# Distributionally Robust Receive Combining
**Authors**: Shixiong Wang, Wei Dai, and Geoffrey Ye Li
> S. Wang, W. Dai, and G. Li are with the Department of Electrical and Electronic Engineering, Imperial College London, London SW7 2AZ, United Kingdom (E-mail: s.wang@u.nus.edu; wei.dai1@imperial.ac.uk; geoffrey.li@imperial.ac.uk).
This work is supported by the UK Department for Science, Innovation
and Technology under the Future Open Networks Research Challenge project
TUDOR (Towards Ubiquitous 3D Open Resilient Network).
Abstract
This article investigates signal estimation in wireless transmission (i.e., receive combining) from the perspective of statistical machine learning, where the transmit signals may be from an integrated sensing and communication system; that is, 1) signals may be not only discrete constellation points but also arbitrary complex values; 2) signals may be spatially correlated. Particular attention is paid to handling various uncertainties such as the uncertainty of the transmit signal covariance, the uncertainty of the channel matrix, the uncertainty of the channel noise covariance, the existence of channel impulse noises, the non-ideality of the power amplifiers, and the limited sample size of pilots. To proceed, a distributionally robust receive combining framework that is insensitive to the above uncertainties is proposed, which reveals that channel estimation is not a necessary operation. For optimal linear estimation, the proposed framework includes several existing combiners as special cases such as diagonal loading and eigenvalue thresholding. For optimal nonlinear estimation, estimators are limited in reproducing kernel Hilbert spaces and neural network function spaces, and corresponding uncertainty-aware solutions (e.g., kernelized diagonal loading) are derived. In addition, we prove that the ridge and kernel ridge regression methods in machine learning are distributionally robust against diagonal perturbation in feature covariance.
Index Terms: Wireless Transmission, Smart Antenna, Machine Learning, Robust Estimation, Robust Combining, Distributional Uncertainty, Channel Uncertainty, Limited Pilot.
I Introduction
In wireless transmission, detection and estimation of transmitted signals is of high importance, and combining at array receivers serves as a key signal-processing technique to suppress interference and environmental noises. The earliest beamforming solutions rely on the use of phase shifters (e.g., phased arrays) to steer and shape wave lobes, while advanced combining methods allow the employment of digital signal processing units, which introduce additional structural freedom (e.g., fully digital, hybrid, nonlinear, wideband) in combiner design and significant performance improvement in signal recovery [1, 2, 3].
In traditional communication systems, transmitted signals are discrete points from constellations. Therefore, signal recovery, commonly referred to as signal detection, can be cast into a classification problem from the perspective of statistical machine learning, and the number of candidate classes is determined by the number of points in the employed constellation. Research in this stream includes, e.g., [4, 5, 6, 7, 8, 9] as well as references therein, and the performance measure for signal detection is usually the misclassification rate (i.e., symbol error rate); representative algorithms encompass the maximum likelihood detector, the sphere decoding, etc. In another research stream, the signal recovery performance is evaluated using mean-squared errors (cf., signal-to-interference-plus-noise ratio), and the resultant signal recovery problem is commonly known as signal estimation, which can be considered as a regression problem from the perspective of statistical machine learning. By comparing the estimated symbols with the constellation points afterward, the detection of discrete symbols can be realized. For this case, till now, typical combining solutions include zero-forcing receivers, Wiener receivers (i.e., linear minimum mean-squared error receivers), Capon receivers (i.e., minimum variance distortionless response receivers), and nonlinear receivers such as neural-network receivers [10, 11, 12]. On the basis of these canonical approaches, variants such as robust beamformers working against the limited size of pilot samples and the uncertainty in steering vectors [13, 14, 15, 16, 17, 18] have also been intensively reported; among these robust solutions, the diagonal loading method [19], [14, Eq. (11)] and the eigenvalue thresholding method [20], [14, Eq. (12)] are popular due to their excellent balance between practical performance and technical simplicity.
Different from traditional paradigms, in emerging communication systems, e.g., integrated sensing and communication (ISAC) systems, transmitted signals may be arbitrary complex values and spatially correlated [21, 22, 23]. As a result, mean-squared error is a preferred performance measure to investigate the receive combining and estimation problem of wireless signals, which is, therefore, the focus of this article.
Although a large body of problems have been attacked in the area, the following signal-processing problems of combining and estimation in wireless transmission remain unsolved.
1. What is the relation between the signal-model-based approaches (e.g., Wiener and Capon receivers) and the data-driven approaches (e.g., deep-learning receivers)? In other words, how can we build a mathematically unified modeling framework to interpret all the existing digital receive combiners?
1. In addition to the limited pilot size and the uncertainty in steering vectors, there exist other uncertainties in the signal model: the uncertainty of the transmit signal covariance, the uncertainty of the communication channel matrix, the uncertainty of the channel noise covariance, the presence of channel impulse noises (i.e., outliers), and the non-ideality of the power amplifiers. Therefore, how can we handle all these types of uncertainties in a unified solution framework?
1. Existing literature mainly studied the robustness theory of linear beamformers against limited pilot size and the uncertainty in steering vectors [13, 14, 15, 16, 17, 18]. However, how can we develop the theory of robust nonlinear combiners against all the aforementioned uncertainties?
To this end, this article designs a unified modeling and solution framework for receive combining of wireless signals, in consideration of the scarcity of the pilot data and the different uncertainties in the signal model.
I-A Contributions
The contributions of this article can be summarized from the aspects of machine learning theory and wireless transmission theory.
In terms of machine learning theory, we give a justification of the popular ridge regression and kernel ridge regression (i.e., quadratic loss function plus squared- $F$ -norm regularization) from the perspective of distributional robustness against diagonal perturbation in feature covariance, which enriches the theory of trustworthy machine learning; see Theorems 2 and 3, as well as Corollaries 3 and 5.
In terms of wireless transmission theory, the contributions are outlined below.
1. We build a fundamentally theoretical framework for receive combining from the perspective of statistical machine learning. In addition to the linear estimation methods, nonlinear approaches (i.e., nonlinear combining) are also discussed in reproducing kernel Hilbert spaces and neural network function spaces. In particular, we reveal that channel estimation is not a necessary operation in receive combining. For details, see Subsection III-A.
1. The presented framework is particularly developed from the perspective of distributional robustness which can therefore combat the limited size of pilot data and several types of uncertainties in the wireless signal model such as the uncertainty in the transmit power matrix, the uncertainty in the communication channel matrix, the existence of channel impulse noises (i.e., outliers), the uncertainty in the covariance matrix of channel noises, the non-ideality of the power amplifiers, etc. For details, see Subsection III-B, and the technical developments in Sections IV and V.
1. Existing methods such as diagonal loading and eigenvalue thresholding are proven to be distributionally robust against the limited pilot size and all the aforementioned uncertainties in the wireless signal model. Extensions of diagonal loading and eigenvalue thresholding are proposed as well. Moreover, the kernelized diagonal loading and the kernelized eigenvalue thresholding methods are put forward for nonlinear estimation cases. For details, see Corollary 1, Examples 4 and 5, and Subsections IV-B.
1. The distributionally robust receive combining and signal estimation problems across multiple frames, where channel conditions may change, are also investigated. For details, see Subsections IV-C and V-A 2.
I-B Notations
The $N$ -dimensional real (coordinate) space and complex (coordinate) space are denoted as $\mathbb{R}^{N}$ and $\mathbb{C}^{N}$ , respectively. Lowercase symbols (e.g., $\bm{x}$ ) denote vectors (column by default) and uppercase ones (e.g., $\bm{X}$ ) denote matrices. We use the Roman font for random quantities (e.g., $\mathbf{x},\mathbf{X}$ ) and the italic font for deterministic quantities (e.g., $\bm{x},\bm{X}$ ). Let $\operatorname{Re}\bm{X}$ be the real part of a complex quantity $\bm{X}$ (a vector or matrix) and $\operatorname{Im}\bm{X}$ be the imaginary part of $\bm{X}$ . For a vector $\bm{x}∈\mathbb{C}^{N}$ , let
$$
\underline{\bm{x}}\coloneqq\left[\begin{array}[]{cc}\operatorname{Re}\bm{x}\\
\operatorname{Im}\bm{x}\end{array}\right]\in\mathbb{R}^{2N}
$$
be the real-space representation of $\bm{x}$ ; for a matrix $\bm{H}∈\mathbb{C}^{N× M}$ , let
$$
\underline{\bm{H}}\coloneqq\left[\begin{array}[]{cc}\operatorname{Re}\bm{H}\\
\operatorname{Im}\bm{H}\end{array}\right],~{}~{}~{}~{}~{}\underline{\underline%
{\bm{H}}}\coloneqq\left[\begin{array}[]{cc}\operatorname{Re}\bm{H}&-%
\operatorname{Im}\bm{H}\\
\operatorname{Im}\bm{H}&\operatorname{Re}\bm{H}\end{array}\right]
$$
be the real-space representations of $\bm{H}$ where $\underline{\bm{H}}∈\mathbb{R}^{2N× M}$ and $\underline{\underline{\bm{H}}}∈\mathbb{R}^{2N× 2M}$ . The running index set induced by an integer $N$ is defined as $[N]\coloneqq\{1,2,...,N\}$ . To concatenate matrices and vectors, MATLAB notations are used: i.e., $[\bm{A},~{}\bm{B}]$ for row stacking and $[\bm{A};~{}\bm{B}]$ for column stacking. We let $\bm{\Gamma}_{M}\coloneqq[\bm{I}_{M},~{}\bm{J}_{M}]∈\mathbb{C}^{M× 2M}$ where $\bm{I}_{M}$ denotes the $M$ -dimensional identity matrix, $\bm{J}_{M}\coloneqq j·\bm{I}_{M}$ , and $j$ denotes the imaginary unit. Let $\mathcal{N}(\bm{\mu},\bm{\Sigma})$ denote a real Gaussian distribution with mean $\bm{\mu}$ and covariance $\bm{\Sigma}$ . We use $\mathcal{CN}(\bm{s},\bm{P},\bm{C})$ to denote a complex Gaussian distribution with mean $\bm{s}$ , covariance $\bm{P}$ , and pseudo-covariance $\bm{C}$ ; if $\bm{C}$ is not specified, we imply $\bm{C}=\bm{0}$ .
II Preliminaries
We review two popular structured representation methods of nonlinear functions $\bm{\phi}:\mathbb{R}^{N}→\mathbb{R}^{M}$ . More details can be seen in Appendix A.
II-A Reproducing Kernel Hilbert Spaces
A reproducing kernel Hilbert space (RKHS) $\mathcal{H}$ induced by the kernel function $\ker:\mathbb{R}^{N}×\mathbb{R}^{N}→\mathbb{R}$ and a collection of points $\{\bm{x}_{1},\bm{x}_{2},...,\bm{x}_{L}\}⊂\mathbb{R}^{N}$ is a set of functions from $\mathbb{R}^{N}$ to $\mathbb{R}$ ; $L$ may be infinite. Every function $\phi:\mathbb{R}^{N}→\mathbb{R}$ in the functional space $\mathcal{H}$ can be represented by a linear combination [24, p. 539; Chap. 14]
$$
\phi(\bm{x})=\sum^{L}_{i=1}\omega_{i}\cdot\ker(\bm{x},\bm{x}_{i}),~{}\forall%
\bm{x}\in\mathbb{R}^{N} \tag{1}
$$
where $\{\omega_{i}\}_{i∈[L]}$ are the combination weights; $\omega_{i}∈\mathbb{R}$ for every $i∈[L]$ . The matrix form of (1) for $M$ -multiple functions are
$$
\bm{\phi}(\bm{x})\coloneqq\left[\begin{array}[]{ccccccc}\phi_{1}(\bm{x})\\
\phi_{2}(\bm{x})\\
\vdots\\
\phi_{M}(\bm{x})\end{array}\right]=\bm{W}\cdot\bm{\varphi}(\bm{x})\coloneqq%
\left[\begin{array}[]{c}\bm{\omega}_{1}\\
\bm{\omega}_{2}\\
\vdots\\
\bm{\omega}_{M}\end{array}\right]\cdot\bm{\varphi}(\bm{x}), \tag{2}
$$
where $\bm{\omega}_{1},\bm{\omega}_{2},...,\bm{\omega}_{M}∈\mathbb{R}^{L}$ are weight row-vectors for functions $\phi_{1}(\bm{x}),\phi_{2}(\bm{x}),...,\phi_{M}(\bm{x})$ , respectively, and
$$
\bm{W}\coloneqq\left[\begin{array}[]{c}\bm{\omega}_{1}\\
\bm{\omega}_{2}\\
\vdots\\
\bm{\omega}_{M}\end{array}\right]\in\mathbb{R}^{M\times L},~{}~{}~{}\bm{%
\varphi}(\bm{x})\coloneqq\left[\begin{array}[]{c}\ker(\bm{x},\bm{x}_{1})\\
\ker(\bm{x},\bm{x}_{2})\\
\vdots\\
\ker(\bm{x},\bm{x}_{L})\end{array}\right]. \tag{3}
$$
Since a kernel function is pre-designed (i.e., fixed) for an RKHS $\mathcal{H}$ , (2) suggests a $\bm{W}$ -linear representation of $\bm{x}$ -nonlinear functions $\bm{\phi}(\bm{x})$ in $\mathcal{H}^{M}$ . Note that there exists a one-to-one correspondence between $\bm{\phi}$ and $\bm{W}$ : for every $\bm{\phi}:\mathbb{R}^{N}→\mathbb{R}^{M}$ , there exists a $\bm{W}∈\mathbb{R}^{M× L}$ , and vice versa.
II-B Neural Networks
Neural networks (NN) are another powerful tool to represent (i.e., approximate) nonlinear functions. A neural network function space (NNFS) $\mathcal{K}$ characterizes (or parameterizes) a set of multi-input multi-output functions. Typical choices are multi-layer feed-forward neural networks, recurrent neural networks, etc. For combining and estimation of wireless signals, the multi-layer feed-forward neural networks are standard [10, 11, 12]. Suppose that we have $R-1$ hidden layers (so in total $R+1$ layers including one input layer and one output layer) and each layer $r=0,1,...,R$ contains $T_{r}$ neurons. To represent a function $\bm{\phi}:\mathbb{R}^{N}→\mathbb{R}^{M}$ , for the input layer $r=0$ and output layer $r=R$ , we have $T_{0}=N$ and $T_{R}=M$ , respectively. Let the output of the $r^{\text{th}}$ layer be $\bm{y}_{r}∈\mathbb{R}^{T_{r}}$ . For every layer $r$ , we have $\bm{y}_{r}=\bm{\sigma}_{r}(\bm{W}^{\circ}_{r}·\bm{y}_{r-1}+\bm{b}_{r})$ where $\bm{W}^{\circ}_{r}∈\mathbb{R}^{T_{r}× T_{r-1}}$ is the weight matrix, $\bm{b}_{r}∈\mathbb{R}^{T_{r}}$ is the bias vector, and the multi-output function $\bm{\sigma}_{r}$ is the activation function which is entry-wise identical. Hence, every function $\bm{\phi}:\mathbb{R}^{N}→\mathbb{R}^{M}$ in a NNFS can be recursively expressed as [25, Chap. 5], [26]
$$
\begin{array}[]{cll}\bm{\phi}(\bm{x})&=\bm{\sigma}_{R}(\bm{W}_{R}\cdot[\bm{y}_%
{R-1}(\bm{x});~{}1])\\
\bm{y}_{r}(\bm{x})&=\bm{\sigma}_{r}(\bm{W}_{r}\cdot[\bm{y}_{r-1}(\bm{x});~{}1]%
),&r\in[R-1]\\
\bm{y}_{0}(\bm{x})&=\bm{x},\end{array} \tag{4}
$$
where $\bm{W}_{r}\coloneqq[\bm{W}^{\circ}_{r},~{}\bm{b}_{r}]$ for $r∈[R]$ . Note that the activation functions can vary from one layer to another.
III Problem Formulation
Consider a narrow-band wireless signal transmission model
$$
\mathbf{x}=\bm{H}\mathbf{s}+\mathbf{v} \tag{5}
$$
where $\mathbf{x}∈\mathbb{C}^{N}$ is the received signal, $\mathbf{s}∈\mathbb{C}^{M}$ is the transmitted signal, $\bm{H}∈\mathbb{C}^{N× M}$ is the channel matrix, and $\mathbf{v}∈\mathbb{C}^{N}$ is the zero-mean channel noise. The precoding operation (if exists) is integrated in $\bm{H}$ . The transmitted symbols $\mathbf{s}$ have zero means, which may be not only discrete symbols from constellations such as quadrature amplitude modulation but also arbitrary values such as integrated sensing and communication signals. We consider $L$ pilots $\mathbf{S}\coloneqq(\mathbf{s}_{1},\mathbf{s}_{2},...,\mathbf{s}_{L})$ in each frame, and the corresponding received symbols are $\mathbf{X}\coloneqq(\mathbf{x}_{1},\mathbf{x}_{2},...,\mathbf{x}_{L})$ under the noise $(\mathbf{v}_{1},\mathbf{v}_{2},...,\mathbf{v}_{L})$ . We suppose that $\bm{R}_{s}\coloneqq\mathbb{E}\mathbf{s}\mathbf{s}^{\mathsf{H}}$ and $\bm{R}_{v}\coloneqq\mathbb{E}\mathbf{v}\mathbf{v}^{\mathsf{H}}$ may not be identity or diagonal matrices: i.e., the components of $\mathbf{s}$ can be correlated (e.g., in ISAC), so can be these of $\mathbf{v}$ . Consider the real-space representation of the signal model (5) by stacking the real and imaginary components:
$$
\underline{\mathbf{x}}=\underline{\underline{\bm{H}}}\cdot\underline{\mathbf{s%
}}+\underline{\mathbf{v}}, \tag{6}
$$
where $\underline{\mathbf{x}}∈\mathbb{R}^{2N}$ , $\underline{\underline{\bm{H}}}∈\mathbb{R}^{2N× 2M}$ , $\underline{\mathbf{s}}∈\mathbb{R}^{2M}$ , and $\underline{\mathbf{v}}∈\mathbb{R}^{2N}$ . The expressions of $\bm{R}_{\underline{x}}\coloneqq\mathbb{E}{\underline{\mathbf{x}}\underline{%
\mathbf{x}}^{\mathsf{T}}}$ , $\bm{R}_{\underline{s}}\coloneqq\mathbb{E}{\underline{\mathbf{s}}\underline{%
\mathbf{s}}^{\mathsf{T}}}$ , $\bm{R}_{\underline{x}\underline{s}}\coloneqq\mathbb{E}{\underline{\mathbf{x}}%
\underline{\mathbf{s}}^{\mathsf{T}}}$ , and $\bm{R}_{\underline{v}}\coloneqq\mathbb{E}{\underline{\mathbf{v}}\underline{%
\mathbf{v}}^{\mathsf{T}}}$ can be readily obtained; see Appendix B. In some cases, signal estimation in real spaces can be technically simpler than that in complex spaces.
III-A Optimal Estimation
III-A 1 Optimal Nonlinear Estimation (Receive Combining)
To recover $\mathbf{s}$ using $\mathbf{x}$ , we consider an estimator $\hat{\mathbf{s}}\coloneqq\bm{\phi}(\mathbf{x})$ , called a receive combiner, at the receiver where $\bm{\phi}:\mathbb{C}^{N}→\mathbb{C}^{M}$ is a Borel-measurable function. Note that $\bm{\phi}(\mathbf{x})$ may be nonlinear in general because the joint distribution of $(\mathbf{x},\mathbf{s})$ is not necessarily Gaussian, for example, when the channel noise $\mathbf{v}$ is non-Gaussian or when the power amplifiers work in non-linear regions. The signal estimation problem at the receiver can be written as a statistical machine-learning problem under the joint data distribution $\mathbb{P}_{\mathbf{x},\mathbf{s}}$ of $(\mathbf{x},\mathbf{s})$ , that is,
$$
\min_{\bm{\phi}\in\mathcal{B}_{\mathbb{C}^{N}\to\mathbb{C}^{M}}}\operatorname{%
Tr}\mathbb{E}_{\mathbf{x},\mathbf{s}}[\bm{\phi}(\mathbf{x})-\mathbf{s}][\bm{%
\phi}(\mathbf{x})-\mathbf{s}]^{\mathsf{H}}, \tag{7}
$$
where $\mathcal{B}_{\mathbb{C}^{N}→\mathbb{C}^{M}}$ contains all Borel-measurable estimators from $\mathbb{C}^{N}$ to $\mathbb{C}^{M}$ . In what follows, we omit the notational dependence on $\mathbb{C}^{N}$ and $\mathbb{C}^{M}$ , and use $\mathcal{B}$ as a shorthand. The optimal estimator, in the sense of minimum mean-squared error, is known as the conditional mean of $\mathbf{s}$ given $\mathbf{x}$ , i.e.,
$$
\hat{\mathbf{s}}=\bm{\phi}(\mathbf{x})=\mathbb{E}({\mathbf{s}|\mathbf{x}}). \tag{8}
$$
Usually, it is computationally complicated to find the optimal $\bm{\phi}(·)$ from the whole space $\mathcal{B}$ of Borel-measurable functions, that is, to compute the conditional mean. Therefore, in practice, we may find the optimal approximation of $\bm{\phi}(·)$ in an RKHS $\mathcal{H}$ or a NNFS $\mathcal{K}$ ; note that $\mathcal{H}$ and $\mathcal{K}$ are two subspaces of $\mathcal{B}$ . However, both $\mathcal{H}$ and $\mathcal{K}$ are sufficiently rich because they can be dense in the space of all continuous bounded functions.
III-A 2 Optimal Linear Estimation (Receive Beamforming)
If $\mathbf{x}$ and $\mathbf{s}$ are jointly Gaussian (e.g., when $\mathbf{s}$ and $\mathbf{v}$ are jointly Gaussian), the optimal estimator $\bm{\phi}$ is linear in $\mathbf{x}$ :
$$
\hat{\mathbf{s}}=\bm{W}\mathbf{x}, \tag{9}
$$
where $\bm{W}∈\mathbb{C}^{M× N}$ is called a receive beamformer or a linear receive combiner. In this linear case, (7) reduces to the usual Wiener–Hopf beamforming problem
$$
\min_{\bm{W}}\operatorname{Tr}\mathbb{E}_{\mathbf{x},\mathbf{s}}[\bm{W}\mathbf%
{x}-\mathbf{s}][\bm{W}\mathbf{x}-\mathbf{s}]^{\mathsf{H}}, \tag{10}
$$
that is,
$$
\min_{\bm{W}}\operatorname{Tr}\big{[}\bm{W}\bm{R}_{x}\bm{W}^{\mathsf{H}}-\bm{W%
}\bm{R}_{xs}-\bm{R}^{\mathsf{H}}_{xs}\bm{W}^{\mathsf{H}}+\bm{R}_{s}\big{]}, \tag{11}
$$
where $\bm{R}_{x}\coloneqq\mathbb{E}{\mathbf{x}\mathbf{x}^{\mathsf{H}}}∈\mathbb{C}^%
{N× N}$ and $\bm{R}_{xs}\coloneqq\mathbb{E}{\mathbf{x}\mathbf{s}^{\mathsf{H}}}∈\mathbb{C}%
^{N× M}$ . Since $\bm{R}_{x}=\bm{H}\bm{R}_{s}\bm{H}^{\mathsf{H}}+\bm{R}_{v}$ and $\bm{R}_{xs}=\bm{H}\bm{R}_{s}+\mathbb{E}{\mathbf{v}\mathbf{s}^{\mathsf{H}}}=\bm%
{H}\bm{R}_{s}$ , the solution of (11), or (10), is
$$
\begin{array}[]{cl}\bm{W}^{\star}_{\text{Wiener}}&=\bm{R}^{\mathsf{H}}_{xs}\bm%
{R}^{-1}_{x}\\
&=\bm{R}_{s}\bm{H}^{\mathsf{H}}[\bm{H}\bm{R}_{s}\bm{H}^{\mathsf{H}}+\bm{R}_{v}%
]^{-1},\end{array} \tag{12}
$$
which is known as the Wiener beamformer. With an additional constraint $\bm{W}\bm{H}=\bm{I}_{M}$ (i.e., distortionless response), (11) gives the Capon beamformer. Both the Wiener beamformer and the Capon beamformer maximize the output signal–to–interference-plus-noise ratio (SINR); hence, both are optimal in the sense of maximum output SINR.
No matter whether $\mathbb{P}_{\mathbf{x},\mathbf{s}}$ is Gaussian or not, (10) or (11) identifies the optimal linear estimator in the sense of minimum mean-squared error among all linear estimators.
III-A 3 Role of Channel Estimation
Eqs. (7) and (10) imply that channel estimation is not a necessary step in receive combining. The only necessary element, from the perspective of statistical machine learning, is the joint distribution $\mathbb{P}_{\mathbf{x},\mathbf{s}}$ of the received signal $\mathbf{x}$ and the transmitted signal $\mathbf{s}$ . Therefore, the following two points can be highlighted.
1. If the joint distribution $\mathbb{P}_{\mathbf{x},\mathbf{s}}$ is non-Gaussian, we just need to learn the mapping $\bm{\phi}$ using (7).
1. If the joint distribution $\mathbb{P}_{\mathbf{x},\mathbf{s}}$ is (or assumed to be) Gaussian, we just learn covariance matrices $\bm{R}_{xs}$ and $\bm{R}_{x}$ ; cf. (12); Gaussianity assumption of $\mathbb{P}_{\mathbf{x},\mathbf{s}}$ is beneficial in reducing computational burdens. If, further, the channel matrix $\bm{H}$ is known, $\bm{R}_{xs}$ and $\bm{R}_{x}$ can be expressed using $\bm{H}$ .
III-B Distributional Uncertainty and Distributional Robustness
For ease of conceptual illustration, we start with the following stationary-channel assumption in this subsection: The channel statistics remain unchanged within the communication frame so that the joint distribution $\mathbb{P}_{\mathbf{x},\mathbf{s}}$ is fixed over time. That is, pilot data $\{(\bm{x}_{1},\bm{s}_{1}),(\bm{x}_{2},\bm{s}_{2}),...,(\bm{x}_{L},\bm{s}_{L%
})\}$ and non-pilot communication data are drawn from the same unknown distribution $\mathbb{P}_{\mathbf{x},\mathbf{s}}$ . For the general case where the channel is not statistically stationary within a frame, see Appendix C; the statistical non-stationarity of $\mathbb{P}_{\mathbf{x},\mathbf{s}}$ may be due to the time-selectivity of the transmit power matrix $\bm{R}_{s}$ , of the channel matrix $\bm{H}$ , and/or of the channel noise covariance $\bm{R}_{v}$ .
