# Monte Carlo Tree Search Boosts Reasoning via Iterative Preference Learning
> Correspondence to: Yuxi Xie ( ) and Anirudh Goyal ( ).
## Abstract
We introduce an approach aimed at enhancing the reasoning capabilities of Large Language Models (LLMs) through an iterative preference learning process inspired by the successful strategy employed by AlphaZero. Our work leverages Monte Carlo Tree Search (MCTS) to iteratively collect preference data, utilizing its look-ahead ability to break down instance-level rewards into more granular step-level signals. To enhance consistency in intermediate steps, we combine outcome validation and stepwise self-evaluation, continually updating the quality assessment of newly generated data. The proposed algorithm employs Direct Preference Optimization (DPO) to update the LLM policy using this newly generated step-level preference data. Theoretical analysis reveals the importance of using on-policy sampled data for successful self-improving. Extensive evaluations on various arithmetic and commonsense reasoning tasks demonstrate remarkable performance improvements over existing models. For instance, our approach outperforms the Mistral-7B Supervised Fine-Tuning (SFT) baseline on GSM8K, MATH, and ARC-C, with substantial increases in accuracy to $81.8\$ (+ $5.9\$ ), $34.7\$ (+ $5.8\$ ), and $76.4\$ (+ $15.8\$ ), respectively. Additionally, our research delves into the training and inference compute tradeoff, providing insights into how our method effectively maximizes performance gains. Our code is publicly available at https://github.com/YuxiXie/MCTS-DPO.
## 1 Introduction
Development of Large Language Models (LLMs), has seen a pivotal shift towards aligning these models more closely with human values and preferences (Stiennon et al., 2020; Ouyang et al., 2022; Bai et al., 2022a). A critical aspect of this process involves the utilization of preference data. There are two prevailing methodologies for incorporating this data: the first entails the construction of a reward model based on preferences, which is then integrated into a Reinforcement Learning (RL) framework to update the policy (Christiano et al., 2017; Bai et al., 2022b); the second, more stable and scalable method, directly applies preferences to update the model’s policy (Rafailov et al., 2023).
In this context, the concept of “iterative” development is a key, especially when contrasted with the conventional Reinforcement Learning from Human Feedback (RLHF) paradigm (Christiano et al., 2017; Stiennon et al., 2020; Ouyang et al., 2022; Bai et al., 2022a), where the reward model is often trained offline and remains static. An iterative approach proposes a dynamic and continuous refinement process (Zelikman et al., 2022; Gülçehre et al., 2023; Huang et al., 2023; Yuan et al., 2024). It involves a cycle that begins with the current policy, progresses through the collection and analysis of data to generate new preference data, and uses this data to update the policy. This approach underlines the importance of ongoing adaptation in LLMs, highlighting the potential for these models to become more attuned to the complexities of human decision-making and reasoning.
<details>
<summary>x1.png Details</summary>
### Visual Description
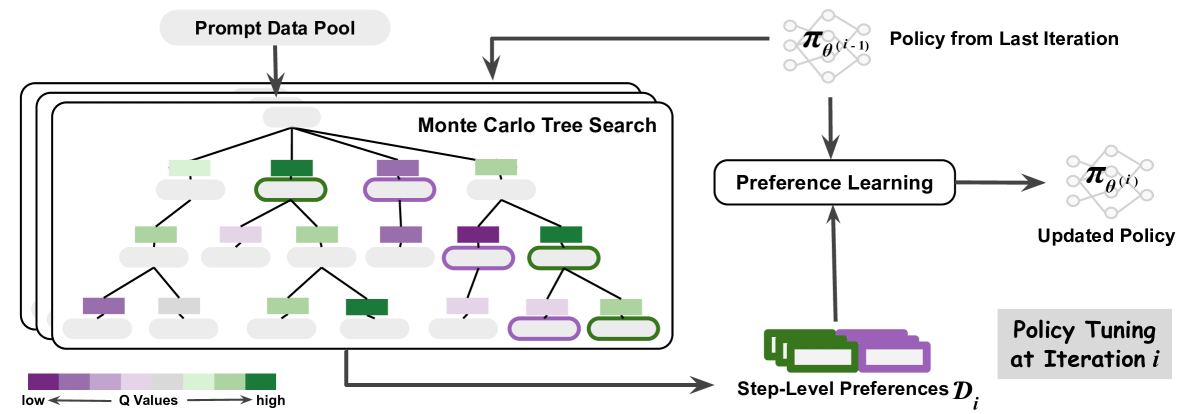
## Diagram: Iterative Policy Tuning via Monte Carlo Tree Search and Preference Learning
### Overview
The image is a technical flowchart illustrating an iterative machine learning process for policy optimization. The system uses a Monte Carlo Tree Search (MCTS) to explore a prompt data pool, generates step-level preferences from the search results, and uses these preferences to update a policy model. The process is cyclical, with the updated policy from one iteration becoming the input for the next.
### Components/Axes
The diagram is divided into two main sections: a left panel detailing the search process and a right panel showing the policy update loop.
**Left Panel - Search Process:**
* **Prompt Data Pool:** A rounded rectangle at the top-left, labeled "Prompt Data Pool". An arrow points downward from it into the main search box.
* **Monte Carlo Tree Search Box:** A large, rounded rectangle containing a tree structure. It is labeled "Monte Carlo Tree Search" in the top-right corner of the box.
* **Tree Structure:** A hierarchical tree with a root node at the top and multiple levels of child nodes. Nodes are represented by rounded rectangles.
* **Node Color Legend:** Located at the bottom-left of the image. It is a horizontal gradient bar labeled "Q Values". The left end is dark purple, labeled "low". The right end is dark green, labeled "high". The gradient transitions through shades of purple, light purple, light green, to green.
* **Output Arrow:** An arrow exits the bottom-right of the MCTS box, pointing to the right towards the "Step-Level Preferences" element.
**Right Panel - Policy Update Loop:**
* **Policy from Last Iteration:** Located at the top-right. It is represented by a network graph icon (nodes and edges) and labeled "Policy from Last Iteration". The mathematical notation `π_θ(i-1)` is written above the icon. An arrow points downward from this element.
* **Preference Learning:** A rounded rectangle in the center-right, labeled "Preference Learning". It receives two inputs: one from "Policy from Last Iteration" (from above) and one from "Step-Level Preferences" (from below).
* **Updated Policy:** To the right of "Preference Learning". It is represented by an identical network graph icon and labeled "Updated Policy". The notation `π_θ(i)` is written above it. An arrow points from "Preference Learning" to this element.
* **Step-Level Preferences:** Located at the bottom-center. It is represented by a stack of three colored rectangles (two green, one purple) and labeled "Step-Level Preferences `D_i`". An arrow points upward from this element to "Preference Learning".
* **Iteration Label:** A gray box in the bottom-right corner, labeled "Policy Tuning at Iteration `i`".
### Detailed Analysis
**1. Monte Carlo Tree Search (MCTS) Component:**
* The tree originates from a single root node (light gray).
* The root has four direct child nodes. From left to right, their approximate colors (based on the Q-Value legend) are: light green, dark green, purple, light green.
* The tree expands to a maximum of four levels deep (root, level 1, level 2, level 3).
* **Node Color Distribution:** The nodes exhibit a range of colors from the Q-Value spectrum.
* **High Q-Value (Green) Nodes:** Several nodes are dark or medium green, indicating high estimated value. Notable examples include a level-1 node (second from left) and a level-3 node (far right).
* **Low Q-Value (Purple) Nodes:** Several nodes are dark or medium purple, indicating low estimated value. Notable examples include a level-1 node (third from left) and a level-2 node (far left).
* **Medium Q-Value Nodes:** Many nodes are light green or light purple, representing intermediate values.
* **Spatial Grounding:** The legend is positioned at the bottom-left, clearly mapping the color gradient to the Q-Value scale from low (purple) to high (green).
**2. Policy Update Loop:**
* The flow is cyclical and iterative, as indicated by the notation `i` and `i-1`.
* The process at iteration `i` takes the policy from the previous iteration (`π_θ(i-1)`) and the newly generated preferences (`D_i`) as inputs to the "Preference Learning" module.
* The output is an updated policy for the current iteration (`π_θ(i)`).
* The "Step-Level Preferences `D_i`" are generated from the results of the Monte Carlo Tree Search, as shown by the connecting arrow.
### Key Observations
1. **Color-Coded Value Assessment:** The MCTS visualization uses a continuous color gradient (purple to green) to represent the estimated quality (Q-Value) of different search paths or states, allowing for a quick visual assessment of promising vs. poor branches.
2. **Hierarchical Exploration:** The tree structure shows a systematic exploration of possibilities from a prompt, branching out into multiple potential sequences of steps or decisions.
3. **Closed-Loop Learning:** The system forms a feedback loop where the policy's performance (evaluated via MCTS and preference learning) is used to directly improve the policy itself for the next cycle.
4. **Data Flow:** The diagram clearly traces the flow of information: from a static data pool, through an active search process, to the generation of preference data, and finally into a learning module that updates the core policy model.
### Interpretation
This diagram depicts a sophisticated reinforcement learning or AI alignment technique. The core idea is to use a planning algorithm (Monte Carlo Tree Search) to explore a vast space of possible actions or responses stemming from a given prompt. The search doesn't just find a single best answer; it generates a rich set of trajectories with associated value estimates (the Q-values shown by color).
These search results are distilled into "Step-Level Preferences" (`D_i`). This likely means the system compares different paths found by the MCTS and creates data that says, "Given this state, path A is preferred over path B." This preference data is more stable and informative for learning than simple reward signals.
The "Preference Learning" module then uses this curated data to adjust the parameters (`θ`) of the policy model (`π`), moving it towards behaviors that are preferred according to the search-based evaluation. By iterating this process (`i-1` to `i`), the policy progressively improves, becoming better at generating high-value responses that are consistent with the preferences extracted from its own simulated search.
The system essentially uses look-ahead planning (MCTS) to create its own training signal (preferences), enabling iterative self-improvement without requiring an external reward model for every step. This is a powerful paradigm for complex decision-making or generation tasks where direct supervision is scarce.
</details>
<details>
<summary>x2.png Details</summary>
### Visual Description
\n
## Line Chart: Accuracy on ARC-C vs. Training Data Percentage
### Overview
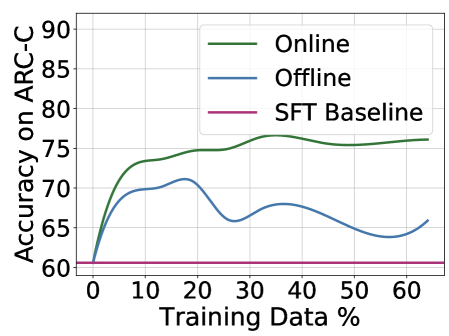
The image is a line chart comparing the performance of three different methods ("Online", "Offline", and "SFT Baseline") on the ARC-C benchmark as a function of the percentage of training data used. The chart demonstrates how accuracy changes with increasing data for each method.
### Components/Axes
* **Chart Type:** Line chart with three data series.
* **Y-Axis:**
* **Label:** "Accuracy on ARC-C"
* **Scale:** Linear, ranging from 60 to 90.
* **Major Tick Marks:** 60, 65, 70, 75, 80, 85, 90.
* **X-Axis:**
* **Label:** "Training Data %"
* **Scale:** Linear, ranging from 0 to 60.
* **Major Tick Marks:** 0, 10, 20, 30, 40, 50, 60.
* **Legend:**
* **Position:** Top-right corner of the plot area.
* **Items:**
1. **Online:** Represented by a solid green line.
2. **Offline:** Represented by a solid blue line.
3. **SFT Baseline:** Represented by a solid pink/magenta line.
### Detailed Analysis
**1. Online (Green Line):**
* **Trend:** Shows a rapid, steep increase in accuracy from 0% to approximately 10% training data, followed by a more gradual, steady increase that plateaus around 35-40% data. The line remains relatively flat with minor fluctuations from 40% to 60%.
* **Approximate Data Points:**
* At 0%: ~60
* At 10%: ~73
* At 20%: ~75
* At 30%: ~75
* At 40%: ~76 (Peak)
* At 50%: ~75
* At 60%: ~76
**2. Offline (Blue Line):**
* **Trend:** Also increases sharply from 0% to about 10% data, but then exhibits significant volatility. It peaks around 20% data, dips sharply around 30%, recovers slightly around 40%, dips again around 50%, and shows a slight upturn at 60%.
* **Approximate Data Points:**
* At 0%: ~60
* At 10%: ~69
* At 20%: ~71 (Peak)
* At 30%: ~66 (Local minimum)
* At 40%: ~68
* At 50%: ~64 (Global minimum after initial rise)
* At 60%: ~66
**3. SFT Baseline (Pink Line):**
* **Trend:** A perfectly horizontal line, indicating constant performance regardless of the training data percentage shown.
* **Approximate Data Point:** Constant at ~60 across the entire x-axis (0% to 60%).
### Key Observations
1. **Performance Hierarchy:** The "Online" method consistently achieves the highest accuracy after the initial training phase (~5% data onward). The "Offline" method performs worse than "Online" but better than the baseline for most data points, except at its lowest dips. The "SFT Baseline" shows no improvement.
2. **Data Efficiency:** Both "Online" and "Offline" methods show their most significant gains with the first 10-20% of training data.
3. **Stability:** The "Online" method demonstrates stable, monotonic improvement after the initial phase. The "Offline" method is highly unstable, with large swings in accuracy as more data is added, suggesting potential issues with optimization or data utilization.
4. **Baseline Ceiling:** The flat baseline at ~60 suggests that the starting model (SFT) has a fixed performance ceiling on this task that is not broken by simply adding more of the same training data without the "Online" or "Offline" adaptation strategies.
### Interpretation
This chart likely illustrates the results of an experiment in machine learning, specifically in adapting a pre-trained model (the SFT Baseline) to a new task (ARC-C). The key finding is that **active adaptation strategies ("Online" and "Offline") are crucial for improving performance beyond the baseline**, and that the **"Online" strategy is significantly more effective and stable** than the "Offline" one.
The "Online" method's curve is characteristic of successful learning: rapid initial gain followed by diminishing returns as it approaches an asymptotic performance limit. The "Offline" method's erratic behavior could indicate problems such as catastrophic forgetting, unstable training dynamics, or poor handling of data distribution shifts as the training set grows. The experiment demonstrates that not all adaptation methods are equal, and the choice between "Online" and "Offline" processing has a major impact on final model accuracy and reliability. The fact that both methods start at the same point as the baseline (60% at 0% data) confirms they are being evaluated from the same starting model.
</details>
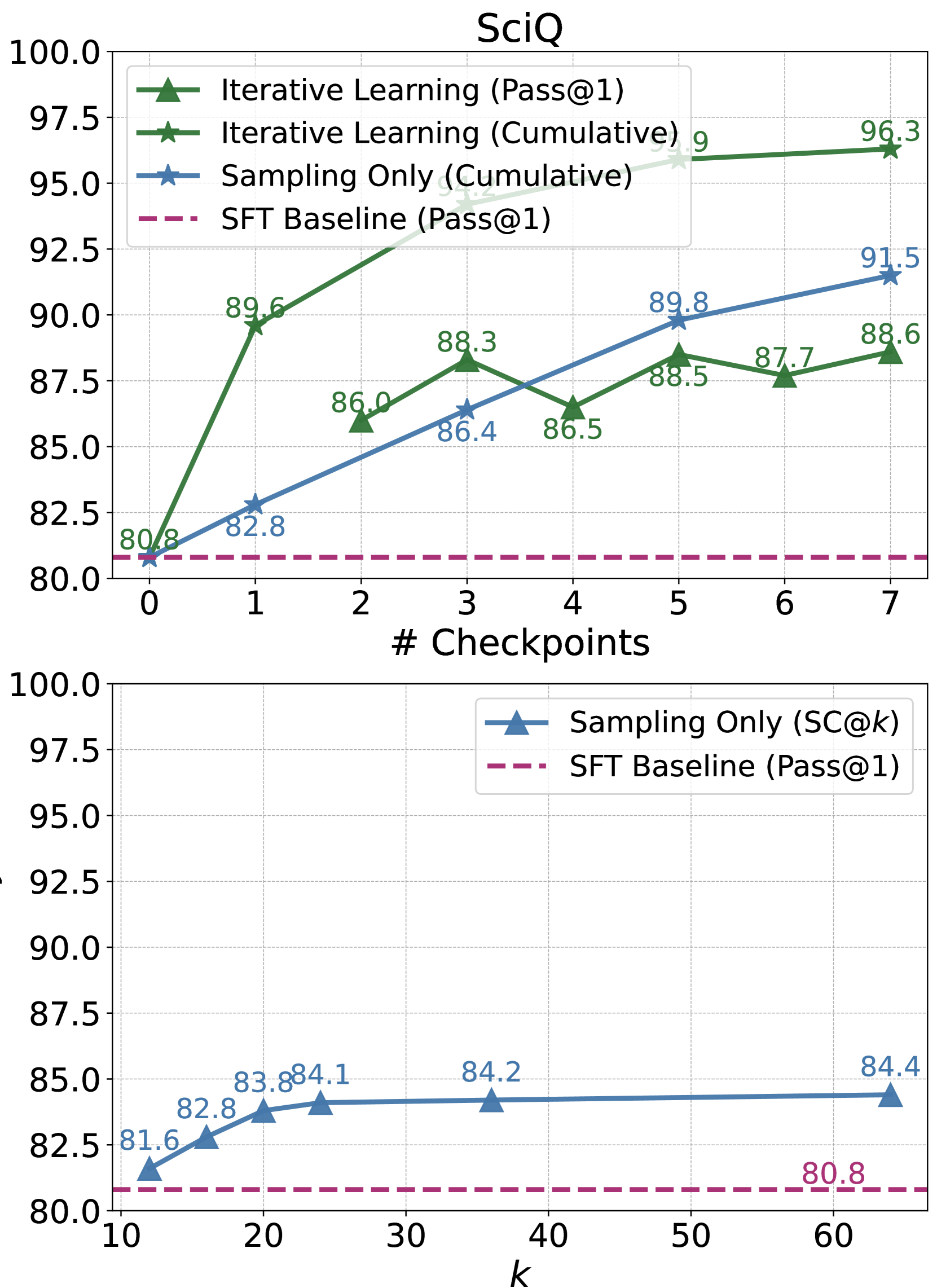
Figure 1: Monte Carlo Tree Search (MCTS) boosts model performance via iterative preference learning. Each iteration of our framework (on the left) consists of two stages: MCTS to collect step-level preferences and preference learning to update the policy. Specifically, we use action values $Q$ estimated by MCTS to assign the preferences, where steps of higher and lower $Q$ values will be labeled as positive and negative data, respectively. The scale of $Q$ is visualized in the colormap. We show the advantage of the online manner in our iterative learning framework using the validation accuracy curves as training progresses on the right. The performance of ARC-C validation illustrates the effectiveness and efficiency of our proposed method compared to its offline variant.
A compelling illustration of the success of such an iterative approach can be seen in the case of AlphaZero (Silver et al., 2017) for its superhuman performance across various domains, which combines the strengths of neural networks, RL techniques, and Monte Carlo Tree Search (MCTS) (Coulom, 2006; Kocsis and Szepesvári, 2006). The integration of MCTS as a policy improvement operator that transforms the current policy into an improved policy (Grill et al., 2020). The effectiveness of AlphaZero underscores the potential of combining these advanced techniques in LLMs. By integrating MCTS into the iterative process of policy development, it is plausible to achieve significant strides in LLMs, particularly in the realm of reasoning and decision-making aligned with human-like preferences (Zhu et al., 2023; Hao et al., 2023).
The integration of MCTS in collecting preference data to improve the current policy iteratively is nuanced and demands careful consideration. One primary challenge lies in determining the appropriate granularity for applying MCTS. Conventionally, preference data is collected at the instance level. The instance-level approach employs sparse supervision, which can lose important information and may not optimally leverage the potential of MCTS in improving the LLMs (Wu et al., 2023). Another challenge is the reliance of MCTS on a critic or a learned reward function. This function is crucial for providing meaningful feedback on different rollouts generated by MCTS, thus guiding the policy improvement process (Liu et al., 2023a).
Addressing this granularity issue, evidence from LLM research indicates the superiority of process-level or stepwise evaluations over instance-level ones (Lightman et al., 2023; Li et al., 2023; Xie et al., 2023; Yao et al., 2023). Our approach utilizes MCTS rollouts for step-level guidance, aligning with a more granular application of MCTS. Moreover, we employ self-evaluation, where the model assesses its outputs, fostering a more efficient policy improvement pipeline by acting as both policy and critic (Kadavath et al., 2022; Xie et al., 2023). This method streamlines the process and ensures more cohesive policy updates, aligning with the iterative nature of policy enhancement and potentially leading to more robust and aligned LLMs.
To summarize, we propose an algorithm based on Monte Carlo Tree Search (MCTS) that breaks down the instance-level preference signals into step-level. MCTS allows us to use the current LLM policy to generate preference data instead of a predetermined set of human preference data, enabling the LLM to receive real-time training signals. During training, we generate sequences of text on the fly and label the preference via MCTS based on feedback from self-evaluation (Figure 1). To update the LLM policy using the preference data, we use Direct Preference Optimization (DPO) (Rafailov et al., 2023). We extensively evaluate the proposed approach on various arithmetic and commonsense reasoning tasks and observe significant performance improvements. For instance, the proposed approach outperforms the Mistral-7B SFT baseline by $81.8\$ (+ $5.9\$ ), $34.7\$ (+ $5.8\$ ), and $76.4\$ (+ $15.8\$ ) on GSM8K, MATH, and SciQ, respectively. Further analysis of the training and test compute tradeoff shows that our method can effectively push the performance gains in a more efficient way compared to sampling-only approaches.
## 2 MCTS-Enhanced Iterative Preference Learning
In this paper, we introduce an approach for improving LLM reasoning, centered around an iterative preference learning process. The proposed method begins with an initial policy $π_θ^(0)$ , and a dataset of prompts $D_P$ . Each iteration $i$ involves selecting a batch of prompts from $D_P$ , from which the model, guided by its current policy $π_θ^(i-1)$ , generates potential responses for each prompt. We then apply a set of dynamically evolving reward criteria to extract preference data $D_i$ from these responses. The model’s policy is subsequently tuned using this preference data, leading to an updated policy $π_θ^(i)$ , for the next iteration. This cycle of sampling, response generation, preference extraction, and policy tuning is repeated, allowing for continuous self-improvement and alignment with evolving preferences. In addressing the critical aspects of this methodology, two key challenges emerge: the effective collection of preference data and the process of updating the policy post-collection.
