# Self-Reflection in LLM Agents: Effects on Problem-Solving Performance
**Authors**:
- Matthew Renze (Johns Hopkins University)
- &Erhan Guven (Johns Hopkins University)
Abstract
In this study, we investigated the effects of self-reflection in large language models (LLMs) on problem-solving performance. We instructed nine popular LLMs to answer a series of multiple-choice questions to provide a performance baseline. For each incorrectly answered question, we instructed eight types of self-reflecting LLM agents to reflect on their mistakes and provide themselves with guidance to improve problem-solving. Then, using this guidance, each self-reflecting agent attempted to re-answer the same questions. Our results indicate that LLM agents are able to significantly improve their problem-solving performance through self-reflection ( $p<0.001$ ). In addition, we compared the various types of self-reflection to determine their individual contribution to performance. All code and data are available on GitHub at https://github.com/matthewrenze/self-reflection
1 Introduction
1.1 Background
Self-reflection is a process in which a person thinks about their thoughts, feelings, and behaviors. In the context of problem-solving, self-reflection allows us to inspect the thought process leading to our solution. This type of self-reflection aims to avoid making similar errors when confronted with similar problems in the future.
Like humans, large language model (LLM) agents can be instructed to produce a chain of thought (CoT) before answering a question. CoT prompting has been shown to significantly improve LLM performance on a variety of problem-solving tasks [1, 2, 3]. However, LLMs still often make errors in their CoT due to logic errors, mathematical errors, hallucination, etc. [4, 5, 6, 7, 8, 9].
Also similar to humans, LLM agents can be instructed to reflect on their own CoT. This allows them to identify errors, explain the cause of these errors, and generate advice to avoid making similar types of errors in the future [10, 11, 12, 13, 14, 15].
Our research investigates the use of self-reflection in LLM agents to improve their problem-solving capabilities.
1.2 Prior Literature
Over the past few years, we’ve seen the emergence of AI agents based on LLM architectures [16, 17]. These agents have demonstrated impressive capabilities in solving multi-step problems [18, 19, 10]. In addition, they’ve been observed successfully using tools, including web browsers, search engines, code interpreters, etc. [20, 19, 10, 21].
However, these LLM agents have several limitations. They have limited knowledge, make errors in reasoning, hallucinate output, and get stuck in unproductive loops [4, 5, 6, 7, 8, 9].
To improve their performance, we can provide them with a series of cognitive capabilities. For example, we can provide them with a CoT [1, 2, 3], access to external memory [22, 23, 24, 25], and the ability to learn from feedback [18, 10, 19].
Learning from feedback can be decomposed into several components. These components include the source of the feedback, the type of feedback, and the strategy used to learn from feedback [11]. There are two sources of feedback (i.e., internal or external feedback) and two main types of feedback (i.e., scalar values or natural language) [11, 12].
There are also several strategies for learning from feedback. These strategies depend on where they occur in the LLM’s output-generation process. They can occur at model-training time, output-generation time, or after the output has been generated. Within each of these three phases, there are various techniques available (e.g., model fine-tuning, output re-ranking, and self-correction) [11].
In terms of learning from self-correction, various methods are currently being investigated. These include iterative refinement, multi-model debate, and self-reflection [11].
Self-reflection in LLM agents is a metacognitive strategy also known as introspection [13, 14]. Some research studies have indicated that LLMs using self-reflection are able to identify and correct their mistakes [12, 10, 8, 15]. Others have indicated that LLMs cannot identify errors in their reasoning; regardless, they still may be able to correct them with external feedback [7, 26].
1.3 Contribution
Our research builds upon the prior literature by determining which aspects of self-reflection are most beneficial in improving an LLM agent’s performance on problem-solving tasks. It decomposes the process of self-reflection into several components and identifies how each component contributes to the agent’s overall increase in performance.
In addition, it provides insight into which types of LLMs and problem domains benefit most from each type of self-reflection. These include LLMs such as GPT-4, Llama 2 70B, and Gemini 1.5 Pro. It also includes various problem domains such as math, science, medicine, etc.
This information is useful to AI engineers attempting to build LLM agents with self-reflection capabilities. In addition, it is valuable to AI researchers studying metacognition in LLM agents.
2 Methods
2.1 Data
Our test dataset consists of a set of multiple-choice question-and-answer (MCQA) problems derived from popular LLM benchmarks. These benchmarks include ARC, AGIEval, HellaSwag, MedMCQA, etc. [27, 28, 29, 30, 31, 32].
We preprocessed and converted these datasets into a standardized format. Then, we randomly selected 100 questions from each of the ten datasets to create a multi-domain exam consisting of 1,000 problems.
For a complete list of the source problem sets used to create the MCQA exam, see Table 1. For a sample of an MCQA problem, see Figure 5 in the appendix.
Table 1: Problem sets used to create the 1,000-question multi-domain MCQA exam.
| ARC Challenge Test | ARC | Science | 1,173 | CC BY-SA | [27] |
| --- | --- | --- | --- | --- | --- |
| AQUA-RAT | AGI Eval | Math | 254 | Apache v2.0 | [30] |
| Hellaswag Val | Hellaswag | Common Sense Reasoning | 10,042 | MIT | [28] |
| LogiQA (English) | AGI Eval | Logic | 651 | GitHub | [30, 31] |
| LSAT-AR | AGI Eval | Law (Analytic Reasoning) | 230 | MIT | [30, 32] |
| LSAT-LR | AGI Eval | Law (Logical Reasoning) | 510 | MIT | [30, 32] |
| LSAT-RC | AGI Eval | Law (Reading Comprehension) | 260 | MIT | [30, 32] |
| MedMCQA Valid | MedMCQA | Medicine | 6,150 | MIT | [29] |
| SAT-English | AGI Eval | English | 206 | MIT | [30] |
| SAT-Math | AGI Eval | Math | 220 | MIT | [30] |
Note: The GitHub repository for LogiQA does not include a license file. However, both the paper and readme.md file states that "The dataset is freely available."
2.2 Models
We evaluated our agents using nine popular LLMs, including GPT-4, Llama 2 70B, Gemini 1.5 Pro, etc. [33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47]. All models were accessed via cloud-based APIs hosted by Microsoft, Anthropic, and Google.
Each of these LLMs has its own unique strengths and weaknesses. For example, LLMs like GPT-4, Gemini 1.5 Pro, and Claude Opus are powerful LLMs with a large number of parameters [44, 40, 34]. However, they have a significantly higher cost per token than smaller models like GPT-3.5 and Llama 2 7B [42, 46].
For a complete list of LLMs used in our experiment, see Table 2.
Table 2: LLMs used in the experiment.
| Claude 3 Opus | Anthropic | 2024-03-04 | Closed | [33, 34] |
| --- | --- | --- | --- | --- |
| Command R+ | Cohere | 2024-04-04 | Open | [35, 36] |
| Gemini 1.0 Pro | Google | 2023-12-06 | Closed | [37, 38] |
| Gemini 1.5 Pro (Preview) | Google | 2024-02-15 | Closed | [39, 40] |
| GPT-3.5 Turbo | OpenAI | 2022-11-30 | Closed | [41, 42] |
| GPT-4 | OpenAI | 2023-03-14 | Closed | [43, 44] |
| Llama 2 7B Chat | Meta | 2023-07-18 | Open | [45, 46] |
| Llama 2 70B Chat | Meta | 2023-07-18 | Open | [45, 46] |
| Mistral Large | Mistral AI | 2024-02-26 | Open | [47] |
2.3 Agents
We investigated eight types of self-reflecting LLM agents. These agents reflect upon their own CoT and then generate self-reflections to use when attempting to re-answer questions. Each of these agents uses a unique type of self-reflection to assist it. We also included a single non-reflecting (i.e., Baseline) agent as our control.
Listed below are the various types of agents and the type of self-reflection they generate and use to re-answer questions:
- Baseline - no self-reflection capabilities.
- Retry - informed that it answered incorrectly and simply tries again.
- Keywords - a list of keywords for each type of error.
- Advice - a list of general advice for improvement.
- Explanation - an explanation of why it made an error.
- Instructions - an ordered list of instructions for how to solve the problem.
- Solution - a step-by-step solution to the problem.
- Composite - all six types of self-reflections.
- Unredacted - all six types without the answers redacted
The Baseline agent is our control for the experiment and a lower bound for the scores. It informs us how well the base model answers the question without using any self-reflection. The Baseline agent used standard prompt-engineering techniques, including domain expertise, CoT, conciseness, and few-shot prompting [48, 49, 1, 2, 3]. The sampling temperature was set to 0.0 for all LLMs to improve reproducibility [50]. See Figure 6 in the appendix for an example of the Baseline answer prompt.
The self-reflecting agents used the same prompt-engineering techniques as the Baseline agent to re-answer questions. However, they also reflected upon their mistakes before attempting to re-answer. While re-answering, the self-reflection was injected into the re-answer prompt to allow the agent to learn from its mistakes. See Figures 7 and 8 in the appendix for examples of the self-reflection prompt and the re-answer prompt.
We redacted all of the answer labels (e.g., "A", "B", "C") and answer descriptions (e.g., "Baltimore", "Des Moines", "Las Vegas") from the agents’ self-reflections. However, the Unredacted agent retains this information. This agent is only used to provide an upper bound for the scores. Essentially, the Unredacted agent tells us how accurately the LLM could answer the questions when given the correct answer in its self-reflection.