III-B 1 Issue of Distributional Uncertainty
In practice, the true joint distribution $\mathbb{P}_{\mathbf{x},\mathbf{s}}$ is unknown but can be estimated by the pilot data. Hence, the estimation of wireless signals is a data-driven statistical inference (i.e., statistical machine learning) problem. We let
$$
\hat{\mathbb{P}}_{\mathbf{x},\mathbf{s}}\coloneqq\frac{1}{L}\sum^{L}_{i=1}%
\delta_{(\bm{x}_{i},\bm{s}_{i})} \tag{13}
$$
denote the empirical distribution supported on the $L$ collected data $\{(\bm{x}_{i},\bm{s}_{i})\}_{i∈[L]}$ , where $\delta_{(\bm{x}_{i},\bm{s}_{i})}$ denotes the Dirac distribution (i.e., point-mass distribution) centered on $(\bm{x}_{i},\bm{s}_{i})$ ; note that $\hat{\mathbb{P}}_{\mathbf{x},\mathbf{s}}$ is a discrete distribution. If we use the estimated joint distribution $\hat{\mathbb{P}}_{\mathbf{x},\mathbf{s}}$ as a surrogate of the true joint distribution $\mathbb{P}_{\mathbf{x},\mathbf{s}}$ , (7) becomes the conventional empirical risk minimization (ERM)
$$
\min_{\bm{\phi}\in\mathcal{B}}\operatorname{Tr}\mathbb{E}_{(\mathbf{x},\mathbf%
{s})\sim\hat{\mathbb{P}}_{\mathbf{x},\mathbf{s}}}[\bm{\phi}(\mathbf{x})-%
\mathbf{s}][\bm{\phi}(\mathbf{x})-\mathbf{s}]^{\mathsf{H}}, \tag{14}
$$
i.e.,
$$
\min_{\bm{\phi}\in\mathcal{B}}\operatorname{Tr}\frac{1}{L}\sum^{L}_{i=1}[\bm{%
\phi}(\bm{x}_{i})-\bm{s}_{i}][\bm{\phi}(\bm{x}_{i})-\bm{s}_{i}]^{\mathsf{H}}. \tag{15}
$$
Likewise, (11) become the conventional beamforming problem
$$
\displaystyle\min_{\bm{W}}\operatorname{Tr}\big{[}\bm{W}\hat{\bm{R}}_{x}\bm{W}%
^{\mathsf{H}}-\bm{W}\hat{\bm{R}}_{xs}-\hat{\bm{R}}^{\mathsf{H}}_{xs}\bm{W}^{%
\mathsf{H}}+\hat{\bm{R}}_{s}\big{]}, \tag{16}
$$
where ${\hat{\bm{R}}}_{x}$ , ${\hat{\bm{R}}}_{xs}$ , and ${\hat{\bm{R}}}_{s}$ are the training-sample-estimated (i.e., nominal) values of $\bm{R}_{x}$ , $\bm{R}_{xs}$ , and $\bm{R}_{s}$ , respectively.
There exists the distributional difference between the sample-defined nominal distribution $\hat{\mathbb{P}}_{\mathbf{x},\mathbf{s}}$ and true data-generating distribution $\mathbb{P}_{\mathbf{x},\mathbf{s}}$ due to the limited size of the training data set (i.e., limited pilot length) and the time-selectivity of $\mathbb{P}_{\mathbf{x},\mathbf{s}}$ . From the perspective of applied statistics and machine learning, the distributional difference between $\hat{\mathbb{P}}_{\mathbf{x},\mathbf{s}}$ and $\mathbb{P}_{\mathbf{x},\mathbf{s}}$ (i.e., the distributional uncertainty of $\hat{\mathbb{P}}_{\mathbf{x},\mathbf{s}}$ compared to $\mathbb{P}_{\mathbf{x},\mathbf{s}}$ ) may cause significant performance degradation of (15) compared to (7), so is the performance deterioration of (16) compared to (11). For extensive reading on this point, see Appendix C. Therefore, to reduce the adverse effect introduced by the distributional uncertainty in $\hat{\mathbb{P}}_{\mathbf{x},\mathbf{s}}$ , a new surrogate of (7) rather than the sample-averaged approximation in (15) is expected.
III-B 2 Distributionally Robust Estimation
To combat the distributional uncertainty in $\hat{\mathbb{P}}_{\mathbf{x},\mathbf{s}}$ , we consider the distributionally robust counterpart of (7)
$$
\min_{\bm{\phi}\in\mathcal{B}}\max_{\mathbb{P}_{\mathbf{x},\mathbf{s}}\in%
\mathcal{U}_{\mathbf{x},\mathbf{s}}}\operatorname{Tr}\mathbb{E}_{\mathbf{x},%
\mathbf{s}}[\bm{\phi}(\mathbf{x})-\mathbf{s}][\bm{\phi}(\mathbf{x})-\mathbf{s}%
]^{\mathsf{H}}, \tag{17}
$$
where $\mathcal{U}_{\mathbf{x},\mathbf{s}}$ , called a distributional uncertainty set, contains a collection of distributions that are close to the nominal distribution (i.e., the sample-estimated distribution) $\hat{\mathbb{P}}_{\mathbf{x},\mathbf{s}}$ ;
$$
\mathcal{U}_{\mathbf{x},\mathbf{s}}\coloneqq\{\mathbb{P}_{\mathbf{x},\mathbf{s%
}}|~{}d(\mathbb{P}_{\mathbf{x},\mathbf{s}},\hat{\mathbb{P}}_{\mathbf{x},%
\mathbf{s}})\leq\epsilon\}, \tag{18}
$$
where $d(·,·)$ denotes a similarity measure (e.g., metric or divergence) between two distributions and $\epsilon≥ 0$ an uncertainty quantification level. Since $\hat{\mathbb{P}}_{\mathbf{x},\mathbf{s}}$ is discrete and $\mathbb{P}_{\mathbf{x},\mathbf{s}}$ is not, the Wasserstein distance [27, Def. 2] and the maximum mean discrepancy (MMD) distance [28, Def. 2.1] are the typical choices of $d(·,·)$ to construct $\mathcal{U}_{\mathbf{x},\mathbf{s}}$ . When $\hat{\mathbb{P}}_{\mathbf{x},\mathbf{s}}$ and $\mathbb{P}_{\mathbf{x},\mathbf{s}}$ are parametric distributions (e.g., Gaussian, exponential family), divergences such as the Kullback-–Leibler (KL) divergence, or more general $\phi$ -divergence, are also applicable to particularize $d(·,·)$ because parameters can be estimated using samples. When $\epsilon=0$ , (17) reduces to (15).
If $\mathcal{U}_{\mathbf{x},\mathbf{s}}$ contains (or is assumed, for computational simplicity, to contain) only Gaussian distributions, (17) particularizes to
$$
\begin{array}[]{cl}\displaystyle\min_{\bm{W}}\max_{\bm{R}}&\operatorname{Tr}%
\big{[}\bm{W}\bm{R}_{x}\bm{W}^{\mathsf{H}}-\bm{W}\bm{R}_{xs}-\bm{R}^{\mathsf{H%
}}_{xs}\bm{W}^{\mathsf{H}}+\bm{R}_{s}\big{]}\\
\text{s.t.}&d_{0}(\bm{R},~{}\hat{\bm{R}})\leq\epsilon_{0},\\
&\bm{R}\succeq\bm{0},\end{array} \tag{19}
$$
where
$$
\bm{R}\coloneqq\left[\begin{array}[]{cc}\bm{R}_{x}&\bm{R}_{xs}\\
\bm{R}^{\mathsf{H}}_{xs}&\bm{R}_{s}\end{array}\right],~{}~{}~{}\hat{\bm{R}}%
\coloneqq\left[\begin{array}[]{cc}\hat{\bm{R}}_{x}&\hat{\bm{R}}_{xs}\\
\hat{\bm{R}}^{\mathsf{H}}_{xs}&\hat{\bm{R}}_{s}\end{array}\right], \tag{20}
$$
because every zero-mean complex Gaussian distribution is uniquely characterized by its covariance and pseudo-covariance, but in receive beamforming, we do not consider pseudo-covariances; cf. (12); $d_{0}$ denotes the matrix similarity measures (e.g., matrix distances); $\epsilon_{0}≥ 0$ is the uncertainty quantification parameter. When $\epsilon_{0}=0$ , (19) reduces to (16).
For additional discussions on the framework of distributionally robust estimation, see Appendix D.
IV Distributionally Robust Linear Estimation
Due to several practical benefits of linear estimation, for example, the simplicity of hardware structures, the clarity of physical meaning (i.e., constructive and destructive interference through beamforming), and the easiness of computations, investigating distributionally robust linear estimation problems is important. This section particularly studies Problem (19).
IV-A General Framework and Concrete Examples
The following lemma solves Problem (19).
**Lemma 1**
*Suppose that the set $\{\bm{R}|~{}d_{0}(\bm{R},~{}\hat{\bm{R}})≤\epsilon_{0}\}$ is compact convex and $\bm{R}_{x}$ is invertible. Let $\bm{R}^{\star}$ solve the problem below:
$$
\begin{array}[]{cl}\displaystyle\max_{\bm{R}}&\operatorname{Tr}\big{[}-\bm{R}^%
{\mathsf{H}}_{xs}\bm{R}^{-1}_{x}\bm{R}_{xs}+\bm{R}_{s}\big{]}\\
\text{s.t.}&d_{0}(\bm{R},~{}\hat{\bm{R}})\leq\epsilon_{0},\\
&\bm{R}\succeq\bm{0},~{}~{}~{}\bm{R}_{x}\succ\bm{0}.\end{array} \tag{21}
$$
Construct $\bm{W}^{\star}$ using $\bm{R}^{\star}$ as follows:
$$
\bm{W}^{\star}\coloneqq\bm{R}^{\star\mathsf{H}}_{xs}\bm{R}^{\star-1}_{x}. \tag{22}
$$
Then $(\bm{W}^{\star},\bm{R}^{\star})$ is a solution to Problem (19). On the other hand, if $(\bm{W}^{\star},\bm{R}^{\star})$ solves Problem (19), then $\bm{R}^{\star}$ is a solution to (21) and $(\bm{W}^{\star},\bm{R}^{\star})$ satisfies (22).*
* Proof:*
See Appendix E. $\square$ ∎
Let
$$
f_{1}(\bm{R})\coloneqq\operatorname{Tr}\big{[}-\bm{R}^{\mathsf{H}}_{xs}\bm{R}^%
{-1}_{x}\bm{R}_{xs}+\bm{R}_{s}\big{]} \tag{23}
$$
denote the objective function of (21). When $\bm{R}_{s}$ and $\bm{R}_{xs}$ are fixed, we define
$$
f_{2}(\bm{R}_{x})\coloneqq\operatorname{Tr}\big{[}-\bm{R}^{\mathsf{H}}_{xs}\bm%
{R}^{-1}_{x}\bm{R}_{xs}+\bm{R}_{s}\big{]}. \tag{24}
$$
The theorem below studies the properties of $f_{1}$ and $f_{2}$ .
**Theorem 1**
*Consider the definition of $\bm{R}$ in (20). The functions $f_{1}$ defined in (23) and $f_{2}$ defined in (24) are monotonically increasing in $\bm{R}$ and $\bm{R}_{x}$ , respectively. To be specific, if $\bm{R}_{1}\succeq\bm{R}_{2}\succeq\bm{0}$ , $\bm{R}_{1,x}\succ\bm{0}$ , and $\bm{R}_{2,x}\succ\bm{0}$ , we have $f_{1}(\bm{R}_{1})≥ f_{1}(\bm{R}_{2})$ . In addition, if $\bm{R}_{1,x}\succeq\bm{R}_{2,x}\succ\bm{0}$ , we have $f_{2}(\bm{R}_{1,x})≥ f_{2}(\bm{R}_{2,x})$ .*
* Proof:*
See Appendix F. $\square$ ∎
To concretely solve (21), we need to particularize $d_{0}$ . This article investigates the following uncertainty sets.
**Definition 1 (Additive Moment Uncertainty Set)**
*The additive moment uncertainty set of $\bm{R}$ is constructed as
$$
\{\bm{R}|~{}\hat{\bm{R}}-\epsilon_{0}\bm{E}\preceq\bm{R}\preceq\hat{\bm{R}}+%
\epsilon_{0}\bm{E},~{}\bm{R}\succeq\bm{0}\} \tag{25}
$$
for some $\bm{E}\succeq\bm{0}$ and $\epsilon_{0}≥ 0$ . $\square$*
Definition 1 is motivated by the fact that the difference $\bm{R}-\hat{\bm{R}}$ is bounded by some threshold matrix $\bm{E}$ and error quantification level $\epsilon_{0}$ : specifically, $-\epsilon_{0}\bm{E}\preceq\bm{R}-\hat{\bm{R}}\preceq\epsilon_{0}\bm{E}$ . In practice, we can consider the threshold as an identity matrix because, for every non-identity $\bm{E}\succeq\bm{0}$ , we have $\bm{E}\preceq\lambda_{1}\bm{I}_{N+M}$ where $\lambda_{1}$ is the largest eigenvalue of $\bm{E}$ .
**Definition 2 (Diagonal-Loading Uncertainty Set)**
*The diagonal-loading uncertainty set of $\bm{R}$ is constructed as
$$
\{\bm{R}|~{}\hat{\bm{R}}-\epsilon_{0}\bm{I}_{N+M}\preceq\bm{R}\preceq\hat{\bm{%
R}}+\epsilon_{0}\bm{I}_{N+M},~{}\bm{R}\succeq\bm{0}\} \tag{26}
$$
for some $\epsilon_{0}≥ 0$ . $\square$*
Due to the concentration property of the sample-covariance $\hat{\bm{R}}$ to the true covariance $\bm{R}$ when the true distribution $\mathbb{P}_{\mathbf{x},\mathbf{s}}$ is fixed within a frame, finite values of $\epsilon_{0}$ exist for every sample size $L$ ; NB: $\epsilon_{0}→ 0$ as $L→∞$ . However, given $L$ , the smallest $\epsilon_{0}$ cannot be practically calculated because it depends on the true but unknown $\mathbb{P}_{\mathbf{x},\mathbf{s}}$ . If $\bm{E}$ is block-diagonal, the generalized diagonal-loading uncertainty set can be motivated.
**Definition 3 (Generalized Diagonal-Loading Uncertainty Set)**
*The generalized diagonal-loading uncertainty set of $\bm{R}$ is constructed by the following constraints: $\bm{R}\succeq\bm{0}$ and
$$
\begin{array}[]{l}\left[\begin{array}[]{cc}\hat{\bm{R}}_{x}&\hat{\bm{R}}_{xs}%
\\
\hat{\bm{R}}^{\mathsf{H}}_{xs}&\hat{\bm{R}}_{s}\end{array}\right]-\epsilon_{0}%
\left[\begin{array}[]{cc}\bm{F}&\bm{0}\\
\bm{0}&\bm{G}\end{array}\right]\\
\quad\quad\preceq\left[\begin{array}[]{cc}\bm{R}_{x}&\bm{R}_{xs}\\
\bm{R}^{\mathsf{H}}_{xs}&\bm{R}_{s}\end{array}\right]\\
\quad\quad\quad\quad\preceq\left[\begin{array}[]{cc}\hat{\bm{R}}_{x}&\hat{\bm{%
R}}_{xs}\\
\hat{\bm{R}}^{\mathsf{H}}_{xs}&\hat{\bm{R}}_{s}\end{array}\right]+\epsilon_{0}%
\left[\begin{array}[]{cc}\bm{F}&\bm{0}\\
\bm{0}&\bm{G}\end{array}\right],\end{array} \tag{27}
$$
for some $\bm{F},\bm{G}\succeq\bm{0}$ and $\epsilon_{0}≥ 0$ . $\square$*
Definitions 1, 2, and 3 are introduced for the first time in this article. Another type of moment-based uncertainty set is popular in the literature, which we refer to as the multiplicative moment uncertainty set for differentiation.
**Definition 4 (Multiplicative Moment Uncertainty Set[29])**
*The multiplicative moment uncertainty set of $\bm{R}$ is given as
$$
\{\bm{R}|~{}\theta_{1}\hat{\bm{R}}\preceq\bm{R}\preceq\theta_{2}\hat{\bm{R}}\} \tag{28}
$$
for some $\theta_{2}≥ 1≥\theta_{1}≥ 0$ . $\square$*
The following corollary shows the distributionally robust linear beamformers associated with the various uncertainty sets in Definitions 1, 2, 3, and 4.
**Corollary 1 (of Theorem1)**
*Consider the moment-based uncertainty sets in Definitions 1, 2, 3, and 4. The distributionally robust linear beamforming (21) is analytically solved by the corresponding upper bounds of $\bm{R}$ . To be specific,
1. Under Definition 1, the additive-moment distributionally robust (DR-AM) beamformer is
$$
\begin{array}[]{cl}\bm{W}^{\star}_{\text{DR-AM}}&=(\hat{\bm{R}}_{xs}+\epsilon_%
{0}\bm{E}_{xs})^{\mathsf{H}}(\hat{\bm{R}}_{x}+\epsilon_{0}\bm{E}_{x})^{-1}\\
&=(\hat{\bm{H}}\hat{\bm{R}}_{s}+\epsilon_{0}\bm{E}_{xs})^{\mathsf{H}}\cdot\\
&\quad\quad\quad[\hat{\bm{H}}\hat{\bm{R}}_{s}\hat{\bm{H}}^{\mathsf{H}}+\hat{%
\bm{R}}_{v}+\epsilon_{0}\bm{E}_{x}]^{-1},\end{array} \tag{29}
$$
where $\hat{\bm{H}}$ , $\hat{\bm{R}}_{s}$ , and $\hat{\bm{R}}_{v}$ denote the estimates of $\bm{H}$ , $\bm{R}_{s}$ , and $\bm{R}_{v}$ , respectively.
1. Under Definition 2, the diagonal-loading distributionally robust (DR-DL) beamformer is
$$
\begin{array}[]{cl}\bm{W}^{\star}_{\text{DR-DL}}&=\hat{\bm{R}}^{\mathsf{H}}_{%
xs}[{\hat{\bm{R}}}_{x}+\epsilon_{0}\bm{I}_{N}]^{-1}\\
&=\hat{\bm{R}}_{s}\hat{\bm{H}}^{\mathsf{H}}[\hat{\bm{H}}\hat{\bm{R}}_{s}\hat{%
\bm{H}}^{\mathsf{H}}+\hat{\bm{R}}_{v}+\epsilon_{0}\bm{I}_{N}]^{-1},\end{array} \tag{30}
$$
which is also known as the loaded sample matrix inversion method [19], [14, Eq. (11)] and widely-used in the practice of wireless communications.
1. Under Definition 3, the generalized diagonal-loading distributionally robust beamformer (DR-GDL) is
$$
\begin{array}[]{cl}\bm{W}^{\star}_{\text{DR-GDL}}&=\hat{\bm{R}}^{\mathsf{H}}_{%
xs}[{\hat{\bm{R}}}_{x}+\epsilon_{0}\bm{F}]^{-1}\\
&=\hat{\bm{R}}_{s}\hat{\bm{H}}^{\mathsf{H}}[\hat{\bm{H}}\hat{\bm{R}}_{s}\hat{%
\bm{H}}^{\mathsf{H}}+\hat{\bm{R}}_{v}+\epsilon_{0}\bm{F}]^{-1}.\end{array} \tag{31}
$$
1. Under Definition 4, the multiplicative-moment (MM) distributionally robust beamformer is identical to the Wiener beamformer (12) at nominal values:
$$
\begin{array}[]{cl}\bm{W}^{\star}_{\text{DR-MM}}&=\hat{\bm{R}}_{xs}^{\mathsf{H%
}}\hat{\bm{R}}_{x}^{-1}\\
&=\hat{\bm{R}}_{s}\hat{\bm{H}}^{\mathsf{H}}[\hat{\bm{H}}\hat{\bm{R}}_{s}\hat{%
\bm{H}}^{\mathsf{H}}+\hat{\bm{R}}_{v}]^{-1}.\end{array} \tag{32}
$$
The corresponding estimation errors are simple to obtain. $\square$*
Corollary 1 implies that, in the sense of the same induced robust beamformers, the diagonal-loading uncertainty set (26) and the generalized diagonal-loading uncertainty set (27) are technically equivalent to the following trimmed versions.
**Definition 5 (Trimmed Diagonal-Loading Uncertainty Sets)**
*By setting $\bm{G}\coloneqq\bm{0}$ in (27), in terms of $\bm{R}_{x}$ , (27) reduces to the trimmed generalized diagonal-loading uncertainty set:
$$
\{\bm{R}_{x}|~{}\hat{\bm{R}}_{x}-\epsilon_{0}\bm{F}\preceq\bm{R}_{x}\preceq%
\hat{\bm{R}}_{x}+\epsilon_{0}\bm{F},~{}\bm{R}_{x}\succeq\bm{0}\}. \tag{33}
$$
The trimmed diagonal-loading uncertainty set
$$
\{\bm{R}_{x}|~{}\hat{\bm{R}}_{x}-\epsilon_{0}\bm{I}_{N}\preceq\bm{R}_{x}%
\preceq\hat{\bm{R}}_{x}+\epsilon_{0}\bm{I}_{N},~{}\bm{R}_{x}\succeq\bm{0}\}, \tag{34}
$$
is obtained by letting $\bm{F}\coloneqq\bm{I}_{N}$ . $\square$*
The robust beamformers corresponding to the trimmed uncertainty sets (33) and (34) remain the same as defined in (31) and (30), respectively; cf. Theorem 1.
As we can see from Corollary 1, the primary benefit of using the moment-based uncertainty sets is the computational simplicity due to the availability of closed-form solutions. If the uncertainty sets are constructed using the Wasserstein distance $\sqrt{\operatorname{Tr}[{\bm{R}+\hat{\bm{R}}-2(\hat{\bm{R}}^{1/2}\bm{R}\hat{%
\bm{R}}^{1/2})^{1/2}}]}≤\epsilon_{0}$ or the KL divergence $\frac{1}{2}[\operatorname{Tr}[{\hat{\bm{R}}^{-1}\bm{R}-\bm{I}_{N+M}}]-\ln\det(%
\hat{\bm{R}}^{-1}\bm{R})]≤\epsilon_{0}$ between $\mathcal{CN}(\bm{0},\bm{R})$ and $\mathcal{CN}(\bm{0},\hat{\bm{R}})$ , the induced distributionally robust linear beamforming problems have no closed-form solutions, and therefore, are computationally prohibitive in practice. In addition, Corollary 1 suggests that the distributionally robust beamformer under the multiplicative moment uncertainty set (28) is the same as the nominal beamformer $\hat{\bm{R}}^{\mathsf{H}}_{xs}\hat{\bm{R}}_{x}^{-1}$ , which essentially does not introduce robustness in wireless signal estimation; this is another motivation why we construct new moment-based uncertainty sets in Definitions 1, 2, and 3. However, we can modify the multiplicative moment uncertainty set in Definition 4 to achieve robustness.
**Definition 6 (Modified Multiplicative Moment Uncertainty Set)**
*The modified multiplicative moment uncertainty set of $\bm{R}$ is defined by the following constraint:
$$
\left[\begin{array}[]{cc}\theta_{1}\hat{\bm{R}}_{x}&\hat{\bm{R}}_{xs}\\
\hat{\bm{R}}^{\mathsf{H}}_{xs}&\theta_{1}\hat{\bm{R}}_{s}\end{array}\right]%
\preceq\left[\begin{array}[]{cc}\bm{R}_{x}&\bm{R}_{xs}\\
\bm{R}^{\mathsf{H}}_{xs}&\bm{R}_{s}\end{array}\right]\preceq\left[\begin{array%
}[]{cc}\theta_{2}\hat{\bm{R}}_{x}&\hat{\bm{R}}_{xs}\\
\hat{\bm{R}}^{\mathsf{H}}_{xs}&\theta_{2}\hat{\bm{R}}_{s}\end{array}\right] \tag{35}
$$
for some $\theta_{2}≥ 1≥\theta_{1}≥ 0$ such that the left-most matrix is positive semi-definite. $\square$*
The robust beamformer under the modified multiplicative moment uncertainty set (35) is
$$
\bm{W}^{\star}_{\text{DR-MMM}}=\hat{\bm{R}}^{\mathsf{H}}_{xs}\cdot[\theta_{2}%
\hat{\bm{R}}_{x}]^{-1}. \tag{36}
$$
In terms of the uncertainties of $\bm{R}_{s}$ and $\bm{R}_{v}$ , Problem (21) can be explicitly written as
$$
\begin{array}[]{cl}\displaystyle\max_{\bm{R}_{s},\bm{R}_{v}}&\operatorname{Tr}%
\big{[}\bm{R}_{s}-\bm{R}_{s}\bm{H}^{\mathsf{H}}(\bm{H}\bm{R}_{s}\bm{H}^{%
\mathsf{H}}+\bm{R}_{v})^{-1}\bm{H}\bm{R}_{s}\big{]}\\
\text{s.t.}&d_{1}(\bm{R}_{s},\hat{\bm{R}}_{s})\leq\epsilon_{1},\\
&d_{2}(\bm{R}_{v},\hat{\bm{R}}_{v})\leq\epsilon_{2},\\
&\bm{R}_{s}\succeq\bm{0},~{}\bm{R}_{v}\succeq\bm{0},\end{array} \tag{37}
$$
for some similarity measures $d_{1}$ and $d_{2}$ and nonnegative scalars $\epsilon_{1}$ and $\epsilon_{2}$ . For every given $(\bm{R}_{s},\bm{R}_{v})$ , the associated beamformer is given in (12). When the uncertainty in the channel matrix must be investigated, we can consider
$$
\begin{array}[]{cl}\displaystyle\max_{\bm{H}}&\operatorname{Tr}\big{[}\bm{R}_{%
s}-\bm{R}_{s}\bm{H}^{\mathsf{H}}(\bm{H}\bm{R}_{s}\bm{H}^{\mathsf{H}}+\bm{R}_{v%
})^{-1}\bm{H}\bm{R}_{s}\big{]}\\
\text{s.t.}&d_{3}(\bm{H},\hat{\bm{H}})\leq\epsilon_{3},\end{array} \tag{38}
$$
which is not a semi-definite program. In addition, the gradient of the objective function with respect to $\bm{H}$ is complicated to obtain. Hence, practically, we should avoid directly attacking Problem (38); this can be done by directly considering the uncertainties of $\bm{R}_{x}$ and $\bm{R}_{xs}$ (i.e., $\bm{R}$ ) because the uncertainties of $\bm{R}_{s}$ , $\bm{R}_{v}$ , and $\bm{H}$ can be reflected in the uncertainties of $\bm{R}_{x}$ and $\bm{R}_{xs}$ ; cf. $\bm{R}_{x}=\bm{H}\bm{R}_{s}\bm{H}^{\mathsf{H}}+\bm{R}_{v}$ and $\bm{R}_{xs}=\bm{H}\bm{R}_{s}$ .
