# When LLMs Meet Cunning Texts: A Fallacy Understanding Benchmark for Large Language Models
## Abstract
Recently, Large Language Models (LLMs) make remarkable evolutions in language understanding and generation. Following this, various benchmarks for measuring all kinds of capabilities of LLMs have sprung up. In this paper, we challenge the reasoning and understanding abilities of LLMs by proposing a F a L lacy U nderstanding B enchmark (FLUB) containing cunning texts that are easy for humans to understand but difficult for models to grasp. Specifically, the cunning texts that FLUB focuses on mainly consist of the tricky, humorous, and misleading texts collected from the real internet environment. And we design three tasks with increasing difficulty in the FLUB benchmark to evaluate the fallacy understanding ability of LLMs. Based on FLUB, we investigate the performance of multiple representative and advanced LLMs, reflecting our FLUB is challenging and worthy of more future study. Interesting discoveries and valuable insights are achieved in our extensive experiments and detailed analyses. We hope that our benchmark can encourage the community to improve LLMs’ ability to understand fallacies. Our data and codes are available at https://github.com/THUKElab/FLUB.
## 1 Introduction
Large Language Models (LLMs) have shown great abilities to understand human languages, including information extraction [1], text correction [2], humor understanding [3], etc. Researchers have constructed numerous benchmarks to evaluate LLMs in various aspects [4, 5, 6, 7, 8]. By using constructed benchmarks to interact with LLMs, researchers can analyze the behavior of LLMs to compare the performance of different LLMs and study how to further improve LLMs in a targeted manner.
Although many LLM benchmarks have sprung up, we believe that existing benchmarks are not challenging enough to truly measure the human-like intelligence of LLMs. In particular, we are still wondering whether LLMs can understand cunning texts that may contain misleading, wrong premise, intentional ambiguity, and so forth, considering that almost all LLMs are trained on “cleaned” and “correct” corpora. Therefore, we build a F a L lacy U nderstanding B enchmark (FLUB) to challenge LLMs for solving these problems.
<details>
<summary>x1.png Details</summary>
### Visual Description
## Diagram: Comparative Responses to "Cunning Texts" by LLMs vs. Humans
### Overview
The image is a diagram illustrating two examples of "Cunning Texts" – questions or statements in Chinese that are ambiguous, tricky, or rely on common-sense knowledge. For each example, it contrasts the typical response from a Large Language Model (LLM) with a typical response from a human. The diagram is structured into two distinct sections separated by a horizontal dashed line.
### Components/Axes
The diagram is not a chart with axes but a structured comparison layout.
* **Structure:** Two main sections, each containing one "Cunning Text" and two responses.
* **Color Coding & Labels:**
* **Blue Header Bars:** Contain the "Cunning Text" questions. The text "Cunning Texts" is written in blue in the top-right corner of each bar.
* **Beige Response Bubbles:** Contain the response attributed to "LLMs". A robot icon is placed to the right of these bubbles, labeled "LLMs".
* **Green Response Bubbles:** Contain the response attributed to a "Human". An icon of a person reading a book is placed to the right of these bubbles, labeled "Human".
* **Language:** All text is presented bilingually. The primary text is in Chinese (Simplified), with an English translation directly below it in italics.
### Detailed Analysis / Content Details
**Section 1 (Top):**
* **Cunning Text (Blue Bar):**
* Chinese: 我买的藕里面为什么都是洞?
* English Translation: *Why are there holes in the lotus roots I bought?*
* **LLM Response (Beige Bubble):**
* Chinese: 藕可能会因为虫蛀导致有洞。
* English Translation: *There may be holes in the lotus roots due to insect infestation.*
* **Human Response (Green Bubble):**
* Chinese: 藕天然就有很多洞。
* English Translation: *Lotus roots naturally have many holes.*
**Section 2 (Bottom, below dashed line):**
* **Cunning Text (Blue Bar):**
* Chinese: 忘记把钱存在哪个ATM机里了怎么办?
* English Translation: *What should I do if I forget which ATM machine I deposited my money in?*
* **LLM Response (Beige Bubble):**
* Chinese: 可以尝试联系银行客服或者访问银行分行。
* English Translation: *Try contacting bank customer service or visiting a bank branch.*
* **Human Response (Green Bubble):**
* Chinese: 你可以通过任何一台ATM机重新取钱。
* English Translation: *You can withdraw money again through any ATM machine.*
### Key Observations
1. **Pattern of Misinterpretation:** In both examples, the LLM response interprets the question literally and provides a plausible but incorrect or overly complicated answer based on surface-level text analysis.
2. **Common-Sense Correction:** The human response corrects the premise of the question by applying fundamental, common-sense knowledge: that lotus roots are naturally porous, and that ATM deposits are account-based, not machine-specific.
3. **Visual Contrast:** The diagram uses color (beige vs. green) and iconography (robot vs. human) to create a clear visual dichotomy between the two types of responders.
### Interpretation
This diagram serves as a critical commentary on a key limitation of current Large Language Models. It demonstrates that LLMs can be "fooled" by cunning texts—questions that contain a false or misleading premise—because they process language statistically without a grounded understanding of the real world. The LLMs in these examples fail to recognize the inherent, common-sense facts that a human would use to reframe and correctly answer the question.
The first example highlights a lack of basic botanical knowledge, while the second reveals a misunderstanding of how banking systems function. The diagram argues that human intelligence integrates vast, implicit world knowledge to navigate ambiguity, whereas LLMs, despite their fluency, can be brittle when faced with questions that require stepping outside the literal text to apply foundational truths. This has significant implications for the reliability of AI in real-world applications where users may pose questions with unstated assumptions or incorrect framing.
</details>
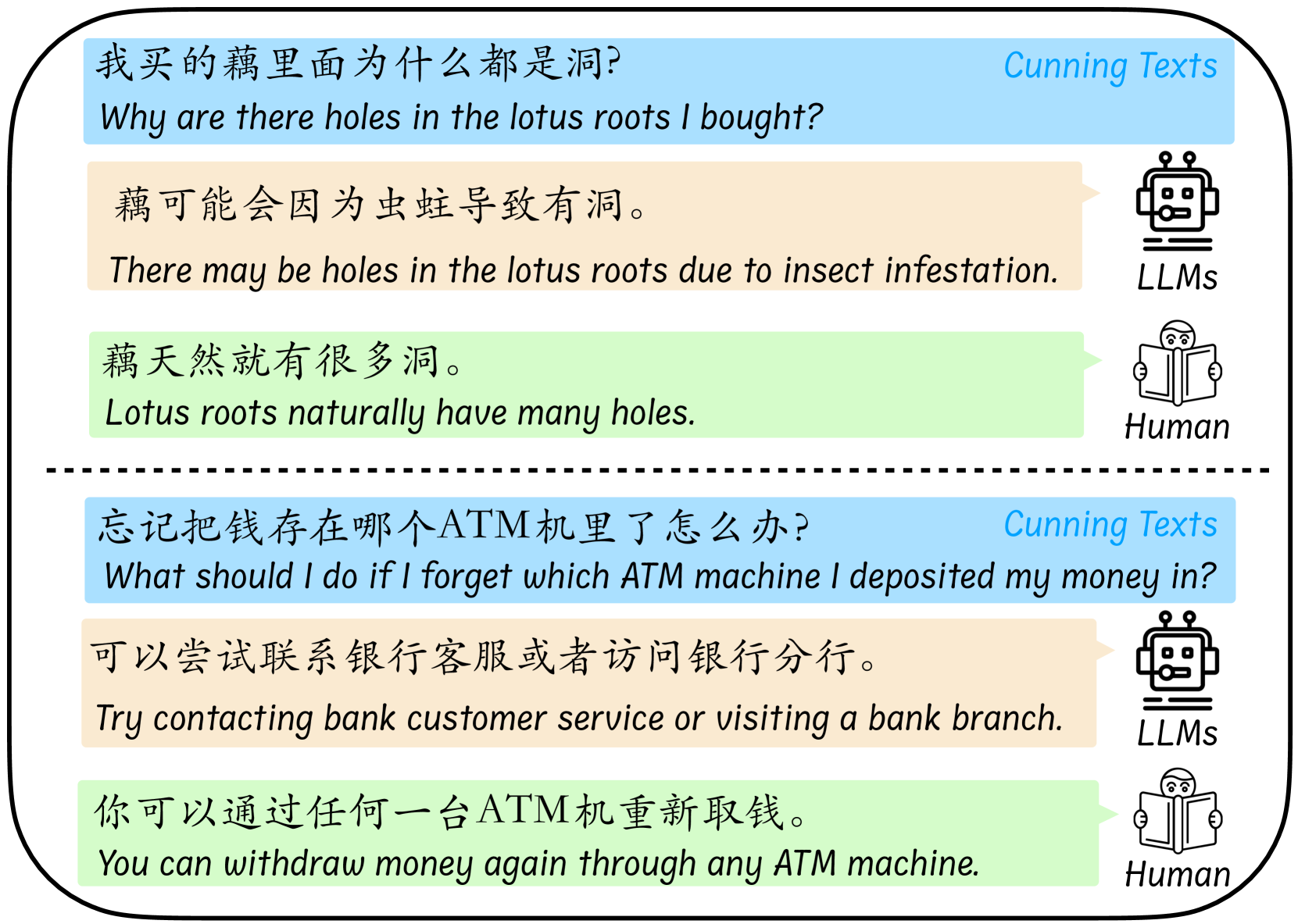
(a) The examples of how LLMs and humans perform when faced with cunning texts. The LLM we use is ChatGPT-3.5 on Jan 23, 2024.
<details>
<summary>x2.png Details</summary>

### Visual Description
## Educational Graphic: Logical Fallacy Example
### Overview
The image is a structured educational graphic designed to illustrate a common logical fallacy or "cunning" question. It presents a classic trick question about comparing weights, provides the correct explanation, and then tests understanding through a multiple-choice question. The graphic uses a light green background with black text and dashed-line borders to separate sections. All text is bilingual, presented in Chinese with an English translation directly below.
### Components/Axes
The graphic is divided into three distinct horizontal sections, each enclosed in a dashed-line box:
1. **Top Section (Two Columns):**
* **Left Column Header:** "Cunning Text"
* **Right Column Header:** "Cunning Type"
2. **Middle Section:**
* **Header:** "Explanation"
3. **Bottom Section:**
* **Header:** "Multiple Choice"
### Detailed Analysis / Content Details
**1. Top Section: The Question**
* **Cunning Text (Chinese):** 一吨的铁和一吨的棉花哪个重啊?
* **Cunning Text (English Translation):** Which one weighs more, a ton of iron or a ton of cotton?
* **Cunning Type (Chinese):** 事实性错误
* **Cunning Type (English Translation):** Factual Error
**2. Middle Section: The Explanation**
* **Explanation (Chinese):** “一吨的铁”和“一吨的棉花”重量都是一吨,是一样重的。
* **Explanation (English Translation):** "A ton of iron" and "a ton of cotton" both weigh one ton and are the same weight.
**3. Bottom Section: The Test**
* **Multiple Choice Options:**
* **A (Chinese):** “一吨的铁”和“一吨的棉花”重量都是一吨,是一样重的。
* **A (English Translation):** "A ton of iron" and "a ton of cotton" both weigh one ton and are the same weight.
* **Marking:** A blue checkmark (✓) is placed to the right, indicating this is the correct answer.
* **B (Chinese):** 一吨的铁更重,因为铁看起来比棉花要重。
* **B (English Translation):** A ton of iron is heavier because iron appears to be heavier than cotton.
* **Marking:** A red cross (✗) is placed to the right, indicating this is incorrect.
* **C (Chinese):** 铁和棉花没有可比性,因为它们的质量单位相同。
* **C (English Translation):** Iron and cotton are not comparable because they have the same unit of mass.
* **Marking:** A red cross (✗) is placed to the right, indicating this is incorrect.
* **D (Chinese):** 从体积的角度来看,一吨铁似乎更重一些。
* **D (English Translation):** From the volume perspective, a ton of iron seems heavier.
* **Marking:** A red cross (✗) is placed to the right, indicating this is incorrect.
### Key Observations
* The graphic explicitly labels the trick question as a "Factual Error" type of cunning text.
* The correct answer (A) is a direct restatement of the factual explanation provided in the middle section.
* All incorrect answers (B, C, D) introduce flawed reasoning:
* **B** relies on a perceptual bias (density/volume confusion).
* **C** presents a nonsensical argument (comparability is not negated by having the same unit).
* **D** introduces an irrelevant perspective (volume) that does not change the defined weight.
* The visual design uses clear headers, consistent bilingual formatting, and symbolic markings (✓/✗) to reinforce learning.
### Interpretation
This graphic serves as a pedagogical tool to combat a specific cognitive bias. The "cunning" or trick lies in the intuitive but incorrect association of material density with weight when the mass is explicitly defined as equal. The structure is designed to:
1. **Present the Fallacy:** Show the common, misleading question.
2. **Correct the Misconception:** Provide a clear, factual explanation.
3. **Assess Understanding:** Use a multiple-choice format where the correct answer is straightforward, and the distractors model common erroneous thought patterns.
The underlying message is the importance of precise language and logical reasoning over intuitive perception. It teaches the listener to focus on the defined parameters ("a ton of") rather than extraneous attributes (material type, appearance, volume). The inclusion of the "Cunning Type" label suggests this is part of a larger series aimed at identifying and deconstructing various types of logical or linguistic traps.
</details>
(b) We design three tasks, namely Cunning Type Classification, Fallacy Explanation, and Answer Selection (i.e., Multiple Choice).
Figure 1: The running examples and annotation examples of FLUB.
Figure 1(a) shows the running examples from FLUB. From these cases, we directly feel the different behaviors of LLMs and humans when facing cunning texts. In the first example, LLMs ignore the common sense that the lotus root itself has many holes in its structure and fall into the trap of the cunning text, wrongly judging that the holes in the lotus root are caused by insect infestation. In the second example, LLMs fail to see the logic that depositing money into random ATMs does not create problems and therefore give an answer that seems reasonable but is absurdly laughable. In fact, these cunning texts for LLMs are very easy to handle for human intelligence. Therefore, it is very urgent and meaningful to construct a benchmark composed of cunning texts to evaluate and thereby promote the improvement of LLMs’ fallacy understanding capabilities.
Inspired by the above motivation, we collect real cunning texts as our raw data from a famous Chinese online forum, the “Ruozhiba” (retard forum) https://tieba.baidu.com/f?kw=%E5%BC%B1%E6%99%BA&ie=utf-8. This forum is popular for its cunning and unreasonable posts, which are generally easy for humans to understand but challenging for LLMs. The characteristics of the posts contained in this forum are consistent with our research motivation, so choosing it as the data source well supports FLUB ’s evaluation of LLMs’ fallacy understanding ability. After data cleaning and annotating of cunning types, FLUB has 8 fine-grained types of cunning texts and most of the texts in FLUB fall into two types of fallacy, namely, faulty reasoning and word game. Moreover, we also manually annotated one correct answer (i.e., the explanation of the cunning text) and three confusing wrong answers for each input text in FLUB, as shown in Figure 1(b).
Based on our constructed FLUB and its annotation information, we design three tasks with increasing difficulty to test whether the LLMs can understand the fallacy and solve the “cunning” texts. Specifically, (1) Answer Selection: The model is asked to select the correct one from the four answers provided by FLUB for each input text. (2) Cunning Type Classification: Given a cunning text as input, the model is expected to directly identify its fallacy type defined in our scheme. (3) Fallacy Explanation: We hope the model sees a cunning text and intelligently generates a correct explanation for the fallacy contained in the text, just like humans, without falling into its trap.
In our experiments, we select representative and advanced LLMs to be evaluated on FLUB. Our empirical study reveals: (1) LLMs are very poor in their ability to perceive fallacy types in cunning texts. (2) For a specific task, LLMs with larger parameter sizes do not always perform better. (3) There is a close relationship between the Answer Selection task and the Fallacy Explanation task, and the interaction between them is critical to promoting the understanding of fallacies in LLMs. (4) On FLUB, the widely used Chain-of-Thought and In-context Learning techniques deserve further improvement and research. We believe that our proposed FLUB and all our findings are crucial for LLMs to comprehend the fallacy and handle cunning texts in the real world.