2.4 Process
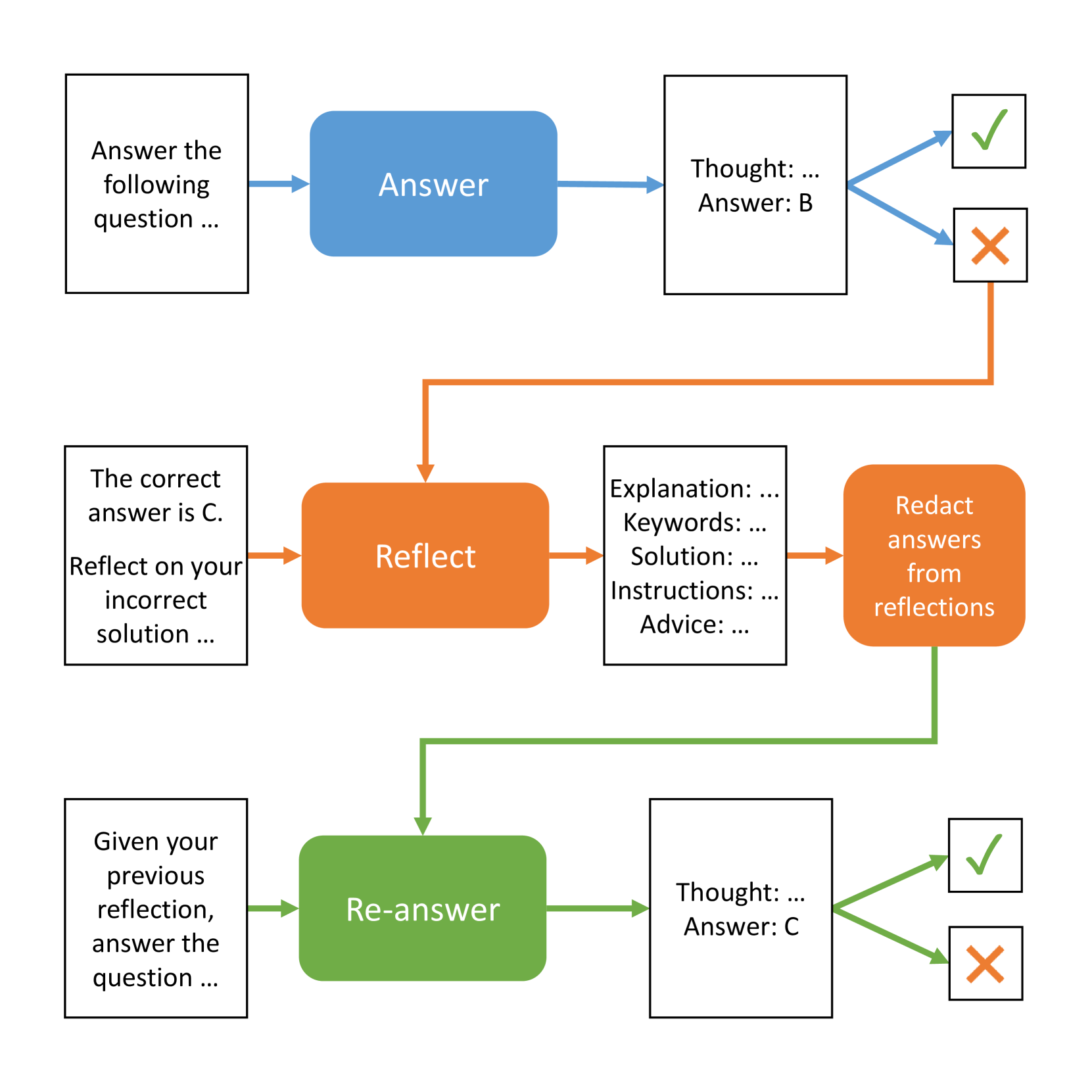
First, the Baseline agent answered all 1,000 questions. If a question was answered correctly, it was added to the Baseline agent’s score. If it was answered incorrectly, it was added to a queue of incorrectly answered questions to be reflected upon (see Figure 1).
Next, for each incorrectly answered question, the self-reflecting agents reflected upon the problem, their incorrect solution, and the correct answer. Using the correct answer as an external feedback signal, they each generated one of the eight types of self-reflection feedback described above.
Then, a find-and-replace operation was performed on the text of each self-reflection to redact the answer labels and answer descriptions. For example, we replaced answer labels (e.g., "A", "B", "C") and answer descriptions (e.g., "Baltimore", "Des Moines", "Las Vegas") with the text "[REDACTED]". The process we used to redact answer labels and descriptions was greedy. It often redacted additional text that did not leak the answer. However, we felt it necessary to err on the side of caution by eliminating any possible answer leakage. This was done to all of the self-reflecting agents, except for the Unredacted agent, to prevent answer leakage in the self-reflections. It is important to note that the self-reflections generated by the Explanation, Instructions, and Solution agents indirectly leak information about the correct answer without directly specifying the correct or incorrect answers. However, they generated this information on their own based on nothing more than being provided the correct answer during the self-reflection process.
Finally, for each incorrectly answered question, the self-reflecting agents used their specific self-reflection text to assist them in re-answering the question. We calculated the scores for all agents and compared them to the Baseline agent for analysis.
While LLM agents typically operate over a series of iterative steps, the code for this experiment was implemented as batch operations to save time and cost. So, each step in the self-reflection process occurred in one of four batch phases described above. Conceptually, the experiment represented virtual multi-step agents. However, the technical implementation of the experiment was actually a series of batch operations (see Algorithm 1).
<details>
<summary>x1.png Details</summary>
### Visual Description
\n
## Diagram: Reflective Reasoning Process
### Overview
The image depicts a flowchart illustrating a reflective reasoning process, likely used in the training or evaluation of a language model. The process involves answering a question, receiving feedback, reflecting on the answer, and re-answering the question. The diagram highlights the flow of information and the iterative nature of the process.
### Components/Axes
The diagram consists of rectangular nodes representing steps in the process, connected by arrows indicating the flow of execution. Each node contains text describing the action or state. There are also two rectangular boxes on the right side of the diagram, representing the outcome of the answer, with a checkmark or an 'X' symbol.
### Detailed Analysis or Content Details
The diagram can be broken down into the following steps:
1. **"Answer the following question..."** (Blue Rectangle, Top-Left): This is the initial step, where a question is presented. An arrow leads to the "Answer" node.
2. **"Answer"** (Blue Rectangle, Top-Center): This node represents the model's response. An arrow leads to an evaluation step. The text within this node is "Thought: ... Answer: B".
3. **Evaluation (Right-Top):** The answer is evaluated, resulting in either a checkmark (correct) or an 'X' (incorrect). The arrow from "Answer" splits into two, one leading to the checkmark and one to the 'X'.
4. **"The correct answer is C. Reflect on your incorrect solution..."** (Orange Rectangle, Center-Left): This step is triggered when the answer is incorrect (indicated by the 'X'). It prompts reflection on the error. An arrow leads to the "Reflect" node.
5. **"Reflect"** (Orange Rectangle, Center): This node represents the reflection process. The text within this node is "Explanation: ... Keywords: ... Solution: ... Instructions: ... Advice: ...". An arrow leads to a redaction step.
6. **"Redact answers from reflections"** (Orange Rectangle, Center-Right): This step involves removing the answer from the reflection to prevent the model from simply recalling the answer.
7. **"Given your previous reflection, answer the question..."** (Green Rectangle, Bottom-Left): This step prompts the model to re-answer the question, incorporating the insights gained from the reflection. An arrow leads to the "Re-answer" node.
8. **"Re-answer"** (Green Rectangle, Bottom-Center): This node represents the model's re-answer. The text within this node is "Thought: ... Answer: C".
9. **Evaluation (Right-Bottom):** The re-answer is evaluated, resulting in either a checkmark (correct) or an 'X' (incorrect). The arrow from "Re-answer" splits into two, one leading to the checkmark and one to the 'X'.
The arrows indicate a clear flow: Initial Answer -> Evaluation -> (If Incorrect) Reflection -> Redaction -> Re-answer -> Evaluation.
### Key Observations
The diagram emphasizes the importance of reflection in improving reasoning abilities. The process is iterative, allowing the model to learn from its mistakes and refine its answers. The redaction step is crucial for preventing the model from simply memorizing the correct answer. The color coding (Blue -> Orange -> Green) visually represents the progression through the process.
### Interpretation
This diagram illustrates a sophisticated approach to training or evaluating a language model. It moves beyond simple question-answering to incorporate a reflective learning loop. The inclusion of "Thought" and "Answer" within the nodes suggests that the model is capable of generating explanations for its reasoning, which is a key aspect of explainable AI. The redaction step is a clever technique to ensure that the model is genuinely learning and not just memorizing. The diagram suggests a commitment to building models that can not only provide correct answers but also understand *why* those answers are correct. The iterative nature of the process implies that the model is expected to improve its performance over time through repeated cycles of answering, reflecting, and re-answering. The diagram is a visual representation of a learning algorithm designed to enhance reasoning capabilities.
</details>
Figure 1: Diagram of the self-reflection experiment.
