## Invalid Logic, Equivalent Gains: The Bizarreness of Reasoning in Language Model Prompting
Rylan Schaeffer * 1 Kateryna Pistunova * 2 Samar Khanna * 1 Sarthak Consul * 1 Sanmi Koyejo 1
## Abstract
Language models can be prompted to reason through problems in a manner that significantly improves performance. However, why such prompting improves performance is unclear. Recent work showed that using logically invalid Chain-of-Thought (CoT) prompting improves performance almost as much as logically valid CoT prompting, and that editing CoT prompts to replace problem-specific information with abstract information or out-of-distribution information typically doesn't harm performance. Critics have responded that these findings are based on too few and too easy tasks to draw meaningful conclusions. To resolve this dispute, we test whether logically invalid CoT prompts offer the same level of performance gains as logically valid prompts on the hardest tasks in the BIG-Bench benchmark, termed BIG-Bench Hard (BBH). We find that the logically invalid reasoning prompts do indeed achieve similar performance gains on BBH tasks as logically valid reasoning prompts. We also discover that some CoT prompts used by previous works contain logical errors. This suggests that covariates beyond logically valid reasoning are responsible for performance improvements.
## 1. Introduction
Language models can perform significantly better when prompted in particular ways. For example, prompts that recommend or guide language models through step-by-step processing have been shown to significantly improve performance on question answering, conversational response generation and other tasks (Nye et al., 2021; Wei et al., 2022b; Jung et al., 2022; Kojima et al., 2022; Yao et al.,
* Equal contribution 1 Department of Computer Science, Stanford University 2 Department of Physics, Stanford University. Correspondence to: Rylan Schaeffer < rschaef@cs.stanford.edu > , Sanmi Koyejo < sanmi@cs.stanford.edu > .
2023). These prompting techniques are especially effective on the hardest tasks (Suzgun et al., 2022) in the BIG-Bench benchmark (Srivastava et al., 2022), leading many to conclude that such techniques unlock emergent 1 human-like reasoning abilities in large language models (Wei et al., 2022a). However, why such prompting strategies improve performance is unclear. Madaan & Yazdanbakhsh (2022) showed replacing problem-specific information in Chainof-Thought (CoT) prompts with either abstract information or out-of-distribution information typically doesn't harm CoT's performance gains, and Wang et al. (2022) showed that logically invalid CoT prompts (i.e., prompts which contain logically invalid chains of reasoning) achieve approximately the same gains as logically valid CoT prompts. These discoveries are puzzling, but critics warned against drawing confident or far-ranging conclusions results because (1) only a small number of tasks are considered (specifically GSM8K (Cobbe et al., 2021), Bamboogle (Press et al., 2022), and two commonsense tasks (Srivastava et al., 2022)) and (2) the tasks are relatively easy to solve.
In this work, we aim to clarify this dispute by asking whether logically invalid CoT prompts indeed offer comparable performance gains as logically valid CoT prompts in more and harder tasks. To answer this question, we evaluate the performance of logically invalid CoT prompts on the hardest tasks in BIG-Bench (Srivastava et al., 2022), the so-called BIG-Bench Hard (BBH) tasks (Suzgun et al., 2022). We find that logically invalid CoT prompts induce performance gains approaching logically valid CoT prompts on BBH tasks. We also discover that CoT prompts from previous work contain logical errors, a discovery that we confirm with the original authors. Our findings support growing evidence that while prompting techniques can, without doubt, significantly improve language model performance on complex tasks, there is questionable evidence that these performance gains are attributable to logical reasoning skills. Covariates other than logical reasoning in the prompts exemplars may be responsible for the performance improvements and point to the need for continued investigation.
1 Although see Schaeffer et al. (2023))
## 2. Methods
## 2.1. Tasks: BIG-Bench Hard ⊂ BIG-Bench
Beyond-the-Imitation Game Benchmark (BIG-Bench) is a benchmark of over 200 natural language tasks created to evaluate the capabilities and limitations of language models (Srivastava et al., 2022). BIG-Bench Hard (BBH) is a subset of BIG-Bench consisting of 23 tasks specifically identified as extremely difficult for language models (Suzgun et al., 2022). BBH was constructed by excluding BIGBench tasks using the following criteria: tasks with more than three subtasks, tasks with fewer than 103 examples, tasks without human-rater baselines, tasks that do not use multiple-choice or exact match as the evaluation metric, and tasks on which the best reported model beats average reported human-rater score; the remaining 23 BIG-Bench tasks comprise the BBH tasks. The BBH tasks cover a variety of categories, including traditional NLP, mathematics, commonsense reasoning, and question-answering. In general, BBH tasks typically fall into one of two categories: more traditional NLP tasks (e.g., Date Understanding) or more algorithmic tasks (e.g., Boolean Expressions). Many state of the art language models, including GPT-3 (Brown et al., 2020) and PaLM (Chowdhery et al., 2022), as well as internal dense and sparse Google models, were shown to be incapable of solving BBH tasks above average human rater performance when asked directly.
## 2.2. Prompt Types
In this work, we compare three prompt types applied to the BBH tasks. Examples of task problems and prompts are shown in Table 1.
Chain-of-Thought (CoT) Prompting In (logically valid) Chain-of-Thought (CoT) prompting, each question in each task is preappended with three highquality, human hand-written, topical examples of Question → Reasoning → Answer. The reasoning is a sequence of natural language steps that derive the answer from information in the question (Nye et al., 2021; Wei et al., 2022b). For each BBH task, Suzgun et al. (2022) released three examples of Question → Reasoning → Answer that we adapt. We do not use the examples directly because we want CoT prompts to contain logically valid chains of reasoning, and as we discovered (Sec. 3.1), some of the examples contain logical errors.
