## Small LLMs Are Weak Tool Learners: A Multi-LLM Agent
Weizhou Shen 1 , Chenliang Li 2 , Hongzhan Chen 1 , Ming Yan 2 * , Xiaojun Quan 1 ∗ , Hehong Chen 2 , Ji Zhang 2 , Fei Huang 2
1 School of Computer Science and Engineering, Sun Yat-sen University, China 2 Alibaba Group shenwzh3@mail2.sysu.edu.cn, quanxj3@mail.sysu.edu.cn,
ym119608@alibaba-inc.com
https://github.com/X-PLUG/Multi-LLM-Agent
## Abstract
Large Language Model (LLM) agents significantly extend the capabilities of standalone LLMs, empowering them to interact with external tools (e.g., APIs, functions) and complete various tasks in a self-directed fashion. The challenge of tool use demands that LLMs not only understand user queries and generate answers accurately but also excel in task planning, tool invocation, and result summarization. While traditional works focus on training a single LLM with all these capabilities, performance limitations become apparent, particularly with smaller models. To overcome these challenges, we propose a novel approach that decomposes the aforementioned capabilities into a planner, caller, and summarizer. Each component is implemented by a single LLM that focuses on a specific capability and collaborates with others to accomplish the task. This modular framework facilitates individual updates and the potential use of smaller LLMs for building each capability. To effectively train this framework, we introduce a two-stage training paradigm. First, we fine-tune a backbone LLM on the entire dataset without discriminating sub-tasks, providing the model with a comprehensive understanding of the task. Second, the fine-tuned LLM is used to instantiate the planner, caller, and summarizer respectively, which are continually fine-tuned on respective sub-tasks. Evaluation across various tool-use benchmarks illustrates that our proposed multi-LLM framework surpasses the traditional single-LLM approach, highlighting its efficacy and advantages in tool learning.
## 1 Introduction
Large Language Models (LLMs) have revolutionized natural language processing with remarkable proficiency in understanding and generating text. Despite their impressive capabilities, LLMs are
* Corresponding authors.
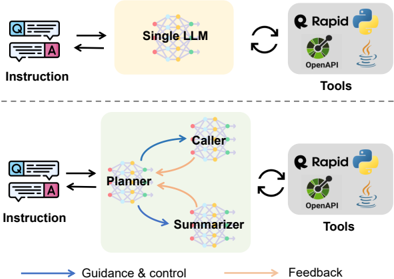
Figure 1: A conceptual comparison of the traditional single-LLM agent framework (top) and the proposed multi-LLM agent framework, α -UMi (bottom).
<details>
<summary>Image 1 Details</summary>
### Visual Description
\n
## Diagram: LLM Tool Use Architectures
### Overview
The image presents a comparative diagram illustrating two architectures for utilizing Large Language Models (LLMs) with external tools. The top panel depicts a single LLM directly interacting with tools, while the bottom panel shows a more complex architecture involving a "Planner," "Caller," and "Summarizer" LLM agents coordinating tool use. The diagram emphasizes the flow of instructions, feedback, and control between the LLMs and tools.
### Components/Axes
The diagram is divided into two main sections separated by a dashed line. Each section contains the following components:
* **Instruction:** Represented by a speech bubble with a question mark ("Q") and a document with text ("A").
* **LLM:** Depicted as a network of nodes. The top panel shows a "Single LLM," while the bottom panel shows three LLMs: "Planner," "Caller," and "Summarizer."
* **Tools:** Represented by icons for "Rapid," "Python," "OpenAPI," and "Java."
* **Arrows:** Blue arrows indicate "Guidance & control," and orange arrows indicate "Feedback."
### Detailed Analysis or Content Details
**Top Panel (Single LLM):**
* The "Instruction" block (Q&A) has a bidirectional arrow connecting it to the "Single LLM."
* The "Single LLM" has a bidirectional arrow connecting it to the "Tools" block (Rapid, Python, OpenAPI, Java).
* This suggests a direct interaction between the instruction and the LLM, which in turn directly interacts with the tools.
**Bottom Panel (Multi-Agent Architecture):**
* The "Instruction" block (Q&A) has a bidirectional arrow connecting it to the "Planner" LLM.
* The "Planner" LLM is connected to the "Caller" LLM with a blue arrow (Guidance & control) and an orange arrow (Feedback).
* The "Planner" LLM is also connected to the "Summarizer" LLM with a blue arrow (Guidance & control) and an orange arrow (Feedback).
* The "Caller" LLM has a bidirectional arrow connecting it to the "Tools" block (Rapid, Python, OpenAPI, Java).
* The "Summarizer" LLM has no direct connection to the tools, but receives feedback from the Planner.
* The "Tools" block (Rapid, Python, OpenAPI, Java) is identical to the top panel.
### Key Observations
* The bottom panel introduces a modular architecture with specialized LLM agents.
* The "Planner" appears to orchestrate the tool usage, delegating tasks to the "Caller" and receiving summaries from the "Summarizer."
* The feedback loops (orange arrows) suggest an iterative process where the LLMs refine their actions based on the results from the tools.
* The use of color-coded arrows clearly distinguishes between control flow and feedback mechanisms.
### Interpretation
This diagram illustrates a shift in how LLMs are being integrated with external tools. The single LLM approach is simple but may lack the sophistication to handle complex tasks requiring multiple tool interactions. The multi-agent architecture, with its specialized LLMs, offers a more structured and potentially more effective approach. The "Planner" acts as a central coordinator, breaking down the instruction into manageable steps and assigning them to the appropriate agents. The "Caller" handles the actual interaction with the tools, while the "Summarizer" provides a consolidated view of the results. The feedback loops are crucial for enabling the LLMs to learn and adapt their strategies over time. This architecture suggests a move towards more autonomous and intelligent agents capable of solving complex problems by leveraging the power of both LLMs and external tools. The diagram does not provide any quantitative data, but rather a conceptual overview of the architectural differences.
</details>
not without limitations. Notably, they lack domain specificity, real-time information, and face challenges in solving specialized problems such as mathematics (Gou et al., 2023) and program compilation (OpenAI, 2023a). Hence, integrating LLMs with external tools, such as API calls and Python functions, becomes imperative to extend their capabilities and enhance the overall performance. Consequently, LLM agents have become a prominent area for both academia and industry, employing large language models to determine when and how to utilize external tools to tackle various tasks.
In addition to exploring proprietary LLMs like GPT-4, researchers have also actively engaged in developing customizable agent systems by finetuning open-source LLMs on diverse tool-use datasets (Patil et al., 2023; Tang et al., 2023; Qin et al., 2023b; Gou et al., 2023). The challenge of tool learning demands sufficiently large and complex LLMs. These models must not only comprehend user queries but also excel in task planning, tool selection and invocation, and result summarization (Yujia et al., 2023). These capabilities draw upon different facets of the LLMs; for instance, planning relies more on reasoning ability, while tool selection and invocation demand legal and ac- curate request writing, and result summarization requires adept conclusion-drawing skills. While conventional approaches (Qin et al., 2023b; Gou et al., 2023; Zeng et al., 2023) focus on training a single open-source LLM with all these capabilities, notable performance limitations have been observed, especially with smaller open-source LLMs (Touvron et al., 2023a,b). Moreover, the tools could be updated frequently in practical scenarios, when the entire LLM requires potential retraining.
To address these challenges, we propose a multiLLM agent framework for tool learning, α -UMi 1 . As illustrated in Figure 1, α -UMi decomposes the capabilities of a single LLM into three components, namely planner, caller, and summarizer. Each of these components is implemented by a single LLM and trained to focus on a specific capability. The planner is designed to generate the rationale based on the current state of the system and weighs between selecting the caller or summarizer to generate downstream output, or even deciding to terminate the execution. The caller is directed by the rationale and responsible for invocating specific tools. The summarizer is guided by the planner to craft the ultimate user answer based on the execution trajectory. These components collaborate seamlessly to accomplish various tasks. Compared to previous approaches, our modular framework has three distinct advantages. First, each component undergoes training for a designated role, ensuring enhanced performance for each capability. Second, the modular structure allows for individual updates to each component as required, ensuring adaptability and streamlined maintenance. Third, since each component focuses solely on a specific capability, potentially smaller LLMs can be employed.
To effectively train this multi-LLM framework, we introduce a novel global-to-local progressive fine-tuning strategy (GLPFT). First, an LLM backbone is trained on the original training dataset without discriminating between sub-tasks, enhancing the comprehensive understanding of the toollearning task. Three copies of this LLM backbone are created to instantiate the planner, caller, and summarizer, respectively. In the second stage, the training dataset is reorganized into new datasets tailored to each LLM's role in tool use, and continual
1 In astronomy, the name ' α -UMi' is an alias of the Polaris Star ( https://en.wikipedia.org/wiki/Polaris ), which is actually a triple star system consisting of a brighter star (corresponding to the planner) and two fainter stars (corresponding to the caller and the summarizer).
fine-tuning of the planner, caller, and summarizer is performed on their respective datasets.
We employ LLaMA-2 (Touvron et al., 2023b) series to implement the LLM backbone and evaluate our α -UMi agent on several tool learning benchmarks (Qin et al., 2023b; Tang et al., 2023). Experimental results demonstrate that our proposed framework outperforms the single-LLM approach across various model and data sizes. Moreover, we show the necessity of the GLPFT strategy for the success of our framework and delve into the reasons behind the improved performance. Finally, the results confirm our assumption that smaller LLMs can be used in our multi-LLM framework to cultivate individual tool learning capabilities and attain a competitive overall performance.
To sum up, this work makes three critical contributions. First, we demonstrate that small LLMs are weak tool learners and introduce α -UMi, a multiLLM framework for building LLM agents, that outperforms the existing single-LLM approach in tool use. Second, we propose a GLPFT fine-tuning strategy, which has proven to be essential for the success of our framework. Third, we perform a thorough analysis, delving into data scaling laws and investigating the underlying reasons behind the superior performance of our framework.
## 2 Related Works
## 2.1 Tool Learning
The ability of LLMs to use external tools has become a pivotal component in the development of AI agents, attracting rapidly growing attention (Qin et al., 2023b; Schick et al., 2023; Yang et al., 2023b; Shen et al., 2023; Patil et al., 2023; Qin et al., 2023a). Toolformer (Schick et al., 2023) was one of the pioneering work in tool learning, employing tools in a self-supervised manner. Subsequently, a diverse array of external tools has been employed to enhance LLMs in various ways, including the improvement of real-time factual knowledge (Yang et al., 2023a; Nakano et al., 2021), multimodal comprehension and generation (Yang et al., 2023b; Wu et al., 2023a; Yang et al., 2023c), code and math reasoning (Gou et al., 2023; OpenAI, 2023a), and domain knowledge of specific AI models and APIs (Shen et al., 2023; Li et al., 2023; Qin et al., 2023b). Different from previous approaches relying on a single LLM for tool learning, we introduce a novel multi-LLM collaborated tool learning framework designed for smaller open-source
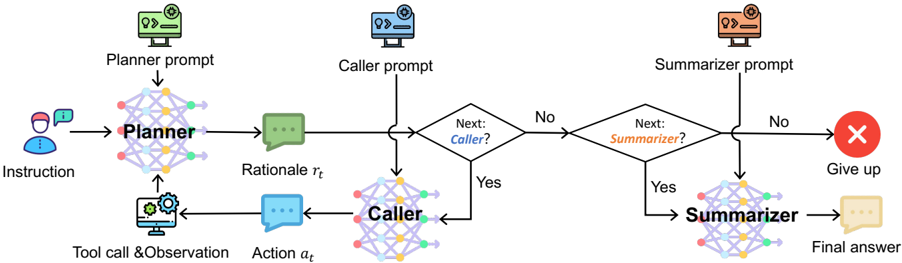
Figure 2: An illustration of how α -UMi works to complete a task.
<details>
<summary>Image 2 Details</summary>
### Visual Description
\n
## Diagram: ReAct Agent Workflow
### Overview
The image depicts a diagram illustrating the workflow of a ReAct (Reason + Act) agent, a type of AI agent that iteratively reasons and acts to solve a task. The diagram shows a sequence of components – Planner, Caller, and Summarizer – connected by arrows indicating the flow of information and control. Decision points are represented by diamond shapes.
### Components/Axes
The diagram consists of the following components:
* **Instruction:** Input to the system, represented by a person icon with a speech bubble.
* **Planner:** A component represented by a head icon with a network of nodes, receiving the instruction and generating a rationale (r<sub>t</sub>).
* **Rationale (r<sub>t</sub>):** Output from the Planner, represented by a speech bubble.
* **Caller:** A component represented by a phone icon with a network of nodes, receiving the rationale and generating an action (a<sub>t</sub>).
