# Program Synthesis using Inductive Logic Programming for the Abstraction and Reasoning Corpus
**Authors**: Filipe Marinho Rocha, Inês Dutra, Vítor Santos Costa
> INESCTEC-FCUP
## Abstract
The Abstraction and Reasoning Corpus (ARC) is a general artificial intelligence benchmark that is currently unsolvable by any Machine Learning method, including Large Language Models (LLMs). It demands strong generalization and reasoning capabilities which are known to be weaknesses of Neural Network based systems. In this work, we propose a Program Synthesis system that uses Inductive Logic Programming (ILP), a branch of Symbolic AI, to solve ARC. We have manually defined a simple Domain Specific Language (DSL) that corresponds to a small set of object-centric abstractions relevant to ARC. This is the Background Knowledge used by ILP to create Logic Programs that provide reasoning capabilities to our system. The full system is capable of generalize to unseen tasks, since ILP can create Logic Program(s) from few examples, in the case of ARC: pairs of Input-Output grids examples for each task. These Logic Programs are able to generate Objects present in the Output grid and the combination of these can form a complete program that transforms an Input grid into an Output grid. We randomly chose some tasks from ARC that don’t require more than the small number of the Object primitives we implemented and show that given only these, our system can solve tasks that require each, such different reasoning.
123
## 1 Introduction
Machine Learning [5], more specifically, Deep Learning [14], has achieved great successes and surpassed human performance in several fields. These successes, though, are in what is called skill-based or narrow AI, since each DL model is prepared to solve a specific task very well but fails at solving different kind of tasks [18] [13].
It is known Artificial Neural Networks (ANNs) and Deep Learning (DL) suffer from lack of generalization capabilities. Their performance degrade when they are applied to Out-of-Distribution data [12] [8] [27].
Large Language Models (LLMs), more recently, have shown amazing capabilities, shortening the gap between Machine and Human Intelligence. But they still show lack of reasoning capabilities and require lots of data and computation.
The ARC challenge was designed by Francois Chollet in order to evaluate whether our artificial intelligent systems have progressed at emulating human like form of general intelligence. ARC can be seen as a general artificial intelligence benchmark, a program synthesis benchmark, or a psychometric intelligence test [6].
It was presented in 2019 but it still remains an unsolved challenge, and even the best DL models, such as LLMs cannot solve it [15] [4] [3]. GPT-4V, which is GPT4 enhanced for visual tasks [1], is unable to solve it too [26] [19] [23].
It targets both humans and artificially intelligent systems and aims to emulate a human-like form of general fluid intelligence. It is somewhat similar in format to Raven’s Progressive Matrices [22], a classic IQ test format.
It requires, what Chollet describes as, developer-aware generalization, which is a stronger form of generalization, than Out-of-Distribution generalization [6]. In ARC, the Evaluation set, with 400 examples, only features tasks that do not appear in the Training set, with also 400 examples, and all each of these tasks require very different Logical patterns to solve, that the developer cannot foresee. There is also a Test set with 200 examples, which is completely private.
For a researcher setting out to solve ARC, it is perhaps best understood as a program synthesis benchmark [6]. Program synthesis [9] [10] is a subfield of AI with the purpose of generating of programs that satisfy a high-level specification, often provided in the form of example pairs of inputs and outputs for the program, which is exactly the ARC format.
Chollet recommends starting by developing a domain-specific language (DSL) capable of expressing all possible solution programs for any ARC task [6]. Since the exact set of ARC tasks is purposely not formally definable, and can be anything that would only involve Core Knowledge priors, this is challenging.
Objectness is considered one of the Core Knowledge prior of humans, necessary to solve ARC [6]. Object-centric abstractions enable object awareness which seems crucial for humans when solving ARC tasks [2] [11] and is central to general human visual understanding [24]. There is previous work using object-centric approaches to ARC that shows its usefulness [16] [2].
Inductive Logic Programming (ILP) [20] is also considered a Machine Learning method, but to our knowledge it was never applied to the ARC challenge. It can perform Program Synthesis [7] and is known for being able to learn and generalize from few training examples [17] [21].
We developed a Program Synthesis system that uses ILP, on top of Object-centric abstractions, manually defined by us. It does Program synthesis by searching the combination of Logic relations between objects existent in the training examples. This Logic relations are defined by Logic Programs, obtained using ILP.
The full program our system builds, is composed by Logic Programs that are capable of generating objects in the Output Grid.
We selected five random examples that contain only simple geometrical objects and applied our system to these.
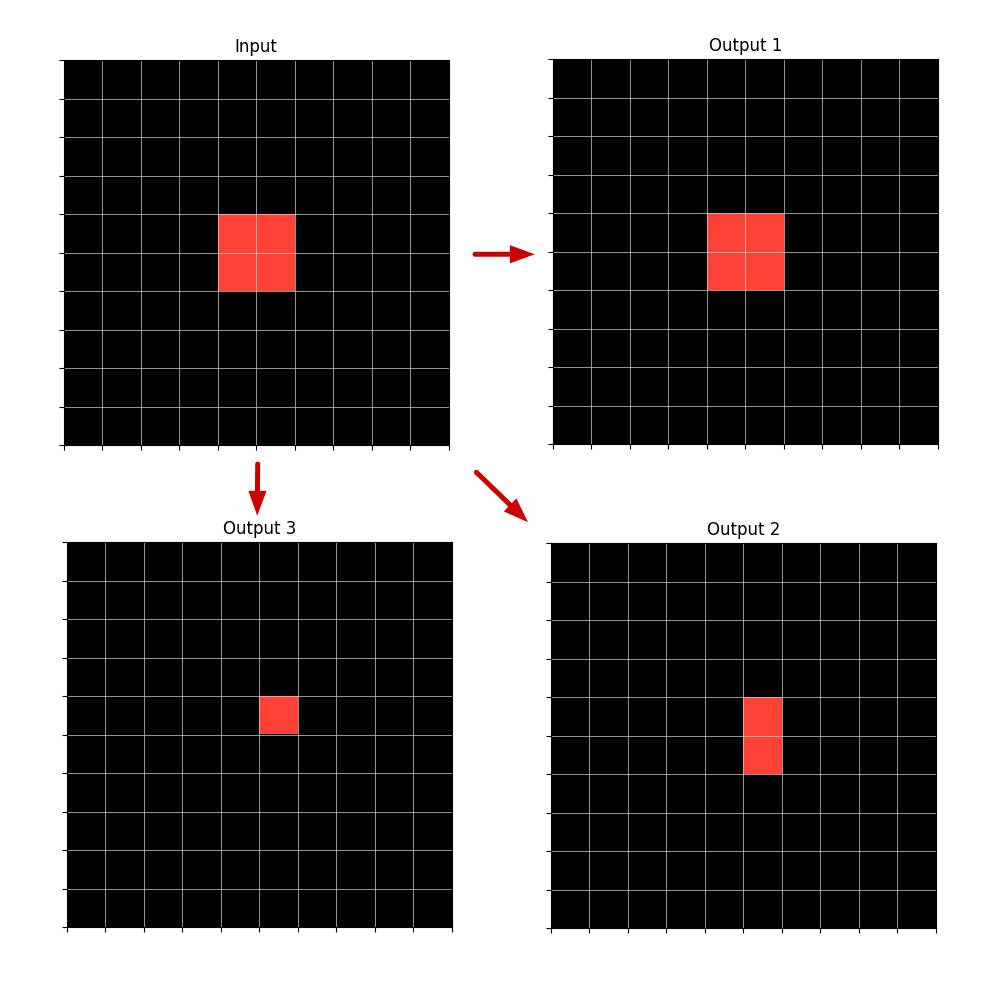
Figure 1: Example tasks of the ARC Training dataset with the solutions shown. The goal is to produce the Test Output grid given the Test Input grid and the Train Input-Output grid pairs. We can see the logic behind each task is very different and the relations between objects are key to the solutions.
## 2 Object-centric Abstractions and Representations
Object-centric abstractions reduce substantially the search space by enabling the focus on the relations between objects, instead of individual pixels.
However, there may be multiple ways to interpret the same image in terms of objects, therefore, we keep multiple, overlapping Object representations for the same image.
### 2.1 Objects and Relations between Objects
We have defined manually a simple DSL that is composed by the Objects: Point, Line and Rectangle and the Relations between Objects: LineFromPoint, Translate, Copy, PointStraightPathTo.
Table 1: Object types.
| Point | (x, y, color) |
| --- | --- |
| Line | (x1, y1, x2, y2, color, len, orientation, direction) |
| Rectangle | (x1, y1, x2, y2, x3, y3, x4, y4, color, clean, area) |
Table 2: Relations types.
| LineFromPoint | (point, line, len, orientation, direction) |
| --- | --- |
| Translate | (obj1, obj2, xdir, ydir, color2) |
| Copy | (obj1, obj2, color2, clean) |
| PointStraightPathTo | (point, obj, xdir, ydir, orientation, direction) |
### 2.2 Multiple Representations
An image representation in our object-centric approach is defined by a list of objects (possibly overlapping) and a background color. This representation can build a target image from an empty grid by firstly filling the grid with the background color and then drawing each object on top of it.
