# CausalVLR: A Toolbox and Benchmark for Visual-Linguistic Causal Reasoning
**Authors**:
- Yang Liu (Sun Yat-sen University)
- Weixing Chen (Sun Yat-sen University)
- Guanbin Li (Sun Yat-sen University)
- Liang Lin (Sun Yat-sen University)
## Abstract
We present CausalVLR (Causal Visual-Linguistic Reasoning), an open-source toolbox containing a rich set of state-of-the-art causal relation discovery and causal inference methods for various visual-linguistic reasoning tasks, such as VQA, image/video captioning, medical report generation, model generalization and robustness, etc. These methods have been included in the toolbox with PyTorch implementations under NVIDIA computing system. It not only includes training and inference codes, but also provides model weights. We believe this toolbox is by far the most complete visual-linguitic causal reasoning toolbox. We wish that the toolbox and benchmark could serve the growing research community by providing a flexible toolkit to re-implement existing methods and develop their own new causal reasoning methods. Code and models are available at https://github.com/HCPLab-SYSU/CausalVLR. The project is under active development by HCP-Lab https://www.sysu-hcp.net ’s contributors and we will keep this document updated.
## 1 Introduction
The emergence of vast amounts of heterogeneous multi-modal data, including images [2; 9], videos [13; 11; 10; 15; 28], languages [8; 7; 25], audios [3], and multi-sensor [12; 14; 30; 18; 23; 5] data, has led to the application of large language models (LLMs) such as ChatGPT [22] and ChatGLM [29] in various vision and language tasks, showing promising performance. However, current LLMs heavily rely on fitting extensive knowledge distributions, often capturing spurious correlations across different modalities. Consequently, they struggle to learn reliable chain-of-thought (COT) [24] that reflects essential causal relations within multi-modal knowledge, limiting their generalization and cognitive abilities. Fortunately, causal inference [19; 20; 16; 17] ] provides a promising alternative for learning robust and reliable cross-modal models due to its promising ability to achieve robust representation and model learning with good cognitive ability. For a detailed review of causal inference and visual representation learning, please refer to our review paper [16].
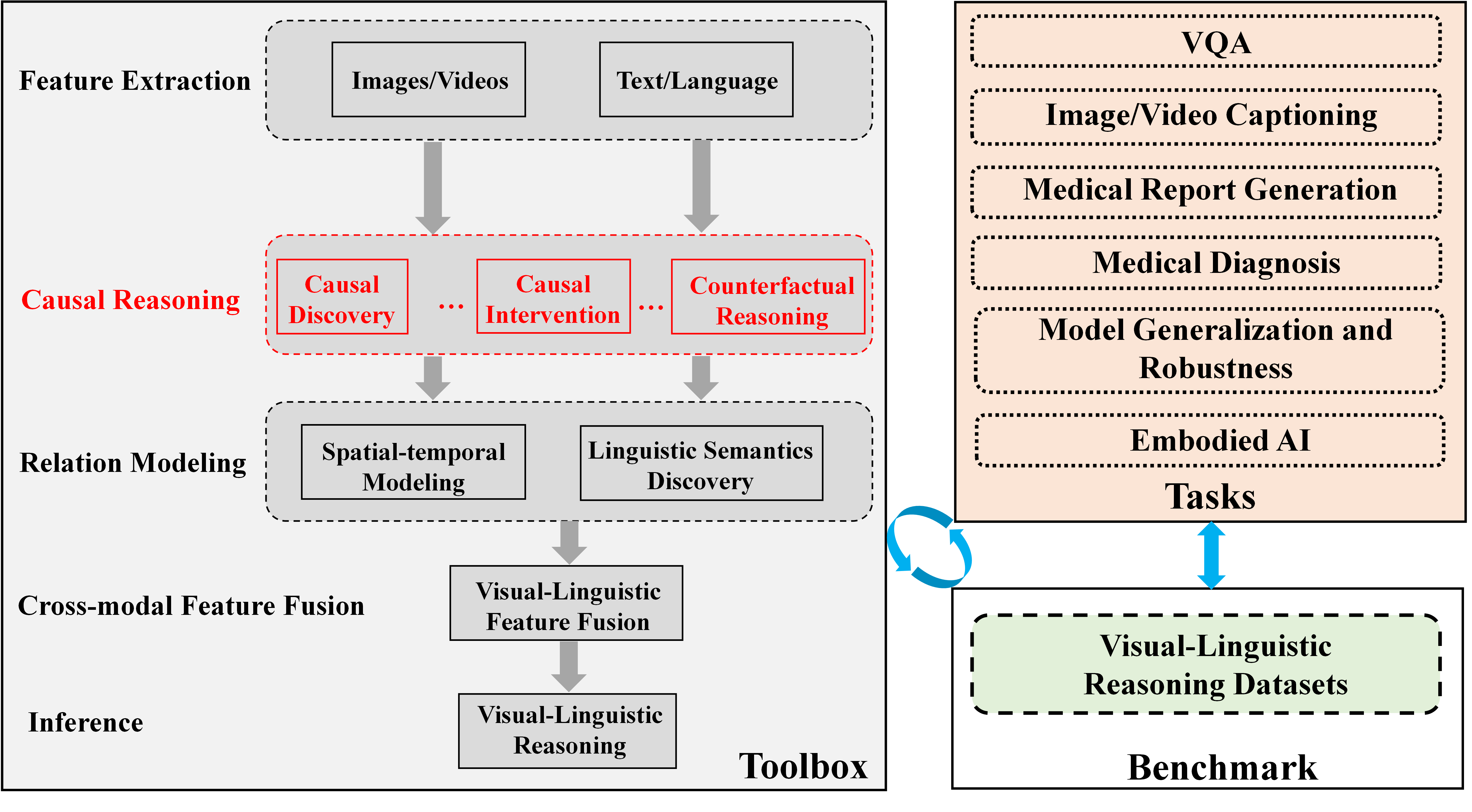
Visual-linguistic reasoning endeavors to comprehend both visual and linguistic content while performing various reasoning tasks, such as visual question answering (VQA), visual dialog, image/video captioning, and medical report generation. However, to date, there has been no comprehensive open-source framework available for causality-aware visual-linguistic reasoning. With the aim of offering a high-quality toolbox and a unified benchmark, we have developed CausalVLR: a pytorch-based open-source toolbox and benchmark designed specifically for visual-linguistic causal reasoning. Figure 1 provides an overview of CausalVLR.