<details>
<summary>x3.png Details</summary>
### Visual Description
## Table: Classification of Cunning Types (Logical/Linguistic Errors)
### Overview
The image displays a structured table that categorizes nine types of "Cunning" (likely referring to logical fallacies, linguistic tricks, or errors in reasoning). Each type is defined in both Chinese and English and is accompanied by an illustrative example, also provided bilingually. The table uses color-coding for visual organization.
### Components/Axes
The table has three columns:
1. **Cunning Type** (Left column, green background): Lists the category name in Chinese and English.
2. **Definition** (Middle column, beige background): Provides a description of the error in Chinese, followed by an English translation.
3. **Example** (Right column, beige background): Gives a concrete example of the error in Chinese, followed by an English translation.
The header row has a blue background. The first column ("Cunning Type") has a light green background for all data rows, while the "Definition" and "Example" columns share a light beige background.
### Detailed Analysis
The table contains nine rows of data, one for each cunning type. Below is the precise transcription and translation of all content.
**Row 1:**
* **Cunning Type:** 错误类比 / False Analogy
* **Definition:**
* Chinese: 由于事件A的发生具有或伴随有某种属性,从而错误地类比出与事件A相似的事件B也应该具有该属性,或者错误地类比出与事件A相反的事件B也应该具有相反的属性。
* English: Due to the occurrence of event A having or being accompanied by a certain attribute, it is erroneously analogized that event B, which is similar to event A, should also have that attribute, or that event B, which is opposite to event A, should have the opposite attribute.
* **Example:**
* Chinese: 很多人出门后担心刚刚没有关门,为什么进门后不担心刚刚没有开门?
* English: Many people worry about forgetting to close the door when they leave home. Why don't they worry about whether they have opened the door when they come in?
**Row 2:**
* **Cunning Type:** 冷笑话 / Lame Jokes
* **Definition:**
* Chinese: 由于缺乏对某个常识或事实的认知,从而得出某个不符合逻辑的问题或结论。注意,该句子往往因为其不寻常的认知缺失从而导致该句子可能令人发笑。
* English: Due to a lack of understanding of a common sense or fact, an illogical question or conclusion can be drawn. Note that this sentence may be funny due to its unusual cognitive impairment.
* **Example:**
* Chinese: 忘记把钱存在哪个ATM机里了怎么办?银行好几台ATM机,还长得都一样。
* English: What should I do if I forgot which ATM I deposited money into? The bank has several ATMs, and they all look the same.
**Row 3:**
* **Cunning Type:** 字音错误 / Phonetic Error
* **Definition:**
* Chinese: 通过改变固定词汇中多音字的发音,从而利用新的发音得到的句子。注意,如果读者没有领会到句子中发音的改变,会导致读者认为该句子不符合逻辑。
* English: Sentences obtained by changing the pronunciation of polyphonic words in fixed vocabulary. Note that if the reader does not appreciate the change in pronunciation in the sentence, it will lead the reader to think that the sentence is illogical.
* **Example:**
* Chinese: 因为美国队长,小明每次在美国排队都要排一个多小时。
* English: Because of Captain America (also read as "long queues in America" in Chinese), XiaoMing has to wait over an hour whenever he queues in the U.S.
**Row 4:**
* **Cunning Type:** 歧义 / Ambiguity
* **Definition:**
* Chinese: 通过改变句子中某个多义词的词义,从而得出不符合逻辑的问题或结论。
* English: By changing the meaning of a polysemy word in a sentence, illogical questions or conclusions can be drawn.
* **Example:**
* Chinese: 语文老师说我的句子是病句,我应该给这个病句吃头孢,还是打点滴呢?
* English: My teacher said the sentence is grammatically wrong. Should I give this sentence some antibiotics or administer an IV drip?
**Row 5:**
* **Cunning Type:** 悖论 / Paradox
* **Definition:**
* Chinese: 句子或者问题的表述前后矛盾。
* English: The expression of a sentence or question is contradictory.
* **Example:**
* Chinese: “凡事无绝对”这句话过于绝对。
* English: The phrase "Nothing is absolute" is too absolute.
**Row 6:**
* **Cunning Type:** 事实性错误 / Factual Error
* **Definition:**
* Chinese: 由于缺乏对某个事实的认知,或者对事实进行扭曲,从而提出无意义的问题或结论。
* English: Due to a lack of understanding or distortion of a fact, meaningless questions or conclusions are raised.
* **Example:**
* Chinese: 一吨的铁和一吨的棉花哪个重啊?
* English: Which one weighs more, a ton of iron or a ton of cotton?
**Row 7:**
* **Cunning Type:** 推理错误 / Reasoning Error
* **Definition:**
* Chinese: 从一个事件中推断出一个错误或者无意义的结论,或者颠倒了事件的因果关系。
* English: Inferring an incorrect or meaningless conclusion from an event, or reversing the causal relationship of the event.
* **Example:**
* Chinese: 根据我在养老院的调查数据,我国的人口老龄化已经相当严重了。
* English: According to my survey data from nursing homes, the aging of the population in our country has become quite severe.
**Row 8:**
* **Cunning Type:** 文字游戏 / Word Game
* **Definition:**
* Chinese: 错误地改变句子中文字的意思或含义,在此基础上提出问题或者得出结论。
* English: Mistakenly changing the meaning of words in a sentence, and based on this, raising questions or drawing conclusions.
* **Example:**
* Chinese: 人类70%是水,所以10个人里有7个人是水伪装成的人!
* English: 70% of the human body is water, so 7 out of 10 people are water disguised as humans!
**Row 9:**
* **Cunning Type:** 未分类 / Undefined
* **Definition:**
* Chinese: 句子本身具有错误,或者句子的表述不符合正常逻辑,但是不属于上述任何一个类别。
* English: The sentence itself has errors, or the expression of the sentence does not conform to normal logic, but does not belong to any of the above categories.
* **Example:**
* Chinese: 在高速路的服务区开酒吧有可行性吗?
* English: Is it feasible to open a bar at a highway service area?
### Key Observations
1. **Bilingual Structure:** Every entry (type, definition, example) is presented in both Chinese and English, making the table accessible to speakers of both languages.
2. **Color-Coded Layout:** The use of green for the "Cunning Type" column and beige for the content columns creates a clear visual hierarchy, separating categories from their explanations.
3. **Progression of Complexity:** The types range from common logical fallacies (False Analogy, Paradox) to more language-specific errors (Phonic Error, Ambiguity, Word Game), culminating in an "Undefined" catch-all category.
4. **Example-Driven:** Each abstract definition is paired with a concrete, often humorous or everyday example, which aids in understanding the practical manifestation of the error.
### Interpretation
This table serves as a **taxonomic reference for identifying flawed reasoning and linguistic manipulation**. It is likely used in fields such as logic, critical thinking, linguistics, rhetoric, or artificial intelligence (specifically for natural language understanding and fallacy detection).
The data suggests a systematic approach to categorizing errors that lead to illogical, absurd, or misleading statements. The inclusion of "Lame Jokes" and "Word Game" indicates an understanding that humor and playfulness can be vehicles for logical errors. The "Undefined" category acknowledges the limitations of any classification system.
The relationship between columns is strictly definitional and illustrative: the "Cunning Type" is the label, the "Definition" provides the theoretical framework, and the "Example" grounds the theory in relatable practice. The bilingual nature implies an intent to bridge understanding across linguistic contexts, perhaps for educational purposes or for training AI models on cross-lingual logical reasoning. The table's structure allows a reader to quickly look up a suspicious statement, identify its potential error type, and understand why it is flawed.
</details>
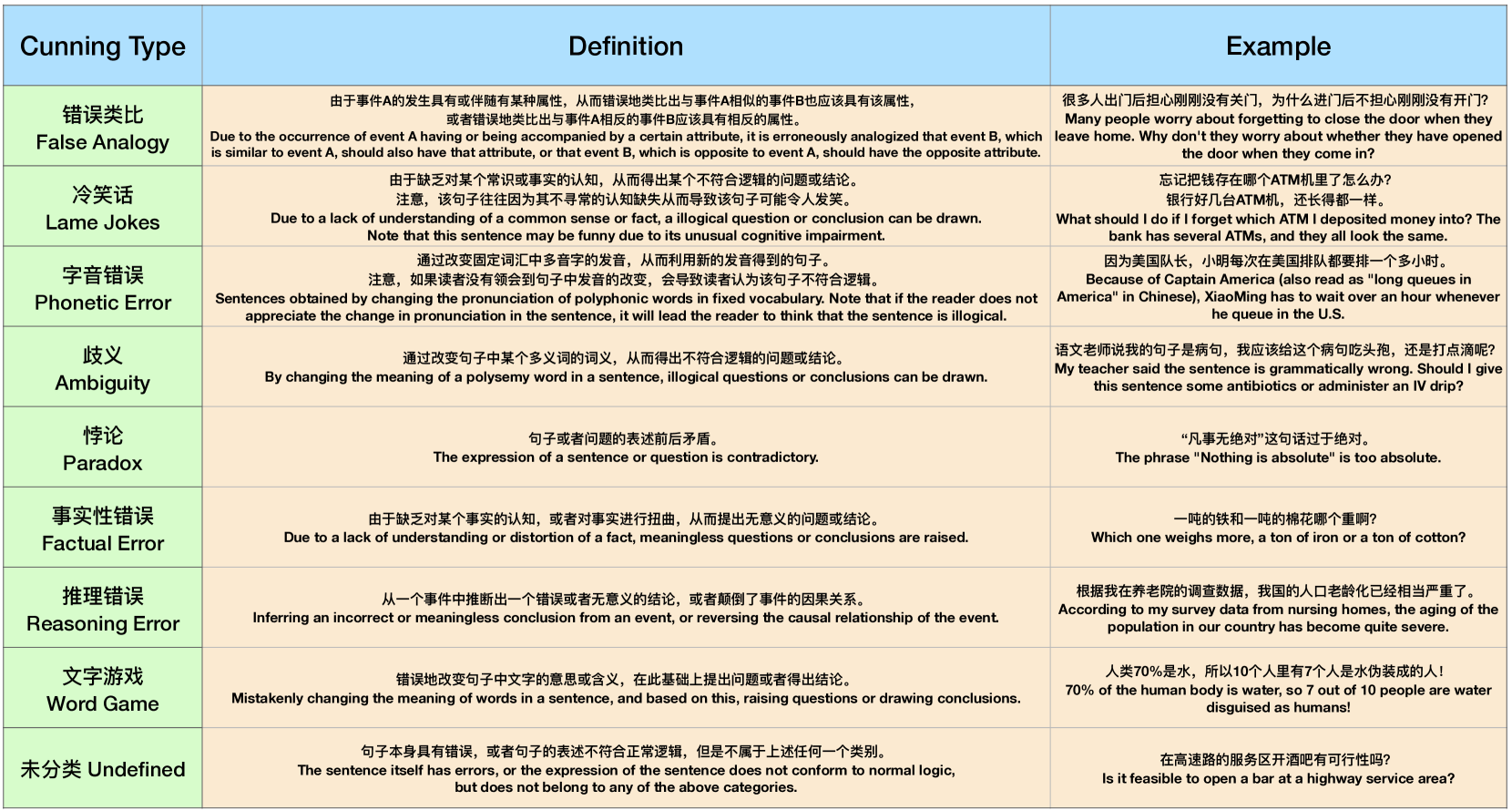
Figure 2: The definitions and examples of the cunning types in FLUB.
## 2 The FLUB Benchmark
### 2.1 Benchmark Construction
Data Collection
We collect raw text data from “Ruozhiba” in Baidu Tieba https://tieba.baidu.com. “Ruozhiba” is one of the most famous online forums in the Chinese internet community, and people often post interesting or “silly” texts on it just for fun. In addition, the recent study [9] also shows that the Ruozhiba data is very useful for improving the ability of Chinese LLMs. We find that many of the posts on this forum are tricky texts or brain-teaser-like texts, which is exactly in line with our purpose of using cunning texts to challenge LLMs, so we utilize this forum as our data source. As a result of automatic crawling, we initially collect 9,927 candidate posts. Notably, according to the Baidu Bar agreement https://baike.baidu.com/item/%E8%B4%B4%E5%90%A7%E5%8D%8F%E8%AE%AE/8397765, the data on Baidu Tieba can be used for academic research free of charge and without liability.
Data Cleaning
We employ annotators to manually filter out irrelevant posts that do not present cunning texts. Since the collected original posts contain irrelevant content such as links and images, we also require annotators to extract the fallacious and illogical contents from the raw post and rewrite them into a complete sentence. Besides, it is worth noting that we carefully ensure that the texts in FLUB are ethical texts. This process includes user information anonymization, sensitive information removal, and filtering of impolite posts. In total, we obtain 834 data samples to form FLUB.
Data Annotation
To ensure the annotation quality, our criteria for selecting annotators is that the person must be a native Chinese speaker and have a bachelor’s degree. In addition, because FLUB comes from the online forum, we also require annotators to have more than five years of experience as netizens. The detailed annotation workflows are as follows:
1. Cunning Type Annotation: We first define 8 cunning types within the collected texts along with their corresponding examples, as shown in Figure 2. Subsequently, each data sample is processed by three junior annotators, who are required to select an appropriate cunning type for the sample. We achieve the initial annotation results based on the voting results among three annotators. The initial annotation results become the final annotation information after being reviewed by the senior annotator (and modified if necessary).
1. Correct Explanation Annotation: We assign two junior annotators to write the explanation or answer for each sample independently. We ask them to try to explain the given text in a detailed, objective, and unambiguous way. The senior annotator then selects (and modifies if necessary) the more suitable text written by the two junior annotators.
1. Wrong Candidates Annotation: This part annotation is to obtain the wrong candidate answer that may be likely to be answered incorrectly for each input text. We assign three junior annotators for each sample and require each of them to write three different incorrect answers based on their understanding of the text. Particularly, we emphasize to each junior annotator that the three different wrong answers they write should ensure diversity and resemble as much as possible the answers that LLMs can easily produce. For each sample’s nine initial incorrect answers, the senior annotator selects the three most challenging sentences as the final wrong candidates.
Since the annotation difficulty of different information is different, the salary we pay to the annotators we employ is also different. Specifically, we pay each person who annotates the cunning type $0.5 per sample, each person who writes the correct explanation $1 per sample, and each person who writes the wrong candidates $2 per sample. In addition to the junior annotators providing the initial annotation results, we also set three senior annotators with a salary of $2 per sample, who are responsible for carefully checking the correctness of the annotation results provided by the junior annotators.
It is worth mentioning that we have prepared sufficient and representative samples for annotators to learn and pre-annotate to ensure that they fully understand the information we want to annotate before they officially start annotation. Our entire annotation process lasted 2 weeks.
### 2.2 Dataset Analysis
Data Size
FLUB comprises 834 samples that span 8 cunning types. It is worth emphasizing that the data size is not directly related to the evaluation effectiveness of a LLM benchmark. For example, TruthfulQA [10] and FreshQA [11], these benchmarks that have been widely used and had deep impacts, only have 817 and 500 test samples respectively. The main reasons limiting the size of FLUB are that it is derived entirely from real-world online forum posts and our rigorous high-quality data cleaning process, which retained 834 final samples from 9,927 candidate posts.
Data Distribution
As for the cunning type distribution of FLUB, most data in FLUB belong to the types of reasoning errors (53.4%) and word games (28.7%). This is because these two types of posts appear widely in “Ruozhi Bar” forum whose purpose is to challenge human intelligence. A large number of cunning texts involving reasoning errors and word games ensure that FLUB is challenging enough. Besides, we observe that some types of texts are relatively rare, such as phonetic errors (0.6%). In fact, this is because our data come entirely from the real world and are all carefully constructed by netizens. Cases of cunning texts caused by phonetic errors are indeed rare in the real world. To eliminate the impact of type imbalance when FLUB evaluating LLMs, we choose the F-1 score as the evaluation metric which comprehensively considers the type coverage.
