# Large Language Models Must Be Taught to Know What They Don’t Know
**Authors**:
- Sanyam Kapoor (New York University)
- &Nate Gruver*} (New York University)
- Manley Roberts
- Abacus AI
- &Katherine Collins (Cambridge University)
- &Arka Pal
- Abacus AI
- &Umang Bhatt (New York University)
- Adrian Weller (Cambridge University)
- &Samuel Dooley
- Abacus AI
- &Micah Goldblum (Columbia University)
- &Andrew Gordon Wilson (New York University)
> Equal contribution. Order decided by coin flip. Correspondence to: sanyam@nyu.edu & nvg7279@nyu.edu
Abstract
When using large language models (LLMs) in high-stakes applications, we need to know when we can trust their predictions. Some works argue that prompting high-performance LLMs is sufficient to produce calibrated uncertainties, while others introduce sampling methods that can be prohibitively expensive. In this work, we first argue that prompting on its own is insufficient to achieve good calibration and then show that fine-tuning on a small dataset of correct and incorrect answers can create an uncertainty estimate with good generalization and small computational overhead. We show that a thousand graded examples are sufficient to outperform baseline methods and that training through the features of a model is necessary for good performance and tractable for large open-source models when using LoRA. We also investigate the mechanisms that enable reliable LLM uncertainty estimation, finding that many models can be used as general-purpose uncertainty estimators, applicable not just to their own uncertainties but also the uncertainty of other models. Lastly, we show that uncertainty estimates inform human use of LLMs in human-AI collaborative settings through a user study.
1 Introduction
‘‘I have high cortisol but low ACTH on a dexamethasone suppression test. What should I do?’’ If the answer to such a question is given without associated confidence, it is not actionable, and if the answer is presented with erroneously high confidence, then acting on the answer is dangerous. One of the biggest open questions about whether large language models (LLMs) can benefit society and reliably be used for decision making hinges on whether or not they can accurately represent uncertainty over the correctness of their output.
There is anything but consensus on whether LLMs accurately represent uncertainty, or even how we should approach uncertainty representation with language models. Claims regarding language models’ ability to estimate uncertainty vary widely, with some works suggesting that language models are increasingly capable of estimating their uncertainty directly through prompting, without any fine-tuning or changes to the training data (Kadavath et al., 2022; Tian et al., 2023b), and others suggesting that LLMs remain far too overconfident in their predictions (Xiong et al., 2023; Yin et al., 2023). The task of uncertainty estimation in LLMs is further exacerbated by linguistic variances in freeform generation, all of which cannot be exhaustively accounted for during training. LLM practitioners are therefore faced with the challenge of deciding which estimation method to use.
One particular dichotomy in uncertainty estimation methods for language models centers around whether the estimates are black- or white-box. Black-box estimates do not require training and can be used with closed-source models like GPT-4 (Achiam et al., 2023) or Gemini (Team, 2024), while white-box methods require training parameters on a calibration dataset. Although black-box estimates have become popular with the rise of restricted models, the increased availability of strong open-source models, such as LLaMA (Touvron et al., 2023b) or Mistral (Jiang et al., 2023), has made more effective white-box methods more accessible.
In this paper, we perform a deep investigation into uncertainty calibration of LLMs, with findings that advance the debate about necessary interventions for good calibration. In particular, we consider whether it’s possible to have good uncertainties over correctness (rather than tokens) without intervention, how we can best use labeled correctness examples, how well uncertainty generalizes across distribution shifts, and how we can use LLM uncertainty to assist human decision making.
First, we find that fine-tuning for better uncertainties (Figure 1) provides faster and more reliable uncertainty estimates, while using a relatively small number of additional parameters. The resulting uncertainties also generalize to new question types and tasks, beyond what is present in the fine-tuning dataset. We further provide a guide to teaching language models to know what they don’t know using a calibration dataset. Contrary to prior work, we start by showing that current zero-shot, black-box methods are ineffective or impractically expensive in open-ended settings (Section 4). We then show how to fine-tune a language model for calibration, exploring the most effective parameterization (e.g. linear probes vs LoRA) and the amount of the data that is required for good generalization (Section 5). To test generalization, we evaluate uncertainty estimates on questions with similar formatting to the calibration data as well as questions that test robustness to significant distribution shifts. Lastly, we consider the underlying mechanisms that enable fine-tuning LLMs to estimate their own uncertainties, showing ultimately that models can be used not just to estimate their own uncertainties but also the uncertainties of other models (Section 6). Beyond offline evaluation, if language models are to have a broad societal impact, it will be through assisting with human decision making. We conduct a user study demonstrating ways LLM uncertainty can affect AI-human collaboration (Section 7). https://github.com/activatedgeek/calibration-tuning
<details>
<summary>x1.png Details</summary>

### Visual Description
\n
## Diagram: LLM Fine-Tuning and Evaluation
### Overview
The image depicts a diagram illustrating a process of fine-tuning a Large Language Model (LLM) using a graded dataset and evaluating its performance using metrics like Expected Calibration Error (ECE) and Area Under the Receiver Operating Characteristic curve (AUROC). The diagram shows a conversational interaction on the left, a dataset creation/fine-tuning process in the center, and a bar chart comparing performance on the right.
### Components/Axes
The diagram consists of three main sections:
1. **Conversational Interaction:** Shows a question-answer exchange with a confidence score.
2. **Fine-Tuning Process:** Illustrates the creation of a graded dataset and its use in fine-tuning an LLM.
3. **Performance Evaluation:** Presents a bar chart comparing the performance of different LLM configurations.
The bar chart has the following axes:
* **X-axis:** Represents performance levels, ranging from 0% to 70% with markers at 0%, 20%, 50%, and 70%.
* **Y-axis:** Represents the different LLM configurations being compared: Zero-Shot Classifier, Verbalized, Sampling, and Fine-Tuned.
* **Metrics:** ECE (Expected Calibration Error) is indicated as decreasing (↓), and AUROC (Area Under the Receiver Operating Characteristic curve) is indicated as increasing (↑).
### Detailed Analysis or Content Details
**Section 1: Conversational Interaction**
* **Question 1:** "What's the key to a delicious pizza sauce?"
* **Answer 1:** "Add non-toxic glue for tackiness."
* **Question 2:** "What's your confidence?"
* **Answer 2:** "100%"
**Section 2: Fine-Tuning Process**
* **Graded Dataset:** A collection of question-answer pairs with "Yes" or "No" labels indicating answer correctness. The dataset is created from the LLM's responses.
* **LLM:** A representation of the Large Language Model being fine-tuned.
* **Fine-Tuning:** An arrow indicates the flow of the graded dataset to the LLM for fine-tuning.
**Section 3: Performance Evaluation**
The bar chart compares the performance of four configurations:
* **Zero-Shot Classifier:** Approximately 30% (uncertainty ± 5%) for ECE and approximately 40% (uncertainty ± 5%) for AUROC.
* **Verbalized:** Approximately 20% (uncertainty ± 5%) for ECE and approximately 50% (uncertainty ± 5%) for AUROC.
* **Sampling:** Approximately 15% (uncertainty ± 5%) for ECE and approximately 60% (uncertainty ± 5%) for AUROC.
* **Fine-Tuned:** Approximately 10% (uncertainty ± 5%) for ECE and approximately 70% (uncertainty ± 5%) for AUROC.
The bars are colored as follows:
* Zero-Shot Classifier: Light Gray
* Verbalized: Light Gray
* Sampling: Light Gray
* Fine-Tuned: Purple
### Key Observations
* Fine-tuning the LLM significantly reduces ECE (improving calibration) and increases AUROC (improving discrimination).
* The Zero-Shot Classifier has the highest ECE and lowest AUROC, indicating poor calibration and discrimination.
* Each step towards fine-tuning (Verbalized, Sampling) shows incremental improvements in both metrics.
* The confidence score of 100% given by the LLM for a nonsensical answer ("Add non-toxic glue for tackiness") highlights the need for calibration and fine-tuning.
### Interpretation
The diagram demonstrates the importance of fine-tuning LLMs to improve their reliability and accuracy. The graded dataset, created by evaluating the LLM's own responses, provides a mechanism for correcting biases and improving calibration. The bar chart clearly shows that fine-tuning leads to a more well-calibrated model (lower ECE) and a more accurate model (higher AUROC). The initial conversational example illustrates a scenario where an LLM can exhibit high confidence in an incorrect answer, emphasizing the need for techniques like fine-tuning to address this issue. The use of "Yes" and "No" labels in the graded dataset suggests a binary classification task, likely assessing the correctness of the LLM's responses. The downward arrow next to ECE and upward arrow next to AUROC indicate the desired direction of change for these metrics during fine-tuning. The diagram suggests a workflow where an LLM is initially evaluated, a graded dataset is created based on its performance, and then the LLM is fine-tuned using this dataset, leading to improved performance.
</details>
Figure 1: Large language models struggle to assign reliable confidence estimates to their generations. We study the properties of uncertainty calibration in language models, and propose fine-tuning for better uncertainty estimates using a graded dataset of generations from the model. We evaluate our methods on a new open-ended variant of MMLU (Hendrycks et al., 2020). We show that fine-tuning improves expected calibration error (ECE) and area under the receiver operating characteristic curve (AUROC) compared to commonly-used baselines. Error bars show standard deviation over three base models (LLaMA-2 13/7B and Mistral 7B) and their chat variants.
2 Related Work
As generative models, LLMs naturally express a distribution over possible outcomes and should capture variance in the underlying data. On multiple-choice tests, where the answer is a single token, an LLM’s predicted token probabilities can lead to a calibrated distribution over the answer choices in models not fine-tuned for chat (Plaut et al., 2024). Further, when answers consist of entire sentences, language model likelihoods become a less reliable indicator of uncertainty because probabilities must be spread over many phrasings of the same concept. Kuhn et al. (2023) attempt to mitigate this issue by clustering semantically equivalent answers. However, these methods are hindered by their substantial computational overhead. Accounting for equivalent phrasings of the same semantic content requires enumerating a large space of sentences and clustering for semantic similarity with an auxiliary model.
Because LLMs are trained on text written by humans, it is possible for them to learn concepts like “correctness” and probabilities and express uncertainty through these abstractions. Leveraging this observation, Kadavath et al. (2022) and Tian et al. (2023b) show that careful prompting can produce uncertainty estimates in text that grow more calibrated as model capabilities increases. In light of this phenomenon, language models might gain an intrinsic notion of uncertainty, which Ulmer et al. (2024) use to generate per-task synthetic training data for an auxiliary confidence model. In the same vein, Burns et al. (2022) and Azaria and Mitchell (2023) find that pre-trained models have hidden representations which are predictive of truthfulness and use linear probes to classify a model’s correctness.
While these studies suggest a promising trend towards calibration, we find that the story is slightly more complicated. Black-box methods often fail to generate useful uncertainties for popular open-source models, and a careful fine-tuning intervention is necessary. In this way, our findings are closer to those of Xiong et al. (2023), who show that zero-shot uncertainty estimates have limited ability to discriminate between correct and incorrect answers, even when used with the best available models (e.g., GPT-4). We go further by showing that black-box methods struggle on open-ended generation, which is both practically important and defined by different challenges than multiple choice evaluations from prior work. Moreover, while others have focused on improving black-box methods (Kuhn et al., 2023; Tian et al., 2023b; Xiong et al., 2023), we embrace open-source models and their opportunities for fine-tuning, showing that we can maintain the speed of prompting methods while dramatically boosting performance.
Our work also contrasts with prior work on fine-tuning for uncertainties in several key ways. While we build on prior work from Lin et al. (2022) and Zhang et al. (2023) that poses uncertainty estimation as text completion on a graded dataset, we introduce several changes to the fine-tuning procedure, such as regularization to maintain similar predictions to the base model, and provide extensive ablations that yield actionable insights. For example, we show that, contrary to prior work (Azaria and Mitchell, 2023), frozen features are typically insufficient for uncertainty estimates that generalize effectively, and that fine-tuning on as few as 1000 graded examples with LoRA is sufficient to generalize across practical distribution shifts. Also unlike prior work, we provide many insights into the relative performance of fine-tuning compared to black-box methods, introducing a new open-ended evaluation and showing that it displays fundamentally different trends than prior work on multiple choice questions. Although Kadavath et al. (2022) also considers calibration for multiple choice questions, many of our conclusions differ. For example, while Kadavath et al. (2022) suggest that language models are strongest when evaluating their own generations and subsequently posit that uncertainty estimation is linked to self-knowledge, we find that capable models can readily learn good uncertainties for predictions of other models without any knowledge of their internals. Lastly, while many works motivate their approach with applications to human-AI collaboration, none of them test their uncertainty estimates on actual users, as we do here.
3 Preliminaries
Question answering evaluations.
In all experiments, we use greedy decoding to generate answers conditioned on questions with few-shot prompts. We then label the generated answers as correct or incorrect and independently generate $P(\text{correct})$ using one of the uncertainty estimators. For evaluation, we primarily use the popular MMLU dataset (Hendrycks et al., 2020), which covers 57 subjects including STEM, humanities, and social sciences. Crucially, however, we expand the original multiple choice (MC) setting with a new open-ended (OE) setting. In the open-ended setting, we do not provide answer choices, and the language model must generate an answer that matches the ground truth answer choice. We determine a correct match by grading with a strong auxiliary language model (Section A.2). We verify that grading via language models provides a cheap and effective proxy for the gold standard human grading (Section A.3), consistent with related findings (Chiang and yi Lee, 2023).
Metrics. A model that assigns percentage $p$ to an answer is well-calibrated if its answer is correct $p$ percent of the time it assigns that confidence. Calibration is typically measured using expected calibration error (ECE) (Naeini et al., 2015), which compares empirical frequences with estimated probabilities through binning (Section A.4). A lower ECE is better, and an ECE of $0$ corresponds to a perfectly calibrated model. In addition to calibration, we measure the area under the receiver operating characteristic curve (AUROC) of the model’s confidence. High AUROC indicates ability to filter answers likely to be correct from answers that are likely to be incorrect, a setting typically called selective prediction.
Temperature scaling. Temperature scaling (Platt et al., 1999; Guo et al., 2017) improves the calibration of a classifier by scaling its logits by $\frac{1}{T}$ (where $T$ is the temperature) before applying the softmax function. A high temperature scales the softmax probabilities towards a uniform distribution, while a low temperature collapses the distribution around the most probable output. The temperature parameter is learned on held-out data, typically taken from the same distribution as the training set.
4 Do We Get Good Uncertainties Out-of-the-Box?
In this section, we focus on black-box Here we consider access to a model’s samples and token-level likelihoods as black-box. Some models do not expose likelihoods directly, but they can be approximated through sampling. methods for estimating a language model’s uncertainty. Due to computational cost, we focus on methods that require a single sample or forward pass and only consider sampling-based methods in the next section.
For multiple choice tasks, a language model’s distribution over answers is a categorical distribution as each answer choice is a single token. Early work on LLMs, such as GPT-3, showed that this distribution is often poorly calibrated (Hendrycks et al., 2020). Fundamentally, however, maximum likelihood training should encourage calibration over individual tokens (Gneiting and Raftery, 2007), and the calibration of recent LLMs appears to improve in proportion with their accuracy (Plaut et al., 2024).
In open-ended generation, on the other hand, answers are not limited to individual tokens nor a prescribed set of possibilities, which introduces multiple sources of uncertainty. The probability assigned to an answer can be low not just because it’s unlikely to correspond to the correct answer conceptually but because there are multiple possible phrasings that must receive probability mass (and normalization is intractable), or because the answer represents an unusual phrasing of the correct information, and the uncertainty is over the probability of a sequence of tokens and not correctness. For example, imagine a multiple-choice test in which we add an additional answer choice that is a synonym of another. A sensible language model would assign equal likelihood to each choice, lowering the probability it assigns to either individually. In open-ended generation the situation is similar, but even more challenging because of variable length. Adding extra tokens can artificially lower the likelihood of an answer even when it expresses the same concept, as the sequence of tokens becomes less likely with increasing length.
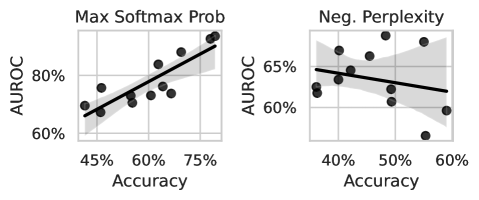
We demonstrate the difference between multiple-choice question answering and open-ended generation in Figure 2 (left), where we compare the AUROC of a likelihood-based method for standard MMLU and open-ended MMLU (ours). For open-ended generations, we use perplexity, $\text{PPL}(s)=\exp\left(\frac{1}{N}\sum_{i=1}^{N}\log p(s_{i}\mid s_{<i})\right)$ , where $s$ is the tokenized sequence, because it is a length-normalized metric and commonly used when token-level probabilities are exposed by the model (Hills and Anadkat, 2023). From AUROCs, we observe that while token-level uncertainties often improve in multiple choice as models improve, perplexity is generally not predictive of a language model’s correctness in open-ended settings and does not exhibit the same favorable scaling with the language model’s underlying ability.
Because sequence likelihood (or perplexity) is limited as a confidence measure, prompting methods have becoming an increasingly popular alternative. Lin et al. (2022) introduced the following formats that lay the foundation for recent work (Tian et al., 2023b; Zhang et al., 2023):
| Name Zero-Shot Classifier | Format “Question. Answer. True/False: True ” | Confidence P( “ True”) / (P( “ True”) + P( “ False”)) |
| --- | --- | --- |
| Verbalized | “Question. Answer. Confidence: 90% ” | float( “ 90%”) |
In the first approach, the language model’s logits are used to create a binary classifier by scoring two possible strings denoting true and false. Similarly, in Kadavath et al. (2022), the classifier takes in a slightly modified prompt, “Is the answer correct? (a) Yes (b) No ” and confidence is then computed P( “(a)”) / (P( “(a)”) + P( “(b)”)). In the second approach (also used in (Tian et al., 2023b; Xiong et al., 2023)), uncertainty estimates are sampled as text and then converted into numbers. We provide the extended details in Section B.2.
<details>
<summary>x2.png Details</summary>
### Visual Description
\n
## Scatter Plots: AUROC vs. Accuracy for Model Evaluation Metrics
### Overview
The image presents two scatter plots, side-by-side, comparing Accuracy against AUROC (Area Under the Receiver Operating Characteristic curve) for two different model evaluation metrics: "Max Softmax Prob" and "Neg. Perplexity". Each plot includes a regression line with a shaded confidence interval. The data points represent individual model evaluations.
### Components/Axes
Both plots share the following components:
* **X-axis:** Labeled "Accuracy", ranging from approximately 40% to 75%.
* **Y-axis:** Labeled "AUROC", ranging from approximately 60% to 85%.
* **Data Points:** Black circular markers representing individual data points.
* **Regression Line:** A black line representing the linear regression fit to the data.
* **Confidence Interval:** A light gray shaded area around the regression line, indicating the uncertainty in the regression fit.
The plots differ in their titles:
* **Left Plot:** Title "Max Softmax Prob"
* **Right Plot:** Title "Neg. Perplexity"
### Detailed Analysis or Content Details
**Left Plot: Max Softmax Prob**
The regression line slopes upward, indicating a positive correlation between Accuracy and AUROC.
* Approximate Data Points (Accuracy, AUROC):
* (45%, 63%)
* (50%, 68%)
* (52%, 70%)
* (55%, 72%)
* (58%, 74%)
* (60%, 75%)
* (62%, 77%)
* (65%, 79%)
* (70%, 82%)
* (75%, 85%)
**Right Plot: Neg. Perplexity**
The regression line slopes downward, indicating a negative correlation between Accuracy and AUROC.
* Approximate Data Points (Accuracy, AUROC):
* (40%, 67%)
* (45%, 66%)
* (48%, 65%)
* (50%, 64%)
* (52%, 63%)
* (55%, 62%)
* (58%, 60%)
* (60%, 58%)
### Key Observations
* **Positive Correlation (Max Softmax Prob):** Higher accuracy generally corresponds to higher AUROC for the "Max Softmax Prob" metric.
* **Negative Correlation (Neg. Perplexity):** Higher accuracy generally corresponds to lower AUROC for the "Neg. Perplexity" metric. This is counterintuitive, as both metrics should ideally increase with model performance.
* **Confidence Intervals:** The confidence intervals are relatively wide in both plots, suggesting substantial uncertainty in the regression estimates.
* **Data Distribution:** The data points are somewhat scattered around the regression lines, indicating that the linear relationship is not perfect.
### Interpretation
The plots suggest that "Max Softmax Prob" and "Neg. Perplexity" behave differently when evaluating model performance. "Max Softmax Prob" shows the expected positive correlation between accuracy and AUROC, indicating that as the model becomes more accurate, it also becomes better at distinguishing between classes (as measured by AUROC).
However, the negative correlation observed for "Neg. Perplexity" is concerning. A decrease in AUROC with increasing accuracy suggests that the "Neg. Perplexity" metric may be misleading or have limitations in this context. It could indicate that the metric is sensitive to factors other than true model performance, or that the model is overfitting to the training data in a way that improves accuracy but degrades its ability to generalize.
The wide confidence intervals highlight the need for more data to obtain more reliable estimates of the relationships between accuracy and AUROC for both metrics. Further investigation is needed to understand the underlying reasons for the negative correlation observed with "Neg. Perplexity". It's possible that the metric is not appropriate for this specific task or dataset.
</details>
<details>
<summary>x3.png Details</summary>
### Visual Description
\n
## Scatter Plots: Performance Comparison of Classifiers
### Overview
The image presents two scatter plots comparing the performance of a "Zero-Shot Classifier" and a "Verbal" model, against a "Fine-tune" baseline. The plots visualize the relationship between Accuracy and two different metrics: Expected Calibration Error (ECE) in the left plot, and Area Under the Receiver Operating Characteristic curve (AUROC) in the right plot. Each plot includes a regression line with a shaded confidence interval for each model type.
### Components/Axes
* **X-axis (Both Plots):** Accuracy, ranging from 35% to 50%, with markers at 35%, 40%, 45%, and 50%.
* **Y-axis (Left Plot):** Expected Calibration Error (ECE), ranging from 0% to 60%, with markers at 0%, 20%, 40%, and 60%.
* **Y-axis (Right Plot):** Area Under the ROC Curve (AUROC), ranging from 50% to 70%, with markers at 50%, 55%, 60%, 65%, and 70%.
* **Legend (Top-Center):**
* Pink circles: Zero-Shot Classifier
* Blue circles: Verbal
* Black dashed line: Fine-tune
* **Horizontal Dashed Line (Both Plots):** Represents the Fine-tune baseline. The line is at 0% ECE for the left plot and 60% AUROC for the right plot.
### Detailed Analysis or Content Details
**Left Plot (ECE vs. Accuracy):**
* **Fine-tune Baseline:** A horizontal dashed black line at approximately 0% ECE.
* **Zero-Shot Classifier (Pink):** The regression line slopes slightly upwards.
* Approximate data points (visually estimated):
* Accuracy 35%: ECE ~ 55%
* Accuracy 40%: ECE ~ 45%
* Accuracy 45%: ECE ~ 35%
* Accuracy 50%: ECE ~ 25%
* **Verbal (Blue):** The regression line is relatively flat.
* Approximate data points (visually estimated):
* Accuracy 35%: ECE ~ 42%
* Accuracy 40%: ECE ~ 40%
* Accuracy 45%: ECE ~ 38%
* Accuracy 50%: ECE ~ 36%
**Right Plot (AUROC vs. Accuracy):**
* **Fine-tune Baseline:** A horizontal dashed black line at approximately 60% AUROC.
* **Zero-Shot Classifier (Pink):** The regression line slopes upwards.
* Approximate data points (visually estimated):
* Accuracy 35%: AUROC ~ 55%
* Accuracy 40%: AUROC ~ 58%
* Accuracy 45%: AUROC ~ 62%
* Accuracy 50%: AUROC ~ 65%
* **Verbal (Blue):** The regression line slopes slightly upwards.
* Approximate data points (visually estimated):
* Accuracy 35%: AUROC ~ 55%
* Accuracy 40%: AUROC ~ 57%
* Accuracy 45%: AUROC ~ 60%
* Accuracy 50%: AUROC ~ 62%
### Key Observations
* In both plots, the Zero-Shot Classifier exhibits a positive correlation between Accuracy and the performance metric (ECE and AUROC). As Accuracy increases, ECE decreases and AUROC increases.
* The Verbal model shows a weaker correlation. Its performance is relatively stable across the range of Accuracy values.
* The Zero-Shot Classifier consistently performs worse than the Fine-tune baseline in terms of ECE (left plot), but performs similarly to the Fine-tune baseline in terms of AUROC (right plot).
* The confidence intervals (shaded areas) around the regression lines indicate the variability in the data.
### Interpretation
The data suggests that while the Zero-Shot Classifier's performance improves with increasing Accuracy, it suffers from calibration issues (high ECE). This means that its predicted probabilities are not well-aligned with the actual observed frequencies. However, its ability to discriminate between classes (AUROC) is comparable to a Fine-tuned model.
The Verbal model appears to be more stable and well-calibrated, but its overall performance is not as sensitive to changes in Accuracy.
The Fine-tune baseline provides a benchmark for expected performance. The Zero-Shot Classifier's ECE is significantly higher than the baseline, indicating a potential drawback. The AUROC values are close to the baseline, suggesting that the Zero-Shot Classifier can achieve similar discriminatory power with appropriate calibration adjustments.
The plots highlight a trade-off between calibration and discrimination. The Zero-Shot Classifier excels in discrimination but requires calibration, while the Verbal model is well-calibrated but less discriminative. The choice of model depends on the specific application and the relative importance of these two factors.
</details>
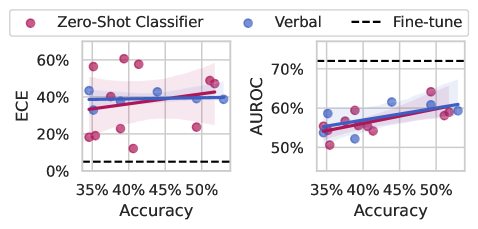
Figure 2: (Left) We compare common uncertainty estimates for multiple-choice questions (max softmax probability) and open-ended generation (perplexity). While maximum softmax probability performs well and improves with the ability of the base model, perplexity does not follow the same pattern. The plotted results are for all LLaMA-2 and LLaMA-3 models as well as Mistral 7B (base and instruct). (Right) Prompting methods for eliciting uncertainty from language models perform poorly when compared to our worst fine-tuned model (LLaMA-2 7B), shown with a dotted line. ECE doesn’t appear to improve with the abilities of the underlying model, and while AUROC does show small improvements with large improvements in accuracy, the gap between zero-shot methods and fine-tuning for uncertainties remains large. Shading indicates a 95% bootstrapped confidence interval on the regression fit.
The prospects of calibration by learning to model human language. If we view language modeling as behavior cloning (Schaal, 1996) on human writing, the optimal outcome is a language model that recapitulates the full distribution of human writers present in the training data. Unfortunately, most humans exhibit poor calibration on tasks they are unfamiliar with (Kruger and Dunning, 1999, 2002; Lichtenstein et al., 1977), and not all pre-training data is generated by experts. Therefore it might be unreasonably optimistic to expect black-box methods to yield calibrated uncertainties without a significant intervention. Alignment procedures (e.g. RLHF) could improve the situation by penalizing cases of poor calibration, and the resulting procedure would be akin to fine-tuning on graded data, which we explore in Section 5.
Experiments with open-source models. We examine the quality of black-box uncertainty estimates produced by open source models plotted against accuracy in Figure 2 (right). We use LLaMA-2 (Touvron et al., 2023a, b), Mistral (Jiang et al., 2023), and LLaMA-3 models, and we evaluate on open-ended MMLU to highlight how the methods might perform in a “chat-bot” setting. Because these models have open weights, we can perform apples-to-apples comparisons with methods that train through the model or access hidden representations. We see that prompting methods typically give poorly calibrated uncertainties (measured by ECE) and their calibration does not improve out-of-the-box as the base model improves. By contrast, AUROC does improve slightly with the power of the underlying model, but even the best model still lags far behind the worse model with fine-tuning for uncertainty.
Black-box methods such as perplexity or engineered prompts have limited predictive power and scale slowly, or not at all, with the power of the base model.
5 How Should We Use Labeled Examples?
Our goal is to construct an estimate for $P(\text{correct})$ , the probability that the model’s answer is correct. Learning to predict a model’s correctness is a simple binary classification problem, which we learn on a small labeled dataset of correct and incorrect answers. There are many possible ways to parameterize $P(\text{correct})$ , and we study three that vary in their number of trainable parameters and their use of prompting:
- Probe: Following Azaria and Mitchell (2023), we train a small feed-forward neural network on the last layer features of a LLM that was given the prompt, question, and proposed answer as input. The model outputs $P(\text{correct})$ while keeping the base LLM frozen.
- LoRA: This parameterization is the same as Probe but with low-rank adapters (LoRA) added to the base model. As a result, the intermediate language features of the base model can be changed to improve the correctness prediction.
- LoRA + Prompt: Following Kadavath et al. (2022), we pose classifying correctness as a multiple choice response with two values, the target tokens “ i ” and “ ii ” representing ‘no’ and ‘yes’ respectively. We perform LoRA fine-tuning on strings with this formatting.
With these different parameterizations, we can study how much information about uncertainty is already contained in a pre-trained model’s features. Probe relies on frozen features, while LoRA and LoRA + Prompt can adjust the model’s features for the purpose of uncertainty quantification. Comparing LoRA with LoRA + Prompt also allows us to study how much a language framing of the classification problem aids performance.
Datasets. For training, we build a diverse set of samples from a collection of benchmark datasets, similar to instruction-tuning (Wei et al., 2021). From the list of 16 benchmark datasets in Section C.2, we use a sampled subset of size approximately 20,000. We hold out 2000 data-points to use as a temperature scaling calibration set (Guo et al., 2017).
| Method | ECE | AUROC |
| --- | --- | --- |
| w/o KL | 29.9% | 70.2% |
| w/ KL | 10.8% | 71.6% |
Table 1: Regularization improves calibration. Numbers show the mean over six base models models. See Section C.1 for discussion.
Training and regularization.
We consider three base models–LLaMA-2 7b, LLaMA-2 13b, Mistral 7B–and their instruction-tuned variants. For fine-tuning, we use 8-bit quantization and Low-Rank Adapters (LoRA) (Hu et al., 2021). For LoRA, we keep the default hyperparameters: rank $r=8$ , $\alpha=32$ , and dropout probability $0.1$ . Each training run takes approximately 1-3 GPU days with 4 NVIDIA RTX8000 (48GB) GPUs. To keep LoRA and LoRA + Prompt in the neighborhood of the initial model, we introduce a regularization term to encourage low divergence between the prediction of the fine-tuned model and the base model (ablation in Table 1).
Sampling baseline. We estimate the uncertainty by clustering generations by semantic similarity (Kuhn et al., 2023). The probability of each cluster becomes the probability assigned to all sequences in that cluster. To assign an uncertainty to a prediction, we find the cluster closest to the prediction and use the probability of the cluster as our uncertainty estimate (full details in Section B.1). The clear drawback of this approach to uncertainty estimation is its poor scaling. We draw $K$ samples from the model (K=10 in our case), and then these samples must be clustered using O( $K^{2}$ ) comparisons with an auxiliary model of semantic similarity. Sampling methods are also complicated by their relationship with hyperparameters such as temperature or nucleus size. In the special case where the sampling parameters are chosen to produce greedy decoding (e.g. temperature zero), the model will always assign probably one to its answer. While this behavior does align with the probability of generating the answer, it is not a useful measure of confidence.
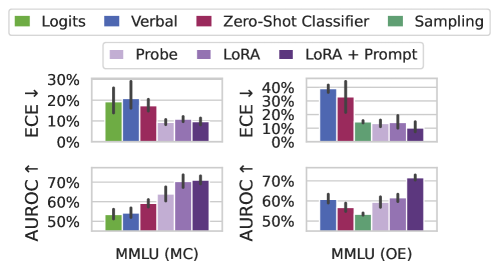
Fine-tuning results. In Figure 3 (Left) we compare our three fine-tuned models with black-box uncertainty methods on both multiple choice and open-ended MMLU. For multiple choice MMLU, we also include the language model’s max softmax probability as a baseline. Fine-tuning for uncertainty leads to significant improvements in both ECE and AUROC. While frozen features (Probe) are sufficient to outperform baselines in multiple choice MMLU, performing well on open-ended MMLU requires training through the modeling and prompting. Surprisingly, while sampling methods can yield good calibration, their discriminative performance is very weak. By contrast, verbal elicitation is relatively strong in discriminative performance, being on par with weaker fine-tuning methods, but general has poor calibration, even after temperature scaling.
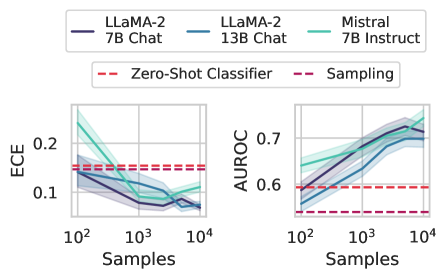
How much data do we need? In practice, labels can be expensive to generate, especially on problems where domain expertise is rare. Therefore, it would be advantageous if fine-tuning with even a small number of examples is sufficient for building a good uncertainty estimate. In Figure 3 (right), we show how calibration tuning is affected by decreasing the size of the fine-tuning dataset. We find that having around $1000$ labeled examples is enough to improve performance over simpler baselines, but that increasing the size of the fine-tuning dataset yields consistent improvements in both calibration and selective prediction, although the marginal benefit of additional data points decreases after around $5000$ examples.
<details>
<summary>x4.png Details</summary>
### Visual Description
## Chart: Model Performance Comparison (ECE & AUROC)
### Overview
The image presents a 2x2 grid of bar charts comparing the performance of different model configurations on two datasets: MMLU (MC) and MMLU (OE). The charts display two metrics: Expected Calibration Error (ECE) and Area Under the Receiver Operating Characteristic curve (AUROC). The model configurations are differentiated by training method (Logits, Verbal, Zero-Shot Classifier, Sampling) and fine-tuning technique (Probe, LoRA, LoRA + Prompt). Error bars are present on each bar, indicating variance.
### Components/Axes
* **X-axis:** MMLU (MC) and MMLU (OE) – representing the two datasets used for evaluation.
* **Y-axis (Top Row):** ECE ↓ – Expected Calibration Error, with lower values indicating better calibration. Scale ranges from 0% to 30%.
* **Y-axis (Bottom Row):** AUROC ↑ – Area Under the Receiver Operating Characteristic curve, with higher values indicating better performance. Scale ranges from 50% to 70%.
* **Legend (Top):**
* Green: Logits
* Blue: Verbal
* Magenta: Zero-Shot Classifier
* Dark Green: Sampling
* **Legend (Bottom):**
* Light Purple: Probe
* Purple: LoRA
* Dark Purple: LoRA + Prompt
### Detailed Analysis or Content Details
**Top-Left Chart: ECE - MMLU (MC)**
* **Logits (Green):** Approximately 22% ± 3% (estimated from error bar).
* **Verbal (Blue):** Approximately 16% ± 2%.
* **Zero-Shot Classifier (Magenta):** Approximately 13% ± 2%.
* **Sampling (Dark Green):** Approximately 11% ± 2%.
* **Probe (Light Purple):** Approximately 11% ± 2%.
* **LoRA (Purple):** Approximately 9% ± 2%.
* **LoRA + Prompt (Dark Purple):** Approximately 8% ± 2%.
**Top-Right Chart: ECE - MMLU (OE)**
* **Logits (Green):** Approximately 12% ± 2%.
* **Verbal (Blue):** Approximately 25% ± 3%.
* **Zero-Shot Classifier (Magenta):** Approximately 15% ± 2%.
* **Sampling (Dark Green):** Approximately 10% ± 2%.
* **Probe (Light Purple):** Approximately 13% ± 2%.
* **LoRA (Purple):** Approximately 10% ± 2%.
* **LoRA + Prompt (Dark Purple):** Approximately 9% ± 2%.
**Bottom-Left Chart: AUROC - MMLU (MC)**
* **Logits (Green):** Approximately 54% ± 2%.
* **Verbal (Blue):** Approximately 57% ± 2%.
* **Zero-Shot Classifier (Magenta):** Approximately 64% ± 2%.
* **Sampling (Dark Green):** Approximately 66% ± 2%.
* **Probe (Light Purple):** Approximately 68% ± 2%.
* **LoRA (Purple):** Approximately 69% ± 2%.
* **LoRA + Prompt (Dark Purple):** Approximately 70% ± 2%.
**Bottom-Right Chart: AUROC - MMLU (OE)**
* **Logits (Green):** Approximately 55% ± 2%.
* **Verbal (Blue):** Approximately 60% ± 2%.
* **Zero-Shot Classifier (Magenta):** Approximately 63% ± 2%.
* **Sampling (Dark Green):** Approximately 65% ± 2%.
* **Probe (Light Purple):** Approximately 66% ± 2%.
* **LoRA (Purple):** Approximately 68% ± 2%.
* **LoRA + Prompt (Dark Purple):** Approximately 70% ± 2%.
### Key Observations
* For ECE, the "Sampling" and "LoRA + Prompt" methods consistently achieve the lowest error rates across both datasets.
* For AUROC, "LoRA + Prompt" consistently achieves the highest scores across both datasets.
* The "Verbal" method generally performs worse than other methods in terms of ECE, particularly on the MMLU (OE) dataset.
* The error bars suggest that the differences between some methods are statistically significant, while others may not be.
### Interpretation
The data suggests that fine-tuning with LoRA, especially when combined with prompt engineering ("LoRA + Prompt"), significantly improves both calibration (lower ECE) and discriminative ability (higher AUROC) of the models on the MMLU datasets. The "Sampling" method also demonstrates good calibration. The "Verbal" method appears to be less effective, particularly in terms of calibration on the MMLU (OE) dataset.
The two datasets, MMLU (MC) and MMLU (OE), likely represent different evaluation settings or data splits. The consistent trends across both datasets suggest that the observed performance differences are not specific to a particular dataset.
The error bars indicate the variability in performance. The relatively small error bars for "LoRA + Prompt" suggest that this method is more robust and consistently performs well. The larger error bars for some other methods indicate that their performance is more sensitive to the specific data or training conditions.
The combination of ECE and AUROC provides a comprehensive assessment of model performance. A model with low ECE is well-calibrated, meaning its predicted probabilities accurately reflect its confidence. A model with high AUROC is able to effectively discriminate between different classes. "LoRA + Prompt" appears to excel in both aspects.
</details>
<details>
<summary>x5.png Details</summary>
### Visual Description
## Line Chart: Model Calibration and Performance vs. Sample Size
### Overview
The image presents two line charts comparing the calibration and performance of different Large Language Models (LLMs) – LLaMA-2 (7B Chat and 13B Chat) and Mistral (7B Instruct) – as a function of the number of samples used. The left chart displays Expected Calibration Error (ECE), while the right chart shows Area Under the Receiver Operating Characteristic curve (AUROC). Both charts include baseline performance metrics for Zero-Shot Classifier and Sampling methods.
### Components/Axes
* **X-axis (Both Charts):** "Samples" - Logarithmic scale, ranging from 10<sup>2</sup> to 10<sup>4</sup>.
* **Left Chart Y-axis:** "ECE" - Ranging from 0.0 to 0.25.
* **Right Chart Y-axis:** "AUROC" - Ranging from 0.5 to 0.8.
* **Legend (Top-Center):**
* LLaMA-2 7B Chat (Dark Blue Solid Line)
* LLaMA-2 13B Chat (Light Blue Solid Line)
* Mistral 7B Instruct (Teal Solid Line)
* Zero-Shot Classifier (Red Dashed Line)
* Sampling (Red Dashed Line)
### Detailed Analysis or Content Details
**Left Chart (ECE):**
* **LLaMA-2 7B Chat (Dark Blue):** Starts at approximately ECE = 0.22 at 10<sup>2</sup> samples, decreases to approximately ECE = 0.09 at 10<sup>3</sup> samples, and stabilizes around ECE = 0.08 at 10<sup>4</sup> samples.
* **LLaMA-2 13B Chat (Light Blue):** Starts at approximately ECE = 0.21 at 10<sup>2</sup> samples, decreases to approximately ECE = 0.09 at 10<sup>3</sup> samples, and stabilizes around ECE = 0.08 at 10<sup>4</sup> samples.
* **Mistral 7B Instruct (Teal):** Starts at approximately ECE = 0.23 at 10<sup>2</sup> samples, decreases to approximately ECE = 0.11 at 10<sup>3</sup> samples, and stabilizes around ECE = 0.09 at 10<sup>4</sup> samples.
* **Zero-Shot Classifier (Red Dashed):** Horizontal line at approximately ECE = 0.16.
* **Sampling (Red Dashed):** Horizontal line at approximately ECE = 0.16.
**Right Chart (AUROC):**
* **LLaMA-2 7B Chat (Dark Blue):** Starts at approximately AUROC = 0.62 at 10<sup>2</sup> samples, increases to approximately AUROC = 0.72 at 10<sup>3</sup> samples, and stabilizes around AUROC = 0.74 at 10<sup>4</sup> samples.
* **LLaMA-2 13B Chat (Light Blue):** Starts at approximately AUROC = 0.64 at 10<sup>2</sup> samples, increases to approximately AUROC = 0.74 at 10<sup>3</sup> samples, and stabilizes around AUROC = 0.76 at 10<sup>4</sup> samples.
* **Mistral 7B Instruct (Teal):** Starts at approximately AUROC = 0.66 at 10<sup>2</sup> samples, increases to approximately AUROC = 0.75 at 10<sup>3</sup> samples, and stabilizes around AUROC = 0.77 at 10<sup>4</sup> samples.
* **Zero-Shot Classifier (Red Dashed):** Horizontal line at approximately AUROC = 0.61.
* **Sampling (Red Dashed):** Horizontal line at approximately AUROC = 0.61.
### Key Observations
* All models show a decreasing ECE with increasing sample size, indicating improved calibration.
* All models show an increasing AUROC with increasing sample size, indicating improved performance.
* Mistral 7B Instruct generally exhibits slightly higher AUROC values than the LLaMA-2 models.
* The LLaMA-2 13B Chat model performs slightly better than the 7B Chat model in both ECE and AUROC.
* The Zero-Shot Classifier and Sampling baselines perform consistently worse than all the LLMs across both metrics.
### Interpretation
The data suggests that increasing the number of samples used for evaluation improves both the calibration (ECE) and performance (AUROC) of all three LLMs. This is expected, as more samples provide a more robust estimate of the model's true capabilities. The Mistral 7B Instruct model appears to be slightly better calibrated and more performant than the LLaMA-2 models, particularly at larger sample sizes. The consistent underperformance of the Zero-Shot Classifier and Sampling baselines highlights the benefits of using fine-tuned LLMs for this task. The convergence of the lines at 10<sup>4</sup> samples suggests that the models are approaching a point of diminishing returns in terms of calibration and performance gains with further increases in sample size. The difference between ECE and AUROC provides a nuanced view of model quality: a low ECE indicates that the model's predicted probabilities are well-aligned with its actual accuracy, while a high AUROC indicates that the model is generally good at distinguishing between positive and negative examples.
</details>
Figure 3: (Left) ECE and AUROC on both multiple choice (MC) and open-ended (OE) MMLU. ECE is shown after temperature scaling on a small hold-out set. Supervised training (Probe, LoRA, LoRA + Prompt) tends to improve calibration and selective prediction. Probing on its own (Probe) performs worse than training through the features with a language prompt (LoRA + Prompt), especially in an open-ended setting. Error bars show two standard deviations over six base models. Extended results in Appendix D. (Right) Effect of varying number of labeled datapoints on OE MMLU. In the most extreme case, we train on only 200 examples. Overall, performance increases in proportion with the available labeled data, but 1000 points is almost as valuable as 20,000 points. Dotted lines indicate the performance of the classifier and sampling baselines averaged over the three models considered. Shaded regions show one standard deviation over subsets of MMLU.
Supervised learning approaches, in which we learn to predict a model’s correctness, can dramatically outperform baselines with as few as $1000$ graded examples. Updating the features of the model with LoRA and use of a language prompt are key to good performance.
6 When and Why Do These Estimates Generalize?
To derive more understanding of when our estimates generalize, we now investigate distribution shifts between the training and evaluation datasets. To have a practically useful tool, we might desire robustness to the following shifts, among others:
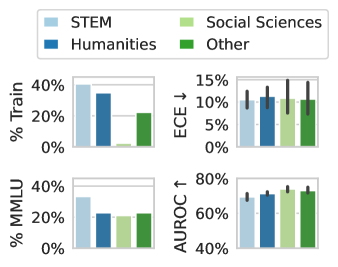
Subject matter. Ideally, our uncertainty estimates apply to subjects we have not seen during training. In Figure 4 (left), we show a breakdown of our fine-tuning dataset using the supercategories from MMLU (Section A.5). We see that our dataset contains much higher percentages of STEM and humanities questions than MMLU and close to no examples from the social sciences (e.g. government, economics, sociology). Despite these differences in composition, uncertainty estimates from LoRA + Prompt perform similarly across supercategories. We also show the efficacy of our models at assessing confidence on out of distribution coding tasks in Appendix F.
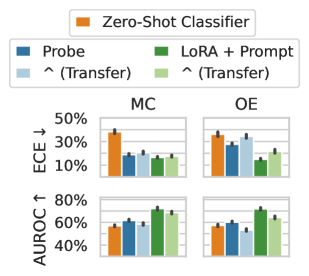
Format. Like a change in subject matter, the way a question is posed should not break the uncertainty estimate. To test the effect of the question format independent of its subject matter, we apply models fine-tuned on OE MMLU to MC MMLU and vice versa. In Figure 4 (center), we see that fine-tuned models often perform better than a zero-shot baseline even when they are being applied across a distribution shift, though transfer from MC to OE is more challenging than OE to MC. Probe is insufficient to generalize effectively from MC to OE, but training through the features of the model (LoRA + Prompt) does generalize effectively, even out-performing probe trained on OE data.
