# Survey of Privacy Threats and Countermeasures in Federated Learning
**Authors**: Masahiro Hayashitani, Junki Mori, and Isamu Teranishi
> M. Hayashitani, J. Mori, and I. Teranishi are with NEC Secure System Platform Research Laboratories. E-mail: hayashitani@nec.com, junki.mori@nec.com, teranisi@nec.com.
Abstract
Federated learning is widely considered to be as a privacy-aware learning method because no training data is exchanged directly between clients. Nevertheless, there are threats to privacy in federated learning, and privacy countermeasures have been studied. However, we note that common and unique privacy threats among typical types of federated learning have not been categorized and described in a comprehensive and specific way. In this paper, we describe privacy threats and countermeasures for the typical types of federated learning; horizontal federated learning, vertical federated learning, and transfer federated learning.
Index Terms: horizontal federated learning, vertical federated learning, transfer federated learning, threat to privacy, countermeasure against privacy threat.
I Introduction
As computing devices become more ubiquitous, people generate vast amounts of data in their daily lives. Collecting this data in centralized storage facilities is costly and time-consuming [1]. Another important concern is user privacy and confidentiality, as usage data typically contains sensitive information. Sensitive data such as biometrics and healthcare can be used for targeted social advertising and recommendations, posing immediate or potential privacy risks. Therefore, private data should not be shared directly without any privacy considerations. As societies become more privacy-conscious, legal restrictions such as the General Data Protection Regulation (GDPR) and the EU AI ACT are emerging, making data aggregation practices less feasible. In this case, federated learning has emerged as a promising machine learning technique where each client learns and sends the information to a server.
Federated learning has attracted attention as a privacy-preserving machine learning technique because it can learn a global model without exchanging private raw data between clients. However, federated learning still poses a threat to privacy. Recent works have shown that federated learning may not always provide sufficient privacy guarantees, since the communication of model updates throughout the training process may still reveal sensitive information, even to a third party or to the central server [1]. Typical examples of federated learning include horizontal federated learning where features are common, vertical federated learning where IDs are common, and federated transfer learning where some features or IDs are common. However, we note that common and unique privacy threats among each type of federated learning have not been categorized and described in a comprehensive and specific way.
For example, in the case of horizontal federated learning, semi-honest server can infer client’s data by inference attacks on a model sent by the client. If the client is an attacker, the attacker can infer the data of other clients by inference attacks on a global model received from the server. Such an attack is possible because the global model is design to reflect the data of all clients. If the attacker is a third party that is neither a server nor a client, it can eavesdrop on models passing through the communication channel and infer client data through inference attacks. In vertical federated learning, the main threat to privacy is the identify leakage through identity matching between clients. In addition, since the intermediate outputs of a model are sent to the server, there is a possibility that client data can be inferred through an inference attack. Also, as in horizontal federated learning, client data can be inferred by an inference attack on the server. Finally, in federated transfer learning, member and attribute guessing attacks are possible by exploiting a prediction network. If IDs are common, gradient information is exchanged when features are made similar. Therefore member and attribute guessing attacks are possible by using gradient information. When there are common features among clients, attribute guessing attacks are possible by exploiting networks that complement the missing features from the common features.
In this paper, we discuss the above threats to privacy in detail and countermeasures against privacy threats in three types of federated learning; horizontal federated learning, vertical federated learning, and federated transfer learning. The paper is organized as follows: Section 2 presents learning methods for horizontal federated learning, vertical federated learning, and federated transfer learning; Section 3 discusses threats to privacy in each federated learning; Section 4 discusses countermeasures against privacy threats in each federated learning; and Section 5 concludes.
II Categorization of Federated Learning
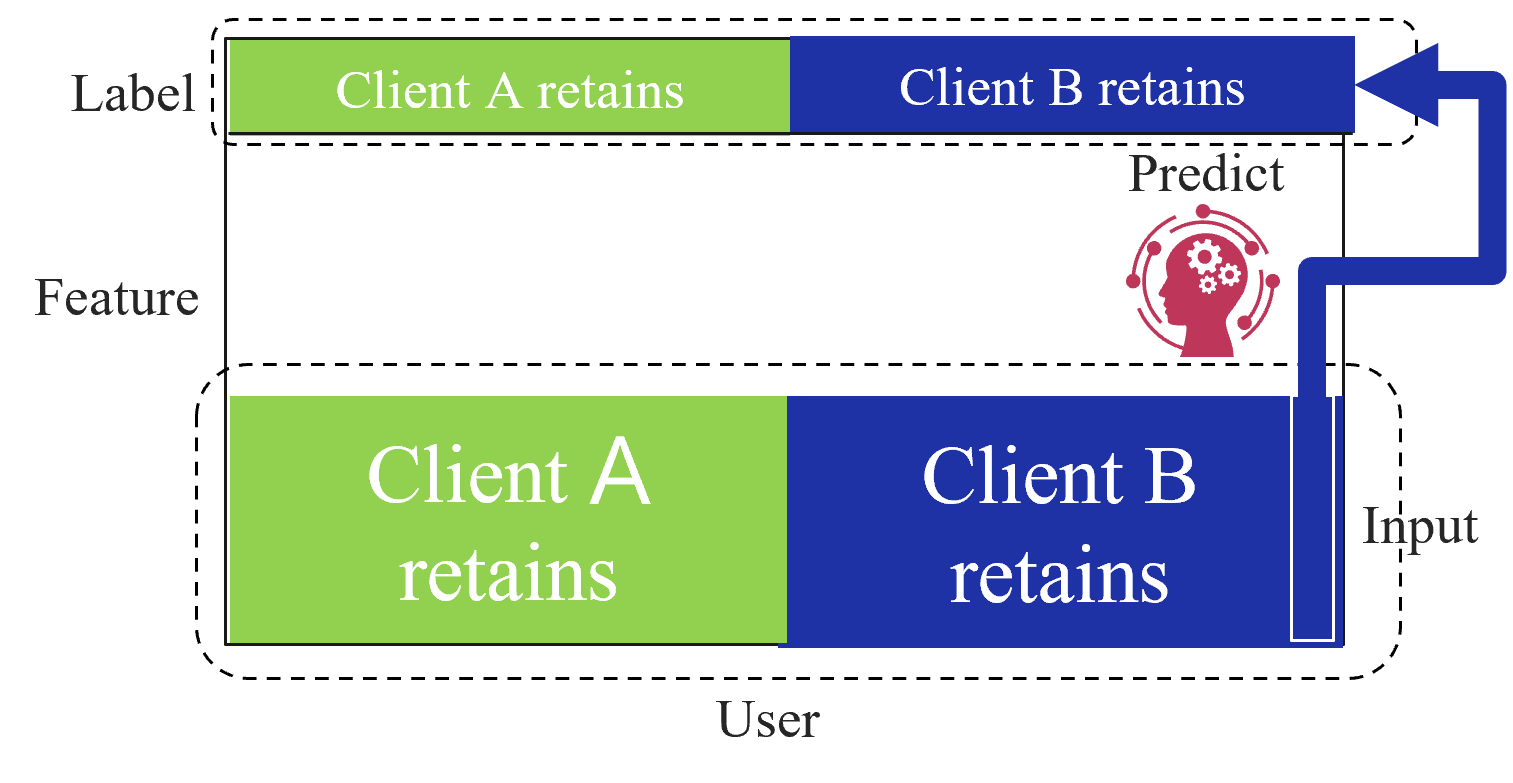
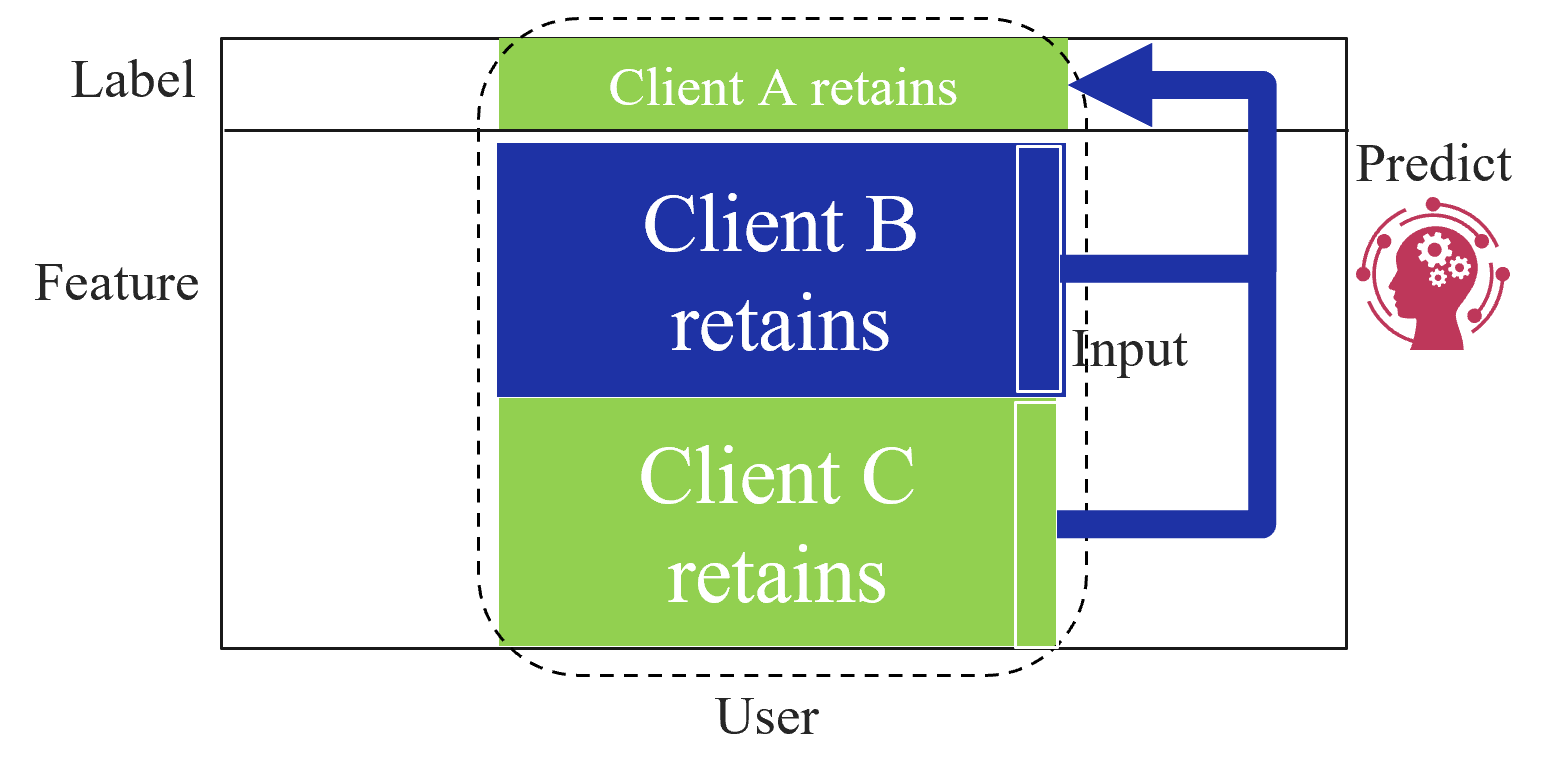
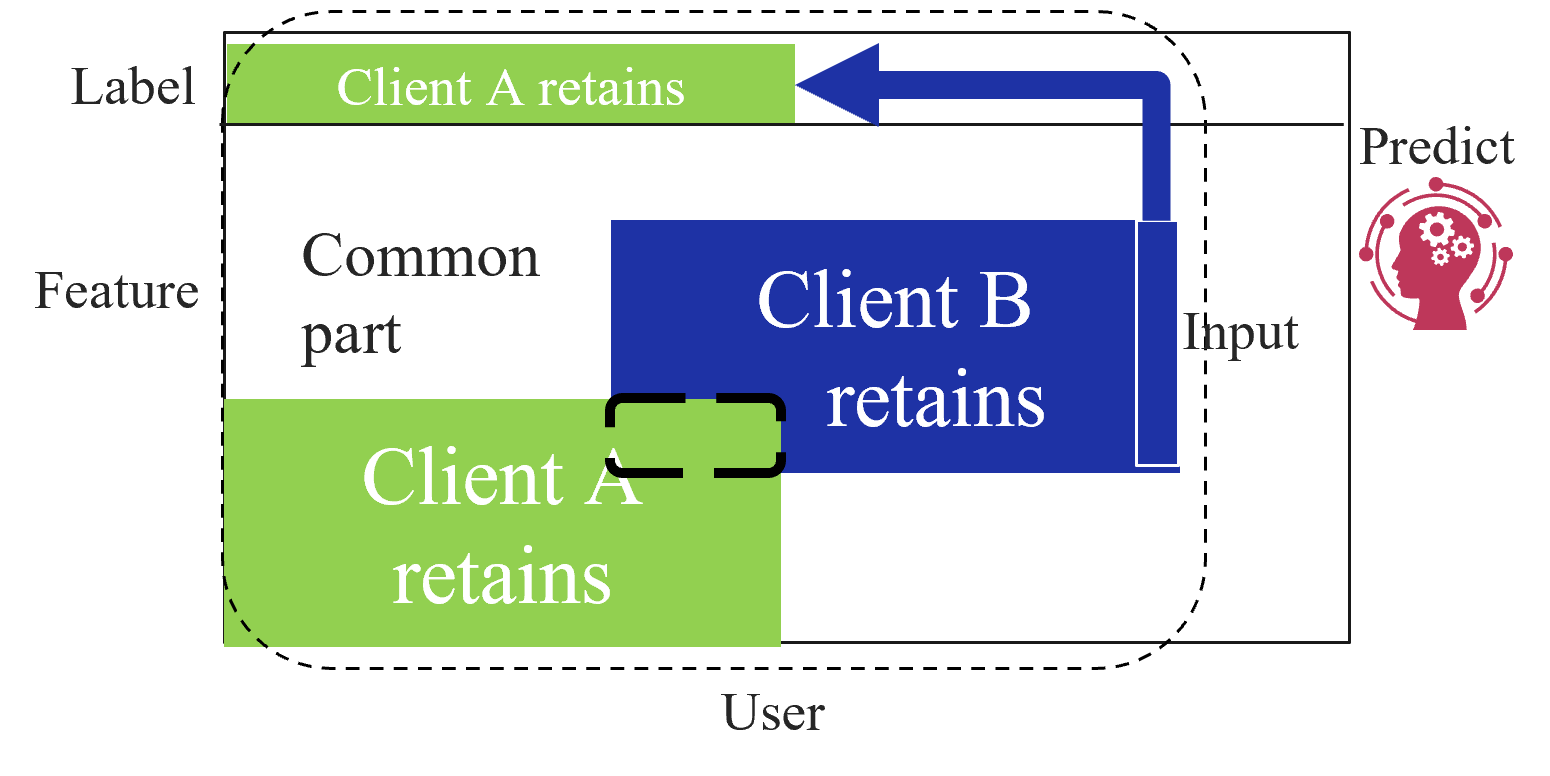
Based on the data structures among clients, federated learning is categorized into three types as first introduced by Yang et al. [2]: horizontal federated learning (HFL), vertical federated learning (VFL), and federated transfer learning (FTL). Figure 1 shows the data structure among clients for each type of federated learning. HFL assumes that each client has the same features and labels but different samples (Figure 1(a)). On the other hand, VFL assumes that each client has the same samples but disjoint features (Figure 1(a)). Finally, FTL applies to the scenario where each of the two clients has data that differ in not only samples but also features (Figure 1(c)).
