# GaLore: Memory-Efficient LLM Training by Gradient Low-Rank Projection
**Authors**: Jiawei Zhao, Zhenyu Zhang, Beidi Chen, Zhangyang Wang, Anima Anandkumar, Yuandong Tian
Abstract
Training Large Language Models (LLMs) presents significant memory challenges, predominantly due to the growing size of weights and optimizer states. Common memory-reduction approaches, such as low-rank adaptation (LoRA), add a trainable low-rank matrix to the frozen pre-trained weight in each layer. However, such approaches typically underperform training with full-rank weights in both pre-training and fine-tuning stages since they limit the parameter search to a low-rank subspace and alter the training dynamics, and further, may require full-rank warm start. In this work, we propose Gradient Low-Rank Projection (GaLore), a training strategy that allows full-parameter learning but is more memory-efficient than common low-rank adaptation methods such as LoRA. Our approach reduces memory usage by up to 65.5% in optimizer states while maintaining both efficiency and performance for pre-training on LLaMA 1B and 7B architectures with C4 dataset with up to 19.7B tokens, and on fine-tuning RoBERTa on GLUE tasks. Our 8-bit GaLore further reduces optimizer memory by up to 82.5% and total training memory by 63.3%, compared to a BF16 baseline. Notably, we demonstrate, for the first time, the feasibility of pre-training a 7B model on consumer GPUs with 24GB memory (e.g., NVIDIA RTX 4090) without model parallel, checkpointing, or offloading strategies. Code is provided in the link.
1 Introduction
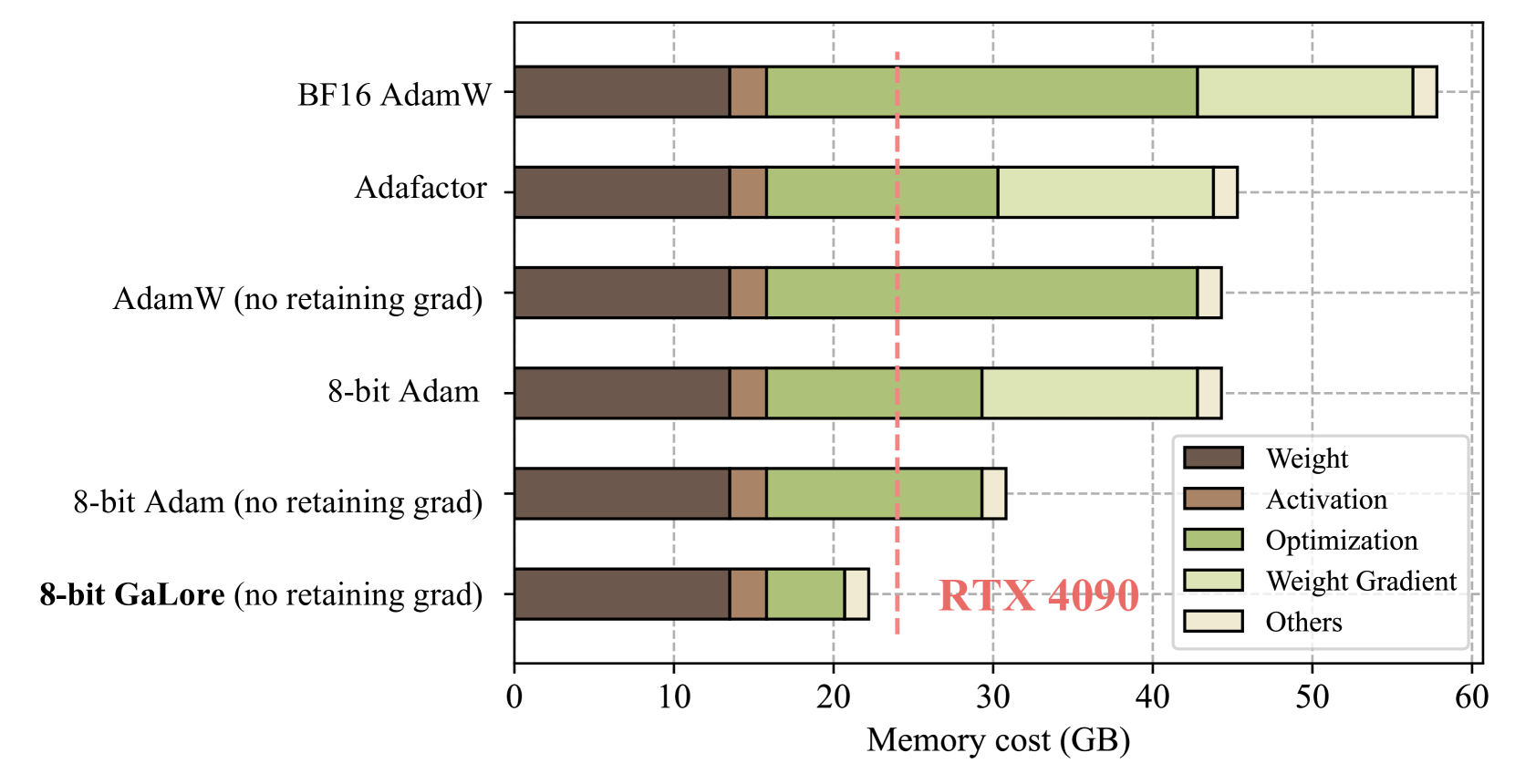
Large Language Models (LLMs) have shown impressive performance across multiple disciplines, including conversational AI and language translation. However, pre-training and fine-tuning LLMs require not only a huge amount of computation but is also memory intensive. The memory requirements include not only billions of trainable parameters, but also their gradients and optimizer states (e.g., gradient momentum and variance in Adam) that can be larger than parameter storage themselves (Raffel et al., 2020; Touvron et al., 2023; Chowdhery et al., 2023). For example, pre-training a LLaMA 7B model from scratch with a single batch size requires at least 58 GB memory (14GB for trainable parameters, 42GB for Adam optimizer states and weight gradients, and 2GB for activations The calculation is based on LLaMA architecture, BF16 numerical format, and maximum sequence length of 2048.). This makes the training not feasible on consumer-level GPUs such as NVIDIA RTX 4090 with 24GB memory.
<details>
<summary>x1.png Details</summary>
### Visual Description
# Technical Document Extraction: Memory Cost Comparison for Optimization Methods
## 1. Image Overview
This image is a horizontal stacked bar chart comparing the memory consumption (in Gigabytes) of six different deep learning optimization configurations. The chart highlights the memory efficiency of "8-bit GaLore" relative to standard optimizers and a specific hardware threshold (NVIDIA RTX 4090).
## 2. Component Isolation
### A. Header / Y-Axis (Optimization Methods)
The Y-axis lists six categories of optimization methods, ordered from highest memory consumption at the top to lowest at the bottom:
1. **BF16 AdamW**
2. **Adafactor**
3. **AdamW (no retaining grad)**
4. **8-bit Adam**
5. **8-bit Adam (no retaining grad)**
6. **8-bit GaLore (no retaining grad)** (Highlighted in bold)
### B. Main Chart Area (Data Visualization)
* **X-Axis:** Labeled "Memory cost (GB)". It ranges from 0 to 60, with major tick marks and dashed vertical grid lines every 10 units (0, 10, 20, 30, 40, 50, 60).
* **Stacked Bars:** Each bar represents the total memory cost, segmented by the type of memory allocation.
* **Threshold Line:** A vertical dashed red line is positioned at approximately **24 GB**.
* **Annotation:** To the right of the 20 GB mark, near the bottom bar, is a red text label: **"RTX 4090"**. This indicates the 24 GB VRAM limit of that specific GPU.
### C. Legend
The legend defines five color-coded categories for the stacked bars:
* **Dark Brown:** Weight
* **Medium Brown:** Activation
* **Olive Green:** Optimization
* **Pale Yellow:** Weight Gradient
* **Cream/Off-White:** Others
## 3. Data Extraction and Table Reconstruction
The following table estimates the numerical values (in GB) based on the X-axis alignment. Note that "Weight" and "Activation" remain constant across all methods.
| Optimization Method | Weight | Activation | Optimization | Weight Gradient | Others | Total (Approx) |
| :--- | :---: | :---: | :---: | :---: | :---: | :---: |
| **BF16 AdamW** | 13.5 | 2.5 | 27.0 | 13.5 | 1.5 | **58.0** |
| **Adafactor** | 13.5 | 2.5 | 14.5 | 13.0 | 2.0 | **45.5** |
| **AdamW (no retaining grad)** | 13.5 | 2.5 | 27.0 | 0.0 | 1.5 | **44.5** |
| **8-bit Adam** | 13.5 | 2.5 | 13.5 | 13.5 | 1.5 | **44.5** |
| **8-bit Adam (no retaining grad)** | 13.5 | 2.5 | 13.5 | 0.0 | 1.5 | **31.0** |
| **8-bit GaLore (no retaining grad)** | 13.5 | 2.5 | 5.0 | 0.0 | 1.5 | **22.5** |
## 4. Trend Verification and Analysis
### Component Trends
* **Weight (Dark Brown):** Constant across all methods (~13.5 GB). This represents the base model size.
* **Activation (Medium Brown):** Constant across all methods (~2.5 GB).
* **Optimization (Olive Green):** This is the primary variable. It is largest in BF16 AdamW and AdamW (~27 GB), reduced in 8-bit Adam (~13.5 GB), and significantly minimized in **8-bit GaLore (~5 GB)**.
* **Weight Gradient (Pale Yellow):** Present in standard methods (~13-13.5 GB) but completely removed in all "(no retaining grad)" configurations.
* **Others (Cream):** A small, consistent overhead of ~1.5–2 GB.
### Key Findings
1. **Hardware Compatibility:** The red dashed line represents the 24 GB limit of an **RTX 4090**. Only the **8-bit GaLore (no retaining grad)** method falls below this line (at ~22.5 GB), making it the only configuration shown capable of running on a single consumer-grade RTX 4090 GPU.
2. **Efficiency of GaLore:** By comparing "8-bit Adam (no retaining grad)" to "8-bit GaLore (no retaining grad)", it is evident that GaLore specifically reduces the "Optimization" memory footprint by more than 60% (from ~13.5 GB to ~5 GB).
3. **Gradient Impact:** Removing the "retaining grad" requirement (Weight Gradient) provides a massive memory saving of roughly 13.5 GB across all applicable methods.
</details>
Figure 1: Estimated memory consumption of pre-training a LLaMA 7B model with a token batch size of 256 on a single device, without activation checkpointing and memory offloading In the figure, “no retaining grad” denotes the application of per-layer weight update to reduce memory consumption of storing weight gradient (Lv et al., 2023b).. Details refer to Section 5.5.
for weight in model.parameters():
grad = weight.grad
# original space -> compact space
lor_grad = project (grad)
# update by Adam, Adafactor, etc.
lor_update = update (lor_grad)
# compact space -> original space
update = project_back (lor_update)
weight.data += update
Algorithm 1 GaLore, PyTorch-like
In addition to engineering and system efforts, such as gradient checkpointing (Chen et al., 2016), memory offloading (Rajbhandari et al., 2020), etc., to achieve faster and more efficient distributed training, researchers also seek to develop various optimization techniques to reduce the memory usage during pre-training and fine-tuning.
Parameter-efficient fine-tuning (PEFT) techniques allow for the efficient adaptation of pre-trained language models (PLMs) to different downstream applications without the need to fine-tune all of the model’s parameters (Ding et al., 2022). Among them, the popular Low-Rank Adaptation (LoRA Hu et al. (2022)) reparameterizes weight matrix $W∈\mathbb{R}^{m× n}$ into $W=W_{0}+BA$ , where $W_{0}$ is a frozen full-rank matrix and $B∈\mathbb{R}^{m× r}$ , $A∈\mathbb{R}^{r× n}$ are additive low-rank adaptors to be learned. Since the rank $r\ll\min(m,n)$ , $A$ and $B$ contain fewer number of trainable parameters and thus smaller optimizer states. LoRA has been used extensively to reduce memory usage for fine-tuning in which $W_{0}$ is the frozen pre-trained weight. Its variant ReLoRA is also used in pre-training, by periodically updating $W_{0}$ using previously learned low-rank adaptors (Lialin et al., 2024).
However, many recent works demonstrate the limitation of such a low-rank reparameterization. For fine-tuning, LoRA is not shown to reach a comparable performance as full-rank fine-tuning (Xia et al., 2024). For pre-training from scratch, it is shown to require a full-rank model training as a warmup (Lialin et al., 2024), before optimizing in the low-rank subspace. There are two possible reasons: (1) the optimal weight matrices may not be low-rank, and (2) the reparameterization changes the gradient training dynamics.
Our approach: To address the above challenge, we propose Gradient Low-Rank Projection (GaLore), a training strategy that allows full-parameter learning but is more memory-efficient than common low-rank adaptation methods, such as LoRA. Our key idea is to leverage the slow-changing low-rank structure of the gradient $G∈\mathbb{R}^{m× n}$ of the weight matrix $W$ , rather than trying to approximate the weight matrix itself as low rank.
We first show theoretically that the gradient matrix $G$ becomes low-rank during training. Then, we propose GaLore that computes two projection matrices $P∈\mathbb{R}^{m× r}$ and $Q∈\mathbb{R}^{n× r}$ to project the gradient matrix $G$ into a low-rank form $P^{→p}GQ$ . In this case, the memory cost of optimizer states, which rely on component-wise gradient statistics, can be substantially reduced. Occasional updates of $P$ and $Q$ (e.g., every 200 iterations) incur minimal amortized additional computational cost. GaLore is more memory-efficient than LoRA as shown in Table 1. In practice, this yields up to 30% memory reduction compared to LoRA during pre-training.
We demonstrate that GaLore works well in both LLM pre-training and fine-tuning. When pre-training LLaMA 7B on C4 dataset, 8-bit GaLore, combined with 8-bit optimizers and layer-wise weight updates techniques, achieves comparable performance to its full-rank counterpart, with less than 10% memory cost of optimizer states.
Notably, for pre-training, GaLore keeps low memory throughout the entire training, without requiring full-rank training warmup like ReLoRA. Thanks to GaLore’s memory efficiency, it is possible to train LLaMA 7B from scratch on a single GPU with 24GB memory (e.g., on NVIDIA RTX 4090), without any costly memory offloading techniques (Fig. 2).
GaLore is also used to fine-tune pre-trained LLMs on GLUE benchmarks with comparable or better results than existing low-rank methods. When fine-tuning RoBERTa-Base on GLUE tasks with a rank of 4, GaLore achieves an average score of 85.89, outperforming LoRA, which achieves a score of 85.61.
As a gradient projection method, GaLore is independent of the choice of optimizers and can be easily plugged into existing ones with only two lines of code, as shown in Algorithm 1. Our experiment (Fig. 3) shows that it works for popular optimizers such as AdamW, 8-bit Adam, and Adafactor. In addition, its performance is insensitive to very few hyper-parameters it introduces. We also provide theoretical justification on the low-rankness of gradient update, as well as the convergence analysis of GaLore.
2 Related Works
Low-rank adaptation.
Hu et al. (2022) proposed Low-Rank Adaptation (LoRA) to fine-tune pre-trained models with low-rank adaptors. This method reduces the memory footprint by maintaining a low-rank weight adaptor for each layer. There are a few variants of LoRA proposed to enhance its performance (Renduchintala et al., 2023; Sheng et al., 2023; Zhang et al., 2023; Xia et al., 2024), supporting multi-task learning (Wang et al., 2023b), and further reducing the memory footprint (Dettmers et al., 2024). Lialin et al. (2024) proposed ReLoRA, a variant of LoRA designed for pre-training, but requires a full-rank training warmup to achieve comparable performance as the standard baseline. Inspired by LoRA, Hao et al. (2024) also suggested that gradients can be compressed in a low-rank subspace, and they proposed to use random projections to compress the gradients. There have also been approaches that propose training networks with low-rank factorized weights from scratch (Kamalakara et al., 2022; Wang et al., 2023a; Zhao et al., 2023).
Subspace learning.
Recent studies have demonstrated that the learning primarily occurs within a significantly low-dimensional parameter subspace (Gur-Ari et al., 2018; Larsen et al., 2022). These findings promote a special type of learning called subspace learning, where the model weights are optimized within a low-rank subspace. This notion has been widely used in different domains of machine learning, including meta-learning and continual learning (Lee & Choi, 2018; Chaudhry et al., 2020).
Projected gradient descent.
GaLore is closely related to the traditional topic of projected gradient descent (PGD) (Chen & Wainwright, 2015; Chen et al., 2019). A key difference is that, GaLore considers the specific gradient form that naturally appears in training multi-layer neural networks (e.g., it is a matrix with specific structures), proving many of its properties (e.g., Lemma 3.3, Theorem 3.2, and Theorem 3.8). In contrast, traditional PGD mostly treats the objective as a general blackbox nonlinear function, and study the gradients in the vector space only.
Low-rank gradient.
Gradient is naturally low-rank during training of neural networks, and this property have been studied in both theory and practice (Zhao et al., 2022; Cosson et al., 2023; Yang et al., 2023). It has been applied to reduce communication cost (Wang et al., 2018; Vogels et al., 2020), and memory footprint during training (Gooneratne et al., 2020; Huang et al., 2023; Modoranu et al., 2023).
Memory-efficient optimization.
There have been some works trying to reduce the memory cost of gradient statistics for adaptive optimization algorithms (Shazeer & Stern, 2018; Anil et al., 2019; Dettmers et al., 2022). Quantization is widely used to reduce the memory cost of optimizer states (Dettmers et al., 2022; Li et al., 2024). Recent works have also proposed to reduce weight gradient memory by fusing the backward operation with the optimizer update (Lv et al., 2023a, b).
3 GaLore: Gradient Low-Rank Projection
3.1 Background
Regular full-rank training. At time step $t$ , $G_{t}=-∇_{W}\varphi_{t}(W_{t})∈\mathbb{R}^{m× n}$ is the backpropagated (negative) gradient matrix. Then the regular pre-training weight update can be written down as follows ( $\eta$ is the learning rate):
$$
W_{T}=W_{0}+\eta\sum_{t=0}^{T-1}\tilde{G}_{t}=W_{0}+\eta\sum_{t=0}^{T-1}\rho_{%
t}(G_{t}) \tag{1}
$$
where $\tilde{G}_{t}$ is the final processed gradient to be added to the weight matrix and $\rho_{t}$ is an entry-wise stateful gradient regularizer (e.g., Adam). The state of $\rho_{t}$ can be memory-intensive. For example, for Adam, we need $M,V∈\mathbb{R}^{m× n}$ to regularize the gradient $G_{t}$ into $\tilde{G}_{t}$ :
$$
\displaystyle M_{t} \displaystyle= \displaystyle\beta_{1}M_{t-1}+(1-\beta_{1})G_{t} \displaystyle V_{t} \displaystyle= \displaystyle\beta_{2}V_{t-1}+(1-\beta_{2})G^{2}_{t} \displaystyle\tilde{G}_{t} \displaystyle= \displaystyle M_{t}/\sqrt{V_{t}+\epsilon} \tag{2}
$$
Here $G_{t}^{2}$ and $M_{t}/\sqrt{V_{t}+\epsilon}$ means element-wise multiplication and division. $\eta$ is the learning rate. Together with $W∈\mathbb{R}^{m× n}$ , this takes $3mn$ memory.