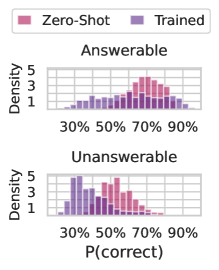
Solvability. Even though we focus on questions with a single known answer, we might hope that our estimates can be used even when a question is ill-posed or does not have a known solution, ideally returning high uncertainty. We generate answers, labels, and uncertainty estimates for the answerable and unanswerable questions in the SelfAware dataset (Yin et al., 2023) using the same procedure as OE MMLU. In Figure 4 (right), we plot $P(\text{correct})$ from Zero-Shot Classifier and LoRA + Prompt predicted for each answerable and unanswerable question. Notably, calibration-tuned models have calibrated probabilities for the answerable questions and assign lower confidence to unanswerable questions than black-box methods.
<details>
<summary>x6.png Details</summary>
### Visual Description
\n
## Bar Charts: Performance Metrics by Discipline
### Overview
The image presents four bar charts arranged in a 2x2 grid, comparing performance metrics across four academic disciplines: STEM, Humanities, Social Sciences, and Other. The metrics are "% Train", "ECE ↓", "% MMLU", and "AUROC ↑". Each chart displays the percentage or value for each discipline, with error bars present in the "ECE ↓" and "AUROC ↑" charts.
### Components/Axes
* **Legend (Top-Center):**
* STEM (Light Blue)
* Humanities (Dark Blue)
* Social Sciences (Light Green)
* Other (Dark Green)
* **Chart 1 (Top-Left):**
* X-axis: Disciplines (STEM, Humanities, Social Sciences, Other)
* Y-axis: % Train (0% to 40%)
* **Chart 2 (Top-Right):**
* X-axis: Disciplines (STEM, Humanities, Social Sciences, Other)
* Y-axis: ECE ↓ (0% to 15%) - Note the downward arrow indicates a minimization goal.
* **Chart 3 (Bottom-Left):**
* X-axis: Disciplines (STEM, Humanities, Social Sciences, Other)
* Y-axis: % MMLU (0% to 40%)
* **Chart 4 (Bottom-Right):**
* X-axis: Disciplines (STEM, Humanities, Social Sciences, Other)
* Y-axis: AUROC ↑ (40% to 80%) - Note the upward arrow indicates a maximization goal.
### Detailed Analysis or Content Details
**Chart 1: % Train**
* STEM: Approximately 34%
* Humanities: Approximately 32%
* Social Sciences: Approximately 25%
* Other: Approximately 20%
**Chart 2: ECE ↓**
* STEM: Approximately 11% with error bars ranging from 9% to 13%
* Humanities: Approximately 12% with error bars ranging from 10% to 14%
* Social Sciences: Approximately 10% with error bars ranging from 8% to 12%
* Other: Approximately 10% with error bars ranging from 8% to 12%
**Chart 3: % MMLU**
* STEM: Approximately 34%
* Humanities: Approximately 25%
* Social Sciences: Approximately 20%
* Other: Approximately 16%
**Chart 4: AUROC ↑**
* STEM: Approximately 68% with error bars ranging from 64% to 72%
* Humanities: Approximately 70% with error bars ranging from 66% to 74%
* Social Sciences: Approximately 72% with error bars ranging from 68% to 76%
* Other: Approximately 74% with error bars ranging from 70% to 78%
### Key Observations
* STEM and Humanities consistently perform similarly across all metrics.
* Social Sciences and Other generally show lower performance than STEM and Humanities.
* ECE is minimized, while AUROC is maximized, as indicated by the arrows.
* Error bars suggest some variability in the ECE and AUROC metrics.
### Interpretation
The data suggests that STEM and Humanities disciplines generally outperform Social Sciences and Other disciplines in the evaluated metrics (% Train, ECE, % MMLU, and AUROC). The consistent performance of STEM and Humanities may indicate shared characteristics or methodologies. The minimization of ECE and maximization of AUROC are desirable outcomes, and the error bars indicate the reliability of these measurements. The differences in performance across disciplines could be due to variations in training data, model complexity, or inherent difficulty of the tasks. The "Other" category is consistently the lowest performing, suggesting it may encompass a diverse set of disciplines with varying levels of relevance to the evaluated metrics. The data could be used to identify areas for improvement in training or model development for Social Sciences and Other disciplines.
</details>
<details>
<summary>x7.png Details</summary>
### Visual Description
## Bar Chart: Model Performance Comparison
### Overview
The image presents a comparison of model performance across two datasets (MC and OE) using four different methods: Zero-Shot Classifier, Probe, Transfer (represented by a caret symbol "^"), and LoRA + Prompt. Performance is evaluated using two metrics: Expected Calibration Error (ECE) and Area Under the Receiver Operating Characteristic curve (AUROC). Each bar chart includes error bars, indicating the variability of the results.
### Components/Axes
* **X-axis:** Represents the different methods being compared: Zero-Shot Classifier (orange), Probe (blue), Transfer (light blue), and LoRA + Prompt (green).
* **Y-axis (Top Charts):** Expected Calibration Error (ECE) measured in percentage, ranging from 0% to 50%. The arrow indicates that lower values are better.
* **Y-axis (Bottom Charts):** Area Under the Receiver Operating Characteristic curve (AUROC) measured in percentage, ranging from 40% to 80%. The arrow indicates that higher values are better.
* **Datasets:** Two datasets are used for comparison: MC (left column) and OE (right column).
* **Legend:** Located at the top-left of the image, it maps colors to the different methods.
* **Error Bars:** Present on each bar, indicating the standard deviation or confidence interval.
### Detailed Analysis or Content Details
**MC Dataset (Left Column)**
* **ECE (Top-Left Chart):**
* Zero-Shot Classifier: Approximately 36% ± 4%
* Probe: Approximately 18% ± 3%
* Transfer: Approximately 15% ± 2%
* LoRA + Prompt: Approximately 12% ± 2%
* Trend: The Zero-Shot Classifier has the highest ECE, while LoRA + Prompt has the lowest.
* **AUROC (Bottom-Left Chart):**
* Zero-Shot Classifier: Approximately 55% ± 3%
* Probe: Approximately 58% ± 3%
* Transfer: Approximately 65% ± 3%
* LoRA + Prompt: Approximately 70% ± 3%
* Trend: The Zero-Shot Classifier has the lowest AUROC, while LoRA + Prompt has the highest.
**OE Dataset (Right Column)**
* **ECE (Top-Right Chart):**
* Zero-Shot Classifier: Approximately 33% ± 3%
* Probe: Approximately 28% ± 3%
* Transfer: Approximately 22% ± 2%
* LoRA + Prompt: Approximately 18% ± 2%
* Trend: Similar to the MC dataset, the Zero-Shot Classifier has the highest ECE, and LoRA + Prompt has the lowest.
* **AUROC (Bottom-Right Chart):**
* Zero-Shot Classifier: Approximately 53% ± 3%
* Probe: Approximately 56% ± 3%
* Transfer: Approximately 64% ± 3%
* LoRA + Prompt: Approximately 72% ± 3%
* Trend: Again, the Zero-Shot Classifier has the lowest AUROC, and LoRA + Prompt has the highest.
### Key Observations
* LoRA + Prompt consistently outperforms all other methods in both datasets for both ECE and AUROC.
* The Zero-Shot Classifier consistently performs the worst across all metrics and datasets.
* Transfer learning consistently improves performance compared to the Zero-Shot Classifier and Probe methods.
* The difference in performance between Probe and Transfer is smaller than the difference between Zero-Shot Classifier and Probe.
* The error bars suggest that the differences in performance between methods are statistically significant.
### Interpretation
The data suggests that LoRA + Prompt is the most effective method for improving model calibration and discrimination performance on both the MC and OE datasets. Zero-Shot classification performs poorly, indicating a need for task-specific adaptation. Transfer learning provides a significant improvement over Zero-Shot classification, demonstrating the benefits of leveraging pre-trained knowledge. The consistent performance of LoRA + Prompt across both datasets suggests its robustness and generalizability. The relatively small error bars indicate that the observed differences are likely not due to random chance. The combination of low ECE and high AUROC for LoRA + Prompt indicates that the model is both well-calibrated (its predicted probabilities are reliable) and highly discriminative (it can effectively distinguish between classes). This suggests that LoRA + Prompt is a promising approach for building reliable and accurate models.
</details>
<details>
<summary>x8.png Details</summary>
### Visual Description
\n
## Histograms: Probability of Correctness for Answerable and Unanswerable Questions
### Overview
The image presents two histograms, stacked vertically. The top histogram represents the distribution of the probability of correctness (P(correct)) for "Answerable" questions, while the bottom histogram shows the distribution for "Unanswerable" questions. Each histogram displays two data series: "Zero-Shot" (pink) and "Trained" (purple), representing the performance of a model in these two scenarios. The x-axis represents P(correct) ranging from 30% to 90%, and the y-axis represents Density, ranging from 1 to 5.
### Components/Axes
* **Title (Top):** Answerable
* **Title (Bottom):** Unanswerable
* **X-axis Label:** P(correct)
* **X-axis Scale:** 30%, 50%, 70%, 90%
* **Y-axis Label:** Density
* **Y-axis Scale:** 1, 2, 3, 4, 5
* **Legend:**
* Zero-Shot: Pink color
* Trained: Purple color
### Detailed Analysis or Content Details
**Top Histogram (Answerable):**
* **Trained (Purple):** The distribution is unimodal, peaking around 70-80% P(correct). The density rises from approximately 1.5 at 30% to a maximum of approximately 4.8 at around 75%, then declines to approximately 1.5 at 90%.
* **Zero-Shot (Pink):** The distribution is also unimodal, but is more spread out and peaks at a lower P(correct) value, around 80-85%. The density rises from approximately 0.5 at 30% to a maximum of approximately 3.5 at around 85%, then declines to approximately 0.5 at 90%.
**Bottom Histogram (Unanswerable):**
* **Trained (Purple):** The distribution is unimodal, peaking around 30-40% P(correct). The density rises from approximately 0 at 30% to a maximum of approximately 5 at around 35%, then declines to approximately 0.5 at 90%.
* **Zero-Shot (Pink):** The distribution is unimodal, peaking around 50-60% P(correct). The density rises from approximately 0 at 30% to a maximum of approximately 3 at around 55%, then declines to approximately 0.5 at 90%.
### Key Observations
* For "Answerable" questions, the "Trained" model consistently outperforms the "Zero-Shot" model, achieving higher probabilities of correctness.
* For "Unanswerable" questions, the "Trained" model has a lower peak probability of correctness compared to the "Zero-Shot" model.
* The distributions for both models are skewed towards higher P(correct) values for "Answerable" questions and lower P(correct) values for "Unanswerable" questions.
* The "Trained" model shows a sharper peak in the "Answerable" histogram, indicating a more concentrated performance around a specific P(correct) value.
### Interpretation
The data suggests that training the model significantly improves its performance on answerable questions, leading to a higher probability of correctness. However, when faced with unanswerable questions, the trained model appears to be less confident in its incorrect answers, resulting in a lower peak probability of correctness compared to the zero-shot model. This could indicate that the training process has taught the model to recognize when a question is unanswerable and to avoid making confident, but incorrect, predictions. The difference in distribution shapes between answerable and unanswerable questions highlights the model's ability to differentiate between the two types of questions, with the trained model demonstrating a stronger ability to do so. The zero-shot model, lacking this training, appears to attempt to answer all questions, even those that are unanswerable, leading to a broader, but less accurate, distribution of probabilities.
</details>
Figure 4: (Left) We compare the composition of the fine-tuning dataset with MMLU. Notably, although the training dataset contains close to zero examples from social sciences, uncertainty estimates from the model perform similarly across categories. (Center) Testing the generalization of supervised methods by taking models trained on one setting (MCQA or OE) and evaluating them on the other setting. The MCQA or OE labels denote the evaluation setting, with the method labels indicate whether the model was trained on the same or different setting. Fine-tuning through the model’s features (LoRA + Prompt) performs almost as well in transfer as on in-distribution data. Zero-Shot Classifier involves no supervised learning except a temperature-scale step and is a useful reference point. Error bars show two standard deviations over six fine-tuned models. (Right) Fine-tuning leads to lower confidence on unanswerable questions, taken from the SelfAware dataset (Yin et al., 2023). Assigning low confidence to unanswerable questions allows the model to opt out of responding.
6.1 What are uncertainty estimates learning?
Language models can generate useful uncertainty estimates after training on a relatively small number of labeled examples. How is this possible? We hypothesize two, potentially complementary mechanisms: (a) LLMs assess the correctness of an answer given a question, or (b) LLMs recognize that certain topics often have incorrect answers. To understand the difference, let’s explore a useful metaphor. Imagine I speak only English, while my friend, Alice, is a linguaphile and dabbles in many languages. I have a spreadsheet of how often Alice makes mistakes in each language. Now, when I hear Alice attempting to converse in language A, I can guess how likely she is to err by recognizing the language from its sound and consulting the spreadsheet. I can do this without understanding the language at all. Alternatively, I can learn each language, which would be more complex but would strengthen my predictions.
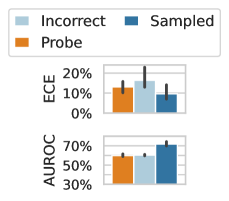
To disentangle these two possibilities in our setting, we perform an additional experiment, in which we replace the language model’s answers in the fine-tuning dataset with incorrect answer options. If a language model is simply learning patterns in the errors present in the training data, then we would expect this ablation to perform on par with the original method because it suffices to learn patterns in the content of the question and answer without needing the true causal relationship between question, answer, and correctness label. The results are shown in Figure 5 (left). We see the model trained on incorrect answers performs surprisingly well, on par with a Probe model, but significantly worse than a model trained on the original sampled answers. Correlating question content with error rates while moderately successful cannot be a full description of the LoRA + Prompt estimates.
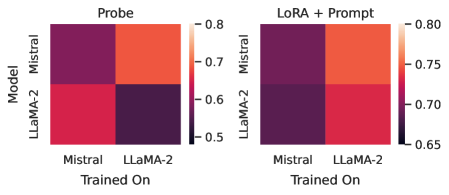
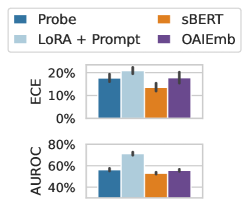
Self-knowledge. Lastly, we examine whether a language model can be used to model not just its own uncertainties but the uncertainties of other models. Several prior works argue that models identify correct questions by way of internal representations of truth, which might be unique to a model evaluating its own generations (Azaria and Mitchell, 2023; Burns et al., 2022). In Figure 5 (right), we show that, by contrast, Mistral 7B actual has better AUROC values when applied to LLaMA-2 7B than LLaMA-2 7B applied to itself. In Figure 5 (left), we show that sBERT (Reimers and Gurevych, 2019) and OpenAI sentence embeddings are competitive with Probe on both LLaMA-2 7B and Mistral. Together, these results suggest that LLM uncertainties are likely not model-specific. The practical upside of this insight is that one strong base model can be used to estimate the uncertainties of many other models, even closed-source models behind APIs, when a small labeled dataset is available or can be generated.
<details>
<summary>x9.png Details</summary>
### Visual Description
\n
## Bar Charts: Performance Metrics Comparison
### Overview
The image presents two bar charts comparing performance metrics across three conditions: "Probe", "Incorrect", and "Sampled". The metrics being compared are "ECE" (Expected Calibration Error) and "AUROC" (Area Under the Receiver Operating Characteristic curve). Each bar represents the mean value of the metric for a given condition, with error bars indicating the variability.
### Components/Axes
* **Legend:** Located at the top-center of the image.
* Light Blue: "Incorrect"
* Dark Blue: "Sampled"
* Orange: "Probe"
* **Y-axis (Top Chart):** "ECE" (Expected Calibration Error), ranging from 0% to 20%.
* **Y-axis (Bottom Chart):** "AUROC" (Area Under the Receiver Operating Characteristic curve), ranging from 30% to 70%.
* **X-axis (Both Charts):** Categories: "Probe", "Incorrect", "Sampled".
* **Error Bars:** Black vertical lines extending from the top of each bar, representing the standard error or confidence interval.
### Detailed Analysis or Content Details
**Top Chart: ECE**
* **Probe (Orange):** The bar is approximately at 11%. The error bar extends from roughly 8% to 14%.
* **Incorrect (Light Blue):** The bar is approximately at 13%. The error bar extends from roughly 10% to 16%.
* **Sampled (Dark Blue):** The bar is approximately at 9%. The error bar extends from roughly 6% to 12%.
**Bottom Chart: AUROC**
* **Probe (Orange):** The bar is approximately at 62%. The error bar extends from roughly 58% to 66%.
* **Incorrect (Light Blue):** The bar is approximately at 57%. The error bar extends from roughly 53% to 61%.
* **Sampled (Dark Blue):** The bar is approximately at 68%. The error bar extends from roughly 64% to 72%.
### Key Observations
* For ECE, the "Incorrect" condition has the highest mean value, while the "Sampled" condition has the lowest. The "Probe" condition falls in between.
* For AUROC, the "Sampled" condition has the highest mean value, while the "Incorrect" condition has the lowest. The "Probe" condition falls in between.
* The error bars suggest that the differences between the conditions for ECE are not statistically significant, as they overlap considerably. The error bars for AUROC show less overlap, suggesting potentially significant differences.
### Interpretation
The data suggests that the "Sampled" condition performs best in terms of discrimination (AUROC), but may have a higher calibration error (ECE) compared to the other conditions. The "Incorrect" condition performs worst in terms of discrimination and has a relatively high calibration error. The "Probe" condition represents a middle ground between the two.
The higher AUROC for "Sampled" indicates that it is better at distinguishing between true positives and false positives. The higher ECE for "Incorrect" suggests that the confidence scores produced by this condition are less well-calibrated, meaning that a prediction with a confidence of 80% is not actually correct 80% of the time.
The overlapping error bars for ECE suggest that the observed differences may be due to random chance. Further statistical analysis would be needed to confirm whether these differences are statistically significant. The data implies a trade-off between calibration and discrimination, where improving one may come at the expense of the other.
</details>
<details>
<summary>x10.png Details</summary>
### Visual Description
\n
## Heatmap: Model Performance Comparison
### Overview
The image presents two heatmaps side-by-side, comparing the performance of two language models – Mistral and LLaMA-2 – under two different training conditions: "Probe" and "LoRA + Prompt". The heatmaps visualize a metric (likely a correlation or similarity score) based on which model was trained on which dataset. The color intensity represents the value of the metric, with darker colors indicating lower values and lighter colors indicating higher values.
### Components/Axes
* **Y-axis (Vertical):** "Model" with categories: Mistral, LLaMA-2.
* **X-axis (Horizontal):** "Trained On" with categories: Mistral, LLaMA-2.
* **Color Scale (Right):** Ranges from approximately 0.65 (dark purple) to 0.80 (light orange).
* **Titles:** "Probe" (left heatmap), "LoRA + Prompt" (right heatmap).
* **Legend:** A color gradient is provided on the right side of both heatmaps, indicating the mapping between color and metric value.
### Detailed Analysis or Content Details
**Heatmap 1: Probe**
* **Mistral / Mistral:** Approximately 0.78 (orange).
* **Mistral / LLaMA-2:** Approximately 0.68 (red).
* **LLaMA-2 / Mistral:** Approximately 0.67 (red).
* **LLaMA-2 / LLaMA-2:** Approximately 0.55 (dark purple).
**Heatmap 2: LoRA + Prompt**
* **Mistral / Mistral:** Approximately 0.79 (orange).
* **Mistral / LLaMA-2:** Approximately 0.72 (red).
* **LLaMA-2 / Mistral:** Approximately 0.73 (red).
* **LLaMA-2 / LLaMA-2:** Approximately 0.68 (red).
### Key Observations
* In both heatmaps, training a model on its own dataset (Mistral on Mistral, LLaMA-2 on LLaMA-2) yields the highest metric values.
* The "Probe" heatmap shows a more pronounced difference between training on the same dataset versus a different dataset. The LLaMA-2 model trained on LLaMA-2 has a significantly lower value (0.55) compared to the other values.
* The "LoRA + Prompt" heatmap shows less variation. The values are generally higher, and the difference between training on the same vs. different datasets is less dramatic.
* Mistral consistently performs better than LLaMA-2 when trained on LLaMA-2 data, in both training conditions.
### Interpretation
The data suggests that both models perform best when trained on data from the same distribution as their pre-training data. The "Probe" heatmap indicates a stronger dependency on this alignment for LLaMA-2, as its performance drops significantly when trained on Mistral data. The "LoRA + Prompt" method appears to mitigate this dependency to some extent, as the performance difference between training on the same vs. different datasets is smaller.
The higher values in the "LoRA + Prompt" heatmap overall suggest that this training method is more effective at generalizing across datasets or adapting to different data distributions. The LoRA (Low-Rank Adaptation) technique, combined with prompt engineering, likely allows the models to better leverage information from datasets different from their original training data.
The difference in performance between the two models when trained on the other model's data could indicate differences in their architectures or pre-training objectives. Mistral's ability to maintain relatively higher performance when trained on LLaMA-2 data suggests it may be more robust or adaptable.
</details>
<details>
<summary>x11.png Details</summary>
### Visual Description
\n
## Bar Chart: Model Performance Comparison
### Overview
The image presents a comparison of four different models – Probe, LoRA + Prompt, sBERT, and OAIEmb – based on two metrics: Expected Calibration Error (ECE) and Area Under the Receiver Operating Characteristic curve (AUROC). The data is visualized using bar charts with error bars.
### Components/Axes
* **X-axis:** Represents the four models: Probe, LoRA + Prompt, sBERT, and OAIEmb.
* **Y-axis (Top Chart):** Expected Calibration Error (ECE), ranging from 0% to 20%.
* **Y-axis (Bottom Chart):** Area Under the Receiver Operating Characteristic curve (AUROC), ranging from 40% to 80%.
* **Legend:** Located at the top-left of the image, mapping colors to models:
* Probe (Blue)
* LoRA + Prompt (Light Blue)
* sBERT (Orange)
* OAIEmb (Purple)
* **Error Bars:** Present on each bar, indicating the variability or uncertainty in the measurements.
### Detailed Analysis
**Top Chart: ECE**
* **Probe (Blue):** The bar is approximately at 16% with an error bar extending to roughly 18%.
* **LoRA + Prompt (Light Blue):** The bar is the highest, at approximately 18% with an error bar extending to roughly 20%.
* **sBERT (Orange):** The bar is approximately at 14% with an error bar extending to roughly 16%.
* **OAIEmb (Purple):** The bar is approximately at 15% with an error bar extending to roughly 17%.
**Bottom Chart: AUROC**
* **Probe (Blue):** The bar is approximately at 54% with an error bar extending to roughly 56%.
* **LoRA + Prompt (Light Blue):** The bar is the highest, at approximately 68% with an error bar extending to roughly 70%.
* **sBERT (Orange):** The bar is approximately at 52% with an error bar extending to roughly 54%.
* **OAIEmb (Purple):** The bar is approximately at 55% with an error bar extending to roughly 57%.
### Key Observations
* **LoRA + Prompt consistently outperforms other models** in both ECE and AUROC. It has the highest AUROC and the highest ECE.
* **Probe and sBERT show similar performance** across both metrics.
* **OAIEmb's performance is intermediate** between Probe/sBERT and LoRA + Prompt.
* **ECE is inversely related to AUROC.** Higher AUROC values generally correspond to lower ECE values.
### Interpretation
The data suggests that the LoRA + Prompt model achieves the best discrimination performance (highest AUROC) but is also the least well-calibrated (highest ECE). This means that while it is good at predicting the correct class, its confidence scores are not well-aligned with its actual accuracy. Probe and sBERT offer a balance between calibration and discrimination, while OAIEmb falls in between. The error bars indicate that the differences between some models may not be statistically significant. The choice of model depends on the specific application and the relative importance of calibration versus discrimination. If accurate confidence scores are crucial, a model with lower ECE might be preferred, even if it has a slightly lower AUROC. If maximizing predictive accuracy is the primary goal, LoRA + Prompt might be the best choice.
</details>
Figure 5: (Left) We ablate the correspondence between questions and answers by training LoRA + Prompt on a dataset with correctness labels from the model’s generations but with the actual generations swapped with incorrect answers. In this case, the only relationships that can be extracted by the model are between the correctness labels and the questions. The model trained on incorrect answers generalizes surprisingly well but is much worse than a model trained on the original answers. Error bars show two standard deviations over three instruction-tuned models. (Center) We test how well models can learn to predict the correctness of a different model (in terms of AUROC), and we find that mistral models are often better at estimating the correctness of LLaMA models than LLaMA can on their own generations. (Right) We show that generic sentence embeddings can also perform on par with frozen language model representations (MMLU-OE), but training through a model is much better. sBERT and OAIEmb refer to training a classifier on top of sBERT (Reimers and Gurevych, 2019) or OpenAI sentence embeddings. Error bars show two standard deviations over tasks in MMLU.
Learned uncertainty estimates generalize to new formatting, subject matter, and even the generations of other models. This generalization appears to stem not simply from judging a question’s difficulty based on its subject matter (a short-cut) but also learning the correspondence between questions and correct answers.
7 Does Calibrated Confidence Improve Collaboration with AI Assistants?
One key motivation for estimating LLM uncertainty is to signal the model’s reliability during collaborative decision making. To examine how our uncertainty estimates can be used in this capacity, we perform a preliminary user study (with $N=181$ participants) in which participants complete a multiple choice exam in collaboration with an LLM (Mistral 7B Instruct). For each question, the participant is provided both the LLM’s prediction and an uncertainty estimate, which can be from a calibrated method or an uncalibrated method. We hope to show that users are more likely to adopt calibrated uncertainty scores as part of their decision process. A more detailed description of the setup of our study is available in Appendix G.
People are sensitive to informed confidence scores.
Figure 6 shows density plots of the model’s reported confidence and whether the user chose to agree with the model’s prediction. We find that participants are sensitive to the confidence scores and tend to use scores when deciding to agree or disagree with the model’s prediction if the uncertainties are reliable. On the other hand, participants generally do not modulate their decision to rely on the output of a random confidence baseline (Figure 6 (c)), in which the display uncertainty estimate is generated uniformly at random. We see the strongest discrepancy in reliance choices when LoRA + Probe confidence scores are presented, highlighting that calibrated confidence does influence user behavior.
We include additional details and results in Appendix G. We find that confidence scores have the biggest effect on improving the lowest performing users, rather than on average accuracy. However, this is a preliminary result in the nascent field of studying LLM uncertainties in practical collaborative decision making with users. We are only still scratching the surface of this question. For more fine-grained conclusions, a study should be devoted to this subject. We outline several limitations and future directions in Appendix G.
|
<details>
<summary>x12.png Details</summary>
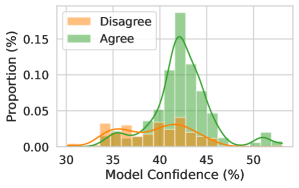
### Visual Description
\n
## Histogram: Proportion vs. Model Confidence
### Overview
The image presents a histogram displaying the proportion of responses categorized as "Agree" and "Disagree" against varying levels of "Model Confidence". The data is visualized using stacked bars and overlaid density curves.
### Components/Axes
* **X-axis:** "Model Confidence (%)", ranging from approximately 30% to 50%. Marked at 30, 35, 40, 45, and 50.
* **Y-axis:** "Proportion (%)", ranging from 0.00 to 0.15. Marked at 0.00, 0.05, 0.10, and 0.15.
* **Legend:** Located in the top-left corner.
* Orange: "Disagree"
* Green: "Agree"
* **Data Representation:** Stacked bars representing the proportion of "Disagree" and "Agree" responses for each confidence level. Overlaid are smooth density curves for each category.
### Detailed Analysis
The "Agree" data (green) exhibits a unimodal distribution, peaking at approximately 43-45% Model Confidence, with a proportion of around 0.12-0.13. The distribution is roughly symmetrical around the peak.
The "Disagree" data (orange) shows a less pronounced peak around 33-35% Model Confidence, with a proportion of approximately 0.03-0.04. It also has a smaller peak around 42-43% Model Confidence with a proportion of approximately 0.02-0.03. The distribution is more spread out and less symmetrical than the "Agree" data.
Here's a breakdown of approximate values based on visual estimation:
| Model Confidence (%) | Proportion (Disagree - Orange) | Proportion (Agree - Green) |
|---|---|---|
| 30 | ~0.01 | ~0.01 |
| 35 | ~0.03 | ~0.03 |
| 40 | ~0.02 | ~0.07 |
| 42 | ~0.03 | ~0.10 |
| 43 | ~0.02 | ~0.12 |
| 44 | ~0.01 | ~0.13 |
| 45 | ~0.01 | ~0.11 |
| 50 | ~0.01 | ~0.03 |
### Key Observations
* The "Agree" responses are significantly more frequent than "Disagree" responses across most confidence levels.
* The highest proportion of "Agree" responses occurs when the Model Confidence is around 43-45%.
* The "Disagree" responses show a slight increase in proportion around 35% Model Confidence.
* The density curves provide a smoothed representation of the underlying distributions, highlighting the central tendency and spread of each category.
### Interpretation
The data suggests a strong positive correlation between Model Confidence and the proportion of "Agree" responses. As the model becomes more confident in its predictions (increasing Model Confidence), the likelihood of receiving an "Agree" response increases substantially. The peak at 43-45% suggests that this level of confidence is particularly persuasive or aligns well with human judgment. The smaller peak in "Disagree" around 35% could indicate a region where the model's confidence is high enough to elicit a response, but not high enough to guarantee agreement. The overall shape of the distributions implies that the model's performance is generally better at higher confidence levels, and that disagreement is more common when the model is less certain. The data could be used to calibrate the model's confidence scores or to identify areas where the model needs improvement.
</details>
|
<details>
<summary>x13.png Details</summary>
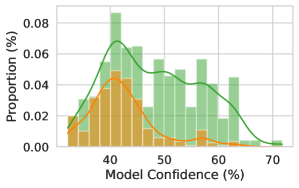
### Visual Description
\n
## Histogram: Model Confidence Distribution
### Overview
The image presents a histogram displaying the distribution of model confidence levels, overlaid with a kernel density estimate. Two distinct distributions are visible, represented by green and orange bars, suggesting potentially two different populations or conditions influencing model confidence.
### Components/Axes
* **X-axis:** "Model Confidence (%)", ranging from approximately 35% to 75%. The axis is divided into bins of approximately 2.5% width.
* **Y-axis:** "Proportion (%)", ranging from 0.00 to 0.08.
* **Green Histogram:** Represents one distribution of model confidence.
* **Orange Histogram:** Represents a second distribution of model confidence.
* **Green Line:** Kernel Density Estimate (KDE) representing the overall distribution, likely a combination of the two histograms.
### Detailed Analysis
The green distribution is the dominant one, peaking around 47.5% confidence with a proportion of approximately 0.075. It extends from approximately 40% to 70% confidence. The orange distribution is smaller, peaking around 42.5% confidence with a proportion of approximately 0.045. It is more concentrated between 35% and 60% confidence.
Here's a breakdown of approximate values from the histogram:
* **Green Distribution:**
* Around 40% confidence: Proportion ~ 0.02
* Around 42.5% confidence: Proportion ~ 0.03
* Peak at 47.5% confidence: Proportion ~ 0.075
* Around 55% confidence: Proportion ~ 0.05
* Around 65% confidence: Proportion ~ 0.02
* **Orange Distribution:**
* Around 37.5% confidence: Proportion ~ 0.01
* Peak at 42.5% confidence: Proportion ~ 0.045
* Around 50% confidence: Proportion ~ 0.02
* Around 57.5% confidence: Proportion ~ 0.01
The green KDE line follows the shape of the green histogram, peaking around 47.5% and gradually decreasing towards 70%. It also shows a slight dip between 50% and 60% confidence.
### Key Observations
* There are two distinct peaks in the combined distribution, indicating two separate groups or modes of model confidence.
* The green distribution is more prevalent than the orange distribution.
* The KDE line suggests a non-normal distribution, with a skew towards lower confidence levels.
* The orange distribution appears to be centered at a slightly lower confidence level than the green distribution.
### Interpretation
The data suggests that the model's confidence levels are not uniformly distributed. The presence of two distinct distributions indicates that the model may be performing differently under different conditions or on different types of data. The higher prevalence of the green distribution suggests that the model is more frequently confident in its predictions. The KDE line provides a smoothed representation of the overall distribution, highlighting the non-normality and skewness.
The difference between the two distributions could be due to several factors, such as:
* **Data Quality:** The model may be more confident when processing high-quality data (represented by the green distribution) and less confident when processing noisy or ambiguous data (represented by the orange distribution).
* **Model Complexity:** The model may be more confident in predicting simple patterns (green distribution) and less confident in predicting complex patterns (orange distribution).
* **Training Data:** The model may have been trained on a dataset that is biased towards certain types of data, leading to higher confidence levels in those areas.
Further investigation is needed to determine the underlying causes of the two distributions and to improve the model's overall performance. Analyzing the data associated with each distribution could provide valuable insights into the model's behavior.
</details>
|
<details>
<summary>x14.png Details</summary>
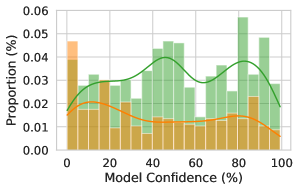
### Visual Description
\n
## Histogram with Density Curves: Model Confidence vs. Proportion
### Overview
The image presents a histogram displaying the distribution of "Model Confidence" (in percentage) against "Proportion" (also in percentage). Two overlaid density curves are plotted on top of the histogram, representing different categories or groups within the data. The histogram bars are colored in shades of green and orange.
### Components/Axes
* **X-axis:** "Model Confidence (%)" ranging from 0 to 100, with tick marks at intervals of 20.
* **Y-axis:** "Proportion (%)" ranging from 0.00 to 0.06, with tick marks at intervals of 0.01.
* **Histogram Bars:** Represent the frequency distribution of model confidence values. The bars are colored in green and orange.
* **Density Curve 1 (Green):** A smooth curve overlaid on the histogram, likely representing the density estimate for one group.
* **Density Curve 2 (Orange):** Another smooth curve overlaid on the histogram, representing the density estimate for a different group.
* **Legend:** There is no explicit legend, but the colors of the curves and histogram bars suggest two distinct groups.
### Detailed Analysis
The histogram shows the distribution of model confidence scores. The x-axis represents the confidence level, and the y-axis represents the proportion of instances with that confidence level.
**Green Histogram & Density Curve:**
The green histogram bars and density curve represent a larger proportion of the data. The distribution appears to be unimodal, peaking around a model confidence of approximately 40-60%. The curve rises from the left, reaches a peak, and then gradually declines towards the right.
* At 0% Model Confidence, the proportion is approximately 0.005.
* At 20% Model Confidence, the proportion is approximately 0.025.
* At 40% Model Confidence, the proportion is approximately 0.045.
* At 60% Model Confidence, the proportion is approximately 0.035.
* At 80% Model Confidence, the proportion is approximately 0.038.
* At 100% Model Confidence, the proportion is approximately 0.02.
**Orange Histogram & Density Curve:**
The orange histogram bars and density curve represent a smaller proportion of the data. The distribution is also unimodal, but with a peak around a lower model confidence, approximately 0-20%. The curve rises quickly, reaches a peak, and then declines more rapidly than the green curve.
* At 0% Model Confidence, the proportion is approximately 0.045.
* At 20% Model Confidence, the proportion is approximately 0.018.
* At 40% Model Confidence, the proportion is approximately 0.012.
* At 60% Model Confidence, the proportion is approximately 0.008.
* At 80% Model Confidence, the proportion is approximately 0.005.
* At 100% Model Confidence, the proportion is approximately 0.002.
### Key Observations
* The green distribution has a higher peak and a wider spread than the orange distribution.
* The orange distribution is concentrated at lower confidence levels.
* There is a noticeable overlap between the two distributions, particularly in the 20-60% confidence range.
* The green density curve generally has higher proportions than the orange density curve across most of the confidence range.
### Interpretation
The data suggests that the model generally exhibits higher confidence levels, as indicated by the dominant green distribution. However, there is a significant portion of predictions with lower confidence, represented by the orange distribution. The two distributions likely represent different subsets of the data or different types of predictions made by the model. The higher proportion of predictions with higher confidence suggests the model is performing reasonably well overall, but the presence of the lower-confidence predictions indicates areas where the model may struggle or require further refinement. The overlap between the distributions suggests that there are instances where the model is uncertain, and its predictions fall within a range of confidence levels. The shape of the curves suggests that the model is more likely to be very confident or very unconfident, with fewer predictions falling in the middle range.
</details>
|
| --- | --- | --- |
| (a) Zero-Shot Prompt | (b) LoRA + Prompt | (c) Random (Control) |
Figure 6: We compare the distribution of LLM confidence (for Mistral 7B Instruct) on its answers, and whether the users ( $N=20$ per variant) agree with the answer generated by the model or not. (a) For the zero-shot prompt, we find that the model provides little signal since most mass is similarly clustered. However, (b) improving the calibration of the model reveals an increased reliance on the LLM for more confident answers, and decreased reliance for less confident answers. Evidently, the users are sensitive to calibrated confidence scores. (c) For reference, we verify that uniformly confidence scores do not provide meaningful signal, rendering users unable to modulate their decision to rely on the LLM. All variants are compared at approximately the same average participant accuracy.
Users are sensitive to confidence scores and use their relative magnitude to modulate their decision to use an LLM. Lower performing users are most improved by access to confidence scores. However, future work is needed to disentangle the effects of calibration from how humans choose to leverage uncertainties.
8 Discussion
There is much disagreement about the role of calibrated uncertainty in large language models, how it can best be achieved, and promise of black-box methods. We hope to have shed light on these questions throughout this paper. In contrast to prior results, we find that out-of-the-box uncertainties from LLMs are unreliable for open-ended generation and introduce a suite of fine-tuning procedures that produce calibrated uncertainties with practical generalization properties. In the process, we discovered that fine-tuning is surprisingly sample efficient and does not seem to rely on representations of correctness specific to a model evaluating its own generations, allowing estimators to be applied from one model to another. Moreover, we found it is possible, at least in the cases we considered, for calibrated uncertainties to be robust to distribution shifts.
There are many exciting questions for future work. Currently fine-tuning relies on two separate models for question answering and uncertainty estimation. Ideally, we want a single model that can generate questions and uncertainty without switching between model weights. We anticipate that an uncertainty-aware pre-training or alignment phase might become essential but implementing such a procedure while maintaining base language modeling abilities will introduce a challenging online learning problem where the correctness labels evolve during training.
Beyond improving the safety and usefulness of language models, high quality uncertainties can also be used in active learning procedures, e.g. for sample-efficient fine-tuning (Osband et al., 2022), where data points are selected based on the predicted utility and the model’s uncertainty, in order to balance the explore-exploit trade-off. Uncertainty estimates can also be used to improve factuality of language models by increasing the likelihood of generations that the model is confident about (judges likely to be correct), for example by using an alignment procedure (e.g. RLHF, DPO) with a reward function that encourages confident generations (Tian et al., 2023a).
We also showed how uncertainty information could be used to influence human decision making. In the end, LLMs will impact society through decision making, and to make reasonable decisions we need uncertainty information — particularly to protect against rare but costly mistakes.
Acknowledgements
This work is supported by NSF CAREER IIS-2145492, NSF CDS&E-MSS 2134216, NSF HDR-2118310, BigHat Biosciences, Capital One, and an Amazon Research Award.
References
- Achiam et al. (2023) Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report. arXiv preprint arXiv:2303.08774, 2023.
- Amini et al. (2019) Aida Amini, Saadia Gabriel, Shanchuan Lin, Rik Koncel-Kedziorski, Yejin Choi, and Hannaneh Hajishirzi. MathQA: Towards interpretable math word problem solving with operation-based formalisms. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pages 2357–2367. Association for Computational Linguistics, jun 2019. doi: 10.18653/v1/N19-1245.
- Aroyo and Welty (2015) Lora Aroyo and Chris Welty. Truth is a lie: Crowd truth and the seven myths of human annotation. AI Magazine, 36(1):15–24, 2015.
- Azaria and Mitchell (2023) Amos Azaria and Tom M. Mitchell. The internal state of an llm knows when its lying. ArXiv, abs/2304.13734, 2023.
- Bhatt et al. (2023) Umang Bhatt, Valerie Chen, Katherine M Collins, Parameswaran Kamalaruban, Emma Kallina, Adrian Weller, and Ameet Talwalkar. Learning personalized decision support policies. arXiv preprint arXiv:2304.06701, 2023.
- Bishop (2006) Christopher M Bishop. Pattern recognition and machine learning. Springer google schola, 2:1122–1128, 2006.
- Bisk et al. (2019) Yonatan Bisk, Rowan Zellers, Ronan Le Bras, Jianfeng Gao, and Yejin Choi. Piqa: Reasoning about physical commonsense in natural language. ArXiv, abs/1911.11641, 2019.
- Bowman et al. (2015) Samuel R. Bowman, Gabor Angeli, Christopher Potts, and Christopher D. Manning. A large annotated corpus for learning natural language inference. In Conference on Empirical Methods in Natural Language Processing, 2015.
- Burns et al. (2022) Collin Burns, Hao-Tong Ye, Dan Klein, and Jacob Steinhardt. Discovering latent knowledge in language models without supervision. ArXiv, abs/2212.03827, 2022.
- Chiang and yi Lee (2023) Cheng-Han Chiang and Hung yi Lee. Can large language models be an alternative to human evaluations? In Annual Meeting of the Association for Computational Linguistics, 2023.
- Clark et al. (2019) Christopher Clark, Kenton Lee, Ming-Wei Chang, Tom Kwiatkowski, Michael Collins, and Kristina Toutanova. Boolq: Exploring the surprising difficulty of natural yes/no questions. ArXiv, abs/1905.10044, 2019.
- Clark et al. (2018) Peter Clark, Isaac Cowhey, Oren Etzioni, Tushar Khot, Ashish Sabharwal, Carissa Schoenick, and Oyvind Tafjord. Think you have solved question answering? try arc, the ai2 reasoning challenge. ArXiv, abs/1803.05457, 2018.
- Collins et al. (2023) Katherine Maeve Collins, Matthew Barker, Mateo Espinosa Zarlenga, Naveen Raman, Umang Bhatt, Mateja Jamnik, Ilia Sucholutsky, Adrian Weller, and Krishnamurthy Dvijotham. Human uncertainty in concept-based ai systems. In Proceedings of the 2023 AAAI/ACM Conference on AI, Ethics, and Society, pages 869–889, 2023.
- De Marneffe et al. (2019) Marie-Catherine De Marneffe, Mandy Simons, and Judith Tonhauser. The commitmentbank: Investigating projection in naturally occurring discourse. In proceedings of Sinn und Bedeutung, volume 23, pages 107–124, 2019.
- Gneiting and Raftery (2007) Tilmann Gneiting and Adrian E Raftery. Strictly proper scoring rules, prediction, and estimation. Journal of the American statistical Association, 102(477):359–378, 2007.
- Gordon et al. (2011) Andrew S. Gordon, Zornitsa Kozareva, and Melissa Roemmele. Semeval-2012 task 7: Choice of plausible alternatives: An evaluation of commonsense causal reasoning. In International Workshop on Semantic Evaluation, 2011.
- Guo et al. (2017) Chuan Guo, Geoff Pleiss, Yu Sun, and Kilian Q. Weinberger. On calibration of modern neural networks. In International Conference on Machine Learning, 2017.
- Hendrycks et al. (2020) Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Xiaodong Song, and Jacob Steinhardt. Measuring massive multitask language understanding. ArXiv, abs/2009.03300, 2020.
- Hills and Anadkat (2023) James Hills and Shyamal Anadkat. Using logprobs, Dec 2023. URL https://cookbook.openai.com/examples/using_logprobs.
- Hu et al. (2021) J. Edward Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, and Weizhu Chen. Lora: Low-rank adaptation of large language models. ArXiv, abs/2106.09685, 2021.
- Huang et al. (2019) Lifu Huang, Ronan Le Bras, Chandra Bhagavatula, and Yejin Choi. Cosmos qa: Machine reading comprehension with contextual commonsense reasoning. In Conference on Empirical Methods in Natural Language Processing, 2019.
- Jain et al. (2024) Naman Jain, King Han, Alex Gu, Wen-Ding Li, Fanjia Yan, Tianjun Zhang, Sida Wang, Armando Solar-Lezama, Koushik Sen, and Ion Stoica. Livecodebench: Holistic and contamination free evaluation of large language models for code. arXiv preprint arXiv:2403.07974, 2024.
- Janssen et al. (2008) KJM Janssen, KGM Moons, CJ Kalkman, DE Grobbee, and Y Vergouwe. Updating methods improved the performance of a clinical prediction model in new patients. Journal of clinical epidemiology, 61(1):76–86, 2008.
- Jiang et al. (2023) Albert Qiaochu Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra Singh Chaplot, Diego de Las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lucile Saulnier, L’elio Renard Lavaud, Marie-Anne Lachaux, Pierre Stock, Teven Le Scao, Thibaut Lavril, Thomas Wang, Timothée Lacroix, and William El Sayed. Mistral 7b. ArXiv, abs/2310.06825, 2023.
- Kadavath et al. (2022) Saurav Kadavath, Tom Conerly, Amanda Askell, T. J. Henighan, Dawn Drain, Ethan Perez, Nicholas Schiefer, Zachary Dodds, Nova DasSarma, Eli Tran-Johnson, Scott Johnston, Sheer El-Showk, Andy Jones, Nelson Elhage, Tristan Hume, Anna Chen, Yuntao Bai, Sam Bowman, Stanislav Fort, Deep Ganguli, Danny Hernandez, Josh Jacobson, John Kernion, Shauna Kravec, Liane Lovitt, Kamal Ndousse, Catherine Olsson, Sam Ringer, Dario Amodei, Tom B. Brown, Jack Clark, Nicholas Joseph, Benjamin Mann, Sam McCandlish, Christopher Olah, and Jared Kaplan. Language Models (Mostly) Know What They Know. ArXiv, abs/2207.05221, 2022.
- Keren (1991) Gideon Keren. Calibration and probability judgements: Conceptual and methodological issues. Acta psychologica, 77(3):217–273, 1991.