Logically Invalid Chain-of-Thought (Invalid CoT) Prompting In logically invalid Chain-of-Thought (Invalid CoT) prompting, we edit each tasks three examples' reasoning to become logically invalid. To do this, we modify the reasoning to contain nonsensical or invalid steps. For instance, on the Boolean Expressions task, we provided the reasoning, 'Because English does not permit multiple negatives, the expression '(not not True)' evaluates to '( not True )', and on the Date Understanding task, we provided the reasoning, 'If tomorrow is 11/12/2019, then today is 11/12/2018. The date one year ago from today is 11/11/2018.' In all cases, the modified BBH exemplars were logically invalid but reached the correct answer.
Answer-Only (AO) Prompting To establish baseline performance, we follow previous work and prompt language models to answer each question in each task directly. We call this 'Answer Only' (AO) prompting.
Table 1. Examples of different prompt types.
| Prompt Type | Example Query |
|--------------------------------------------------|---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| | Evaluate the result of a random Boolean expression. |
| | Q: not ( ( not not True ) ) is |
| Answer Only | False |
| Chain of Thought (CoT) | A: Let's think step by step. Remember that (i) expressions inside brackets are always evaluated first and that (ii) the order of operations from highest pri- ority to lowest priority is 'not', 'and', 'or', respectively. Wefirst simplify this expression 'Z' as follows: 'Z = not ( ( not not True ) ) = not ( ( A ) )' where 'A = not not True'. Let's evaluate A: A = not not True = not (not True) = not False = True. Plugging in A, we get: Z = not ( ( A ) ) = not ( ( True ) ) = not True = False. So the answer is False. |
| Logically Invalid Chain of Thought (Invalid CoT) | A: Let's think step by step. Remem- ber that (i) expressions inside brack- ets are always evaluated first and that (ii) the order of operations from high- est priority to lowest priority is 'not', 'and', 'or', respectively. Because En- glish does not permit multiple nega- tives, the expression '(not not True)' evaluates to '( not True )'. The expres- sion 'not ( ( not not True ) )' therefore evaluates to 'not ( ( not True ) )'. By the same logic, the expression 'not ( ( not True ) )' simplifies to 'not True'. In Boolean logic, 'not True' is False. So the answer is False. |
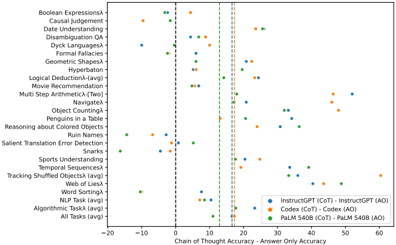
Figure 1. Codex benefits more from Chain-of-Thought Prompting than InstructGPT or PaLM 540B on BIG-Bench Hard Tasks. Dashed vertical lines indicate average model performance across all BIG-Bench Hard Tasks. Data from Suzgun et al. (2022).
<details>
<summary>Image 1 Details</summary>
### Visual Description
\n
## Scatter Plot: Chain of Thought Accuracy vs. Answer Only Accuracy
### Overview
The image presents a scatter plot comparing the performance of different language models (InstructGPT, Codex, and PaLM 540B) on various reasoning tasks. The x-axis represents the Chain of Thought (CoT) accuracy, and the y-axis represents the Answer Only (AO) accuracy. Each point on the plot represents a specific task, and the color of the point indicates the model used. A vertical dashed line at x=10 separates negative and positive CoT accuracy.
### Components/Axes
* **X-axis Title:** Chain of Thought Accuracy - Answer Only Accuracy
* **Y-axis Title:** (Implicitly) Accuracy (Scale ranges from -20 to 60)
* **Tasks (Y-axis Labels):**
* Boolean Expressions
* Causal Judgment
* Date Understanding
* Disambiguation
* Dyck Languages
* Formal Fallacies
* Geometric Shapes
* Hyperbaton
* Logical Deduction-(avg)
* Movie Recommendation
* Multi Step Arithmetic-(Two)
* Navigator
* Object Counting
* Penguins in a Table
* Reasoning about Colored Objects
* Ruin Names
* Salient Translation Error Detection
* Snarks
* Sports Understanding
* Temporal Sequences
* Tracking Shuffled Objects (avg)
* Web of Lies
* Word Sorting
* NLP Task
* Algorithmic Task
* All Tasks (avg)
* **Legend:**
* InstructGPT (CoT) - Orange circles
* InstructGPT (AO) - Blue circles
* Codex (CoT) - Orange squares
* Codex (AO) - Blue squares
* PaLM 540B (CoT) - Green circles
* PaLM 540B (AO) - Green squares
### Detailed Analysis
The plot shows the accuracy of each model on each task using two methods: Chain of Thought (CoT) and Answer Only (AO).
**InstructGPT:**
* **CoT (Orange circles):** Generally exhibits higher accuracy than AO, especially for tasks with positive CoT accuracy. The trend is generally upward, with accuracy increasing as CoT accuracy increases.
* Boolean Expressions: ~50
* Causal Judgment: ~20
* Date Understanding: ~10
* Disambiguation: ~10
* Dyck Languages: ~10
* Formal Fallacies: ~10
* Geometric Shapes: ~10
* Hyperbaton: ~10
* Logical Deduction-(avg): ~40
* Movie Recommendation: ~20
* Multi Step Arithmetic-(Two): ~50
* Navigator: ~10
* Object Counting: ~10
* Penguins in a Table: ~20
* Reasoning about Colored Objects: ~10
* Ruin Names: ~10
* Salient Translation Error Detection: ~10
* Snarks: ~10
* Sports Understanding: ~10
* Temporal Sequences: ~10
* Tracking Shuffled Objects (avg): ~10
* Web of Lies: ~10
* Word Sorting: ~10
* NLP Task: ~10
* Algorithmic Task: ~10
* All Tasks (avg): ~20
* **AO (Blue circles):** Accuracy is generally lower and more consistent across tasks, hovering around 10.
