## SIMD Everywhere Optimization from ARM NEON to RISC-V Vector Extensions
Ju-Hung Li jhlee@pllab.cs.nthu.edu.tw National Tsing Hua University Taiwan
## Chi-Wei Chu
Jhih-Kuan Lin jklin@pllab.cs.nthu.edu.tw National Tsing Hua University Taiwan
## Lai-Tak Kuok
cwchu@pllab.cs.nthu.edu.tw National Tsing Hua University Taiwan ltkuok@pllab.cs.nthu.edu.tw National Tsing Hua University Taiwan
## Chao-Lin Lee
clli@pllab.cs.nthu.edu.tw National Tsing Hua University PeakHills Group
Taiwan
Yung-Cheng Su ycsu@pllab.cs.nthu.edu.tw National Tsing Hua University
Taiwan
## Hung-Ming Lai
hmlai@pllab.cs.nthu.edu.tw National Tsing Hua University Taiwan
## Jenq-Kuen Lee
jklee@cs.nthu.edu.tw
National Tsing Hua University Taiwan to RISC-V Vector Extensions is expected to enhance several key applications. Android Runtime (ART) could witness enhanced system efficiency. Libraries like OpenCV and FFmpeg could experience faster processing times for computer vision tasks and multimedia data processing respectively. TensorFlow Lite could see improved execution speed, crucial for edge device deployment. Other Android applications could also see performance improvements. Machine learning libraries like XNNPACK could benefit in terms of on-device task performance, and the Eigen library could see improved calculation efficiency. In essence, this migration strategy is poised to drive significant enhancements across a range of applications in the Android ecosystem. Currently, the migration of NEON code to RVV code requires manual rewriting. Manual rewriting requires a good understanding of the architectural differences between the two instruction sets. It involves carefully modifying the instructions and data types in the code, which can be time-consuming, especially for larger codebases or when utilizing multiple Intrinsics. In this work, we attempt to automate the rewriting process with the open source tool, SIMD Everywhere (SIMDe).
In this paper, we devise strategies to convert Neon Intrinsics types to RVV Intrinsics types. We also analyze commonly used conversion methods in SIMDe and develop customized conversions for each function based on the results of RVV code generation. Neon Intrinsics types have lengths of 64 bits and 128 bits, while the type length of RVV Intrinsics is determined by the hardware implementation. This poses challenges in directly substituting Neon Intrinsics types with RVV Intrinsics types. Currently, SIMDe project does not yet have an implementation for converting instruction sets to the vector length agnostic (vla) architecture. Additionally, there are many Intrinsics in Neon that can not be directly replaced one-to-one with RVV Intrinsics. That makes it a
## Abstract
Many libraries, such as OpenCV, FFmpeg, XNNPACK, and Eigen, utilize Arm or x86 SIMD Intrinsics to optimize programs for performance. With the emergence of RISC-V Vector Extensions (RVV), there is a need to migrate these performance legacy codes for RVV. Currently, the migration of NEONcode to RVV code requires manual rewriting, which is a time-consuming and error-prone process. In this work, we use the open source tool, "SIMD Everywhere" (SIMDe), to automate the migration. Our primary task is to enhance SIMDe to enable the conversion of ARM NEON Intrinsics types and functions to their corresponding RVV Intrinsics types and functions. For type conversion, we devise strategies to convert Neon Intrinsics types to RVV Intrinsics by considering the vector length agnostic (vla) architectures. With function conversions, we analyze commonly used conversion methods in SIMDe and develop customized conversions for each function based on the results of RVV code generations. In our experiments with Google XNNPACK library, our enhanced SIMDe achieves speedup ranging from 1.51x to 5.13x compared to the original SIMDe, which does not utilize customized RVV implementations for the conversions.
## 1 Introduction
Many libraries, such as ComputeLibrary [1], OpenCV [5], FFmpeg [17], XNNPACK [4], and Eigen [9], utilize Arm or x86 SIMD Intrinsics to optimize specific core algorithms and leverage the parallel processing capabilities of SIMD. With the emergence of RISC-V Vector Extensions (RVV) [11], there is a need to migrate these libraries and legacy codes to take advantage of RVV instructions for improved performance on RISC-V platforms. Figure 1 illustrates key applications that can benefit from the migration flow of Neon intrinsics to RVV intrinsics [12]. Our migration from ARM NEON Intrinsics
Figure 1. Key Applications Benefit from the Optimized Intrinsics Migration Flow for RVV
<details>
<summary>Image 1 Details</summary>
### Visual Description
\n
## Diagram: NEON-RVV Intrinsics Migration
### Overview
The image is a diagram illustrating the components feeding into a "Proposed NEON-RVV Intrinsics Migration". It depicts eight different software/library components arranged horizontally above converging arrows that point to the migration proposal. Each component is labeled with its name and a brief description.
