# Survey of Privacy Threats and Countermeasures in Federated Learning
**Authors**: Masahiro Hayashitani, Junki Mori, and Isamu Teranishi
> M. Hayashitani, J. Mori, and I. Teranishi are with NEC Secure System Platform Research Laboratories. E-mail:
## Abstract
Federated learning is widely considered to be as a privacy-aware learning method because no training data is exchanged directly between clients. Nevertheless, there are threats to privacy in federated learning, and privacy countermeasures have been studied. However, we note that common and unique privacy threats among typical types of federated learning have not been categorized and described in a comprehensive and specific way. In this paper, we describe privacy threats and countermeasures for the typical types of federated learning; horizontal federated learning, vertical federated learning, and transfer federated learning.
Index Terms: horizontal federated learning, vertical federated learning, transfer federated learning, threat to privacy, countermeasure against privacy threat.
## I Introduction
As computing devices become more ubiquitous, people generate vast amounts of data in their daily lives. Collecting this data in centralized storage facilities is costly and time-consuming [1]. Another important concern is user privacy and confidentiality, as usage data typically contains sensitive information. Sensitive data such as biometrics and healthcare can be used for targeted social advertising and recommendations, posing immediate or potential privacy risks. Therefore, private data should not be shared directly without any privacy considerations. As societies become more privacy-conscious, legal restrictions such as the General Data Protection Regulation (GDPR) and the EU AI ACT are emerging, making data aggregation practices less feasible. In this case, federated learning has emerged as a promising machine learning technique where each client learns and sends the information to a server.
Federated learning has attracted attention as a privacy-preserving machine learning technique because it can learn a global model without exchanging private raw data between clients. However, federated learning still poses a threat to privacy. Recent works have shown that federated learning may not always provide sufficient privacy guarantees, since the communication of model updates throughout the training process may still reveal sensitive information, even to a third party or to the central server [1]. Typical examples of federated learning include horizontal federated learning where features are common, vertical federated learning where IDs are common, and federated transfer learning where some features or IDs are common. However, we note that common and unique privacy threats among each type of federated learning have not been categorized and described in a comprehensive and specific way.
For example, in the case of horizontal federated learning, semi-honest server can infer client’s data by inference attacks on a model sent by the client. If the client is an attacker, the attacker can infer the data of other clients by inference attacks on a global model received from the server. Such an attack is possible because the global model is design to reflect the data of all clients. If the attacker is a third party that is neither a server nor a client, it can eavesdrop on models passing through the communication channel and infer client data through inference attacks. In vertical federated learning, the main threat to privacy is the identify leakage through identity matching between clients. In addition, since the intermediate outputs of a model are sent to the server, there is a possibility that client data can be inferred through an inference attack. Also, as in horizontal federated learning, client data can be inferred by an inference attack on the server. Finally, in federated transfer learning, member and attribute guessing attacks are possible by exploiting a prediction network. If IDs are common, gradient information is exchanged when features are made similar. Therefore member and attribute guessing attacks are possible by using gradient information. When there are common features among clients, attribute guessing attacks are possible by exploiting networks that complement the missing features from the common features.
In this paper, we discuss the above threats to privacy in detail and countermeasures against privacy threats in three types of federated learning; horizontal federated learning, vertical federated learning, and federated transfer learning. The paper is organized as follows: Section 2 presents learning methods for horizontal federated learning, vertical federated learning, and federated transfer learning; Section 3 discusses threats to privacy in each federated learning; Section 4 discusses countermeasures against privacy threats in each federated learning; and Section 5 concludes.
## II Categorization of Federated Learning
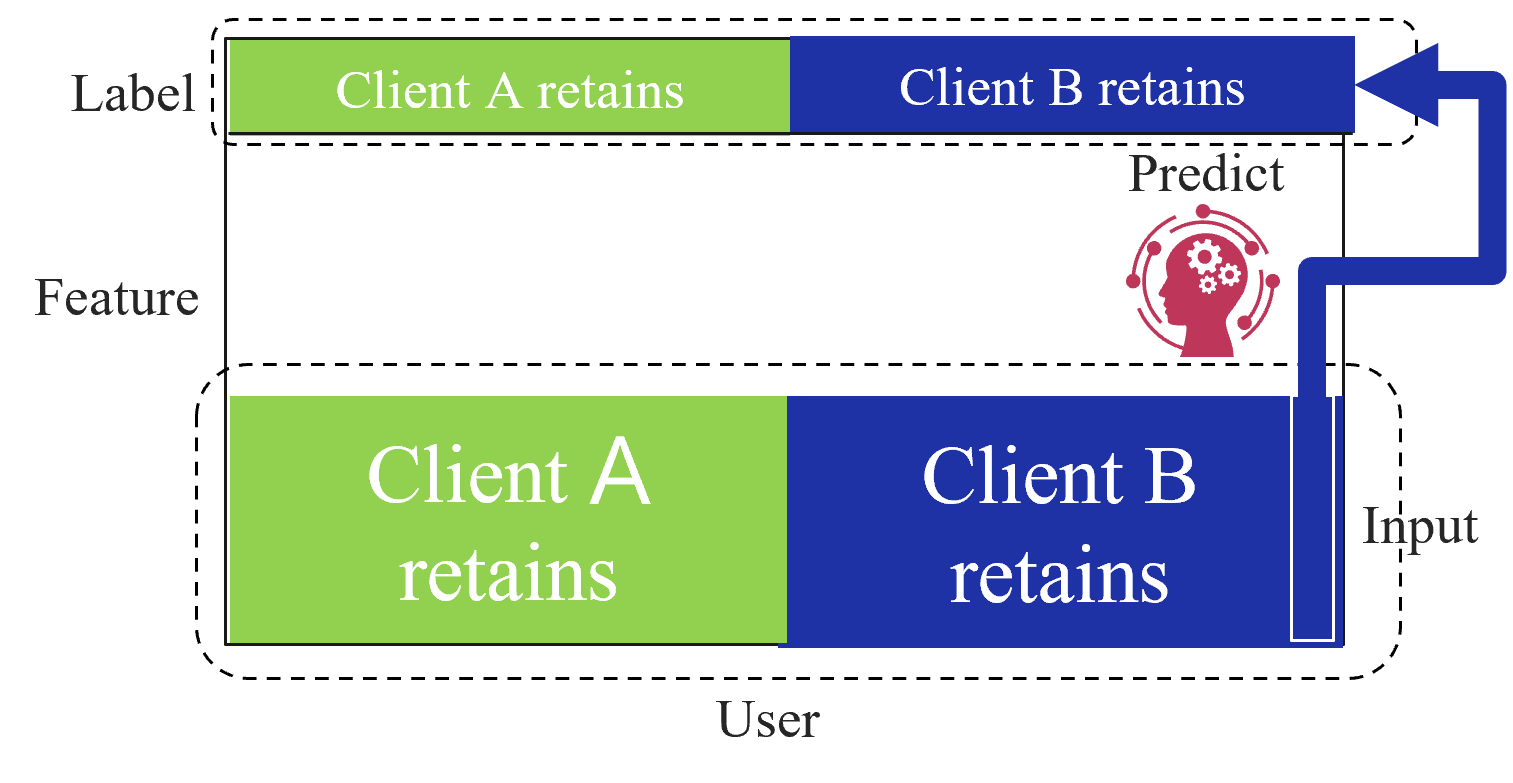
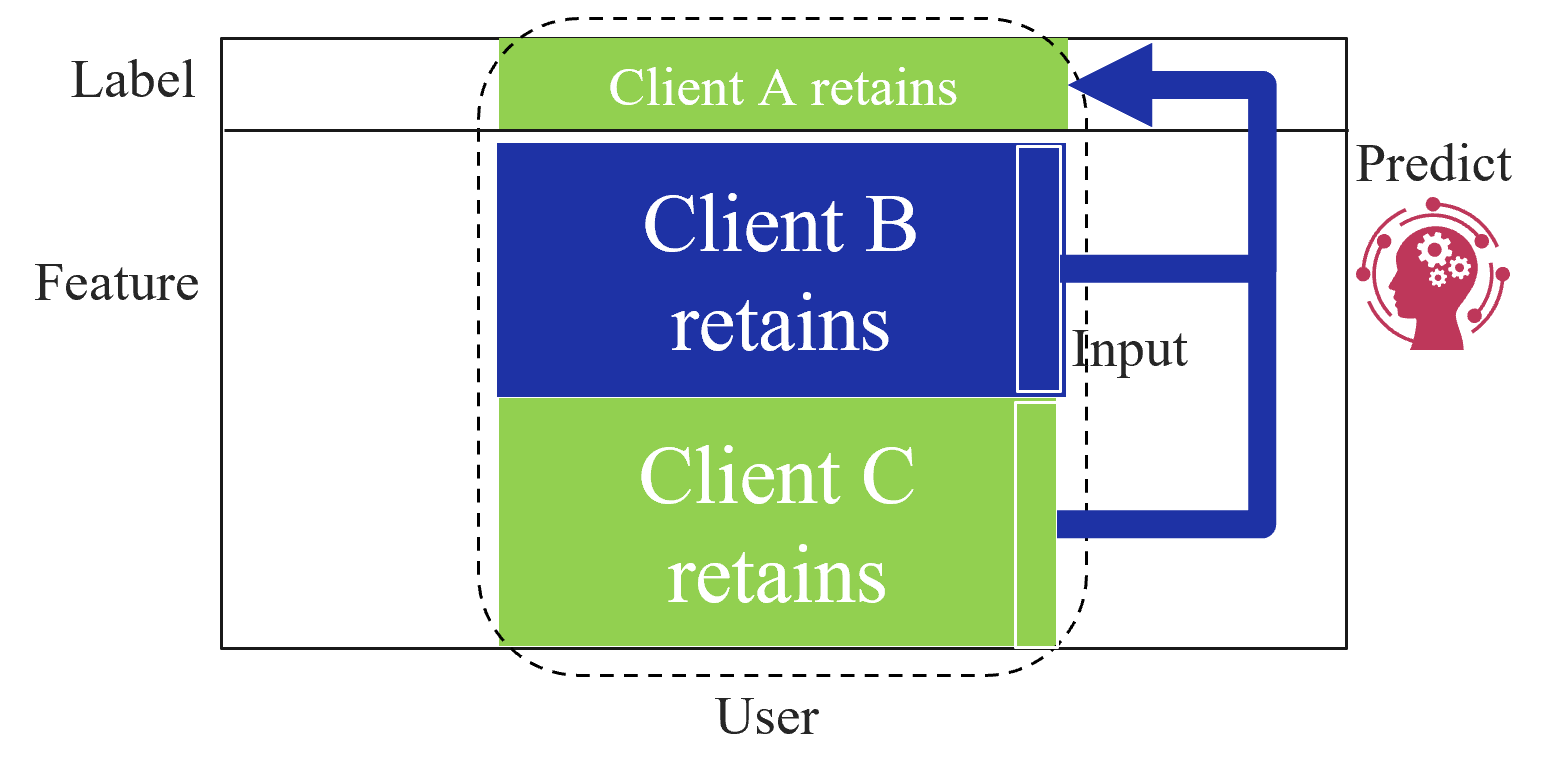
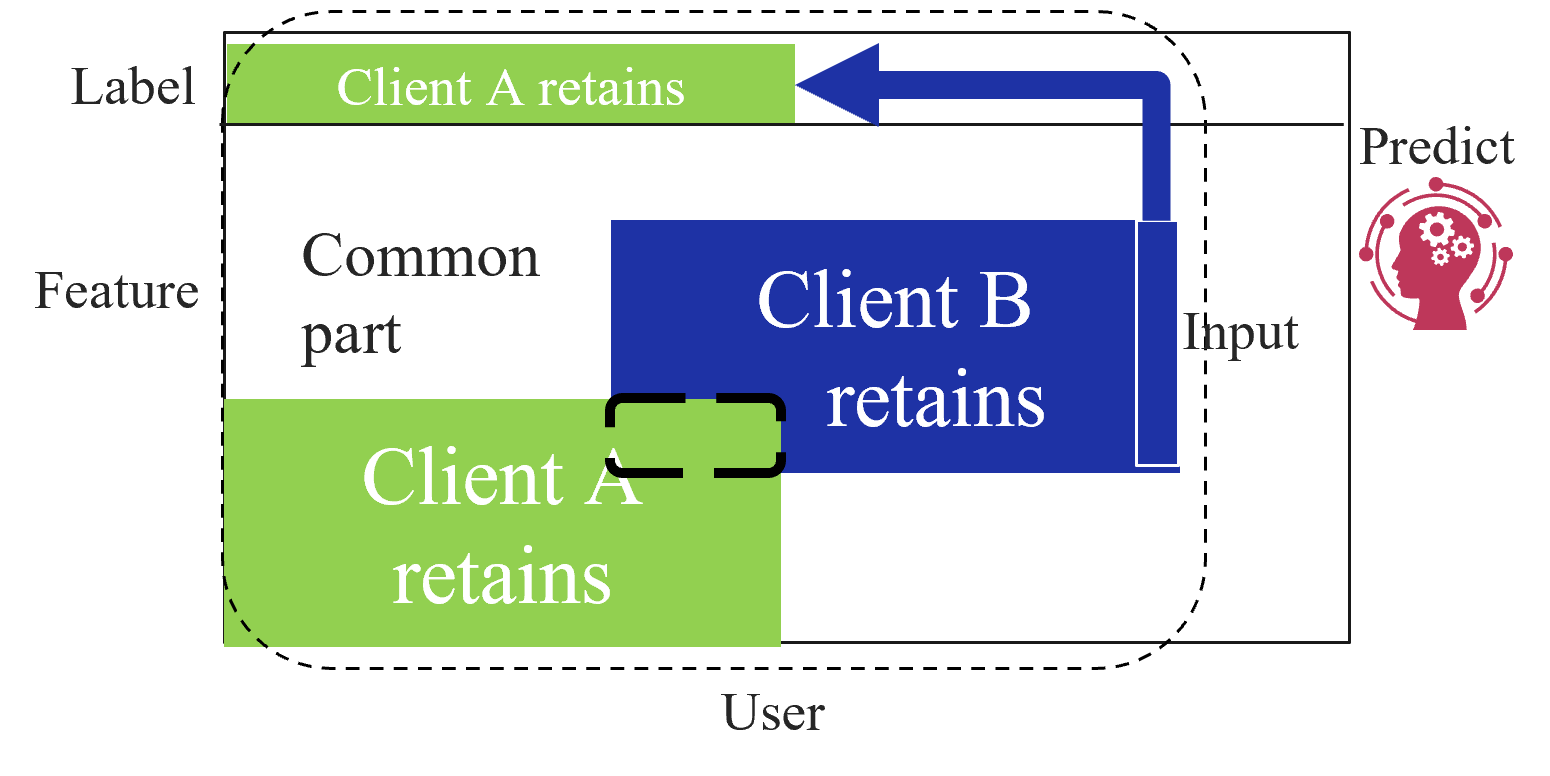
Based on the data structures among clients, federated learning is categorized into three types as first introduced by Yang et al. [2]: horizontal federated learning (HFL), vertical federated learning (VFL), and federated transfer learning (FTL). Figure 1 shows the data structure among clients for each type of federated learning. HFL assumes that each client has the same features and labels but different samples (Figure 1(a)). On the other hand, VFL assumes that each client has the same samples but disjoint features (Figure 1(a)). Finally, FTL applies to the scenario where each of the two clients has data that differ in not only samples but also features (Figure 1(c)).