Algorithm 1 Self-reflection Experiment (Batch)
1: for each model, exam, and problem do
2: Create the answer prompt
3: Answer the question
4: if the answer is incorrect then
5: Add the problem to the incorrect list
6: end if
7: end for
8: Calculate the Baseline agent scores
9:
10: for each model, exam, and problem do
11: Reflect upon the incorrect solution
12: Generate the self-reflections
13: if not the Unredacted agent then
14: Redact the answers
15: end if
16: Separate the reflections by type
17: end for
18:
19: for each model, agent, exam, and problem do
20: Create the re-answer prompt
21: Inject the agent’s reflection
22: Re-answer the question
23: end for
24: Calculate the reflected agent scores
2.5 Metrics
We used correct-answer accuracy as our primary metric to measure the performance of the agents. Accuracy is calculated by dividing the number of correctly answered questions by the total number of questions.
However, to reduce the cost of running our experiment, we did not have the self-reflecting agents re-answer all of the questions that were correctly answered by the Baseline agent. Rather, the self-reflecting agents only re-answered the incorrectly answered questions. We then added the self-reflecting agent’s correct re-answer score to the Baseline agent’s score to create a new total score for the self-reflecting agent.
The calculations for accuracy used in our experiment are listed in Equation(s) 1. In these equations, the subscript base refers to the Baseline agent’s correct-answer score, and the subscript ref is the reflection agent’s correct re-answer score.
$$
\displaystyle\text{Accuracy}_{\text{base}} \displaystyle=\frac{\text{Correct}_{\text{base}}}{\text{Total}_{\text{base}}} \displaystyle\hskip 56.9055pt\text{Accuracy}_{\text{ref}} \displaystyle=\frac{\text{Correct}_{\text{base}}+\text{Correct}_{\text{ref}}}{%
\text{Total}_{\text{base}}} \tag{1}
$$
2.6 Analysis
When comparing the scores of the self-reflecting agents to the Baseline agent, we performed the McNemar test to determine statistical significance and report p-values. This test was specifically chosen because our analysis compared two series of binary outcomes (i.e., correct or incorrect answers). These outcomes were paired question-by-question across both the Baseline agent and self-reflecting agent being compared.
The McNemar test compares the number of discordant pairs in the two sets of pair-wise outcomes. To compute the test statistic, we create a $2× 2$ contingency table of the outcomes. In cell $a$ , we state the number of cases where both agents answered incorrectly. Cell $d$ contains the cases where they both answered correctly. Cell $b$ contains incorrect-correct answer pairs and cell $c$ contains correct-incorrect answer pairs (which, in our case, will always be zero) [51].
The McNemar’s test statistic is calculated as:
$$
\chi^{2}=\frac{(b-c)^{2}}{b+c}\quad\text{where }b\text{ and }c\text{ are the %
discordant pairs in }\left[\begin{array}[]{cc}a&b\\
c&d\\
\end{array}\right]
$$
3 Results
3.1 Performance by Agent
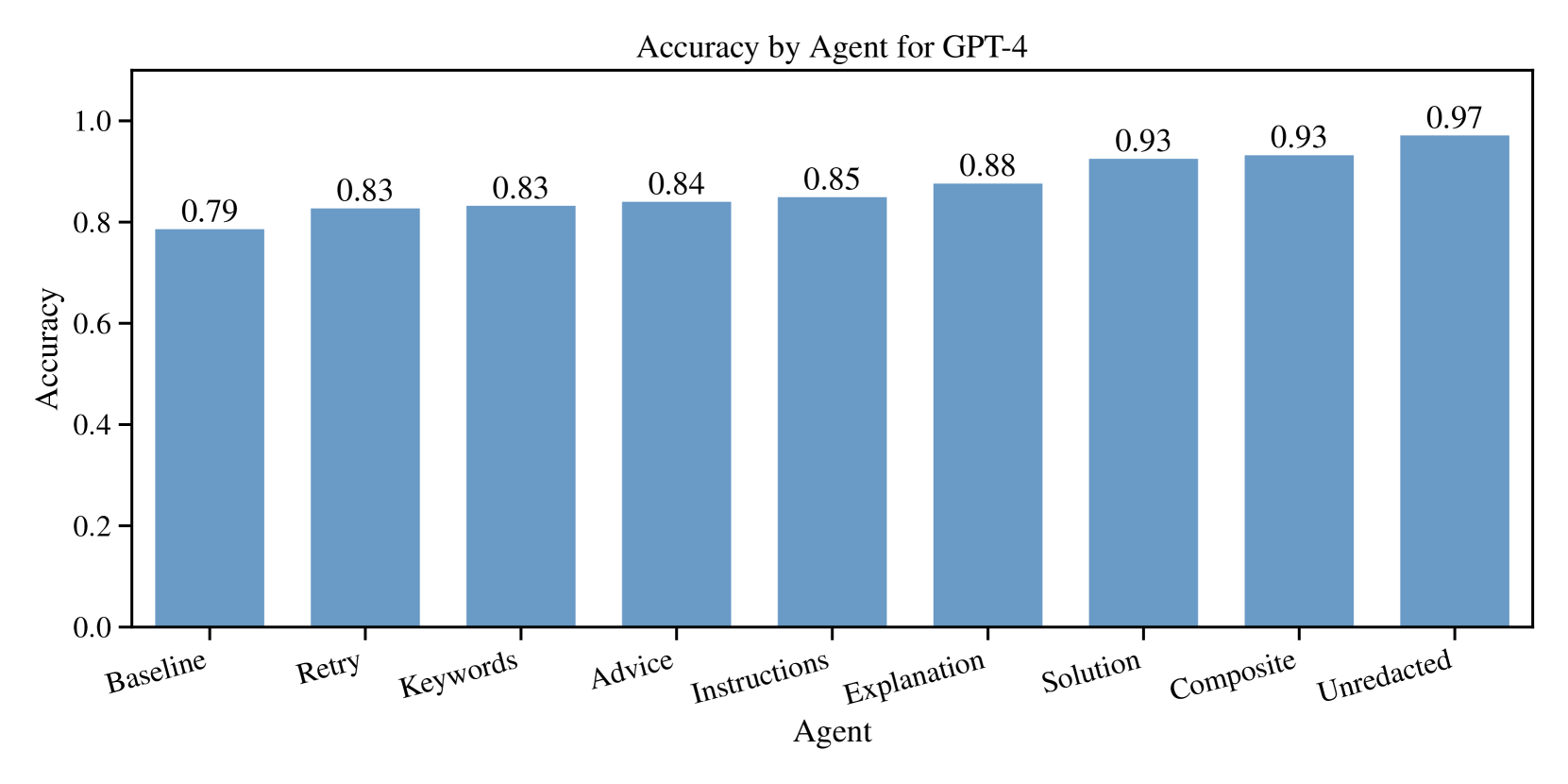
Our analysis revealed that agents using various types of self-reflection outperformed our Baseline agent. The increase in performance was statistically significant ( $p<0.001$ ) for all types of self-reflection across all LLMs. We can use GPT-4 as an example case. In Figure 2, we can see that all types of self-reflection improve the accuracy of the agent in solving MCQA problems. See Table 3 in the appendix for a numerical analysis of the results for GPT-4.
<details>
<summary>x2.png Details</summary>
### Visual Description
\n
## Bar Chart: Accuracy by Agent for GPT-4
### Overview
This image presents a bar chart illustrating the accuracy of GPT-4 across different "Agent" configurations. The chart compares the performance of GPT-4 with a baseline and several agent-assisted approaches. The y-axis represents accuracy, ranging from 0.0 to 1.0, while the x-axis lists the different agent types.
### Components/Axes
* **Title:** "Accuracy by Agent for GPT-4" - positioned at the top-center of the chart.
* **X-axis Label:** "Agent" - positioned at the bottom-center of the chart.
* **Y-axis Label:** "Accuracy" - positioned vertically along the left side of the chart.
* **X-axis Categories:** Baseline, Retry, Keywords, Advice, Instructions, Explanation, Solution, Composite, Unredacted.
* **Y-axis Scale:** Ranges from 0.0 to 1.0, with increments of 0.2.
### Detailed Analysis
The chart consists of nine vertical bars, each representing the accuracy score for a specific agent. The bars are all the same color (a shade of blue).
* **Baseline:** Accuracy = 0.79
* **Retry:** Accuracy = 0.83
* **Keywords:** Accuracy = 0.83
* **Advice:** Accuracy = 0.84
* **Instructions:** Accuracy = 0.85
* **Explanation:** Accuracy = 0.88
* **Solution:** Accuracy = 0.93
* **Composite:** Accuracy = 0.93
* **Unredacted:** Accuracy = 0.97
The bars generally increase in height from left to right, indicating a trend of increasing accuracy as more sophisticated agent configurations are used.
### Key Observations
* The "Unredacted" agent achieves the highest accuracy (0.97).
* The "Baseline" agent has the lowest accuracy (0.79).
* The "Solution" and "Composite" agents have the same accuracy (0.93).
* The accuracy increases steadily from "Baseline" to "Explanation", then shows a more significant jump to "Solution" and "Unredacted".
* The difference in accuracy between "Baseline" and "Retry" is 0.04.
* The difference in accuracy between "Unredacted" and "Solution" is 0.04.
