# Open-LLM-Leaderboard: From Multi-choice to Open-style Questions for LLMs Evaluation, Benchmark, and Arena
> Joint first author & equal contribution.
## Abstract
Multiple-choice questions (MCQ) are frequently used to assess large language models (LLMs). Typically, an LLM is given a question and selects the answer deemed most probable after adjustments for factors like length. Unfortunately, LLMs may inherently favor certain answer choice IDs, such as A/B/C/D, due to inherent biases of priori unbalanced probabilities, influencing the prediction of answers based on these IDs. Previous research has introduced methods to reduce this “selection bias” by simply permutating options on a few test samples and applying them to new ones. Another problem of MCQ is the lottery ticket choice by “random guessing”. The LLM does not learn particular knowledge, but the option is guessed correctly. This situation is especially serious for those small-scale LLMs For instance, on MMLU, the random guessing accuracy is 25%, and most small-scale LLMs obtain results around this value as shown in [35, 46]. It is difficult to distinguish which model is better under this situation.. To address them, a more thorough approach involves shifting from MCQ to open-style questions, which can fundamentally eliminate selection bias and random guessing issues. However, transitioning causes its own set of challenges in (1) identifying suitable open-style questions and (2) validating the correctness of LLM open-style responses against human-annotated ground-truths. This work aims to tackle these significant difficulties, and establish a new LLM evaluation benchmark through entirely open-style questions. Consequently, we introduce the Open-LLM-Leaderboard to track various LLMs’ performance and reflect true capability of them, such as GPT-4o/4/3.5, Claude 3, Gemini, etc. Our code and dataset are available at https://github.com/VILA-Lab/Open-LLM-Leaderboard.
## 1 Introduction
| Question that is suitable for open-style: Let x = 1. What is x << 3 in Python 3? |
| --- |
| Options: A. 1 B. 3 C. 8 D. 16 |
| Answer: C |
| Question that is not suitable for open-style: Which of the following statements is true? |
| Options: |
| A. Every equivalence relation is a partial-ordering relation. |
| B. Number of relations form A = x, y, z to B= (1, 2), is 64. |
| C. Empty relation _ is reflexive |
| D. Properties of a relation being symmetric and being un-symmetric are negative of each other. |
| Answer: B |
Figure 1: Examples of MCQ from MMLU.
Large language models (LLMs) are increasingly excelling at various natural language processing tasks, including text generation [11], translation [45, 50], summarization [22], code generation [20, 33], and chatbot interaction [28]. With the rising capability, the need for a robust evaluation strategy that can accurately assess the performance of these models is becoming crucial in order to identify their true effectiveness and choose the most appropriate one for a given task. Common metrics for assessing LLMs today include relevance, frequency of hallucinations, accuracy in question answering, toxicity, and retrieval-specific metrics, among others. In the context of question-answering evaluations, prior works usually investigate the model’s performance in terms of answer accuracy, courtesy, and conciseness. And multiple choice questions (MCQ) have emerged as a predominant format for such assessments, wherein a question is presented with several possible responses, and the model is required to select the most fitting choice ID, as exemplified in Figure 1. Lately, the MCQ format has seen widespread application in LLM-focused contexts, including benchmarks [18, 44, 12] that examine LLM capabilities and automated/crowdsourcing evaluation frameworks [21, 49, 5] that streamline the assessment process.
However, previous studies [48, 32] have discussed that the lack of resilience of LLMs to changes in the positioning of options stems from their tendency to exhibit biased behavior: they often favor choosing certain option IDs (such as “Option A”) as responses, a phenomenon that is referred to as selection bias. Moreover, it shows that selection bias exists widely across various LLMs and cannot be mitigated by simple prompting skills. The underlying reason of this issue comes from the condition that the model is trained with a priori distribution that assigns more probabilistic choices to specific ID tokens. Another issue of MCQ is the “random guessing” that is discussed in [35]. Specifically, small models such as the 1B-level variants, may struggle to achieve reliable predictions on many benchmarks like MMLU which uses four choices as the answer candidates of the questions. Their results could resemble random choices, not truly capturing the model’s actual capabilities.
To fundamentally eliminate selection bias and random guessing in LLMs, in this work, we build an open-style question benchmark for LLM evaluation. Leveraging this benchmark, we present the Open-LLM-Leaderboard, a new automated framework designed to refine the assessment process of LLMs. This framework functions in supplement to prior evaluation frameworks such as [21, 49, 5] with several advantages as presented in Sec. 4.4. However, constructing such a benchmark has two significant challenges: (1) how to determine the appropriate questions that can be effectively transformed from MCQ into open-style questions, and (2) how to establish an approach to accurately validate the correctness of the LLM’s open-style answers in comparison to human-annotated ground-truths, especially in contrast to MCQ, which typically have defined single-choice standard answers.
For the first challenge of identifying the multiple-choice questions that are suitable for converting to open-style questions, we design an automatic coarse-to-fine selecting protocol through customized prompts and multi-stage filtering process. Specifically, in the first stage, we use the binary classification to filter the questions with high confidence as the positive pool and others are assigned as negative. Our second stage uses a soft scoring method (1-10 ratings) to judge the suitability of the questions for the open-style from the questions that are clarified as negative in the first stage. For the second challenge of evaluating the correctness of the LLM’s open-style answers in comparison to human-annotated ground-truths, we further design a task-specific prompt and leverage GPT-4 to examine if the response is correct. To validate the accuracy of the automatic evaluation strategy, we randomly sample 100 results and manually check the automatic evaluation results with the corresponding responses, and confirm that it is reliable with an error rate of less than 5%.
In our end-to-end assessment of the LLM evaluation and ranking process, we conduct a comprehensive analysis on the well-recognized LLMs, including GPT-4o, GPT-4, ChatGPT, Claude-3 Opus, Gemini-Pro and Mistral-Large. Our benchmarking results indicate that GPT-4o currently holds the position as the strongest LLM. We further provide a small regime LLM leaderboard targeting at LLMs smaller than 3B. Moreover, our study demonstrates a high correlation between the rankings produced by our open-style benchmark and those derived from user-based evaluations or direct human assessments.
## 2 Related Work
Large Language Models (LLMs). Recent advancements in LLMs, such as GPT-3 [9] and GPT-4 [28] have had a significant impact in the field of natural language processing and have found widespread application across various domains. It has indeed initiated a kind of chain reaction within the community and beyond. As each new iteration of LLMs demonstrates enhanced capabilities, organizations and researchers across various sectors are motivated to develop their own models, such as LLaMA [40, 41], Gemini [38], and Claude [2], or find innovative ways to improve existing LLMs through instruction tuning, like Alpaca [37], and Vicuna [10].
Multiple Choice Questions (MCQ). In the realm of LLM research, MCQ has become a pivotal tool for evaluating and enhancing the capabilities of these models. Notable datasets like the MMLU [18], HellaSwag [44], and ARC [12] have been instrumental in this regard. Their diverse assessment of broad knowledge and commonsense reasoning help in benchmarking the depth and versatility of LLMs in understanding, reasoning, and applying knowledge across various domains. MCSB [31] introduces a natural prompting strategy for LLMs, which presents questions and answer choices together, allowing the model to explicitly compare options.
Bias in LLMs. Selection bias, a specific form of bias relevant to the evaluation of LLMs through MCQ, has garnered attention due to its understated and widespread impact. A series of works [49, 30, 48, 42] have shown that LLMs may develop a propensity to favor certain answer choices based on their position or encoding, such as the alphabetical ordering of A/B/C/D in MCQ. This phenomenon can lead to skewed evaluation results, misrepresenting a model’s true understanding and reasoning capabilities.
## 3 Approach
<details>
<summary>x1.png Details</summary>
### Visual Description
## Diagram: LLM Evaluation Workflow for Multiple-Choice and Open-Style Questions
### Overview
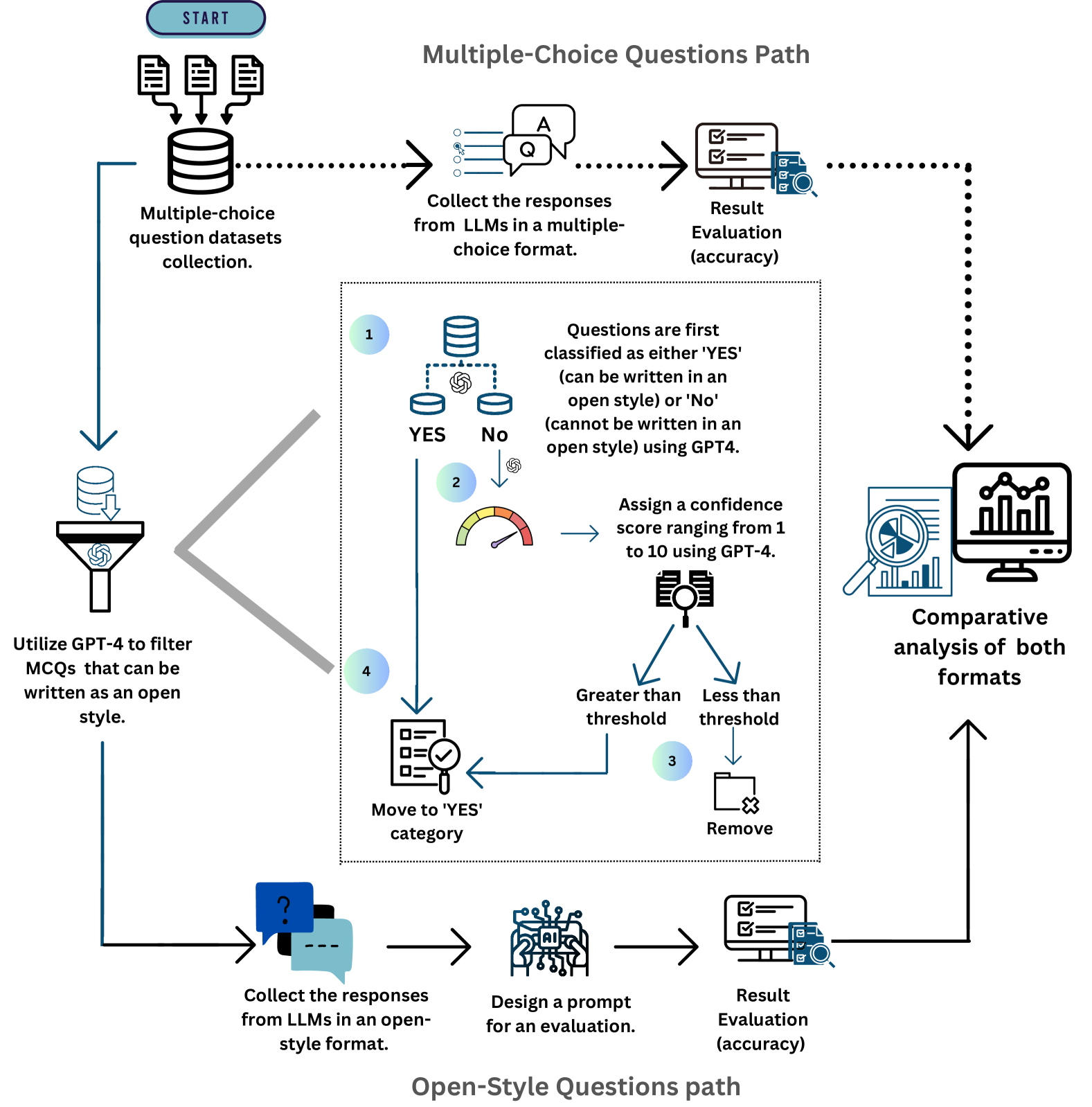
The image is a technical flowchart diagram illustrating a two-path workflow for evaluating Large Language Model (LLM) performance. The process begins with a collection of multiple-choice question (MCQ) datasets and diverges into separate evaluation pipelines for "Multiple-Choice Questions Path" (top) and "Open-Style Questions Path" (bottom). A central, detailed sub-process filters and classifies the MCQs to determine which can be converted into an open-ended format. The workflow culminates in a comparative analysis of the results from both evaluation formats.
### Components/Axes
The diagram is structured as a flowchart with the following key components:
- **Start Node:** A blue rounded rectangle labeled "START" at the top-left.
- **Data Source:** An icon of a database labeled "Multiple-choice question datasets collection."
- **Two Main Paths:**
1. **Multiple-Choice Questions Path:** A horizontal flow across the top of the diagram.
2. **Open-Style Questions Path:** A horizontal flow across the bottom of the diagram.
- **Central Processing Block:** A large, dashed-border rectangle in the center containing a detailed 4-step filtering and classification sub-process.
- **Icons:** Various icons represent actions (funnel, magnifying glass, gauge, checklist), data (databases, documents), and analysis (computer with charts).
- **Arrows:** Solid and dotted arrows indicate the flow of data and process steps. A large, grey, double-headed arrow connects the initial data source to the central processing block.
- **Final Output:** A computer monitor icon labeled "Comparative analysis of both formats" on the right side, which receives input from both main paths.
### Detailed Analysis
The workflow proceeds as follows:
**1. Initial Data Flow:**
- The process starts at the "START" node.
- Data flows to the "Multiple-choice question datasets collection" (database icon).
- From here, the data splits:
- **Path A (Top):** Flows directly into the "Multiple-Choice Questions Path."
- **Path B (Left & Center):** Flows into a funnel icon labeled "Utilize GPT-4 to filter MCQs that can be written as an open style." This filtered data then enters the central processing block.
**2. Multiple-Choice Questions Path (Top Flow):**
- **Step 1:** "Collect the responses from LLMs in a multiple-choice format." (Icon: Speech bubbles with 'Q' and 'A').
- **Step 2:** "Result Evaluation (accuracy)." (Icon: Computer monitor with a checklist and magnifying glass).
- The output of this evaluation flows via a dotted arrow to the final "Comparative analysis" stage.
**3. Central Processing Block (Filtering & Classification):**
This block details how MCQs are prepared for the open-style path. It contains four numbered steps:
- **Step 1:** "Questions are first classified as either 'YES' (can be written in an open style) or 'No' (cannot be written in an open style) using GPT4." This is depicted with a database icon splitting into "YES" and "No" paths.
- **Step 2:** For the "No" path, the system will "Assign a confidence score ranging from 1 to 10 using GPT-4." (Icon: A gauge/meter).
- **Step 3:** A decision point based on the confidence score. If the score is "Greater than threshold," the question is moved to the "YES" category. If "Less than threshold," it is "Remove[d]." (Icon: A folder with an 'X').
- **Step 4:** The final action for approved questions is "Move to 'YES' category." (Icon: A checklist with a magnifying glass).
**4. Open-Style Questions Path (Bottom Flow):**
- **Step 1:** "Collect the responses from LLMs in an open-style format." (Icon: Speech bubbles with a question mark and ellipsis).
- **Step 2:** "Design a prompt for an evaluation." (Icon: A brain/chip circuit icon labeled "AI").
- **Step 3:** "Result Evaluation (accuracy)." (Icon: Same as in the MCQ path).
- The output of this evaluation flows via a solid arrow to the final "Comparative analysis" stage.
