# Prometheus: Inducing Fine-grained Evaluation Capability in Language Models
> denotes equal contribution. Work was done while Seungone was interning at NAVER AI Lab.Corresponding authors
## Abstract
Recently, using a powerful proprietary Large Language Model (LLM) (e.g., GPT-4) as an evaluator for long-form responses has become the de facto standard. However, for practitioners with large-scale evaluation tasks and custom criteria in consideration (e.g., child-readability), using proprietary LLMs as an evaluator is unreliable due to the closed-source nature, uncontrolled versioning, and prohibitive costs. In this work, we propose Prometheus, a fully open-source LLM that is on par with GPT-4’s evaluation capabilities when the appropriate reference materials (reference answer, score rubric) are accompanied. We first construct the Feedback Collection, a new dataset that consists of 1K fine-grained score rubrics, 20K instructions, and 100K responses and language feedback generated by GPT-4. Using the Feedback Collection, we train Prometheus, a 13B evaluator LLM that can assess any given long-form text based on customized score rubric provided by the user. Experimental results show that Prometheus scores a Pearson correlation of 0.897 with human evaluators when evaluating with 45 customized score rubrics, which is on par with GPT-4 (0.882), and greatly outperforms ChatGPT (0.392). Furthermore, measuring correlation with GPT-4 with 1222 customized score rubrics across four benchmarks (MT Bench, Vicuna Bench, Feedback Bench, Flask Eval) shows similar trends, bolstering Prometheus ’s capability as an evaluator LLM. Lastly, Prometheus achieves the highest accuracy on two human preference benchmarks (HHH Alignment & MT Bench Human Judgment) compared to open-sourced reward models explicitly trained on human preference datasets, highlighting its potential as an universal reward model. We open-source our code, dataset, and model https://kaistai.github.io/prometheus/.
## 1 Introduction
Evaluating the quality of machine-generated text has been a long-standing challenge in Natural Language Processing (NLP) and remains especially essential in the era of Large Language Models (LLMs) to understand their properties and behaviors (Liang et al., 2022; Chang et al., 2023; Zhong et al., 2023; Chia et al., 2023; Holtzman et al., 2023). Human evaluation has consistently been the predominant method, for its inherent reliability and capacity to assess nuanced and subjective dimensions in texts. In many situations, humans can naturally discern the most important factors of assessment, such as brevity, creativity, tone, and cultural sensitivities. On the other hand, conventional automated evaluation metrics (e.g., BLEU, ROUGE) cannot capture the depth and granularity of human evaluation (Papineni et al., 2002; Lin, 2004b; Zhang et al., 2019; Krishna et al., 2021).
Applying LLMs (e.g. GPT-4) as an evaluator has received substantial attention due to its potential parity with human evaluation (Chiang & yi Lee, 2023; Dubois et al., 2023; Li et al., 2023; Liu et al., 2023; Peng et al., 2023; Zheng et al., 2023; Ye et al., 2023b; Min et al., 2023). Initial investigations and observations indicate that, when aptly prompted, LLMs can emulate the fineness of human evaluations. However, while the merits of using proprietary LLMs as an evaluation tool are evident, there exist some critical disadvantages:
1. Closed-source Nature: The proprietary nature of LLMs brings transparency concerns as internal workings are not disclosed to the broader academic community. Such a lack of transparency hinders collective academic efforts to refine or enhance its evaluation capabilities. Furthermore, this places fair evaluation, a core tenet in academia, under control of for-profit entity and raises concerns about neutrality and autonomy.
1. Uncontrolled Versioning: Proprietary models undergo version updates that are often beyond the users’ purview or control (Pozzobon et al., 2023). This introduces a reproducibility challenge. As reproducibility is a cornerstone of scientific inquiry, any inconsistency stemming from version changes can undermine the robustness of research findings that depend on specific versions of the model, especially in the context of evaluation.
1. Prohibitive Costs: Financial constraints associated with LLM APIs are not trivial. For example, evaluating four LLMs variants across four sizes (ranging from 7B to 65B) using GPT-4 on 1000 evaluation instances can cost over $2000. Such scaling costs can be prohibitive, especially for academic institutions or researchers operating on limited budgets.
<details>
<summary>x1.png Details</summary>
### Visual Description
# Technical Document Extraction: LLM Evaluation Methods Flowchart
## Diagram Overview
The image presents a comparative analysis of Large Language Model (LLM) evaluation methodologies through a multi-section flowchart. Key components include conventional benchmarks, coarse-grained evaluations, fine-grained evaluations with custom rubrics, and a proposed evaluation approach.
---
## Section 1: Conventional LLM Evaluation
**Title**: Conventional LLM Evaluation
**Components**:
- **Benchmarks**: MMLU, Big Bench, MATH, HumanEval
- **Evaluation Metrics**: Accuracy, EM (Exact Match), Rouge
- **Output**: Score for specific domain/task
**Flow**:
```
Benchmarks → Accuracy/EM/Rouge → Domain-specific Score
```
---
## Section 2: Coarse-Grained Evaluation
**Title**: Coarse-Grained Evaluation
**Components**:
- **Benchmarks**: Vicuna Bench, MT Bench, AlpacaFarm
- **Evaluation Method**: GPT-4 Evaluation
- **Output**: Score based on Helpfulness/Harmlessness
**Flow**:
```
Benchmarks → GPT-4 Evaluation → Helpfulness/Harmlessness Score
```
---
## Section 3: Fine-grained Evaluation with User-Defined Score Rubrics
**Title**: Fine-grained Evaluation with User-Defined Score Rubrics
**Components**:
- **Instruction Set**: Vicuna Bench, MT Bench, AlpacaFarm
- **Score Rubric**: Cultural sensitivity assessment (1-5 scale)
- Score 1: `~~~` (Low sensitivity)
- Score 5: `~~~` (High sensitivity)
- **Reference Answer**: Placeholder for ground truth
- **Evaluation Methods**:
- GPT-4 Evaluation → Customized Criteria
- Prometheus Evaluation (🔥 icon) → Customized Criteria
**Flow**:
```
Instruction Set + Score Rubric → GPT-4 Evaluation → Customized Criteria
Instruction Set + Score Rubric → Prometheus Evaluation → Customized Criteria
```
---
## Section 4: Proposed Approach
**Components**:
1. **Domain-specific Diagnostics**
- 🤔 Emoji: "Only diagnoses about a specific domain or task"
- Limitation: Narrow focus
2. **General Preference Diagnostics**
- 🤔 Emoji: "Only diagnoses about the general preference of the public"
- Limitation: Public bias
3. **Close-source Nature**
- 🤔 Emoji: "Uncontrolled Versioning"
- 💸 Emoji: "Prohibitive Costs"
4. **Fully Open-source**
- 🤔 Emoji: "Reproducible Evaluation"
- 💸 Emoji: "Inexpensive Costs"
---
## Dialogue Bubble Analysis
**LLM User**:
"Which LLM is the most humorous one out there?"
**LLM Developer**:
"Is the LLM I’m developing inspiring while being culturally sensitive?"
---
## Key Observations
1. **Color Coding**:
- Red: Conventional/Coarse-grained evaluations
- Blue: Fine-grained evaluations
- Purple: Proposed approach
2. **Evaluation Philosophy**:
- Traditional methods focus on accuracy metrics
- Modern approaches emphasize cultural sensitivity and user-defined criteria
- Proposed method advocates for open-source reproducibility and cost efficiency
3. **Critical Gaps**:
- Conventional methods lack cultural sensitivity assessment
- Coarse-grained evaluations depend on third-party models (GPT-4)
- Close-source systems face versioning and cost challenges
---
## Diagram Structure
```
[Conventional LLM Evaluation]
↓
[Accuracy/EM/Rouge]
↓
[Domain-specific Score]
[Coarse-Grained Evaluation]
↓
[GPT-4 Evaluation]
↓
[Helpfulness/Harmlessness Score]
[Fine-grained Evaluation]
↓
[GPT-4 Evaluation]
↓
[Customized Criteria]
[Proposed Approach]
├─ Domain-specific Diagnostics
├─ General Preference Diagnostics
├─ Close-source Nature (Uncontrolled Versioning, Prohibitive Costs)
└─ Fully Open-source (Reproducible Evaluation, Inexpensive Costs)
```
---
## Language Notes
- **Primary Language**: English
- **Emojis**: Used as visual indicators (no translation required)
- **Special Characters**:
- `~~~` (tilde symbols) for score representation
- `🔥` (fire emoji) for Prometheus Evaluation
---
## Conclusion
The flowchart illustrates the evolution of LLM evaluation from traditional accuracy metrics to culturally sensitive, user-defined frameworks. The proposed approach emphasizes open-source reproducibility and cost efficiency while addressing limitations in existing methods.
</details>
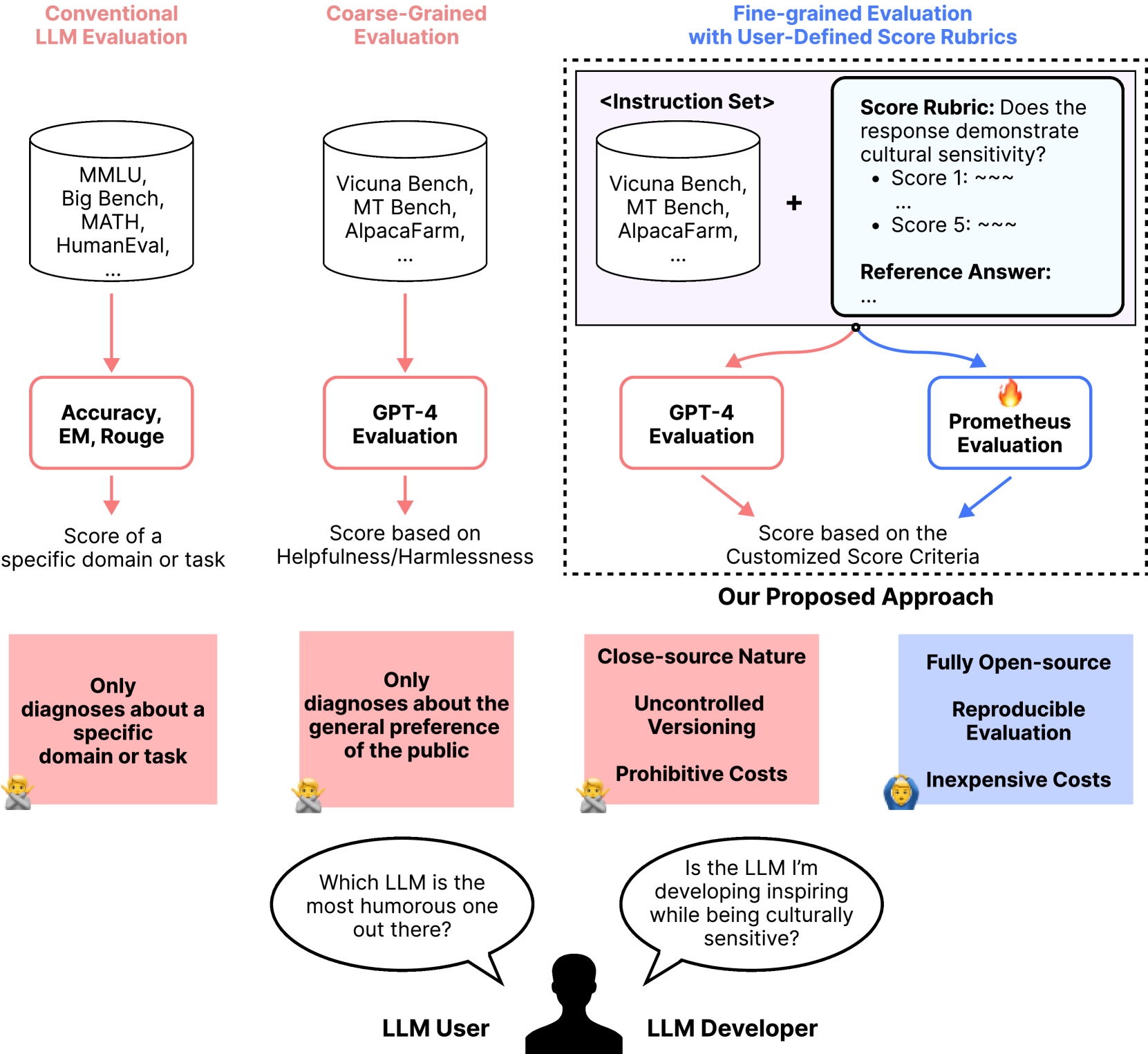
Figure 1: Compared to conventional, coarse-grained LLM evaluation, we propose a fine-grained approach that takes user-defined score rubrics as input.
Despite these limitations, proprietary LLMs such as GPT-4 are able to evaluate scores based on customized score rubrics. Specifically, current resources are confined to generic, single-dimensional evaluation metrics that are either too domain/task-specific (e.g. EM, Rouge) or coarse-grained (e.g. helpfulness/harmlessness (Dubois et al., 2023; Chiang et al., 2023; Liu et al., 2023) as shown in left-side of Figure 1. For instance, AlpacaFarm’s (Dubois et al., 2023) prompt gives a single definition of preference, asking the model to choose the model response that is generally preferred. However, response preferences are subject to variation based on specific applications and values. In real-world scenarios, users may be interested in customized rubric such as “Which LLM generates responses that are playful and humorous” or “Which LLM answers with particularly care for cultural sensitivities?” Yet, in our initial experiments, we observe that even the largest open-source LLM (70B) is insufficient to evaluate based on a customized score rubric compared to proprietary LLMs.
To this end, we propose Prometheus, a 13B LM that aims to induce fine-grained evaluation capability of GPT-4, while being open-source, reproducible, and inexpensive. We first create the Feedback Collection, a new dataset that is crafted to encapsulate diverse and fine-grained user assessment score rubric that represent realistic user demands (example shown in Figure 2). We design the Feedback Collection with the aforementioned consideration in mind, encompassing thousands of unique preference criteria encoded by a user-injected score rubric. Unlike prior feedback datasets (Ye et al., 2023a; Wang et al., 2023a), it uses custom, not generic preference score rubric, to train models to flexibly generalize to practical and diverse evaluation preferences. Also, to best of our knowledge, we are first to explore the importance of including various reference materials – particularly the ‘Reference Answers’ – to effectively induce fine-grained evaluation capability.
We use the Feedback Collection to fine-tune Llama-2-Chat-13B in creating Prometheus. On 45 customized score rubrics sampled across three test sets (MT Bench, Vicuna Bench, Feedback Bench), Prometheus obtains a Pearson correlation of 0.897 with human evaluators, which is similar with GPT-4 (0.882), and has a significant gap with GPT-3.5-Turbo (0.392). Unexpectely, when asking human evaluators to choose a feedback with better quality in a pairwise setting, Prometheus was preferred over GPT-4 in 58.67% of the time, while greatly outperformed GPT-3.5-Turbo with a 79.57% win rate. Also, when measuring the Pearson correlation with GPT-4 evaluation across 1222 customized score rubrics across 4 test sets (MT Bench, Vicuna Bench, Feedback Bench, Flask Eval), Prometheus showed higher correlation compared to GPT-3.5-Turbo and Llama-2-Chat 70B. Lastly, when testing on 2 unseen human preference datasets (MT Bench Human Judgments, HHH Alignment), Prometheus outperforms two state-of-the-art reward models and GPT-3.5-Turbo, highlighting its potential as an universal reward model.
Our contributions are summarized as follows:
- We introduce the Feedback Collection dataset specifically designed to train an evaluator LM. Compared to previous feedback datasets, it includes customized scoring rubrics and reference answers in addition to the instructions, responses, and feedback.
- We train Prometheus, the first open-source LLM specialized for fine-grained evaluation that can generalize to diverse, real-world scoring rubrics beyond a single-dimensional preference such as helpfulness and harmlessness.
- We conduct extensive experiments showing that by appending reference materials (reference answers, fine-grained score rubrics) and fine-tuning on feedback, we can induce evaluation capability into language models. Prometheus shows high correlation with human evaluation, GPT-4 evaluation in absolute scoring settings, and also shows high accuracy in ranking scoring settings.
## 2 Related Work
Reference-based text evaluation
Previously, model-free scores that evaluate machine-generated text based on a golden candidate reference such as BLEU (Papineni et al., 2002) and ROUGE (Lin, 2004a) scores were used as the dominant approach. However, Krishna et al. (2021) reported limitations in reference-based metrics, such as ROUGE, observing that they are not reliable for evaluation. In recent years, model-based approaches have been widely adopted such as BERTScore (Zhang et al., 2019), BLEURT (Sellam et al., 2020), and BARTScore (Yuan et al., 2021) which are able to capture semantic information rather than only evaluating on lexical components.
LLM-based text evaluation
Recent work has used GPT-4 or a fine-tuned critique LLM as an evaluator along a single dimension of “preference” (Chiang & yi Lee, 2023; Li et al., 2023; Dubois et al., 2023; Zheng et al., 2023; Liu et al., 2023). For instance, AlpacaFarm (Dubois et al., 2023) asks the model to select “which response is better based on your judgment and based on your own preference” Another example is recent work that showed ChatGPT can outperform crowd-workers for text-annotation tasks (Gilardi et al., 2023; Chiang & yi Lee, 2023). Wang et al. (2023b) introduced PandaLM, a fine-tuned LLM to evaluate the generated text and explain its reliability on various preference datasets. Similarly, Ye et al. (2023a) and Wang et al. (2023a) create critique LLMs. However, the correct preference is often subjective and depends on applications, cultures, and objectives, where degrees of brevity, formality, honesty, creativity, and political tone, among many other potentially desirable traits that may vary (Chiang & yi Lee, 2023). While GPT-4 is unreliable due to its close-source nature, uncontrolled versioning, and prohibitive costs, it was the only option explored for fine-grained and customized evaluation based on the score rubric (Ye et al., 2023b). On the contrary, we train, to best of our knowledge, the first evaluator sensitive to thousands of unique preference criteria, and show it significantly outperforms uni-dimensional preference evaluators in a number of realistic settings. Most importantly, compared to previous work, we strongly argue the importance of appending reference materials (score rubric and reference answer) in addition to fine-tuning on the feedback in order to effectively induce fine-grained evaluation capability.
## 3 The Feedback Collection Dataset
While previous work has demonstrated that fine-tuning on feedback is effective for improving LMs to function as a critique (Ye et al., 2023a; Wang et al., 2023a), the datasets used in previous work are not directly applicable for improving LMs to function as a fine-grained evaluator. We thus introduce the Feedback Collection, a new dataset for the sole purpose of fine-tuning an open-sourced evaluator LLM. Our 4 main considerations during dataset construction are: (1) including as many reference materials (i.e. reference answer, and scoring rubric) as possible, (2) maintaining a uniform length among the reference answers for each score (1 to 5) to prevent undesired length bias, (3) maintaining a uniform score distribution to prevent undesired decision bias, and (4) limiting the scope of our instructions and responses to realistic situations where a user is interacting with a LLM.
<details>
<summary>x2.png Details</summary>
### Visual Description
# Technical Document Extraction: FinTech Startup Business Strategy Evaluation
## Section 1: Instruction
**Title**: Instruction
**Content**:
"Develop me a business strategy for creating a FinTech startup that offers online banking services."
## Section 2: Customized Score Rubric
**Title**: Customized Score Rubric
**Criteria**:
- **Does the response consider regulations and compliance requirements?**
- [Score 1] The response disregards regulations and compliance requirements.
- [Score 2] The response shows minimal awareness of regulatory compliance, making several errors.
- [Score 3] The response recognizes certain regulatory requirements but lacks depth.
- [Score 4] The response mostly considers regulatory compliance, with only minor oversights.
- [Score 5] The response perfectly accounts for and integrates regulatory compliance requirements.
## Section 3: Response to Evaluate
**Title**: Response to Evaluate
**Subtitle**: Online Banking Service FinTech Startup Business Strategy
**Executive Summary**:
"Our startup, 'DigitalBank', aims to revolutionize the traditional banking industry by providing an innovative ..."
**Reference Answer**:
**Title**: Reference Answer
**Content**:
"Establishing a FinTech startup that offers online banking services requires a comprehensive strategy to tackle various challenges inherent to the industry and capitalize on market opportunities.
1. Market Research: ...
2. Regulatory and Compliance: ...
3. Product Development: ...
4. Service Differentiation: ...
5. Go-to-Market Strategy: ...
6. Growth and Expansion: ...
7. Sustainability and Trust: ...
These items are important aspects to consider when starting a FinTech startup that offers online banking services."
## Section 4: Feedback
**Title**: Feedback
**Content**:
"The response provides a comprehensive overview.
Overall, it includes a detailed plan of how to start a FinTech startup by presenting an imaginary startup 'DigitalBank'.
However, it lacks a deeper dive into regulatory compliance.
...
**Score**: 3 out of 5"
## Diagram Structure
1. **Left Column**:
- Instruction (White background with red oval)
- Customized Score Rubric (Peach background with red oval)
2. **Center Column**:
- Response to Evaluate (Gray background with red oval)
- Reference Answer (Blue background with red oval)
3. **Right Column**:
- Prometheus (Blue background with flame emoji)
- Feedback (Yellow background with red oval)
## Key Observations
- **Regulatory Compliance Focus**: The rubric emphasizes regulatory compliance as a critical evaluation criterion.
- **Feedback Score**: The response received a score of 3/5, indicating partial alignment with compliance requirements.
- **Placeholder Content**: The Reference Answer includes ellipses (...) for detailed subpoints, suggesting incomplete transcription.