* **Action (a<sub>t</sub>):** Output from the Caller, represented by a speech bubble.
* **Tool call & Observation:** Feedback loop from the environment, represented by a computer icon with gears.
* **Summarizer:** A component represented by a person icon with a document, receiving information and generating a final answer.
* **Final answer:** Output from the Summarizer, represented by a speech bubble.
* **Decision Points:** Diamond shapes labeled "Next: Caller?" and "Next: Summarizer?".
* **Termination:** A red "X" symbol indicating the agent gives up.
* **Prompts:** Labels above the components indicating the type of prompt used: "Planner prompt", "Caller prompt", "Summarizer prompt".
### Detailed Analysis / Content Details
The diagram illustrates a cyclical process.
1. The process begins with an **Instruction** being fed into the **Planner**.
2. The **Planner** generates a **Rationale (r<sub>t</sub>)**.
3. The **Rationale** is passed to the **Caller**.
4. The **Caller** generates an **Action (a<sub>t</sub>)**.
5. The **Action** interacts with the environment via **Tool call & Observation**, providing feedback to the **Planner**.
6. A decision point asks: "Next: Caller?".
* If "Yes", the process loops back to the **Caller**.
* If "No", the process moves to the next decision point.
7. The next decision point asks: "Next: Summarizer?".
* If "Yes", the process moves to the **Summarizer**.
* If "No", the process terminates with a "Give up" signal.
8. The **Summarizer** generates a **Final answer**.
### Key Observations
The diagram highlights the iterative nature of the ReAct agent. The agent continuously plans, acts, observes, and refines its actions based on the feedback received from the environment. The decision points allow the agent to determine whether to continue calling tools or to summarize the results and provide a final answer. The "Give up" signal indicates a mechanism for handling situations where the agent cannot find a solution.
### Interpretation
This diagram demonstrates a control flow for an AI agent designed to solve complex tasks through iterative reasoning and action. The ReAct framework allows the agent to dynamically adapt its strategy based on the results of its actions. The loop between the Caller and Planner, driven by Tool call & Observation, is crucial for exploration and learning. The decision points represent the agent's ability to assess its progress and determine the next best course of action. The inclusion of a "Give up" mechanism suggests a practical consideration for handling unsolvable or intractable problems. The diagram effectively visualizes the interplay between reasoning, acting, and observing, which are the core principles of the ReAct approach. The prompts above each component indicate the type of input each module receives, suggesting a modular design.
</details>
LLMs. This framework decomposes the comprehensive abilities of LLMs into distinct roles, namely a planner, caller, and summarizer.
## 2.2 LLM-powered Agents
Leveraging the capabilities of LLMs such as ChatGPT (OpenAI, 2022) and GPT-4 (OpenAI, 2023b), AI agent systems have found application in diverse scenarios. For instance, solutions like BabyAGI (Nakajima, 2023) and AutoGPT (Gravitas, 2023) have been developed to address daily problems, while Voyager (Wang et al., 2023) and Ghost (Zhu et al., 2023) engage in free exploration within Minecraft games. Additionally, MetaGPT (Hong et al., 2023), ChatDev (Qian et al., 2023), and AutoGen (Wu et al., 2023b) contribute to the development of multi-agent frameworks tailored for software development and problem-solving.
Various techniques have been proposed to augment agent capabilities from different perspectives. The chain-of-thought series (Wei et al., 2022; Wang et al., 2022; Yao et al., 2022, 2023) and Reflextion (Shinn et al., 2023) contribute to enhancing agents' reasoning abilities, while MemoryBank (Zhong et al., 2023) enriches agents with long-term memory. Recent efforts have also emerged in fine-tuning open-source LLMs as agents, exemplified by works like FiREACT (Chen et al., 2023) and AgentTuning (Zeng et al., 2023). However, these endeavors primarily focus on finetuning a single LLM, unlike our approach, which explores an effective method for fine-tuning a multiLLM agent specifically for tool learning.
## 3 Methodology
## 3.1 Preliminary
Agents for tool learning are systems designed to assist users in completing tasks through a series of decision-making processes and tool use (Yujia et al., 2023). In recent years, these agents commonly adhere to the ReACT framework (Yao et al., 2022). The backbone of the agent is an LLM denoted as M . Given the user instruction q and the system prompt P , the agent solves the instruction step by step. In the t th step, the LLM M generates a rationale r t and an action a t based on the instruction and the current state of the system:
$$r _ { t } , a _ { t } = \mathcal { M } ( \mathcal { P } , \tau _ { t - 1 } , q ) , \quad ( 1 )$$
where τ t -1 = { r 1 , a 1 , o 1 , ..., r t -1 , a t -1 , o t -1 } denotes the previous execution trajectory. Here, o t denotes the observation returned by tools when the action a t is supplied. In the final step of the interaction, the agent generates rationale r n indicating that the instruction q is solved along with the final answer a n or that it will abandon this execution run. Therefore, no observation is included in this step.
## 3.2 The α -UMi Framework
As previously mentioned, the task of tool learning imposes a significant demand on the capabilities of LLMs, including task planning, tool invocation, and result summarization. Coping with all these capabilities using a single open-source LLM, especially when opting for a smaller LLM, appears to be challenging. To address this challenge, we introduce the α -UMi framework, which breaks down the tool learning task into three sub-tasks and assigns each sub-task to a dedicated LLM. Figure 1 presents an illustration of our framework, which incorporates three distinct LLM components: planner M plan, caller M call, and summarizer M sum. These components are differentiated by their roles in tool use, and each component model has a unique task definition, system prompt 2 , and model input.
2 The prompts for each LLM are provided in Appendix A.
The workflow of α -UMi is shown in Figure 2. Upon receiving the user instruction q , the planner generates a rationale comprising hints for the this step. This may trigger the caller to engage with the tools and subsequently receive observations from the tools. This iterative planner-caller-tool loop continues until the planner determines that it has gathered sufficient information to resolve the instruction. At this point, the planner transitions to the summarizer to generate the final answer. Alternatively, if the planner deems the instruction unsolvable, it may abandon the execution.
Planner : The planner assumes responsibility for planning and decision-making, serving as the 'brain' of our agent framework. Specifically, the model input for the planner comprises the system prompt P plan, the user instruction q , and the previous execution trajectory τ t -1 . Using this input, the planner generates the rationale r t :
$$r _ { t } = \mathcal { M } _ { p l a n } ( \mathcal { P } _ { p l a n } , \tau _ { t - 1 } , q ) . \quad ( 2 ) \quad o f \, c o r d$$
Following the rationale, the planner generates the decision for the next step: (1) If the decision is 'Next: Caller', the caller will be activated and an action will be generated for calling tools. (2) If the decision is 'Next: Summarizer', the summarizer will be activated to generate the final answer for the user, and the agent execution will finish. (3) If the decision is 'Next: Give up', it means that the user's instruction cannot be solved in the current situation, and the system will be terminated.
Caller: Interacting with the tools requires the LLM to generate legal and useful requests, which may conflict with other abilities such as reasoning and general response generation during fine-tuning. Therefore, we train a specialized caller to generate the action for using tools. The caller takes the user instruction q and the previous execution trajectory τ t -1 as input. To make the caller focus on the planner's rationale r t in the current step, we also design a prompt P call to explicitly remind the caller:
$$a _ { t } = \mathcal { M } _ { c a l l } ( \mathcal { P } _ { c a l l } , \tau _ { t - 1 } , q , r _ { t } ) . \quad ( 3 ) \quad m a n$$
Summarizer: The agent's final response, which aims to offer informative and helpful information to the user, is distinct from the rationales that primarily focus on planning and reasoning. Therefore, we employ a dedicated summarizer tasked with generating the final answer a n . This model utilizes a concise prompt P sum designed to guide the model
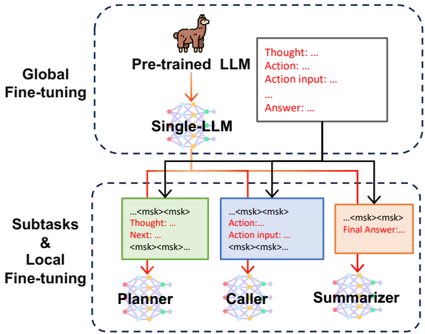
Figure 3: Global-to-local progressive fine-tuning.
<details>
<summary>Image 3 Details</summary>
### Visual Description
\n
## Diagram: LLM Fine-tuning and Subtask Decomposition
### Overview
The image is a diagram illustrating a process of fine-tuning a Large Language Model (LLM) and decomposing tasks into subtasks handled by specialized modules. It depicts a two-stage process: Global Fine-tuning and Subtasks & Local Fine-tuning. The diagram uses a network-like structure with arrows indicating the flow of information.
### Components/Axes
The diagram is divided into two main sections, visually separated by dashed blue rectangles:
* **Global Fine-tuning:** Located at the top of the image.
* **Subtasks & Local Fine-tuning:** Located at the bottom of the image.
Key components within these sections include:
* **Pre-trained LLM:** Represented by a llama icon and the text "Pre-trained LLM".
* **Single-LLM:** A network-like structure representing the LLM after global fine-tuning.
* **Planner:** A network-like structure with a green box containing text "...<msk><msk> Thought: ... Next: ...<msk>".
* **Caller:** A network-like structure with a blue box containing text "...<msk><msk> Action: ... Action input: ...<msk>".
* **Summarizer:** A network-like structure with an orange box containing text "...<msk><msk> Final Answer: ...".
* **Thought/Action/Answer:** A white box with red text "Thought: ...", blue text "Action: ...", and red text "Action input: ...", and red text "Answer: ...".
Arrows indicate the flow of information between these components.
### Detailed Analysis or Content Details
The diagram shows the following flow:
1. **Pre-trained LLM to Single-LLM:** A red arrow points from the llama icon (Pre-trained LLM) to the "Single-LLM" network.
2. **Single-LLM to Subtask Modules:** Three arrows originate from the "Single-LLM" network:
* A red arrow points to the "Planner".
* An orange arrow points to the "Caller".
* A blue arrow points to the "Summarizer".
3. **Subtask Modules:** Each subtask module (Planner, Caller, Summarizer) is a network-like structure.
* The "Planner" contains the text "...<msk><msk> Thought: ... Next: ...<msk>".
* The "Caller" contains the text "...<msk><msk> Action: ... Action input: ...<msk>".
* The "Summarizer" contains the text "...<msk><msk> Final Answer: ...".
4. **Single-LLM to Thought/Action/Answer:** A white box with red text "Thought: ...", blue text "Action: ...", and red text "Action input: ...", and red text "Answer: ..." is connected to the "Single-LLM" network.
The text "<msk><msk>" appears repeatedly within the subtask modules, likely representing masked tokens or placeholders.
### Key Observations
* The diagram highlights a two-stage fine-tuning process.
* The "Single-LLM" acts as a central hub, distributing tasks to specialized modules.
* Each subtask module focuses on a specific aspect of the overall task (planning, action execution, summarization).
* The use of "<msk><msk>" suggests a focus on token manipulation or generation.
### Interpretation
The diagram illustrates a method for improving LLM performance by combining global fine-tuning with task decomposition. The initial "Global Fine-tuning" stage prepares the LLM for a broader range of tasks. Subsequently, "Subtasks & Local Fine-tuning" breaks down complex tasks into smaller, more manageable subtasks, each handled by a specialized module. This approach allows for more targeted fine-tuning and potentially improves the accuracy and efficiency of the LLM. The llama icon likely represents a specific LLM architecture. The use of masked tokens suggests a focus on generative modeling or sequence-to-sequence tasks. The diagram suggests a modular approach to LLM development, where different modules can be trained and optimized independently. The flow of information from the "Single-LLM" to the subtask modules indicates that the LLM acts as a coordinator, directing the overall process. The diagram does not provide any quantitative data or performance metrics. It is a conceptual illustration of a system architecture.
</details>
in concentrating on summarizing the execution trajectory and presenting the answer to the user:
$$a _ { n } = \mathcal { M } _ { s u m } ( \mathcal { P } _ { s u m } , \tau _ { n - 1 } , q , r _ { n } ) . \quad ( 4 )$$
In Figure 6 and Figure 7, we show several cases of our α -UMi on downstream tasks.
## 3.3 Global-to-Local Progressive Fine-Tuning
To effectively fine-tune the above multi-LLM system is a complex endeavor: On one hand, generating the rationale, action, and final answer can facilitate each other during the training process, and enhance the model's comprehension of the entire agent task (Chen et al., 2023). On the other hand, the constraints on model capacity make it challenging to fine-tune a small LLM to achieve peak performance in generating rationales, actions, and final answers simultaneously (Dong et al., 2023). Taking into account these two points, we propose a global-to-local progressive fine-tuning (GLPFT) strategy for α -UMi. The motivation behind this strategy is to first exploit the mechanism by which the generation of rationale, action, and final answer can mutually enhance each other. Then, once the single LLM reaches its performance ceiling, it is subsequently split into planner, caller and summarizer for further fine-tuning, in order to enhance its capabilities in the subtasks and mitigate the performance constraints due to limited model capacity.