**5. Final Stage:**
- Both the MCQ path (dotted arrow) and the Open-Style path (solid arrow) feed into the "Comparative analysis of both formats" (icon: computer monitor with bar and pie charts).
### Key Observations
- **Parallel Structure:** The diagram clearly shows two parallel evaluation pipelines (MCQ vs. Open-Style) originating from the same source data.
- **Central Filtering Mechanism:** A significant portion of the diagram is dedicated to the nuanced process of determining which MCQs are suitable for conversion to an open-ended format, using GPT-4 for both classification and confidence scoring.
- **Role of GPT-4:** GPT-4 is explicitly mentioned as a tool for two key tasks: initial filtering of MCQs and assigning confidence scores during classification.
- **Evaluation Consistency:** The "Result Evaluation (accuracy)" step uses identical icons and labels in both paths, suggesting a consistent evaluation metric is applied to both response formats.
- **Flow Direction:** The overall flow is from left (data source) to right (comparative analysis), with the central block acting as a processing hub for the bottom path.
### Interpretation
This diagram outlines a methodology for rigorously comparing LLM performance across two fundamental question formats. The core insight is that not all multiple-choice questions can or should be converted into open-ended questions. The central filtering process is critical for ensuring a valid comparison; it uses an LLM (GPT-4) to create a high-quality, "open-style" test set derived from MCQs.
The workflow suggests that the ultimate goal is not just to evaluate accuracy in isolation, but to perform a **comparative analysis**. This implies the researchers are interested in understanding the *delta* in LLM performance when the same underlying knowledge is tested via constrained selection (MCQ) versus free-form generation (Open-Style). Such an analysis could reveal biases in MCQ design, strengths/weaknesses of different LLMs in recall vs. reasoning, or the impact of question format on measured accuracy. The use of a confidence threshold in the filtering step adds a layer of quality control, ensuring that only questions reliably convertible to an open format are included in the comparative study.
</details>
Figure 2: An overview of a dual-path evaluation pipeline for LLMs, starting with the collection of MCQ datasets. It branches into two paths, with the MCQ path proceeding directly from response collection to evaluation, while the open-style path passes through an additional filtering phase. After evaluation, both paths converge in a comparative analysis.
### 3.1 Defining Open-style Questions
Open-style questions, aka open-ended questions, require the model to generate an answer without being constrained by a set of predetermined choices. In the context of LLM evaluation, these questions are designed to assess the model’s ability to generate coherent, relevant, and contextually appropriate responses based on the input query. While multiple-choice questions can efficiently assess specific factual knowledge and comprehension, open-style questions offer a deeper insight into the LLM’s generative capabilities, understanding of context, and ability to engage with complex tasks. Also, open-style questions can avoid the inherent selection bias and random guessing weaknesses compared to multiple-choice questions.
### 3.2 Automatic Open-style Question Filtering and Generation
Multi-stage Filtering and Postprocessing via Coarse-to-fine Process. Our proposed multi-stage filtering approach consists of four main steps to streamline the conversion: (1) Initially classify datasets as either convertible or non-convertible. (2) Assign each question a confidence score to indicate the likelihood that it can be framed as an open-style question. (3) Exclude questions with confidence scores below a specified threshold and classified as non-convertible. (4) Combine questions that are labeled as non-convertible but have high confidence scores with those labeled as convertible.
Stage1: Preliminary Filter using Binary Classification. Considering that the structure of MCQ varies, converting them into an open-style format is not always possible, particularly because certain questions are strongly linked to their choices. For instance, questions formulated as “Which one of the following is true” or “All except” or “Which of these”. Such questions are typically unsuitable for conversion into an open-style format since the absence of the options could change the question’s core, resulting in incomplete questions.
Table 1: Prompt design for two-stage filtering and post verification.
| Stage One: Coarse Filtering Prompt |
| --- |
| """Your task is to review a series of multiple-choice questions and evaluate their ability to be answered without the provided answer choices. For questions that begin with an incomplete sentence (e.g., "During swallowing, ..."), use your knowledge to attempt to complete the sentence accurately. For direct questions that ask for specific information or identification (e.g., "Which of the following structures is part of the small intestine?"), assess whether the question is formulated clearly enough that an informed answer can be given without seeing the multiple-choice options. For mathematical or analytical questions (e.g., "Find all cosets of the subgroup 4Z of 2Z"), determine if the question provides enough context and information for a solution to be formulated without additional options. Please follow this format for your evaluation: QUESTION: [Insert the question here] VERDICT: Respond with "YES" if the question is clear and can be directly answered based on its content alone, or "NO" if it relies on the answer choices to be understood or answered. Your response should include only the verdict without any justification or reasoning.""" |
| Stage Two: Fine-grained Filtering Prompt |
| You will assign a numerical score from 1 to 10 based on how confidently it can be answered without the choices. The scoring criteria are as follows: 1: The question is entirely dependent on its choices for an answer, making it impossible to answer without them. Example: ‘Which of the following statements is correct?’ 10: The question can be easily and confidently answered based solely on the question stem, without any need to refer to the provided options. Example: ‘What is the first law of thermodynamics in physics?’ Intermediate Scores: 2-4: The question stem gives very little information and is highly reliant on the choices for context. Example: ‘Which of these is a prime number?’ 5: The question provides some context or information, that gives a moderate possibility to answer the question. Example: ‘Which of the following best describes the structure that collects urine in the body?’ 6: The question provides a good amount of context or information, that gives a moderate possibility to answer the question. Example: ‘Statement 1 | A factor group of a non-Abelian group is non-Abelian. Statement 2 | If K is a normal subgroup of H and H is a normal subgroup of G, then K is a normal subgroup of G.’ 7: The question provides a good amount of context or information, that gives a high possibility to answer the question. Example: ‘The element (4, 2) of Z_12 x Z_8 has order’ 8-9: The question provides a good amount of context or information, that gives a high possibility to answer the question. Example: ‘A "dished face" profile is often associated with’ ONLY GIVE THE VALUE BETWEEN 1-10 AS YOUR ANSWER. DO NOT INCLUDE ANY OTHER INFORMATION IN YOUR RESPONSE Example Format: QUESTION: question here VERDICT: value in [1-10] here |
| GPT-4 Prompt for Verification |
| """Evaluate the answer of a AI model to a question. You will be provided with the question, the AI model’s answer, and the correct answer. Your task is to evaluate the AI model’s response and determine whether it is Correct or Incorrect. Grade the AI model answers based ONLY on their factual accuracy. It is OK if the AI model answer contains more information than the true answer, as long as it does not contain any conflicting statements. Otherwise, it should be marked as Incorrect. Ignore differences in punctuation and phrasing between the AI model’s answer and the true answer. Example Format: QUESTION: question here STUDENT ANSWER: student’s answer here TRUE ANSWER: true answer here GRADE: Correct or Incorrect here
Your response should include only the verdict without any justification or reasoning.""" |
To effectively handle this challenge of identifying whether multiple-choice questions are suitable for open-style conversion, we leverage the power of prompting techniques to create a customized classification prompt as shown in Table 1. In the prompt, we integrate different types of questions from different datasets to demonstrate how an LLM may evaluate each question to be written in an open-style way, eventually classifying them as convertible “YES” or non-convertible “NO”. It will determine whether a question provides a clear context and information without relying on the provided options or not. In the prompt we integrate different types of questions from different datasets to demonstrate how an LLM like GPT-4 may evaluate each question to be written in an open-style way, eventually classifying them as convertible “YES” or non-convertible “NO”. We set the prompt to eliminate any additional explanations, by stating that “Your response should include only the verdict without any justification or reasoning.” This guarantees that the answer to each inquiry is conveyed concisely as “YES” or “NO”.
To understand our initial filtering results, we conduct an error analysis manually by selecting 100 questions in the “YES” and “NO” pools separately. In the samples classified as “YES”, we find that only around 5% of the questions are false positive cases, verifying a low misclassification error for the positive question selection by our filtering strategy. Conversely, within the “NO” sample, around 40% of the questions are actually suitable for open-style questions but mistakenly classified as negative. This situation often arises from questions that include phrases like “Which of”. Similarly, questions involving true/false statements, sentence completions, or fill-in-the-blanks are also sometimes inappropriately classified as non-convertible. This analysis motivates us to develop a cascaded fine-grained stage to further filter more positive questions in “NO” pool using particular prompts, as described in the following Stage 2 process.
Stage2: Confidence Score Assignment. As we aim to overcome the issue of classifying questions with specific patterns as non-convertible, we introduce a second stage of filtering centered on confidence score assignment. This involves instructing the large language model to assign a confidence score on a scale from 1 to 10, reflecting the possibility of the question being written in an open-style format. Since a significant number of questions are unsuitable for an open-style format, categorized as “NO” and have a confidence score below 5, we set a confidence score threshold to be 5. Therefore, questions classified as non-convertible with a confidence score lower than this threshold are excluded, while those remaining above the threshold and those initially classified as convertible are moved into the “YES” category to be converted to an open-style format.
### 3.3 Open-style Question Answer Evaluation
After establishing a set of convertible questions from various datasets and obtaining their responses from several LLMs, there arises a need to evaluate these questions. Given that our ground truth answers are based on the MCQ format with defined answers, it necessitates a method for efficiently and accurately validating the correctness of responses to open-style questions. To this end, we design a customized prompt, as shown in Figure 2 that utilizes the correct MCQ answer as the ground truth to determine if the open-style responses are correct or incorrect by the prediction $\hat{y}$ :
$$
\hat{y}=\texttt{LLM}_\texttt{e}(prompt(q,\hat{a},a)) \tag{1}
$$
where $\hat{y}$ represents the prediction and $\texttt{LLM}_\texttt{e}$ is the LLM evaluator. $q$ , $\hat{a}$ and $a$ represent the question, LLM generated answer, and correct answer from MCQ, respectively, and the prompt is provided in Table 1 of Appendix. While these open-style answers are evaluated based on the MCQ’s ground truth, issues of misevaluation might arise. This includes scenarios where a response is inaccurately classified as correct simply because it contains certain keywords also found in the ground truth. To tackle this issue we include specific phrases in the prompt. These phrases, such as “as long as it does not contain any conflicting statements”, ensure that a response is not automatically classified as correct based on the presence of a keyword, avoiding incorrect markings when the response contradicts the correct answer. Additionally, to prevent the exclusion of correct answers that incorporate extra information, we incorporate the phrase “It is OK if the AI model’s answer contains more information than the true answer”. Furthermore, we highlight that minor differences in punctuation and phrasing between the open-style responses and the ground truth answers should not lead to their being classified as incorrect. To see the correctness of the LLM judgement we take the randomly drawn 100 responses from all models. The human evaluation process for our study was conducted by the authors themselves. The agreement between the LLM evaluations and those of a human evaluator was quantitatively assessed using Cohen’s kappa [13], which yielded a score of 0.83. This substantial kappa score The Kappa score is a statistical measure of inter-rater agreement for categorical items, defined by the equation: $κ=\frac{P_o-P_e}{1-P_e}$ where $P_o$ is the observed agreement and $P_e$ is the expected agreement by chance. verifies that the LLM’s ability to determine the correctness of responses aligns closely with human judgment, demonstrating strong reliability in its evaluation process.
## 4 An Open-style Question Benchmark (OSQ-bench)
### 4.1 Statistics and Distributions
Table 2 describes the basic statistics of the dataset questions that are suitable for answering in open-style format. In total, we have evaluated 42K questions from 9 different datasets and more than 23K of them are classified as appropriate for open-style answering.
Table 2: Statistics on open-style questions across different datasets.
| MMLU ARC MedMCQA | 14,042 3,428 4,183 | 7,784 3,118 2,318 | 36.6 21.1 14.1 |
| --- | --- | --- | --- |
| CommonsenseQA | 1,221 | 710 | 13.1 |
| Race | 4,934 | 3,520 | 10.0 |
| OpenbookQA | 1,000 | 491 | 10.3 |
| WinoGrande | 1,267 | 1,267 | 19.1 |
| HellaSwag | 10,042 | 3,915 | 40.1 |
| PIQA | 1,838 | 696 | 7.1 |
| Overall | 41,955 | 23,839 | 19.05 |
### 4.2 Diversity
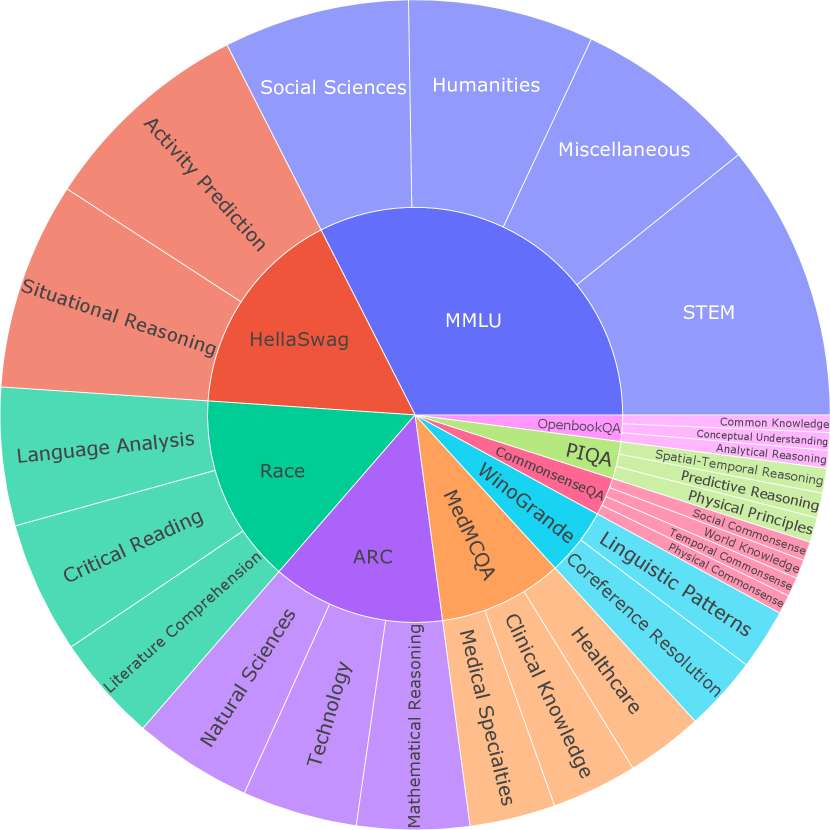
Our investigation into the diversity of questions within our benchmark is foundational for understanding the landscape of open-ended question answering. To comprehensively assess the breadth of question diversity, we have conducted a systematic categorization of the question types sourced from an array of distinct datasets. From the total initial pool of 41,955 questions, we refine the selection to 23,839 questions, ensuring that each one is conducive to open-ended responses. The distribution of those questions is illustrated in Figure 3, which segments the data into several domains based on the content of the questions. The segmentation of the plot underscores the interdisciplinary nature of our dataset. It features a broad spectrum of categories such as literature and reading comprehension, commonsense reasoning, domain-specific (medicine, STEM, and etc), and multi-topic knowledge. Also, Table 2 demonstrates the diversity of question length used for the benchmark.