CausalVLR offers several key features: (1) Modular design: We decompose the visual-linguistic reasoning framework into different components, allowing for the easy construction of customized visual-linguistic reasoning frameworks by combining various modules. (2) Support for multiple frameworks out of the box: The toolbox provides support for popular and contemporary visual-linguistic reasoning frameworks. (3) High efficiency: All basic modules and operations are executed on GPUs to ensure optimal performance. (4) State of the art: The toolbox is derived from the codebase developed by the experienced HCP-Lab team, specializing in causal inference and visual-linguistic reasoning, and continuous improvements are made. In addition to introducing the codebase and benchmark results, we also share our experiences and best practices for visual-linguistic causal reasoning. Ablation experiments involving hyperparameters, architectures, and training strategies are conducted and discussed. Our aim is to contribute to future research and facilitate comparisons between different methods. The remaining sections are organized as follows: First, we present the various supported methods and highlight important features of CausalVLR. Next, we present the benchmark results. Finally, we showcase representative studies on selected baselines. Table 1 provides a summary of representative algorithms from the HCP-Lab team.
<details>
<summary>extracted/5291756/Fig1.png Details</summary>
### Visual Description
\n
## Diagram: Visual-Linguistic Reasoning Framework
### Overview
The image is a technical diagram illustrating a conceptual framework for a visual-linguistic reasoning system. It is divided into two primary sections: a **Toolbox** on the left, which outlines a sequential processing pipeline, and a **Benchmark** section on the right, which lists application tasks and datasets. The diagram uses boxes, arrows, and color-coding to denote components, data flow, and relationships.
### Components/Axes
The diagram is structured into two main vertical panels.
**Left Panel: Toolbox**
This panel is a vertical flowchart with labeled stages on the left and corresponding processing blocks on the right. The stages are:
1. **Feature Extraction** (top): Contains two input blocks: "Images/Videos" and "Text/Language".
2. **Causal Reasoning** (highlighted in red): Contains three sub-components in red-outlined boxes: "Causal Discovery", "Causal Intervention", and "Counterfactual Reasoning". Ellipses (`...`) are placed between these boxes.
