# Chapter 0 Statistical Mechanics and Artificial Neural Networks: Principles, Models, and Applications
Abstract
The field of neuroscience and the development of artificial neural networks (ANNs) have mutually influenced each other, drawing from and contributing to many concepts initially developed in statistical mechanics. Notably, Hopfield networks and Boltzmann machines are versions of the Ising model, a model extensively studied in statistical mechanics for over a century. In the first part of this chapter, we provide an overview of the principles, models, and applications of ANNs, highlighting their connections to statistical mechanics and statistical learning theory.
Artificial neural networks can be seen as high-dimensional mathematical functions, and understanding the geometric properties of their loss landscapes (i.e., the high-dimensional space on which one wishes to find extrema or saddles) can provide valuable insights into their optimization behavior, generalization abilities, and overall performance. Visualizing these functions can help us design better optimization methods and improve their generalization abilities. Thus, the second part of this chapter focuses on quantifying geometric properties and visualizing loss functions associated with deep ANNs.
\body Contents
1. 1 Introduction
1. 1 The McCulloch–Pitts calculus and Hebbian learning
1. 2 The Perceptron
1. 3 Objective Bayes, entropy, and information theory
1. 4 Connections to the Ising model
1. 2 Hopfield network
1. 3 Boltzmann machine learning
1. 1 Boltzmann machines
1. 2 Restricted Boltzmann machines
1. 3 Derivation of the learning algorithm
1. 4 Loss landscapes of artificial neural networks
1. 1 Principal curvature in random projections
1. 2 Extracting curvature information
1. 3 Hessian directions
1. 5 Conclusions
1 Introduction
There has been a long tradition in studying learning systems within statistical mechanics. [1, 2, 3] Some versions of artificial neural networks (ANNs) were, in fact, inspired by the Ising model that has been proposed in 1920 by Wilhelm Lenz as a model for ferromagnetism and solved in one dimension by his doctoral student, Ernst Ising, in 1924. [4, 5, 6] In the language of machine learning, the Ising model can be considered as a non-learning recurrent neural network (RNN).
Contributions to ANN research extend beyond statistical mechanics, however, requiring a broad range of scientific disciplines. Historically, these efforts have been marked by eras of interdisciplinary collaboration referred to as cybernetics [7, 8], connectionism [9, 10], artificial intelligence [11, 12], and machine learning [13, 14]. To emphasize the importance of multidisciplinary contributions in ANN research, we will often highlight the research disciplines of individuals who have played pivotal roles in the advancement of ANNs.
1 The McCulloch–Pitts calculus and Hebbian learning
An influential paper by the neuroscientist Warren S. McCulloch and logician Walter Pitts published in 1943 is often regarded as inaugurating neural network research, [15] but in fact there was an active research community at that time working on the mathematics of neural activity. [16] McCulloch and Pitts’s pivotal contribution was to join propositional logic and Alan Turing’s mathematical notion of computation [17] to propose a calculus for creating compositional representations of neural behavior. Their work has later on been picked up by the mathematician Stephen C. Kleene [18], who made some of their work more accessible. Kleene comments on the work by McCulloch and Pitts in his 1956 article [18]: “The present memorandum is partly an exposition of the McCulloch–Pitts results; but we found the part of their paper which treats of arbitrary nets obscure; so we have proceeded independently here.”
Contemporaneously, the physchologist Donald O. Hebb formulated in his 1949 book “The Organization of Behavior” [19] a neurophysiological postulate, which is known today as “Hebb’s rule” or “Hebbian learning”: \MakeFramed \FrameRestore Let us assume then that the persistence or repetition of a reverberatory activity (or “trace”) tends to induce lasting cellular changes that add to its stability. … When an axon of cell $A$ is near enough to excite a cell $B$ and repeatedly or persistently takes part in firing it, some growth process or metabolic change takes place in one or both cells such that $A$ ’s efficiency, as one of the cells firing $B$ , is increased. Donald O. Hebb in “The Organization of Behavior” (1949) \endMakeFramed In the modern literature, Hebbian learning is often summarized by the slogan “neurons wire together if they fire together”. [20]
2 The Perceptron
In 1958, the psychologist Frank Rosenblatt developed the perceptron [21, 22], which is essentially a binary classifier that is based on a single artificial neuron and a Hebbian-type learning rule. The artificial neuron of this type is sometimes referred to as “McCulloch–Pitts neuron”, owing to its connection to the foundational work of McCulloch and Pitts [15]. Some authors distinguish McCulloch–Pitts neurons from perceptrons by noting that the former handle binary signals, while the latter can process real-valued inputs. In parallel to Rosenblatt’s work, the electrical engineers Bernard Widrow and Ted Hoff developed a similar ANN named ADALINE (Adaptive Linear Neuron). [23]
We show a schematic of a perceptron in Fig. 1. It receives inputs $x_{1},x_{2},...,x_{n}$ that are weighted with $w_{1},w_{2},...,w_{n}$ . Within the summer (indicated by a $\Sigma$ symbol), the artificial neuron computes $\sum_{i}w_{i}x_{i}+b$ , where $b$ is a bias term. This quantity is then used as input of a step activation function (indicated by a step symbol). The output of this function is $y$ . Such simple artificial neurons can be used to implement logical functions including AND, OR, and NOT. For example, consider a perceptron with Heaviside activation, two binary inputs $x_{1},x_{2}∈\{0,1\}$ , weights $w_{1},w_{1}=1$ and bias $b=-1.5$ . We can readily verify that $y=x_{1}\wedge x_{2}$ . An example of a logical function that cannot be represented by a perceptron is XOR. This was shown by the computer scientists Marvin L. Minsky and Seymour A. Papert in their 1969 book “Perceptrons: An Introduction to Computational Geometry” [11]. Based on their analysis of perceptrons they considered the extension of research on this topic to be “sterile”.
Problems like the one associated with representing XOR using a single perceptron can be overcome by employing multilayer perceptrons (MLPs) or, in a broader sense, multilayer feedforward networks equipped with various types of activation functions. [24, 25, 26] One effective way to train such multilayered structures is reverse mode automatic differentiation (i.e., backpropagation). [27, 28, 29, 30, 31]
Notice that perceptrons and other ANNs predominantly operate on real-valued data. Nevertheless, there is an expanding body of research focused on ANNs that are designed to handle complex-valued and, in some cases, quaternion-based information. [32, 33, 34, 35, 36, 37, 38]
$x_{1}$
$x_{2}$
$...$
$x_{n}$ $\Sigma$ $w_{1}$ $w_{2}$ $...$ $w_{n}$ $b$ $y$
Figure 1: A schematic of a perceptron with output $y$ , inputs $x_{1},x_{2},...,x_{n}$ , corresponding weights $w_{1},w_{2},...,w_{n}$ , and a bias term $b$ . Traditionally, the inputs and outputs of perceptrons were considered to be binary (e.g., $\{-1,1\}$ or $\{0,1\}$ ), while weights and biases are generally represented as real numbers. The symbol $\Sigma$ signifies the summation process wherein the artificial neuron computes $\sum_{i}w_{i}x_{i}+b$ . This computed value then becomes the input for a step activation function, denoted by a step symbol. We denote the final output as $y$ . While the original perceptron employed a step activation function, contemporary applications frequently utilize a variety of functions including sigmoid, $\tanh$ , and rectified linear unit (ReLU).
3 Objective Bayes, entropy, and information theory
Over the same period of time, seminal work in probability and statistics appeared that would later prove crucial to the development of ANNs. In the early 20th century, a renewed interest in inverse “Bayesian“ inference [39, 40] met strong resistance from the emerging frequentist school of statistics led by Jerzy Neyman, Karl Pearson, and especially Ronald Fisher, who advocated his own fiducial inference as a better alternative to Bayesian inference [41, 42]. In response to criticism that Bayesian methods were irredeemably subjective, Harold Jeffreys presented a methodology for “objectively” assigning prior probabilities based on symmetry principles and invariance properties. [43]
Edwin Jaynes, building on Jeffreys’s ideas for objective Bayesian priors and Shannon’s quantification of uncertainty [44], proposed the Maximum Entropy (MaxEnt) principle as a rationality criteria for assigning prior probabilities that are at once consistent with known information while remaining maximally uncommitted about what remains uncertain [45, 46, 47]. Jaynes envisioned the MaxEnt principle as the basis for a “logic of science” [48]. For instance, he proposed a reinterpretation of the principles of thermodynamics in information-theoretic terms where macro-states of a physical system are understood through the partial information they provide about the possible underlying microstates, showing how the original Boltzmann–Gibbs interpretation of entropy could be replaced by a more general single framework based on Shannon entropy. Objective Bayesianism does not remove subjective judgment [49], MaxEnt is far from a universal principle for encoding prior information [50], and the terms ‘objective’ and ‘subjective’ are outdated. [51, 52]
For example, the MaxEnt principle can be used to select the least biased distribution from many common exponential family distributions by imposing constraints that match the expectation values of their sufficient statistics. That is, from constraints on the expected values of some function $h(x)$ on data parameterized by $\theta$ , applying the MaxEnt principle to find the probability distribution that maximizes entropy under those constraints often takes the form of an exponential family distribution
$$
p(x\mid\theta)=h(x)\,\exp\!\left(\theta^{\top}T(x)-A(\theta)\right)\,, \tag{1}
$$
where $h(x)$ is the underlying base measure, $\theta$ is the natural parameter of the distribution, $A(\theta)$ is the log normalizer, and $T(x)$ is the sufficient statistic determined by MaxEnt under the given constraints. MaxEnt derived distributions depend on contingencies of the data and the availability of the right constraints to ensure the derivation goes through, however–contingencies that undermine viewing MaxEnt as a fundamental principle of rational inference.
Nevertheless, Jaynes’s notion of treating probability as an extension of logic [48, 48, 53] and probabilistic inference as governed by coherence conditions on information states [54, 55] has proved useful in optimization (e.g., cross-entropy loss [56]), entropy-based regularization of ANNs [57], and Bayesian neural networks. [58]
4 Connections to the Ising model
Returning to the Ising model, a modified version of it has been endowed with a learning algorithm by the mathematical neuroscientist Shun’ichi Amari in 1972 and has been employed for learning patterns and sequences of patterns. [59] Amari’s self-organizing ANN is an early model of associative memory that has later been popularized by the physicist John Hopfield. [60] Despite its limited representational capacity and use in practical applications, the study of Hopfield-type learning systems is still an active research area. [61, 36, 62, 63]
The Hopfield network shares the Hamiltonian with the Ising model. Its learning algorithm is deterministic and aims at minimizing the “energy” of the system. One problem with the deterministic learning algorithm of Hopfield networks is that it cannot escape local minima. A solution to this problem is to employ a stochastic learning rule akin to Monte-Carlo methods that are used to generate Ising configurations. [64] In 1985, David H. Ackley, Geoffrey E. Hinton, and Terrence J. Sejnowski proposed such a learning algorithm for an Ising-type ANN which they called “Boltzmann machine” (BM). [65, 66, 67, 68] In 1986, Smolensky introduced the concept of “Harmonium” [69], which later evolved into restricted Boltzmann machines (RBMs). In contrast to Boltzmann machines, RBMs benefit from more efficient training algorithms that were developed in the early 2000s. [70, 71] Since then, RBMs have been applied in various context such as to reduce dimensionality of datasets [72], study phase transitions [73, 74, 3, 75], represent wave functions [76, 77].
Our historical overview of ANNs aims at emphasizing the strong interplay between statistical mechanics and related fields in the investigation of learning systems. Given the extensive span of over eight decades since the pioneering work of McCulloch and Pitts, summarizing the history of ANNs within a few pages cannot do justice to its depth and significance. We therefore refer the reader to the excellent review by Jürgen Schmidhuber (see Ref. 78) for a more detailed overview of the history of deep learning in ANNs.
As computing power continues to increase, deep (i.e., multilayer) ANNs have, over the past decade, become pervasive across various scientific domains. [79] Different established and newly developed ANN architectures have not only been employed to tackle scientific problems but have also found extensive applications in tasks such as image classification and natural language processing. [80, 81, 82, 83]
Finally, we would also like to emphasize an area of research that has significantly advanced due to the availability of automatic differentiation [84] and the utilization of ANNs as universal function approximators. [85, 86, 87] This area resides at the intersection of non-linear dynamics [88, 89], control theory [90, 91, 92, 93, 94, 95, 96, 97, 98], and dynamics-informed learning, where researchers often aim to integrate ANNs and their associated learning algorithms with domain-specific knowledge. [99, 100, 101, 102, 103, 104] This integration introduces an inductive bias that facilitates effective learning.
The outline of this chapter is as follows. To better illustrate the connections between the Ising model and ANNs, we devote Secs. 2 and 3 to the Hopfield model and Boltzmann machines, respectively. In Sec. 4, we discuss how mathematical tools from high-dimensional probability and differential geometry can help us study the loss landscape of deep ANNs. [105] We conclude this chapter in Sec. 5.
2 Hopfield network
A Hopfield network is a complete (i.e., fully connected) undirected graph in which each node is an artificial neuron of McCulloch–Pitts type (see Fig. 1). We show an example of a Hopfield network with $n=5$ neurons in Fig. 2. We use $x_{i}∈\{-1,1\}$ to denote the state of neuron $i$ ( $i∈\{1,...,n\}$ ). Because the underlying graph is fully connected, neuron $i$ receives $n-1$ inputs $x_{j}$ ( $j≠ i$ ). The inputs $x_{j}$ associated with neuron $i$ are assigned weights $w_{ij}∈\mathbb{R}$ . In a Hopfield network, weights are assumed to be symmetric (i.e., $w_{ij}=w_{ji}$ ), and self-weights are considered to be absent (i.e., $w_{ii}=0$ ). $x_{1}$ $x_{2}$ $x_{3}$ $x_{4}$ $x_{5}$ $w_{12}$ $w_{15}$
Figure 2: An example of a Hopfield network with $n=5$ neurons. Each neuron is connected to all other neurons through black edges, representing both inputs and outputs. (Adapted from 106.)
With these definitions in place, the activation of neuron $i$ is given by
$$
a_{i}=\sum_{j}w_{ij}x_{j}+b_{i}\,, \tag{2}
$$
where $b_{i}$ is the bias term of neuron $i$ .
Regarding connections between the Ising model and Hopfield networks, the states of artificial neurons align with the binary values employed in the Ising model to model the orientations of elementary magnets, often referred to as classical “spins”. The weights in a Hopfield network represent the potentially diverse couplings between different elementary magnets. Lastly, the bias terms assume the function of external magnetic fields that act on these elementary magnets. Given these structural similarities between the Ising model and Hopfield networks, it is natural to assign them the Ising-type energy function
$$
E=-\frac{1}{2}\sum_{i,j}w_{ij}x_{i}x_{j}-\sum_{i}b_{i}x_{i}\,. \tag{3}
$$
Hopfield networks are not just a collection of interconnected artificial neurons, but they are dynamical systems whose states $x_{i}$ evolve in discrete time according to
$$
x_{i}\leftarrow\begin{cases}1\,,&\text{if }a_{i}\geq 0\\
-1\,,&\text{otherwise}\,,\end{cases} \tag{4}
$$
where $a_{i}$ is the activation of neuron $i$ [see Eq. (2)].
For asynchronous updates in which the state of one neuron is updated at a time, the update rule (4) has an interesting property: Under this update rule, the energy $E$ [see Eq. (3)] of a Hopfield network never increases.
The proof of this statement is straightforward. We are interested in the cases where an update of $x_{i}$ causes this quantity to change its sign. Otherwise the energy will stay constant. Consider the two cases (i) $a_{i}=\sum_{j}w_{ij}x_{j}+b_{i}<0$ with $x_{i}=1$ , and (ii) $a_{i}≥ 0$ with $x_{i}=-1$ . In the first case, the energy difference is
$$
\Delta E_{i}=E(x_{i}=-1)-E(x_{i}=1)=2\Bigl{(}b_{i}+\sum_{j}w_{ij}x_{j}\Bigr{)}=2a_{i}\,. \tag{5}
$$
Notice that $\Delta E_{i}<0$ because $a_{i}=\sum_{j}w_{ij}x_{j}+b_{i}<0$ .
In the second case, we have
$$
\Delta E_{i}=E(x_{i}=1)-E(x_{i}=-1)=-2\Bigl{(}b_{i}+\sum_{j}w_{ij}x_{j}\Bigr{)}=-2a_{i}\,. \tag{6}
$$
The energy difference satisfies $\Delta E_{i}≤ 0$ because $a_{i}≥ 0$ . In summary, we have shown that $\Delta E_{i}≤ 0$ for all changes of the state variable $x_{i}$ according to update rule (4).
Equations (5) and (6) also show that the energy difference associated with a change of sign in $x_{i}$ is $2a_{i}$ and $-2a_{i}$ for $a_{i}<0$ and $a_{i}≥ 0$ , respectively. Absorbing the bias term $b_{i}$ in the weights $w_{ij}$ by associating an extra active unit to every node in the network yields for the corresponding energy differences
$$
\Delta E_{i}=\pm 2\sum_{j}w_{ij}x_{j}\,. \tag{7}
$$
One potential application of Hopfield networks is to store and retrieve information in local minima by adjusting their weights. For instance, consider the task of storing $N$ binary (black and white) patterns in a Hopfield network. Let these $N$ patterns be represented by the set $\{p_{i}^{\nu}=± 1|1≤ i≤ n\}$ with $\nu∈\{1,...,N\}$ .
To learn the weights that represent our binary patterns, we can apply the Hebbian-type rule
$$
w_{ij}=w_{ji}=\frac{1}{N}\sum_{\nu=1}^{N}p_{i}^{\nu}p_{j}^{\nu}\,. \tag{8}
$$
In Hopfield networks with a large number of neurons, the capacity for storing and retrieving patterns is limited to approximately 14% of the total number of neurons. [107] However, it is possible to enhance this capacity through the use of modified versions of the learning rule (8). [108]
After applying the Hebbian learning rule to adjust the weights of a given Hopfield network, we may be interested in studying the evolution of different initial configurations $\{x_{i}\}$ according to update rule (4). A Hopfield network accurately represents a pattern $\{p_{i}^{\nu}=± 1|1≤ i≤ n\}$ if $x_{i}$ remains equal to $p_{i}^{\nu}$ both before and after an update for all $i$ (meaning $\{p_{i}^{\nu}\}$ is a fixed point of the system). Depending on the number of stored patterns and the chosen initial configuration, the Hopfield network may converge to a local minimum that does not align with the desired pattern. To mitigate this behavior, one can employ a stochastic update rule instead of the deterministic rule (4). This will be the topic that we are going to discuss in the following section.
3 Boltzmann machine learning
In Hopfield networks, if we start with an initial configuration that is close enough to a desired local energy minimum, we can recover the corresponding pattern $\{p_{i}^{\nu}\}$ . However, for certain applications, relying solely on the deterministic update rule (4) may not be enough as it never accepts transitions that are associated with an increase in energy. In constraint satisfaction tasks, we often require learning algorithms to have the capability to occasionally accept transitions to configurations of higher energy and move the system under consideration away from local minima towards a global minimum. A method that is commonly used in this context is the M(RT) 2 algorithm introduced by Nicholas Metropolis, Arianna W. Rosenbluth, Marshall N. Rosenbluth, Augusta H. Teller, and Edward Teller in their seminal 1953 paper “Equation of State Calculations by Fast Computing Machines”. [109, 110] This algorithm became the basis of many optimization methods, such as simulated annealing. [111]
In the 1980s, the M(RT) 2 algorithm has been adopted to equip Hopfield-type systems with a stochastic update rule, in which neuron $i$ is activated (set to $1$ ) regardless of its current state, with probability
$$
\sigma_{i}\equiv\sigma(\Delta E_{i}/T)=\sigma(2a_{i}/T)=\frac{1}{1+\exp(-\Delta E_{i}/T)}\,. \tag{9}
$$
Otherwise, it is set to $-1$ . The corresponding ANNs were dubbed “’Boltzmann machines”. [65, 66, 67, 68] $-10$ $-8$ $-6$ $-4$ $-2$ $0$ $2$ $4$ $6$ $8$ $10$ $0$ $0.2$ $0.4$ $0.6$ $0.8$ $1$ $\Delta E_{i}$ $\sigma_{i}$ $T=0.5$ $T=1$ $T=2$
Figure 3: The sigmoid function $\sigma_{i}\equiv\sigma(\Delta E_{i}/T)$ [see Eq. (9)] as function of $\Delta E_{i}$ for $T=0.5,1,2$ .
In Eq. (9), the quantity $\Delta E_{i}=2a_{i}$ is the energy difference between an inactive neuron $i$ and an active one [see Eq. (5)]. We use the convention employed in Refs. 67, 68. The authors of Ref. 66, use the convention that $\Delta E_{i}=-2a_{i}$ and $\sigma_{i}\equiv\sigma(\Delta E_{i}/T)=1/(1+\exp(\Delta E_{i}/T))$ . The function $\sigma(x)=1/\left(1+\exp(-x)\right)$ represents the sigmoid function, and the parameter $T$ serves as an equivalent to temperature. In the limit $T→ 0$ , we recover the deterministic update rule (4). In Fig. 3, we show $\sigma(\Delta E_{i}/T)$ as a function of $\Delta E_{i}$ for $T=0.5,1,2$ .
Examining Eqs. (3) and (9), we notice that we are simulating a system akin to the Ising model with Glauber (heat bath) dynamics. [112, 64] Because Glauber dynamics satisfy the detailed balance condition, Boltzmann machines will eventually reach thermal equilibrium. The corresponding probabilities $p_{\mathrm{eq}}(X)$ and $p_{\mathrm{eq}}(Y)$ for the ANN to be in states $X$ and $Y$ , respectively, will satisfy We set the Boltzmann constant $k_{B}$ to 1.
$$
\frac{p_{\mathrm{eq}}(Y)}{p_{\mathrm{eq}}(X)}=\exp\left(-\frac{E(Y)-E(X)}{T}\right)\,. \tag{10}
$$
In other words, the Boltzmann distribution provides the relative probability $p_{\mathrm{eq}}(Y)/p_{\mathrm{eq}}(X)$ associated with the states $X$ and $Y$ of a “thermalized” Boltzmann machine. Regardless of the initial configuration, at a given temperature $T$ , the stochastic update rule in which neurons are activated with probability $\sigma_{i}$ always leads to a thermal equilibrium configuration that is solely determined by its energy.
1 Boltzmann machines
Unlike Hopfield networks, Boltzmann machines have two types of nodes: visible units and hidden units. We denote the corresponding sets of visible and hidden units by $V$ and $H$ , respectively. Notice that the set $H$ may be empty. In Fig. 4, we show an example of a Boltzmann machine with five visible units and three hidden units.
During the training of a Boltzmann machine, the visible units are “clamped” to the environment, which means they are set to binary vectors drawn from an empirical distribution. Hidden units may be used to account for constraints involving more than two visible units. $h_{1}$ $h_{2}$ $h_{3}$ $v_{1}$ $v_{2}$ $v_{3}$ $v_{4}$ $v_{5}$
Figure 4: Boltzmann machines consist of visible units (blue) and hidden units (red). In the shown example, there are five visible units $\left\{v_{i}\right\}$ $({i∈\{1,...,5\}})$ and three hidden units $\left\{h_{j}\right\}$ $(j∈\{1,2,3\})$ . Similar to Hopfield networks, the network architecture in a Boltzmann machine is complete.