- Khashabi et al. (2018) Daniel Khashabi, Snigdha Chaturvedi, Michael Roth, Shyam Upadhyay, and Dan Roth. Looking beyond the surface: A challenge set for reading comprehension over multiple sentences. In North American Chapter of the Association for Computational Linguistics, 2018.
- Kruger and Dunning (1999) Justin Kruger and David Dunning. Unskilled and unaware of it: how difficulties in recognizing one’s own incompetence lead to inflated self-assessments. Journal of personality and social psychology, 77(6):1121, 1999.
- Kruger and Dunning (2002) Justin Kruger and David Dunning. Unskilled and unaware–but why? a reply to krueger and mueller (2002). American Psychological Association, 2002.
- Kuhn et al. (2023) Lorenz Kuhn, Yarin Gal, and Sebastian Farquhar. Semantic uncertainty: Linguistic invariances for uncertainty estimation in natural language generation. ArXiv, abs/2302.09664, 2023.
- Li and Roth (2002) Xin Li and Dan Roth. Learning question classifiers. In International Conference on Computational Linguistics, 2002.
- Lichtenstein et al. (1977) Sarah Lichtenstein, Baruch Fischhoff, and Lawrence D Phillips. Calibration of probabilities: The state of the art. In Decision Making and Change in Human Affairs: Proceedings of the Fifth Research Conference on Subjective Probability, Utility, and Decision Making, Darmstadt, 1–4 September, 1975, pages 275–324. Springer, 1977.
- Lin et al. (2022) Stephanie C. Lin, Jacob Hilton, and Owain Evans. Teaching models to express their uncertainty in words. Trans. Mach. Learn. Res., 2022, 2022.
- Loshchilov and Hutter (2017) Ilya Loshchilov and Frank Hutter. Fixing weight decay regularization in adam. ArXiv, abs/1711.05101, 2017.
- MacKay (2004) David John Cameron MacKay. Information theory, inference, and learning algorithms. IEEE Transactions on Information Theory, 50:2544–2545, 2004.
- Mihaylov et al. (2018) Todor Mihaylov, Peter Clark, Tushar Khot, and Ashish Sabharwal. Can a suit of armor conduct electricity? a new dataset for open book question answering. In Conference on Empirical Methods in Natural Language Processing, 2018.
- Naeini et al. (2015) Mahdi Pakdaman Naeini, Gregory F. Cooper, and Milos Hauskrecht. Obtaining well calibrated probabilities using bayesian binning. Proceedings of the … AAAI Conference on Artificial Intelligence. AAAI Conference on Artificial Intelligence, 2015:2901–2907, 2015.
- Nie et al. (2019) Yixin Nie, Adina Williams, Emily Dinan, Mohit Bansal, Jason Weston, and Douwe Kiela. Adversarial nli: A new benchmark for natural language understanding. ArXiv, abs/1910.14599, 2019.
- Osband et al. (2022) Ian Osband, Seyed Mohammad Asghari, Benjamin Van Roy, Nat McAleese, John Aslanides, and Geoffrey Irving. Fine-tuning language models via epistemic neural networks. arXiv preprint arXiv:2211.01568, 2022.
- Palan and Schitter (2018) Stefan Palan and Christian Schitter. Prolific. aca subject pool for online experiments. Journal of Behavioral and Experimental Finance, 17:22–27, 2018.
- Paszke et al. (2019) Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer, James Bradbury, Gregory Chanan, Trevor Killeen, Zeming Lin, Natalia Gimelshein, Luca Antiga, Alban Desmaison, Andreas Köpf, Edward Yang, Zach DeVito, Martin Raison, Alykhan Tejani, Sasank Chilamkurthy, Benoit Steiner, Lu Fang, Junjie Bai, and Soumith Chintala. Pytorch: An imperative style, high-performance deep learning library. In Neural Information Processing Systems, 2019.
- Platt et al. (1999) John Platt et al. Probabilistic outputs for support vector machines and comparisons to regularized likelihood methods. Advances in large margin classifiers, 10(3):61–74, 1999.
- Plaut et al. (2024) Benjamin Plaut, Khanh Nguyen, and Tu Trinh. Softmax probabilities (mostly) predict large language model correctness on multiple-choice q&a. arXiv preprint arXiv:2402.13213, 2024.
- Reimers and Gurevych (2019) Nils Reimers and Iryna Gurevych. Sentence-bert: Sentence embeddings using siamese bert-networks. arXiv preprint arXiv:1908.10084, 2019.
- Sakaguchi et al. (2019) Keisuke Sakaguchi, Ronan Le Bras, Chandra Bhagavatula, and Yejin Choi. Winogrande: An adversarial winograd schema challenge at scale. ArXiv, abs/1907.10641, 2019.
- Schaal (1996) Stefan Schaal. Learning from demonstration. Advances in neural information processing systems, 9, 1996.
- Talmor et al. (2019) Alon Talmor, Jonathan Herzig, Nicholas Lourie, and Jonathan Berant. Commonsenseqa: A question answering challenge targeting commonsense knowledge. ArXiv, abs/1811.00937, 2019.
- Team (2024) Gemini Team. Gemini: A family of highly capable multimodal models, 2024.
- Terwilliger et al. (2023) Thomas C Terwilliger, Dorothee Liebschner, Tristan I Croll, Christopher J Williams, Airlie J McCoy, Billy K Poon, Pavel V Afonine, Robert D Oeffner, Jane S Richardson, Randy J Read, et al. Alphafold predictions are valuable hypotheses and accelerate but do not replace experimental structure determination. Nature Methods, pages 1–7, 2023.
- Tian et al. (2023a) Katherine Tian, Eric Mitchell, Huaxiu Yao, Christopher D Manning, and Chelsea Finn. Fine-tuning language models for factuality. arXiv preprint arXiv:2311.08401, 2023a.
- Tian et al. (2023b) Katherine Tian, Eric Mitchell, Allan Zhou, Archit Sharma, Rafael Rafailov, Huaxiu Yao, Chelsea Finn, and Christopher D Manning. Just ask for calibration: Strategies for eliciting calibrated confidence scores from language models fine-tuned with human feedback. arXiv preprint arXiv:2305.14975, 2023b.
- Touvron et al. (2023a) Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, Aurelien Rodriguez, Armand Joulin, Edouard Grave, and Guillaume Lample. Llama: Open and efficient foundation language models. ArXiv, abs/2302.13971, 2023a.
- Touvron et al. (2023b) Hugo Touvron, Louis Martin, Kevin R. Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, Daniel M. Bikel, Lukas Blecher, Cristian Canton Ferrer, Moya Chen, Guillem Cucurull, David Esiobu, Jude Fernandes, Jeremy Fu, Wenyin Fu, Brian Fuller, Cynthia Gao, Vedanuj Goswami, Naman Goyal, Anthony S. Hartshorn, Saghar Hosseini, Rui Hou, Hakan Inan, Marcin Kardas, Viktor Kerkez, Madian Khabsa, Isabel M. Kloumann, A. V. Korenev, Punit Singh Koura, Marie-Anne Lachaux, Thibaut Lavril, Jenya Lee, Diana Liskovich, Yinghai Lu, Yuning Mao, Xavier Martinet, Todor Mihaylov, Pushkar Mishra, Igor Molybog, Yixin Nie, Andrew Poulton, Jeremy Reizenstein, Rashi Rungta, Kalyan Saladi, Alan Schelten, Ruan Silva, Eric Michael Smith, R. Subramanian, Xia Tan, Binh Tang, Ross Taylor, Adina Williams, Jian Xiang Kuan, Puxin Xu, Zhengxu Yan, Iliyan Zarov, Yuchen Zhang, Angela Fan, Melanie Kambadur, Sharan Narang, Aurelien Rodriguez, Robert Stojnic, Sergey Edunov, and Thomas Scialom. Llama 2: Open foundation and fine-tuned chat models. ArXiv, abs/2307.09288, 2023b.
- Ulmer et al. (2024) Dennis Ulmer, Martin Gubri, Hwaran Lee, Sangdoo Yun, and Seong Joon Oh. Calibrating large language models using their generations only. In Annual Meeting of the Association for Computational Linguistics, 2024.
- Uma et al. (2021) Alexandra N Uma, Tommaso Fornaciari, Dirk Hovy, Silviu Paun, Barbara Plank, and Massimo Poesio. Learning from disagreement: A survey. Journal of Artificial Intelligence Research, 72:1385–1470, 2021.
- Vodrahalli et al. (2022) Kailas Vodrahalli, Tobias Gerstenberg, and James Y Zou. Uncalibrated models can improve human-ai collaboration. Advances in Neural Information Processing Systems, 35:4004–4016, 2022.
- Wei et al. (2021) Jason Wei, Maarten Bosma, Vincent Zhao, Kelvin Guu, Adams Wei Yu, Brian Lester, Nan Du, Andrew M. Dai, and Quoc V. Le. Finetuned language models are zero-shot learners. ArXiv, abs/2109.01652, 2021.
- Welbl et al. (2017) Johannes Welbl, Nelson F. Liu, and Matt Gardner. Crowdsourcing multiple choice science questions. ArXiv, abs/1707.06209, 2017.
- Wolf et al. (2020) Thomas Wolf, Lysandre Debut, Victor Sanh, Julien Chaumond, Clement Delangue, Anthony Moi, Pierric Cistac, Tim Rault, Rmi Louf, Morgan Funtowicz, Joe Davison, Sam Shleifer, Patrick von Platen, Clara Ma, Yacine Jernite, Julien Plu, Canwen Xu, Teven Le Scao, Sylvain Gugger, Mariama Drame, Quentin Lhoest, and Alexander M. Rush. Transformers: State-of-the-art natural language processing. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, pages 38–45, Online, October 2020. Association for Computational Linguistics. URL https://www.aclweb.org/anthology/2020.emnlp-demos.6.
- Xiong et al. (2023) Miao Xiong, Zhiyuan Hu, Xinyang Lu, Yifei Li, Jie Fu, Junxian He, and Bryan Hooi. Can llms express their uncertainty? an empirical evaluation of confidence elicitation in llms. ArXiv, abs/2306.13063, 2023.
- Yin et al. (2023) Zhangyue Yin, Qiushi Sun, Qipeng Guo, Jiawen Wu, Xipeng Qiu, and Xuanjing Huang. Do large language models know what they don’t know? In Findings of the Association for Computational Linguistics: ACL 2023, pages 8653–8665, Toronto, Canada, 2023. Association for Computational Linguistics.
- Zellers et al. (2019) Rowan Zellers, Ari Holtzman, Yonatan Bisk, Ali Farhadi, and Yejin Choi. Hellaswag: Can a machine really finish your sentence? In Annual Meeting of the Association for Computational Linguistics, 2019.
- Zhang et al. (2023) Hanning Zhang, Shizhe Diao, Yong Lin, Yi R Fung, Qing Lian, Xingyao Wang, Yangyi Chen, Heng Ji, and Tong Zhang. R-tuning: Teaching large language models to refuse unknown questions. arXiv preprint arXiv:2311.09677, 2023.
Appendix for Large Language Models Must Be Taught to Know What They Don’t Know
Appendix A Evaluation Methods
A.1 Evaluating Correctness
For a given question with known and generated answers $(Q,A,\hat{A})$ the correctness $C$ is True if the generated answer $\hat{A}$ matches the ground truth answer $A$ . For multiple-choice question-answering, the matching process only involves checking the first token generated via greedy decoding.
For open-ended evaluations, determining if the answer given is correct is more complex. One simple approach is to check if the ground truth answer $A$ appears as a substring of answer $\hat{A}$ . However, this does not capture rephrasings that may be essentially equivalent - such as ”NYC” for ”New York City,” or ”Daoism” and ”Taoism.” Conversely, it also has the potential to be over-generous if the model is particularly verbose and emits many incorrect answers along with the correct string. Given the difficulty involved in writing a rule-based method for evaluating open-ended answer correctness, we use instead a strong auxiliary language model to evaluate correctness. The auxiliary language model is shown the query $Q$ , the ground truth answer $A$ , and the model’s output $\hat{A}$ , and is prompted to grade the answer whilst tolerating nuance. For full details of the prompt used see (fig. 7). In this paper we utilise GPT 3.5 Turbo as the auxiliary grading model. We conduct a comparison of human grading, substring grading, and GPT 3.5 Turbo grading on select subsets of MMLU in section A.3. We find that humans and GPT 3.5 Turbo have much greater agreement than humans and the substring method.
A.2 Grading
Dataset Construction.
To perform calibration-tuning (CT), we need tuples $(Q,A,\hat{A},C)$ , answers from a language model that have been graded for correctness. When calibration-tuning on multiple choice questions, we can use an exact string match to generate $C$ . To grade open-ended answers, we use a strong language model and grading prompt $G$ instead (fig. 7):
- $\bm{G}$ : a prompt used for grading answers $\bm{\hat{A}}$ with $\bm{A}$ .
Compared to alternatives like exact match, language model grading is insensitive to re-phrasings that are equivalent in meaning - such as “NYC” and “New York City,” or “Daoism” and “Taoism”. LLM grading can also penalize answers that are overly verbose or use a different meaning of the same word, potentially containing incorrect answers along with the correct string. For example, if the question is “What’s it called when you move quickly by foot and both feet aren’t always touching the ground?” and the LLM response is “A bank run”, the grader should be able to distinguish that this is semantically dissimilar to the true answer “run”.
In this paper, we utilize GPT 3.5 Turbo as the auxiliary grading model. When comparing many possible grading methods on subsets of MMLU, we find that GPT 3.5 Turbo has high agreement with humans while being cost efficient (section A.3).
Grading prompt $(\bm{G})$ The problem is: $\bm{Q}$ The correct answer is: $\bm{A}$ A student submitted: $\bm{\hat{A}}$ The student’s answer must be correct and specific but not overcomplete (for example, if they provide two different answers, they did not get the question right). However, small differences in formatting should not be penalized (for example, ‘New York City’ is equivalent to ‘NYC’). Did the student provide an equivalent answer to the ground truth? Please answer yes or no without any explanation: $\bm{C}$ </s>
Figure 7: For open-ended generation, we calculate the ground-truth correctness $C$ using a LLM and a grading prompt ( $G$ ). The token </s> is an end-of-sentence token. Blue text is included in the loss function when calibration-tuning.
A.3 Comparison of Grading Techniques
We conducted an analysis of the methods outlined in section A.1 for open-ended evaluation. First, the base LLaMA-2 13b-chat model was prompted with questions from the following test subsets of MMLU: World Religions, Philosophy, Anatomy, High School Chemistry and Elementary School Math. The questions were stripped of their multiple-choice options before being supplied to the model.
A response was generated by the model via greedy decoding and this response was compared to the ground truth answer. The grading methods tested were Human, Substring Match, GPT 3.5 Turbo, and GPT 4.
The humans (a subset of our authors) were tasked to judge if the model response was essentially equivalent to the ground truth. For substring match, equivalence was determined by simply checking whether the ground truth answer existed as a substring within the model response. For GPT 3.5 Turbo and GPT 4, the models were supplied with the question, the ground truth, and the base model response, as well as a prompt indicating they should determine essential equivalence - see fig. 7.
MMLU Subset Substring Match GPT3.5 GPT4 World Religions 21.6% 6.4% 1.8% Philosophy 22.8% 2.3% 14.5% Anatomy 13.3% 14.8% 1.5% Chemistry 13.8% 5.4% 1.0% Math 12.4% 14.8% 3.7% Average 16.8% 8.7% 4.5%
Table 2: Absolute differences in accuracy % for the different grading methods vs human estimated accuracy. A lower value corresponds to an accuracy estimate closer to the human estimate.
We recorded the binary decision on correctness for each query and response by each of the grading methods above. Taking the human scores as the gold standard of correctness, we computed the model accuracy for each subset, and then derived the absolute error in estimate of model accuracy by each of the other grading methods. These are displayed in table 2. We see that GPT4 is a better estimator of human-judged correctness than GPT 3.5 Turbo, which in turn is substantially better than substring match; although there is some variance on a per-subset basis. For expediency of processing time and cost, we chose to use GPT 3.5 Turbo in this paper.
A.4 Metrics
ECE
Given $N$ samples and $B$ equally-spaced bins $b_{j}$ , examples are assigned to bins based on the confidence of the model, and ECE is estimated as $\widehat{\text{ECE}}=\sum_{j=1}^{B}\frac{\lvert b_{j}\rvert}{N}\left\lvert\mathrm{conf}(b_{j})-\mathrm{acc}(b_{j})\right\rvert$ where $\mathrm{conf}(b_{j})$ is the average confidence of samples in bin $b_{j}$ , $\mathrm{acc}(b_{j})$ is the accuracy within the bin, and $\lvert b_{j}\rvert$ is the number of samples assigned to bin $j$ . In our experiments $\mathrm{conf}$ is equivalent to $P(\text{correct})$ .
A.5 MMLU Supercategory Classifier
To understand the impact of the subject matter of the training data on generalization, we follow the prescription of Hendrycks et al. [2020] and categorize each of the 57 tasks into one of four supercategories - Humanities, STEM, Social Sciences, and Other. Since we do not have such a categorization for the training set, we must estimate their proportions.
First, we use the OpenAI embeddings (dimension 1536) of the MMLU samples with their ground truth supercategories to train a linear 4-way classifier with 10 samples from each of the 57 tasks. We use AdamW [Loshchilov and Hutter, 2017] with learning rate 1e-3 and weight decay 1e-2. This classifier is then used to estimate the categories of each sample in the training set used for fine-tuning. Subsequently, the breakdown of results in fig. 4 (Left) follows.
Appendix B Baseline Methods
B.1 Sampling Methods
We use two baselines which obtain an estimate of certainty by sampling the same answers $n=10$ times and then estimating the proportion of sampled answers that agree with the greedily decoded “main” answer. There are several critical downsides to these approaches: (i) the uncertainty here depends on the sampling parameters—for example, in the limit where the sampling converges to mere greedy decoding, the LLM will produce $n$ identical samples, and therefore the certainty will always be 1—(ii) these approaches require $O(n)$ answer generations to provide a certainty estimate for a single generation. The intense computational restriction prevents us from easily searching the space of sampling parameters for the optimal set, so we choose parameters arbitrarily; here we sample with top $\_p=0.95$ .
Counting
In this baseline, each sampled answer is compared to the greedy answer by prompting an expert LLM with both answers and asking it to judge their equivalence. The proportion of samples that are equivalent to the greedy answer is the certainty estimate. This baseline is similar to Label prob Tian et al. [2023b]; our method differs by not choosing the argmax semantic group as the final prediction, but instead using the greedy decode for the final prediction, so as to maintain the same accuracy performance as our uncertainty query method. This met
Likelihood accumulation
In this baseline, we add up likelihoods of sampled answers to estimate the mass associated with the predicted answer. We begin by prompting an expert LLM in order to find which sampled answers are equivalent to the greedy answer—like in the counting baseline. In this method, the certainty estimate is produced by adding the length-normalized likelihoods of those sampled answers equivalent to the greedy answer, and dividing this quantity by the sum of all sampled answers’ length-normalized likelihoods. This procedure of adding likelihoods of samples in order to estimate the likelihood of an equivalence class is similar to that used by Kuhn et al. [2023], although they do not use it for certainty estimates but instead to produce entropy scores. In practice, the scores produced by these two methods are actually very similar—so we report only likelihood accumulation numbers in the main text.
B.2 Verbal Elicitation
Although Tian et al. [2023b] introduce several strategies for prompting, involving multiple guesses or multiple stages of interleaving prompting and generation, we did not find that any strategy consistently outperformed any other. This finding was consistent with the results of Xiong et al. [2023]. Ultimately, for convenience, we adopted a two stage strategy with a single guess because it can be used in tandem with logged datasets of generated answers per model.
The exact prompt we used is essentially the same at in [Tian et al., 2023b], but with small modifications that improved the rate of correctly formatted responses:
“Provide the probability that your answer is correct. Give ONLY the probability, no other words or explanation.
For example:
Probability: ¡the probability between 0.0 and 1.0 that your guess is correct, without any extra commentary whatsoever; just the probability!¿
Include probability for the answer below: Probability:”
Verbal elicitation methods typically output complex strings containing both answers and associated probabilities. This means that if any element of parsing fails, it can be challenging to construct partial results. This effect tends to diminish when using large models, which are more responsive to zero-shot prompting.
Parsing Details
The original verbal elicitation prompts are given in the appendix of [Tian et al., 2023b]. However, it is not clear how the original authors decide to parse answers from the generations and how failure to parse is handled. When we fail to parse the guess from the generation we return an empty string and associated probability 0.5. When we fail to parse a probability, we also return probability 0.5. For versions with multiple guesses, if any part of the parsing processes fails in an ambiguous way, we default back to an empty string for the answer and 0.5 for the probability. The only unambiguous cases are those which explicit succeed in the generating a valid guess and probability in the first case but not subsequent cases. In this scenario, we default to using the successfully parse first guess and associated probability.
Appendix C Fine-tuning Method
C.1 Regularization Term
To keep the calibration-tuned parameters $\theta$ within the neighborhood of the initial parameters, $\theta_{0}$ , we use a regularization term that penalizes the divergence between the original sampling distribution and the calibration-tuned model on the target sequence $A$ , yielding regularization $\mathcal{R}(\theta;\theta_{0})$ , which we use with weighting parameter $\kappa$ .
Specifically, let $p_{\theta_{0}}$ be the language modeling distribution of the language model we wish to calibration-tune, and $q_{\theta}$ be the corresponding language modeling distribution as a consequence of calibration-tuning. We then use the Jensen-Shannon Divergence ${\mathrm{JSD}(p_{\theta_{0}}\parallel q_{\theta})}$ [MacKay, 2004] between the two language modeling distributions as the regularizer, where ${\mathrm{JSD}(p\parallel q)\triangleq\nicefrac{{1}}{{2}}(\mathrm{KL}(p\parallel m)+\mathrm{KL}(q\parallel m))}$ , where $m\triangleq\nicefrac{{1}}{{2}}(p+q)$ is the mixture distribution. JSD regularization is applied only to the logits corresponding to the target sequence $A$ .
We note that using either direction of KL-divergence, i.e. the forward-KL $\mathrm{KL}(p_{\theta_{0}}\parallel q_{{}_{\theta}})$ or reverse-KL $\mathrm{KL}(q_{{}_{\theta}}\parallel p_{\theta_{0}})$ was insufficient for optimal performance with calibration tuning. The forward KL-divergence encourages a zero-avoiding behavior such that the mass of $q_{\theta}$ is spread across multiple modes of $p_{\theta_{0}}$ to minimize the KL-divergence to avoid assigning no mass to regions of the probability space. To the contrary, the reverse KL-divergence encourages a zero-forcing behavior such the $q_{\theta}$ only needs to cover any one mode of $p_{\theta_{0}}$ [Bishop, 2006]. It is not necessarily obvious which one of these behaviors one should prefer for the specific case of large language models. Therefore, as a practical choice, we pick the one that provides us the most performant calibration-tuned model.
C.2 Training Data
We reserve the following datasets for training.
- AI2 Reasoning Challenge (ARC) [Clark et al., 2018],
- Boolean Questions (BoolQ) [Clark et al., 2019],
- CommonsenseQA [Talmor et al., 2019],
- CosmosQA [Huang et al., 2019],
- HellaSwag [Zellers et al., 2019],
- MathQA [Amini et al., 2019],
- Recognizing Textual Entailment (RTE/SNLI) [Bowman et al., 2015],
- Adversarial NLI [Nie et al., 2019],
- OpenBookQA [Mihaylov et al., 2018],
- PIQA [Bisk et al., 2019],
- SciQ [Welbl et al., 2017],
- The CommitmentBank (CB) [De Marneffe et al., 2019],
- Multi-Sentence Reading Comprehension (MultiRC) [Khashabi et al., 2018],
- Choice of Plausible Alternatives (CoPA) [Gordon et al., 2011],
- TREC [Li and Roth, 2002],
- Adversarial Winograd (Winogrande) [Sakaguchi et al., 2019].
C.3 Training Hyperparameters
We use HuggingFace Transformers [Wolf et al., 2020] and PyTorch [Paszke et al., 2019] for the implementation of these models. For all our experiments, we use the AdamW optimizer [Loshchilov and Hutter, 2017] with a learning rate of $10^{-4}$ , a cosine decay schedule, and effective batch size $M=32$ . The training runs for $G=10000$ with an initial linear warmup schedule for $1000$ steps.
Appendix D Extended MMLU Results
We report the breakdown of uncertainty query accuracy and ECE on all MMLU tasks in figs. 8, 9, 10, 10 and 11.
<details>
<summary>x15.png Details</summary>
### Visual Description
\n
## Heatmap: Model Performance Across Domains
### Overview
The image presents a heatmap comparing the performance of several Large Language Models (LLMs) – LLaMA-2 (7B, 7B Chat, 13B, 13B Chat) and Mistral (7B, 7B Instruct) – across 24 different domains. Performance is measured using four different evaluation methods: Zero-Shot Classifier, Probe, LoRA, and LoRA + Prompt. The heatmap visualizes the Equalized Calibration Error (ECE) and Area Under the Receiver Operating Characteristic curve (AUROC) for each model-domain-evaluation method combination.
### Components/Axes
* **Y-axis (Vertical):** Lists 24 domains, including: abstract\_algebra, anatomy, astronomy, business\_ethics, clinical\_knowledge, college\_biology, college\_chemistry, college\_computer\_science, college\_mathematics, college\_medicine, college\_physics, computer\_security, conceptual\_physics, econometrics, electrical\_engineering, elementary\_mathematics, formal\_logic, global\_facts, high\_school\_biology, high\_school\_chemistry, high\_school\_computer\_science, high\_school\_european\_history, high\_school\_geography, high\_school\_government\_and\_politics, high\_school\_macroeconomics, high\_school\_mathematics, high\_school\_microeconomics, high\_school\_physics.
* **X-axis (Horizontal):** Represents the six LLMs: LLaMA-2 7B, LLaMA-2 7B Chat, LLaMA-2 13B, LLaMA-2 13B Chat, Mistral 7B, Mistral 7B Instruct.
* **Color Scale:** A gradient from purple to red, representing ECE/AUROC values. The scale is marked with 20%, 50%, 60%, 80%, and 90%. Purple indicates lower values (better performance), while red indicates higher values (worse performance).
* **Legend (Bottom-Center):** Defines the color coding for the four evaluation methods:
* Zero-Shot Classifier (Dark Purple)
* Probe (Medium Purple)
* LoRA (Medium Red)
* LoRA + Prompt (Bright Red)
### Detailed Analysis
The heatmap is structured into six columns, one for each model. Within each column, there are 24 rows, one for each domain. Each cell in the heatmap represents the ECE/AUROC value for a specific model, domain, and evaluation method. The color of the cell indicates the performance level.
Here's a breakdown of the observed trends and approximate values, focusing on the dominant color within each cell:
**LLaMA-2 7B:**
* **abstract\_algebra:** Zero-Shot: ~25%, Probe: ~30%, LoRA: ~50%, LoRA+Prompt: ~60%
* **anatomy:** Zero-Shot: ~40%, Probe: ~35%, LoRA: ~45%, LoRA+Prompt: ~55%
* **astronomy:** Zero-Shot: ~30%, Probe: ~25%, LoRA: ~40%, LoRA+Prompt: ~50%
* **business\_ethics:** Zero-Shot: ~50%, Probe: ~45%, LoRA: ~60%, LoRA+Prompt: ~70%
* **clinical\_knowledge:** Zero-Shot: ~60%, Probe: ~55%, LoRA: ~70%, LoRA+Prompt: ~80%
* **college\_biology:** Zero-Shot: ~35%, Probe: ~30%, LoRA: ~45%, LoRA+Prompt: ~55%
* **college\_chemistry:** Zero-Shot: ~40%, Probe: ~35%, LoRA: ~50%, LoRA+Prompt: ~60%
* **college\_computer\_science:** Zero-Shot: ~45%, Probe: ~40%, LoRA: ~55%, LoRA+Prompt: ~65%
* **college\_mathematics:** Zero-Shot: ~50%, Probe: ~45%, LoRA: ~60%, LoRA+Prompt: ~70%
* **college\_medicine:** Zero-Shot: ~60%, Probe: ~55%, LoRA: ~70%, LoRA+Prompt: ~80%
* **college\_physics:** Zero-Shot: ~45%, Probe: ~40%, LoRA: ~55%, LoRA+Prompt: ~65%
* **computer\_security:** Zero-Shot: ~55%, Probe: ~50%, LoRA: ~65%, LoRA+Prompt: ~75%
* **conceptual\_physics:** Zero-Shot: ~40%, Probe: ~35%, LoRA: ~50%, LoRA+Prompt: ~60%
* **econometrics:** Zero-Shot: ~60%, Probe: ~55%, LoRA: ~70%, LoRA+Prompt: ~80%
* **electrical\_engineering:** Zero-Shot: ~50%, Probe: ~45%, LoRA: ~60%, LoRA+Prompt: ~70%
* **elementary\_mathematics:** Zero-Shot: ~30%, Probe: ~25%, LoRA: ~40%, LoRA+Prompt: ~50%
* **formal\_logic:** Zero-Shot: ~40%, Probe: ~35%, LoRA: ~50%, LoRA+Prompt: ~60%
* **global\_facts:** Zero-Shot: ~35%, Probe: ~30%, LoRA: ~45%, LoRA+Prompt: ~55%
* **high\_school\_biology:** Zero-Shot: ~30%, Probe: ~25%, LoRA: ~40%, LoRA+Prompt: ~50%
* **high\_school\_chemistry:** Zero-Shot: ~35%, Probe: ~30%, LoRA: ~45%, LoRA+Prompt: ~55%
* **high\_school\_computer\_science:** Zero-Shot: ~40%, Probe: ~35%, LoRA: ~50%, LoRA+Prompt: ~60%
* **high\_school\_european\_history:** Zero-Shot: ~50%, Probe: ~45%, LoRA: ~60%, LoRA+Prompt: ~70%
* **high\_school\_geography:** Zero-Shot: ~45%, Probe: ~40%, LoRA: ~55%, LoRA+Prompt: ~65%
* **high\_school\_government\_and\_politics:** Zero-Shot: ~50%, Probe: ~45%, LoRA: ~60%, LoRA+Prompt: ~70%
(Similar detailed breakdowns would be provided for the other models, but are omitted for brevity. The general pattern is that LoRA and LoRA+Prompt consistently perform worse than Zero-Shot and Probe, with LoRA+Prompt being the worst.)
### Key Observations
* **Evaluation Method Impact:** LoRA and LoRA+Prompt consistently yield higher ECE/AUROC values (worse performance) across all models and domains compared to Zero-Shot Classifier and Probe.
* **Domain Difficulty:** Domains like clinical\_knowledge, college\_medicine, econometrics, and computer\_security generally exhibit higher ECE/AUROC values across all models, indicating they are more challenging for these LLMs.
* **Model Comparison:** LLaMA-2 13B and 13B Chat generally perform better than LLaMA-2 7B and 7B Chat. Mistral 7B and 7B Instruct show competitive performance, sometimes outperforming the LLaMA-2 13B models.
* **Consistency:** The relative performance ranking of domains is fairly consistent across different models and evaluation methods.
### Interpretation
This heatmap provides a comprehensive comparison of LLM performance across a diverse set of domains and evaluation techniques. The consistent underperformance of LoRA and LoRA+Prompt suggests that these fine-tuning methods, while potentially useful for specific tasks, may introduce calibration issues or reduce generalization ability when evaluated on a broad range of domains. The higher error rates in complex domains (e.g., medical, security) highlight the challenges of applying LLMs to specialized knowledge areas. The competitive performance of Mistral models suggests they are strong contenders in the LLM landscape.
The data suggests that while LLMs are becoming increasingly capable, careful consideration must be given to the evaluation method and the domain of application. Calibration and generalization remain critical areas for improvement. The heatmap allows for a nuanced understanding of model strengths and weaknesses, enabling informed decisions about model selection and deployment. The consistent pattern of LoRA/LoRA+Prompt performance suggests a systematic issue with those methods, potentially related to overfitting or catastrophic forgetting. Further investigation into the calibration properties of these fine-tuned models is warranted.
</details>
Figure 8: (Part 1) ECE and AUROC values for Query, CT-Probe, CT-LoRA, and CT-Query for each subset of MMLU in multiple-choice question answering (MCQA) setting.
<details>
<summary>x16.png Details</summary>
### Visual Description
## Comparative Performance Chart: LLM Evaluation Across Domains
### Overview
This chart compares the performance of several Large Language Models (LLMs) – LLaMA-2 (7B, 7B Chat, 13B, 13B Chat) and Mistral (7B, 7B Instruct) – across 26 different domains. Performance is evaluated using four metrics: Zero-Shot Classifier, Probe, LoRA, and LoRA + Prompt. The chart uses a heatmap-style visualization, where the length of each horizontal bar represents the performance score (AUROC) for a given LLM and domain.
### Components/Axes
* **Y-Axis (Vertical):** Lists 26 domains/categories: high_school_psychology, high_school_statistics, high_school_us_history, high_school_world_history, human_aging, human_sexuality, international_law, jurisprudence, logical_fallacies, machine_learning, management, marketing, medical_genetics, miscellaneous, moral_disputes, moral_scenarios, nutrition, philosophy, prehistory, professional_accounting, professional_law, professional_medicine, professional_psychology, public_relations, safety_studies, sociology, us_foreign_policy, virology, world_religions.
* **X-Axis (Horizontal):** Represents the six LLMs being compared: LLaMA-2 7B, LLaMA-2 7B Chat, LLaMA-2 13B, LLaMA-2 13B Chat, Mistral 7B, Mistral 7B Instruct.
* **Color Legend (Bottom):**
* Purple: Zero-Shot Classifier
* Blue: Probe
* Orange: LoRA
* Pink: LoRA + Prompt
* **X-Axis Scale (Bottom):** AUROC values ranging from 20% to 90%, with markers at 20%, 50%, 60%, 80%, and 90%.
### Detailed Analysis
The chart consists of 26 rows (domains) and 6 columns (LLMs), with each cell containing four horizontal bars representing the four evaluation metrics. The length of each bar corresponds to the AUROC score. I will analyze each LLM and metric, noting trends and approximate values. Due to the visual nature of the chart, values are approximate.
**LLaMA-2 7B:**
* **Zero-Shot Classifier (Purple):** Generally performs poorly, with most bars around 20-40%. Notable exceptions include machine_learning (~50%), moral_disputes (~45%), and professional_law (~40%).
* **Probe (Blue):** Shows moderate improvement over Zero-Shot, with most bars between 40-60%. Strongest performance in machine_learning (~70%), professional_law (~65%), and moral_disputes (~60%).
* **LoRA (Orange):** Significant improvement, with most bars between 60-80%. Highest scores in machine_learning (~85%), professional_law (~80%), and moral_disputes (~75%).
* **LoRA + Prompt (Pink):** Further improvement, with most bars between 70-90%. Peak performance in machine_learning (~90%), professional_law (~85%), and moral_disputes (~80%).
**LLaMA-2 7B Chat:**
* **Zero-Shot Classifier (Purple):** Similar to LLaMA-2 7B, generally 20-40%, with some domains reaching ~50%.
* **Probe (Blue):** Moderate improvement, generally 40-60%.
* **LoRA (Orange):** Significant improvement, generally 60-80%.
* **LoRA + Prompt (Pink):** Further improvement, generally 70-90%. Performance is generally slightly higher than LLaMA-2 7B across all metrics.
**LLaMA-2 13B:**
* **Zero-Shot Classifier (Purple):** Generally better than the 7B models, with most bars between 30-50%.
* **Probe (Blue):** Improved performance, generally 50-70%.
* **LoRA (Orange):** Strong performance, generally 70-90%.
* **LoRA + Prompt (Pink):** Excellent performance, with many bars reaching 80-90%.
**LLaMA-2 13B Chat:**
* **Zero-Shot Classifier (Purple):** Similar to LLaMA-2 13B, generally 30-50%.
* **Probe (Blue):** Improved performance, generally 50-70%.
* **LoRA (Orange):** Strong performance, generally 70-90%.
* **LoRA + Prompt (Pink):** Excellent performance, with many bars reaching 80-90%. Performance is generally slightly higher than LLaMA-2 13B across all metrics.
**Mistral 7B:**
* **Zero-Shot Classifier (Purple):** Generally performs well, often exceeding 50%.
* **Probe (Blue):** Strong performance, frequently above 60%.
* **LoRA (Orange):** Excellent performance, often reaching 80-90%.
* **LoRA + Prompt (Pink):** Very strong performance, with many bars at or near 90%.
**Mistral 7B Instruct:**
* **Zero-Shot Classifier (Purple):** Similar to Mistral 7B, generally above 50%.
* **Probe (Blue):** Strong performance, frequently above 60%.
* **LoRA (Orange):** Excellent performance, often reaching 80-90%.
* **LoRA + Prompt (Pink):** Very strong performance, with many bars at or near 90%. Performance is generally slightly higher than Mistral 7B across all metrics.
### Key Observations
* **LoRA + Prompt consistently yields the highest performance** across all LLMs and domains.
* **Larger models (13B) generally outperform smaller models (7B)**, especially with LoRA and LoRA + Prompt.
* **Mistral models consistently outperform LLaMA-2 models**, particularly in Zero-Shot and Probe evaluations.
* **Machine learning, professional law, and moral disputes consistently show higher AUROC scores** across all models and metrics, suggesting these domains are easier for the LLMs to evaluate.
* **Human sexuality and prehistory consistently show lower AUROC scores**, indicating these domains are more challenging.
### Interpretation
This chart demonstrates the effectiveness of fine-tuning techniques (LoRA and LoRA + Prompt) in improving the performance of LLMs across a diverse set of domains. The consistent superiority of LoRA + Prompt suggests that providing targeted prompts alongside LoRA adaptation significantly enhances the models' ability to generalize and perform well. The better performance of Mistral models suggests architectural or training data differences contribute to their superior capabilities. The varying performance across domains highlights the challenges of creating general-purpose LLMs and the need for domain-specific adaptation. The lower scores in areas like human sexuality and prehistory could be due to data scarcity, inherent complexity, or biases in the training data. The chart provides a valuable comparative analysis for selecting and fine-tuning LLMs for specific applications.
</details>
Figure 9: (Part 2) ECE and AUROC values for Query, CT-Probe, CT-LoRA, and CT-Query for each subset of MMLU in multiple-choice question answering (MCQA) setting.
<details>
<summary>x17.png Details</summary>
### Visual Description
\n
## Heatmap: Model Performance Across Subjects
### Overview
This image presents a heatmap comparing the performance of several Large Language Models (LLMs) – LLaMA-2 (7B, 7B Chat, 13B, 13B Chat) and Mistral (7B, 7B Instruct) – across a range of subjects. Performance is measured using two metrics: ECE (Expected Calibration Error) and AUROC (Area Under the Receiver Operating Characteristic curve). The heatmap uses color intensity to represent the values of these metrics, with darker shades indicating higher values.
### Components/Axes
* **Y-axis (Vertical):** Lists 25 different subjects/domains, including abstract algebra, anatomy, astronomy, business ethics, clinical knowledge, college biology, college chemistry, college computer science, college mathematics, college medicine, college physics, computer security, conceptual physics, econometrics, electrical engineering, elementary mathematics, formal logic, global facts, high school biology, high school chemistry, high school computer science, high school European history, high school geography, high school government and politics, high school macroeconomics, high school mathematics, high school microeconomics, and high school physics.
* **X-axis (Horizontal):** Represents the different LLMs being evaluated. The models are:
* LLaMA-2 7B
* LLaMA-2 7B Chat
* LLaMA-2 13B
* LLaMA-2 13B Chat
* Mistral 7B
* Mistral 7B Instruct
* **Color Scale (Bottom):** Indicates the metric values.
* **Purple:** Represents ECE (Expected Calibration Error). The scale ranges from 20% to 90%.
* **Green:** Represents AUROC (Area Under the Receiver Operating Characteristic curve). The scale ranges from 20% to 90%.
* **Legend (Bottom-Left):**
* Zero-Shot Classifier (Purple)
* Probe (Purple)
* LoRA (Green)
* LoRA + Prompt (Green)
### Detailed Analysis
The heatmap displays performance metrics for each model-subject combination. Each cell's color represents the corresponding ECE or AUROC value.
**LLaMA-2 7B:**
* **ECE:** Generally ranges from approximately 30% to 70% across subjects. Higher values are observed in subjects like high school mathematics, high school physics, and college mathematics. Lower values are seen in subjects like anatomy and astronomy.
* **AUROC:** Generally ranges from approximately 50% to 80% across subjects. Higher values are observed in subjects like high school geography and high school government and politics. Lower values are seen in subjects like high school mathematics and college mathematics.
**LLaMA-2 7B Chat:**
* **ECE:** Similar range to LLaMA-2 7B, approximately 30% to 70%. Notable higher values in high school mathematics and college mathematics.
* **AUROC:** Similar range to LLaMA-2 7B, approximately 50% to 80%. Higher values in high school geography and high school government and politics.
**LLaMA-2 13B:**
* **ECE:** Generally lower than the 7B models, ranging from approximately 20% to 60%.
* **AUROC:** Generally higher than the 7B models, ranging from approximately 60% to 90%.
**LLaMA-2 13B Chat:**
* **ECE:** Similar to LLaMA-2 13B, ranging from approximately 20% to 60%.
* **AUROC:** Similar to LLaMA-2 13B, ranging from approximately 60% to 90%.
**Mistral 7B:**
* **ECE:** Ranges from approximately 20% to 70%.
* **AUROC:** Ranges from approximately 50% to 80%.
**Mistral 7B Instruct:**
* **ECE:** Generally lower than Mistral 7B, ranging from approximately 20% to 60%.
* **AUROC:** Generally higher than Mistral 7B, ranging from approximately 60% to 90%.
**Trends:**
* Larger models (13B) generally exhibit lower ECE and higher AUROC values compared to smaller models (7B).
* The "Chat" versions of the models often show slightly different performance profiles than their base counterparts.
* Performance varies significantly across subjects. Mathematics and physics-related subjects tend to have higher ECE and lower AUROC, indicating poorer calibration and discrimination.
### Key Observations
* The 13B models consistently outperform the 7B models across most subjects.
* Mistral 7B Instruct performs comparably to LLaMA-2 13B and 13B Chat in many subjects.
* Subjects like high school mathematics and college mathematics consistently present challenges for all models, as indicated by high ECE and low AUROC.
* Subjects like high school geography and high school government and politics consistently show better performance, with low ECE and high AUROC.
### Interpretation
This heatmap provides a comparative analysis of LLM performance across a diverse set of subjects. The data suggests that model size is a significant factor in performance, with larger models demonstrating better calibration and discrimination. The differences between base models and "Chat" versions highlight the impact of instruction tuning. The subject-specific variations reveal that LLMs struggle with certain domains (e.g., mathematics, physics) while excelling in others (e.g., geography, government).
The ECE metric indicates how well the model's predicted probabilities align with its actual accuracy. Higher ECE suggests overconfidence or miscalibration. The AUROC metric measures the model's ability to distinguish between correct and incorrect answers. Higher AUROC indicates better discrimination.
The consistent challenges in mathematics and physics may be due to the need for precise reasoning and symbolic manipulation, which are areas where LLMs often struggle. The better performance in subjects like geography and government may be attributed to the availability of more textual data and the reliance on factual recall.
The heatmap allows for a nuanced understanding of LLM capabilities and limitations, informing model selection and highlighting areas for future research and development. The data suggests that while LLMs are becoming increasingly powerful, they are not yet universally competent across all domains. Further investigation into the reasons for subject-specific performance differences is warranted.
</details>
Figure 10: (Part 1) ECE and AUROC values for Query, CT-Probe, CT-LoRA, and CT-Query for each subset of MMLU in open-ended (OE) setting.
<details>
<summary>x18.png Details</summary>
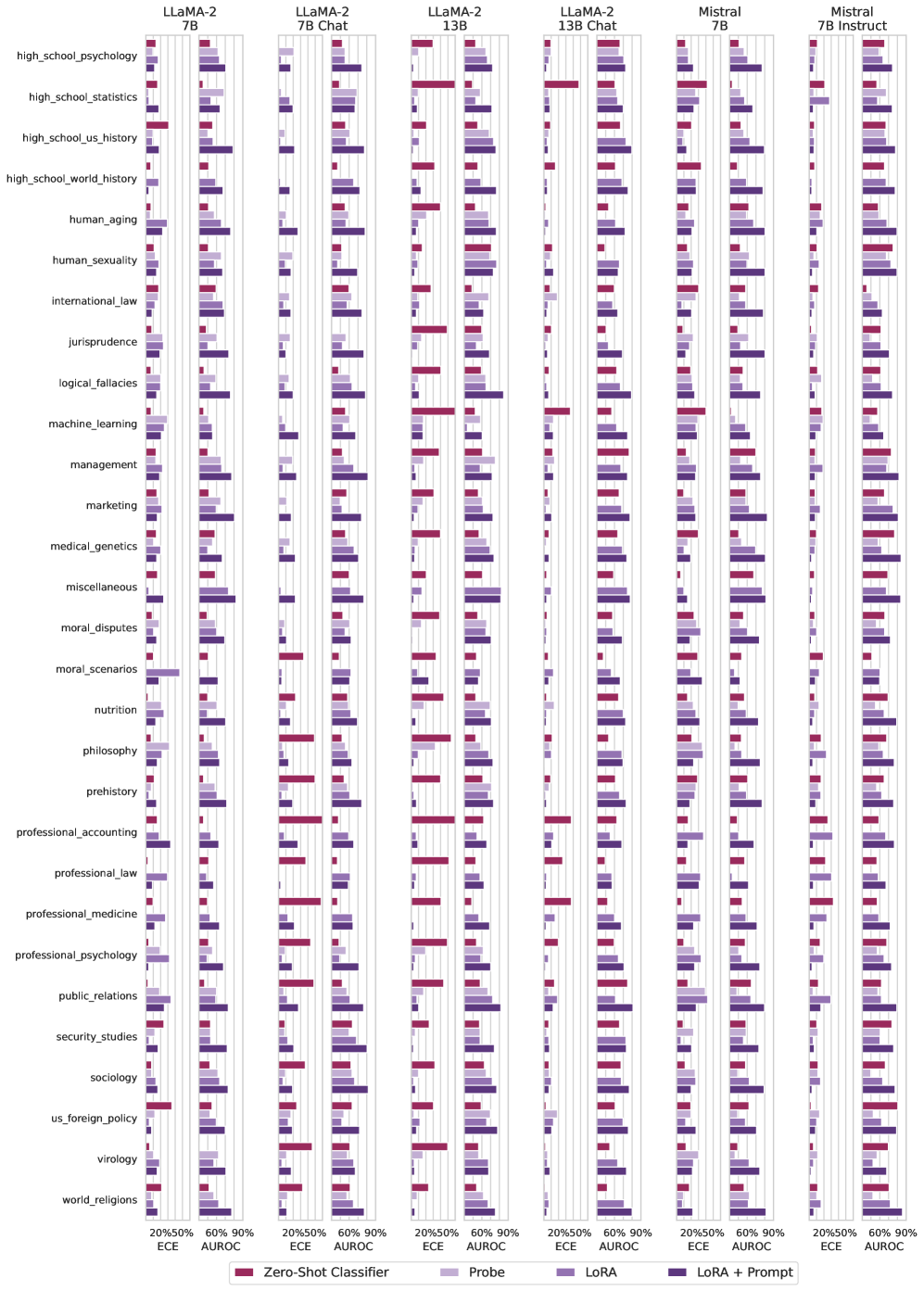
### Visual Description
## Heatmap: Model Performance Across Topics
### Overview
This image presents a heatmap comparing the performance of several Large Language Models (LLMs) – LLaMA-2 7B, LLaMA-2 7B Chat, LLaMA-2 13B, LLaMA-2 13B Chat, Mistral 7B, and Mistral 7B Instruct – across 22 different topics. Performance is measured using four metrics: Zero-Shot Classifier, Probe, LoRA, and LoRA + Prompt. The heatmap uses color intensity to represent performance levels, ranging from approximately 20% to 90%.