We draw upon the concept that MCTS can act as an approximate policy improvement operator, transforming the current policy into an improved one. Our work leverages MCTS to iteratively collect preference data, utilizing its look-ahead ability to break down instance-level rewards into more granular step-level signals. To enhance consistency in intermediate steps, we incorporate stepwise self-evaluation, continually updating the quality assessment of newly generated data. This process, as depicted in Figure 1, enables MCTS to balance quality exploitation and diversity exploration during preference data sampling at each iteration. Detailed in section 2.1, our approach utilizes MCTS for step-level preference data collection. Once this data is collected, the policy is updated using DPO, as outlined in section 2.2. Our method can be viewed as an online version of DPO, where the updated policy is iteratively employed to collect preferences via MCTS. Our methodology, thus, not only addresses the challenges in preference data collection and policy updating but also introduces a dynamic, iterative framework that significantly enhances LLM reasoning.
[tb] . MCTS-Enhanced Iterative Preference Learning. Given an initial policy $π_θ^(0)=π_sft$ , our algorithm iteratively conducts step-level preference data sampling via MCTS and preference learning via DPO to update the policy. Input: $D_P$ : prompt dataset; $q(·\mid x)$ : MCTS sampling strategy that constructs a tree-structured set of possible responses given a prompt $x$ , where $q_π$ represents that the strategy is based on the policy $π$ for both response generation and self-evaluation; $\ell_i(x,y_w,y_l;θ)$ : loss function of preference learning at the $i$ -th iteration, where the corresponding sampling policy is $π^(i)$ ; $M$ : number of iterations; $B$ : number of samples per iteration; $T$ : average number of steps per sample Train $π_θ$ on $D_P$ using step-level preference learning. $i=1$ to $M$ $π^(i)←π_θ←π_θ^(i-1)$ Sample a batch of $B$ samples from $D_P$ as $D_P^(i)$ . MCTS for Step-Level Preference Data Collection For each $x∈D_P^(i)$ , elicit a search tree of depth $T$ via $q_π_{θ}(·\mid x)$ . Collect a batch of preferences $D_i=\{$ $\{(x^j,y_l^(j,t),y_l^(j,t))|_t=1^T\}|_j=1^B$ s.t. $x^j∼D_P^(i),y_w^(j,t)≠ y_w^(j,t)∼ q _π_{θ}(·\mid x^j)$ $\}$ , where $y_w^(j,t)$ and $y_l^(j,t)$ is the nodes at depth $t$ , with the highest and lowest $Q$ values, respectively, among all the children nodes of their parent node. Preference Learning for Policy Improvement Optimize $θ$ by minimizing $J(θ)=E_(x,y_{w,y_l)∼D_i}\ell_i(x,y_w,y_l ;θ)$ . Obtain the updated policy $π_θ^(i)$ $π_θ←π_θ^(M)$ Output: Policy $π_θ$
### 2.1 MCTS for Step-Level Preference
To transform instance-level rewards into granular, step-level signals, we dissect the reasoning process into discrete steps, each represented by a token sequence. We define the state at step $t$ , $s_t$ , as the prefix of the reasoning chain, with the addition of a new reasoning step $a$ transitioning the state to $s_t+1$ , where $s_t+1$ is the concatenation of $s_t$ and $a$ . Utilizing the model’s current policy $π_θ$ , we sample candidate steps from its probability distribution $π_θ(a\mid x,s_t)$ For tasks (e.g., MATH) where the initial policy performs poorly, we also include the ground-truth reasoning steps for training. We detail the step definition for different tasks with examples in Appendices C and D., with $x$ being the task’s input prompt. MCTS serves as an approximate policy improvement operator by leveraging its look-ahead capability to predict the expected future reward. This prediction is refined through stepwise self-evaluation (Kadavath et al., 2022; Xie et al., 2023), enhancing process consistency and decision accuracy. The tree-structured search supports a balance between exploring diverse possibilities and exploiting promising paths, essential for navigating the vast search space in LLM reasoning.
The MCTS process begins from a root node, $s_0$ , as the sentence start or incomplete response, and unfolds in three iterative stages: selection, expansion, and backup, which we detail further.
#### Select.
The objective of this phase is to identify nodes that balance search quality and computational efficiency. The selection is guided by two key variables: $Q(s_t,a)$ , the value of taking action $a$ in state $s_t$ , and $N(s_t)$ , the visitation frequency of state $s_t$ . These variables are crucial for updating the search strategy, as explained in the backup section. To navigate the trade-off between exploring new nodes and exploiting visited ones, we employ the Predictor + Upper Confidence bounds applied to Trees (PUCT) (Rosin, 2011). At node $s_t$ , the choice of the subsequent node follows the formula:
$$
\displaystyle{s_t+1}^* \displaystyle=\arg\max_s_{t}\Bigl{[}Q(s_t,a)+c_puct· p(a
\mid s_t)\frac{√{N(s_t)}}{1+N(s_t+1)}\Bigl{]} \tag{1}
$$
where $p(a\mid s_t)=π_θ(a\mid x,s_t)/|a|^λ$ denotes the policy $π_θ$ ’s probability distribution for generating a step $a$ , adjusted by a $λ$ -weighted length penalty to prevent overly long reasoning chains.
#### Expand.
Expansion occurs at a leaf node during the selection process to integrate new nodes and assess rewards. The reward $r(s_t,a)$ for executing step $a$ in state $s_t$ is quantified by the reward difference between states $R(s_t)$ and $R(s_t+1)$ , highlighting the advantage of action $a$ at $s_t$ . As defined in Eq. (2), reward computation merges outcome correctness $O$ with self-evaluation $C$ . We assign the outcome correctness to be $1$ , $-1$ , and $0 0$ for correct terminal, incorrect terminal, and unfinished intermediate states, respectively. Following Xie et al. (2023), we define self-evaluation as Eq. (3), where $A$ denotes the confidence score in token-level probability for the option indicating correctness We show an example of evaluation prompt in Table 6.. Future rewards are anticipated by simulating upcoming scenarios through roll-outs, following the selection and expansion process until reaching a terminal state The terminal state is reached when the whole response is complete or exceeds the maximum length..
$$
R(s_t)=O(s_t)+C(s_t) \tag{2}
$$
$$
C(s_t)=π_θ(A\mid{prompt}_eval
,x,s_t) \tag{3}
$$
#### Backup.
Once a terminal state is reached, we carry out a bottom-up update from the terminal node back to the root. We update the visit count $N$ , the state value $V$ , and the transition value $Q$ :
$$
Q(s_t,a)← r(s_t,a)+γ V(s_t+1) \tag{4}
$$
$$
V(s_t)←∑_aN(s_t+1)Q(s_t,a)/∑_aN(s_t+1) \tag{5}
$$
$$
N(s_t)← N(s_t)+1 \tag{6}
$$
where $γ$ is the discount for future state values.
For each step in the response generation, we conduct $K$ iterations of MCTS to construct the search tree while updating $Q$ values and visit counts $N$ . To balance the diversity, quality, and efficiency of the tree construction, we initialize the search breadth as $b_1$ and anneal it to be a smaller $b_2<b_1$ for the subsequent steps. We use the result $Q$ value corresponding to each candidate step to label its preference, where higher $Q$ values indicate preferred next steps. For a result search tree of depth $T$ , we obtain $T$ pairs of step-level preference data. Specifically, we select the candidate steps of highest and lowest $Q$ values as positive and negative samples at each tree depth, respectively. The parent node selected at each tree depth has the highest value calculated by multiplying its visit count and the range of its children nodes’ visit counts, indicating both the quality and diversity of the generations.
### 2.2 Iterative Preference Learning
Given the step-level preferences collected via MCTS, we tune the policy via DPO (Rafailov et al., 2023). Considering the noise in the preference labels determined by $Q$ values, we employ the conservative version of DPO (Mitchell, 2023) and use the visit counts simulated in MCTS to apply adaptive label smoothing on each preference pair. Using the shorthand $h_π_{θ}^y_w,y_l=\log\frac{π_θ(y_w\mid x)}{π_ ref(y_w\mid x)}-\log\frac{π_θ(y_l\mid x)}{π_ ref(y_l\mid x)}$ , at the $i$ -th iteration, given a batch of preference data $D_i$ sampled with the latest policy $π_θ^(i-1)$ , we denote the policy objective $\ell_i(θ)$ as follows:
$$
\displaystyle\ell_i(θ)= \displaystyle-E_(x,y_{w,y_l)∼D_i}\Bigr{[}(1-α
_x,y_{w,y_l})\logσ(β≤ft.h_π_{θ}^y_w,y_l\right)+ \displaystyleα_x,y_{w,y_l}\logσ(-β h_π_{θ}^y_w,y
_l)\Bigr{]} \tag{7}
$$
where $y_w$ and $y_l$ represent the step-level preferred and dispreferred responses, respectively, and the hyperparameter $β$ scales the KL constraint. Here, $α_x,y_{w,y_l}$ is a label smoothing variable calculated using the visit counts at the corresponding states of the preference data $y_w$ , $y_l$ in the search tree:
$$
α_x,y_{w,y_l}=\frac{1}{N(x,y_w)/N(x,y_l)+1} \tag{8}
$$
where $N(x,y_w)$ and $N(x,y_l)$ represent the states taking the actions of generating $y_w$ and $y_l$ , respectively, from their previous state as input $x$ .
After optimization, we obtain the updated policy $π_θ^(i)$ and repeat the data collection process in Section 2.1 to iteratively update the LLM policy. We outline the full algorithm of our MCTS-enhanced Iterative Preference Learning in Algorithm 2.
## 3 Theoretical Analysis
Our approach can be viewed as an online version of DPO, where we iteratively use the updated policy to sample preferences via MCTS. In this section, we provide theoretical analysis to interpret the advantages of our online learning framework compared to the conventional alignment techniques that critically depend on offline preference data. We review the typical RLHF and DPO paradigms in Appendix B.
We now consider the following abstract formulation for clean theoretical insights to analyze our online setting of preference learning. Given a prompt $x$ , there exist $n$ possible suboptimal responses $\{\bar{y}_1,\dots,\bar{y}_n\}=Y$ and an optimal outcome $y^*$ . As specified in Equation 7, at the $i$ -th iteration, a pair of responses $(y,{y^\prime})$ are sampled from some sampling policy $π^(i)$ without replacement so that $y≠{y^\prime}$ as $y∼π^(i)(·\mid x)$ and ${y^\prime}∼π^(i)(·\mid x,y)$ . Then, these are labeled to be $y_w$ and $y_l$ according to the preference. Define $Θ$ be a set of all global optimizers of the preference loss for all $M$ iterations, i.e., for any $θ∈Θ$ , $\ell_i(θ)=0$ for all $i∈\{1,2,⋯,M\}$ . Similarly, let ${θ^(i)}$ be a parameter vector such that $\ell_j(θ^(i))=0$ for all $j∈\{1,2,⋯,i-1\}$ for $i≥ 1$ whereas $θ^(0)$ is the initial parameter vector.
This abstract formulation covers both the offline and online settings. The offline setting in previous works is obtained by setting $π^(i)=π$ for some fixed distribution $π$ . The online setting is obtained by setting $π^(i)=π_θ^(i-1)$ where $π_θ^(i-1)$ is the latest policy at beginning of the $i$ -th iteration.
The following theorem shows that the offline setting can fail with high probability if the sampling policy $π^(i)$ differs too much from the current policy $π_θ^(i-1)$ :
**Theorem 3.1 (Offline setting can fail with high probability)**
*Let $π$ be any distribution for which there exists $\bar{y}∈ Y$ such that $π(\bar{y}\mid x),π(\bar{y}\mid x,y)≤ε$ for all $y∈(Y∖\bar{y})∪\{y^*\}$ and $π_θ^(i-1)(\bar{y}\mid x)≥ c$ for some $i∈\{1,2,⋯,M\}$ . Set $π^(i)=π$ for all $i∈\{1,2,⋯,M\}$ . Then, there exists $θ∈Θ$ such that with probability at least $1-2ε M$ (over the samples of $π^(i)=π$ ), the following holds: $π_θ(y^*\mid x)≤ 1-c$ .*
If the current policy and the sampling policy differ too much, it is possible that $ε=0$ and $c≈ 1.0$ , for which Theorem 3.1 can conclude $π_θ(y^*\mid x)≈ 0$ with probability $1$ for any number of steps $M$ . When $ε≠ 0$ , the lower bound of the failure probability decreases towards zero as we increase $M$ . Thus, it is important to make sure that $ε≠ 0$ and $ε$ is not too low. This is achieved by using the online setting, i.e., $π^(i)=π_θ^(i)$ . Therefore, Theorem 3.1 motivates us to use the online setting. Theorem 3.2 confirms that we can indeed avoid this failure case in the online setting.
**Theorem 3.2 (Online setting can avoid offline failure case)**
*Let $π^(i)=π_θ^(i-1)$ . Then, for any $θ∈Θ$ , it holds that $π_θ(y^*\mid x)=1$ if $M≥ n+1$ .*
See Appendix B for the proofs of Theorems 3.1 and 3.2. As suggested by the theorems, a better sampling policy is to use both the latest policy and the optimal policy for preference sampling. However, since we cannot access the optimal policy $π^*$ in practice, we adopt online DPO via sampling from the latest policy $π_θ^(i-1)$ . The key insight of our iterative preference learning approach is that online DPO is proven to enable us to converge to an optimal policy even if it is inaccessible to sample outputs. We provide further discussion and additional insights in Appendix B.
## 4 Experiments
We evaluate the effectiveness of MCTS-enhanced iterative preference learning on arithmetic and commonsense reasoning tasks. We employ Mistral-7B (Jiang et al., 2023) as the base pre-trained model. We conduct supervised training using Arithmo https://huggingface.co/datasets/akjindal53244/Arithmo-Data which comprises approximately $540$ K mathematical and coding problems. Detailed information regarding the task formats, specific implementation procedures, and parameter settings of our experiments can be found in Appendix C.
#### Datasets.
We aim to demonstrate the effectiveness and versatility of our approach by focusing on two types of reasoning: arithmetic and commonsense reasoning. For arithmetic reasoning, we utilize two datasets: GSM8K (Cobbe et al., 2021), which consists of grade school math word problems, and MATH (Hendrycks et al., 2021), featuring challenging competition math problems. Specifically, in the GSM8K dataset, we assess both chain-of-thought (CoT) and program-of-thought (PoT) reasoning abilities. We integrate the training data from GSM8K and MATH to construct the prompt data for our preference learning framework, aligning with a subset of the Arithmo data used for Supervised Fine-Tuning (SFT). This approach allows us to evaluate whether our method enhances reasoning abilities on specific arithmetic tasks. For commonsense reasoning, we use four multiple-choice datasets: ARC (easy and challenge splits) (Clark et al., 2018), focusing on science exams; AI2Science (elementary and middle splits) (Clark et al., 2018), containing science questions from student assessments; OpenBookQA (OBQA) (Mihaylov et al., 2018), which involves open book exams requiring broad common knowledge; and CommonSenseQA (CSQA) (Talmor et al., 2019), featuring commonsense questions necessitating prior world knowledge. The diversity of these datasets, with different splits representing various grade levels, enables a comprehensive assessment of our method’s generalizability in learning various reasoning tasks through self-distillation. Performance evaluation is conducted using the corresponding validation sets of each dataset. Furthermore, we employ an unseen evaluation using the validation set of an additional dataset, SciQ (Welbl et al., 2017), following the approach of Liu et al. (2023b), to test our model’s ability to generalize to novel reasoning contexts.
Baselines. Our study involves a comparative evaluation of our method against several prominent approaches and fair comparison against variants including instance-level iterative preference learning and offline MCTS-enhanced learning. We use instance-level sampling as a counterpart of step-level preference collection via MCTS. For a fair comparison, we also apply self-evaluation and correctness assessment and control the number of samples under a comparable compute budget with MCTS in instance-level sampling. The offline version uses the initial policy for sampling rather than the updated one at each iteration.
We contrast our approach with the Self-Taught Reasoner (STaR) (Zelikman et al., 2022), an iterated learning model based on instance-level rationale generation, and Crystal (Liu et al., 2023b), an RL-tuned model with a focus on knowledge introspection in commonsense reasoning. Considering the variation in base models used by these methods, we include comparisons with Direct Tuning, which entails fine-tuning base models directly bypassing chain-of-thought reasoning. In the context of arithmetic reasoning tasks, our analysis includes Language Model Self-Improvement (LMSI) (Huang et al., 2023), a self-training method using self-consistency to gather positive data, and Math-Shepherd (Wang et al., 2023a), which integrates process supervision within Proximal Policy Optimization (PPO). To account for differences in base models and experimental setups across these methods, we also present result performance of SFT models as baselines for each respective approach.
Table 1: Result comparison (accuracy $\$ ) on arithmetic tasks. We supervised fine-tune the base model Mistral-7B on Arithmo data, while Math-Shepherd (Wang et al., 2023a) use MetaMATH (Yu et al., 2023b) for SFT. We highlight the advantages of our approach via conceptual comparison with other methods, where NR, OG, OF, and NS represent “w/o Reward Model”, “On-policy Generation”, “Online Feedback”, and “w/ Negative Samples”.
| Approach | Base Model | Conceptual Comparison | GSM8K | MATH | | | |
| --- | --- | --- | --- | --- | --- | --- | --- |
| NR | OG | OF | NS | | | | |
| LMSI | PaLM-540B | ✓ | ✓ | ✗ | ✗ | $73.5$ | $-$ |
| SFT (MetaMath) | Mistral-7B | $-$ | $-$ | $-$ | $-$ | $77.7$ | $28.2$ |
| Math-Shepherd | ✗ | ✓ | ✗ | ✓ | $84.1$ | $33.0$ | |
| SFT (Arithmo) | Mistral-7B | $-$ | $-$ | $-$ | $-$ | $75.9$ | $28.9$ |
| MCTS Offline-DPO | ✓ | ✗ | ✗ | ✓ | $79.9$ | $31.9$ | |
| Instance-level Online-DPO | ✓ | ✓ | ✓ | ✓ | $79.7$ | $32.9$ | |
| Ours | ✓ | ✓ | ✓ | ✓ | $80.7$ | $32.2$ | |
| Ours (w/ G.T.) | | ✓ | ✓ | ✓ | ✓ | $81.8$ | $34.7$ |
<details>
<summary>x3.png Details</summary>
### Visual Description
## Line Chart: ARC-C Accuracy vs. Training Data Percentage
### Overview
The image is a line chart titled "ARC-C" that plots the performance (Accuracy) of three different training methods and one baseline against the percentage of training data used. The chart compares "Step-Level (Online)", "Instance-Level (Online)", and "Step-Level (Offline)" methods against a fixed "SFT Baseline".
### Components/Axes
* **Title:** "ARC-C" (centered at the top).
* **Y-Axis:** Labeled "Accuracy". The scale runs from 55 to 75, with major gridlines at intervals of 5 (55, 60, 65, 70, 75).
* **X-Axis:** Labeled "Training Data %". The scale runs from approximately 5 to 55, with labeled tick marks at 10, 20, 30, 40, and 50.
* **Legend:** Located in the bottom-left quadrant of the plot area. It contains four entries:
1. **Step-Level (Online):** Represented by a solid green line with star (★) markers.
2. **Instance-Level (Online):** Represented by a solid blue line with upward-pointing triangle (▲) markers.
3. **Step-Level (Offline):** Represented by a solid yellow/gold line with star (★) markers.
4. **SFT Baseline:** Represented by a dashed pink/magenta horizontal line.
### Detailed Analysis
**Data Series and Exact Values:**
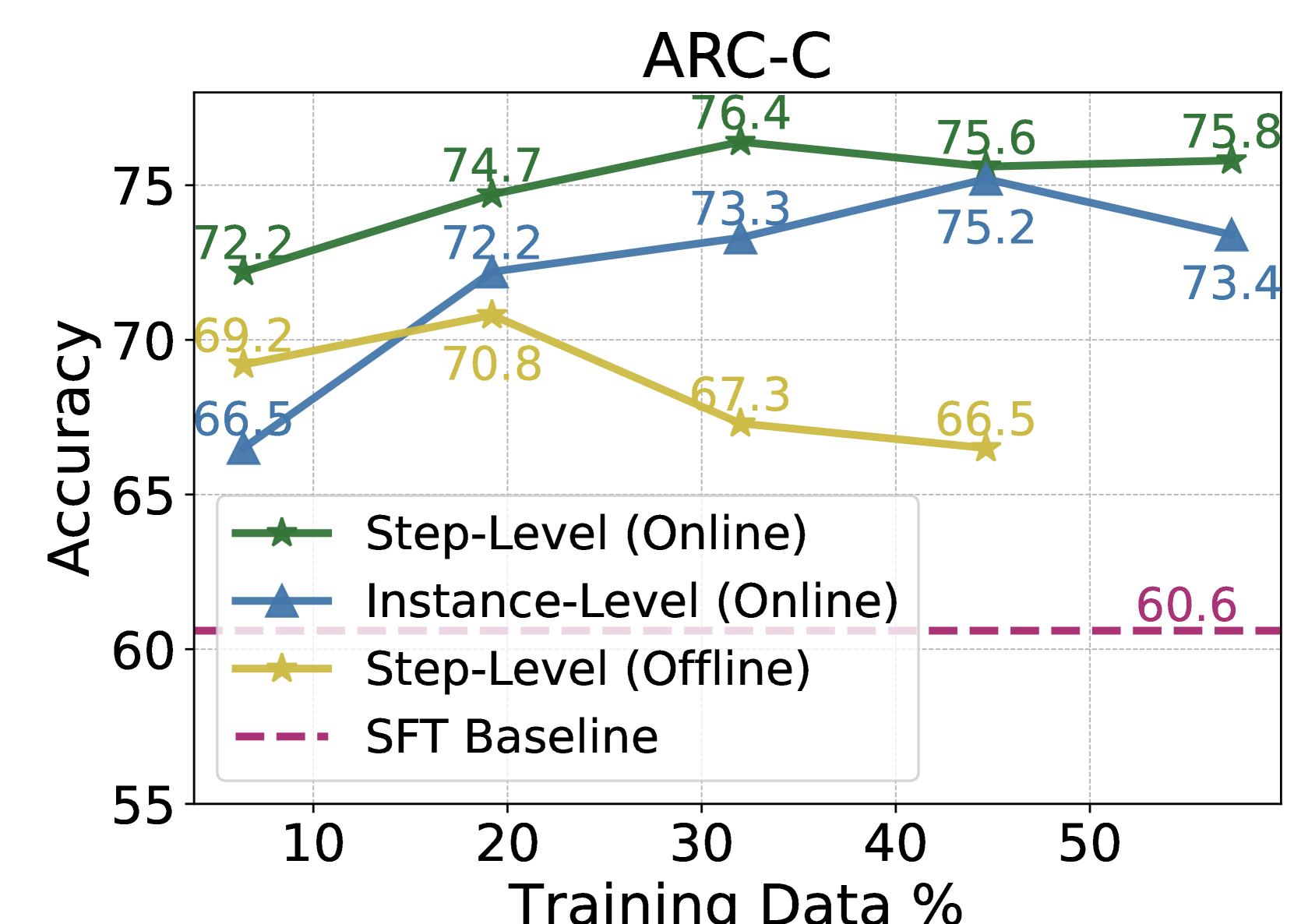
1. **Step-Level (Online) - Green Line with Stars:**
* Trend: Shows a steady upward trend from 10% to 30% training data, peaks at 30%, then slightly declines and plateaus.