3. **Relation Modeling**: Contains two blocks: "Spatial-temporal Modeling" and "Linguistic Semantics Discovery".
4. **Cross-modal Feature Fusion**: Contains a single block: "Visual-Linguistic Feature Fusion".
5. **Inference** (bottom): Contains a single block: "Visual-Linguistic Reasoning".
Thick grey arrows point downward from each stage to the next, indicating a sequential processing pipeline from feature extraction to final inference.
**Right Panel: Benchmark**
This panel is divided into two stacked boxes:
1. **Tasks** (top, peach-colored background): A list of six application domains in dashed-outline boxes:
* VQA
* Image/Video Captioning
* Medical Report Generation
* Medical Diagnosis
* Model Generalization and Robustness
* Embodied AI
2. **Visual-Linguistic Reasoning Datasets** (bottom, light green background): A single dashed-outline box containing the text "Visual-Linguistic Reasoning Datasets".
**Connections Between Panels:**
* A blue, double-headed vertical arrow connects the "Tasks" box and the "Visual-Linguistic Reasoning Datasets" box, indicating a bidirectional relationship (e.g., tasks define dataset needs, datasets enable task evaluation).
* A blue, circular arrow (↻) connects the right side of the "Toolbox" panel to the left side of the "Benchmark" panel, suggesting an iterative or feedback loop between the reasoning system and its evaluation.
### Detailed Analysis
The diagram explicitly details the following textual elements and their spatial relationships:
* **Toolbox Flow:** The pipeline is strictly linear from top to bottom: Feature Extraction → Causal Reasoning → Relation Modeling → Cross-modal Feature Fusion → Inference.
* **Causal Reasoning Emphasis:** The "Causal Reasoning" stage and its three sub-components are uniquely highlighted with red text and red box outlines, drawing specific attention to this part of the process.
* **Task List:** The six tasks under "Benchmark" are presented as a vertical list, suggesting they are key application areas for the visual-linguistic reasoning system.
* **Data Flow:** The primary data flow is downward through the Toolbox. The circular arrow introduces a secondary, cyclical flow between the entire Toolbox and the Benchmark suite.
### Key Observations
1. **Highlighted Causal Reasoning:** The use of red for the "Causal Reasoning" stage is the most prominent visual cue, indicating it is a core or novel component of this framework.
2. **Bidirectional Benchmark Link:** The double-headed arrow between Tasks and Datasets is significant, implying that benchmark development is not a one-way street; tasks inform dataset creation, and new datasets can enable or redefine tasks.
3. **Holistic Evaluation Loop:** The circular arrow connecting the Toolbox to the Benchmark suggests the system is designed for iterative improvement, where performance on benchmark tasks feeds back into refining the reasoning toolbox.
4. **Cross-Modal Focus:** The framework explicitly names "Visual-Linguistic" as the target modality for fusion and reasoning, and the tasks (VQA, Captioning) align with this focus.
### Interpretation
This diagram outlines a comprehensive research and development framework for advanced AI systems that integrate visual and linguistic understanding. It moves beyond simple pattern recognition by incorporating a dedicated **Causal Reasoning** module, which suggests an aim to build models that can understand "why" and "what if," not just "what."
The structure implies a hypothesis: robust visual-linguistic reasoning requires a pipeline that extracts features, applies causal logic, models relationships across space/time and language, fuses these modalities, and then performs high-level inference. The **Benchmark** section grounds this theoretical toolbox in practical applications, from medical diagnosis to embodied AI, showing the framework's intended scope.
The iterative loop between the Toolbox and Benchmark is critical. It represents the scientific cycle of building systems, testing them against standardized challenges (datasets), and using the results to improve the systems. This framework is likely intended to guide the creation of more generalizable, robust, and causally-aware multimodal AI models.
</details>
Figure 1: Overview of CausalVLR. CausalVLR is a python open-source framework for causal relation discovery, causal inference that implements state-of-the-art causal learning algorithms for various visual-linguistic reasoning tasks, such as VQA, image/video captioning, medical report generation, medical diagnosis, model generalization and robustness, etc.
## 2 Algorithms
This section provides a summary of three representative state-of-the-art (SOTA) algorithms for visual question answering (VQA) and medical report generation tasks. All algorithms have been implemented using PyTorch. The CausalVLR library will be continuously updated in the coming years. In this section, we will provide a concise introduction to the selected algorithms.