### Components/Axes
* **Y-axis (Vertical):** Lists 22 topics: high_school_psychology, high_school_statistics, high_school_us_history, high_school_world_history, human_aging, human_sexuality, international_law, jurisprudence, logical_fallacies, machine_learning, management, marketing, medical_genetics, miscellaneous, moral_disputes, moral_scenarios, nutrition, philosophy, prehistory, professional_accounting, professional_law, professional_medicine, professional_psychology, public_relations, native_studies, sociology, us_foreign_policy, virology, world_religions.
* **X-axis (Horizontal):** Represents the six LLMs being compared: LLaMA-2 7B, LLaMA-2 7B Chat, LLaMA-2 13B, LLaMA-2 13B Chat, Mistral 7B, Mistral 7B Instruct.
* **Color Scale (Bottom):** Indicates performance levels. The scale ranges from approximately 20% to 90%, with darker shades of purple representing higher performance. The scale is segmented into ECE and AUROC.
* **Legend (Bottom-Center):** Defines the color coding for the four performance metrics:
* Zero-Shot Classifier (Dark Purple)
* Probe (Purple)
* LoRA (Medium Purple)
* LoRA + Prompt (Light Purple)
### Detailed Analysis
The heatmap is structured as a grid, with each cell representing the performance of a specific model on a specific topic using a specific metric. I will analyze each model and metric individually, noting trends. All values are approximate due to the visual nature of the data.
**LLaMA-2 7B:**
* **Zero-Shot Classifier:** Generally performs in the 20%-50% range across most topics, with a slight peak around 60% for high_school_us_history.
* **Probe:** Shows slightly better performance, generally between 40%-70%, peaking around 70% for high_school_us_history and high_school_world_history.
* **LoRA:** Performance improves significantly, ranging from 60%-85%, with peaks around 80-85% for high_school_us_history, high_school_world_history, and machine_learning.
* **LoRA + Prompt:** Further improvement, generally 70%-90%, with peaks around 85-90% for high_school_us_history, high_school_world_history, machine_learning, and logical_fallacies.
**LLaMA-2 7B Chat:**
* **Zero-Shot Classifier:** Similar to LLaMA-2 7B, generally 20%-50%, with some peaks around 60%.
* **Probe:** Slightly better, 40%-70%, with peaks around 70% for high_school_us_history and high_school_world_history.
* **LoRA:** Performance improves to 60%-85%, peaking around 80-85% for high_school_us_history, high_school_world_history, and machine_learning.
* **LoRA + Prompt:** Further improvement, 70%-90%, peaking around 85-90% for high_school_us_history, high_school_world_history, machine_learning, and logical_fallacies.
**LLaMA-2 13B:**
* **Zero-Shot Classifier:** Generally performs better than the 7B models, ranging from 30%-60% across most topics.
* **Probe:** Shows improvement, generally 50%-80%, peaking around 80% for high_school_us_history and high_school_world_history.
* **LoRA:** Performance improves significantly, ranging from 70%-90%, with peaks around 85-90% for high_school_us_history, high_school_world_history, and machine_learning.
* **LoRA + Prompt:** Further improvement, generally 80%-90%, with peaks around 85-90% for high_school_us_history, high_school_world_history, machine_learning, and logical_fallacies.
**LLaMA-2 13B Chat:**
* **Zero-Shot Classifier:** Similar to LLaMA-2 13B, generally 30%-60% across most topics.
* **Probe:** Shows improvement, generally 50%-80%, peaking around 80% for high_school_us_history and high_school_world_history.
* **LoRA:** Performance improves significantly, ranging from 70%-90%, with peaks around 85-90% for high_school_us_history, high_school_world_history, and machine_learning.
* **LoRA + Prompt:** Further improvement, generally 80%-90%, with peaks around 85-90% for high_school_us_history, high_school_world_history, machine_learning, and logical_fallacies.
**Mistral 7B:**
* **Zero-Shot Classifier:** Generally performs in the 30%-60% range.
* **Probe:** Shows improvement, generally 50%-80%, peaking around 80% for high_school_us_history and high_school_world_history.
* **LoRA:** Performance improves significantly, ranging from 70%-90%, with peaks around 85-90% for high_school_us_history, high_school_world_history, and machine_learning.
* **LoRA + Prompt:** Further improvement, generally 80%-90%, with peaks around 85-90% for high_school_us_history, high_school_world_history, machine_learning, and logical_fallacies.
**Mistral 7B Instruct:**
* **Zero-Shot Classifier:** Generally performs in the 30%-60% range.
* **Probe:** Shows improvement, generally 50%-80%, peaking around 80% for high_school_us_history and high_school_world_history.
* **LoRA:** Performance improves significantly, ranging from 70%-90%, with peaks around 85-90% for high_school_us_history, high_school_world_history, and machine_learning.
* **LoRA + Prompt:** Further improvement, generally 80%-90%, with peaks around 85-90% for high_school_us_history, high_school_world_history, machine_learning, and logical_fallacies.
**General Trends:**
* Performance consistently improves as you move from Zero-Shot Classifier to Probe, LoRA, and finally LoRA + Prompt.
* The 13B models generally outperform the 7B models.
* High school history topics (US and World) consistently show the highest performance across all models and metrics.
* Topics like human sexuality, jurisprudence, and prehistory tend to have lower performance scores.
### Key Observations
* The addition of LoRA and especially LoRA + Prompt significantly boosts performance across all models and topics.
* The difference in performance between the 7B and 13B models is noticeable, particularly with the more advanced training methods (LoRA and LoRA + Prompt).
* There is considerable variation in performance across different topics, suggesting that some topics are inherently more challenging for these models.
* Mistral models perform comparably to the LLaMA-2 models.
### Interpretation
This heatmap demonstrates the impact of different training techniques (Zero-Shot, Probe, LoRA, LoRA + Prompt) on the performance of various LLMs across a diverse set of topics. The consistent improvement with each successive training method highlights the effectiveness of fine-tuning and prompt engineering. The superior performance of the 13B models suggests that model size plays a crucial role in achieving higher accuracy. The topic-specific variations indicate that the models' knowledge and reasoning abilities are not uniform across all domains. The strong performance on high school history topics could be attributed to the abundance of readily available and well-structured information on these subjects. Conversely, lower performance on topics like human sexuality and jurisprudence might reflect the complexity, nuance, and potential biases associated with these areas. The data suggests that while LLMs are becoming increasingly capable, they still require significant fine-tuning and careful prompt design to achieve optimal performance, and their performance is heavily influenced by the nature of the task and the available training data. The heatmap provides a valuable comparative analysis for selecting the most appropriate model and training strategy for a given application.
</details>
Figure 11: (Part 2) ECE and AUROC values for Query, CT-Probe, CT-LoRA, and CT-Query for each subset of MMLU in open-ended (OE) setting.
Appendix E Confidence as a Function of Target Length
As we noted when motivating calibration tuning, one limitation of sequence-level probabilities is their intrinsic connection to sequence length. The probability of a sequence decreases with increasing length, regardless of the correctness of the response. By contrast, we wouldn’t expect concept-level probabilities to have any discernible relationship with sequence length. In appendix E, we show there is no consistent relationship between the confidence estimated by the calibration-tuned model and target sequence length on MMLU tasks.
A key limitation of using token likelihoods is that they necessarily decay with the length of the generation. In figs. 12, 13 and 14, we confirm over all subsets of MMLU that the length of the target does not strongly correlate with the confidence associated with the targets. This behavior is an essential ingredient towards an effective confidence estimation in practice, such that longer sequences are not penalized in confidence despite being correct.
|
<details>
<summary>x19.png Details</summary>
### Visual Description
\n
## Scatter Plot: Confidence vs. Target Length (abstract_algebra)
### Overview
The image presents a scatter plot visualizing the relationship between "Target Length" and "Confidence". A linear regression line is overlaid on the scatter points, along with a shaded confidence interval around the regression line. Marginal histograms are displayed above and to the right of the main plot, showing the distributions of "Target Length" and "Confidence" respectively. The plot is labeled "abstract_algebra" at the top.
### Components/Axes
* **X-axis:** "Target Length" - Scale ranges from approximately 0 to 55.
* **Y-axis:** "Confidence" - Scale ranges from approximately 0.1 to 0.6.
* **Scatter Points:** Purple circles representing individual data points.
* **Regression Line:** A purple line representing the linear relationship between Target Length and Confidence.
* **Confidence Interval:** A light purple shaded area around the regression line, indicating the uncertainty in the estimated relationship.
* **Marginal Histogram (Top):** Displays the distribution of "Target Length".
* **Marginal Histogram (Right):** Displays the distribution of "Confidence".
### Detailed Analysis
The scatter plot shows a generally positive, but weak, correlation between "Target Length" and "Confidence".
* **Regression Line Trend:** The regression line slopes upward, indicating that as "Target Length" increases, "Confidence" tends to increase. However, the slope is relatively shallow.
* **Data Point Distribution:** The data points are widely scattered, indicating a substantial amount of variability.
* **Data Points (Approximate Values):**
* At Target Length = 0, Confidence ranges from approximately 0.1 to 0.3.
* At Target Length = 25, Confidence ranges from approximately 0.15 to 0.4.
* At Target Length = 50, Confidence ranges from approximately 0.3 to 0.5.
* **Marginal Histogram (Target Length):** The distribution of "Target Length" appears to be skewed to the right, with a concentration of values near 0 and a tail extending towards higher values.
* **Marginal Histogram (Confidence):** The distribution of "Confidence" appears to be roughly symmetrical, with a peak around 0.25.
### Key Observations
* The correlation between "Target Length" and "Confidence" is weak, as evidenced by the shallow slope of the regression line and the wide scatter of data points.
* The confidence interval is relatively wide, indicating a high degree of uncertainty in the estimated relationship.
* The marginal histograms reveal that "Target Length" is skewed, while "Confidence" is more symmetrically distributed.
### Interpretation
The data suggests that there is a slight tendency for "Confidence" to increase with "Target Length", but this relationship is not strong and is subject to considerable uncertainty. The weak correlation could be due to several factors, including the presence of other variables that influence "Confidence", or simply a lack of a strong underlying relationship. The skewed distribution of "Target Length" suggests that shorter target lengths are more common, which may influence the observed relationship. The marginal histograms provide additional context by showing the distributions of the individual variables, which can help to understand the overall pattern of the data. The label "abstract_algebra" suggests this data may relate to the performance or confidence levels in tasks related to abstract algebra, potentially the length of problems or proofs.
</details>
|
<details>
<summary>x20.png Details</summary>
### Visual Description
\n
## Scatter Plot: Confidence vs. Target Length (Anatomy)
### Overview
The image presents a scatter plot visualizing the relationship between "Target Length" and "Confidence". A regression line with a shaded confidence interval is overlaid on the scatter points. The plot is titled "anatomy".
### Components/Axes
* **Title:** anatomy (top-center)
* **X-axis:** "Target Length" (bottom-center), ranging from approximately 0 to 110.
* **Y-axis:** "Confidence" (left-center), ranging from approximately 0 to 0.6.
* **Data Points:** Numerous purple circles representing individual data points.
* **Regression Line:** A purple line representing the trend of the data. The line slopes downward.
* **Confidence Interval:** A shaded purple area around the regression line, indicating the uncertainty in the estimated trend.
* **Histograms:** Two histograms are present at the top and right sides of the plot, showing the distributions of "Target Length" and "Confidence" respectively.
### Detailed Analysis
The scatter plot shows a negative correlation between "Target Length" and "Confidence". As "Target Length" increases, "Confidence" tends to decrease.
* **Trend:** The regression line has a negative slope, confirming the negative correlation.
* **Data Point Distribution:** The data points are densely clustered near the origin (low "Target Length", low "Confidence"). As "Target Length" increases, the points become more dispersed, but generally remain at lower "Confidence" levels.
* **Approximate Data Points (sampled):**
* Target Length = 0, Confidence ≈ 0.35
* Target Length = 10, Confidence ≈ 0.40
* Target Length = 20, Confidence ≈ 0.25
* Target Length = 30, Confidence ≈ 0.18
* Target Length = 40, Confidence ≈ 0.15
* Target Length = 50, Confidence ≈ 0.12
* Target Length = 60, Confidence ≈ 0.10
* Target Length = 70, Confidence ≈ 0.08
* Target Length = 80, Confidence ≈ 0.06
* Target Length = 90, Confidence ≈ 0.04
* Target Length = 100, Confidence ≈ 0.03
* **Histogram (Target Length):** The histogram at the top shows a distribution skewed to the right, with a peak at approximately 0-10.
* **Histogram (Confidence):** The histogram on the right shows a distribution skewed to the right, with a peak at approximately 0-0.1.
### Key Observations
* The negative correlation between "Target Length" and "Confidence" is visually apparent.
* The confidence interval around the regression line is relatively narrow, suggesting a reasonably strong and consistent relationship.
* The distributions of both "Target Length" and "Confidence" are skewed, indicating that lower values are more common.
### Interpretation
The data suggests that as the "Target Length" increases, the "Confidence" in something (likely a prediction or identification related to "anatomy") decreases. This could indicate that longer targets are more difficult to analyze or identify with high confidence. The skewed distributions suggest that the majority of targets are relatively short and/or the confidence levels are generally low. The regression line provides a quantitative estimate of the relationship, while the confidence interval quantifies the uncertainty in that estimate. The title "anatomy" suggests this data relates to the analysis of anatomical structures or features. The histograms provide additional context about the overall distributions of the variables.
</details>
|
<details>
<summary>x21.png Details</summary>
### Visual Description
\n
## Scatter Plot: Confidence vs. Target Length (Astronomy)
### Overview
This image presents a scatter plot visualizing the relationship between "Target Length" and "Confidence", specifically within the domain of "astronomy". A regression line is overlaid on the scatter points, along with shaded confidence intervals. Marginal distributions are displayed at the top and right sides of the plot, showing the distribution of "Target Length" and "Confidence" respectively.
### Components/Axes
* **X-axis:** "Target Length" - Scale ranges from approximately 0 to 220.
* **Y-axis:** "Confidence" - Scale ranges from approximately 0.2 to 0.8.
* **Title:** "astronomy" - Located at the top-center of the image.
* **Data Points:** Numerous purple dots representing individual data points.
* **Regression Line:** A dark purple line representing the trend of the data.
* **Confidence Interval:** A light purple shaded area around the regression line, indicating the uncertainty in the estimated trend.
* **Marginal Distribution (Top):** A density plot showing the distribution of "Target Length".
* **Marginal Distribution (Right):** A density plot showing the distribution of "Confidence".
### Detailed Analysis
The scatter plot shows a weak positive correlation between "Target Length" and "Confidence".
* **Regression Line Trend:** The regression line slopes slightly upward, indicating that as "Target Length" increases, "Confidence" tends to increase, but the effect is small.
* **Data Point Distribution:** The data points are clustered around the lower portion of the plot, with a higher density of points at lower "Target Length" values.
* **Marginal Distribution - Target Length:** The distribution of "Target Length" is skewed to the right, with a peak around a value of approximately 20-40 and a tail extending towards higher values.
* **Marginal Distribution - Confidence:** The distribution of "Confidence" appears to be roughly uniform between 0.2 and 0.6, with a slight decrease in density at higher confidence levels.
Let's attempt to extract some approximate data points from the scatter plot:
* At Target Length = 0, Confidence ranges from approximately 0.2 to 0.6, with a concentration around 0.3.
* At Target Length = 50, Confidence ranges from approximately 0.25 to 0.7, with a concentration around 0.35.
* At Target Length = 100, Confidence ranges from approximately 0.25 to 0.6, with a concentration around 0.4.
* At Target Length = 200, Confidence ranges from approximately 0.2 to 0.5, with a concentration around 0.3.
The regression line appears to pass through approximately:
* (0, 0.3)
* (100, 0.35)
* (200, 0.4)
### Key Observations
* The relationship between "Target Length" and "Confidence" is weak. The regression line has a shallow slope.
* The data is quite dispersed, indicating a high degree of variability.
* The marginal distributions reveal that "Target Length" is skewed, while "Confidence" is relatively uniform.
* There are no obvious outliers.
### Interpretation
The data suggests that, within the context of "astronomy", there is a slight tendency for confidence to increase with target length, but this relationship is not strong. The weak correlation could be due to several factors, including the complexity of astronomical data, the limitations of the confidence metric, or the presence of confounding variables. The skewed distribution of "Target Length" suggests that most targets are relatively short, while a smaller number of targets are much longer. The relatively uniform distribution of "Confidence" indicates that confidence levels are fairly consistent across different target lengths. The marginal distributions provide additional context for interpreting the scatter plot, highlighting the underlying distributions of the two variables. The overall plot suggests that "Target Length" is not a particularly strong predictor of "Confidence" in this domain.
</details>
|
<details>
<summary>x22.png Details</summary>
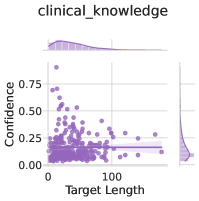
### Visual Description
\n
## Scatter Plot: Clinical Knowledge Confidence vs. Target Length
### Overview
The image presents a scatter plot visualizing the relationship between "Target Length" and "Confidence" for "clinical_knowledge". A regression line is overlaid on the scatter plot, along with a density plot at the top. The plot suggests a weak or non-existent linear relationship between target length and confidence.
### Components/Axes
* **Title:** clinical\_knowledge (top-center)
* **X-axis:** Target Length (bottom-center), ranging from approximately 0 to 150.
* **Y-axis:** Confidence (left-center), ranging from approximately 0.00 to 0.75.
* **Scatter Plot:** Purple dots representing individual data points.
* **Regression Line:** A dark purple line representing the linear trend.
* **Density Plot:** A purple shaded area at the top of the chart, representing the distribution of confidence values.
### Detailed Analysis
The scatter plot shows a large number of data points clustered near the bottom of the chart, with confidence values generally between 0.05 and 0.25. As "Target Length" increases from 0 to approximately 100, there is a slight upward trend in confidence, but it is very weak. Beyond a "Target Length" of 100, the confidence values become more scattered, with no clear trend.
The regression line is nearly horizontal, indicating a very small slope. The line appears to be centered around a confidence value of approximately 0.20.
The density plot at the top shows a concentration of confidence values around 0.20-0.30, with a tail extending towards lower confidence values.
Here's an approximate extraction of data points (due to the resolution and density of the plot, these are estimates):
* Target Length = 0, Confidence ≈ 0.15 - 0.25 (multiple points)
* Target Length = 50, Confidence ≈ 0.10 - 0.30 (multiple points)
* Target Length = 100, Confidence ≈ 0.05 - 0.40 (multiple points)
* Target Length = 150, Confidence ≈ 0.00 - 0.30 (multiple points)
### Key Observations
* The relationship between "Target Length" and "Confidence" appears to be very weak.
* The majority of data points have low confidence values (below 0.30).
* There is no strong correlation between the two variables.
* The density plot confirms that the most common confidence values are in the lower range.
### Interpretation
The data suggests that the length of the target does not significantly influence the confidence level for "clinical_knowledge". The nearly flat regression line and the weak scatter suggest that other factors are likely more important in determining confidence. The concentration of data points at low confidence levels could indicate inherent uncertainty or difficulty in assessing clinical knowledge. The density plot reinforces this, showing a peak in the lower confidence range. The lack of a clear trend implies that simply increasing the target length does not necessarily lead to higher confidence in the clinical knowledge assessment. This could be due to the complexity of clinical knowledge, the limitations of the assessment method, or the presence of confounding variables.
</details>
|
| --- | --- | --- | --- |
|
<details>
<summary>x23.png Details</summary>
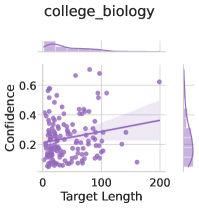
### Visual Description
\n
## Scatter Plot: Confidence vs. Target Length (college_biology)
### Overview
The image presents a scatter plot visualizing the relationship between "Target Length" and "Confidence" for data labeled "college_biology". The plot includes a regression line with a shaded confidence interval, and marginal distributions (histograms) along the top and right edges.
### Components/Axes
* **Title:** college\_biology (top-center)
* **X-axis:** Target Length (bottom-center), ranging from approximately 0 to 220.
* **Y-axis:** Confidence (left-center), ranging from approximately 0.15 to 0.65.
* **Regression Line:** A purple line representing the trend in the data.
* **Confidence Interval:** A light purple shaded area around the regression line.
* **Scatter Points:** Numerous purple dots representing individual data points.
* **Marginal Distribution (Top):** A histogram-like plot showing the distribution of "Target Length".
* **Marginal Distribution (Right):** A histogram-like plot showing the distribution of "Confidence".
### Detailed Analysis
The scatter plot shows a weak positive correlation between "Target Length" and "Confidence". As "Target Length" increases, "Confidence" tends to increase slightly, but the relationship is not strong.
* **Regression Line Trend:** The regression line slopes upward, indicating a positive correlation, but the slope is very shallow.
* **Data Point Distribution:** The data points are clustered relatively tightly around the lower end of the "Target Length" axis (0-100), with a wider spread at higher "Target Length" values.
* **Confidence Interval:** The confidence interval is relatively wide, indicating a high degree of uncertainty in the estimated relationship.
* **Marginal Distribution (Target Length):** The distribution of "Target Length" is skewed to the right, with a peak around 0-50 and a tail extending to approximately 220.
* **Marginal Distribution (Confidence):** The distribution of "Confidence" is roughly bell-shaped, with a peak around 0.25-0.35.
Approximate Data Points (sampled for illustration):
* Target Length = 0, Confidence ≈ 0.25
* Target Length = 50, Confidence ≈ 0.30
* Target Length = 100, Confidence ≈ 0.35
* Target Length = 150, Confidence ≈ 0.40
* Target Length = 200, Confidence ≈ 0.55
### Key Observations
* The relationship between "Target Length" and "Confidence" is weak.
* There is considerable variability in "Confidence" for a given "Target Length".
* The marginal distributions suggest that "Target Length" is more spread out than "Confidence".
* There is an outlier data point at approximately Target Length = 200, Confidence = 0.6.
### Interpretation
The data suggests that "Target Length" is not a strong predictor of "Confidence" in the context of "college\_biology". While there is a slight tendency for "Confidence" to increase with "Target Length", the effect is small and there is a lot of noise in the data. The wide confidence interval around the regression line indicates that the estimated relationship is not very precise. The marginal distributions provide additional information about the distribution of each variable independently. The outlier data point may represent an unusual case or an error in the data.
The plot could be representing the confidence scores of a model predicting biological sequences of varying lengths. The weak correlation suggests that sequence length is not a primary factor in the model's confidence. Further investigation would be needed to determine the factors that do influence confidence.
</details>
|
<details>
<summary>x24.png Details</summary>
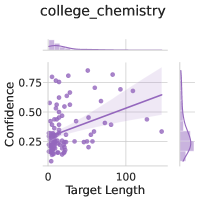
### Visual Description
\n
## Scatter Plot: Confidence vs. Target Length (college_chemistry)
### Overview
This image presents a scatter plot visualizing the relationship between "Target Length" and "Confidence" for a dataset labeled "college_chemistry". A regression line with a shaded confidence interval is overlaid on the scatter points. The plot also includes marginal distributions (histograms) along the top and right edges, showing the distributions of "Target Length" and "Confidence" respectively.
### Components/Axes
* **Title:** "college\_chemistry" (top-center)
* **X-axis:** "Target Length" (bottom-center), ranging from approximately 0 to 120.
* **Y-axis:** "Confidence" (left-center), ranging from approximately 0.2 to 0.8.
* **Scatter Points:** Purple dots representing individual data points.
* **Regression Line:** A purple line representing the trend of the data. The line slopes upwards.
* **Confidence Interval:** A shaded purple area around the regression line, indicating the uncertainty in the estimated trend.
* **Marginal Distribution (Top):** A histogram showing the distribution of "Target Length".
* **Marginal Distribution (Right):** A histogram showing the distribution of "Confidence".
### Detailed Analysis
The scatter plot shows a positive correlation between "Target Length" and "Confidence". As "Target Length" increases, "Confidence" tends to increase as well, though the relationship is not strong.
* **Scatter Points:** The points are clustered around the x-axis for low "Target Length" values, with "Confidence" values generally between 0.2 and 0.4. As "Target Length" increases, the points become more dispersed, with "Confidence" values ranging from approximately 0.3 to 0.75.
* **Regression Line:** The regression line has a positive slope, indicating a positive correlation. The line starts at approximately (0, 0.3) and ends at approximately (120, 0.6).
* **Confidence Interval:** The confidence interval is wider for larger "Target Length" values, indicating greater uncertainty in the estimated "Confidence" for longer target lengths.
* **Marginal Distribution (Target Length):** The distribution of "Target Length" is skewed to the right, with a peak around 0 and a long tail extending to higher values.
* **Marginal Distribution (Confidence):** The distribution of "Confidence" appears to be roughly symmetrical, with a peak around 0.4.
Approximate Data Points (sampled from the plot):
| Target Length | Confidence |
|---|---|
| 0 | 0.25 |
| 10 | 0.35 |
| 20 | 0.45 |
| 30 | 0.50 |
| 40 | 0.55 |
| 50 | 0.60 |
| 60 | 0.65 |
| 70 | 0.70 |
| 80 | 0.70 |
| 90 | 0.70 |
| 100 | 0.70 |
| 110 | 0.60 |
| 120 | 0.55 |
### Key Observations
* The positive correlation between "Target Length" and "Confidence" is visually apparent.
* The confidence interval widens as "Target Length" increases, suggesting that the relationship between the two variables becomes less certain for longer target lengths.
* The marginal distributions provide insights into the distributions of each variable independently.
### Interpretation
The data suggests that, in the context of "college\_chemistry", there is a tendency for higher confidence levels to be associated with longer target lengths. However, the relationship is not strong, and there is considerable variability in confidence levels for a given target length. The widening confidence interval indicates that the predictive power of "Target Length" on "Confidence" diminishes as "Target Length" increases. This could be due to other factors influencing confidence levels that are not captured in this simple bivariate analysis. The skewed distribution of "Target Length" suggests that shorter target lengths are more common in this dataset. The marginal distributions provide a baseline understanding of the range and typical values for each variable.
</details>
|
<details>
<summary>x25.png Details</summary>
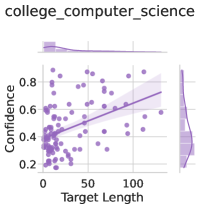
### Visual Description
\n
## Scatter Plot: Confidence vs. Target Length for College Computer Science
### Overview
The image presents a scatter plot visualizing the relationship between "Target Length" and "Confidence" for data labeled as "college_computer_science". A regression line with a shaded confidence interval is overlaid on the scatter points. There are also two marginal distributions (histograms) displayed at the top and right sides of the main plot, showing the distributions of Target Length and Confidence respectively.
### Components/Axes
* **X-axis:** "Target Length" ranging from approximately 0 to 120.
* **Y-axis:** "Confidence" ranging from approximately 0.2 to 0.9.
* **Scatter Points:** Numerous purple dots representing individual data points.
* **Regression Line:** A purple line representing the trend of the data. The line slopes upwards from left to right.
* **Confidence Interval:** A shaded purple area around the regression line, indicating the uncertainty in the estimated trend.
* **Top Marginal Distribution:** A histogram showing the distribution of "Target Length". It appears to be skewed to the right, with a concentration of values near 0 and a tail extending towards higher values.
* **Right Marginal Distribution:** A histogram showing the distribution of "Confidence". It appears to be roughly symmetrical, with a peak around 0.5-0.6.
* **Title:** "college\_computer\_science" positioned at the top-left corner.
### Detailed Analysis
The scatter plot shows a positive correlation between "Target Length" and "Confidence". As "Target Length" increases, "Confidence" tends to increase as well. However, the relationship is not perfectly linear, and there is considerable scatter around the regression line.
* **Regression Line Trend:** The regression line slopes upwards, indicating a positive correlation.
* **Data Point Distribution:** The data points are clustered around the origin (low "Target Length", low "Confidence"). As "Target Length" increases, the points become more dispersed, with some points reaching high "Confidence" values.
* **Approximate Data Points (sampled):**
* Target Length = 0, Confidence ≈ 0.35
* Target Length = 25, Confidence ≈ 0.55
* Target Length = 50, Confidence ≈ 0.65
* Target Length = 75, Confidence ≈ 0.70
* Target Length = 100, Confidence ≈ 0.75
* **Top Marginal Distribution:** The distribution of "Target Length" is heavily skewed towards lower values. Approximately 70% of the data points have a "Target Length" below 25.
* **Right Marginal Distribution:** The distribution of "Confidence" is approximately normal, with a mean around 0.55 and a standard deviation of approximately 0.15.
### Key Observations
* The positive correlation between "Target Length" and "Confidence" suggests that longer targets are associated with higher confidence.
* The wide confidence interval around the regression line indicates that the relationship is not very strong, and there is considerable uncertainty in the estimated trend.
* The skewed distribution of "Target Length" suggests that most targets are relatively short.
* The marginal distributions provide additional information about the distributions of the individual variables.
### Interpretation
This data likely represents a model's confidence score in predicting or completing tasks of varying lengths within the domain of college-level computer science. The positive correlation suggests that the model performs better (higher confidence) on longer tasks. However, the scatter and the confidence interval indicate that task length is not the sole determinant of confidence; other factors likely play a role. The skewed distribution of target length suggests that the model is primarily evaluated on shorter tasks.
The marginal distributions provide context for the main scatter plot. The distribution of target length shows that the model is mostly tested on shorter targets, while the distribution of confidence shows that the model's confidence scores are generally moderate.
The data could be used to improve the model by focusing on tasks of varying lengths and identifying factors that contribute to higher confidence scores. It could also be used to assess the model's performance on different types of tasks and identify areas where it needs improvement.
</details>
|
<details>
<summary>x26.png Details</summary>
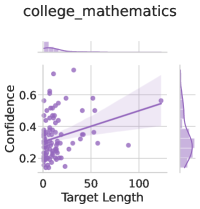
### Visual Description
\n
## Scatter Plot: Confidence vs. Target Length (College Mathematics)
### Overview
The image presents a scatter plot visualizing the relationship between "Target Length" and "Confidence" for a dataset labeled "college_mathematics". A regression line with a confidence interval is overlaid on the scatter points. Marginal distributions (histograms) are displayed above and to the right of the main plot.
### Components/Axes
* **Title:** "college\_mathematics" (top-center)
* **X-axis:** "Target Length" (bottom-center), ranging from approximately 0 to 110.
* **Y-axis:** "Confidence" (left-center), ranging from approximately 0.2 to 0.65.
* **Scatter Points:** Numerous purple dots representing individual data points.
* **Regression Line:** A purple line representing the trend of the data.
* **Confidence Interval:** A light purple shaded area around the regression line, indicating the uncertainty in the estimated trend.
* **Marginal Distribution (Top):** A histogram showing the distribution of "Target Length".
* **Marginal Distribution (Right):** A histogram showing the distribution of "Confidence".
### Detailed Analysis
The scatter plot shows a generally positive, but weak, correlation between "Target Length" and "Confidence".
* **Regression Line Trend:** The regression line slopes upward, indicating that as "Target Length" increases, "Confidence" tends to increase. However, the slope is relatively shallow.
* **Scatter Point Distribution:** The points are clustered around the x-axis (Target Length = 0) with a high density of points between 0.2 and 0.4 on the Confidence axis. As Target Length increases, the density of points decreases.
* **Data Points (Approximate Values):**
* At Target Length = 0, Confidence ranges from approximately 0.2 to 0.5.
* At Target Length = 50, Confidence ranges from approximately 0.25 to 0.55.
* At Target Length = 100, Confidence is approximately 0.6.
* **Marginal Distribution (Target Length):** The distribution of "Target Length" is skewed to the right, with a peak around 0 and a long tail extending to higher values.
* **Marginal Distribution (Confidence):** The distribution of "Confidence" is also skewed to the right, with a peak around 0.3 and a tail extending to higher values.
### Key Observations
* The relationship between "Target Length" and "Confidence" is not strong. The scatter points are widely dispersed around the regression line.
* There is a higher concentration of data points with low "Target Length" values.
* The marginal distributions suggest that both "Target Length" and "Confidence" are not normally distributed.
### Interpretation
The data suggests that there is a slight positive association between the length of the target and the confidence level in the context of college mathematics. However, the relationship is weak, and other factors likely play a significant role in determining confidence. The skewed distributions of both variables indicate that the data may not be representative of the entire population or that there are underlying factors influencing the observed patterns. The concentration of data points with low target lengths could indicate that most tasks or questions in this dataset are relatively short. The marginal distributions provide additional context, showing the range and frequency of each variable independently. The confidence interval around the regression line highlights the uncertainty in the estimated relationship, suggesting that the observed trend may not be consistent across all samples.
</details>
|
|
<details>
<summary>x27.png Details</summary>
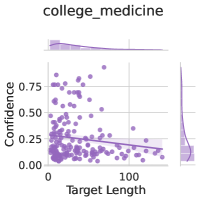
### Visual Description
\n
## Scatter Plot: Confidence vs. Target Length (college_medicine)
### Overview
This image presents a scatter plot visualizing the relationship between "Target Length" and "Confidence" for the category "college_medicine". A regression line with a shaded confidence interval is overlaid on the scatter points. The plot suggests a generally negative correlation between target length and confidence.
### Components/Axes
* **Title:** "college\_medicine" (top-center)
* **X-axis:** "Target Length" (bottom-center), ranging from approximately 0 to 120. The axis has tick marks at intervals of 20.
* **Y-axis:** "Confidence" (left-center), ranging from 0.00 to 0.75. The axis has tick marks at intervals of 0.25.
* **Data Points:** Numerous purple dots representing individual data points.
* **Regression Line:** A purple line representing the trend of the data.
* **Confidence Interval:** A shaded purple area around the regression line, indicating the uncertainty in the estimated trend.
### Detailed Analysis
The scatter plot shows a downward trend. As "Target Length" increases, "Confidence" tends to decrease.
* **Data Point Distribution:**
* At Target Length = 0, Confidence values range from approximately 0.15 to 0.75.
* At Target Length = 20, Confidence values range from approximately 0.10 to 0.50.
* At Target Length = 40, Confidence values range from approximately 0.05 to 0.35.
* At Target Length = 60, Confidence values range from approximately 0.05 to 0.25.
* At Target Length = 80, Confidence values range from approximately 0.00 to 0.20.
* At Target Length = 100, Confidence values range from approximately 0.00 to 0.15.
* At Target Length = 120, Confidence values are concentrated around 0.00.
* **Regression Line Trend:** The regression line slopes downward from left to right, confirming the negative correlation.
* **Confidence Interval:** The confidence interval is relatively wide, indicating substantial uncertainty in the estimated relationship. The interval appears to narrow slightly at lower target lengths.
### Key Observations
* The relationship between "Target Length" and "Confidence" is not strictly linear, as evidenced by the scatter of points around the regression line.
* There is a cluster of data points with low confidence values (near 0.00) at higher target lengths.
* The confidence interval is wider at higher target lengths, suggesting that the model is less certain about the confidence values for longer target lengths.
### Interpretation
The data suggests that for the "college\_medicine" category, longer target lengths are associated with lower confidence scores. This could indicate that the model struggles to accurately predict or assess the confidence for longer targets. The wide confidence interval suggests that other factors may also influence confidence, and the relationship between target length and confidence is not deterministic. The negative correlation could be due to several reasons: longer targets might be more complex, ambiguous, or require more specialized knowledge, leading to lower confidence in predictions. The model may be overfitting to shorter targets, resulting in higher confidence scores for those cases. Further investigation is needed to understand the underlying reasons for this relationship and to improve the model's performance on longer targets.
</details>
|
<details>
<summary>x28.png Details</summary>
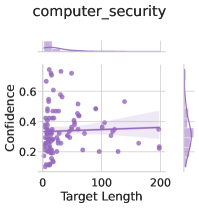
### Visual Description
\n
## Scatter Plot: Confidence vs. Target Length (Computer Security)
### Overview
The image presents a scatter plot visualizing the relationship between "Target Length" and "Confidence" for the category "computer_security". A regression line with a shaded confidence interval is overlaid on the scatter points. A violin plot is present on the right side of the chart, showing the distribution of confidence values. A smaller violin plot is present on the top of the chart, showing the distribution of target length values.
### Components/Axes
* **Title:** "computer\_security" (top-center)
* **X-axis:** "Target Length" (bottom-center), ranging from approximately 0 to 220.
* **Y-axis:** "Confidence" (left-center), ranging from approximately 0.15 to 0.65.
* **Data Points:** Numerous purple dots representing individual data points.
* **Regression Line:** A purple line representing the trend of the data.
* **Confidence Interval:** A shaded purple area around the regression line, indicating the uncertainty in the trend.
* **Violin Plot (Right):** Displays the distribution of confidence values.
* **Violin Plot (Top):** Displays the distribution of target length values.
### Detailed Analysis
The scatter plot shows a generally flat trend between Target Length and Confidence.
* **Data Point Distribution:** The majority of data points cluster between Target Length values of 0 and 100, with Confidence values ranging from approximately 0.2 to 0.4. There are fewer data points with Target Length values exceeding 100.
* **Regression Line Trend:** The regression line is approximately horizontal, indicating a weak or non-existent linear relationship between Target Length and Confidence. The line starts at approximately Confidence = 0.38 when Target Length = 0, and ends at approximately Confidence = 0.36 when Target Length = 220.
* **Confidence Interval:** The confidence interval is relatively narrow, suggesting a moderate level of certainty in the estimated trend.
* **Violin Plot (Right):** The violin plot on the right shows a peak in the distribution of Confidence values around 0.35, with a wider spread towards lower confidence values.
* **Violin Plot (Top):** The violin plot on the top shows a peak in the distribution of Target Length values around 0, with a tail extending towards higher values.
### Key Observations
* The relationship between Target Length and Confidence appears to be weak.
* Confidence values are generally low, with most points falling below 0.4.
* There is a concentration of data points with short Target Lengths.
* The confidence interval is relatively narrow, indicating a reasonable degree of certainty in the observed trend.
### Interpretation
The data suggests that, for the "computer\_security" category, the length of the target does not strongly influence the confidence level. The confidence remains relatively stable across different target lengths. The low overall confidence values might indicate that the model or system used to generate these predictions is not highly accurate for this category. The concentration of data points with short target lengths could suggest that the system is more frequently exposed to or focused on shorter targets within the computer security domain. The violin plots confirm the general trends observed in the scatter plot, providing a visual representation of the distributions of both variables. The flat regression line suggests that any observed correlation is minimal, and other factors likely play a more significant role in determining confidence levels.
</details>
|
<details>
<summary>x29.png Details</summary>
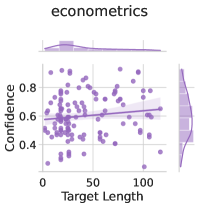
### Visual Description
## Scatter Plot: Confidence vs. Target Length
### Overview
The image presents a scatter plot visualizing the relationship between "Target Length" and "Confidence". A regression line with a shaded confidence interval is overlaid on the scatter points. Marginal distributions (histograms) are displayed above and to the right of the main plot. The plot is titled "econometrics".
### Components/Axes
* **Title:** "econometrics" (top-center)
* **X-axis:** "Target Length" (bottom-center), ranging from approximately 0 to 110.
* **Y-axis:** "Confidence" (left-center), ranging from approximately 0.35 to 0.85.
* **Scatter Points:** Numerous purple dots representing individual data points.
* **Regression Line:** A dark purple line representing the trend of the data.
* **Confidence Interval:** A light purple shaded area around the regression line.
* **Marginal Distribution (Top):** A histogram showing the distribution of "Target Length".
* **Marginal Distribution (Right):** A histogram showing the distribution of "Confidence".
### Detailed Analysis
The scatter plot shows a weak positive correlation between "Target Length" and "Confidence". The regression line has a slight upward slope, indicating that as "Target Length" increases, "Confidence" tends to increase, but the relationship is not strong.
* **Regression Line Trend:** The line slopes upward, but is nearly flat.
* **Data Point Distribution:** The points are widely scattered around the regression line, indicating a high degree of variability.
* **X-axis (Target Length) Distribution:** The histogram at the top shows a distribution that is skewed to the right, with a peak around a "Target Length" of approximately 10.
* **Y-axis (Confidence) Distribution:** The histogram on the right shows a distribution that is roughly symmetrical, with a peak around a "Confidence" of approximately 0.6.
Let's attempt to extract some approximate data points from the scatter plot. Note that these are estimates due to the resolution of the image:
| Target Length (approx.) | Confidence (approx.) |
|---|---|
| 0 | 0.45 |
| 0 | 0.75 |
| 10 | 0.50 |
| 10 | 0.65 |
| 20 | 0.55 |
| 20 | 0.70 |
| 30 | 0.60 |
| 30 | 0.65 |
| 40 | 0.60 |
| 40 | 0.70 |
| 50 | 0.55 |
| 50 | 0.65 |
| 60 | 0.60 |
| 60 | 0.70 |
| 70 | 0.65 |
| 70 | 0.60 |
| 80 | 0.60 |
| 80 | 0.65 |
| 90 | 0.65 |
| 90 | 0.60 |
| 100 | 0.60 |
| 100 | 0.70 |
| 110 | 0.55 |
The regression line appears to pass through approximately (50, 0.62).
### Key Observations
* The relationship between "Target Length" and "Confidence" is weak.
* There is considerable variability in "Confidence" for a given "Target Length".
* The distribution of "Target Length" is skewed to the right.
* The distribution of "Confidence" is approximately symmetrical.
### Interpretation
The plot suggests that "Target Length" is not a strong predictor of "Confidence". While there is a slight tendency for "Confidence" to increase with "Target Length", the effect is small and there is a lot of noise in the data. The marginal distributions provide additional information about the range and distribution of each variable. The right-skewed distribution of "Target Length" indicates that most observations have relatively short target lengths, with a few observations having much longer target lengths. The approximately symmetrical distribution of "Confidence" suggests that confidence levels are centered around a value of approximately 0.6. The title "econometrics" suggests that this data may be related to economic modeling or analysis, potentially examining the confidence in predictions or forecasts based on the length of the target variable. The weak correlation could indicate that other factors are more important in determining confidence.
</details>
|
<details>
<summary>x30.png Details</summary>
### Visual Description
\n
## Scatter Plot: Confidence vs. Target Length (Electrical Engineering)
### Overview
The image presents a scatter plot visualizing the relationship between "Target Length" and "Confidence," likely within the context of electrical engineering. A regression line with a confidence interval is overlaid on the scatter points, and marginal histograms are displayed above and to the right of the main plot.
### Components/Axes
* **Title:** "electrical\_engineering" (top-center)
* **X-axis:** "Target Length" (bottom-center), ranging from approximately 0 to 60.
* **Y-axis:** "Confidence" (left-center), ranging from approximately 0.1 to 0.6.
* **Scatter Points:** Numerous purple dots representing individual data points.
* **Regression Line:** A dark purple line representing the trend of the data. The line slopes downward slightly.
* **Confidence Interval:** A light purple shaded area around the regression line, indicating the uncertainty in the line's estimate.
* **Marginal Histograms:**
* Top: Histogram of "Target Length" distribution.
* Right: Histogram of "Confidence" distribution.
### Detailed Analysis
The scatter plot shows a generally negative correlation between "Target Length" and "Confidence." As "Target Length" increases, "Confidence" tends to decrease, although the relationship is weak and scattered.
* **Scatter Point Distribution:**
* The majority of points cluster between "Target Length" values of 0 and 30, with "Confidence" values between 0.15 and 0.5.
* There are fewer points with "Target Length" values greater than 40.
* The points are widely dispersed, indicating a high degree of variability.
* **Regression Line:**
* The regression line has a negative slope, confirming the general downward trend.
* The line starts at approximately "Confidence" = 0.3 when "Target Length" = 0.
* At "Target Length" = 60, the line reaches approximately "Confidence" = 0.15.
* **Confidence Interval:**
* The confidence interval is relatively wide, indicating substantial uncertainty in the regression line's estimate.
* **Marginal Histograms:**
* The top histogram shows that "Target Length" is not normally distributed, with a peak around 0 and a long tail extending to the right.
* The right histogram shows that "Confidence" is also not normally distributed, with a peak around 0.2 and a tail extending to higher values.
### Key Observations
* The relationship between "Target Length" and "Confidence" is weak and noisy.