Low-rank updates. For a linear layer $W∈\mathbb{R}^{m× n}$ , LoRA and its variants utilize the low-rank structure of the update matrix by introducing a low-rank adaptor $AB$ :
$$
W_{T}=W_{0}+B_{T}A_{T}, \tag{5}
$$
where $B∈\mathbb{R}^{m× r}$ and $A∈\mathbb{R}^{r× n}$ , and $r\ll\min(m,n)$ . $A$ and $B$ are the learnable low-rank adaptors and $W_{0}$ is a fixed weight matrix (e.g., pre-trained weight).
3.2 Low-Rank Property of Weight Gradient
While low-rank updates are proposed to reduce memory usage, it remains an open question whether the weight matrix should be parameterized as low-rank. In many situations, this may not be true. For example, in linear regression ${\bm{y}}=W{\bm{x}}$ , if the optimal $W^{*}$ is high-rank, then imposing a low-rank assumption on $W$ never leads to the optimal solution, regardless of what optimizers are used.
Surprisingly, while the weight matrices are not necessarily low-rank, the gradient indeed becomes low-rank during the training for certain gradient forms and associated network architectures.
Reversible networks. Obviously, for a general loss function, its gradient can be arbitrary and is not necessarily low rank. Here we study the gradient structure for a general family of nonlinear networks known as “reversible networks” (Tian et al., 2020), which includes not only simple linear networks but also deep ReLU/polynomial networks:
**Definition 3.1 (Reversiblity(Tian et al.,2020))**
*A network $\mathcal{N}$ that maps input ${\bm{x}}$ to output ${\bm{y}}=\mathcal{N}({\bm{x}})$ is reversible, if there exists $L({\bm{x}};W)$ so that ${\bm{y}}=L({\bm{x}};W){\bm{x}}$ , and the backpropagated gradient ${\bm{g}}_{\bm{x}}$ satisfies ${\bm{g}}_{\bm{x}}=L^{→p}({\bm{x}};W){\bm{g}}_{\bm{y}}$ , where ${\bm{g}}_{\bm{y}}$ is the backpropagated gradient at the output ${\bm{y}}$ . Here $L({\bm{x}};W)$ depends on the input ${\bm{x}}$ and weight $W$ in the network $\mathcal{N}$ .*
Please check Appendix B.1 for its properties. For reversible networks, the gradient takes a specific form.
**Theorem 3.2 (Gradient Form of reversible models)**
*Consider a chained reversible neural network $\mathcal{N}({\bm{x}}):=\mathcal{N}_{L}(\mathcal{N}_{L-1}(...\mathcal{N}_{1}%
({\bm{x}})))$ and define $J_{l}:=\mathrm{Jacobian}(\mathcal{N}_{L})...\mathrm{Jacobian}(\mathcal{N}_{%
l+1})$ and ${\bm{f}}_{l}:=\mathcal{N}_{l}(...\mathcal{N}_{1}({\bm{x}}))$ . Then the weight matrix $W_{l}$ at layer $l$ has gradient $G_{l}$ in the following form for batch size 1: (a) For $\ell_{2}$ -objective $\varphi:=\frac{1}{2}\|{\bm{y}}-{\bm{f}}_{L}\|_{2}^{2}$ :
$$
G_{l}=\left(J_{l}^{\top}{\bm{y}}-J^{\top}_{l}J_{l}W_{l}{\bm{f}}_{l-1}\right){%
\bm{f}}_{l-1}^{\top} \tag{6}
$$ (b) Left $P^{\perp}_{\bm{1}}:=I-\frac{1}{K}{\bm{1}}{\bm{1}}^{→p}$ be the zero-mean PSD projection matrix. For $K$ -way logsoftmax loss $\varphi({\bm{y}};{\bm{f}}_{L}):=-\log\left(\frac{\exp({\bm{y}}^{→p}{\bm{f}}_%
{L})}{{\bm{1}}^{→p}\exp({\bm{f}}_{L})}\right)$ with small logits $\|P^{\perp}_{\bm{1}}{\bm{f}}_{L}\|_{∞}\ll\sqrt{K}$ :
$$
G_{l}=\left(J_{l}P^{\perp}_{\bm{1}}{\bm{y}}-\gamma K^{-1}J_{l}^{\top}P^{\perp}%
_{\bm{1}}J_{l}W_{l}{\bm{f}}_{l-1}\right){\bm{f}}_{l-1}^{\top} \tag{7}
$$
where $\gamma≈ 1$ and ${\bm{y}}$ is a data label with ${\bm{y}}^{→p}{\bm{1}}=1$ .*
From the theoretical analysis above, we can see that for batch size $N$ , the gradient $G$ has certain structures: $G=\frac{1}{N}\sum_{i=1}^{N}(A_{i}-B_{i}WC_{i})$ for input-dependent matrix $A_{i}$ , Positive Semi-definite (PSD) matrices $B_{i}$ and $C_{i}$ . In the following, we prove that such a gradient will become low-rank during training in certain conditions:
**Lemma 3.3 (Gradient becomes low-rank during training)**
*Suppose the gradient follows the parametric form:
$$
\displaystyle G_{t}=\frac{1}{N}\sum_{i=1}^{N}(A_{i}-B_{i}W_{t}C_{i}) \tag{8}
$$
with constant $A_{i}$ , PSD matrices $B_{i}$ and $C_{i}$ after $t≥ t_{0}$ . We study vanilla SGD weight update: $W_{t}=W_{t-1}+\eta G_{t-1}$ . Let $S:=\frac{1}{N}\sum_{i=1}^{N}C_{i}\otimes B_{i}$ and $\lambda_{1}<\lambda_{2}$ its two smallest distinct eigenvalues. Then the stable rank $\mathrm{sr}(G_{t})$ satisfies:
$$
\mathrm{sr}(G_{t})\leq\mathrm{sr}(G_{t_{0}}^{\parallel})\!+\!\left(\frac{1\!-%
\!\eta\lambda_{2}}{1\!-\!\eta\lambda_{1}}\right)^{2(t-t_{0})}\frac{\|G_{0}\!-%
\!G_{t_{0}}^{\parallel}\|_{F}^{2}}{\|G_{t_{0}}^{\parallel}\|_{2}^{2}} \tag{9}
$$
where $G_{t_{0}}^{\parallel}$ is the projection of $G_{t_{0}}$ onto the minimal eigenspace $\mathcal{V}_{1}$ of $S$ corresponding to $\lambda_{1}$ .*
In practice, the constant assumption can approximately hold for some time, in which the second term in Eq. 9 goes to zero exponentially and the stable rank of $G_{t}$ goes down, yielding low-rank gradient $G_{t}$ . The final stable rank is determined by $\mathrm{sr}(G_{t_{0}}^{\parallel})$ , which is estimated to be low-rank by the following:
**Corollary 3.4 (Low-rankGtsubscript𝐺𝑡G_{t}italic_G start_POSTSUBSCRIPT italic_t end_POSTSUBSCRIPT)**
*If the gradient takes the parametric form $G_{t}=\frac{1}{N}\sum_{i=1}^{N}({\bm{a}}_{i}-B_{i}W_{t}{\bm{f}}_{i}){\bm{f}}_{%
i}^{→p}$ with all $B_{i}$ full-rank, and $N^{\prime}:=\operatorname{rank}(\{{\bm{f}}_{i}\})<n$ , then $\mathrm{sr}(G_{t_{0}}^{\parallel})≤ n-N^{\prime}$ and thus $\mathrm{sr}(G_{t})≤ n/2$ for large $t$ .*
Remarks. The gradient form is justified by Theorem 3.2. Intuitively, when $N^{\prime}$ is small, $G_{t}$ is a summation of $N^{\prime}$ rank-1 update and is naturally low rank; on the other hand, when $N^{\prime}$ becomes larger and closer to $n$ , then the training dynamics has smaller null space $\mathcal{V}_{1}$ , which also makes $G_{t}$ low-rank. The full-rank assumption of $\{B_{i}\}$ is reasonable, e.g., in LLMs, the output dimensions of the networks (i.e., the vocabulary size) is often huge compared to matrix dimensions.
In general if the batch size $N$ is large, then it becomes a bit tricky to characterize the minimal eigenspace $\mathcal{V}_{1}$ of $S$ . On the other hand, if $\mathcal{V}_{1}$ has nice structure, then $\mathrm{sr}(G_{t})$ can be bounded even further:
**Corollary 3.5 (Low-rankGtsubscript𝐺𝑡G_{t}italic_G start_POSTSUBSCRIPT italic_t end_POSTSUBSCRIPTwith special structure of𝒱1subscript𝒱1\mathcal{V}_{1}caligraphic_V start_POSTSUBSCRIPT 1 end_POSTSUBSCRIPT)**
*If $\mathcal{V}_{1}(S)$ is 1-dimensional with decomposable eigenvector ${\bm{v}}={\bm{y}}\otimes{\bm{z}}$ , then $\mathrm{sr}(G_{t_{0}}^{\parallel})=1$ and thus $G_{t}$ becomes rank-1.*
One rare failure case of Lemma 3.3 is when $G_{t_{0}}^{\parallel}$ is precisely zero, in which $\mathrm{sr}(G_{t_{0}}^{\parallel})$ becomes undefined. This happens to be true if $t_{0}=0$ , i.e., $A_{i}$ , $B_{i}$ and $C_{i}$ are constant throughout the entire training process. Fortunately, for practical training, this does not happen.
Transformers. For Transformers, we can also separately prove that the weight gradient of the lower layer (i.e., project-up) weight of feed forward network (FFN) becomes low rank over time, using the JoMA framework (Tian et al., 2024). Please check Appendix (Sec. B.3) for details.
3.3 Gradient Low-rank Projection (GaLore)
Since the gradient $G$ may have a low-rank structure, if we can keep the gradient statistics of a small “core” of gradient $G$ in optimizer states, rather than $G$ itself, then the memory consumption can be reduced substantially. This leads to our proposed GaLore strategy:
**Definition 3.6 (Gradient Low-rank Projection (GaLore))**
*Gradient low-rank projection (GaLore) denotes the following gradient update rules ( $\eta$ is the learning rate):
$$
W_{T}=W_{0}+\eta\sum_{t=0}^{T-1}\tilde{G}_{t},\quad\tilde{G}_{t}=P_{t}\rho_{t}%
(P_{t}^{\top}G_{t}Q_{t})Q^{\top}_{t} \tag{10}
$$
where $P_{t}∈\mathbb{R}^{m× r}$ and $Q_{t}∈\mathbb{R}^{n× r}$ are projection matrices.*
Different from LoRA, GaLore explicitly utilizes the low-rank updates instead of introducing additional low-rank adaptors and hence does not alter the training dynamics.
In the following, we show that GaLore converges under a similar (but more general) form of gradient update rule (Eqn. 8). This form corresponds to Eqn. 6 but with a larger batch size.
**Definition 3.7 (L𝐿Litalic_L-continuity)**
*A function ${\bm{h}}(W)$ has (Lipschitz) $L$ -continuity, if for any $W_{1}$ and $W_{2}$ , $\|{\bm{h}}(W_{1})-{\bm{h}}(W_{2})\|_{F}≤ L\|W_{1}-W_{2}\|_{F}$ .*
**Theorem 3.8 (Convergence of GaLore with fixed projections)**
*Suppose the gradient has the form of Eqn. 8 and $A_{i}$ , $B_{i}$ and $C_{i}$ have $L_{A}$ , $L_{B}$ and $L_{C}$ continuity with respect to $W$ and $\|W_{t}\|≤ D$ . Let $R_{t}:=P_{t}^{→p}G_{t}Q_{t}$ , $\hat{B}_{it}:=P_{t}^{→p}B_{i}(W_{t})P_{t}$ , $\hat{C}_{it}:=Q_{t}^{→p}C_{i}(W_{t})Q_{t}$ and $\kappa_{t}:=\frac{1}{N}\sum_{i}\lambda_{\min}(\hat{B}_{it})\lambda_{\min}(\hat%
{C}_{it})$ . If we choose constant $P_{t}=P$ and $Q_{t}=Q$ , then GaLore with $\rho_{t}\equiv 1$ satisfies:
$$
\|R_{t}\|_{F}\leq\left[1\!-\!\eta(\kappa_{t-1}\!-\!L_{A}\!-\!L_{B}L_{C}D^{2})%
\right]\|R_{t-1}\|_{F} \tag{11}
$$
As a result, if $\min_{t}\kappa_{t}>L_{A}+L_{B}L_{C}D^{2}$ , $R_{t}→ 0$ and thus GaLore converges with fixed $P_{t}$ and $Q_{t}$ .*
Setting $P$ and $Q$ . The theorem tells that $P$ and $Q$ should project into the subspaces corresponding to the first few largest eigenvectors of $\hat{B}_{it}$ and $\hat{C}_{it}$ for faster convergence (large $\kappa_{t}$ ). While all eigenvalues of the positive semidefinite (PSD) matrix $B$ and $C$ are non-negative, some of them can be very small and hinder convergence (i.e., it takes a long time for $G_{t}$ to become $0 0$ ). With the projection $P$ and $Q$ , $P^{→p}B_{it}P$ and $Q^{→p}C_{it}Q$ only contain the largest eigen subspaces of $B$ and $C$ , improving the convergence of $R_{t}$ and at the same time, reduces the memory usage.
While it is tricky to obtain the eigenstructure of $\hat{B}_{it}$ and $\hat{C}_{it}$ (they are parts of Jacobian), one way is to instead use the spectrum of $G_{t}$ via Singular Value Decomposition (SVD):
$$
\displaystyle G_{t} \displaystyle=USV^{\top}\approx\sum_{i=1}^{r}s_{i}u_{i}v_{i}^{\top} \displaystyle P_{t} \displaystyle=[u_{1},u_{2},...,u_{r}],\quad Q_{t}=[v_{1},v_{2},...,v_{r}] \tag{12}
$$
Difference between GaLore and LoRA. While both GaLore and LoRA have “low-rank” in their names, they follow very different training trajectories. For example, when $r=\min(m,n)$ , GaLore with $\rho_{t}\equiv 1$ follows the exact training trajectory of the original model, as $\tilde{G}_{t}=P_{t}P_{t}^{→p}G_{t}Q_{t}Q_{t}^{→p}=G_{t}$ . On the other hand, when $BA$ reaches full rank (i.e., $B∈\mathbb{R}^{m× m}$ and $A∈\mathbb{R}^{m× n}$ ), optimizing $B$ and $A$ simultaneously follows a very different training trajectory compared to the original model.
4 GaLore for Memory-Efficient Training
For a complex optimization problem such as LLM pre-training, it may be difficult to capture the entire gradient trajectory with a single low-rank subspace. One reason is that the principal subspaces of $B_{t}$ and $C_{t}$ (and thus $G_{t}$ ) may change over time. In fact, if we keep the same projection $P$ and $Q$ , then the learned weights will only grow along these subspaces, which is not longer full-parameter training. Fortunately, for this, GaLore can switch subspaces during training and learn full-rank weights without increasing the memory footprint.
4.1 Composition of Low-Rank Subspaces
<details>
<summary>x2.png Details</summary>
### Visual Description
# Technical Document Extraction: Vector Space Optimization Diagram
## 1. Image Overview
This image is a technical mathematical diagram illustrating a sequential optimization process or weight update trajectory within a high-dimensional space. It utilizes vectors, planes, and directed paths to represent the evolution of a state (likely neural network weights) across two distinct tasks or time intervals.
## 2. Coordinate System and Spatial Grounding
* **Axes:** The diagram is set against a 3D coordinate system represented by three black arrows originating from a common origin $[0, 0]$ at the bottom left.
* **Vertical Axis:** Points upward.
* **Horizontal Axis:** Points to the right.
* **Depth Axis:** Points diagonally upward and to the right.
* **Planes:** Two intersecting tilted planes represent distinct subspaces or manifolds.
* **Blue Plane (Background/Left):** Represents the subspace associated with the first task ($T_1$).
* **Orange Plane (Foreground/Right):** Represents the subspace associated with the second task ($T_2$). It intersects the blue plane along a vertical-diagonal line.
## 3. Component Analysis and Mathematical Notation
### A. Initial State
* **Vector $W_0$:** A solid green arrow originating from the origin and pointing to the bottom-left corner of the blue plane.
* **Label:** $W_0$ (Green text).
### B. First Phase (Task $T_1$)
* **Trajectory:** A series of four blue dashed arrows forming a curved path upward and to the right across the surface of the blue plane.
* **Gradient Label:** $\tilde{G}_{t_1}$ (Blue text with a tilde) is positioned above the first half of this trajectory, indicating the stochastic gradient or update direction for task 1.
* **Endpoint:** The path terminates at the intersection of the blue and orange planes.
* **State Label:** $W_0 + \Delta W_{T_1}$
* $W_0$ is in green.
* $+ \Delta W_{T_1}$ is in blue.
* This represents the accumulated weights after the first optimization phase.
### C. Second Phase (Task $T_2$)
* **Trajectory:** A series of four orange dashed arrows forming a curved path downward and to the right across the surface of the orange plane.
* **Gradient Label:** $\tilde{G}_{t_2}$ (Orange text with a tilde) is positioned below the start of this trajectory, indicating the update direction for task 2.
* **Endpoint:** The path terminates at the bottom-right section of the orange plane.
* **Final State Label:** $W_0 + \Delta W_{T_1} + \Delta W_{T_2}$
* $W_0$ is in green.
* $+ \Delta W_{T_1}$ is in blue.
* $+ \Delta W_{T_2}$ is in orange.
* This represents the final weight state after both optimization phases.
### D. Auxiliary Elements
* **Black Dashed Arrow:** Originates from the origin and points toward the center of the blue plane. This likely represents a projection or a reference vector (such as a meta-learning initialization or a direct path) that is not part of the sequential update trajectory.
## 4. Process Flow and Logic
1. **Initialization:** The process starts at the origin with initial weights $W_0$.
