# Federated Model Heterogeneous Matryoshka Representation Learning
## Abstract
Model heterogeneous federated learning (MHeteroFL) enables FL clients to collaboratively train models with heterogeneous structures in a distributed fashion. However, existing MHeteroFL methods rely on training loss to transfer knowledge between the client model and the server model, resulting in limited knowledge exchange. To address this limitation, we propose the Fed erated model heterogeneous M atryoshka R epresentation L earning (FedMRL) approach for supervised learning tasks. It adds an auxiliary small homogeneous model shared by clients with heterogeneous local models. (1) The generalized and personalized representations extracted by the two models’ feature extractors are fused by a personalized lightweight representation projector. This step enables representation fusion to adapt to local data distribution. (2) The fused representation is then used to construct Matryoshka representations with multi-dimensional and multi-granular embedded representations learned by the global homogeneous model header and the local heterogeneous model header. This step facilitates multi-perspective representation learning and improves model learning capability. Theoretical analysis shows that FedMRL achieves a $\mathcal{O}(1/T)$ non-convex convergence rate. Extensive experiments on benchmark datasets demonstrate its superior model accuracy with low communication and computational costs compared to seven state-of-the-art baselines. It achieves up to $8.48\$ and $24.94\$ accuracy improvement compared with the state-of-the-art and the best same-category baseline, respectively.
## 1 Introduction
Traditional federated learning (FL) [29] often relies on a central FL server to coordinate multiple data owners (a.k.a., FL clients) to train a global shared model without exposing local data. In each communication round, the server broadcasts the global model to the clients. A client trains it on its local data and sends the updated local model to the FL server. The server aggregates local models to produce a new global model. These steps are repeated until the global model converges.
However, the above design cannot handle the following heterogeneity challenges [49] commonly found in practical FL applications: (1) Data heterogeneity [40, 45, 44, 47, 39, 55]: FL clients’ local data often follow non-independent and identically distributions (non-IID). A single global model produced by aggregating local models trained on non-IID data might not perform well on all clients. (2) System heterogeneity [11, 46, 48]: FL clients can have diverse system configurations in terms of computing power and network bandwidth. Training the same model structure among such clients means that the global model size must accommodate the weakest device, leading to sub-optimal performance on other more powerful clients. (3) Model heterogeneity [41]: When FL clients are enterprises, they might have heterogeneous proprietary models which cannot be directly shared with others during FL training due to intellectual property (IP) protection concerns.
To address these challenges, the field of model heterogeneous federated learning (MHeteroFL) [52, 49, 53, 54, 51, 50] has emerged. It enables FL clients to train local models with tailored structures suitable for local system resources and local data distributions. Existing MHeteroFL methods [38, 43] are limited in terms of knowledge transfer capabilities as they commonly leverage the training loss between server and client models for this purpose. This design leads to model performance bottlenecks, incurs high communication and computation costs, and risks exposing private local model structures and data.
<details>
<summary>x1.png Details</summary>
### Visual Description
## Diagram: Matryoshka Representation Learning Architecture
### Overview
This image is a technical diagram illustrating a machine learning architecture called "Matryoshka Representation Learning." It depicts a data flow from an input `x` through a feature extractor to produce nested representations ("Matryoshka Reps"), which are then processed by multiple parallel "Headers" to generate predictions and individual losses, finally aggregated into a single total loss `ℓ`. The diagram uses a left-to-right flow with color-coded components and a Russian Matryoshka doll icon to symbolize the nested, multi-scale nature of the representations.
### Components/Axes
The diagram contains the following labeled components and symbols, listed in order of data flow from left to right:
1. **Input**: Labeled `x` (italicized mathematical symbol).
2. **Feature Extractor**: A teal-colored trapezoid block with the text "Feature Extractor" inside.
3. **Matryoshka Reps**: A central block with the title "Matryoshka Reps" above it. This block contains:
* A green dashed-line rectangle.
* Inside it, a nested set of three rectangles with dashed borders: a large light orange rectangle, a medium pink rectangle inside that, and a small red rectangle inside the pink one.
* A small icon of a traditional Russian Matryoshka doll placed at the bottom of the green dashed rectangle.
4. **Headers**: Three parallel rectangular blocks to the right of the Matryoshka Reps, collectively labeled "Headers" below them. They are color-coded:
* **Top Header**: Pink rectangle.
* **Middle Header**: Light orange/yellow rectangle.
* **Bottom Header**: Green rectangle.
5. **Predictions**: Mathematical symbols for predicted outputs, each connected to a header:
* `ŷ₁` (y-hat subscript 1) from the pink header.
* `ŷ₂` (y-hat subscript 2) from the light orange header.
* `ŷ₃` (y-hat subscript 3) from the green header.
6. **Individual Losses**: Mathematical symbols for loss values, each connected to a prediction:
* `ℓ₁` (script l subscript 1) from `ŷ₁`.
* `ℓ₂` (script l subscript 2) from `ŷ₂`.
* `ℓ₃` (script l subscript 3) from `ŷ₃`.
7. **Aggregation Node**: A blue circle with a plus sign (`+`) inside, located to the right of the individual losses.
8. **Total Loss**: The final output, labeled `ℓ` (script l), connected from the aggregation node.
### Detailed Analysis
**Spatial Layout and Flow:**
* The flow is strictly left-to-right, indicated by black arrows connecting each component.
* The **Matryoshka Reps** block is the central hub. Three arrows originate from its right side, each pointing to one of the three **Headers**. This visually represents that the nested representations are being "unpacked" or accessed at different scales.
* The three parallel processing paths (Header -> Prediction -> Loss) are vertically stacked. The **pink path** is top, the **light orange path** is middle, and the **green path** is bottom.
* The three individual loss values (`ℓ₁`, `ℓ₂`, `ℓ₃`) are connected by arrows to the central **aggregation node** (blue circle with `+`), indicating they are summed or combined.
* The final arrow from the aggregation node points to the total loss `ℓ`.
**Component Relationships & Color Coding:**
* There is a direct visual correspondence between the nested rectangles inside the **Matryoshka Reps** and the **Headers**:
* The innermost **red** rectangle corresponds to the **pink** header (top path).
* The middle **pink** rectangle corresponds to the **light orange** header (middle path).
* The outermost **light orange** rectangle corresponds to the **green** header (bottom path).
* *Note: There is a slight color mismatch between the innermost rectangle (red) and its corresponding header (pink), but the positional and sequential logic is clear.*
* This color/position mapping reinforces the core concept: the model produces a single, nested representation from which features of different granularities (small/precise to large/general) can be extracted by different headers.
### Key Observations
1. **Nested Representation Core**: The diagram's central metaphor is the Matryoshka doll, explicitly shown and named. This indicates the model learns a single representation that contains useful sub-representations of varying sizes/dimensions.
2. **Multi-Task or Multi-Scale Learning**: The architecture has three distinct prediction heads (`ŷ₁`, `ŷ₂`, `ŷ₃`) operating on different "layers" of the same core representation. This suggests the model is trained on multiple tasks simultaneously or at multiple scales of abstraction.
3. **Loss Aggregation**: The individual losses (`ℓ₁`, `ℓ₂`, `ℓ₃`) are combined into a single total loss (`ℓ`). This is a standard multi-task learning setup where the model is optimized to perform well on all tasks/scales jointly.
4. **Directional Data Flow**: The arrows are unidirectional, showing a feed-forward process without feedback loops in this diagram. The training process (backpropagation) is implied but not visualized.
### Interpretation
This diagram illustrates a **multi-scale representation learning framework**. The key innovation is the "Matryoshka" property: instead of learning separate features for different tasks or resolutions, the model learns one rich, hierarchical representation. The innermost part of this representation (the smallest "doll") contains the most essential, high-level features, while outer layers add progressively more detailed or specialized information.
The three parallel headers demonstrate how this single representation can be flexibly utilized. For example:
* The **pink header** (connected to the innermost representation) might perform a coarse, high-level classification task.
* The **green header** (connected to the outermost representation) might perform a fine-grained segmentation or detailed regression task.
* The **light orange header** operates at an intermediate level.
By training all headers jointly via the aggregated loss `ℓ`, the feature extractor is forced to create a representation that is simultaneously useful at multiple levels of abstraction. This is highly efficient and can improve generalization, as the model must find features that are robust across different tasks or scales. The diagram effectively communicates this complex concept through clear visual metaphors (the doll), color-coding, and a logical left-to-right data flow.
</details>
<details>
<summary>x2.png Details</summary>
### Visual Description
## Diagram: Neural Network Architecture
### Overview
The image displays a block diagram of a feedforward neural network architecture, specifically a convolutional neural network (CNN) followed by fully connected layers. The diagram illustrates the data flow from an input `x` to a predicted output `ŷ`. The architecture is segmented into two primary, visually distinct modules: a "Feature Extractor" and a "Header," with an intermediate representation block labeled "Rep."
### Components/Axes
The diagram is composed of labeled blocks connected by directional arrows indicating data flow from left to right.
**1. Input:**
* **Label:** `x` (italicized, mathematical notation).
* **Position:** Far left, with an arrow pointing into the first block.
**2. Feature Extractor Module:**
* **Container:** A large, light blue rectangle with a dashed black border.
* **Title:** "Feature Extractor" (centered above the container).
* **Internal Components (in sequence):**
* `Conv1`: A rounded rectangle, first layer in the sequence.
* `Conv2`: A rounded rectangle, second layer.
* `FC1`: A narrower, taller rectangle, third layer.
* `FC2`: A narrower, taller rectangle, fourth layer.
* **Flow:** Arrows connect `x` → `Conv1` → `Conv2` → `FC1` → `FC2`.
**3. Intermediate Representation:**
* **Label:** "Rep" (positioned above the block).
* **Component:** A vertical, light gray rectangle with a dashed black border.
* **Position:** Located between the "Feature Extractor" and "Header" modules.
* **Flow:** An arrow connects `FC2` to "Rep," and another arrow connects "Rep" to the next module.
**4. Header Module:**
* **Container:** A smaller, light pink rectangle with a dashed black border.
* **Title:** "Header" (centered above the container).
* **Internal Component:**
* `FC3`: A rounded rectangle inside the Header container.
* **Flow:** An arrow connects "Rep" to `FC3`.
**5. Output:**
* **Label:** `ŷ` (y-hat, italicized, mathematical notation).
* **Position:** Far right, with an arrow pointing out from `FC3`.
### Detailed Analysis
The diagram explicitly defines the network's layer sequence and modular organization.
* **Layer Sequence:** The complete forward pass is: `x` → `Conv1` → `Conv2` → `FC1` → `FC2` → `Rep` → `FC3` → `ŷ`.
* **Module Composition:**
* The **Feature Extractor** contains two convolutional layers (`Conv1`, `Conv2`) followed by two fully connected layers (`FC1`, `FC2`). This suggests it is designed to transform raw input into a high-level feature representation.
* The **Header** contains a single fully connected layer (`FC3`). This is typically the task-specific part of the network (e.g., a classifier or regressor head).
* The **Rep** block is a distinct, unlabeled (beyond "Rep") intermediate stage, likely representing the final feature vector output by the Feature Extractor before it is passed to the Header.
### Key Observations
1. **Modular Design:** The use of dashed-border containers clearly separates the architecture into two main functional modules (Feature Extractor and Header), which is a common pattern in transfer learning or multi-task learning setups.
2. **Layer Type Progression:** The network progresses from convolutional layers (typically for spatial feature extraction) to fully connected layers (for global reasoning and decision-making).
3. **Visual Hierarchy:** The "Feature Extractor" is the largest and most complex component, visually emphasizing its role as the primary processing engine. The "Header" is simpler, indicating it performs a final transformation.
4. **Notation:** Standard mathematical notation (`x`, `ŷ`) is used for input and output. Layer names (`Conv`, `FC`) are standard abbreviations for "Convolutional" and "Fully Connected."
### Interpretation
This diagram represents a standard CNN-based model architecture, likely for an image processing task given the convolutional layers. The clear separation between the **Feature Extractor** and the **Header** is the most significant architectural insight.
* **Functional Relationship:** The Feature Extractor's role is to learn a generic, informative representation (`Rep`) from the input data. The Header's role is to map this generic representation to a specific output prediction (`ŷ`). This decoupling allows for flexibility; the same Feature Extractor could be paired with different Headers for different tasks (e.g., classification vs. detection) by only retraining the Header module.
* **Data Transformation:** The flow shows a transformation from high-dimensional, structured input (like an image) through successive layers that reduce spatial dimensions while increasing feature abstraction (`Conv1` → `Conv2`), followed by a flattening and further processing into a dense feature vector (`FC1` → `FC2` → `Rep`). The final layer (`FC3`) projects this vector into the output space.
* **Implied Context:** The architecture suggests a supervised learning context. The presence of a distinct "Header" often implies that the Feature Extractor may be pre-trained on a large dataset (like ImageNet) and then frozen, while only the Header is trained on a smaller, specific dataset—a common and effective transfer learning strategy. The "Rep" block is the critical interface point for this process.
</details>
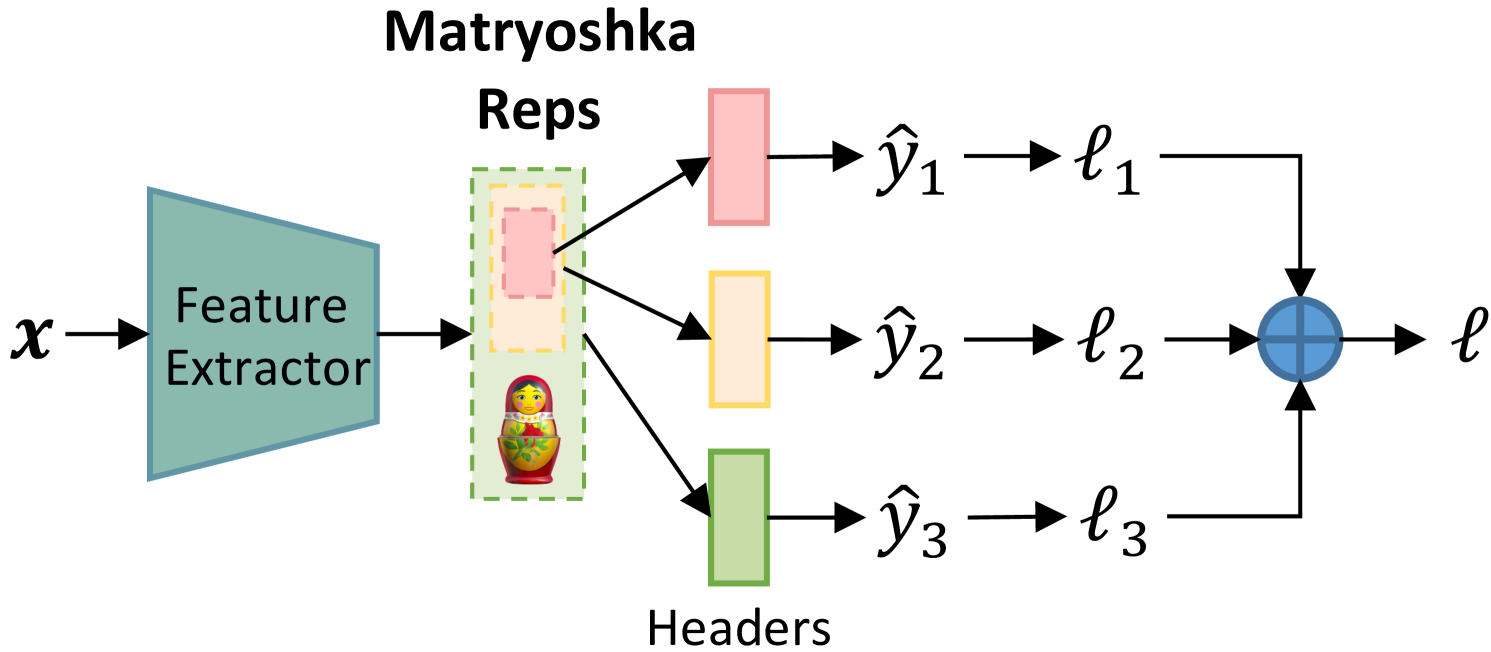
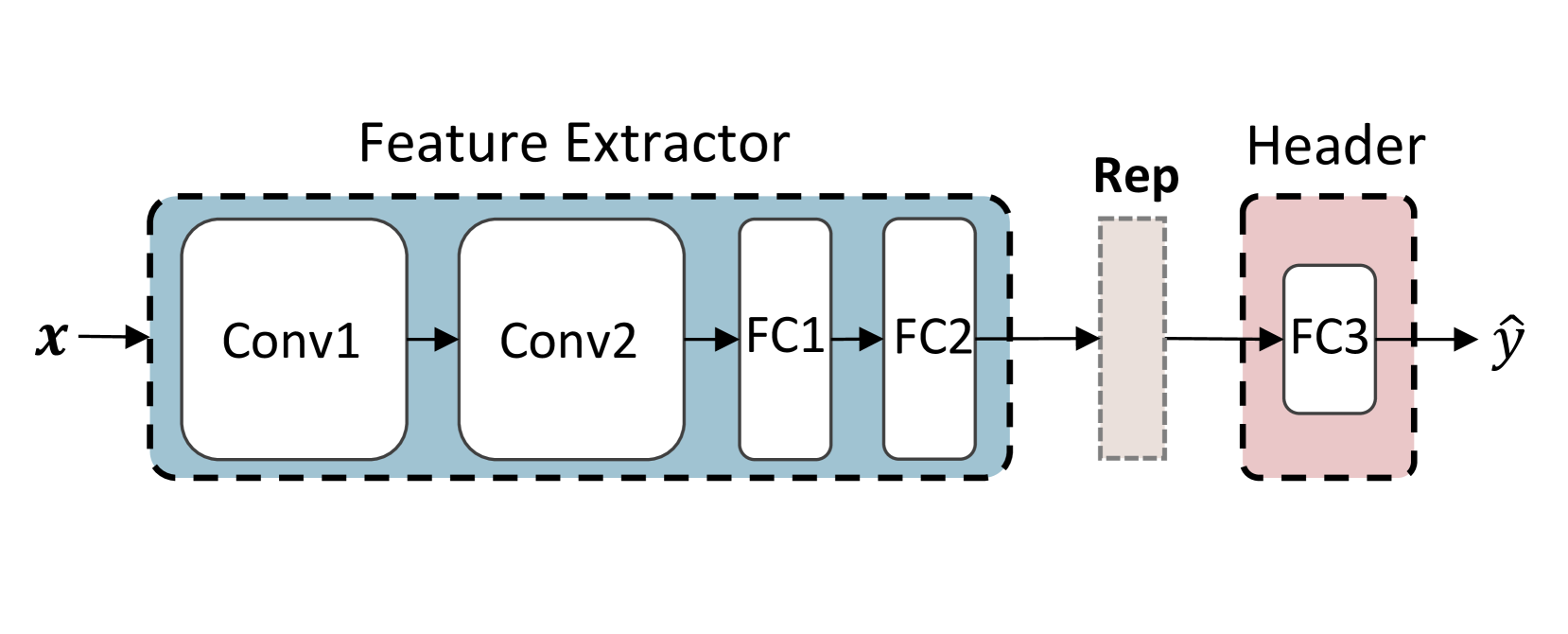
Figure 1: Left: Matryoshka Representation Learning. Right: Feature extractor and prediction header.
Recently, Matryoshka Representation Learning (MRL) [21] has emerged to tailor representation dimensions based on the computational and storage costs required by downstream tasks to achieve a near-optimal trade-off between model performance and inference costs. As shown in Figure 1 (left), the representation extracted by the feature extractor is constructed to form Matryoshka Representations involving a series of embedded representations ranging from low-to-high dimensions and coarse-to-fine granularities. Each of them is processed by a single output layer for calculating loss, and the sum of losses from all branches is used to update model parameters. This design is inspired by the insight that people often first perceive the coarse aspect of a target before observing the details, with multi-perspective observations enhancing understanding.
Inspired by MRL, we address the aforementioned limitations of MHeteroFL by proposing the Fed erated model heterogeneous M atryoshka R epresentation L earning (FedMRL) approach for supervised learning tasks. For each client, a shared global auxiliary homogeneous small model is added to interact with its heterogeneous local model. Both two models consist of a feature extractor and a prediction header, as depicted in Figure 1 (right). FedMRL has two key design innovations. (1) Adaptive Representation Fusion: for each local data sample, the feature extractors of the two local models extract generalized and personalized representations, respectively. The two representations are spliced and then mapped to a fused representation by a lightweight personalized representation projector adapting to local non-IID data. (2) Multi-Granularity Representation Learning: the fused representation is used to construct Matryoshka Representations involving multi-dimension and multi-granularity embedded representations, which are processed by the prediction headers of the two models, respectively. The sum of their losses is used to update all models, which enhances the model learning capability owing to multi-perspective representation learning.
The personalized multi-granularity MRL enhances representation knowledge interaction between the homogeneous global model and the heterogeneous client local model. Each client’s local model and data are not exposed during training for privacy-preservation. The server and clients only transmit the small homogeneous models, thereby incurring low communication costs. Each client only trains a small homogeneous model and a lightweight representation projector in addition, incurring low extra computational costs. We theoretically derive the $\mathcal{O}(1/T)$ non-convex convergence rate of FedMRL and verify that it can converge over time. Experiments on benchmark datasets comparing FedMRL against seven state-of-the-art baselines demonstrate its superiority. It improves model accuracy by up to $8.48\$ and $24.94\$ over the best baseline and the best same-category baseline, while incurring lower communication and computation costs.
## 2 Related Work
Existing MHeteroFL works can be divided into the following four categories.
MHeteroFL with Adaptive Subnets. These methods [3, 4, 5, 11, 14, 56, 64] construct heterogeneous local subnets of the global model by parameter pruning or special designs to match with each client’s local system resources. The server aggregates heterogeneous local subnets wise parameters to generate a new global model. In cases where clients hold black-box local models with heterogeneous structures not derived from a common global model, the server is unable to aggregate them.
MHeteroFL with Knowledge Distillation. These methods [6, 8, 9, 15, 16, 17, 22, 23, 25, 27, 30, 32, 35, 36, 42, 57, 59] often perform knowledge distillation on heterogeneous client models by leveraging a public dataset with the same data distribution as the learning task. In practice, such a suitable public dataset can be hard to find. Others [12, 60, 61, 63] train a generator to synthesize a shared dataset to deal with this issue. However, this incurs high training costs. The rest (FD [19], FedProto [41] and others [1, 2, 13, 49, 58]) share the intermediate information of client local data for knowledge fusion.
MHeteroFL with Model Split. These methods split models into feature extractors and predictors. Some [7, 10, 31, 33] share homogeneous feature extractors across clients and personalize predictors, while others (LG-FedAvg [24] and [18, 26]) do the opposite. Such methods expose part of the local model structures, which might not be acceptable if the models are proprietary IPs of the clients.
MHeteroFL with Mutual Learning. These methods (FedAPEN [34], FML [38], FedKD [43] and others [28]) add a shared global homogeneous small model on top of each client’s heterogeneous local model. For each local data sample, the distance of the outputs from these two models is used as the mutual loss to update model parameters. Nevertheless, the mutual loss only transfers limited knowledge between the two models, resulting in model performance bottlenecks.
The proposed FedMRL approach further optimizes mutual learning-based MHeteroFL by enhancing the knowledge transfer between the server and client models. It achieves personalized adaptive representation fusion and multi-perspective representation learning, thereby facilitating more knowledge interaction across the two models and improving model performance.