Annotation Quality
Since cunning type annotation is essentially a classification process performed by multiple annotators, we analyze the annotation quality of this information. Specifically, we calculate Fleiss’ Kappa [12] to reflect the three junior annotator’s Inter-Annotator Agreement (IAA). Our final obtained Fleiss Kappa result is greater than 0.767, which shows that our annotation results have excellent consistency and quality [13].
### 2.3 Benchmark Task Setups
To evaluate the fallacy understanding ability of LLMs, we design three benchmark tasks on FLUB: Answer Selection, Cunning Type Classification, and Fallacy Explanation. For each task, we design prompts to guide LLMs on the expected output. We also explore the prompting strategies of Chain-of-Thought and In-context Learning to conduct in-depth exploration on FLUB. The details of our designed prompts are shown in Appendix A. Below we introduce the details of our three tasks:
Task 1: Answer Selection
In Task 1, LLMs are required to select the correct answer from four given candidate explanations for each input text. The annotation of candidate explanations is illustrated in Figure 1(b). In general, each sample in this task is a tuple $\{p,q,O_{A},O_{B},O_{C},O_{D},l\}$ , where $p$ is our given prompt as shown in Appendix A, $q$ is the input text, $O_{A}$ , $O_{B}$ , $O_{C}$ , and $O_{D}$ are four candidate explanations, and $l\in\{A,B,C,D\}$ is the golden label indicating $O_{l}$ is the correct explanation. The design motivation of this task is to test whether LLMs can distinguish right from wrong when seeing the correct and wrong answers in the context of a given cunning text.
Task 2: Cunning Type Classification
If LLMs are directly tasked with determining the corresponding cunning type, it will help us in conducting an initial automated assessment of the LLM’s understanding ability. The cunning type classification task is specifically designed to evaluate whether LLMs can classify the cunning text into categories aligned with human intuition based on the hidden irrational aspects within the current text. The annotated problem types are shown in Figure 2. During task evaluation, all the problem types will be combined with the prompt to allow LLMs to directly pick the correct type of cunning text.
Task 3: Fallacy Explanation
To further test whether LLMs truly understand the given cunning text, we design the explanation task. In this task, the designed prompt and input texts are directly input into LLMs, enabling them to “read” input texts and generate corresponding explanations. Note that since some texts are not expressed in the form of inquiries, we also set a prompt to guide LLMs in identifying the question (See Appendix A). The generated explanations will be compared with the correct explanation for evaluation. If LLMs can generate reasonable explanations, we believe that they have at least developed the ability to identify and avoid the traps of cunning texts.
Automatic Evaluation Metrics
For Task 1, we calculate Accuracy directly based on the LLMs’ selection results. For Task 2, considering that there are a few cunning types in FLUB with small sample size, we choose the F-1 Score to measure the performance of LLMs because it focuses on both the accuracy of model prediction and the coverage for positive class samples, thereby effectively avoiding bias caused by type imbalance and ensuring the rationality and reliability of evaluation. To evaluate the quality of LLMs’ generated explanations in Task 3, inspired by MT-Bench [14], we construct prompts that incorporate the task instruction, input texts, LLM’s explanations, and reference answers. These prompts are fed into GPT-4, which is tasked with assigning a GPT-4 Score ranging from 1 to 10. The prompt for the automated evaluation is illustrated in Appendix B.
Human Evaluation Settings
For Task 1 and Task 2, we conduct human evaluations to explore how well human-level intelligence could perform these two tasks. To ensure the fairness of the comparison between humans and LLMs, we hire 3 new persons who do not participate in the construction process of FLUB. After briefly introducing them to the objectives of Task 1 and Task 2 (without introducing additional knowledge and information), let them directly carry out selection and classification. For the human evaluation of Task 3, we mainly want to verify the effectiveness of the automatic GPT-4 score we use, therefore, we hire 3 evaluation annotators to rate LLMs’ explanations, with scores ranging from $\{1,2,3,4,5\}$ . To ensure an accurate evaluation of the explanations of LLMs, we developed a set of scoring guidelines for annotators, including the definitions and relevant examples for each score. The scoring guidelines of human evaluation are presented in Appendix C.
## 3 Experiments
### 3.1 Experimental Settings
To better reflect the evaluation of FLUB ’s fallacy understanding ability of LLMs, we select some advanced LLMs that are widely used in the Chinese community: (1) ERNIE-Bot [15] is a series of closed-sourced commercial LLMs released by Baidu. We evaluate the three latest chat models, including ERNIE-Bot-3.5, ERNIE-Bot-3.5-Turbo, and ERNIE-Bot-4.0. (2) ChatGPT [16] ChatGPT is undoubtedly the hottest model developed by OpenAI. We evaluate GPT-3.5-Turbo and GPT-4-Turbo. (3) ChatGLM3 [17] is the latest open-sourced model of the ChatGLM which is a series of bilingual LLMs. We evaluate the only open-sourced parameter size of ChatGLM3-6B. (4) Qwen [18] is the open-sourced LLMs developed by the Alibaba Group. We select three chat Qwen models, including Qwen-7B-Chat, Qwen-14B-Chat, and Qwen-72B-Chat. (5) Yi [19] series models are open-sourced LLMs trained from scratch by 01-AI. In our experiments, we select Yi-6B-Chat and Yi-34B-Chat to be evaluated on FLUB. (6) Baichuan2 [20] has achieved the competitive performance of its size on many Chinese benchmarks. We select Baichuan2-7B-Chat and Baichuan2-13B-Chat.
When running LLMs inference, for closed-sourced LLMs, we access corresponding models via the official APIs. Meanwhile, open-sourced models are deployed on 1 to 4 NVIDIA A100 GPUs depending on their parameter size.
Table 1: We bold the optimal and underline the suboptimal of closed/open-source models. We report the overall performance by calculating the geometric mean of the three tasks. We color the result that Chain-of-Thought (CoT) brings positive / negative gain as green ↑ / red ↓.
| Models | Open | Selection | Classification | Explanation | Overall | | | | |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| Accuracy | F-1 Score | GPT-4 Score | Performance | | | | | | |
| Source | w/o CoT | CoT | w/o CoT | CoT | w/o CoT | CoT | w/o CoT | CoT | |
| ERNIE-Bot-3.5-Turbo [15] | ✗ | 32.97 | 34.65 ↓ | 1.99 | 6.09 ↑ | 5.78 | 5.83 ↑ | 7.24 | 10.72 ↑ |
| ERNIE-Bot-3.5 [15] | ✗ | 52.76 | 38.37 ↓ | 10.33 | 11.15 ↑ | 6.35 | 6.22 ↓ | 15.13 | 13.86 ↓ |
| ERNIE-Bot-4.0 [15] | ✗ | 75.66 | 71.34 ↓ | 11.84 | 14.42 ↑ | 7.73 | 8.11 ↑ | 19.06 | 20.28 ↑ |
| GPT-3.5-Turbo [16] | ✗ | 50.48 | 48.08 ↓ | 3.09 | 6.15 ↑ | 6.23 | 7.00 ↑ | 9.91 | 12.74 ↑ |
| GPT-4-Turbo [16] | ✗ | 79.38 | 82.73 ↑ | 12.31 | 13.97 ↑ | 8.95 | 9.21 ↑ | 20.60 | 22.00 ↑ |
| ChatGLM3-6B [17] | ✓ | 35.85 | 35.01 ↓ | 7.48 | 9.34 ↑ | 4.98 | 4.82 ↓ | 11.01 | 11.64 ↑ |
| Qwen-7B-Chat [18] | ✓ | 38.49 | 33.69 ↓ | 8.00 | 10.97 ↑ | 5.39 | 5.65 ↑ | 11.84 | 11.98 ↑ |
| Qwen-14B-Chat [18] | ✓ | 42.57 | 43.05 ↑ | 10.34 | 10.44 ↑ | 5.24 | 6.24 ↑ | 13.21 | 14.10 ↑ |
| Qwen-72B-Chat [18] | ✓ | 58.63 | 61.51 ↑ | 9.32 | 12.26 ↑ | 7.34 | 7.90 ↑ | 15.89 | 18.13 ↑ |
| Yi-6B-Chat [19] | ✓ | 32.37 | 29.26 ↓ | 8.87 | 9.84 ↑ | 5.73 | 5.39 ↓ | 11.81 | 11.58 ↓ |
| Yi-34B-Chat [19] | ✓ | 47.96 | 48.80 ↑ | 4.74 | 11.70 ↑ | 6.97 | 7.52 ↑ | 11.66 | 16.17 ↑ |
| Baichuan2-7B-Chat [20] | ✓ | 43.17 | 37.17 ↓ | 1.02 | 4.45 ↑ | 5.48 | 4.85 ↓ | 6.23 | 9.29 ↑ |
| Baichuan2-13B-Chat [20] | ✓ | 37.05 | 38.01 ↑ | 3.52 | 4.58 ↑ | 5.79 | 5.84 ↑ | 9.11 | 10.06 ↑ |
| Random | - | 25.00 | 7.90 | - | - | | | | |
| Human | - | 93.35 | 63.69 | - | - | | | | |
### 3.2 Automatic Evaluation Results
The main results are presented in Table 1 and we have the following insights:
1. For the difficulty of different tasks, the Answer Selection task is the simplest, which shows that LLMs should have a certain ability to distinguish right from wrong when seeing correct and wrong answers. However, we also see that the performance of all models on the Cunning Type Classification task is unsatisfactory, with F-1 scores below 15.0, and some models even perform below random performance. This deficiency may stem from the models’ limited capability to comprehend the semantics of various cunning types.
1. For the connection between different tasks, the comparative outcomes among different models across the three tasks are not consistent. Nevertheless, models that exhibit superior performance in the Answer Selection task tend to generate more plausible explanations. This phenomenon reminds us that there is a close relationship between the Answer Selection task and the Fallacy Explanation task. The interaction between these two tasks is very critical for improving the fallacy understanding ability of LLMs.
1. For the model performance of different scale parameters, overall, models of larger scale are better equipped to understand cunning texts, which aligns with intuitive expectations. Of course, there are exceptions. We find that for the Qwen and Yi models, as the parameter size increases, the performance of the Cunning Type Classification task decreases. This is because this task requires a deep understanding of the Chinese language, especially the popular Internet language, and we observe that as the Qwen and Yi models become larger, their ability to understand special Internet language becomes poorer.
1. For the impact of Chain-of-Thought, to our surprise, Chain-of-Thought (CoT) does not bring stable improvements to LLMs’ fallacy understanding ability. Especially for the Answer Selection and Fallacy Explanation tasks, CoT even has negative impacts on some models. We think there are two main reasons for this phenomenon: (1) We notice that when the model size exceeds 10B, CoT still has positive effects on these two tasks. This reflects the challenge of our tasks, which makes CoT unable to stimulate the small models to have sufficient capabilities to cope with them. (2) For traditional QA tasks (such as commonsense reasoning, mathematical reasoning, etc.), CoT can improve performance because these tasks themselves are relatively logical, and the process of solving their questions can be modeled as the logical reasoning process. Unlike these tasks, our tasks are not very logical problems but require more intuition about the language. Hence, adding intermediate steps by the CoT has no significant effect on our tasks. In summary, our proposed tasks deserve further research to improve the fallacy understanding ability of LLMs.
1. For the overall performance, considering that the performance values of the three sub-tasks are very different, we use the geometric mean to balance the impact of each sub-task and avoid the excessive impact of a single extreme value on the overall performance. We see that the overall performance of each model is basically consistent with common sense, that is, the larger the model, the better the performance, and CoT also brings positive effects. This shows that FLUB is of high quality and suitable to measure the fallacy understanding ability of LLMs from an overall perspective.
1. For the human performance, we see that humans perform well on the Answer Selection and Cunning Type Classification tasks, which reflects the considerable gap in fallacy understanding between human intelligence and LLMs. It also shows that our proposed new benchmark and tasks are conducive to further promoting the progress of LLMs. Note that the reason why the Fallacy Explanation task is not suitable for evaluating human performance is that its automatic evaluation indicator is the GPT-4 Score. We think that using GPT-4 to evaluate explanations written by humans is unreasonable and unnecessary.
<details>
<summary>x4.png Details</summary>
### Visual Description
## Comparative Performance of AI Models Across Three Metrics
### Overview
The image displays three line charts arranged horizontally, comparing the performance of five different AI models across three distinct metrics as a function of "Shot" (likely few-shot learning examples). The charts share a common x-axis ("Shot") and a common legend, but have different y-axes representing different performance measures.
### Components/Axes
* **Common X-Axis (All Charts):** Labeled "Shot". The axis markers are at values 0, 1, 2, and 5.
* **Legend:** Located in the bottom-right corner of the third chart. It maps line colors to model names:
* Purple Line: `Qwen-72B-Chat`
* Orange Line: `ERNIE-Bot-4.0`
* Green Line: `Baichuan2-13B-Chat`
* Yellow Line: `Yi-34B-Chat`
* Blue Line: `GPT-4-Turbo`
* **Chart 1 (Left):**
* **Title/Y-Axis:** "Selection Accuracy"
* **Y-Axis Scale:** Ranges from approximately 40 to 90. Major gridlines are at 40, 60, 80.
* **Chart 2 (Center):**
* **Title/Y-Axis:** "Classification Accuracy"
* **Y-Axis Scale:** Ranges from approximately 5 to 14. Major gridlines are at 5.0, 7.5, 10.0, 12.5.
* **Chart 3 (Right):**
* **Title/Y-Axis:** "Explanation GPT-4 Score"
* **Y-Axis Scale:** Ranges from approximately 6 to 9. Major gridlines are at 6, 7, 8, 9.
### Detailed Analysis
**Chart 1: Selection Accuracy**
* **Trend Verification:** All lines show a general upward or stable trend as the number of shots increases from 0 to 5.
* **Data Points (Approximate):**
* **GPT-4-Turbo (Blue):** Starts high (~80 at 0-shot), increases slightly and plateaus around 85-86.
* **ERNIE-Bot-4.0 (Orange):** Starts around 76, increases sharply to ~84 at 1-shot, then continues a steady rise to ~88 at 5-shot.
* **Qwen-72B-Chat (Purple):** Starts around 59, dips to ~53 at 1-shot, recovers to ~60 at 2-shot, and ends near 61 at 5-shot.
* **Yi-34B-Chat (Yellow):** Starts around 48, increases steadily to ~58 at 5-shot.
* **Baichuan2-13B-Chat (Green):** Starts lowest at ~37, increases gradually to ~47 at 5-shot.
**Chart 2: Classification Accuracy**
* **Trend Verification:** All lines show an upward trend. The rate of increase varies significantly between models.
* **Data Points (Approximate):**
* **GPT-4-Turbo (Blue):** Highest throughout. Starts ~12.2, rises steadily to ~13.8 at 5-shot.
* **ERNIE-Bot-4.0 (Orange):** Starts ~11.8, remains flat to 1-shot, then increases sharply to ~13.5 at 5-shot.
* **Yi-34B-Chat (Yellow):** Shows the most dramatic initial increase. Starts very low (~4.8), jumps to ~11.2 at 1-shot, then plateaus around 12.6.
* **Qwen-72B-Chat (Purple):** Starts ~9.2, increases steadily to ~12.2 at 5-shot.
* **Baichuan2-13B-Chat (Green):** Lowest throughout. Starts ~3.5, increases slowly to ~4.8 at 5-shot.
**Chart 3: Explanation GPT-4 Score**
* **Trend Verification:** All lines show a general upward trend, with some models plateauing after an initial rise.
* **Data Points (Approximate):**
* **GPT-4-Turbo (Blue):** Highest and most stable. Hovers around 9.0 across all shots.
* **ERNIE-Bot-4.0 (Orange):** Starts ~7.7, increases to ~8.9 at 2-shot, and plateaus there.
* **Qwen-72B-Chat (Purple):** Starts ~7.3, increases steadily to ~8.0 at 5-shot.
* **Yi-34B-Chat (Yellow):** Starts ~7.0, increases to ~7.6 at 5-shot.
* **Baichuan2-13B-Chat (Green):** Lowest throughout. Starts ~5.8, increases slowly to ~6.2 at 5-shot.