* Data Points:
* At 10%: Accuracy = 72.2
* At 20%: Accuracy = 74.7
* At 30%: Accuracy = 76.4 (Peak)
* At 40%: Accuracy = 75.6
* At 50%: Accuracy = 75.8
2. **Instance-Level (Online) - Blue Line with Triangles:**
* Trend: Shows a strong upward trend from 10% to 40%, then a noticeable drop at 50%.
* Data Points:
* At 10%: Accuracy = 66.5
* At 20%: Accuracy = 72.2
* At 30%: Accuracy = 73.3
* At 40%: Accuracy = 75.2 (Peak)
* At 50%: Accuracy = 73.4
3. **Step-Level (Offline) - Yellow Line with Stars:**
* Trend: Increases slightly from 10% to 20%, then shows a consistent downward trend as training data increases beyond 20%.
* Data Points:
* At 10%: Accuracy = 69.2
* At 20%: Accuracy = 70.8 (Peak)
* At 30%: Accuracy = 67.3
* At 40%: Accuracy = 66.5
* (No data point is plotted for 50%).
4. **SFT Baseline - Dashed Pink Line:**
* Trend: Constant horizontal line, indicating a fixed performance level independent of the training data percentage shown.
* Value: Accuracy = 60.6 (labeled on the right side of the chart).
### Key Observations
* **Performance Hierarchy:** The "Step-Level (Online)" method consistently achieves the highest accuracy across all training data percentages shown.
* **Online vs. Offline:** Both online methods (Step-Level and Instance-Level) significantly outperform the offline method ("Step-Level (Offline)") and the SFT Baseline at all data points.
* **Diminishing Returns/Overfitting:** The "Step-Level (Online)" method's performance plateaus after 30% data. The "Instance-Level (Online)" method's performance drops after 40% data, suggesting potential overfitting or diminishing returns with more data for this method.
* **Offline Method Decline:** The "Step-Level (Offline)" method shows a clear negative correlation between training data percentage and accuracy beyond the 20% mark.
* **Baseline Comparison:** All three experimental methods provide a substantial improvement over the "SFT Baseline" of 60.6 accuracy.
### Interpretation
This chart demonstrates the comparative effectiveness of different training paradigms on the ARC-C benchmark. The data suggests that **online training methods (both Step-Level and Instance-Level) are superior to the offline method and the standard SFT baseline** for this task, yielding accuracy gains of approximately 10-16 percentage points.
The **"Step-Level (Online)" approach appears to be the most robust and effective**, maintaining high performance even as training data increases. The peak performance for this method occurs with 30% of the training data, after which additional data provides minimal benefit.
The **decline in performance for the "Instance-Level (Online)" method at 50% data and the consistent decline for the "Step-Level (Offline)" method** are critical anomalies. They indicate that simply adding more data is not universally beneficial and can be detrimental depending on the training strategy. This could point to issues like overfitting, noise in the additional data, or a mismatch between the training objective and the evaluation metric when data scales.
In summary, the chart argues for the efficacy of online, step-level training for maximizing accuracy on ARC-C, while cautioning that the benefits of increased data are not automatic and are highly dependent on the specific training methodology employed.
</details>
Figure 2: Performance on the validation set of ARC-C via training with different settings.
Table 2: Result comparisons (accuracy $\$ ) on commonsense reasoning tasks. The results based on GPT-3-curie (Brown et al., 2020) and T5 (Raffel et al., 2020) are reported from Liu et al. (2023b). For CSQA, we also include the GPT-J (Wang and Komatsuzaki, 2021) results reported by Zelikman et al. (2022). We follow Liu et al. (2023b) to combine the training data of ARC, AI2Sci, OBQA, and CSQA for training , while STaR (Zelikman et al., 2022) only use CSQA for training.
| Approach | Base Model | Conceptual Comparison | ARC-c | AI2Sci-m | CSQA | SciQ | Train Data Used ( $\$ ) | | | |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| NR | OG | OF | NS | | | | | | | |
| CoT Tuning | GPT-3-curie (6.7B) | ✓ | ✗ | ✗ | ✗ | $-$ | $-$ | $56.8$ | $-$ | $100$ |
| Direct Tuning | GPT-J (6B) | ✓ | ✗ | ✗ | ✗ | $-$ | $-$ | $60.0$ | $-$ | $100$ |
| STaR | ✓ | ✓ | ✓ | ✗ | $-$ | $-$ | $72.5$ | $-$ | $86.7$ | |
| Direct TUning | T5-11B | ✓ | ✗ | ✗ | ✗ | $72.9$ | $84.0$ | $82.0$ | $83.2$ | $100$ |
| Crystal | ✗ | ✓ | ✓ | ✓ | $73.2$ | $84.8$ | $82.3$ | $85.3$ | $100$ | |
| SFT Base (Arithmo) | Mistral-7B | $-$ | $-$ | $-$ | $-$ | $60.6$ | $70.9$ | $54.1$ | $80.8$ | $-$ |
| Direct Tuning | ✓ | ✗ | ✗ | ✗ | $73.9$ | $85.2$ | $79.3$ | $86.4$ | $100$ | |
| MCTS Offline-DPO | ✓ | ✗ | ✗ | ✓ | $70.8$ | $82.6$ | $68.5$ | $87.4$ | $19.2$ | |
| Instance-level Online-DPO | ✓ | ✓ | ✓ | ✓ | $75.3$ | $87.3$ | $63.1$ | $87.6$ | $45.6$ | |
| Ours | ✓ | ✓ | ✓ | ✓ | $76.4$ | $88.2$ | $74.8$ | $88.5$ | $47.8$ | |
### 4.1 Main Results
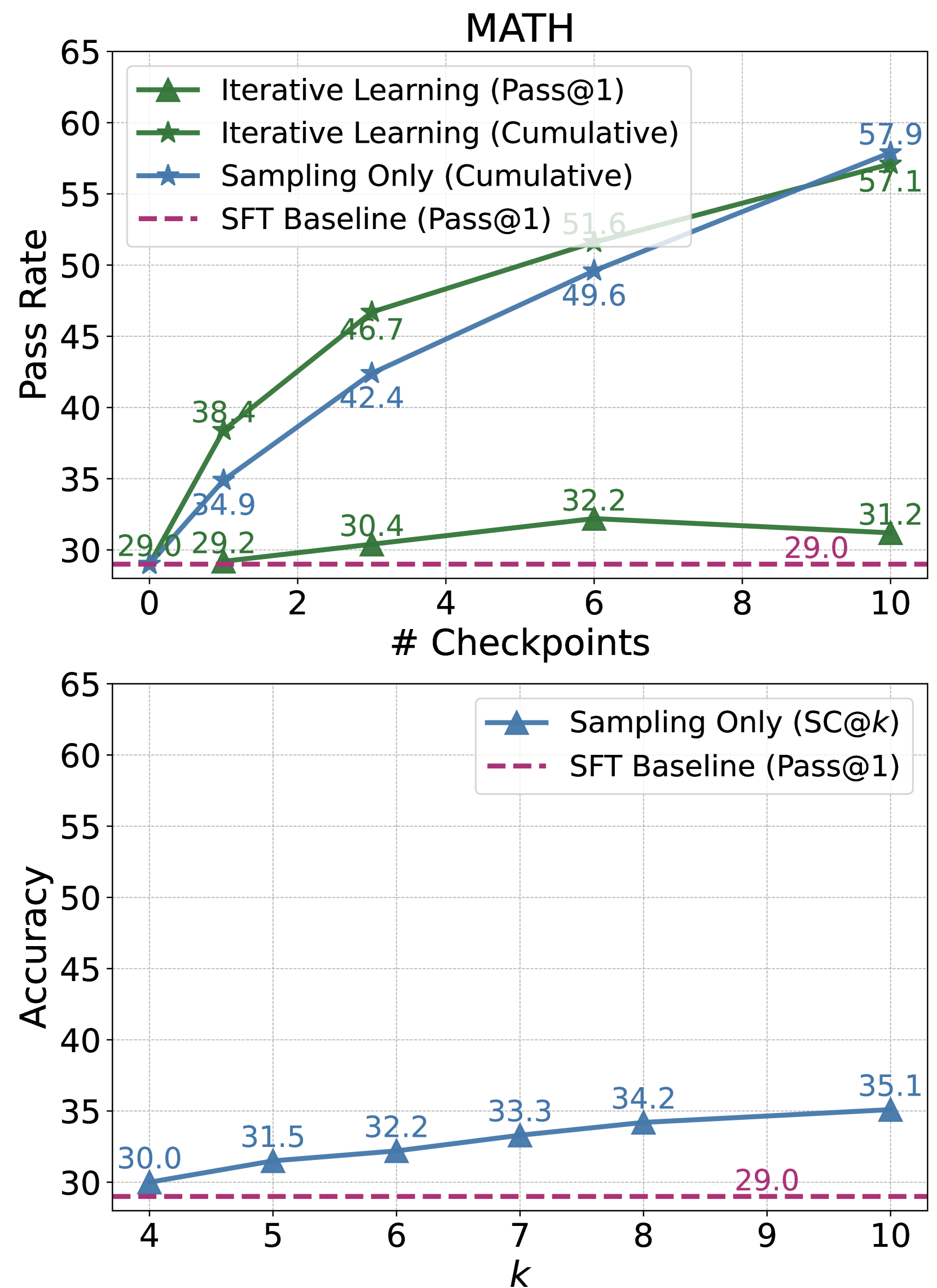
Arithmetic Reasoning. In Table 1, we present a comparative analysis of performance gains in arithmetic reasoning tasks. Our method demonstrates substantial improvements, notably on GSM8K, increasing from $75.9\$ , and on MATH, enhancing from $28.9\$ . When compared to Math-Shepherd, which also utilizes process supervision in preference learning, our approach achieves similar performance enhancements without the necessity of training separate reward or value networks. This suggests the potential of integrating trained reward model signals into our MCTS stage to further augment performance. Furthermore, we observe significant performance gain on MATH when incorporating the ground-truth solutions in the MCTS process for preference data collection, illustrating an effective way to refine the preference data quality with G.T. guidance.
<details>
<summary>x4.png Details</summary>
### Visual Description
## [Line Charts]: ARC-C Performance Metrics
### Overview
The image contains two line charts stacked vertically, both titled "ARC-C". They display performance metrics (Pass Rate and Accuracy) for different machine learning training/evaluation methods across varying parameters (Checkpoints and k). The charts compare "Iterative Learning", "Sampling Only", and an "SFT Baseline".
### Components/Axes
**Top Chart:**
* **Title:** ARC-C
* **Y-axis:** Label: "Pass Rate". Scale: 60 to 95, with major ticks every 5 units.
* **X-axis:** Label: "# Checkpoints". Scale: 0 to 7, with integer ticks.
* **Legend (Center-Right):**
* Green line with upward-pointing triangle markers: "Iterative Learning (Pass@1)"
* Green line with star markers: "Iterative Learning (Cumulative)"
* Blue line with star markers: "Sampling Only (Cumulative)"
* Pink dashed line: "SFT Baseline (Pass@1)"
**Bottom Chart:**
* **Y-axis:** Label: "Accuracy". Scale: 60 to 95, with major ticks every 5 units.
* **X-axis:** Label: "k". Scale: 10 to 60, with major ticks at 10, 20, 30, 40, 50, 60.
* **Legend (Top-Right):**
* Blue line with upward-pointing triangle markers: "Sampling Only (SC@k)"
* Pink dashed line: "SFT Baseline (Pass@1)"
### Detailed Analysis
**Top Chart - Data Points & Trends:**
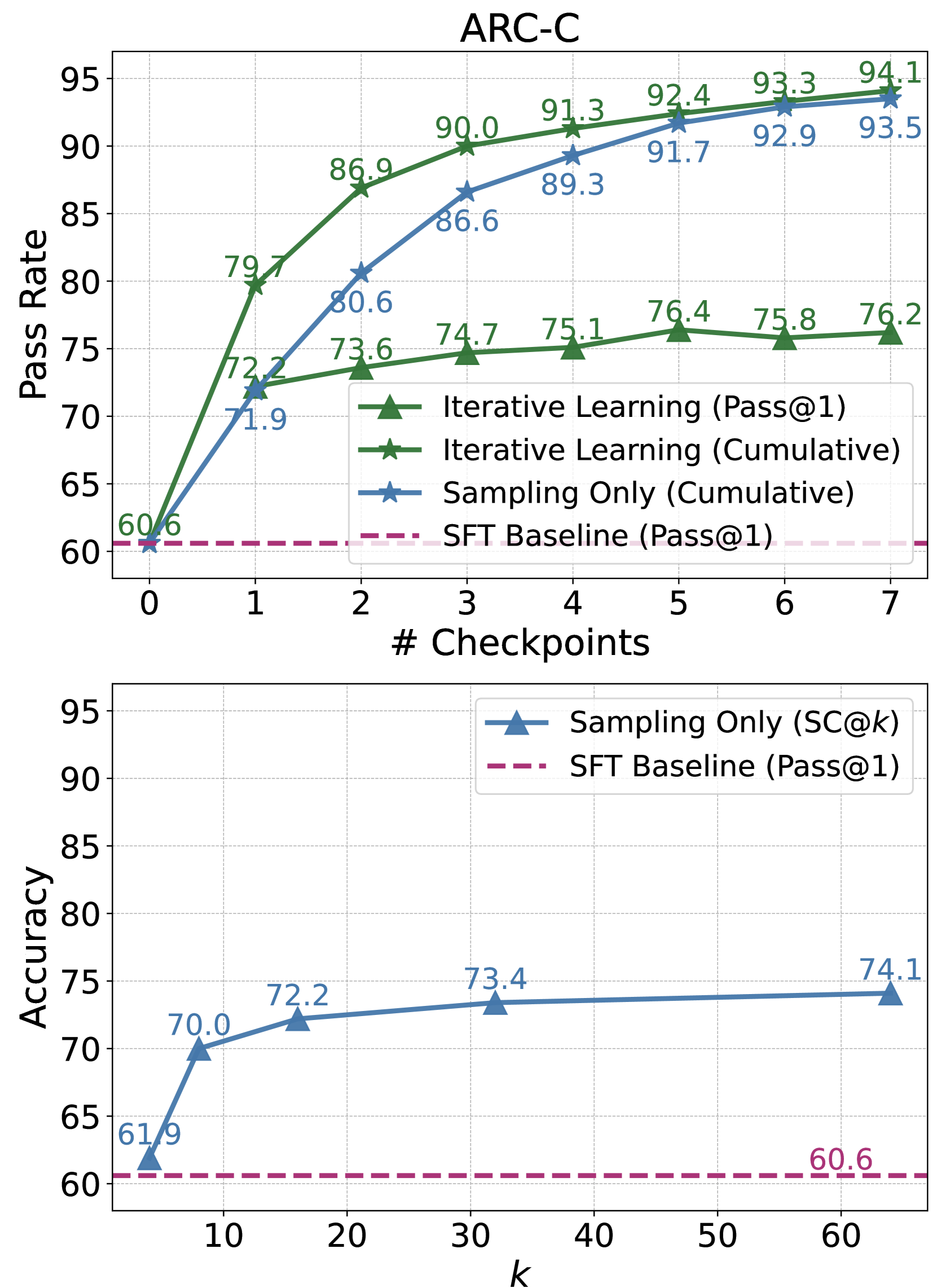
* **Iterative Learning (Pass@1) [Green Triangles]:** Starts at 60.6 (k=0). Increases sharply to 72.2 (k=1), then rises more gradually: 73.6 (k=2), 74.7 (k=3), 75.1 (k=4), 76.4 (k=5), 75.8 (k=6), 76.2 (k=7). **Trend:** Steep initial rise, followed by a plateau around 76.
* **Iterative Learning (Cumulative) [Green Stars]:** Starts at 60.6 (k=0). Increases sharply to 79.7 (k=1), then continues a strong upward trend: 86.9 (k=2), 90.0 (k=3), 91.3 (k=4), 92.4 (k=5), 93.3 (k=6), 94.1 (k=7). **Trend:** Consistent, strong upward slope, approaching 95.
* **Sampling Only (Cumulative) [Blue Stars]:** Starts at 60.6 (k=0). Increases to 71.9 (k=1), then follows a steady upward curve: 80.6 (k=2), 86.6 (k=3), 89.3 (k=4), 91.7 (k=5), 92.9 (k=6), 93.5 (k=7). **Trend:** Steady upward slope, consistently below the Iterative Learning (Cumulative) line but converging towards it at higher checkpoints.
* **SFT Baseline (Pass@1) [Pink Dashed Line]:** Constant horizontal line at approximately 60.6 across all checkpoints.
**Bottom Chart - Data Points & Trends:**
* **Sampling Only (SC@k) [Blue Triangles]:** Data points at specific k values: 61.9 (k=1), 70.0 (k=8), 72.2 (k=16), 73.4 (k=32), 74.1 (k=64). **Trend:** Increases with k, but the rate of improvement diminishes significantly after k=16, showing a logarithmic-like growth curve.
* **SFT Baseline (Pass@1) [Pink Dashed Line]:** Constant horizontal line at 60.6 across all k values.
### Key Observations
1. **Performance Hierarchy:** In the top chart, "Iterative Learning (Cumulative)" achieves the highest Pass Rate, followed closely by "Sampling Only (Cumulative)". "Iterative Learning (Pass@1)" performs significantly lower than the cumulative methods but still well above the baseline.
2. **Baseline Comparison:** All active learning/sampling methods substantially outperform the static "SFT Baseline" of 60.6.
3. **Diminishing Returns:** Both charts show diminishing returns. In the top chart, the rate of improvement for all lines slows after Checkpoint 3. In the bottom chart, increasing `k` beyond 16 yields only marginal gains in Accuracy.
4. **Method Comparison:** The "Iterative Learning (Cumulative)" method shows a clear advantage over "Sampling Only (Cumulative)" at every checkpoint, though the gap narrows slightly at the highest values.
### Interpretation
These charts likely evaluate techniques for improving a language model's reasoning or problem-solving capabilities on the ARC (Abstraction and Reasoning Corpus) benchmark, specifically the "C" (likely "Challenge") subset.
* **What the data suggests:** The data demonstrates that both iterative learning and sampling-based methods are highly effective at improving model performance beyond a standard supervised fine-tuning (SFT) baseline. The cumulative metrics (which likely aggregate success across multiple attempts or steps) show that the model's *potential* to solve problems is much higher than its single-attempt (Pass@1) performance.
* **How elements relate:** The top chart shows the learning trajectory over training iterations (checkpoints). The bottom chart isolates the effect of the sampling parameter `k` (likely the number of samples generated per problem) on accuracy for the "Sampling Only" method. The consistent SFT baseline in both provides a fixed reference point.
* **Notable trends/anomalies:** The most significant trend is the superiority of cumulative evaluation over single-pass evaluation, highlighting the model's ability to self-correct or explore solution spaces when given multiple chances. The plateau in the "Iterative Learning (Pass@1)" line suggests a limit to the model's single-shot reasoning capability under this training regime, even as its cumulative capability continues to grow. The clear, consistent ordering of the methods provides strong evidence for the efficacy of iterative learning approaches over pure sampling for this task.
</details>
<details>
<summary>x5.png Details</summary>
### Visual Description
## Line Chart: SciQ Dataset Performance Comparison
### Overview
The image contains two line charts stacked vertically, both titled "SciQ". They compare the performance of different learning or sampling methods on the SciQ question-answering dataset. The top chart tracks performance across training checkpoints, while the bottom chart examines performance as a function of a parameter `k`.
### Components/Axes
**Top Chart:**
* **Title:** SciQ
* **X-axis:** Label: "# Checkpoints". Scale: Linear, from 0 to 7, with integer markers.
* **Y-axis:** Unlabeled, but represents a performance metric (likely accuracy percentage). Scale: Linear, from 80.0 to 100.0, with increments of 2.5.
* **Legend (Top-Left):**
* `Iterative Learning (Pass@1)`: Green line with upward-pointing triangle markers.
* `Iterative Learning (Cumulative)`: Dark green line with star markers.
* `Sampling Only (Cumulative)`: Blue line with star markers.
* `SFT Baseline (Pass@1)`: Magenta dashed line.
**Bottom Chart:**
* **X-axis:** Label: "k". Scale: Linear, from 10 to 60, with increments of 10.
* **Y-axis:** Unlabeled, same scale as top chart (80.0 to 100.0).
* **Legend (Top-Right):**
* `Sampling Only (SC@k)`: Blue line with upward-pointing triangle markers.
* `SFT Baseline (Pass@1)`: Magenta dashed line.
### Detailed Analysis
**Top Chart - Performance vs. Checkpoints:**
1. **Iterative Learning (Cumulative) [Dark Green, Star]:**
* **Trend:** Strong, consistent upward trend. Starts at the baseline and ends as the highest-performing method.