### Components/Axes
The diagram consists of the following components, arranged horizontally from left to right:
1. **Android Runtime:** "Software for Android operating system"
2. **OpenCV:** "Open-source computer vision"
3. **FFmpeg:** "Multimedia processing library"
4. **Tensorflow Lite:** "Lightweight ML deployment"
5. **ARM Compute Library:** "ARM-optimized computing functions"
6. **Android APP:** "JNI with neon intrinsic"
7. **XNNPACK:** "Optimized solution for neural network inference"
8. **Eigen:** "High-performance linear algebra"
Below these components is a rectangular box labeled:
**Proposed NEON-RVV Intrinsics Migration**
Arrows converge from each component towards this box.
### Detailed Analysis or Content Details
The diagram does not contain numerical data or axes. It is a visual representation of dependencies or inputs to a proposed migration. The components are positioned in a single row, with the migration proposal positioned centrally below them. The arrows indicate a flow of information or dependency towards the migration.
### Key Observations
The diagram highlights the diverse range of software components involved in the proposed NEON-RVV Intrinsics Migration. These components span operating system runtime, computer vision, multimedia processing, machine learning, and numerical computation. The inclusion of "JNI with neon intrinsic" suggests a focus on leveraging existing Neon intrinsics during the migration process.
### Interpretation
The diagram suggests that the "Proposed NEON-RVV Intrinsics Migration" aims to integrate or optimize these eight components with a new architecture (RVV). The convergence of arrows indicates that the migration will likely involve modifications or adaptations to each of these components. The diversity of the components suggests a broad scope for the migration, potentially impacting various aspects of Android software development and performance. The diagram doesn't provide details on *how* the migration will be achieved, only *what* components are involved. The emphasis on Neon intrinsics suggests a phased approach, potentially leveraging existing optimizations before fully transitioning to RVV. The diagram is a high-level overview and doesn't delve into the technical specifics of the migration process.
</details>
challenge to effectively utilize RVV Intrinsics to achieve the functionality of Neon Intrinsics. In our work, we adopt the new proposal from LLVM that D145088 [2] proposes a fixed-size attribute for RISC-V Vector Extensions types , which allows declaring fixed-length RVV Intrinsics types given the length of a single register, making it easier to map NEON types to RVV types. Overall, we predominantly use customized RVV Intrinsics implementations for the conversions. The experiment shows our SIMDe achieved speedup ranging from 1.51x to 5.13x compared to the original SIMDe, which did not utilize customized RVV implementations for the conversions, when using XNNPACK as our benchmark. This work builds upon our prior efforts to enhance RISC-V software environments [6, 7, 13-16, 18, 19]. Our previous work sets the stage for the next step in advancing the RISC-V ecosystem.
The remainder of the paper is organized as follows. In Section 2, we first introduce the Neon and RVV instruction sets. Next, in Section 3.1, we introduce the SIMD Everywhere design pattern for intrinsics function and type conversion. Next, we detail our strategies for leveraging SIMD Everywhere to migrate ARM NEON Intrinsics to RISC-V Vector Extensions Intrinsics in Sections 3.2 and 3.3. We explain how to use SIMD Everywhere for code porting in Section 3.4. Finally, in Section 4, we present the experimental results, comparing the native SIMDe with our RVV-enhanced SIMDe.
## 2 Background
## 2.1 Neon
ArmNeonis an single instruction multiple data (SIMD) architecture extension for the Arm Cortex-A and Arm Cortex-R series of processors with capabilities that vastly improve use cases on mobile devices, such as multimedia encoding/decoding, user interface, 2D/3D graphics, and gaming. Arm Neon has a total of 4344 Intrinsics. Table 1 categorizes the total number of Intrinsics by their Return base type.
Table 1. Categorization of Neon Intrinsics with types
| Return base type | Intrinsics counts |
|--------------------|---------------------|
| int | 1279 |
| uint | 1448 |
| float | 834 |
| poly | 371 |
| void | 331 |
| bfloat | 81 |
## 2.2 RISC-V Vector Extensions
RISC-V Vector Extension (RVV) is an optional addition to the base RISC-V ISA, providing parallel computing capabilities. Unlike the RISC-V P extension [10], which uses generalpurpose registers (GPR) for packed-SIMD execution, RVV introduces a separate vector register file with 32 registers dedicated to SIMD operations. One notable feature of RVV is its flexibility in defining the vector length. Instead of being a fixed architectural constant, the vector length is determined by the implementation, allowing different microarchitectures to have varying vector lengths. This flexibility enables RVV programs to automatically scale across different implementations without the need for recompilation or rewriting.