### Key Observations
1. **Consistent Hierarchy:** `GPT-4-Turbo` (Blue) is the top performer across all three metrics at nearly every shot level.
2. **Strong Improver:** `ERNIE-Bot-4.0` (Orange) shows significant gains with more shots, particularly in Selection and Classification Accuracy, often closing the gap with the top model.
3. **Variable Starting Points:** Models have vastly different zero-shot performance. For example, in Classification Accuracy, `Yi-34B-Chat` starts extremely low but improves dramatically with one shot.
4. **Consistent Laggard:** `Baichuan2-13B-Chat` (Green) consistently performs the worst across all metrics and shot counts, though it still shows improvement.
5. **Metric Sensitivity:** The relative ranking of models (excluding the top and bottom) shifts between metrics. For instance, `Qwen-72B-Chat` outperforms `Yi-34B-Chat` in Selection Accuracy but underperforms it in Classification Accuracy after 1-shot.
### Interpretation
The data demonstrates the impact of few-shot learning (increasing "Shot" count) on the performance of various large language models. The consistent upward trends indicate that providing examples generally helps all models improve on these tasks.
The charts reveal a clear performance tier: `GPT-4-Turbo` operates at a high, stable level, suggesting robustness. `ERNIE-Bot-4.0` and `Yi-34B-Chat` are highly responsive to in-context learning, with `Yi-34B-Chat` showing a particularly steep learning curve for classification. `Qwen-72B-Chat` shows moderate, steady improvement. `Baichuan2-13B-Chat`'s lower performance may indicate a smaller model capacity or less optimization for these specific tasks.
The divergence in model rankings across metrics (Selection vs. Classification vs. Explanation) suggests that model capabilities are not uniform. A model strong at selecting information may not be equally strong at classifying it or generating high-quality explanations, highlighting the importance of multi-faceted evaluation. The "Explanation GPT-4 Score" being evaluated by GPT-4 itself introduces a potential bias, where models more similar to GPT-4 in style may score higher.
</details>
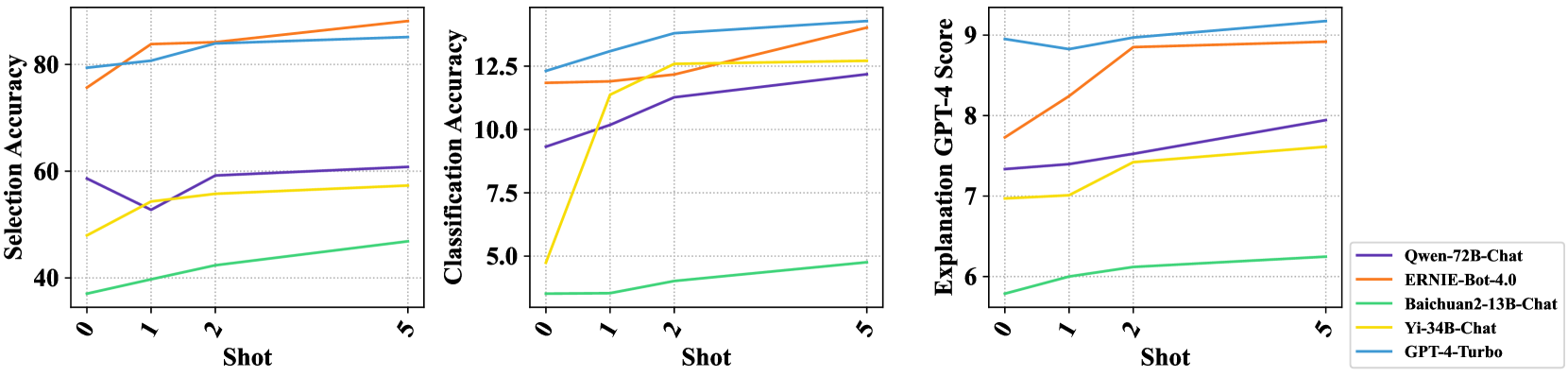
Figure 3: The results of in-context learning with 0/1/2/5-shots demonstrations.
### 3.3 The Impact of In-context Learning
We select 5 high-performing LLMs to study the impact of in-context learning on LLMs’ fallacy understanding ability. Demonstrations used for in-context learning are randomly selected. As shown in Figure 3, unlike Chain-of-Thought which has no stable positive effect, the LLMs’ performance with in-context learning is basically on the rise as demonstrations increase. This indicates that letting LLMs see more examples can improve their fallacy understanding ability, but the number of examples must be large enough because we have also seen that when only one shot example is added, the performance of LLMs sometimes declines compared to the zero-shot cases.
Table 2: Human evaluation on the explanation task. Note that we multiply the human results by 2 to normalize their range to be the same as the GPT-4 results’ range. The reported correlations are Spearman’s rank correlation coefficients. All correlations are extremely significant with $p<0.01$ .
| Models | Human | GPT-4 | Correlation |
| --- | --- | --- | --- |
| GPT-4-Turbo | 7.12 | 8.60 | 0.57 |
| ERNIE-Bot-4.0 | 5.82 | 7.20 | 0.71 |
| Qwen-72B-Chat | 5.74 | 7.82 | 0.42 |
| Yi-34B-Chat | 5.42 | 6.44 | 0.74 |
| Baichuan2-13B-Chat | 4.42 | 5.84 | 0.63 |
| Overall | - | - | 0.69 |
Table 3: We mark correct / partially correct / wrong explanations in green / orange / red.
| Input Text 1 | UTF8gbsn有个问题,鸡蛋干加水会变成鸡蛋吗? |
| --- | --- |
| I have a question, will dried eggs turn into eggs if water is added to them? | |
| Correct Answer | UTF8gbsn鸡蛋干是将鸡蛋浓缩加工,而不是表面上“鸡蛋缺水变干”的意思,所以鸡蛋干加水不会变成鸡蛋。 |
| Dried eggs are concentrated and processed eggs, rather than the superficial meaning of “eggs become dry | |
| due to lack of water”, so adding water to dried eggs will not turn them into eggs. | |
| ERNIE-Bot-4.0 | UTF8gbsn…鸡蛋干是鸡蛋的加工制品,不是鸡蛋。加水不能使鸡蛋干还原成鸡蛋… |
| Dried eggs are processed products of eggs, not eggs. Adding water will not | |
| turn the dried eggs back into eggs. | |
| GPT-4-Turbo | UTF8gbsn…鸡蛋干是经过脱水处理的鸡蛋产品,加水只能使其回软,但不能恢复到原始的鸡蛋状态… |
| Dried eggs are dehydrated egg products. Adding water can only soften them, but cannot return | |
| them to their original egg state. | |
| Input Text 2 | UTF8gbsn游泳初学者怕呛死,下水前能先把头放岸边吗? |
| Beginner swimmers are afraid of choking. Can they put their heads on the shore before entering the water? | |
| Correct Answer | UTF8gbsn头是人身体的一部分,如果头离开了身体,不用呛死人就已经死亡了。 |
| The head is part of the human body. If the head leaves the body, the person will die without choking him. | |
| ERNIE-Bot-4.0 | UTF8gbsn…将头部放在岸边并不是一种标准的游泳训练做法。游泳初学者下水前不应将头放在岸边… |
| Keeping your head on the bank is not a standard swim training practice. Beginner swimmers | |
| should not put their heads on the shore before entering the water. | |
| GPT-4-Turbo | UTF8gbsn…游泳初学者在下水前可以先在岸边练习将头部放入水中并慢慢学会控制呼吸… |
| Beginner swimmers can practice putting their heads in the water on the shore and | |
| slowly learn to control their breathing before entering the water. | |
### 3.4 Human Evaluation of Explanation
To verify the effectiveness of our designed automatic GPT-4 score for Task 3, we randomly select 50 data samples from FLUB, along with outputs from 5 high-performing LLMs for human evaluation by our contracted annotators. From the human evaluation results in Table 2, we observe that:
1. The overall correlation coefficient between the automatic and human evaluation is 0.69, indicating a high consistency between GPT-4 scores and human preferences. Besides, the correlation results also verify the effectiveness of our designed GPT-4 score for Task 3.
1. Both automatic and human evaluations exhibit a broadly consistent ranking across the selected five models. The GPT-4-Turbo achieves superior performance over all other models. In contrast, human annotators perceive marginal performance disparities among ERNIE-Bot-4.0, Qwen-72B-Chat, and Yi-34B-Chat models.
1. From the human evaluation results, except for GPT-4-Turbo, which can exceed the passing score of 6, the performance of other LLMs is still not ideal, which shows that the community still needs to further study how to improve the fallacy understanding ability of LLMs.
### 3.5 Case Study
To analyze FLUB ’s challenges, we conduct case studies on the two advanced models with better performance in the fallacy explanation task in Table 3. From the first case, we see that GPT-4-Turbo gives a relatively perfect explanation, while ERNIE-Bot-4.0 ’s answer does not explain the causal relationship clearly although its final conclusion is correct. According to ERNIE-Bot-4.0 ’s explanation, if the egg is added with water, it can be restored. This is obviously wrong. In the second case which is more difficult, both ERNIE-Bot-4.0 and GPT-4-Turbo easily fail when facing these cunning texts. Specifically, ERNIE-Bot-4.0 follows the trap of the input text, not clearly stating that “putting heads on the shore” is an impossible operation, but giving a dumbfounding explanation. In comparison, GPT-4-Turbo ’s performance is slightly better, but it does not perceive the trap in the input text at all, resulting in an answer that is not what is questioned. It can be seen from these two cases that LLMs’ ability to handle cunning texts is still insufficient.
## 4 Related Work
Reasoning Evaluation of LLMs
Our FLUB is for evaluating the fallacy understanding ability of LLMs, which is closely related to the reasoning of LLMs [21, 22, 23]. Therefore, we first review related works on the commonsense and logical reasoning of LLMs. Commonsense Reasoning: Existing commonsense reasoning benchmarks include CommonsenseQA [24], PIQA [25], Social IQA [26], HellaSWAG [27], and MCTACO [28]. Their task is presented in the form of multiple-choice questions. The recent LLMs reasoning evaluation works [29, 30] have demonstrated that LLMs represented by ChatGPT often cannot accurately utilize commonsense knowledge for the reasoning process. Logical Reasoning: For logical reasoning data resources, they can be mainly divided into two categories: Natural Language Inference [31, 32, 33] and Multiple-Choice Reading Comprehension [34, 35, 36, 37]. [38] show that logical reasoning is very challenging for LLMs, especially for out-of-distribution data samples. In summary, research on reasoning ability is the focus of the LLMs-centric research.
Humor in NLP
We notice that some samples in FLUB contain humorous expressions. Therefore, NLP research on humor [39, 3] is instructive for future exploration on FLUB. Particularly, as a representative humor task, the word game task with puns as the core has been continuously paid attention to by researchers [40, 41, 42, 43]. According to our statistics, a large proportion of FLUB are cunning texts belonging to word games. Therefore, we believe that how to improve the humor recognition and processing capabilities of LLMs is also the key to improving the performance of LLMs on FLUB.
## 5 Limitations
One limitation of FLUB may be that it consists of Chinese data. In particular, many of the cunning texts in FLUB have certain Chinese cultural and language characteristics as backgrounds, which places extremely high demands on LLMs’ knowledge storage. However, as a community that cannot be ignored in NLP, the development of Chinese LLMs has been devoted by generations of researchers.
## 6 Ethics Statement
In this paper, we present a new benchmark, FLUB. We have described the details of the collection, preprocessing, and annotation of FLUB. And we ensure that no infringement or unethical behavior occurred during the dataset construction. In terms of the data itself, to ensure that the dataset we need to release in the future meets ethical requirements, we spend lots of energy on data anonymization, data desensitization, improper data cleaning, etc. Besides, the cunning texts we are concerned about come from daily life and are very common. Therefore, the new research direction and tasks we propose will not cause harm to human society.
## 7 Conclusion
In this work, we construct FLUB, a high-quality benchmark consisting of cunning texts designed to evaluate the fallacy understanding ability of LLMs. Furthermore, we evaluate advanced LLMs on FLUB. Detailed analyses indicate FLUB is very challenging and of great research value. To date, most existing LLMs still can not understand the fallacy well, which results in them being far from dealing with complex problems in the real world as easily as humans. We believe that the benchmark and the research direction we provide are valuable for the LLMs community.
## Acknowledgments and Disclosure of Funding
This research is supported by National Natural Science Foundation of China (Grant No. 62276154), the Natural Science Foundation of Guangdong Province (Grant No. 2023A1515012914), Shenzhen Science and Technology Program (Grant No. WDZC20231128091437002), Basic Research Fund of Shenzhen City (Grant No. JCYJ20210324120012033 and GJHZ202402183000101), the Major Key Project of PCL for Experiments and Applications (PCL2021A06), and Overseas Cooperation Research Fund of Tsinghua Shenzhen International Graduate School (HW2021008).
## References
- [1] T. Yu, C. Jiang, C. Lou, S. Huang, X. Wang, W. Liu, J. Cai, Y. Li, Y. Li, K. Tu, H. Zheng, N. Zhang, P. Xie, F. Huang, and Y. Jiang, “Seqgpt: An out-of-the-box large language model for open domain sequence understanding,” CoRR, vol. abs/2308.10529, 2023.
- [2] Y. Li, H. Huang, S. Ma, Y. Jiang, Y. Li, F. Zhou, H. Zheng, and Q. Zhou, “On the (in)effectiveness of large language models for chinese text correction,” CoRR, vol. abs/2307.09007, 2023.
- [3] J. Hessel, A. Marasovic, J. D. Hwang, L. Lee, J. Da, R. Zellers, R. Mankoff, and Y. Choi, “Do androids laugh at electric sheep? humor “understanding” benchmarks from the new yorker caption contest,” in Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) (A. Rogers, J. Boyd-Graber, and N. Okazaki, eds.), (Toronto, Canada), pp. 688–714, Association for Computational Linguistics, July 2023.
- [4] S. Ma, Y. Li, R. Sun, Q. Zhou, S. Huang, D. Zhang, Y. Li, R. Liu, Z. Li, Y. Cao, H. Zheng, and Y. Shen, “Linguistic rules-based corpus generation for native chinese grammatical error correction,” in Findings of the Association for Computational Linguistics: EMNLP 2022, Abu Dhabi, United Arab Emirates, December 7-11, 2022 (Y. Goldberg, Z. Kozareva, and Y. Zhang, eds.), pp. 576–589, Association for Computational Linguistics, 2022.
- [5] S. Huang, S. Ma, Y. Li, L. Yangning, S. Lin, H. Zheng, and Y. Shen, “Towards attribute-entangled controllable text generation: A pilot study of blessing generation,” in Proceedings of the 2nd Workshop on Natural Language Generation, Evaluation, and Metrics (GEM) (A. Bosselut, K. Chandu, K. Dhole, V. Gangal, S. Gehrmann, Y. Jernite, J. Novikova, and L. Perez-Beltrachini, eds.), (Abu Dhabi, United Arab Emirates (Hybrid)), pp. 235–247, Association for Computational Linguistics, Dec. 2022.
- [6] S. Huang, S. Ma, Y. Li, M. Huang, W. Zou, W. Zhang, and H. Zheng, “Lateval: An interactive llms evaluation benchmark with incomplete information from lateral thinking puzzles,” CoRR, vol. abs/2308.10855, 2023.
- [7] Y. Li, Z. Xu, S. Chen, H. Huang, Y. Li, Y. Jiang, Z. Li, Q. Zhou, H. Zheng, and Y. Shen, “Towards real-world writing assistance: A chinese character checking benchmark with faked and misspelled characters,” CoRR, vol. abs/2311.11268, 2023.
- [8] Y. Li, T. Lu, Y. Li, T. Yu, S. Huang, H. Zheng, R. Zhang, and J. Yuan, “MESED: A multi-modal entity set expansion dataset with fine-grained semantic classes and hard negative entities,” CoRR, vol. abs/2307.14878, 2023.
- [9] Y. Bai, X. Du, Y. Liang, Y. Jin, Z. Liu, J. Zhou, T. Zheng, X. Zhang, N. Ma, Z. Wang, et al., “Coig-cqia: Quality is all you need for chinese instruction fine-tuning,” arXiv preprint arXiv:2403.18058, 2024.
