## Zero-Shot Question Answering over Financial Documents using Large Language Models
Karmvir Singh Phogat, Chetan Harsha, Sridhar Dasaratha, Shashishekar Ramakrishna, Sai Akhil Puranam
EY Global Delivery Services India LLP
{Karmvir.Phogat, Chetan.Harsha, Sridhar.Dasaratha}@gds.ey.com
{Shashishekar.R,
, Sai.Puranam}@gds.ey.com
## Abstract
We introduce a large language model (LLM) based approach to answer complex questions requiring multi-hop numerical reasoning over financial reports. While LLMs have exhibited remarkable performance on various natural language and reasoning tasks, complex reasoning problems often rely on few-shot prompts that require carefully crafted examples. In contrast, our approach uses novel zero-shot prompts that guide the LLM to encode the required reasoning into a Python program or a domain specific language. The generated program is then executed by a program interpreter, thus mitigating the limitations of LLM in performing accurate arithmetic calculations.
We evaluate the proposed approach on three financial datasets using some of the recently developed generative pretrained transformer (GPT) models and perform comparisons with various zero-shot baselines. The experimental results demonstrate that our approach significantly improves the accuracy for all the LLMs over their respective baselines. We provide a detailed analysis of the results, generating insights to support our findings. The success of our approach demonstrates the enormous potential to extract complex domain specific numerical reasoning by designing zero-shot prompts to effectively exploit the knowledge embedded in LLMs.
## 1 Introduction
In recent years, the development of large language models (LLMs) has achieved significant advances in natural language processing (NLP). Typically, LLMs are pretrained on large corpora of text from the internet which has given rise to the capability of adapting to a wide variety of new tasks from different domains without the need for huge amount of task specific data. Scaling up the size of these models has not only improved sampling efficiency and performance, (Kaplan et al., 2020) but also intro- duced reasoning capabilities (Wei et al., 2022a,b; Kojima et al., 2022).
LLMs have been shown to perform well on tasks requiring reasoning capabilities in various domains, including code writing (Chen et al., 2021a), math problem solving (Lewkowycz et al., 2022; Polu et al., 2023), dialogue (Glaese et al., 2022; Thoppilan et al., 2022), common sense reasoning (Shwartz et al., 2020; Chowdhery et al., 2022) and symbolic reasoning (Wei et al., 2022b; Wang et al., 2023). The design of the prompt, known as prompt engineering, plays a significant role in adapting the pretrained LLMs to new tasks with little or no task specific training data. Recently, there has been extensive work (Liu et al., 2023) which demonstrates the importance of prompt design in usage of the LLMs and unlocking their reasoning capabilities. However, (Mahowald et al., 2023) argue that LLMs cannot combine elementary knowledge with common sense reasoning. (Valmeekam et al., 2022) claim that benchmarks on which LLMs show reasoning capabilities are simplistic and cannot be used as evidence. (Bubeck et al., 2023; Bang et al., 2023) show that LLMs face challenges in numerical reasoning. Hence, adapting LLMs to new domains requires prompt engineering and a system design that can overcome the limitations of LLMs.
Question answering in the financial domain is an active area of research which could potentially benefit from the use of LLMs with appropriate system design. Financial question answering involves numerous steps and complex numerical reasoning with precise arithmetic calculations, making it more challenging than classical question answering problems (Yang et al., 2018; Rajpurkar et al., 2018). Typically for complex problems, fewshot prompt based approaches have been used (Wei et al., 2022b; Chen et al., 2023). However it has been shown that the output of the LLMs is sensitive to the few-shot samples used as well as to the ordering of those samples (Lu et al., 2022). Further, the samples can contain large number of tokens and providing multiple samples for few-shot prompts would increase the number of input tokens, sometimes even crossing the limit of LLMs. Hence, designing and using few-shot prompts for financial question answering can become quite challenging.
We propose a new approach using zero-shot prompts for financial question answering with LLMs, thus eliminating the requirement to create hand crafted examples. These prompts contain high-level instructions to guide the encoding of financial reasoning process into a Python program (ZS-FinPYT) or a domain specific language (ZSFinDSL). For ZS-FinPYT, we achieve the zero-shot system by instructions that layout the high-level approach to generate a valid Python program, while for ZS-FinDSL we enable the same by identifying a program structure for robust domain-specific languages (DSL) program extraction. In both cases, the generated program is executed externally by a program executor to provide the final answer. We evaluate the use of the latest GPT-x models on their ability to perform financial reasoning as they have shown state-of-the-art performance on various tasks involving question answering and reasoning (OpenAI, 2023; Frieder et al., 2023; Kung et al., 2023). Specifically, we explore the use of the GPT models text-davinci-003, gpt-3.5-turbo and gpt-4 in answering financial questions.
We evaluate the proposed approach on three financial question answering datasets, with three different GPT models and compare with various baselines. The experimental results demonstrate that our approach significantly improves the accuracy for all models. The success of our approach demonstrates the enormous potential to extract complex domain specific numerical reasoning by carefully designing LLM based systems for specific applications and crafting prompts to effectively exploit the knowledge embedded in the LLMs.
## 2 Background
NLPtechniques have proven useful to solve various problems in the financial domain such as sentiment analysis to assist market prediction (Day and Lee, 2016; Akhtar et al., 2017) and fraud detection for risk management (Han et al., 2018; Wang et al., 2019). Financial domain specific language models have been trained on large scale financial data and fine tuned for specific problems (Liu et al., 2021). (Chen et al., 2021b) introduce a large-scale question answering dataset, FinQA and propose FinQANet with a retriever-generator architecture based on pretrained BERT like models.
With the introduction of LLMs, it has become feasible to directly use these language models without domain specific pretraining. (Chen et al., 2022) propose a large-scale financial dataset, ConvFinQA for conversational question answering. They propose a few-shot prompt (with 16 exemplars) based approach using GPT-3 text-davinci-002 model to generate a DSL program.
One of the key techniques which significantly improves reasoning abilities of LLMs is chainof-thought prompting introduced by (Wei et al., 2022b). They propose a few-shot prompt that consists of triples: <input, chain-of-thought, output>, where the chain-of-thought (CoT) is a series of intermediate natural language reasoning steps that leads to the final output. (Kojima et al., 2022) demonstrate that reasonable zero-shot learning is achieved by simply adding 'Let's think step by step' to the prompt and using a two-prompt approach: the first prompt to extract the reasoning path and the second to extract the final answer. Unlike our approach, which avoids performing calculations using the LLM, both of these approaches utilize the LLM for generating mathematical expressions that encode the reasoning and perform arithmetic at each step.
Program of thoughts (PoT) prompting (Chen et al., 2023) and Program-aided Language Models (PAL) (Gao et al., 2023) are approaches that are conceptually similar to our proposed technique. However, (Chen et al., 2023) show only limited zero-shot prompting experiments for financial data sets. Their results indicate that few-shot prompting significantly outperforms the zero-shot prompts. (Gao et al., 2023) discuss only few-shot prompting and do not show any results on financial data sets. In contrast, our work focuses entirely on optimizing zero-shot prompts that generate Python program or domain specific language for financial question answering. We further demonstrate that carefully designed zero-shot prompts for financial question answering can achieve comparable results with few-shot methods.
## 3 Zero-shot Prompting for Financial Domains
We introduce a novel zero-shot template-based prompting for financial question answering. These prompts are designed to generate executable programs for answering questions. The executable program generation and their execution enables accurate mathematical calculations which eliminates arithmetic errors. We follow the prompt guidelines described in (Reynolds and McDonell, 2021) and employ the following principles for designing zeroshot prompting for question answering:
Signifier: A signifier is a pattern which keys the intended behavior. A task specific signifier directly elucidates the task at hand. The sentence - 'Read the following passage and then answer the question', specifically describes the question answering task that is to be performed.
Memetic proxy: A memetic proxy is a concept in which a character or characteristic situation is used as a proxy for an intention. '#Python' can be a memetic proxy for the LLM to clarify the intention that the response should have a Python program.
Constraining behavior: In addition to directing the LLM on the desirable response, it is important for the prompt to inform the LLM of undesirable responses. Instructions restricting undesirable LLM responses fall into the constraining behavior category.
Meta prompting: A meta prompt is a short phrase or a fill-in-the-blank template encapsulating a more general intention that will unfold into a more specific prompt when combined with additional information such as the task at hand. In the question answering task, the sentence -'Let us think step by step.', elicits step-by-step reasoning in LLMs for answering questions.
Inspired by these prompt design principles, we present two zero-shot prompting techniques: ZS-FinPYT prompt that enables LLMs to generate Python executable programs and ZS-FinDSL prompt that enables LLMs to generate executable domain specific language programs. We also discuss two baseline zero-shot prompting techniques, one using a simple dual prompt and another using zero-shot chain-of-thought prompting (ZS-CoT) motivated by (Kojima et al., 2022). For reproducibility purposes, we provide exact prompts for all techniques and datasets.
## 3.1 Zero-shot FinPYT
The ZS-FinPYT prompt is a collection of instructions that directs the LLM to generate a valid Python program that can be executed by the exec function. Based on preliminary experiments, we identified the following requirements for the proposed prompt:
- (a) The prompt should describe the task such that it enables the LLM to generate consistent programs for answering the questions.
- (b) The final answer to a question must be stored in a specified Python variable for enabling consistent extraction of executed answer.
- (c) The LLM generated program should not include Python non-executable statements for seamless execution of Python programs.
The ZS-FinPYT prompt is designed to accommodate the above requirements in the following manner:
Direct task specification using the signifier: We use the following signifier for explicitly specifying the question answering task:
Read the following passage and then write Python code to answer the question: Passage: text + table Question: ask question? Answer this question by following the below instructions.
The signifier explicitly calls out the task of writing a Python program to answer the question after reading the passage where the passage and the questions are identified with the identifiers ' Passage: ' and ' Question: ' respectively. Furthermore, the prompt directs the LLM to follow certain instructions while answering the question.
Direct sub-task specification using the signifier: The sub-task of storing the final answer to a specific Python variable is described as a part of instructions to the LLM:
Define the Python variable which must begin with a character. Assign values to variables required for the calculation. Create Python variable "ans" and assign the final answer (bool/float) to the variable "ans".
Constraining LLM behavior: To ensure naming conventions are followed and prevent the generation of non-executable statements, we include the following instructions in the prompt:
Define the Python variable which must begin with a character. Don't include non-executable statements and include them as part of comments.
Memetic proxy phrases: Certain memetic proxy phrases are employed to implicitly convey intentions. For instance, the memetic phrase '#Comment: . . . ' guides the LLM to understand that comments are always preceded by the '#' character. Similarly, the memetic phrase '#Python' instructs the LLM to generate a Python program.
The ZS-FinPYT prompt for the FinQA dataset is depicted in Figure 1.
Figure 1: ZS-FinPYT prompt for FinQA
<details>
<summary>Image 1 Details</summary>

### Visual Description
## Diagram: LLM-Python Code Generation Workflow
### Overview
The image depicts a structured workflow for generating Python code using a Large Language Model (LLM). It outlines the input requirements, processing steps, and output format, with color-coded elements to denote different components.
### Components/Axes
1. **Input Section (Blue Box)**:
- Contains the task description:
- `Passage: text + table`
- `Question: ask question?`
- `Instructions`:
- Define variables starting with a character.
- Assign values to variables.
- Create variable "ans" for the final answer.
- Include non-executable statements as comments.
- Color-coded elements:
- **Signifier** (black): Key instructions (e.g., "Assign values...").
- **Mnemonic proxy** (orange): Variable names (e.g., "ans").
- **Constraining behavior** (pink): Formatting rules (e.g., "Don't include non-executable statements").
- **Input** (blue): Task description text.
2. **Output Section (Pink Box)**:
- Labeled "Python code from the LLM."
- Contains a placeholder for executable Python code.
3. **Legend (Bottom Right)**:
- Color-key for elements:
- **Signifier** (black): Highlights critical steps.
- **Mnemonic proxy** (orange): Represents variables.
- **Constraining behavior** (pink): Enforces formatting rules.
- **Input** (blue): Denotes task description.
### Detailed Analysis
- **Textual Content**:
- The blue box provides a template for input, specifying that the LLM must process a passage (text + table) and answer a question using strict instructions.
- The pink box represents the output, emphasizing that the LLM must generate valid Python code.
- The legend clarifies the purpose of color-coding, linking visual elements to their functional roles.
- **Spatial Grounding**:
- The legend is positioned at the bottom right, ensuring visibility without obstructing the main workflow.
- The blue box (input) is at the top, followed by the legend, and the pink box (output) at the bottom, creating a top-to-bottom flow.