* **Data Points:**
* Checkpoint 0: 80.8
* Checkpoint 1: 89.6
* Checkpoint 2: 93.2 (approximate, label partially obscured)
* Checkpoint 3: 94.9 (approximate, label partially obscured)
* Checkpoint 4: 95.9 (approximate, label partially obscured)
* Checkpoint 5: 96.3
2. **Sampling Only (Cumulative) [Blue, Star]:**
* **Trend:** Steady, linear upward trend. Consistently outperforms the SFT baseline and the Pass@1 methods after the first checkpoint.
* **Data Points:**
* Checkpoint 0: 80.8
* Checkpoint 1: 82.8
* Checkpoint 2: 84.5 (approximate, interpolated between labeled points)
* Checkpoint 3: 86.4
* Checkpoint 4: 88.1 (approximate, interpolated)
* Checkpoint 5: 89.8
* Checkpoint 6: 90.7 (approximate, interpolated)
* Checkpoint 7: 91.5
3. **Iterative Learning (Pass@1) [Green, Triangle]:**
* **Trend:** Volatile. Shows an initial sharp increase, then fluctuates with a slight overall upward trend, but remains below the cumulative methods.
* **Data Points:**
* Checkpoint 0: 80.8
* Checkpoint 1: 89.6
* Checkpoint 2: 86.0
* Checkpoint 3: 88.3
* Checkpoint 4: 86.5
* Checkpoint 5: 88.5
* Checkpoint 6: 87.7
* Checkpoint 7: 88.6
4. **SFT Baseline (Pass@1) [Magenta, Dashed]:**
* **Trend:** Flat horizontal line, indicating constant performance.
* **Data Point:** Constant at 80.8 across all checkpoints.
**Bottom Chart - Performance vs. k:**
1. **Sampling Only (SC@k) [Blue, Triangle]:**
* **Trend:** Logarithmic-like growth. Performance increases rapidly for low `k` values and then plateaus, showing diminishing returns.
* **Data Points:**
* k=10: 81.6
* k=15: 82.8
* k=20: 83.8
* k=25: 84.1
* k=40: 84.2
* k=60: 84.4
2. **SFT Baseline (Pass@1) [Magenta, Dashed]:**
* **Trend:** Flat horizontal line.
* **Data Point:** Constant at 80.8.
### Key Observations
* **Cumulative Superiority:** Both "Cumulative" methods (Iterative Learning and Sampling Only) significantly and consistently outperform their "Pass@1" counterparts and the SFT baseline as training progresses.
* **Iterative Learning Peak:** The "Iterative Learning (Cumulative)" method achieves the highest overall performance (96.3 at checkpoint 5).
* **Baseline Performance:** The SFT Baseline is static at 80.8, serving as a fixed reference point.
* **Diminishing Returns on k:** The bottom chart shows that increasing `k` beyond ~25 yields minimal performance gains for the "Sampling Only (SC@k)" method.
* **Volatility in Pass@1:** The "Iterative Learning (Pass@1)" metric shows significant checkpoint-to-checkpoint variance, unlike the smoother cumulative curves.
### Interpretation
The data demonstrates the effectiveness of iterative and cumulative learning strategies over simple supervised fine-tuning (SFT) and single-pass (Pass@1) evaluation on the SciQ benchmark.
1. **Methodological Insight:** The stark difference between the "Cumulative" and "Pass@1" lines for the same underlying method (Iterative Learning) suggests that the model's ability to generate multiple correct answers (captured by cumulative metrics) improves more reliably and dramatically than its top-1 accuracy during training. This highlights the value of methods that leverage multiple samples or iterations.
2. **Training Progression:** The top chart shows that performance gains are not linear. The most substantial improvements for the best method occur in the first few checkpoints (0 to 1), after which gains continue but at a slower rate.
3. **Resource vs. Performance Trade-off:** The bottom chart provides a practical guide for the `k` parameter in self-consistency (SC) decoding. It suggests that using a `k` value between 20 and 40 offers a good balance, capturing most of the performance benefit without the computational cost of sampling a very large number of answers (e.g., k=60).
4. **Overall Conclusion:** For maximizing performance on SciQ, an iterative learning approach evaluated with a cumulative metric is most effective. If using sampling-based methods (like SC@k), a moderate `k` value is sufficient, and these methods also reliably surpass the static SFT baseline.
</details>
<details>
<summary>x6.png Details</summary>
### Visual Description
## Line Chart: MATH Performance Metrics
### Overview
The image displays two line charts under the main title "MATH". The top chart plots "Pass Rate" against the number of checkpoints ("# Checkpoints"). The bottom chart plots "Accuracy" against a variable "k". Both charts compare different learning or sampling methods against a baseline.
### Components/Axes
**Top Chart:**
* **Title:** MATH
* **Y-axis:** Label: "Pass Rate". Scale: 30 to 65, with increments of 5.
* **X-axis:** Label: "# Checkpoints". Scale: 0 to 10, with increments of 2.
* **Legend (Top-Left):**
* `Iterative Learning (Pass@1)`: Green line with upward-pointing triangle markers.
* `Iterative Learning (Cumulative)`: Green line with star markers.
* `Sampling Only (Cumulative)`: Blue line with star markers.
* `SFT Baseline (Pass@1)`: Magenta dashed line.
**Bottom Chart:**
* **Y-axis:** Label: "Accuracy". Scale: 30 to 65, with increments of 5.
* **X-axis:** Label: "k". Scale: 4 to 10, with increments of 1.
* **Legend (Top-Right):**
* `Sampling Only (SC@k)`: Blue line with upward-pointing triangle markers.
* `SFT Baseline (Pass@1)`: Magenta dashed line.
### Detailed Analysis
**Top Chart Data Points & Trends:**
1. **Iterative Learning (Pass@1) [Green, Triangles]:** The line shows a slight upward trend, then plateaus.
* Checkpoint 0: ~29.0
* Checkpoint 1: 29.2
* Checkpoint 3: 30.4
* Checkpoint 6: 32.2
* Checkpoint 10: 31.2
2. **Iterative Learning (Cumulative) [Green, Stars]:** The line shows a strong, consistent upward trend.
* Checkpoint 0: ~29.0
* Checkpoint 1: 38.4
* Checkpoint 3: 46.7
* Checkpoint 6: 51.6
* Checkpoint 10: 57.1
3. **Sampling Only (Cumulative) [Blue, Stars]:** The line shows a strong, consistent upward trend, closely following but slightly below the Iterative Learning (Cumulative) line.
* Checkpoint 0: ~29.0
* Checkpoint 1: 34.9
* Checkpoint 3: 42.4
* Checkpoint 6: 49.6
* Checkpoint 10: 57.9
4. **SFT Baseline (Pass@1) [Magenta, Dashed]:** A flat, horizontal line indicating a constant baseline performance.
* All Checkpoints: 29.0
**Bottom Chart Data Points & Trends:**
1. **Sampling Only (SC@k) [Blue, Triangles]:** The line shows a steady, linear upward trend as k increases.
* k=4: 30.0
* k=5: 31.5
* k=6: 32.2
* k=7: 33.3
* k=8: 34.2
* k=10: 35.1
2. **SFT Baseline (Pass@1) [Magenta, Dashed]:** A flat, horizontal line indicating a constant baseline performance.
* All k values: 29.0
### Key Observations
* **Cumulative vs. Pass@1:** For Iterative Learning, the "Cumulative" metric shows dramatically higher improvement (from ~29 to 57.1) compared to the "Pass@1" metric (from ~29 to 31.2).
* **Method Comparison:** At the final checkpoint (10), "Sampling Only (Cumulative)" achieves the highest Pass Rate (57.9), slightly surpassing "Iterative Learning (Cumulative)" (57.1). Both significantly outperform the baseline.
* **Baseline:** The SFT Baseline remains constant at 29.0 across all checkpoints and k values in both charts.
* **SC@k Trend:** The "Sampling Only (SC@k)" accuracy in the bottom chart improves linearly with k, but the gains are modest (from 30.0 to 35.1 over k=4 to 10).
### Interpretation
The data demonstrates the effectiveness of iterative learning and sampling strategies over a static supervised fine-tuning (SFT) baseline on the MATH benchmark. The key insight is the power of **cumulative evaluation**. While the single-attempt performance (Pass@1) of Iterative Learning improves only marginally, its cumulative performance—likely measuring success across multiple attempts or steps—shows substantial gains. This suggests the model's ability to arrive at correct solutions improves significantly when allowed multiple opportunities or when building upon previous steps.
The "Sampling Only (Cumulative)" method performs comparably to the iterative approach, indicating that repeated sampling without an explicit iterative learning loop can also yield high cumulative success rates. The bottom chart shows that increasing the number of samples (k) for the "Sampling Only" method leads to a predictable, linear increase in accuracy (SC@k), but the absolute improvement per unit of k is relatively small. This implies that while more samples help, the most significant performance leap comes from switching from a single-attempt to a cumulative evaluation framework, as seen in the top chart. The consistent 29.0 baseline provides a clear reference point, highlighting the magnitude of improvement achieved by the other methods.
</details>
Figure 3: Training- vs. Test- Time Compute Scaling on ARC-C, SciQ, and MATH evaluation sets. The cumulative pass rate of our iterative learning method can be seen as the pass rate of an ensemble of different model checkpoints. We use greedy decoding to obtain the inference time performance of our method of iterative learning.
Table 3: Ablation of “EXAMPLE ANSWER” in self-evaluation on GSM8K, MATH, and ARC-C. We report AUC and accuracy ( $\$ ) to compare the discriminative abilities of self-evaluation scores.
| w/ example answer-w/o example answer | $74.7$ $62.0$ | $72.5$ $69.5$ | $76.6$ $48.1$ | $48.8$ $42.3$ | $65.2$ $55.8$ | $57.5$ $48.4$ |
| --- | --- | --- | --- | --- | --- | --- |
Commonsense Reasoning. In Table 2, we report the performance on commonsense reasoning tasks, where our method shows consistent improvements. Notably, we achieve absolute accuracy increases of $2.5\$ , $3.0\$ , and $2.1\$ on ARC-Challenge (ARC-C), AI2Sci-Middle (AI2Sci-M), and SciQ, respectively, surpassing the results of direct tuning. However, in tasks like OBQA and CSQA, our method, focusing on intermediate reasoning refinement, is less efficient compared to direct tuning. Despite significant improvements over the Supervised Fine-Tuning (SFT) baseline (for instance, from $59.8\$ to $79.2\$ on OBQA, and from $54.1\$ to $74.8\$ on CSQA), the gains are modest relative to direct tuning. This discrepancy could be attributed to the base model’s lack of specific knowledge, where eliciting intermediate reasoning chains may introduce increased uncertainty in model generations, leading to incorrect predictions. We delve deeper into this issue of hallucination and its implications in our qualitative analysis, as detailed in Section 4.2.
### 4.2 Further Analysis
Training- vs. Test- Time Compute Scaling. Our method integrates MCTS with preference learning, aiming to enhance both preference quality and policy reasoning via step-level alignment. We analyze the impact of training-time compute scaling versus increased inference-time sampling.
We measure success by the pass rate, indicating the percentage of correctly elicited answers. Figure 3 displays the cumulative pass rate at each checkpoint, aggregating the pass rates up to that point. For test-time scaling, we increase the number of sampled reasoning chains. Additionally, we compare the inference performance of our checkpoints with a sampling-only method, self-consistency, to assess their potential performance ceilings. The pass rate curves on ARC-C, SciQ, and MATH datasets reveal that our MCTS-enhanced approach yields a higher training compute scaling exponent. This effect is particularly pronounced on the unseen SciQ dataset, highlighting our method’s efficiency and effectiveness in enhancing specific reasoning abilities with broad applicability. Inference-time performance analysis shows higher performance upper bounds of our method on ARC-C and SciQ. For instance, while self-consistency on SciQ plateaus at around $84\$ , our framework pushes performance to $88.6\$ . However, on MATH, the sampling-only approach outperforms training compute scaling: more sampling consistently enhances performance beyond $35\$ , whereas post-training performance hovers around $32.2\$ . This observation suggests that in-domain SFT already aligns the model well with task-specific requirements.
#### Functions of Self-Evaluation Mechanism.
As illustrated in Section 2.1, the self-evaluation score inherently revises the $Q$ value estimation for subsequent preference data collection. In practice, we find that the ground-truth information, i.e., the “EXAMPLE ANSWER” in Table 6, is crucial to ensure the reliability of self-evaluation. We now compare the score distribution and discriminative abilities when including v.s. excluding this ground-truth information in Table 3. With this information , the accuracy of self-evaluation significantly improves across GSM8K, MATH, and ARC-C datasets.
#### Ablation Study.
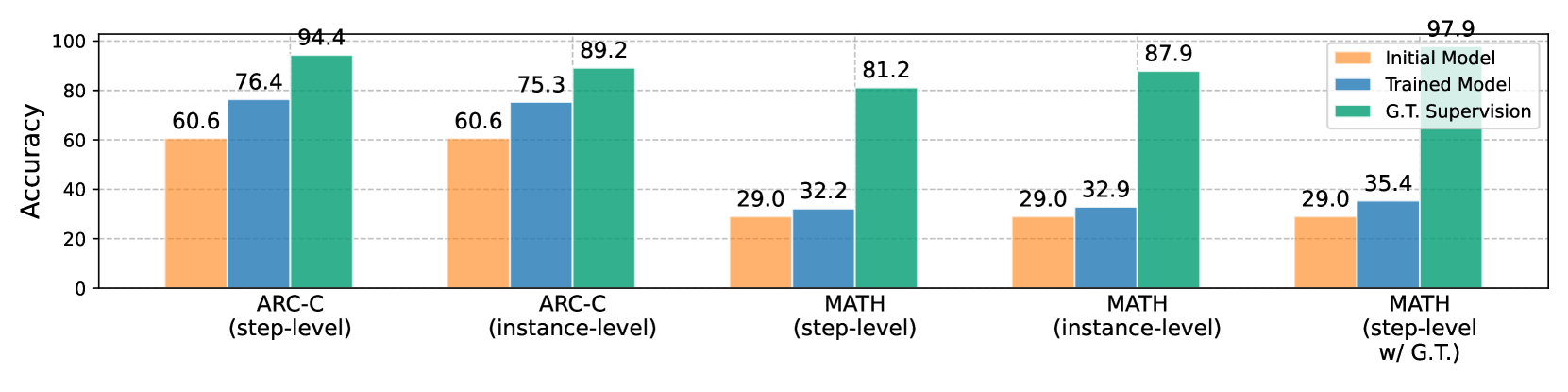
We ablate the impact of step-level supervision signals and the online learning aspect of our MCTS-based approach. Tables 1 and 2 shows performance comparisons across commonsense and arithmetic reasoning tasks under different settings. Our method, focusing on step-level online preference learning, consistently outperforms both instance-level and offline approaches in commonsense reasoning. For example, we achieve $76.4\$ on ARC-C and $88.5\$ on SciQ, surpassing $70.8\$ and $87.4\$ of the offline variant, and $75.3\$ and $87.6\$ of the instance-level approach.
<details>
<summary>x7.png Details</summary>
### Visual Description
\n
## Grouped Bar Chart: Model Accuracy Comparison on ARC-C and MATH Tasks
### Overview
The image displays a grouped bar chart comparing the accuracy percentages of three different model types ("Initial Model," "Trained Model," and "G.T. Supervision") across five distinct evaluation settings related to the ARC-C and MATH benchmarks. The chart clearly demonstrates the performance hierarchy and the impact of training and ground truth supervision.
### Components/Axes
* **Chart Type:** Grouped Bar Chart.
* **Y-Axis:** Labeled "Accuracy." The scale runs from 0 to 100 in increments of 20, with horizontal grid lines at these intervals.
* **X-Axis:** Contains five categorical groups representing different evaluation tasks:
1. ARC-C (step-level)
2. ARC-C (instance-level)
3. MATH (step-level)
4. MATH (instance-level)
5. MATH (step-level w/ G.T.)
* **Legend:** Positioned in the top-right corner of the chart area. It defines the three data series:
* **Initial Model:** Represented by orange bars.
* **Trained Model:** Represented by blue bars.
* **G.T. Supervision:** Represented by green bars. ("G.T." likely stands for "Ground Truth").
### Detailed Analysis
The chart presents the following specific accuracy values for each model in each task category:
**1. ARC-C (step-level)**
* Initial Model (Orange): 60.6
* Trained Model (Blue): 76.4
* G.T. Supervision (Green): 94.4
**2. ARC-C (instance-level)**
* Initial Model (Orange): 60.6
* Trained Model (Blue): 75.3
* G.T. Supervision (Green): 89.2
**3. MATH (step-level)**
* Initial Model (Orange): 29.0
* Trained Model (Blue): 32.2
* G.T. Supervision (Green): 81.2
**4. MATH (instance-level)**
* Initial Model (Orange): 29.0
* Trained Model (Blue): 32.9
* G.T. Supervision (Green): 87.9
**5. MATH (step-level w/ G.T.)**
* Initial Model (Orange): 29.0
* Trained Model (Blue): 35.4
* G.T. Supervision (Green): 97.9
### Key Observations
1. **Consistent Performance Hierarchy:** In every single task category, the "G.T. Supervision" model (green) achieves the highest accuracy, followed by the "Trained Model" (blue), with the "Initial Model" (orange) performing the worst.
2. **Task Difficulty Disparity:** There is a stark contrast in baseline performance between ARC-C and MATH tasks. The "Initial Model" scores ~60.6% on ARC-C tasks but only 29.0% on all MATH tasks, indicating MATH is a significantly more challenging benchmark for the base model.
3. **Impact of Training:** Training ("Trained Model") provides a substantial accuracy boost over the "Initial Model" on ARC-C tasks (+15.8 and +14.7 percentage points). The improvement on MATH tasks is much smaller (+3.2, +3.9, and +6.4 percentage points).
4. **Dominance of Ground Truth Supervision:** The "G.T. Supervision" model shows dramatic performance gains, especially on the difficult MATH tasks. Its accuracy on "MATH (step-level w/ G.T.)" reaches 97.9%, nearly perfect performance.
5. **Instance vs. Step-level:** For ARC-C, step-level evaluation yields slightly higher accuracy for G.T. Supervision (94.4 vs. 89.2). For MATH, the pattern is less clear, with instance-level (87.9) outperforming step-level (81.2) for G.T. Supervision, but step-level with G.T. (97.9) being the highest overall.
### Interpretation
This chart illustrates a clear narrative about model capability and the value of supervision. The data suggests that:
* **The core reasoning ability (Initial Model) is insufficient for complex mathematical problems,** as evidenced by the low 29% baseline on MATH versus ~60% on ARC-C.
* **Standard training provides moderate improvements,** but is particularly limited in elevating performance on the hardest tasks (MATH).
* **Access to ground truth (G.T. Supervision) is the most critical factor for high performance,** enabling near-perfect scores even on the most difficult task variant. This implies that the model's underlying architecture may be capable, but it relies heavily on correct guidance or supervision to apply that capability effectively.
* The **"MATH (step-level w/ G.T.)"** result (97.9%) is a key outlier, demonstrating a ceiling effect when the model is provided with perfect intermediate steps. This highlights a potential pathway for improving model performance: not just training on final answers, but on the correctness of the reasoning process itself.
The chart effectively argues that while training helps, the provision of ground truth supervision—particularly at the step-level for complex problems—is the dominant driver of high accuracy in these evaluations.
</details>
Figure 4: Abltation study on step- vs. instance-level supervision, online vs. offline learning, and w/ vs. w/o G.T. supervision. We also compare the accuracy of the training signals collected via MCTS or instance-level sampling.
Table 4: Qualitative Analysis of model outputs on OBQA, AI2Sci, and MATH. We highlight correct and incorrect keywords. The predicted answers on MATH are boxed, where our method solves the complex problem while SFT baseline failed to elicit a complete reasoning chain.
$$
f(x)=x^7+ax^3+cx f(5)=3, f(-5) f(5)=5^7+5a+5c=3. f(-5), (-5)^7+(-5a) +(-5c). (-5)^7=-5^7=-3, f(-5)=-3-5a-5c. f(-5)=-3-5(-3)-5c=-3+15-5c=\boxed{{\color[rgb]{0.609375,0.37890625,0.71875}12-
5c}}. f(5)=5^7+5a+5c=3. f(x) f(-5)=(-5)^7-5a-5c=\boxed{{\color[rgb]{0,0.88,0}-3}}. f(c)=\frac{3}{2c-3} \frac{kn^2}{lm} f^-1(c)× c× f(c) \frac{kc+l}{mc+n} k,l,m, and n f^-1(c) f(c)=x c \frac{3}{2c-3}=x 2c-3=\frac{3}{x} 2c=\frac{3}{x}+3 c=\frac{\frac{3}{x}+3}{2} f^-1(c)=\frac{\frac{3}{c}+3}{2c} f^-1(c) f^-1(c)× c× f(c) \frac{\frac{3}{c}+3}{2c}× c×\frac{3}{2c-3} \frac{3+3c}{2c}×\frac{3}{2c-3} \frac{9+9c}{4c^2-6c} \frac{9+9c}{4c(c-1)} \frac{kc+l}{mc+n} k,l,m, n \frac{9+9c}{4c(c-1)}=\frac{kc+l}{mc+n} 9+9c=4c(c-1)(kc+l) 9+9c=4c^2k-4ck-4cl+l 4c^2k-4 f(f^-1(c))=c c f^-1 f(f^-1(c))=f(c) c f^-1 f(f^-1(c))=f(c) f(c)=c c f^-1 f(c)=\frac{3}{2c-3} f(c)=c c f^-1 2c-3=c c f^-1 c=3 c f^-1 f^-1(c)=3 c f^-1 f^-1(c)=3 f^-1(c)× c× f(c) 3× 3×\frac{3}{2(3)-3} 9×\frac{3}{3}=9 \frac{kn^2}{lm}=\boxed{{\color[rgb]{0,0.88,0}9}} \tag{5}
$$
In arithmetic reasoning, performance differences among settings are less pronounced for challenging task such as MATH without the incorporation of ground-truth solutions (e.g., $32.2\$ for our method (w/o G.T.) vs. $31.9\$ and $32.9\$ for offline and instance-level on MATH). The comparable performance of offline learning aligns with our theoretical analysis that offline approaches can be effective when the initial policy is already well-tuned with high-quality, in-domain data. We further interpret how G.T. guidance integration to enhance the effectiveness of our framework in Figure 4. With G.T. supervision, the accuracy of training signals improve significantly from $81.2\$ to $97.9\$ , leading to substantial performance gain on model performance. This also explains the similar performance (w/o G.T.) between corresponding using step- and instance-level supervision, where our step-level approach shows effectiveness in narrowing the gap between accuracies of corresponding supervisions.