## 3 Migration Strategies
## 3.1 SIMD Everywhere
SIMD Everywhere (SIMDe) [3] is a header-only library designed to convert SIMD code across different architectures. It enables rapid transformation of SIMD libraries, enhancing the portability of SIMD code and reducing the time required for programmers to port SIMD libraries. SIMDe leverages the reuse of types and function conversions between various architectures, employing a general conversion approach. Regarding type conversions, SIMDe utilizes a union as a generic type. Within this union, besides the architecture-specific simd vector type variables, there is also a declaration of a type that is universally applicable across different architectures, typically an array or a variable with vector attributes. For example, Listing 1 is a universal int32x4 union used to convert NEON to other implementations. When the target ISA is SSE2, NEON, or WebAssembly, the union declares the corresponding simd vector types. Additionally, in all cases, a variable with vector attributes is also declared. In this work, we enhance SIMDe with the RVV target.
As for function conversions, SIMDe employs specific ISA intrinsics for conversion and also utilizes compiler-specific vector extensions, built-in functions, and auto vectorization hints in a general conversion approach to enhance the portability of the SIMDe framework. For example, in Listing 2, the code converts Neon Intrinsics to other implementations. If the target ISA is Neon, AltiVec, SSE2, or WebAssembly,
```
typedef union {
int32_t values __attribute__((__vector_size__(16)));
#if defined(SIMDE_X86_SSE2_NATIVE)
__m128i m128i;
#endif
#if defined(SIMDE_ARM_NEON_A32V7_NATIVE)
int32x4_t neon;
#endif
#if defined(SIMDE_WASM_SIMD128_NATIVE)
v128_t v128;
#endif
} simde_int32x4_private;
```
Listing 1. int32x4 union
Neon Intrinsic vaddq\_s32 is transformed into the corresponding ISA implementation. If the target ISA is not one of the aforementioned options, the code utilizes variables with vector attributes for computations or auto vectorizes the scalar implementation. In our case for RVV, we can utilize LLVM backend for RVV so that the auto-vectorization flow can be obtained with a baseline solution. We further enhance the flow with RVV intrinsics in the transformation.
```
implementation. In our case for RVV, we can utilize LLVM backend for RVV so that the auto-vectorization flow can be obtained with a baseline solution. We further enhance the flow with RVV intrinsics in the transformation.
SIMDE_FUNCTION_ATTRIBUTES
simde_int32x4_t
simde_vaddq_s32(simde_int32x4_t a, simde_int32x4_t b) {
#if defined(SIMDE_ARM_NEON_A32V7_NATIVE)
return vaddq_s32(a, b);
#elif defined(SIMDE_POWER_ALTIVEC_P6_NATIVE)
return vec_add(a, b);
#else
simde_int32x4_private
r_,
a_ = simde_int32x4_to_private(a),
b_ = simde_int32x4_to_private(b);
#if defined(SIMDE_X86_SSE2_NATIVE)
r_.m128i = _mm_add_epi32(a_.m128i, b_.m128i);
#elif defined(SIMDE_WASM_SIMD128_NATIVE)
r_.v128 = wasm_i32x4_add(a_.v128, b_.v128);
#elif defined(SIMDE_VECTOR_SUBSCRIPT_OPS)
r_.values = a_.values + b_.values;
#else
clang loop vectorize(enable)
for (size_t i = 0 ; i < (sizeof(r_.values) / sizeof(r_.values[i])) ; i++) {
r_.values[i] = a_.values[i] + b_.values[i];
}
#endif
return simde_int32x4_from_private(a_);
#endif
return simde_int32x4_from_private(r_);
#endif
}
```
Listing 2. Neon intrinsics vaddq\_s32 conversion
## 3.2 Migration Strategies with Type Conversion
Neon Intrinsics types have lengths of 64 bits and 128 bits, while the type length (vlen) of RVV Intrinsics is determined by the hardware implementation. This makes it difficult to directly substitute Neon Intrinsics types with RVV Intrinsics types. Additionally, because RVV vlen is known at runtime, RVV Intrinsics types are sizeless types. Sizeless types have greater limitations, such as not being able to be declared in global variables, structs, or unions. This poses a challenge when replacing Neon Intrinsics types within specific areas. To address the inconvenience of sizeless types, LLVM recently introduced a new attribute for RVV Intrinsics types. With this attribute, RVV Intrinsics types can be treated as fixed-size vectors when the architecture's vlen is known.
