallel by three distinct ethical models. The outputs from these models are aggregated by a central algorithm, which produces a final ranked output. The diagram uses a top-down flow with clear directional arrows.
### Components/Axes
The diagram consists of five main rectangular boxes connected by directional arrows. The boxes are arranged in four distinct horizontal layers.
1. **Top Layer (Input):** A single white box with a black border.
* **Text Content:**
```
Input:
context sentence
and options (actions)
```
* **Position:** Centered at the top of the diagram.
2. **Middle Layer (Parallel Models):** Three light-yellow boxes with gold borders, arranged horizontally and centered below the input box.
* **Left Box Text:** `Utilitarianism Model`
* **Center Box Text:** `Deontology Model`
* **Right Box Text:** `Virtue Ethics Model`
* **Position:** These three boxes are in a row, directly below the input box. Arrows from the input box point down to each of these three boxes.
3. **Aggregation Layer:** A single light-red box with a dark red border.
* **Text Content:**
```
Aggregation by Maximizing Expected
Choiceworthiness Algorithm
```
* **Position:** Centered below the three model boxes. Arrows from all three model boxes converge and point down into this box.
4. **Bottom Layer (Output):** A single white box with a black border.
* **Text Content:**
```
Output:
ranking of options
```
* **Position:** Centered at the bottom of the diagram. An arrow from the aggregation box points down into this box.
**Flow Direction:** The arrows indicate a strict top-down, parallel-then-convergent flow: Input → [Utilitarianism Model, Deontology Model, Virtue Ethics Model] (in parallel) → Aggregation Algorithm → Output.
### Detailed Analysis
* **Component Isolation & Spatial Grounding:**
* **Header Region:** Contains only the "Input" box.
* **Main Processing Region:** Contains the three parallel ethical model boxes and the aggregation algorithm box. The three models are positioned equidistantly in a horizontal line.
* **Footer Region:** Contains only the "Output" box.
* **Text Transcription:** All text within the boxes has been transcribed exactly as it appears, preserving line breaks.
* **Relationships:** The diagram explicitly shows that the single input is fed simultaneously into three separate ethical frameworks. The outputs of these frameworks are not shown individually but are implied to be inputs to the aggregation algorithm. The aggregation algorithm then produces a single, final output.
### Key Observations
1. **Parallel Processing:** The core of the system is the parallel application of three major ethical theories (Utilitarianism, Deontology, Virtue Ethics) to the same problem.
2. **Centralized Aggregation:** A specific algorithm ("Maximizing Expected Choiceworthiness") is used to combine the potentially conflicting recommendations from the three ethical models.
3. **Unidirectional Flow:** The process is strictly feed-forward with no feedback loops or iterative steps shown.
4. **Abstraction:** The diagram is a high-level architectural view. It does not detail the internal workings of the individual ethical models or the aggregation algorithm.
### Interpretation
This flowchart represents a structured, computational approach to ethical reasoning. It suggests a system designed to make moral decisions by synthesizing multiple ethical perspectives rather than relying on a single doctrine.
* **What it demonstrates:** The system acknowledges that different ethical frameworks (consequence-based, duty-based, character-based) can lead to different conclusions. Instead of choosing one, it uses a meta-algorithm to find a consensus or optimal choice based on "expected choiceworthiness," which likely involves weighing the outputs from each model.
* **How elements relate:** The input provides the moral dilemma. The three models act as specialized "ethical sensors," each analyzing the dilemma through its own lens. The aggregation algorithm functions as a "moral integrator," resolving the analyses into a single actionable ranking.
* **Notable implications:** The design implies that a robust ethical decision can be achieved through the systematic combination of established moral philosophies. The final output is a "ranking of options," indicating the system is designed for scenarios with multiple possible actions, providing a prioritized list rather than a single binary choice. The absence of a "human-in-the-loop" component in the diagram suggests a fully automated decision-support or decision-making system.
</details>
Figure 1: This figure shows the overall picture of the aggregation model in this paper. In this paper, we use a theory-based model based on utilitarianism, deontology, and virtue ethics.
Maximizing Expected Choiceworthiness (MEC) is one of the solutions to decision-making problems in moral uncertain situations. This section describes this framework following Bogosian (2017, sec. 5) ’s explanation (cf. MacAskill et al., 2020).
### 3.1 Preliminary Definition
An AI chooses an action in a decision situation $<S,t,A,T,C>$ where $S$ is the decision maker, $t$ is the time, and $A$ is the set of possible actions (options) to take. $T$ is the set of normative theories under consideration. A theory $T_i$ is a function of decision that produces a cardinal or ordinal choiceworthiness score for actions $CW_i(A)$ for all actions $a∈A$ . $C(T_i)$ is a credence function that assigns values in $[0,1]$ to every $T_i∈ T$ . A metanormative theory is a function of decision-situations that produces an ordering of the actions in $A$ regarding their appropriateness.