## Language Notes
- **Primary Language**: English
- **No Additional Languages Detected**
</details>
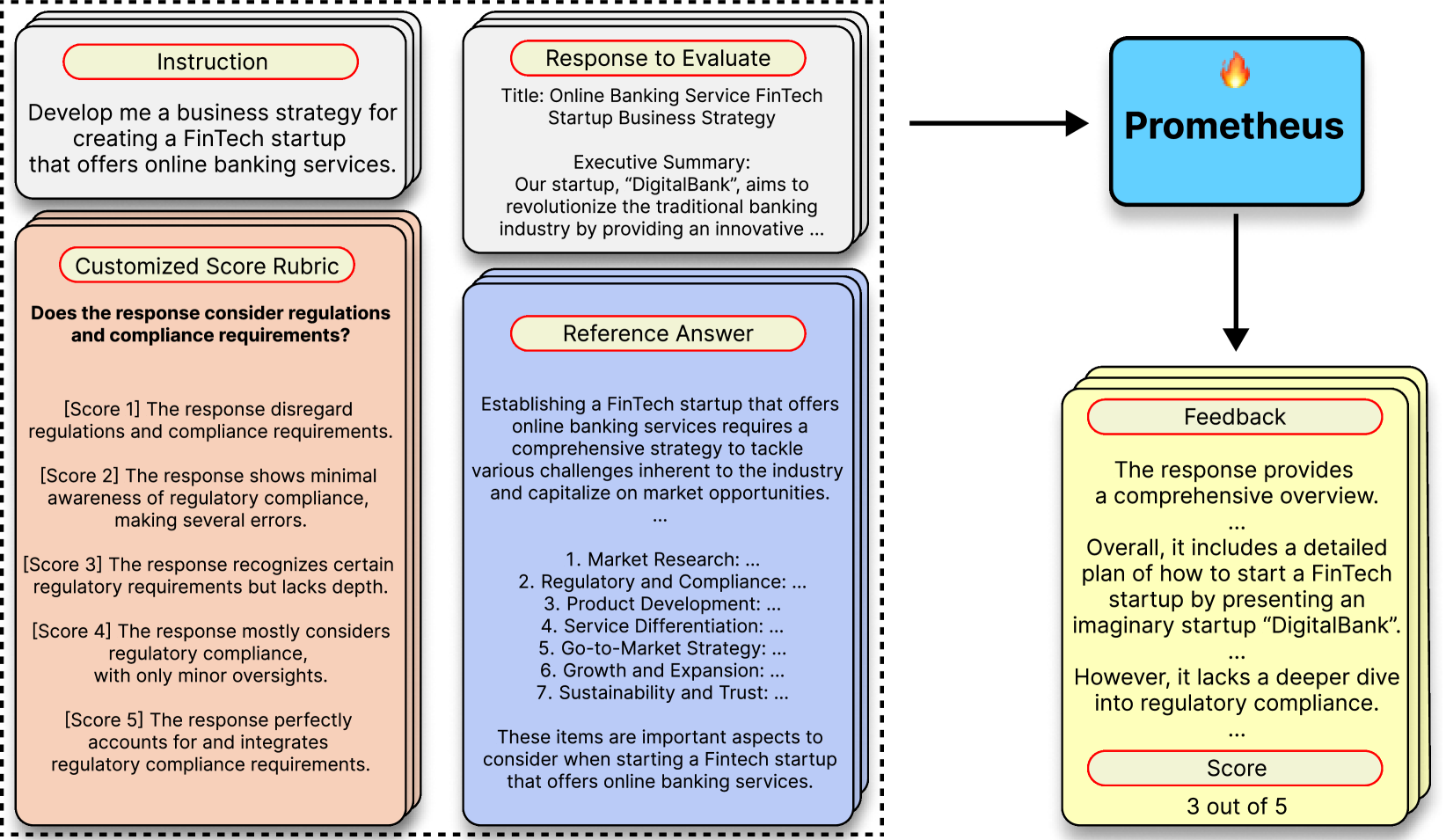
Figure 2: The individual components of the Feedback Collection. By adding the appropriate reference materials (Score Rubric and Reference Answer) and training on GPT-4’s feedback, we show that we could obtain a strong open-source evaluator LM.
Taking these into consideration, we construct each instance within the Feedback Collection to encompass four components for the input (instruction, response to evaluate, customized score rubric, reference answer) and two components in the output (feedback, score). An example of an instance is shown in Figure 2 and the number of each component is shown in Table 1.
The four components for the input are as follows:
1. Instruction: An instruction that a user would prompt to an arbitrary LLM.
1. Response to Evaluate: A response to the instruction that the evaluator LM has to evaluate.
1. Customized Score Rubric: A specification of novel criteria decided by the user. The evaluator should focus on this aspect during evaluation. The rubric consists of (1) a description of the criteria and (2) a description of each scoring decision (1 to 5).
1. Reference Answer: A reference answer that would receive a score of 5. Instead of requiring the evaluator LM to solve the instruction, it enables the evaluator to use the mutual information between the reference answer and the response to make a scoring decision.
The two components for the output are as follows:
1. Feedback: A rationale of why the provided response would receive a particular score. This is analogous to Chain-of-Thoughts (CoT), making the evaluation process interpretable.
1. Score: An integer score for the provided response that ranges from 1 to 5.
Table 1: Information about our training dataset Feedback Collection. Note that there are 20 instructions accompanied for each score rubric, leading to a total number of 20K. Also, there is a score 1-5 response and feedback for each instruction, leading to a total number of 100K.
| Evaluation Mode | Data | # Score Rubrics | # Instructions & Reference Answer | # Responses & Feedback |
| --- | --- | --- | --- | --- |
| Absolute Evaluation | Feedback Collection | 1K (Fine-grained & Customized) | Total 20K (20 for each score rubric) | Total 100K(5 for each instruction; 20K for each score within 1-5) |
<details>
<summary>x3.png Details</summary>

### Visual Description
# Technical Document Extraction: Image Analysis
## Overview
The image is a **flowchart** depicting a structured process for evaluating and refining responses using **score rubrics** and **feedback mechanisms**. It includes textual descriptions, hierarchical categories, and directional arrows indicating workflow. Below is a detailed breakdown of all textual components, diagrams, and data points.
---
## 1. Seed Score Rubrics
### Labels and Text
- **Question 1**:
*"Is the answer explained like a formal proof?"*
- Score 1: The answer lacks any structure resembling a formal proof.
- Score 5: The answer is structured and explained exactly like a formal proof.
- **Question 2**:
*"Does the response utilize appropriate professional jargon and terminology suited for an academic or expert audience?"*
- Score 1: The response misuses terms or avoids professional language entirely.
- Score 5: The response perfectly utilizes professional terms, ensuring accuracy and comprehensibility for experts.
---
## 2. Feedback Collection Score Rubrics (1K)
### Circular Diagram Structure
The central diagram is a **radial chart** with hierarchical categories and subcategories. Key components include:
#### Main Categories (Colored Segments)
1. **Tone & Style Modulation** (Pink)
- Emotionally Attuned Responses
- Contextual Language Adaptation
2. **Adaptive Communication** (Light Pink)
- Tone & Style Modulation
- Contextual Language Adaptation
3. **Ambiguity Navigation** (Orange)
- Proactive Clarification Seeking
- Ambiguous Input Clarification
- Unclear Query Handling
4. **Global Cultural Awareness** (Yellow)
- Sensitivity to Cultural Differences
- Respect for Cultural Diversity
- Understanding of Global Traditions
5. **Emotional Intelligence in Communication** (Green)
- Emotionally Considerate Communication
- Recognition & Acknowledgment of Emotions
- Empathetic & Supportive Responses
6. **Specialized Language Mastery** (Blue)
- Precise Technical Language Use
- Technical Vocabulary Interpretation
- Sector-Specific Terminology
7. **Cultural Sensitivity & Respect** (Purple)
- Nuanced Cultural Understanding
- Avoidance of Cultural Stereotypes
- Societal Manners & Etiquette
8. **Problem Solving** (Light Purple)
- Innovative Problem Solving
- Error & Misinterpretation Management
9. **Industry & Technical Language Proficiency** (Red)
- Accurate Industry Terminology Use
- Effective Misconception Handling
- Misinterpretation Mitigation
10. **Technical Term Mastery** (Dark Red)
- Novel Idea Generation
- Specialized Language Fluency
11. **Child Safety Promotion** (Light Orange)
- Engagement Enhancement Strategies
- Clear & Concise Information Provision
#### Arrows and Connections
- Red arrows indicate **feedback flow** between components (e.g., from Seed Score Rubrics to Feedback Collection Instance Augmentation).
- Dotted lines separate distinct sections (e.g., Seed Score Rubrics, Feedback Collection Score Rubrics, Feedback Collection Instance Augmentation).
---
## 3. Feedback Collection Instance Augmentation
### Textual Components
#### Instruction Block
- **Task**:
*"I am an entry-level employee at a multinational corporation and have been asked to write a report on the current trends in our industry."*
- **Uncertainty**:
*"I am unsure how to structure the report and level of formality required. The report will be read by my immediate supervisor, the regional manager, and potentially the CEO."*
- **Request**:
*"Can you give me a sample of how the report should be written?"*
#### Reference Answer (Score 5)
- **Guidelines**:
1. Research all the latest stuff in your industry.
2. Create an outline organized with thoughts.
3. Include a title page, executive summary, introduction, body, conclusion, and references.
4. Use formal language but avoid stiffness.
5. Add charts or graphs (example provided).
#### Feedback Block
- **Positive Feedback**:
*"The response provides a helpful guide to approaching the task but could be more professional in tone and phrasing."*
- **Constructive Criticism**:
*"Some sentences feel too casual and informal for a report to be read by the supervisor or CEO."*
- **Suggestions**:
*"Keep your language formal, use headings, subheadings, and add charts or graphs. Here’s an example: [example text]."*
#### Score
- **Overall Score**: 3
---
## 4. Customized Score Rubric
### Labels and Text
- **Question**:
*"Is the answer written professionally and formally, so that I could send it to my boss?"*
- Score 1: The answer lacks any sense of professionalism and is informal.
- Score 5: The answer is completely professional and suitable for a formal setting.
---
## Diagram Components and Flow
1. **Seed Score Rubrics** (Left) → **Feedback Collection Score Rubrics (1K)** (Center) → **Feedback Collection Instance Augmentation** (Right) → **Customized Score Rubric** (Bottom Left).
2. Arrows indicate **evaluation progression** and **feedback integration**.
3. Dotted lines separate distinct evaluation phases.
---
## Key Trends and Data Points
- **Hierarchical Evaluation**:
- Feedback Collection Score Rubrics (1K) is the most detailed, with 11 main categories and 25+ subcategories.
- Seed and Customized Score Rubrics focus on **formality** and **professionalism**.
- **Feedback Loop**:
- The process emphasizes iterative refinement (e.g., from Seed to Customized Rubrics).
- **Cultural and Technical Focus**:
- Categories like *Global Cultural Awareness* and *Technical Term Mastery* highlight cross-cultural and domain-specific requirements.
---
## Notes
- **No Data Tables**: The image uses textual descriptions and hierarchical diagrams instead of numerical data.
- **Language**: All text is in **English**.
- **Spatial Grounding**:
- Seed Score Rubrics: Top-left quadrant.
- Feedback Collection Score Rubrics: Central circular diagram.
- Feedback Collection Instance Augmentation: Right side.
- Customized Score Rubric: Bottom-left quadrant.
---
## Final Output
This flowchart outlines a **multi-stage evaluation process** for technical documents, emphasizing **formality**, **professionalism**, and **cultural/technical adaptability**. The Feedback Collection Score Rubrics (1K) serves as the core evaluation framework, while the Customized Score Rubric tailors criteria for specific audiences (e.g., executives).
</details>
Figure 3: Overview of the augmentation process of the Feedback Collection. The keywords included within the score rubrics of the Feedback Collection is also displayed.
Each instance has an accompanying scoring rubric and reference answer upon the instruction in order to include as much reference material as possible. Also, we include an equal number of 20K instances for each score in the range of 1 to 5, preventing undesired decision bias while training the evaluator LLM. A detailed analysis of the Feedback Collection dataset is in Appendix A.
### 3.1 Dataset Construction Process
We construct a large-scale Feedback Collection dataset by prompting GPT-4. Specifically, the collection process consists of (1) the curation of 50 initial seed rubrics, (2) the expansion of 1K new score rubrics through GPT-4, (3) the augmentation of realistic instructions, and (4) the augmentation of the remaining components in the training instances (i.e. responses including the reference answers, feedback, and scores). Figure 3 shows the overall augmentation process.
Step 1: Creation of the Seed Rubrics
We begin with the creation of a foundational seed dataset of scoring rubrics. Each author curates a detailed and fine-grained scoring rubric that each personnel considers pivotal in evaluating outputs from LLMs. This results in an initial batch of 50 seed rubrics.
Step 2: Augmenting the Seed Rubrics with GPT-4
Using GPT-4 and our initial seed rubrics, we expand the score rubrics from the initial 50 to a more robust and diverse set of 1000 score rubrics. Specifically, by sampling 4 random score rubrics from the initial seed, we use them as demonstrations for in-context learning (ICL), and prompt GPT-4 to brainstorm a new novel score rubric. Also, we prompt GPT-4 to paraphrase the newly generated rubrics in order to ensure Prometheus could generalize to the similar score rubric that uses different words. We iterate the brainstorming $→$ paraphrasing process for 10 rounds. The detailed prompt used for this procedure is in Appendix G.
Step 3: Crafting Novel Instructions related to the Score Rubrics
With a comprehensive dataset of 1000 rubrics at our disposal, the subsequent challenge was to craft pertinent training instances. For example, a score rubric asking “Is it formal enough to send to my boss” is not related to a math problem. Considering the need for a set of instructions closely related to the score rubrics, we prompt GPT-4 to generate 20K unique instructions that are highly relevant to the given score rubric.
Step 4: Crafting Training Instances
Lastly, we sequentially generate a response to evaluate and corresponding feedback by prompting GPT-4 to generate each component that will get a score of $i$ (1 $≤ i≤$ 5). This leads to 20 instructions for each score rubric, and 5 responses & feedback for each instruction. To eliminate the effect of decision bias when fine-tuning our evaluator LM, we generate an equal number of 20K responses for each score. Note that for the response with a score of 5, we generate two distinctive responses so we could use one of them as an input (reference answer).
### 3.2 Fine-tuning an Evaluator LM
Using the Feedback Collection dataset, we fine-tune Llama-2-Chat (7B & 13B) and obtain Prometheus to induce fine-grained evaluation capability. Similar to Chain-of-Thought Fine-tuning (Ho et al., 2022; Kim et al., 2023a), we fine-tune to sequentially generate the feedback and then the score. We highlight that it is important to include a phrase such as ‘ [RESULT] ’ in between the feedback and the score to prevent degeneration during inference. We include the details of fine-tuning, inference, and ablation experiments (reference materials, base model) in Appendix C.
## 4 Experimental Setting: Evaluating an Evaluator LM
In this section, we explain our experiment setting, including the list of experiments, metrics, and baselines that we use to evaluate fine-grained evaluation capabilities of an evaluator LLM. Compared to measuring the instruction-following capability of a LLM, it is not straightforward to directly measure the capability to evaluate. Therefore, we use human evaluation and GPT-4 evaluation as a standard and measure how similarly our evaluator model and baselines could closely simulate them. We mainly employ two types of evaluation methods: Absolute Grading and Ranking Grading. Detailed information on the datasets used for the experiment is included in Table 2.
### 4.1 List of Experiments and Metrics
Absolute Grading
We first test in an Absolute Grading setting, where the evaluator LM should generate a feedback and score within the range of 1 to 5 given an instruction, a response to evaluate, and reference materials (as shown in Figure 2). Absolute Grading is challenging compared to Ranking Grading since the evaluator LM does not have access to an opponent to compare with and it is required to provide a score solely based on its internal decision. Yet, it is more practical for users since it relieves the need to prepare an opponent to compare with during evaluation.
We mainly conduct three experiments in this setting: (1) measuring the correlation with human evaluators (Section 5.1), (2) comparing the quality of the feedback using human evaluation (Section 5.1), and (3) measuring the correlation with GPT-4 evaluation (Section 5.2). For the experiments that measure the correlation, we use 3 different correlation metrics: Pearson, Kdendall-Tau, and Spearman. For measuring the quality of the generated feedback, we conduct a pairwise comparison between the feedback generated by Prometheus, GPT-3.5-Turbo, and GPT-4, asking human evaluators to choose which has better quality and why they thought so. Specifically, we recruited 9 crowdsource workers and split them into three groups: Prometheus vs GPT-4, Prometheus vs ChatGPT, and GPT-4 vs ChatGPT. The annotators are asked to answer the following three questions:
1. What score would you give to the response based on the given score rubric?
1. Among the two Feedback, which is better for critiquing the given response?
1. Why did you reject that particular feedback?
Table 2: Information about the datasets we use to test evaulator LMs. Note that Feedback Bench is a dataset that is crafted with the exact same procedure as the Feedback Collection as explained in Section 3.1. We include additional analysis of Feedback Bench in Appendix B. Simulated GPT-4 $†$ denotes GPT-4 prompted to write a score of $i$ $(1≤ i≤ 5$ ) during augmentation.
We use the following four benchmarks to measure the correlation with human evaluation and GPT-4 evaluation. Note that Feedback Bench is a dataset generated with the same procedure as the Feedback Collection, and is divided into two subsets (Seen Rubric and Unseen Rubric).
- Feedback Bench: The Seen Rubric subset shares the same 1K score rubrics with the Feedback Collection across 1K instructions (1 per score rubric). The Unseen Rubric subset also consists of 1K new instructions but with 50 new score rubrics that are generated the same way as the training set. Details are included in Appendix B.
- Vicuna Bench: We adapt the 80 test prompt set from Vicuna (Chiang et al., 2023) and hand-craft customized score rubrics for each test prompt. In order to obtain reference answers, we concatenate the hand-crafted score rubric and instruction to prompt GPT-4.
- MT Bench: We adapt the 80 test prompt set from MT Bench (Zheng et al., 2023), a multi-turn instruction dataset. We hand-craft customized score rubrics and generate a reference answer using GPT-4 for each test prompt as well. Note that we only use the last turn of this dataset for evaluation, providing the previous dialogue as input to the evaluator LM.
- FLASK Eval: We adapt the 200 test prompt set from FLASK (Ye et al., 2023b), a fine-grained evaluation dataset that includes multiple conventional NLP datasets and instruction datasets. We use the 12 score rubrics (that are relatively coarse-grained compared to the 1K score rubrics used in the Feedback Collection) such as Logical Thinking, Background Knowledge, Problem Handling, and User Alignment.
Ranking Grading
To test if an evaluator LM trained only on Absolute Grading could be utilized as a universal reward model based on any criteria, we use existing human preference benchmarks and use accuracy as our metric (Section 5.3). Specifically, we check whether the evaluator LM could give a higher score to the response that is preferred by human evaluators. The biggest challenge of employing an evaluator LM trained in an Absolute Grading setting and testing it on Ranking Grading was that it could give the same score for both candidates. Therefore, we use a temperature of 1.0 when evaluating each candidate independently and iterate until there is a winner. Hence, it’s noteworthy that the settings are not exactly fair compared to other ranking models. This setting is NOT designed to claim SOTA position in these benchmarks, but is conducted only for the purpose of checking whether an evaluator LM trained in an Absolute Grading setting could also generalize in a Ranking Grading setting according to general human preference. Also, in this setting, we do not provide a reference answer to check whether Prometheus could function as a reward model. We use the following two benchmarks to measure the accuracy with human preference datasets:
- MT Bench Human Judgement: This data is another version of the aforementioned MT Bench (Zheng et al., 2023). Note that it includes a tie option as well and does not require iterative inference to obtain a clear winner. We use Human Preference as our criteria.
- HHH Alignment: Introduced by Anthropic (Askell et al., 2021), this dataset (221 pairs) is one of the most widely chosen reward-model test-beds that measures preference accuracy in Helpfulness, Harmlessness, Honesty, and in General (Other) among two response choices.
### 4.2 Baselines
The following list shows the baselines we used for comparison in the experiments:
- Llama2-Chat- {7,13,70} B (Touvron et al., 2023): The base model of Prometheus when fine-tuning on the Feedback Collection. Also, it is considered as the best option among the open-source LLMs, which we use as an evaluator in this work.
- LLama-2-Chat-13B + Coarse: To analyze the effectiveness of training on thousands of fine-grained score rubrics, we train a comparing model only using 12 coarse-grained score rubrics from Ye et al. (2023b). Detailed information on this model is in Appendix D.
- GPT-3.5-turbo-0613: Proprietary LLM that offers a cheaper price when employed as an evaluator LLM. While it is relatively inexpensive compared to GPT-4, it still has the issue of uncontrolled versioning and close-source nature.
- GPT-4- {0314,0613, Recent}: One of the most powerful proprietary LLM that is considered the main option when using LLMs as evaluators. Despite its reliability as an evaluator LM due to its superior performance, it has several issues of prohibitive costs, uncontrolled versioning, and close-source nature.
- StanfordNLP Reward Model https://huggingface.co/stanfordnlp/SteamSHP-flan-t5-xl: One of the state-of-the-art reward model directly trained on multiple human preference datasets in a ranking grading setting.
- ALMOST Reward Model (Kim et al., 2023b): Another state-of-the-art reward model trained on synthetic preference datasets in a ranking grading setting.
## 5 Experimental Results
<details>
<summary>x4.png Details</summary>
### Visual Description
# Technical Document Extraction: Pearson Correlation Heatmap
## Image Description
The image is a **heatmap** visualizing Pearson correlation coefficients between Large Language Model (LLM) evaluators and human evaluators' scores. The chart uses a **color gradient** (from light green to dark blue) to represent correlation strength, with darker blues indicating higher correlation (closer to 1.0).
---
### Key Components
1. **Title**:
`"Pearson Correlation Between LLM Evaluators and Human Evaluators Scores"`
2. **Axes**:
- **X-axis (Columns)**:
Categories:
- `Overall`
- `Feedback Collection (Unseen)`
- `MT Bench`
- `Vicuna Bench`
- **Y-axis (Rows)**:
Models:
- `GPT-3.5 turbo`
- `GPT-4`
- `Prometheus 13B`
3. **Legend**:
- Located on the **right edge** of the chart.
- **Color Scale**:
- Light green (`~0.3`) to dark blue (`~0.9`).
- Label: `"Pearson Correlation (higher is better)"`
4. **Data Table**:
Reconstructed from the heatmap cells (values rounded to 3 decimal places):
| Model | Overall | Feedback Collection (Unseen) | MT Bench | Vicuna Bench |
|------------------|---------|------------------------------|----------|--------------|
| GPT-3.5 turbo | 0.392 | 0.567 | 0.277 | 0.743 |
| GPT-4 | 0.882 | 0.924 | 0.883 | 0.717 |
| Prometheus 13B | 0.897 | 0.934 | 0.927 | 0.716 |
---
### Spatial Grounding
- **Legend Position**: Right edge of the chart (x = 1.0, y = 0.5 ± 0.5 height).
- **Color Matching**:
- Light green cells (e.g., GPT-3.5 turbo's `MT Bench`) align with the lower end of the legend.
- Dark blue cells (e.g., Prometheus 13B's `Feedback Collection`) align with the upper end.
---
### Trend Verification
1. **GPT-3.5 turbo**:
- Weakest correlations overall (light green to medium blue).
- Strongest in `Vicuna Bench` (0.743).
2. **GPT-4**:
- Strong correlations (dark blue to near-black).
- Highest in `Feedback Collection` (0.924).
3. **Prometheus 13B**:
- Strongest correlations overall (darkest blue).
- Peak in `Feedback Collection` (0.934) and `MT Bench` (0.927).
---
### Notes
- **No additional text or diagrams** are present.
- **No non-English content** detected.
- **No legends for lines or colors beyond the Pearson scale**.
This heatmap highlights that **Prometheus 13B** and **GPT-4** show the strongest alignment with human evaluators across benchmarks, while **GPT-3.5 turbo** exhibits weaker correlations, particularly in `MT Bench`.