In the following subsections, we describe the learning and prediction methods for each type of federated learning.
<details>
<summary>extracted/5379099/fig/HFL_structure.png Details</summary>
### Visual Description
## Diagram: Client Retention Prediction
### Overview
The image is a diagram illustrating a process for predicting client retention. It shows how user features are used as input to predict whether Client A or Client B will retain the user.
### Components/Axes
* **Vertical Axis (Left):**
* Label
* Feature
* **Horizontal Axis (Bottom):**
* User
* **Elements:**
* Two horizontal bars representing "Label" and "Feature" respectively.
* Each bar is divided into two sections: "Client A retains" (green) and "Client B retains" (blue).
* A "Predict" section with an icon of a head containing gears.
* An "Input" section.
* A blue arrow connecting the "Input" section to the "Predict" section, and then looping back to the "Label" section.
### Detailed Analysis or ### Content Details
* **Top Bar (Label):**
* Left Section (Green): "Client A retains"
* Right Section (Blue): "Client B retains"
* **Bottom Bar (Feature):**
* Left Section (Green): "Client A retains"
* Right Section (Blue): "Client B retains"
* **Predict:** Located to the right of the bars, above the "Input" section. Contains a red icon of a head silhouette with gears inside.
* **Input:** Located to the right of the bottom bar.
* **Arrow:** A thick blue arrow starts from the "Input" section, curves upwards and to the left, points to the "Predict" section, then curves further left and points to the "Client B retains" section of the "Label" bar.
### Key Observations
* The diagram suggests a cyclical process where user features are used to predict client retention, and the prediction is then used to refine the model.
* The green and blue sections in both bars represent the proportion or likelihood of a client retaining the user.
* The arrow indicates the flow of information from input features to prediction and then back to the label.
### Interpretation
The diagram illustrates a machine learning model for predicting client retention. User features are fed into the model ("Input"), which then predicts whether Client A or Client B will retain the user ("Predict"). This prediction is then compared to the actual outcome ("Label"), and the model is updated based on the difference between the prediction and the actual outcome. The cyclical nature of the diagram suggests a continuous learning process where the model is constantly being refined based on new data. The head with gears icon symbolizes the cognitive or computational process of prediction.
</details>
(a) Horizontal federated learning.
<details>
<summary>extracted/5379099/fig/VFL_structure.png Details</summary>
### Visual Description
## Diagram: Client Retention Prediction
### Overview
The image is a diagram illustrating a process for predicting client retention. It shows how user features are used as input to predict whether clients A, B, and C will retain.
### Components/Axes
* **Y-Axis Labels:**
* Label
* Feature
* User
* **Client Blocks:**
* Client A retains (light green)
* Client B retains (dark blue)
* Client C retains (light green)
* **Input/Output:**
* Input (dark blue arrow)
* Predict (reddish-pink icon of a head with gears)
### Detailed Analysis
* **Client A retains:** Located at the top, colored light green.
* **Client B retains:** Located in the middle, colored dark blue.
* **Client C retains:** Located at the bottom, colored light green.
* **Input Arrow:** A thick, dark blue arrow originates from the right side of the Client B and Client C blocks, curves upward, and points to the left side of the Client A block.
* **Predict Icon:** A reddish-pink icon depicting a head in profile with gears inside is located to the right of the input arrow.
* The client blocks are enclosed within a dashed line.
### Key Observations
* The diagram suggests a flow of information from the "User" (represented by Clients B and C) to the "Label" (represented by Client A).
* The "Feature" axis seems to represent the characteristics or attributes of the user.
* The "Input" arrow indicates that features from Clients B and C are used to predict the retention of Client A.
### Interpretation
The diagram illustrates a model where user features (from Clients B and C) are used as input to predict the retention of a "Label" (Client A). This could represent a scenario where the behavior or attributes of certain user groups (B and C) are used to predict the retention of another user group (A). The "Predict" icon signifies the application of a predictive model, likely using machine learning, to determine the likelihood of Client A retaining based on the input features. The dashed line enclosing the client blocks suggests that these clients are part of a larger user base or system.
</details>
(b) Vertical federated learning.
<details>
<summary>extracted/5379099/fig/FTL_structure.png Details</summary>
### Visual Description
## Diagram: Client Data Retention
### Overview
The image is a diagram illustrating how data is retained by different clients (Client A and Client B) and used for prediction. It shows the flow of data from the user, through a common feature part, and how each client retains specific portions of the data. The retained data is then used as input for a prediction model.
### Components/Axes
* **Labels:**
* Label (top-left)
* Feature (left)
* User (bottom)
* Input (right, slightly below center)
* Predict (top-right)
* **Data Blocks:**
* Client A retains (green block, top and bottom)
* Client B retains (blue block, center-right)
* Common part (white space between the green blocks)
* **Flow:** A blue arrow indicates the flow of data from "Client A retains" (top) to "Client B retains".
* **Predict Icon:** A red icon depicting a head with gears inside, representing the prediction process.
* **Outline:** A dashed line outlines the entire data flow process.
### Detailed Analysis
* **Client A retains (Top):** A green block labeled "Client A retains" is positioned at the top of the diagram, under the "Label" axis.
* **Common part:** The space between the two green blocks is labeled "Common part" under the "Feature" axis.
* **Client A retains (Bottom):** A green block labeled "Client A retains" is positioned at the bottom of the diagram, above the "User" axis.
* **Client B retains:** A blue block labeled "Client B retains" is positioned in the center-right of the diagram, partially overlapping the "Common part" and the bottom "Client A retains" block.
* **Data Flow:** A thick blue arrow originates from the top "Client A retains" block and points towards the "Client B retains" block, indicating the flow of data.
* **Input/Predict:** The "Client B retains" block is connected to the "Input" label, which leads to the "Predict" icon.
### Key Observations
* Client A retains data at both the label and user levels.
* Client B retains data that is influenced by the data retained by Client A.
* There is a "Common part" feature, suggesting shared data or processing.
* The retained data serves as input for a prediction model.
### Interpretation
The diagram illustrates a data retention and prediction process where Client A and Client B retain different parts of the data. Client A retains data related to labels and user information, while Client B retains data that is influenced by Client A's retained data. The "Common part" suggests a shared feature or processing step. The data retained by both clients is then used as input for a prediction model. This setup could represent a scenario where different clients have access to different aspects of the data, and their combined data is used for making predictions. The dashed line encompassing the entire process suggests a defined boundary or scope for the data flow.
</details>
(c) Federated transfer learning.
Figure 1: Categorization of federated learning based on data structure owned by clients.
II-A Horizontal Federated Learning
HFL is the most common federated learning category which was first introduced by Google [3]. The goal of HFL is for each client holding different samples to collaboratively improve the accuracy of a model with a common structure.
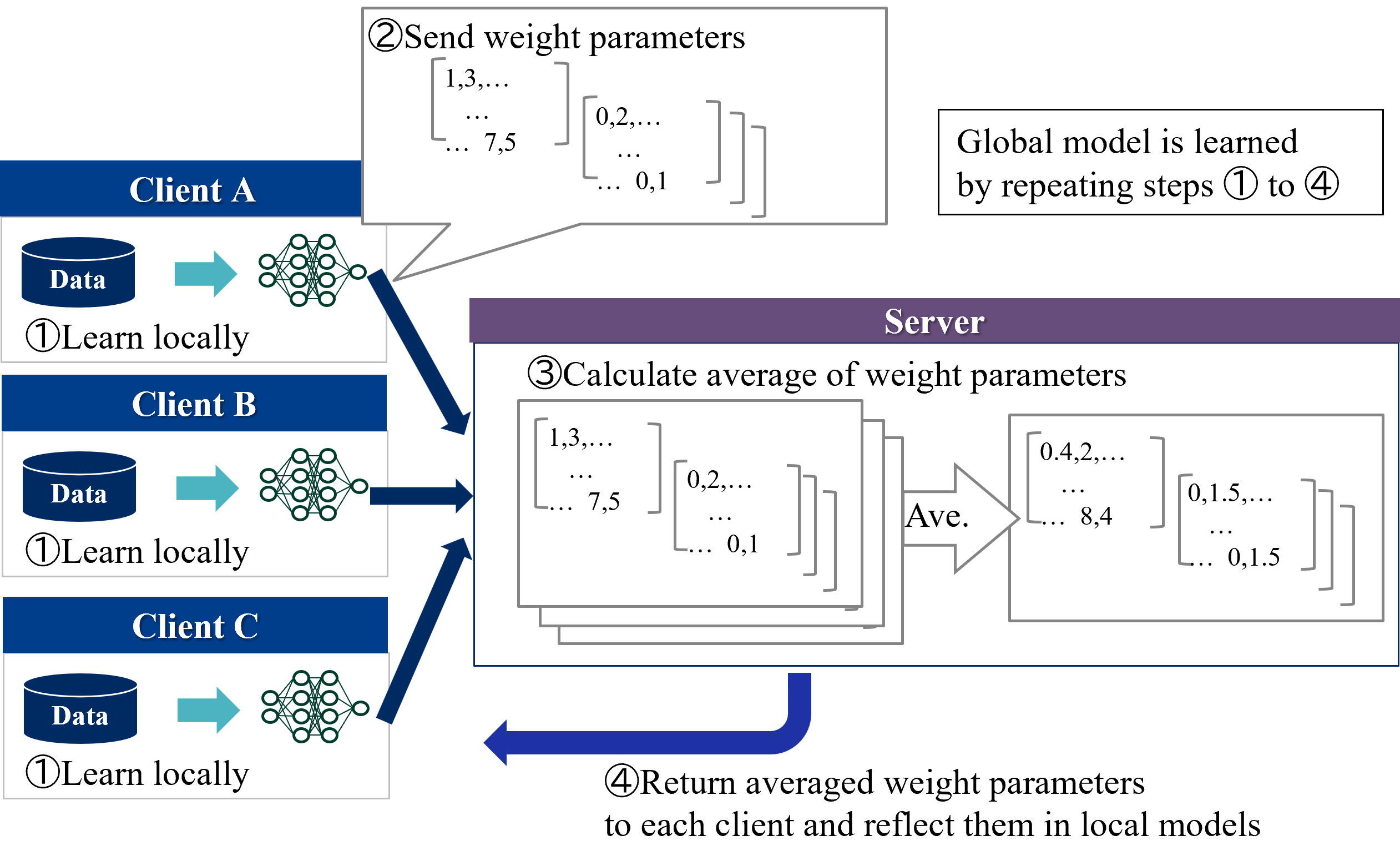
Figure 2 shows an overview of the HFL learning protocol. Two types of entities participate in learning of HFL:
1. Server - Coordinator. Server exchanges model parameters with the clients and aggregates model parameters received from the clients.
1. Clients - Data owners. Each client locally trains a model using their own private data and exchanges model parameters with the server.
Each clients first trains a local model for a few steps and sends the model parameters to the server. Next, the server updates a global model by aggregating (in standard methods such as FedAvg, simply averaging) the local models and sends it to all clients. This process is repeated until the convergence. During inference time, each client separately predicts the label using a global model and its own features.
The protocol described above is called centralized HFL because it requires a trusted third party, a central server. On the other hand, decentralized HFL, which eliminates the need for a central server, has emerged in recent years [4]. In decentralized HFL, clients directly communicates with each other, resulting in communication resource savings. There are various possible methods of communication between clients [4]. For example, the most common method for HFL of gradient boosting decision trees is for each client to add trees to the global model by sequence [5, 6, 7].
<details>
<summary>extracted/5379099/fig/LM_HFL.png Details</summary>
### Visual Description
## Diagram: Federated Learning Process
### Overview
The image illustrates the federated learning process, where multiple clients train models locally on their data and then send weight parameters to a central server. The server averages these parameters and sends the averaged parameters back to the clients, who update their local models. This process is repeated to learn a global model.
### Components/Axes
* **Clients:** Client A, Client B, and Client C. Each client has its own data and a local model (represented as a neural network).
* **Server:** A central server that aggregates the weight parameters from the clients.
* **Steps:**
1. Learn locally: Each client trains a model locally on its data.
2. Send weight parameters: Each client sends its model's weight parameters to the server.
3. Calculate average of weight parameters: The server calculates the average of the received weight parameters.
4. Return averaged weight parameters: The server sends the averaged weight parameters back to each client, who then reflects them in their local models.
* **Data Representation:** Weight parameters are represented as matrices. Examples of values are shown, such as 1.3, 7.5, 0.2, 0.1, 0.4, 8.4, 0.1.5, and 0.1.5.
### Detailed Analysis or Content Details
* **Client A:**
* Has a "Data" storage icon.
* Performs "①Learn locally" using its data to train a neural network.
* Sends weight parameters to the server in step "② Send weight parameters". The parameters are represented as matrices with example values like 1.3, 7.5, 0.2, and 0.1.
* **Client B:**
* Has a "Data" storage icon.
* Performs "①Learn locally" using its data to train a neural network.
* Sends weight parameters to the server.
* **Client C:**
* Has a "Data" storage icon.