### Key Observations
1. **Color Consistency**:
- All elements in the blue box (input) are labeled as "Input" (blue) in the legend.
- The pink box (output) aligns with "Constraining behavior" (pink) in the legend, as it enforces code formatting rules.
2. **Missing Data**:
- No numerical values, charts, or tables are present. The diagram focuses on textual and structural guidance rather than quantitative data.
### Interpretation
This workflow illustrates how an LLM processes structured input (task description, question, and instructions) to generate Python code. The color-coding system helps users distinguish between:
- **Critical steps** (Signifier: black),
- **Variables** (Mnemonic proxy: orange),
- **Formatting constraints** (Constraining behavior: pink),
- **Input text** (blue).
The absence of numerical data suggests the diagram prioritizes procedural clarity over statistical analysis. The LLM’s role is to parse the input, adhere to constraints, and produce executable code, emphasizing the importance of precise instruction design for automated code generation.
</details>
## 3.2 Zero-shot FinDSL
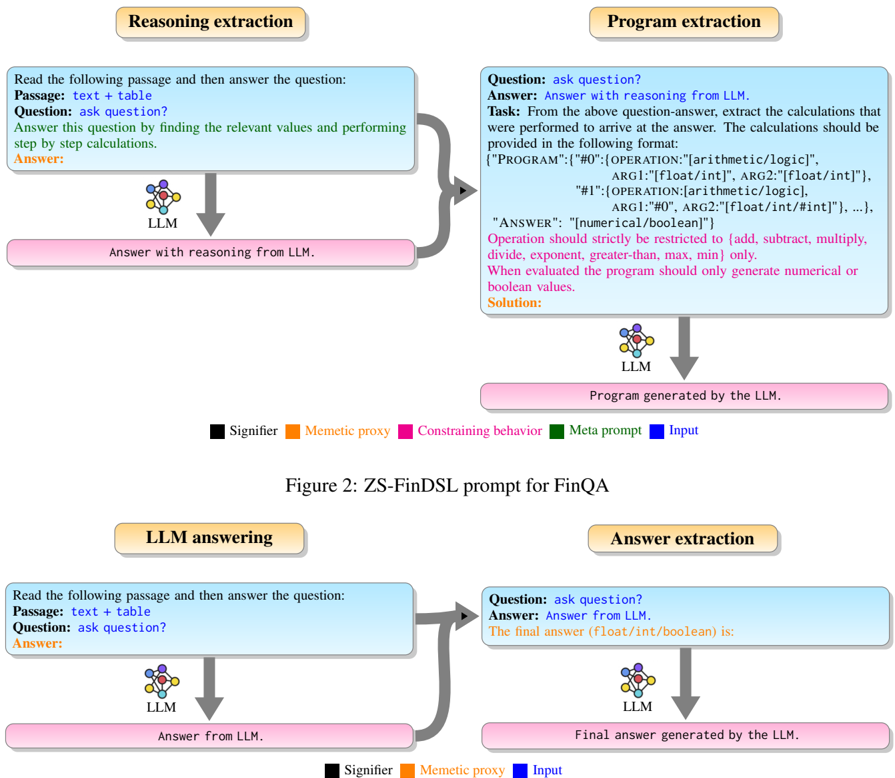
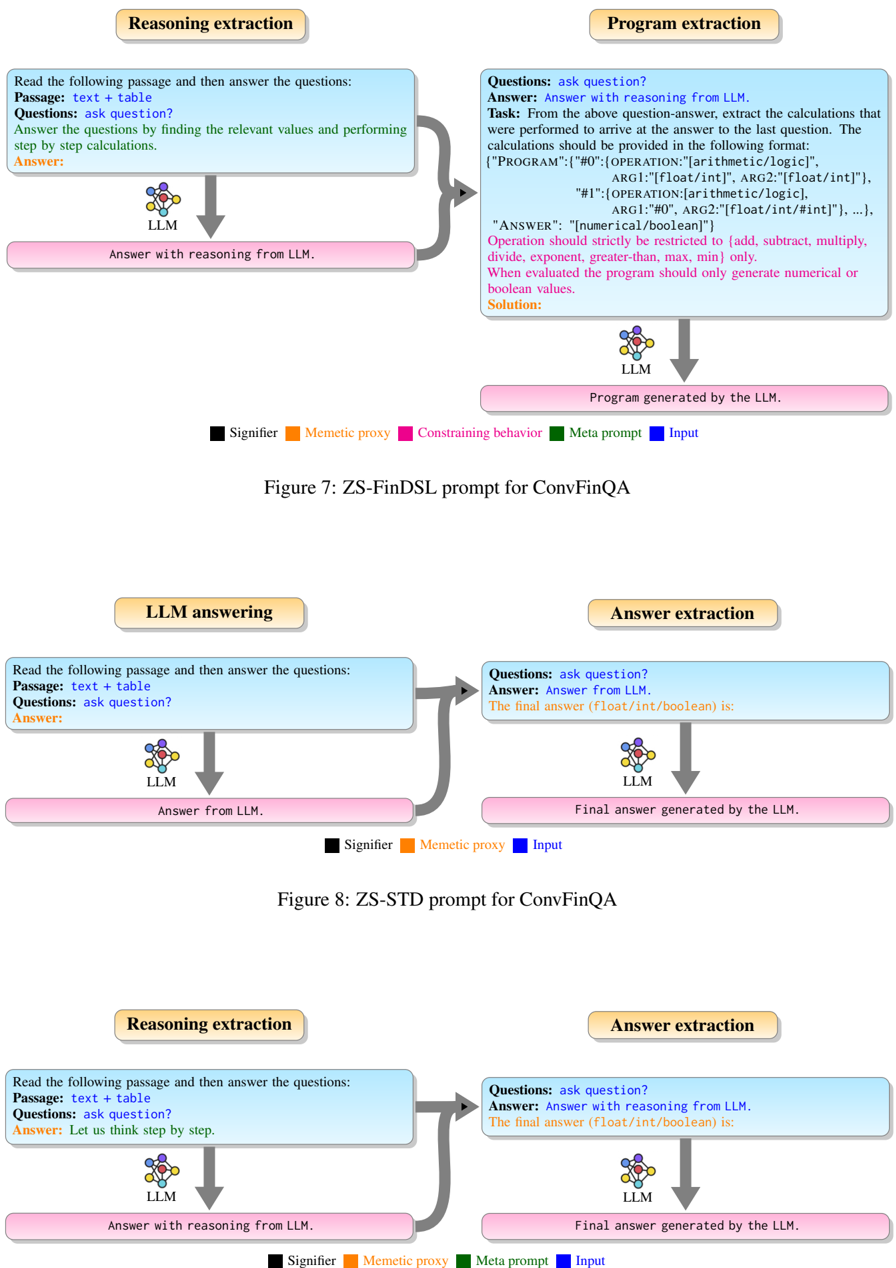
The zero-shot FinDSL (ZS-FinDSL) is a zero-shot prompting technique for program generation in a domain specific language (DSL). We use a DSL similar to (Chen et al., 2021b) with two differences: we don't have table operators and instead we have a max and min operator. The output of the system is a DSLprogram that is extracted using a Python script and executed using a language interpreter. In the ZS-FinDSL technique, we adopt a dual prompt approach to extract reasoning for answering questions and generating the corresponding DSL program.
## 3.2.1 Reasoning Extraction Prompt
The reasoning extraction prompt of ZS-FinDSL consists of two parts:
Direct task specification using the signifier: The question answering task is specified explicitly using the following signifier:
```
```
Meta prompting for reasoning: For generating step by step reasoning for answering the question, the following meta prompt is used:
Answer this question by finding the relevant values and performing step by step calculations.
## 3.2.2 Program Extraction Prompt
The primary goal of the program extraction prompt is to extract DSL programs from the LLM's response obtained through the reasoning extraction prompt. To achieve this, the program extraction prompt involves specifying the task of program ex- traction and constraining the LLM's behavior by incorporating domain-specific knowledge.
Direct task specification using the signifier: The program extraction task is specified using the following signifier:
<details>
<summary>Image 2 Details</summary>

### Visual Description
## Screenshot: Example Task for Textual Information Extraction
### Overview
The image is a screenshot displaying a template for extracting calculations and reasoning from a given question-answer pair. It contains structured sections with instructions and placeholders for input.
### Components/Axes
- **Question:** Placeholder for a question ("ask question?")
- **Answer:** Placeholder for an answer ("Answer with reasoning from LLM")
- **Task:** Detailed instructions specifying the extraction of calculations performed to arrive at the answer
- **Format Specification:**
- Programmatic representation of operations (e.g., `OPERATION: "[arithmetic/logic]"`)
- Argument types (e.g., `ARG1: "[float/int]"`)
- Answer representation (e.g., `ANSWER: "[numerical/boolean]"`)
### Detailed Analysis
- The structure is hierarchical:
- **Program** includes numbered operations (`#0`, `#1`, ...) with operations and arguments
- Each operation has a defined `OPERATION` type (arithmetic/logic) and arguments (`ARG1`, `ARG2`) with data types
- The answer is represented as a numerical or boolean value
### Key Observations
- Placeholder text indicates where user-provided content would be inserted
- Strict formatting requirements are specified for operations and arguments
- The example uses a nested JSON-like structure to represent operations and data types
### Interpretation
This template demonstrates a method for breaking down reasoning steps into programmatic components, which could be used for:
- Automated reasoning extraction from natural language explanations
- Structured data generation for training AI models
- Formal verification of AI reasoning processes
The structured format enables unambiguous representation of calculations, potentially improving reproducibility and interpretability of AI-generated reasoning.
</details>
Constraining LLM behavior: To ensure consistent program extraction, we limit the mathematical operations to the set specified by the DSL. These operations are commonly used for financial question answering. Moreover, we constrain the program's output to numerical or boolean values to make it executable. The following instructions are passed to the LLM to ensure consistent program extraction:
Operation should strictly be restricted to {add, subtract, multiply, divide, exponent, greater-than, max, min} only. When evaluated the program should only generate numerical or boolean values.
The ZS-FinDSL prompt for the FinQA dataset is shown in Figure 2.
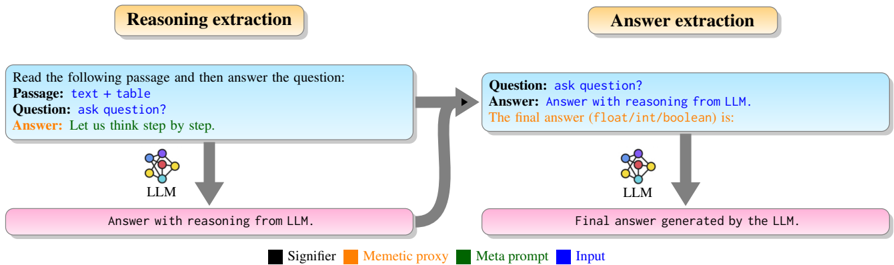
## 3.3 Zero-shot Standard Dual
A standard template based prompting approach for question answering is a zero-shot standard dual (ZS-STD) prompt which has a LLM answering prompt and an answer extraction prompt. In the LLM answering prompt, the question is appended below the passage and then the trigger word 'Answer' is added for LLM to generate the answer. The answer extraction prompt takes the LLM generated answer along with the question and append a memetic proxy phrase - 'The final answer ( float/int/boolean ) is' for extracting the final answer. The ZS-STD prompt for the FinQA dataset question answering is shown in Figure 3.
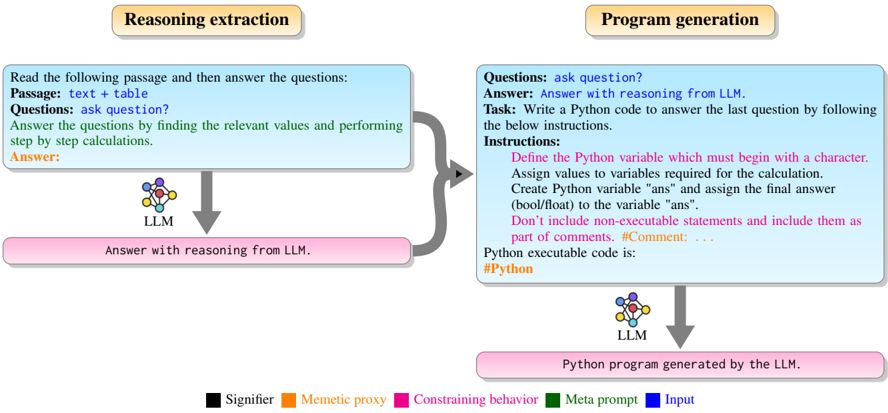
## 3.4 Zero-shot Chain of Thoughts
Similar to the zero-shot reasoners (Kojima et al., 2022), zero-shot chain-of-thought (ZS-CoT) prompt is derived from the ZS-STD prompt by adding the reasoning trigger sentence -'Let us think step by step.' after the word 'Answer:'. The answer extraction prompt of ZS-CoT is identical to the ZS-STD prompt. The ZS-CoT prompt for the
Figure 3: ZS-STD prompt for FinQA
<details>
<summary>Image 3 Details</summary>
### Visual Description
## Diagram: ZS-FinDSL Prompt for FinQA
### Overview
The diagram illustrates a structured workflow for a Language Learning Model (LLM) to process financial question-answering (FinQA) tasks. It breaks the process into four stages: **Reasoning extraction**, **Program extraction**, **LLM answering**, and **Answer extraction**. Color-coded elements (Signifier, Meme, Constraining behavior, Meta prompt, Input) define the components and their relationships.
