## Towards Better Chain-of-Thought Prompting Strategies: A Survey
Zihan Yu Liang He Zhen Wu ∗ Xinyu Dai Jiajun Chen
National Key Laboratory for Novel Software Technology, Nanjing University, China Collaborative Innovation Center of Novel Software Technology and Industrialization, China {zihan.y, heliang}@smail.nju.edu.cn {wuz, daixinyu, chenjj}@nju.edu.cn
## Abstract
Chain-of-Thought (CoT), a step-wise and coherent reasoning chain, shows its impressive strength when used as a prompting strategy for large language models (LLM). Recent years, the prominent effect of CoT prompting has attracted emerging research. However, there still lacks of a systematic summary about key factors of CoT prompting and comprehensive guide for prompts utilizing. For a deeper understanding about CoT prompting, we survey on a wide range of current research, presenting a systematic and comprehensive analysis on several factors that may influence the effect of CoT prompting, and introduce how to better apply it in different applications under these discussions. We further analyze the challenges and propose some future directions about CoT prompting. This survey could provide an overall reference on related research.
## 1 Introduction
Recent years, large language models (LLM) with prompting strategies have achieved prominent performance on many traditional NLP benchmarks (Brown et al., 2020; Cui et al., 2021; Chowdhery et al., 2022; Chung et al., 2022; Li et al., 2022a). But some work finds vanilla prompting strategies still struggle to improve LLM performance on multi-step tasks (Wei et al., 2022b; Kojima et al., 2022; Lyu et al., 2023; Shao et al., 2023).
Based on natural step-by-step thinking ability of humans, Chain-of-Thought (CoT) prompting is proposed for LLM to solve multi-step reasoning problems (Wei et al., 2022b). This prompting strategy tries to incorporate intermediate steps to guide a progressive reasoning, achieving surprising improvement on many reasoning benchmarks (Wei et al., 2022b; Wang et al., 2022e) even in some special scenarios including cross-domain (Huang et al., 2022), length-generalization (Anil
∗ *Corresponding author
et al., 2022; Zhou et al., 2022a) and cross-lingual reasoning (Shi et al., 2022a). Additionally, CoT prompting ensures a logical and traceable reasoning process, which is more interpretable for humans (Jung et al., 2022; Weng et al., 2022).
The impressive result of CoT prompting provokes an upsurge of explorations on CoT prompting strategies design across different tasks on different models (Shao et al., 2023; Wang et al., 2022e; Khot et al., 2022; Zhou et al., 2022a). But before designing a specific strategy, it's necessary to systematically understand what factors may influence the performance of CoT prompting. Besides, although CoT prompting shows its advantages in reasoning tasks, it still has some limitations on generality and concerning on its opaque mechanism as well as unfaithful generation (Lyu et al., 2023; Shi et al., 2022a; Suzgun et al., 2022; Zhang et al., 2023b). To better guide further work, it is essential to make a discussion on current challenges of CoT. Existing surveys lack of a specialized formulation as well as a deep analysis on CoT prompting. We discuss existing surveys and compare them to our work in Appendix A.
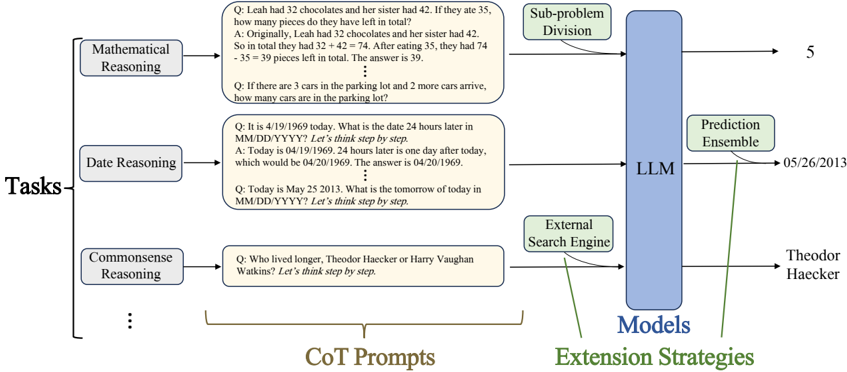
This survey presents a comprehensive and systematic analysis of the CoT prompting effect, making several noteworthy contributions to this field. First, we formalize the CoT prompting and summarize the pipeline when using it (as shown in Figure 1), which forms the basis of our analysis and discussions. Then, we identify four key factors that significantly affect the performance of CoT prompting: task types, prompts design, extension strategies, and models. We conduct a detailed exploration on how these factors impact the prompting effect and introduce innovative methods inspired by them. Moreover, we provide a comprehensive vision of current challenges of CoT prompting and outline numerous opportunities for future research.
Figure 1: Illustration of the general pipeline to utilize Chain-of-Thought prompting strategy. Given a specific task, CoT prompts are designed on it. With the assistance of optional extension strategies, models predict the answers (typically with CoT rationales) based on the input prompts.
<details>
<summary>Image 1 Details</summary>
### Visual Description
## Diagram: LLM Task Processing Architecture
### Overview
The diagram illustrates a technical architecture for processing reasoning tasks using a Large Language Model (LLM) with extension strategies. It shows a flow from task categorization through model processing to prediction enhancement.
### Components/Axes
1. **Left Panel (Tasks)**:
- **Mathematical Reasoning**: Example question about chocolate quantities (32 + 42 - 35 = 39)
- **Date Reasoning**: Example question about date calculation (1969-04-19 + 24h = 1969-04-20)
- **Commonsense Reasoning**: Example question comparing lifespans of Theodore Haecker and Harry Vaughan Watkins
- Visual structure: Three labeled boxes with example questions in beige text boxes
2. **Center Panel (CoT Prompts)**:
- Contains example prompts with "Let's think step by step" instructions
- Connects Tasks to LLM via arrows
3. **Right Panel (Models)**:
- Central blue rectangle labeled "LLM"
- Arrows from CoT Prompts and Tasks pointing to LLM
- Arrows from LLM to Extension Strategies
4. **Bottom Panel (Extension Strategies)**:
- **Prediction Ensemble**: Connected to LLM with arrow
- **External Search Engine**: Connected to LLM with arrow
- Example answer: "Theodor Haecker" (from Commonsense Reasoning task)
### Detailed Analysis
- **Flow Direction**:
Tasks → CoT Prompts → LLM → Extension Strategies
- **Key Connections**:
- Mathematical/Date/Commonsense tasks feed into CoT prompts
- CoT prompts and raw tasks both connect to LLM
- LLM outputs connect to both Prediction Ensemble and External Search Engine
- **Textual Elements**:
- All example questions use "Let's think step by step" format
- Final answer format: "The answer is [value]"
- Final answer example: "Theodor Haecker" (from Commonsense task)
### Key Observations
1. The architecture emphasizes multi-step reasoning through Chain-of-Thought (CoT) prompting
2. External search capabilities are integrated at the final prediction stage
3. Mathematical and date reasoning tasks show explicit numerical examples
4. Commonsense reasoning uses historical figure comparison as test case
### Interpretation
This architecture demonstrates a hybrid approach to LLM reasoning:
1. **Task Categorization**: Problems are first classified into mathematical, temporal, or commonsense domains
2. **Structured Reasoning**: CoT prompts enforce step-by-step logical decomposition
3. **Model Processing**: The LLM acts as the core reasoning engine
4. **Prediction Enhancement**: Final answers are refined through ensemble methods and external verification
The inclusion of both internal (CoT) and external (search engine) extension strategies suggests an emphasis on verifiable, multi-modal reasoning capabilities. The specific example answers (39 chocolates, 1969-04-20 date, Theodor Haecker) demonstrate the system's ability to handle different reasoning domains while maintaining consistent output formatting.
</details>
Overview of this survey: We first present some background knowledge in § 2 then make an introduction of CoT prompting in § 3. Subsequently, we discuss several key factors about CoT prompting including tasks (§ 4), prompts (§ 5), extension strategies (§ 6) and models (§ 7). We further discuss the challenges and future directions in § 8.
## 2 Background Knowledge
In this part, we will make a brief introduction about background knowledge before talking about CoT.
## 2.1 Large Language Models
Large Language Models (LLM) refer to huge transformer architecture models (typically above ten billions of parameters) pre-trained with massive corpus (Zhao et al., 2023). With the increment of model size and training corpus, it starts to emerge some new abilities (Wei et al., 2022a). Recent years, LLM have achieved remarkable progress in many NLP fields (Brown et al., 2020; Chowdhery et al., 2022; Chung et al., 2022).
## 2.2 Prompting and In-context-learning
Prompting is a strategy to better elicit the knowledge and ability acquired during training stage of language models by modifying the input samples in a specific manner (Liu et al., 2023; Brown et al., 2020; Schick and Schütze, 2021). In-contextlearning is a special designed prompting strategy, which prefixed the query sample with a few example demonstrations including both queries and answers (Wei et al., 2022a), enabling the model to analogously make predictions (Dong et al., 2023). In-context-learning is a training-free paradigm and can significantly boost LLM performance and dataefficiency across many NLP benchmarks on fewshot scenarios (Sun et al., 2022).
## 2.3 Reasoning on LLM
Reasoning is a complex process which involves using evidence, logically thinking and making arguments (Huang and Chang, 2022). It has been a long journey to explore the way to make neural network a reasoning machine (Peng et al., 2015; Barrett et al., 2018; Qu and Tang, 2019; Angelov and Soares, 2020). Recently, combined with incontext-learning strategy, LLM showed the prominent progress in reasoning tasks (Brown et al., 2020; Chowdhery et al., 2022; Chung et al., 2022). Especially, with assistance of Chain-of-Thought prompt (Wei et al., 2022b), neural networks made an unprecedented breakthrough on many reasoning benchmarks (Wang et al., 2022e; Lyu et al., 2023; Fu et al., 2022). Some work showed that the reasoning ability may emerge when language models are at a certain scale (Cobbe et al., 2021; Wei et al., 2022a,b; Huang and Chang, 2022).