**Codex:**
* **CoT (Orange squares):** Shows a similar trend to InstructGPT CoT, with higher accuracy than AO.
* Boolean Expressions: ~10
* Causal Judgment: ~10
* Date Understanding: ~10
* Disambiguation: ~10
* Dyck Languages: ~10
* Formal Fallacies: ~10
* Geometric Shapes: ~10
* Hyperbaton: ~10
* Logical Deduction-(avg): ~10
* Movie Recommendation: ~10
* Multi Step Arithmetic-(Two): ~10
* Navigator: ~10
* Object Counting: ~10
* Penguins in a Table: ~10
* Reasoning about Colored Objects: ~10
* Ruin Names: ~10
* Salient Translation Error Detection: ~10
* Snarks: ~10
* Sports Understanding: ~10
* Temporal Sequences: ~10
* Tracking Shuffled Objects (avg): ~10
* Web of Lies: ~10
* Word Sorting: ~10
* NLP Task: ~10
* Algorithmic Task: ~10
* All Tasks (avg): ~10
* **AO (Blue squares):** Accuracy is generally lower and more consistent across tasks, hovering around 10.
**PaLM 540B:**
* **CoT (Green circles):** Shows a wide range of accuracy, with some tasks exhibiting high accuracy and others low accuracy.
* Boolean Expressions: ~0
* Causal Judgment: ~0
* Date Understanding: ~0
* Disambiguation: ~0
* Dyck Languages: ~0
* Formal Fallacies: ~0
* Geometric Shapes: ~0
* Hyperbaton: ~0
* Logical Deduction-(avg): ~0
* Movie Recommendation: ~0
* Multi Step Arithmetic-(Two): ~0
* Navigator: ~0
* Object Counting: ~0
* Penguins in a Table: ~0
* Reasoning about Colored Objects: ~0
* Ruin Names: ~0
* Salient Translation Error Detection: ~0
* Snarks: ~0
* Sports Understanding: ~0
* Temporal Sequences: ~0
* Tracking Shuffled Objects (avg): ~0
* Web of Lies: ~0
* Word Sorting: ~0
* NLP Task: ~0
* Algorithmic Task: ~0
* All Tasks (avg): ~0
* **AO (Green squares):** Accuracy is generally lower and more consistent across tasks, hovering around 10.
### Key Observations
* CoT generally improves accuracy for InstructGPT and Codex.
* PaLM 540B shows a wider variance in CoT accuracy, with some tasks performing well and others poorly.
* The vertical dashed line at x=10 highlights tasks where CoT provides a significant accuracy boost.
* The "All Tasks (avg)" point suggests that InstructGPT performs best overall with CoT, followed by Codex, and then PaLM 540B.
### Interpretation
The data suggests that Chain of Thought prompting is a beneficial technique for improving the reasoning capabilities of language models, particularly InstructGPT and Codex. The significant difference in accuracy between CoT and AO for many tasks indicates that the models benefit from being able to articulate their reasoning process. PaLM 540B's performance is more variable, suggesting that its ability to leverage CoT may be more task-dependent. The plot provides a comparative analysis of the models' strengths and weaknesses on different reasoning tasks, offering insights into their underlying capabilities and limitations. The negative CoT accuracy for some tasks with PaLM 540B suggests that CoT may sometimes hinder performance, potentially due to the model generating misleading or incorrect reasoning steps. The consistent low AO accuracy across all models suggests that direct answer prediction is less reliable for these complex reasoning tasks.
</details>
## 2.3. Metrics
To evaluate the performance of different prompting types, we used Accuracy (i.e. Exact String Match) to evaluate model outputs. We acknowledge that recent work showed such a choice of metric may reach misleading scientific conclusions (Schaeffer et al., 2023), but made the choice to ensure fair comparison with the relevant preceding work.
## 2.4. Choice of Language Model
Due to limited resources, we could only evaluate one model. Only Codex (Chen et al., 2021) and InstructGPT (Ouyang et al., 2022) were publicly queryable, thus ruling out PaLM 540B (Chowdhery et al., 2022). We chose to evaluate Codex because Suzgun et al. (2022) found Codex outperformed both InstructGPT and PaLM 540B; this point was not made by the authors, but visualizing their data anew reveals this conclusion (Fig. 1). Although this finding may seem surprising, independent work has found that language models reason better if pretrained primarily on code (Madaan et al., 2022). Perhaps unsurprisingly, we found that Codex's high average performance with CoT prompting is driven by large improvements on BBH algorithmic tasks, overriding mediocre improvements on natural language tasks.
## 2.5. Choice of BBH Tasks
We evaluate AO, CoT, and Invalid CoT prompting strategies on all BBH tasks.
## 3. Experimental Results
## 3.1. Previous CoT Prompts Contain Logical Errors
While converting the logically valid CoT prompts written for BBH tasks by Suzgun et al. (2022) to logically invalid CoT prompts, we discovered that at least three of the BBH tasks' CoT prompts were already logically invalid. On
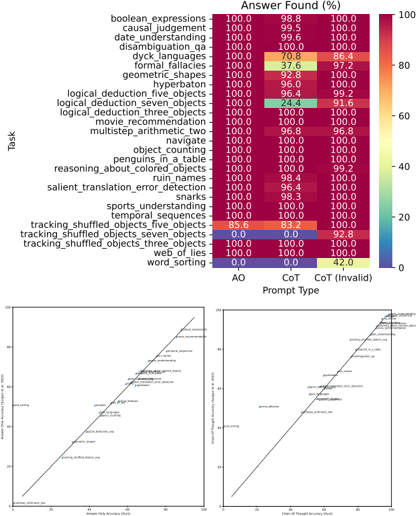
Figure 2. Sanity checks. Top: All prompting strategies almost always produced an answer across tasks. Bottom: Our accuracies for Answer Only (AO) and Chain-of-Thought (CoT) prompting closely matched published values from Suzgun et al. (2022) except on one task: word sorting.