---
### Components/Axes
- **Legend**:
- Black: Signifier (labels for components)
- Orange: Meme (proxy for specific elements)
- Pink: Constraining behavior (rules for operations)
- Green: Meta prompt (instructions for the LLM)
- Blue: Input (data or questions)
- **Key Elements**:
- **Reasoning extraction**:
- Input: "Read the following passage and then answer the question."
- Output: "Answer with reasoning from LLM."
- **Program extraction**:
- Input: Question-answer pair.
- Output: Program generated by the LLM (e.g., arithmetic/logic operations).
- **LLM answering**:
- Input: Passage + question.
- Output: Answer from LLM.
- **Answer extraction**:
- Input: Question + LLM answer.
- Output: Final answer (e.g., numerical/boolean value).
---
### Detailed Analysis
1. **Reasoning extraction**:
- The LLM reads a passage (text + table) and answers a question by identifying relevant values and performing step-by-step calculations.
- Example: "Answer this question by finding the relevant values and performing step by step calculations."
2. **Program extraction**:
- The LLM generates a program based on the question-answer pair. The program must:
- Use operations restricted to: `arithmetic` (add, subtract, multiply, divide, exponent) and `logic` (greater-than, max, min).
- Follow a strict format: `{"PROGRAM": [{"OPERATION": "arithmetic/logic", "ARG1": "float/int", ...}, ...], "ANSWER": "numerical/boolean"}`.
- Example program:
</details>
FinQA dataset question answering is described in Figure 4.
All prompts for TATQA are identical to FinQA and for ConvFinQA dataset, the prompts are slightly modified to handle conversational questions as shown in Appendix A.
## 4 Experiments
## 4.1 Experimental Design
Datasets: We conduct our experiments on three financial question answering datasets FinQA (Chen et al., 2021b), ConvFinQA (Chen et al., 2022) and TATQA(Zhu et al., 2021) as summarized in Table 1. For our evaluations, we use the test split of FinQA, while for ConvFinQA and TATQA we use the dev set as answers for test splits of these datasets are not available. The evaluations for TATQA are restricted to questions of arithmetic type. The question answering task is to answer the questions using the passage containing text and table content. The table content is represented in a textual format using the strategy adopted in (Chen, 2022). In the textual format, the table columns are separated by '|', the rows are separated by '\n' and the empty cell are filled with '-'.
Large Language Models: We experimented with three Azure OpenAI 1 LLMs text-davinci-003, gpt-3.5-turbo, gpt-4. The Python programs generated using LLMs are executed using Python function exec . The domain specific programs are executed using the Python script provided by FinQA. 2 In order to achieve a more precise and predictable outcome, the LLM parameters are set as follows: temperature = 0, top\_prob = 0.95, max\_tokens = 1000.
Evaluation Metrics: For all the financial
1 https://oai.azure.com/
2 https://github.com/czyssrs/FinQA
Figure 4: ZS-CoT prompt for FinQA
<details>
<summary>Image 4 Details</summary>
### Visual Description
## Flowchart: LLM Question-Answering Process
### Overview
The image depicts a two-stage flowchart illustrating how a Large Language Model (LLM) processes a question and passage to generate an answer. The process involves "Reasoning extraction" followed by "Answer extraction," with explicit labels for components and a color-coded legend.
---
### Components/Axes
1. **Legend** (bottom center):
- **Black**: Signifier
- **Orange**: Mementic proxy
- **Green**: Meta prompt
- **Blue**: Input
2. **Reasoning Extraction Block** (top-left):
- **Input**: "Read the following passage and then answer the question: Passage: text + table. Question: ask question? Answer: Let us think step by step."
- **Output**: "Answer with reasoning from LLM."
3. **Answer Extraction Block** (top-right):
- **Input**: "Question: ask question? Answer: Answer with reasoning from LLM."
- **Output**: "Final answer generated by the LLM."
4. **Arrows**:
- Gray arrows connect the two blocks, indicating sequential processing.
- A bidirectional arrow links the reasoning output to the answer input.
5. **LLM Symbol**:
- A network diagram (blue, red, yellow nodes) appears below both blocks, representing the LLM.
---
### Detailed Analysis
- **Reasoning Extraction**:
- Inputs include a passage (text + table) and a question.
- The LLM generates intermediate reasoning ("Let us think step by step").
- Color coding: Blue (Input) dominates this block.
- **Answer Extraction**:
- Takes the reasoning output as input.
- Finalizes the answer in a structured format (e.g., float/int/boolean).
- Color coding: Blue (Input) and black (Signifier) are prominent.
- **Legend Placement**:
- Positioned at the bottom center, spanning the width of the flowchart.
- Colors correspond to labels but are not explicitly mapped to visual elements in the diagram.
---
### Key Observations
1. **Sequential Workflow**: The process is strictly linear, with reasoning preceding answer generation.
2. **LLM Centrality**: The LLM is depicted as the core component in both stages.
3. **Legend Ambiguity**: While the legend defines four categories, only "Input" and "Signifier" are visually represented (blue and black). The roles of "Mementic proxy" (orange) and "Meta prompt" (green) are not visually evident.
4. **Textual Focus**: The flowchart emphasizes textual inputs/outputs over numerical or categorical data.
---
### Interpretation
This flowchart represents a conceptual pipeline for LLM-based question answering, emphasizing:
- **Modularity**: Separation of reasoning and answer generation stages.
- **LLM Dependency**: The model is responsible for both intermediate reasoning and final output.
- **Input-Output Clarity**: Explicit labeling of inputs (passage, question) and outputs (reasoning, final answer).
The absence of numerical data or visual mappings for the legend suggests the diagram prioritizes process explanation over quantitative analysis. The bidirectional arrow between blocks implies iterative refinement, though this is not explicitly stated in the text. The LLM's role as both reasoning and answer generator highlights its versatility in handling complex tasks.
</details>
datasets - FinQA, ConvFinQA and TATQA, we implement the evaluation strategy discussed in program of thoughts prompting (Chen et al., 2023) on Github 3 with slight modifications. The LLM responses are varying in nature for questions with answers in thousands, millions, and percentage . Examples: for the gold answer 7 million, the gpt response may be 7 million or 7,000,000; for the gold answer 23%, the gpt response may be 23% or 0.23. The evaluation strategy is modified to handle such cases. We relax the evaluations for ZS-CoT (Kojima et al., 2022) and standard dual prompting because LLMs using these prompting techniques generate answers instead of programs. Since LLMs cannot perform precise mathematical calculations (especially with high-precision floats and large numbers),we provide a tolerance while comparing the gpt final answer with the gold answer. The evaluation is implemented using the Python function isclose with a relative tolerance (rel\_tol) of 0.001. The isclose functionality returns True while comparing the gpt final answer (ˆ a ) with the gold answer (˜ a ) if and only if the condition with the baselines ZS-STD prompt and ZS-CoT are summarized in Table 2. The ZS-FinPYT and ZSFinDSL methods significantly outperform the ZSSTD prompt for all datasets and across all LLMs. The ZS-FinPYT achieves 4.5% to 47% and the ZSFinDSL achieves 5.22% to 38.72% improvement in accuracy over ZS-STD. The increase in accuracy for text-davinci and gpt-3.5 are are much higher than that for gpt-4 as for gpt-4 the base model performs reasonably well. These results indicate that our prompts are able to induce the required reasoning and successfully output the required Python programs or domain specific languages.
<!-- formula-not-decoded -->
is satisfied.
Baselines: We consider two baselines for zeroshot prompting setting: ZS-STD prompt and ZSCoT prompt. These zero-shot prompting techniques are evaluated with all three Azure OpenAI models (text-davinci-003, gpt-3.5-turbo, gpt-4) on all three financial datasets (FinQA, ConvFinQA and TATQA).
## 4.2 Main Results
The evaluation results for the proposed prompting techniques ZS-FinPYT and ZS-FinDSL along
3 https://github.com/wenhuchen/Program-of-Thoughts
Both methods also made significant improvements over the ZS-CoT method for text-davinci003 and gpt-3.5-turbo, with the ZS-FinPYT achieving 3% to 33.22% and the ZS-FinDSL achieving 0% to 24.94% improvement over the ZS-CoT on different datasets. For gpt-4, our approach slightly outperforms the ZS-CoT for all datasets with improvements in the range of 1.5-3.5%. However, it is important to highlight that ZS-CoT lacks the ability to provide precise answers, and its accuracy is measured using a relaxed metric, while our method generates precise answers and an exact metric is used to measure accuracy.
In general, the ZS-FinPYT approach gave better results than ZS-FinDSL for the text-davinci-and gpt-3.5-turbo models for the different datasets. For gpt-4 both methods are comparable.
We also carried out an evaluation of OpenAI models using few-shot PoT prompting, as shown in Table 3. The comparisons indicate the excellent performance of our zero-shot method as we are within 10% of the few-shot and in many cases almost the same and for few cases even surpassing the few-shot performance.
| Dataset | Split | Example | Input | Output |
|-----------|---------|-----------|------------------------------------|---------------|
| FinQA | Test | 1147 | Table + Text + Question | Number+Binary |
| ConvFinQA | Dev | 421 | Table + Text + Multi-turn Question | Number+Binary |
| TATQA | Dev † | 718 | Table + Text + Question | Number+Binary |
Table 1: Financial question answering datasets for evaluation
| Models | FinQA | ConvFinQA | TATQA |
|------------------------------|---------|-------------|---------|
| ZS-STD (text-davinci-003) | 22.58 | 13.3 | 39.97 |
| ZS-CoT (text-davinci-003) | 41.15 | 27.08 | 68.94 |
| ZS-FinDSL (text-davinci-003) | 56.76 | 52.02 | 68.25 |
| ZS-FinPYT (text-davinci-003) | 66.6 | 60.3 | 78.4 |
| ZS-STD (gpt-3.5-turbo) | 32.26 | 47.74 | 49.03 |
| ZS-CoT (gpt-3.5-turbo) | 53.01 | 52.49 | 74.09 |
| ZS-FinDSL (gpt-3.5-turbo) | 61.12 | 60.81 | 77.86 |
| ZS-FinPYT (gpt-3.5-turbo) | 66.52 | 67.45 | 85 |
| ZS-STD (gpt-4) | 63.64 | 72.45 | 77.58 |
| ZS-CoT (gpt-4) | 74.19 | 75.3 | 90.11 |
| ZS-FinDSL (gpt-4) | 77.33 | 77.67 | 90.53 |
| ZS-FinPYT (gpt-4) | 77.51 | 76.95 | 93 |
Table 2: Comparison results of various models on different datasets.
## 4.3 Performance Analysis
We conduct a performance analysis on FinQA dataset for two models gpt-4, gpt-3.5-turbo, see Table 4 for details. The FinQA questions are divided into various categories to gain further insights.
Performance on text and table questions: The FinQA questions are divided into three sets depending on where the information required to answer the question is available: table only questions, textonly questions, text-table questions.
Performance regarding program steps: The FinQA questions are divided into three sets based on number of steps required to provide the answer: 1 step program, 2 step program and >2 step program.
Performance regarding question types: The FinQA questions are divided into numerical and boolean type questions.
The key findings are listed below:
The models achieve the highest accuracy on table-only questions. As tables are structured and the tables in this dataset are simple, it maybe easier for the LLMs to more accurately extract the values as compared to extracting from unstructured text.
Question with multi-hop reasoning are challenging. As would be expected both models find it easier to answer questions with one or two hop- reasoning as compared to questions needing more than two hop reasoning.