In addition to Corollary 1, below we provide other concrete examples to further showcase the usefulness and applications of the distributionally robust beamforming formulations (21) and (37), where the trimmed uncertainty sets are employed.
**Example 1 (Distributionally Robust Capon Beamforming)**
*We consider a distributionally robust Capon beamforming problem under the trimmed uncertainty set (34):
$$
\begin{array}[]{cl}\displaystyle\min_{\bm{W}}\max_{\bm{R}_{x}}&\operatorname{%
Tr}\big{[}\bm{W}\bm{R}_{x}\bm{W}^{\mathsf{H}}-2\bm{R}_{s}+\bm{R}_{s}\big{]}\\
\text{s.t.}&\bm{W}\bm{H}=\bm{I}_{M},\\
&{\hat{\bm{R}}}_{x}-\epsilon_{0}\bm{I}_{N}\preceq\bm{R}_{x}\preceq{\hat{\bm{R}%
}}_{x}+\epsilon_{0}\bm{I}_{N},\\
&\bm{R}_{x}\succeq\bm{0},\end{array}
$$
which is equivalent, in the sense of the same solutions, to
$$
\begin{array}[]{cl}\displaystyle\min_{\bm{W}}\max_{\bm{R}_{x}}&\operatorname{%
Tr}\big{[}\bm{W}\bm{R}_{x}\bm{W}^{\mathsf{H}}\big{]}\\
\text{s.t.}&\bm{W}\bm{H}=\bm{I}_{M},\\
&{\hat{\bm{R}}}_{x}-\epsilon_{0}\bm{I}_{N}\preceq\bm{R}_{x}\preceq{\hat{\bm{R}%
}}_{x}+\epsilon_{0}\bm{I}_{N},\\
&\bm{R}_{x}\succeq\bm{0}.\end{array}
$$
According to Theorem 1, the above display is equivalent to
$$
\begin{array}[]{cl}\displaystyle\min_{\bm{W}}&\operatorname{Tr}\big{[}\bm{W}{%
\hat{\bm{R}}}_{x}\bm{W}^{\mathsf{H}}\big{]}+\epsilon_{0}\cdot\operatorname{Tr}%
\big{[}\bm{W}\bm{W}^{\mathsf{H}}\big{]}\\
\text{s.t.}&\bm{W}\bm{H}=\bm{I}_{M}.\end{array}
$$
The above formulation is the squared- $F$ -norm–regularized Capon beamformer [14, Eq. (10)] whose solution is
$$
\begin{array}[]{l}\bm{W}^{\star}_{\text{DR-Capon}}=[\bm{H}^{\mathsf{H}}(\hat{%
\bm{R}}_{x}+\epsilon_{0}\bm{I}_{N})^{-1}\bm{H}]^{-1}\cdot\\
\quad\quad\quad\quad\quad\quad\quad\quad\quad\quad\quad\quad\bm{H}^{\mathsf{H}%
}(\hat{\bm{R}}_{x}+\epsilon_{0}\bm{I}_{N})^{-1},\end{array} \tag{39}
$$
which is the diagonal-loading Capon beamformer. $\square$*
**Example 2 (Eigenvalue Thresholding)**
*Suppose that $\hat{\bm{R}}_{x}$ admits the eigenvalues of $\operatorname{diag}\{\lambda_{1},\lambda_{2},...,\lambda_{N}\}$ in descending order and the eigenvectors in $\bm{Q}$ (columns). Let $0≤\mu≤ 1$ be a shrinking coefficient. If we assume $\bm{R}_{x}\preceq\hat{\bm{R}}_{x,\text{thr}}$ where
$$
\begin{array}[]{l}\hat{\bm{R}}_{x,\text{thr}}\coloneqq\\
\quad\bm{Q}\left[\begin{array}[]{cccc}\lambda_{1}&&&\\
&\max\{\mu\lambda_{1},\lambda_{2}\}&&\\
&&\ddots&\\
&&&\max\{\mu\lambda_{1},\lambda_{N}\}\end{array}\right]\bm{Q}^{-1},\end{array} \tag{40}
$$
we have the distributionally robust beamformer
$$
\bm{W}^{\star}_{\text{DR-ET}}=\bm{R}^{\mathsf{H}}_{xs}\hat{\bm{R}}^{-1}_{x,%
\text{thr}}, \tag{41}
$$
which is known as the eigenvalue thresholding method [20], [14, Eq. (12)]. $\square$*
**Example 3 (Distributionally Robust Beamforming for UncertainRssubscript𝑅𝑠\bm{R}_{s}bold_italic_R start_POSTSUBSCRIPT italic_s end_POSTSUBSCRIPTandRvsubscript𝑅𝑣\bm{R}_{v}bold_italic_R start_POSTSUBSCRIPT italic_v end_POSTSUBSCRIPT)**
*Consider Problem (37). Since the objective of (37) is increasing in both $\bm{R}_{s}$ and $\bm{R}_{v}$ , This claim can be routinely proven in analogy to Theorem 1 and a real-space case in [30, Thm. 1]. if
$$
\hat{\bm{R}}_{s}-\epsilon_{1}\bm{I}_{M}\preceq\bm{R}_{s}\preceq\hat{\bm{R}}_{s%
}+\epsilon_{1}\bm{I}_{M},
$$
we have a distributionally robust beamformer
$$
\begin{array}[]{cl}\bm{W}^{\star}_{\text{DR}}&=(\hat{\bm{R}}_{s}+\epsilon_{1}%
\bm{I}_{M})\bm{H}^{\mathsf{H}}[\bm{H}(\hat{\bm{R}}_{s}+\epsilon_{1}\bm{I}_{M})%
\bm{H}^{\mathsf{H}}+\bm{R}_{v}]^{-1}\\
&=(\hat{\bm{R}}_{s}+\epsilon_{1}\bm{I}_{M})\bm{H}^{\mathsf{H}}[\bm{H}\hat{\bm{%
R}}_{s}\bm{H}^{\mathsf{H}}+\bm{R}_{v}+\epsilon_{1}\bm{H}\bm{H}^{\mathsf{H}}]^{%
-1};\end{array} \tag{42}
$$
if instead
$$
\hat{\bm{R}}_{s}-\epsilon_{1}\bm{H}^{\mathsf{H}}(\bm{H}\bm{H}^{\mathsf{H}})^{-%
2}\bm{H}\preceq\bm{R}_{s}\preceq\hat{\bm{R}}_{s}+\epsilon_{1}\bm{H}^{\mathsf{H%
}}(\bm{H}\bm{H}^{\mathsf{H}})^{-2}\bm{H}, \tag{43}
$$
we have
$$
\begin{array}[]{l}\bm{W}^{\star}_{\text{DR}}=[\hat{\bm{R}}_{s}\bm{H}^{\mathsf{%
H}}+\epsilon_{1}\bm{H}^{\mathsf{H}}(\bm{H}\bm{H}^{\mathsf{H}})^{-1}]\cdot\\
\quad\quad\quad\quad\quad[\bm{H}\hat{\bm{R}}_{s}\bm{H}^{\mathsf{H}}+\bm{R}_{v}%
+\epsilon_{1}\bm{I}_{N}]^{-1},\end{array} \tag{44}
$$
which is a modified diagonal-loading beamformer. On the other hand, if
$$
\hat{\bm{R}}_{v}-\epsilon_{2}\bm{I}_{N}\preceq\bm{R}_{v}\preceq\hat{\bm{R}}_{v%
}+\epsilon_{2}\bm{I}_{N},
$$
we have
$$
\bm{W}^{\star}_{\text{DR}}=\bm{R}_{s}\bm{H}^{\mathsf{H}}[\bm{H}\bm{R}_{s}\bm{H%
}^{\mathsf{H}}+\hat{\bm{R}}_{v}+\epsilon_{2}\bm{I}_{N}]^{-1}, \tag{45}
$$
which is also a diagonal-loading beamformer. $\square$*
Motivated by Corollary 1 and Examples 1 $\sim$ 3, as well as the trimmed uncertainty sets in Definition 5, we have the following important theorem, which justifies the popular ridge regression in machine learning.
**Theorem 2 (Ridge Regression and Tikhonov Regularization)**
*Consider a linear regression problem on $(\mathbf{x},\mathbf{s})$ , i.e.,
$$
\mathbf{s}=\bm{W}\mathbf{x}+\mathbf{e},
$$
where $\mathbf{e}$ denotes the error term and the distributionally robust estimator of $\bm{W}$ , i.e.,
$$
\min_{\bm{W}\in\mathbb{C}^{M\times N}}\max_{\mathbb{P}_{\mathbf{x},\mathbf{s}}%
\in\mathcal{U}_{\mathbf{x},\mathbf{s}}}\operatorname{Tr}\mathbb{E}_{\mathbf{x}%
,\mathbf{s}}[\bm{W}\mathbf{x}-\mathbf{s}][\bm{W}\mathbf{x}-\mathbf{s}]^{%
\mathsf{H}},
$$
which can be particularized to (19). Supposing that the second-order moment of $\mathbf{x}$ is uncertain and quantified as
$$
{\hat{\bm{R}}}_{x}-\epsilon_{0}\bm{I}_{N}\preceq\bm{R}_{x}\preceq{\hat{\bm{R}}%
}_{x}+\epsilon_{0}\bm{I}_{N},
$$
then the distributionally robust estimator of $\bm{W}$ becomes a ridge regression (i.e., squared- $F$ -norm regularized) method
$$
\displaystyle\min_{\bm{W}}\operatorname{Tr}\big{[}\bm{W}\hat{\bm{R}}_{x}\bm{W}%
^{\mathsf{H}}-\bm{W}\hat{\bm{R}}_{xs}-\hat{\bm{R}}^{\mathsf{H}}_{xs}\bm{W}^{%
\mathsf{H}}+\hat{\bm{R}}_{s}\big{]}+\epsilon_{0}\operatorname{Tr}\big{[}\bm{W}%
\bm{W}^{\mathsf{H}}\big{]}.
$$
The regularization term becomes $\operatorname{Tr}\big{[}\bm{W}\bm{F}\bm{W}^{\mathsf{H}}\big{]}$ , which is known as the Tikhonov regularizer, if
$$
{\hat{\bm{R}}}_{x}-\epsilon_{0}\bm{F}\preceq\bm{R}_{x}\preceq{\hat{\bm{R}}}_{x%
}+\epsilon_{0}\bm{F}
$$
for some $\bm{F}\succeq\bm{0}$ .*
* Proof:*
This is due to Lemma 1 and Theorem 1. Just note that $\operatorname{Tr}\big{[}\bm{W}(\hat{\bm{R}}_{x}+\epsilon_{0}\bm{F})\bm{W}^{%
\mathsf{H}}-\bm{W}\hat{\bm{R}}_{xs}-\hat{\bm{R}}^{\mathsf{H}}_{xs}\bm{W}^{%
\mathsf{H}}+\hat{\bm{R}}_{s}\big{]}=\\
\operatorname{Tr}\big{[}\bm{W}\hat{\bm{R}}_{x}\bm{W}^{\mathsf{H}}-\bm{W}\hat{%
\bm{R}}_{xs}-\hat{\bm{R}}^{\mathsf{H}}_{xs}\bm{W}^{\mathsf{H}}+\hat{\bm{R}}_{s%
}\big{]}+\epsilon_{0}\operatorname{Tr}\big{[}\bm{W}\bm{F}\bm{W}^{\mathsf{H}}%
\big{]}$ . This completes the proof. $\square$ ∎
Note that in Theorem 2, the second-order moment of $\mathbf{s}$ is not considered because it does not influence the optimal solution of $\bm{W}$ : i.e., the optimal solution of $\bm{W}$ does not depend on the value of $\bm{R}_{s}$ . Theorem 2 gives a new theoretical interpretation of the popular ridge regression in machine learning from the perspective of distributional robustness against second-moment uncertainties of the feature vector $\mathbf{x}$ ; another interpretation of ridge regression from the perspective of distributional robustness under martingale constraints is identified in [31, Ex. 3.3]. When the uncertainty is quantified by the Wasserstein distance, a similar result can be seen in [32, Prop. 3], [33, Prop. 2], which however is not a ridge regression formulation because in [32, Prop. 3] and [33, Prop. 2], the loss function is square-rooted and the norm regularizer is not squared; cf. also [27, Rem. 18 and 19]. The corollary below justifies the rationale of any norm-regularized method.
**Corollary 2**
*The following squared-norm-regularized beamforming formulation can combat the distributional uncertainty:
$$
\displaystyle\min_{\bm{W}}\operatorname{Tr}\big{[}\bm{W}\hat{\bm{R}}_{x}\bm{W}%
^{\mathsf{H}}-\bm{W}\hat{\bm{R}}_{xs}-\hat{\bm{R}}^{\mathsf{H}}_{xs}\bm{W}^{%
\mathsf{H}}+\hat{\bm{R}}_{s}\big{]}+\lambda\|\bm{W}\|^{2}, \tag{46}
$$
where $\|·\|$ denotes any matrix norm. This is because all norms on $\mathbb{C}^{M× N}$ are equivalent; hence, there exists some $\lambda≥ 0$ such that $\lambda\|\bm{W}\|^{2}≥\epsilon_{0}\|\bm{W}\|^{2}_{F}=\epsilon_{0}%
\operatorname{Tr}\big{[}\bm{W}\bm{W}^{\mathsf{H}}\big{]}$ . As a result, (46) can upper bound the ridge cost in Theorem 2. $\square$*
Motivated by Theorem 2, the following corollary is immediate, which gives another interpretation of ridge regression and Tikhonov regularization from the perspective of data augmentation through data perturbation (cf. noise injection in image [34] and speech [35] processing).
**Corollary 3 (Data Augmentation for Linear Regression)**
*Consider a linear regression problem on $(\mathbf{x},\mathbf{s})$ with data perturbation vectors $(\mathbf{\Delta}_{x},\mathbf{\Delta}_{s})$
$$
(\mathbf{s}+\mathbf{\Delta}_{s})=\bm{W}(\mathbf{x}+\mathbf{\Delta}_{x})+%
\mathbf{e},
$$
and the distributionally robust estimator of $\bm{W}$
$$
\begin{array}[]{l}\displaystyle\min_{\bm{W}\in\mathbb{C}^{M\times N}}\max_{%
\mathbb{P}_{\mathbf{\Delta}_{x},\mathbf{\Delta}_{s}}\in\mathcal{U}_{{\mathbf{%
\Delta}_{x},\mathbf{\Delta}_{s}}}}\operatorname{Tr}\mathbb{E}_{(\mathbf{x},%
\mathbf{s})\sim\hat{\mathbb{P}}_{\mathbf{x},\mathbf{s}}}\mathbb{E}_{\mathbf{%
\Delta}_{x},\mathbf{\Delta}_{s}}\Big{\{}\\
\quad[\bm{W}(\mathbf{x}+\mathbf{\Delta}_{x})-(\mathbf{s}+\mathbf{\Delta}_{s})]%
[\bm{W}(\mathbf{x}+\mathbf{\Delta}_{x})-(\mathbf{s}+\mathbf{\Delta}_{s})]^{%
\mathsf{H}}\Big{\}}.\end{array}
$$
Suppose that $\mathbf{\Delta}_{x}$ is uncorrelated with $\mathbf{x}$ , with $\mathbf{s}$ , and with $\mathbf{\Delta}_{s}$ ; in addition, $\mathbf{\Delta}_{s}$ is uncorrelated with $\mathbf{x}$ . If the second-order moment of $\mathbf{\Delta}_{x}$ is upper bounded as $\mathbb{E}\mathbf{\Delta}_{x}\mathbf{\Delta}^{\mathsf{H}}_{x}\preceq\epsilon_{%
0}\bm{I}_{N}$ , then the distributionally robust estimator of $\bm{W}$ becomes a ridge regression (i.e., squared- $F$ -norm regularized) method
$$
\displaystyle\min_{\bm{W}}\operatorname{Tr}\big{[}\bm{W}\hat{\bm{R}}_{x}\bm{W}%
^{\mathsf{H}}-\bm{W}\hat{\bm{R}}_{xs}-\hat{\bm{R}}^{\mathsf{H}}_{xs}\bm{W}^{%
\mathsf{H}}+\hat{\bm{R}}_{s}\big{]}+\epsilon_{0}\operatorname{Tr}\big{[}\bm{W}%
\bm{W}^{\mathsf{H}}\big{]}.
$$
The regularization term becomes $\operatorname{Tr}\big{[}\bm{W}\bm{F}\bm{W}^{\mathsf{H}}\big{]}$ , which is known as the Tikhonov regularizer, if $\mathbb{E}\mathbf{\Delta}_{x}\mathbf{\Delta}^{\mathsf{H}}_{x}\preceq\epsilon_{%
0}\bm{F}$ , for some $\bm{F}\succeq\bm{0}$ . $\square$*
The second-order moment of $\mathbf{\Delta}_{s}$ is not considered in Corollary 3 as it does not influence the optimal value of $\bm{W}$ .
IV-B Complex Uncertainty Sets
Below we remark on more general construction methods for the uncertainty set of $\bm{R}$ using the Wasserstein distance and the $F$ -norm, beyond the moment-based methods in Definitions 1 $\sim$ 6. However, note that such complicated approaches are computationally prohibitive in practice when $N$ or $M$ is large.
IV-B 1 Wasserstein Distributionally Robust Beamforming
We start with the Wasserstein distance:
$$
\begin{array}[]{cl}\displaystyle\max_{\bm{R}}&\operatorname{Tr}\big{[}-\bm{R}^%
{\mathsf{H}}_{xs}\bm{R}^{-1}_{x}\bm{R}_{xs}+\bm{R}_{s}\big{]}\\
\text{s.t.}&\operatorname{Tr}\left[{\bm{R}+\hat{\bm{R}}-2(\hat{\bm{R}}^{1/2}%
\bm{R}\hat{\bm{R}}^{1/2})^{1/2}}\right]\leq\epsilon^{2}_{0}\\
&\bm{R}\succeq\bm{0},~{}\bm{R}_{x}\succ\bm{0}.\end{array} \tag{47}
$$
The first constraint in the above display is a particularization of the Wasserstein distance between $\mathcal{CN}(\bm{0},\bm{R})$ and $\mathcal{CN}(\bm{0},\hat{\bm{R}})$ .
Problem (47) is a nonlinear positive semi-definite program (P-SDP). However, we can give it a linear reformulation.
**Proposition 1**
*Problem (47) can be equivalently reformulated into a linear P-SDP
$$
\begin{array}[]{cl}\displaystyle\max_{\bm{R},\bm{V},\bm{U}}&\operatorname{Tr}[%
\bm{R}_{s}-\bm{V}]\\
\text{s.t.}&\left[\begin{array}[]{cc}\bm{V}&\bm{R}^{\mathsf{H}}_{xs}\\
\bm{R}_{xs}&\bm{R}_{x}\end{array}\right]\succeq\bm{0}\\
&\operatorname{Tr}\left[{\bm{R}+\hat{\bm{R}}-2\bm{U}}\right]\leq\epsilon^{2}_{%
0}\\
&\left[\begin{array}[]{cc}\hat{\bm{R}}^{1/2}\bm{R}\hat{\bm{R}}^{1/2}&\bm{U}\\
\bm{U}&\bm{I}_{N+M}\end{array}\right]\succeq\bm{0}\\
&\bm{R}\succeq\bm{0},~{}\bm{R}_{x}\succ\bm{0},~{}\bm{V}\succeq\bm{0},~{}\bm{U}%
\succeq\bm{0}.\end{array} \tag{48}
$$*
* Proof:*
This is by applying the Schur complement. $\square$ ∎
Complex-valued linear P-SDP can be solved using, e.g., the YALMIP solver. See https://yalmip.github.io/inside/complexproblems/.
Suppose that $\bm{R}^{\star}$ solves (48). The corresponding Wasserstein distributionally robust beamformer is given as
$$
\bm{W}^{\star}_{\text{DR-Wasserstein}}=\bm{R}^{\star\mathsf{H}}_{xs}\bm{R}^{%
\star-1}_{x}. \tag{49}
$$
Next, we separately investigate the uncertainties in $\hat{\bm{R}}_{s}$ and $\hat{\bm{R}}_{v}$ . From (37), we have
$$
\begin{array}[]{cl}\displaystyle\max_{\bm{R}_{s},\bm{R}_{v}}&\operatorname{Tr}%
\big{[}\bm{R}_{s}-\bm{R}_{s}\bm{H}^{\mathsf{H}}(\bm{H}\bm{R}_{s}\bm{H}^{%
\mathsf{H}}+\bm{R}_{v})^{-1}\bm{H}\bm{R}_{s}\big{]}\\
\text{s.t.}&\operatorname{Tr}\left[{\bm{R}_{s}+\hat{\bm{R}}_{s}-2(\hat{\bm{R}}%
_{s}^{1/2}\bm{R}_{s}\hat{\bm{R}}_{s}^{1/2})^{1/2}}\right]\leq\epsilon^{2}_{1}%
\\
&\operatorname{Tr}\left[{\bm{R}_{v}+\hat{\bm{R}}_{v}-2(\hat{\bm{R}}_{v}^{1/2}%
\bm{R}_{v}\hat{\bm{R}}_{v}^{1/2})^{1/2}}\right]\leq\epsilon^{2}_{2}\\
&\bm{R}_{s}\succeq\bm{0},~{}\bm{R}_{v}\succeq\bm{0},\end{array} \tag{50}
$$
where we ignore the uncertainty of $\bm{H}$ for technical tractability. Problem (50) can be transformed into a linear P-SDP using a similar technique as in Proposition 1. One can just introduce an inequality $\bm{U}\succeq\bm{R}_{s}\bm{H}^{\mathsf{H}}(\bm{H}\bm{R}_{s}\bm{H}^{\mathsf{H}}%
+\bm{R})^{-1}\bm{H}\bm{R}_{s}$ and the objective function will become $\operatorname{Tr}\left[{\bm{R}_{s}-\bm{U}}\right]$ .
Suppose that $(\bm{R}_{s}^{\star},\bm{R}_{v}^{\star})$ solves (50). The corresponding Wasserstein distributionally robust beamformer is given as
$$
\bm{W}^{\star}_{\text{DR-Wasserstein-Individual}}=\bm{R}_{s}^{\star}\bm{H}^{%
\mathsf{H}}[\bm{H}\bm{R}_{s}^{\star}\bm{H}^{\mathsf{H}}+\bm{R}_{v}^{\star}]^{-%
1}. \tag{51}
$$
IV-B 2 F-Norm Distributionally Robust Beamforming
Under the $F$ -norm, we just need to replace the Wasserstein distance. To be specific, (47) becomes
$$
\begin{array}[]{cl}\displaystyle\max_{\bm{R}}&\operatorname{Tr}\big{[}-\bm{R}^%
{\mathsf{H}}_{xs}\bm{R}^{-1}_{x}\bm{R}_{xs}+\bm{R}_{s}\big{]}\\
\text{s.t.}&\operatorname{Tr}\left[{(\bm{R}-\hat{\bm{R}})^{\mathsf{H}}(\bm{R}-%
\hat{\bm{R}})}\right]\leq\epsilon^{2}_{0}\\
&\bm{R}\succeq\bm{0},~{}\bm{R}_{x}\succ\bm{0}.\end{array} \tag{52}
$$
The linear reformulation of the above display is given in the proposition below.
**Proposition 2**
*The nonlinear P-SDP (52) can be equivalently reformulated into a linear P-SDP
$$
\begin{array}[]{cl}\displaystyle\max_{\bm{R},\bm{V},\bm{U}}&\operatorname{Tr}[%
\bm{R}_{s}-\bm{V}]\\
\text{s.t.}&\left[\begin{array}[]{cc}\bm{V}&\bm{R}^{\mathsf{H}}_{xs}\\
\bm{R}_{xs}&\bm{R}_{x}\end{array}\right]\succeq\bm{0}\\
&\operatorname{Tr}\left[{\bm{U}}\right]\leq\epsilon^{2}_{0},\\
&\left[\begin{array}[]{cc}\bm{U}&(\bm{R}-\hat{\bm{R}})^{\mathsf{H}}\\
(\bm{R}-\hat{\bm{R}})&\bm{I}_{N+M}\end{array}\right]\succeq\bm{0},\\
&\bm{R}\succeq\bm{0},~{}\bm{R}_{x}\succ\bm{0},~{}\bm{V}\succeq\bm{0},~{}\bm{U}%
\succeq\bm{0}.\end{array} \tag{53}
$$*
* Proof:*
This is by applying the Schur complement. $\square$ ∎
IV-C Multi-Frame Case: Dynamic Channel Evolution
Each frame contains a pilot block used for beamformer design. Although the channel state information (CSI) may change from one frame to another, the CSI between the two consecutive frames is highly correlated. This correlation can benefit beamformer design across multiple frames. Suppose that $\{(\bm{s}_{1},\bm{x}_{1}),(\bm{s}_{2},\bm{x}_{2}),...,(\bm{s}_{L},\bm{x}_{L%
})\}$ is the training data in the current frame and $\{(\bm{s}^{\prime}_{1},\bm{x}^{\prime}_{1}),(\bm{s}^{\prime}_{2},\bm{x}^{%
\prime}_{2}),...,(\bm{s}^{\prime}_{L},\bm{x}^{\prime}_{L})\}$ is the history data in the immediately preceding frame. In such a case, the distributional difference between $\hat{\mathbb{P}}_{\mathbf{x},\mathbf{s}}$ and $\hat{\mathbb{P}}_{\mathbf{x}^{\prime},\mathbf{s}^{\prime}}$ is upper bounded, that is, $d(\hat{\mathbb{P}}_{\mathbf{x},\mathbf{s}},~{}\hat{\mathbb{P}}_{\mathbf{x}^{%
\prime},\mathbf{s}^{\prime}})≤\epsilon^{\prime}$ for some proper distance $d$ and a real number $\epsilon^{\prime}≥ 0$ where $\hat{\mathbb{P}}_{\mathbf{x},\mathbf{s}}\coloneqq\frac{1}{L}\sum^{L}_{i=1}%
\delta_{(\bm{x}_{i},\bm{s}_{i})}$ and $\hat{\mathbb{P}}_{\mathbf{x}^{\prime},\mathbf{s}^{\prime}}\coloneqq\frac{1}{L}%
\sum^{L}_{i=1}\delta_{(\bm{x}^{\prime}_{i},\bm{s}^{\prime}_{i})}$ .