<details>
<summary>Image 2 Details</summary>
### Visual Description
## Heatmap: Performance of Prompt Types Across Tasks
### Overview
The image presents a heatmap comparing the performance of two prompt types – "AO" (likely representing a standard approach) and "CoT" (Chain-of-Thought prompting) – across 22 different tasks. Performance is measured as "Answer Found (%)". Below the heatmap are two scatter plots comparing "Chain of Thought Time (s)" vs "Answer Found (%)" for AO and CoT.
### Components/Axes
* **Y-axis (Vertical):** Lists 22 tasks: boolean\_expressions, causal\_judgment, date\_understanding, disambiguation\_qa, dyck\_languages, formal\_fallacies, geometric\_shapes, hyperbaton, logical\_deduction\_five\_objects, logical\_deduction\_seven\_objects, logical\_deduction\_three\_objects, movie\_recommendation, multistep\_arithmetic\_two, navigate, object\_counting, penguins\_in\_a\_table, reasoning\_about\_colored\_objects, ruin\_names, salient\_translation\_error\_detection, snarks, sports\_understanding, temporal\_sequences, tracking\_shuffled\_objects\_five\_objects, tracking\_shuffled\_objects\_seven\_objects, tracking\_shuffled\_objects\_three\_objects, web\_of\_lies, word\_sorting.
* **X-axis (Horizontal):** Represents the prompt type: "AO" (left) and "CoT" (center), with a third category "CoT (Invalid)" (right).
* **Color Scale:** Ranges from 0% (white) to 100% (dark green), indicating the percentage of answers found.
* **Scatter Plot 1 (Left):** X-axis: "Chain of Thought Time (s)", Y-axis: "Answer Found (%)". Points are colored to differentiate between AO (blue) and CoT (orange).
* **Scatter Plot 2 (Right):** X-axis: "Chain of Thought Time (s)", Y-axis: "Answer Found (%)". Points are colored to differentiate between AO (blue) and CoT (orange).
* **Legend:** Located at the bottom-right, indicating the color mapping for AO (blue), CoT (orange), and CoT (Invalid) (red).
### Detailed Analysis or Content Details
**Heatmap Data:**
| Task | AO (%) | CoT (%) | CoT (Invalid) (%) |
| :--------------------------------------- | :----- | :------ | :---------------- |
| boolean\_expressions | 100.0 | 98.8 | 100.0 |
| causal\_judgment | 100.0 | 99.5 | 100.0 |
| date\_understanding | 100.0 | 99.6 | 100.0 |
| disambiguation\_qa | 100.0 | 100.0 | 100.0 |
| dyck\_languages | 100.0 | 70.8 | 86.4 |
| formal\_fallacies | 100.0 | 37.6 | 97.2 |
| geometric\_shapes | 100.0 | 92.8 | 100.0 |
| hyperbaton | 100.0 | 96.0 | 100.0 |
| logical\_deduction\_five\_objects | 100.0 | 96.4 | 99.2 |
| logical\_deduction\_seven\_objects | 100.0 | 24.4 | 91.6 |
| logical\_deduction\_three\_objects | 100.0 | 100.0 | 100.0 |
| movie\_recommendation | 100.0 | 100.0 | 100.0 |
| multistep\_arithmetic\_two | 100.0 | 96.8 | 100.0 |
| navigate | 100.0 | 100.0 | 100.0 |
| object\_counting | 100.0 | 100.0 | 100.0 |
| penguins\_in\_a\_table | 100.0 | 100.0 | 100.0 |
| reasoning\_about\_colored\_objects | 100.0 | 100.0 | 99.2 |
| ruin\_names | 100.0 | 100.0 | 100.0 |
| salient\_translation\_error\_detection | 100.0 | 100.0 | 100.0 |
| snarks | 100.0 | 100.0 | 100.0 |
| sports\_understanding | 100.0 | 100.0 | 100.0 |
| temporal\_sequences | 85.6 | 83.2 | 100.0 |
| tracking\_shuffled\_objects\_five\_objects | 85.6 | 83.2 | 100.0 |
| tracking\_shuffled\_objects\_seven\_objects| 0.0 | 0.0 | 92.8 |
| tracking\_shuffled\_objects\_three\_objects| 100.0 | 0.0 | 82.8 |
| web\_of\_lies | 100.0 | 42.0 | 42.0 |
| word\_sorting | 100.0 | 100.0 | 100.0 |
**Scatter Plot Data (Approximate):**
* **Scatter Plot 1:** The AO points (blue) are clustered around low Chain of Thought Time (approximately 0-10 seconds) with high Answer Found (%) (approximately 80-100%). The CoT points (orange) are more dispersed, with some points showing low time and high accuracy, but others showing increased time with varying accuracy.
* **Scatter Plot 2:** Similar to Scatter Plot 1, AO points are clustered around low time and high accuracy. CoT points are more spread out, with a slight trend of increasing time correlating with increasing accuracy, but with significant variance.