</details>
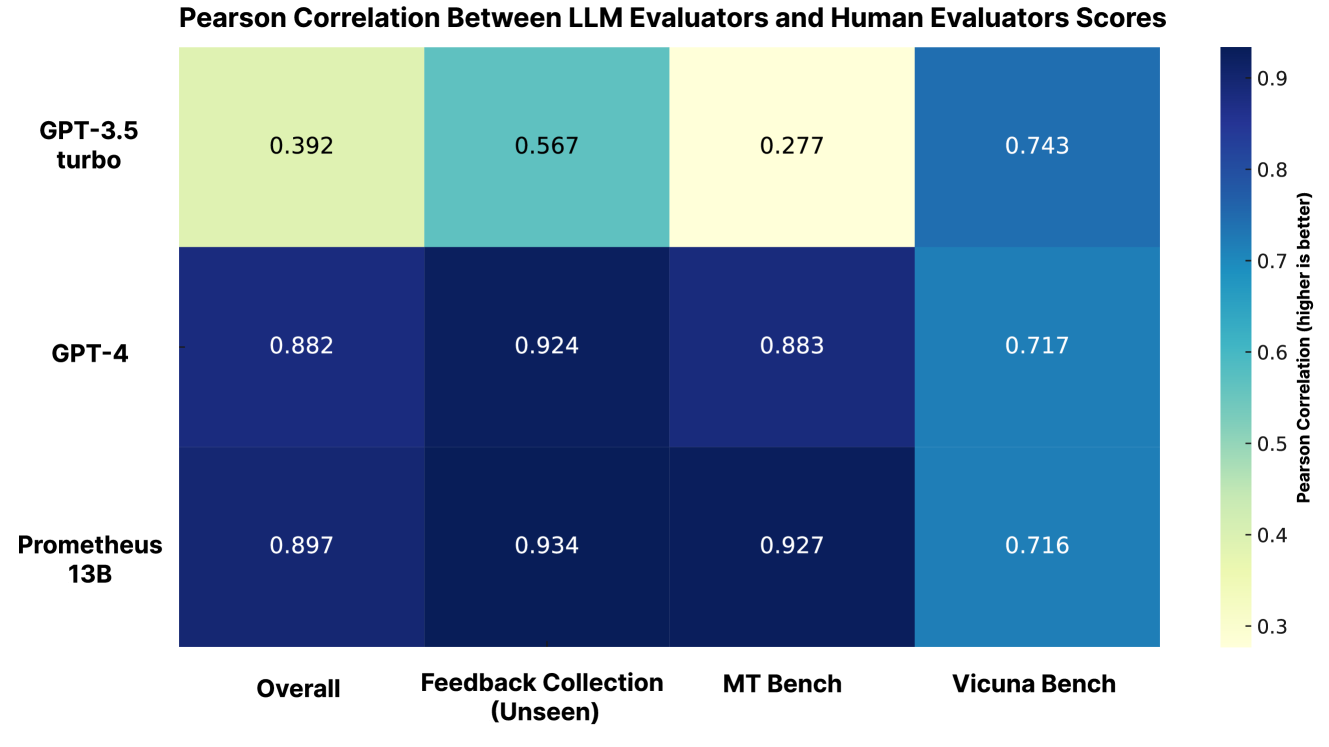
Figure 4: The Pearson correlation between scores from human annotators and the score from GPT-3.5-Turbo, Prometheus, and GPT-4 on 45 customized score rubrics from the Feedback Bench, Vicuna Bench, and MT Bench. Prometheus shows a high correlation with human evaluators.
<details>
<summary>x5.png Details</summary>
### Visual Description
# Technical Document Extraction: Horizontal Bar Chart Analysis
## 1. Chart Structure and Components
- **Chart Type**: Horizontal stacked bar chart
- **Orientation**: Vertical y-axis (categories), horizontal x-axis (count)
- **Legend**: Located at top-right corner
- **Color Legend**:
- `Blue`: Left Wins
- `Red`: Right Wins
- `Purple`: Both are Good
- `Yellow`: Both are Bad
## 2. Axis Labels and Markers
- **X-Axis**:
- Title: "Count"
- Range: 0 to 140
- Grid lines: Every 20 units
- **Y-Axis**:
- Categories (top to bottom):
1. GPT-4 VS ChatGPT
2. Prometheus VS ChatGPT
3. Prometheus VS GPT-4
## 3. Data Points and Trends
### Category 1: GPT-4 VS ChatGPT
- **Blue (Left Wins)**: 74 (Dominant segment, 54.8% of total)
- **Red (Right Wins)**: 19 (14.1%)
- **Purple (Both are Good)**: 32 (23.7%)
- **Yellow (Both are Bad)**: 10 (7.4%)
- **Total**: 135
- **Trend**: Left Wins > Both are Good > Right Wins > Both are Bad
### Category 2: Prometheus VS ChatGPT
- **Blue (Left Wins)**: 59 (43.7%)
- **Red (Right Wins)**: 19 (14.1%)
- **Purple (Both are Good)**: 49 (36.3%)
- **Yellow (Both are Bad)**: 8 (6.0%)
- **Total**: 135
- **Trend**: Left Wins > Both are Good > Right Wins > Both are Bad
### Category 3: Prometheus VS GPT-4
- **Blue (Left Wins)**: 51 (37.8%)
- **Red (Right Wins)**: 36 (26.7%)
- **Purple (Both are Good)**: 37 (27.4%)
- **Yellow (Both are Bad)**: 11 (8.1%)
- **Total**: 135
- **Trend**: Left Wins > Both are Good > Right Wins > Both are Bad
## 4. Key Observations
1. **Consistent Totals**: All categories sum to 135, suggesting uniform sample size.
2. **Dominant Outcome**: "Left Wins" (blue) consistently holds the largest share across all comparisons.
3. **Performance Patterns**:
- GPT-4 outperforms ChatGPT in "Left Wins" (74 vs 59)
- Prometheus shows stronger performance against ChatGPT in "Both are Good" (49 vs 32)
- Prometheus vs GPT-4 shows closest competition in "Right Wins" (36 vs 51)
## 5. Spatial Grounding
- **Legend Position**: Top-right quadrant
- **Bar Alignment**: Segments stacked left-to-right per category
- **Grid Alignment**: Bars aligned with x-axis grid lines
## 6. Data Table Reconstruction
| Category | Left Wins | Right Wins | Both are Good | Both are Bad |
|------------------------|-----------|------------|---------------|--------------|
| GPT-4 VS ChatGPT | 74 | 19 | 32 | 10 |
| Prometheus VS ChatGPT | 59 | 19 | 49 | 8 |
| Prometheus VS GPT-4 | 51 | 36 | 37 | 11 |
## 7. Validation Checks
- **Color Consistency**: All legend colors match bar segments exactly
- **Trend Verification**: Numerical values align with visual segment sizes
- **Total Accuracy**: All category totals match sum of segments (135)
## 8. Missing Information
- No textual annotations within bars
- No additional metadata (e.g., time period, source)
- No comparative metrics beyond raw counts
</details>
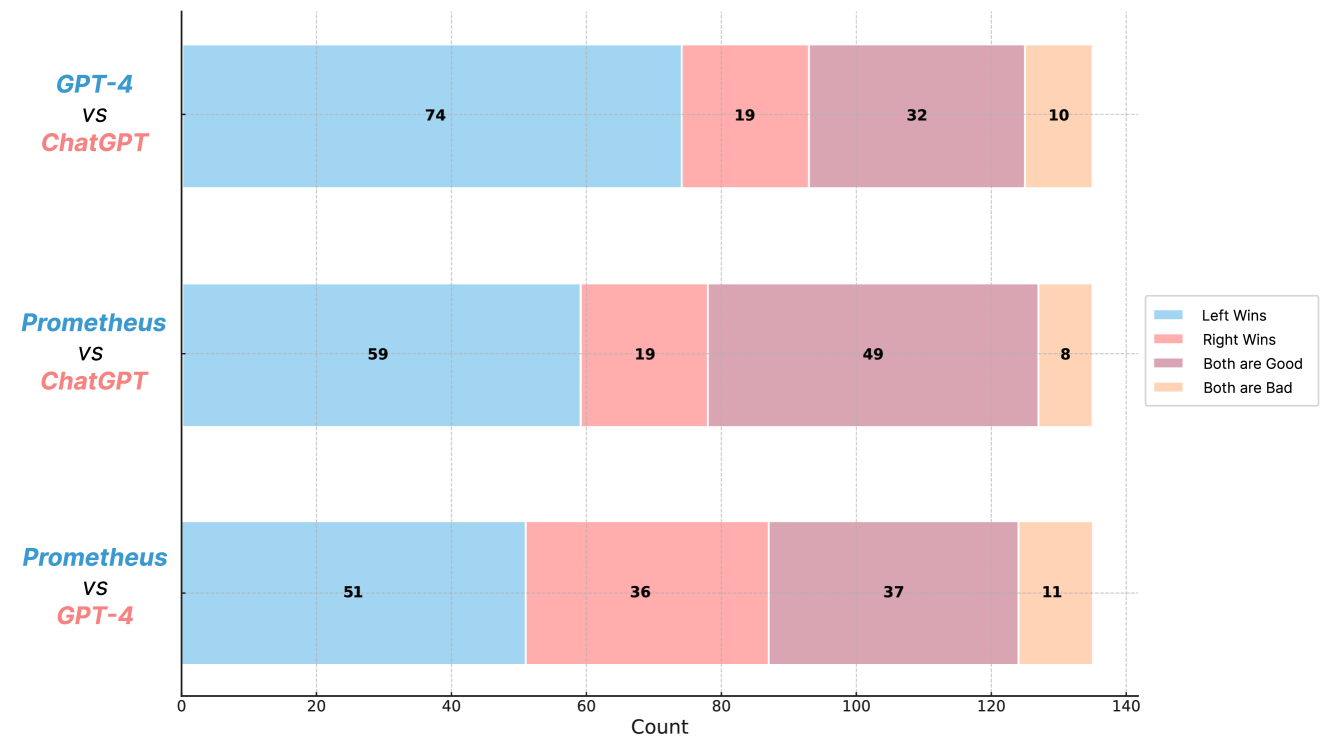
Figure 5: Pairwise comparison of the quality of the feedback generated by GPT-4, Prometheus and GPT-3.5-Turbo. Annotators are asked to choose which feedback is better at assessing the given response. Prometheus shows a win-rate of 58.62% over GPT-4 and 79.57% over GPT-3.5-Turbo.
<details>
<summary>x6.png Details</summary>
### Visual Description
# Technical Document Extraction: GPT-4 vs Prometheus Analysis
## 1. Chart Identification
- **Type**: Stacked bar chart
- **Title**: "GPT-4 vs Prometheus"
- **Purpose**: Comparative analysis of response quality metrics between two AI models
## 2. Axis Labels and Markers
- **X-axis**:
- Labels: ["GPT-4", "Prometheus"]
- Position: Horizontal axis at bottom
- **Y-axis**:
- Label: "Percentage"
- Range: 0–100% (increments of 20%)
- Position: Vertical axis on left
## 3. Legend Analysis
- **Location**: Right side of chart
- **Color-Category Mapping**:
- Purple: "not consistent with score"
- Dark Blue: "too general and abstract"
- Teal: "overly optimistic"
- Green: "not relevant to the response"
- Light Green: "overly critical"
- Yellow: "unrelated to the score rubric"
## 4. Data Extraction
### GPT-4 Bar (Left)
- **Total Height**: 100%
- **Segment Breakdown**:
- Purple: 2.00% ("not consistent with score")
- Dark Blue: 44.00% ("too general and abstract")
- Teal: 18.00% ("overly optimistic")
- Green: 14.00% ("not relevant to the response")
- Light Green: 14.00% ("overly critical")
- Yellow: 8.00% ("unrelated to the score rubric")
### Prometheus Bar (Right)
- **Total Height**: 100%
- **Segment Breakdown**:
- Purple: 2.86% ("not consistent with score")
- Dark Blue: 14.29% ("too general and abstract")
- Teal: 34.29% ("overly optimistic")
- Green: 11.43% ("not relevant to the response")
- Light Green: 31.43% ("overly critical")
- Yellow: 5.71% ("unrelated to the score rubric")
## 5. Trend Verification
- **GPT-4 Dominant Category**:
- "too general and abstract" (44.00%) - tallest segment
- **Prometheus Dominant Category**:
- "overly critical" (31.43%) - tallest segment
- **Notable Differences**:
- Prometheus shows 19.29% higher "overly optimistic" responses vs GPT-4
- GPT-4 has 29.71% higher "too general and abstract" responses vs Prometheus
- Prometheus has 22.43% higher "overly critical" responses vs GPT-4
## 6. Spatial Grounding
- **Legend Position**: [x=100%, y=0–100%] (right edge)
- **Bar Orientation**: Vertical stacking from bottom (lowest category) to top (highest category)
- **Color Consistency Check**:
- All purple segments match "not consistent with score" category
- All dark blue segments match "too general and abstract" category
- (Repeat verification for all six categories)
## 7. Component Isolation
### Header
- Title: "GPT-4 vs Prometheus"
- Subtitle: None
### Main Chart
- Two vertical bars side-by-side
- Each bar divided into six color-coded segments
- Percentage labels inside each segment
### Footer
- No visible footer elements in image
## 8. Data Table Reconstruction
| Model | not consistent with score | too general and abstract | overly optimistic | not relevant to response | overly critical | unrelated to rubric |
|-------------|---------------------------|--------------------------|-------------------|--------------------------|-----------------|---------------------|
| GPT-4 | 2.00% | 44.00% | 18.00% | 14.00% | 14.00% | 8.00% |
| Prometheus | 2.86% | 14.29% | 34.29% | 11.43% | 31.43% | 5.71% |
## 9. Language Analysis
- **Primary Language**: English
- **Secondary Language**: None detected
## 10. Critical Observations
1. Prometheus demonstrates significantly higher criticism tendency (31.43% vs 14.00%)
2. GPT-4 shows stronger tendency toward generic responses (44.00% vs 14.29%)
3. Both models exhibit similar "not consistent with score" rates (<3%)
4. Optimism bias is 91% higher in Prometheus responses
</details>
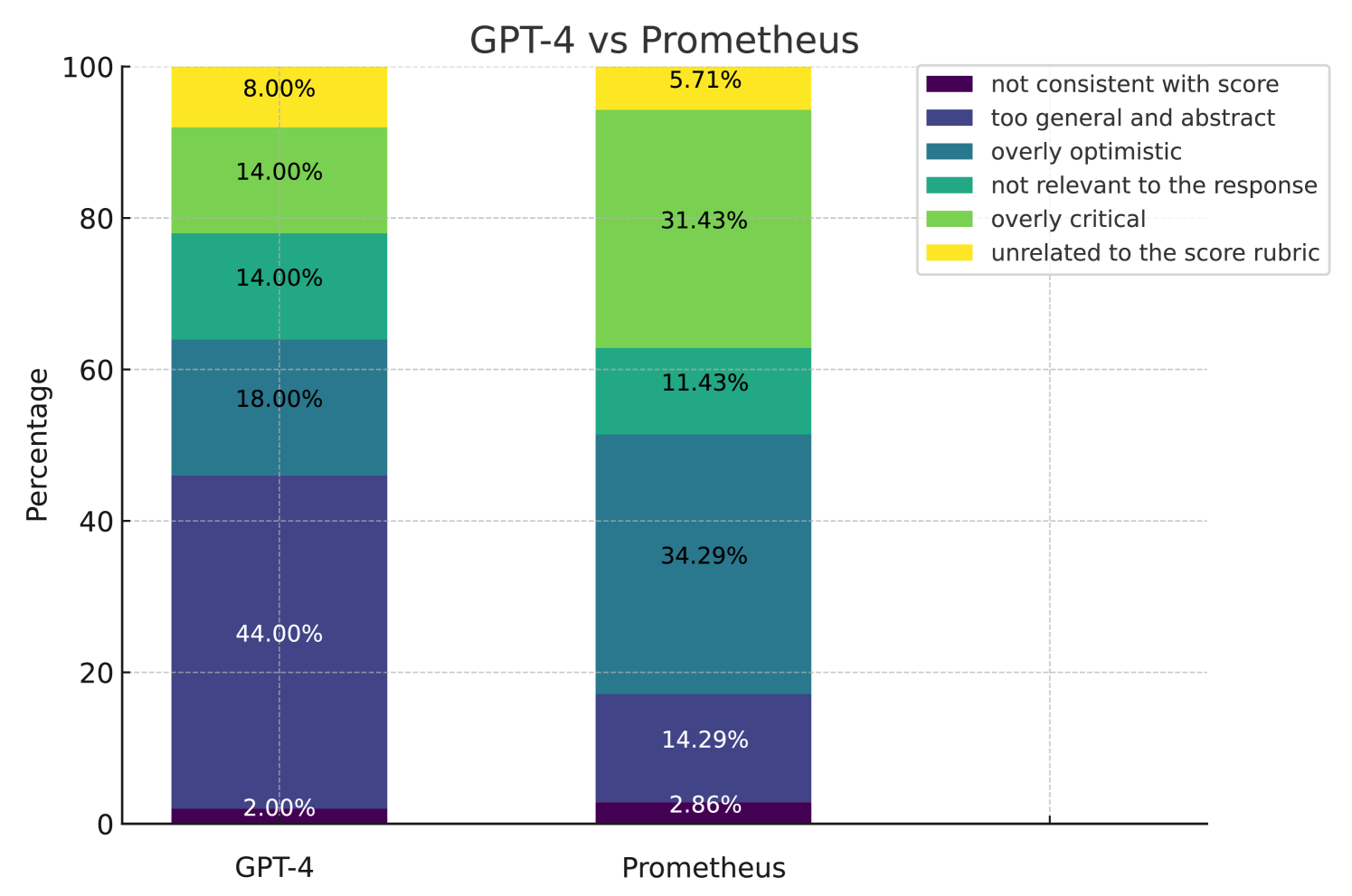
Figure 6: The reason why GPT-4’s or Prometheus’s feedback was not chosen over the other. Prometheus generates less abstract and general feedback, but tends to write overly critical ones.
### 5.1 Can Prometheus Closely Simulate Human Evaluation?
Correlation with Human Scoring
We first compare the correlation between human annotators and our baselines using 45 instances each with an unique customized score rubric, namely the Feedback Bench (Unseen Score Rubric subset), MT Bench (Zheng et al., 2023), and Vicuna Bench (Chiang et al., 2023). The results are shown in Figure 4, showing that Prometheus is on par with GPT-4 across all the three evaluation datasets, where Prometheus obtains a 0.897 Pearson correlation, GPT-4 obtains 0.882, and GPT-3.5-Turbo obtains 0.392.
Pairwise Comparison of the Feedback with Human Evaluation
To validate the effect of whether Prometheus generates helpful/meaningful feedback in addition to its scoring decision, we ask human annotators to choose a better feedback. The results are shown in Figure 5, showing that Prometheus is preferred over GPT-4 58.62% of the times, and over GPT-3.5-Turbo 79.57% of the times. This shows that Prometheus ’s feedback is also meaningful and helpful.
Analysis of Why Prometheus’s Feedback was Preferred
In addition to a pairwise comparison of the feedback quality, we also conduct an analysis asking human annotators to choose why they preferred one feedback over the other by choosing at least one of the comprehensive 6 options (“rejected feedback is not consistent with its score” / “too general and abstract” / “overly optimistic” / “not relevant to the response” / “overly critical” / “unrelated to the score rubric”). In Figure 6, we show the percentage of why each evaluator LLM (GPT-4 and Prometheus) was rejected. It shows that while GPT-4 was mainly not chosen due to providing general or abstract feedback, Prometheus was mainly not chosen because it was too critical about the given response. Based on this result, we conclude that whereas GPT-4 tends to be more neutral and abstract, Prometheus shows a clear trend of expressing its opinion of whether the given response is good or not. We conjecture this is an effect of directly fine-tuning Prometheus to ONLY perform fine-grained evaluation, essentially converting it to an evaluator rather than a generator. We include (1) additional results of analyzing “ Prometheus vs GPT-3.5-Turbo” and “GPT-4 vs GPT-3.5-Turbo” in Appendix E and (2) a detailed explanation of the experimental setting of human evaluation in Appendix J.
### 5.2 Can Prometheus Closely Simulate GPT-4 Evaluation?
Correlation with GPT-4 Scoring
We compare the correlation between GPT-4 evaluation and our baselines using 1222 score rubrics across 2360 instances from the Feedback Bench (Seen and Unseen Score Rubric Subset), Vicuna Bench (Chiang et al., 2023), MT Bench (Zheng et al., 2023), and Flask Eval (Ye et al., 2023b) in an absolute grading scheme. Note that for the Feedback Bench, we measure the correlation with the scores augmented from GPT-4-0613, and for the other 3 datasets, we measure the correlation with the scores acquired by inferencing GPT-4-0613.
The results on these benchmarks are shown across Table 3 and Table 4.
Table 3: Pearson, Kendall-Tau, Spearman correlation with data generated by GPT-4-0613. All scores were sampled across 3 inferences. The best comparable statistics are bolded and second best underlined.
| Evaluator LM | Feedback Collection Test set (Generated by GPT-4-0613) | | | | | |
| --- | --- | --- | --- | --- | --- | --- |
| Seen Customized Rubrics | Unseen Customized Rubric | | | | | |
| Pearson | Kendall-Tau | Spearman | Pearson | Kendall-Tau | Spearman | |
| Llama2-Chat 7B | 0.485 | 0.422 | 0.478 | 0.463 | 0.402 | 0.465 |
| Llama2-Chat 13B | 0.441 | 0.387 | 0.452 | 0.450 | 0.379 | 0.431 |
| Llama2-Chat 70B | 0.572 | 0.491 | 0.564 | 0.558 | 0.477 | 0.549 |
| Llama2-Chat 13B + Coarse. | 0.482 | 0.406 | 0.475 | 0.454 | 0.361 | 0.427 |
| Prometheus 7B | 0.860 | 0.781 | 0.863 | 0.847 | 0.767 | 0.849 |
| Prometheus 13B | 0.861 | 0.776 | 0.858 | 0.860 | 0.771 | 0.858 |
| GPT-3.5-Turbo-0613 | 0.636 | 0.536 | 0.617 | 0.563 | 0.453 | 0.521 |
| GPT-4-0314 | 0.754 | 0.671 | 0.762 | 0.753 | 0.673 | 0.761 |
| GPT-4-0613 | 0.742 | 0.659 | 0.747 | 0.743 | 0.660 | 0.747 |
| GPT-4 (Recent) | 0.745 | 0.659 | 0.748 | 0.733 | 0.641 | 0.728 |
In Table 3, the performance of Llama-2-Chat 13B degrades over the 7B model and slightly improves when scaled up to 70B size, indicating that naively increasing the size of a model does not necessarily improve an LLM’s evaluation capabilities. On the other hand, Prometheus 13B shows a +0.420 and +0.397 improvement over its base model Llama2-Chat 13B in terms of Pearson correlation on the seen and unseen rubric set, respectively. Moreover, it even outperforms Llama2-Chat 70B, GPT-3.5-Turbo-0613, and different versions of GPT-4. We conjecture the high performance of Prometheus is mainly because the instructions and responses within the test set might share a similar distribution with the train set we used (simulating a scenario where a user is interacting with a LLM) even if the score rubric holds unseen. Also, training on feedback derived from coarse-grained score rubrics (denoted as Llama2-Chat 13B + Coarse) only slightly improves performance, indicating the importance of training on a wide range of score rubric is important to handle customized rubrics that different LLM user or researcher would desire.