Since a beamformer $\bm{W}=\mathcal{F}(\mathbb{P}_{\mathbf{x},\mathbf{s}})$ is a continuous functional $\mathcal{F}(·)$ of data distribution $\mathbb{P}_{\mathbf{x},\mathbf{s}}$ , cf. (10), we have $\|\bm{W}-\bm{W}^{\prime}\|_{F}=\|\mathcal{F}(\hat{\mathbb{P}}_{\mathbf{x},%
\mathbf{s}})-\mathcal{F}(\hat{\mathbb{P}}_{\mathbf{x}^{\prime},\mathbf{s}^{%
\prime}})\|_{F}≤ C· d(\hat{\mathbb{P}}_{\mathbf{x},\mathbf{s}},~{}\hat{%
\mathbb{P}}_{\mathbf{x}^{\prime},\mathbf{s}^{\prime}})≤\epsilon$ for some positive constant $C≥ 0$ and upper bound $\epsilon≥ 0$ where $\bm{W}^{\prime}$ is the beamformer associated with $\hat{\mathbb{P}}_{\mathbf{x}^{\prime},\mathbf{s}^{\prime}}$ in the previous frame. Therefore, the beamforming problem (11) becomes a constrained problem
$$
\begin{array}[]{cl}\displaystyle\min_{\bm{W}}&\operatorname{Tr}\big{[}\bm{W}%
\bm{R}_{x}\bm{W}^{\mathsf{H}}-\bm{W}\bm{R}_{xs}-\bm{R}^{\mathsf{H}}_{xs}\bm{W}%
^{\mathsf{H}}+\bm{R}_{s}\big{]}\\
\text{s.t.}&\operatorname{Tr}[\bm{W}-\bm{W}^{\prime}][\bm{W}-\bm{W}^{\prime}]^%
{\mathsf{H}}\leq\epsilon^{2}.\end{array}
$$
By the Lagrange duality theory, it is equivalent to
$$
\begin{array}[]{l}\displaystyle\min_{\bm{W}}\operatorname{Tr}\big{[}\bm{W}\bm{%
R}_{x}\bm{W}^{\mathsf{H}}-\bm{W}\bm{R}_{xs}-\bm{R}^{\mathsf{H}}_{xs}\bm{W}^{%
\mathsf{H}}+\bm{R}_{s}\big{]}+\\
\quad\quad\quad\quad\quad\quad\lambda\cdot\operatorname{Tr}[\bm{W}-\bm{W}^{%
\prime}][\bm{W}-\bm{W}^{\prime}]^{\mathsf{H}}\\
=\displaystyle\min_{\bm{W}}\operatorname{Tr}\big{[}\bm{W}(\bm{R}_{x}+\lambda%
\bm{I}_{N})\bm{W}^{\mathsf{H}}-\bm{W}(\bm{R}_{xs}+\lambda\bm{W}^{\prime\mathsf%
{H}})-\\
\quad\quad\quad\quad\quad\quad(\bm{R}_{xs}+\lambda\bm{W}^{\prime\mathsf{H}})^{%
\mathsf{H}}\bm{W}^{\mathsf{H}}+(\bm{R}_{s}+\lambda\bm{W}^{\prime}\bm{W}^{%
\prime\mathsf{H}})\big{]},\end{array} \tag{54}
$$
for some $\lambda≥ 0$ . As a result, we have the Wiener beamformer for the multi-frame case, where we can treat $\bm{W}^{\prime}$ as a prior knowledge of $\bm{W}$ .
**Claim 1 (Multi-Frame Beamforming)**
*The Wiener beamformer for the multi-frame case is given by
$$
\begin{array}[]{cl}\bm{W}^{\star}_{\text{Wiener-MF}}&=[\bm{R}_{xs}+\lambda\bm{%
W}^{\prime\mathsf{H}}]^{\mathsf{H}}[\bm{R}_{x}+\lambda\bm{I}_{N}]^{-1}\\
&=[\bm{R}_{s}\bm{H}^{\mathsf{H}}+\lambda\bm{W}^{\prime}][\bm{H}\bm{R}_{s}\bm{H%
}^{\mathsf{H}}+\bm{R}_{v}+\lambda\bm{I}_{N}]^{-1},\end{array} \tag{55}
$$
where $\lambda≥ 0$ is a tuning parameter to control the similarity between $\bm{W}$ and $\bm{W}^{\prime}$ . Specifically, if $\lambda$ is large, $\bm{W}$ must be close to $\bm{W}^{\prime}$ ; if $\lambda$ is small, $\bm{W}$ can be far away from $\bm{W}^{\prime}$ . $\square$*
With the result in Claim 1, (21) becomes
$$
\begin{array}[]{cl}\displaystyle\max_{\bm{R}}&\operatorname{Tr}\big{[}-(\bm{R}%
_{xs}+\lambda\bm{W}^{\prime\mathsf{H}})^{\mathsf{H}}\cdot(\bm{R}_{x}+\lambda%
\bm{I}_{N})^{-1}\cdot\\
&\quad\quad\quad(\bm{R}_{xs}+\lambda\bm{W}^{\prime\mathsf{H}})+(\bm{R}_{s}+%
\lambda\bm{W}^{\prime}\bm{W}^{\prime\mathsf{H}})\big{]}\\
\text{s.t.}&d_{0}(\bm{R},{\hat{\bm{R}}})\leq\epsilon_{0},\\
&\bm{R}\succeq\bm{0},\end{array} \tag{56}
$$
whose objective function is monotonically increasing in $\bm{R}$ .
The remaining distributional robustness modeling and analyses against the uncertainties in $\bm{R}$ are technically straightforward, and therefore, we omit them here. Upon using the diagonal-loading method on $\bm{R}$ , a distributionally robust beamformer for the multi-frame case is
$$
\begin{array}[]{l}\bm{W}^{\star}_{\text{DR-Wiener-MF}}=[\hat{\bm{R}}_{xs}+%
\lambda\bm{W}^{\prime\mathsf{H}}]^{\mathsf{H}}\cdot[\hat{\bm{R}}_{x}+\lambda%
\bm{I}_{N}+\epsilon_{0}\bm{I}_{N}]^{-1},\end{array}
$$
where $\epsilon_{0}$ is an uncertainty quantification parameter for $\bm{R}$ .
V Distributionally Robust Nonlinear Estimation
For the convenience of the technical treatment, we study the estimation problem in real spaces. Nonlinear estimators, which are suitable for non-Gaussian $\mathbb{P}_{\mathbf{x},\mathbf{s}}$ , are to be limited in reproducing kernel Hilbert spaces and feedforward multi-layer neural network function spaces.
V-A Reproducing Kernel Hilbert Spaces
V-A 1 General Framework and Concrete Examples
As a standard treatment in machine learning, we use the partial pilot data $\{\underline{\bm{x}}_{1},\underline{\bm{x}}_{2},...,\underline{\bm{x}}_{L}\}$ to construct the reproducing kernel Hilbert spaces, and use the whole pilot data $\{(\underline{\bm{x}}_{1},\underline{\bm{s}}_{1}),(\underline{\bm{x}}_{2},%
\underline{\bm{s}}_{2}),...,(\underline{\bm{x}}_{L},\underline{\bm{s}}_{L})\}$ to train the optimal estimator in an RKHS.
With the $\bm{W}$ -linear representation of $\bm{\phi}(·)$ in (2), i.e., $\bm{\phi}(·)=\bm{W}\bm{\varphi}(·)$ , the distributionally robust estimation problem (17) becomes
$$
\min_{\bm{W}\in\mathbb{R}^{2M\times L}}\max_{\mathbb{P}_{\underline{\mathbf{x}%
},\underline{\mathbf{s}}}\in\mathcal{U}_{\underline{\mathbf{x}},\underline{%
\mathbf{s}}}}\operatorname{Tr}\mathbb{E}_{\underline{\mathbf{x}},\underline{%
\mathbf{s}}}[\bm{W}\cdot\bm{\varphi}(\underline{\mathbf{x}})-\underline{%
\mathbf{s}}][\bm{W}\cdot\bm{\varphi}(\underline{\mathbf{x}})-\underline{%
\mathbf{s}}]^{\mathsf{T}}. \tag{57}
$$
The proposition below reformulates and solves (57).
**Proposition 3**
*Let $\bm{K}$ denote the kernel matrix associated with the kernel function $\ker(·,·)$ whose $(i,j)$ -entry is defined as
$$
\bm{K}_{i,j}\coloneqq\ker(\underline{\bm{x}}_{i},\underline{\bm{x}}_{j}),~{}~{%
}~{}\forall i,j\in[L].
$$
Let $\underline{\mathbf{z}}\coloneqq\bm{\varphi}(\underline{\mathbf{x}})$ . Then, the distributionally robust $\underline{\mathbf{x}}$ -nonlinear estimation problem (57) can be rewritten as a distributionally robust $\underline{\mathbf{z}}$ -linear beamforming problem as
$$
\begin{array}[]{cl}\displaystyle\min_{\bm{W}}\max_{\bm{R}_{\underline{z}},\bm{%
R}_{\underline{zs}},\bm{R}_{\underline{s}}}&\operatorname{Tr}\big{[}\bm{W}\bm{%
R}_{\underline{z}}\bm{W}^{\mathsf{T}}-\bm{W}\bm{R}_{\underline{zs}}-\bm{R}^{%
\mathsf{T}}_{\underline{zs}}\bm{W}^{\mathsf{T}}+\bm{R}_{\underline{s}}\big{]}%
\\
\text{s.t.}&d_{0}\left(\left[\begin{array}[]{cc}\bm{R}_{\underline{z}}&\bm{R}_%
{\underline{zs}}\\
\bm{R}^{\mathsf{T}}_{\underline{zs}}&\bm{R}_{\underline{s}}\end{array}\right],%
\left[\begin{array}[]{cc}\hat{\bm{R}}_{\underline{z}}&\hat{\bm{R}}_{\underline%
{zs}}\\
\hat{\bm{R}}^{\mathsf{T}}_{\underline{zs}}&\hat{\bm{R}}_{\underline{s}}\end{%
array}\right]\right)\leq\epsilon_{0},\\
&\left[\begin{array}[]{cc}\bm{R}_{\underline{z}}&\bm{R}_{\underline{zs}}\\
\bm{R}^{\mathsf{T}}_{\underline{zs}}&\bm{R}_{\underline{s}}\end{array}\right]%
\succeq\bm{0},\end{array} \tag{58}
$$
where $\hat{\bm{R}}_{\underline{z}}=\frac{1}{L}\bm{K}^{2}$ , $\hat{\bm{R}}_{\underline{zs}}=\frac{1}{L}\bm{K}\underline{\bm{S}}^{\mathsf{T}}$ , $\hat{\bm{R}}_{\underline{s}}=\frac{1}{L}\underline{\bm{S}}\underline{\bm{S}}^{%
\mathsf{T}}$ , and $\underline{\bm{S}}\coloneqq[\operatorname{Re}\bm{S};~{}\operatorname{Im}\bm{S}%
]=[\underline{\bm{s}}_{1},\underline{\bm{s}}_{2},...,\underline{\bm{s}}_{L}]$ . In addition, the strong min-max property holds for (58): i.e., the order of $\min$ and $\max$ can be exchanged provided that the first constraint is compact convex. As a result, given every pair of $(\bm{R}_{\underline{z}},\bm{R}_{\underline{zs}},\bm{R}_{\underline{s}})$ , the optimal Wiener beamformer is
$$
\bm{W}^{\star}_{\text{RKHS}}=\bm{R}^{\mathsf{T}}_{\underline{zs}}\cdot\bm{R}^{%
-1}_{\underline{z}} \tag{59}
$$
which transforms (58) to
$$
\begin{array}[]{cl}\displaystyle\max_{\bm{R}_{\underline{z}},\bm{R}_{%
\underline{zs}},\bm{R}_{\underline{s}}}&\operatorname{Tr}\big{[}-\bm{R}^{%
\mathsf{T}}_{\underline{zs}}\bm{R}^{-1}_{\underline{z}}\bm{R}_{\underline{zs}}%
+\bm{R}_{\underline{s}}\big{]}\\
\text{s.t.}&d_{0}\left(\left[\begin{array}[]{cc}\bm{R}_{\underline{z}}&\bm{R}_%
{\underline{zs}}\\
\bm{R}^{\mathsf{T}}_{\underline{zs}}&\bm{R}_{\underline{s}}\end{array}\right],%
~{}\left[\begin{array}[]{cc}\hat{\bm{R}}_{\underline{z}}&\hat{\bm{R}}_{%
\underline{zs}}\\
\hat{\bm{R}}^{\mathsf{T}}_{\underline{zs}}&\hat{\bm{R}}_{\underline{s}}\end{%
array}\right]\right)\leq\epsilon_{0},\\
&\left[\begin{array}[]{cc}\bm{R}_{\underline{z}}&\bm{R}_{\underline{zs}}\\
\bm{R}^{\mathsf{T}}_{\underline{zs}}&\bm{R}_{\underline{s}}\end{array}\right]%
\succeq\bm{0},~{}~{}~{}\bm{R}_{\underline{z}}\succ\bm{0}.\end{array} \tag{60}
$$*
* Proof:*
Treating $[\underline{\mathbf{z}};\underline{\mathbf{s}}]$ as, or approximating $[\underline{\mathbf{z}};\underline{\mathbf{s}}]$ using, a joint Gaussian random vector due to the linear estimation relation $\hat{\underline{\mathbf{s}}}=\bm{W}\underline{\mathbf{z}}$ in RKHS [cf. (57)], then the results in Lemma 1 apply. For details, see Appendix G. $\square$ ∎
In (58), $d_{0}$ defines a matrix similarity measure to quantify the uncertainty of the covariance matrix of $[\underline{\mathbf{z}};\underline{\mathbf{s}}]$ , and $\epsilon_{0}≥ 0$ quantifies the uncertainty level. Proposition 3 reveals the benefit of the kernel trick (2), that is, the possibility to represent a nonlinear estimation problem as a linear one.
The claim below summarizes the solution of (17) in the RKHS induced by the kernel function $\ker(·,·)$ .
**Claim 2**
*Suppose that $(\bm{R}^{\star}_{\underline{z}},\bm{R}^{\star}_{\underline{zs}},\bm{R}^{\star}%
_{\underline{s}})$ solves (60). Then the optimal estimator of (17) in the RKHS induced by $\ker(·,·)$ is given by
$$
\bm{\phi}^{\star}(\mathbf{x})=\bm{\Gamma}_{M}\cdot\bm{R}^{\star\mathsf{T}}_{%
\underline{zs}}\cdot\bm{R}^{\star-1}_{\underline{z}}\cdot\bm{\varphi}(%
\underline{\mathbf{x}}), \tag{61}
$$
where $\underline{\mathbf{x}}=[\operatorname{Re}\mathbf{x};~{}\operatorname{Im}%
\mathbf{x}]$ is the real-space representation of $\mathbf{x}$ , $\bm{\Gamma}_{M}\coloneqq[\bm{I}_{M},\bm{J}_{M}]$ is defined in Subsection I-B, and
$$
\bm{\varphi}(\underline{\mathbf{x}})\coloneqq\left[\begin{array}[]{c}\ker(%
\underline{\mathbf{x}},\underline{\bm{x}}_{1})\\
\ker(\underline{\mathbf{x}},\underline{\bm{x}}_{2})\\
\vdots\\
\ker(\underline{\mathbf{x}},\underline{\bm{x}}_{L})\end{array}\right].
$$
In addition, the corresponding worst-case estimation error covariance is
$$
\bm{\Gamma}_{M}\cdot\big{[}-\bm{R}^{\star\mathsf{T}}_{\underline{zs}}\bm{R}^{%
\star-1}_{\underline{z}}\bm{R}^{\star}_{\underline{zs}}+\bm{R}^{\star}_{%
\underline{s}}\big{]}\cdot\bm{\Gamma}_{M}^{\mathsf{H}}, \tag{62}
$$
which upper bounds the true estimation error covariance. $\square$*
Concrete examples of Claim 2 are given as follows.
**Example 4 (Kernelized Diagonal Loading)**
*By using the trimmed diagonal-loading uncertainty set for $\bm{R}_{\underline{z}}$ , i.e.,
$$
\hat{\bm{R}}_{\underline{z}}-\epsilon_{0}\bm{I}_{L}\preceq\bm{R}_{\underline{z%
}}\preceq\hat{\bm{R}}_{\underline{z}}+\epsilon_{0}\bm{I}_{L},
$$
we have the kernelized diagonal loading method
$$
\bm{\phi}^{\star}(\mathbf{x})=\bm{\Gamma}_{M}\cdot\frac{1}{L}\underline{\bm{S}%
}\bm{K}\cdot\left(\frac{1}{L}\bm{K}^{2}+\epsilon_{0}\bm{I}_{L}\right)^{-1}%
\cdot\bm{\varphi}(\underline{\mathbf{x}}), \tag{63}
$$
which is obtained at the upper bound of $\bm{R}_{\underline{z}}$ . Furthermore, in this case, the distributionally robust formulation (57) is equivalent to a squared- $F$ -norm-regularized formulation
$$
\begin{array}[]{l}\displaystyle\min_{\bm{W}}\operatorname{Tr}\mathbb{E}_{(%
\underline{\mathbf{x}},\underline{\mathbf{s}})\sim\hat{\mathbb{P}}_{\underline%
{\mathbf{x}},\underline{\mathbf{s}}}}[\bm{W}\cdot\bm{\varphi}(\underline{%
\mathbf{x}})-\underline{\mathbf{s}}][\bm{W}\cdot\bm{\varphi}(\underline{%
\mathbf{x}})-\underline{\mathbf{s}}]^{\mathsf{T}}+\\
\quad\quad\quad\quad\quad\quad\quad\quad\quad\quad\epsilon_{0}\cdot%
\operatorname{Tr}[\bm{W}\bm{W}^{\mathsf{T}}],\end{array} \tag{64}
$$
which can be proven by replacing $\bm{R}_{\underline{z}}$ in (58) with its upper bound. $\square$*
**Example 5 (Kernelized Eigenvalue Thresholding)**
*The kernelized eigenvalue thresholding method can be designed in analogy to Example 2. The two key steps are to obtain the eigenvalue decomposition of $\hat{\bm{R}}_{\underline{z}}=\bm{K}^{2}/L$ and then lift the eigenvalues; cf. (40). $\square$*
In addition, Example 4 motivates the following important theorem for statistical machine learning.
**Theorem 3 (Kernel Ridge Regression and Kernel Tikhonov Regularization)**
*Consider the nonlinear regression problem
$$
\mathbf{s}=\bm{\phi}(\mathbf{x})+\mathbf{e},
$$
and the distributionally robust estimator of $\bm{\phi}(\underline{\mathbf{x}})=\bm{W}·\bm{\varphi}(\underline{\mathbf{x%
}})$ in the RKHS induced by the kernel function $\ker(·,·)$ , i.e.,
$$
\min_{\bm{W}\in\mathbb{R}^{2M\times L}}\max_{\mathbb{P}_{\underline{\mathbf{x}%
},\underline{\mathbf{s}}}\in\mathcal{U}_{\underline{\mathbf{x}},\underline{%
\mathbf{s}}}}\operatorname{Tr}\mathbb{E}_{\underline{\mathbf{x}},\underline{%
\mathbf{s}}}[\bm{W}\cdot\bm{\varphi}(\underline{\mathbf{x}})-\underline{%
\mathbf{s}}][\bm{W}\cdot\bm{\varphi}(\underline{\mathbf{x}})-\underline{%
\mathbf{s}}]^{\mathsf{T}}.
$$
Supposing that only the second-order moment of $\underline{\mathbf{z}}\coloneqq\bm{\varphi}(\underline{\mathbf{x}})$ is uncertain and quantified as
$$
{\hat{\bm{R}}}_{\underline{z}}-\epsilon_{0}\bm{I}_{L}\preceq{\bm{R}}_{%
\underline{z}}\preceq{\hat{\bm{R}}}_{\underline{z}}+\epsilon_{0}\bm{I}_{L},
$$
then the distributionally robust estimator of $\bm{W}$ becomes a kernel ridge regression method (64). The regularization term in (64) becomes the Tikhonov regularizer $\operatorname{Tr}[\bm{W}\bm{F}\bm{W}^{\mathsf{T}}]$ if
$$
{\hat{\bm{R}}}_{\underline{z}}-\epsilon_{0}\bm{F}\preceq{\bm{R}}_{\underline{z%
}}\preceq{\hat{\bm{R}}}_{\underline{z}}+\epsilon_{0}\bm{F}
$$
for some $\bm{F}\succeq\bm{0}$ .*
* Proof:*
See Example 4; cf. Theorem 2. $\square$ ∎
Theorem 3 gives the kernel ridge regression an interpretation of distributional robustness. The usual choice of $\bm{F}$ in Theorem 3 is the $L$ -divided kernel matrix $\bm{K}/L$ ; see, e.g., [36, Eq. (4)], [24, Eqs. (15.110) and (15.113)]. As a result, from (63), we have
$$
\bm{\phi}^{\star}(\mathbf{x})=\bm{\Gamma}_{M}\cdot\underline{\bm{S}}\cdot\left%
(\bm{K}+\epsilon_{0}\bm{I}_{L}\right)^{-1}\cdot\bm{\varphi}(\underline{\mathbf%
{x}}), \tag{65}
$$
which is another type of kernel ridge regression (i.e., a new kernelized diagonal-loading method).
In analogy to Corollary 2, the following corollary motivated from (64) is immediate.
**Corollary 4**
*The following squared-norm-regularized method in RKHSs can combat the distributional uncertainty:
$$
\begin{array}[]{l}\displaystyle\min_{\bm{W}}\operatorname{Tr}\mathbb{E}_{(%
\underline{\mathbf{x}},\underline{\mathbf{s}})\sim\hat{\mathbb{P}}_{\underline%
{\mathbf{x}},\underline{\mathbf{s}}}}[\bm{W}\cdot\bm{\varphi}(\underline{%
\mathbf{x}})-\underline{\mathbf{s}}][\bm{W}\cdot\bm{\varphi}(\underline{%
\mathbf{x}})-\underline{\mathbf{s}}]^{\mathsf{T}}+\\
\quad\quad\quad\quad\quad\quad\quad\quad\quad\quad\lambda\cdot\|\bm{W}\|^{2},%
\end{array} \tag{66}
$$
for any matrix norm $\|·\|$ ; cf. Corollary 2. $\square$*
Moreover, in analogy to Corollary 3, the following corollary is immediate.
**Corollary 5 (Data Augmentation for Kernel Regression)**
*Consider the nonlinear regression problem in Theorem 3. Its data-perturbed counterpart can be constructed by taking into account the data perturbation vectors $(\mathbf{\Delta}_{\underline{s}},\mathbf{\Delta}_{\underline{z}})$ . Suppose that $\mathbf{\Delta}_{\underline{z}}$ is uncorrelated with $\underline{\mathbf{z}}$ , with $\underline{\mathbf{s}}$ , and with $\mathbf{\Delta}_{\underline{s}}$ ; in addition, $\mathbf{\Delta}_{\underline{s}}$ is uncorrelated with $\underline{\mathbf{z}}$ . If the second-order moment of $\mathbf{\Delta}_{\underline{z}}$ is upper bounded by $\epsilon_{0}\bm{I}_{L}$ , then the distributionally robust estimator of $\bm{W}$ becomes a kernel ridge regression (i.e., squared- $F$ -norm regularized) method (64). The regularization term becomes $\operatorname{Tr}\big{[}\bm{W}\bm{F}\bm{W}^{\mathsf{H}}\big{]}$ , which is known as the Tikhonov regularizer, if the second-order moment of $\mathbf{\Delta}_{\underline{z}}$ is upper bounded by $\epsilon_{0}\bm{F}$ for some $\bm{F}\succeq\bm{0}$ . $\square$*
General uncertainty sets using the Wasserstein distance or the $F$ -norm, beyond the diagonal $\epsilon_{0}$ -perturbation (cf. Example 4), can be straightforwardly employed and the distributional robustness modeling and analyses remain routine; cf. Subsection IV-B. Hence, we omit them here. However, such complicated approaches are computationally prohibitive in practice when $L$ or $M$ is large.
V-A 2 Multi-Frame Case: Dynamic Channel Evolution
As in (54), the multi-frame formulation in RKHSs is
$$
\begin{array}[]{l}\displaystyle\min_{\bm{W}\in\mathbb{R}^{2M\times L}}%
\operatorname{Tr}\mathbb{E}_{\underline{\mathbf{x}},\underline{\mathbf{s}}}[%
\bm{W}\cdot\bm{\varphi}(\underline{\mathbf{x}})-\underline{\mathbf{s}}][\bm{W}%
\cdot\bm{\varphi}(\underline{\mathbf{x}})-\underline{\mathbf{s}}]^{\mathsf{T}}%
+\\
\quad\quad\quad\quad\quad\quad\quad\quad\lambda\cdot\operatorname{Tr}[\bm{W}-%
\bm{W}^{\prime}][\bm{W}-\bm{W}^{\prime}]^{\mathsf{T}},\end{array} \tag{67}
$$
where $\bm{W}^{\prime}$ denotes the beamformer in the immediately preceding frame and serves as a prior knowledge of $\bm{W}$ .
**Claim 3 (Multi-Frame Estimation in RHKS)**
*The solution to (67) is given by (cf. (59))
$$
\begin{array}[]{cl}\bm{W}^{\star}_{\text{RKHS-MF}}&=[\bm{R}_{\underline{zs}}+%
\lambda\bm{W}^{\prime\mathsf{T}}]^{\mathsf{T}}[\bm{R}_{\underline{z}}+\lambda%
\bm{I}_{L}]^{-1}\\
&=\left(\frac{1}{L}\underline{\bm{S}}\bm{K}+\lambda\bm{W}^{\prime}\right)\cdot%
\left(\frac{1}{L}\bm{K}^{2}+\lambda\bm{I}_{L}\right)^{-1},\end{array} \tag{68}
$$
where $\lambda≥ 0$ is a tuning parameter to control the similarity between $\bm{W}$ and $\bm{W}^{\prime}$ ; cf. Claim 1. $\square$*
The remaining distributional robustness modeling and analyses on (67) against the uncertainties in $\hat{\bm{R}}_{\underline{z}}$ , $\hat{\bm{R}}_{\underline{xz}}$ , and $\hat{\bm{R}}_{\underline{s}}$ are technically straightforward; cf. Subsection IV-C. Therefore, we omit them here.