Table 1: Representative visual-linguistic causal reasoning algorithms in CausalVLR.
| Task | Algorithm | Highlight | Pytorch |
| --- | --- | --- | --- |
| Causal CoT | CausalGPT [21] | Causality-aware CoT | Yes |
| VQA | CMCIR [8; 6] | Causal front-door and back-door interventions | Yes |
| VQA | VCSR [25] | Visual causal scene discovery | Yes |
| Image Captioning | AAAI2023 [26] | Knowledge consensus | Yes |
| Medical Report Generation | VLCI [1] | Implicit visual causal intervention | Yes |
| Medical Diagnosis | TPAMI2023 [4] | Causality-aware medical diagnosis | Yes |
| Model Generalization and Robustness | CVPR2023 [27] | Counterfactual Fine-tuning | Yes |
### 2.1 CausalGPT
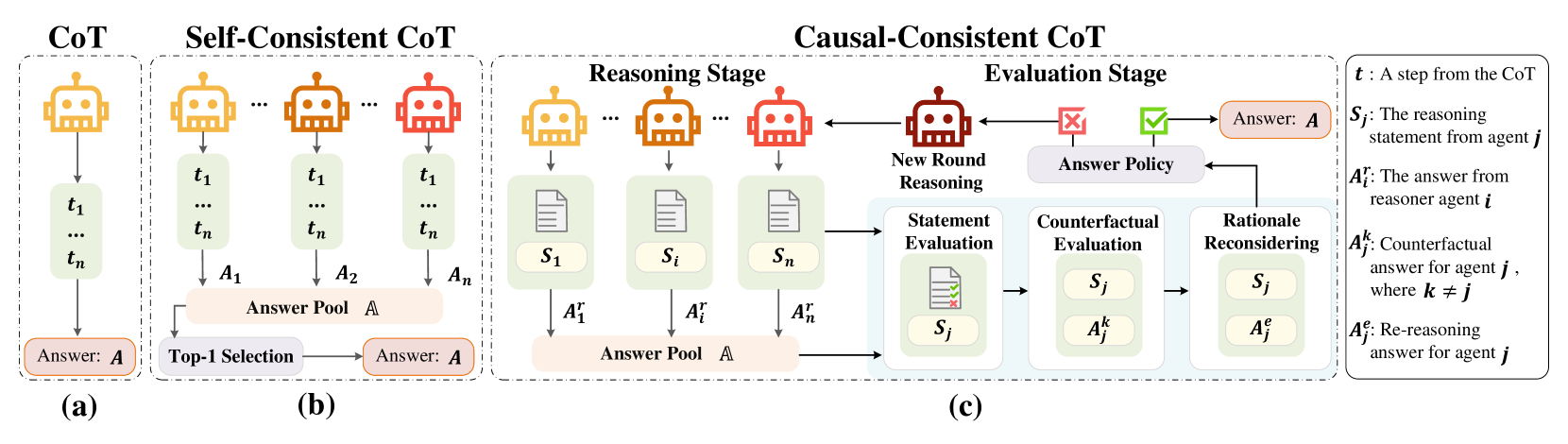
Caco-CoT [21]. The framework of causal-consistency CoT (CaCo-CoT is shown in Figure 2.The contribution of Caco-CoT is listed as follows:
<details>
<summary>x1.png Details</summary>
### Visual Description
## Diagram: Comparison of Chain-of-Thought (CoT) Reasoning Methods
### Overview
The image is a technical diagram illustrating and comparing three distinct methodologies for generating answers using Chain-of-Thought (CoT) reasoning in AI systems. The diagram is divided into three main panels, labeled (a), (b), and (c), each representing a different approach: standard CoT, Self-Consistent CoT, and Causal-Consistent CoT. A legend on the far right defines the symbolic notation used throughout the diagram.
### Components/Axes
The diagram is structured horizontally into three primary sections, each enclosed in a dashed box.
1. **Panel (a) - CoT (Leftmost):**
* **Header:** "CoT"
* **Components:** A single yellow robot icon representing a reasoning agent. An arrow points down to a vertical list of steps labeled `t₁`, `...`, `tₙ`. A final arrow points to a box labeled "Answer: **A**".