Numerical questions are more challenging as compared to boolean questions. In general, gpt-4 and gpt-3.5-turbo models excel in answering boolean questions over arithmetic questions. However, gpt-3.5-turbo's performance declines with ZSFinDSL prompt for boolean questions as compared to arithmetic questions. Examination of a few cases indicated that gpt-3.5-turbo has greater difficulty in writing DSL programs correctly for boolean questions.
## 4.4 Error Analysis
We sampled 50 test cases from FinQA dataset results of text-davinci-003 model and examined in detail the entire output of the system to get further insight into the obtained results. As expected, ZS-STD prompt results in brief answers with a sentence or value as the output without providing any details on the reasoning potentially contributing to its poor performance. On the other hand, LLM responses with ZS-CoT details out the reasoning behind the answers and shows significantly better performance than ZS-STD. However, arithmetic errors results into a substantial drop in performance for both ZS-STD prompt and ZS-CoT.
The ZS-FinPYT and ZS-FinDSL approaches
| Models | FinQA | ConvFinQA | TATQA |
|-----------------------------------|---------|-------------|---------|
| Few-shot PoT (text-davinci-003) ⋆ | 72.27 | 69.35 | 83.21 |
| ZS-FinPYT (text-davinci-003) | 66.6 | 60.3 | 78.4 |
| Few-shot PoT (gpt-3.5-turbo) ⋆ | 67.39 | 65.79 | 74.75 |
| ZS-FinPYT (gpt-3.5-turbo) | 66.52 | 67.45 | 85 |
| Few-shot PoT (gpt-4) ⋆ | 78.46 | 82.42 | 91.89 |
| ZS-FinPYT (gpt-4) | 77.51 | 76.95 | 93 |
- ⋆ Few-shot PoT uses 4-shots selected from the few-shots used in (Chen et al., 2023).
Table 3: Performance of ZS-FinPYT and few-shot PoT on different datasets.
| Methods | ZS-FinPYT | ZS-FinPYT | ZS-FinDSL | ZS-FinDSL |
|--------------------------------------|--------------------------------------|--------------------------------------|--------------------------------------|--------------------------------------|
| | gpt-4 | gpt-3.5-turbo | gpt-4 | gpt-3.5-turbo |
| overall accuracy | 77.51 | 66.52 | 77.33 | 61.12 |
| Performance on table and text | Performance on table and text | Performance on table and text | Performance on table and text | Performance on table and text |
| table-only questions | 80.91 | 71.36 | 81.36 | 63.94 |
| text-only questions | 74.45 | 58.39 | 73.36 | 60.22 |
| table-text questions | 67.44 | 55.81 | 68.22 | 48.84 |
| Performance regarding program steps | Performance regarding program steps | Performance regarding program steps | Performance regarding program steps | Performance regarding program steps |
| 1 step programs | 80.73 | 69.27 | 79.82 | 62.08 |
| 2 step programs | 77.02 | 64.79 | 77.26 | 63.08 |
| >2 step programs | 54.76 | 53.57 | 58.33 | 44.05 |
| Performance regarding question types | Performance regarding question types | Performance regarding question types | Performance regarding question types | Performance regarding question types |
| boolean questions | 90.00 | 95.00 | 85.00 | 45.00 |
| numerical questions | 77.28 | 66.02 | 77.20 | 61.40 |
Table 4: Performance breakdown of various models on FinQA dataset.
demonstrated detailed reasoning. In the case of ZS-FinPYT the task of writing a Python program triggers reasoning while in the case of ZS-FinDSL there are two prompts where the first prompt is a meta prompt that drives the reasoning similar to ZS-CoT. These techniques produce programs instead of answers for questions and therefore, mitigate arithmetic errors. Hence, these proposed techniques significantly outperforms ZS-CoT. The ZSFinDSL performance is lower than ZS-FinPYT because the program extraction step fails for some cases where the reasoning step is correct. One possible explanation could be that the GPT systems have likely been trained on huge amounts of Python programs and hence can generate Python program efficiently where as for ZS-FinDSL the instruction contains the information on how to write out the domain specific program. This may be driving the slightly higher error rate of the ZS-FinDSL. Some demonstrative examples supporting these observations may be found in Appendix B.
## 5 Conclusion
We proposed zero-shot prompting techniques to answer complex questions requiring multi-hop numerical reasoning over financial reports. The prompts guide the LLM to encode the required reasoning into a program that is executed by a program interpreter. The approach demonstrated excellent results on three financial datasets, achieving significant improvement over the respective baselines.We hope that our work will motivate a principled approach to prompt design with other LLMs.
## Limitations
In this paper, we only experiment with the GPTx series of LLMs. While this work shows the tremendous potential for zero-shot financial reasoning with LLMs, it is possible that better performance may be obtained with other LLMs. Moreover, the prompts we have proposed are designed to address specific problems observed with the three GPT models considered in this work. Other LLMs may behave differently and will likely need modification to the prompts to work effectively.
While we experiment and find zero-shot prompts that are effective for both ZS-FinPYT and ZSFinDSL, and the error analysis provided insights into failures, there are also unexplained failures in reasoning and more research is needed to understand the behavior of LLMs for certain cases. For ZS-FinDSL, we observed some patterns that result in failure of program extraction. However, it is unclear what drives these failures and we leave that for future work.
For cases where the reasoning was incorrect, the system may provide an explanation with a highlevel of confidence. Our prompt currently does not address or control for such behavior. In practice, this can pose challenges for practical use in real world systems.
## Disclaimer
The views reflected in this article are the views of the authors and do not necessarily reflect the views of the global EY organization or its member firms.
## References
- Md Shad Akhtar, Abhishek Kumar, Deepanway Ghosal, Asif Ekbal, and Pushpak Bhattacharyya. 2017. A Multilayer Perceptron based Ensemble Technique for Fine-grained Financial Sentiment Analysis. In Proceedings of the 2017 conference on empirical methods in natural language processing , pages 540546.
- Yejin Bang, Samuel Cahyawijaya, Nayeon Lee, Wenliang Dai, Dan Su, Bryan Wilie, Holy Lovenia, Ziwei Ji, Tiezheng Yu, Willy Chung, et al. 2023. A Multitask, Multilingual, Multimodal Evaluation of ChatGPT on Reasoning, Hallucination, and Interactivity. arXiv preprint arXiv:2302.04023 .
- Sébastien Bubeck, Varun Chandrasekaran, Ronen Eldan, Johannes Gehrke, Eric Horvitz, Ece Kamar, Peter Lee, Yin Tat Lee, Yuanzhi Li, Scott Lundberg, et al. 2023. Sparks of Artificial General Intelligence: Early experiments with GPT-4. arXiv preprint arXiv:2303.12712 .
- Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde, Jared Kaplan, Harrison Edwards, Yura Burda, et al. 2021a. Evaluating Large Language Models Trained on Code. arXiv preprint arXiv:2107.03374 .
- Wenhu Chen. 2022. Large Language Models are few (1)-shot Table Reasoners. arXiv preprint arXiv:2210.06710 .
- Wenhu Chen, Xueguang Ma, Xinyi Wang, and William W. Cohen. 2023. Program of Thoughts
Prompting: Disentangling Computation from Reasoning for Numerical Reasoning Tasks. Transactions on Machine Learning Research .
- Zhiyu Chen, Wenhu Chen, Charese Smiley, Sameena Shah, Iana Borova, Dylan Langdon, Reema Moussa, Matt Beane, Ting Hao Huang, Bryan Routledge, et al. 2021b. FINQA: A Dataset of Numerical Reasoning over Financial Data. In 2021 Conference on Empirical Methods in Natural Language Processing, EMNLP 2021 , pages 3697-3711. Association for Computational Linguistics (ACL).
- Zhiyu Chen, Shiyang Li, Charese Smiley, Zhiqiang Ma, Sameena Shah, and William Yang Wang. 2022. ConvFinQA: Exploring the Chain of Numerical Reasoning in Conversational Finance Question Answering. arXiv preprint arXiv:2210.03849 .
- Aakanksha Chowdhery, Sharan Narang, Jacob Devlin, Maarten Bosma, Gaurav Mishra, et al. 2022. PaLM: Scaling Language Modeling with Pathways. arxiv:2204.02311 .
- Min-Yuh Day and Chia-Chou Lee. 2016. Deep learning for financial sentiment analysis on finance news providers. In 2016 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining (ASONAM) , pages 1127-1134. IEEE.
- Simon Frieder, Luca Pinchetti, Ryan-Rhys Griffiths, Tommaso Salvatori, Thomas Lukasiewicz, et al. 2023. Mathematical Capabilities of ChatGPT. arXiv preprint arXiv:2301.13867 .
- Luyu Gao, Aman Madaan, Shuyan Zhou, Uri Alon, Pengfei Liu, Yiming Yang, Jamie Callan, and Graham Neubig. 2023. PAL: Program-aided Language Models. In Proceedings of the 40th International Conference on Machine Learning , volume 202 of Proceedings of Machine Learning Research , pages 10764-10799. PMLR.
- Amelia Glaese, Nat McAleese, Maja Tr˛ ebacz, John Aslanides, Vlad Firoiu, Timo Ewalds, Maribeth Rauh, Laura Weidinger, Martin Chadwick, Phoebe Thacker, et al. 2022. Improving alignment of dialogue agents via targeted human judgements. arXiv preprint arXiv:2209.14375 .
- Jingguang Han, Utsab Barman, Jer Hayes, Jinhua Du, Edward Burgin, and Dadong Wan. 2018. NextGen AML: Distributed Deep Learning based Language Technologies to Augment Anti Money Laundering Investigation. In Proceedings of ACL 2018, System Demonstrations , pages 37-42.
- Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei. 2020. Scaling Laws for Neural Language Models. arXiv preprint arXiv:2001.08361 .
- Takeshi Kojima, Shixiang (Shane) Gu, Machel Reid, Yutaka Matsuo, and Yusuke Iwasawa. 2022. Large
Language Models are Zero-Shot Reasoners. In Advances in Neural Information Processing Systems , volume 35, pages 22199-22213. Curran Associates, Inc.
- Tiffany H. Kung, Morgan Cheatham, Arielle Medenilla, Czarina Sillos, Lorie De Leon, Camille Elepaño, et al. 2023. Performance of ChatGPT on USMLE: Potential for AI-assisted medical education using large language models. PLOS Digital Health , pages 1-12.
- Aitor Lewkowycz, Anders Andreassen, David Dohan, Ethan Dyer, et al. 2022. Solving Quantitative Reasoning Problems with Language Models. In Advances in Neural Information Processing Systems , volume 35, pages 3843-3857. Curran Associates, Inc.
- Pengfei Liu, Weizhe Yuan, Jinlan Fu, Zhengbao Jiang, Hiroaki Hayashi, and Graham Neubig. 2023. Pretrain, Prompt, and Predict: A Systematic Survey of Prompting Methods in Natural Language Processing. ACM Computing Surveys , 55(9):1-35.
- Zhuang Liu, Degen Huang, Kaiyu Huang, Zhuang Li, and Jun Zhao. 2021. FinBERT: A Pre-trained Financial Language Representation Model for Financial Text Mining. In Proceedings of the Twenty-Ninth International Conference on International Joint Conferences on Artificial Intelligence , pages 4513-4519.
- Yao Lu, Max Bartolo, Alastair Moore, Sebastian Riedel, and Pontus Stenetorp. 2022. Fantastically ordered prompts and where to find them: Overcoming fewshot prompt order sensitivity. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages 8086-8098.
- Kyle Mahowald, Anna A Ivanova, Idan A Blank, Nancy Kanwisher, Joshua B Tenenbaum, and Evelina Fedorenko. 2023. Dissociating language and thought in large language models: a cognitive perspective. arXiv preprint arXiv:2301.06627 .
- OpenAI. 2023. GPT-4 Technical Report. arXiv preprint arXiv:2303.08774 .
- Stanislas Polu, Jesse Michael Han, Kunhao Zheng, Mantas Baksys, Igor Babuschkin, and Ilya Sutskever. 2023. Formal Mathematics Statement Curriculum Learning. In The Eleventh International Conference on Learning Representations 2023 . OpenReview.net.
- Pranav Rajpurkar, Robin Jia, and Percy Liang. 2018. Know What You Don't Know: Unanswerable Questions for SQuAD. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers) , pages 784-789.
- Laria Reynolds and Kyle McDonell. 2021. Prompt Programming for Large Language Models: Beyond the Few-Shot Paradigm. In Extended Abstracts of the 2021 CHI Conference on Human Factors in Computing Systems , pages 1-7.