As depicted in Figure 3, this GLPFT strategy comprises two distinct stages. The first stage involves global fine-tuning, where we fine-tune a backbone LLM on the original training dataset without distinguishing between sub-tasks. After this stage, the backbone LLM is trained to sequentially output the rationale, action, and answer as introduced in Section 3.1. Then, we create three copies of the backbone LLM, designated as the planner, caller, and summarizer, respectively.
The second stage is local fine-tuning, where we reorganize the training dataset tailored to each LLM's role, as introduced in Section 3.2. We then proceed to fine-tune the planner, caller, and summarizer on their respective datasets, thereby further enhancing their specific abilities in each sub-task. During this local fine-tuning stage, we opt to reuse the set of user instructions curated in the global fine-tuning stage. The only adjustment made to the training set is the change in the format of the training data. As illustrated in Figure 3, the finetuning objective during the second stage for the planner, caller, and summarizer is oriented towards generating the rationale, action, and final answer, respectively. While the gradients from other text spans are stopped. Simultaneously, we refine the system prompts for the training data of the planner, caller, and summarizer, as detailed in Appendix A.
## 3.4 Discussions
The proposed α -UMi framework and GLPFT strategy are founded on three main principles. Firstly, the limited ability and capacity of small LLMs, such as LLaMA-7B, pose challenges during finetuning in tool learning tasks. In contrast, α -UMi decomposes complex tasks into simpler ones, reducing the workload on LLMs. Secondly, α -UMi offers increased flexibility in prompt design, allowing us to create specific prompts and model inputs for each LLM to fully leverage its capabilities in sub-tasks. Thirdly, the GLPFT strategy bridges the gap between fine-tuning on the whole tool learning task and on each sub-task, leading to a more successful fine-tuning process of the multi-LLM system. In the following experimental sections, we will focus on demonstrating these principles.
Recent studies have explored multi-agent systems based on LLMs across various domains, such as social communication (Park et al., 2023; Wei et al., 2023), software development (Qian et al., 2023; Hong et al., 2023), and problem solving (Wu et al., 2023b). These frameworks typically rely on powerful closed-source LLMs, demanding advanced capabilities such as automatic cooperation and feedback-abilities that extend beyond those of open-source small LLMs. In contrast, our α -UMi aims to ease the LLM's workload in tool-use tasks by integrating multiple LLMs to form an agent, particularly suitable for open-source, small LLMs. Additionally, we introduce the novel GLPFT method for fine-tuning the multi-LLM system, a contribution not found in existing multi-agent works.
## 4 Experimental Settings
## 4.1 Benchmarks
We evaluate the effectiveness of our α -UMi on two tool learning benchmarks: ToolBench (Qin et al., 2023b) and ToolAlpaca (Tang et al., 2023). These tasks involve integrating API calls to accomplish tasks, where the agent must accurately select the appropriate API and compose necessary API requests. Moreover, we partition the test set of ToolBench into in-domain and out-of-domain based on whether the tools used in the test instances have been seen during training. This division allows us to evaluate performance in both in-distribution and out-of-distribution scenarios. For additional details and statistics regarding these datasets, please refer to Appendix B. We also evaluate α -UMi on other benchmarks such as program-aided agent for mathematical reasoning (Hendrycks et al., 2021; Cobbe et al., 2021). The results are shown in Appendix D.
## 4.2 Metrics
The tasks in ToolBench involve calling APIs through RapidAPI 3 . This process frequently encounters problems such as API breakdowns, which impacts the fairness of the comparison. To address this problem, we introduce two types of evaluations for ToolBench. In Section 5.1, we first compare the output of agent with the annotated reference at each step 4 , which avoids real-time API callings. The metrics for this evaluation include Action EM (Act. EM), Argument F1 (Arg. F1), and Rouge-L (R-L) as proposed by Li et al. (2023). Moreover, we examine the frequency of API name hallucinations (Hallu.) and the accuracy (Plan ACC) of the agent's planning decisions at each step for using tools invocation, generating answer, or giving up. The reference annotations are based on verified ChatGPT execution results provided in ToolBench. We also provide the results based on real-time RapidAPI calling in Section 5.2, which is the original evaluation method used by the ToolBench team.
For ToolAlpaca, we assess the process correctness rate (Proc.) and the final answer correctness rate (Ans.) (Tang et al., 2023), both by GPT-4.
3 https://rapidapi.com/hub.
4 Refer to Appendix C for more details of the evaluation.
Table 1: Overall evaluation results on ToolBench and ToolAlpaca. 'ToolLLaMA (len = 4096)' and 'ToolLLaMA (len = 8192)' mean setting the max input length of ToolLLaMA to 4096 and 8192, respectively.
| Model | | ToolBench (in-domain) | ToolBench (in-domain) | ToolBench (in-domain) | ToolBench (in-domain) | ToolBench (out-of-domain) | ToolBench (out-of-domain) | ToolBench (out-of-domain) | ToolBench (out-of-domain) | | ToolAlpaca | ToolAlpaca |
|---------------------------------|------------------|-------------------------|-------------------------|-------------------------|-------------------------|-----------------------------|-----------------------------|-----------------------------|-----------------------------|------------------|------------------|------------------|
| | Plan ACC | Act. EM | Hallu. | Arg. F1 | R-L | Plan ACC | Act. EM | Hallu. | Arg. F1 | R-L | Proc. | Ans. |
| Close-SourceLLM | Close-SourceLLM | Close-SourceLLM | Close-SourceLLM | Close-SourceLLM | Close-SourceLLM | Close-SourceLLM | Close-SourceLLM | Close-SourceLLM | Close-SourceLLM | Close-SourceLLM | Close-SourceLLM | Close-SourceLLM |
| ChatGPT (0-shot) GPT-4 (0-shot) | 83.33 80.28 | 58.67 55.52 | 7.40 5.98 | 45.61 48.74 | 23.08 28.69 | 81.62 77.80 | 54.67 55.26 | 8.19 5.12 | 40.08 47.45 | 22.85 30.61 | 33 41 | 37 44 |
| Model Size = 7B | Model Size = 7B | Model Size = 7B | Model Size = 7B | Model Size = 7B | Model Size = 7B | Model Size = 7B | Model Size = 7B | Model Size = 7B | Model Size = 7B | Model Size = 7B | Model Size = 7B | Model Size = 7B |
| ToolLLaMA (len = 4096) | 66.42 | 19.47 | 33.94 | 15.98 | 2.06 | 68.21 | 30.75 | 25.35 | 25.07 | 5.78 | - | - |
| ToolLLaMA (len = 8192) | 77.02 | 47.56 | 4.03 | 42.00 | 15.26 | 77.76 | 45.07 | 3.45 | 40.41 | 18.10 | - | - |
| Single-LLM | 81.92 | 53.26 | 2.32 | 45.57 | 42.66 | 84.61 | 56.54 | 2.26 | 50.09 | 47.99 | 11 | 11 |
| Multi-LLM one-stage | 87.52 | 45.11 | 7.71 | 38.02 | 41.01 | 88.42 | 53.40 | 2.52 | 45.79 | 46.39 | 2 | 9 |
| Single-LLM multi-task | 85.06 | 51.83 | 2.96 | 44.25 | 27.40 | 86.55 | 56.89 | 2.77 | 49.50 | 32.58 | 28 | 18 |
| α -UMi w/o reuse | 88.24 | 55.50 | 0.53 | 48.97 | 39.98 | 87.91 | 58.02 | 2.32 | 50.55 | 42.59 | - | - |
| α -UMi w/ reuse | 88.92 | 58.94 | 0.57 | 52.24 | 43.17 | 89.72 | 60.47 | 0.45 | 53.60 | 46.26 | 41 | 35 |
| Model Size = 13B | Model Size = 13B | Model Size = 13B | Model Size = 13B | Model Size = 13B | Model Size = 13B | Model Size = 13B | Model Size = 13B | Model Size = 13B | Model Size = 13B | Model Size = 13B | Model Size = 13B | Model Size = 13B |
| Single-LLM | 81.01 | 59.67 | 1.53 | 52.35 | 42.16 | 86.74 | 60.04 | 2.03 | 52.94 | 48.46 | 33 | 29 |
| Multi-LLM one-stage | 86.49 | 50.54 | 5.11 | 41.96 | 36.21 | 87.45 | 56.71 | 3.23 | 47.49 | 41.62 | 22 | 19 |
| Single-LLM multi-task | 86.36 | 58.96 | 2.00 | 49.28 | 28.41 | 86.64 | 62.78 | 3.42 | 53.29 | 35.46 | 28 | 16 |
| α -UMi w/o reuse | 86.33 | 60.07 | 0.39 | 53.11 | 35.09 | 87.75 | 61.63 | 2.95 | 52.54 | 37.70 | - | - |
| α -UMi w/ reuse | 87.87 | 63.03 | 0.37 | 57.65 | 43.46 | 88.73 | 64.21 | 0.24 | 57.38 | 42.50 | 41 | 35 |
## 4.3 Implementation Details
We opt for LLaMA-2-chat-7B/13B (Touvron et al., 2023b) as the backbone to implement our framework. In the first stage of our GLPFT, we conduct fine-tuning for the backbone LLM with a learning rate of 5e-5 for 2 epochs. Then, we create three copies of this fine-tuned backbone to instantiate the planner, caller, and summarizer, respectively. In the second stage, we fine-tune the three LLMs with a reduced learning rate of 1e-5. The planner and caller undergo fine-tuning for 1 epoch, while the summarizer undergoes fine-tuning for 2 epochs. Weset the global batch size to 48 and employ DeepSpeed ZeRO Stage3 (Rajbhandari et al., 2021) to speed up the fine-tuning process. All experimental results are obtained using greedy decoding, with the maximum sequence length set at 4096.
## 4.4 Baselines
We compare our method with three baseline methods, namely Single-LLM, Multi-LLMone-stage and Single-LLM multi-task . Single-LLM refers to the traditional single-LLM tool learning approach. Multi-LLMone-stage involves directly fine-tuning the planner, caller, and summarizer on their own sub-task datasets, without employing our two-stage fine-tuning strategy. Single-LLM multi-task refers to using the same LLM to fulfill the roles of planner, caller, and summarizer. This particular LLM is fine-tuned on a combined dataset comprising the three sub-task datasets and functions similarly to our multi-LLM framework. We also evaluate the performance of ChatGPT and GPT-4 with 0-shot setting, and ToolLLaMA (Qin et al., 2023b), which is a 7B LLaMA model fine-tuned on ToolBench.
## 5 Results and Analysis
## 5.1 Overall Results
The main results are presented in Table 1. We elaborate on our observations from five perspectives:
First, when compared to ChatGPT and ToolLLama, our α -UMi outperforms them on all metrics except for the answer correctness on ToolAlpaca. α -UMi exceeds these two baselines in terms of Plan ACCand R-L considerably, demonstrating its alignment with annotated reference in terms of planning execution steps and generating final answers. It is worth mentioning that ToolLLaMA only exhibits acceptable performance when the input length is 8192. At an input length of 4096, ToolLLaMA shows deterioration across various metrics, particularly exhibiting a very high hallucination rate. In contrast, α -UMi only requires the input length of 4096 to achieve a satisfying performance. We attribute this to our multi-LLM system design, which allows each small LLM to focus on its sub-task, thereby reducing the requirement for input length.
Second, α -UMi outperforms the Single-LLM agent. On ToolBench, we unveil substantial improvements with α -UMi, particularly in Plan ACC, Act. EM, Hallu., and Arg. F1. On ToolAlpaca, α -UMi also surpasses Single-LLM with both 7B and 13B backbones. These findings not only confirm the effectiveness of α -UMi in enhancing the agent's planning and API calling capabilities but also suggest a notable decrease in hallucinations, which can significantly elevate user satisfaction.