V-B Neural Networks
With the $\bm{W}$ -parameterization $\bm{\phi}_{\bm{W}_{[R]}}(\underline{\mathbf{x}})$ of $\bm{\phi}(\underline{\mathbf{x}})$ in feedforward multi-layer neural networks, i.e., (4), the distributionally robust estimation problem (17) becomes
$$
\min_{\bm{W}_{[R]}}~{}~{}\max_{\mathbb{P}_{\underline{\mathbf{x}},\underline{%
\mathbf{s}}}\in\mathcal{U}_{\underline{\mathbf{x}},\underline{\mathbf{s}}}}%
\operatorname{Tr}\mathbb{E}_{\underline{\mathbf{x}},\underline{\mathbf{s}}}[%
\bm{\phi}_{\bm{W}_{[R]}}(\underline{\mathbf{x}})-\underline{\mathbf{s}}][\bm{%
\phi}_{\bm{W}_{[R]}}(\underline{\mathbf{x}})-\underline{\mathbf{s}}]^{\mathsf{%
T}}, \tag{69}
$$
where $\bm{W}_{[R]}\coloneqq\{\bm{W}_{1},\bm{W}_{2},...,\bm{W}_{R}\}$ and $\bm{\phi}_{\bm{W}_{[R]}}(\underline{\mathbf{x}})$ is defined in (4). Problem (69) is highly nonlinear in both argument $\underline{\mathbf{x}}$ and parameter $\bm{W}_{[R]}$ , which is different from the case in reproducing kernel Hilbert spaces where the $\bm{W}$ -linearization features. Hence, problem (69) is too complicated to solve to global optimality. According to [27, Cor. 33], under several technical conditions (plus the boundedness of the feasible region of $\bm{W}_{[R]}$ ), (69) is upper bounded by a spectral-norm-regularized empirical risk minimization problem
$$
\begin{array}[]{l}\displaystyle\min_{\bm{W}_{[R]}}\displaystyle\frac{1}{L}\sum%
^{L}_{i=1}\operatorname{Tr}[\bm{\phi}_{\bm{W}_{[R]}}(\underline{\bm{x}}_{i})-%
\underline{\bm{s}}_{i}][\bm{\phi}_{\bm{W}_{[R]}}(\underline{\bm{x}}_{i})-%
\underline{\bm{s}}_{i}]^{\mathsf{T}}+\\
\quad\quad\quad\quad\quad\quad\displaystyle\lambda^{\prime}\cdot\sum^{R}_{r=1}%
\|\bm{W}_{r}\|_{2},\end{array} \tag{70}
$$
for some regularization coefficient $\lambda^{\prime}≥ 0$ , where $\|·\|_{2}$ denotes the spectral norm of a matrix (i.e., the induced $2$ -norm). Eq. (70) rigorously justifies the popular norm regularization method in training neural networks: By diminishing the upper bound (70) of (69), the true error in (69) can be controlled from above. The regularized ERM problem (70) is reminiscent of the ridge regression and the kernel ridge regression methods in Theorems 2 and 3 for distributional robustness in linear regression and RKHS linear regression, respectively. Supposing that $\bm{W}^{\star}_{[R]}$ is an (approximated, or sub-optimal) solution Neural networks are hard to be globally optimized. of (70), then the distributionally robust optimal estimator of the transmitted signal $\mathbf{s}$ can be obtained as
$$
\hat{\mathbf{s}}=\bm{\Gamma}_{M}\cdot\bm{\phi}_{\bm{W}^{\star}_{[R]}}(%
\underline{\mathbf{x}}).
$$
Therefore, in training a neural network for wireless signal estimation, it is recommended to apply the norm regularization methods. Since norms on real spaces are equivalent, (70) can be further upper bounded by
$$
\begin{array}[]{l}\displaystyle\min_{\bm{W}_{[R]}}\displaystyle\frac{1}{L}\sum%
^{L}_{i=1}\operatorname{Tr}[\bm{\phi}_{\bm{W}_{[R]}}(\underline{\bm{x}}_{i})-%
\underline{\bm{s}}_{i}][\bm{\phi}_{\bm{W}_{[R]}}(\underline{\bm{x}}_{i})-%
\underline{\bm{s}}_{i}]^{\mathsf{T}}+\\
\quad\quad\quad\quad\quad\quad\displaystyle\lambda\cdot\sum^{R}_{r=1}\|\bm{W}_%
{r}\|,\end{array} \tag{71}
$$
for any matrix norm $\|·\|$ and some $\lambda≥ 0$ ; $\lambda$ depends on $\lambda^{\prime}$ and $\|·\|$ . As a result, to achieve distributional robustness in training a neural network, any-norm-regularized learning method in (71) can be considered.
VI Experiments
We consider a point-to-point multiple-input-multiple-output (MIMO) wireless communication problem where the transmitter is located at $[0,0]$ and the receiver is at $[500\text{m},450\text{m}]$ . We randomly sample $25$ points according to the uniform distribution on the square of $[0,500\text{m}]×[0,500\text{m}]$ to denote the scatters’ positions; i.e., there exist $26$ radio paths. All the source data and codes are available online at GitHub with thorough implementation comments: https://github.com/Spratm-Asleaf/DRRC. In this section, we only present major experimental setups and results; readers can use the shared source codes to explore (or verify) minor ones.
The following eleven methods are implemented in the experiments: 1) Wiener: Wiener beamformer (12), upper expression; 2) Wiener-DL: Wiener beamformer with diagonal loading (30), upper expression; 3) Wiener-DR: Distributionally robust Wiener beamformer (49) and (53); 4) Wiener-CE: Channel-estimation-based Wiener beamformer (12), lower expression; 5) Wiener-CE-DL: Channel-estimation-based Wiener beamformer with diagonal loading (30), lower expression; 6) Wiener-CE-DR: Distributionally robust channel-estimation-based Wiener beamformer (42) and (31); 7) Capon: Capon beamformer (39) for $\epsilon_{0}=0$ ; 8) Capon-DL: Capon beamformer with diagonal loading (39); 9) ZF: Zero-forcing beamformer where $\bm{W}_{\text{ZF}}\coloneqq(\hat{\bm{H}}^{\mathsf{H}}\hat{\bm{H}})^{-1}\hat{%
\bm{H}}^{\mathsf{H}}$ and $\hat{\bm{H}}$ denotes the estimated channel matrix; 10) Kernel: Kernel receiver (61) with $\epsilon_{0}=0$ in (60); and 11) Kernel-DL: Kernel receiver with diagonal loading (65). Note that the diagonal-loading-based methods are particular cases of distributionally robust combiners; see, e.g., Corollary 1 and Example 4. The deep-learning-based (DL-based) methods in Subsection V-B are not implemented in this section because they have been deeply studied in our previous publications, e.g., [10, 12]; we only comment on the advantages and disadvantages of DL-based methods compared with the listed eleven methods in Section VII (Conclusions).
When covariance matrix $\bm{R}_{s}$ of transmitted signal $\mathbf{s}$ is unknown for the receiver (e.g., in ISAC systems, $\bm{R}_{s}$ needs to vary from one frame to another for sensing), $\bm{R}_{s}$ is estimated by the sample covariance matrix $\hat{\bm{R}}_{s}=\bm{S}\bm{S}^{\mathsf{H}}/L$ . The channel matrix $\bm{H}$ is estimated using the minimum mean-squared error method, i.e., $\hat{\bm{H}}=\bm{X}\bm{S}^{\mathsf{H}}(\bm{S}\bm{S}^{\mathsf{H}})^{-1}$ . Covariance matrix $\bm{R}_{v}$ of channel noise $\mathbf{v}$ is estimated using the least-square method, i.e., $\hat{\bm{R}}_{v}=(\bm{X}-\hat{\bm{H}}\bm{S})(\bm{X}-\hat{\bm{H}}\bm{S})^{%
\mathsf{H}}/L$ . The matrices $\hat{\bm{R}}_{s}$ , $\hat{\bm{H}}$ , and $\hat{\bm{R}}_{v}$ are therefore uncertain compared to their true (but unknown; possibly time-varying) values $\bm{R}_{s}$ , $\bm{H}$ , and $\bm{R}_{v}$ , respectively. The matrices $\hat{\bm{R}}_{s}$ , $\hat{\bm{H}}$ , and $\hat{\bm{R}}_{v}$ are used in beamformers such as the channel-estimation-based Wiener beamformer (30), the Capon beamformer, and the zero-forcing beamformer.
The combiners are determined on the training data set (i.e., pilot data). The performance evaluation method of combiners is mean-squared estimation error (MSE) on the test data set (i.e., non-pilot communication data): to be specific, $\|\bm{S}_{\text{test}}-\hat{\bm{S}}_{\text{test}}\|^{2}_{F}/(M× L_{\text{%
test}})$ where $\bm{S}_{\text{test}}∈\mathbb{C}^{M× L_{\text{test}}}$ is the test data block, $\hat{\bm{S}}_{\text{test}}$ is its estimate, and $L_{\text{test}}$ is the length of non-pilot test data units. As data-driven machine learning methods, all parameters (e.g., uncertainty quantification coefficients $\epsilon$ ’s) of combiners can be tuned using the popular cross-validation (e.g., one-shot cross-validation) method. The parameters can also be empirically tuned to save training times because cross-validation imposes a significant computational burden. This article mainly uses the empirical tuning method (i.e., trial-and-error) to tune each combiner to achieve its best average performance. For each test case, the MSE performances are averaged on $250$ Monte–Carlo episodes.
We consider an experimental scenario where impulse channel noises exist; i.e., the channel is non-Gaussian so linear beamformers are no longer sufficient. (Complementary experimental setups and results can be seen in online supplementary materials.) The detailed setups are as follows. The transmitter has four antennas (i.e., $M=4$ ) with unit transmit power; without loss of generality, each antenna is assumed to emit continuous-valued complex Gaussian signals. The receiver has eight antennas (i.e., $N=8$ ). The SNR is $-10$ dB, which is a challenging situation. The channel has impulse noises: i.e., in $L$ received signals (i.e., $[\mathbf{x}_{1},\mathbf{x}_{2},...,\mathbf{x}_{L}]$ ) that are contaminated by usual complex Gaussian channel noises, $10\%$ of them are also contaminated by uniform noises with the maximum amplitude of $1.5$ , which is a relatively large value compared to the amplitude of the usual Gaussian channel noises. We assume that a communication frame contains $500$ non-pilot data units; i.e., $L_{\text{test}}=500$ . The experimental results are shown in Tables I $\sim$ VI, from which the following main points can be outlined.
1. A larger number of pilot data benefits the estimation performances of wireless signals.
1. The diagonal loading operation can significantly improve the estimation performances especially when the pilot data size is relatively small.
1. Since the signal model under impulse channel noises is no longer linear Gaussian, the optimal combiner in the MSE sense must be nonlinear. Therefore, the Kernel and the Kernel-DL methods have the potential to outperform other linear beamformers, i.e., to suppress outliers. However, in practice, the non-robust Kernel method may undergo numerical instability in calculating the inverse of the kernel matrix $\bm{K}$ . Therefore, its actual MSEs are not necessarily smaller than those of linear beamformers. Nevertheless, the robust Kernel-DL method consistently outperforms all other beamformers.
1. Distributionally robust combiners (including diagonal-loading ones) can combat the adverse effect introduced by the limited pilot size and several types of uncertainties in the signal model (e.g., outliers). To be specific, for example, all diagonal-loading combiners can outperform their original non-diagonal-loading counterparts; cf. the Wiener and the Wiener-DL methods, the Wiener-CE and the Wiener-CE-DL methods, the Capon and the Capon-DL methods, and the Kernel and the Kernel-DL methods. In addition, the Wiener-DR beamformer (53) using the $F$ -norm uncertainty set has the potential to outperform the Wiener-DL beamformer (30) that employs the simple uncertainty set (26).
1. Although the Wiener-DR beamformer has the potential to work better than the Wiener-DL beamformer, it has a significant computational burden, which may not be suitable for timely use in practice especially when the computing resources are limited. Hence, the Wiener-DL beamformer is practically promising because it can provide an excellent balance between the computational burden and the actual performance.
Remarks on Parameter Tuning: From experiments, we find that the uncertainty quantification coefficients $\epsilon$ ’s (e.g., in diagonal loading) can be neither too large nor too small. When $\epsilon$ ’s are too large, the combiners become overly conservative, while when $\epsilon$ ’s are too small, the combiners cannot offer sufficient robustness against data scarcity and model uncertainties. In both cases of inappropriate $\epsilon$ ’s, the performances of combiners degrade significantly. Therefore, $\epsilon$ ’s must be carefully tuned in practice, and a rigorous method to tune $\epsilon$ ’s can be the cross-validation method on the training data set (i.e., the pilot data set). If practitioners just pursue satisfaction rather than optimality, the empirical tuning method is recommended to save training times.
TABLE I: Experimental Results (Pilot Size = 10)
| Combiner Wnr Wnr-DR | MSE 3.30 1.97 | Time 1.49e-04 3.16e+00 | Combiner Wnr-DL Wnr-CE | MSE 2.11 3.30 | Time 9.81e-06 4.59e-05 |
| --- | --- | --- | --- | --- | --- |
| Wnr-CE-DL | 2.50 | 2.17e-05 | Wnr-CE-DR | 3.31 | 4.63e-05 |
| Capon | 5.44 | 4.42e-05 | Capon-DL | 4.52 | 2.50e-05 |
| ZF | 2.12 | 2.54e-05 | Kernel | 1.07 | 1.60e-04 |
| Kernel-DL | 0.80 | 5.59e-05 | | | |
TABLE II: Experimental Results (Pilot Size = 15)
| Wnr Wnr-DR Wnr-CE-DL | 1.38 1.07 1.30 | 1.65e-04 3.21e+00 2.12e-05 | Wnr-DL Wnr-CE Wnr-CE-DR | 1.23 1.38 1.39 | 1.10e-05 4.44e-05 4.28e-05 |
| --- | --- | --- | --- | --- | --- |
| Capon | 4.48 | 4.31e-05 | Capon-DL | 4.34 | 2.42e-05 |
| ZF | 2.97 | 2.44e-05 | Kernel | 1.12 | 1.94e-04 |
| Kernel-DL | 0.70 | 9.23e-05 | | | |
TABLE III: Experimental Results (Pilot Size = 20)
| Wnr Wnr-DR Wnr-CE-DL | 1.12 0.93 1.08 | 1.86e-04 7.19e+00 3.14e-05 | Wnr-DL Wnr-CE Wnr-CE-DR | 1.05 1.12 1.13 | 1.87e-05 5.78e-05 6.01e-05 |
| --- | --- | --- | --- | --- | --- |
| Capon | 5.01 | 5.93e-05 | Capon-DL | 4.94 | 3.81e-05 |
| ZF | 3.82 | 3.56e-05 | Kernel | 1.20 | 4.48e-04 |
| Kernel-DL | 0.66 | 3.11e-04 | | | |
TABLE IV: Experimental Results (Pilot Size = 25)
| Wnr Wnr-DR Wnr-CE-DL | 0.92 0.80 0.90 | 1.41e-04 4.22e+00 2.44e-05 | Wnr-DL Wnr-CE Wnr-CE-DR | 0.88 0.92 0.92 | 1.11e-05 5.02e-05 4.78e-05 |
| --- | --- | --- | --- | --- | --- |
| Capon | 4.94 | 4.93e-05 | Capon-DL | 4.89 | 2.85e-05 |
| ZF | 4.06 | 2.72e-05 | Kernel | 1.14 | 4.26e-04 |
| Kernel-DL | 0.60 | 2.95e-04 | | | |
TABLE V: Experimental Results (Pilot Size = 50)
| Wnr Wnr-DR Wnr-CE-DL | 0.69 0.65 0.68 | 1.75e-04 6.10e+00 3.03e-05 | Wnr-DL Wnr-CE Wnr-CE-DR | 0.68 0.69 0.70 | 1.85e-05 5.81e-05 5.90e-05 |
| --- | --- | --- | --- | --- | --- |
| Capon | 6.95 | 5.97e-05 | Capon-DL | 6.93 | 3.75e-05 |
| ZF | 6.36 | 3.38e-05 | Kernel | 0.92 | 1.81e-03 |
| Kernel-DL | 0.53 | 1.67e-03 | | | |
TABLE VI: Experimental Results (Pilot Size = 100)
| Wnr Wnr-DR Wnr-CE-DL | 0.57 0.55 0.57 | 3.41e-04 4.96e+00 2.93e-05 | Wnr-DL Wnr-CE Wnr-CE-DR | 0.57 0.57 0.58 | 3.64e-05 6.35e-05 6.07e-05 |
| --- | --- | --- | --- | --- | --- |
| Capon | 9.89 | 6.88e-05 | Capon-DL | 9.88 | 3.99e-05 |
| ZF | 9.45 | 3.27e-05 | Kernel | 0.72 | 5.93e-03 |
| Kernel-DL | 0.49 | 5.83e-03 | | | |
VII Conclusions
This article introduces a unified mathematical framework for receive combining of wireless signals from the perspective of data-driven machine learning, which reveals that channel estimation is not a necessary operation. To combat the limited pilot size and several types of uncertainties in the signal model, the distributionally robust (DR) receive combining framework is then suggested. We prove that the diagonal-loading (DL) methods are distributionally robust against the scarcity of pilot data and the uncertainties in the signal model. In addition, we generalize the diagonal-loading methods to achieve better estimation performance (e.g., the DR Wiener beamformer using $F$ -norm for uncertainty quantification), at the cost of significantly higher computational burdens. Experiments suggest that nonlinear combiners such as the Kernel and the Kernel-DL methods have the potential when the pilot size is small and/or the signal model is not linear Gaussian. Compared with the Kernel and the Kernel-DL combiners, neural-network-based solutions [10, 12] have a stronger expressive capability of nonlinearities, which however are unscalable in the numbers of transmit and receive antennas, and significantly more time-consuming in training and more troublesome in tuning hyper-parameters (e.g., the number of layers and the number of neurons in each layer) than the studied eleven combiners.
Appendix A Structured Representation of Nonlinear Functions
In Section II, we have reviewed two popular frameworks for representing (nonlinear) functions: reproducing kernel Hilbert spaces (RKHS) and neural network function spaces (NNFS). Typical kernel functions $\ker(·,·)$ to define RKHSs include Gaussian kernel, Matern kernel, Linear kernel, Laplacian kernel, and Polynomial kernel. Mathematical details of these kernel functions can be found in [24, Subsec. 14.2], [27, Ex. 1]. Typical activation functions $\sigma(·)$ to define NNFSs include Hyperbolic tangent (i.e, tanh) function, Softmax function, Sigmoid function, Rectified linear unit (ReLU) function, and Exponential linear unit (ELU) function. Mathematical details of these activation functions can be found in [27, Ex. 2].
Appendix B Details on Real-Space Signal Representation
Let $\bm{R}_{x}\coloneqq\mathbb{E}\mathbf{x}\mathbf{x}^{\mathsf{H}}$ , $\bm{C}_{x}\coloneqq\mathbb{E}\mathbf{x}\mathbf{x}^{\mathsf{T}}$ , $\bm{C}_{s}\coloneqq\mathbb{E}\mathbf{s}\mathbf{s}^{\mathsf{T}}$ , and $\bm{C}_{v}\coloneqq\mathbb{E}\mathbf{v}\mathbf{v}^{\mathsf{T}}=\bm{0}$ . We have
$$
\begin{array}[]{cl}\bm{R}_{\underline{x}}\coloneqq\mathbb{E}{\underline{%
\mathbf{x}}\underline{\mathbf{x}}^{\mathsf{T}}}=\displaystyle\frac{1}{2}\left[%
\begin{array}[]{cc}\operatorname{Re}(\bm{R}_{x}+\bm{C}_{x})&\operatorname{Im}(%
-\bm{R}_{x}+\bm{C}_{x})\\
\operatorname{Im}(\bm{R}_{x}+\bm{C}_{x})&\operatorname{Re}(\bm{R}_{x}-\bm{C}_{%
x})\end{array}\right].\end{array}
$$
$$
\begin{array}[]{cl}\bm{R}_{\underline{s}}\coloneqq\mathbb{E}{\underline{%
\mathbf{s}}\underline{\mathbf{s}}^{\mathsf{T}}}&=\displaystyle\frac{1}{2}\left%
[\begin{array}[]{cc}\operatorname{Re}(\bm{R}_{s}+\bm{C}_{s})&\operatorname{Im}%
(-\bm{R}_{s}+\bm{C}_{s})\\
\operatorname{Im}(\bm{R}_{s}+\bm{C}_{s})&\operatorname{Re}(\bm{R}_{s}-\bm{C}_{%
s})\end{array}\right],\end{array}
$$
and
$$
\begin{array}[]{cl}\bm{R}_{\underline{v}}\coloneqq\mathbb{E}{\underline{%
\mathbf{v}}\underline{\mathbf{v}}^{\mathsf{T}}}&=\displaystyle\frac{1}{2}\left%
[\begin{array}[]{cc}\operatorname{Re}\bm{R}_{v}&\operatorname{Im}-\bm{R}_{v}\\
\operatorname{Im}\bm{R}_{v}&\operatorname{Re}\bm{R}_{v}\end{array}\right].\end%
{array}
$$
Note that the following identities hold: $\bm{R}_{x}=\bm{H}\bm{R}_{s}\bm{H}^{\mathsf{H}}+\bm{R}_{v}$ , $\bm{C}_{x}=\bm{H}\bm{C}_{s}\bm{H}^{\mathsf{T}}$ , $\bm{R}_{\underline{x}}=\underline{\underline{\bm{H}}}·\bm{R}_{\underline{s%
}}·\underline{\underline{\bm{H}}}^{\mathsf{T}}+\bm{R}_{\underline{v}}$ , and $\bm{R}_{\underline{xs}}=\underline{\underline{\bm{H}}}·\bm{R}_{\underline{%
s}}$ .
Appendix C Extensive Reading on Distributional Uncertainty
C-A Generalization Error and Distributional Robustness
We use (7) and (15) as examples to illustrate the concepts. Supposing that $\bm{\phi}^{\star}$ solves the true problem (7) and $\bm{\phi}^{\star}_{\text{ERM}}$ solves the surrogate problem (15), we have
$$
\begin{array}[]{l}\displaystyle\min_{\bm{\phi}}\operatorname{Tr}\mathbb{E}_{(%
\mathbf{x},\mathbf{s})\sim\mathbb{P}_{\mathbf{x},\mathbf{s}}}[\bm{\phi}(%
\mathbf{x})-\mathbf{s}][\bm{\phi}(\mathbf{x})-\mathbf{s}]^{\mathsf{H}}\\
\quad\quad=\operatorname{Tr}\mathbb{E}_{(\mathbf{x},\mathbf{s})\sim\mathbb{P}_%
{\mathbf{x},\mathbf{s}}}[\bm{\phi}^{\star}(\mathbf{x})-\mathbf{s}][\bm{\phi}^{%
\star}(\mathbf{x})-\mathbf{s}]^{\mathsf{H}}\\
\quad\quad\leq\operatorname{Tr}\mathbb{E}_{(\mathbf{x},\mathbf{s})\sim\mathbb{%
P}_{\mathbf{x},\mathbf{s}}}[\bm{\phi}^{\star}_{\text{ERM}}(\mathbf{x})-\mathbf%
{s}][\bm{\phi}^{\star}_{\text{ERM}}(\mathbf{x})-\mathbf{s}]^{\mathsf{H}}.\end{array} \tag{72}
$$
To clarify further, the testing error in the last line (evaluated at the true distribution $\mathbb{P}_{\mathbf{x},\mathbf{s}}$ ) of the learned estimator $\bm{\phi}^{\star}_{\text{ERM}}$ may be (much) larger than the optimal error in the first two lines, although $\bm{\phi}^{\star}_{\text{ERM}}$ has the smallest training error (evaluated at the nominal distribution $\hat{\mathbb{P}}_{\mathbf{x},\mathbf{s}}$ ), i.e.,
$$
\begin{array}[]{l}\displaystyle\min_{\bm{\phi}}\operatorname{Tr}\mathbb{E}_{(%
\mathbf{x},\mathbf{s})\sim\hat{\mathbb{P}}_{\mathbf{x},\mathbf{s}}}[\bm{\phi}(%
\mathbf{x})-\mathbf{s}][\bm{\phi}(\mathbf{x})-\mathbf{s}]^{\mathsf{H}}\\
\quad\quad=\min_{\bm{\phi}}\operatorname{Tr}\frac{1}{L}\sum^{L}_{i=1}[\bm{\phi%
}(\bm{x}_{i})-\bm{s}_{i}][\bm{\phi}(\bm{x}_{i})-\bm{s}_{i}]^{\mathsf{H}}\\
\quad\quad=\operatorname{Tr}\frac{1}{L}\sum^{L}_{i=1}[\bm{\phi}^{\star}_{\text%
{ERM}}(\bm{x}_{i})-\bm{s}_{i}][\bm{\phi}^{\star}_{\text{ERM}}(\bm{x}_{i})-\bm{%
s}_{i}]^{\mathsf{H}}\\
\quad\quad\leq\operatorname{Tr}\frac{1}{L}\sum^{L}_{i=1}[\bm{\phi}^{\star}(\bm%
{x}_{i})-\bm{s}_{i}][\bm{\phi}^{\star}(\bm{x}_{i})-\bm{s}_{i}]^{\mathsf{H}}.%
\end{array} \tag{73}
$$
In the terminologies of machine learning, the difference between the testing error and the training error, i.e.,
$$
\begin{array}[]{l}\operatorname{Tr}\mathbb{E}_{(\mathbf{x},\mathbf{s})\sim%
\mathbb{P}_{\mathbf{x},\mathbf{s}}}[\bm{\phi}^{\star}_{\text{ERM}}(\mathbf{x})%
-\mathbf{s}][\bm{\phi}^{\star}_{\text{ERM}}(\mathbf{x})-\mathbf{s}]^{\mathsf{H%
}}-\\
\quad\quad\quad\displaystyle\operatorname{Tr}\mathbb{E}_{(\mathbf{x},\mathbf{s%
})\sim\hat{\mathbb{P}}_{\mathbf{x},\mathbf{s}}}[\bm{\phi}^{\star}_{\text{ERM}}%
(\mathbf{x})-\mathbf{s}][\bm{\phi}^{\star}_{\text{ERM}}(\mathbf{x})-\mathbf{s}%
]^{\mathsf{H}}\\
=\operatorname{Tr}\mathbb{E}_{\mathbf{x},\mathbf{s}}[\bm{\phi}^{\star}_{\text{%
ERM}}(\mathbf{x})-\mathbf{s}][\bm{\phi}^{\star}_{\text{ERM}}(\mathbf{x})-%
\mathbf{s}]^{\mathsf{H}}-\\
\quad\quad\quad\displaystyle\operatorname{Tr}\frac{1}{L}\sum^{L}_{i=1}[\bm{%
\phi}^{\star}_{\text{ERM}}(\bm{x}_{i})-\bm{s}_{i}][\bm{\phi}^{\star}_{\text{%
ERM}}(\bm{x}_{i})-\bm{s}_{i}]^{\mathsf{H}}\end{array}
$$
is called the generalization error of $\bm{\phi}^{\star}_{\text{ERM}}$ ; the difference between the testing error and the optimal error, i.e.,
$$
\begin{array}[]{l}\operatorname{Tr}\mathbb{E}_{\mathbf{x},\mathbf{s}}[\bm{\phi%
}^{\star}_{\text{ERM}}(\mathbf{x})-\mathbf{s}][\bm{\phi}^{\star}_{\text{ERM}}(%
\mathbf{x})-\mathbf{s}]^{\mathsf{H}}-\\
\quad\quad\quad\displaystyle\operatorname{Tr}\mathbb{E}_{\mathbf{x},\mathbf{s}%
}[\bm{\phi}^{\star}(\mathbf{x})-\mathbf{s}][\bm{\phi}^{\star}(\mathbf{x})-%
\mathbf{s}]^{\mathsf{H}}\end{array}
$$
is called the excess risk of $\bm{\phi}^{\star}_{\text{ERM}}$ . In machine learning practice, we want to reduce both the generalization error and the excess risk. Most attention in the literature has been particularly paid to reducing generalization errors. Specifically, an upper bound of the true cost $\operatorname{Tr}\mathbb{E}_{(\mathbf{x},\mathbf{s})\sim\mathbb{P}_{\mathbf{x}%
,\mathbf{s}}}[\bm{\phi}(\mathbf{x})-\mathbf{s}][\bm{\phi}(\mathbf{x})-\mathbf{%
s}]^{\mathsf{H}}$ is first found and then minimize the upper bound: by minimizing the upper bound, the true cost can also be reduced.