## 3 The Proposed FedMRL Approach
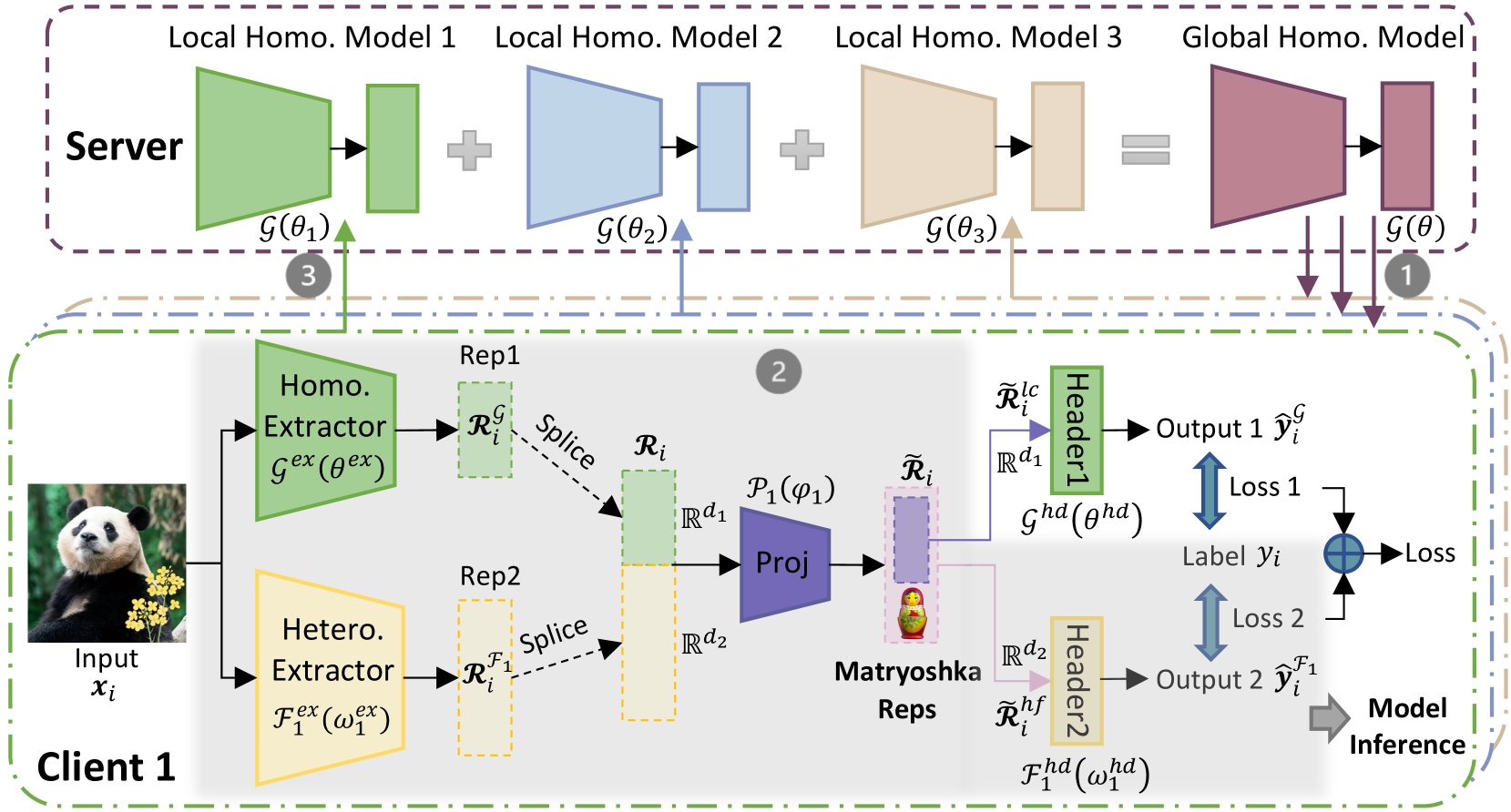
FedMRL aims to tackle data, system, and model heterogeneity in supervised learning tasks, where a central FL server coordinates $N$ FL clients to train heterogeneous local models. The server maintains a global homogeneous small model $\mathcal{G}(\theta)$ shared by all clients. Figure 2 depicts its workflow Algorithm 1 in Appendix A describes the FedMRL algorithm.:
1. In each communication round, $K$ clients participate in FL (i.e., the client participant rate $C=K/N$ ). The global homogeneous small model $\mathcal{G}(\theta)$ is broadcast to them.
1. Each client $k$ holds a heterogeneous local model $\mathcal{F}_{k}(\omega_{k})$ ( $\mathcal{F}_{k}(\cdot)$ is the heterogeneous model structure, and $\omega_{k}$ are personalized model parameters). Client $k$ simultaneously trains the heterogeneous local model and the global homogeneous small model on local non-IID data $D_{k}$ ( $D_{k}$ follows the non-IID distribution $P_{k}$ ) via personalized Matryoshka Representations Learning with a personalized representation projector $\mathcal{P}_{k}(\varphi_{k})$ .
1. The updated homogeneous small models are uploaded to the server for aggregation to produce a new global model for knowledge fusion across heterogeneous clients.
The objective of FedMRL is to minimize the sum of the loss from the combined models ( $\mathcal{W}_{k}(w_{k})=(\mathcal{G}(\theta)\circ\mathcal{F}_{k}(\omega_{k})| \mathcal{P}_{k}(\varphi_{k}))$ ) on all clients, i.e.,
$$
\min_{\theta,\omega_{0,\ldots,N-1}}\sum_{k=0}^{N-1}\ell\left(\mathcal{W}_{k}
\left(D_{k};\left(\theta\circ\omega_{k}\mid\varphi_{k}\right)\right)\right). \tag{1}
$$
These steps repeat until each client’s model converges. After FL training, a client uses its local combined model without the global header for inference. Appendix C.3 provides experimental evidence for inference model selection.
<details>
<summary>x3.png Details</summary>
### Visual Description
## System Architecture Diagram: Federated Learning with Homogeneous and Heterogeneous Feature Extractors
### Overview
This image is a technical system architecture diagram illustrating a federated learning framework. It depicts a two-tiered process involving a central **Server** and a **Client** (specifically "Client 1"). The system processes an input image through parallel feature extractors (homogeneous and heterogeneous), projects and combines these features into "Matryoshka Representations," and uses them for model training and inference. The diagram uses color-coding, mathematical notation, and directional arrows to show data flow and component relationships.
### Components/Axes
The diagram is segmented into two primary regions, demarcated by dashed boxes:
1. **Server Region (Top, Purple Dashed Box):**
* **Components:** Three "Local Homo. Model" blocks (1, 2, 3) and one "Global Homo. Model" block.
* **Visual Structure:** Each model is represented by a trapezoid (likely a neural network layer) feeding into a rectangle (likely a feature representation or parameter set).
* **Labels & Notation:**
* `Local Homo. Model 1`, `Local Homo. Model 2`, `Local Homo. Model 3`, `Global Homo. Model`.
* Mathematical function notation below each model: `G(θ₁)`, `G(θ₂)`, `G(θ₃)`, and `G(θ)`.
* **Flow Indicators:** Plus signs (`+`) between the local models and an equals sign (`=`) before the global model, indicating an aggregation or averaging operation. Arrows labeled `1` (purple, downward from Global Model) and `3` (green, upward to Local Model 1) show communication with the client.
2. **Client 1 Region (Bottom, Green Dashed Box):**
* **Input:** An image of a panda, labeled `Input xᵢ`.
* **Feature Extractors (Parallel Paths):**
* **Path 1 (Green):** `Homo. Extractor` with notation `G^ex(θ^ex)`. Produces `Rep1` labeled `Rᵢ^G`.
* **Path 2 (Yellow):** `Hetero. Extractor` with notation `F₁^ex(ω₁^ex)`. Produces `Rep2` labeled `Rᵢ^{F₁}`.
* **Feature Fusion & Projection:**
* Both representations (`Rᵢ^G` and `Rᵢ^{F₁}`) undergo a `Splice` operation.
* The spliced result is fed into a `Proj` (Projection) block, denoted `P₁(φ₁)`.
* The output of the projection is labeled `R̃ᵢ` and visualized with a **Matryoshka doll icon**, explicitly labeled `Matryoshka Reps`.
* **Task-Specific Heads & Loss:**
* The Matryoshka Representation `R̃ᵢ` splits into two paths:
* **Path A (Green):** Labeled `R̃ᵢ^{lc}` with dimension `ℝ^{d₁}`. Goes to `Header1` (`G^{hd}(θ^{hd})`), producing `Output 1 ŷᵢ^G`.
* **Path B (Yellow):** Labeled `R̃ᵢ^{hf}` with dimension `ℝ^{d₂}`. Goes to `Header2` (`F₁^{hd}(ω₁^{hd})`), producing `Output 2 ŷᵢ^{F₁}`.
* **Loss Calculation:** Both outputs are compared against a `Label yᵢ` to compute `Loss 1` and `Loss 2`. These are combined (via a circled plus symbol) into a final `Loss`.
* **Inference:** A gray arrow labeled `Model Inference` points from the final loss/output area, indicating the trained model's use.
* **Communication Arrow:** A green arrow labeled `3` points from the `Homo. Extractor` path up to the Server's `Local Homo. Model 1`.
### Detailed Analysis
**Data Flow & Process:**
1. **Step 1 (Server to Client):** The global model `G(θ)` sends parameters (arrow `1`) to the client.
2. **Step 2 (Client Processing):** The client processes input `xᵢ`:
* Extracts homogeneous features `Rᵢ^G` and heterogeneous features `Rᵢ^{F₁}`.
* Splices and projects them into a unified, multi-scale representation `R̃ᵢ` (Matryoshka Reps).
* Uses two separate headers for specific tasks, generating predictions and computing a combined loss.
3. **Step 3 (Client to Server):** Updated parameters from the homogeneous extractor path (arrow `3`) are sent back to update the corresponding local model on the server.
**Mathematical & Notational Details:**
* **Functions:** `G` likely denotes a homogeneous model/function, `F₁` a heterogeneous one. Superscripts `ex` and `hd` probably stand for "extractor" and "header," respectively.
* **Parameters:** `θ`, `ω`, `φ` represent learnable parameters for different components.
* **Representations:** `R` denotes a representation tensor. Superscripts `G` and `F₁` denote the source extractor. `R̃` denotes the projected/fused representation. Subscript `i` likely indexes the data sample.
* **Dimensions:** The projected representation splits into subspaces of dimensions `ℝ^{d₁}` and `ℝ^{d₂}`.
**Spatial Grounding & Color Coding:**
* **Green** is consistently used for the homogeneous pathway: `Homo. Extractor`, `Header1`, `Local Homo. Model 1`, and the communication arrow `3`.
* **Yellow** is used for the heterogeneous pathway: `Hetero. Extractor` and `Header2`.
* **Purple** is used for the server's global model and its downward communication arrow `1`.
* The **Matryoshka doll icon** is centrally placed within the client box, visually anchoring the core concept of nested or multi-scale representations.
### Key Observations
1. **Hybrid Feature Learning:** The system explicitly combines features from two distinct types of extractors (homogeneous and heterogeneous) before projection.
2. **Matryoshka Representation:** The use of a nesting doll icon is a deliberate metaphor, suggesting the projected representation `R̃ᵢ` contains nested or hierarchical subspaces (`d₁` and `d₂`) suitable for different tasks or granularities.
3. **Federated Learning Structure:** The server aggregates multiple local homogeneous models (`G(θ₁)`, `G(θ₂)`, `G(θ₃)`) into a global model (`G(θ)`), a classic federated averaging pattern. The client updates only the homogeneous part (`G^ex`) based on arrow `3`.
4. **Multi-Task Objective:** The client computes two separate losses (`Loss 1`, `Loss 2`) from two headers, which are combined. This suggests the model is trained to perform two related tasks simultaneously, possibly leveraging the different feature subspaces.
### Interpretation
This diagram outlines a sophisticated federated learning system designed for **multi-task learning with heterogeneous data sources**. The core innovation appears to be the "Matryoshka Representation" module.
* **Purpose:** The framework likely aims to train a global model (`G(θ)`) on data from multiple clients while respecting data heterogeneity. Each client may have unique data distributions (hence the `Hetero. Extractor`).
* **Mechanism:** Instead of forcing all clients into a single homogeneous feature space, the system:
1. Learns client-specific heterogeneous features (`F₁`).
2. Projects these alongside generic homogeneous features (`G`) into a shared, structured latent space (`R̃ᵢ`).
3. This latent space is explicitly structured (like Matryoshka dolls) to contain information at different scales or for different tasks, served by dedicated headers.
* **Why It Matters:** This approach could improve model personalization and performance on non-IID (non-identically and independently distributed) data in federated learning. The homogeneous extractor facilitates knowledge aggregation on the server, while the heterogeneous extractor and Matryoshka projection allow the client to retain and utilize unique local information. The multi-task loss ensures the representation is useful for multiple objectives.
* **Notable Design Choice:** The server only aggregates homogeneous models. The heterogeneous component (`F₁`) remains entirely on the client side, which is a privacy-conscious design, preventing unique client data characteristics from being directly shared.
</details>
Figure 2: The workflow of FedMRL.
### 3.1 Adaptive Representation Fusion
We denote client $k$ ’s heterogeneous local model feature extractor as $\mathcal{F}_{k}^{ex}(\omega_{k}^{ex})$ , and prediction header as $\mathcal{F}_{k}^{hd}(\omega_{k}^{hd})$ . We denote the homogeneous global model feature extractor as $\mathcal{G}^{ex}(\theta^{ex})$ and prediction header as $\mathcal{G}^{hd}(\theta^{hd})$ . Client $k$ ’s local personalized representation projector is denoted as $\mathcal{P}_{k}(\varphi_{k})$ . In the $t$ -th communication round, client $k$ inputs its local data sample $(\boldsymbol{x}_{i},y_{i})\in D_{k}$ into the two feature extractors to extract generalized and personalized representations as:
$$
\boldsymbol{\mathcal{R}}_{i}^{\mathcal{G}}=\ \mathcal{G}^{ex}({\boldsymbol{x}_
{i};\theta}^{ex,t-1}),\boldsymbol{\mathcal{R}}_{i}^{\mathcal{F}_{k}}=\
\mathcal{F}_{k}^{ex}(\boldsymbol{x}_{i};\omega_{k}^{ex,t-1}). \tag{2}
$$
The two extracted representations $\boldsymbol{\mathcal{R}}_{i}^{\mathcal{G}}\in\mathbb{R}^{d_{1}}$ and $\boldsymbol{\mathcal{R}}_{i}^{\mathcal{F}_{k}}\in\mathbb{R}^{d_{2}}$ are spliced as:
$$
\boldsymbol{\mathcal{R}}_{i}=\boldsymbol{\mathcal{R}}_{i}^{\mathcal{G}}\circ
\boldsymbol{\mathcal{R}}_{i}^{\mathcal{F}_{k}}. \tag{3}
$$
Then, the spliced representation is mapped into a fused representation by the lightweight representation projector $\mathcal{P}_{k}(\varphi_{k}^{t-1})$ as:
$$
{\widetilde{\boldsymbol{\mathcal{R}}}}_{i}=\mathcal{P}_{k}(\boldsymbol{
\mathcal{R}}_{i}{;\varphi}_{k}^{t-1}), \tag{4}
$$
where the projector can be a one-layer linear model or multi-layer perceptron. The fused representation ${\widetilde{\boldsymbol{\mathcal{R}}}}_{i}$ contains both generalized and personalized feature information. It has the same dimension as the client’s local heterogeneous model representation $\mathbb{R}^{d_{2}}$ , which ensures the representation dimension $\mathbb{R}^{d_{2}}$ and the client local heterogeneous model header parameter dimension $\mathbb{R}^{d_{2}\times L}$ ( $L$ is the label dimension) match.
The representation projector can be updated as the two models are being trained on local non-IID data. Hence, it achieves personalized representation fusion adaptive to local data distributions. Splicing the representations extracted by two feature extractors can keep the relative semantic space positions of the generalized and personalized representations, benefiting the construction of multi-granularity Matryoshka Representations. Owing to representation splicing, the representation dimensions of the two feature extractors can be different (i.e., $d_{1}\leq d_{2}$ ). Therefore, we can vary the representation dimension of the small homogeneous global model to improve the trade-off among model performance, storage requirement and communication costs.
In addition, each client’s local model is treated as a black box by the FL server. When the server broadcasts the global homogeneous small model to the clients, each client can adjust the linear layer dimension of the representation projector to align it with the dimension of the spliced representation. In this way, different clients may hold different representation projectors. When a new model-agnostic client joins in FedMRL, it can adjust its representation projector structure for local model training. Therefore, FedMRL can accommodate FL clients owning local models with diverse structures.
### 3.2 Multi-Granular Representation Learning
To construct multi-dimensional and multi-granular Matryoshka Representations, we further extract a low-dimension coarse-granularity representation ${\widetilde{\boldsymbol{\mathcal{R}}}}_{i}^{lc}$ and a high-dimension fine-granularity representation ${\widetilde{\boldsymbol{\mathcal{R}}}}_{i}^{hf}$ from the fused representation ${\widetilde{\boldsymbol{\mathcal{R}}}}_{i}$ . They align with the representation dimensions $\{\mathbb{R}^{d_{1}},\mathbb{R}^{d_{2}}\}$ of two feature extractors for matching the parameter dimensions $\{\mathbb{R}^{d_{1}\times L},\mathbb{R}^{d_{2}\times L}\}$ of the two prediction headers,
$$
{\widetilde{\boldsymbol{\mathcal{R}}}}_{i}^{lc}={{\widetilde{\boldsymbol{
\mathcal{R}}}}_{i}}^{1:d_{1}},{\widetilde{\boldsymbol{\mathcal{R}}}}_{i}^{hf}=
{{\widetilde{\boldsymbol{\mathcal{R}}}}_{i}}^{1:d_{2}}. \tag{5}
$$
The embedded low-dimension coarse-granularity representation ${\widetilde{\boldsymbol{\mathcal{R}}}}_{i}^{lc}\in\mathbb{R}^{d_{1}}$ incorporates coarse generalized and personalized feature information. It is learned by the global homogeneous model header $\mathcal{G}^{hd}(\theta^{hd,t-1})$ (parameter space: $\mathbb{R}^{d_{1}\times L}$ ) with generalized prediction information to produce:
$$
{\hat{{y}}}_{i}^{\mathcal{G}}=\mathcal{G}^{hd}({\widetilde{\boldsymbol{
\mathcal{R}}}}_{i}^{lc};\theta^{hd,t-1}). \tag{6}
$$
The embedded high-dimension fine-granularity representation ${\widetilde{\boldsymbol{\mathcal{R}}}}_{i}^{hf}\in\mathbb{R}^{d_{2}}$ carries finer generalized and personalized feature information, which is further processed by the heterogeneous local model header $\mathcal{F}_{k}^{hd}(\omega_{k}^{hd,t-1})$ (parameter space: $\mathbb{R}^{d_{2}\times L}$ ) with personalized prediction information to generate:
$$
{\hat{{y}}}_{i}^{\mathcal{F}_{k}}=\mathcal{F}_{k}^{hd}({\widetilde{\boldsymbol
{\mathcal{R}}}}_{i}^{hf};\omega_{k}^{hd,t-1}). \tag{7}
$$
We compute the losses $\ell$ (e.g., cross-entropy loss [62]) between the two outputs and the label $y_{i}$ as:
$$
\ell_{i}^{\mathcal{G}}=\ell({\hat{{y}}}_{i}^{\mathcal{G}},y_{i}),\ \ell_{i}^{
\mathcal{F}_{k}}=\ell({\hat{{y}}}_{i}^{\mathcal{F}_{k}},y_{i}). \tag{8}
$$
Then, the losses of the two branches are weighted by their importance $m_{i}^{\mathcal{G}}$ and $m_{i}^{\mathcal{F}_{k}}$ and summed as:
$$
\ell_{i}=m_{i}^{\mathcal{G}}\cdot\ell_{i}^{\mathcal{G}}+m_{i}^{\mathcal{F}_{k}
}\cdot\ell_{i}^{\mathcal{F}_{k}}. \tag{9}
$$
We set $m_{i}^{\mathcal{G}}=m_{i}^{\mathcal{F}_{k}}=1$ by default to make the two models contribute equally to model performance. The complete loss $\ell_{i}$ is used to simultaneously update the homogeneous global small model, the heterogeneous client local model, and the representation projector via gradient descent:
$$
\displaystyle\theta_{k}^{t} \displaystyle\leftarrow\theta^{t-1}-\eta_{\theta}\nabla\ell_{i}, \displaystyle\omega_{k}^{t} \displaystyle\leftarrow\omega_{k}^{t-1}-\eta_{\omega}\nabla\ell_{i}, \displaystyle\varphi_{k}^{t} \displaystyle\leftarrow\varphi_{k}^{t-1}-\eta_{\varphi}\nabla\ell_{i}, \tag{10}
$$
where $\eta_{\theta},\eta_{\omega},\ \eta_{\varphi}$ are the learning rates of the homogeneous global small model, the heterogeneous local model and the representation projector. We set $\eta_{\theta}=\eta_{\omega}=\ \eta_{\varphi}$ by default to ensure stable model convergence. In this way, the generalized and personalized fused representation is learned from multiple perspectives, thereby improving model learning capability.
## 4 Convergence Analysis
Based on notations, assumptions and proofs in Appendix B, we analyse the convergence of FedMRL.
**Lemma 1**
*Local Training. Given Assumptions 1 and 2, the loss of an arbitrary client’s local model $w$ in local training round $(t+1)$ is bounded by:
$$
\mathbb{E}[\mathcal{L}_{(t+1)E}]\leq\mathcal{L}_{tE+0}+(\frac{L_{1}\eta^{2}}{2
}-\eta)\sum_{e=0}^{E}\|\nabla\mathcal{L}_{tE+e}\|_{2}^{2}+\frac{L_{1}E\eta^{2}
\sigma^{2}}{2}. \tag{11}
$$*
**Lemma 2**
*Model Aggregation. Given Assumptions 2 and 3, after local training round $(t+1)$ , a client’s loss before and after receiving the updated global homogeneous small models is bounded by:
$$
\mathbb{E}[\mathcal{L}_{(t+1)E+0}]\leq\mathbb{E}[\mathcal{L}_{tE+1}]+{\eta
\delta}^{2}. \tag{12}
$$*
**Theorem 1**
*One Complete Round of FL. Given the above lemmas, for any client, after receiving the updated global homogeneous small model, we have:
$$
\mathbb{E}[\mathcal{L}_{(t+1)E+0}]\leq\mathcal{L}_{tE+0}+(\frac{L_{1}\eta^{2}}
{2}-\eta)\sum_{e=0}^{E}\|\nabla\mathcal{L}_{tE+e}\|_{2}^{2}+\frac{L_{1}E\eta^{
2}\sigma^{2}}{2}+\eta\delta^{2}. \tag{13}
$$*
**Theorem 2**
*Non-convex Convergence Rate of FedMRL. Given Theorem 1, for any client and an arbitrary constant $\epsilon>0$ , the following holds:
$$
\displaystyle\frac{1}{T}\sum_{t=0}^{T-1}\sum_{e=0}^{E-1}\|\nabla\mathcal{L}_{
tE+e}\|_{2}^{2} \displaystyle\leq\frac{\frac{1}{T}\sum_{t=0}^{T-1}[\mathcal{L}_{tE+0}-\mathbb{
E}[\mathcal{L}_{(t+1)E+0}]]+\frac{L_{1}E\eta^{2}\sigma^{2}}{2}+\eta\delta^{2}}
{\eta-\frac{L_{1}\eta^{2}}{2}}<\epsilon, \displaystyle s.t. \displaystyle\eta<\frac{2(\epsilon-\delta^{2})}{L_{1}(\epsilon+E\sigma^{2})}. \tag{14}
$$*
Therefore, we conclude that any client’s local model can converge at a non-convex rate of $\epsilon\sim\mathcal{O}(1/T)$ in FedMRL if the learning rates of the homogeneous small model, the client local heterogeneous model and the personalized representation projector satisfy the above conditions.
## 5 Experimental Evaluation
We implement FedMRL on Pytorch, and compare it with seven state-of-the-art MHeteroFL methods. The experiments are carried out over two benchmark supervised image classification datasets on $4$ NVIDIA GeForce 3090 GPUs (24GB Memory). Codes are available in supplemental materials.
### 5.1 Experiment Setup
Datasets. The benchmark datasets adopted are CIFAR-10 and CIFAR-100 https://www.cs.toronto.edu/%7Ekriz/cifar.html [20], which are commonly used in FL image classification tasks for the evaluating existing MHeteroFL algorithms. CIFAR-10 has $60,000$ $32\times 32$ colour images across $10$ classes, with $50,000$ for training and $10,000$ for testing. CIFAR-100 has $60,000$ $32\times 32$ colour images across $100$ classes, with $50,000$ for training and $10,000$ for testing. We follow [37] and [34] to construct two types of non-IID datasets. Each client’s non-IID data are further divided into a training set and a testing set with a ratio of $8:2$ .