$T$ includes three kinds of moral theories: (1) theories that assign a cardinal ranking to options, and these rankings are comparable, (2) theories that assign a cardinal ranking to options, and these rankings are incomparable and (3) theories that assign ordinal rankings to options. For example, typically, utilitarianism is a cardinal theory, and deontology is an ordinal theory.
In the case of current AI models, because they can output the probability of a given label in the range of $[0,1]$ , we can interpret all outputs as cardinal values. However, probability is not a choiceworthiness itself, so we treat the values assigned by AI models based on ordinal theories as ordinal scale values.
### 3.2 Calculating Choiceworthiness
Maximizing Expected Choiceworthiness (MEC) consists of four steps of calculating choiceworthiness scores.
Step 1: Merging commensurable cardinal theories
Given a set of $k$ intertheoretically comparable cardinal theories and $k$ sets of actions assigned choiceworthiness scores by each theory, these theories are merged into a single theory $K$ :
$$
\displaystyle C≤ft({T_{K}}\right) \displaystyle=\mathop{∑}\limits_i=1^kC(T_i) \displaystyle CW_{K}≤ft(A\right) \displaystyle=\frac{{\mathop{∑}\nolimits_i=1^kCW_i≤ft(A\right)C
≤ft({T_i}\right)}}{{\mathop{∑}\nolimits_i=1^kC≤ft({T_i}\right)}} \tag{1}
$$
Step 2: Assigning choiceworthiness scores by ordinal theories
A modified Borda scoring rule is used to generate scores for each action based on the ranking of actions which is provided on each ordinal theory $o$ , considering ties. These scores are represented as $CW^B$ . The score of an action is determined by the difference between the number of actions inferior to it and the number of actions superior to it.
$$
\begin{split}CW_o^B&≤ft(A\right)=\\
&≤ft|{a∈{A}:CW_o≤ft(a\right)<CW_o≤ft(A\right)}\right|\\
&-≤ft|{a∈{A}:CW_o≤ft(a\right)}\right>CW_o≤ft(A\right)|
\end{split} \tag{3}
$$
An AI model outputs the probability of given labels. Here, we have two ways of treating this probability. First, we can treat this probability as a cardinal value. For example, if an AI model outputs 0.8 for an action $a_1$ and 0.6 for $a_2$ for the probability that the label is “1” (e.g., wrong), we treat $a_1$ as having a higher choiceworthiness score than $a_2$ . Second, we can use threshold and treat model outputs as ordinal values. For instance, if an AI model outputs 0.8 for an action $a_1$ and 0.6 for $a_2$ and we set 0.5 as a threshold, we treat both $a_1$ and $a_2$ as “1” (e.g., wrong) equally.
Step 3: Normalization
To equalize the value of voting for each value system, all choiceworthiness scores $CW_i(A)$ are divided by their respective standard deviations:
$$
\displaystyle CW_{K}^N(A) \displaystyle=\frac{{CW_{K}(A)}}{{σ≤ft({CW_{K}(
{G})}\right)}} \displaystyle CW_o^N(A) \displaystyle=\frac{{CW_o^B(A)}}{{{σ}≤ft({CW_o^B≤ft({\mathcal
{G}}\right)}\right)}} \displaystyle CW_p^N≤ft(A\right) \displaystyle=\frac{{CW_p≤ft(A\right)}}{{{σ}≤ft({CW_p≤ft({
G}\right)}\right)}} \tag{4}
$$
where theories $p$ means intertheoretically incomparable cardinal theories, $G$ is a representative set of actions (the “general set”), which actions may not be included $A$ . Bogosian (2017) stated the choiceworthiness score should be divided by standard deviations of ${CW_o^B≤ft({G}\right)}$ , because we should think about whether each considered action “is comparatively important or comparatively unimportant from the point of view of a particular theory” (Bogosian, 2017, p.597). However, since it is difficult to select representative actions (cf. MacAskill et al., 2020, p.102), we treat $G$ as $A$ in our experiment. This way of normalization relativizes the choiceworthiness scores to $A$ .
Step 4: Aggregation
Finally, we obtain expected choiceworthiness by following equation:
$$
CW^E≤ft(A\right)=\mathop{∑}\limits_i=1^nCW_i^N≤ft(A\right)C
≤ft({T_i}\right) \tag{7}
$$
The decision maker selects the action $A$ which maximizes $CW^E(A)$ .