In the following subsections, we describe the learning and prediction methods for each type of federated learning.
<details>
<summary>extracted/5379099/fig/HFL_structure.png Details</summary>
### Visual Description
## Diagram: Client Data Retention and Prediction Flow
### Overview
The diagram illustrates a two-client system (Client A and Client B) with distinct data retention zones for "Label" and "Feature" categories. A predictive process connects Client B's retained data to a feedback loop involving user input.
### Components/Axes
1. **Vertical Sections**:
- **Top Section**: Labeled "Label" with two color-coded zones:
- Green: "Client A retains"
- Blue: "Client B retains"
- **Bottom Section**: Labeled "Feature" with identical color coding:
- Green: "Client A retains"
- Blue: "Client B retains"
2. **Central Element**:
- A pink brain icon with gear motifs labeled "Predict"
3. **Flow Elements**:
- Blue arrow originating from "Client B retains" (Feature section)
- Connects to "Predict" icon
- Continues to "Input" section
- Final arrow loops back to "User" at the bottom
4. **Legend**:
- Green = Client A
- Blue = Client B
- Positioned at the top of the diagram
### Detailed Analysis
- **Client Data Retention**:
- Both clients maintain separate Label and Feature zones
- Client A's zones are consistently green
- Client B's zones are consistently blue
- No overlap between client zones in either section
- **Prediction Flow**:
- Client B's Feature data directly feeds into the prediction process
- Prediction output becomes input for the system
- Final arrow creates a closed loop back to the user
- **Color Consistency**:
- Green exclusively represents Client A in all instances
- Blue exclusively represents Client B in all instances
- No color mixing or ambiguity observed
### Key Observations
1. Client A's data remains isolated from Client B's data throughout the system
2. Client B's data is the sole input for the prediction process
3. The system creates a feedback loop between prediction output and user input
4. Color coding maintains strict client separation with no exceptions
### Interpretation
This diagram represents a client-specific machine learning architecture where:
1. **Data Isolation**: Client A and B maintain completely separate data repositories for both labels and features
2. **Client-Specific Processing**: Client B's data is prioritized for prediction tasks, suggesting it may contain more relevant or recent information
3. **User Feedback Loop**: The system incorporates user input to refine predictions, creating an iterative improvement cycle
4. **Architectural Design**: The strict color coding and physical separation of client zones emphasize data privacy and prevent cross-contamination between client datasets
The system appears designed for personalized prediction services where client data remains siloed but can be leveraged individually for model training and inference. The feedback loop suggests continuous model refinement based on user interactions.
</details>
(a) Horizontal federated learning.
<details>
<summary>extracted/5379099/fig/VFL_structure.png Details</summary>
### Visual Description
## Diagram: Client Data Processing Architecture
### Overview
The diagram illustrates a multi-client data processing system with labeled sections for "Label," "Feature," and "User." Three clients (A, B, C) are represented with colored blocks, and arrows indicate data flow from input to prediction.
### Components/Axes
- **Vertical Sections**:
- **Label**: Topmost section, containing client-specific labels.
- **Feature**: Middle section, containing client-specific features.
- **User**: Bottom section, demarcated by a dashed line around Client C.
- **Horizontal Arrows**:
- **Input**: Blue arrow pointing to Client B’s feature block.
- **Predict**: Blue arrow with a brain icon (symbolizing neural processing) pointing to the right.
- **Color Coding**:
- **Green**: Client A and C (retains label/feature).
- **Blue**: Client B (retains feature, input focus).
### Detailed Analysis
- **Client A**: Green block in both "Label" and "Feature" sections, indicating retained data.
- **Client B**: Blue block in "Feature" section; input arrow highlights its role as the active input source.
- **Client C**: Green block in "Feature" section, enclosed by a dashed line in the "User" section, suggesting user-specific context.
- **Predict**: Arrows converge on a brain icon with gears/dots, symbolizing predictive modeling or inference.
### Key Observations
1. **Input Focus**: Client B’s feature is explicitly marked as the input source.
2. **Client Retention**: All clients retain labels/features, but Client B is prioritized for processing.
3. **User Context**: Client C’s dashed boundary implies segmentation for user-specific data.
4. **Predictive Flow**: Data from Client B’s features is routed to the prediction model.
### Interpretation
This diagram likely represents a federated learning or multi-client ML system where:
- **Client Data**: Each client (A, B, C) contributes labeled features, but Client B’s data is actively used for input.
- **Prediction**: The system processes Client B’s features to generate predictions, possibly for personalized recommendations or anomaly detection.
- **User Segmentation**: Client C’s dashed boundary suggests isolation for privacy or contextual relevance.
- **Color Significance**: Green (A/C) may denote stable/non-active clients, while blue (B) highlights active processing.
The architecture emphasizes modular client data handling with a focus on Client B for real-time prediction tasks.
</details>
(b) Vertical federated learning.
<details>
<summary>extracted/5379099/fig/FTL_structure.png Details</summary>
### Visual Description
## Diagram: Client Data Flow and Prediction System
### Overview
The diagram illustrates a data flow system involving two clients (A and B), a shared feature space, and a prediction mechanism. It uses color-coded sections to differentiate client-specific data retention and a common processing area, culminating in a predictive output represented by a brain icon.
### Components/Axes
1. **Main Structure**:
- A large dashed rectangle labeled "User" contains three vertical sections:
- **Top**: "Label" section with a green sub-section "Client A retains"
- **Middle**: "Common part" shared by both clients
- **Bottom**: "Client A retains" (green) and "Client B retains" (blue) overlapping the common part
- A blue arrow connects "Client A retains" to "Client B retains" via the common part
- A vertical "Input" section on the right side of the diagram
- A "Predict" section with a brain icon (gears and neural network motifs) outside the main rectangle
2. **Color Coding**:
- Green: Client A-specific data
- Blue: Client B-specific data
- Gray: Common/shared features
3. **Flow Direction**:
- Left-to-right progression from "Label" → "Common part" → "Client B retains" → "Input" → "Predict"
### Detailed Analysis
1. **Data Segmentation**:
- Client A's data is split into:
- 60% retained exclusively by Client A (green section)
- 40% shared in the common part (gray)
- Client B's data is split into:
- 70% retained exclusively by Client B (blue section)
- 30% shared in the common part (gray)
2. **Processing Flow**:
- Client A's retained data (60%) directly feeds into the common processing area
- Client B's retained data (70%) merges with Client A's data in the common part
- The combined data (common part + Client B retains) flows into the "Input" section
- The "Input" section connects to the "Predict" output via a blue arrow
3. **Predictive Component**:
- The brain icon contains three gear-like elements, suggesting:
- Feature engineering (gears)
- Model training (brain)
- Prediction execution (circular flow)
### Key Observations
1. Client A and B share 30% of their data in the common part despite different retention percentages
2. The predictive system receives input from both clients' retained data and the common part
3. The brain icon's circular flow implies iterative processing or feedback loops
4. No explicit numerical values are provided for data proportions
### Interpretation
This diagram represents a hybrid machine learning architecture where:
1. **Client-Specific Data** (60% A, 70% B) is maintained separately
2. **Shared Features** (30% overlap) enable cross-client learning
3. The predictive system combines both client-specific and shared data for output
4. The brain icon suggests the use of neural networks or cognitive computing for prediction
The system appears designed for federated learning or collaborative filtering scenarios where:
- Client privacy is maintained through data segmentation
- Shared features enable generalization across clients
- Predictive power comes from both individual and collective data patterns
The absence of explicit numerical values suggests this is a conceptual architecture rather than a specific implementation with measured performance metrics.
</details>
(c) Federated transfer learning.
Figure 1: Categorization of federated learning based on data structure owned by clients.
### II-A Horizontal Federated Learning
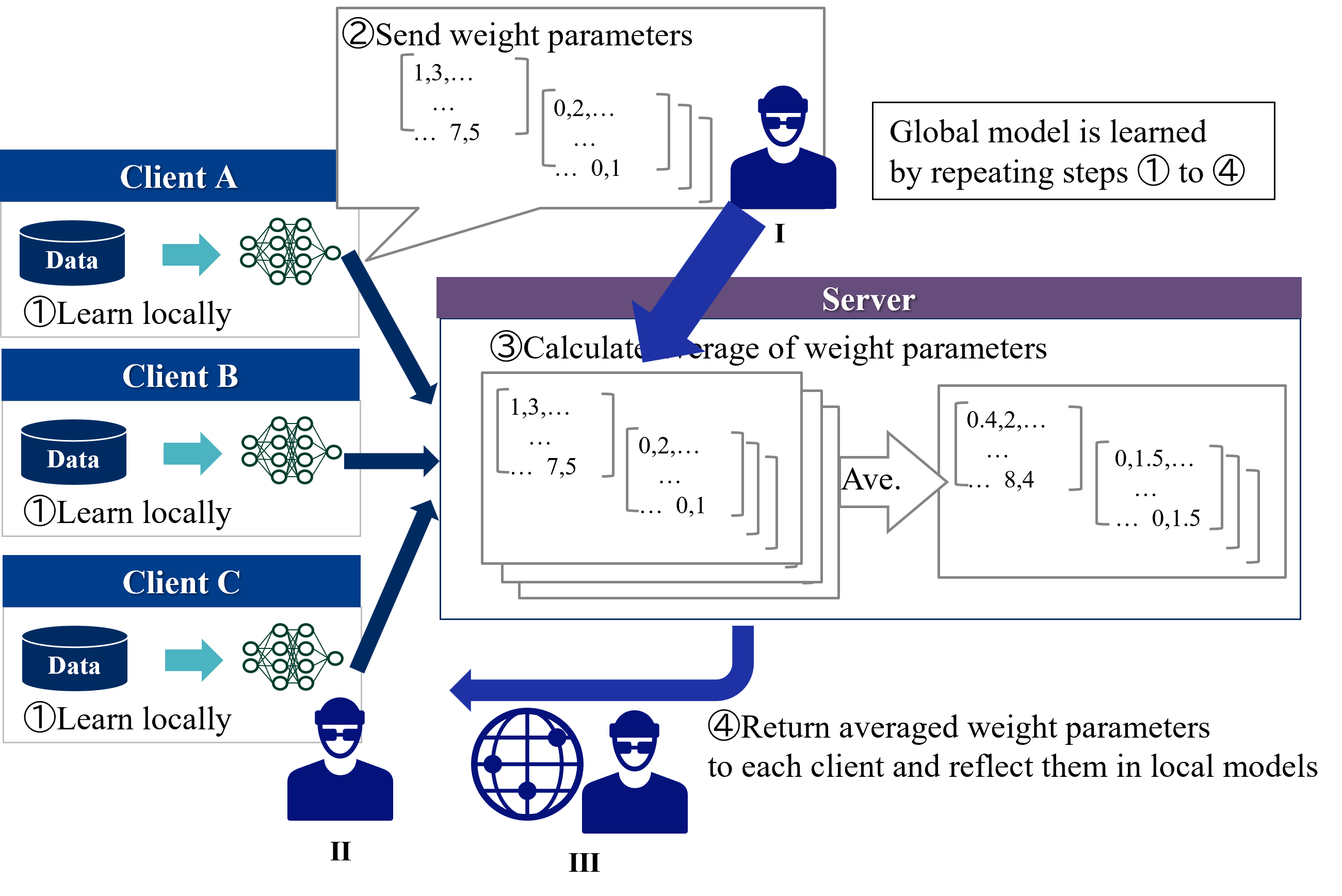
HFL is the most common federated learning category which was first introduced by Google [3]. The goal of HFL is for each client holding different samples to collaboratively improve the accuracy of a model with a common structure.