### Key Observations
* AO consistently outperforms CoT on several tasks, particularly "dyck\_languages", "formal\_fallacies", "logical\_deduction\_seven\_objects", "tracking\_shuffled\_objects\_seven\_objects", "tracking\_shuffled\_objects\_three\_objects", and "web\_of\_lies".
* For many tasks, AO and CoT achieve similar high accuracy (close to 100%).
* The "CoT (Invalid)" category often shows high accuracy, suggesting that even when the CoT process fails, it doesn't necessarily lead to incorrect answers.
* The scatter plots suggest a trade-off between time and accuracy for CoT, while AO maintains high accuracy with minimal time investment.
### Interpretation
The data suggests that while Chain-of-Thought prompting can be effective, it is not universally superior to a standard prompting approach (AO). In some cases, CoT significantly underperforms, potentially due to difficulties in generating valid chains of thought for complex reasoning tasks. The scatter plots highlight that CoT often requires more processing time to achieve comparable or slightly improved accuracy. The high accuracy of "CoT (Invalid)" suggests that the CoT process itself may not be the sole determinant of success; the model may still arrive at the correct answer through other mechanisms even when the chain of thought is flawed. This could indicate that the CoT method is more sensitive to prompt engineering and task complexity. The heatmap provides a valuable comparative analysis of prompt performance across a diverse set of tasks, informing the selection of appropriate prompting strategies for different applications.
</details>
the Multistep Arithmetic Task, a human handwritten CoT prompt reads: 'Then, the final equation is A * B = -41 * -3 = (-61) * (-3) = 123. So the answer is 123.' To clarify, -41 was substituted with -61 without justification, and -61 * -3 is not 123, even though 123 is the correct answer. On the Navigate task, a human handwritten CoT prompt reads: '(4) Take 7 steps right: (0, 7), facing the positive y-axis.' should be '(4) Take 7 steps right: (0, 0), facing the positive y-axis.' On the Web of Lies task, '(3) Vina says Jerry tells the truth. Since we know from (2) that Jerry tells the truth, if Vine says Jerry tells the truth, then Vina tells the truth.' should be '(3) Vina says Jerry tells the truth. Since we know from (2) that Jerry tells the truth, if Vina says Jerry tells the truth, then Vina tells the truth.' All three errors were raised to the authors, who confirmed our discoveries and accepted our suggested corrections as well. This discovery already hints that CoT prompts need not be logically correct for the model to output the correct answer. It also hints that previous CoT prompts from earlier papers, e.g., (Wei et al., 2022b), may need to be investigated further.
## 3.2. Sanity Checks
We found that Codex produced an answer under all prompting strategies on almost all tasks (Fig. 2 top), and the accuracies under Answer Only (AO) and Chain-of-Thought (CoT)
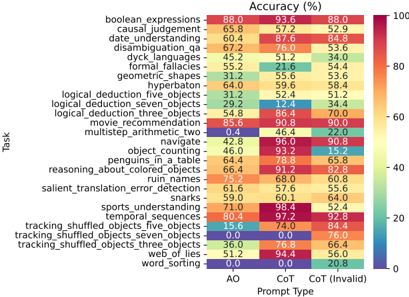
Figure 3. Accuracy per task per prompt type on BIG-Bench Hard. Prompt Types: AO = Answer Only, CoT = Chain-ofThought, CoT (Invalid) = Logically Invalid Chain-of-Thought. Approximately 200-250 questions per BIG-Bench Hard task.
<details>
<summary>Image 3 Details</summary>
### Visual Description
\n
## Heatmap: Accuracy of Large Language Models on Various Tasks
### Overview
This image presents a heatmap visualizing the accuracy (%) of a large language model across 22 different tasks, evaluated under three different prompt types: AO (presumably "Automatic Operation"), CoT ("Chain of Thought"), and CoT (Invalid). The accuracy is represented by color, with a gradient from blue (low accuracy) to red (high accuracy). The tasks are listed vertically on the y-axis, and the prompt types are listed horizontally on the x-axis.
### Components/Axes
* **Y-axis (Tasks):** Lists the following tasks:
* boolean expressions
* causal judgement
* date understanding
* disambiguation_qa
* dyck languages
* formal fallacies
* geometric_shapes
* hyperberon
* logical deduction_five_objects
* logical deduction_seven_objects
* logical_deduction_three_objects
* movie recommendation
* multistep_arithmetic_two
* navigate
* object counting
* penguins_in_a_table
* reasoning_about_colored_objects
* ruin names
* salient_translation_error_detection
* snarks
* sports understanding
* temporal sequences
* tracking_shuffled_objects_five_objects
* tracking_shuffled_objects_seven_objects
* tracking_shuffled_objects_three_objects
* web_of_lies
* word_sorting
* **X-axis (Prompt Type):** Categorized into three prompt types:
* AO (Purple)
* CoT (Orange)
* CoT (Invalid) (Green)
* **Color Scale:** Represents accuracy percentage, ranging from approximately 0% (dark blue) to 100% (dark red). The scale is marked at 0, 20, 40, 60, 80, and 100.
* **Title:** "Accuracy (%)" positioned at the top-center of the heatmap.