2. **Panel (b) - Self-Consistent CoT (Center-Left):**
* **Header:** "Self-Consistent CoT"
* **Components:** Multiple robot icons (two yellow, one orange, one red) representing multiple reasoning agents. Each agent generates its own sequence of steps (`t₁ ... tₙ`) leading to individual answers (`A₁`, `A₂`, `...`, `Aₙ`). These answers feed into a central "Answer Pool **A**". An arrow from the pool points to a "Top-1 Selection" process, which outputs the final "Answer: **A**".
3. **Panel (c) - Causal-Consistent CoT (Center-Right to Right):**
* **Header:** "Causal-Consistent CoT"
* **Sub-sections:** This panel is further divided into a "Reasoning Stage" and an "Evaluation Stage".
* **Reasoning Stage:**
* Multiple robot icons (yellow, orange, red) generate reasoning statements (`S₁`, `...`, `Sᵢ`, `...`, `Sₙ`) and corresponding answers (`A₁ʳ`, `...`, `Aᵢʳ`, `...`, `Aₙʳ`).
* These answers populate an "Answer Pool **A**".
* **Evaluation Stage:**
* A red robot icon labeled "New Round Reasoning" is central.
* A flowchart processes statements and answers from the pool:
1. **Statement Evaluation:** Evaluates a statement `Sⱼ` (shown with a document icon containing a green check and red cross).
2. **Counterfactual Evaluation:** Considers the statement `Sⱼ` alongside a counterfactual answer `Aⱼᵏ` (where `k ≠ j`).
3. **Rationale Reconsidering:** Reconsiders the statement `Sⱼ` with a re-reasoning answer `Aⱼᵉ`.
* The output of this evaluation feeds into an "Answer Policy" (shown with a red cross and green checkmark icon).
* The "Answer Policy" determines the final "Answer: **A**" and can trigger a "New Round Reasoning" loop back to the reasoning stage.
4. **Legend (Far Right):**
* A box containing definitions for the symbolic notation:
* `t`: A step from the CoT
* `Sⱼ`: The reasoning statement from agent `j`
* `Aᵢʳ`: The answer from reasoner agent `i`
* `Aⱼᵏ`: Counterfactual answer for agent `j`, where `k ≠ j`
* `Aⱼᵉ`: Re-reasoning answer for agent `j`
### Detailed Analysis
The diagram visually maps the flow of information and decision-making in each method.
* **CoT (a):** A simple, linear pipeline. One agent performs a sequence of reasoning steps (`t₁` to `tₙ`) to produce a single answer `A`.
* **Self-Consistent CoT (b):** Introduces parallelism and aggregation. Multiple independent agents (`A₁` through `Aₙ`) generate diverse reasoning paths and answers. These are collected in a pool, and a "Top-1 Selection" mechanism (e.g., majority vote) chooses the final answer `A`. This method aims for robustness through diversity.
* **Causal-Consistent CoT (c):** Introduces a complex, iterative evaluation loop.
* **Reasoning Stage:** Similar to Self-Consistent, multiple agents generate statements (`S`) and answers (`Aʳ`).
* **Evaluation Stage:** This is the core innovation. It doesn't just select an answer; it critically evaluates the *reasoning statements* (`Sⱼ`) themselves.
* **Statement Evaluation:** Assesses the validity of a statement.
* **Counterfactual Evaluation:** Tests the statement against alternative, counterfactual answers (`Aⱼᵏ`), probing for causal consistency.
* **Rationale Reconsidering:** Allows for re-reasoning (`Aⱼᵉ`) based on the evaluation.
* The "Answer Policy" uses the results of this multi-faceted evaluation to either finalize an answer or trigger a new round of reasoning, creating a feedback loop for refinement.
### Key Observations
1. **Increasing Complexity:** The methods progress from a single linear path (CoT), to parallel paths with selection (Self-Consistent), to parallel paths with deep, iterative evaluation and feedback (Causal-Consistent).
2. **Shift from Answer-Centric to Reasoning-Centric:** While CoT and Self-Consistent CoT focus on generating and selecting final *answers* (`A`), Causal-Consistent CoT places primary emphasis on evaluating the underlying *reasoning statements* (`Sⱼ`).
3. **Introduction of Counterfactuals:** The Causal-Consistent method uniquely incorporates "Counterfactual Evaluation" (`Aⱼᵏ`), explicitly testing reasoning against alternative scenarios to ensure causal robustness.