2. **Task 1 Optimization:** The system follows the gradient $\tilde{G}_{t_1}$ within the blue subspace. The total displacement in this phase is $\Delta W_{T_1}$.
3. **Intermediate State:** The weights reach the intersection point $W_0 + \Delta W_{T_1}$.
4. **Task 2 Optimization:** From the intersection, the system follows the gradient $\tilde{G}_{t_2}$ within the orange subspace. The additional displacement is $\Delta W_{T_2}$.
5. **Final State:** The resulting weights are the sum of the initial state and the displacements from both tasks.
## 5. Text Extraction Summary
| Label | Color | Meaning |
| :--- | :--- | :--- |
| $W_0$ | Green | Initial weight vector/state. |
| $\tilde{G}_{t_1}$ | Blue | Stochastic gradient/update for Task 1. |
| $W_0 + \Delta W_{T_1}$ | Green/Blue | Weight state after Task 1. |
| $\tilde{G}_{t_2}$ | Orange | Stochastic gradient/update for Task 2. |
| $W_0 + \Delta W_{T_1} + \Delta W_{T_2}$ | Green/Blue/Orange | Final weight state after Task 1 and Task 2. |
</details>
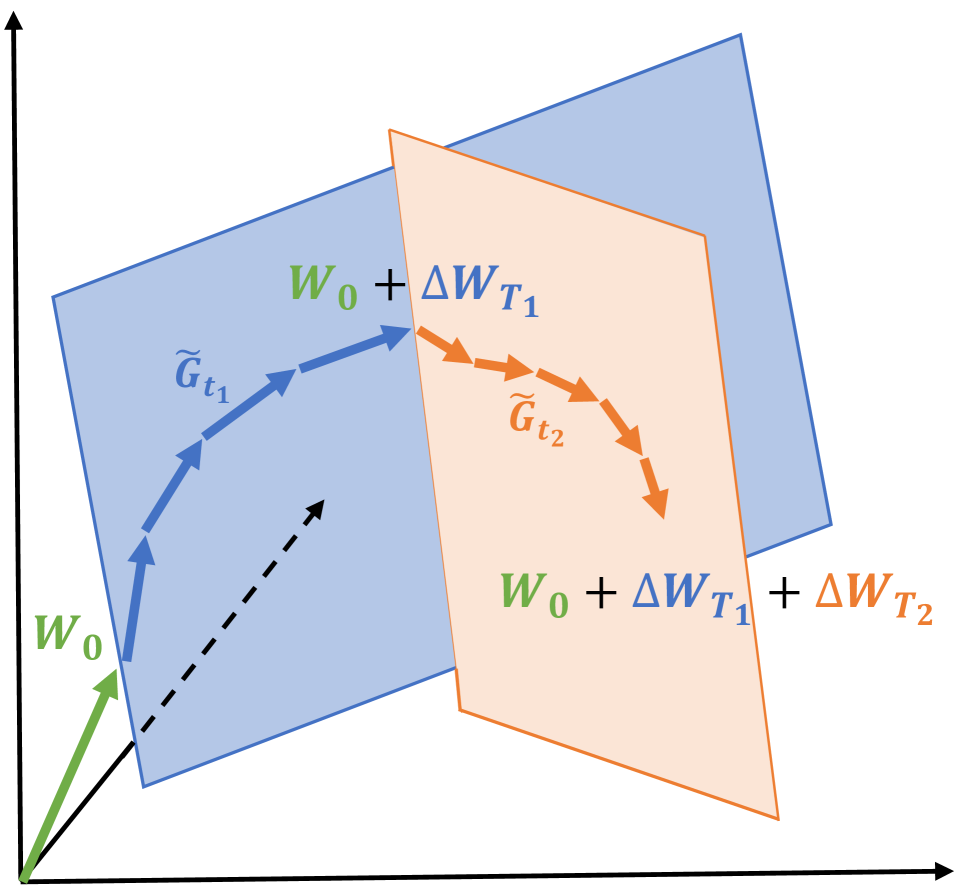
Figure 2: Learning through low-rank subspaces $\Delta W_{T_{1}}$ and $\Delta W_{T_{2}}$ using GaLore. For $t_{1}∈[0,T_{1}-1]$ , $W$ are updated by projected gradients $\tilde{G}_{t_{1}}$ in a subspace determined by fixed $P_{t_{1}}$ and $Q_{t_{1}}$ . After $T_{1}$ steps, the subspace is changed by recomputing $P_{t_{2}}$ and $Q_{t_{2}}$ for $t_{2}∈[T_{1},T_{2}-1]$ , and the process repeats until convergence.
We allow GaLore to switch across low-rank subspaces:
$$
W_{t}=W_{0}+\Delta W_{T_{1}}+\Delta W_{T_{2}}+\ldots+\Delta W_{T_{n}}, \tag{14}
$$
where $t∈\left[\sum_{i=1}^{n-1}T_{i},\sum_{i=1}^{n}T_{i}\right]$ and $\Delta W_{T_{i}}=\eta\sum_{t=0}^{T_{i}-1}\tilde{G_{t}}$ is the summation of all $T_{i}$ updates within the $i$ -th subspace. When switching to $i$ -th subspace at step $t=T_{i}$ , we re-initialize the projector $P_{t}$ and $Q_{t}$ by performing SVD on the current gradient $G_{t}$ by Equation 12. We illustrate how the trajectory of $\tilde{G_{t}}$ traverses through multiple low-rank subspaces in Fig. 2. In the experiment section, we show that allowing multiple low-rank subspaces is the key to achieving the successful pre-training of LLMs.
Following the above procedure, the switching frequency $T$ becomes a hyperparameter. The ablation study (Fig. 5) shows a sweet spot exists. A very frequent subspace change increases the overhead (since new $P_{t}$ and $Q_{t}$ need to be computed) and breaks the condition of constant projection in Theorem 3.8. In practice, it may also impact the fidelity of the optimizer states, which accumulate over multiple training steps. On the other hand, a less frequent change may make the algorithm stuck into a region that is no longer important to optimize (convergence proof in Theorem 3.8 only means good progress in the designated subspace, but does not mean good overall performance). While optimal $T$ depends on the total training iterations and task complexity, we find that a value between $T=50$ to $T=1000$ makes no much difference. Thus, the total computational overhead induced by SVD is negligible ( $<10\%$ ) compared to other memory-efficient training techniques such as memory offloading (Rajbhandari et al., 2020).
4.2 Memory-Efficient Optimization
Input: A layer weight matrix $W∈\mathbb{R}^{m× n}$ with $m≤ n$ . Step size $\eta$ , scale factor $\alpha$ , decay rates $\beta_{1},\beta_{2}$ , rank $r$ , subspace change frequency $T$ .
Initialize first-order moment $M_{0}∈\mathbb{R}^{n× r}← 0$
Initialize second-order moment $V_{0}∈\mathbb{R}^{n× r}← 0$
Initialize step $t← 0$
repeat
$G_{t}∈\mathbb{R}^{m× n}←-∇_{W}\varphi_{t}(W_{t})$
if $t\bmod T=0$ then
$U,S,V←\text{SVD}(G_{t})$
$P_{t}← U[:,:r]$ {Initialize left projector as $m≤ n$ }
else
$P_{t}← P_{t-1}$ {Reuse the previous projector}
end if
$R_{t}← P_{t}^{→p}G_{t}$ {Project gradient into compact space}
$\textsc{update}(R_{t})$ by Adam
$M_{t}←\beta_{1}· M_{t-1}+(1-\beta_{1})· R_{t}$
$V_{t}←\beta_{2}· V_{t-1}+(1-\beta_{2})· R_{t}^{2}$
$M_{t}← M_{t}/(1-\beta_{1}^{t})$
$V_{t}← V_{t}/(1-\beta_{2}^{t})$
$N_{t}← M_{t}/(\sqrt{V_{t}}+\epsilon)$
$\tilde{G}_{t}←\alpha· PN_{t}$ {Project back to original space}
$W_{t}← W_{t-1}+\eta·\tilde{G}_{t}$
$t← t+1$
until convergence criteria met
return $W_{t}$
Algorithm 2 Adam with GaLore
Reducing memory footprint of gradient statistics. GaLore significantly reduces the memory cost of optimizer that heavily rely on component-wise gradient statistics, such as Adam (Kingma & Ba, 2015). When $\rho_{t}\equiv\mathrm{Adam}$ , by projecting $G_{t}$ into its low-rank form $R_{t}$ , Adam’s gradient regularizer $\rho_{t}(R_{t})$ only needs to track low-rank gradient statistics. where $M_{t}$ and $V_{t}$ are the first-order and second-order momentum, respectively. GaLore computes the low-rank normalized gradient $N_{t}$ as follows:
$$
N_{t}=\rho_{t}(R_{t})=M_{t}/(\sqrt{V_{t}}+\epsilon). \tag{15}
$$
GaLore can also apply to other optimizers (e.g., Adafactor) that have similar update rules and require a large amount of memory to store gradient statistics.
Reducing memory usage of projection matrices.
To achieve the best memory-performance trade-off, we only use one project matrix $P$ or $Q$ , projecting the gradient $G$ into $P^{→p}G$ if $m≤ n$ and $GQ$ otherwise. We present the algorithm applying GaLore to Adam in Algorithm 2.
With this setting, GaLore requires less memory than LoRA during training. As GaLore can always merge $\Delta W_{t}$ to $W_{0}$ during weight updates, it does not need to store a separate low-rank factorization $BA$ . In total, GaLore requires $(mn+mr+2nr)$ memory, while LoRA requires $(mn+3mr+3nr)$ memory. A comparison between GaLore and LoRA is shown in Table 1.
As Theorem 3.8 does not require the projection matrix to be carefully calibrated, we can further reduce the memory cost of projection matrices by quantization and efficient parameterization, which we leave for future work.
4.3 Combining with Existing Techniques
GaLore is compatible with existing memory-efficient optimization techniques. In our work, we mainly consider applying GaLore with 8-bit optimizers and per-layer weight updates.
8-bit optimizers.
Dettmers et al. (2022) proposed 8-bit Adam optimizer that maintains 32-bit optimizer performance at a fraction of the memory footprint. We apply GaLore directly to the existing implementation of 8-bit Adam.
Per-layer weight updates.
In practice, the optimizer typically performs a single weight update for all layers after backpropagation. This is done by storing the entire weight gradients in memory. To further reduce the memory footprint during training, we adopt per-layer weight updates to GaLore, which performs the weight updates during backpropagation. This is the same technique proposed in recent works to reduce memory requirement (Lv et al., 2023a, b).
4.4 Hyperparameters of GaLore
In addition to Adam’s original hyperparameters, GaLore only introduces very few additional hyperparameters: the rank $r$ which is also present in LoRA, the subspace change frequency $T$ (see Sec. 4.1), and the scale factor $\alpha$ .
Scale factor $\alpha$ controls the strength of the low-rank update, which is similar to the scale factor $\alpha/r$ appended to the low-rank adaptor in Hu et al. (2022). We note that the $\alpha$ does not depend on the rank $r$ in our case. This is because, when $r$ is small during pre-training, $\alpha/r$ significantly affects the convergence rate, unlike fine-tuning.
Table 1: Comparison between GaLore and LoRA. Assume $W∈\mathbb{R}^{m× n}$ ( $m≤ n$ ), rank $r$ .
| Weights Optim States | GaLore $mn$ $mr+2nr$ | LoRA $mn+mr+nr$ $2mr+2nr$ |
| --- | --- | --- |
| Multi-Subspace | ✓ | ✗ |
| Pre-Training | ✓ | ✗ |
| Fine-Tuning | ✓ | ✓ |
5 Experiments
Table 2: Comparison with low-rank algorithms on pre-training various sizes of LLaMA models on C4 dataset. Validation perplexity is reported, along with a memory estimate of the total of parameters and optimizer states based on BF16 format. The actual memory footprint of GaLore is reported in Fig. 4.
| Full-Rank GaLore | 60M 34.06 (0.36G) 34.88 (0.24G) | 130M 25.08 (0.76G) 25.36 (0.52G) | 350M 18.80 (2.06G) 18.95 (1.22G) | 1B 15.56 (7.80G) 15.64 (4.38G) |
| --- | --- | --- | --- | --- |
| Low-Rank | 78.18 (0.26G) | 45.51 (0.54G) | 37.41 (1.08G) | 142.53 (3.57G) |
| LoRA | 34.99 (0.36G) | 33.92 (0.80G) | 25.58 (1.76G) | 19.21 (6.17G) |
| ReLoRA | 37.04 (0.36G) | 29.37 (0.80G) | 29.08 (1.76G) | 18.33 (6.17G) |
| $r/d_{model}$ | 128 / 256 | 256 / 768 | 256 / 1024 | 512 / 2048 |
| Training Tokens | 1.1B | 2.2B | 6.4B | 13.1B |
We evaluate GaLore on both pre-training and fine-tuning of LLMs. All experiments run on NVIDIA A100 GPUs.
Table 3: Pre-training LLaMA 7B on C4 dataset for 150K steps. Validation perplexity and memory estimate are reported.
| 8-bit GaLore 8-bit Adam Tokens (B) | 18G 26G | 17.94 18.09 5.2 | 15.39 15.47 10.5 | 14.95 14.83 15.7 | 14.65 14.61 19.7 |
| --- | --- | --- | --- | --- | --- |
<details>
<summary>x3.png Details</summary>
### Visual Description
# Technical Data Extraction: Optimizer Performance Comparison
This document contains a detailed extraction of data from a set of three line charts comparing the performance of different optimizers (AdamW, 8-Bit Adam, and Adafactor) across varying ranks against a baseline.
## 1. Global Metadata and Layout
* **Image Type:** Three-panel line chart.
* **Language:** English.
* **Common Y-Axis:** Perplexity ($\downarrow$) - Lower is better.
* **Range:** 20 to 50.
* **Markers:** 20, 25, 30, 35, 40, 45, 50.
* **Common X-Axis:** Training Iterations.
* **Range:** 0 to 10k.
* **Markers:** 2k, 4k, 6k, 8k, 10k.
* **Common Legend (Top Right of each panel):**
* **Baseline:** Dark Brown, Dash-Dot line style.
* **Rank=1024:** Light Green, Solid line style.
* **Rank=512:** Light Blue, Solid line style.
---
## 2. Panel 1: AdamW
**Header:** AdamW
### Trend Analysis
* **Baseline (Brown Dash-Dot):** Starts highest (off-chart at 1k), drops sharply, and converges to approximately 22.5 at 10k.
* **Rank=1024 (Green Solid):** Starts lower than the baseline at 1k (~48), maintains the lowest perplexity throughout the training, ending at approximately 21.
* **Rank=512 (Blue Solid):** Follows a similar curve to Rank=1024 but remains consistently higher, ending at approximately 23.
### Data Point Extraction (Approximate)
| Iterations | Baseline | Rank=1024 | Rank=512 |
| :--- | :--- | :--- | :--- |
| 2k | ~40 | ~34 | ~36 |
| 4k | ~28 | ~27 | ~28 |
| 6k | ~24 | ~23 | ~25 |
| 10k | ~22.5 | ~21 | ~23 |
---
## 3. Panel 2: 8-Bit Adam
**Header:** 8-Bit Adam
### Trend Analysis
* **Baseline (Brown Dash-Dot):** Shows a steep decline, crossing below the Rank=512 line around 3k iterations and ending as the lowest perplexity at 10k.
* **Rank=1024 (Green Solid):** Starts at ~48 at 1k, tracks very closely with the baseline after 4k iterations.
* **Rank=512 (Blue Solid):** Consistently the highest perplexity after the initial 2k iterations, ending at approximately 24.
### Data Point Extraction (Approximate)
| Iterations | Baseline | Rank=1024 | Rank=512 |
| :--- | :--- | :--- | :--- |
| 2k | ~42 | ~38 | ~40 |
| 4k | ~29 | ~29 | ~31 |
| 6k | ~25 | ~25 | ~27 |
| 10k | ~22 | ~22.5 | ~24 |
---
## 4. Panel 3: Adafactor
**Header:** Adafactor
### Trend Analysis
* **Baseline (Brown Dash-Dot):** Starts high, converges with Rank=1024 around 8k iterations, and ends slightly above it.
* **Rank=1024 (Green Solid):** Shows the most efficient reduction in perplexity, maintaining the lowest position for the majority of the timeline, ending at ~20.5.
* **Rank=512 (Blue Solid):** Tracks above Rank=1024 throughout the duration, ending at ~22.
### Data Point Extraction (Approximate)
| Iterations | Baseline | Rank=1024 | Rank=512 |
| :--- | :--- | :--- | :--- |
| 2k | ~36 | ~33 | ~36 |
| 4k | ~27 | ~26 | ~28 |
| 6k | ~23 | ~22 | ~24 |
| 10k | ~21 | ~20.5 | ~22 |
---
## 5. Summary of Findings
* **Rank Performance:** In all three optimizers, **Rank=1024** (Green) consistently outperforms **Rank=512** (Blue), achieving lower perplexity.
* **Optimizer Comparison:**
* For **AdamW** and **Adafactor**, the Rank=1024 configuration manages to beat or match the Baseline performance.
* For **8-Bit Adam**, the Baseline eventually achieves a slightly lower perplexity than the Rank-based configurations by the 10k iteration mark.
* **Convergence:** All models show rapid improvement (perplexity drop) between 0 and 4k iterations, with significant flattening of the curves occurring after 6k iterations.
</details>
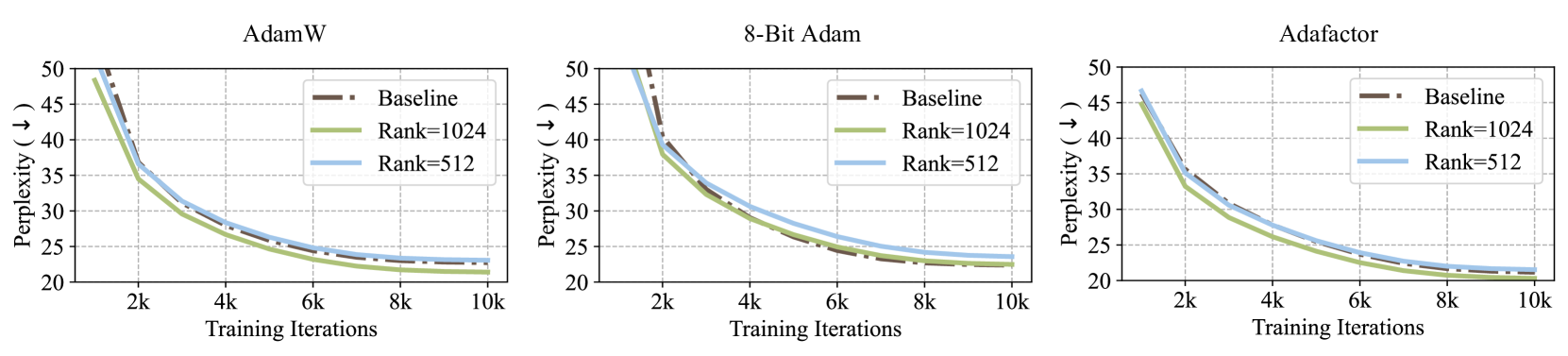
Figure 3: Applying GaLore to different optimizers for pre-training LLaMA 1B on C4 dataset for 10K steps. Validation perplexity over training steps is reported. We apply GaLore to each optimizer with the rank of 512 and 1024, where the 1B model dimension is 2048.