An image grid can be defined by multiple Object representations. For example a single Rectangle in an empty grid can also be defined as several Line or Point objects that form the same Rectangle.
Since we don’t know from the start, the Logic behind the transformation of the Input grid into the Output grid, we don’t know if the Object Rectangle is key to this logic (relation between rectangles) or if instead the logic demands using a Line representation for it may involve a relation dependent on lines, such as the LineFromPoint relation.
<details>
<summary>extracted/2405.06399v1/multiple_representations.png Details</summary>
### Visual Description
## Diagram: Convolutional Neural Network Layer Visualization
### Overview
The image depicts a simplified visualization of a convolutional neural network layer. It shows an "Input" grid with a highlighted region, and three "Output" grids, each representing a different transformation of the input. Arrows indicate the flow of data from the input to each output.
### Components/Axes
* **Input:** A 10x10 grid with a 2x2 region highlighted in the center.
* **Output 1:** A 10x10 grid with a 2x2 region highlighted in the center.
* **Output 2:** A 10x10 grid with a 1x3 region highlighted in the center.
* **Output 3:** A 10x10 grid with a 1x1 region highlighted in the center.
* **Arrows:** Arrows indicate the flow from the "Input" to "Output 1", "Output 2", and "Output 3".
### Detailed Analysis
* **Input:** The input grid is 10x10, with a 2x2 square highlighted in the center. The highlighted region spans rows 4-5 and columns 4-5.
* **Output 1:** The output grid is 10x10, with a 2x2 square highlighted in the center. The highlighted region spans rows 4-5 and columns 4-5.
* **Output 2:** The output grid is 10x10, with a 1x3 rectangle highlighted in the center. The highlighted region spans rows 4-6 and column 4.
* **Output 3:** The output grid is 10x10, with a 1x1 square highlighted in the center. The highlighted region spans row 5 and column 5.
### Key Observations
* The "Input" and "Output 1" have the same highlighted region size and position.
* "Output 2" has a vertically elongated highlighted region.
* "Output 3" has a single-cell highlighted region.
* The arrows indicate a parallel processing flow from the input to the three outputs.
### Interpretation
The diagram illustrates how a convolutional layer might transform an input feature map into multiple output feature maps. Each output represents a different filter applied to the input. "Output 1" could represent an identity filter, preserving the original feature. "Output 2" could represent a vertical edge detection filter, and "Output 3" could represent a point detection filter. The diagram demonstrates the concept of feature extraction and transformation in convolutional neural networks.
</details>
Figure 2: Example of an Input grid with a Rectangle (or with several contiguous Points or Lines) and three possible Output grids, built from the Input, depending on which type of Object representation is used. The Output object can be described by the relation Copy applied to the Input Rectangle or to just one Input Point or Input Line that is part of the same Rectangle.
Likewise, the same image transformation can be explained by different relations.
So we work with multiple and intermingled representations of objects and relations until we get the final program or programs that can transform each of the Training input grids into the output grids and also produce a valid Output grid for the Test Example, which will be the output solution given by our system.
If multiple programs applied separately can produce successfully the same Input-Output Train images transformation, we can use any of this, or select one, for example: the shortest program, which will have more probability of being the correct one, according to the Occam principle.
## 3 ILP
Inductive Logic Programming (ILP) is a form of logic-based Machine Learning. The goal is to induce a hypothesis, a Logic Program or set of Logical Rules, that generalizes given training examples and Background Knowledge (BK). Our DSL composed by Objects and Relations, is the BK given.
As with other forms of ML, the goal is to induce a hypothesis that generalizes training examples. However, whereas most forms of ML use vectors/tensors to represent data, ILP uses logic programs. And whereas most forms of ML learn functions, ILP learns relations.
The fundamental ILP problem is to efficiently search a large hypothesis space. There are ILP approaches that search in either a top-down or bottom-up fashion and others that combine both. We use a top-down approach in our system.
Learning a large program with ILP is very challenging, since the search space can get very big. There are some approaches that try to overcome this.
### 3.1 Divide-and-conquer
Divide-and-conquer approaches [25] divide the examples into subsets and search for a program for each subset. We use a Divide-and-conquer approach but instead of applying it to examples, we apply it to the Objects inside the examples.
## 4 Program Synthesis using ILP
ILP is usually seen as a method for Concept Learning but is capable of building a Logic Program in Prolog, which is Turing-complete, hence, it does Program Synthesis. We extend this by combining Logic Programs to build a bigger program that generates objects in sequence, to fill an empty grid, which corresponds to, procedurally, applying grids transformations to reach the solution.
A Relation can be used to generate objects. All of our Relations, except for PointStraightPathTo, are able to generate Objects given the first Object of the Relation. To generate an unambiguous output, the Relation should be defined by a Logic Program. This Logic Program is built by using ILP in our system.
Example of a logic program in Prolog:
⬇
line_from_point (Point, Line, Len, Orientation, Direction):-
member (Point, Input_points),
equal (Len,5),
equal (Orientation, ’vertical’).
<details>
<summary>extracted/2405.06399v1/line_from_point_example1.png Details</summary>
### Visual Description
## Diagram: Input-Output Transformation
### Overview
The image depicts a transformation from an "Input" grid to an "Output" grid, represented by a red arrow pointing from the left grid to the right grid. Each grid is 8x8, with a black background and white grid lines. The transformation involves the movement and alteration of colored blocks (red and light blue) between the input and output grids.
### Components/Axes
* **Grids:** Two 8x8 grids, labeled "Input" (left) and "Output" (right).
* **Colored Blocks:** Red and light blue blocks within the grids.
* **Arrow:** A red arrow pointing from the "Input" grid to the "Output" grid, indicating the transformation process.
### Detailed Analysis
**Input Grid:**
* A single red block is located at the top-left of the grid, specifically at row 1, column 1.
* A single light blue block is located at the bottom-right of the grid, specifically at row 8, column 6.
**Output Grid:**
* A vertical stack of three red blocks is located at the top-left of the grid, specifically spanning rows 1-3, column 1.
* A vertical stack of three light blue blocks is located below the red blocks, spanning rows 4-6, column 1.
**Transformation:**
* The red block from the input grid is transformed into a stack of three red blocks in the output grid.
* The light blue block from the input grid is transformed into a stack of three light blue blocks in the output grid.
* The horizontal position of the blocks changes from column 1 and 6 in the input to column 1 in the output.
* The vertical position of the blocks changes from row 1 and 8 in the input to row 1-3 and 4-6 in the output.
### Key Observations
* The transformation involves both a change in the size (number of blocks) and position of the colored blocks.
* The red and light blue blocks are stacked vertically in the output grid.
* The horizontal position of both blocks is the same in the output grid.
### Interpretation
The diagram illustrates a simple transformation process where single blocks in the input grid are converted into vertical stacks of blocks in the output grid. This could represent a basic data processing step, such as feature extraction or signal amplification. The change in position suggests a re-organization or re-alignment of the data. The diagram does not provide specific details about the nature of the data or the transformation process, but it visually represents a clear input-output relationship.
</details>
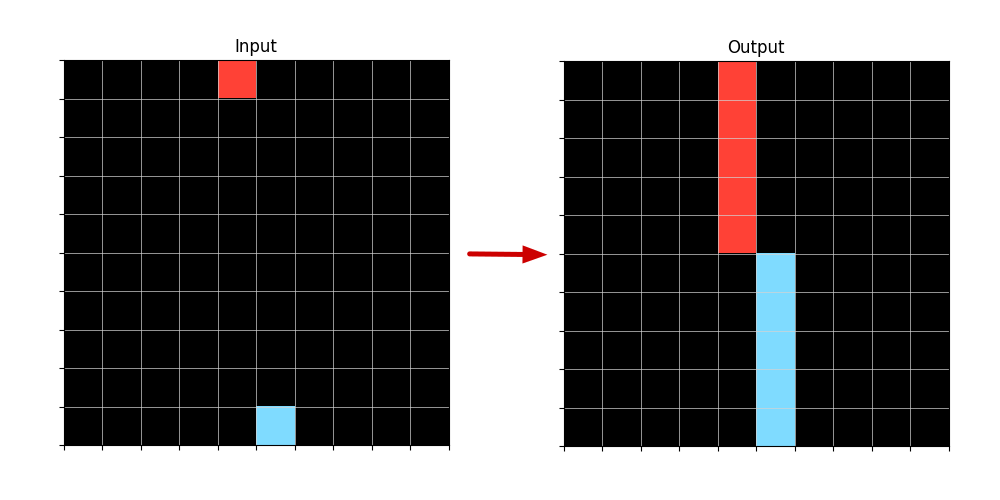
Figure 3: Example of an Input-Output transformation when applied a LineFromPoint Logic Program that is able to generate Lines from Points.