Third, when comparing the results of methods with different model sizes, we note that agents with a 13B backbone exhibit superior performance com-
Table 2: Results of real-time evaluation on ToolBench. 'ReACT' and 'DFSDT' denote reasoning strategies used to construct agents, as detailed in Section 5.2. 'Win' measures the relative win rate of each agent compared to ChatGPT-ReACT ('Method'=ReACT, 'Model'=ChatGPT), which does not have an associated win rate.
| Method | Model | I1-Inst. | I1-Inst. | I1-Tool | I1-Tool | I1-Cat. | I1-Cat. | I2-Inst. | I2-Inst. | I2-Cat. | I2-Cat. | I3-Inst. | I3-Inst. | Average | Average |
|----------|--------------|------------|------------|-----------|-----------|-----------|-----------|------------|------------|-----------|-----------|------------|------------|-----------|-----------|
| Method | Model | Pass | Win | Pass | Win | Pass | Win | Pass | Win | Pass | Win | Pass | Win | Pass | Win |
| | Claude-2 | 5.5 | 31.0 | 3.5 | 27.8 | 5.5 | 33.8 | 6.0 | 35.0 | 6.0 | 31.5 | 14.0 | 47.5 | 6.8 | 34.4 |
| | ChatGPT | 41.5 | - | 44.0 | - | 44.5 | - | 42.5 | - | 46.5 | - | 22.0 | - | 40.2 | - |
| | ToolLLaMA | 25.0 | 45.0 | 29.0 | 42.0 | 33.0 | 47.5 | 30.5 | 50.8 | 31.5 | 41.8 | 25.0 | 55.0 | 29.0 | 47.0 |
| | GPT-4 | 53.5 | 60.0 | 50.0 | 58.8 | 53.5 | 63.5 | 67.0 | 65.8 | 72.0 | 60.3 | 47.0 | 78.0 | 57.2 | 64.4 |
| | Claude-2 | 20.5 | 38.0 | 31.0 | 44.3 | 18.5 | 43.3 | 17.0 | 36.8 | 20.5 | 33.5 | 28.0 | 65.0 | 43.1 | 43.5 |
| | ChatGPT | 54.5 | 60.5 | 65.0 | 62.0 | 60.5 | 57.3 | 75.0 | 72.0 | 71.5 | 64.8 | 62.0 | 69.0 | 64.8 | 64.3 |
| | ToolLLaMA | 57.0 | 55.0 | 61.0 | 55.3 | 62.0 | 54.5 | 77.0 | 68.5 | 77.0 | 58.0 | 66.0 | 69.0 | 60.7 | 60.0 |
| | GPT-4 | 60.0 | 67.5 | 71.5 | 67.8 | 67.0 | 66.5 | 79.5 | 73.3 | 77.5 | 63.3 | 71.0 | 84.0 | 71.1 | 70.4 |
| | α -UMi (7B) | 65.0 | 59.5 | 68.0 | 66.0 | 64.0 | 57.0 | 81.5 | 76.5 | 76.5 | 72.0 | 70.0 | 63.0 | 70.9 | 65.9 |
| | α -UMi (13B) | 65.5 | 61.5 | 69.0 | 66.0 | 65.0 | 62.5 | 84.5 | 75.0 | 81.0 | 74.5 | 71.0 | 66.0 | 72.2 | 67.7 |
pared to their 7B counterparts. This observation implies that the shift from a 7B to a 13B model results in a noteworthy improvement in tool utilization capabilities. Significantly, α -UMi with a 7B backbone even outperforms the Single-LLM baseline with a 13B LLM, confirming our earlier assumption that smaller LLMs can be utilized in our multi-LLM framework to develop each capability and achieve competitive overall performance.
Fourth, α -UMi outperforms Multi-LLMone-stage and Single-LLM multi-task . Multi-LLMone-stage even exhibits suboptimal performance compared to the Single-LLM baseline in metrics assessing API calling abilities, such as Act. EM, Hallu., and Arg. F1. This finding highlights the limitations of Multi-LLMone-stage when training each LLM on individual sub-tasks, compromising the comprehensive understanding of the tool-use task. Moreover, the subpar performance of Single-LLM multi-task reveals a limitation associated with the capacity of 7B and 13B models. The limited model capacity hinders the agent from effectively fulfilling the roles of planner, caller, and summarizer simultaneously. In contrast, through the application of the GLPFT strategy, α -UMi successfully mitigates this limitation, showcasing its effectiveness in achieving comprehensive tool learning capabilities.
Finally, α -UMi w/o reuse represents that instead of reusing the user instructions in the first fine-tuning stage of GLPFT, a new set of user instructions are employed for the second stage of GLPFT. This setup is inspired by Chung et al. (2022), which has demonstrated that increasing the diversity of user instructions during fine-tuning can improve the performance and generalizability of LLMs. However, as presented in Table 1 and visualized in Figure 4, despite the increased diversity of instructions compared to α -UMiw/ reuse, α -UMiw/o reuse does not outperform α -UMiw/ reuse. We attribute this unexpected result to the following explanation: Since the objectives of the two training stages are different, using distinct sets of user instructions, each with its unique distribution, may introduces a harmful inductive bias that solving one group of the instructions in single-LLM format while the other group in multi-LLM format. In contrast, through the reuse of user instructions, the impact of varying distributions from different sets is mitigated.
## 5.2 Real-Time Test on ToolBench
To assess the performance of LLMs for solving real tasks via RapidAPI, we follow the ToolEval method (Qin et al., 2023b) proposed by the ToolBench team to conduct a real-time evaluation on the test set of ToolBench. The LLMs under consideration include Claude-2 (Anthropic, 2023), ChatGPT, GPT-4, and ToolLLaMA. We apply two reasoning strategies for these LLMs to construct tool learning agents: the ReACT method, as introduced in Section 3.1, and the Depth First Search-based Decision Tree (DFSDT) (Qin et al., 2023b), which empowers the agent to evaluate and select between different execution paths. Two metrics are included to measure these LLMs' performance: pass rate , which calculates the percentage of tasks successfully completed, and win rate , which compares the agent's solution path with that of the standard baseline, ChatGPT-ReACT. The above two metrics are assessed by a ChatGPT evaluator with carefully crafted criteria. The empirical results presented in Table 2 demonstrate that our α -UMi (7B) surpasses both ChatGPT and ToolLLaMA by significant margins in terms of pass rate (+6.1 and +10.2, respectively) and win rate (+1.6 and +5.9, respectively).
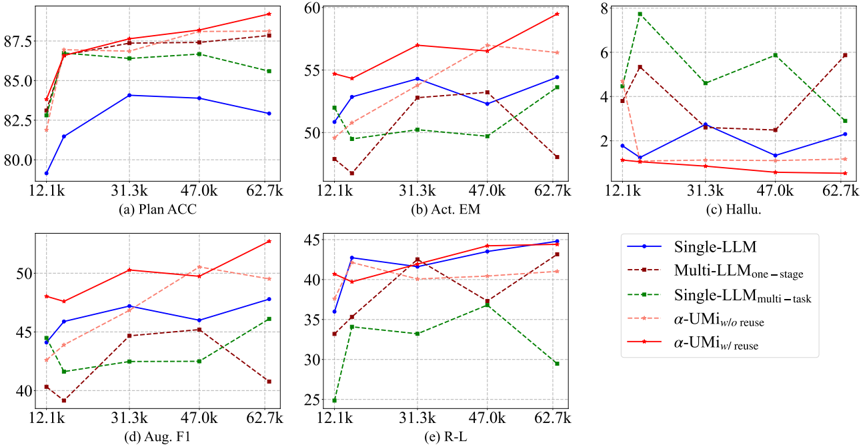
Figure 4: Results of data scaling law study on ToolBench with different evaluation metrics: (a) Plan ACC, (b) Act. EM, (c) Hallu, (d) Arg. F1, and (e) R-L. We randomly sampled five training sets with the scales of 12.1k, 15.7k, 31.3k, 47.0k, and 62.7k instances, accounting for 19.2%, 25%, 50%, 75%, and 100% of the training set, respectively.
<details>
<summary>Image 4 Details</summary>
### Visual Description
\n
## Line Charts: Performance Metrics
</details>
While α -UMi underperforms GPT-4 in win rate , it exhibits pass rates on par with GPT-4 or even exceeds it in certain test groups such as I1-Inst. and I2-Inst. . Combining the findings from Section 5.1 and this section, we note that our multi-LLM agent outperforms several established baselines across diverse metrics on ToolBench, validating its efficacy.
## 5.3 Data Scaling Law
To assess the impact of the amount of training data on performance, we conduct a data scaling law analysis with the 7B backbone on ToolBench, varying the number of annotated training instances from 12.1k to 62.7k. The results in different metrics are depicted in Figure 4. Several observations can be drawn from the results. Firstly, when comparing α -UMi (solid red curves) to Single-LLM (solid blue curves), there are significant and consistent enhancements in metrics such as Plan ACC, Act. EM, Hallu., and Arg. F1 across various scales of training data. While only minor improvements are observed in the R-L metric, which directly reflects the performance of the summarizer, this suggests that the performance enhancement of our framework is mainly attributed to the separation of the planner and the caller. Secondly, the performances of Multi-LLMone-stage and Single-LLM multi-task exhibit severe fluctuations in all metrics except for Plan ACC, indicating instability in training the framework through direct fine-tuning or multi-task fine-tuning. Thirdly, Single-LLM achieves opti-
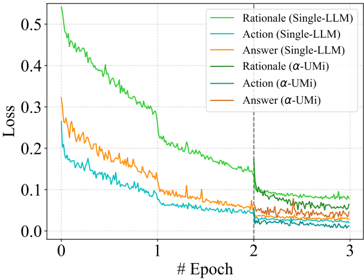
Figure 5: Curves of training loss.
<details>
<summary>Image 5 Details</summary>
### Visual Description
\n
## Line Chart: Loss vs. Epoch for Different Models
### Overview
The image presents a line chart illustrating the loss function values over epochs for six different models or configurations. The chart compares the performance of "Single-LLM" and "α-UMi" approaches across three tasks: "Rationale", "Action", and "Answer". The y-axis represents "Loss", while the x-axis represents "# Epoch".
### Components/Axes
* **X-axis:** "# Epoch" - Ranges from approximately 0 to 3.
* **Y-axis:** "Loss" - Ranges from approximately 0.0 to 0.55.
* **Legend:** Located in the top-right corner, listing the following data series:
* Rationale (Single-LLM) - Green line
* Action (Single-LLM) - Light-blue line
* Answer (Single-LLM) - Orange line
* Rationale (α-UMi) - Dark-blue line
* Action (α-UMi) - Teal line
* Answer (α-UMi) - Brown line
### Detailed Analysis
Here's a breakdown of each line's trend and approximate data points:
* **Rationale (Single-LLM) - Green Line:** Starts at approximately 0.52 at Epoch 0, steadily decreases to around 0.12 at Epoch 2, and then fluctuates between 0.06 and 0.12 until Epoch 3.
* **Action (Single-LLM) - Light-blue Line:** Begins at approximately 0.25 at Epoch 0, decreases to around 0.08 at Epoch 2, and remains relatively stable between 0.06 and 0.09 until Epoch 3.
* **Answer (Single-LLM) - Orange Line:** Starts at approximately 0.32 at Epoch 0, decreases to around 0.07 at Epoch 2, and fluctuates between 0.05 and 0.08 until Epoch 3.
* **Rationale (α-UMi) - Dark-blue Line:** Starts at approximately 0.18 at Epoch 0, decreases to around 0.05 at Epoch 1.5, and remains relatively stable between 0.04 and 0.06 until Epoch 3.
* **Action (α-UMi) - Teal Line:** Begins at approximately 0.15 at Epoch 0, decreases to around 0.04 at Epoch 1.5, and remains relatively stable between 0.03 and 0.05 until Epoch 3.
* **Answer (α-UMi) - Brown Line:** Starts at approximately 0.12 at Epoch 0, decreases to around 0.04 at Epoch 1.5, and remains relatively stable between 0.03 and 0.05 until Epoch 3.
All lines exhibit a decreasing trend initially, indicating that the loss is decreasing as the models are trained. There is a noticeable drop in loss for all models around Epoch 2.
### Key Observations
* The "Rationale (Single-LLM)" line consistently has the highest loss values throughout the training process.
* The "α-UMi" models consistently exhibit lower loss values compared to their "Single-LLM" counterparts.
* The loss values for all models appear to converge towards a stable level after Epoch 2.
* The "Action" and "Answer" tasks for both model types show similar loss trajectories.
### Interpretation
The chart demonstrates that the "α-UMi" approach generally outperforms the "Single-LLM" approach across all three tasks ("Rationale", "Action", and "Answer") in terms of minimizing loss. The consistent lower loss values for "α-UMi" suggest that this model is learning more effectively and achieving better performance. The sharp decrease in loss around Epoch 2 could indicate a significant learning event or a change in the model's optimization process. The convergence of loss values after Epoch 2 suggests that the models are approaching a point of diminishing returns in terms of further training. The higher loss associated with the "Rationale" task for the "Single-LLM" model might indicate that generating rationales is a more challenging task for this model compared to performing actions or providing answers. The data suggests that the α-UMi model is more efficient at learning and generalizing across the different tasks.