<details>
<summary>x2.png Details</summary>
### Visual Description
## Nested Pie Chart (Sunburst Chart): AI Evaluation Benchmark Taxonomy
### Overview
The image displays a complex, multi-level pie chart (sunburst chart) that categorizes various artificial intelligence evaluation benchmarks. The chart is organized hierarchically, with broad domains in the outer ring and more specific tasks or sub-domains in the inner ring. Each segment is color-coded, and labels are placed directly on or adjacent to their corresponding slices. The chart visually represents the composition and relative scope of different benchmark categories.
### Components/Axes
* **Chart Type:** Nested Pie Chart / Sunburst Chart.
* **Structure:** Two concentric rings.
* **Outer Ring:** Represents broad, high-level domains or benchmark suites.
* **Inner Ring:** Represents specific tasks, sub-domains, or knowledge areas within the outer ring categories.
* **Legend:** The legend is integrated directly into the chart via color-coded labels placed on or next to each segment. There is no separate legend box.
* **Color Scheme:** A diverse palette is used, with distinct colors for each major category (e.g., blue for STEM, red-orange for HellaSwag, green for Race, purple for ARC, etc.). Sub-categories within a major category share a similar hue but may vary in shade.
### Detailed Analysis
The chart is segmented as follows, moving clockwise from the top. Segment sizes are approximate based on visual angle.
**1. Outer Ring - Major Categories (Clockwise from ~12 o'clock):**
* **STEM** (Blue, largest segment, ~25-30% of chart): Positioned top-right.
* **Miscellaneous** (Lighter Blue): Adjacent to STEM, clockwise.
* **Humanities** (Light Blue): Adjacent to Miscellaneous.
* **Social Sciences** (Light Blue): Adjacent to Humanities.
* **Activity Prediction** (Salmon/Pink): Adjacent to Social Sciences.
* **Situational Reasoning** (Salmon/Pink): Adjacent to Activity Prediction.
* **HellaSwag** (Red-Orange): Adjacent to Situational Reasoning.
* **Language Analysis** (Teal/Green): Adjacent to HellaSwag.
* **Critical Reading** (Teal/Green): Adjacent to Language Analysis.
* **Literature Comprehension** (Teal/Green): Adjacent to Critical Reading.
* **Race** (Green): Adjacent to Literature Comprehension.
* **ARC** (Purple): Adjacent to Race.
* **Natural Sciences** (Purple): Adjacent to ARC.
* **Technology** (Purple): Adjacent to Natural Sciences.
* **Mathematical Reasoning** (Purple): Adjacent to Technology.
* **Medical Specialties** (Orange): Adjacent to Mathematical Reasoning.
* **Clinical Knowledge** (Orange): Adjacent to Medical Specialties.
* **Healthcare** (Orange): Adjacent to Clinical Knowledge.
* **Coreference Resolution** (Cyan): Adjacent to Healthcare.
* **Linguistic Patterns** (Cyan): Adjacent to Coreference Resolution.
* **Physical Commonsense** (Light Green): Adjacent to Linguistic Patterns.
* **Temporal Commonsense** (Light Green): Adjacent to Physical Commonsense.
* **World Knowledge** (Light Green): Adjacent to Temporal Commonsense.
* **Social Commonsense** (Light Green): Adjacent to World Knowledge.
* **Physical Principles** (Light Green): Adjacent to Social Commonsense.
* **Predictive Reasoning** (Light Green): Adjacent to Physical Principles.
* **Spatial-Temporal Reasoning** (Light Green): Adjacent to Predictive Reasoning.
* **Conceptual Understanding** (Light Green): Adjacent to Spatial-Temporal Reasoning.
* **Common Knowledge** (Light Green): Adjacent to Conceptual Understanding.
* **Analytical Reasoning** (Light Green): Adjacent to Common Knowledge.
* **OpenbookQA** (Pink): Adjacent to Analytical Reasoning.
* **PIQA** (Pink): Adjacent to OpenbookQA.
* **CommonsenseQA** (Pink): Adjacent to PIQA.
* **WinoGrande** (Pink): Adjacent to CommonsenseQA.
* **MedMCQA** (Orange): Adjacent to WinoGrande.
**2. Inner Ring - Sub-Categories (Nested within Outer Ring segments):**
* **Within STEM:** No distinct inner ring labels are visible; the STEM segment appears as a single block.
* **Within HellaSwag:** The inner ring is labeled **"MMLU"** (Massive Multitask Language Understanding), which occupies a large portion of the inner circle, suggesting it is a major component or related benchmark.
* **Within ARC:** The inner ring is labeled **"ARC"** (AI2 Reasoning Challenge), indicating the outer and inner segments share the same name.
* **Within Medical Specialties/Clinical Knowledge/Healthcare:** The inner ring contains the label **"MedMCQA"**, indicating this benchmark spans these medical categories.
* **Within Coreference Resolution/Linguistic Patterns:** The inner ring contains the label **"WinoGrande"**, indicating this benchmark spans these language categories.
* **Within Physical Commonsense...Analytical Reasoning:** The inner ring contains the label **"CommonsenseQA"**, indicating this benchmark spans these reasoning categories.
* **Within OpenbookQA/PIQA:** The inner ring contains the label **"PIQA"** (Physical Interaction QA), suggesting a relationship or overlap.
* **Other Inner Ring Labels:** **"CommonsenseQA"** also appears as a standalone segment in the inner ring, adjacent to the PIQA segment.
### Key Observations
1. **Dominance of STEM and MMLU:** The STEM category is the largest single segment in the outer ring. The MMLU benchmark occupies a very large portion of the inner ring, indicating its central importance or broad coverage across multiple domains.
2. **Granularity of Reasoning and Language:** A significant portion of the chart (roughly the bottom-right quadrant) is dedicated to fine-grained categories of reasoning (e.g., Physical, Temporal, Social, Predictive) and language tasks (Coreference Resolution, Linguistic Patterns), many of which are associated with benchmarks like CommonsenseQA and WinoGrande.
3. **Medical Domain Clustering:** Medical-related categories (Medical Specialties, Clinical Knowledge, Healthcare) are grouped together and associated with the MedMCQA benchmark.
4. **Color-Coding Logic:** Colors are used thematically. For example:
* Blues for broad academic/knowledge domains (STEM, Humanities, Social Sciences).
* Greens for language and reading tasks (Language Analysis, Critical Reading, Race).
* Purples for science and technology (ARC, Natural Sciences, Technology).
* Oranges for medical fields.
* Pinks/Salmons for reasoning and prediction tasks.
* Light Greens for a cluster of specific reasoning types.
5. **Hierarchical Relationships:** The nesting shows which specific benchmarks (inner ring) are composed of or evaluated across which broader categories (outer ring). For instance, MedMCQA is evaluated across Medical Specialties, Clinical Knowledge, and Healthcare.
### Interpretation
This chart serves as a **taxonomy or map of the AI evaluation landscape**, specifically for language and reasoning models. It visually answers the question: "What kinds of tasks and knowledge areas are used to test AI systems, and how are they grouped?"
* **What it demonstrates:** The field of AI evaluation is highly specialized. It has moved beyond general language understanding to include highly specific reasoning types (e.g., spatial-temporal, physical principles) and domain-specific knowledge (e.g., medical, STEM). The prominence of benchmarks like MMLU, HellaSwag, ARC, and CommonsenseQA highlights the community's focus on measuring multitask ability, commonsense reasoning, and scientific problem-solving.
* **Relationships between elements:** The hierarchy shows that benchmarks are not monolithic. A single benchmark like MedMCQA is designed to test knowledge across multiple related medical sub-fields. Conversely, a broad domain like "Reasoning" is broken down into many specific, measurable competencies.
* **Notable patterns/anomalies:** The sheer number of fine-grained reasoning categories in the light-green cluster suggests a significant research focus on dissecting and measuring different facets of "common sense" and logical deduction. The large, undivided STEM block might indicate that STEM benchmarks are often treated as a unified category, or that this particular visualization chose not to decompose it further. The central placement and size of MMLU underscore its role as a comprehensive, "Swiss Army knife" benchmark for evaluating broad knowledge and task-solving ability.
</details>
Figure 3: Diversity and distribution of used datasets for our OSQ-bench.
### 4.3 Quality
Our newly developed benchmark, curated from widely recognized datasets, stands out by focusing on questions suitable to open-style answering, i.e., a format that demands a deep understanding and an ability to generate informative, unrestricted responses. Given that the datasets from which these questions originate are widely utilized and highly recognizable within the research community, it follows that the questions have good quality to assess the models’ capabilities. Moreover, due to the thorough filtering process it has undergone, it results in a low false positive rate (questions not suitable for open-style that are classified as suitable) of around 5%. This indicates that the vast majority of questions categorized as suitable for open-style answers indeed meet the criteria.
### 4.4 Property and Advantage
As shown in Table 3, our leaderboard exhibits several advantages: first is the debiased results compared to the MCQ-based leaderboard, which has been discussed thoroughly. Another advantage is the faster and cheaper evaluation over crowduser-based leaderboards. Our results and rankings can be generated automatically without any human intervention.
Table 3: Comparison with different LLM leaderboards. “Biased” indicates the selection bias.
| Huggingface Leaderboard [5] | Multiple Choices Questions | High | ✓ | Automatically |
| --- | --- | --- | --- | --- |
| AlpacaEval Leaderboard [21] | Human Questions&Feedback | Low | ✗ | GPT-4 |
| Chatbot Arena Leaderboard [49] | Human Questions&Feedback | Low | ✗ | GPT-4/Crowdusers |
| Open-LLM-Leaderboard (Ours) | Open Style Questions | High | ✗ | GPT-4 |
## 5 Experiments
<details>
<summary>x3.png Details</summary>
### Visual Description
\n
## Comparative Analysis of MCQ vs. OSQ Performance Across Four Large Language Models
### Overview
The image presents a comparative analysis of four Large Language Models (LLMs)—GPT-4, GPT-3.5, Claude-3 Opus, and Mistral-large—across eight benchmark datasets. For each model, performance is visualized using two complementary charts: a stacked bar chart showing the count distribution of correct/incorrect responses for Multiple-Choice Questions (MCQs) and Open-Ended/Short-Answer Questions (OSQs), and a radar chart comparing the overall accuracy percentages for MCQs and OSQs.
### Components/Axes
**Common Elements Across All Four Panels:**
* **Datasets (X-axis for Bar Charts, Categories for Radar Charts):** MMLU, HellaSwag, Race, ARC, MedMCQA, WinoGrande, CommonsenseQA, PIQA, OpenbookQA.
* **Bar Chart Y-axis:** "Count", with a scale from 0 to 8000.
* **Bar Chart Legend (Top-Left of each bar chart):**
* Orange: Incorrect MCQs, Correct OSQs
* Green: Correct MCQs, Incorrect OSQs
* Red: Correct MCQs, Correct OSQs
* Gray: Incorrect MCQs, Incorrect OSQs
* **Radar Chart Legend (Top-Center of each panel):**
* Pink Line/Area: MCQs Accuracies
* Green Line/Area: OSQs Accuracies
* **Radar Chart Scale:** Concentric circles marked at 0.2, 0.4, 0.6, 0.8, and 1.0 (representing 20% to 100% accuracy).
**Panel-Specific Labels:**
* Panel (1): GPT-4
* Panel (2): GPT-3.5
* Panel (3): Claude-3 Opus
* Panel (4): Mistral-large
### Detailed Analysis
**1. GPT-4 (Panel 1)**
* **Bar Chart:** The "Correct MCQs, Correct OSQs" (red) segment is dominant across most datasets, especially for MMLU (~7000 count). The "Incorrect MCQs, Correct OSQs" (orange) segment is notably small. The "Correct MCQs, Incorrect OSQs" (green) segment is significant for HellaSwag and Race.
* **Radar Chart:** The pink area (MCQ accuracy) is larger than the green area (OSQ accuracy) for all datasets. MCQ accuracy is highest for CommonsenseQA (~0.9) and lowest for MedMCQA (~0.7). OSQ accuracy is highest for CommonsenseQA (~0.8) and lowest for MedMCQA (~0.5).
**2. GPT-3.5 (Panel 2)**
* **Bar Chart:** The total counts are lower than GPT-4. The "Correct MCQs, Correct OSQs" (red) segment is still prominent but smaller. The "Incorrect MCQs, Correct OSQs" (orange) segment is more visible, particularly for MMLU and HellaSwag.
* **Radar Chart:** The gap between MCQ (pink) and OSQ (green) accuracy is wider than for GPT-4. MCQ accuracy peaks at CommonsenseQA (~0.8) and dips at MedMCQA (~0.6). OSQ accuracy is generally lower, with a notable low point at MedMCQA (~0.3).
**3. Claude-3 Opus (Panel 3)**
* **Bar Chart:** The distribution resembles GPT-4's pattern, with a strong red segment. The green segment ("Correct MCQs, Incorrect OSQs") appears slightly larger for some datasets like HellaSwag compared to GPT-4.
* **Radar Chart:** The performance profile is very similar to GPT-4. MCQ accuracy is high, peaking near 0.9 for CommonsenseQA. OSQ accuracy is also strong, with the smallest gap between the two accuracies observed on the CommonsenseQA dataset.
**4. Mistral-large (Panel 4)**
* **Bar Chart:** Shows a pattern similar to GPT-3.5, with lower overall counts and a more pronounced orange segment ("Incorrect MCQs, Correct OSQs") compared to GPT-4 and Claude-3 Opus.
* **Radar Chart:** Exhibits a performance profile between GPT-3.5 and the top models. The MCQ accuracy (pink) is respectable, peaking around 0.85 for CommonsenseQA. The OSQ accuracy (green) is lower, with a significant dip for MedMCQA (~0.4).
