# Active Inference and Intentional Behaviour
**Authors**: Karl J. Friston, Tommaso Salvatori, Takuya Isomura, Alexander Tschantz, Alex Kiefer, Tim Verbelen, Magnus Koudahl, Aswin Paul, Thomas Parr, Adeel Razi, Brett Kagan, Christopher L. Buckley, Maxwell J. D. Ramstead
> Wellcome Trust Centre for Neuroimaging, Institute of Neurology, University College London, UK.VERSES AI Research Lab, Los Angeles, California, 90016, USA
> VERSES AI Research Lab, Los Angeles, California, 90016, USA
> Brain Intelligence Theory Unit, RIKEN Center for Brain Science, Wako, Saitama, Japan
> VERSES AI Research Lab, Los Angeles, California, 90016, USANuffield Department of Clinical Neurosciences, University of Oxford, UK
> VERSES AI Research Lab, Los Angeles, California, 90016, USATurner Institute for Brain and Mental Health, School of Psychological Sciences, Monash University, Clayton, AustraliaIITB-Monash Research Academy, Mumbai-76, India
> Nuffield Department of Clinical Neurosciences, University of Oxford, UK
> Turner Institute for Brain and Mental Health, School of Psychological Sciences, Monash University, Clayton, AustraliaMonash Biomedical Imaging, Monash University, Clayton, AustraliaCIFAR Azrieli Global Scholars Program, Toronto, Canada
> Cortical Labs, Melbourne, Australia
Abstract
Recent advances in theoretical biology suggest that basal cognition and sentient behaviour are emergent properties of in vitro cell cultures and neuronal networks, respectively. Such neuronal networks spontaneously learn structured behaviours in the absence of reward or reinforcement. In this paper, we characterise this kind of self-organisation through the lens of the free energy principle, i.e., as self-evidencing. We do this by first discussing the definitions of reactive and sentient behaviour in the setting of active inference, which describes the behaviour of agents that model the consequences of their actions. We then introduce a formal account of intentional behaviour, that describes agents as driven by a preferred endpoint or goal in latent state-spaces. We then investigate these forms of (reactive, sentient, and intentional) behaviour using simulations. First, we simulate the aforementioned in vitro experiments, in which neuronal cultures spontaneously learn to play Pong, by implementing nested, free energy minimising processes. The simulations are then used to deconstruct the ensuing predictive behaviour—leading to the distinction between merely reactive, sentient, and intentional behaviour, with the latter formalised in terms of inductive planning. This distinction is further studied using simple machine learning benchmarks (navigation in a grid world and the Tower of Hanoi problem), that show how quickly and efficiently adaptive behaviour emerges under an inductive form of active inference.
Keywords: active inference; active learning; backwards induction;planning as inference; free energy principle.
1 Introduction
In 2022, a paper was published that claimed to demonstrate sentient behaviour in a neuronal culture grown in a dish (an in vitro neuronal network) [1]. The behaviour in question was the spontaneous emergence of controlled movements of a paddle to hit a ball—and thereby play Pong. This study has several sources of inspiration that speak to the notion of basal cognition; see, e.g., [2, 3, 4] (and related work, e.g. [5]). In particular, the hypothesis that adaptive and predictive behaviour would emerge spontaneously was based on earlier work showing that in vitro neuronal cultures could be described as minimising variational free energy [6] and thereby evince active inference and learning. This application of the free energy principle (FEP) to neuronal cultures was subsequently validated empirically [7]: in the sense that changes in neuronal activity and synaptic efficacy—that underwrite learning—could be predicted quantitatively, as a variational free energy minimising process. So, are these findings remarkable, or were they predictable?
In one sense, these results were entirely predictable. Indeed, they were predictable from the FEP, which states that any two networks—that are coupled in a certain sparse fashion—will come to manifest a generalised synchrony [8, 9]. More formally, the FEP states that if the probability density that underwrites the dynamics of coupled random dynamical systems contains a Markov blanket—which shields internal states from external states, given blanket (sensory and active) states—then internal states will look as if they track the statistics of external states—or more precisely, as if they encode the parameters of a variational density (or best guess about) external states beyond the blanket. Empirically, this synchronisation was observed when the neuronal cultures learned to play Pong. However, the FEP goes further and says that the internal and active states (together, autonomous states) of either network can be described as minimising a variational free energy functional. This functional is exactly the same used to optimise generative models in statistics and machine learning [10]. On this reading, one can interpret the autonomous states—of a network, particle or person—as minimising variational free energy or surprise (a.k.a., self-information) or, equivalently, maximising Bayesian model evidence (a.k.a., the marginal likelihood of sensory states). This leads to an implicit teleology, in the sense that one can describe self-organisation in terms of self-evidencing [11] that entails active inference and learning, planning, purpose, intentions and, perhaps, sentience. The underlying free energy minimising processes—and their teleological interpretation—are the focus of this paper.
The results reported in [1] were considered by some to be unremarkable for a different reason: learning to play (Atari) games like Pong was something that had been accomplished with machine learning systems years earlier using neural networks and (deep) reinforcement learning [12, 13]. So, what is remarkable about a neuronal network reproducing the same kind of behaviour? It is remarkable because one cannot use the reinforcement learning (RL) paradigm to explain the emergence of self-evidencing behaviour seen in vitro. This follows from the fact that one cannot reward a neuronal network—because no one knows what any given in vitro neuronal network finds rewarding. However, the FEP theorist knows exactly what a self-evidencing network finds aversive; namely, surprise and unpredictability. This was a rationale for delivering unpredictable noise to the sensory electrodes of the cell culture (or restarting the game in an unpredictable way), whenever the neuronal network failed to hit the ball [1].
Some found the results reported in [1] remarkable, but not in a good way: they disagreed with the claim that the behaviour could be described as ‘sentient’ [14]. Here, we hope to make sense of the notion of sentient behaviour in terms of Bayesian belief updating; where ‘sentient behaviour’ denotes the capacity to generate appropriate responses to sensory perturbations (as opposed to merely reactive behaviour). We pursue the narrative established by the cell culture experiments above to illustrate why Pong-playing behaviour was considered sentient, as opposed to reactive. In brief, we consider a bright line between actions based upon the predictions of a generative model that does, and does not, entail the consequences of action.
Specifically, this paper differentiates between three kinds of behaviour: reactive, sentient, and intentional. The first two have formulations that have been extensively studied in the literature, under the frameworks of model-free reinforcement learning (RL) and active inference, respectively. In model-free RL, the system selects actions using either a lookup table (Q-learning), or a neural network (deep Q-learning). In standard active inference, the action selection depends on the expected free energy of policies (Equation 2), where the expectation is over observations in the future that become random variables. This means that preferred outcomes—that subtend expected cost and risk—are prior beliefs that constrain the implicit planning as inference [15, 16, 17]. Things that evince this kind of behaviour can hence be described as planning their actions, based upon a generative model of the consequences of those actions [15, 16, 18]. It was this sense in which the behaviour of the cell cultures was considered sentient.
This form of sentient behaviour —described in terms of Bayesian mechanics [19, 20, 21] —can be augmented with intended endpoints or goals. This leads to a novel kind of sentient behaviour that not only predicts the consequences of its actions, but is also able to select them to reach a goal state that may be many steps in the future. This kind of behaviour, that we call intentional behaviour, generally requires some form of backwards induction [22, 23] of the kind found in dynamic programming [24, 25, 26, 27]: this is, starting from the intended goal state, and working backwards, inductively, to the current state of affairs, in order to plan moves to that goal state. Backwards induction was applied to the partially observable setting and explored in the context of active inference in [27]. In that work, dynamic programming was shown to be more efficient than traditional planning methods in active inference.
The focus of this work is to formally define a framework for intentional behaviour, where the agent minimises a constrained form of expected free energy—and to demonstrate this framework in silico. These constraints are defined on a subset of latent states that represent the intended goals of the agent, and propagated to the agent via a form of backward induction. As a result, states that do not allow the agent to make any ‘progress’ towards one of the intended goals are penalised, and so are actions that lead to such disfavoured states. This leads to a distinction between sentient and intentional behaviour, were intentional behaviour is equipped with inductive constraints.
In this treatment, the word inductive is used in several senses. First, to distinguish inductive planning from the abductive kind of inference that usually figures in applications of Bayesian mechanics; i.e., to distinguish between mere inference to the best explanation (abductive inference) and genuinely goal-directed inference (inductive planning) [28, 29]. Second, it is used with a nod to backwards induction in dynamic programming, where one starts from an intended endpoint and works backwards in time to the present, to decide what to do next [24, 25, 30, 27]. Under this naturalisation of behaviours, a thermostat would not exhibit sentient behaviour, but insects might (i.e., thermostats exhibit merely reactive behaviour). Similarly, insects would not exhibit intentional behaviour, but mammals might (i.e., insects exhibit merely sentient behaviour). The numerical analyses presented below suggest that in vitro neuronal cultures may exhibit sentient behaviour, but not intentional behaviour. Crucially, we show that neither sentient nor intentional behaviour can be explained by reinforcement learning. In the experimental sections of this work, we study and compare the performance of active inference agents with and without intended goal states. For ease of reference, we will call active inference agents without goal states abductive agents, and agents with intended goals inductive agents.
This paper comprises four sections. The first briefly rehearses active inference and learning—as a set of nested free energy minimising processes—applied to a generic generative model of exchange with some world or environment. This model is a partially observed Markov decision process that is conciliatory with canonical neural networks in machine learning and apt to describe the self-evidencing of in vitro neuronal networks [6, 7]. This section has a special focus on inductive planning and its relationship to expected free energy. The subsequent sections use numerical studies to make a series of key points. The second section reproduces the empirical behaviour of in vitro neuronal networks playing Pong. Crucially, this behaviour emerges purely in terms of free energy minimising processes, starting with a naïve neuronal network. This section illustrates the failure of a (simulated) abductive agent when the game is made more difficult. This failure is used to illustrate the role of inductive planning, which restores performance and underwrites a fluent engagement with the sensorium. The final two sections illustrate inductive planning using navigation in a maze and the Tower of Hanoi problem, respectively. These numerical studies illustrate how the simple application of inductive constraints to active inference allows tasks—that would be otherwise intractable in discrete state spaces—to be solved efficiently. This efficiency rests on the fact that distal goals can be reached by only planning a few steps in the future, thanks to constraints furnished by inductive planning. Effectively, inductive planning takes the pressure off deep tree searches by identifying ’blind alleys’ or ’dead ends’.
1.1 Glossary of definitions
Before introducing the inductive planning algorithm, we frame our treatment by clarifying our use of some key terms. This framing is important, given that the goal of the present work is not simply to describe a useful heuristic for efficient inference (i.e., inductive planning), but to provide an account of how a new form of decision-making, characteristic of more complex forms of agency, may be combined with, and folded into, a generic Bayesian (active) inference scheme.
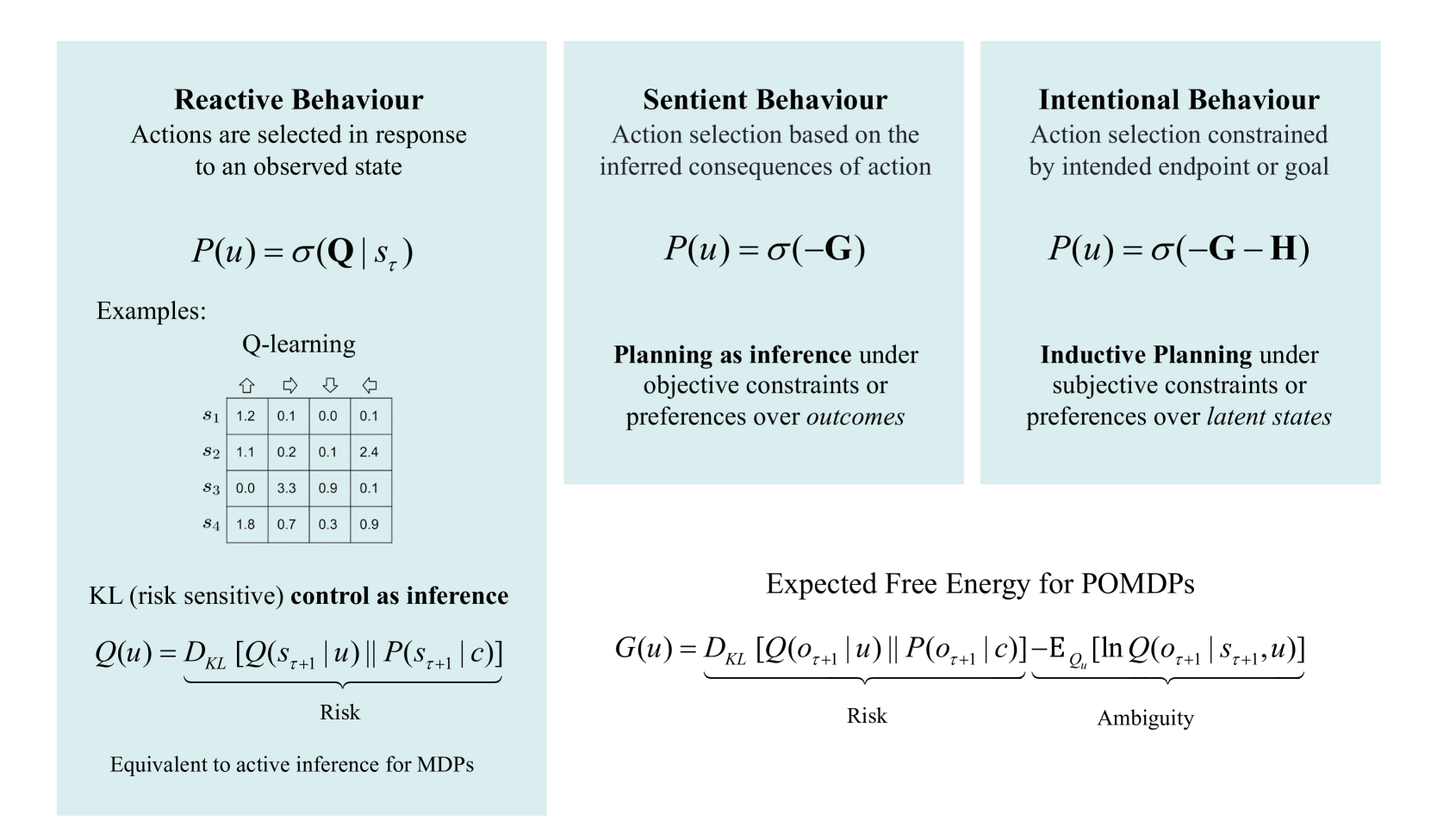
Figure 1 describes increasingly complex forms of behaviour—from reactive (merely responding to stimuli), to sentient (planning based on the sensory consequences of actions), to intentional (planning in order to bring about intended states)—and corresponding forms of decision-making that may underwrite such behaviour.
Reactive behaviour characterises simple sensorimotor reflex arcs and the mere realisation of set points or trajectories (e.g., simple cases of homeostasis and homeorhesis). This form of behaviour can be accounted for acting in a way that realises predicted sensations, with no anticipation of the future sensory consequences of action.
Sentient behaviour characterises the paradigmatic case of active inference, in which the influence of perception on action is mediated by the results of planning, with a distribution over policies derived from a model endowed with counterfactual depth (i.e., beliefs about the future sensory consequences of action pursuant to a policy). In this case, we may characterise the form of inference over actions or policies as abductive —i.e., as an inference to the policy that best explains current and future observations under a generative model (see below).
Intentional behaviour is driven not simply by the generic imperative to minimise sensory prediction error, present and future, but toward the attainment of a particular future endpoint or goal state. This form of behaviour can be subserved by backward induction or inductive planning, as defined below, which supplies a specific form of constraint on the Bayesian (abductive) inference characteristic of (mere) sentient behaviour. In particular, it implies not merely beliefs about sensory consequences of actions but rather beliefs about the inferred or latent causes of sensory input.