* Performs "①Learn locally" using its data to train a neural network.
* Sends weight parameters to the server.
* **Server:**
* Receives weight parameters from all clients.
* Performs "③ Calculate average of weight parameters".
* Averages the weight parameters. The averaged parameters are represented as matrices with example values like 0.4, 8.4, 0.1.5, and 0.1.5.
* Performs "④ Return averaged weight parameters to each client and reflect them in local models".
### Key Observations
* The process is iterative, with steps 1 to 4 being repeated to refine the global model.
* The weight parameters are represented as matrices, and the server calculates the average of these matrices.
* The clients update their local models with the averaged weight parameters.
### Interpretation
The diagram illustrates the federated learning process, which allows multiple clients to collaboratively train a global model without sharing their raw data. This is achieved by averaging the weight parameters of the local models on a central server. The process is iterative, with the clients and server repeatedly exchanging weight parameters until the global model converges. This approach is particularly useful when data is distributed across multiple devices or organizations and cannot be easily centralized due to privacy or regulatory constraints. The example values provided for the weight parameters are illustrative and would vary depending on the specific model and data being used.
</details>
Figure 2: Overview of the HFL learning protocol.
II-B Vertical Federated Learning
VFL enables clients holding the different features of the same samples to collaboratively train a model which takes all of the various features each client has as input. There are VFL studies to deal with various models including linear/logistic regression [8, 9, 10, 11, 12], decision trees [13, 14, 15, 16, 17], neural networks [18, 19, 20, 21], and other non-linear models [22, 23].
Figure 3 shows an overview of the standard VFL learning protocol. In VFL, only one client holds labels and it plays the role of a server. Therefore, two types of entities participate in learning of VFL:
1. Active client - Features and labels owner. Active client coordinates the learning procedure. It calculates the loss and exchanges intermediate results with the passive clients.
1. Passive clients - Features owners. Each passive client keeps both its features and model local but exchanges intermediate results with the active client.
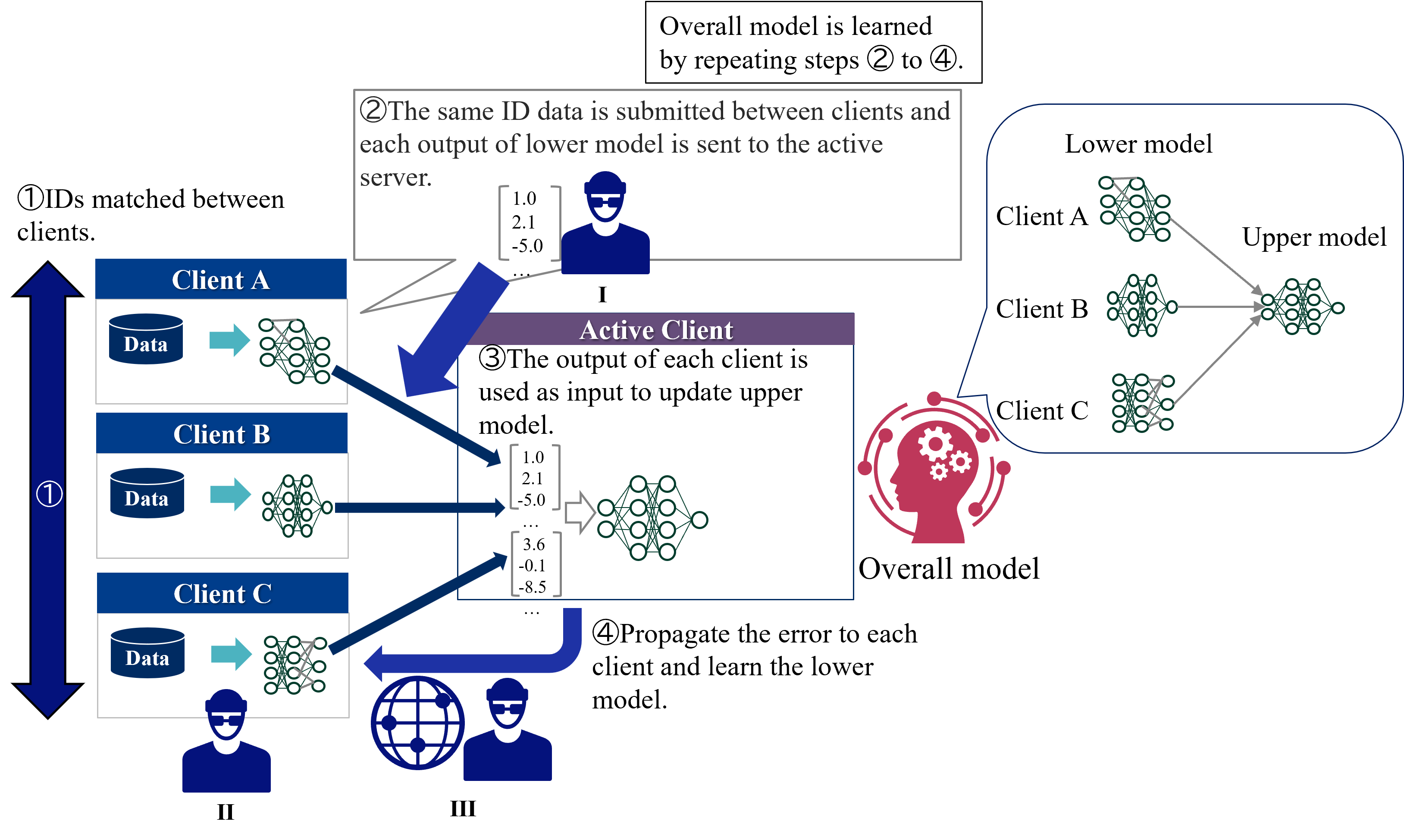
VFL consists of two phases: IDs matching and learning phases. In IDs matching phases, all clients shares the common sample IDs. In learning phase, each client has a separate model with its own features as input, and the passive clients send the computed intermediate outputs to the active client. The active client calculates the loss based on the aggregated intermediate outputs and sends the gradients to all passive clients. Then, the passive clients updates its own model parameters. This process is repeated until the convergence. During inference time, all clients need to cooperate to predict the label of a sample.
<details>
<summary>extracted/5379099/fig/LM_VFL.png Details</summary>
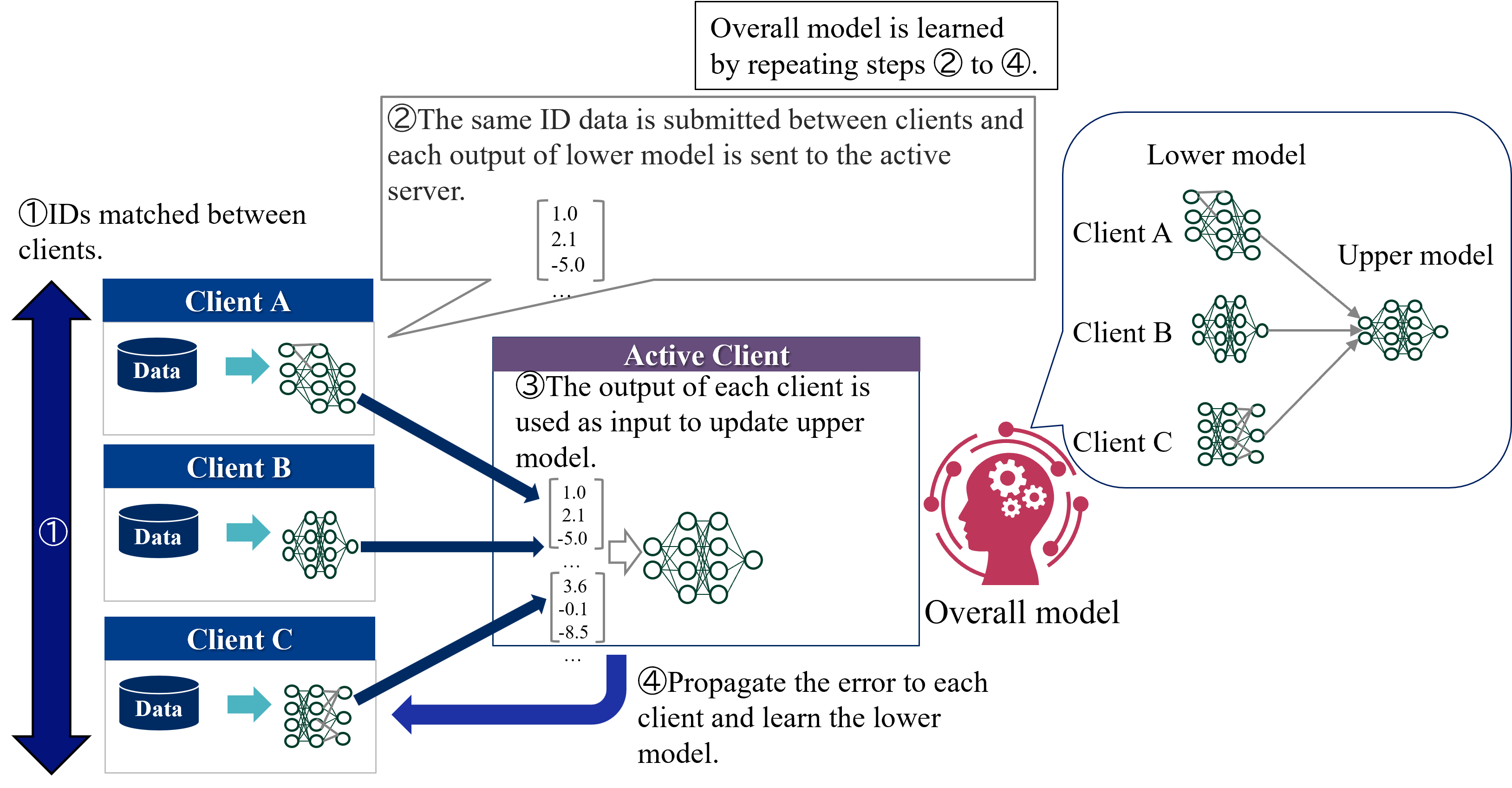
### Visual Description
## Federated Learning Diagram: Model Training Process
### Overview
The image illustrates a federated learning process involving multiple clients (A, B, and C) and an active server. The diagram outlines the steps for training an overall model by iteratively updating lower models on each client and an upper model on the active server.
### Components/Axes
* **Clients:** Client A, Client B, and Client C, each with local data.
* **Active Client:** Represents the server where the upper model is updated.
* **Lower Model:** A model trained on each client's local data.
* **Upper Model:** A model updated on the active server using the outputs from the lower models.
* **Overall Model:** The final trained model, represented by a head with gears.
* **Flow Arrows:** Indicate the direction of data and error propagation.
* **Numerical Data:** Example vectors representing the output of the lower models.
* **Step Numbers:** Numbered annotations indicating the sequence of steps in the federated learning process.
### Detailed Analysis or ### Content Details
1. **Step 1: IDs matched between clients.** A large blue arrow points downwards, indicating that the IDs are matched between Client A, Client B, and Client C.
2. **Step 2: The same ID data is submitted between clients and each output of lower model is sent to the active server.** A grey box with a pointer to Client A, Client B, and Client C's lower models contains the text. Example data vectors are shown:
* \[1.0, 2.1, -5.0, ... ]
3. **Step 3: The output of each client is used as input to update upper model.** A purple box labeled "Active Client" contains the text. Example data vectors are shown:
* \[1.0, 2.1, -5.0, ... , 3.6, -0.1, -8.5]
4. **Step 4: Propagate the error to each client and learn the lower model.** A blue arrow points from the active client back to Client A, Client B, and Client C.
5. **Overall Model:** A red silhouette of a head with gears inside, labeled "Overall model".
6. **Lower Model and Upper Model:** A blue rounded rectangle contains the text "Lower model" and "Upper model". Inside this rectangle are the neural network diagrams for Client A, Client B, and Client C. The outputs of Client A, Client B, and Client C's lower models are fed into the upper model.
7. **Overall model is learned by repeating steps 2 to 4.** A grey box in the top-right corner contains the text.
### Key Observations
* The diagram illustrates a cyclical process where data flows from clients to the server, the model is updated, and errors are propagated back to the clients.
* The use of the same ID data across clients is a key aspect of this federated learning approach.
* The active server aggregates the outputs from the lower models to update the upper model.
### Interpretation
The diagram depicts a federated learning approach where multiple clients contribute to training a global model without directly sharing their raw data. The process involves iteratively updating local models on each client and aggregating their outputs on a central server to update a global model. This approach preserves data privacy while still enabling collaborative model training. The matching of IDs between clients suggests that the data is aligned across clients, which is important for effective model training. The propagation of errors back to the clients allows them to refine their local models based on the global model's performance.
</details>
Figure 3: Overview of the standard VFL learning protocol.
II-C Federated Transfer Learning
FTL assumes two clients that shares only a small portion of samples or features. The goal of FTL is to create a model that can predict labels on the client that does not possess labels (target client), by transferring the knowledge of the other client that does possess labels (source client) to the target client.
Figure 4 shows an overall of the FTL learning protocol. As noted above, two types of entities participate in FTL:
1. Source client - Features and labels owner. Source client exchanges intermediate results such as outputs and gradients with the target client and calculates the loss.
1. Target client - Features owners. Target client exchanges intermediate results with the source client.
In FTL, two clients exchange intermediate outputs to learn a common representation. The source client uses the labeled data to compute the loss and sends the gradient to the target client, which updates the target client’s representation. This process is repeated until the convergence. During inference time, the target client predicts the label of a sample using its own model and features.
The detail of the learning protocol varies depending on the specific method. Although only a limited number of FTL methods have been proposed, we introduce three major types of methods. FTL requires some supplementary information to bridge two clients, such as common IDs [24, 25, 26, 27], common features [28, 29], and labels of target client [30, 31].
II-C 1 Common IDs
Most FTL methods assumes the existence of the common ID’s samples between two clients. This type of FTL requires ID matching before the learning phase as with VFL. Liu et al. [24] proposed the first FTL protocol, which learns feature transformation functions so that the different features of the common samples are mapped into the same features. The following work by Sharma et al. [25] improved communication overhead of the first FTL using multi-party computation and enhanced the security by incorporating malicious clients. Gao et al. [27] proposed a dual learning framework in which two clients impute each other’s missing features by exchanging the outputs of the imputation models for the common samples.