## 4 Why is MEC preferable in Moral AI?
As described above, MEC algorithm aggregates the output of models based on each normative ethical theory to output a final moral evaluation. There are at least three reasons why this algorithm is desirable in Moral AI.
First, if one creates models based on theories, one can, in principle, evaluate the output of each theory-based model since there is a correct answer relative to the theory for every question. For example, when creating a utilitarian model, the evaluation of the utilitarian model can be evaluated by whether the model’s output is appropriate from a utilitarian point of view. However, in the case of a model based on commonsense morality, not theory, such as Delphi, it is difficult to evaluate the model because people sometimes have differing opinions about moral problems such as moral dilemmas or political issues.
Second, because MEC is a general framework, it can be used for the models developed in this paper and other models that may be proposed or developed by others in the future. Although we have only used three theories in this experiment, we can use existing models such as Delphi and future proposed models to produce moral evaluations.
Third, the models aggregated in the MEC need not necessarily be theory-based. For example, if one wants to reflect cultural diversity, one can create a Delphi-like model for each culture, and MEC can aggregate the output of each model. Of course, reflecting the commonsense morality of each culture without being based on ethical theory makes evaluation difficult, as noted in the first point, but the ability to reflect cultural diversity in this way is another advantage of MEC being a general framework. Although we did not use a model that reflects cultural diversity in our experiments, we plan to develop it in the future.
We did not use a model reflecting cultural diversity in this experiment, but plan to develop one in the future.
## 5 Experiment
### 5.1 Implementation
To calculate expected choiceworthiness, we need AI models based on ethical theories. For this purpose, we fine-tune DeBERTa-v3 ${}_\rm large$ (He et al., 2021) https://huggingface.co/microsoft/deberta-v3-large We do not have enough computational resources to fine-tune large models such as T5 ${}_11B$ . We use DeBERTa-v3 ${}_\rm large$ because it is one of the best performing models. on datasets included in ETHICS (Hendrycks et al., 2021). DeBERTa-v3 is an ELECTRA-style pretrained model. ELECTRA (Clark et al., 2020) is a model pre-trained through Replaced Token Detection (RTD). RTD is a model training method where some tokens in the original sentence are masked, Generator (Masked Language Model (cf. Devlin et al., 2019)) fills the masked tokens with words using, and Detector detects the words filled in the mask. He et al. (2021) improved the RTD by Gradient-Disentangled Embedding Sharing. While the gradient is shared between Generator and Detector during training in ELECTRA, the gradient is split between Generator and Detector in DeBERTa-v3.
For fine-tuning DeBERTa-v3, we use three datasets: “utilitarianism”, “deontology” and “virtue”. These theories are the most endorsed theories in normative ethics (Bourget and Chalmers, ms) https://survey2020.philpeople.org/survey/results/4890 PhilPapers Survey did not use “utilitarianism” but “consequentialism”. Utilitarianism is a particular type of consequentialism, therefore we can use the “utilitarianism” dataset as a consequentialist dataset.. We set all $C(T_i)$ to 1. Bogosian (2017) suggested some ways of assigning $C(T_i)$ , one of which is to assign the philosopher’s endorsement rate. According to PhilPapers Survey (Bourget and Chalmers, ms), the supporters of each theory ( consequentialism, deontology, and virtue ethics) are roughly equal (32%, 31%, and 37%, respectively). Therefore we assign hypothetically equal values in this experiment. Hyperparameters are shown on Table 7.
| Hyperparameter learning rate batch size | $1× 10^-5$ , $2× 10^-5$ , $3× 10^-5$ 64 |
| --- | --- |
| epoch | 4 |
| optimizer | AdamW |
| warmup ratio | 0.1 |
Table 1: Hyperparameters. We use AdamW (Loshchilov and Hutter, 2019) as an optimizer with default hyperparameters in Pytorch (Paszke et al., 2019) https://pytorch.org/docs/stable/generated/torch.optim.AdamW.html.
There are two problems with using ETHICS dataset. First, this dataset was created by nonspecialist crowdworkers. Second, this dataset was not annotated directly according to each normative theory. For example, according to utilitarianism, an action is right if and only if the action maximizes the total well-being of all sentient beings affected by the action. However, Hendrycks et al. (2021) asked crowdworkers to evaluate the well-being of the person who is presented in the given sentence, not all sentient beings. Hence, this dataset is not perfectly based on moral theories. Nevertheless, we use ETHICS in our experiment because it is the only dataset created based on ethical theories. As already mentioned, an advantage of our approach is that such a dataset and AI models can be refined based on moral theories. We plan to develop a more theory-informed dataset than ETHICS in the future.