Pre-training on C4.
To evaluate its performance, we apply GaLore to train LLaMA-based large language models on the C4 dataset. C4 dataset is a colossal, cleaned version of Common Crawl’s web crawl corpus, which is mainly intended to pre-train language models and word representations (Raffel et al., 2020). To best simulate the practical pre-training scenario, we train without data repetition over a sufficiently large amount of data, across a range of model sizes up to 7 Billion parameters.
Architecture and hyperparameters.
We follow the experiment setup from Lialin et al. (2024), which adopts a LLaMA-based LLaMA materials in our paper are subject to LLaMA community license. architecture with RMSNorm and SwiGLU activations (Zhang & Sennrich, 2019; Shazeer, 2020; Touvron et al., 2023). For each model size, we use the same set of hyperparameters across methods, except the learning rate. We run all experiments with BF16 format to reduce memory usage, and we tune the learning rate for each method under the same amount of computational budget and report the best performance. The details of our task setups and hyperparameters are provided in the appendix.
Fine-tuning on GLUE tasks.
GLUE is a benchmark for evaluating the performance of NLP models on a variety of tasks, including sentiment analysis, question answering, and textual entailment (Wang et al., 2019). We use GLUE tasks to benchmark GaLore against LoRA for memory-efficient fine-tuning.
5.1 Comparison with Existing Low-Rank Methods
We first compare GaLore with existing low-rank methods using Adam optimizer across a range of model sizes.
Full-Rank
Our baseline method that applies Adam optimizer with full-rank weights and optimizer states.
Low-Rank
We also evaluate a traditional low-rank approach that represents the weights by learnable low-rank factorization: $W=BA$ (Kamalakara et al., 2022).
LoRA
Hu et al. (2022) proposed LoRA to fine-tune pre-trained models with low-rank adaptors: $W=W_{0}+BA$ , where $W_{0}$ is fixed initial weights and $BA$ is a learnable low-rank adaptor. In the case of pre-training, $W_{0}$ is the full-rank initialization matrix. We set LoRA alpha to 32 and LoRA dropout to 0.05 as their default settings.
ReLoRA
Lialin et al. (2024) proposed ReLoRA, a variant of LoRA designed for pre-training, which periodically merges $BA$ into $W$ , and initializes new $BA$ with a reset on optimizer states and learning rate. ReLoRA requires careful tuning of merging frequency, learning rate reset, and optimizer states reset. We evaluate ReLoRA without a full-rank training warmup for a fair comparison.
For GaLore, we set subspace frequency $T$ to 200 and scale factor $\alpha$ to 0.25 across all model sizes in Table 2. For each model size, we pick the same rank $r$ for all low-rank methods, and we apply them to all multi-head attention layers and feed-forward layers in the models. We train all models using Adam optimizer with the default hyperparameters (e.g., $\beta_{1}=0.9$ , $\beta_{2}=0.999$ , $\epsilon=10^{-8}$ ). We also estimate the memory usage based on BF16 format, including the memory for weight parameters and optimizer states. As shown in Table 2, GaLore outperforms other low-rank methods and achieves comparable performance to full-rank training. We note that for 1B model size, GaLore even outperforms full-rank baseline when $r=1024$ instead of $r=512$ . Compared to LoRA and ReLoRA, GaLore requires less memory for storing model parameters and optimizer states. A detailed training setting of each model and memory estimation for each method are in the appendix.
5.2 GaLore with Memory-Efficient Optimizers
We demonstrate that GaLore can be applied to various learning algorithms, especially memory-efficient optimizers, to further reduce the memory footprint. We apply GaLore to AdamW, 8-bit Adam, and Adafactor optimizers (Shazeer & Stern, 2018; Loshchilov & Hutter, 2019; Dettmers et al., 2022). We consider Adafactor with first-order statistics to avoid performance degradation.
We evaluate them on LLaMA 1B architecture with 10K training steps, and we tune the learning rate for each setting and report the best performance. As shown in Fig. 3, applying GaLore does not significantly affect their convergence. By using GaLore with a rank of 512, the memory footprint is reduced by up to 62.5%, on top of the memory savings from using 8-bit Adam or Adafactor optimizer. Since 8-bit Adam requires less memory than others, we denote 8-bit GaLore as GaLore with 8-bit Adam, and use it as the default method for the following experiments on 7B model pre-training and memory measurement.
5.3 Scaling up to LLaMA 7B Architecture
Scaling ability to 7B models is a key factor for demonstrating if GaLore is effective for practical LLM pre-training scenarios. We evaluate GaLore on an LLaMA 7B architecture with an embedding size of 4096 and total layers of 32. We train the model for 150K steps with 19.7B tokens, using 8-node training in parallel with a total of 64 A100 GPUs. Due to computational constraints, we compare 8-bit GaLore ( $r=1024$ ) with 8-bit Adam with a single trial without tuning the hyperparameters. As shown in Table 3, after 150K steps, 8-bit GaLore achieves a perplexity of 14.65, comparable to 8-bit Adam with a perplexity of 14.61.
<details>
<summary>x4.png Details</summary>
### Visual Description
# Technical Document Extraction: Memory Comparison Chart
## 1. Document Overview
This image is a grouped bar chart titled **"Memory Comparison"** (corrected from the original typo "Comparsion"). It illustrates the memory cost in Gigabytes (GB) for different optimization techniques across four specific Large Language Model (LLM) sizes.
## 2. Component Isolation
### A. Header
* **Title:** Memory Comparison
### B. Main Chart Area
* **Y-Axis Label:** Memory cost (GB)
* **Y-Axis Scale:** 0 to 60, with major gridlines every 10 units (0, 10, 20, 30, 40, 50, 60).
* **X-Axis Label:** Model Size
* **X-Axis Categories:** 350M, 1B, 3B, 7B.
* **Reference Line:** A horizontal dashed red line is positioned at approximately **24 GB**.
* **Reference Label:** "RTX 4090" (written in red text above the dashed line).
### C. Legend
The legend identifies five data series, distinguished by color and texture:
1. **BF16:** Light cream/off-white solid fill.
2. **Adafactor:** Pale lime green solid fill.
3. **8-bit Adam:** Olive green solid fill.
4. **8-bit GaLore (retaining grad):** Light brown fill with diagonal hatching.
5. **8-bit GaLore:** Dark brown fill with diagonal hatching.
---
## 3. Data Extraction and Trend Analysis
### Trend Verification
Across all model sizes (350M to 7B), the memory cost follows a consistent pattern:
* **BF16** always consumes the most memory.
* Memory cost decreases sequentially: BF16 > Adafactor > 8-bit Adam > 8-bit GaLore (retaining grad) > 8-bit GaLore.
* **8-bit GaLore** consistently represents the most memory-efficient method.
* The memory cost scales near-linearly with the model parameter count (Model Size).
### Data Table (Estimated Values in GB)
The following table reconstructs the visual data points. Values are estimated based on the Y-axis scale.
| Model Size | BF16 | Adafactor | 8-bit Adam | 8-bit GaLore (retaining grad) | 8-bit GaLore |
| :--- | :--- | :--- | :--- | :--- | :--- |
| **350M** | ~4.5 | ~4.2 | ~3.5 | ~2.8 | ~2.2 |
| **1B** | ~14.5 | ~13.0 | ~9.5 | ~8.0 | ~5.5 |
| **3B** | ~28.0 | ~25.0 | ~18.0 | ~15.0 | ~10.0 |
| **7B** | ~60.0 | ~52.0 | ~46.5 | ~37.0 | ~22.0 |
---
## 4. Key Technical Insights
* **Hardware Constraint (RTX 4090):** The red dashed line at 24 GB represents the VRAM limit of a consumer-grade NVIDIA RTX 4090 GPU.
* **3B Model Threshold:** For a 3B parameter model, standard BF16 and Adafactor exceed the 24 GB limit of an RTX 4090. Only 8-bit Adam and both GaLore variants stay below this threshold.
* **7B Model Threshold:** For a 7B parameter model, almost all methods significantly exceed the 24 GB limit. **8-bit GaLore** is the only method shown that brings the memory cost below the 24 GB threshold (appearing at approximately 22 GB), making it the only viable option for training/fine-tuning a 7B model on a single RTX 4090 according to this data.
* **Efficiency Gain:** At the 7B scale, 8-bit GaLore reduces memory consumption by approximately 63% compared to the BF16 baseline.
</details>
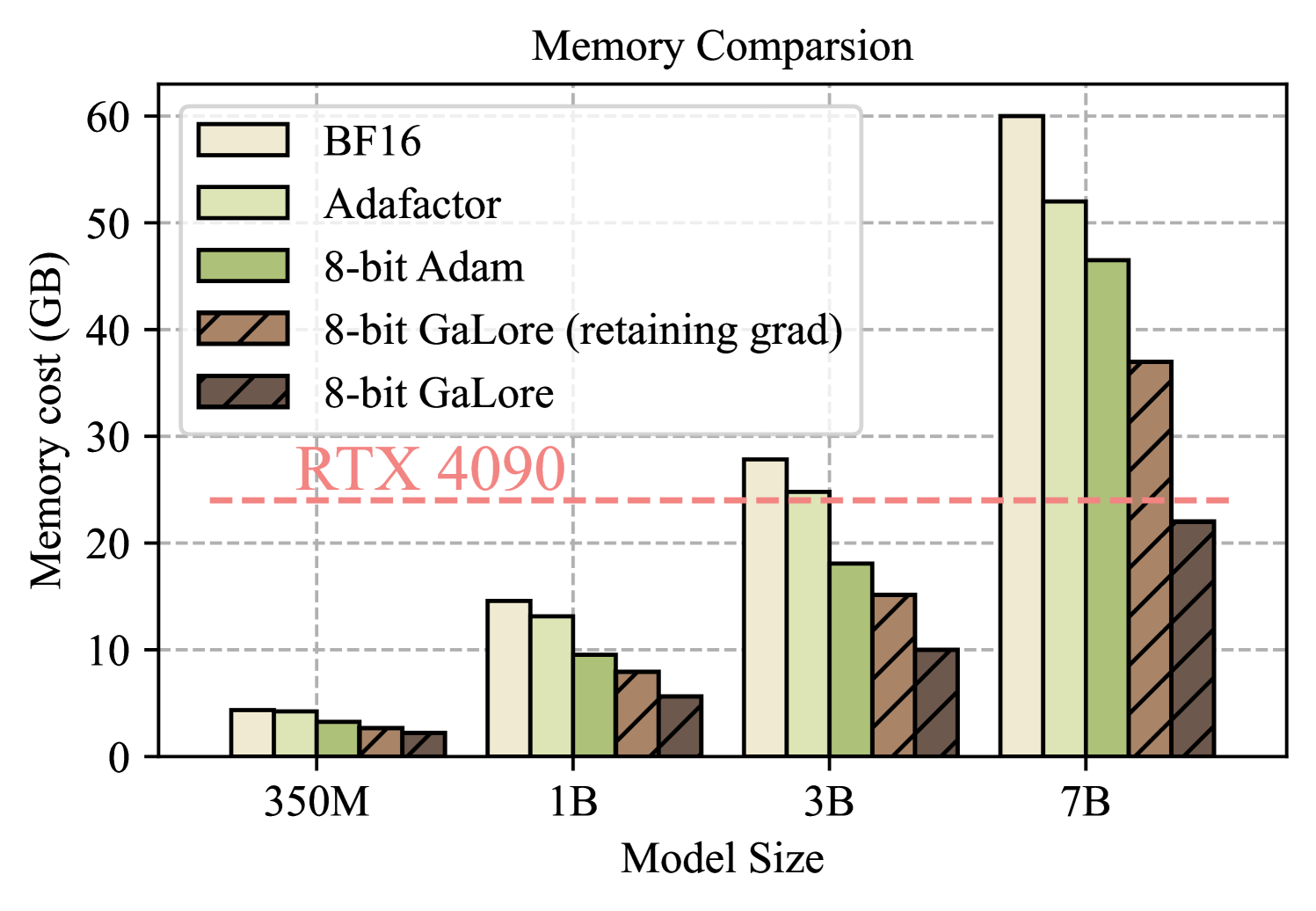
Figure 4: Memory usage for different methods at various model sizes, evaluated with a token batch size of 256. 8-bit GaLore (retaining grad) disables per-layer weight updates but stores weight gradients during training.
5.4 Memory-Efficient Fine-Tuning
GaLore not only achieves memory-efficient pre-training but also can be used for memory-efficient fine-tuning. We fine-tune pre-trained RoBERTa models on GLUE tasks using GaLore and compare its performance with a full fine-tuning baseline and LoRA. We use hyperparameters from Hu et al. (2022) for LoRA and tune the learning rate and scale factor for GaLore. As shown in Table 4, GaLore achieves better performance than LoRA on most tasks with less memory footprint. This demonstrates that GaLore can serve as a full-stack memory-efficient training strategy for both LLM pre-training and fine-tuning.
Table 4: Evaluating GaLore for memory-efficient fine-tuning on GLUE benchmark using pre-trained RoBERTa-Base. We report the average score of all tasks.
| GaLore (rank=4) LoRA (rank=4) GaLore (rank=8) | 253M 257M 257M | 60.35 61.38 60.06 | 90.73 90.57 90.82 | 92.25 91.07 92.01 | 79.42 78.70 79.78 | 94.04 92.89 94.38 | 87.00 86.82 87.17 | 92.24 92.18 92.20 | 91.06 91.29 91.11 | 85.89 85.61 85.94 |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| LoRA (rank=8) | 264M | 61.83 | 90.80 | 91.90 | 79.06 | 93.46 | 86.94 | 92.25 | 91.22 | 85.93 |
5.5 Measurement of Memory and Throughput
While Table 2 gives the theoretical benefit of GaLore compared to other methods in terms of memory usage, we also measure the actual memory footprint of training LLaMA models by various methods, with a token batch size of 256. The training is conducted on a single device setup without activation checkpointing, memory offloading, and optimizer states partitioning (Rajbhandari et al., 2020).
Training 7B models on consumer GPUs with 24G memory. As shown in Fig. 4, 8-bit GaLore requires significantly less memory than BF16 baseline and 8-bit Adam, and only requires 22.0G memory to pre-train LLaMA 7B with a small per-GPU token batch size (up to 500 tokens). This memory footprint is within 24GB VRAM capacity of a single GPU such as NVIDIA RTX 4090. In addition, when activation checkpointing is enabled, per-GPU token batch size can be increased up to 4096. While the batch size is small per GPU, it can be scaled up with data parallelism, which requires much lower bandwidth for inter-GPU communication, compared to model parallelism. Therefore, it is possible that GaLore can be used for elastic training (Lin et al., 2019) 7B models on consumer GPUs such as RTX 4090s.
Specifically, we present the memory breakdown in Fig. 2. It shows that 8-bit GaLore reduces 37.92G (63.3%) and 24.5G (52.3%) total memory compared to BF16 Adam baseline and 8-bit Adam, respectively. Compared to 8-bit Adam, 8-bit GaLore mainly reduces the memory in two parts: (1) low-rank gradient projection reduces 9.6G (65.5%) memory of storing optimizer states, and (2) using per-layer weight updates reduces 13.5G memory of storing weight gradients.
Throughput overhead of GaLore. We also measure the throughput of the pre-training LLaMA 1B model with 8-bit GaLore and other methods, where the results can be found in the appendix. Particularly, the current implementation of 8-bit GaLore achieves 1019.63 tokens/second, which induces 17% overhead compared to 8-bit Adam implementation. Disabling per-layer weight updates for GaLore achieves 1109.38 tokens/second, improving the throughput by 8.8%. We note that our results do not require offloading strategies or checkpointing, which can significantly impact training throughput. We leave optimizing the efficiency of GaLore implementation for future work.
6 Ablation Study
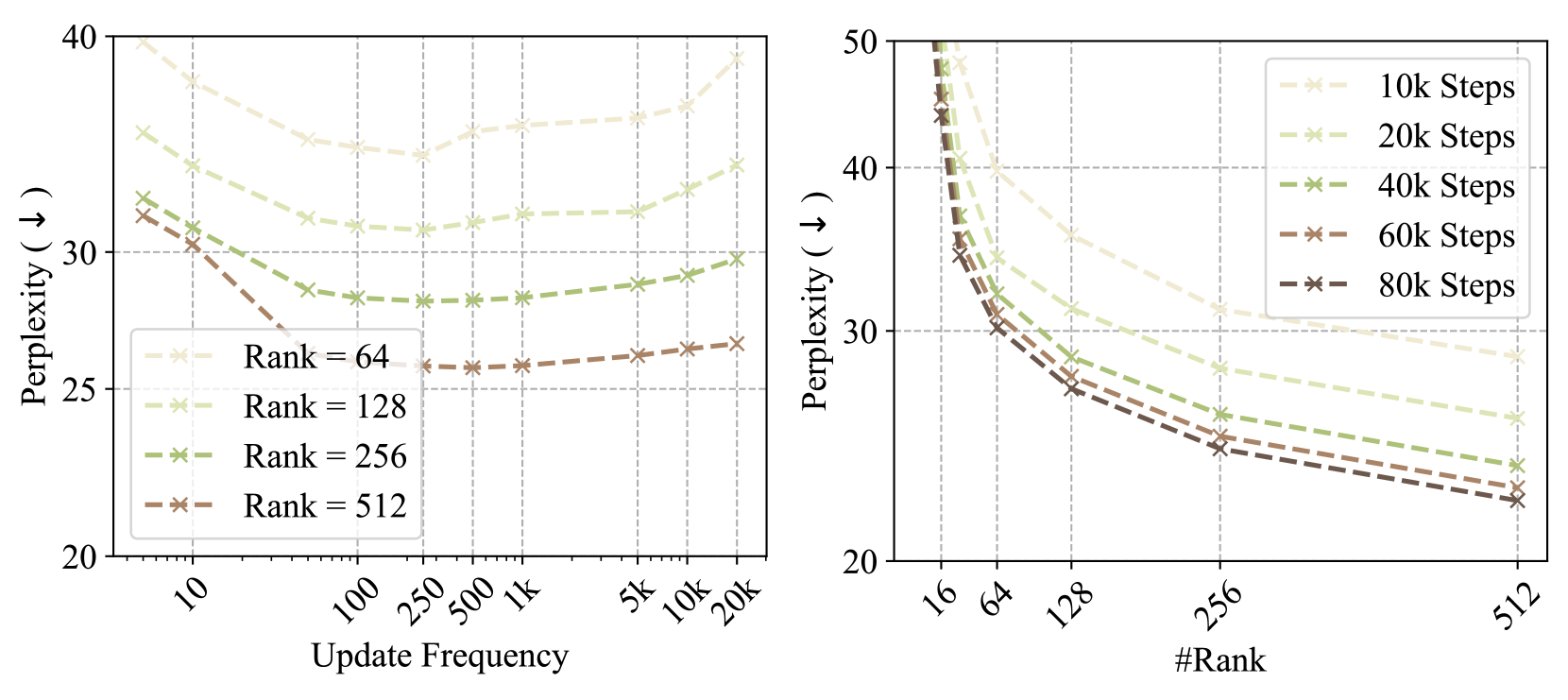
How many subspaces are needed during pre-training?
