## Contrastive Chain-of-Thought Prompting
Yew Ken Chia ∗ 1, DeCLaRe Guizhen Chen ∗ 1, 2
Luu Anh Tuan
Soujanya Poria
DeCLaRe
Lidong Bing
†
1 DAMO Academy, Alibaba Group, Singapore DeCLaRe Singapore University of Technology and Design 2 Nanyang Technological University, Singapore
{yewken\_chia, sporia}@sutd.edu.sg
{guizhen001, anhtuan.luu}@ntu.edu.sg {yewken.chia, guizhen.chen, l.bing}@alibaba-inc.com
## Abstract
Despite the success of chain of thought in enhancing language model reasoning, the underlying process remains less well understood. Although logically sound reasoning appears inherently crucial for chain of thought, prior studies surprisingly reveal minimal impact when using invalid demonstrations instead. Furthermore, the conventional chain of thought does not inform language models on what mistakes to avoid, which potentially leads to more errors. Hence, inspired by how humans can learn from both positive and negative examples, we propose contrastive chain of thought to enhance language model reasoning. Compared to the conventional chain of thought, our approach provides both valid and invalid reasoning demonstrations, to guide the model to reason step-by-step while reducing reasoning mistakes. To improve generalization, we introduce an automatic method to construct contrastive demonstrations. Our experiments on reasoning benchmarks demonstrate that contrastive chain of thought can serve as a general enhancement of chain-of-thought prompting. 1
## 1 Introduction
With the trend of large language models (LLMs), massively scaling the model size has enabled greater generalization (Brown et al., 2020) and the emergent ability to perform new tasks when given suitable prompts (Wei et al., 2022a). However, solely increasing the model size cannot solve complex reasoning tasks (Rae et al., 2022). To this end, chain-of-thought prompting was proposed to unlock the reasoning ability of LLMs by generating intermediate reasoning steps (Wei et al., 2022b). In
∗ Equal contribution. Yew Ken and Guizhen are students under the Joint PhD Program between Alibaba and their corresponding university.
† Corresponding author.
1 Our code implementation will be released at https://github.com/DAMO-NLP-SG/contrastive-cot
Figure 1: Example of contrastive chain-of-thought which leverages both positive and negative demonstrations to enhance language model reasoning.
<details>
<summary>Image 1 Details</summary>

### Visual Description
\n
## Document: Math Problem Explanations
### Overview
The image presents a document showcasing examples of math problem explanations, contrasting correct and incorrect reasoning. It's structured as a "Model Input" section with a question, followed by a "Model Output" section providing the explanation. Two examples are given, one involving letter writing and the other involving dental work. The correct steps in the explanation are highlighted in green, while incorrect steps are highlighted in red.
### Components/Axes
The document is divided into sections labeled "Model Input" and "Model Output". Within each section, there are questions and explanations. Visual cues (checkmarks and X marks) indicate whether the explanation is correct or incorrect. Numbers within the explanations are color-coded to highlight the calculation steps.
### Detailed Analysis or Content Details
**Example 1: Letter Writing**
* **Question:** James writes a 3-page letter to 2 different friends twice a week. How many pages does he write a year?
* **Correct Explanation:**
* He writes each friend 3\*2=6 pages a week.
* He writes 6\*2=12 pages every week.
* He writes 12\*52=624 pages a year.
* **Incorrect Explanation:**
* He writes each friend 12\*52=624 pages a week.
* He writes 3\*2=6 pages every week.
* He writes 6\*2=12 pages a year.
**Example 2: Dental Work**
* **Question:** James has 30 teeth. His dentist drills 4 of them and caps 7 more teeth than he drills. What percentage of James' teeth does the dentist fix?
* **Explanation:**
* The dentist drills 4 teeth, so there are 30 - 4 = 26 teeth left.
* He caps 4 + 7 = 11 teeth.
* Therefore, the dentist fixes a total of 4 + 11 = 15 teeth.
* To find the percentage of teeth the dentist fixes, we divide the number of teeth fixed by the total number of teeth and multiply by 100: 15/30 x 100 = 50%.
### Key Observations
The document focuses on demonstrating the importance of correct order of operations in problem-solving. The color-coding effectively highlights the critical steps and where errors occur. The second example demonstrates a multi-step problem requiring several calculations to arrive at the final answer.
### Interpretation
This document serves as an educational tool to illustrate common mistakes in mathematical reasoning. By presenting both correct and incorrect solutions side-by-side, it allows learners to identify and understand the flaws in the incorrect approach. The use of color-coding and clear step-by-step explanations enhances comprehension. The examples are designed to be simple enough to grasp the underlying principles of problem-solving without being overwhelmed by complex calculations. The document emphasizes the importance of following the correct sequence of operations and accurately interpreting the problem statement. The document is not presenting data, but rather demonstrating a pedagogical approach to teaching math.
</details>
practice, most methods based on chain of thought leverage in-context learning (Brown et al., 2020)by prompting the model with demonstrations of the input, chain-of-thought, and output (Chu et al., 2023).
However, despite its success, we lack a thorough understanding of the chain of thought (Cooper et al., 2021). For example, it was shown that even demonstrations with invalid reasoning can lead to similar performance compared to valid demonstrations (Wang et al., 2023) 2 . Hence, it is not clear how language models learn to reason effectively based on the chain-of-thought demonstrations. On the other hand, mistakes in the intermediate steps can compound and derail the reasoning process
2 Note that while chain-of-thought can be performed in a zero-shot fashion with prompts, we focus on the few-shot setting, as it was originally proposed in Wei et al. (2022b).
(Ling et al., 2023). Any potential error in the reasoning process not only affects the accuracy of the final result but also undermines the trustworthiness of the language model (Turpin et al., 2023). Thus, it is also important to reduce mistakes in intermediate reasoning steps.