In using each model for MEC, the following input-output structure is used. First, the utilitarian model outputs a scalar value and treats it directly as a choiceworthiness score, following the construct of Hendrycks et al. (2021). Next, for the deontology model, we use the form “I am a human [SEP] $a_s$ ” as input, following the input form of the Role subtask, and treat its output value (the probability that the $a_s$ is permissible) as the choiceworthiness score, where $a_s$ denotes an action statement under consideration. This input form is intended to allow the model to determine whether an action is morally permissible or impermissible as a human being. Finally, for the virtue ethics model, we first list all character trait terms in the “virtue” train set and assign sentiment by SenticNet (Cambria et al., 2022). Terms not included in SenticNet are excluded. As a result, we collected 695 character trait terms and their sentiment. Let $v_t$ be the term of a character trait, the input format is “ $a_s$ [SEP] $v_t$ ”, and the sentiment of $v_t$ with the highest probability is treated as the choiceworthiness score of $a_s$ .
### 5.2 Evaluation
We assess the performance of our model through a evaluation process, which involves two distinct methods
#### 5.2.1 Experiment 1: Evaluate the performance and generalizability of each model using the ETHICS dataset
First, we assess the results for the test set of each sub-dataset, i.e., “utilitarianism”, “deontology”, and “virtue”. We also use “commonsense” in ETHICS to evaluate generalizability of our models. We expect the accuracy of MEC in this dataset to be superior to the accuracy of each model because of aggregation. In the case of the “commonsense” dataset, we set the threshold of the utilitarianism model for classification using 1,000 samples train data of the “commonsense” dataset. For the other two models (the deontology and the virtue ethics model), the output is positive if it is greater than zero and negative otherwise.
| Model | Deontology | Virtue | Utilitarianism |
| --- | --- | --- | --- |
| Random Baseline | 6.3 / 6.3 | 8.2 / 8.2 | 50.0 / 50.0 |
| BERT ${}_\rm large$ | 44.2 / 13.6 | 40.6 / 13.5 | 74.6 / 49.1 |
| RoBERTa ${}_\rm large$ | 60.3 / 30.8 | 53.0 / 25.5 | 79.5 / 62.9 |
| ALBERT ${}_\rm xxlarge$ | 64.1 / 37.2 | 64.1 / 37.8 | 81.9 / 67.4 |
| T5 ${}_\rm 11B$ * | 16.9 / 11.0 | 1.6 / 0.8 | 82.8 / 70.4 |
| Delphi* | 49.6 / 31.0 | 29.5 / 18.2 | 84.9 / 76.0 |
| DeBERTa-v3 ${}_\rm large$ | 78.0 / 59.4 | 76.3 / 50.9 | 81.6 / 73.6 |
Table 2: The results (Test / Hard Test) for the test set of ETHICS dataset (Hendrycks et al., 2021). The scores of BERT ${}_\rm large$ (Devlin et al., 2019), RoBERTa ${}_\rm large$ (Liu et al., 2019) and ALBERT ${}_\rm xxlarge$ (Lan et al., 2020) are reported by Hendrycks et al. (2021), scores of T5 ${}_\rm 11B$ (Raffel et al., 2020) and Delphi are reported by Jiang et al. (2021). The best scores are shown in bold font. * T5 ${}_\rm 11B$ and Delphi are fine-tuned with only 100 sampled training instances.
#### 5.2.2 Experiment 2: Comparison with Delphi by asking Ph.D. students
Second, we compare our model with Delphi (Jiang et al., 2021) by asking three Ph.D. students majoring in philosophy We asked, in English, three Japanese Ph.D. students who are fluent in English. There might be some minor language problems, but we do not think they significantly influence the results..
There are two kinds of evaluation: each output and the overall. First, we asses the output of our models using 40 sampled data (20 pairs) of test sets of “commonsense” in ETHICS dataset. We ask the annotators if the outputs of each of the models were properly theory-based, respectively. We also asked whether the Delphi’s outputs and the aggregated output (i.e. MEC’s output) were consistent with the annotators’ moral judgments.
Second, in overall evaluation, we ask the Ph.D. students to compare Delphi and MEC model with three metrics and the reasons:
1. Which is preferred: one answer output to one question (like Delphi) or a comparative ranking for options (like MEC)? Why?
1. The former is more preferable than the latter.
1. The latter is more preferable than the former.
1. Both are preferable.
1. Both are not preferable.
1. When a non-expert in ethics were to use Delphi or MEC as an AI advisor in moral deliberation, which model would be helpful? Why?
1. Delphi is more helpful than MEC.
1. MEC is more helpful than Delphi.
1. Both are helpful.
1. Both are not helpful.
1. When an expert in ethics were to use Delphi or MEC as an AI advisor in moral deliberation, which model would be helpful? Why?