</details>
mal results in different metrics at different data scales. For example, it attains peak performance in Plan ACC with 31.3k instances and the best Arg. F1 and R-L with 62.7k instances. This suggests the challenge of obtaining a single LLM that uniformly performs well across all metrics. In contrast, the performance of our framework consistently improves with increased data scale across all metrics.
## 5.4 Why α -UMi Works?
We track the training process of our α -UMi approach to examine what makes it different from the Single-LLM baseline. To further investigate how each capability of the model evolves during training, we track the training loss on the rationale, action, and answer components of target responses. The results are depicted in Figure 5. As introduced in Section 4.3, α -UMi employs GLPFT and deviates from Single-LLM after two training epochs.
Table 3: The cost of training and inference.
| Model | Storage | Flops | Train Time | GPU Mem. | Infer. Time (Per Inst.) |
|-------------------|------------------|-----------------------------|------------------|------------------|---------------------------|
| Model Size = 7B | Model Size = 7B | Model Size = 7B | Model Size = 7B | Model Size = 7B | Model Size = 7B |
| Single-LLM α -UMi | 7B 7B*3 | 4 . 8 ∗ 10 15 6 . 2 ∗ 10 15 | 41.54h 63.34h | 206G 206G | 6.41s 6.27s |
| Model Size = 13B | Model Size = 13B | Model Size = 13B | Model Size = 13B | Model Size = 13B | Model Size = 13B |
| Single-LLM α -UMi | 13B 13B*3 | 7 . 2 ∗ 10 15 9 . 7 ∗ 10 15 | 89.56h 129.96h | 308G 308G | 11.91s 11.09s |
Therefore, our discussion focuses on the training curves of α -UMi from the third epoch.
The plotted curves reveal a consistent decrease in the training loss for rationale, action, and answer components during the initial two epochs. However, in the third epoch, the losses of Single-LLM exhibit a nearly stagnant trend. In contrast, α -UMi experiences continued reductions in the losses associated with rationale and action, indicating further optimization within our α -UMi framework.
These observations suggest that the key factor contributing to the success of α -UMi lies in its ability to surpass the performance upper-bound of Single-LLM. This is achieved by leveraging GLPFT and decomposing the agent into a multiLLM system, even after Single-LLM has attained its upper-bound abilities via sufficient fine-tuning.
## 5.5 Cost of α -UMi
Given that α -UMi operates as a multi-LLM framework, it introduces potential additional costs in terms of training, storage, and deployment. Table 3 provides a summary of the costs associated with Single-LLM and α -UMi, based on execution logs on 8 Nvidia A100 GPUs with a 40G capacity. Our observations are threefold. Firstly, owing to its composition of a planner, a caller, and a summarizer, α -UMi demands three times the storage capacity compared to the Single-LLM framework, assuming they employ backbones of the same size. Secondly, the training of α -UMi requires 1.3 times the computational resources and 1.5 times the training duration compared to Single-LLM, while the GPU memory cost for training remains consistent between the two methods. Thirdly, during inference, the time required for both Single-LLM and α -UMi is similar, as we only distribute sub-tasks (rationale, action, and answer) to the three LLMs, without forcing them to generate extra contents, thus bringing nearly no extra cost when inference.
Note that based on the findings presented in Table 1, α -UMi with a 7B backbone can outperform Single-LLM with a 13B backbone. Furthermore, the cost associated with α -UMi featuring a 7B model is lower than that of Single-LLM featuring a 13B model, both in terms of training and inference. This underscores the cost-effectiveness of α -UMi as a means to achieve, and even surpass, the performance of a larger LLM.
## 5.6 Case Study
Figure 6 and Figure 7 show two cases of our α -UMi executing real tasks in ToolBench. In the case of Figure 6, the user specifies the available tools in the instructions, making the tool invocation process simpler. The α -UMi framework completes the task within two steps through the collaboration of the planner, caller, and summarizer. In the case of Figure 7, α -UMi initially attempts to use the 'video\_for\_simple\_youtube\_search' to obtain detailed video information at step 0. However, it realizes that this API has broken and cannot be invoked. Therefore, the planner informs the caller to try an alternative API and obtain accurate information. Ultimately, the user's task is successfully resolved.
To further analyze the specific advantages of our α -UMi and Single-LLM frameworks in task execution, we have presented some comparative examples of the two frameworks in Tables 5, 6, 7, and 8. Tables 5 and 6 illustrate simple tasks that require only a single step tool invocation to be completed, in which case both α -UMi and Single-LLM can successfully accomplish the tasks. However, in the complex tasks presented in Tables 7 and 8, where the tasks require the models to accomplish some composite objectives, α -UMi's planner can quickly understand the user's intentions and plan out steps based on the prompts provided by the caller and summarizer. On the other hand, Single-LLM exhibited some behaviors that did not align with the user's intentions during planning, such as invoking APIs that did not match the intent and entering loops in these misaligned APIs, ultimately failing to provide sufficient information to complete the user's instructions. This result indicates that α -UMi's decomposing Single-LLM into a planner, caller, and summarizer reduces the burden on the model during reasoning, allowing the planner model to focus solely on understanding the user's intentions and making effective plans, thereby better accomplishing the tasks.
## 6 Conclusion
The objective of this paper is to address the challenge of designing and fine-tuning a single small
LLM to acquire the extensive abilities required for a tool learning agent. To this end, we introduce α -UMi, a multi-LLM tool learning agent framework that breaks down the tool learning task into three distinct sub-tasks delegated to three small LLMs: planner, caller, and summarizer. Moreover, we propose a global-to-local progressive fine-tuning strategy and demonstrate its effectiveness in training the multi-LLM framework. We evaluate our approach against single-LLM baselines on four tool learning benchmarks, supplemented by various indepth analyses, including a data scaling law experiment. Our findings highlight the significance of our proposed method, validating that the system's design for decomposing tool learning tasks and the progressive fine-tuning strategy contribute to enhancing the upper-bound ability of a single LLM. Besides, we acknowledge the potential to utilize small LLMs to surpass the capabilities of an agent framework that relies on a single, larger LLM.
## 7 Limitations
While our framework has been demonstrated to outperform the single-LLM framework in tool learning tasks, there are still some limitations to this work. Firstly, there are additional avenues for exploration, such as integrating small LLMs with a powerful closed-source LLM like GPT-4 to create a 'large + small' collaborative multi-LLM tool learning agent. Secondly, our framework could be further optimized to enhance its flexibility and applicability to a wider range of agent tasks.
## 8 Ethical Statement
The α -UMi framework is trained on the public ToolBench and ToolAlpaca benchmarks, with their original purpose being to enhance the tool invocation capabilities of LLMs and improve their performance in assisting users to complete tasks. This framework has not been trained on any data that poses ethical risks. The backbone model it uses, LLaMA-2-chat, has undergone safety alignment.
## References
Anthropic. 2023. Claude-2. Website. https://www. anthropic.com/news/claude-2 .
Baian Chen, Chang Shu, Ehsan Shareghi, Nigel Collier, Karthik Narasimhan, and Shunyu Yao. 2023. Fireact: Toward language agent fine-tuning. arXiv preprint arXiv:2310.05915 .
Hyung Won Chung, Le Hou, Shayne Longpre, Barret Zoph, Yi Tay, William Fedus, Yunxuan Li, Xuezhi Wang, Mostafa Dehghani, Siddhartha Brahma, et al. 2022. Scaling instruction-finetuned language models. arXiv preprint arXiv:2210.11416 .
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, et al. 2021. Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 .
Guanting Dong, Hongyi Yuan, Keming Lu, Chengpeng Li, Mingfeng Xue, Dayiheng Liu, Wei Wang, Zheng Yuan, Chang Zhou, and Jingren Zhou. 2023. How abilities in large language models are affected by supervised fine-tuning data composition. arXiv preprint arXiv:2310.05492 .
Zhibin Gou, Zhihong Shao, Yeyun Gong, Yujiu Yang, Minlie Huang, Nan Duan, Weizhu Chen, et al. 2023. Tora: A tool-integrated reasoning agent for mathematical problem solving. arXiv preprint arXiv:2309.17452 .
Significant Gravitas. 2023. Autogpt: the heart of the open-source agent ecosystem. Github repository. https://github.com/Significant-Gravitas/ Auto-GPT .
Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. 2021. Measuring mathematical problem solving with the math dataset. In Thirtyfifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 2) .
Sirui Hong, Xiawu Zheng, Jonathan Chen, Yuheng Cheng, Ceyao Zhang, Zili Wang, Steven Ka Shing Yau, Zijuan Lin, Liyang Zhou, Chenyu Ran, et al. 2023. Metagpt: Meta programming for multiagent collaborative framework. arXiv preprint arXiv:2308.00352 .
Chenliang Li, Hehong Chen, Ming Yan, Weizhou Shen, Haiyang Xu, Zhikai Wu, Zhicheng Zhang, Wenmeng Zhou, Yingda Chen, Chen Cheng, Hongzhu Shi, Ji Zhang, Fei Huang, and Jingren Zhou. 2023. Modelscope-agent: Building your customizable agent system with open-source large language models.
Yohei Nakajima. 2023. Babyagi. Github repository. https://github.com/yoheinakajima/babyagi .
Reiichiro Nakano, Jacob Hilton, Suchir Balaji, Jeff Wu, Long Ouyang, Christina Kim, Christopher Hesse, Shantanu Jain, Vineet Kosaraju, William Saunders, et al. 2021. Webgpt: Browser-assisted questionanswering with human feedback. arXiv preprint arXiv:2112.09332 .
OpenAI. 2022. Chatgpt: Conversational ai language model. Website. https://openai.com/chatgpt .
- OpenAI. 2023a. Gpt-4 code interpreter. Website. https://chat.openai.com/?model= gpt-4-code-interpreter .
OpenAI. 2023b. Gpt-4 technical report.
- Joon Sung Park, Joseph O'Brien, Carrie Jun Cai, Meredith Ringel Morris, Percy Liang, and Michael S Bernstein. 2023. Generative agents: Interactive simulacra of human behavior. In Proceedings of the 36th Annual ACM Symposium on User Interface Software and Technology , pages 1-22.
- Shishir G. Patil, Tianjun Zhang, Xin Wang, and Joseph E. Gonzalez. 2023. Gorilla: Large language model connected with massive apis. arXiv preprint arXiv:2305.15334 .
- Chen Qian, Xin Cong, Cheng Yang, Weize Chen, Yusheng Su, Juyuan Xu, Zhiyuan Liu, and Maosong Sun. 2023. Communicative agents for software development. arXiv preprint arXiv:2307.07924 .
- Yujia Qin, Shengding Hu, Yankai Lin, Weize Chen, Ning Ding, Ganqu Cui, Zheni Zeng, Yufei Huang, Chaojun Xiao, Chi Han, et al. 2023a. Tool learning with foundation models. arXiv preprint arXiv:2304.08354 .
- Yujia Qin, Shihao Liang, Yining Ye, Kunlun Zhu, Lan Yan, Yaxi Lu, Yankai Lin, Xin Cong, Xiangru Tang, Bill Qian, Sihan Zhao, Runchu Tian, Ruobing Xie, Jie Zhou, Mark Gerstein, Dahai Li, Zhiyuan Liu, and Maosong Sun. 2023b. Toolllm: Facilitating large language models to master 16000+ real-world apis.
- Samyam Rajbhandari, Olatunji Ruwase, Jeff Rasley, Shaden Smith, and Yuxiong He. 2021. Zero-infinity: Breaking the gpu memory wall for extreme scale deep learning. In SC21: International Conference for High Performance Computing, Networking, Storage and Analysis , pages 1-15. IEEE Computer Society.
- Timo Schick, Jane Dwivedi-Yu, Roberto Dessì, Roberta Raileanu, Maria Lomeli, Luke Zettlemoyer, Nicola Cancedda, and Thomas Scialom. 2023. Toolformer: Language models can teach themselves to use tools. arXiv preprint arXiv:2302.04761 .
- Yongliang Shen, Kaitao Song, Xu Tan, Dongsheng Li, Weiming Lu, and Yueting Zhuang. 2023. Hugginggpt: Solving ai tasks with chatgpt and its friends in hugging face. arXiv preprint arXiv:2303.17580 .
- Noah Shinn, Federico Cassano, Ashwin Gopinath, Karthik R Narasimhan, and Shunyu Yao. 2023. Reflexion: Language agents with verbal reinforcement learning. In Thirty-seventh Conference on Neural Information Processing Systems .
- Qiaoyu Tang, Ziliang Deng, Hongyu Lin, Xianpei Han, Qiao Liang, and Le Sun. 2023. Toolalpaca: Generalized tool learning for language models with 3000 simulated cases. arXiv preprint arXiv:2306.05301 .
- Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, Aurelien Rodriguez, Armand Joulin, Edouard Grave, and Guillaume Lample. 2023a. Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971 .
- Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, et al. 2023b. Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288 .
- Guanzhi Wang, Yuqi Xie, Yunfan Jiang, Ajay Mandlekar, Chaowei Xiao, Yuke Zhu, Linxi Fan, and Anima Anandkumar. 2023. Voyager: An open-ended embodied agent with large language models. arXiv preprint arXiv:2305.16291 .
- Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc V Le, Ed H Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. 2022. Self-consistency improves chain of thought reasoning in language models. In The Eleventh International Conference on Learning Representations .
- Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. 2022. Chain-of-thought prompting elicits reasoning in large language models. Advances in Neural Information Processing Systems , 35:24824-24837.
- Jimmy Wei, Kurt Shuster, Arthur Szlam, Jason Weston, Jack Urbanek, and Mojtaba Komeili. 2023. Multi-party chat: Conversational agents in group settings with humans and models. arXiv preprint arXiv:2304.13835 .
- Chenfei Wu, Shengming Yin, Weizhen Qi, Xiaodong Wang, Zecheng Tang, and Nan Duan. 2023a. Visual chatgpt: Talking, drawing and editing with visual foundation models. arXiv preprint arXiv:2303.04671 .
- Qingyun Wu, Gagan Bansal, Jieyu Zhang, Yiran Wu, Shaokun Zhang, Erkang Zhu, Beibin Li, Li Jiang, Xiaoyun Zhang, and Chi Wang. 2023b. Autogen: Enabling next-gen llm applications via multiagent conversation framework. arXiv preprint arXiv:2308.08155 .
- Linyao Yang, Hongyang Chen, Zhao Li, Xiao Ding, and Xindong Wu. 2023a. Chatgpt is not enough: Enhancing large language models with knowledge graphs for fact-aware language modeling. arXiv preprint arXiv:2306.11489 .
- Rui Yang, Lin Song, Yanwei Li, Sijie Zhao, Yixiao Ge, Xiu Li, and Ying Shan. 2023b. Gpt4tools: Teaching large language model to use tools via self-instruction. arXiv preprint arXiv:2305.18752 .
- Zhengyuan Yang, Linjie Li, Jianfeng Wang, Kevin Lin, Ehsan Azarnasab, Faisal Ahmed, Zicheng Liu,
Ce Liu, Michael Zeng, and Lijuan Wang. 2023c. Mmreact: Prompting chatgpt for multimodal reasoning and action. arXiv preprint arXiv:2303.11381 .
- Shunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Shafran, Thomas L Griffiths, Yuan Cao, and Karthik Narasimhan. 2023. Tree of thoughts: Deliberate problem solving with large language models. arXiv preprint arXiv:2305.10601 .
- Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik R Narasimhan, and Yuan Cao. 2022. React: Synergizing reasoning and acting in language models. In The Eleventh International Conference on Learning Representations .
- Qin Yujia, Yankai Lin Shengding Hu, Weize Chen, Ning Ding, Ganqu Cui, Zheni Zeng, et al. 2023. Tool learning with foundation models. arXiv preprint arXiv:2304.08354 .
- Aohan Zeng, Mingdao Liu, Rui Lu, Bowen Wang, Xiao Liu, Yuxiao Dong, and Jie Tang. 2023. Agenttuning: Enabling generalized agent abilities for llms. arXiv preprint arXiv:2310.12823 .
- Wanjun Zhong, Lianghong Guo, Qiqi Gao, and Yanlin Wang. 2023. Memorybank: Enhancing large language models with long-term memory. arXiv preprint arXiv:2305.10250 .
Xizhou Zhu, Yuntao Chen, Hao Tian, Chenxin Tao, Weijie Su, Chenyu Yang, Gao Huang, Bin Li, Lewei Lu, Xiaogang Wang, et al. 2023. Ghost in the minecraft: Generally capable agents for open-world enviroments via large language models with text-based knowledge and memory. arXiv preprint arXiv:2305.17144 .
## A System prompts
## A.1 P plan for ToolBench and ToolAlpaca
You have assess to the following apis: {doc}
The conversation history is:
{history}
You are the assistant to plan what to do next and whether is caller's or conclusion's turn to answer.
Answer with a following format:
The thought of the next step, followed by Next: caller or conclusion or give up.
## A.2 P call for ToolBench and ToolAlpaca
You have assess to the following apis: {doc}
The conversation history is:
{history}
The thought of this step is:
{thought}
Base on the thought make an api call in the following format:
Action: the name of api that should be called in this step, should be exactly in {tool\_names},
Action Input: the api call request.
## A.3 P sum for ToolBench and ToolAlpaca
Make a conclusion based on the conversation history: {history}
## A.4 P plan for MATH and GSM8K
Solve the math problem step by step by integrating step-by-step reasoning and Python code,
The problem is: {instruction}
The historical execution logs are:
{history} You are the assistant to plan what to do next, and shooce caller to generate code or conclusion to answer the problem.
Answer with a following format:
The thought of the next step, followed by Next: caller or conclusion.
## A.5 P call for MATH and GSM8K
The problem is: {instruction} The historical execution logs are: {history}
The thought of this step is:
{thought} generate the code for this step
## A.6 P sum for MATH and GSM8K
The problem is: {instruction} The historical execution logs are: {history} Make a conclusion based on the conversation history
## B Details of Benchmarks
## B.1 ToolBench
ToolBench (Qin et al., 2023b) is a benchmark for evaluating an agent's ability to call APIs. The ToolBench team collects 16,464 real-world APIs from RapidAPI and a total of 125,387 execution trajectories as the training corpus. We randomly sample 62,694 execution trajectories as the training set, and the average number of execution steps is 4.1.
The test set of ToolBench is divided into 6 groups, namely I1-instruction, I1-tool, I1-category, I2-instruction, I2-category, and I3-instruction. The groups whose name ends with 'instruction' means the test instructions in these groups use the tools in the training set, which is the in-domain test data. Otherwise, the groups whose name ends with 'tool' or 'category' means the test instructions do not use the tools in the training set, which is the outof-domain test data. Each group contains 100 user instructions, therefore the total in-domain test set contains 400 instructions, while the out-of-domain test set contains 200 instructions.
The original evaluation metrics in ToolBench are the pass rate and win rate judged by ChatGPT. However, as introduced in Section 4.2, the APIs in RapidAPI update every day, which can cause network block, API breakdown, and exhausted quota. Therefore, to make a relatively fair comparison, we adopt the idea of Modelscope-Agent (Li et al., 2023) to compare the predictions of our model with the annotated GPT-4 outputs on the step level. Specifically, for the t th step, we input the model with the previous trajectory of GPT-4, ask our framework to generate the rationale and action of this step, and then compare the generated rationale and action of this step with the output of GPT-4.
## B.2 ToolAlpaca
ToolAlpaca is another benchmark for evaluating API calling. Unlike ToolBench, the APIs and API calling results in ToolAlpaca are mocked from ChatGPT by imitating how the real APIs work. The
Table 4: Overall results on MATH and GSM8K.
| Model | MATH GSM8K ACC | MATH GSM8K ACC |
|-----------------------|------------------|------------------|
| Model Size = 7B | Model Size = 7B | Model Size = 7B |
| Single-LLM | 17.38 | 37.90 |
| Multi-LLM one-stage | 15.46 | 38.96 |
| Single-LLM multi-task | 14.18 | 27.97 |
| α -UMi | 25.60 | 49.73 |
| Model Size = 13B | Model Size = 13B | Model Size = 13B |
| Single-LLM | 20.26 | 44.88 |
| Multi-LLM one-stage | 20.32 | 44.57 |
| Single-LLM multi-task | 15.34 | 34.79 |
| α -UMi | 28.54 | 54.20 |
total number of training instances in ToolAlpaca is 4098, with an average of 2.66 execution steps per instance. The test set of ToolAlpaca contains 100 user instructions. The evaluation of ToolAlpaca is carried out by a simulator where the agent solves the instruction with the tools mocked by ChatGPT. Finally, GPT-4 judges if the execution process of the agent is consistent with the reference process pre-generated by ChatGPT (Proc. correctness) and whether the final answer generated by the agent can solve the user instruction (Ans. correctness).
## C Static Evaluation on ToolBench
The evaluation method for ToolBench introduced in Section 4.2 is a static approach that assesses the output of the agent at each step individually. Specifically, for each step t , given the ground-truth annotation of the previous execution trajectory τ ∗ <t , the agent generates the rationale ˆ r t and action ˆ a t for this step:
$$\hat { r } _ { t } , \hat { a } _ { t } = A g e n t ( \tau _ { < t } ^ { * } ) . \quad ( 5 )$$
Then, metrics are computed by comparing the generated ˆ r t and ˆ a t with the annotated ground-truth rationale r ∗ t and action a ∗ t for this step:
$$M e t r i c = E v a l u a t e ( \hat { r } _ { t } , \hat { a } _ { t } , r _ { t } ^ { * } , a _ { t } ^ { * } ) . \quad ( 6 )$$
The advantage of this evaluation method is as follows. At each step, the agent only needs to take the previous ground-truth trajectory as input and outputs the current step's rationale and action. This prevents error propagation due to factors such as network blocks, API breakdowns, and exhausted quotas in any particular step, which could affect the fairness of comparison. This evaluation method is an effective complement to real-time evaluation.
## D α -UMi on Other Benchmarks
## D.1 MATH and GSM8K
The MATH (Hendrycks et al., 2021) and GSM8K (Cobbe et al., 2021) benchmarks are originally designed to test the mathematical reasoning ability of LLMs. Following ToRA (Gou et al., 2023), we employ a program-aided agent to solve the mathematical problems presented in these datasets. In our scenario, the planner will generate certain rationales and comments to guide the generation of program, the caller will generate program to conduct mathematical calculation, and finally the summarizer will conclude the final answer. Since ToRA has not released its training data, to facilitate the training of our framework, we utilize gpt-3.5-turbo-1106 (OpenAI, 2022) and gpt-4 (OpenAI, 2023b) to collect execution trajectories in the training set of MATH and GSM8K and filter out the trajectories that do not lead to the correct final answer. Finally, we collect 5536 trajectories from ChatGPT, 573 trajectories from GPT-4 on MATH, and 6213 from ChatGPT on GSM8K.
The test set sizes of MATH and GSM8K are 5000 and 1319, respectively. During testing, we feed our agent with each of the test instructions and execute the agent with a Python code interpreter. We follow the original evaluation methods of MATH and GSM8K to evaluate the performance of the agent with the accuracy of the final answer. As the evaluation results shown in Table 4, our α -UMi can still outperform the baselines on MATH and GSM8K, verifying its effectiveness.
Figure 6: A case study of α -UMi. In this case, the user specifies the available tools in the instructions, making the tool invocation process simpler. The α -UMi framework completes the task within two steps through the collaboration of the planner, caller, and summarizer.
<details>
<summary>Image 6 Details</summary>

### Visual Description
\n
## Diagram: Multi-Step API Interaction Flow
### Overview
This diagram illustrates a multi-step interaction flow between a User, a Planner, and API Callers (Deezer and Shazam). The diagram depicts a conversation where the user requests to search for music using both the Deezer and Shazam APIs. Each step shows the actions taken by each participant and the observations made. The diagram is segmented into three main steps, visually separated by colored boxes (blue, red, and green).
### Components/Axes
The diagram consists of three main steps, labeled "Step 0", "Step 1", and "Step 2" in the top-right corner of each colored box. Each step contains text boxes representing the User, Planner, and Caller. Each box also contains a green checkmark. The diagram uses arrows to indicate the flow of interaction.
### Detailed Analysis or Content Details
**Step 0 (Blue Box):**
* **User:** "I'm a music enthusiast and I want to explore different genres and artists. Can you help me search for tracks and artists using the Deezer API? Additionally, I would like to search for songs and artists using the Shazam API."
* **Planner:** "Sure! I can help you with that. We can start by using the Deezer API to search for tracks and artists. First, we'll make a call to the “search_for_deezer” function and provide the query term as “genre” or “artist” to find relevant tracks and artists. Next: caller."
* **Caller (Deezer):**
* Action: `search_for_deezer`
* Action Input: `{q: "genre"}`
* Observation: `(data: {id: 579916362, readable: True, title: Genre, title_short: Genre, link:https://www.deezer.com/track/579916362, ...}`
**Step 1 (Red Box):**
* **Planner:** "found a track titled “Genre” by artist Eddy de Pretto using the Deezer API. Here are the details: - Title: Genre ... - Artist: Eddy de Pretto - Link: https://www.shazam.com..."