- Non-IID (Class): For CIFAR-10 with $10$ classes, we randomly assign $2$ classes to each FL client. For CIFAR-100 with $100$ classes, we randomly assign $10$ classes to each FL client. The fewer classes each client possesses, the higher the non-IIDness.
- Non-IID (Dirichlet): To produce more sophisticated non-IID data settings, for each class of CIFAR-10/CIFAR-100, we use a Dirichlet( $\alpha$ ) function to adjust the ratio between the number of FL clients and the assigned data. A smaller $\alpha$ indicates more pronounced non-IIDness.
Models. We evaluate MHeteroFL algorithms under model-homogeneous and heterogeneous FL scenarios. FedMRL ’s representation projector is a one-layer linear model (parameter space: $\mathbb{R}^{d2\times(d_{1}+d_{2})}$ ).
- Model-Homogeneous FL: All clients train CNN-1 in Table 2 (Appendix C.1). The homogeneous global small models in FML and FedKD are also CNN-1. The extra homogeneous global small model in FedMRL is CNN-1 with a smaller representation dimension $d_{1}$ (i.e., the penultimate linear layer dimension) than the CNN-1 model’s representation dimension $d_{2}$ , $d_{1}\leq d_{2}$ .
- Model-Heterogeneous FL: The $5$ heterogeneous models {CNN-1, $\ldots$ , CNN-5} in Table 2 (Appendix C.1) are evenly distributed among FL clients. The homogeneous global small models in FML and FedKD are the smallest CNN-5 models. The homogeneous global small model in FedMRL is the smallest CNN-5 with a reduced representation dimension $d_{1}$ compared with the CNN-5 model representation dimension $d_{2}$ , i.e., $d_{1}\leq d_{2}$ .
Comparison Baselines. We compare FedMRL with state-of-the-art algorithms belonging to the following three categories of MHeteroFL methods:
- Standalone. Each client trains its heterogeneous local model only with its local data.
- Knowledge Distillation Without Public Data: FD [19] and FedProto [41].
- Model Split: LG-FedAvg [24].
- Mutual Learning: FML [38], FedKD [43] and FedAPEN [34].
Evaluation Metrics. We evaluate MHeteroFL algorithms from the following three aspects:
- Model Accuracy. We record the test accuracy of each client’s model in each round, and compute the average test accuracy.
- Communication Cost. We compute the number of parameters sent between the server and one client in one communication round, and record the required rounds for reaching the target average accuracy. The overall communication cost of one client for target average accuracy is the product between the cost per round and the number of rounds.
- Computation Overhead. We compute the computation FLOPs of one client in one communication round, and record the required communication rounds for reaching the target average accuracy. The overall computation overall for one client achieving the target average accuracy is the product between the FLOPs per round and the number of rounds.
Training Strategy. We search optimal FL hyperparameters and unique hyperparameters for all MHeteroFL algorithms. For FL hyperparameters, we test MHeteroFL algorithms with a $\{64,128,256,512\}$ batch size, $\{1,10\}$ epochs, $T=\{100,500\}$ communication rounds and an SGD optimizer with a $0.01$ learning rate. The unique hyperparameter of FedMRL is the representation dimension $d_{1}$ of the homogeneous global small model, we vary $d_{1}=\{100,\ 150,...,500\}$ to obtain the best-performing FedMRL.
### 5.2 Results and Discussion
We design three FL settings with different numbers of clients ( $N$ ) and client participation rates ( $C$ ): ( $N=10,C=100\$ ), ( $N=50,C=20\$ ), ( $N=100,C=10\$ ) for both model-homogeneous and model-heterogeneous FL scenarios.
#### 5.2.1 Average Test Accuracy
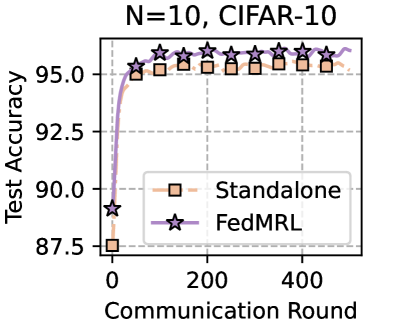
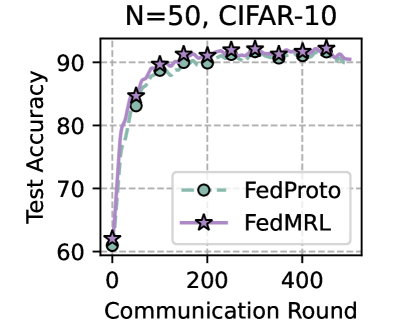
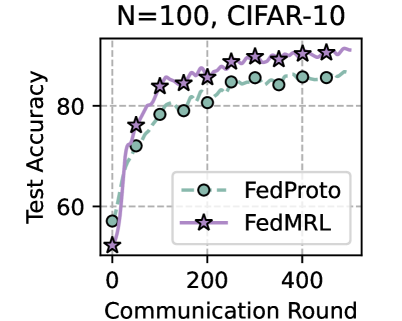
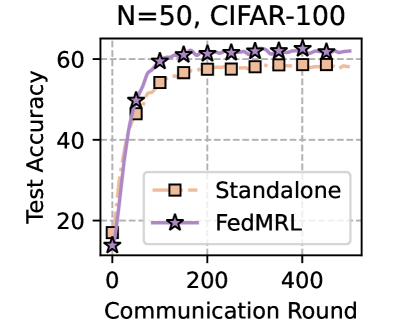
Table 1 and Table 3 (Appendix C.2) show that FedMRL consistently outperforms all baselines under both model-heterogeneous or homogeneous settings. It achieves up to a $8.48\$ improvement in average test accuracy compared with the best baseline under each setting. Furthermore, it achieves up to a $24.94\$ average test accuracy improvement than the best same-category (i.e., mutual learning-based MHeteroFL) baseline under each setting. These results demonstrate the superiority of FedMRL in model performance owing to its adaptive personalized representation fusion and multi-granularity representation learning capabilities. Figure 3 (left six) shows that FedMRL consistently achieves faster convergence speed and higher average test accuracy than the best baseline under each setting.
#### 5.2.2 Individual Client Test Accuracy
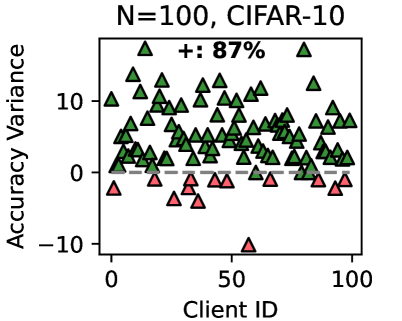
Figure 3 (right two) shows the difference between the test accuracy achieved by FedMRL vs. the best-performing baseline FedProto (i.e., FedMRL - FedProto) under ( $N=100,C=10\$ ) for each individual client. It can be observed that $87\$ and $99\$ of all clients achieve better performance under FedMRL than under FedProto on CIFAR-10 and CIFAR-100, respectively. This demonstrates that FedMRL possesses stronger personalization capability than FedProto owing to its adaptive personalized multi-granularity representation learning design.
Table 1: Average test accuracy (%) in model-heterogeneous FL.
| FL Setting Method Standalone | N=10, C=100% CIFAR-10 96.53 | N=50, C=20% CIFAR-100 72.53 | N=100, C=10% CIFAR-10 95.14 | CIFAR-100 62.71 | CIFAR-10 91.97 | CIFAR-100 53.04 |
| --- | --- | --- | --- | --- | --- | --- |
| LG-FedAvg [24] | 96.30 | 72.20 | 94.83 | 60.95 | 91.27 | 45.83 |
| FD [19] | 96.21 | - | - | - | - | - |
| FedProto [41] | 96.51 | 72.59 | 95.48 | 62.69 | 92.49 | 53.67 |
| FML [38] | 30.48 | 16.84 | - | 21.96 | - | 15.21 |
| FedKD [43] | 80.20 | 53.23 | 77.37 | 44.27 | 73.21 | 37.21 |
| FedAPEN [34] | - | - | - | - | - | - |
| FedMRL | 96.63 | 74.37 | 95.70 | 66.04 | 95.85 | 62.15 |
| FedMRL -Best B. | 0.10 | 1.78 | 0.22 | 3.33 | 3.36 | 8.48 |
| FedMRL -Best S.C.B. | 16.43 | 21.14 | 18.33 | 21.77 | 22.64 | 24.94 |
“-”: failing to converge. “ ”: the best MHeteroFL method. “ Best B.”: the best baseline. “ Best S.C.B.”: the best same-category (mutual learning-based MHeteroFL) baseline. The underscored values denote the largest accuracy improvement of FedMRL across $6$ settings.
<details>
<summary>x4.png Details</summary>
### Visual Description
\n
## Line Chart: N=10, CIFAR-10 Test Accuracy vs. Communication Round
### Overview
The image is a line chart comparing the test accuracy of two machine learning methods, "Standalone" and "FedMRL," over a series of communication rounds. The chart is titled "N=10, CIFAR-10," indicating the experiment likely involves 10 clients or participants (N=10) using the CIFAR-10 dataset. The plot shows both methods improving in accuracy as communication rounds increase, with FedMRL demonstrating a performance advantage, particularly in the early rounds.
### Components/Axes
* **Title:** "N=10, CIFAR-10" (centered at the top).
* **Y-Axis:** Labeled "Test Accuracy". The scale runs from approximately 87.5 to 95.0, with major tick marks at 87.5, 90.0, 92.5, and 95.0.
* **X-Axis:** Labeled "Communication Round". The scale runs from 0 to approximately 500, with major tick marks labeled at 0, 200, and 400.
* **Legend:** Positioned in the bottom-right quadrant of the chart area. It contains two entries:
* An orange square symbol labeled "Standalone".
* A purple star symbol labeled "FedMRL".
* **Data Series:**
1. **Standalone:** Represented by an orange line with square markers.
2. **FedMRL:** Represented by a purple line with star markers.
* **Grid:** A light gray dashed grid is present in the background.
### Detailed Analysis
**Trend Verification & Data Points (Approximate):**
* **Standalone (Orange Squares):**
* **Trend:** The line shows a steep, concave-down increase from round 0, then plateaus.
* **Data Points:**
* Round 0: ~87.5%
* Round ~50: ~94.0%
* Round ~100: ~95.0%
* Round ~150 to ~450: Hovers consistently around 95.0% - 95.5%.
* **FedMRL (Purple Stars):**
* **Trend:** The line shows an even steeper initial increase than Standalone, reaching a high accuracy faster, and then maintains a slight but consistent lead.
* **Data Points:**
* Round 0: ~89.0%
* Round ~50: ~95.0%
* Round ~100: ~95.5%
* Round ~150 to ~450: Maintains a level slightly above the Standalone line, approximately between 95.5% and 96.0%.
**Spatial Grounding:** The FedMRL (purple star) data points are consistently positioned vertically higher than the corresponding Standalone (orange square) data points at the same communication round, confirming its performance advantage as per the legend.
### Key Observations
1. **Initial Performance Gap:** At round 0, FedMRL starts at a higher accuracy (~89.0%) compared to Standalone (~87.5%).
2. **Convergence Speed:** FedMRL reaches the ~95.0% accuracy threshold significantly earlier (around round 50) than Standalone (around round 100).
3. **Final Performance Plateau:** Both methods plateau after approximately round 150. FedMRL maintains a small but consistent lead of roughly 0.5-1.0 percentage points in test accuracy over Standalone throughout the plateau phase.
4. **No Significant Degradation:** Neither method shows a decline in accuracy within the observed 450+ rounds, indicating stable training.
### Interpretation
The chart demonstrates the comparative effectiveness of the "FedMRL" federated learning method against a "Standalone" baseline on the CIFAR-10 image classification task with 10 participants.
* **What the data suggests:** FedMRL is more communication-efficient. It achieves high model accuracy (≥95%) in fewer communication rounds and sustains a slight performance edge. This implies that the FedMRL algorithm likely improves the learning process, possibly through better model aggregation or personalization, leading to a more accurate final global model with less communication overhead.
* **How elements relate:** The x-axis (Communication Round) represents the cost or time in a federated learning system. The y-axis (Test Accuracy) represents the primary performance metric. The relationship shows that investing communication rounds yields diminishing returns after about 150 rounds for both methods, but FedMRL extracts more value (accuracy) from each early round.
* **Notable patterns/anomalies:** The most notable pattern is the consistent, parallel plateau of both lines after round 150. This suggests that both methods have converged to their respective maximum achievable accuracies under the given experimental setup (N=10, CIFAR-10). The lack of crossover indicates FedMRL's advantage is robust throughout the training process. There are no anomalous drops or spikes, indicating stable experimental conditions.
</details>
<details>
<summary>x5.png Details</summary>
### Visual Description
## Line Chart: Federated Learning Performance on CIFAR-10
### Overview
The image is a line chart comparing the test accuracy of two federated learning methods, FedProto and FedMRL, over the course of training. The chart is titled "N=50, CIFAR-10", indicating the experiment was conducted with 50 clients on the CIFAR-10 dataset. The x-axis represents the communication rounds between clients and a central server, while the y-axis shows the test accuracy percentage.
### Components/Axes
* **Title:** "N=50, CIFAR-10" (Top center)
* **Y-Axis:** Label is "Test Accuracy". Scale ranges from 60 to 90, with major tick marks at 60, 70, 80, and 90.
* **X-Axis:** Label is "Communication Round". Scale ranges from 0 to approximately 500, with major tick marks labeled at 0, 200, and 400.
* **Legend:** Located in the bottom-right quadrant of the chart area.
* **FedProto:** Represented by a green dashed line with open circle markers.
* **FedMRL:** Represented by a purple solid line with star markers.
* **Grid:** A light gray grid is present in the background.
### Detailed Analysis
**Trend Verification:**
* **FedProto (Green, Circles):** The line shows a steep, logarithmic-like increase in accuracy from round 0, then plateaus. The trend is strongly upward initially, then flattens.
* **FedMRL (Purple, Stars):** This line follows a very similar trajectory to FedProto but maintains a consistently higher accuracy after the initial rounds. Its trend is also steeply upward before plateauing.
**Data Point Extraction (Approximate Values):**
* **Round 0:** Both methods start at approximately **60%** accuracy.
* **Round ~50:** FedProto is at ~83%. FedMRL is at ~85%.
* **Round ~100:** FedProto reaches ~90%. FedMRL is at ~91%.
* **Round 200:** FedProto is at ~91%. FedMRL is at ~92%.
* **Rounds 200-500:** Both lines plateau with minor fluctuations.
* FedProto fluctuates between approximately **91% and 92%**.
* FedMRL fluctuates between approximately **92% and 93%**, consistently appearing 1-2 percentage points above FedProto.
* **Final Round (~500):** FedProto is at ~92%. FedMRL is at ~93%.
### Key Observations
1. **Rapid Convergence:** Both models achieve over 90% test accuracy within the first 100-150 communication rounds.
2. **Performance Gap:** FedMRL demonstrates a small but consistent performance advantage over FedProto throughout the training process after the initial rounds.
3. **Stability:** After round 200, both methods show stable performance with very low variance, indicating convergence.
4. **Identical Starting Point:** Both methods begin at the same baseline accuracy (~60%) at round 0.
### Interpretation
The chart demonstrates the effectiveness of both FedProto and FedMRL federated learning algorithms on the CIFAR-10 image classification task with 50 participating clients. The key takeaway is that **FedMRL achieves a slightly higher final test accuracy (~93%) compared to FedProto (~92%)** under these experimental conditions.
The steep initial ascent indicates that both methods are highly efficient at learning from distributed data in the early stages of communication. The plateau suggests that further communication rounds beyond 200 yield diminishing returns for accuracy improvement. The consistent gap between the lines implies that the FedMRL method may have a superior model aggregation or personalization mechanism that leads to better generalization on the test set. The "N=50" parameter is crucial context, as federated learning performance can be highly sensitive to the number of clients.
</details>
<details>
<summary>x6.png Details</summary>
### Visual Description
## Line Chart: Federated Learning Performance on CIFAR-10
### Overview
The image is a line chart comparing the test accuracy of two federated learning algorithms, FedProto and FedMRL, over 500 communication rounds. The experiment uses the CIFAR-10 dataset with N=100 (likely indicating 100 clients or participants). The chart demonstrates that both methods improve over time, but FedMRL achieves higher final accuracy and a faster convergence rate after an initial period.
### Components/Axes
* **Title:** "N=100, CIFAR-10" (Top center)
* **Y-Axis:** Label is "Test Accuracy". The scale runs from approximately 50 to 90, with major tick marks labeled at 60 and 80.
* **X-Axis:** Label is "Communication Round". The scale runs from 0 to 500, with major tick marks labeled at 0, 200, and 400.
* **Legend:** Located in the bottom-right quadrant of the chart area.
* **FedProto:** Represented by a dashed green line with circular markers (○).
* **FedMRL:** Represented by a solid purple line with star markers (☆).
* **Grid:** A light gray dashed grid is present, aligned with the major tick marks on both axes.
### Detailed Analysis
**Data Series & Trends:**
1. **FedProto (Green line, ○ markers):**
* **Trend:** Shows a steep, logarithmic-style increase in accuracy that gradually plateaus.
* **Approximate Data Points:**
* Round 0: ~58%
* Round ~50: ~72%
* Round ~100: ~78%
* Round ~150: ~80%
* Round ~200: ~82%
* Round ~250: ~84%
* Round ~300: ~85%
* Round ~350: ~86%
* Round ~400: ~87%
* Round ~450: ~88%
* Round 500: ~88%
2. **FedMRL (Purple line, ☆ markers):**
* **Trend:** Starts lower than FedProto but exhibits a steeper initial ascent, surpassing FedProto around round 150-200, and continues to climb to a higher final accuracy.
* **Approximate Data Points:**
* Round 0: ~52%
* Round ~50: ~76%
* Round ~100: ~82%
* Round ~150: ~84%
* Round ~200: ~86%
* Round ~250: ~87%
* Round ~300: ~88%
* Round ~350: ~89%
* Round ~400: ~90%
* Round ~450: ~91%
* Round 500: ~91%
### Key Observations
1. **Crossover Point:** The FedMRL line (purple stars) crosses above the FedProto line (green circles) between communication rounds 150 and 200. Before this point, FedProto has a slight accuracy lead; after it, FedMRL maintains a consistent and growing lead.
2. **Convergence:** Both curves show diminishing returns, with the rate of accuracy improvement slowing significantly after round 300. However, FedMRL's plateau occurs at a higher accuracy level (~91%) compared to FedProto (~88%).
3. **Initial Performance:** FedProto has a higher starting accuracy at round 0 (~58% vs. ~52%), suggesting it may have a better initial model or warm-start procedure.
4. **Growth Rate:** FedMRL demonstrates a more aggressive learning curve in the first 100 rounds, gaining approximately 30 percentage points (from ~52% to ~82%), while FedProto gains about 20 points (from ~58% to ~78%) in the same period.
### Interpretation
This chart provides a performance comparison in a federated learning context, where multiple clients collaboratively train a model without sharing raw data. The "Communication Round" axis represents iterations of this collaborative process.
* **What the data suggests:** The FedMRL algorithm is more effective than FedProto for this specific task (CIFAR-10 classification with 100 clients). While it may start from a weaker position, its learning efficiency is superior, allowing it to overtake FedProto and achieve a final model with approximately 3 percentage points higher test accuracy.
* **How elements relate:** The legend is critical for correctly attributing the performance curves. The green circle line (FedProto) shows steady but slower improvement. The purple star line (FedMRL) shows a "catch-up and surpass" pattern. The grid helps in estimating the numerical values and confirming the crossover point.
* **Notable patterns/anomalies:** The most significant pattern is the performance inversion. This could indicate that FedMRL's method of handling non-IID data (common in federated settings) or its model aggregation technique is more robust or efficient in the long run, despite a potentially less optimal initialization. The consistent gap in the later rounds suggests the advantage is stable and not due to noise. There are no obvious anomalies; the curves are smooth and follow expected learning trajectories.
</details>
<details>
<summary>x7.png Details</summary>
### Visual Description
## Scatter Plot: Accuracy Variance Across Clients (CIFAR-10)
### Overview
This is a scatter plot visualizing the "Accuracy Variance" for 100 distinct clients (N=100) on the CIFAR-10 dataset. The plot compares individual client performance against a baseline, indicated by a dashed horizontal line at zero variance. Data points are represented as triangles, colored either green or red based on their position relative to the baseline.
### Components/Axes
* **Title:** "N=100, CIFAR-10" (Top center)
* **X-Axis:** Labeled "Client ID". Scale runs from 0 to 100, with major tick marks at 0, 50, and 100.
* **Y-Axis:** Labeled "Accuracy Variance". Scale runs from -10 to 10, with major tick marks at -10, 0, and 10.
* **Legend:** Positioned in the top-right quadrant of the plot area. Contains a plus symbol (`+`) followed by the text "87%".
* **Baseline:** A dashed horizontal line at y = 0.
* **Data Points:** 100 triangle markers. The color coding is as follows:
* **Green Triangles:** Positioned above the y=0 baseline (positive accuracy variance).
* **Red Triangles:** Positioned below the y=0 baseline (negative accuracy variance).
### Detailed Analysis
* **Data Distribution:** The 100 data points (Client IDs 0-99) are scattered across the plot. The majority of points are green triangles located above the dashed zero line.
* **Green Points (Positive Variance):** These points are densely clustered between y=0 and y=15 (approximate upper bound of the visible cluster). Their distribution along the x-axis (Client ID) appears relatively uniform, with no obvious concentration in a specific ID range.
* **Red Points (Negative Variance):** These points are fewer in number and are located below the y=0 line. Most red points cluster between y=0 and y=-5. There is one significant outlier: a single red triangle located at approximately Client ID 55, with a y-value of -10 (the lowest point on the chart).
* **Legend Interpretation:** The legend entry "+: 87%" is placed in the top-right. Given the context, this likely indicates that 87% of the clients (87 out of 100) have a positive accuracy variance (i.e., are represented by green triangles above the line).
### Key Observations
1. **Predominance of Positive Variance:** The visual impression is dominated by green triangles, consistent with the 87% figure in the legend. This suggests most clients performed better than the baseline.
2. **Notable Outlier:** One client (ID ~55) shows a severe negative variance of -10, which is a clear outlier compared to the rest of the negative-variance clients.
3. **Variance Range:** The positive variance for most clients is contained within a band of approximately 0 to +12. The negative variance, excluding the outlier, is generally within 0 to -5.
4. **No Clear ID-Based Trend:** There is no apparent upward or downward trend in accuracy variance as the Client ID increases from 0 to 100. The performance appears independent of the client's numerical identifier.
### Interpretation
This chart likely originates from a **federated learning** or **distributed machine learning** experiment. In such setups, a model is trained across multiple decentralized clients (e.g., mobile devices or different data silos) holding local data samples.
* **"Accuracy Variance"** probably measures the difference in a client's local model accuracy compared to a global model's accuracy or a central baseline. A positive value means the client's local data allowed for better performance than the baseline.
* The **87% metric** is a key performance indicator, showing that the vast majority of clients achieved a local accuracy superior to the reference point. This suggests the federated training process was broadly effective across the client population.
* The **outlier at Client ID 55** is critically important. It represents a client whose local model performed significantly worse. This could be due to:
* **Non-IID Data:** The data on this client is fundamentally different or of much lower quality than the average.
* **System Issues:** Problems like network dropout, hardware limitations, or software bugs during that client's training round.
* **Adversarial Behavior:** In some contexts, this could indicate a malicious client attempting to degrade model performance.
* The **lack of correlation with Client ID** implies that performance is not tied to the order in which clients were registered or sampled, but rather to the intrinsic properties of each client's data or system.
**In summary, the visualization demonstrates a successful federated learning outcome for the CIFAR-10 task across 100 clients, with high overall positive variance (87%), but highlights the presence of at least one severely underperforming client that requires investigation.**
</details>
<details>
<summary>x8.png Details</summary>

### Visual Description
\n
## Line Chart: Test Accuracy vs. Communication Round for Federated Learning Methods
### Overview
The image is a line chart comparing the test accuracy of two federated learning methods, FedProto and FedMRL, over a series of communication rounds. The chart is titled "N=10, CIFAR-100," indicating the experiment was conducted with 10 clients on the CIFAR-100 dataset.
### Components/Axes
* **Title:** "N=10, CIFAR-100" (Top center)
* **Y-Axis:** Labeled "Test Accuracy". The scale runs from 20 to 60, with major tick marks and grid lines at 20, 40, and 60. The axis extends slightly below 20 and above 60.