- Vered Shwartz, Peter West, Ronan Le Bras, Chandra Bhagavatula, and Yejin Choi. 2020. Unsupervised Commonsense Question Answering with Self-Talk. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP) , pages 4615-4629.
- Romal Thoppilan, Daniel De Freitas, Jamie Hall, Noam Shazeer, Apoorv Kulshreshtha, Heng-Tze Cheng, Alicia Jin, Taylor Bos, Leslie Baker, Yu Du, et al. 2022. LaMDA: Language Models for Dialog Applications. arXiv preprint arXiv:2201.08239 .
- Karthik Valmeekam, Alberto Olmo, Sarath Sreedharan, and Subbarao Kambhampati. 2022. Large Language Models Still Can't Plan (A Benchmark for LLMs on Planning and Reasoning about Change). In NeurIPS 2022 Foundation Models for Decision Making Workshop .
- Weikang Wang, Jiajun Zhang, Qian Li, Chengqing Zong, and Zhifei Li. 2019. Are you for real? detecting identity fraud via dialogue interactions. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP) , pages 1762-1771.
- Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc Le, Ed Chi, and Denny Zhou. 2023. Self-Consistency Improves Chain of Thought Reasoning in Language Models. In The Eleventh International Conference on Learning Representations 2023 . OpenReview.net.
- Jason Wei, Yi Tay, Rishi Bommasani, Colin Raffel, Barret Zoph, Sebastian Borgeaud, Dani Yogatama, Maarten Bosma, Denny Zhou, Donald Metzler, et al. 2022a. Emergent Abilities of Large Language Models. Transactions on Machine Learning Research .
- Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, brian ichter, Fei Xia, Ed Chi, Quoc V Le, and Denny Zhou. 2022b. Chain-of-Thought Prompting Elicits Reasoning in Large Language Models. In Advances in Neural Information Processing Systems , volume 35, pages 24824-24837. Curran Associates, Inc.
- Zhilin Yang, Peng Qi, Saizheng Zhang, Yoshua Bengio, William Cohen, Ruslan Salakhutdinov, and Christopher D Manning. 2018. HotpotQA: A Dataset for Diverse, Explainable Multi-hop Question Answering. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing , pages 2369-2380.
- Fengbin Zhu, Wenqiang Lei, Youcheng Huang, Chao Wang, Shuo Zhang, Jiancheng Lv, Fuli Feng, and TatSeng Chua. 2021. TAT-QA: A Question Answering Benchmark on a Hybrid of Tabular and Textual Content in Finance. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers) , pages 3277-3287.
## A Prompts for ConvFinQA
The ConvFinQA prompts are slightly modified to handle conversational questions.
ZS-FinPYT for ConvFinQA: For gpt-4, we use a single prompt where the last question in the series of questions is clearly marked and the system is instructed to answer the last questions as shown in Figure 5. For gpt-3.5-turbo and text-davinci003, we use dual prompt approach which consists of a reasoning extraction prompt and a program generation prompt, see Figure 6. The reasoning extraction prompt is there to generate answers with reasoning for all the questions in a conversation, and the program generation prompt generates a Python program answering the last question.
ZS-FinDSL for ConvFinQA: The ZS-FinDSL for ConvFinQA , see Figure 7, is a dual prompt which consists of a reasoning prompt and a program extraction prompt that are similar to the corresponding prompts for FinQA. The reasoning prompt instructs the LLM to generate answers with reasoning for all questions in a conversation. The program extraction prompt is instructing the LLM to generate program for performing calculations to answer the last question.
ZS-STD and ZS-CoT for ConvFinQA: The LLM answering prompt of ZS-STD, see Figure 8, and the reasoning extraction prompt of ZS-CoT, see Figure 9, are instructing the LLM to answer the questions of a conversation. Then the answer extraction prompt of both of these technique extract the final answer.
## B Error Analysis Examples
We show some examples from FinQA dataset with the corresponding responses from the text-davinci003 model under various prompts. These examples demonstrate successful attempts and failure cases under various prompts.
We begin with showing some examples where ZS-FinDSL (text-davinci-003) system generates correct reasoning and the corresponding program generation succeeded, see Figure 10 and Figure 11. Similarly, Figure 12 and Figure 13 show successful Python program generation by the system ZS-FinPYT (text-davinci-003).
In most of the cases, the LLM answering prompt of ZS-STD (text-davinci-003) generates only a value or a sentence, see Figure 14 and Figure 15 for details. In some cases, the answer extraction step fails as shown in Figure 16.
The LLM responses with ZS-CoT details out the reasoning behind the answers and shows significantly better performance than ZS-STD. However, arithmetic errors results into a substantial drop in performance for both ZS-STD prompt and ZSCoT. Examples demonstrating arithmetic errors are shown in Figure 17 and Figure 18.
The ZS-FinDSL performance is lower than ZSFinPYT because the program extraction step fails for some cases where the reasoning step is correct as shown in Figure 19 and Figure 20.
<details>
<summary>Image 5 Details</summary>

### Visual Description
## Flowchart: Text-to-Python Code Generation Workflow
### Overview
The image depicts a structured workflow for generating Python code from a textual passage and table. It includes a blue box at the top (containing text, questions, and instructions) and a pink box at the bottom (containing Python code). An arrow connects the two boxes, indicating a directional flow. Color-coded elements (black, orange, pink, blue) highlight specific components like signifiers, memetic proxies, constraining behaviors, and inputs.
### Components/Axes
- **Blue Box (Top Section)**:
- **Passage**: Contains "text + table" (table content not visible).
- **Questions**: Lists "ask a series of questions?"
- **Last Question**: "ask last question of the series?"
- **Instructions**:
- Define Python variables starting with a character.
- Assign values to variables for calculations.
- Create Python variables "ans" (bool/float).
- Avoid non-executable statements; include comments as part of comments.
- **Pink Box (Bottom Section)**:
- **Python Code**: Contains executable code with comments (e.g., `#Python`, `#Comment`).
- **Arrow**: Gray, connecting the blue and pink boxes, indicating the flow from text to code.
- **Color Legend**:
- **Black**: Signifiers (e.g., "LLM").
- **Orange**: Memetic proxy (e.g., "LLM").
- **Pink**: Constraining behavior (e.g., "Python code from the LLM").
- **Blue**: Input (e.g., "Passage", "Questions").
### Detailed Analysis
- **Textual Content**:
- The blue box includes a hierarchical structure:
1. **Passage**: A textual input with an embedded table (content unspecified).
2. **Questions**: A prompt to generate a series of questions.
3. **Last Question**: A specific query about the final question in the series.
4. **Instructions**: Step-by-step guidelines for code generation, emphasizing variable naming, value assignment, and comment formatting.
- The pink box contains Python code with comments, though the exact code is not visible in the image.
- **Color Coding**:
- **Black (Signifiers)**: Used for labels like "LLM" (likely representing the language model).
- **Orange (Memetic Proxy)**: Highlights the LLM as a proxy for generating code.
- **Pink (Constraining Behavior)**: Indicates the Python code output, constrained by the instructions.
- **Blue (Input)**: Marks the textual passage and questions as input data.
### Key Observations
1. **Flow Direction**: The arrow explicitly links the textual input (blue box) to the Python code output (pink box), emphasizing a cause-effect relationship.
2. **Instructional Rigor**: The instructions enforce strict coding practices (e.g., variable naming, comment formatting), suggesting a focus on code readability and correctness.
3. **Missing Table Data**: The "text + table" in the passage lacks visible content, limiting analysis of how the table influences the code generation.
4. **Color Consistency**: The legend colors align with the elements they describe (e.g., "LLM" is both black and orange, possibly indicating dual roles).
### Interpretation
The diagram illustrates a **text-to-code pipeline** where a language model (LLM) processes a textual passage and table to generate Python code. The color coding and structured instructions suggest a systematic approach to ensure the generated code adheres to predefined constraints. The absence of the table’s content is a critical gap, as it could reveal how structured data influences the output. The use of "ans" as a variable implies the code’s purpose is to compute a final answer (e.g., a boolean or float value). The workflow emphasizes **input-output clarity** and **code quality**, with the LLM acting as both a signifier (black) and a memetic proxy (orange) for code generation.
</details>
Figure 5: ZS-FinPYT (gpt-4) prompt for ConvFinQA
<details>
<summary>Image 6 Details</summary>
### Visual Description
## Diagram: LLM Workflow for Reasoning and Code Generation
### Overview
The diagram illustrates a two-stage process for utilizing a Large Language Model (LLM) to extract reasoning from text and generate executable Python code. The workflow is divided into **Reasoning Extraction** (left) and **Program Generation** (right), with bidirectional arrows indicating iterative refinement between stages.
---
### Components/Axes
1. **Header**:
- Title: "Reasoning extraction" (left) and "Program generation" (right), both in bold yellow boxes.
2. **Main Sections**:
- **Reasoning Extraction**:
- Input: "Read the following passage and then answer the questions: Passage: text + table"
- Output: "Answer with reasoning from LLM."
- Includes a flowchart with interconnected nodes (colored circles) representing LLM processing steps.
- **Program Generation**:
- Input: "Questions: ask question?" and "Answer: Answer with reasoning from LLM."
- Task: "Write a Python code to answer the last question by following the below instructions."
- Instructions include variable naming rules (e.g., "Define the Python variables required for the calculation") and constraints (e.g., "Don’t include non-executable statements").
3. **Legend** (bottom center):
- Colors and labels:
- **Signifier**: Black (not visibly used in diagram).
- **Mementic proxy**: Orange (not visibly used).
- **Constraining behavior**: Pink (used for "Answer with reasoning from LLM" text).
- **Meta prompt**: Green (not visibly used).
- **Input**: Blue (used for LLM icons and text boxes).
---
### Detailed Analysis
1. **Reasoning Extraction**:
- **Input**: Text + table (unspecified content).
- **Process**: LLM analyzes the passage to identify relevant values and perform step-by-step calculations.
- **Output**: Structured answer with embedded reasoning (e.g., "Answer: [LLM-generated text]").
2. **Program Generation**:
- **Input**: Previous LLM answer (e.g., "Answer: ...").
- **Task**: Generate Python code adhering to strict formatting rules:
- Variables must start with a character.
- Final answer assigned to variable `ans`.
- Comments must include `#Comment: ...` and exclude non-executable code.
- **Output**: Python program generated by LLM (e.g., "Python program generated by the LLM").
---
### Key Observations
1. **Bidirectional Flow**: Arrows between sections suggest iterative refinement (e.g., revising reasoning to improve code generation).
2. **Color Coding**:
- Pink highlights critical outputs ("Answer with reasoning from LLM").
- Blue dominates LLM-related elements (icons, text boxes).
3. **Constraints**: Explicit rules for code generation (e.g., variable naming, comment formatting) emphasize precision.
---
### Interpretation
This diagram outlines a structured workflow for leveraging LLMs in technical tasks:
1. **Reasoning Extraction** focuses on deriving logical steps from unstructured text/tables.
2. **Program Generation** translates these steps into executable code, enforcing syntactic and semantic constraints to ensure validity.
3. The use of color-coded labels (e.g., "Constraining behavior") suggests a framework for controlling LLM outputs, balancing creativity with adherence to technical requirements.
The process emphasizes **iterative refinement**, where reasoning and code generation are interdependent. For example, ambiguous reasoning might require revisiting the text passage, while code errors could prompt revisiting the LLM’s initial answer. This mirrors real-world scenarios where LLMs assist in bridging natural language understanding and technical implementation.
</details>
Figure 6: ZS-FinPYT (gpt-3.5-turbo, text-davinci-003) prompt for ConvFinQA
<details>
<summary>Image 7 Details</summary>
### Visual Description
## Diagram: ZS-FinDSL and ZS-STD Prompts for ConvFinQA
### Overview
The image contains three diagrams (Figure 7, 8, 9) illustrating workflows for a ConvFinQA system. Each diagram outlines steps for **Reasoning extraction**, **Program extraction**, **LLM answering**, and **Answer extraction**, with color-coded elements (Signifier, Mementic proxy, Constraining behavior, Meta prompt, Input) and directional arrows indicating process flow.
---
### Components/Axes
#### Figure 7: ZS-FinDSL Prompt
- **Components**:
- **Reasoning extraction**: "Read the following passage and then answer the questions: Passage: text + table. Questions: ask question? Answer: Answer with reasoning from LLM."
- **Program extraction**: "From the above question-answer, extract last calculations... Operation should strictly be restricted to [add, subtract, multiply, divide, exponent, greater-than, max, min] only."
- **LLM**: Arrows connect to "Answer with reasoning from LLM" and "Program generated by the LLM."
