<details>
<summary>Image 1 Details</summary>

### Visual Description
## Logo: LLM Reasoners
### Overview
The image is a logo featuring a cartoon llama and the text "LLM Reasoners". The llama is positioned to the left of the text.
### Components/Axes
* **Llama:** A cartoon llama with its eyes closed, appearing to be in a thoughtful pose.
* **Text:** The text "LLM Reasoners" is in a golden color.
### Detailed Analysis or ### Content Details
* The llama is light beige with brown details. It appears to be resting its chin on its hand.
* The text "LLM Reasoners" is in a serif font.
### Key Observations
* The logo combines an animal mascot with text, likely representing a company or project related to Large Language Models (LLMs).
### Interpretation
The logo likely represents a company or project focused on reasoning capabilities of Large Language Models. The llama, in a thoughtful pose, symbolizes intelligence and problem-solving. The golden color of the text may suggest value or quality.
</details>
## New Evaluation, Library, and Analysis of Step-by-Step Reasoning with Large Language Models
Shibo Hao 1 ∗ , Yi Gu 1 ∗ , Haotian Luo 1 ∗ , Tianyang Liu 1 , Xiyan Shao 1 , Xinyuan Wang 1 , Shuhua Xie 1 , Haodi Ma 2 , Adithya Samavedhi 1 , Qiyue Gao 1 , Zhen Wang 1,3 , Zhiting Hu 1 1 UC San Diego, 2 University of Florida, 3 MBZUAI https://www.llm-reasoners.net/
## Abstract
Generating accurate step-by-step reasoning is essential for Large Language Models (LLMs) to address complex problems and enhance robustness and interpretability. Despite the flux of research on developing advanced reasoning approaches, systematically analyzing the diverse LLMs and reasoning strategies in generating reasoning chains remains a significant challenge. The difficulties stem from the lack of two key elements: (1) an automatic method for evaluating the generated reasoning chains on different tasks, and (2) a unified formalism and implementation of the diverse reasoning approaches for systematic comparison. This paper aims to close the gap: (1) We introduce AutoRace for fully automated reasoning chain evaluation. Existing metrics rely on expensive human annotations or pre-defined LLM prompts not adaptable to different tasks. In contrast, AutoRace automatically creates detailed evaluation criteria tailored for each task, and uses GPT-4 for accurate evaluation following the criteria. (2) We develop LLM Reasoners , a library for standardized modular implementation of existing and new reasoning algorithms, under a unified formulation of the search , reward and world model components. With the new evaluation and library, (3) we conduct extensive study of different reasoning approaches (e.g., CoT, ToT, RAP). The analysis reveals interesting findings about different factors contributing to reasoning, including the reward-guidance, breadth-vs-depth in search, world model, and prompt formats, etc.
## 1 Introduction
A central topic in Large Language Model (LLM) research is to enhance their ability of complex reasoning on diverse problems (e.g., logical reasoning, mathematical derivations, and embodied planning). Rich research has been done to generate multi-step reasoning chains with LLMs, such as Chain-of-Thoughts (CoT, Wei et al., 2022), Tree-of-Thoughts (ToT, Yao et al., 2023), Reasoning-via-Planning (RAP, Hao et al., 2023a), among others (Zhu et al., 2022; Xie et al., 2023; Zhuang et al., 2023; Khalifa et al., 2023; Creswell & Shanahan, 2022). However, despite the burgeoning body of literature, there lacks a systematic analysis and understanding of the diverse approaches, mainly due to two key challenges:
First, automatic evaluation of multi-step reasoning chains is difficult. Previous studies mostly rely on the accuracy of the final answers as a proxy for assessing the reasoning processes. However, as LLMs tend to produce unfaithful outputs or hallucinate, a correct final answer does not necessarily imply a logically sound reasoning chain (Figure 1, a) (Golovneva et al., 2022; Prasad et al., 2023; Tyen et al., 2023; Lyu et al., 2023; Liu et al., 2023).
∗ Equal contribution.
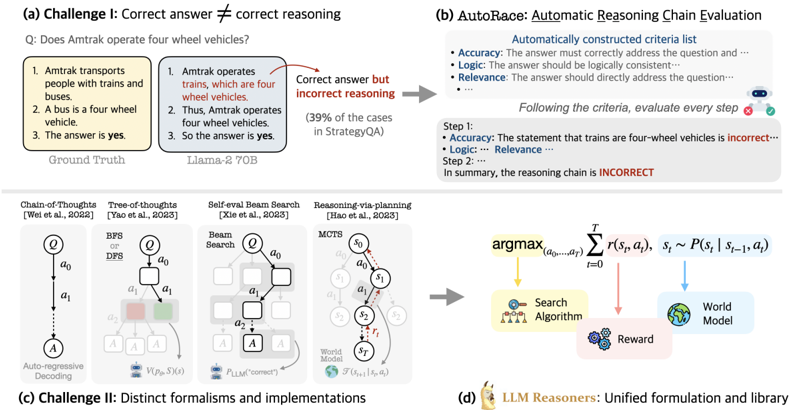
Figure 1: (a) The first challenge for analyzing step-by-step reasoning with LLMs: correct final answer may be derived from incorrect reasoning chains ( false-positive chains), making it necessary to evaluate the reasoning chains directly. (b) Our proposed AutoRace for fully automated evaluation. (c) The second challenge stems from the diverse reasoning algorithms with seemingly distinct designs. (d) Our LLM Reasoners provides a unified formulation and standardized implementation.
<details>
<summary>Image 2 Details</summary>
### Visual Description
## Diagram: Reasoning Challenges and Solutions
### Overview
The image presents a multi-part diagram illustrating challenges in reasoning for language models and potential solutions. It covers issues like correct answers with incorrect reasoning, distinct formalisms in reasoning implementations, and introduces a method called AutoRace for automatic reasoning chain evaluation.
### Components/Axes
* **(a) Challenge I: Correct answer ≠ correct reasoning:** This section highlights a scenario where a language model (Llama-2 70B) arrives at the correct answer but through flawed reasoning, contrasted with the "Ground Truth."
* **Question:** "Does Amtrak operate four wheel vehicles?"
* **Ground Truth:**
1. "Amtrak transports people with trains and buses."
2. "A bus is a four wheel vehicle."
3. "The answer is yes."
* **Llama-2 70B:**
1. "Amtrak operates trains, which are four wheel vehicles."
2. "Thus, Amtrak operates four wheel vehicles."
3. "So the answer is yes."
* **Annotation:** "Correct answer but incorrect reasoning" points from the Llama-2 70B example.
* "(39% of the cases in StrategyQA)" is noted below the Llama-2 70B example.
* **(b) AutoRace: Automatic Reasoning Chain Evaluation:** This section describes a method for evaluating the reasoning chain of a language model.
* **Automatically constructed criteria list:**
* "Accuracy: The answer must correctly address the question and..."
* "Logic: The answer should be logically consistent..."
* "Relevance: The answer should directly address the question..."
* **Process:** "Following the criteria, evaluate every step."
* "Step 1: Accuracy: The statement that trains are four-wheel vehicles is incorrect..."
* "Logic: Relevance..."
* "Step 2: ..."
* **Conclusion:** "In summary, the reasoning chain is INCORRECT."
* **(c) Challenge II: Distinct formalisms and implementations:** This section illustrates different approaches to reasoning, including:
* **Chain-of-Thoughts [Wei et al., 2022]:** A diagram shows a sequential process: Q -> a0 -> a1 -> A, labeled "Auto-regressive Decoding."
* **Tree-of-thoughts [Yao et al., 2023]:** A tree-like structure with nodes labeled Q, a0, a1, a2, and A. "BFS or DFS" is noted at the top. There is a V(P(s), S)(s) at the bottom.
* **Self-eval Beam Search [Xie et al., 2023]:** A diagram shows a beam search process with nodes labeled Q, a0, a1, a2, and A. "Beam Search" is noted at the top. There is a P_LLM("correct") at the bottom.
* **Reasoning-via-planning [Hao et al., 2023]:** A diagram shows a process with nodes labeled s0, s1, s2, and sT. "MCTS" is noted at the top. There is a F(s_t+1 | s_t, a_t) at the bottom.
* **(d) LLM Reasoners: Unified formulation and library:** This section presents a unified formulation for LLM reasoners.
* **Equation:** argmax_(a0,...,aT) Σ_(t=0)^T r(s_t, a_t), s_t ~ P(s_t | s_(t-1), a_t)
* **Components:**
* "Search Algorithm" (yellow)
* "Reward" (pink)
* "World Model" (blue)
### Detailed Analysis
* **Challenge I:** The example highlights that language models can arrive at the correct answer through incorrect reasoning. The Llama-2 70B model incorrectly assumes that Amtrak operates four-wheel vehicles, leading to the correct answer but based on a false premise.
* **AutoRace:** This method provides a structured way to evaluate the reasoning chain of a language model by assessing accuracy, logic, and relevance at each step.
* **Challenge II:** The diagrams illustrate different approaches to reasoning, including chain-of-thoughts, tree-of-thoughts, self-eval beam search, and reasoning-via-planning. Each approach has its own structure and implementation.
* **LLM Reasoners:** The unified formulation presents a general framework for LLM reasoners, incorporating a search algorithm, reward function, and world model.
### Key Observations
* Language models can arrive at the correct answer through incorrect reasoning.
* AutoRace provides a structured way to evaluate the reasoning chain of a language model.
* There are different approaches to reasoning, each with its own structure and implementation.
* The unified formulation presents a general framework for LLM reasoners.
### Interpretation
The diagram highlights the challenges in reasoning for language models and presents potential solutions. The example in Challenge I demonstrates that language models can arrive at the correct answer through incorrect reasoning, which can be problematic in many applications. AutoRace provides a structured way to evaluate the reasoning chain of a language model, which can help to identify and correct errors in reasoning. The diagrams in Challenge II illustrate different approaches to reasoning, each with its own strengths and weaknesses. The unified formulation presents a general framework for LLM reasoners, which can help to develop more robust and reliable reasoning systems.
</details>
Indeed, by manually evaluating 100 reasoning chains generated by Llama-2-70B on the StrategyQA questions (Geva et al., 2021), we found up to 39% of such false-positive cases that contain reasoning errors despite having correct final answers. Recent efforts have attempted to evaluate the reasoning chains directly, but often require non-trivial human efforts, such as human-written reasoning chains as references (Celikyilmaz et al., 2020), or manuallyannotated datasets for training evaluation models (Golovneva et al., 2022; Prasad et al., 2023; Xia et al., 2024). He et al. (2023); Tyen et al. (2023) use GPT-4 to alleviate human cost, but still require demonstration questions and in-depth error analyses by human experts before applying to each new task. In addition, their instructions that prompt GPT-4 for evaluation are not adaptive to different tasks, leading to suboptimal performance (Section 3.2).
Second, the varied reasoning approaches present distinct formalisms and implementations (Figure 1, c). The disparity makes it difficult to analyze the nuanced differences of their reasoning chain generation and compare their critical design elements. Therefore, it is desirable to have a more holistic formulation and unified implementation. This would reveal the underlying connections among different approaches, and facilitate a more systematic comparison when combined with automatic reasoning evaluation discussed above.
To tackle the challenges, this paper proposes an automatic method for reasoning chain evaluation, develops a cohesive library for various latest reasoning approaches, and on this basis, performs extensive analysis of LLM step-by-step reasoning. More specifically, we first present AutoRace (Automatic Reasoning Chain Evaluation) , a fully automated approach for evaluating reasoning chains that adapts to different tasks without human efforts (Figure 1, b). For each reasoning task (e.g., math reasoning), AutoRace autonomously constructs a detailed evaluation criteria list by summarizing errors in LLM-generated reasoning chains. The criteria list is then used to instruct GPT-4 to evaluate any given reasoning chains on the task. Compared to the predefined human-written prompts (Tyen et al., 2023; He et al., 2023), the AutoRace criteria lists are automatically customized for each task with GPT-4 to ensure accurate evaluation. On a wide range of tasks, AutoRace shows strong correlation with human evaluation, and manages to detect 70.4% of incorrect reasoning chains that cannot be captured by the conventional final-answer-based evaluation.
We then introduce a unified perspective of reasoning algorithms, formulating them as a search process towards maximizing accumulated rewards (Figure 1, d). A wide range of
existing reasoning algorithms can be interpreted as specific choices of the components in the unified formulation, including a reward function r to decide preferences on different reasoning steps, world model T to specify the reasoning state transition, and search algorithm (e.g., beam search, Monte-Carlo tree search) to explore the expansive reasoning space. Based on the unified perspective, we further develop the LLM Reasoners library that provides standardized implementation of these components with configurable options, plus rich LLM APIs and intuitive visualizations. As a result, LLM Reasoners allows us to easily reproduce the existing reasoning algorithms, and also compose new algorithms and apply to new tasks with minimal efforts.