* **X-Axis:** Labeled "Communication Round". The scale runs from 0 to 400, with major tick marks and grid lines at 0, 200, and 400.
* **Legend:** Located in the bottom-right quadrant of the chart area.
* A teal circle symbol corresponds to the label "FedProto".
* A purple star symbol corresponds to the label "FedMRL".
* **Data Series:**
1. **FedProto:** Represented by a dashed teal line connecting teal circle markers.
2. **FedMRL:** Represented by a solid purple line connecting purple star markers.
### Detailed Analysis
**Trend Verification & Data Points (Approximate):**
* **FedMRL (Purple Stars, Solid Line):**
* **Trend:** The line shows a very steep initial increase in accuracy, followed by a plateau. It starts at a higher accuracy than FedProto and maintains a lead throughout, though the gap narrows significantly.
* **Data Points:**
* Round 0: ~50% accuracy.
* Round ~50: Accuracy rises sharply to ~68%.
* Round 100: Accuracy is approximately 70%.
* Rounds 200-400: Accuracy remains stable, hovering just above 70% (approximately 71-72%).
* **FedProto (Teal Circles, Dashed Line):**
* **Trend:** The line shows a steady, consistent logarithmic-like increase in accuracy over time. It starts at a much lower point but continuously improves, nearly converging with FedMRL by the end of the observed rounds.
* **Data Points:**
* Round 0: ~15% accuracy.
* Round ~50: ~50% accuracy.
* Round 100: ~60% accuracy.
* Round 200: ~65% accuracy.
* Round 300: ~68% accuracy.
* Round 400: ~69-70% accuracy.
### Key Observations
1. **Performance Gap and Convergence:** FedMRL demonstrates significantly faster initial convergence, reaching near-peak performance within the first 50-100 rounds. FedProto starts much lower but exhibits a strong, sustained learning curve, almost closing the performance gap by round 400.
2. **Final Accuracy:** By communication round 400, both methods achieve very similar test accuracy, in the approximate range of 70-72%.
3. **Stability:** After its initial rapid rise, FedMRL's performance is highly stable with minimal fluctuation. FedProto's performance continues to show slight, incremental gains even in later rounds.
### Interpretation
This chart illustrates a classic trade-off in federated learning optimization between convergence speed and final model performance. The data suggests that for the given task (CIFAR-100 with 10 clients):
* **FedMRL** is highly effective for scenarios requiring rapid model deployment or where communication costs are a primary concern, as it achieves high accuracy with very few communication rounds.
* **FedProto** may be preferable in settings where training can afford more communication rounds, as it demonstrates robust and continuous learning, ultimately matching the performance of the faster-converging method.
* The near-convergence of the two lines by round 400 indicates that both methods are capable of reaching a similar optimum for this specific problem setup. The choice between them would therefore depend on the operational constraints (time vs. communication budget) rather than a fundamental difference in achievable accuracy. The "N=10" parameter is critical context, as the relative performance of these methods could change with a different number of clients.
</details>
<details>
<summary>x9.png Details</summary>
### Visual Description
\n
## Line Chart: N=50, CIFAR-100 Test Accuracy vs. Communication Round
### Overview
The image is a line chart comparing the test accuracy of two machine learning training methods over communication rounds in a federated learning context. The chart is titled "N=50, CIFAR-100," indicating the experiment involves 50 clients (or agents) and uses the CIFAR-100 image classification dataset. The plot shows two data series: "Standalone" and "FedMRL," both demonstrating learning curves that improve with more communication rounds.
### Components/Axes
* **Title:** "N=50, CIFAR-100" (Top center)
* **Y-Axis:** Label is "Test Accuracy". Scale ranges from 20 to 60, with major tick marks at 20, 40, and 60. The axis appears to start slightly below 20.
* **X-Axis:** Label is "Communication Round". Scale ranges from 0 to 400, with major tick marks at 0, 200, and 400.
* **Legend:** Located in the bottom-right quadrant of the chart area.
* **Standalone:** Represented by an orange line with square markers (□).
* **FedMRL:** Represented by a purple line with star markers (☆).
* **Grid:** A light gray dashed grid is present in the background.
### Detailed Analysis
**Data Series & Trends:**
1. **Standalone (Orange Squares):**
* **Trend:** The line shows a steep initial increase in accuracy followed by a gradual plateau. It starts low and rises quickly before the rate of improvement slows significantly after approximately 100-150 rounds.
* **Approximate Data Points:**
* Round 0: ~15% accuracy
* Round 50: ~45% accuracy
* Round 100: ~55% accuracy
* Round 150: ~57% accuracy
* Round 200: ~58% accuracy
* Round 250: ~58% accuracy
* Round 300: ~58% accuracy
* Round 350: ~58% accuracy
* Round 400: ~58% accuracy
2. **FedMRL (Purple Stars):**
* **Trend:** This line also shows a steep initial rise, but it consistently achieves higher accuracy than the Standalone method after the very first data point. It continues to improve slightly even in later rounds where the Standalone method has plateaued.
* **Approximate Data Points:**
* Round 0: ~15% accuracy (similar starting point to Standalone)
* Round 50: ~50% accuracy
* Round 100: ~60% accuracy
* Round 150: ~61% accuracy
* Round 200: ~62% accuracy
* Round 250: ~62% accuracy
* Round 300: ~62% accuracy
* Round 350: ~62% accuracy
* Round 400: ~62% accuracy
**Spatial Grounding:** The FedMRL (purple star) line is positioned vertically above the Standalone (orange square) line for all communication rounds after 0. The legend is placed in the bottom-right, not obscuring the primary data trends which are concentrated in the left and center of the plot.
### Key Observations
1. **Performance Gap:** The FedMRL method demonstrates a clear and consistent performance advantage over the Standalone method. The gap is established early (by round 50) and maintained throughout the experiment.
2. **Convergence Behavior:** Both methods show logarithmic-style learning curves. The Standalone method appears to converge to a final accuracy of approximately 58%. The FedMRL method converges to a higher final accuracy of approximately 62%.
3. **Initial Learning Rate:** Both methods learn rapidly in the first 50-100 communication rounds. FedMRL's initial slope is slightly steeper.
4. **Plateau:** After round ~200, both curves show minimal improvement, indicating convergence for this experimental setup.
### Interpretation
This chart presents empirical evidence comparing two federated learning strategies on the CIFAR-100 task with 50 participants. The "Standalone" line likely represents a baseline where clients train independently or with minimal collaboration. "FedMRL" represents a proposed collaborative method (the name suggests it involves Federated Learning and Meta-Reinforcement Learning or a similar technique).
The data suggests that the FedMRL strategy is more effective than the standalone approach for this specific task and configuration. It not only achieves a higher final model accuracy (~4 percentage points higher) but also reaches a high level of performance faster (e.g., it hits 60% accuracy around round 100, a level the Standalone method never reaches). This implies that the collaborative mechanism in FedMRL successfully leverages the distributed data from the 50 clients to build a superior global model. The persistent gap indicates the benefit is not transient but leads to a better final converged model. The experiment demonstrates the value of the FedMRL algorithm for improving model performance in a federated learning setting with a non-IID image classification dataset.
</details>
<details>
<summary>x10.png Details</summary>
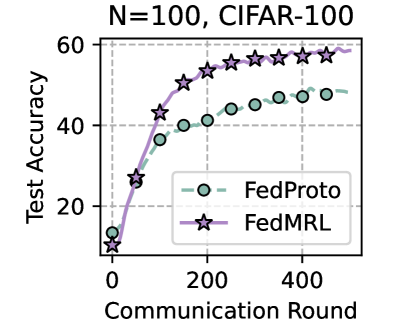
### Visual Description
## Line Chart: Federated Learning Performance on CIFAR-100
### Overview
The image is a line chart comparing the test accuracy of two federated learning algorithms, FedProto and FedMRL, over a series of communication rounds. The chart is titled "N=100, CIFAR-100," indicating the experiment was conducted with 100 clients on the CIFAR-100 image classification dataset.
### Components/Axes
* **Title:** "N=100, CIFAR-100" (Top center)
* **Y-Axis:** Labeled "Test Accuracy". The scale runs from 0 to 60, with major tick marks and grid lines at intervals of 20 (0, 20, 40, 60).
* **X-Axis:** Labeled "Communication Round". The scale runs from 0 to approximately 500, with major labeled tick marks at 0, 200, and 400.
* **Legend:** Positioned in the bottom-right quadrant of the chart area.
* **FedProto:** Represented by a dashed green line with circular markers (○).
* **FedMRL:** Represented by a solid purple line with star-shaped markers (☆).
* **Grid:** A light gray grid is present, aligned with the major ticks on both axes.
### Detailed Analysis
**Data Series & Trends:**
1. **FedProto (Green line, circle markers):**
* **Trend:** Shows a steady, logarithmic-style increase. It rises quickly in the initial rounds and then continues to improve at a gradually decreasing rate.
* **Approximate Data Points:**
* Round 0: ~10% accuracy
* Round 100: ~35% accuracy
* Round 200: ~40% accuracy
* Round 300: ~45% accuracy
* Round 400: ~48% accuracy
* Final Point (~Round 480): ~49% accuracy
2. **FedMRL (Purple line, star markers):**
* **Trend:** Shows a steeper initial ascent compared to FedProto, followed by a strong, sustained increase that plateaus at a higher level. It consistently outperforms FedProto after the first few rounds.
* **Approximate Data Points:**
* Round 0: ~5% accuracy (lower starting point than FedProto)
* Round 100: ~50% accuracy
* Round 200: ~55% accuracy
* Round 300: ~58% accuracy
* Round 400: ~59% accuracy
* Final Point (~Round 480): ~60% accuracy
### Key Observations
* **Performance Gap:** FedMRL achieves a significantly higher final test accuracy (~60%) compared to FedProto (~49%).
* **Convergence Speed:** FedMRL not only reaches a higher accuracy but also converges to a high-performance region faster. By round 100, FedMRL (~50%) has already surpassed the final accuracy of FedProto.
* **Initial Conditions:** FedProto starts with a higher accuracy at round 0 (~10% vs. ~5%), but this advantage is quickly overtaken by FedMRL's superior learning trajectory.
* **Plateau Behavior:** Both curves show signs of plateauing towards the end of the plotted rounds, but FedMRL's plateau is at a substantially higher accuracy level.
### Interpretation
This chart demonstrates the comparative effectiveness of two federated learning algorithms on a standard image classification task (CIFAR-100) with a large client population (N=100). The data suggests that the **FedMRL algorithm is substantially more efficient and effective** than FedProto in this setting.
* **Why it matters:** In federated learning, communication rounds are a primary cost. An algorithm that achieves higher accuracy in fewer rounds (like FedMRL here) is highly desirable as it reduces communication overhead and training time.
* **Reading between the lines:** The steeper initial slope of FedMRL indicates it may have a better mechanism for aggregating knowledge from diverse clients early in the process. The persistent gap suggests its final model generalizes better to the test set. The experiment likely aims to showcase FedMRL as a state-of-the-art method for federated learning on non-IID image data. The "N=100" condition highlights the algorithm's scalability to many clients.
</details>
<details>
<summary>x11.png Details</summary>
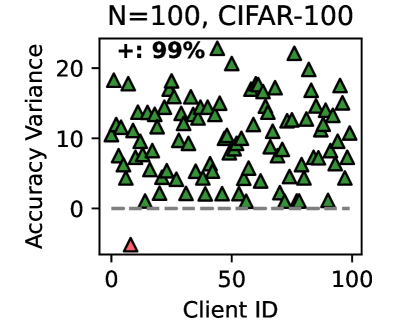
### Visual Description
## Scatter Plot: Accuracy Variance Across 100 Clients on CIFAR-100
### Overview
The image is a scatter plot visualizing the "Accuracy Variance" for 100 distinct clients, identified by their "Client ID," in an experiment using the CIFAR-100 dataset. The plot contains 100 data points, with 99 represented by green triangles and one represented by a red triangle.
### Components/Axes
* **Title:** "N=100, CIFAR-100" (Top center)
* **Y-Axis:** Labeled "Accuracy Variance". The scale runs from 0 to 20, with major tick marks at 0, 10, and 20. A dashed horizontal line is present at y=0.
* **X-Axis:** Labeled "Client ID". The scale runs from 0 to 100, with major tick marks at 0, 50, and 100.
* **Legend:** Located in the top-left corner of the plot area. It shows a green triangle symbol followed by the text "+: 99%". This indicates that 99 of the 100 data points (99%) are of this type.
* **Data Points:**
* **Green Triangles:** 99 points, scattered across the plot.
* **Red Triangle:** 1 point, located as an outlier.
### Detailed Analysis
* **Data Distribution (Green Triangles):** The 99 green triangles are distributed across the full range of Client IDs (approximately 1 to 99). Their Accuracy Variance values are predominantly positive, ranging from just above 0 to just above 20. The points form a dense cloud with no single, clear linear trend. The highest concentration appears between Client IDs ~10-90 and Accuracy Variance ~0-15.
* **Outlier (Red Triangle):** A single red triangle is positioned at approximately Client ID = 5 and Accuracy Variance = -5. This point is a clear outlier, lying significantly below the y=0 baseline and outside the main cluster of data.
* **Legend Cross-Reference:** The legend explicitly states that the green triangle symbol represents 99% of the data. Visually, this is confirmed: 99 out of 100 points are green triangles. The red triangle is not represented in the legend, marking it as an exceptional case.
### Key Observations
1. **High Variance Prevalence:** The vast majority of clients (99%) exhibit a positive Accuracy Variance, with values spread widely between 0 and over 20.
2. **Single Critical Outlier:** One client (ID ~5) shows a negative Accuracy Variance (approx. -5), which is anomalous compared to the entire dataset.
3. **No Client ID Correlation:** There is no apparent visual correlation between the Client ID (x-axis) and the Accuracy Variance (y-axis). High and low variance values appear across the entire range of client identifiers.
4. **Baseline Reference:** The dashed line at y=0 serves as a critical reference, highlighting that nearly all variance is positive, except for the single outlier.
### Interpretation
This plot likely originates from a **federated or distributed machine learning** context, where a model is trained across 100 different clients (e.g., devices or institutions) using the CIFAR-100 image classification dataset.
* **What the Data Suggests:** "Accuracy Variance" probably measures the instability or fluctuation in a client's model performance (e.g., across training rounds or data batches). The high positive variance for 99 clients indicates that their model accuracy is **unstable**, changing significantly during the process. This could be due to non-IID (non-identically and independently distributed) data across clients, small local datasets, or high learning rates.
* **The Outlier's Significance:** The single client with *negative* variance is a major anomaly. In many contexts, negative variance is a mathematical impossibility, suggesting this could be a **measurement error, a malicious client** submitting corrupted updates, or a client with a fundamentally different data distribution causing a breakdown in the variance calculation. Its identification is crucial for debugging or ensuring robust aggregation in federated learning.
* **Overall Implication:** The system exhibits high heterogeneity and instability across nearly all participants. The federated learning process is not converging to a stable state for individual clients. The presence of one severely anomalous client further complicates aggregation and could poison the global model if not detected and handled. The plot argues for the need for techniques like variance reduction, robust aggregation rules, or outlier detection mechanisms.
</details>
Figure 3: Left six: average test accuracy vs. communication rounds. Right two: individual clients’ test accuracy (%) differences (FedMRL - FedProto).
<details>
<summary>x12.png Details</summary>
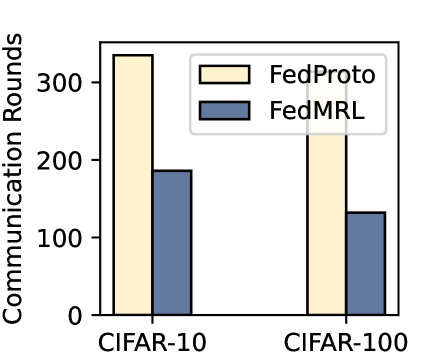
### Visual Description
## Bar Chart: Communication Rounds for Federated Learning Methods
### Overview
The image is a vertical bar chart comparing the number of communication rounds required by two federated learning methods, **FedProto** and **FedMRL**, across two different datasets: **CIFAR-10** and **CIFAR-100**. The chart visually demonstrates the communication efficiency of the two methods.
### Components/Axes
* **Chart Type:** Grouped Bar Chart.
* **Y-Axis:**
* **Label:** "Communication Rounds"
* **Scale:** Linear scale from 0 to 300, with major tick marks at 0, 100, 200, and 300.
* **X-Axis:**
* **Categories:** Two primary categories representing datasets: "CIFAR-10" (left group) and "CIFAR-100" (right group).
* **Legend:**
* **Position:** Top-right corner of the chart area.
* **Items:**
1. **FedProto:** Represented by a light yellow/cream-colored bar.
2. **FedMRL:** Represented by a medium blue bar.
* **Data Series:** Two bars per dataset category, corresponding to the two methods in the legend.
### Detailed Analysis
**Data Points and Trends:**
1. **CIFAR-10 Dataset (Left Group):**
* **FedProto (Light Yellow Bar):** This is the tallest bar in the chart. Its top aligns slightly above the 300 mark on the y-axis. **Approximate Value: ~330 communication rounds.**
* **FedMRL (Blue Bar):** This bar is significantly shorter than its FedProto counterpart. Its top aligns just below the 200 mark. **Approximate Value: ~190 communication rounds.**
* **Trend:** For the CIFAR-10 dataset, FedProto requires substantially more communication rounds than FedMRL.
2. **CIFAR-100 Dataset (Right Group):**
* **FedProto (Light Yellow Bar):** This bar is shorter than the FedProto bar for CIFAR-10. Its top aligns between the 200 and 300 marks, closer to 200. **Approximate Value: ~230 communication rounds.**
* **FedMRL (Blue Bar):** This is the shortest bar in the chart. Its top aligns just above the 100 mark. **Approximate Value: ~130 communication rounds.**
* **Trend:** For the CIFAR-100 dataset, FedProto again requires more communication rounds than FedMRL. The absolute number of rounds for both methods is lower than for CIFAR-10.
**Cross-Reference Verification:**
* The legend correctly maps the light yellow color to "FedProto" and the blue color to "FedMRL."
* In both dataset groups, the light yellow (FedProto) bar is positioned to the left of the blue (FedMRL) bar.
* The visual trend (FedProto bars are always taller than FedMRL bars) is consistent with the extracted numerical approximations.
### Key Observations
1. **Consistent Performance Gap:** FedMRL consistently requires fewer communication rounds than FedProto across both datasets.
2. **Dataset Complexity Impact:** Both methods require fewer communication rounds on the CIFAR-100 dataset compared to CIFAR-10. This is a notable pattern, as CIFAR-100 is generally considered a more complex classification task (100 classes vs. 10 classes).
3. **Magnitude of Difference:** The performance gap (in absolute rounds) between the two methods is larger for the CIFAR-10 dataset (~140 rounds difference) than for the CIFAR-100 dataset (~100 rounds difference).
### Interpretation
The data suggests that the **FedMRL** method is more communication-efficient than **FedProto** in the context of federated learning on image classification tasks. Communication rounds are a critical resource in federated learning, as each round involves transmitting model updates between clients and a server, consuming bandwidth and time. Therefore, a method requiring fewer rounds to achieve its goal (presumably convergence or a target accuracy) is advantageous.
The fact that both methods show lower round counts on the more complex CIFAR-100 dataset is intriguing and warrants further investigation. It could indicate differences in the experimental setup, convergence criteria, or inherent properties of the methods when dealing with a larger number of classes. The chart effectively communicates that FedMRL offers a potential reduction in communication overhead, which is a key practical consideration for deploying federated learning systems.
</details>
<details>
<summary>x13.png Details</summary>
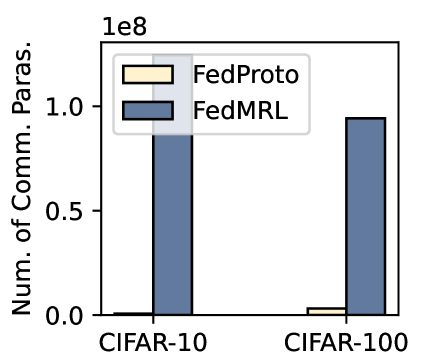
### Visual Description
\n
## Bar Chart: Communication Parameters Comparison
### Overview
The image is a vertical bar chart comparing the number of communication parameters for two federated learning methods, FedProto and FedMRL, across two standard image classification datasets: CIFAR-10 and CIFAR-100. The chart demonstrates a significant disparity in the communication cost between the two methods.
### Components/Axes
* **Y-Axis (Vertical):**
* **Label:** "Num. of Comm. Paras." (Abbreviation for "Number of Communication Parameters").
* **Scale:** Linear scale with a multiplier of `1e8` (100 million) indicated at the top of the axis.
* **Tick Marks:** Labeled at `0.0`, `0.5`, and `1.0`. These correspond to values of 0, 50 million, and 100 million parameters, respectively.
* **X-Axis (Horizontal):**
* **Categories:** Two distinct datasets are labeled: "CIFAR-10" (left group) and "CIFAR-100" (right group).
* **Legend:**
* **Position:** Top-left corner within the chart area.
* **Items:**
* A light yellow/cream-colored box labeled "FedProto".
* A dark blue/gray-blue box labeled "FedMRL".
* **Data Series:** Two bars are plotted for each dataset category, corresponding to the two methods in the legend.
### Detailed Analysis
**Data Series & Values (Approximate):**
1. **CIFAR-10 Dataset:**
* **FedProto (Light Yellow Bar):** The bar is extremely short, visually just above the `0.0` baseline. Estimated value: **~1-5 million parameters** (0.01-0.05 on the y-axis scale).
* **FedMRL (Dark Blue Bar):** The bar is tall, extending to approximately the `1.0` mark on the y-axis. Estimated value: **~100 million parameters** (1.0 x 1e8).
2. **CIFAR-100 Dataset:**
* **FedProto (Light Yellow Bar):** The bar is slightly taller than its CIFAR-10 counterpart but remains very low. Estimated value: **~5-10 million parameters** (0.05-0.1 on the y-axis scale).
* **FedMRL (Dark Blue Bar):** The bar is very similar in height to the FedMRL bar for CIFAR-10, reaching near the `1.0` mark. Estimated value: **~95-100 million parameters** (0.95-1.0 x 1e8).
**Trend Verification:**
* **FedProto Trend:** The line of tops of the yellow bars shows a very slight upward slope from CIFAR-10 to CIFAR-100, indicating a minor increase in parameters for the more complex dataset.
* **FedMRL Trend:** The line of tops of the blue bars is nearly flat, showing almost no change in the number of communication parameters between the two datasets.
### Key Observations
1. **Massive Disparity:** The most striking observation is the orders-of-magnitude difference between FedMRL and FedProto. FedMRL's communication parameter count is approximately 20 to 100 times higher than FedProto's for both datasets.
2. **Dataset Insensitivity for FedMRL:** The communication cost for FedMRL appears largely independent of the dataset complexity (CIFAR-10 vs. CIFAR-100), as the bar heights are nearly identical.
3. **Low Baseline for FedProto:** FedProto maintains a very low communication footprint across both tasks, with only a marginal increase for the more challenging CIFAR-100 dataset.
### Interpretation
This chart provides a clear quantitative comparison of communication efficiency between two federated learning algorithms. The data strongly suggests that **FedProto is designed for or results in significantly lower communication overhead** compared to FedMRL.
* **Implication for Federated Learning:** In scenarios where communication bandwidth is a critical bottleneck (e.g., mobile or edge devices), FedProto would be the far more efficient choice. The high parameter count of FedMRL implies it may require transmitting much larger model updates or auxiliary information during the federated training rounds.
* **Relationship Between Components:** The chart isolates the "communication parameters" metric, showing that the choice of algorithm (FedProto vs. FedMRL) has a dramatically larger impact on this metric than the choice of dataset (CIFAR-10 vs. CIFAR-100). This indicates the architectural or procedural differences between the two methods are the primary driver of communication cost.
* **Anomaly/Notable Point:** The near-constant value for FedMRL across datasets is noteworthy. It suggests its communication load is tied to a fixed component (e.g., a global model size or a fixed set of prototypes) rather than scaling with the number of classes (10 vs. 100), which might be expected. FedProto's slight increase aligns more intuitively with the increased complexity of CIFAR-100.