II-C 2 Common features
In real-world applications, it is difficult to share samples with the same IDs. Therefore, Gao et al. [28] proposed a method to realize FTL by assuming common features instead of common samples. In that method, two clients mutually reconstruct the missing features by using exchanged feature mapping models. Then,using all features, the clients conduct HFL to obtain a label prediction model. In the original paper, the authors assumes that all clients posses labels, but this method is applicable to the target client that does not posses labels because the source client can learn the label prediction model only by itself. Mori et al. [29] proposed a method for neural networks in which each client incorporates its own unique features in addition to common features into HFL training. However, their method is based on HFL and cannot be applied to the target clients that does not possess labels.
II-C 3 Labels of target client
This type of methods assumes neither common IDs nor features, but instead assumes that all clients possess labels, allowing a common representation to be learned across clients. Since it is based on HFL, the participating entities are the same as in HFL. Gao et al. [30] learns a common representation by exchanging the intermediate outputs with the server and reducing maximum mean discrepancy loss. Rakotomamonjy et al. [31] proposed a method to learn a common representation by using Wasserstein distance for intermediate outputs, which enables that the clients only need to exchange statistical information such as mean and variance with the server.
<details>
<summary>extracted/5379099/fig/LM_FTL.png Details</summary>
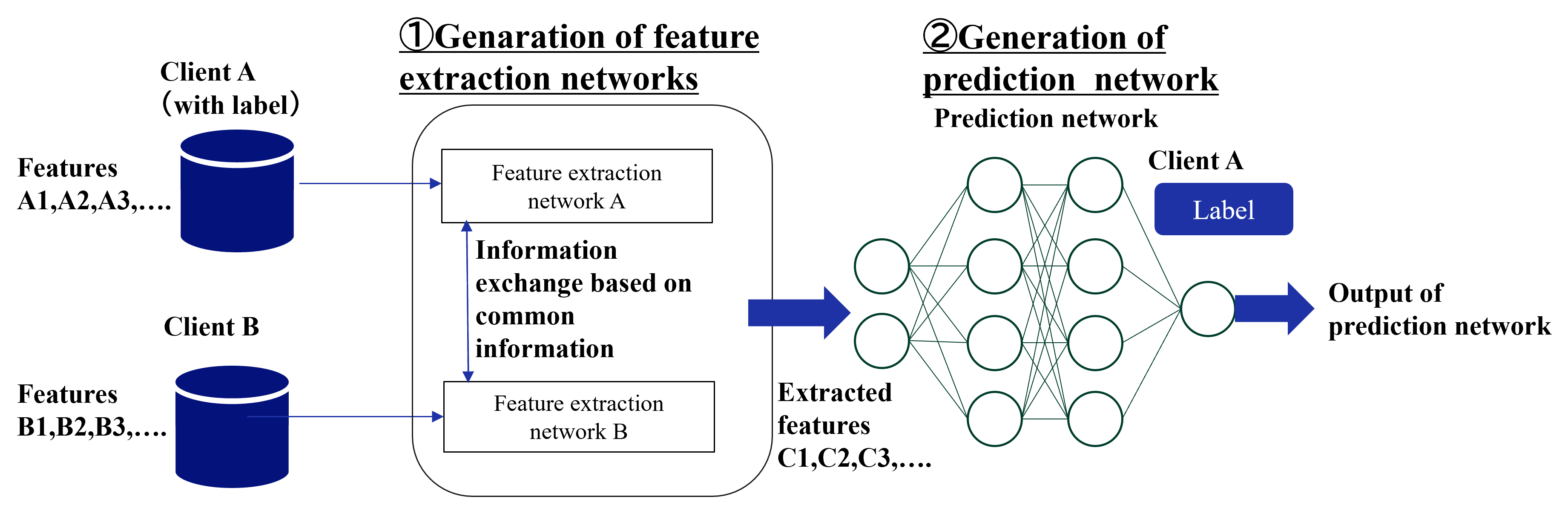
### Visual Description
## Diagram: Feature Extraction and Prediction Network Generation
### Overview
The image is a diagram illustrating the generation of feature extraction networks and a prediction network. It shows two clients (A and B) with their respective features, the process of feature extraction, information exchange, and the final prediction network.
### Components/Axes
* **Title 1:** ① Genaration of feature extraction networks
* **Title 2:** ② Generation of prediction network
* **Sub-title:** Prediction network
* **Client A:** (with label)
* **Features:** A1, A2, A3,...
* **Label:** Label
* **Client B:**
* **Features:** B1, B2, B3,...
* **Feature extraction network A**
* **Feature extraction network B**
* **Information exchange based on common information**
* **Extracted features:** C1, C2, C3,...
* **Output of prediction network**
### Detailed Analysis or Content Details
The diagram is divided into two main sections, labeled ① and ②.
**Section ①: Generation of feature extraction networks**
* Two data sources, Client A and Client B, are represented as blue cylinders.
* Client A is labeled "(with label)" and has features A1, A2, A3,...
* Client B has features B1, B2, B3,...
* Data from Client A flows into "Feature extraction network A".
* Data from Client B flows into "Feature extraction network B".
* A bidirectional arrow between the two feature extraction networks is labeled "Information exchange based on common information".
**Section ②: Generation of prediction network**
* The output of the feature extraction networks (A and B) flows into a prediction network.
* The prediction network is represented as a multi-layered neural network with interconnected nodes.
* The input to the prediction network is labeled "Extracted features C1, C2, C3,...".
* The output of the prediction network is labeled "Output of prediction network".
* A blue box labeled "Label" is associated with Client A within the prediction network.
### Key Observations
* The diagram illustrates a process where two clients contribute data to generate feature extraction networks.
* The feature extraction networks exchange information.
* The extracted features are then used to train a prediction network.
* Client A has a label associated with it, which is used in the prediction network.
### Interpretation
The diagram depicts a federated learning or distributed learning scenario where multiple clients contribute to training a model without directly sharing their raw data. The feature extraction networks likely learn representations of the data, and the information exchange allows them to learn from each other's data distributions. The prediction network then uses these extracted features to make predictions, leveraging the knowledge gained from both clients. The presence of a label for Client A suggests a supervised learning task.
</details>
Figure 4: Overall of the FTL learning protocol.
III Threats to Privacy in Each Federated Learning
In this section, we describe threats to privacy in each federated learning. Table I shows threads to privacy addressed in each federated learning. An inference attack uses data analysis to gather unauthorized information about a subject or database. If an attacker can confidently estimate the true value of a subject’s confidential information, it can be said to have been leaked. The most frequent variants of this approach are membership inference and feature [32]. In addition, we address privacy threats of label inference and ID leakage.
TABLE I: Threads to privacy addressed in each federated learning
| HFL VFL FTL (common features) | Low or above Already known Low | Already known Low or above Low or above | None Low or above Low or above | None High None |
| --- | --- | --- | --- | --- |
| FTL (common IDs) | Low | Low or above | Low or above | High |
III-A Horizontal Federated Learning
In HFL, client data is a major threat to privacy. Figure 5 shows threats to privacy in HFL. Possible attackers are as follows:
1. Server: Inference attack against the model to infer client data.
1. Clients: Inference attack against the global model received from the server to infer other clients’ data.
1. Third party: Eavesdrop on models that pass through the communication channel and infer client data through inference attacks.
<details>
<summary>extracted/5379099/fig/TP_HFL.png Details</summary>
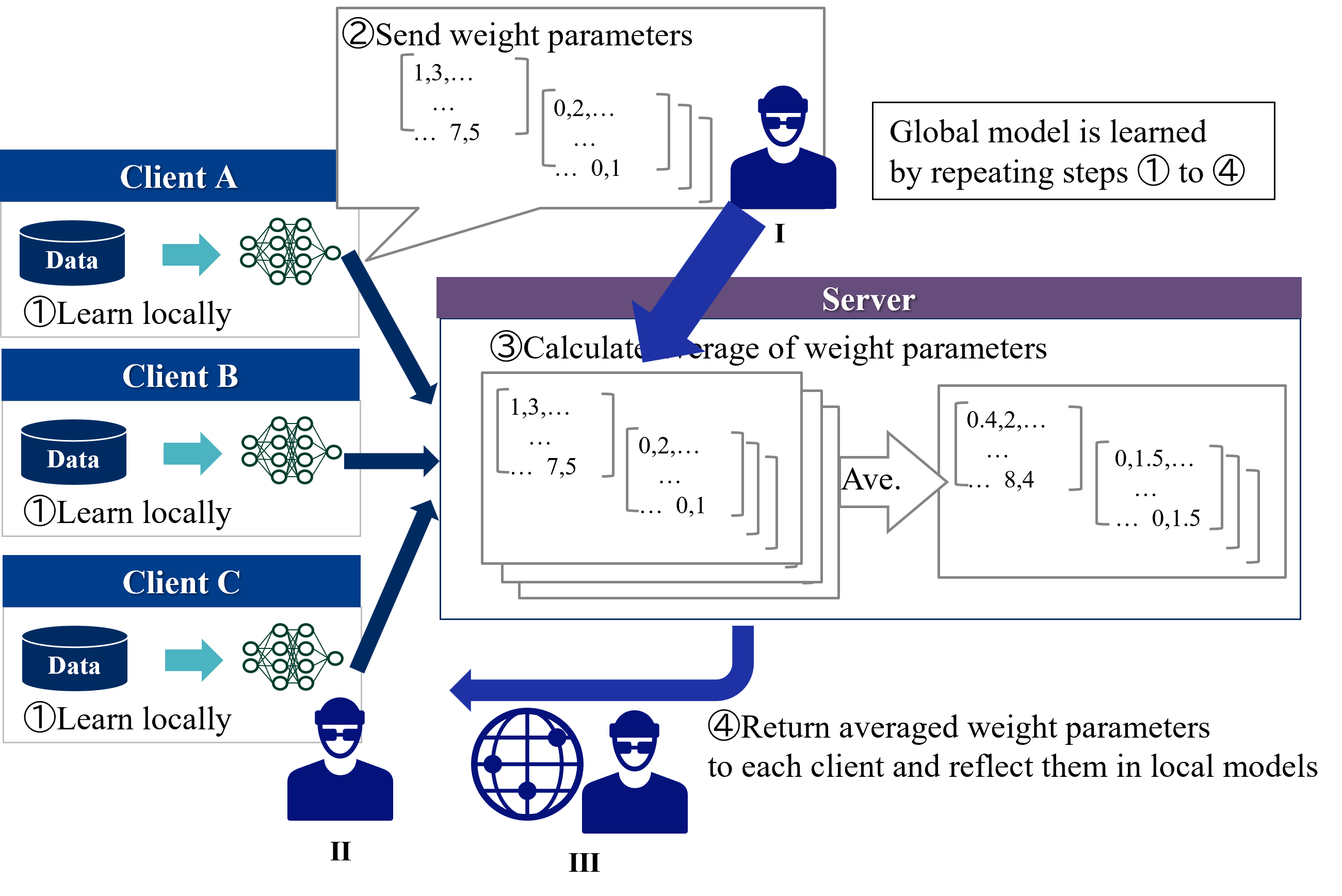
### Visual Description
## Diagram: Federated Learning Process
### Overview
The image illustrates the federated learning process, where multiple clients train a model locally and then send weight parameters to a central server. The server averages these parameters to create a global model, which is then sent back to the clients. This process repeats iteratively.
### Components/Axes
* **Clients:** Client A, Client B, Client C. Each client has its own data and trains a local model.
* Each client block contains the client name, a data icon labeled "Data", and the text "①Learn locally".
* **Server:** The central server aggregates the weight parameters from the clients.
* The server block is labeled "Server".
* **Data Flow:** The diagram shows the flow of data and weight parameters between the clients and the server using arrows.
* **Icons:**
* Data: Represents the data stored at each client.
* Neural Network: Represents the local model trained at each client.
* Person Icon: Represents the client or server.
* Globe Icon: Represents the global model.
* **Steps:** The process is broken down into four steps, labeled ① to ④.
### Detailed Analysis or ### Content Details
1. **Client-Side Learning (①Learn locally):**
* Each client (A, B, and C) has a "Data" store and a neural network.
* The text "①Learn locally" indicates that each client trains a model using its local data.
2. **Sending Weight Parameters (②Send weight parameters):**
* Client A sends weight parameters to the server.
* The weight parameters are represented as matrices with values like "1,3,...", "7,5", "0,2,...", and "0,1".
* A person icon labeled "I" is present near the server.
3. **Server-Side Aggregation (③Calculate average of weight parameters):**
* The server calculates the average of the weight parameters received from the clients.
* The text "③Calculate average of weight parameters" describes this step.
* The averaging process is represented by an arrow labeled "Ave.".
* The averaged weight parameters are represented as matrices with values like "0.4,2,...", "8,4", "0,1.5,...", and "0,1.5".
4. **Returning Averaged Weight Parameters (④Return averaged weight parameters):**
* The server returns the averaged weight parameters to each client.
* The text "④Return averaged weight parameters to each client and reflect them in local models" describes this step.
* A globe icon and a person icon labeled "III" are present, representing the global model being distributed.
5. **Iteration:**
* The text "Global model is learned by repeating steps ① to ④" indicates that the process is iterative.
6. **Client Icons:**
* A person icon labeled "II" is present near the clients.
### Key Observations
* The diagram illustrates a standard federated learning setup with multiple clients and a central server.
* The process involves local training, parameter aggregation, and global model distribution.
* The iterative nature of the process is emphasized.
### Interpretation
The diagram provides a high-level overview of the federated learning process. It highlights the key steps involved in training a global model without directly accessing the clients' data. The process is iterative, allowing the global model to improve over time as the clients continue to train on their local data and contribute to the global model. The use of weight parameters allows the server to aggregate the knowledge learned by each client without compromising data privacy.
</details>
Figure 5: Threats to privacy in HFL.
III-B Vertical Federated Learning
In VFL, a major threat to privacy is the leakage of identities due to identity matching between clients [33]. In addition to the leakage of identities, partial output from clients is also a threat. In case of ID matching, in order to create a single model for the overall system, it is necessary to match IDs that are common to each client’s data. This will reveal the presence of the same user to other clients. Figure 6 shows threats to privacy in VFL in case of partial output from clients, and possible attackers are as follows:
1. Active client: Inference attack against the output of lower model to infer client data.
1. Passive Clients: Inference attack against the output of upper model received from the active client to infer other clients’ data.