4. **Feedback Loop:** Only the Causal-Consistent method features a cyclical process ("New Round Reasoning"), allowing the system to iteratively improve its reasoning based on internal evaluation.
5. **Color Coding:** Robots are colored yellow, orange, and red, likely to visually distinguish different agents or reasoning instances, though the specific meaning of each color is not defined in the legend.
### Interpretation
This diagram illustrates an evolution in AI reasoning strategies aimed at improving reliability and robustness.
* **CoT** represents the foundational approach of breaking down problems into steps.
* **Self-Consistent CoT** addresses the brittleness of a single reasoning path by leveraging multiple attempts and consensus, akin to "wisdom of the crowd" for a single model.
* **Causal-Consistent CoT** proposes a more sophisticated, self-critical framework. It moves beyond aggregating outputs to actively *auditing the reasoning process itself*. By evaluating statements, testing them against counterfactuals, and allowing for re-reasoning, it seeks to ensure that the final answer is not just statistically likely but *causally sound* and logically consistent. The "Answer Policy" acts as a gatekeeper informed by this deep audit.
The progression suggests a research direction focused on building AI systems that can internally validate and correct their own reasoning chains, moving towards more trustworthy and explainable AI. The complexity of the Causal-Consistent method implies a trade-off between computational cost and the robustness of the final answer.
</details>
Figure 2: Comparison between existing approaches and causal-consistency CoT (CaCo-CoT). In CaCo-CoT, reasoner agents and an evaluator agent cooperate to facilitate a causally consistent reasoning process, thereby minimizing factual and inferential errors.
To ensure reasoning faithfulness of the solutions by inspecting causal consistency, an evaluator is introduced. Initially, the evaluator is prompted to examine the statements in the solution step by step while considering the whole reasoning structure, which is in a non-causal direction. For further causal consistency assessment, the evaluator then moves on to apply a counterfactual answer to the original question and look for any contradiction therein. Finally, it turns out a modified answer after its reconsideration. The group of agents cooperates for a consensual answer if the most frequent solution is accepted by the evaluator. In the tasks of science question answering and commonsense reasoning, we demonstrate that our causal-consistency framework outperforms the existing approaches through a series of experiments and comparisons.
The official codes and data are available at https://github.com/HCPLab-SYSU/CausalVLR.
### 2.2 VQA
CMCIR [8]. The contribution of CMCIR is listed as follows:
- We propose a causality-aware event-level visual question answering framework named Cross-Modal Causal RelatIonal Reasoning (CMCIR), to discover true causal structures via causal intervention on the integration of visual and linguistic modalities and achieve robust event-level visual question answering performance. To the best of our knowledge, we are the first to discover cross-modal causal structures for the event-level visual question answering task.
- We introduce a linguistic back-door causal intervention module guided by linguistic semantic relations to mitigate the spurious biases and uncover the causal dependencies within the linguistic modality. To disentangle the visual spurious correlations, we propose a Local-Global Causal Attention Module (LGCAM) that aggregates the local and global visual representations by front-door causal intervention.
- We construct a Spatial-Temporal Transformer (STT) that models the multi-modal co-occurrence interactions between the visual and linguistic knowledge, to discover the fine-grained interactions among linguistic semantics, spatial, and temporal representations.
- To adaptively fuse the causality-aware visual and linguistic features, we introduce a Visual-Linguistic Feature Fusion (VLFF) module that leverages the hierarchical linguistic semantic relations to learn the global semantic-aware visual-linguistic features.
- Extensive experiments on SUTD-TrafficQA, TGIF-QA, MSVD-QA, and MSRVTT-QA datasets show the effectiveness of our CMCIR for discovering visuallinguistic causal structures and achieving promising event-level visual question answering performance.
The official codes and data are available at https://github.com/HCPLab-SYSU/CMCIR.
VCSR [25]. The contribution of CMCIR is listed as follows:
- We propose the Visual Causal Scene Refinement (VCSR) framework, to explicitly discover true causal visual scenes from the perspective of causal front-door intervention. To the best of our knowledge, we are the first to discover visual causal scenes for video question answering.