</details>
<details>
<summary>x14.png Details</summary>
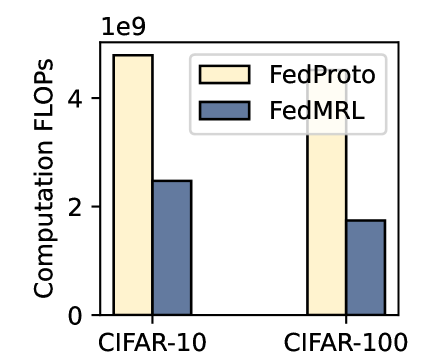
### Visual Description
## Bar Chart: Computation FLOPs Comparison for Federated Learning Methods
### Overview
The image is a vertical bar chart comparing the computational cost, measured in FLOPs (Floating Point Operations), of two federated learning methods—FedProto and FedMRL—across two standard image classification datasets: CIFAR-10 and CIFAR-100. The chart visually demonstrates that FedMRL requires significantly fewer computations than FedProto for both datasets.
### Components/Axes
* **Y-Axis:** Labeled "Computation FLOPs". The scale is linear and marked with major ticks at 0, 2, and 4. A multiplier of `1e9` (1 billion) is indicated at the top of the axis, meaning the values represent billions of FLOPs.
* **X-Axis:** Represents the datasets. Two categorical groups are present: "CIFAR-10" on the left and "CIFAR-100" on the right.
* **Legend:** Positioned in the top-right corner of the chart area. It contains two entries:
* A light yellow (cream) rectangle labeled "FedProto".
* A blue-gray rectangle labeled "FedMRL".
* **Data Series:** Two bars are plotted for each dataset category, corresponding to the two methods in the legend.
### Detailed Analysis
**Spatial Grounding & Trend Verification:**
For each dataset group on the x-axis, the FedProto bar (light yellow) is on the left, and the FedMRL bar (blue-gray) is on the right.
1. **CIFAR-10 Group (Left):**
* **FedProto (Yellow, Left Bar):** The bar extends upward to a value of approximately **4.5e9 FLOPs** (4.5 billion). The trend is a high computational cost.
* **FedMRL (Blue, Right Bar):** The bar is substantially shorter, reaching approximately **2.5e9 FLOPs** (2.5 billion). The trend shows a significant reduction in computation compared to FedProto.
2. **CIFAR-100 Group (Right):**
* **FedProto (Yellow, Left Bar):** The bar reaches approximately **3.5e9 FLOPs** (3.5 billion). This is lower than its cost on CIFAR-10.
* **FedMRL (Blue, Right Bar):** The bar is the shortest on the chart, at approximately **1.8e9 FLOPs** (1.8 billion). This represents the lowest computational cost shown.
**Data Table Reconstruction (Approximate Values):**
| Dataset | Method | Computation FLOPs (Approx.) |
| :-------- | :------- | :-------------------------- |
| CIFAR-10 | FedProto | 4.5 x 10^9 |
| CIFAR-10 | FedMRL | 2.5 x 10^9 |
| CIFAR-100 | FedProto | 3.5 x 10^9 |
| CIFAR-100 | FedMRL | 1.8 x 10^9 |
### Key Observations
1. **Consistent Efficiency Advantage:** FedMRL demonstrates a consistent and substantial reduction in computational FLOPs compared to FedProto across both datasets.
2. **Dataset Impact:** For both methods, the computational cost is higher on the CIFAR-10 dataset than on the CIFAR-100 dataset. This is an interesting observation, as CIFAR-100 is a more complex classification task (100 classes vs. 10 classes). The chart suggests the measured FLOPs may be more related to the specific model architecture or training protocol used for each dataset benchmark rather than task complexity alone.
3. **Magnitude of Difference:** The relative computational saving of FedMRL over FedProto is more pronounced on CIFAR-10 (a reduction of ~2.0e9 FLOPs, or ~44%) than on CIFAR-100 (a reduction of ~1.7e9 FLOPs, or ~49%).
### Interpretation
This chart provides a clear performance metric—computational efficiency—for evaluating federated learning algorithms. The data strongly suggests that the **FedMRL method is designed to be significantly more computationally efficient than FedProto**. In the context of federated learning, where client devices (like mobile phones or IoT devices) often have limited processing power and battery life, reducing FLOPs is a critical advantage. It implies faster training rounds, lower energy consumption, and broader feasibility for deployment on resource-constrained edge devices.
The Peircean investigative reading suggests the chart is an **index** of a causal relationship: the algorithmic design of FedMRL (the cause) leads to a measurable reduction in computational load (the effect). The consistent pattern across two different datasets (CIFAR-10 and CIFAR-100) strengthens the claim that this efficiency is a robust property of the FedMRL method, not an artifact of a single test scenario. The anomaly that both methods show lower FLOPs on the more complex CIFAR-100 dataset invites further investigation into the experimental setup, hinting that factors like model size, number of local epochs, or communication rounds might differ between the two dataset benchmarks.
</details>
Figure 4: Communication rounds, number of communicated parameters, and computation FLOPs required to reach $90\$ and $50\$ average test accuracy targets on CIFAR-10 and CIFAR-100.
#### 5.2.3 Communication Cost
We record the communication rounds and the number of parameters sent per client to achieve $90\$ and $50\$ target test average accuracy on CIFAR-10 and CIFAR-100, respectively. Figure 4 (left) shows that FedMRL requires fewer rounds and achieves faster convergence than FedProto. Figure 4 (middle) shows that FedMRL incurs higher communication costs than FedProto as it transmits the full homogeneous small model, while FedProto only transmits each local seen-class average representation between the server and the client. Nevertheless, FedMRL with an optional smaller representation dimension ( $d_{1}$ ) of the homogeneous small model still achieves higher communication efficiency than same-category mutual learning-based MHeteroFL baselines (FML, FedKD, FedAPEN) with a larger representation dimension.
#### 5.2.4 Computation Overhead
We also calculate the computation FLOPs consumed per client to reach $90\$ and $50\$ target average test accuracy on CIFAR-10 and CIFAR-100, respectively. Figure 4 (right) shows that FedMRL incurs lower computation costs than FedProto, owing to its faster convergence (i.e., fewer rounds) even with higher computation overhead per round due to the need to train an additional homogeneous small model and a linear representation projector.
### 5.3 Case Studies
#### 5.3.1 Robustness to Non-IIDness (Class)
We evaluate the robustness of FedMRL to different non-IIDnesses as a result of the number of classes assigned to each client under the ( $N=100,C=10\$ ) setting. The fewer classes assigned to each client, the higher the non-IIDness. For CIFAR-10, we assign $\{2,4,\ldots,10\}$ classes out of total $10$ classes to each client. For CIFAR-100, we assign $\{10,30,\ldots,100\}$ classes out of total $100$ classes to each client. Figure 5 (left two) shows that FedMRL consistently achieves higher average test accuracy than the best-performing baseline - FedProto on both datasets, demonstrating its robustness to non-IIDness by class.
<details>
<summary>x15.png Details</summary>
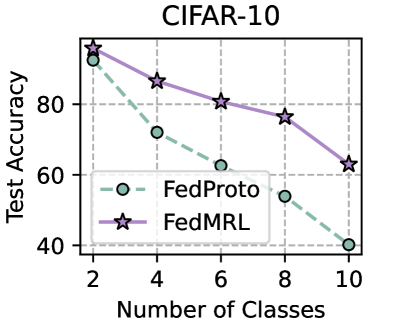
### Visual Description
## Line Chart: CIFAR-10 Test Accuracy vs. Number of Classes
### Overview
The image is a line chart titled "CIFAR-10" that compares the test accuracy of two machine learning methods, FedProto and FedMRL, as the number of classes in the classification task increases. The chart demonstrates a clear negative correlation between the number of classes and test accuracy for both methods, with FedMRL consistently outperforming FedProto.
### Components/Axes
* **Chart Title:** "CIFAR-10" (centered at the top).
* **Y-Axis:**
* **Label:** "Test Accuracy" (rotated vertically on the left).
* **Scale:** Linear scale from 40 to 80, with major tick marks and labels at 40, 60, and 80.
* **X-Axis:**
* **Label:** "Number of Classes" (centered at the bottom).
* **Scale:** Linear scale from 2 to 10, with major tick marks and labels at 2, 4, 6, 8, and 10.
* **Legend:** Positioned in the top-right quadrant of the chart area.
* **FedProto:** Represented by a green dashed line with circular markers (○).
* **FedMRL:** Represented by a purple solid line with star markers (☆).
* **Grid:** A dashed grid is present for both major x and y ticks.
### Detailed Analysis
**Data Series & Trends:**
1. **FedProto (Green, Dashed Line, Circles):**
* **Trend:** Shows a steep, consistent downward slope. Accuracy decreases significantly as the number of classes increases.
* **Data Points (Approximate):**
* At 2 Classes: ~92% accuracy.
* At 4 Classes: ~72% accuracy.
* At 6 Classes: ~62% accuracy.
* At 8 Classes: ~54% accuracy.
* At 10 Classes: ~40% accuracy.
2. **FedMRL (Purple, Solid Line, Stars):**
* **Trend:** Also shows a downward slope, but it is less steep than FedProto. The decline is more gradual, especially between 6 and 8 classes.
* **Data Points (Approximate):**
* At 2 Classes: ~94% accuracy.
* At 4 Classes: ~86% accuracy.
* At 6 Classes: ~80% accuracy.
* At 8 Classes: ~77% accuracy.
* At 10 Classes: ~63% accuracy.
**Spatial & Visual Grounding:**
* The legend is placed in the upper right, overlapping the chart area but not obscuring any data points.
* The green circle marker for FedProto at x=10 is positioned directly on the y=40 grid line.
* The purple star marker for FedMRL at x=10 is positioned slightly above the y=60 grid line.
* The gap between the two lines widens progressively from left to right.
### Key Observations
1. **Performance Gap:** FedMRL maintains a significant accuracy advantage over FedProto at every measured number of classes.
2. **Diverging Performance:** The performance gap between the two methods increases as the task becomes more complex (more classes). At 2 classes, the difference is minor (~2%), but at 10 classes, the difference is substantial (~23%).
3. **Rate of Decline:** FedProto's accuracy drops by approximately 52 percentage points (from ~92% to ~40%) when moving from 2 to 10 classes. FedMRL's accuracy drops by approximately 31 percentage points (from ~94% to ~63%) over the same range.
4. **Plateau Hint:** The FedMRL line shows a slight flattening between 6 and 8 classes (from ~80% to ~77%), suggesting a potential region of more stable performance before dropping again at 10 classes.
### Interpretation
The chart presents a comparative analysis of two federated learning methods on the CIFAR-10 dataset under a class-incremental or multi-class scenario. The data suggests that **FedMRL is a more robust and scalable method** than FedProto for handling an increasing number of classes.
* **Scalability:** The shallower slope of the FedMRL line indicates it scales better with problem complexity. Its architecture or learning mechanism appears better suited to managing the interference or confusion that arises when distinguishing between a larger set of categories.
* **Practical Implication:** For real-world applications where the number of target classes may grow or be large, FedMRL would be the preferable choice based on this evidence. FedProto's sharp decline suggests it may suffer from catastrophic forgetting or an inability to form sufficiently distinct prototypes as the class count rises.
* **Underlying Mechanism:** The names hint at the reason. "FedProto" likely relies on class prototypes, which may become crowded and less separable in high-dimensional space as classes multiply. "FedMRL" (possibly Federated Meta-Reinforcement Learning) might employ a more adaptive, meta-learning strategy that allows it to better navigate the expanding decision space.
**Language Declaration:** All text in the image is in English.
</details>
<details>
<summary>x16.png Details</summary>
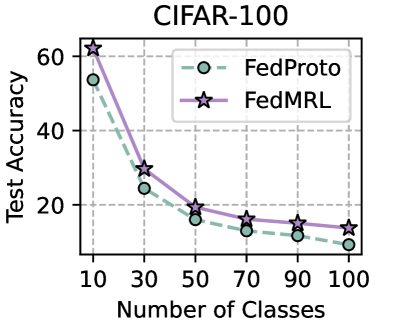
### Visual Description
## Line Chart: CIFAR-100 Test Accuracy vs. Number of Classes
### Overview
This is a line chart comparing the test accuracy of two federated learning methods, FedProto and FedMRL, on the CIFAR-100 dataset as the number of classification classes increases. The chart demonstrates a clear negative correlation between the number of classes and model accuracy for both methods.
### Components/Axes
* **Title:** "CIFAR-100" (centered at the top).
* **Y-Axis:** Labeled "Test Accuracy". The scale runs from 0 to 60, with major tick marks at 20, 40, and 60.
* **X-Axis:** Labeled "Number of Classes". The scale shows discrete values: 10, 30, 50, 70, 90, 100.
* **Legend:** Located in the top-right quadrant of the chart area.
* **FedProto:** Represented by a green dashed line with circular markers (○).
* **FedMRL:** Represented by a purple solid line with star markers (☆).
* **Grid:** A light gray grid is present, aiding in value estimation.
### Detailed Analysis
**Data Series & Trends:**
1. **FedProto (Green, Dashed Line with Circles):**
* **Trend:** The line slopes steeply downward from left to right, indicating a significant decrease in accuracy as the number of classes grows.
* **Approximate Data Points:**
* 10 Classes: ~55% accuracy
* 30 Classes: ~25% accuracy
* 50 Classes: ~15% accuracy
* 70 Classes: ~12% accuracy
* 90 Classes: ~10% accuracy
* 100 Classes: ~8% accuracy
2. **FedMRL (Purple, Solid Line with Stars):**
* **Trend:** Also slopes downward, but maintains a consistent performance advantage over FedProto at every measured point. The rate of decline appears slightly less severe after the initial drop.
* **Approximate Data Points:**
* 10 Classes: ~60% accuracy
* 30 Classes: ~30% accuracy
* 50 Classes: ~19% accuracy
* 70 Classes: ~16% accuracy
* 90 Classes: ~14% accuracy
* 100 Classes: ~13% accuracy
**Spatial Grounding & Verification:**
* The legend is positioned in the top-right, clearly associating the green circle with "FedProto" and the purple star with "FedMRL".
* At each x-axis value (10, 30, 50, etc.), the purple star marker is positioned vertically higher than the corresponding green circle marker, confirming FedMRL's superior accuracy at each point.
* The vertical gap between the two lines is largest at 10 classes (~5 percentage points) and narrows as the number of classes increases, but FedMRL remains above FedProto throughout.
### Key Observations
1. **Performance Degradation:** Both methods experience a sharp decline in test accuracy when moving from 10 to 30 classes, with the decline continuing at a slower rate thereafter.
2. **Consistent Superiority:** FedMRL outperforms FedProto at every data point shown on the chart.
3. **Convergence of Performance:** The absolute difference in accuracy between the two methods decreases as the task becomes more complex (more classes). The gap is approximately 5% at 10 classes and narrows to about 5% again at 100 classes, but the relative advantage of FedMRL is more pronounced at lower class counts.
4. **Low Final Accuracy:** Both methods achieve very low accuracy (below 20%) when classifying 100 classes, highlighting the difficulty of the task.
### Interpretation
The chart illustrates a fundamental challenge in machine learning: scalability to a large number of categories. The steep initial drop suggests that the core difficulty lies in distinguishing between a moderately increased set of classes (from 10 to 30), rather than a linear increase in difficulty with each added class.
FedMRL's consistent lead implies its underlying methodology (likely involving meta-learning or representation learning in a federated setting) provides more robust or generalizable features than FedProto's approach. This advantage is most impactful when the classification problem is less complex (fewer classes). As the problem becomes extremely complex (100 classes), the inherent difficulty overwhelms the architectural advantages of both methods, leading to similarly poor performance.
The data suggests that for practical applications on CIFAR-100-like data, FedMRL is the preferable method, but neither approach scales well to the full 100-class problem under the conditions tested. This could indicate a need for more data, more sophisticated models, or different federated learning strategies for high-class-count scenarios.
</details>
<details>
<summary>x17.png Details</summary>
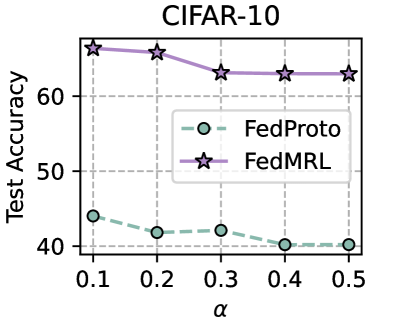
### Visual Description
## Line Chart: CIFAR-10 Test Accuracy vs. Alpha (α)
### Overview
The image is a line chart comparing the test accuracy of two federated learning methods, FedProto and FedMRL, on the CIFAR-10 dataset as a function of a parameter labeled "α". The chart shows that FedMRL consistently achieves significantly higher accuracy than FedProto across the entire range of α values tested.
### Components/Axes
* **Chart Title:** "CIFAR-10" (centered at the top).
* **Y-Axis:**
* **Label:** "Test Accuracy" (rotated vertically on the left).
* **Scale:** Linear scale from 40 to 60, with major tick marks and grid lines at 40, 50, and 60.
* **X-Axis:**
* **Label:** "α" (centered at the bottom).
* **Scale:** Linear scale from 0.1 to 0.5, with major tick marks at 0.1, 0.2, 0.3, 0.4, and 0.5.
* **Legend:** Positioned in the center-right area of the plot.
* **FedProto:** Represented by a green, dashed line with circular markers (○).
* **FedMRL:** Represented by a purple, solid line with star-shaped markers (☆).
### Detailed Analysis
**Data Series 1: FedMRL (Purple, Solid Line, Star Markers)**
* **Trend:** The line shows a slight, gradual decline as α increases, but remains relatively stable and high.
* **Data Points (Approximate):**
* α = 0.1: ~65.5%
* α = 0.2: ~65.0%
* α = 0.3: ~63.0%
* α = 0.4: ~63.0%
* α = 0.5: ~63.0%
**Data Series 2: FedProto (Green, Dashed Line, Circle Markers)**
* **Trend:** The line shows a general downward trend as α increases, with a minor fluctuation.
* **Data Points (Approximate):**
* α = 0.1: ~44.0%
* α = 0.2: ~42.0%
* α = 0.3: ~42.5%
* α = 0.4: ~40.0%
* α = 0.5: ~40.0%
### Key Observations
1. **Performance Gap:** There is a substantial and consistent performance gap between the two methods. FedMRL's accuracy is approximately 20-23 percentage points higher than FedProto's at every measured α value.
2. **Stability:** FedMRL demonstrates greater stability. Its accuracy decreases by only about 2.5 percentage points across the α range. FedProto's accuracy decreases by approximately 4 percentage points.
3. **Parameter Sensitivity:** Both methods show some sensitivity to the α parameter, with performance generally decreasing as α increases from 0.1 to 0.5. The decline is more pronounced for FedProto.
4. **Plateau:** Both methods appear to plateau after α = 0.3 or 0.4, showing little to no change in accuracy between α = 0.4 and α = 0.5.
### Interpretation
This chart presents a comparative analysis of two algorithms (FedProto and FedMRL) in a federated learning context, likely evaluating their robustness or performance under varying conditions controlled by the parameter α (which could represent a heterogeneity factor, a weighting term, or a communication round parameter).
The data strongly suggests that **FedMRL is the superior method** for the CIFAR-10 task under the tested conditions. It not only achieves a much higher baseline accuracy but also maintains its performance more robustly as the α parameter changes. The consistent gap indicates a fundamental advantage in FedMRL's approach, possibly in how it handles model aggregation, feature representation, or non-IID data distributions common in federated settings.
The downward trend for both lines implies that increasing α (whatever it concretely represents) introduces a challenge that degrades model performance. The fact that FedMRL's decline is shallower suggests it is more resilient to this challenge. The plateau at higher α values could indicate a saturation point where further increases in the parameter no longer impact the models' convergence or final accuracy.
</details>
<details>
<summary>x18.png Details</summary>
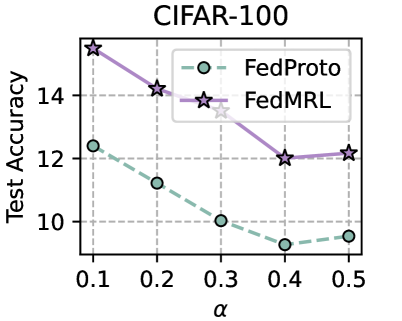
### Visual Description
## Line Chart: CIFAR-100 Test Accuracy vs. Alpha (α)
### Overview
The image is a line chart comparing the test accuracy of two federated learning methods, FedProto and FedMRL, on the CIFAR-100 dataset as a function of the parameter alpha (α). The chart demonstrates that both methods experience a decline in accuracy as α increases, but FedMRL consistently achieves higher accuracy than FedProto across all tested values.
### Components/Axes
* **Title:** "CIFAR-100" (centered at the top).
* **Y-Axis:** Labeled "Test Accuracy". The scale runs from 10 to 14, with major tick marks at 10, 12, and 14. The axis extends slightly below 10 and above 14.
* **X-Axis:** Labeled "α" (the Greek letter alpha). The scale shows discrete values: 0.1, 0.2, 0.3, 0.4, and 0.5.
* **Legend:** Positioned in the top-right quadrant of the chart area.
* **FedProto:** Represented by a green circle (○) connected by a dashed green line.
* **FedMRL:** Represented by a purple star (☆) connected by a solid purple line.
* **Grid:** A light gray, dashed grid is present for both major x and y ticks.
### Detailed Analysis
**Data Series & Trends:**
1. **FedProto (Green Circles, Dashed Line):**
* **Trend:** The line shows a consistent downward slope from left to right, indicating decreasing accuracy with increasing α. The rate of decrease slows slightly between α=0.4 and α=0.5.
* **Data Points (Approximate):**
* α = 0.1: ~12.3
* α = 0.2: ~11.2
* α = 0.3: ~10.0
* α = 0.4: ~9.2
* α = 0.5: ~9.5
2. **FedMRL (Purple Stars, Solid Line):**
* **Trend:** The line also slopes downward overall. It shows a steeper initial decline from α=0.1 to α=0.4, followed by a near-plateau or very slight increase between α=0.4 and α=0.5.
* **Data Points (Approximate):**
* α = 0.1: ~15.5
* α = 0.2: ~14.2
* α = 0.3: ~13.5
* α = 0.4: ~12.1
* α = 0.5: ~12.2
**Spatial & Visual Confirmation:**
* The FedMRL line (purple stars) is positioned vertically above the FedProto line (green circles) at every corresponding α value on the x-axis.
* The gap between the two lines is largest at α=0.1 (~3.2 difference) and narrows as α increases, being smallest at α=0.5 (~2.7 difference).
### Key Observations
1. **Performance Hierarchy:** FedMRL outperforms FedProto at every measured point of α.
2. **Negative Correlation:** For both methods, test accuracy is negatively correlated with the parameter α within the range [0.1, 0.5].
3. **Convergence of Performance:** The performance gap between the two methods decreases as α increases.
4. **Inflection Point:** Both methods show a change in trend slope at α=0.4. FedProto's decline halts and slightly reverses, while FedMRL's decline nearly stops.
### Interpretation
The chart presents a comparative analysis of two algorithms' sensitivity to a hyperparameter (α) on a standard image classification benchmark (CIFAR-100). The data suggests that:
* **Methodological Robustness:** FedMRL is a more robust method than FedProto for this task, as it maintains a higher accuracy under the same conditions (same α value). This could imply better feature representation or more effective model aggregation in the federated learning setting.
* **Hyperparameter Sensitivity:** The parameter α has a significant detrimental effect on the final model performance for both approaches. Without additional context, α could represent a factor like data heterogeneity, client drift, or a regularization term. The negative trend indicates that increasing this factor makes the learning task harder.
* **Diminishing Returns of Mitigation:** The narrowing performance gap suggests that as the problem becomes more challenging (higher α), the relative advantage of the more sophisticated FedMRL method over FedProto diminishes, though it remains superior.
* **Potential Optimal Range:** The data implies that lower values of α (closer to 0.1) are preferable for achieving higher test accuracy with either method. The slight upturn for both at α=0.5 is an interesting anomaly that might warrant further investigation to determine if it's a consistent pattern or noise.
</details>
Figure 5: Robustness to non-IIDness (Class & Dirichlet).