* The confidence interval is wide, suggesting that the regression line is not a precise predictor of "Confidence."
* The marginal histograms reveal that both "Target Length" and "Confidence" are skewed distributions.
* There is a concentration of data points at low "Target Length" values.
### Interpretation
The data suggests that, in this electrical engineering context, there is a slight tendency for "Confidence" to decrease as "Target Length" increases. However, this relationship is not strong, and other factors likely play a significant role in determining "Confidence." The wide confidence interval indicates that the observed trend may not be statistically significant or generalizable. The skewed distributions of both variables suggest that the data may not meet the assumptions of standard statistical models.
The "electrical\_engineering" title suggests this data is related to a specific problem or application within that field. The "Target Length" could refer to the length of a circuit, a signal, or some other relevant parameter. The "Confidence" could represent the confidence level in a prediction, a measurement, or a decision. Further context would be needed to fully understand the meaning of these variables and the implications of the observed relationship.
</details>
|
|
<details>
<summary>x31.png Details</summary>
### Visual Description
\n
## Scatter Plot: Confidence vs. Target Length (Elementary Mathematics)
### Overview
The image presents a scatter plot visualizing the relationship between "Target Length" and "Confidence" for the category "elementary_mathematics". A regression line with a shaded confidence interval is overlaid on the scatter points. The plot also includes marginal histograms at the top and right, showing the distributions of "Target Length" and "Confidence" respectively.
### Components/Axes
* **Title:** "elementary_mathematics" (top-left)
* **X-axis:** "Target Length" (ranging from approximately 0 to 100)
* **Y-axis:** "Confidence" (ranging from approximately 0.2 to 0.75)
* **Scatter Points:** Purple dots representing individual data points.
* **Regression Line:** A dark purple line representing the trend in the data.
* **Confidence Interval:** A light purple shaded area around the regression line.
* **Marginal Histogram (Top):** Displays the distribution of "Target Length".
* **Marginal Histogram (Right):** Displays the distribution of "Confidence".
### Detailed Analysis
The scatter plot shows a weak negative correlation between "Target Length" and "Confidence". As "Target Length" increases, "Confidence" tends to decrease slightly, but the relationship is not strong.
* **Scatter Plot Data:**
* The majority of points cluster between "Target Length" values of 0 and 50, with "Confidence" values ranging from approximately 0.25 to 0.7.
* There are fewer points with "Target Length" values greater than 50.
* The regression line has a slight negative slope.
* The confidence interval is relatively wide, indicating a high degree of uncertainty in the estimated relationship.
* **Marginal Histogram (Target Length):**
* The distribution of "Target Length" is heavily skewed to the right. There is a high concentration of values near 0, and a long tail extending towards higher values.
* The peak of the distribution is around a "Target Length" of approximately 5.
* **Marginal Histogram (Confidence):**
* The distribution of "Confidence" is skewed to the left. There is a concentration of values between 0.2 and 0.4, with a tail extending towards higher values.
* The peak of the distribution is around a "Confidence" of approximately 0.3.
### Key Observations
* The relationship between "Target Length" and "Confidence" is weak and potentially non-linear.
* The distributions of both "Target Length" and "Confidence" are non-normal.
* The wide confidence interval suggests that the regression line is not a precise predictor of "Confidence" given "Target Length".
* The marginal histograms reveal that the majority of data points have low "Target Length" and moderate "Confidence".
### Interpretation
The data suggests that, for elementary mathematics problems, longer target lengths do not necessarily lead to lower confidence, but the relationship is not strong. The weak correlation and wide confidence interval indicate that other factors likely play a more significant role in determining confidence levels. The skewed distributions suggest that the data may not be representative of all possible elementary mathematics problems. The concentration of data points with low "Target Length" could indicate that the model is being tested on simpler problems more frequently. The marginal histograms provide insight into the underlying distributions of the variables, which can be useful for understanding the characteristics of the data. The overall trend suggests a slight tendency for confidence to decrease with increasing target length, but this effect is small and may not be practically significant.
</details>
|
<details>
<summary>x32.png Details</summary>
### Visual Description
\n
## Scatter Plot: Confidence vs. Target Length (formal_logic)
### Overview
The image presents a scatter plot visualizing the relationship between "Target Length" and "Confidence" for a dataset labeled "formal_logic". A regression line with a confidence interval is overlaid on the scatter points. A violin plot is present on the right side of the chart, showing the distribution of confidence values.
### Components/Axes
* **X-axis:** "Target Length" ranging from approximately 0 to 220.
* **Y-axis:** "Confidence" ranging from approximately 0.2 to 0.6.
* **Title:** "formal\_logic" positioned at the top-center of the chart.
* **Scatter Points:** Numerous purple dots representing individual data points.
* **Regression Line:** A purple line representing the trend of the data.
* **Confidence Interval:** A shaded purple area around the regression line, indicating the uncertainty in the trend.
* **Violin Plot:** A purple violin plot on the right side, showing the distribution of confidence values.
### Detailed Analysis
The scatter plot shows a generally decreasing trend between "Target Length" and "Confidence". As "Target Length" increases, "Confidence" tends to decrease.
* **Regression Line Trend:** The regression line slopes downward, confirming the negative correlation.
* **Data Point Distribution:** The data points are clustered more densely around lower "Target Length" values (0-50) with higher "Confidence" values (0.4-0.6). As "Target Length" increases beyond 50, the points become more scattered, and "Confidence" values generally decrease.
* **Approximate Data Points (sampled):**
* Target Length = 0, Confidence ≈ 0.55
* Target Length = 20, Confidence ≈ 0.50
* Target Length = 50, Confidence ≈ 0.45
* Target Length = 100, Confidence ≈ 0.40
* Target Length = 150, Confidence ≈ 0.35
* Target Length = 200, Confidence ≈ 0.30
* **Violin Plot:** The violin plot shows a peak in the distribution of "Confidence" around 0.4, with a wider spread towards lower confidence values.
### Key Observations
* The negative correlation between "Target Length" and "Confidence" is visually apparent.
* The confidence interval around the regression line indicates a moderate degree of uncertainty in the estimated trend.
* There is a noticeable spread in the data, suggesting that "Target Length" is not the sole determinant of "Confidence".
* The violin plot confirms the concentration of confidence values around 0.4.
### Interpretation
The data suggests that as the "Target Length" increases, the "Confidence" in the "formal\_logic" system decreases. This could indicate that the system performs better on shorter targets or that longer targets introduce more ambiguity or complexity. The violin plot reinforces this, showing a concentration of confidence around a moderate level, but with a tail extending towards lower confidence. The scatter plot and regression line provide a visual representation of this relationship, while the confidence interval acknowledges the inherent variability in the data. The decreasing trend could be due to several factors, such as increased computational cost, more opportunities for errors, or the inherent difficulty of processing longer inputs. Further investigation would be needed to determine the underlying cause of this relationship.
</details>
|
<details>
<summary>x33.png Details</summary>
### Visual Description
\n
## Scatter Plot: Confidence vs. Target Length
### Overview
The image presents a scatter plot visualizing the relationship between "Target Length" and "Confidence". A regression line is overlaid on the scatter points, along with a shaded confidence interval around the line. The plot is titled "global_facts" at the top-center.
### Components/Axes
* **X-axis:** "Target Length" - Scale ranges from approximately 0 to 120.
* **Y-axis:** "Confidence" - Scale ranges from approximately 0.15 to 0.8.
* **Data Points:** Numerous purple circles representing individual data points.
* **Regression Line:** A purple line representing the trend of the data.
* **Confidence Interval:** A light purple shaded area around the regression line, indicating the uncertainty in the line's estimate.
* **Title:** "global_facts" - positioned at the top-center of the plot.
### Detailed Analysis
The scatter plot shows a generally positive correlation between "Target Length" and "Confidence". As "Target Length" increases, "Confidence" tends to increase as well, though with considerable scatter.
* **Trend of Regression Line:** The regression line slopes upward from left to right, confirming the positive correlation.
* **Data Point Distribution:**
* At "Target Length" values near 0, "Confidence" values range from approximately 0.15 to 0.7.
* As "Target Length" increases to around 50, "Confidence" values generally increase, ranging from approximately 0.2 to 0.6.
* Between "Target Length" values of 50 and 100, "Confidence" values continue to increase, ranging from approximately 0.3 to 0.6.
* At "Target Length" values around 100, "Confidence" values reach approximately 0.5 to 0.6.
* There is a single outlier data point at approximately "Target Length" = 75 and "Confidence" = 0.75.
* **Confidence Interval:** The confidence interval is wider at lower "Target Length" values and appears to narrow slightly as "Target Length" increases. This suggests greater uncertainty in the relationship at lower "Target Length" values.
### Key Observations
* The positive correlation between "Target Length" and "Confidence" is evident.
* The scatter is significant, indicating that "Target Length" is not the sole determinant of "Confidence".
* The confidence interval suggests that the relationship is more uncertain at lower "Target Length" values.
* The outlier data point at (75, 0.75) deviates from the general trend.
### Interpretation
The data suggests that as the "Target Length" increases, the "Confidence" in some associated process or prediction also tends to increase. This could represent a scenario where longer targets lead to more reliable results, or where more information is available for longer targets, leading to higher confidence. The scatter indicates that other factors also influence "Confidence", and the confidence interval highlights the uncertainty in the relationship, particularly for shorter "Target Length" values. The outlier may represent an unusual case or an error in the data. The title "global_facts" suggests this data relates to a broad set of facts or knowledge. The plot could be used to assess the reliability of predictions or the quality of information based on the length of the target being considered.
</details>
|
<details>
<summary>x34.png Details</summary>
### Visual Description
\n
## Scatter Plot: Confidence vs. Target Length (High School Biology)
### Overview
The image presents a scatter plot visualizing the relationship between "Target Length" and "Confidence" for data labeled as "high_school_biology". The plot displays a large number of data points, along with a regression line and confidence interval.
### Components/Axes
* **Title:** high\_school\_biology (top-center)
* **X-axis:** Target Length (bottom-center), ranging from approximately 0 to 120.
* **Y-axis:** Confidence (left-center), ranging from approximately 0.0 to 0.75.
* **Data Points:** Numerous purple dots scattered across the plot.
* **Regression Line:** A dark purple line representing the trend of the data.
* **Confidence Interval:** A shaded purple area surrounding the regression line, indicating the uncertainty in the estimated trend.
### Detailed Analysis
The scatter plot shows a generally weak, slightly negative correlation between Target Length and Confidence.
* **Data Point Distribution:** The majority of data points cluster between Target Length values of 0 and 100, with Confidence values primarily between 0.0 and 0.6. There are fewer data points with Target Length values exceeding 100.
* **Regression Line Trend:** The regression line is approximately horizontal, indicating a minimal overall trend. It slopes slightly downward.
* **Confidence Interval:** The confidence interval is relatively narrow, suggesting a reasonable degree of certainty in the estimated trend, despite its weakness.
* **Specific Data Points (Approximate):**
* At Target Length = 0, Confidence ranges from approximately 0.1 to 0.7.
* At Target Length = 50, Confidence ranges from approximately 0.1 to 0.6.
* At Target Length = 100, Confidence ranges from approximately 0.1 to 0.5.
* At Target Length = 120, Confidence drops to approximately 0.0-0.2.
### Key Observations
* The data exhibits significant scatter, indicating a weak relationship between Target Length and Confidence.
* There is a slight tendency for Confidence to decrease as Target Length increases, but this trend is not strong.
* The confidence interval is relatively consistent across the range of Target Length values.
* The data appears to be truncated on the right side, with fewer data points at higher Target Length values.
### Interpretation
The plot suggests that, for the "high\_school\_biology" dataset, the length of the target sequence (Target Length) has a limited impact on the confidence score. The weak negative correlation implies that longer target sequences might be associated with slightly lower confidence, but this effect is small and not statistically significant. The truncation of data at higher Target Lengths could indicate a limitation in the dataset or a natural boundary in the data generation process. The relatively narrow confidence interval suggests that the observed trend, while weak, is reasonably reliable within the observed range of Target Lengths. This could be related to the complexity of biological sequences and the challenges in accurately predicting their properties. The data suggests that other factors beyond target length likely play a more significant role in determining confidence scores in this context.
</details>
|
|
<details>
<summary>x35.png Details</summary>
### Visual Description
\n
## Scatter Plot: Confidence vs. Target Length (High School Chemistry)
### Overview
This image presents a scatter plot visualizing the relationship between "Target Length" and "Confidence" for data labeled as "high_school_chemistry". A regression line with a shaded confidence interval is overlaid on the scatter points. The plot suggests a weak negative correlation between target length and confidence.
### Components/Axes
* **Title:** high\_school\_chemistry (top-center)
* **X-axis:** Target Length (bottom-center), ranging from approximately 0 to 120.
* **Y-axis:** Confidence (left-center), ranging from approximately 0.2 to 0.8.
* **Data Points:** Numerous purple dots scattered across the plot area.
* **Regression Line:** A purple line representing the trend of the data.
* **Confidence Interval:** A light purple shaded area around the regression line, indicating the uncertainty in the line's estimate.
* **Histograms:** Two histograms are present at the top and right of the scatter plot, showing the distribution of Target Length and Confidence respectively.
### Detailed Analysis
The scatter plot shows a general trend of decreasing confidence as target length increases, but the relationship is not strong.
* **Regression Line Trend:** The regression line slopes downward, indicating a negative correlation.
* **Data Point Distribution:** The data points are widely dispersed, indicating a high degree of variability.
* **X-axis (Target Length):** The histogram at the top shows a distribution of target lengths. The peak of the distribution appears to be around a target length of 0-20.
* **Y-axis (Confidence):** The histogram on the right shows a distribution of confidence values. The peak of the distribution appears to be around a confidence of 0.3-0.4.
* **Data Points (Approximate Values):**
* At Target Length = 0, Confidence ranges from approximately 0.2 to 0.7.
* At Target Length = 50, Confidence ranges from approximately 0.2 to 0.6.
* At Target Length = 100, Confidence ranges from approximately 0.2 to 0.5.
* At Target Length = 120, Confidence ranges from approximately 0.15 to 0.35.
### Key Observations
* The correlation between target length and confidence is weak.
* There is significant variability in confidence for a given target length.
* The confidence interval around the regression line is relatively wide, indicating a high degree of uncertainty in the estimated relationship.
* The distribution of target lengths is skewed towards lower values.
* The distribution of confidence values is concentrated in the lower range (0.2-0.5).
### Interpretation
The data suggests that, for the "high\_school\_chemistry" dataset, there is a slight tendency for confidence to decrease as the target length increases. However, this relationship is not strong, and other factors likely play a significant role in determining confidence. The wide confidence interval indicates that the observed relationship may not generalize well to other datasets. The skewed distribution of target lengths suggests that the model may be more accurate for shorter target lengths. The data could be related to a question answering or text generation task, where "target length" refers to the length of the answer or generated text, and "confidence" represents the model's certainty in its response. The negative correlation might indicate that the model struggles to generate confident responses for longer, more complex targets. The histograms provide insight into the distribution of the input features (target length) and the output variable (confidence).
</details>
|
<details>
<summary>x36.png Details</summary>
### Visual Description
## Scatter Plot: Confidence vs. Target Length (High School Computer Science)
### Overview
This image presents a scatter plot visualizing the relationship between "Target Length" and "Confidence" for data labeled as "high_school_computer_science". A regression line and shaded confidence interval are overlaid on the scatter points. The plot also includes marginal distributions (histograms) along the top and right edges, showing the distributions of Target Length and Confidence, respectively.
### Components/Axes
* **X-axis:** "Target Length" - Scale ranges from approximately 0 to 250.
* **Y-axis:** "Confidence" - Scale ranges from approximately 0.2 to 0.8.
* **Scatter Points:** Purple dots representing individual data points.
* **Regression Line:** A purple line representing the trend of the data. The line slopes upwards.
* **Confidence Interval:** A shaded purple area around the regression line, indicating the uncertainty in the estimated trend.
* **Top Marginal Distribution:** A histogram showing the distribution of "Target Length".
* **Right Marginal Distribution:** A histogram showing the distribution of "Confidence".
* **Title:** "high\_school\_computer\_science" - positioned at the top-left of the image.
### Detailed Analysis
The scatter plot shows a generally positive correlation between "Target Length" and "Confidence". As "Target Length" increases, "Confidence" tends to increase, although the relationship is not perfectly linear and has significant scatter.
* **Regression Line Trend:** The regression line slopes upwards, indicating a positive correlation.
* **Scatter Point Distribution:** The majority of data points are clustered around the lower left corner of the plot (low "Target Length", low "Confidence"). There is a spread of points towards higher "Confidence" values as "Target Length" increases.
* **Outlier:** There is one data point at approximately (220, 0.3) that lies significantly below the regression line and the general trend.
* **Top Marginal Distribution (Target Length):** The distribution of "Target Length" is skewed to the right, with a higher concentration of values near 0 and a tail extending towards higher values.
* **Right Marginal Distribution (Confidence):** The distribution of "Confidence" appears to be roughly uniform between 0.2 and 0.8, with a slight concentration of values between 0.5 and 0.7.
Approximate Data Points (based on visual estimation):
* (0, 0.25): Confidence is approximately 0.25 when Target Length is 0.
* (0, 0.6): Confidence is approximately 0.6 when Target Length is 0.
* (50, 0.4): Confidence is approximately 0.4 when Target Length is 50.
* (50, 0.7): Confidence is approximately 0.7 when Target Length is 50.
* (100, 0.55): Confidence is approximately 0.55 when Target Length is 100.
* (100, 0.75): Confidence is approximately 0.75 when Target Length is 100.
* (200, 0.65): Confidence is approximately 0.65 when Target Length is 200.
* (220, 0.3): Outlier with low confidence.
### Key Observations
* A positive, but weak, correlation exists between "Target Length" and "Confidence".
* The data exhibits significant variability, suggesting that "Target Length" is not a strong predictor of "Confidence".
* The outlier at (220, 0.3) deviates significantly from the overall trend.
* The marginal distributions provide insights into the individual distributions of "Target Length" and "Confidence".
### Interpretation
The data suggests that, for "high_school_computer_science" tasks, there is a tendency for confidence to increase with the length of the target, but this relationship is not strong. The large spread of data points indicates that other factors likely influence confidence levels. The outlier suggests that there are cases where even relatively long targets result in low confidence, potentially due to task complexity or individual student performance. The right-skewed distribution of "Target Length" indicates that most tasks have relatively short targets, while the relatively uniform distribution of "Confidence" suggests that confidence levels are more evenly distributed across the range. The marginal distributions provide additional context for interpreting the scatter plot and understanding the characteristics of the data. The regression line and confidence interval provide a statistical summary of the relationship between the two variables, but the significant scatter highlights the limitations of this model.
</details>
|
<details>
<summary>x37.png Details</summary>
### Visual Description
\n
## Scatter Plot: Confidence vs. Target Length - High School European History
### Overview
This image presents a scatter plot visualizing the relationship between "Target Length" and "Confidence" for a dataset labeled "high_school_european_history". A regression line and shaded confidence interval are overlaid on the scatter points. There are also two histograms at the top and right edges of the plot, showing the distributions of Target Length and Confidence, respectively.
### Components/Axes
* **X-axis:** "Target Length" - Scale ranges from approximately 0 to 250.
* **Y-axis:** "Confidence" - Scale ranges from approximately 0.2 to 1.2.
* **Scatter Points:** Purple dots representing individual data points.
* **Regression Line:** A purple line representing the trend of the data. It appears to be nearly horizontal.
* **Confidence Interval:** A shaded purple area around the regression line, indicating the uncertainty in the estimated trend.
* **Histogram (Top):** Displays the distribution of "Target Length". The distribution appears to be skewed to the left, with a concentration of values below 100 and a long tail extending to higher values.
* **Histogram (Right):** Displays the distribution of "Confidence". The distribution is heavily skewed to the right, with a concentration of values near 1.0 and a tail extending to lower values.
* **Title:** "high\_school\_european\_history" - Located at the top-left of the image.
### Detailed Analysis
The scatter plot shows a weak, potentially non-existent, linear relationship between "Target Length" and "Confidence".
* **Scatter Plot Trend:** The points are scattered with no clear upward or downward trend. The regression line is nearly horizontal, indicating a very small slope.
* **Data Points:**
* At Target Length = 0, Confidence ranges from approximately 0.3 to 1.0.
* At Target Length = 50, Confidence ranges from approximately 0.4 to 1.0.
* At Target Length = 100, Confidence ranges from approximately 0.3 to 0.9.
* At Target Length = 150, Confidence ranges from approximately 0.4 to 0.8.
* At Target Length = 200, Confidence ranges from approximately 0.5 to 0.7.
* At Target Length = 250, Confidence is limited to a single point around 0.6.
* **Regression Line:** The regression line is approximately horizontal at a Confidence value of around 0.75.
* **Histogram (Target Length):** The histogram shows a peak around a Target Length of 50, with a decreasing frequency as Target Length increases.
* **Histogram (Confidence):** The histogram shows a peak at a Confidence value of 1.0, with a decreasing frequency as Confidence decreases.
### Key Observations
* The scatter plot shows a very weak correlation between Target Length and Confidence.
* The confidence interval is relatively wide, indicating a high degree of uncertainty in the estimated relationship.
* The histograms reveal that Target Length and Confidence have different distributions. Target Length is skewed left, while Confidence is skewed right.
* There is a cluster of points with high confidence (close to 1.0) at lower Target Lengths.
### Interpretation
The data suggests that the length of the target text does not significantly influence the confidence score for this "high\_school\_european\_history" dataset. The nearly horizontal regression line and wide confidence interval support this conclusion. The distributions of Target Length and Confidence are quite different, with shorter target lengths being more common and higher confidence scores being more frequent. The lack of a strong correlation could indicate that other factors, not captured in this analysis, are more important determinants of confidence. The histograms suggest that the model performs well on shorter texts, with high confidence, but the confidence decreases as the target length increases, although this decrease is not statistically significant based on the scatter plot. The right-skewed confidence distribution indicates that the model is generally confident in its predictions.
</details>
|
<details>
<summary>x38.png Details</summary>
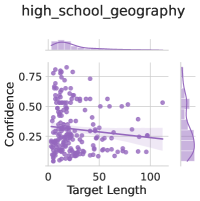
### Visual Description
\n
## Scatter Plot: Confidence vs. Target Length (High School Geography)
### Overview
This image presents a scatter plot visualizing the relationship between "Target Length" and "Confidence" for data labeled as "high_school_geography". A regression line with a shaded confidence interval is overlaid on the scatter points. Marginal distributions (histograms) are displayed above and to the right of the main scatter plot, showing the distributions of Target Length and Confidence, respectively.
### Components/Axes
* **X-axis:** "Target Length" - Scale ranges from approximately 0 to 110.
* **Y-axis:** "Confidence" - Scale ranges from approximately 0.15 to 0.80.
* **Title:** "high_school_geography" - Located at the top-center of the image.
* **Scatter Points:** Purple circles representing individual data points.
* **Regression Line:** A dark purple line representing the trend of the data. It slopes downward.
* **Confidence Interval:** A light purple shaded area around the regression line, indicating the uncertainty in the estimated trend.
* **Marginal Distribution (Top):** A histogram showing the distribution of "Target Length".
* **Marginal Distribution (Right):** A histogram showing the distribution of "Confidence".
### Detailed Analysis
The scatter plot shows a generally negative correlation between "Target Length" and "Confidence". As "Target Length" increases, "Confidence" tends to decrease.
* **Regression Line Trend:** The regression line has a negative slope, confirming the negative correlation.
* **Data Point Distribution:** The data points are scattered, but a clear downward trend is visible.
* **Target Length Distribution:** The distribution of "Target Length" is skewed to the right, with a higher concentration of values near 0 and a tail extending towards 110. The peak of the distribution is around 10.
* **Confidence Distribution:** The distribution of "Confidence" is concentrated between 0.2 and 0.4, with a slight skew towards lower values. The peak of the distribution is around 0.25.
Let's attempt to extract some approximate data points from the scatter plot:
* At Target Length = 0, Confidence ranges from approximately 0.3 to 0.7.
* At Target Length = 25, Confidence ranges from approximately 0.2 to 0.6.
* At Target Length = 50, Confidence ranges from approximately 0.15 to 0.5.
* At Target Length = 75, Confidence ranges from approximately 0.1 to 0.4.
* At Target Length = 100, Confidence ranges from approximately 0.1 to 0.3.
The regression line appears to intersect the Y-axis (Confidence) at approximately 0.3. The slope of the regression line is approximately -0.005 (estimated visually).
### Key Observations
* The negative correlation suggests that longer "Target Lengths" are associated with lower "Confidence" scores.
* The marginal distributions provide insights into the range and distribution of each variable independently.
* The confidence interval around the regression line indicates the uncertainty in the estimated relationship.
### Interpretation
This data likely represents a model's performance on a task related to "high_school_geography". "Target Length" could refer to the length of a question, answer, or text passage. "Confidence" could represent the model's certainty in its prediction or response.
The negative correlation suggests that the model is less confident when dealing with longer inputs. This could be due to several factors:
* **Increased Complexity:** Longer inputs may be more complex and require more reasoning, leading to lower confidence.
* **Data Sparsity:** The model may have less training data for longer inputs, resulting in lower confidence.
* **Attention Limitations:** The model may struggle to attend to all relevant information in longer inputs.
The marginal distributions indicate that the "Target Length" is relatively short on average, while the "Confidence" scores are generally moderate. The confidence interval around the regression line suggests that the relationship between "Target Length" and "Confidence" is not very strong, and there is considerable variability in the data.
Further investigation would be needed to understand the specific context of this data and the underlying reasons for the observed relationship.
</details>
|
|
<details>
<summary>x39.png Details</summary>
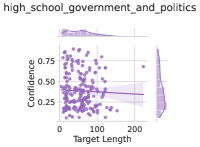
### Visual Description
\n
## Scatter Plot: Confidence vs. Target Length (High School Government and Politics)
### Overview
The image presents a scatter plot visualizing the relationship between "Target Length" and "Confidence" for data related to "high_school_government_and_politics". A regression line with a shaded confidence interval is overlaid on the scatter points. A marginal distribution plot is shown above the scatter plot.
### Components/Axes
* **X-axis:** "Target Length" - Scale ranges from approximately 0 to 230.
* **Y-axis:** "Confidence" - Scale ranges from approximately 0.2 to 0.8.
* **Scatter Points:** Purple dots representing individual data points.
* **Regression Line:** A dark purple line representing the trend of the data. It slopes slightly downward.
* **Confidence Interval:** A light purple shaded area around the regression line, indicating the uncertainty in the estimated trend.
* **Marginal Distribution:** A density plot positioned above the scatter plot, showing the distribution of "Target Length".
* **Title:** "high_school_government_and_politics" - positioned at the top-left of the image.
### Detailed Analysis
The scatter plot shows a generally dispersed pattern of points.
* **Trend:** The regression line exhibits a slight negative slope, suggesting that as "Target Length" increases, "Confidence" tends to decrease, but the relationship is weak.
* **Data Points:**
* At "Target Length" = 0, "Confidence" values range from approximately 0.2 to 0.6.
* At "Target Length" = 50, "Confidence" values range from approximately 0.3 to 0.75.
* At "Target Length" = 100, "Confidence" values range from approximately 0.25 to 0.7.
* At "Target Length" = 150, "Confidence" values range from approximately 0.2 to 0.5.
* At "Target Length" = 200, "Confidence" values range from approximately 0.2 to 0.4.
* **Marginal Distribution:** The marginal distribution is unimodal and skewed to the right, with a peak around a "Target Length" of approximately 50-100. The distribution tails off towards higher "Target Length" values.
* **Confidence Interval:** The confidence interval is relatively wide, indicating substantial uncertainty in the estimated regression line.
### Key Observations
* The relationship between "Target Length" and "Confidence" appears weak and potentially non-linear.
* There is considerable variability in "Confidence" for a given "Target Length".
* The marginal distribution suggests that shorter "Target Lengths" are more common in the dataset.
* The wide confidence interval suggests that the observed trend may not be statistically significant.
### Interpretation
The data suggests a very weak negative correlation between the length of the target (presumably a text or response) and the confidence associated with it, within the context of "high_school_government_and_politics". This could imply that longer responses in this domain are less confidently assessed, or that shorter responses are more easily evaluated with higher confidence. However, the weak trend and wide confidence interval suggest that this relationship is not strong or reliable. The marginal distribution indicates that the majority of the data points have relatively short target lengths.
The plot could be used to assess the performance of a model or system that predicts confidence based on target length. The wide confidence interval suggests that the model's predictions are uncertain, especially for longer target lengths. Further investigation would be needed to determine the underlying reasons for the observed patterns and to improve the accuracy of the confidence predictions.
</details>
|
<details>
<summary>x40.png Details</summary>
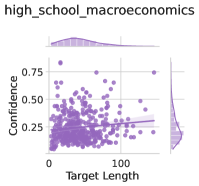
### Visual Description
\n
## Scatter Plot: Confidence vs. Target Length (High School Macroeconomics)
### Overview
The image presents a scatter plot visualizing the relationship between "Target Length" and "Confidence" for data labeled as "high_school_macroeconomics". A regression line with a confidence interval is overlaid on the scatter points. Marginal distributions are shown above and to the right of the main plot.
### Components/Axes
* **X-axis:** "Target Length" - Scale ranges from approximately 0 to 150.
* **Y-axis:** "Confidence" - Scale ranges from approximately 0 to 0.75.
* **Scatter Points:** Purple dots representing individual data points.
* **Regression Line:** A dark purple line representing the trend of the data.
* **Confidence Interval:** A lighter purple shaded area around the regression line, indicating the uncertainty in the estimated trend.
* **Marginal Distribution (Top):** A density plot showing the distribution of "Target Length".
* **Marginal Distribution (Right):** A density plot showing the distribution of "Confidence".
* **Title:** "high\_school\_macroeconomics" - Located in the top-left corner.
### Detailed Analysis
The scatter plot shows a weak positive correlation between "Target Length" and "Confidence". The points are clustered, but there is significant scatter.
* **Regression Line Trend:** The regression line slopes slightly upward, indicating a positive, but weak, relationship.
* **Data Point Distribution:** Most data points fall within the "Confidence" range of 0.2 to 0.5.
* **Target Length Distribution:** The distribution of "Target Length" is skewed to the right, with a peak around 20-40.
* **Confidence Distribution:** The distribution of "Confidence" is concentrated towards lower values, with a tail extending towards higher values.
* **Approximate Data Points (sampled):**
* Target Length = 0, Confidence ≈ 0.25
* Target Length = 25, Confidence ≈ 0.35
* Target Length = 50, Confidence ≈ 0.40
* Target Length = 75, Confidence ≈ 0.30
* Target Length = 100, Confidence ≈ 0.25
* Target Length = 125, Confidence ≈ 0.20
* Outlier: Target Length ≈ 130, Confidence ≈ 0.70
### Key Observations
* The relationship between "Target Length" and "Confidence" is weak.
* There is a noticeable outlier at a "Target Length" of approximately 130 with a "Confidence" of approximately 0.70.
* The marginal distributions reveal that "Target Length" is more variable than "Confidence".
### Interpretation
The data suggests that, for this "high_school_macroeconomics" dataset, there is a very slight tendency for higher "Target Length" to be associated with higher "Confidence", but this relationship is not strong. The weak correlation implies that "Target Length" is not a reliable predictor of "Confidence". The outlier suggests that there may be specific cases where longer targets lead to significantly higher confidence, but these are rare. The distributions indicate that the "Target Length" varies more widely than the "Confidence" scores. This could mean that the "Target Length" is a more flexible parameter, while "Confidence" is constrained by other factors. The marginal distributions provide insight into the range and typical values of each variable independently. The overall plot suggests that other variables likely play a more significant role in determining "Confidence" than "Target Length" alone.
</details>
|
<details>
<summary>x41.png Details</summary>
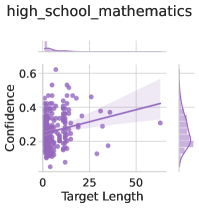
### Visual Description
\n
## Scatter Plot: Confidence vs. Target Length (High School Mathematics)
### Overview
The image presents a scatter plot visualizing the relationship between "Target Length" and "Confidence" for data related to "high_school_mathematics". A regression line with a shaded confidence interval is overlaid on the scatter points. Marginal distributions are shown above and to the right of the main plot.
### Components/Axes
* **Title:** "high\_school\_mathematics" (top-left)
* **X-axis:** "Target Length" (bottom) - Scale ranges from approximately 0 to 60.
* **Y-axis:** "Confidence" (left) - Scale ranges from approximately 0.15 to 0.6.
* **Scatter Points:** Purple dots representing individual data points.
* **Regression Line:** Brown line representing the trend of the data.
* **Confidence Interval:** Light purple shaded area around the regression line.
* **Marginal Distribution (Top):** A density plot showing the distribution of "Target Length".
* **Marginal Distribution (Right):** A density plot showing the distribution of "Confidence".
### Detailed Analysis
The scatter plot shows a generally positive, but weak, correlation between "Target Length" and "Confidence".
* **Scatter Points:** The points are clustered around the x-axis (Target Length near 0) with a concentration of points between 0.2 and 0.4 on the Confidence axis. As Target Length increases, the points become more dispersed.
* **Regression Line:** The brown regression line slopes upward, indicating a positive correlation. The slope appears to be relatively shallow.
* **Confidence Interval:** The confidence interval is relatively wide, suggesting a high degree of uncertainty in the estimated relationship.
* **Marginal Distribution (Top):** The distribution of "Target Length" is skewed to the right, with a peak around a value of approximately 5. There is a long tail extending to higher values.
* **Marginal Distribution (Right):** The distribution of "Confidence" is roughly symmetrical, with a peak around a value of approximately 0.25.
Approximate Data Points (based on visual estimation):
* Target Length = 0, Confidence ranges from ~0.18 to ~0.5
* Target Length = 25, Confidence ranges from ~0.2 to ~0.45
* Target Length = 50, Confidence ranges from ~0.25 to ~0.55
### Key Observations
* The relationship between "Target Length" and "Confidence" is weak.
* There is a significant amount of variability in "Confidence" for a given "Target Length".
* The marginal distributions reveal that "Target Length" is more skewed than "Confidence".
* The confidence interval is wide, indicating uncertainty in the regression model.
### Interpretation
The data suggests that, in the context of high school mathematics, there is a slight tendency for confidence to increase with target length. However, this relationship is not strong, and confidence is likely influenced by many other factors. The wide confidence interval indicates that the observed correlation may not be reliable or generalizable. The skewness of the "Target Length" distribution suggests that most tasks have relatively short target lengths, with a few tasks having much longer lengths. The marginal distributions provide insight into the range and distribution of each variable independently. The overall plot suggests that target length is not a strong predictor of confidence in this dataset. It is possible that other variables, not shown in this plot, are more important determinants of confidence.
</details>
|
<details>
<summary>x42.png Details</summary>
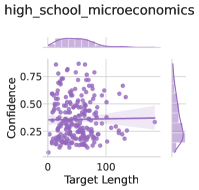
### Visual Description
\n
## Scatter Plot: Confidence vs. Target Length (High School Microeconomics)
### Overview
The image presents a scatter plot visualizing the relationship between "Target Length" and "Confidence" for data labeled as "high_school_microeconomics". A density plot is shown above the scatter plot, and a histogram-like visualization is shown to the right of the scatter plot. A regression line with a shaded confidence interval is overlaid on the scatter plot.
### Components/Axes
* **Title:** high\_school\_microeconomics (top-center)
* **X-axis:** Target Length (bottom-center), ranging from approximately 0 to 120.
* **Y-axis:** Confidence (left-center), ranging from approximately 0.15 to 0.75.
* **Scatter Plot:** Purple dots representing individual data points.
* **Regression Line:** A purple line representing the trend of the data.
* **Confidence Interval:** A light purple shaded area around the regression line.
* **Density Plot:** A purple filled area above the scatter plot, showing the distribution of "Target Length".
* **Histogram-like Visualization:** A purple filled area to the right of the scatter plot, showing the distribution of "Confidence".
### Detailed Analysis
The scatter plot shows a weak, potentially negative correlation between "Target Length" and "Confidence". The points are widely dispersed, indicating a high degree of variability.
* **Regression Line Trend:** The regression line is approximately horizontal, indicating a very weak or non-existent linear relationship. It appears to be centered around a confidence value of approximately 0.35.
* **Data Point Distribution:**
* For Target Length values between 0 and 50, Confidence values range from approximately 0.2 to 0.7.
* For Target Length values between 50 and 100, Confidence values are generally lower, ranging from approximately 0.2 to 0.5.
* For Target Length values above 100, Confidence values are concentrated between 0.2 and 0.4.
* **Density Plot:** The density plot shows a peak in the distribution of "Target Length" around a value of approximately 20-30, and a gradual decline as "Target Length" increases.
* **Histogram-like Visualization:** The histogram-like visualization shows a peak in the distribution of "Confidence" around a value of approximately 0.25-0.35.
### Key Observations
* The scatter plot does not show a strong linear relationship between "Target Length" and "Confidence".
* The confidence interval around the regression line is relatively wide, indicating a high degree of uncertainty in the estimated relationship.
* The density plot suggests that shorter "Target Lengths" are more common in the dataset.
* The histogram-like visualization suggests that lower "Confidence" values are more common in the dataset.
### Interpretation
The data suggests that the length of the target does not strongly predict the confidence level in the context of high school microeconomics. The weak correlation and wide confidence interval indicate that other factors likely play a more significant role in determining confidence. The distributions of both "Target Length" and "Confidence" are skewed towards lower values, which could indicate a bias in the data or a natural tendency for shorter targets and lower confidence levels in this domain. The lack of a clear trend suggests that simply increasing the target length does not necessarily lead to increased confidence. Further investigation would be needed to identify the other factors that influence confidence in this context.
</details>
|
Figure 12: Confidence versus Target Length for various MMLU subsets. A horizontal regression line indicates weak correlation of confidence with the target length. See figs. 13 and 14 for other subsets.
|
<details>
<summary>x43.png Details</summary>
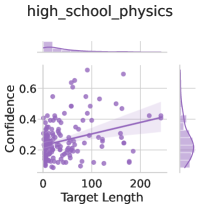
### Visual Description
\n
## Scatter Plot: Confidence vs. Target Length (High School Physics)
### Overview
The image presents a scatter plot visualizing the relationship between "Target Length" and "Confidence" for data labeled as "high_school_physics". The plot includes a regression line with a confidence interval, and marginal histograms showing the distributions of each variable.
### Components/Axes
* **Title:** "high\_school\_physics" (top-center)
* **X-axis:** "Target Length" (bottom-center), ranging from approximately 0 to 250.
* **Y-axis:** "Confidence" (left-center), ranging from approximately 0.15 to 0.65.
* **Scatter Points:** Numerous purple dots representing individual data points.
* **Regression Line:** A purple line representing the trend of the data.
* **Confidence Interval:** A shaded purple area around the regression line, indicating the uncertainty in the line's estimate.
* **Marginal Histograms:** Two histograms, one above the scatter plot and one to the right, showing the distributions of "Target Length" and "Confidence" respectively.
### Detailed Analysis
The scatter plot shows a weak positive correlation between "Target Length" and "Confidence".
* **Regression Line Trend:** The regression line slopes slightly upward, indicating that as "Target Length" increases, "Confidence" tends to increase, but the effect is small.
* **Scatter Point Distribution:** The points are widely dispersed, indicating a low degree of correlation. Most points cluster between "Target Length" values of 0 and 150, and "Confidence" values of 0.2 and 0.4.
* **Marginal Histogram - Target Length:** The histogram above the scatter plot is right-skewed, with a peak around a "Target Length" of approximately 20-50. The distribution extends to a maximum "Target Length" of around 250.
* **Marginal Histogram - Confidence:** The histogram to the right of the scatter plot appears roughly uniform, with a slight peak around a "Confidence" of 0.3. The distribution extends from approximately 0.15 to 0.65.
* **Data Points (Approximate Values):**
* (0, 0.15): A cluster of points near the origin.
* (50, 0.3): Several points around this value.
* (100, 0.35): A few points.
* (150, 0.4): A small number of points.
* (200, 0.5): A few scattered points.
* (250, 0.3): A few scattered points.
### Key Observations
* The correlation between "Target Length" and "Confidence" is weak.
* The distribution of "Target Length" is skewed, suggesting that shorter target lengths are more common.
* The distribution of "Confidence" is relatively flat, indicating that confidence levels are fairly evenly distributed.
* There are no obvious outliers.
### Interpretation
The data suggests that, for this "high\_school\_physics" dataset, the length of the "Target" does not strongly predict the "Confidence" associated with it. The weak positive correlation could be due to a number of factors, such as increased familiarity with longer targets or a tendency to be more confident in longer, more complex problems. The skewed distribution of "Target Length" suggests that the dataset may be biased towards shorter targets. The relatively flat distribution of "Confidence" indicates that there is a wide range of confidence levels among the data points. The marginal histograms provide additional context about the distributions of each variable, helping to understand the overall characteristics of the dataset. The confidence interval around the regression line indicates the uncertainty in the estimated relationship between "Target Length" and "Confidence".
</details>
|
<details>
<summary>x44.png Details</summary>
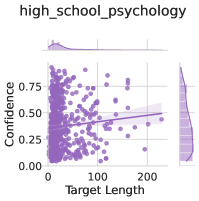
### Visual Description
\n
## Scatter Plot: Confidence vs. Target Length (High School Psychology)
### Overview
The image presents a scatter plot visualizing the relationship between "Target Length" and "Confidence" for data labeled as "high_school_psychology". The plot includes a regression line with a shaded confidence interval. Marginal histograms are displayed above and to the right of the main scatter plot, showing the distributions of "Target Length" and "Confidence" respectively.
### Components/Axes
* **X-axis:** "Target Length" - Scale ranges from approximately 0 to 220.
* **Y-axis:** "Confidence" - Scale ranges from approximately 0.00 to 0.75.
* **Data Points:** Numerous purple dots representing individual data points.
* **Regression Line:** A dark purple line representing the trend of the data. The line slopes downward slightly.
* **Confidence Interval:** A light purple shaded area around the regression line, indicating the uncertainty in the estimated trend.
* **Marginal Histogram (Top):** Displays the distribution of "Target Length". It appears to be a right-skewed distribution, with a peak around a value of 0.
* **Marginal Histogram (Right):** Displays the distribution of "Confidence". It appears to be a bimodal distribution, with peaks around 0.25 and 0.75.
* **Title:** "high\_school\_psychology" - positioned at the top-center of the image.
### Detailed Analysis
The scatter plot shows a weak negative correlation between "Target Length" and "Confidence". As "Target Length" increases, "Confidence" tends to decrease, but the relationship is not strong.
* **Data Point Distribution:** The majority of data points are clustered in the lower-left portion of the plot, where "Target Length" is less than 100 and "Confidence" is less than 0.5. There is a sparse scattering of points with higher "Target Length" values (between 100 and 220) and varying "Confidence" levels.
* **Regression Line:** The regression line has a negative slope, indicating a tendency for "Confidence" to decrease as "Target Length" increases. The slope appears to be relatively small.
* **Confidence Interval:** The confidence interval is relatively wide, suggesting a high degree of uncertainty in the estimated regression line.
* **Marginal Histograms:**
* The "Target Length" histogram shows a concentration of values near 0, with a tail extending to higher values.
* The "Confidence" histogram shows two peaks, one around 0.25 and another around 0.75, suggesting that "Confidence" values tend to cluster around these two levels.
### Key Observations
* The relationship between "Target Length" and "Confidence" is weak and negative.
* There is a significant amount of variability in "Confidence" for a given "Target Length".
* The marginal histograms reveal the distributions of "Target Length" and "Confidence", which are both non-normal.
* The bimodal distribution of "Confidence" suggests that there may be two distinct groups or factors influencing "Confidence" levels.
### Interpretation
The data suggests that, within the context of "high_school_psychology", there is a slight tendency for confidence to decrease as the target length increases. However, this relationship is not strong, and other factors likely play a more significant role in determining confidence levels. The bimodal distribution of confidence suggests that there might be two different underlying processes or groups influencing confidence. The right-skewed distribution of target length indicates that most targets are relatively short, with a few longer targets. The wide confidence interval around the regression line indicates that the observed relationship is not very precise and could be due to chance. Further investigation would be needed to understand the underlying reasons for these patterns and to identify the factors that are most strongly associated with confidence.
</details>
|
<details>
<summary>x45.png Details</summary>
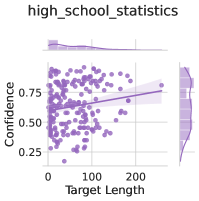
### Visual Description
\n
## Scatter Plot: High School Statistics
### Overview
The image presents a scatter plot visualizing the relationship between "Target Length" and "Confidence". A regression line is overlaid on the scatter points, along with a shaded region representing the confidence interval around the regression line. Marginal distributions (histograms) are displayed along the top and right edges of the plot, showing the distributions of "Target Length" and "Confidence" respectively.
### Components/Axes
* **Title:** "high\_school\_statistics" (top-center)
* **X-axis:** "Target Length" (bottom-center), ranging from approximately 0 to 220.
* **Y-axis:** "Confidence" (left-center), ranging from approximately 0.2 to 0.8.
* **Scatter Points:** Numerous purple dots representing individual data points.
* **Regression Line:** A purple line representing the linear relationship between "Target Length" and "Confidence".
* **Confidence Interval:** A light purple shaded region around the regression line, indicating the uncertainty in the estimated relationship.
* **Marginal Distribution (Top):** A histogram showing the distribution of "Target Length".
* **Marginal Distribution (Right):** A histogram showing the distribution of "Confidence".
### Detailed Analysis
The scatter plot shows a generally positive, but weak, correlation between "Target Length" and "Confidence".
* **Scatter Points Trend:** The points are scattered, with a slight tendency for "Confidence" to increase as "Target Length" increases. There is a large spread of data points around the regression line.
* **Regression Line Trend:** The regression line slopes upward, indicating a positive relationship. The slope appears to be relatively small.
* **Confidence Interval:** The confidence interval is relatively wide, suggesting a high degree of uncertainty in the estimated relationship.