To perform type conversion, we modify simde/arm/neon/types.h so that it includes corresponding RVV Intrinsics types. Since Neon Intrinsics types have lengths of 64 bits and 128 bits, we consider that for effective substitution, RVV vlen should be at least 64 bits for replacing Neon 64-bit types, and at least 128 bits for replacing Neon 128-bit types. This allows for substitution without relying on loops for operations. Additionally, in RVV, the number of processed elements is determined by setting vector length register vl. RVV vlen only restricts the maximum number of processed elements and does not solely determine it. Therefore, as long as the RVV vlen is greater than the vector length of Neon, type substitution can be performed. Listing 3 shows the code that adds RVV types to Neon generic int32x4 type. The variable "\_\_riscv\_v\_fixed\_vlen" determines the length of RVV vector, which is currently determined by the compiler flag.
```
typedef vint32m1_t fixed_vint32m1_t __attribute__((riscv_rvv_vector_bits(__riscv_v_fixed_vlen)));
typedef union {
...
#if defined(SIMDE_RISCV_V_NATIVE) && SIMDE_NATURAL_VECTOR_SIZE >= 128
fixed_vint32m1_t sv128;
#endif
...
} simde_int32x4_private;
```
Listing 3. int32x4 union with RVV type
Since the size of the union depends on the size of the largest variable, when the size of the Neon type is smaller than the size of the RVV type, the size of the union increases. Currently, in the conversion implementation of store intrinsics in SIMDe, memcpy is used to copy a number of bytes equal to the size of the union from the memory location of the union to the destination memory address. This can lead to errors in SIMDe during partial conversions. Therefore, regardless of the quality of SIMDe's original implementation,
in this scenario, we use customized RVV Intrinsics implementation to correctly store the desired number of elements in memory, as shown in the code in Listing 4.
```
void
simde_vst1q_s32(int32_t ptr[HEDLEY_ARRAY_PARAM(4)], simde_int32x4_t val) {
...
simde_int32x4_private val_ =
simde_int32x4_to_private(val);
#if defined(SIMDE_RISCV_V_NATIVE) && (SIMDE_NATURAL_VECTOR_SIZE >= 128)
--riscv_vse32_v_i32m1(ptr , val_.sv128 , 4); // Ensure that we save the correct number of elements into memory.
#else
simde_memcpy(ptr, &val_, sizeof(val_));
#endif
#endif
}
Listing 4. Neon intrinsics vst1q_s32 conversion
```
Listing 4. Neon intrinsics vst1q\_s32 conversion
If there is no corresponding RVV type for a Neon type, the RVV type variable is not declared in the union. Possible scenarios include:
1. If vlen is less than 64 bits, substitution is not straightforward for Neon 64-bit types.
2. If vlen is less than 128 bits, substitution is not straightforward for Neon 128-bit types.
3. Without the Zvfh extension, f16 vectors can not be replaced straightforwardly in RVV.
In cases where substitution is not possible, the variables with vector attribute in the union can still be used for intrinsics conversion. Table 2 is the mapping table for RVV and Neon types, assuming that the Zvfh extension is enabled. LLVM D145088 proposes a fixed-length attribute for RVV intrinsics type with LMUL=1. Therefore, we currently use RVV intrinsics type with LMUL=1 for the conversion.
## 3.3 Migration Strategies with Function Conversion
Here are five commonly used conversion methods in the SIMDe framework.
1. Utilizing ISA-specific Intrinsics functions
2. Utilizing vector built-in functions.
3. Performing vector operations utilizing variables with vector attributes.
4. Vectorizing scalar implementations through the compiler's auto-vectorization pass.
5. Combine other functions.
Currently, SIMDe has implementations for converting Neon intrinsics to generic architecture code. However, since there is no specific implementation for converting Neon Intrinsics to RVV Intrinsics, it can only utilize vector attributes or use compiler auto-vectorization pass implementations.
Unfortunately, these methods are unable to generate the optimal RVV code in many cases. Overall, in our design, we
Table 2. Mapping table for Neon types and RVV types with fixed-size attribute
| Neon | vlen<64 | 64<=vlen<128 | vlen>=128 |
|-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|---------------------------------------------|--------------------------------------------------------------------------------------------------------------------------------------------------------|---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| int8x8_t int16x4_t int32x2_t int64x1_t uint8x8_t uint16x4_t uint32x2_t uint64x1_t float16x4_t float32x2_t float64x1_t int8x16_t int16x8_t int32x4_t int64x2_t uint8x16_t uint16x8_t uint32x4_t uint64x2_t float16x8_t float32x4_t float64x2_t | x x x x x x x x x x x x x x x x x x x x x x | vint8m1_t vint16m1_t vint32m1_t vint64m1_t vuint8m1_t vuint16m1_t vuint32m1_t vuint64m1_t vfloat16m1_t vfloat32m1_t vfloat64m1_t x x x x x x x x x x x | vint8m1_t vint16m1_t vint32m1_t vint64m1_t vuint8m1_t vuint16m1_t vuint32m1_t vuint64m1_t vfloat16m1_t vfloat32m1_t vfloat64m1_t vint8m1_t vint8m1_t vint8m1_t vint8m1_t vint8m1_t vint8m1_t vint8m1_t vint8m1_t vfloat16m1_t vfloat32m1_t vfloat64m1_t |
present customized RVV Intrinsics implementations for the conversions and have implemented conversions for a total of 1520 Intrinsics. RVV has many Intrinsics that have the same functionality as Neon Intrinsics and can be directly substituted one to one. For some Intrinsics, by combining a few RVV Intrinsics, we can achieve the same functionality as the corresponding Neon Intrinsics. For example, Listing 5 provides the code for converting Neon's vget\_high\_s32 using a customized RVV Intrinsics implementation. Neon "get\_high" Intrinsics is used to extract the upper N/2 elements from a vector of width N and generate a new vector of width N/2. We replaced it with RVV "slidedown" Intrinsics, which shifts the vector elements down by a specified number of positions.