We observe that both too frequent and too slow changes of subspaces hurt the convergence, as shown in Fig. 5 (left). The reason has been discussed in Sec. 4.1. In general, for small $r$ , the subspace switching should happen more to avoid wasting optimization steps in the wrong subspace, while for large $r$ the gradient updates cover more subspaces, providing more cushion.
<details>
<summary>x5.png Details</summary>
### Visual Description
# Technical Data Extraction: Perplexity Analysis of Rank and Update Frequency
This document provides a detailed extraction of data from two line charts analyzing model performance (measured in Perplexity) relative to Rank and Update Frequency.
## General Metadata
* **Metric:** Perplexity ($\downarrow$) - Lower values indicate better performance.
* **Language:** English.
* **Visual Style:** Line charts with markers ('x') and dashed lines. A color gradient is used where lighter colors represent smaller values (lower rank or fewer steps) and darker/browner colors represent larger values (higher rank or more steps).
---
## Component 1: Left Chart - Perplexity vs. Update Frequency
### Axis and Labels
* **Y-Axis:** Perplexity ($\downarrow$). Scale: 20 to 40. Major ticks at 20, 25, 30, 40.
* **X-Axis:** Update Frequency. Logarithmic-style scale with specific categorical markers.
* **X-Axis Markers:** 10, 100, 250, 500, 1k, 5k, 10k, 20k.
* **Legend Location:** Bottom-left [x $\approx$ 0.1, y $\approx$ 0.2].
### Data Series (Legend: Rank)
The chart tracks four data series representing different Rank configurations.
| Series Color | Label | Trend Description |
| :--- | :--- | :--- |
| Lightest Cream | **Rank = 64** | Starts high (~40), dips to a minimum at Update Frequency 250 (~34), then rises sharply toward 20k (~39). |
| Pale Yellow | **Rank = 128** | Starts at ~35, reaches a minimum at Update Frequency 250 (~31), then rises slightly toward 20k (~34). |
| Light Green | **Rank = 256** | Starts at ~32, reaches a minimum at Update Frequency 250 (~28), then rises slightly toward 20k (~30). |
| Brown | **Rank = 512** | Starts at ~31, reaches a minimum at Update Frequency 500 (~26), then rises slightly toward 20k (~27). |
### Key Observations
* **Optimal Frequency:** All ranks show a "U-shaped" curve, indicating an optimal update frequency between 250 and 500.
* **Rank Impact:** Increasing the Rank consistently lowers the perplexity across all update frequencies.
---
## Component 2: Right Chart - Perplexity vs. #Rank
### Axis and Labels
* **Y-Axis:** Perplexity ($\downarrow$). Scale: 20 to 50. Major ticks at 20, 30, 40, 50.
* **X-Axis:** #Rank. Non-linear scale.
* **X-Axis Markers:** 16, 64, 128, 256, 512.
* **Legend Location:** Top-right [x $\approx$ 0.8, y $\approx$ 0.8].
### Data Series (Legend: Training Steps)
The chart tracks five data series representing the model's performance at different stages of training.
| Series Color | Label | Trend Description |
| :--- | :--- | :--- |
| Lightest Cream | **10k Steps** | Slopes downward sharply from Rank 16 (>50) to Rank 512 (~29). Highest perplexity overall. |
| Pale Yellow | **20k Steps** | Slopes downward; consistently lower than 10k steps. Ends at ~26 for Rank 512. |
| Light Green | **40k Steps** | Slopes downward; consistently lower than 20k steps. Ends at ~24 for Rank 512. |
| Medium Brown | **60k Steps** | Slopes downward; very close to the 80k steps line. Ends at ~23 for Rank 512. |
| Dark Brown | **80k Steps** | Slopes downward; represents the best performance (lowest perplexity). Ends at ~22 for Rank 512. |
### Data Point Extraction (Approximate)
| #Rank | 10k Steps | 20k Steps | 40k Steps | 60k Steps | 80k Steps |
| :--- | :--- | :--- | :--- | :--- | :--- |
| **16** | >50 | ~49 | ~47 | ~45 | ~44 |
| **64** | ~40 | ~34 | ~32 | ~31 | ~30 |
| **128** | ~35 | ~31 | ~29 | ~28 | ~27 |
| **256** | ~31 | ~28 | ~26 | ~25 | ~24 |
| **512** | ~29 | ~26 | ~24 | ~23 | ~22 |
### Key Observations
* **Diminishing Returns:** While increasing Rank always improves perplexity, the rate of improvement slows down significantly after Rank 256.
* **Training Convergence:** The gap between 60k and 80k steps is much smaller than the gap between 10k and 20k steps, suggesting the model is approaching convergence.
</details>
Figure 5: Ablation study of GaLore on 130M models. Left: varying subspace update frequency $T$ . Right: varying subspace rank and training iterations.
How does the rank of subspace affect the convergence?
Within a certain range of rank values, decreasing the rank only slightly affects the convergence rate, causing a slowdown with a nearly linear trend. As shown in Fig. 5 (right), training with a rank of 128 using 80K steps achieves a lower loss than training with a rank of 512 using 20K steps. This shows that GaLore can be used to trade-off between memory and computational cost. In a memory-constrained scenario, reducing the rank allows us to stay within the memory budget while training for more steps to preserve the performance.
7 Conclusion
We propose GaLore, a memory-efficient pre-training and fine-tuning strategy for large language models. GaLore significantly reduces memory usage by up to 65.5% in optimizer states while maintaining both efficiency and performance for large-scale LLM pre-training and fine-tuning.
We identify several open problems for GaLore, which include (1) applying GaLore on training of various models such as vision transformers (Dosovitskiy et al., 2021) and diffusion models (Ho et al., 2020), (2) further enhancing memory efficiency by employing low-memory projection matrices, and (3) exploring the feasibility of elastic data distributed training on low-bandwidth consumer-grade hardware.
We hope that our work will inspire future research on memory-efficient training from the perspective of gradient low-rank projection. We believe that GaLore will be a valuable tool for the community, enabling the training of large-scale models on consumer-grade hardware with limited resources.
Impact Statement
This paper aims to improve the memory efficiency of training LLMs in order to reduce the environmental impact of LLM pre-training and fine-tuning. By enabling the training of larger models on hardware with lower memory, our approach helps to minimize energy consumption and carbon footprint associated with training LLMs.
Acknowledgments
We thank Meta AI for computational support. We appreciate the helpful feedback and discussion from Florian Schäfer, Jeremy Bernstein, and Vladislav Lialin. B. Chen greatly appreciates the support by Moffett AI. Z. Wang is in part supported by NSF Awards 2145346 (CAREER), 02133861 (DMS), 2113904 (CCSS), and the NSF AI Institute for Foundations of Machine Learning (IFML). A. Anandkumar is supported by the Bren Foundation and the Schmidt Sciences through AI 2050 senior fellow program.
References
- Anil et al. (2019) Anil, R., Gupta, V., Koren, T., and Singer, Y. Memory efficient adaptive optimization. Advances in Neural Information Processing Systems, 2019.
- BELLEGroup (2023) BELLEGroup. Belle: Be everyone’s large language model engine. https://github.com/LianjiaTech/BELLE, 2023.
- Chaudhry et al. (2020) Chaudhry, A., Khan, N., Dokania, P., and Torr, P. Continual learning in low-rank orthogonal subspaces. Advances in Neural Information Processing Systems, 2020.
- Chen et al. (2019) Chen, H., Raskutti, G., and Yuan, M. Non-Convex Projected Gradient Descent for Generalized Low-Rank Tensor Regression. Journal of Machine Learning Research, 2019.
- Chen et al. (2016) Chen, T., Xu, B., Zhang, C., and Guestrin, C. Training Deep Nets with Sublinear Memory Cost. ArXiv preprint arXiv:1604.06174, 2016.
- Chen & Wainwright (2015) Chen, Y. and Wainwright, M. J. Fast low-rank estimation by projected gradient descent: General statistical and algorithmic guarantees. ArXiv preprint arXiv:1509.03025, 2015.
- Chowdhery et al. (2023) Chowdhery, A., Narang, S., Devlin, J., Bosma, M., Mishra, G., Roberts, A., Barham, P., Chung, H. W., Sutton, C., Gehrmann, S., et al. Palm: Scaling language modeling with pathways. Journal of Machine Learning Research, 2023.
- Cosson et al. (2023) Cosson, R., Jadbabaie, A., Makur, A., Reisizadeh, A., and Shah, D. Low-Rank Gradient Descent. IEEE Open Journal of Control Systems, 2023.
- Dettmers et al. (2022) Dettmers, T., Lewis, M., Shleifer, S., and Zettlemoyer, L. 8-bit optimizers via block-wise quantization. In The Tenth International Conference on Learning Representations, ICLR 2022, Virtual Event, April 25-29, 2022. OpenReview.net, 2022.
- Dettmers et al. (2024) Dettmers, T., Pagnoni, A., Holtzman, A., and Zettlemoyer, L. Qlora: Efficient finetuning of quantized llms. Advances in Neural Information Processing Systems, 2024.
- Ding et al. (2022) Ding, N., Qin, Y., Yang, G., Wei, F., Yang, Z., Su, Y., Hu, S., Chen, Y., Chan, C.-M., Chen, W., Yi, J., Zhao, W., Wang, X., Liu, Z., Zheng, H.-T., Chen, J., Liu, Y., Tang, J., Li, J., and Sun, M. Delta Tuning: A Comprehensive Study of Parameter Efficient Methods for Pre-trained Language Models. ArXiv preprint arXiv:2203.06904, 2022.
- Dosovitskiy et al. (2021) Dosovitskiy, A., Beyer, L., Kolesnikov, A., Weissenborn, D., Zhai, X., Unterthiner, T., Dehghani, M., Minderer, M., Heigold, G., Gelly, S., Uszkoreit, J., and Houlsby, N. An image is worth 16x16 words: Transformers for image recognition at scale. In International Conference on Learning Representations, 2021.
- Gooneratne et al. (2020) Gooneratne, M., Sim, K. C., Zadrazil, P., Kabel, A., Beaufays, F., and Motta, G. Low-rank gradient approximation for memory-efficient on-device training of deep neural network. In 2020 IEEE International Conference on Acoustics, Speech and Signal Processing, ICASSP 2020, Barcelona, Spain, May 4-8, 2020. IEEE, 2020.
- Gur-Ari et al. (2018) Gur-Ari, G., Roberts, D. A., and Dyer, E. Gradient Descent Happens in a Tiny Subspace. ArXiv preprint arXiv:1812.04754, 2018.
- Hao et al. (2024) Hao, Y., Cao, Y., and Mou, L. Flora: Low-Rank Adapters Are Secretly Gradient Compressors. ArXiv preprint arXiv:2402.03293, 2024.
- Ho et al. (2020) Ho, J., Jain, A., and Abbeel, P. Denoising diffusion probabilistic models. Advances in neural information processing systems, 2020.
- Hu et al. (2022) Hu, E. J., Shen, Y., Wallis, P., Allen-Zhu, Z., Li, Y., Wang, S., Wang, L., and Chen, W. Lora: Low-rank adaptation of large language models. In The Tenth International Conference on Learning Representations, ICLR 2022, Virtual Event, April 25-29, 2022. OpenReview.net, 2022.
- Huang et al. (2023) Huang, S., Hoskins, B. D., Daniels, M. W., Stiles, M. D., and Adam, G. C. Low-Rank Gradient Descent for Memory-Efficient Training of Deep In-Memory Arrays. ACM Journal on Emerging Technologies in Computing Systems, 2023.
- Kamalakara et al. (2022) Kamalakara, S. R., Locatelli, A., Venkitesh, B., Ba, J., Gal, Y., and Gomez, A. N. Exploring Low Rank Training of Deep Neural Networks. ArXiv preprint arXiv:2209.13569, 2022.
- Kingma & Ba (2015) Kingma, D. P. and Ba, J. Adam: A method for stochastic optimization. In 3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, May 7-9, 2015, Conference Track Proceedings, 2015.
- Köpf et al. (2024) Köpf, A., Kilcher, Y., von Rütte, D., Anagnostidis, S., Tam, Z. R., Stevens, K., Barhoum, A., Nguyen, D., Stanley, O., Nagyfi, R., et al. Openassistant conversations-democratizing large language model alignment. Advances in Neural Information Processing Systems, 2024.
- Larsen et al. (2022) Larsen, B. W., Fort, S., Becker, N., and Ganguli, S. How many degrees of freedom do we need to train deep networks: a loss landscape perspective. In The Tenth International Conference on Learning Representations, ICLR 2022, Virtual Event, April 25-29, 2022. OpenReview.net, 2022.
- Lee & Choi (2018) Lee, Y. and Choi, S. Gradient-based meta-learning with learned layerwise metric and subspace. In Proceedings of the 35th International Conference on Machine Learning, ICML 2018, Stockholmsmässan, Stockholm, Sweden, July 10-15, 2018. PMLR, 2018.
- Li et al. (2024) Li, B., Chen, J., and Zhu, J. Memory efficient optimizers with 4-bit states. Advances in Neural Information Processing Systems, 2024.
- Lialin et al. (2024) Lialin, V., Muckatira, S., Shivagunde, N., and Rumshisky, A. ReloRA: High-rank training through low-rank updates. In The Twelfth International Conference on Learning Representations, 2024.
- Lin et al. (2019) Lin, H., Zhang, H., Ma, Y., He, T., Zhang, Z., Zha, S., and Li, M. Dynamic mini-batch sgd for elastic distributed training: Learning in the limbo of resources. arXiv preprint arXiv:1904.12043, 2019.
- Loshchilov & Hutter (2019) Loshchilov, I. and Hutter, F. Decoupled weight decay regularization. In 7th International Conference on Learning Representations, ICLR 2019, New Orleans, LA, USA, May 6-9, 2019. OpenReview.net, 2019.
- Lv et al. (2023a) Lv, K., Yan, H., Guo, Q., Lv, H., and Qiu, X. AdaLomo: Low-memory Optimization with Adaptive Learning Rate. ArXiv preprint arXiv:2310.10195, 2023a.
- Lv et al. (2023b) Lv, K., Yang, Y., Liu, T., Gao, Q., Guo, Q., and Qiu, X. Full Parameter Fine-tuning for Large Language Models with Limited Resources. ArXiv preprint arXiv:2306.09782, 2023b.
- Modoranu et al. (2023) Modoranu, I.-V., Kalinov, A., Kurtic, E., Frantar, E., and Alistarh, D. Error Feedback Can Accurately Compress Preconditioners. ArXiv preprint arXiv:2306.06098, 2023.
- Rae et al. (2021) Rae, J. W., Borgeaud, S., Cai, T., Millican, K., Hoffmann, J., Song, F., Aslanides, J., Henderson, S., Ring, R., Young, S., et al. Scaling language models: Methods, analysis & insights from training gopher. arXiv preprint arXiv:2112.11446, 2021.
- Raffel et al. (2020) Raffel, C., Shazeer, N., Roberts, A., Lee, K., Narang, S., Matena, M., Zhou, Y., Li, W., and Liu, P. J. Exploring the limits of transfer learning with a unified text-to-text transformer. J. Mach. Learn. Res., 2020.
- Rajbhandari et al. (2020) Rajbhandari, S., Rasley, J., Ruwase, O., and He, Y. Zero: Memory optimizations toward training trillion parameter models. In SC20: International Conference for High Performance Computing, Networking, Storage and Analysis, 2020.
- Rajpurkar et al. (2016) Rajpurkar, P., Zhang, J., Lopyrev, K., and Liang, P. SQuAD: 100,000+ questions for machine comprehension of text. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics, 2016.
- Renduchintala et al. (2023) Renduchintala, A., Konuk, T., and Kuchaiev, O. Tied-Lora: Enhacing parameter efficiency of LoRA with weight tying. ArXiv preprint arXiv:2311.09578, 2023.
- Shazeer (2020) Shazeer, N. Glu variants improve transformer. arXiv preprint arXiv:2002.05202, 2020.
- Shazeer & Stern (2018) Shazeer, N. and Stern, M. Adafactor: Adaptive learning rates with sublinear memory cost. In Proceedings of the 35th International Conference on Machine Learning, ICML 2018, Stockholmsmässan, Stockholm, Sweden, July 10-15, 2018. PMLR, 2018.
- Sheng et al. (2023) Sheng, Y., Cao, S., Li, D., Hooper, C., Lee, N., Yang, S., Chou, C., Zhu, B., Zheng, L., Keutzer, K., Gonzalez, J. E., and Stoica, I. S-LoRA: Serving Thousands of Concurrent LoRA Adapters. ArXiv preprint arXiv:2311.03285, 2023.
- Team et al. (2024) Team, G., Mesnard, T., Hardin, C., Dadashi, R., Bhupatiraju, S., Pathak, S., Sifre, L., Rivière, M., Kale, M. S., Love, J., et al. Gemma: Open models based on gemini research and technology. arXiv preprint arXiv:2403.08295, 2024.
- Tian et al. (2020) Tian, Y., Yu, L., Chen, X., and Ganguli, S. Understanding self-supervised learning with dual deep networks. ArXiv preprint arXiv:2010.00578, 2020.