We denote the probability distribution of all configurations of visible units $\{\nu\}$ in a freely running network as $P^{\prime}\left(\{\nu\}\right)$ . Here, “freely running” means that no external inputs are fixed (or “clamped”) to the visible units. We derive the distribution $P^{\prime}\left(\{\nu\}\right)$ by summing (i.e., marginalizing) over the corresponding joint probability distribution. That is,
$$
P^{\prime}\left(\{\nu\}\right)=\sum_{\{h\}}P^{\prime}\left(\{\nu\},\{h\}\right)\,, \tag{11}
$$
where the summation is performed over all possible configurations of hidden units $\{h\}$ .
Our objective is now to devise a method such that $P^{\prime}\left(\{\nu\}\right)$ converges to the unknown environment (i.e., data) distribution $P\left(\{\nu\}\right)$ . To do so, we quantity the disparity between $P^{\prime}\left(\{\nu\}\right)$ and $P\left(\{\nu\}\right)$ using the Kullback–Leibler (KL) divergence (or relative entropy)
$$
G(P,P^{\prime})=\sum_{\{\nu\}}P\left(\{\nu\}\right)\ln\left[\frac{P\left(\{\nu\}\right)}{P^{\prime}\left(\{\nu\}\right)}\right]\,. \tag{12}
$$
To minimize the KL divergence $G(P,P^{\prime})$ , we perform a gradient descent according to
$$
\frac{\partial G}{\partial w_{ij}}=-\frac{1}{T}\left(p_{ij}-p^{\prime}_{ij}\right)\,, \tag{13}
$$
where $p_{ij}$ represents the probability of both units $i$ and $j$ being active when the environment dictates the states of the visible units, and $p^{\prime}_{ij}$ is the corresponding probability in a freely running network without any connection to the environment. [66, 67, 68] We derive Eq. (13) in Sec. 3.
Both probabilities $p_{ij}$ and $p_{ij}^{\prime}$ are measured once the Boltzmann machine has reached thermal equilibrium. Subsequently, the weights $w_{ij}$ of the network are then updated according to
$$
\Delta w_{ij}=\epsilon\left(p_{ij}-p^{\prime}_{ij}\right)\,, \tag{14}
$$
where $\epsilon$ is the learning rate. To reach thermal equilibrium, the states of the visible and hidden units are updated using the update probability (9).
In summary, the steps relevant for training a Boltzmann machine are as follows. 1.
Clamp the input data (environment distribution) to the visible units. 2.
Update the state of all hidden units according to Eq. (9) until the system reaches thermal equilibrium and then compute $p_{ij}$ . 3.
Unclamp the input data from the visible units. 4.
Update the state of all neurons according to Eq. (9) until the system reaches thermal equilibrium and then compute $p_{ij}^{\prime}$ . 5.
Update all weights according to Eq. (14) and return to step 2 or stop if the weight updates are sufficiently small. After training a Boltzmann machine, we can unclamp the visible units from the environment and generate samples to evaluate their quality. To do this, we use various initial configurations and activate neurons according to Eq. (9) until thermal equilibrium is reached. If the Boltzmann machine was trained successfully, the distribution of states for the unclamped visible units should align with the environment distribution.
2 Restricted Boltzmann machines
Boltzmann machines are not widely used in general learning tasks. Their impracticality arises from the significant computational burden associated with achieving thermal equilibrium, especially in instances involving large system sizes. $h_{1}$ $h_{2}$ $h_{3}$ $h_{4}$ $v_{1}$ $v_{2}$ $v_{3}$ $v_{4}$ $v_{5}$ $v_{6}$
Figure 5: Restricted Boltzmann machines consist of a visible layer (blue) and a hidden layer (red). In the shown example, the respective layers comprise six visible units $\left\{v_{i}\right\}$ $(i∈\{1,...,6\})$ and four hidden units $\left\{h_{j}\right\}$ $(j∈\{1,...,4\})$ . The network structure of an RBM is bipartite and undirected.
Restricted Boltzmann machines provide an ANN structure that can be trained more efficiently by omitting connections between the hidden and visible units (see Fig. 5). Because of these missing intra-layer connections, the network architecture of an RBM is bipartite.
In RBMs, updates for visible and hidden units are performed alternately. Because there are no connections within each layer, we can update all units within each layer in parallel. Specifically, visible unit $v_{i}$ is activated with conditional probability
$$
p(v_{i}=1|\{h_{j}\})=\sigma\Bigl{(}\sum_{j}w_{ij}h_{j}+b_{i}\Bigr{)}\,, \tag{15}
$$
where $b_{i}$ is the bias of visible unit $v_{i}$ and $\{h_{j}\}$ is a given configuration of hidden units. We then activate all hidden units based on their conditional probabilities
$$
p(h_{j}=1|\{v_{i}\})=\sigma\Bigl{(}\sum_{i}w_{ij}v_{i}+c_{j}\Bigr{)}\,, \tag{16}
$$
where $h_{j}$ represents hidden unit $j$ , $c_{j}$ is its associated bias, and $\{v_{i}\}$ denotes a specific configuration of visible units. This technique of sampling is referred to as “block Gibbs sampling”.
Training an RBM shares similarities with training a BM. The key difference lies in the need to consider the bipartite network structure in the weight update equation (14). For an RBM, the weight updates are
$$
\Delta w_{ij}=\epsilon(\langle\nu_{i}h_{j}\rangle_{\text{data}}-\langle\nu_{i}h_{j}\rangle_{\text{model}})\,. \tag{17}
$$
Instead of sampling configurations to compute $\langle\nu_{i}h_{j}\rangle_{\text{data}}$ and $\langle\nu_{i}h_{j}\rangle_{\text{model}}$ at thermal equilibrium, we can instead employ a few relaxation steps. This approach is known as “contrastive divergence”. [70, 113] The corresponding weight updates are
$$
\Delta w_{ij}^{\text{CD}}=\epsilon(\langle\nu_{i}h_{j}\rangle_{\text{data}}-\langle\nu_{i}h_{j}\rangle_{\text{model}}^{k})\,. \tag{18}
$$
The superscript $k$ indicates the number of block Gibbs updates performed. For a more detailed discussion on the contrastive divergence training of RBMs, see Ref. 114.
<details>
<summary>x1.png Details</summary>
### Visual Description
## Image Grid: M(RT)^2 vs. RBM at Varying Temperatures
### Overview
The image presents a 2x3 grid of plots. The top row represents data for "M(RT)^2", and the bottom row represents data for "RBM". The columns represent different temperature regimes: T < Tc, T ≈ Tc, and T > Tc, where Tc is a critical temperature. Each plot displays a binary pattern of black and white pixels, visually representing the state of the system under the specified conditions.
### Components/Axes
* **Rows:**
* Row 1: M(RT)^2
* Row 2: RBM
* **Columns (Temperature Regimes):**
* Column 1: T < Tc (Temperature less than critical temperature)
* Column 2: T ≈ Tc (Temperature approximately equal to critical temperature)
* Column 3: T > Tc (Temperature greater than critical temperature)
* **Pixel Representation:**
* Black pixels: Represent one state (e.g., spin up)
* White pixels: Represent another state (e.g., spin down)
### Detailed Analysis
**Row 1: M(RT)^2**
* **T < Tc:** The plot shows a predominantly white background with a sparse scattering of black pixels. The black pixels appear randomly distributed.
* **T ≈ Tc:** The plot shows a mix of black and white regions. The regions are larger and more interconnected than in the T < Tc case. There are large clusters of black and white pixels.
* **T > Tc:** The plot shows a more even distribution of black and white pixels, with smaller, more fragmented regions compared to T ≈ Tc. The black and white pixels are more evenly mixed.
**Row 2: RBM**
* **T < Tc:** Similar to the M(RT)^2 case, this plot shows a predominantly white background with a sparse scattering of black pixels.
* **T ≈ Tc:** The plot shows a mix of black and white regions, similar to the M(RT)^2 case, but the regions might be slightly smaller or more fragmented.
* **T > Tc:** The plot shows a more even distribution of black and white pixels, similar to the M(RT)^2 case, with smaller, more fragmented regions compared to T ≈ Tc.
### Key Observations
* At T < Tc, both M(RT)^2 and RBM show a state dominated by one color (white), indicating a more ordered phase.
* As the temperature approaches Tc (T ≈ Tc), both M(RT)^2 and RBM exhibit larger, interconnected regions of both colors, suggesting the emergence of phase coexistence or critical fluctuations.
* At T > Tc, both M(RT)^2 and RBM show a more disordered state with a more even distribution of black and white pixels, indicating a transition to a different phase.
### Interpretation
The image visually represents the behavior of two systems, M(RT)^2 and RBM, as they transition through a critical temperature (Tc). The plots suggest that both systems undergo a phase transition from an ordered state (T < Tc) to a disordered state (T > Tc), with a critical region (T ≈ Tc) characterized by large fluctuations and phase coexistence. The similarity in the patterns between M(RT)^2 and RBM suggests that they may exhibit similar critical behavior or belong to the same universality class. The visual representation allows for a qualitative understanding of the system's behavior as a function of temperature.
</details>
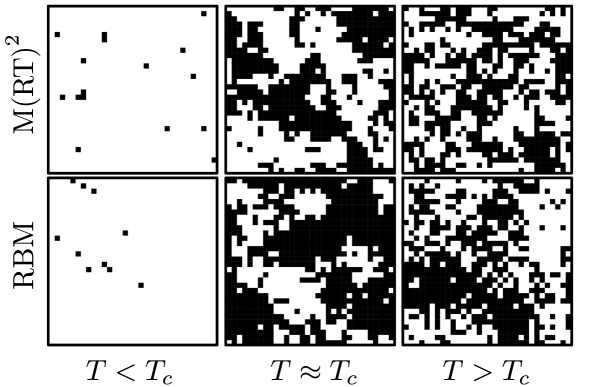
Figure 6: Snapshots of $32× 32$ Ising configurations are shown for $T∈\{1.5,2.5,4\}$ . These configurations are derived from both M(RT) 2 and RBM samples. The quantity $T_{c}=2/\ln(1+\sqrt{2})≈ 2.269$ is the critical temperature of the two-dimensional Ising model.
Restricted Boltzmann machines have been employed in diverse contexts, including dimensionality reduction of datasets [72], the study of phase transitions [73, 74, 3, 75], and the representation of wave functions [76, 77]. In Fig. 6, we show three snapshots of Ising configurations, generated using both M(RT) 2 sampling and RBMs, each comprising $32× 32$ spins. The RBM was trained using $20× 10^{4}$ realizations of Ising configurations sampled at various temperatures. [75]
3 Derivation of the learning algorithm
To derive Eq. (13), we follow the approach outlined in Ref. 68. Notice that the environment distribution $P\left(\{\nu\}\right)$ does not depend $w_{ij}$ . Hence, we have
$$
\frac{\partial G}{\partial w_{ij}}=-\sum_{\{\nu\}}\frac{P\left(\{\nu\}\right)}{P^{\prime}\left(\{\nu\}\right)}\frac{\partial P^{\prime}\left(\{\nu\}\right)}{\partial w_{ij}}\,. \tag{19}
$$
Next, we wish to compute the gradient $∂ P^{\prime}(\{\nu\})/∂ w_{ij}$ . In a freely running BM, the equilibrium distribution of the visible units follows a Boltzmann distribution. That is,
$$
P^{\prime}(\{\nu\})=\sum_{\{h\}}P^{\prime}\left(\{\nu\},\{h\}\right)=\frac{\sum_{\{h\}}e^{-E\left({\{\nu,h\}}\right)/T}}{\sum_{\{\nu,h\}}e^{-E\left({\{\nu,h\}}\right)/T}}\,. \tag{20}
$$
Here, the quantity
$$
E\left({\{\nu,h\}}\right)=-\frac{1}{2}\sum_{i,j}w_{ij}x_{i}^{\{\nu,h\}}x_{j}^{\{\nu,h\}} \tag{21}
$$
is the Ising-type energy function in which field (or bias) terms are absorbed in the weights $w_{ij}$ [see Eqs. (3) and (7)]. For a BM in state ${\{\nu,h\}}$ , we denote the state of neuron $i$ by $x_{i}^{\{\nu,h\}}$ . Using
$$
\frac{\partial e^{-E\left({\{\nu,h\}}\right)/T}}{\partial w_{ij}}=\frac{1}{T}x_{i}^{\{\nu,h\}}x_{j}^{\{\nu,h\}}e^{-E\left({\{\nu,h\}}\right)/T} \tag{22}
$$
yields
$$
\displaystyle\begin{split}\frac{\partial P^{\prime}\left(\{\nu\}\right)}{\partial w_{ij}}&=\frac{\frac{1}{T}\sum_{\{h\}}x_{i}^{\{\nu,h\}}x_{j}^{\{\nu,h\}}e^{-E\left({\{\nu,h\}}\right)/T}}{\sum_{\{\nu,h\}}e^{-E\left({\{\nu,h\}}\right)/T}}\\
&-\frac{\sum_{\{h\}}e^{-E\left({\{\nu,h\}}\right)/T}\frac{1}{T}\sum_{\{\nu,h\}}x_{i}^{\{\nu,h\}}x_{j}^{\{\nu,h\}}e^{-E\left({\{\nu,h\}}\right)/T}}{\left(\sum_{\{\nu,h\}}e^{-E\left({\{\nu,h\}}\right)/T}\right)^{2}}\\
&=\frac{1}{T}\left[\sum_{\{h\}}x_{i}^{\{\nu,h\}}x_{j}^{\{\nu,h\}}P^{\prime}\left(\{\nu\},\{h\}\right)\right.\\
&\hskip 28.45274pt\left.-P^{\prime}(\{\nu\})\sum_{\{\nu,h\}}x_{i}^{\{\nu,h\}}x_{j}^{\{\nu,h\}}P^{\prime}\left(\{\nu\},\{h\}\right)\right]\,.\end{split} \tag{23}
$$
We will now substitute this result into Eq. (19) to obtain
$$
\displaystyle\begin{split}\frac{\partial G}{\partial w_{ij}}&=-\sum_{\{\nu\}}\frac{P\left(\{\nu\}\right)}{P^{\prime}\left(\{\nu\}\right)}\frac{1}{T}\left[\sum_{\{h\}}x_{i}^{\{\nu,h\}}x_{j}^{\{\nu,h\}}P^{\prime}\left(\{\nu\},\{h\}\right)\right.\\
&\hskip 91.04872pt\left.-P^{\prime}\left(\{\nu\}\right)\sum_{\{\nu,h\}}x_{i}^{\{\nu,h\}}x_{j}^{\{\nu,h\}}P^{\prime}\left(\{\nu\},\{h\}\right)\right]\\
&=-\frac{1}{T}\left[\sum_{\{\nu,h\}}x_{i}^{\{\nu,h\}}x_{j}^{\{\nu,h\}}P\left(\{\nu\},\{h\}\right)-\sum_{\{\nu,h\}}x_{i}^{\{\nu,h\}}x_{j}^{\{\nu,h\}}P^{\prime}\left(\{\nu\},\{h\}\right)\right]\,,\end{split} \tag{24}
$$
where we used that $\sum_{\{\nu\}}P\left(\{\nu\}\right)=1$ and $P\left(\{\nu\}\right)/P^{\prime}\left(\{\nu\}\right)P^{\prime}\left(\{\nu\},\{h\}\right)=P\left(\{\nu\},\{h\}\right)\,.$ The latter equation follows from the definition of joint probability distributions
$$
P\left(\{\nu\},\{h\}\right)=P\left(\{h\}|\{\nu\}\right)P\left(\{\nu\}\right) \tag{25}
$$
and
$$
P^{\prime}\left(\{\nu\},\{h\}\right)=P^{\prime}\left(\{h\}|\{\nu\}\right)P^{\prime}\left(\{\nu\}\right)\,, \tag{26}
$$
with $P\left(\{h\}|\{\nu\}\right)=P^{\prime}\left(\{h\}|\{\nu\}\right)$ . The conditional distributions $P(\{h\}|\{\nu\})$ and $P^{\prime}(\{h\}|\{\nu\})$ are identical, as the probability of observing a certain hidden state given a visible one is independent of the origin of the visible state in an equilibrated system. In other words, for the conditional distributions in an equilibrated system, it is irrelevant whether the visible state is provided by the environment or generated by a freely running machine. Defining
$$
p_{ij}\coloneqq\sum_{\{\nu,h\}}x_{i}^{\{\nu,h\}}x_{j}^{\{\nu,h\}}P\left(\{\nu\},\{h\}\right) \tag{27}
$$
and
$$
p_{ij}^{\prime}\coloneqq\sum_{\{\nu,h\}}x_{i}^{\{\nu,h\}}x_{j}^{\{\nu,h\}}P^{\prime}\left(\{\nu\},\{h\}\right)\,, \tag{28}
$$
we finally obtain Eq. (13).
4 Loss landscapes of artificial neural networks
Training an ANN involves minimizing a given loss function such as the KL divergence [see Eq. (12)]. The loss landscapes of ANNs are affected by several factors, including structural properties [86, 87, 115] and a range of implementation attributes [116, 117, 118]. Knowledge of their precise effects on learning performance, however, remains incomplete.
One path to a better understanding of the relationships between ANN structure, implementation attributes, and learning performance is through a more in-depth analysis of the geometric properties of loss landscapes. For instance, Keskar et al. [119] analyze the local curvature around candidate minimizers via the spectrum of the underlying Hessian to characterize the flatness and sharpness of loss minima, and Dinh et al. [120] demonstrate that reparameterizations can render flat minima sharp without affecting generalization properties. Even so, one challenge to the study of geometric properties of loss landscapes is high dimensionality. To meet that challenge, some propose to visualize the curvature around a given point by projecting curvature properties of high-dimensional loss functions to a lower-dimensional (and often random) projection of two or three dimensions [121, 122, 123, 124, 125]. Horoi et al. [125], building on this approach, pursue improvements in learning by dynamically sampling points in projected low-loss regions surrounding local minima during training.
However, visualizing high-dimensional loss landscape curvature relies on accurate projections of curvature properties to lower dimensions. Unfortunately, random projections do not preserve curvature information, thus do not afford accurate low-dimensional representations of curvature information. This argument is given in Sec. 1 and illustrated with a simulation example in Sec. 2. Principal curvatures in a low-dimensional projection are nevertheless given by functions of weighted ensemble means of the Hessian elements in the original, high-dimensional space, a result also established in Sec. 1. Instead of using random projections to visualize loss functions, we propose to analyze projections along dominant Hessian directions associated with the largest-magnitude positive and negative principal curvatures.
1 Principal curvature in random projections
To describe the connection between the principal curvature of a loss function $L(\theta)$ with ANN parameters $\theta∈\mathbb{R}^{N}$ and that associated with a lower-dimensional, random projection, we provide in Sec. 1 an overview of concepts from differential geometry [126, 127, 128] that are useful to mathematically describe curvature in high-dimensional spaces. In Secs. 1 and 1, we show the relationship between principal curvature and random projections. Finally, in Sec. 1, we highlight a relationship between measures of curvature presented in Sec. 1 and Hessian trace estimates, which affords an alternative to Hutchinson’s method for computing unbiased Hessian trace estimates.
Differential and information geometry concepts
In differential geometry, the principal curvatures are the eigenvalues of the shape operator (or Weingarten map Some authors distinguish between the shape operator and the Weingarten map depending on if the change of the underlying tangent vector is described in the original manifold or in Euclidean space (see, e.g., chapter 3 in [129]).), a linear endomorphism defined on the tangent space $T_{p}$ of $L$ at a point $p$ . For the original high-dimensional space, we have $(\theta,L(\theta))⊂eq\mathbb{R}^{N+1}$ and there are $N$ principal curvatures $\kappa_{1}^{\theta}≥\kappa_{2}^{\theta}≥...≥\kappa_{N}^{\theta}$ . At a non-degenerate critical point $\theta^{*}$ where the gradient $∇_{\theta}L$ vanishes, the matrix of the shape parameter is given by the Hessian $H_{\theta}$ with elements $(H_{\theta})_{ij}=∂^{2}L/(∂\theta_{i}∂\theta_{j})$ ( $i,j∈\{1,...,N\}$ ). A critical point is degenerate if the Hessian $H_{\theta}$ at this point is singular (i.e., $\mathrm{det}(H_{\theta})=0$ ). At degenerate critical points, one cannot use the eigenvalues of $H_{\theta}$ to determine if the critical point is a minimum (positive definite $H_{\theta}$ ) or a maximum (negative definite $H_{\theta}$ ). Geometrically, at a degenerate critical point, a quadratic approximation fails to capture the local behavior of the function that one wishes to study. Some works refer to the Hessian as the “curvature matrix” [130] or use it to characterize the curvature properties of $L(\theta)$ [122]. In the vicinity of a non-degenerate critical point $\theta^{*}$ , the eigenvalues of the Hessian $H_{\theta}$ are the principal curvatures and describe the loss function in the eigenbasis of $H_{\theta}$ according to
$$
L(\theta^{*}+\Delta\theta)=L(\theta^{*})+\frac{1}{2}\sum_{i=1}^{N}\kappa_{i}^{\theta}\Delta\theta_{i}^{2}\,. \tag{29}
$$
The Morse lemma states that, if a critical point $\theta^{*}$ of $L(\theta)$ is non-degenerate, then there exists a chart $(\tilde{\theta}_{1},...,\tilde{\theta}_{N})$ in a neighborhood of $\theta^{*}$ such that
$$
L(\tilde{\theta})=-\tilde{\theta}^{2}_{1}-\cdots-\tilde{\theta}^{2}_{i}+\tilde{\theta}^{2}_{i+1}+\cdots+\tilde{\theta}^{2}_{N}+L(\theta^{*})\,, \tag{30}
$$
where $\tilde{\theta}_{i}(\theta)=0$ for $i∈\{1,...,N\}$ . The loss function $L(\tilde{\theta})$ in Eq. (30) is decreasing along $i$ directions and increasing along the remaining $i+1$ to $N$ directions. Further, the index $i$ of a critical point $\theta^{*}$ is the number of negative eigenvalues of the Hessian $H_{\theta}$ at that point.
In the standard basis, the Hessian is
$$
H_{\theta}\coloneqq\nabla_{\theta}\nabla_{\theta}L(\theta)=\begin{pmatrix}\frac{\partial^{2}L}{\partial\theta_{1}^{2}}&\cdots&\frac{\partial^{2}L}{\partial\theta_{1}\partial\theta_{N}}\\
\vdots&\ddots&\vdots\\
\frac{\partial^{2}L}{\partial\theta_{N}\partial\theta_{1}}&\cdots&\frac{\partial^{2}L}{\partial\theta_{N}^{2}}\end{pmatrix}\,. \tag{31}
$$
Random projections
To graphically explore an $N$ -dimensional loss function $L$ around a critical point $\theta^{*}$ , one may wish to work in a lower-dimensional representation. For example, a two-dimensional projection of $L$ around $\theta^{*}$ is provided by
$$
L(\theta^{*}+\alpha\eta+\beta\delta)\,, \tag{32}
$$
where the parameters $\alpha,\beta∈\mathbb{R}$ scale the directions $\eta,\delta∈\mathbb{R}^{N}$ . The corresponding graph representation is $(\alpha,\beta,L(\alpha,\beta))⊂eq\mathbb{R}^{3}$ .