#### Training Dynamics in Iterative Learning.
As shown in Figure 2, online learning exhibits cyclic performance fluctuations, with validation performance peaking before dipping. We conduct theoretical analysis on this in Appendix B and shows that continuous policy updates with the latest models can lead to periodic knowledge loss due to insufficient optimization in iterative updates. We further probe these phenomena qualitatively next.
#### Qualitative Analysis.
Our qualitative analysis in Table 4 examines the impact of step-level supervision on intermediate reasoning correctness across different tasks. In OBQA, the implementation of MCTS, as discussed in Section 4.1, often leads to longer reasoning chains. This can introduce errors in commonsense reasoning tasks, as seen in our OBQA example, where an extended chain results in an incorrect final prediction. Conversely, in the MATH dataset, our approach successfully guides the model to rectify mistakes and formulates accurate, extended reasoning chains, demonstrating its effectiveness in complex math word problems. This analysis underscores the need to balance reasoning chain length and logical coherence, particularly in tasks with higher uncertainty, such as commonsense reasoning.
## 5 Related Work
Various studies focus on self-improvement to exploit the model’s capability. One line of work focuses on collecting high-quality positive data from model generations guided by static reward heuristic (Zelikman et al., 2022; Gülçehre et al., 2023; Polu et al., 2023). Recently, Yuan et al. (2024) utilize the continuously updated LLM self-rewarding to collect both positive and negative data for preference learning. Fu et al. (2023) adopt exploration strategy via rejection sampling to do online data collection for iterative preference learning. Different from prior works at instance-level alignment, we leverage MCTS as a policy improvement operator to iteratively facilitate step-level preference learning. We discuss additional related work in Appendix A.
## 6 Conclusion
In this paper, we propose MCTS-enhanced iterative preference learning, utilizing MCTS as a policy improvement operator to enhance LLM alignment via step-level preference learning. MCTS balances quality exploitation and diversity exploration to produce high-quality training data, efficiently pushing the ceiling performance of the LLM on various reasoning tasks. Theoretical analysis shows that online sampling in our iterative learning framework is key to improving the LLM policy toward optimal alignment. We hope our proposed approach can inspire future research on LLM alignment from both data-centric and algorithm-improving aspects: to explore searching strategies and utilization of history data and policies to augment and diversify training examples; to strategically employ a tradeoff between offline and online learning to address the problem of cyclic performance change of the online learning framework as discussed in our theoretical analysis.
## Acknowledgments and Disclosure of Funding
The computational work for this article was partially performed on resources of the National Supercomputing Centre (NSCC), Singapore https://www.nscc.sg/.
## References
- Anthony et al. (2017) Thomas Anthony, Zheng Tian, and David Barber. 2017. Thinking fast and slow with deep learning and tree search. In Advances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems 2017, December 4-9, 2017, Long Beach, CA, USA, pages 5360–5370.
- Azar et al. (2023) Mohammad Gheshlaghi Azar, Mark Rowland, Bilal Piot, Daniel Guo, Daniele Calandriello, Michal Valko, and Rémi Munos. 2023. A general theoretical paradigm to understand learning from human preferences. CoRR, abs/2310.12036.
- Bai et al. (2022a) Yuntao Bai, Andy Jones, Kamal Ndousse, Amanda Askell, Anna Chen, Nova DasSarma, Dawn Drain, Stanislav Fort, Deep Ganguli, Tom Henighan, Nicholas Joseph, Saurav Kadavath, Jackson Kernion, Tom Conerly, Sheer El Showk, Nelson Elhage, Zac Hatfield-Dodds, Danny Hernandez, Tristan Hume, Scott Johnston, Shauna Kravec, Liane Lovitt, Neel Nanda, Catherine Olsson, Dario Amodei, Tom B. Brown, Jack Clark, Sam McCandlish, Chris Olah, Benjamin Mann, and Jared Kaplan. 2022a. Training a helpful and harmless assistant with reinforcement learning from human feedback. CoRR, abs/2204.05862.
- Bai et al. (2022b) Yuntao Bai, Saurav Kadavath, Sandipan Kundu, Amanda Askell, Jackson Kernion, Andy Jones, Anna Chen, Anna Goldie, Azalia Mirhoseini, Cameron McKinnon, et al. 2022b. Constitutional ai: Harmlessness from ai feedback. arXiv preprint arXiv:2212.08073.
- Bradley and Terry (1952) Ralph Allan Bradley and Milton E Terry. 1952. Rank analysis of incomplete block designs: I. the method of paired comparisons. Biometrika, 39(3/4):324–345.
- Brown et al. (2020) Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. 2020. Language models are few-shot learners. Advances in neural information processing systems, 33:1877–1901.
- Christiano et al. (2017) Paul F. Christiano, Jan Leike, Tom B. Brown, Miljan Martic, Shane Legg, and Dario Amodei. 2017. Deep reinforcement learning from human preferences. In Advances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems 2017, December 4-9, 2017, Long Beach, CA, USA, pages 4299–4307.
- Clark et al. (2018) Peter Clark, Isaac Cowhey, Oren Etzioni, Tushar Khot, Ashish Sabharwal, Carissa Schoenick, and Oyvind Tafjord. 2018. Think you have solved question answering? try arc, the AI2 reasoning challenge. CoRR, abs/1803.05457.
- Cobbe et al. (2021) Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. 2021. Training verifiers to solve math word problems. CoRR, abs/2110.14168.
- Coulom (2006) Rémi Coulom. 2006. Efficient selectivity and backup operators in monte-carlo tree search. In International conference on computers and games, pages 72–83. Springer.
- Fu et al. (2023) Chaoyou Fu, Peixian Chen, Yunhang Shen, Yulei Qin, Mengdan Zhang, Xu Lin, Zhenyu Qiu, Wei Lin, Jinrui Yang, Xiawu Zheng, Ke Li, Xing Sun, and Rongrong Ji. 2023. MME: A comprehensive evaluation benchmark for multimodal large language models. CoRR, abs/2306.13394.
- Grill et al. (2020) Jean-Bastien Grill, Florent Altché, Yunhao Tang, Thomas Hubert, Michal Valko, Ioannis Antonoglou, and Rémi Munos. 2020. Monte-carlo tree search as regularized policy optimization. In International Conference on Machine Learning, pages 3769–3778. PMLR.
- Gülçehre et al. (2023) Çaglar Gülçehre, Tom Le Paine, Srivatsan Srinivasan, Ksenia Konyushkova, Lotte Weerts, Abhishek Sharma, Aditya Siddhant, Alex Ahern, Miaosen Wang, Chenjie Gu, Wolfgang Macherey, Arnaud Doucet, Orhan Firat, and Nando de Freitas. 2023. Reinforced self-training (rest) for language modeling. CoRR, abs/2308.08998.
- Hao et al. (2023) Shibo Hao, Yi Gu, Haodi Ma, Joshua Jiahua Hong, Zhen Wang, Daisy Zhe Wang, and Zhiting Hu. 2023. Reasoning with language model is planning with world model. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, EMNLP 2023, Singapore, December 6-10, 2023, pages 8154–8173. Association for Computational Linguistics.
- He et al. (2020) Junxian He, Jiatao Gu, Jiajun Shen, and Marc’Aurelio Ranzato. 2020. Revisiting self-training for neural sequence generation. In 8th International Conference on Learning Representations, ICLR 2020, Addis Ababa, Ethiopia, April 26-30, 2020. OpenReview.net.
- Hendrycks et al. (2021) Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. 2021. Measuring mathematical problem solving with the MATH dataset. In Proceedings of the Neural Information Processing Systems Track on Datasets and Benchmarks 1, NeurIPS Datasets and Benchmarks 2021, December 2021, virtual.
- Huang et al. (2023) Jiaxin Huang, Shixiang Gu, Le Hou, Yuexin Wu, Xuezhi Wang, Hongkun Yu, and Jiawei Han. 2023. Large language models can self-improve. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, EMNLP 2023, Singapore, December 6-10, 2023, pages 1051–1068. Association for Computational Linguistics.
- III (1965) H. J. Scudder III. 1965. Probability of error of some adaptive pattern-recognition machines. IEEE Trans. Inf. Theory, 11(3):363–371.
- Jiang et al. (2023) Albert Q. Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra Singh Chaplot, Diego de Las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lucile Saulnier, Lélio Renard Lavaud, Marie-Anne Lachaux, Pierre Stock, Teven Le Scao, Thibaut Lavril, Thomas Wang, Timothée Lacroix, and William El Sayed. 2023. Mistral 7b. CoRR, abs/2310.06825.
- Kadavath et al. (2022) Saurav Kadavath, Tom Conerly, Amanda Askell, Tom Henighan, Dawn Drain, Ethan Perez, Nicholas Schiefer, Zac Hatfield-Dodds, Nova DasSarma, Eli Tran-Johnson, Scott Johnston, Sheer El Showk, Andy Jones, Nelson Elhage, Tristan Hume, Anna Chen, Yuntao Bai, Sam Bowman, Stanislav Fort, Deep Ganguli, Danny Hernandez, Josh Jacobson, Jackson Kernion, Shauna Kravec, Liane Lovitt, Kamal Ndousse, Catherine Olsson, Sam Ringer, Dario Amodei, Tom Brown, Jack Clark, Nicholas Joseph, Ben Mann, Sam McCandlish, Chris Olah, and Jared Kaplan. 2022. Language models (mostly) know what they know. CoRR, abs/2207.05221.
- Kocsis and Szepesvári (2006) Levente Kocsis and Csaba Szepesvári. 2006. Bandit based monte-carlo planning. In European conference on machine learning, pages 282–293. Springer.
- Lee et al. (2023) Harrison Lee, Samrat Phatale, Hassan Mansoor, Kellie Lu, Thomas Mesnard, Colton Bishop, Victor Carbune, and Abhinav Rastogi. 2023. RLAIF: scaling reinforcement learning from human feedback with AI feedback. CoRR, abs/2309.00267.
- Li et al. (2023) Yifei Li, Zeqi Lin, Shizhuo Zhang, Qiang Fu, Bei Chen, Jian-Guang Lou, and Weizhu Chen. 2023. Making language models better reasoners with step-aware verifier. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 5315–5333.
- Lightman et al. (2023) Hunter Lightman, Vineet Kosaraju, Yura Burda, Harrison Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe. 2023. Let’s verify step by step. CoRR, abs/2305.20050.
- Liu et al. (2023a) Jiacheng Liu, Andrew Cohen, Ramakanth Pasunuru, Yejin Choi, Hannaneh Hajishirzi, and Asli Celikyilmaz. 2023a. Making PPO even better: Value-guided monte-carlo tree search decoding. CoRR, abs/2309.15028.
- Liu et al. (2023b) Jiacheng Liu, Ramakanth Pasunuru, Hannaneh Hajishirzi, Yejin Choi, and Asli Celikyilmaz. 2023b. Crystal: Introspective reasoners reinforced with self-feedback. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 11557–11572, Singapore. Association for Computational Linguistics.
- Liu et al. (2023c) Tianqi Liu, Yao Zhao, Rishabh Joshi, Misha Khalman, Mohammad Saleh, Peter J. Liu, and Jialu Liu. 2023c. Statistical rejection sampling improves preference optimization. CoRR, abs/2309.06657.
- Mihaylov et al. (2018) Todor Mihaylov, Peter Clark, Tushar Khot, and Ashish Sabharwal. 2018. Can a suit of armor conduct electricity? A new dataset for open book question answering. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, October 31 - November 4, 2018, pages 2381–2391. Association for Computational Linguistics.
- Mitchell (2023) Eric Mitchell. 2023. A note on dpo with noisy preferences & relationship to ipo.
- Ouyang et al. (2022) Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll L. Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, John Schulman, Jacob Hilton, Fraser Kelton, Luke Miller, Maddie Simens, Amanda Askell, Peter Welinder, Paul F. Christiano, Jan Leike, and Ryan Lowe. 2022. Training language models to follow instructions with human feedback. In NeurIPS.
- Park et al. (2020) Daniel S Park, Yu Zhang, Ye Jia, Wei Han, Chung-Cheng Chiu, Bo Li, Yonghui Wu, and Quoc V Le. 2020. Improved noisy student training for automatic speech recognition. arXiv preprint arXiv:2005.09629.
- Polu et al. (2023) Stanislas Polu, Jesse Michael Han, Kunhao Zheng, Mantas Baksys, Igor Babuschkin, and Ilya Sutskever. 2023. Formal mathematics statement curriculum learning. In The Eleventh International Conference on Learning Representations, ICLR 2023, Kigali, Rwanda, May 1-5, 2023. OpenReview.net.
- Rafailov et al. (2023) Rafael Rafailov, Archit Sharma, Eric Mitchell, Stefano Ermon, Christopher D. Manning, and Chelsea Finn. 2023. Direct preference optimization: Your language model is secretly a reward model. CoRR, abs/2305.18290.
- Raffel et al. (2020) Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J Liu. 2020. Exploring the limits of transfer learning with a unified text-to-text transformer. The Journal of Machine Learning Research, 21(1):5485–5551.
- Ren et al. (2023) Jie Ren, Yao Zhao, Tu Vu, Peter J Liu, and Balaji Lakshminarayanan. 2023. Self-evaluation improves selective generation in large language models. arXiv preprint arXiv:2312.09300.
- Rosin (2011) Christopher D Rosin. 2011. Multi-armed bandits with episode context. Annals of Mathematics and Artificial Intelligence, 61(3):203–230.
- Schulman et al. (2017) John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. 2017. Proximal policy optimization algorithms. CoRR, abs/1707.06347.
- Silver et al. (2017) David Silver, Thomas Hubert, Julian Schrittwieser, Ioannis Antonoglou, Matthew Lai, Arthur Guez, Marc Lanctot, Laurent Sifre, Dharshan Kumaran, Thore Graepel, Timothy P. Lillicrap, Karen Simonyan, and Demis Hassabis. 2017. Mastering chess and shogi by self-play with a general reinforcement learning algorithm. CoRR, abs/1712.01815.
- Stiennon et al. (2020) Nisan Stiennon, Long Ouyang, Jeff Wu, Daniel M. Ziegler, Ryan Lowe, Chelsea Voss, Alec Radford, Dario Amodei, and Paul F. Christiano. 2020. Learning to summarize from human feedback. CoRR, abs/2009.01325.
- Talmor et al. (2019) Alon Talmor, Jonathan Herzig, Nicholas Lourie, and Jonathan Berant. 2019. CommonsenseQA: A question answering challenge targeting commonsense knowledge. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pages 4149–4158, Minneapolis, Minnesota. Association for Computational Linguistics.
- Touvron et al. (2023) Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, Dan Bikel, Lukas Blecher, Cristian Canton-Ferrer, Moya Chen, Guillem Cucurull, David Esiobu, Jude Fernandes, Jeremy Fu, Wenyin Fu, Brian Fuller, Cynthia Gao, Vedanuj Goswami, Naman Goyal, Anthony Hartshorn, Saghar Hosseini, Rui Hou, Hakan Inan, Marcin Kardas, Viktor Kerkez, Madian Khabsa, Isabel Kloumann, Artem Korenev, Punit Singh Koura, Marie-Anne Lachaux, Thibaut Lavril, Jenya Lee, Diana Liskovich, Yinghai Lu, Yuning Mao, Xavier Martinet, Todor Mihaylov, Pushkar Mishra, Igor Molybog, Yixin Nie, Andrew Poulton, Jeremy Reizenstein, Rashi Rungta, Kalyan Saladi, Alan Schelten, Ruan Silva, Eric Michael Smith, Ranjan Subramanian, Xiaoqing Ellen Tan, Binh Tang, Ross Taylor, Adina Williams, Jian Xiang Kuan, Puxin Xu, Zheng Yan, Iliyan Zarov, Yuchen Zhang, Angela Fan, Melanie Kambadur, Sharan Narang, Aurélien Rodriguez, Robert Stojnic, Sergey Edunov, and Thomas Scialom. 2023. Llama 2: Open foundation and fine-tuned chat models. CoRR, abs/2307.09288.
- Uesato et al. (2022) Jonathan Uesato, Nate Kushman, Ramana Kumar, H. Francis Song, Noah Y. Siegel, Lisa Wang, Antonia Creswell, Geoffrey Irving, and Irina Higgins. 2022. Solving math word problems with process- and outcome-based feedback. CoRR, abs/2211.14275.
- Wang and Komatsuzaki (2021) Ben Wang and Aran Komatsuzaki. 2021. GPT-J-6B: A 6 Billion Parameter Autoregressive Language Model. https://github.com/kingoflolz/mesh-transformer-jax.
- Wang et al. (2023a) Peiyi Wang, Lei Li, Zhihong Shao, RX Xu, Damai Dai, Yifei Li, Deli Chen, Y Wu, and Zhifang Sui. 2023a. Math-shepherd: A label-free step-by-step verifier for llms in mathematical reasoning. arXiv preprint arXiv:2312.08935.
- Wang et al. (2023b) Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc V. Le, Ed H. Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. 2023b. Self-consistency improves chain of thought reasoning in language models. In The Eleventh International Conference on Learning Representations, ICLR 2023, Kigali, Rwanda, May 1-5, 2023. OpenReview.net.
- Wei et al. (2022) Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed H. Chi, Quoc V. Le, and Denny Zhou. 2022. Chain-of-thought prompting elicits reasoning in large language models. In Advances in Neural Information Processing Systems 35: Annual Conference on Neural Information Processing Systems 2022, NeurIPS 2022, New Orleans, LA, USA, November 28 - December 9, 2022.
- Welbl et al. (2017) Johannes Welbl, Nelson F. Liu, and Matt Gardner. 2017. Crowdsourcing multiple choice science questions. In Proceedings of the 3rd Workshop on Noisy User-generated Text, NUT@EMNLP 2017, Copenhagen, Denmark, September 7, 2017, pages 94–106. Association for Computational Linguistics.
- Wu et al. (2023) Zeqiu Wu, Yushi Hu, Weijia Shi, Nouha Dziri, Alane Suhr, Prithviraj Ammanabrolu, Noah A. Smith, Mari Ostendorf, and Hannaneh Hajishirzi. 2023. Fine-grained human feedback gives better rewards for language model training. CoRR, abs/2306.01693.
- Xie et al. (2020) Qizhe Xie, Minh-Thang Luong, Eduard H. Hovy, and Quoc V. Le. 2020. Self-training with noisy student improves imagenet classification. In 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2020, Seattle, WA, USA, June 13-19, 2020, pages 10684–10695. Computer Vision Foundation / IEEE.
- Xie et al. (2023) Yuxi Xie, Kenji Kawaguchi, Yiran Zhao, Xu Zhao, Min-Yen Kan, Junxian He, and Qizhe Xie. 2023. Decomposition enhances reasoning via self-evaluation guided decoding. CoRR, abs/2305.00633.
- Yao et al. (2023) Shunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Shafran, Thomas L. Griffiths, Yuan Cao, and Karthik Narasimhan. 2023. Tree of thoughts: Deliberate problem solving with large language models. CoRR, abs/2305.10601.
- Yarowsky (1995) David Yarowsky. 1995. Unsupervised word sense disambiguation rivaling supervised methods. In 33rd Annual Meeting of the Association for Computational Linguistics, 26-30 June 1995, MIT, Cambridge, Massachusetts, USA, Proceedings, pages 189–196. Morgan Kaufmann Publishers / ACL.
- Yu et al. (2023a) Fei Yu, Anningzhe Gao, and Benyou Wang. 2023a. Outcome-supervised verifiers for planning in mathematical reasoning. CoRR, abs/2311.09724.
- Yu et al. (2023b) Longhui Yu, Weisen Jiang, Han Shi, Jincheng Yu, Zhengying Liu, Yu Zhang, James T Kwok, Zhenguo Li, Adrian Weller, and Weiyang Liu. 2023b. Metamath: Bootstrap your own mathematical questions for large language models. arXiv preprint arXiv:2309.12284.
- Yuan et al. (2024) Weizhe Yuan, Richard Yuanzhe Pang, Kyunghyun Cho, Sainbayar Sukhbaatar, Jing Xu, and Jason Weston. 2024. Self-rewarding language models. arXiv preprint arXiv:2401.10020.
- Zelikman et al. (2022) Eric Zelikman, Yuhuai Wu, Jesse Mu, and Noah D. Goodman. 2022. Star: Bootstrapping reasoning with reasoning. In NeurIPS.
- Zhang et al. (2023) Tianjun Zhang, Fangchen Liu, Justin Wong, Pieter Abbeel, and Joseph E. Gonzalez. 2023. The wisdom of hindsight makes language models better instruction followers. In International Conference on Machine Learning, ICML 2023, 23-29 July 2023, Honolulu, Hawaii, USA, volume 202 of Proceedings of Machine Learning Research, pages 41414–41428. PMLR.
- Zheng et al. (2023) Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric P. Xing, Hao Zhang, Joseph E. Gonzalez, and Ion Stoica. 2023. Judging llm-as-a-judge with mt-bench and chatbot arena. CoRR, abs/2306.05685.
- Zhu et al. (2023) Xinyu Zhu, Junjie Wang, Lin Zhang, Yuxiang Zhang, Yongfeng Huang, Ruyi Gan, Jiaxing Zhang, and Yujiu Yang. 2023. Solving math word problems via cooperative reasoning induced language models. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), ACL 2023, Toronto, Canada, July 9-14, 2023, pages 4471–4485. Association for Computational Linguistics.
- Zoph et al. (2020) Barret Zoph, Golnaz Ghiasi, Tsung-Yi Lin, Yin Cui, Hanxiao Liu, Ekin Dogus Cubuk, and Quoc Le. 2020. Rethinking pre-training and self-training. Advances in neural information processing systems, 33:3833–3845.