To address the challenges of chain of thought, we are inspired by how humans can learn from positive as well as negative examples. For instance, when solving a complex task where the intermediate steps are not well-defined, it is useful to learn the correct steps from positive demonstrations, as well as avoiding faults in negative demonstrations. Hence, we propose contrastive chain of thought, which provides both positive and negative demonstrations to enhance the reasoning of language models. Naturally, this raises the question of how to design effective negative demonstrations, as well as whether they can be generalized to diverse tasks. Through our analysis of multiple invalid reasoning types, we design a simple and effective method that can automatically generate contrastive demonstrations from existing valid reasoning chains. Furthermore, as contrastive chain-of-thought is taskagnostic and compatible with methods such as selfconsistency (Wang et al., 2022), we believe that it can serve as a general enhancement of chain of thought.
To measure the effectiveness of contrastive chain of thought, we present evaluations on a wide range of reasoning benchmarks, and find significant benefits. Notably, compared to conventional chain of thought, we observe improvements of 9.8 and 16.0 points for GSM-8K (Cobbe et al., 2021) and Bamboogle (Press et al., 2023) respectively when using GPT-3.5-Turbo 3 , a widely used LLM. Further analysis of the reasoning chains generated from our method also shows significant reduction in errors.
In summary, our main contributions include: (1) We analyse various invalid reasoning types and find that combining positive and negative demonstrations generally boost the effectiveness of chainof-thought. (2) Based on the analysis above, we propose contrastive chain of thought to enhance language model reasoning. To improve generalization, we also propose an automatic method to construct contrastive demonstrations. (3) Evaluations on multiple reasoning benchmarks demonstrate significant improvements compared to conventional chain of thought.
3 https://platform.openai.com/docs/models
## 2 Preliminary Study: Effect of Different Types of Contrastive Demonstrations
While chain of thought (CoT) prompting has enhanced the reasoning of large language models, it remains less well understood. For instance, while sound reasoning seems intuitively important to effective chain of thought, previous work has shown that there is little effect when using invalid demonstrations. On the other hand, previous works in contrastive learning (Khosla et al., 2020) and alignment (Ouyang et al., 2022) have demonstrated how language models can learn more effectively from both valid and invalid examples. Hence, we conduct a preliminary study with the following research question: Can invalid reasoning demonstrations be instead used to enhance chain of thought? Specifically, we aim to study the effect of providing chain-of-thought demonstrations in a 'contrastive' manner, i.e., demonstrations containing both valid and invalid rationales.
## 2.1 Components of Chain of Thought
Compared to standard prompting with in-context demonstrations (Brown et al., 2020), chain-ofthought (CoT) prompting (Wei et al., 2022b) includes a rationale for each demonstration example. Each rationale consists of a series of intermediate reasoning steps, guiding the language model to solve tasks in a step-by-step manner. Following the formulation of (Wang et al., 2023), we identify two distinct components of each CoT rationale:
- Bridging objects are the symbolic items that the model traverses in order to reach the final solution. For example, the objects could be numbers and equations in arithmetic tasks, or the names of entities in factual tasks.
- Language templates are the textual hints that guide the language model to derive and contextualize the correct bridging objects during the reasoning process.
## 2.2 What is Invalid Chain of Thought?
Given the distinct components of chain of thought, we are now able to systematically identify the aspects which lead to invalid rationales. Concretely there are two main aspects which are applicable to both the language and object components:
- Coherence refers to the correct ordering of steps in a rationale, and is necessary for successful chain of thought. Specifically, as chain
<details>
<summary>Image 2 Details</summary>

### Visual Description
\n
## Comparison of Prompting Methods: Arithmetic & Factual Reasoning
### Overview
The image presents a comparison of different prompting methods (Standard, Chain-of-Thought (CoT) with varying degrees of coherence: Invalid Reasoning, Incoherent Objects, Incoherent Language, and Logically Consistent) applied to two distinct question types: Arithmetic Reasoning and Factual Reasoning. Each method is demonstrated with a question, an answer, and a step-by-step explanation.
### Components/Axes
The image is structured into a table with two main columns: "Arithmetic Reasoning Example" and "Factual Reasoning Example". Each column is further divided into rows representing the different prompting methods. Each cell contains:
* **Prompting Method:** (Standard, CoT: Invalid Reasoning, CoT: Incoherent Objects, CoT: Incoherent Language, CoT: Logically Consistent, SoTA: Logically Consistent)
* **Question:** The posed question.
* **Answer:** The provided answer.
* **Step-by-step answer:** The reasoning process leading to the answer.
### Detailed Analysis or Content Details
**Arithmetic Reasoning Example:**
* **Question:** "Leah had 32 chocolates and her sister had 42. If they ate 35, how many pieces do they have left in total?"
* **Standard:** Answer: 39
* **CoT: Invalid Reasoning:** Answer: 39. Step-by-step answer: "Originally, Leah had 32 chocolates and her sister had 42. So her sister had 42 - 32 = 10 chocolates more than Leah has. After eating 35, since 10 + 35 = 45, they had 45 - 6 = 39 pieces left in total. The answer is 39."
* **CoT: Incoherent Objects:** Answer: 39. Step-by-step answer: "Originally, Leah had 32 chocolates and her sister had 42 + 74 chocolates. So in total they had 32 + 42 + 74 = 39 pieces left in total. The answer is 39."
* **CoT: Incoherent Language:** Answer: 39. Step-by-step answer: "Originally, Leah had 32, they had 42 pieces left in total. Originally, Leah had 32 chocolates and her sister had 35. So in total they had 32 + 74 - 39 = 35. The answer is 39."