Note that words like ‘sentient behaviour’ and ‘intentional behaviour’ are deliberately defined here such that they can be operationalized within the framework of generative modelling, in which terms like ‘state’, ‘belief’, and ‘confidence’ have precise, if narrow, interpretations in terms of belief structures of a mathematical sort [31]. Whether the phenomenology of (propositional or subjective) beliefs—or sentience—could yield to the same naturalisation remains to be seen: see [32, 33, 34] for treatments in this direction. Note further that a key distinction between sentient and intentional behaviour rests upon the consequences of behaviour in (observable) outcome and (unobservable) latent spaces, respectively.
<details>
<summary>x1.png Details</summary>
### Visual Description
## Conceptual Diagram: Behavioural Decision-Making Frameworks
### Overview
The image presents a comparative framework of three behavioural paradigms (Reactive, Sentient, Intentional) and two decision-making principles (KL control, Expected Free Energy for POMDPs). It combines textual descriptions, mathematical formulas, and a Q-learning example table.
### Components/Axes
1. **Left Panel (Reactive Behaviour)**
- Title: "Reactive Behaviour"
- Description: "Actions are selected in response to an observed state"
- Formula: $ P(u) = \sigma(\mathbf{Q} | s_\tau) $
- Example: Q-learning with a 4x4 state-value table (states $ s_1 $ to $ s_4 $, values 0.0–1.2)
- Additional: "KL (risk sensitive) control as inference" with formula $ Q(u) = \underbrace{D_{KL}[Q(s_{\tau+1}|u)||P(s_{\tau+1}|c)]}_{\text{Risk}} $
2. **Middle Panel (Sentient Behaviour)**
- Title: "Sentient Behaviour"
- Description: "Action selection based on the inferred consequences of action"
- Formula: $ P(u) = \sigma(-\mathbf{G}) $
- Additional: "Planning as inference under objective constraints or preferences over outcomes"
3. **Right Panel (Intentional Behaviour)**
- Title: "Intentional Behaviour"
- Description: "Action selection constrained by intended endpoint or goal"
- Formula: $ P(u) = \sigma(-\mathbf{G} - \mathbf{H}) $
- Additional: "Inductive Planning under subjective constraints or preferences over latent states"
4. **Bottom Section (Expected Free Energy for POMDPs)**
- Title: "Expected Free Energy for POMDPs"
- Formula: $ G(u) = \underbrace{D_{KL}[Q(o_{\tau+1}|u)||P(o_{\tau+1}|c)]}_{\text{Risk}} \underbrace{-\mathbb{E}_{Q_u}[\ln Q(o_{\tau+1}|s_{\tau+1},u)]}_{\text{Ambiguity}} $
### Detailed Analysis
- **Q-learning Table**:
| State | 1.2 | 0.1 | 0.0 | 0.1 |
|-------|-----|-----|-----|-----|
| $ s_1 $ | 1.1 | 0.2 | 0.1 | 2.4 |
| $ s_2 $ | 0.0 | 3.3 | 0.9 | 0.1 |
| $ s_3 $ | 1.8 | 0.7 | 0.3 | 0.9 |
- **Mathematical Notation**:
- $ \sigma $: Sigmoid function (implied but not explicitly labeled)
- $ D_{KL} $: Kullback-Leibler divergence (risk term)
- $ \mathbb{E} $: Expected value (ambiguity term)
### Key Observations
1. **Hierarchical Structure**:
- Reactive < Sentient < Intentional (increasing complexity of constraints)
- KL control and Expected Free Energy represent complementary decision-making principles.
2. **Contrast in Constraints**:
- Reactive: Observed states only
- Sentient: Objective consequences
- Intentional: Subjective latent states
3. **Mathematical Relationships**:
- Risk (KL divergence) and Ambiguity (negative log-probability) are combined additively in Expected Free Energy.
### Interpretation
This diagram illustrates a theoretical taxonomy of decision-making systems, progressing from simple reactive responses to complex goal-directed planning. The inclusion of KL divergence and Expected Free Energy suggests a Bayesian framework for handling uncertainty, where:
- **Risk** quantifies distributional mismatch between predictions and outcomes
- **Ambiguity** measures epistemic uncertainty in latent states
The Q-learning example grounds the theory in reinforcement learning, while the formulas formalize the transition from reactive policies to intentional planning. The absence of explicit numerical trends implies a focus on conceptual relationships rather than empirical data.
</details>
Figure 1: Glossary. In this figure, we provide illustrative definitions of the three kinds of behaviour considered in this work, In terms of examples, and mathematical differences. Examples of agents with reactive behaviours are (1) Model-free reinforcement learning schemes, such as Q-learning, where the agent makes use of a lookup table to select actions (more generally, a state-action policy). In this table, rows correspond to states, actions to columns, and every entry encodes the value of taking a specific action (in this case: go up, right, down, left) when in state $s_{\tau}$ . There is no inference over policies, as for every state the agent automatically selects the action with the highest value; and (2) KL control (a.k.a., risk-sensitive control) methods, that automatically select actions that minimise a KL divergence between anticipated and preferred states (where there is no uncertainty about the current state). Sentient agents, on the other hand, plan by taking into account future outcomes and their uncertainty, as they act by minimising an expected free energy $\mathbf{G}$ , that includes risk and ambiguity terms. More details on this can be found in Equation 5. Finally, inductive agents add constraints ( $\mathbf{H}$ in the figure) in the action selection, by penalising actions that preclude an intended goal. For a formal derivation of $\mathbf{H}$ , we refer to Section 3.
2 Active inference
Here, we introduce the generative model used in the following sections, which can be seen as a generalisation of a partially observed Markov decision process (POMDP). The generalisation in question covers trajectories, narratives or syntax—which may or may not be controllable—by equipping a POMDP with random variables called paths. Paths effectively pick out transitions among latent states. These models are designed to be composed hierarchically, in a way that speaks to a separation of temporal scales in deep generative models. In other words, the number of transitions among latent states at any given level is greater than the number of transitions at the level above. This furnishes a unique specification of a hierarchy, in which the parents of any latent factor (associated with unique states and paths) contextualise the dynamics of their children.
The variational inference scheme [35] used to invert these models inherits from their application to online decision-making tasks. This means that action selection rests primarily on current beliefs about latent states and structures, and expectations about future observations. In that sense, the beliefs are updated sequentially—and in an online fashion—with each new action-outcome pair. This calls for Bayesian filtering (i.e., forward message passing) during the active sampling of observations, followed by Bayesian smoothing (i.e., forward and backward message passing) to revise posterior beliefs about past states at the end of an epoch. The implicit Bayesian smoothing ensures that the beliefs about latent states at any moment in the past are informed by all available observations when updating model parameters (and latent states of parents in deep models).
In neurobiology, this combination of Bayesian filtering and smoothing would correspond to evidence accumulation during active engagement with the environment, followed by a ‘replay’ before the next epoch [36, 37, 38, 39]. From a machine learning perspective, this can be regarded as a forward pass (c.f., belief propagation) for online active inference, followed by a backwards pass (implemented with variational message passing) for active learning. The implicit belief updates, pertaining to states, parameters and structure, foreground the conditional dependencies between active inference, learning, and selection, respectively.
Generative modelling
Active inference rests upon a generative model of observable outcomes (observations). This model is used to infer the most likely causes of outcomes in terms of expected states of the world. These states (and paths) are latent or hidden because they can only be inferred through observations. Some paths are controllable in the sense they can be realised through action. Therefore, certain observations depend upon action (e.g., where one is looking), which requires the generative model to entertain expectations about outcomes under different combinations of actions (i.e., policies) Note that in this setting, a policy is not a sequence of actions, but simply a combination of paths, where each hidden factor has an associated state and path. This means there are, potentially, as many policies as there are combinations of paths..
These expectations are optimised by minimising the variational free energy, defined in Equation (1). Variational free energy scores the discrepancy between the data expected under the generative model and the actual data. Crucially, the prior probability of a policy depends upon its expected free energy. Expected free energy, described in more detail in Equation (2), is a universal objective function that can be read as augmenting mutual information with a expected costs or constraints that need to be satisfied. Heuristically, it scores the free energy expected under each course of action. Having evaluated the expected free energy of each policy, the most likely action can be selected and the perception-action cycle continues [40].
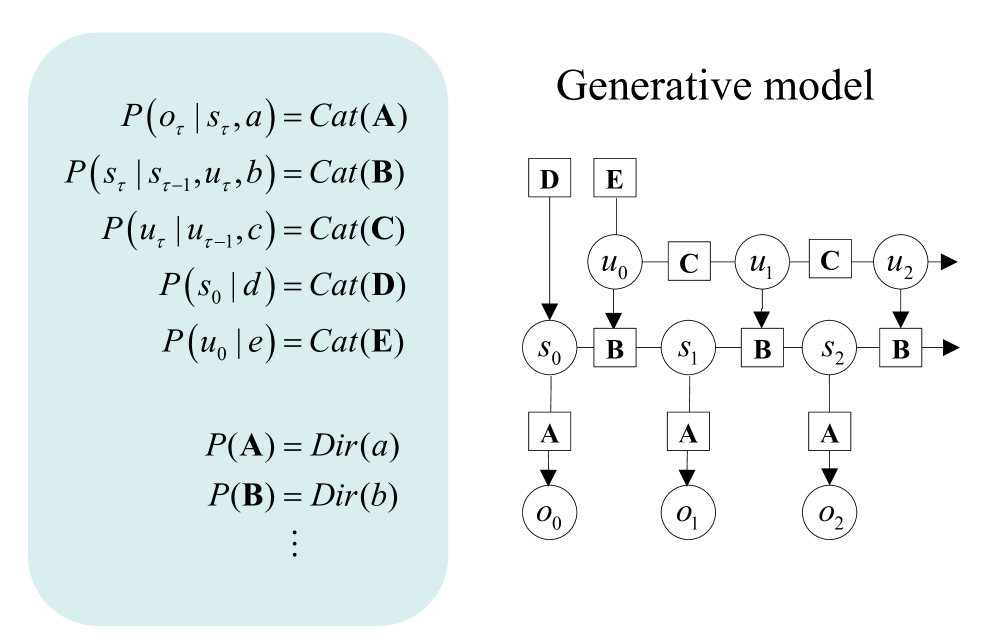
The generative model
Figure 2 provides a schematic overview of the generative model used for the simulations considered in this paper. Outcomes at any particular time depend upon hidden states, while transitions among hidden states depend upon paths. Note that paths are random variables, in the sense that a particle can have both a position (i.e., a state) and momentum (i.e., a path). Paths may or may not depend upon action. The resulting POMDP is specified by a set of tensors. The first set of parameters, denoted $\mathbf{A}$ , maps from hidden states to outcome modalities; for example, exteroceptive (e.g., visual) or proprioceptive (e.g., eye position) modalities. These parameters encode the likelihood of an outcome given their hidden causes. The second set $\mathbf{B}$ prescribes transitions among the hidden states of a factor, under a particular path. Factors correspond to different kinds of causes; e.g., the location versus the class of an object. The remaining tensors encode prior beliefs about paths $\mathbf{C}$ , and initial states $\mathbf{D}$ . The tensors—encoding probabilistic mappings or contingencies—are generally parameterised as Dirichlet distributions, whose sufficient statistics are concentration parameters or Dirichlet counts. These count the number of times a particular combination of states or outcomes has been inferred. We will focus on learning the likelihood model, encoded by Dirichlet counts, $\boldsymbol{a}$ .
<details>
<summary>x2.png Details</summary>
### Visual Description
## Diagram: Generative Model with Probabilistic Transitions
### Overview
The image presents a hybrid representation of a probabilistic generative model, combining mathematical equations on the left with a state transition diagram on the right. The model appears to describe sequential decision-making processes with observable outputs and hidden states.
### Components/Axes
**Left Panel (Equations):**
- **Probability Definitions:**
- $ P(o_\tau | s_\tau, a) = \text{Cat}(A) $: Observation probability given state and action
- $ P(s_\tau | s_{\tau-1}, u_\tau, b) = \text{Cat}(B) $: State transition probability
- $ P(u_\tau | u_{\tau-1}, c) = \text{Cat}(C) $: Action selection probability
- $ P(s_0 | d) = \text{Cat}(D) $: Initial state distribution
- $ P(u_0 | e) = \text{Cat}(E) $: Initial action distribution
- **Dirichlet Priors:**
- $ P(A) = \text{Dir}(a) $
- $ P(B) = \text{Dir}(b) $
- ... (continuation implied)
**Right Panel (Diagram):**
- **Nodes:**
- **Inputs:** D, E (connected to initial state/action)
- **States:** $ s_0 \rightarrow s_1 \rightarrow s_2 $
- **Actions:** $ u_0 \rightarrow u_1 \rightarrow u_2 $
- **Observations:** $ o_0 \rightarrow o_1 \rightarrow o_2 $
- **Transitions:**
- Solid arrows between states (B transitions)
- Dashed arrows from states to observations (A transitions)
- Input nodes D/E connected to initial state/action via arrows
### Detailed Analysis
**Mathematical Structure:**
1. **Observation Model:** $ P(o_\tau | s_\tau, a) $ suggests observations depend on current state and action
2. **State Dynamics:** $ P(s_\tau | s_{\tau-1}, u_\tau, b) $ indicates Markovian state transitions influenced by actions
3. **Action Selection:** $ P(u_\tau | u_{\tau-1}, c) $ implies action persistence/change over time
4. **Initial Conditions:** $ P(s_0 | d) $ and $ P(u_0 | e) $ define starting distributions
**Diagram Flow:**
- Inputs D → Initial state $ s_0 $
- Input E → Initial action $ u_0 $
- State transitions: $ s_0 \xrightarrow{B} s_1 \xrightarrow{B} s_2 $
- Action transitions: $ u_0 \xrightarrow{C} u_1 \xrightarrow{C} u_2 $
- Observation emissions: Each state emits observation via $ P(o_\tau | s_\tau, a) = \text{Cat}(A) $
### Key Observations
1. **Markovian Structure:** The model assumes Markov properties for both state transitions and action selection
2. **Categorical Distributions:** All probability distributions are categorical (Cat), suggesting discrete state/action spaces
3. **Hierarchical Priors:** Dirichlet distributions provide conjugate priors for the categorical parameters
4. **Temporal Coupling:** Actions persist across time steps ($ u_\tau $ depends on $ u_{\tau-1} $)
### Interpretation
This appears to be a **Partially Observable Markov Decision Process (POMDP)** framework with:
- **Hidden States:** $ s_\tau $ (only partially observable through $ o_\tau $)
- **Temporal Dependencies:** Both state transitions and action selection exhibit temporal correlation
- **Bayesian Inference:** The use of Dirichlet priors suggests a Bayesian approach to parameter estimation
- **Sequential Decision Making:** The model captures the interplay between observations, hidden states, and actions over time
The diagram visually reinforces the equations by showing:
1. Input nodes D/E seeding initial conditions
2. Sequential state transitions governed by parameter B
3. Action persistence through parameter C
4. Observation generation through parameter A
5. The cyclical nature of perception-action loops in sequential decision-making systems
</details>
Figure 2: Generative models as agents. A generative model specifies the joint probability of observable consequences and their hidden causes. Usually, the model is expressed in terms of a likelihood (the probability of consequences given their causes) and priors (over causes). When a prior depends upon a random variable it is called an empirical prior. Here, the likelihood is specified by a tensor $\mathbf{A}$ , encoding the probability of an outcome under every combination of states ( $s$ ). The empirical priors pertain to transitions among hidden states, $\mathbf{B}$ , that depend upon paths ( $u$ ), whose transition probabilities are encoded in $\mathbf{C}$ . $\mathbf{E}$ specifies the empirical prior probability of each path. The subscripts in this graphic pertain to time.