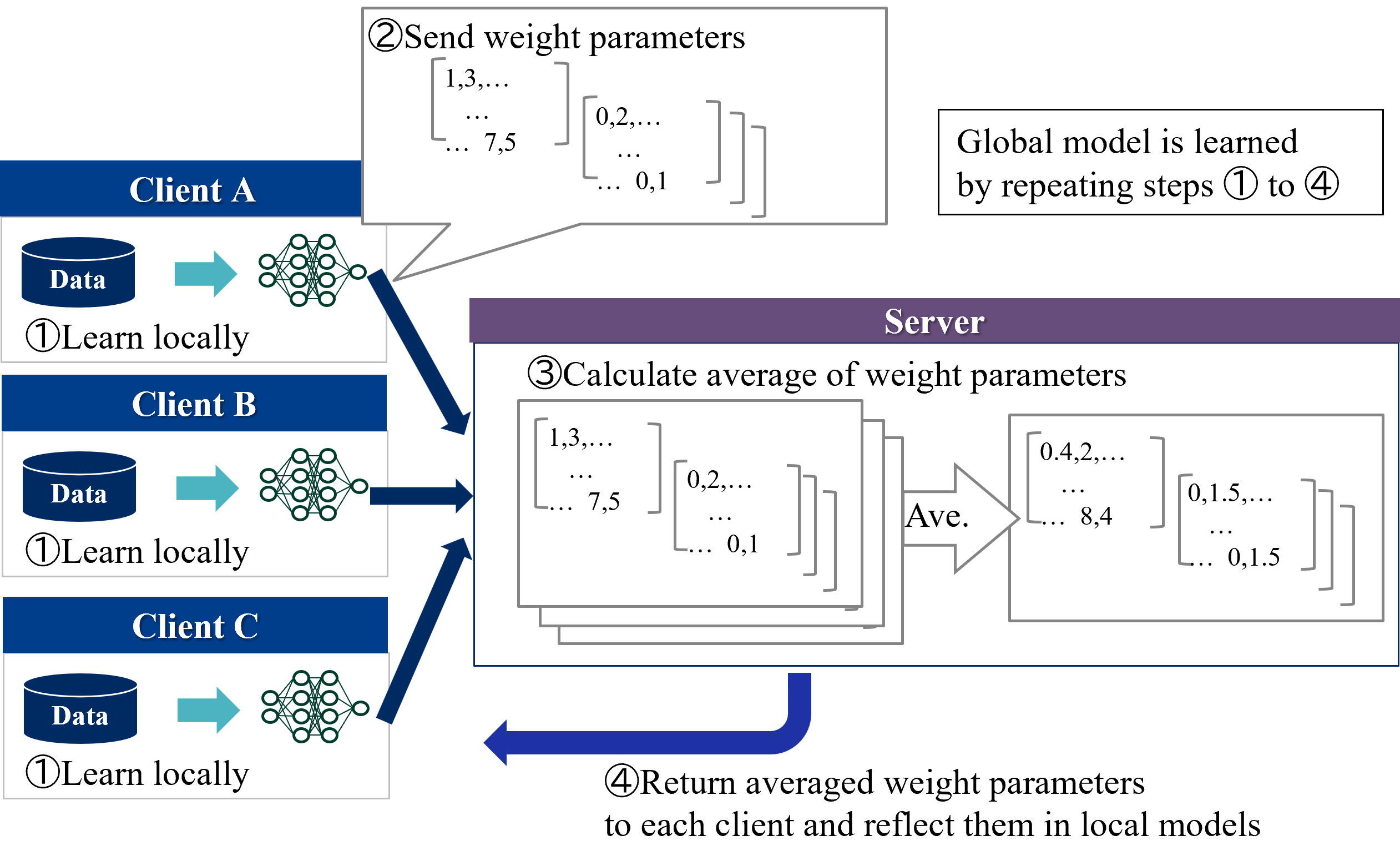
Figure 2 shows an overview of the HFL learning protocol. Two types of entities participate in learning of HFL:
1. Server - Coordinator. Server exchanges model parameters with the clients and aggregates model parameters received from the clients.
1. Clients - Data owners. Each client locally trains a model using their own private data and exchanges model parameters with the server.
Each clients first trains a local model for a few steps and sends the model parameters to the server. Next, the server updates a global model by aggregating (in standard methods such as FedAvg, simply averaging) the local models and sends it to all clients. This process is repeated until the convergence. During inference time, each client separately predicts the label using a global model and its own features.
The protocol described above is called centralized HFL because it requires a trusted third party, a central server. On the other hand, decentralized HFL, which eliminates the need for a central server, has emerged in recent years [4]. In decentralized HFL, clients directly communicates with each other, resulting in communication resource savings. There are various possible methods of communication between clients [4]. For example, the most common method for HFL of gradient boosting decision trees is for each client to add trees to the global model by sequence [5, 6, 7].
<details>
<summary>extracted/5379099/fig/LM_HFL.png Details</summary>
### Visual Description
## Federated Learning Architecture Diagram
### Overview
The diagram illustrates a federated learning workflow involving three clients (A, B, C) and a central server. It depicts four iterative steps for collaborative model training without centralized data sharing.
### Components/Axes
1. **Clients (A, B, C)**:
- Positioned left-aligned in vertical stack
- Each contains:
- Data container (blue cylinder icon)
- Neural network diagram (green nodes/edges)
- Step 1 label: "Learn locally" (①)
2. **Server**:
- Positioned right-aligned
- Contains:
- Step 2: "Send weight parameters" (②)
- Step 3: "Calculate average of weight parameters" (③)
- Step 4: "Return averaged weight parameters" (④)
3. **Flow Arrows**:
- Blue arrows connect clients to server (Step 2)
- Purple arrow connects server back to clients (Step 4)
- Dashed gray arrow indicates iterative repetition
4. **Text Elements**:
- Speech bubble in Step 2 shows parameter examples:
- `[1,3,...]`, `[0,2,...]`, `[7,5]`, `[... 0,1]`
- Server output shows averaged parameters:
- `[0.4,2,...]`, `[0,1.5,...]`, `[8,4]`, `[... 0,1.5]`
### Detailed Analysis
- **Client Operations**:
- Each client independently trains a local model (①)
- Neural network architecture appears identical across clients
- Data containers suggest heterogeneous data sources
- **Server Operations**:
- Aggregates weight parameters from all clients (③)
- Calculates weighted averages (e.g., 0.4 vs original 1.0)
- Returns updated parameters to all participants (④)
- **Iterative Process**:
- Dashed arrow indicates cyclical nature of steps ①-④
- Implies continuous model improvement through repetition
### Key Observations
1. **Decentralized Data Handling**:
- No raw data leaves client devices (only model parameters)
- Preserves privacy while enabling collaboration
2. **Parameter Averaging**:
- Server uses weighted averaging (not simple mean)
- Example: 1.0 → 0.4 suggests weighting by client contribution
3. **Architectural Symmetry**:
- Identical neural network structures across clients
- Uniform communication protocol with server
### Interpretation
This diagram demonstrates the core mechanics of federated learning:
1. **Privacy Preservation**: Clients retain raw data while sharing only model updates
2. **Collaborative Intelligence**: Diverse data sources contribute to a shared model
3. **Iterative Refinement**: Repeated cycles improve model accuracy through aggregation
The architecture suggests:
- Potential for handling non-IID data distributions
- Scalability to many clients through parameter averaging
- Trade-off between communication overhead and model accuracy
The use of weighted averaging (rather than simple mean) implies consideration of client contribution size, though specific weighting mechanisms aren't shown. The neural network complexity appears moderate (multiple hidden layers), suggesting capability for complex pattern recognition while maintaining communication efficiency.
</details>
Figure 2: Overview of the HFL learning protocol.
### II-B Vertical Federated Learning
VFL enables clients holding the different features of the same samples to collaboratively train a model which takes all of the various features each client has as input. There are VFL studies to deal with various models including linear/logistic regression [8, 9, 10, 11, 12], decision trees [13, 14, 15, 16, 17], neural networks [18, 19, 20, 21], and other non-linear models [22, 23].
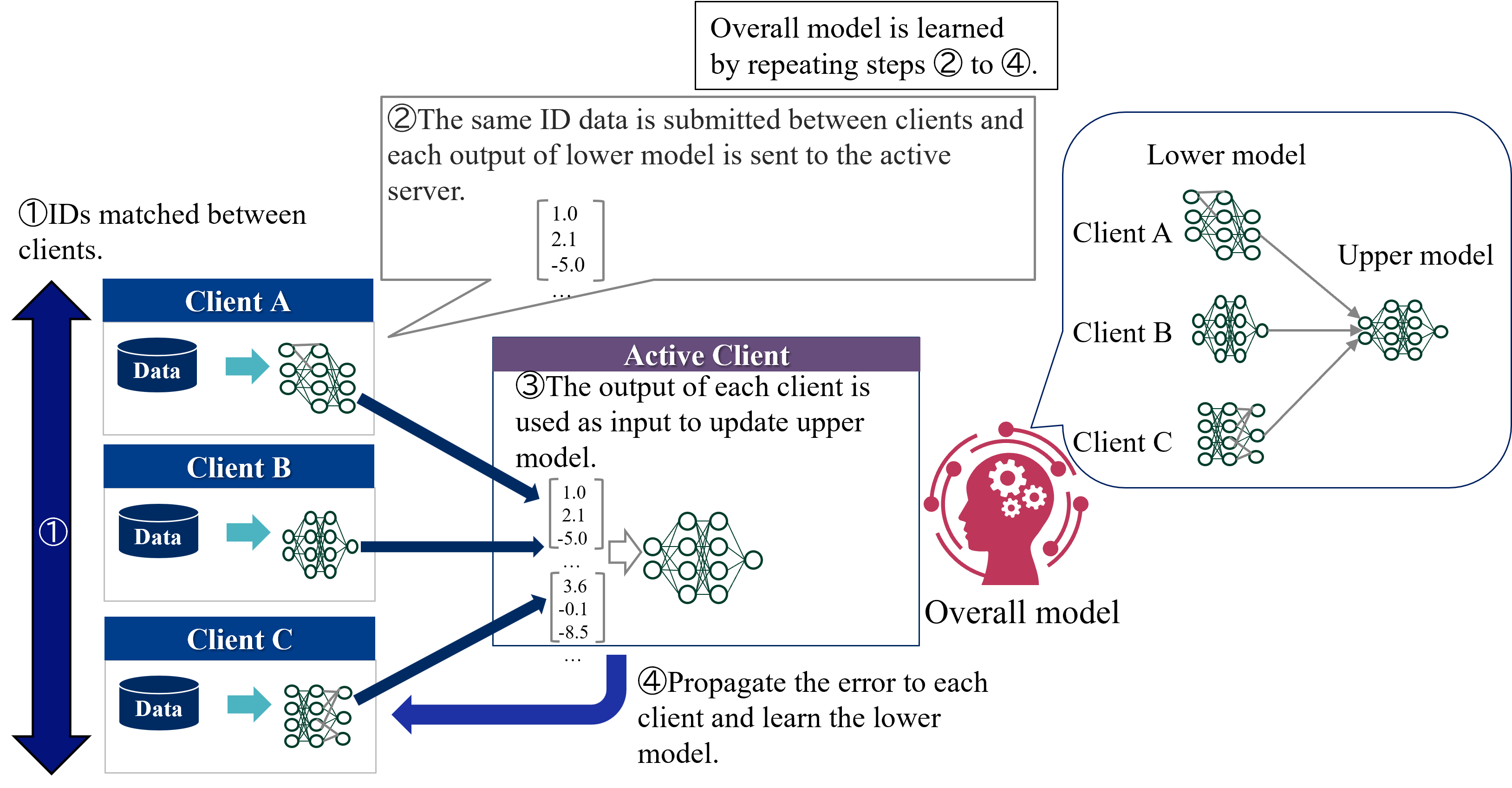
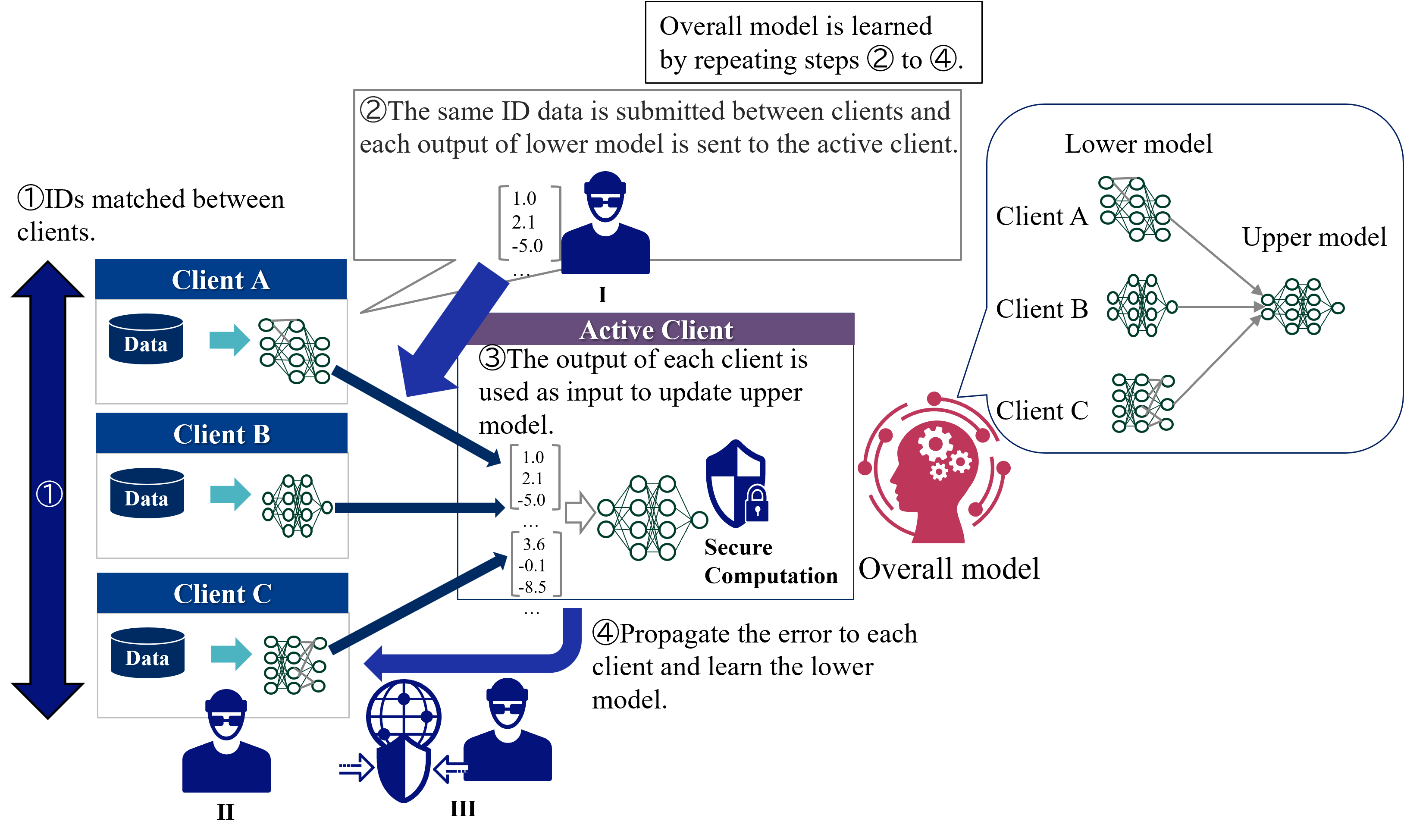
Figure 3 shows an overview of the standard VFL learning protocol. In VFL, only one client holds labels and it plays the role of a server. Therefore, two types of entities participate in learning of VFL:
1. Active client - Features and labels owner. Active client coordinates the learning procedure. It calculates the loss and exchanges intermediate results with the passive clients.
1. Passive clients - Features owners. Each passive client keeps both its features and model local but exchanges intermediate results with the active client.