<details>
<summary>x19.png Details</summary>
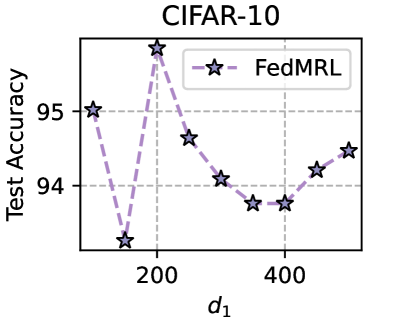
### Visual Description
\n
## Line Chart: CIFAR-10 Test Accuracy vs. Parameter d₁
### Overview
The image is a line chart displaying the performance of a method called "FedMRL" on the CIFAR-10 dataset. It plots "Test Accuracy" against a parameter labeled "d₁". The chart shows a non-monotonic relationship, with accuracy fluctuating significantly as d₁ increases.
### Components/Axes
* **Chart Title:** "CIFAR-10" (centered at the top).
* **Y-Axis:** Labeled "Test Accuracy". The visible scale has major tick marks at 94 and 95. The axis extends slightly below 94 and above 95.
* **X-Axis:** Labeled "d₁". The visible scale has major tick marks at 200 and 400. The axis starts before 200 and ends after 400.
* **Legend:** Located in the top-right corner of the plot area. It contains one entry:
* A purple dashed line with a star marker, labeled "FedMRL".
* **Data Series:** A single series represented by a purple dashed line connecting star-shaped markers.
### Detailed Analysis
The data series "FedMRL" consists of 9 distinct points. The approximate values, read from the chart, are as follows (listed in order of increasing d₁):
1. **Point 1 (d₁ ≈ 100):** Test Accuracy ≈ 95.0
2. **Point 2 (d₁ ≈ 150):** Test Accuracy ≈ 93.3 (This is the lowest point on the chart).
3. **Point 3 (d₁ ≈ 200):** Test Accuracy ≈ 95.8 (This is the highest point on the chart).
4. **Point 4 (d₁ ≈ 250):** Test Accuracy ≈ 94.7
5. **Point 5 (d₁ ≈ 300):** Test Accuracy ≈ 94.1
6. **Point 6 (d₁ ≈ 350):** Test Accuracy ≈ 93.8
7. **Point 7 (d₁ ≈ 400):** Test Accuracy ≈ 93.8
8. **Point 8 (d₁ ≈ 450):** Test Accuracy ≈ 94.2
9. **Point 9 (d₁ ≈ 500):** Test Accuracy ≈ 94.5
**Trend Verification:** The line does not follow a simple linear trend. It begins high, dips sharply to a minimum, spikes to a maximum, then follows a general downward trend with a slight recovery at the end.
### Key Observations
1. **High Volatility:** The most notable feature is the extreme volatility in the lower range of d₁ (100-200), where accuracy swings from ~95.0 down to ~93.3 and then up to ~95.8.
2. **Peak Performance:** The optimal performance for FedMRL on this task, according to this chart, occurs at d₁ ≈ 200.
3. **General Decline Post-Peak:** After the peak at d₁=200, there is a general, though not perfectly smooth, decline in test accuracy as d₁ increases to 400.
4. **Late-Stage Recovery:** There is a modest recovery in accuracy as d₁ increases from 400 to 500.
5. **Legend Placement:** The legend is positioned in the top-right, overlapping slightly with the grid lines but not obscuring any data points.
### Interpretation
This chart demonstrates the sensitivity of the FedMRL algorithm's performance on the CIFAR-10 benchmark to the hyperparameter `d₁`. The data suggests that `d₁` is a critical parameter with a narrow optimal range.
* **The sharp dip and peak** between d₁=100 and d₁=200 indicate a highly non-linear response. This could imply a phase transition in the model's behavior or optimization landscape within this parameter range.
* **The peak at d₁=200** represents the "sweet spot" for this configuration. Values significantly lower or higher lead to worse performance.
* **The gradual decline from 200 to 400** suggests that increasing `d₁` beyond the optimum generally harms generalization (test accuracy), possibly due to overfitting, increased communication overhead in a federated setting, or a mismatch with the underlying data distribution.
* **The slight uptick at the end (450-500)** is interesting but minor. It could be noise, or it might hint at a more complex, multi-modal relationship where very high values of `d₁` begin to confer some benefit again, though not reaching the peak.
In summary, the chart provides a clear empirical argument for carefully tuning `d₁` when using FedMRL, as its value has a dramatic and non-intuitive impact on final model accuracy. The optimal setting is not at the extremes of the tested range but at a specific intermediate value.
</details>
<details>
<summary>x20.png Details</summary>
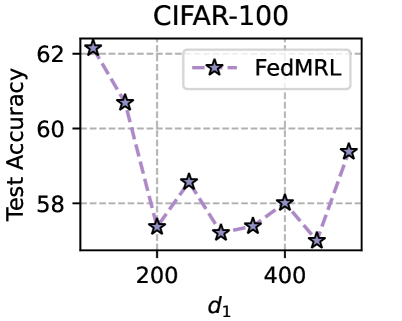
### Visual Description
## Line Chart: CIFAR-100 Test Accuracy vs. d₁
### Overview
The image is a line chart titled "CIFAR-100," plotting "Test Accuracy" against a parameter labeled "d₁." It displays a single data series for a method or model named "FedMRL." The chart shows how the test accuracy on the CIFAR-100 dataset changes as the value of d₁ increases.
### Components/Axes
* **Chart Title:** "CIFAR-100" (centered at the top).
* **Y-Axis:**
* **Label:** "Test Accuracy" (rotated vertically on the left).
* **Scale:** Linear scale with major tick marks and grid lines at 58, 60, and 62.
* **X-Axis:**
* **Label:** "d₁" (centered at the bottom).
* **Scale:** Linear scale with major tick marks and grid lines at 200 and 400. The axis appears to start at approximately 100 and end at approximately 500.
* **Legend:**
* **Placement:** Top-right corner, inside the plot area.
* **Content:** A purple dashed line with a star marker, labeled "FedMRL."
* **Data Series:**
* **Label:** "FedMRL" (from legend).
* **Visual Style:** A purple dashed line connecting star-shaped markers (☆).
### Detailed Analysis
The data series "FedMRL" is plotted as a series of discrete points connected by a dashed line. The approximate values, read from the chart, are as follows. (Note: Values are estimated based on visual alignment with the grid lines; inherent uncertainty exists.)
| Approximate d₁ Value | Approximate Test Accuracy | Visual Trend Description |
| :--- | :--- | :--- |
| ~100 | ~62.1 | Starting point, highest accuracy on the chart. |
| ~150 | ~60.7 | Sharp downward slope from the first point. |
| ~200 | ~57.5 | Continues steep decline, reaching a local minimum. |
| ~250 | ~58.6 | Slopes upward from the previous point. |
| ~300 | ~57.3 | Slopes downward again. |
| ~350 | ~57.5 | Slight upward slope. |
| ~400 | ~58.0 | Continues slight upward slope. |
| ~450 | ~57.0 | Slopes downward to the lowest point on the chart. |
| ~500 | ~59.4 | Sharp upward slope to the final point. |
**Trend Verification:** The overall visual trend is a steep initial decline from d₁≈100 to d₁≈200, followed by a period of fluctuation between approximately 57% and 59.5% accuracy for d₁ values between 200 and 500. The line does not show a consistent monotonic increase or decrease after the initial drop.
### Key Observations
1. **Initial Sensitivity:** The FedMRL model's test accuracy is highly sensitive to the parameter d₁ in the lower range (100 to 200), showing a significant drop of approximately 4.6 percentage points.
2. **Performance Plateau/Fluctuation:** For d₁ values greater than 200, the accuracy stabilizes within a relatively narrow band (57.0% to 59.4%), suggesting a region of reduced sensitivity or a performance plateau with minor fluctuations.
3. **Non-Monotonic Behavior:** The relationship is non-monotonic. After the initial drop, accuracy does not consistently improve or degrade with increasing d₁ but oscillates.
4. **Extremes:** The highest observed accuracy (~62.1%) occurs at the smallest d₁ value (~100). The lowest observed accuracy (~57.0%) occurs at d₁≈450.
### Interpretation
This chart demonstrates the impact of the hyperparameter `d₁` on the generalization performance (test accuracy) of the "FedMRL" method on the CIFAR-100 benchmark. The data suggests a critical trade-off or an optimal operating point.
* **Underlying Relationship:** The steep initial decline implies that very small values of `d₁` (around 100) are highly beneficial for this model's accuracy. Increasing `d₁` beyond this point initially harms performance significantly.
* **Stability Region:** The subsequent fluctuation indicates that for a wide range of larger `d₁` values (200-500), the model's performance is relatively stable but suboptimal compared to the low-`d₁` regime. The fluctuations may be due to stochasticity in training or a complex, non-linear interaction between `d₁` and other factors.
* **Practical Implication:** For practitioners using FedMRL on CIFAR-100, this chart argues for selecting a small `d₁` value (near 100) to maximize accuracy. The parameter should be tuned carefully in this lower range, as performance degrades rapidly with increase. The lack of a clear upward trend at higher values suggests that simply increasing `d₁` is not a viable strategy for improving accuracy beyond the initial peak.
* **Investigative Question:** The chart raises the question of what `d₁` represents (e.g., a dimension, a distance threshold, a regularization parameter). Its strong negative correlation with accuracy in the initial phase is the key finding, warranting further investigation into the mechanism by which `d₁` influences the FedMRL learning process.
</details>
<details>
<summary>x21.png Details</summary>
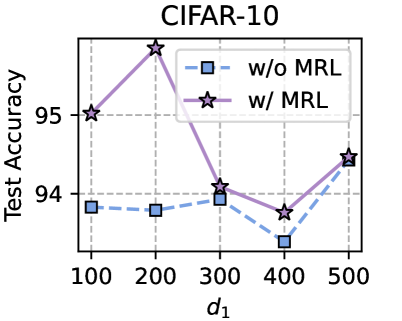
### Visual Description
\n
## Line Chart: CIFAR-10 Test Accuracy vs. Parameter d1
### Overview
The image is a line chart comparing the test accuracy of two models on the CIFAR-10 dataset across different values of a parameter labeled `d1`. The chart demonstrates the performance impact of a technique or component referred to as "MRL".
### Components/Axes
* **Title:** "CIFAR-10" (centered at the top).
* **Y-Axis:** Labeled "Test Accuracy". The scale runs from approximately 93.5 to 96, with major grid lines and labels at 94 and 95.
* **X-Axis:** Labeled "d1". The scale has discrete markers at 100, 200, 300, 400, and 500.
* **Legend:** Located in the top-right quadrant of the chart area.
* **Series 1:** "w/o MRL" (without MRL). Represented by a blue dashed line (`--`) with square markers (`□`).
* **Series 2:** "w/ MRL" (with MRL). Represented by a purple solid line (`—`) with star markers (`☆`).
* **Grid:** A light gray dashed grid is present in the background.
### Detailed Analysis
**Data Series: "w/o MRL" (Blue Squares, Dashed Line)**
* **Trend:** The line shows relatively stable performance with a notable dip at `d1=400`.
* **Data Points (Approximate):**
* d1=100: ~93.9%
* d1=200: ~93.8%
* d1=300: ~94.1%
* d1=400: ~93.5% (lowest point)
* d1=500: ~94.5%
**Data Series: "w/ MRL" (Purple Stars, Solid Line)**
* **Trend:** The line shows a sharp peak at `d1=200`, followed by a decline and a partial recovery.
* **Data Points (Approximate):**
* d1=100: 95.0%
* d1=200: ~95.8% (highest point on the chart)
* d1=300: ~94.1%
* d1=400: ~93.8%
* d1=500: ~94.5%
### Key Observations
1. **Peak Performance:** The highest accuracy (~95.8%) is achieved by the "w/ MRL" model at `d1=200`.
2. **Performance Crossover:** The two models have nearly identical accuracy at `d1=300` (~94.1%) and `d1=500` (~94.5%).
3. **Significant Dip:** Both models experience their lowest performance at `d1=400`, with "w/o MRL" dropping more sharply.
4. **MRL Impact:** The "w/ MRL" model significantly outperforms the "w/o MRL" model at lower `d1` values (100 and 200), but this advantage disappears at higher values (300 and above).
### Interpretation
The chart suggests that the "MRL" technique provides a substantial accuracy boost for the CIFAR-10 task when the parameter `d1` is set to a low value (100-200). The peak at `d1=200` indicates an optimal configuration for the "w/ MRL" model. However, the benefit of MRL diminishes as `d1` increases beyond 200, with both models converging to similar performance at `d1=300` and `d1=500`. The universal dip at `d1=400` points to a potential problematic configuration or a common limitation in the model architecture or training regimen at that specific parameter setting. The data implies that `d1` is a critical hyperparameter whose optimal value is dependent on whether MRL is employed.
</details>
<details>
<summary>x22.png Details</summary>
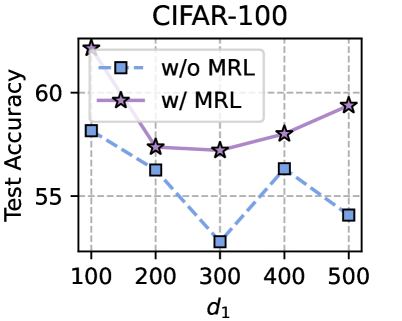
### Visual Description
## Line Chart: CIFAR-100 Test Accuracy vs. d₁
### Overview
The image is a line chart comparing the test accuracy on the CIFAR-100 dataset for two different methods across a range of a parameter labeled `d₁`. The chart demonstrates the performance impact of a technique referred to as "MRL".
### Components/Axes
* **Chart Title:** "CIFAR-100" (centered at the top).
* **Y-Axis:**
* **Label:** "Test Accuracy" (rotated vertically on the left).
* **Scale:** Linear scale ranging from 55 to 60, with major tick marks at 55, 60.
* **X-Axis:**
* **Label:** "d₁" (centered at the bottom).
* **Scale:** Linear scale with discrete values: 100, 200, 300, 400, 500.
* **Legend:** Positioned in the top-left corner of the chart area.
* **Entry 1:** "w/o MRL" - Represented by a blue square marker (■) connected by a blue dashed line.
* **Entry 2:** "w/ MRL" - Represented by a purple star marker (★) connected by a purple solid line.
* **Grid:** A light gray grid is present in the background.
### Detailed Analysis
**Data Series 1: "w/o MRL" (Blue Squares, Dashed Line)**
* **Trend:** The line shows a general downward trend from d₁=100 to d₁=300, followed by a partial recovery and then another decline.
* **Data Points (Approximate):**
* d₁ = 100: Test Accuracy ≈ 58.0
* d₁ = 200: Test Accuracy ≈ 56.0
* d₁ = 300: Test Accuracy ≈ 53.0 (This is the lowest point for this series).
* d₁ = 400: Test Accuracy ≈ 56.0
* d₁ = 500: Test Accuracy ≈ 54.0
**Data Series 2: "w/ MRL" (Purple Stars, Solid Line)**
* **Trend:** The line shows a sharp initial drop from d₁=100 to d₁=200, then remains relatively stable with a slight upward trend from d₁=300 to d₁=500.
* **Data Points (Approximate):**
* d₁ = 100: Test Accuracy ≈ 62.0 (This is the highest point on the entire chart).
* d₁ = 200: Test Accuracy ≈ 57.0
* d₁ = 300: Test Accuracy ≈ 57.0
* d₁ = 400: Test Accuracy ≈ 58.0
* d₁ = 500: Test Accuracy ≈ 59.0
### Key Observations
1. **Performance Gap:** The "w/ MRL" method consistently achieves higher test accuracy than the "w/o MRL" method at every measured value of `d₁`.
2. **Divergent Behavior at d₁=300:** The most significant performance gap occurs at `d₁=300`, where "w/o MRL" hits its minimum (~53) while "w/ MRL" maintains a stable accuracy (~57).
3. **Trend Reversal:** After `d₁=300`, the "w/ MRL" series shows a clear improving trend, while the "w/o MRL" series is volatile and ends lower than it started.
4. **Peak Performance:** The absolute highest accuracy is achieved by the "w/ MRL" method at the smallest parameter value (`d₁=100`).
### Interpretation
This chart presents an ablation study or hyperparameter analysis for a machine learning model on the CIFAR-100 image classification task. The parameter `d₁` likely represents a dimensionality or capacity-related hyperparameter (e.g., embedding dimension, number of channels, or a rank in a low-rank adaptation method).
The data strongly suggests that incorporating the "MRL" technique provides two key benefits:
1. **Robustness:** It prevents the severe performance degradation seen in the baseline ("w/o MRL") at intermediate values of `d₁` (specifically around 300).
2. **Improved Scaling:** It enables the model to effectively utilize larger values of `d₁` (400, 500) to recover and even improve accuracy, whereas the baseline model's performance deteriorates.
The investigation implies that "MRL" is a beneficial regularization or architectural component that stabilizes training and leads to better generalization across a wider range of model configurations. The sharp drop for both methods from `d₁=100` to `d₁=200` may indicate an initial overfitting or optimization challenge that is more pronounced without MRL.
</details>
Figure 6: Left two: sensitivity analysis results. Right two: ablation study results.
#### 5.3.2 Robustness to Non-IIDness (Dirichlet)
We also test the robustness of FedMRL to various non-IIDnesses controlled by $\alpha$ in the Dirichlet function under the ( $N=100,C=10\$ ) setting. A smaller $\alpha$ indicates a higher non-IIDness. For both datasets, we vary $\alpha$ in the range of $\{0.1,\ldots,0.5\}$ . Figure 5 (right two) shows that FedMRL significantly outperforms FedProto under all non-IIDness settings, validating its robustness to Dirichlet non-IIDness.
#### 5.3.3 Sensitivity Analysis - $d_{1}$
FedMRL relies on a hyperparameter $d_{1}$ - the representation dimension of the homogeneous small model. To evaluate its sensitivity to $d_{1}$ , we test FedMRL with $d_{1}=\{100,150,\ldots,500\}$ under the ( $N=100,C=10\$ ) setting. Figure 6 (left two) shows that smaller $d_{1}$ values result in higher average test accuracy on both datasets. It is clear that a smaller $d_{1}$ also reduces communication and computation overheads, thereby helping FedMRL achieve the best trade-off among model performance, communication efficiency, and computational efficiency.
### 5.4 Ablation Study
We conduct ablation experiments to validate the usefulness of MRL. For FedMRL with MRL, the global header and the local header learn multi-granularity representations. For FedMRL without MRL, we directly input the representation fused by the representation projector into the client’s local header for loss computation (i.e., we do not extract Matryoshka Representations and remove the global header). Figure 6 (right two) shows that FedMRL with MRL consistently outperforms FedMRL without MRL, demonstrating the effectiveness of the design to incorporate MRL into MHeteroFL. Besides, the accuracy gap between them decreases as $d_{1}$ rises. This shows that as the global and local headers learn increasingly overlapping representation information, the benefits of MRL are reduced.
## 6 Conclusions
This paper proposes a novel MHeteroFL approach - FedMRL - to jointly address data, system and model heterogeneity challenges in FL. The key design insight is the addition of a global homogeneous small model shared by FL clients for enhanced knowledge interaction among heterogeneous local models. Adaptive personalized representation fusion and multi-granularity Matryoshka Representations learning further boosts model learning capability. The client and the server only need to exchange the homogeneous small model, while the clients’ heterogeneous local models and data remain unexposed, thereby enhancing the preservation of both model and data privacy. Theoretical analysis shows that FedMRL is guaranteed to converge over time. Extensive experiments demonstrate that FedMRL significantly outperforms state-of-the-art models regarding test accuracy, while incurring low communication and computation costs. Appendix D discusses FedMRL ’s privacy, communication and computation. Appendix E elaborates FedMRL ’s border impact and limitations.
## References
- [1] Jin-Hyun Ahn et al. Wireless federated distillation for distributed edge learning with heterogeneous data. In Proc. PIMRC, pages 1–6, Istanbul, Turkey, 2019. IEEE.
- [2] Jin-Hyun Ahn et al. Cooperative learning VIA federated distillation OVER fading channels. In Proc. ICASSP, pages 8856–8860, Barcelona, Spain, 2020. IEEE.
- [3] Samiul Alam et al. Fedrolex: Model-heterogeneous federated learning with rolling sub-model extraction. In Proc. NeurIPS, virtual, 2022. .
- [4] Sara Babakniya et al. Revisiting sparsity hunting in federated learning: Why does sparsity consensus matter? Transactions on Machine Learning Research, 1(1):1, 2023.
- [5] Yun-Hin Chan, Rui Zhou, Running Zhao, Zhihan JIANG, and Edith C. H. Ngai. Internal cross-layer gradients for extending homogeneity to heterogeneity in federated learning. In Proc. ICLR, page 1, Vienna, Austria, 2024. OpenReview.net.
- [6] Hongyan Chang et al. Cronus: Robust and heterogeneous collaborative learning with black-box knowledge transfer. In Proc. NeurIPS Workshop, virtual, 2021. .
- [7] Jiangui Chen et al. Fedmatch: Federated learning over heterogeneous question answering data. In Proc. CIKM, pages 181–190, virtual, 2021. ACM.
- [8] Sijie Cheng et al. Fedgems: Federated learning of larger server models via selective knowledge fusion. CoRR, abs/2110.11027, 2021.
- [9] Yae Jee Cho et al. Heterogeneous ensemble knowledge transfer for training large models in federated learning. In Proc. IJCAI, pages 2881–2887, virtual, 2022. ijcai.org.
- [10] Liam Collins et al. Exploiting shared representations for personalized federated learning. In Proc. ICML, volume 139, pages 2089–2099, virtual, 2021. PMLR.
- [11] Enmao Diao. Heterofl: Computation and communication efficient federated learning for heterogeneous clients. In Proc. ICLR, page 1, Virtual Event, Austria, 2021. OpenReview.net.
- [12] Xuan Gong et al. Federated learning via input-output collaborative distillation. In Proc. AAAI, pages 22058–22066, Vancouver, Canada, 2024. AAAI Press.
- [13] Chaoyang He et al. Group knowledge transfer: Federated learning of large cnns at the edge. In Proc. NeurIPS, virtual, 2020. .
- [14] S. Horváth. FjORD: Fair and accurate federated learning under heterogeneous targets with ordered dropout. In Proc. NIPS, pages 12876–12889, Virtual, 2021. OpenReview.net.
- [15] Wenke Huang et al. Few-shot model agnostic federated learning. In Proc. MM, pages 7309–7316, Lisboa, Portugal, 2022. ACM.
- [16] Wenke Huang et al. Learn from others and be yourself in heterogeneous federated learning. In Proc. CVPR, pages 10133–10143, virtual, 2022. IEEE.
- [17] Sohei Itahara et al. Distillation-based semi-supervised federated learning for communication-efficient collaborative training with non-iid private data. IEEE Trans. Mob. Comput., 22(1):191–205, 2023.
- [18] Jaehee Jang et al. Fedclassavg: Local representation learning for personalized federated learning on heterogeneous neural networks. In Proc. ICPP, pages 76:1–76:10, virtual, 2022. ACM.
- [19] Eunjeong Jeong et al. Communication-efficient on-device machine learning: Federated distillation and augmentation under non-iid private data. In Proc. NeurIPS Workshop on Machine Learning on the Phone and other Consumer Devices, virtual, 2018. .
- [20] Alex Krizhevsky et al. Learning multiple layers of features from tiny images. Toronto, ON, Canada, , 2009.
- [21] Aditya Kusupati et al. Matryoshka representation learning. In Proc. NeurIPS, New Orleans, LA, USA, 2022.
- [22] Daliang Li and Junpu Wang. Fedmd: Heterogenous federated learning via model distillation. In Proc. NeurIPS Workshop, virtual, 2019. .
- [23] Qinbin Li et al. Practical one-shot federated learning for cross-silo setting. In Proc. IJCAI, pages 1484–1490, virtual, 2021. ijcai.org.
- [24] Paul Pu Liang et al. Think locally, act globally: Federated learning with local and global representations. arXiv preprint arXiv:2001.01523, 1(1), 2020.
- [25] Tao Lin et al. Ensemble distillation for robust model fusion in federated learning. In Proc. NeurIPS, virtual, 2020. .
- [26] Chang Liu et al. Completely heterogeneous federated learning. CoRR, abs/2210.15865, 2022.
- [27] Disha Makhija et al. Architecture agnostic federated learning for neural networks. In Proc. ICML, volume 162, pages 14860–14870, virtual, 2022. PMLR.