The generative model in Figure 2 means that outcomes are generated as follows: first, a policy is selected using a softmax function of expected free energy. Sequences of hidden states are generated using the probability transitions specified by the selected combination of paths (i.e., policy). Finally, these hidden states generate outcomes in one or more modalities. Perception or inference about hidden states (i.e., state estimation) corresponds to inverting a generative model, given a sequence of outcomes, while learning corresponds to updating model parameters. Perception therefore corresponds to updating beliefs about hidden states and paths, while learning corresponds to accumulating knowledge in the form of Dirichlet counts. The requisite expectations constitute the sufficient statistics $(\mathbf{s},\mathbf{u},\mathbf{a})$ of posterior beliefs $Q(s,u,a)=Q_{\mathbf{s}}(s)Q_{\mathbf{u}}(u)Q_{\mathbf{a}}(a)$ . The implicit factorisation of this approximate posterior effectively partitions model inversion into inference, planning, and learning.
Variational free energy and inference
In variational Bayesian inference (a form of approximate Bayesian inference), model inversion entails the minimisation of variational free energy with respect to the sufficient statistics of approximate posterior beliefs. This can be expressed as follows, where, for clarity, we will deal with a single factor, such that the policy (i.e., combination of paths) becomes the path, $\pi=u$ . Omitting dependencies on previous states, we have for model $m$ :
$$
\displaystyle Q\left(s_{\tau},u_{\tau},a\right) \displaystyle=\arg\min_{Q}F \displaystyle F \displaystyle=\mathbb{E}_{Q}[\ln\underbrace{Q\left(s_{\tau},u_{\tau},a\right)}%
_{\text{posterior }}-\ln\underbrace{P\left(o_{\tau}\mid s_{\tau},u_{\tau},a%
\right)}_{\text{likelihood }}-\ln\underbrace{P\left(s_{\tau},u_{\tau},a\right)%
}_{\text{prior }}] \displaystyle=\underbrace{D_{KL}\left[Q\left(s_{\tau},u_{\tau},a\right)\|P%
\left(s_{\tau},u_{\tau},a\mid o_{\tau}\right)\right]}_{\text{divergence }}-%
\underbrace{\ln P\left(o_{\tau}\mid m\right)}_{\text{log evidence }} \displaystyle=\underbrace{D_{KL}\left[Q\left(s_{\tau},u_{\tau},a\right)\|P%
\left(s_{\tau},u_{\tau},a\right)\right]}_{\text{complexity }}-\underbrace{%
\mathbb{E}_{Q}\left[\ln P\left(o_{\tau}\mid s_{\tau},u_{\tau},a\right)\right]}%
_{\text{accuracy }} \tag{1}
$$
Because the (KL) divergences cannot be less than zero, the penultimate equality means that free energy is minimised when the (approximate) posterior is equal to the true posterior. At this point, the free energy is equal to the negative log evidence for the generative model [35]. This means minimising free energy is mathematically equivalent to maximising model evidence, which is, in turn, equivalent to minimising the complexity of accurate explanations for observed outcomes.
Planning emerges under active inference by placing priors over (controllable) paths to minimise expected free energy [41]:
$$
\displaystyle G(u) \displaystyle=\mathbb{E}_{Q_{u}}\left[\ln Q\left(s_{\tau+1},a\mid u\right)-\ln
Q%
\left(s_{\tau+1},a\mid o_{\tau+1},u\right)-\ln P\left(o_{\tau+1}\mid c\right)\right] \displaystyle=-\underbrace{\mathbb{E}_{Q_{u}}\left[\ln Q\left(a\mid s_{\tau+1}%
,o_{\tau+1},u\right)-\ln Q(a\mid s_{\tau+1},u)\right]}_{\text{expected %
information gain (learning) }}- \displaystyle\ \ \ \ \ \underbrace{\mathbb{E}_{Q_{u}}\left[\ln Q\left(s_{\tau+%
1}\mid o_{\tau+1},u\right)-\ln Q\left(s_{\tau+1}\mid u\right)\right]}_{\text{%
expected information gain (inference) }}\underbrace{-\mathbb{E}_{Q_{u}}\left[%
\ln P\left(o_{\tau+1}\mid c\right)\right]}_{\text{expected cost }} \displaystyle=-\underbrace{\mathbb{E}_{Q_{u}}\left[D_{KL}\left[Q\left(a\mid s_%
{\tau+1},o_{\tau+1},u\right)\|Q(a\mid s_{\tau+1},u)\right]\right]}_{\text{%
novelty }}+ \displaystyle\ \ \ \ \ \underbrace{D_{KL}\left[Q\left(o_{\tau+1}\mid u\right)%
\|P\left(o_{\tau+1}\mid c\right)\right]}_{\text{risk }}\underbrace{-\mathbb{E}%
_{Q_{u}}\left[\ln Q\left(o_{\tau+1}\mid s_{\tau+1},u\right)\right]}_{\text{%
ambiguity }} \tag{3}
$$
Here, the posterior predictive distribution over parameters, hidden states and outcomes at the next time step, under a particular path, is defined as follows:
| | $\displaystyle Q_{u}$ | $\displaystyle=Q\left(o_{\tau+1},s_{\tau+1},a\mid u\right)$ | |
| --- | --- | --- | --- |
One can also express the prior over the parameters in terms of an expected free energy, where, marginalising over paths:
$$
\displaystyle P(a) \displaystyle=\sigma(-G) \displaystyle G(a) \displaystyle=\mathbb{E}_{Q_{a}}[\ln P(s\mid a)-\ln P(s\mid o,a)-\ln P(o\mid c)] \displaystyle=-\underbrace{\mathbb{E}_{Q_{a}}[\ln P(s\mid o,a)-\ln P(s\mid a)]%
}_{\text{expected information gain }}\underbrace{-\mathbb{E}_{Q_{a}}[\ln P(o%
\mid c)]}_{\text{expected cost }} \displaystyle=-\underbrace{\mathbb{E}_{Q_{a}}\left[D_{KL}[P(o,s\mid a)\|P(o%
\mid a)P(s\mid a)]\right.}_{\text{mutual information }}\underbrace{-\mathbb{E}%
_{Q_{a}}[\ln P(o\mid c)]}_{\text{expected cost }} \tag{5}
$$
where $Q_{a}=P(o|s,a)P(s|a)=P(o,s|a)$ is the joint distribution over outcomes and hidden states, encoded by the Dirichlet parameters, $a$ , and $\sigma(·)$ is the softmax function. Note that the Dirichlet parameters encode the mutual information, in the sense that they implicitly encode the joint distribution over outcomes and their hidden causes. When normalising each column of the $a$ tensor, we recover the likelihood distribution (as in Figure 2); however, we could normalise over every element, to recover a joint distribution.
As discussed above, expected free energy can be regarded as a universal objective function that augments mutual information with expected costs or constraints. Constraints — parameterised by $c$ — reflect the fact that we are dealing with open systems with characteristic outcomes. This allows an optimal trade-off between exploration and exploitation, that can be read as an expression of the constrained maximum entropy principle that is dual to the free energy principle [19]. Alternatively, it can be read as a constrained principle of maximum mutual information or minimum redundancy [42, 43, 44, 45]. In machine learning, this kind of objective function underwrites disentanglement [46, 47], and generally leads to sparse representations [48, 45, 49, 50].
When comparing the expressions for expected free energy in Equation 2 with variational free energy in Equation 1, the expected divergence becomes expected information gain. Expected information gain about the parameters and states are sometimes associated with distinct epistemic affordances; namely, novelty and salience, respectively [51]. Similarly, expected log evidence becomes expected value, where value is the logarithm of prior preferences. The last equality in Equation 2 provides a complementary interpretation; in which the expected complexity becomes risk, while expected inaccuracy becomes ambiguity.
There are many special cases of minimising expected free energy. For example, maximising expected information gain maximises (expected) Bayesian surprise [52], in accord with the principles of optimal (Bayesian) experimental design [53]. This resolution of uncertainty is related to artificial curiosity [54, 55] and speaks to the value of information [56].
Expected complexity or risk is the same quantity minimised in risk sensitive or KL control [57, 58], and underpins (free energy) formulations of bounded rationality based on complexity costs [59, 60] and related schemes in machine learning; e.g., Bayesian reinforcement learning [61]. More generally, minimising expected cost subsumes Bayesian decision theory [62].
<details>
<summary>x3.png Details</summary>
### Visual Description
## Diagram: Inductive Planning Framework
### Overview
The image presents a technical framework for inductive planning, combining mathematical equations, a decision diagram, and a heatmap. It illustrates a recursive process for optimizing actions over time, with spatial grounding of variables and thresholds.
### Components/Axes
#### Left Section: Equations
- **Variables**:
- `I₀ = h` (initial state)
- `I_{n+1} = B̃^T ⊙ I_n` (recursive update)
- `B̃ = B > ε : ∃u` (thresholded belief)
- `p_n = I_n ⊙ s_τ` (action probability)
- `m = arg max_n p_n < sup p` (optimal action index)
- `H = ln ε · I_m ⊙ s_{τ+1}` (entropy term)
- `P(u) = σ(-G - H)` (policy function)
#### Middle Diagram: Decision Process
- **Axes**:
- Vertical: `s_τ` (state/action space, 10–100)
- Horizontal: `n` (time steps, 5–30)
- **Key Elements**:
- Black bar: Represents `I = [I₀, I₁, ..., I_N]` (sequence of states).
- Red arrow: Points to `I_m` (optimal state at time `m = 10`).
- Dotted line: Marks `p_n = I_n ⊙ s_τ` (action probability threshold).
- Legend: `s_τ` (black) and `p_n` (red).
- Arrows: "future" (left) and "past" (right) temporal orientation.
#### Right Section: Heatmap
- **Axes**:
- X-axis: 20–100 (possibly indices or thresholds).
- Y-axis: 10–100 (same scale as middle diagram).
- **Pattern**: Diagonal white lines suggest a threshold or boundary defined by `B̃ = B > ε : ∃u`.
### Detailed Analysis
1. **Recursive State Update**:
- `I_{n+1}` depends on `B̃^T ⊙ I_n`, indicating a feedback loop where beliefs (`B̃`) modulate state transitions.
- `B̃ = B > ε : ∃u` implies beliefs are filtered by a threshold `ε` and existential uncertainty (`∃u`).
2. **Action Selection**:
- `p_n = I_n ⊙ s_τ` computes action probabilities via element-wise multiplication of state `I_n` and action space `s_τ`.
- `m = arg max_n p_n` identifies the optimal time step `m = 10` (marked by red arrow).
3. **Entropy and Policy**:
- `H = ln ε · I_m ⊙ s_{τ+1}` introduces entropy regularization, balancing exploration/exploitation.
- `P(u) = σ(-G - H)` defines a policy using a sigmoid function, where `G` likely represents a goal term.
4. **Heatmap Interpretation**:
- Diagonal lines in the heatmap correspond to `B̃ = B > ε : ∃u`, suggesting a critical boundary where beliefs exceed a threshold.
### Key Observations
- **Temporal Focus**: The red arrow at `m = 10` highlights the optimal action point in the sequence.
- **Threshold Dynamics**: Both `B̃` and the heatmap diagonal emphasize the role of `ε` in filtering uncertainty.
- **Spatial Grounding**: The middle diagram’s `I_m` aligns with the heatmap’s diagonal, linking state selection to thresholded beliefs.
### Interpretation
This framework models decision-making under uncertainty, where:
1. **Recursive Belief Updates** (`I_n`) refine state estimates over time.
2. **Thresholded Beliefs** (`B̃`) filter noise, ensuring actions (`p_n`) are grounded in reliable states.
3. **Optimal Action Selection** (`m = 10`) balances immediate rewards (`p_n`) and long-term entropy (`H`).
4. The heatmap visualizes how beliefs (`B̃`) partition the state-action space, guiding the policy `P(u)`.
The system prioritizes actions that maximize immediate utility while maintaining robustness to uncertainty (`ε`). The diagonal in the heatmap suggests a critical threshold where beliefs transition from reliable to uncertain, influencing the policy’s exploration strategy.
</details>
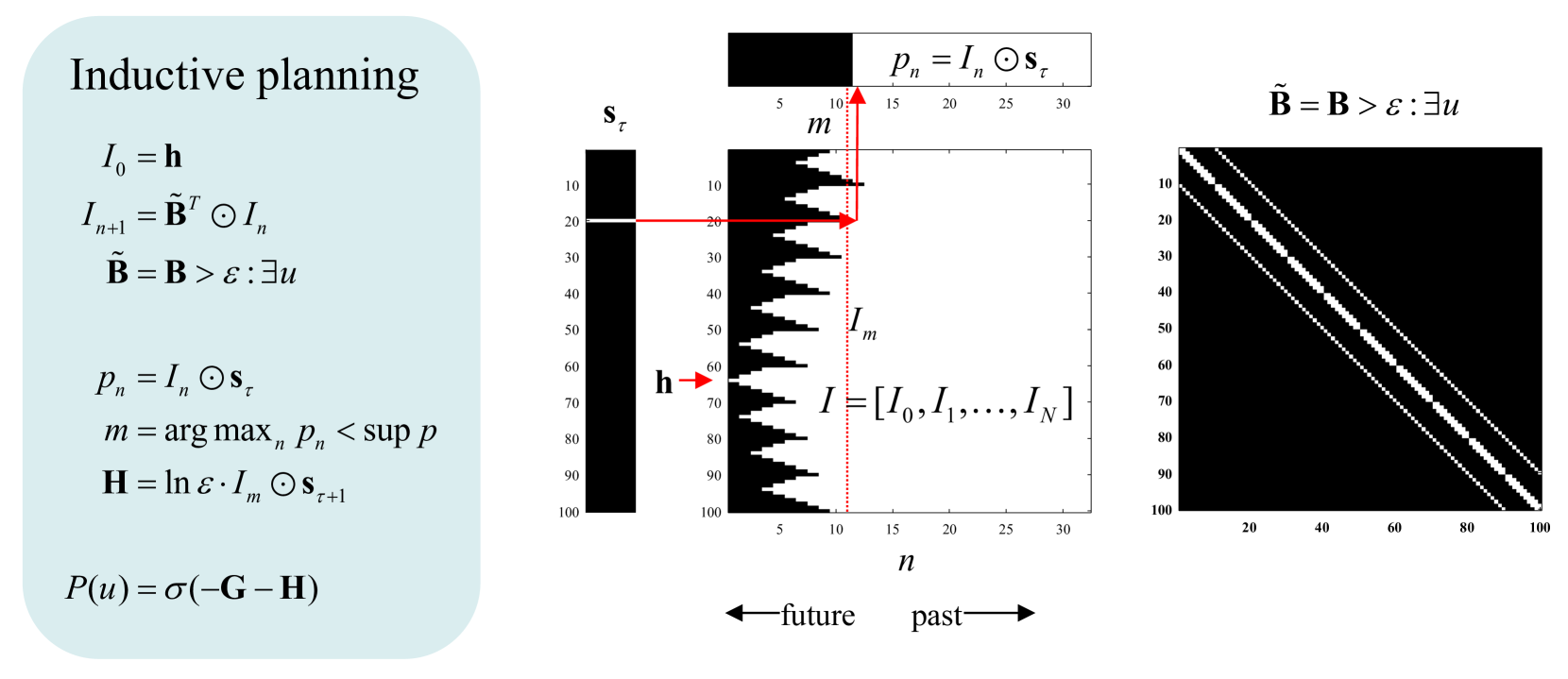
Figure 3: Inductive Planning. This figure provides an overview of inductive planning used in this paper. The left panel provides the expressions used to induce which subsequent states do and do not contain paths to some intended end state, encoded by a one hot vector $\mathbf{h}$ . The central panel illustrates this induction graphically, where vectors and matrices are shown in image format (black equals zero or false and white equals one or true). Working down the equalities in the left panel, we first initialise a logical vector of states, $I$ , to the intended state $\mathbf{h}$ . Recursively, we evaluate all the states from which the previous state can be accessed (a state can be accessed if the probability of transitioning from an adjacent state is larger than $\varepsilon$ ). Because this recursive induction works backwards in time, the allowable transition matrix is transposed. Having induced the reverse history of states—that contain paths to the intended state—one can then evaluate the length of the shortest path to the intended state. This depends upon posterior beliefs about the current state. In the example shown on the left, we are currently in state $20$ , which means that the shortest path to the intended state (state $64$ ) is $12$ time steps. This tells us that if we are pursuing the shortest path then there are certain states we need to avoid—from which the intended state cannot be reached. These states are encoded by the logical vector I at the next time step; namely, the last time before the probability $p$ of being on a path to the intended state reaches its supremum. Because the eligible states can only increase—as we move backwards in time—this probability can only increase, until all states are eligible (or there are no further eligible states). The first time that the probability reaches its supremum tells us where we are on the path to our intended state and, crucially, the ineligible states at the next time step. We now know the states to avoid at the next time step. If ineligible states are precluded, the next state must be on the path to the intended state. Ineligible states can be assigned a high cost (here, the log of a small value) to evaluate the expected cost incurred by each policy, using its predictive posterior over states (see Figure 2). Finally, we can supplement the expected free energy, $\mathbf{G}$ of each policy with the ensuing inductive cost, $\mathbf{H}$ . In principle, this guarantees the selection of paths or policies that lead to the intended state, provided that state can be reached. The example shown on the right is taken from the maze navigation task described later. For clarity, this example only considers a single factor. The mathematical expressions use the notation of Figure 2: The dotted red line indicates the logical vector encoding which of the $100$ states will lead to the intended state at the next time point; here, $11$ time steps from the intended state (indicated with a small red arrow).