### Interpretation
The data suggests that incorporating agent-assisted techniques significantly improves the accuracy of GPT-4. The "Unredacted" agent, presumably representing the most complete or least restricted configuration, yields the best performance. The steady increase in accuracy with each agent type indicates that each technique contributes positively to the overall result. The relatively large jump in accuracy when moving from "Explanation" to "Solution" suggests that providing a solution-focused approach is particularly effective. The fact that "Solution" and "Composite" have the same accuracy could indicate that the composite approach doesn't add significant value over simply providing a solution. This chart demonstrates the potential for enhancing large language model performance through strategic agent design and configuration. The baseline provides a reference point for evaluating the effectiveness of these agent-based improvements.
</details>
Figure 2: All self-reflection types improved the accuracy of GPT-4 agents.
3.2 Performance by Model
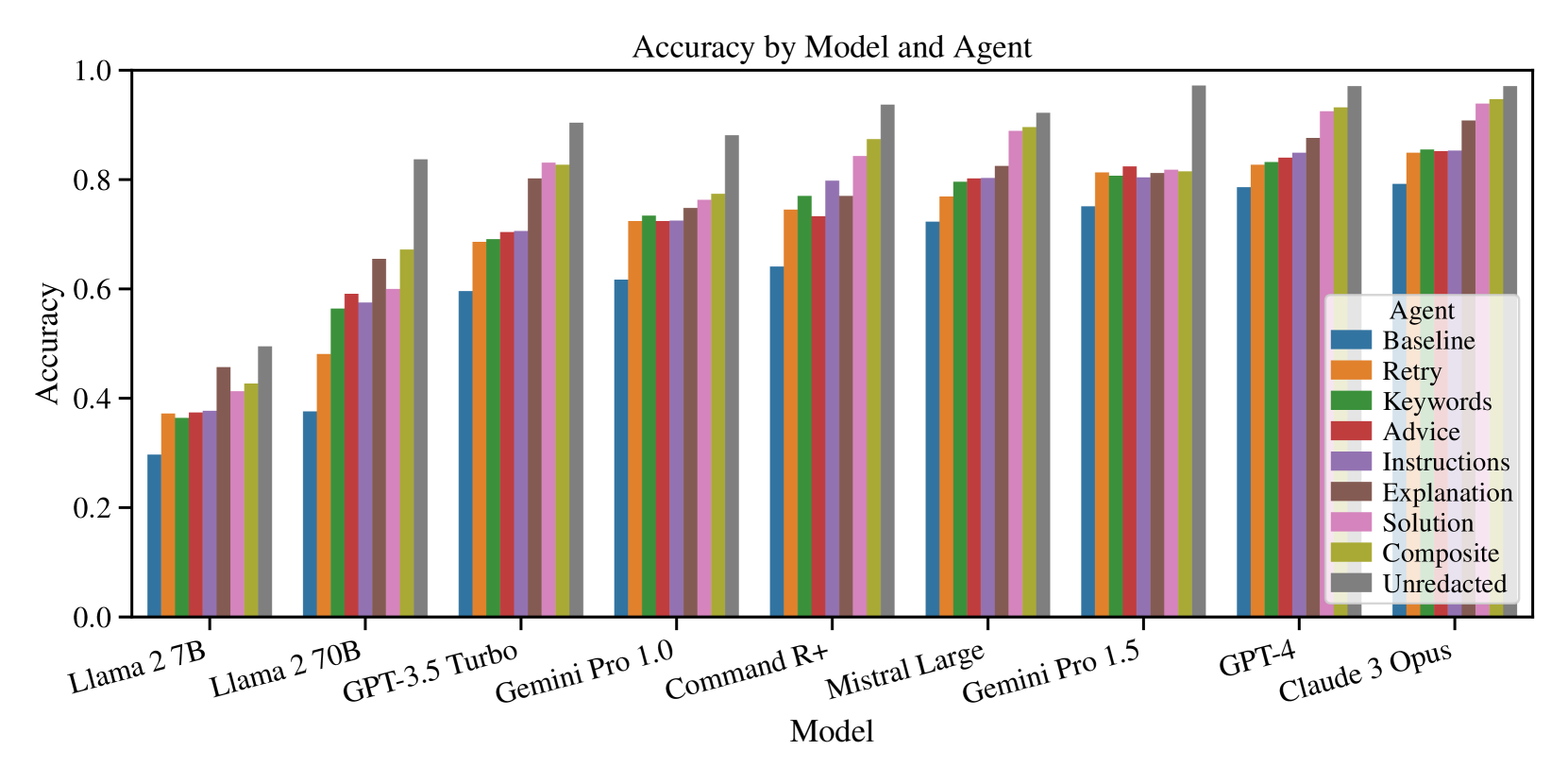
In terms of performance by model, every LLM that we tested demonstrated similar increases in accuracy across all types of self-reflection. In all cases, the improvement in performance was statistically significant ( $p<0.001$ ). See Figure 3 for a plot of accuracy by model and agent. See Table 4 for a numerical analysis of accuracy across all models.
<details>
<summary>x3.png Details</summary>
### Visual Description
## Bar Chart: Accuracy by Model and Agent
### Overview
This bar chart visualizes the accuracy achieved by different language models when paired with various agent strategies. The x-axis represents the language model, and the y-axis represents the accuracy score, ranging from 0.0 to 1.0. Each model has a group of bars, each representing a different agent strategy.
### Components/Axes
* **Title:** Accuracy by Model and Agent
* **X-axis:** Model (Labels: Llama 2 7B, Llama 2 70B, GPT-3.5 Turbo, Gemini Pro 1.0, Command R+, Mistral Large, Gemini Pro 1.5, GPT-4, Claude 3 Opus)
* **Y-axis:** Accuracy (Scale: 0.0 to 1.0)
* **Legend:**
* Agent (Blue)
* Baseline (Orange)
* Retry (Yellow)
* Keywords (Red)
* Advice (Brown)
* Instructions (Dark Gray)
* Explanation (Light Gray)
* Solution (Purple)
* Composite (Green)
* Unredacted (Teal)
### Detailed Analysis
The chart consists of grouped bar plots for each model. I will analyze each model and its corresponding agent strategies. Note that values are approximate due to the resolution of the image.
* **Llama 2 7B:**
* Agent: ~0.48
* Baseline: ~0.45
* Retry: ~0.47
* Keywords: ~0.46
* Advice: ~0.44
* Instructions: ~0.43
* Explanation: ~0.42
* Solution: ~0.41
* Composite: ~0.40
* Unredacted: ~0.39
* **Llama 2 70B:**
* Agent: ~0.58
* Baseline: ~0.55
* Retry: ~0.57
* Keywords: ~0.56
* Advice: ~0.54
* Instructions: ~0.53
* Explanation: ~0.52
* Solution: ~0.51
* Composite: ~0.50
* Unredacted: ~0.49
* **GPT-3.5 Turbo:**
* Agent: ~0.75
* Baseline: ~0.72
* Retry: ~0.74
* Keywords: ~0.73
* Advice: ~0.71
* Instructions: ~0.70
* Explanation: ~0.69
* Solution: ~0.68
* Composite: ~0.67
* Unredacted: ~0.66
* **Gemini Pro 1.0:**
* Agent: ~0.78
* Baseline: ~0.75
* Retry: ~0.77
* Keywords: ~0.76
* Advice: ~0.74
* Instructions: ~0.73
* Explanation: ~0.72
* Solution: ~0.71
* Composite: ~0.70
* Unredacted: ~0.69
* **Command R+:**
* Agent: ~0.72
* Baseline: ~0.69
* Retry: ~0.71
* Keywords: ~0.70
* Advice: ~0.68
* Instructions: ~0.67
* Explanation: ~0.66
* Solution: ~0.65
* Composite: ~0.64
* Unredacted: ~0.63
* **Mistral Large:**
* Agent: ~0.85
* Baseline: ~0.82
* Retry: ~0.84
* Keywords: ~0.83
* Advice: ~0.81
* Instructions: ~0.80
* Explanation: ~0.79
* Solution: ~0.78
* Composite: ~0.77
* Unredacted: ~0.76
* **Gemini Pro 1.5:**
* Agent: ~0.88
* Baseline: ~0.85
* Retry: ~0.87
* Keywords: ~0.86
* Advice: ~0.84
* Instructions: ~0.83
* Explanation: ~0.82
* Solution: ~0.81
* Composite: ~0.80
* Unredacted: ~0.79
* **GPT-4:**
* Agent: ~0.92
* Baseline: ~0.89
* Retry: ~0.91
* Keywords: ~0.90
* Advice: ~0.88
* Instructions: ~0.87
* Explanation: ~0.86
* Solution: ~0.85
* Composite: ~0.84
* Unredacted: ~0.83
* **Claude 3 Opus:**
* Agent: ~0.95
* Baseline: ~0.92
* Retry: ~0.94
* Keywords: ~0.93
* Advice: ~0.91
* Instructions: ~0.90
* Explanation: ~0.89
* Solution: ~0.88
* Composite: ~0.87
* Unredacted: ~0.86
### Key Observations
* Accuracy generally increases with more powerful models (moving from left to right on the x-axis).
* The "Agent" strategy consistently outperforms other strategies across all models.
* The difference in accuracy between strategies is more pronounced for stronger models.
* Llama 2 7B and Llama 2 70B have significantly lower accuracy scores compared to the other models.
* The "Unredacted" strategy consistently has the lowest accuracy across all models.