* **CoT: Logically Consistent:** Answer: 39. Step-by-step answer: "Originally, Leah had 32 chocolates and her sister had 42. So in total they had 32 + 42 = 74. After eating 35, they had 74 - 35 = 39 pieces left in total. The answer is 39."
* **SoTA: Logically Consistent:** Answer: 39. Step-by-step answer: "Originally, Leah had 32 chocolates and her sister had 42. So in total they had 32 + 42 = 74. After eating 35, they had 74 - 35 = 39 pieces left in total. The answer is 39."
**Factual Reasoning Example:**
* **Question:** "Who is the grandchild of Dambar Shah?"
* **Standard:** Answer: Rudra Shah
* **CoT: Invalid Reasoning:** Answer: Rudra Shah. Step-by-step answer: "Dambar Shah (? - 1645) was the king of the Gorkha Kingdom. The Gorkha Kingdom was established by Prince Dravya Shah. Dravya Shah has a child named Rudra Shah. So the final answer (the name of the grandchild) is: Rudra Shah."
* **CoT: Incoherent Objects:** Answer: Rudra Shah. Step-by-step answer: "Dambar Shah (? - 1645) was the father of Krishna Shah. Krishna Shah was the child of Krishna Shah (? - 1661). So the final answer (the name of the grandchild) is: Rudra Shah."
* **CoT: Incoherent Language:** Answer: Rudra Shah. Step-by-step answer: "Dambar Shah (? - 1645) was the father of Krishna Shah. Rudra Shah was the father of Krishna Shah (? - 1661). So the final answer (the name of the grandchild) is: Rudra Shah."
* **CoT: Logically Consistent:** Answer: Rudra Shah. Step-by-step answer: "Dambar Shah (? - 1645) was the father of Krishna Shah. Rudra Shah was the child of Krishna Shah (? - 1661). So the final answer (the name of the grandchild) is: Rudra Shah."
* **SoTA: Logically Consistent:** Answer: Rudra Shah. Step-by-step answer: "Dambar Shah (? - 1645) was the father of Krishna Shah. Rudra Shah was the child of Krishna Shah (? - 1661). So the final answer (the name of the grandchild) is: Rudra Shah."
### Key Observations
* All methods, including the "invalid" and "incoherent" CoT approaches, arrive at the correct answer for both questions.
* The "invalid" and "incoherent" CoT explanations demonstrate flawed or nonsensical reasoning, yet still produce the correct result. This highlights the potential for CoT to generate plausible-sounding but incorrect justifications.
* The "Logically Consistent" CoT and SoTA methods provide clear and accurate step-by-step reasoning.
* The factual reasoning examples include dates (e.g., "? - 1645", "? - 1661") associated with individuals.
### Interpretation
The image demonstrates the complexities of evaluating Large Language Models (LLMs) and the importance of examining not only the final answer but also the reasoning process. While CoT aims to improve reasoning, the examples show that it can be susceptible to generating incorrect or illogical explanations that nonetheless lead to the correct answer. This suggests that simply obtaining the correct answer is insufficient for assessing the true reasoning capabilities of an LLM. The "SoTA" (State-of-the-Art) method, in this case, is identical to the "Logically Consistent" CoT, indicating that a well-structured and accurate CoT approach can achieve performance comparable to the best available models. The inclusion of dates in the factual reasoning examples suggests a focus on historical context and the ability to retrieve and utilize factual information. The image serves as a cautionary tale about the potential for LLMs to "hallucinate" or generate plausible but incorrect explanations, even when arriving at the correct answer.
</details>
| Prompting Method | Arithmetic Reasoning Example | Factual Reasoning Example |
|--------------------------|---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| Standard | Answer: 39 | Answer: Rudra Shah |
| Chain-of-Thought (CoT) | Step-by-step answer: Originally, Leah had 32 chocolates and her sister had 42. So in total they had 32 + 42 = 74. After eating 35, they had 74 - 35 = 39 pieces left in total. The answer is 39. | Step-by-step answer: Dambar Shah (? - 1645) was the father of Krishna Shah. Rudra Shah was the child of Krishna Shah (? - 1661). So the final answer (the name of the grandchild) is: Rudra Shah. |
| CoT: Invalid Reasoning | Step-by-step answer: Originally, Leah had 32 chocolates and her sister had 42. So her sister had 42 - 32 = 10 chocolates more than Leah has. After eating 35, since 10 + 35 = 45, they had 45 - 6 = 39 pieces left in total. The answer is 39. | Step-by-step answer: Dambar Shah (? - 1645) was the king of the Gorkha Kingdom. The Gorkha Kingdom was established by Prince Dravya Shah. Dravya Shah has a child named Rudra Shah. So the final answer (the name of the grandchild) is: Rudra Shah. |
| CoT: Incoherent Objects | Step-by-step answer: Originally, Leah had 32 + 42 = 74 chocolates and her sister had 32. So in total they had 74 - 35 = 39. After eating 35, they had 42 pieces left in total. The answer is 39. | Step-by-step answer: Krishna Shah was the father of Rudra Shah. Dambar Shah (? - 1645) was the child of Krishna Shah (? - 1661). So the final answer (the name of the grandchild) is: Rudra Shah. |
| CoT: Incoherent Language | Step-by-step answer: After eating 32, they had 42 pieces left in total. Originally, Leah had 32 + 42 = 74 chocolates and her sister had 35. So in total they had 74 - 35 = 39. The answer is 39. | Step-by-step answer: Dambar Shah (? - 1645) was the child of Krishna Shah. Rudra Shah was the father of Krishna Shah (? - 1661). So the final answer (the name of the grandchild) is: Rudra Shah. |
| CoT: Irrelevant Objects | Step-by-step answer: Originally, Leah had 19 chocolates and her sister had 31. So in total they had 19 + 31 = 50. After eating 29, they had 50 - 29 = 21 pieces left in total. The answer is 21. | Step-by-step answer: Metis Amando was the father of David Amando. Randall Amando was the child of David Amando. So the final answer (the name of the grandchild) is: Randall Amando. |
| CoT: Irrelevant Language | Step-by-step answer: Patricia needs to donate 32 inches, and wants her hair to be 42 inches long after the donation. Her hair is 35 inches long currently. Her hair needs to be 32 + 42 = 74 inches long when she cuts it. So she needs to grow 74 - 35 = 39 more inches. The answer is 39. | Step-by-step answer: The husband of Dambar Shah (? - 1645) is Krishna Shah. Krishna Shah (? - 1661) has a brother called Rudra Shah. So the final answer (the name of the brother-in-law) is: Rudra Shah. |
<details>
<summary>Image 3 Details</summary>

### Visual Description
Icon/Small Image (21x22)
</details>
Language Component
Object Component
Invalid Component (Reasoning / Language / Object)
Figure 2: Categorization of invalid chain-of-thought examples, following Wang et al. (2023).