This Logic Program can generate unambiguously, two lines in the Output. The variable Direction is not needed for this, since the points are on the edges of the Grid and so, can only grow into lines in one Direction each.
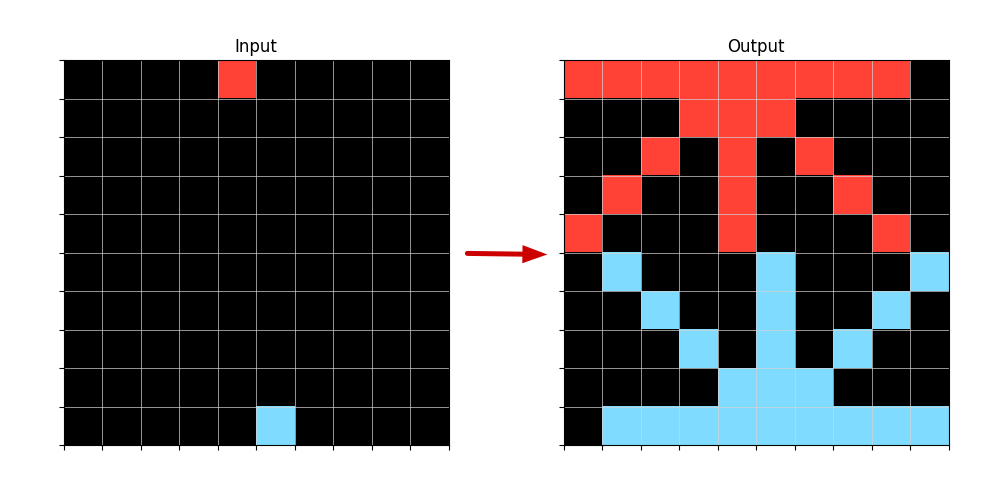
If the program was shorter, it would generate multiple Lines from each Input Point. Example of the same Logic Program without the last term in the body:
⬇
line_from_point (Point, Line, Len, Orientation, Direction):-
member (Point, Input_points),
equal (Len,5).
<details>
<summary>extracted/2405.06399v1/line_from_point_example2.png Details</summary>
### Visual Description
## Diagram: Input-Output Transformation
### Overview
The image shows a transformation diagram. It depicts an 8x8 grid labeled "Input" on the left, which is mostly black with a single red square in the top-left corner and a single light blue square in the bottom-left corner. An arrow points from the "Input" grid to an "Output" grid on the right. The "Output" grid shows a transformed pattern of red and light blue squares against a black background.
### Components/Axes
* **Input Grid:** An 8x8 grid labeled "Input" at the top. The grid cells are primarily black, with one red cell at the top-left (row 1, column 1) and one light blue cell at the bottom-left (row 8, column 1).
* **Output Grid:** An 8x8 grid labeled "Output" at the top. The grid cells contain a pattern of red and light blue cells against a black background.
* **Transformation Arrow:** A red arrow pointing from the "Input" grid to the "Output" grid, indicating a transformation process.
### Detailed Analysis or ### Content Details
**Input Grid:**
* The grid is 8x8.
* The majority of the cells are black.
* One cell is red, located at row 1, column 1.
* One cell is light blue, located at row 8, column 1.
**Output Grid:**
* The grid is 8x8.
* The grid contains a pattern of red and light blue cells against a black background.
* **Red Cells:**
* Row 1: Columns 1, 2, 6, 7, 8
* Row 2: Columns 1, 2, 6, 7, 8
* Row 3: Columns 1, 6
* Row 4: Columns 1, 6
* **Light Blue Cells:**
* Row 5: Columns 1, 3, 5, 7
* Row 6: Columns 2, 4, 6
* Row 7: Columns 1, 2, 3, 4, 5, 6, 7, 8
* Row 8: Columns 1, 2, 3, 4, 5, 6, 7, 8
### Key Observations
* The "Input" grid has only two colored cells, one red and one light blue, both located in the first column.
* The "Output" grid shows a more complex pattern of red and light blue cells.
* The red cells in the "Output" grid are concentrated in the upper rows, while the light blue cells are concentrated in the lower rows.
### Interpretation
The diagram illustrates a transformation process where a simple "Input" pattern is converted into a more complex "Output" pattern. The transformation appears to distribute the initial red and light blue cells from the first column of the "Input" grid into a specific arrangement in the "Output" grid. This could represent a simplified model of a neural network layer, where the input signals are processed and transformed into a different output representation. The specific pattern in the "Output" grid suggests a defined transformation rule or algorithm.
</details>
Figure 4: Example of an Input-Output transformation when applied a LineFromPoint Logic Program without having the Orientation defined.
So by obtaining Logic Programs through ILP we are indeed constructing a program that generates objects that can fill an empty Test Output grid, in order to reach the solution.
## 5 System Overview
### 5.1 Objects and Relations Retrieval
Our system begins by retrieving all Objects defined in our DSL, in the Input and Output grids for each example of a task. As we reported before, we keep multiple object representations that may overlap in terms of occupying the same pixels in a image.
Then we search for Relations defined in our DSL betweeen the found objects. We search for Relations between Objects only present in the Input Grid: Input-Input Relations, only present in the Output Grid: Output-Output Relations and between Objects in the Input Grid and Output Grid: Input-Output Relations.
The type of Objects previously found can constraint the search for Relations, since some Relations are specific to some kind of Objects.
### 5.2 ILP calls
We then call ILP to create Logic Programs to define only the Relations found in the previous step. This also reduces the space of the search. We start with the Input-Output Relations, since we need to build the Output objects using information from the Input. After we generate some Object(s) in the Output grid we can starting using also Output-Output relations to generate Output Objects from other Output Objects. Input-Input relations can appear in the body of the rules but won’t be the Target Relations to be defined by ILP, since they don’t generate any Object in the Output.
After each ILP call what is considered Input information, increases. The relations and Objects returned by the ILP call that produce an updated Grid, are considered now as it were present in the Input, and this updated Grid is taken as the initial Output grid where to build on, in the subsequent ILP calls.
#### 5.2.1 Candidate Generation
The candidates terms to be added to the Body of the Rule (Horn Clause) are the Objects and Relations found in the Retrieval step (5.1) plus the Equal(X,…), GreaterThan(X,…), LowerThan(X,…), Member(X,…) predicates. GreaterThan and Lowerthan relate only number variables. We also consider aX+b , being X a number variable and a and b, constants in some interval we predefine.
Since we are using Typed Objects and Relations we only need to generate those candidates that are related to each Target Relation variable by type.
For example, in building a Logic Program that defines the Relation: LineFromPoint(point,line,len,orientation,direction) we are going to generate candidates that relate Points or attributes of Points in order to instantiate the first variable Point of the relation. Then we proceed to the other variables (besides the line variable): len, orientation and direction. Len is of type Int, so it is only relevant to be related to other Int variables or constants. The variable Line remains free because it is the Object we want the relation to generate.
#### 5.2.2 Positive and Negative examples
As we have seen in Section 3, FOIL requires positive and negative examples to induce a program. ARC dataset is only composed of Positive examples. So we created a way to represent negative examples.
In our system for each Logic Program the Positive examples are the Objects that this program generates that exist in the Training Data, and the Negative examples are the Objects that the program generates, but don’t exist in the Training Data.
For example, imagine the Ouput in Figure 3 is the correct one, but the program generates all the Lines in Figure 4 like the shorter Prolog program we presented. For this Program the positives it covers would be the two Lines in Figure 3 and the negatives covered would be all the Lines in Figure 4, except for the vertical ones.
Here, our Object-centric approach also reduces the complexity of the search, compared with taking the entire Grid into account, to define what is a positive example or not.
#### 5.2.3 Unification between Training examples
An ILP call is made for each Relation and all of the Task’s Training examples. Our ILP system is constrained to produce Programs that can unify between examples, that is, they are abstract and generalize to two or more of the training examples.
Why two and not all of the training examples? One of the five examples we selected to help us develop our system showed us that a program that solves all Training examples can be too complex and not necessary to solve the Test example.
<details>
<summary>extracted/2405.06399v1/example_unification2.png Details</summary>
### Visual Description
## Image Analysis: Task 0a938d79 - Input/Output Pattern Recognition
### Overview
The image presents a series of input-output pairs, labeled as "Train Input," "Train Output," "Test Input," and "Test Output." Each pair consists of a small, sparse input pattern and a corresponding output pattern. The task appears to involve learning a transformation or mapping from the input to the output based on the training examples and then applying this learned transformation to the test input.
### Components/Axes
* **Title:** Task 0a938d79
* **Labels:**
* Train Input (appears four times)
* Train Output (appears four times)
* Test Input
* Test Output
* **Input Patterns:** Each "Input" pattern is a small grid (likely 5x5 or similar) with a black background and one or two colored squares.