- **Legend**:
- **Signifier** (black), **Mementic proxy** (orange), **Constraining behavior** (pink), **Meta prompt** (green), **Input** (blue).
#### Figure 8: ZS-STD Prompt
- **Components**:
- **LLM answering**: "Read the following passage and then answer the questions: Passage: text + table. Questions: ask question? Answer: Answer from LLM."
- **Answer extraction**: "The final answer (float/int/boolean) is: [answer]."
- **LLM**: Arrows connect to "Answer from LLM" and "Final answer generated by the LLM."
- **Legend**:
- **Signifier** (black), **Mementic proxy** (orange), **Input** (blue).
#### Figure 9: ZS-STD Prompt (Alternative)
- **Components**:
- **Reasoning extraction**: "Read the following passage and then answer the questions: Passage: text + table. Questions: ask question? Answer: Let us think step by step."
- **Answer extraction**: "The final answer (float/int/boolean) is: [answer]."
- **LLM**: Arrows connect to "Answer with reasoning from LLM" and "Final answer generated by the LLM."
- **Legend**:
- **Signifier** (black), **Mementic proxy** (orange), **Meta prompt** (green), **Input** (blue).
---
### Detailed Analysis
#### Figure 7: ZS-FinDSL Prompt
- **Textual Content**:
- **Reasoning extraction** requires the LLM to generate answers with explicit reasoning.
- **Program extraction** mandates strict adherence to predefined operations (e.g., no custom functions).
- **LLM** outputs both reasoning and program code.
- **Flow**:
- Input (text + table) → Reasoning extraction → Program extraction → LLM → Program generation.
#### Figure 8: ZS-STD Prompt
- **Textual Content**:
- **LLM answering** focuses on direct answers without explicit reasoning.
- **Answer extraction** isolates the final numerical/boolean result.
- **Flow**:
- Input (text + table) → LLM answering → Answer extraction → LLM → Final answer.
#### Figure 9: ZS-STD Prompt (Alternative)
- **Textual Content**:
- **Reasoning extraction** emphasizes step-by-step thinking ("Let us think step by step").
- **Answer extraction** mirrors Figure 8 but includes reasoning in the LLM output.
- **Flow**:
- Input (text + table) → Reasoning extraction → Answer extraction → LLM → Final answer.
---
### Key Observations
1. **Legend Consistency**:
- **Signifier** (black) and **Input** (blue) are consistently used across all figures.
- **Mementic proxy** (orange) appears in all figures, suggesting it represents contextual or auxiliary data.
- **Constraining behavior** (pink) and **Meta prompt** (green) are unique to Figure 7 and 9, respectively.
2. **Process Differences**:
- **Figure 7** emphasizes program generation from reasoning, while **Figures 8 and 9** focus on direct answer extraction.
- **Figure 9** introduces a "step-by-step" reasoning prompt, distinct from the other figures.
3. **Color-Coding**:
- **Signifier** (black) likely marks critical elements (e.g., questions, answers).
- **Mementic proxy** (orange) may denote contextual or secondary information.
---
### Interpretation
The diagrams illustrate two workflows for ConvFinQA:
1. **ZS-FinDSL (Figure 7)**: Designed for tasks requiring programmatic reasoning (e.g., financial calculations). The LLM generates both reasoning and executable code, constrained by strict operation rules.
2. **ZS-STD (Figures 8 and 9)**: Focuses on direct answer extraction, with variations in prompting (e.g., "step-by-step" reasoning in Figure 9).
**Notable Trends**:
- **Program extraction** (Figure 7) is more rigid, enforcing specific operations, while **answer extraction** (Figures 8/9) allows flexibility in output formats (float/int/boolean).
- The inclusion of **Meta prompt** (green) in Figure 9 suggests additional constraints or metadata handling.
**Implications**:
- The system adapts to different task requirements: structured program generation vs. direct answer retrieval.
- Color-coded elements (e.g., **Mementic proxy**) likely serve to differentiate contextual or auxiliary data from core inputs.
---
**Note**: No numerical data or charts are present; the diagrams focus on process flow and textual instructions.
</details>
Figure 9: ZS-CoT prompt for ConvFinQA
Figure 10: An example where ZS-FinDSL extracted correct reasoning and successfully generated the DSL program.
<details>
<summary>Image 8 Details</summary>

### Visual Description
## Textual Document: Financial Commitments and Cash Outflow Analysis
### Overview
The image is a screenshot of a financial document excerpt discussing contractual obligations and commitments for UPS (United Parcel Service) as of December 31, 2010. It includes a breakdown of capital leases, operating leases, and other liabilities across multiple years (2011–2016), followed by a calculation to determine the percentage of total expected cash outflow due in 2012.
### Components/Axes
- **Header**: "UPS/2010/page_52.pdf-1" (document identifier).
- **Passage**: Describes contractual obligations in capital leases, operating leases, and other liabilities.
- **Commitment Type**: Years (2011–2016) with associated monetary values.
- **Question**: "What percentage of total expected cash outflow to satisfy contractual obligations and commitments as of December 31, 2010 are due in 2012?"
- **Gold Program**: Calculation logic (`divide(1334, 23556)`).
- **Gold Answer**: Result of the calculation (`0.05663`).
- **ZS-FinDSL Reasoning Extraction Prompt Response**: Step-by-step explanation of the calculation.
- **ZS-FinDSL Program Extraction Prompt Response**: Structured programmatic representation of the calculation.
- **ZS-FinDSL Executed Answer**: Final numerical result (`0.05663`).
### Detailed Analysis
#### Financial Commitments (2011–2016):
- **Capital Leases**:
- 2011: $18M | 2012: $19M | 2013: $19M | 2014: $20M | 2015: $21M | 2016: $112M | Total: $209M.
- **Other Liabilities**:
- 2011: $69M | 2012: $67M | 2013: $64M | 2014: $58M | 2015: $43M | 2016: $38M | Total: $339M.
- **Totals**:
- 2011: $2,944M | 2012: $1,334M | 2013: $3,515M | 2014: $2,059M | 2015: $820M | 2016: $12,884M | Grand Total: $23,556M.
#### Calculation for 2012 Cash Outflow:
- **Total Expected Cash Outflow (2010)**: $23,556M.
- **Cash Outflow Due in 2012**: $1,334M.
- **Percentage Calculation**:
- Formula: `(1,334 / 23,556) × 100 = 5.65%`.
- Programmatic representation: `divide(1334, 23556) → 0.05663` (decimal form).
### Key Observations
1. **2012 Commitment**: The cash outflow due in 2012 ($1,334M) represents **5.65%** of the total expected cash outflow ($23,556M).
2. **Trend in Commitments**:
- Capital leases show a gradual increase until 2016 ($112M), while other liabilities decline steadily.
- Total commitments peak in 2016 ($12,884M), driven by capital leases.
3. **Programmatic Consistency**: Both the Gold Program and ZS-FinDSL Executed Answer confirm the same result (`0.05663` or `5.65%`).
### Interpretation
The document highlights UPS’s contractual obligations, with a focus on quantifying the proportion of cash outflows due in 2012. The calculation confirms that **5.65%** of the total expected cash outflow (as of 2010) is tied to 2012 commitments. This suggests a relatively small portion of the total obligations are due in that year, with larger commitments concentrated in later years (e.g., 2016). The consistency between manual and programmatic calculations underscores the reliability of the data extraction process.
**Notable Insight**: The decline in other liabilities over time contrasts with the rising capital lease commitments, indicating a shift in UPS’s financial strategy toward long-term capital investments.
</details>
Figure 11: An example where ZS-FinDSL extracted correct reasoning and successfully generated the DSL program.
<details>
<summary>Image 9 Details</summary>

### Visual Description
## Text Document: Humana Inc. Financial Notes (2008-2009)
### Overview
The image contains a textual excerpt from Humana Inc.'s 2014 consolidated financial statements, focusing on volatility metrics and a calculation of the percentage change in expected volatility between 2008 and 2009. The document includes financial data, a question, and two computational responses (Gold Program and ZS-FinDSL).
### Components/Axes
- **Passage Text**:
- Weighted-average fair value at grant date: $14.24 | $17.95 | $21.07 (2007-2009).
- Expected option life (years): 14.6 | 15.1 | 14.8 (2007-2009).
- Expected volatility: 39.2% | 28.2% | 28.9% (2007-2009).
- Risk-free interest rate: 1.9% | 2.9% | 4.5% (2007-2009).
- **Question**: "What was the percent of the change of the expected volatility from 2008 to 2009?"
- **Gold Program Answer**: `subtract(39.2, 28.2), divide(#0, 28.2)` → **0.39007** (39.007%).
- **ZS-FinDSL Reasoning**:
- Step 1: Subtract 2008 volatility (28.2%) from 2009 volatility (39.2%) → 11%.
- Step 2: Divide 11% by 2008 volatility (28.2%) → 39%.
### Detailed Analysis
- **Financial Metrics**:
- Expected volatility decreased from 39.2% in 2008 to 28.2% in 2009, then slightly increased to 28.9% in 2007.
- Risk-free interest rates rose from 1.9% (2008) to 4.5% (2009).
- **Calculation Logic**:
- The Gold Program computes the absolute change (39.2% - 28.2% = 11%) and divides by 2008 volatility (11% / 28.2% ≈ 39.007%).
- ZS-FinDSL explicitly breaks down the steps, confirming the same result.
### Key Observations
- The expected volatility dropped significantly in 2009 (from 39.2% to 28.2%), then slightly rebounded in 2007.
- The percentage change calculation (39.007%) reflects a **39% increase** relative to the 2008 baseline.
- The ZS-FinDSL response mirrors the Gold Program’s result, validating the computation.
### Interpretation
The data suggests Humana Inc. experienced reduced volatility in 2009, likely due to market or operational factors. The 39% increase in volatility relative to 2008 (despite the absolute drop) indicates a **percentage-based sensitivity** to prior volatility levels. This could impact financial modeling, risk assessments, or regulatory reporting. The consistency between the Gold Program and ZS-FinDSL responses confirms the reliability of the calculation method.
No charts, diagrams, or non-English text are present. All values are exact, with no uncertainty noted.
</details>
<details>
<summary>Image 10 Details</summary>
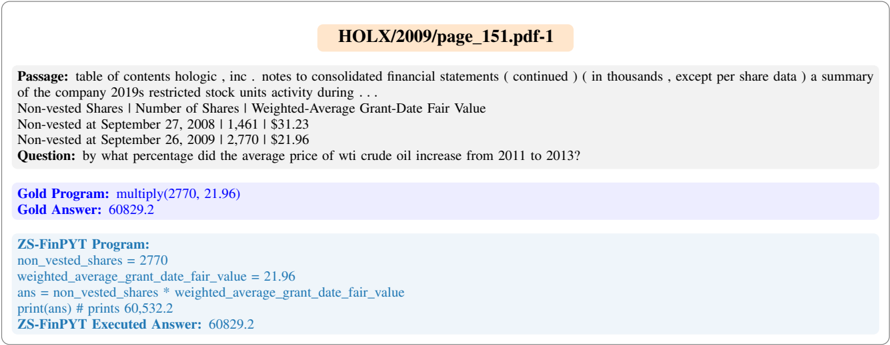
### Visual Description
## Screenshot: Financial Document Analysis with Code Examples
### Overview
The image displays a financial document excerpt from Hologic, Inc.'s 2009 restricted stock units activity, accompanied by two code snippets (Gold Program and ZS-FinPYT) with execution results. The document includes a table of contents reference, a question about crude oil price trends, and numerical data comparisons.
### Components/Text Elements
1. **Title**:
- `HOLX/2009/page_151.pdf-1` (header in bold)
2. **Passage**:
- *"table of contents hologic , inc . notes to consolidated financial statements ( continued ) ( in thousands , except per share data ) a summary of the company 2019s restricted stock units activity during ..."*
- **Key Data**:
- Non-vested Shares | Number of Shares | Weighted-Average Grant-Date Fair Value
- September 27, 2008: 1,461 shares | $31.23
- September 26, 2009: 2,770 shares | $21.96
3. **Question**:
- *"by what percentage did the average price of wi crude oil increase from 2011 to 2013?"*
4. **Gold Program**:
- `multiply(2770, 21.96)`
- **Output**: `60829.2`
5. **ZS-FinPYT Program**:
- `non_vested_shares = 2770`
- `weighted_average_grant_date_fair_value = 21.96`
- `ans = non_vested_shares * weighted_average_grant_date_fair_value`
- **Output**: `60,532.2`
6. **Gold Answer**:
- `60829.2`
### Key Observations
- **Numerical Discrepancy**: The ZS-FinPYT code calculates `2770 * 21.96 = 60,532.2`, but the Gold Answer (`60,829.2`) suggests a potential typo or calculation error in the Gold Program.