With the new evaluation method and library, we conduct extensive analysis of reasoning chain generation of diverse LLMs and reasoning algorithms. We collect 6 challenging reasoning tasks that cover different reasoning skills (logical deduction, math, and embodied planning). Using a standardized evaluation protocol, we compare various most popular reasoning algorithms (e.g., CoT, ToT, RAP). The results offer a number of new insights into reasoning algorithm design-for example: (1) Reasoning as reward-guided search helps not only improve final accuracy, but also effectively alleviate false-positive reasoning chains; (2) For efficient search in the reasoning space, the breadth of search is generally more important than the depth for most tasks; (3) incorporating a world model that explicitly infers reasoning state would effectively improve the LLM reasoning ability, particularly for tasks in embodied environments; (4) inappropriate prompt format design might inadvertently lead to falsepositive reasoning chains. We also compare across diverse LLMs (GPT-4, Claude-3, Gemini, etc.) on their CoT reasoning chains. We release all code and experiments of AutoRace and LLM Reasoners at https://www.llm-reasoners.net/ , hoping to spur the progress of research on LLM complex reasoning.
## 2 Related Work
Evaluation of Reasoning Chains. Traditionally, to evaluate the reasoning process, generated reasoning chains are compared with human-written explanations, which is known as reference-based reasoning evaluation. Conventional natural language generation (NLG) metrics were applied to calculate the similarity between machine-generated chains and human-crafted ones (Celikyilmaz et al., 2020; Clinciu et al., 2021; Welleck et al., 2022). Towards reference-free reasoning evaluation, Dalvi et al. (2021); Saparov & He (2022); Han et al. (2022) designed structured reasoning tasks so that the reasoning process can be checked by a program automatically. Recently, ROSCOE (Golovneva et al., 2022) and ReCEval (Prasad et al., 2023) proposed reference-free metrics on general domains, measuring similarity, informativeness and correctness among steps. With the rapid development of LLM, Tyen et al. (2023) proposed to prompt GPT-4 with few-shot demonstrations, and Liu et al. (2023) experimented with knowledge-enhanced prompting by providing LLMs with relevant information. However, the results indicate that it's still challenging for LLMs to evaluate reasoning chains. He et al. (2023) crafted a detailed instruction inspired by the Socratic method, but the method requires GPT-4 to generate a reference chain at first, limiting its performance for challenging reasoning tasks that GPT-4 fails to solve. Besides, the fixed prompt template is not adjustable to different tasks, which also leads to suboptimal evaluation accuracy. In this work, we focus on LLM-based reference-free reasoning chain evaluation. Our method is generally more accurate and robust than existing metrics, while also saving any additional human efforts. Concurrent to our work, Xia et al. (2024) focused on the false postivie problem in mathmatical reasoning with a fine-tuned LLM as the evaluator. Paul et al. (2024) attempted to measure and improve the faithfulness of reasoning with causal inference.
Step-by-step Reasoning with LLMs. A common practice to enhance the reasoning with LLMs is to generate intermediate reasoning steps, employing methods such as chain-ofthought prompting (Wei et al., 2022; Kojima et al., 2022) or question decomposition (Zhou et al., 2022; Li et al., 2023). Inspired by the deliberate reasoning of humans, recent research has focused on searching for better reasoning chains guided by reward (Zhu et al., 2022; Xie et al., 2023; Yao et al., 2023; Zhuang et al., 2023; Khalifa et al., 2023; Creswell & Shanahan, 2022). Hao et al. (2023a) proposed to incorporate a world model into reasoning, which
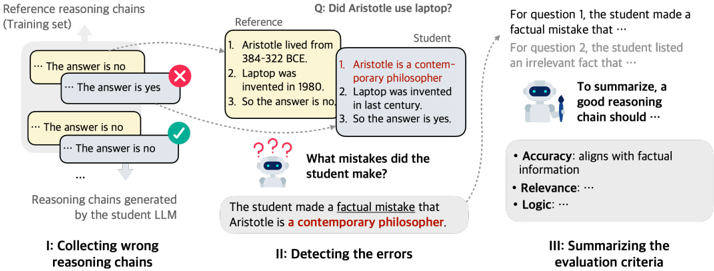
Figure 2: For any reasoning tasks (e.g., commonsense reasoning), AutoRace automatically constructs an evaluation criteria list to help itself evaluate reasoning chains in this domain.
<details>
<summary>Image 3 Details</summary>
### Visual Description
## Diagram: Reasoning Chain Evaluation
### Overview
The image illustrates a process for evaluating the reasoning chains generated by a student Large Language Model (LLM). It involves collecting wrong reasoning chains, detecting errors, and summarizing the evaluation criteria. The diagram compares reference reasoning chains with those produced by the student LLM, highlighting factual inaccuracies and irrelevant information.
### Components/Axes
* **Title:** Q: Did Aristotle use laptop?
* **Sections:** The diagram is divided into three sections, labeled I, II, and III.
* I: Collecting wrong reasoning chains
* II: Detecting the errors
* III: Summarizing the evaluation criteria
* **Reference Reasoning Chains (Training set):** Located in the top-left corner. Contains example reasoning chains.
* **Reasoning chains generated by the student LLM:** Located below the "Reference Reasoning Chains".
* **Reference:** A box containing factual statements.
* 1. Aristotle lived from 384-322 BCE.
* 2. Laptop was invented in 1980.
* 3. So the answer is no.
* **Student:** A box containing the student LLM's reasoning.
* 1. Aristotle is a contemporary philosopher.
* 2. Laptop was invented in last century.
* 3. So the answer is yes.
* **Error Detection:** A question mark icon with the text "What mistakes did the student make?"
* **Error Summary:** "The student made a factual mistake that Aristotle is a contemporary philosopher."
* **Evaluation Criteria:**
* Accuracy: aligns with factual information
* Relevance: ...
* Logic: ...
### Detailed Analysis
* **Section I: Collecting wrong reasoning chains:**
* Shows a series of reasoning chains. Some are marked with a red "X" indicating an error, while others are marked with a green checkmark indicating correctness.
* Example reasoning chains include phrases like "... The answer is no" and "... The answer is yes".
* **Section II: Detecting the errors:**
* Compares the "Reference" and "Student" reasoning.
* The "Reference" provides factual information: Aristotle's lifespan and the invention year of the laptop.
* The "Student" provides incorrect reasoning: stating Aristotle is a contemporary philosopher and misdating the laptop invention.
* The error summary highlights the factual mistake regarding Aristotle.
* **Section III: Summarizing the evaluation criteria:**
* Lists the criteria for evaluating reasoning chains: Accuracy, Relevance, and Logic.
* Provides a partial description of Accuracy: "aligns with factual information".
### Key Observations
* The diagram focuses on identifying and categorizing errors in the reasoning chains generated by an LLM.
* The comparison between "Reference" and "Student" reasoning is central to the error detection process.
* The evaluation criteria emphasize the importance of factual accuracy, relevance, and logical consistency.
### Interpretation
The diagram illustrates a method for evaluating the quality of reasoning chains produced by a student LLM. It highlights the importance of comparing the LLM's reasoning with factual information to identify errors. The process involves collecting examples of incorrect reasoning, pinpointing the specific mistakes made by the LLM, and summarizing the key criteria for evaluating reasoning chains. The diagram suggests that a good reasoning chain should be accurate, relevant, and logically sound. The example provided shows the LLM making a factual error by mischaracterizing Aristotle as a contemporary philosopher, demonstrating the need for rigorous evaluation of LLM-generated content.
</details>
simulates the state of the world. This enables LLMs to reason in a manner close to humans' conscious planning. Hu & Shu (2023) presented the LAW formulation that connects the concepts of language models, agent models, and world models for more advanced and robust reasoning. Xiang et al. (2024) delivered a towards the goal of building a general world model for machine reasoning. We include a more systematic summary of reasoning algorithms in Section 4. Related to the scope of this paper, recent works (Welleck et al., 2024; Chen et al., 2024) also surveyed and analyzed tree search for reasoning.
## 3 AutoRace: Automatic Reasoning Chain Evaluation
In this section, we present AutoRace that offers more insights into the LLM reasoning process than final answer correctness (Figure 1). Compared to previous works (Tyen et al., 2023; He et al., 2023) that prompt GPT-4 with fixed human-written instructions, AutoRace involves a 'learning' process, which helps it to adapt to any problem domains. Specifically, for each task, AutoRace automatically collects LLM-generated incorrect reasoning chains, and summarizes evaluation criteria from them (Figure 2). With the criteria, GPT-4 can pay more attention to common errors for this certain domain, and make a more accurate evaluation. Compared to previous works that train an evaluation model (Golovneva et al., 2022; Prasad et al., 2023) by optimization model parameters, AutoRace effectively leverages GPT-4's strong prior knowledge, so that it is able to learn from only incorrect reasoning chains, which can be collected automatically.
## 3.1 Evaluation Method
To formulate the problem, we consider a reasoning question x , and LLM-generated reasoning chains z , and the predicted answer y . Additionally, we have the reference answer yr , accompanied by a reference reasoning chain zr , which are available in the training set Dtrain of most existing reasoning datasets. Our goal is to develop an automatic evaluation metric for the reasoning chain, s ( z ) ∈ { 0, 1 } , which is better aligned with human evaluation of the reasoning chains.
̸
As the first step to criteria list construction, one needs to find out what kinds of errors are common for a task. Therefore, AutoRace is designed to condense the criteria from real mistakes in LLM-generated reasoning chains (Figure 2, I). Here, we make use of the fact that a reasoning chain reaching a wrong answer must include an intermediate mistake. Given a sub-sampled training set D = { ( x , yr , zr ) } ⊂ Dtrain , we run Chain-of-Thoughts reasoning with an LLM (referred as the student LLM) to expand the dataset to D ′ = { x , yr , zr , y , z } , where z is the reasoning chain generated by the student and y is the predicted answer extracted from z . Then, we can filter out a subset where the generated answers disagree with the reference answers, D error = { ( x , yr , zr , y , z ) ∈ D ′ | yr = y } .
Table 1: Evaluation accuracy of various reasoning chain evaluation metrics. We also list the accuracy of answer-based evaluation as a reference. Note that AutoRace is the only metric that does not take any human inputs specific to reasoning tasks (i.e., fully automated). We highlight the best reasoning chain metrics (dark green) and metrics within 5% of the best performance (light green) for each task. AutoRace achieves the best average accuracy and is robust across datasets.
| Method | Math | Math | Common | Common | Logical | Logical | Average | Fully Auto. |
|-----------------|--------|--------|----------|----------|-----------|-----------|-----------|---------------|
| Method | GSM8k | Arith | Strategy | Cosmos | Logic | Sort | Average | Fully Auto. |
| Answer-based | 0.94 | 0.94 | 0.76 | 0.67 | 0.87 | 0.94 | 0.85 | |
| SocREval | 0.89 | 0.85 | 0.71 | 0.80 | 0.89 | 0.77 | 0.82 | ✗ |
| Direct (trace) | 0.90 | 0.38 | 0.80 | 0.72 | 0.21 | 0.36 | 0.56 | ✗ |
| Direct (step) | 0.85 | 0.43 | 0.83 | 0.73 | 0.75 | 0.33 | 0.65 | ✗ |
| CoT (step) | 0.78 | 0.74 | 0.78 | 0.72 | 1.00 | 0.86 | 0.81 | ✗ |
| AutoRace (Ours) | 0.91 | 0.85 | 0.79 | 0.78 | 0.97 | 0.86 | 0.86 | ✓ |
Having these reasoning chains with errors, the next goal is to compile a criteria list. To reduce the difficulty, we divide it into two simple steps: Detection and Summarization . The Detection step identifies the specific errors in a reasoning chain. GPT-4 is presented with the question, the reference reasoning chain, and the student reasoning chain. It is then instructed to point to the mistake in the student reasoning chain (Figure 2, II). The underlying rationale is that, even if the question x might be challenging for GPT-4 to solve on its own, it has a good chance of understanding the question and identifying the mistakes once it has access to the reference reasoning chain.
After collecting the errors in reasoning chains, GPT-4 is prompted to summarize these specific instances into a criteria list (Figure 2, III). Eventually, GPT-4 is able to evaluate any new reasoning chain z given a question x , by checking each criteria on each reasoning step. The prompt template of each phrase is in Appendix A.7.
## 3.2 Experiments
To measure the efficacy of reasoning chain evaluation metrics, we use human-annotated binary labels of reasoning chains as the ground truth, and calculate their accuracy.
Datasets. We experiment on 6 datasets covering mathematical, commonsense and logical reasoning. 5 of them are from previous works (Golovneva et al., 2022; Tyen et al., 2023), originating from GSM8K (Cobbe et al., 2021), Multistep-Arithmetics (Srivastava et al., 2023), DROP (Dua et al., 2019), COSMOS-QA (Huang et al., 2019), Logical-Deduction (Srivastava et al., 2023) and Word-Sorting (Srivastava et al., 2023). We additionally sample and manually label reasoning chains from StrategyQA (Geva et al., 2021). The detailed statistics of these datasets can be found in Appendix A.