### Interpretation
The data demonstrates a clear correlation between model capability and accuracy when combined with different agent strategies. More advanced models like Claude 3 Opus and GPT-4 achieve significantly higher accuracy scores than less powerful models like Llama 2 7B. The "Agent" strategy appears to be the most effective overall, suggesting that a well-designed agent can significantly improve the performance of a language model. The consistently lower performance of the "Unredacted" strategy suggests that redacting information may be beneficial for certain tasks, potentially by reducing noise or ambiguity. The increasing gap in performance between strategies as model capability increases suggests that more powerful models are better able to leverage the benefits of sophisticated agent strategies. This data could be used to inform the selection of appropriate models and agent strategies for specific applications, optimizing for accuracy and performance. The consistent trend across all models suggests a robust relationship between these variables.
</details>
Figure 3: All LLMs we tested showed a similar pattern of improvement across self-reflection agents.
3.3 Performance by Exam
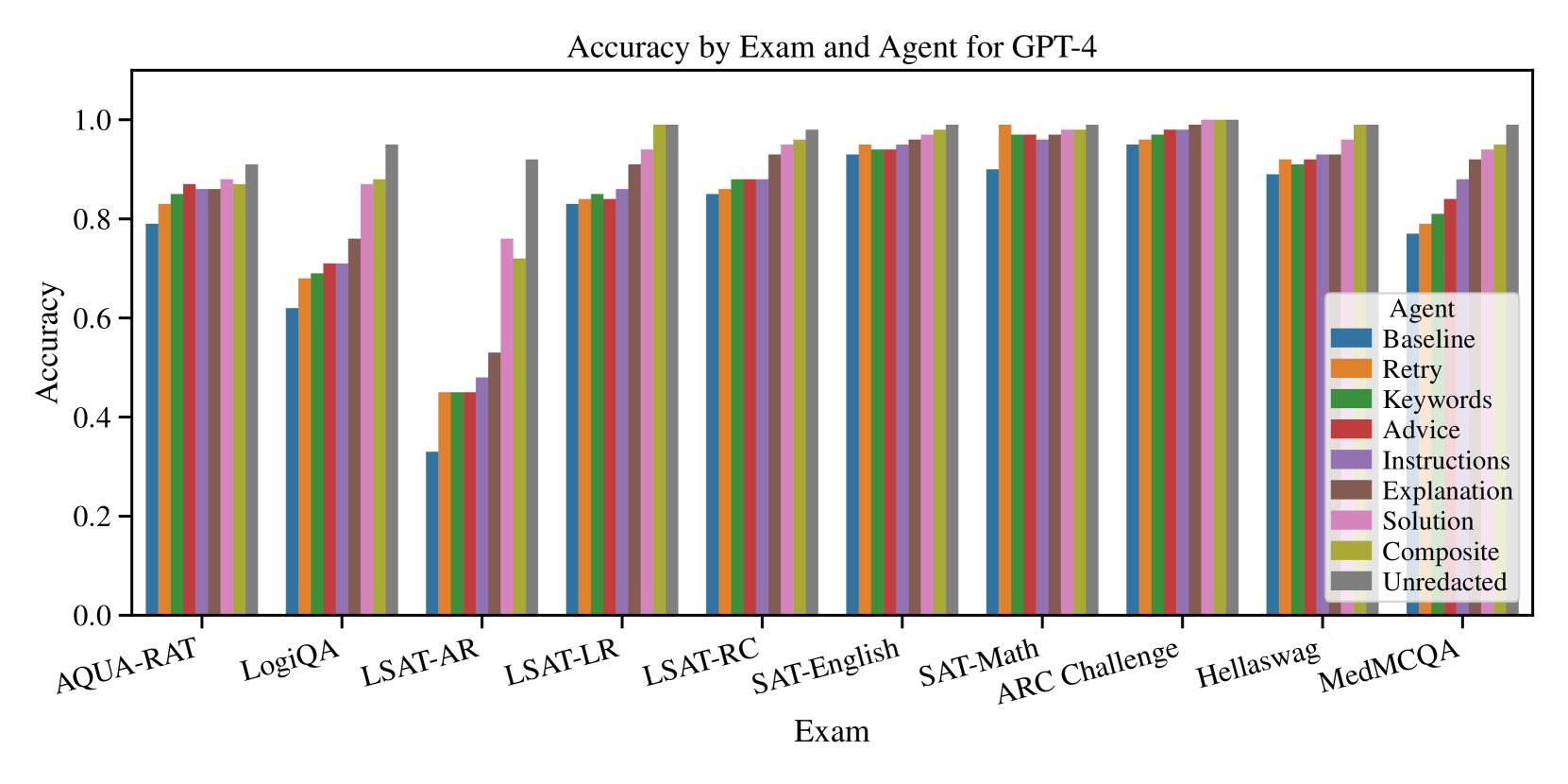
In terms of performance by exam, we saw that self-reflection significantly increased performance for some problem domains. However, other problem domains were less affected. For example, we saw the largest improvement on the LSAT-AR (Analytical Reasoning) exam. Other exams, like the SAT English exam, had much smaller effects. See Figure 4 for a plot of accuracy by exam and agent for GPT-4. See Table 5 in the appendix for a numerical analysis of the results.
<details>
<summary>x4.png Details</summary>
### Visual Description
\n
## Bar Chart: Accuracy by Exam and Agent for GPT-4
### Overview
This bar chart compares the accuracy of GPT-4 on various exams under different agent conditions. The x-axis represents the exam name, and the y-axis represents the accuracy score, ranging from 0.0 to 1.0. Multiple bars are shown for each exam, each representing a different agent configuration.
### Components/Axes
* **Title:** "Accuracy by Exam and Agent for GPT-4" (positioned at the top-center)
* **X-axis Label:** "Exam" (positioned at the bottom-center)
* **Exam Categories:** AQUA-RAT, LogiQA, LSAT-AR, LSAT-LR, LSAT-RC, SAT-English, SAT-Math, ARC Challenge, Hellaswag, MedMCQA.
* **Y-axis Label:** "Accuracy" (positioned at the left-center)
* **Y-axis Scale:** 0.0 to 1.0, with increments of 0.2.
* **Legend:** Located in the top-right corner.
* **Agent Types (and corresponding colors):**
* Baseline (Blue)
* Retry (Orange)
* Keywords (Red)
* Advice (Purple)
* Instructions (Gray)
* Explanation (Light Blue)
* Solution (Pink)
* Composite (Green)
* Unredacted (Yellow)
### Detailed Analysis
The chart consists of 10 groups of bars, one for each exam. Within each group, there are 9 bars, one for each agent type. I will analyze each exam individually, noting approximate accuracy values for each agent.
* **AQUA-RAT:** Baseline ~0.92, Retry ~0.92, Keywords ~0.88, Advice ~0.88, Instructions ~0.88, Explanation ~0.88, Solution ~0.88, Composite ~0.90, Unredacted ~0.90.
* **LogiQA:** Baseline ~0.88, Retry ~0.88, Keywords ~0.76, Advice ~0.76, Instructions ~0.76, Explanation ~0.76, Solution ~0.76, Composite ~0.84, Unredacted ~0.84.
* **LSAT-AR:** Baseline ~0.84, Retry ~0.84, Keywords ~0.72, Advice ~0.72, Instructions ~0.72, Explanation ~0.72, Solution ~0.72, Composite ~0.80, Unredacted ~0.80.
* **LSAT-LR:** Baseline ~0.92, Retry ~0.92, Keywords ~0.84, Advice ~0.84, Instructions ~0.84, Explanation ~0.84, Solution ~0.84, Composite ~0.90, Unredacted ~0.90.
* **LSAT-RC:** Baseline ~0.90, Retry ~0.90, Keywords ~0.80, Advice ~0.80, Instructions ~0.80, Explanation ~0.80, Solution ~0.80, Composite ~0.88, Unredacted ~0.88.
* **SAT-English:** Baseline ~0.96, Retry ~0.96, Keywords ~0.92, Advice ~0.92, Instructions ~0.92, Explanation ~0.92, Solution ~0.92, Composite ~0.96, Unredacted ~0.96.
* **SAT-Math:** Baseline ~0.92, Retry ~0.92, Keywords ~0.84, Advice ~0.84, Instructions ~0.84, Explanation ~0.84, Solution ~0.84, Composite ~0.90, Unredacted ~0.90.
* **ARC Challenge:** Baseline ~0.92, Retry ~0.92, Keywords ~0.84, Advice ~0.84, Instructions ~0.84, Explanation ~0.84, Solution ~0.84, Composite ~0.90, Unredacted ~0.90.
* **Hellaswag:** Baseline ~0.96, Retry ~0.96, Keywords ~0.92, Advice ~0.92, Instructions ~0.92, Explanation ~0.92, Solution ~0.92, Composite ~0.96, Unredacted ~0.96.
* **MedMCQA:** Baseline ~0.92, Retry ~0.92, Keywords ~0.84, Advice ~0.84, Instructions ~0.84, Explanation ~0.84, Solution ~0.84, Composite ~0.90, Unredacted ~0.90.
Generally, the "Baseline" and "Retry" agents achieve the highest accuracy across all exams. The "Keywords", "Advice", "Instructions", "Explanation", and "Solution" agents consistently show lower accuracy. The "Composite" and "Unredacted" agents fall in between.
### Key Observations
* The "Baseline" agent consistently performs very well, often achieving accuracy scores close to 1.0.