Table 4: Pearson, Kendall-Tau, Spearman correlation with scores sampled from GPT-4-0613 across 3 inferences. Note that GPT-4-0613 was sampled 6 times in total to measure self-consistency. The best comparable statistics are bolded and second best underlined among baselines. We include GPT-4 as reference to show it self-consistency when inferenced multiple times.
| Evaluator LM | Vicuna Bench | MT Bench | FLASK EVAL | | | | | | |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| Pearson | Kendall-Tau | Spearman | Pearson | Kendall-Tau | Spearman | Pearson | Kendall-Tau | Spearman | |
| Llama2-Chat 7B | 0.175 | 0.143 | 0.176 | 0.132 | 0.113 | 0.143 | 0.271 | 0.180 | 0.235 |
| Llama2-Chat 13B | 0.211 | 0.203 | 0.253 | -0.020 | -0.029 | -0.038 | 0.265 | 0.182 | 0.235 |
| Llama2-Chat 70B | 0.376 | 0.318 | 0.391 | 0.226 | 0.175 | 0.224 | 0.336 | 0.267 | 0.346 |
| Llama2-Chat 13B + Coarse. | 0.307 | 0.196 | 0.245 | 0.417 | 0.328 | 0.420 | 0.517 | 0.349 | 0.451 |
| Prometheus-7B | 0.457 | 0.365 | 0.457 | 0.293 | 0.216 | 0.295 | 0.367 | 0.285 | 0.371 |
| Prometheus-13B | 0.466 | 0.346 | 0.429 | 0.473 | 0.341 | 0.451 | 0.467 | 0.345 | 0.455 |
| GPT-3.5-Turbo-0613 | 0.270 | 0.187 | 0.232 | 0.275 | 0.202 | 0.267 | 0.422 | 0.299 | 0.371 |
| GPT-4-0314 | 0.833 | 0.679 | 0.775 | 0.857 | 0.713 | 0.849 | 0.785 | 0.621 | 0.747 |
| GPT-4-0613 | 0.925 | 0.783 | 0.864 | 0.952 | 0.834 | 0.927 | 0.835 | 0.672 | 0.798 |
| GPT-4 (RECENT) | 0.932 | 0.801 | 0.877 | 0.944 | 0.812 | 0.914 | 0.832 | 0.667 | 0.794 |
In Table 4, the trends of Llama2-Chat among different sizes hold similar; simply increasing size does not greatly improve the LLM’s evaluation capabilities. On these benchmarks, Prometheus shows a +0.255, +0.493, and +0.202 improvement over its base model Llama2-Chat-13B in terms of Pearson correlation on the Vicuna Bench, MT Bench, and Flask Eval dataset, respectively. While Prometheus outperforms Llama2-Chat 70B and GPT-3.5-Turbo-0613, it lacks behind GPT-4. We conjecture that this might be because the instructions from the Feedback Collection and these evaluation datasets have different characteristics; the Feedback Collection are relatively long and detailed (e.g., I’m a city planner … I’m looking for a novel and progressive solution to handle traffic congestion and air problems derived from population increase), while the datasets used for evaluation hold short (e.g., Can you explain about quantum mechanics?).
On the other hand, it is important to note that on the Flask Eval dataset, Llama2-Chat 13B + Coarse (specifically trained with the Flask Eval dataset) outperforms Prometheus. This indicates that training directly on the evaluation dataset might be the best option to acquire a task-specific evaluator LLM, and we further discuss this in Section 6.4.
Table 5: Human Agreement accuracy among ranking datasets. The best comparable statistics are bolded.
| Evaluator LM | HHH Alignment | MT Bench Human Judg. | | | | |
| --- | --- | --- | --- | --- | --- | --- |
| Help. | Harm. | Hon. | Other | Total Avg. | Human Preference | |
| Random | 50.00 | 50.00 | 50.00 | 50.00 | 50.00 | 34.26 |
| StanfordNLP Reward Model | 69.49 | 60.34 | 52.46 | 51.16 | 58.82 | 44.79 |
| ALMOST Reward Model | 74.58 | 67.24 | 78.69 | 86.05 | 76.02 | 49.90 |
| Llama2-Chat 7B | 66.10 | 81.03 | 70.49 | 74.42 | 72.85 | 51.78 |
| Llama2-Chat 13B | 74.58 | 87.93 | 55.74 | 79.07 | 73.76 | 52.34 |
| Llama2-Chat 70B | 66.10 | 89.66 | 67.21 | 74.42 | 74.21 | 53.67 |
| Llama2-Chat 13B + Coarse. | 68.74 | 68.97 | 65.57 | 67.44 | 67.42 | 46.89 |
| GPT-3.5-Turbo-0613 | 76.27 | 87.93 | 67.21 | 86.05 | 78.73 | 57.12 |
| Prometheus 7B | 69.49 | 84.48 | 78.69 | 90.70 | 80.09 | 55.14 |
| Prometheus 13B | 81.36 | 82.76 | 75.41 | 76.74 | 79.19 | 57.72 |
| GPT-4-0613 | 91.53 | 93.10 | 85.25 | 83.72 | 88.69 | 63.87 |
### 5.3 Can Prometheus Function as a Reward Model?
We conduct experiments on 2 human preference datasets: HHH Alignment (Askell et al., 2021) and MT Bench Human Judgment (Zheng et al., 2023) that use a ranking grading scheme. In Table 5, results show that prompting Llama-2-Chat surprisingly obtains reasonable performance, which we conjecture might be the effect of using a base model that is trained with Reinforcement Learning from Human Feedback (RLHF). When training on feedback derived from coarse-grained score rubrics (denoted as Llama2-Chat 13B + Coarse), it only hurts performance. On the other hand, Prometheus 13B shows a +5.43% and +5.38% margin over its base model Llama2-Chat-13B on the HHH Alignment and MT Bench Human Judgement dataset, respectively. These results are surprising because they indicate that training on an absolute grading scheme could also improve performance on a ranking grading scheme even without directly training on ranking evaluation instances. Moreover, it shows the possibilities of using a generative LLM (Prometheus) as a reward model for RLHF (Kim et al., 2023b). We leave the exploration of this research to future work.
## 6 Discussions and Analysis
### 6.1 Why is it important to include Reference Materials?
Evaluating a given response without any reference material is a very challenging task (i.e., Directly asking to decide a score only when an instruction and response are given), since the evaluation LM should be able to (1) know what the important aspects tailored with the instruction is, (2) internally estimate what the answer of the instruction might be, and (3) assess the quality of responses based on the information derived from the previous two steps. Our intuition is that by incorporating each component within the reference material, the evaluator LM could solely focus on assessing the quality of the response instead of determining the important aspects or solving the instruction. Specifically, we analyze the role of each component as follows:
- Score Rubric: Giving information of the the pivotal aspects essential for addressing the given instruction. Without the score rubric, the evaluator LM should inherently know what details should be considered from the given instruction.
- Reference Answer: Decomposing the process of estimating a reference answer and evaluating it at the same time into two steps. Since the reference answer is given as an additional input, the evaluator LM could only focus on evaluating the given response. This enables to bypass a natural proposition that if an evaluator LM doesn’t have the ability to solve the problem, it’s likely that it cannot evaluate different responses effectively as well.
As shown in Table 6, we conduct an ablation experiment by excluding each reference material and also training only on the score rubric without generating a feedback. Additionally, we also ablate the effect of using different model variants (Llama-2, Vicuna, Code-Llama) instead of Llama-2-Chat.
Training Ablation
The results indicate that each component contributes orthogonally to Prometheus ’s superior evaluation performance. Especially, excluding the reference answer shows the most significant amount of performance degradation, supporting our claim that including a reference answer relieves the need for the evaluator LM to internally solve the instruction and only focus on assessing the response. Also, while excluding the score rubric on the Feedback Bench does not harm performance a lot, the performance drops a lot when evaluating on Vicuna Bench. As in our hypothesis, we conjecture that in order to generalize on other datasets, the role of providing what aspect to evaluate holds relatively crucial.
Model Ablation
To test the effect using Llama2-Chat, a model that has been instruction-tuned with both supervised fine-tuning and RLHF, we ablate by using different models as a starting point. Results show that different model choices do not harm performance significantly, yet a model trained with both supervised fine-tuning and RLHF shows the best performance, possibly due to additional training to follow instructions. However, we find that using Code-Llama has some benefits when evaluating on code domain, and we discuss the effect on Section 6.5.
Table 6: Pearson, Kendall-Tau, Spearman correlation with data generated by GPT-4-0613 (Feedback Collection Test set) and scores sampled from GPT-4-0613 across 3 inferences (Vicuna Bench).
| Evaluator LM | Feedback Collection Test set | Vicuna Bench | |
| --- | --- | --- | --- |
| Seen Score Rubric | Unseen Score Rubric | - | |
| Pearson | Pearson | Pearson | |
| Prometheus 7B | 0.860 | 0.847 | 0.457 |
| Training Ablation | | | |
| w/o Score Rubric | 0.837 | 0.745 | 0.355 |
| w/o Feedback Distillation | 0.668 | 0.673 | 0.413 |
| w/o Reference Answer | 0.642 | 0.626 | 0.349 |
| Model Ablation | | | |
| Llama-2 7B Baseline | 0.839 | 0.818 | 0.404 |
| Vicuna-v1.5 7B Baseline | 0.860 | 0.829 | 0.430 |
| Code-Llama 7B Baseline | 0.823 | 0.761 | 0.470 |
### 6.2 Narrowing Performance Gap to GPT-4 Evaluation
The observed outcomes, in which Prometheus consistently surpasses GPT-4 based on human evaluations encompassing both scores and quality of feedback, as well as correlations in the Feedback Bench, are indeed noteworthy. We firmly posit that these findings are not merely serendipitous and offer the following justifications:
- Regarding results on Feedback Bench, our model is directly fine-tuned on this data, so it’s natural to beat GPT-4 on a similar distribution test set if it is well-trained. In addition, for GPT-4, we compare the outputs of inferencing on the instructions and augmenting new instances, causing the self-consistency to be lower.
- Regarding score correlation for human evaluation, our model shows similar or slightly higher trends. First, our human evaluation set-up excluded all coding or math-related questions, which is where it is non-trivial to beat GPT-4 yet. Secondly, there’s always the margin of human error that needs to be accounted for. Nonetheless, we highlight that we are the first work to argue that an open-source evaluator LM could closely reach GPT-4 evaluation only when the appropriate reference materials are accompanied.
- As shown in Figure 6, Prometheus tends to be critical compared to GPT-4. We conjecture this is because since it is specialized for evaluation, it acquires the characteristics of seeking for improvement when assessing responses.
### 6.3 Qualitative Examples of Feedback Generated by Prometheus
We present five qualitative examples to compare the feedback generated by Prometheus and GPT-4 in Appendix I. Specifically, Figure 16 shows an example where human annotators labeled that GPT-4 generate an abstract/general feedback not suitable for criticizing the response. Figure 17 shows an example where human annotators labeled that Prometheus generate overly critical feedback. Figure 18 shows an example of human annotators labeled as a tie. In general, Prometheus generates a detailed feedback criticizing which component within the response is wrong and seek improvement. This qualitatively shows that Prometheus could function as an evaluator LM.
Moreover, we present an example of evaluating python code responses using Prometheus, GPT-4, and Code-Llama in Figure 19. We discuss the effect of using a base model specialized on code domain for code evaluation in Section 6.5.
### 6.4 A Practitioner’s Guide for Directly Using Prometheus Evaluation
Preparing an Evaluation Dataset
As shown in the previous sections, Prometheus functions as a good evaluator LM not only on the Feedback Bench (a dataset that has a similar distribution with the dataset it was trained on), but also on other widely used evaluation datasets such as the Vicuna Bench, MT Bench, and Flask Eval. As shown in Figure 1, users should prepare the instruction dataset they wish to evaluate their target LLM on. This could either be a widely used instruction dataset or a custom evaluation users might have.
Deciding a Score Rubric to Evaluate on
The next step is to choose the score rubric users would want to test their target LLM on. This could be confined to generic metrics such as helpfulness/harmlessness, but Prometheus also supports fine-grained score rubrics such as “Child-Safety”, “Creativity” or even “Is the response formal enough to send to my boss”.
Preparing Reference Answers
While evaluating without any reference is also possible, as shown in Table 6, Prometheus shows superior performance when the reference answer is provided. Therefore, users should prepare the reference answer they might consider most appropriate based on the instructions and score rubrics they would want to test on. While this might require additional cost to prepare, there is a clear trade-off in order to improve the precision or accuracy of the overall evaluation process, hence it holds crucial.
Generating Responses using the Target LLM
The last step is to prepare responses acquired from the target LLM that users might want to evaluate. By providing the reference materials (score rubrics, reference answers) along with the instruction and responses to evaluate on, Prometheus generates a feedback and a score. Users could use the score to determine how their target LLM is performing based on customized criteria and also refer to the feedback to analyze and check the properties and behaviors of their target LLM. For instance, Prometheus could be used as a good alternative for GPT-4 evaluation while training a new LLM. Specifically, the field has not yet come up with a formalized procedure to decide the details of instruction-tuning or RLHF while developing a new LLM. This includes deciding how many training instances to use, how to systematically decide the training hyperparameters, and quantitatively analyzing the behaviors of LLMs across multiple versions. Most importantly, users might not want to send the outputs generated by their LLMs to OpenAI API calls. In this regard, Prometheus provides an appealing solution of having control over the whole evaluation process, also supporting customized score rubrics.
### 6.5 A Practitioner’s Guide for Training a New Evaluation Model
Users might also want to train their customized evaluator LM as Prometheus for different use cases. As shown in Table 4, training directly on the Flask dataset (denoted as Llama2-Chat 13B + Coarse) shows a higher correlation with GPT-4 on the Flask Eval dataset compared to Prometheus that is trained on the Feedback Collection. This implies that directly training on a target feedback dataset holds the best performance when evaluating on it. Yet, this requires going through the process of preparing a new feedback dataset (described in Section 3.1). This implies that there is a trade-off between obtaining a strong evaluator LM on a target task and paying the initial cost to prepare a new feedback dataset. In this subsection, we provide some guidelines for how users could also train their evaluator LM using feedback datasets.
Preparing a Feedback Dataset to train on
As described in Section 3, some important considerations to prepare a new feedback dataset are: (1) including as many reference materials as possible, (2) maintaining a uniform length among the reference answers for each score (1 to 5) to prevent undesired length bias, (3) maintaining a uniform score distribution to prevent undesired decision bias. While we did not explore the effect of including other possible reference materials such as a “Score 1 Reference Answer” or “Background Knowledge” due to limited context length, future work could also explore this aspect. The main intuition is that providing more reference materials could enable the evaluator LM to solely focus on evaluation instead of solving the instruction.
Choosing a Base Model to Train an Evaluator LM
As shown in Figure 19, we find that training on Code-Llama provides more detailed feedback and a reasonable score decision when evaluating responses on code domains (7 instances included within the Vicuna Bench dataset). This indicates that choosing a different base model based on the domain to evaluate might be crucial when designing an evaluator LM. We also leave the exploration of training an evaluator LM specialized on different domains (e.g., code and math) as future work.
## 7 Conclusion
In this paper, we discuss the possibility of obtaining an open-source LM that is specialized for fine-grained evaluation. While text evaluation is an inherently difficult task that requires multi-faceted considerations, we show that by incorporating the appropriate reference material, we can effectively induce evaluation capability into an LM. We propose a new dataset called the Feedback Collection that encompasses thousands of customized score rubrics and train an open-source evaluator model, Prometheus. Surprisingly, when comparing the correlation with human evaluators, Prometheus obtains a Pearson correlation on par with GPT-4, while the quality of the feedback was preferred over GPT-4 58.62% of the time. When comparing Pearson correlation with GPT-4, Prometheus shows the highest correlation even outperforming GPT-3.5-Turbo. Lastly, we show that Prometheus shows superior performance on human preference datasets, indicating its possibility as an universal reward model. We hope that our work could stimulate future work on using open-source LLMs as evaluators instead of solely relying on proprietary LLMs.
#### Acknowledgments
This work was partly supported by KAIST-NAVER Hypercreative AI Center and Institute of Information & communications Technology Planning & Evaluation (IITP) grant funded by the Korea government (MSIT) (No.2022-0-00264, Comprehensive Video Understanding and Generation with Knowledge-based Deep Logic Neural Network, 40%; No.2021-0-02068, Artificial Intelligence Innovation Hub, 20%). We thank Minkyeong Moon, Geonwoo Kim, Minkyeong Cho, Yerim Kim, Sora Lee, Seunghwan Lim, Jinheon Lee, Minji Kim, and Hyorin Lee for helping with the human evaluation experiments. We thank Se June Joo, Dongkeun Yoon, Doyoung Kim, Seonghyeon Ye, Gichang Lee, and Yehbin Lee for helpful feedback and discussions.
## References
- Askell et al. (2021) Amanda Askell, Yuntao Bai, Anna Chen, Dawn Drain, Deep Ganguli, Tom Henighan, Andy Jones, Nicholas Joseph, Ben Mann, Nova DasSarma, Nelson Elhage, Zac Hatfield-Dodds, Danny Hernandez, Jackson Kernion, Kamal Ndousse, Catherine Olsson, Dario Amodei, Tom Brown, Jack Clark, Sam McCandlish, Chris Olah, and Jared Kaplan. A general language assistant as a laboratory for alignment, 2021.
- Chang et al. (2023) Yupeng Chang, Xu Wang, Jindong Wang, Yuan Wu, Kaijie Zhu, Hao Chen, Linyi Yang, Xiaoyuan Yi, Cunxiang Wang, Yidong Wang, et al. A survey on evaluation of large language models. arXiv preprint arXiv:2307.03109, 2023.
- Chia et al. (2023) Yew Ken Chia, Pengfei Hong, Lidong Bing, and Soujanya Poria. Instructeval: Towards holistic evaluation of instruction-tuned large language models. arXiv preprint arXiv:2306.04757, 2023.
- Chiang & yi Lee (2023) Cheng-Han Chiang and Hung yi Lee. Can large language models be an alternative to human evaluations?, 2023.
- Chiang et al. (2023) Wei-Lin Chiang, Zhuohan Li, Zi Lin, Ying Sheng, Zhanghao Wu, Hao Zhang, Lianmin Zheng, Siyuan Zhuang, Yonghao Zhuang, Joseph E. Gonzalez, Ion Stoica, and Eric P. Xing. Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality, March 2023. URL https://lmsys.org/blog/2023-03-30-vicuna/.
- Dubois et al. (2023) Yann Dubois, Xuechen Li, Rohan Taori, Tianyi Zhang, Ishaan Gulrajani, Jimmy Ba, Carlos Guestrin, Percy Liang, and Tatsunori B Hashimoto. Alpacafarm: A simulation framework for methods that learn from human feedback. arXiv preprint arXiv:2305.14387, 2023.
- Gilardi et al. (2023) Fabrizio Gilardi, Meysam Alizadeh, and Maël Kubli. Chatgpt outperforms crowd-workers for text-annotation tasks. arXiv preprint arXiv:2303.15056, 2023.
- Ho et al. (2022) Namgyu Ho, Laura Schmid, and Se-Young Yun. Large language models are reasoning teachers. arXiv preprint arXiv:2212.10071, 2022.
- Holtzman et al. (2023) Ari Holtzman, Peter West, and Luke Zettlemoyer. Generative models as a complex systems science: How can we make sense of large language model behavior? arXiv preprint arXiv:2308.00189, 2023.
- Honovich et al. (2022) Or Honovich, Thomas Scialom, Omer Levy, and Timo Schick. Unnatural instructions: Tuning language models with (almost) no human labor. arXiv preprint arXiv:2212.09689, 2022.
- Kim et al. (2023a) Seungone Kim, Se June Joo, Doyoung Kim, Joel Jang, Seonghyeon Ye, Jamin Shin, and Minjoon Seo. The cot collection: Improving zero-shot and few-shot learning of language models via chain-of-thought fine-tuning. arXiv preprint arXiv:2305.14045, 2023a.
- Kim et al. (2023b) Sungdong Kim, Sanghwan Bae, Jamin Shin, Soyoung Kang, Donghyun Kwak, Kang Min Yoo, and Minjoon Seo. Aligning large language models through synthetic feedback. arXiv preprint arXiv:2305.13735, 2023b.
- Krishna et al. (2021) Kalpesh Krishna, Aurko Roy, and Mohit Iyyer. Hurdles to progress in long-form question answering. arXiv preprint arXiv:2103.06332, 2021.
- Li et al. (2023) Xuechen Li, Tianyi Zhang, Yann Dubois, Rohan Taori, Ishaan Gulrajani, Carlos Guestrin, Percy Liang, and Tatsunori B. Hashimoto. Alpacaeval: An automatic evaluator of instruction-following models. https://github.com/tatsu-lab/alpaca_eval, 2023.
- Liang et al. (2022) Percy Liang, Rishi Bommasani, Tony Lee, Dimitris Tsipras, Dilara Soylu, Michihiro Yasunaga, Yian Zhang, Deepak Narayanan, Yuhuai Wu, Ananya Kumar, et al. Holistic evaluation of language models. arXiv preprint arXiv:2211.09110, 2022.
- Lin (2004a) Chin-Yew Lin. ROUGE: A package for automatic evaluation of summaries. In Text Summarization Branches Out, pp. 74–81, Barcelona, Spain, July 2004a. Association for Computational Linguistics. URL https://aclanthology.org/W04-1013.
- Lin (2004b) Chin-Yew Lin. Rouge: A package for automatic evaluation of summaries. In Text summarization branches out, pp. 74–81, 2004b.
- Liu et al. (2023) Yang Liu, Dan Iter, Yichong Xu, Shuohang Wang, Ruochen Xu, and Chenguang Zhu. Gpteval: Nlg evaluation using gpt-4 with better human alignment. arXiv preprint arXiv:2303.16634, 2023.
- Min et al. (2023) Sewon Min, Kalpesh Krishna, Xinxi Lyu, Mike Lewis, Wen-tau Yih, Pang Wei Koh, Mohit Iyyer, Luke Zettlemoyer, and Hannaneh Hajishirzi. Factscore: Fine-grained atomic evaluation of factual precision in long form text generation. arXiv preprint arXiv:2305.14251, 2023.
- Papineni et al. (2002) Kishore Papineni, Salim Roukos, Todd Ward, and Wei-Jing Zhu. Bleu: a method for automatic evaluation of machine translation. In Proceedings of the 40th annual meeting of the Association for Computational Linguistics, pp. 311–318, 2002.
- Peng et al. (2023) Baolin Peng, Chunyuan Li, Pengcheng He, Michel Galley, and Jianfeng Gao. Instruction tuning with gpt-4. arXiv preprint arXiv:2304.03277, 2023.
- Pozzobon et al. (2023) Luiza Pozzobon, Beyza Ermis, Patrick Lewis, and Sara Hooker. On the challenges of using black-box apis for toxicity evaluation in research, 2023.
- Sellam et al. (2020) Thibault Sellam, Dipanjan Das, and Ankur P. Parikh. Bleurt: Learning robust metrics for text generation. In Annual Meeting of the Association for Computational Linguistics, 2020. URL https://api.semanticscholar.org/CorpusID:215548699.
- Touvron et al. (2023) Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, Dan Bikel, Lukas Blecher, Cristian Canton Ferrer, Moya Chen, Guillem Cucurull, David Esiobu, Jude Fernandes, Jeremy Fu, Wenyin Fu, Brian Fuller, Cynthia Gao, Vedanuj Goswami, Naman Goyal, Anthony Hartshorn, Saghar Hosseini, Rui Hou, Hakan Inan, Marcin Kardas, Viktor Kerkez, Madian Khabsa, Isabel Kloumann, Artem Korenev, Punit Singh Koura, Marie-Anne Lachaux, Thibaut Lavril, Jenya Lee, Diana Liskovich, Yinghai Lu, Yuning Mao, Xavier Martinet, Todor Mihaylov, Pushkar Mishra, Igor Molybog, Yixin Nie, Andrew Poulton, Jeremy Reizenstein, Rashi Rungta, Kalyan Saladi, Alan Schelten, Ruan Silva, Eric Michael Smith, Ranjan Subramanian, Xiaoqing Ellen Tan, Binh Tang, Ross Taylor, Adina Williams, Jian Xiang Kuan, Puxin Xu, Zheng Yan, Iliyan Zarov, Yuchen Zhang, Angela Fan, Melanie Kambadur, Sharan Narang, Aurelien Rodriguez, Robert Stojnic, Sergey Edunov, and Thomas Scialom. Llama 2: Open foundation and fine-tuned chat models, 2023.