## 3 What is Chain-of-Thought Prompting?
Before formally introducing Chain-of-Thought prompting, we first give a definition of CoT prompts. CoT prompts are special designed input sequences to instruct the model to generate co-
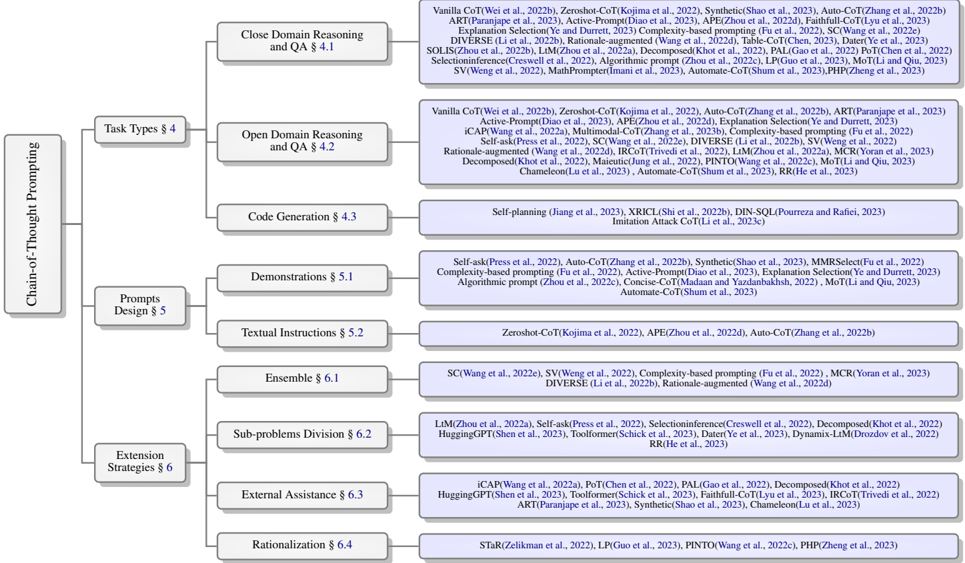
Figure 2: Taxonomy of Chain-of-Thought Prompting Strategies
<details>
<summary>Image 2 Details</summary>
### Visual Description
## Flowchart: Chain-of-Thought Prompting Framework
### Overview
The flowchart illustrates a hierarchical framework for Chain-of-Thought (CoT) prompting, categorizing techniques into three main sections: **Chain-of-Thought Prompting**, **Prompts Design**, and **Extension Strategies**. Each section contains subcategories with specific methods and associated research references.
### Components/Axes
- **Main Categories**:
1. **Chain-of-Thought Prompting**
2. **Prompts Design**
3. **Extension Strategies**
- **Subcategories and References**:
- **Task Types (§4)**:
- Close Domain Reasoning and QA (§4.1)
- Open Domain Reasoning and QA (§4.2)
- Code Generation (§4.3)
- **Prompts Design (§5)**:
- Demonstrations (§5.1)
- Textual Instructions (§5.2)
- **Extension Strategies (§6)**:
- Sub-problems Division (§6.2)
- External Assistance (§6.3)
- Rationalization (§6.4)
### Detailed Analysis
#### Chain-of-Thought Prompting
- **Task Types (§4)**:
- **Close Domain Reasoning and QA (§4.1)**:
- References: Vanilla CoT (Wei et al., 2022b), Zeroshot-CoT (Kojima et al., 2022), Synthetic (Shao et al., 2023), Auto-CoT (Zhang et al., 2022b), ART (Paranjape et al., 2023), Explanation Selection (Ye et al., 2023), DIVERSE (Li et al., 2022b), Rationale-augmented (Wang et al., 2022d), SOLIS (Zhou et al., 2022b), Selectioninference (Creswell et al., 2022), Algorithmic prompt (Zhou et al., 2022c), LP (Guo et al., 2023), MoT (Li and Qiu, 2023), SV (Weng et al., 2022), MathPrompter (Imani et al., 2023), Automate-CoT (Shum et al., 2023), PHP (Zheng et al., 2023).
- **Open Domain Reasoning and QA (§4.2)**:
- References: Vanilla CoT (Wei et al., 2022b), Zeroshot-CoT (Kojima et al., 2022), Auto-CoT (Zhang et al., 2022b), ART (Paranjape et al., 2023), Active-Prompt (Diao et al., 2023), APE (Zhou et al., 2022d), iCAP (Wang et al., 2022a), Multimodal-CoT (Zhang et al., 2023b), Complexity-based prompting (Fu et al., 2022), Self-ask (Press et al., 2022), SC (Wang et al., 2022e), DIVERSE (Li et al., 2022b), SV (Weng et al., 2022), Rationale-augmented (Wang et al., 2022d), LLM (Zhou et al., 2022d), IRCoT (Trivedi et al., 2022), Decomposed (Khot et al., 2022), Maieutic (Jung et al., 2022), PINTO (Wang et al., 2022c), MCR (Yoran et al., 2023), Chameleon (Lu et al., 2023), Automate-CoT (Shum et al., 2023), RR (He et al., 2023).
- **Code Generation (§4.3)**:
- References: Self-planning (Jiang et al., 2023), XRICL (Shi et al., 2022b), DIN-SQL (Pourreza and Rafiei, 2023), Imitation Attack CoT (Li et al., 2023c).
#### Prompts Design (§5)
- **Demonstrations (§5.1)**:
- References: Self-ask (Press et al., 2022), Auto-CoT (Zhang et al., 2022b), Synthetic (Shao et al., 2023), MMRSelect (Fu et al., 2022), Complexity-based prompting (Fu et al., 2022), Active-Prompt (Diao et al., 2023), Explanation Selection (Ye et al., 2023), Algorithmic prompt (Zhou et al., 2022c), Concise-CoT (Madaan and Yazdanbakhsh, 2022), MoT (Li and Qiu, 2023), Automate-CoT (Shum et al., 2023).
- **Textual Instructions (§5.2)**:
- References: Zeroshot-CoT (Kojima et al., 2022), APE (Zhou et al., 2022d), Auto-CoT (Zhang et al., 2022b).
#### Extension Strategies (§6)
- **Sub-problems Division (§6.2)**:
- References: LLM (Zhou et al., 2022a), Self-ask (Press et al., 2022), Selectioninference (Creswell et al., 2022), Decomposed (Khot et al., 2022), HuggingGPT (Shen et al., 2023), Toolformer (Schick et al., 2023), Dynamix-LLM (Drozdov et al., 2022), RR (He et al., 2023).
- **External Assistance (§6.3)**:
- References: iCAP (Wang et al., 2022a), PoT (Chen et al., 2022), PAL (Gao et al., 2022), Decomposed (Khot et al., 2022), HuggingGPT (Shen et al., 2023), Toolformer (Schick et al., 2023), Faithfull-CoT (Lyu et al., 2023), IRCoT (Trivedi et al., 2022), ART (Paranjape et al., 2023), Synthetic (Shao et al., 2023), Chameleon (Lu et al., 2023).
- **Rationalization (§6.4)**:
- References: STaR (Zelikman et al., 2022), LP (Guo et al., 2023), PINTO (Wang et al., 2022c), PHP (Zheng et al., 2023).
### Key Observations
1. **Research Focus**: Most references cluster around **CoT variants** (e.g., Auto-CoT, Zeroshot-CoT) and **reasoning enhancements** (e.g., DIVERSE, Rationale-augmented).
2. **Code Generation**: Limited to self-planning and imitation attack methods, suggesting a niche focus.
3. **External Assistance**: Dominated by tool integration (e.g., HuggingGPT, Toolformer) and decomposition strategies.
4. **Temporal Spread**: References span 2022–2023, indicating rapid development in this area.
### Interpretation
The flowchart maps the evolution of CoT prompting strategies, emphasizing **task-specific adaptations** (e.g., code generation) and **scalability solutions** (e.g., decomposition, external tools). The dominance of **reasoning augmentation** (DIVERSE, Rationale-augmented) highlights efforts to improve model robustness. The inclusion of **automation frameworks** (Automate-CoT) and **multi-modal approaches** (APE, IRCoT) reflects trends toward practical deployment. Notably, the absence of **human-in-the-loop** methods suggests a focus on fully automated systems. This structure provides a roadmap for researchers to identify gaps (e.g., underrepresented domains) and prioritize innovations.
</details>
herent series of intermediate reasoning steps (Wei et al., 2022b). Specially, what refers to the ' intermediate reasoning steps " shows discrepancy in different work. The scope of our survey is a more general covering of present work on prompts for multi-step tasks, which ranges from common stepwise reasoning to multi-step tasks deployment, so we encompass various non-programmatic problems division process including sub-problems decomposition (Zhou et al., 2022a; Press et al., 2022) and multi-step deployment (Khot et al., 2022; Shen et al., 2023; Schick et al., 2023) into our definition.
CoT prompting is a strategy to utilize CoT prompts, which works as following pipeline. As shown in Figure 1, given a specific task , CoT prompts are designed on it. With the assistance of optional extension strategies , models predict the answers (typically as well as CoT rationales) based on the input prompts. Above four elements in bold are key factors of CoT prompting pipeline which make significant impact on the final performance. We will separately discuss how these factors influence the prompting effect and introduce the work motivated by these factors in remaining survey. We present the taxonomy of various CoT prompting strategies in Figure 2.
## 4 Task Types
Task is the target when utilizing CoT prompting, which makes a foundational difference. Before designing CoT prompting strategies, it is necessary to clarify what types of tasks are prone to being boosted by CoT prompts.