Listing 6 presents another example for converting Neon's vceqq\_s32 using a customized RVV Intrinsics implementation. Neon "ceq" Intrinsics compare two vectors, and if the corresponding elements are equal, it sets all the bits of the corresponding elements in the result vector to 1; otherwise, it sets them to 0. We achieve the same functionality by combining different RVV instructions. In this process, the vmv instruction is used to generate a vector, vs\_0, with all elements set to 0. Then, the vmseq instruction compares the corresponding elements of the two vectors and generates a mask vector. Finally, the vmerge function combines vs\_0
```
SIMD Everywhere Optimization NOLON to RISc-V vector Extensions
simde_int32x2_t
simde_vget_high_s32(simde_int32x4_t a) {
...
simde_int32x2_private r_;
simde_int32x4_private a_ =
simde_int32x4_to_private(a);
#if defined(SIMDE_RISCV_V_NATIVE)
&& (SIMDE_NATURAL_VECTOR_SIZE >= 128)
r_.sv64 = __riscv_vlslidedown_vx_i32m1(a_.sv128 , 2 , 4);
...
return simde_int32x2_from_private(r_);
#endif
}
```
Listing 5. Neon intrinsics vget\_high\_s32 conversion
and -1 based on the mask vector, resulting in the final output vector.
```
and -1 based on the mask vector, resulting in the final output
vector.
vuint8m1_t mask;
simde_vceqq_s32(simde_int32x4_t a, simde_int32x4_t b) {
...
simde_uint32x4_private r_;
simde_int32x4_private
a_ = simde_int32x4_to_private(a),
b_ = simde_int32x4_to_private(b);
#if defined(SIMDE_RISCV_V_NATIVE)
&& (SIMDE_NATURAL_VECTOR_SIZE >= 128)
vuint32m1_t vs_0 = __riscv_vmv_v_x_u32m1(UINT32_C(0), 4);
vbool32_t mask = __riscv_vmseq_vv_i32m1_b32(a_.sv128, b_.sv128, 4);
r_.sv128 = __riscv_vmmerge_vxm_u32m1(vs_0, -1, mask, 4);
}
Listing 6. Neon intrinsics vceqq_s32 conversion
```
Listing 6. Neon intrinsics vceqq\_s32 conversion
We now give an example that Neon Intrinsics may require more complex conversions. This example is for Neon 'rbit' Intrinsics, which reverses the bit order of each element in a vector. To achieve the same functionality using RVV, we refer to Edwin Freed's article 'Binary Magic Numbers' from Dr. Dobb's Journal 1983 [8] for the bit reverse solution. Listing 7 provides code implementing an algorithm that reverses the bit order in an unsigned integer 'v'. It accomplishes the result by swapping odd and even bits, consecutive pairs of bits, nibbles (groups of 4 bits), bytes (groups of 8 bits), and 2-byte long pairs through a series of bitwise operations and shifts. We implement a SIMD version of this algorithm using RVV bitwise operation intrinsics.
```
v = ((v >> 1) & 0x555555555) | ((v & 0x555555555) << 1);
v = ((v >> 2) & 0x333333333) | ((v & 0x333333333) << 2);
```
Listing 7. Bit reverse solution
```
```
While we primarily use customized RVV implementations, we also retain the use of vector attributes in certain cases. These cases include situations where Neon Intrinsics types in the parameters can not be replaced with RVV types, as well as Intrinsics that are specifically designed for simple vector arithmetic or shift operations. Using vector attributes for such Intrinsics often leads to optimal RVV code generation. This ensures that we can produce optimal RVV code and maximize the reuse of conversions in SIMDe. Listing 8 provides the code for converting Neon's simde\_vaddq\_s32 using variables with vector attributes.
```
x4_t
SIMDE_FUNCTION_ATTRIBUTES
simde_int32x4_t
simde_vaddq_s32(simde_int32x4_t a, simde_int32x4_t b) {
...
simde_int32x4_private
r_,
a_ = simde_int32x4_to_private(a),
b_ = simde_int32x4_to_private(b);
...