- [28] Koji Matsuda et al. Fedme: Federated learning via model exchange. In Proc. SDM, pages 459–467, Alexandria, VA, USA, 2022. SIAM.
- [29] Brendan McMahan et al. Communication-efficient learning of deep networks from decentralized data. In Proc. AISTATS, volume 54, pages 1273–1282, Fort Lauderdale, FL, USA, 2017. PMLR.
- [30] Duy Phuong Nguyen et al. Enhancing heterogeneous federated learning with knowledge extraction and multi-model fusion. In Proc. SC Workshop, pages 36–43, Denver, CO, USA, 2023. ACM.
- [31] Jaehoon Oh et al. Fedbabu: Toward enhanced representation for federated image classification. In Proc. ICLR, virtual, 2022. OpenReview.net.
- [32] Sejun Park et al. Towards understanding ensemble distillation in federated learning. In Proc. ICML, volume 202, pages 27132–27187, Honolulu, Hawaii, USA, 2023. PMLR.
- [33] Krishna Pillutla et al. Federated learning with partial model personalization. In Proc. ICML, volume 162, pages 17716–17758, virtual, 2022. PMLR.
- [34] Zhen Qin et al. Fedapen: Personalized cross-silo federated learning with adaptability to statistical heterogeneity. In Proc. KDD, pages 1954–1964, Long Beach, CA, USA, 2023. ACM.
- [35] Felix Sattler et al. Fedaux: Leveraging unlabeled auxiliary data in federated learning. IEEE Trans. Neural Networks Learn. Syst., 1(1):1–13, 2021.
- [36] Felix Sattler et al. CFD: communication-efficient federated distillation via soft-label quantization and delta coding. IEEE Trans. Netw. Sci. Eng., 9(4):2025–2038, 2022.
- [37] Aviv Shamsian et al. Personalized federated learning using hypernetworks. In Proc. ICML, volume 139, pages 9489–9502, virtual, 2021. PMLR.
- [38] Tao Shen et al. Federated mutual learning. CoRR, abs/2006.16765, 2020.
- [39] Xiaorong Shi, Liping Yi, Xiaoguang Liu, and Gang Wang. FFEDCL: fair federated learning with contrastive learning. In Proc. ICASSP, Rhodes Island, Greece,, pages 1–5. IEEE, 2023.
- [40] Alysa Ziying Tan et al. Towards personalized federated learning. IEEE Trans. Neural Networks Learn. Syst., 1(1):1–17, 2022.
- [41] Yue Tan et al. Fedproto: Federated prototype learning across heterogeneous clients. In Proc. AAAI, pages 8432–8440, virtual, 2022. AAAI Press.
- [42] Jiaqi Wang et al. Towards personalized federated learning via heterogeneous model reassembly. In Proc. NeurIPS, page 13, New Orleans, Louisiana, USA, 2023. OpenReview.net.
- [43] Chuhan Wu et al. Communication-efficient federated learning via knowledge distillation. Nature Communications, 13(1):2032, 2022.
- [44] Liping Yi, Xiaorong Shi, Nan Wang, Gang Wang, Xiaoguang Liu, Zhuan Shi, and Han Yu. pfedkt: Personalized federated learning with dual knowledge transfer. Knowledge-Based Systems, 292:111633, 2024.
- [45] Liping Yi, Xiaorong Shi, Nan Wang, Ziyue Xu, Gang Wang, and Xiaoguang Liu. pfedlhns: Personalized federated learning via local hypernetworks. In Proc. ICANN, volume 1, page 516–528. Springer, 2023.
- [46] Liping Yi, Xiaorong Shi, Nan Wang, Jinsong Zhang, Gang Wang, and Xiaoguang Liu. Fedpe: Adaptive model pruning-expanding for federated learning on mobile devices. IEEE Transactions on Mobile Computing, pages 1–18, 2024.
- [47] Liping Yi, Xiaorong Shi, Wenrui Wang, Gang Wang, and Xiaoguang Liu. Fedrra: Reputation-aware robust federated learning against poisoning attacks. In Proc. IJCNN, pages 1–8. IEEE, 2023.
- [48] Liping Yi, Gang Wang, and Xiaoguang Liu. QSFL: A two-level uplink communication optimization framework for federated learning. In Proc. ICML, volume 162, pages 25501–25513. PMLR, 2022.
- [49] Liping Yi, Gang Wang, Xiaoguang Liu, Zhuan Shi, and Han Yu. Fedgh: Heterogeneous federated learning with generalized global header. In Proceedings of the 31st ACM International Conference on Multimedia (ACM MM’23), page 11, Canada, 2023. ACM.
- [50] Liping Yi, Han Yu, Chao Ren, Heng Zhang, Gang Wang, Xiaoguang Liu, and Xiaoxiao Li. pfedafm: Adaptive feature mixture for batch-level personalization in heterogeneous federated learning. CoRR, abs/2404.17847, 2024.
- [51] Liping Yi, Han Yu, Chao Ren, Heng Zhang, Gang Wang, Xiaoguang Liu, and Xiaoxiao Li. pfedmoe: Data-level personalization with mixture of experts for model-heterogeneous personalized federated learning. CoRR, abs/2402.01350, 2024.
- [52] Liping Yi, Han Yu, Zhuan Shi, Gang Wang, Xiaoguang Liu, Lizhen Cui, and Xiaoxiao Li. FedSSA: Semantic Similarity-based Aggregation for Efficient Model-Heterogeneous Personalized Federated Learning. In IJCAI, 2024.
- [53] Liping Yi, Han Yu, Gang Wang, and Xiaoguang Liu. Fedlora: Model-heterogeneous personalized federated learning with lora tuning. CoRR, abs/2310.13283, 2023.
- [54] Liping Yi, Han Yu, Gang Wang, and Xiaoguang Liu. pfedes: Model heterogeneous personalized federated learning with feature extractor sharing. CoRR, abs/2311.06879, 2023.
- [55] Liping Yi, Jinsong Zhang, Rui Zhang, Jiaqi Shi, Gang Wang, and Xiaoguang Liu. Su-net: An efficient encoder-decoder model of federated learning for brain tumor segmentation. In Proc. ICANN, volume 12396, pages 761–773. Springer, 2020.
- [56] Fuxun Yu et al. Fed2: Feature-aligned federated learning. In Proc. KDD, pages 2066–2074, virtual, 2021. ACM.
- [57] Sixing Yu et al. Resource-aware federated learning using knowledge extraction and multi-model fusion. CoRR, abs/2208.07978, 2022.
- [58] Jianqing Zhang, Yang Liu, Yang Hua, and Jian Cao. Fedtgp: Trainable global prototypes with adaptive-margin-enhanced contrastive learning for data and model heterogeneity in federated learning. In Proc. AAAI, pages 16768–16776, Vancouver, Canada, 2024. AAAI Press.
- [59] Jie Zhang et al. Parameterized knowledge transfer for personalized federated learning. In Proc. NeurIPS, pages 10092–10104, virtual, 2021. OpenReview.net.
- [60] Jie Zhang et al. Towards data-independent knowledge transfer in model-heterogeneous federated learning. IEEE Trans. Computers, 72(10):2888–2901, 2023.
- [61] Lan Zhang et al. Fedzkt: Zero-shot knowledge transfer towards resource-constrained federated learning with heterogeneous on-device models. In Proc. ICDCS, pages 928–938, virtual, 2022. IEEE.
- [62] Zhilu Zhang and Mert R. Sabuncu. Generalized cross entropy loss for training deep neural networks with noisy labels. In Proc. NeurIPS, pages 8792–8802, Montréal, Canada, 2018. Curran Associates Inc.
- [63] Zhuangdi Zhu et al. Data-free knowledge distillation for heterogeneous federated learning. In Proc. ICML, volume 139, pages 12878–12889, virtual, 2021. PMLR.
- [64] Zhuangdi Zhu et al. Resilient and communication efficient learning for heterogeneous federated systems. In Proc. ICML, volume 162, pages 27504–27526, virtual, 2022. PMLR.
## Appendix A Pseudo codes of FedMRL
Input: $N$ , total number of clients; $K$ , number of selected clients in one round; $T$ , total number of rounds; $\eta_{\omega}$ , learning rate of client local heterogeneous models; $\eta_{\theta}$ , learning rate of homogeneous small model; $\eta_{\varphi}$ , learning rate of the representation projector.
Output: client whole models removing the global header $[\mathcal{G}(\theta^{ex,T-1})\circ\mathcal{F}_{0}(\omega_{0}^{T-1})|\mathcal{P }_{0}(\varphi_{0}^{T-1}),\ldots,\mathcal{G}(\theta^{ex,T-1})\circ\mathcal{F}_{ N-1}(\omega_{N-1}^{T-1})|\mathcal{P}_{N-1}(\varphi_{N-1}^{T-1})]$ .
Randomly initialize the global homogeneous small model $\mathcal{G}(\theta^{\mathbf{0}})$ , client local heterogeneous models $[\mathcal{F}_{0}(\omega_{0}^{0}),\ldots,\mathcal{F}_{N-1}(\omega_{N-1}^{0})]$ and local heterogeneous representation projectors $[\mathcal{P}_{0}(\varphi_{0}^{0}),\ldots,\mathcal{P}_{N-1}(\varphi_{N-1}^{0})]$ .
for each round t=1,…,T-1 do
// Server Side:
$S^{t}$ $\leftarrow$ Randomly sample $K$ clients from $N$ clients;
Broadcast the global homogeneous small model $\theta^{t-1}$ to sampled $K$ clients;
$\theta_{k}^{t}\leftarrow$ ClientUpdate ( $\theta^{t-1}$ );
/* Aggregate Local Homogeneous Small Models */
$\theta^{t}=\sum_{k=0}^{K-1}{\frac{n_{k}}{n}\theta_{k}^{t}}$ .
// ClientUpdate:
Receive the global homogeneous small model $\theta^{t-1}$ from the server;
for $k\in S^{t}$ do
/* Local Training with MRL */
for $(\boldsymbol{x}_{i},y_{i})\in D_{k}$ do
$\boldsymbol{\mathcal{R}}_{i}^{\mathcal{G}}=\ \mathcal{G}^{ex}({\boldsymbol{x}_ {i};\theta}^{ex,t-1}),\boldsymbol{\mathcal{R}}_{i}^{\mathcal{F}_{k}}=\ \mathcal{F}_{k}^{ex}(\boldsymbol{x}_{i};\omega_{k}^{ex,t-1})$ ;
$\boldsymbol{\mathcal{R}}_{i}=\boldsymbol{\mathcal{R}}_{i}^{\mathcal{G}}\circ \boldsymbol{\mathcal{R}}_{i}^{\mathcal{F}_{k}}$ ;
${\widetilde{\boldsymbol{\mathcal{R}}}}_{i}=\mathcal{P}_{k}(\boldsymbol{ \mathcal{R}}_{i}{;\varphi}_{k}^{t-1})$ ;
${\widetilde{\boldsymbol{\mathcal{R}}}}_{i}^{lc}={{\widetilde{\boldsymbol{ \mathcal{R}}}}_{i}}^{1:d_{1}},{\widetilde{\boldsymbol{\mathcal{R}}}}_{i}^{hf}= {{\widetilde{\boldsymbol{\mathcal{R}}}}_{i}}^{1:d_{2}}$ ;
${\hat{{y}}}_{i}^{\mathcal{G}}=\mathcal{G}^{hd}({\widetilde{\boldsymbol{ \mathcal{R}}}}_{i}^{lc};\theta^{hd,t-1});{\hat{{y}}}_{i}^{\mathcal{F}_{k}}= \mathcal{F}_{k}^{hd}(\omega_{k}^{hd,t-1})$ ;
$\ell_{i}^{\mathcal{G}}=\ell({\hat{{y}}}_{i}^{\mathcal{G}},y_{i});\ell_{i}^{ \mathcal{F}_{k}}=\ell({\hat{{y}}}_{i}^{\mathcal{F}_{k}},y_{i})$ ;
$\ell_{i}=m_{i}^{\mathcal{G}}\cdot\ell_{i}^{\mathcal{G}}+m_{i}^{\mathcal{F}_{k} }\cdot\ell_{i}^{\mathcal{F}_{k}}$ ;
$\theta_{k}^{t}\leftarrow\theta^{t-1}-\eta_{\theta}\nabla\ell_{i}$ ;
$\omega_{k}^{t}\leftarrow\omega_{k}^{t-1}-\eta_{\omega}\nabla\ell_{i}$ ;
$\varphi_{k}^{t}\leftarrow\varphi_{k}^{t-1}-\eta_{\varphi}\nabla\ell_{i}$ ;
end for
Upload updated local homogeneous small model $\theta_{k}^{t}$ to the server.
end for
end for
Algorithm 1 FedMRL
## Appendix B Theoretical Proofs
We first define the following additional notations. $t\in\{0,\ldots,T-1\}$ denotes the $t$ -th round. $e\in\{0,1,\ldots,E\}$ denotes the $e$ -th iteration of local training. $tE+0$ indicates that clients receive the global homogeneous small model $\mathcal{G}(\theta^{t})$ from the server before the $(t+1)$ -th round’s local training. $tE+e$ denotes the $e$ -th iteration of the $(t+1)$ -th round’s local training. $tE+E$ marks the ending of the $(t+1)$ -th round’s local training. After that, clients upload their updated local homogeneous small models to the server for aggregation. $\mathcal{W}_{k}(w_{k})$ denotes the whole model trained on client $k$ , including the global homogeneous small model $\mathcal{G}(\theta)$ , the client $k$ ’s local heterogeneous model $\mathcal{F}_{k}(\omega_{k})$ , and the personalized representation projector $\mathcal{P}_{k}(\varphi_{k})$ . $\eta$ is the learning rate of the whole model trained on client $k$ , including $\{\eta_{\theta},\eta_{\omega},\eta_{\boldsymbol{\varphi}}\}$ .
**Assumption 1**
*Lipschitz Smoothness. The gradients of client $k$ ’s whole local model $w_{k}$ are $L1$ –Lipschitz smooth [41],
$$
\begin{gathered}\|\nabla\mathcal{L}_{k}^{t_{1}}(w_{k}^{t_{1}};\boldsymbol{x},y
)-\nabla\mathcal{L}_{k}^{t_{2}}(w_{k}^{t_{2}};\boldsymbol{x},y)\|\leq L_{1}\|w
_{k}^{t_{1}}-w_{k}^{t_{2}}\|,\\
\forall t_{1},t_{2}>0,k\in\{0,1,\ldots,N-1\},(\boldsymbol{x},y)\in D_{k}.\end{gathered} \tag{15}
$$
The above formulation can be re-expressed as:
$$
\mathcal{L}_{k}^{t_{1}}-\mathcal{L}_{k}^{t_{2}}\leq\langle\nabla\mathcal{L}_{k
}^{t_{2}},(w_{k}^{t_{1}}-w_{k}^{t_{2}})\rangle+\frac{L_{1}}{2}\|w_{k}^{t_{1}}-
w_{k}^{t_{2}}\|_{2}^{2}. \tag{16}
$$*
**Assumption 2**
*Unbiased Gradient and Bounded Variance. Client $k$ ’s random gradient $g_{w,k}^{t}=\nabla\mathcal{L}_{k}^{t}(w_{k}^{t};\mathcal{B}_{k}^{t})$ ( $\mathcal{B}$ is a batch of local data) is unbiased,
$$
\mathbb{E}_{\mathcal{B}_{k}^{t}\subseteq D_{k}}[g_{w,k}^{t}]=\nabla\mathcal{L}
_{k}^{t}(w_{k}^{t}), \tag{17}
$$
and the variance of random gradient $g_{w,k}^{t}$ is bounded by:
$$
\begin{split}\mathbb{E}_{\mathcal{B}_{k}^{t}\subseteq D_{k}}[\|\nabla\mathcal{
L}_{k}^{t}(w_{k}^{t};\mathcal{B}_{k}^{t})-\nabla\mathcal{L}_{k}^{t}(w_{k}^{t})
\|_{2}^{2}]\leq\sigma^{2}.\end{split} \tag{18}
$$*
**Assumption 3**
*Bounded Parameter Variation. The parameter variations of the homogeneous small model $\theta_{k}^{t}$ and $\theta^{t}$ before and after aggregation at the FL server are bounded by:
$$
{\|\theta^{t}-\theta_{k}^{t}\|}_{2}^{2}\leq\delta^{2}. \tag{19}
$$*
### B.1 Proof of Lemma 1
**Proof 1**
*An arbitrary client $k$ ’s local whole model $w$ can be updated by $w_{t+1}=w_{t}-\eta g_{w,t}$ in the (t+1)-th round, and following Assumption 1, we can obtain
$$
\displaystyle\mathcal{L}_{tE+1} \displaystyle\leq\mathcal{L}_{tE+0}+\langle\nabla\mathcal{L}_{tE+0},(w_{tE+1}-
w_{tE+0})\rangle+\frac{L_{1}}{2}\|w_{tE+1}-w_{tE+0}\|_{2}^{2} \displaystyle=\mathcal{L}_{tE+0}-\eta\langle\nabla\mathcal{L}_{tE+0},g_{w,tE+0
}\rangle+\frac{L_{1}\eta^{2}}{2}\|g_{w,tE+0}\|_{2}^{2}. \tag{20}
$$ Taking the expectation of both sides of the inequality concerning the random variable $\xi_{tE+0}$ ,
$$
\displaystyle\mathbb{E}[\mathcal{L}_{tE+1}] \displaystyle\leq\mathcal{L}_{tE+0}-\eta\mathbb{E}[\langle\nabla\mathcal{L}_{
tE+0},g_{w,tE+0}\rangle]+\frac{L_{1}\eta^{2}}{2}\mathbb{E}[\|g_{w,tE+0}\|_{2}^
{2}] \displaystyle\stackrel{{\scriptstyle(a)}}{{=}}\mathcal{L}_{tE+0}-\eta\|\nabla
\mathcal{L}_{tE+0}\|_{2}^{2}+\frac{L_{1}\eta^{2}}{2}\mathbb{E}[\|g_{w,tE+0}\|_
{2}^{2}] \displaystyle\stackrel{{\scriptstyle(b)}}{{\leq}}\mathcal{L}_{tE+0}-\eta\|
\nabla\mathcal{L}_{tE+0}\|_{2}^{2}+\frac{L_{1}\eta^{2}}{2}(\mathbb{E}[\|g_{w,
tE+0}\|]_{2}^{2}+\operatorname{Var}(g_{w,tE+0})) \displaystyle\stackrel{{\scriptstyle(c)}}{{=}}\mathcal{L}_{tE+0}-\eta\|\nabla
\mathcal{L}_{tE+0}\|_{2}^{2}+\frac{L_{1}\eta^{2}}{2}(\|\nabla\mathcal{L}_{tE+0
}\|_{2}^{2}+\operatorname{Var}(g_{w,tE+0})) \displaystyle\stackrel{{\scriptstyle(d)}}{{\leq}}\mathcal{L}_{tE+0}-\eta\|
\nabla\mathcal{L}_{tE+0}\|_{2}^{2}+\frac{L_{1}\eta^{2}}{2}(\|\nabla\mathcal{L}
_{tE+0}\|_{2}^{2}+\sigma^{2}) \displaystyle=\mathcal{L}_{tE+0}+(\frac{L_{1}\eta^{2}}{2}-\eta)\|\nabla
\mathcal{L}_{tE+0}\|_{2}^{2}+\frac{L_{1}\eta^{2}\sigma^{2}}{2}. \tag{21}
$$ (a), (c), (d) follow Assumption 2 and (b) follows $Var(x)=\mathbb{E}[x^{2}]-(\mathbb{E}[x])^{2}$ . Taking the expectation of both sides of the inequality for the model $w$ over $E$ iterations, we obtain $$
\mathbb{E}[\mathcal{L}_{tE+1}]\leq\mathcal{L}_{tE+0}+(\frac{L_{1}\eta^{2}}{2}-
\eta)\sum_{e=1}^{E}\|\nabla\mathcal{L}_{tE+e}\|_{2}^{2}+\frac{L_{1}E\eta^{2}
\sigma^{2}}{2}. \tag{22}
$$*
### B.2 Proof of Lemma 2
**Proof 2**
*$$
\displaystyle\mathcal{L}_{(t+1)E+0} \displaystyle=\mathcal{L}_{(t+1)E}+\mathcal{L}_{(t+1)E+0}-\mathcal{L}_{(t+1)E} \displaystyle\stackrel{{\scriptstyle(a)}}{{\approx}}\mathcal{L}_{(t+1)E}+\eta
\|\theta_{(t+1)E+0}-\theta_{(t+1)E}\|_{2}^{2} \displaystyle\stackrel{{\scriptstyle(b)}}{{\leq}}\mathcal{L}_{(t+1)E}+\eta
\delta^{2}. \tag{23}
$$ (a): we can use the gradient of parameter variations to approximate the loss variations, i.e., $\Delta\mathcal{L}\approx\eta\cdot\|\Delta\theta\|_{2}^{2}$ . (b) follows Assumption 3. Taking the expectation of both sides of the inequality to the random variable $\xi$ , we obtain
$$
\mathbb{E}[\mathcal{L}_{(t+1)E+0}]\leq\mathbb{E}[\mathcal{L}_{tE+1}]+{\eta
\delta}^{2}. \tag{24}
$$*
### B.3 Proof of Theorem 1
**Proof 3**
*Substituting Lemma 1 into the right side of Lemma 2 ’s inequality, we obtain
$$
\mathbb{E}[\mathcal{L}_{(t+1)E+0}]\leq\mathcal{L}_{tE+0}+(\frac{L_{1}\eta^{2}}
{2}-\eta)\sum_{e=0}^{E}\|\nabla\mathcal{L}_{tE+e}\|_{2}^{2}+\frac{L_{1}E\eta^{
2}\sigma^{2}}{2}+\eta\delta^{2}. \tag{25}
$$*
### B.4 Proof of Theorem 2
**Proof 4**
*Interchanging the left and right sides of Eq. (25), we obtain
$$
\sum_{e=0}^{E}\|\nabla\mathcal{L}_{tE+e}\|_{2}^{2}\leq\frac{\mathcal{L}_{tE+0}
-\mathbb{E}[\mathcal{L}_{(t+1)E+0}]+\frac{L_{1}E\eta^{2}\sigma^{2}}{2}+\eta
\delta^{2}}{\eta-\frac{L_{1}\eta^{2}}{2}}. \tag{26}
$$ Taking the expectation of both sides of the inequality over rounds $t=[0,T-1]$ to $w$ , we obtain
$$
\frac{1}{T}\sum_{t=0}^{T-1}\sum_{e=0}^{E-1}\|\nabla\mathcal{L}_{tE+e}\|_{2}^{2
}\leq\frac{\frac{1}{T}\sum_{t=0}^{T-1}[\mathcal{L}_{tE+0}-\mathbb{E}[\mathcal{
L}_{(t+1)E+0}]]+\frac{L_{1}E\eta^{2}\sigma^{2}}{2}+\eta\delta^{2}}{\eta-\frac{
L_{1}\eta^{2}}{2}}. \tag{27}
$$ Let $\Delta=\mathcal{L}_{t=0}-\mathcal{L}^{*}>0$ , then $\sum_{t=0}^{T-1}[\mathcal{L}_{tE+0}-\mathbb{E}[\mathcal{L}_{(t+1)E+0}]]\leq\Delta$ , we can get
$$
\frac{1}{T}\sum_{t=0}^{T-1}\sum_{e=0}^{E-1}\|\nabla\mathcal{L}_{tE+e}\|_{2}^{2
}\leq\frac{\frac{\Delta}{T}+\frac{L_{1}E\eta^{2}\sigma^{2}}{2}+\eta\delta^{2}}
{\eta-\frac{L_{1}\eta^{2}}{2}}. \tag{28}
$$ If the above equation converges to a constant $\epsilon$ , i.e., $$
\frac{\frac{\Delta}{T}+\frac{L_{1}E\eta^{2}\sigma^{2}}{2}+\eta\delta^{2}}{\eta
-\frac{L_{1}\eta^{2}}{2}}<\epsilon, \tag{29}
$$
then
$$
T>\frac{\Delta}{\epsilon(\eta-\frac{L_{1}\eta^{2}}{2})-\frac{L_{1}E\eta^{2}
\sigma^{2}}{2}-\eta\delta^{2}}. \tag{30}
$$ Since $T>0,\Delta>0$ , we can get
$$
\epsilon(\eta-\frac{L_{1}\eta^{2}}{2})-\frac{L_{1}E\eta^{2}\sigma^{2}}{2}-\eta
\delta^{2}>0. \tag{31}
$$ Solving the above inequality yields $$
\eta<\frac{2(\epsilon-\delta^{2})}{L_{1}(\epsilon+E\sigma^{2})}. \tag{32}
$$ Since $\epsilon,\ L_{1},\ \sigma^{2},\ \delta^{2}$ are all constants greater than 0, $\eta$ has solutions. Therefore, when the learning rate $\eta=\{\eta_{\theta},\eta_{\omega},\eta_{\boldsymbol{\varphi}}\}$ satisfies the above condition, any client’s local whole model can converge. Since all terms on the right side of Eq. (28) except for $1/T$ are constants, hence FedMRL ’s non-convex convergence rate is $\epsilon\sim\mathcal{O}(1/T)$ .*
## Appendix C More Experimental Details
Here, we provide more experimental details of used model structures, more experimental results of model-homogeneous FL scenarios, and also the experimental evidence of inference model selection.