* **Output Patterns:** Each "Output" pattern is a grid (likely 5x5 or similar) with vertical colored bars against a black background. The colors and arrangement of these bars seem to be related to the colors and positions of the squares in the corresponding input pattern.
* **Colors:** The colors used in the patterns include red, light blue, dark blue, green, and yellow.
### Detailed Analysis
**Training Pairs:**
1. **Pair 1:**
* Train Input: A red square in the top-right corner and a light blue square near the center.
* Train Output: Alternating light blue and red vertical bars. There are 9 bars in total.
2. **Pair 2:**
* Train Input: A dark blue square in the top-left corner and a green square near the center.
* Train Output: Alternating dark blue and green vertical bars. There are 7 bars in total.
3. **Pair 3:**
* Train Input: A red square in the top-left corner and a green horizontal bar near the center.
* Train Output: Alternating green and red horizontal bars. There are 6 bars in total.
4. **Pair 4:**
* Train Input: A yellow horizontal bar near the top and a dark blue square near the center.
* Train Output: Alternating yellow and dark blue horizontal bars. There are 6 bars in total.
**Testing Pair:**
1. **Test Input:** A green square in the top-left corner and a yellow square near the bottom.
2. **Test Output:** Alternating green and yellow vertical bars. There are 7 bars in total.
### Key Observations
* The input patterns are sparse, containing only a few colored elements.
* The output patterns are more structured, consisting of alternating colored bars.
* The colors in the input patterns seem to directly correspond to the colors in the output patterns.
* The position of the colored squares in the input might influence the arrangement or number of bars in the output.
* The test output follows the same alternating color pattern as the training outputs, using the colors present in the test input.
### Interpretation
The image represents a visual pattern recognition task. The goal is to learn the relationship between the input and output patterns from the training examples and then predict the output for the test input. The task likely involves identifying the colors present in the input and generating an output pattern with alternating bars of those colors. The number of bars or their arrangement might be influenced by the position or type of the colored elements in the input. The test output suggests that the model has learned to associate the colors in the input with the colors in the output and to generate the alternating bar pattern.
</details>
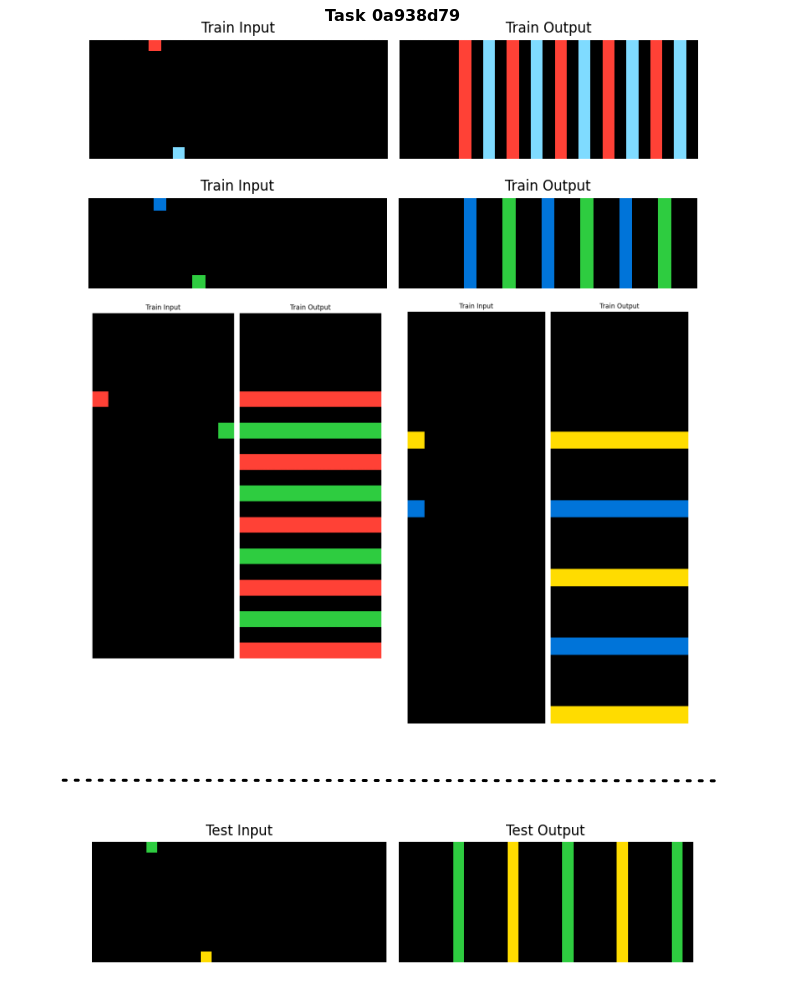
Figure 5: Example task that contains two Train examples with vertical lines and two Train examples with horizontal lines, in the Output grids. The Test example only requires vertical Lines in the same way as the first two Train examples.
In Figure 5 we can see a sample task and derive the logic for its solution: draw Lines from Points until the opposite border of the grid and then Translate these Lines repeatedly in the perpendicular direction of the Lines until the end of the grid.
To unify the four Train examples in this task and following the logic we described for this solution, it would require a more complex program than a solution that only unifies the first two examples.
Let’s see one sequence of Logic programs that solves the first two Train examples, and it would also solve, sucessfully, the Test example:
⬇
line_from_point (Point, Line, Len, Orientation, Direction):-
member (Point, Input_points),
equal (Len, X_dim),
equal (Orientation, ’vertical’).
translate (Line1, Line2, X_dir, Y_dir):-
member (Line1, Input_lines),
equal (X_dir,0),
translate (Input_point1, Input_point2, X_dir, Y_dir),
equal (Y_dir,2* Y_dir).
…
(the same translate program three more times)
The sequence of Logic Programs that would solve the last two Train examples with the Horizontal lines, but wouldn’t solve sucessfully the Test example which has Vertical lines:
⬇
line_from_point (Point, Line, Len, Orientation, Direction):-
member (Point, Input_points),
equal (Len, Y_dim),
equal (Orientation, ’horizontal’).
translate (Line1, Line2, X_dir, Y_dir):-
member (Line1, Input_lines),
equal (Y_dir,0),
translate (Input_point1, Input_point2, X_dir, Y_dir),
equal (X_dir,2* X_dir).
…
(the same translate program three more times)
The Test example only needs two translations in the Output Grid, so a program with more translations would work, since it would fill the entire grid and the extra translations just wouldn’t apply. Our system consider this a valid program.
But if the Test grid was longer and required more translations than present in the Training examples, our program wouldn’t work, since the number of translations wouldn’t produce the exact solution, but an incomplete one. For this kind of tasks we would need to use higher-order constructs as: Do Until, Repeat While or Recursion with a condition, to apply the same Relation a number of times or until some condition fails or is triggered. This is scope of future work.
### 5.3 Rules, Grid states and Search
The first ILP call is made on empty grid states. Each ILP call produces a rule that defines a Relation that generates objects, and returns new Output grid states with these objects added, for each example and the Test example. Each subsequent ILP call is made on the updated Output Grid states.
The search will be on finding the right sequence of Logic Programs that can build the Output Grids, starting from the empty grid. When we have one Program that builds at least one complete Training example Output Grid, consisting of a program that is unified between two or more examples and can also produce a valid solution (not necessarily the correct one) in the Test Output Grid, we consider it the final program.
A valid program is one that builds a consistent theory. For example, a program that generates different colored Lines that intersect with each other, is inconsistent, since both Lines cannot exist in the Output grid (one overlaps the other). We consider programs like this invalid, and discard them, when searching for the complete program.
<details>
<summary>extracted/2405.06399v1/output_state_transition.png Details</summary>
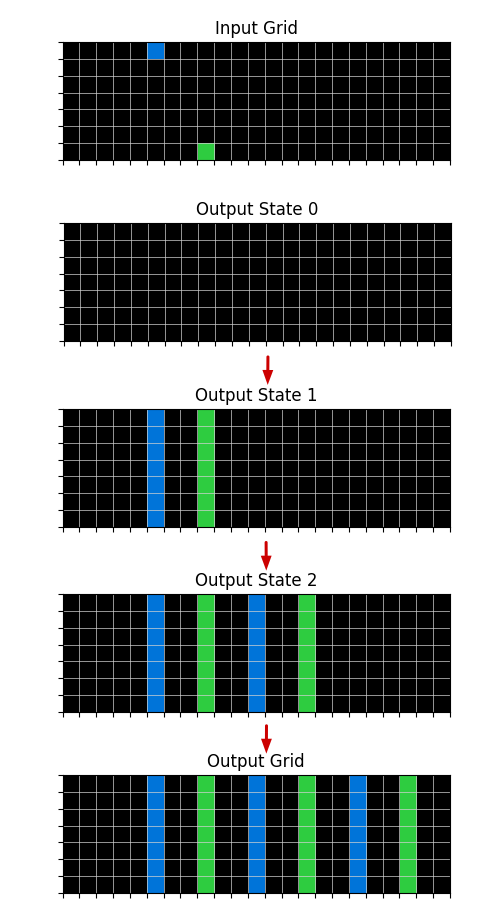
### Visual Description
## Diagram: Grid Transformation
### Overview
The image depicts a transformation process on a grid, showing an input grid and a series of output states leading to a final output grid. The transformation involves the propagation or modification of colored cells (blue and green) across the grid through several intermediate states.