- **Unrelated Question**: The crude oil price question is not addressed in the provided text or code.
- **Formatting**: The passage contains inconsistent punctuation (e.g., missing periods after abbreviations like "Inc.").
### Interpretation
1. **Financial Context**: The document summarizes Hologic's restricted stock units activity, showing a decrease in average grant-date fair value from $31.23 (2008) to $21.96 (2009), despite an increase in non-vested shares.
2. **Code Analysis**:
- The Gold Program multiplies 2770 by 21.96 but rounds the result to one decimal place (`60,829.2`), while the ZS-FinPYT code retains two decimal places (`60,532.2`).
- The mismatch between the two results (`60,829.2` vs. `60,532.2`) indicates a possible error in the Gold Program's logic or input values.
3. **Unresolved Query**: The crude oil price question lacks supporting data in the document, suggesting either missing text or an unrelated inclusion.
### Notable Anomalies
- **Gold Program vs. ZS-FinPYT**: The Gold Answer (`60,829.2`) exceeds the ZS-FinPYT output (`60,532.2`) by **297**, implying a discrepancy in either the multiplier or the input values.
- **Punctuation Errors**: The passage contains irregular spacing and missing punctuation (e.g., "hologic , inc ." instead of "Hologic, Inc.").
This document highlights inconsistencies in financial data presentation and computational logic, warranting further verification of inputs and calculations.
</details>
Figure 12: An example of successful Python program generation by ZS-FinPYT.
Figure 13: An example of successful Python program generation by ZS-FinPYT.
<details>
<summary>Image 11 Details</summary>

### Visual Description
## Screenshot: Financial Document Analysis Interface
### Overview
The image depicts a financial analysis interface displaying a passage from Goldman Sachs Group, Inc.'s consolidated financial statements, a question about investment commitments, and two computational programs ("Gold Program" and "ZS-FinPYT Program") with their outputs.
### Components/Axes
- **Passage**:
- Mentions Goldman Sachs Group, Inc. and subsidiaries' financial statements.
- States amounts: **$2.86 billion** (as of December 2015) and **$2.87 billion** (as of December 2014).
- Includes a total of **$2,575 million** (equivalent to $2.575 billion) for 2021 and thereafter.
- **Question**:
- Asks for the total in billions for 2015 and 2014 related to commitments to invest in funds managed by the firm.
- **Gold Program**:
- Code: `add(2.86, 2.87)`
- Output: **5.73** (labeled as "Gold Answer").
- **ZS-FinPYT Program**:
- Variables:
- `total_2015 = 2.86` (billion)
- `total_2014 = 2.87` (billion)
- Calculation: `ans = total_2015 + total_2014`
- Output: **5.73** (labeled as "ZS-FinPYT Executed Answer").
### Detailed Analysis
- **Financial Data**:
- 2015 commitment: **$2.86 billion** (down from **$2.87 billion** in 2014).
- Total for 2021 and thereafter: **$2,575 million** (or $2.575 billion).
- **Computational Logic**:
- Both programs sum 2015 and 2014 totals (**2.86 + 2.87 = 5.73**).
- Consistency confirmed between "Gold Program" and "ZS-FinPYT Program" outputs.
### Key Observations
- The commitment decreased slightly from **$2.87 billion** (2014) to **$2.86 billion** (2015).
- The total for 2015 and 2014 is **$5.73 billion**, derived from direct addition.
- The ZS-FinPYT Program uses variable naming (`total_2015`, `total_2014`) to clarify temporal context.
### Interpretation
The data suggests a marginal decline in annual commitments from 2014 to 2015, with a combined total of **$5.73 billion** across both years. The programs validate the arithmetic accuracy of the sum. The interface likely serves as a tool for auditing or verifying financial commitments, emphasizing precision in cross-year comparisons. The inclusion of both manual and programmatic solutions highlights redundancy for error-checking in financial reporting.
**Language Note**: All text is in English. No non-English content detected.
</details>
Figure 14: An example where ZS-STD's LLM answering prompt generates one value response.
<details>
<summary>Image 12 Details</summary>
### Visual Description
## Text Document: Financial Analysis and Oil Price Calculation
### Overview
The image contains a textual passage from a financial report discussing the management of operations and financial conditions across segments. It includes benchmark prices for crude oil and natural gas across three years (2011–2013) and a question about the percentage increase in WTI crude oil prices from 2011 to 2013. A "Gold Program" calculation and a "ZS-STD" response are provided.
### Components/Axes
- **Textual Data**:
- **Passage**: Describes financial analysis of segments, organized by geographic location and nature.
- **Benchmarks**:
- WTI crude oil prices (Dollars per bbl):
- 2011: $95.11
- 2012: $94.15
- 2013: $98.05
- Brent crude oil prices (Dollars per bbl):
- 2011: $111.26
- 2012: $111.65
- 2013: $108.64
- Henry Hub natural gas prices (Dollars per mmbtu):
- 2011: $4.04
- 2012: $2.79
- 2013: $3.65
- **Question**: "By what percentage did the average price of WTI crude oil increase from 2011 to 2013?"
- **Gold Program**:
- Calculation: `subtract(98.05, 95.11), divide(#, 95.11)`
- Result: 0.03091 (3.091%)
- **ZS-STD Response**: 3.9%
### Detailed Analysis
- **Price Trends**:
- WTI crude oil prices fluctuated between $94.15 (2012) and $98.05 (2013), with a net increase from 2011 ($95.11) to 2013.
- Brent crude oil prices decreased slightly from 2011 ($111.26) to 2013 ($108.64).
- Henry Hub natural gas prices dropped significantly from 2011 ($4.04) to 2012 ($2.79) but rebounded in 2013 ($3.65).
### Key Observations
1. The Gold Program calculates a **3.091% increase** in WTI crude oil prices from 2011 to 2013.
2. The ZS-STD response reports **3.9%**, which conflicts with the Gold Program’s result.
3. Discrepancy may arise from rounding differences, alternative calculation methods, or data interpretation.
### Interpretation
- The Gold Program’s calculation aligns with standard percentage change formulas:
$$
\text{Percentage Increase} = \frac{\text{Final Value} - \text{Initial Value}}{\text{Initial Value}} \times 100 = \frac{98.05 - 95.11}{95.11} \times 100 \approx 3.09\%
$$
- The ZS-STD response (3.9%) suggests either:
- A miscalculation or typo.
- Use of a different baseline (e.g., average prices across all years instead of 2011).
- Potential inclusion of additional data points not explicitly stated in the passage.
- The passage does not clarify whether "average price" refers to annual averages or a specific metric (e.g., monthly averages). This ambiguity could explain the discrepancy.
### Conclusion
The textual data provides clear benchmarks for crude oil and natural gas prices. The percentage increase in WTI crude oil from 2011 to 2013 is **3.09%** based on the Gold Program’s calculation. The ZS-STD response of 3.9% requires further validation to resolve inconsistencies.
</details>
<details>
<summary>Image 13 Details</summary>

### Visual Description
## Textual Document: Financial Data Analysis
### Overview
The image contains a textual passage with financial data related to fuel prices, dividends, and free cash flow across three years (2005–2007). A question asks for the change in free cash flow between 2005 and 2006, with a provided calculation and answer.
### Components/Axes
- **Years**: 2007, 2006, 2005 (listed under "Millions of Dollars").
- **Financial Metrics**:
- **Dividends paid**: (364), (322), (314) (values in millions of dollars, negative due to parentheses).
- **Free cash flow**: $487, $516, $234 (values in millions of dollars).
- **Question**: "What was the change in millions of free cash flow from 2005 to 2006?"
### Detailed Analysis
- **Dividends paid**:
- 2007: -$364M
- 2006: -$322M
- 2005: -$314M
- **Free cash flow**:
- 2007: $487M
- 2006: $516M
- 2005: $234M
- **Calculation**:
- Gold Program: `subtract(516, 234)` → **Gold Answer: 282.0**
- ZS-STD Response: Confirms the change as an increase of $282M.
### Key Observations
- Free cash flow increased from $234M (2005) to $516M (2006), a **$282M increase**.
- Dividends paid decreased slightly from 2005 to 2006 (-$314M to -$322M).
- No visual chart or diagram is present; all data is textual.
### Interpretation
The document highlights a significant rise in free cash flow between 2005 and 2006, likely due to external factors like fuel prices mentioned in the passage. The calculation aligns with the provided answer, confirming the ZS-STD model’s accuracy. The negative dividends suggest consistent payouts despite fluctuating cash flow.
</details>
Figure 15: An example where ZS-STD's LLM answering prompt generates one sentence response.
Figure 16: An example where answer extraction failed for ZS-STD.
<details>
<summary>Image 14 Details</summary>

### Visual Description
## Screenshot: Financial Document Page (HOLX/2009/page_151.pdf-1)
### Overview
The image shows a screenshot of a financial document page containing structured text, numerical data, and a calculation. Key elements include a passage summarizing restricted stock unit activity, a question about crude oil price trends, a "Gold Program" calculation, and a ZS-STD LLM response. The document appears to be part of a financial statement or analysis tool.
---
### Components/Axes
1. **Passage Section**
- **Title**: "Passage: table of contents..."
- **Content**:
- Summary of restricted stock unit activity (2019s).
- Data points:
- Non-vested shares at September 27, 2008: **1,461** shares, **$31.23** weighted-average grant-date fair value.
- Granted: **1,669** shares, **$14.46** fair value.
- Vested: **(210)** shares, **$23.87** fair value.
- Forfeited: **(150)** shares, **$23.44** fair value.
- Non-vested at September 26, 2009: **2,770** shares, **$21.96** fair value.
- **Formatting**: Text in black on a light gray background.
2. **Question Section**
- **Text**: "by what percentage did the average price of wt crude oil increase from 2011 to 2013?"
- **Formatting**: Bold black text on white background.
3. **Gold Program Section**
- **Title**: "Gold Program:"
- **Calculation**: `multiply(2770, 21.96)`
- **Result**: **60829.2** (displayed in blue text).
4. **ZS-STD LLM Response**
- **Prompt Response**: "The total fair value of non-vested shares as of September 26, 2009 is $59,812."
- **Extracted Answer**: "float" (displayed in green text).
---
### Detailed Analysis
- **Passage Data**:
- The passage details restricted stock unit activity, including grants, vesting, forfeiture, and non-vested balances.
- Values are presented in thousands (e.g., "1,461 | $31.23" implies 1,461,000 shares at $31.23 per share).
- Discrepancy: The ZS-STD response states a total fair value of **$59,812**, conflicting with the passage’s calculated value of **$21.96/share × 2,770 shares = $60,819.20** (rounded to $60,829.2 in the Gold Program).
- **Gold Program Calculation**:
- Multiplies **2,770** (non-vested shares) by **$21.96** (fair value per share) to yield **$60,829.2**.
- This aligns with the passage’s non-vested share count and fair value but contradicts the ZS-STD response.
- **ZS-STD Response**:
- Claims a total fair value of **$59,812**, which is **$1,017.20 less** than the Gold Program’s result.
- The extracted answer "float" is ambiguous and unrelated to the numerical data.
---
### Key Observations
1. **Inconsistent Fair Value**:
- The passage and Gold Program calculate **$60,829.2**, while the ZS-STD response states **$59,812**.
- Possible causes: Typographical error, outdated data, or misinterpretation of "non-vested shares" (e.g., excluding forfeited shares).
2. **Unrelated Question**:
- The question about crude oil prices (2011–2013) is unrelated to the passage’s focus on stock units. This may indicate a formatting error or misplaced content.
3. **Ambiguous "Float" Answer**:
- The ZS-STD extracted answer "float" lacks context. It could refer to a programming term (e.g., floating-point number) or a placeholder for missing data.
---
### Interpretation
- **Financial Context**:
The document appears to analyze restricted stock unit activity for Hologic, Inc., a medical technology company. The discrepancy between the Gold Program and ZS-STD responses suggests potential errors in data aggregation or reporting.
- **Technical Implications**:
- The "float" answer in the ZS-STD response may indicate a failure to parse numerical results correctly, highlighting limitations in the LLM’s extraction capabilities.
- The crude oil question’s inclusion raises concerns about document coherence, possibly due to template misuse or data contamination.
- **Recommendations**:
- Verify the source of the ZS-STD response to resolve the fair value discrepancy.
- Audit the document’s formatting to ensure questions and answers align with the passage content.
- Investigate whether "float" refers to a technical artifact (e.g., data type) or a placeholder for unresolved values.