- Tian et al. (2024) Tian, Y., Wang, Y., Zhang, Z., Chen, B., and Du, S. S. JoMA: Demystifying multilayer transformers via joint dynamics of MLP and attention. In The Twelfth International Conference on Learning Representations, 2024.
- Touvron et al. (2023) Touvron, H., Martin, L., Stone, K., Albert, P., Almahairi, A., Babaei, Y., Bashlykov, N., Batra, S., Bhargava, P., Bhosale, S., et al. Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288, 2023.
- Vogels et al. (2020) Vogels, T., Karimireddy, S. P., and Jaggi, M. Practical low-rank communication compression in decentralized deep learning. Advances in Neural Information Processing Systems, 2020.
- Wang et al. (2019) Wang, A., Singh, A., Michael, J., Hill, F., Levy, O., and Bowman, S. R. GLUE: A multi-task benchmark and analysis platform for natural language understanding. In 7th International Conference on Learning Representations, ICLR 2019, New Orleans, LA, USA, May 6-9, 2019. OpenReview.net, 2019.
- Wang et al. (2018) Wang, H., Sievert, S., Liu, S., Charles, Z., Papailiopoulos, D., and Wright, S. Atomo: Communication-efficient learning via atomic sparsification. Advances in neural information processing systems, 31, 2018.
- Wang et al. (2023a) Wang, H., Agarwal, S., Tanaka, Y., Xing, E., Papailiopoulos, D., et al. Cuttlefish: Low-rank model training without all the tuning. Proceedings of Machine Learning and Systems, 2023a.
- Wang et al. (2023b) Wang, Y., Lin, Y., Zeng, X., and Zhang, G. MultiLoRA: Democratizing LoRA for Better Multi-Task Learning. ArXiv preprint arXiv:2311.11501, 2023b.
- Wortsman et al. (2023) Wortsman, M., Dettmers, T., Zettlemoyer, L., Morcos, A., Farhadi, A., and Schmidt, L. Stable and low-precision training for large-scale vision-language models. Advances in Neural Information Processing Systems, 2023.
- Xia et al. (2024) Xia, W., Qin, C., and Hazan, E. Chain of LoRA: Efficient Fine-tuning of Language Models via Residual Learning. ArXiv preprint arXiv:2401.04151, 2024.
- Yang et al. (2023) Yang, G., Simon, J. B., and Bernstein, J. A spectral condition for feature learning. arXiv preprint arXiv:2310.17813, 2023.
- Zhai et al. (2022) Zhai, X., Kolesnikov, A., Houlsby, N., and Beyer, L. Scaling Vision Transformers. In 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). IEEE, 2022.
- Zhang & Sennrich (2019) Zhang, B. and Sennrich, R. Root mean square layer normalization. Advances in Neural Information Processing Systems, 32, 2019.
- Zhang et al. (2023) Zhang, L., Zhang, L., Shi, S., Chu, X., and Li, B. Lora-fa: Memory-efficient low-rank adaptation for large language models fine-tuning. arXiv preprint arXiv:2308.03303, 2023.
- Zhao et al. (2022) Zhao, J., Schaefer, F. T., and Anandkumar, A. Zero initialization: Initializing neural networks with only zeros and ones. Transactions on Machine Learning Research, 2022.
- Zhao et al. (2023) Zhao, J., Zhang, Y., Chen, B., Schäfer, F., and Anandkumar, A. Inrank: Incremental low-rank learning. arXiv preprint arXiv:2306.11250, 2023.
Appendix A Additional Related Works
Adafactor (Shazeer & Stern, 2018) achieves sub-linear memory cost by factorizing the second-order statistics by a row-column outer product. GaLore shares similarities with Adafactor in terms of utilizing low-rank factorization to reduce memory cost, but GaLore focuses on the low-rank structure of the gradients, while Adafactor focuses on the low-rank structure of the second-order statistics.
GaLore can reduce the memory cost for both first-order and second-order statistics, and can be combined with Adafactor to achieve further memory reduction. In contrast to the previous memory-efficient optimization methods, GaLore operates independently as the optimizers directly receive the low-rank gradients without knowing their full-rank counterparts.
The fused backward operation proposed by LOMO (Lv et al., 2023b) mitigates the memory cost of storing weight gradients during training. Integrated with the standard SGD optimizer, LOMO achieves zero optimizer and gradient memory cost during training. AdaLOMO (Lv et al., 2023a) enhances this approach by combining the fused backward operation with adaptive learning rate for each parameter, similarly achieving minimal optimizer memory cost.
While LOMO and AdaLOMO represent significant advancements in memory-efficient optimization for fine-tuning or continual pre-training, they might not be directly applicable to pre-training from scratch at larger scales. For example, the vanilla Adafactor, adopted by AdaLOMO, has been demonstrated to lead to increased training instabilities at larger scales (Rae et al., 2021; Chowdhery et al., 2023; Wortsman et al., 2023; Zhai et al., 2022). We believe integrating GaLore with the fused backward operation may offer a promising avenue for achieving memory-efficient large-scale pre-training from scratch.
Appendix B Proofs
B.1 Reversibility
**Definition B.1 (Reversiblity(Tian et al.,2020))**
*A network $\mathcal{N}$ that maps input ${\bm{x}}$ to output ${\bm{y}}=\mathcal{N}({\bm{x}})$ is reversible, if there exists $L({\bm{x}};W)$ so that ${\bm{y}}=L({\bm{x}};W){\bm{x}}$ , and the backpropagated gradient ${\bm{g}}_{\bm{x}}$ satisfies ${\bm{g}}_{\bm{x}}=L^{→p}({\bm{x}};W){\bm{g}}_{\bm{y}}$ , where ${\bm{g}}_{\bm{y}}$ is the backpropagated gradient at the output ${\bm{y}}$ . Here $L({\bm{x}};W)$ depends on the input ${\bm{x}}$ and weight $W$ in the network $\mathcal{N}$ .*
Note that many layers are reversible, including linear layer (without bias), reversible activations (e.g., ReLU, leaky ReLU, polynomials, etc). Furthermore, they can be combined to construct more complicated architectures:
**Property 1**
*If $\mathcal{N}_{1}$ and $\mathcal{N}_{2}$ are reversible networks, then (Parallel) ${\bm{y}}=\alpha_{1}\mathcal{N}_{1}({\bm{x}})+\alpha_{2}\mathcal{N}_{2}({\bm{x}})$ is reversible for constants $\alpha_{1}$ and $\alpha_{2}$ , and (Composition) ${\bm{y}}=\mathcal{N}_{2}(\mathcal{N}_{1}({\bm{x}}))$ is reversible.*
From this property, it is clear that ResNet architecture ${\bm{x}}+\mathcal{N}({\bm{x}})$ is reversible, if $\mathcal{N}$ contains bias-free linear layers and reversible activations, which is often the case in practice. For a detailed analysis, please check Appendix A in (Tian et al., 2020). For architectures like self-attention, one possibility is to leverage JoMA (Tian et al., 2024) to analyze, and we leave for future work.
The gradient of chained reversible networks has the following structure: See 3.2
* Proof*
Note that for layered reversible network, we have
$$
\mathcal{N}({\bm{x}})=\mathcal{N}_{L}(\mathcal{N}_{L-1}(...\mathcal{N}_{1}({%
\bm{x}})))=K_{L}({\bm{x}})K_{L-1}({\bm{x}})\ldots K_{1}({\bm{x}}){\bm{x}} \tag{16}
$$
Let ${\bm{f}}_{l}:=\mathcal{N}_{l}(\mathcal{N}_{l-1}(...\mathcal{N}_{1}({\bm{x}}%
)))$ and $J_{l}:=K_{L}({\bm{x}})... K_{l+1}({\bm{x}})$ , and for linear layer $l$ , we can write $\mathcal{N}({\bm{x}})=J_{l}W_{l}{\bm{f}}_{l-1}$ . Therefore, for the linear layer $l$ with weight matrix $W_{l}$ , we have:
$$
\displaystyle\mathrm{d}\varphi \displaystyle= \displaystyle({\bm{y}}-\mathcal{N}({\bm{x}}))^{\top}\mathrm{d}\mathcal{N}({\bm%
{x}}) \displaystyle= \displaystyle({\bm{y}}-\mathcal{N}({\bm{x}}))^{\top}K_{L}({\bm{x}})\ldots K_{l%
+1}({\bm{x}})\mathrm{d}W_{l}{\bm{f}}_{l-1}\ \ +\ \ \mathrm{terms\ not\ related%
\ to\ }\mathrm{d}W_{l} \displaystyle= \displaystyle({\bm{y}}-J_{l}W_{l}{\bm{f}}_{l-1})^{\top}J_{l}\mathrm{d}W_{l}{%
\bm{f}}_{l-1} \displaystyle= \displaystyle\mathrm{tr}(\mathrm{d}W_{l}^{\top}J_{l}^{\top}({\bm{y}}-J_{l}W_{l%
}{\bm{f}}_{l-1}){\bm{f}}^{\top}_{l-1}) \tag{17}
$$
This gives the gradient of $W_{l}$ :
$$
G_{l}=J_{l}^{\top}{\bm{y}}{\bm{f}}^{\top}_{l-1}-J_{l}^{\top}J_{l}W_{l}{\bm{f}}%
_{l-1}{\bm{f}}^{\top}_{l-1} \tag{21}
$$
∎
Softmax Case. Note that for softmax objective with small logits, we can also prove a similar structure of backpropagated gradient, and thus Theorem 3.2 can also apply.
**Lemma B.2 (Gradient structure of softmax loss)**
*For $K$ -way logsoftmax loss $\varphi({\bm{y}};{\bm{f}}):=-\log\left(\frac{\exp({\bm{y}}^{→p}{\bm{f}})}{{%
\bm{1}}^{→p}\exp({\bm{f}})}\right)$ , let $\hat{\bm{f}}=P^{\perp}_{\bm{1}}{\bm{f}}$ be the zero-mean version of network output ${\bm{f}}$ , where $P^{\perp}_{\bm{1}}:=I-\frac{1}{K}{\bm{1}}{\bm{1}}^{→p}$ , then we have:
$$
-\mathrm{d}\varphi={\bm{y}}^{\top}\mathrm{d}\hat{\bm{f}}-\gamma\hat{\bm{f}}^{%
\top}\mathrm{d}\hat{\bm{f}}/K+O(\hat{\bm{f}}^{2}/K)\mathrm{d}\hat{\bm{f}} \tag{22}
$$
where $\gamma({\bm{y}},{\bm{f}})≈ 1$ and ${\bm{y}}$ is a data label with ${\bm{y}}^{→p}{\bm{1}}=1$ .*
* Proof*
Let $\hat{\bm{f}}:=P^{\perp}_{\bm{1}}{\bm{f}}$ be the zero-mean version of network output ${\bm{f}}$ . Then we have ${\bm{1}}^{→p}\hat{\bm{f}}=0$ and ${\bm{f}}=\hat{\bm{f}}+c{\bm{1}}$ . Therefore, we have:
$$
-\varphi=\log\left(\frac{\exp(c)\exp({\bm{y}}^{\top}\hat{\bm{f}})}{\exp(c){\bm%
{1}}^{\top}\exp(\hat{\bm{f}})}\right)={\bm{y}}^{\top}\hat{\bm{f}}-\log({\bm{1}%
}^{\top}\exp(\hat{\bm{f}})) \tag{23}
$$
Using the Taylor expansion $\exp(x)=1+x+\frac{x^{2}}{2}+o(x^{2})$ , we have:
$$
{\bm{1}}^{\top}\exp(\hat{\bm{f}})={\bm{1}}^{\top}({\bm{1}}+\hat{\bm{f}}+\frac{%
1}{2}\hat{\bm{f}}^{2})+o(\hat{\bm{f}}^{2})=K(1+\hat{\bm{f}}^{\top}\hat{\bm{f}}%
/2K+o(\hat{\bm{f}}^{2}/K)) \tag{24}
$$
So
$$
-\varphi={\bm{y}}^{\top}\hat{\bm{f}}-\log(1+\hat{\bm{f}}^{\top}\hat{\bm{f}}/2K%
+o(\hat{\bm{f}}^{2}/K))-\log K \tag{25}
$$
Therefore
$$
-\mathrm{d}\varphi={\bm{y}}^{\top}\mathrm{d}\hat{\bm{f}}-\frac{\gamma}{K}\hat{%
\bm{f}}^{\top}\mathrm{d}\hat{\bm{f}}+O\left(\frac{\hat{\bm{f}}^{2}}{K}\right)%
\mathrm{d}\hat{\bm{f}} \tag{26}
$$
where $\gamma:=(1+\hat{\bm{f}}^{→p}\hat{\bm{f}}/2K+o(\hat{\bm{f}}^{2}/K))^{-1}≈
1$ . ∎
Remarks. With this lemma, it is clear that for a reversible network ${\bm{f}}:=\mathcal{N}({\bm{x}})=J_{l}({\bm{x}})W_{l}{\bm{f}}_{l-1}({\bm{x}})$ , the gradient $G_{l}$ of $W_{l}$ has the following form:
$$
G_{l}=\underbrace{J_{l}P^{\perp}_{\bm{1}}{\bm{y}}{\bm{f}}_{l-1}}_{A}-%
\underbrace{\gamma J_{l}^{\top}P^{\perp}_{\bm{1}}J_{l}}_{B}W_{l}\underbrace{{%
\bm{f}}_{l-1}{\bm{f}}_{l-1}^{\top}/K}_{C} \tag{27}
$$
B.2 Gradient becomes low-rank
See 3.3
* Proof*
We have
$$
G_{t}=\frac{1}{N}\sum_{i=1}^{N}(A_{i}-B_{i}W_{t}C_{i})=\frac{1}{N}\sum_{i=1}^{%
N}A_{i}-B_{i}(W_{t-1}+\eta G_{t-1})C_{i}=G_{t-1}-\frac{\eta}{N}\sum_{i=1}^{N}B%
_{i}G_{t-1}C_{i} \tag{28}
$$
Let $S:=\frac{1}{N}\sum_{i=1}^{N}C_{i}\otimes B_{i}$ , and $g_{t}:=\mathrm{vec}(G_{t})∈\mathbb{R}^{mn}$ be a vectorized version of the gradient $G_{t}∈\mathbb{R}^{m× n}$ . Using $\mathrm{vec}(BWC)=(C^{→p}\otimes B)\mathrm{vec}(W)$ , we have:
$$
g_{t}=(I-\eta S)g_{t-1} \tag{29}
$$
Now let’s bound the stable rank of $G_{t}$ :
$$
\text{stable-rank}(G_{t}):=\frac{\|G_{t}\|_{F}^{2}}{\|G_{t}\|^{2}_{2}} \tag{30}
$$
Now $\lambda_{1}<\lambda_{2}$ are the smallest two distinct eigenvectors of $S$ . The smallest eigenvalue $\lambda_{1}$ has multiplicity $\kappa_{1}$ . We can decompose $g_{0}$ into two components, $g_{0}=g^{\parallel}_{0}+g^{\perp}_{0}$ , in which $g^{\parallel}_{0}$ lies in the $\kappa_{1}$ -dimensional eigenspace $\mathcal{V}_{1}$ that corresponds to the minimal eigenvalue $\lambda_{1}$ , and $g^{\perp}_{0}$ is its residue. Then $\mathcal{V}_{1}⊂\mathbb{R}^{mn}$ and its orthogonal complements are invariant subspaces under $S$ and thus:
$$
\displaystyle\|G_{t}\|_{F}^{2} \displaystyle= \displaystyle\|g_{t}\|_{2}^{2}=\|(I-\eta S)^{t}g_{0}\|^{2}_{2}=\|(I-\eta S)^{t%
}g^{\parallel}_{0}\|^{2}_{2}+\|(I-\eta S)^{t}g^{\perp}_{0}\|^{2}_{2} \displaystyle\leq \displaystyle(1-\eta\lambda_{2})^{2t}\|g^{\perp}_{0}\|_{2}^{2}+(1-\eta\lambda_%
{1})^{2t}\|g^{\parallel}_{0}\|_{2}^{2} \tag{31}
$$
On the other hand, by our assumption, $G^{\parallel}_{0}$ is rank $L$ and thus has SVD decomposition:
$$
G^{\parallel}_{0}=\sum_{l=1}^{L}c_{l}{\bm{z}}_{l}{\bm{y}}_{l}^{\top} \tag{33}
$$
with orthonormal unit vectors $\{{\bm{z}}_{l}\}_{l=1}^{L}$ and $\{{\bm{y}}_{l}\}_{l=1}^{L}$ and singular values $\{c_{l}\}_{l=1}^{L}1$ . This means that
$$
g^{\parallel}_{0}=\mathrm{vec}(G^{\parallel}_{0})=\sum_{l=1}^{L}c_{l}({\bm{y}}%
_{l}\otimes{\bm{z}}_{l})=:\sum_{l=1}^{L}c_{l}{\bm{v}}_{l} \tag{34}
$$
with unit vector ${\bm{v}}_{l}:={\bm{y}}_{l}\otimes{\bm{z}}_{l}∈\mathcal{V}_{1}$ . It is clear that
$$
{\bm{v}}^{\top}_{l}{\bm{v}}_{l^{\prime}}=({\bm{y}}^{\top}_{l}\otimes{\bm{z}}^{%
\top}_{l})({\bm{y}}_{l^{\prime}}\otimes{\bm{z}}_{l^{\prime}})=({\bm{y}}^{\top}%
_{l}{\bm{y}}_{l^{\prime}})({\bm{z}}^{\top}_{l}{\bm{z}}_{l^{\prime}})=\mathbb{I%
}(l=l^{\prime}) \tag{35}
$$ Therefore, by the definition of spectral norm (or matrix 2-norm), we know it corresponds to the largest singular value, which means:
$$
\displaystyle\|G_{t}\|_{2} \displaystyle= \displaystyle\max_{\|{\bm{y}}^{\prime}\|_{2}=1,\|{\bm{z}}^{\prime}\|_{2}=1}{%
\bm{z}}^{{}^{\prime}\top}G_{t}{\bm{y}}^{\prime} \displaystyle\geq \displaystyle\max_{l}{\bm{z}}_{l}^{\top}G_{t}{\bm{y}}_{l}=\max_{l}({\bm{y}}_{l%
}\otimes{\bm{z}}_{l})^{\top}g_{t} \displaystyle= \displaystyle\max_{l}{\bm{v}}_{l}^{\top}(1-\eta S)^{t}g_{0}=(1-\eta\lambda_{1}%
)^{t}\max_{l}{\bm{v}}_{l}^{\top}g_{0} \tag{36}
$$
Note that the last equation is because any ${\bm{v}}∈\mathcal{V}_{1}$ is an eigenvector of $S$ with eigenvalue of $\lambda_{1}$ . Since ${\bm{v}}_{l}^{→p}g_{0}={\bm{v}}_{l}^{→p}(g^{\perp}_{0}+g^{\parallel}_{0})=%
c_{l}$ , $\max_{l}c_{l}=\|G^{\parallel}_{0}\|_{2}$ and $\|g^{\parallel}_{0}\|_{2}^{2}=\|G^{\parallel}_{0}\|_{F}^{2}$ , we have:
$$
\text{stable-rank}(G_{t}):=\frac{\|G_{t}\|_{F}^{2}}{\|G_{t}\|^{2}_{2}}\leq%
\text{stable-rank}(G^{\parallel}_{0})+\left(\frac{1-\eta\lambda_{2}}{1-\eta%
\lambda_{1}}\right)^{2t}\frac{\|G^{\perp}_{0}\|_{F}^{2}}{\|G_{0}^{\parallel}\|%
_{2}^{2}} \tag{39}
$$
∎
See 3.4
* Proof*
Let $C_{i}={\bm{f}}_{i}{\bm{f}}_{i}^{→p}∈\mathbb{R}^{n× n}$ . Since $N^{\prime}:=\mathrm{rank}(\{{\bm{f}}_{i}\}_{i=1}^{N})<n$ and $f_{i}∈\mathbb{R}^{n}$ , the collections of vectors $\{{\bm{f}}_{i}\}_{i=1}^{N}$ cannot span the entire space $\mathbb{R}^{n}$ . Let $\{{\bm{u}}_{j}\}_{j=1}^{n-N^{\prime}}$ be the orthonormal bases for the null space of $\{{\bm{f}}_{i}\}_{i=1}^{N}$ , and $\{{\bm{e}}_{k}\}_{k=1}^{m}$ be any orthonormal bases for $\mathbb{R}^{m}$ . Then the product bases $\{{\bm{u}}_{j}\otimes{\bm{e}}_{k}\}$ form a set of bases for the minimal eigenspace $\mathcal{V}_{1}$ of $S$ with the minimal eigenvalue of $0 0$ . Since $B_{i}$ are full-rank, no extra dimensions exist for $\mathcal{V}_{1}$ . Therefore, when we project $G_{t_{0}}$ onto $\mathcal{V}_{1}$ , we have:
$$
G_{t_{0}}^{\parallel}=\sum_{j=1}^{n-N^{\prime}}\sum_{k=1}^{m}c_{jk}{\bm{u}}_{j%
}{\bm{e}}^{\top}_{k}=\sum_{j=1}^{n-N^{\prime}}{\bm{u}}_{j}\left(\sum_{k=1}^{m}%
c_{jk}{\bm{e}}_{k}\right)^{\top} \tag{40}
$$
and thus $\mathrm{sr}(G_{t_{0}}^{\parallel})≤\mathrm{rank}(G_{t_{0}}^{\parallel})≤
n%
-N^{\prime}$ , since stable rank is a lower-bound of the rank. On the other hand, $G_{t}$ can be written as a summation of $N^{\prime}$ rank-1 matrices, by representing each ${\bm{f}}_{i}=\sum_{j=1}^{N^{\prime}}b_{ij}{\bm{f}}^{\prime}_{j}$ as a linear combination of $\{{\bm{f}}^{\prime}_{j}\}_{j=1}^{N^{\prime}}$ :
$$
G_{t}=\frac{1}{N}\sum_{i=1}^{N}({\bm{a}}_{i}-B_{i}W_{t}{\bm{f}}_{i})\left(\sum%
_{j=1}^{N^{\prime}}b_{ij}{\bm{f}}^{\prime}_{j}\right)^{\top}=\frac{1}{N}\sum_{%
j=1}^{N^{\prime}}\left[\sum_{i=1}^{N}b_{ij}({\bm{a}}_{i}-B_{i}W_{t}{\bm{f}}_{i%
})\right]{\bm{f}}^{{}^{\prime}\top}_{j} \tag{41}
$$
and thus has rank at most $N^{\prime}$ . Therefore, when $t$ is sufficiently large so that the second term in Eqn. 39 is negligible, by Lemma 3.3, we have (notice that $N^{\prime}<n$ ):
$$
\mathrm{sr}(G_{t})\leq\min(n-N^{\prime},N^{\prime})\leq n/2 \tag{42}
$$
∎
See 3.5
* Proof*
In this case, we have $g^{\parallel}_{0}={\bm{v}}{\bm{v}}^{→p}g_{0}\propto{\bm{v}}$ . Since ${\bm{v}}={\bm{y}}\otimes{\bm{z}}$ , the resulting $G^{\parallel}_{0}$ is a rank-1 matrix and thus $\mathrm{sr}(G_{t_{0}}^{\parallel})=1$ . ∎
B.3 Gradient Low-rank property for Transformers
Note that Transformers do not belong to the family of reversible networks. However, we can still show that the gradient of the lower layer (i.e., project-up) weight $W∈\mathbb{R}^{m× n}$ of feed forward network (FFN) becomes low rank over time, using the JoMA framework (Tian et al., 2024). Here $m$ is the embedding dimension, and $n$ is the number of hidden nodes in FFNs.