3 Inductive Planning
What we call inductive planning—in this setting—recalls the notion of backwards induction in dynamic programming and related schemes [63, 25, 30, 23, 26, 64, 27]. In this form of inference, precise beliefs about state transitions are leveraged to rule out actions that are inconsistent with the attainment of future goals, defined in belief or state space as a final (or intended) state. This is a limiting case of inductive (Bayesian) inference [65, 66, 67] in which the very high precision of beliefs about final or intended states allows one to use logical operators in place of tensor operations; thereby vastly simplifying computations. In brief, we will use this simplification to furnish constraints on action selection that inherit from priors over intended states in the future.
Active inference rests on priors that place constraints on paths or trajectories through state space. For example, a sparse prior preference with knowledge only about the final state warrants deep planning to demonstrate intentional behaviour [27]. One can either specify these constraints in terms of states that are unlikely to traversed, or in terms of the final state. In other words, the agent may, a priori, believe it will navigate state space in a way that avoids unlikely or surprising outcomes, or that it will reach some final destination (in state space, not outcome space), irrespective of the path taken. These are distinct kinds of constraints. The first is implemented by $\mathbf{c}$ , in terms of the cost or constraints that apply during the entire path. We now introduce another prior or constraint $\mathbf{h}$ , over the final state. The priors, $\mathbf{d}$ and $\mathbf{h}$ play reciprocal roles; in the sense they specify prior beliefs about the initial and final states, respectively. Backwards induction now follows simply from this prior; provided it is specified sufficiently precisely. We will refer to these final states as intended states While $\mathbf{c}$ , $\mathbf{d}$ , and $\mathbf{h}$ are usually hard coded, they can be learnt very efficiently, for example using Z-learning for certain classes of MDPs [68, 27].
The basic idea is that although we may be uncertain about the next latent state, we can be certain about which states cannot be accessed from the current state. This means we can use induction to identify subsequent states that cannot be on a path to an intended state; thereby rendering actions—(i.e., state transitions) to those ineligible, ’dead-end’ states—highly unlikely (assuming that we are on a path to an intended state). The requisite induction goes as follows:
Imagine that we know our current state and that we will be in a certain (intended) state in the future. Imagine further that we know all possible transitions, afforded by action, among states. This means we can identify all the states from which the intended state is accessible. We can now repeat this and identify all the states from which the eligible states at the penultimate time point can be accessed, and so on. We now repeat this recursively—moving backwards in time—until our current state becomes eligible. At this point, we select an action that precludes ineligible states at the preceding point in backwards time (or next point in forwards time), bringing us one step closer to the intended state. We now repeat the backwards induction, until we arrive at the intended state, via the shortest path. This backwards induction is computationally cheap because it entails logical operations on a sparse logical tensor, encoding allowable state transitions.
Figure 3 provides a pseudocode and graphical abstraction based upon the MATLAB scripts implementing this inductive logic. For clarity, we have assumed a single factor and that there are no constraints on the paths, other than those specified by a one hot vector $\mathbf{h}$ , specifying the agent’s intended states In our MATLAB implementation of inductive planning, constraints due to prior preferences in outcome space are accommodated by precluding transitions to costly states during construction of the logical matrix encoding possible or true transitions. Furthermore, the implementation deals with multiple factors using appropriate tensor products. Finally, when multiple intended states are supplied, the nearest state is chosen for induction; where nearest is defined in terms of the number of timesteps required to access an intended state..
Note that this is not vanilla backwards induction. It is simply a way of placing precise priors on paths that render certain paths—that cannot access an intended state—highly unlikely. The requisite priors complement expected free energy in the following sense (see Figure 3): inductive priors over policies, $\mathbf{H}$ are derived from priors over intended states $\mathbf{h}$ , while the priors over policies scored by expected free energy, $\mathbf{G}$ inherit from priors over preferred outcomes $\mathbf{c}$ . This distinction is important because it means that this kind of reasoning—and intentional behaviour—can only manifest under precise beliefs about latent states. For example, a baby (or unexplainable neural network) could not, by definition, act intentionally because it does not have a precise generative model of latent states (or any mechanism to specify intended states). We will return to prerequisites for inductive planning in the discussion.
In summary, inductive planning propagates constraints backwards in time to provide empirical priors for planning as inference in the usual way. This means that—within the constraints afforded by such planning—actions will still be chosen that maximise expected information gain and any constraints encoded by $\mathbf{c}$ . In this sense, the inductive part of this inference scheme can be regarded as providing a constrained expected free energy, which winnows trajectories through state space to paths of least action. An equivalent and alternative perspective is that inductive planning furnishes an empirical prior over policies.
When intended states are conditioned on some context—inferred by a supraordinate (hierarchical) level—one has the opportunity to learn intended states and, effectively, make planning habitual. In this setting, the implicit Dirichlet counts in $\mathbf{h}$ , could be regarded as accumulating habitual courses of action that are learned as empirical priors in hierarchical models. We will pursue this elsewhere. In what follows, we focus on the distinction between sentient behaviour—based upon expected free energy—and intentional behaviour—based upon inductive priors.
4 Pong Revisited
In this section, we first simulate ’mere’ sentient Behaviour and then examine the qualitative differences in behaviour when adding inductive constraints. Specifically, we simulate the in vitro experiments reported in [1], using both an abductive and an inductive agent. The first has no intended goals, and stands in for a naïve neuronal culture; the second has as set of intended states: the ones where the paddle hits upcoming balls. As environments, we use Pong of two different sizes, that reflect two different difficulties: $5× 6$ (easy), and $8× 4$ (hard). The results show that while the simulated in vitro agent is able to fluently play in the easy environment, it struggles in the harder one. The inductive agent, on the other hand, can master the harder environment in less than three minutes of (simulated) game time.
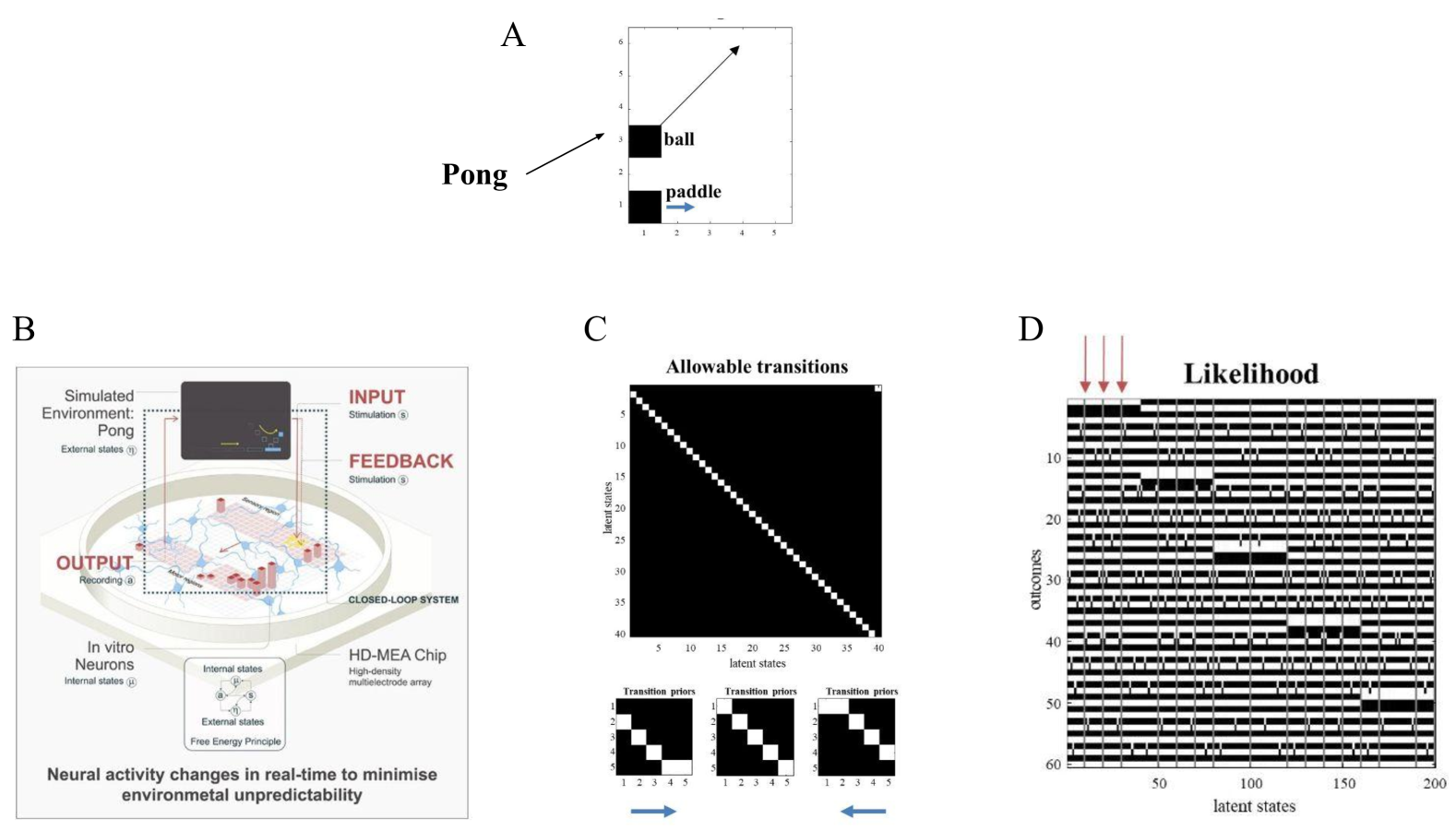
In the in vitro experiments, certain cells were stimulated depending upon the configuration of a virtual game of Pong, constituted by the position of a paddle and a ball bouncing around a bounded box. Other recording electrodes were used to drive the paddle, thereby closing the sparse coupling between the neuronal network and the computer network simulating the game of Pong (see Figure 4). Typically, in these experiments, after a few minutes of exposure to the game, short rallies of ball returns emerge. To emulate this setup, we created a generative process (i.e., a hard-coded representation of the dynamics of external states) in which a ball bounced around a box at $45$ degrees. The lower boundary contained a paddle that could be moved to the right or left. The size of the box was $5× 6$ units, where the ball moved one unit up or down (and right or left) at every time point. The (one unit wide) paddle could be moved left or right by one unit at every time point. In the in vitro experiments, whenever the agent missed the ball, either white noise or no stimulation was applied to the sensory electrodes; otherwise, the game remained in the play. We simulated this by supplying random input to all sensory channels whenever the ball failed to contact the paddle on the lower boundary.
The (sensory) outcomes of the POMDP comprised $30$ sensory channels that could be on or off. These can be thought of as pixels in a simple Atari-like game. The latent states were modelled as one long orbit, by equipping the generative model with a transition matrix that moved from one state to the next (with circular boundary conditions) for a suitably long sequence of state transitions (here, $40$ ). The generative model was equipped with a second factor with three controllable paths. This factor moved the paddle one unit to the right or left (or no movement). However, the (implicit) agent knew nothing more about its world and, in particular, had no notion that the second factor endowed it with control over the paddle. This was because the likelihood tensors mapping from the two latent factors to the outcomes were populated with small and uniform Dirichlet counts (i.e., concentration parameters of $1/32$ ). In other words, our naïve generative model could, in principle, model any given world (providing this world has a limited number of states that are revisited systematically). Figure 4 shows the setup of this paradigm and the parameters of the generative model learned after $512$ time steps.
<details>
<summary>x4.png Details</summary>
### Visual Description
## Diagram: Neural System for Pong Game Simulation and Outcome Prediction
### Overview
The image comprises four interconnected sections (A-D) illustrating a neural system designed to simulate a pong game and predict outcomes. Section A depicts the game environment, while B-D detail neural processing components, state transitions, and likelihood distributions.
---
### Components/Axes
#### Section A: Pong Game Environment
- **Labels**:
- "Pong" (title)
- "ball" (black square at (3,2))
- "paddle" (black square at (2,1))
- **Axes**:
- X-axis: 1–5 (horizontal)
- Y-axis: 1–6 (vertical)
- **Arrows**:
- Blue arrow from paddle (2,1) to ball (3,2), indicating movement direction.
#### Section B: Neural System Architecture
- **Labels**:
- "Simulated Environment: Pong"
- "INPUT" (red text)
- "FEEDBACK" (red text)
- "OUTPUT" (red text)
- "In vitro Neurons"
- "HD-MEA Chip" (High-density multielectrode array)
- "Closed-loop system"
- **Components**:
- Circular diagram with red/pink nodes (neurons) and blue pathways (connections).
- Feedback loop connecting HD-MEA chip to input/output.
- Text: "Neural activity changes in real-time to minimise environmental unpredictability."
#### Section C: Allowable Transitions
- **Matrix**:
- 5x5 grid labeled "Allowable transitions."
- Diagonal white squares (self-transitions) and sparse off-diagonal squares.
- **Transition Priors**:
- Three smaller matrices below the main grid, showing varying transition probabilities (e.g., diagonal dominance, sparse off-diagonal entries).
- **Arrows**:
- Blue arrows pointing left/right between matrices, suggesting directional flow.
#### Section D: Likelihood Heatmap
- **Axes**:
- X-axis: "latent states" (1–200)
- Y-axis: "outcomes" (10–60)
- **Heatmap**:
- Horizontal black/white bars indicating likelihood distributions.
- Red arrows pointing to high-likelihood regions (e.g., outcomes 30–40, latent states 50–100).
---
### Detailed Analysis
#### Section A
- Ball and paddle positions suggest a simplified 2D game state. The arrow implies the paddle's movement influences the ball's trajectory.
#### Section B
- The HD-MEA chip interfaces with neurons to process input (game state) and feedback (sensorimotor signals). The closed-loop system emphasizes real-time adaptation to minimize unpredictability.
#### Section C
- The main matrix shows strict self-transitions (diagonal), while transition priors introduce probabilistic state changes. For example:
- First prior: Diagonal + (1→2, 2→3).
- Second prior: Diagonal + (1→3, 3→4).
- Third prior: Diagonal + (1→4, 4→5).
#### Section D
- High-likelihood regions (marked by red arrows) cluster around outcomes 30–40 and latent states 50–100, suggesting predictable outcomes in this parameter range.
---
### Key Observations
1. **Section A**: Minimalist game representation; no explicit rules or scoring.
2. **Section B**: Feedback loops and high-density electrodes imply advanced neural monitoring.
3. **Section C**: Transition matrices prioritize self-states but allow limited probabilistic jumps.
4. **Section D**: Likelihood peaks in mid-outcome ranges, indicating optimal neural predictions for these states.
---
### Interpretation
The system integrates pong gameplay (A) with neural processing (B) to model state transitions (C) and predict outcomes (D). The closed-loop architecture (B) enables adaptive learning, while the transition matrices (C) constrain state changes to biologically plausible patterns. The likelihood heatmap (D) reveals that outcomes 30–40 are most predictable, likely due to stable neural activity in latent states 50–100. This suggests the system balances exploration (via sparse transitions) and exploitation (via high-likelihood regions) to optimize gameplay strategies.