## 4.1 Close Domain Reasoning and QA
These kinds of tasks include all necessary conditions and background knowledge in the problems. Models need to select informative materials and conduct reasoning on these materials. CoT prompts could provide a reasoning pattern to instruct how to select key materials and reason on them, showing superiority on these tasks like mathematical reasoning (Zhang et al., 2022b; Shao et al., 2023; Wang et al., 2022e), symbolic reasoning (Wei et al., 2022b; Anil et al., 2022; Suzgun et al., 2022) and table QA (Ye et al., 2023; Chen, 2023).
## 4.2 Open Domain Reasoning and QA
These kinds of tasks aim to answer questions based on a large-scale unstructured knowledge base, and don't include all of necessary knowledge in the problem. In this case, LLM are forced to use their own knowledge to solve the problems and the performance of CoT prompting highly depends on
Figure 3: Some example CoT prompts. For rationales in § 5.1.2, bridging objects are marked in red and language templates are marked in blue.
<details>
<summary>Image 3 Details</summary>

### Visual Description
## Diagram: Comparison of Chain-of-Thought (CoT) Prompts for Reasoning Tasks
### Overview
The image compares three types of CoT prompts across reasoning tasks:
1. **Mathematical Reasoning** (few-shot with textual instructions)
2. **Date Reasoning** (few-shot with textual instructions)
3. **Commonsense Reasoning** (zero-shot without textual instructions)
Each section demonstrates how prompts are structured, with color-coded elements (e.g., questions, demonstrations, answers) and textual instructions highlighted in green.
---
### Components/Axes
#### Labels and Structure
- **Legend**:
- "Textual Instructions" (highlighted in green, positioned on the far right).
- **Sections**:
1. **Mathematical Reasoning** (leftmost):
- Title: "A CoT prompt for Mathematical Reasoning"
- Subsections:
- **Demonstrations**: Labeled "Demonstrations" (blue), containing:
- **Rationale** (orange): Step-by-step reasoning.
- **Answer** (blue): Final answer.
- **Query**: Purple box with a new problem.
2. **Date Reasoning** (middle):
- Title: "A CoT prompt for Date Reasoning"
- Subsections:
- **Demonstrations**: Same structure as Mathematical Reasoning.
- **Query**: Purple box with a date-related problem.
3. **Commonsense Reasoning** (rightmost):
- Title: "A CoT prompt for Commonsense Reasoning"
- Subsections:
- **Demonstrations**: Absent (zero-shot).
- **Query**: Purple box with a commonsense question.
#### Color Coding
- **Blue**: Questions, answers, and titles.
- **Green**: Textual instructions (e.g., "Let's think step by step").
- **Orange**: Rationale (step-by-step reasoning).
- **Purple**: Queries (new problems).
- **Yellow/Red**: Highlighted text in examples (e.g., numbers in math problems).
---
### Detailed Analysis
#### Mathematical Reasoning (Few-Shot)
- **Question**: "Leah had 32 chocolates and her sister had 42. If they ate 35, how many pieces do they have left in total?"
- **Demonstration**:
- **Rationale**:
- "Originally, Leah had 32 chocolates and her sister had 42. So in total they had 32 + 42 = 74. After eating 35, they had 74 - 35 = 39 pieces left in total."
- **Answer**: "The answer is 39."
- **Query**: "If there are 3 cars in the parking lot and 2 more cars arrive, how many cars are in the parking lot?"
#### Date Reasoning (Few-Shot)
- **Question**: "It is 4/19/1969 today. What is the date 24 hours later in MM/DD/YYYY?"
- **Demonstration**:
- **Rationale**:
- "Today is 04/19/1969. 24 hours later is one day after today, which would be 04/20/1969."
- **Answer**: "The answer is 04/20/1969."
- **Query**: "Today is May 25 2013. What is the tomorrow of today in MM/DD/YYYY?"
#### Commonsense Reasoning (Zero-Shot)
- **Question**: "Who lived longer, Theodor Haecker or Harry Vaughan Watkins?"
- **Demonstration**: None (zero-shot).
- **Query**: Same as the question above.
---
### Key Observations
1. **Textual Instructions**:
- Green-highlighted phrases like "Let's think step by step" guide reasoning in few-shot examples.
2. **Color Consistency**:
- Blue consistently marks questions/answers, while orange denotes rationale.
3. **Zero-Shot Limitation**:
- The Commonsense Reasoning section lacks demonstrations, relying solely on the query.
4. **Numerical Examples**:
- Math and date examples use explicit arithmetic (e.g., 32 + 42 = 74, 74 - 35 = 39).
---
### Interpretation
- **Purpose**: The diagram illustrates how CoT prompts improve reasoning by providing structured examples (few-shot) versus relying on raw queries (zero-shot).
- **Effectiveness**:
- Few-shot prompts with textual instructions (green) enable step-by-step reasoning, as seen in math and date examples.
- Zero-shot prompts (Commonsense Reasoning) lack scaffolding, potentially reducing accuracy.
- **Design Choice**:
- Color coding enhances readability, separating questions (blue), reasoning (orange), and answers (blue).
- Textual instructions act as a "scaffold" for logical progression.
This visualization emphasizes the importance of guided examples in complex reasoning tasks, while highlighting the limitations of zero-shot approaches.
</details>
the LLM knowledge quality (Suzgun et al., 2022). Some tasks even require a deeper understanding on the semantic meaning of natural language (Shi et al., 2022a; Suzgun et al., 2022; Zhang et al., 2023b). Improperly involving CoT prompting into these knowledge or semantic oriented tasks may even hurt the performance (Shi et al., 2022a). To address these problems, some work uses external tools to inject required knowledge (We will introduce in § 6.3).
## 4.3 Code Generation
Code generation aims to generate codes according to an input instruction. Due to the internal logical form of codes, the step-by-step reasoning chain of CoT is coherent with abilities needed for code generation (Shi et al., 2022b; Chen et al., 2022; Gao et al., 2022; Jiang et al., 2023; Pourreza and Rafiei, 2023).
## 5 Prompts Design
When the task is determined, it's necessary to design an effective CoT prompt. Besides the query, there are two special elements in CoT prompts: CoT demonstrations and textual instructions . CoT demonstrations are several step-wise reasoning exemplars and textual instructions are textual sequences to actively guide a progressive solving process. A CoT prompt should contain at least one of these elements. Typically, a CoT prompt with (or without) demonstrations is called few-shot CoT (or zero-shot CoT). We present several example CoT prompts in Figure 3.
In this section, we will discuss how to design an effective CoT prompt from each element.
## 5.1 Demonstrations
In few-shot CoT, demonstrations are the indispensable part. As shown in Figure 3, a CoT demonstra- tion is a (problem, rationale, answer) triple, where the rationale contains the intermediate reasoning steps that lead from the problem to the answer . In this part, we will discuss what factors of demonstrations may affect the final prompting performance from problem, rationale and holistic perspectives 1 .
## 5.1.1 Problem Perspective
Complexity: Complexity measures the difficulty of a problem, which can be reflected as the number, the length and the logical difficulty of reasoning steps to solve this problem.
Empirically, more complex demonstration problems usually guarantee longer reasoning steps, which can provide more reasoning context and induce the model to generate a longer rationale, avoiding a short-cut prediction (Shao et al., 2023; Anil et al., 2022; Saparov and He, 2022). To get more complex demonstration problems, a direct way is to select the samples with most reasoning steps (Shao et al., 2023; Fu et al., 2022). Diao et al. (2023) select the demonstrations with higher uncertainty, which represents the extent a problem is able to confuse the model.
Relevance and Diversity: Relevance measures how similar the demonstration problems are to the query problem. Relevant demonstration problems could provide similar knowledge and reasoning pattern for the query, which make LLM easier to imitate (Ye et al., 2022).
Diversity measures how different a demonstration problem is from other demonstration problems within a single prompt. Diverse demonstrations could fuse different reasoning process and make model less sensitive to a specific reasoning process,
1 We don't specially analyze factors of the answer since the answer is directly associated with the problem.
increasing the prompt robustness (Shao et al., 2023; Zhang et al., 2022b).
Both relevance and diversity can be ensured by representative features of problems (Ye et al., 2022; Zhang et al., 2022b) or manual topic informing (Shao et al., 2023). Specially, we need to point out that diversity and relevance are a trade-off process (Ye et al., 2022). Too monotonous demonstrations may lead to a less robust model performance while involving too many irrelevant demonstrations may inject more noise.
## 5.1.2 Rationale Perspective
Structural Completeness: A CoT rationale can be divided into two fine-grained components 2 : bridging objects and language templates (Wang et al., 2022b; Ye et al., 2022). A structural complete rationale should contain both of two components.
Bridging objects refer to the critical elements that convey the logical process when solving problems, which are meant to be traversed in a single prediction. Language templates refer to complementary textual parts that connect the bridging objects, which involve complementary knowledge for the problems and construct logical connections with bridging objects (Wang et al., 2022b). Figure 3 presents some examples about each component of CoT rationales on different tasks. For a sound reasoning, bridging objects provide the reasoning materials and lead to logical language templates, while language templates provide the essential knowledge and help to better organize bridging objects in back (Madaan and Yazdanbakhsh, 2022). In a word, bridging objects and language templates are two codependent and indispensable components for an effective CoT rationale. More detailed two components can also jointly reduce the ambiguity of demonstration rationales (Zhou et al., 2022c).
Validity: Validity measures the correctness and coherence of a reasoning chain. The validity of a CoT rationale can be measured from different metrics like accuracy of answers (Ye and Durrett, 2022; Saparov and He, 2022), perplexity (Press et al., 2022) and more detailed measurement on each reasoning step (Saparov and He, 2022). It's also possible to train a verifier model to evaluate
2 Besides, Madaan and Yazdanbakhsh (2022) decomposed a CoT prompt into a finer granularity: symbols (the tokens which are meant to be reasoned), patterns (the essential or structural tokens which connect symbols) and text (other textual components). This division scheme can be easily inducted into the scheme we introduced.
the validity of CoT rationales (Li et al., 2022b).