1. Delphi is more helpful than MEC.
1. MEC is more helpful than Delphi.
1. Both are helpful.
1. Both are not helpful.
We ask people to evaluate these models as AI advisors for two reasons. First, when people use these models, they ask the AI for opinions about ethics and use it as a decision-making tools (Anderson et al., 2006; Anderson and Anderson, 2018). Second, there may be a kind of explanation of the model’s output by showing users not only the aggregated results of the MEC outputs but also the outputs of each model on which the aggregation is based. If this explains the model’s output, it should be more useful in moral deliberation. In contrast, since Delphi does not know the reason for its outputs, we believe that the outputs from MEC are superior in this respect, and we use this metric to confirm this. Also, for these reasons, MEC may be helpful to non-expert but not to experts in ethics. Therefore, we examine this hypothesis through questions 2 and 3.
| Random Baseline | 50.0 |
| --- | --- |
| Utilitarianism Model | 76.5 |
| Deontology Model | 71.5 |
| Virtue Ethics Model | 77.1 |
| MEC | 82.3 |
Table 3: The results for the test set (only short sentence) of “commonsense” dataset in ETHICS (Hendrycks et al., 2021). The best score is shown in bold font.
## 6 Results
### 6.1 Experiment 1: performance and generalizability of each model using the ETHICS dataset
| Which is preferred, outputting one answer to one question (like Delphi) or a comparative ranking for options (like MEC)? When a non-expert in ethics were to use Delphi or MEC as an AI advisor in moral deliberation, which model would be helpful? When an expert in ethics were to use Delphi or MEC as an AI advisor in moral deliberation, which model would be helpful? | The former (like Delphi) is more preferable than the latter. (2/3) The latter (like MEC) is more preferable than the former. (1/3) MEC is more helpful than Delphi. (1/3) Both are not helpful. (2/3) Both are not helpful. (3/3) |
| --- | --- |
Table 4: The results for each response in Experiment 2. Numbers in parentheses indicate the number of annotators who chose that response.
| Delphi | MEC |
| --- | --- |
| 13/16 (81%) | 14/16 (88%) |
Table 5: The results for the paired test set of the ETHICS dataset obtained by asking Ph.D. students. The reason for the 16 instead of 20 evaluations is that some instances were not considered evaluable due to a lack of context.
| Utilitarianism | Deontology | Virtue Ethics |
| --- | --- | --- |
| 12/12 (100%) | 13/15 (87%) | 17/17 (100%) |
Table 6: The results for the paired test set of the ETHICS dataset were obtained by asking Ph.D. students. The reason for number of evaluations smaller than 20 is that some instances were not considered evaluable due to a lack of context.
We show the results of ETHICS dataset as the test set in Tables 2 and 3. Except for utilitarianism dataset, DeBERTa results are better than BERT, RoBERTa, and ALBERT results, which are fine-tuned with all train data. It also outperforms the T5 and Delphi, which are fine-tuned with 100 sampled train data. The higher accuracy for the other models on the utilitarian dataset is likely because this task was designed as a binary classification task.
Regarding the results for the commonsense dataset, since MEC is an ensemble model of each theory-based model, the results are better than the other three models as expected. In addition, each model outperforms the random baseline even though it was not fine-tuned on the commonsense dataset. These results indicate that the verdict based on each theory correlates to some extent with the commonsense morality verdict. This correlation suggests generalizability from learning on each theory to commonsense morality. However, the accuracy of each theory-based model on this dataset is relatively low, and we will examine how it could achieve higher performance in the future.
### 6.2 Experiment 2: Comparison with Delphi by asking Ph.D. students
In Table 5 we show the results of the questioning Ph.D. students majoring in philosophy . We asked three annotators to evaluate 20 paired sentences, but they were not able to evaluate four paired sentences because of a lack of context. Therefore, we are showing the results for 16 pairs. Delphi and MEC showed little difference in the results. Delphi, trained on the “commonsense” dataset, was expected to be more accurate than MEC, but this was not the case.
We also show the results based on each theory (see Table 6) only for the paired sentences answered by all three students because some paired sentences were not evaluated due to a lack of context. All three models used in MEC had a high percentage of correct answers.
Next, Table 4 shows the results of the overall evaluation of Delphi and MEC. Regarding the first question, most annotators preferred to give one answer to one question, as in Delphi. The reasons given were that people only care about the absolute evaluation (non-comparative evaluation) of the alternatives and that it does not work well when the evaluations are in the same order. On the other hand, one annotator answered that it is preferable to provide a ranking of options, as in the MEC. The reason is that if only a single answer is output and different from the expectation, the impression is that it cannot be used as a reference. However, if it is output as a ranking, it is likely to generate a certain degree of acceptance.