### C.1 Model Structures
Table 2 shows the structures of models used in experiments.
Table 2: Structures of $5$ heterogeneous CNN models.
| Layer Name Conv1 Maxpool1 | CNN-1 5 $\times$ 5, 16 2 $\times$ 2 | CNN-2 5 $\times$ 5, 16 2 $\times$ 2 | CNN-3 5 $\times$ 5, 16 2 $\times$ 2 | CNN-4 5 $\times$ 5, 16 2 $\times$ 2 | CNN-5 5 $\times$ 5, 16 2 $\times$ 2 |
| --- | --- | --- | --- | --- | --- |
| Conv2 | 5 $\times$ 5, 32 | 5 $\times$ 5, 16 | 5 $\times$ 5, 32 | 5 $\times$ 5, 32 | 5 $\times$ 5, 32 |
| Maxpool2 | 2 $\times$ 2 | 2 $\times$ 2 | 2 $\times$ 2 | 2 $\times$ 2 | 2 $\times$ 2 |
| FC1 | 2000 | 2000 | 1000 | 800 | 500 |
| FC2 | 500 | 500 | 500 | 500 | 500 |
| FC3 | 10/100 | 10/100 | 10/100 | 10/100 | 10/100 |
| model size | 10.00 MB | 6.92 MB | 5.04 MB | 3.81 MB | 2.55 MB |
Note: $5\times 5$ denotes kernel size. $16$ or $32$ are filters in convolutional layers.
### C.2 Homogeneous FL Results
Table 3 presents the results of FedMRL and baselines in model-homogeneous FL scenarios.
Table 3: Average test accuracy (%) in model-homogeneous FL.
| FL Setting Method Standalone | N=10, C=100% CIFAR-10 96.35 | N=50, C=20% CIFAR-100 74.32 | N=100, C=10% CIFAR-10 95.25 | CIFAR-100 62.38 | CIFAR-10 92.58 | CIFAR-100 54.93 |
| --- | --- | --- | --- | --- | --- | --- |
| LG-FedAvg [24] | 96.47 | 73.43 | 94.20 | 61.77 | 90.25 | 46.64 |
| FD [19] | 96.30 | - | - | - | - | - |
| FedProto [41] | 95.83 | 72.79 | 95.10 | 62.55 | 91.19 | 54.01 |
| FML [38] | 94.83 | 70.02 | 93.18 | 57.56 | 87.93 | 46.20 |
| FedKD [43] | 94.77 | 70.04 | 92.93 | 57.56 | 90.23 | 50.99 |
| FedAPEN [34] | 95.38 | 71.48 | 93.31 | 57.62 | 87.97 | 46.85 |
| FedMRL | 96.71 | 74.52 | 95.76 | 66.46 | 95.52 | 60.64 |
| FedMRL -Best B. | 0.24 | 0.20 | 0.51 | 3.91 | 2.94 | 5.71 |
| FedMRL -Best S.C.B. | 1.33 | 3.04 | 2.45 | 8.84 | 5.29 | 9.65 |
“-”: failing to converge. “ ”: the best MHeteroFL method. “ Best B.”: the best baseline. “ Best S.C.B.”: the best same-category (mutual learning-based MHeteroFL) baseline. The underscored values denote the largest accuracy improvement of FedMRL across $6$ settings.
### C.3 Inference Model Comparison
There are $4$ alternative models for model inference in FedMRL: (1) mix-small (the combination of the homogeneous small model, the client heterogeneous model’s feature extractor, and the representation projector, i.e., removing the local header), (2) mix-large (the combination of the homogeneous small model’s feature extractor, the client heterogeneous model, and the representation projector, i.e., removing the global header), (3) single-small (the homogeneous small model), (4) single-large (the client heterogeneous model). We compare their model performances under $(N=100,C=10\$ settings. Figure 7 presents that mix-small has a similar accuracy to mix-large which is used as the default inference model, and they significantly outperform the single homogeneous small model and the single heterogeneous client model. Therefore, users can choose mix-small or mix-large for model inference based on their inference costs in practical applications.
<details>
<summary>x23.png Details</summary>
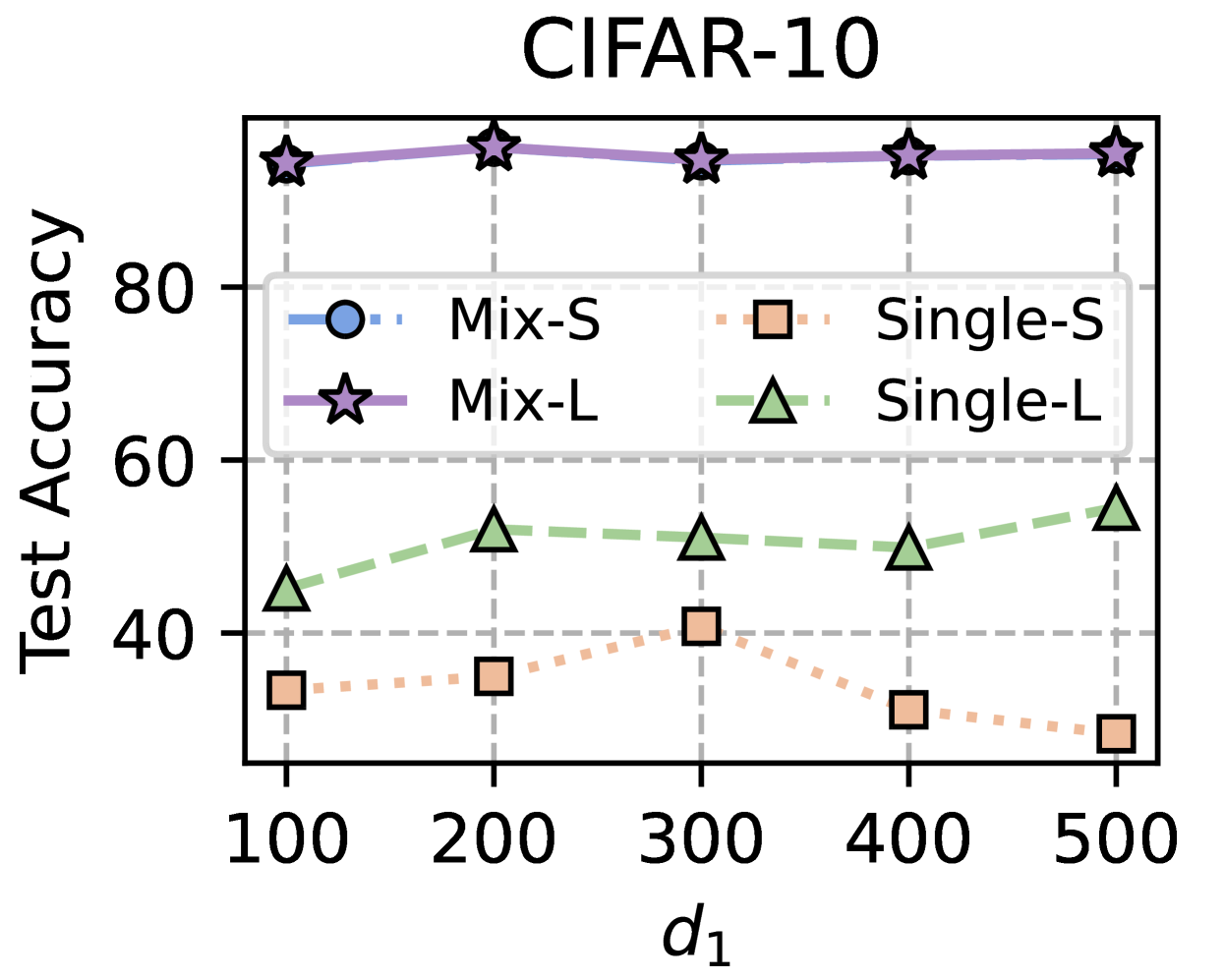
### Visual Description
\n
## Line Chart: CIFAR-10 Test Accuracy vs. d₁
### Overview
The image is a line chart titled "CIFAR-10," plotting "Test Accuracy" against a parameter labeled "d₁". It compares the performance of four distinct methods or models: Mix-S, Mix-L, Single-S, and Single-L. The chart shows how the test accuracy of each method changes as the value of d₁ increases from 100 to 500.
### Components/Axes
* **Title:** "CIFAR-10" (centered at the top).
* **Y-axis:** Labeled "Test Accuracy". The scale runs from 40 to 80, with major tick marks and grid lines at 40, 60, and 80. The data for one series extends above the 80 mark.
* **X-axis:** Labeled "d₁". The scale has discrete, evenly spaced values: 100, 200, 300, 400, 500.
* **Legend:** Located in the top-right quadrant of the chart area. It defines four data series:
* `Mix-S`: Blue circle marker with a dash-dot line style.
* `Mix-L`: Purple star marker with a solid line style.
* `Single-S`: Orange square marker with a dotted line style.
* `Single-L`: Green triangle marker with a dashed line style.
* **Grid:** Dashed grey grid lines are present for both the x and y axes.
### Detailed Analysis
The chart displays the following trends and approximate data points for each series:
1. **Mix-L (Purple star, solid line):**
* **Trend:** This series is positioned at the top of the chart and exhibits a very stable, high accuracy with minimal fluctuation across all d₁ values. The line is nearly flat.
* **Data Points (Approximate):**
* d₁=100: ~92%
* d₁=200: ~94%
* d₁=300: ~93%
* d₁=400: ~93%
* d₁=500: ~94%
2. **Single-L (Green triangle, dashed line):**
* **Trend:** This series is in the middle range of the chart. It shows a general, slight upward trend as d₁ increases, with a small dip around d₁=400.
* **Data Points (Approximate):**
* d₁=100: ~45%
* d₁=200: ~52%
* d₁=300: ~51%
* d₁=400: ~50%
* d₁=500: ~55%
3. **Single-S (Orange square, dotted line):**
* **Trend:** This series is in the lower range of the chart. It shows an initial increase, peaking at d₁=300, followed by a clear decline as d₁ increases further.
* **Data Points (Approximate):**
* d₁=100: ~33%
* d₁=200: ~35%
* d₁=300: ~41%
* d₁=400: ~31%
* d₁=500: ~28%
4. **Mix-S (Blue circle, dash-dot line):**
* **CRITICAL OBSERVATION:** Although `Mix-S` is defined in the legend, **no corresponding blue circle markers or dash-dot line are visible on the chart**. This series appears to be missing from the plot.
### Key Observations
* **Performance Hierarchy:** There is a clear and consistent separation in performance. `Mix-L` significantly outperforms all other methods, maintaining accuracy above 90%. `Single-L` performs in the 45-55% range, while `Single-S` performs the worst, generally below 40%.
* **Stability vs. Sensitivity:** `Mix-L` is highly stable with respect to the parameter d₁. In contrast, `Single-S` is highly sensitive, showing a performance peak at d₁=300 before degrading. `Single-L` shows moderate sensitivity with a slight positive trend.
* **Missing Data:** The absence of the `Mix-S` data series is a major anomaly. It is unclear if this method was not evaluated, if its performance was off the chart scale, or if there is a plotting error.
* **Scale:** The y-axis is labeled up to 80, but the `Mix-L` data points are clearly above this line, suggesting the actual accuracy values are in the low-to-mid 90s.
### Interpretation
This chart likely compares different training or architectural strategies (denoted by "Mix" vs. "Single" and "S" vs. "L") for a machine learning model on the CIFAR-10 image classification task. The parameter `d₁` could represent a dimension, such as the width of a layer or a latent space size.
The data suggests that the "Mix-L" strategy is by far the most effective and robust, delivering high accuracy that is largely unaffected by changes in `d₁` within the tested range. The "Single" strategies are less effective, with "Single-L" (likely a larger model) outperforming "Single-S" (likely a smaller model). The peaking behavior of "Single-S" indicates there is an optimal value for `d₁` around 300 for that specific configuration, beyond which performance suffers, possibly due to overfitting or optimization difficulties.
The most significant finding is the missing `Mix-S` series. Its absence prevents a complete comparison. If it performed poorly, it would reinforce the superiority of the "Mix-L" approach. If it performed well but was omitted, it would represent a critical gap in the presented results. A viewer must conclude that either the experiment for `Mix-S` failed, the data was lost, or the chart is incomplete.
</details>
<details>
<summary>x24.png Details</summary>
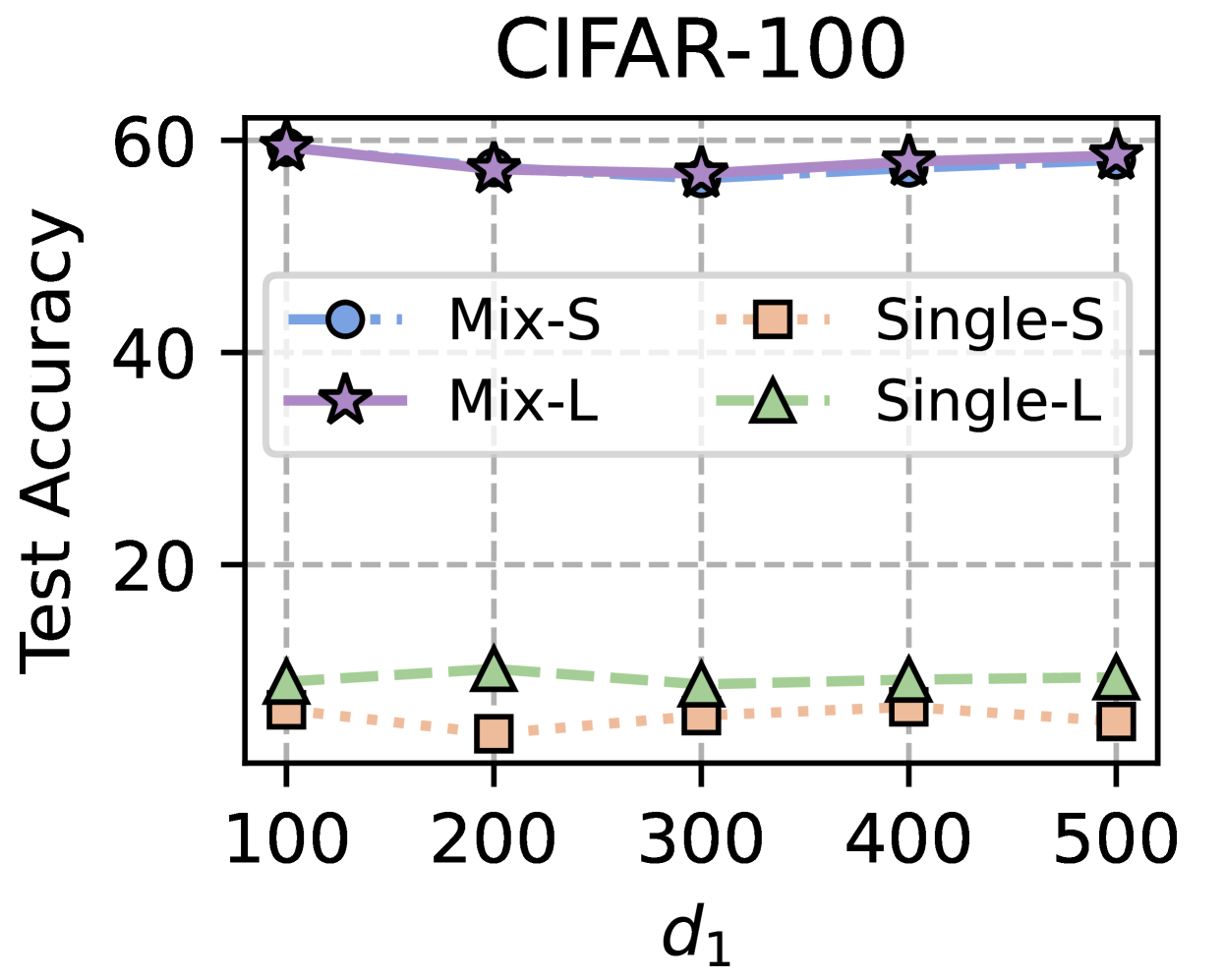
### Visual Description
## Line Chart: CIFAR-100 Test Accuracy vs. Parameter d₁
### Overview
The image displays a line chart titled "CIFAR-100," plotting "Test Accuracy" (y-axis) against a parameter labeled "d₁" (x-axis). The chart compares the performance of four different methods or model variants across five discrete values of d₁. The data is presented using lines with distinct markers, and a legend is provided to identify each series.
### Components/Axes
* **Title:** "CIFAR-100" (centered at the top).
* **Y-Axis:**
* **Label:** "Test Accuracy" (rotated vertically on the left).
* **Scale:** Linear scale from 0 to 60, with major tick marks and labels at 0, 20, 40, and 60.
* **X-Axis:**
* **Label:** "d₁" (centered at the bottom).
* **Scale:** Discrete values at 100, 200, 300, 400, and 500.
* **Legend:** Positioned in the upper-middle area of the plot, slightly overlapping the data lines. It contains four entries:
1. **Mix-S:** Blue circle marker with a dash-dot line (`-·-`).
2. **Mix-L:** Purple star marker with a solid line (`-`).
3. **Single-S:** Orange square marker with a dotted line (`···`).
4. **Single-L:** Green triangle marker with a dashed line (`--`).
* **Grid:** A light gray dashed grid is present for both major x and y ticks.
### Detailed Analysis
The chart shows the test accuracy for four series as d₁ increases from 100 to 500.
**1. Mix-L (Purple Stars, Solid Line):**
* **Trend:** This series exhibits the highest accuracy overall. It starts at approximately 59.5 at d₁=100, shows a very slight dip to around 58 at d₁=200 and 300, then recovers to approximately 59 at d₁=400 and 500. The line is nearly flat, indicating high and stable performance.
* **Data Points (Approximate):**
* d₁=100: ~59.5
* d₁=200: ~58.0
* d₁=300: ~57.5
* d₁=400: ~58.5
* d₁=500: ~59.0
**2. Mix-S (Blue Circles, Dash-Dot Line):**
* **Trend:** This series performs just below Mix-L. It follows a similar pattern: starting high (~58.5 at d₁=100), dipping slightly at d₁=200 (~57.5) and 300 (~57.0), then rising again at d₁=400 (~58.0) and 500 (~58.5). The performance gap between Mix-L and Mix-S is small but consistent.
* **Data Points (Approximate):**
* d₁=100: ~58.5
* d₁=200: ~57.5
* d₁=300: ~57.0
* d₁=400: ~58.0
* d₁=500: ~58.5
**3. Single-L (Green Triangles, Dashed Line):**
* **Trend:** This series shows significantly lower accuracy than the "Mix" variants. It starts at ~10 at d₁=100, peaks at ~12 at d₁=200, then gradually declines to ~10 at d₁=300, ~9 at d₁=400, and ~8 at d₁=500. The trend is a slight arch, peaking at d₁=200.
* **Data Points (Approximate):**
* d₁=100: ~10.0
* d₁=200: ~12.0
* d₁=300: ~10.0
* d₁=400: ~9.0
* d₁=500: ~8.0
**4. Single-S (Orange Squares, Dotted Line):**
* **Trend:** This series has the lowest accuracy. It begins at ~7 at d₁=100, dips to its lowest point of ~5 at d₁=200, then slowly increases to ~7 at d₁=300, ~8 at d₁=400, and ~7 at d₁=500. Its trend is roughly inverse to Single-L between d₁=100 and 300.
* **Data Points (Approximate):**
* d₁=100: ~7.0
* d₁=200: ~5.0
* d₁=300: ~7.0
* d₁=400: ~8.0
* d₁=500: ~7.0
### Key Observations
1. **Performance Hierarchy:** There is a clear and large performance gap between the "Mix" methods (Mix-L, Mix-S) and the "Single" methods (Single-L, Single-S). The "Mix" methods achieve ~57-60% accuracy, while the "Single" methods are below ~12%.
2. **Stability:** The "Mix" methods are remarkably stable across the range of d₁, with variations of only ~2-3 percentage points. The "Single" methods show more relative volatility but within a very low accuracy band.
3. **L vs. S:** Within each group ("Mix" and "Single"), the "L" variant consistently outperforms the "S" variant, though the margin is much smaller in the high-performing "Mix" group.
4. **Anomaly at d₁=200:** At d₁=200, the two "Single" methods show opposite movements: Single-L reaches its peak, while Single-S reaches its trough. This suggests a potential interaction effect at this specific parameter value.
### Interpretation
This chart likely comes from a machine learning paper evaluating model performance on the CIFAR-100 image classification dataset. The parameter `d₁` could represent a dimensionality, width, or capacity parameter of the model.
The data strongly suggests that the "Mix" strategy (which might involve mixing data, features, or models) is fundamentally superior to the "Single" strategy for this task, yielding a ~50 percentage point advantage. The "L" (likely "Large") variants outperforming "S" ("Small") variants is expected, as larger models typically have greater capacity.
The most intriguing finding is the divergent behavior of the Single-L and Single-S models at `d₁=200`. This could indicate that for smaller, single-component models, there is a specific, non-monotonic optimal capacity point. In contrast, the mixed approaches are robust to changes in this parameter. The primary takeaway is that the "Mix" strategy is not only more effective but also more stable, making it a more reliable choice regardless of the specific `d₁` setting within the tested range.
</details>
Figure 7: Accuracy of four optional inference models: mix-small (the whole model without the local header), mix-large (the whole model without the global header), single-small (the homogeneous small model), single-large (the client heterogeneous model).
## Appendix D Discussion
We discuss how FedMRL tackles heterogeneity and its privacy, communication and computation.
Tackling Heterogeneity. FedMRL allows each client to tailor its heterogeneous local model according to its system resources, which addresses system and model heterogeneity. Each client achieves multi-granularity representation learning adapting to local non-IID data distribution through a personalized heterogeneous representation projector, alleviating data heterogeneity.
Privacy. The server and clients communicate the homogeneous small models while the heterogeneous local model is always stored in the client. Besides, representation splicing enables the structures of the homogeneous global model and the heterogeneous local model to be not related. Therefore, the parameters and structure privacy of the heterogeneous client model is protected strongly. Meanwhile, the local data are always stored in clients for local training, so local data privacy is also protected.
Communication Cost. The server and clients transmit homogeneous small models with fewer parameters than the client’s heterogeneous local model, consuming significantly lower communication costs in one communication round compared with transmitting complete local models like FedAvg.
Computational Overhead. Except for training the client’s heterogeneous local model, each client also trains the homogeneous global small model and a lightweight representation projector which have far fewer parameters than the heterogeneous local model. The computational overhead in one training round is slightly increased. Since we design personalized Matryoshka Representations learning adapting to local data distribution from multiple perspectives, the model learning capability is improved, accelerating model convergence and consuming fewer training rounds. Therefore, the total computational cost may also be reduced.
## Appendix E Broader Impacts and Limitations
Broader Impacts. FedMRL improves model performance, communication and computational efficiency for heterogeneous federated learning while effectively protecting the privacy of the client heterogeneous local model and non-IID data. It can be applied in various practical FL applications.
Limitations. The multi-granularity embedded representations within Matryoshka Representations are processed by the global small model’s header and the local client model’s header, respectively. This increases the storage cost, communication costs and training overhead for the global header even though it only involves one linear layer. In future work, we will follow the more effective Matryoshka Representation learning method (MRL-E) [21], removing the global header and only using the local model header to process multi-granularity Matryoshka Representations simultaneously, to enable a better trade-off among model performance and costs of storage, communication and computation.