Baselines. We compare AutoRace with other LLM-based evaluation metrics for reasoning chains. (a) SocREval (He et al., 2023) crafted a detailed instruction prompt for GPT-4 through the Socratic method, which includes asking it to generate a reference reasoning chain before evaluation. This method also requires a one-shot demonstration written by humans for each task. Tyen et al. (2023) proposed three methods: (b) Direct (trace) asks GPT-4 to directly evaluate a reasoning chain; (c) Direct (step) asks GPT-4 to check the reasoning step by step; (d) CoT (step) asks GPT-4 to generate a reasoning process before evaluating each reasoning step. All these methods require 3-shot demonstrations written by humans. We don't experiment with metrics based on fine-tuned small models (Golovneva et al., 2022; Prasad et al., 2023), as existing literature has already indicated a substantial performance gap between these methods and LLM-based metrics (He et al., 2023).
Results. We collect 4 incorrect reasoning chains for each task to create the criterion list. The results are presented in Table 1. We can observe that among all metrics for reasoning chains, AutoRace achieves the best overall performance. It excels in 3 out of 6 tasks and exhibits robustness, maintaining performance levels within 5% of the best results across the
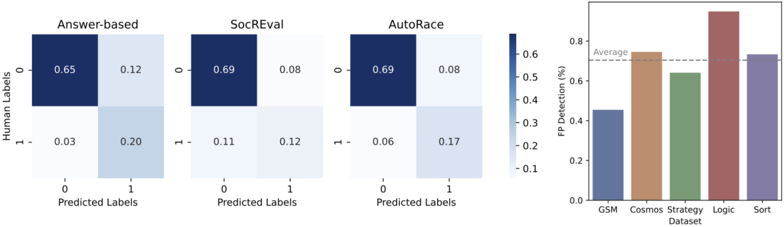
Figure 3: Analysis on different reasoning chain evaluation methods: (Left) The macroaveraged confusion matrix of these methods. SocREval and AutoRace are both good at detecting incorrect reasoning chains, while SocREval mistakenly classifies correct reasoning chains as wrong more frequently. (Right) AutoRace can recognize 70.4% of the false positive reasoning chains, showing the promise to be a great complement to answer accuracy.
<details>
<summary>Image 4 Details</summary>
### Visual Description
## Chart Type: Combined Confusion Matrices and Bar Chart
### Overview
The image presents a combination of confusion matrices and a bar chart. The confusion matrices show the performance of three different models ("Answer-based", "SocREval", and "AutoRace") in predicting labels. The bar chart displays the False Positive (FP) detection rates (%) for different datasets ("GSM", "Cosmos", "Strategy", "Logic", and "Sort").
### Components/Axes
**Confusion Matrices (Left Side):**
* **Titles:** "Answer-based", "SocREval", "AutoRace" (placed above each matrix)
* **Axes:**
* Y-axis (vertical): "Human Labels" with values 0 and 1.
* X-axis (horizontal): "Predicted Labels" with values 0 and 1.
* **Cells:** Each cell contains a numerical value representing the proportion of predictions. The color of the cell corresponds to the value, with darker blue indicating higher values.
* **Color Scale:** A vertical color bar indicates the mapping between color and value, ranging from approximately 0.1 to 0.6.
**Bar Chart (Right Side):**
* **Title:** Implicitly represents FP Detection rates across different datasets.
* **Axes:**
* Y-axis (vertical): "FP Detection (%)" ranging from 0.0 to 0.8.
* X-axis (horizontal): "Dataset" with categories "GSM", "Cosmos", "Strategy", "Logic", and "Sort".
* **Bars:** Each bar represents the FP detection rate for a specific dataset.
* **Average Line:** A dashed horizontal line labeled "Average" is present at approximately 0.7.
### Detailed Analysis
**Confusion Matrices:**
* **Answer-based:**
* (0, 0): 0.65 (dark blue)
* (0, 1): 0.12 (light blue)
* (1, 0): 0.03 (very light blue)
* (1, 1): 0.20 (light blue)
* **SocREval:**
* (0, 0): 0.69 (dark blue)
* (0, 1): 0.08 (very light blue)
* (1, 0): 0.11 (light blue)
* (1, 1): 0.12 (light blue)
* **AutoRace:**
* (0, 0): 0.69 (dark blue)
* (0, 1): 0.08 (very light blue)
* (1, 0): 0.06 (very light blue)
* (1, 1): 0.17 (light blue)
**Bar Chart:**
* **GSM:** Approximately 0.45 (blue-gray)
* **Cosmos:** Approximately 0.75 (brown)
* **Strategy:** Approximately 0.63 (green)
* **Logic:** Approximately 0.90 (red-brown)
* **Sort:** Approximately 0.72 (purple)
### Key Observations
* The confusion matrices show that all three models ("Answer-based", "SocREval", and "AutoRace") perform well in predicting the '0' label, as indicated by the high values in the top-left cells.
* The "Logic" dataset has the highest FP detection rate, significantly above the average.
* The "GSM" dataset has the lowest FP detection rate.
* "Cosmos" and "Sort" datasets have similar FP detection rates, close to the average.
### Interpretation
The confusion matrices provide insights into the classification performance of the three models. The high values on the diagonal suggest that the models are generally accurate in their predictions. The bar chart highlights the variability in FP detection rates across different datasets. The "Logic" dataset's high FP detection rate could indicate that it is more challenging for the models to classify correctly, leading to more false positives. The "GSM" dataset, on the other hand, appears to be easier to classify. The average line provides a benchmark for comparing the performance of the models on different datasets.
</details>
board. Note that different from all baseline, which requires human-written demonstrations, AutoRace does not need any human input specific to reasoning tasks. Indicated by the confusion matrix (Figure 3, left), AutoRace is good at detecting incorrect reasoning chains, without sacrificing the performance in correct reasoning chains. On the contrary, SocREval mistakenly classifies many correct reasoning chains to be incorrect. Since SocREval asks GPT-4 to generate its own response as the reference, whenever GPT-4 fails to solve the problem itself, it's very likely to evaluate the reasoning chain to be incorrect, misled by the wrong reference. AutoRace enables GPT-4 to evaluate reasoning chains on problems that it fails to solve itself, as a case study shown in Figure 7. Specifically, in a problem from MultiArith, a task for testing multi-digit arithmetic, SocREval fails because GPT-4 generates the reference with the same mistakes as the reasoning chain to be evaluated, but AutoRace identifies the subtle errors with the detailed criteria. We include more detailed results in Appendix A, that indicate AutoRace is robust to the number of incorrect reasoning chains used for construct criteria construction, the required cost for API call is reasonable, and the criteria lists are transferable across tasks to a certain extent.
Moreover, when compared with the answer-based metric, AutoRace also outperforms it in 3 of 6 tasks and exhibits better overall performance. We additionally calculate the accuracy of AutoRace on reasoning chains with mistakes but reaching a correct answer (false positive reasoning chains), and it turns out that AutoRace managed to detect 70.4% of the false positive reasoning chains averaged across different tasks (Figure 3, right). We examine some false positive reasoning chains detected by AutoRace , and find the explanation given by AutoRace is mostly reasonable. The false positive reasoning chains can be classified into 3 types (Table 10). Based on these results, we believe AutoRace would be a useful metric complementary to answer-based evaluation.
## 4 LLM Reasoners: A Unified Formulation and Library
Besides reasoning chain evaluation, another difficulty in the analysis of reasoning algorithms lies in their distinct formulations and implementations. To investigate the critical design elements that affect the nuanced performance, we aim to deliver a more holistic formulation (Section 4.1) and unified implementation (Section 4.2) in this section.
## 4.1 Unified Formulation
There has been rich research on constructing reasoning chains to solve problems using LLMs, from the simplest CoT prompting (Wei et al., 2022), to tree search algorithms guided by a reward function (Yao et al., 2022; Xie et al., 2023; Hao et al., 2023a) and a world model (Hao et al., 2023a). These methods, among many others, can be formulated as a search
process that maximizes the accumulated reward argmax ( a 0 ,..., a T ) ∑ T t = 0 r ( st , at ) , with a world model that predicts state transition st ∼ T ( ·| st -1 , at -1 ) , and a search algorithm to optimize the objective. This section elaborates on these three crucial components and demonstrates how recent reasoning algorithms can be interpreted as special cases within this framework, with specific choices of these three components (Table 2).
World model. The world model defines the state transition distribution T ( st | st -1 , at -1 ) . For example, we can formulate the reasoning state of CoT (Wei et al., 2022) as the list of all previous actions, i.e., st = ( a 0, a 1 , ..., at -1 ) , and thus the world model represents a deterministic transition which always appends an action to the action history. Beyond this trivial definition, recent studies seek a more substantive depiction of the reasoning state, e.g., the description of the physical environment, or the set of known variables, etc. To track the reasoning state, Liu et al. (2022); Guan et al. (2023) augment LLMs with a physical engine or PDDL domain model. Li et al. (2023) train a model to predict the entity states as a latent variable, and RAP (Hao et al., 2023a) apply the LLM as a general world model for reasoning. When the LLM can interact with the external environment, e.g., calling tools (Zhuang et al., 2023), the environment is the world model. For prompt optimization (Wang et al., 2023b) or adversarial attack (Guo et al., 2024), the target LLM also performs the role of a world model as it provides a feedback to a prompt. Recent work started to develop multi-modal world models at scale, such as GAIA-1 (Hu et al., 2023) for auto-driving, UniSim (Yang et al., 2023) for robotic manipulation, Genie (Bruce et al., 2024) for 2D games, and Pandora (Xiang et al., 2024), towards a general world model that generates next video state given natural language as inputs.
Reward function. The reward function r ( st , at ) decides whether a reasoning step is desired. CoT implicitly employs the likelihood predicted by the language models as the reward, as it generates the next reasoning step with high likelihood conditioned on previous steps and a CoT prompt, i.e., r ( st , at ) = pLLM ( at | a 0, ..., at -1 , PCoT ) . Yao et al. (2023); Hao et al. (2023a); Xie et al. (2023); Ouyang et al. (2023) propose to use self-evaluation as the reward, asking the LLM to choose if the last action is "correct" or "wrong", or output a confidence score with a self-evaluation prompt, e.g., r ( st , at ) = pLLM ( "correct" | st , at , Psel f -eval ) . Cobbe et al. (2021); Paul et al. (2023); Yuan et al. (2024) train outcome-supervised reward models (ORMs) to evaluate a reasoning chain, which predicts the reward for a complete reasoning chain. More recent works (Khalifa et al., 2023; Lightman et al., 2023; Sun et al., 2024; Wang et al., 2023a) train step-by-step reward models with process supervision (PRM), to provide a more accurate reward for every step. One can also define task-specific heuristic functions as rewards (Zhuang et al., 2023; Hao et al., 2023a).
Search Algorithm. The expansive reasoning space makes exhaustive search infeasible and calls for the use of more efficient search algorithms. For example, CoT implicitly applies greedy decoding for the reasoning step with the highest reward 1 . Another common technique is to sample multiple reasoning chains, and return the one with the highest accumulated reward (Cobbe et al., 2021; Lightman et al., 2023; Wang et al., 2023a), which in essence is a random shooting algorithm (Kothare et al., 1996). Other widely used search algorithms include DFS (Yao et al., 2023), beam search (Xie et al., 2023), A* (Zhuang et al., 2023), and MCTS (Hao et al., 2023a; Zhao et al., 2024; Chi et al., 2024). An alternative paradigm is learning a policy model to maximize the reward (Havrilla et al., 2024; Shao et al., 2024) with RL, or sample proportional to reward (Yu et al., 2024) for diverse reasoning.
## 4.2 Library Design
LLM Reasoners implements our unified formulation for multi-step reasoning with a modular design. As illustrated in Figure 4, users can easily set up a reasoning method by defining the WorldModel and SearchConfig , and importing a SearchAlgorithm . Building on these three main base classes, LLM Reasoners has included new components to augment reasoning, e.g., pre-trained reward models (Yuan et al., 2024), tool-calling modules (Yao et al., 2022; Hao et al., 2023b), and new examples like scientific reasoning, e.g., for chemistry (Ouyang et al.,
1 It's usually implemented as token-level greedy decoding.
Table 2: Representative reasoning algorithms, including CoT (Wei et al., 2022), ToT (Yao et al., 2023), Self-Eval (Xie et al., 2023), Toolchain ∗ (Zhuang et al., 2023), ORM (Cobbe et al., 2021), PRM (Lightman et al., 2023), SitSup (Li et al., 2023), RAP (Hao et al., 2023a), summarized in terms of the reward function, world model, and search algorithm.
| Method | Reward r | World Model | Search Alg. |
|-------------|------------------------------------------------------------|--------------------------------------------------|---------------|
| CoT | p LLM ( a t | a 0 , ..., a t - 1 , P CoT ) | s t = ( a 0 , ..., a t - 1 ) | Gready |
| ToT | p LLM ( "correct" | a 0 , ..., a t , P sel f _ eval ) | s t = ( a 0 , ..., a t - 1 ) | BFS/DFS |
| Self-Eval | p LLM ( "correct" | a 0 , ..., a t , P sel f _ eval ) | s t = ( a 0 , ..., a t - 1 ) | Beam search |
| Toolchain ∗ | LST, self-consistency, etc. | s t = f tool ( s t - 1 , a t - 1 ) | A* search |
| ORM | f ORM ( s t , a t ) if t = T , else 0 | s t = ( a 0 , ..., a t - 1 ) | Rand. Shoot. |
| PRM | f PRM ( s t , a t ) | s t = ( a 0 , ..., a t - 1 ) | Rand. Shoot. |
| SitSup | f finetuned ( s t , a t ) | s t ∼ p finetuned ( · | s t - 1 , a t - 1 ) | Greedy |
| RAP | Likelihood, self-eval., etc. | s t ∼ p LLM ( · | s t - 1 , a t - 1 ) | MCTS |
2023). We have also integrated rich LLM APIs, standard evaluation pipelines, and a general interactive visualization tool visualizer .