Some work is conducted to explore how the validity plays a role in CoT prompt. In a nutshell, a valid CoT rationale does promote a better prompting performance while an effective CoT prompt does not necessarily demand a totally valid rationale (Wang et al., 2022b; Madaan and Yazdanbakhsh, 2022; Ye et al., 2022; Chen et al., 2023). Wang et al. (2022b) found that a completely wrong rationale may bring a similar reasoning boost as vanilla CoT as long as it is coherent, i.e. , latter steps should not contain any condition or text information which doesn't present in previous steps. It seems that a coherent CoT rationale demonstrates a relative logical manner of reasoning, which help to elicit the LLM ability of progressive reasoning. Thus, the coherence should be primarily ensured if we have to compromise to incorrect CoT rationales.
## 5.1.3 Holistic Perspective
Number and Order: When prompted with multiple CoT demonstrations, the model accesses the intersection information of each demonstration (Ye et al., 2022). The number and order of demonstrations leave a impact on the final performance (Wei et al., 2022b; Lu et al., 2022a; Chen et al., 2023)
Some work finds model performance would gain prominently when the CoT demonstrations number is gradually increasing from zero to two while the improvement remains slowly and negligibly if demonstrations number continually increases (Shi et al., 2022a; Lu et al., 2022a; Chen, 2023; Chen et al., 2023). Too many demonstrations can lead to a mass of computation cost while insufficient demonstrations may make LLM more sensitive to a single demonstration and increase the variance (Chen et al., 2022).
Changing the order of demonstrations may result in a non-trivial effect, but we still can't draw a conclusion for a universal order strategy since the impact of order may vary according to the models, tasks and dataset (Lu et al., 2022b; Liu et al., 2022). An compromised method is to use some prompting searching strategies (Lu et al., 2022b; Ye and Durrett, 2023) or some heuristic measurements like complexity and relevance order Liu et al. (2022).
## 5.2 Textual Instructions
LLM show ability to follow explicit instructions even in zero-shot scenarios (Ouyang et al., 2022; Sanh et al., 2022). Inspired by this, some work finds explicitly prompting LLM with an active tex- tual instruction like ' Let's think step by step " can guide a progressive reasoning (Kojima et al., 2022; Zhou et al., 2022d). Without any demonstrations, this simple zero-shot strategy shows impressive result comparing to non-CoT methods, implying these textual instructions can similarly elicit the reasoning ability of LLM. Some work also finds combining these textual instruction with few-shot CoT can achieve a further performance increment (Kojima et al., 2022).
## 6 Extension Strategies
Given a CoT prompt, there are many possible extension strategies to enhance the prompt performance. In this section, we will highlight four CoT-related strategies and analyze when and how to use them.
## 6.1 Ensemble
Ensemble learning is an effective strategy which combines diverse learners, enhancing the model performance comparing to a single learner (Zhou, 2012). Recent work achieved superior performance when using ensemble strategy on CoT prompting (Wang et al., 2022d; Li et al., 2022b; Wang et al., 2022e), which can help to correct errors made by individual reasoning process and integrate diverse prompts and demonstrations into a single prediction. Wang et al. (2022e) point out ensemble methods can even bring performance increment on tasks where vanilla CoT fails. However, unnecessary ensembles on problems which vanilla CoT can already effectively solve may inject noise to a confident prediction and instead do harm to model performance (Wang et al., 2022d).
To go a step further, what elements should be embraced into ensemble also matters a lot. According to different ensemble materials, we categorize these methods into prompts ensemble method and predictions ensemble method. Prompts ensemble focuses on the ensemble of results generated with various prompts. This method construct diverse CoT prompts by repeating sampling different demonstrations from exemplars set (Li et al., 2022b). Predictions ensemble focuses on integrating output space materials including rationales and answers. This method generates various predictions given a fixed input query by LLM sampling algorithms (Wang et al., 2022e; Fu et al., 2022; Yoran et al., 2023). It is found predictions ensemble may lead to more performance gain comparing to prompts ensemble (Wang et al., 2022d), but mul- tiple decoding for predictions ensemble may lead to higher computation cost. How to choose the ensemble strategy depends on the access of demonstrations number and computing resource. It's also possible to jointly combine two ensemble methods (Wang et al., 2022d).
## 6.2 Sub-problems Division
When confronting a problem needs to be recursively inferred or harder than demonstrations, dividing a problem into several sub-problems could be a better option (Zhou et al., 2022a; Press et al., 2022; Khot et al., 2022; Schick et al., 2023). Comparing to vanilla CoT, sub-problems division strategy decomposes a complex problem into a series of simple sub-problems, which are much easier to solve, enabling models to accomplish query problems harder than demonstrations (Zhou et al., 2022a; Press et al., 2022). Also, when dealing with each sub-problem, model is free from information which is irrelevant to current sub-problem and more informative information is prone to guiding a valid reasoning (Creswell et al., 2022; Zhou et al., 2022a). Additionally, the required abilities for separate subproblems are different. This strategy makes it more convenient to deploy each sub-problem with different modules and inject external assistance (Khot et al., 2022; Schick et al., 2023; Shen et al., 2023), which we will introduce in § 6.3.
## 6.3 External Assistance
In order to expand the ability of LLM and assist LLMto perform on broader applications, it's useful to introduce external sources including knowledge, tools or codes interpreters into reasoning process.
Knowledge injection is especially helpful in tasks which need external knowledge like commonsense QA (Wang et al., 2022a). Tools and codes assisted strategies show preponderance in problems which need abilities beyond LLM capacities such as accurate numerical calculation or search engine (Chen et al., 2022; Khot et al., 2022; Schick et al., 2023; Paranjape et al., 2023). With proper prompts, LLM can generate task deployment chains to instruct when and where to call external tools (Khot et al., 2022; Schick et al., 2023), codes interpreter (Gao et al., 2022; Chen et al., 2022; Lyu et al., 2023) or even other models (Shen et al., 2023), to solve more complex problems.
Codes interpreters can also serve as external verifiers to check the validity of generated rationales by checking whether they can be interpreted and lead to a correct answer (Shao et al., 2023; Gao et al., 2022; Chen et al., 2022). Additionally, Lyu et al. (2023) point out executing reasoning chains with programmatic modules can enhance the faithfulness of CoT (We will discuss in § 8).
## 6.4 Rationalization
Usually, the rationales predicted by LLM would make some mistakes and lead to wrong answers. If these mistakes can be corrected, it is possible to rationalize the reasoning process and boost the performance.
Manual rationalization would be effective but sometimes too costly (Wang et al., 2022c; Kim et al., 2023). A simple way is to use some hints to guide the model to rethink (Zelikman et al., 2022; Guo et al., 2023). When the model produces a wrong answer, we can tell model the correct answer and ask it to self-revise illogical reasoning and regenerate a rationale based on the golden answer. This process can be regarded as a self-learning process, where the model can progressively improve its reasoning ability just with answers supervised. However, it's still hard to rationalize imperfect rationales which lead to correct answers.
## 7 Models
LLM, as the primary role of solving problems, makes a significant difference to the final prediction. In this section, we will discuss from model size and training corpus to introduce what kinds of models are more effective with CoT prompting.
## 7.1 Model Size
Many researches have found as the model size is relatively small (typically below ten billions parameters), CoT doesn't remain a positive impact. But as the model size increases to a certain size (above ten billions parameters), it will exhibit a sudden performance breakout (Wei et al., 2022b; Suzgun et al., 2022; Magister et al., 2022; Fu et al., 2023). This implies CoT is an emergent ability (Wei et al., 2022a) of LLM. Prompting small models with CoT will commonly lead to hallucination (Ji et al., 2023), which often presents as fluent but illogical generation (Wei et al., 2022b).
But it's still possible to enhance small models reasoning ability by CoT. Some work fine-tuned a small-scaled model with self-constructed CoT dataset(Zelikman et al., 2022) or knowledge distillation (Magister et al., 2022; Ho et al., 2022; Wang et al., 2022c; Fu et al., 2023), making small models compatible to perform step-by-step reasoning even on few-shot scenarios. However, small models will forget general abilities on other tasks except stepby-step reasoning after CoT tuning (Fu et al., 2023) and still lag behind large models on tasks which demands substantial knowledge to conduct reasoning (Magister et al., 2022).
## 7.2 Training Corpus
It is believed that the abilities LLM exhibit originate from training corpus. Some work finds models pre-trained with codes could acquire more performance gain when prompted with CoT (Diao et al., 2023). Instruction tuning also shows relevance to the CoT prompting and zero-shot learning performance(Chung et al., 2022; Fu et al., 2023), which may be illustrated by the presence of CoT-like samples in the training corpus of instruction tuning. Recent work even tries to explicitly involve CoT samples into training corpus to enhance the stepby-step reasoning ability and avoid over-fitting to monotonous sample templates (Chung et al., 2022; Ho et al., 2022; Yu et al., 2022). In a word, embracing aforementioned contents into training corpus could introduce more reasoning materials and necessary knowledge for LLM, leading to a profound influence on CoT reasoning ability.
## 8 Discussion and Future Work
Faithfulness: Though CoT prompting increases the reasoning interpretability, it still remains a problem whether present methods for generating CoT rationales are faithful. A faithful reasoning process implies the answer generated by model is accurately reasoned from corresponding generated rationale, which can ensure the controllability and credibility of reasoning process. The rationale which looks like plausible but unfaithful may make humans over-trust the model, resulting in implicit bias risk on realistic applications (Pruthi et al., 2020; Slack et al., 2020).