For the second question, there was only one answer that MEC is more helpful than Delphi, and the reason was “because referencing multiple positions seems more plausible. The remaining answers were that both are not helpful because reasons are essential in moral deliberation, but neither model provides any.
Concerning the third question, all annotators indicated that both systems are not helpful, and the reason given was that neither model provided a reason. In the case of the experts, it seems to be more preferable to think for themselves.
## 7 Discussion
### 7.1 On the performance of MEC and theory-based models
As seen from the results of Experiment 1 (Table 2), DeBERTa-v3 yielded superior performance compared to the baseline model, T5 and Delphi. In addition, Experiment 2 (Table 6) also showed that DeBERTa-v3 is reliable enough to be used in this experiment, as it produces appropriate results based on each theory. However, the evaluation of the ETHICS dataset on the Hard Test set is still low and needs further improvement for a practical use.
All models outperform the random baseline for the results for the MEC “commonsense” dataset in Experiment 1, suggesting that each theory generally reflects commonsense morality. Although it is said that utilitarianism is generally counterintuitive, this theory reflects some of our commonsense morality. The results suggest utilitarianism is not entirely uncorrelated with commonsense morality. Moreover, other theories may also make counterintuitive judgments in some cases (e.g. Kantian obligation to never lie). The advantage of being theory-based is that theory-based judgment does not follow directly from our commonsense morality. Therefore, it is desirable that the model based on each theory does not perfectly agree with our commonsense moral evaluations. Nevertheless, a theory-based model must correlate with common sense morality because if it is too different from common sense morality, people will not want to use such a model. The extent to which commonsense morality and the evaluation of each theory should be correlated, and the extent to which they should not be correlated, is a controversial problem. Furthermore, we will examine situations where there is a discrepancy between commonsense morality judgments and theoretical judgments since the “commonsense” dataset does not cover controversial or politically divisive topics.
### 7.2 Comparing MEC with Delphi
Annotators answered that models such as Delphi and MEC are not helpful in moral deliberation, both for experts and non-experts, because they do not provide reasons, i.e., they do not explain their choices. This result rejects our original hypothesis that MEC is a kind of explanation because the model outputs the results of theory-based models. It may not be an explanation unless the models also provide reasons for why the model on which each theory is based produces the output it does. We can solve this problem by preparing a template for the output of each theory-based model. For example, a utilitarian model could have a template such as ”Action A is more choiceworthy than action B because action A has higher utility than action B.” In addition, it would be desirable if it is possible to explain, for example, why action A has higher utility than action B (cf. Bang et al., 2022). We will investigate what type of output format is appropriate in the future.
One of the annotators also stated that MEC could be more helpful depending on its use. For example, Delphi and MEC would promote moral deliberation if users reconsidered their judgment based on their output. In this case, MEC can provide aggregated outputs and the outputs of each theory-based model, respectively, promoting moral deliberation more than Delphi. Takeshita (2023) suggests a variety of possible uses for such Moral AI, some of which would assist users in moral deliberation and help them make more appropriate moral decisions than those not used. In the future, we will investigate what outputs can better support users’ moral deliberation.
Next, regarding the comparison between experts and non-experts, it was found that both MEC and Delphi were not helpful for experts, as we hypothesized. However, our hypothesis that MEC is helpful for non-experts was not supported because, as already mentioned, MEC does not provide reasons or explanations. On the other hand, one of the annotators stated that MEC is more likely to guide the user’s moral judgment more appropriately because it refers to multiple theories. This result was expected, because the output of the MEC algorithm is more appropriate than if it were based on only a single theory since it maximizes the expected choice worthiness. Thus, in some cases, MEC may be useful to non-experts. We will explore in which cases MEC may be helpful to non-experts.
## 8 Conclusion
In this paper, we implemented and evaluated Maximizing Expected Choiceworthiness algorithm. This algorithm aggregates the output of models based on multiple normative theories to generate a morally correct output. Furthermore, this model produces appropriate outputs under moral uncertainty when the morally correct theory is unknown. Experimental results show that MEC is more compatible with commonsense morality than a single model and performs as well as Delphi, an existing method. However, this model does not provide enough reasons or explanations, and we plan to create models that provide more reasons or explanations in the future.
## Limitations
The dataset based on each theory included in the ETHICS dataset used in this study does not precisely match the evaluation based on each theory discussed in Section 5.1. Therefore, the model created in this study may not be ideally based on each theory. Moreover, the scale of the experiments is small. In Experiment 2, where the model is evaluated by asking Ph.D. students, only a maximum of 16 pairs of sentences are used. Furthermore, we did not evaluate our model in complex cases such as moral dilemmas.