#elif defined(SIMDE_VECTOR_SUBSCRIPT_OPS)
r_.values = a_.values + b_.values;
return simde_int32x4_from_private(r_);
#endif
}
```
Listing 8. Neon intrinsics vaddq\_s32 conversion
## 3.4 SIMDe Usage
The usage of SIMDe is straightforward. Simply includes the SIMDe header file in the code that needs to be converted. In Listing 9, the code uses our RVV-enhanced SIMDe header file to convert the vector addition code implemented with Neon Intrinsics, we include neon.h header file in line 3. After compilation, it produces the RVV code shown in Listing 10. In lines 7 and 10, the Neon vld1q\_s32 instruction is converted to the RVV vle32 instruction. In line 11, the Neon vaddq\_s32 instruction is converted to the RVV vadd instruction. Finally, in line 12, the Neon vst1q\_s32 instruction is converted to the RVV vse32 instruction.
## 4 Experiments
## 4.1 Validation Workflow
SIMDe includes unit tests for converting Neon code to other ISAs. These unit tests validate each instruction using multiple test cases to ensure the conversion functions correctly under
```
#include <stdio.h>
#define SIMDE_ENABLE_NATIVE_ALIASES
#include "simde/arm/neon.h" // header file for conversion Neon to RVV
int A[] = { 0 , 1 , 2 , 3 };
int B[] = { 4 , 5 , 6 , 7 };
int main(void){
int32x4_t va , vb , vc;
va = vld1q_s32(A);
vb = vld1q_s32(B);
va = vaddq_s32(va , vb);
vb = vaddq_s32(vb , A[0]);
return 0;
}
```
Listing 9. Neon vector addition
```
<main>:
sp,sp,-16
sd ra,8(sp)
lui a0,0x1e
add a1,a0,1800 # 1e708 <A>
vsetivli zero,4,e32,m1,ta,ma
vle32.v v8,(a1) // va = vld1q_s32(A);
lui a2,0x1e
add a2,a2,1816 # 1e718 <B>
vle32.v v9,(a2) // vb = vld1q_s32(B);
vadd.vv v8,v8,v9 // va = vaddq_s32(va , vb);
vse32.v v8,(a1) // vst1q_s32(A , va);
lw a1,1800(a0)
lui a0,0x1c
add a0,a0,2000 # 1c7d0 <__clzdi2+0x42>
jal 1034c <printf>
li a0,0
ld ra,8(sp)
add sp,sp,16
```
Listing 10. RVV vector addition
different scenarios. We reused the unit tests within SIMDe and validated them using Spike simulator.
## 4.2 Benchmark Experiments
We use XNNPACK as our benchmark. XNNPACK is an opensource software library developed by the Google team, aims to optimize neural network computations across different hardware platforms. Within XNNPACK, there are various neural network computation functions implemented using NEON Intrinsics.
Experiments were conducted to compare native SIMDe with our implementation. We specifically chose 10 commonly used neural network computation functions that are implemented using NEON Intrinsics in XNNPACK. Below are brief descriptions of the 10 functions. Gemm is a highperformance function for general matrix multiplication. Convhwc is a convolution function specifically for input data arranged in the Height-Width-Channel format. Dwconv is optimized for depthwise separable convolution with reduced parameters and computation. Maxpool extracts the maximum value from each region during pooling. Argmaxpool performs maxpooling while returning the index of the maximum value. Vrelu applies the ReLU activation function element-wise. Vsqrt calculates the square root of each element in the input vector. Vtanh applies the hyperbolic tangent activation function element-wise. Vsigmoid applies the sigmoid activation function element-wise. Lastly, Ibilinear is a high-performance function specialized in performing bilinear interpolation.
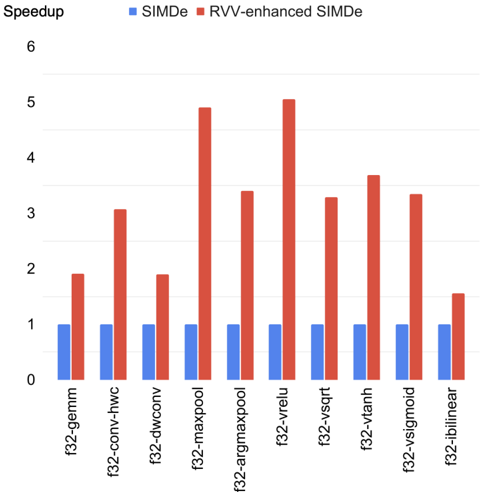
TheSIMDeheaderfile was included in these functions, and the code was compiled using Clang compiler with O3 optimization level. During the preprocessing stage, the functions accelerated with NEON Intrinsics were transformed into RVV Intrinsics. Following compilation, we executed the executable file using Spike simulator to verify correctness and calculate the instruction counts. Since Spike is a functional model rather than a cycle-accurate simulator, we employed dynamic instruction count as the performance metric instead. In this experiment, we used Spike 1.1.1 and Clang 17.0.0 ( commit hash 5326c9e480d70e16c2504cb5143524aff3ee2605 ). Figure 2 illustrates our experimental results, indicating that SIMDe achieved speedup ranging from 1.51x to 5.13x compared to the original SIMDe, which did not utilize customized RVV implementations for the conversions. The original flow goes with clang vector attributes for computations or auto vectorization of the scalar implementation. It then utilizes LLVM backend for RVV so that the clang vector attribute and the auto-vectorization flow can be obtained as a baseline solution.