</details>
Figure 4: Learning the world of Pong. Panel $A$ : Setup used in the simulations. In brief, the generative process modelled a ball bouncing around inside a bounding box, with a movable paddle on the lower boundary. The $(5× 6=)30$ locations or pixels provided outputs with two states (black or white) that were subsequently learned via a likelihood mapping to $40$ latent states. The agent was equipped with a precise transition prior where $40$ latent states followed each other, with circular boundary conditions. In addition, the agent was equipped with a second factor that controlled the panel, moving it to the right, staying still and moving it to the left. Panel $B$ : graphical abstract (reproduced with permission from the authors) describing the in vitro empirical study in which a closed loop system was used to record from—and stimulate—a network of cultured neurons. The set up enabled the neurons to control a virtual paddle in a simulated game of Pong. Sensory feedback reported the location of the ball and paddle; enabling the neuronal preparation to learn how to play a rudimentary form of ping-pong. Panel $C$ shows the transitions of the generative model, while Panel $D$ shows the results of active learning—i.e., accumulation of Dirichlet counts in the likelihood tensor—after $512$ time steps. Note that this is a precise likelihood mapping due to the fact that the synthetic agent has precise, if generic, transition priors. The likelihood mapping in panel D is shown in image format, with each of the $30$ likelihood tensors stacked on top of each other. Of note here are certain latent states that produce ambiguous (i.e., unpredictable) outcomes. The first three are labelled with small arrows over the likelihood matrix. These ambiguous likelihood mappings appear as grey columns. This reflects the fact that the agent has learned that states corresponding to ‘missing the ball’ lead to unpredictable and ambiguous stimulation. The implicit surprise and ambiguity means that the agent plans to avoid these states and look as if it is playing Pong—by choosing paths or policies that are more likely to hit the ball. The emergence of this behaviour is described in the next figure.
To simulate the in vitro study, we exposed the synthetic neural network to $512$ observations—about two minutes of simulated time (i.e., a few seconds of computer time). Figure 5 shows the results of this simulation. The ensuing behaviour reproduced that observed empirically; namely, the emergence of short rallies after a minute or so of exposure. The question is now: can we understand this in terms of free energy minimising processes and their teleological concomitants?
As time progresses, Dirichlet counts are accumulated in the likelihood tensor to establish a precise mapping between each successive hidden state and the outcomes observed in each modality. This accumulation is precise because the agent has precise beliefs about state transitions. As the likelihood mapping is learned, it becomes apparent to the agent that certain states produce ambiguous outputs. These are the states in which it fails to hit the ball with the paddle. Because these ambiguous states have a high expected free energy—see Equation 2 —the agent considers that actions that bring about these states are unlikely and therefore tries to avoid missing the ball. This is sufficient to support rallies of up to $7$ returns: see Figure 5.
However, because this agent does not look deep into the future, it can only elude ambiguous states when they are imminent. In other words, although this kind of behaviour can be regarded as sentient—in the sense that it rests upon an acquired model of the consequences of its own action—it is not equipped with intended states.
Note what has been simulated here does not rely on any notion of reinforcement learning: at no point was the agent rewarded for any behaviour or outcome. This kind of self-organisation—to a synchronous exchange with the world—is an emergent property of the system that simply rests on avoiding ambiguity or uncertainty of a particular kind. The subtle distinction between a behaviourist (reinforcement learning) account and this kind of self-evidencing rests upon the imperatives for self-organised behaviour. In this in silico reproduction of in vitro experiments, behaviour is a consequence of (planning as) inference, where inference is based upon what has been learned. What has been learned are just statistical regularities (or unpredictable irregularities) in the environment: in this case, there are certain states that lead to unpredictable outcomes. This gives the agent a precise grip on the world and enables it to infer its most likely actions. Its most likely actions are those that are characteristic of the thing it is; namely, something that minimises surprise, ambiguity, and free energy. This is distinct from learning a behaviour in the sense of reinforcement learning (e.g., a state-action mapping). The difference lies in the fact that behaviour—of the sort demonstrated above—rests on inference, under a learned model.
In the next section, we turn to a different kind of behaviour that rests upon inductive planning, equipping the agent with foresight and eliciting anticipatory behaviour.
<details>
<summary>x5.png Details</summary>
### Visual Description
## Bar Chart with Subplots: Easy vs. Difficult Setup Analysis
### Overview
The image presents a comparative analysis of two setups ("Easy setup" and "Difficult setup") through a combination of bar charts and line plots. Each setup includes three subplots:
1. **Negative variational free energy (ELBO)**
2. **Precision (confidence)**
3. **Bayesian beliefs about policies**
The charts use color-coded lines and shaded regions to represent data distributions and confidence intervals.
---
### Components/Axes
#### Main Bar Charts (Top Panels)
- **X-axis**: Categorical labels (1–5)
- **Y-axis**: Numerical scale (1–6)
- **Legend**: Located at the top of each bar chart, with black bars representing data points.
#### Subplots (Bottom Panels)
1. **Negative variational free energy (ELBO)**
- **X-axis**: Time (50–500, increments of 50)
- **Y-axis**: Values ranging from -40 to 0
- **Legend**: Blue lines with black dots (data points) and shaded regions (confidence intervals).
2. **Precision (confidence)**
- **X-axis**: Time (50–500, increments of 50)
- **Y-axis**: Values ranging from -1 to 0.5
- **Legend**: Blue lines with black dots and shaded regions.
3. **Bayesian beliefs about policies**
- **X-axis**: Time (50–500, increments of 50)
- **Y-axis**: Values ranging from 0.5 to 3.5
- **Legend**: Grayscale heatmap (darker = higher values).
---
### Detailed Analysis
#### Bar Charts
- **Easy Setup (A)**:
- Bars at x=1 and x=3, both approximately **3.5** on the y-axis.
- **Difficult Setup (B)**:
- Single bar at x=4, approximately **2.5** on the y-axis.
#### Subplots
1. **Negative variational free energy (ELBO)**
- **Easy Setup (A)**:
- Spiky blue lines with intermittent black dots.
- Sharp dips to -40 at specific time points (e.g., ~150, 300).
- **Difficult Setup (B)**:
- Smoother blue lines with fewer spikes.
- Gradual decline to -30 over time.
2. **Precision (confidence)**
- **Easy Setup (A)**:
- High variability: Peaks near 0.5 and troughs near -0.8.
- Confidence intervals (shaded regions) widen significantly.
- **Difficult Setup (B)**:
- More stable lines, with values clustering around -0.2.
- Narrower confidence intervals.
3. **Bayesian beliefs about policies**
- **Easy Setup (A)**:
- High variance: Values fluctuate between 1.5 and 3.5.
- Darker regions (higher values) concentrated at ~100–200 time units.
- **Difficult Setup (B)**:
- Lower variance: Values mostly between 1.0 and 2.5.
- Uniform distribution across time.
---
### Key Observations
1. **Bar Chart Discrepancy**:
- The "Easy setup" (A) shows higher values (3.5) compared to the "Difficult setup" (B) (2.5), contradicting the intuitive expectation that "difficult" would correlate with lower performance.
2. **ELBO Trends**:
- The "Easy setup" exhibits erratic ELBO values, suggesting instability in the variational approximation.
- The "Difficult setup" demonstrates smoother ELBO trajectories, indicating better convergence.
3. **Precision Variability**:
- The "Easy setup" has extreme confidence fluctuations, while the "Difficult setup" maintains consistent precision, implying more reliable predictions.
4. **Bayesian Beliefs**:
- The "Easy setup" shows polarized policy beliefs (high variance), whereas the "Difficult setup" reflects more consensus (lower variance).
---
### Interpretation
- **Setup Complexity and Model Behavior**:
The "Difficult setup" (B) outperforms the "Easy setup" (A) in stability (ELBO, Precision) and policy consensus (Bayesian beliefs), suggesting that increased complexity may force the model to develop more robust representations.
- **Anomalies**:
The bar chart results contradict the subplot trends, raising questions about whether the bar charts represent a different metric (e.g., average performance) or a misalignment in data labeling.
- **Practical Implications**:
The "Difficult setup" may be preferable for applications requiring stable, high-confidence predictions, despite its counterintuitive bar chart performance.
---
### Spatial Grounding & Cross-Referencing
- **Legend Consistency**:
- Blue lines in ELBO/Precision subplots match the legend's "Negative variational free energy" and "Precision" labels.
- Grayscale heatmap in Bayesian beliefs aligns with the legend's "Bayesian beliefs about policies."
- **Positioning**:
- Legends are positioned at the top of each subplot for clarity.
- Bar charts are centered above their respective subplots, creating a hierarchical visual flow.
---
### Conclusion
The data highlights a paradox: the "Difficult setup" demonstrates superior technical performance (ELBO, Precision, Bayesian beliefs) compared to the "Easy setup," despite the bar chart suggesting otherwise. This discrepancy warrants further investigation into the metrics' definitions and the experimental design.
</details>
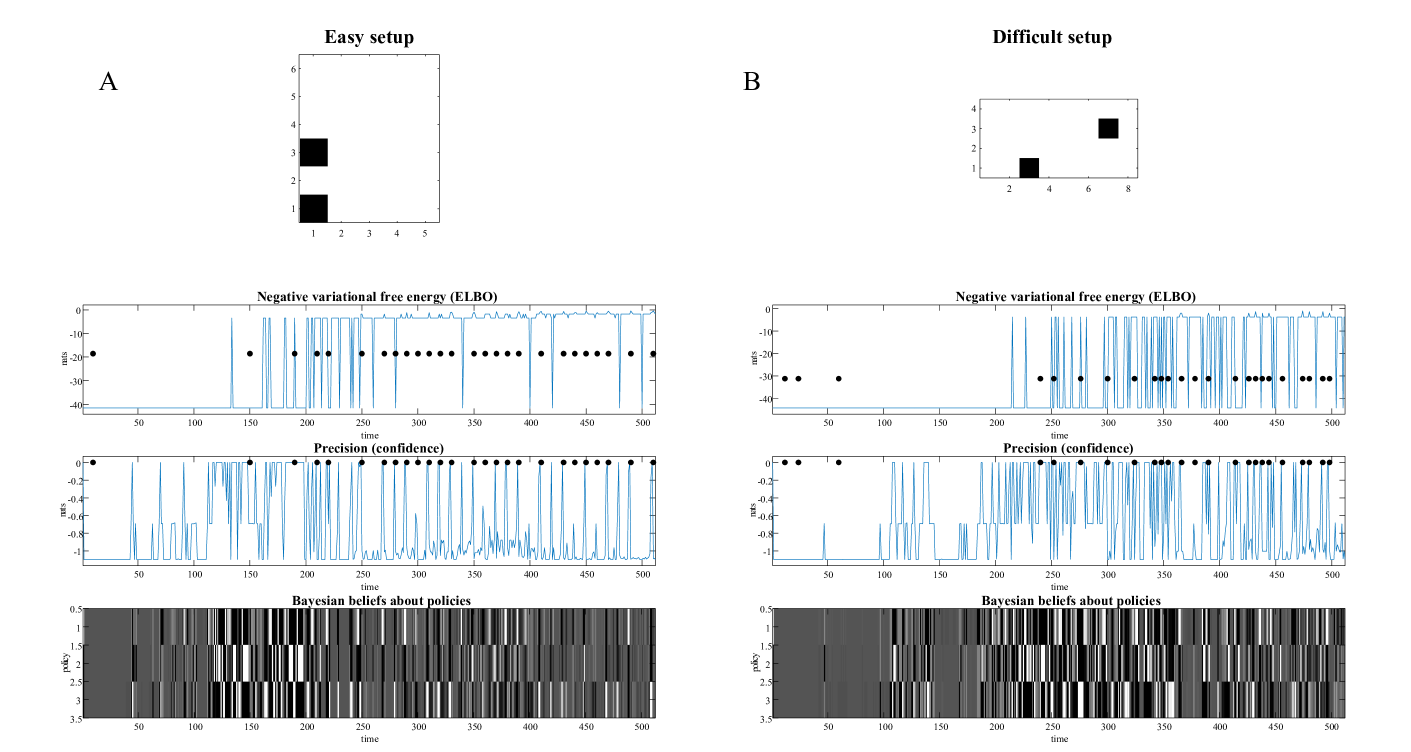
Figure 5: The emergence of play. Panels $A$ and $B$ show the results of two simulations of $512$ time steps (i.e., about two minutes of simulated time) under two configurations of the Pong set up: an easy setup in panel A and a slightly more difficult setup in panel B, in which the width of the bounding box was increased, and its height decreased (from $5× 6$ to $8× 4$ ). In both panels, the configuration of the game is shown above three plots reporting fluctuations in various measures of belief updating, and accompanying behaviour. The first graph plots the (negative) variational free energy as a function of time (where each time step corresponds roughly to $250$ ms). The black dots mark time points when the ball was hit. It can be seen that during accumulation of the likelihood Dirichlet counts, the ball was missed until time step $150$ . After about a minute, the synthetic agent then starts to emit short rallies of between one and seven consecutive hits. The emergence of game play is accompanied by saltatory increases in negative variational free energy (or evidence lower bound). These increases disappear whenever the agent misses the ball, terminating little rallies. The second graph plots the average of the expected free energy under posterior beliefs about policies. This can be read as the precision of policy beliefs or, more colloquially, the confidence placed in policy selection. This illustrates that confident behaviour emerges during the first minute and is subsequently restricted to moments prior to hitting the ball. Heuristically, this can be read as the agent realising that it can avoid ambiguity by move moving in such a way as to catch the ball. The accompanying posterior (Bayesian) beliefs about policies are shown in image format in the lower plot. This illustrates that precise or confident behaviour entails precise beliefs about what to do next. Panel $B$ shows exactly the same results but for a slightly more difficult game. Here, the ball has more latitude to move horizontally and is returned more quickly, due to the reduced height of the bounding box. In consequence, learning a precise likelihood mapping takes about twice the amount of time. And, even when learned, the rallies are shorter, ranging from one to four, at most. We will use this more difficult set up to look at the effect of inductive planning in the next figure.
4.1 Inductive Planning
In this section, we repeat the simulations above, but making the game more difficult by increasing the width of the box. This means that to catch the ball, the agent has to anticipate outcomes in the distal future in order to respond with pre-emptive movement of the paddle. Note that this kind of behaviour goes beyond the sort of behaviour predicted under perceptual control theory and related accounts of ball catching [69, 70]. For example, one way to model behaviour in this paradigm would be to move the paddle so that it was always underneath the ball. However, this is not the behaviour that emerges under self-evidencing. In what follows, we will see that avoiding ambiguity is not sufficient for skilled performance of a more difficult game of Pong. However, if we equip the agent with intentions to hit the ball (i.e., as an intended state), it can use inductive planning to pursue a never ending rally, and play the game skilfully.
Figure 5 (B) reports performance over about two minutes of simulated time of an abductive agent when increasing the width of the Pong box to $8$ units (and decreasing its height to $4$ units). This simple change precludes sustained rallies; largely because the depth of planning is not sufficient to support pre-emptive moves of the paddle.