VFL consists of two phases: IDs matching and learning phases. In IDs matching phases, all clients shares the common sample IDs. In learning phase, each client has a separate model with its own features as input, and the passive clients send the computed intermediate outputs to the active client. The active client calculates the loss based on the aggregated intermediate outputs and sends the gradients to all passive clients. Then, the passive clients updates its own model parameters. This process is repeated until the convergence. During inference time, all clients need to cooperate to predict the label of a sample.
<details>
<summary>extracted/5379099/fig/LM_VFL.png Details</summary>
### Visual Description
## System Architecture Diagram: Federated Learning Workflow
### Overview
This diagram illustrates a federated learning system where multiple clients (A, B, C) collaboratively train a shared model while preserving data privacy. The workflow involves four key steps: data matching, output aggregation, active client training, and error propagation.
### Components/Axes
1. **Clients (A, B, C)**:
- Each client has a local "Data" repository and a "Lower model" (neural network).
- Positioned on the left side of the diagram.
2. **Server**:
- Central hub for aggregating outputs from lower models.
- Not explicitly labeled but implied by bidirectional arrows.
3. **Active Client**:
- Central node processing aggregated outputs to update the "Upper model."
- Contains a speech bubble with numerical outputs from lower models.
4. **Upper Model**:
- Global model updated by the active client.
- Connected to all clients via bidirectional arrows.
5. **Overall Model**:
- Learned iteratively by repeating steps 2–4.
- Represented by a brain icon with gears.
**Legend**:
- **Blue**: Data repositories.
- **Green**: Neural network layers (lower/upper models).
- **Purple**: Active client section.
- **Red**: Overall model (brain icon).
- **Gray**: Arrows indicating data/model flow.
### Detailed Analysis
1. **Step 1 (IDs Matched)**:
- Clients (A, B, C) share identifiers (IDs) to synchronize data.
- Arrows point downward from clients to the server.
2. **Step 2 (Output Submission)**:
- Lower models from clients A, B, and C send outputs to the server.
- Speech bubble in the active client shows example outputs:
```
[1.0, 2.1, -5.0, 3.6, -0.1, -8.5]
```
3. **Step 3 (Active Client Training)**:
- The active client uses aggregated outputs to update the upper model.
- Arrows flow from the server to the active client.
4. **Step 4 (Error Propagation)**:
- Errors from the upper model are propagated back to lower models.
- Arrows flow from the active client to all clients.
### Key Observations
- **Cyclic Workflow**: Steps 2–4 repeat iteratively to refine the overall model.
- **Data Privacy**: Clients retain raw data locally; only model outputs are shared.
- **Numerical Outputs**: The speech bubble values suggest heterogeneous contributions from clients (e.g., Client A: 1.0, 2.1, -5.0; Client B: 3.6, -0.1, -8.5).
- **Color Consistency**:
- Blue data repositories match Client A/B/C labels.
- Green neural networks align with lower/upper model layers.
### Interpretation
This diagram represents a **federated learning architecture** where:
1. **Decentralized Training**: Clients train local models on private data without sharing raw datasets.
2. **Aggregation**: The server combines model outputs (Step 2) to update a global model.
3. **Error Feedback**: The active client refines the upper model and distributes improvements to lower models (Step 4).
4. **Iterative Learning**: Repeating steps 2–4 enhances the overall model’s accuracy over time.
**Notable Patterns**:
- The active client acts as a central coordinator, balancing contributions from all clients.
- Negative values in the speech bubble (-5.0, -8.5) may indicate outlier predictions or adversarial data points.
- The brain icon symbolizes the "intelligence" of the overall model, which evolves through client collaboration.
**Why It Matters**:
This workflow enables scalable machine learning in distributed systems (e.g., healthcare, IoT) while complying with data privacy regulations like GDPR. The error propagation mechanism ensures continuous model improvement without centralizing sensitive data.
</details>
Figure 3: Overview of the standard VFL learning protocol.
### II-C Federated Transfer Learning
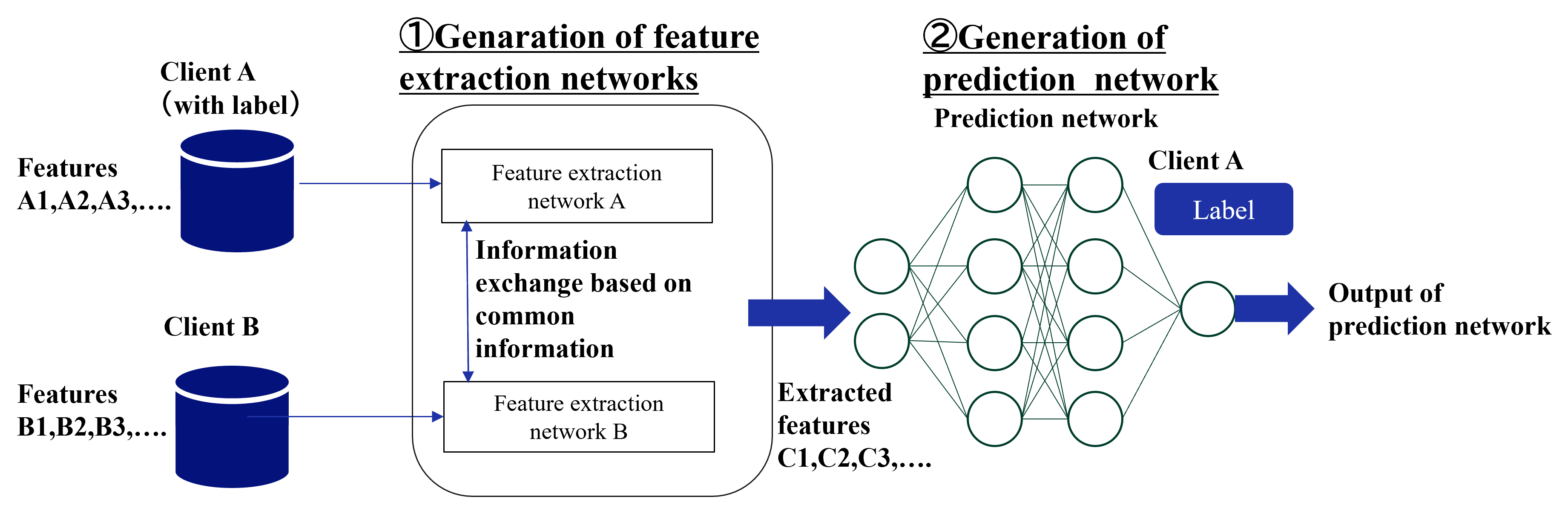
FTL assumes two clients that shares only a small portion of samples or features. The goal of FTL is to create a model that can predict labels on the client that does not possess labels (target client), by transferring the knowledge of the other client that does possess labels (source client) to the target client.
Figure 4 shows an overall of the FTL learning protocol. As noted above, two types of entities participate in FTL:
1. Source client - Features and labels owner. Source client exchanges intermediate results such as outputs and gradients with the target client and calculates the loss.
1. Target client - Features owners. Target client exchanges intermediate results with the source client.
In FTL, two clients exchange intermediate outputs to learn a common representation. The source client uses the labeled data to compute the loss and sends the gradient to the target client, which updates the target client’s representation. This process is repeated until the convergence. During inference time, the target client predicts the label of a sample using its own model and features.
The detail of the learning protocol varies depending on the specific method. Although only a limited number of FTL methods have been proposed, we introduce three major types of methods. FTL requires some supplementary information to bridge two clients, such as common IDs [24, 25, 26, 27], common features [28, 29], and labels of target client [30, 31].
#### II-C 1 Common IDs
Most FTL methods assumes the existence of the common ID’s samples between two clients. This type of FTL requires ID matching before the learning phase as with VFL. Liu et al. [24] proposed the first FTL protocol, which learns feature transformation functions so that the different features of the common samples are mapped into the same features. The following work by Sharma et al. [25] improved communication overhead of the first FTL using multi-party computation and enhanced the security by incorporating malicious clients. Gao et al. [27] proposed a dual learning framework in which two clients impute each other’s missing features by exchanging the outputs of the imputation models for the common samples.
#### II-C 2 Common features
In real-world applications, it is difficult to share samples with the same IDs. Therefore, Gao et al. [28] proposed a method to realize FTL by assuming common features instead of common samples. In that method, two clients mutually reconstruct the missing features by using exchanged feature mapping models. Then,using all features, the clients conduct HFL to obtain a label prediction model. In the original paper, the authors assumes that all clients posses labels, but this method is applicable to the target client that does not posses labels because the source client can learn the label prediction model only by itself. Mori et al. [29] proposed a method for neural networks in which each client incorporates its own unique features in addition to common features into HFL training. However, their method is based on HFL and cannot be applied to the target clients that does not possess labels.
#### II-C 3 Labels of target client
This type of methods assumes neither common IDs nor features, but instead assumes that all clients possess labels, allowing a common representation to be learned across clients. Since it is based on HFL, the participating entities are the same as in HFL. Gao et al. [30] learns a common representation by exchanging the intermediate outputs with the server and reducing maximum mean discrepancy loss. Rakotomamonjy et al. [31] proposed a method to learn a common representation by using Wasserstein distance for intermediate outputs, which enables that the clients only need to exchange statistical information such as mean and variance with the server.
<details>
<summary>extracted/5379099/fig/LM_FTL.png Details</summary>
### Visual Description
## Flowchart: Collaborative Machine Learning Process with Feature Extraction and Prediction Networks
### Overview
The diagram illustrates a two-stage collaborative machine learning workflow involving two clients (A and B) and shared feature extraction/prediction networks. It emphasizes information exchange between client-specific networks and a centralized prediction system.
### Components/Axes
1. **Input Data Sources**:
- Client A (with label): Contains features A1, A2, A3, ...
- Client B: Contains features B1, B2, B3, ...
- Visual representation: Blue cylindrical containers with white text labels
2. **Feature Extraction Stage**:
- Two parallel feature extraction networks:
- Network A (processes Client A's features)
- Network B (processes Client B's features)
- Information exchange mechanism: Arrows between networks indicate shared learning
3. **Prediction Stage**:
- Central prediction network with 10 interconnected nodes
- Inputs: Extracted features (C1, C2, C3, ...) and Client A's label
- Output: Final prediction result
4. **Flow Direction**:
- Left-to-right progression from data sources to final output
- Vertical connections between network layers in prediction stage
### Content Details
- **Client Data**:
- Client A: Features A1-A3+ (exact count unspecified)
- Client B: Features B1-B3+ (exact count unspecified)
- Label: Explicitly marked for Client A only
- **Network Architecture**:
- Feature extraction networks: Rectangular boxes with rounded corners
- Prediction network: 10-node interconnected structure with green edges
- **Extracted Features**:
- Labeled as C1, C2, C3, ... (exact count unspecified)
- Positioned between feature extraction and prediction stages
### Key Observations
1. Asymmetric labeling: Only Client A's data includes explicit label information
2. Bidirectional information flow: Networks A and B share common information despite initial separation
3. Centralized prediction: Final output depends on combined features from both clients
4. Node complexity: Prediction network contains 10 interconnected processing units
### Interpretation
This architecture demonstrates a federated learning approach where:
1. Client-specific feature extraction networks maintain data privacy while learning local patterns
2. Information exchange enables cross-client knowledge transfer without raw data sharing
3. The prediction network synthesizes distributed knowledge for final output
4. Client A's label suggests it may be the primary target for prediction tasks
The design prioritizes collaborative learning while maintaining data locality, with Client A's labeled data serving as the ground truth for the prediction task. The 10-node prediction network implies a complex decision-making process that integrates features from both clients' data distributions.
</details>
Figure 4: Overall of the FTL learning protocol.
## III Threats to Privacy in Each Federated Learning
In this section, we describe threats to privacy in each federated learning. Table I shows threads to privacy addressed in each federated learning. An inference attack uses data analysis to gather unauthorized information about a subject or database. If an attacker can confidently estimate the true value of a subject’s confidential information, it can be said to have been leaked. The most frequent variants of this approach are membership inference and feature [32]. In addition, we address privacy threats of label inference and ID leakage.
TABLE I: Threads to privacy addressed in each federated learning
| HFL VFL FTL (common features) | Low or above Already known Low | Already known Low or above Low or above | None Low or above Low or above | None High None |
| --- | --- | --- | --- | --- |
| FTL (common IDs) | Low | Low or above | Low or above | High |
### III-A Horizontal Federated Learning
In HFL, client data is a major threat to privacy. Figure 5 shows threats to privacy in HFL. Possible attackers are as follows:
1. Server: Inference attack against the model to infer client data.
1. Clients: Inference attack against the global model received from the server to infer other clients’ data.
1. Third party: Eavesdrop on models that pass through the communication channel and infer client data through inference attacks.
<details>
<summary>extracted/5379099/fig/TP_HFL.png Details</summary>
### Visual Description
## Flowchart: Federated Learning Process
### Overview
The diagram illustrates a federated learning workflow where multiple clients (A, B, C) collaboratively train a global machine learning model while keeping their raw data decentralized. The process involves four iterative steps: local training, parameter aggregation, and model updating.
### Components/Axes
1. **Clients (A, B, C)**:
- Each client has:
- A "Data" container (blue cylinder)
- A neural network symbol (green circles)
- A "Learn locally" label (①)
2. **Server**:
- Central processing unit with:
- "Send weight parameters" (②)
- "Calculate average of weight parameters" (③)
- "Return averaged weight parameters" (④)
3. **Flow Indicators**:
- Blue arrows showing data/parameter movement
- Speech bubbles with example numerical values
- Global model learning statement
### Detailed Analysis
1. **Local Training Phase**:
- Each client independently trains a model on its local data
- Example parameters shown in speech bubble:
- Client A: [1,3,7.5], [0.2,0.1]
- Client B: [1,3,7.5], [0.2,0.1]
- Client C: [1,3,7.5], [0.2,0.1]
2. **Parameter Aggregation**:
- Server receives parameters from all clients
- Calculates average weights:
- First parameter: (1+1+1)/3 = 1.0
- Second parameter: (3+3+3)/3 = 3.0
- Third parameter: (7.5+7.5+7.5)/3 = 7.5
- Fourth parameter: (0.2+0.2+0.2)/3 = 0.2
- Fifth parameter: (0.1+0.1+0.1)/3 = 0.1
3. **Model Update**:
- Averaged parameters (1.0, 3.0, 7.5, 0.2, 0.1) are sent back to clients
- Clients update their local models with these global parameters
### Key Observations
- All clients show identical parameter values in the example, suggesting homogeneous training conditions
- The server acts as a neutral aggregator without access to raw data
- The process is explicitly iterative ("repeating steps ① to ④")
- Numerical examples use simple arithmetic for clarity
### Interpretation
This diagram demonstrates a privacy-preserving machine learning paradigm where:
1. **Data Localization**: Raw data never leaves client devices, addressing privacy concerns
2. **Collaborative Intelligence**: Decentralized data sources contribute to a shared model
3. **Iterative Improvement**: Continuous parameter updates refine the global model
4. **Simplified Aggregation**: The example uses arithmetic mean, though real implementations might use more sophisticated methods (e.g., federated averaging)
The workflow emphasizes trust minimization between clients and the server, making it suitable for healthcare, finance, and IoT applications where data sovereignty is critical. The numerical examples, while simplified, illustrate the core concept of parameter averaging across distributed systems.