- We build the Causal Scene Separator (CSS) module that learns to discover a collection of visual causal and non-causal scenes based on the visual-linguistic causal relevance and estimates the causal effect of the scene-separating intervention in a contrastive learning manner.
- We introduce the Question-Guided Refiner (QGR) module that refines consecutive video frames guided by the question semantics to obtain more representative segment features for causal front-door intervention.
The official codes and data are available at https://github.com/HCPLab-SYSU/CausalVLR.
### 2.3 Medical Report Generation
VLCI [1]. The contribution of CMCIR is listed as follows:
- To implicitly mitigate cross-modal confounders and discover the true cross-modal causality, we propose visual-linguistic causal front-door intervention modules VDM and LDM. The VDM aims to disentangle the region-based features from images in the encoder, and the LDM aims to eliminate the spurious correlations caused by the visual-linguistic embedding.
- To alleviate the problem of unpaired data when pretraining visual-linguistic RRG data, we combine the PLM and MIM for cross-modal pre-training in various data situations (e.g., unpaired, single modality), which is efficient and easy to implement.
- We propose a lightweight Visual-Linguistic Causal Intervention (VLCI) framework for RRG, which introduces mediators without additional knowledge, to implicitly deconfound the visual-linguistic confounder by causal front-door intervention. Experimental results show that VLCI achieves state-of-the-art performance on two datasets IU-Xray and MIMIC-CXR.
The official codes and data are available at https://github.com/WissingChen/VLCI.
## 3 Conclusions and future works
This paper presents CausalVLR, an open-source toolbox that offers a comprehensive collection of state-of-the-art methods for causal relation discovery and causal inference in visual-linguistic reasoning tasks. We highlight the contributions of representative state-of-the-art visual-linguistic causal reasoning methods. CausalVLR aims to enhance the development of causal inference in the visual-linguistic reasoning domain by providing easily accessible open-source implementations, benchmarking models, and computational resources. We plan to incorporate additional state-of-the-art algorithms and benchmarks in future updates.
## References
- [1] Weixing Chen, Yang Liu, Ce Wang, Guanbin Li, Jiarui Zhu, and Liang Lin. Visual-linguistic causal intervention for radiology report generation. arXiv preprint arXiv:2303.09117, 2023.
- [2] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 770–778, 2016.
- [3] Haoyuan Lan, Yang Liu, and Liang Lin. Audio-visual contrastive learning for self-supervised action recognition. arXiv preprint arXiv:2204.13386, 2022.
- [4] Junfan Lin, Keze Wang, Ziliang Chen, Xiaodan Liang, and Liang Lin. Towards causality-aware inferring: A sequential discriminative approach for medical diagnosis. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2023.
- [5] Junfan Lin, Yuying Zhu, Lingbo Liu, Yang Liu, Guanbin Li, and Liang Lin. Denselight: Efficient control for large-scale traffic signals with dense feedback. arXiv preprint arXiv:2306.07553, 2023.
- [6] Yang Liu, Guanbin Li, and Liang Lin. Cross-modal causal relational reasoning for event-level visual question answering. arXiv preprint arXiv:2207.12647, 2022.
- [7] Yang Liu, Guanbin Li, and Liang Lin. Causality-aware visual scene discovery for cross-modal question reasoning. arXiv preprint arXiv:2304.08083, 2023.
- [8] Yang Liu, Guanbin Li, and Liang Lin. Cross-modal causal relational reasoning for event-level visual question answering. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2023.
- [9] Yang Liu, Jing Li, ZhaoYang Lu, Tao Yang, and ZiJian Liu. Combining multiple features for cross-domain face sketch recognition. In Biometric Recognition: 11th Chinese Conference, CCBR 2016, Chengdu, China, October 14-16, 2016, Proceedings 11, pages 139–146. Springer, 2016.
- [10] Yang Liu, Zhaoyang Lu, Jing Li, and Tao Yang. Hierarchically learned view-invariant representations for cross-view action recognition. IEEE Transactions on Circuits and Systems for Video Technology, 29(8):2416–2430, 2018.
- [11] Yang Liu, Zhaoyang Lu, Jing Li, Tao Yang, and Chao Yao. Global temporal representation based cnns for infrared action recognition. IEEE Signal Processing Letters, 25(6):848–852, 2018.