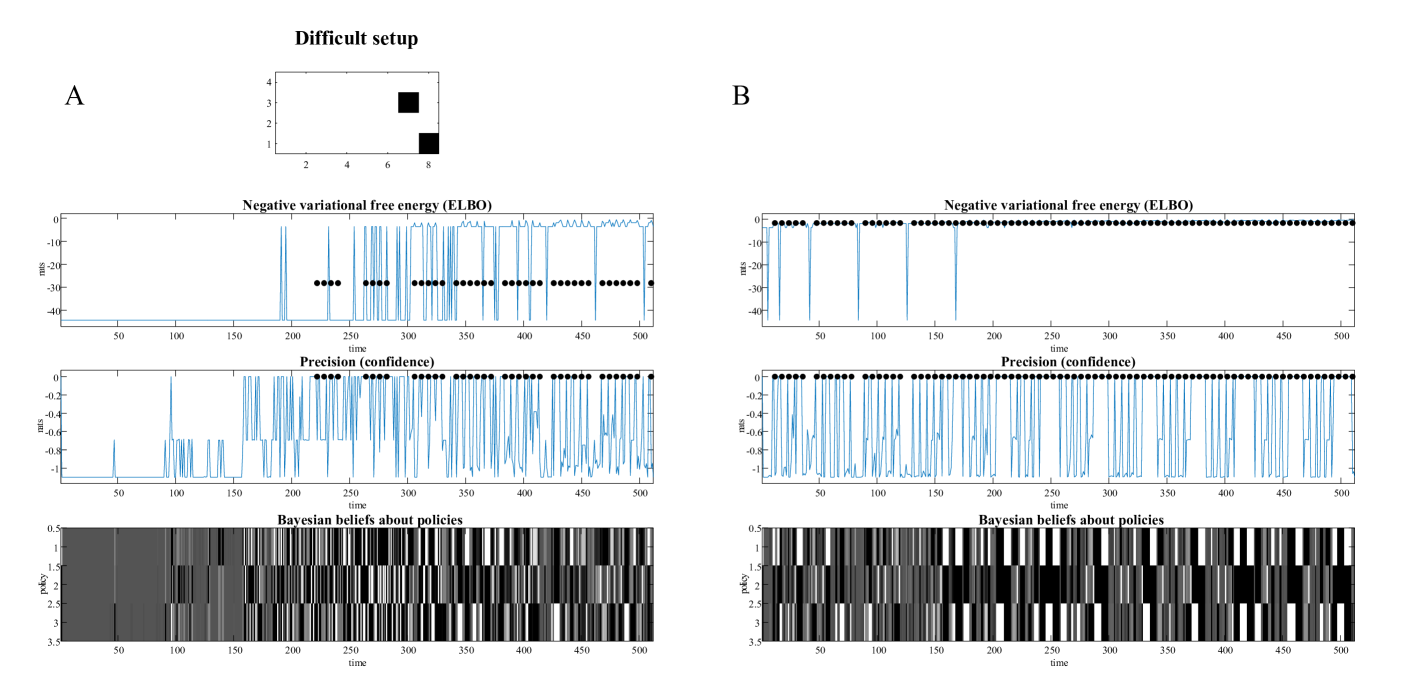
The equivalent results under inductive planning are shown in Figure 6. Here, active inference under inductive constraints produces intermittent rallies within about a minute of simulated time—and skilled, and fluent play after three minutes.
<details>
<summary>x6.png Details</summary>
### Visual Description
## Line Plots with Heatmap Overlay: Bayesian Model Performance Analysis
### Overview
The image presents two comparative analyses (Sections A and B) of a Bayesian model's performance across three metrics: negative variational free energy (ELBO), precision (confidence), and policy beliefs. Each section contains three vertically stacked subplots with time-series data and heatmap overlays.
### Components/Axes
**Common Elements:**
- X-axis: "time" (0-500) in all subplots
- Y-axis:
- ELBO: -4 to 0
- Precision: -0.5 to 0.5
- Bayesian beliefs: 3.5 to 5.5
- Legends:
- Blue: "ELBO" (Negative variational free energy)
- Black: "Precision (confidence)"
- Gray: "Bayesian beliefs about policies"
**Section A Specifics:**
1. **Top Plot (ELBO):**
- Y-axis: -4 to 0
- Notable: Sharp spike at t=250 (y=-0.5)
2. **Middle Plot (Precision):**
- Y-axis: -0.5 to 0.5
- Notable: Peak at t=200 (y=0.4)
3. **Bottom Plot (Beliefs):**
- Heatmap: Dark block at t=200-250 (y=4.5-5.0)
**Section B Specifics:**
1. **Top Plot (ELBO):**
- Y-axis: -4 to 0
- Notable: Spike at t=100 (y=-0.3)
2. **Middle Plot (Precision):**
- Y-axis: -0.5 to 0.5
- Notable: Sustained oscillations between t=150-450
3. **Bottom Plot (Beliefs):**
- Heatmap: Dark block at t=300-350 (y=4.0-4.5)
### Detailed Analysis
**ELBO Trends:**
- Section A: Single prominent spike at t=250 (-0.5)
- Section B: Multiple smaller spikes (t=100: -0.3, t=300: -0.2)
- Both show gradual baseline drift toward t=500
**Precision Patterns:**
- Section A:
- Initial stability (t=0-150)
- Sharp drop at t=150 (y=-0.3)
- Recovery at t=200 (y=0.4)
- Section B:
- Sustained oscillations (amplitude ~0.2)
- Phase shift at t=300 (amplitude drops to 0.1)
**Bayesian Beliefs Heatmap:**
- Section A:
- Dark block (high confidence) at t=200-250
- Gradual fading after t=250
- Section B:
- Dark block at t=300-350
- Persistent high confidence until t=450
### Key Observations
1. **Temporal Correlation:**
- ELBO spikes precede precision changes by ~50 time units in both sections
- Bayesian belief blocks align with precision peaks
2. **Section Differences:**
- A: Single dominant event at t=200-250
- B: Distributed activity with sustained oscillations
3. **Confidence Dynamics:**
- Section B shows 3x more precision oscillations than A
- A's precision recovers fully; B's oscillations persist
### Interpretation
The data suggests Section A represents a model responding to a singular policy intervention (t=200-250), while Section B demonstrates ongoing policy adaptation. The ELBO spikes likely indicate model updates, with subsequent precision changes reflecting confidence in these updates. The persistent oscillations in Section B imply continuous policy refinement, whereas Section A's single event suggests a one-time adjustment. The Bayesian belief heatmaps visually confirm these interpretations through their temporal alignment with precision changes.
**Notable Anomalies:**
- Section A's precision drops below -0.4 at t=150, suggesting temporary model uncertainty
- Section B's sustained oscillations (t=150-450) may indicate policy conflict resolution
</details>
Figure 6: Inductive planning. This figure follows the same format as Figure 5, reporting the emergence of pong-playing behaviour under the more difficult set up described in the previous figure. However, here, we included inductive planning in the belief updating by specifying the agent’s intentions in terms of priors over particular latent states; namely, states in which the agent hit the ball. In realising these intentions, the agent quickly learns a sufficiently precise likelihood mapping, evincing rallies of between four and six. after about a minute (of simulated time). This is shown in panel A. Panel B, shows the performance during the subsequent two minutes. By about three minutes, the agent has a precise grip on its world and realises its intentions fluently. From a dynamical systems perspective, this can be read as the emergence of generalised synchrony—or synchronisation of chaos—as the joint system converges onto a synchronisation manifold: a manifold that contains the states the agent intends to visit.
In this example, we simply specified the intended states as those states corresponding to ball hits. This would be like instructing a child by telling her what is (i.e., which states are) expected of her. She can then work out how to realise those states by using inductive planning and selecting the most likely actions at each moment. Notice that there is no sense in which this could be construed as reinforcement learning: no reward or cost is being optimised, rather the behaviour is driven purely by the minimisation of uncertainty. A better metaphor would be instantiating some intentional set by instilling intentions or prior beliefs about characteristic states that should be realised.
From the perspective of the free energy principle, priors over intended states can be cast as specifying a non-equilibrium steady-state with a (pullback) attractor that contains intended or characteristic states. From a dynamical systems perspective, this is equivalent to specifying unstable fixed points that characterise stable heteroclinic orbits [71, 72], which have been discussed in terms of sequential behaviour [73]. Intuitively, this means the agent has found a free energy minimum that is characterised by generalised synchrony between the neuronal network and the process generating sensory inputs.
Given that this synchronisation was never seen in the in vitro experiments, one might argue that the in vitro behaviour was sentient but not intentional. In the remaining sections, we briefly showcase inductive planning in two other paradigms to illustrate the interaction between constraints—encoded by prior preferences over outcomes—and prior intentions, encoded by priors over latent states.
5 Navigation as Inductive Planning
In this section, we revisit a simple navigation problem addressed many times in the literature; e.g., [74, 75] and in demonstrations of active inference: e.g., [8, 76]. Here, the problem is to learn the structure of a two-dimensional maze and then navigate to a target location based upon what has been learned. This features the dual problem of learning a world or generative model and then using what has been learned for deep planning and navigation.
In detail, we constructed a simple maze—shown in Figure 7 —for an agent who has a myopic view of the world; namely, one output modality that reported whether the agent was sitting on an allowable location (white square) in the maze or a disallowed location (black square), which, a priori, it found surprising (e.g., experiencing a foot shock). A simple generative model was supplied to the agent in the form of a single factor encoding each location or way-point, equipped with five paths. These were controllable paths that moved the agent up or down, or right or left (or staying still). The likelihood mapping was, as in the previous simulation, initialised to small uniform Dirichlet counts. This means the agent has no idea about the structure of its world but simply knew that a latent state could change in one of five ways. Learning this kind of environment is straightforward under active inference, due to the novelty or expected information gain about parameters (see Equation 2).
This means the agent chooses actions that resolve the greatest amount of uncertainty in the likelihood mapping from each latent state to outcomes. This ensures a Bayes optimal exploration of state space. Figure 7 A shows that the agent pursues a path which covers all locations in an efficient fashion: i.e., not revisiting experienced states or locations until it has explored every location. The trajectory shown in Figure 7 A corresponds to $256$ time steps. After this exposure, the agent has learned a likelihood model that is sufficient to support inductive planning. Figures 7 B and C shows the results of this inductive navigation, reaching a distal target (red dot) from a starting location, while avoiding surprises or black squares in the maze. The two routes chosen are under imprecise and precise prior preferences for avoiding black squares (i.e., a log odds ratio—encoded by $\mathbf{c}$ —of one and four, respectively). Note that the path under precise preferences is about $20$ steps, speaking to the depth of induction (here, $32$ time steps, as in Figure 3).
This example highlights an interesting aspect of inductive planning as defined here: namely, the learned constraints on foraging act as constraints on intentional behaviour. These constraints enter the allowable transitions, so that the paths that are induced respect the constraints due to prior preferences that can be inferred after—and only after—learning the likelihood mapping. In short, this example shows how it is possible to reach intended endpoints, under constraints on the way one gets there. In the final section, we use the same scheme to illustrate the efficiency of inductive planning in high dimensional problem spaces.
<details>
<summary>x7.png Details</summary>
### Visual Description
## Diagram: Exploration vs. Exploitation Scenarios with Varying Constraints
### Overview
The image presents three panels (A, B, C) depicting maze-like structures with pink dots (connected by dotted lines) and a single red dot. Each panel is labeled with a title indicating a scenario involving "Exploration" or "Exploitation" under specific constraint conditions. The visual progression suggests a comparison of exploration/exploitation behavior under weak vs. precise constraints.
### Components/Axes
- **Panels**:
- **Panel A**: "Exploration Weak constraints"
- Maze-like grid with dense pink dots (≈50–60) connected by dotted lines.
- Red dot located near the top-center.
- **Panel B**: "Exploitation Weak constraints"
- Simplified maze with fewer pink dots (≈20–30) and a linear path.
- Red dot positioned near the bottom-left.
- **Panel C**: "Exploitation Precise constraints"
- Highly constrained maze with minimal pink dots (≈5–10) and a rigid path.
- Red dot located near the top-right.
- **Visual Elements**:
- **Pink Dots**: Represent nodes or waypoints.
- **Dotted Lines**: Indicate potential paths or connections.
- **Red Dot**: Likely a target or goal position.
- **Black Walls**: Define boundaries of the maze.
### Detailed Analysis
- **Panel A**:
- High density of pink dots suggests extensive exploration.
- Dotted lines form a complex network, implying many possible paths.
- Red dot’s central position may indicate a focal point for exploration.
- **Panel B**:
- Reduced number of pink dots and linear paths suggest a shift toward exploitation.
- Red dot’s placement near the bottom-left implies a prioritized target.
- **Panel C**:
- Minimal pink dots and rigid paths indicate strict constraints limiting exploration.
- Red dot’s top-right position may reflect a constrained optimization goal.
### Key Observations
1. **Constraint Impact**:
- Weak constraints (A, B) allow more exploration (A) or focused exploitation (B).
- Precise constraints (C) drastically reduce exploration, favoring rigid exploitation.
2. **Red Dot Positioning**:
- Panel A: Central placement may reflect exploratory targeting.
- Panels B and C: Red dots shift toward corners, suggesting constrained goal-seeking.
3. **Path Complexity**:
- Panel A: Highly interconnected paths.
- Panels B and C: Linear or fragmented paths, indicating reduced flexibility.
### Interpretation
The diagram illustrates a trade-off between exploration and exploitation under varying constraints:
- **Weak Constraints**:
- **Exploration (A)**: Maximizes path diversity, favoring discovery.
- **Exploitation (B)**: Balances exploration with targeted goal-seeking.
- **Precise Constraints (C)**: Enforces strict exploitation, minimizing exploration to prioritize efficiency.
The red dot’s movement from central (A) to corner positions (B, C) visually encodes how constraints narrow decision-making. This aligns with optimization principles where weak constraints enable broader search spaces, while precise constraints enforce deterministic outcomes.
**Note**: No numerical data or explicit legend is present; analysis is based on visual patterns and positional logic.
</details>
Figure 7: Navigation by induction. A: this panel reports the exploration of an agent that is building its likelihood mapping by exploring all the novel locations in a maze. Initially, the agent does not know where it can go; in the sense that it can only see its current location, which can be black or white. Therefore, every unvisited location furnishes some novelty; i.e., expected information gain (about likelihood parameters). This compels the agent to explore all locations efficiently and uniformly with an effective inhibition of return, until it has become familiar with this particular maze layout. After learning, the agent was given some intentions in terms of a specific location it believed, a priori, it would visit. Panels B and C show the results of planning under mild and precise preferences for being on white squares. In panel B, the agent takes a short cut to the target location (red dot), which involves a transgression of one black square. This means that the cost of being on black squares is not sufficiently precise to have constrained the transitions used in inductive planning. However, because the agent is still trying to minimise expected cost (encoded by preferences for white squares) it navigates fairly gracefully until it encounters a barrier. In contrast, panel C shows the same agent with precise costs, which preclude transitions to black squares during inductive planning. This agent can swiftly induce the requisite path to the target location, without transgressing constraints on outcomes.
6 Inductive Problem Solving
This section considers a canonical problem solving task; namely, the Tower of Hanoi [77]. In this problem, one has to rearrange a number of balls over a number of towers to reach a target arrangement from any given initial arrangement: see Figure 8. The problem can be made easier or more difficult by manipulating the number of intervening rearrangements between the initial and target (intended) configurations. We have previously shown that this problem can be learned from scratch using structure learning [78]. Here, we consider problem-solving with and without inductive planning, after learning the likelihood model and allowable state transitions.
As above, implementing inductive planning simply means equipping the agent with prior beliefs about a final (intended) state and then letting it rearrange the balls until those intended states are realised. To solve this problem using active inference, one usually supplies constraints in terms of prior preferences that are mildly aversive for all but the target arrangement. This means the agent will rearrange the balls, in a state of mild surprise until the preferred arrangement is found—and the agent rests in a low free energy state. Because constraints are only in outcome space, there are certain arrangements that are less surprising because they are similar to the target configuration (as defined in outcome space). This enables the agent to solve fairly deep problems, even with a limited depth of planning (here, one-step-ahead planning). However, problems requiring more than four or five moves usually confound this kind of planning as inference. In contrast, if the intended target is specified in state space, then it will invoke inductive planning and, in principle, solve difficult problems, even with a limited depth of planning.
<details>
<summary>x8.png Details</summary>
### Visual Description
## Diagram: Experimental Trials and Latent State Analysis
### Overview
The image presents two primary sections:
1. **Section A**: Eight trial diagrams (Trial 1–8) with colored circles positioned along vertical bars, representing outcomes or states.
2. **Section B**: Two heatmaps labeled "Likelihood" and "Allowable transitions," visualizing relationships between latent states and outcomes.