```
```
Figure 4: The three key components in a reasoning algorithm, reward function , world model , and search algorithm in the formulation (top), correspond to three classes in LLM Reasoners . To implement a reasoning algorithm for a certain domain (a Reasoner object), a user may inherit the SearchConfig and WorldModel class, and import any SearchAlgorithm .
World Model. The WorldModel class is responsible for managing all the state changes during reasoning. It includes init\_state to create the initial state, step to predict the next states, and is\_terminal to identify terminal states. Utilizing our consistent API, users can effortlessly implement a world model for a specific task, or adapt the default world model recording previous actions, as done in CoT (Wei et al., 2022), ToT (Yao et al., 2023), etc.
Search Configuration. The SearchConfig class mainly includes two important functions: get\_actions to decide the action space under each state to facilitate searching, and reward to assess the quality of each reasoning step.
Search Algorithm. The SearchAlgorithm specifies the strategy to explore the reasoning space. We have implemented several search algorithms in our library, e.g., Greedy Decoding (Khalifa et al., 2023), Beam Search (Xie et al., 2023; Creswell & Shanahan, 2022), Depth-first Search (Yao et al., 2023), and Monte-Carlo Tree Search (Hao et al., 2023a). These algorithms are designed to work seamlessly with any world model and search configuration on any reasoning task.
Other Features. LLM Reasoners has integrated To power these modules above with LLMs conveniently, we offer a standardized interface LanguageModel that supports a range of LLM libraries, including HuggingFace transformers (Wolf et al., 2020), facebookresearch/llama (Touvron et al., 2023a;b), APIs of GPT (OpenAI, 2023), Claude and Gemini (Team et al., 2023). We also integrated libraries specialized in quantization, like Exllama (Frantar et al.,
2022), to reduce the hardware requirements. Additionally, the Benchmark class provides a standard platform (e.g., standard prompts, evaluation methods) for a collection of widely recognized reasoning tasks, such as GSM8k (Cobbe et al., 2021), StrategyQA (Geva et al., 2021), and Blocksworld (Valmeekam et al., 2023). We also include Visualizer , an interactive visualization tool that allows for the straightforward depiction of the search trees. This tool significantly lowers the complexity of developing and analyzing the complicated reasoning process. More details with an example are shown in Appendix B.1.
## 5 Analysis of LLM Step-by-step Reasoning
To better understand multi-step reasoning algorithms and analyze the design elements critical to better reasoning performance, we evaluate them on diverse reasoning datasets, utilizing our AutoRace metric and LLM Reasoners library.
## 5.1 Datasets
For a comprehensive evaluation, we first collect reasoning tasks of several categories, where each category requires different reasoning skills.
Mathematical Reasoning. We select (1) GSM8k (Cobbe et al., 2021), a popular dataset of math word problems that requires understanding the relationship between numbers and multiple steps of mathematical calculation; (2) AQuA (Ling et al., 2017), which additionally requires the skill to perform algebra operations. Both answer-based and AutoRace metrics are employed on these two datasets. We also include the famous (3) Game of 24 , following the settings in Yao et al. (2023). This task requires constructing an equation with four given numbers and basic arithmetic operations. We evaluate the reasoning chain on Game of 24 with a program.
Commonsense Reasoning. We take StrategyQA (Geva et al., 2021) as the commonsense reasoning dataset. Each sample is an open-domain yes-no question that requires raising related commonsense knowledge and multiple steps of inference. We evaluate the reasoning chain using both answer-based and AutoRace metrics.
Logical Reasoning. The tasks involve a set of logical principles, initial statements, and a concluding hypothesis. The challenge is to perform multi-step deductions to determine if the final hypothesis is true. We use PrOntoQA (Saparov & He, 2022) in this category. The evaluation is based on a rule-based program, since the problems are from a close domain.
Embodied Planning. The capability of LLMs to power embodied agents presents an interesting area of study, as it involves the understanding of the physical world, and requires a strong planning ability toward the goal. To assess this capacity for embodied planning, we employ the Blocksworld benchmark (Valmeekam et al., 2023), where an agent must reach a specific block stacking arrangement through moving operations such as PickUp and Stack . For evaluation, we examine whether the generated chain is valid and can lead to the target state with a simulator.
## 5.2 Evaluating Reasoning Algorithms
Compared methods. To analyze the connections between recent step-by-step reasoning methods, we pick three representative methods, CoT (Wei et al., 2022), ToT (Yao et al., 2023), and RAP (Hao et al., 2023a). Different CoT which autoregressively decodes the reasoning chain, ToT and RAP define the reward and include tree search algorithms. RAP additionally incorporates an explicit world model.
Configurations. For ToT and RAP, we mainly apply the combination of two rewards: (1) Self-evaluation: Prompting the LLMs to evaluate the new action, and use the logits of 'good' as the reward, P θ ( "Good" | s , a ) . (2) Likelihood: Calculating the log-likelihood of predicting the next action given the current state, i.e., P θ ( a | s ) . The definition of states and the world model for RAP depends on the reasoning tasks. Benefiting from the explicit world model,
Table 3: Experimental results of various reasoning methods on every dataset. On three datasets marked with ∗ , we evaluate with AutoRace , and also show the answer-based (in brackets) for reference. On other datasets, we evaluate the reasoning chain with oracle verifiers (e.g., a rule-based program, or a simulator) due to their nature of close domains. The best method in every metric is highlighted in bold .
| Method | Math | Math | Math | Logical | Common StrategyQA ∗ | Embodied Blocks |
|-----------|---------------|---------------|--------|-----------|-----------------------|-------------------|
| Method | GSM8k ∗ | AQuA ∗ | Game24 | PrOnto | | |
| CoT | 0.37 (0.54) | 0.09 (0.34) | 0.04 | 0.58 | 0.34 (0.76) | 0.05 |
| ToT (BFS) | 0.53 (0.58) | 0.15 (0.42) | 0.04 | 0.52 | 0.41 (0.76) | 0.09 |
| ToT (DFS) | 0.45 (0.52) | 0.10 (0.36) | 0.07 | 0.44 | 0.42 (0.76) | 0.08 |
| RAP | 0.58 ( 0.64 ) | 0.20 ( 0.47 ) | 0.07 | 0.59 | 0.28 ( 0.77 ) | 0.51 |
there are also other rewards available for RAP on certain tasks. More details about RAP implementation are described in Appendix C.1.
Implementation details. To ensure reproducibility and accessibility, we use one of the leading open-sourced LLMs, Llama 2 70B (Touvron et al., 2023b), quantized with GPT-Q (Frantar et al., 2022) for all tasks and methods. To make a fair comparison, we restrict search-based methods to explore up to 10 reasoning chains: The breadth limit is 10 for ToT (BFS), the maximum number of visited terminal nodes is 10 for ToT (DFS), and the maximum number of iterations is 10 in RAP, which is based on Monte-Carlo Tree Search. We manually crafted 10 examples of reasoning chains for each task, and all methods share this same example pool. For each test case, 4 examples are randomly sampled to form the demonstrations in the prompt, resulting in a 4-shot learning setting.
## 5.2.1 Results
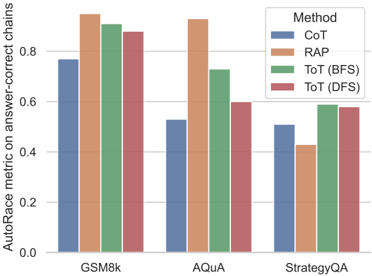
Table 1 shows a comparative analysis of step-by-step reasoning algorithms. Overall, ToT consistently outperforms the vanilla CoT, and RAP further improves upon ToT. Notably, the evaluation metric ( AutoRace ) is generally lower than the answer-based metric, especially in the AQuA and StrategyQA datasets. This discrepancy suggests significant potential for enhancements in future reasoning algorithms. We outline several key findings below.
Reward-guided Search Reduces False Positives. Enhanced exploration in the reasoning space, facilitated by effective reward functions, naturally leads to the superior performance of search-based methods (ToT and RAP) over the autoregressive decoding method CoT. However, a noteworthy observation is that these search-based methods also yield fewer false positive reasoning chains, indicated by the smaller gap between AutoRace and answerbased metric (Table 3), and higher AutoRace score of reasoning chains with correct answers (Figure 5). Further examination of examples with ToT (BFS) reveals that it effectively avoids some false positives by discarding reasoning steps with low rewards. In contrast, CoT lacks this mechanism to 'regret'. E.g., in type-A false positive chains made by CoT (Table 10), while some reasoning mistakes are identifiable by the LLM itself, CoT fails to amend errors from previous steps, only able to overlook them in the following steps.
Importance of Search Breadth Over Depth. By comparing two variants of ToT, ToT (BFS) and ToT (DFS), our results show that BFS is relatively better on two math word problems, logical and embodied tasks. This indicates that when the search space is expansive, such as in these complex math, logic, and embodied planning tasks, DFS may sink into inappropriate reasoning subspace with the first steps, thereby failing to explore the full space. In contrast, for tasks with a limited search space, such as Game-24, DFS doesn't hamper the exploration.
Crucial Role of World Model in Embodied Tasks. RAP stands out as the most effective method across most datasets, thanks to its explicit world model. This enables the LLM to predict and track state changes during reasoning, allowing for decisions based on the current state. Specifically, it outperforms ToT by 42% on Blocksworld. As previous research suggests (Xiang et al., 2023), LLMs miss essential embodied knowledge and skills, e.g., tracking objects over long action sequences. Thus, an explicit world model that maintains
the current state would greatly reduce the difficulties in memorizing or reasoning about previous actions in an embodied environment.
Impact of Prompt Format on False Positives. Interestingly, StrategyQA witnesses a higher false positive rate of RAP (Figure 5). Based on errors identified by AutoRace , we discovered a common failure mode from the reasoning chains generated by RAP: The prompt design that guides LLMs to iteratively ask and answer sub-questions encourages LLMs to generate excessive details. This makes it easier to introduce factual errors but does not necessarily affect the accuracy of final answers. For example, for the problem presented in Appendix C.2, RAP raises the incorrect number 7,000 in the explanation, which is identified as an error by AutoRace . Conversely, CoT avoids this pitfall by not delving into unnecessary details. It's worth noting that, this prompt format is not a problem for math reasoning tasks, including GSM8k and AQuA, because every detail needs to be accurate to solve a math problem.
Figure 5: AutoRace metric of different reasoning methods on answer-correct chains. We find search-based methods, ToT and RAP have higher AutoRace scores, indicating fewer false positive reasoning chains.
<details>
<summary>Image 5 Details</summary>
### Visual Description
## Bar Chart: AutoRace Metric Comparison
### Overview
The image is a bar chart comparing the performance of different methods (CoT, RAP, ToT (BFS), ToT (DFS)) on three datasets (GSM8k, AQuA, StrategyQA) using the AutoRace metric on answer-correct chains. The chart displays the metric values for each method on each dataset, allowing for a direct comparison of their effectiveness.
### Components/Axes
* **Y-axis:** "AutoRace metric on answer-correct chains". The scale ranges from 0.0 to 0.8, with increments of 0.2.
* **X-axis:** Datasets: GSM8k, AQuA, StrategyQA.
* **Legend:** Located at the top-right of the chart.
* CoT (Chain-of-Thought): Blue
* RAP (Retrieval-Augmented Prompting): Orange
* ToT (BFS) (Tree of Thoughts, Breadth-First Search): Green
* ToT (DFS) (Tree of Thoughts, Depth-First Search): Red
### Detailed Analysis
**GSM8k Dataset:**
* CoT (Blue): Approximately 0.77
* RAP (Orange): Approximately 0.92
* ToT (BFS) (Green): Approximately 0.90
* ToT (DFS) (Red): Approximately 0.88
**AQuA Dataset:**
* CoT (Blue): Approximately 0.53
* RAP (Orange): Approximately 0.91
* ToT (BFS) (Green): Approximately 0.70
* ToT (DFS) (Red): Approximately 0.90
**StrategyQA Dataset:**
* CoT (Blue): Approximately 0.51
* RAP (Orange): Approximately 0.43
* ToT (BFS) (Green): Approximately 0.59
* ToT (DFS) (Red): Approximately 0.58
### Key Observations
* RAP consistently performs well across all datasets, often achieving the highest AutoRace metric.