## Appendix A Related Work
#### Iterated Learning.
Typical iterated learning operates in a multi-agent scenario, consisting of a loop where an apprentice self-plays, learns from expert feedback, and replaces the current expert for the new iteration (Anthony et al., 2017). Polu et al. (2023) apply expert iteration on formal mathematical reasoning to conduct proof search interleaved with learning. Zelikman et al. (2022) avoid the need for training a separate value function by directly assessing the final outcomes of reasoning to filter generated examples for iterated learning. Recently, Yuan et al. (2024) leverage the technique of LLM-as-a-Judge (Zheng et al., 2023) and introduce self-rewarding language models to improve LLM alignment with self-feedback. Differently, we combine the feedback of outcome assessment and LLM self-evaluation and further decompose them into fine-grained signals via MCTS for step-level iterative preference learning.
#### Self-Training.
Self-training uses unlabeled data to improve model training by assigning pseudo labels from a learned labeler (III, 1965; Yarowsky, 1995; Xie et al., 2020; He et al., 2020; Park et al., 2020; Zoph et al., 2020). Recent research has explored several alternatives to label the examples. Zelikman et al. (2022) and Gülçehre et al. (2023) use static reward heuristic to curate high-quality examples, while Huang et al. (2023) collect high-confidence outputs as training data via chain-of-thought prompting (Wei et al., 2022) and self-consistency (Wang et al., 2023b). Lee et al. (2023) and Yuan et al. (2024) utilize the off-the-shelf LLM to reward its generations for preference learning. To mitigate the noise from the sparse instance-level signals, we further refine the preference labels via stepwise tree search and LLM self-evaluation.
#### Preference Learning.
The empirical achievements of LLMs have identified the benefits of RL techniques to better align with human preferences (Touvron et al., 2023; Stiennon et al., 2020; Ouyang et al., 2022; Bai et al., 2022a). The standard preference learning process learns a reward model to provide feedback in online RL (Schulman et al., 2017). Recently, a variety of studies avoid training separate reward or value networks by hindsight instruction relabeling (Zhang et al., 2023), direct preference optimization (Rafailov et al., 2023) and LLM self-evaluation (Ren et al., 2023). We further explore automatic supervision with MCTS to collect step-level preferences by breaking down outcome correctness integrated with self-evaluation. Our approach enables the continual collection of better-quality data via iterative learning, mitigating the limit of preference data when using a frozen reward model or offline learning algorithms.
#### Guided Search for Reasoning.
Recent works improve the LLM reasoning ability by eliciting the intermediate reasoning chain (Wei et al., 2022) and breaking it down into multiple steps via searching (Yao et al., 2023; Hao et al., 2023; Yu et al., 2023a). The decomposition of the reasoning process has also been shown effective in reinforcement learning. Lightman et al. (2023) and Li et al. (2023) apply process supervision to train more reliable reward models than outcome supervision in mathematical reasoning (Uesato et al., 2022). Wang et al. (2023a) reinforce LLMs step-by-step with process supervision data automatically collected via model sampling and annotation. We leverage the look-ahead ability of MCTS and integrate it with step-by-step self-evaluation to provide refined process supervision for reasoning. This improves the generalization ability of our framework to update the policy via real-time collected preferences iteratively.
## Appendix B Theoretical Analysis of Online DPO
#### Preliminaries.
A typical alignment technique begins with a policy $π_sft(y\mid x)$ supervisedly fine-tuned on high-quality data from the target domain, where $x$ and $y$ are the prompt and the response, respectively. The SFT policy is used to sample pairs of responses $(y_1,y_2)∼π_sft(y\mid x)$ with prompts $x$ , which will be further labeled as pairwise preference data $y_w\succ y_l\mid x$ , where $y_w$ and $y_l$ represent the preferred and dispreferred responses respectively. The standard RLHF paradigm trains a reward model (Ouyang et al., 2022) on the preference data and employs PPO (Schulman et al., 2017) to optimize the policy $π_θ$ with the feedback provided by the reward model, where $π_θ$ is also initialized to $π_sft$ in practice. DPO avoids fitting a reward model by optimizing the policy $π_θ$ using preferences directly.
Given a reward function $r(x,y)$ and prompt distribution $P$ , RLHF and DPO optimize the KL-constrained reward maximization objective as follows:
$$
\max_πE_x∼P,y∼π[r(x,y)]-βD_
KL[π(y\mid x)\parallelπ_sft(y\mid x)] \tag{9}
$$
where $β$ scales the strength of the KL constraint. Let the ground-truth reward function be $r^*$ , then Rafailov et al. (2023) estimate the optimal policy $π^*$ by fitting the Bradley-Terry model (Bradley and Terry, 1952) on preference data:
$$
\displaystyle p^*(y_1\succ y_1\mid x)=σ(r^*(x,y_1)-r^*(x,y_2
)) \displaystyle= \displaystyle\frac{1}{1+\exp≤ft(β\log\frac{π^*(y_2\mid x)}{π_
sft(y_2\mid x)}-β\log\frac{π^*(y_1\mid x)}{π_
sft(y_1\mid x)}\right)} \tag{10}
$$
As the maximum likelihood estimator (MLE) of the optimal policy requires preferences sampled from the target policy (Liu et al., 2023c), DPO uses a fixed, potentially optimal but unknown policy to collect preference data of good quality. This discrepancy can be a problem when the sampling policy differs dramatically from the current policy. Moreover, the absence of a reward model in DPO presents challenges in learning from additional policy-generated data that lacks explicit preference indicators. We further discuss the offline and online settings of DPO in Section 3.
#### Additional details on labeling outcomes.
After a pair of outcomes $(y^(i),{y^\prime}^(i))$ are sampled from some sampling policy $π^(i)$ , these are labeled to be $y_w^(i)$ and $y_l^(i)$ according to some preference density $p$ . That is, $\Pr[(y_w^(i),y_l^(i))=(y^(i),{y^\prime}^(i))]=p(y^(i)\succ y^ \prime(i)\mid x)$ and $\Pr[(y_w^(i),y_l^(i))=({y^\prime}^(i),y^(i))]=1-p(y^(i)\succ{y ^\prime}^(i)\mid x)$ . For simplicity, a preference density is set to be $p(y^*\succ\bar{y}\mid x)=1$ for every optima-suboptimal pairs $(y^*,\bar{y})$ for all $\bar{y}∈ Y$ . We do not specify the preference density for other pairs, i.e., $p(\bar{y}\succ\bar{y}^\prime\mid x)$ is arbitrary for $(\bar{y},\bar{y}^\prime)∈ Y× Y$ .
#### Abstract formulation for both offline and online settings.
Our abstract formulation covers both the offline and online settings. The offline setting in previous papers is obtained by setting $π^(i)$ to be a single distribution fixed over $i∈\{1,2,⋯,M\}$ , e.g., an initial policy, an optimal policy, or an empirical data distribution of a given preference data. In the case of the empirical data distribution, the preference density $p$ is set to the function outputting only $0 0$ or $1$ to recover the given preference data. The online setting is obtained by setting $π^(i)=π_θ^(i-1)$ where $π_θ^(i-1)$ is the latest policy at the beginning of the $i$ -th iteration, i.e., for $i≥ 1$ , ${θ^(i)}$ satisfies $\ell_j(θ^(i))=0$ for $j∈\{1,2,⋯,i-1\}$ and $θ^(0)$ is the initialization. Thus, we can analyze both offline and online settings with this abstract framework.
#### Proof of Theorem 3.1 .
* Proof*
The intuition behind the proof of Theorem 3.1 is that the current policy $π_θ^(i)$ may not be corrected if a fixed sampling policy $π$ never samples a suboptimal output $\bar{y}∈ Y$ whose probability is high for the current policy $π_θ^(i)$ . Let $\bar{y}$ be the suboptimal output such that $π(\bar{y}\mid x)≤ε$ and $π_θ^(i)(\bar{y}\mid x)≥ c$ for some $i∈\{1,2,⋯,M\}$ . Denote preferences sampled by policy $π^(i)$ as $(y_w^(i),y_l^(i))$ . From the definition of the logistic function, we can rewrite
| | $\displaystyle\ell_i(θ)$ | $\displaystyle=-\logσ≤ft(β\log\frac{π_θ(y_w^(i)\mid x)} {π_ref(y_w^(i)\mid x)}-β\log\frac{π_θ(y_l^(i) \mid x)}{π_ref(y_l^(i)\mid x)}\right)$ | |
| --- | --- | --- | --- |
From this equation, we observe that $\ell_i(θ)$ can be minimized to be zero by minimizing $π_θ(y_l^(i)\mid x)$ to be zero without maximizing $π_θ(y_w^(i)\mid x)$ . That is, for any $β>0$ , if $π_θ(y_l^(i)\mid x)=0$ ,
$$
\ell_i(θ)=-\log\frac{π_θ(y_w^(i)\mid x)^β}{π_
θ(y_w^(i)\mid x)^β+0}=-\log 1=0.
$$
Thus, even if we sample $y^*$ with the optimal policy, $\ell_i(θ)$ can be minimized without maximizing $π_θ(y^*\mid x)$ and minimizing $π_θ(\bar{y}|x)$ for $\bar{y}≠ y_l^(i)$ . Thus, if $\bar{y}≠ y_l^(i)$ for all $i∈\{1,2,⋯,M\}$ , there exists $θ$ such that $\ell_i(θ)≤ 0$ for all $i=1,\dots,M$ , and
$$
π_θ(\bar{y}\mid x)≥ c,
$$
because of the condition that $π_θ(\bar{y}\mid x)≥ c$ for some $i∈\{1,2,⋯,M\}$ : i.e., $π_θ(\bar{y}\mid x)$ is never minimized from the $i$ -th iteration while minimizing $\ell_i(θ)$ arbitrarily well, if $\bar{y}$ is never sampled. Therefore, if $\bar{y}$ is never sampled over $m$ iterations, since the probabilities sums up to one, we have
$$
π_θ(y^*\mid x)≤ 1-π_θ(\bar{y}|x)≤ 1-c.
$$
Moreover,
$$
\Pr[ $\bar{y$ being never sampled over $m$ iterations }]≥(1-2
ε)^m≥ 1-2ε m,
$$
where the last line follows Bernoulli’s inequality. By combining the above two equations, it holds that
$$
\Pr[π_θ(y^*|x)≤ 1-c]≥ 1-2ε M.
$$
∎
#### Proof of Theorem 3.2 .
* Proof*
From the proof of Theorem 3.1, we have
$$
\ell_i(θ)=-\log\frac{π_θ(y_w^(i)\mid x)^β}{π_
θ(y_w^(i)\mid x)^β+π_θ(y_l^(i)\mid x)^β(
\frac{π_ref(y_w^(i)\mid x)}{π_ref(y_l^(i)
\mid x)})^β}.
$$
For $α≥ 0$ and $β>0$ , the condition $\ell_i(θ)≤α$ implies that
| | $\displaystyle-\log\frac{π_θ(y_w^(i)\mid x)^β}{π_θ( y_w^(i)\mid x)^β+π_θ(y_l^(i)\mid x)^β(\frac{π_ ref(y_w^(i)\mid x)}{π_ref(y_l^(i)\mid x)})^ β}≤α$ | |
| --- | --- | --- |
Since $π_θ(y_w^(i)\mid x)≤ 1$ , this implies that
| | $\displaystyleπ_θ(y_l^(i)\mid x)$ | $\displaystyle≤π_θ(y_w^(i)\mid x)(\exp(α)-1)^1/β \frac{π_ref(y_l^(i)\mid x)}{π_ref(y_w^(i) \mid x)}$ | |
| --- | --- | --- | --- | Thus, while we can prove a similar statement for $α>0$ with this equation, we set $α=0$ for this theorem for a cleaner insight, yielding the following: the condition $\ell_i(θ)≤ 0$ implies that
$$
π_θ(y_l^(i)\mid x)=0.
$$
Since $y^(i)$ and ${y^\prime}^(i)$ are sampled from $π_θ^(i)$ without replacement, this means that we have $π_θ^(i+k)(y_l^(i)\mid x)=0$ for all $k≥ 1$ from the definition of $π_θ^(i)$ : i.e., $π_θ^(i)$ is the policy such that $\ell_j(θ^(i))=0$ for all $j=1,\dots,i-1$ . Since $π_θ^(i+k)$ is then used to sample $y^(i)$ and ${y^\prime}^(i)$ in the followings iterations for $k≥ 1$ , we will never sample this $y_l^(i)$ again. Thus, at each iteration, we always sample pairs of $y$ and $y^\prime$ such that these do not include an output judged to be not preferred in a previous iteration. This implies that at each iteration, we increase the number of suboptimal samples $\bar{y}∈ Y$ such that $π_θ^(i)(\bar{y}\mid x)=0$ . In other words, we have
$$
|\{\bar{y}∈ Y\midπ_θ^(i)(\bar{y}\mid x)=0\}\mid≥ i-1.
$$
Thus,
$$
π_θ^(i)(y^*\mid x)=1-∑_j=1^nπ_θ^(i)(\bar{y}_j
\mid x)=1-∑_j∈ Sπ_θ^(i)(\bar{y}_j\mid x).
$$
where $|S|≤ n+1-i$ . Therefore, $π_θ^(i)(y^*\mid x)=1$ when $i≥ n+1$ . ∎
#### Additional discussion.
We list the additional insights gained from the theoritical analysis.
$\bullet$ The proofs of Theorems 3.1 – 3.2 suggest that a better sampling policy is to use both the current policy and the optimal policy at the same time in the preference learning loss, i.e., sample $y∼π^*$ and $y^\prime∼π_θ^(i-1)$ . This avoids the failure case of Theorem 3.1 and improves the convergence speed in Theorem 3.2. However, since we cannot access the optimal policy $π^*$ in practice, Theorems 3.1 – 3.2 motivate online DPO. Online DPO is proven to enable us to converge to an optimal policy even if we cannot sample outputs from the optimal policy.
$\bullet$ The proofs of Theorems 3.1 – 3.2 suggest that if we can sample from the optimal policy, then we can also use the samples of the optimal policy with the negative log-likelihood loss $-\logπ_θ(y^*\mid x)$ instead of DPO loss to avoid the failure case.
$\bullet$ The proofs of Theorems 3.1 – 3.2 suggest that in the online setting, we should minimize the DPO loss to a certain low degree per iteration, i.e., we should take several rounds of minimization of DPO loss per online iteration, instead of only taking one round of minimization per iteration. This is because the proofs of Theorems 3.1 – 3.2 show that we can get into the cyclic situation in the online setting if the DPO loss is not minimized sufficiently per iteration. For example, we can sample $\bar{y}_1$ and $\bar{y}_2$ in one iteration and $\bar{y}_2$ and $\bar{y}_3$ in another iteration where $\bar{y}_1\succ\bar{y}_2\succ\bar{y}_3$ . If the probability of sampling $\bar{y}_2$ is not minimized sufficiently in the first iteration, it can be sampled again in the second iteration, where the probability of sampling $\bar{y}_2$ can be increased as $\bar{y}_2\succ\bar{y}_3$ . Then, this can repeat indefinitely. Thus, it is important to minimize DPO loss with several optimizer iterations per iteration.
## Appendix C Implementation Details
We use Mistral-7B as our base pre-trained model. The supervised fine-tuning and preference learning experiments are conducted with a maximum of $4× 40$ GB GPUs (NVIDIA A100).
We choose the learning rates 5e-6 and 1e-6 for SFT and DPO training, respectively, with a cosine learning rate scheduler. The maximum sequence length of models is $512$ . We train the model with a batch size of $128$ and $32$ for SFT and DPO, respectively. For DPO, we follow the DPO paper to set the KL constraint parameter $β$ as $0.1$ . Each sample in DPO is a set of step-level preference data decomposed by MCTS. We set the max length for each step as $64$ . The number of MCTS iterations is set as $K=5$ for all tasks.
For arithmetic reasoning, we combine the problems in GSM8K and MATH training sets as the prompt data containing a total of $24$ K samples for preference learning. For each sample, we conduct MCTS with an initial breadth of $b_1=5$ and decrease it to $b_2=3$ for the subsequent steps, with a maximum search depth $d=4$ . It takes about $2$ minutes per sample to collect the step-level preferences via MCTS. This requires about 30 A100 days of compute to train one whole epoch. In practice, we can adopt an early stop when the performance saturates, which usually only needs $30\$ of the training data.
For commonsense reasoning, we combine the training data of ARC, AI2Science, OBQA, and CSQA, which produces a total of $12$ K samples. As the model generations are more diversified on these tasks, we set the initial breadth as $b_1=4$ and decrease it to $b_2=2$ for subsequent steps. As the intermediate reasoning chains are relatively shorter than those in arithmetic reasoning, we set the maximum search depth $d=3$ . Likewise, we also adopt an early stop at around $50\$ of the training progress where the performance saturates.
#### Hyperparameter Tuning of MCTS.
We compare the performance in commonsense reasoning when employing different searching breadths in MCTS. Table 5 shows how different search heuristics impact learning performance. O2 produces better performance, highlighting the importance of increasing the search space at the beginning point of MCTS. One can efficiently reduce compute while maintaining good performance by using a small search space for the subsequent steps. For future work, we will explore the hyperparameter settings in MCTS, including the search breadth, depth, number of steps, and iteration time, to probe the cost–performance tradeoff of our MCTS-enhanced iterative learning framework.
| O1 ( $b_1=3,b_2=3$ ) O2 ( $b_1=4,b_2=2$ ) | $88.4$ $88.5$ | $74.7$ $76.4$ | $92.1$ $91.7$ | $88.5$ $88.2$ | $77.8$ $79.2$ | $73.2$ $74.8$ | $88.3$ $88.5$ |
| --- | --- | --- | --- | --- | --- | --- | --- |
Table 5: Result comparison of using different search breadths in MCTS. For O2, we have a broader spectrum for the initial step and narrow the search space for the subsequent steps of each path.
#### Prompt Example.
See an example of the evaluation prompt we use for self-evalution in Table 6. For more details, please refer to our implementation code.
Table 6: Evaluation Prompt Template. The text underlined will be replaced with content from different examples.
| QUESTION: Which of the following is an example of the formation of a mixture? |
| --- |
| Answer Choices: (A) rust forming on an iron nail (B) sugar crystals dissolving in water (C) sodium and |
| chlorine forming table salt (D) hydrogen and oxygen reacting to produce water |
| EXAMPLE ANSWER: The answer is (B) sugar crystals dissolving in water |
| PROPOSED SOLUTION: The formation of a mixture occurs when two or more substances are |
| combined together without changing their individual properties. In the given options, rust forming on an |
| iron nail is an example of the formation of a mixture. The iron nail and the oxygen in the air combine to |
| form iron oxide, which is a mixture. The answer is A. |
| QUESTION: Evaluate if the proposed solution is logically heading in the correct direction. |
| Provide an answer of (A) correct or (B) incorrect. |
| ANSWER: The answer is |
## Appendix D Further Analysis
#### Reward Criteria in MCTS.
We probe the effect of different reward guidance of MCTS in terms of both searching and training. Table 7 shows how different reward signals impact the pass rate of searching. The guidance of outcome correctness is substantially dominant in eliciting correct outcomes. We see that MCTS can produce significant improvement across various tasks with the reward signals integrated of outcome correctness and self-evaluation, increasing the baseline performance from $60.6\$ to $83.0\$ on ARC-C, $70.9\$ to $90.5\$ on AI2Sci-M, and $75.9\$ to $85.8\$ on GSM8K. We observe a significant performance gain from learning when using greedy decoding on commonsense reasoning. For example, learning increases the accuracy to $76.4\$ (+ $16.4\$ ) on ARC-C, compared to the increase of $9.1\$ on MCTS performance. This suggests a substantial improvement in the model’s policy when applying our MCTS-enhanced iterative learning to tasks that the initial policy is not good at. Furthermore, the ablation study on the reward components shows consistent improvement brought by self-evaluation to increase the MCTS performance in both before- and after- learning cases, suggesting the effectiveness of the integration of self-evaluation in our approach.
Table 7: Pass Rates when Ablating MCTS Settings. SE represents the guidance from self-evaluation.
| Greedy Decoding | ✗ | $60.6$ | $70.9$ | $75.9$ |
| --- | --- | --- | --- | --- |
| $\checkmark$ | $76.4$ $↑$ $16.4$ | $88.2$ $↑$ $17.3$ | $80.7$ $↑$ $5.2$ | |
| MCTS w/o SE | ✗ | $82.5$ | $87.3$ | $84.4$ |
| $\checkmark$ | $91.0$ $↑$ $8.5$ | $96.1$ $↑$ $9.8$ | $89.0$ $↑$ $5.6$ | |
| MCTS | ✗ | $83.0$ | $90.5$ | $85.8$ |
| $\checkmark$ | $92.1$ $↑$ $9.1$ | $97.3$ $↑$ $6.8$ | $90.2$ $↑$ $4.4$ | |
#### Qualitative Analysis on Collected Preferences.
We show examples of the result search trees elicited via MCTS on different tasks in Figures 5 – 9.
Figures 5 and 6 show the result search trees to answer the same science question using MCTS employed with different search breadths. We see that MCTS not only figures out the correct answer (i.e., the option “D”) via broad searching but also serves as a policy improvement optimizer to collect steps along this path as positive samples for preference learning. For example, the $Q$ values of the preference pair at the last step (at the bottom right of Figure 5) are $0.70838$ and $-0.45433$ , compared to the original probability in the policy generation as $0.37989$ and $0.38789$ . Compared to searching with breadth $b_1=4,b_2=2$ in Figure 5, Figure 6 shows that a higher breadth for the subsequent steps can produce an even larger search tree. However, as we only collect preference pairs alongside the paths leading to correct prediction, these two search heuristics can result in preference data of similar size.
Figure 7 shows the search tree using the trained policy on commonsense reasoning. Compared to the one generated by the initial policy in Figure 5, the policy has a higher chance to elicit correct reasoning chains, as we see more successful predictions of the ground-truth option “D”. We also observe that the policy tends to generate longer reasoning chains after being motivated to conduct chain-of-thought reasoning with fine-grained process supervision.
On arithmetic reasoning, we also probe the impact of diversity in model generations using policies trained for different numbers of epochs in SFT. Figures 8 and 9 show the elicited search trees with data sampled by policies corresponding to different levels of diversity, where the policy used in Figure 8 has generations with higher diversity. With higher diversity, MCTS can explore more alternatives of the correct solutions, as there are more paths of correct predictions, as shown in Figure 8 than Figure 9. Furthermore, higher diversity with reasonable quality also provide more fine-grained supervision signals as there are more branches alongside the reasoning path of correct predictions.