### Components/Axes
* **Titles:**
* Input Grid
* Output State 0
* Output State 1
* Output State 2
* Output Grid
* **Grids:** Each state (Input Grid, Output State 0, Output State 1, Output State 2, Output Grid) is represented as a grid. Each grid appears to be 16x8 (16 columns and 8 rows).
* **Arrows:** Red arrows indicate the flow of transformation from one state to the next.
### Detailed Analysis
* **Input Grid:**
* A single blue cell is present in the top row, approximately in the 4th column.
* A single green cell is present in the 2nd row, approximately in the 2nd column.
* **Output State 0:**
* The grid is entirely black, indicating an initial state with no active cells.
* **Output State 1:**
* A blue vertical bar (one cell wide, 8 cells tall) appears in approximately the 4th column.
* A green vertical bar (one cell wide, 8 cells tall) appears in approximately the 6th column.
* **Output State 2:**
* A blue vertical bar appears in approximately the 2nd column.
* A green vertical bar appears in approximately the 4th column.
* A blue vertical bar appears in approximately the 6th column.
* A green vertical bar appears in approximately the 8th column.
* **Output Grid:**
* A green vertical bar appears in approximately the 2nd column.
* A blue vertical bar appears in approximately the 4th column.
* A green vertical bar appears in approximately the 6th column.
* A blue vertical bar appears in approximately the 8th column.
* A green vertical bar appears in approximately the 10th column.
### Key Observations
* The initial blue and green cells in the Input Grid seem to trigger the formation of vertical bars in subsequent states.
* The transformation process involves the propagation and alternation of blue and green bars across the grid.
* The number of bars increases with each state until the final Output Grid is reached.
### Interpretation
The diagram illustrates a cellular automaton or a similar grid-based transformation process. The initial configuration of cells in the Input Grid determines the evolution of the grid through several states, resulting in a final pattern in the Output Grid. The process appears to involve a rule-based system where the presence of a cell in one state influences the state of neighboring cells in the next state. The alternation of blue and green bars suggests a specific rule set governing the transformation.
</details>
Figure 6: Example of a sucessful sequence of transformations to the Output grid state reaching the final state which is the correct Output grid. These transformations correspond to a sequence of Logic Programs: first transition comes from LineFromPoint Input-Output program, the second and third transitions correspond to the Translate Output-Output programs.
### 5.4 Deductive Search
In Figure 7 we can see an example Task that in order to be solved, it would be easier to do it in reverse, that is, the Input Grid being generated from Output information, but since we cannot solve the Test Output Grid by working in this direction, we use a form of Deductive Search to overcome this.
When we apply a Logic Program constructed by ILP, we can have different results depending on the order of the Object Generation. When an Object is generated in the Output Grid, none other Object generated afterwards, can intersect with it.
So the coverage of grid space of the same Logic Program may vary depending on the order of the program application. It is the procedural aspect of our system. When applying several Logic Programs in sequence, this problem gets even bigger.
So when applying the full program to produce the Test Output grid, we use Deductive search to apply the whole program in the way that covers the most surface. Since the final program is one that can cover the whole surface of Train Output grids, we should have a solution that can cover all of the Test Output grid too.
<details>
<summary>extracted/2405.06399v1/last_sample_task.png Details</summary>
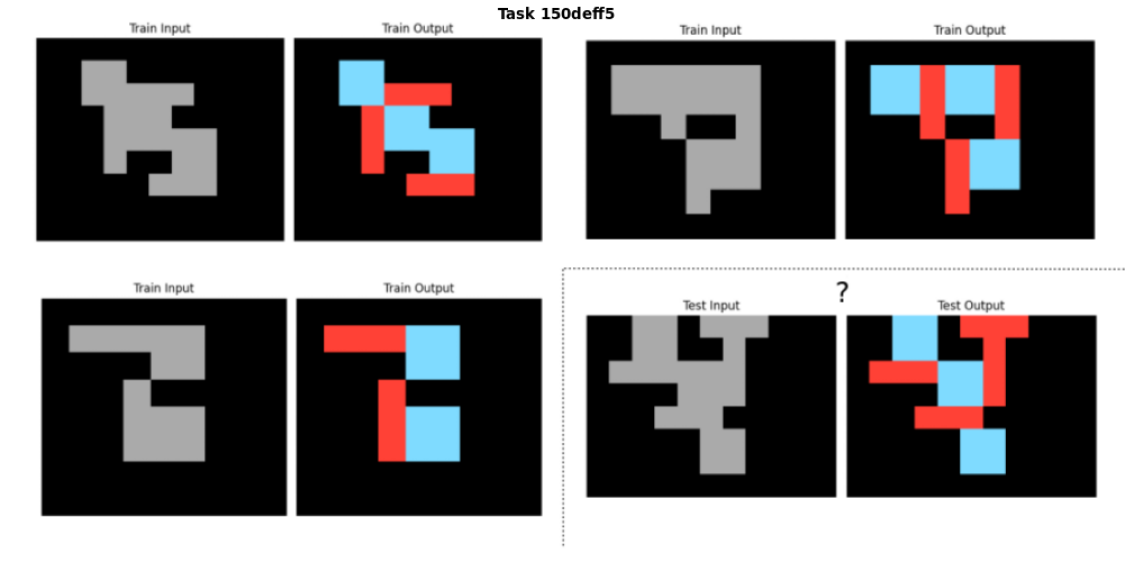
### Visual Description
## Abstract Reasoning Task: Task 150deff5
### Overview
The image presents an abstract reasoning task, labeled "Task 150deff5". It consists of three pairs of "Train Input" and "Train Output" images, followed by a "Test Input" image and a question mark where the "Test Output" should be. The task involves identifying the pattern or transformation that relates the input to the output in the training examples and applying it to the test input to predict the corresponding output. The images are composed of gray shapes on a black background, with the outputs containing red and blue shapes.
### Components/Axes
* **Title:** Task 150deff5 (located at the top-center of the image)
* **Labels:**
* Train Input (appears three times, above the input images)
* Train Output (appears three times, above the output images)
* Test Input (appears once, below the last input image)
* Test Output (appears once, below the last output image)
* ? (appears above the last output image)
* **Image Structure:** The image is divided into six cells arranged in a 2x3 grid, plus two cells in the bottom row. Each cell contains a small image.
* **Color Palette:** The images use a limited color palette: black (background), gray (input shapes), red and blue (output shapes).
### Detailed Analysis or ### Content Details
**Training Examples:**
* **Train Input 1:** A gray shape resembling a stylized "5" on a black background.
* **Train Output 1:** The "5" shape is transformed. Some parts are colored red, and other parts are colored blue. The red and blue shapes appear to be added to the original gray shape.
* **Train Input 2:** A gray shape resembling a stylized "7" on a black background.
* **Train Output 2:** The "7" shape is transformed. Some parts are colored red, and other parts are colored blue. The red and blue shapes appear to be added to the original gray shape.
* **Train Input 3:** A gray shape resembling a stylized "2" on a black background.
* **Train Output 3:** The "2" shape is transformed. Some parts are colored red, and other parts are colored blue. The red and blue shapes appear to be added to the original gray shape.
**Test Example:**
* **Test Input:** A gray shape resembling a stylized "4" on a black background.
* **Test Output:** The cell contains a question mark, indicating that the corresponding output needs to be determined based on the patterns observed in the training examples. The output contains red and blue shapes. The red and blue shapes appear to be added to the original gray shape.
### Key Observations
* The task involves recognizing a transformation rule that converts the gray input shapes into colored output shapes.
* The transformation seems to involve adding red and blue shapes to the original gray shape in a specific pattern.
* The challenge is to identify the pattern and apply it to the "Test Input" to predict the correct "Test Output".
### Interpretation
The image presents a visual analogy problem common in abstract reasoning tests. The goal is to infer a rule from the training examples and apply it to the test case. The specific rule governing the transformation from input to output is not immediately obvious and requires careful analysis of the spatial relationships between the gray input shapes and the added red and blue shapes in the outputs. The task likely assesses pattern recognition, spatial reasoning, and problem-solving skills.
</details>
Figure 7: Example task where the Output Grids are more informative than the Input Grids, to define and apply the Object Relations for the solution.
## 6 Experiments
Our system was applied sucessfully to five tasks, the three tasks in Figure 1: 08ed6ac7, a48eeaf7, 7e0986d6, the task in Figure 5: 0a938d79 and the task in Figure 7: 150deff5.
In the Appendices we present the Output solutions in Prolog for each task.