</details>
Figure 5: Threats to privacy in HFL.
### III-B Vertical Federated Learning
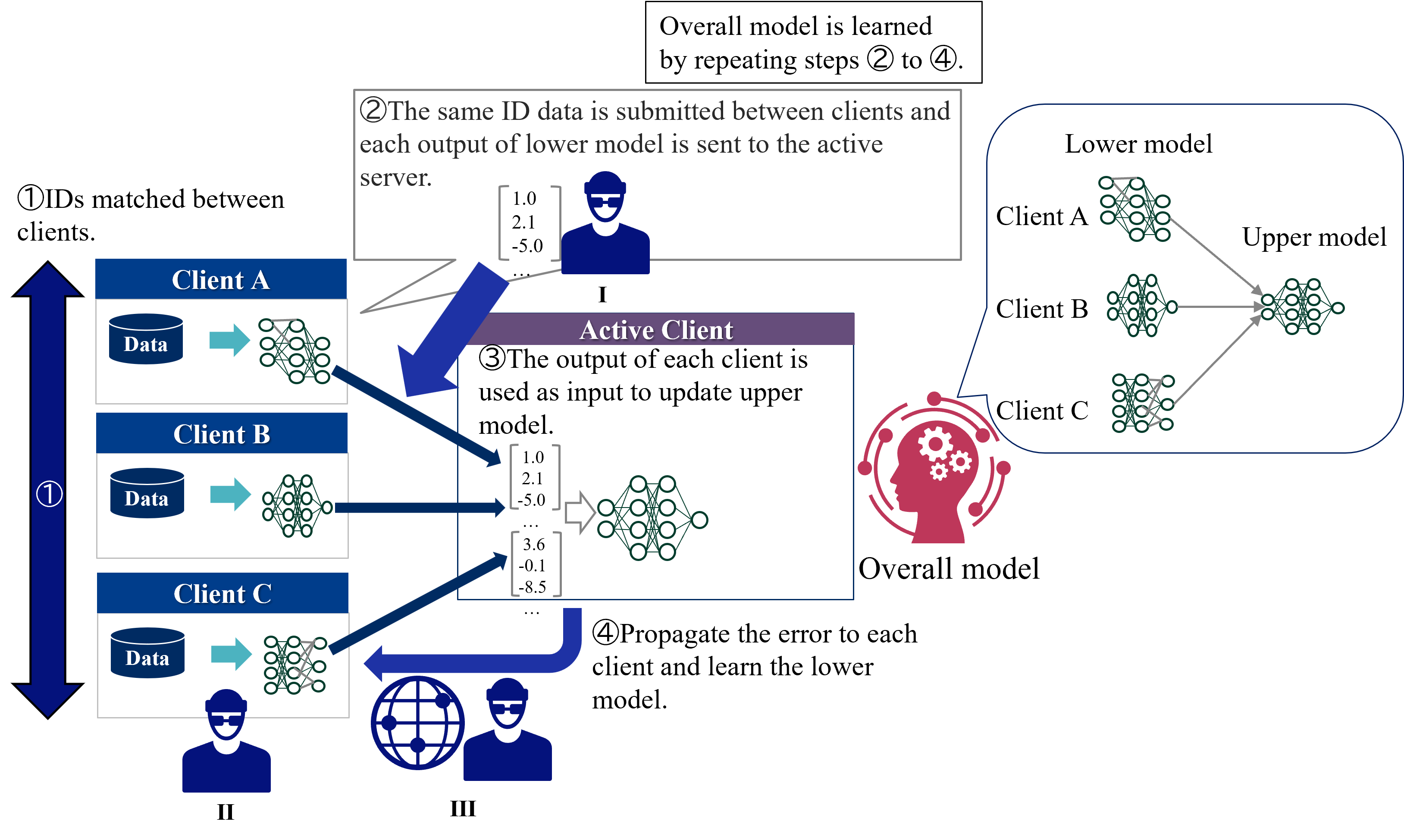
In VFL, a major threat to privacy is the leakage of identities due to identity matching between clients [33]. In addition to the leakage of identities, partial output from clients is also a threat. In case of ID matching, in order to create a single model for the overall system, it is necessary to match IDs that are common to each client’s data. This will reveal the presence of the same user to other clients. Figure 6 shows threats to privacy in VFL in case of partial output from clients, and possible attackers are as follows:
1. Active client: Inference attack against the output of lower model to infer client data.
1. Passive Clients: Inference attack against the output of upper model received from the active client to infer other clients’ data.
1. Third party: Eavesdrop on outputs that pass through the communication channel and infer client data through inference attacks.
<details>
<summary>extracted/5379099/fig/TP_VFL.png Details</summary>
### Visual Description
## System Architecture Diagram: Federated Learning Workflow
### Overview
This diagram illustrates a federated learning system where multiple clients (A, B, C) collaboratively train a shared "overall model" while maintaining data privacy. The workflow involves iterative steps of model training, error propagation, and synchronization between clients and a central server.
### Components/Axes
1. **Clients (A, B, C)**:
- Each client has:
- **Data**: Represented by blue database icons.
- **Lower Model**: Neural network diagrams (green nodes) processing client-specific data.
- Positioned on the left side of the diagram.
2. **Active Client (Client A)**:
- Highlighted with a purple banner.
- Sends its lower model's output (numerical values: `1.0`, `2.1`, `-5.0`, `3.6`, `-0.1`, `-8.5`) to the server.
3. **Server**:
- Central node receiving inputs from clients.
- Updates the **Upper Model** (global model) using the active client's output.
4. **Upper Model**:
- Aggregates contributions from all clients' lower models.
- Positioned on the right side, connected to clients via gray arrows.
5. **Error Propagation**:
- Red arrows indicate error feedback from the server to all clients.
- Clients update their lower models using propagated errors.
### Detailed Analysis
- **Step ①**: Client IDs are matched between clients (blue vertical arrow).
- **Step ②**: Active client (A) sends its lower model's output to the server.
- **Step ③**: Server uses the active client's output to update the upper model.
- **Step ④**: Error from the upper model is propagated back to all clients to refine their lower models.
- **Overall Model**: Learned iteratively by repeating steps ②–④.
### Key Observations
- **Hierarchical Structure**: Clients train local models (lower) that contribute to a global model (upper).
- **Data Flow**:
- Client data → Lower model → Active client output → Server → Upper model → Error → Clients.
- **Numerical Values**:
- Active client's output includes values like `1.0`, `2.1`, `-5.0`, `3.6`, `-0.1`, `-8.5`.
- **Color Coding**:
- Blue: Clients and data.
- Purple: Active client.
- Red: Error propagation.
- Green: Neural network nodes.
### Interpretation
This system demonstrates a **decentralized machine learning framework** where:
1. **Privacy Preservation**: Raw data remains on clients; only model updates are shared.
2. **Collaborative Learning**: The upper model aggregates knowledge from all clients' local models.
3. **Iterative Refinement**: Error feedback ensures continuous improvement of both local and global models.
4. **Scalability**: The workflow can accommodate additional clients (e.g., Client D, E) without structural changes.
The diagram emphasizes **federated averaging** principles, where local model updates are combined to form a robust global model while minimizing data exposure. The error propagation step ensures that discrepancies between local and global models are addressed, enhancing overall accuracy.
</details>
Figure 6: Threads to privacy in VFL.
### III-C Federated Transfer Learning
In federated transfer learning, threats to privacy vary depending on the information in common [24]. We explain the case when features are common and when IDs are common, respectively.
#### III-C 1 Common Features
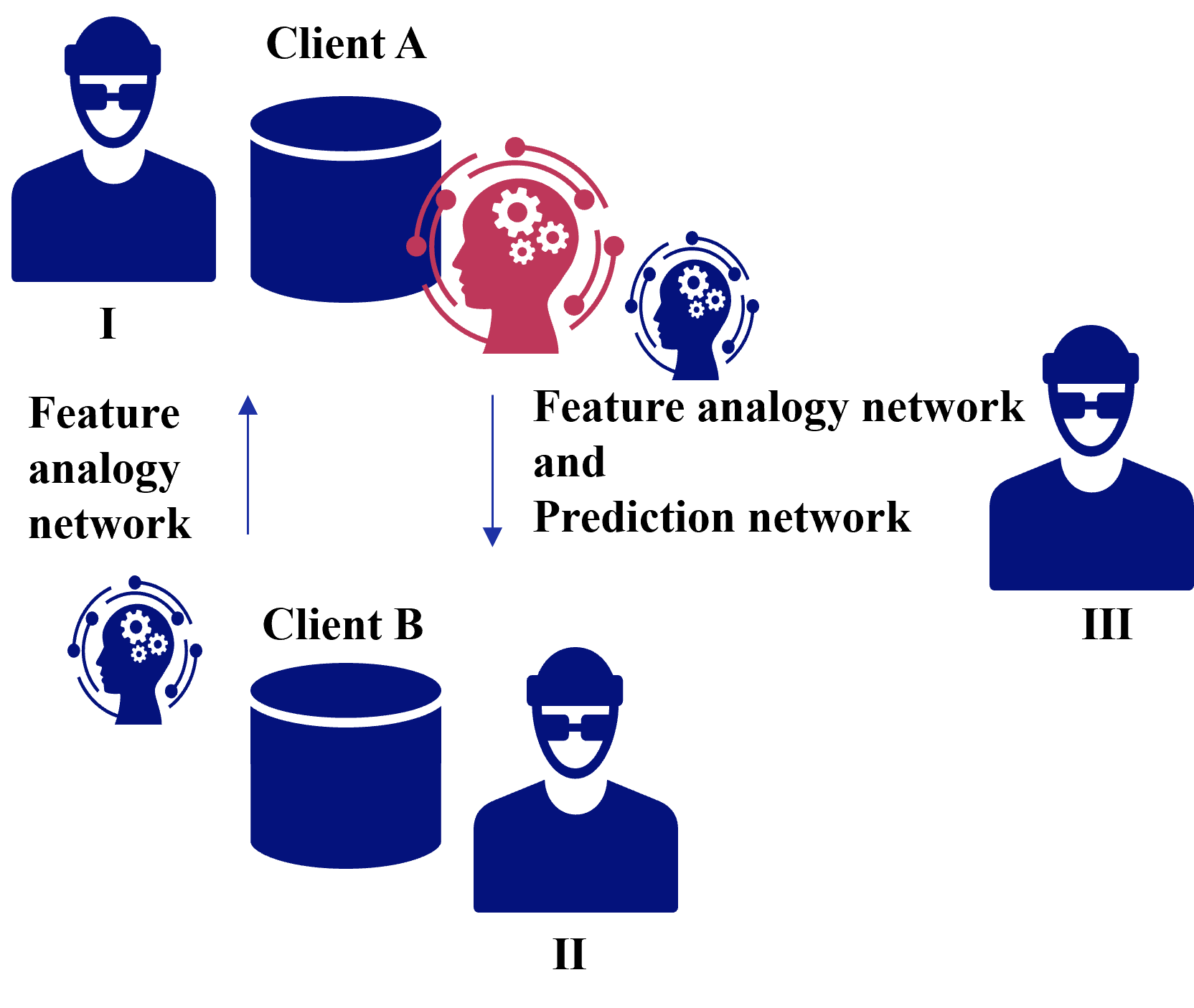
Figure 7 shows threats to privacy in case of common features in FTL, and possible attackers are as follows:
1. Client receiving a feature analogy network: Inference attack against feature analogy network to infer client data.
1. Client receiving a feature analogy network and prediction network: Inference attack against feature analogy network and prediction network to infer client data.
1. Third party: Eavesdrop on feature analogy network and prediction network pass through the communication channel and infer client data through inference attacks.
<details>
<summary>extracted/5379099/fig/CFTP_FTL.png Details</summary>
### Visual Description
## Diagram: Client Interaction Architecture with Feature and Prediction Networks
### Overview
The diagram illustrates a technical architecture involving two clients (Client A and Client B) and a third entity (Client III), connected through two specialized networks: a **Feature Analogy Network** and a **Prediction Network**. Arrows indicate directional data flow, with color-coded components (blue, red, dark blue) representing distinct elements.
---
### Components/Axes
1. **Entities**:
- **Client A** (Top-left): Represented by a blue silhouette with a database (blue cylinder) and a person icon wearing a helmet.
- **Client B** (Bottom-left): Mirroring Client A’s structure but with a red feature analogy network.
- **Client III** (Top-right): A standalone blue silhouette with a helmet, connected to the prediction network.
2. **Networks**:
- **Feature Analogy Network** (Red): Connects Client A’s database to Client B’s database via a bidirectional arrow.
- **Prediction Network** (Dark Blue): Links Client B’s database to Client III via a unidirectional arrow.
3. **Labels**:
- Roman numerals (I, II, III) label the clients.
- Text annotations explicitly name the networks and their functions.
---
### Detailed Analysis
- **Data Flow**:
- **Feature Analogy Network**: Transfers features from Client A’s database to Client B’s database (bidirectional flow).
- **Prediction Network**: Uses Client B’s database to generate predictions for Client III (unidirectional flow).
- **Color Coding**:
- **Blue**: Databases and client silhouettes.
- **Red**: Feature Analogy Network (highlighting its role in feature transfer).
- **Dark Blue**: Prediction Network (emphasizing its predictive function).
- **Structural Relationships**:
- Client A and Client B share a collaborative relationship via the Feature Analogy Network.