### Key Observations
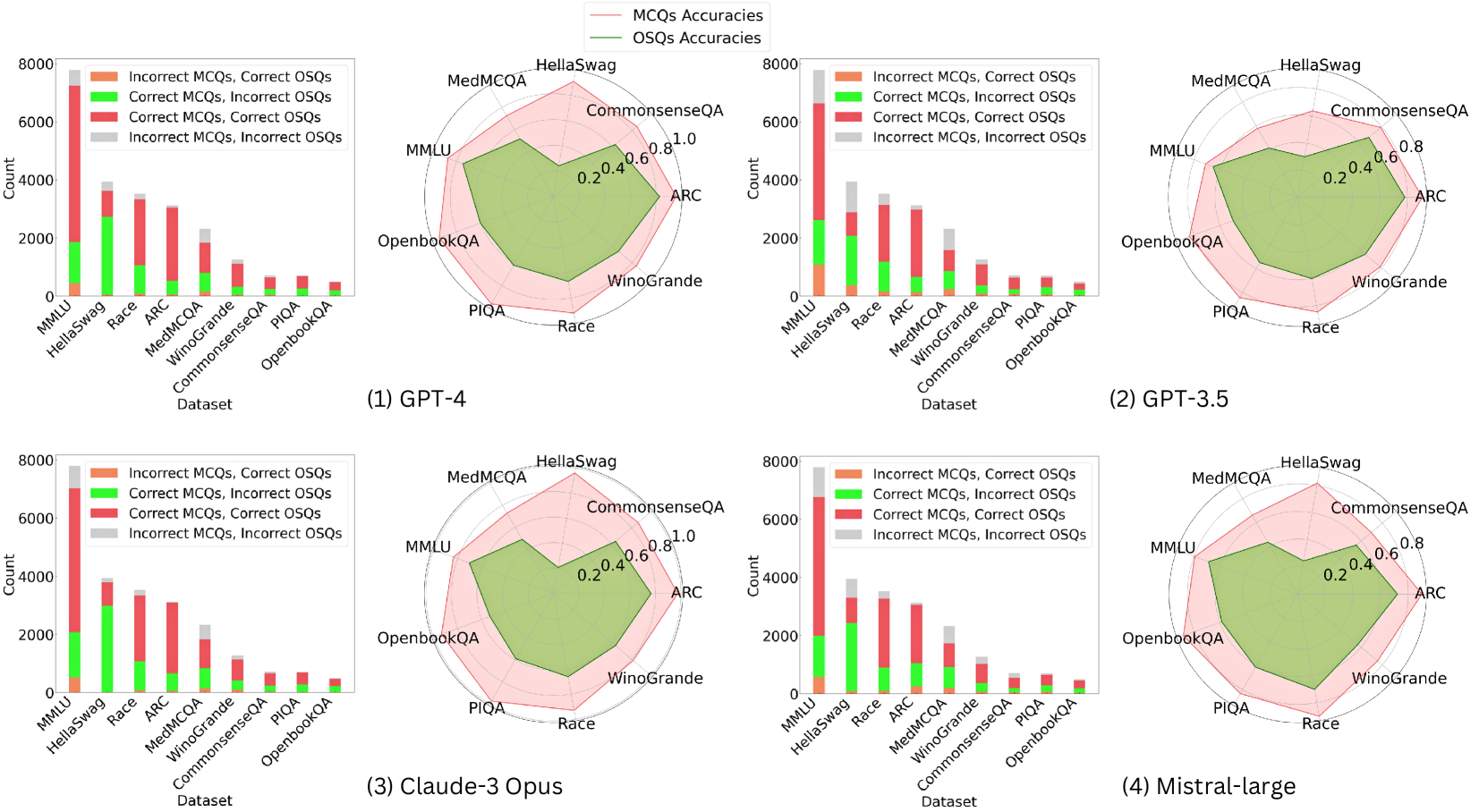
1. **Consistent Dataset Hierarchy:** Across all four models, CommonsenseQA consistently yields the highest accuracies for both MCQs and OSQs. Conversely, MedMCQA consistently results in the lowest accuracies, especially for OSQs.
2. **MCQ vs. OSQ Gap:** In every model and on nearly every dataset, MCQ accuracy (pink line/area) is higher than OSQ accuracy (green line/area). This gap is smallest for GPT-4 and Claude-3 Opus and largest for GPT-3.5.
3. **Model Performance Tiers:** GPT-4 and Claude-3 Opus form a top tier with very similar, high-performance profiles. Mistral-large occupies a middle tier, and GPT-3.5 shows the lowest relative performance, particularly on OSQs.
4. **Bar Chart Correlation:** The models with the highest radar chart accuracies (GPT-4, Claude-3) also have the largest red segments ("Correct MCQs, Correct OSQs") in their bar charts, indicating consistent correctness across both question formats.
### Interpretation
This visualization provides a multi-faceted view of LLM capabilities, moving beyond simple accuracy scores. The data suggests a fundamental challenge: **generating correct open-ended answers (OSQs) is consistently harder for these models than selecting the correct multiple-choice option (MCQs), even when testing the same underlying knowledge.**
The strong correlation between high MCQ/OSQ accuracy and a large "Correct/Correct" (red) bar segment indicates that models which are robustly knowledgeable perform well regardless of answer format. The notable dip in OSQ performance on the MedMCQA dataset across all models may point to a specific weakness in medical domain knowledge retrieval or generation, or it may reflect a characteristic of that dataset's OSQ format.
The near-identical performance profiles of GPT-4 and Claude-3 Opus suggest a potential convergence in capability among top-tier models on these benchmarks. The analysis highlights that evaluating LLMs requires examining performance across different interaction modalities (selection vs. generation) and diverse knowledge domains, as strengths in one area (e.g., MCQs on CommonsenseQA) do not guarantee equivalent strength in another (e.g., OSQs on MedMCQA).
</details>
Figure 4: Performance comparison of various LLMs on multiple-choice (MCQ) and open-style questions (OSQ) across different datasets. The bar graphs on the left show the counts of correct and incorrect responses (✗ MCQ vs. ✓ OSQ; ✓ MCQ vs. ✗ OSQ; ✓ MCQ vs. ✓ OSQ; ✗ MCQ vs. ✗ OSQ), while the radar charts on the right illustrate the accuracy comparisons between MCQ and OSQ for each language model (Pink is the MCQ accuracy and LimeGreen is the OSQ accuracy).
<details>
<summary>x4.png Details</summary>
### Visual Description
## Pie Chart Grid: Benchmark Performance (YES/NO)
### Overview
The image displays a 3x3 grid of nine pie charts, each representing the performance distribution (YES vs. NO) on a different benchmark or dataset. A single legend is positioned in the top-right corner of the overall image. The charts are arranged in three rows and three columns.
### Components/Axes
* **Legend:** Located in the top-right corner. It defines two categories:
* **YES:** Represented by a red/salmon color.
* **NO:** Represented by a light blue color.
* **Chart Labels:** Each pie chart is labeled with the name of a benchmark dataset. The label is placed within the larger segment of the pie.
* **Data Labels:** Each segment of every pie chart contains a percentage value.
### Detailed Analysis
The following is a breakdown of each pie chart, listed in reading order (left to right, top to bottom).
**Row 1:**
1. **Top-Left Chart: ARC**
* **YES (Red):** 91.2% (Label "ARC" is within this segment)
* **NO (Blue):** 8.8%
* *Trend:* Overwhelming majority YES.
2. **Top-Center Chart: CommonsenseQA**
* **YES (Red):** 58.1% (Label "CommonsenseQA" is within this segment)
* **NO (Blue):** 41.9%
* *Trend:* Majority YES, but with a significant NO portion.
3. **Top-Right Chart: Hellaswag**
* **YES (Red):** 39.2%
* **NO (Blue):** 60.8% (Label "Hellaswag" is within this segment)
* *Trend:* Majority NO.
**Row 2:**
4. **Middle-Left Chart: MedMCQA**
* **YES (Red):** 55.4% (Label "MedMCQA" is within this segment)
* **NO (Blue):** 44.6%
* *Trend:* Majority YES, similar split to CommonsenseQA.
5. **Middle-Center Chart: MMLU**
* **YES (Red):** 55.4% (Label "MMLU" is within this segment)
* **NO (Blue):** 44.6%
* *Trend:* Identical distribution to MedMCQA.
6. **Middle-Right Chart: OpenbookQA**
* **YES (Red):** 49.1%
* **NO (Blue):** 50.9% (Label "OpenbookQA" is within this segment)
* *Trend:* Nearly even split, with a slight majority NO.
**Row 3:**
7. **Bottom-Left Chart: PIQA**
* **YES (Red):** 37.9%
* **NO (Blue):** 62.1% (Label "PIQA" is within this segment)
* *Trend:* Strong majority NO.
8. **Bottom-Center Chart: Race**
* **YES (Red):** 71.3% (Label "Race" is within this segment)
* **NO (Blue):** 28.7%
* *Trend:* Strong majority YES.
9. **Bottom-Right Chart: Winogrande**
* **YES (Red):** 100.0% (Label "Winogrande" is within this segment)
* **NO (Blue):** 0.0%
* *Trend:* Perfect YES score. This is an extreme outlier.
### Key Observations
1. **Extreme Variability:** Performance varies dramatically across benchmarks, from 100% YES (Winogrande) to 37.9% YES (PIQA).
2. **Identical Distributions:** MedMCQA and MMLU show identical performance splits (55.4% YES / 44.6% NO).
3. **Perfect Score:** Winogrande is the only benchmark with a 100% YES result, indicating no NO responses.
4. **Majority Splits:** Benchmarks fall into three groups: strong majority YES (ARC, Race), moderate majority YES (CommonsenseQA, MedMCQA, MMLU), and majority NO (Hellaswag, OpenbookQA, PIQA).
5. **Label Placement:** The benchmark name is consistently placed within the larger segment of its pie chart.
### Interpretation
This visualization compares the binary (YES/NO) outcome distribution across nine distinct evaluation benchmarks, likely for an AI model or system. The "YES" outcome could represent correct answers, successful task completions, or positive classifications, depending on the benchmark's nature.
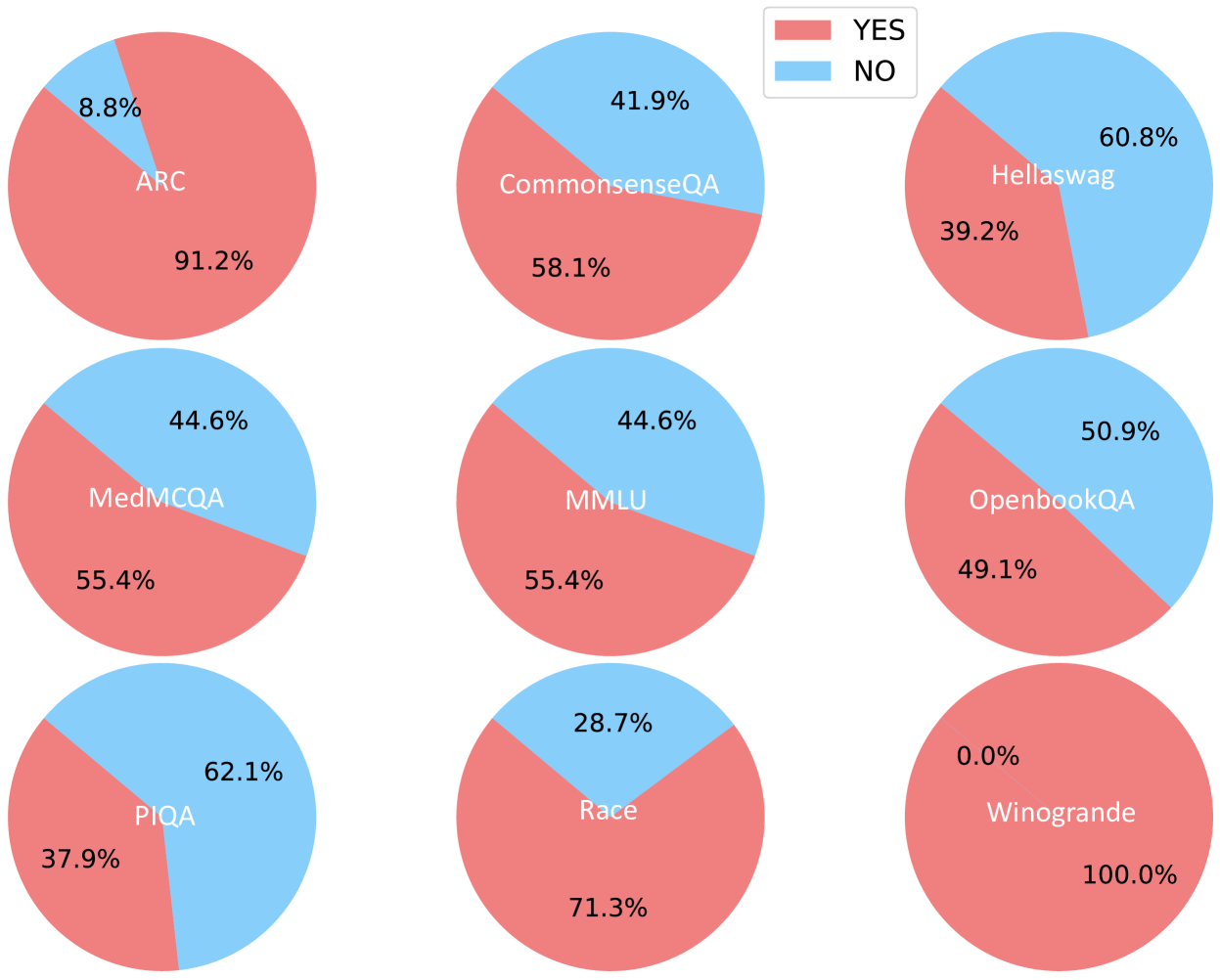
The data suggests the evaluated system has highly variable proficiency:
* It excels on the **Winogrande** and **ARC** benchmarks, achieving perfect or near-perfect YES rates.
* It performs moderately on knowledge-intensive or reasoning benchmarks like **CommonsenseQA**, **MedMCQA**, and **MMLU**.
* It struggles most with **Hellaswag**, **OpenbookQA**, and **PIQA**, where the NO outcome is more frequent. This could indicate specific weaknesses in areas like commonsense reasoning, physical intuition, or open-book question answering.
The identical scores for MedMCQA and MMLU are noteworthy and could imply either a coincidence in performance or that the model's capabilities on these two specific medical and general knowledge tasks are perfectly aligned. The perfect score on Winogrande is a significant outlier and may warrant investigation into whether the benchmark was appropriately challenging for the system or if there was a methodological factor at play.
Overall, the chart provides a clear, at-a-glance comparison of performance across diverse tasks, highlighting both strengths and clear areas for potential improvement.
</details>
Figure 5: Percentage of convertible MCQ to open style questions on various datasets.
### 5.1 Models
We generate responses from LLMs of different sizes. The large-scale LLMs: gpt-3.5-turbo, gpt-4-1106-preview, gpt-4o [27], claude-3-opus-20240229 [3], mistral-large-latest [24], gemini-pro [16], and llama3 [1]. We use the commercial APIs to collect responses from all of these models. The small-scale LLMs: qwen1.5 [4], gemma [39], SlimPajama-DC [35], RedPajama [25], OLMo [17], Pythia [6], TinyLlama [46], OPT [47], GPT-Neo [8], and Cerebras-GPT [14]. All of the small-scale model responses are collected using Huggingface [43] and lm-evaluation-harness framework [15] with 4 $×$ 4090 RTX GPUs.
### 5.2 Datasets
We present a brief overview of used datasets, highlighting their distinctive characteristics and the specific aspects they aim to evaluate. MMLU [18], ARC [12], and MedMCQA [29] stand out with their comprehensive range of tasks spanning across various disciplines. PIQA [7], CommonsenseQA [36], OpenBookQA [23], and HellaSwag [44] focus on the different aspects of commonsense reasoning, such as physical interaction, everyday concepts, and their interrelations. RACE [19] provides a source of reading comprehension challenges. WinoGrande [34] is designed to test the model on resolving coreferences and understanding nuanced relationships in text. This dataset with its unique fill-in-a-blank tasks, inherently aligns with open-ended question formats, negating the need for our multi-stage filtering process. For other datasets, questions are filtered using gpt-4-0125-preview using prompts from Table 1. The prompts for both MCQ and OSQ on each dataset are in Appendix D.