- [10] S. Lin, J. Hilton, and O. Evans, “TruthfulQA: Measuring how models mimic human falsehoods,” in Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) (S. Muresan, P. Nakov, and A. Villavicencio, eds.), (Dublin, Ireland), pp. 3214–3252, Association for Computational Linguistics, May 2022.
- [11] T. Vu, M. Iyyer, X. Wang, N. Constant, J. Wei, J. Wei, C. Tar, Y.-H. Sung, D. Zhou, Q. Le, et al., “Freshllms: Refreshing large language models with search engine augmentation,” arXiv preprint arXiv:2310.03214, 2023.
- [12] R. Falotico and P. Quatto, “Fleiss’ kappa statistic without paradoxes,” Quality & Quantity, vol. 49, pp. 463–470, 2015.
- [13] J. R. Landis and G. G. Koch, “The measurement of observer agreement for categorical data,” biometrics, pp. 159–174, 1977.
- [14] L. Zheng, W.-L. Chiang, Y. Sheng, S. Zhuang, Z. Wu, Y. Zhuang, Z. Lin, Z. Li, D. Li, E. Xing, et al., “Judging llm-as-a-judge with mt-bench and chatbot arena,” arXiv preprint arXiv:2306.05685, 2023.
- [15] Baidu, “Ernie-bot, https://cloud.baidu.com/product/wenxinworkshop,” 2023.
- [16] OpenAI, “GPT-4 technical report,” CoRR, vol. abs/2303.08774, 2023.
- [17] Z. Du, Y. Qian, X. Liu, M. Ding, J. Qiu, Z. Yang, and J. Tang, “GLM: General language model pretraining with autoregressive blank infilling,” in Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) (S. Muresan, P. Nakov, and A. Villavicencio, eds.), (Dublin, Ireland), pp. 320–335, Association for Computational Linguistics, May 2022.
- [18] J. Bai, S. Bai, Y. Chu, Z. Cui, K. Dang, X. Deng, Y. Fan, W. Ge, Y. Han, F. Huang, et al., “Qwen technical report,” arXiv preprint arXiv:2309.16609, 2023.
- [19] 01-AI, “Yi, https://github.com/01-ai/Yi,” 2023.
- [20] A. Yang, B. Xiao, B. Wang, B. Zhang, C. Bian, C. Yin, C. Lv, D. Pan, D. Wang, D. Yan, et al., “Baichuan 2: Open large-scale language models,” arXiv preprint arXiv:2309.10305, 2023.
- [21] C. Dong, Y. Li, H. Gong, M. Chen, J. Li, Y. Shen, and M. Yang, “A survey of natural language generation,” ACM Comput. Surv., vol. 55, no. 8, pp. 173:1–173:38, 2023.
- [22] Y. Chang, X. Wang, J. Wang, Y. Wu, K. Zhu, H. Chen, L. Yang, X. Yi, C. Wang, Y. Wang, et al., “A survey on evaluation of large language models,” arXiv preprint arXiv:2307.03109, 2023.
- [23] Z. Guo, R. Jin, C. Liu, Y. Huang, D. Shi, L. Yu, Y. Liu, J. Li, B. Xiong, D. Xiong, et al., “Evaluating large language models: A comprehensive survey,” arXiv preprint arXiv:2310.19736, 2023.
- [24] A. Talmor, J. Herzig, N. Lourie, and J. Berant, “Commonsenseqa: A question answering challenge targeting commonsense knowledge,” in Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, NAACL-HLT 2019, Minneapolis, MN, USA, June 2-7, 2019, Volume 1 (Long and Short Papers) (J. Burstein, C. Doran, and T. Solorio, eds.), pp. 4149–4158, Association for Computational Linguistics, 2019.
- [25] Y. Bisk, R. Zellers, R. L. Bras, J. Gao, and Y. Choi, “PIQA: reasoning about physical commonsense in natural language,” in The Thirty-Fourth AAAI Conference on Artificial Intelligence, AAAI 2020, The Thirty-Second Innovative Applications of Artificial Intelligence Conference, IAAI 2020, The Tenth AAAI Symposium on Educational Advances in Artificial Intelligence, EAAI 2020, New York, NY, USA, February 7-12, 2020, pp. 7432–7439, AAAI Press, 2020.
- [26] M. Sap, H. Rashkin, D. Chen, R. L. Bras, and Y. Choi, “Social iqa: Commonsense reasoning about social interactions,” in Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing, EMNLP-IJCNLP 2019, Hong Kong, China, November 3-7, 2019 (K. Inui, J. Jiang, V. Ng, and X. Wan, eds.), pp. 4462–4472, Association for Computational Linguistics, 2019.
- [27] R. Zellers, A. Holtzman, Y. Bisk, A. Farhadi, and Y. Choi, “Hellaswag: Can a machine really finish your sentence?,” in Proceedings of the 57th Conference of the Association for Computational Linguistics, ACL 2019, Florence, Italy, July 28- August 2, 2019, Volume 1: Long Papers (A. Korhonen, D. R. Traum, and L. Màrquez, eds.), pp. 4791–4800, Association for Computational Linguistics, 2019.
- [28] B. Zhou, D. Khashabi, Q. Ning, and D. Roth, “"going on a vacation" takes longer than "going for a walk": A study of temporal commonsense understanding,” in Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing, EMNLP-IJCNLP 2019, Hong Kong, China, November 3-7, 2019 (K. Inui, J. Jiang, V. Ng, and X. Wan, eds.), pp. 3361–3367, Association for Computational Linguistics, 2019.
- [29] Y. Bang, S. Cahyawijaya, N. Lee, W. Dai, D. Su, B. Wilie, H. Lovenia, Z. Ji, T. Yu, W. Chung, Q. V. Do, Y. Xu, and P. Fung, “A multitask, multilingual, multimodal evaluation of chatgpt on reasoning, hallucination, and interactivity,” CoRR, vol. abs/2302.04023, 2023.
- [30] N. Bian, X. Han, L. Sun, H. Lin, Y. Lu, and B. He, “Chatgpt is a knowledgeable but inexperienced solver: An investigation of commonsense problem in large language models,” CoRR, vol. abs/2303.16421, 2023.
- [31] S. Saha, Y. Nie, and M. Bansal, “Conjnli: Natural language inference over conjunctive sentences,” in Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing, EMNLP 2020, Online, November 16-20, 2020 (B. Webber, T. Cohn, Y. He, and Y. Liu, eds.), pp. 8240–8252, Association for Computational Linguistics, 2020.
- [32] J. Tian, Y. Li, W. Chen, L. Xiao, H. He, and Y. Jin, “Diagnosing the first-order logical reasoning ability through logicnli,” in Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, EMNLP 2021, Virtual Event / Punta Cana, Dominican Republic, 7-11 November, 2021 (M. Moens, X. Huang, L. Specia, and S. W. Yih, eds.), pp. 3738–3747, Association for Computational Linguistics, 2021.
- [33] H. Liu, L. Cui, J. Liu, and Y. Zhang, “Natural language inference in context - investigating contextual reasoning over long texts,” in Thirty-Fifth AAAI Conference on Artificial Intelligence, AAAI 2021, Thirty-Third Conference on Innovative Applications of Artificial Intelligence, IAAI 2021, The Eleventh Symposium on Educational Advances in Artificial Intelligence, EAAI 2021, Virtual Event, February 2-9, 2021, pp. 13388–13396, AAAI Press, 2021.
- [34] J. Liu, L. Cui, H. Liu, D. Huang, Y. Wang, and Y. Zhang, “Logiqa: A challenge dataset for machine reading comprehension with logical reasoning,” in Proceedings of the Twenty-Ninth International Joint Conference on Artificial Intelligence, IJCAI 2020 (C. Bessiere, ed.), pp. 3622–3628, ijcai.org, 2020.
- [35] R. Liu, Y. Li, L. Tao, D. Liang, and H. Zheng, “Are we ready for a new paradigm shift? A survey on visual deep MLP,” Patterns, vol. 3, no. 7, p. 100520, 2022.
- [36] S. Wang, Z. Liu, W. Zhong, M. Zhou, Z. Wei, Z. Chen, and N. Duan, “From LSAT: the progress and challenges of complex reasoning,” IEEE ACM Trans. Audio Speech Lang. Process., vol. 30, pp. 2201–2216, 2022.
- [37] H. Liu, J. Liu, L. Cui, Z. Teng, N. Duan, M. Zhou, and Y. Zhang, “Logiqa 2.0 - an improved dataset for logical reasoning in natural language understanding,” IEEE ACM Trans. Audio Speech Lang. Process., vol. 31, pp. 2947–2962, 2023.
- [38] H. Liu, R. Ning, Z. Teng, J. Liu, Q. Zhou, and Y. Zhang, “Evaluating the logical reasoning ability of chatgpt and GPT-4,” CoRR, vol. abs/2304.03439, 2023.
- [39] A. Anjum and N. Lieberum, “Exploring humor in natural language processing: A comprehensive review of JOKER tasks at CLEF symposium 2023,” in Working Notes of the Conference and Labs of the Evaluation Forum (CLEF 2023), Thessaloniki, Greece, September 18th to 21st, 2023 (M. Aliannejadi, G. Faggioli, N. Ferro, and M. Vlachos, eds.), vol. 3497 of CEUR Workshop Proceedings, pp. 1828–1837, CEUR-WS.org, 2023.
- [40] C. F. Hempelmann, “Computational humor: Beyond the pun?,” The Primer of Humor Research. Humor Research, vol. 8, pp. 333–360, 2008.
- [41] Y. Li, Q. Zhou, Y. Li, Z. Li, R. Liu, R. Sun, Z. Wang, C. Li, Y. Cao, and H. Zheng, “The past mistake is the future wisdom: Error-driven contrastive probability optimization for chinese spell checking,” in Findings of the Association for Computational Linguistics: ACL 2022, Dublin, Ireland, May 22-27, 2022 (S. Muresan, P. Nakov, and A. Villavicencio, eds.), pp. 3202–3213, Association for Computational Linguistics, 2022.
- [42] P. Chen and V. Soo, “Humor recognition using deep learning,” in Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, NAACL-HLT, New Orleans, Louisiana, USA, June 1-6, 2018, Volume 2 (Short Papers) (M. A. Walker, H. Ji, and A. Stent, eds.), pp. 113–117, Association for Computational Linguistics, 2018.
- [43] O. Popova and P. Dadić, “Does ai have a sense of humor? clef 2023 joker tasks 1, 2 and 3: using bloom, gpt, simplet5, and more for pun detection, location, interpretation and translation,” Proceedings of the Working Notes of CLEF, vol. 3, 2023.
## Checklist
The checklist follows the references. Please read the checklist guidelines carefully for information on how to answer these questions. For each question, change the default [TODO] to [Yes] , [No] , or [N/A] . You are strongly encouraged to include a justification to your answer, either by referencing the appropriate section of your paper or providing a brief inline description. For example:
- Did you include the license to the code and datasets? [Yes] See Section LABEL:gen_inst.
- Did you include the license to the code and datasets? [No] The code and the data are proprietary.
- Did you include the license to the code and datasets? [N/A]
Please do not modify the questions and only use the provided macros for your answers. Note that the Checklist section does not count towards the page limit. In your paper, please delete this instructions block and only keep the Checklist section heading above along with the questions/answers below.
1. For all authors…
1. Do the main claims made in the abstract and introduction accurately reflect the paper’s contributions and scope? [Yes] See Abstract and Section 1.
1. Did you describe the limitations of your work? [Yes] See Section 5.
1. Did you discuss any potential negative societal impacts of your work? [Yes] See Section 6.
1. Have you read the ethics review guidelines and ensured that your paper conforms to them? [Yes] See Section 6.
1. If you are including theoretical results…
1. Did you state the full set of assumptions of all theoretical results? [N/A]
1. Did you include complete proofs of all theoretical results? [N/A]
1. If you ran experiments (e.g. for benchmarks)…
1. Did you include the code, data, and instructions needed to reproduce the main experimental results (either in the supplemental material or as a URL)? [Yes] See Abstract, Section 3, Appendix A, Appendix B.
1. Did you specify all the training details (e.g., data splits, hyperparameters, how they were chosen)? [N/A]
1. Did you report error bars (e.g., with respect to the random seed after running experiments multiple times)? [Yes] See Section 2.3 and Section 3.3.
1. Did you include the total amount of compute and the type of resources used (e.g., type of GPUs, internal cluster, or cloud provider)? [Yes] See Section 3.1.
1. If you are using existing assets (e.g., code, data, models) or curating/releasing new assets…
1. If your work uses existing assets, did you cite the creators? [Yes] See Section 2.1 and Section 3.1.
1. Did you mention the license of the assets? [Yes] See Section 2.1.
1. Did you include any new assets either in the supplemental material or as a URL? [Yes] See Abstract.
1. Did you discuss whether and how consent was obtained from people whose data you’re using/curating? [Yes] See Section 2.1.
1. Did you discuss whether the data you are using/curating contains personally identifiable information or offensive content? [Yes] See Section 2.1.
1. If you used crowdsourcing or conducted research with human subjects…
1. Did you include the full text of instructions given to participants and screenshots, if applicable? [Yes] See Appendix C.
1. Did you describe any potential participant risks, with links to Institutional Review Board (IRB) approvals, if applicable? [N/A]
1. Did you include the estimated hourly wage paid to participants and the total amount spent on participant compensation? [Yes] See Section 2.1.
<details>
<summary>x5.png Details</summary>

### Visual Description
## Diagram: Task Template Grid for Evaluating Irrationality/Humor in Language
### Overview
The image displays a 4x2 grid of colored rectangular boxes, each containing a task template for processing sentences or questions that contain "irrationality or humor." The grid is organized into two rows. The top row contains four distinct task templates, and the bottom row contains two task templates, each split into two sub-variants (a and b). The templates are presented in both Chinese and English, with a clear color-coding scheme: orange for Task 1, purple for Task 2, and blue for Task 3. The purpose appears to be defining standardized prompts for an AI or human evaluator to analyze linguistic irrationality or humor.
### Components/Axes
The image is a diagram, not a chart, so it has no axes. The components are the eight task template boxes, arranged in a grid.
**Spatial Layout & Color Coding:**
* **Top Row (Left to Right):**
1. **Top-Left (Orange):** Task 1 (Chinese version)
2. **Top-Center-Left (Purple):** Task 2 (Chinese version)
3. **Top-Center-Right (Orange):** Task 1 (English version)
4. **Top-Right (Purple):** Task 2 (English version)
* **Bottom Row (Left to Right):**
1. **Bottom-Left (Blue):** Task 3(a) (Chinese version)
2. **Bottom-Center-Left (Blue):** Task 3(b) (Chinese version)
3. **Bottom-Center-Right (Blue):** Task 3(a) (English version)
4. **Bottom-Right (Blue):** Task 3(b) (English version)
### Detailed Analysis / Content Details
Below is the precise transcription of all text within each box, followed by its English translation where applicable.
**1. Top-Left Box (Orange, Task 1 - Chinese)**
* **Text (Chinese):**
> 给你输入一个句子或问题,其中存在不合理或幽默之处。另外给出四个选项,你需要选出最能准确描述给定句子或问题的不合理或幽默之处的一个选项。
>
> 注意,你必须直接输出你的答案,不能包含任何解释,答案必须属于"A, B, C, D"中的一个。
>
> 以下是输入:
> {sentence}
>
> 选项:
> {options}
>
> Task 1
* **English Translation:**
> We input a sentence or question to you, which contains some irrationality or humor. Additionally, four options are given. You need to select the one option that most accurately describes the irrationality or humor of the given sentence or question.
>
> Note that you must directly output your answer, without any explanation. The answer must belong to one of "A, B, C, D".
>
> The following is the input:
> {sentence}
>
> Options:
> {options}
>
> Task 1
**2. Top-Center-Left Box (Purple, Task 2 - Chinese)**
* **Text (Chinese):**
> 给你输入一个句子或问题,其中存在不合理或幽默之处。你需要从“候选分类”中选出一个最适合该句子或问题的类别。
>
> 候选分类:{candidates}
>
> 注意,你必须直接输出你的答案,不能包含任何解释,答案必须属于候选分类中的一个。
>
> 以下是输入:
> {sentence}
>
> Task 2
* **English Translation:**
> We input a sentence or question to you, which contains some irrationality or humor. You need to choose a category from the "candidate types" that best fits the sentence or question.