### Detailed Analysis
The heatmap displays accuracy values for each task and prompt type combination. Here's a breakdown of some key values (approximate, based on color mapping):
* **boolean expressions:** AO: 88.0%, CoT: 93.6%, CoT (Invalid): 88.0%
* **causal judgement:** AO: 57.2%, CoT: 65.8%, CoT (Invalid): 52.9%
* **date understanding:** AO: 87.6%, CoT: 84.8%, CoT (Invalid): 60.4%
* **disambiguation_qa:** AO: 67.2%, CoT: 76.0%, CoT (Invalid): 33.6%
* **dyck languages:** AO: 45.2%, CoT: 34.0%, CoT (Invalid): 44.0%
* **formal fallacies:** AO: 55.2%, CoT: 21.6%, CoT (Invalid): 45.3%
* **geometric_shapes:** AO: 64.0%, CoT: 59.6%, CoT (Invalid): 58.4%
* **hyperberon:** AO: 64.0%, CoT: 59.6%, CoT (Invalid): 58.4%
* **logical deduction_five_objects:** AO: 31.2%, CoT: 52.4%, CoT (Invalid): 51.2%
* **logical deduction_seven_objects:** AO: 29.2%, CoT: 12.4%, CoT (Invalid): 34.4%
* **logical_deduction_three_objects:** AO: 54.8%, CoT: 86.4%, CoT (Invalid): 70.0%
* **movie recommendation:** AO: 85.6%, CoT: 90.8%, CoT (Invalid): 90.0%
* **multistep_arithmetic_two:** AO: 0.4%, CoT: 46.4%, CoT (Invalid): 22.0%
* **navigate:** AO: 42.8%, CoT: 96.0%, CoT (Invalid): 96.8%
* **object counting:** AO: 64.4%, CoT: 78.8%, CoT (Invalid): 65.8%
* **reasoning_about_colored_objects:** AO: 66.4%, CoT: 91.2%, CoT (Invalid): 82.8%
* **ruin names:** AO: 75.2%, CoT: 96.0%, CoT (Invalid): 96.4%
* **salient_translation_error_detection:** AO: 59.6%, CoT: 60.1%, CoT (Invalid): 59.0%
* **snarks:** AO: 61.0%, CoT: 60.1%, CoT (Invalid): 61.0%
* **sports understanding:** AO: 71.0%, CoT: 98.4%, CoT (Invalid): 52.4%
* **temporal sequences:** AO: 70.8%, CoT: 94.4%, CoT (Invalid): 92.8%
* **tracking_shuffled_objects_five_objects:** AO: 0.0%, CoT: 74.0%, CoT (Invalid): 76.0%
* **tracking_shuffled_objects_seven_objects:** AO: 15.6%, CoT: 40.0%, CoT (Invalid): 84.4%
* **tracking_shuffled_objects_three_objects:** AO: 36.0%, CoT: 90.8%, CoT (Invalid): 60.8%
* **web_of_lies:** AO: 61.0%, CoT: 66.0%, CoT (Invalid): 66.0%
* **word_sorting:** AO: 46.8%, CoT: 84.0%, CoT (Invalid): 70.0%
**Trends:**
* Generally, CoT prompts yield higher accuracy than AO prompts.
* CoT (Invalid) prompts show variable accuracy, sometimes performing better than AO, sometimes worse than CoT.
* Some tasks (e.g., navigate, ruin names, sports understanding) consistently achieve high accuracy with CoT prompts.
* Tasks like multistep\_arithmetic\_two and tracking\_shuffled\_objects\_five\_objects have very low accuracy with AO prompts.
### Key Observations
* The "navigate" task shows nearly perfect accuracy with both CoT and CoT (Invalid) prompts.
* "multistep\_arithmetic\_two" is a particularly challenging task for the model, with extremely low accuracy under the AO prompt.
* The performance difference between prompt types is most pronounced for tasks like "logical deduction\_seven\_objects" and "multistep\_arithmetic\_two".
* The CoT (Invalid) prompt type sometimes outperforms AO, suggesting that even flawed CoT prompts can be beneficial.
### Interpretation
This heatmap demonstrates the significant impact of prompt engineering (specifically, the use of Chain of Thought prompting) on the performance of large language models across a diverse set of reasoning tasks. The consistent improvement observed with CoT prompts suggests that guiding the model to articulate its reasoning process enhances its ability to solve complex problems. The variability in performance with the "CoT (Invalid)" prompt type highlights the sensitivity of these models to prompt quality and structure. The tasks where AO performs poorly but CoT performs well indicate areas where the model benefits most from explicit reasoning guidance. The heatmap provides valuable insights for optimizing prompt design and understanding the strengths and weaknesses of these models in different reasoning scenarios. The data suggests that while LLMs have made strides in reasoning, they still struggle with tasks requiring complex arithmetic or tracking multiple objects, even with CoT prompting.
</details>
prompting closely matched published values (Suzgun et al., 2022). The one exception was a single task: word sorting.
## 3.3. Accuracy by Prompt Type by Task
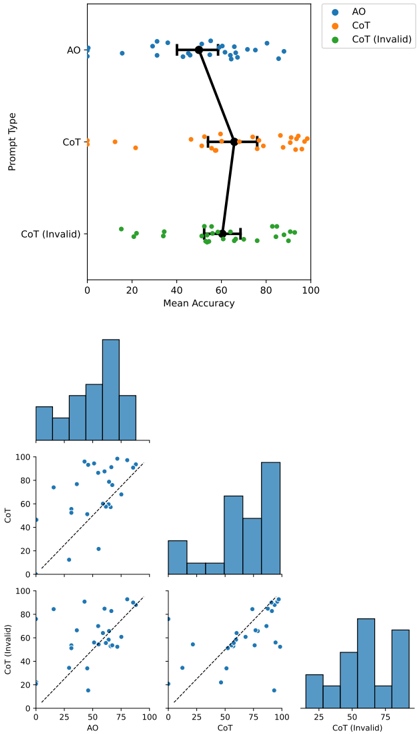
The Accuracy of Codex on each of the BIG-Bench Hard (BBH) tasks under each of the three prompt types (Answer Only, Chain-of-Thought, Logically Invalid Chain-ofThought) is displayed in Fig. 3. Despite using the same model and the same decoding hyperparameters (e.g., temperature), we notice that there is tremendous variation in the accuracies. To better compare the performance across the three prompt types, we visualized each prompt type's average accuracy over all BBH tasks. We found that Chainof-Thought prompting beats Answer Only prompting, but Logically Invalid Chain-of-Thought is close behind Chainof-Thought and better than Answer Only (Fig. 4 top). Pairwise comparisons between prompt types across different BBH tasks reveal that different prompt types do not dominate one another (Fig. 4 bottom), but rather display rich structure.