### 5.3 Evaluation
Table 4: Comparison of multiple choice (MCQ) and open style questions (OSQ) accuracy.
| MMLU | 87.28 | 74.77 | 71.25 | 65.38 | 65.71 | 56.04 | 83.52 | 70.23 | 79.50 | 68.76 |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| ARC | 95.54 | 82.68 | 90.64 | 78.42 | 90.96 | 72.35 | 97.50 | 75.47 | 89.96 | 72.32 |
| HellaSwag | 90.98 | 24.35 | 63.84 | 29.99 | 69.05 | 25.69 | 96.04 | 20.79 | 81.78 | 24.47 |
| WinoGrande | 84.14 | 66.22 | 78.77 | 64.56 | 66.85 | 56.35 | 81.69 | 63.54 | 75.45 | 56.83 |
| PIQA | 96.41 | 61.64 | 84.34 | 54.89 | 83.33 | 47.70 | 97.41 | 59.05 | 83.33 | 61.21 |
| CommonsenseQA | 84.93 | 62.96 | 79.15 | 67.89 | 66.62 | 50.56 | 86.76 | 63.66 | 69.58 | 55.35 |
| Race | 92.02 | 67.05 | 84.80 | 60.11 | 87.73 | 61.02 | 93.04 | 66.22 | 89.97 | 70.17 |
| MedMCQA | 72.65 | 51.81 | 58.02 | 41.42 | 58.02 | 35.89 | 72.91 | 49.14 | 66.05 | 43.44 |
| OpenbookQA | 94.30 | 60.29 | 83.71 | 49.90 | 86.97 | 52.55 | 93.48 | 52.95 | 88.19 | 58.66 |
| Average | 88.69 | 61.31 | 78.28 | 56.95 | 75.03 | 50.91 | 90.26 | 57.89 | 80.42 | 56.80 |
Our assessment approach for both MCQ and OSQ aligns with widely recognized evaluation frameworks and leaderboards for LLMs. The evaluation of MCQ is conducted utilizing the OpenAI Evals framework [26] with the zero-shot setting, which involves comparing the generated response with the ground truth ID. In contrast, for evaluating responses to open-ended questions, we employ the gpt-4-0125-preview model to determine the correctness of responses generated by LLMs relative to a pre-established ground truth answer from the dataset using the prompt from Table 1.
The results in Table 4 and Figure 4 are based on filtered questions. They show that every model experiences a significant drop in the accuracy for OSQ compared to MCQ. On average, the accuracy of OSQ is lower than MCQ by about 25% for all models. This result can correlate with our concern that the model will “randomly guess” to correct choices but it cannot answer. This discrepancy in performance between OSQ and MCQ is not necessarily a negative reflection of the models’ overall capabilities. Instead, it can be viewed as a true comparison of the models’ abilities to process and understand diverse types of questions.
The most significant difference in models between OSQ and MCQ is observed for Claude-3 Opus, by 31%. The dataset with the largest fall between MCQ and OSQ is HellaSwag. This is because of the type of questions in this dataset. It asks to choose the most plausible continuation for the scenarios presented. Evaluating the OSQ responses of LLMs against the ground truth in this dataset presents a significant challenge due to the different plausible completions. It means that a multitude of valid and contextually appropriate answers can exist, which makes it difficult to evaluate with single-choice ground truth. This contrasts with WinoGrande, which consists of questions that require fill-in-the-blank in sentences with correct words. As a result, HellaSwag does not seem well-suited for open-style questions, and we have chosen to omit it from our final leaderboard.
Table 5: Open-LLM Leaderboard for Large-scale Models. WG, CSQA, OBQA, and HS represent WinoGrande, CommonsenseQA, OpenbookQA, and HellaSwag respectively. We did not include HellaSwag results in the overall accuracy as the evaluation difficulties mentioned in Sec. 5.3.
| GPT-4o
<details>
<summary>extracted/5652609/fig/ranking/1_fig.png Details</summary>

### Visual Description
## Icon/Symbol: First Place Gold Medal
### Overview
The image is a flat-design, stylized icon of a first-place award medal. It features a circular gold medal suspended from a blue ribbon. The design is simple, using solid colors and minimal shading to create a clean, modern graphic suitable for digital interfaces or print materials. There is no embedded data chart, graph, or complex diagram; the image is purely symbolic.
### Components/Axes
The image consists of two primary components:
1. **Ribbon:** A V-shaped ribbon attached to the top of the medal. It is composed of two distinct blue segments.
2. **Medal:** A circular gold medal with a raised outer rim and a central emblem.
**Textual Elements:**
* A single numeral **"1"** is centered on the face of the medal.
### Detailed Analysis
* **Ribbon:**
* **Left Segment:** A lighter shade of blue (approximate hex: #3B82F6). It angles down from the top-left towards the center.
* **Right Segment:** A darker shade of blue (approximate hex: #1D4ED8). It angles down from the top-right towards the center.
* The two segments meet at a central point where they connect to the medal's suspension loop.
* **Medal:**
* **Shape:** Perfectly circular.
* **Color:** Primarily a bright gold/yellow (approximate hex: #FBBF24).
* **Rim:** A slightly darker gold/orange ring (approximate hex: #F59E0B) defines the outer edge, giving a sense of depth.
* **Central Emblem:** The numeral **"1"** is rendered in a bold, sans-serif font. Its color is a darker orange (approximate hex: #EA580C), providing clear contrast against the gold background.
* **Highlights:** Two white, curved shapes (approximate hex: #FFFFFF) are placed on the upper-left and lower-right of the medal's face, simulating a reflective shine.
* **Suspension Loop:** A small, gold rectangular loop connects the ribbon to the top of the medal.
### Key Observations
1. **Symbolic, Not Data-Driven:** The image contains no quantitative data, trends, or axes. Its purpose is purely representational.
2. **Color Symbolism:** The color palette is conventional for awards: gold for first place, blue often associated with trust, excellence, or official recognition.
3. **Design Style:** The icon uses a flat design aesthetic with minimal gradients or shadows, making it scalable and suitable for various digital contexts.
4. **Textual Content:** The only text is the numeral "1," which is the central and most important informational element, explicitly denoting "first place" or "number one."
### Interpretation
This icon is a universal symbol for **first-place achievement, victory, or top ranking**. It is designed to be instantly recognizable and is commonly used in contexts such as:
* Award ceremonies or competitions.
* Leaderboards in games or applications.
* Badges for user accomplishments.
* Marketing materials highlighting a "top-rated" or "#1" product or service.
The design prioritizes clarity and immediate comprehension over detailed information. The bold "1" leaves no ambiguity about its meaning, while the gold and blue color scheme reinforces the concepts of value, quality, and success. The lack of additional text or data makes it a versatile symbol that can be understood across different languages and cultures.
</details>
GPT-4-1106-preview
<details>
<summary>extracted/5652609/fig/ranking/2_fig.png Details</summary>

### Visual Description
## Icon/Symbol: Silver Medal with Blue Ribbon
### Overview
The image is a flat-design, vector-style graphic illustration of a silver medal, typically used to represent second place or a runner-up position in a competition or ranking system. The design is minimalist, using solid colors and subtle shading to create a sense of depth and form.
### Components/Axes
This is not a chart or data diagram, so it has no axes, legends, or data points. The components are purely graphical:
1. **Medal Body:** A circular, silver-colored medal with a raised outer rim and a recessed inner circle.
2. **Numeral:** The number "2" is prominently displayed in the center of the medal in a darker gray.
3. **Ribbon:** A V-shaped ribbon attached to the top of the medal via a suspension bar. The ribbon is split into two distinct blue sections.
4. **Background:** A solid, light gray background (#f0f0f0 approximate).
### Detailed Analysis
* **Textual Content:** The only text present is the numeral **"2"**.
* **Color Palette:**
* **Medal:** Uses three shades of gray/silver. The main face is a light gray, the outer rim is a slightly darker gray, and the numeral "2" is a medium-dark gray. White highlights on the left and bottom-right of the rim suggest a light source from the upper left.
* **Ribbon:** Composed of two blue tones. The left section is a bright, light blue (approximate hex: #3B82F6). The right section is a darker, more saturated blue (approximate hex: #1D4ED8). The two sections meet at a sharp diagonal line.
* **Spatial Grounding:** The medal is centered in the frame. The ribbon extends upwards from the top-center of the medal, forming a symmetrical "V" shape that points towards the top edge of the image. The numeral "2" is perfectly centered within the inner circle of the medal.
* **Design Style:** The illustration uses a flat design aesthetic with minimal gradients. Depth is implied through the use of layered shapes (the rim over the face, the ribbon over the suspension bar) and strategic highlight/shadow shapes, not through complex shading or textures.
### Key Observations
* The design is highly symbolic and generic, lacking any specific branding, event names, or organizational logos.
* The use of two distinct blues in the ribbon is a notable design choice, adding visual interest compared to a single-color ribbon.
* The numeral "2" is the sole and unambiguous focal point, clearly communicating the medal's rank.
### Interpretation
This image is a symbolic representation, not a presentation of factual data. Its meaning is derived from universal cultural conventions:
* **Primary Meaning:** It universally signifies **second place** or a **silver medal** achievement.
* **Contextual Use:** Such an icon is commonly used in user interfaces for leaderboards, award systems, educational apps, or competition results to visually denote the runner-up position.
* **Design Intent:** The clean, flat design ensures it is easily recognizable at various sizes (e.g., as an app icon or within a list). The blue ribbon may be a deliberate choice to convey a sense of trust, professionalism, or calm, as opposed to the more common red or gold associated with first place. The lack of specific text makes it a versatile asset applicable to any context requiring a "second place" indicator.
</details>
Claude-3 Opus
<details>
<summary>extracted/5652609/fig/ranking/3_fig.png Details</summary>

### Visual Description
## Icon/Symbol: Third Place Medal
### Overview
The image is a flat, stylized digital icon or illustration of a medal, specifically representing a third-place award. It features a circular orange medal suspended from a blue V-shaped ribbon against a plain, light gray background. The design is simple, using solid colors with minimal shading to suggest dimension.
### Components
1. **Ribbon:**
* **Shape:** A symmetrical "V" shape, composed of two trapezoidal segments that meet at a point where they connect to the medal's suspension loop.
* **Color & Positioning:** The left segment is a bright, light blue. The right segment is a darker, royal blue. The ribbon is positioned at the top of the image, centered horizontally.
2. **Suspension Loop:**
* **Shape:** A small, orange, rectangular loop with rounded top corners, connecting the ribbon to the main medal body.
* **Color:** Same orange as the medal's outer rim.
3. **Medal Body:**
* **Shape:** A perfect circle.
* **Structure:** Composed of three concentric visual layers:
* **Outer Rim:** A thick, solid orange border.
* **Inner Field:** A slightly lighter orange circle set within the rim.
* **Central Emblem:** A large, dark orange numeral "3" centered within the inner field.
* **Highlights:** Two curved, white lines are placed on the medal to simulate a glossy reflection. One is a longer arc on the upper-left quadrant of the inner field. The other is a shorter, thicker arc on the lower-right quadrant of the outer rim.
### Detailed Analysis
* **Textual Content:** The only text present is the numeral **"3"**. It is rendered in a bold, sans-serif typeface with rounded terminals, colored dark orange, and centered on the medal.
* **Color Palette:**
* Ribbon Left: Light Blue (approx. Hex #4FC3F7)
* Ribbon Right: Dark Blue (approx. Hex #1976D2)
* Medal Outer Rim: Orange (approx. Hex #FFA726)
* Medal Inner Field: Lighter Orange (approx. Hex #FFB74D)
* Numeral "3": Dark Orange (approx. Hex #F57C00)
* Highlights: White (#FFFFFF)
* Background: Light Gray (approx. Hex #EEEEEE)
* **Spatial Grounding:** The ribbon occupies the top ~40% of the vertical space. The medal body is centered below it, occupying the lower ~60%. The numeral "3" is the absolute focal point, centered both horizontally and vertically within the medal's circular boundary.
### Key Observations
* The icon uses a limited, flat color palette with no gradients, relying on color contrast and simple white highlights to create a sense of depth and shine.
* The two-tone blue ribbon is a common design trope for award ribbons, adding visual interest without complexity.
* The design is highly symbolic and generic; it contains no specific text (e.g., "3rd Place," "Bronze") beyond the numeral, making it a versatile icon for representing third rank or achievement.
### Interpretation
This image is a symbolic representation, not a data chart. Its primary function is to communicate the concept of **third place, a bronze medal, or a third-tier achievement** in a competition, ranking, or reward system.
* **Meaning:** The numeral "3" is the definitive element, universally understood to denote third position. The medal form reinforces this as an award or token of accomplishment.
* **Design Intent:** The clean, flat design suggests it is intended for use in digital interfaces—such as websites, apps, or dashboards—where it would serve as a clear, instantly recognizable visual indicator. It could be used in leaderboards, progress trackers, or award sections.
* **Notable Absence:** The lack of the word "Bronze" or a bronze color (the medal is distinctly orange) is interesting. It relies solely on the numeral and the medal archetype to convey its meaning, making it slightly more abstract than a literal bronze medal icon. The orange color may be a stylistic choice for better visibility or to fit a specific color scheme.
</details>
| 70.15 65.93 62.53 | 79.09 74.77 70.23 | 86.31 82.68 75.47 | 72.22 66.22 63.54 | 60.34 61.64 59.05 | 70.28 62.96 63.66 | 67.87 67.05 66.22 | 57.85 51.81 49.14 | 67.21 60.29 52.95 | – 24.35 20.79 |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| Mistral Large | 60.84 | 68.76 | 72.32 | 56.83 | 61.21 | 55.35 | 70.17 | 43.44 | 58.66 | 24.47 |
| GPT-3.5 | 60.32 | 65.38 | 78.42 | 64.56 | 54.89 | 67.89 | 60.11 | 41.42 | 49.90 | 29.99 |
| Gemini 1.0 Pro | 54.06 | 56.04 | 72.35 | 56.35 | 47.70 | 50.56 | 61.02 | 35.89 | 52.55 | 25.69 |
| Llama3-70b-Instruct | 52.92 | 59.67 | 67.09 | 57.14 | 43.10 | 55.49 | 58.21 | 41.67 | 40.94 | – |
Table 6: Open-LLM Leaderboard for small-scale model regime.
| Qwen1.5 (1.8B) Gemma (2B) SlimPajama-DC (1.3B) | 21.68 16.66 9.60 | 9.99 17.52 9.22 | 15.84 23.93 14.95 | 40.96 16.10 14.76 | 15.52 15.09 5.32 | 31.13 27.46 9.01 | 34.91 14.32 16.19 | 4.70 4.57 1.68 | 20.37 14.26 5.70 |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| RedPajama (1.3B) | 9.00 | 9.21 | 13.50 | 16.97 | 0.86 | 11.41 | 14.35 | 1.86 | 3.87 |
| OLMo (1.2B) | 8.85 | 8.54 | 13.18 | 6.16 | 8.05 | 13.10 | 13.61 | 2.07 | 6.11 |
| Pythia (1.4B) | 8.79 | 9.66 | 14.69 | 11.52 | 4.17 | 9.01 | 12.76 | 3.19 | 5.30 |
| TinyLlama (1.1B) | 8.45 | 8.94 | 13.31 | 12.23 | 3.59 | 6.06 | 16.7 | 2.07 | 4.68 |
| OPT (1.3B) | 7.89 | 7.40 | 11.83 | 12.47 | 4.48 | 7.61 | 13.61 | 1.25 | 4.48 |
| GPT-Neo (1.3B) | 7.42 | 6.94 | 9.69 | 10.81 | 4.31 | 6.34 | 13.75 | 2.63 | 4.89 |
| Cerebras-GPT (1.3B) | 4.86 | 5.37 | 4.43 | 9.31 | 2.16 | 6.20 | 6.90 | 1.04 | 3.46 |
### 5.4 Leaderboard and Arena
The overall ranking of models for our benchmark is represented in Table 6 and Table 6. The performance of GPT-4o overall demonstrates its leading edge, with an accuracy of 70.15%, which indicates its robustness in open-style question answering tasks compared to other models. It is followed by GPT-4-1106-preview with 65.93%, and Claude-3 Opus with 62.68%. These results highlight the advanced capabilities of the GPT-4 series. Mid-tier models like Mistral Large and GPT-3.5 perform well but are not on par with the top performers. On the other hand, models like Gemini 1.0 Pro and Llama3-70b-Instruct lag behind in terms of the capabilities to answer the open-style questions.