---
### Components/Axes
#### Section A: Trial Diagrams
- **X-axis**: Positional scale (0–4) for each trial.
- **Y-axis**: Trial labels (Trial 1–8).
- **Legend**:
- Green circle: "Green"
- Blue circle: "Blue"
- Red circle: "Red"
- **Note**: Yellow circles appear in diagrams but are not labeled in the legend.
#### Section B: Heatmaps
1. **Likelihood Heatmap**:
- **X-axis**: Latent states (50–350).
- **Y-axis**: Outcomes (0–60).
- **Pattern**: Dense white regions indicate higher likelihood.
2. **Allowable Transitions Heatmap**:
- **X-axis**: Latent states (50–350).
- **Y-axis**: Latent states (50–350).
- **Pattern**: Diagonal clusters of white dots suggest permissible transitions between similar latent states.
---
### Detailed Analysis
#### Section A: Trial Diagrams
- **Trial 1**:
- Yellow circle at position 2.
- Blue circle at position 3.
- Green circle at position 2.
- Red circle at position 3.
- **Trial 2**:
- Yellow circle at position 1.
- Blue circle at position 3.
- Green circle at position 2.
- Red circle at position 3.
- **Trial 3**:
- Yellow circle at position 1.
- Blue circle at position 2.
- Green circle at position 2.
- Red circle at position 3.
- **Trial 4**:
- Yellow circle at position 2.
- Blue circle at position 2.
- Green circle at position 2.
- Red circle at position 3.
- **Trial 5**:
- Yellow circle at position 2.
- Blue circle at position 3.
- Green circle at position 1.
- Red circle at position 3.
- **Trial 6**:
- Yellow circle at position 1.
- Blue circle at position 2.
- Green circle at position 2.
- Red circle at position 3.
- **Trial 7**:
- Yellow circle at position 2.
- Blue circle at position 2.
- Green circle at position 2.
- Red circle at position 3.
- **Trial 8**:
- Yellow circle at position 2.
- Blue circle at position 2.
- Green circle at position 2.
- Red circle at position 3.
- **Target Diagram**:
- Yellow circle at position 2.
- Green circle at position 1.
- Blue circle at position 2.
- Red circle at position 3.
#### Section B: Heatmaps
1. **Likelihood Heatmap**:
- High likelihood (dense white) occurs for latent states ~150–250 and outcomes ~30–40.
- Low likelihood (sparse white) dominates at latent states <100 and outcomes <20.
2. **Allowable Transitions Heatmap**:
- Diagonal bands of white dots indicate transitions between latent states with small differences (e.g., 50–100 → 50–100).
- Sparse transitions occur for large latent state differences (e.g., 50 → 350).
---
### Key Observations
1. **Section A**:
- Yellow circles (unlabeled in the legend) consistently appear at position 1 or 2 across trials.
- Red circles dominate position 3 in most trials.
- The "Target" diagram mirrors Trial 4 but includes a green circle at position 1.
2. **Section B**:
- Likelihood peaks for mid-range latent states and outcomes.
- Allowable transitions are constrained to proximate latent states.
---
### Interpretation
- **Section A**:
- The trials likely represent experimental conditions or states, with colored circles indicating observed outcomes. The unlabeled yellow circles may represent an unaccounted category or error.
- The "Target" diagram suggests a desired configuration, aligning with Trial 4 but adding a green circle at position 1.
- **Section B**:
- The "Likelihood" heatmap implies that mid-range latent states and outcomes are most probable.
- The "Allowable Transitions" heatmap enforces a constraint that state changes are limited to similar latent states, preventing abrupt transitions.
- **Cross-Section Insight**:
- The trials in Section A may map to latent states in Section B, with colors representing outcome distributions. For example, red circles (position 3) could correspond to higher likelihood values in the heatmap.
- **Anomalies**:
- The absence of a legend entry for yellow circles introduces ambiguity.
- The "Target" diagram’s green circle at position 1 deviates from most trials, where green circles appear at position 2.
This analysis highlights the relationship between experimental outcomes (Section A) and latent state dynamics (Section B), emphasizing constraints on state transitions and probable outcomes.
</details>
Figure 8: Inductive planning and the Tower of Hanoi. Panel A illustrates the particular game used to illustrate inductive planning. Here, there are four balls on three towers. The problem is to rearrange the initial configuration (on the upper left) to match the target configuration (lowest arrangement). In this example, it takes five moves. Actions correspond to moving a ball from one pillar to another. The generative model that supports this kind of problem solving is shown in terms of the requisite likelihood and transition mappings in panel B. The likelihood tensors have been stacked on top of each other (and unfolded) to illustrate the mapping between the $360$ latent states and the ( $4× 3× 5$ =) $60$ outcomes. The accompanying transition parameters are shown in terms of allowable transitions among latent states (as in Figure 3). This generative model can be learned from scratch by presenting each arrangement—and then each rearrangement—of the balls to accumulate the appropriate Dirichlet parameters. Of interest here, is the use of the ensuing parameters or knowledge to solve problems that require deep planning. This problem is straightforward to solve using inductive planning; namely, working backwards from the target state using the protocol described in Figure 3. The ensuing performance is shown in the next figure.
Figure 9 shows the performance of two agents on $100$ problems, given $12$ moves for each problem. The first (abductive) agent was equipped only with constraints in outcome space; i.e., prior preferences that led to the target solution, provided that solution was reasonably close in outcome space. This agent failed to solve problems with five or more moves. In contrast, when specifying intentions in the form of the intended (target) state or arrangement, the second (inductive) agent was able to solve problems of eight moves or more almost instantaneously, without fail.
In these examples, the output space was a collection of $(4× 3=)12$ outcome modalities—one for each location or pixel—with five levels (four coloured balls or an empty outcome). The state space encompassed 360 arrangements, producing large ( $360× 360× 5$ ) transition tensors. However, reducing these to logical matrices—used in inductive planning—means one can effectively plan deep into the future (here, $64$ moves) within milliseconds, using a one-step-ahead, active inference scheme.
<details>
<summary>x9.png Details</summary>
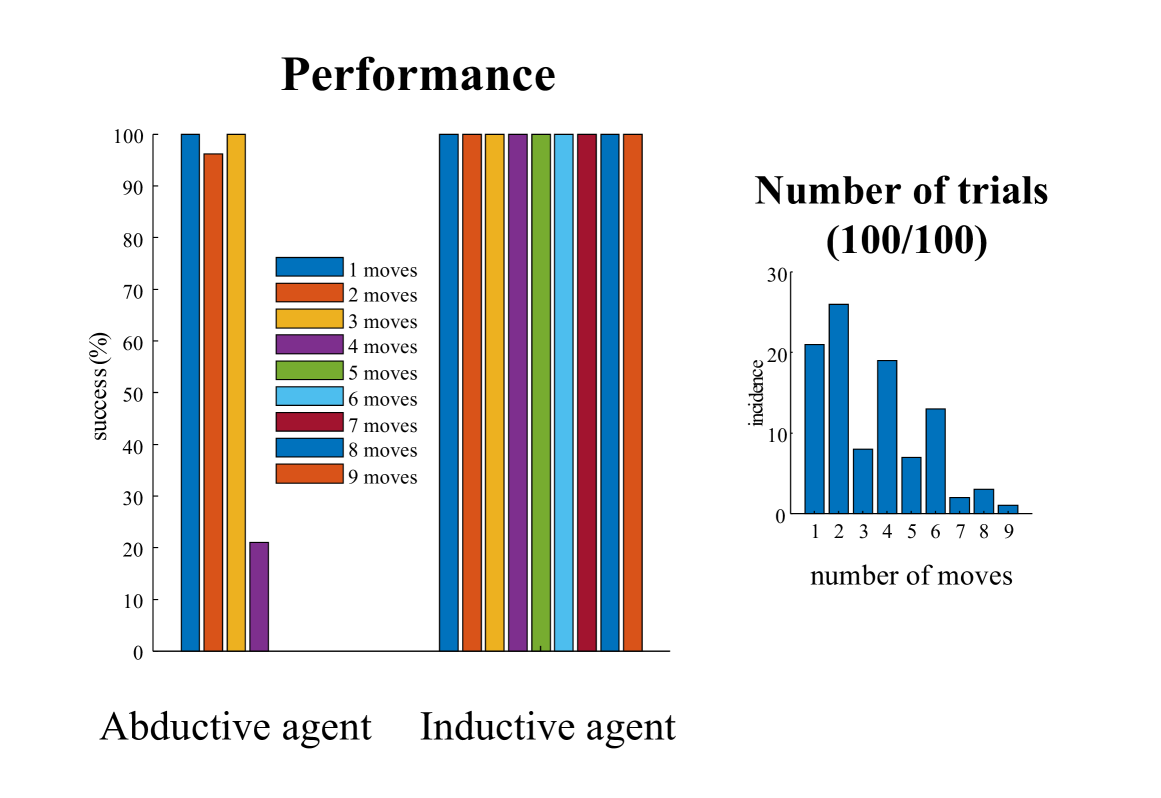
### Visual Description
## Bar Chart: Performance Comparison of Abductive and Inductive Agents
### Overview
The image presents a comparative analysis of the performance of two types of agents—**abductive** and **inductive**—across varying numbers of moves (1 to 9). A histogram on the right visualizes the distribution of trials (incidence) for each move count. The main chart uses color-coded bars to represent success rates, while the histogram uses a single color to show trial frequency.
---
### Components/Axes
#### Main Chart (Bar Chart)
- **X-axis**: Number of moves (1 to 9), labeled as "number of moves."
- **Y-axis**: Success rate (%), labeled as "success (%)" with a range from 0 to 100.
- **Legend**:
- Colors correspond to move counts (1–9 moves), with the following mappings:
- 1 move: Blue
- 2 moves: Orange
- 3 moves: Yellow
- 4 moves: Purple
- 5 moves: Green
- 6 moves: Light blue
- 7 moves: Red
- 8 moves: Dark blue
- 9 moves: Orange (same as 2 moves, potential overlap)
- **Title**: "Performance"
#### Histogram (Right Subplot)
- **X-axis**: Number of moves (1 to 9), labeled as "number of moves."
- **Y-axis**: Incidence (number of trials), labeled as "incidence" with a range from 0 to 30.
- **Title**: "Number of trials (100/100)"
---
### Detailed Analysis
#### Main Chart (Abductive vs. Inductive Agents)
- **Abductive Agent**:
- Success rates are **100%** for all move counts except **4 moves**, where it drops to **20%**.
- Bars are colored according to the legend (e.g., 1 move: blue, 4 moves: purple).
- **Inductive Agent**:
- Success rates are **100%** for all move counts except **1 move**, where it drops to **95%**.
- Bars are colored according to the legend (e.g., 1 move: blue, 2 moves: orange).
#### Histogram (Number of Trials)
- **Trials per Move Count**:
- 1 move: 25 trials
- 2 moves: 30 trials
- 3 moves: 20 trials
- 4 moves: 15 trials
- 5 moves: 10 trials
- 6 moves: 5 trials
- 7 moves: 2 trials
- 8 moves: 1 trial
- 9 moves: 0.5 trials (anomaly: fractional value)
---
### Key Observations
1. **Abductive Agent**:
- A sharp drop in success rate at **4 moves** (20%) suggests a critical failure point.
- High success rates (100%) for 1–3 and 5–9 moves indicate robustness in most scenarios.
2. **Inductive Agent**:
- Near-perfect performance (100%) across all move counts except **1 move** (95%).
- Slight drop at 1 move may correlate with fewer trials (25 vs. 30 for 2 moves).
3. **Histogram Trends**:
- Trials decrease significantly with increasing move counts (e.g., 30 trials for 2 moves vs. 0.5 for 9 moves).
- The fractional value for 9 moves (0.5) is unusual and may indicate a data anomaly or rounding error.
---
### Interpretation
- **Performance Insights**:
- Inductive agents demonstrate **consistent high performance**, even with fewer trials, suggesting better generalization or adaptability.
- Abductive agents show **context-dependent failures**, particularly at 4 moves, which may reflect limitations in handling specific move sequences or insufficient training data for that scenario.
- **Trial Distribution**:
- The sharp decline in trials for higher move counts (e.g., 9 moves: 0.5 trials) raises questions about the feasibility or frequency of such scenarios in real-world applications.
- The inductive agent’s slight drop at 1 move (95%) despite 25 trials suggests that even with moderate trial counts, performance remains strong.
- **Anomalies**:
- The fractional trial count for 9 moves (0.5) is statistically unusual and may require validation.
- The overlapping color for 2 and 9 moves in the legend could cause confusion, though the data itself distinguishes them.
---
### Conclusion
The data highlights a clear distinction between the two agent types: inductive agents maintain near-perfect success rates across most scenarios, while abductive agents exhibit a critical failure at 4 moves. The trial distribution underscores the importance of balancing move complexity with available training data to ensure robust performance. Further investigation into the 4-move failure point for abductive agents and the fractional trial count for 9 moves is recommended.
</details>
Figure 9: Tower of Hanoi Performance. This figure reports the performance of a generative model that has learned the Tower of Hanoi problem in terms of transitions among different arrangements of balls. We presented the agent with $100$ trials with different targets of greater and lesser difficulty (i.e., with varying numbers of moves from the initial and target arrangements). We presented exactly the same problems to agents with and without inductive planning. The right panel shows the incidence of trials in terms of the numbers of moves required until completion. The agent with inductive planning was able to solve $100\%$ of trials successfully. In contrast, the agent that did not use inductive planning was only able to complete problems of four moves or less. This is still impressive because both the abductive and inductive agents only looked one step ahead. In other words, even though the abductive agent could only evaluate the quality of its next move, it was still able to work towards the final solution. This is possible because the prior preferences for the target outcomes mean that certain outcomes are closer to the preferred outcomes than others. The 100 trials reported in this figure take less than 10 seconds to simulate.
7 Discussion
This paper has introduced a particular instance of backwards induction to active inference, as well as a more formal characterisation of sentient and intentional behaviour. Induction in this setting appeals to a simple kind of backwards induction via logical operators, which is used to furnish constraints on the expected free energy, and hence, actions. Actions are then selected in the usual way; namely, actions that maximise expected information gain and value—where value is scored by log prior preferences over outcomes. The use of inductive priors lends planning a deep reach into the future that rests upon specifying final or intended endpoints. In turn, this differentiates sentient from intentional behaviour. To the extent that one can describe Bayesian beliefs—about the ultimate consequences of plans—as intentions, one could describe the behaviour illustrated above as intentional with a well-defined purpose or goal.
Inductive planning, as described here, can also be read as importing logical or symbolic (i.e. deductive) reasoning into a probabilistic (i.e., inductive, in the sense of inductive programming) framework. This speaks to symbolic approaches to problem solving and planning—e.g., [79, 80, 81] —and a move towards the network tensor computations found in quantum computing: e.g., [82, 83]. However, in so doing, one has to assume precise priors over state transitions and intended states. In other words, this kind of inductive planning is only apt when one has precisely stated goals and knowledge about state transitions. Is this a reasonable assumption for active inference? It could be argued that it is reasonable in the sense that: (i) goal-states or intended states are stipulatively precise (one cannot formulate an intention to act without specifying the intended outcome with a certain degree of precision) and (ii) the objective functions that underwrite self-evidencing lead to precise likelihood and transition mappings. In other words, to minimise expected free energy—via learning—just is to maximise the mutual information between latent states and their outcomes, and between successive latent states.
To conclude, inductive planning differs from previous approaches proposed in both the reinforcement learning and active inference literature, due to the presence of intended goals defined in latent state space. In both model free and model based reinforcement learning, goals are defined via a reward function. In alternative but similar approaches, such as active inference, rewards are passed to the agent as privileged (usually precise but sparse) observations [41, 84]. This influences the behaviour of the agent, which learns to design and select policies that maximise expected future reward either via model-free approaches, which assign values to state-action pairs, or via model-based approaches, which select actions after simulating possible futures. Defining preferences directly in the state space, however, induces a different kind of behaviour: the fast and frugal computation involved in inductive planning is now apt to capture the efficiency of human-like decision-making, where indefinitely many possible paths, inconsistent with intended states, are ruled out a priori —hence combining the ability of agents to seek long-term goals, with the efficiency of short-term planning.