Most of current work generates CoT rationales together with the final answer, which can't guarantee the answer is directly acquired from rationales. Although there exists some work that tries to construct a faithful process by directly reasoning answers on generated rationales (Lyu et al., 2023; Wang et al., 2022c), it still can't ensure the faithfulness about how rationales generated from the query problem (Lyu et al., 2023). How to perform a truly faithful step-by-step reasoning on LLM can be critical for controllable and reliable CoT reasoning.
Generality: Currently, it has still a challenge for CoT-assisted LLM to handle the problems which need a great amount of external knowledge or deeper understanding of language (Shi et al., 2022a; Suzgun et al., 2022; Zhang et al., 2023b). Much relevant work focus on an external retriever to supplement necessary knowledge for conduct reasoning. However, a pre-trained LLM has already obtained a tremendous amount of knowledge. The key conundrum is how to instruct LLM to recognize and make use of learned knowledge.
Besides, although LLM with CoT assistance have already showed impressive advantages on some reasoning tasks, these tasks are a little bit naïve and still far from complicated realistic applications, which demand a high level of perception on external environments, deduction of potential results and planning on the final goal even with cost restriction. Valmeekam et al. (2022) proposed a more complicated planning benchmark which evaluates the model reasoning ability about actions execution and environment change, finding that LLM have dismal performance on this benchmark. How to combine the CoT prompting with LLM on more challenging and realistic benchmarks can be a promising future direction.
Self-rationalization: Recent work has proposed effective self-rationalization methods by informing the model correct answers and ask models to self-revise the mistakes(Zelikman et al., 2022; Guo et al., 2023). But sometimes models may learn some short-cut and generate correct answers while incorrect rationales (Saparov and He, 2022). In this scenario, answer accuracy is not enough to measure the validity of reasoning process. How to spot these short-cut and help models to self-rationalize incorrect reasoning should be carefully discussed.
Rationale Analysis: Existing work has made a step towards a clear understanding of CoT rationale, but most existing conclusions are confined to limited models and tasks (Wang et al., 2022b; Ye et al., 2022; Madaan and Yazdanbakhsh, 2022). The specific form of CoT rationale varies according to the specific task setting. How a certain component is represented and how each component behaves on the given setting may leave a great distinction. Therefore, for a more practical application, it's vital to thoroughly analyze the function of each rationale component among different settings.
As we discussed in § 5.1, in order to achieve a promising prompt performance, a relatively complex and detailed reasoning chain is needed. With this purpose, the input tokens are usually long, increasing the inference cost and noise interference. Madaan and Yazdanbakhsh (2022) proposed Concise-CoT to prune a few trivial tokens but there is still a long journey to go. If we could fully understand how each component work for each task, we could directly prompt partial demanded reasoning materials instead of a complete reasoning chain to improve the efficiency of CoT prompting.
Theoretical Analysis: We have already showed CoT prompting can benefit the reasoning performance from different dimensions. But it naturally leaves a question about the theoretical explanation about CoT prompt effect.
There are some hypotheses to explain the mechanism of in-context-learning (Chan et al., 2022; Xie et al., 2022; Olsson et al., 2022; Garg et al., 2022; Li et al., 2023a; Dai et al., 2023). But CoT prompts are typically more complicated due to the step-bystep reasoning chains, thus there may exist more to explore for CoT prompting. Unfortunately, there isn't enough theoretical analysis on CoT prompting and more work draws empirical conclusions. Some work finds prompting with wrong and irrelevant rationales can somewhat boost the reasoning performance of LLM (Wang et al., 2022b; Madaan and Yazdanbakhsh, 2022). This may imply CoT prompts don't 'teach" LLM how to reason, but instead provide necessary reasoning materials to help LLM to recall what they have learned at training stage. Prystawski and Goodman (2023) give a hypothesis from training data locality structure and Li et al. (2023b) provide an explanation from learning perspective. But how these hypotheses can explain aforementioned demonstration factors we emphasized is still a mystery. Also, we still don't know how a simple ' Let's think step by step " help to boost the performance. Clarifying the working mechanism of CoT prompting is a fundamental milestone to ensure a truly interpretable and transparent prompting strategy.
## 9 Conclusion
In this survey, we reviewed the research status of Chain-of-Thought prompting. We highlighted four factors that may affect the CoT prompting performance and introduced methods based on these fac- tors. We gave a general direction to properly utilize CoT prompting when confronting different setting. Furthermore, we discussed current challenges about CoT prompting and proposed some potential directions. We hope this survey could provide an overall reference on future research.
## Limitations
Due to the page limitation, we couldn't concretely introduce the methods designed on various tasks and applications setting, but only provide an systematic analysis and instructive perspective on prompting applications. We don't specifically introduce the work which tries to use CoT prompting for more realistic applications such as examinations problems answering (Zhang et al., 2022a), domain specialization (Singhal et al., 2022; Prystawski et al., 2022; Zhang et al., 2023a), since these work doesn't exceed the scope we discussed in § 4. There are also other applications for CoT on imitation learning and reinforced learning (Yang et al., 2022; Jia et al., 2023; Bai et al., 2022). We don't discuss in out paper because we only focus on prompting applications of CoT.
Besides, since the scope of our survey focuses on the factors analysis and strategies designing of CoT prompting, we don't encompass application resources in main text (refer to Appendix B).
## References
Plamen P. Angelov and Eduardo A. Soares. 2020. Towards deep machine reasoning: a prototype-based deep neural network with decision tree inference. In 2020 IEEE International Conference on Systems, Man, and Cybernetics, SMC 2020, Toronto, ON, Canada, October 11-14, 2020 , pages 2092-2099. IEEE.
Cem Anil, Yuhuai Wu, Anders Andreassen, Aitor Lewkowycz, Vedant Misra, Vinay Ramasesh, Ambrose Slone, Guy Gur-Ari, Ethan Dyer, and Behnam Neyshabur. 2022. Exploring length generalization in large language models. In Advances in Neural Information Processing Systems , volume 35, pages 38546-38556. Curran Associates, Inc.
Yuntao Bai, Saurav Kadavath, Sandipan Kundu, Amanda Askell, Jackson Kernion, Andy Jones, Anna Chen, Anna Goldie, Azalia Mirhoseini, Cameron McKinnon, Carol Chen, Catherine Olsson, Christopher Olah, Danny Hernandez, Dawn Drain, Deep Ganguli, Dustin Li, Eli Tran-Johnson, Ethan Perez, Jamie Kerr, Jared Mueller, Jeffrey Ladish, Joshua Landau, Kamal Ndousse, Kamile Lukosiute, Liane Lovitt, Michael Sellitto, Nelson Elhage, Nicholas
Schiefer, Noemí Mercado, Nova DasSarma, Robert Lasenby, Robin Larson, Sam Ringer, Scott Johnston, Shauna Kravec, Sheer El Showk, Stanislav Fort, Tamera Lanham, Timothy Telleen-Lawton, Tom Conerly, Tom Henighan, Tristan Hume, Samuel R. Bowman, Zac Hatfield-Dodds, Ben Mann, Dario Amodei, Nicholas Joseph, Sam McCandlish, Tom Brown, and Jared Kaplan. 2022. Constitutional AI: harmlessness from AI feedback. CoRR , abs/2212.08073.
David Barrett, Felix Hill, Adam Santoro, Ari Morcos, and Timothy Lillicrap. 2018. Measuring abstract reasoning in neural networks. In Proceedings of the 35th International Conference on Machine Learning , volume 80 of Proceedings of Machine Learning Research , pages 511-520. PMLR.
Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-Voss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel M. Ziegler, Jeffrey Wu, Clemens Winter, Christopher Hesse, Mark Chen, Eric Sigler, Mateusz Litwin, Scott Gray, Benjamin Chess, Jack Clark, Christopher Berner, Sam McCandlish, Alec Radford, Ilya Sutskever, and Dario Amodei. 2020. Language models are few-shot learners. In Proceedings of the 34th International Conference on Neural Information Processing Systems , NIPS'20, Red Hook, NY, USA. Curran Associates Inc.
Stephanie Chan, Adam Santoro, Andrew Lampinen, Jane Wang, Aaditya Singh, Pierre Richemond, James McClelland, and Felix Hill. 2022. Data distributional properties drive emergent in-context learning in transformers. In Advances in Neural Information Processing Systems , volume 35, pages 18878-18891. Curran Associates, Inc.
Jiuhai Chen, Lichang Chen, Chen Zhu, and Tianyi Zhou. 2023. How many demonstrations do you need for in-context learning? CoRR , abs/2303.08119.
Wenhu Chen. 2023. Large language models are few(1)shot table reasoners. In Findings of the Association for Computational Linguistics: EACL 2023, Dubrovnik, Croatia, May 2-6, 2023 , pages 10901100. Association for Computational Linguistics.
Wenhu Chen, Xueguang Ma, Xinyi Wang, and William W. Cohen. 2022. Program of thoughts prompting: Disentangling computation from reasoning for numerical reasoning tasks. CoRR , abs/2211.12588.
Aakanksha Chowdhery, Sharan Narang, Jacob Devlin, Maarten Bosma, Gaurav Mishra, Adam Roberts, Paul Barham, Hyung Won Chung, Charles Sutton, Sebastian Gehrmann, Parker Schuh, Kensen Shi, Sasha Tsvyashchenko, Joshua Maynez, Abhishek Rao, Parker Barnes, Yi Tay, Noam Shazeer, Vinodkumar Prabhakaran, Emily Reif, Nan Du, Ben Hutchinson, Reiner Pope, James Bradbury, Jacob Austin, Michael Isard, Guy Gur-Ari, Pengcheng Yin,
- Toju Duke, Anselm Levskaya, Sanjay Ghemawat, Sunipa Dev, Henryk Michalewski, Xavier Garcia, Vedant Misra, Kevin Robinson, Liam Fedus, Denny Zhou, Daphne Ippolito, David Luan, Hyeontaek Lim, Barret Zoph, Alexander Spiridonov, Ryan Sepassi, David Dohan, Shivani Agrawal, Mark Omernick, Andrew M. Dai, Thanumalayan Sankaranarayana Pillai, Marie Pellat, Aitor Lewkowycz, Erica Moreira, Rewon Child, Oleksandr Polozov, Katherine Lee, Zongwei Zhou, Xuezhi Wang, Brennan Saeta, Mark Diaz, Orhan Firat, Michele Catasta, Jason Wei, Kathy Meier-Hellstern, Douglas Eck, Jeff Dean, Slav Petrov, and Noah Fiedel. 2022. Palm: Scaling language modeling with pathways. CoRR , abs/2204.02311.