- Wang et al. (2023a) Tianlu Wang, Ping Yu, Xiaoqing Ellen Tan, Sean O’Brien, Ramakanth Pasunuru, Jane Dwivedi-Yu, Olga Golovneva, Luke Zettlemoyer, Maryam Fazel-Zarandi, and Asli Celikyilmaz. Shepherd: A critic for language model generation. arXiv preprint arXiv:2308.04592, 2023a.
- Wang et al. (2023b) Yidong Wang, Zhuohao Yu, Zhengran Zeng, Linyi Yang, Cunxiang Wang, Hao Chen, Chaoya Jiang, Rui Xie, Jindong Wang, Xing Xie, et al. Pandalm: An automatic evaluation benchmark for llm instruction tuning optimization. arXiv preprint arXiv:2306.05087, 2023b.
- Wang et al. (2022) Yizhong Wang, Yeganeh Kordi, Swaroop Mishra, Alisa Liu, Noah A Smith, Daniel Khashabi, and Hannaneh Hajishirzi. Self-instruct: Aligning language model with self generated instructions. arXiv preprint arXiv:2212.10560, 2022.
- Ye et al. (2023a) Seonghyeon Ye, Yongrae Jo, Doyoung Kim, Sungdong Kim, Hyeonbin Hwang, and Minjoon Seo. Selfee: Iterative self-revising llm empowered by self-feedback generation. Blog post, May 2023a. URL https://kaistai.github.io/SelFee/.
- Ye et al. (2023b) Seonghyeon Ye, Doyoung Kim, Sungdong Kim, Hyeonbin Hwang, Seungone Kim, Yongrae Jo, James Thorne, Juho Kim, and Minjoon Seo. Flask: Fine-grained language model evaluation based on alignment skill sets. arXiv preprint arXiv:2307.10928, 2023b.
- Yuan et al. (2021) Weizhe Yuan, Graham Neubig, and Pengfei Liu. BARTScore: Evaluating generated text as text generation. In A. Beygelzimer, Y. Dauphin, P. Liang, and J. Wortman Vaughan (eds.), Advances in Neural Information Processing Systems, 2021. URL https://openreview.net/forum?id=5Ya8PbvpZ9.
- Zhang et al. (2019) Tianyi Zhang, Varsha Kishore, Felix Wu, Kilian Q Weinberger, and Yoav Artzi. Bertscore: Evaluating text generation with bert. arXiv preprint arXiv:1904.09675, 2019.
- Zheng et al. (2023) Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric Xing, et al. Judging llm-as-a-judge with mt-bench and chatbot arena. arXiv preprint arXiv:2306.05685, 2023.
- Zhong et al. (2023) Wanjun Zhong, Ruixiang Cui, Yiduo Guo, Yaobo Liang, Shuai Lu, Yanlin Wang, Amin Saied, Weizhu Chen, and Nan Duan. Agieval: A human-centric benchmark for evaluating foundation models. arXiv preprint arXiv:2304.06364, 2023.
<details>
<summary>x7.png Details</summary>
### Visual Description
# Technical Document Extraction: Distribution of ROUGE-L Scores
## Header
- **Title**: "Distribution of ROUGE-L Scores Within Criteria Descriptions"
## Main Chart
### Axes
- **X-Axis (Horizontal)**:
- **Label**: "ROUGE Score"
- **Range**: 0.0 to 1.0
- **Tick Marks**: 0.0, 0.2, 0.4, 0.6, 0.8, 1.0
- **Y-Axis (Vertical)**:
- **Label**: "Frequency"
- **Range**: 0 to 180,000
- **Tick Marks**: 0, 25,000, 50,000, 75,000, 100,000, 125,000, 150,000, 175,000, 180,000
### Chart Components
- **Bars**:
- **Color**: Blue
- **Distribution**:
- **Peak**: At ROUGE Score ~0.2 with frequency ~180,000
- **Trend**: Right-skewed distribution (frequencies decrease as ROUGE Score increases)
- **Secondary Peak**: Small spike near ROUGE Score ~1.0 (~2,000 frequency)
- **Overlay Curve**:
- **Color**: Blue (matches bar color)
- **Type**: Normal distribution curve
- **Alignment**: Peaks at ~0.2, follows general trend of bar distribution
### Legend
- **Placement**: Not explicitly visible in the image
- **Color Reference**: Blue (bars and curve share the same color; no distinct legend entries)
## Footer
- **No explicit footer content** visible in the image.
## Key Trends and Data Points
1. **Primary Distribution**:
- **Mode**: ROUGE Score ~0.2 (highest frequency: ~180,000)
- **Decline**: Frequency drops sharply after 0.2, reaching ~50,000 at 0.4 and ~10,000 at 0.6
2. **Secondary Peak**:
- **Location**: Near ROUGE Score ~1.0
- **Frequency**: ~2,000 (outlier compared to main distribution)
3. **Skewness**:
- Right-skewed distribution (long tail toward higher ROUGE Scores)
## Verification
- **Trend Consistency**: Overlay curve aligns with bar distribution, confirming normal distribution approximation.
- **Color Matching**: All elements (bars, curve) use blue; no discrepancies in legend references.
## Notes
- No additional textual data, tables, or embedded descriptions present.
- No other languages detected in the image.
</details>
Figure 7: Rouge-L score distribution among two randomly sampled score rubrics from the Feedback Collection. A left-skewed distribution with low values shows the score rubrics are diverse.
<details>
<summary>x8.png Details</summary>
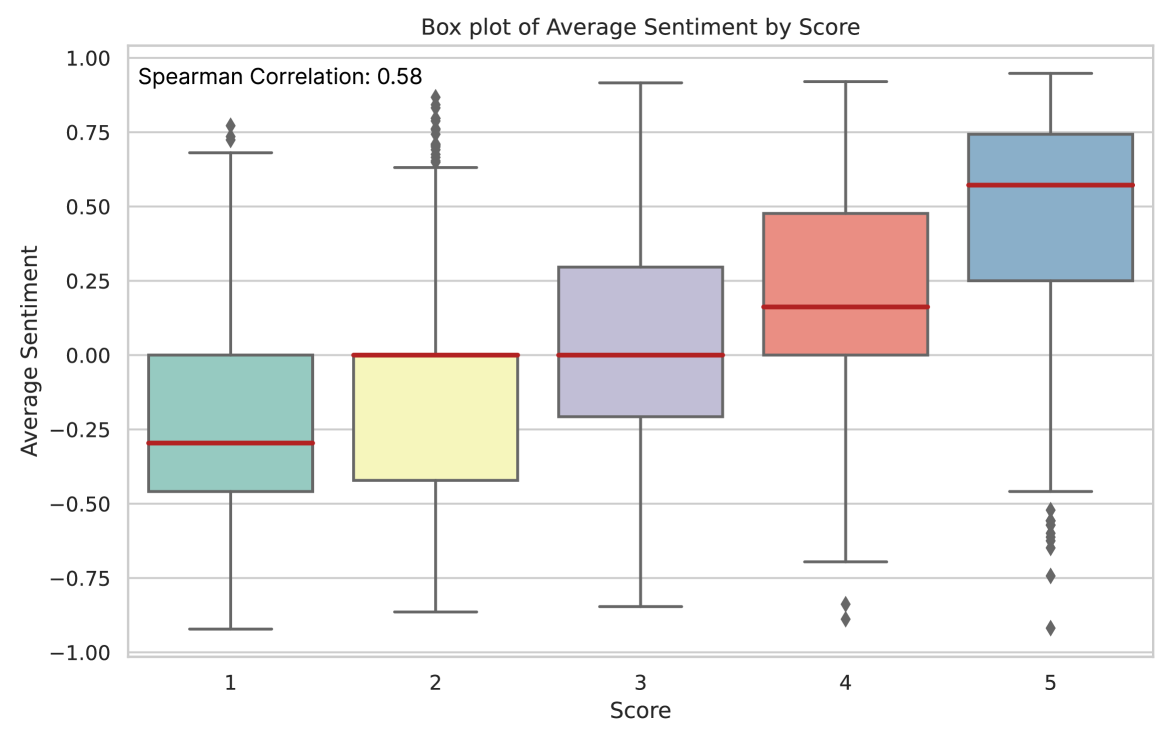
### Visual Description
# Technical Document Extraction: Box Plot of Average Sentiment by Score
## 1. Labels and Axis Titles
- **Title**: "Box plot of Average Sentiment by Score"
- **Y-Axis Label**: "Average Sentiment" (range: -1.00 to 1.00)
- **X-Axis Label**: "Score" (categories: 1, 2, 3, 4, 5)
- **Spearman Correlation**: 0.58 (annotated in the title)
## 2. Legend and Color Mapping
- **Legend Placement**: Top-right corner
- **Color-Score Mapping**:
- **Teal (#008080)**: Score 1
- **Yellow (#FFFF00)**: Score 2
- **Purple (#800080)**: Score 3
- **Red (#FF0000)**: Score 4
- **Blue (#0000FF)**: Score 5
## 3. Box Plot Components
### Score 1 (Teal)
- **Median**: -0.25
- **Interquartile Range (IQR)**: -0.50 to 0.00
- **Whiskers**: -0.90 to 0.75
- **Outliers**: 0.70, 0.75
### Score 2 (Yellow)
- **Median**: 0.00
- **IQR**: -0.50 to 0.25
- **Whiskers**: -0.90 to 0.80
- **Outliers**: 0.70, 0.75
### Score 3 (Purple)
- **Median**: 0.00
- **IQR**: -0.25 to 0.25
- **Whiskers**: -0.90 to 0.90
- **Outliers**: None
### Score 4 (Red)
- **Median**: 0.20
- **IQR**: 0.00 to 0.50
- **Whiskers**: -0.80 to 0.90
- **Outliers**: -0.85, -0.80
### Score 5 (Blue)
- **Median**: 0.60
- **IQR**: 0.25 to 0.75
- **Whiskers**: -0.90 to 0.95
- **Outliers**: -0.95, -0.85, -0.75, -0.70
## 4. Key Trends
1. **Negative Sentiment Dominance**: Scores 1 and 2 exhibit medians below zero (-0.25 and 0.00, respectively).
2. **Positive Sentiment Shift**: Scores 4 and 5 show medians above zero (0.20 and 0.60).
3. **Increasing Variability**: The spread (IQR) widens from Score 1 to Score 5.
4. **Outlier Distribution**: Outliers are most frequent in Scores 1, 2, and 5, with extreme values near -1.00 and 1.00.
## 5. Spatial Grounding
- **Legend**: Top-right corner (confirmed color-score alignment).
- **Data Point Verification**:
- Score 5 outliers (-0.95, -0.85, -0.75, -0.70) match the blue box plot.
- Score 1 outliers (0.70, 0.75) align with the teal box plot.
## 6. Trend Verification
- **Score 1**: Median at -0.25, with outliers extending to 0.75 (upward trend in variability).
- **Score 2**: Median at 0.00, with outliers reaching 0.80 (moderate spread).
- **Score 3**: Symmetrical distribution around 0.00, no outliers.
- **Score 4**: Median at 0.20, with outliers dipping to -0.85 (asymmetric spread).
- **Score 5**: Highest median (0.60) and widest IQR, indicating strong positive sentiment with variability.
## 7. Component Isolation
- **Header**: Title and Spearman correlation (0.58).
- **Main Chart**: Five box plots (Scores 1–5) with distinct colors and medians.
- **Footer**: No explicit footer content.
## 8. Data Table Reconstruction
No explicit data table is present. Box plot components (median, IQR, whiskers, outliers) are derived visually.
## 9. Final Notes
- **Language**: All text is in English.
- **Critical Data Points**:
- Spearman correlation (0.58) indicates moderate positive association between scores and sentiment.
- Score 5 demonstrates the strongest positive sentiment (median: 0.60).
- Score 1 exhibits the most negative median (-0.25) with significant outliers.
</details>
Figure 8: Box and whisker plot for average sentiment per score description. A linearly increasing trend is crucial for the evaluator LM to decide a score in an Absolute Scoring setting.
## Appendix A Analysis of the Feedback Collection Dataset
In this section, we provide a comprehensive analysis of the characteristics of the Feedback Collection dataset. To ensure the quality, we answer each question one by one, emphasizing our main considerations during the creation of the dataset.
Are the Score Criteria Diverse Enough?
Following previous work (Wang et al., 2022; Honovich et al., 2022), we plot the rouge-L distribution between two instances among our whole set of 1K score rubrics. Specifically, we use the score criteria (description of the criteria) and measure the rouge-L value between the two score criteria. Figure 7 shows the overall distribution plot. The results indicate that each criteria does not overlap with one another, ensuring that we include many novel score rubrics in our training set.
<details>
<summary>x9.png Details</summary>
### Visual Description
# Technical Document Extraction: Feedback Collection Training Set
## Chart Overview
The image presents a **box plot** titled **"Feedback Collection Training Set"** with a **Spearman Correlation** value of **0.12** (weak positive relationship). The chart visualizes the distribution of **Response Length** across five **Score** categories (1–5).
---
### Key Components
1. **Axes**:
- **X-axis**: Labeled **"Score"**, with discrete categories **1, 2, 3, 4, 5**.
- **Y-axis**: Labeled **"Response Length"**, scaled from **0 to 1000** in increments of 200.
2. **Legend**:
- Located at **[x: 0.8, y: 0.95]** (top-right corner).
- Maps colors to **Score** categories:
- **Blue**: Score 1
- **Green**: Score 2
- **Red**: Score 3
- **Yellow**: Score 4
- **Pink**: Score 5
3. **Data Representation**:
- Each **Score** category has a corresponding **box plot** (IQR, median, whiskers) and **outliers** (marked with open circles).
- Outliers are defined as points outside the whiskers (1.5×IQR).
---
### Data Trends and Observations
1. **Score 1 (Blue)**:
- **Median**: ~180
- **IQR**: ~150–220
- **Outliers**: 1000, 900, 800, 600, 500, 400, 300
- **Trend**: High variability with extreme outliers.
2. **Score 2 (Green)**:
- **Median**: ~160
- **IQR**: ~120–180
- **Outliers**: 500, 400, 300
- **Trend**: Moderate spread with fewer outliers.
3. **Score 3 (Red)**:
- **Median**: ~180
- **IQR**: ~140–220
- **Outliers**: 500, 400
- **Trend**: Similar median to Score 1 but tighter distribution.
4. **Score 4 (Yellow)**:
- **Median**: ~160
- **IQR**: ~120–180
- **Outliers**: 500, 400
- **Trend**: Consistent with Score 2 but slightly higher median.
5. **Score 5 (Pink)**:
- **Median**: ~220
- **IQR**: ~180–260
- **Outliers**: 600, 500, 400
- **Trend**: Highest median and moderate outliers.
---
### Spatial Grounding and Validation
- **Legend Colors**: Confirmed to match box plot colors (e.g., blue for Score 1, pink for Score 5).
- **Outlier Placement**: Outliers are consistently marked above/below whiskers across all categories.
- **Spearman Correlation**: Value **0.12** suggests a weak positive trend between **Score** and **Response Length**.
---
### Missing Elements
- No **data table** is present in the image.
- No textual annotations beyond axis labels, title, and legend.
---
### Conclusion
The chart highlights variability in **Response Length** across **Score** categories, with **Score 1** exhibiting the highest outliers and **Score 5** the highest median. The weak positive correlation (0.12) indicates a minimal relationship between these variables.
</details>
Figure 9: Box and whisker plot plotting the length distribution of responses on each score range. We check whether there is a length bias (i.e., a higher score given for longer responses).
Table 7: Distinct N-gram measured on each component of the training instance. A higher diversity ratio indicates that each component tends to be more diverse.
| Distinct N-gram | Bigram Diversity Ratio | Trigram Diversity Ratio |
| --- | --- | --- |
| Instruction | 0.43 | 0.79 |
| Reference | 0.43 | 0.82 |
| Score Rubric | 0.60 | 0.81 |
| Responses | 0.32 | 0.77 |
| Feedback | 0.26 | 0.66 |
Are the Score Descriptions Well Formulated?
Another component in the score rubric is a description of each score (i.e., A comprehensive reason why a score of $i$ $(1≤ i≤ 5$ should be given). In an Absolute Scoring setting, it is important to evaluate the given response based on the score descriptions instead of giving a score of 1 for all responses that lack a minor detail or giving a score of 5 for all responses that seem to be good on the surface. Due to these reasons, the role of the score descriptions hold crucial, where the main role is to show a monotonically increasing tendency of sentiment, not dramatically. Figure 8 shows that the Feedback Collection holds a smoothly increasing sentiment tendency for each score description. This ensures the quality of the score rubric, confirming that it plays a role in deciding the score.
Is there a length bias among the Responses?
Previous work has demonstrated that when LMs are used as evaluators, they tend to give higher scores to longer responses (Li et al., 2023; Dubois et al., 2023; Zheng et al., 2023). In order to minimize this effect during fine-tuning Prometheus, one of our main consideration was to maintain a length distribution equal among the score range of 1 to 5. As shown in Figure 9, most of the responses within the Feedback Collection maintained a similar length among different scores (near 200 tokens). We also include a comprehensive analysis of whether Prometheus possessed any length bias during evaluation in Appendix F.
Are the Instructions, Responses, and Feedback Diverse as Well?
In addition to the analysis of the score rubric and responses, we also analyze whether the instructions, responses, and feedback within the Feedback Collection are diverse enough. For this purpose, we examine the bigram and trigram ratios. The results are shown in Table 7, indicating a variety in how terms are expressed, and our findings suggest a moderate level of diversity. While there is some term repetition, the dataset also showcases a notable range of expressions.
## Appendix B Analysis of the Feedback Bench Evaluation Dataset
In this section, we provide a analysis of whether the Feedback Bench consists of unseen score rubrics against the score rubrics from the Feedback Collection.
<details>
<summary>x10.png Details</summary>
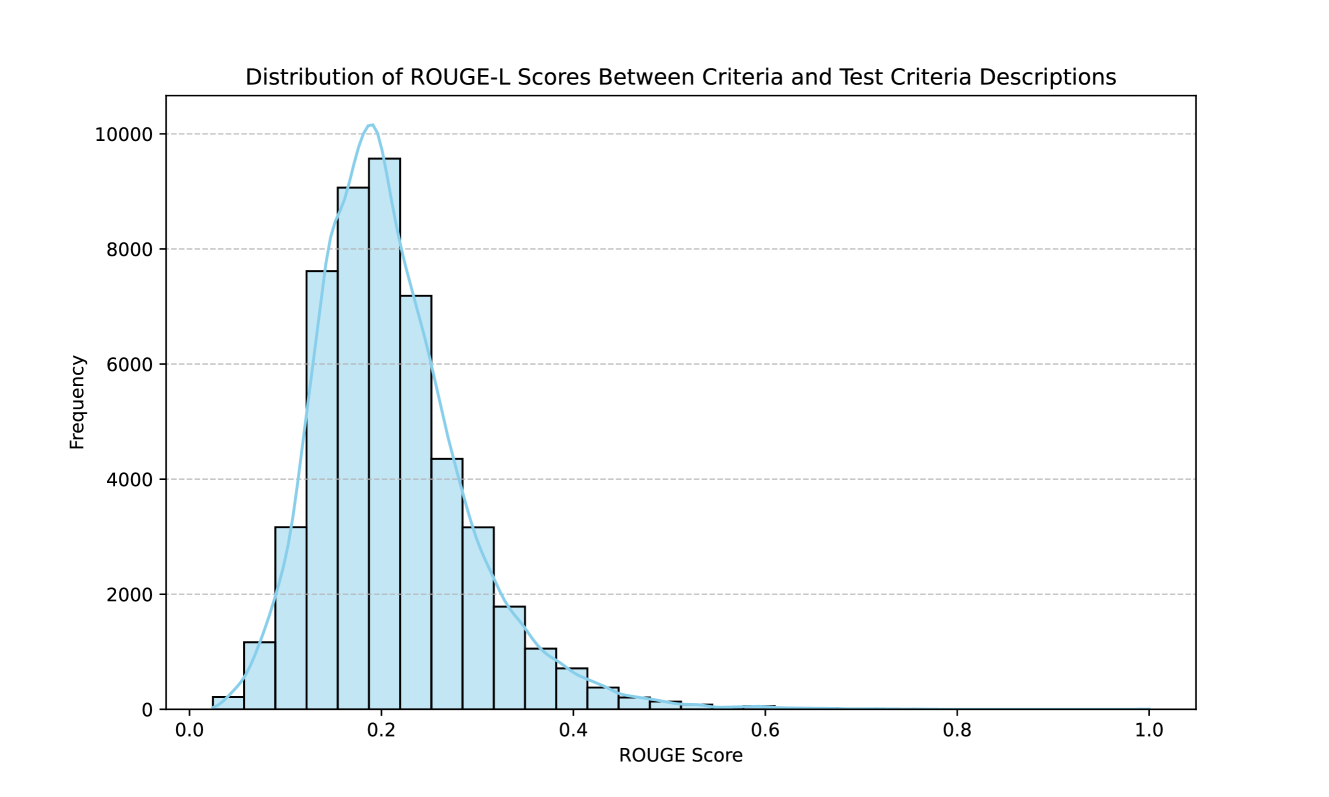
### Visual Description
# Technical Document Extraction: ROUGE-L Score Distribution Analysis
## 1. Title and Main Components
**Title**:
"Distribution of ROUGE-L Scores Between Criteria and Test Criteria Descriptions"
**Key Components**:
- Histogram with overlaid normal distribution curve
- X-axis: ROUGE Score (0.0–1.0)
- Y-axis: Frequency (0–10,000)
- Color scheme: Blue bars and blue line (no explicit legend present)
---
## 2. Axis Labels and Markers
### X-axis (ROUGE Score)
- **Range**: 0.0 to 1.0
- **Markers**: 0.0, 0.2, 0.4, 0.6, 0.8, 1.0
- **Units**: Dimensionless (ROUGE-L score)
### Y-axis (Frequency)
- **Range**: 0 to 10,000
- **Markers**: 0, 2000, 4000, 6000, 8000, 10,000
- **Units**: Count (frequency of occurrences)
---
## 3. Data Representation
### Histogram Bars
- **Color**: Blue
- **Distribution**:
- **Peak**: ~0.2 (highest frequency near 10,000)
- **Symmetry**: Decreases symmetrically toward 0.0 and 1.0
- **Trend**:
- Left tail (0.0–0.2): Gradual increase to peak
- Right tail (0.2–1.0): Steeper decline after peak
### Overlaid Normal Distribution Curve
- **Color**: Blue (matches histogram bars)
- **Purpose**: Models the data distribution
- **Key Observation**:
- Matches histogram shape closely, confirming Gaussian-like distribution
---
## 4. Spatial Grounding and Legend Analysis
- **Legend**:
- **Placement**: Not explicitly visible in the image
- **Color Matching**:
- Blue bars and line correspond to the same dataset (no sub-categories)
- **Conclusion**: No distinct legend required due to single data series
---
## 5. Trend Verification
- **Primary Trend**:
- Frequency increases to a peak at ~0.2, then decreases
- Symmetrical decay on both sides of the peak
- **Secondary Trend**:
- Overlaid curve validates the unimodal, bell-shaped distribution
---
## 6. Missing Elements
- **Data Table**: Not present (data represented visually via histogram)
- **Additional Text**: No embedded annotations or sub-titles
---
## 7. Language and Transcription
- **Language**: English (no non-English text detected)
- **Transcription Accuracy**: All labels and axis titles transcribed verbatim
---
## 8. Summary of Key Data Points
| ROUGE Score Range | Approximate Frequency |
|-------------------|-----------------------|
| 0.0–0.1 | <2000 |
| 0.1–0.2 | 3,000–10,000 |
| 0.2–0.3 | 7,000–9,000 |
| 0.3–0.4 | 4,000–5,000 |
| 0.4–0.5 | 1,000–2,000 |
| 0.5–1.0 | <500 |
---
## 9. Conclusion
The histogram and overlaid curve confirm a unimodal distribution of ROUGE-L scores, with the majority of values clustering around 0.2. The absence of a legend simplifies interpretation, as only one data series is represented. The symmetric decay of frequencies suggests a normal-like distribution, though slight asymmetry in the right tail may indicate minor skewness.