1. Third party: Eavesdrop on outputs that pass through the communication channel and infer client data through inference attacks.
<details>
<summary>extracted/5379099/fig/TP_VFL.png Details</summary>
### Visual Description
## Federated Learning Diagram: Model Training Process
### Overview
The image illustrates a federated learning process involving multiple clients (A, B, and C) and an active client/server. The diagram outlines the steps for training an overall model by iteratively updating lower models on each client and aggregating their outputs to update an upper model on the active client. Error propagation is used to refine the lower models.
### Components/Axes
* **Clients:** Client A, Client B, Client C
* Each client has a "Data" storage component and a "Lower model" (neural network).
* **Active Client:** Represents the server or aggregator.
* Contains an "Upper model" (neural network).
* **Overall Model:** A visual representation of the final trained model.
* **Flow Arrows:** Indicate the direction of data and model updates.
* **Numerical Data:** Sample output values from the lower models.
* **Icons:** Represent users and a global network.
* **Step Indicators:** Numbered circles indicating the sequence of steps.
### Detailed Analysis or ### Content Details
1. **Step 1: IDs matched between clients.**
* A large blue arrow points downwards, indicating the initial step of matching IDs between clients.
* Clients A, B, and C each have a "Data" storage component (represented by a cylinder) and a lower model (neural network).
* Data flows from the "Data" storage to the lower model on each client, indicated by a light blue arrow.
2. **Step 2: The same ID data is submitted between clients and each output of lower model is sent to the active server.**
* A grey box contains the text describing this step.
* A sample output vector `[1.0, 2.1, -5.0, ...]` is shown, representing the data sent to the active client.
* A user icon labeled "I" is present below the data.
3. **Step 3: The output of each client is used as input to update upper model.**
* A purple box contains the text describing this step.
* Sample output vectors `[1.0, 2.1, -5.0, ...]` and `[3.6, -0.1, -8.5, ...]` are shown, representing the data used to update the upper model.
* The upper model is a neural network.
4. **Step 4: Propagate the error to each client and learn the lower model.**
* A blue arrow points from a globe icon (labeled "III") and a user icon (labeled "II") back towards the clients.
* The globe icon likely represents a global network or server.
5. **Overall Model Learning:**
* A text box at the top states: "Overall model is learned by repeating steps 2 to 4."
6. **Model Architecture:**
* The "Lower model" and "Upper model" are represented as neural networks.
* The "Overall model" is represented by a head with gears inside, suggesting a complex, integrated system.
### Key Observations
* The diagram illustrates a cyclical process of federated learning.
* Data privacy is implied, as raw data remains on the clients.
* The active client aggregates the outputs of the lower models to update the upper model.
* Error propagation is used to refine the lower models on each client.
### Interpretation
The diagram depicts a federated learning approach where a global model is trained without directly accessing the raw data on individual clients. The process involves iterative updates of local models on each client, aggregation of these updates on a central server (active client), and propagation of errors back to the clients for further refinement. This approach is beneficial for scenarios where data privacy is paramount, as the raw data remains distributed across the clients. The cyclical nature of the process (repeating steps 2 to 4) highlights the iterative refinement of the overall model through continuous learning and error correction.
</details>
Figure 6: Threads to privacy in VFL.
III-C Federated Transfer Learning
In federated transfer learning, threats to privacy vary depending on the information in common [24]. We explain the case when features are common and when IDs are common, respectively.
III-C 1 Common Features
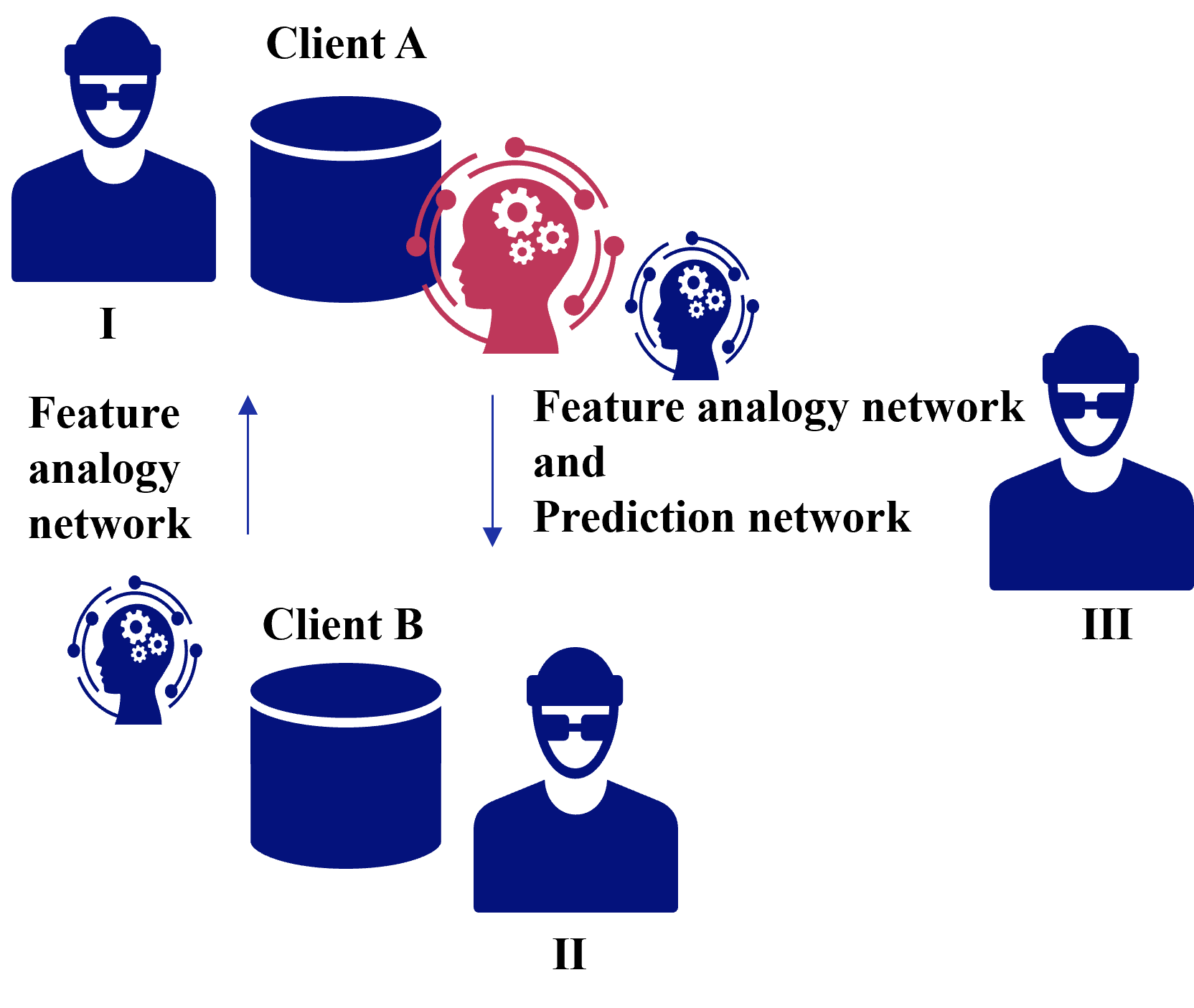
Figure 7 shows threats to privacy in case of common features in FTL, and possible attackers are as follows:
1. Client receiving a feature analogy network: Inference attack against feature analogy network to infer client data.
1. Client receiving a feature analogy network and prediction network: Inference attack against feature analogy network and prediction network to infer client data.
1. Third party: Eavesdrop on feature analogy network and prediction network pass through the communication channel and infer client data through inference attacks.
<details>
<summary>extracted/5379099/fig/CFTP_FTL.png Details</summary>
### Visual Description
## Diagram: Feature Analogy and Prediction Network
### Overview
The image is a diagram illustrating a feature analogy and prediction network involving two clients (Client A and Client B) and three entities labeled I, II, and III. The diagram shows the flow of information and processing between these entities.
### Components/Axes
* **Clients:** Client A (top) and Client B (bottom) are represented with a label and a database icon.
* **Entities:** Three entities labeled I (top-left), II (bottom-center), and III (top-right) are represented by a user icon.
* **Networks:**
* "Feature analogy network" - connects entity I to Client B.
* "Feature analogy network and Prediction network" - connects Client A to Client B and entity III.
* **Processing Units:** Head icons with gears inside represent processing units. One is colored red and located near Client A, and the other is blue and located near Client B.
* **Arrows:** Arrows indicate the direction of information flow.
### Detailed Analysis
* **Client A:** Located at the top of the diagram. It is connected to entity I via the "Feature analogy network" (upward arrow). A red processing unit is located to the right of Client A.
* **Client B:** Located at the bottom of the diagram. It is connected to entity II. Client A is connected to Client B via the "Feature analogy network and Prediction network" (downward arrow). A blue processing unit is located to the left of Client B.
* **Entity I:** Located on the top-left.
* **Entity II:** Located on the bottom-center.
* **Entity III:** Located on the top-right.
* **Processing Units:** The red processing unit near Client A is larger than the blue processing unit near Client B.
### Key Observations
* The diagram illustrates a flow of information from Client A to Client B, and from entity I to Client B.
* The "Feature analogy network and Prediction network" connects Client A to Client B and entity III.
* The red processing unit near Client A might represent a more complex or intensive processing compared to the blue processing unit near Client B.
### Interpretation
The diagram depicts a system where Client A and Client B exchange information through feature analogy and prediction networks. Entity I provides input to Client B through a feature analogy network. The red processing unit near Client A suggests that Client A might be performing more complex processing or analysis compared to Client B. The connection between Client A, Client B, and entity III through the "Feature analogy network and Prediction network" suggests a collaborative or distributed processing model. The diagram highlights the relationships and information flow between different components in the system.
</details>
Figure 7: Threats to privacy in case of common features in FTL.
III-C 2 Common IDs
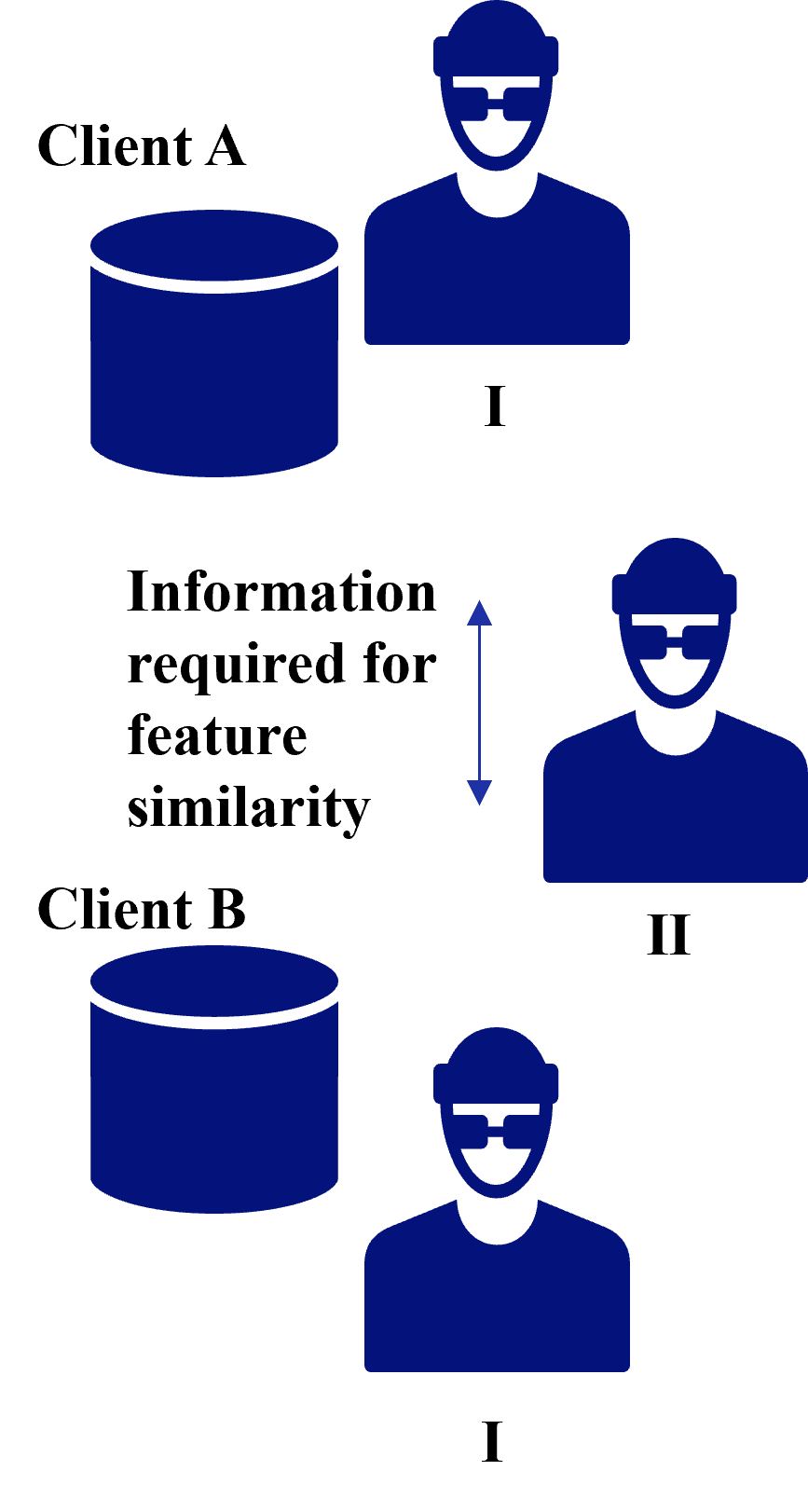
In case of Common IDs, a threat to privacy is the leakage of identities due to identity matching between clients as shown in VFL [33]. In addition to the leakage of identities, information required for feature similarity from clients is also a threat. Figure 8 shows threats to privacy in case of common IDs in FTL in case of information required for feature similarity, and possible attackers are as follows:
1. Client receiving information for feature similarity: Inference attack against information required for feature similarity to infer client data.
1. Third party: Eavesdrop on information required for feature similarity pass through the communication channel and infer client data through inference attacks.