- Hyung Won Chung, Le Hou, Shayne Longpre, Barret Zoph, Yi Tay, William Fedus, Eric Li, Xuezhi Wang, Mostafa Dehghani, Siddhartha Brahma, Albert Webson, Shixiang Shane Gu, Zhuyun Dai, Mirac Suzgun, Xinyun Chen, Aakanksha Chowdhery, Sharan Narang, Gaurav Mishra, Adams Yu, Vincent Y. Zhao, Yanping Huang, Andrew M. Dai, Hongkun Yu, Slav Petrov, Ed H. Chi, Jeff Dean, Jacob Devlin, Adam Roberts, Denny Zhou, Quoc V. Le, and Jason Wei. 2022. Scaling instruction-finetuned language models. CoRR , abs/2210.11416.
- Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. 2021. Training verifiers to solve math word problems. CoRR , abs/2110.14168.
- Antonia Creswell, Murray Shanahan, and Irina Higgins. 2022. Selection-inference: Exploiting large language models for interpretable logical reasoning. CoRR , abs/2205.09712.
- Leyang Cui, Yu Wu, Jian Liu, Sen Yang, and Yue Zhang. 2021. Template-based named entity recognition using BART. In Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021 , pages 1835-1845, Online. Association for Computational Linguistics.
- Damai Dai, Yutao Sun, Li Dong, Yaru Hao, Shuming Ma, Zhifang Sui, and Furu Wei. 2023. Why can gpt learn in-context? language models implicitly perform gradient descent as meta-optimizers. CoRR , abs/2212.10559.
- Xavier Daull, Patrice Bellot, Emmanuel Bruno, Vincent Martin, and Elisabeth Murisasco. 2023. Complex QA and language models hybrid architectures, survey. CoRR , abs/2302.09051.
- Shizhe Diao, Pengcheng Wang, Yong Lin, and Tong Zhang. 2023. Active prompting with chainof-thought for large language models. CoRR , abs/2302.12246.
- Qingxiu Dong, Lei Li, Damai Dai, Ce Zheng, Zhiyong Wu, Baobao Chang, Xu Sun, Jingjing Xu, Lei Li, and Zhifang Sui. 2023. A survey on in-context learning. CoRR , abs/2301.00234.
- Andrew Drozdov, Nathanael Schärli, Ekin Akyürek, Nathan Scales, Xinying Song, Xinyun Chen, Olivier Bousquet, and Denny Zhou. 2022. Compositional semantic parsing with large language models. CoRR , abs/2209.15003.
- Yao Fu, Hao Peng, Litu Ou, Ashish Sabharwal, and Tushar Khot. 2023. Specializing smaller language models towards multi-step reasoning. CoRR , abs/2301.12726.
- Yao Fu, Hao Peng, Ashish Sabharwal, Peter Clark, and Tushar Khot. 2022. Complexity-based prompting for multi-step reasoning. CoRR , abs/2210.00720.
- Luyu Gao, Aman Madaan, Shuyan Zhou, Uri Alon, Pengfei Liu, Yiming Yang, Jamie Callan, and Graham Neubig. 2022. PAL: program-aided language models. CoRR , abs/2211.10435.
- Shivam Garg, Dimitris Tsipras, Percy S Liang, and Gregory Valiant. 2022. What can transformers learn incontext? a case study of simple function classes. In Advances in Neural Information Processing Systems , volume 35, pages 30583-30598. Curran Associates, Inc.
- Yiduo Guo, Yaobo Liang, Chenfei Wu, Wenshan Wu, Dongyan Zhao, and Nan Duan. 2023. Learning to program with natural language. CoRR , abs/2304.10464.
- Hangfeng He, Hongming Zhang, and Dan Roth. 2023. Rethinking with retrieval: Faithful large language model inference. CoRR , abs/2301.00303.
- Namgyu Ho, Laura Schmid, and Se-Young Yun. 2022. Large language models are reasoning teachers. CoRR , abs/2212.10071.
- Jiaxin Huang, Shixiang Shane Gu, Le Hou, Yuexin Wu, Xuezhi Wang, Hongkun Yu, and Jiawei Han. 2022. Large language models can self-improve. CoRR , abs/2210.11610.
- Jie Huang and Kevin Chen-Chuan Chang. 2022. Towards reasoning in large language models: A survey. CoRR , abs/2212.10403.
- Shima Imani, Liang Du, and Harsh Shrivastava. 2023. Mathprompter: Mathematical reasoning using large language models. In ICLR 2023 Workshop on Trustworthy and Reliable Large-Scale Machine Learning Models .
- Ziwei Ji, Nayeon Lee, Rita Frieske, Tiezheng Yu, Dan Su, Yan Xu, Etsuko Ishii, Ye Jin Bang, Andrea Madotto, and Pascale Fung. 2023. Survey of hallucination in natural language generation. ACM Comput. Surv. , 55(12).
- Zhiwei Jia, Fangchen Liu, Vineet Thumuluri, Linghao Chen, Zhiao Huang, and Hao Su. 2023. Chain-ofthought predictive control. CoRR , abs/2304.00776.
- Xue Jiang, Yihong Dong, Lecheng Wang, Qiwei Shang, and Ge Li. 2023. Self-planning code generation with large language model. CoRR , abs/2303.06689.
- Jaehun Jung, Lianhui Qin, Sean Welleck, Faeze Brahman, Chandra Bhagavatula, Ronan Le Bras, and Yejin Choi. 2022. Maieutic prompting: Logically consistent reasoning with recursive explanations. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, EMNLP 2022, Abu Dhabi, United Arab Emirates, December 7-11, 2022 , pages 1266-1279. Association for Computational Linguistics.
- Tushar Khot, Harsh Trivedi, Matthew Finlayson, Yao Fu, Kyle Richardson, Peter Clark, and Ashish Sabharwal. 2022. Decomposed prompting: A modular approach for solving complex tasks. CoRR , abs/2210.02406.
- Seungone Kim, Se June Joo, Yul Jang, Hyungjoo Chae, and Jinyoung Yeo. 2023. Cotever: Chain of thought prompting annotation toolkit for explanation verification. In Proceedings of the 17th Conference of the European Chapter of the Association for Computational Linguistics. EACL 2023 - System Demonstrations, Dubrovnik, Croatia, May 2-4, 2023 , pages 195-208. Association for Computational Linguistics.
- Takeshi Kojima, Shixiang (Shane) Gu, Machel Reid, Yutaka Matsuo, and Yusuke Iwasawa. 2022. Large language models are zero-shot reasoners. In Advances in Neural Information Processing Systems , volume 35, pages 22199-22213. Curran Associates, Inc.
- Junlong Li, Zhuosheng Zhang, and Hai Zhao. 2022a. Self-prompting large language models for opendomain QA. CoRR , abs/2212.08635.
- Xiaonan Li and Xipeng Qiu. 2023. Mot: Pre-thinking and recalling enable chatgpt to self-improve with memory-of-thoughts. CoRR , abs/2305.05181.
- Yifei Li, Zeqi Lin, Shizhuo Zhang, Qiang Fu, Bei Chen, Jian-Guang Lou, and Weizhu Chen. 2022b. On the advance of making language models better reasoners. CoRR , abs/2206.02336.
- Yingcong Li, M. Emrullah Ildiz, Dimitris Papailiopoulos, and Samet Oymak. 2023a. Transformers as algorithms: Generalization and stability in in-context learning. CoRR , abs/2301.07067.
- Yingcong Li, Kartik Sreenivasan, Angeliki Giannou, Dimitris S. Papailiopoulos, and Samet Oymak. 2023b. Dissecting chain-of-thought: A study on compositional in-context learning of mlps. CoRR , abs/2305.18869.
- Zongjie Li, Chaozheng Wang, Pingchuan Ma, Chaowei Liu, Shuai Wang, Daoyuan Wu, and Cuiyun Gao. 2023c. On the feasibility of specialized ability extracting for large language code models. CoRR , abs/2303.03012.
- Jiachang Liu, Dinghan Shen, Yizhe Zhang, Bill Dolan, Lawrence Carin, and Weizhu Chen. 2022. What makes good in-context examples for GPT-3? In Proceedings of Deep Learning Inside Out (DeeLIO 2022): The 3rd Workshop on Knowledge Extraction and Integration for Deep Learning Architectures , pages 100-114, Dublin, Ireland and Online. Association for Computational Linguistics.
- Pengfei Liu, Weizhe Yuan, Jinlan Fu, Zhengbao Jiang, Hiroaki Hayashi, and Graham Neubig. 2023. Pretrain, prompt, and predict: A systematic survey of prompting methods in natural language processing. ACM Comput. Surv. , 55(9).
- Pan Lu, Swaroop Mishra, Tanglin Xia, Liang Qiu, KaiWei Chang, Song-Chun Zhu, Oyvind Tafjord, Peter Clark, and Ashwin Kalyan. 2022a. Learn to explain: Multimodal reasoning via thought chains for science question answering. In Advances in Neural Information Processing Systems , volume 35, pages 25072521. Curran Associates, Inc.