* The "Retry" agent performs almost identically to the "Baseline" agent.
* The agent types "Keywords", "Advice", "Instructions", "Explanation", and "Solution" consistently underperform compared to "Baseline" and "Retry".
* There is little difference in performance between the "Composite" and "Unredacted" agents.
* The exams "SAT-English" and "Hellaswag" show the highest overall accuracy scores across all agent types.
* The exam "LogiQA" shows the lowest overall accuracy scores.
### Interpretation
The data suggests that GPT-4 performs strongly on these exams, particularly with the baseline configuration. The "Retry" agent provides no significant improvement over the baseline. The addition of keywords, advice, instructions, explanations, or solutions does not consistently improve performance and often *decreases* accuracy. This could indicate that these additional agent components introduce noise or distract the model. The consistently high performance of the baseline suggests that GPT-4 already possesses a strong inherent ability to answer these questions without needing additional guidance. The variation in performance across exams suggests that the difficulty and nature of the exams influence the model's accuracy. The high accuracy on "SAT-English" and "Hellaswag" might be due to the prevalence of similar data in the model's training set. The lower accuracy on "LogiQA" could indicate that this exam requires a different type of reasoning or knowledge that the model lacks. Further investigation is needed to understand why certain agent configurations are detrimental to performance. The fact that "Composite" and "Unredacted" are similar suggests that the combination of techniques doesn't add value.
</details>
Figure 4: The increase in performance from self-reflection was larger for some exams and smaller for others.
4 Discussion
4.1 Interpretation
Based on these results, all types of self-reflection improve the performance of LLM agents. In addition, these effects were observed across every LLM we tested. Self-reflections that contain more information (e.g., Instructions, Explanation, and Solution) outperform types of self-reflection with limited information (e.g., Retry, Keywords, and Advice).
The difference in accuracy between the self-reflecting agents and the Unredacted agent demonstrates that we were effectively eliminating direct answer leakage from the self-reflections. However, the structure of feedback generated by the Instruction, Explanation, Solution, and Composite agents clearly provides indirect guidance toward the correct answer without directly giving the answer away.
Interestingly, the Retry agent significantly improved performance across all LLMs. As a result, it appears that even the mere knowledge that the agent previously made a mistake improves the agent’s performance while re-answering the question. We hypothesize that this is either the result of the agent being more diligent in its second attempt or choosing the second most likely answer based on its re-answer CoT. Further investigation will be required to answer this question.
4.2 Limitations
First, the LLM agent we created for this experiment only solved a single-step problem. The real value in LLM agents is their ability to solve complex multi-step problems by iteratively choosing actions that lead them toward their goal. As a result, this experiment does not fully demonstrate the potential of self-reflecting LLM agents.
Second, API response errors may have introduced a small amount of error into our results. API errors typically occurred when content-safety filters were triggered by the questions being asked. In most cases, this may have amounted to an error in reporting an agent’s accuracy of less than 1%. However, in the case of the Gemini 1.0 Pro and Mistral Large models, this error could be as high as 2.8%.
Third, the top-performing LLMs scored above 90% accuracy for most exams. As a result, the increase in scores for the top exams was compressed near the upper limit of 100% (i.e., a perfect score). This compression effect makes it difficult to accurately assess the performance increase. As a result, our analysis would benefit from exams with a higher level of difficulty.
Finally, for all models and agents, the LSAT-AR (Analytical Reasoning) exam was the most difficult and also the most benefited by self-reflection. This large increase in performance from a single exam had the potential to skew the aggregate results across all exams. Using a set of exams with more uniform difficulty would eliminate this skewness.
4.3 Implications
Our research builds upon prior work on LLM agents and self-reflection.
It has practical implications for AI engineers who are building agentic LLM systems. Agents that can self-reflect on their own mistakes based on error signals from the environment can learn to avoid similar mistakes in the future. This will also help prevent the common issue of agents getting stuck in unproductive loops because they continue repeating the same mistake indefinitely.
In addition, our research has theoretical implications for AI researchers studying metacognition in LLMs. If LLMs are able to self-reflect on their own CoT, other similar metacognitive processes may also be leveraged to improve their performance.
4.4 Future Research
First, we recommend repeating this experiment using a more complex set of problems. Using problems as difficult or more difficult than the LSAT-AR exam would better reflect the performance improvement from self-reflection by avoiding compression of the scores around 100% accuracy.
Second, we recommend performing an experiment using multi-step problems. This would allow the agents to receive feedback from their environment after each step to use as external signals for error correction. It would also demonstrate the potential of self-reflection on long-horizon problems.
Third, we recommend repeating this experiment while providing the agents with access to external tools. This would allow us to see how error signals from the tools benefit self-reflection. For example, we could observe how an agent adapts to compiler errors from a Python interpreter or low-rank search results from a search engine.
Fourth, we recommend repeating this experiment with agents that possess external memory. Having an agent answer the same questions based on self-reflection is only beneficial from an experimental standpoint. Real-world agents need to store self-reflections and retrieve them (using Retrieval Augmented Generation) when encountering similar but not necessarily identical problems.
Finally, we recommend a survey of self-reflection across a wider set of LLMs, agent types, and problem domains. This would help us better characterize the effects of self-reflection and provide further empirical evidence for the potential benefits of self-reflecting LLM agents.
5 Conclusion
In this study, we investigated the effects of self-reflection in LLM agents on problem-solving tasks. Our results indicate that LLMs are able to reflect upon their own CoT and produce guidance that can significantly improve problem-solving performance. These performance improvements were observed across multiple LLMs, self-reflection types, and problem domains. This research has practical implications for AI engineers building agentic AI systems as well as theoretical implications for AI researchers studying metacognition in LLMs.
6 Acknowledgements
Funding for this research was provided by Microsoft and the Renze AI Research Institute.
References
- [1] T. Kojima, S. S. Gu, M. Reid, Y. Matsuo, and Y. Iwasawa, “Large language models are zero-shot reasoners,” in Advances in Neural Information Processing Systems, vol. 35, 5 2022, pp. 22 199–22 213. [Online]. Available: https://arxiv.org/abs/2205.11916
- [2] J. Wei, X. Wang, D. Schuurmans, M. Bosma, B. Ichter, F. Xia, E. Chi, Q. Le, and D. Zhou, “Chain-of-thought prompting elicits reasoning in large language models,” arXiv, 1 2022. [Online]. Available: https://arxiv.org/abs/2201.11903