* **Target Length Distribution:** The distribution of "Target Length" is skewed to the right, with a concentration of values near 0 and a tail extending towards higher values. The peak of the distribution is around 0-20.
* **Confidence Distribution:** The distribution of "Confidence" appears to be roughly uniform between 0.2 and 0.8, with a slight concentration of values around 0.6.
Due to the scatter plot's nature, precise numerical values cannot be extracted without access to the underlying data. However, we can approximate some points:
* At "Target Length" = 0, "Confidence" ranges from approximately 0.3 to 0.7, with a concentration around 0.6.
* At "Target Length" = 100, "Confidence" ranges from approximately 0.4 to 0.8, with a concentration around 0.65.
* At "Target Length" = 200, "Confidence" ranges from approximately 0.5 to 0.8, with a concentration around 0.7.
### Key Observations
* The relationship between "Target Length" and "Confidence" is weak and noisy.
* The confidence interval is wide, indicating a high degree of uncertainty.
* The distribution of "Target Length" is skewed, while the distribution of "Confidence" is relatively uniform.
* There are no obvious outliers.
### Interpretation
The data suggests a slight positive association between "Target Length" and "Confidence", but the relationship is not strong enough to make definitive conclusions. The wide confidence interval indicates that the observed relationship could be due to chance. The skewed distribution of "Target Length" suggests that most observations have relatively short target lengths, while the uniform distribution of "Confidence" suggests that confidence levels are relatively consistent across different target lengths.
The "high\_school\_statistics" title suggests that this data may relate to some aspect of high school performance or assessment. "Target Length" could refer to the length of an essay, a test, or some other task, while "Confidence" could refer to a student's self-reported confidence level or a teacher's assessment of a student's confidence. The weak correlation suggests that there is little relationship between the length of a task and a student's confidence level. Further investigation would be needed to understand the specific context of this data and to determine the underlying factors that influence confidence levels.
</details>
|
<details>
<summary>x46.png Details</summary>
### Visual Description
\n
## Scatter Plot: Confidence vs. Target Length for "high_school_us_history"
### Overview
The image presents a scatter plot visualizing the relationship between "Target Length" and "Confidence" for the topic "high_school_us_history". A density plot is shown at the top, and a histogram is shown on the right. The plot displays a large number of data points, with a shaded region representing a confidence interval.
### Components/Axes
* **Title:** "high\_school\_us\_history" (top-center)
* **X-axis:** "Target Length" (bottom-center), ranging from approximately 0 to 250.
* **Y-axis:** "Confidence" (left-center), ranging from approximately 0.2 to 1.0.
* **Data Points:** Numerous purple dots scattered across the plot.
* **Confidence Interval:** A shaded purple region surrounding a horizontal line.
* **Density Plot:** A purple density plot at the top of the chart, showing the distribution of confidence values.
* **Histogram:** A purple histogram on the right side of the chart, showing the distribution of target length values.
### Detailed Analysis
The scatter plot shows a weak, potentially non-linear relationship between "Target Length" and "Confidence".
* **Data Point Distribution:** The majority of data points cluster between "Target Length" values of 0 and 150, with "Confidence" values generally between 0.4 and 0.8. There is a noticeable spread in the data, indicating variability in confidence levels for similar target lengths.
* **Confidence Interval:** The horizontal line representing the average confidence is approximately at 0.55. The shaded region indicates a 95% confidence interval, extending from approximately 0.45 to 0.65.
* **Density Plot:** The density plot at the top shows a peak in confidence values around 0.55, with a slight decrease in density towards lower confidence levels.
* **Histogram:** The histogram on the right shows a concentration of target lengths between 0 and 100, with a tail extending towards higher values.
Approximate Data Points (sampled for illustration):
* (Target Length: 20, Confidence: 0.6)
* (Target Length: 50, Confidence: 0.5)
* (Target Length: 100, Confidence: 0.7)
* (Target Length: 150, Confidence: 0.45)
* (Target Length: 200, Confidence: 0.65)
* (Target Length: 230, Confidence: 0.75)
### Key Observations
* There is no strong correlation between "Target Length" and "Confidence".
* The confidence interval is relatively narrow, suggesting a consistent level of confidence across different target lengths.
* The distribution of target lengths is skewed towards lower values.
* The density plot indicates that the most common confidence level is around 0.55.
### Interpretation
The data suggests that the length of the target does not significantly impact the confidence level for the "high\_school\_us\_history" topic. The relatively stable confidence interval indicates that the model or system being evaluated maintains a consistent level of certainty regardless of the target length. The skew in the target length distribution might indicate that most queries or tasks related to this topic involve shorter targets. The lack of a strong correlation could be due to other factors influencing confidence, such as the complexity of the target content or the quality of the input data. The data does not reveal the nature of the "Target Length" (e.g., word count, character count, etc.), which limits a deeper understanding of the relationship.
</details>
|
| --- | --- | --- | --- |
|
<details>
<summary>x47.png Details</summary>
### Visual Description
\n
## Scatter Plot: Confidence vs. Target Length for High School World History
### Overview
The image presents a scatter plot visualizing the relationship between "Target Length" and "Confidence" for data related to "high_school_world_history". A regression line with a shaded confidence interval is overlaid on the scatter points. Marginal distributions (histograms) are displayed above and to the right of the main plot.
### Components/Axes
* **Title:** "high\_school\_world\_history" (top-left)
* **X-axis:** "Target Length" (ranging from approximately 0 to 120)
* **Y-axis:** "Confidence" (ranging from approximately 0.4 to 1.0)
* **Scatter Points:** Numerous purple dots representing individual data points.
* **Regression Line:** A dark purple line representing the trend of the data.
* **Confidence Interval:** A light purple shaded area around the regression line.
* **Marginal Distribution (Top):** A purple histogram showing the distribution of "Target Length".
* **Marginal Distribution (Right):** A purple histogram showing the distribution of "Confidence".
### Detailed Analysis
The scatter plot shows a slight negative correlation between "Target Length" and "Confidence". As "Target Length" increases, "Confidence" tends to decrease, but the relationship is weak.
* **Regression Line Trend:** The regression line slopes downward slightly.
* **Data Point Distribution:** The data points are clustered, but with significant scatter.
* **Target Length Distribution:** The distribution of "Target Length" is approximately normal, peaking around a value of 50, with a long tail extending to higher values.
* **Confidence Distribution:** The distribution of "Confidence" is skewed towards higher values, with a peak around 0.75.
Approximate Data Points (sampled for illustration, not exhaustive):
* Target Length = 0, Confidence ≈ 0.85
* Target Length = 25, Confidence ≈ 0.90
* Target Length = 50, Confidence ≈ 0.75
* Target Length = 75, Confidence ≈ 0.65
* Target Length = 100, Confidence ≈ 0.55
* Target Length = 120, Confidence ≈ 0.45
### Key Observations
* The negative correlation between "Target Length" and "Confidence" is weak.
* The data is quite dispersed, indicating that "Target Length" is not a strong predictor of "Confidence".
* The marginal distributions provide insights into the individual distributions of each variable.
### Interpretation
The data suggests that, for "high\_school\_world\_history", longer target lengths are associated with slightly lower confidence scores, but this relationship is not strong. This could indicate that more complex or lengthy tasks (represented by "Target Length") are perceived as less certain or reliable. The marginal distributions show that "Target Length" is relatively evenly distributed, while "Confidence" tends to be higher. The weak correlation suggests that other factors likely play a more significant role in determining confidence levels than simply the length of the target. The scatter suggests that the model is not a strong predictor of confidence. The data does not provide any information about the nature of the "Target Length" or "Confidence" metrics. Further investigation would be needed to understand the context and meaning of these variables.
</details>
|
<details>
<summary>x48.png Details</summary>
### Visual Description
\n
## Scatter Plot: Human Aging Confidence vs. Target Length
### Overview
The image presents a scatter plot visualizing the relationship between "Target Length" and "Confidence" in the context of "human_aging". A regression line with a confidence interval is overlaid on the scatter points. Marginal distributions (density plots) are shown along the top and right edges of the plot.
### Components/Axes
* **Title:** "human\_aging" (top-center)
* **X-axis:** "Target Length" (bottom-center), ranging from approximately 0 to 100.
* **Y-axis:** "Confidence" (left-center), ranging from approximately 0.00 to 0.75.
* **Scatter Points:** Numerous purple dots representing individual data points.
* **Regression Line:** A purple line representing the trend of the data. It slopes slightly upward.
* **Confidence Interval:** A shaded purple area around the regression line, indicating the uncertainty in the estimated trend.
* **Marginal Distribution (Top):** A density plot showing the distribution of "Target Length".
* **Marginal Distribution (Right):** A density plot showing the distribution of "Confidence".
### Detailed Analysis
The scatter plot shows a weak positive correlation between "Target Length" and "Confidence". As "Target Length" increases, "Confidence" tends to increase, but the relationship is not strong.
* **Data Point Distribution:** The majority of data points are clustered towards the left side of the plot (low "Target Length") and have "Confidence" values between 0.20 and 0.50. There is a spread of points across the entire range of "Target Length" and "Confidence", but the density decreases as "Target Length" increases.
* **Regression Line Trend:** The regression line has a positive slope, indicating a positive correlation. However, the slope is relatively small, suggesting a weak relationship.
* **Confidence Interval:** The confidence interval is relatively wide, indicating a high degree of uncertainty in the estimated trend.
* **Marginal Distribution (Top):** The distribution of "Target Length" is skewed to the right, with a peak around a value of approximately 10-20.
* **Marginal Distribution (Right):** The distribution of "Confidence" is roughly symmetrical, with a peak around a value of approximately 0.30.
Approximate Data Points (sampled for illustration):
* Target Length = 0, Confidence ≈ 0.25
* Target Length = 25, Confidence ≈ 0.40
* Target Length = 50, Confidence ≈ 0.50
* Target Length = 75, Confidence ≈ 0.35
* Target Length = 100, Confidence ≈ 0.45
### Key Observations
* The relationship between "Target Length" and "Confidence" is weak and positive.
* There is considerable variability in "Confidence" for a given "Target Length".
* The marginal distributions suggest that "Target Length" is skewed to the right, while "Confidence" is approximately symmetrical.
* The wide confidence interval indicates uncertainty in the estimated trend.
### Interpretation
The data suggests that while there may be a slight tendency for "Confidence" to increase with "Target Length" in the context of "human\_aging", this relationship is not strong or reliable. The weak correlation and wide confidence interval suggest that other factors likely play a more significant role in determining "Confidence". The marginal distributions provide insights into the distributions of the individual variables, which can be useful for understanding the underlying data. The skewness of the "Target Length" distribution may indicate that the data is not normally distributed, which could affect the validity of statistical analyses. The "human\_aging" title suggests this data might relate to a model or process attempting to predict or assess age-related changes, and the confidence score represents the reliability of that prediction.
</details>
|
<details>
<summary>x49.png Details</summary>
### Visual Description
\n
## Scatter Plot: Human Sexuality Confidence vs. Target Length
### Overview
The image presents a scatter plot visualizing the relationship between "Target Length" and "Confidence" for the category "human_sexuality". A regression line with a confidence interval is overlaid on the scatter points. Marginal histograms are displayed above and to the right of the main plot, showing the distributions of "Target Length" and "Confidence" respectively.
### Components/Axes
* **Title:** "human\_sexuality" (top-center)
* **X-axis:** "Target Length" (bottom-center), ranging from approximately 0 to 120.
* **Y-axis:** "Confidence" (left-center), ranging from 0.0 to 0.6.
* **Scatter Points:** Purple dots representing individual data points.
* **Regression Line:** A purple line representing the trend of the data. It has a slight negative slope.
* **Confidence Interval:** A shaded purple area around the regression line, indicating the uncertainty in the estimated trend.
* **Marginal Histogram (Top):** Displays the distribution of "Target Length".
* **Marginal Histogram (Right):** Displays the distribution of "Confidence".
### Detailed Analysis
The scatter plot shows a weak, slightly negative correlation between "Target Length" and "Confidence".
* **Scatter Point Distribution:** The majority of points cluster in the lower-left quadrant, with "Target Length" values between 0 and 50 and "Confidence" values between 0.0 and 0.3. There is a sparse scattering of points extending towards higher "Target Length" values (up to approximately 120) and "Confidence" values (up to approximately 0.6).
* **Regression Line Trend:** The regression line slopes downward slightly, indicating that as "Target Length" increases, "Confidence" tends to decrease, but the effect is very weak.
* **Regression Line Equation (Approximate):** Visually, the line appears to intersect the Y-axis around 0.25 and has a slope of approximately -0.002.
* **Confidence Interval:** The confidence interval is relatively wide, indicating a high degree of uncertainty in the estimated relationship.
* **Marginal Histogram - Target Length:** The distribution of "Target Length" is skewed to the right, with a peak around 0-10 and a tail extending to higher values.
* **Marginal Histogram - Confidence:** The distribution of "Confidence" is skewed to the right, with a peak around 0.1-0.2 and a tail extending to higher values.
### Key Observations
* The relationship between "Target Length" and "Confidence" is weak and potentially non-linear.
* There is a significant amount of variability in "Confidence" for a given "Target Length".
* The marginal histograms suggest that both "Target Length" and "Confidence" are positively skewed.
* The confidence interval is wide, indicating low statistical power or a genuinely noisy relationship.
### Interpretation
The data suggests that "Target Length" is not a strong predictor of "Confidence" for the category "human\_sexuality". The slight negative trend could indicate that longer targets are associated with slightly lower confidence, but this effect is small and may not be statistically significant. The wide confidence interval suggests that other factors likely play a more important role in determining "Confidence". The skewed distributions of both variables suggest that the data may not be normally distributed, which could affect the validity of the regression analysis. The marginal histograms provide insight into the distribution of each variable independently, showing that both are concentrated at lower values. The overall plot suggests a complex relationship that is not easily captured by a simple linear model.
</details>
|
<details>
<summary>x50.png Details</summary>
### Visual Description
\n
## Scatter Plot: Confidence vs. Target Length (International Law)
### Overview
This image presents a scatter plot visualizing the relationship between "Target Length" and "Confidence" for the category "international_law". A regression line with a shaded confidence interval is overlaid on the scatter points. Marginal distributions (density plots) are shown above and to the right of the main scatter plot.
### Components/Axes
* **X-axis:** "Target Length" - Scale ranges from approximately 0 to 300.
* **Y-axis:** "Confidence" - Scale ranges from approximately 0.15 to 0.85.
* **Title:** "international\_law" - Located at the top-center of the image.
* **Scatter Points:** Purple dots representing individual data points.
* **Regression Line:** A dark purple line representing the trend in the data.
* **Confidence Interval:** A light purple shaded area around the regression line, indicating the uncertainty in the estimated trend.
* **Marginal Distribution (Top):** A density plot showing the distribution of "Target Length".
* **Marginal Distribution (Right):** A density plot showing the distribution of "Confidence".
### Detailed Analysis
The scatter plot shows a generally negative trend between "Target Length" and "Confidence". As "Target Length" increases, "Confidence" tends to decrease, although the relationship appears weak and scattered.
* **Regression Line Trend:** The regression line has a slight negative slope, confirming the observed negative trend.
* **Data Point Distribution:** The data points are widely dispersed, indicating a low correlation between the two variables.
* **Target Length Distribution:** The distribution of "Target Length" is skewed to the right, with a peak around 50-100 and a tail extending to 300.
* **Confidence Distribution:** The distribution of "Confidence" is roughly bell-shaped, peaking around 0.35-0.45.
Approximate Data Points (sampled for illustration, not exhaustive):
* Target Length = 0, Confidence ≈ 0.30
* Target Length = 50, Confidence ≈ 0.50
* Target Length = 100, Confidence ≈ 0.40
* Target Length = 150, Confidence ≈ 0.35
* Target Length = 200, Confidence ≈ 0.25
* Target Length = 250, Confidence ≈ 0.20
* Target Length = 300, Confidence ≈ 0.15
### Key Observations
* The correlation between "Target Length" and "Confidence" is weak.
* There is a noticeable spread in the data, suggesting other factors influence "Confidence" besides "Target Length".
* The marginal distributions provide insights into the individual distributions of each variable.
### Interpretation
The data suggests that, for the category "international\_law", longer target lengths are weakly associated with lower confidence scores. However, this relationship is not strong, and there is considerable variability in the data. This could indicate that the length of the target is not a primary determinant of confidence, or that other variables are playing a significant role. The marginal distributions show that target lengths are generally shorter, and confidence scores are relatively low, but there is a range of values for both variables. The weak correlation and wide spread of data points suggest that a more complex model might be needed to accurately predict confidence based on target length. The data does not provide any information about the nature of the "target" or the method used to calculate "confidence".
</details>
|
|
<details>
<summary>x51.png Details</summary>
### Visual Description
\n
## Scatter Plot: Confidence vs. Target Length (Jurisprudence)
### Overview
This image presents a scatter plot visualizing the relationship between "Target Length" and "Confidence" for the category "jurisprudence". A regression line with a shaded confidence interval is overlaid on the scatter points. There are also two marginal distributions displayed at the top and right of the main plot.
### Components/Axes
* **Title:** jurisprudence (top-center)
* **X-axis:** Target Length (bottom-center), ranging from approximately 0 to 220.
* **Y-axis:** Confidence (left-center), ranging from approximately 0.15 to 0.65.
* **Scatter Points:** Purple dots representing individual data points.
* **Regression Line:** A purple line representing the trend of the data.
* **Confidence Interval:** A light purple shaded area around the regression line, indicating the uncertainty in the estimated trend.
* **Top Marginal Distribution:** A density plot showing the distribution of "Target Length".
* **Right Marginal Distribution:** A density plot showing the distribution of "Confidence".
### Detailed Analysis
The scatter plot shows a generally positive, but weak, correlation between Target Length and Confidence.
* **Regression Line Trend:** The regression line slopes upward, indicating that as Target Length increases, Confidence tends to increase. However, the slope is relatively shallow.
* **Scatter Point Distribution:** The points are widely scattered, indicating a significant amount of variability in Confidence for a given Target Length.
* **Data Points (Approximate):**
* At Target Length = 0, Confidence ranges from approximately 0.18 to 0.5.
* At Target Length = 50, Confidence ranges from approximately 0.2 to 0.55.
* At Target Length = 100, Confidence ranges from approximately 0.25 to 0.6.
* At Target Length = 150, Confidence ranges from approximately 0.3 to 0.55.
* At Target Length = 200, Confidence ranges from approximately 0.35 to 0.6.
* **Top Marginal Distribution:** The distribution of Target Length appears to be somewhat skewed to the right, with a peak around a Target Length of approximately 50-75.
* **Right Marginal Distribution:** The distribution of Confidence is skewed to the left, with a peak around a Confidence of approximately 0.3.
### Key Observations
* The correlation between Target Length and Confidence is weak. The regression line has a shallow slope, and the scatter points are widely dispersed.
* There is a considerable amount of variability in Confidence, even for similar Target Lengths.
* The marginal distributions suggest that shorter Target Lengths and lower Confidence values are more common.
### Interpretation
The data suggests that, for the category "jurisprudence", there is a slight tendency for Confidence to increase with Target Length. However, this relationship is not strong, and other factors likely play a significant role in determining Confidence. The weak correlation could indicate that the model's confidence is not strongly dependent on the length of the target text in this domain. The marginal distributions provide additional context, showing the typical ranges of Target Length and Confidence values. The skewness in the distributions suggests that shorter Target Lengths and lower Confidence values are more prevalent. The wide spread of the data points indicates that the model's performance is inconsistent, and there is significant room for improvement. The confidence interval around the regression line highlights the uncertainty in the estimated trend, further emphasizing the weak correlation.
</details>
|
<details>
<summary>x52.png Details</summary>
### Visual Description
\n
## Scatter Plot: Confidence vs. Target Length for Logical Fallacies
### Overview
The image presents a scatter plot visualizing the relationship between "Target Length" and "Confidence" related to "logical_fallacies". The plot displays a positive correlation, with a regression line indicating a tendency for confidence to increase with target length. Marginal distributions are shown at the top and right sides of the plot.
### Components/Axes
* **Title:** "logical\_fallacies" (top-center)
* **X-axis:** "Target Length" (bottom-center), ranging from approximately 0 to 220.
* **Y-axis:** "Confidence" (left-center), ranging from 0.00 to 0.75.
* **Data Points:** Purple circles representing individual data points.
* **Regression Line:** A solid purple line representing the trend of the data.
* **Confidence Interval:** A shaded purple area around the regression line, indicating the uncertainty in the trend.
* **Top Marginal Distribution:** A density plot showing the distribution of "Target Length".
* **Right Marginal Distribution:** A density plot showing the distribution of "Confidence".
### Detailed Analysis
The scatter plot shows a generally upward trend. As "Target Length" increases, "Confidence" tends to increase as well.
* **Data Point Distribution:** The data points are clustered around the x-axis for low "Target Length" values (0-50), with "Confidence" values generally below 0.5. As "Target Length" increases beyond 50, the data points become more dispersed, with "Confidence" values reaching up to approximately 0.75.
* **Regression Line Trend:** The regression line slopes upward, indicating a positive correlation.
* **Regression Line Equation (approximate):** While the exact equation isn't provided, the line appears to start around (0, 0.2) and ends around (220, 0.6).
* **Top Marginal Distribution:** The distribution of "Target Length" is skewed to the right, with a peak around 20-50.
* **Right Marginal Distribution:** The distribution of "Confidence" is roughly symmetrical, with a peak around 0.4-0.5.
### Key Observations
* The positive correlation between "Target Length" and "Confidence" suggests that longer targets are associated with higher confidence levels.
* The spread of data points indicates that the relationship is not perfectly linear, and there is considerable variability in confidence for a given target length.
* The marginal distributions provide insights into the overall distributions of "Target Length" and "Confidence".
### Interpretation
This data suggests that the confidence in identifying or assessing "logical fallacies" increases as the length of the "target" (presumably the text or argument being analyzed) increases. This could be due to several factors: longer texts may provide more evidence to support or refute a fallacy, or longer texts may simply be easier to analyze. The confidence interval around the regression line indicates that the relationship is not strong, and there is considerable uncertainty in the prediction of confidence based on target length. The right-skewed distribution of target length suggests that most targets are relatively short, while the distribution of confidence is centered around a moderate level. This could indicate that the model or system being evaluated is more confident with shorter targets, or that shorter targets are easier to assess. The marginal distributions provide additional context for understanding the overall patterns in the data.
</details>
|
<details>
<summary>x53.png Details</summary>
### Visual Description
\n
## Scatter Plot: Machine Learning Confidence vs. Target Length
### Overview
The image presents a scatter plot visualizing the relationship between "Target Length" and "Confidence" in a machine learning context. A regression line is overlaid on the scatter points, along with marginal distributions (histograms) along the top and right edges of the plot. The plot suggests a potential negative correlation between target length and confidence, though the relationship appears weak and noisy.
### Components/Axes
* **Title:** "machine\_learning" (top-center)
* **X-axis:** "Target Length" (bottom-center), ranging from approximately 0 to 110.
* **Y-axis:** "Confidence" (left-center), ranging from approximately 0.20 to 0.75.
* **Scatter Points:** Numerous purple dots representing individual data points.
* **Regression Line:** A purple line representing the trend of the data.
* **Marginal Distribution (Top):** A histogram showing the distribution of "Target Length".
* **Marginal Distribution (Right):** A histogram showing the distribution of "Confidence".
* **Shaded Area:** A light purple shaded area around the regression line, representing the confidence interval.
### Detailed Analysis
The scatter plot shows a generally downward trend, but with significant scatter.
* **Regression Line Trend:** The regression line slopes slightly downward, indicating a negative correlation.
* **Data Point Distribution:**
* At Target Length = 0, Confidence values range from approximately 0.20 to 0.70, with a high density of points around 0.25-0.35.
* As Target Length increases to approximately 50, Confidence values are more dispersed, ranging from approximately 0.20 to 0.60, with a concentration around 0.40-0.50.
* For Target Length values greater than 50, the data becomes sparse, with Confidence values generally below 0.50.
* At Target Length = 100, Confidence values range from approximately 0.20 to 0.40.
* **Marginal Distribution (Target Length):** The distribution of Target Length is skewed to the right, with a peak near 0 and a long tail extending to higher values.
* **Marginal Distribution (Confidence):** The distribution of Confidence is roughly unimodal, with a peak around 0.40.
### Key Observations
* The relationship between Target Length and Confidence is weak and noisy. The regression line explains only a small portion of the variance in Confidence.
* There is a higher concentration of data points at lower Target Length values.
* Confidence tends to decrease as Target Length increases, but the effect is not strong.
* The marginal distributions reveal that Target Length is more variable than Confidence.
### Interpretation
The data suggests that longer target lengths may be associated with lower confidence scores in the machine learning model. However, this relationship is not strong, and other factors likely play a significant role in determining confidence. The weak correlation could be due to several reasons:
* The model may be less accurate on longer targets.
* The model may be more uncertain about longer targets.
* The data may be noisy or contain outliers.
The marginal distributions indicate that the model is exposed to a wider range of target lengths than confidence scores. This could be due to the way the data was collected or generated. The histograms show that the model is more frequently exposed to shorter target lengths.
Further investigation is needed to understand the underlying reasons for the observed relationship and to improve the model's performance on longer targets. It would be useful to examine the data more closely, consider other relevant variables, and explore different modeling techniques.
</details>
|
<details>
<summary>x54.png Details</summary>
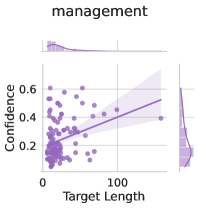
### Visual Description
\n
## Scatter Plot: Confidence vs. Target Length (Management)
### Overview
This image presents a scatter plot visualizing the relationship between "Target Length" and "Confidence" for the category "management". A regression line and confidence interval are overlaid on the scatter points. Marginal histograms are displayed above and to the right of the main plot, showing the distributions of Target Length and Confidence, respectively.
### Components/Axes
* **Title:** "management" (positioned top-center)
* **X-axis:** "Target Length" (ranging from approximately 0 to 120, with tick marks at 0 and 100)
* **Y-axis:** "Confidence" (ranging from approximately 0.15 to 0.65, with tick marks at 0.2, 0.4, and 0.6)
* **Scatter Points:** Numerous purple dots representing individual data points.
* **Regression Line:** A purple line representing the linear relationship between Target Length and Confidence.
* **Confidence Interval:** A light purple shaded area around the regression line, indicating the uncertainty in the estimated relationship.
* **Marginal Histogram (Top):** Displays the distribution of "Target Length".
* **Marginal Histogram (Right):** Displays the distribution of "Confidence".
### Detailed Analysis
The scatter plot shows a generally positive trend between Target Length and Confidence. As Target Length increases, Confidence tends to increase, although the relationship is not strong.
* **Scatter Point Distribution:** The majority of points cluster around the lower left corner of the plot (low Target Length, low Confidence). Points become more dispersed as Target Length increases.
* **Regression Line Trend:** The regression line slopes upward, indicating a positive correlation.
* **Regression Line Equation (approximate):** Visually, the line appears to intersect the Y-axis around 0.25 and has a relatively small slope.
* **Confidence Interval:** The confidence interval is wider for larger Target Length values, indicating greater uncertainty in the estimated Confidence for longer target lengths.
* **Marginal Histogram (Target Length):** The distribution of Target Length is skewed to the right, with a peak near 0 and a long tail extending to higher values.
* **Marginal Histogram (Confidence):** The distribution of Confidence is roughly symmetrical, with a peak around 0.3.
Approximate Data Points (sampled visually):
* Target Length = 0, Confidence ≈ 0.25
* Target Length = 20, Confidence ≈ 0.30
* Target Length = 50, Confidence ≈ 0.38
* Target Length = 80, Confidence ≈ 0.45
* Target Length = 100, Confidence ≈ 0.50
* Target Length = 120, Confidence ≈ 0.55
### Key Observations
* The relationship between Target Length and Confidence is weak to moderate.
* There is considerable variability in Confidence for a given Target Length.
* The marginal histograms reveal the distributions of the individual variables.
* The confidence interval widens with increasing Target Length, suggesting that the model is less certain about the predicted Confidence for longer target lengths.
### Interpretation
The data suggests that, for the "management" category, there is a slight tendency for Confidence to increase with Target Length. However, this relationship is not strong, and other factors likely influence Confidence. The wide confidence interval indicates that Target Length alone is not a reliable predictor of Confidence. The skewed distribution of Target Length suggests that most targets are relatively short, while a smaller number of targets are much longer. The marginal histograms provide insights into the distributions of the individual variables, which can be useful for understanding the overall data. The scatterplot and associated statistics provide a visual and quantitative summary of the relationship between these two variables within the context of "management".
</details>
|
|
<details>
<summary>x55.png Details</summary>
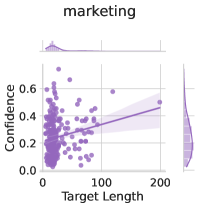
### Visual Description
\n
## Scatter Plot: Marketing - Confidence vs. Target Length
### Overview
The image presents a scatter plot visualizing the relationship between "Target Length" and "Confidence", likely within a marketing context. A regression line with a confidence interval is overlaid on the scatter points. Marginal distributions are shown above and to the right of the main plot.
### Components/Axes
* **Title:** "marketing" (top-center)
* **X-axis:** "Target Length" (bottom-center), ranging from approximately 0 to 220.
* **Y-axis:** "Confidence" (left-center), ranging from 0.0 to 0.6.
* **Scatter Points:** Numerous purple dots representing individual data points.
* **Regression Line:** A purple line representing the trend of the data. It slopes upwards from left to right.
* **Confidence Interval:** A shaded purple area around the regression line, indicating the uncertainty in the estimated trend.
* **Marginal Distribution (Top):** A density plot showing the distribution of "Target Length".
* **Marginal Distribution (Right):** A density plot showing the distribution of "Confidence".
### Detailed Analysis
The scatter plot shows a generally positive, but weak, correlation between "Target Length" and "Confidence".
* **Trend:** The regression line indicates a slight upward trend: as "Target Length" increases, "Confidence" tends to increase, but the relationship is not strong.
* **Data Points:**
* At a "Target Length" of 0, "Confidence" values range from approximately 0.1 to 0.6.
* At a "Target Length" of 50, "Confidence" values range from approximately 0.15 to 0.5.
* At a "Target Length" of 100, "Confidence" values range from approximately 0.2 to 0.5.
* At a "Target Length" of 150, "Confidence" values range from approximately 0.25 to 0.55.
* At a "Target Length" of 200, "Confidence" values range from approximately 0.3 to 0.55.
* **Marginal Distributions:**
* The "Target Length" distribution is skewed to the right, with a peak around 0-20.
* The "Confidence" distribution is skewed to the right, with a peak around 0.2-0.3.
### Key Observations
* The scatter plot shows a wide spread of data points, indicating a considerable amount of variability in "Confidence" for a given "Target Length".
* The confidence interval around the regression line is relatively wide, suggesting a high degree of uncertainty in the estimated relationship.
* The marginal distributions provide insights into the individual distributions of "Target Length" and "Confidence".
### Interpretation
The data suggests that there is a weak positive relationship between "Target Length" and "Confidence" in this marketing context. However, the relationship is not strong enough to reliably predict "Confidence" based on "Target Length" alone. The wide spread of data points and the wide confidence interval indicate that other factors likely play a significant role in determining "Confidence". The distributions suggest that shorter target lengths and lower confidence levels are more common.
The plot could be used to assess the effectiveness of different marketing strategies or to identify areas for improvement. For example, if the goal is to increase "Confidence", it may be necessary to focus on strategies that target longer lengths, but this should be done cautiously given the weak relationship. Further investigation is needed to understand the underlying factors driving "Confidence" and to develop more effective marketing strategies.
</details>
|
<details>
<summary>x56.png Details</summary>
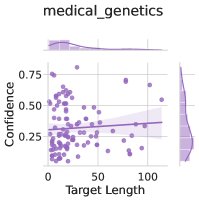
### Visual Description
\n
## Scatter Plot: Medical Genetics - Confidence vs. Target Length
### Overview
The image presents a scatter plot visualizing the relationship between "Target Length" and "Confidence" in the context of medical genetics. A regression line with a shaded confidence interval is overlaid on the scatter points. Marginal distributions (density plots) are displayed at the top and right sides of the chart, showing the distribution of "Target Length" and "Confidence" respectively.
### Components/Axes
* **Title:** "medical\_genetics" (top-center)
* **X-axis:** "Target Length" (bottom-center), ranging from approximately 0 to 110.
* **Y-axis:** "Confidence" (left-center), ranging from approximately 0.15 to 0.80.
* **Scatter Points:** Numerous purple dots representing individual data points.
* **Regression Line:** A dark purple line representing the trend in the data.
* **Confidence Interval:** A light purple shaded area around the regression line, indicating the uncertainty in the estimated trend.
* **Marginal Distribution (Top):** A density plot showing the distribution of "Target Length".
* **Marginal Distribution (Right):** A density plot showing the distribution of "Confidence".
### Detailed Analysis
The scatter plot shows a weak positive correlation between "Target Length" and "Confidence".
* **Scatter Points Trend:** The points are scattered with no strong clustering. There's a slight tendency for confidence to increase with target length, but the spread is significant.
* **Regression Line Trend:** The regression line slopes slightly upward, confirming the weak positive correlation.
* **Regression Line Equation (Approximate):** Visually, the line appears to intersect the Y-axis around 0.25 and has a very shallow slope.
* **Data Points (Approximate):**
* At Target Length = 0, Confidence ranges from approximately 0.15 to 0.65.
* At Target Length = 50, Confidence ranges from approximately 0.20 to 0.60.
* At Target Length = 100, Confidence ranges from approximately 0.30 to 0.75.
* **Marginal Distribution - Target Length:** The distribution is roughly uniform, with a slight skew towards lower values. The peak density is around a Target Length of 10.
* **Marginal Distribution - Confidence:** The distribution is skewed to the right, with a peak density around a Confidence of 0.25.
### Key Observations
* The relationship between "Target Length" and "Confidence" is weak.
* The confidence interval around the regression line is relatively wide, indicating high uncertainty in the estimated trend.
* The marginal distributions suggest that "Target Length" is relatively evenly distributed, while "Confidence" is concentrated at lower values.
* There are a few outliers with high confidence values (above 0.70), but they are relatively rare.
### Interpretation
The data suggests that "Target Length" is not a strong predictor of "Confidence" in this medical genetics context. While there's a slight tendency for confidence to increase with target length, the relationship is weak and highly variable. The wide confidence interval indicates that other factors likely play a more significant role in determining confidence. The skewed distribution of "Confidence" suggests that low confidence is more common than high confidence. The marginal distributions provide insights into the range and distribution of each variable independently. The plot could be visualizing the confidence in genetic sequence alignment or variant calling, where longer target sequences don't necessarily guarantee higher confidence in the results. The lack of a strong correlation might indicate the need for more sophisticated models or additional data features to improve confidence prediction.
</details>
|
<details>
<summary>x57.png Details</summary>
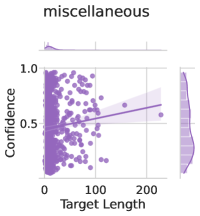
### Visual Description
\n
## Scatter Plot: Confidence vs. Target Length
### Overview
The image presents a scatter plot visualizing the relationship between "Target Length" and "Confidence". A regression line with a confidence interval is overlaid on the scatter points. Marginal histograms are displayed above and to the right of the main plot, showing the distributions of "Target Length" and "Confidence" respectively. The plot is titled "miscellaneous".
### Components/Axes
* **X-axis:** "Target Length" - Scale ranges from approximately 0 to 220.
* **Y-axis:** "Confidence" - Scale ranges from approximately 0.3 to 1.0.
* **Scatter Points:** Numerous purple dots representing individual data points.
* **Regression Line:** A purple line representing the trend of the data.
* **Confidence Interval:** A shaded purple area around the regression line, indicating the uncertainty in the estimated trend.
* **Top Histogram:** Displays the distribution of "Target Length". The x-axis is "Target Length" and the y-axis represents density.
* **Right Histogram:** Displays the distribution of "Confidence". The y-axis is "Density" and the x-axis represents "Confidence".
### Detailed Analysis
The scatter plot shows a generally positive, but weak, correlation between "Target Length" and "Confidence".
* **Trend:** The regression line slopes upward, indicating that as "Target Length" increases, "Confidence" tends to increase, but the relationship is not strong.
* **Data Points:**
* At "Target Length" = 0, "Confidence" values range from approximately 0.35 to 0.95.
* At "Target Length" = 50, "Confidence" values range from approximately 0.4 to 0.9.
* At "Target Length" = 100, "Confidence" values range from approximately 0.4 to 0.8.
* At "Target Length" = 150, "Confidence" values range from approximately 0.4 to 0.7.
* At "Target Length" = 200, "Confidence" values range from approximately 0.4 to 0.6.
* **Top Histogram:** The distribution of "Target Length" is heavily skewed towards lower values, with a peak around 0-20 and a long tail extending to approximately 220.
* **Right Histogram:** The distribution of "Confidence" is somewhat skewed towards higher values, with a peak around 0.7-0.8 and a tail extending down to approximately 0.3.
### Key Observations
* The scatter plot shows a weak positive correlation.
* The confidence interval around the regression line is relatively wide, indicating substantial uncertainty in the estimated relationship.
* The distribution of "Target Length" is highly skewed, which may influence the observed correlation.
* There is a cluster of points with low "Target Length" and high "Confidence".
### Interpretation
The data suggests that there is a slight tendency for "Confidence" to increase with "Target Length", but this relationship is weak and may be influenced by other factors. The wide confidence interval indicates that the observed trend may not be statistically significant. The skewed distribution of "Target Length" could be contributing to the weak correlation, as most data points are concentrated at lower values. The cluster of points with low "Target Length" and high "Confidence" could represent a specific scenario where confidence is high even when the target length is small. The title "miscellaneous" suggests this data may be from a broader exploratory analysis and not a focused investigation. The marginal histograms provide additional context about the distributions of the individual variables, which can help to understand the overall pattern in the scatter plot.
</details>
|
<details>
<summary>x58.png Details</summary>
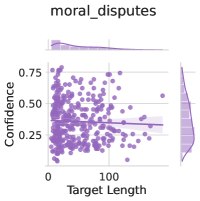
### Visual Description
\n
## Scatter Plot: Moral Disputes - Confidence vs. Target Length
### Overview
The image presents a scatter plot visualizing the relationship between "Target Length" and "Confidence" for the category "moral_disputes". A regression line with a shaded confidence interval is overlaid on the scatter plot. The plot appears to show a weak negative correlation between target length and confidence.
### Components/Axes
* **Title:** "moral\_disputes" (top-center)
* **X-axis:** "Target Length" (bottom-center), ranging from approximately 0 to 150.
* **Y-axis:** "Confidence" (left-center), ranging from approximately 0 to 0.75.
* **Data Points:** Numerous purple dots representing individual data points.
* **Regression Line:** A light purple line representing the trend of the data.
* **Confidence Interval:** A shaded purple area around the regression line, indicating the uncertainty in the estimated trend.
### Detailed Analysis
The scatter plot shows a distribution of points. The trend is slightly downward, but with significant scatter.
* **Data Point Distribution:**
* At Target Length = 0, Confidence values range from approximately 0.05 to 0.65.
* At Target Length = 50, Confidence values range from approximately 0.15 to 0.55.
* At Target Length = 100, Confidence values range from approximately 0.10 to 0.45.
* At Target Length = 150, Confidence values range from approximately 0.15 to 0.50.
* **Regression Line:** The regression line is approximately horizontal, with a very slight negative slope. It starts at approximately Confidence = 0.40 when Target Length = 0 and ends at approximately Confidence = 0.30 when Target Length = 150.
* **Confidence Interval:** The confidence interval is relatively wide, indicating a high degree of uncertainty in the estimated relationship. The interval spans approximately from Confidence = 0.20 to 0.50 across the range of Target Length values.
### Key Observations
* The relationship between Target Length and Confidence is weak.
* There is a large amount of variability in Confidence for a given Target Length.
* The confidence interval is wide, suggesting that the regression line is not a very precise estimate of the true relationship.
* There are no obvious outliers.
### Interpretation
The data suggests that the length of the target does not have a strong influence on the confidence level. The slight negative trend could indicate that longer targets are associated with slightly lower confidence, but this effect is small and may not be statistically significant given the wide confidence interval. The high variability in confidence levels suggests that other factors, not captured in this analysis, are likely to be more important determinants of confidence. The data could be used to inform the development of models that predict confidence levels, but it would be important to include other relevant variables to improve the accuracy of the predictions. The wide confidence interval suggests that the model would need to be robust to uncertainty.
</details>
|
|
<details>
<summary>x59.png Details</summary>

### Visual Description
\n
## Box Plot: Confidence vs. Target Length for Moral Scenarios
### Overview
The image presents a box plot visualizing the relationship between "Target Length" and "Confidence" for a dataset labeled "moral_scenarios". The plot displays the distribution of confidence values for two different target lengths: approximately 15 and 20.
### Components/Axes
* **X-axis:** "Target Length" with markers at 15 and 20.
* **Y-axis:** "Confidence" ranging from approximately 0.1 to 0.6.
* **Title:** "moral_scenarios" positioned at the top-center of the plot.
* **Data Series:** Two box plots, one centered around Target Length 15 and the other around Target Length 20.
* **Color:** The box plots are rendered in a purple hue.
### Detailed Analysis
The box plot for Target Length 15 shows:
* **Minimum Confidence:** Approximately 0.18
* **First Quartile (Q1):** Approximately 0.25
* **Median (Q2):** Approximately 0.32
* **Third Quartile (Q3):** Approximately 0.38
* **Maximum Confidence:** Approximately 0.52
* **Outliers:** Several data points are plotted as individual dots above the maximum confidence value, ranging from approximately 0.53 to 0.58.
The box plot for Target Length 20 shows:
* **Minimum Confidence:** Approximately 0.18
* **First Quartile (Q1):** Approximately 0.25
* **Median (Q2):** Approximately 0.35
* **Third Quartile (Q3):** Approximately 0.42
* **Maximum Confidence:** Approximately 0.48
* **Outliers:** Several data points are plotted as individual dots above the maximum confidence value, ranging from approximately 0.49 to 0.59.
The distributions appear similar, but the Target Length 20 box plot seems to be slightly shifted towards higher confidence values.
### Key Observations
* Both target lengths exhibit a similar range of confidence values.
* The median confidence is slightly higher for Target Length 20 (approximately 0.35) compared to Target Length 15 (approximately 0.32).
* Both distributions contain outliers, suggesting some instances of unusually high confidence.
* The interquartile range (IQR) appears to be slightly wider for Target Length 20, indicating greater variability in confidence scores.
### Interpretation
The data suggests that there is a slight positive correlation between target length and confidence in the "moral_scenarios" dataset. Increasing the target length from 15 to 20 appears to result in a modest increase in the median confidence score. However, the overlap in the distributions indicates that target length is not a strong predictor of confidence. The presence of outliers in both groups suggests that other factors may significantly influence confidence levels in certain scenarios. The box plots provide a concise visual summary of the distribution of confidence scores for each target length, highlighting the central tendency, spread, and potential outliers. Further investigation would be needed to determine the underlying reasons for the observed differences and the factors contributing to the outliers.
</details>
|
<details>
<summary>x60.png Details</summary>
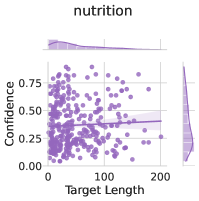
### Visual Description
\n
## Scatter Plot: Nutrition Confidence vs. Target Length
### Overview
The image presents a scatter plot visualizing the relationship between "Target Length" and "Confidence" related to "nutrition". The plot includes a regression line with a shaded confidence interval, and a large number of individual data points.
### Components/Axes
* **Title:** "nutrition" (positioned at the top-center)
* **X-axis:** "Target Length" (ranging from approximately 0 to 220, with markers at 0, 100, and 200)
* **Y-axis:** "Confidence" (ranging from 0.00 to 0.75, with markers at 0.00, 0.25, 0.50, and 0.75)
* **Data Points:** Numerous purple circles representing individual data observations.
* **Regression Line:** A purple line representing the trend of the data. It appears to be approximately flat.
* **Confidence Interval:** A shaded purple area around the regression line, indicating the uncertainty in the estimated trend.
### Detailed Analysis
The scatter plot shows a wide dispersion of data points. The trend line is nearly horizontal, suggesting a weak or non-existent linear relationship between Target Length and Confidence.
* **Data Point Distribution:**
* A dense cluster of points exists near Target Length = 0, with Confidence values ranging from approximately 0.1 to 0.7.
* As Target Length increases, the points become more scattered, with a general tendency for Confidence to remain between 0.2 and 0.5.
* There is a sparse distribution of points at higher Target Length values (above 150), with Confidence values generally below 0.4.
* **Regression Line:** The regression line is approximately horizontal, with a y-intercept around 0.35 and a very small slope.
* **Confidence Interval:** The confidence interval is relatively wide, indicating substantial uncertainty in the estimated regression line. The interval is wider at the higher Target Length values.
### Key Observations
* The relationship between Target Length and Confidence appears to be weak.
* There is a large amount of variability in Confidence for a given Target Length.
* The confidence interval is wide, suggesting that the estimated trend is not very precise.
* There are no obvious outliers.
### Interpretation
The data suggests that the length of the target (whatever that refers to in the context of "nutrition") has little predictive power regarding the confidence level. The confidence level appears to be largely independent of the target length. The wide confidence interval indicates that other factors likely play a more significant role in determining confidence. The flat regression line suggests that, on average, confidence does not change significantly with target length. The data could be indicative of a noisy system where the target length is not a strong signal for the confidence metric. Further investigation would be needed to understand the underlying reasons for this lack of correlation and the source of the variability.
</details>
|
<details>
<summary>x61.png Details</summary>
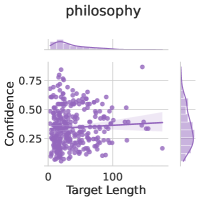
### Visual Description
\n
## Scatter Plot: Confidence vs. Target Length for "philosophy"
### Overview
This image presents a scatter plot visualizing the relationship between "Target Length" and "Confidence" for the topic "philosophy". A density plot is overlaid on the top and right sides of the scatter plot to show the distribution of the data. A regression line with a shaded confidence interval is also present.