## Ethical and Social Implications
There is no guarantee that the output of the model implemented in this study is morally correct. Continued refinement of this model will yield more appropriate outputs, but the current model is inadequate. We also do not recommend that users rely on the output of our model (or its improved versions) to make decisions. Our model is only a decision support tool, not a substitute for user decision-making.
Our model can contribute to the AI safety. Moreover, as ethical theory developed and models based on them can be created, MEC algorithm will make AI behavior more ethically appropriate.
## Acknowledgement
This work was supported by JSPS KAKENHI Grant Number JP22J21160. We would like to thank the anonymous reviewers for their valuable comments.
## References
- Allen et al. [2005] Colin Allen, Iva Smit, and Wendell Wallach. Artificial morality: Top-down, bottom-up, and hybrid approaches. Ethics and information technology, 7:149–155, 2005.
- Anderson and Anderson [2018] Michael Anderson and Susan Leigh Anderson. GenEth: A general ethical dilemma analyzer. Paladyn, Journal of Behavioral Robotics, 9(1):337–357, 2018.
- Anderson et al. [2006] Michael Anderson, Susan Leigh Anderson, and Chris Armen. MedEthEx: a prototype medical ethics advisor. In Proceedings of the National Conference on Artificial Intelligence, volume 21, page 1759. Menlo Park, CA; Cambridge, MA; London; AAAI Press; MIT Press; 1999, 2006.
- Awad et al. [2018] Edmond Awad, Sohan Dsouza, Richard Kim, Jonathan Schulz, Joseph Henrich, Azim Shariff, Jean-François Bonnefon, and Iyad Rahwan. The moral machine experiment. Nature, 563(7729):59–64, 2018.
- Bang et al. [2022] Yejin Bang, Nayeon Lee, Tiezheng Yu, Leila Khalatbari, Yan Xu, Samuel Cahyawijaya, Dan Su, Bryan Wilie, Romain Barraud, Elham J. Barezi, Andrea Madotto, Hayden Kee, and Pascale Fung. Towards answering open-ended ethical quandary questions. arXiv preprint arXiv:2205.05989, 2022.
- Bogosian [2017] Kyle Bogosian. Implementation of moral uncertainty in intelligent machines. Minds and Machines, 27:591–608, 2017.
- Bommasani et al. [2021] Rishi Bommasani, Drew A Hudson, Ehsan Adeli, Russ Altman, Simran Arora, Sydney von Arx, Michael S Bernstein, Jeannette Bohg, Antoine Bosselut, Emma Brunskill, et al. On the opportunities and risks of foundation models. arXiv preprint arXiv:2108.07258, 2021.
- Bourget and Chalmers [ms] David Bourget and David Chalmers. Philosophers on philosophy: The philpapers 2020 survey, ms.
- Braun et al. [2021] Matthias Braun, Patrik Hummel, Susanne Beck, and Peter Dabrock. Primer on an ethics of AI-based decision support systems in the clinic. Journal of Medical Ethics, 47(12):e3–e3, 2021.
- Brown et al. [2020] Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners. Advances in neural information processing systems, 33:1877–1901, 2020.
- Cambria et al. [2022] Erik Cambria, Qian Liu, Sergio Decherchi, Frank Xing, and Kenneth Kwok. SenticNet 7: A commonsense-based neurosymbolic AI framework for explainable sentiment analysis. In Proceedings of the Thirteenth Language Resources and Evaluation Conference, pages 3829–3839, Marseille, France, June 2022. European Language Resources Association.
- Clark et al. [2020] Kevin Clark, Minh-Thang Luong, Quoc V. Le, and Christopher D. Manning. Electra: Pre-training text encoders as discriminators rather than generators. In International Conference on Learning Representations, 2020.
- Devlin et al. [2019] Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. BERT: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pages 4171–4186. Association for Computational Linguistics, 2019.
- Emelin et al. [2021] Denis Emelin, Ronan Le Bras, Jena D. Hwang, Maxwell Forbes, and Yejin Choi. Moral Stories: Situated reasoning about norms, intents, actions, and their consequences. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pages 698–718. Association for Computational Linguistics, 2021.
- Forbes et al. [2020] Maxwell Forbes, Jena D. Hwang, Vered Shwartz, Maarten Sap, and Yejin Choi. Social chemistry 101: Learning to reason about social and moral norms. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 653–670. Association for Computational Linguistics, 2020.
- Ganguli et al. [2022] Deep Ganguli, Liane Lovitt, Jackson Kernion, Amanda Askell, Yuntao Bai, Saurav Kadavath, Ben Mann, Ethan Perez, Nicholas Schiefer, Kamal Ndousse, et al. Red teaming language models to reduce harms: Methods, scaling behaviors, and lessons learned. arXiv preprint arXiv:2209.07858, 2022.