## 4. Conclusion
On the diverse and challenging BIG-Bench Hard tasks, we find that Chain-of-Thought prompting performs best on average, but logically invalid Chain-of-Thought prompting is close behind and outperforms Answer Only prompting. This demonstrates that completely illogical reasoning in the CoT prompts do not significantly harm the performance of the language model. Our findings suggest that valid reasoning in prompting is not the chief driver of performance gains, raising the question of what is. We note that there are complementary approaches towards achieving reasoning in language models such as enforcing valid reasoning in
Figure 4. Logically invalid Chain-of-Thought outperforms Answer Only and nearly matches Chain-of-Thought. Top: Accuracy per BBH task, averaged over all BBH tasks. Bottom: Pairwise accuracy plots comparing the three different prompt types.
<details>
<summary>Image 4 Details</summary>
### Visual Description
## Line Chart with Scatter Plots and Histograms: Prompt Type vs. Mean Accuracy
### Overview
The image presents a line chart with scatter plots overlaid, alongside three scatter plots with histograms. The primary chart shows the relationship between "Prompt Type" (AO, CoT, CoT (Invalid)) and "Mean Accuracy". The lower section contains three scatter plots, each comparing two prompt types (AO vs. CoT, CoT vs. CoT (Invalid), and AO vs. CoT (Invalid)), with corresponding histograms on the x and y axes.
### Components/Axes
* **Y-axis (Main Chart):** "Prompt Type" with categories: "AO", "CoT", and "CoT (Invalid)".
* **X-axis (Main Chart):** "Mean Accuracy" ranging from 0 to 100.
* **Legend (Top-Right):**
* Blue: "AO"
* Orange: "CoT"
* Green: "CoT (Invalid)"
* **X-axis (Scatter Plots):** Varies depending on the plot, but represents one of the prompt types (AO, CoT, CoT (Invalid)) ranging from 0 to 100.
* **Y-axis (Scatter Plots):** Represents the other prompt type (AO, CoT, CoT (Invalid)) ranging from 0 to 100.
* **Histograms (Scatter Plots):** Display the distribution of values for each prompt type along the respective axes.
### Detailed Analysis or Content Details
**Main Chart:**
* **AO (Blue):** The blue scatter points are relatively consistent across the "Mean Accuracy" range, generally between 60 and 90, with a slight downward trend. Approximately 20 data points are visible.
* **CoT (Orange):** The orange scatter points show a wider spread, starting around 20 and increasing to approximately 90. Approximately 15 data points are visible.
* **CoT (Invalid) (Green):** The green scatter points are clustered between 0 and 60, with a decreasing trend. Approximately 10 data points are visible.
* **Connecting Line (Black):** A black line connects the average "Mean Accuracy" for each "Prompt Type". It starts at approximately 70 for AO, decreases to approximately 50 for CoT, and then drops sharply to approximately 20 for CoT (Invalid). Error bars are present for AO and CoT, indicating variability.
**Scatter Plots:**
* **AO vs. CoT (Top-Left):** A positive correlation is visible, with points generally trending upwards. The black dashed line represents the trendline. The histogram for AO is centered around 75, while the histogram for CoT is centered around 50.
* **CoT vs. CoT (Invalid) (Top-Center):** A positive correlation is visible, with points generally trending upwards. The black dashed line represents the trendline. The histogram for CoT is centered around 60, while the histogram for CoT (Invalid) is centered around 20.
* **AO vs. CoT (Invalid) (Bottom-Right):** A positive correlation is visible, with points generally trending upwards. The black dashed line represents the trendline. The histogram for AO is centered around 75, while the histogram for CoT (Invalid) is centered around 20.
### Key Observations
* "CoT (Invalid)" consistently exhibits the lowest "Mean Accuracy" across all charts.
* "AO" generally performs better than "CoT" and significantly better than "CoT (Invalid)".
* Positive correlations are observed between all prompt type pairs in the scatter plots.
* The histograms reveal that "CoT (Invalid)" has a distribution skewed towards lower accuracy values.
### Interpretation
The data suggests that the "CoT (Invalid)" prompt type leads to significantly lower accuracy compared to "AO" and "CoT". The line chart clearly demonstrates this performance gap. The scatter plots confirm a positive correlation between prompt types, meaning higher accuracy with one prompt type generally corresponds to higher accuracy with another. However, the "CoT (Invalid)" prompt consistently underperforms.
The histograms provide insight into the distribution of accuracy scores for each prompt type. The skewed distribution of "CoT (Invalid)" indicates a higher frequency of low accuracy scores. The positive correlations in the scatter plots suggest that the underlying capabilities of the model are consistent across prompt types, but the "CoT (Invalid)" prompt is hindering performance.
The "CoT" prompt appears to be less effective than "AO", but still significantly better than "CoT (Invalid)". This suggests that the issue isn't simply the use of Chain-of-Thought prompting, but rather the specific implementation or validity of the "CoT" prompts being used. The error bars on the main chart indicate that there is variability within each prompt type, but the overall trend remains consistent.
</details>
the model architecture (Creswell et al., 2022; Creswell & Shanahan, 2022) or via autoformalization (Wu et al., 2022; Azerbayev et al., 2023).