In high-dimensional spaces, there exist vastly many more almost-orthogonal than orthogonal directions. In fact, if the dimension of our space is large enough, with high probability, random vectors will be sufficiently close to orthogonal [131]. Following this result, many related works [122, 124, 125] use random Gaussian directions with independent and identically distributed vector elements $\eta_{i},\delta_{i}\sim\mathcal{N}(0,1)$ ( $i∈\{1,...,N\}$ ).
The scalar product of random Gaussian vectors $\eta,\delta$ is a sum of the difference between two chi-squared distributed random variables because
$$
\sum_{i=1}^{N}\eta_{i}\delta_{i}=\sum_{i=1}^{N}\frac{1}{4}(\eta_{i}+\delta_{i})^{2}-\frac{1}{4}(\eta_{i}-\delta_{i})^{2}=\sum_{i=1}^{N}\frac{1}{2}X_{i}^{2}-\frac{1}{2}Y_{i}^{2}\,, \tag{33}
$$
where $X_{i},Y_{i}\sim\mathcal{N}(0,1)$ .
Notice that $\eta,\delta$ are almost orthogonal, which can be proved using a concentration inequality for chi-squared distributed random variables. For further details, see Ref. 105.
Principal curvature
With the form of random Gaussian projections in hand, we now analyze the principal curvatures in both the original and lower-dimensional spaces. The Hessian associated with the two-dimensional loss projection (32) is
$$
\displaystyle\begin{split}H_{\alpha,\beta}&=\begin{pmatrix}\frac{\partial^{2}L}{\partial\alpha^{2}}&\frac{\partial^{2}L}{\partial\alpha\partial\beta}\\
\frac{\partial^{2}L}{\partial\beta\partial\alpha}&\frac{\partial^{2}L}{\partial\beta^{2}}\\
\end{pmatrix}\\
&=\begin{pmatrix}\sum_{i,j}\eta_{i}\eta_{j}\frac{\partial^{2}L}{\partial\theta_{i}\theta_{j}}&\sum_{i,j}\eta_{i}\delta_{j}\frac{\partial^{2}L}{\partial\theta_{i}\theta_{j}}\\
\sum_{i,j}\eta_{i}\delta_{j}\frac{\partial^{2}L}{\partial\theta_{i}\theta_{j}}&\sum_{i,j}\delta_{i}\delta_{j}\frac{\partial^{2}L}{\partial\theta_{i}\theta_{j}}\\
\end{pmatrix}\\
&=\begin{pmatrix}(H_{\theta})_{ij}\eta^{i}\eta^{j}&(H_{\theta})_{ij}\eta^{i}\delta^{j}\\
(H_{\theta})_{ij}\eta^{i}\delta^{j}&(H_{\theta})_{ij}\delta^{i}\delta^{j}\\
\end{pmatrix}\,,\end{split} \tag{34}
$$
where we use Einstein notation in the last equality.
Because the elements of $\delta,\eta$ are distributed according to a standard normal distribution, the second derivatives of the loss function $L$ in Eq. (34) have prefactors that are products of standard normal variables and, hence, can be expressed as sums of chi-squared distributed random variables as in Eq. (33). To summarize, elements of $H_{\alpha,\beta}$ are sums of second derivatives of $L$ in the original space weighted with chi-squared distributed prefactors.
The principal curvatures $\kappa_{±}^{\alpha,\beta}$ (i.e., the eigenvalues of $H_{\alpha,\beta}$ ) are
$$
\kappa_{\pm}^{\alpha,\beta}=\frac{1}{2}\left(A+C\pm\sqrt{4B^{2}+(A-C)^{2}}\right)\,, \tag{35}
$$
where $A=(H_{\theta})_{ij}\eta^{i}\eta^{j}$ , $B=(H_{\theta})_{ij}\eta^{i}\delta^{j}$ , and $C=(H_{\theta})_{ij}\delta^{i}\delta^{j}$ . To the best of our knowledge, a closed, analytic expression for the distribution of the quantities $A,B,C$ is not yet known [132, 133, 134, 135].
Returning to principal curvature, since $\sum_{i,j}a_{ij}\eta^{i}\eta^{j}=\sum_{i}a_{ii}\eta^{i}\eta^{i}+\sum_{i≠ j}a_{ij}\eta^{i}\eta^{j}$ ( $a_{ij}∈\mathbb{R}$ ), we find that $\mathds{E}[A]=\mathds{E}[C]={(H_{\theta})^{i}}_{i}$ and $\mathds{E}[B]=0$ where ${(H_{\theta})^{i}}_{i}\equiv\mathrm{tr}(H_{\theta})=\sum_{i=1}^{N}\kappa_{i}^{\theta}$ . The expected values of the quantities $A$ , $B$ , and $C$ correspond to ensemble means (43) in the limit $S→∞$ , where $S$ is the number of independent realizations of the underlying random variable. To show that the expected values of $a_{ij}\eta^{i}\eta^{j}$ ( $i≠ j$ ) or $a_{ij}\eta^{i}\delta^{j}$ vanish, one can either invoke independence of $\eta^{i},\eta^{j}$ ( $i≠ j$ ) and $\eta^{i},\delta^{j}$ or transform both products into corresponding differences of two chi-squared random variables with the same mean [see Eq. (33)].
Hence, the expected, dimension-reduced Hessian (34) is
$$
\mathds{E}[H_{\alpha,\beta}]=\begin{pmatrix}{(H_{\theta})^{i}}_{i}&0\\
0&{(H_{\theta})^{i}}_{i}\\
\end{pmatrix}\,. \tag{36}
$$
The corresponding eigenvalue (or principal curvature) $\bar{\kappa}^{\alpha,\beta}$ is therefore given by the sum over all principal curvatures in the original space (i.e., $\bar{\kappa}^{\alpha,\beta}=\sum_{i=1}^{N}\kappa_{i}^{\theta}$ ). Hence, the value of the principal curvature $\bar{\kappa}^{\alpha,\beta}$ in the expected dimension-reduced space will be either positive (if the positive principal curvatures in the original space dominate), negative (if the negative principal curvatures in the original space dominate), or close to zero (if positive and negative principal curvatures in the original space cancel out each other). As a result, saddle points will not appear as such in the expected random projection.
In addition to the connection between $\bar{\kappa}^{\alpha,\beta}$ and the principal curvatures $\kappa_{i}^{\theta}$ , we now provide an overview of additional mathematical relations between different curvature measures that are useful to quantify curvature properties of high-dimensional loss functions and their two-dimensional random projections.
\tbl
Quantities to characterize curvature. Symbol Definition $H_{\theta}∈\mathbb{R}^{N× N}$ Hessian in original loss space $\kappa_{i}^{\theta}∈\mathbb{R}$ principal curvatures in original loss space with $i∈\{1,...,N\}$ (i.e., the eigenvalues of $H_{\theta}$ ) $H_{\alpha,\beta}∈\mathbb{R}^{2× 2}$ Hessian in a two-dimensional projection of an $N$ -dimensional loss function $\kappa_{±}^{\alpha,\beta}∈\mathbb{R}$ principal curvatures in a two-dimensional loss projection (i.e., the eigenvalues of $H_{\alpha,\beta}$ ) $\bar{\kappa}^{\alpha,\beta}∈\mathbb{R}$ principal curvature in expected, two-dimensional loss projection (i.e., the eigenvalues of $\mathbb{E}[H_{\alpha,\beta}]$ ) $H∈\mathbb{R}$ mean curvature (i.e., $\sum_{i=1}^{N}\kappa_{i}^{\theta}/N=\bar{\kappa}^{\alpha,\beta}/N$ )
Invoking Eq. (35), we can relate $\bar{\kappa}^{\alpha,\beta}$ to $\mathrm{tr}(H_{\theta})$ and $\kappa_{±}^{\alpha,\beta}$ . Because $\kappa_{+}^{\alpha,\beta}+\kappa_{-}^{\alpha,\beta}=A+C$ , we have
$$
\mathrm{tr}(H_{\theta})=\bar{\kappa}^{\alpha,\beta}=\sum_{i=1}^{N}\kappa_{i}^{\theta}=\frac{1}{2}\left(\mathbb{E}[\kappa_{-}^{\alpha,\beta}]+\mathbb{E}[\kappa_{+}^{\alpha,\beta}]\right)\,. \tag{37}
$$
The mean curvature $H$ in the original space is related to $\bar{\kappa}^{\alpha,\beta}$ via
$$
H=\frac{1}{N}\bar{\kappa}^{\alpha,\beta}=\frac{1}{N}\sum_{i=1}^{N}\kappa_{i}^{\theta}\,. \tag{38}
$$
We summarize the definitions of the employed Hessians and curvature measures in Tab. 1.
The appeal of random projections is that pairwise distances between points in a high-dimensional space can be nearly preserved by a lower-dimensional linear embedding, affording a low-dimensional representation of mean and variance information with minimal distortion [136]. The relationship between random Gaussian directions and principal curvature is less straightforward. Our results show that the principal curvatures $\kappa_{±}^{\alpha,\beta}$ in a two-dimensional loss projection are weighted averages of the Hessian elements $(H_{\theta})_{ij}$ in the original space, not weighted averages of the principal curvatures $\kappa_{i}^{\theta}$ as claimed by Ref. 122. Similar arguments apply to projections with dimension larger than 2.
Hessian trace estimates
Finally, we point to a connection between curvature measures and Hessian trace estimates. A common way of estimating $\mathrm{tr}(H_{\theta})$ without explicitly computing all eigenvalues of $H_{\theta}$ is based on Hutchinson’s method [137] and random numerical linear algebra [138, 139]. The basic idea behind this approach is to (i) use a random vector $z∈\mathbb{R}^{N}$ with elements $z_{i}$ that are distributed according to a distribution function with zero mean and unit variance (e.g., a Rademacher distribution with $\Pr\left(z_{i}=± 1\right)=1/2$ ), and (ii) compute $z^{→p}H_{\theta}z$ , an unbiased estimator of $\mathrm{tr}(H_{\theta})$ . That is,
$$
\mathrm{tr}(H_{\theta})=\mathbb{E}[z^{\top}H_{\theta}z]\,. \tag{39}
$$
Recall that Eq. (37) shows that the principal curvature of the expected random loss projection, $\bar{\kappa}^{\alpha,\beta}$ , is equal to $\mathrm{tr}(H_{\theta})$ . Instead of estimating $\mathrm{tr}(H_{\theta})$ using Hutchinson’s method (39), an alternative Hutchinson-type estimate of this quantity is provided by the mean of the expected values of $\kappa_{-}^{\alpha,\beta}$ and $\kappa_{+}^{\alpha,\beta}$ [see Eq. (37)].
2 Extracting curvature information
We now study two examples that will help build intuitions. In the first example presented in Sec. 2, we study a critical point $\theta^{*}$ of an $N$ -dimensional loss function $L(\theta)$ for which (i) all principal curvatures have the same magnitude and (ii) the number of positive curvature directions is equal to the number of negative curvature directions. In this example, saddles can be correctly detected by ensemble means but success depends on the averaging process used. In the second example presented in Sec. 2, we use a loss function associated with an unequal number of negative and positive curvature directions. For the different curvature measures derived in Sec. 1, we find that random projections cannot identify the underlying saddle point. In Sec. 2, we will use the two example loss functions to discuss how curvature-based Hessian trace estimates relate to those obtained with the original Hutchinson’s method.
Equal number of curvature directions
The loss function of our first example is
$$
L(\theta)=\frac{1}{2}\theta_{2n+1}\left(\sum_{i=1}^{n}\theta_{i}^{2}-\theta_{i+n}^{2}\right)\,,\quad n\in\mathbb{Z}_{+}\,, \tag{40}
$$
where we set $N=2n+1$ . A critical point $\theta^{*}$ of the loss function (40) satisfies
$$
(\nabla_{\theta}L)(\theta^{*})=\left(\begin{array}[]{c}\theta^{*}_{1}\theta^{*}_{2n+1}\\
\vdots\\
\theta^{*}_{n}\theta^{*}_{2n+1}\\
-\theta^{*}_{n+1}\theta^{*}_{2n+1}\\
\vdots\\
-\theta^{*}_{2n}\theta^{*}_{2n+1}\\
\frac{1}{2}\left(\sum_{i=1}^{n}{\theta_{i}^{{*\textsuperscript{2}}}}-{\theta_{i+n}^{{*\textsuperscript{2}}}}\right)\end{array}\right)=0\,. \tag{41}
$$
The Hessian at the critical point $\theta^{*}=(\theta^{*}_{1},...,\theta^{*}_{2n},\theta^{*}_{2n+1})$ $=(0,...,0,1)$ is
$$
H_{\theta}=\mathrm{diag}(\underbrace{1,\dots,1}_{n~\mathrm{times}},\underbrace{-1,\dots,-1}_{n~\mathrm{times}},0)\,. \tag{42}
$$
<details>
<summary>hessian_alpha_beta_left.png Details</summary>
### Visual Description
## Chart: Convergence of Estimators
### Overview
The image contains two line charts, labeled (a) and (c), displaying the convergence behavior of estimators as the number of samples increases. The y-axis represents the difference between the estimator and its expected value, while the x-axis represents the number of samples on a logarithmic scale. Three different data series are plotted in each chart, corresponding to different index pairs (i, j).
### Components/Axes
* **Chart Titles:** (a) and (c) in the top-left corner of each chart.
* **Y-axis Label:** "⟨⟨(Hα,β)ij⟩⟩ – E[(Hα,β)ij]" for both charts. The y-axis ranges from -20 to 20 with tick marks at -20, -10, 0, 10, and 20.
* **X-axis Label:** "number of samples S" for the bottom chart. The x-axis is a logarithmic scale ranging from 10^0 to 10^4, with tick marks at 10^0, 10^1, 10^2, 10^3, and 10^4.
* **Horizontal Dashed Line:** A gray dashed line is present at y = 0 on both charts.
* **Legend:** Located in the top-right of each chart.
* Black solid line: (i, j) = (1, 1)
* Blue dashed line: (i, j) = (2, 2)
* Red dashed line: (i, j) = (1, 2), (i, j) = (2, 1)
### Detailed Analysis
**Chart (a):**
* **(i, j) = (1, 1) (Black solid line):** Starts around y=20 at x=10^0, fluctuates significantly between 10^0 and 10^2, and then converges towards 0 as the number of samples increases to 10^4.
* **(i, j) = (2, 2) (Blue dashed line):** Starts around y= -10 at x=10^0, fluctuates significantly between 10^0 and 10^2, and then converges towards 0 as the number of samples increases to 10^4.
* **(i, j) = (1, 2), (i, j) = (2, 1) (Red dashed line):** Starts around y=-15 at x=10^0, fluctuates significantly between 10^0 and 10^2, and then converges towards 0 as the number of samples increases to 10^4.
**Chart (c):**
* **(i, j) = (1, 1) (Black solid line):** Starts around y=0 at x=10^0, fluctuates significantly between 10^0 and 10^2, and then converges towards 0 as the number of samples increases to 10^4.
* **(i, j) = (2, 2) (Blue dashed line):** Starts around y= -10 at x=10^0, fluctuates significantly between 10^0 and 10^2, and then converges towards 0 as the number of samples increases to 10^4.
* **(i, j) = (1, 2), (i, j) = (2, 1) (Red dashed line):** Starts around y=-15 at x=10^0, fluctuates significantly between 10^0 and 10^2, and then converges towards 0 as the number of samples increases to 10^4.
### Key Observations
* All three data series in both charts converge towards 0 as the number of samples increases.
* The fluctuations are more pronounced at lower sample sizes (between 10^0 and 10^2).
* The convergence rate appears to be similar for all three data series in each chart.
* Chart (a) and (c) show similar convergence behavior for the same (i,j) values.
### Interpretation
The charts demonstrate the convergence of estimators to their expected values as the number of samples increases. The fluctuations at lower sample sizes indicate higher variance in the estimates, which decreases as more data is used. The convergence towards 0 suggests that the estimators are unbiased. The similarity between charts (a) and (c) suggests that the underlying process being estimated is consistent across different conditions or parameters represented by (a) and (c). The data suggests that a larger number of samples is required to obtain more accurate and reliable estimates.
</details>
<details>
<summary>hessian_alpha_beta_right.png Details</summary>
### Visual Description
## Line Charts: Principal Curvatures vs. Number of Samples
### Overview
The image contains two line charts, (b) and (d), each plotting principal curvatures against the number of samples. Both charts display two data series: `<κ±α,β>` (solid black line) and `<κ~±α,β>` (dashed red line). The x-axis (number of samples) is on a logarithmic scale.
### Components/Axes
**Chart (b):**
* **Title:** (b) (located in the top-left corner of the chart)
* **Y-axis:** "principal curvatures" (vertical axis label). Scale ranges from -50 to 75, with tick marks at -50, -25, 0, 25, 50, and 75.
* **X-axis:** "number of samples" S (horizontal axis label). Logarithmic scale ranging from 10^0 to 10^4.
* **Legend:** Located in the top-right corner.
* Solid black line: `<κ±α,β>`
* Dashed red line: `<κ~±α,β>`
* A horizontal dashed gray line is present at y = 0.
**Chart (d):**
* **Title:** (d) (located in the top-left corner of the chart)
* **Y-axis:** "principal curvatures" (vertical axis label). Scale ranges from 550 to 700, with tick marks at 550, 600, 650, and 700.
* **X-axis:** "number of samples" S (horizontal axis label). Logarithmic scale ranging from 10^0 to 10^4.
* **Legend:** Located in the top-right corner.
* Solid black line: `<κ±α,β>`
* Dashed red line: `<κ~±α,β>`
* A horizontal dashed gray line is present at y = 600.
### Detailed Analysis
**Chart (b):**
* **`<κ±α,β>` (solid black line):** Starts at approximately -15 at x=10^0, rises sharply to a peak around 70 at x=10^1, then decreases to approximately 35 and stabilizes around x=10^2, remaining relatively constant until x=10^4.
* **`<κ~±α,β>` (dashed red line):** Starts at approximately 25 at x=10^0, rises to a peak around 50 at x=10^0.5, then decreases and oscillates around 0, stabilizing around x=10^3.
**Chart (d):**
* **`<κ±α,β>` (solid black line):** Starts at approximately 600 at x=10^0, rises to a peak around 675 at x=10^1, then decreases to approximately 635 and stabilizes around x=10^2, remaining relatively constant until x=10^4.
* **`<κ~±α,β>` (dashed red line):** Starts at approximately 630 at x=10^0, decreases to approximately 595 and oscillates around 600, stabilizing around x=10^2.
### Key Observations
* Both charts show that the principal curvatures converge as the number of samples increases.
* The `<κ±α,β>` series (solid black line) in both charts exhibits a more pronounced initial peak and subsequent stabilization compared to the `<κ~±α,β>` series (dashed red line).
* In chart (b), the `<κ~±α,β>` series oscillates around 0, suggesting a possible convergence towards zero curvature.
* In chart (d), the `<κ~±α,β>` series oscillates around 600, suggesting a possible convergence towards a curvature of 600.
### Interpretation
The charts illustrate the convergence behavior of two different measures of principal curvature, `<κ±α,β>` and `<κ~±α,β>`, as the number of samples increases. The initial fluctuations in curvature are likely due to the limited number of samples, while the stabilization at higher sample counts indicates a more reliable estimate of the true curvature. The difference in the convergence values and the initial peaks between the two curvature measures suggests that they may be sensitive to different aspects of the underlying data or calculation method. The stabilization of `<κ~±α,β>` around 0 in chart (b) could indicate a region of zero curvature, while the stabilization around 600 in chart (d) suggests a region with a constant positive curvature.