## Appendix E Extended Experiments
#### Loss Function.
DPO is one of the reward-model-free loss functions we can use for preference learning. We now illustrate the generalizability of our approach using another loss function, Identity Preference Optimization (IPO) (Azar et al., 2023), which addresses the overfitting problem of DPO. Table 8 shows that IPO achieves similar performance as DPO. In practice, we find that IPO boosts the reasoning on validation tasks while maintaining a more stable performance on the held-out dataset, as indicated by the higher accuracy $89.8\$ obtained on SciQ.
Table 8: Result comparison of employing our approach with different loss functions.
| O1 (IPO) O2 (DPO) | $88.1$ $88.5$ | $75.1$ $76.4$ | $92.1$ $91.7$ | $89.6$ $88.2$ | $76.8$ $79.2$ | $74.3$ $74.8$ | $89.8$ $88.5$ |
| --- | --- | --- | --- | --- | --- | --- | --- |
#### Base Model.
We extensively validate the generalizability of our approach on Llama2-13B (Touvron et al., 2023) on arithmetic reasoning. We employ the same process of SFT on Arithmo and preference learning with DPO on GSM8K and MATH. This experiment is done on a maximum of $2× 80$ GB GPUs (NVIDIA A100).
Table 9: Result comparison (accuracy $\$ ) for Llama2-13B on arithmetic tasks.
| SFT (Arithmo) Ours | Llama2-13B $78.9$ $↑$ $4.4$ | $74.5$ $67.0$ $↑$ $4.7$ | $62.3$ $26.1$ $↑$ $2.3$ | $23.8$ |
| --- | --- | --- | --- | --- |
<details>
<summary>x8.png Details</summary>
### Visual Description
## Diagram: Reasoning Tree for Balancing a Chemical Equation
### Overview
The image displays a complex, branching diagram that appears to be a reasoning tree or a trace of multiple solution paths for a chemistry problem. The central task is to balance the chemical equation for the combustion of methane: **CH₄ + O₂ → CO₂ + H₂O**. The diagram consists of numerous text boxes (nodes) connected by lines, illustrating different logical steps, calculations, and conclusions. Several nodes are outlined in red or green, likely highlighting key steps, correct/incorrect reasoning, or final answers. Each node contains explanatory text and, in many cases, a pair of values in parentheses formatted as `(Q:...)(P:...)`.
### Components/Axes
* **Structure:** A non-linear, branching tree diagram with a central cluster and nodes radiating outward. Lines connect parent nodes to child nodes, indicating a flow of reasoning or derivation.
* **Node Content:** Each node contains a block of text describing a step in solving the balancing problem. Text includes chemical formulas, mathematical operations, and logical statements.
* **Highlighted Nodes:** Several nodes are framed with colored borders:
* **Red Borders:** Approximately 7 nodes have red outlines.
* **Green Borders:** Approximately 5 nodes have green outlines.
* **Annotations:** Most nodes include a parenthetical annotation at the end: `(Q:<number>)(P:<number>)`. The numbers are floating-point values (e.g., `Q:-1.07136`, `P:0.26702`). The meaning of 'Q' and 'P' is not defined within the image.
* **Language:** All text is in English. Chemical notation (e.g., CH₄, O₂, CO₂, H₂O) is used throughout.
### Detailed Analysis
**Text Transcription and Spatial Grounding:**
The diagram is densely packed. Below is a structured transcription of the visible text nodes, grouped by their approximate location and connected reasoning paths. The flow is complex, but a primary path can be traced from the left-center towards the right.
**Left & Central Region (Starting Points and Early Reasoning):**
1. **[Top-Left, Red Box]:** `[5] . CH4 + O2 -> 2CO2 + 4H2O By looking at Answer choices We can see that we need to find a multiple of O2. If we take 2 O2. Then we can have 2 CO2 (Q:-0.28709)(P:0.33311)`
2. **[Left-Center, Green Box]:** `[29] CH4 + O2 -> 2CO2 + 4H2O, On the RHS, 2CO2 combines with water to form carboxylic acid. Hence, the number of water molecules should be 2 (Q:1.02593)(P:0.36184)`
3. **[Center, Red Box]:** `[2] . Hence, the Equation should be CH4 + 2 O2 -> 2CO2 + 4H2O. Now, the number of H on either side of the equation should be equal. On the LHS: H4 C (Q:-1.10386)(P:0.34391)`
4. **[Center-Left]:** `[3] . The overall reaction is 24 in H, 32 in C, and 0 in O, so it's clearly a hydrocarbon combustion. Balancing the overall equation is not very clear. This unbalanced equation can be balanced to show the oxygen requirement. (Q:-0.02361)(P:0.15714)`
5. **[Center-Left]:** `[51] <s> (Q:0.00000)(P:1.00000)` (This appears to be a root or starting node).
**Central & Right Region (Converging on an Answer):**
6. **[Center-Right]:** `[2] So answer is 2. CH4 + 2 O2 -> 2 CO2 + 2 H2O (Q:-1.41080)(P:0.52668)`
7. **[Center-Right]:** `[1] 24 in H, 32 in C, and 0 in O and it is already balanced, so the overall balanced is: CH4 + xO2 -> 2 CO2 + 2 H2O The answer is 2. ANSWER: B</s> (Q:-1.39894)(P:0.33174)`
8. **[Right, Green Box]:** `[29] 2 H2O -> 4 H2O Now, the RHS has 4 water molecules and 4 O atoms but the LHS has only 2 water molecules and 1 O atom. Hence, Both water molecules should have 2 O atoms each, hence (Q:0.37176)(P:0.33691)`
9. **[Right, Red Box]:** `[4] 2 water molecules have 2 X 4 = 8 O atoms 1 water molecule has 1 X 2 = 2 O atoms. Hence, 8 - 2 = 6 O atoms come from O2 molecules Answer (Q:-0.45433)(P:0.37989)`
10. **[Far Right]:** `[0] O2 The correct answer is B hence B</s> (Q:-1.05593)(P:0.18124)`
11. **[Far Right]:** `[1] CH4 + O2 -> 2CO2 + 4H2O 2x( H ) + 1x( O ) -> 2x( C ) + 4x( O ) H2O + O -> (Q:-0.00086)(P:0.48775)`
**Top & Bottom Regions (Alternative Paths and Details):**
12. **[Top-Center]:** `[2] Since CH4 + (2 O2) > 2 CO2 + 4 H2O So CH4 + O2 + O2 > 2 CO2 + 4 H2O... (Q:-1.10341)(P:0.35997)`
13. **[Top-Right]:** `[0] Thus O2 is the missing molecule. The answer is option A</s> (Q:-1.07136)(P:0.26702)`
14. **[Top-Right]:** `[1] So 2 O2 are needed to balance O2. The answer is B</s> (Q:-1.06490)(P:0.51277)`
15. **[Bottom-Center, Green Box]:** `[32] CO2 (Q:0.21432)(P:0.04583)`
16. **[Bottom-Right, Red Box]:** `[7] 2H2O -> CO2x2H2 On the RHS, 2CO2 x 2H2O -> CO2x2H2O2 On the LHS, CH4 : C1 H4 - C1 H1 On the LHS, CH4 - (Q:-0.06057)(P:0.30056)`
17. **[Bottom-Right, Green Box]:** `[12] , total 4 O atoms. So O2 is needed to balance the equation The answer is D</s> (Q:0.70838)(P:0.38789)`
**Common Conclusion:** Multiple nodes, particularly those on the right side (e.g., nodes 6, 7, 10, 14), converge on the conclusion that the balanced equation is **CH₄ + 2O₂ → 2CO₂ + 2H₂O** and that the answer to the implied multiple-choice question is **"B"** (or sometimes "2").
### Key Observations
1. **Multiple Solution Paths:** The diagram does not show a single, linear solution. Instead, it maps out various reasoning attempts, some of which contain errors or lead to different intermediate conclusions (e.g., suggesting 4 H₂O instead of 2 H₂O).
2. **Highlighted Discrepancies:** The red and green boxes often contain statements that are chemically incorrect or represent critical decision points. For example:
* A red box (Node 1) incorrectly states `CH4 + O2 -> 2CO2 + 4H2O`.
* A green box (Node 2) incorrectly mentions forming "carboxylic acid."
* Another red box (Node 3) correctly identifies the need for equal hydrogen but uses an incorrect product coefficient (`4H2O`).
3. **Convergence on Answer "B":** Despite the convoluted paths, a significant number of terminal nodes (especially those with `</s>` tags, possibly indicating an end state) conclude that the correct answer is **B**, corresponding to a coefficient of **2** for O₂.
4. **Anomalous Annotations:** The `(Q:...)(P:...)` values are present in nearly every node. Their purpose is unclear from the context—they could represent confidence scores, probabilities, or some other metric from a model's reasoning process. The 'Q' values are often negative.
### Interpretation
This diagram is not a standard educational flowchart. It appears to be a **visualization of an AI or computational model's internal reasoning process** when solving a chemistry problem. The branching structure, numerical annotations, and mix of correct/incorrect steps suggest it might be a trace from a system that explores multiple reasoning paths simultaneously or sequentially.
* **What it Demonstrates:** The image exposes the "black box" of problem-solving, showing how a system might generate hypotheses (e.g., "the answer is A"), test them against chemical principles (atom counting), and self-correct. The prevalence of the answer "B" indicates the model's final, aggregated conclusion.
* **Relationship Between Elements:** The lines represent logical dependencies. A parent node's statement leads to the calculations or conclusions in its child nodes. The colored boxes likely flag nodes that are pivotal, erroneous, or high-confidence according to the system's own metrics.
* **Notable Patterns:** The struggle to correctly balance hydrogen and oxygen atoms is a recurring theme across many nodes, mirroring a common student difficulty. The system eventually overcomes this, as seen in the converging correct conclusions on the right.
* **Underlying Purpose:** This type of visualization is crucial for **AI interpretability and debugging**. It allows developers to see *how* a model arrived at an answer, identify where its reasoning falters (e.g., the persistent incorrect `4H2O` in some paths), and understand the reliability of its output. The `(Q, P)` values are likely key to this diagnostic process, quantifying aspects of the model's decision-making at each step.
</details>
Figure 5: Example of the result search tree of a science question “An unbalanced equation for the reaction of methane gas ( $CH_4$ ) with oxygen is shown below. $CH_4+\BoxO_2→ 2CO_2+4H_2 O$ How many molecules of oxygen gas ( $O_2$ ) are needed to properly balance this equation? Answer Choices: (A) 1 (B) 2 (C) 3 (D) 4”. The ground truth answer is “(D) 4”. Here, we set the search breadth as $b_1=4,b_2=2$ . The numbers at the beginning of each sequence indicate the visit count $N$ of the corresponding node, while the $Q$ and $P$ values at the end of the sequence represent the $Q$ values and the sentence probability, respectively.
<details>
<summary>x9.png Details</summary>
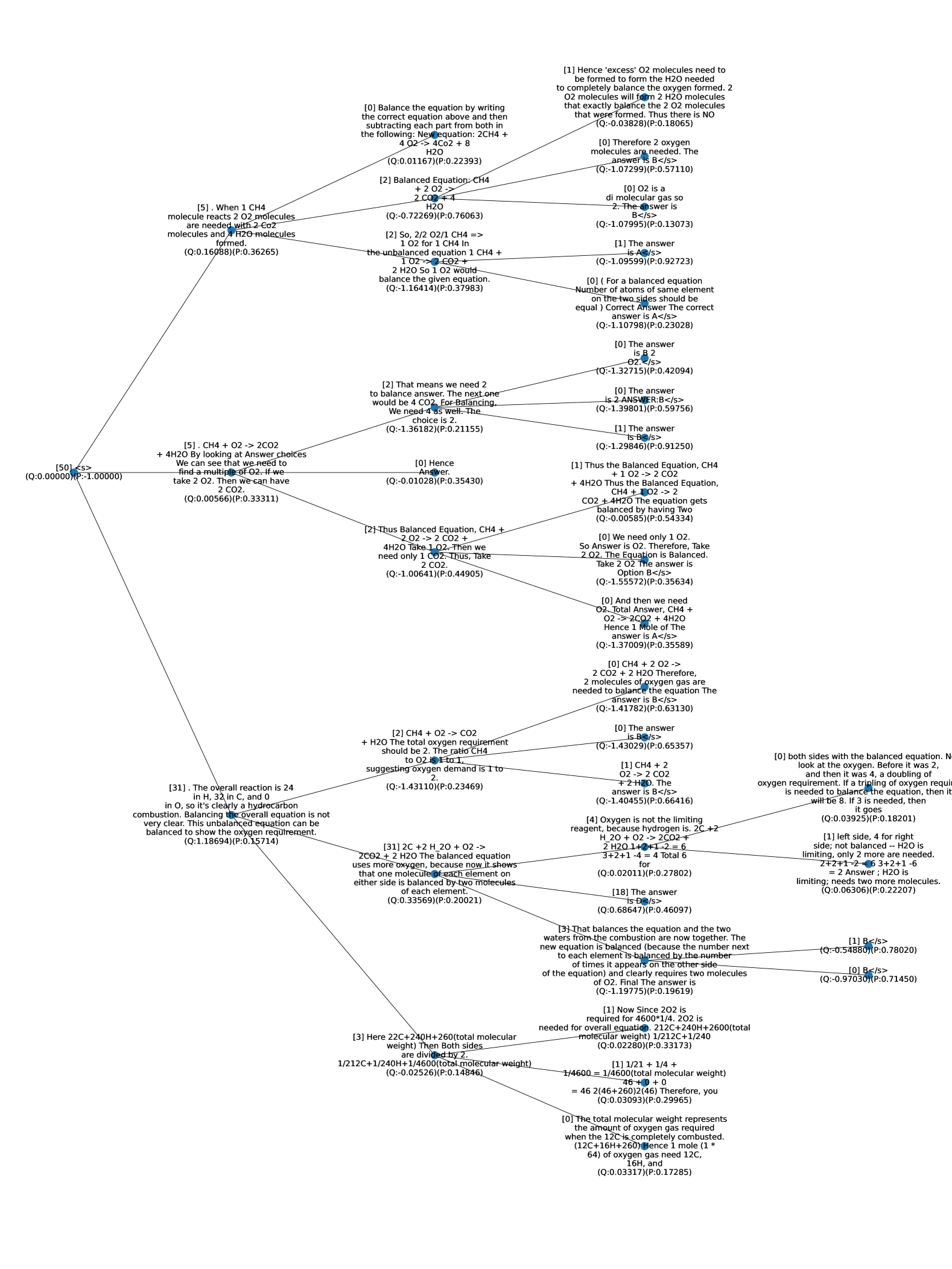
### Visual Description
\n
## Reasoning Diagram: Balancing Chemical Equations for Hydrocarbon Combustion
### Overview
The image displays a complex, hierarchical reasoning tree or flowchart. It visualizes multiple, branching logical pathways for solving a chemistry problem: balancing the chemical equation for the combustion of methane (CH₄) and determining the required oxygen (O₂). The diagram is structured as a tree, originating from a single root node on the left and expanding rightward into numerous interconnected text blocks. Each block contains a step in the reasoning process, a chemical equation, a conclusion (often a multiple-choice answer like A, B, or D), and associated numerical values labeled (Q:...)(P:...).
### Components/Axes
* **Structure:** A directed graph/tree. Lines connect parent reasoning steps to child steps or conclusions.
* **Nodes:** Text blocks containing:
1. A step identifier in square brackets (e.g., `[0]`, `[1]`, `[2]`, `[3]`, `[4]`, `[5]`, `[18]`, `[31]`, `[50]`).
2. Reasoning text explaining a step in balancing the equation.
3. Chemical equations (e.g., `CH4 + 2 O2 -> CO2 + 2 H2O`).
4. A final answer statement (e.g., "The answer is B", "Correct Answer The correct answer is A").
5. A pair of numerical values in parentheses: `(Q:...)(P:...)`. These appear to be quantitative metrics associated with each reasoning node.
* **Root Node:** Located at the far left, labeled `[50] <s>` with values `(Q:0.00000)(P:1.00000)`.
* **Language:** The text is entirely in English. Chemical notation is used.
### Detailed Analysis
The diagram traces multiple reasoning paths to balance the equation `CH4 + O2 -> CO2 + H2O`. Key branches and conclusions include:
**1. Primary Branches from Root:**
* **Upper Path:** Starts with `[5] . When 1 CH4 molecule reacts 2 O2 molecules are needed with 2 Co2 molecules and 4 H2O molecules formed. (Q:0.16088)(P:0.36265)`. This leads to further reasoning about balancing.
* **Middle Path:** Starts with `[5] . CH4 + O2 -> 2CO2 + 4H2O By looking at Answer choices We can see that we need to find a multiple of O2. If we take 2 O2. Then we can have 2 CO2. (Q:0.00566)(P:0.33311)`.
* **Lower Path:** Starts with `[31] . The overall reaction is 24 in H, 32 in C, and 0 in O, so it's clearly a hydrocarbon combustion. Balancing the overall equation is not very clear. This unbalanced equation can be balanced to show the oxygen requirement. (Q:1.18694)(P:0.15714)`.
**2. Common Reasoning Steps & Equations:**
* **Goal:** Balance `CH4 + O2 -> CO2 + H2O`.
* **Frequent Correct Balanced Equation:** Many paths converge on `CH4 + 2 O2 -> CO2 + 2 H2O` or its equivalent `CH4 + 2 O2 -> 2 CO2 + 2 H2O` (note: the latter has a typo, showing 2CO2 instead of CO2).
* **Key Reasoning Points:**
* Counting atoms of C, H, and O on both sides.
* Determining the ratio of CH₄ to O₂ is 1:2.
* Concluding that 2 molecules of O₂ are required.
* Identifying the correct multiple-choice answer (often "B" for 2 O₂ molecules).
**3. Answer Conclusions:**
The diagram shows multiple terminal nodes with different final answers:
* **Answer A:** Found in nodes like `[0] ( For a balanced equation Number of atoms of same element on the two sides should be equal ) Correct Answer The correct answer is A</s> (Q:-1.10796)(P:0.23028)` and `[0] And then we need O2. Total Answer, CH4 + O2 -> 2CO2 + 4H2O Hence 1 Mole of The answer is A</s> (Q:-1.37009)(P:0.35589)`.
* **Answer B:** The most frequent conclusion. Examples: `[0] Therefore 2 oxygen molecules are needed. The answer is B</s> (Q:-1.07299)(P:0.57110)`, `[1] CH4 + 2 O2 -> 2 CO2 + 2 H2O. The answer is B</s> (Q:-1.40455)(P:0.66416)`.
* **Answer D:** Appears in at least one node: `[18] The answer is D</s> (Q:0.68647)(P:0.46097)`.
**4. Numerical Values (Q and P):**
Every text block is followed by `(Q:...)(P:...)`. These are likely model-generated scores.
* **Q-values:** Range widely, from negative (e.g., -1.55572) to positive (e.g., 1.18694). They may represent a quality, confidence, or log-likelihood score for the reasoning step.
* **P-values:** All are between 0 and 1 (e.g., 0.15714, 0.92723). They likely represent a probability or confidence score associated with the node or its conclusion.
### Key Observations
1. **Multiple Valid Paths:** The diagram explicitly shows that the same problem can be approached through different sequences of logical steps, all aiming to reach a correct balanced equation.
2. **Answer Discrepancy:** While the chemically correct balanced equation is `CH4 + 2 O2 -> CO2 + 2 H2O` (requiring 2 O₂ molecules), some reasoning paths in the diagram incorrectly conclude with answers A or D, or arrive at unbalanced equations like `CH4 + O2 -> 2CO2 + 4H2O`.
3. **Quantitative Metrics:** The consistent presence of Q and P values suggests this diagram is output from an AI or computational model that evaluates reasoning chains, assigning scores to each step.
4. **Hierarchical Complexity:** The tree is deep and wide, indicating a complex reasoning space with many potential intermediate steps, assumptions, and errors.
### Interpretation
This diagram is a **visualization of a reasoning process**, likely generated by an AI model or an educational tool designed to trace problem-solving steps in chemistry. It serves as a "thought map" for balancing a combustion equation.
* **What it demonstrates:** It shows that solving a seemingly straightforward chemistry problem involves multiple cognitive steps: interpreting the question, recalling principles (conservation of mass), performing atom counts, testing coefficients, and matching results to given options. The branching structure highlights how different initial assumptions or minor errors in early steps can lead to divergent conclusions.
* **Relationship between elements:** The root represents the initial problem state. Each branch represents a distinct line of reasoning. The lines show the dependency of later conclusions on earlier steps. The Q/P values provide a meta-layer of analysis, possibly indicating the model's confidence in each step's validity or the step's contribution to the final answer's probability.
* **Notable Anomalies:** The presence of confidently stated but incorrect answers (like A or D) alongside correct ones (B) is the most significant feature. This could illustrate:
* Common student misconceptions being modeled.
* The model's exploration of incorrect reasoning paths before converging on the correct one.
* The inherent ambiguity in interpreting the initial question (e.g., if it was "How many O₂ molecules are needed?" vs. "What is the coefficient of O₂ in the balanced equation?").
* **Peircean Investigation:** From a semiotic perspective, the diagram is an **icon** of the reasoning process, resembling a neural pathway or decision tree. It is an **index** of the underlying model's operation, directly pointing to its computational steps. The text and equations are **symbols** conveying chemical knowledge. The Q/P values are symbolic representations of the model's internal confidence metrics. Together, they create a multi-layered representation of machine reasoning about a scientific problem.
In essence, this is not just a chemistry answer key; it is a diagnostic tool for understanding *how* an answer is derived, revealing the complexity, potential pitfalls, and quantitative evaluation embedded within the problem-solving process.
</details>
Figure 6: Example of the result search tree of the same science question as in Figure 5. Here, we set the search breadth as $b_1=3,b_2=3$ .
<details>
<summary>x10.png Details</summary>
### Visual Description
\n
## Reasoning Diagram: Balancing the Combustion of Methane (CH₄)
### Overview
The image is a complex reasoning tree or flowchart illustrating the step-by-step logical process for balancing the chemical equation for the combustion of methane: **CH₄ + O₂ → CO₂ + H₂O**. It is not a data chart but a conceptual diagram mapping out multiple reasoning paths, considerations, and intermediate conclusions. The diagram consists of numbered text nodes (e.g., [0], [1], [2]) connected by lines, indicating the flow of logic from a starting point to various conclusions. Each node contains explanatory text and a pair of values labeled (Q: value)(P: value), which appear to be confidence or quality scores associated with that reasoning step.