## 7 Conclusion
We showed our system is able to solve the 5 sample tasks selected. When we finish our software implementation we will apply our system to the full Training and Evaluation datasets.
ILP is at the core of our system and we showed that only by providing it with a small DSL or Background Knowledge, ILP is able to construct and represent the Logic behind solutions of ARC tasks.
ILP gives our system abstract learning and generalization capabilities, which is at the core of the ARC challenge.
Since the other ARC tasks may depend on many different DSL primitives, we plan to develop a way to automate the DSL creation.
As we mentioned before, potentially, we are going to need higher-order constructs to solve other tasks and plan to incorporate this into our system.
## References
- Achiam et al. [2023] J. Achiam, S. Adler, S. Agarwal, L. Ahmad, I. Akkaya, F. L. Aleman, D. Almeida, J. Altenschmidt, S. Altman, S. Anadkat, et al. Gpt-4 technical report. arXiv preprint arXiv:2303.08774, 2023.
- Acquaviva et al. [2022] S. Acquaviva, Y. Pu, M. Kryven, T. Sechopoulos, C. Wong, G. Ecanow, M. Nye, M. Tessler, and J. Tenenbaum. Communicating natural programs to humans and machines. Advances in Neural Information Processing Systems, 35:3731–3743, 2022.
- Bober-Irizar and Banerjee [2024] M. Bober-Irizar and S. Banerjee. Neural networks for abstraction and reasoning: Towards broad generalization in machines. arXiv preprint arXiv:2402.03507, 2024.
- Butt et al. [2024] N. Butt, B. Manczak, A. Wiggers, C. Rainone, D. Zhang, M. Defferrard, and T. Cohen. Codeit: Self-improving language models with prioritized hindsight replay. arXiv preprint arXiv:2402.04858, 2024.
- Carbonell et al. [1983] J. G. Carbonell, R. S. Michalski, and T. M. Mitchell. An overview of machine learning. Machine learning, pages 3–23, 1983.
- Chollet [2019] F. Chollet. On the measure of intelligence. arXiv preprint arXiv:1911.01547, 2019.
- Cropper et al. [2022] A. Cropper, S. Dumančić, R. Evans, and S. H. Muggleton. Inductive logic programming at 30. Machine Learning, 111(1):147–172, 2022.
- Farquhar and Gal [2022] S. Farquhar and Y. Gal. What’out-of-distribution’is and is not. In NeurIPS ML Safety Workshop, 2022.
- Gulwani et al. [2015] S. Gulwani, J. Hernández-Orallo, E. Kitzelmann, S. H. Muggleton, U. Schmid, and B. Zorn. Inductive programming meets the real world. Communications of the ACM, 58(11):90–99, 2015.
- Gulwani et al. [2017] S. Gulwani, O. Polozov, R. Singh, et al. Program synthesis. Foundations and Trends® in Programming Languages, 4(1-2):1–119, 2017.
- Johnson et al. [2021] A. Johnson, W. K. Vong, B. M. Lake, and T. M. Gureckis. Fast and flexible: Human program induction in abstract reasoning tasks. arXiv preprint arXiv:2103.05823, 2021.
- Kirchheim et al. [2024] K. Kirchheim, T. Gonschorek, and F. Ortmeier. Out-of-distribution detection with logical reasoning. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pages 2122–2131, 2024.
- Lake et al. [2017] B. M. Lake, T. D. Ullman, J. B. Tenenbaum, and S. J. Gershman. Building machines that learn and think like people. Behavioral and brain sciences, 40:e253, 2017.
- LeCun et al. [2015] Y. LeCun, Y. Bengio, and G. Hinton. Deep learning. nature, 521(7553):436–444, 2015.
- Lee et al. [2024] S. Lee, W. Sim, D. Shin, S. Hwang, W. Seo, J. Park, S. Lee, S. Kim, and S. Kim. Reasoning abilities of large language models: In-depth analysis on the abstraction and reasoning corpus. arXiv preprint arXiv:2403.11793, 2024.
- Lei et al. [2024] C. Lei, N. Lipovetzky, and K. A. Ehinger. Generalized planning for the abstraction and reasoning corpus. arXiv preprint arXiv:2401.07426, 2024.
- Lin et al. [2014] D. Lin, E. Dechter, K. Ellis, J. B. Tenenbaum, and S. H. Muggleton. Bias reformulation for one-shot function induction. 2014.
- Marcus [2018] G. Marcus. Deep learning: A critical appraisal. arXiv preprint arXiv:1801.00631, 2018.
- Mitchell et al. [2023] M. Mitchell, A. B. Palmarini, and A. Moskvichev. Comparing humans, gpt-4, and gpt-4v on abstraction and reasoning tasks. arXiv preprint arXiv:2311.09247, 2023.
- Muggleton and De Raedt [1994] S. Muggleton and L. De Raedt. Inductive logic programming: Theory and methods. The Journal of Logic Programming, 19:629–679, 1994.
- Muggleton et al. [2018] S. Muggleton, W.-Z. Dai, C. Sammut, A. Tamaddoni-Nezhad, J. Wen, and Z.-H. Zhou. Meta-interpretive learning from noisy images. Machine Learning, 107:1097–1118, 2018.
- Raven [2003] J. Raven. Raven progressive matrices. In Handbook of nonverbal assessment, pages 223–237. Springer, 2003.
- Singh et al. [2023] M. Singh, J. Cambronero, S. Gulwani, V. Le, and G. Verbruggen. Assessing gpt4-v on structured reasoning tasks. arXiv preprint arXiv:2312.11524, 2023.
- Spelke and Kinzler [2007] E. S. Spelke and K. D. Kinzler. Core knowledge. Developmental science, 10(1):89–96, 2007.
- Witt et al. [2023] J. Witt, S. Rasing, S. Dumančić, T. Guns, and C.-C. Carbon. A divide-align-conquer strategy for program synthesis. arXiv preprint arXiv:2301.03094, 2023.
- Xu et al. [2023] Y. Xu, W. Li, P. Vaezipoor, S. Sanner, and E. B. Khalil. Llms and the abstraction and reasoning corpus: Successes, failures, and the importance of object-based representations. arXiv preprint arXiv:2305.18354, 2023.
- Ye et al. [2022] N. Ye, K. Li, H. Bai, R. Yu, L. Hong, F. Zhou, Z. Li, and J. Zhu. Ood-bench: Quantifying and understanding two dimensions of out-of-distribution generalization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 7947–7958, 2022.
## Appendices
<details>
<summary>extracted/2405.06399v1/08ed6ac7.png Details</summary>
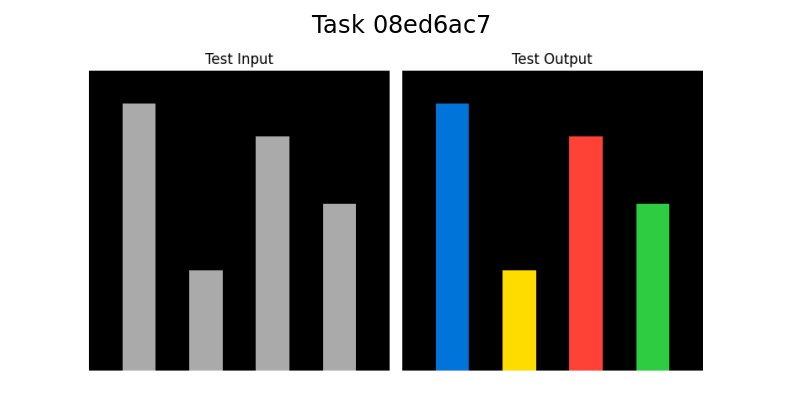
### Visual Description
## Bar Chart: Task 08ed6ac7
### Overview
The image presents two bar charts side-by-side, labeled "Test Input" and "Test Output." The "Test Input" chart displays three gray bars of varying heights against a black background. The "Test Output" chart displays four colored bars (blue, yellow, red, and green) of varying heights against a black background. The image is titled "Task 08ed6ac7".
### Components/Axes
* **Title:** Task 08ed6ac7
* **Left Chart Title:** Test Input
* **Right Chart Title:** Test Output
* **Left Chart Bars:** Three gray bars of different heights.
* **Right Chart Bars:** Four bars colored blue, yellow, red, and green, of different heights.
* **Background:** Black for both charts.
* **X-axis:** Implicit categorical axis, with no labels.
* **Y-axis:** Implicit numerical axis, with no labels or scale.
### Detailed Analysis
**Test Input (Left Chart):**
* **Bar 1 (Gray):** Height is approximately 80% of the chart height.
* **Bar 2 (Gray):** Height is approximately 30% of the chart height.
* **Bar 3 (Gray):** Height is approximately 60% of the chart height.
**Test Output (Right Chart):**
* **Bar 1 (Blue):** Height is approximately 90% of the chart height.
* **Bar 2 (Yellow):** Height is approximately 25% of the chart height.
* **Bar 3 (Red):** Height is approximately 70% of the chart height.