- Pan Lu, Baolin Peng, Hao Cheng, Michel Galley, KaiWei Chang, Ying Nian Wu, Song-Chun Zhu, and Jianfeng Gao. 2023. Chameleon: Plug-and-play compositional reasoning with large language models. CoRR , abs/2304.09842.
- Yao Lu, Max Bartolo, Alastair Moore, Sebastian Riedel, and Pontus Stenetorp. 2022b. Fantastically ordered prompts and where to find them: Overcoming fewshot prompt order sensitivity. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages 8086-8098, Dublin, Ireland. Association for Computational Linguistics.
- Qing Lyu, Shreya Havaldar, Adam Stein, Li Zhang, Delip Rao, Eric Wong, Marianna Apidianaki, and Chris Callison-Burch. 2023. Faithful chain-ofthought reasoning. CoRR , abs/2301.13379.
- Aman Madaan and Amir Yazdanbakhsh. 2022. Text and patterns: For effective chain of thought, it takes two to tango. CoRR , abs/2209.07686.
- Lucie Charlotte Magister, Jonathan Mallinson, Jakub Adámek, Eric Malmi, and Aliaksei Severyn. 2022. Teaching small language models to reason. CoRR , abs/2212.08410.
- Catherine Olsson, Nelson Elhage, Neel Nanda, Nicholas Joseph, Nova DasSarma, Tom Henighan, Ben Mann, Amanda Askell, Yuntao Bai, Anna Chen, Tom Conerly, Dawn Drain, Deep Ganguli, Zac Hatfield-Dodds, Danny Hernandez, Scott Johnston, Andy Jones, Jackson Kernion, Liane Lovitt, Kamal Ndousse, Dario Amodei, Tom Brown, Jack Clark, Jared Kaplan, Sam McCandlish, and Chris Olah. 2022. In-context learning and induction heads. CoRR , abs/2209.11895.
- Simon Ott, Konstantin Hebenstreit, Valentin Liévin, Christoffer Egeberg Hother, Milad Moradi, Maximilian Mayrhauser, Robert Praas, Ole Winther, and
- Matthias Samwald. 2023. Thoughtsource: A central hub for large language model reasoning data. CoRR , abs/2301.11596.
- Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, John Schulman, Jacob Hilton, Fraser Kelton, Luke Miller, Maddie Simens, Amanda Askell, Peter Welinder, Paul F Christiano, Jan Leike, and Ryan Lowe. 2022. Training language models to follow instructions with human feedback. In Advances in Neural Information Processing Systems , volume 35, pages 27730-27744. Curran Associates, Inc.
- Bhargavi Paranjape, Scott M. Lundberg, Sameer Singh, Hannaneh Hajishirzi, Luke Zettlemoyer, and Marco Túlio Ribeiro. 2023. ART: automatic multistep reasoning and tool-use for large language models. CoRR , abs/2303.09014.
- Baolin Peng, Zhengdong Lu, Hang Li, and Kam-Fai Wong. 2015. Towards neural network-based reasoning. CoRR , abs/1508.05508.
- Mohammadreza Pourreza and Davood Rafiei. 2023. DIN-SQL: decomposed in-context learning of textto-sql with self-correction. CoRR , abs/2304.11015.
- Ofir Press, Muru Zhang, Sewon Min, Ludwig Schmidt, Noah A. Smith, and Mike Lewis. 2022. Measuring and narrowing the compositionality gap in language models. CoRR , abs/2210.03350.
- Danish Pruthi, Mansi Gupta, Bhuwan Dhingra, Graham Neubig, and Zachary C. Lipton. 2020. Learning to deceive with attention-based explanations. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics , pages 47824793, Online. Association for Computational Linguistics.
- Ben Prystawski and Noah D. Goodman. 2023. Why think step-by-step? reasoning emerges from the locality of experience. CoRR , abs/2304.03843.
- Ben Prystawski, Paul H. Thibodeau, and Noah D. Goodman. 2022. Psychologically-informed chainof-thought prompts for metaphor understanding in large language models. CoRR , abs/2209.08141.
- Shuofei Qiao, Yixin Ou, Ningyu Zhang, Xiang Chen, Yunzhi Yao, Shumin Deng, Chuanqi Tan, Fei Huang, and Huajun Chen. 2022. Reasoning with language model prompting: A survey. CoRR , abs/2212.09597.
- Meng Qu and Jian Tang. 2019. Probabilistic logic neural networks for reasoning. In Advances in Neural Information Processing Systems , volume 32. Curran Associates, Inc.
- Victor Sanh, Albert Webson, Colin Raffel, Stephen Bach, Lintang Sutawika, Zaid Alyafeai, Antoine Chaffin, Arnaud Stiegler, Arun Raja, Manan Dey, M Saiful Bari, Canwen Xu, Urmish Thakker, Shanya Sharma Sharma, Eliza Szczechla, Taewoon
- Kim, Gunjan Chhablani, Nihal Nayak, Debajyoti Datta, Jonathan Chang, Mike Tian-Jian Jiang, Han Wang, Matteo Manica, Sheng Shen, Zheng Xin Yong, Harshit Pandey, Rachel Bawden, Thomas Wang, Trishala Neeraj, Jos Rozen, Abheesht Sharma, Andrea Santilli, Thibault Fevry, Jason Alan Fries, Ryan Teehan, Teven Le Scao, Stella Biderman, Leo Gao, Thomas Wolf, and Alexander M Rush. 2022. Multitask prompted training enables zero-shot task generalization. In International Conference on Learning Representations .
- Abulhair Saparov and He He. 2022. Language models are greedy reasoners: A systematic formal analysis of chain-of-thought. CoRR , abs/2210.01240.
- Timo Schick, Jane Dwivedi-Yu, Roberto Dessì, Roberta Raileanu, Maria Lomeli, Luke Zettlemoyer, Nicola Cancedda, and Thomas Scialom. 2023. Toolformer: Language models can teach themselves to use tools. CoRR , abs/2302.04761.
- Timo Schick and Hinrich Schütze. 2021. It's not just size that matters: Small language models are also fewshot learners. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies , pages 2339-2352, Online. Association for Computational Linguistics.
- Zhihong Shao, Yeyun Gong, Yelong Shen, Minlie Huang, Nan Duan, and Weizhu Chen. 2023. Synthetic prompting: Generating chain-of-thought demonstrations for large language models. CoRR , abs/2302.00618.
- Yongliang Shen, Kaitao Song, Xu Tan, Dongsheng Li, Weiming Lu, and Yueting Zhuang. 2023. Hugginggpt: Solving AI tasks with chatgpt and its friends in huggingface. CoRR , abs/2303.17580.
- Freda Shi, Mirac Suzgun, Markus Freitag, Xuezhi Wang, Suraj Srivats, Soroush Vosoughi, Hyung Won Chung, Yi Tay, Sebastian Ruder, Denny Zhou, Dipanjan Das, and Jason Wei. 2022a. Language models are multilingual chain-of-thought reasoners. CoRR , abs/2210.03057.
- Peng Shi, Rui Zhang, He Bai, and Jimmy Lin. 2022b. XRICL: cross-lingual retrieval-augmented in-context learning for cross-lingual text-to-sql semantic parsing. In Findings of the Association for Computational Linguistics: EMNLP 2022, Abu Dhabi, United Arab Emirates, December 7-11, 2022 , pages 52485259. Association for Computational Linguistics.
- Kashun Shum, Shizhe Diao, and Tong Zhang. 2023. Automatic prompt augmentation and selection with chain-of-thought from labeled data. CoRR , abs/2302.12822.
- Karan Singhal, Shekoofeh Azizi, Tao Tu, S. Sara Mahdavi, Jason Wei, Hyung Won Chung, Nathan Scales, Ajay Kumar Tanwani, Heather Cole-Lewis, Stephen Pfohl, Perry Payne, Martin Seneviratne, Paul Gamble,
- Chris Kelly, Nathaneal Schärli, Aakanksha Chowdhery, Philip Andrew Mansfield, Blaise Agüera y Arcas, Dale R. Webster, Gregory S. Corrado, Yossi Matias, Katherine Chou, Juraj Gottweis, Nenad Tomasev, Yun Liu, Alvin Rajkomar, Joelle K. Barral, Christopher Semturs, Alan Karthikesalingam, and Vivek Natarajan. 2022. Large language models encode clinical knowledge. CoRR , abs/2212.13138.
- Dylan Slack, Sophie Hilgard, Emily Jia, Sameer Singh, and Himabindu Lakkaraju. 2020. Fooling lime and shap: Adversarial attacks on post hoc explanation methods. In Proceedings of the AAAI/ACM Conference on AI, Ethics, and Society , AIES '20, page 180-186, New York, NY, USA. Association for Computing Machinery.
- Tianxiang Sun, Yunfan Shao, Hong Qian, Xuanjing Huang, and Xipeng Qiu. 2022. Black-box tuning for language-model-as-a-service. In International Conference on Machine Learning, ICML 2022, 17-23 July 2022, Baltimore, Maryland, USA , volume 162 of Proceedings of Machine Learning Research , pages 20841-20855. PMLR.
- Mirac Suzgun, Nathan Scales, Nathanael Schärli, Sebastian Gehrmann, Yi Tay, Hyung Won Chung, Aakanksha Chowdhery, Quoc V. Le, Ed H. Chi, Denny Zhou, and Jason Wei. 2022. Challenging big-bench tasks and whether chain-of-thought can solve them. CoRR , abs/2210.09261.
- Harsh Trivedi, Niranjan Balasubramanian, Tushar Khot, and Ashish Sabharwal. 2022. Interleaving retrieval with chain-of-thought reasoning for knowledge-intensive multi-step questions. CoRR , abs/2212.10509.