</details>
Figure 10: Rouge-L score distribution among a randomly sampled score rubric from the Feedback Collection and a score rubric from the Feedback Bench. A left-skewed distribution with low values shows that they do not overlap with each other, hence meaning that a unseen score rubric assumption is satisfied.
Does the testset maintain Unseen Score Rubrics?
One of the main considerations of our experiments in Section 5.2 using the Feedback Bench was testing whether Prometheus could generalize to unseen customized score rubrics. For this purpose, we built an unseen customized rubric subset. We plot the rouge-L distribution between a random score rubric within the Feedback Collection and a random score rubric within the Feedback Bench. As shown in Figure 10, there is a low overlap among the train and test sets, confirming that the Feedback Bench is valid to be claimed as an unseen test set to measure the evaluation capability of evaluator LMs.
## Appendix C Fine-tuning and Inference Details of Prometheus
We use 8xA100 (80GB) GPUs to train our models with PyTorch Fully-Sharded Data Parallel (FSDP) option. The code we used for training and inference is the official Llama2 fine-tuning code released by Meta AI https://github.com/facebookresearch/llama-recipes. The hyper-parameters we used are the basic settings in the fine-tuning code except for the training batch size which was set according to the model size: for 7B models we used 28 and for 13B models we used 20 to fully leverage GPU memory. Note that in the official Llama2 fine-tuning code, the loss is only calculated on the feedback and score decision, not the instruction. We empirically find that not masking out the instruction leads to poor performance while evaluating responses. The detailed hyper-parameters are shown in Table 8.
Table 8: Hyperparameters used for fine-tuning Prometheus.
| Model | Base Model | Batch size | LR | LR Scheduler | Optimizer | Max Length (Input & Output) |
| --- | --- | --- | --- | --- | --- | --- |
| Prometheus -7B | Llama-2-Chat-7B | 28 | 1e-5 | StepLR | AdamW | 4096 |
| Prometheus -13B | Llama-2-Chat-13B | 20 | 1e-5 | StepLR | AdamW | 4096 |
Table 9: Hyperparameters used for inferencing Prometheus, GPT-3.5-Turbo, and GPT-4. Verbalizer denotes accepting outputs such as ”[Score 5]” or ”Score: 4 out of 5” whereas the exact format is ”[Result] 5” (format is mentioned concretely within the instruction given to the evaluator LM). Even after applying a verbalizer, Llama-2-Chat is not able to generate a score decision that could easily be parsed, highlighting the benefits of fine-tuning it on feedback data.
| Params | Model | Temperature | Top-p | Repetition Penalty | Max Output Length | Verbalizer |
| --- | --- | --- | --- | --- | --- | --- |
| 7B | Llama-2-Chat-7B | 1.0 | 0.9 | 1.03 | 256 | Yes |
| 13B | Llama-2-Chat-13B | 1.0 | 0.9 | 1.03 | 256 | Yes |
| 70B | Llama-2-Chat-70B | 1.0 | 0.9 | 1.03 | 256 | Yes |
| 7B | Prometheus -7B | 1.0 | 0.9 | 1.03 | 256 | No |
| 13B | Prometheus -13B | 1.0 | 0.9 | 1.03 | 256 | No |
| - | GPT-3.5-Turbo | 1.0 | 0.9 | - | 256 | No |
| - | GPT-4 | 1.0 | 0.9 | - | 256 | No |
For inference, we use the hyper-parameters as shown in Table 9. When inferencing with the naive Llama-2-Chat model (not trained on the Feedback Collection) it was extremely difficult to steer the model to generate a final score in the form to be easily parsed (e.g., “[RESULT] 3”). While in-context learning (ICL) could solve this issue, most of our instances contained a maximum of 3072 tokens, so we could not utilize demonstrations during inference. Therefore, we empirically found patterns such as “[SCORE 5]” or “Score: 4 out of 5” and applied verbalizer to map those outputs to a final score decision. This highlights the benefits of directly training to generate in a structured format as Prometheus. On the other hand, we also find that proprietary LLMs such as GPT-3.5-Turbo and GPT-4 excel at generating structured outputs when the prompt is adeptly given. Also, note that we found that if we set the temperature to 0.0, evaluator LMs are not able to generate meaningful feedback compared to using a temperature of 1.0.
## Appendix D Training a Evaluator LM on Coarse-grained Score Rubrics
For the purpose of exploring the benefits of training on thousands of fine-grained and customized score rubrics, we employ a baseline of only training on relatively coarse-grained score rubrics. Since the Feedback Collection ’s instructions are closely tied with the score rubrics during its creation process, we could not directly use it and only change the score rubrics into coarse-grained ones.
So, we used the Flask dataset (Ye et al., 2023b) and split it into training data and evaluation data. The evaluation data is denoted as Flask Eval throughout the paper. Specifically, the Flask dataset consists of 1.7K instructions acquired across conventional NLP datasets and instruction datasets. Also, there exists 76.5K responses acquired across 15 response LMs. Each instance has a score rubric among 12 options (Logical Robustness, Logical Correctness, Logical Efficiency, Factuality, Commonsense Understanding, Harmlessness, Readability, Comprehension, Insightfulness, Completeness, Metacognition, Conciseness). While these 12 score rubrics are more fine-grained and diverse compared to previous works only using helpfulness and harmlessness, they are coarse-grained compared to the thousands of score rubrics included within the Feedback Collection, so we denote as coarse-grained in this work.
Among the 1.5K instructions & 67.5K responses as training data, we found that the score distribution is extremely skewed towards the score of 5. We distributed the instances so that the number of instances within the score range of 1 to 5 remains equal, which leads to 30K training instances. We trained the Llama-2-Chat model on the Flask train set, which led to one of our baselines denoted as Llama-2-Chat + Coarse in Table 3, Table 4, Table 5, Table 6.
<details>
<summary>x11.png Details</summary>
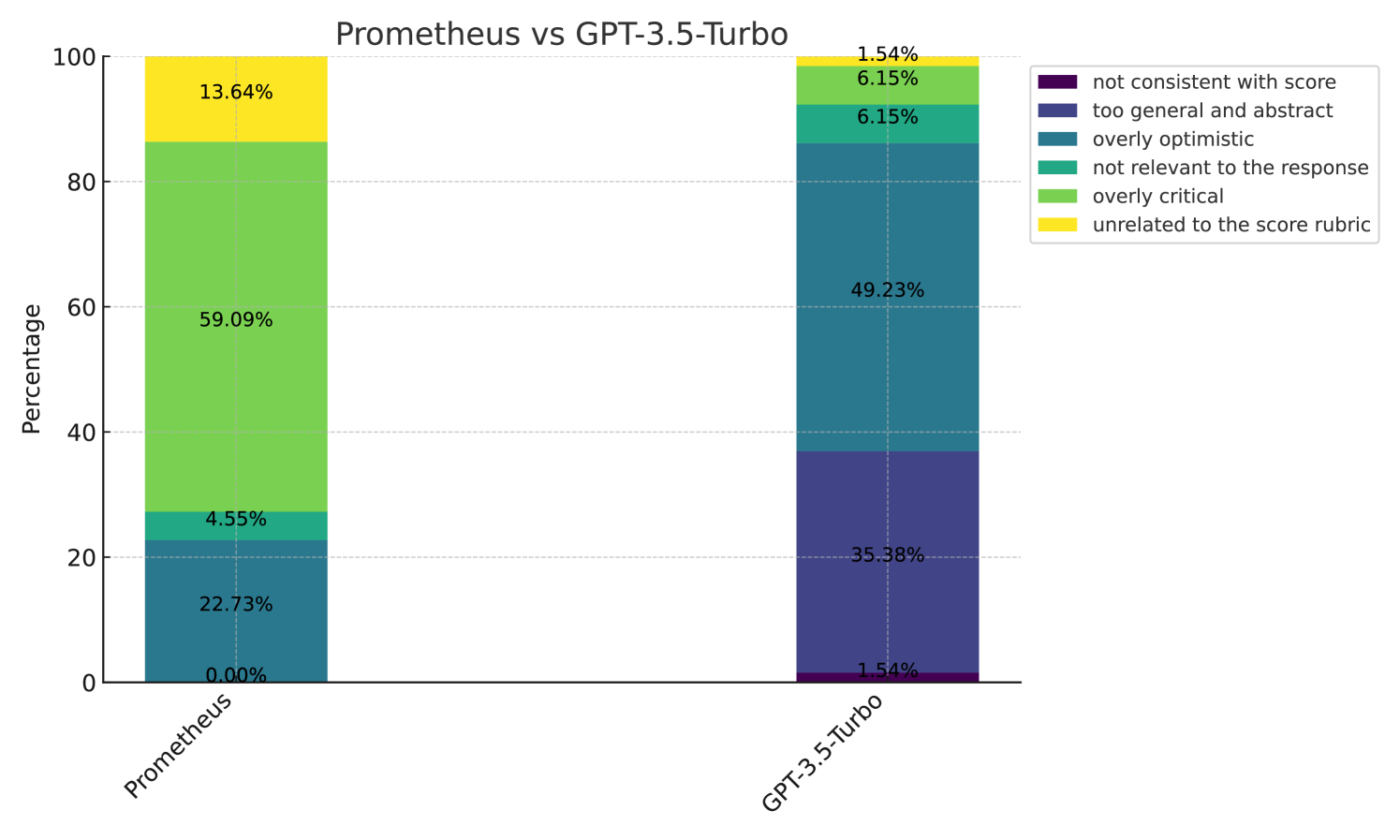
### Visual Description
# Technical Document Extraction: Prometheus vs GPT-3.5-Turbo Evaluation
## Chart Overview
**Title**: Prometheus vs GPT-3.5-Turbo
**Type**: Stacked Bar Chart
**Y-Axis**: Percentage (0–100)
**X-Axis**: Models (Prometheus, GPT-3.5-Turbo)
**Legend**: Located on the right, mapping colors to evaluation categories.
---
## Legend (Spatial Grounding: [x, y] = Right Side)
| Color | Category |
|-------------|-----------------------------------|
| Purple | not consistent with score |
| Dark Blue | too general and abstract |
| Teal | overly optimistic |
| Light Blue | not relevant to the response |
| Green | overly critical |
| Yellow | unrelated to the score rubric |
---
## Key Data Points & Trends
### Prometheus
- **Not consistent with score**: 0.00% (no purple segment)
- **Too general and abstract**: 22.73% (dark blue)
- **Overly optimistic**: 22.73% (teal)
- **Not relevant to the response**: 4.55% (light blue)
- **Overly critical**: 59.09% (green)
- **Unrelated to the score rubric**: 13.64% (yellow)
**Trend**: Dominated by "overly critical" (59.09%), followed by "unrelated" (13.64%) and "too general/abstract" (22.73%). Minimal "not consistent" (0%) and "not relevant" (4.55%).
### GPT-3.5-Turbo
- **Not consistent with score**: 1.54% (purple)
- **Too general and abstract**: 35.38% (dark blue)
- **Overly optimistic**: 49.23% (teal)
- **Not relevant to the response**: 6.15% (light blue)
- **Overly critical**: 6.15% (green)
- **Unrelated to the score rubric**: 1.54% (yellow)
**Trend**: Dominated by "overly optimistic" (49.23%) and "too general/abstract" (35.38%). "Not consistent" and "unrelated" are minimal (1.54% each). "Not relevant" and "overly critical" are equal at 6.15%.
---
## Data Table Reconstruction
| Category | Prometheus (%) | GPT-3.5-Turbo (%) |
|-----------------------------------|----------------|-------------------|
| not consistent with score | 0.00 | 1.54 |
| too general and abstract | 22.73 | 35.38 |
| overly optimistic | 22.73 | 49.23 |
| not relevant to the response | 4.55 | 6.15 |
| overly critical | 59.09 | 6.15 |
| unrelated to the score rubric | 13.64 | 1.54 |
---
## Validation Checks
1. **Legend Consistency**:
- Purple (not consistent) matches 0% in Prometheus and 1.54% in GPT-3.5-Turbo.
- Yellow (unrelated) matches 13.64% in Prometheus and 1.54% in GPT-3.5-Turbo.
2. **Percentage Summation**:
- Prometheus: 0.00 + 22.73 + 22.73 + 4.55 + 59.09 + 13.64 = **100.74%** (minor rounding discrepancy).
- GPT-3.5-Turbo: 1.54 + 35.38 + 49.23 + 6.15 + 6.15 + 1.54 = **99.99%** (minor rounding discrepancy).
3. **Trend Verification**:
- Prometheus shows a clear dominance in "overly critical" (green), while GPT-3.5-Turbo emphasizes "overly optimistic" (teal).
---
## Conclusion
The chart highlights distinct evaluation patterns:
- **Prometheus** is heavily criticized as "overly critical" (59.09%) and "unrelated" (13.64%).
- **GPT-3.5-Turbo** is more frequently labeled "overly optimistic" (49.23%) and "too general/abstract" (35.38%).
No textual data beyond the chart is present. All information is derived from the visual representation.
</details>
Figure 11: The reason why GPT-3.5-Turbo’s or Prometheus’s feedback was not chosen over the other. Prometheus generates less abstract and general feedback, but tends to write overly critical ones.
<details>
<summary>x12.png Details</summary>
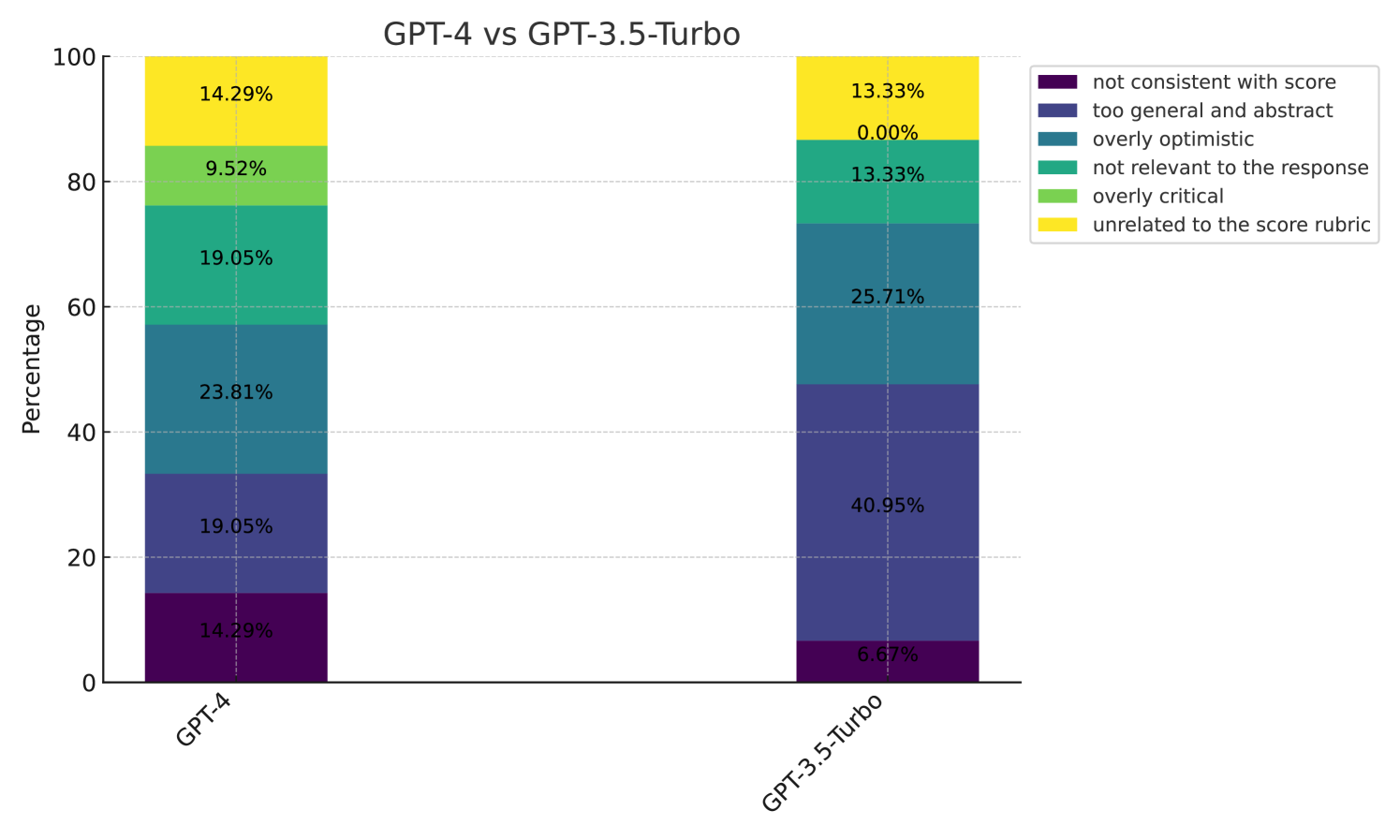
### Visual Description
# Technical Document Analysis: GPT-4 vs GPT-3.5-Turbo Evaluation Chart
## Chart Type
Stacked bar chart comparing performance metrics of two AI models across evaluation categories.
## Axes
- **X-axis**: Model names ("GPT-4", "GPT-3.5-Turbo")
- **Y-axis**: Percentage scale (0–100) labeled "Percentage"
## Legend
Positioned on the right side of the chart. Color-coded categories:
1. **Purple**: "not consistent with score"
2. **Dark Blue**: "too general and abstract"
3. **Teal**: "overly optimistic"
4. **Green**: "not relevant to the response"
5. **Light Green**: "overly critical"
6. **Yellow**: "unrelated to the score rubric"
## Data Points
### GPT-4
- **Purple** ("not consistent with score"): 14.29%
- **Dark Blue** ("too general and abstract"): 19.05%
- **Teal** ("overly optimistic"): 23.81%
- **Green** ("not relevant to the response"): 19.05%
- **Light Green** ("overly critical"): 9.52%
- **Yellow** ("unrelated to the score rubric"): 14.29%
### GPT-3.5-Turbo
- **Purple** ("not consistent with score"): 6.67%
- **Dark Blue** ("too general and abstract"): 40.95%
- **Teal** ("overly optimistic"): 25.71%
- **Green** ("not relevant to the response"): 13.33%
- **Light Green** ("overly critical"): 0.00%
- **Yellow** ("unrelated to the score rubric"): 13.33%
## Key Observations
1. **GPT-4** shows a more balanced distribution across categories, with the largest segment being "overly optimistic" (23.81%).
2. **GPT-3.5-Turbo** has a significantly higher proportion of responses categorized as "too general and abstract" (40.95%), the largest segment.
3. Both models have identical "unrelated to the score rubric" percentages (14.29% for GPT-4, 13.33% for GPT-3.5-Turbo).
4. GPT-3.5-Turbo has no responses in the "overly critical" category (0.00%).
## Spatial Grounding
- Legend: Right-aligned, adjacent to the bars.
- Data segments: Horizontally stacked within each bar, ordered by legend sequence.
## Trend Verification
- **GPT-4**: Segments decrease in size from "overly optimistic" (23.81%) to "overly critical" (9.52%).
- **GPT-3.5-Turbo**: Segments increase from "not consistent with score" (6.67%) to "too general and abstract" (40.95%), then decrease to "unrelated" (13.33%).
## Component Isolation
- **Header**: Chart title "GPT-4 vs GPT-3.5-Turbo"
- **Main Chart**: Stacked bars with percentage values
- **Footer**: Legend with color-coded categories
## Data Table Reconstruction
| Category | GPT-4 (%) | GPT-3.5-Turbo (%) |
|------------------------------|-----------|-------------------|
| Not consistent with score | 14.29 | 6.67 |
| Too general and abstract | 19.05 | 40.95 |
| Overly optimistic | 23.81 | 25.71 |
| Not relevant to the response | 19.05 | 13.33 |
| Overly critical | 9.52 | 0.00 |
| Unrelated to the score rubric| 14.29 | 13.33 |
## Color Consistency Check
- All legend colors match the corresponding bar segments.
- Example: Purple segments (14.29% for GPT-4, 6.67% for GPT-3.5-Turbo) align with "not consistent with score" label.
</details>
Figure 12: The reason why GPT-4’s or GPT-3.5-Turbo’s feedback was not chosen over the other. GPT-4 generates less abstract and general feedback, but tends to write overly critical ones.
## Appendix E Pairwise Comparison of the Quality of the Feedback
In this section, we further explain the experimental setting and present additional results & analysis for the experiment of comparing the quality of the generated feedback (Section 5.1).
In addition to Figure 6, the reason why each annotator rejected the feedback from either Prometheus, GPT-3.5-Turbo, GPT-4 is shown in Figure 11 and Figure 12.
The results further support our claim that Prometheus tends to be critical over GPT-4 and GPT-3.5-Turbo. Interestingly, GPT-4 was considered to be more critical compared to GPT-3.5-Turbo and the gap was even wider when comparing GPT-3.5-Turbo and Prometheus. This indicates that Prometheus can serve as a critical judge when evaluating responses generated by LLMs, but it could also be biased towards not being optimistic generally. The degree of being critical could be useful or a limitation based on different use cases. For instance, we conjecture that it could be helpful when analyzing the limitations of LLMs or providing feedback as supervision to further improve a target LLM (e.g., RLHF), yet we leave this exploration to future work.
## Appendix F Is there a Length Bias during Evaluation?
<details>
<summary>x13.png Details</summary>
### Visual Description
# Technical Document Extraction: GPT-4 vs Prometheus Eval
## 1. Labels and Axis Titles
- **X-Axis**: Labeled "Score" with discrete categories: 1, 2, 3, 4, 5.
- **Y-Axis**: Labeled "Response Length" (logarithmic scale, 100–1000).
- **Title**: "GPT-4 vs Prometheus Eval (Feedback Collection Seen Rubric Testset)".
## 2. Legend
- **Placement**: Top-left corner.
- **Colors**:
- Blue: GPT-4
- Orange: Prometheus
## 3. Box Plot Details
### Score 1
- **GPT-4 (Blue)**:
- Median: ~550
- IQR: ~500–650
- Min: ~200
- Max: ~850
- Outliers: ~250, ~300
- **Prometheus (Orange)**:
- Median: ~580
- IQR: ~520–680
- Min: ~220
- Max: ~800
- Outliers: ~200, ~350
### Score 2
- **GPT-4 (Blue)**:
- Median: ~580
- IQR: ~530–670
- Min: ~220
- Max: ~850
- Outliers: ~250, ~300
- **Prometheus (Orange)**:
- Median: ~590
- IQR: ~540–690
- Min: ~200
- Max: ~800
- Outliers: ~220, ~380
### Score 3
- **GPT-4 (Blue)**:
- Median: ~560
- IQR: ~510–660
- Min: ~200
- Max: ~850
- Outliers: ~250, ~300
- **Prometheus (Orange)**:
- Median: ~570
- IQR: ~520–680
- Min: ~220
- Max: ~800
- Outliers: ~200, ~350
### Score 4
- **GPT-4 (Blue)**:
- Median: ~550
- IQR: ~500–650
- Min: ~200
- Max: ~850
- Outliers: ~250, ~300
- **Prometheus (Orange)**:
- Median: ~580
- IQR: ~530–680
- Min: ~220
- Max: ~800
- Outliers: ~200, ~350
### Score 5
- **GPT-4 (Blue)**:
- Median: ~600
- IQR: ~550–650
- Min: ~200
- Max: ~1000
- Outliers: ~250, ~300
- **Prometheus (Orange)**:
- Median: ~610
- IQR: ~560–660
- Min: ~220
- Max: ~1000
- Outliers: ~200, ~350
## 4. Key Trends
- **Median Response Length**:
- Both models show similar medians (~550–600) across all scores.