* CoT generally has the lowest performance compared to the other methods.
* The performance of ToT (BFS) and ToT (DFS) is relatively similar within each dataset.
* The performance variance across datasets is significant for all methods.
### Interpretation
The bar chart provides a comparative analysis of different methods for improving the accuracy of answer chains. The AutoRace metric on answer-correct chains serves as the evaluation criterion.
* **RAP's Superiority:** The consistently high performance of RAP suggests that retrieval-augmented prompting is an effective strategy for enhancing the quality of answer chains across various datasets.
* **CoT's Limitations:** The lower performance of CoT indicates that simply generating chains of thought may not be sufficient for achieving high accuracy, especially when compared to methods that incorporate retrieval or tree-based search.
* **ToT's Effectiveness:** The performance of ToT (BFS) and ToT (DFS) demonstrates the potential of tree-based search strategies for improving answer chain accuracy. The similarity in performance between BFS and DFS suggests that the search strategy may not be as critical as the overall tree-of-thoughts approach.
* **Dataset Dependency:** The significant performance variance across datasets highlights the importance of considering the specific characteristics of each dataset when evaluating and comparing different methods. Some methods may be more suitable for certain types of questions or reasoning tasks.
In summary, the data suggests that retrieval-augmented prompting (RAP) is a particularly effective strategy for improving the accuracy of answer chains, while simple chain-of-thought generation (CoT) may be less effective. Tree-of-thoughts approaches (ToT) also show promise, and the choice of search strategy (BFS vs. DFS) may not be as critical as the overall tree-based approach. The performance of each method is also highly dependent on the specific dataset being used.
</details>
This suggests that prompt design should be tailored to the task domain.
## 5.3 Evaluating Leading LLMs
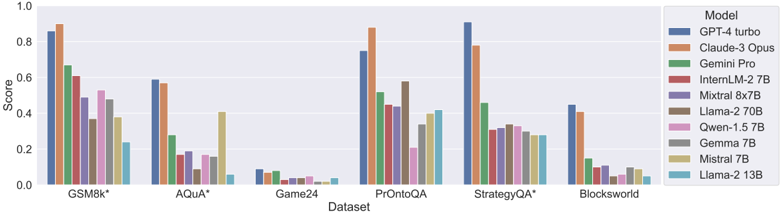
We also use the same experimental setting to compare the step-by-step reasoning ability of multiple popular LLMs, including GPT-4 (OpenAI, 2023), Claude-3 Opus 2 , Gemeni pro (Team et al., 2023), InternLM-2 (Cai et al., 2024), Mistral (Jiang et al., 2023), Mixtral (Jiang et al., 2024), Llama-2 (Touvron et al., 2023b), Qwen (Bai et al., 2023), and Gemma (Team et al., 2024). The overall results are shown in Figure 6, with more details in Table 11
Overall Rankings. GPT-4 turbo and Claude-3 Opus are the two with the strongest reasoning abilities, and they lead on almost every reasoning task. Surprisingly, InternLM-2 7B surpasses much larger models (e.g., Llama-2 70B) on average performance. We also notice the ranking of Top-3 models is aligned with ChatArena leaderboard 3 , which indicates that the reasoning ability is indeed crucial to power the SOTA chatbot.
Reasoning Tasks. Top models have achieved remarkable performance on math word problems (GSM8k) and commonsense reasoning (StrategyQA), but reasoning tasks that require strong planning abilities (e.g., Game-24 and Blocksworld) remain unsolved, which leaves room for future research. Interestingly, on StrategyQA, the answer accuracy of different models is similar (0.63 - 0.79), but the AutoRace results differ a lot, ranging from 0.28 to 0.91, with a totally different ranking. Further examination reveals the questions in StrategyQA are often ambiguous and overly simplified. GPT-4, Claude-3, and Gemini demonstrate a more thorough consideration of these problems, unlike other models (and sometimes even the ground truth reasoning chains) which can suffer from baseless assumptions and flawed logic. The difference might be attributed to the RLHF process, which aligns model response to human preference.
2 https://www.anthropic.com/news/claude-3-family
3 https://huggingface.co/spaces/lmsys/chatbot-arena-leaderboard
Figure 6: Results of various LLMs using CoT on every dataset. We apply AutoRace on three datasets with *, and oracle verifiers on other datasets. On three datasets marked with ∗ , LLMs are ordered by average performance.
<details>
<summary>Image 6 Details</summary>
### Visual Description
## Bar Chart: Model Performance on Datasets
### Overview
The image is a bar chart comparing the performance of various language models on different datasets. The chart displays the "Score" achieved by each model on each dataset, allowing for a comparison of their effectiveness across different tasks.
### Components/Axes
* **X-axis:** "Dataset" with the following categories: GSM8k*, AQUA*, Game24, PrOntoQA, StrategyQA*, Blocksworld.
* **Y-axis:** "Score" ranging from 0.0 to 1.0, with increments of 0.2.
* **Legend (Top-Right):** Lists the models, each associated with a specific color:
* GPT-4 turbo (Dark Blue)
* Claude-3 Opus (Orange)
* Gemini Pro (Green)
* InternLM-2 7B (Red-Brown)
* Mixtral 8x7B (Purple)
* Llama-2 70B (Brown)
* Qwen-1.5 7B (Pink)
* Gemma 7B (Gray)
* Mistral 7B (Tan)
* Llama-2 13B (Light Blue)
### Detailed Analysis
**Dataset: GSM8k***
* GPT-4 turbo (Dark Blue): Score ~0.86
* Claude-3 Opus (Orange): Score ~0.90
* Gemini Pro (Green): Score ~0.67
* InternLM-2 7B (Red-Brown): Score ~0.52
* Mixtral 8x7B (Purple): Score ~0.48
* Llama-2 70B (Brown): Score ~0.58
* Qwen-1.5 7B (Pink): Score ~0.40
* Gemma 7B (Gray): Score ~0.36
* Mistral 7B (Tan): Score ~0.24
* Llama-2 13B (Light Blue): Score ~0.22
**Dataset: AQUA***
* GPT-4 turbo (Dark Blue): Score ~0.59
* Claude-3 Opus (Orange): Score ~0.57
* Gemini Pro (Green): Score ~0.28
* InternLM-2 7B (Red-Brown): Score ~0.17
* Mixtral 8x7B (Purple): Score ~0.09
* Llama-2 70B (Brown): Score ~0.16
* Qwen-1.5 7B (Pink): Score ~0.16
* Gemma 7B (Gray): Score ~0.14
* Mistral 7B (Tan): Score ~0.06
* Llama-2 13B (Light Blue): Score ~0.05
**Dataset: Game24**
* GPT-4 turbo (Dark Blue): Score ~0.08
* Claude-3 Opus (Orange): Score ~0.07
* Gemini Pro (Green): Score ~0.07
* InternLM-2 7B (Red-Brown): Score ~0.03
* Mixtral 8x7B (Purple): Score ~0.04
* Llama-2 70B (Brown): Score ~0.03
* Qwen-1.5 7B (Pink): Score ~0.03
* Gemma 7B (Gray): Score ~0.02
* Mistral 7B (Tan): Score ~0.04
* Llama-2 13B (Light Blue): Score ~0.01
**Dataset: PrOntoQA**
* GPT-4 turbo (Dark Blue): Score ~0.42
* Claude-3 Opus (Orange): Score ~0.88
* Gemini Pro (Green): Score ~0.43
* InternLM-2 7B (Red-Brown): Score ~0.20
* Mixtral 8x7B (Purple): Score ~0.40
* Llama-2 70B (Brown): Score ~0.34
* Qwen-1.5 7B (Pink): Score ~0.22
* Gemma 7B (Gray): Score ~0.32
* Mistral 7B (Tan): Score ~0.41
* Llama-2 13B (Light Blue): Score ~0.10
**Dataset: StrategyQA***
* GPT-4 turbo (Dark Blue): Score ~0.92
* Claude-3 Opus (Orange): Score ~0.80
* Gemini Pro (Green): Score ~0.42
* InternLM-2 7B (Red-Brown): Score ~0.32
* Mixtral 8x7B (Purple): Score ~0.30
* Llama-2 70B (Brown): Score ~0.33
* Qwen-1.5 7B (Pink): Score ~0.30
* Gemma 7B (Gray): Score ~0.29
* Mistral 7B (Tan): Score ~0.30
* Llama-2 13B (Light Blue): Score ~0.29
**Dataset: Blocksworld**
* GPT-4 turbo (Dark Blue): Score ~0.44
* Claude-3 Opus (Orange): Score ~0.12
* Gemini Pro (Green): Score ~0.21
* InternLM-2 7B (Red-Brown): Score ~0.05
* Mixtral 8x7B (Purple): Score ~0.03
* Llama-2 70B (Brown): Score ~0.08
* Qwen-1.5 7B (Pink): Score ~0.07
* Gemma 7B (Gray): Score ~0.04
* Mistral 7B (Tan): Score ~0.10
* Llama-2 13B (Light Blue): Score ~0.40
### Key Observations
* GPT-4 turbo and Claude-3 Opus generally outperform the other models across most datasets.
* Game24 appears to be a particularly challenging dataset for all models, with scores consistently low.
* The performance of different models varies significantly depending on the dataset.
* The models Llama-2 13B, Mistral 7B, and Gemma 7B generally have lower scores compared to the top performers.
### Interpretation
The bar chart provides a comparative analysis of the performance of different language models on a range of datasets. The data suggests that GPT-4 turbo and Claude-3 Opus are the most effective models overall, achieving higher scores across most tasks. However, the relative performance of the models varies depending on the specific dataset, indicating that some models are better suited for certain types of tasks than others. The low scores on the Game24 dataset suggest that this task is particularly challenging for all the models tested. The chart highlights the importance of selecting the appropriate model for a given task based on its strengths and weaknesses.
</details>
## 6 Conclusion
We propose AutoRace , LLM-powered automated evaluation of reasoning chains, and LLM Reasoners , a unified formulation and library for diverse step-by-step reasoning algorithms. On this basis, we conducted comprehensive experiments to analyze the factors contributing to reasoning. In the future, it will be interesting to extend LLM Reasoners by including more algorithms, supporting fine-tuning methods natively, exploring multi-modal reasoning, and we plan to apply AutoRace for broader comparison.
## References
- Jinze Bai, Shuai Bai, Yunfei Chu, Zeyu Cui, Kai Dang, Xiaodong Deng, Yang Fan, Wenbin Ge, Yu Han, Fei Huang, et al. Qwen technical report. arXiv preprint arXiv:2309.16609 , 2023.
- Jake Bruce, Michael D Dennis, Ashley Edwards, Jack Parker-Holder, Yuge Shi, Edward Hughes, Matthew Lai, Aditi Mavalankar, Richie Steigerwald, Chris Apps, et al. Genie: Generative interactive environments. In Forty-first International Conference on Machine Learning , 2024.
- Zheng Cai, Maosong Cao, Haojiong Chen, Kai Chen, Keyu Chen, Xin Chen, Xun Chen, Zehui Chen, Zhi Chen, Pei Chu, et al. Internlm2 technical report. arXiv preprint arXiv:2403.17297 , 2024.
- Asli Celikyilmaz, Elizabeth Clark, and Jianfeng Gao. Evaluation of text generation: A survey. arXiv preprint arXiv:2006.14799 , 2020.
- Ziru Chen, Michael White, Raymond Mooney, Ali Payani, Yu Su, and Huan Sun. When is tree search useful for llm planning? it depends on the discriminator. arXiv preprint arXiv:2402.10890 , 2024.
- Yizhou Chi, Kevin Yang, and Dan Klein. Thoughtsculpt: Reasoning with intermediate revision and search. arXiv preprint arXiv:2404.05966 , 2024.
- Miruna Clinciu, Arash Eshghi, and Helen Hastie. A study of automatic metrics for the evaluation of natural language explanations. arXiv preprint arXiv:2103.08545 , 2021.
- Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, et al. Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 , 2021.
- Antonia Creswell and Murray Shanahan. Faithful reasoning using large language models. arXiv preprint arXiv:2208.14271 , 2022.
- Bhavana Dalvi, Peter Jansen, Oyvind Tafjord, Zhengnan Xie, Hannah Smith, Leighanna Pipatanangkura, and Peter Clark. Explaining answers with entailment trees. arXiv preprint arXiv:2104.08661 , 2021.
- Dheeru Dua, Yizhong Wang, Pradeep Dasigi, Gabriel Stanovsky, Sameer Singh, and Matt Gardner. Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. arXiv preprint arXiv:1903.00161 , 2019.
- Elias Frantar, Saleh Ashkboos, Torsten Hoefler, and Dan Alistarh. Gptq: Accurate post-training quantization for generative pre-trained transformers. arXiv preprint arXiv:2210.17323 , 2022.
- Mor Geva, Daniel Khashabi, Elad Segal, Tushar Khot, Dan Roth, and Jonathan Berant. Did aristotle use a laptop? a question answering benchmark with implicit reasoning strategies. Transactions of the Association for Computational Linguistics , 9:346-361, 2021.