The performance evaluation of smaller-scale LLMs reveals that Qwen1.5 leads with an overall accuracy of 21.68%, significantly outperforming the other models in this category. Gemma follows with 16.66%, indicating a considerable gap in performance compared to the top model. The remaining models score below 10.00%, highlighting their limited abilities to answer the open-style questions. Almost all of the models struggle significantly with questions from MedMCQA dataset, showing an accuracy below of 5%.
## 6 Conclusion
We proposed Open-LLM-Leaderboard for LLM evaluation and comprehensively examined its efficacy using open-style questions from nine datasets on OSQ-bench. Different from previous works that rely on human evaluation or thousands of crowd users on Chatbot Arena, we can have a benchmark for chat LLMs in a fast, automatic, and cheap scheme. Our results show a highly correlated level of agreement with humans, indicating a foundation for an LLM-based evaluation benchmark and framework using open-style questions.
## Limitations and Ethics Statement
We have discussed multiple advantages of employing open-style questions over multiple-choice questions used in prior works. However, the LLM Leaderboard, as a tool for evaluating and benchmarking LLMs, has several common limitations itself. Firstly, the performance metrics used may not fully capture the nuanced capabilities of each model, especially in areas that require an understanding of context, creativity, or common sense reasoning. Secondly, the benchmark datasets may not be comprehensive enough to cover all possible domains and scenarios, leading to a potential bias towards certain types of questions or tasks. Thirdly, due to the rapidly evolving nature of the field, models may quickly become outdated, meaning the leaderboard may not always reflect the most current state of the art. Since our benchmark utilizes public datasets and our corpus consists of questions and answers, user privacy concerns are minimal.
## References
- [1] AI@Meta. Llama 3 model card. 2024.
- [2] Anthropic. Model card and evaluations for claude models, 2023.
- [3] Anthropic. https://www.anthropic.com/claude, 2024.
- [4] Jinze Bai, Shuai Bai, Yunfei Chu, Zeyu Cui, Kai Dang, Xiaodong Deng, Yang Fan, Wenbin Ge, Yu Han, Fei Huang, Binyuan Hui, Luo Ji, Mei Li, Junyang Lin, Runji Lin, Dayiheng Liu, Gao Liu, Chengqiang Lu, Keming Lu, Jianxin Ma, Rui Men, Xingzhang Ren, Xuancheng Ren, Chuanqi Tan, Sinan Tan, Jianhong Tu, Peng Wang, Shijie Wang, Wei Wang, Shengguang Wu, Benfeng Xu, Jin Xu, An Yang, Hao Yang, Jian Yang, Shusheng Yang, Yang Yao, Bowen Yu, Hongyi Yuan, Zheng Yuan, Jianwei Zhang, Xingxuan Zhang, Yichang Zhang, Zhenru Zhang, Chang Zhou, Jingren Zhou, Xiaohuan Zhou, and Tianhang Zhu. Qwen technical report. arXiv preprint arXiv:2309.16609, 2023.
- [5] Edward Beeching, Clémentine Fourrier, Nathan Habib, Sheon Han, Nathan Lambert, Nazneen Rajani, Omar Sanseviero, Lewis Tunstall, and Thomas Wolf. Open llm leaderboard. https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard, 2023.
- [6] Stella Biderman, Hailey Schoelkopf, Quentin Gregory Anthony, Herbie Bradley, Kyle O’Brien, Eric Hallahan, Mohammad Aflah Khan, Shivanshu Purohit, USVSN Sai Prashanth, Edward Raff, et al. Pythia: A suite for analyzing large language models across training and scaling. In International Conference on Machine Learning, pages 2397–2430. PMLR, 2023.
- [7] Yonatan Bisk, Rowan Zellers, Ronan Le bras, Jianfeng Gao, and Yejin Choi. Piqa: Reasoning about physical commonsense in natural language. Proceedings of the AAAI Conference on Artificial Intelligence, 34(05):7432–7439, Apr. 2020.
- [8] Sid Black, Gao Leo, Phil Wang, Connor Leahy, and Stella Biderman. GPT-Neo: Large Scale Autoregressive Language Modeling with Mesh-Tensorflow, March 2021. If you use this software, please cite it using these metadata.
- [9] Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, et al. Language models are few-shot learners. In H. Larochelle, M. Ranzato, R. Hadsell, M.F. Balcan, and H. Lin, editors, Advances in Neural Information Processing Systems, volume 33, pages 1877–1901. Curran Associates, Inc., 2020.
- [10] Wei-Lin Chiang, Zhuohan Li, Zi Lin, Ying Sheng, Zhanghao Wu, Hao Zhang, Lianmin Zheng, Siyuan Zhuang, Yonghao Zhuang, Joseph E. Gonzalez, Ion Stoica, and Eric P. Xing. Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality, March 2023.
- [11] John Chung, Ece Kamar, and Saleema Amershi. Increasing diversity while maintaining accuracy: Text data generation with large language models and human interventions. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 2023.
- [12] Peter Clark, Isaac Cowhey, Oren Etzioni, Tushar Khot, Ashish Sabharwal, Carissa Schoenick, and Oyvind Tafjord. Think you have solved question answering? try arc, the ai2 reasoning challenge. ArXiv, abs/1803.05457, 2018.
- [13] Jacob Cohen. A coefficient of agreement for nominal scales. Educational and Psychological Measurement, 20(1):37–46, 1960.
- [14] Nolan Dey, Gurpreet Gosal, Zhiming, Chen, Hemant Khachane, William Marshall, Ribhu Pathria, Marvin Tom, and Joel Hestness. Cerebras-gpt: Open compute-optimal language models trained on the cerebras wafer-scale cluster. arXiv preprint:2304.03208, 2023.
- [15] Leo Gao, Jonathan Tow, Baber Abbasi, Stella Biderman, Sid Black, Anthony DiPofi, Charles Foster, Laurence Golding, Jeffrey Hsu, Alain Le Noac’h, Haonan Li, Kyle McDonell, Niklas Muennighoff, Chris Ociepa, Jason Phang, Laria Reynolds, Hailey Schoelkopf, Aviya Skowron, Lintang Sutawika, Eric Tang, Anish Thite, Ben Wang, Kevin Wang, and Andy Zou. A framework for few-shot language model evaluation, 12 2023.
- [16] Google. https://ai.google.dev/, 2023.
- [17] Dirk Groeneveld, Iz Beltagy, Pete Walsh, Akshita Bhagia, Rodney Kinney, Oyvind Tafjord, Ananya Harsh Jha, Hamish Ivison, Ian Magnusson, Yizhong Wang, Shane Arora, David Atkinson, Russell Authur, Khyathi Chandu, Arman Cohan, Jennifer Dumas, Yanai Elazar, Yuling Gu, Jack Hessel, Tushar Khot, William Merrill, Jacob Morrison, Niklas Muennighoff, Aakanksha Naik, Crystal Nam, Matthew E. Peters, Valentina Pyatkin, Abhilasha Ravichander, Dustin Schwenk, Saurabh Shah, Will Smith, Nishant Subramani, Mitchell Wortsman, Pradeep Dasigi, Nathan Lambert, Kyle Richardson, Jesse Dodge, Kyle Lo, Luca Soldaini, Noah A. Smith, and Hannaneh Hajishirzi. Olmo: Accelerating the science of language models. Preprint, 2024.
- [18] Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. Measuring massive multitask language understanding. Proceedings of the International Conference on Learning Representations (ICLR), 2021.
- [19] Guokun Lai, Qizhe Xie, Hanxiao Liu, Yiming Yang, and Eduard Hovy. RACE: Large-scale ReAding comprehension dataset from examinations. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, 2017.
- [20] Raymond Li, Loubna Ben Allal, Yangtian Zi, Niklas Muennighoff, Denis Kocetkov, Chenghao Mou, Marc Marone, Christopher Akiki, et al. Starcoder: may the source be with you! arXiv preprint arXiv:23.05.061161, 2023.
- [21] Xuechen Li, Tianyi Zhang, Yann Dubois, Rohan Taori, Ishaan Gulrajani, Carlos Guestrin, Percy Liang, and Tatsunori B. Hashimoto. Alpacaeval: An automatic evaluator of instruction-following models. https://github.com/tatsu-lab/alpaca_eval, 2023.
- [22] Yixin Liu, Kejian Shi, Katherine S He, Longtian Ye, Alexander R. Fabbri, Pengfei Liu, Dragomir Radev, and Arman Cohan. On learning to summarize with large language models as references. arXiv preprint arXiv:2305.14239, 2023.
- [23] Todor Mihaylov, Peter Clark, Tushar Khot, and Ashish Sabharwal. Can a suit of armor conduct electricity? a new dataset for open book question answering. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, 2018.
- [24] Mistral. https://chat.mistral.ai/chat, 2024.
- [25] MosaicML. Mpt-1b redpajama-200b. https://huggingface.co/mosaicml/mpt-1b-redpajama-200b. Accessed: 2024-04-29.
- [26] OpenAI. Openai evals. https://github.com/openai/evals.
- [27] OpenAI. https://chat.openai.com/chat, 2022.
- [28] OpenAI. Gpt-4 technical report. arxiv preprint arXiv:2303.08774, 2024.
- [29] Ankit Pal, Logesh Kumar Umapathi, and Malaikannan Sankarasubbu. Medmcqa: A large-scale multi-subject multi-choice dataset for medical domain question answering. In Proceedings of the Conference on Health, Inference, and Learning, 2022.
- [30] Pouya Pezeshkpour and Estevam Hruschka. Large language models sensitivity to the order of options in multiple-choice questions. arXiv preprint arXiv:2308.11483, 2023.
- [31] Joshua Robinson, Christopher Rytting, and David Wingate. Leveraging large language models for multiple choice question answering. ArXiv, abs/2210.12353, 2022.
- [32] Joshua Robinson, Christopher Michael Rytting, and David Wingate. Leveraging large language models for multiple choice question answering. arXiv preprint arXiv:2210.12353, 2023.
- [33] Baptiste Rozière, Jonas Gehring, Fabian Gloeckle, Sten Sootla, Itai Gat, Xiaoqing Ellen Tan, Yossi Adi, Jingyu Liu, Romain Sauvestre, Tal Remez, Jérémy Rapin, Artyom Kozhevnikov, Ivan Evtimov, Joanna Bitton, Manish Bhatt, Cristian Canton Ferrer, Aaron Grattafiori, Wenhan Xiong, Alexandre Défossez, Jade Copet, Faisal Azhar, Hugo Touvron, Louis Martin, Nicolas Usunier, Thomas Scialom, and Gabriel Synnaeve. Code llama: Open foundation models for code. arXiv preprint arXiv:2308.12950, 2024.
- [34] Keisuke Sakaguchi, Ronan Le Bras, Chandra Bhagavatula, and Yejin Choi. Winogrande: an adversarial winograd schema challenge at scale. Commun. ACM, 64(9):99–106, aug 2021.
- [35] Zhiqiang Shen, Tianhua Tao, Liqun Ma, Willie Neiswanger, Joel Hestness, Natalia Vassilieva, Daria Soboleva, and Eric Xing. Slimpajama-dc: Understanding data combinations for llm training. arXiv preprint arXiv:2309.10818, 2023.
- [36] Alon Talmor, Jonathan Herzig, Nicholas Lourie, and Jonathan Berant. CommonsenseQA: A question answering challenge targeting commonsense knowledge. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), 2019.
- [37] Rohan Taori, Ishaan Gulrajani, Tianyi Zhang, Yann Dubois, Xuechen Li, Carlos Guestrin, Percy Liang, and Tatsunori B. Hashimoto. Stanford alpaca: An instruction-following llama model. https://github.com/tatsu-lab/stanford_alpaca, 2023.
- [38] Gemini Team. Gemini: A family of highly capable multimodal models. arXiv preprint arXiv:2312.11805, 2023.
- [39] Gemma Team. Gemma: Open models based on gemini research and technology. arXiv preprint arXiv:2403.08295, 2024.
- [40] Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, et al. Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971, 2023.
- [41] Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, et al. Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288, 2023.
- [42] Peiyi Wang, Lei Li, Liang Chen, Zefan Cai, Dawei Zhu, Binghuai Lin, Yunbo Cao, Qi Liu, Tianyu Liu, and Zhifang Sui. Large language models are not fair evaluators. arXiv preprint arXiv:2305.17926, 2023.
- [43] Thomas Wolf, Lysandre Debut, Victor Sanh, Julien Chaumond, Clement Delangue, Anthony Moi, Pierric Cistac, Tim Rault, Rémi Louf, Morgan Funtowicz, and Jamie Brew. Huggingface’s transformers: State-of-the-art natural language processing. CoRR, abs/1910.03771, 2019.
- [44] Rowan Zellers, Ari Holtzman, Yonatan Bisk, Ali Farhadi, and Yejin Choi. HellaSwag: Can a machine really finish your sentence? In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, 2019.
- [45] Biao Zhang, Barry Haddow, and Alexandra Birch. Prompting large language model for machine translation: A case study. In Proceedings of the 40th International Conference on Machine Learning, 2023.
- [46] Peiyuan Zhang, Guangtao Zeng, Tianduo Wang, and Wei Lu. Tinyllama: An open-source small language model. arXiv preprint:2401.02385, 2024.
- [47] Susan Zhang, Stephen Roller, Naman Goyal, Mikel Artetxe, Moya Chen, Shuohui Chen, Christopher Dewan, Mona Diab, Xian Li, Xi Victoria Lin, Todor Mihaylov, Myle Ott, Sam Shleifer, Kurt Shuster, Daniel Simig, Punit Singh Koura, Anjali Sridhar, Tianlu Wang, and Luke Zettlemoyer. Opt: Open pre-trained transformer language models. arXiv preprint:2205.01068, 2022.