>
> Candidate types: {candidates}
>
> Note that you must directly output your answer, without any explanation. The answer must belong to one of the candidate types.
>
> The following is the input:
> {sentence}
>
> Task 2
**3. Top-Center-Right Box (Orange, Task 1 - English)**
* **Text (English):**
> Give you a sentence or question that contains some irrationality or humor. Give you four options, you need to choose the one that best describes the irrationality or humor of the given sentence or question.
>
> Note that you must output your answer directly without any explanation. The answer must belong to one of "A, B, C, D".
>
> The following is the input:
> {sentence}
>
> Options:
> {options}
>
> Task 1
**4. Top-Right Box (Purple, Task 2 - English)**
* **Text (English):**
> Give you a sentence or question that contains some irrationality or humor. You need to choose a type from the “candidate types” that best fits the sentence or question.
>
> Candidate types: {candidates}
>
> Note that you must output your answer directly, without any explanation, and the answer must belong to one of the candidate types.
>
> The following is the input:
> {sentence}
>
> Task 2
**5. Bottom-Left Box (Blue, Task 3(a) - Chinese)**
* **Text (Chinese):**
> 给你输入以下的句子,其中存在不合理或幽默之处。请在三句话以内简要地解释该句子的不合理或幽默之处。
>
> {sentence}
>
> Task 3(a)
* **English Translation:**
> Input the following sentence to you, which contains some irrationality or humor. Please briefly explain what makes this sentence unreasonable or humorous within three sentences.
>
> {sentence}
>
> Task 3(a)
**6. Bottom-Center-Left Box (Blue, Task 3(b) - Chinese)**
* **Text (Chinese):**
> 请你在三句话以内简要地回答下面的问题:
>
> {sentence}
>
> Task 3(b)
* **English Translation:**
> Please briefly answer the following questions within three sentences:
>
> {sentence}
>
> Task 3(b)
**7. Bottom-Center-Right Box (Blue, Task 3(a) - English)**
* **Text (English):**
> Input the following sentence to you, which contains some irrationality or humor. Please briefly explain what makes this sentence unreasonable or humorous within three sentences.
>
> {sentence}
>
> Task 3(a)
**8. Bottom-Right Box (Blue, Task 3(b) - English)**
* **Text (English):**
> Please briefly answer the following questions within three sentences:
>
> {sentence}
>
> Task 3(b)
### Key Observations
1. **Parallel Structure:** The grid presents a direct parallel between Chinese and English versions of the same tasks. Task 1 (orange) and Task 2 (purple) are mirrored in the top row. Task 3 (blue) is split into two sub-tasks (a and b) in the bottom row, also mirrored.
2. **Task Differentiation:**
* **Task 1:** A multiple-choice task with fixed options (A, B, C, D).
* **Task 2:** A classification task with a dynamic set of candidate types (`{candidates}`).
* **Task 3(a):** A generative/explanatory task requiring a brief explanation (max 3 sentences) of the irrationality/humor.
* **Task 3(b):** A generative/answering task requiring a brief answer (max 3 sentences) to a question posed within the `{sentence}`.
3. **Placeholders:** All tasks use curly-brace placeholders (`{sentence}`, `{options}`, `{candidates}`) indicating where dynamic input content would be inserted.
4. **Constraint Emphasis:** Tasks 1 and 2 strongly emphasize output constraints: "directly output," "without any explanation," and strict adherence to the answer format (specific letters or candidate types). Task 3 emphasizes a length constraint ("within three sentences").
5. **Color as Identifier:** Color is used consistently to group task types across languages (Orange=Task1, Purple=Task2, Blue=Task3).
### Interpretation
This diagram serves as a **specification sheet for a benchmark or evaluation suite** designed to test an AI system's (or human's) ability to understand and categorize non-literal, humorous, or illogical language.
* **Purpose:** The structured tasks suggest a methodology for quantitatively and qualitatively assessing language model performance on pragmatic understanding, specifically targeting the nuanced domains of humor and logical inconsistency.
* **Relationships:** The tasks form a progression or complementary set. Tasks 1 and 2 are **classification/selection** tasks, suitable for automated scoring. Task 3 is a **generation/explanation** task, requiring more complex language production and likely needing human or advanced model evaluation. The split between 3(a) and 3(b) distinguishes between *explaining* the humor/irrationality and *answering* a question that may be inherently humorous or irrational.
* **Underlying Need:** The existence of both Chinese and English versions indicates an intent for **cross-lingual evaluation**, ensuring the assessment isn't biased towards a single language's cultural or linguistic nuances of humor.
* **Notable Design Choice:** The strict output constraints in Tasks 1 and 2 are typical for creating clean, machine-readable evaluation data, minimizing the noise from explanatory text. This contrasts with the open-ended but length-constrained nature of Task 3, which captures a different dimension of understanding.
In essence, this image outlines a framework for probing how well an intelligence can navigate the gap between literal meaning and intended, often playful or absurd, meaning in human communication.
</details>
Figure 4: Our designed prompts without the Chain-of-Thought idea. Task 3(a) is for the texts that are not expressed in the form of inquiries. Task 3(b) is for inquiries.
<details>
<summary>x6.png Details</summary>

### Visual Description
## Diagram: Task Instruction Templates for Analyzing Irrationality or Humor
### Overview
The image displays a structured grid of eight colored text boxes, each containing instructions for a specific task. The tasks involve analyzing a given sentence or question that contains irrationality or humor. The boxes are arranged in two rows of four. The top row contains four boxes (two orange, two purple) detailing "Task 1" and "Task 2" with multiple-choice formats. The bottom row contains four blue boxes detailing "Task 3(a)" and "Task 3(b)" with a step-by-step reasoning format. The instructions are presented bilingually, with the left half of the image in Chinese and the right half providing direct English translations of the same instructions.
### Components/Axes
The image is a diagram, not a chart. Its components are the eight instruction boxes.
* **Layout**: 2 rows x 4 columns grid.
* **Color Coding**:
* Top Row, Column 1: Orange box (Chinese, Task 1)
* Top Row, Column 2: Purple box (Chinese, Task 2)
* Top Row, Column 3: Orange box (English, Task 1)
* Top Row, Column 4: Purple box (English, Task 2)
* Bottom Row, Columns 1-4: All Blue boxes. Columns 1 & 3 are Task 3(a), Columns 2 & 4 are Task 3(b). Left two are Chinese, right two are English.
* **Text Language**: The left two columns contain instructions in **Chinese**. The right two columns contain the corresponding **English** translations.
### Detailed Analysis
**Top Row - Task 1 (Multiple-Choice Selection)**
* **Position**: Top-left (Chinese) and Top-center-right (English).
* **Color**: Orange.
* **Task Label**: "Task 1".
* **Content (Chinese Transcription)**:
> 给你输入一个句子或问题,其中存在不合理或幽默之处。另外给出四个选项,你需要选出最能准确描述给定句子或问题的不合理或幽默之处的一个选项,并说明选择该选项的理由。
> 你的输出必须严格遵循以下格式:
> 分析:<简要地分析四个选项中哪一个准确描述给定句子或问题的不合理或幽默之处,说明选择该项的理由>
> 答案:<只能输出 “A, B, C, D” 中的一个>
> 以下是输入:
> {sentence}
> 选项:
> {options}
* **Content (English Translation - as provided in the image)**:
> Give you a sentence or question that contains some irrationality or humor. Then give you four options, you need to choose the one that best describes the irrationality or humor of the given sentence or question, and give your reasons for choosing that option.
> Your output must strictly follow the following format:
> Analyze: <Briefly analyze which of the four options accurately describes the irrationality or humor of the given sentence or question, and explain why you chose that option>
> Answer: <Only one of “A, B, C, D” can be output>
> The following is the input:
> {sentence}
> Options:
> {options}
**Top Row - Task 2 (Categorization)**
* **Position**: Top-center-left (Chinese) and Top-right (English).
* **Color**: Purple.
* **Task Label**: "Task 2".
* **Content (Chinese Transcription)**:
> 给你输入一个句子或问题,其中存在不合理或幽默之处。你需要用一句话解释其中的不合理或幽默之处,然后从“候选分类”中选出一个最适合该句子或问题的类别,并说明理由。
> 候选分类:{candidates}
> 你的输出必须严格遵循以下格式:
> 解释:<用一句话解释输入句子或问题的不合理或幽默之处>
> 理由:<解释符合“候选分类”中某一类别的理由>
> 分类:<从“候选分类”中选出的类别>
> 以下是输入:
> {sentence}
* **Content (English Translation - as provided in the image)**:
> Give you a sentence or question that contains some irrationality or humor. You need to explain what is unreasonable or humorous in one sentence, and then choose a type from the “candidate types” that best fits the sentence or question and explain why.
> Candidate types: {candidates}
> Your output must strictly follow the following format:
> Explain: <Explain what is unreasonable or humorous in one sentence>
> Reason: <Explain the reason for choosing the type from “candidate types”>
> Type: <The type selected from “candidate types”>
> The following is the input:
> {sentence}
**Bottom Row - Task 3(a) (Step-by-Step Reasoning with Brief Explanation)**
* **Position**: Bottom-left (Chinese) and Bottom-center-right (English).
* **Color**: Blue.
* **Task Label**: "Task 3(a)".
* **Content (Chinese Transcription)**:
> 给你输入以下的句子,其中存在不合理或幽默之处。请一步一步地思考和推理该句子的不合理或幽默指出,给出你的分析过程,最后给出三句话以内的简要解释。
> {sentence}
* **Content (English Translation - as provided in the image)**:
> Input the following sentence to you, which contains some irrationality or humor. Please think and reason step by step to point out the unreasonableness or humor of the sentence, give your analysis process, and finally give a brief explanation within three sentences.
> {sentence}
**Bottom Row - Task 3(b) (Step-by-Step Reasoning with Brief Answer)**
* **Position**: Bottom-center-left (Chinese) and Bottom-right (English).
* **Color**: Blue.
* **Task Label**: "Task 3(b)".
* **Content (Chinese Transcription)**:
> 请一步一步地思考和推理下面的问题,给出你的分析过程,最后给出三句话以内的简要答案。
> {sentence}
* **Content (English Translation - as provided in the image)**:
> Please think and reason about the following questions step by step, give your analysis process, and finally give a brief answer within three sentences.
> {sentence}
### Key Observations
1. **Bilingual Presentation**: The diagram is explicitly bilingual. The left half (Columns 1 & 2) presents all instructions in **Chinese**. The right half (Columns 3 & 4) provides direct English translations of the corresponding tasks from the left.
2. **Task Taxonomy**: There are three primary task types:
* **Task 1**: Multiple-choice selection with justification.
* **Task 2**: Open-ended explanation followed by categorization from a provided list.
* **Task 3**: Step-by-step reasoning leading to a brief output. Task 3 is split into two sub-variants: 3(a) asks for a brief *explanation*, while 3(b) asks for a brief *answer*.
3. **Structured Output Format**: Each task mandates a strict, labeled output format (e.g., "Analyze:", "Answer:", "Explain:", "Reason:", "Type:").
4. **Input Placeholders**: All tasks use `{sentence}` as a placeholder for the input text. Tasks 1 and 2 also use `{options}` and `{candidates}` respectively for their additional input parameters.
5. **Color-Coded Grouping**: Color is used to group related tasks. Orange for Task 1, purple for Task 2, and blue for all Task 3 variants.
### Interpretation
This image serves as a technical specification or prompt template sheet for a natural language processing (NLP) system or human annotators tasked with analyzing linguistic irrationality or humor. It defines a clear, multi-faceted evaluation framework.
* **Purpose**: The diagram outlines a methodology for dissecting non-literal language. It moves from simple recognition and selection (Task 1) to explanation and classification (Task 2), and finally to deep, transparent reasoning (Task 3). This progression suggests a need to test or implement different levels of analytical depth.
* **Relationship Between Elements**: The tasks are complementary. Task 1 tests discriminative ability among predefined descriptions. Task 2 tests generative explanation and taxonomic understanding. Task 3 tests the reasoning chain itself, prioritizing process over a specific output format. The bilingual nature indicates the framework is designed for a cross-lingual context or for validation across language speakers.
* **Notable Design Choices**: The strict output formatting is critical for automated processing or consistent human evaluation. The separation of Task 3 into (a) and (b) highlights a nuanced distinction between providing an explanatory summary versus a concise answer, both derived from the same reasoning process. The use of placeholders (`{sentence}`, etc.) confirms these are templates meant to be populated with specific test cases.
</details>
Figure 5: Our designed prompts with the Chain-of-Thought idea. Task 3(a) is for the texts that are not expressed in the form of inquiries. Task 3(b) is for inquiries.
<details>
<summary>x7.png Details</summary>

### Visual Description
## Screenshot: AI Response Evaluation Template
### Overview
The image displays a structured text template or instruction set for evaluating the quality of an AI assistant's response. It is a monospaced, text-based document with clear section headers and placeholders for dynamic content. The document is designed to guide a human or automated evaluator through a standardized comparison between a reference answer and an assistant's answer.
### Components/Axes
The document is organized into distinct, bordered sections with the following labels and content:
1. **[Instruction]**: The top section containing the core evaluation directive.
* **Text**: "Please act as an impartial judge and evaluate the quality of the response provided by an AI assistant to the user question displayed below. Your evaluation should consider correctness and helpfulness. You will be given a reference answer and the assistant's answer. Begin your evaluation by comparing the assistant's answer with the reference answer. Identify and correct any mistakes. Be as objective as possible. After providing your explanation, you must rate the response on a scale of 1 to 10 by strictly following this format: \"[[rating]]\", for example: \"Rating: [[5]]\"."
2. **[Question]**: A section header for the user's original query.
* **Placeholder**: `{question}`
3. **[The Start of Reference Answer]**: A section header marking the beginning of the correct or expected answer.
* **Placeholder**: `{answer}`
* **Closing Header**: `[The End of Reference Answer]`
4. **[The Start of Assistant's Answer]**: A section header marking the beginning of the AI-generated response to be evaluated.
* **Placeholder**: `{response}`
* **Closing Header**: `[The End of Assistant's Answer]`
### Detailed Analysis
* **Structure**: The template uses a clear, hierarchical structure with square-bracketed headers to define sections. Placeholders in curly braces (`{question}`, `{answer}`, `{response}`) indicate where variable text should be inserted.
* **Language**: The entire document is in English.
* **Formatting**: The text is presented in a monospaced font, resembling code or a formal template. Sections are visually separated by horizontal lines and blank lines.
* **Key Instruction**: The evaluator is mandated to provide an explanation of their comparison before giving a final numerical rating. The rating format is explicitly defined as `"Rating: [[n]]"` where `n` is a number from 1 to 10.
### Key Observations
* The template is designed for **objective, comparative evaluation**, focusing on "correctness and helpfulness."
* It enforces a **structured workflow**: compare, explain, then rate.
* The use of **placeholders** makes this a reusable framework for any question-answer pair.
* The **rating scale** (1-10) and its specific formatting are critical components of the output.
### Interpretation
This image is not a chart or diagram containing data, but a **meta-document**—a tool for creating consistent evaluations. Its purpose is to standardize the assessment of AI outputs, reducing subjectivity by requiring a direct comparison to a reference and a written justification before scoring. The design prioritizes clarity and repeatability, making it suitable for benchmarking, quality assurance, or research contexts where consistent evaluation of AI assistants is necessary. The presence of placeholders indicates this is a template to be populated with specific instances for evaluation.
</details>
Figure 6: The designed prompt of automatic evaluation for Task 3.
## Appendix A Our Designed Prompts for FLUB
Our designed prompts without Chain-of-Thought for FLUB are shown in Figure 4. And the Chain-of-Thought prompts for Task 1 and Task 2 are presented in Figure 5. For the convenience of reading, we provide both prompts and their English translations. Note that we use Chinese prompts in specific experiments because our data samples are in Chinese.