- Client III depends on Client B’s processed data through the Prediction Network.
---
### Key Observations
1. **Bidirectional vs. Unidirectional Flow**:
- The Feature Analogy Network allows mutual data exchange between Clients A and B.
- The Prediction Network is strictly one-way, from Client B to Client III.
2. **Color Significance**:
- Red (Feature Analogy Network) and dark blue (Prediction Network) visually distinguish the two core processes.
3. **Client Roles**:
- Client A and B are active participants in feature sharing.
- Client III is a passive recipient of predictions derived from Client B’s data.
---
### Interpretation
This architecture suggests a federated learning or collaborative AI system where:
1. **Feature Analogy** enables knowledge transfer between Clients A and B, likely to improve model generalizability.
2. **Prediction Network** specializes in generating outcomes for Client III using Client B’s data, implying a hierarchical or dependency-based relationship.
3. The use of distinct colors and directional arrows emphasizes modularity and separation of concerns, critical for scalability and security in distributed systems.
No numerical data or trends are present; the diagram focuses on structural and functional relationships.
</details>
Figure 7: Threats to privacy in case of common features in FTL.
#### III-C 2 Common IDs
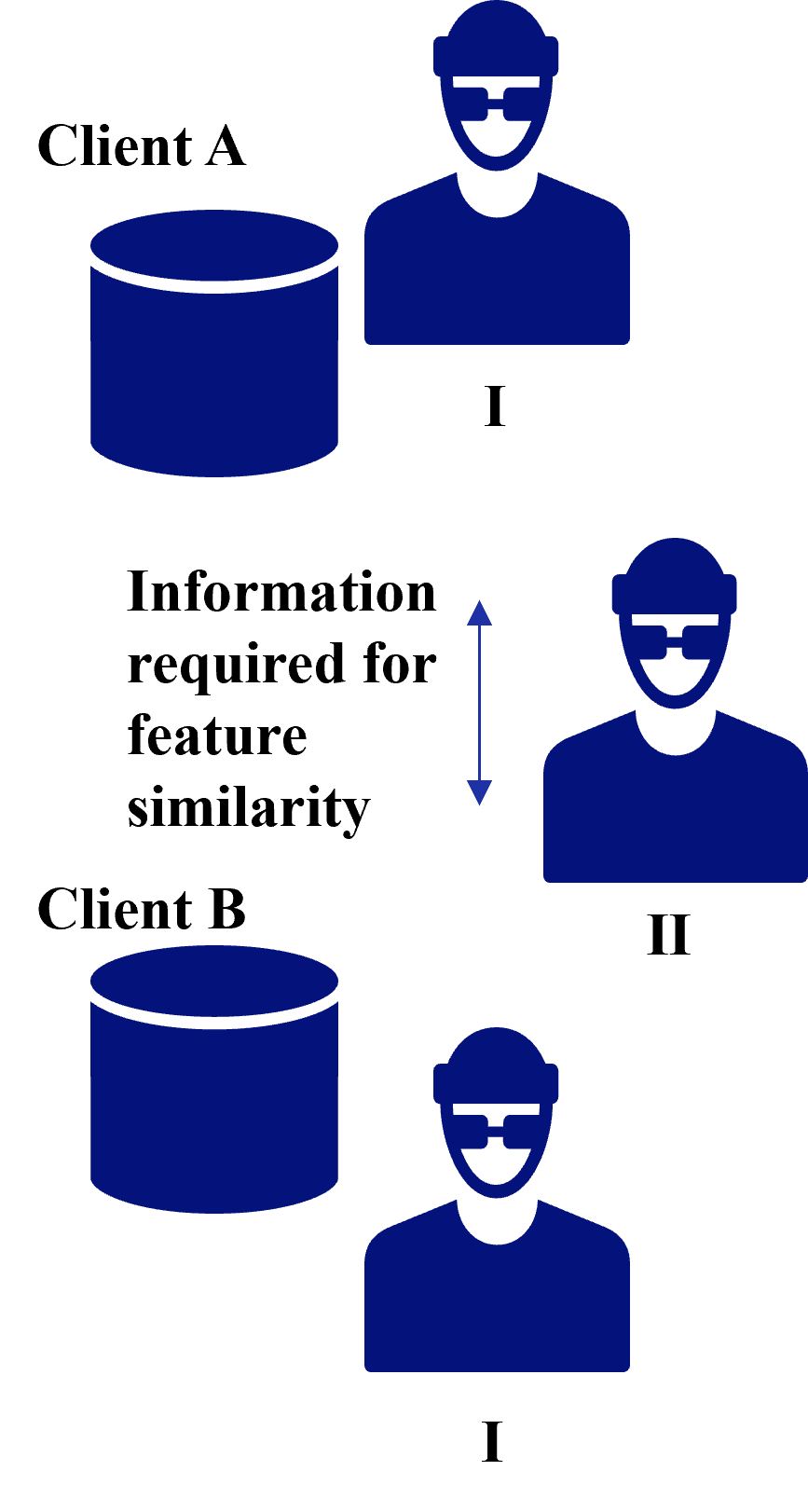
In case of Common IDs, a threat to privacy is the leakage of identities due to identity matching between clients as shown in VFL [33]. In addition to the leakage of identities, information required for feature similarity from clients is also a threat. Figure 8 shows threats to privacy in case of common IDs in FTL in case of information required for feature similarity, and possible attackers are as follows:
1. Client receiving information for feature similarity: Inference attack against information required for feature similarity to infer client data.
1. Third party: Eavesdrop on information required for feature similarity pass through the communication channel and infer client data through inference attacks.
<details>
<summary>extracted/5379099/fig/CITP_FTL.png Details</summary>
### Visual Description
## Diagram: Client Interaction for Feature Similarity
### Overview
The diagram illustrates a two-way information exchange process between two entities labeled "Client A" and "Client B." Each client is represented by a blue cylindrical shape with a white outline, positioned adjacent to a stylized human figure wearing a blue helmet and visor. The figures are labeled "I" (Client A) and "II" (Client B), connected by a bidirectional arrow labeled "Information required for feature similarity."
### Components/Axes
- **Left Side (Client A)**:
- Blue cylinder labeled "Client A"
- Human figure labeled "I" wearing blue helmet/visor
- **Right Side (Client B)**:
- Blue cylinder labeled "Client B"
- Human figure labeled "II" wearing blue helmet/visor
- **Connecting Element**:
- Bidirectional blue arrow between figures I and II
- Arrow text: "Information required for feature similarity"
### Detailed Analysis
- **Client Representation**: Both clients use identical visual metaphors (blue cylinders with white outlines), suggesting standardized or comparable systems.
- **Human Figures**: The helmet/visor design implies technical or security roles, possibly data analysts or system operators.
- **Bidirectional Flow**: The arrow indicates mutual dependency in feature similarity assessment between the two clients.
### Key Observations
1. Symmetrical design emphasizes equal participation between Client A and Client B.
2. No numerical data or quantitative metrics are present in the diagram.
3. The use of "I" and "II" suggests sequential or hierarchical roles, though the bidirectional arrow contradicts strict hierarchy.
### Interpretation
This diagram represents a collaborative framework where two clients must exchange information to achieve feature similarity. The identical visual treatment of both clients implies they operate under the same technical constraints or standards. The human figures with protective gear suggest the process requires specialized expertise, possibly in data science or cybersecurity. The bidirectional arrow highlights that feature similarity is not a one-way process but requires continuous mutual validation. The absence of quantitative data points suggests this is a conceptual model rather than a measurement tool, focusing on process flow rather than performance metrics.
</details>
Figure 8: Threads to privacy in case of common IDs in FTL.
## IV Countermeasures against Threats to Privacy in Each Federated Learning
In this section, we describe countermeasures against threats to privacy in each federated learning. Table II shows countermeasures against privacy threats addressed in each federated learning. Despite the wide variety of previous efforts to secure privacy in federated learning, the proposed methods typically fall into one of these categories: differential privacy, secure computation, encryption of communication, and ID dummying [32].
TABLE II: Countermeasures against privacy threats addressed in each federated learning.
| HFL VFL FTL (common features) | Client Side - Feature Analogy Network Exchange | Server Side Active Client Side - | Communication Line Communication Line Communication Line | - Client Table - |
| --- | --- | --- | --- | --- |
| FTL (common IDs) | - | Gradient Exchange | Communication Line | Client Table |
### IV-A Horizontal Federated Learning
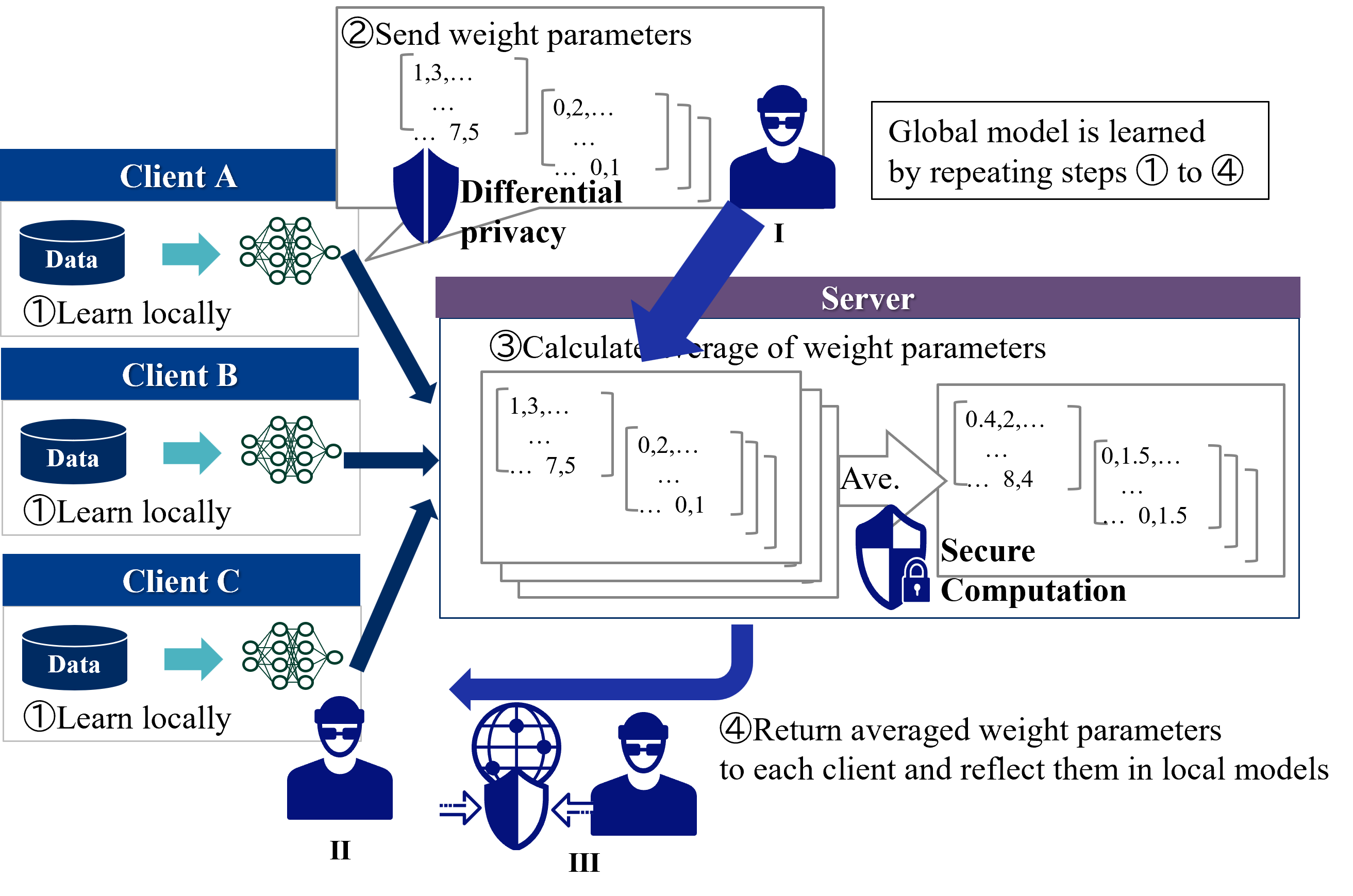
In HFL, a typical privacy measure for client data is to protect attacks by the server side with secure computation and attacks by the client side with differential privacy [34]. Figure 9 shows countermeasures against threads to privacy in HFL. The position of the attacker by these privacy measures is described as follows.
1. Server: Secure computation realizes global model integration calculations without seeing the model by the server [35, 36]
1. Client: Client A creates a model by adding noise through differential privacy [37, 38]. Client B receives the parameters of the global model via the server, but Client A’s model is protected by differential privacy.
1. Third party: Achieved by encryption of communication.
<details>
<summary>extracted/5379099/fig/CM_HFL.png Details</summary>
### Visual Description
## Flowchart: Federated Learning Process with Differential Privacy and Secure Computation
### Overview
The diagram illustrates a federated learning workflow where multiple clients (A, B, C) collaboratively train a global model while preserving data privacy. The process involves four iterative steps: local learning, secure parameter transmission, server-side aggregation, and model update. Key elements include differential privacy mechanisms and secure computation protocols.
### Components/Axes
1. **Clients (A, B, C)**
- Each client has a "Data" repository and a neural network (represented by interconnected nodes).
- All clients perform identical local learning (Step 1).
2. **Server**
- Central node responsible for aggregating weight parameters from clients.
- Implements "Secure Computation" (lock icon) and "Differential Privacy" (shield icon).
3. **Steps**
- **Step 1**: "Learn locally" (circle icon)
- **Step 2**: "Send weight parameters" (arrow with shield)
- **Step 3**: "Calculate average of weight parameters" (server-side aggregation)
- **Step 4**: "Return averaged weight parameters" (arrow with globe icon)
4. **Textual Elements**
- "Global model is learned by repeating steps ① to ④" (top-right box).
- "Differential privacy" and "Secure Computation" labels with corresponding icons.
### Detailed Analysis
- **Client Workflow**:
- Each client trains a local neural network on its own data (Step 1).
- Weight parameters (e.g., `1,3,...,7.5`, `0.2,...,0.1`) are sent to the server with differential privacy (Step 2).
- **Server Workflow**:
- Receives encrypted weight parameters from all clients.
- Computes the average of these parameters using secure computation (Step 3).