</details>
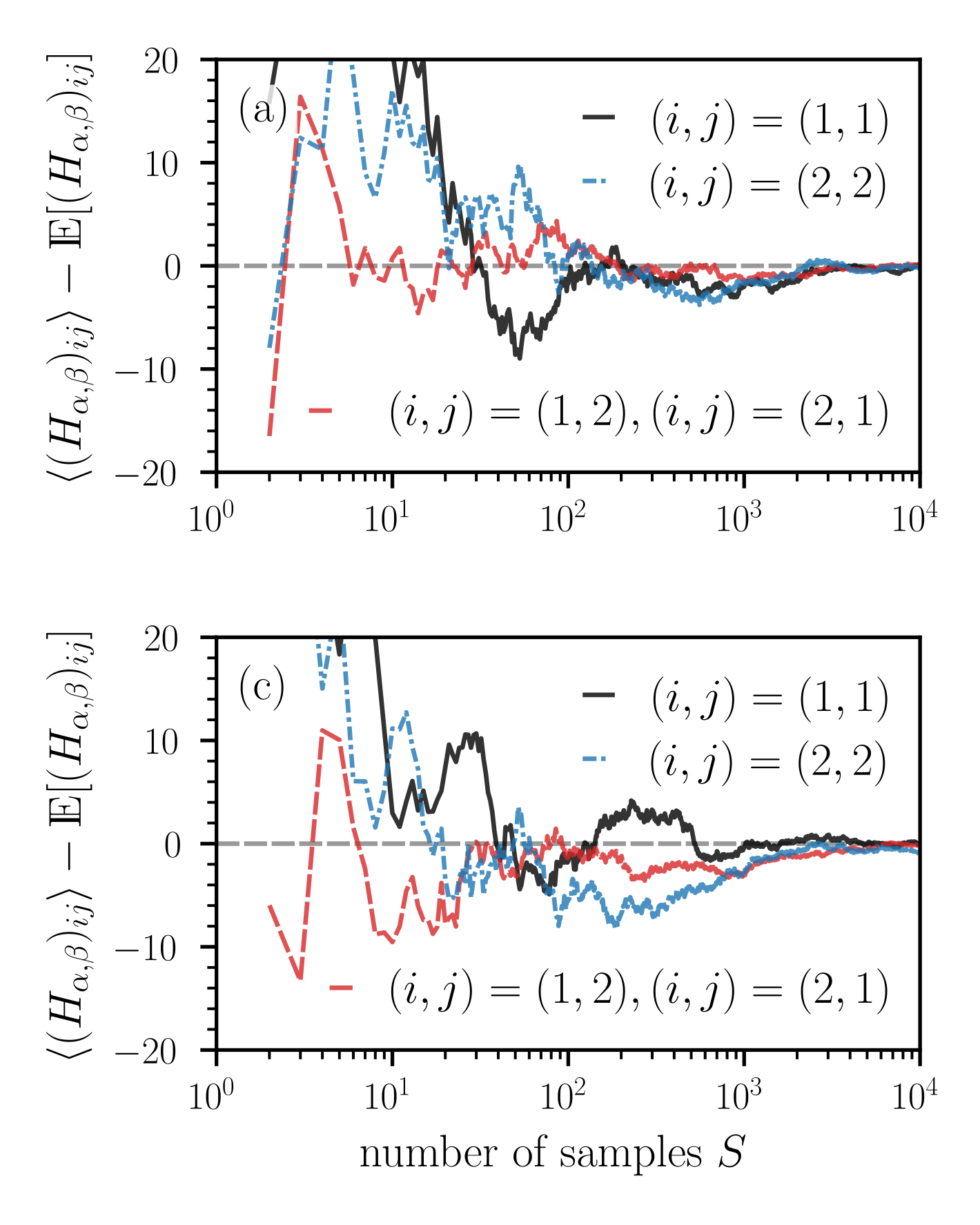
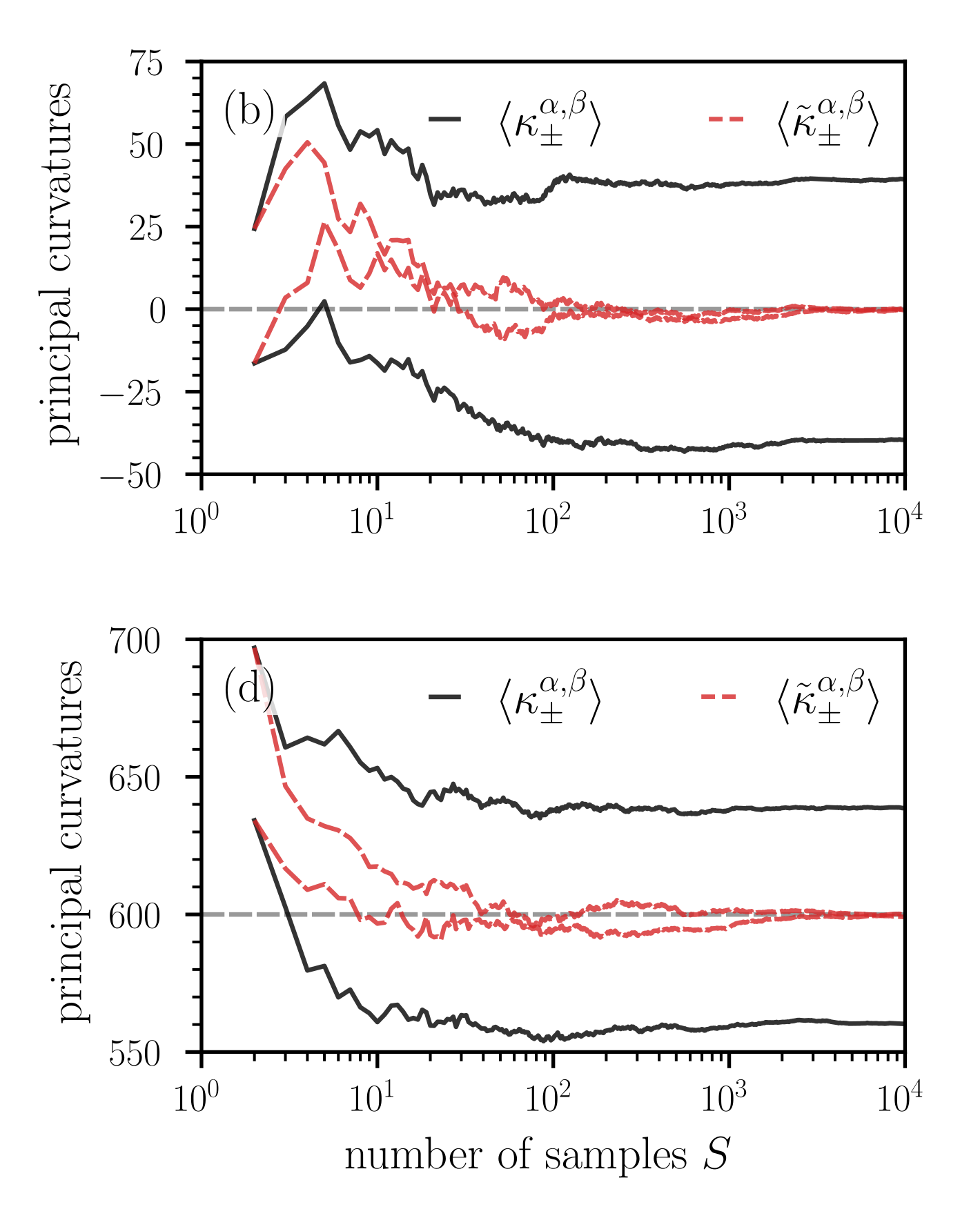
Figure 7: Convergence of the ensemble mean (43) of Hessian elements and curvatures measures as a function of the number of random projections $S$ . (a,c) The deviation of the ensemble means $\langle(H_{\alpha,\beta})_{ij}\rangle$ ( ${i,j∈\{1,2\}}$ ) of Hessian elements from the corresponding expected values as a function of $S$ . Notice that the expected value of the diagonal elements $(H_{\alpha,\beta})_{11}$ and $(H_{\alpha,\beta})_{22}$ is equal to $\bar{\kappa}^{\alpha,\beta}$ (i.e., to the sum of principal curvatures in the original space) [see Eqs. (36) and (37)]. A relatively large number of random projections between $10^{3}$ and $10^{4}$ is required to keep the deviations at values smaller than about 2–4. (b,d) The ensemble means $\langle\kappa^{\alpha,\beta}_{±}\rangle$ [see Eq. (35)] and $\langle\tilde{\kappa}^{\alpha,\beta}_{±}\rangle$ [see Eq. (44)] as a function of $S$ . Dashed grey lines represent $\bar{\kappa}^{\alpha,\beta}=\mathrm{tr}(H_{\theta})$ . In panels (a,b) and (c,d), the $N$ -dimensional loss functions are given by Eqs. (40) and (45), respectively. We evaluate the corresponding Hessians (42) and (46) at the saddle point $\theta^{*}=(\theta^{*}_{1},...,\theta^{*}_{2n},\theta^{*}_{2n+1})=(0,...,0,1)$ . In both loss functions, we set $n=500$ and in loss function (45) we set $\tilde{n}=800$ .
Because $H_{\theta}$ has positive and negative eigenvalues, the critical point is a saddle. The corresponding principal curvatures are $\kappa_{i}^{\theta}∈\{-1,1\}$ ( $i∈\{1,...,N-1\}$ ) and $\kappa^{\theta}_{N}=0$ . In this example, the mean curvature $H$ , as defined in Eq. (38), is equal to 0. According to Eq. (36), the principal curvature, $\bar{\kappa}^{\alpha,\beta}$ , associated with the expected, dimension-reduced Hessian $H_{\alpha,\beta}$ is also equal to 0, erroneously indicating an apparently flat loss landscape if one would use $\bar{\kappa}^{\alpha,\beta}$ as the main measure of curvature. To compare the convergence of different curvature measures as a function of the number of loss projections $S$ , we will now study the ensemble mean
$$
\langle X\rangle=\frac{1}{S}\sum_{k=1}^{S}X^{(k)} \tag{43}
$$
of different quantities of interest $X$ such as Hessian elements and principal curvature measures in dimension-reduced space. Here, $X^{(k)}$ is the $k$ -th realization (or sample) of $X$ .
<details>
<summary>curvature_pdfs_left.png Details</summary>
### Visual Description
## Histogram: Principal Curvatures Distribution
### Overview
The image is a histogram displaying the distribution of principal curvatures, denoted as κ, with two distinct distributions represented by red and gray bars. Each distribution is overlaid with a smoothed curve. The x-axis represents the principal curvatures (κ), and the y-axis represents the probability density function (PDF). The plot includes a legend in the top-center, identifying the red distribution as κ<sup>α,β</sup><sub>-</sub> and the gray distribution as κ<sup>α,β</sup><sub>+</sub>. The plot is labeled with "(a)" in the top-left corner.
### Components/Axes
* **X-axis:** "principal curvatures κ<sup>α,β</sup><sub>±</sub>" with scale from -150 to 150, incrementing by 50.
* **Y-axis:** "PDF" (Probability Density Function) with scale from 0.0 to 1.5, incrementing by 0.5.
* **Legend:** Located at the top-center of the plot.
* Red line: κ<sup>α,β</sup><sub>-</sub>
* Black line: κ<sup>α,β</sup><sub>+</sub>
* **Title/Label:** "(a)" in the top-left corner.
### Detailed Analysis
* **Red Distribution (κ<sup>α,β</sup><sub>-</sub>):**
* Trend: The red distribution is a bell-shaped curve, peaking around -50.
* Approximate Values: The distribution ranges from approximately -150 to 50. The peak PDF value is approximately 1.1.
* **Gray Distribution (κ<sup>α,β</sup><sub>+</sub>):**
* Trend: The gray distribution is a bell-shaped curve, peaking around 50.
* Approximate Values: The distribution ranges from approximately -50 to 150. The peak PDF value is approximately 1.1.
* **Overlaid Curves:** Both distributions have smoothed curves overlaid, closely following the shape of the histograms. These curves are dark gray.
### Key Observations
* The two distributions are approximately symmetrical and bell-shaped.
* The red distribution (κ<sup>α,β</sup><sub>-</sub>) is centered around a negative value, while the gray distribution (κ<sup>α,β</sup><sub>+</sub>) is centered around a positive value.
* The peak PDF values for both distributions are approximately equal.
* There is some overlap between the two distributions around 0.
### Interpretation
The plot illustrates the distribution of principal curvatures, showing two distinct populations with opposing signs. The symmetrical bell-shaped distributions suggest a balanced presence of positive and negative curvatures. The overlap indicates that some data points exhibit both positive and negative curvatures. The plot likely represents a characteristic of a surface or material where both concave and convex features are present. The "a" label suggests this is part of a larger series of plots.
</details>
<details>
<summary>curvature_pdfs_right.png Details</summary>
### Visual Description
## Histogram: Principal Curvatures
### Overview
The image is a histogram displaying the distribution of principal curvatures, denoted as κ, with two distinct distributions shown. One distribution is represented in red (κ<sup>α,β</sup><sub>-</sub>) and the other in gray (κ<sup>α,β</sup><sub>+</sub>). Each distribution is overlaid with a fitted curve. The x-axis represents the principal curvatures, and the y-axis represents the frequency or density. The plot includes the label "(b)" in the top-left corner.
### Components/Axes
* **X-axis:** "principal curvatures κ<sup>α,β</sup><sub>±</sub>". The axis ranges from 450 to 750, with tick marks at intervals of 50.
* **Y-axis:** The y-axis is not explicitly labeled but represents a density or frequency. The axis ranges from 0.0 to 1.5, with tick marks at intervals of 0.5.
* **Legend:** Located at the top-center of the plot.
* Red: κ<sup>α,β</sup><sub>-</sub>
* Black: κ<sup>α,β</sup><sub>+</sub>
### Detailed Analysis
* **Red Distribution (κ<sup>α,β</sup><sub>-</sub>):**
* The red histogram represents the distribution of κ<sup>α,β</sup><sub>-</sub>.
* The distribution is approximately normal, centered around 550.
* The fitted curve (gray) closely matches the histogram.
* The frequency peaks at approximately 1.1.
* **Gray Distribution (κ<sup>α,β</sup><sub>+</sub>):**
* The gray histogram represents the distribution of κ<sup>α,β</sup><sub>+</sub>.
* The distribution is approximately normal, centered around 650.
* The fitted curve (gray) closely matches the histogram.
* The frequency peaks at approximately 1.1.
### Key Observations
* Both distributions are approximately normal.
* The gray distribution (κ<sup>α,β</sup><sub>+</sub>) is shifted to the right compared to the red distribution (κ<sup>α,β</sup><sub>-</sub>), indicating that the principal curvatures κ<sup>α,β</sup><sub>+</sub> tend to have higher values than κ<sup>α,β</sup><sub>-</sub>.
* The peak frequency for both distributions is approximately the same (around 1.1).
* The standard deviation appears similar for both distributions.
### Interpretation
The plot compares the distributions of two principal curvatures, κ<sup>α,β</sup><sub>-</sub> and κ<sup>α,β</sup><sub>+</sub>. The shift in the distributions suggests that κ<sup>α,β</sup><sub>+</sub> values are generally higher than κ<sup>α,β</sup><sub>-</sub> values. The similar shapes of the distributions indicate that the variability in both sets of curvatures is comparable. The fitted curves provide a smoothed representation of the underlying distributions, suggesting that the data may be modeled using normal distributions. The label "(b)" suggests that this plot is part of a larger set of figures or analysis.
</details>
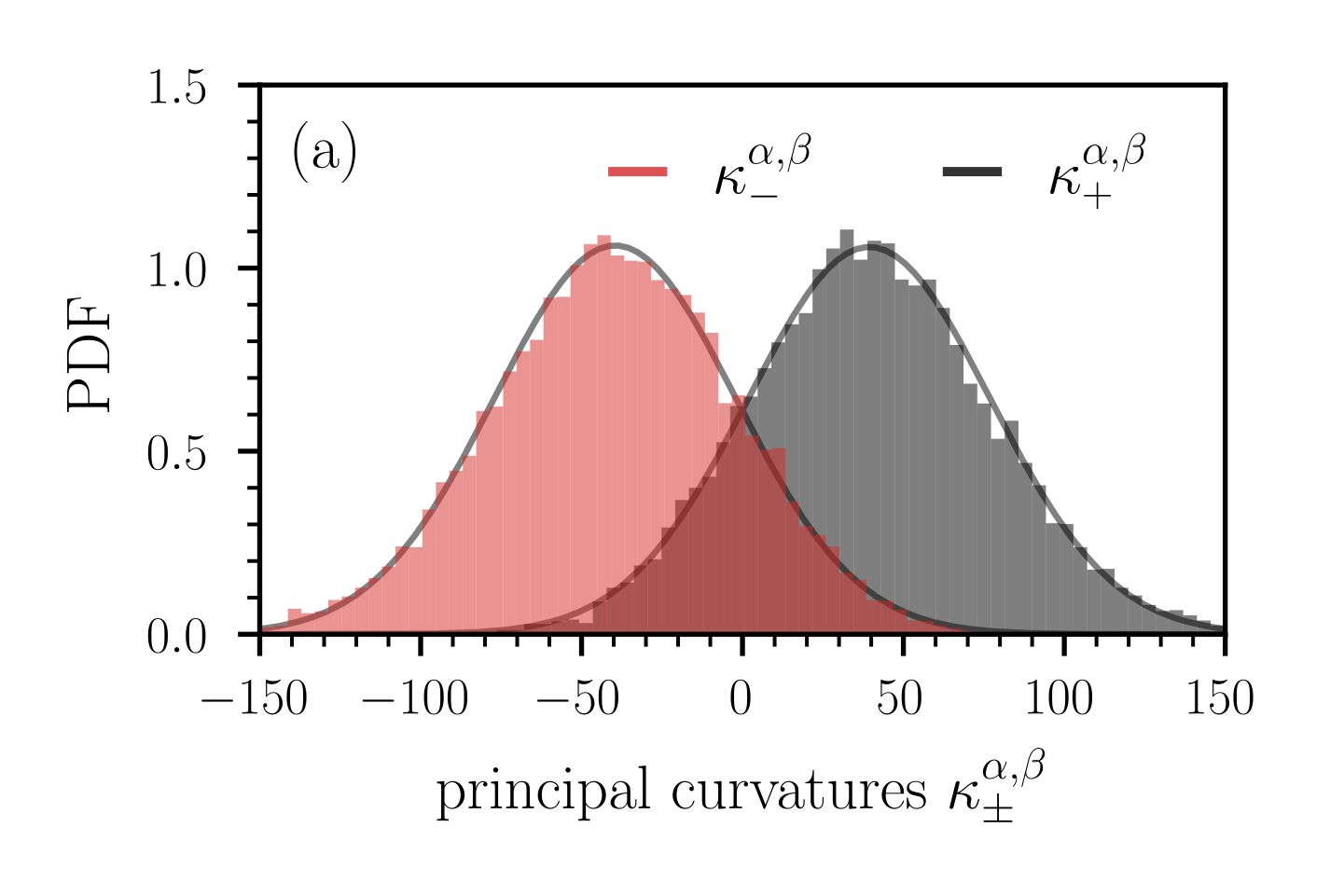
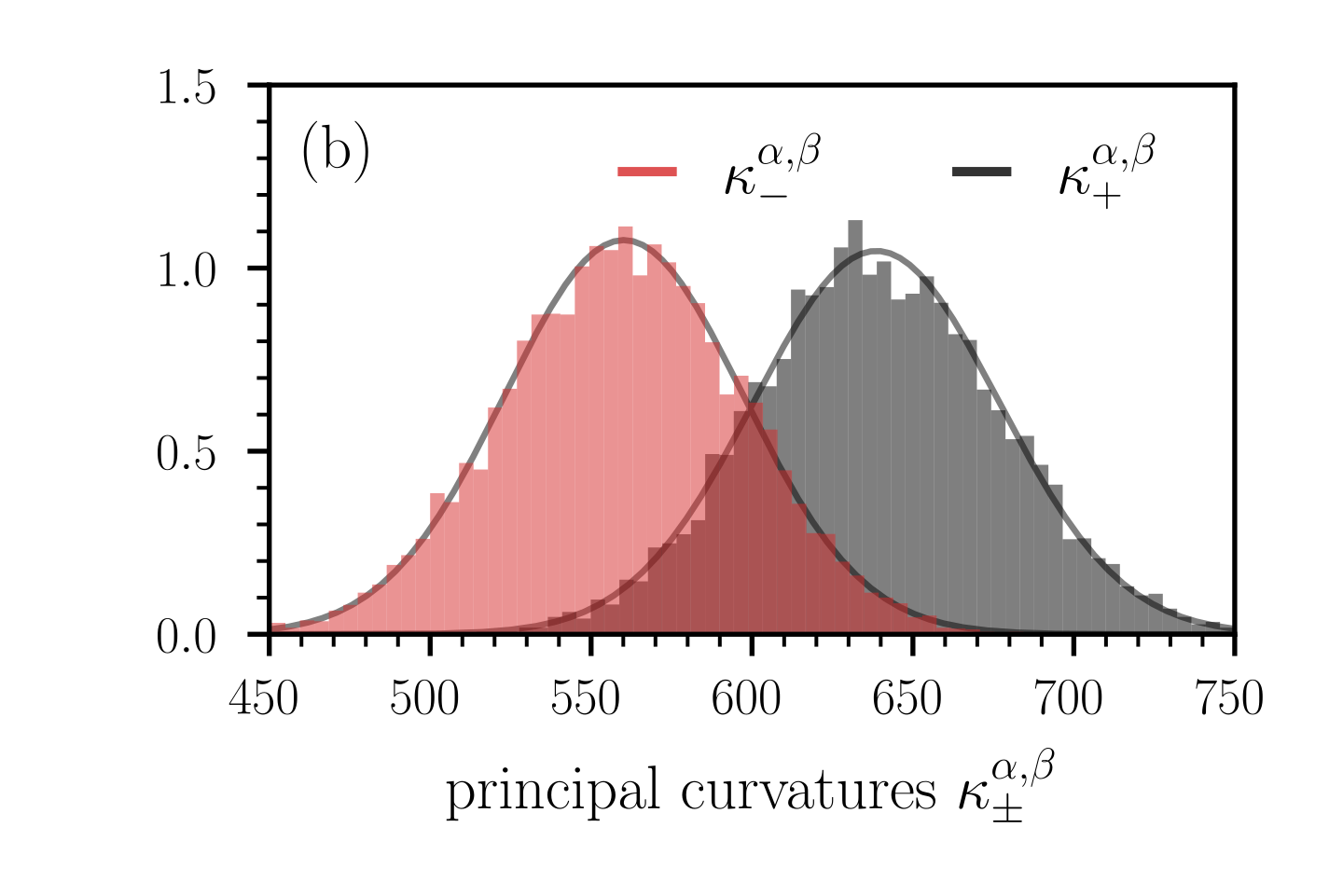
Figure 8: Distribution of principal curvatures $\kappa_{-}^{\alpha,\beta}$ (red bars) and $\kappa_{+}^{\alpha,\beta}$ (black bars). In panels (a) and (b), the loss functions are given by Eqs. (40) and (45), respectively. We evaluate the corresponding Hessians (42) and (46) at the saddle point $\theta^{*}=(\theta^{*}_{1},...,\theta^{*}_{2n},\theta^{*}_{2n+1})=(0,...,0,1)$ . In both loss functions, we set $n=500$ and in loss function (45) we set $\tilde{n}=800$ . In panel (a), the probability $\Pr(\kappa_{+}^{\alpha,\beta}\kappa_{-}^{\alpha,\beta}>0)$ that the critical point in the lower-dimensional, random projection does not appear as a saddle is about 0.3, and it is 1 in panel (b). Histograms are based on 10,000 random projections used to compute $\kappa_{±}^{\alpha,\beta}$ . Solid grey lines are Gaussian approximations of the empirical distributions.
We first study the dependence of ensemble means $\langle(H_{\alpha,\beta})_{ij}\rangle$ ( $i,j∈\{1,2\}$ ) of elements of the dimension-reduced Hessian $H_{\alpha,\beta}$ on the number of samples $S$ . According to Eq. (36), the diagonal elements of $\mathds{E}[H_{\alpha,\beta}]$ are proportional to the mean curvature of the original high-dimensional space and are thus useful to examine curvature properties of high-dimensional loss functions. Figure 7 (a) shows the convergence of the ensemble means $\langle(H_{\alpha,\beta})_{ij}\rangle$ toward the expected values $\mathds{E}[(H_{\alpha,\beta})_{ij}]$ as a function of $S$ . Note that $\mathds{E}[(H_{\alpha,\beta})_{ij}]=0$ for all $i,j$ . For a few dozen loss projections, the deviations of some of the ensemble means from the corresponding expected values reach values larger than 20. A relatively large number of loss projections $S$ between $10^{3}$ – $10^{4}$ is required to keep these deviations at values that are smaller than about 2–4. The solid black and red lines in Fig. 7 (b), respectively, show the ensemble means $\langle\kappa_{±}^{\alpha,\beta}\rangle$ and
$$
\langle\tilde{\kappa}_{\pm}^{\alpha,\beta}\rangle=\frac{1}{2}\left(\langle A\rangle+\langle C\rangle\pm\sqrt{4\langle B\rangle^{2}+(\langle A\rangle-\langle C\rangle)^{2}}\right) \tag{44}
$$
as a function of $S$ . Since $\mathds{E}[A]=\mathds{E}[C]={(H_{\theta})^{i}}_{i}$ and $\mathds{E}[B]=0$ [see Eq. (36)], we have that $\langle\tilde{\kappa}_{±}^{\alpha,\beta}\rangle=\bar{\kappa}^{\alpha,\beta}$ in the limit $S→∞$ . In the current example, the ensemble means $\langle\tilde{\kappa}_{±}^{\alpha,\beta}\rangle$ thus approach $\bar{\kappa}^{\alpha,\beta}=0$ for large numbers of samples $S$ , represented by the dashed red lines in Fig. 7 (b). The ensemble means $\langle\kappa_{±}^{\alpha,\beta}\rangle$ converge towards values of opposite sign, indicating a saddle point.