<details>
<summary>extracted/5379099/fig/CITP_FTL.png Details</summary>
### Visual Description
## Diagram: Feature Similarity Information Flow
### Overview
The image is a diagram illustrating the flow of information required for feature similarity between two clients, Client A and Client B. The diagram uses icons to represent clients, data stores, and a process involving information exchange.
### Components/Axes
* **Client A:** Labeled "Client A" at the top-left.
* **Client B:** Labeled "Client B" at the bottom-left.
* **Data Stores:** Two cylindrical icons, one next to each client label, representing data storage.
* **Process I:** A person icon with a hat and glasses, labeled "I" below, appears next to both Client A and Client B.
* **Process II:** A person icon with glasses, labeled "II" below, is positioned between Client A and Client B.
* **Information Flow:** A double-headed arrow pointing upwards and downwards, located between Client A and Client B, accompanied by the text "Information required for feature similarity".
### Detailed Analysis
* **Client A:**
* Data Store: A blue cylinder with a white outline.
* Process I: A blue person icon with a hat and glasses, labeled "I".
* **Client B:**
* Data Store: A blue cylinder with a white outline.
* Process I: A blue person icon with a hat and glasses, labeled "I".
* **Information Flow:**
* The text "Information required for feature similarity" is centered vertically between Client A and Client B.
* A blue double-headed arrow points upwards towards Client A and downwards towards Client B.
* **Process II:**
* A blue person icon with glasses, labeled "II", is positioned between the information flow arrow and the two Process I icons.
### Key Observations
* The diagram suggests a two-step process involving Process I and Process II.
* Information flows between Client A and Client B, facilitated by Process II.
* Both clients have their own data stores and instances of Process I.
### Interpretation
The diagram illustrates a system where feature similarity is determined by exchanging information between two clients. Each client has a data store and an initial processing step (Process I). The information required for feature similarity is then exchanged, potentially involving a second processing step (Process II), to determine the similarity between the clients' features. The diagram implies that Process II requires information from both Client A and Client B to perform its function. The presence of Process I at both clients suggests a pre-processing or data preparation step before the information is exchanged.
</details>
Figure 8: Threads to privacy in case of common IDs in FTL.
IV Countermeasures against Threats to Privacy in Each Federated Learning
In this section, we describe countermeasures against threats to privacy in each federated learning. Table II shows countermeasures against privacy threats addressed in each federated learning. Despite the wide variety of previous efforts to secure privacy in federated learning, the proposed methods typically fall into one of these categories: differential privacy, secure computation, encryption of communication, and ID dummying [32].
TABLE II: Countermeasures against privacy threats addressed in each federated learning.
| HFL VFL FTL (common features) | Client Side - Feature Analogy Network Exchange | Server Side Active Client Side - | Communication Line Communication Line Communication Line | - Client Table - |
| --- | --- | --- | --- | --- |
| FTL (common IDs) | - | Gradient Exchange | Communication Line | Client Table |
IV-A Horizontal Federated Learning
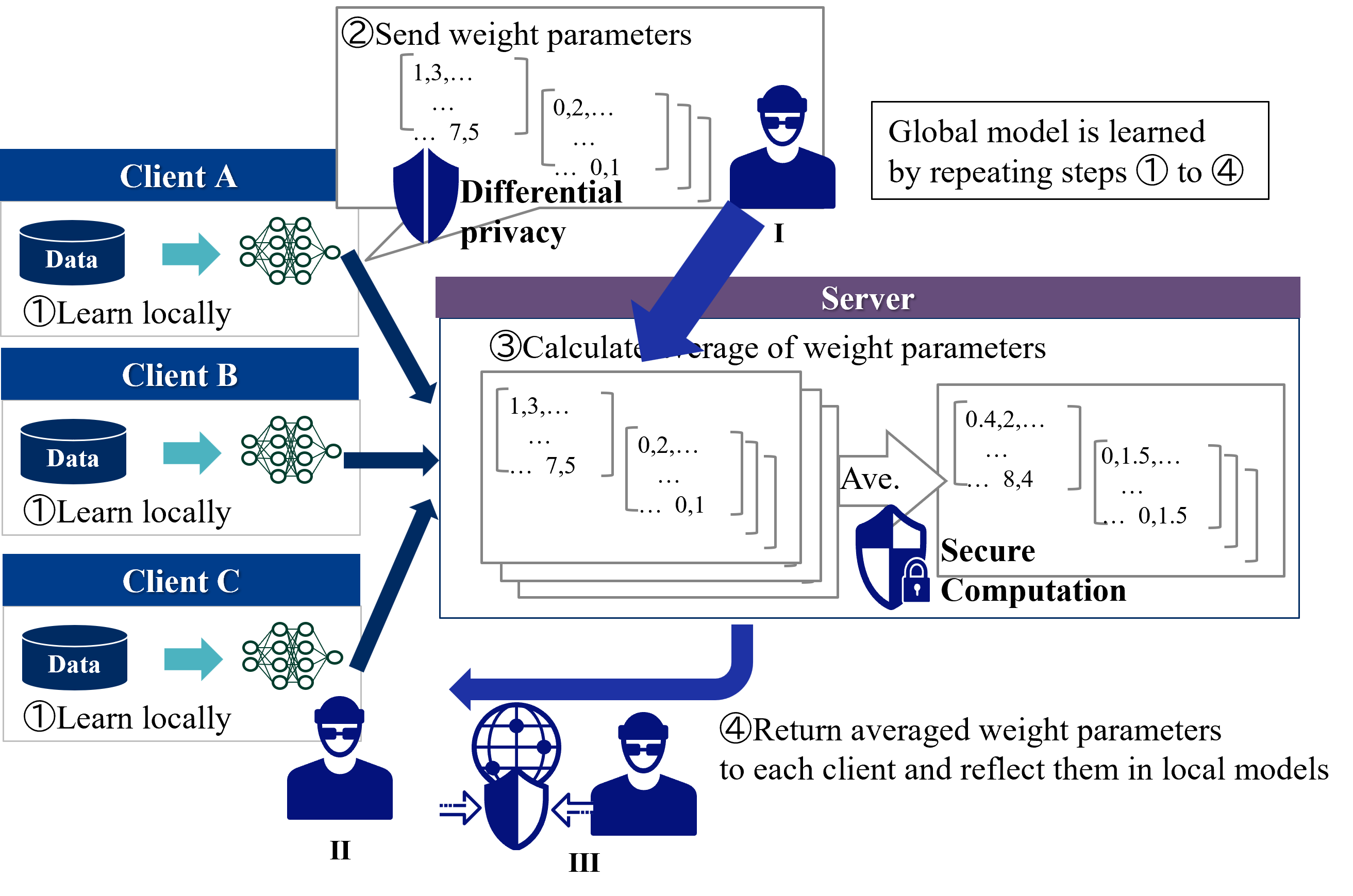
In HFL, a typical privacy measure for client data is to protect attacks by the server side with secure computation and attacks by the client side with differential privacy [34]. Figure 9 shows countermeasures against threads to privacy in HFL. The position of the attacker by these privacy measures is described as follows.
1. Server: Secure computation realizes global model integration calculations without seeing the model by the server [35, 36]
1. Client: Client A creates a model by adding noise through differential privacy [37, 38]. Client B receives the parameters of the global model via the server, but Client A’s model is protected by differential privacy.
1. Third party: Achieved by encryption of communication.
<details>
<summary>extracted/5379099/fig/CM_HFL.png Details</summary>
### Visual Description
## Diagram: Federated Learning with Differential Privacy and Secure Computation
### Overview
The image illustrates a federated learning process involving multiple clients (A, B, C) and a central server. The process includes local learning, sending weight parameters with differential privacy, averaging weight parameters with secure computation, and returning averaged parameters to clients. The diagram highlights the iterative nature of the process and the security measures implemented.
### Components/Axes
* **Clients (A, B, C):** Represented as blue rectangles on the left side of the diagram. Each client has a "Data" icon and a neural network icon.
* Label: "Client A", "Client B", "Client C"
* Action: "① Learn locally"
* **Server:** Represented as a purple rectangle in the center of the diagram.
* Label: "Server"
* Action: "③ Calculate average of weight parameters"
* **Data:** Represented as a blue cylinder icon.
* **Neural Network:** Represented as a green network diagram.
* **Weight Parameters:** Represented as matrices with numerical values (e.g., [1,3,...], [0,2,...], [0.4,2,...], [0,1.5,...]).
* **Differential Privacy:** Represented by a blue shield icon and the text "Differential privacy".
* **Secure Computation:** Represented by a blue shield with a lock icon and the text "Secure Computation".
* **Arrows:** Blue arrows indicate the flow of information and actions.
* **Icons:**
* "I", "II", "III": Represented as a blue person icon with glasses and a hat.
* Globe with shield: Represents the return of averaged weight parameters.
* **Text Box:** "Global model is learned by repeating steps ① to ④"
### Detailed Analysis or ### Content Details
1. **Client-Side Learning (Step 1):**
* Each client (A, B, C) has its own local "Data" and performs local learning using a neural network.
* Action: "① Learn locally"
2. **Sending Weight Parameters (Step 2):**
* Clients send their weight parameters to the server.
* Action: "② Send weight parameters"
* Weight parameters are represented as matrices:
* `[1,3,...; ... 7,5]`
* `[0,2,...; ... 0,1]`
* Differential privacy is applied during this step, indicated by a shield icon and the label "Differential privacy".
* A blue person icon labeled "I" is present.
3. **Server-Side Averaging (Step 3):**
* The server calculates the average of the weight parameters received from the clients.
* Action: "③ Calculate average of weight parameters"
* Averaging is represented by "Ave." and an arrow pointing to the averaged weight parameters.
* Averaged weight parameters are represented as matrices:
* `[0.4,2,...; ... 8,4]`
* `[0,1.5,...; ... 0,1.5]`
* Secure computation is applied during this step, indicated by a shield with a lock icon and the label "Secure Computation".
4. **Returning Averaged Parameters (Step 4):**
* The server returns the averaged weight parameters to each client.
* Action: "④ Return averaged weight parameters to each client and reflect them in local models"
* A blue person icon labeled "III" is present.
* A globe icon with a shield is present.
### Key Observations
* The diagram illustrates a cyclical process of federated learning.
* Differential privacy is applied when sending weight parameters from clients to the server.
* Secure computation is applied when averaging weight parameters on the server.
* The process involves multiple clients and a central server.
* The global model is learned iteratively by repeating steps 1 to 4.
* Blue person icons labeled "I", "II", and "III" are present at different stages of the process.
### Interpretation
The diagram depicts a federated learning system designed to protect data privacy. By implementing differential privacy when clients send weight parameters and secure computation when the server averages them, the system aims to prevent sensitive information from being exposed. The iterative nature of the process allows the global model to improve over time while maintaining data privacy. The presence of the blue person icons labeled "I", "II", and "III" suggests potential security threats or adversaries at different stages of the process. The globe icon with a shield represents the secure return of averaged weight parameters to the clients.
</details>
Figure 9: Countermeasures against threads to privacy in HFL.
IV-B Vertical Federated Learning
In VFL, the threads to privacy are the leakage of identities and partial output from clients. We show how to respond in the case of each threat.
IV-B 1 IDs Matching
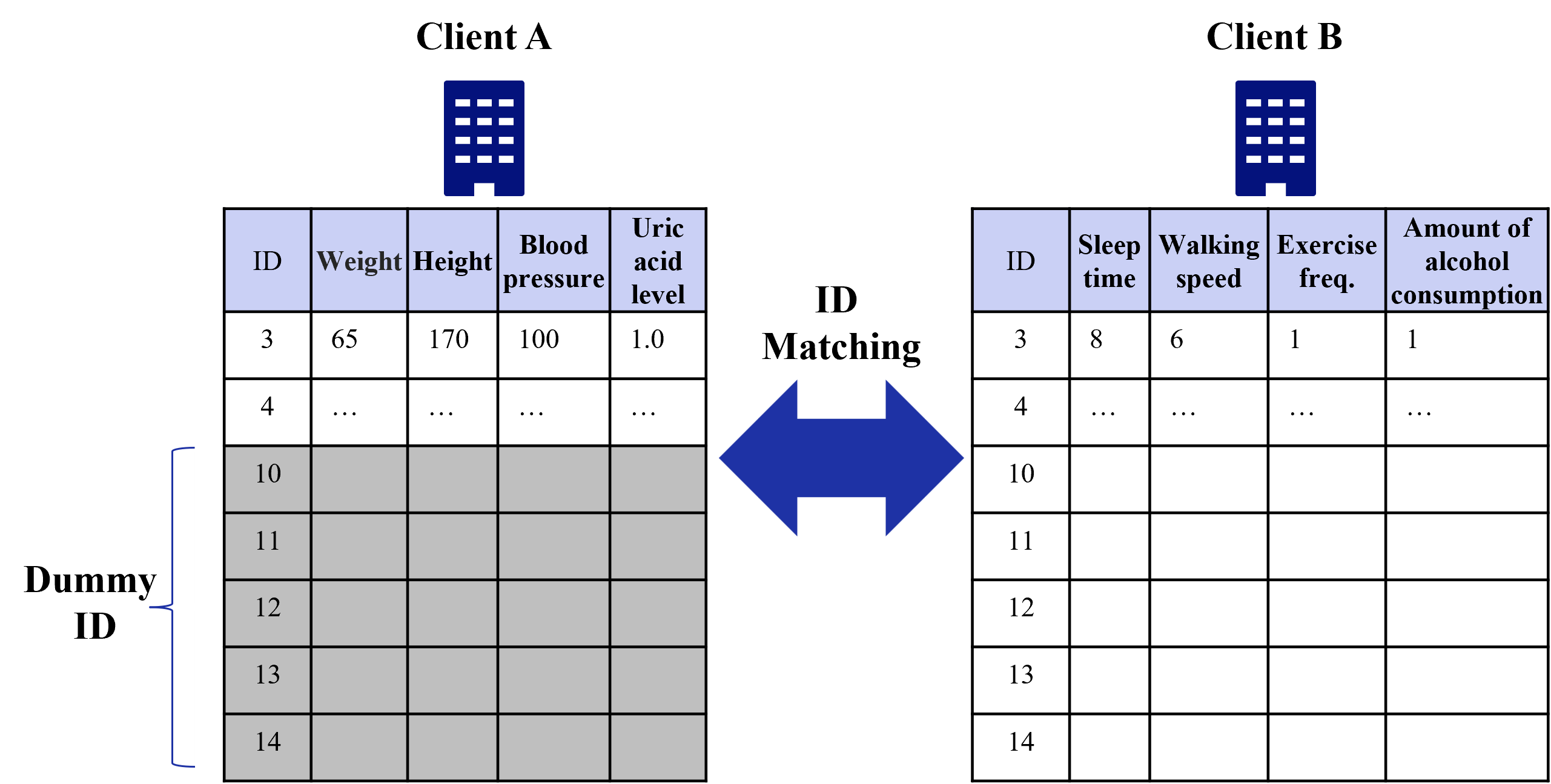
In case of IDs matching, Dummy IDs are prepared in addition to the original IDs [39]. For the dummy part of the ID, dummy variables that have no effect on learning are sent. Figure 10 shows an example of dummy IDs. Before dummy IDs are used, all IDs that match Client A are known to Client B (cf. ID 3,4). After dummy IDs are used, Client B does not know which of the IDs that match Client A is the real ID of Client A.