- [12] Yang Liu, Zhaoyang Lu, Jing Li, Tao Yang, and Chao Yao. Deep image-to-video adaptation and fusion networks for action recognition. IEEE Transactions on Image Processing, 29:3168–3182, 2019.
- [13] Yang Liu, Zhaoyang Lu, Jing Li, Chao Yao, and Yanzi Deng. Transferable feature representation for visible-to-infrared cross-dataset human action recognition. Complexity, 2018:1–20, 2018.
- [14] Yang Liu, Keze Wang, Guanbin Li, and Liang Lin. Semantics-aware adaptive knowledge distillation for sensor-to-vision action recognition. IEEE Transactions on Image Processing, 30:5573–5588, 2021.
- [15] Yang Liu, Keze Wang, Lingbo Liu, Haoyuan Lan, and Liang Lin. Tcgl: Temporal contrastive graph for self-supervised video representation learning. IEEE Transactions on Image Processing, 31:1978–1993, 2022.
- [16] Yang Liu, Yu-Shen Wei, Hong Yan, Guan-Bin Li, and Liang Lin. Causal reasoning meets visual representation learning: A prospective study. Machine Intelligence Research, pages 1–27, 2022.
- [17] Yang Liu, Yushen Wei, Hong Yan, Guanbin Li, and Liang Lin. Causal reasoning with spatial-temporal representation learning: A prospective study. arXiv preprint arXiv:2204.12037, 2022.
- [18] Jianyuan Ni, Raunak Sarbajna, Yang Liu, Anne HH Ngu, and Yan Yan. Cross-modal knowledge distillation for vision-to-sensor action recognition. In ICASSP 2022-2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 4448–4452. IEEE, 2022.
- [19] Judea Pearl. Causality. Cambridge university press, 2009.
- [20] Bernhard Schölkopf, Francesco Locatello, Stefan Bauer, Nan Rosemary Ke, Nal Kalchbrenner, Anirudh Goyal, and Yoshua Bengio. Toward causal representation learning. Proceedings of the IEEE, 109(5):612–634, 2021.
- [21] Ziyi Tang, Ruilin Wang, Weixing Chen, Keze Wang, Yang Liu, Tianshui Chen, and Liang Lin. Towards causalgpt: A multi-agent approach for faithful knowledge reasoning via promoting causal consistency in llms. arXiv preprint arXiv:2308.11914, 2023.
- [22] Eva AM Van Dis, Johan Bollen, Willem Zuidema, Robert van Rooij, and Claudi L Bockting. Chatgpt: five priorities for research. Nature, 614(7947):224–226, 2023.
- [23] Kuo Wang, LingBo Liu, Yang Liu, GuanBin Li, Fan Zhou, and Liang Lin. Urban regional function guided traffic flow prediction. Information Sciences, 634:308–320, 2023.
- [24] Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed H Chi, Quoc V Le, Denny Zhou, et al. Chain-of-thought prompting elicits reasoning in large language models. In NeurIPS Systems, 2022.
- [25] Yushen Wei, Yang Liu, Hong Yan, Guanbin Li, and Liang Lin. Visual causal scene refinement for video question answering. MM ’23, page 377–386, New York, NY, USA, 2023. Association for Computing Machinery.
- [26] Yang Wu, Pengxu Wei, and Liang Lin. Scene graph to image synthesis via knowledge consensus. In AAAI, 2023.
- [27] Yao Xiao, Ziyi Tang, Pengxu Wei, Cong Liu, and Liang Lin. Masked images are counterfactual samples for robust fine-tuning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 20301–20310, 2023.
- [28] Hong Yan, Yang Liu, Yushen Wei, Zhen Li, Guanbin Li, and Liang Lin. Skeletonmae: graph-based masked autoencoder for skeleton sequence pre-training. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 5606–5618, 2023.
- [29] Aohan Zeng, Xiao Liu, Zhengxiao Du, Zihan Wang, Hanyu Lai, Ming Ding, Zhuoyi Yang, Yifan Xu, Wendi Zheng, Xiao Xia, et al. Glm-130b: An open bilingual pre-trained model. ICLR, 2023.
- [30] Yuying Zhu, Yang Zhang, Lingbo Liu, Yang Liu, Guanbin Li, Mingzhi Mao, and Liang Lin. Hybrid-order representation learning for electricity theft detection. IEEE Transactions on Industrial Informatics, 19(2):1248–1259, 2022.