- Prometheus exhibits slightly higher medians in Scores 2–5.
- **Variability**:
- GPT-4 has tighter interquartile ranges (IQR) in Scores 1–3.
- Prometheus shows broader IQRs in Scores 4–5.
- **Outliers**:
- Both models have outliers below 300 and above 800, with GPT-4 occasionally exceeding 1000 in Score 5.
## 5. Spatial Grounding
- **Legend Coordinates**: Top-left corner (exact [x, y] unspecified in image).
- **Color Consistency**: Blue consistently represents GPT-4; orange represents Prometheus.
## 6. Missing Elements
- No data table or numerical values explicitly provided in the image.
- No textual annotations within the box plots (e.g., exact median values).
## 7. Language
- All text is in English. No non-English content detected.
</details>
Figure 13: Box and whisker plot describing a relationship between a given response and its corresponding score. We check if the response lengths correlate with its scores.
<details>
<summary>x14.png Details</summary>
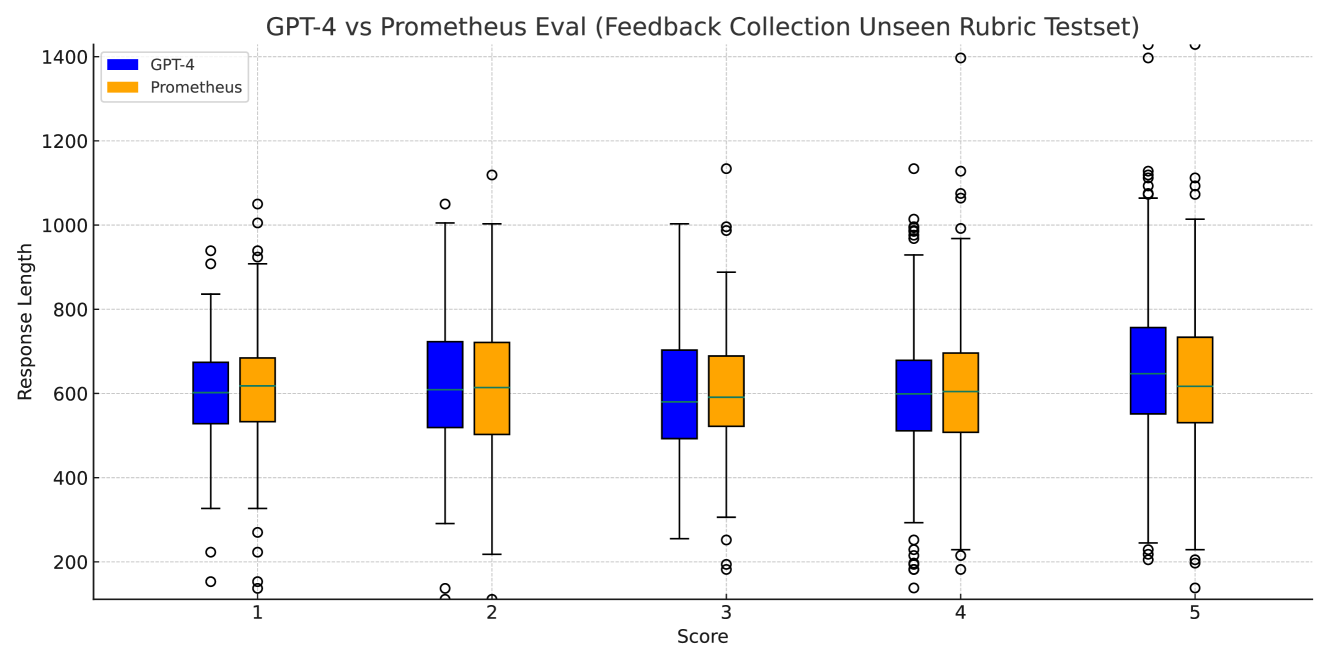
### Visual Description
# Technical Document Extraction: GPT-4 vs Prometheus Eval
## Image Description
The image is a comparative box plot chart titled **"GPT-4 vs Prometheus Eval (Feedback Collection Unseen Rubric Testset)"**. It visualizes response length distributions for two systems (GPT-4 and Prometheus) across five scores (1–5). The chart uses distinct colors for each system: **blue for GPT-4** and **orange for Prometheus**.
---
## Key Components
### 1. **Legend**
- **Position**: Top-left corner.
- **Labels**:
- Blue: GPT-4
- Orange: Prometheus
### 2. **Axes**
- **X-axis**: Labeled **"Score"**, with discrete categories **1, 2, 3, 4, 5**.
- **Y-axis**: Labeled **"Response Length"**, ranging from **0 to 1400** in increments of 200.
### 3. **Box Plot Structure**
Each score (1–5) has two box plots (one per system). Components include:
- **Median**: Green line within each box.
- **Interquartile Range (IQR)**: Box boundaries (25th–75th percentiles).
- **Whiskers**: Extend to 1.5×IQR from the box edges.
- **Outliers**: Marked as individual dots beyond whiskers.
---
## Data Trends
### GPT-4 (Blue)
- **Score 1**: Median ~650, IQR ~550–700, outliers at ~200 and ~900.
- **Score 2**: Median ~700, IQR ~600–750, outliers at ~150 and ~1050.
- **Score 3**: Median ~650, IQR ~550–700, outliers at ~200 and ~1000.
- **Score 4**: Median ~650, IQR ~550–700, outliers at ~150 and ~1000.
- **Score 5**: Median ~700, IQR ~600–750, outliers at ~1400 and ~1100.
### Prometheus (Orange)
- **Score 1**: Median ~600, IQR ~500–650, outliers at ~200 and ~850.
- **Score 2**: Median ~650, IQR ~550–700, outliers at ~150 and ~1050.
- **Score 3**: Median ~600, IQR ~500–650, outliers at ~200 and ~950.
- **Score 4**: Median ~650, IQR ~550–700, outliers at ~150 and ~1000.
- **Score 5**: Median ~650, IQR ~550–700, outliers at ~200 and ~1100.
---
## Observations
1. **Median Response Length**:
- GPT-4 consistently has higher medians than Prometheus across all scores (e.g., Score 5: GPT-4 ~700 vs. Prometheus ~650).
- The largest gap occurs at Score 5 (~50 units difference).
2. **Variability**:
- Both systems show similar IQRs, but GPT-4 exhibits more extreme outliers (e.g., ~1400 at Score 5).
3. **Outliers**:
- GPT-4 has more frequent and extreme outliers (e.g., ~1400 at Score 5).
- Prometheus has fewer outliers, with the highest at ~1100 (Score 5).
4. **Overlap**:
- At Scores 3 and 4, the IQRs of both systems overlap significantly (~550–700).
---
## Spatial Grounding
- **Legend**: Top-left corner (confirmed via visual alignment).
- **Axis Titles**: Centered above/below axes (standard box plot conventions).
- **Data Points**: All dots (outliers) align with their respective system colors.
---
## Language Notes
- **Primary Language**: English (all labels, titles, and annotations).
- **No Additional Languages Detected**.
---
## Conclusion
The chart demonstrates that GPT-4 generally produces longer responses than Prometheus, with higher variability and more extreme outliers. Prometheus shows more consistent response lengths but lower median values. This suggests GPT-4 may prioritize depth over conciseness in unseen rubric tasks.
</details>
Figure 14: Box and whisker plot describing a relationship between a given response and its corresponding score. We check if the response lengths correlate with its scores.
<details>
<summary>x15.png Details</summary>
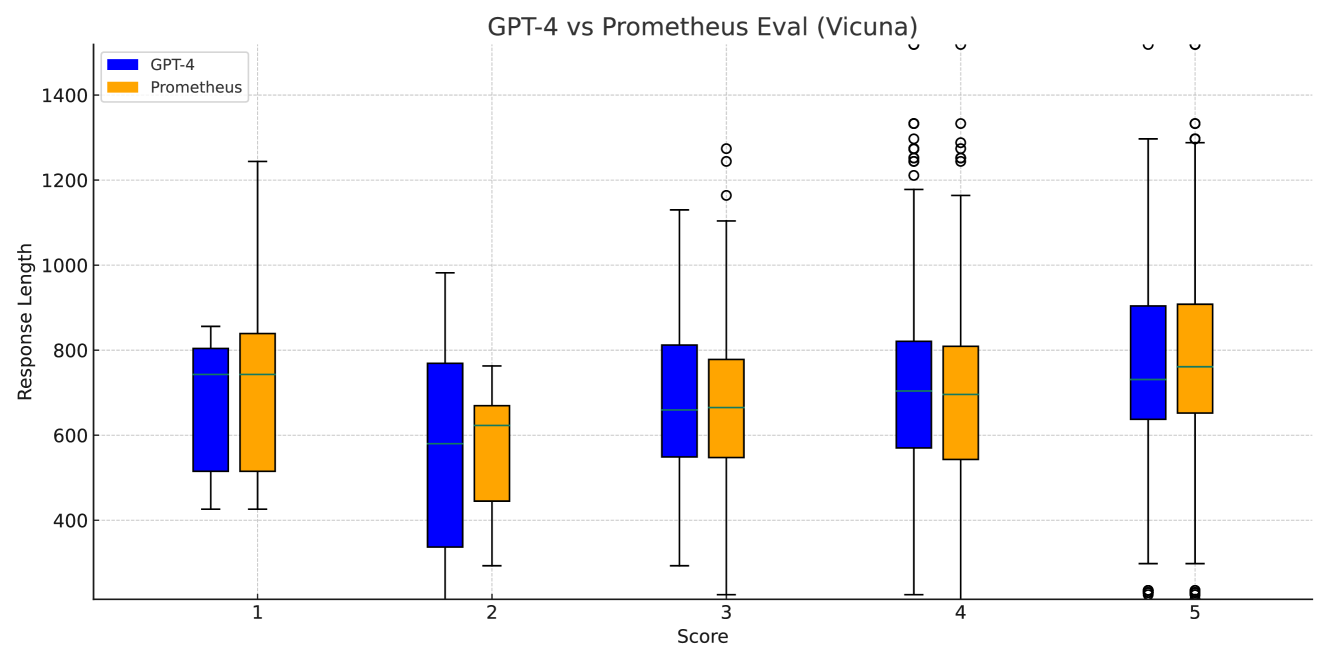
### Visual Description
# Technical Document Extraction: GPT-4 vs Prometheus Eval (Vicuna)
## 1. Title
- **Title**: "GPT-4 vs Prometheus Eval (Vicuna)"
- **Language**: English
## 2. Axes and Labels
- **X-Axis**:
- Label: "Score"
- Categories: 1, 2, 3, 4, 5 (ordinal)
- **Y-Axis**:
- Label: "Response Length"
- Units: Implicit (numeric, no explicit units provided)
## 3. Legend
- **Position**: Top-left corner
- **Labels**:
- Blue: "GPT-4"
- Orange: "Prometheus"
- **Color Verification**:
- Blue boxes correspond to GPT-4 data.
- Orange boxes correspond to Prometheus data.
## 4. Box Plot Components
### General Structure
- **Components per Score**:
- Median (green line)
- Interquartile Range (IQR) (box)
- Whiskers (min/max excluding outliers)
- Outliers (black dots)
### Score-Specific Data
#### Score 1
- **GPT-4**:
- Median: ~750
- IQR: ~500–800
- Whiskers: 400–1200
- Outliers: 400, 1200
- **Prometheus**:
- Median: ~800
- IQR: ~550–850
- Whiskers: 450–1250
- Outliers: None
#### Score 2
- **GPT-4**:
- Median: ~700
- IQR: ~400–850
- Whiskers: 300–950
- Outliers: 300, 950
- **Prometheus**:
- Median: ~600
- IQR: ~450–700
- Whiskers: 350–900
- Outliers: None
#### Score 3
- **GPT-4**:
- Median: ~800
- IQR: ~550–850
- Whiskers: 300–1100
- Outliers: 300, 1100
- **Prometheus**:
- Median: ~750
- IQR: ~600–800
- Whiskers: 400–1050
- Outliers: None
#### Score 4
- **GPT-4**:
- Median: ~800
- IQR: ~550–850
- Whiskers: 200–1300
- Outliers: 200, 1300
- **Prometheus**:
- Median: ~750
- IQR: ~600–800
- Whiskers: 400–1050
- Outliers: None
#### Score 5
- **GPT-4**:
- Median: ~900
- IQR: ~650–950
- Whiskers: 100–1400
- Outliers: 100, 1400
- **Prometheus**:
- Median: ~900
- IQR: ~650–950
- Whiskers: 400–1050
- Outliers: None
## 5. Outliers
- **Distribution**:
- GPT-4: Outliers present in all scores (1–5).
- Prometheus: Outliers only in Scores 1 and 5.
- **Extreme Values**:
- Minimum: 100 (Score 5, GPT-4)
- Maximum: 1400 (Score 5, GPT-4)
## 6. Trends
- **GPT-4**:
- Median response length increases with score (750 → 900).
- Whisker spread widens at higher scores (e.g., Score 5: 100–1400).
- **Prometheus**:
- Median response length remains stable (~750–900).
- Whisker spread narrows at higher scores (e.g., Score 5: 400–1050).
## 7. Spatial Grounding
- **Legend**: Top-left corner (x=0, y=0 in normalized coordinates).
- **Box Plots**: Centered under each score category (x=1–5).
## 8. Missing Elements
- **Data Table**: Not present in the image.
- **Additional Text**: No embedded text outside the legend and axis labels.
## 9. Validation
- **Color Consistency**: Confirmed legend colors match box plot colors.
- **Trend Verification**:
- GPT-4’s upward trend aligns with increasing medians.
- Prometheus’ stability matches consistent medians across scores.
</details>
Figure 15: Box and whisker plot describing a relationship between a given response and its corresponding score. We check if the response lengths correlate with its scores.
One of the limitations of employing an LLM as an evaluator LM is that it could be vulnerable to various biases. In this work, we train/test on an Absolute Scoring evaluation setting, hence there exists no position bias. Yet, it is crucial to analyze whether Prometheus showed any bias towards favoring longer responses. Hence, we conduct a comprehensive analysis in this section.
As shown in Figure 13, Figure 14, and Figure 15, both GPT-4 and Prometheus and GPT-4 shows a similar trend of not favoring longer responses (i.e., similar length distribution among different scores). However, as mentioned in Zheng et al. (2023), LLM evaluators might favor more verbose responses, yet the responses from our test instances (Feedback Bench and Vicuna Bench) did not include any adversarial examples to test this phenomenon. More extensive research on whether the length bias is also transferred to fine-tuned evaluator LMs should be explored in future work.
## Appendix G Prompt for Feedback Collection Creation
In this section, we provide the extensive list of prompts used to create the Feedback Collection.
Note that in the prompt of generating a response and a feedback, we use the sentence length of the reference answer and append it to “{SENT NUM}” within the prompt. This was crucial to make the length even across different scores as shown in Figure 9. Also, note that for the 1K score rubrics, 20K instructions & reference answers, and 100K responses & feedback within the Feedback Collection, each prompt was sequentially used. In early experiments, we found that generating every component all at once leads to very poor generation quality (i.e., similar responses & feedback across different score ranges). Yet, we found that grouping (1) the instruction and reference answer generation and (2) the response and feedback generation had a positive synergy, leading to better generation quality and less amount of cost. Also, to the best of our knowledge, we are first to explore acquiring negative and neutral responses (Score 1 $∼$ 4 responses) through GPT-4 augmentation. We hope future work could also explore applying this strategy to different use cases.
Prompt for Brainstorming New Score Rubrics
We are brainstorming criteria with which to grade a language model on its responses in diverse situations. A ‘criteria‘ is some useful, real-world objective, and associated rubric for scores 1-5, that tests a capability. Here you will see 4 examples of ‘criteria‘, and their scoring rubrics, formatted as JSON. Criteria 1: {JSON LIST 1} Criteria 2: {JSON LIST 2} Criteria 3: {JSON LIST 3} Criteria 4: {JSON LIST 4} Please brainstorm a new criteria and scoring rubrics. Be creative and create new but useful criteria that people in different settings or industries might find practical. Please format the output as same as the above examples with no extra or surrounding text. Write [END] after you are done. New Criteria:
Prompt for Paraphrasing as a New Score Rubric
Please paraphrase the sentences inside the dictionary below. Each paraphrase should not change the meaning or substance of the original sentence, be naturally written, but sufficiently diverse from one another. Diversity can come from differences in diction, phrasing, sentence structure, formality, detail, and/or other stylistic changes. The dictionary: {CRITERIA} Respond with only dictionary (same format as the given dictionary) with no extra or surrounding text. Write [END] after you are done. Dictionary with Paraphrased Sentences:
Prompt for Generating an Instruction and Reference Answer
Your job is to generate a new novel problem and a response that is related to the given score rubric. The score rubric: {CRITERIA} * Problem - The problem should inherently be related to the score criteria and score rubric given above. Specifically, the score criteria should be the core attributes required to solve the problem. - The problem itself should not be too generic or easy to solve. - If the score rubric is related to logical abilities, generate problems that require math or coding abilities. - Try to make the person who might solve the problem not notice the existence of the score rubric by not explicitly mentioning it, and also provide additional inputs and options if needed. - Assume a situation where a user is interacting with an AI model. The user would try to ask in a first-person point of view, but not using terms like ”I”, ”A User” or ”You” in the first sentence. - Do not give a role to the AI, assume that the user is asking a question from his point of view. - Do not include any phrase related to AI model in the problem. * Response - The response should be a response that would get a score of 5 from the score rubric. - The response should be as detailed as possible unless the score rubric is related to conciseness or brevity. It should consist of multiple paragraphs, a list of items, or a step-by-step reasoning process. - The response should look like how a well-prompted GPT-4 would normally answer your problem. * Format - DO NOT WRITE ANY GREETING MESSAGES, just write the problem and response only. - In front of the problem, append the phrase ”Problem:” and in front of the response, append the phrase ”Response:”. - Write in the order of ”Problem” - ”Response”, where the two items are separated by the phrase ”[NEXT]”. - Write [END] after you are done. Data Generation:
Prompt for Generating Responses and Feedback
Your job is to generate a response that would get a score of {SCORE} and corresponding feedback based on the given score rubric. For reference, a reference response that would get a score of 5 is also given. Instruction: {INSTRUCTION} The score rubric: {CRITERIA} Reference response (Score 5): {REFERENCE} * Response - The quality of the score {SCORE} response should be determined based on the score rubric, not by its length. - The score {SCORE} response should have the same length as the reference response, composed of {SENT NUM} sentences. - Do not explicitly state the keywords of the score rubric inside the response. * Feedback - The score {SCORE} feedback should each be an explanation of why the response would get a score of {SCORE}. It should be written based on the generated response and score rubric. - The score {SCORE} feedback shouldn’t just copy and paste the score rubric, but it should also give very detailed feedback on the content of the corresponding response. - The score {SCORE} feedback should include the phrase ”So the overall score is {SCORE}” in the last sentence. * Format - DO NOT WRITE ANY GREETING MESSAGES, just write the problem and response only. - In front of the response, append the phrase ”Response:” and in front of the feedback, append the phrase ”Feedback:”. - Write in the order of ”Response” - ”Feedback”, where the two items are separated by the phrase ”[NEXT]”. - Write [END] after you are done. Data Generation:
## Appendix H Prompt used for Prometheus
In this section, we provide the prompt used for training/inferencing Prometheus. Note that after applying the prompt template shown below, we also apply Llama-2’s basic conversation prompt template in order to minimize the discrepancy between the training process of Llama-2 and training on the Feedback Collection.
Prompt for Prometheus
###Task Description: An instruction (might include an Input inside it), a response to evaluate, a reference answer that gets a score of 5, and a score rubric representing an evaluation criterion is given. 1. Write a detailed feedback that assesses the quality of the response strictly based on the given score rubric, not evaluating in general. 2. After writing a feedback, write a score that is an integer between 1 and 5. You should refer to the score rubric. 3. The output format should look as follows: F̈eedback: (write a feedback for criteria) [RESULT] (an integer number between 1 and 5)\̈lx@parboxnewline 4. Please do not generate any other opening, closing, and explanations. ###The instruction to evaluate: {instruction} ###Response to evaluate: {response} ###Reference Answer (Score 5): {reference answer} ###Score Rubrics: $[$ { criteria description } $]$ Score 1: {score1 description} Score 2: {score2 description} Score 3: {score3 description} Score 4: {score4 description} Score 5: {score5 description} ###Feedback:
## Appendix I Qualitative Examples of Generated Feedback
Figure 16, Figure 17, Figure 18, Figure 19 shows a qualitative example of feedback generated by either GPT-4, Prometheus (13B), and Code-Llama trained on the Feedback Collection.
## Appendix J Experimental Details for Human Evaluation
The user interface used for human evaluation is shown in Figure 20. In order to acquire a score decision for the response, a decision of which feedback is better, and an annotation of why they made a decision to choose one of the feedback, we constructed the user interface in sequential order. Each annotator was informed not to solve the questions below before solving the ones above them. The test instances were randomly selected among Feedback Bench (Customized Unseen Rubric set), Vicuna Bench, and MT Bench except for math and coding instances. The experiments were conducted on LabelStudio, hosted on Huggingface Spaces. We asked each annotator to spend at least 3 hours annotating 45 instances each and paid $ 50. The 9 annotators were divided into 3 groups: (1) Prometheus vs GPT-4, (2) Prometheus vs GPT-3.5-Turbo, and (3) GPT-4 vs GPT-3.5-Turbo. The order of the feedback was randomly decided in order to prevent order bias during annotation.
<details>
<summary>x16.png Details</summary>

### Visual Description
# Technical Document Analysis
## Document Structure
The image contains a structured technical document with the following sections:
1. **Score Rubric** (Header)
2. **Instruction** (Main Content)
3. **Response from ChatGPT** (Subsection)
4. **GPT-4's Feedback** (Subsection)
5. **Prometheus's Feedback** (Subsection)
---
## Score Rubric
**Text**:
"Does the model demonstrate an ability to logically process and interpret given information, apply relevant knowledge, and present an insightful conclusion?"
---
## Instruction
**Text**:
"Here is a dialogue between an assistant and an user. Generate a human preferable response by the assistant."
### Dialogue
**User**:
"One morning after sunrise, Suresh was standing facing a pole. The shadow of the pole fell exactly to his right. Can you tell me the direction towards which the shadow was pointing - east, south, west, or north? Explain your reasoning steps."
**Assistant**:
"Based on the given information, Suresh was standing facing a pole, and the shadow of the pole fell exactly to his right. To determine the direction towards which the shadow was pointing, we need to consider the movement of the sun during the day. The sun rises in the east and sets in the west. In the morning, when Suresh was standing facing the pole, the sun would have been in the eastern sky. Since the shadow of the pole fell exactly to Suresh's right, it means that the shadow was pointing towards the west."
**User Follow-up**:
"To which direction was Suresh facing? How do you solve this?"