## Appendix B Automatic Evaluation Prompt in Task 3
To enable GPT-4 can automatically score explanations generated by other LLMs according to the settings of Task 3, we carefully design the corresponding prompt, as shown in Figure 6.
## Appendix C Scoring Guidelines in Task 3
Scoring Objective
For the LLMs’ output response to each input cunning text, please refer to the given annotated answer to score the output response. This score will be used to measure the quality of the model response and the degree of matching with the answer.
Scoring Rules
The scoring values are defined as {1, 2, 3, 4, 5}. The higher the score, the higher the quality of the model output. The specific definitions and examples of each score are as follows:
### C.1 Definition and Examples of Score 1
Definition
The LLM’s response doesn’t point out the irrationality or humor in the given text, which is completely unrelated to the correct answer.
#### C.1.1 The First Example of Score 1
Input Text:
Since instant noodles can be eaten dry, then dry crispy noodles can also be boiled? (UTF8gbsn既然方便面可以干吃,那干脆面也可以水煮?)
Model Response:
Yes, dry crispy noodles can also be boiled. Boil in boiling water until softened and serve. (UTF8gbsn是的,干脆面也可以水煮。将其放入沸水中煮至软化即可食用。)
Correct Answer:
Dry crispy noodles are crispy and delicious ready-to-eat snack food. You can eat them as soon as you open the package. What people need is its crispness. So its taste will be lost after being boiled. Therefore, crispy noodles cannot be boiled. (UTF8gbsn干脆面是一种香脆可口的即食型休闲食品,打开包装就可以吃,吃的就是它的香脆,水煮之后会失去它的口感。所以干脆面不可以水煮。)
#### C.1.2 The Second Example of Score 1
Input Text:
To say that Ruozhi Bar is all a bunch of retards is that considered a compliment or an insult? (UTF8gbsn说弱智吧都是一帮弱智,算夸奖还是辱骂?)
Model Response:
This sentence is insulting because it uses the derogatory term “retarded” to describe a group of people and expresses contempt and insult to them. (UTF8gbsn这句话是辱骂,因为它使用贬义词汇“弱智”来形容一群人,表达了对他们的轻视和侮辱。)
Correct Answer:
“Ruozhi Bar” is the name of the post bar, and the IQ of the members inside has nothing to do with what the post bar name is. “Retarded” means intelligence below the normal level, and to say ‘Ruozhi Bar” is a bunch of retarded is an insult. (UTF8gbsn“弱智吧”是贴吧名,里面成员的智商与贴吧名是什么无关。“弱智”的意思是智力低于正常水平,说弱智吧都是一帮弱智是一种辱骂。)
### C.2 Definition and Examples of Score 2
Definition
Although LLM’s response points out the unreasonable/humorous points in the given text, the types and key points pointed out are inconsistent with the opinions of explanations.
#### C.2.1 The First Example of Score 2
Input Text:
Dreams are all reversed. I dream of myself looking in the mirror, so I am the one in the mirror. (UTF8gbsn梦都是反的,我梦到自己照镜子,所以我才是镜子里的人。)
Model Response:
The humor of this sentence lies in the literal interpretation of the saying “Dreams are all reversed”. Usually, people think that the scene in a dream is the opposite of reality, but in this sentence, the author dreams of himself looking in the mirror, if we understand that “Dreams are all reversed”, then the author is actually a reflection in the mirror, which is obviously an absurd interpretation of reality, and therefore has a sense of humor. (UTF8gbsn这个句子的幽默之处在于对“梦都是反的”这一说法的字面解释。通常,人们认为梦中的情景与现实相反,但在这个句子中,作者梦到自己照镜子,如果按照“梦都是反的”来理解,那么作者实际上是镜子里的倒影,这显然是对现实的荒诞解释,因此具有幽默感。)
Correct Answer:
“Dreams are all reversed” means that the dream is opposite to reality. If “I dream of myself looking in the mirror” is contrary to reality, the reality should be “I do not look in the mirror in reality”, rather than “I dream of myself looking in the mirror, and I am the person in the mirror”. (UTF8gbsn“梦都是反的”是指梦境与现实是相反的,“我梦到自己照镜子”与现实相反,应该是“现实中没有照镜子”,而不是“我梦到自己照镜子,反过来我是镜中人”。)
#### C.2.2 The Second Example of Score 2
Input Text:
If all three of Nezha’s heads suffered from cerebral thrombosis for ten years, did he have cerebral thrombosis for ten years or thirty years? (UTF8gbsn哪吒三头都得了十年脑血栓那是算十年脑血栓还是三十年脑血栓?)
Model Response:
Nezha is a fictional character in Chinese mythology that does not exist. Cerebral thrombosis is a cerebrovascular disease, usually caused by blood clotting in the blood vessels of the brain resulting in brain hypoxia and ischemia. Therefore, the claim that Nezha’s three heads have cerebral thrombosis is not realistic, let alone calculate whether it is ten years or thirty years. (UTF8gbsn哪吒是中国神话中的虚构人物,没有真实存在。脑血栓是一种脑血管疾病,通常是由于脑部血管内的血液凝固形成的血栓导致脑部缺氧缺血。因此,哪吒三头得脑血栓的说法是不符合实际的,更不用计算是十年还是三十年。)
Correct Answer:
Nezha is an individual, assuming Nezha’s three heads all have cerebral thrombosis, it should be something that happens at the same time, and will not produce accumulation, so it should not be 30 years. (UTF8gbsn哪吒是一个个体,假设哪吒的三个头都得了脑血栓,那应该是同时发生的事情,并不会产生累加,所以不应该是三十年。)
### C.3 Definition and Examples of Score 3
Definition
The LLM’s response correctly points out the type of irrationality/humor, but the key points of irrationality/humor pointed out by the correct answer are inconsistent. Alternatively, the response is consistent with the key points of irrationality/humor pointed out by the correct answer, but the judgment on the type of cunning text is inconsistent.
#### C.3.1 The First Example of Score 3
Input Text:
The drug is partially poisonous with side effects, so we should not take the drug in parts. (UTF8gbsn是药三分毒,所以药不能分三次喝。)
Model Response:
The humor of this sentence lies in the misunderstanding of the literal and actual meaning of the idiom “The drug is partially poisonous with side effects”. This idiom is meant to say that any drug has potential side effects, while the sentence misunderstands “partially” to mean that the drug should not be taken in parts, and thus draws the absurd conclusion that the drug cannot be taken in three separate doses, which is obviously a comical distortion of the original meaning. (UTF8gbsn这句子的幽默之处在于对成语“是药三分毒”的字面意思和实际含义的误解。成语本意是说任何药物都有潜在的副作用,而句子却把“三分”误解为药物应该分成三个部分服用,因此得出了一个荒谬的结论,即药物不能按照三次分开服用,这显然是对原意的一种滑稽曲解。)
Correct Answer:
“The drug is partially poisonous with side effects” refers to any drug will have certain side effects if used improperly. “Partially” indicates that to a certain extent, there is no meaning of “in parts”. Therefore, the conclusion “we should not take the drug in parts” cannot be drawn from this sentence. (UTF8gbsn“是药三分毒”指的是任何的药品如果使用不当的话都会存在一定的副作用,“三分”表示的是在一定程度上,并没有分三次的意思,所以“是药三分毒”这句话并不能得出”药不能分三次喝“这一结论。)
#### C.3.2 The Second Example of Score 3
Input Text:
Did a knee-jerk reflex test on a friend, and the result was that his leg never lifted again after the hammer was knocked down. This reflex arc is too long! (UTF8gbsn给朋友做膝跳测试,结果锤下去之后他的腿再也没抬起过,这反射弧也太长了吧!)
Model Response:
The knee-jerk reflex test is a simple test to check the function of the nervous system. Normally, a light tap on the tendon below the knee will cause the leg to make a quick leg lift motion. This sentence humorously exaggerates the amount of time the friend does not respond, indicating that the reflex arc is unusually long, when in fact, if there is really no response, it may indicate a neurological problem rather than the reflex arc length. In addition, using “never lifted again” has a more humorous effect because it indicates a permanent state, which is impossible in reality. (UTF8gbsn膝跳反射测试是一种检查神经系统功能的简单测试,正常情况,轻轻敲击膝盖下方的腱会导致腿部做出快速的抬腿动作。这句话幽默地夸张了朋友没有反应的时间,暗示反射弧异常地长,实际上如果真的没有反应,那可能表明存在神经系统问题,而不是反射弧长。此外,用“再也没抬起过”增加了幽默效果,因为它暗示了一种永久性的状态,这在现实中是不可能的。)
Correct Answer:
“His leg never lifted again after the hammer” indicates that the friend’s leg was broken, and is not related to the length of the reflex arc, here is actually a humorous way to express the matter of “breaking the friend’s leg”. (UTF8gbsn“锤下去之后他的腿再也没抬起过”说明把朋友的腿打断了,与反射弧长短没有关系,这里实际上是用幽默的方式将“把朋友腿打断”表达出来。)
### C.4 Definition and Examples of Score 4
Definition
The response correctly points out the type of irrationality/humor in the input text, and the key points pointed out are correct, but the interpretation is not consistent with the correct answer.
#### C.4.1 The First Example of Score 4
Input Text:
In a vegetable market, one finds vegetative persons instead. So it must have been a job market before. (UTF8gbsn去素材库发现几个植物人躺在里面,原来之前这里是人材市场。)
Model Response:
The humor of this sentence lies in the pun on the word “vegetative”. Usually, “vegetative” refers to patients who have fallen into a persistent vegetative state due to a major illness or injury, but here it is used to refer to “vegetable” in the literal sense, i.e., real plants. At the same time, “job market” usually refers to a market for hiring “people” with the appropriate skill, but here it is used teasingly to refer to a market with vegetative “people”. This linguistic coincidence creates an absurd humorous effect. (UTF8gbsn这个句子的幽默之处在于使用了“植物人”这个词语的双关意味。通常,“植物人”指的是那些因为重大疾病或伤害而陷入持续植物状态的病人,但在这里它被用来指代字面意义上的“植物”,即真正的植物。同时,“人材市场”通常是指招聘人才的市场,而在这里它被戏谑地用来指一个植物市场,这种语言上的巧合创造了一种荒谬的幽默效果。)
Correct Answer:
The vegetable market refers to the market where vegetables are sold. “Vegetative” is a special human state similar to the living state of plants, and the human body cannot lie in the vegetable market. (UTF8gbsn素材库是指销售蔬菜的市场。“植物人”是与植物生存状态相似的特殊的人体状态,人体是无法躺进素材库中的。)
#### C.4.2 The Second Example of Score 4
Input Text:
If you drink 82 Lafite, then you’ll live at least 82 years. (UTF8gbsn喝了82年拉菲至少能活82岁。)
Model Response:
The humor or irrationality of the sentence is that it establishes a false cause-and-effect relationship, implying that drinking a certain vintage of wine guarantees living to the same age as the vintage, which obviously has no scientific basis. In fact, a person’s lifespan is affected by many factors, including genetics, lifestyle, medical conditions, and so on, rather than a single diet. In addition, this statement also carries a kind of humorous exaggeration, because it uses an absurd logic to attract attention and increase the interest of the words. (UTF8gbsn该句子的幽默或不合理之处在于它建立了一种错误的因果关系,暗示喝了某年份的葡萄酒能保证活到与年份相同的年龄,这显然没有科学依据。实际上,人的寿命受多种因素影响,包括遗传、生活方式、医疗条件等,而非单一的饮食习惯。此外,这种说法也带有一种幽默的夸张,因为它用一种荒谬的逻辑来吸引注意,增加话语的趣味性。)
Correct Answer:
“82 Lafite” is a network buzzword that originated from scenes of opening Lafite wine in movies and TV series. Since the Lafite red wine produced in 1982 is of good quality and expensive, “82 Lafite” is synonymous with high standards to set off the character’s extravagant spending and taste, rather than “Lafite has been drunk for 82 years”. (UTF8gbsn82年的拉菲,网络流行语,源自影视剧中开拉菲的桥段,由于82年的拉菲红酒品质好、价格昂贵,所以“82年的拉菲”是高规格的代名词,来衬托人物的挥金如土和品味,而不是“喝了八十二年的拉菲”的意思。)
### C.5 Definition and Examples of Score 5
Definition
The LLM’s response and the correct explanation are basically matched, the response correctly points out the type of unreasonable/humorous points in the input text, the key points are correct, and the explanation is basically consistent with the explanation.
#### C.5.1 The First Example of Score 5
Input Text:
If a police officer commits a crime and turns himself in, is it considered to have made meritorious contributions? (UTF8gbsn警察犯了事去自首算不算戴罪立功啊?)
Model Response:
“Meritorious service” usually refers to the behavior of criminals who actively cooperate with the police to detect other cases or fight criminal activities after committing a crime, so as to reduce their own punishment. If the police officer has committed a crime and turned himself in, and there is no further meritorious service, then this can usually only be counted as surrender, and cannot be directly referred to as meritorious service. However, surrendering may lead to reduced punishment according to relevant legal provisions. (UTF8gbsn"戴罪立功"通常指的是犯罪分子在犯罪后,积极配合警方侦破其他案件或对抗犯罪活动,从而争取减轻自己刑罚的行为。如果警察犯了罪后去自首,并且没有进一步的立功表现,那么这通常只能算作自首,并不能直接称为戴罪立功。不过,自首可能会根据相关法律规定减轻处罚。)
Correct Answer:
According to the provisions of Article 67 of the Criminal Law, “Surrender” refers to the act of automatically surrendering to the police after committing a crime and truthfully confessing one’s crime. If a criminal suspect or defendant under compulsory measures or a criminal serving a sentence truthfully confesses other crimes that are not yet known to the judicial organs, he shall be regarded as surrendering. “Meritorious service” means that the meritorious service performance in criminal law refers to the performance of criminal suspects providing important clues, exposing others’ crimes, etc., and can be mitigated after verification. Surrender confession by oneself is one’s own crime, while meritorious service is to expose the crime of others, so the police committing the crime to surrender is not regarded as meritorious service. (UTF8gbsn根据刑法第67条的规定,“自首”是指犯罪以后自动投案,如实供述自己的罪行的行为。被采取强制措施的犯罪嫌疑人、被告人和正在服刑的罪犯,如实供述司法机关还未掌握的本人其他罪行的,以自首论。“戴罪立功”就是指刑法中的立功表现是指犯罪嫌疑人提供重要线索、揭发他人犯罪行等的表现,经查实的可以获得减轻处罚。自首供述的是本人的罪行,戴罪立功是揭发他人罪行,所以条子犯了事去自首不算戴罪立功。)
#### C.5.2 The Second Example of Score 5
Input Text:
Officer Wang shot the hostage and saved the robber who could have been killed at any time. (UTF8gbsn王警官击毙人质,解救了随时可能被狙杀的劫匪。)
Model Response:
The unreasonableness of this sentence lies in the fact that Officer Wang’s actions are contrary to the duties of ordinary police officers. Usually, the task of the police is to protect the hostages and try to arrest the criminals, not to kill the hostages to protect the criminals. Thus, the sentence reverses the duties of the police with an absurd logic that produces a humorous effect. (UTF8gbsn这句子的不合理之处在于王警官的行动与一般警察的职责相反。通常情况下,警察的任务是保护人质并尽量逮捕犯罪分子,而不是击毙人质来保护犯罪分子。因此,这个句子以一种荒谬的逻辑颠倒了警察的职责,产生了幽默效果。)
Correct Answer:
As a police officer, what Wang should do is shoot the robber to save the hostage, not shoot the hostage to save the robber. The fact that Wang killed the hostage by mistake is described humorously. (UTF8gbsn王警官作为警察,应该做的是击毙劫匪解救人质,而不是击毙人质解救劫匪,这里用幽默的方式阐述了王警官误杀人质这一事实。)
## Appendix D Datasheet For FLUB
### D.1 Motivation
1. For what purpose was the dataset created? Was there a specific task in mind? Was there a specific gap that needed to be filled? Please provide a description.