- [48] Chujie Zheng, Hao Zhou, Fandong Meng, Jie Zhou, and Minlie Huang. Large language models are not robust multiple choice selectors. arXiv preprint arXiv:2309.03882, 2024.
- [49] Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric P. Xing, Hao Zhang, Joseph E. Gonzalez, and Ion Stoica. Judging llm-as-a-judge with mt-bench and chatbot arena. arXiv preprint arXiv:2306.05685, 2023.
- [50] Wenhao Zhu, Hongyi Liu, Qingxiu Dong, Jingjing Xu, Shujian Huang, Lingpeng Kong, Jiajun Chen, and Lei Li. Multilingual machine translation with large language models: Empirical results and analysis. arXiv preprint 2304.04675, 2023.
## Appendix
## Appendix A Reproducibility Statement
We will make all our filtered open-style data (MMLU, ARC, HellaSwag, WinoGrande, PIQA, CommonsenseQA, Race, MedMCQA, and OpenbookQA) used in our experiments of Sec. 5 and preprocessing scripts publicly available. Detailed data statistics are provided in Sec. 4.1. Considering the potential high costs associated with gathering and reproducing our LLM response data from the ground up, we will make available all responses from the various LLMs and their corresponding evaluation results to support and simplify the reproducibility of our work. The OpenAI APIs we used include gpt-3.5-turbo-1106, gpt-4.0-1106-preview, gpt-4o (for response collection), and gpt-4.0-0125-preview (for filtering and post-evaluation); Claude 3: claude-3-opus-20240229; Gemini-Pro: gemini-pro, and Mistral: mistral-large-latest.
## Appendix B More Results on Gemini Pro and Stage1 Filtering
<details>
<summary>x5.png Details</summary>
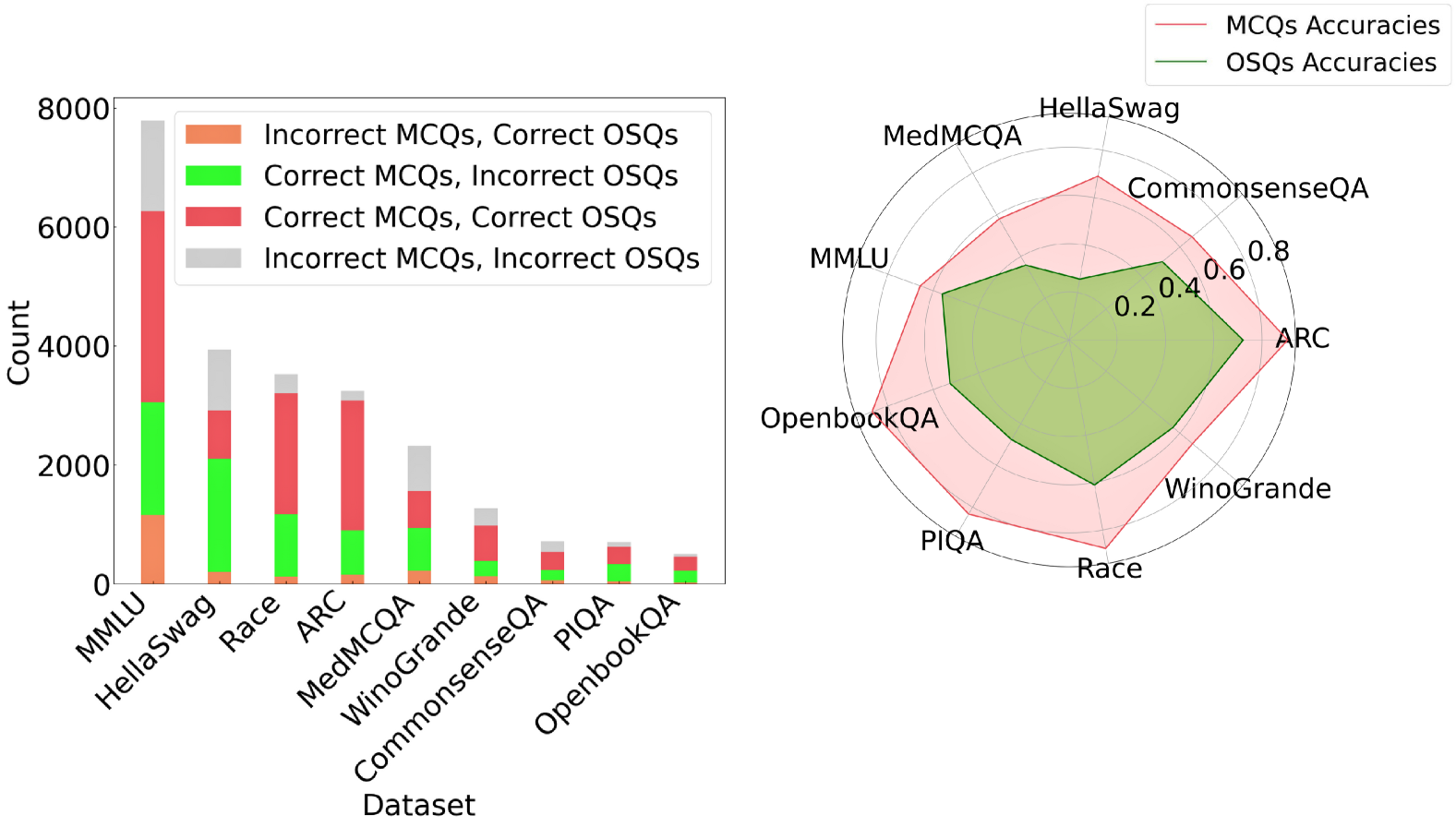
### Visual Description
## Stacked Bar Chart & Radar Chart: Model Performance Analysis
### Overview
The image contains two distinct charts analyzing the performance of a model (or models) on various question-answering datasets. The left chart is a stacked bar chart showing the count of questions categorized by the correctness of the model's answers on Multiple Choice Questions (MCQs) and Open-Ended/Short-form Questions (OSQs). The right chart is a radar chart comparing the overall accuracy percentages for MCQs and OSQs across the same datasets.
### Components/Axes
**Left Chart (Stacked Bar Chart):**
* **X-axis (Dataset):** Lists 9 datasets: MMLU, HellaSwag, Race, ARC, MedMCQA, WinoGrande, CommonsenseQA, PIQA, OpenbookQA.
* **Y-axis (Count):** Linear scale from 0 to 8000, with major ticks at 2000 intervals.
* **Legend (Top-Left):** Defines four stacked categories:
* Orange: Incorrect MCQs, Correct OSQs
* Green: Correct MCQs, Incorrect OSQs
* Red: Correct MCQs, Correct OSQs
* Grey: Incorrect MCQs, Incorrect OSQs
**Right Chart (Radar Chart):**
* **Radial Axes:** Represent the 9 datasets, arranged clockwise: HellaSwag, CommonsenseQA, ARC, WinoGrande, Race, PIQA, OpenbookQA, MMLU, MedMCQA.
* **Concentric Circles:** Represent accuracy values, with labeled rings at 0.2, 0.4, 0.6, and 0.8 (20%, 40%, 60%, 80%).
* **Legend (Top-Right):**
* Red Line & Shaded Area: MCQs Accuracies
* Green Line & Shaded Area: OSQs Accuracies
### Detailed Analysis
**Stacked Bar Chart Data (Approximate Counts):**
* **MMLU:** Total ~7800. Breakdown (bottom to top): Orange ~1200, Green ~1800, Red ~3200, Grey ~1600.
* **HellaSwag:** Total ~3900. Breakdown: Orange ~200, Green ~1900, Red ~800, Grey ~1000.
* **Race:** Total ~3500. Breakdown: Orange ~100, Green ~1100, Red ~2000, Grey ~300.
* **ARC:** Total ~3200. Breakdown: Orange ~100, Green ~800, Red ~2200, Grey ~100.
* **MedMCQA:** Total ~2300. Breakdown: Orange ~200, Green ~700, Red ~700, Grey ~700.
* **WinoGrande:** Total ~1200. Breakdown: Orange ~100, Green ~300, Red ~600, Grey ~200.
* **CommonsenseQA:** Total ~700. Breakdown: Orange ~50, Green ~150, Red ~400, Grey ~100.
* **PIQA:** Total ~650. Breakdown: Orange ~50, Green ~250, Red ~300, Grey ~50.
* **OpenbookQA:** Total ~450. Breakdown: Orange ~50, Green ~150, Red ~200, Grey ~50.
**Radar Chart Data (Approximate Accuracies):**
* **MCQs (Red Line):** HellaSwag ~0.75, CommonsenseQA ~0.70, ARC ~0.75, WinoGrande ~0.65, Race ~0.80, PIQA ~0.70, OpenbookQA ~0.65, MMLU ~0.65, MedMCQA ~0.60.
* **OSQs (Green Line):** HellaSwag ~0.55, CommonsenseQA ~0.50, ARC ~0.60, WinoGrande ~0.55, Race ~0.65, PIQA ~0.55, OpenbookQA ~0.50, MMLU ~0.50, MedMCQA ~0.45.
### Key Observations
1. **Dataset Size Disparity:** MMLU is the largest dataset by a significant margin (~7800 questions), while OpenbookQA is the smallest (~450).
2. **Performance Consistency:** The "Correct MCQs, Correct OSQs" (Red) segment is consistently the largest or second-largest segment across all datasets, indicating the model often gets both question types right.
3. **MCQ vs. OSQ Accuracy Gap:** The radar chart shows a consistent pattern where MCQ accuracy (red area) is higher than OSQ accuracy (green area) for every single dataset. The gap appears largest for MedMCQA and MMLU.
4. **Highest/Lowest Accuracy:** The model achieves its highest MCQ accuracy on Race (~80%) and its lowest on MedMCQA (~60%). For OSQs, the highest is on Race (~65%) and the lowest on MedMCQA (~45%).
5. **Correlation in Performance:** Datasets where the model performs well on MCQs (e.g., Race, ARC) also tend to show relatively better performance on OSQs, though the gap remains.
### Interpretation
This visualization provides a multi-faceted view of model performance across diverse benchmarks. The stacked bar chart reveals the *composition* of errors and successes, showing not just overall volume but the relationship between performance on two distinct task formats (MCQ vs. OSQ) within the same dataset. The radar chart provides a direct, normalized *comparison* of accuracy rates.
The data suggests a few key insights:
1. **Task Format Matters:** The consistent accuracy gap indicates the model finds generating correct short-form answers (OSQs) more challenging than selecting from given options (MCQs). This is a common pattern in language models, where recognition (MCQ) often outperforms recall/generation (OSQ).
2. **Dataset Difficulty:** Datasets like MedMCQA and MMLU appear to be more challenging for the model on both task formats, as indicated by lower accuracy scores and a larger proportion of "Incorrect/Incorrect" (grey) segments in the bar chart.
3. **Error Analysis Potential:** The bar chart's four-category breakdown is particularly useful for diagnostic analysis. For instance, a large "Correct MCQs, Incorrect OSQs" (green) segment would suggest the model has knowledge but struggles to articulate it, while a large "Incorrect MCQs, Correct OSQs" (orange) segment would be unusual and might indicate issues with the MCQ format or options.
4. **Complementary Views:** The two charts are complementary. The bar chart shows absolute counts (influenced by dataset size), while the radar chart shows normalized rates. A dataset can have a large red bar (many questions got both right) but a moderate accuracy point if the total dataset size is very large.
In summary, the model demonstrates competent but uneven performance across benchmarks, with a clear and persistent advantage on multiple-choice tasks over open-ended generation tasks. The analysis highlights specific datasets where performance lags, guiding potential areas for model improvement or data curation.
</details>
Figure 6: Performance comparison of Gemini Pro on multiple-choice and open-style response questions across diverse datasets, as shown by the count of correct and incorrect answers in the left bar chart and model accuracy in the right radar chart.
<details>
<summary>x6.png Details</summary>
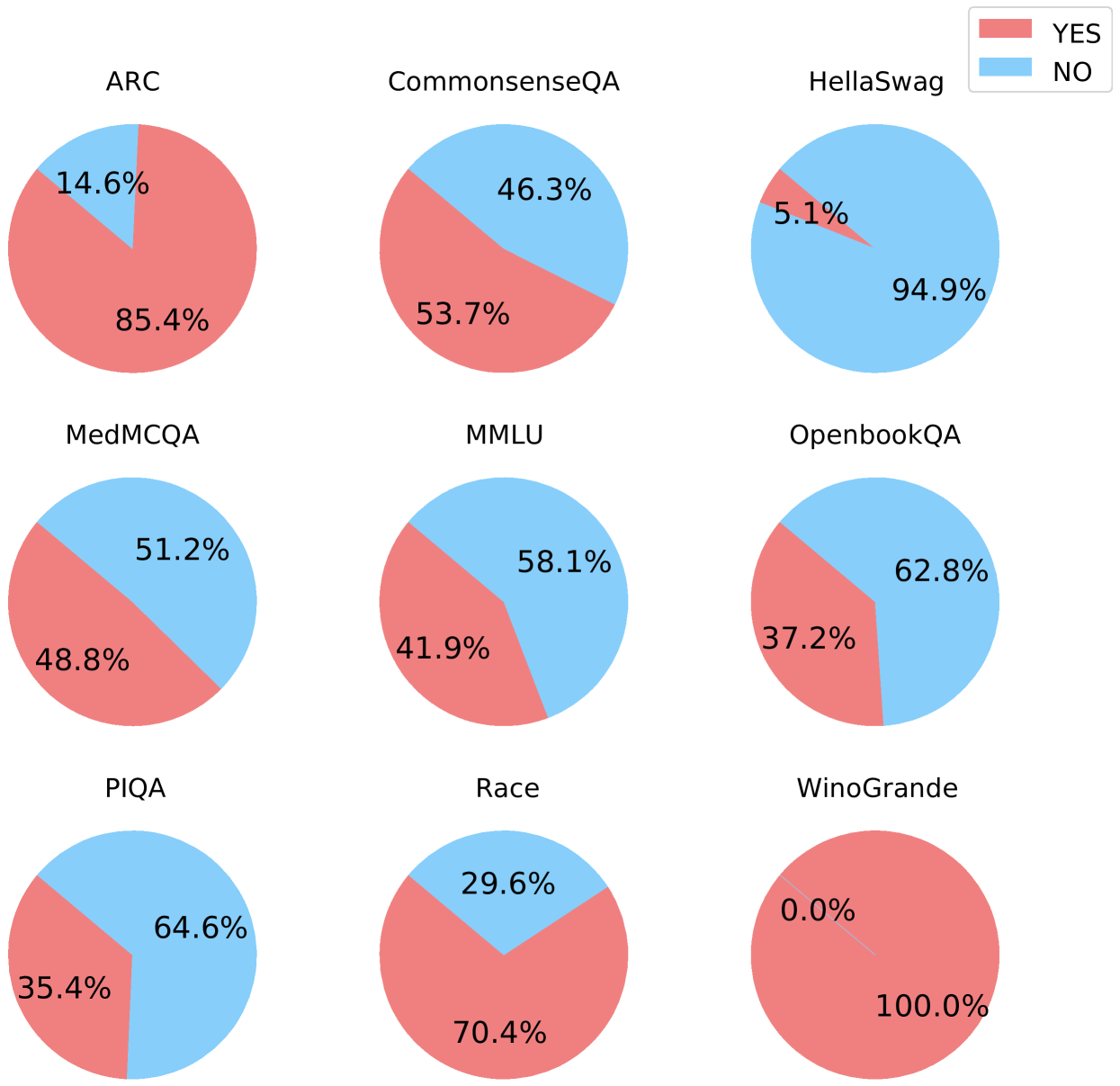
### Visual Description
## Pie Chart Grid: Benchmark Performance (YES/NO)
### Overview
The image displays a 3x3 grid of nine pie charts, each representing the performance distribution (YES vs. NO) on a different natural language processing or reasoning benchmark. A single legend is positioned in the top-right corner of the entire figure.