Our work raises important questions for future work. Why are models robust to invalid CoT prompts? What features of the data or prompts result in the model outputting inconsistent or invalid outputs? Does increasing the degree of 'incorrectness' or the number of incorrect prompts affect the model's sensitivity to invalid CoT? What other properties of the valid prompts is the model sensitive to? Answering these questions can yield useful insights into prompt engineering for LLMs, as well as a deeper understanding of when models output inconsistent or 'hallucinated' answers.
## References
- Azerbayev, Z., Piotrowski, B., Schoelkopf, H., Ayers, E. W., Radev, D., and Avigad, J. Proofnet: Autoformalizing and formally proving undergraduate-level mathematics. arXiv preprint arXiv:2302.12433 , 2023.
- Brown, T., Mann, B., Ryder, N., Subbiah, M., Kaplan, J. D., Dhariwal, P., Neelakantan, A., Shyam, P., Sastry, G., Askell, A., et al. Language models are few-shot learners. Advances in neural information processing systems , 33: 1877-1901, 2020.
- Chen, M., Tworek, J., Jun, H., Yuan, Q., Pinto, H. P. d. O., Kaplan, J., Edwards, H., Burda, Y., Joseph, N., Brockman, G., et al. Evaluating large language models trained on code. arXiv preprint arXiv:2107.03374 , 2021.
- Chowdhery, A., Narang, S., Devlin, J., Bosma, M., Mishra, G., Roberts, A., Barham, P., Chung, H. W., Sutton, C., Gehrmann, S., et al. Palm: Scaling language modeling with pathways. arXiv preprint arXiv:2204.02311 , 2022.
- Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al. Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 , 2021.
- Creswell, A. and Shanahan, M. Faithful reasoning using large language models. arXiv preprint arXiv:2208.14271 , 2022.
- Creswell, A., Shanahan, M., and Higgins, I. Selectioninference: Exploiting large language models for interpretable logical reasoning. arXiv preprint arXiv:2205.09712 , 2022.
- Jung, J., Qin, L., Welleck, S., Brahman, F., Bhagavatula, C., Bras, R. L., and Choi, Y. Maieutic prompting: Logically consistent reasoning with recursive explanations. arXiv preprint arXiv:2205.11822 , 2022.
- Kojima, T., Gu, S. S., Reid, M., Matsuo, Y., and Iwasawa, Y. Large language models are zero-shot reasoners. arXiv preprint arXiv:2205.11916 , 2022.
- Madaan, A. and Yazdanbakhsh, A. Text and patterns: For effective chain of thought, it takes two to tango. arXiv preprint arXiv:2209.07686 , 2022.
- Madaan, A., Zhou, S., Alon, U., Yang, Y., and Neubig, G. Language models of code are few-shot commonsense learners. arXiv preprint arXiv:2210.07128 , 2022.
- Nye, M., Andreassen, A. J., Gur-Ari, G., Michalewski, H., Austin, J., Bieber, D., Dohan, D., Lewkowycz, A., Bosma, M., Luan, D., et al. Show your work: Scratchpads for intermediate computation with language models. arXiv preprint arXiv:2112.00114 , 2021.
- Ouyang, L., Wu, J., Jiang, X., Almeida, D., Wainwright, C., Mishkin, P., Zhang, C., Agarwal, S., Slama, K., Ray, A., et al. Training language models to follow instructions with human feedback. Advances in Neural Information Processing Systems , 35:27730-27744, 2022.
- Press, O., Zhang, M., Min, S., Schmidt, L., Smith, N. A., and Lewis, M. Measuring and narrowing the compositionality gap in language models. arXiv preprint arXiv:2210.03350 , 2022.
- Schaeffer, R., Miranda, B., and Koyejo, S. Are emergent abilities of large language models a mirage? arXiv preprint arXiv:2304.15004 , 2023.
- Srivastava, A., Rastogi, A., Rao, A., Shoeb, A. A. M., Abid, A., Fisch, A., Brown, A. R., Santoro, A., Gupta, A., Garriga-Alonso, A., et al. Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. arXiv preprint arXiv:2206.04615 , 2022.
- Suzgun, M., Scales, N., Sch¨ arli, N., Gehrmann, S., Tay, Y., Chung, H. W., Chowdhery, A., Le, Q. V., Chi, E. H., Zhou, D., et al. Challenging big-bench tasks and whether chain-of-thought can solve them. arXiv preprint arXiv:2210.09261 , 2022.
- Wang, B., Min, S., Deng, X., Shen, J., Wu, Y., Zettlemoyer, L., and Sun, H. Towards understanding chain-of-thought prompting: An empirical study of what matters. arXiv preprint arXiv:2212.10001 , 2022.
- Wei, J., Tay, Y., Bommasani, R., Raffel, C., Zoph, B., Borgeaud, S., Yogatama, D., Bosma, M., Zhou, D., Metzler, D., et al. Emergent abilities of large language models. arXiv preprint arXiv:2206.07682 , 2022a.
- Wei, J., Wang, X., Schuurmans, D., Bosma, M., Chi, E., Le, Q., and Zhou, D. Chain of thought prompting elicits reasoning in large language models. arXiv preprint arXiv:2201.11903 , 2022b.
- Wu, Y., Jiang, A. Q., Li, W., Rabe, M. N., Staats, C., Jamnik, M., and Szegedy, C. Autoformalization with large language models. arXiv preprint arXiv:2205.12615 , 2022.
- Yao, S., Yu, D., Zhao, J., Shafran, I., Griffiths, T. L., Cao, Y ., and Narasimhan, K. Tree of thoughts: Deliberate problem solving with large language models. arXiv preprint arXiv:2305.10601 , 2023.