For a sample size of $S=10^{4}$ , we show the distribution of the principal curvatures $\kappa_{±}^{\alpha,\beta}$ in Fig. 8 (a). We observe that the distributions are plausibly Gaussian. We also calculate the probability $\Pr(\kappa_{+}^{\alpha,\beta}\kappa_{-}^{\alpha,\beta}>0)$ that the critical point in the lower-dimensional, random projection does not appear as a saddle (i.e., $\kappa_{+}^{\alpha,\beta}\kappa_{-}^{\alpha,\beta}>0$ ). For the example shown in Fig. 8 (a), we find that $\Pr(\kappa_{+}^{\alpha,\beta}\kappa_{-}^{\alpha,\beta}>0)≈ 0.3$ . That is, in about 30% of the simulated projections, the lower-dimensional loss landscape wrongly indicates that it does not correspond to a saddle.
Our first example, which is based on the loss function (40), shows that the principal curvatures in the lower-dimensional representation of $L(\theta)$ may capture the saddle behavior in the original space if one computes ensemble means $\langle\kappa_{±}^{\alpha,\beta}\rangle$ in the lower-dimensional space [see Fig. 7 (b)]. However, if one first calculates ensemble means of the elements of the dimension-reduced Hessian $H_{\alpha,\beta}$ to infer $\langle\tilde{\kappa}_{±}^{\alpha,\beta}\rangle$ , the loss landscape appears to be flat in this example. We thus conclude that different ways of computing ensemble means (either before or after calculating the principal curvatures) may lead to different results with respect to the “flatness” of a dimension-reduced loss landscape.
Unequal number of curvature directions
In the next example, we will show that random projections cannot identify certain saddle points regardless of the underlying averaging process. We consider the loss function
$$
L(\theta)=\frac{1}{2}\theta_{2n+1}\left(\sum_{i=1}^{\tilde{n}}\theta_{i}^{2}-\sum_{i=\tilde{n}+1}^{2n}\theta_{i}^{2}\right)\,,\quad n\in\mathbb{Z}_{+}\,,n<\tilde{n}\leq 2n\,, \tag{45}
$$
where we use the convention $\sum_{i=a}^{b}(·)=0$ if $a>b$ . The Hessian at the critical point $(\theta^{*}_{1},...,\theta^{*}_{2n},\theta^{*}_{2n+1})=(0,...,0,1)$ is
$$
H_{\theta}=\mathrm{diag}(\underbrace{1,\dots,1}_{\tilde{n}~\mathrm{times}},\underbrace{-1,\dots,-1}_{2n-\tilde{n}~\mathrm{times}},0)\,. \tag{46}
$$
As in the previous example, the critical point is again a saddle, but the mean curvature is ${H=2(\tilde{n}-n)/N>0}$ . In the following numerical experiments, we set $n=500$ and $\tilde{n}=800$ . Figure 7 (c) shows that the ensemble means $\langle(H_{\alpha,\beta})_{ij}\rangle$ converge towards the expected value $\mathds{E}[(H_{\alpha,\beta})_{ij}]$ as the number of samples increases. We again observe that a relatively large number of random loss projections $S$ between $10^{3}$ and $10^{4}$ is required to keep the deviations of ensemble means from their corresponding expected values small. Because of the dominance of positive principal curvatures $\kappa_{i}^{\theta}$ in the original space, the corresponding ensemble means of principal curvatures (i.e., $\langle\kappa_{±}^{\alpha,\beta}\rangle$ , $\langle\tilde{\kappa}_{±}^{\alpha,\beta}\rangle$ ) in the lower-dimensional representation approach positive values [see Fig. 7 (d)]. The distribution of $\kappa_{±}^{\alpha,\beta}$ indicates that the probability of observing a saddle in the lower-dimensional loss landscape is vanishingly small [see Fig. 8 (b)]. In this second example, both ways of computing ensemble means, before and after calculating the lower-dimensional principal curvatures, mistakenly suggest that the saddle in the original space is a minimum in dimension-reduced space.
To summarize, for both loss functions (40) and (45), the saddle point $\theta^{*}=(0,...,0,1)$ in the original loss function $L(\theta)$ is often misrepresented in lower-dimensional representations $L(\theta+\alpha\eta+\beta\delta)$ if random directions are used. Depending on (i) the employed curvature measure and (ii) the index of the underlying Hessian $H_{\theta}$ in the original space, the saddle $\theta^{*}=(0,...,0,1)$ may appear erroneously as either a minimum, maximum, or an almost flat region.
If the critical point were a minimum or maximum (i.e., a critical point associated with a positive definite or negative definite Hessian $H_{\theta}$ ), it would be correctly represented in the corresponding expected random projection because the sign of its principal curvature $\bar{\kappa}^{\alpha,\beta}$ , which is proportional to the sum of all eigenvalues $\kappa_{i}^{\theta}$ of the Hessian $H_{\theta}$ in the original loss space, would be equal to the sign of the principal curvatures $\kappa_{i}^{\theta}$ . However, such points are scarce in high-dimensional loss spaces [140, 141].
Finally, because of the confounding factors associated with the inability of random projections to correctly identify saddle information, it does not appear advisable to use “flatness” around a critical point in a lower-dimensional random loss projection as a measure of generalization error [122].
Curvature-based Hessian trace estimation
<details>
<summary>trace_estimate_top.png Details</summary>
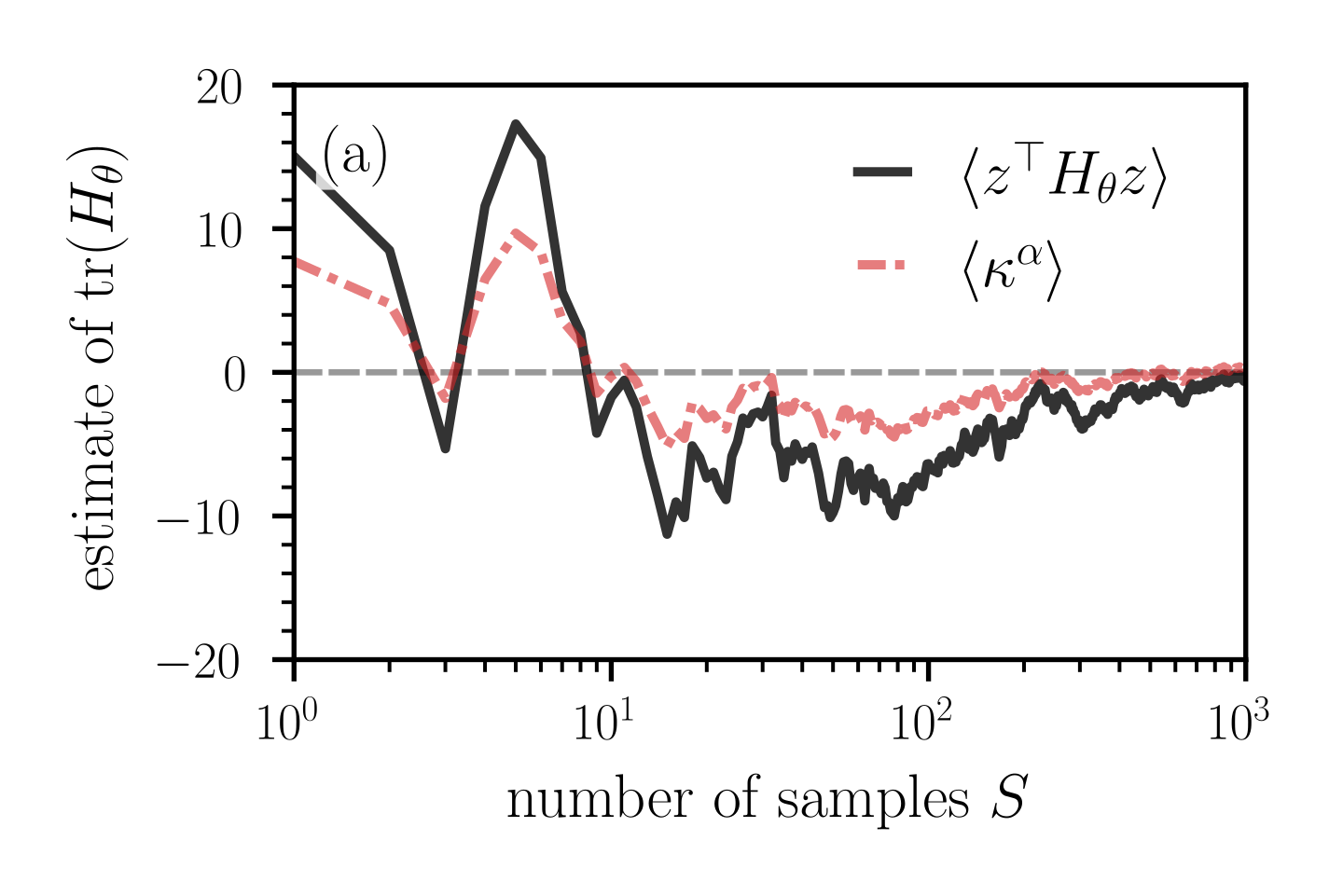
### Visual Description
## Line Chart: Estimate of tr(Hθ) vs. Number of Samples
### Overview
The image is a line chart comparing two data series: `<z^T Hθz>` (black solid line) and `<κ^α>` (red dashed line), plotted against the number of samples S on a logarithmic scale. The y-axis represents the estimate of tr(Hθ). Both series converge towards zero as the number of samples increases.
### Components/Axes
* **Title:** There is no overall title for the chart.
* **X-axis:**
* Label: "number of samples S"
* Scale: Logarithmic, ranging from 10^0 (1) to 10^3 (1000).
* Tick marks are present at 10^0, 10^1, 10^2, and 10^3.
* **Y-axis:**
* Label: "estimate of tr(Hθ)"
* Scale: Linear, ranging from -20 to 20.
* Tick marks are present at -20, -10, 0, 10, and 20.
* **Legend:** Located in the top-right corner.
* Black solid line: `<z^T Hθz>`
* Red dashed line: `<κ^α>`
* **Horizontal Line:** A dashed gray line is present at y = 0.
* **(a):** The letter (a) is present in the top-left corner of the chart.
### Detailed Analysis
* **`<z^T Hθz>` (Black Solid Line):**
* Trend: Starts at approximately 14 at S=1, fluctuates significantly, and converges towards 0 as S increases.
* Data Points:
* S = 1: approximately 14
* S = 5: approximately -6
* S = 8: approximately 18
* S = 10: approximately 10
* S = 20: approximately -5
* S = 50: approximately -8
* S = 100: approximately -5
* S = 1000: approximately 0
* **`<κ^α>` (Red Dashed Line):**
* Trend: Starts at approximately 8 at S=1, fluctuates, and converges towards 0 as S increases.
* Data Points:
* S = 1: approximately 8
* S = 5: approximately 10
* S = 8: approximately 0
* S = 10: approximately -2
* S = 20: approximately -5
* S = 50: approximately -3
* S = 100: approximately 0
* S = 1000: approximately 0
### Key Observations
* Both data series exhibit significant fluctuations for small values of S (number of samples).
* As the number of samples increases, both series converge towards 0.
* The black line `<z^T Hθz>` shows more extreme fluctuations than the red line `<κ^α>` for smaller values of S.
* The dashed gray line at y=0 represents a reference point, indicating the convergence value for both series.
### Interpretation
The chart illustrates how the estimates of tr(Hθ) for two different methods, represented by `<z^T Hθz>` and `<κ^α>`, change with an increasing number of samples. The convergence of both series towards zero suggests that both methods provide increasingly accurate estimates as the sample size grows. The fluctuations at smaller sample sizes indicate that the estimates are less stable and more sensitive to the specific samples used. The black line's greater fluctuations suggest that the corresponding method may be more sensitive to sample variations than the method represented by the red line, especially when the number of samples is limited. The logarithmic scale on the x-axis emphasizes the behavior of the estimates at smaller sample sizes.
</details>
<details>
<summary>trace_estimate_bottom.png Details</summary>
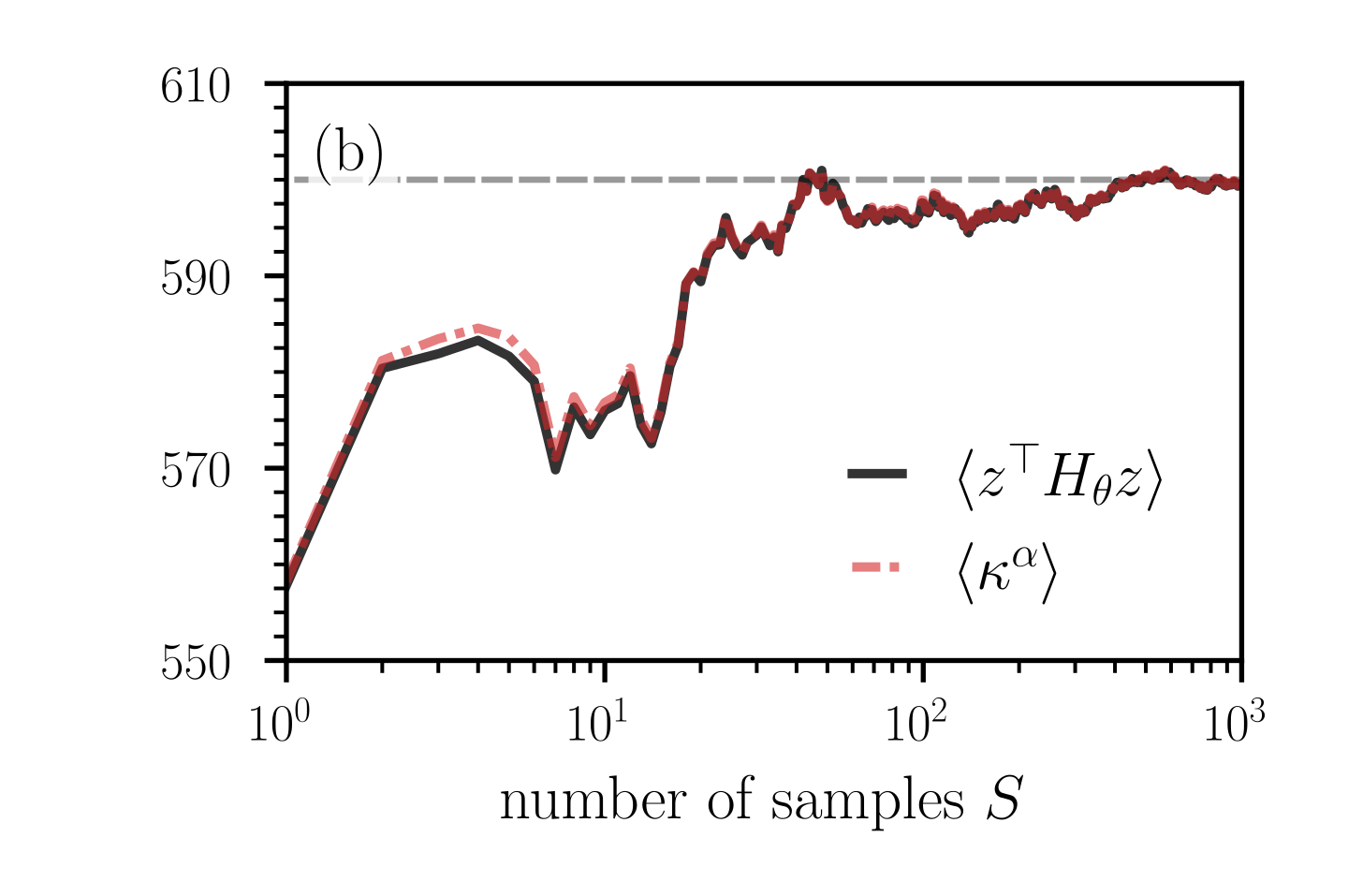
### Visual Description
## Chart: Sample Number vs. Value
### Overview
The image is a line chart comparing two data series, `<z^T H_θ z>` and `<κ^α>`, against the number of samples (S) on a logarithmic scale. The chart shows how the values of these two series change as the number of samples increases from 10^0 to 10^3. A horizontal dashed line is present at approximately y=600, labeled "(b)".
### Components/Axes
* **X-axis:** "number of samples S". The scale is logarithmic, ranging from 10^0 to 10^3.
* **Y-axis:** The y-axis is not explicitly labeled, but it represents the value of the two data series. The scale ranges from 550 to 610.
* **Legend:** Located on the right side of the chart.
* Black solid line: `<z^T H_θ z>`
* Red dashed line: `<κ^α>`
* **Horizontal Dashed Line:** A grey dashed line is present at approximately y=600, labeled "(b)".
### Detailed Analysis
* **`<z^T H_θ z>` (Black Solid Line):**
* Trend: Initially increases sharply, then decreases, fluctuates, and eventually plateaus around 600.
* Data Points:
* At S = 10^0 (1), the value is approximately 550.
* Peaks around S = 5 at approximately 585.
* Dips around S = 8 at approximately 570.
* Plateaus around S = 10^2 (100) at approximately 600.
* **`<κ^α>` (Red Dashed Line):**
* Trend: Mirrors the trend of `<z^T H_θ z>`, initially increasing sharply, then decreasing, fluctuating, and eventually plateauing around 600.
* Data Points:
* At S = 10^0 (1), the value is approximately 550.
* Peaks around S = 5 at approximately 585.
* Dips around S = 8 at approximately 570.
* Plateaus around S = 10^2 (100) at approximately 600.
* **Horizontal Dashed Line (Grey):**
* The grey dashed line is at approximately y=600.
### Key Observations
* The two data series, `<z^T H_θ z>` and `<κ^α>`, exhibit very similar behavior across the range of sample numbers.
* Both series show a rapid increase initially, followed by fluctuations, and then converge to a stable value around 600 as the number of samples increases.
* The horizontal dashed line at y=600 seems to represent a target or reference value.
### Interpretation
The chart suggests that both `<z^T H_θ z>` and `<κ^α>` converge to a similar value as the number of samples increases. The initial fluctuations indicate that the estimates are unstable with fewer samples, but as the sample size grows, the estimates become more reliable and converge towards a stable value, potentially indicated by the horizontal dashed line. The close tracking of the two series suggests a strong correlation or relationship between them. The label "(b)" on the horizontal line might refer to a specific parameter or condition being met when the values reach this level.
</details>
Figure 9: Estimating the trace of the Hessian $H_{\theta}$ . In panels (a) and (b), the loss functions are given by Eqs. (40) and (45), respectively. We evaluate the corresponding Hessians (42) and (46) at the saddle point $\theta^{*}=(\theta^{*}_{1},...,\theta^{*}_{2n},\theta^{*}_{2n+1})=(0,...,0,1)$ . In both loss functions, we set $n=500$ and in loss function (45) we set $\tilde{n}=800$ . Solid black and dash-dotted red lines represent Hutchinson [ $\langle z^{→p}H_{\theta}z\rangle$ ; see Eq. (39)] and curvature-based ( $\langle\kappa^{\alpha}\rangle$ ) estimates of $\mathrm{tr}(H_{\theta})$ , respectively. We compute ensemble means $\langle·\rangle$ as defined in Eq. (43) for different numbers of random projections $S$ . The trace estimates in panels (a) and (b), respectively, converge towards the true trace values $\mathrm{tr}(H_{\theta})=0$ and $\mathrm{tr}(H_{\theta})=600$ that are indicated by dashed grey lines. In both methods, the same random vectors with elements that are distributed according to a standard normal distribution are used. For the curvature-based estimation of $\mathrm{tr}(H_{\theta})$ , we perform least-square fits of $L(\theta^{*}+\alpha\eta)$ over an interval $\alpha∈[-0.05,0.05]$ .
In accordance with Sec. 1, we now use the loss functions (40) and (45) to compare the convergence behavior between the original Hutchinson method (39) and the curvature-based trace estimation (37). Instead of two random directions, we use one random Gaussian direction $\eta$ and perform least-squares fits for 50 equidistant values of $\alpha$ in the interval $[-0.05,0.05]$ to extract estimates of $\mathrm{tr}(H_{\theta})$ from $L(\theta^{*}+\alpha\eta)$ . We use the same random Gaussian directions in Hutchinson’s method.
Figure 9 shows how the Hutchinson and curvature-based trace estimates converge towards the true trace values, 0 for the loss function (40) and 600 for the loss function (45) with $n=500$ and $\tilde{n}=800$ . Given that we use the same random vectors in both methods, their convergence behavior towards the true trace value is similar.
With the curvature-based method, one can produce Hutchinson-type trace estimates without computing Hessian-vector products. However, it requires the user to specify an appropriate interval for $\alpha$ so that the mean curvature can be properly estimated in a quadratic-approximation regime. It also requires a sufficiently large number of points in this interval. Therefore, it may be less accurate than the original Hutchinson method.
3 Hessian directions
<details>
<summary>loss_projection_top.png Details</summary>
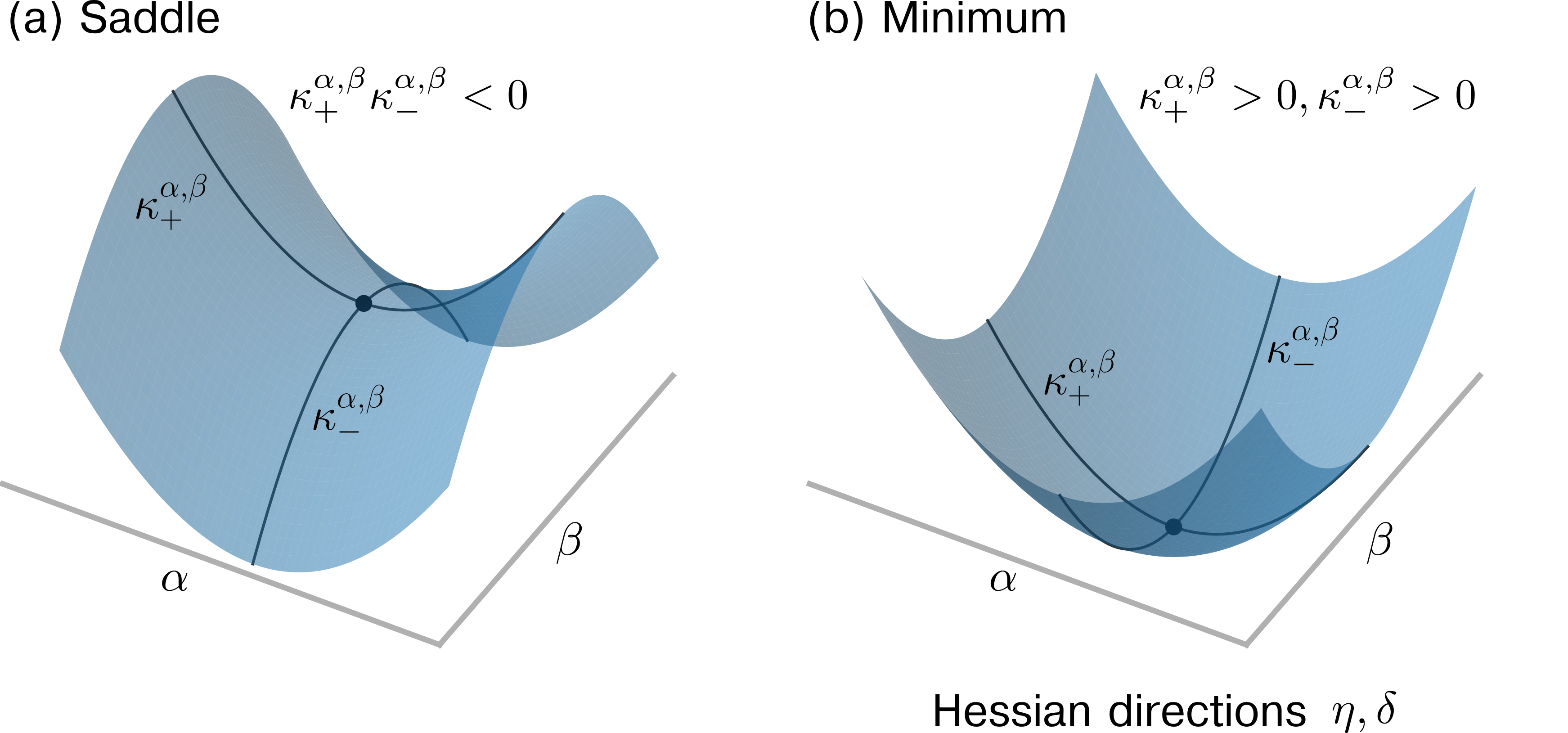
### Visual Description
## Diagram: Saddle Point vs. Minimum
### Overview
The image presents two 3D diagrams illustrating the concepts of a saddle point and a minimum in a two-dimensional space defined by parameters alpha (α) and beta (β). Each diagram shows a surface representing a function's value over the α-β plane, along with curves indicating the Hessian directions.