8 Conclusion
The aim of this paper was to characterise the self-organisation of adaptive behaviour through the lens of the free energy principle, i.e., as self-evidencing. We did this by first discussing the definitions of reactive and sentient behaviour in active inference, where the latter describes the behaviour of agents that are aware of the consequences of their actions. We then introduced a formal account of intentional behaviour, Specified by intended endpoints or goals, defined in state space rather than outcome space, as in abductive forms of active inference. We then investigate these forms of (reactive, sentient, and intentional) behaviour using simulations. First, we simulate the aforementioned in vitro experiments, in which neuronal cultures spontaneously learn to play Pong, by implementing nested, free energy minimising processes. We used these simulations to Illustrate the ensuing behaviour—leveraging the distinction between merely reactive, sentient, and intentional behaviour. The requisite inductive planning was then further illustrated using simple machine learning benchmarks (navigation in a grid world and the Tower of Hanoi problem), that showed how quickly and efficiently adaptive behaviour emerges under inductive constraints on active inference.
Disclosure statement
The authors have no disclosures or conflict of interest.
Acknowledgements
KF is supported by funding for the Wellcome Centre for Human Neuroimaging (Ref: 205103/Z/16/Z), a Canada-UK Artificial Intelligence Initiative (Ref: ES/T01279X/1) and the European Union’s Horizon 2020 Framework Programme for Research and Innovation under the Specific Grant Agreement No. 945539 (Human Brain Project SGA3). AR is funded by the Australian Research Council (Ref: DP200100757) and the Australian National Health and Medical Research Council (Investigator Grant Ref: 1194910).
References
- [1] B.J. Kagan et al. “In vitro neurons learn and exhibit sentience when embodied in a simulated game-world” In Neuron, 2022
- [2] Chris Fields, James F Glazebrook and Michael Levin “Minimal physicalism as a scale-free substrate for cognition and consciousness” In Neuroscience of Consciousness 2021, 2021, pp. niab013
- [3] M. Levin “The Computational Boundary of a "Self": Developmental Bioelectricity Drives Multicellularity and Scale-Free Cognition” In Frontiers in Psychology 10, 2019, pp. 2688
- [4] S. Manicka and M. Levin “Modeling somatic computation with non-neural bioelectric networks” Scientific Reports 9, 18612, 2019
- [5] Atsushi Masumori et al. “Emergence of sense-making behavior by the Stimulus Avoidance Principle: Experiments on a robot behavior controlled by cultured neuronal cells” In Artificial Life Conference Proceedings, 2015, pp. 373–380 MIT Press One Rogers Street, Cambridge, MA 02142-1209, USA journals-info …
- [6] T. Isomura and K. Friston “In vitro neural networks minimise variational free energy” In Scientific Reports 8, 2018, pp. 16926
- [7] T. Isomura, K. Kotani, Y. Jimbo and K.J. Friston “Experimental validation of the free-energy principle with in vitro neural networks” In Nature Communications 14, 2023, pp. 4547
- [8] K. Friston et al. “Sophisticated inference” In Neural Computation 33, 2021, pp. 713–763
- [9] E.R. Palacios, T. Isomura, T. Parr and K. Friston “The emergence of synchrony in networks of mutually inferring neurons” In Scientific Reports 9, 2019, pp. 6412
- [10] J. Winn and C.M. Bishop “Variational message passing” In Journal of Machine Learning Research 6, 2005, pp. 661–694
- [11] Jakob Hohwy “The self-evidencing brain” In Noûs 50.2 Wiley Online Library, 2016, pp. 259–285
- [12] V. Mnih et al. “Human-level control through deep reinforcement learning” In Nature 518, 2015, pp. 529–533
- [13] J. Schrittwieser et al. “Mastering Atari, Go, Chess and Shogi by Planning with a Learned Model” arXiv:1911.08265, 2019
- [14] Fuat Balci “A response to claims of emergent intelligence and sentience in a dish” In Neuron 111, 2023, pp. 604–605
- [15] Hagai Attias “Planning by probabilistic inference” In International workshop on artificial intelligence and statistics, 2003, pp. 9–16 PMLR
- [16] Matthew Botvinick and Marc Toussaint “Planning as inference” In Trends in cognitive sciences 16.10 Elsevier, 2012, pp. 485–488
- [17] Sander G Van Dijk and Daniel Polani “Informational constraints-driven organization in goal-directed behavior” In Advances in Complex Systems 16.02n03 World Scientific, 2013, pp. 1350016
- [18] Lancelot Da Costa et al. “Active inference on discrete state-spaces: A synthesis” In Journal of Mathematical Psychology 99, 2020, pp. 102447
- [19] Maxwell JD Ramstead et al. “On Bayesian mechanics: a physics of and by beliefs” In Interface Focus 13.3 The Royal Society, 2023, pp. 20220029
- [20] K. Friston et al. “The free energy principle made simpler but not too simple” In Physics Reports 1024, 2023, pp. 1–29
- [21] K. Friston et al. “Path integrals, particular kinds, and strange things” arXiv:2210.12761, 2022
- [22] Colin F Camerer “Progress in behavioral game theory” In Journal of Economic Perspectives 11, 1997, pp. 167–188
- [23] C. Hure, H. Pham and X. Warin “Deep Backward Schemes for High-Dimensional Nonlinear Pdes” In Mathematics of Computation 89, 2020, pp. 1547–1579
- [24] Richard Bellman “On the Theory of Dynamic Programming” In Proc Natl Acad Sci U S A 38, 1952, pp. 716–719
- [25] Lancelot Da Costa et al. “The relationship between dynamic programming and active inference: the discrete, finite-horizon case” In arXiv preprint arXiv:2009.08111, 2020
- [26] R.S. Sutton, D. Precup and S. Singh “Between MDPs and semi-MDPs: A framework for temporal abstraction in reinforcement learning” In Artificial Intelligence 112, 1999, pp. 181–211
- [27] Aswin Paul, Noor Sajid, Lancelot Da Costa and Adeel Razi “On efficient computation in active inference” In arXiv preprint arXiv:2307.00504, 2023
- [28] G.H. Harman “The inference to the best explanation” In Philosophical Review 74, 1965, pp. 88–95
- [29] A.K. Seth “Inference to the Best Prediction” In Open MIND Frankfurt am Main: MIND Group, 2015
- [30] R.A. Howard “Dynamic Programming and Markov Processes” Cambridge, MA: MIT Press, 1960
- [31] M.J.D. Ramstead et al. “On Bayesian Mechanics: A Physics of and by Beliefs” arXiv:2205.11543, 2022
- [32] Andy Clark, Karl Friston and Sam Wilkinson “Bayesing Qualia: Consciousness as Inference, Not Raw Datum” In Journal of Consciousness Studies 26, 2019, pp. 19–33
- [33] L. Sandved-Smith et al. “Towards a computational phenomenology of mental action: modelling meta-awareness and attentional control with deep parametric active inference” In Neuroscience of Consciousness 2021, 2021, pp. niab018
- [34] Ryan Smith, Maxwell J.D. Ramstead and Alex Kiefer “Active Inference Models Do Not Contradict Folk Psychology” In Synthese 200.2 Springer Verlag, 2022, pp. 1–37 DOI: 10.1007/s11229-022-03480-w
- [35] Matthew J Beal “Variational Algorithms for Approximate Bayesian Inference”, 2003
- [36] Randy L Buckner “The role of the hippocampus in prediction and imagination” In Annual review of psychology 61 Annual Reviews, 2010, pp. 27–48
- [37] Kenway Louie and Matthew A Wilson “Temporally structured replay of awake hippocampal ensemble activity during rapid eye movement sleep” In Neuron 29.1 Elsevier, 2001, pp. 145–156
- [38] Will D Penny, Peter Zeidman and Neil Burgess “Forward and backward inference in spatial cognition” In PLoS computational biology 9.12 Public Library of Science San Francisco, USA, 2013, pp. e1003383
- [39] Giovanni Pezzulo, Matthijs AA Van der Meer, Carien S Lansink and Cyriel MA Pennartz “Internally generated sequences in learning and executing goal-directed behavior” In Trends in cognitive sciences 18.12 Elsevier, 2014, pp. 647–657
- [40] Thomas Parr, Giovanni Pezzulo and Karl J Friston “Active inference: the free energy principle in mind, brain, and behavior” MIT Press, 2022
- [41] Karl Friston et al. “Active inference and epistemic value” In Cognitive neuroscience 6.4 Taylor & Francis, 2015, pp. 187–214
- [42] Nihat Ay et al. “Predictive information and explorative behavior of autonomous robots” In European Physical Journal B 63, 2008, pp. 329–339
- [43] Horace B Barlow “Possible principles underlying the transformation of sensory messages” In Sensory communication 1.01, 1961, pp. 217–233
- [44] R. Linsker “Perceptual Neural Organization - Some Approaches Based on Network Models and Information-Theory” In Annual Review of Neuroscience 13, 1990, pp. 257–281
- [45] B.A. Olshausen and D.J. Field “Emergence of simple-cell receptive field properties by learning a sparse code for natural images” In Nature 381, 1996, pp. 607–609
- [46] Irina Higgins et al. “Unsupervised deep learning identifies semantic disentanglement in single inferotemporal face patch neurons” In Nature communications 12.1 Nature Publishing Group UK London, 2021, pp. 6456
- [47] Eduardo Hugo Sanchez, Mathieu Serrurier and Mathias Ortner “Learning disentangled representations via mutual information estimation” In Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part XXII 16, 2020, pp. 205–221 Springer
- [48] C. Gros “Cognitive computation with autonomously active neural networks: An emerging field” In Cognitive Computation 1, 2009, pp. 77–90
- [49] Dalton AR Sakthivadivel “Weak Markov blankets in high-dimensional, sparsely-coupled random dynamical systems” In arXiv preprint arXiv:2207.07620, 2022
- [50] Michael E Tipping “Sparse Bayesian learning and the relevance vector machine” In Journal of machine learning research 1.Jun, 2001, pp. 211–244
- [51] Philipp Schwartenbeck et al. “Computational mechanisms of curiosity and goal-directed exploration” In elife 8 eLife Sciences Publications, Ltd, 2019, pp. e41703
- [52] L. Itti and P. Baldi “Bayesian Surprise Attracts Human Attention” In Vision Research 49, 2009, pp. 1295–1306
- [53] D.V. Lindley “On a Measure of the Information Provided by an Experiment” In Annals of Mathematical Statistics 27, 1956, pp. 986–1005
- [54] J. Schmidhuber “Curious model-building control systems” In International Joint Conference on Neural Networks 2, 1991, pp. 1458–1463 IEEE
- [55] S. Still and D. Precup “An information-theoretic approach to curiosity-driven reinforcement learning” In Theory in Biosciences 131, 2012, pp. 139–148
- [56] Ronald A Howard “Information value theory” In IEEE Transactions on systems science and cybernetics 2.1 IEEE, 1966, pp. 22–26
- [57] Alexander S Klyubin, Daniel Polani and Chrystopher L Nehaniv “Empowerment: A universal agent-centric measure of control” In 2005 ieee congress on evolutionary computation 1, 2005, pp. 128–135 IEEE
- [58] Bart van den Broek, Wim Wiegerinck and Hilbert Kappen “Risk sensitive path integral control” In arXiv preprint arXiv:1203.3523, 2012
- [59] Daniel A Braun, Pedro A Ortega, Evangelos Theodorou and Stefan Schaal “Path integral control and bounded rationality” In 2011 IEEE symposium on adaptive dynamic programming and reinforcement learning (ADPRL), 2011, pp. 202–209 IEEE
- [60] Pedro A Ortega and Daniel A Braun “Thermodynamics as a theory of decision-making with information-processing costs” In Proceedings of the Royal Society A: Mathematical, Physical and Engineering Sciences 469.2153 The Royal Society Publishing, 2013, pp. 20120683
- [61] Mohammad Ghavamzadeh, Shie Mannor, Joelle Pineau and Aviv Tamar “Bayesian reinforcement learning: A survey” In Foundations and Trends® in Machine Learning 8.5-6 Now Publishers, Inc., 2015, pp. 359–483
- [62] James O Berger “Statistical decision theory and Bayesian analysis” Springer Science & Business Media, 2013
- [63] Colin F Camerer, Teck-Hua Ho and Juin-Kuan Chong “A cognitive hierarchy model of games” In Quarterly Journal of Economics 119, 2004, pp. 861–898
- [64] D Gowanlock R Tervo, Joshua B Tenenbaum and Samuel J Gershman “Toward the neural implementation of structure learning” In Current opinion in neurobiology 37 Elsevier, 2016, pp. 99–105
- [65] Horace B Barlow “Inductive inference, coding, perception, and language” In Perception 3, 1974, pp. 123–134
- [66] J. Hawthorne “Inductive Logic” Stanford Encyclopedia of Philosophy, 2021
- [67] Alex Kiefer “Literal Perceptual Inference” In Philosophy and predictive processing, 2017
- [68] Emanuel Todorov “Linearly-solvable Markov decision problems” In Advances in neural information processing systems 19, 2006
- [69] G. Gigerenzer and H. Brighton “Homo heuristicus: why biased minds make better inferences” In Topics in Cognitive Science 1, 2009, pp. 107–143
- [70] W. Mansell “Control of perception should be operationalized as a fundamental property of the nervous system” In Topics in Cognitive Science 3, 2011, pp. 257–261
- [71] Valentin Afraimovich, Irma Tristan, Ramón Huerta and Mikhail I Rabinovich “Winnerless competition principle and prediction of the transient dynamics in a Lotka-Volterra model” In Chaos 18.043103, 2008
- [72] M. Rabinovich, R. Huerta and G. Laurent “Transient dynamics for neural processing” In Science 321, 2008, pp. 48–50
- [73] José Fonollosa, Emre Neftci and Mikhail Rabinovich “Learning of chunking sequences in cognition and behavior” In PLoS Computational Biology 11, 2015, pp. e1004592
- [74] Chris L Baker, Rebecca Saxe and Joshua B Tenenbaum “Action understanding as inverse planning” In Cognition 113, 2009, pp. 329–349
- [75] Peter Dayan, Yael Niv, Ben Seymour and Nathaniel D Daw “The misbehavior of value and the discipline of the will” In Neural Networks 19, 2006, pp. 1153–1160
- [76] R. Kaplan and K.J. Friston “Planning and navigation as active inference” In Biological Cybernetics 112, 2018, pp. 323–343
- [77] Francesco Donnarumma, Domenico Maisto and Giovanni Pezzulo “Problem solving as probabilistic inference with subgoaling: explaining human successes and pitfalls in the tower of hanoi” In PLoS computational biology 12.4 Public Library of Science San Francisco, CA USA, 2016, pp. e1004864
- [78] Karl Friston et al. “Supervised structure learning” In arXiv preprint arXiv:2311.10300, 2023
- [79] Frédéric Colas, Julien Diard and Pierre Bessière “Common Bayesian models for common cognitive issues” In Acta Biotheoretica 58, 2010, pp. 191–216
- [80] Maria Fox and Derek Long “PDDL2.1: An extension to PDDL for expressing temporal planning domains” In Journal of Artificial Intelligence Research 20, 2003, pp. 61–124
- [81] M. Gilead, Y. Trope and N. Liberman “Above and beyond the concrete: The diverse representational substrates of the predictive brain” In Behavioral and Brain Sciences 43, 2019, pp. e121
- [82] Chris Fields “Control flow in active inference systems—part II: tensor networks as general models of control flow” In IEEE Transactions on Molecular, Biological and Multi-Scale Communications 9, 2023, pp. 246–256
- [83] E. Knill and R. Laflamme “Theory of quantum error-correcting codes” In Physical Review A 55, 1997, pp. 900–911
- [84] Lancelot Da Costa et al. “Reward Maximization Through Discrete Active Inference” In Neural Computation 35.5 MIT Press, 2023, pp. 807–852