- [3] Y. Zhou, A. I. Muresanu, Z. Han, K. Paster, S. Pitis, H. Chan, and J. Ba, “Large language models are human-level prompt engineers,” The Eleventh International Conference on Learning Representations, 11 2023. [Online]. Available: https://arxiv.org/abs/2211.01910
- [4] Z. Ji, N. Lee, R. Frieske, T. Yu, D. Su, Y. Xu, E. Ishii, Y. Bang, D. Chen, H. S. Chan, W. Dai, A. Madotto, and P. Fung, “Survey of hallucination in natural language generation,” ACM Computing Surveys, vol. 55, 2 2022. [Online]. Available: http://dx.doi.org/10.1145/3571730
- [5] M. U. Hadi, qasem al tashi, R. Qureshi, A. Shah, amgad muneer, M. Irfan, A. Zafar, M. B. Shaikh, N. Akhtar, J. Wu, S. Mirjalili, Q. Al-Tashi, and A. Muneer, “A survey on large language models: Applications, challenges, limitations, and practical usage,” Authorea Preprints, 10 2023. [Online]. Available: https://doi.org/10.36227/techrxiv.23589741.v1
- [6] A. Payandeh, D. Pluth, J. Hosier, X. Xiao, and V. K. Gurbani, “How susceptible are llms to logical fallacies?” arXiv, 8 2023. [Online]. Available: https://arxiv.org/abs/2308.09853v1
- [7] J. Huang, X. Chen, S. Mishra, H. S. Zheng, A. W. Yu, X. Song, and D. Zhou, “Large language models cannot self-correct reasoning yet,” arXiv, 10 2023. [Online]. Available: https://arxiv.org/abs/2310.01798
- [8] Z. Ji, T. Yu, Y. Xu, N. Lee, E. Ishii, and P. Fung, “Towards mitigating hallucination in large language models via self-reflection,” arXiv, 10 2023. [Online]. Available: https://arxiv.org/abs/2310.06271
- [9] S. Minaee, T. Mikolov, N. Nikzad, M. Chenaghlu, R. Socher, X. Amatriain, and J. Gao, “Large language models: A survey,” arXiv, 2 2024. [Online]. Available: https://arxiv.org/abs/2402.06196
- [10] N. Shinn, F. Cassano, E. Berman, A. Gopinath, K. Narasimhan, and S. Yao, “Reflexion: Language agents with verbal reinforcement learning,” arXiv, 3 2023. [Online]. Available: https://arxiv.org/abs/2303.11366
- [11] L. Pan, M. Saxon, W. Xu, D. Nathani, X. Wang, and W. Y. Wang, “Automatically correcting large language models: Surveying the landscape of diverse self-correction strategies,” arXiv, 8 2023. [Online]. Available: https://arxiv.org/abs/2308.03188
- [12] A. Madaan, N. Tandon, P. Gupta, S. Hallinan, L. Gao, S. Wiegreffe, U. Alon, N. Dziri, S. Prabhumoye, Y. Yang, S. Gupta, B. P. Majumder, K. Hermann, S. Welleck, A. Yazdanbakhsh, and P. Clark, “Self-refine: Iterative refinement with self-feedback,” arXiv, 3 2023. [Online]. Available: https://arxiv.org/abs/2303.17651v2
- [13] J. Toy, J. MacAdam, and P. Tabor, “Metacognition is all you need? using introspection in generative agents to improve goal-directed behavior,” arXiv, 1 2024. [Online]. Available: https://arxiv.org/abs/2401.10910
- [14] Y. Wang and Y. Zhao, “Metacognitive prompting improves understanding in large language models,” arXiv, 8 2023. [Online]. Available: https://arxiv.org/abs/2308.05342
- [15] A. Asai, Z. Wu, Y. Wang, A. Sil, and H. Hajishirzi, “Self-rag: Learning to retrieve, generate, and critique through self-reflection,” arXiv, 10 2023. [Online]. Available: https://arxiv.org/abs/2310.11511v1
- [16] G. Wang, Y. Xie, Y. Jiang, A. Mandlekar, C. Xiao, Y. Zhu, A. Anandkumar, U. Austin, and U. Madison, “Voyager: An open-ended embodied agent with large language models,” arXiv, 5 2023. [Online]. Available: https://arxiv.org/abs/2305.16291v2
- [17] Z. Xi, W. Chen, X. Guo, W. He, Y. Ding, B. Hong, M. Zhang, J. Wang, S. Jin, E. Zhou, R. Zheng, X. Fan, X. Wang, L. Xiong, Y. Zhou, W. Wang, C. Jiang, Y. Zou, X. Liu, Z. Yin, S. Dou, R. Weng, W. Cheng, Q. Zhang, W. Qin, Y. Zheng, X. Qiu, X. Huang, and T. Gui, “The rise and potential of large language model based agents: A survey,” arXiv, 9 2023. [Online]. Available: https://arxiv.org/abs/2309.07864v3
- [18] S. Yao, J. Zhao, D. Yu, N. Du, I. Shafran, K. Narasimhan, and Y. Cao, “React: Synergizing reasoning and acting in language models,” arXiv, 10 2022. [Online]. Available: https://arxiv.org/abs/2210.03629
- [19] N. Miao, Y. W. Teh, and T. Rainforth, “Selfcheck: Using llms to zero-shot check their own step-by-step reasoning,” arXiv, 8 2023. [Online]. Available: https://arxiv.org/abs/2308.00436v3
- [20] R. Nakano, J. Hilton, S. Balaji, J. Wu, L. Ouyang, C. Kim, C. Hesse, S. Jain, V. Kosaraju, W. Saunders, X. Jiang, K. Cobbe, T. Eloundou, G. Krueger, K. Button, M. Knight, B. Chess, and J. S. Openai, “Webgpt: Browser-assisted question-answering with human feedback,” arXiv, 12 2021. [Online]. Available: https://arxiv.org/abs/2112.09332v3
- [21] T. Schick, J. Dwivedi-Yu, R. Dessì, R. Raileanu, M. Lomeli, L. Zettlemoyer, N. Cancedda, and T. Scialom, “Toolformer: Language models can teach themselves to use tools,” arXiv, 2 2023. [Online]. Available: https://arxiv.org/abs/2302.04761v1
- [22] P. Lewis and et al., “Retrieval-augmented generation for knowledge-intensive nlp tasks,” arXiv, 5 2020. [Online]. Available: https://arxiv.org/abs/2005.11401
- [23] Y. Gao, Y. Xiong, X. Gao, K. Jia, J. Pan, Y. Bi, Y. Dai, J. Sun, M. Wang, and H. Wang, “Retrieval-augmented generation for large language models: A survey,” arXiv, 12 2023. [Online]. Available: https://arxiv.org/abs/2312.10997v5
- [24] W. Zhong, L. Guo, Q. Gao, H. Ye, and Y. Wang, “Memorybank: Enhancing large language models with long-term memory,” Proceedings of the AAAI Conference on Artificial Intelligence, vol. 38, pp. 19 724–19 731, 5 2023. [Online]. Available: https://arxiv.org/abs/2305.10250v3
- [25] Z. Wang, A. Liu, H. Lin, J. Li, X. Ma, and Y. Liang, “Rat: Retrieval augmented thoughts elicit context-aware reasoning in long-horizon generation,” arXiv, 3 2024. [Online]. Available: https://arxiv.org/abs/2403.05313
- [26] G. Tyen, H. Mansoor, V. Cărbune, P. Chen, and T. Mak, “Llms cannot find reasoning errors, but can correct them!” arXiv, 11 2023. [Online]. Available: https://arxiv.org/abs/2311.08516v2
- [27] P. Clark, I. Cowhey, O. Etzioni, T. Khot, A. Sabharwal, C. Schoenick, and O. Tafjord, “Think you have solved question answering? try arc, the ai2 reasoning challenge,” ArXiv, 3 2018. [Online]. Available: https://arxiv.org/abs/1803.05457
- [28] R. Zellers, A. Holtzman, Y. Bisk, A. Farhadi, and Y. Choi, “Hellaswag: Can a machine really finish your sentence?” in Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, 2019. [Online]. Available: https://arxiv.org/abs/1905.07830
- [29] A. Pal, L. K. Umapathi, and M. Sankarasubbu, “Medmcqa: A large-scale multi-subject multi-choice dataset for medical domain question answering,” in Proceedings of the Conference on Health, Inference, and Learning. PMLR, 2022, pp. 248–260. [Online]. Available: https://proceedings.mlr.press/v174/pal22a.html
- [30] W. Zhong, R. Cui, Y. Guo, Y. Liang, S. Lu, Y. Wang, A. Saied, W. Chen, and N. Duan, “Agieval: A human-centric benchmark for evaluating foundation models,” ArXiv, 4 2023. [Online]. Available: https://arxiv.org/abs/2304.06364
- [31] J. Liu, L. Cui, H. Liu, D. Huang, Y. Wang, and Y. Zhang, “Logiqa: A challenge dataset for machine reading comprehension with logical reasoning,” in International Joint Conference on Artificial Intelligence, 2020. [Online]. Available: https://arxiv.org/abs/2007.08124
- [32] S. Wang, Z. Liu, W. Zhong, M. Zhou, Z. Wei, Z. Chen, and N. Duan, “From lsat: The progress and challenges of complex reasoning,” IEEE/ACM Transactions on Audio, Speech and Language Processing, vol. 30, pp. 2201–2216, 8 2021. [Online]. Available: https://doi.org/10.1109/TASLP.2022.3164218
- [33] Anthropic, “Introducing the next generation of claude anthropic,” 2024. [Online]. Available: https://www.anthropic.com/news/claude-3-family
- [34] ——, “The claude 3 model family: Opus, sonnet, haiku,” 2024. [Online]. Available: https://www.anthropic.com/claude-3-model-card
- [35] Cohere, “Command r+,” 2024. [Online]. Available: https://docs.cohere.com/docs/command-r-plus
- [36] ——, “Model card for c4ai command r+,” 2024. [Online]. Available: https://huggingface.co/CohereForAI/c4ai-command-r-plus
- [37] S. Pichai and D. Hassabis, “Introducing gemini: Google’s most capable ai model yet,” 2023. [Online]. Available: https://blog.google/technology/ai/google-gemini-ai/
- [38] Gemini-Team, “Gemini: A family of highly capable multimodal models,” arXiv, 12 2023.