of thought is a sequential reasoning process, it is not possible for later steps to be preconditions of earlier steps.
- Relevance refers to whether the rationale contains corresponding information from the question. For instance, if the question mentions a person named Leah eating chocolates, it would be irrelevant to discuss a different person cutting their hair.
In addition, following Wang et al. (2023), we include invalid reasoning as a category of invalid chain of thought, which is neither incoherent nor irrelevant, but contains logical mistakes. Hence, we aim to study the five main categories of invalid chain-of-thought, as shown in Figure 2.
## 2.3 Experimental Setup
To conduct the experiments for the preliminary study, we leverage the GSM8K (Cobbe et al., 2021) and Bamboogle (Press et al., 2023) datasets for arithmetic and factual reasoning respectively. We use the OpenAI Chat Completions API 4 which is one of the most popular and well-performing language models with reasonable cost. Specifically, we use the GPT-3.5-Turbo (0301) version. To study the effect of contrastive demonstrations under various settings, we evaluate the five main invalid categories as shown in Figure 2. Note that we use 4-shot prompting for each dataset, and the chain-ofthought demonstrations are manually constructed by previous works (Wei et al., 2022b; Wang et al., 2023). To standardize the prompting process, we use a simplified chain-of-thought prompt format, as shown in Figure 1.
## 2.4 Preliminary Results
Based on the preliminary results in Table 1, we observe significant gains across all invalid rationale categories compared to conventional chainof-thought. Notably, leveraging chain of thought with contrastive demonstrations containing incoherent objects yields the highest average performance
4 https://platform.openai.com/docs/api-reference
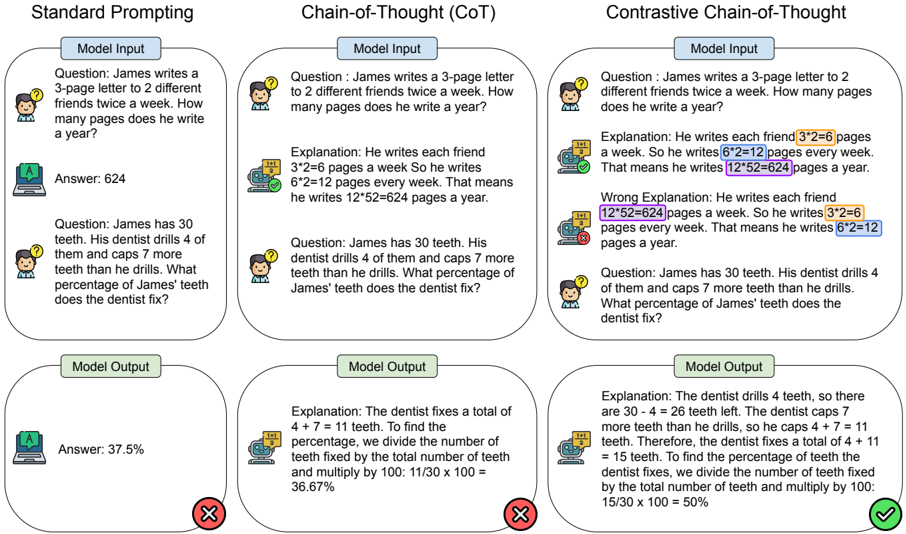
Figure 3: Overview of contrastive chain-of-thought (right), with comparison to common prompting methods.
<details>
<summary>Image 4 Details</summary>
### Visual Description
## Comparison of Prompting Techniques: Standard, CoT, and Contrastive CoT
### Overview
The image presents a comparison of three different prompting techniques for Large Language Models (LLMs): Standard Prompting, Chain-of-Thought (CoT) Prompting, and Contrastive Chain-of-Thought (Contrastive CoT) Prompting. Each technique is demonstrated with two example questions, showing the "Model Input", "Explanation" (where applicable), and "Model Output". The results are visually indicated with checkmarks (correct) and crosses (incorrect).
### Components/Axes
The image is divided into three columns, one for each prompting technique. Each column is further divided into two sections, each representing a question-answer pair. Within each section, there are three sub-sections: "Model Input", "Explanation" (for CoT and Contrastive CoT), and "Model Output". Visual cues (checkmarks and crosses) indicate the correctness of the "Model Output".
### Detailed Analysis or Content Details
**Column 1: Standard Prompting**
* **Question 1:** "James writes a 3-page letter to 2 different friends twice a week. How many pages does he write a year?"
* **Model Input:** The question is directly stated.
* **Model Output:** "Answer: 624" (marked with a checkmark)
* **Question 2:** "James has 30 teeth. His dentist drills 4 of them and caps 7 more teeth than he drills. What percentage of James’ teeth does the dentist fix?"
* **Model Input:** The question is directly stated.