## 5 Conclusion
In this paper, we use the open source tool, "SIMD Everywhere" (SIMDe), to automate the migration from Neon code to RVV code. Our primary task is to enhance SIMDe to enable the conversion of ARM NEON Intrinsics types and functions to their corresponding RVV Intrinsics types and functions. In our experiments with Google XNNPACK library, our RVVenhanced SIMDe achieves speedup ranging from 1.51x to 5.13x compared to the original SIMDe, which does not utilize customized RVV implementations for the conversions.
## References
- [1] 2023. ComputeLibrary . Retrieved June 10, 2023 from https://github. com/ARM-software/ComputeLibrary
- [2] 2023. RVV fixed length attribute . Retrieved June 10, 2023 from https: //reviews.llvm.org/D145088
- [3] 2023. SIMD Everywhere . Retrieved June 10, 2023 from https://github. com/simd-everywhere/simde
- [4] 2023. XNNPACK . Retrieved July 7, 2023 from https://github.com/ google/XNNPACK
- [5] G. Bradski. 2000. The OpenCV Library. Dr. Dobb's Journal of Software Tools (2000).
Figure 2. RVV-enhanced SIMDe Performance Comparison
<details>
<summary>Image 2 Details</summary>
### Visual Description
## Bar Chart: Speedup Comparison of SIMDe vs. RVV-enhanced SIMDe
### Overview
This bar chart compares the speedup achieved by two methods: SIMDe (Single Instruction Multiple Data extension) and RVV-enhanced SIMDe (Radeon Vector Vision enhanced SIMDe) across various operations. The chart displays the speedup factor for each operation, with bars representing the performance of each method.
### Components/Axes
* **Y-axis:** "Speedup" ranging from 0 to 6, with tick marks at intervals of 1.
* **X-axis:** Represents different operations: "f32-gemm", "f32-conv-hwc", "f32-dconv", "f32-maxpool", "f32-argmaxpool", "f32-vrelu", "f32-vsqrt", "f32-vtanh", "f32-vsigmoid", "f32-ibilinear".
* **Legend:** Located at the top-left corner, distinguishing between "SIMDe" (represented by blue bars) and "RVV-enhanced SIMDe" (represented by red bars).
### Detailed Analysis
The chart consists of paired bars for each operation, one blue (SIMDe) and one red (RVV-enhanced SIMDe).
* **f32-gemm:** SIMDe speedup is approximately 0.8. RVV-enhanced SIMDe speedup is approximately 2.1.
* **f32-conv-hwc:** SIMDe speedup is approximately 1.1. RVV-enhanced SIMDe speedup is approximately 3.4.
* **f32-dconv:** SIMDe speedup is approximately 0.9. RVV-enhanced SIMDe speedup is approximately 2.0.
* **f32-maxpool:** SIMDe speedup is approximately 0.7. RVV-enhanced SIMDe speedup is approximately 4.8.
* **f32-argmaxpool:** SIMDe speedup is approximately 1.0. RVV-enhanced SIMDe speedup is approximately 3.5.
* **f32-vrelu:** SIMDe speedup is approximately 1.2. RVV-enhanced SIMDe speedup is approximately 5.2.
* **f32-vsqrt:** SIMDe speedup is approximately 1.1. RVV-enhanced SIMDe speedup is approximately 3.7.
* **f32-vtanh:** SIMDe speedup is approximately 1.2. RVV-enhanced SIMDe speedup is approximately 3.9.
* **f32-vsigmoid:** SIMDe speedup is approximately 1.0. RVV-enhanced SIMDe speedup is approximately 3.4.
* **f32-ibilinear:** SIMDe speedup is approximately 1.1. RVV-enhanced SIMDe speedup is approximately 2.2.
For all operations, the RVV-enhanced SIMDe consistently demonstrates a higher speedup than the standard SIMDe.