* **Caller (Shazam):**
* Action: `search_for_shazam`
* Action Input: `{term: "Eddy de Pretto"}`
* Observation: `(tracks: [hits: {track: {layout: 5, type: MUSIC, key: 372962066, title: Kid, subtitle: Eddy de Pretto, share: (subject: Kid - Eddy de Pretto, text: Kid by Eddy de Pretto, ...}`
**Step 2 (Green Box):**
* **Planner:** "Next: Conclusion. Summarizer: I found a track titled ‘Genre’ by artist Eddy de Prettos using the Deezer API. Here are the details. - Title: Genre ... - Artist: Eddy de Pretto - Link: https://www.shazam.com..."
### Key Observations
The diagram demonstrates a sequential process of API calls. The Planner acts as an intermediary, guiding the process and interpreting the results. The Deezer API is used first to search for a genre, and then the Shazam API is used to search for an artist ("Eddy de Pretto") related to the initial search. The observations from each API call are presented as JSON-like data structures. The diagram highlights the interaction between a user's request, the planner's logic, and the API responses.
### Interpretation
This diagram illustrates a basic example of a conversational AI system utilizing multiple APIs to fulfill a user's request. The flow demonstrates how a planner component can orchestrate API calls based on user input and the results of previous calls. The use of both Deezer and Shazam APIs suggests a desire to combine information from different music databases. The JSON-like output from the APIs indicates that the system is capable of parsing and interpreting structured data. The repetition of the "Genre" and "Eddy de Pretto" information across steps suggests a successful retrieval of relevant data. The diagram is a simplified representation of a more complex system, but it effectively conveys the core concepts of API integration and conversational flow.
</details>
Figure 7: A case study of α -UMi, in which α -UMi initially attempts to use the 'video\_for\_simple\_youtube\_search' to obtain detailed video information at step 0. However, it realizes that this API has broken and cannot be invoked. Therefore, the planner informs the caller to try an alternative API and obtain accurate information. Ultimately, the user's task is successfully resolved.
<details>
<summary>Image 7 Details</summary>
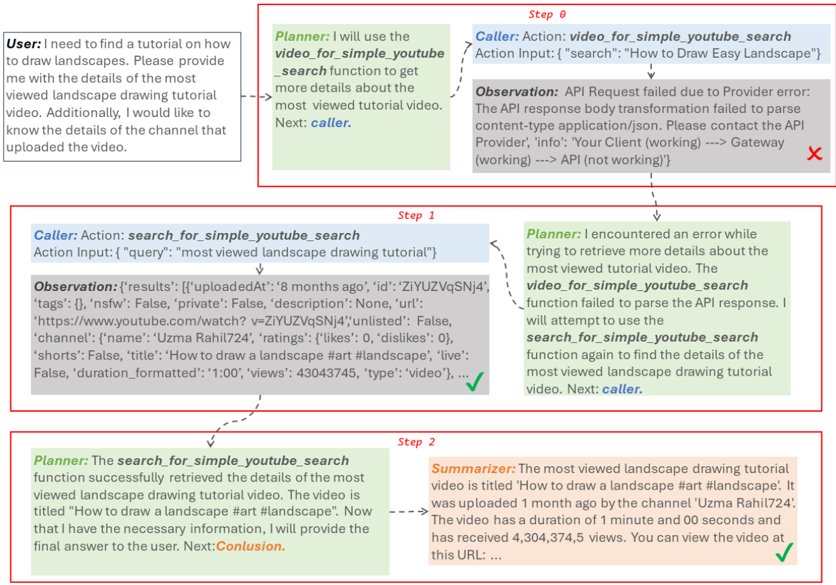
### Visual Description
\n
## Diagram: Multi-Step Process for Finding a YouTube Tutorial
### Overview
This diagram illustrates a multi-step process involving a user request, a planner, a caller, a search function (`search_for_simple_youtube_search`), a summarizer, and observations/errors encountered during the process of finding the most viewed landscape drawing tutorial on YouTube. The diagram depicts a flow of actions and responses across these components, with error handling and iterative attempts to fulfill the user's request.
### Components/Axes
The diagram is structured as a series of steps (Step 1, Step 2, Step 9) arranged vertically. Each step contains three sections: "User", "Planner", and "Caller". Arrows indicate the flow of information and actions between these components. There are also "Observation" boxes that display results or error messages. The diagram uses color-coding: green for successful actions, red for errors.
### Detailed Analysis or Content Details
**Step 1:**
* **User:** "I need to find a tutorial on how to draw landscapes. Please provide me with the details of the most viewed landscape drawing tutorial video. Additionally, I would like to know the details of the channel that uploaded the video."
* **Planner:** "I will use the `video_for_simple_youtube_search` function to get -> more details about the most viewed tutorial video. Next: caller."
* **Caller:** Action: `search_for_simple_youtube_search`
* Action Input: `{"query": "most viewed landscape drawing tutorial"}`
* **Observation:** `{"results": [{"uploadedAt": "8 months ago", "id": "ZIYUZvQSNj4", "tags": [], "nsfw": false, "private": false, "description": None, "url": "https://www.youtube.com/watch?v=ZIYUZvQSNj4", "unlisted": false, "channel": {"name": "Uzma Rahil724", "ratings": {"likes": 0, "dislikes": 0}, "shorts": false, "title": "How to draw a landscape #art #landscape", "live": false, "duration_formatted": "1:00", "views": 43047345, "type": "video"}}]}`
**Step 2:**
* **Planner:** The `search_for_simple_youtube_search` function successfully retrieved the details of the most viewed landscape drawing tutorial video. The video is titled "How to draw a landscape #art #landscape". Now that I have the necessary information, I will provide the final answer to the user. Next: Conclusion.
* **Summarizer:** The most viewed landscape drawing tutorial video is titled "How to draw a landscape #art #landscape". It was uploaded 1 month ago by a channel "Uzma Rahil724". The video has a duration of 1 minute and 00 seconds and has received 43,304,374 views. You can view the video at this URL: [URL omitted].
**Step 9:**
* **Caller:** Action: `video_for_simple_youtube_search`
* Action Input: `{"search": "How to Draw Easy Landscape"}`
* **Observation:** API Request failed due to Parser error: The API response body transformation failed to provide content-type application/json. Please contact the API Provider, 'info': 'Your Client (working) ---> Gateway (working) ---> API (not working!)' (Red X icon)
* **Planner:** Encountered an error while trying to retrieve more details about the most viewed tutorial video. The `video_for_simple_youtube_search` function failed to parse the API response. I will attempt to use the `search_for_simple_youtube_search` function again to find the details of the most viewed landscape tutorial video. Next: caller.
### Key Observations
* The process initially succeeds in finding the video details in Step 1.
* Step 9 demonstrates an API error, specifically a parsing error related to the API response format. The error message indicates the client and gateway are working, but the API is not.
* The diagram highlights the iterative nature of the process, with the planner attempting to retry the search function after encountering an error.
* The video identified in Step 1 has 43,304,374 views and is 1 minute long.
* The channel name is "Uzma Rahil724".
### Interpretation
This diagram illustrates a typical workflow for a task involving API calls and data retrieval. It demonstrates the importance of error handling and the need for fallback mechanisms when APIs fail. The diagram also highlights the potential for discrepancies between initial search results and subsequent attempts to retrieve detailed information. The API error in Step 9 suggests a potential issue with the API's response format or the parsing logic on the client side. The diagram effectively visualizes the interaction between different components in a complex system and the challenges that can arise during the process. The use of color-coding (green for success, red for error) provides a clear visual indication of the process's status at each step. The diagram is a good example of a system design document or a debugging log, showing the flow of information and the points of failure.
</details>
## Case #1 of α -UMi In ToolBench
Table 5: A case of α -UMi in ToolBench.
| Instruction: I want to explore the catalog of products available in the 'Electronics' category. Please provide me with the list of products along with their details. | Instruction: I want to explore the catalog of products available in the 'Electronics' category. Please provide me with the list of products along with their details. |
|-------------------------------------------------------------------------------------------------------------------------------------------------------------------------|-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| Planner | Based on the user's request to explore the catalog of products in the 'Electronics' cate- gory, I need to call the 'get_products_in_category_for_demo_project_v13' function with the arguments 'limit': 10, 'skip': 0, and 'category': 'Electronics'. This will allow me to retrieve the list of products along with their details specifically from the 'Electronics' category. By calling this function, I can fulfill the user's request and provide them with the desired information. Next: caller. |
| Caller | Action: get_products_in_category_for_demo_project_v13 Action Input: "{ "limit": 10, "skip": 0, "category": "Electronics"}" |
| Observation | {'products': [{'id': 893292, 'name': 'TV', 'category': 'electronics'}, {'id': 893293, 'name': 'TV', 'category': 'electronics'}, {'id': 894481, 'name': 'Gorgeous Plastic Bench', 'category': 'Electronics'}, {'id': 896484, 'name': 'Fantastic Rubber Gloves', 'category': 'Electronics'}, {'id': 912179, 'name': 'daniel', 'category': 'electron- ics'}, {'id': 916400, 'name': 'Tasty Frozen Pants', 'category': 'Electronics'}, {'id': 917106, 'name': 'Tasty Wooden Chips', 'category': 'Electronics'}, {'id': 917821, 'name': 'Pizza', 'category': 'Electronics'}, {'id': 917875, 'name': 'Tuna', 'cate- gory': 'Electronics'}, {'id': 917998, 'name': 'Intelligent Frozen Pizza', 'category': 'Electronics'}], 'summary': {'count': 105}} |
| Planner | I have retrieved the list of products available in the 'Electronics' category. Here are some of the products along with their details: 1. Product ID: 893292, Name: TV, Category: Electronics 2. Product ID: 893293, Name: TV, Category: Electronics 3. Product ID: 894481, Name: Gorgeous Plastic Bench, Category: Electronics 4. Product ID: 896484, Name: Fantastic Rubber Gloves, Category: Electronics 5. Product ID: 912179, Name: daniel, Category: Electronics 6. Product ID: 916400, Name: Tasty Frozen Pants, Category: Electronics 7. Product ID: 917106, Name: Tasty Wooden Chips, Category: Electronics 8. Product ID: 917821, Name: Pizza, Category: Electronics 9. Product ID: 917875, Name: Tuna, Category: Electronics 10. Product ID: 917998, Name: Intelligent Frozen Pizza, Category: Electronics Next: conclusion. |
| Summarizer | Here are some of the products available in the 'Electronics' category: 1. Product ID: 893292, Name: TV, Category: Electronics 2. Product ID: 893293, Name: TV, Category: Electronics 3. Product ID: 894481, Name: Gorgeous Plastic Bench, Category: Electronics 4. Product ID: 896484, Name: Fantastic Rubber Gloves, Category: Electronics 5. Product ID: 912179, Name: daniel, Category: Electronics 6. Product ID: 916400, Name: Tasty Frozen Pants, Category: Electronics 7. Product ID: 917106, Name: Tasty Wooden Chips, Category: Electronics 8. Product ID: 917821, Name: Pizza, Category: Electronics 9. Product ID: 917875, Name: Tuna, Category: Electronics 10. Product ID: 917998, Name: Intelligent Frozen Pizza, Category: Electronics |
## Case #1 of Single-LLM In ToolBench
Table 6: A case of Single-LLM in ToolBench.