- In this work, we aim to challenge the reasoning and understanding abilities of LLMs by proposing the FLUB containing cunning texts that are easy for humans to understand but difficult for models to grasp. Specifically, we design three tasks with increasing difficulty to test whether the LLMs can understand the fallacy and solve the “cunning” texts: Answer Selection, (2) Cunning Type Classification, (3) Fallacy Explanation. We hope and believe that our proposed FLUB and all our findings are crucial for LLMs to comprehend the fallacy and handle cunning texts in the real world.
1. Who created the dataset (e.g., which team, research group) and on behalf of which entity (e.g., company, institution, organization)?
- The dataset is presented by Tsinghua Knowledge Engineering Laboratory (SZ).
1. Who funded the creation of the dataset? If there is an associated grant, please provide the name of the grantor and the grant name and number.
- This work is sponsored by NSFC, Guangdong Province, Shenzhen City, Peng Cheng Laboratory, and Tsinghua Univerisity.
1. Any other comments?
- No.
### D.2 Composition
1. What do the instances that comprise the dataset represent (e.g., documents, photos, people, countries)? Are there multiple types of instances (e.g., movies, users, and ratings; people and interactions between them; nodes and edges)? Please provide a description.
- All the instances in FLUB are represented by texts. We make our benchmark openly available on the GitHub page (https://github.com/THUKElab/FLUB).
1. How many instances are there in total (of each type, if appropriate)?
- FLUB includes 834 instances. For fine-grained cunning types, “False Analogy” has 11 instances, “Lame Jokes” has 44 instances, “Phonetic Error” has 5 instances, “Ambiguity” has 35 instances, “Paradox” has 29 instances, “Factual Error” has 12 instances, “Reasoning Error” has 445 instances, “Word Game” has 239 instances, and “Undefined” has 14 instances.
1. Does the dataset contain all possible instances or is it a sample (not necessarily random) of instances from a larger set? If the dataset is a sample, then what is the larger set? Is the sample representative of the larger set (e.g., geographic coverage)? If so, please describe how this representativeness was validated/verified. If it is not representative of the larger set, please describe why not (e.g., to cover a more diverse range of instances, because instances were withheld or unavailable).
- FLUB has contained all possible instances, because we have tried our best to collect as much data as possible from “Ruozhiba” and conducted strict manual annotation.
1. What data does each instance consist of? “Raw” data (e.g., unprocessed text or images) or features? In either case, please provide a description.
- Each instance consists of the input cunning text, cunning type, fallacy explanation, candidate answers, and the corresponding correct option, as illustrated in Figure 1(b).
1. Is there a label or target associated with each instance? If so, please provide a description.
- There is a cunning type for each instance, which describes the cunning type of each input text.
1. Is any information missing from individual instances? If so, please provide a description, explaining why this information is missing (e.g., because it was unavailable). This does not include intentionally removed information, but might include, e.g., redacted text.
- No.
1. Are relationships between individual instances made explicit (e.g., users’ movie ratings, social network links)? If so, please describe how these relationships are made explicit.
- Not applicable.
1. Are there recommended data splits (e.g., training, development/validation, testing)? If so, please provide a description of these splits, explaining the rationale behind them.
- No, because FLUB is a benchmark test set, all its instances are used for testing LLMs, regardless of training/validation.
1. Are there any errors, sources of noise, or redundancies in the dataset? If so, please provide a description.
- No.
1. Is the dataset self-contained, or does it link to or otherwise rely on external resources (e.g., websites, tweets, other datasets)? If it links to or relies on external resources, a) are there guarantees that they will exist, and remain constant, over time; b) are there official archival versions of the complete dataset (i.e., including the external resources as they existed at the time the dataset was created); c) are there any restrictions (e.g., licenses, fees) associated with any of the external resources that might apply to a dataset consumer? Please provide descriptions of all external resources and any restrictions associated with them, as well as links or other access points, as appropriate.
- FLUB is self-contained.
1. Does the dataset contain data that might be considered confidential (e.g., data that is protected by legal privilege or by doctor–patient confidentiality, data that includes the content of individuals’ non-public communications)? If so, please provide a description.
- No.
1. Does the dataset contain data that, if viewed directly, might be offensive, insulting, threatening, or might otherwise cause anxiety? If so, please describe why.
- No. We have conducted a strict data cleaning process to ensure that FLUB does not contain unethical data.
1. Does the dataset identify any subpopulations (e.g., by age, gender)? If so, please describe how these subpopulations are identified and provide a description of their respective distributions within the dataset.
- No.
1. Is it possible to identify individuals (i.e., one or more natural persons), either directly or indirectly (i.e., in combination with other data) from the dataset? If so, please describe how.
- No.
1. Does the dataset contain data that might be considered sensitive in any way (e.g., data that reveals race or ethnic origins, sexual orientations, religious beliefs, political opinions or union memberships, or locations; financial or health data; biometric or genetic data; forms of government identification, such as social security numbers; criminal history)? If so, please provide a description.
- No.
1. Any other comments?
- No.
### D.3 Collection Process
1. How was the data associated with each instance acquired? Was the data directly observable (e.g., raw text, movie ratings), reported by subjects (e.g., survey responses), or indirectly inferred/derived from other data (e.g., part-of-speech tags, model-based guesses for age or language)? If the data was reported by subjects or indirectly inferred/derived from other data, was the data validated/verified? If so, please describe how.
- We collect raw text data from “Ruozhiba” in Baidu Tieba, as described in Section 2.1. The data is directly observable at https://github.com/THUKElab/FLUB.
1. What mechanisms or procedures were used to collect the data (e.g., hardware apparatuses or sensors, manual human curation, software programs, software APIs)? How were these mechanisms or procedures validated?
- We use web crawlers to automatically crawl the raw data, and we perform manual filtering and filtering to validate the crawled data, as described in Section 2.1.
1. If the dataset is a sample from a larger set, what was the sampling strategy (e.g., deterministic, probabilistic with specific sampling probabilities)?
- Not applicable.
1. Who was involved in the data collection process (e.g., students, crowdworkers, contractors) and how were they compensated (e.g., how much were crowdworkers paid)?
- We hired crowdworkers to clean the raw data and paid each person $0.50 per piece of raw data.
1. Over what timeframe was the data collected? Does this timeframe match the creation timeframe of the data associated with the instances (e.g., recent crawl of old news articles)? If not, please describe the timeframe in which the data associated with the instances was created.
- The raw data of FLUB was collected in in October 2023. The task characteristics of FLUB are not time-sensitive, so the collection time is not associated with the data instances.
1. Were any ethical review processes conducted (e.g., by an institutional review board)? If so, please provide a description of these review processes, including the outcomes, as well as a link or other access point to any supporting documentation.
- Not applicable. Our data collection process does not involve human or animal experiments. In addition, according to the Baidu Bar agreement, the data on Baidu Tieba can be used for academic research free of charge and without liability. Therefore, our data collection process does not require the involvement of an ethical review board.
1. Did you collect the data from the individuals in question directly, or obtain it via third parties or other sources (e.g., websites)?
- We collect raw text data from “Ruozhiba” in Baidu Tieba, as described in Section 2.1.
1. Were the individuals in question notified about the data collection? If so, please describe (or show with screenshots or other information) how notice was provided, and provide a link or other access point to, or otherwise reproduce, the exact language of the notification itself.
- Not applicable. According to the Baidu Bar agreement, the data on Baidu Tieba can be used for academic research free of charge and without liability.
1. Did the individuals in question consent to the collection and use of their data? If so, please describe (or show with screenshots or other information) how consent was requested and provided, and provide a link or other access point to, or otherwise reproduce, the exact language to which the individuals consented.
- Yes. According to the Baidu Bar agreement, the data on Baidu Tieba can be used for academic research free of charge and without liability.
1. If consent was obtained, were the consenting individuals provided with a mechanism to revoke their consent in the future or for certain uses? If so, please provide a description, as well as a link or other access point to the mechanism (if appropriate).
- Not applicable.
1. Has an analysis of the potential impact of the dataset and its use on data subjects (e.g., a data protection impact analysis) been conducted? If so, please provide a description of this analysis, including the outcomes, as well as a link or other access point to any supporting documentation.
- Yes. The cunning texts we are concerned about come from daily life and are very common. Therefore, the new research direction and tasks we propose will not cause harm to human society.
1. Any other comments?
- No.
### D.4 Preprocessing/cleaning/labeling
1. Was any preprocessing/cleaning/labeling of the data done (e.g., discretization or bucketing, tokenization, part-of-speech tagging, SIFT feature extraction, removal of instances, processing of missing values)? If so, please provide a description. If not, you may skip the remaining questions in this section.
- Yes. We employ annotators to manually filter out irrelevant posts that do not present cunning texts. Since the collected original posts contain irrelevant content such as links and images, we also require annotators to extract the fallacious and illogical contents from the raw post and rewrite them into a complete sentence. Besides, it is worth noting that we carefully ensure that the texts in FLUB are ethical texts. This process includes user information anonymization, sensitive information removal, and filtering of impolite posts.
1. Was the “raw” data saved in addition to the preprocessed/cleaned/labeled data (e.g., to support unanticipated future uses)? If so, please provide a link or other access point to the “raw” data.
- No.
1. Is the software that was used to preprocess/clean/label the data available? If so, please provide a link or other access point.
- No.
1. Any other comments?
- No.
### D.5 Uses
1. Has the dataset been used for any tasks already? If so, please provide a description.
- No.
1. Is there a repository that links to any or all papers or systems that use the dataset? If so, please provide a link or other access point.
- No.
1. What (other) tasks could the dataset be used for?
- Based on our constructed FLUB and its annotation information, we design three tasks with increasing difficulty to test whether the LLMs can understand the fallacy and solve the “cunning” texts. Specifically, (1) Answer Selection: The model is asked to select the correct one from the four answers provided by FLUB for each input text. (2) Cunning Type Classification: Given a cunning text as input, the model is expected to directly identify its fallacy type defined in our scheme. (3) Fallacy Explanation: We hope the model sees a cunning text and intelligently generates a correct explanation for the fallacy contained in the text, just like humans, without falling into its trap.
1. Is there anything about the composition of the dataset or the way it was collected and preprocessed/cleaned/labeled that might impact future uses? For example, is there anything that a dataset consumer might need to know to avoid uses that could result in unfair treatment of individuals or groups (e.g., stereotyping, quality of service issues) or other risks or harms (e.g., legal risks, financial harms)? If so, please provide a description. Is there anything a dataset consumer could do to mitigate these risks or harms?
- No.
1. Are there tasks for which the dataset should not be used? If so, please provide a description.
- According to the characteristics of the data in FLUB, it is known that in addition to the three benchmark tasks we designed, we think that it may also be suitable for improving the reasoning ability and humor ability of LLMs. Beyond that, FLUB may not be suitable for other tasks.
1. Any other comments?
- No.
### D.6 Distribution
1. Will the dataset be distributed to third parties outside of the entity (e.g., company, institution, organization) on behalf of which the dataset was created? If so, please provide a description.
- Yes, the dataset has been open-source.
1. How will the dataset will be distributed (e.g., tarball on website, API, GitHub)? Does the dataset have a digital object identifier (DOI)?
- The data is available through https://github.com/THUKElab/FLUB.
1. When will the dataset be distributed?
- The dataset has been open-source.
1. Will the dataset be distributed under a copyright or other intellectual property (IP) license, and/or under applicable terms of use (ToU)? If so, please describe this license and/or ToU, and provide a link or other access point to, or otherwise reproduce, any relevant licensing terms or ToU, as well as any fees associated with these restrictions.
- FLUB is published under Creative Commons Attribution 4.0 International (CC BY 4.0), which means everyone can use this dataset for non-commercial research purposes.
1. Have any third parties imposed IP-based or other restrictions on the data associated with the instances? If so, please describe these restrictions, and provide a link or other access point to, or otherwise reproduce, any relevant licensing terms, as well as any fees associated with these restrictions.
- We collect raw text data from “Ruozhiba” in Baidu Tieba. According to the Baidu Bar agreement, the data on Baidu Tieba can be used for academic research free of charge and without liability.
1. Do any export controls or other regulatory restrictions apply to the dataset or to individual instances? If so, please describe these restrictions, and provide a link or other access point to, or otherwise reproduce, any supporting documentation.
- No.
1. Any other comments?
- No.
### D.7 Maintenance
1. Who will be supporting/hosting/maintaining the dataset?
- Tsinghua Knowledge Engineering Laboratory (SZ) will support hosting of the dataset.
1. How can the owner/curator/manager of the dataset be contacted (e.g., email address)?
- The manager of FLUB can be contacted through:
- Email (liyinghu20@mails.tsinghua.edu.cn)
- GitHub issues (https://github.com/THUKElab/FLUB/issues).
1. Is there an erratum? If so, please provide a link or other access point.
- There is no erratum for our first release. Errata will be documented on the dataset website as a future release.
1. Will the dataset be updated (e.g., to correct labeling errors, add new instances, delete instances)? If so, please describe how often, by whom, and how updates will be communicated to dataset consumers (e.g., mailing list, GitHub)?
- Yes. Once any other researchers find that FLUB needs to be updated, we will immediately update it through GitHub.
1. If the dataset relates to people, are there applicable limits on the retention of the data associated with the instances (e.g., were the individuals in question told that their data would be retained for a fixed period of time and then deleted)? If so, please describe these limits and explain how they will be enforced.
- Not applicable.
1. Will older versions of the dataset continue to be supported/hosted/maintained? If so, please describe how. If not, please describe how its obsolescence will be communicated to dataset consumers.
- Yes. We will continue to support FLUB. Once any other researchers find that FLUB needs to be updated, we will immediately update it through GitHub.
1. If others want to extend/augment/build on/contribute to the dataset, is there a mechanism for them to do so? If so, please provide a description. Will these contributions be validated/verified? If so, please describe how. If not, why not? Is there a process for communicating/distributing these contributions to dataset consumers? If so, please provide a description.
- Yes. Once any other researchers find that FLUB needs to be updated, after they contact us via email or GitHub, we will review the data they want to expand. After the new data passes review, we will immediately update it to GitHub.
1. Any other comments?
- No.
## Appendix E Metadata and Data Format of FLUB
### E.1 Croissant Metadata
To provide the key descriptive information of FLUB more clearly and improve the traceability and reproducibility of our data, we also provide the Croissant metadata of FLUB, please refer to the link https://github.com/THUKElab/FLUB/blob/main/FLUB_croissant_metadata.json for details.
### E.2 Data Format
Listing 1: The data format of our FLUB.
⬇
1 {
2 " text ": " The input cunning text ",
3 " is_question ": " Is the input cunning text a question?",
4 " type ": " The cunning type of the input text for the Cunning Type Classification task.",
5 " explanation ": " The correct explanation of the input text for the Fallacy Explanation task.",
6 " id ": " The id of each data sample ",
7 " options ": {
8 " A ": " The candidate answer 1 for the input text (question)",
9 " B ": " The candidate answer 2 for the input text (question)",
10 " C ": " The candidate answer 3 for the input text (question)",
11 " D ": " The candidate answer 4 for the input text (question)"
12 },
13 " answer ": " The correct answer for the Answer Selection (Multiple Choice) task."
14}
## Appendix F Author Statement of FLUB
We, as the authors of the FLUB dataset, hereby declare the following:
1. Responsibility Statement: The creation, organization, and publication of FLUB are entirely our responsibility. We confirm that all data were legally obtained and do not infringe on the intellectual property or other rights of any third party. In the event of any disputes or legal liabilities arising from the use of this dataset, we, as the authors, will assume full responsibility.
1. Data License: This dataset is released under the following license: Creative Commons Attribution 4.0 International (CC BY 4.0). Users must comply with the terms of this license agreement when using this dataset. For detailed license terms, please refer to CC BY 4.0.
1. Data Integrity and Quality: We have made every effort to ensure the integrity and quality of FLUB. However, due to the dataset’s size and complexity, we cannot guarantee it to be completely error-free. If any errors or omissions are discovered, please contact us for corrections and updates.
1. Ethical Statement: We have strictly adhered to relevant ethical guidelines during the data collection and processing stages to ensure that the use of this dataset does not negatively impact or harm any individual or organization.