**Fact 1**
*Suppose that the true distribution $\mathbb{P}_{0,\mathbf{x},\mathbf{s}}$ of $(\mathbf{x},\mathbf{s})$ is included in $\mathcal{U}_{\mathbf{x},\mathbf{s}}$ ; for notational clarity, we hereafter distinguish $\mathbb{P}_{0,\mathbf{x},\mathbf{s}}$ from $\mathbb{P}_{\mathbf{x},\mathbf{s}}$ . The true objective function evaluated at $\mathbb{P}_{0,\mathbf{x},\mathbf{s}}$ , i.e.,
$$
\operatorname{Tr}\mathbb{E}_{(\mathbf{x},\mathbf{s})\sim\mathbb{P}_{0,\mathbf{%
x},\mathbf{s}}}[\bm{\phi}(\mathbf{x})-\mathbf{s}][\bm{\phi}(\mathbf{x})-%
\mathbf{s}]^{\mathsf{H}},~{}~{}~{}\forall\bm{\phi}\in\mathcal{B}, \tag{74}
$$
is upper bounded by the worst-case objective function of (17), i.e.,
$$
\max_{\mathbb{P}_{\mathbf{x},\mathbf{s}}\in\mathcal{U}_{\mathbf{x},\mathbf{s}}%
}\operatorname{Tr}\mathbb{E}_{(\mathbf{x},\mathbf{s})\sim\mathbb{P}_{\mathbf{x%
},\mathbf{s}}}[\bm{\phi}(\mathbf{x})-\mathbf{s}][\bm{\phi}(\mathbf{x})-\mathbf%
{s}]^{\mathsf{H}},~{}~{}~{}\forall\bm{\phi}\in\mathcal{B}. \tag{75}
$$
Therefore, by diminishing the upper bound in (75), the true estimation error evaluated at $\mathbb{P}_{0,\mathbf{x},\mathbf{s}}$ can also be reduced. However, the conventional empirical estimation error evaluated at $\hat{\mathbb{P}}_{\mathbf{x},\mathbf{s}}$ cannot upper bound the true estimation error (74). This performance guarantee is the benefit of considering the distributionally robust method (17). Due to the weak convergence property of the empirical distribution to the true data-generating distribution, that is, $d(\mathbb{P}_{0,\mathbf{x},\mathbf{s}},~{}\hat{\mathbb{P}}_{\mathbf{x},\mathbf%
{s}})→ 0$ as the sample size $L→∞$ , there exists $\epsilon$ in (18) for every $L$ , such that $\mathbb{P}_{0,\mathbf{x},\mathbf{s}}$ is included in $\mathcal{U}_{\mathbf{x},\mathbf{s}}$ in $\mathbb{P}^{L}_{0,\mathbf{x},\mathbf{s}}$ -probability ( $L$ -fold product measure of $\mathbb{P}_{0,\mathbf{x},\mathbf{s}}$ ). $\square$*
C-B Non-Stationary Channel Statistics
In the main body of the article (see also Fact 1), we assume that the true data-generating distribution $\mathbb{P}_{0,\mathbf{x},\mathbf{s}}$ is time-invariant within a frame. In real-world operations, however, this assumption might be untenable.
As shown in Fig. 1, the frame contains eight data units; we suppose that the first four units are pilot symbols and the rest four units are communication-data symbols.
<details>
<summary>x1.png Details</summary>
### Visual Description
# Technical Document Extraction: Time-Series Frame Diagram
## 1. Image Overview
This image is a technical diagram illustrating the concept of a "Frame" within a temporal sequence. It uses a horizontal timeline with specific markers to define the boundaries and internal subdivisions of a single frame.
## 2. Component Isolation
### Header / Top Annotation
- **Label:** "A Frame"
- **Visual Indicator:** A green horizontal double-headed arrow.
- **Spatial Grounding:** The arrow spans the distance between the first vertical marker ($t_0$) and the last vertical marker ($t_8$).
- **Function:** Defines the total duration of one frame.
### Main Axis (Timeline)
- **Axis Type:** Horizontal line with a right-pointing arrowhead.
- **Axis Label:** "Time" (located at the far right of the axis).
- **Markers:** There are 9 vertical tick marks intersecting the horizontal axis.
### Tick Marks and Labels
The diagram uses color-coding and subscripts to differentiate between frame boundaries and internal time steps.
| Marker Position | Color | Label | Description |
| :--- | :--- | :--- | :--- |
| 1st Tick | Red | $t_0$ | Start boundary of the frame. |
| 2nd Tick | Blue | (None) | Internal time step ($t_1$ implied). |
| 3rd Tick | Blue | $t_2$ | Internal time step. |
| 4th Tick | Blue | (None) | Internal time step ($t_3$ implied). |
| 5th Tick | Blue | $t_4$ | Internal time step (Mid-point). |
| 6th Tick | Blue | (None) | Internal time step ($t_5$ implied). |
| 7th Tick | Blue | $t_6$ | Internal time step. |
| 8th Tick | Blue | (None) | Internal time step ($t_7$ implied). |
| 9th Tick | Red | $t_8$ | End boundary of the frame. |
## 3. Technical Analysis and Flow
- **Frame Composition:** A single "Frame" is composed of 8 equal temporal intervals.
- **Boundary Markers:** Red markers signify the start ($t_0$) and end ($t_8$) of the frame. These align with the vertical green lines of the "A Frame" span indicator.
- **Sub-intervals:** The frame is divided by blue markers. While only even-numbered subscripts ($t_2, t_4, t_6$) are explicitly labeled for the blue markers, the visual spacing indicates a linear progression of 8 units ($t_0$ through $t_8$).
- **Trend/Logic Check:** The timeline progresses linearly from left to right. The distance between each tick mark (red or blue) is uniform, suggesting a constant sampling rate or time delta ($\Delta t$) between each point.
## 4. Textual Transcription
- **Primary Text:** "A Frame"
- **Axis Label:** "Time"
- **Subscript Notations:** $t_0, t_2, t_4, t_6, t_8$
</details>
Figure 1: True data-generating distributions might be time-varying in a frame.
Let $\mathbb{P}_{0,\mathbf{x},\mathbf{s},i}$ denote the true data-generating distribution at time point $t_{i}$ where $i=1,2,...,8$ . Specifically, we have $(\mathbf{x}_{i},\mathbf{s}_{i})\sim\mathbb{P}_{0,\mathbf{x},\mathbf{s},i}$ for every $i$ . Therefore, the pilot data set (i.e., the training data set) $\{(\bm{x}_{1},\bm{s}_{1}),(\bm{x}_{2},\bm{s}_{2}),(\bm{x}_{3},\bm{s}_{3}),(\bm%
{x}_{4},\bm{s}_{4})\}$ can be seen as realizations of the mean distribution $\mathbb{P}_{\text{train},0,\mathbf{x},\mathbf{s}}$ of underlying true training-data distributions where $\mathbb{P}_{\text{train},0,\mathbf{x},\mathbf{s}}=\sum^{4}_{i=1}h_{i}\mathbb{P%
}_{0,\mathbf{x},\mathbf{s},i}$ , which is a mixture distribution with mixing weights $0≤ h_{1},h_{2},h_{3},h_{4}≤ 1$ ; $\sum^{4}_{i=1}h_{i}=1$ . Similarly, the communication data set (i.e., the testing data set) $\{(\bm{x}_{5},\bm{s}_{5}),(\bm{x}_{6},\bm{s}_{6}),(\bm{x}_{7},\bm{s}_{7}),(\bm%
{x}_{8},\bm{s}_{8})\}$ can be seen as realizations of the mean $\mathbb{P}_{\text{test},0,\mathbf{x},\mathbf{s}}$ of the underlying true testing-data distributions where $\mathbb{P}_{\text{test},0,\mathbf{x},\mathbf{s}}=\sum^{8}_{i=5}h_{i}\mathbb{P}%
_{0,\mathbf{x},\mathbf{s},i}$ , with mixing weights $0≤ h_{5},h_{6},h_{7},h_{8}≤ 1$ ; $\sum^{8}_{i=5}h_{i}=1$ .
Suppose that
$$
d(\hat{\mathbb{P}}_{\text{train},\mathbf{x},\mathbf{s}},~{}\mathbb{P}_{\text{%
train},0,\mathbf{x},\mathbf{s}})\leq\epsilon_{1},
$$
where $\hat{\mathbb{P}}_{\text{train},\mathbf{x},\mathbf{s}}\coloneqq\frac{1}{4}\sum^%
{4}_{i=1}\delta_{(\bm{x}_{i},\bm{s}_{i})}$ is the data-driven estimate of $\mathbb{P}_{\text{train},0,\mathbf{x},\mathbf{s}}$ and
$$
d(\mathbb{P}_{\text{train},0,\mathbf{x},\mathbf{s}},~{}\mathbb{P}_{\text{test}%
,0,\mathbf{x},\mathbf{s}})\leq\epsilon_{2},
$$
for some $\epsilon_{1},\epsilon_{2}≥ 0$ . We have the uncertainty quantification
$$
d(\mathbb{P}_{\text{test},0,\mathbf{x},\mathbf{s}},~{}\hat{\mathbb{P}}_{\text{%
train},\mathbf{x},\mathbf{s}})\leq\epsilon\coloneqq\epsilon_{1}+\epsilon_{2}.
$$
Therefore, the distributionally robust modeling and solution framework is still valid to hedge against the distributional uncertainty in the nominal distribution $\hat{\mathbb{P}}_{\text{train},\mathbf{x},\mathbf{s}}$ compared to the underlying true distribution $\mathbb{P}_{\text{test},0,\mathbf{x},\mathbf{s}}$ . When $\mathbb{P}_{\text{train},0,\mathbf{x},\mathbf{s}}=\mathbb{P}_{\text{test},0,%
\mathbf{x},\mathbf{s}}$ , as assumed in the main body of the article, we have $\epsilon_{1}→ 0$ and $\epsilon→\epsilon_{2}=0$ as the pilot size tends to infinity; however, when $\mathbb{P}_{\text{train},0,\mathbf{x},\mathbf{s}}≠\mathbb{P}_{\text{test},0%
,\mathbf{x},\mathbf{s}}$ , the radius $\epsilon→\epsilon_{2}≠ 0$ although $\epsilon_{1}→ 0$ .
Another justification for the DRO method is as follows. Suppose that there exists $\epsilon≥ 0$ such that
$$
d(\mathbb{P}_{0,\mathbf{x},\mathbf{s},i},~{}\hat{\mathbb{P}}_{\text{train},%
\mathbf{x},\mathbf{s}})\leq\epsilon,~{}~{}~{}\forall i\in\{1,2,\ldots,8\}.
$$
It means that, at every snapshot in the frame, the true data-generating distribution is included in the uncertainty set. Hence, the DRO cost can still upper bound the true cost even though the true distribution is time-varying; cf. Fact 1.
Appendix D Additional Discussions on Distributionally Robust Estimation
To develop this article, the typical minimum mean-squared error (MSE) criterion is employed; see (7) and (10). Accordingly, the distributionally robust receive combining framework in this article is exemplified using the MSE cost function. The cost function for wireless signal estimation, however, can be any Borel-measurable function $h:\mathbb{C}^{M}×\mathbb{C}^{M}→\mathbb{R}_{+}$ . As a result, the optimal estimation problem under the distribution $\mathbb{P}_{\mathbf{x},\mathbf{s}}$ is given by
$$
\min_{\bm{\phi}\in\mathcal{B}_{\mathbb{C}^{N}\to\mathbb{C}^{M}}}\mathbb{E}_{%
\mathbf{x},\mathbf{s}}h[\bm{\phi}(\mathbf{x}),\mathbf{s}]. \tag{76}
$$
Specific examples of $h$ in wireless communications can be, e.g., mean absolute error, Huber’s cost function [37, 38] where $h$ is no longer quadratic as in (7) and (10). Accordingly, when the distributional uncertainty exists in $\mathbb{P}_{\mathbf{x},\mathbf{s}}$ , the distributionally robust receive combining framework becomes
$$
\min_{\bm{\phi}\in\mathcal{B}_{\mathbb{C}^{N}\to\mathbb{C}^{M}}}\max_{\mathbb{%
P}_{\mathbf{x},\mathbf{s}}\in\mathcal{U}_{\mathbf{x},\mathbf{s}}}\mathbb{E}_{%
\mathbf{x},\mathbf{s}}h[\bm{\phi}(\mathbf{x}),\mathbf{s}]. \tag{77}
$$
Problem (77) is generally challenging to solve because it is an infinite-dimensional program. Therefore, in practice, we can limit the feasible region of $\bm{\phi}$ to a parameterized subspace of $\mathcal{B}_{\mathbb{C}^{N}→\mathbb{C}^{M}}$ , for example, a reproducing kernel Hilbert space $\mathcal{H}$ or a neural network function space $\mathcal{K}$ ; see Section II. Consequently, Problem (77) is approximated by the following finite-dimensional (in terms of $\bm{W}$ ) program
$$
\min_{\bm{W}}\max_{\mathbb{P}_{\mathbf{x},\mathbf{s}}\in\mathcal{U}_{\mathbf{x%
},\mathbf{s}}}\mathbb{E}_{\mathbf{x},\mathbf{s}}h[\bm{\phi}_{\bm{W}}(\mathbf{x%
}),\mathbf{s}], \tag{78}
$$
where $\bm{W}$ parameterizes $\bm{\phi}$ and lies in real or complex coordinate spaces; note that both $\mathcal{H}$ and $\mathcal{K}$ can be dense in $\mathcal{B}$ . Under the MSE cost function, (78) is particularized in (19) for linear function spaces, in (57) for reproducing kernel Hilbert spaces, and in (69) for neural network function spaces, which build this article in a technically tractable manner.
The distributionally robust receive combining problem (77) under generic cost functions $h$ and generic feasible regions of $\bm{\phi}$ can be technically challenging. Even for the simplified problem (78), the solution method can be quite complex, and closed-form solutions cannot be generally guaranteed; see, e.g., [39, 40]. The complication further arises when the distributional uncertainty sets $\mathcal{U}_{\mathbf{x},\mathbf{s}}$ for $\mathbb{P}_{\mathbf{x},\mathbf{s}}$ are complicated; see, e.g., [32]. Therefore, this article serves as the starting point of distributionally robust receive combining, in which closed-form solutions are largely ensured by leveraging
1. the MSE cost function as in (7) and (10);
1. the linear function spaces as in (19) and reproducing kernel Hilbert spaces as in (57);
1. the second-moment-based uncertainty sets in Definitions 1, 2, 3, and 4; see also Corollary 1, Claim 2, and Example 4.
Note that even under the features F1) and F2), the closed-form solutions cannot be guaranteed. For example, if Wasserstein or F-norm uncertainty sets are used, the associated distributionally robust receive combining problems can be computationally heavy; see (47) and (52) as well as Propositions 1 and 2. However, for emerging high-performance computing devices, the computational burden may be no longer an issue in the future. Hence, advanced distributionally robust receive combining formulations based on (77) and (78) are still attractive for future-generation communication systems. This article seeks to provide a foundation for this direction.
Appendix E Proof of Lemma 1
* Proof:*
The objective function of Problem (19) equals to
$$
\left\langle\left[\begin{array}[]{cc}\bm{W}^{\mathsf{H}}\bm{W}&-\bm{W}^{%
\mathsf{H}}\\
-\bm{W}&\bm{I}_{M}\end{array}\right],~{}\left[\begin{array}[]{cc}\bm{R}_{x}&%
\bm{R}_{xs}\\
\bm{R}^{\mathsf{H}}_{xs}&\bm{R}_{s}\end{array}\right]\right\rangle, \tag{79}
$$
where $\langle\bm{A},\bm{B}\rangle\coloneqq\operatorname{Tr}\bm{A}^{\mathsf{H}}\bm{B}$ for two matrices $\bm{A}$ and $\bm{B}$ . Therefore, the objective function of (19) is convex in $\bm{W}$ and linear (thus concave) in the matrix variable $\bm{R}$ . Hence, due to Sion’s minimax theorem [41, Corollary 3.3], Problem (19) is equivalent to
$$
\begin{array}[]{cl}\displaystyle\max_{\bm{R}}\min_{\bm{W}}&\operatorname{Tr}%
\big{[}\bm{W}\bm{R}_{x}\bm{W}^{\mathsf{H}}-\bm{W}\bm{R}_{xs}-\bm{R}^{\mathsf{H%
}}_{xs}\bm{W}^{\mathsf{H}}+\bm{R}_{s}\big{]}\\
\text{s.t.}&d_{0}(\bm{R},~{}\hat{\bm{R}})\leq\epsilon_{0},\\
&\bm{R}\succeq\bm{0}.\end{array} \tag{80}
$$
Note that the feasible region of $\bm{R}$ is compact convex, and that of $\bm{W}$ (i.e., $\mathbb{C}^{M× N}$ ) is convex. For every given $\bm{R}$ , the inner minimization sub-problem of (80) is solved by the Wiener beamformer $\bm{W}^{\star}_{\text{Wiener}}=\bm{R}^{\mathsf{H}}_{xs}\bm{R}^{-1}_{x}$ , which transforms (80) to (21). This completes the proof. $\square$ ∎
Appendix F Proof of Theorem 1
* Proof:*
Consider the following optimization problem
$$
\begin{array}[]{cl}\displaystyle\max_{\bm{R}}&\operatorname{Tr}\big{[}-\bm{R}^%
{\mathsf{H}}_{xs}\bm{R}^{-1}_{x}\bm{R}_{xs}+\bm{R}_{s}\big{]}\\
\text{s.t.}&\bm{R}\succeq\bm{R}_{2},\\
&\bm{R}_{x}\succ\bm{0},\end{array} \tag{81}
$$
which, due to Lemma 1, is equivalent [in the sense of the same optimal objective value and maximizer(s) $\bm{R}^{\star}$ ] to
$$
\begin{array}[]{cl}\displaystyle\min_{\bm{W}}\max_{\bm{R}}&\left\langle\left[%
\begin{array}[]{cc}\bm{W}^{\mathsf{H}}\bm{W}&-\bm{W}^{\mathsf{H}}\\
-\bm{W}&\bm{I}_{M}\end{array}\right],~{}\left[\begin{array}[]{cc}\bm{R}_{x}&%
\bm{R}_{xs}\\
\bm{R}^{\mathsf{H}}_{xs}&\bm{R}_{s}\end{array}\right]\right\rangle\\
\text{s.t.}&\bm{R}\succeq\bm{R}_{2},\\
&\bm{R}_{x}\succ\bm{0}.\end{array} \tag{82}
$$
Note that $\left[\begin{array}[]{cc}\bm{W}^{\mathsf{H}}\bm{W}&-\bm{W}^{\mathsf{H}}\\
-\bm{W}&\bm{I}_{M}\end{array}\right]\succeq\bm{0},$ because for all $\bm{x}∈\mathbb{C}^{N}$ and $\bm{y}∈\mathbb{C}^{M}$ , we have
$$
[\bm{x}^{\mathsf{H}},~{}\bm{y}^{\mathsf{H}}]\left[\begin{array}[]{cc}\bm{W}^{%
\mathsf{H}}\bm{W}&-\bm{W}^{\mathsf{H}}\\
-\bm{W}&\bm{I}_{M}\end{array}\right]\left[\begin{array}[]{c}\bm{x}\\
\bm{y}\end{array}\right]=\|\bm{W}\bm{x}-\bm{y}\|^{2}_{2}\geq 0.
$$
Therefore, for every given $\bm{W}$ , the objective function of (82) is increasing in $\bm{R}$ . As a result, the objective value of (81) is lower-bounded at $\bm{R}_{2}$ : To be specific, $∀\bm{R}\succeq\bm{R}_{2}$ , we have
$$
\operatorname{Tr}\big{[}-\bm{R}^{\mathsf{H}}_{xs}\bm{R}^{-1}_{x}\bm{R}_{xs}+%
\bm{R}_{s}\big{]}\\
\geq\operatorname{Tr}\big{[}-\bm{R}^{\mathsf{H}}_{2,xs}\bm{R}^{-1}_{2,x}\bm{R}%
_{2,xs}+\bm{R}_{2,s}\big{]},
$$
i.e., $f_{1}(\bm{R})≥ f_{1}(\bm{R}_{2})$ , which proves the first part. On the other hand, if $\bm{R}_{1,x}\succeq\bm{R}_{2,x}\succ\bm{0}$ , we have $\bm{R}^{-1}_{2,x}\succeq\bm{R}^{-1}_{1,x}$ . As a result, $f_{2}(\bm{R}_{1,x})-f_{2}(\bm{R}_{2,x})=\operatorname{Tr}\left[{\bm{R}^{%
\mathsf{H}}_{xs}(\bm{R}^{-1}_{2,x}-\bm{R}^{-1}_{1,x})\bm{R}_{xs}}\right]≥ 0$ , completing the proof. $\square$ ∎
Appendix G Proof of Proposition 3
* Proof:*
Letting $\underline{\mathbf{z}}\coloneqq\bm{\varphi}(\underline{\mathbf{x}})$ , (57) can be rewritten as
$$
\min_{\bm{W}\in\mathbb{R}^{2M\times L}}\max_{\mathbb{P}_{\underline{\mathbf{z}%
},\underline{\mathbf{s}}}\in\mathcal{U}_{\underline{\mathbf{z}},\underline{%
\mathbf{s}}}}\operatorname{Tr}\mathbb{E}_{\underline{\mathbf{z}},\underline{%
\mathbf{s}}}[\bm{W}\underline{\mathbf{z}}-\underline{\mathbf{s}}][\bm{W}%
\underline{\mathbf{z}}-\underline{\mathbf{s}}]^{\mathsf{T}}. \tag{83}
$$
Tantamount to the distributionally robust beamforming problem (19), Problem (83) reduces to (58) where
$$
\hat{\bm{R}}_{\underline{z}}\coloneqq\frac{1}{L}\sum^{L}_{i=1}\underline{\bm{z%
}}_{i}\underline{\bm{z}}^{\mathsf{T}}_{i}=\frac{1}{L}\sum^{L}_{i=1}\bm{\varphi%
}(\underline{\bm{x}}_{i})\bm{\varphi}^{\mathsf{T}}(\underline{\bm{x}}_{i})=%
\frac{1}{L}\bm{K}^{2},
$$
$$
\hat{\bm{R}}_{\underline{zs}}\coloneqq\frac{1}{L}\sum^{L}_{i=1}\underline{\bm{%
z}}_{i}\underline{\bm{s}}^{\mathsf{T}}_{i}=\frac{1}{L}\sum^{L}_{i=1}\bm{%
\varphi}(\underline{\bm{x}}_{i})\cdot\underline{\bm{s}}^{\mathsf{T}}_{i}=\frac%
{1}{L}\bm{K}\underline{\bm{S}}^{\mathsf{T}},
$$
$$
\hat{\bm{R}}_{\underline{s}}\coloneqq\frac{1}{L}\sum^{L}_{i=1}\underline{\bm{s%
}}_{i}\underline{\bm{s}}^{\mathsf{T}}_{i}=\frac{1}{L}\sum^{L}_{i=1}\underline{%
\bm{s}}_{i}\cdot\underline{\bm{s}}^{\mathsf{T}}_{i}=\frac{1}{L}\underline{\bm{%
S}}\underline{\bm{S}}^{\mathsf{T}},
$$
and
$$
\bm{K}\coloneqq[\bm{\varphi}(\underline{\bm{x}}_{1}),\bm{\varphi}(\underline{%
\bm{x}}_{2}),\ldots,\bm{\varphi}(\underline{\bm{x}}_{L})]\in\mathbb{R}^{L%
\times L}.
$$
The rest claims are due to Lemma 1; NB: $\bm{K}$ is invertible. $\square$ ∎
References
- [1] T. Lo, H. Leung, and J. Litva, “Nonlinear beamforming,” Electronics Letters, vol. 4, no. 27, pp. 350–352, 1991.
- [2] S. Yang and L. Hanzo, “Fifty years of MIMO detection: The road to large-scale MIMOs,” IEEE Commun. Surveys Tuts., vol. 17, no. 4, pp. 1941–1988, 2015.
- [3] A. M. Elbir, K. V. Mishra, S. A. Vorobyov, and R. W. Heath, “Twenty-five years of advances in beamforming: From convex and nonconvex optimization to learning techniques,” IEEE Signal Processing Mag., vol. 40, no. 4, pp. 118–131, 2023.
- [4] S. Chen, S. Tan, L. Xu, and L. Hanzo, “Adaptive minimum error-rate filtering design: A review,” Signal Processing, vol. 88, no. 7, pp. 1671–1697, 2008.
- [5] S. Chen, A. Wolfgang, C. J. Harris, and L. Hanzo, “Symmetric RBF classifier for nonlinear detection in multiple-antenna-aided systems,” IEEE Trans. Neural Networks, vol. 19, no. 5, pp. 737–745, 2008.