- Olga Golovneva, Moya Chen, Spencer Poff, Martin Corredor, Luke Zettlemoyer, Maryam Fazel-Zarandi, and Asli Celikyilmaz. Roscoe: A suite of metrics for scoring step-by-step reasoning. arXiv preprint arXiv:2212.07919 , 2022.
- Lin Guan, Karthik Valmeekam, Sarath Sreedharan, and Subbarao Kambhampati. Leveraging pre-trained large language models to construct and utilize world models for model-based task planning. Advances in Neural Information Processing Systems , 36:79081-79094, 2023.
- Xingang Guo, Fangxu Yu, Huan Zhang, Lianhui Qin, and Bin Hu. Cold-attack: Jailbreaking llms with stealthiness and controllability. arXiv preprint arXiv:2402.08679 , 2024.
- Simeng Han, Hailey Schoelkopf, Yilun Zhao, Zhenting Qi, Martin Riddell, Luke Benson, Lucy Sun, Ekaterina Zubova, Yujie Qiao, Matthew Burtell, et al. Folio: Natural language reasoning with first-order logic. arXiv preprint arXiv:2209.00840 , 2022.
- Shibo Hao, Yi Gu, Haodi Ma, Joshua Jiahua Hong, Zhen Wang, Daisy Zhe Wang, and Zhiting Hu. Reasoning with language model is planning with world model. arXiv preprint arXiv:2305.14992 , 2023a.
- Shibo Hao, Tianyang Liu, Zhen Wang, and Zhiting Hu. Toolkengpt: Augmenting frozen language models with massive tools via tool embeddings. arXiv preprint arXiv:2305.11554 , 2023b.
- Alex Havrilla, Yuqing Du, Sharath Chandra Raparthy, Christoforos Nalmpantis, Jane Dwivedi-Yu, Maksym Zhuravinskyi, Eric Hambro, Sainbayar Sukhbaatar, and Roberta Raileanu. Teaching large language models to reason with reinforcement learning. arXiv preprint arXiv:2403.04642 , 2024.
- Hangfeng He, Hongming Zhang, and Dan Roth. Socreval: Large language models with the socratic method for reference-free reasoning evaluation. arXiv preprint arXiv:2310.00074 , 2023.
- Anthony Hu, Lloyd Russell, Hudson Yeo, Zak Murez, George Fedoseev, Alex Kendall, Jamie Shotton, and Gianluca Corrado. Gaia-1: A generative world model for autonomous driving. arXiv preprint arXiv:2309.17080 , 2023.
- Zhiting Hu and Tianmin Shu. Language models, agent models, and world models: The law for machine reasoning and planning. arXiv preprint arXiv:2312.05230 , 2023.
- Lifu Huang, Ronan Le Bras, Chandra Bhagavatula, and Yejin Choi. Cosmos qa: Machine reading comprehension with contextual commonsense reasoning. arXiv preprint arXiv:1909.00277 , 2019.
- Albert Q Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lucile Saulnier, et al. Mistral 7b. arXiv preprint arXiv:2310.06825 , 2023.
- Albert Q Jiang, Alexandre Sablayrolles, Antoine Roux, Arthur Mensch, Blanche Savary, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Emma Bou Hanna, Florian Bressand, et al. Mixtral of experts. arXiv preprint arXiv:2401.04088 , 2024.
- Muhammad Khalifa, Lajanugen Logeswaran, Moontae Lee, Honglak Lee, and Lu Wang. Grace: Discriminator-guided chain-of-thought reasoning. In Findings of the Association for Computational Linguistics: EMNLP 2023 , pp. 15299-15328, 2023.
- Takeshi Kojima, Shixiang Shane Gu, Machel Reid, Yutaka Matsuo, and Yusuke Iwasawa. Large language models are zero-shot reasoners. arXiv preprint arXiv:2205.11916 , 2022.
- Mayuresh V Kothare, Venkataramanan Balakrishnan, and Manfred Morari. Robust constrained model predictive control using linear matrix inequalities. Automatica , 32(10): 1361-1379, 1996.
- Belinda Z. Li, Maxwell Nye, and Jacob Andreas. Language modeling with latent situations. In Anna Rogers, Jordan Boyd-Graber, and Naoaki Okazaki (eds.), Findings of the Association for Computational Linguistics: ACL 2023 , pp. 12556-12571, Toronto, Canada, July 2023. Association for Computational Linguistics. doi: 10.18653/v1/2023.findings-acl.795. URL https://aclanthology.org/2023.findings-acl.795 .
- Hunter Lightman, Vineet Kosaraju, Yura Burda, Harri Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe. Let's verify step by step. arXiv preprint arXiv:2305.20050 , 2023.
- Wang Ling, Dani Yogatama, Chris Dyer, and Phil Blunsom. Program induction by rationale generation: Learning to solve and explain algebraic word problems. arXiv preprint arXiv:1705.04146 , 2017.
- Ruibo Liu, Jason Wei, Shixiang Shane Gu, Te-Yen Wu, Soroush Vosoughi, Claire Cui, Denny Zhou, and Andrew M Dai. Mind's eye: Grounded language model reasoning through simulation. arXiv preprint arXiv:2210.05359 , 2022.
- Ziyi Liu, Isabelle Lee, Yongkang Du, Soumya Sanyal, and Jieyu Zhao. Score: A framework for self-contradictory reasoning evaluation. arXiv preprint arXiv:2311.09603 , 2023.
- Qing Lyu, Shreya Havaldar, Adam Stein, Li Zhang, Delip Rao, Eric Wong, Marianna Apidianaki, and Chris Callison-Burch. Faithful chain-of-thought reasoning. arXiv preprint arXiv:2301.13379 , 2023.
- OpenAI. Gpt-4 technical report, 2023.
- Siru Ouyang, Zhuosheng Zhang, Bing Yan, Xuan Liu, Jiawei Han, and Lianhui Qin. Structured chemistry reasoning with large language models. arXiv preprint arXiv:2311.09656 , 2023.
- Debjit Paul, Mete Ismayilzada, Maxime Peyrard, Beatriz Borges, Antoine Bosselut, Robert West, and Boi Faltings. Refiner: Reasoning feedback on intermediate representations. arXiv preprint arXiv:2304.01904 , 2023.
- Debjit Paul, Robert West, Antoine Bosselut, and Boi Faltings. Making reasoning matter: Measuring and improving faithfulness of chain-of-thought reasoning. arXiv preprint arXiv:2402.13950 , 2024.
- Archiki Prasad, Swarnadeep Saha, Xiang Zhou, and Mohit Bansal. Receval: Evaluating reasoning chains via correctness and informativeness. arXiv preprint arXiv:2304.10703 , 2023.
- Abulhair Saparov and He He. Language models are greedy reasoners: A systematic formal analysis of chain-of-thought. arXiv preprint arXiv:2210.01240 , 2022.
- Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Mingchuan Zhang, YK Li, Yu Wu, and Daya Guo. Deepseekmath: Pushing the limits of mathematical reasoning in open language models. arXiv preprint arXiv:2402.03300 , 2024.
- Aarohi Srivastava, Abhinav Rastogi, Abhishek Rao, Abu Awal Md Shoeb, Abubakar Abid, Adam Fisch, Adam R Brown, Adam Santoro, Aditya Gupta, Adrià Garriga-Alonso, et al. Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research , 2023.
- Zhiqing Sun, Longhui Yu, Yikang Shen, Weiyang Liu, Yiming Yang, Sean Welleck, and Chuang Gan. Easy-to-hard generalization: Scalable alignment beyond human supervision. arXiv preprint arXiv:2403.09472 , 2024.
- Gemini Team, Rohan Anil, Sebastian Borgeaud, Yonghui Wu, Jean-Baptiste Alayrac, Jiahui Yu, Radu Soricut, Johan Schalkwyk, Andrew M Dai, Anja Hauth, et al. Gemini: a family of highly capable multimodal models. arXiv preprint arXiv:2312.11805 , 2023.
- Gemma Team, Thomas Mesnard, Cassidy Hardin, Robert Dadashi, Surya Bhupatiraju, Shreya Pathak, Laurent Sifre, Morgane Rivière, Mihir Sanjay Kale, Juliette Love, et al. Gemma: Open models based on gemini research and technology. arXiv preprint arXiv:2403.08295 , 2024.
- Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, et al. Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971 , 2023a.
- Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, et al. Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288 , 2023b.
- Gladys Tyen, Hassan Mansoor, Peter Chen, Tony Mak, and Victor C˘ arbune. Llms cannot find reasoning errors, but can correct them! arXiv preprint arXiv:2311.08516 , 2023.
- Karthik Valmeekam, Sarath Sreedharan, Matthew Marquez, Alberto Olmo, and Subbarao Kambhampati. On the planning abilities of large language models (a critical investigation with a proposed benchmark). arXiv preprint arXiv:2302.06706 , 2023.
- Peiyi Wang, Lei Li, Zhihong Shao, RX Xu, Damai Dai, Yifei Li, Deli Chen, Y Wu, and Zhifang Sui. Math-shepherd: A label-free step-by-step verifier for llms in mathematical reasoning. arXiv preprint arXiv:2312.08935 , 2023a.
- Xinyuan Wang, Chenxi Li, Zhen Wang, Fan Bai, Haotian Luo, Jiayou Zhang, Nebojsa Jojic, Eric P Xing, and Zhiting Hu. Promptagent: Strategic planning with language models enables expert-level prompt optimization. arXiv preprint arXiv:2310.16427 , 2023b.
- Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Ed Chi, Quoc Le, and Denny Zhou. Chain of thought prompting elicits reasoning in large language models. arXiv preprint arXiv:2201.11903 , 2022.
- Sean Welleck, Jiacheng Liu, Ximing Lu, Hannaneh Hajishirzi, and Yejin Choi. Naturalprover: Grounded mathematical proof generation with language models. Advances in Neural Information Processing Systems , 35:4913-4927, 2022.
- Sean Welleck, Amanda Bertsch, Matthew Finlayson, Hailey Schoelkopf, Alex Xie, Graham Neubig, Ilia Kulikov, and Zaid Harchaoui. From decoding to meta-generation: Inferencetime algorithms for large language models. arXiv preprint arXiv:2406.16838 , 2024.
- Thomas Wolf, Lysandre Debut, Victor Sanh, Julien Chaumond, Clement Delangue, Anthony Moi, Pierric Cistac, Tim Rault, Rémi Louf, Morgan Funtowicz, Joe Davison, Sam Shleifer, Patrick von Platen, Clara Ma, Yacine Jernite, Julien Plu, Canwen Xu, Teven Le Scao, Sylvain Gugger, Mariama Drame, Quentin Lhoest, and Alexander M. Rush. Transformers: State-of-the-art natural language processing. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations , pp. 38-45, Online, October 2020. Association for Computational Linguistics. URL https://www.aclweb.org/ anthology/2020.emnlp-demos.6 .
- Shijie Xia, Xuefeng Li, Yixin Liu, Tongshuang Wu, and Pengfei Liu. Evaluating mathematical reasoning beyond accuracy. arXiv preprint arXiv:2404.05692 , 2024.
- Jiannan Xiang, Tianhua Tao, Yi Gu, Tianmin Shu, Zirui Wang, Zichao Yang, and Zhiting Hu. Language models meet world models: Embodied experiences enhance language models. Advances in neural information processing systems , 36, 2023.
- Jiannan Xiang, Guangyi Liu, Yi Gu, Qiyue Gao, Yuting Ning, Yuheng Zha, Zeyu Feng, Tianhua Tao, Shibo Hao, Yemin Shi, et al. Pandora: Towards general world model with natural language actions and video states. arXiv preprint arXiv:2406.09455 , 2024.
- Yuxi Xie, Kenji Kawaguchi, Yiran Zhao, Xu Zhao, Min-Yen Kan, Junxian He, and Qizhe Xie. Self-evaluation guided beam search for reasoning. In Thirty-seventh Conference on Neural Information Processing Systems , 2023.
- Ze Yang, Yun Chen, Jingkang Wang, Sivabalan Manivasagam, Wei-Chiu Ma, Anqi Joyce Yang, and Raquel Urtasun. Unisim: A neural closed-loop sensor simulator. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pp. 1389-1399, 2023.
- Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. React: Synergizing reasoning and acting in language models. arXiv preprint arXiv:2210.03629 , 2022.
- Shunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Shafran, Thomas L Griffiths, Yuan Cao, and Karthik Narasimhan. Tree of thoughts: Deliberate problem solving with large language models. arXiv preprint arXiv:2305.10601 , 2023.
- Fangxu Yu, Lai Jiang, Haoqiang Kang, Shibo Hao, and Lianhui Qin. Flow of reasoning: Efficient training of llm policy with divergent thinking. arXiv preprint arXiv:2406.05673 , 2024.
- Lifan Yuan, Ganqu Cui, Hanbin Wang, Ning Ding, Xingyao Wang, Jia Deng, Boji Shan, Huimin Chen, Ruobing Xie, Yankai Lin, et al. Advancing llm reasoning generalists with preference trees. arXiv preprint arXiv:2404.02078 , 2024.