### Components/Axes
* **Legend:** Located in the top-right corner. It defines two categories:
* **YES:** Represented by a red/salmon color.
* **NO:** Represented by a light blue color.
* **Chart Titles:** Each pie chart has a title directly above it, naming a specific benchmark dataset.
* **Data Labels:** Each pie slice contains a percentage label indicating its proportion of the whole (100%).
### Detailed Analysis
The grid is processed row by row, from left to right.
**Row 1 (Top):**
1. **Top-Left: ARC**
* **YES (Red):** 85.4%
* **NO (Blue):** 14.6%
* *Trend:* The red slice dominates, indicating a high YES rate.
2. **Top-Center: CommonsenseQA**
* **YES (Red):** 53.7%
* **NO (Blue):** 46.3%
* *Trend:* The slices are nearly equal, with a slight majority for YES.
3. **Top-Right: HellaSwag**
* **YES (Red):** 5.1%
* **NO (Blue):** 94.9%
* *Trend:* The blue slice overwhelmingly dominates, indicating a very low YES rate.
**Row 2 (Middle):**
4. **Middle-Left: MedMCQA**
* **YES (Red):** 48.8%
* **NO (Blue):** 51.2%
* *Trend:* The slices are nearly equal, with a slight majority for NO.
5. **Middle-Center: MMLU**
* **YES (Red):** 41.9%
* **NO (Blue):** 58.1%
* *Trend:* The blue slice is larger, indicating a majority NO rate.
6. **Middle-Right: OpenbookQA**
* **YES (Red):** 37.2%
* **NO (Blue):** 62.8%
* *Trend:* The blue slice is significantly larger, indicating a strong majority NO rate.
**Row 3 (Bottom):**
7. **Bottom-Left: PIQA**
* **YES (Red):** 35.4%
* **NO (Blue):** 64.6%
* *Trend:* The blue slice is significantly larger, indicating a strong majority NO rate.
8. **Bottom-Center: Race**
* **YES (Red):** 70.4%
* **NO (Blue):** 29.6%
* *Trend:* The red slice is dominant, indicating a high YES rate.
9. **Bottom-Right: WinoGrande**
* **YES (Red):** 100.0%
* **NO (Blue):** 0.0%
* *Trend:* The pie is entirely red, indicating a perfect or near-perfect YES rate. The blue slice is not visible.
### Key Observations
* **Extreme Performance Spread:** The YES rates vary dramatically across benchmarks, from 0.0% (WinoGrande NO) to 100.0% (WinoGrande YES).
* **High-YES Benchmarks:** ARC (85.4%), Race (70.4%), and WinoGrande (100.0%) show strong performance (high YES).
* **Low-YES Benchmarks:** HellaSwag (5.1%), PIQA (35.4%), and OpenbookQA (37.2%) show weak performance (low YES).
* **Balanced Benchmarks:** CommonsenseQA (53.7% YES) and MedMCQA (48.8% YES) are close to a 50/50 split.
* **Visual Consistency:** All charts correctly use the red color for YES and blue for NO as defined in the legend.
### Interpretation
This grid visualizes the performance of a system (likely an AI model) across nine distinct evaluation benchmarks. The "YES" and "NO" labels most likely correspond to correct and incorrect answers, respectively, making these charts a representation of accuracy rates.
The data demonstrates that the system's capability is highly benchmark-dependent. It excels at tasks represented by ARC, Race, and especially WinoGrande, suggesting strength in areas like commonsense reasoning or specific linguistic patterns tested by those datasets. Conversely, it struggles significantly with HellaSwag and shows below-average performance on PIQA and OpenbookQA, indicating potential weaknesses in the skills those benchmarks target, such as narrative completion or physical reasoning.
The near-even splits on CommonsenseQA and MedMCQA suggest these are challenging benchmarks where the system's performance is essentially at chance level. The stark contrast between 100% on WinoGrande and 5.1% on HellaSwag highlights the importance of evaluating AI models across a diverse suite of tests, as performance on one task does not generalize to another. This visualization effectively communicates the model's profile of strengths and weaknesses.
</details>
Figure 7: Initial filtering results across datasets, showcasing the percentages of questions that are suitable (Yes) for open-style formatting and those that are not (No).
## Appendix C More Sample Questions
We provide more sample questions that are correct for open-style and incorrect for multiple choice in Table 7, and vice versa in Table 8. These examples demonstrate how the model’s ability varies in handling different question formats.
Table 7: Example of an Incorrect MCQ and a Correct OSQ in MMLU.
| Question that is correct for OSQ and incorrect for MCQ: How many CO2 and ATP molecules are formed during one complete turn of the tricarboxylic acid cycle (Krebs’ cycle)? |
| --- |
| Options: A. 2CO2 and 2ATP B. 2CO2 and 16ATP C. 2CO2 and 12ATP D. 2CO2 and 1ATP |
| Ground Truth: D |
| MCQ_Answer: A |
| OSQ_Answer: During one complete turn of the tricarboxylic acid cycle (also known as the Krebs’ cycle or the citric acid cycle), a series of chemical reactions occur in the mitochondria of cells that result in the production of carbon dioxide (CO2) and adenosine triphosphate (ATP), among other molecules. |
| For each acetyl-CoA molecule that enters the cycle, the following are produced: |
| - 2 molecules of CO2: Each acetyl-CoA contributes two carbons to the cycle, which are eventually released as two molecules of carbon dioxide. |
| - 1 molecule of ATP: One molecule of ATP (or an equivalent, such as GTP, depending on the cell type) is produced directly in the cycle through substrate-level phosphorylation. |
| However, the cycle also produces reduced coenzymes, specifically NADH and FADH2, which are used in the electron transport chain to produce additional ATP through oxidative phosphorylation. For each acetyl-CoA that enters the cycle: |
| - 3 molecules of NADH are produced, which can be used to generate approximately 2.5 ATP each through the electron transport chain. |
| - 1 molecule of FADH2 is produced, which can be used to generate approximately 1.5 ATP through the electron transport chain. |
| Therefore, while only 1 ATP is produced directly in the cycle per acetyl-CoA, the NADH and FADH2 generated can lead to the production of additional ATP in the electron transport chain. The exact number of ATP molecules produced can vary depending on the efficiency of the electron transport chain and the ATP synthase complex in different organisms and cell types. |
Table 8: Example of a Correct MCQ and an Incorrect OSQ in MMLU.
| Question that is correct for MCQ and incorrect for OSQ: A tree is a connected graph with no cycles. How many nonisomorphic trees with 5 vertices exist? |
| --- |
| Options: A. 1 B. 2 C. 3 D. 4 |
| Ground Truth: C |
| MCQ_Answer: C |
| OSQ_Answer: To determine the number of nonisomorphic trees with 5 vertices, we can use Cayley’s formula, which states that the number of trees on $n$ labeled vertices is $n^n-2$ . However, this formula gives the number of trees when vertices are labeled, meaning that it counts different labelings of the same tree shape as distinct. Since we are interested in nonisomorphic trees (which do not consider different labelings as distinct), we cannot directly use Cayley’s formula. |
| Instead, we need to enumerate the trees by considering their possible structures. For a tree with 5 vertices, we can have the following configurations: |
| 1. A linear chain (path) where each vertex is connected to two others except for the two end vertices, which are connected to only one other vertex. This is one possible tree. |
| 2. A "star" tree where one central vertex is connected to the other four vertices. This is another possible tree. |
| 3. A tree where one vertex is connected to three others, and one of those three is connected to the fifth vertex. This structure can be seen as a "T" shape with an extra branch on one of the endpoints. There are three nonisomorphic trees of this type because the branch can be on any of the three endpoints. |
| 4. A tree where two vertices are connected to a central vertex, and each of those two vertices is connected to one other vertex (creating a structure with a central vertex, two intermediate vertices, and two leaf vertices). This structure can be seen as a "Y" shape. There is only one nonisomorphic tree of this type because any permutation of the leaf vertices does not create a fundamentally different tree structure. |
| Adding these up, we have: |
| 1 (linear chain) + 1 (star) + 3 (T-shaped with an extra branch) + 1 (Y-shaped) = 6 nonisomorphic trees with 5 vertices. |
## Appendix D Prompts for Different Datasets
The following are examples of prompts for different datasets. They allow models to better understand and respond to specific contexts and objectives in each dataset.
Table 9: Prompt for MMLU dataset.
Table 10: Prompt for ARC dataset.
| MCQ Prompt: The following is the multiple choice question. Please select the correct answer from the options A, B, C, D. For example, if you think the correct answer is A, your response should be ’A’. |
| --- |
| Question: Tiny organisms called plankton live in oceans. Some plankton can take energy from the Sun and turn it into food. How are plankton most useful to the animals that live in the ocean? |
| A. Plankton are colorful. |
| B. Plankton clean the water. |
| C. Plankton release oxygen. |
| D. Plankton reproduce quickly. |
| Answer: |
| Open-Style Prompt: Answer the following question. |
| Question: Tiny organisms called plankton live in oceans. Some plankton can take energy from the Sun and turn it into food. How are plankton most useful to the animals that live in the ocean? |
| Answer: |
Table 11: Prompt for CommonsenseQA dataset.
| MCQ Prompt: The following is the multiple choice question. Please select the correct answer from the options A, B, C, D, E. For example, if you think the correct answer is A, your response should be ’A’. |
| --- |
| Question: A revolving door is convenient for two direction travel, but it also serves as a security measure at a what? |
| A. bank |
| B. library |
| C. department store |
| D. mall |
| E. New York |
| Answer: |
| Open-Style Prompt: You will be presented with a variety of questions that require an understanding of everyday scenarios, human behaviors, and common sense. Your task is to provide the best possible answer to each question based solely on your understanding and reasoning. |
| Question: A revolving door is convenient for two direction travel, but it also serves as a security measure at a what? |
| Answer: |
Table 12: Prompt for MedMCQA dataset.
| MCQ Prompt: The following is the multiple choice question about medicine. Please select the correct answer from the options A, B, C, D. For example, if you think the correct answer is A, your response should be ’A’. |
| --- |
| Question: Modulus of elasticity means: |
| A. Rigidity or stiffness of the material |
| B. Ability to be stretched with permanent deformation |
| C. Ductility of a material |
| D. Malleability of the metal |
| Answer: |
| Open-Style Prompt: Answer the following question about medicine. |
| Question: Modulus of elasticity means: |
| Answer: |
Table 13: Prompt for HellaSwag dataset.
| MCQ Prompt: The following is the multiple choice question. Please select the correct answer from the options A, B, C, D. For example, if you think the correct answer is A, your response should be ’A’. |
| --- |
| Question: How to clean your rv windows and mirrors fast without using any spray. you |
| A. also have a bucket that you spray paint a window in. |
| B. can reach for a running water hose and clean the inside of your rv quickly. |
| C. get a wash cloth and you put it under the faucet to get wet and then you rinse it out so it’s not soaking. |
| D. meticulously clean the window in the glass shop and then take the plastic off and start taking the hood off. |
| Answer: |
| Open-Style Prompt: Imagine you are provided with a scenario or a partial story taken from everyday life or a common activity. Your task is to continue this story or scenario in a way that makes the most sense based on what typically happens in such situations. Please complete the sentence. |
| Question: How to clean your rv windows and mirrors fast without using any spray. you |
| Answer: |
Table 14: Prompt for OpenbookQA dataset.
| MCQ Prompt: The following is the multiple choice question. Please select the correct answer from the options A, B, C, D. For example, if you think the correct answer is A, your response should be ’A’. |
| --- |
| Question: what system is needed for a body to get its needed supply of the gas humans breathe in? |
| A. the circulatory system |
| B. the digestive system |
| C. the school system |
| D. central nervous system |
| Answer: |
| Open-Style Prompt: Consider common scenarios or outcomes that fit the context of the sentence. Attempt to logically complete the sentences based on common knowledge and reasoning. |
| Question: what system is needed for a body to get its needed supply of the gas humans breathe in? |
| Answer: |
Table 15: Prompt for PIQA dataset.
| MCQ Prompt: The following is the multiple choice question. Please select the correct answer from the options A, B. For example, if you think the correct answer is A, your response should be ’A’. |
| --- |
| Question: How do I ready a guinea pig cage for it’s new occupants? |
| A. Provide the guinea pig with a cage full of a few inches of bedding made of ripped paper strips, you will also need to supply it with a water bottle and a food dish. |
| B. Provide the guinea pig with a cage full of a few inches of bedding made of ripped jeans material, you will also need to supply it with a water bottle and a food dish. |
| Answer: |
| Open-Style Prompt: Consider common scenarios or outcomes that fit the context of the sentence. Attempt to logically complete the sentences based on common knowledge and reasoning. |
| Question: How do I ready a guinea pig cage for it’s new occupants? |
| Answer: |
Table 16: Prompt for Race dataset.
| MCQ Prompt: I will give you a passage with multiple-choice question. Please select the correct answer from the options A, B, C, D. For example, if you think the correct answer is A, your response should be ’A’. |
| --- |
| Passage:... |
| Question: What did Nancy try to do before she fell over? |
| A. Measure the depth of the river |
| B. Look for a fallen tree trunk |
| C. Protect her cows from being drowned |
| D. Run away from the flooded farm |
| Answer: |
| Open-Style Prompt: I will give you passage with question. Please, answer the question. |
| Passage:... |
| Question: What did Nancy try to do before she fell over? |
| Answer: |
Table 17: Prompt for WinoGrande dataset.
| MCQ Prompt: The following is the multiple choice question. Please put the correct words in place of _. Your response should include only the option without any justification or reasoning. Please select the correct answer from the options A, B. |
| --- |
| Question: Sarah was a much better surgeon than Maria so _ always got the easier cases. |
| A. Sarah |
| B. Maria |
| Answer: |
| Open-Style Prompt: Please put the correct words in place of _. Give only the word that fits the sentence. |
| Question: Sarah was a much better surgeon than Maria so _ always got the easier cases. |
| Answer: |