- [6] A. Navia-Vazquez, M. Martinez-Ramon, L. E. Garcia-Munoz, and C. G. Christodoulou, “Approximate kernel orthogonalization for antenna array processing,” IEEE Trans. Antennas Propagat., vol. 58, no. 12, pp. 3942–3950, 2010.
- [7] M. Neinavaie, M. Derakhtian, and S. A. Vorobyov, “Lossless dimension reduction for integer least squares with application to sphere decoding,” IEEE Trans. Signal Processing, vol. 68, pp. 6547–6561, 2020.
- [8] J. Liao, J. Zhao, F. Gao, and G. Y. Li, “Deep learning aided low complex breadth-first tree search for MIMO detection,” IEEE Trans. Wireless Commun., 2023.
- [9] D. A. Awan, R. L. Cavalcante, M. Yukawa, and S. Stanczak, “Robust online multiuser detection: A hybrid model-data driven approach,” IEEE Trans. Signal Processing, 2023.
- [10] H. Ye, G. Y. Li, and B.-H. Juang, “Power of deep learning for channel estimation and signal detection in OFDM systems,” IEEE Wireless Commun. Lett., vol. 7, no. 1, pp. 114–117, 2017.
- [11] H. He, C.-K. Wen, S. Jin, and G. Y. Li, “Model-driven deep learning for MIMO detection,” IEEE Trans. Signal Processing, vol. 68, pp. 1702–1715, 2020.
- [12] N. Van Huynh and G. Y. Li, “Transfer learning for signal detection in wireless networks,” IEEE Wireless Commun. Lett., vol. 11, no. 11, pp. 2325–2329, 2022.
- [13] J. Li, P. Stoica, and Z. Wang, “On robust Capon beamforming and diagonal loading,” IEEE Trans. Signal Processing, vol. 51, no. 7, pp. 1702–1715, 2003.
- [14] R. G. Lorenz and S. P. Boyd, “Robust minimum variance beamforming,” IEEE Trans. Signal Processing, vol. 53, no. 5, pp. 1684–1696, 2005.
- [15] X. Zhang, Y. Li, N. Ge, and J. Lu, “Robust minimum variance beamforming under distributional uncertainty,” in 2015 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2015, pp. 2514–2518.
- [16] B. Li, Y. Rong, J. Sun, and K. L. Teo, “A distributionally robust minimum variance beamformer design,” IEEE Signal Processing Lett., vol. 25, no. 1, pp. 105–109, 2017.
- [17] Y. Huang, W. Yang, and S. A. Vorobyov, “Robust adaptive beamforming maximizing the worst-case SINR over distributional uncertainty sets for random inc matrix and signal steering vector,” in ICASSP 2022-2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2022, pp. 4918–4922.
- [18] Y. Huang, H. Fu, S. A. Vorobyov, and Z.-Q. Luo, “Robust adaptive beamforming via worst-case SINR maximization with nonconvex uncertainty sets,” IEEE Trans. Signal Processing, vol. 71, pp. 218–232, 2023.
- [19] H. Cox, R. Zeskind, and M. Owen, “Robust adaptive beamforming,” IEEE Trans. Acoust., Speech, Signal Processing, vol. 35, no. 10, pp. 1365–1376, 1987.
- [20] K. Harmanci, J. Tabrikian, and J. L. Krolik, “Relationships between adaptive minimum variance beamforming and optimal source localization,” IEEE Trans. Signal Processing, vol. 48, no. 1, pp. 1–12, 2000.
- [21] F. Liu, L. Zhou, C. Masouros, A. Li, W. Luo, and A. Petropulu, “Toward dual-functional radar-communication systems: Optimal waveform design,” IEEE Trans. Signal Processing, vol. 66, no. 16, pp. 4264–4279, 2018.
- [22] J. A. Zhang, F. Liu, C. Masouros, R. W. Heath, Z. Feng, L. Zheng, and A. Petropulu, “An overview of signal processing techniques for joint communication and radar sensing,” IEEE J. Select. Topics Signal Processing, vol. 15, no. 6, pp. 1295–1315, 2021.
- [23] Y. Xiong, F. Liu, Y. Cui, W. Yuan, T. X. Han, and G. Caire, “On the fundamental tradeoff of integrated sensing and communications under Gaussian channels,” IEEE Trans. Inform. Theory, 2023.
- [24] K. P. Murphy, Machine Learning: A Probabilistic Perspective. MIT Press, 2012.
- [25] C. M. Bishop and N. M. Nasrabadi, Pattern Recognition and Machine Learning. Springer, 2006, vol. 4, no. 4.
- [26] G. Li and J. Ding, “Towards understanding variation-constrained deep neural networks,” IEEE Trans. Signal Processing, vol. 71, pp. 631–640, 2023.
- [27] S. Shafieezadeh-Abadeh, D. Kuhn, and P. M. Esfahani, “Regularization via mass transportation,” Journal of Machine Learning Research, vol. 20, no. 103, pp. 1–68, 2019.
- [28] M. Staib and S. Jegelka, “Distributionally robust optimization and generalization in kernel methods,” Advances in Neural Information Processing Systems, vol. 32, 2019.
- [29] E. Delage and Y. Ye, “Distributionally robust optimization under moment uncertainty with application to data-driven problems,” Operations Research, vol. 58, no. 3, pp. 595–612, 2010.
- [30] S. Wang, “Distributionally robust state estimation for jump linear systems,” IEEE Trans. Signal Processing, 2023.
- [31] J. Li, S. Lin, J. Blanchet, and V. A. Nguyen, “Tikhonov regularization is optimal transport robust under martingale constraints,” Advances in Neural Information Processing Systems, vol. 35, pp. 17 677–17 689, 2022.
- [32] D. Kuhn, P. M. Esfahani, V. A. Nguyen, and S. Shafieezadeh-Abadeh, “Wasserstein distributionally robust optimization: Theory and applications in machine learning,” in Operations Research & Management Science in the Age of Analytics. Informs, 2019, pp. 130–166.
- [33] J. Blanchet, Y. Kang, and K. Murthy, “Robust Wasserstein profile inference and applications to machine learning,” Journal of Applied Probability, vol. 56, no. 3, pp. 830–857, 2019.
- [34] C. Shorten and T. M. Khoshgoftaar, “A survey on image data augmentation for deep learning,” Journal of Big Data, vol. 6, 2019.
- [35] G. Saon, Z. Tüske, K. Audhkhasi, and B. Kingsbury, “Sequence noise injected training for end-to-end speech recognition,” in ICASSP 2019-2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2019, pp. 6261–6265.
- [36] K. Vu, J. C. Snyder, L. Li, M. Rupp, B. F. Chen, T. Khelif, K.-R. Müller, and K. Burke, “Understanding kernel ridge regression: Common behaviors from simple functions to density functionals,” International Journal of Quantum Chemistry, vol. 115, no. 16, pp. 1115–1128, 2015.
- [37] X. Wang and H. V. Poor, “Robust adaptive array for wireless communications,” IEEE J. Select. Areas in Commun., vol. 16, no. 8, pp. 1352–1366, 1998.
- [38] V. Katkovnik, M.-S. Lee, and Y.-H. Kim, “Performance study of the minimax robust phased array for wireless communications,” IEEE Trans. Wireless Commun., vol. 54, no. 4, pp. 608–613, 2006.
- [39] H. Rahimian and S. Mehrotra, “Frameworks and results in distributionally robust optimization,” Open Journal of Mathematical Optimization, vol. 3, pp. 1–85, 2022.
- [40] D. Kuhn, S. Shafiee, and W. Wiesemann, “Distributionally robust optimization,” Acta Numerica, 2024.
- [41] M. Sion, “On general minimax theorems.” Pacific Journal of Mathematics, vol. 8, no. 1, pp. 171 – 176, 1958.
|
<details>
<summary>x2.png Details</summary>

### Visual Description
# Technical Image Analysis Report
## 1. Image Classification
This image is a **standard identification (ID) photograph** of an individual. It does not contain charts, graphs, data tables, or technical diagrams.
## 2. Component Isolation
### Region: Header / Background
* **Content:** Solid white background.
* **Data:** No textual or numerical information present.
### Region: Main Subject (Portrait)
* **Subject:** A young adult male of East Asian descent.
* **Orientation:** Front-facing, centered, head-and-shoulders view.
* **Physical Characteristics:**
* **Hair:** Short, dark brown/black hair.
* **Eyes:** Dark brown.
* **Facial Features:** Neutral expression, closed mouth.
* **Attire:** The subject is wearing a blue, heathered (textured) crew-neck t-shirt.
### Region: Embedded Text (Clothing)
* **Location:** Center-chest area of the t-shirt.
* **Transcription:** `P E R F E C T`
* **Style:** White, sans-serif, uppercase lettering with wide kerning (spacing between letters).
## 3. Data Extraction Summary
* **Language:** English (Text on shirt).
* **Numerical Data:** None present.
* **Key Trends:** Not applicable (non-chart image).
* **Legend/Axis:** None present.
## 4. Conclusion
The image serves as a visual identification record. Aside from the word "PERFECT" printed on the subject's garment, the image does not provide quantitative facts, technical data, or flow-based information.
</details>
| Shixiong Wang (Member, IEEE) received the B.Eng. degree in detection, guidance, and control technology, and the M.Eng. degree in systems and control engineering from the School of Electronics and Information, Northwestern Polytechnical University, China, in 2016 and 2018, respectively. He received his Ph.D. degree from the Department of Industrial Systems Engineering and Management, National University of Singapore, Singapore, in 2022. He is currently a Postdoctoral Research Associate with the Intelligent Transmission and Processing Laboratory, Imperial College London, London, United Kingdom, from May 2023. He was a Postdoctoral Research Fellow with the Institute of Data Science, National University of Singapore, Singapore, from March 2022 to March 2023. His research interest includes statistics and optimization theories with applications in signal processing (especially optimal estimation theory), machine learning (especially generalization error theory), and control technology. |
| --- | --- |
|
<details>
<summary>extracted/6550238/Figures/dw.jpg Details</summary>

### Visual Description
# Technical Image Analysis Report
## 1. Image Classification and Overview
* **Image Type:** Portrait Photograph (Headshot)
* **Subject:** An adult male of East Asian descent.
* **Context:** Likely a professional identification photo or faculty/staff directory headshot.
* **Data/Fact Content:** This image does not contain charts, diagrams, tables, or textual data. It is a purely visual representation of an individual.
## 2. Visual Component Analysis
### Subject Details
* **Orientation:** Front-facing, slightly angled toward the viewer's right.
* **Hair:** Short, black, straight hair with a textured/spiky style on top.
* **Facial Features:** Dark brown eyes, black eyebrows, and a neutral to slight smile.
* **Attire:** The subject is wearing a light-colored (white or light grey) button-down collared shirt with a subtle horizontal pinstripe or textured pattern.
### Technical Composition
* **Background:** Solid, dark navy blue or charcoal grey matte background.
* **Lighting:** Soft, directional lighting coming from the upper left (viewer's perspective), creating subtle highlights on the right side of the face and a soft shadow on the left side of the neck.
* **Framing:** Close-up crop, focusing on the head and shoulders (standard headshot framing).
## 3. Textual Extraction
* **Embedded Text:** None.
* **Labels/Axis/Legends:** None.
* **Language:** Not applicable (no text present).
## 4. Summary of Information
The image serves as a visual identifier for an individual. It contains no quantitative data, technical schematics, or linguistic information to transcribe. The image quality is clear, with a professional depth of field that keeps the subject in sharp focus against a neutral, non-distracting background.
</details>
| Wei Dai (Member, IEEE) received the Ph.D. degree from the University of Colorado Boulder, Boulder, Colorado, in 2007. He is currently a Senior Lecturer (Associate Professor) in the Department of Electrical and Electronic Engineering, Imperial College London, London, UK. From 2007 to 2011, he was a Postdoctoral Research Associate with the University of Illinois Urbana-Champaign, Champaign, IL, USA. His research interests include electromagnetic sensing, biomedical imaging, wireless communications, and information theory. |
| --- | --- |
|
<details>
<summary>extracted/6550238/Figures/LiG_Photo24.jpg Details</summary>

### Visual Description
# Technical Image Analysis Report
## 1. Document Classification
* **Image Type:** Portrait Photograph (Professional Headshot)
* **Subject:** Individual Male
* **Textual Content:** None (0% text density)
* **Data Visualization:** None (No charts, graphs, or diagrams present)
## 2. Visual Component Analysis
As this image does not contain charts, tables, or technical diagrams, the following section provides a detailed visual description of the subject for identification and documentation purposes.
### Subject Characteristics
* **Demographic Appearance:** East Asian male, middle-aged to elderly.
* **Hair:** Short, salt-and-pepper (grey and black) hair, styled with a side part.
* **Facial Features:**
* Dark brown eyes.
* Visible age-related skin texture and light freckling/pigmentation on the cheeks and forehead.
* Neutral facial expression.
* **Attire:**
* **Outerwear:** Dark charcoal or black professional suit jacket with visible lapel stitching.
* **Shirt:** Crisp white collared dress shirt.
* **Neckwear:** Blue silk tie featuring a repeating white/light-blue teardrop or paisley-style pattern.
### Composition and Lighting
* **Background:** Solid white, high-key background, typical of official identification or corporate directory photography.
* **Framing:** Close-up headshot, centered, capturing the head and shoulders.
* **Lighting:** Even, frontal lighting with minimal shadowing, ensuring clear visibility of all facial features.
## 3. Data Extraction Summary
| Category | Status | Details |
| :--- | :--- | :--- |
| **Text/Labels** | Not Present | No alphanumeric characters detected. |
| **Charts/Graphs** | Not Present | No quantitative data series or axes. |
| **Diagrams/Flows** | Not Present | No process flows or component mappings. |
| **Legends/Keys** | Not Present | No symbolic references. |
## 4. Conclusion
The provided image is a **non-technical portrait**. It does not provide facts, numerical data, or linguistic information. It serves exclusively as a visual representation of an individual. No further technical extraction is possible from this source.
</details>
| Geoffrey Ye Li is currently a Chair Professor at Imperial College London, UK. Before joining Imperial in 2020, he was a Professor at Georgia Institute of Technology for 20 years and a Principal Technical Staff Member with AT&T Labs – Research (previous Bell Labs) for five years. He made fundamental contributions to orthogonal frequency division multiplexing (OFDM) for wireless communications, established a framework on resource cooperation in wireless networks, and introduced deep learning to communications. In these areas, he has published over 700 journal and conference papers in addition to over 40 granted patents. His publications have been cited around 80,000 times with an H-index over 130. He has been listed as a Highly Cited Researcher by Clarivate/Web of Science almost every year. Dr. Geoffrey Ye Li was elected to Fellow of the Royal Academic of Engineering (FREng), IEEE Fellow, and IET Fellow for his contributions to signal processing for wireless communications. He received 2024 IEEE Eric E. Sumner Award, 2019 IEEE ComSoc Edwin Howard Armstrong Achievement Award, and several other awards from IEEE Signal Processing, Vehicular Technology, and Communications Societies. |
| --- | --- |
Supplementary Materials
Appendix H Additional Experimental Results
Complementary to experimental setups in Section VI, we consider pure complex Gaussian channel noises. First, we suppose that the transmit antennas emit continuous-valued complex signals; without loss of generality, Gaussian signals are used in experiments. The performance evaluation measure is therefore the mean-squared error (MSE). The experimental results are shown in Fig. 2.
<details>
<summary>x3.png Details</summary>
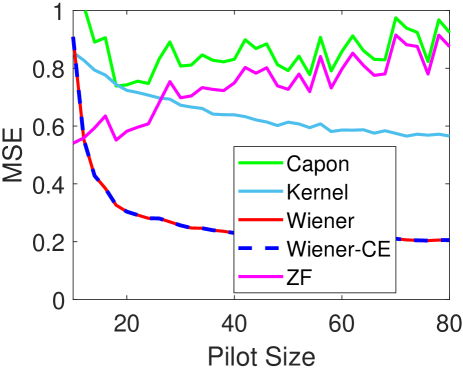
### Visual Description
# Technical Data Extraction: MSE vs. Pilot Size Performance Chart
## 1. Document Classification
* **Type:** Line Graph (Performance Comparison)
* **Language:** English
* **Primary Metrics:** Mean Squared Error (MSE) vs. Pilot Size
## 2. Axis and Legend Extraction
### Axis Labels
* **Y-Axis (Vertical):** `MSE` (Mean Squared Error)
* **Scale:** 0 to 1
* **Markers:** 0, 0.2, 0.4, 0.6, 0.8, 1
* **X-Axis (Horizontal):** `Pilot Size`
* **Scale:** Approximately 10 to 80
* **Markers:** 20, 40, 60, 80
### Legend Information
The legend is located in the lower-right quadrant of the plot area. It contains five entries:
1. **Capon:** Solid Green line
2. **Kernel:** Solid Light Blue line
3. **Wiener:** Solid Red line
4. **Wiener-CE:** Dashed Dark Blue line (Overlaid on Wiener)
5. **ZF:** Solid Magenta line
---
## 3. Component Analysis and Trend Verification
### Region 1: High-Performance Series (Wiener & Wiener-CE)
* **Trend:** Both lines follow an identical downward exponential-like decay. They start at the highest MSE (~0.9) at the lowest pilot size and rapidly drop, stabilizing at the lowest MSE relative to all other methods.
* **Visual Check:** The dashed dark blue line (Wiener-CE) sits directly on top of the solid red line (Wiener), indicating identical performance across the pilot size range.
* **Data Points:**
* Pilot Size ~10: MSE ≈ 0.9
* Pilot Size ~20: MSE ≈ 0.3
* Pilot Size 40-80: MSE plateaus between 0.2 and 0.25.
### Region 2: Mid-Performance Series (Kernel)
* **Trend:** A steady, linear-like downward slope. It does not exhibit the rapid initial drop of the Wiener filters but shows consistent improvement as pilot size increases.
* **Visual Check:** Solid light blue line.
* **Data Points:**
* Pilot Size ~10: MSE ≈ 0.85
* Pilot Size 40: MSE ≈ 0.65
* Pilot Size 80: MSE ≈ 0.58
### Region 3: High-Error/Unstable Series (Capon & ZF)
* **Trend (Capon):** Highly volatile with a general downward trend initially, followed by significant fluctuations at higher pilot sizes. It maintains the highest overall MSE.
* **Trend (ZF):** Starts low (~0.55), but trends **upward** with significant volatility as pilot size increases, eventually performing worse than the Kernel method.
* **Visual Check:** Capon (Green) is consistently the top-most line; ZF (Magenta) fluctuates between the Kernel and Capon lines.
* **Data Points (Capon):**
* Pilot Size ~10: MSE ≈ 1.0
* Pilot Size 40: MSE ≈ 0.82
* Pilot Size 80: MSE ≈ 0.92 (Fluctuating)
* **Data Points (ZF):**
* Pilot Size ~10: MSE ≈ 0.55
* Pilot Size 40: MSE ≈ 0.75
* Pilot Size 80: MSE ≈ 0.88 (Fluctuating)
---
## 4. Summary of Findings
* **Best Performers:** **Wiener** and **Wiener-CE** are the most effective, achieving the lowest MSE (~0.2) with a pilot size of 40 or greater. Their performance is indistinguishable from each other.
* **Most Stable Improvement:** The **Kernel** method shows the most predictable, steady improvement, though it never reaches the low error levels of the Wiener methods.
* **Least Effective:** The **Capon** method consistently yields the highest error.
* **Counter-Intuitive Trend:** The **ZF** (Zero Forcing) method shows a general **increase** in MSE as Pilot Size increases, suggesting it may be sensitive to noise or overfitting as more pilot data is introduced in this specific scenario.
</details>
(a) $N$ =8, SNR 10dB, $\bm{R}_{v}$ Estimated
<details>
<summary>x4.png Details</summary>
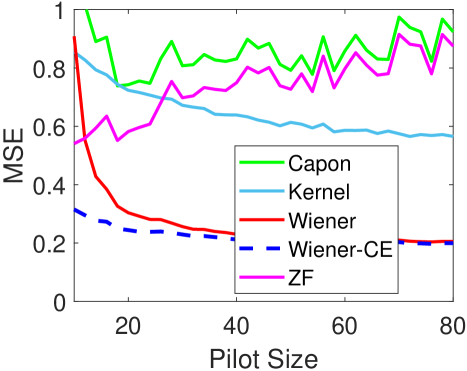
### Visual Description
# Technical Data Extraction: MSE vs. Pilot Size Performance Chart
## 1. Image Overview
This image is a line graph illustrating the relationship between **Pilot Size** (independent variable) and **MSE** (Mean Squared Error, dependent variable) for five different signal processing or estimation algorithms.
## 2. Component Isolation
### A. Axis Labels and Markers
* **Y-Axis (Vertical):**
* **Label:** `MSE`
* **Scale:** Linear, ranging from `0` to `1`.
* **Major Tick Marks:** `0`, `0.2`, `0.4`, `0.6`, `0.8`, `1`.
* **X-Axis (Horizontal):**
* **Label:** `Pilot Size`
* **Scale:** Linear, ranging from approximately `10` to `80`.
* **Major Tick Marks:** `20`, `40`, `60`, `80`.
### B. Legend (Spatial Grounding: Center-Right [~650, 550])
The legend is contained within a black-bordered box and identifies five data series:
1. **Capon:** Solid Green line.
2. **Kernel:** Solid Light Blue line.
3. **Wiener:** Solid Red line.
4. **Wiener-CE:** Dashed Dark Blue line.
5. **ZF:** Solid Magenta line.
---
## 3. Data Series Analysis and Trends
### Capon (Solid Green Line)
* **Trend:** Highly volatile with a general downward slope initially, followed by significant fluctuations. It maintains the highest MSE throughout most of the range.
* **Key Points:** Starts near `1.0` at low pilot sizes, drops to ~`0.75` around pilot size 20, then fluctuates between `0.8` and `1.0` for the remainder of the plot.
### Kernel (Solid Light Blue Line)
* **Trend:** Smooth, monotonic decrease.
* **Key Points:** Starts at ~`0.85` (Pilot Size 10) and steadily declines to ~`0.58` (Pilot Size 80). It shows the most consistent improvement as pilot size increases without the noise seen in Capon or ZF.
### Wiener (Solid Red Line)
* **Trend:** Sharp exponential-like decay, flattening out at higher pilot sizes.
* **Key Points:** Starts very high (~`0.9` at Pilot Size 10), drops rapidly to ~`0.3` by Pilot Size 20, and eventually converges with the Wiener-CE line at ~`0.2` for Pilot Sizes > 60.
### Wiener-CE (Dashed Dark Blue Line)
* **Trend:** Gradual, smooth decrease. This is the best-performing algorithm across the entire range.
* **Key Points:** Starts at the lowest point (~`0.32` at Pilot Size 10) and slowly declines to a floor of ~`0.2` at Pilot Size 80.
### ZF (Solid Magenta Line)
* **Trend:** Highly volatile with an overall upward (worsening) trend as pilot size increases.
* **Key Points:** Starts at ~`0.55` (Pilot Size 10). Despite some dips, it trends upward, ending near ~`0.9` at Pilot Size 80. This suggests the Zero Forcing (ZF) method performs worse or becomes more unstable as the pilot size grows in this specific context.
---
## 4. Comparative Summary Table
| Algorithm | Color/Style | Initial MSE (approx.) | Final MSE (approx.) | Stability |
| :--- | :--- | :--- | :--- | :--- |
| **Wiener-CE** | Dashed Blue | 0.32 | 0.20 | Very Stable (Best) |
| **Wiener** | Solid Red | 0.90 | 0.20 | High initial error, converges to best |
| **Kernel** | Solid Light Blue | 0.85 | 0.58 | Stable/Predictable |
| **Capon** | Solid Green | 1.00 | 0.95 | Highly Volatile (Worst) |
| **ZF** | Solid Magenta | 0.55 | 0.90 | Volatile/Degrading |
## 5. Technical Observations
* **Convergence:** The `Wiener` and `Wiener-CE` algorithms converge to the same minimum error floor of approximately `0.2` as the Pilot Size exceeds 60.
* **Performance Gap:** There is a significant performance gap (approx. 0.4 MSE units) between the Wiener-based methods and the other three methods (Capon, Kernel, ZF) at larger pilot sizes.
* **Anomalous Trend:** The `ZF` (Magenta) line is unique in that its performance generally degrades (MSE increases) as the Pilot Size increases, whereas most estimation models typically improve with more data.
</details>
(b) $N$ =8, SNR 10dB, $\bm{R}_{v}$ Known
<details>
<summary>x5.png Details</summary>
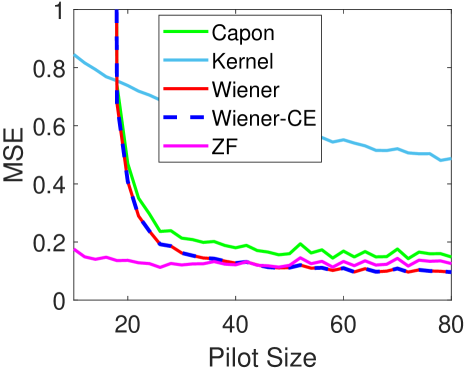
### Visual Description
# Technical Data Extraction: MSE vs. Pilot Size Performance Chart
## 1. Image Classification and Overview
This image is a 2D line graph illustrating the relationship between **Mean Squared Error (MSE)** and **Pilot Size** for five different signal processing or estimation algorithms. The chart evaluates performance (lower MSE is better) as the sample size (Pilot Size) increases.
## 2. Component Isolation
### Header / Metadata
* **Language:** English.
* **Title:** None present within the image frame.
### Main Chart Area
* **Y-Axis Label:** `MSE` (Mean Squared Error).
* **Y-Axis Scale:** Linear, ranging from `0` to `1` with major tick marks at `0`, `0.2`, `0.4`, `0.6`, `0.8`, and `1`.
* **X-Axis Label:** `Pilot Size`.
* **X-Axis Scale:** Linear, ranging from approximately `10` to `80` with major tick marks labeled at `20`, `40`, `60`, and `80`.
### Legend (Spatial Grounding: Top-Center [x: ~0.5, y: ~0.2])
The legend is contained within a black-bordered box and identifies five data series:
1. **Capon:** Solid bright green line.
2. **Kernel:** Solid light blue line.
3. **Wiener:** Solid red line.
4. **Wiener-CE:** Dashed dark blue line (overlaid on the Wiener line).
5. **ZF:** Solid magenta line.
---
## 3. Trend Verification and Data Extraction
### Series 1: Kernel (Light Blue)
* **Visual Trend:** Slopes downward gradually from left to right. It maintains the highest MSE across the entire range of Pilot Sizes.