* **Model Output:** "Answer: 37.5%" (marked with a checkmark)
**Column 2: Chain-of-Thought (CoT) Prompting**
* **Question 1:** "James writes a 3-page letter to 2 different friends twice a week. How many pages does he write a year?"
* **Model Input:** The question is directly stated.
* **Explanation:** "Explanation: He writes each friend 3\*2=6 pages a week. So he writes 6\*2=12 pages every week. That means he writes 12\*52=624 pages a year."
* **Model Output:** (No explicit output shown, but the explanation leads to the correct answer) (marked with a checkmark)
* **Question 2:** "James has 30 teeth. His dentist drills 4 of them and caps 7 more teeth than he drills. What percentage of James’ teeth does the dentist fix?"
* **Model Input:** The question is directly stated.
* **Explanation:** "Explanation: The dentist fixes a total of 4 + 7 = 11 teeth. To find the percentage, we divide the number of teeth fixed by the total number of teeth and multiply by 100: 11/30 x 100 = 36.67%"
* **Model Output:** (No explicit output shown, but the explanation leads to the correct answer) (marked with a cross)
**Column 3: Contrastive Chain-of-Thought (Contrastive CoT) Prompting**
* **Question 1:** "James writes a 3-page letter to 2 different friends twice a week. How many pages does he write a year?"
* **Model Input:** The question is directly stated.
* **Explanation:** "Explanation: James writes each friend 3\*2=6 pages a week. So he writes 6\*2=12 pages every week. That means he writes 12\*52=624 pages a year. Wrong Explanation: He writes each friend 12\*52=624 pages a week. So he writes 3\*2=6 pages every week. That means he writes 6\*2=12 pages a year."
* **Model Output:** (No explicit output shown, but the explanation leads to the correct answer) (marked with a checkmark)
* **Question 2:** "James has 30 teeth. His dentist drills 4 of them and caps 7 more teeth than he drills. What percentage of James’ teeth does the dentist fix?"
* **Model Input:** The question is directly stated.
* **Explanation:** "Explanation: The dentist drills 4 teeth, so there are 30 - 4 = 26 teeth left. The dentist caps 7 more teeth than he drills, so he caps 4 + 7 = 11 teeth. Therefore, the dentist fixes a total of 4 + 11 teeth. To find the percentage of teeth the dentist fixes, we divide the number of teeth fixed by the total number of teeth and multiply by 100: 15/30 x 100 = 50%"
* **Model Output:** (No explicit output shown, but the explanation leads to the correct answer) (marked with a checkmark)
### Key Observations
* Standard Prompting and Contrastive CoT both achieve correct answers for both questions.
* CoT Prompting fails on the second question, providing an incorrect percentage (36.67% instead of 50%).
* Contrastive CoT includes a "Wrong Explanation" alongside the correct one, demonstrating the model's ability to identify and contrast incorrect reasoning paths.
* The checkmarks and crosses clearly indicate the success rate of each prompting technique.
### Interpretation
The image demonstrates the effectiveness of different prompting techniques for LLMs. Standard prompting can work well for simple problems, but struggles with more complex reasoning. Chain-of-Thought prompting improves reasoning ability but can still lead to errors, as seen in the second question. Contrastive Chain-of-Thought prompting appears to be the most robust, as it not only provides a correct explanation but also highlights potential pitfalls in reasoning, leading to a higher success rate. The inclusion of a "Wrong Explanation" in Contrastive CoT is a key feature, allowing the model to self-critique and refine its reasoning process. This suggests that explicitly contrasting correct and incorrect reasoning paths can significantly improve the reliability of LLM outputs. The image highlights the importance of prompt engineering in eliciting accurate and reliable responses from LLMs.
</details>
Table 1: Preliminary results on the effect of contrastive demonstrations for chain of thought.
| Prompting Method | GSM8K | Bamboogle | Avg. |
|------------------------|---------|-------------|--------|
| Standard | 27.4 | 11.2 | 19.3 |
| Chain-of-Thought | 69.2 | 40.8 | 55 |
| w/ Invalid Reasoning | 76 | 45.6 | 60.8 |
| w/ Incoherent Objects | 79.6 | 53.6 | 66.6 |
| w/ Incoherent Language | 78.8 | 52.8 | 65.8 |
| w/ Irrelevant Objects | 79.8 | 48.8 | 64.3 |
| w/ Irrelevant Language | 80.2 | 49.6 | 64.9 |
on GSM8K and Bamboogle. This suggests that language models are better able to learning stepby-step reasoning when provided with both valid and invalid rationales. Hence, we believe that contrastive demonstrations have the potential to greatly enhance language model reasoning ability.
## 3 Contrastive Chain of Thought
Chain-of-thought (CoT) prompting, as evidenced by prior research, has indeed elevated the reasoning capabilities of large language models (Wei et al., 2022b). However, a comprehensive understanding of this phenomenon is still lacking. Although logically sound reasoning appears to be inherently crucial for chain of thought, prior studies surprisingly reveal minimal impact when employing invalid demonstrations. To this end, based on our preliminary study in Section 2, we found that providing both valid and invalid reasoning demonstrations in a 'contrastive' manner greatly improves reasoning performance. However, this approach may not generalize well to new tasks, as it requires manual construction of the invalid rationales.
Thus, we propose a general prompting method known as contrastive chain of thought, which includes automatic construction of contrastive demonstrations. Figure 3 presents an overview of our approach. Specifically, the language model is provided with the question, ground truth answer explanation and incorrect answer explanation. Compared to standard prompting, our method enables models to perform more complex reasoning by decomposing problems into intermediate steps. Compared to conventional chain-of-thought prompting, our method contrasts the valid and invalid answer explanations, guiding the model to generate more accurate reasoning chains.