### Components/Axes
* **Axes:** The diagrams have two axes labeled α and β, representing the two parameters. The vertical axis implicitly represents the function's value.
* **Surface:** A blue-shaded surface represents the function's value over the α-β plane. The surface has a grid on it.
* **Hessian Directions:** Two dark blue curves on each surface indicate the Hessian directions. These are labeled as κ₊^(α,β) and κ₋^(α,β).
* **Critical Point:** A dark blue dot marks the critical point (where the gradient is zero) on each surface.
* **Titles:** The diagrams are titled "(a) Saddle" and "(b) Minimum".
* **Conditions:** Above each diagram, conditions are stated regarding the curvatures:
* Saddle: κ₊^(α,β) * κ₋^(α,β) < 0
* Minimum: κ₊^(α,β) > 0, κ₋^(α,β) > 0
* **Footer:** "Hessian directions η, δ"
### Detailed Analysis
**Diagram (a): Saddle**
* The surface has a saddle shape, with a minimum along one direction and a maximum along another.
* The critical point is located at the saddle point.
* The curve labeled κ₊^(α,β) rises away from the saddle point.
* The curve labeled κ₋^(α,β) descends away from the saddle point.
* The condition κ₊^(α,β) * κ₋^(α,β) < 0 indicates that the product of the curvatures along the two Hessian directions is negative, which is characteristic of a saddle point.
**Diagram (b): Minimum**
* The surface has a bowl shape, indicating a minimum.
* The critical point is located at the minimum.
* Both curves labeled κ₊^(α,β) and κ₋^(α,β) rise away from the minimum.
* The condition κ₊^(α,β) > 0, κ₋^(α,β) > 0 indicates that the curvatures along both Hessian directions are positive, which is characteristic of a minimum.
### Key Observations
* The diagrams visually represent the difference between a saddle point and a minimum based on the shape of the surface and the curvatures along the Hessian directions.
* The conditions stated above each diagram mathematically define the nature of the critical point.
### Interpretation
The image illustrates how the Hessian matrix (specifically, the curvatures along the Hessian directions) can be used to classify critical points of a function. A saddle point occurs when the curvatures have opposite signs (one positive, one negative), while a minimum occurs when both curvatures are positive. This is a fundamental concept in optimization and calculus, used to find and characterize extrema of functions. The Hessian directions η, δ are the eigenvectors of the Hessian matrix, indicating the directions of maximum and minimum curvature.
</details>
<details>
<summary>loss_projection_bottom.png Details</summary>
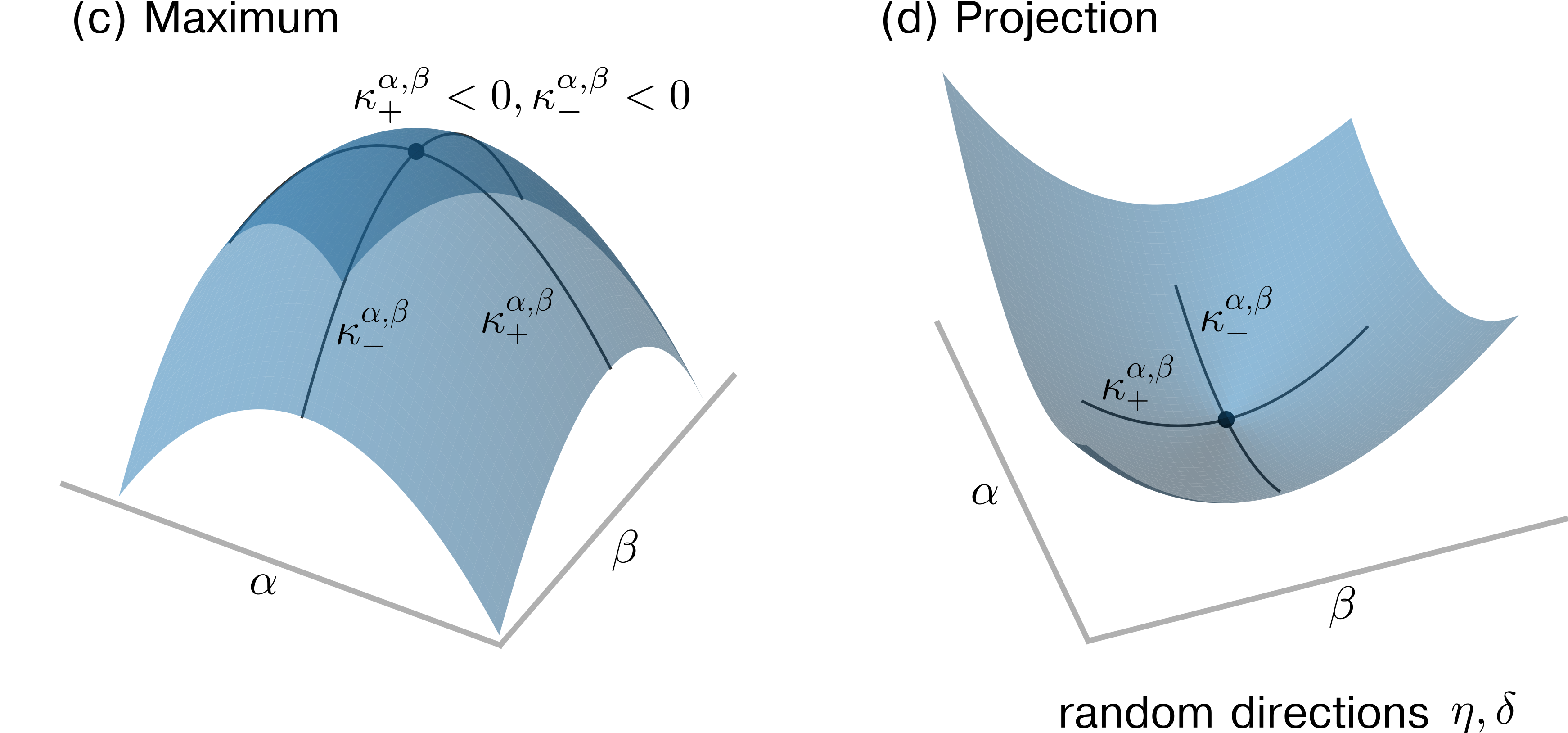
### Visual Description
## Diagram: Maximum and Projection
### Overview
The image presents two 3D surface diagrams, labeled (c) Maximum and (d) Projection. Both diagrams depict surfaces in relation to axes labeled α and β. Diagram (c) shows a surface with a maximum point, while diagram (d) shows a surface with a minimum point. Both diagrams include curves on the surface labeled with κ symbols.
### Components/Axes
**Diagram (c) Maximum:**
* **Title:** (c) Maximum
* **Axes:**
* α (horizontal axis)
* β (axis extending into the page)
* **Surface:** A curved surface with a maximum point. The surface is shaded in varying tones of blue.
* **Curves:** Two curves on the surface, intersecting at the maximum point.
* Curve 1: Labeled "κ₊^(α,β)" near the maximum point.
* Curve 2: Labeled "κ₋^(α,β)" near the maximum point.
* **Inequality:** "κ₊^(α,β) < 0, κ₋^(α,β) < 0" is displayed above the surface.
**Diagram (d) Projection:**
* **Title:** (d) Projection
* **Axes:**
* α (horizontal axis)
* β (axis extending into the page)
* **Surface:** A curved surface with a minimum point. The surface is shaded in varying tones of blue.
* **Curves:** Two curves on the surface, intersecting at the minimum point.
* Curve 1: Labeled "κ₊^(α,β)" near the minimum point.
* Curve 2: Labeled "κ₋^(α,β)" near the minimum point.
* **Text:** "random directions η, δ" is displayed below the diagram.
### Detailed Analysis
**Diagram (c) Maximum:**
* The surface appears to be a section of a paraboloid, opening downwards.
* The maximum point is located at the intersection of the two curves.
* The inequality "κ₊^(α,β) < 0, κ₋^(α,β) < 0" indicates that the curvatures in both directions are negative at the maximum point.
**Diagram (d) Projection:**
* The surface appears to be a section of a paraboloid, opening upwards.
* The minimum point is located at the intersection of the two curves.
* The text "random directions η, δ" suggests that the projection is related to random directions.
### Key Observations
* Both diagrams depict surfaces with critical points (maximum and minimum).
* The curves on the surfaces are labeled with κ symbols, likely representing curvatures.
* The inequality in diagram (c) indicates negative curvatures at the maximum point.
### Interpretation
The diagrams illustrate the concepts of maximum and projection in relation to a surface defined by parameters α and β. The curvatures (κ₊^(α,β) and κ₋^(α,β)) play a role in characterizing the shape of the surface at these critical points. The negative curvatures at the maximum point in diagram (c) are consistent with the surface being concave downwards. Diagram (d) shows the projection of the surface, potentially along random directions η and δ, resulting in a surface with a minimum point. The relationship between the original surface and its projection is not explicitly defined in the image, but it suggests a transformation or mapping of the surface.
</details>
Figure 10: Dimensionality-reduced loss $L(\theta^{*}+\alpha\eta+\beta\delta)$ of Eq. (45) with $n=900,\tilde{n}=1000$ for different directions $\eta,\delta$ . (a–c) The directions $\eta,\delta$ correspond to eigenvectors of the Hessian $H_{\theta}$ of Eq. (45). If the eigenvalues associated with $\eta,\delta$ have different signs, the corresponding loss landscape is a saddle as depicted in panel (a). If the eigenvalues associated with $\eta,\delta$ have the same sign, the corresponding loss landscape is either a minimum (both signs are positive) as shown in panel (b) or a maximum (both signs are negative) as shown in panel (c). Because there is an excess of $\tilde{n}-n=100$ positive eigenvalues in $H_{\theta}$ , a projection onto a dimension-reduced space that is spanned by the random directions $\eta,\delta$ is often associated with an apparently convex loss landscape. An example of such an apparent minimum is shown in panel (d).
Given the described shortcomings of random projections incorrectly identifying saddles of high-dimensional loss functions, we suggest to use Hessian directions (i.e., the eigenbasis of $H_{\theta}$ ) as directions $\eta,\delta$ in $L(\theta^{*}+\alpha\eta+\beta\delta)$ .
For Eq. (45) with $n=900,\tilde{n}=1000$ , we show projections along different Hessian directions in Fig. 10 (a–c). We observe that different Hessian directions indicate different types of critical points in dimension-reduced space. If the eigenvalues associated with the Hessian directions $\eta,\delta$ have different signs, the corresponding lower-dimensional loss landscape is a saddle [see Fig. 10 (a)]. If both eigenvalues have the same sign, the loss landscape is either a minimum [see Fig. 10 (b): both signs are positive] or it is a maximum [see Fig. 10 (c): both signs are negative]. If one uses a random projection instead, the resulting lower-dimensional loss landscape often appears to be a minimum in this example [see Fig. 10 (d)]. To quantify the proportion of random projections that correctly identify the saddle with $n=900,\tilde{n}=1000$ , we generated 10,000 realizations of $\kappa_{±}^{\alpha,\beta}$ [see Eq. (35)]. We find that the signs of $\kappa_{±}^{\alpha,\beta}$ were different in only about 0.5% of all simulated realizations. That is, in this example the principal curvatures $\kappa_{±}^{\alpha,\beta}$ indicate a saddle in only about 0.5% of the studied projections.
In accordance with related works that use Hessian information [142, 143], our proposal uses Hessian-vector products (HVPs). We first compute the largest-magnitude eigenvalue and then use an annihilation method [144] to compute the second largest-magnitude eigenvalue of opposite sign (see Algorithm 1). The corresponding eigenvectors are the dominant Hessian directions. Other deflation techniques can be used to find additional Hessian directions.
We employ HVPs to compute Hessian directions without an explicit representation of $H_{\theta}$ using the identity
$$
\nabla_{\theta}[(\nabla_{\theta}L)^{\top}v]=(\nabla_{\theta}\nabla_{\theta}L)v+(\nabla_{\theta}L)^{\top}\nabla_{\theta}v=H_{\theta}v\,. \tag{47}
$$
In the first step, the gradient $(∇_{\theta}L)^{→p}$ is computed using reverse-mode autodifferentiation (AD) to then compute the scalar product $[(∇_{\theta}L)^{→p}v]$ . In the second step, we again apply reverse-mode AD to the computational graph associated with the scalar product $[(∇_{\theta}L)^{→p}v]$ . Because the vector $v$ does not depend on $\theta$ (i.e., $∇_{\theta}v=0$ ), the result is $H_{\theta}v$ . One may also use forward-mode AD in the second step to provide a more memory efficient implementation.
Algorithm 1 Compute dominant Hessian directions
1: $L_{1}=\mathrm{LinearOperator((N,N),~matvec=hvp)}$ initialize linear operator for HVP calculation
2: eigval1, eigvec1 = solve_lm_evp( $L_{1}$ ) compute largest-magnitude eigenvalue and corresponding eigenvector associated with operator $L_{1}$
3: shifted_hvp(vec) = hvp(vec) - eigval1*vec define shifted HVP
4: $L_{2}=\mathrm{LinearOperator((N,N),~matvec=shifted\_hvp)}$ initialize linear operator for shifted HVP calculation
5: eigval2, eigvec2 = solve_lm_evp( $L_{2}$ ) compute largest-magnitude eigenvalue and corresponding eigenvector associated with operator $L_{2}$
6: eigval2 += eigval1
7: if eigval1 $>=$ 0 then
8: maxeigval, maxeigvec = eigval1, eigvec1
9: mineigval, mineigvec = eigval2, eigvec2
10: else
11: maxeigval, maxeigvec = eigval2, eigvec2
12: mineigval, mineigvec = eigval1, eigvec1
13: end if
14: return: maxeigval, maxeigvec, mineigval, mineigvec
Image classification
<details>
<summary>resnet_panel.png Details</summary>
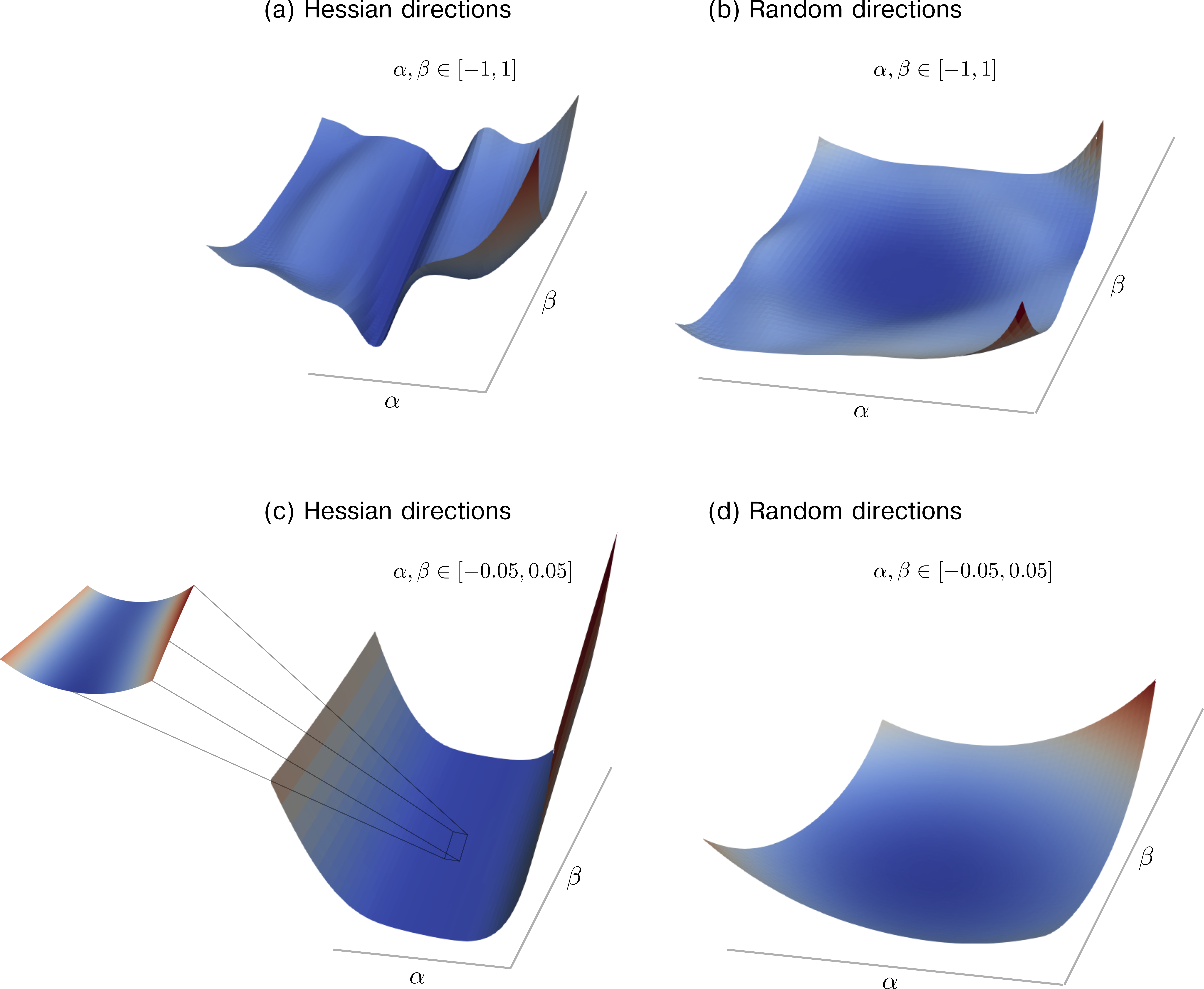
### Visual Description
## Surface Plots: Hessian vs. Random Directions
### Overview
The image presents four 3D surface plots, arranged in a 2x2 grid. Each plot visualizes a function's behavior with respect to two variables, alpha (α) and beta (β). The plots are distinguished by the method used to determine the directions (Hessian vs. Random) and the range of alpha and beta values. The surface color represents the function's output, transitioning from blue (low values) to red (high values).
### Components/Axes
Each plot has the following components:
* **Axes:** Two axes labeled α (alpha) and β (beta) form the base of each plot.
* **Surface:** A colored surface represents the function's output for different combinations of α and β. The color gradient ranges from blue to red.
* **Titles:** Each plot has a title indicating the direction type (Hessian or Random) and a range for α and β.
Specific labels and ranges:
* **(a) Hessian directions:** α, β ∈ [-1, 1]
* **(b) Random directions:** α, β ∈ [-1, 1]
* **(c) Hessian directions:** α, β ∈ [-0.05, 0.05]
* **(d) Random directions:** α, β ∈ [-0.05, 0.05]
### Detailed Analysis
**Plot (a): Hessian directions, α, β ∈ [-1, 1]**
* The surface exhibits significant undulations and variations.
* There's a distinct "valley" or trough running across the surface.
* The color varies considerably, indicating a wide range of function values.
* The surface reaches higher values (red) at the edges, particularly along the β axis.
**Plot (b): Random directions, α, β ∈ [-1, 1]**
* The surface is smoother compared to plot (a).
* It has a bowl-like shape, with the lowest point in the center.
* The color gradient is more gradual, suggesting a smaller range of function values.
* The surface also reaches higher values (red) at the edges, particularly along the β axis.
**Plot (c): Hessian directions, α, β ∈ [-0.05, 0.05]**
* This plot shows a zoomed-in view of the Hessian directions around the origin.
* The surface is relatively smooth and bowl-shaped.
* The color is predominantly blue, indicating low function values in this region.
* A small inset diagram shows a further zoomed-in view of a region on the surface. The inset is connected to the main plot by several lines.
**Plot (d): Random directions, α, β ∈ [-0.05, 0.05]**
* This plot shows a zoomed-in view of the Random directions around the origin.
* The surface is smooth and bowl-shaped, similar to plot (c).
* The color is predominantly blue, indicating low function values in this region.
### Key Observations
* **Direction Type:** Hessian directions (a, c) result in more complex and variable surfaces compared to Random directions (b, d).
* **Range of α and β:** Reducing the range of α and β to [-0.05, 0.05] (c, d) reveals a smoother, bowl-shaped behavior near the origin for both Hessian and Random directions.
* **Surface Color:** The color gradient indicates the function's output value, with blue representing lower values and red representing higher values.
### Interpretation
The plots illustrate how different methods for choosing directions (Hessian vs. Random) affect the shape of the function's surface. Hessian directions, which are based on the function's curvature, lead to more complex and potentially unstable behavior, especially when considering a wider range of α and β values. Random directions, on the other hand, result in a smoother and more predictable surface.
The zoomed-in views (c, d) suggest that near the origin, both methods exhibit a similar bowl-shaped behavior, indicating a local minimum. However, the behavior diverges significantly as α and β move away from the origin, as seen in plots (a) and (b). This suggests that the choice of direction method can have a significant impact on the optimization process, particularly when dealing with non-convex functions.
</details>
Figure 11: Loss landscape projections for ResNet-56. (a,c) The projection directions $\eta,\delta$ are given by the eigenvectors associated with the largest and smallest eigenvalues of the Hessian $H_{\theta}$ , respectively. The zoomed inset in panel (c) shows the loss landscape for $(\alpha,\beta)∈[-0.01,0.005]×[-0.05,0.05]$ . We observe a decreasing loss along the negative $\beta$ -axis. (b,d) The projection directions $\eta,\delta$ are given by random vectors. The domains of $(\alpha,\beta)$ in panels (a,b) and (c,d) are $[-1,1]×[-1,1]$ and $[-0.05,0.05]×[-0.05,0.05]$ , respectively. All shown cross-entropy loss landscapes are based on evaluating the CIFAR-10 training dataset that consists of 50,000 images.