**Lemma B.3 (Gradient of Project-up in Transformer FFNs)**
*Suppose the embedding matrix $U∈\mathbb{R}^{m× M}$ is fixed and column-orthonormal ( $M$ is vocabulary size), the activation functions are linear and the backpropagated gradient are stationary (Tian et al., 2024), then the training dynamics of transformed project-up matrix $V:=U^{→p}W∈\mathbb{R}^{M× n}$ satisfies the following:
$$
\dot{V}=\frac{1}{A}\operatorname{diag}\left(\exp\left(\frac{V\circ V}{2}\right%
){\bm{1}}\right)\Delta \tag{43}
$$
where $A$ is the normalization factor of softmax, $\circ$ is the Hadamard (element-wise) product and $\Delta$ is defined in the proof. As a result, the gradient of $V$ is “exponentially more low-rank” than $V$ itself.*
* Proof*
Let $\Delta:=[\bm{\Delta}_{1},...,\bm{\Delta}_{n}]∈\mathbb{R}^{M× n}$ , where $\bm{\Delta}_{j}:=\mathbb{E}_{q}[g_{j}{\bm{x}}]∈\mathbb{R}^{M}$ . Here $g_{j}$ is the backpropagated gradient of hidden node $j$ in FFN layer, $\mathbb{E}_{q}[·]$ is the conditional expectation given the query is token $q$ , and ${\bm{x}}$ is the representation of token distribution in the previous layer of Transformer. Specifically, for intermediate layer, ${\bm{x}}$ represents the activation output of the previous project-up layer; for the first layer, ${\bm{x}}$ represents the frequency count of the input tokens. Then following the derivation of Theorem 2 (Tian et al., 2024), we have for each hidden node $j$ and its weight ${\bm{w}}_{j}$ , the transformed weight ${\bm{v}}_{j}:=U^{→p}{\bm{w}}_{j}$ satisfies the following dynamics:
$$
\dot{\bm{v}}_{j}=\frac{1}{A}\bm{\Delta}_{j}\circ\exp({\bm{v}}_{j}^{2}/2) \tag{44}
$$
where ${\bm{v}}^{2}_{j}:={\bm{v}}_{j}\circ{\bm{v}}_{j}$ is the element-wise square of a vector and $\circ$ is the Hadamard (element-wise) product. Since $V:=[{\bm{v}}_{1},...,{\bm{v}}_{n}]$ , Eqn. 43 follows. Note that the dynamics of ${\bm{v}}_{j}$ shows that the direction of ${\bm{v}}_{j}$ will change over time (because of $\exp({\bm{v}}_{j}^{2}/2)$ ), and it is not clear how such dynamics leads to low-rank $V$ and even more low-rank $\dot{V}$ . For this, we per-row decompose the matrix $V$ :
$$
V:=\left[\begin{array}[]{c}{\bm{u}}_{1}^{\top}\\
{\bm{u}}_{2}^{\top}\\
\ldots\\
{\bm{u}}_{M}^{\top}\end{array}\right] \tag{45}
$$
where ${\bm{u}}_{l}∈\mathbb{R}^{n}$ . We can also do the same for $\Delta$ :
$$
\Delta:=\left[\begin{array}[]{c}{\bm{\mu}}_{1}^{\top}\\
{\bm{\mu}}_{2}^{\top}\\
\ldots\\
{\bm{\mu}}_{M}^{\top}\end{array}\ \right] \tag{46}
$$
where ${\bm{\mu}}_{l}∈\mathbb{R}^{n}$ . Then Eqn. 43 can be decomposed along each row:
$$
\dot{\bm{u}}_{l}=\frac{1}{A}(e^{{\bm{u}}^{2}_{l}}\cdot{\bm{1}}){\bm{\mu}}_{l} \tag{47}
$$
Then it is clear that ${\bm{u}}_{l}$ is always along the direction of ${\bm{\mu}}_{l}$ , which is a fixed quality since the backpropagated gradient $g_{j}$ and input ${\bm{x}}$ are assumed to be stationary (and thus $\bm{\Delta}_{j}:=\mathbb{E}_{q}[g_{j}{\bm{x}}]$ is a constant). Therefore, let ${\bm{u}}_{l}(t)=\alpha_{l}(t){\bm{\mu}}_{l}$ with initial condition of the magnitude $\alpha_{l}(0)=0$ , and we have:
$$
\dot{\alpha}_{l}=\frac{1}{A}e^{\alpha_{l}^{2}{\bm{\mu}}_{l}^{2}}\cdot{\bm{1}}=%
\frac{1}{A}\sum_{j=1}^{n}e^{\alpha_{l}^{2}\mu^{2}_{lj}} \tag{48}
$$
where $1≤ l≤ M$ is the token index. In the following we will show that for different $l$ , the growth of $\alpha_{l}$ can be very different. This leads to very different row norms of $V$ and $\dot{V}$ over time, leading to their low-rank structures. Note that Eqn. 48 does not have a close form solution, instead we could estimate its growth:
$$
\frac{1}{A}e^{\alpha_{l}^{2}\bar{\mu}^{2}_{l}}\leq\dot{\alpha}_{l}\leq\frac{n}%
{A}e^{\alpha_{l}^{2}\bar{\mu}^{2}_{l}} \tag{49}
$$
where $\bar{\mu}^{2}_{l}:=\max_{j}\mu^{2}_{lj}$ . Note that both sides have analytic solutions using Gaussian error functions $\mathrm{erf}(x)=\frac{2}{\sqrt{\pi}}∈t_{0}^{x}e^{-t^{2}}\mathrm{d}t∈[-1,1]$ . Specifically, for dynamic system like $\dot{x}=Ce^{\beta^{2}x^{2}}$ , we have
$$
e^{-\beta^{2}x^{2}}\mathrm{d}x=C\mathrm{d}t \tag{50}
$$
which gives:
$$
\frac{\sqrt{\pi}}{2\beta}\mathrm{erf}\left(\beta x(t)\right)=\int_{0}^{x(t)}e^%
{-\beta^{2}y^{2}}\mathrm{d}y=Ct \tag{51}
$$
or
$$
x(t)=\frac{1}{\beta}\mathrm{erf}^{-1}\left(\frac{2\beta C}{\sqrt{\pi}}t\right) \tag{52}
$$ For inequality like $\dot{x}≥ Ce^{\beta^{2}x^{2}}$ or $\dot{x}≤ Ce^{\beta^{2}x^{2}}$ , similar equation can be derived. Plug that in, we have:
$$
\frac{1}{\bar{\mu}_{l}}\mathrm{erf}^{-1}\left(\frac{2\bar{\mu}_{l}}{A\sqrt{\pi%
}}t\right)\leq\alpha_{l}(t)\leq\frac{1}{\bar{\mu}_{l}}\mathrm{erf}^{-1}\left(%
\frac{2n\bar{\mu}_{l}}{A\sqrt{\pi}}t\right) \tag{53}
$$
Let
$$
h(t;a):=\frac{1}{a}\mathrm{erf}^{-1}\left(\frac{2}{\sqrt{\pi}}\frac{a}{A}t\right) \tag{54}
$$
then $\lim_{t→ A\sqrt{\pi}/2a}h(t;a)=+∞$ , and $h(t;\bar{\mu}_{l})≤\alpha_{l}(t)≤ nh(t;n\bar{\mu}_{l})$ . Let $l^{*}=\arg\max_{l}\bar{\mu}_{l}^{*}$ be the row with the largest entry of $\mu$ , then if $\bar{\mu}_{l}^{*}>n\bar{\mu}_{l}$ for all $l≠ l^{*}$ , then when $t→ t^{*}:=\frac{A\sqrt{\pi}}{2\bar{\mu}_{l}^{*}}$ , the magnitude $\alpha_{l^{*}}(t)≥ h(t;\bar{\mu}_{l^{*}})→+∞$ , while $\alpha_{l}(t)≤ nh(t;n\bar{\mu}_{l})$ still stay finite, since its critical time $t^{\prime}:=\frac{A\sqrt{\pi}}{2n\bar{\mu}_{l}}>t^{*}$ . Since $\alpha_{l}(t)$ controls the magnitude of each row of $V$ , This means that $V$ eventually becomes rank-1 and so does $W$ . Finally, $\dot{V}$ is even more low rank than $V$ , since $\dot{\alpha}_{l}$ has $\alpha_{l}$ in its exponents. ∎
B.4 Convergence of GaLore
See 3.8
* Proof*
Using $\mathrm{vec}(AXB)=(B^{→p}\otimes A)\mathrm{vec}(X)$ where $\otimes$ is the Kronecker product, the gradient assumption can be written as the following:
$$
g_{t}=a_{t}-S_{t}w_{t} \tag{55}
$$
where $g_{t}:=\mathrm{vec}(G_{t})∈\mathbb{R}^{mn}$ , $w_{t}:=\mathrm{vec}(W_{t})∈\mathbb{R}^{mn}$ be the vectorized versions of $G_{t}$ and $W_{t}$ , $a_{t}:=\frac{1}{N}\sum_{i}\mathrm{vec}(A_{it})$ and $S_{t}=\frac{1}{N}\sum_{i}C_{it}\otimes B_{it}$ are $mn$ -by- $mn$ PSD matrix. Using the same notation, it is clear to show that:
$$
\displaystyle(Q\otimes P)^{\top}g_{t} \displaystyle= \displaystyle(Q^{\top}\otimes P^{\top})\mathrm{vec}(G_{t})=\mathrm{vec}(P^{%
\top}G_{t}Q)=\mathrm{vec}(R_{t})=:r_{t} \displaystyle\tilde{g}_{t}:=\mathrm{vec}(\tilde{G}_{t}) \displaystyle= \displaystyle\mathrm{vec}(PP^{\top}G_{t}QQ^{\top})=(Q\otimes P)\mathrm{vec}(R_%
{t})=(Q\otimes P)r_{t} \tag{56}
$$ Then we derive the recursive update rule for $g_{t}$ :
$$
\displaystyle g_{t} \displaystyle= \displaystyle a_{t}-S_{t}w_{t} \displaystyle= \displaystyle(a_{t}-a_{t-1})+(S_{t-1}-S_{t})w_{t}+a_{t-1}-S_{t-1}w_{t} \displaystyle= \displaystyle e_{t}+a_{t-1}-S_{t-1}(w_{t-1}+\eta\tilde{g}_{t-1}) \displaystyle= \displaystyle e_{t}+g_{t-1}-\eta S_{t-1}\tilde{g}_{t-1} \tag{58}
$$
where $e_{t}:=(a_{t}-a_{t-1})+(S_{t-1}-S_{t})w_{t}$ . Left multiplying by $(Q\otimes P)^{→p}$ , we have:
$$
\displaystyle r_{t}=(Q\otimes P)^{\top}e_{t}+r_{t-1}-\eta(Q\otimes P)^{\top}S_%
{t-1}(Q\otimes P)r_{t-1} \tag{62}
$$
Let
$$
\hat{S}_{t}:=(Q\otimes P)^{\top}S_{t}(Q\otimes P)=\frac{1}{N}\sum_{i}(Q\otimes
P%
)^{\top}(C_{it}\otimes B_{it})(Q\otimes P)=\frac{1}{N}\sum_{i}(Q^{\top}C_{it}Q%
)\otimes(P^{\top}B_{it}P) \tag{63}
$$
Then we have:
$$
r_{t}=(I-\eta\hat{S}_{t-1})r_{t-1}+(Q\otimes P)^{\top}e_{t} \tag{64}
$$
Now we bound the norm. Note that since $P$ and $Q$ are projection matrices with $P^{→p}P=I$ and $Q^{→p}Q=I$ , we have:
$$
\|(Q\otimes P)^{\top}e_{t}\|_{2}=\|\mathrm{vec}(P^{\top}E_{t}Q)\|_{2}=\|P^{%
\top}E_{t}Q\|_{F}\leq\|E_{t}\|_{F} \tag{65}
$$
where $E_{t}:=\frac{1}{N}\sum_{i}(A_{it}-A_{i,t-1})+\frac{1}{N}\sum_{i}(B_{i,t-1}W_{t%
}C_{i,t-1}-B_{it}W_{t}C_{it})$ . So we only need to bound $\|E_{t}\|_{F}$ . Note that:
$$
\displaystyle\|A_{t}-A_{t-1}\|_{F} \displaystyle\leq \displaystyle L_{A}\|W_{t}-W_{t-1}\|_{F}=\eta L_{A}\|\tilde{G}_{t-1}\|_{F}\leq%
\eta L_{A}\|R_{t-1}\|_{F} \displaystyle\|(B_{t}-B_{t-1})W_{t}C_{t-1}\|_{F} \displaystyle\leq \displaystyle L_{B}\|W_{t}-W_{t-1}\|_{F}\|W_{t}\|_{F}\|C_{t-1}\|_{F}=\eta L_{B%
}L_{C}D^{2}\|R_{t-1}\|_{F} \displaystyle\|B_{t}W_{t}(C_{t-1}-C_{t})\|_{F} \displaystyle\leq \displaystyle L_{C}\|B_{t}\|_{F}\|W_{t}\|_{F}\|W_{t-1}-W_{t}\|_{F}=\eta L_{B}L%
_{C}D^{2}\|R_{t-1}\|_{F} \tag{66}
$$ Now we estimate the minimal eigenvalue of $\hat{S}_{t-1}$ . Let $\underline{\lambda}_{it}:=\lambda_{\min}(P^{→p}B_{it}P)$ and $\underline{\nu}_{it}:=\lambda_{\min}(Q^{→p}C_{it}Q)$ , then $\lambda_{\min}((P^{→p}B_{it}P)\otimes(Q^{→p}C_{it}Q))=\underline{\lambda}_%
{it}\underline{\nu}_{it}$ and for any unit vector ${\bm{v}}$ :
$$
{\bm{v}}^{\top}\hat{S}_{t}{\bm{v}}=\frac{1}{N}\sum_{i}{\bm{v}}^{\top}\left[(P^%
{\top}B_{it}P)\otimes(Q^{\top}C_{it}Q)\right]{\bm{v}}\geq\frac{1}{N}\sum_{i}%
\underline{\lambda}_{it}\underline{\nu}_{it} \tag{69}
$$
And thus $\lambda_{\min}(\hat{S}_{t})≥\frac{1}{N}\sum_{i}\underline{\lambda}_{it}%
\underline{\nu}_{it}$ . Therefore, $\lambda_{\max}(I-\eta\hat{S}_{t-1})≤ 1-\frac{\eta}{N}\sum_{i}\underline{%
\lambda}_{i,t-1}\underline{\nu}_{i,t-1}$ . Therefore, let $\kappa_{t}:=\frac{1}{N}\sum_{i}\underline{\lambda}_{it}\underline{\nu}_{it}$ and using the fact that $\|r_{t}\|_{2}=\|R_{t}\|_{F}$ , we have:
$$
\|R_{t}\|_{F}\leq\left[1-\eta(\kappa_{t-1}-L_{A}-2L_{B}L_{C}D^{2})\right]\|R_{%
t-1}\|_{F} \tag{70}
$$
and the conclusion follows. ∎
Appendix C Details of Pre-Training Experiment
C.1 Architecture and Hyperparameters
We introduce details of the LLaMA architecture and hyperparameters used for pre-training. Table 5 shows the most hyperparameters of LLaMA models across model sizes. We use a max sequence length of 256 for all models, with a batch size of 131K tokens. For all experiments, we adopt learning rate warmup for the first 10% of the training steps, and use cosine annealing for the learning rate schedule, decaying to 10% of the initial learning rate.