Concretely, given a small set of n in-context demonstration examples D = { E 1 , . . . , E | n | } , and a query Q , the goal of the model is to generate a suitable answer A . For standard prompting, the demonstration examples consist of just the question and answer, i.e., E j = ( Q j , A j ) . On the other hand, chain-of-thought is a more advanced prompting method that guides the model with intermediate
Table 2: Main evaluation results for contrastive chain-of-thought on several reasoning tasks.
| Prompting Method | Arithmetic Reasoning | Arithmetic Reasoning | Arithmetic Reasoning | Arithmetic Reasoning | Arithmetic Reasoning | Factual QA | Factual QA |
|--------------------|------------------------|------------------------|------------------------|------------------------|------------------------|--------------|--------------|
| | GSM8K | AQuA | GSM-Hard | SVAMP | ASDIV | Bamboogle | StrategyQA |
| Standard | 27.4 | 29.5 | 11.2 | 69.3 | 75.8 | 12.0 | 59.4 |
| CoT | 69.2 | 53.5 | 33.8 | 67.2 | 70.8 | 40.8 | 55.8 |
| Contrastive CoT | 79.0 (+9.8) | 57.5 (+3.9) | 44.2 (+10.4) | 81.6 (+14.4) | 84.4 (+13.6) | 56.8 (+16.0) | 66.2 (+10.4) |
| Standard-SC | 28.0 | 29.9 | 11.0 | 69.0 | 76.0 | 11.2 | 59.6 |
| CoT-SC | 71.0 | 55.9 | 34.0 | 71.6 | 74.0 | 40.8 | 57.0 |
| Contrastive CoT-SC | 86.2 (+15.2) | 71.7 (+15.7) | 50.0 (+16.0) | 85.2 (+13.6) | 89.6 (+15.6) | 58.4 (+17.6) | 69.6 (+12.6) |
Table 3: Details of datasets used.
| Dataset | Type | | Train | | | Test | |
|------------|----------------------|-----------------------|----------------------|
| GSM8K | Arithmetic Reasoning | 4 | 500 |
| AQuA | Arithmetic Reasoning | 4 | 254 |
| GSM-Hard | Arithmetic Reasoning | 4 | 500 |
| SVAMP | Arithmetic Reasoning | 4 | 500 |
| ASDIV | Arithmetic Reasoning | 4 | 500 |
| Bamboogle | Factual QA | 4 | 125 |
| StrategyQA | Factual QA | 4 | 500 |
reasoning steps T . As shown in the figure above, the reasoning steps T typically consist of multiple sentences where each sentence describes one reasoning step. Hence, chain-of-thought prompting examples consist of the question, reasoning steps, and final answer, i.e., E j = ( Q j , T j , A j ) . However, the model does not know what faults to avoid in conventional chain-of-thought, which could lead to increased mistakes and error propagation. Hence, our contrastive chain of thought method provides both the correct and incorrect reasoning steps in the demonstration examples, i.e., E j = ( Q j , T j, + , A j, + , T j, -, A j, -) .
To obtain the correct reasoning steps T + for the demonstration examples, we use the annotated examples from the previous chain-of-thought works. For the incorrect reasoning steps T -, we automatically construct it from the correct reasoning steps T + , based on the "Incoherent Objects" category in Section 2. Concretely, we use an existing entity recognition model 5 to extract the object spans such as numbers, equations, or persons from a given chain-of-thought rationale. Consequently, we randomly shuffle the position of the objects within the rationale, thus constructing a rationale with incoherent bridging objects. Note that when testing with a new question, only the question and demonstration examples are provided to the model, and the model must generate its own reasoning steps before producing the final answer.
## 4 Experiments
## 4.1 Experimental Setup
We focus our study on two main types of reasoning tasks: arithmetic reasoning and factual question answering (QA). For arithmetic reasoning, we conduct experiments on a range of datasets including GSM8K (Cobbe et al., 2021), AQuA (Ling et al., 2017), GSM-Hard (Gao et al., 2023), SVAMP (Patel et al., 2021), and ASDIV (Miao et al., 2020). For factual QA, we include two datasets: Bamboogle (Press et al., 2023) and StrategyQA (Geva et al., 2021). To maintain a reasonable computing budget, we limit each dataset to a maximum of 500 test samples through random sampling. For datasets that contain less than 500 test samples, we instead use all available test samples. The datasets' details are included in Table 3. Regarding model and prompting details, we use the same experimental setup as for our preliminary study in Section 2.
## 4.2 Main Results
To assess the effectiveness of our method, we evaluate on several reasoning tasks and report the main results in Table 2. Our main findings are as follows:
Contrastive CoT demonstrates consistent improvements over conventional CoT. Contrastive CoT consistently outperforms conventional CoT across the datasets in both arithmetic and factual reasoning categories. Notably, we observe substantial gains of more than 10 points on GSMHard, SVAMP, ASDIV, Bamboogle and StrategyQA. Thus, the consistent and significant performance improvements demonstrate the general effectiveness of our proposed method. As contrastive chain of thought can be automatically constructed from existing rationales, the annotation cost is the same as conventional chain of thought. Hence, it
can be viewed as a general enhancement of chain of thought.
Contrastive CoT is more effective when applied with self-consistency. As self-consistency (Wang et al., 2022) is a popular decoding strategy to boost the chain-of-thought performance of large language models, we are interested to see if contrastive chain of thought can benefit similarly from self-consistency. In general, we observe that selfconsistency further enhances the performance of contrastive CoT. This enhancement is particularly evident in the case of the AQuA dataset. While contrastive CoT alone results in a modest performance improvement of 4.0%, applying self-consistency amplifies this gain significantly, achieving an additional improvement of 14.2%.