* **Bar 4 (Green):** Height is approximately 50% of the chart height.
### Key Observations
* The "Test Input" chart has three bars, while the "Test Output" chart has four.
* The heights of the bars vary significantly in both charts.
* The "Test Input" chart uses only gray bars, while the "Test Output" chart uses blue, yellow, red, and green bars.
### Interpretation
The image likely represents a comparison between an input state and an output state, where the bars represent some quantifiable feature or value. The change in the number of bars and their respective heights, as well as the change in color, suggests a transformation or processing step has occurred between the input and output. Without further context, the specific meaning of the bars and their colors is unknown. The task ID "08ed6ac7" may refer to a specific experiment or process.
</details>
⬇
copy (Line1, Line_out, Color_out, Clean):-
member (Line1, Input_lines),
member (Line2, Input_lines),
member (Line3, Input_lines),
member (Line4, Input_lines),
line_attrs (Line1, X11, Y11, X12, Y12, Color1, Len1,
Orientation1, Direction1),
line_attrs (Line2, X21, Y21, X22, Y22, Color2, Len2,
Orientation2, Direction2),
line_attrs (Line3, X31, Y31, X32, Y32, Color3, Len3,
Orientation3, Direction3),
line_attrs (Line4, X41, Y41, X42, Y42, Color4, Len4,
Orientation4, Direction4),
equal (Color_out, ’blue’),
equal (Clean,100),
greaterthan (Len1, Len2),
greaterthan (Len1, Len3),
greaterthan (Len1, Len4).
copy (Line1, Line_out, Color_out, Clean):-
member (Line1, Input_lines),
member (Line2, Input_lines),
member (Line3, Input_lines),
member (Line4, Input_lines),
line_attrs (Line1, X11, Y11, X12, Y12, Color1, Len1,
Orientation1, Direction1),
line_attrs (Line2, X21, Y21, X22, Y22, Color2, Len2,
Orientation2, Direction2),
line_attrs (Line3, X31, Y31, X32, Y32, Color3, Len3,
Orientation3, Direction3),
line_attrs (Line4, X41, Y41, X42, Y42, Color4, Len4,
Orientation4, Direction4),
equal (Color_out, ’red’),
equal (Clean,100),
lowerthan (Len1, Len2),
greaterthan (Len1, Len3),
greaterthan (Len1, Len4).
copy (Line1, Line_out, Color_out, Clean):-
member (Line1, Input_lines),
member (Line2, Input_lines),
member (Line3, Input_lines),
member (Line4, Input_lines),
line_attrs (Line1, X11, Y11, X12, Y12, Color1, Len1,
Orientation1, Direction1),
line_attrs (Line2, X21, Y21, X22, Y22, Color2, Len2,
Orientation2, Direction2),
line_attrs (Line3, X31, Y31, X32, Y32, Color3, Len3,
Orientation3, Direction3),
line_attrs (Line4, X41, Y41, X42, Y42, Color4, Len4,
Orientation4, Direction4),
equal (Color_out, ’green’),
equal (Clean,100),
lowerthan (Len1, Len2),
lowerthan (Len1, Len3),
greaterthan (Len1, Len4).
copy (Line1, Line_out, Color_out, Clean):-
member (Line1, Input_lines),
member (Line2, Input_lines),
member (Line3, Input_lines),
member (Line4, Input_lines),
line_attrs (Line1, X11, Y11, X12, Y12, Color1, Len1,
Orientation1, Direction1),
line_attrs (Line2, X21, Y21, X22, Y22, Color2, Len2,
Orientation2, Direction2),
line_attrs (Line3, X31, Y31, X32, Y32, Color3, Len3,
Orientation3, Direction3),
line_attrs (Line4, X41, Y41, X42, Y42, Color4, Len4,
Orientation4, Direction4),
equal (Color_out, ’yellow’),
equal (Clean,100),
lowerthan (Len1, Len2),
lowerthan (Len1, Len3),
lowerthan (Len1, Len4).
<details>
<summary>extracted/2405.06399v1/a48eeaf7.png Details</summary>
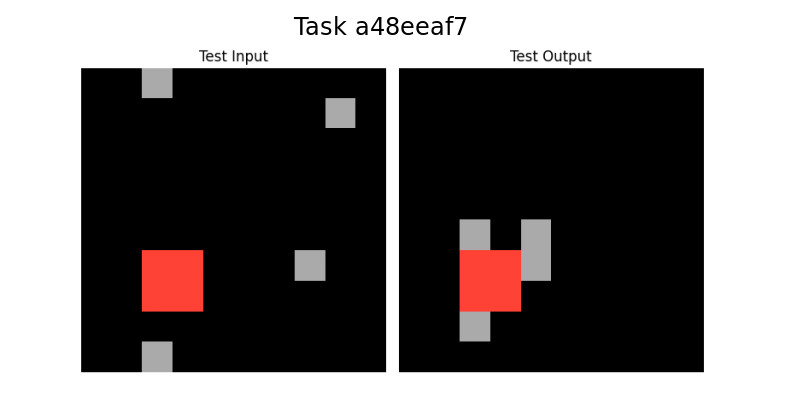
### Visual Description
## Image: Test Input/Output Grid
### Overview
The image shows two grids side-by-side, labeled "Test Input" and "Test Output". Each grid is primarily black, with a few gray squares and one red square. The "Test Input" grid has the red square in the lower-left quadrant, while the "Test Output" grid has the red square in a similar position but surrounded by gray squares. The image is titled "Task a48eeaf7".
### Components/Axes
* **Title:** Task a48eeaf7 (centered at the top)
* **Left Grid:** Labeled "Test Input" (top-left of the grid)
* **Right Grid:** Labeled "Test Output" (top-right of the grid)
* **Grid Colors:** Black (background), Gray, Red
### Detailed Analysis or ### Content Details
**Test Input Grid:**
* Background: Black
* Red Square: Located in the lower-left quadrant. It's a single square.
* Gray Squares: There are four gray squares.
* One in the top-left quadrant.
* One in the top-right quadrant.
* One in the lower-left quadrant, below the red square.
* One in the lower-right quadrant.
**Test Output Grid:**
* Background: Black
* Red Square: Located in the lower-left quadrant, in the same relative position as in the "Test Input" grid.
* Gray Squares: There are three gray squares surrounding the red square.
* One above the red square.
* One to the left of the red square.
* One to the right of the red square.
### Key Observations
* The red square's position is consistent between the "Test Input" and "Test Output" grids.
* The "Test Output" grid shows the red square surrounded by gray squares, while the "Test Input" grid has scattered gray squares.
* The task appears to involve transforming the "Test Input" grid into the "Test Output" grid, specifically by adding gray squares around the red square.
### Interpretation
The image likely represents a visual reasoning task where the goal is to infer a rule or pattern that transforms the "Test Input" into the "Test Output". In this case, the rule seems to be to surround the red square with gray squares. This suggests a spatial reasoning or pattern recognition problem. The task ID "a48eeaf7" likely refers to a specific instance of this type of problem.
</details>
⬇
translate (Point1, Point2, X_dir, Y_dir):-
member (Point1, Input_points),
member (Rectangle1, Input_rectangles),
point_straight_path_to (Point1, Rectangle1, X_dir,
Y_dir, Orientation, Direction).
copy (Rectangle1, Rectangle2, Color_out, Clean_out):-
member (Rectangle1, Input_rectangles),
rectangle_attrs (Rectangle1, X1, Y1, X2, Y2, X3, Y3, X4,
Y4, Color, Clean, Area),
equal (Color_out, Color),
equal (Clean_out,100).
<details>
<summary>extracted/2405.06399v1/7e0986d6.png Details</summary>
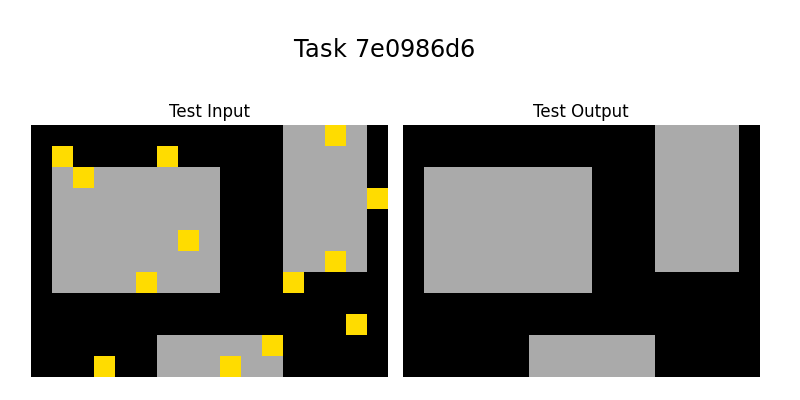
### Visual Description
## Image Analysis: Task 7e0986d6
### Overview
The image presents a visual task, labeled "Task 7e0986d6". It consists of two panels: "Test Input" and "Test Output". Both panels display a black background with gray rectangular shapes. The "Test Input" panel also contains several small yellow squares scattered across the scene, some of which are located on the gray rectangles. The "Test Output" panel shows the expected output, with only the gray rectangles present and no yellow squares.