<details>
<summary>extracted/5379099/fig/CMID_VFL.png Details</summary>
### Visual Description
## Data Table Comparison: Client A vs. Client B
### Overview
The image presents a comparison of data tables for two clients, Client A and Client B. Each table contains an ID column and several health-related metrics. The tables are linked by an "ID Matching" arrow, suggesting a comparison or correlation between the data. Some rows are filled with "..." indicating missing data, and some rows are grayed out and labeled as "Dummy ID".
### Components/Axes
* **Titles:** "Client A" (top-left), "Client B" (top-right), "ID Matching" (center)
* **Client A Table:**
* Columns: "ID", "Weight", "Height", "Blood pressure", "Uric acid level"
* Rows: ID values 3, 4, 10, 11, 12, 13, 14
* **Client B Table:**
* Columns: "ID", "Sleep time", "Walking speed", "Exercise freq.", "Amount of alcohol consumption"
* Rows: ID values 3, 4, 10, 11, 12, 13, 14
* **Dummy ID:** A bracket on the left side of the table indicates that IDs 10, 11, 12, 13, and 14 are "Dummy ID".
* **Arrow:** A large, dark blue, double-headed arrow points from the Client A table to the Client B table, labeled "ID Matching".
### Detailed Analysis or ### Content Details
**Client A Table:**
| ID | Weight | Height | Blood pressure | Uric acid level |
|---|---|---|---|---|
| 3 | 65 | 170 | 100 | 1.0 |
| 4 | ... | ... | ... | ... |
| 10 | | | | |
| 11 | | | | |
| 12 | | | | |
| 13 | | | | |
| 14 | | | | |
* ID 3: Weight = 65, Height = 170, Blood pressure = 100, Uric acid level = 1.0
* ID 4: All data is missing ("...")
* IDs 10-14: Data is missing (cells are empty and grayed out)
**Client B Table:**
| ID | Sleep time | Walking speed | Exercise freq. | Amount of alcohol consumption |
|---|---|---|---|---|
| 3 | 8 | 6 | 1 | 1 |
| 4 | ... | ... | ... | ... |
| 10 | | | | |
| 11 | | | | |
| 12 | | | | |
| 13 | | | | |
| 14 | | | | |
* ID 3: Sleep time = 8, Walking speed = 6, Exercise freq. = 1, Amount of alcohol consumption = 1
* ID 4: All data is missing ("...")
* IDs 10-14: Data is missing (cells are empty)
### Key Observations
* Data is only fully populated for ID 3 in both tables.
* Data for ID 4 is missing in both tables.
* IDs 10-14 are marked as "Dummy ID" and have no data.
* The "ID Matching" arrow suggests a relationship or comparison between the two datasets based on the ID.
### Interpretation
The image illustrates a scenario where health data is being compared between two clients based on a common ID. The presence of missing data ("...") and "Dummy ID" entries suggests that the dataset is incomplete or contains placeholder entries. The "ID Matching" arrow implies that the analysis aims to find correlations or patterns between the different health metrics recorded for each client. The limited data available makes it difficult to draw any concrete conclusions, but the structure indicates an intention to analyze the relationship between weight, height, blood pressure, uric acid level (Client A) and sleep time, walking speed, exercise frequency, and alcohol consumption (Client B).
</details>
Figure 10: Example of dummy IDs.
IV-B 2 Output from Clients
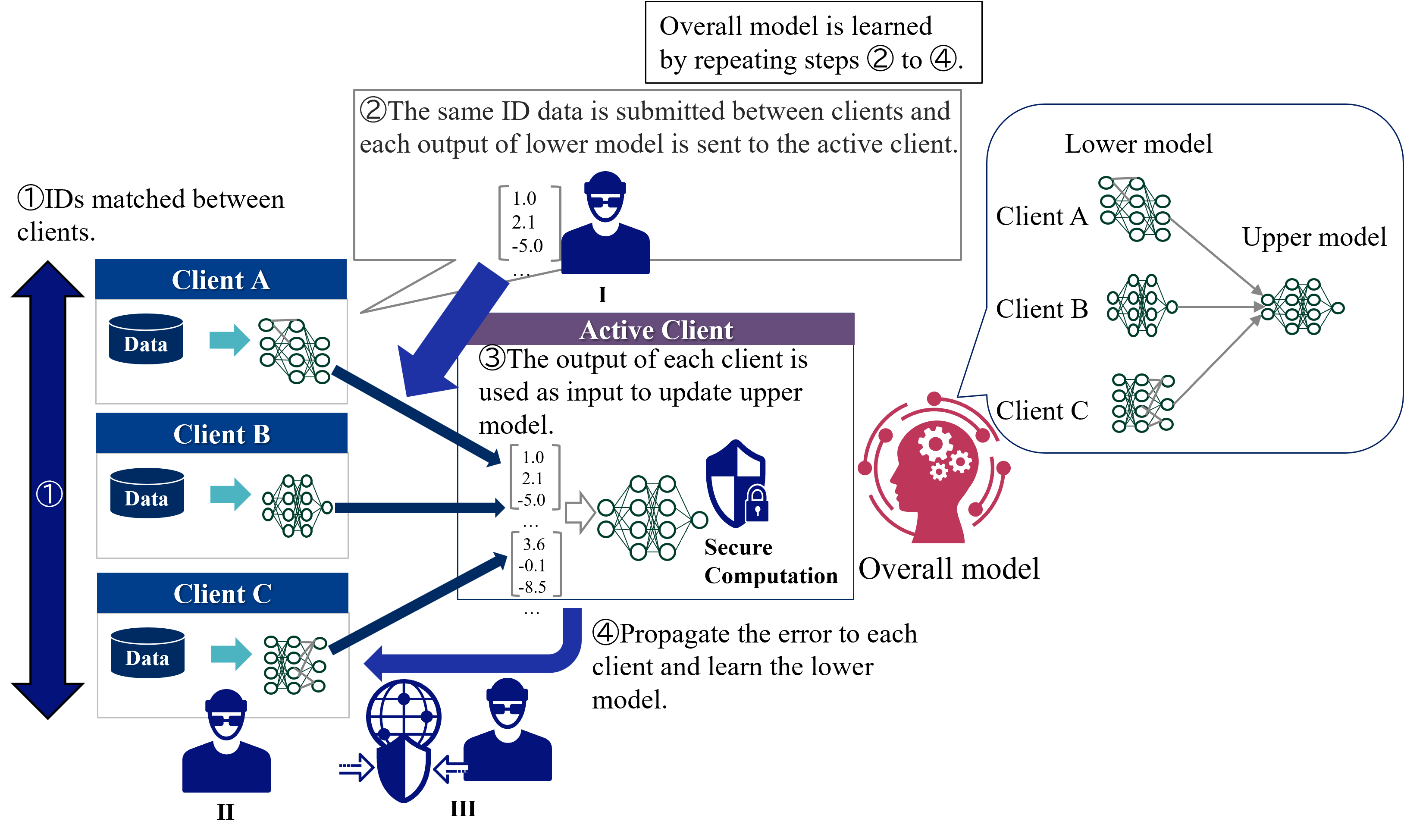
In case of output from clients, the typical privacy measure is the use of secure calculations [33]. Figure 11 shows countermeasures against threads in case of output from clients. The position of the attacker by these privacy measures is described as follows.
1. Active Client: Secure computation realizes global model integration calculations without seeing the model by the active client. [35].
1. Passive Clients: Client B receives the information used for updating from the upper model via the active client, but it is protected by secure computation.
1. Third party: Achieved by encryption of communication.
<details>
<summary>extracted/5379099/fig/CMOC_VFL.png Details</summary>
### Visual Description
## Diagram: Secure Computation Model
### Overview
The image illustrates a secure computation model involving multiple clients (A, B, and C), an active client, and an overall model. The diagram outlines the flow of data and computations between these components, emphasizing the iterative process of learning the overall model while maintaining data privacy.
### Components/Axes
* **Clients (A, B, C):** Represented as rectangular boxes with the client name and a "Data" storage icon. Each client also has a neural network representation.
* **Active Client:** A central processing unit that receives data from the clients and updates the upper model.
* **Overall Model:** A representation of the final learned model, depicted as a head with gears inside, symbolizing computation.
* **Lower Model:** Neural networks associated with each client.
* **Upper Model:** A neural network that combines the outputs of the lower models.
* **Secure Computation:** A shield icon with a lock, indicating the use of secure computation techniques.
* **Arrows:** Indicate the flow of data and computations.
* **Numerical Data:** Vectors of numbers representing data being passed between clients.
* **Numbered Steps:** Indicate the sequence of operations in the model.
### Detailed Analysis
The diagram outlines a four-step process:
1. **IDs matched between clients:** A large blue arrow pointing downwards indicates the matching of IDs between clients A, B, and C.
2. **The same ID data is submitted between clients and each output of lower model is sent to the active client:** Data from each client is sent to the "Active Client" (labeled as 'I'). The data is represented as vectors of numbers:
* Client A: \[1.0, 2.1, -5.0, ... ]
* Client C: \[3.6, -0.1, -8.5, ... ]
A man icon is present near the active client.
3. **The output of each client is used as input to update upper model:** The active client processes the data and updates the upper model. A secure computation icon (shield with a lock) is shown.
4. **Propagate the error to each client and learn the lower model:** The error is propagated back to each client, and the lower models are updated. This is represented by a blue arrow pointing from the "Overall Model" back to the clients. A globe icon with a shield is present.
The diagram also shows a "Lower model" and "Upper model" section on the right side. The lower model consists of neural networks for each client (A, B, and C). The outputs of these lower models are combined in the upper model.
Two additional man icons are present, labeled II and III.
The text "Overall model is learned by repeating steps 2 to 4." is present at the top of the diagram.
### Key Observations
* The diagram illustrates a federated learning approach where clients contribute to a global model without sharing their raw data directly.
* Secure computation techniques are used to protect data privacy during the learning process.
* The model involves iterative updates of both lower and upper models.
### Interpretation
The diagram presents a secure federated learning framework. The clients (A, B, and C) each possess local data. The process begins with matching IDs across clients. The data is then processed locally by each client's "lower model." The outputs of these lower models are sent to an "active client," which aggregates the information and updates an "upper model." Secure computation techniques are employed to ensure data privacy during this aggregation. The error from the upper model is then propagated back to the clients, allowing them to refine their lower models. This iterative process (steps 2-4) continues until the overall model converges. The presence of man icons near the data flow suggests potential security considerations or roles within the system. The globe icon with a shield further emphasizes the security aspect of the data transfer.
</details>
Figure 11: Countermeasures against threads in case of output from clients.
IV-C Federated Transfer Learning
In FTL, the threads to privacy depend on common information between clients [24]. We show how to respond in the case of each thread.
IV-C 1 Common Features
In case of common features, the threads to privacy are exchanges of feature analogy network and prediction network. Figure 12 shows countermeasures against threads in case of common features.
1. Client receiving a feature analogy network: Differential privacy makes it difficult to infer the model [37].
1. Client receiving a feature analogy network and prediction network: Differential privacy makes it difficult to infer the model.
1. Third party: Achieved by encryption of communication.
<details>
<summary>extracted/5379099/fig/CMCF_FTL.png Details</summary>

### Visual Description
## Data Flow Diagram: Federated Learning with Differential Privacy
### Overview
The image is a data flow diagram illustrating a federated learning system with differential privacy. It depicts two clients (A and B) interacting with a central entity (III) through feature analogy and prediction networks, while incorporating differential privacy mechanisms.
### Components/Axes
* **Clients:** Client A and Client B, represented by data storage icons and user icons labeled I and II respectively.
* **Central Entity:** Represented by a user icon labeled III.
* **Data Flow:** Arrows indicate the direction of data flow between clients and the central entity.
* **Feature Analogy Network:** Text label indicating the network used for feature analogy between Client A and Client B.
* **Prediction Network:** Text label indicating the network used for prediction.
* **Differential Privacy:** Text labels indicating the application of differential privacy at Client A and Client B.
* **Privacy Shields:** Shield icons represent privacy mechanisms.
* **Processing Heads:** Head icons with gears represent data processing.
### Detailed Analysis or Content Details
1. **Client A (Top-Left):**
* Labeled "Client A".
* A user icon labeled "I" is positioned to the left of a cylindrical data storage icon.
* A red head icon with gears inside a red circle and a blue shield is positioned to the right of the data storage.
* "Feature analogy network" text is positioned below the user icon.
* An upward arrow points from a globe icon with a shield towards Client A's data storage.
2. **Client B (Bottom-Left):**
* Labeled "Client B".
* A cylindrical data storage icon is positioned to the left of a user icon labeled "II".
* A blue head icon with gears inside a blue circle and a blue shield is positioned below and to the left of the data storage.
* "Differential privacy" text is positioned below the head icon.
* A downward arrow points from the globe icon with a shield towards Client B's data storage.
3. **Central Entity (Right):**
* Represented by a user icon labeled "III".
* Positioned to the right of the diagram.
4. **Data Flow and Networks:**
* "Feature analogy network" text is positioned between Client A and Client B, with arrows indicating data flow between them via a globe icon with a shield.