- [39] S. Pichai and D. Hassabis, “Introducing gemini 1.5, google’s next-generation ai model,” 2024. [Online]. Available: https://blog.google/technology/ai/google-gemini-next-generation-model-february-2024/
- [40] Gemini-Team, “Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context,” 2024. [Online]. Available: https://arxiv.org/abs/2403.05530
- [41] OpenAI, “Introducing chatgpt,” 11 2022. [Online]. Available: https://openai.com/blog/chatgpt
- [42] ——, “Models - openai api.” [Online]. Available: https://platform.openai.com/docs/models/gpt-3-5-turbo
- [43] ——, “Gpt-4,” 3 2023. [Online]. Available: https://openai.com/research/gpt-4
- [44] ——, “Gpt-4 technical report,” arXiv, 3 2023. [Online]. Available: https://arxiv.org/abs/2303.08774
- [45] Meta, “Meta and microsoft introduce the next generation of llama | meta,” 2023. [Online]. Available: https://about.meta.com/news/2023/07/llama-2/
- [46] H. Touvron, L. Martin, K. Stone, P. Albert, A. Almahairi, Y. Babaei, N. Bashlykov, S. Batra, P. Bhargava, S. Bhosale, D. Bikel, L. Blecher, C. C. Ferrer, M. Chen, G. Cucurull, D. Esiobu, J. Fernandes, J. Fu, W. Fu, B. Fuller, C. Gao, V. Goswami, N. Goyal, A. Hartshorn, S. Hosseini, R. Hou, H. Inan, M. Kardas, V. Kerkez, M. Khabsa, I. Kloumann, A. Korenev, P. S. Koura, M.-A. Lachaux, T. Lavril, J. Lee, D. Liskovich, Y. Lu, Y. Mao, X. Martinet, T. Mihaylov, P. Mishra, I. Molybog, Y. Nie, A. Poulton, J. Reizenstein, R. Rungta, K. Saladi, A. Schelten, R. Silva, E. M. Smith, R. Subramanian, X. E. Tan, B. Tang, R. Taylor, A. Williams, J. X. Kuan, P. Xu, Z. Yan, I. Zarov, Y. Zhang, A. Fan, M. Kambadur, S. Narang, A. Rodriguez, R. Stojnic, S. Edunov, and T. Scialom, “Llama 2: Open foundation and fine-tuned chat models,” arXiv, 7 2023. [Online]. Available: https://arxiv.org/abs/2307.09288
- [47] Mistral-AI-Team, “Au large | mistral ai | frontier ai in your hands,” 2024. [Online]. Available: https://mistral.ai/news/mistral-large/
- [48] S. M. Bsharat, A. Myrzakhan, and Z. Shen, “Principled instructions are all you need for questioning llama-1/2, gpt-3.5/4,” arXiv, 12 2023. [Online]. Available: https://arxiv.org/abs/2312.16171
- [49] M. Renze and E. Guven, “The benefits of a concise chain of thought on problem-solving in large language models,” arXiv, 1 2024. [Online]. Available: https://arxiv.org/abs/2401.05618v1
- [50] ——, “The effect of sampling temperature on problem solving in large language models,” arXiv, 2 2024. [Online]. Available: https://arxiv.org/abs/2402.05201v1
- [51] Q. McNemar, “Note on the sampling error of the difference between correlated proportions or percentages,” Psychometrika, vol. 12, pp. 153–157, 6 1947. [Online]. Available: https://doi.org/10.1007/BF02295996
Appendix A Appendix
A.1 Results
Table 3: Comparison of accuracy by agent for GPT-4
| Baseline | 0.786 | N/A | N/A | N/A |
| --- | --- | --- | --- | --- |
| Retry | 0.827 | 0.041 | 39.024 | $<0.001$ |
| Keywords | 0.832 | 0.046 | 44.022 | $<0.001$ |
| Advice | 0.840 | 0.054 | 52.019 | $<0.001$ |
| Instructions | 0.849 | 0.063 | 61.016 | $<0.001$ |
| Explanation | 0.876 | 0.090 | 88.011 | $<0.001$ |
| Solution | 0.925 | 0.139 | 137.007 | $<0.001$ |
| Composite | 0.932 | 0.146 | 144.007 | $<0.001$ |
| Unredacted | 0.971 | 0.185 | 183.005 | $<0.001$ |
Table 4: Accuracy by model and agent
| Claude 3 Opus Cohere Command R+ Gemini 1.0 Pro | 0.792 0.641 0.617 | 0.849 0.745 0.724 | 0.855 0.770 0.734 | 0.852 0.733 0.724 | 0.853 0.798 0.725 | 0.908 0.770 0.748 | 0.939 0.843 0.763 | 0.947 0.874 0.774 | 0.971 0.937 0.881 |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| Gemini 1.5 Pro | 0.751 | 0.813 | 0.807 | 0.824 | 0.804 | 0.812 | 0.818 | 0.815 | 0.972 |
| GPT-3.5 Turbo | 0.596 | 0.686 | 0.691 | 0.704 | 0.706 | 0.802 | 0.831 | 0.827 | 0.904 |
| GPT-4 | 0.786 | 0.827 | 0.832 | 0.840 | 0.849 | 0.876 | 0.925 | 0.932 | 0.971 |
| Llama 2 70b | 0.376 | 0.481 | 0.564 | 0.591 | 0.575 | 0.655 | 0.600 | 0.672 | 0.837 |
| Llama 2 7b | 0.297 | 0.372 | 0.364 | 0.374 | 0.377 | 0.457 | 0.413 | 0.427 | 0.495 |
| Mistral Large | 0.723 | 0.769 | 0.796 | 0.802 | 0.803 | 0.825 | 0.889 | 0.896 | 0.922 |
Table 5: Accuracy by agent and exam for GPT-4
| Baseline Retry Keywords | 0.79 0.83 0.85 | 0.95 0.96 0.97 | 0.89 0.92 0.91 | 0.33 0.45 0.45 | 0.83 0.84 0.85 | 0.85 0.86 0.88 | 0.62 0.68 0.69 | 0.77 0.79 0.81 | 0.93 0.95 0.94 | 0.90 0.99 0.97 |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| Advice | 0.87 | 0.98 | 0.92 | 0.45 | 0.84 | 0.88 | 0.71 | 0.84 | 0.94 | 0.97 |
| Instructions | 0.86 | 0.98 | 0.93 | 0.48 | 0.86 | 0.88 | 0.71 | 0.88 | 0.95 | 0.96 |
| Explanation | 0.86 | 0.99 | 0.93 | 0.53 | 0.91 | 0.93 | 0.76 | 0.92 | 0.96 | 0.97 |
| Solution | 0.88 | 1.00 | 0.96 | 0.76 | 0.94 | 0.95 | 0.87 | 0.94 | 0.97 | 0.98 |
| Composite | 0.87 | 1.00 | 0.99 | 0.72 | 0.99 | 0.96 | 0.88 | 0.95 | 0.98 | 0.98 |
| Unredacted | 0.91 | 1.00 | 0.99 | 0.92 | 0.99 | 0.98 | 0.95 | 0.99 | 0.99 | 0.99 |
A.2 Data { "source": "arc/arc-challenge-test", "source_id": 1, "topic": "Science", "context": "", "question": "An astronomer observes that a planet rotates faster after a meteorite impact. Which is the most likely effect of this increase in rotation?", "choices": { "A": "Planetary density will decrease.", "B": "Planetary years will become longer.", "C": "Planetary days will become shorter.", "D": "Planetary gravity will become stronger." }, "answer": "C", "solution":"" }
Figure 5: Sample of an MCQA problem in JSON-L format – with whitespace added for readability. [System Prompt] You are an expert in {{topic}}. Your task is to answer the following multiple-choice questions. Think step-by-step to ensure you have the correct answer. Then, answer the question using the following format ’Action: Answer("[choice]")’ The parameter [choice] is the letter or number of the answer you want to select (e.g. "A", "B", "C", or "D") For example, ’Answer("C")’ will select the choice "C" as the best answer. You MUST select one of the available choices; the answer CANNOT be "None of the Above". Be concise in your response but include any essential information. [Example Problem] Topic: Geography Question: What is the capital of the state where Johns Hopkins University is located? Choices: A: Baltimore B: Annapolis C: Des Moines D: Las Vegas [Example Solution] Thought: Johns Hopkins University is located in Baltimore, Maryland. The capital of Maryland is Annapolis. Action: Answer("B")
Figure 6: Sample of the answer prompt used by the baseline agent to solve MCQA problems. [System Prompt] You are an expert in {{topic}}. You have incorrectly answered the following multiple-choice question. Your task is to reflect on the problem, your solution, and the correct answer. You will then use this information help you answer the same question in the future. First, explain why you answered the question incorrectly. Second, list the keywords that describe the type of your errors from most general to most specific. Third, solve the problem again, step-by-step, based on your knowledge of the correct answer. Fourth, create a list of detailed instructions to help you correctly solve this problem in the future. Finally, create a list of general advice to help you solve similar types of problems in the future. Be concise in your response; however, capture all of the essential information. For guidance, I will provide you with a single generic example problem and reflection (below). [Example Input] Topic: Geography and Math Question: What is the product of the number of letters contained in the name of the city where Iowa State University is located multiplied by the number of letters contained in the name of the state? Choices: A: 16 B: 20 C: 24 D: 32 Thought: Iowa State University is located in the city of Ames ISU is located in the state of Iowa. Action: Answer("D") --- Correct Answer: A [Example Output] Explanation: I miscalculated the product of the number of letters in the city and state names. The gap in my knowledge was not in geography but in basic arithmetic. I knew the correct city and state but made a calculation error. Error Keywords: - Calculation error - Arithmetic error - Multiplication error Solution: Iowa State University is located in the city of Ames Iowa State University is located in the state of Iowa. The city name "Ames" contains 4 letters. The state name "Iowa" contains 4 letters. The product of 4*4 is 16. Instructions: 1. Identify the city where the university is located. 2. Identify the state where the university is located. 3. Count the number of letters in the name of the city. 4. Count the number of letters in the name of the state. 5. Multiply the number of letters in the city by the number of letters in the state. 6. Work step-by-step through your mathematical calculations. 7. Double-check your calculations to ensure accuracy. 8. Choose the answer that matches your calculated result. Advice: - Always read the question carefully and understand the problem. - Always decompose complex problems into multiple simple steps. - Always think through each subproblem step-by-step. - Never skip any steps; be explicit in each step of your reasoning. - Always double-check your calculations and final answer. - Remember that the product of two numbers is the result of multiplying them together, not adding them.
Figure 7: Sample of the self-reflection prompt used to reflect on incorrectly answered MCQA problems. [System Prompt (same)] [Example Problem (same)] [Example Solution (same)] [Reflection Prompt] Reflection: You previously answered this question incorrectly. Then you reflected on the problem, your solution, and the correct answer. Use your self-reflection (below) to help you answer this question. Any information that you are not allowed to see will be marked [REDACTED]. {{reflection}}
Figure 8: Sample of the re-answer prompt used by the self-reflecting agents. The system prompt, example problem, and example solution are identical to the answer prompt and thus omitted for clarity.