- Returns the averaged parameters (e.g., `0.4,2,...,8.4`, `0.1.5,...,0.1.5`) to clients (Step 4).
- **Iterative Process**:
- The cycle repeats (①→④) to refine the global model.
### Key Observations
1. **Privacy Preservation**: Differential privacy (shield icon) ensures raw data remains decentralized.
2. **Security**: Secure computation (lock icon) protects aggregated parameters during transmission.
3. **Decentralization**: No client shares raw data; only model weights are exchanged.
4. **Scalability**: The process is identical across clients (A, B, C), suggesting uniformity in data structure.
### Interpretation
This diagram represents a **federated learning architecture** designed for privacy-sensitive applications (e.g., healthcare, finance). By combining differential privacy and secure computation, it balances model accuracy with data confidentiality. The iterative refinement of the global model through repeated steps ensures convergence over time. The use of standardized workflows across clients implies scalability for large-scale deployments. The emphasis on secure parameter transmission highlights compliance with regulations like GDPR, making it suitable for industries with strict data governance requirements.
</details>
Figure 9: Countermeasures against threads to privacy in HFL.
### IV-B Vertical Federated Learning
In VFL, the threads to privacy are the leakage of identities and partial output from clients. We show how to respond in the case of each threat.
#### IV-B 1 IDs Matching
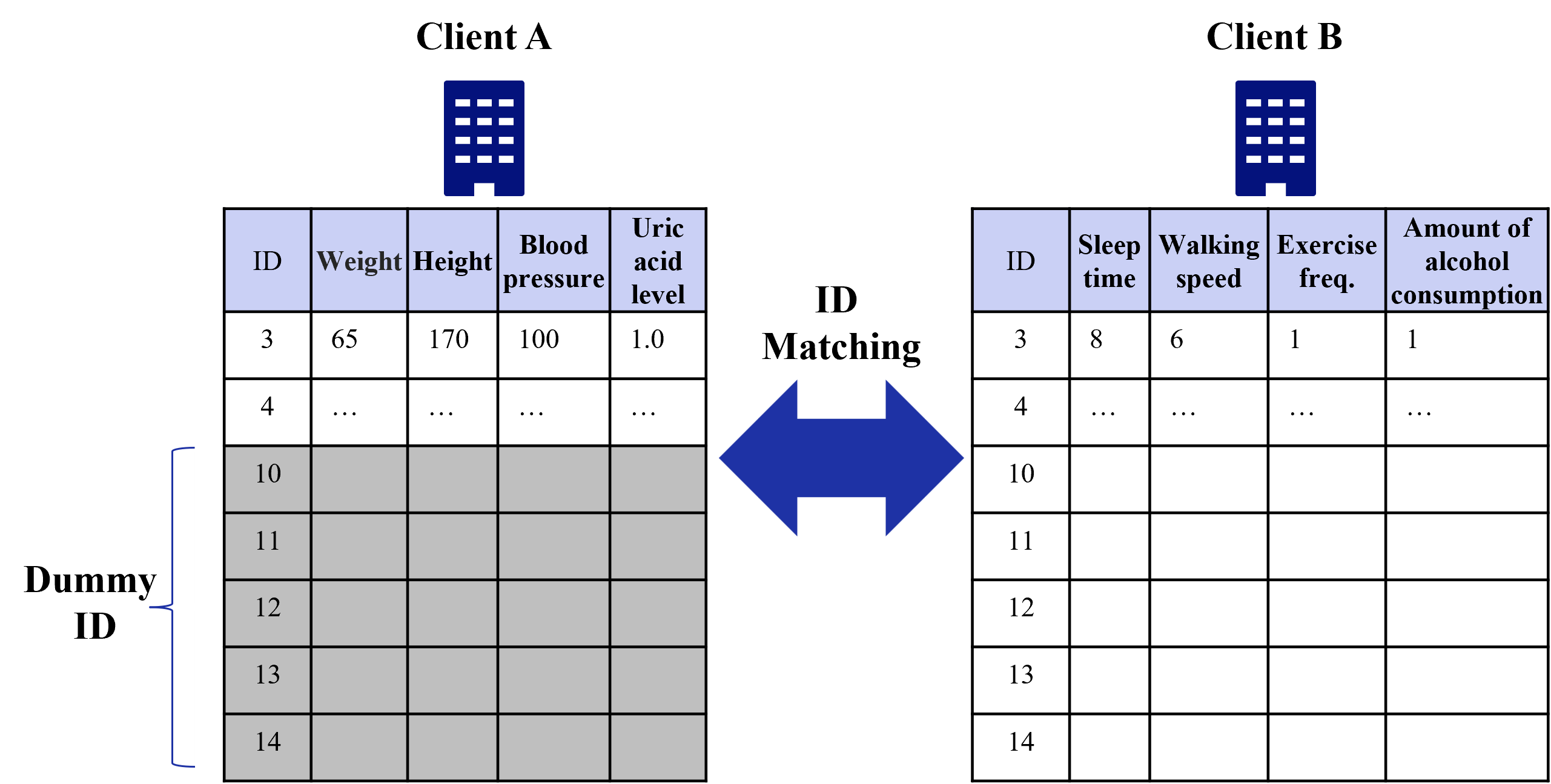
In case of IDs matching, Dummy IDs are prepared in addition to the original IDs [39]. For the dummy part of the ID, dummy variables that have no effect on learning are sent. Figure 10 shows an example of dummy IDs. Before dummy IDs are used, all IDs that match Client A are known to Client B (cf. ID 3,4). After dummy IDs are used, Client B does not know which of the IDs that match Client A is the real ID of Client A.
<details>
<summary>extracted/5379099/fig/CMID_VFL.png Details</summary>
### Visual Description
## Diagram: Client Data Matching System
### Overview
The image depicts a two-part data matching system comparing health metrics (Client A) and lifestyle data (Client B), connected by an "ID Matching" arrow. A "Dummy ID" section on the left links to Client B's table, suggesting a data integration or validation process.
### Components/Axes
1. **Client A Table**
- **Columns**: ID, Weight, Height, Blood pressure, Uric acid level
- **Data**:
- ID 3: Weight = 65, Height = 170, Blood pressure = 100, Uric acid level = 1.0
- IDs 4, 10–14: Empty
2. **Client B Table**
- **Columns**: ID, Sleep time, Walking speed, Exercise freq., Amount of alcohol consumption
- **Data**:
- ID 3: Sleep time = 8, Walking speed = 6, Exercise freq. = 1, Alcohol consumption = 1
- IDs 4, 10–14: Empty
3. **Dummy ID Section**
- Labels IDs 10–14 as "Dummy ID" with no associated data.
4. **ID Matching Arrow**
- Connects Dummy ID section to Client B's table, indicating a mapping relationship.
### Detailed Analysis
- **Client A Data**: Only ID 3 contains complete health metrics. Other IDs (4, 10–14) are placeholders.
- **Client B Data**: ID 3 has lifestyle data (e.g., 8 hours sleep, 6 km/h walking speed). Other IDs lack entries.
- **Dummy IDs**: IDs 10–14 are explicitly labeled as "Dummy ID" but have no data in either table.
- **Matching Logic**: The arrow implies Dummy IDs (10–14) are intended to map to Client B's IDs, but no data exists for these in Client B's table.
### Key Observations
1. **Sparse Data**: Only ID 3 has populated entries in both tables, suggesting it may be a test case or primary subject.
2. **Dummy ID Purpose**: The "Dummy ID" label indicates these IDs are placeholders for future data, but they remain unpopulated.
3. **Mismatched Granularity**: Client A focuses on physiological metrics, while Client B tracks behavioral/lifestyle factors, implying separate data collection purposes.
### Interpretation
The diagram illustrates a data integration framework where dummy IDs (10–14) are designed to link Client A's health metrics to Client B's lifestyle data. However, the absence of data for IDs 4, 10–14 in both tables raises questions about the system's current functionality:
- **Testing Hypothesis**: ID 3 may serve as a validation example to demonstrate the matching logic.
- **Data Gaps**: The empty Dummy IDs suggest the system is either in development or awaiting data population.
- **Cross-Client Relationships**: The lack of overlap between Client A and Client B's data categories (health vs. lifestyle) implies the matching process may require additional contextual mapping rules.
The system appears to prioritize structural alignment over actual data integration at this stage, with ID 3 acting as a proof-of-concept anchor.
</details>
Figure 10: Example of dummy IDs.
#### IV-B 2 Output from Clients
In case of output from clients, the typical privacy measure is the use of secure calculations [33]. Figure 11 shows countermeasures against threads in case of output from clients. The position of the attacker by these privacy measures is described as follows.
1. Active Client: Secure computation realizes global model integration calculations without seeing the model by the active client. [35].
1. Passive Clients: Client B receives the information used for updating from the upper model via the active client, but it is protected by secure computation.
1. Third party: Achieved by encryption of communication.
<details>
<summary>extracted/5379099/fig/CMOC_VFL.png Details</summary>
### Visual Description
## Flowchart: Federated Learning System Architecture
### Overview
The diagram illustrates a federated learning system where multiple clients (A, B, C) collaboratively train a shared model while maintaining data privacy. The process involves iterative steps of data matching, secure computation, and model updates across distributed clients.
### Components/Axes
1. **Clients**:
- Client A, Client B, Client C (each with private data and local lower models)
- Active Client (highlighted in purple, receiving outputs from other clients)
2. **Models**:
- Lower models (client-specific neural networks)
- Upper model (global model updated by aggregated client outputs)
3. **Process Flow**:
- Step ①: ID matching between clients
- Step ②: Data submission between clients
- Step ③: Secure computation using client outputs
- Step ④: Error propagation for model refinement
### Detailed Analysis
- **Client Data Flow**:
- Each client (A/B/C) processes local data through their lower model
- Outputs (numerical values like 1.0, 2.1, -5.0) are sent to the active client
- Example outputs shown: Client A → [1.0], Client B → [2.1, -5.0], Client C → [3.6, -0.1, -8.5]
- **Secure Computation**:
- Shield icon with lock symbol indicates encrypted data processing
- Outputs are combined securely to update the upper model
- **Model Update Mechanism**:
- Upper model receives aggregated client outputs
- Error propagation (Step ④) sends feedback to individual clients
- Lower models are refined iteratively through this feedback loop
### Key Observations
1. **Cyclical Process**: Steps ②-④ form a closed loop for continuous model improvement
2. **Privacy Preservation**: Data remains localized (Step ① ensures ID matching without raw data sharing)
3. **Hierarchical Structure**: Two-tier model architecture (lower models → upper model)
4. **Active Client Role**: Central node coordinating updates from multiple clients
### Interpretation
This architecture demonstrates a privacy-preserving machine learning framework where:
- Clients maintain data sovereignty while contributing to global model training
- Secure computation enables collaborative learning without data exposure
- Iterative error propagation creates a feedback loop for model refinement
- The active client acts as a coordinator, aggregating updates while preserving individual client privacy
The system's strength lies in its balance between collaborative learning and data security, with the active client serving as both coordinator and computational hub. The numerical outputs suggest a regression-type task where clients contribute partial solutions that are combined to form a comprehensive model.
</details>
Figure 11: Countermeasures against threads in case of output from clients.
### IV-C Federated Transfer Learning
In FTL, the threads to privacy depend on common information between clients [24]. We show how to respond in the case of each thread.
#### IV-C 1 Common Features
In case of common features, the threads to privacy are exchanges of feature analogy network and prediction network. Figure 12 shows countermeasures against threads in case of common features.
1. Client receiving a feature analogy network: Differential privacy makes it difficult to infer the model [37].
1. Client receiving a feature analogy network and prediction network: Differential privacy makes it difficult to infer the model.
1. Third party: Achieved by encryption of communication.
<details>
<summary>extracted/5379099/fig/CMCF_FTL.png Details</summary>

### Visual Description
## Diagram: Federated Learning System with Differential Privacy
### Overview
The diagram illustrates a federated learning architecture involving three entities (Client A, Client B, and Client III) and two data containers (I and II). It emphasizes data privacy through differential privacy mechanisms and feature analogy networks. Arrows indicate data flow, and shields/gears symbolize privacy and processing steps.
### Components/Axes
- **Entities**:
- Client A (I), Client B (II), Client III (III)
- Data containers (blue cylinders) labeled I and II
- **Networks**:
- Feature analogy network (red gears/shield)
- Prediction network (blue shield)
- **Privacy Mechanisms**:
- Differential privacy (blue shields with "Differential privacy" labels)
- **Flow Direction**:
- Data moves from Client A → Feature analogy network → Prediction network → Client B (via differential privacy).
- Data moves from Client B → Differential privacy → Feature analogy network → Prediction network → Client III.
### Detailed Analysis
1. **Client A (I)**:
- Data container (blue cylinder) labeled "Client A."
- Outputs to a **feature analogy network** (red gears/shield), which connects to a **prediction network** (blue shield).
- Differential privacy is applied before data reaches Client B.
2. **Client B (II)**:
- Data container (blue cylinder) labeled "Client B."
- Receives data from Client A’s prediction network via differential privacy.
- Outputs to a **feature analogy network** and **prediction network**, then to Client III via differential privacy.
3. **Client III (III)**:
- Receives processed data from Client B’s prediction network after differential privacy.
4. **Key Symbols**:
- **Shields**: Represent differential privacy (blue) and prediction networks (blue).
- **Gears**: Represent feature analogy networks (red).
- **Arrows**: Indicate data flow direction.
### Key Observations
- **Bidirectional Collaboration**: Client A and Client B exchange data through shared networks, suggesting collaborative model training.
- **Privacy Emphasis**: Differential privacy is applied at multiple stages (before data leaves Client A, before data reaches Client B, and before data reaches Client III).
- **Feature Alignment**: The feature analogy network (red gears) likely aligns data features between clients to improve prediction accuracy.
### Interpretation
This diagram represents a **secure, privacy-preserving federated learning system**. Clients (A and B) contribute data without sharing raw information, using differential privacy to anonymize data at each transfer. The feature analogy network ensures compatibility between clients’ data features, while the prediction network aggregates insights. Client III may act as a central server or another participant in the federated system. The use of shields and gears visually reinforces the balance between data utility (gears) and privacy (shields).
**Notable Patterns**:
- Differential privacy is prioritized at every data handoff, minimizing exposure.
- The feature analogy network acts as a bridge between disparate data sources, enabling cross-client collaboration.