- Gehman et al. [2020] Samuel Gehman, Suchin Gururangan, Maarten Sap, Yejin Choi, and Noah A. Smith. RealToxicityPrompts: Evaluating neural toxic degeneration in language models. In Findings of the Association for Computational Linguistics: EMNLP 2020, pages 3356–3369, Online, November 2020. Association for Computational Linguistics.
- He et al. [2021] Pengcheng He, Jianfeng Gao, and Weizhu Chen. Debertav3: Improving deberta using ELECTRA-style pre-training with gradient-disentangled embedding sharing. arXiv preprint arXiv:2111.09543, 2021.
- Hendrycks et al. [2021] Dan Hendrycks, Collin Burns, Steven Basart, Andrew Critch, Jerry Li, Dawn Song, and Jacob Steinhardt. Aligning AI with shared human values. In International Conference on Learning Representations, 2021.
- Jiang et al. [2021] Liwei Jiang, Jena D. Hwang, Chandra Bhagavatula, Ronan Le Bras, Jenny Liang, Jesse Dodge, Keisuke Sakaguchi, Maxwell Forbes, Jon Borchardt, Saadia Gabriel, Yulia Tsvetkov, Oren Etzioni, Maarten Sap, Regina Rini, and Yejin Choi. Can machines learn morality? the Delphi experiment. arXiv preprint arXiv:2110.07574, 2021.
- Jin et al. [2022] Zhijing Jin, Sydney Levine, Fernando Gonzalez Adauto, Ojasv Kamal, Maarten Sap, Mrinmaya Sachan, Rada Mihalcea, Josh Tenenbaum, and Bernhard Schölkopf. When to make exceptions: Exploring language models as accounts of human moral judgment. In S. Koyejo, S. Mohamed, A. Agarwal, D. Belgrave, K. Cho, and A. Oh, editors, Advances in Neural Information Processing Systems, volume 35, pages 28458–28473. Curran Associates, Inc., 2022.
- Lan et al. [2020] Zhenzhong Lan, Mingda Chen, Sebastian Goodman, Kevin Gimpel, Piyush Sharma, and Radu Soricut. ALBERT: A lite BERT for self-supervised learning of language representations. In International Conference on Learning Representations, 2020.
- Liu et al. [2019] Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, and Veselin Stoyanov. RoBERTa: A robustly optimized BERT pretraining approach. Computing Research Repository, arXiv:1907.11692, 2019.
- Loshchilov and Hutter [2019] Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization. In International Conference on Learning Representations, 2019.
- Lourie et al. [2021] Nicholas Lourie, Ronan Le Bras, Chandra Bhagavatula, and Yejin Choi. Unicorn on rainbow: A universal commonsense reasoning model on a new multitask benchmark. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 35, pages 13480–13488, 2021.
- MacAskill et al. [2020] Michael MacAskill, Krister Bykvist, and Toby Ord. Moral uncertainty. Oxford University Press, 2020.
- Paszke et al. [2019] Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer, James Bradbury, Gregory Chanan, Trevor Killeen, Zeming Lin, Natalia Gimelshein, Luca Antiga, Alban Desmaison, Andreas Kopf, Edward Yang, Zachary DeVito, Martin Raison, Alykhan Tejani, Sasank Chilamkurthy, Benoit Steiner, Lu Fang, Junjie Bai, and Soumith Chintala. Pytorch: An imperative style, high-performance deep learning library. In H. Wallach, H. Larochelle, A. Beygelzimer, F. d'Alché-Buc, E. Fox, and R. Garnett, editors, Advances in Neural Information Processing Systems, volume 32. Curran Associates, Inc., 2019.
- Raffel et al. [2020] Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J. Liu. Exploring the limits of transfer learning with a unified text-to-text transformer. Journal of Machine Learning Research, 21(140):1–67, 2020.
- Rzepka and Araki [2017] Rafal Rzepka and Kenji Araki. What people say? web-based casuistry for artificial morality experiments. In Artificial General Intelligence, 2017.
- Takeshita [2023] Masashi Takeshita. A defense of moral AI enhancement (in Japansese). Applied Ethics, 14:3–20, 2023.
- Tolmeijer et al. [2020] Suzanne Tolmeijer, Markus Kneer, Cristina Sarasua, Markus Christen, and Abraham Bernstein. Implementations in machine ethics: A survey. ACM Computing Surveys (CSUR), 53(6):1–38, 2020.
- Wallach and Allen [2008] Wendell Wallach and Colin Allen. Moral machines: Teaching robots right from wrong. Oxford University Press, 2008.