Table 5: Hyperparameters of LLaMA models for evaluation. Data amount are specified in tokens.
| 60M | 512 | 1376 | 8 | 8 | 10K | $1.3\mathrm{~{}B}$ |
| --- | --- | --- | --- | --- | --- | --- |
| 130M | 768 | 2048 | 12 | 12 | 20K | $2.6\mathrm{~{}B}$ |
| 350M | 1024 | 2736 | 16 | 24 | 60K | $7.8\mathrm{~{}B}$ |
| $1\mathrm{~{}B}$ | 2048 | 5461 | 24 | 32 | 100K | $13.1\mathrm{~{}B}$ |
| $7\mathrm{~{}B}$ | 4096 | 11008 | 32 | 32 | 150K | $19.7\mathrm{~{}B}$ |
For all methods on each size of models (from 60M to 1B), we tune their favorite learning rate from a set of $\{0.01,0.005,0.001,0.0005,0.0001\}$ , and the best learning rate is chosen based on the validation perplexity. We find GaLore is insensitive to hyperparameters and tends to be stable with the same learning rate across different model sizes. For all models, GaLore use the same hyperparameters, including the learning rate of $0.01$ , scale factor $\alpha$ of $0.25$ , and the subspace change frequency of $T$ of $200$ . We note that since $\alpha$ can be viewed as a fractional learning rate, most of the modules (e.g., multi-head attention and feed-forward layers) in LLaMA models have the actual learning rate of $0.0025$ . This is, still, a relatively large stable learning rate compared to the full-rank baseline, which usually uses a learning rate $≤ 0.001$ to avoid spikes in the training loss.
C.2 Memory Estimates
As the GPU memory usage for a specific component is hard to measure directly, we estimate the memory usage of the weight parameters and optimizer states for each method on different model sizes. The estimation is based on the number of original parameters and the number of low-rank parameters, trained by BF16 format. For example, for a 60M model, LoRA ( $r=128$ ) requires $42.7$ M parameters on low-rank adaptors and $60M$ parameters on the original weights, resulting in a memory cost of $0.20$ G for weight parameters and $0.17$ G for optimizer states. Table 6 shows the memory estimates for weight parameters and optimizer states for different methods on different model sizes, as a compliment to the total memory reported in the main text.
Table 6: Memory estimates for weight parameters and optimizer states.
(a) Memory estimate of weight parameters.
| GaLore Low-Rank LoRA | 0.12G 0.08G 0.20G | 0.25G 0.18G 0.44G | 0.68G 0.36G 1.04G | 2.60G 1.19G 3.79G |
| --- | --- | --- | --- | --- |
| ReLoRA | 0.20G | 0.44G | 1.04G | 3.79G |
(b) Memory estimate of optimizer states.
| GaLore Low-Rank LoRA | 0.13G 0.17G 0.17G | 0.28G 0.37G 0.37G | 0.54G 0.72G 0.72G | 1.78G 2.38G 2.38G |
| --- | --- | --- | --- | --- |
| ReLoRA | 0.17G | 0.37G | 0.72G | 2.38G |
C.3 Training Progression
We show the training progression of 130M, 350M, 1B and 7B models in Figure 6. Compared to LoRA, GaLore closely matches the training trajectory of the full-rank baseline, and it even converges slightly faster at the beginning of the training.
<details>
<summary>x6.png Details</summary>
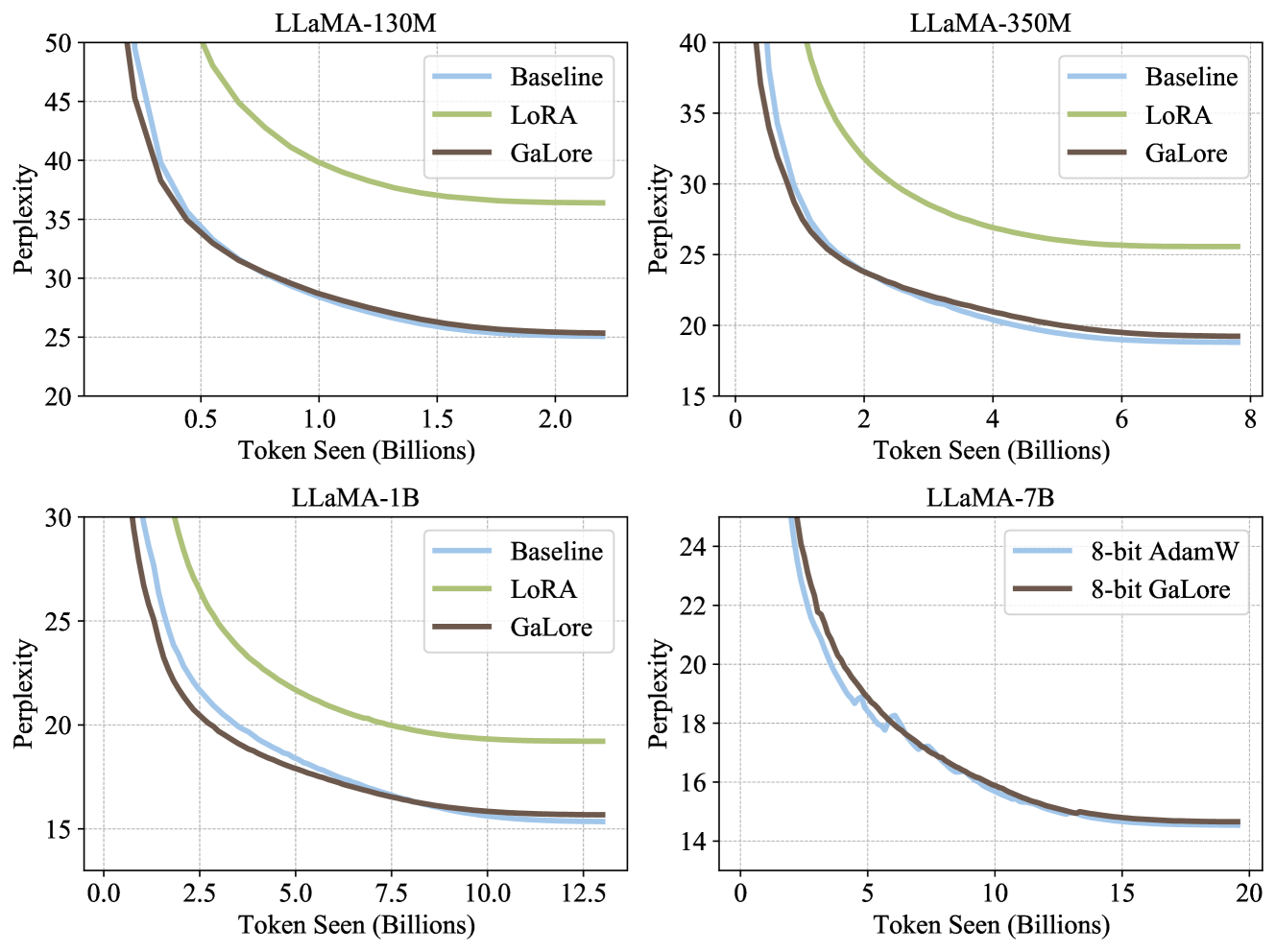
### Visual Description
# Technical Data Extraction: LLaMA Model Training Performance Comparison
This document provides a comprehensive extraction of data from a set of four line charts comparing the training performance (Perplexity vs. Tokens Seen) of different optimization methods across various LLaMA model sizes.
## 1. Document Overview
The image consists of four sub-plots arranged in a 2x2 grid. Each plot represents a different model scale: **LLaMA-130M**, **LLaMA-350M**, **LLaMA-1B**, and **LLaMA-7B**. The primary metric for all charts is **Perplexity** (y-axis), and the independent variable is **Token Seen (Billions)** (x-axis).
### Common Legend and Color Coding
Across the first three charts (130M, 350M, 1B), the following legend applies:
* **Baseline (Light Blue):** Represents the standard full-parameter training.
* **LoRA (Light Green):** Low-Rank Adaptation method.
* **GaLore (Dark Brown):** Gradient Low-Rank Projection method.
In the fourth chart (7B), the legend changes to:
* **8-bit AdamW (Light Blue)**
* **8-bit GaLore (Dark Brown)**
---
## 2. Detailed Chart Analysis
### Sub-plot 1: LLaMA-130M
* **X-axis:** Token Seen (Billions) [Range: 0.0 to 2.0+]
* **Y-axis:** Perplexity [Range: 20 to 50]
* **Trend Analysis:**
* **LoRA (Green):** Slopes downward but plateaus significantly higher than the others, ending near ~36.
* **Baseline (Blue) & GaLore (Brown):** Both show a steep downward curve, converging almost perfectly.
* **Final Data Points (approx. 2.2B tokens):**
* LoRA: ~36.5
* Baseline: ~25.3
* GaLore: ~25.3
### Sub-plot 2: LLaMA-350M
* **X-axis:** Token Seen (Billions) [Range: 0 to 8]
* **Y-axis:** Perplexity [Range: 15 to 40]
* **Trend Analysis:**
* **LoRA (Green):** Slopes downward, plateauing around ~25.5.
* **Baseline (Blue):** Slopes downward, reaching the lowest perplexity.
* **GaLore (Brown):** Follows the Baseline very closely, though it stays slightly above the Baseline in the final stages.
* **Final Data Points (approx. 8B tokens):**
* LoRA: ~25.5
* GaLore: ~19.2
* Baseline: ~18.8
### Sub-plot 3: LLaMA-1B
* **X-axis:** Token Seen (Billions) [Range: 0.0 to 12.5+]
* **Y-axis:** Perplexity [Range: 15 to 30]
* **Trend Analysis:**
* **LoRA (Green):** Slopes downward, plateauing near ~19.
* **Baseline (Blue):** Slopes downward. Interestingly, in this model size, the Baseline curve is slightly *above* GaLore during the mid-training phase (2.5B - 7.5B tokens) before converging.
* **GaLore (Brown):** Slopes downward aggressively, showing superior performance to LoRA and matching/slightly exceeding Baseline efficiency.
* **Final Data Points (approx. 13B tokens):**
* LoRA: ~19.2
* GaLore: ~15.6
* Baseline: ~15.4
### Sub-plot 4: LLaMA-7B
* **X-axis:** Token Seen (Billions) [Range: 0 to 20]
* **Y-axis:** Perplexity [Range: 14 to 24]
* **Trend Analysis:**
* **8-bit AdamW (Blue):** Shows a jagged downward trend (indicating some instability or noise in 8-bit training) but reaches a low perplexity.
* **8-bit GaLore (Brown):** Shows a much smoother downward curve compared to 8-bit AdamW, tracking the same final performance level.
* **Final Data Points (approx. 20B tokens):**
* 8-bit AdamW: ~14.6
* 8-bit GaLore: ~14.6
---
## 3. Summary of Key Findings
1. **GaLore vs. LoRA:** In all tested model sizes (130M, 350M, 1B), **GaLore** significantly outperforms **LoRA**, achieving a much lower perplexity that is nearly identical to the full-parameter **Baseline**.
2. **GaLore vs. Baseline:** GaLore effectively recovers the performance of full-parameter training (Baseline) across all scales.
3. **8-bit Optimization (7B Model):** In the 7B model, **8-bit GaLore** achieves the same final perplexity as **8-bit AdamW** but exhibits a significantly smoother convergence curve with less volatility during the training process.
4. **Scaling:** As model size increases, the final perplexity achieved within the token limit decreases (e.g., 130M ends at ~25, while 7B ends at ~14.6).
</details>
Figure 6: Training progression for pre-training LLaMA models on C4 dataset.
Appendix D Fine-Tuning Experiments
D.1 Details of Fine-Tuning on GLUE
We fine-tune the pre-trained RoBERTa-Base model on the GLUE benchmark using the model provided by the Hugging Face https://huggingface.co/transformers/model_doc/roberta.html. We trained the model for 30 epochs with a batch size of 16 for all tasks except for CoLA, which uses a batch size of 32. We tune the learning rate and scale factor for GaLore. Table 7 shows the hyperparameters used for fine-tuning RoBERTa-Base for GaLore.
Table 7: Hyperparameters of fine-tuning RoBERTa base for GaLore.
| Batch Size # Epochs | MNLI 16 30 | SST-2 16 30 | MRPC 16 30 | CoLA 32 30 | QNLI 16 30 | QQP 16 30 | RTE 16 30 | STS-B 16 30 |
| --- | --- | --- | --- | --- | --- | --- | --- | --- |
| Learning Rate | 1E-05 | 1E-05 | 3E-05 | 3E-05 | 1E-05 | 1E-05 | 1E-05 | 1E-05 |
| Rank Config. | | | | $r=4$ | | | | |
| GaLore $\alpha$ | | | | 4 | | | | |
| Max Seq. Len. | | | | 512 | | | | |
| Batch Size # Epochs | MNLI 16 30 | SST-2 16 30 | MRPC 16 30 | CoLA 32 30 | QNLI 16 30 | QQP 16 30 | RTE 16 30 | STS-B 16 30 |
| --- | --- | --- | --- | --- | --- | --- | --- | --- |
| Learning Rate | 1E-05 | 2E-05 | 2E-05 | 1E-05 | 1E-05 | 2E-05 | 2E-05 | 3E-05 |
| Rank Config. | | | | $r=8$ | | | | |
| GaLore $\alpha$ | | | | 2 | | | | |
| Max Seq. Len. | | | | 512 | | | | |
D.2 Fine-Tuning on SQuAD dataset
We evaluate GaLore on the SQuAD dataset (Rajpurkar et al., 2016) using the pre-trained BERT-Base model. We use rank $16$ for both GaLore and LoRA. GaLore outperforms LoRA in both Exact Match and F1 scores.
Table 8: Evaluating GaLore on SQuAD dataset. Both Exact Match and F1 scores are reported.
| Baseline | Exact Match 80.83 | F1 88.41 |
| --- | --- | --- |
| GaLore | 80.52 | 88.29 |
| LoRA | 77.99 | 86.11 |
D.3 Fine-Tuning on OpenAssistant Conversations Dataset
We apply GaLore on fine-tuning experiments on the OpenAssistant Conversations dataset (Köpf et al., 2024), using the pre-trained models, including Gemma-2b, Phi-2, and LLaMA-7B (Touvron et al., 2023; Team et al., 2024). We use rank of 128 for both GaLore and LoRA. The results are shown in Table 9.
Table 9: Evaluating GaLore on OpenAssistant Conversations dataset. Testing perplexity is reported.
| Baseline | Gemma-2b 4.53 | Phi-2 3.81 | LLaMA-7B 2.98 |
| --- | --- | --- | --- |
| GaLore | 4.51 | 3.83 | 2.95 |
| LoRA | 4.56 | 4.24 | 2.94 |
D.4 Fine-Tuning on Belle-1M Dataset
We also apply GaLore on fine-tuning experiments on the Belle-1M dataset (BELLEGroup, 2023), using the pre-trained models, including Gemma-2b, Phi-2, and LLaMA-7B. We use rank of 128 for both GaLore and LoRA. The results are shown in Table 10.
Table 10: Evaluating GaLore on Belle-1M dataset. Testing perplexity is reported.
| Baseline | Gemma-2b 5.44 | Phi-2 2.66 | LLaMA-7B 2.27 |
| --- | --- | --- | --- |
| GaLore | 5.35 | 2.62 | 2.28 |
| LoRA | 5.37 | 2.75 | 2.30 |
Appendix E Additional Memory Measurements
We empirically measure the memory usage of different methods for pre-training LLaMA 1B model on C4 dataset with a token batch size of 256, as shown in Table 11.
Table 11: Measuring memory and throughput on LLaMA 1B model.
| Model Size | Layer Wise | Methods | Token Batch Size | Memory Cost | Throughput | |
| --- | --- | --- | --- | --- | --- | --- |
| #Tokens / s | #Samples / s | | | | | |
| 1B | ✘ | AdamW | 256 | 13.60 | 1256.98 | 6.33 |
| Adafactor | 256 | 13.15 | 581.02 | 2.92 | | |
| Adam8bit | 256 | 9.54 | 1569.89 | 7.90 | | |
| 8-bit GaLore | 256 | 7.95 | 1109.38 | 5.59 | | |
| 1B | ✔ | AdamW | 256 | 9.63 | 1354.37 | 6.81 |
| Adafactor | 256 | 10.32 | 613.90 | 3.09 | | |
| Adam8bit | 256 | 6.93 | 1205.31 | 6.07 | | |
| 8-bit GaLore | 256 | 5.63 | 1019.63 | 5.13 | | |