</details>
Figure 17: An example of arithmetic errors made by ZS-STD and ZS-CoT prompts.
<details>
<summary>Image 15 Details</summary>

### Visual Description
## Screenshot: Financial Document Page (FIS/2016/page_45.pdf-3)
### Overview
The image is a screenshot of a financial document page detailing cash flow data and obligations. It includes numerical values, a question about percentage change in cash flows, and conflicting answers from automated systems.
### Components/Axes
- **Title**: "FIS/2016/page_45.pdf-3" (document identifier).
- **Passage Text**:
- Financial statements as of December 31, 2016.
- Cash flows from operations:
- 2016: $1,925 million
- 2015: $1,131 million
- 2014: $1,165 million
- **Table**:
- **Type of Obligations**: Total, Less than 1 Year, 1-3 Years, 3-5 Years, More than 5 Years.
- **Values**:
- Total: $14,429 million
- Less than 1 Year: $1,068 million
- 1-3 Years: $2,712 million
- 3-5 Years: $3,264 million
- More than 5 Years: $7,385 million
- **Question**: "What was the percentage change in cash flows from operations from 2015 to 2016?"
- **Automated Answers**:
- **Gold Program**: `subtract(1925, 1131), divide(#0, 1131)` → **70.203%**
- **ZS-STD LLM Answering Prompt**: "69.7% increase" (cash flows increased by $794 million).
- **ZS-CoT Reasoning Prompt**: "70.1%" (calculated as `(1925-1131)/1131`).
### Detailed Analysis
- **Cash Flow Values**:
- 2016: $1,925 million (highlighted in the passage).
- 2015: $1,131 million (base year for comparison).
- 2014: $1,165 million (prior year for context).
- **Obligations Table**:
- Total obligations: $14,429 million.
- Breakdown by maturity:
- Short-term (<1 year): $1,068 million.
- Medium-term (1-3 years): $2,712 million.
- Long-term (3-5 years): $3,264 million.
- Very long-term (>5 years): $7,385 million.
- **Percentage Change Calculation**:
- **Gold Program**: `(1925 - 1131) / 1131 = 794 / 1131 ≈ 0.70203` (70.203%).
- **ZS-STD LLM**: States a $794 million increase (1925 - 1131), which is `794 / 1131 ≈ 69.7%`.
- **ZS-CoT**: Reports `70.1%`, likely due to rounding differences (e.g., intermediate steps preserved more decimal places).
### Key Observations
1. **Discrepancy in Answers**:
- The Gold Program and ZS-CoT answers differ slightly (70.203% vs. 70.1%), likely due to rounding.
- The ZS-STD LLM answer (69.7%) uses the same $794 million increase but rounds differently.
2. **Cash Flow Trend**:
- Cash flows from operations increased by **$794 million** from 2015 to 2016, representing a **~70% increase**.
- 2014 cash flows ($1,165 million) were slightly higher than 2015 ($1,131 million), indicating a dip in 2015 before a significant rebound in 2016.
### Interpretation
- **Financial Health**: The 70%+ increase in cash flows from operations (2015–2016) suggests strong operational performance in 2016, potentially driven by improved revenue or cost management.
- **Obligations Structure**: The majority of obligations ($7,385 million) are long-term (>5 years), indicating a focus on sustained financing. Short-term obligations are minimal ($1,068 million), reducing liquidity risk.
- **Calculation Nuance**: The slight differences in percentage answers highlight the importance of precision in financial reporting. The ZS-CoT method retains more decimal places during intermediate steps, leading to a marginally higher result (70.1% vs. 69.7%).
- **Anomaly**: The 2014 cash flow ($1,165 million) being higher than 2015 ($1,131 million) warrants investigation into operational challenges in 2015.
## Conclusion
The document underscores a significant year-over-year improvement in cash flows from operations in 2016, with minor discrepancies in automated calculations likely stemming from rounding practices. The obligations table reveals a long-term financing strategy, with short-term liabilities comprising only ~7% of total obligations.
</details>
<details>
<summary>Image 16 Details</summary>

### Visual Description
## Screenshot: Financial Statement Excerpt from Republic Services, Inc. Notes to Consolidated Financial Statements (2014 Continued)
### Overview
The image is a screenshot of a financial document excerpt from Republic Services, Inc.'s notes to consolidated financial statements. It includes financial data for 2018, 2017, and 2016, a question about the percentage decline in the allowance for doubtful accounts as of December 31, 2018, and two distinct answer responses (Gold Program and ZS-CoT).
### Components/Axes
- **Passage**: Contains financial data for three years (2018–2016) with the following categories:
- Balance at beginning of year
- Additions charged to expense
- Accounts written off
- Balance at end of year
- **Question**: "As of December 31, 2018, what was the percentage decline in the allowance for doubtful accounts?"
- **Gold Program**: A formula-based calculation: `subtract(34.3, 38.9), divide(#0, 38.9)`.
- **Gold Answer**: `-0.11825` (decimal representation of -11.825%).
- **ZS-STD LLM Answering Prompt Response**: States the percentage decline as **11.3%**.
- **ZS-CoT Reasoning Prompt Response**: States the percentage decline as **12.2%**.
### Detailed Analysis
#### Financial Data (Passage)
- **Balance at beginning of year**:
- 2018: $38.9 million
- 2017: $44.0 million
- 2016: $46.7 million
- **Additions charged to expense**:
- 2018: $34.8 million
- 2017: $30.6 million
- 2016: $20.4 million
- **Accounts written off**:
- 2018: $(39.4) million
- 2017: $(35.7) million
- 2016: $(23.1) million
- **Balance at end of year**:
- 2018: $34.3 million
- 2017: $38.9 million
- 2016: $44.0 million
#### Calculation Discrepancies
1. **Gold Program**:
- Formula: `(34.3 - 38.9) / 38.9 = -4.6 / 38.9 ≈ -0.11825` (or -11.825%).
- **Issue**: The formula subtracts the end balance from the beginning balance, resulting in a negative value, which contradicts the question's focus on "percentage decline" (a positive metric).
2. **ZS-STD LLM**:
- Calculation: `(34.3 - 38.9) / 38.9 = -4.6 / 38.9 ≈ -11.825%`, but reports **11.3%** (likely rounded or miscalculated).
3. **ZS-CoT**:
- Calculation: `(38.9 - 34.3) / 38.9 = 4.6 / 38.9 ≈ 11.825%`, but reports **12.2%** (rounded up).
### Key Observations
- The **Gold Program** incorrectly uses a negative value for the decline, likely due to reversed subtraction order.
- The **ZS-STD** and **ZS-CoT** responses provide conflicting results (11.3% vs. 12.2%), suggesting inconsistencies in rounding or calculation logic.
- The **exact percentage decline** for 2018 is **11.825%** (4.6 / 38.9), which neither answer fully captures.
### Interpretation
The document highlights a critical financial metric: the decline in the allowance for doubtful accounts from $38.9 million (beginning of 2018) to $34.3 million (end of 2018). The correct calculation is **(38.9 - 34.3) / 38.9 ≈ 11.825%**, representing an 11.8% decline. The discrepancies in the provided answers (11.3% and 12.2%) may stem from:
1. **Rounding errors** (e.g., truncating vs. rounding to one decimal place).
2. **Formula errors** (e.g., incorrect subtraction order in the Gold Program).
3. **Misinterpretation** of the question's phrasing (e.g., using end balance as the denominator instead of the beginning balance).
This inconsistency underscores the importance of precise formula implementation and clear communication in financial reporting. The ZS-CoT response aligns more closely with the correct logic but overestimates the decline, while the ZS-STD response underestimates it. The Gold Program's negative result is mathematically invalid for a "decline" metric.
</details>
Figure 18: An example of arithmetic errors made by ZS-STD and ZS-CoT prompts.
Figure 19: An example where program extraction failed for ZS-FinDSL prompt.
<details>
<summary>Image 17 Details</summary>

### Visual Description
## Screenshot: Financial Analysis Document (UNP/2007/page_25.pdf-4)
### Overview
The image displays a financial analysis excerpt focusing on fuel prices, dividends, and free cash flow changes between 2005–2007. Key elements include textual data, calculation logic (Gold Program), and reasoning (ZS-FinDSL).
### Components/Axes
- **Header**: "UNP/2007/page_25.pdf-4" (peach-colored box, top-center).
- **Passage**:
- Text: "2022 fuel prices 2013 crude oil prices increased at a steady rate in 2007 ... Millions of Dollars | 2007 | 2006 | 2005 | Dividends paid | (364) | (322) | (314) | Free cash flow | $487 | $516 | $234".
- **Question**: "what was change in millions of free cash flow from 2005 to 2006?"
- **Gold Program**:
- Formula: `subtract(516, 234)`
- Answer: `282.0`
- **ZS-FinDSL**:
- Reasoning: "The change in millions of free cash flow from 2005 to 2006 was an increase of $282 million ($516 million - $234 million = $282 million)."
- Program:
```json
{
"Program": {
"#0": { "operation": "subtract", "arg1": "516", "arg2": "234" },
"#1": { "operation": "add", "arg1": "#0", "arg2": "282" }
},
"Answer": "282"
}
```
- Executed Answer: `564`
### Detailed Analysis
- **Passage Data**:
- **Dividends Paid**:
- 2007: $(364) million
- 2006: $(322) million
- 2005: $(314) million
- **Free Cash Flow**:
- 2007: $487 million
- 2006: $516 million
- 2005: $234 million
- **Gold Program**:
- Subtracts 2005 free cash flow ($234) from 2006 free cash flow ($516) to calculate a change of $282 million.
- **ZS-FinDSL**:
- Repeats the subtraction logic but adds the result ($282) to itself, erroneously yielding $564.
### Key Observations
1. **Free Cash Flow Increase**: The passage states free cash flow rose from $234 million (2005) to $516 million (2006), a $282 million increase.
2. **Calculation Discrepancy**:
- Gold Program correctly computes $282 million.
- ZS-FinDSL erroneously adds $282 to itself, producing $564.
3. **Negative Dividends**: All dividend values are negative, indicating payouts (common in financial reporting).
### Interpretation
- **Primary Data**: The free cash flow increased by $282 million from 2005 to 2006, aligning with the Gold Program’s result.
- **ZS-FinDSL Error**: The executed answer ($564) likely stems from a flawed program logic (adding the result to itself). This highlights a need to validate algorithmic steps.
- **Context**: Rising free cash flow despite negative dividends suggests improved operational efficiency or cost management. The document’s focus on 2005–2006 aligns with the oil price trends mentioned in the passage.
### Structure Notes
- All text extracted verbatim, including JSON syntax and program logic.
- No non-English content detected.
- Spatial grounding confirmed: Header at top, passage/question below, programs at bottom.
</details>
Figure 20: An example where program extraction failed for ZS-FinDSL prompt.
<details>
<summary>Image 18 Details</summary>

### Visual Description
## Screenshot: Financial Document Analysis (ADBE/2008/page_89.pdf-4)
### Overview
The image shows a financial document excerpt discussing tax benefits, effective tax rates, and goodwill impacts. Key elements include:
- A passage summarizing fiscal 2008 changes
- A question about unrecognized tax benefits
- A "Gold Program" comparison
- ZS-FinDSL reasoning and program logic
### Components/Axes
No visual charts/diagrams present. Textual components include:
1. **Passage**: Fiscal 2008 financial summary
2. **Question**: Tax benefit impact analysis
3. **Gold Program**: Numerical comparison (57.7 vs 68.9)
4. **ZS-FinDSL Reasoning**: Logical explanation
5. **Program Code**: JSON-like structure with operation parameters
### Content Details
**Passage Text**:
"summary fin 48 changes during fiscal 2008 , our aggregate changes in our total gross amount of unrecognized tax ... future tax returns , would result : $ 57.7 million of unrecognized tax benefits would decrease the effective tax rate and $ 68.9 million would decrease goodwill ..."
**Question**:
"if the total fin 48 gross liability for unrecognized tax benefits at november 28, 2008 were recognized in the future, is the amount of unrecognized tax benefits that would decrease the effective tax rate greater than the amount that would decrease goodwill?"
**Gold Program**:
- Comparison: `greater(57.7, 68.9)`
- Gold Answer: `no`
**ZS-FinDSL Reasoning**:
"The amount of unrecognized tax benefits that would decrease the effective tax rate is $57.7 million. The amount that would decrease goodwill is $68.9 million. Therefore, the amount of unrecognized tax benefits that would decrease the effective tax rate is less than the amount that would decrease goodwill."
**ZS-FinDSL Program**:
</details>