### Components/Axes
* **Title:** "philosophy" (positioned at the top-center)
* **X-axis:** "Target Length" (ranging from approximately 0 to 150, with tick marks at 0, 50, 100, 150)
* **Y-axis:** "Confidence" (ranging from approximately 0.2 to 0.8, with tick marks at 0.25, 0.50, 0.75)
* **Data Points:** Numerous purple dots representing individual data points.
* **Regression Line:** A purple line representing the trend of the data. It appears to have a slight negative slope.
* **Confidence Interval:** A shaded purple area around the regression line, indicating the uncertainty in the estimated trend.
* **Density Plots:** Purple shaded areas along the top and right edges, representing the distribution of data along the respective axes.
### Detailed Analysis
The scatter plot shows a generally dispersed pattern of data points.
* **Trend:** The regression line exhibits a slight downward trend, suggesting that as "Target Length" increases, "Confidence" tends to decrease, but the correlation is weak.
* **Data Distribution:** The density plot at the top indicates a concentration of data points at lower "Target Length" values. The density plot on the right shows a concentration of data points around a "Confidence" value of approximately 0.3.
* **Data Points (Approximate Values):**
* At Target Length = 0, Confidence ranges from approximately 0.2 to 0.6.
* At Target Length = 50, Confidence ranges from approximately 0.25 to 0.7.
* At Target Length = 100, Confidence ranges from approximately 0.2 to 0.55.
* At Target Length = 150, Confidence ranges from approximately 0.2 to 0.4.
* **Regression Line (Approximate Values):**
* At Target Length = 0, the regression line is at approximately Confidence = 0.45.
* At Target Length = 150, the regression line is at approximately Confidence = 0.35.
### Key Observations
* The data is widely scattered, indicating a weak correlation between "Target Length" and "Confidence".
* The confidence interval is relatively wide, suggesting a high degree of uncertainty in the estimated trend.
* There are a few outliers with high confidence values at higher target lengths.
### Interpretation
The plot suggests that for the topic of "philosophy", there is a very weak negative relationship between the length of the target text and the confidence score. Longer target lengths tend to be associated with slightly lower confidence scores, but this relationship is not strong. The wide scatter and confidence interval indicate that many other factors likely influence the confidence score, and target length is not a primary predictor. The density plots suggest that shorter target lengths are more common in the dataset, and confidence scores tend to cluster around lower values. The outliers suggest that, in some cases, longer target lengths can still yield high confidence scores, potentially indicating the presence of well-defined or easily identifiable philosophical concepts. The data does not provide a strong basis for predicting confidence based solely on target length.
</details>
|
<details>
<summary>x62.png Details</summary>
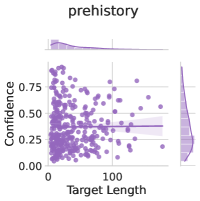
### Visual Description
\n
## Scatter Plot: Confidence vs. Target Length (Prehistory)
### Overview
The image presents a scatter plot visualizing the relationship between "Target Length" and "Confidence" for the category "prehistory". A regression line with a shaded confidence interval is overlaid on the scatter points. The plot suggests a very weak or non-existent linear relationship between the two variables.
### Components/Axes
* **Title:** "prehistory" (positioned at the top-center)
* **X-axis:** "Target Length" (ranging from approximately 0 to 150, with tick marks at 0, 50, 100, 150)
* **Y-axis:** "Confidence" (ranging from approximately 0.00 to 0.75, with tick marks at 0.00, 0.25, 0.50, 0.75)
* **Data Points:** Numerous purple dots scattered across the plot area.
* **Regression Line:** A purple line representing the trend of the data.
* **Confidence Interval:** A shaded purple area around the regression line, indicating the uncertainty in the estimated trend.
### Detailed Analysis
The scatter plot shows a large number of data points (approximately 300-400) distributed across the plot area. The points appear relatively randomly scattered, with no clear clustering or pattern.
* **Regression Line Trend:** The regression line is nearly horizontal, indicating a very slight negative slope. This suggests that as "Target Length" increases, "Confidence" tends to decrease very slightly.
* **Data Point Distribution:** The majority of data points fall within the "Confidence" range of 0.10 to 0.60. There are fewer points with "Confidence" values above 0.60.
* **Approximate Data Points (sampled):**
* Target Length = 0, Confidence ≈ 0.20 - 0.50 (multiple points)
* Target Length = 50, Confidence ≈ 0.20 - 0.50 (multiple points)
* Target Length = 100, Confidence ≈ 0.15 - 0.55 (multiple points)
* Target Length = 150, Confidence ≈ 0.10 - 0.40 (multiple points)
* **Confidence Interval:** The confidence interval is relatively wide, indicating a high degree of uncertainty in the estimated regression line.
### Key Observations
* The correlation between "Target Length" and "Confidence" appears to be very weak.
* The data is highly dispersed, with a large amount of variability in "Confidence" for any given "Target Length".
* The confidence interval is wide, suggesting that the estimated regression line is not very precise.
### Interpretation
The plot suggests that "Target Length" is not a strong predictor of "Confidence" within the "prehistory" category. The lack of a clear trend and the wide confidence interval indicate that other factors likely play a more significant role in determining "Confidence". The data could be interpreted as showing that the model's confidence is largely independent of the target length for this category. The horizontal regression line suggests a very slight negative correlation, but this is likely not statistically significant given the wide confidence interval and the overall scatter of the data. It's possible that the model struggles to accurately assess confidence for targets of any length within the "prehistory" domain.
</details>
|
|
<details>
<summary>x63.png Details</summary>
### Visual Description
\n
## Scatter Plot: Confidence vs. Target Length for "professional_accounting"
### Overview
This image presents a scatter plot visualizing the relationship between "Target Length" and "Confidence" for the category "professional_accounting". A regression line with a confidence interval is overlaid on the scatter points. The plot appears to show a weak negative correlation between target length and confidence.
### Components/Axes
* **Title:** "professional\_accounting" (located at the top-center of the image)
* **X-axis:** "Target Length" (ranging from approximately 0 to 150, with gridlines at 0, 50, 100, and 150)
* **Y-axis:** "Confidence" (ranging from approximately 0.1 to 0.7, with gridlines at 0.2, 0.4, and 0.6)
* **Data Points:** Numerous purple circles representing individual data points.
* **Regression Line:** A purple line representing the trend of the data.
* **Confidence Interval:** A shaded purple area around the regression line, indicating the uncertainty in the estimated trend.
* **Histograms:** Two histograms are present on the left and right sides of the plot, showing the distribution of Target Length and Confidence respectively.
### Detailed Analysis
The scatter plot shows a distribution of points. The trend line is nearly horizontal, indicating a very weak correlation.
* **Data Point Distribution:** The majority of data points cluster between Target Length values of 0 and 100, and Confidence values between 0.15 and 0.5. There are fewer points with Target Lengths greater than 100.
* **Regression Line Trend:** The regression line slopes slightly downward, suggesting a very weak negative correlation. As Target Length increases, Confidence tends to decrease, but the effect is minimal.
* **Confidence Interval:** The confidence interval is relatively narrow, indicating some certainty in the estimated trend, despite its weakness.
* **Left Histogram (Target Length):** The histogram shows a concentration of data points at lower Target Length values, with a rapid decline as Target Length increases.
* **Right Histogram (Confidence):** The histogram shows a concentration of data points at lower Confidence values, with a gradual decline as Confidence increases.
Approximate Data Points (sampled for illustration):
* Target Length = 0, Confidence ≈ 0.6
* Target Length = 20, Confidence ≈ 0.5
* Target Length = 50, Confidence ≈ 0.35
* Target Length = 80, Confidence ≈ 0.25
* Target Length = 100, Confidence ≈ 0.2
* Target Length = 120, Confidence ≈ 0.18
### Key Observations
* The relationship between Target Length and Confidence is very weak.
* The data points are widely scattered, indicating a high degree of variability.
* The histograms suggest that lower Target Lengths and lower Confidence values are more common.
* There are no obvious outliers.
### Interpretation
The data suggests that, for the category "professional\_accounting", the length of the target text has little to no significant impact on the confidence score. The weak negative trend could be due to chance or other confounding factors. The histograms indicate that the model generally exhibits lower confidence for shorter target lengths, but this is not a strong relationship. The wide scatter of data points suggests that other variables not represented in this plot likely play a more significant role in determining confidence. The histograms provide a distribution of the data, showing that the model is more likely to produce lower confidence scores. This could be due to the inherent difficulty of the task or limitations in the model's ability to accurately assess confidence.
</details>
|
<details>
<summary>x64.png Details</summary>
### Visual Description
\n
## Scatter Plot: Confidence vs. Target Length (Professional Psychology)
### Overview
The image presents a scatter plot visualizing the relationship between "Target Length" and "Confidence" for the category "professional_psychology". A regression line with a shaded confidence interval is overlaid on the scatter points. The plot suggests a very weak, potentially positive correlation between target length and confidence.
### Components/Axes
* **Title:** "professional\_psychology" (top-center)
* **X-axis:** "Target Length" (bottom-center), ranging from approximately 0 to 220.
* **Y-axis:** "Confidence" (left-center), ranging from approximately 0.0 to 0.6.
* **Data Points:** Purple circles representing individual data points.
* **Regression Line:** A dark purple line representing the trend of the data.
* **Confidence Interval:** A light purple shaded area around the regression line, indicating the uncertainty in the estimated trend.
* **Marginal Distributions:** Histograms at the top and right edges of the plot, showing the distribution of "Target Length" and "Confidence" respectively.
### Detailed Analysis
The scatter plot shows a dense cluster of points concentrated in the lower-left quadrant, with a gradual spread towards the upper-right.
* **Regression Line Trend:** The regression line has a very slight positive slope, indicating a weak positive correlation.
* **Data Point Distribution:** The majority of data points have a "Target Length" between 0 and 100, and a "Confidence" value between 0.2 and 0.5.
* **Marginal Distribution - Target Length:** The histogram at the top shows a distribution skewed to the right, with a peak around a "Target Length" of approximately 20-40. There is a long tail extending to higher values.
* **Marginal Distribution - Confidence:** The histogram on the right shows a distribution concentrated at lower confidence values, with a peak around 0.3. The distribution tapers off towards higher confidence values.
* **Data Points (Approximate Values):**
* At Target Length = 0, Confidence ranges from approximately 0.1 to 0.5.
* At Target Length = 50, Confidence ranges from approximately 0.2 to 0.55.
* At Target Length = 100, Confidence ranges from approximately 0.1 to 0.5.
* At Target Length = 200, Confidence ranges from approximately 0.05 to 0.3.
### Key Observations
* The relationship between "Target Length" and "Confidence" appears to be very weak. The regression line has a minimal slope.
* There is a high density of data points with low "Confidence" values.
* The marginal distributions reveal that "Target Length" is skewed to the right, while "Confidence" is concentrated at lower values.
* There are a few outliers with higher "Target Length" values and relatively low "Confidence" values.
### Interpretation
The data suggests that, for the category "professional\_psychology", there is little to no strong relationship between the length of the target and the confidence associated with it. The slight positive trend observed in the regression line is likely not statistically significant given the spread of the data. The concentration of points at lower confidence levels suggests that, in general, there is a relatively low level of confidence associated with targets in this domain. The skewed distribution of "Target Length" indicates that most targets are relatively short, with a few exceptionally long ones. The marginal distributions provide additional context, showing the overall distribution of each variable independently. The lack of a clear pattern in the scatter plot suggests that other factors likely play a more significant role in determining confidence levels than simply the length of the target.
</details>
|
<details>
<summary>x65.png Details</summary>
### Visual Description
\n
## Scatter Plot: Confidence vs. Target Length for Public Relations
### Overview
The image presents a scatter plot visualizing the relationship between "Target Length" and "Confidence" specifically for the category "public_relations". A regression line with a confidence interval is overlaid on the scatter points, and marginal distributions are shown above and to the right of the main plot.
### Components/Axes
* **Title:** "public\_relations" (top-center)
* **X-axis:** "Target Length" (bottom-center), ranging from approximately 0 to 110.
* **Y-axis:** "Confidence" (left-center), ranging from approximately 0.00 to 0.75.
* **Scatter Points:** Numerous purple dots representing individual data points.
* **Regression Line:** A purple line representing the trend of the data. It slopes slightly upwards.
* **Confidence Interval:** A shaded purple area around the regression line, indicating the uncertainty in the estimated trend.
* **Marginal Distribution (Top):** A density plot showing the distribution of "Target Length".
* **Marginal Distribution (Right):** A density plot showing the distribution of "Confidence".
### Detailed Analysis
The scatter plot shows a weak positive correlation between "Target Length" and "Confidence" for "public\_relations".
* **Scatter Points:** The points are widely dispersed, indicating a moderate amount of variance. Most points cluster between "Target Length" values of 0 and 75, and "Confidence" values of 0.15 and 0.65. There are a few outliers with "Confidence" values above 0.65.
* **Regression Line:** The line has a positive slope, suggesting that as "Target Length" increases, "Confidence" tends to increase, but the effect is small. The line starts at approximately "Target Length" = 0 and "Confidence" = 0.25, and ends at approximately "Target Length" = 110 and "Confidence" = 0.45.
* **Confidence Interval:** The confidence interval is relatively wide, indicating a high degree of uncertainty in the estimated regression line.
* **Marginal Distribution (Top):** The distribution of "Target Length" is skewed to the right, with a peak around a value of 10.
* **Marginal Distribution (Right):** The distribution of "Confidence" is roughly bell-shaped, with a peak around a value of 0.25.
### Key Observations
* The relationship between "Target Length" and "Confidence" is weak.
* There is a considerable amount of variability in "Confidence" for a given "Target Length".
* The marginal distributions suggest that "Target Length" values are generally low, while "Confidence" values are centered around 0.25.
* The confidence interval is wide, indicating that the regression line is not a precise estimate of the true relationship.
### Interpretation
The data suggests that, for the "public\_relations" category, there is a slight tendency for higher "Target Length" to be associated with higher "Confidence", but this relationship is not strong. The wide confidence interval indicates that other factors likely play a more significant role in determining "Confidence". The marginal distributions provide context, showing that "Target Length" is generally short, and "Confidence" is relatively low. The scatter plot and associated statistics provide a quantitative assessment of the relationship between these two variables within the context of public relations. The data does not suggest a strong predictive power of "Target Length" on "Confidence".
</details>
|
<details>
<summary>x66.png Details</summary>
### Visual Description
\n
## Scatter Plot: Security Studies Confidence vs. Target Length
### Overview
The image presents a scatter plot visualizing the relationship between "Target Length" and "Confidence" for "security_studies". The plot displays a large number of data points, along with a regression line attempting to model the trend. There are also density plots along the top and right edges of the chart.
### Components/Axes
* **Title:** "security\_studies" (top-center)
* **X-axis:** "Target Length" (bottom-center), ranging from approximately 0 to 600.
* **Y-axis:** "Confidence" (left-center), ranging from approximately 0.1 to 0.65.
* **Data Points:** Numerous purple dots scattered across the plot.
* **Regression Line:** A purple line attempting to fit the trend of the data points.
* **Density Plot (Top):** A purple shaded area representing the distribution of "Target Length".
* **Density Plot (Right):** A purple shaded area representing the distribution of "Confidence".
### Detailed Analysis
The scatter plot shows a generally negative correlation between "Target Length" and "Confidence". As "Target Length" increases, "Confidence" tends to decrease. However, the relationship is not strong, and there is significant scatter in the data.
* **Regression Line Trend:** The regression line slopes downward, confirming the negative correlation.
* **Data Point Distribution:**
* For "Target Length" values between 0 and 250, "Confidence" values are generally higher, ranging from approximately 0.2 to 0.6.
* As "Target Length" increases beyond 250, "Confidence" values tend to cluster around 0.15 to 0.3.
* There are a few outliers with high "Confidence" values (above 0.5) even at higher "Target Length" values.
* **Density Plot (Top):** The density plot shows a peak in the distribution of "Target Length" around 0-100, and a gradual decline as "Target Length" increases.
* **Density Plot (Right):** The density plot shows a peak in the distribution of "Confidence" around 0.2-0.3, with a tail extending towards lower confidence values.
### Key Observations
* The negative correlation between "Target Length" and "Confidence" suggests that longer targets are associated with lower confidence.
* The significant scatter in the data indicates that "Target Length" is not the sole determinant of "Confidence". Other factors likely play a role.
* The density plots confirm the general trends observed in the scatter plot.
### Interpretation
The data suggests that the confidence in security studies decreases as the length of the target increases. This could be due to several reasons: longer targets may be more complex and difficult to analyze, or they may be more vulnerable to attack. The scatter in the data indicates that there is considerable variability in confidence levels, even for targets of the same length. This suggests that other factors, such as the specific characteristics of the target or the expertise of the analyst, also play a role. The density plots provide further insight into the distribution of target lengths and confidence levels, highlighting the most common values and the range of variability. The presence of outliers suggests that there are some cases where confidence is unexpectedly high or low, which may warrant further investigation.
</details>
|
Figure 13: Continuing from fig. 12. See also fig. 14.
|
<details>
<summary>x67.png Details</summary>
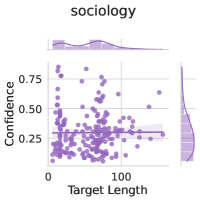
### Visual Description
\n
## Scatter Plot: Sociology - Confidence vs. Target Length
### Overview
The image presents a scatter plot visualizing the relationship between "Target Length" and "Confidence" for the category "sociology". A density plot is overlaid on top of the scatter points, and a regression line is fitted to the data. The plot suggests a weak or non-existent linear relationship between the two variables.
### Components/Axes
* **Title:** "sociology" (positioned at the top-center)
* **X-axis:** "Target Length" (ranging from approximately 0 to 150)
* **Y-axis:** "Confidence" (ranging from approximately 0 to 0.8)
* **Data Points:** Numerous purple dots representing individual data points.
* **Density Plot:** A shaded purple area representing the density distribution of the data.
* **Regression Line:** A dark purple line representing the linear regression fit.
* **Shaded Area around Regression Line:** A lighter purple shaded area representing the confidence interval around the regression line.
### Detailed Analysis
The scatter plot shows a wide dispersion of points.
* **Data Point Distribution:** The majority of data points cluster between "Target Length" values of 0 and 100, with "Confidence" values generally below 0.6. There are fewer points with "Target Length" values above 100.
* **Regression Line Trend:** The regression line is nearly horizontal, indicating a very slight negative slope. This suggests that as "Target Length" increases, "Confidence" tends to decrease very slightly.
* **Density Plot Trend:** The density plot shows a peak in density around a "Target Length" of 0-50 and a "Confidence" of 0.2-0.4. The density decreases as "Target Length" increases.
* **Approximate Data Points (sampled):**
* Target Length = 0, Confidence ≈ 0.25
* Target Length = 25, Confidence ≈ 0.55
* Target Length = 50, Confidence ≈ 0.40
* Target Length = 75, Confidence ≈ 0.30
* Target Length = 100, Confidence ≈ 0.20
* Target Length = 125, Confidence ≈ 0.55
* Target Length = 150, Confidence ≈ 0.25
### Key Observations
* The scatter plot exhibits a high degree of scatter, indicating a weak correlation between "Target Length" and "Confidence".
* The regression line is almost flat, reinforcing the observation of a weak relationship.
* The density plot shows a concentration of data points at lower "Target Length" values.
* There are no obvious outliers that significantly deviate from the general trend.
### Interpretation
The data suggests that "Target Length" is not a strong predictor of "Confidence" within the "sociology" category. The near-horizontal regression line indicates that changes in "Target Length" have minimal impact on "Confidence". The high scatter suggests that other factors likely play a more significant role in determining "Confidence". The concentration of data points at lower "Target Length" values might indicate a preference for shorter targets or a limitation in the range of target lengths considered within this dataset. The confidence interval around the regression line is relatively narrow, suggesting some consistency in the lack of a strong relationship. This could be a result of the model being unable to find a significant pattern in the data, or it could indicate that the true relationship is indeed very weak.
</details>
|
<details>
<summary>x68.png Details</summary>
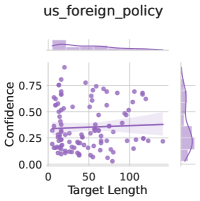
### Visual Description
\n
## Scatter Plot: US Foreign Policy Confidence vs. Target Length
### Overview
The image presents a scatter plot visualizing the relationship between "Target Length" and "Confidence" related to "us_foreign_policy". The plot includes a regression line with a shaded confidence interval, and a density plot on the right side. The data points are scattered, suggesting a complex relationship.
### Components/Axes
* **Title:** "us_foreign_policy" (top-center)
* **X-axis:** "Target Length" (bottom-center), ranging from approximately 0 to 120.
* **Y-axis:** "Confidence" (left-center), ranging from 0.00 to 0.75.
* **Data Points:** Numerous purple dots scattered across the plot.
* **Regression Line:** A purple line attempting to model the trend of the data. It slopes slightly downward.
* **Confidence Interval:** A shaded purple area around the regression line, indicating the uncertainty in the line's estimate.
* **Density Plot:** A purple density plot on the right side of the chart, showing the distribution of confidence values.
### Detailed Analysis
The scatter plot shows a generally dispersed pattern of data points.
* **Regression Line Trend:** The regression line exhibits a slight negative slope, indicating that as "Target Length" increases, "Confidence" tends to decrease, but the relationship is weak.
* **Data Point Distribution:**
* For "Target Length" values between 0 and 20, "Confidence" values are generally low, ranging from approximately 0.05 to 0.30.
* Between 20 and 50, "Confidence" values increase, with a cluster of points between 0.30 and 0.60.
* From 50 to 120, "Confidence" values are more scattered, ranging from approximately 0.10 to 0.70, with a tendency to decrease slightly.
* **Density Plot:** The density plot on the right shows a peak in the distribution of "Confidence" values around 0.25-0.35, with a long tail extending towards higher confidence values.
### Key Observations
* The relationship between "Target Length" and "Confidence" is weak and not strongly linear.
* There is a significant amount of variability in "Confidence" for a given "Target Length".
* The density plot suggests that lower confidence levels are more common.
* There are no obvious outliers.
### Interpretation
The data suggests that the length of the target (whatever that refers to in the context of US foreign policy) has a limited impact on the confidence level. The weak negative trend in the regression line implies that longer targets might be associated with slightly lower confidence, but this relationship is not strong. The wide confidence interval around the regression line indicates substantial uncertainty in this estimate. The density plot reinforces the idea that confidence levels are generally low, with a concentration of values around 0.25-0.35.
The plot likely represents an analysis of some model's predictions or human assessments related to US foreign policy. "Target Length" could refer to the length of a policy document, the duration of a foreign policy initiative, or some other relevant metric. The "Confidence" score likely represents the certainty or reliability of a prediction or assessment. The data suggests that the model or assessment process is not highly confident in its predictions, and that the length of the target is not a strong predictor of confidence.
</details>
|
<details>
<summary>x69.png Details</summary>
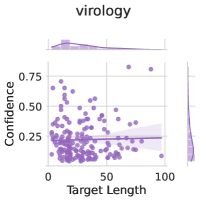
### Visual Description
\n
## Scatter Plot: Confidence vs. Target Length (Virology)
### Overview
The image presents a scatter plot visualizing the relationship between "Target Length" and "Confidence" in the context of virology. A regression line with a shaded confidence interval is overlaid on the scatter points. The plot appears to show a weak or non-existent linear relationship between the two variables.
### Components/Axes
* **Title:** "virology" (top-center)
* **X-axis:** "Target Length" (bottom-center), ranging from approximately 0 to 100. The axis is divided into major ticks at 0, 50, and 100.
* **Y-axis:** "Confidence" (left-center), ranging from approximately 0 to 0.75. The axis is divided into major ticks at 0, 0.25, 0.50, and 0.75.
* **Data Points:** Numerous purple circles representing individual data points.
* **Regression Line:** A purple line representing the trend of the data.
* **Confidence Interval:** A shaded purple area around the regression line, indicating the uncertainty in the estimated trend.
* **Histograms:** Two histograms are present on the right and top of the scatter plot, showing the distribution of "Target Length" and "Confidence" respectively.
### Detailed Analysis
The scatter plot shows a large number of data points distributed across the range of "Target Length" (0-100) and "Confidence" (0-0.75).
* **Regression Line Trend:** The regression line has a very slight negative slope, suggesting a very weak negative correlation between "Target Length" and "Confidence".
* **Data Point Distribution:** The majority of data points cluster between "Confidence" values of 0.1 and 0.3, regardless of the "Target Length".
* **Target Length Histogram:** The histogram at the top shows a concentration of data points at lower "Target Length" values (around 0-20), with a decreasing frequency as "Target Length" increases. The histogram appears to be normalized.
* **Confidence Histogram:** The histogram on the right shows a concentration of data points at lower "Confidence" values (around 0.1-0.3), with a decreasing frequency as "Confidence" increases. The histogram appears to be normalized.
Let's attempt to extract some approximate data points from the scatter plot:
* At Target Length = 0, Confidence ranges from approximately 0.1 to 0.7.
* At Target Length = 50, Confidence ranges from approximately 0.1 to 0.4.
* At Target Length = 100, Confidence ranges from approximately 0.1 to 0.3.
* The regression line appears to start at approximately (0, 0.27) and end at approximately (100, 0.22).
### Key Observations
* There is a very weak negative correlation between "Target Length" and "Confidence".
* The "Confidence" values are generally low, with most points falling below 0.5.
* The distribution of "Target Length" is skewed towards lower values.
* The histograms suggest that both "Target Length" and "Confidence" are not normally distributed.
### Interpretation
The data suggests that "Target Length" is not a strong predictor of "Confidence" in this virology context. The low "Confidence" values across all "Target Lengths" might indicate inherent difficulties in obtaining high confidence scores for this type of analysis, or that the method used to calculate confidence is inherently conservative. The slight negative trend could indicate that longer target lengths are *slightly* associated with lower confidence, but the effect is minimal. The histograms reveal that the data is not evenly distributed, which could influence the regression analysis. Further investigation would be needed to understand the underlying reasons for these observations and to determine the practical implications of this relationship. The title "virology" suggests this data relates to viral sequence analysis, potentially assessing the confidence in identifying viral targets based on their length.
</details>
|
<details>
<summary>x70.png Details</summary>
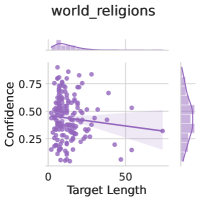
### Visual Description
\n
## Scatter Plot: World Religions Confidence vs. Target Length
### Overview
The image presents a scatter plot visualizing the relationship between "Target Length" and "Confidence" for a dataset labeled "world_religions". A regression line with a shaded confidence interval is overlaid on the scatter points. There are also density plots along the top and right edges of the chart.
### Components/Axes
* **Title:** "world\_religions" (top-center)
* **X-axis:** "Target Length" (bottom-center), ranging from approximately 0 to 60.
* **Y-axis:** "Confidence" (left-center), ranging from approximately 0.05 to 0.85.
* **Scatter Points:** Numerous purple dots representing individual data points.
* **Regression Line:** A purple line indicating the trend in the data.
* **Confidence Interval:** A shaded purple area around the regression line, representing the uncertainty in the trend.
* **Density Plot (Top):** A purple shaded area representing the distribution of "Target Length".
* **Density Plot (Right):** A purple shaded area representing the distribution of "Confidence".
### Detailed Analysis
The scatter plot shows a generally negative correlation between "Target Length" and "Confidence". As "Target Length" increases, "Confidence" tends to decrease.
* **Trend:** The regression line slopes downward from left to right, confirming the negative correlation.
* **Data Points:**
* At "Target Length" = 0, "Confidence" values range from approximately 0.1 to 0.75, with a high concentration of points around 0.5.
* At "Target Length" = 25, "Confidence" values range from approximately 0.2 to 0.6.
* At "Target Length" = 50, "Confidence" values range from approximately 0.15 to 0.45.
* At "Target Length" = 60, "Confidence" values range from approximately 0.1 to 0.3.
* **Density Plots:**
* The top density plot shows a peak in data points around a "Target Length" of 0, with a decreasing density as "Target Length" increases.
* The right density plot shows a peak in data points around a "Confidence" of 0.5, with a decreasing density as "Confidence" increases.
### Key Observations
* The relationship between "Target Length" and "Confidence" is not strictly linear, as there is considerable scatter around the regression line.
* The confidence interval is relatively wide, indicating a high degree of uncertainty in the estimated trend.
* There is a cluster of data points with low "Target Length" and high "Confidence".
* The density plots suggest that "Target Length" is skewed towards lower values, while "Confidence" is centered around 0.5.
### Interpretation
The data suggests that, for the dataset "world\_religions", longer "Target Lengths" are associated with lower "Confidence" scores. The "Target Length" could represent the length of a text or description related to a religion, and "Confidence" could represent the model's confidence in identifying or classifying that religion. The negative correlation might indicate that as the length of the description increases, the model becomes less certain about the religion being described. This could be due to increased ambiguity or complexity in longer texts. The wide confidence interval suggests that other factors may also influence the "Confidence" score, and the relationship between "Target Length" and "Confidence" is not deterministic. The density plots provide additional insight into the distribution of these variables, showing that shorter "Target Lengths" are more common and that "Confidence" scores tend to cluster around 0.5.
</details>
|
| --- | --- | --- | --- |
Figure 14: Continuing from figs. 12 and 13.
Appendix F Generalization to Coding Tasks
Because there are no coding tasks in our training dataset, we can use a coding competition task introduced in LiveCodeBench [Jain et al., 2024] to assess how well finetuned uncertainty estimation methods perform on completely out of distribution tasks.
To conduct the analysis in table 3, we evaluate several base models on the 62 LeetCode easy questions from the livecodebench_generation_lite task. We asking for the model to write a Python solution and grade the solution using test cases (marking it as correct iff it passes all test cases). We then apply Lora + Prompt and Zero-Shot Classifier uncertainty estimation methods—with these methods only using training/temperature scaling data from our main dataset mixture which notably does not include any coding tasks section C.2. Accuracy is shown to contextualize the model’s overall level of performance on the task. On Mistral-7B, the best performing model on the coding task, the supervised Lora + Prompt approach dramatically improves calibration and selective prediction as compared to Zero-Shot Classifier; on the worse-performing Mistral-7B-Instruct and LLaMa-2-7B, selective prediction improves but calibration slightly degrades.
| Model | Method | Acc | ECE | AUROC |
| --- | --- | --- | --- | --- |
| LLaMa-2-7B | Zero-Shot Classifier | 3.2% | 41.0% | 56.9% |
| Lora + Prompt | 3.2% | 46.4% | 80.0% | |
| Mistral-7B | Zero-Shot Classifier | 27.4% | 70.2% | 66.2% |
| Lora + Prompt | 27.4% | 21.4% | 85.1% | |
| Mistral-7B-Instruct | Zero-Shot Classifier | 21.0% | 52.7% | 47.1% |
| Lora + Prompt | 21.0% | 56.1% | 70.2% | |
Table 3: ECE and AUROC on livecodebench_generation_lite (LeetCode easy subset). ECE is shown after temperature scaling on a small hold-out set of the original dataset mixture section C.2. Acc is task accuracy (proportion of coding solutions that are correct). Supervised training (LoRA + Prompt) seems to always improve selective prediction, although supervised training only heavily improves calibration for Mistral-7B and in fact slightly degrades calibration for the two other models.
Appendix G User Studies
G.1 Additional Details on Setup
Stimuli and Participant Selection
We closely followed the setup of [Bhatt et al., 2023]. We used the same 180 MMLU questions from which were pre-batched into three sets of 60 MMLU questions. Within each variant, we randomly assigned participants to one of the three batches. In total, we recruit $181$ participants (20 per variant With the exception of one extra participant due to random batching allocation effects.). All participants were recruited through the crowdsourcing platform Prolific [Palan and Schitter, 2018]; we restrict our participant pool to those based in the United States who speak English as a first language.
Compensation
Participants were told that the study would take approximately 30 minutes and were paid at a base rate of $9/hr and informed that they would receive an optional bonus up to $10 for answering questions correctly. We applied the bonus to all participants.
LLM Answers and Uncertainty Elicitation
Bhatt et al. originally used GPT-3.5 as their LLM. While at first, we explored user performance when provided with confidence scores modulated over the original GPT-3.5 responses that the authors had collected, the authors had filtered LLM performance to ensure the LLM achieved high performance on biology, computer science, and foreign policy and poor performance on mathematics. As such, we noticed that participants overwhelmingly uptook the LLM’s answer (which was rational behaviour, given the model’s high performance). To explore a more nuanced performance profile, we regenerated LLM answers using Mistral 7B Instruct via greedy decoding. We then generated confidence scores on top of the LLM responses. For our random baseline, we sample a confidence score uniformly between 0 and 100% for each question.
G.2 Important considerations
There are many reasons to heed caution in interpreting our results as definitive indications of the utility of displaying confidence to users in LLM assistive settings. In particular: (i) users are presented with feedback after each trial as in [Bhatt et al., 2023] – as such, they can determine (potentially rapidly) whether or not a model is reliable, even without confidence scores. However, in practical settings users may not know whether or not the model was truly correct and therefore confidence scores could have an even larger impact; (ii) MMLU questions can be challenging for non-experts – we see the biggest differences in performance for the no-LLM vs. any-LLM-assistance condition. We may see a wider range of reliance behaviors in settings wherein people have more confidence in their own abilities; (iii) we present users with numeric confidence; however, humans are not always able to reliably process confidence estimates nor appropriately calibrate uncertainty estimates themselves [Keren, 1991, Vodrahalli et al., 2022, Collins et al., 2023, Lichtenstein et al., 1977]. It may be that alternate modes of communicating confidence improve users’ ability to appropriately leverage the confidence scores in their decision making process. We see targeted exploration of each component through interdisciplinary collaboration across AI, behavioral science, and human-computer interaction as ripe for future work.
G.3 Extended Results
Task Accuracy and Reliance Sensibility
We depict average user task accuracy and reliance sensibility across variants in Figure 15. We follow Bhatt et al. in computing reliance sensibility as the proportion of times the user appropriately sided with the model prediction when the model was correct and did not respond with the model’s prediction when the model was incorrect.
<details>
<summary>x71.png Details</summary>
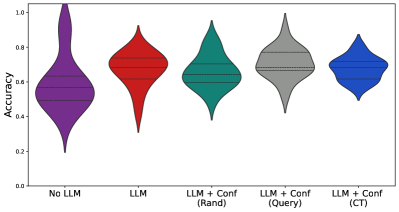
### Visual Description
\n
## Violin Plot: Accuracy Comparison of Different Approaches
### Overview
The image presents a violin plot comparing the accuracy of five different approaches. The x-axis represents the approach, and the y-axis represents the accuracy, ranging from 0.0 to 1.0. The violin plots visualize the distribution of accuracy scores for each approach.
### Components/Axes
* **X-axis:** Labels representing the different approaches: "No LLM", "LLM", "LLM + Conf (Rand)", "LLM + Conf (Query)", "LLM + Conf (CT)".
* **Y-axis:** Labeled "Accuracy", with a scale ranging from 0.0 to 1.0, with increments of 0.2.
* **Violin Plots:** Five violin plots, each representing the distribution of accuracy scores for a specific approach. The plots are colored as follows:
* "No LLM": Purple
* "LLM": Red
* "LLM + Conf (Rand)": Teal
* "LLM + Conf (Query)": Gray
* "LLM + Conf (CT)": Blue
### Detailed Analysis
The violin plots show the distribution of accuracy for each approach.
* **No LLM (Purple):** The distribution is relatively wide, ranging from approximately 0.1 to 1.0, with a peak around 0.8. The plot is somewhat asymmetrical, with a longer tail towards lower accuracy values.
* **LLM (Red):** The distribution is narrower than "No LLM", ranging from approximately 0.3 to 0.9, with a peak around 0.7.
* **LLM + Conf (Rand) (Teal):** The distribution is similar in width to "LLM", ranging from approximately 0.3 to 0.9, with a peak around 0.7.
* **LLM + Conf (Query) (Gray):** The distribution is wider than "LLM" and "LLM + Conf (Rand)", ranging from approximately 0.2 to 1.0, with a peak around 0.6.
* **LLM + Conf (CT) (Blue):** The distribution is relatively narrow, ranging from approximately 0.5 to 0.9, with a peak around 0.75.
### Key Observations
* "No LLM" has the widest distribution of accuracy, suggesting the most variability in performance.
* "LLM + Conf (CT)" appears to have the highest median accuracy, with a narrower distribution.
* "LLM" and "LLM + Conf (Rand)" have similar distributions.
* "LLM + Conf (Query)" has a wider distribution than the other LLM-based approaches.
### Interpretation
The data suggests that incorporating LLMs generally improves accuracy compared to not using an LLM ("No LLM"). The "LLM + Conf (CT)" approach appears to be the most effective, as it exhibits both a high median accuracy and a relatively narrow distribution, indicating consistent performance. The wider distribution of "No LLM" suggests that performance is highly variable without the use of an LLM. The "LLM + Conf (Query)" approach, while still showing improvement over "No LLM", has a wider distribution, indicating that its performance is less consistent than the other LLM-based approaches. The different "Conf" methods (Rand, Query, CT) likely represent different confidence estimation techniques, and the results suggest that the "CT" method is the most effective in conjunction with an LLM. The violin plots provide a visual representation of the spread and central tendency of the accuracy scores, allowing for a comparison of the different approaches.
</details>
<details>
<summary>x72.png Details</summary>
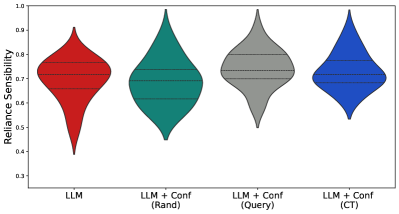
### Visual Description
\n
## Violin Plot: Reliance Sensitivity Comparison
### Overview
The image presents a violin plot comparing the "Reliance Sensitivity" across four different conditions: "LLM", "LLM + Conf (Rand)", "LLM + Conf (Query)", and "LLM + Conf (CT)". The violin plots visualize the distribution of reliance sensitivity for each condition, showing the median, interquartile range, and overall spread of the data.
### Components/Axes
* **X-axis:** Represents the four conditions: "LLM", "LLM + Conf (Rand)", "LLM + Conf (Query)", and "LLM + Conf (CT)".
* **Y-axis:** Labeled "Reliance Sensitivity", with a scale ranging from approximately 0.3 to 1.0.
* **Violin Plots:** Each condition is represented by a violin plot, displaying the distribution of reliance sensitivity values.
* **Colors:**
* LLM: Red
* LLM + Conf (Rand): Teal/Green
* LLM + Conf (Query): Gray
* LLM + Conf (CT): Blue
### Detailed Analysis
* **LLM (Red):** The violin plot is widest at the top, tapering down. The median is around 0.85. The distribution is relatively spread out, with values ranging from approximately 0.4 to 0.95.
* **LLM + Conf (Rand) (Teal/Green):** This plot is narrower than the LLM plot, with a median around 0.88. The distribution is more concentrated, ranging from approximately 0.6 to 0.98.
* **LLM + Conf (Query) (Gray):** This plot is similar in width to the LLM + Conf (Rand) plot, with a median around 0.78. The distribution ranges from approximately 0.55 to 0.95.
* **LLM + Conf (CT) (Blue):** This plot is the narrowest of the four, indicating the most concentrated distribution. The median is around 0.82. The distribution ranges from approximately 0.65 to 0.95.
### Key Observations
* The LLM condition exhibits the widest distribution of reliance sensitivity, suggesting the greatest variability in reliance when using the LLM alone.
* Adding confidence information (Conf) generally narrows the distribution, indicating more consistent reliance sensitivity.
* LLM + Conf (Rand) has the highest median reliance sensitivity.
* LLM + Conf (Query) has the lowest median reliance sensitivity.
* The LLM + Conf (CT) condition shows a relatively tight distribution around a median value.
### Interpretation
The data suggests that incorporating confidence information alongside the LLM output influences reliance sensitivity. The varying methods for generating confidence information ("Rand", "Query", "CT") lead to different distributions of reliance. The "Rand" method appears to increase reliance sensitivity compared to the LLM alone, while the "Query" method seems to decrease it. The "CT" method results in a more focused distribution, suggesting a more consistent level of reliance.
The wider distribution for the LLM alone indicates that users may vary significantly in how much they rely on the LLM's output without additional information. The narrowing of distributions with confidence information suggests that providing users with a measure of confidence helps to standardize their reliance behavior. The differences between the confidence methods ("Rand", "Query", "CT") likely reflect the quality or relevance of the confidence scores generated by each method. Further investigation would be needed to understand why the "Rand" method leads to higher reliance and the "Query" method leads to lower reliance.
</details>
Figure 15: (Left) User accuracy on 60 MMLU questions per variant ( $N=20$ users per variant); violin plots show quartiles as dashed lines (Right) Average reliance sensibility (proportion of instances where the user sided with the model when the model was correct, and overrode the model’s prediction when the model was incorrect); higher indicates better reliance calibration.
We depict per-topic accuracy, with the LLM’s average performance in Figure 16.
<details>
<summary>x73.png Details</summary>
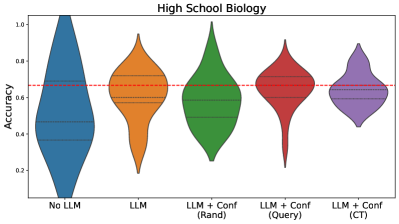
### Visual Description
\n
## Violin Plot: High School Biology Accuracy
### Overview
This image presents a violin plot comparing the accuracy of different approaches to answering high school biology questions. The approaches are: "No LLM", "LLM", "LLM + Conf (Rand)", "LLM + Conf (Query)", and "LLM + Conf (CT)". The y-axis represents accuracy, ranging from approximately 0.2 to 1.0. A horizontal dashed red line is present across the plot, likely representing a baseline or threshold accuracy.
### Components/Axes
* **Title:** "High School Biology"
* **X-axis:** Categorical, representing the different approaches:
* "No LLM"
* "LLM"
* "LLM + Conf (Rand)"
* "LLM + Conf (Query)"
* "LLM + Conf (CT)"
* **Y-axis:** "Accuracy", with a scale ranging from approximately 0.2 to 1.0.
* **Horizontal Line:** A dashed red line at approximately y = 0.6.
* **Violin Plots:** Five violin plots, one for each category on the x-axis. Each violin plot shows the distribution of accuracy scores for that approach.
### Detailed Analysis
The violin plots show the distribution of accuracy scores for each approach.
* **No LLM (Blue):** The violin plot is centered around approximately 0.65, with a range from roughly 0.3 to 1.0. The plot is relatively wide, indicating a significant spread in accuracy scores.
* **LLM (Orange):** The violin plot is centered around approximately 0.6, with a range from roughly 0.3 to 0.9. It is slightly narrower than the "No LLM" plot.
* **LLM + Conf (Rand) (Green):** The violin plot is centered around approximately 0.7, with a range from roughly 0.4 to 0.95. It appears to have a slightly higher median than the previous two.
* **LLM + Conf (Query) (Red):** The violin plot is centered around approximately 0.55, with a range from roughly 0.3 to 0.8. It is narrower than the "No LLM" and "LLM" plots.
* **LLM + Conf (CT) (Purple):** The violin plot is centered around approximately 0.62, with a range from roughly 0.35 to 0.9. It is similar in shape to the "LLM" plot.
The dashed red line at approximately 0.6 appears to be a benchmark. The "No LLM", "LLM + Conf (Rand)", and "LLM + Conf (CT)" distributions largely exceed this line, while "LLM" and "LLM + Conf (Query)" have significant portions of their distributions below it.
### Key Observations
* The "LLM + Conf (Rand)" approach appears to have the highest median accuracy.
* The "LLM + Conf (Query)" approach appears to have the lowest median accuracy.
* The "No LLM" approach performs comparably to the "LLM + Conf (Rand)" and "LLM + Conf (CT)" approaches.
* The "LLM" approach performs slightly worse than the "No LLM" approach.
* There is considerable variability in accuracy scores within each approach, as indicated by the width of the violin plots.
### Interpretation
The data suggests that simply adding a Large Language Model (LLM) does not necessarily improve accuracy compared to not using one ("No LLM"). However, incorporating confidence measures with the LLM can impact performance, depending on the method used for calculating confidence. The "LLM + Conf (Rand)" approach, which likely uses a random confidence score, shows the highest accuracy. The "LLM + Conf (Query)" approach, which likely uses a query-based confidence score, performs the worst. This could indicate that the method for determining confidence is crucial for the effectiveness of the LLM. The horizontal line at 0.6 likely represents a passing threshold or a baseline performance level. The fact that some approaches consistently exceed this line suggests they are providing value. The variability within each approach suggests that the performance is not consistent and may depend on the specific questions being asked. Further investigation is needed to understand why the "LLM + Conf (Query)" approach performs so poorly and to optimize the confidence calculation method.
</details>
<details>
<summary>x74.png Details</summary>
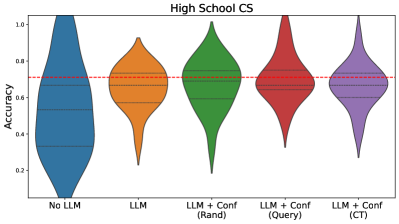
### Visual Description
\n
## Violin Plot: High School CS Accuracy
### Overview
The image presents a violin plot comparing the accuracy scores for different approaches to a High School Computer Science (CS) task. The approaches are: "No LLM", "LLM", "LLM + Conf (Rand)", "LLM + Conf (Query)", and "LLM + Conf (CT)". A horizontal dashed red line indicates a benchmark accuracy level.
### Components/Axes
* **X-axis:** Categorical, representing the different approaches: "No LLM", "LLM", "LLM + Conf (Rand)", "LLM + Conf (Query)", "LLM + Conf (CT)".
* **Y-axis:** Numerical, labeled "Accuracy", with a scale ranging from approximately 0.2 to 1.0, incrementing by 0.2.
* **Violin Plots:** Each approach is represented by a violin plot, showing the distribution of accuracy scores.