* **Data Points:**
* Starts at ~0.85 MSE (Pilot Size 10).
* Crosses 0.6 MSE at ~Pilot Size 45.
* Ends at ~0.5 MSE (Pilot Size 80).
### Series 2: Capon (Green)
* **Visual Trend:** Sharp exponential decay initially, then plateaus with minor fluctuations.
* **Data Points:**
* Starts off-chart (>1.0 MSE) at Pilot Size 10.
* Drops sharply to ~0.25 MSE at Pilot Size 25.
* Levels off between 0.15 and 0.2 MSE for Pilot Sizes 40–80.
### Series 3 & 4: Wiener (Red) and Wiener-CE (Dashed Blue)
* **Visual Trend:** These two lines are nearly identical and perfectly overlaid. They show a very sharp initial drop, reaching the lowest MSE values among all algorithms for Pilot Sizes > 30.
* **Data Points:**
* Starts off-chart (>1.0 MSE) at Pilot Size 10.
* Drops to ~0.2 MSE at Pilot Size 25.
* Converges to ~0.1 MSE at Pilot Size 80.
### Series 5: ZF (Magenta)
* **Visual Trend:** Relatively flat compared to others. It starts with the lowest MSE at small Pilot Sizes but is overtaken by the Wiener methods as Pilot Size increases.
* **Data Points:**
* Starts at ~0.18 MSE (Pilot Size 10).
* Slightly decreases and fluctuates around 0.12 - 0.15 MSE.
* Ends at ~0.13 MSE (Pilot Size 80).
---
## 4. Comparative Analysis Summary
| Algorithm | Performance at Low Pilot Size (<20) | Performance at High Pilot Size (80) | Overall Rank (Lower is Better) |
| :--- | :--- | :--- | :--- |
| **ZF** | Best (Lowest MSE) | Good | 2nd |
| **Wiener / Wiener-CE** | Poor (High MSE) | Best (Lowest MSE) | 1st (Optimal at scale) |
| **Capon** | Poor (High MSE) | Moderate | 3rd |
| **Kernel** | Moderate | Worst (Highest MSE) | 4th |
**Key Observation:** The **Wiener** and **Wiener-CE** methods are highly sensitive to Pilot Size; they perform poorly with very few samples but become the most accurate once the Pilot Size exceeds approximately 30. Conversely, **ZF** is the most robust when data is extremely scarce (Pilot Size < 20).
</details>
(c) $N$ =16, SNR 10dB, $\bm{R}_{v}$ Estimated
<details>
<summary>x6.png Details</summary>
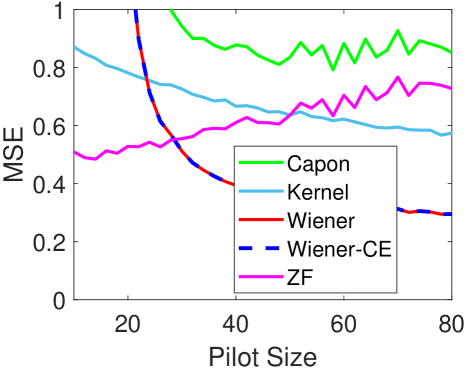
### Visual Description
# Technical Data Extraction: MSE vs. Pilot Size Performance Chart
## 1. Component Isolation
* **Header:** None present.
* **Main Chart Area:** A 2D line graph plotting Mean Squared Error (MSE) against Pilot Size. It contains five distinct data series.
* **Legend:** Located in the lower-right quadrant of the plot area (approximate spatial grounding: [x=0.5 to 0.9, y=0.1 to 0.5]). It is enclosed in a black rectangular border with a white background.
* **Axes:**
* **Y-Axis (Vertical):** Labeled "MSE". Scale ranges from 0 to 1 with major tick marks at intervals of 0.2.
* **X-Axis (Horizontal):** Labeled "Pilot Size". Scale ranges from approximately 10 to 80 with major tick marks labeled at 20, 40, 60, and 80.
---
## 2. Legend and Series Identification
| Series Label | Line Color | Line Style | Visual Trend Description |
| :--- | :--- | :--- | :--- |
| **Capon** | Green | Solid | Starts high (>1.0), drops quickly, then fluctuates with a slight downward trend, remaining the highest MSE overall. |
| **Kernel** | Light Blue | Solid | Steady, linear-like downward slope across the entire x-axis range. |
| **Wiener** | Red | Solid | Sharp exponential-like decay. Note: This line is overlaid by the Wiener-CE dashed line. |
| **Wiener-CE** | Dark Blue | Dashed | Identical path to "Wiener". Sharp decay, flattening out as Pilot Size increases. |
| **ZF** | Magenta | Solid | Steady upward slope; performance degrades (MSE increases) as Pilot Size increases. |
---
## 3. Data Extraction and Trend Analysis
### Series 1: Capon (Green Solid Line)
* **Trend:** High initial error with significant variance/noise.
* **Key Points:**
* At Pilot Size ~30: MSE $\approx$ 1.0
* At Pilot Size ~50: MSE $\approx$ 0.82
* At Pilot Size ~80: MSE $\approx$ 0.85 (with peaks reaching ~0.95 near Pilot Size 70).
### Series 2: Kernel (Light Blue Solid Line)
* **Trend:** Consistent improvement.
* **Key Points:**
* At Pilot Size 10: MSE $\approx$ 0.88
* At Pilot Size 40: MSE $\approx$ 0.68
* At Pilot Size 80: MSE $\approx$ 0.58
### Series 3 & 4: Wiener & Wiener-CE (Red Solid / Blue Dashed)
* **Trend:** These two series are perfectly correlated in this visualization. They show the most rapid improvement, starting off-chart (MSE > 1) and becoming the best-performing methods (lowest MSE) after a Pilot Size of approximately 30.
* **Key Points:**
* At Pilot Size 20: MSE $\approx$ 1.0
* At Pilot Size 30: MSE $\approx$ 0.55 (Crosses the ZF line here)
* At Pilot Size 40: MSE $\approx$ 0.40
* At Pilot Size 80: MSE $\approx$ 0.30
### Series 5: ZF (Magenta Solid Line)
* **Trend:** Counter-intuitive upward trend; as Pilot Size increases, the Mean Squared Error increases.
* **Key Points:**
* At Pilot Size 10: MSE $\approx$ 0.50
* At Pilot Size 40: MSE $\approx$ 0.60
* At Pilot Size 80: MSE $\approx$ 0.75
---
## 4. Summary of Findings
* **Optimal Method:** The **Wiener** and **Wiener-CE** methods provide the lowest MSE for Pilot Sizes greater than 30.
* **Crossover Point:** At a Pilot Size of approximately 28-30, the Wiener methods overtake the ZF method in accuracy.
* **Performance Degradation:** The **ZF** (Zero Forcing) method is the only one that shows a positive correlation between Pilot Size and MSE, indicating it performs worse with more data in this specific simulation.
* **Stability:** The **Kernel** method shows the most stable and predictable rate of improvement, while the **Capon** method exhibits the highest level of volatility.
</details>
(d) $N$ =16, SNR -10dB, $\bm{R}_{v}$ Estimated
Figure 2: Testing MSE against training pilot sizes under different numbers of receive antennas; only non-robust beamformers including non-diagonal-loading ones are considered. The true value of $\bm{R}_{v}$ can be unknown and estimated using pilot data. The signal-to-noise ratio (SNR) is $10$ dB or $-10$ dB.
From Fig. 2, the following main points can be outlined.
1. For a fixed number $M$ of transmit antennas, the larger the number $N$ of receive antennas, the smaller the MSE; cf. Figs. 2(a) and 2(c). This fact is well-established and is due to the benefit of antenna diversity. In addition, for fixed $N$ and $M$ , the higher the SNR, the smaller the MSE; cf. Figs. 2(c) and 2(d); this is also well believed.
1. As the pilot size increases, the Wiener beamformer tends to have the best performance because the Wiener beamformer is optimal for the linear Gaussian signal model. When $\bm{R}_{v}$ is accurately known, the Wiener-CE beamformer outperforms the general Wiener beamformer (cf. Fig. 2(b)) because the former also exploits the information of the linear signal model in addition to the pilot data, while the latter only utilizes the pilot data. However, when $\bm{R}_{v}$ is estimated using the pilot data, the performances of the general Wiener beamformer and the Wiener-CE beamformer have no significant difference; cf. Figs. 2(a) and 2(c). Therefore, Fig. 2 validates our claim that channel estimation is not a necessary operation in receive beamforming and estimation of wireless signals; recall Subsection III-A 3.
1. The ZF beamformer tends to be more efficient as $N$ increases; cf. Figs. 2(a) and 2(c). However, the ZF beamformer becomes less satisfactory when the SNR decreases; cf. Figs. 2(c) and 2(d). The Capon beamformer is also unsatisfactory when $N$ is small or the SNR is low.
1. The kernel beamformer, as a nonlinear method, cannot outperform linear beamformers because, for a linear Gaussian signal model, the optimal beamformer is linear. From the perspective of machine learning, nonlinear methods tend to overfit the limited training samples.
Second, we suppose that the transmit antennas emit discrete-valued symbols from a constellation that is modulated using quadrature phase-shift keying (QPSK). The performance evaluation measure is therefore the symbol error rate (SER). The experimental results are shown in Fig. 3. We find that all the conclusive main points from Fig. 2 can be obtained from Fig. 3 as well: this validates that minimizing MSE reduces SER. In addition, Figs. 3(c) and 3(d) reveal that the Wiener beamformer even slightly works better than the Wiener-CE beamformer when the pilot size is smaller than $15$ because the uncertainty in the estimated $\hat{\bm{R}}_{v}$ , on the contrary, misleads the latter. Nevertheless, as the pilot size increases, the Wiener-CE beamformer tends to overlap the Wiener beamformer quickly.
<details>
<summary>x7.png Details</summary>
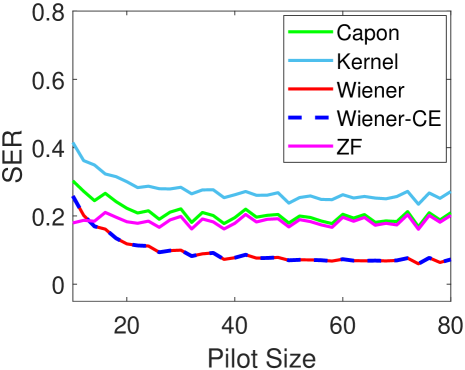
### Visual Description
# Technical Document Extraction: SER vs. Pilot Size Performance Chart
## 1. Component Isolation
* **Header:** None present.
* **Main Chart Area:** A 2D line graph plotting Symbol Error Rate (SER) against Pilot Size.
* **Legend:** Located in the upper-right quadrant of the plot area.
* **Axes:** Y-axis (Vertical) representing SER; X-axis (Horizontal) representing Pilot Size.
---
## 2. Metadata and Axis Extraction
* **Y-Axis Label:** `SER` (Symbol Error Rate)
* **Y-Axis Scale:** Linear, ranging from `0` to `0.8`.
* **Y-Axis Markers:** `0`, `0.2`, `0.4`, `0.6`, `0.8`.
* **X-Axis Label:** `Pilot Size`
* **X-Axis Scale:** Linear, ranging from approximately `8` to `80`.
* **X-Axis Markers:** `20`, `40`, `60`, `80`.
---
## 3. Legend and Series Identification
The legend is located at approximately `[x=0.65, y=0.15]` relative to the top-left corner of the image frame.
| Legend Label | Line Color | Line Style | Visual Trend Description |
| :--- | :--- | :--- | :--- |
| **Capon** | Green | Solid | Starts at ~0.3, drops quickly, then fluctuates between 0.18 and 0.22. |
| **Kernel** | Light Blue | Solid | Highest error rate; starts at ~0.42, stabilizes around 0.25–0.28. |
| **Wiener** | Red | Solid | Starts at ~0.25, drops sharply, stabilizes at the lowest level (~0.08). |
| **Wiener-CE** | Blue | Dashed | Overlays the "Wiener" line almost perfectly; follows the same downward trend to ~0.08. |
| **ZF** | Magenta | Solid | Starts lowest (~0.18), remains relatively flat with minor fluctuations around 0.18–0.20. |
---
## 4. Data Analysis and Key Trends
### General Observations
All methods show an initial improvement (decrease in SER) as the Pilot Size increases from the starting point to approximately 20. Beyond a Pilot Size of 30, the performance for all methods reaches a "steady state" where the SER fluctuates within a narrow band but does not significantly decrease further.
### Comparative Performance
1. **Best Performers (Lowest SER):** The **Wiener** and **Wiener-CE** methods are the most effective. They converge to an SER of approximately **0.08**. The dashed blue line (Wiener-CE) and solid red line (Wiener) are visually indistinguishable for most of the plot, indicating identical or near-identical performance.
2. **Mid-Tier Performers:**
* **ZF (Zero Forcing):** Maintains a consistent SER around **0.18–0.20**. Interestingly, it starts with the lowest error at the smallest pilot size but is overtaken by the Wiener methods as pilot size increases.
* **Capon:** Performs slightly worse than ZF, stabilizing around an SER of **0.20–0.22**.
3. **Worst Performer (Highest SER):** The **Kernel** method consistently exhibits the highest Symbol Error Rate, stabilizing at approximately **0.26**.
---
## 5. Estimated Data Points (Sampling)
| Pilot Size (Approx) | Kernel (Blue) | Capon (Green) | ZF (Magenta) | Wiener/Wiener-CE (Red/Blue Dash) |
| :--- | :--- | :--- | :--- | :--- |
| **10** | 0.38 | 0.28 | 0.18 | 0.22 |
| **20** | 0.30 | 0.22 | 0.18 | 0.12 |
| **40** | 0.26 | 0.20 | 0.18 | 0.08 |
| **60** | 0.26 | 0.20 | 0.19 | 0.07 |
| **80** | 0.27 | 0.21 | 0.20 | 0.08 |
---
## 6. Language Declaration
The text in this image is entirely in **English**. No other languages were detected.
</details>
(a) $N$ =8, SNR 10dB, $\bm{R}_{v}$ Estimated
<details>
<summary>x8.png Details</summary>
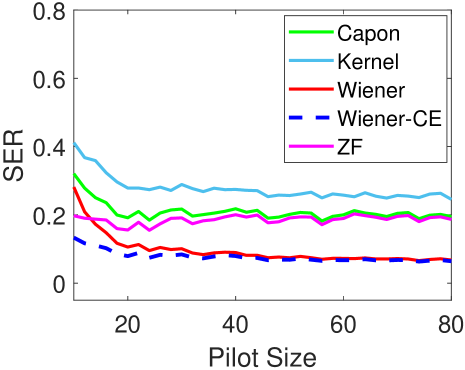
### Visual Description
# Technical Data Extraction: SER vs. Pilot Size Performance Chart
## 1. Image Metadata & Overview
- **Type:** Line Graph (Performance Comparison)
- **Language:** English
- **Primary Subject:** Symbol Error Rate (SER) performance of various signal processing/estimation algorithms relative to Pilot Size.
## 2. Component Isolation
### A. Header/Legend
- **Location:** Top-right quadrant.
- **Legend Items (Color/Style Coded):**
- **Capon:** Solid Green line.
- **Kernel:** Solid Light Blue line.
- **Wiener:** Solid Red line.
- **Wiener-CE:** Dashed Dark Blue line.
- **ZF (Zero Forcing):** Solid Magenta line.
### B. Main Chart Area (Axes)
- **Y-Axis (Vertical):**
- **Label:** SER (Symbol Error Rate)
- **Scale:** 0 to 0.8
- **Markers:** 0, 0.2, 0.4, 0.6, 0.8
- **X-Axis (Horizontal):**
- **Label:** Pilot Size
- **Scale:** 10 to 80 (implied start near 5)
- **Markers:** 20, 40, 60, 80
---
## 3. Trend Verification & Data Extraction
All data series exhibit a "decay and plateau" trend: a sharp decrease in SER as Pilot Size increases from the minimum value, followed by stabilization (convergence) after a Pilot Size of approximately 20-30.
### Data Series Analysis (Ordered by Performance - Lowest SER is Best)
| Algorithm | Line Style | Initial Trend (Pilot Size < 20) | Convergence Level (SER) | Relative Performance |
| :--- | :--- | :--- | :--- | :--- |
| **Wiener-CE** | Dashed Dark Blue | Slopes downward from ~0.14 to ~0.08. | ~0.07 - 0.08 | **Best Overall.** Lowest error rate across all pilot sizes. |
| **Wiener** | Solid Red | Sharp downward slope from ~0.28 to ~0.11. | ~0.07 - 0.09 | Converges to nearly the same level as Wiener-CE after Pilot Size 40. |
| **ZF** | Solid Magenta | Slight downward slope from ~0.20 to ~0.16. | ~0.18 - 0.20 | Mid-tier performance; very stable after initial drop. |
| **Capon** | Solid Green | Sharp downward slope from ~0.32 to ~0.20. | ~0.20 - 0.22 | Slightly worse than ZF; exhibits minor fluctuations. |
| **Kernel** | Solid Light Blue | Downward slope from ~0.42 to ~0.28. | ~0.25 - 0.28 | **Worst Overall.** Highest error rate across the entire range. |
---
## 4. Key Observations & Technical Insights
1. **Convergence Point:** Most algorithms reach a point of diminishing returns regarding Pilot Size around the **20-30 mark**. Increasing the Pilot Size beyond 40 yields negligible improvements in SER for all tested methods.
2. **Wiener Superiority:** Both Wiener-based methods (Wiener and Wiener-CE) significantly outperform the other three methods.
3. **Wiener vs. Wiener-CE:** The "Wiener-CE" (dashed blue) maintains a lower SER at very small pilot sizes compared to the standard "Wiener" (solid red), though they converge to nearly identical values as the pilot size increases.
4. **Stability:** The "Kernel" and "Capon" methods show more visual "jitter" or variance in their SER values across the horizontal axis compared to the smoother "Wiener-CE" line.
5. **Ranking:** At any given Pilot Size (e.g., at x=40), the performance ranking from best to worst is:
* `Wiener-CE ≈ Wiener > ZF > Capon > Kernel`
</details>
(b) $N$ =8, SNR 10dB, $\bm{R}_{v}$ Known
<details>
<summary>x9.png Details</summary>
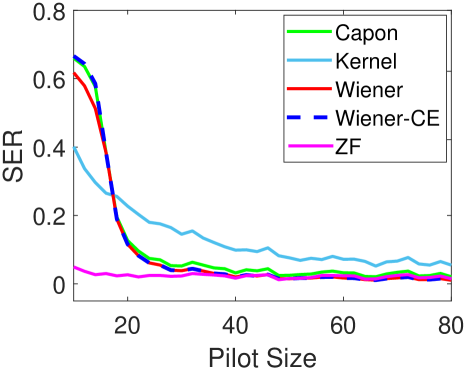
### Visual Description
# Technical Data Extraction: SER vs. Pilot Size Performance Chart
## 1. Document Overview
This image is a line graph illustrating the relationship between **Pilot Size** (independent variable) and **SER** (Symbol Error Rate, dependent variable) for five different signal processing or channel estimation algorithms.
## 2. Component Isolation
### A. Header/Metadata
* **Language:** English
* **Type:** 2D Line Plot
### B. Axis Definitions
* **Y-Axis (Vertical):**
* **Label:** `SER` (Symbol Error Rate)
* **Scale:** Linear, ranging from `0` to `0.8`.
* **Major Tick Markers:** `0`, `0.2`, `0.4`, `0.6`, `0.8`.
* **X-Axis (Horizontal):**
* **Label:** `Pilot Size`
* **Scale:** Linear, ranging from approximately `10` to `80`.
* **Major Tick Markers:** `20`, `40`, `60`, `80`.
### C. Legend (Spatial Grounding: Top-Right Quadrant)
The legend is contained within a black-bordered box.
* **Capon:** Solid Green line.
* **Kernel:** Solid Light Blue line.
* **Wiener:** Solid Red line.
* **Wiener-CE:** Dashed Dark Blue line.
* **ZF:** Solid Magenta (Pink) line.
---
## 3. Data Series Analysis and Trend Verification
### ZF (Solid Magenta Line)
* **Trend:** This line remains consistently low and nearly flat across the entire x-axis range. It represents the best performance (lowest error) at low pilot sizes.
* **Data Points:** Starts at ~0.05 (Pilot Size 10) and fluctuates slightly between 0.01 and 0.03 as Pilot Size increases to 80.
### Kernel (Solid Light Blue Line)
* **Trend:** Slopes downward moderately. It starts with a high error rate that gradually improves as Pilot Size increases, but it remains significantly higher than all other methods for Pilot Sizes > 20.
* **Data Points:** Starts at ~0.4 (Pilot Size 10), drops to ~0.2 at Pilot Size 25, and levels off around 0.05–0.10 by Pilot Size 80.
### Capon (Solid Green Line)
* **Trend:** Sharp exponential decay. Very high error at low pilot sizes, dropping rapidly to converge with the Wiener methods.
* **Data Points:** Starts at ~0.65 (Pilot Size 10), drops sharply to ~0.1 by Pilot Size 20, and stabilizes near 0.02 for Pilot Sizes > 40.
### Wiener (Solid Red Line)
* **Trend:** Sharp exponential decay, very similar to Capon but starting slightly lower.
* **Data Points:** Starts at ~0.6 (Pilot Size 10), drops sharply to ~0.1 by Pilot Size 20, and stabilizes near 0.01–0.02 for Pilot Sizes > 40.
### Wiener-CE (Dashed Dark Blue Line)
* **Trend:** Sharp exponential decay. This line is almost perfectly overlaid with the Capon and Wiener lines, indicating nearly identical performance at higher pilot sizes.
* **Data Points:** Starts at ~0.65 (Pilot Size 10), drops sharply to ~0.1 by Pilot Size 20, and stabilizes near 0.01–0.02 for Pilot Sizes > 40.
---
## 4. Key Findings and Observations
1. **Convergence:** For a Pilot Size greater than 40, the **Capon**, **Wiener**, **Wiener-CE**, and **ZF** methods all converge to a very low SER (near zero).
2. **Low Pilot Size Performance:** The **ZF** (Zero Forcing) method is the most robust when the Pilot Size is small (< 20), maintaining a low SER while all other methods exhibit high error rates.
3. **Underperformance:** The **Kernel** method consistently shows the highest SER once the Pilot Size exceeds 20, failing to converge as efficiently as the other four methods.
4. **Critical Threshold:** There is a significant performance "knee" or threshold around **Pilot Size 20**. Below this value, most methods (except ZF) fail significantly; above this value, they improve rapidly.
</details>
(c) $N$ =16, SNR 10dB, $\bm{R}_{v}$ Estimated
<details>
<summary>x10.png Details</summary>
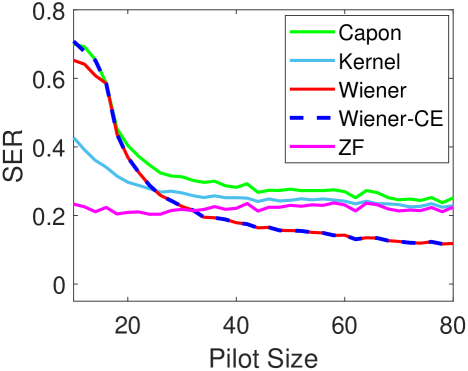
### Visual Description
# Technical Data Extraction: SER vs. Pilot Size Performance Chart
## 1. Image Classification and Overview
This image is a line graph depicting the relationship between **Pilot Size** (independent variable) and **SER** (Symbol Error Rate, dependent variable) for five different signal processing or estimation algorithms.
## 2. Component Isolation
### A. Header/Metadata
* **Language:** English.
* **Title:** None present within the image frame.
### B. Axis Configuration
* **Y-Axis (Vertical):**
* **Label:** `SER` (Symbol Error Rate).
* **Scale:** Linear, ranging from `0` to `0.8`.
* **Markers:** `0`, `0.2`, `0.4`, `0.6`, `0.8`.
* **X-Axis (Horizontal):**
* **Label:** `Pilot Size`.
* **Scale:** Linear, ranging from approximately `10` to `80`.
* **Markers:** `20`, `40`, `60`, `80`.
### C. Legend (Spatial Grounding: Top-Right Quadrant)
The legend is enclosed in a black bounding box.
* **Capon:** Solid Green line.
* **Kernel:** Solid Light Blue line.
* **Wiener:** Solid Red line.
* **Wiener-CE:** Dashed Dark Blue line (Note: This line overlaps the Wiener line almost perfectly).
* **ZF:** Solid Magenta line.
---
## 3. Trend Verification and Data Extraction
| Algorithm | Pilot Size 10 (Approx) | Pilot Size 20 (Approx) | Pilot Size 40 (Approx) | Pilot Size 80 (Approx) | Trend Description |
| :--- | :--- | :--- | :--- | :--- | :--- |
| **Capon** | 0.70 | 0.42 | 0.28 | 0.25 | Starts very high, drops sharply until size 25, then levels off. Highest error rate for sizes > 25. |
| **Kernel** | 0.42 | 0.30 | 0.25 | 0.23 | Moderate initial error, decreases steadily until size 30, then plateaus. |
| **Wiener** | 0.65 | 0.40 | 0.18 | 0.12 | Significant downward slope; achieves lowest SER as Pilot Size increases. |
| **Wiener-CE**| 0.70 | 0.40 | 0.18 | 0.12 | Virtually identical to Wiener; tracks closely as a single dashed line. |
| **ZF** | 0.23 | 0.23 | 0.22 | 0.22 | Relatively flat/invariant; unaffected by Pilot Size increase. |
---
## 4. Comparative Analysis and Summary
* **Best Performance (High Pilot Size):** The **Wiener** and **Wiener-CE** methods are the most efficient as Pilot Size increases, achieving the lowest SER (~0.12).
* **Best Performance (Low Pilot Size):** The **ZF** (Magenta) method is superior when the Pilot Size is very small (< 25), as it remains stable while others have high initial error rates.
* **Worst Performance:** The **Capon** (Green) method consistently results in the highest SER once the Pilot Size exceeds 25.
* **Convergence:** The Wiener and Wiener-CE lines track each other so closely that they appear as a single red-and-blue dashed line for the majority of the plot.
</details>
(d) $N$ =16, SNR -10dB, $\bm{R}_{v}$ Estimated
Figure 3: Testing SER against training pilot sizes under different numbers of receive antennas; only non-robust beamformers including non-diagonal-loading ones are considered. The true value of $\bm{R}_{v}$ can be unknown and estimated using pilot data. The signal-to-noise ratio (SNR) is $10$ dB or $-10$ dB.