## 5 Related Work
Large Language Models Recent developments in large language models have shown that massively scaling the size and training data of models can greatly improve generalization (Kaplan et al., 2020). Notably, large language models have been shown to generalize to new tasks when given suitable prompts and demonstrations (Brown et al., 2020). This has brought about a new paradigm of leveraging language models for tasks without the need for additional training (Liu et al., 2023). However, simply scaling language models has not been sufficient to attain good performance on challenging tasks such as arithmetic reasoning and factual question answering (Wei et al., 2022b). Hence, in this work, we focus on enhancing the reasoning ability of large language models through prompts.
Chain of Thought Chain-of-thought prompting was introduced by Wei et al. (2022b) to enhance language model reasoning by generating intermediate steps. Notably, this has inspired numerous works that build upon this direction of step-bystep reasoning. For instance, automatic chain-ofthought (Zhang et al., 2023) was proposed to address the challenges in manually annotating chainof-thought demonstrations. On the other hand, it was shown that specific prompts such as 'Let's think step-by-step' can enable language models to perform chain-of-thought in a zero-shot manner, without any demonstrations (Kojima et al., 2022). In addition, challenging problems can be decomposed into multiple sub-problems (Zhou et al., 2023), or even into code programs that can be au- tomatically executed (Gao et al., 2023). Despite the progress in chain-of-thought on multiple fronts, we still lack a rigorous understanding of the underlying mechanism (Turpin et al., 2023; Feng et al., 2023). In this work, inspired by the findings of previous works regarding invalid demonstrations, we propose contrastive chain-of-thought to enhance language model reasoning. As contrastive chainof-thought leverages both valid and invalid reasoning demonstrations, we believe this may encourage other researchers to fundamentally rethink the chain-of-thought process.
Learning from Negative Examples While chain-of-thought prompting typically involves only valid demonstrations, it is not clear whether invalid demonstrations can also benefit the reasoning process (Wang et al., 2023). On the other hand, learning from negative or invalid samples is not new. For instance, contrastive learning is a well-established deep learning approach that encourages models to distinguish between 'positive' and 'negative' samples, thus learning better representations (Khosla et al., 2020). Similarly, reinforcement learning from human feedback (RLHF) trains a reward model based on positive and negative samples of human preference data (Ouyang et al., 2022; Christiano et al., 2017). Hence, inspired by the previous approaches, we propose contrastive chain-of-thought, a general enhancement of chain-of-thought prompting, by enabling models to learn from both valid and invalid reasoning demonstrations.
## 6 Conclusions
In this work, we have explored the effect of leveraging invalid reasoning demonstrations for enhancing chain of thought. Through our preliminary study on different invalid chain-of-thought categories, we found that providing both valid and invalid demonstrations in a contrastive manner greatly improves reasoning ability in language models. To overcome the challenge of manually annotating invalid rationales, we propose contrastive chain of thought, a general prompting method which can automatically construct contrastive demonstrations from existing rationales. Through experiments on several reasoning tasks, we find contrastive chain of thought to be a general enhancement of chain-of-thought prompting. Further investigation into alternative forms of chain-of-thought prompting will hopefully inspire future advancements in language-based reasoning.
## References
- Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-Voss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel Ziegler, Jeffrey Wu, Clemens Winter, Chris Hesse, Mark Chen, Eric Sigler, Mateusz Litwin, Scott Gray, Benjamin Chess, Jack Clark, Christopher Berner, Sam McCandlish, Alec Radford, Ilya Sutskever, and Dario Amodei. 2020. Language models are few-shot learners. In Advances in Neural Information Processing Systems , volume 33, pages 1877-1901. Curran Associates, Inc.
- Paul F Christiano, Jan Leike, Tom Brown, Miljan Martic, Shane Legg, and Dario Amodei. 2017. Deep reinforcement learning from human preferences. In Advances in Neural Information Processing Systems , volume 30. Curran Associates, Inc.
- Zheng Chu, Jingchang Chen, Qianglong Chen, Weijiang Yu, Tao He, Haotian Wang, Weihua Peng, Ming Liu, Bing Qin, and Ting Liu. 2023. A survey of chain of thought reasoning: Advances, frontiers and future.
- Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. 2021. Training verifiers to solve math word problems. CoRR , abs/2110.14168.
- Nathan Cooper, Carlos Bernal-Cárdenas, Oscar Chaparro, Kevin Moran, and Denys Poshyvanyk. 2021. It takes two to tango: Combining visual and textual information for detecting duplicate video-based bug reports. CoRR , abs/2101.09194.
- Guhao Feng, Bohang Zhang, Yuntian Gu, Haotian Ye, Di He, and Liwei Wang. 2023. Towards revealing the mystery behind chain of thought: A theoretical perspective. In Thirty-seventh Conference on Neural Information Processing Systems .
- Luyu Gao, Aman Madaan, Shuyan Zhou, Uri Alon, Pengfei Liu, Yiming Yang, Jamie Callan, and Graham Neubig. 2023. PAL: Program-aided language models. In Proceedings of the 40th International Conference on Machine Learning , volume 202 of Proceedings of Machine Learning Research , pages 10764-10799. PMLR.
- Mor Geva, Daniel Khashabi, Elad Segal, Tushar Khot, Dan Roth, and Jonathan Berant. 2021. Did aristotle use a laptop? a question answering benchmark with implicit reasoning strategies. Transactions of the Association for Computational Linguistics , 9:346361.
- Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B. Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei. 2020. Scaling laws for neural language models. CoRR , abs/2001.08361.
- Prannay Khosla, Piotr Teterwak, Chen Wang, Aaron Sarna, Yonglong Tian, Phillip Isola, Aaron Maschinot, Ce Liu, and Dilip Krishnan. 2020. Supervised contrastive learning. In Advances in Neural Information Processing Systems , volume 33, pages 18661-18673. Curran Associates, Inc.