### Components/Axes
* **Title:** Task 7e0986d6
* **Left Panel Label:** Test Input
* **Right Panel Label:** Test Output
* **Elements:**
* Black background
* Gray rectangles of varying sizes and positions
* Yellow squares (present only in the "Test Input" panel)
### Detailed Analysis
**Test Input Panel:**
* Contains approximately 12 yellow squares.
* The yellow squares are scattered randomly, some on the black background and some on the gray rectangles.
* There are three gray rectangles of different sizes and positions.
**Test Output Panel:**
* Contains only the gray rectangles, matching the positions and sizes of those in the "Test Input" panel.
* The yellow squares are absent.
* The gray rectangles are identical in shape and position to those in the "Test Input" panel.
### Key Observations
* The task appears to involve removing the yellow squares from the input image to produce the output image.
* The gray rectangles remain unchanged between the input and output.
* The number of yellow squares in the input is approximately 12.
### Interpretation
The image likely represents a visual reasoning task where the objective is to identify and remove specific elements (yellow squares) from an input scene while preserving other elements (gray rectangles). This suggests a task related to object recognition, filtering, or noise removal. The task could be used to evaluate the performance of a computer vision algorithm or a human participant in identifying and isolating specific objects within an image.
</details>
⬇
copy (Rectangle1, Rectangle2, Color_out, Clean):-
member (Rectangle1, Input_rectangles),
rectangle_attrs (Rectangle1, X1, Y1, X2, Y2, X3, Y3, X4,
Y4, Color, Clean, Area),
equal (Color_out, Color),
equal (Clean,100).
<details>
<summary>extracted/2405.06399v1/0a938d79.png Details</summary>

### Visual Description
## Image Analysis: Test Input/Output Visualization
### Overview
The image presents a visualization of a "Test Input" and "Test Output" for a task identified as "Task 0a938d79". The visualization consists of two rectangular areas, each filled with a black background. The "Test Input" area contains a small green square in the top-left corner and a small yellow square in the bottom-center. The "Test Output" area contains alternating vertical bars of green and yellow.
### Components/Axes
* **Title:** Task 0a938d79
* **Left Rectangle:** Labeled "Test Input". Contains a green square in the top-left and a yellow square near the bottom-center.
* **Right Rectangle:** Labeled "Test Output". Contains alternating vertical bars of green and yellow.
### Detailed Analysis or ### Content Details
**Test Input:**
* Background color: Black
* Green Square: Located in the top-left corner. Approximate size: 5% of the rectangle's height and width.
* Yellow Square: Located near the bottom-center. Approximate size: 5% of the rectangle's height and width.
**Test Output:**
* Background color: Black
* Vertical Bars: Alternating green and yellow bars.
* The sequence of the bars is: Green, Yellow, Green, Yellow, Green, Yellow, Green.
* There are 4 green bars and 3 yellow bars.
* The bars are approximately equal in width.
* The width of each bar is approximately 1/7 of the total width of the "Test Output" rectangle.
### Key Observations
* The "Test Input" has two distinct colored squares in specific locations.
* The "Test Output" consists of a regular pattern of alternating green and yellow vertical bars.
### Interpretation
The image likely represents a test case for a system or algorithm. The "Test Input" shows the initial state, and the "Test Output" shows the expected result after processing the input. The task "0a938d79" seems to involve transforming the two colored squares into a specific pattern of vertical bars. The system under test successfully converted the input into the output.
</details>
⬇
line_from_point (Point, Line, Len, Orientation, Direction):-
member (Point, Input_points),
equal (Len, X_dim),
equal (Orientation, ’vertical’).
translate (Line1, Line2, X_dir, Y_dir):-
member (Line1, Input_lines),
equal (X_dir,0),
translate (Input_point1, Input_point2, X_dir, Y_dir),
equal (Y_dir,2* Y_dir).
translate (Line1, Line2, X_dir, Y_dir):-
member (Line1, Input_lines),
equal (X_dir,0),
translate (Input_point1, Input_point2, X_dir, Y_dir),
equal (Y_dir,2* Y_dir).
translate (Line1, Line2, X_dir, Y_dir):-
member (Line1, Input_lines),
equal (X_dir,0),
translate (Input_point1, Input_point2, X_dir, Y_dir),
equal (Y_dir,2* Y_dir).
translate (Line1, Line2, X_dir, Y_dir):-
member (Line1, Input_lines),
equal (X_dir,0),
translate (Input_point1, Input_point2, X_dir, Y_dir),
equal (Y_dir,2* Y_dir).
<details>
<summary>extracted/2405.06399v1/150deff5.png Details</summary>
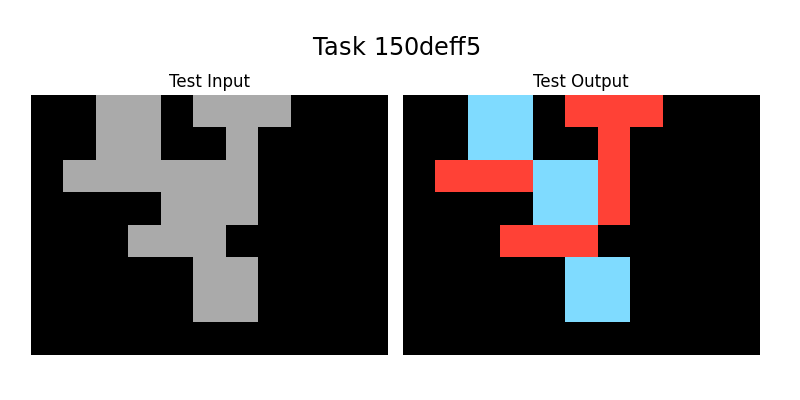
### Visual Description
## Image Analysis: Task 150deff5
### Overview
The image presents a visual puzzle or task labeled "Task 150deff5". It consists of two separate images: "Test Input" on the left, showing a pattern of gray blocks on a black background, and "Test Output" on the right, showing a corresponding pattern of red and light blue blocks on a black background. The task likely involves identifying the transformation or rule that converts the input pattern into the output pattern.
### Components/Axes
* **Title:** "Task 150deff5" (centered at the top)
* **Left Image:**
* Label: "Test Input" (top-left)
* Content: A pattern of gray blocks on a black background.
* **Right Image:**
* Label: "Test Output" (top-right)
* Content: A pattern of red and light blue blocks on a black background.
### Detailed Analysis or ### Content Details
**Test Input (Left Image):**
* The image is a 2D grid, with gray blocks forming a specific shape.
* The gray blocks are arranged in a connected manner, with some blocks adjacent horizontally and vertically.
* The pattern can be described as follows (from top to bottom):
* Two blocks wide, one block high.
* One block wide, one block high, offset to the right.
* Two blocks wide, one block high, offset to the left.
* One block wide, one block high, offset to the right.
* Two blocks wide, one block high, aligned with the first row.
* One block wide, one block high, offset to the left.
**Test Output (Right Image):**
* The image is a 2D grid, with red and light blue blocks forming a specific shape.
* The red and light blue blocks are arranged in a connected manner, with some blocks adjacent horizontally and vertically.
* The pattern can be described as follows (from top to bottom):
* One red block wide, one block high, with a red block extending to the right.
* One light blue block wide, one block high, offset to the left.
* One red block wide, one block high, offset to the right.
* One light blue block wide, one block high, aligned with the second row.
### Key Observations
* The "Test Input" uses gray blocks, while the "Test Output" uses red and light blue blocks.
* The patterns in the "Test Input" and "Test Output" appear related, suggesting a transformation rule.
* The arrangement of blocks in both images is relatively simple, suggesting a straightforward transformation.
### Interpretation
The image presents a visual reasoning task. The goal is to determine the rule or algorithm that transforms the "Test Input" pattern into the "Test Output" pattern. This could involve identifying patterns, spatial relationships, or logical operations. The solution would likely involve understanding how the gray blocks in the input are mapped to the red and light blue blocks in the output. Without further examples or instructions, the exact transformation rule is not immediately obvious, but the task is clearly designed to assess pattern recognition and problem-solving skills.
</details>
⬇
copy (Rectangle1, Rectangle2, Color_out, Clear):-
member (Rectangle1, Input_rectangles),
rectangle_attrs (X1, Y1, X2, Y2, X3, Y3, X4, Y4, Color,
Rectangle1, Clear, Area),
equiv (Area,4),
equal (Color_out, ’blue’),
equal (Clear,100).
copy (Line1, Line2, Color_out, Clear):-
member (Line1, Input_lines),
line_attrs (Line1, X1, Y1, X2, Y2, Color, Len,
Orientation, Direction),
equiv (Len,3),
equal (Color_out, ’red’),
equal (Clear,100).