### Key Observations
* The largest speedup difference between the two methods is observed in "f32-vrelu" (RVV-enhanced SIMDe speedup of ~5.2 vs. SIMDe speedup of ~1.2).
* The smallest speedup difference is observed in "f32-gemm" (RVV-enhanced SIMDe speedup of ~2.1 vs. SIMDe speedup of ~0.8).
* SIMDe speedups generally range between 0.7 and 1.2.
* RVV-enhanced SIMDe speedups generally range between 2.0 and 5.2.
### Interpretation
The data strongly suggests that incorporating Radeon Vector Vision (RVV) significantly enhances the performance of SIMDe operations. The consistent and substantial speedups across all tested operations indicate that RVV is an effective optimization for these types of computations. The variation in speedup across different operations suggests that the benefits of RVV may be more pronounced for certain operations (like "f32-vrelu") than others (like "f32-gemm"). This could be due to the specific characteristics of each operation and how well they align with the RVV architecture. The chart provides compelling evidence for the advantages of using RVV-enhanced SIMDe for improved computational efficiency.
</details>
- [6] Chuanhua Chang, Chun-Ping Chung, Yu-Tse Huang, Chao-Lin Lee, Jenq-Kuen Lee, Yu-Wen Shao, Charlie Su, Chia-Hui Su, Bow-Yaw Wang, and Ti-Han Wu. 2021. Sail Specification for RISC-V P-Extension. RISC-V Summit, San Francisco, Dec 5-8, 2021. (2021).
- [7] Yi-Ru Chen, Hui-Hsin Liao, Chia-Hsuan Chang, Che-Chia Lin, ChaoLin Lee, Yuan-Ming Chang, Chun-Chieh Yang, and Jenq-Kuen Lee. 2020. Experiments and optimizations for TVM on RISC-V architectures with p extension. In 2020 International Symposium on VLSI Design, Automation and Test (VLSI-DAT) . IEEE, 1-4.
- [8] Edwin Freed. 1983. Binary Magic Numbers: Efficient Bit Reversal Techniques. Dr. Dobb's Journal (1983).
- [9] Gaël Guennebaud, Benoît Jacob, et al. 2010. Eigen v3. http://eigen.tuxfamily.org.
- [10] RISC-V International. 2023. riscv-p-spec . Retrieved July 7, 2023 from https://github.com/riscv/riscv-p-spec
- [11] RISC-V International. 2023. riscv-v-spec . Retrieved July 7, 2023 from https://github.com/riscv/riscv-v-spec
- [12] RISC-V International. 2023. rvv-intrinsic-doc . Retrieved July 7, 2023 from https://github.com/riscv-non-isa/rvv-intrinsic-doc
- [13] Hung-Ming Lai and Jenq-Kuen Lee. 2022. Efficient Support of the Scan Vector Model for RISC-V Vector Extension. In Workshop Proceedings of the 51st International Conference on Parallel Processing . 1-8.
- [14] Jenq-Kuen Lee, Yi-Ru Chen, Chia-Hsuan Chang, Hui-Hsin Liao, ChaoLin Lee, Chun-Chieh Yang, Che-Chia Lin, Yuan-Ming Chang, ChunPing Chung, and Ming-Han Yang. 2020. Enable TVM QNN on RISC-V with Subword SIMD Computation. In TVM and Deep Learning Compilation Conference, Seattle, Dec 2020, (Virtual Conference, lightning talk and slides) .
- [15] Jenq-Kuen Lee and Hung-Ming Lai. 2023. Efficient Support of TVM Scan OP on RISC-V Vector Extension. TVMcon, Seattle, March 15-17, 2023, (Virtual Conference, lightning talk and slides). (2023).
- [16] Che-Chia Lin, Chao-Lin Lee, Jenq-Kuen Lee, Howard Wang, and MingYu Hung. 2021. Accelerate binarized neural networks with processingin-memory enabled by RISC-V custom instructions. In 50th International Conference on Parallel Processing Workshop . 1-8.
- [17] Suramya Tomar. 2006. Converting video formats with FFmpeg. Linux journal 2006, 146 (2006), 10.
- [18] Chun-Chieh Yang, Yi-Ru Chen, Hui-Hsin Liao, Yuan-Ming Chang, and Jenq-Kuen Lee. 2023. Auto-tuning Fixed-point Precision with TVMon RISC-V Packed SIMD Extension. ACM Transactions on Design Automation of Electronic Systems 28, 3 (2023), 1-21.
- [19] Chuan-Yue Yuan, Meng-Shiun Yu, Chao-Lin Lee, Chun-Chieh Yang, and Jenq-Kuen Lee. 2021. Optimization with TVM Hybrid OP on RISC-V with P Extension. TVMcon, Seattle, Dec. 15-17, 2021, (Virtual Conference, lightning talk and slides (2021).