As an illustration of a loss landscape of an ANN employed in image classification, we focus on the ResNet-56 architecture that has been trained as detailed in Ref. 122 on CIFAR-10 using stochastic gradient descent (SGD) with Nesterov momentum. The number of parameters of this ANN is 855,770. The training and test losses at the local optimum found by SGD are ${9.20× 10^{-4}}$ and 0.29, respectively; the corresponding accuracies are 100.00 and 93.66, respectively.
In accordance with Ref. 122, we apply filter normalization to random directions. This and related normalization methods are often employed when generating random projections. One reason is that simply adding random vectors to parameters of a neural network loss function (or parameters of other functions) does not consider the range of parameters associated with different elements of that function. As a result, random perturbations may be too small or large to properly resolve the influence of certain parameters on a given function.
When calculating Hessian directions, we are directly taking into account the parameterization of the underlying functions that we want to visualize. Therefore, there is no need for an additional rescaling of different parts of the perturbation vector. Still, reparameterizations of a neural network can result in changes of curvature properties (see, e.g., Theorem 4 in Ref. 120).
Figure 11 shows the two-dimensional projections of the loss function (cross entropy loss) around a local critical point. The smallest and largest eigenvalues are $-16.4$ and $5007.9$ , respectively. This means that the found critical point is a saddle with a maximum negative curvature that is more than two orders of magnitude smaller than the maximum positive curvature at that point. The saddle point is clearly visible in Fig. 11 (a,c). We observe in the zoomed inset in Fig. 11 (c) that the loss decreases along the negative $\beta$ -axis.
If random directions are used, the corresponding projections indicate that the optimizer converged to a local minimum and not to a saddle point [see Fig. 11 (b,d)]. Overall, the ResNet-56 visualizations that we show in Fig. 11 exhibit structural similarities to those that we generated using the simple loss model (45) [see Fig. 10 (a,d)].
Function approximation
<details>
<summary>heatmap_function_approximation.png Details</summary>
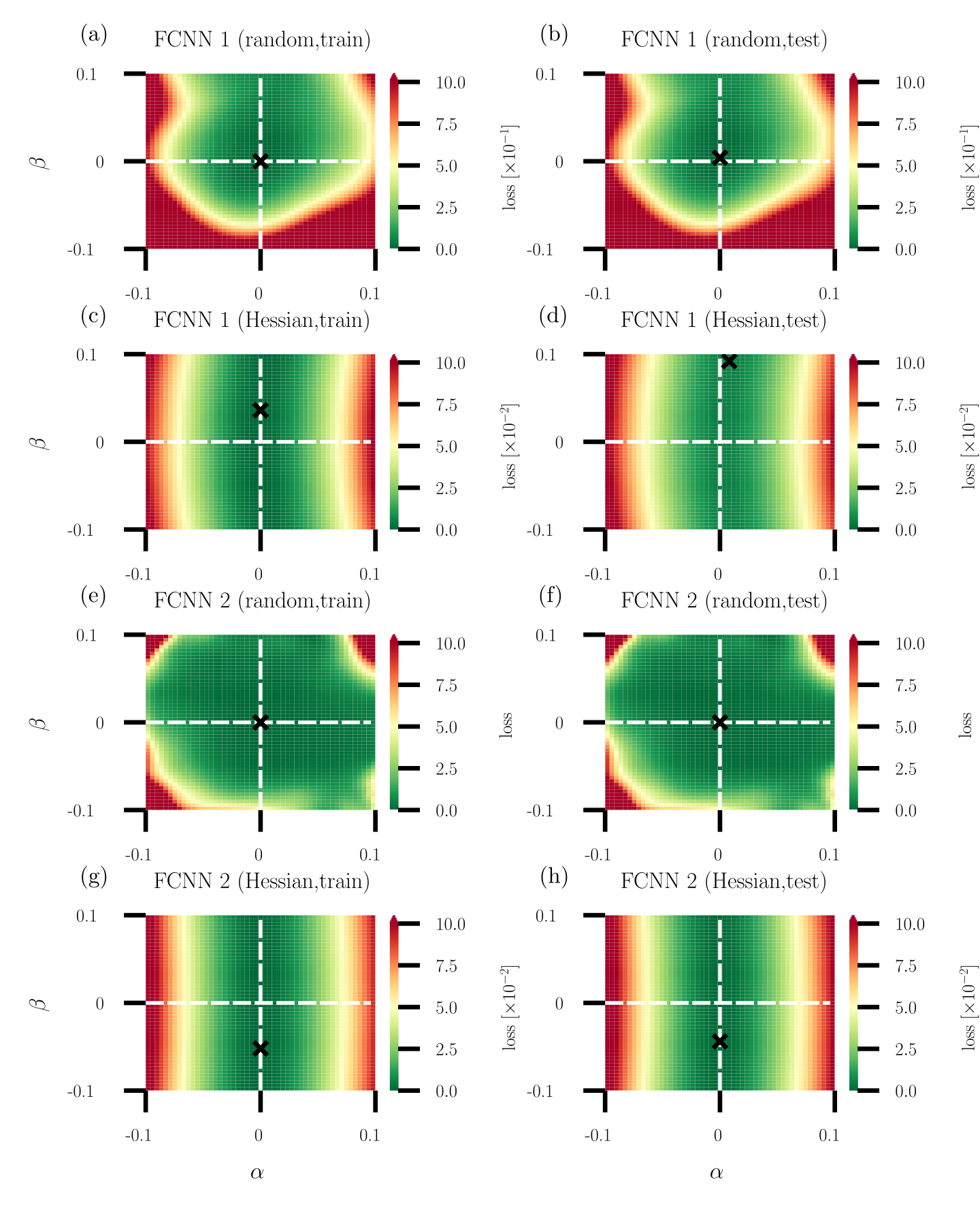
### Visual Description
## Heatmap: Loss Landscapes of FCNN Models
### Overview
The image presents a series of heatmaps visualizing the loss landscapes of Fully Connected Neural Networks (FCNNs) under different training conditions and architectures. Each heatmap represents the loss value as a function of two parameters, alpha (α) and beta (β). The heatmaps are arranged in a 2x4 grid, varying by network architecture (FCNN 1 vs. FCNN 2), training method (random vs. Hessian), and dataset (train vs. test).
### Components/Axes
* **X-axis (Horizontal):** α (alpha), ranging from -0.1 to 0.1.
* **Y-axis (Vertical):** β (beta), ranging from -0.1 to 0.1.
* **Color Scale (Right):** Represents the loss value. The scale ranges from 0.0 to 10.0, with color transitions indicating different loss levels. Red indicates higher loss, and green indicates lower loss. The loss is scaled by 10^-1 for the top row and 10^-2 for the remaining rows.
* **Titles:** Each subplot has a title indicating the FCNN architecture (1 or 2), training method (random or Hessian), and dataset (train or test).
* (a) FCNN 1 (random, train)
* (b) FCNN 1 (random, test)
* (c) FCNN 1 (Hessian, train)
* (d) FCNN 1 (Hessian, test)
* (e) FCNN 2 (random, train)
* (f) FCNN 2 (random, test)
* (g) FCNN 2 (Hessian, train)
* (h) FCNN 2 (Hessian, test)
* **Axes Markers:** The axes are marked at -0.1, 0, and 0.1 for both α and β.
* **Crosshair:** Each plot contains a dashed white crosshair centered at (0,0). A black 'X' is located at the intersection of the crosshair.
### Detailed Analysis
**Subplot (a): FCNN 1 (random, train)**
* Trend: A green (low loss) region is centered around (0,0), surrounded by a red (high loss) region in the corners.
* Loss values: The minimum loss (green) is approximately 0 near the center. The maximum loss (red) reaches approximately 10 * 10^-1 = 1.0 in the corners.
**Subplot (b): FCNN 1 (random, test)**
* Trend: Similar to (a), a green (low loss) region is centered around (0,0), surrounded by a red (high loss) region in the corners.
* Loss values: The minimum loss (green) is approximately 0 near the center. The maximum loss (red) reaches approximately 10 * 10^-1 = 1.0 in the corners.
**Subplot (c): FCNN 1 (Hessian, train)**
* Trend: A horizontal green band (low loss) is centered around β = 0, with red regions (high loss) above and below.
* Loss values: The minimum loss (green) is approximately 0 along the horizontal band. The maximum loss (red) reaches approximately 10 * 10^-2 = 0.1 at the top and bottom edges.
**Subplot (d): FCNN 1 (Hessian, test)**
* Trend: Similar to (c), a horizontal green band (low loss) is centered around β = 0, with red regions (high loss) above and below.
* Loss values: The minimum loss (green) is approximately 0 along the horizontal band. The maximum loss (red) reaches approximately 10 * 10^-2 = 0.1 at the top and bottom edges.
**Subplot (e): FCNN 2 (random, train)**
* Trend: A green (low loss) region is centered around (0,0), with red regions (high loss) in the corners. The green region appears slightly more elongated vertically compared to FCNN 1.
* Loss values: The minimum loss (green) is approximately 0 near the center. The maximum loss (red) reaches approximately 10 * 10^-2 = 0.1 in the corners.
**Subplot (f): FCNN 2 (random, test)**
* Trend: Similar to (e), a green (low loss) region is centered around (0,0), with red regions (high loss) in the corners.
* Loss values: The minimum loss (green) is approximately 0 near the center. The maximum loss (red) reaches approximately 10 * 10^-2 = 0.1 in the corners.
**Subplot (g): FCNN 2 (Hessian, train)**
* Trend: A horizontal green band (low loss) is centered around β = 0, with red regions (high loss) above and below.
* Loss values: The minimum loss (green) is approximately 0 along the horizontal band. The maximum loss (red) reaches approximately 10 * 10^-2 = 0.1 at the top and bottom edges.
**Subplot (h): FCNN 2 (Hessian, test)**
* Trend: Similar to (g), a horizontal green band (low loss) is centered around β = 0, with red regions (high loss) above and below.
* Loss values: The minimum loss (green) is approximately 0 along the horizontal band. The maximum loss (red) reaches approximately 10 * 10^-2 = 0.1 at the top and bottom edges.
### Key Observations
* **Training Method Impact:** The Hessian training method results in a loss landscape with a clear horizontal band of low loss around β = 0 for both FCNN 1 and FCNN 2. The random training method results in a more localized low-loss region around (0,0).
* **Network Architecture Impact:** The loss landscapes for FCNN 1 and FCNN 2 are qualitatively similar for both random and Hessian training methods. However, the scale of the loss differs, with FCNN 1 (random) having a higher loss scale (10^-1) compared to the others (10^-2).
* **Train vs. Test:** The loss landscapes for train and test datasets are very similar for each combination of network architecture and training method, suggesting good generalization.
### Interpretation
The heatmaps visualize how the loss function changes as the parameters α and β are varied. The goal is to find the values of α and β that minimize the loss, represented by the green regions.
The Hessian training method appears to create a loss landscape where the loss is less sensitive to changes in α, as indicated by the horizontal bands of low loss. This might suggest that the Hessian method leads to a more robust solution with respect to variations in α.
The random training method, on the other hand, results in a more localized minimum around (0,0), suggesting that the solution is more sensitive to changes in both α and β.
The similarity between the train and test loss landscapes indicates that the models are generalizing well to unseen data. The difference in loss scale between FCNN 1 (random) and the other configurations suggests that FCNN 1 (random) might be less efficient or require further optimization.
</details>
Figure 12: Heatmaps of the mean squared error (MSE) loss along random and dominant Hessian directions for a function-approximation task. (a–d) Loss heatmaps for a fully connected neural network (FCNN) with 2 layers and 100 ReLU activations per layer [(a,c): training data, (b,d): test data]. (e–h) Loss heatmaps for an FCNN with 10 layers and 100 ReLU activations per layer [(e,g): training data, (f,h): test data]. Random directions are used in panels (a,b,e,f) while Hessian directions are used in panels (c,d,g,h). Green and red regions indicate small and large mean squared error (MSE) loss values, respectively. Black crosses indicate the positions of loss minima in the shown domain. Both neural networks, FCNN 1 and FCNN 2, are trained to approximate the smooth one-dimensional function (48).
As another example, we compare loss function visualizations that are based on random and Hessian directions in a function-approximation task. In accordance with Ref. 145, we consider the smooth one-dimensional function
$$
f(x)=\log(\sin(10x)+2)+\sin(x)\,, \tag{48}
$$
where $x∈[-1,1)$ . To approximate $f(x)$ , we use two fully connected neural networks (FCNNs) with 2 and 10 layers, respectively. Each layer has 100 ReLU activations. The numbers of parameters of the 2 and 10 layer architectures are 20,501 and 101,301, respectively. The training data is based on 50 points that are sampled uniformly at random from the interval $[-1,1)$ . We train both ANNs using a mean squared error (MSE) loss function and SGD with a learning rate of 0.1. The 2 and 10 layer architectures are respectively trained for 100,000 and 50,000 epochs to reach loss values of less than $10^{-4}$ . The best model was saved and evaluated by calculating the MSE loss for 1,000 points that were sampled uniformly at random from the interval $[-1,1)$ . We present an animation illustrating the evolution of random and Hessian loss projections during training at https://vimeo.com/787174225.
Figure 12 shows heatmaps of the training and test loss landscapes of both ANNs along random and dominant Hessian directions. Black crosses in Fig. 12 indicate loss minima. In line with the previous example, which focused on an image classification ANN, we observe for both FCNNs that random projections are associated with loss values that increase along both directions $\delta,\eta$ and for both training and test data [see Fig. 12 (a,b,e,f)]. For these projections, we find that the loss minima are very close to or at the origin of the loss space. The situation is different in the loss projections that are based on Hessian directions. Figure 12 (c) shows that the loss minimum for the 2-layer FCNN is not located at the origin but at $(\alpha,\beta)≈(0,0.04)$ .
We find that the value of the training loss at that point is more than 9% smaller than the smallest training loss found in a random projection plot. The corresponding test loss is about 1% smaller than the test loss associated with the smallest training loss in the random projection plot. For the 10-layer FCNN, the smallest training loss in the Hessian direction projection is more than 26% smaller than the smallest training loss in the randomly projected loss landscape [see Fig. 12 (e,g)]. The corresponding test loss in the Hessian direction plot is about 6% smaller than the corresponding test loss minimum in the random direction plot [see Fig. 12 (f,h)]. Notice that both the training and test loss minima in the random direction heatmaps in Fig. 12 (e,f) are located at the origin while they are located at $(\alpha,\beta)≈(0,-0.05)$ in the Hessian direction heatmaps in Fig. 12 (g,h).
These results show that it is possible to improve the training loss values along the dominant negative curvature direction. Smaller loss values may also be achievable with further gradient-based training iterations, so one has to consider tradeoffs between gradient and curvature-based optimization methods.
5 Conclusions
Over several decades, research at the intersection of statistical mechanics, neuroscience, and computer science has significantly enhanced our understanding of information processing in both living systems and machines. With the increasing computing power, numerous learning algorithms conceived in the latter half of the 20th century have found widespread application in tasks such as image classification, natural language processing, and anomaly detection.
The Ising model, one of the most thoroughly studied models in statistical mechanics, shares close connections with ANNs such as Hopfield networks and Boltzmann machines. In the first part of this chapter, we described these connections and provided an illustrative example of a Boltzmann machine that learned to generate new Ising configurations based on a set of training samples.
Despite decades of active research in artificial intelligence and machine learning, providing mechanistic insights into the representational capacity and learning dynamics of modern ANNs remains challenging due to their high dimensionality and complex, non-linear structure. Visualizing the loss landscapes associated with ANNs poses a particular challenge, as one must appropriately reduce dimensionality to visualize landscapes in two or three dimensions. To put it in the words of Ker-Chau Li, “There are too many directions to project a high-dimensional data set and unguided plotting can be time-consuming and fruitless”. One approach is to employ random projections. However, this method often inaccurately depicts saddle points in high-dimensional loss landscapes as apparent minima in low-dimensional random projections.
In the second part of this chapter, we discussed various curvature measures that can be employed to characterize critical points in high-dimensional loss landscapes. Additionally, we outlined how Hessian directions (i.e., the eigenvectors of the Hessian at a critical point) can inform a more structured approach to projecting high-dimensional functions onto lower-dimensional representations.
While much of contemporary research in machine learning is driven by practical applications, incorporating theoretical contributions rooted in concepts from statistical mechanics and related disciplines holds promise for continuing to guide the development of learning algorithms.
Acknowledgements
LB acknowledges financial support from hessian.AI and the ARO through grant W911NF-23-1-0129.
References
- 1. L. Zdeborová and F. Krzakala, Statistical physics of inference: Thresholds and algorithms, Advances in Physics. 65 (5), 453–552 (2016).
- 2. G. Carleo, I. Cirac, K. Cranmer, L. Daudet, M. Schuld, N. Tishby, L. Vogt-Maranto, and L. Zdeborová, Machine learning and the physical sciences, Reviews of Modern Physics. 91 (4), 045002 (2019).
- 3. P. Mehta, M. Bukov, C.-H. Wang, A. G. Day, C. Richardson, C. K. Fisher, and D. J. Schwab, A high-bias, low-variance introduction to machine learning for physicists, Physics Reports. 810, 1–124 (2019).
- 4. D. J. Amit, H. Gutfreund, and H. Sompolinsky, Spin-glass models of neural networks, Physical Review A. 32 (2), 1007 (1985).
- 5. T. Ising, R. Folk, R. Kenna, B. Berche, and Y. Holovatch, The fate of Ernst Ising and the fate of his model, Journal of Physical Studies. 21, 3002 (2017).
- 6. R. Folk. The survival of Ernst Ising and the struggle to solve his model. In ed. Y. Holovatch, Order, Disorder and Criticality: Advanced Problems of Phase Transition Theory, pp. 1–77. World Scientific, Singapore (2023).
- 7. A. Rosenblueth, N. Wiener, and J. Bigelow, Behavior, purpose and teleology, Philosophy of Science. 10 (1), 18–24 (1943).
- 8. N. Wiener, Cybernetics or Control and Communication in the Animal and the Machine. MIT Press, Boston, MA, USA (1948).
- 9. E. Thorndike, Fundamentals of Learning. Teachers College, Columbia University, New York City, NY, USA (1932).
- 10. I. S. Berkeley, The curious case of connectionism, Open Philosophy. 2 (1), 190–205 (2019).
- 11. M. Minsky and S. Papert, Perceptrons: An Introduction to Computational Geometry, 2nd edn. MIT Press, Cambridge, MA, USA (1972).
- 12. S. Russell and P. Norvig, Artificial Intelligence: A Modern Approach, 3rd edn. Prentice Hall, Upper Saddle River, NJ, USA (2009).
- 13. V. Vapnik and A. Chervonenkis, Theory of Pattern Recognition: Statistical Learning Problems. Nauka, Moscow, Russia (1974). In Russian.
- 14. T. M. Mitchell, Machine Learning. McGraw-Hill, New York City, NY, USA (1997).
- 15. W. S. McCulloch and W. Pitts, A logical calculus of the ideas immanent in nervous activity, The Bulletin of Mathematical Biophysics. 5, 115–133 (1943).
- 16. T. H. Abraham, Nicolas Rashevsky’s mathematical biophysics, Journal of the History of Biology. 37 (2), 333–385 (2004).
- 17. A. Turing, On computable numbers with an application to the Entscheidungsproblem, Proceedings of the London Mathematical Society. 58, 230–265 (1937).
- 18. S. C. Kleene, Representation of Events in Nerve Nets and Finite Automata, In eds. C. E. Shannon and J. McCarthy, Automata Studies. (AM-34), vol. 34, pp. 3–42. Princeton University Press, Princeton, MA, USA (1956).
- 19. D. O. Hebb, The organization of behavior: A neuropsychological theory. Wiley & Sons, New York City, NY, USA (1949).
- 20. S. Löwel and W. Singer, Selection of intrinsic horizontal connections in the visual cortex by correlated neuronal activity, Science. 255 (5041), 209–212 (1992).
- 21. F. Rosenblatt, The perceptron: a probabilistic model for information storage and organization in the brain, Psychological Review. 65 (6), 386 (1958).
- 22. F. Rosenblatt et al., Principles of neurodynamics: Perceptrons and the theory of brain mechanisms. vol. 55, Spartan Books, Washington, DC, USA (1962).
- 23. B. Widrow and M. Hoff. Adaptive switching circuits. In 1960 IRE WESCON Convention Record, pp. 96–104 (1960).
- 24. S. Amari, A theory of adaptive pattern classifiers, IEEE Transactions on Electronic Computers. EC-16 (3), 299–307 (1967).
- 25. A. G. Ivakhnenko and V. G. Lapa, Cybernetics and Forecasting Techniques. American Elsevier Publishing Company, Philadelphia, PA, USA (1967).
- 26. A. G. Ivakhnenko, Polynomial theory of complex systems, IEEE Transactions on Systems, Man, and Cybernetics. (4), 364–378 (1971).
- 27. H. J. Kelley, Gradient theory of optimal flight paths, Ars Journal. 30 (10), 947–954 (1960).
- 28. S. Linnainmaa. The representation of the cumulative rounding error of an algorithm as a taylor expansion of the local rounding errors. Master’s thesis, University of Helsinki (1970).
- 29. S. Linnainmaa, Taylor expansion of the accumulated rounding error, BIT Numerical Mathematics. 16 (2), 146–160 (1976).
- 30. P. J. Werbos. Applications of advances in nonlinear sensitivity analysis. In eds. R. F. Drenick and F. Kozin, System Modeling and Optimization, pp. 762–770, Springer Berlin Heidelberg, Berlin, Heidelberg, DE (1982).
- 31. D. E. Rumelhart, G. E. Hinton, and R. J. Williams, Learning representations by back-propagating errors, Nature. 323 (6088), 533–536 (1986).
- 32. A. J. Noest. Phasor neural networks. In ed. D. Z. Anderson, Neural Information Processing Systems, Denver, Colorado, USA, 1987, pp. 584–591, American Institue of Physics (1987).
- 33. A. J. Noest, Discrete-state phasor neural networks, Physical Review A. 38 (4), 2196 (1988).
- 34. A. J. Noest, Associative memory in sparse phasor neural networks, Europhysics Letters. 6 (5), 469 (1988).
- 35. M. Kobayashi, Exceptional reducibility of complex-valued neural networks, IEEE Transactions on Neural Networks. 21 (7), 1060–1072 (2010).
- 36. T. Minemoto, T. Isokawa, H. Nishimura, and N. Matsui, Quaternionic multistate Hopfield neural network with extended projection rule, Artificial Life and Robotics. 21, 106–111 (2016).
- 37. H. Zhang, M. Gu, X. Jiang, J. Thompson, H. Cai, S. Paesani, R. Santagati, A. Laing, Y. Zhang, M. Yung, et al., An optical neural chip for implementing complex-valued neural network, Nature Communications. 12 (1), 457 (2021).
- 38. L. Böttcher and M. A. Porter, Complex networks with complex weights, Physical Review E. 109 (2), 024314 (2024).
- 39. T. Bayes, An essay towards solving a problem in the doctrine of chances, Philosophical Transactions of the Royal Society of London. 53, 370–418 (1763).