---
## Response from ChatGPT
**Text**:
"Apologies for the confusion. To determine the direction Suresh was facing, we need to consider the position of the shadow in relation to him. If the shadow fell exactly to his right, it means that Suresh was facing towards the west. The shadow is formed when an object blocks the light from the sun. In this case, since the shadow is to Suresh's right, it indicates that the sun is in front of him, casting the shadow towards his back. Therefore, Suresh was facing towards the east."
---
## GPT-4's Feedback
**Text**:
"The model interprets the information from the user accurately and applies the concept of the sun's position and its effect on the formation of shadows. However, it fails to reach the correct conclusion that Suresh is facing the south. Instead, it incorrectly concludes that Suresh is facing the east. The response demonstrates a partial understanding of the problem but lacks complete logical coherence in the solution. The final score is 3 out of 5."
---
## Prometheus's Feedback
**Text**:
"The response provided by the model is inaccurate and doesn't demonstrate a clear understanding of the given information and task. According to the user's query, Suresh was standing facing a pole, and the shadow of the pole fell exactly to his right. This implies that Suresh was facing towards the west, not the east as the model suggests. Furthermore, the model failed to properly explain the reasoning behind its conclusion, leading to an illogical conclusion that contradicts the initial information provided. The model didn't correctly apply the knowledge of the movement of the sun during the day, nor did it take into account the position of the shadow in relation to Suresh. The final score is 1 out of 5."
---
## Key Observations
1. **Logical Flow**: The document evaluates a model's ability to reason about shadow direction based on sun position.
2. **Contradictory Conclusions**: Both feedback systems identify inconsistencies in the model's reasoning.
3. **Scoring**: GPT-4 assigns 3/5, while Prometheus assigns 1/5, highlighting differing evaluation criteria.
4. **Critical Flaw**: The model misinterprets the relationship between shadow direction and facing direction.
---
## Spatial Grounding (Textual Elements)
- **Legend**: Not applicable (no visual legend present).
- **Axis Titles**: Not applicable (no chart/diagram).
- **Data Points**: Scores (3/5, 1/5) are explicitly stated in feedback sections.
---
## Trend Verification
- **GPT-4 Feedback**: Partial understanding with logical gaps.
- **Prometheus Feedback**: Complete failure to align with user-provided information.
---
## Component Isolation
1. **Header**: Score Rubric (evaluation criteria).
2. **Main Content**: Dialogue and model response.
3. **Footer**: Dual feedback analyses with scores.
---
## Conclusion
The document evaluates a model's reasoning about shadow direction but contains critical errors in its conclusion. Feedback systems highlight inconsistencies in logical coherence and factual accuracy.
</details>
Figure 16: An example of comparing the feedback generated by Prometheus and GPT-4. GPT-4 was labeled to generate an abstract feedback.
<details>
<summary>x17.png Details</summary>

### Visual Description
# Technical Document Extraction: Shopping Preference Analysis
## Document Structure
The document is a structured analysis of factors influencing consumer preference for small, locally-owned businesses over large chain stores. It includes a rubric, instructional prompt, AI-generated response, and evaluator feedback.
---
### 1. Score Rubric
**Title**: "Does the Response represent a balanced view of the factors?"
**Instruction**:
> "Why might someone prefer to shop at a small, locally-owned business instead of a large chain store, even if the prices are higher?"
---
### 2. Response from Vicuna 13B
**Content**:
A detailed list of six reasons why consumers might prefer small businesses despite higher prices:
1. **Supporting the local economy**: Direct economic benefits to the community.
2. **Personalized service**: Tailored attention and product knowledge.
3. **Unique products**: Niche or custom-made items unavailable in chains.
4. **Community involvement**: Sponsorship of local events/charities.
5. **Better customer service**: Stronger personal relationships with staff.
6. **Environmental/ethical considerations**: Sustainable/socially responsible practices.
**Conclusion**:
> "Overall, shopping at a small, locally-owned business can be a way to support the local community, get personalized service, and find unique products that you may not be able to find at a large chain store."
---
### 3. GPT-4's Feedback
**Evaluation**:
- **Strengths**:
- Balanced presentation of six factors.
- Thorough, unbiased explanations for each reason.
- Equal emphasis on all factors.
- **Weaknesses**:
- Failed to address factors favoring large chain stores (e.g., price, convenience, product range).
- **Score**: 4/5
---
### 4. Prometheus's Feedback
**Evaluation**:
- **Strengths**:
- Comprehensive coverage of six factors.
- Clear articulation of community and ethical motivations.
- **Weaknesses**:
- Lacks depth in explaining *how* small businesses support the local economy or foster community involvement.
- Does not discuss trade-offs (e.g., price, convenience) that might favor large chains.
- **Score**: 4/5
---
### Key Observations
1. **Balanced Perspective**: Both evaluators acknowledge the response’s fairness but note omissions (e.g., large chain advantages).
2. **Structural Consistency**: The response uses numbered lists for clarity, though deeper contextual analysis is recommended.
3. **Scoring Alignment**: Both GPT-4 and Prometheus assign a 4/5 score, indicating near-complete but not fully comprehensive coverage.
---
### Final Output
The document provides a structured analysis of consumer preferences, with evaluators highlighting strengths in factor coverage and weaknesses in addressing counterarguments. No charts, diagrams, or non-English text are present.
</details>
Figure 17: An example of comparing the feedback generated by Prometheus and GPT-4. Prometheus was labeled to generate an overly critical feedback.
<details>
<summary>x18.png Details</summary>

### Visual Description
# Technical Document Extraction: Photosynthesis Explanation Rubric and Feedback
## Score Rubric
**Question**: Can the model's response be understood by a non-expert in the subject?
## Instruction
**Task**: Explain the process of photosynthesis in plants in a way that a middle school student could understand.
## Response from Simulated GPT-4
**Content**:
Photosynthesis, essentially, is a biochemical reaction in which plants use sunlight (solar energy), water (H₂O), and carbon dioxide (CO₂) to produce glucose (C₆H₁₂O₆) and oxygen (O₂).
It's the key method that plants use for their nutritional requirements. To begin with, plants capture solar energy with the chlorophyll in their leaves.
Then, with the absorbed solar energy, the plant's chloroplasts take water from the ground and CO₂ from the atmosphere to perform the complex photosynthesis process.
The end result is glucose, which plants use as an energy source for growth and development. Additionally, plants emit oxygen, which is beneficial for us as it's necessary for our respiration.
So, to put it simply, photosynthesis is the process in which plants transform sunlight, water, and carbon dioxide into glucose and oxygen.
## GPT-4's Feedback
**Critique**:
- Your explanation of photosynthesis is decent and uses analogies to make some aspects more relatable to a non-expert, such as a middle school student.
- However, there are still areas that could be challenging for them.
- The use of terms like "biochemical reaction," "chlorophyll," "chloroplasts," and the chemical formulas for water, carbon dioxide, and glucose could confuse a non-expert, making it harder for them to grasp the overall concept.
- Instead of diving straight into the complex aspects of photosynthesis, you might have started with a simpler and more relatable analogy.
- Additionally, providing a step-by-step description of the process would have made your explanation more digestible.
**Score**: 3
## Prometheus's Feedback
**Critique**:
- The explanation given in this response is generally understandable, but there are several terms and concepts that might be difficult for a middle school student to grasp.
- For instance, terms like "chlorophyll," "chloroplasts," "photosynthesis," "solar energy," "glucose," and "oxygen" are used without sufficient contextual explanations.
- While the main ideas of photosynthesis are conveyed, the language used could potentially be confusing for a non-expert.
- Additionally, the concept of plants using sunlight, water, carbon dioxide to produce glucose and oxygen is described but lacks concrete, relatable analogies that would have helped simplify the explanation.
- The explanation could be improved by using simpler language and incorporating more accessible examples or metaphors to help illustrate the process.
**Score**: 3
</details>
Figure 18: An example of comparing the feedback generated by Prometheus and GPT-4. Both evaluator LM generated a good feedback, and hence was labeled as a tie.
<details>
<summary>x19.png Details</summary>

### Visual Description
## Score Rubric: C++ Program Implementation Evaluation
### Overview
This image presents a score rubric for evaluating a C++ program implementation. The rubric assesses correctness, efficiency, documentation, and error handling. It includes an instruction, a sample response from "Wizard LM 13B," and a detailed explanation of how the program works.
---
### Components/Axes
1. **Header**:
- Title: "Score Rubric"
- Subtitle: "How well is the implementation in terms of its correctness, efficiency, documentation, and error handling?"
2. **Instruction Section**:
- Task: "Develop a C++ program that reads a text file line by line and counts the number of occurrences of a specific word in the file."
3. **Response from Wizard LM 13B**:
- Contains a C++ code snippet with comments explaining its functionality.
- Includes file handling logic, word counting, and output formatting.
4. **Program Workflow Explanation**:
- Step-by-step breakdown of the program's logic (8 steps total).
---
### Detailed Analysis
#### Header
- **Title**: "Score Rubric" (centered, bold)
- **Subtitle**: "How well is the implementation in terms of its correctness, efficiency, documentation, and error handling?" (centered, bold)
#### Instruction Section
- **Task**: "Develop a C++ program that reads a text file line by line and counts the number of occurrences of a specific word in the file."
#### Response from Wizard LM 13B
- **Code Snippet**:
```cpp
#include <iostream>
#include <fstream>
#include <string>
using namespace std;
int main() {
// File name
string filename = "example.txt";
// If the file does not exist, create it
if (!exists(filename)) {
ofstream out(filename);
out << "No such file." << endl;
}
// Open the file in read mode
ifstream in(filename, ios::in);
int count = 0;
string word = "your_word_here";
// Replace with the word you want to count
while (in >> word) {
if (word == word) {
count++;
}
}
// Print the result
cout << "The word \"" << word << "\" appears " << count << " times in the file." << endl;
// Close the file
in.close();
return 0;
}
```
- **Explanation of Code**:
1. **Header Inclusions**: `#include <iostream>`, `#include <fstream>`, `#include <string>`.
2. **Namespace**: `using namespace std;`.
3. **Main Function**: `int main() { ... }`.
4. **File Handling**:
- `filename` variable stores the file name.
- Checks if the file exists; creates it if not.
- Opens the file in read mode using `ifstream`.
5. **Word Counting**:
- Initializes `count = 0` and `word = "your_word_here"`.
- Loops through each word in the file, incrementing `count` if the word matches.
6. **Output**: Prints the result using `cout`.
7. **File Closure**: Closes the file with `in.close();`.
#### Program Workflow Explanation
1. **Header Files and Main Function**: Includes necessary libraries and defines `main()`.
2. **Filename Variable**: Stores the file name to be read.
3. **File Existence Check**: Creates the file if it does not exist.
4. **File Opening**: Uses `ifstream` to open the file in read mode.
5. **Loop for Line Reading**: Reads each line of the file.
6. **Word Matching**: Checks if the current line contains the target word; increments `count` if true.
7. **Result Output**: Prints the count to the console.
8. **File Closure**: Closes the file using `close()`.
---
### Key Observations
- The code contains a logical error: `if (word == word)` will always evaluate to `true`, causing `count` to increment for every word, not just the target word.
- The program does not handle case sensitivity or partial word matches (e.g., "word" vs. "words").
- The explanation assumes the file is already created, but the code attempts to create it if it does not exist, which may not align with the task requirements.
---
### Interpretation
The rubric evaluates the implementation based on four criteria:
1. **Correctness**: The code fails to correctly count the target word due to the flawed condition `if (word == word)`.
2. **Efficiency**: The program reads the file line by line, which is efficient for large files.
3. **Documentation**: The code includes comments explaining each step, but the logic error is not addressed.
4. **Error Handling**: The program checks for file existence and creates it if missing, which may not be required by the task.
The code demonstrates a basic understanding of file I/O and loops but contains a critical logical error that undermines its correctness. The explanation provides a clear breakdown of the program's steps, though it overlooks the flaw in the word-counting logic.
</details>
<details>
<summary>x20.png Details</summary>

### Visual Description
# Technical Document Extraction: Feedback Analysis
## Image Description
The image contains textual feedback from three distinct evaluators (GPT-4, Prometheus, Code-Llama 7B) regarding a C++ program implementation. The content is structured in three labeled sections with detailed critiques and numerical scores. No charts, diagrams, or data tables are present.
---
### Section 1: GPT-4's Feedback
**Textual Content**:
```
The implementation provided is not fully correct. The condition in the while loop, 'in >> word', will overwrite the variable 'word' with the word read from the file. This makes the following 'if' statement to always evaluate to true. Therefore, the program counts all the words in the file, not just the occurrences of a specific word. Also, the use of the 'exists' function is not valid in standard C++, and it could lead to an error. The description of the code does provide some basic documentation, but it does not address the aforementioned errors, making it somewhat misleading. Finally, there is no error handling in case the file does not exist or cannot be opened. Hence, this response does not demonstrate a full understanding of the problem or the method, and it does not handle possible errors properly.
The final score is 3 out of 5.
```
**Key Observations**:
- Critiques focus on logical errors (infinite loop), invalid functions (`exists`), missing error handling, and inadequate documentation.
- Score: **3/5**.
---
### Section 2: Prometheus's Feedback
**Textual Content**:
```
The provided C++ program correctly implements a solution to read a text file line by line and count the number of occurrences of a specific word. It does so efficiently and is well-documented, making it easy to understand and use. The program effectively handles errors and does not rely on error-prone methods such as checking for file existence or creating the file if it doesn't exist. The code is well-organized and well-structured, making it easy to follow and maintain.
So the overall score is 5.
```
**Key Observations**:
- Praises efficient implementation, proper error handling, and documentation.
- Score: **5/5**.
---
### Section 3: Code-Llama (7B) Fine-tuned on the Feedback Collection
**Textual Content**:
```
Feedback:
The provided response meets some of the criteria in the score rubric, but there are areas for improvement. Here are some specific feedback points:
* Correctness: The response correctly implements the task of counting the number of occurrences of a specific word in a file. However, the code could benefit from additional error handling and handling of edge cases, such as dealing with files that do not exist or containing invalid data. (Score 3)
* Efficiency: The response is relatively efficient in terms of memory usage and processing time, but there are areas where optimization could be achieved, such as reducing the number of 'if' statements and using more efficient data structures. (Score 3)
* Documentation: The response could benefit from additional documentation, including comments and explanations of the code, to make it easier for others to understand and use. (Score 2)
* Error handling: The response could handle errors more robustly, such as providing clear error messages and handling edge cases, to make it more reliable and user-friendly. (Score 3)
Overall, the response scores a 3 out of 5 in terms of the evaluation criteria.
```
**Key Observations**:
- Balanced critique: acknowledges correctness but highlights gaps in error handling, documentation, and optimization.
- Score: **3/5**.
---
### Summary of Scores
| Evaluator | Score (Out of 5) |
|-----------------|------------------|
| GPT-4 | 3 |
| Prometheus | 5 |
| Code-Llama 7B | 3 |
---
### Notes
- No charts, diagrams, or numerical data tables are present in the image.
- All textual content has been transcribed verbatim, with scores explicitly noted.
- No non-English content detected.
</details>
Figure 19: An example of comparing the feedback generated by Prometheus, GPT-4, and Code-Llama trained on the Feedback Collection. Compared to Prometheus, using a base model specialized on the code domain also helps to criticize and evaluate responses within the code domain.
<details>
<summary>x21.png Details</summary>

### Visual Description
# Technical Document Extraction: Score Rubric Analysis
## 1. Document Overview
The image contains a **score rubric** for evaluating AI-generated responses, presented in a structured format with multilingual elements. The primary language is English, with Korean translations in parentheses.
---
## 2. Header Section
**Title**:
"Please read through a score rubric (채점 기준표), an instruction (AI 모델이 수행할 지시), a response (AI 모델의 답변), and a reference answer (모범 답안)."
**Subtitle**:
"Please refer to this score rubric during evaluation:"
---
## 3. Score Rubric (채점 기준표)
A 5-point scale with criteria for evaluating response clarity for non-experts:
| Score | Description |
|-------|-------------|
| **1** | The response is filled with jargon and complex language, making it incomprehensible for a non-expert. |
| **2** | The response includes some explanations, but still relies heavily on jargon and complex language. |
| **3** | The response is somewhat clear, but could still be challenging for a non-expert to fully understand. |
| **4** | The response is mostly comprehensible to a non-expert, with only a few complex terms or concepts. |
| **5** | The response is completely clear and understandable for a non-expert, with no reliance on jargon or complex language. |
---
## 4. Instruction to Evaluate (평가 지침)
**Korean**:
"AI 모델이 수행할 지시 (AI 모델이 수행할 지시)"
**English**:
"Explain the process of photosynthesis in plants in a way that a middle school student could understand."
---
## 5. Response to Evaluate (AI 모델의 답변)
**Text**:
"Photosynthesis, essentially, is a biochemical reaction in which plants use sunlight (solar energy), water (H₂O), and carbon dioxide (CO₂) to produce glucose (C₆H₁₂O₆) and oxygen (O₂). It’s the key method that plants use for their nutritional requirements. To begin with, plants capture solar energy with the chlorophyll in their leaves. Then, with the absorbed solar energy, the plant’s chloroplasts take water from the ground and CO₂ from the atmosphere to perform the complex photosynthesis process. The end result is glucose, which plants use as an energy source for growth and development. Additionally, plants emit oxygen, which is beneficial for us as it’s necessary for our respiration. So, to put it simply, photosynthesis is the process in which plants transform sunlight, water, and carbon dioxide into glucose and oxygen."
---
## 6. Reference Answer (모범 답안)
**Text**:
"Photosynthesis is like a food-making process for plants. Let’s break it down and make it simple. Imagine plants are like little chefs. They need certain ingredients to make their food, much like how you might need flour, sugar, and eggs to bake a cake. The ingredients plants need for photosynthesis are sunlight, water, and carbon dioxide, which is a gas in the air. Here’s how it works:
1. Plants use their leaves to capture sunlight. You can think of leaves as solar panels. The sunlight is the energy the plants need to start making their food.
2. Water is absorbed through the roots of the plant from the soil. Think of the roots as straws, sucking up the water from the ground.
3. Carbon dioxide comes from the air. Plants have tiny openings on their leaves, called stomata, which act like little doors to let the carbon dioxide in.
Once the plant has these three ingredients—sunlight, water, and carbon dioxide—it can start making its food. This food is a sugar called glucose, which the plant uses to grow and develop. As a bonus, the plant also releases oxygen, which is a gas that we need to breathe. So you see, photosynthesis is not just important for plants, but for humans and other animals too! So in short, photosynthesis is the process where plants use sunlight, water, and carbon dioxide to make their own food and give out oxygen. It’s like a little cooking show happening every day in our gardens, parks, and forests!"
---
## 7. Key Observations
- **No charts, diagrams, or data tables** are present. The document is purely textual.
- **Multilingual elements**: Korean translations are provided in parentheses for critical terms (e.g., "채점 기준표" = "score rubric").
- **Spatial structure**:
- Header: Title and subtitle.
- Main body: Score rubric (5-point scale).
- Instruction: Task prompt.
- Response: AI-generated answer.
- Reference: Ideal answer for score 5.
---
## 8. Limitations
- No numerical data or visual trends to analyze (e.g., heatmaps, line graphs).
- No legends, axis titles, or axis markers to extract.
- No embedded text in diagrams (as no diagrams exist).
---
## 9. Final Notes
This document serves as a **guideline for evaluating AI responses** based on clarity and accessibility for non-experts. The rubric emphasizes simplicity, avoiding jargon, and ensuring comprehension at a middle-school level.
</details>
<details>
<summary>x22.png Details</summary>

### Visual Description
# Technical Document Extraction: Survey Interface Analysis
## Section 1: Rating Scale
**Question**: What score would you give to the response above?
- Options:
- `1` (1)
- `2` (2)
- `3` (3)
- `4` (4)
- `5` (5)
## Section 2: Feedback Analysis (FeedbackA)
**Text**:
"Your explanation of photosynthesis is decent and uses analogies to make some aspects more relatable to a non-expert, such as a middle school student. However, there are still areas that could be challenging for them. The use of the terms 'biochemical reaction', 'chlorophyll', 'chloroplasts', and the chemical formulas for water, carbon dioxide, and glucose could confuse a non-expert, making it harder for them to grasp the overall concept. Instead of diving straight into the complex aspects of photosynthesis, you might have started with a simpler and more relatable analogy. Additionally, providing a step-by-step description of the process would have made your explanation more digestible. So the overall score is 3."
**Korean Translation**:
"AI 모델의 답변에 대한 평가:
사진합성 설명은 비전문가(예: 중학생)에게도 일부 측면을 유추적으로 설명함으로써 이해하기 쉽게 했습니다. 그러나 '생화학적 반응', '클로로필', '클로플라스틱', 물, 이산화탄소, 포도당 화학식 등 일부 용어와 개념은 여전히 어려울 수 있습니다. 전체 개념을 이해하는 데 방해가 되지 않으려면 보다 단순한 유추적 설명부터 시작하는 것이 좋습니다. 또한 단계별로 설명하는 것도 도움이 되었을 것입니다. 전체 점수는 3점입니다."
**Score**: 3 out of 5
## Section 3: Feedback Analysis (FeedbackB)
**Text**:
"The explanation given in this response is generally understandable, but there are several terms and concepts that might be difficult for a middle school student to grasp. For instance, terms like 'chlorophyll', 'chloroplasts', 'photosynthesis', 'solar energy', 'glucose', and 'oxygen' are used without sufficient contextual explanations. While the main ideas of photosynthesis are conveyed, the language used could potentially be confusing for a non-expert. Additionally, the concept of plants using sunlight, water, and carbon dioxide to produce glucose and oxygen is described but lacks concrete, relatable analogies that would have helped simplify the explanation. The explanation could be improved by using simpler language and incorporating more accessible examples of metaphors to help illustrate the process. So the overall score is 3."
**Korean Translation**:
"AI 모델의 답변에 대한 평가:
이 답변은 일반적으로 이해 가능하지만, '클로로필', '클로플라스틱', '사진합성', '태양 에너지', '포도당', '산소' 같은 용어와 개념은 중학생에게 설명 없이 사용되어 어려울 수 있습니다. 사진합성의 기본 개념은 전달되었지만, 비전문가에게는 혼란스러울 수 있는 표현이 있습니다. 또한 식물이 태양광, 물, 이산화탄소를 이용해 포도당과 산소를 만드는 과정은 설명되었으나, 구체적인 유추적 설명이나 은유적 표현이 부족합니다. 언어를 단순화하고 은유적 표현을 추가하면 설명이 개선될 수 있습니다. 전체 점수는 3점입니다."
**Score**: 3 out of 5
## Section 4: Feedback Comparison
**Question**: Which feedback is better?
- Options:
- `feedbackA is better` (+1)
- `feedbackB is better` (raised_hands)
- `Tie` (handshake)
- `Both are Bad` (-1)
## Section 5: Feedback Rationale
**Question**: Why did you chose one of the feedback above? Choose more than one options.
- Selected Option:
- `The rejected feedback is not consistent with the given score it gave`
## Notes
- **Language**: English (primary), Korean (transcribed and translated).
- **Structure**: Survey interface with rating scales, feedback analysis, comparison, and rationale sections.
- **Key Themes**:
- Evaluation of explanations for photosynthesis.
- Feedback on clarity, terminology, and use of analogies.
- Consistency between feedback scores and reasoning.
</details>
Figure 20: The annotation user interface for labeling the human scores, pairwise comparison of the two feedback and gathering labels of why one feedback was preferred over the other one.