### Components/Structure
* **Node Structure:** Each element is a text block prefixed with a number in square brackets (e.g., `[50]`, `[29]`, `[2]`). These likely represent steps or propositions in the reasoning chain.
* **Connections:** Lines connect the nodes, showing the dependency and flow of logic. The diagram branches extensively, indicating multiple parallel or alternative lines of reasoning.
* **Content:** The text within nodes details chemical principles, atom counting, equation balancing steps, and final answers. Chemical formulas (CH₄, O₂, CO₂, H₂O) and balanced equations are frequently mentioned.
* **Metrics:** Every node includes a pair of values in the format `(Q: value)(P: value)`. These are numerical, often with several decimal places (e.g., `Q:0.29509`, `P:0.42767`). Some Q values are negative.
* **Spatial Layout:** The diagram is organized with a root node at the top-left (`[50]`) from which major branches emanate. The layout spreads out downwards and to the right, with nodes clustered in logical groupings. There is no traditional chart legend; the node numbers and connecting lines serve as the key to following the logic.
### Detailed Analysis: Transcription of Key Nodes and Paths
The diagram contains a large amount of text. Below is a structured transcription of the primary reasoning paths and node contents, following the logical flow from the root.
**Root Node (Top-Left):**
* `[50] <s> (Q:0.00000)(P:1.00000)` - This appears to be the starting point or root of the reasoning tree.
**Major Branch 1 (Left Side - Initial Problem Setup):**
* `[29] . First, we need to check which element is missing on both sides of the equation. We know that oxygen (O) is missing on the left side. (Q:1.73437)(P:0.39171)`
* `[3] . When an equation is unbalance, we have to add the same molecule to both sides so they will balance. In this case, we need to add equal number of oxygen atoms to both sides. The overall reaction is: (Q:0.53122)(P:0.24138)`
* `[5] . The chemical formula for methane gas is CH4. The chemical formula for oxygen gas is O2. The chemical formula for carbon-dioxide is CO2. The chemical formula for water is H2O. (Q:0.31012)(P:0.81115)`
**Major Branch 2 (Center/Right - Atom Counting & Balancing Logic):**
This branch contains the core balancing steps.
* `[0] Since there are 2 hydrogen atoms in methane (CH4), 2 hydrogen atoms are converted to 2 water molecules (2 H2O) that yield 2 oxygen atoms in the process. Balance equation: (Q:0.01158)(P:0.32396)`
* `[0] CH_{4} + 2CO_{2} + 4H_{2}O. This now balances the equation. (Q:0.01760)(P:0.25560)` **Note:** This node presents an *incorrect* intermediate equation.
* `[2] CH_{4} + /Box O_{2} -> 2CO_{2} + 4H_{2}O Since, CH_{4} has 4 Hydrogen and 1 Carbon atoms. Hence, (Q:-0.27509)(P:0.59783)`
* `[22] 2CO2 has a total of 4 oxygen atoms. So, we can place 4 oxygen atoms on the left side and balance the equation. The equation is now: CH4 + 4O2 -> 2CO2 + 4H2O. The answer is D.</s> (Q:1.17833)(P:0.63351)` **Note:** This node presents the **correctly balanced equation**.
* `[1] On the right side of the equation, we have 2 molecules of CO2 and 4 molecules of H2O. To balance the number of molecules, we need to have 2 molecules of CO2 for every 1 molecule of CH4, and we need to have (Q:-0.02205)(P:0.81702)`
* `[0] On the right side of the equation, we have 2 molecules of CO2 and 4 molecules of H2O. Since the coefficient of CO2 is 2 and the coefficient of H2O is 4, the ratio of the number of molecules of O2 to the number of (Q:-0.04654)(P:0.79002)`
**Major Branch 3 (Right Side - Final Answer Derivation):**
* `[1] number of elements with the right atomic weights. So, we can add 4 molecules of oxygen gas (O2) on the left side. The final equation is: CH4 + 4O2 -> 2CO2 + 4H2O The answer is D.</s> (Q:1.30184)(P:0.55775)` **Note:** Another node stating the correct final answer.
* `[0] number of each element on both sides. The left side has 4 oxygen atoms, so we need 2 molecules of oxygen gas (O2) to complete the reaction. The answer is B.</s> (Q:-0.74346)(P:0.58410)` **Note:** This node concludes with an *incorrect* answer (B).
* `[1] Since each oxygen atom consists of 2 atoms (O2), we need 2 molecules of oxygen gas (O2). The answer is B.</s> (Q:-0.77903)(P:0.74965)` **Note:** Another node concluding with the incorrect answer B.
**Other Notable Nodes (Scattered):**
* `[33] So we need to find the number of oxygen atoms we can get from the right side and place that many on the left side. (Q:1.16743)(P:0.35560)`
* `[5] On the right side, we have 2 molecules of carbon dioxide (CO2) and 4 molecules of water (H2O). Each molecule of carbon dioxide has 2 oxygen atoms, so 2 x 2 = 4 oxygen atoms from the carbon dioxide (Q:0.05621)(P:0.76038)`
* `[1] Each molecule of water has 1 oxygen atom, so 4 x 1 = 4 oxygen atoms from the water. So, we can place 4 oxygen atoms from the right side on the left side. Now, we have a balanced equation on the left side, which means we have the right (Q:0.28120)(P:0.57643)`
* `[0] Each molecule of water has 2 hydrogen atoms and 1 oxygen atom, so 4 x 1 = 4 oxygen atoms from water. A total of 4 oxygen atoms is available from the right side. Now, we need to place 2 oxygen atoms on the left side of the equation (Q:-0.08359)(P:0.63161)`
### Key Observations
1. **Multiple Reasoning Paths:** The diagram explicitly shows that there are several valid logical sequences to arrive at the balanced equation (e.g., starting by balancing C, then H, then O; or counting total O atoms on the product side first).
2. **Presence of Incorrect Paths:** The tree includes nodes that lead to incorrect conclusions (e.g., answer "B" or the intermediate equation `CH4 + 2CO2 + 4H2O`). This suggests the diagram may be modeling a learning or problem-solving process that includes common errors.
3. **Quantitative Metrics (Q & P):** Every reasoning step is annotated with Q and P values. The Q values vary widely, including negatives, while P values are mostly between 0 and 1. These likely represent internal confidence scores, probability estimates, or quality assessments from the AI model generating the reasoning. Steps leading to the correct answer (D) often have high positive Q values (e.g., `Q:1.17833`, `Q:1.30184`).
4. **Final Answer Discrepancy:** While the correct balanced equation `CH4 + 4O2 -> 2CO2 + 4H2O` (Answer D) is derived in multiple nodes, other branches incorrectly conclude the answer is B.
5. **Focus on Foundational Concepts:** The reasoning heavily emphasizes basic principles: identifying missing elements, the rule of adding the same to both sides, atom counting per molecule, and the law of conservation of mass.
### Interpretation
This diagram is a **visualization of an AI's internal reasoning process** for solving a standard chemistry problem. It serves as a "thinking map" that exposes the step-by-step logic, including intermediate hypotheses and dead ends, rather than just presenting the final answer.
* **What it Demonstrates:** It shows that balancing an equation is not a single linear path but a network of interdependent checks (C atoms, H atoms, O atoms). The branching structure highlights how an initial observation (e.g., "O is missing on the left") can lead to multiple subsequent calculations.
* **Relationship Between Elements:** The connecting lines are crucial. They show how a conclusion in one node (e.g., counting H atoms in CH₄) becomes the premise for the next step (determining H₂O molecules). The Q/P scores attached to each node suggest a system that evaluates the reliability or strength of each logical link.
* **Notable Anomalies:** The inclusion of incorrect paths (leading to answer B) is the most significant feature. This could be for educational purposes—to illustrate common mistakes—or it could be an artifact of the AI's exploration of the problem space, where some branches of reasoning are less confident (often with negative Q scores) and ultimately pruned or marked as invalid.
* **Underlying Message:** The diagram argues that the correct answer (D) is supported by a robust, multi-faceted reasoning chain with high-confidence steps. It implicitly validates the process of systematic atom counting and coefficient adjustment as the reliable method, while showing how shortcuts or miscounts can lead to erroneous conclusions. The Q/P metrics add a layer of meta-cognition, quantifying the "certainty" of each logical move.
</details>
Figure 7: Example of the result search tree of the same science question as in Figure 5. Here, we use the policy after preference learning and set the search breadth as $b_1=4,b_2=2$ .
<details>
<summary>x11.png Details</summary>
### Visual Description
\n
## Diagram: Multi-Path Reasoning Tree for a Word Problem
### Overview
The image displays a hierarchical decision tree or reasoning graph, likely generated by an AI model, visualizing multiple computational pathways to solve a word problem about loaves of bread. The tree originates from a single root node on the left and branches rightward into three primary reasoning chains, which further subdivide into terminal nodes containing final answers. Each node contains a textual step in the reasoning, a calculation, and associated probability scores (Q and P values).
### Components/Axes
* **Structure:** A directed graph with nodes connected by lines. The root is at the far left, center. Branches extend to the right.
* **Node Content:** Each node contains:
* A bracketed identifier (e.g., `[6]`, `[0]`, `[49]`).
* A textual description of a reasoning step or calculation.
* Probability scores in the format `(Q:xxxxx)(P:xxxxx)`.
* Terminal nodes often conclude with "The answer is: [number]</s>".
* **Visual Elements:** Lines connect parent nodes to child nodes. Some text within nodes has strikethrough formatting (e.g., `200 - 132` is struck through in one node).
### Detailed Analysis
The tree represents divergent reasoning paths for a problem involving baking, selling, and returning loaves of bread. The root node is `[49]<s>` with probabilities `(Q:0.00000)(P:1.00000)`.
**Primary Branch 1 (Upward Path):**
* **Node `[6]`:** "The bakers baked 200 loaves of bread in total. They sold 93 loaves in the morning and 39 loaves in the afternoon, so they sold 93 + 39 = 132 loaves." `(Q:0.74724)(P:0.87045)`
* **Sub-branch 1.1:** Leads to Node `[0]`: "A grocery store returned 6 unsold loaves, so they have 200 - 132 + 6 = 74 loaves left." `(Q:0.02081)(P:0.79960)`
* **Terminal 1.1a:** `[1] Therefore, they had 126 loaves of bread left. The answer is: 126</s>` `(Q:-0.89611)(P:0.95100)`
* **Terminal 1.1b:** `[0] The answer is: 120</s>` `(Q:-0.90947)(P:0.96013)`
* **Sub-branch 1.2:** Leads to Node `[3]`: "After selling, they had 200 - 132 = 68 loaves of bread left. The grocery store returned 6 unsold loaves, so they had 68 + 6 = 74 loaves of bread left." `(Q:1.18816)(P:0.89653)`
* **Terminal 1.2a:** `[2] The answer is: 74</s>` `(Q:1.06829)(P:0.99951)`
**Primary Branch 2 (Middle Path):**
* **Node `[3]`:** "The bacon factory produced 200 - 93 = 107 loaves on Monday. Then they produced 200 - 39 = 161 loaves on Tuesday." `(Q:-0.06717)(P:0.47614)`
* **Sub-branch 2.1:** Leads to Node `[0]`: "So the company baked a total of 107 + 161 = 268 loaves of bread." `(Q:0.00192)(P:0.62347)`
* Leads to Node `[0]`: "They had 161 + 107 - 6 = 252 - 6 = 246 loaves on hand. They have 246 loaves of bread left." `(Q:-0.01176)(P:0.51426)`
* **Terminal 2.1a:** `[1] The answer is: 254</s>` `(Q:-1.00238)(P:0.99992)`
* **Sub-branch 2.2:** Leads to Node `[2]`: "They have 107 + 161 - 6 = 254 loaves left." `(Q:-1.01392)(P:0.71103)`
* **Terminal 2.2a:** `[1] The answer is: 254</s>` (Same terminal as 2.1a)
* **Sub-branch 2.3:** Leads to Node `[11]`: "So, they have 200 - 132 = 68 loaves of bread left. The grocery store returned 6 unsold loaves, so they have 68 + 6 = 74 loaves of bread left." `(Q:1.13120)(P:0.80345)`
* **Terminal 2.3a:** `[10] The answer is: 74</s>` `(Q:0.99283)(P:0.99903)`
**Primary Branch 3 (Downward Path):**
* **Node `[30]`:** "They sold 93 loaves in the morning and 39 loaves in the afternoon, so they sold a total of 93 + 39 = 132 loaves of bread." `(Q:1.44411)(P:0.84645)`
* **Sub-branch 3.1:** Leads to Node `[2]`: "The grocery store returned 6 unsold loaves, so the total number of loaves of bread they did not sell is 132 + 6 = 138 loaves." `(Q:-0.49569)(P:0.65347)`
* **Terminal 3.1a:** `[0] They started with 200 loaves and sold 138 loaves, so they have 200 - 138 = 62 loaves of bread left. The answer is: 62</s>` `(Q:-0.99929)(P:0.93266)`
* **Sub-branch 3.2:** Leads to Node `[21]`: "They had 200 loaves baked and sold 132 loaves, so they had 200 - 132 = 68 loaves of bread left." `(Q:1.14610)(P:0.89809)`
* **Terminal 3.2a:** `[15] The grocery store returned 6 unsold loaves, so they had 68 + 6 = 74 loaves of bread left. The answer is: 74</s>` `(Q:1.08365)(P:0.98273)`
### Key Observations
1. **Multiple Final Answers:** The tree produces six distinct terminal answers: **126, 120, 74, 254, 62, and 74**. The answer **74** appears from three different reasoning paths.
2. **Divergent Interpretations:** The branches represent fundamentally different interpretations of the problem statement. For example, Branch 2 interprets "produced" as creating new loaves on separate days, leading to a much higher total (254). Branch 3 interprets "sold" as the number of loaves *not* sold, leading to the answer 62.
3. **Probability Scores:** Each node has Q and P scores. The P scores (often high, >0.8) may represent the model's confidence in that step, while Q scores vary widely, possibly representing a different metric like value or advantage.
4. **Textual Errors:** Some nodes contain logical or textual inconsistencies. For instance, Node `[0]` in Sub-branch 2.1 calculates a total of 268 loaves, but the subsequent node and terminal answer are 254, suggesting a disconnect in the reasoning chain.
### Interpretation
This diagram is a visualization of an AI model's **exploratory reasoning process**. It does not represent a single, coherent solution but rather a map of possible computational paths generated when attempting to solve a word problem. The tree exposes how slight variations in interpreting the problem's semantics (e.g., the meaning of "returned unsold loaves," or whether production is cumulative) lead to drastically different numerical outcomes.
The presence of multiple terminal nodes with the same answer (74) suggests that this solution is robust, being reachable via several logical interpretations. Conversely, the outlier answers (254, 62) highlight potential failure modes or misinterpretations within the model's reasoning. The probability scores attached to each node offer a window into the model's internal confidence metrics at each step of its deliberation. Ultimately, the image serves as a diagnostic tool for understanding the strengths, weaknesses, and decision-making pathways of a language model engaged in multi-step arithmetic reasoning.
</details>
Figure 8: Example of the result search tree of a GSM8K question “The bakers at the Beverly Hills Bakery baked 200 loaves of bread on Monday morning. They sold 93 loaves in the morning and 39 loaves in the afternoon. A grocery store returned 6 unsold loaves. How many loaves of bread did they have left?”. The example solution is “The Bakery sold 93 + 39 = 132 loaves. The Bakery made 200 loaves and sold 132, leaving 200 - 132 = 68 loaves remaining. The grocery store returned 6 loaves, so there were 6 + 68 = 74 loaves left.”. The policy we use here is the one only tuned for $1$ epoch on SFT training data. We conduct MCTS with breadth $b_1=5,b_2=3$ . Duplicate generations are merged into one node.
<details>
<summary>x12.png Details</summary>
### Visual Description
## Diagram: Bakery Bread Inventory Decision Tree
### Overview
The image displays a decision tree or problem-solving flowchart illustrating multiple reasoning paths to solve a word problem about a bakery's remaining bread inventory. The diagram is structured with a root node on the left, branching out to the right into several intermediate and terminal nodes. Each node contains a step in the reasoning process, a mathematical calculation, and associated numerical values labeled "Q" and "P". The final answers proposed vary across different branches.
### Components/Axes
* **Structure:** A tree diagram with nodes connected by lines. The root is on the far left. Branches extend rightward, splitting into multiple paths.
* **Node Content:** Each node contains:
* A bracketed number (e.g., `[3]`, `[0]`, `[46]`).
* A textual description of a step in solving the problem.
* A mathematical expression or calculation.
* A line with values in the format `(Q:...)(P:...)`.
* **Legend/Labels:** There is no separate legend. The bracketed numbers and the Q/P values serve as identifiers and metadata for each node.
* **Spatial Layout:** The root node `[46]` is positioned at the center-left. It branches into three primary paths (upper, middle, lower). Each of these paths further subdivides. Terminal nodes (providing final answers) are located on the far right.
### Detailed Analysis
The diagram traces different logical approaches to the same core problem: "A bakery baked 200 loaves of bread. They sold some in the morning and some in the afternoon. A grocery store returned some unsold loaves. How many loaves are left?"
**Root Node:**
* **Position:** Center-left.
* **Content:** `[46] <s>` (Q:0.00000)(P:-1.00000)
**Primary Branch 1 (Upper Path):**
1. **Node [3]:** "The bakery baked 200 loaves of bread on Monday morning. They sold 93 loaves in the morning and 39 loaves in the afternoon, so they sold a total of 93 + 39 = 132 loaves." (Q:0.25430)(P:0.93239)
2. **Node [2] (from [3]):** "They also had 6 loaves returned by the grocery store. To find out how many loaves of bread they have left, we need to subtract the loaves they sold and the returned loaves from the total number of loaves baked." (Q:-1.05085)(P:0.79282)
3. **Terminal Node [0] (from [2]):** `[0] 200 - 132 + 6 = 78 The bakery has 78 loaves of bread left. The answer is: 78</s>` (Q:-1.07053)(P:0.84111)
**Primary Branch 2 (Middle Path):**
1. **Node [3]:** "They had 200 - 93 = 107 loaves left after the morning sales. They had 107 - 39 = 68 loaves left after the afternoon sales." (Q:-0.52703)(P:0.86016)
2. **Node [2] (from [3]):** "They had 68 - 6 = 62 loaves of bread left after the grocery store returned the unsold loaves." (Q:-1.05568)(P:0.80182)
3. **Terminal Node [1] (from [2]):** `[1] The answer is 62</s>` (Q:-1.06738)(P:0.99711)
**Primary Branch 3 (Lower Path):**
1. **Node [30]:** "After the morning sales, they had 200 - 93 = 107 loaves of bread left. After the afternoon sales, they had 107 - 39 = 68 loaves of bread left." (Q:1.65898)(P:0.80497)
2. **Node [34] (from [30]):** "After the grocery store returned the loaves, they had 68 + 6 = 74 loaves of bread left." (Q:1.13097)(P:0.91597)
3. **Terminal Node [28] (from [34]):** `[28] The answer is 74</s>` (Q:0.98327)(P:0.99718)
**Additional Nodes (Branching from the Middle Path):**
* **Node [0] (from Middle Path Node [3]):** "A grocery store returned 6 unsold loaves, so the total number of loaves they have left is 200 - 132 + 6 = 88 loaves." (Q:-0.02430)(P:0.80175)
* **Node [0] (from Middle Path Node [3]):** "A grocery store returned 6 unsold loaves, so they had 132 - 6 = 126 loaves left. Therefore, the bakery had 200 - 126 = 74 loaves of bread left." (Q:-0.03073)(P:0.89432)
* **Terminal Node [1] (from Upper Path Node [2]):** `[1] So, 200 - 132 - 6 = 62 Therefore, they have 62 loaves of bread left. The answer is: 62</s>` (Q:-1.07033)(P:0.91906)
### Key Observations
1. **Multiple Answers:** The tree produces at least four distinct final answers: **78, 62, 88, and 74**.
2. **Divergent Logic:** The paths differ in the *order of operations* and the *interpretation of the return*.
* **Path to 78:** Calculates total sold (132), then does `Total Baked - Sold + Returns` (200 - 132 + 6).
* **Paths to 62:** One path subtracts returns from the post-sales inventory (68 - 6). Another incorrectly subtracts the return from the total sold (200 - 132 - 6).
* **Path to 74:** Correctly adds the return to the post-sales inventory (68 + 6).
* **Path to 88:** Contains an arithmetic error (200 - 132 + 6 is calculated as 88, not 78).
3. **Metadata:** Each node has associated `(Q:...)(P:...)` values, which likely represent confidence scores (Q for question confidence, P for probability/confidence in the step) from a language model's reasoning process. These values vary significantly across nodes.
### Interpretation
This diagram is a visualization of **chain-of-thought reasoning** or a **search tree** generated by an AI model solving a multi-step arithmetic word problem. It demonstrates how the same initial problem statement can lead to different conclusions based on subtle variations in logical sequencing and arithmetic execution.
* **What it shows:** It exposes the model's internal "reasoning" process, including correct steps, common errors (like misapplying the return), and arithmetic mistakes. The branching represents different hypotheses the model considered.
* **Relationships:** The tree structure shows dependency; each node's calculation relies on the output of its parent node. The Q/P scores suggest the model's internal confidence in each step, which doesn't always correlate with correctness (e.g., a node with a high P score can still contain an error).
* **Notable Anomalies:** The presence of multiple terminal answers highlights the challenge of consistent reasoning in language models. The node leading to "88" is a clear arithmetic error (200-132=68, 68+6=74, not 88). The node that incorrectly subtracts the return (200-132-6) represents a logical flaw in interpreting "returned loaves" as a reduction rather than an addition to inventory.
* **Peircean Investigation:** From a semiotic perspective, the diagram is an *icon* of the model's cognitive process. The tree structure is an *index* of branching possibilities, and the text/math are *symbols* of the problem. The variance in answers is a *symptom* of the model's probabilistic nature and its struggle with precise, deterministic logic. The correct answer (78) is present but is just one of many possibilities the model generated, requiring external validation to identify.
</details>
Figure 9: Example of the result search tree of the same GSM8K question as in Figure 8 with the same search breadth. We use the policy tuned after $3$ epochs to sample the generations.