- Takeshi Kojima, Shixiang Shane Gu, Machel Reid, Yutaka Matsuo, and Yusuke Iwasawa. 2022. Large language models are zero-shot reasoners. In Advances in Neural Information Processing Systems .
- Wang Ling, Dani Yogatama, Chris Dyer, and Phil Blunsom. 2017. Program induction by rationale generation: Learning to solve and explain algebraic word problems. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages 158-167, Vancouver, Canada. Association for Computational Linguistics.
- Zhan Ling, Yunhao Fang, Xuanlin Li, Zhiao Huang, Mingu Lee, Roland Memisevic, and Hao Su. 2023. Deductive verification of chain-of-thought reasoning. In Thirty-seventh Conference on Neural Information Processing Systems .
- Pengfei Liu, Weizhe Yuan, Jinlan Fu, Zhengbao Jiang, Hiroaki Hayashi, and Graham Neubig. 2023. Pretrain, prompt, and predict: A systematic survey of prompting methods in natural language processing. ACM Comput. Surv. , 55(9).
- Shen-yun Miao, Chao-Chun Liang, and Keh-Yih Su. 2020. A diverse corpus for evaluating and developing English math word problem solvers. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics , pages 975-984, Online. Association for Computational Linguistics.
- Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Gray, John Schulman, Jacob Hilton, Fraser Kelton, Luke Miller, Maddie Simens, Amanda Askell, Peter Welinder, Paul Christiano, Jan Leike, and Ryan Lowe. 2022. Training language models to follow instructions with human feedback. In Advances in Neural Information Processing Systems .
- Arkil Patel, Satwik Bhattamishra, and Navin Goyal. 2021. Are NLP models really able to solve simple math word problems? In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies , pages 2080-2094, Online. Association for Computational Linguistics.
- Ofir Press, Muru Zhang, Sewon Min, Ludwig Schmidt, Noah A. Smith, and Mike Lewis. 2023. Measuring and narrowing the compositionality gap in language models.
- Jack W. Rae, Sebastian Borgeaud, Trevor Cai, Katie Millican, Jordan Hoffmann, Francis Song, John
Aslanides, Sarah Henderson, Roman Ring, Susannah Young, Eliza Rutherford, Tom Hennigan, Jacob Menick, Albin Cassirer, Richard Powell, George van den Driessche, Lisa Anne Hendricks, Maribeth Rauh, Po-Sen Huang, Amelia Glaese, Johannes Welbl, Sumanth Dathathri, Saffron Huang, Jonathan Uesato, John Mellor, Irina Higgins, Antonia Creswell, Nat McAleese, Amy Wu, Erich Elsen, Siddhant Jayakumar, Elena Buchatskaya, David Budden, Esme Sutherland, Karen Simonyan, Michela Paganini, Laurent Sifre, Lena Martens, Xiang Lorraine Li, Adhiguna Kuncoro, Aida Nematzadeh, Elena Gribovskaya, Domenic Donato, Angeliki Lazaridou, Arthur Mensch, Jean-Baptiste Lespiau, Maria Tsimpoukelli, Nikolai Grigorev, Doug Fritz, Thibault Sottiaux, Mantas Pajarskas, Toby Pohlen, Zhitao Gong, Daniel Toyama, Cyprien de Masson d'Autume, Yujia Li, Tayfun Terzi, Vladimir Mikulik, Igor Babuschkin, Aidan Clark, Diego de Las Casas, Aurelia Guy, Chris Jones, James Bradbury, Matthew Johnson, Blake Hechtman, Laura Weidinger, Iason Gabriel, William Isaac, Ed Lockhart, Simon Osindero, Laura Rimell, Chris Dyer, Oriol Vinyals, Kareem Ayoub, Jeff Stanway, Lorrayne Bennett, Demis Hassabis, Koray Kavukcuoglu, and Geoffrey Irving. 2022. Scaling language models: Methods, analysis & insights from training gopher.
- Miles Turpin, Julian Michael, Ethan Perez, and Samuel R. Bowman. 2023. Language models don't always say what they think: Unfaithful explanations in chain-of-thought prompting. In Thirty-seventh Conference on Neural Information Processing Systems .
- Boshi Wang, Sewon Min, Xiang Deng, Jiaming Shen, You Wu, Luke Zettlemoyer, and Huan Sun. 2023. Towards understanding chain-of-thought prompting: An empirical study of what matters. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages 2717-2739, Toronto, Canada. Association for Computational Linguistics.
- Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc Le, Ed Huai hsin Chi, and Denny Zhou. 2022. Selfconsistency improves chain of thought reasoning in language models. ArXiv , abs/2203.11171.
- Jason Wei, Yi Tay, Rishi Bommasani, Colin Raffel, Barret Zoph, Sebastian Borgeaud, Dani Yogatama, Maarten Bosma, Denny Zhou, Donald Metzler, Ed Huai hsin Chi, Tatsunori Hashimoto, Oriol Vinyals, Percy Liang, Jeff Dean, and William Fedus. 2022a. Emergent abilities of large language models. Trans. Mach. Learn. Res. , 2022.
- Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, brian ichter, Fei Xia, Ed H. Chi, Quoc V Le, and Denny Zhou. 2022b. Chain of thought prompting elicits reasoning in large language models. In Advances in Neural Information Processing Systems .
- Zhuosheng Zhang, Aston Zhang, Mu Li, and Alex Smola. 2023. Automatic chain of thought prompting
in large language models. In The Eleventh International Conference on Learning Representations .
- Denny Zhou, Nathanael Schärli, Le Hou, Jason Wei, Nathan Scales, Xuezhi Wang, Dale Schuurmans, Claire Cui, Olivier Bousquet, Quoc V Le, and Ed H. Chi. 2023. Least-to-most prompting enables complex reasoning in large language models. In The Eleventh International Conference on Learning Representations .