- Client III’s role is ambiguous but likely involves receiving finalized, privacy-protected insights.
**Underlying Logic**:
The system prioritizes **data minimization** (only sharing necessary features) and **privacy guarantees** (differential privacy at every stage). The red gears (feature analogy network) suggest a focus on aligning heterogeneous data, while blue shields (prediction/differential privacy) emphasize secure processing.
</details>
Figure 12: Countermeasures against threads in case of common features.
#### IV-C 2 Common IDs
In case of common IDs, the threads to privacy are the leakage of identities and information required for feature similarity [24]. For the leakage of identities, Dummy IDs are prepared in addition to the original IDs as shown in Section IV-B 1 [39]. For information required for feature similarity, figure 13 shows countermeasures against threads in case of common IDs.
1. Client receiving information for feature similarity: Difficult to guess information due to secure computation [35].
1. Third party: Achieved by encryption of communication.
<details>
<summary>extracted/5379099/fig/CMCI_FTL.png Details</summary>

### Visual Description
## Diagram: Secure Multi-Party Computation Workflow
### Overview
The diagram illustrates a secure computation process between two clients (Client A and Client B) involving encrypted data exchange and feature similarity analysis. It uses symbolic representations (shields, locks, arrows) to depict secure information flow.
### Components/Axes
- **Clients**:
- **Client A**: Positioned at the top-left, represented by a blue silhouette with a hoodie and sunglasses.
- **Client B**: Positioned at the bottom-left, identical visual representation to Client A.
- **Data Stores**:
- **Database A**: A blue cylinder with a white outline, adjacent to Client A.
- **Database B**: A blue cylinder with a white outline, adjacent to Client B.
- **Secure Computation**:
- Two shield icons with padlocks labeled "Secure Computation" (one near Client A, one near Client B).
- **Information Flow**:
- Arrows connecting the shields, labeled "Information required for feature similarity."
- A globe icon with grid lines and dots, positioned between the shields, symbolizing encrypted data transmission.
- **Legend**:
- No explicit legend present, but symbols are standardized:
- **Shield + Lock**: Represents secure computation.
- **Arrows**: Indicate data flow direction.
- **Globe**: Symbolizes encrypted data transmission.
### Detailed Analysis
- **Client A and Client B**: Both clients are visually identical, suggesting symmetric roles in the process.
- **Secure Computation**: The shields with locks are placed symmetrically, indicating mutual participation in the secure process.
- **Information Flow**:
- The text "Information required for feature similarity" is centrally located, emphasizing its role as the core data exchanged.
- Arrows point bidirectionally between the shields, implying mutual exchange of encrypted data.
- The globe icon bridges the shields, reinforcing the idea of secure, encrypted communication.
### Key Observations
1. **Symmetry**: The diagram emphasizes equal roles for both clients in the secure computation process.
2. **Encryption Focus**: The repeated use of shields and locks highlights data privacy and security as central themes.
3. **Feature Similarity**: The explicit label indicates the purpose of the data exchange—comparing features while maintaining confidentiality.
### Interpretation
This diagram represents a **secure multi-party computation (MPC)** framework where two clients collaborate to analyze feature similarity without exposing raw data. The shields and locks symbolize cryptographic techniques (e.g., homomorphic encryption or secure enclaves) that protect data during processing. The bidirectional arrows and globe icon suggest a decentralized, trustless environment where neither client has direct access to the other’s data.
The absence of a traditional legend implies the diagram relies on universally recognized symbols (e.g., shields for security, arrows for flow). The central placement of "Information required for feature similarity" underscores its importance as the actionable outcome of the secure computation.
This setup is critical in privacy-preserving machine learning, where clients must collaborate on model training or analysis without compromising sensitive data. The diagram abstracts the technical complexity (e.g., cryptographic protocols) into a high-level workflow, making it accessible for stakeholders focused on data governance or system design.
</details>
Figure 13: Countermeasures against threads in case of common IDs.
## V Conclusion
In this paper, we have described privacy threats and countermeasures for federated learning in terms of HFL, VFL, and FTL. Privacy measures for federated learning include differential privacy to reduce the leakage of training data from the model, secure computation to keep the model computation process secret between clients and servers, encryption of communications to prevent information leakage to third parties, and ID dummying to prevent ID leakage.
## Acknowledgment
This R&D includes the results of ” Research and development of optimized AI technology by secure data coordination (JPMI00316)” by the Ministry of Internal Affairs and Communications (MIC), Japan.
## References
- [1] L. Lyu, H. Yu, and Q. Yang, “Threats to federated learning: A survey,” arXiv preprint arXiv:2003.02133, 2020.
- [2] Q. Yang, Y. Liu, T. Chen, and Y. Tong, “Federated machine learning: Concept and applications,” ACM Trans. Intell. Syst. Technol., vol. 10, no. 2, 2019.
- [3] B. McMahan, E. Moore, D. Ramage, S. Hampson, and B. A. y. Arcas, “Communication-Efficient Learning of Deep Networks from Decentralized Data,” in Proceedings of the 20th International Conference on Artificial Intelligence and Statistics, ser. Proceedings of Machine Learning Research, vol. 54. PMLR, 2017, pp. 1273–1282.
- [4] E. T. Martínez Beltrán, M. Q. Pérez, P. M. S. Sánchez, S. L. Bernal, G. Bovet, M. G. Pérez, G. M. Pérez, and A. H. Celdrán, “Decentralized federated learning: Fundamentals, state of the art, frameworks, trends, and challenges,” IEEE Communications Surveys & Tutorials, vol. 25, no. 4, pp. 2983–3013, 2023.
- [5] L. Zhao, L. Ni, S. Hu, Y. Chen, P. Zhou, F. Xiao, and L. Wu, “Inprivate digging: Enabling tree-based distributed data mining with differential privacy,” in IEEE INFOCOM 2018 - IEEE Conference on Computer Communications, 2018, pp. 2087–2095.
- [6] Q. Li, Z. Wen, and B. He, “Practical federated gradient boosting decision trees,” Proceedings of the AAAI Conference on Artificial Intelligence, vol. 34, no. 04, pp. 4642–4649, 2020.
- [7] F. Wang, J. Ou, and H. Lv, “Gradient boosting forest: a two-stage ensemble method enabling federated learning of gbdts,” in Neural Information Processing, T. Mantoro, M. Lee, M. A. Ayu, K. W. Wong, and A. N. Hidayanto, Eds. Cham: Springer International Publishing, 2021, pp. 75–86.
- [8] A. Gascón, P. Schoppmann, B. Balle, M. Raykova, J. Doerner, S. Zahur, and D. Evans, “Secure linear regression on vertically partitioned datasets,” IACR Cryptol. ePrint Arch., vol. 2016, p. 892, 2016.
- [9] S. Hardy, W. Henecka, H. Ivey-Law, R. Nock, G. Patrini, G. Smith, and B. Thorne, “Private federated learning on vertically partitioned data via entity resolution and additively homomorphic encryption,” CoRR, vol. abs/1711.10677, 2017.
- [10] R. Nock, S. Hardy, W. Henecka, H. Ivey-Law, G. Patrini, G. Smith, and B. Thorne, “Entity resolution and federated learning get a federated resolution,” CoRR, vol. abs/1803.04035, 2018.
- [11] S. Yang, B. Ren, X. Zhou, and L. Liu, “Parallel distributed logistic regression for vertical federated learning without third-party coordinator,” CoRR, vol. abs/1911.09824, 2019.
- [12] Q. Zhang, B. Gu, C. Deng, and H. Huang, “Secure bilevel asynchronous vertical federated learning with backward updating,” Proceedings of the AAAI Conference on Artificial Intelligence, vol. 35, no. 12, pp. 10 896–10 904, May 2021.
- [13] K. Cheng, T. Fan, Y. Jin, Y. Liu, T. Chen, D. Papadopoulos, and Q. Yang, “Secureboost: A lossless federated learning framework,” IEEE Intelligent Systems, vol. 36, no. 6, pp. 87–98, 2021.
- [14] J. Vaidya, C. Clifton, M. Kantarcioglu, and A. S. Patterson, “Privacy-preserving decision trees over vertically partitioned data,” ACM Trans. Knowl. Discov. Data, vol. 2, no. 3, oct 2008.
- [15] Y. Wu, S. Cai, X. Xiao, G. Chen, and B. C. Ooi, “Privacy preserving vertical federated learning for tree-based models,” Proc. VLDB Endow., vol. 13, no. 12, p. 2090–2103, jul 2020.
- [16] Y. Liu, Y. Liu, Z. Liu, Y. Liang, C. Meng, J. Zhang, and Y. Zheng, “Federated forest,” IEEE Transactions on Big Data, pp. 1–1, 2020.
- [17] Z. Tian, R. Zhang, X. Hou, J. Liu, and K. Ren, “Federboost: Private federated learning for GBDT,” CoRR, vol. abs/2011.02796, 2020.
- [18] Y. Hu, D. Niu, J. Yang, and S. Zhou, “Fdml: A collaborative machine learning framework for distributed features,” in Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, ser. KDD ’19. New York, NY, USA: Association for Computing Machinery, 2019, p. 2232–2240.
- [19] Y. Liu, Y. Kang, X. Zhang, L. Li, Y. Cheng, T. Chen, M. Hong, and Q. Yang, “A communication efficient collaborative learning framework for distributed features,” CoRR, vol. abs/1912.11187, 2019.
- [20] D. Romanini, A. J. Hall, P. Papadopoulos, T. Titcombe, A. Ismail, T. Cebere, R. Sandmann, R. Roehm, and M. A. Hoeh, “Pyvertical: A vertical federated learning framework for multi-headed splitnn,” CoRR, vol. abs/2104.00489, 2021.
- [21] Q. He, W. Yang, B. Chen, Y. Geng, and L. Huang, “Transnet: Training privacy-preserving neural network over transformed layer,” Proc. VLDB Endow., vol. 13, no. 12, p. 1849–1862, jul 2020.
- [22] B. Gu, Z. Dang, X. Li, and H. Huang, “Federated doubly stochastic kernel learning for vertically partitioned data,” in Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. New York, NY, USA: Association for Computing Machinery, 2020, p. 2483–2493.
- [23] R. Xu, N. Baracaldo, Y. Zhou, A. Anwar, J. Joshi, and H. Ludwig, “Fedv: Privacy-preserving federated learning over vertically partitioned data,” CoRR, vol. abs/2103.03918, 2021.
- [24] Y. Liu, Y. Kang, C. Xing, T. Chen, and Q. Yang, “A secure federated transfer learning framework,” IEEE Intelligent Systems, vol. 35, no. 4, pp. 70–82, 2020.
- [25] S. Sharma, C. Xing, Y. Liu, and Y. Kang, “Secure and efficient federated transfer learning,” in 2019 IEEE International Conference on Big Data (Big Data), 2019, pp. 2569–2576.
- [26] B. Zhang, C. Chen, and L. Wang, “Privacy-preserving transfer learning via secure maximum mean discrepancy,” arXiv preprint arXiv:2009.11680, 2020.
- [27] Y. Gao, M. Gong, Y. Xie, A. K. Qin, K. Pan, and Y.-S. Ong, “Multiparty dual learning,” IEEE Transactions on Cybernetics, vol. 53, no. 5, pp. 2955–2968, 2023.
- [28] D. Gao, Y. Liu, A. Huang, C. Ju, H. Yu, and Q. Yang, “Privacy-preserving heterogeneous federated transfer learning,” in 2019 IEEE International Conference on Big Data (Big Data), 2019, pp. 2552–2559.
- [29] J. Mori, I. Teranishi, and R. Furukawa, “Continual horizontal federated learning for heterogeneous data,” in 2022 International Joint Conference on Neural Networks (IJCNN), 2022, pp. 1–8.
- [30] D. Gao, C. Ju, X. Wei, Y. Liu, T. Chen, and Q. Yang, “Hhhfl: Hierarchical heterogeneous horizontal federated learning for electroencephalography,” arXiv preprint arXiv:1909.05784, 2019.
- [31] A. Rakotomamonjy, M. Vono, H. J. M. Ruiz, and L. Ralaivola, “Personalised federated learning on heterogeneous feature spaces,” arXiv preprint arXiv:2301.11447, 2023.
- [32] E. Hallaji, R. Razavi-Far, and M. Saif, Federated and Transfer Learning: A Survey on Adversaries and Defense Mechanisms. Cham: Springer International Publishing, 2023, pp. 29–55.
- [33] S. Hardy, W. Henecka, H. Ivey-Law, R. Nock, G. Patrini, G. Smith, and B. Thorne, “Private federated learning on vertically partitioned data via entity resolution and additively homomorphic encryption,” arXiv preprint arXiv:1711.10677, 2017.
- [34] K. Bonawitz, V. Ivanov, B. Kreuter, A. Marcedone, H. B. McMahan, S. Patel, D. Ramage, A. Segal, and K. Seth, “Practical secure aggregation for privacy-preserving machine learning,” in Proceedings of the 2017 ACM SIGSAC Conference on Computer and Communications Security, ser. CCS ’17. New York, NY, USA: Association for Computing Machinery, 2017, p. 1175–1191.
- [35] P. Mohassel and Y. Zhang, “Secureml: A system for scalable privacy-preserving machine learning,” in 2017 IEEE Symposium on Security and Privacy (SP), 2017, pp. 19–38.
- [36] T. Araki, J. Furukawa, Y. Lindell, A. Nof, and K. Ohara, “High-throughput semi-honest secure three-party computation with an honest majority,” in Proceedings of the 2016 ACM SIGSAC Conference on Computer and Communications Security, ser. CCS ’16. New York, NY, USA: Association for Computing Machinery, 2016, p. 805–817.
- [37] M. Abadi, A. Chu, I. Goodfellow, H. B. McMahan, I. Mironov, K. Talwar, and L. Zhang, “Deep learning with differential privacy,” in Proceedings of the 2016 ACM SIGSAC Conference on Computer and Communications Security, ser. CCS ’16. New York, NY, USA: Association for Computing Machinery, 2016, p. 308–318.
- [38] R. C. Geyer, T. Klein, and M. Nabi, “Differentially private federated learning: A client level perspective,” arXiv preprint arXiv:1712.07557, 2017.
- [39] Y. Liu, X. Zhang, and L. Wang, “Asymmetrical vertical federated learning,” arXiv preprint arXiv:2004.07427, 2020.