| Instruction: I want to explore the catalog of products available in the 'Electronics' category. Please provide me with the list of products along with their details. | Instruction: I want to explore the catalog of products available in the 'Electronics' category. Please provide me with the list of products along with their details. |
|-------------------------------------------------------------------------------------------------------------------------------------------------------------------------|-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| Assistant | Based on the previous actions, it seems that the function "get_categories_for_demo_project_v13" was called to retrieve the categories, but it returned an error. To proceed differently, I will call the function "get_products_in_category_for_demo_project_v13" with the category set to "Electronics" to fetch the products in the Electronics category. Action: get_products_in_category_for_demo_project_v13 Action Input: { "limit": 10, "skip": 0, "category": "Electronics" } |
| Observation | {'products': [{'id': 893292, 'name': 'TV', 'category': 'electronics'}, {'id': 893293, 'name': 'TV', 'category': 'electronics'}, {'id': 894481, 'name': 'Gorgeous Plastic Bench', 'category': 'Electronics'}, {'id': 896484, 'name': 'Fantastic Rubber Gloves', 'category': 'Electronics'}, {'id': 912179, 'name': 'daniel', 'category': 'electron- ics'}, {'id': 916400, 'name': 'Tasty Frozen Pants', 'category': 'Electronics'}, {'id': 917106, 'name': 'Tasty Wooden Chips', 'category': 'Electronics'}, {'id': 917821, 'name': 'Pizza', 'category': 'Electronics'}, {'id': 917875, 'name': 'Tuna', 'cate- gory': 'Electronics'}, {'id': 917998, 'name': 'Intelligent Frozen Pizza', 'category': 'Electronics'}], 'summary': {'count': 105}} |
| Assistant | I have retrieved the list of products available in the 'Electronics' category. Here are some of the products along with their details: 1. Product ID: 893292, Name: TV, Category: Electronics 2. Product ID: 893293, Name: TV, Category: Electronics 3. Product ID: 894481, Name: Gorgeous Plastic Bench, Category: Electronics 4. Product ID: 896484, Name: Fantastic Rubber Gloves, Category: Electronics 5. Product ID: 912179, Name: daniel, Category: Electronics 6. Product ID: 916400, Name: Tasty Frozen Pants, Category: Electronics 7. Product ID: 917106, Name: Tasty Wooden Chips, Category: Electronics 8. Product ID: 917821, Name: Pizza, Category: Electronics 9. Product ID: 917875, Name: Tuna, Category: Electronics 10. Product ID: 917998, Name: Intelligent Frozen Pizza, Category: Electronics |
## Case #2 of α -UMi In ToolBench
| Instruction: I am planning a vacation with my family and we are interested in scuba diving. Can you recommend some dive sites in Thailand? Additionally, we would like to know the top-tier stays available in that area for accommodation options. | Instruction: I am planning a vacation with my family and we are interested in scuba diving. Can you recommend some dive sites in Thailand? Additionally, we would like to know the top-tier stays available in that area for accommodation options. |
|-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| Planner | Based on the user's request, I need to recommend dive sites in Thailand and provide information about the top-tier stays in the area. To accomplish this, I will call the "esites_by_a_country_or_a_region_for_world_scuba_diving_sites_api" function with the argument "country" set to "Thailand". This will allow me to retrieve the relevant dive sites and accommodation options specifically for Thailand. By using this API, I can efficiently gather the necessary information for the user's vacation planning. Next: caller. |
| Caller | Action: esites_by_a_country_or_a_region_for_world_scuba_diving_sites_api Action Input: "{ "country": "Thailand" }" |
Table 7: A case of α -UMi in ToolBench.
| Observation | {'data': [{'id': '0126ccc3-6d33-4cb9-a6dd-1519273acf43', 'name': 'The Rock', 'region': 'Racha Noi Island, Phuket', 'lat': '7.552420449639636', 'lng': '98.33433151245119', 'ocean': 'Indian Ocean, Andaman Sea, Strait Of Malacca', 'Location': 'Asia, Thailand, Southern Thailand, Phuket, Racha Noi Island'}, {'id': '01c6e49f-45ab-4bb4-bfee-eff9c67f9d22', 'name': 'Paradise Reef', 'region': 'Phuket, Southern Thailand', 'lat': '7.893819147272116', 'lng': '98.2584571838379', 'ocean': 'Indian Ocean, Andaman Sea, Strait Of Malacca', 'Location': 'Asia, Thailand, Southern Thailand, Phuket'}, {'id': '02446f8e-9466-4cec-8a7e-940fa2946c44', 'name': 'Shark Fin Reef', 'region': 'Payang Island, Similan Islands', 'lat': '8.50966017107524', 'lng': '97.66388654708864', 'ocean': 'Indian Ocean, Andaman Sea', 'Location': 'Asia, Thailand, Southern Thailand, Phang Nga, Similan Islands, Payang Island'}, {'id': '02dea021-ef79-4ee4-929a-46dfb03e5f6e', 'name': 'Bang Bao Reef', 'region': 'Kut Island, Trat', 'lat': '11.612304159956192', 'lng... |
|---------------|----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| Planner | Based on the user's request, I need to recommend dive sites in Thailand and provide information about the top-tier stays in the area. To accomplish this, I will call the "get_top_tier_stays_filter_for_airbnb_v2" function. Since the user specifically mentioned the need for top-tier accommodations, I will call this function without any arguments to retrieve the relevant options. By using this API, I can efficiently gather the necessary information for the user's vacation planning and ensure they have a great experience during their trip. Next: caller. |
| Caller | Action: get_top_tier_stays_filter_for_airbnb_v2 Action Input: "{}" |
| Observation | {'status': True, 'message': 'Success', 'timestamp': 1688973421406, 'data': [{'id': '1', 'title': 'Airbnb Plus', 'subtitle': 'Every Plus home is reviewed for quality'}, {'id': '2', 'title': 'Airbnb Luxe', 'subtitle': 'Handpicked luxury homes with personally arranged services'}]} |
| Planner | The user has requested recommendations for dive sites in Thailand and informa- tion about top-tier stays in the area. To fulfill their request, I called the "es- ites_by_a_country_or_a_region_for_world_scuba_diving_sites_api" function with the argument "country" set to "Thailand". This API allows me to efficiently retrieve relevant dive sites and accommodation options specifically for Thailand. By using this function, I can provide the user with accurate and up-to-date information for their vacation planning. Additionally, I called the "get_top_tier_stays_filter_for_airbnb_v2" function to retrieve the available options for top-tier accommodations. By using these APIs, I can ensure that the user has a great experience during their trip. Next: conclusion. |
| Summarizer | Here are some dive sites in Thailand: The Rock in Racha Noi Island, Phuket; Paradise Reef in Phuket, Southern Thailand; Shark Fin Reef in Payang Island, Similan Islands; Bang Bao Reef in Kut Island, Trat. For accommodation options, you can consider Airbnb Plus and Airbnb Luxe, which offer high-quality and luxury homes respectively. Enjoy your scuba diving adventures in Thailand! |
## Case #2 of Single-LLM In ToolBench
Instruction: I am planning a vacation with my family and we are interested in scuba diving. Can you recommend some dive sites in Thailand? Additionally, we would like to know the top-tier stays available in that area for accommodation options.
| Assistant | Based on the previous action, it seems that the API call to get dive sites in Thai- land was not successful. To generate a different action, I will try using the "ranked_world_crime_cities_for_ranked_crime_cities" function to get a list of ranked crime cities. This will help me identify if Thailand is listed as a crime-free city. Action:ranked_world_crime_cities_for_ranked_crime_cities Action Input: {} |
|-------------|--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| Observation | {'products': [{'id': 893292, 'name': 'TV', 'category': 'electronics'}, {'id': 893293, 'name': 'TV', 'category': 'electronics'}, {'id': 894481, 'name': 'Gorgeous Plastic Bench', 'category': 'Electronics'}, {'id': 896484, 'name': 'Fantastic Rubber Gloves', 'category': 'Electronics'}, {'id': 912179, 'name': 'daniel', 'category': 'electron- ics'}, {'id': 916400, 'name': 'Tasty Frozen Pants', 'category': 'Electronics'}, {'id': 917106, 'name': 'Tasty Wooden Chips', 'category': 'Electronics'}, {'id': 917821, 'name': 'Pizza', 'category': 'Electronics'}, {'id': 917875, 'name': 'Tuna', 'cate- gory': 'Electronics'}, {'id': 917998, 'name': 'Intelligent Frozen Pizza', 'category': 'Electronics'}], 'summary': {'count': 105}} |
| Assistant | Based on the previous action, it seems that the API call to get dive sites in Thai- land was not successful. To generate a different action, I will try using the "get_city_by_filter_for_ranked_crime_cities" function to get the details of a spe- cific city in Thailand. This will help me determine if Thailand is listed as a crime-free city. Action: get_city_by_filter_for_ranked_crime_cities Action Input: {"id":1} |
| Observation | {"message": "Function executing from my_tools.Travel.ranked_crime_cities.api im- port get_city_by_filter error... get_city_by_filter() got an unexpected keyword argu- ment 'id'"} |
| Assistant | Based on the current state and the previous actions, it seems that the API calls to get dive sites in Thailand have been unsuccessful. To generate a different action, I will try using the "esites_by_a_country_or_a_region_for_world_scuba_diving_sites_api" function to get a list of dive sites in Thailand. This might provide the desired informa- tion about dive sites in the country. Action: esites_by_a_country_or_a_region_for_world_scuba_diving_sites_api Action Input: {"country": "Thailand"} |
| Observation | {'data': [{'id': '0126ccc3-6d33-4cb9-a6dd-1519273acf43', 'name': 'The Rock', 'region': 'Racha Noi Island, Phuket', 'lat': '7.552420449639636', 'lng': '98.33433151245119', 'ocean': 'Indian Ocean, Andaman Sea, Strait Of Malacca', 'Location': 'Asia, Thailand, Southern Thailand, Phuket, Racha Noi Island'}, {'id': '01c6e49f-45ab-4bb4-bfee-eff9c67f9d22', 'name': 'Paradise Reef', 'region': 'Phuket, Southern Thailand', 'lat': '7.893819147272116', 'lng': '98.2584571838379', 'ocean': 'Indian Ocean, Andaman Sea, Strait Of Malacca', 'Location': 'Asia, Thailand, Southern Thailand, Phuket'}, {'id': '02446f8e-9466-4cec-8a7e-940fa2946c44', 'name': 'Shark Fin Reef', 'region': 'Payang Island, Similan Islands', 'lat': '8.50966017107524', 'lng': '97.66388654708864', 'ocean': 'Indian Ocean, Andaman Sea', 'Location': 'Asia, Thailand, Southern Thailand, Phang Nga, Similan Islands, Payang Island'}, {'id': '02dea021-ef79-4ee4-929a-46dfb03e5f6e', 'name': 'Bang Bao Reef', 'region': 'Kut Island, Trat', 'lat': '11.612304159956192', 'lng... |
Table 8: A case of Single-LLM in ToolBench.
| Assistant | Based on the current state and the previous actions, it seems that the API calls to get dive sites in Thailand have been successful. I have retrieved a list of dive sites in Thailand, including The Rock in Racha Noi Island, Phuket, Paradise Reef in Phuket, Southern Thailand, and Shark Fin Reef in Payang Island, Similan Islands. These dive sites offer potential accommodation options for your family vacation. Now, I will proceed to provide you with the final answer. conclusion:Here are some dive sites in Thailand that you might find interesting: 1. The Rock - Racha Noi Island, Phuket 2. Paradise Reef - Phuket, Southern Thailand 3. Shark Fin Reef - Payang Island, Similan Islands 4. Bang Bao Reef - Kut Island, Trat These dive sites offer potential accommodation options for your family vacation. Enjoy your scuba diving adventure in Thailand! |
|-------------|------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
## Case In ToolAlpaca
| Instruction: I'm moving to a new apartment and need to update my address with various companies. Can you first verify if my new address is valid and then standardize it? Here's the address: 321 Maple Dr, Apt 12C, Houston, TX, 77002. | Instruction: I'm moving to a new apartment and need to update my address with various companies. Can you first verify if my new address is valid and then standardize it? Here's the address: 321 Maple Dr, Apt 12C, Houston, TX, 77002. |
|--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| Planner | I need to verify the address and then standardize it. Next: caller. |
| Caller | Action: verifyUSAddress Action Input: {"addressLine1": "321 Maple Dr", "addressLine2":"Apt 12C", "city": "Houston", "state": "TX", "zipCode": "77002"} |
| Observation | {"status":"valid","standardizedAddress":{"addressLine1":"123 Main St","addressLine2":"Apt 4B","city":"New York","state":"NY","zipCode":"10001"}} |
| Planner | The address is valid and has been successfully standardized. Next: conclusion. |
| Summarizer | The address you provided is valid and has been successfully standardized. The standardized address is 123 Main St, Apt 4B, New York, NY, 10001 |
Table 9: A case study of α -UMi in ToolAlpaca.
| Case In MATH | Case In MATH |
|----------------------------------------------------------------------|--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| Instruction: Compute the range of the function $f(x) = sqrt{x**2}$ . | Instruction: Compute the range of the function $f(x) = sqrt{x**2}$ . |
| Planner | Next: caller. |
| Caller | from sympy import symbols, Interval, oo def function_range(): x = symbols('x') f = sqrt(x**2) range_f = Interval(0, oo) return range_f result = function_range() print(result) |
| Observation | NameError: name 'sqrt' is not defined |
| Planner | The code provided for the solution to the given problem will result in an error. To fix this error, the 'sqrt' function needs to be imported from the 'sympy' library. Next: caller. |
Table 10: A case study of α -UMi in MATH.
| Caller | from sympy import symbols, Interval, oo, sqrt def function_range(): x = symbols('x') f = sqrt(x**2) range_f = Interval(0, oo) return range_f result = function_range() print(result) |
|-------------|----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| Observation | Interval(0, oo) |
| Planner | Next: conclusion. |
| Summarizer | The range of the function $f(x) = sqrt{x*2}$ is $boxed{[0, infty)}$. |