- Zirui Zhao, Wee Sun Lee, and David Hsu. Large language models as commonsense knowledge for large-scale task planning. Advances in Neural Information Processing Systems , 36, 2024.
- Denny Zhou, Nathanael Schärli, Le Hou, Jason Wei, Nathan Scales, Xuezhi Wang, Dale Schuurmans, Olivier Bousquet, Quoc Le, and Ed Chi. Least-to-most prompting enables complex reasoning in large language models. arXiv preprint arXiv:2205.10625 , 2022.
- Xinyu Zhu, Junjie Wang, Lin Zhang, Yuxiang Zhang, Ruyi Gan, Jiaxing Zhang, and Yujiu Yang. Solving math word problem via cooperative reasoning induced language models. arXiv preprint arXiv:2210.16257 , 2022.
- Yuchen Zhuang, Xiang Chen, Tong Yu, Saayan Mitra, Victor Bursztyn, Ryan A Rossi, Somdeb Sarkhel, and Chao Zhang. Toolchain*: Efficient action space navigation in large language models with a* search. arXiv preprint arXiv:2310.13227 , 2023.
Table 4: The distribution of datasets for evaluation metrics.
| Method | Math | Math | Common | Common | Logical | Logical |
|-------------------------------|--------|--------|----------|----------|-----------|-----------|
| Dataset | GSM8k | Arith | Strategy | Cosmos | Logic | Sort |
| Correct ans Incorrect ans | 110 90 | 45 255 | 100 100 | 82 97 | 45 255 | 45 255 |
| Correct human Incorrect human | 101 99 | 62 238 | 71 129 | 31 148 | 6 294 | 34 266 |
| FP rate | 0.16 | 0 | 0.39 | 0.67 | 0.87 | 0.33 |
Table 5: Evaluation accuracy for reasoning chains labeled incorrect by humans.
| Method | Math | Math | Common | Common | Logical | Logical |
|-----------------|--------|--------|----------|----------|-----------|-----------|
| Dataset | GSM8k | Arith | Strategy | Cosmos | Logic | Sort |
| Answer-based | 0.89 | 0.99 | 0.76 | 0.63 | 0.87 | 0.94 |
| SocREval | 0.89 | 0.92 | 0.96 | 0.91 | 0.89 | 0.76 |
| Direct (trace) | 0.90 | 0.34 | 0.78 | 0.74 | 0.21 | 0.33 |
| Direct (step) | 0.96 | 0.44 | 0.85 | 0.87 | 0.75 | 0.32 |
| CoT (step) | 0.93 | 0.88 | 0.78 | 0.84 | 1.00 | 0.87 |
| AutoRace (Ours) | 0.91 | 0.90 | 0.82 | 0.84 | 0.97 | 0.87 |
## A Additional Details of AutoRace
## A.1 Dataset Statistics
For all datasets we experiment on, we list the statistics by answer labels and human labels in Table 4. We also include the false positive (FP) rate, defined as the proportion of instances with correct answers but labeled as incorrect by human evaluators, relative to the total number of instances with correct answers.
## A.2 Results on Reasoning Chains of Different Human Labels
We calculate the accuracy on two subsets: (1) reasoning chains labeled correct by human, and (2) reasoning chains labeled incorrect by human. The results are listed in Table 5 and Table 6. Generally, AutoRace balances the performance on both datasets, while SocREval suffers from a severe drop on the reasoning chains labeled incorrect.
Table 6: Evaluation accuracy for reasoning chains labeled correct by humans.
| Method | Math | Math | Common | Common | Logical | Logical |
|-----------------|--------|--------|----------|----------|-----------|-----------|
| Dataset | GSM8k | Arith | Strategy | Cosmos | Logic | Sort |
| Answer-based | 0.99 | 0.71 | 0.76 | 0.87 | 1.00 | 0.88 |
| SocREval | 0.89 | 0.55 | 0.24 | 0.29 | 1.00 | 0.85 |
| Direct(trace) | 0.89 | 0.58 | 0.83 | 0.58 | 1.00 | 0.68 |
| Direct(step) | 0.74 | 0.40 | 0.78 | 0.03 | 0.83 | 0.38 |
| CoT(step) | 0.82 | 0.11 | 0.78 | 0.13 | 1.00 | 0.14 |
| AutoRace (Ours) | 0.90 | 0.85 | 0.72 | 0.45 | 1.00 | 0.74 |
Figure 7: A case study on MultiArith (Srivastava et al., 2023). SocREval (He et al., 2023) requires GPT-4 to generate its own response to the problem, and then use it as the reference to evaluate the reasoning chain. In this case, it makes the same mistake as the reasoning chain. AutoRace successfully recognized the calculation error, guided by the criterion list learned for this task.
<details>
<summary>Image 7 Details</summary>

### Visual Description
## Chart/Diagram Type: Comparison of Reasoning Chain Evaluation
### Overview
The image presents a comparison of how different systems (SocREval and AutoRace) evaluate the reasoning chain of a solution to a mathematical problem. It highlights a scenario where GPT-4 evaluator made the same mistake.
### Components/Axes
* **Question:** A complex arithmetic expression is presented.
* **Reasoning Chain (Left):** Shows the steps taken to solve the problem, with intermediate calculations.
* **SocREval (Baseline) (Center):** Displays the system's response, analysis, and overall quality assessment.
* **AutoRace (Right):** Shows AutoRace's evaluation, including error detection and reasoning chain assessment.
* **(Criteria learned for Multi-Arith) (Top-Right):** Lists the criteria used for evaluation: Proper Operation Order, Correct Interpretation of Signs, and Logical Consistency.
### Detailed Analysis or ### Content Details
**1. Question and Reasoning Chain (Left):**
* **Question:** What is the result of (((-9+5+-7-8)-(1\*-7\*-2\*8))+((3\*2+2+2)\*(4\*3-9\*-6))) ?
* **Step 1:** This equation can be written as "A - B + C"...
* **Step 2:** Let's calculate A...
* **Step 4:** Let's calculate C = ((3\*2+2+2)\*(4\*3-9\*-6)) = ((6+2+2)\*(12-54)) = (10\*-42) = -420.
* **Step 6:** So the answer is -521
* **(Reasoning chain to be evaluated)**
**2. SocREval (Baseline) (Center):**
* **Own response:** ... Part C simplifies into (10 \* (-42)) = -420. So the entire equation simplifies into 11 - 112 - 420 which equals -521.
* **Analysis:** The generated response is correct and detailed...
* **Overall quality:** 5.0 (Correct)
* **GPT-4 evaluator made the same mistake** (indicated by a sad face emoji)
**3. AutoRace (Right):**
* AutoRace icon with a green checkmark and a red X.
* **(Criteria learned for Multi-Arith):**
* Proper Operation Order
* Correct Interpretation of Signs
* Logical Consistency
* **Step 4:** This is an incorrect calculation. The error lies in the calculation of the second part of C, specifically '(4\*3-9\*-6)'. The correct calculation should be...
* So the reasoning chain is not correct.
* Successfully recognized the error (indicated by a happy face emoji)
### Key Observations
* SocREval incorrectly identifies the solution as correct, despite an error in the intermediate calculation of 'C'.
* AutoRace correctly identifies the error in the calculation of 'C' and flags the reasoning chain as incorrect.
* GPT-4 evaluator made the same mistake as SocREval.
### Interpretation
The image demonstrates a scenario where a baseline system (SocREval) fails to identify an error in a complex arithmetic problem, while another system (AutoRace) successfully detects the mistake. This highlights the importance of robust error detection mechanisms in automated reasoning systems. The fact that GPT-4 evaluator made the same mistake as SocREval suggests that even advanced models can be susceptible to similar errors. The criteria listed (Proper Operation Order, Correct Interpretation of Signs, Logical Consistency) are crucial for accurate evaluation of mathematical reasoning.
</details>
Table 7: Average cost on one problem for different evaluation methods, in the form of (input token number / output token number / cost per question).
| Method | Word-Sort (Long) | StrategyQA (Short) |
|--------------------------------------------------|---------------------------------------------------------------------------------|---------------------------------------------------------------------------|
| SocREval Direct (trace) Direct (step) CoT (step) | 1686 / 427 / $0.030 2265 / 1 / $0.023 17517 / 12 / $0.176 26839 / 5504 / $0.434 | 357 / 269 / $0.012 507 / 1 / $0.005 1349 / 4 / $0.014 2688 / 575 / $0.044 |
| AutoRace (Ours) | 1382 / 435 / | 270 / 389 / $0.014 |
| | $0.027 | |
## A.3 Case Study
In Figure 7, we show a case study of AutoRace on MultiArith (Srivastava et al., 2023), in comparison with SocREval (He et al., 2023).
## A.4 Comparison on the Cost of Reasoning Chain Evaluation Metrics
Table 7 shows the average input token number, output token number, and the cost per question using different evaluation methods. We list the statistics on two tasks: Word-Sort, which usually has long reasoning chains, and StrategyQA, which has shorter reasoning chains.
## A.5 Example Number of Criteria List Construction
For each task in Table 11, we use 4 incorrect reasoning chains to create a criterion list. Here, we further explored different sample sizes (2, 4, 10) in Table 8.
The results indicate that AutoRace is relatively robust to the sample set size. We found that it's because:
Table 8: The performance of AutoRace with different number of incorrect reasoning chains (2, 4, 10) to construct the criteria list.
| Method | Math | Math | Common | Common | Logical | Logical | Average |
|---------------|--------|--------|----------|----------|-----------|-----------|-----------|
| Method | GSM8k | Arith | Strategy | Cosmos | Logic | Sort | Average |
| AutoRace (2) | 0.88 | 0.84 | 0.84 | 0.75 | 0.96 | 0.86 | 0.85 |
| AutoRace (4) | 0.91 | 0.85 | 0.79 | 0.78 | 0.97 | 0.86 | 0.86 |
| AutoRace (10) | 0.86 | 0.82 | 0.84 | 0.77 | 0.98 | 0.89 | 0.86 |
Table 9: The performance of AutoRace and SocREval (He et al., 2023) using the criteria list/prompt for GSM8k.
| Method | Math | Math | Common | Common | Logical | Logical | Average |
|------------------|--------|--------|----------|----------|-----------|-----------|-----------|
| Method | GSM8k | Arith | Strategy | Cosmos | Logic | Sort | Average |
| AutoRace | 0.91 | 0.85 | 0.79 | 0.78 | 0.97 | 0.86 | 0.86 |
| SocREval | 0.89 | 0.85 | 0.71 | 0.80 | 0.89 | 0.77 | 0.82 |
| SocREval (GSM8k) | 0.89 | 0.84 | 0.63 | 0.74 | 0.85 | 0.81 | 0.79 |
| AutoRace (GSM8k) | 0.91 | 0.83 | 0.73 | 0.69 | 0.99 | 0.89 | 0.84 |
- Besides concrete errors in examples, GPT-4 can also infer some evaluation criteria from the problem domain. E.g., For math word problems, even if there is no calculation error in the examples, GPT-4 may supplement a criterion about 'accurate calculation'.
- GPT-4 has certain prior knowledge on how to evaluate a reasoning chain. Thus, even if a criterion list misses some items, GPT-4 still has a chance to correctly evaluate a reasoning chain with that type of error.
## A.6 Generalization of Criteria List
To understand how general the criteria list constructed by AutoRace is, we test with the AutoRace criterion list of GSM8k on all tasks. We also test SocREval (He et al., 2023) on all tasks with its prompt for GSM8k. As shown in Table 9, AutoRace shows good generalization across different reasoning tasks.
## A.7 AutoRace Prompt
In this section, we demonstrate the pipeline of AutoRace for GSM8k (Cobbe et al., 2021) as examples. For other reasoning tasks, the template is the same, and only the questions, student answers, and extracted criteria need to be replaced.
## Prompt for detection and summarization
You are a teacher. Below are some questions, reference answers and the answers from students.
## Question:
Janet's ducks lay 16 eggs per day. She eats three for breakfast every morning and bakes muffins for her friends every day with four. She sells the remainder at the farmers' market daily for $2 per fresh duck egg. How much in dollars does she make every day at the farmers' market? Reference answer:
Janet sells 16 -3 -4 = 9 duck eggs a day. She makes 9 * 2 = 18 every day at the farmer's market.
Student answer:
Janet's ducks lay 16 eggs per day. She eats three for breakfast every morning and bakes muffins for her friends every day with four. This means she uses 3 + 4 = 7 eggs every day. She sells the remainder at the farmers' market daily for $2 per fresh duck egg. So she sells (16 -7) * $2 = $6 worth of eggs every day. The answer is 6.
## Question:
Claire makes a 3 egg omelet every morning for breakfast. How many dozens of eggs will she eat in 4 weeks?
Reference answer:
She eats 3 eggs every day and there are 7 days in a week so she eats 3*7 = 21 eggs a week After 4 weeks she will have eaten 4*21 = 84 eggs There are 12 eggs in 1 dozen and she'll eat 84 eggs so that's 84/12 = 7 dozen eggs. Student answer:
Claire makes a 3 egg omelet every morning. In one week she will eat 3 * 7 = 21 eggs. In 4 weeks she will eat 4 * 21 = 84 eggs. The answer is 84.