- 40. P. Laplace, M’emoire sur la probabilité des causes par les Événements, M’emoires de Mathématique et de Physique Presentés á l/Académie Royale des Sciences, Par Divers Davans, Lûs dans ses Assemblées. 6, 621–656 (1774).
- 41. T. Seidenfeld, R. A. Fisher’s fiducial argument and Bayes’ theorem, Statistical Science. 7, 358–368 (1992).
- 42. T. Seidenfeld. Forbidden fruit: When Epistemic Probability may not take a bite of the Bayesian apple. In eds. W. Harper and G. Wheeler, Probability and Inference: Essays in Honor of Henry E. Kyburg, Jr. King’s College Publications, London (2007).
- 43. H. Jeffrey, The Theory of Probability, 3rd edn. Oxford Classic Texts in the Physical Sciences, Oxford University Press, Oxford, UK (1939).
- 44. C. E. Shannon, A mathematical theory of communication, The Bell System Technical Journal. 27 (3), 379–423 (1948).
- 45. E. T. Jaynes, Information theory and statistical mechanics, Physical Review. 106 (4), 620 (1957).
- 46. E. T. Jaynes, Information theory and statistical mechanics. II, Physical Review. 108 (2), 171 (1957).
- 47. E. T. Jaynes, The well-posed problem, Foundations of Physics. 3 (4), 477–493 (1973).
- 48. E. T. Jaynes, Probability Theory: The Logic of Science. Cambridge University Press, Cambridge, UK (2003).
- 49. T. Seidenfeld, Why I am not an objective Bayesian., Theory and Decision. 11 (4), 413–440 (1979).
- 50. G. Wheeler, Objective Bayesianism and the problem of non-convex evidence, The British Journal for the Philosophy of Science. 63 (3), 841–50 (2012).
- 51. I. Hacking. Let’s not talk about objectivity. In eds. F. Padovani, A. Richardson, and J. Y. Tsou, Objectivity in Science, vol. 310, Boston Studies in the Philosophy and History of Science, pp. 19–33. Springer, Cham, CH (2015).
- 52. A. Gelman, Beyond subjective and objective in statistics, Journal of the Royal Statistical Society. Series A. 180 (4), 967–1033 (2017).
- 53. R. Haenni, J.-W. Romeijn, G. Wheeler, and J. Williamson. Logical relations in a statistical problem. In eds. B. Löwe, E. Pacuit, and J.-W. Romeijn, Foundations of the Formal Sciences VI: Reasoning about probabilities and probabilistic reasoning, vol. 16, Studies in Logic, pp. 49–79, College Publications, London, UK (2009).
- 54. G. de Cooman, Belief models: An order-theoretic investigation, Annals of Mathematics and Artificial Intelligence. 45 (5–34) (2005).
- 55. R. Haenni, J.-W. Romeijn, G. Wheeler, and J. Williamson, Probabilistic Logics and Probabilistic Networks. Synthese Library, Springer, Dordrecht (2011).
- 56. D. R. Cox, The regression analysis of binary sequences, Journal of the Royal Statistical Society. 20 (2), 215–242 (1958).
- 57. G. E. Hinton and D. van Camp. Keeping the neural networks simple by minimizing the description length of the weights. In ed. L. Pitt, Proceedings of the Sixth Annual ACM Conference on Computational Learning Theory, COLT 1993, Santa Cruz, CA, USA, July 26-28, 1993, pp. 5–13, ACM (1993).
- 58. R. M. Neal, Bayesian learning for neural networks. vol. 118, Lecture Notes in Statistics, Springer Verlog, New York City, NY, USA (1996).
- 59. S.-I. Amari, Learning patterns and pattern sequences by self-organizing nets of threshold elements, IEEE Transactions on Computers. 100 (11), 1197–1206 (1972).
- 60. J. J. Hopfield, Neural networks and physical systems with emergent collective computational abilities, Proceedings of the National Academy of Sciences of the United States of America. 79 (8), 2554–2558 (1982).
- 61. T. Isokawa, H. Nishimura, N. Kamiura, and N. Matsui, Associative memory in quaternionic Hopfield neural network, International Journal of Neural Systems. 18 (02), 135–145 (2008).
- 62. H. Ramsauer, B. Schäfl, J. Lehner, P. Seidl, M. Widrich, L. Gruber, M. Holzleitner, T. Adler, D. P. Kreil, M. K. Kopp, G. Klambauer, J. Brandstetter, and S. Hochreiter. Hopfield networks is all you need. In 9th International Conference on Learning Representations, ICLR 2021, Virtual Event, Austria, May 3-7, 2021 (2021).
- 63. M. Benedetti, E. Ventura, E. Marinari, G. Ruocco, and F. Zamponi, Supervised perceptron learning vs unsupervised Hebbian unlearning: Approaching optimal memory retrieval in Hopfield-like networks, The Journal of Chemical Physics. 156 (10) (2022).
- 64. L. Böttcher and H. J. Herrmann, Computational Statistical Physics. Cambridge University Press, Cambridge, UK (2021).
- 65. S. E. Fahlman, G. E. Hinton, and T. J. Sejnowski. Massively Parallel Architectures for AI: NETL, Thistle, and Boltzmann Machines. In ed. M. R. Genesereth, Proceedings of the National Conference on Artificial Intelligence, Washington, DC, USA, August 22-26, 1983, pp. 109–113, AAAI Press (1983).
- 66. G. E. Hinton and T. J. Sejnowski. Analyzing cooperative computation. In Proceedings of the Fifth Annual Conference of the Cognitive Science Society, Rochester, NY, USA (1983).
- 67. G. E. Hinton and T. J. Sejnowski. Optimal perceptual inference. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Washington, DC, USA, vol. 448, pp. 448–453 (1983).
- 68. D. H. Ackley, G. E. Hinton, and T. J. Sejnowski, A learning algorithm for Boltzmann machines, Cognitive Science. 9 (1), 147–169 (1985).
- 69. P. Smolensky. Information processing in dynamical systems: Foundations of harmony theory. In Parallel Distributed Processing: Explorations in the Microstructure of Cognition, vol. 1, pp. 194–281. MIT Press, Cambridge, MA, USA (1986).
- 70. G. E. Hinton, Training products of experts by minimizing contrastive divergence, Neural Computation. 14 (8), 1771–1800 (2002).
- 71. G. E. Hinton, S. Osindero, and Y.-W. Teh, A fast learning algorithm for deep belief nets, Neural computation. 18 (7), 1527–1554 (2006).
- 72. G. E. Hinton and R. R. Salakhutdinov, Reducing the dimensionality of data with neural networks, Science. 313 (5786), 504–507 (2006).
- 73. D. Kim and D.-H. Kim, Smallest neural network to learn the Ising criticality, Physical Review E. 98 (2), 022138 (2018).
- 74. S. Efthymiou, M. J. Beach, and R. G. Melko, Super-resolving the ising model with convolutional neural networks, Physical Review B. 99 (7), 075113 (2019).
- 75. F. D’Angelo and L. Böttcher, Learning the Ising model with generative neural networks, Physical Review Research. 2 (2), 023266 (2020).
- 76. G. Carleo and M. Troyer, Solving the quantum many-body problem with artificial neural networks, Science. 355 (6325), 602–606 (2017).
- 77. G. Torlai, G. Mazzola, J. Carrasquilla, M. Troyer, R. Melko, and G. Carleo, Neural-network quantum state tomography, Nature Physics. 14 (5), 447–450 (2018).
- 78. J. Schmidhuber, Deep learning in neural networks: An overview, Neural Networks. 61, 85–117 (2015).
- 79. J. Dean, A golden decade of deep learning: Computing systems & applications, Daedalus. 151 (2), 58–74 (2022).
- 80. S. Hochreiter and J. Schmidhuber, Long short-term memory, Neural Computation. 9 (8), 1735–1780 (1997).
- 81. Y. LeCun, L. Bottou, Y. Bengio, and P. Haffner, Gradient-based learning applied to document recognition, Proceedings of the IEEE. 86 (11), 2278–2324 (1998).
- 82. I. J. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde-Farley, S. Ozair, A. C. Courville, and Y. Bengio. Generative adversarial nets. In eds. Z. Ghahramani, M. Welling, C. Cortes, N. D. Lawrence, and K. Q. Weinberger, Advances in Neural Information Processing Systems 27: Annual Conference on Neural Information Processing Systems 2014, December 8-13 2014, Montreal, Quebec, Canada, pp. 2672–2680 (2014).
- 83. A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. Kaiser, and I. Polosukhin. Attention is all you need. In eds. I. Guyon, U. von Luxburg, S. Bengio, H. M. Wallach, R. Fergus, S. V. N. Vishwanathan, and R. Garnett, Advances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems 2017, December 4-9, 2017, Long Beach, CA, USA, pp. 5998–6008 (2017).
- 84. A. Paszke, S. Gross, S. Chintala, G. Chanan, E. Yang, Z. DeVito, Z. Lin, A. Desmaison, L. Antiga, and A. Lerer, Automatic differentiation in PyTorch (2017).
- 85. G. Cybenko, Approximation by superpositions of a sigmoidal function, Mathematics of Control, Signals and Systems. 2 (4), 303–314 (1989).
- 86. K. Hornik, M. Stinchcombe, and H. White, Multilayer feedforward networks are universal approximators, Neural Networks. 2 (5), 359–366 (1989).
- 87. K. Hornik, Approximation capabilities of multilayer feedforward networks, Neural Networks. 4 (2), 251–257 (1991).
- 88. Y.-J. Wang and C.-T. Lin, Runge-Kutta neural network for identification of dynamical systems in high accuracy, IEEE Transactions on Neural Networks. 9 (2), 294–307 (1998).
- 89. T. Q. Chen, Y. Rubanova, J. Bettencourt, and D. Duvenaud. Neural ordinary differential equations. In eds. S. Bengio, H. M. Wallach, H. Larochelle, K. Grauman, N. Cesa-Bianchi, and R. Garnett, Advances in Neural Information Processing Systems 31: Annual Conference on Neural Information Processing Systems 2018, NeurIPS 2018, December 3-8, 2018, Montréal, Canada, pp. 6572–6583 (2018).
- 90. E. Kaiser, J. N. Kutz, and S. L. Brunton, Data-driven discovery of Koopman eigenfunctions for control, Machine Learning: Science and Technology. 2 (3), 035023 (2021).
- 91. F. Schäfer, P. Sekatski, M. Koppenhöfer, C. Bruder, and M. Kloc, Control of stochastic quantum dynamics by differentiable programming, Machine Learning: Science and Technology. 2 (3), 035004 (2021).
- 92. L. Böttcher, N. Antulov-Fantulin, and T. Asikis, AI Pontryagin or how artificial neural networks learn to control dynamical systems, Nature Communications. 13 (1), 333 (2022).
- 93. T. Asikis, L. Böttcher, and N. Antulov-Fantulin, Neural ordinary differential equation control of dynamics on graphs, Physical Review Research. 4 (1), 013221 (2022).
- 94. L. Böttcher and T. Asikis, Near-optimal control of dynamical systems with neural ordinary differential equations, Machine Learning: Science and Technology. 3 (4), 045004 (2022).
- 95. L. Böttcher, T. Asikis, and I. Fragkos, Control of dual-sourcing inventory systems using recurrent neural networks, INFORMS Journal on Computing. 35 (6), 1308–1328 (2023).
- 96. L. Böttcher. Gradient-free training of neural ODEs for system identification and control using ensemble Kalman inversion. In ICML Workshop on New Frontiers in Learning, Control, and Dynamical Systems, Honolulu, HI, USA, 2023 (2023).
- 97. D. Ruiz-Balet and E. Zuazua, Neural ODE control for classification, approximation, and transport, SIAM Review. 65 (3), 735–773 (2023).
- 98. T. Asikis. Towards recommendations for value sensitive sustainable consumption. In NeurIPS 2023 Workshop on Tackling Climate Change with Machine Learning: Blending New and Existing Knowledge Systems (2023). URL https://nips.cc/virtual/2023/76939.
- 99. M. Raissi, P. Perdikaris, and G. E. Karniadakis, Physics-informed neural networks: A deep learning framework for solving forward and inverse problems involving nonlinear partial differential equations, Journal of Computational physics. 378, 686–707 (2019).
- 100. S. L. Brunton and J. N. Kutz, Data-driven science and engineering: Machine learning, dynamical systems, and control. Cambridge University Press, Cambridge, UK (2022).
- 101. S. Mowlavi and S. Nabi, Optimal control of PDEs using physics-informed neural networks, Journal of Computational Physics. 473, 111731 (2023).
- 102. C. Fronk and L. Petzold, Interpretable polynomial neural ordinary differential equations, Chaos: An Interdisciplinary Journal of Nonlinear Science. 33 (4) (2023).
- 103. M. Xia, L. Böttcher, and T. Chou, Spectrally adapted physics-informed neural networks for solving unbounded domain problems, Machine Learning: Science and Technology. 4 (2), 025024 (2023).
- 104. L. Böttcher, L. L. Fonseca, and R. C. Laubenbacher, Control of medical digital twins with artificial neural networks, arXiv preprint arXiv:2403.13851 (2024).
- 105. L. Böttcher and G. Wheeler, Visualizing high-dimensional loss landscapes with Hessian directions, Journal of Statistical Mechanics: Theory and Experiment. p. 023401 (2024).
- 106. M. Thoma. LaTeX Examples: Hopfield Network. URL https://github.com/MartinThoma/LaTeX-examples/tree/master/tikz/hopfield-network (Accessed: September 16, 2023).
- 107. J. Hertz, R. G. Palmer, and A. S. Krogh, Introduction to the Theory of Neural Computation, 1st edn. Perseus Publishing, New York City, New York, USA (1991).
- 108. A. J. Storkey. Increasing the capacity of a Hopfield network without sacrificing functionality. In eds. W. Gerstner, A. Germond, M. Hasler, and J. Nicoud, Artificial Neural Networks - ICANN ’97, 7th International Conference, Lausanne, Switzerland, October 8-10, 1997, Proceedings, vol. 1327, Lecture Notes in Computer Science, pp. 451–456, Springer (1997).
- 109. N. Metropolis, A. W. Rosenbluth, M. N. Rosenbluth, A. H. Teller, and E. Teller, Equation of state calculations by fast computing machines, The Journal of Chemical Physics. 21 (6), 1087–1092 (1953).
- 110. J. E. Gubernatis, Marshall Rosenbluth and the Metropolis algorithm, Physics of Plasmas. 12 (5) (2005).
- 111. S. Kirkpatrick, C. D. Gelatt Jr, and M. P. Vecchi, Optimization by simulated annealing, Science. 220 (4598), 671–680 (1983).
- 112. R. J. Glauber, Time-dependent statistics of the Ising model, Journal of Mathematical Physics. 4 (2), 294–307 (1963).
- 113. M. Á. Carreira-Perpiñán and G. E. Hinton. On contrastive divergence learning. In eds. R. G. Cowell and Z. Ghahramani, Proceedings of the Tenth International Workshop on Artificial Intelligence and Statistics, AISTATS 2005, Bridgetown, Barbados, January 6-8, 2005, Society for Artificial Intelligence and Statistics (2005).
- 114. G. Hinton, A practical guide to training restricted Boltzmann machines, Momentum. 9 (1), 926 (2010).
- 115. S. Park, C. Yun, J. Lee, and J. Shin. Minimum width for universal approximation. In 9th International Conference on Learning Representations, ICLR 2021, Virtual Event, Austria, May 3-7, 2021 (2021).
- 116. M. Hardt, B. Recht, and Y. Singer. Train faster, generalize better: Stability of stochastic gradient descent. In eds. M. Balcan and K. Q. Weinberger, Proceedings of the 33nd International Conference on Machine Learning, ICML 2016, New York City, NY, USA, June 19-24, 2016, vol. 48, JMLR Workshop and Conference Proceedings, pp. 1225–1234, JMLR.org (2016).
- 117. A. C. Wilson, R. Roelofs, M. Stern, N. Srebro, and B. Recht, The marginal value of adaptive gradient methods in machine learning. pp. 4148–4158 (2017).
- 118. D. Choi, C. J. Shallue, Z. Nado, J. Lee, C. J. Maddison, and G. E. Dahl, On empirical comparisons of optimizers for deep learning, arXiv preprint arXiv:1910.05446 (2019).
- 119. N. S. Keskar, D. Mudigere, J. Nocedal, M. Smelyanskiy, and P. T. P. Tang. On large-batch training for deep learning: Generalization gap and sharp minima. In 5th International Conference on Learning Representations, ICLR 2017, Toulon, France, April 24-26, 2017, Conference Track Proceedings (2017).
- 120. L. Dinh, R. Pascanu, S. Bengio, and Y. Bengio. Sharp minima can generalize for deep nets. In eds. D. Precup and Y. W. Teh, Proceedings of the 34th International Conference on Machine Learning, ICML 2017, Sydney, NSW, Australia, 6-11 August 2017, vol. 70, Proceedings of Machine Learning Research, pp. 1019–1028 (2017).
- 121. I. J. Goodfellow and O. Vinyals. Qualitatively characterizing neural network optimization problems. In eds. Y. Bengio and Y. LeCun, 3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, May 7-9, 2015, Conference Track Proceedings (2015).
- 122. H. Li, Z. Xu, G. Taylor, C. Studer, and T. Goldstein. Visualizing the loss landscape of neural nets. In eds. S. Bengio, H. M. Wallach, H. Larochelle, K. Grauman, N. Cesa-Bianchi, and R. Garnett, Advances in Neural Information Processing Systems 31: Annual Conference on Neural Information Processing Systems 2018, NeurIPS 2018, December 3-8, 2018, Montréal, Canada, pp. 6391–6401 (2018).
- 123. Y. Hao, L. Dong, F. Wei, and K. Xu. Visualizing and understanding the effectiveness of BERT. In eds. K. Inui, J. Jiang, V. Ng, and X. Wan, Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing, EMNLP-IJCNLP 2019, Hong Kong, China, November 3-7, 2019, pp. 4141–4150, Association for Computational Linguistics (2019).
- 124. D. Wu, S. Xia, and Y. Wang. Adversarial weight perturbation helps robust generalization. In eds. H. Larochelle, M. Ranzato, R. Hadsell, M. Balcan, and H. Lin, Advances in Neural Information Processing Systems 33: Annual Conference on Neural Information Processing Systems 2020, NeurIPS 2020, December 6-12, 2020, virtual (2020).
- 125. S. Horoi, J. Huang, B. Rieck, G. Lajoie, G. Wolf, and S. Krishnaswamy. Exploring the geometry and topology of neural network loss landscapes. In eds. T. Bouadi, É. Fromont, and E. Hüllermeier, Advances in Intelligent Data Analysis XX - 20th International Symposium on Intelligent Data Analysis, IDA 2022, Rennes, France, April 20-22, 2022, Proceedings, vol. 13205, Lecture Notes in Computer Science, pp. 171–184, Springer (2022).
- 126. J. M. Lee, Riemannian manifolds: An introduction to curvature. vol. 176, Springer Science & Business Media, New York City, NY, USA (2006).
- 127. M. Berger and B. Gostiaux, Differential Geometry: Manifolds, Curves, and Surfaces. Springer Science & Business Media, New York City, NY, USA (2012).
- 128. W. Kühnel, Differential Geometry. American Mathematical Society, Providence, RI, USA (2015).
- 129. K. Crane, Discrete differential geometry: An applied introduction, Notices of the AMS, Communication. pp. 1153–1159 (2018).
- 130. J. Martens, New insights and perspectives on the natural gradient method, Journal of Machine Learning Research. 21 (146), 1–76 (2020).
- 131. R. Hecht-Nielsen, Context vectors: general purpose approximate meaning representations self-organized from raw data, Computational Intelligence: Imitating Life, IEEE Press. pp. 43–56 (1994).
- 132. R. B. Davies, Algorithm AS 155: The distribution of a linear combination of $\chi^{2}$ random variables, Applied Statistics. 29 (3), 323–333 (1980).
- 133. B. Laurent and P. Massart, Adaptive estimation of a quadratic functional by model selection, Annals of Statistics. 28 (5), 1302–1338 (2000).
- 134. J. Bausch, On the efficient calculation of a linear combination of chi-square random variables with an application in counting string vacua, Journal of Physics A: Mathematical and Theoretical. 46 (50), 505202 (2013).
- 135. T. Chen and T. Lumley, Numerical evaluation of methods approximating the distribution of a large quadratic form in normal variables, Computational Statistics & Data Analysis. 139, 75–81 (2019).
- 136. J. Matoušek, On variants of the Johnson–Lindenstrauss lemma, Random Structures and Algorithms. 33 (2), 142–156 (2008).
- 137. M. F. Hutchinson, A stochastic estimator of the trace of the influence matrix for Laplacian smoothing splines, Communications in Statistics-Simulation and Computation. 18 (3), 1059–1076 (1989).
- 138. Z. Bai, G. Fahey, and G. Golub, Some large-scale matrix computation problems, Journal of Computational and Applied Mathematics. 74 (1-2), 71–89 (1996).
- 139. H. Avron and S. Toledo, Randomized algorithms for estimating the trace of an implicit symmetric positive semi-definite matrix, Journal of the ACM (JACM). 58 (2), 1–34 (2011).
- 140. Y. N. Dauphin, R. Pascanu, Ç. Gülçehre, K. Cho, S. Ganguli, and Y. Bengio. Identifying and attacking the saddle point problem in high-dimensional non-convex optimization. In eds. Z. Ghahramani, M. Welling, C. Cortes, N. D. Lawrence, and K. Q. Weinberger, Advances in Neural Information Processing Systems 27: Annual Conference on Neural Information Processing Systems 2014, December 8-13 2014, Montreal, Quebec, Canada, pp. 2933–2941 (2014).
- 141. P. Baldi and K. Hornik, Neural networks and principal component analysis: Learning from examples without local minima, Neural Networks. 2 (1), 53–58 (1989).
- 142. Z. Yao, A. Gholami, K. Keutzer, and M. W. Mahoney. PyHessian: Neural networks through the lens of the Hessian. In eds. X. Wu, C. Jermaine, L. Xiong, X. Hu, O. Kotevska, S. Lu, W. Xu, S. Aluru, C. Zhai, E. Al-Masri, Z. Chen, and J. Saltz, 2020 IEEE International Conference on Big Data (IEEE BigData 2020), Atlanta, GA, USA, December 10-13, 2020, pp. 581–590, IEEE (2020).
- 143. Z. Liao and M. W. Mahoney. Hessian eigenspectra of more realistic nonlinear models. In eds. M. Ranzato, A. Beygelzimer, Y. N. Dauphin, P. Liang, and J. W. Vaughan, Advances in Neural Information Processing Systems 34: Annual Conference on Neural Information Processing Systems 2021, NeurIPS 2021, December 6-14, 2021, virtual, pp. 20104–20117 (2021).
- 144. R. L. Burden, J. D. Faires, and A. M. Burden, Numerical Analysis; 10th edition. Cengage Learning, Boston, MA, USA (2015).
- 145. B. Adcock and N. Dexter, The gap between theory and practice in function approximation with deep neural networks, SIAM Journal on Mathematics of Data Science. 3 (2), 624–655 (2021).