- Karthik Valmeekam, Alberto Olmo Hernandez, Sarath Sreedharan, and Subbarao Kambhampati. 2022. Large language models still can't plan (A benchmark for llms on planning and reasoning about change). CoRR , abs/2206.10498.
- Boshi Wang, Xiang Deng, and Huan Sun. 2022a. Iteratively prompt pre-trained language models for chain of thought. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, EMNLP 2022, Abu Dhabi, United Arab Emirates, December 7-11, 2022 , pages 2714-2730. Association for Computational Linguistics.
- Boshi Wang, Sewon Min, Xiang Deng, Jiaming Shen, You Wu, Luke Zettlemoyer, and Huan Sun. 2022b. Towards understanding chain-of-thought prompting: An empirical study of what matters. CoRR , abs/2212.10001.
- Peifeng Wang, Aaron Chan, Filip Ilievski, Muhao Chen, and Xiang Ren. 2022c. PINTO: faithful language reasoning using prompt-generated rationales. CoRR , abs/2211.01562.
- Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc V. Le, Ed H. Chi, and Denny Zhou. 2022d. Rationaleaugmented ensembles in language models. CoRR , abs/2207.00747.
- Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc V. Le, Ed H. Chi, and Denny Zhou. 2022e. Selfconsistency improves chain of thought reasoning in language models. CoRR , abs/2203.11171.
- Jason Wei, Yi Tay, Rishi Bommasani, Colin Raffel, Barret Zoph, Sebastian Borgeaud, Dani Yogatama, Maarten Bosma, Denny Zhou, Donald Metzler, Ed H. Chi, Tatsunori Hashimoto, Oriol Vinyals, Percy Liang, Jeff Dean, and William Fedus. 2022a. Emergent abilities of large language models. Trans. Mach. Learn. Res. , 2022.
- Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, brian ichter, Fei Xia, Ed Chi, Quoc V Le, and Denny Zhou. 2022b. Chain-of-thought prompting elicits reasoning in large language models. In Advances in Neural Information Processing Systems , volume 35, pages 24824-24837. Curran Associates, Inc.
- Yixuan Weng, Minjun Zhu, Shizhu He, Kang Liu, and Jun Zhao. 2022. Large language models are reasoners with self-verification. CoRR , abs/2212.09561.
- Sang Michael Xie, Aditi Raghunathan, Percy Liang, and Tengyu Ma. 2022. An explanation of in-context learning as implicit bayesian inference. In International Conference on Learning Representations .
- Mengjiao (Sherry) Yang, Dale Schuurmans, Pieter Abbeel, and Ofir Nachum. 2022. Chain of thought imitation with procedure cloning. In Advances in Neural Information Processing Systems , volume 35, pages 36366-36381. Curran Associates, Inc.
- Zonglin Yang, Xinya Du, Rui Mao, Jinjie Ni, and Erik Cambria. 2023. Logical reasoning over natural language as knowledge representation: A survey. CoRR , abs/2303.12023.
- Xi Ye and Greg Durrett. 2022. The unreliability of explanations in few-shot prompting for textual reasoning. In Advances in Neural Information Processing Systems , volume 35, pages 30378-30392. Curran Associates, Inc.
- Xi Ye and Greg Durrett. 2023. Explanation selection using unlabeled data for in-context learning. CoRR , abs/2302.04813.
- Xi Ye, Srinivasan Iyer, Asli Celikyilmaz, Ves Stoyanov, Greg Durrett, and Ramakanth Pasunuru. 2022. Complementary explanations for effective in-context learning. CoRR , abs/2211.13892.
- Yunhu Ye, Binyuan Hui, Min Yang, Binhua Li, Fei Huang, and Yongbin Li. 2023. Large language models are versatile decomposers: Decompose evidence and questions for table-based reasoning. CoRR , abs/2301.13808.
- Ori Yoran, Tomer Wolfson, Ben Bogin, Uri Katz, Daniel Deutch, and Jonathan Berant. 2023. Answering questions by meta-reasoning over multiple chains of thought. CoRR , abs/2304.13007.
Ping Yu, Tianlu Wang, Olga Golovneva, Badr AlKhamissy, Gargi Ghosh, Mona T. Diab, and Asli Celikyilmaz. 2022. ALERT: adapting language models to reasoning tasks. CoRR , abs/2212.08286.
- Eric Zelikman, Yuhuai Wu, Jesse Mu, and Noah Goodman. 2022. Star: Bootstrapping reasoning with reasoning. In Advances in Neural Information Processing Systems , volume 35, pages 15476-15488. Curran Associates, Inc.
Li Zhang, Hainiu Xu, Yue Yang, Shuyan Zhou, Weiqiu You, Manni Arora, and Chris Callison-Burch. 2023a. Causal reasoning of entities and events in procedural texts. In Findings of the Association for Computational Linguistics: EACL 2023, Dubrovnik, Croatia, May 2-6, 2023 , pages 415-431. Association for Computational Linguistics.
- Sarah J. Zhang, Reece Shuttleworth, Derek Austin, Yann Hicke, Leonard Tang, Sathwik Karnik, Darnell Granberry, and Iddo Drori. 2022a. A dataset and benchmark for automatically answering and generating machine learning final exams. CoRR , abs/2206.05442.
- Zhuosheng Zhang, Aston Zhang, Mu Li, and Alex Smola. 2022b. Automatic chain of thought prompting in large language models. CoRR , abs/2210.03493.
Zhuosheng Zhang, Aston Zhang, Mu Li, Hai Zhao, George Karypis, and Alex Smola. 2023b. Multimodal chain-of-thought reasoning in language models. CoRR , abs/2302.00923.
Wayne Xin Zhao, Kun Zhou, Junyi Li, Tianyi Tang, Xiaolei Wang, Yupeng Hou, Yingqian Min, Beichen Zhang, Junjie Zhang, Zican Dong, Yifan Du, Chen Yang, Yushuo Chen, Zhipeng Chen, Jinhao Jiang, Ruiyang Ren, Yifan Li, Xinyu Tang, Zikang Liu, Peiyu Liu, Jian-Yun Nie, and Ji-Rong Wen. 2023. A survey of large language models. CoRR , abs/2303.18223.
Chuanyang Zheng, Zhengying Liu, Enze Xie, Zhenguo Li, and Yu Li. 2023. Progressive-hint prompting improves reasoning in large language models. CoRR , abs/2304.09797.
Denny Zhou, Nathanael Schärli, Le Hou, Jason Wei, Nathan Scales, Xuezhi Wang, Dale Schuurmans, Olivier Bousquet, Quoc Le, and Ed H. Chi. 2022a. Least-to-most prompting enables complex reasoning in large language models. CoRR , abs/2205.10625.
Fan Zhou, Haoyu Dong, Qian Liu, Zhoujun Cheng, Shi Han, and Dongmei Zhang. 2022b. Reflection of thought: Inversely eliciting numerical reasoning in language models via solving linear systems. CoRR , abs/2210.05075.
Hattie Zhou, Azade Nova, Hugo Larochelle, Aaron C. Courville, Behnam Neyshabur, and Hanie Sedghi. 2022c. Teaching algorithmic reasoning via incontext learning. CoRR , abs/2211.09066.
- Yongchao Zhou, Andrei Ioan Muresanu, Ziwen Han, Keiran Paster, Silviu Pitis, Harris Chan, and Jimmy Ba. 2022d. Large language models are human-level prompt engineers. CoRR , abs/2211.01910.
Zhi-Hua Zhou. 2012. Ensemble methods: foundations and algorithms . CRC press.
## A Related Surveys
Some recent surveys on prompts and in-contextlearning contain the introduction of Chain-ofThought prompting but most of them only briefly introduce some relevant methods and lack of a systematic and comprehensive analysis. Daull et al. (2023) and Yang et al. (2023) focused on techniques on QA and reasoning tasks and just contain a brief mention on CoT prompting. Zhao et al. (2023) introduced Chain-of-Thought prompting on few-shot and zero-shot scenarios but did not make a deep analysis on CoT prompting strategies designing. Huang and Chang (2022) and Dong et al. (2023) introduced common methods of CoT prompting, but they did not give a detailed formalization on CoT prompt and a systematic taxonomy of these methods. These work also didn't cover comprehensive work of CoT prompting. Closer to our work, Qiao et al. (2022) presented a survey on prompts for reasoning tasks and introduced some work on CoT prompting. Comparing to their work, we focus more on the deep analysis when utilizing CoT prompting. For example, when it comes to task applications, Qiao et al. (2022) just introduce the form of different tasks while we discussed the characteristic of these tasks and explained why and how to use CoT prompting on these tasks. We are also the only survey which contains a fine-grained formulation of CoT prompt.
In short, unlike methods collection surveys, our survey aims to provide a deeper and more comprehensive analysis on CoT prompting. We want to give a general guide for communities to better utilize the CoT prompting and provide a clear vision on prompting strategies designing.
## B Relevant Resources
Since CoT shows prominent strength in many tasks involving multi-steps, the acquisition of step-wise data is a key aspect for CoT application. Considering the great manual efforts demand for CoT data annotation, a comprehensive dataset and efficient annotation tool is of great importance. We will introduce some CoT resources in this section.
Saparov and He (2022) presented a ontology structure based CoT logical reasoning dataset, PRONTOQA. Ott et al. (2023) proposed a CoT reasoning meta-dataset, ThoughtSource, which integrates six scientific/medical , three general-domain and five math word question answering datasets with manual or AI-generated CoT annotated. The dataset embraces various types of question answering including number, multiple choice, text, bool, etc . This dataset can be effectively used in both fewshot in-context-learning and fine-tuning paradigm.
For more efficient CoT data annotation, Kim et al. (2023) proposed a CoT annotation toolkit, CoTEVer, enabling a more applicable manner to reduce manual efforts. CoTEVer can retrieve evidence for generate CoT explanations and provide a more efficient way to verify and correct the wrong explanations.