## Question:
Gloria is shoe shopping when she comes across a pair of boots that fit her shoe budget. However, she has to choose between the boots and two pairs of high heels that together cost five dollars less than the boots. If one pair of heels costs $33 and the other costs twice as much, how many dollars are the boots?
Reference answer:
The second pair of heels costs 33 * 2 = $66. The heels together cost 66 + 33 = $99. The boots cost $5 more than both pairs of heels together, so the boots cost 99 + 5 = $104.
Student answer:
We know that one pair of heels costs $33 and the other pair costs twice as much. This means that the other pair costs $33 * 2 = $66. Together, the two pairs of heels cost $33 + $66 = $99. The boots cost five dollars less than the heels, so the boots cost $99 - $5 = $94. The answer is $94.
## Question:
Mark's car breaks down and he needs to get a new radiator. The cost for a new radiator is $400 but he goes to get it at a junk shop and gets it for 80% off. He then hires a mechanic to install it and it takes 3 hours at $50 an hour. How much did he pay?
Reference answer:
The discount on the radiator was 400*.8=$320 So he paid 400-320=$80 The mechanic charges 3*50=$150 So in total he paid 80+150=$230 Student answer:
The cost for a new radiator is $400. He got it at a junk shop for 80% off, so he paid $400 * 0.8 = $320 for the radiator. The mechanic charged him $50 per hour for 3 hours, so he paid $50 * 3 = $150 for the labor. In total, he paid $320 + $150 = $470. The answer is 470.
Please summarize the mistakes in a short sentence for the question. At the end, please make a brief list of criteria. Make sure they are general and not specific to these questions so that others can grade the answers for other answers by following these criteria.
## Prompt for Evaluation
Below is a question and an answer from a student. You are required to check the correctness of the reasoning chains step by step. The criteria are as follows:
- **Accuracy in Mathematical Operations:** Ensure calculations are correct and follow logical mathematical principles.
**Understanding the Problem Statement:** Comprehend the details and conditions of the question accurately. **Correct Application of Mathematical Concepts:** Apply the right mathematical formulas, operations, or concepts to solve the problem. convert
**Unit Conversion and Appropriateness:** When required, correctly units and use appropriate units in the answer.
- **Final Answer Relevance:** Ensure the final answer directly addresses the question asked, and is presented clearly and concisely.
Table 10: Common types of false positive reasoning chains detected by AutoRace . The example questions are from StrategyQA (Geva et al., 2021) and GSM8k (Cobbe et al., 2021), and the reasoning chains are generated by Llama-2 70B. An explanation for each type of false positive reasoning chain is attached.
| Type | Question | Reasoning Chain | Explanation |
|--------|-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|-----------------------------------------------------------------------------------------------------------------------------------------|
| A | Henry made two stops during his 60-mile bike trip. He first stopped af- ter 20 miles. His second stop was 15 miles before the end of the trip. How many miles did he travel between his first and sec- ond stops? | Step 1 - Henry traveled 20 miles + 15 miles = 35 miles between his first and sec- ond stops . Step 2 - Henry traveled 60 miles - 35 miles = 25 miles without stopping. Step 3 - The answer is 25 | There is a hallucination in an early reasoning step, but the following reasoning steps ignore the mistake and reach the correct answer. |
| B | Is "A Tale of Two Cities" a parody of the Bible? | "A Tale of Two Cities" was published in 1859, and the Bible was published much earlier. Thus , "A Tale of TwoCities" is not a parody of the Bible. So the answer is no. | The reasoning chain has obvious or multi- ple mistakes, but hits the correct answer by chance. |
| C | Is clementine pith highly sought after? | Clementine pith is not highly sought after. So the answer is no. | The reasoning chain is not informative at all, though the answer is correct. |
**Logical Reasoning and Step-by-Step Explanation:** The answer should include a logical, step-by-step explanation that demonstrates how the final answer was reached.
Question: [QUESTION]
Student answer: [INPUT]
Please check the answer through each criterion, and make sure you carefully examine each reasoning step. Finally, if there is any step that fails the verification, output an INCORRECT, or else output a CORRECT.
The criteria are provided by the GPT in the Summarization step.
## A.8 False Positive Reasoning Chains Detected by AutoRace
AutoRace can serve as a scalable way to detect false positive reasoning chains. Here, we summarize several types of false positive reasoning chains in Table 10.
## A.9 Pseudo-code of AutoRace
We present the pseudo-code of AutoRace in Algorithm 1.
## Algorithm 1 Criteria list construction of AutoRace
- 1: Input: Student LLM f Student -LLM , GPT-4 fGPT -4 , a training set of questions, reference answers, and reasoning chains Dtrain = { x , yr , zr } , a prompt template to create criterion Tcriterion , the expected number of error examples n
```
```
▷
▷ Initialize the incorrect reasoning chain set ▷ Randomly sample a subset of the training set
- ▷ Answer the question with the student LLM
- ▷ Collect incorrect reasoning chains
- ▷ Already enough error examples
Let GPT-4 summarize from error examples
Figure 8: A screenshot of the visualization tool to diagnose the RAP algorithms on the Blocksworld task.
<details>
<summary>Image 8 Details</summary>
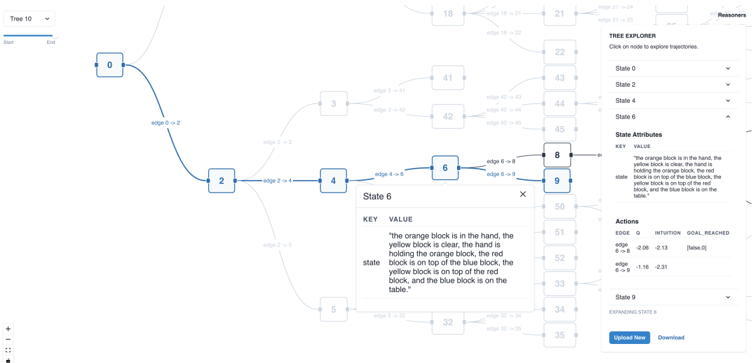
### Visual Description
## Tree Diagram: State Exploration
### Overview
The image presents a tree diagram visualizing the exploration of states in a reasoning process. The diagram shows nodes representing states, connected by edges representing transitions between states. The diagram also includes a "Tree Explorer" panel, "State Attributes" and "Actions" panel, providing details about the selected state and actions taken.
### Components/Axes
* **Nodes:** Represent states in the reasoning process. Each node is labeled with a number (e.g., 0, 2, 4, 6, 8, 9).
* **Edges:** Represent transitions between states. Each edge is labeled with the transition (e.g., "edge 0 -> 2", "edge 2 -> 4", "edge 4 -> 6", "edge 6 -> 8", "edge 6 -> 9").
* **Tree Explorer (Right Panel):** A panel on the right side allows the user to select and explore different states in the tree. It lists states (State 0, State 2, State 4, State 6, State 9) and provides dropdown menus for each.
* **State Attributes (Right Panel):** Displays the attributes of the selected state. It shows a "KEY" and "VALUE" pair. For State 6, the value is: "the orange block is in the hand, the yellow block is clear, the hand is holding the orange block, the red block is on top of the blue block, the yellow block is on top of the red block, and the blue block is on the table."
* **Actions (Right Panel):** Displays the actions taken to transition between states. It shows "EDGE", "Q", "INTUITION", and "GOAL REACHED" values.
* edge 6 -> 8: Q = -2.06, INTUITION = 2.13, GOAL REACHED = [false, 0]
* edge 6 -> 9: Q = -1.16, INTUITION = -2.31
* **Tree 10 (Top-Left):** A dropdown menu labeled "Tree 10" is present in the top-left corner.
### Detailed Analysis or ### Content Details
* **State 0:** The starting state, connected to State 2 via "edge 0 -> 2".
* **State 2:** Connected to State 4 via "edge 2 -> 4".
* **State 4:** Connected to State 6 via "edge 4 -> 6".
* **State 6:** Connected to State 8 via "edge 6 -> 8" and to State 9 via "edge 6 -> 9".
* **State 8:** No outgoing edges are visible in the image.
* **State 9:** No outgoing edges are visible in the image.
* **Other States:** Several other states (e.g., 3, 5, 18, 21, 22, 32, 33, 34, 35, 41, 42, 43, 44, 45, 50, 51, 52) are present in the diagram but are less prominent and have faded lines.
### Key Observations
* The diagram visualizes a branching exploration of states, starting from State 0 and branching out to other states.
* The "Tree Explorer" panel allows users to navigate and examine the attributes and actions associated with each state.
* The "State Attributes" provide a textual description of the state.
* The "Actions" panel provides numerical values for "Q" and "INTUITION" associated with each transition.
### Interpretation
The diagram represents a decision-making or problem-solving process where different states are explored based on certain actions. The "Q" and "INTUITION" values likely represent some form of evaluation or prediction associated with each action. The "GOAL REACHED" value indicates whether a particular action led to the desired goal. The state attributes provide context and meaning to each state, allowing for a deeper understanding of the reasoning process. The tree structure shows how the process branches out as different options are considered. The faded lines and less prominent states suggest that some paths were explored but not pursued as deeply as others.
</details>
## B Additional Details of LLM Reasoners
## B.1 Visualizer in LLM Reasoners
We show a screenshot of the visualization module of LLM Reasoners in Figure 8. Users have the option to upload the log file to our server with one line of code and use the web-based visualization to debug the reasoning algorithms. It allows users to interact with the log by selecting different reasoning trees, and checking the details of each node and edge in the tree. This tool significantly lowers the difficulty of applying a complex reasoning algorithm to new tasks.
## C Additional Details of Experiment Analysis
## C.1 Details of RAP Implementation
We explicitly define states and world models in RAP. For free-form question-answering tasks, including GSM8k, AQuA, and StrategyQA, a state is considered as the set of known variables. An action involves posing a sub-question about an unknown variable. The world model then responds to this sub-question, thereby augmenting the state with the value of a new intermediate variable. For tasks with a clearly defined intermediate state,
̸
such as the remaining numbers in Game of 24, the latest facts in PrOntoQA, and the current block arrangement in Blocksworld, we directly employ these intermediate states in natural language description. Actions in these scenarios are defined respectively as a basic arithmetic operation, a one-hop logic reasoning, and a single block movement. The world model is prompted to predict the subsequent state as per the task's definition.
In GSM8k, AQuA, and StrategyQA, we use the rewards from the confidence of state transition and self-evaluation of usefulness of each step. In Game of 24, we use the rewards from self-evaluation of the possibility to achieve 24 for the state after each step. In PrOntoQA, we use the rewards of action likelihood and self-evaluation of the correctness of each step. In Blocksworld, we use the rewards from the action likelihood and task-specific heuristics, i.e., the number of achieved subgoals.
## C.2 Case Study on Prompt formats
Below, we present the reasoning chain of RAP and CoT to a question in StrategyQA.
```
```
## C.3 AutoRace Leaderboard
We show the detailed evaluation results on leading LLMs in Table 11.
Table 11: The comparison of different models across various tasks. GSM8k, AQuA and Strategy are evaluated with AutoRace (The answer accuracy is shown as a reference in the bracket). Other results use the oracle verifier.
| Model | GSM8k | AQuA | Game24 | Pronto | Strategy | Block | Average |
|---------------|-------------|-------------|----------|----------|-------------|---------|-----------|
| GPT-4 turbo | 0.86 (0.93) | 0.59 (0.71) | 0.09 | 0.75 | 0.91 (0.65) | 0.45 | 0.66 |
| Claude-3 Opus | 0.90 (0.90) | 0.57 (0.79) | 0.07 | 0.88 | 0.78 (0.63) | 0.41 | 0.66 |
| Gemini pro | 0.67 (0.72) | 0.28 (0.48) | 0.08 | 0.52 | 0.46 (0.71) | 0.15 | 0.45 |
| InternLM-2 7B | 0.61 (0.68) | 0.17 (0.45) | 0.03 | 0.45 | 0.31 (0.69) | 0.1 | 0.39 |
| Llama-2 70B | 0.37 (0.54) | 0.09 (0.34) | 0.04 | 0.58 | 0.34 (0.76) | 0.05 | 0.35 |
| Qwen-1.5 7B | 0.53 (0.56) | 0.17 (0.28) | 0.05 | 0.21 | 0.33 (0.79) | 0.06 | 0.33 |
| Gemma-7B | 0.48 (0.57) | 0.16 (0.34) | 0.02 | 0.34 | 0.30 (0.66) | 0.1 | 0.33 |
| Mistral 7B | 0.38 (0.41) | 0.12 (0.32) | 0.02 | 0.4 | 0.28 (0.66) | 0.09 | 0.33 |
| Llama-2 13B | 0.24 (0.29) | 0.06 (0.20) | 0.04 | 0.42 | 0.28 (0.66) | 0.05 | 0.25 |