* "Feature analogy network and Prediction network" text is positioned between Client A and the central entity.
* "Differential privacy" text is positioned between Client A and the central entity.
### Key Observations
* The diagram illustrates a federated learning setup where Client A and Client B exchange feature information through a feature analogy network.
* Differential privacy is applied at both Client A and Client B to protect data privacy.
* A prediction network is used to send data from Client A to the central entity.
### Interpretation
The diagram depicts a federated learning system designed to protect data privacy. Clients A and B collaborate by sharing feature analogies, while differential privacy mechanisms are implemented to prevent the disclosure of sensitive information. The central entity receives data from Client A through a prediction network, enabling model training without direct access to raw client data. The globe icon with a shield suggests a secure communication channel between the clients. The red color of the head icon with gears and shield near Client A may indicate a potential risk or a different type of privacy mechanism compared to Client B.
</details>
Figure 12: Countermeasures against threads in case of common features.
IV-C 2 Common IDs
In case of common IDs, the threads to privacy are the leakage of identities and information required for feature similarity [24]. For the leakage of identities, Dummy IDs are prepared in addition to the original IDs as shown in Section IV-B 1 [39]. For information required for feature similarity, figure 13 shows countermeasures against threads in case of common IDs.
1. Client receiving information for feature similarity: Difficult to guess information due to secure computation [35].
1. Third party: Achieved by encryption of communication.
<details>
<summary>extracted/5379099/fig/CMCI_FTL.png Details</summary>

### Visual Description
## Diagram: Secure Computation for Feature Similarity
### Overview
The image illustrates a secure computation process for determining feature similarity between two clients (Client A and Client B). The diagram highlights the flow of information and the involvement of secure computation entities.
### Components/Axes
* **Clients:** Client A (top-left) and Client B (bottom-left), each represented by a database icon and a person icon.
* **Secure Computation Entities:** Two entities labeled "I" (bottom) and "II" (right), each represented by a person icon.
* **Secure Computation Blocks:** Two blocks labeled "Secure Computation" associated with each client, represented by a shield icon with a padlock.
* **Information Flow:** Arrows indicate the flow of "Information required for feature similarity" from both clients to a central secure computation block.
* **Central Secure Computation Block:** A shield icon with a globe inside, positioned between the two clients.
### Detailed Analysis
* **Client A:** Located at the top-left. It consists of a database icon and a person icon.
* **Client B:** Located at the bottom-left. It consists of a database icon and a person icon.
* **Information Flow:** The text "Information required for feature similarity" is positioned between the two clients. A double-headed arrow points upwards from Client B and downwards from Client A towards a central shield icon with a globe inside. Two arrows point from the central shield icon to the right.
* **Secure Computation Blocks:** Each client has a "Secure Computation" block associated with it, represented by a shield icon with a padlock.
* **Secure Computation Entities:** Two entities labeled "I" and "II" are present. Entity "I" is located below Client B, and Entity "II" is located to the right of Client A. Each entity is represented by a person icon.
### Key Observations
* The diagram emphasizes the secure exchange of information between clients and secure computation entities.
* The central secure computation block acts as an intermediary for processing information from both clients.
* The presence of "Secure Computation" blocks near each client suggests that some computation is performed locally before sending information to the central block.
### Interpretation
The diagram illustrates a secure multi-party computation (MPC) scenario where two clients want to determine the similarity of their features without revealing the actual features to each other or to a single third party. The "Secure Computation" blocks likely represent cryptographic protocols that ensure the privacy of the data during computation. The central secure computation block performs the similarity calculation based on the encrypted or masked data received from the clients. The entities "I" and "II" could represent different parties involved in the secure computation protocol, such as data providers or computation servers. The diagram highlights the importance of secure computation in protecting sensitive information while still enabling collaborative analysis.
</details>
Figure 13: Countermeasures against threads in case of common IDs.
V Conclusion
In this paper, we have described privacy threats and countermeasures for federated learning in terms of HFL, VFL, and FTL. Privacy measures for federated learning include differential privacy to reduce the leakage of training data from the model, secure computation to keep the model computation process secret between clients and servers, encryption of communications to prevent information leakage to third parties, and ID dummying to prevent ID leakage.
Acknowledgment
This R&D includes the results of ” Research and development of optimized AI technology by secure data coordination (JPMI00316)” by the Ministry of Internal Affairs and Communications (MIC), Japan.
References
- [1] L. Lyu, H. Yu, and Q. Yang, “Threats to federated learning: A survey,” arXiv preprint arXiv:2003.02133, 2020.
- [2] Q. Yang, Y. Liu, T. Chen, and Y. Tong, “Federated machine learning: Concept and applications,” ACM Trans. Intell. Syst. Technol., vol. 10, no. 2, 2019.
- [3] B. McMahan, E. Moore, D. Ramage, S. Hampson, and B. A. y. Arcas, “Communication-Efficient Learning of Deep Networks from Decentralized Data,” in Proceedings of the 20th International Conference on Artificial Intelligence and Statistics, ser. Proceedings of Machine Learning Research, vol. 54. PMLR, 2017, pp. 1273–1282.
- [4] E. T. Martínez Beltrán, M. Q. Pérez, P. M. S. Sánchez, S. L. Bernal, G. Bovet, M. G. Pérez, G. M. Pérez, and A. H. Celdrán, “Decentralized federated learning: Fundamentals, state of the art, frameworks, trends, and challenges,” IEEE Communications Surveys & Tutorials, vol. 25, no. 4, pp. 2983–3013, 2023.
- [5] L. Zhao, L. Ni, S. Hu, Y. Chen, P. Zhou, F. Xiao, and L. Wu, “Inprivate digging: Enabling tree-based distributed data mining with differential privacy,” in IEEE INFOCOM 2018 - IEEE Conference on Computer Communications, 2018, pp. 2087–2095.
- [6] Q. Li, Z. Wen, and B. He, “Practical federated gradient boosting decision trees,” Proceedings of the AAAI Conference on Artificial Intelligence, vol. 34, no. 04, pp. 4642–4649, 2020.
- [7] F. Wang, J. Ou, and H. Lv, “Gradient boosting forest: a two-stage ensemble method enabling federated learning of gbdts,” in Neural Information Processing, T. Mantoro, M. Lee, M. A. Ayu, K. W. Wong, and A. N. Hidayanto, Eds. Cham: Springer International Publishing, 2021, pp. 75–86.
- [8] A. Gascón, P. Schoppmann, B. Balle, M. Raykova, J. Doerner, S. Zahur, and D. Evans, “Secure linear regression on vertically partitioned datasets,” IACR Cryptol. ePrint Arch., vol. 2016, p. 892, 2016.
- [9] S. Hardy, W. Henecka, H. Ivey-Law, R. Nock, G. Patrini, G. Smith, and B. Thorne, “Private federated learning on vertically partitioned data via entity resolution and additively homomorphic encryption,” CoRR, vol. abs/1711.10677, 2017.
- [10] R. Nock, S. Hardy, W. Henecka, H. Ivey-Law, G. Patrini, G. Smith, and B. Thorne, “Entity resolution and federated learning get a federated resolution,” CoRR, vol. abs/1803.04035, 2018.
- [11] S. Yang, B. Ren, X. Zhou, and L. Liu, “Parallel distributed logistic regression for vertical federated learning without third-party coordinator,” CoRR, vol. abs/1911.09824, 2019.
- [12] Q. Zhang, B. Gu, C. Deng, and H. Huang, “Secure bilevel asynchronous vertical federated learning with backward updating,” Proceedings of the AAAI Conference on Artificial Intelligence, vol. 35, no. 12, pp. 10 896–10 904, May 2021.
- [13] K. Cheng, T. Fan, Y. Jin, Y. Liu, T. Chen, D. Papadopoulos, and Q. Yang, “Secureboost: A lossless federated learning framework,” IEEE Intelligent Systems, vol. 36, no. 6, pp. 87–98, 2021.
- [14] J. Vaidya, C. Clifton, M. Kantarcioglu, and A. S. Patterson, “Privacy-preserving decision trees over vertically partitioned data,” ACM Trans. Knowl. Discov. Data, vol. 2, no. 3, oct 2008.
- [15] Y. Wu, S. Cai, X. Xiao, G. Chen, and B. C. Ooi, “Privacy preserving vertical federated learning for tree-based models,” Proc. VLDB Endow., vol. 13, no. 12, p. 2090–2103, jul 2020.
- [16] Y. Liu, Y. Liu, Z. Liu, Y. Liang, C. Meng, J. Zhang, and Y. Zheng, “Federated forest,” IEEE Transactions on Big Data, pp. 1–1, 2020.
- [17] Z. Tian, R. Zhang, X. Hou, J. Liu, and K. Ren, “Federboost: Private federated learning for GBDT,” CoRR, vol. abs/2011.02796, 2020.
- [18] Y. Hu, D. Niu, J. Yang, and S. Zhou, “Fdml: A collaborative machine learning framework for distributed features,” in Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, ser. KDD ’19. New York, NY, USA: Association for Computing Machinery, 2019, p. 2232–2240.
- [19] Y. Liu, Y. Kang, X. Zhang, L. Li, Y. Cheng, T. Chen, M. Hong, and Q. Yang, “A communication efficient collaborative learning framework for distributed features,” CoRR, vol. abs/1912.11187, 2019.
- [20] D. Romanini, A. J. Hall, P. Papadopoulos, T. Titcombe, A. Ismail, T. Cebere, R. Sandmann, R. Roehm, and M. A. Hoeh, “Pyvertical: A vertical federated learning framework for multi-headed splitnn,” CoRR, vol. abs/2104.00489, 2021.
- [21] Q. He, W. Yang, B. Chen, Y. Geng, and L. Huang, “Transnet: Training privacy-preserving neural network over transformed layer,” Proc. VLDB Endow., vol. 13, no. 12, p. 1849–1862, jul 2020.
- [22] B. Gu, Z. Dang, X. Li, and H. Huang, “Federated doubly stochastic kernel learning for vertically partitioned data,” in Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. New York, NY, USA: Association for Computing Machinery, 2020, p. 2483–2493.
- [23] R. Xu, N. Baracaldo, Y. Zhou, A. Anwar, J. Joshi, and H. Ludwig, “Fedv: Privacy-preserving federated learning over vertically partitioned data,” CoRR, vol. abs/2103.03918, 2021.
- [24] Y. Liu, Y. Kang, C. Xing, T. Chen, and Q. Yang, “A secure federated transfer learning framework,” IEEE Intelligent Systems, vol. 35, no. 4, pp. 70–82, 2020.
- [25] S. Sharma, C. Xing, Y. Liu, and Y. Kang, “Secure and efficient federated transfer learning,” in 2019 IEEE International Conference on Big Data (Big Data), 2019, pp. 2569–2576.
- [26] B. Zhang, C. Chen, and L. Wang, “Privacy-preserving transfer learning via secure maximum mean discrepancy,” arXiv preprint arXiv:2009.11680, 2020.
- [27] Y. Gao, M. Gong, Y. Xie, A. K. Qin, K. Pan, and Y.-S. Ong, “Multiparty dual learning,” IEEE Transactions on Cybernetics, vol. 53, no. 5, pp. 2955–2968, 2023.
- [28] D. Gao, Y. Liu, A. Huang, C. Ju, H. Yu, and Q. Yang, “Privacy-preserving heterogeneous federated transfer learning,” in 2019 IEEE International Conference on Big Data (Big Data), 2019, pp. 2552–2559.
- [29] J. Mori, I. Teranishi, and R. Furukawa, “Continual horizontal federated learning for heterogeneous data,” in 2022 International Joint Conference on Neural Networks (IJCNN), 2022, pp. 1–8.
- [30] D. Gao, C. Ju, X. Wei, Y. Liu, T. Chen, and Q. Yang, “Hhhfl: Hierarchical heterogeneous horizontal federated learning for electroencephalography,” arXiv preprint arXiv:1909.05784, 2019.
- [31] A. Rakotomamonjy, M. Vono, H. J. M. Ruiz, and L. Ralaivola, “Personalised federated learning on heterogeneous feature spaces,” arXiv preprint arXiv:2301.11447, 2023.
- [32] E. Hallaji, R. Razavi-Far, and M. Saif, Federated and Transfer Learning: A Survey on Adversaries and Defense Mechanisms. Cham: Springer International Publishing, 2023, pp. 29–55.
- [33] S. Hardy, W. Henecka, H. Ivey-Law, R. Nock, G. Patrini, G. Smith, and B. Thorne, “Private federated learning on vertically partitioned data via entity resolution and additively homomorphic encryption,” arXiv preprint arXiv:1711.10677, 2017.
- [34] K. Bonawitz, V. Ivanov, B. Kreuter, A. Marcedone, H. B. McMahan, S. Patel, D. Ramage, A. Segal, and K. Seth, “Practical secure aggregation for privacy-preserving machine learning,” in Proceedings of the 2017 ACM SIGSAC Conference on Computer and Communications Security, ser. CCS ’17. New York, NY, USA: Association for Computing Machinery, 2017, p. 1175–1191.
- [35] P. Mohassel and Y. Zhang, “Secureml: A system for scalable privacy-preserving machine learning,” in 2017 IEEE Symposium on Security and Privacy (SP), 2017, pp. 19–38.
- [36] T. Araki, J. Furukawa, Y. Lindell, A. Nof, and K. Ohara, “High-throughput semi-honest secure three-party computation with an honest majority,” in Proceedings of the 2016 ACM SIGSAC Conference on Computer and Communications Security, ser. CCS ’16. New York, NY, USA: Association for Computing Machinery, 2016, p. 805–817.
- [37] M. Abadi, A. Chu, I. Goodfellow, H. B. McMahan, I. Mironov, K. Talwar, and L. Zhang, “Deep learning with differential privacy,” in Proceedings of the 2016 ACM SIGSAC Conference on Computer and Communications Security, ser. CCS ’16. New York, NY, USA: Association for Computing Machinery, 2016, p. 308–318.
- [38] R. C. Geyer, T. Klein, and M. Nabi, “Differentially private federated learning: A client level perspective,” arXiv preprint arXiv:1712.07557, 2017.
- [39] Y. Liu, X. Zhang, and L. Wang, “Asymmetrical vertical federated learning,” arXiv preprint arXiv:2004.07427, 2020.