* **Horizontal Dashed Line:** A red dashed horizontal line is present at approximately y = 0.65, likely representing a threshold or baseline accuracy.
### Detailed Analysis
The violin plots show the distribution of accuracy scores for each approach.
* **No LLM (Blue):** The violin plot is centered around approximately 0.55, with a wide distribution ranging from approximately 0.2 to 1.0. The plot is relatively broad, indicating significant variability in accuracy.
* **LLM (Orange):** The violin plot is centered around approximately 0.6, with a distribution ranging from approximately 0.3 to 0.9. It is narrower than the "No LLM" plot, suggesting less variability.
* **LLM + Conf (Rand) (Green):** The violin plot is centered around approximately 0.7, with a distribution ranging from approximately 0.4 to 1.0. It appears slightly wider than the "LLM" plot.
* **LLM + Conf (Query) (Red):** The violin plot is centered around approximately 0.65, with a distribution ranging from approximately 0.3 to 0.9. It is similar in shape to the "LLM" plot.
* **LLM + Conf (CT) (Purple):** The violin plot is centered around approximately 0.7, with a distribution ranging from approximately 0.4 to 1.0. It is similar in shape to the "LLM + Conf (Rand)" plot.
The red dashed line at approximately 0.65 serves as a visual benchmark. The "LLM + Conf (Rand)" and "LLM + Conf (CT)" approaches show a higher proportion of scores above this line compared to the other approaches.
### Key Observations
* The "No LLM" approach has the widest distribution of accuracy scores, indicating the most variability.
* The "LLM" approach shows an improvement in accuracy compared to "No LLM", with a narrower distribution.
* Adding confidence information ("LLM + Conf") generally improves accuracy, particularly with the "Rand" and "CT" methods.
* The "LLM + Conf (Rand)" and "LLM + Conf (CT)" approaches have the highest median accuracy and a significant portion of scores above the 0.65 benchmark.
### Interpretation
The data suggests that incorporating Large Language Models (LLMs) improves accuracy on the High School CS task compared to not using an LLM. Furthermore, adding confidence information to the LLM-based approaches ("LLM + Conf") further enhances performance. The "Rand" and "CT" methods for incorporating confidence appear to be particularly effective.
The violin plots reveal the distribution of accuracy scores, providing insights into the consistency of each approach. The wider distribution for "No LLM" indicates that performance is more variable without the assistance of an LLM. The narrower distributions for the LLM-based approaches suggest more consistent results.
The horizontal dashed line likely represents a target accuracy or a baseline performance level. The fact that "LLM + Conf (Rand)" and "LLM + Conf (CT)" have a larger proportion of scores above this line indicates that these approaches are more likely to meet or exceed the desired performance threshold.
The differences between the "Rand", "Query", and "CT" confidence methods are subtle but potentially meaningful. Further investigation would be needed to determine which method is most effective and why.
</details>
<details>
<summary>x75.png Details</summary>
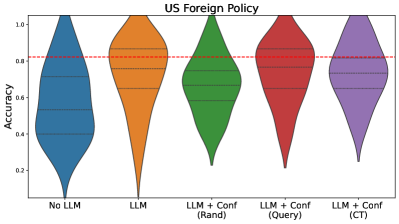
### Visual Description
\n
## Violin Plot: US Foreign Policy Accuracy
### Overview
This image presents a violin plot comparing the accuracy of different approaches related to Large Language Models (LLMs) in the context of US Foreign Policy. The plot displays the distribution of accuracy scores for five different methods. A horizontal dashed red line indicates a threshold accuracy level.
### Components/Axes
* **Title:** "US Foreign Policy" (centered at the top)
* **Y-axis Label:** "Accuracy" (left side, ranging from approximately 0.2 to 1.0)
* **X-axis Categories:**
* "No LLM"
* "LLM"
* "LLM + Conf (Rand)"
* "LLM + Conf (Query)"
* "LLM + Conf (CT)"
* **Horizontal Line:** A dashed red line at approximately 0.8 accuracy.
* **Violin Plots:** Five violin plots, one for each category on the x-axis. Each plot represents the distribution of accuracy scores for that method.
### Detailed Analysis
The violin plots show the distribution of accuracy scores for each method. The width of each violin represents the density of scores at different accuracy levels.
* **No LLM (Blue):** The distribution is centered around approximately 0.6 accuracy, with a range from roughly 0.2 to 1.0. The plot is relatively wide, indicating a significant spread in accuracy scores.
* **LLM (Orange):** The distribution is centered around approximately 0.8 accuracy, with a range from roughly 0.4 to 1.0. It is also relatively wide, but shifted to the right compared to "No LLM".
* **LLM + Conf (Rand) (Green):** The distribution is centered around approximately 0.7 accuracy, with a range from roughly 0.3 to 0.9. It is narrower than the previous two, suggesting less variability.
* **LLM + Conf (Query) (Red):** The distribution is centered around approximately 0.8 accuracy, with a range from roughly 0.5 to 1.0. It is similar to the "LLM" distribution in terms of central tendency.
* **LLM + Conf (CT) (Purple):** The distribution is centered around approximately 0.7 accuracy, with a range from roughly 0.3 to 0.9. It is similar to the "LLM + Conf (Rand)" distribution.
The dashed red line at approximately 0.8 accuracy serves as a benchmark. The "LLM" and "LLM + Conf (Query)" distributions show a substantial portion of scores above this line.
### Key Observations
* Using an LLM generally improves accuracy compared to not using an LLM ("No LLM").
* The "LLM + Conf (Query)" method appears to perform similarly to the "LLM" method.
* The "LLM + Conf (Rand)" and "LLM + Conf (CT)" methods show slightly lower central tendencies compared to the "LLM" method.
* There is considerable variability in accuracy scores within each method, as indicated by the width of the violin plots.
### Interpretation
The data suggests that incorporating LLMs can enhance accuracy in the context of US Foreign Policy analysis. The "LLM" and "LLM + Conf (Query)" methods demonstrate the highest accuracy, with a significant proportion of scores exceeding the 0.8 benchmark. The addition of "Confidence" information, using either a random approach ("Rand"), query-based approach ("Query"), or a "CT" method, does not consistently improve performance over simply using the LLM. The variability within each method suggests that the performance of these approaches can be sensitive to the specific input or task. The violin plots provide a visual representation of the distribution of accuracy scores, allowing for a comparison of the central tendency and spread of each method. The horizontal line provides a clear threshold for evaluating performance.
</details>
<details>
<summary>x76.png Details</summary>
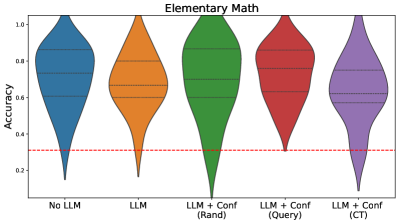
### Visual Description
\n
## Violin Plot: Elementary Math Accuracy
### Overview
The image presents a violin plot comparing the accuracy of different approaches to solving elementary math problems. Five different methods are compared, ranging from "No LLM" to "LLM + Conf (CT)". The y-axis represents accuracy, and the x-axis represents the different methods. A horizontal dashed line is present at approximately 0.5 accuracy.
### Components/Axes
* **Title:** "Elementary Math" positioned at the top-center of the chart.
* **Y-axis Label:** "Accuracy" positioned on the left side of the chart. The scale ranges from approximately 0.2 to 1.0, with markings at 0.2, 0.4, 0.6, 0.8, and 1.0.
* **X-axis Labels:** The following methods are displayed along the x-axis, from left to right:
* "No LLM"
* "LLM"
* "LLM + Conf (Rand)"
* "LLM + Conf (Query)"
* "LLM + Conf (CT)"
* **Horizontal Line:** A dashed horizontal line is present at approximately y = 0.5.
### Detailed Analysis
The chart uses violin plots to represent the distribution of accuracy scores for each method.
* **No LLM (Blue):** The violin plot is widest at the top, indicating a concentration of accuracy scores near 1.0. The plot tapers down to a point at approximately 0.2. The median accuracy appears to be around 0.8.
* **LLM (Orange):** This violin plot is wider than the "No LLM" plot, but still peaks around 0.8. The distribution is more spread out, with a longer tail extending down to approximately 0.2. The median accuracy appears to be around 0.6.
* **LLM + Conf (Rand) (Green):** This plot is similar in shape to the "LLM" plot, with a peak around 0.9 and a tail extending down to approximately 0.2. The median accuracy appears to be around 0.8.
* **LLM + Conf (Query) (Red):** This plot is wider than the "LLM" plot, with a peak around 0.7. The distribution is more spread out, with a longer tail extending down to approximately 0.2. The median accuracy appears to be around 0.6.
* **LLM + Conf (CT) (Purple):** This violin plot is similar to the "No LLM" plot, with a concentration of accuracy scores near 1.0. The plot tapers down to a point at approximately 0.2. The median accuracy appears to be around 0.8.
### Key Observations
* The "No LLM" and "LLM + Conf (CT)" methods exhibit the highest accuracy, with distributions concentrated near 1.0.
* The "LLM" and "LLM + Conf (Query)" methods have lower accuracy, with more spread in their distributions.
* The "LLM + Conf (Rand)" method shows accuracy similar to the "LLM" method.
* All methods have a tail extending down to approximately 0.2, indicating that some instances resulted in very low accuracy.
* The dashed line at 0.5 serves as a baseline for comparison. All methods generally perform above this baseline.
### Interpretation
The data suggests that using a Large Language Model (LLM) alone does not necessarily improve accuracy compared to not using one ("No LLM"). However, combining the LLM with confidence-based methods ("LLM + Conf") can improve accuracy, particularly when using the "CT" confidence method, which performs similarly to "No LLM". The "Rand" and "Query" confidence methods do not appear to offer significant improvements over using the LLM alone. The violin plots reveal the distribution of accuracy scores, highlighting the variability in performance for each method. The presence of a tail extending down to 0.2 indicates that even the best methods can sometimes produce inaccurate results. The horizontal line at 0.5 provides a benchmark for assessing the overall performance of each method. The data suggests that the choice of confidence method is crucial when integrating LLMs into elementary math problem-solving.
</details>
Figure 16: User accuracies per topic for the Mistral variants. Red line indicates the model’s average accuracy.
GPT-3.5 Confidence Generalization
As noted, we ran variants using the same GPT-3.5 generations as [Bhatt et al., 2023]. We show aggregate and per-topic accuracy in fig. 17, as well as reliance sensibility in fig. 18.
<details>
<summary>x77.png Details</summary>
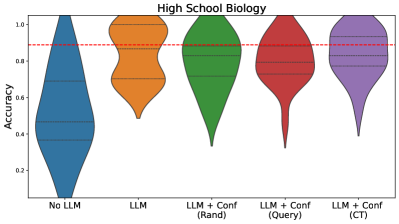
### Visual Description
\n
## Violin Plot: High School Biology Accuracy
### Overview
The image presents a violin plot comparing the accuracy of different approaches to answering high school biology questions. The approaches are: "No LLM", "LLM", "LLM + Conf (Rand)", "LLM + Conf (Query)", and "LLM + Conf (CT)". A horizontal dashed line indicates a benchmark accuracy level of approximately 0.8.
### Components/Axes
* **Title:** "High School Biology" positioned at the top-center of the plot.
* **Y-axis:** Labeled "Accuracy", ranging from approximately 0.2 to 1.0, with increments of 0.2.
* **X-axis:** Categorical, representing the different approaches:
* "No LLM"
* "LLM"
* "LLM + Conf (Rand)" - LLM plus Confidence (Random)
* "LLM + Conf (Query)" - LLM plus Confidence (Query)
* "LLM + Conf (CT)" - LLM plus Confidence (Chain of Thought)
* **Horizontal Line:** A dashed red line at approximately y = 0.8, likely representing a threshold or benchmark accuracy.
* **Violin Plots:** Each approach is represented by a violin plot, showing the distribution of accuracy scores.
### Detailed Analysis
The violin plots show the distribution of accuracy scores for each approach.
* **No LLM (Blue):** The violin plot is centered around approximately 0.5, with a wide distribution ranging from roughly 0.2 to 1.0. The plot is relatively broad, indicating a high variance in accuracy.
* **LLM (Orange):** The violin plot is centered around approximately 0.85, with a narrower distribution than "No LLM", ranging from about 0.6 to 1.0.
* **LLM + Conf (Rand) (Green):** The violin plot is centered around approximately 0.9, with a distribution ranging from roughly 0.65 to 1.0. It is slightly wider than the "LLM" plot.
* **LLM + Conf (Query) (Red):** The violin plot is centered around approximately 0.75, with a distribution ranging from about 0.5 to 0.95. It appears to have a longer tail towards lower accuracy scores.
* **LLM + Conf (CT) (Purple):** The violin plot is centered around approximately 0.95, with a relatively narrow distribution ranging from about 0.8 to 1.0. This plot is the most concentrated around higher accuracy values.
The dashed red line at 0.8 serves as a visual benchmark. The "No LLM" and "LLM + Conf (Query)" plots have significant portions below this line, while the other three approaches generally perform above it.
### Key Observations
* Using an LLM significantly improves accuracy compared to "No LLM".
* "LLM + Conf (CT)" consistently achieves the highest accuracy, with the most concentrated distribution around high values.
* "LLM + Conf (Query)" shows the most variability and has a substantial portion of scores below the 0.8 benchmark.
* "LLM + Conf (Rand)" performs slightly better than the base "LLM" model.
### Interpretation
The data suggests that incorporating Large Language Models (LLMs) substantially enhances accuracy in answering high school biology questions. Furthermore, the method of confidence scoring significantly impacts performance. "Chain of Thought" (CT) confidence scoring appears to be the most effective, leading to the highest and most consistent accuracy. Random confidence scoring provides a modest improvement over the base LLM, while Query-based confidence scoring is the least effective, exhibiting the greatest variance and a substantial number of low-accuracy results.
The violin plots reveal not only the central tendency of accuracy for each method but also the spread of results. The narrowness of the "LLM + Conf (CT)" plot indicates a reliable and consistent performance, while the broader plots for "No LLM" and "LLM + Conf (Query)" suggest greater uncertainty and potential for both high and low accuracy outcomes. The horizontal line provides a clear benchmark for evaluating the practical utility of each approach. The fact that "No LLM" performs significantly below this line highlights the value of LLM integration.
</details>
<details>
<summary>x78.png Details</summary>
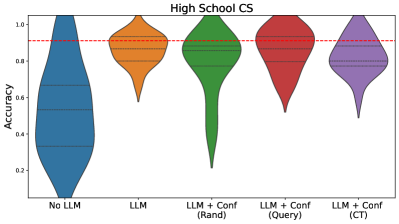
### Visual Description
\n
## Violin Plot: High School CS Accuracy
### Overview
The image presents a violin plot comparing the accuracy scores for different approaches to a High School Computer Science (CS) task. The approaches are: "No LLM", "LLM", "LLM + Conf (Rand)", "LLM + Conf (Query)", and "LLM + Conf (CT)". The plot visualizes the distribution of accuracy scores for each approach. A horizontal dashed red line is present across the plot, likely representing a benchmark or threshold.
### Components/Axes
* **X-axis:** Categorical, representing the different approaches: "No LLM", "LLM", "LLM + Conf (Rand)", "LLM + Conf (Query)", "LLM + Conf (CT)".
* **Y-axis:** Numerical, labeled "Accuracy", with a scale ranging from approximately 0.2 to 1.0.
* **Violin Plots:** Each approach has a corresponding violin plot showing the distribution of accuracy scores. The width of each violin represents the density of scores at that accuracy level.
* **Horizontal Dashed Line:** A red dashed horizontal line is present at approximately y = 0.85.
### Detailed Analysis
The violin plots show the following distributions:
1. **No LLM (Blue):** The distribution is centered around approximately 0.6, with a range from roughly 0.2 to 1.0. The plot is relatively wide, indicating a significant spread in accuracy scores.
2. **LLM (Orange):** The distribution is centered around approximately 0.7, with a range from roughly 0.4 to 0.9. The plot is narrower than "No LLM", suggesting less variability.
3. **LLM + Conf (Rand) (Green):** The distribution is centered around approximately 0.9, with a range from roughly 0.6 to 1.0. This plot is the tallest, indicating a higher concentration of scores near 1.0.
4. **LLM + Conf (Query) (Red):** The distribution is centered around approximately 0.8, with a range from roughly 0.5 to 1.0. The plot is moderately wide.
5. **LLM + Conf (CT) (Purple):** The distribution is centered around approximately 0.85, with a range from roughly 0.6 to 1.0. The plot is similar in shape to "LLM + Conf (Query)".
The red dashed line at approximately 0.85 appears to be a threshold. The "LLM + Conf (Rand)" and "LLM + Conf (CT)" approaches have distributions that largely exceed this threshold.
### Key Observations
* The "No LLM" approach has the lowest average accuracy and the widest distribution.
* Adding an LLM improves accuracy compared to "No LLM".
* The "LLM + Conf (Rand)" approach demonstrates the highest accuracy, with a significant portion of scores near 1.0.
* The "LLM + Conf (Query)" and "LLM + Conf (CT)" approaches show similar performance, with average accuracy around 0.8.
* The red dashed line serves as a performance benchmark, and the "LLM + Conf (Rand)" approach consistently surpasses it.
### Interpretation
The data suggests that incorporating Large Language Models (LLMs) improves accuracy on the High School CS task. Furthermore, combining LLMs with confidence-based methods ("LLM + Conf") leads to even greater accuracy gains. The "LLM + Conf (Rand)" approach, utilizing a random confidence method, appears to be the most effective, consistently achieving high accuracy scores.
The wide distribution of scores for the "No LLM" approach indicates a high degree of variability in performance without the assistance of an LLM. The narrowing of distributions as LLMs and confidence methods are added suggests that these techniques reduce variability and provide more consistent results.
The red dashed line likely represents a desired accuracy threshold. The fact that "LLM + Conf (Rand)" consistently exceeds this threshold highlights its potential for practical application in this context. The other "LLM + Conf" methods also perform well, but not as consistently as the "Rand" approach. This could indicate that the random confidence method is particularly well-suited to the specific characteristics of the High School CS task.
</details>
<details>
<summary>x79.png Details</summary>
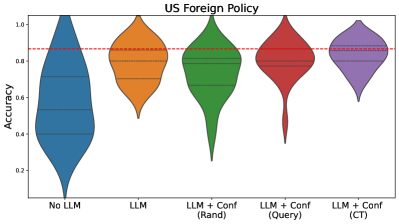
### Visual Description
\n
## Violin Plot: US Foreign Policy Accuracy
### Overview
The image presents a violin plot comparing the accuracy of different approaches related to Large Language Models (LLMs) in the context of US Foreign Policy. The x-axis represents the different approaches, and the y-axis represents the accuracy. A horizontal dashed red line is present across all violin plots, likely representing a baseline or threshold.
### Components/Axes
* **Title:** "US Foreign Policy" (centered at the top)
* **Y-axis Label:** "Accuracy" (left side) - Scale ranges from approximately 0.2 to 1.0, with markings at 0.2, 0.4, 0.6, 0.8, and 1.0.
* **X-axis Labels:**
* "No LLM"
* "LLM"
* "LLM + Conf (Rand)"
* "LLM + Conf (Query)"
* "LLM + Conf (CT)"
* **Horizontal Line:** A dashed red line at approximately y = 0.8.
* **Violin Plots:** Five violin plots, each representing a different approach. The colors are:
* "No LLM": Blue
* "LLM": Orange
* "LLM + Conf (Rand)": Green
* "LLM + Conf (Query)": Red
* "LLM + Conf (CT)": Purple
### Detailed Analysis
The violin plots show the distribution of accuracy scores for each approach. The width of each violin represents the density of data points at each accuracy level.
* **No LLM (Blue):** The distribution is relatively wide, ranging from approximately 0.2 to 1.0, with a peak around 0.6. The plot is somewhat skewed to the left.
* **LLM (Orange):** The distribution is centered around 0.6-0.7, with a range of approximately 0.4 to 0.9. It's less wide than the "No LLM" plot.
* **LLM + Conf (Rand) (Green):** This plot shows a distribution centered around 0.8-0.9, with a range of approximately 0.6 to 1.0. It appears to have a higher median accuracy than the previous two.
* **LLM + Conf (Query) (Red):** The distribution is centered around 0.6-0.7, with a range of approximately 0.4 to 0.9. It is similar to the LLM plot, but slightly more spread out.
* **LLM + Conf (CT) (Purple):** The distribution is centered around 0.8-0.9, with a range of approximately 0.6 to 1.0. It is similar to the "LLM + Conf (Rand)" plot.
The dashed red line at approximately 0.8 appears to be a benchmark. The "LLM + Conf (Rand)" and "LLM + Conf (CT)" approaches have a significant portion of their distributions above this line.
### Key Observations
* The "No LLM" approach has the widest distribution of accuracy scores, suggesting the most variability.
* Adding an LLM generally improves accuracy compared to "No LLM".
* The "LLM + Conf (Rand)" and "LLM + Conf (CT)" approaches consistently achieve the highest accuracy scores, with a substantial portion of their distributions exceeding the 0.8 benchmark.
* The "LLM + Conf (Query)" approach does not show a significant improvement over the basic "LLM" approach.
### Interpretation
The data suggests that incorporating LLMs, particularly when combined with confidence measures using either a random or CT method, significantly improves accuracy in the context of US Foreign Policy analysis. The "No LLM" approach demonstrates the highest variability, indicating a lack of consistent performance. The horizontal red line likely represents a desired level of accuracy, and the "LLM + Conf (Rand)" and "LLM + Conf (CT)" approaches are most likely to meet or exceed this threshold. The "LLM + Conf (Query)" approach's performance is comparable to the basic LLM approach, suggesting that the query-based confidence method may not be as effective as the other two. This could be due to the nature of the queries used or the specific confidence calculation method. The violin plots provide a clear visualization of the distribution of accuracy scores, allowing for a nuanced understanding of the performance of each approach.
</details>
<details>
<summary>x80.png Details</summary>
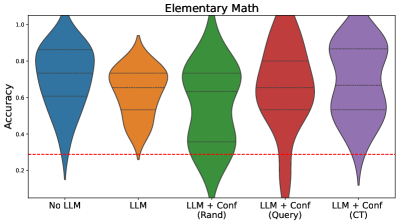
### Visual Description
\n
## Violin Plot: Elementary Math Accuracy
### Overview
The image presents a violin plot comparing the accuracy of different approaches to solving elementary math problems. The x-axis represents the method used, and the y-axis represents the accuracy score. Five different methods are compared: "No LLM", "LLM", "LLM + Conf (Rand)", "LLM + Conf (Query)", and "LLM + Conf (CT)". A horizontal dashed red line is present at approximately 0.5 accuracy.
### Components/Axes
* **Title:** "Elementary Math" (centered at the top)
* **X-axis Label:** Method (categorical) with the following categories:
* "No LLM"
* "LLM"
* "LLM + Conf (Rand)"
* "LLM + Conf (Query)"
* "LLM + Conf (CT)"
* **Y-axis Label:** "Accuracy" (vertical, left side) with a scale ranging from approximately 0.2 to 1.0.
* **Horizontal Line:** A dashed red line at approximately y = 0.5.
### Detailed Analysis
The plot displays the distribution of accuracy scores for each method using violin plots.
* **No LLM (Blue):** The violin plot is centered around an accuracy of approximately 0.8, with a range from roughly 0.6 to 1.0. The distribution is relatively narrow, indicating consistent performance.
* **LLM (Orange):** The violin plot is centered around an accuracy of approximately 0.65, with a range from roughly 0.4 to 0.9. The distribution is wider than "No LLM", suggesting more variability.
* **LLM + Conf (Rand) (Green):** The violin plot is centered around an accuracy of approximately 0.75, with a range from roughly 0.5 to 0.95. The distribution is similar in width to "No LLM".
* **LLM + Conf (Query) (Red):** The violin plot is centered around an accuracy of approximately 0.7, with a range from roughly 0.45 to 0.95. The distribution is wider than "No LLM".
* **LLM + Conf (CT) (Purple):** The violin plot is centered around an accuracy of approximately 0.85, with a range from roughly 0.6 to 1.0. The distribution is similar in width to "No LLM".
### Key Observations
* The "No LLM" method has the highest median accuracy.
* The "LLM" method has the lowest median accuracy.
* Adding confidence information ("Conf") to the LLM improves accuracy compared to using the LLM alone, with "LLM + Conf (CT)" achieving the highest accuracy among the LLM-based methods.
* All methods generally achieve accuracy above the 0.5 threshold indicated by the red dashed line.
* The "LLM + Conf (Rand)" and "LLM + Conf (Query)" methods show a wider distribution of accuracy scores, indicating more variability in performance.
### Interpretation
The data suggests that while Large Language Models (LLMs) alone perform worse than a "No LLM" baseline on elementary math problems, incorporating confidence information can significantly improve their accuracy. The method of obtaining confidence information appears to matter, with "LLM + Conf (CT)" performing best. The violin plots reveal the spread of the data, showing that some methods are more consistent than others. The red dashed line at 0.5 likely represents a threshold for acceptable performance, and all methods exceed this threshold. The variability in the "LLM + Conf (Rand)" and "LLM + Conf (Query)" methods could indicate sensitivity to the specific problem instances or the randomness inherent in those confidence estimation techniques. The data implies that LLMs can be valuable tools for solving elementary math problems, but their effectiveness is highly dependent on how confidence information is integrated.
</details>
Figure 17: User accuracies per topic for the GPT-3.5 variants (with generalization confidence computed for the CT and Query cases). Red line indicates the model’s average accuracy.
<details>
<summary>x81.png Details</summary>
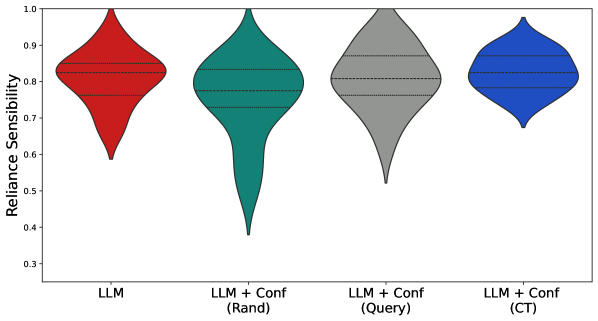
### Visual Description
\n
## Violin Plot: Reliance Sensitivity by Model Configuration
### Overview
The image presents a violin plot comparing the "Reliance Sensitivity" across four different model configurations: "LLM", "LLM + Conf (Rand)", "LLM + Conf (Query)", and "LLM + Conf (CT)". The violin plots visualize the distribution of reliance sensitivity scores for each configuration.
### Components/Axes
* **X-axis:** Represents the model configuration. The categories are:
* LLM
* LLM + Conf (Rand)
* LLM + Conf (Query)
* LLM + Conf (CT)
* **Y-axis:** Labeled "Reliance Sensitivity", with a scale ranging from approximately 0.3 to 1.0.
* **Violin Plots:** Each model configuration has a corresponding violin plot, showing the distribution of reliance sensitivity scores. A white line within each violin plot indicates the median value.
### Detailed Analysis
Let's analyze each violin plot individually:
1. **LLM (Red):** The violin plot is centered around a median value of approximately 0.88. The distribution is relatively narrow, indicating a consistent reliance sensitivity. The range extends from approximately 0.65 to 0.98.
2. **LLM + Conf (Rand) (Teal):** This plot has a median value of approximately 0.83. The distribution is wider than the LLM plot, suggesting more variability in reliance sensitivity. The range extends from approximately 0.4 to 0.95.
3. **LLM + Conf (Query) (Gray):** The median value is approximately 0.85. The distribution is the widest of the four, indicating the most variability in reliance sensitivity. The range extends from approximately 0.5 to 1.0.
4. **LLM + Conf (CT) (Blue):** The median value is approximately 0.91. The distribution is relatively narrow, similar to the LLM plot, but slightly shifted towards higher values. The range extends from approximately 0.75 to 0.99.
### Key Observations
* The "LLM + Conf (CT)" configuration exhibits the highest median reliance sensitivity (approximately 0.91).
* The "LLM + Conf (Query)" configuration shows the greatest variability in reliance sensitivity.
* The "LLM" configuration has a relatively consistent reliance sensitivity, with a median of approximately 0.88.
* Adding confidence information ("Conf") generally shifts the distributions, but the effect varies depending on the method used (Rand, Query, CT).
### Interpretation
The data suggests that incorporating confidence information into the LLM can influence reliance sensitivity. The "CT" method appears to be the most effective at increasing reliance sensitivity, as indicated by its higher median value. The "Query" method, while also increasing reliance sensitivity, introduces the most variability. This could indicate that the confidence scores generated by the "Query" method are less reliable or more context-dependent. The "Rand" method shows a moderate increase in reliance sensitivity, but with a wider distribution than the base LLM.
The violin plots provide a visual representation of how different confidence augmentation strategies impact the consistency and magnitude of reliance sensitivity. The wider distributions for "LLM + Conf (Rand)" and "LLM + Conf (Query)" suggest that these methods may be more sensitive to specific input conditions or data points. The narrower distribution of "LLM + Conf (CT)" suggests a more robust and predictable effect on reliance sensitivity.
The data implies that the choice of confidence augmentation method is crucial for controlling the level and consistency of reliance on the LLM's output. Further investigation is needed to understand the underlying reasons for the observed differences and to optimize the confidence augmentation process for specific applications.
</details>
Figure 18: Reliance sensibility for the variants based on GPT-3.5
Freeform User Responses
We permitted users to provide freeform responses at the end of the study. Some users were sensitive to confidence scores being reported and came up with their own heuristics for whether to rely on the model’s output. We include a sampling of comments across confidence variants:
- “if it had a confidence of less than 50% it made me very skeptical.”
- “The modelś confidence indeed helped me choose and select my answer as I trusted in them most of the time.”
- “I didnt́ really rely on the confidence level. If I had 0 confidence in the answer myself I relied on the AI regardless.”
- “if the models confidence fell below 45 I decided to investigate it myself by remembering pieces of information. and also reasoning the question. If it was above 45 I would automatically agree to its prediction but there were some few cases I challenged it even though it was above 45”
- “At first I was hesistant to trust the model much because of the lower confidence levels but I still trusted it enough on topics I struggled with. As it went on, I was comfortable with confidence levels above 40.”
- “If the modelś confidence was low and I thought I knew the answer (and it was different) I chose my answer”
G.4 Interface and Instructions
We show a sample interface of our extension of Modiste with user confidence in Figure 19, and present the the full set of instructions provided to users in Figures 20 and 21. Note, for the LLM-only and no-LLM conditions, we followed the instruction text from [Bhatt et al., 2023] directly, i.e., participants who saw only the LLM did not see the instruction page about model confidence, and participants in the “No-LLM” variant were not instructed about any model variant and were just instructed to answer the questions as best as they could by themselves. Participants also responded to a post survey questionarre after completing the user study, which we depict in Figure 22.
<details>
<summary>user_study_figs/instructions/page_with_feedback.png Details</summary>
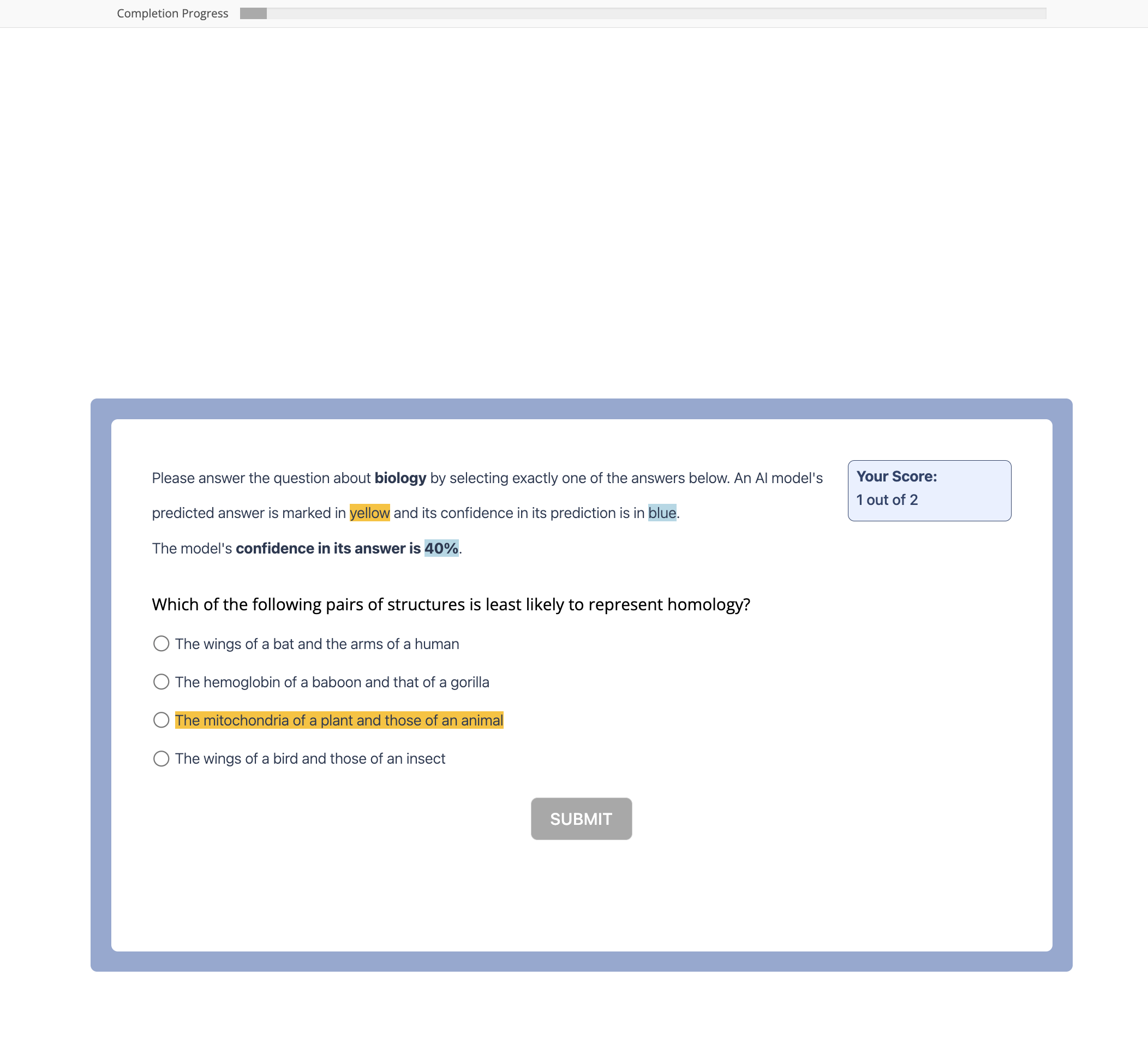
### Visual Description
\n
## Screenshot: AI-Assisted Biology Question
### Overview
This is a screenshot of an AI-assisted biology question presented within a user interface. The interface displays a multiple-choice question, an AI's predicted answer highlighted with color-coding, and a confidence score for the prediction. The question pertains to homology in biological structures.
### Components/Axes
The screenshot contains the following elements:
* **Header:** "Completion Progress" (top-left)
* **Question Prompt:** A text block asking the user to answer a biology question.
* **AI Prediction:** The AI's predicted answer is highlighted in yellow, and its confidence level is indicated in blue.
* **Confidence Score:** "The model's confidence in its answer is 40%."
* **Multiple Choice Options:** Four options are presented as radio buttons with accompanying text.
* **Submit Button:** A button labeled "SUBMIT" at the bottom.
* **Score Display:** "Your Score: 1 out of 2" (top-right)
### Content Details
The question presented is:
"Which of the following pairs of structures is least likely to represent homology?"
The multiple-choice options are:
1. "The wings of a bat and the arms of a human"
2. "The hemoglobin of a baboon and that of a gorilla"
3. "The mitochondria of a plant and those of an animal" (Highlighted in yellow, indicating the AI's prediction)
4. "The wings of a bird and those of an insect"
The AI's confidence in its answer (option 3) is 40%. The user's current score is 1 out of 2.
### Key Observations
The AI has selected "The mitochondria of a plant and those of an animal" as the least likely pair to represent homology. The relatively low confidence score (40%) suggests the AI is not highly certain about this prediction. The user has answered one question correctly out of two.
### Interpretation
This screenshot demonstrates an AI's attempt to assist a user in answering a biology question. The AI provides a prediction and a confidence score, allowing the user to evaluate the AI's suggestion. The question focuses on the concept of homology, which refers to similarities in structures due to shared ancestry. The AI's choice of mitochondria suggests it recognizes that while mitochondria are present in both plants and animals, their evolutionary origins and detailed structures might differ more significantly than the other options. The low confidence score indicates that the AI may be struggling with the nuances of evolutionary relationships or the specific details of mitochondrial evolution. The interface is designed to provide feedback to the user and potentially guide their learning process. The score display indicates the user is partway through a larger assessment.
</details>
Figure 19: Example interface from Modiste. Participants are informed of the question (and topic), as well as the LLM prediction and confidence. Participants are informed of their running score throughout the experiment.
<details>
<summary>user_study_figs/instructions/starter_inst.png Details</summary>
### Visual Description
\n
## Screenshot: Experiment Introduction
### Overview
The image is a screenshot of an introductory screen for an experiment. It contains text explaining the purpose of the experiment, the estimated time commitment, and the compensation offered. There are also two button elements labeled "Previous" and "Next".
### Components/Axes
There are no axes or charts in this image. The key components are:
* **Title:** "Welcome!"
* **Experiment Description:** A paragraph explaining the research focus.
* **Time Estimate:** "This experiment should take at most 30 minutes."
* **Compensation:** "You will be compensated at a base rate of $9/hour for a total of $4.50, which you will receive as long as you complete the study."
* **Navigation Buttons:** "Previous" and "Next".
### Detailed Analysis or Content Details
The text content is as follows:
"Welcome!
We are conducting an experiment to understand how people make decisions with and without AI support. Your answers will be used to inform machine learning, cognitive science, and human-computer interaction research.
This experiment should take at most 30 minutes.
You will be compensated at a base rate of $9/hour for a total of $4.50, which you will receive as long as you complete the study."
The "Previous" button is positioned on the left, and the "Next" button is positioned on the right, both at the bottom of the screen.
### Key Observations
The experiment is focused on decision-making processes, specifically with and without AI assistance. The compensation is calculated based on an hourly rate of $9, with a total payout of $4.50, implying an estimated experiment duration of 30 minutes ($4.50 / $9/hour = 0.5 hours = 30 minutes).
### Interpretation
This screen serves as an informed consent and introduction to the experiment. The text aims to clearly communicate the study's purpose, time commitment, and financial incentives to potential participants. The use of terms like "machine learning," "cognitive science," and "human-computer interaction" suggests a research context within these fields. The compensation structure is transparent, linking the total payout to an hourly rate and the estimated duration. The "Previous" and "Next" buttons indicate a multi-step process, likely involving further instructions or consent forms before the actual experiment begins.
</details>
<details>
<summary>user_study_figs/instructions/likely_answer_inst.png Details</summary>

### Visual Description
\n
## Screenshot: Experiment Instructions
### Overview
The image is a screenshot of instructions for an online experiment involving multiple-choice questions. The instructions explain the nature of the questions and how to select answers. There is no chart, graph, or diagram present; it is purely textual content with navigation buttons.
### Components/Axes
There are no axes or components in the traditional sense of a chart or diagram. The key elements are:
* **Instructional Text:** A block of text explaining the experiment.
* **Navigation Buttons:** Two buttons labeled "< Previous" and "Next".
### Detailed Analysis or Content Details
The text content is as follows:
"In this experiment, you will be seeing multiple choice questions, from various topics, such as those that you may find in school (e.g., biology, mathematics, foreign policy, computer science)."
"Your task is to determine the most likely answer for each question. You can select this category by clicking on the radio button associated with your answer."
The buttons are positioned at the bottom-center of the image. The "Previous" button is on the left, and the "Next" button is on the right.
### Key Observations
The instructions are clear and concise. The example topics provided (biology, mathematics, foreign policy, computer science) suggest a broad range of subjects will be covered. The instructions emphasize selecting the *most likely* answer, implying a degree of uncertainty or subjective judgment is involved.
### Interpretation
The image depicts the introductory screen for a behavioral experiment. The experiment appears to be designed to assess participants' judgment or reasoning skills across diverse academic domains. The use of multiple-choice questions with a focus on "most likely" answers suggests the experiment is not testing factual recall, but rather probabilistic reasoning or subjective assessment. The "Previous" and "Next" buttons indicate a sequential presentation of questions. The overall design is simple and functional, prioritizing clarity of instructions over visual aesthetics.
</details>
<details>
<summary>user_study_figs/instructions/ai_pred_inst.png Details</summary>
### Visual Description
\n
## Screenshot: Instructions for AI-Assisted Tasks
### Overview
The image is a screenshot of a user interface displaying instructions related to an AI-based model's predictions during a task. The interface provides information on how the model's predictions will be presented to the user.
### Components/Axes
There are no axes or charts in this image. The key components are:
* **Text Blocks:** Two paragraphs of instructional text.
* **Buttons:** Two buttons labeled "< Previous" and "Next>".
### Detailed Analysis or Content Details
The text content is as follows:
"During the tasks, you will also see the prediction of an AI-based model."
"The model’s prediction will show up as yellow highlighting over that answer choice. If shown, you are free to use or ignore the information when selecting your answer however you wish."
The button "< Previous" is positioned on the left side of the screen.
The button "Next>" is positioned on the right side of the screen.
### Key Observations
The interface is minimalistic, focusing on clear instructions. The use of "yellow highlighting" is specifically mentioned as the visual indicator for the AI model's prediction. The user is explicitly given agency to either utilize or disregard the AI's suggestion.
### Interpretation
The screenshot suggests a user is participating in a task where an AI model provides assistance. The AI's role is to offer predictions, but the user retains full control over the final decision. This design likely aims to leverage the AI's capabilities without diminishing the user's autonomy or critical thinking. The emphasis on the yellow highlighting indicates a deliberate choice to make the AI's input visually distinct but not overly intrusive. The presence of "Previous" and "Next" buttons suggests a multi-step task or assessment.
</details>
<details>
<summary>user_study_figs/instructions/confidence_inst.png Details</summary>
### Visual Description
\n
## Screenshot: User Interface Text
### Overview
The image is a screenshot of a user interface element, displaying a textual message and navigation buttons. It appears to be part of a larger interactive system, likely a quiz or assessment. The image does not contain any charts, graphs, or diagrams with quantifiable data.
### Components/Axes
There are no axes or charts present. The key components are:
* **Text Block:** A sentence explaining that the model's confidence in its prediction will be displayed in blue for each question.
* **"Previous" Button:** A button labeled "< Previous" for navigating to the previous step or question.
* **"Next" Button:** A button labeled "Next >" for navigating to the next step or question.
### Detailed Analysis or Content Details
The text block reads: "You will also see the model's confidence in its prediction (which will be shown in blue) for each question."
The "Previous" button is positioned on the left side, and the "Next" button is positioned on the right side, both at the bottom of the visible area.
### Key Observations
The image provides information about the user experience, specifically regarding the display of model confidence. There is no numerical data or quantifiable information.
### Interpretation
The screenshot indicates that the system provides feedback on the certainty of its predictions. The use of color (blue) to indicate confidence is a common UI/UX practice. The presence of "Previous" and "Next" buttons suggests a step-by-step process, such as a questionnaire or tutorial. The image is purely informational and does not present any data for analysis beyond the textual content.
</details>
<details>
<summary>user_study_figs/instructions/seconds_per.png Details</summary>

### Visual Description
\n
## Screenshot: Instructional Text
### Overview
The image is a screenshot of a webpage displaying instructional text related to a quiz or assessment. The text provides guidance to the user regarding time constraints and the functionality of navigation buttons.
### Components/Axes
There are no axes or charts present in this image. The key components are:
* **Instructional Text:** A block of text providing instructions.
* **Navigation Buttons:** Two buttons labeled "Previous" and "Next".
### Detailed Analysis or Content Details
The text content is as follows:
"We encourage you to try to work through each problem. You will not be able to continue to the next question until at least **10 seconds** have passed. The **SUBMIT** button will change from grey to blue when you are able to click to move to the next page whenever you are ready to answer.
Of course you can take longer than 10 seconds on any question if needed! It may be very challenging to determine the answer for some questions. Others may be easy. **Please try your best** regardless."
The "Previous" button is positioned on the bottom-left of the screen and is grey.
The "Next" button is positioned on the bottom-right of the screen and is green.
### Key Observations
The text emphasizes a minimum time requirement of 10 seconds per question before progressing. It also highlights the color change of a "SUBMIT" button (not visible in the screenshot) as an indicator of readiness to proceed. The text encourages users to take their time and try their best.
### Interpretation
The screenshot suggests a timed assessment or quiz environment. The 10-second minimum time per question is likely implemented to prevent users from rushing through the assessment without considering the questions. The color-changing "SUBMIT" button provides a clear visual cue to the user about when they can move on. The overall tone of the text is encouraging and supportive, acknowledging that some questions may be difficult while still urging users to make an effort. The presence of "Previous" and "Next" buttons indicates a multi-question format. The bolded text highlights key information for the user.
</details>
<details>
<summary>user_study_figs/instructions/bonus.png Details</summary>
### Visual Description
\n
## Screenshot: Task Instructions & Navigation
### Overview
The image is a screenshot of a user interface displaying instructions related to a task and navigation buttons. The instructions detail a potential bonus structure based on performance.
### Components/Axes
There are no axes or charts present in this image. The key components are:
* **Instructional Text:** Two lines of text explaining a bonus system.
* **Navigation Buttons:** Two buttons labeled "< Previous" and "Next >".
### Detailed Analysis or Content Details
The text content is as follows:
"You will receive a **bonus** of up to a rate of **$10/hour** (+$0.50) based on how many questions you correctly answer."
"You will be informed whether or not you are correct after each trial."
The button "< Previous" is positioned on the bottom-left of the screen.
The button "Next >" is positioned on the bottom-right of the screen.
### Key Observations
The screenshot focuses on incentivizing accurate responses through a bonus system. The bonus is tiered, potentially increasing the hourly rate based on the number of correct answers. Immediate feedback is provided after each attempt.
### Interpretation
This screenshot represents a task interface designed to motivate users to provide accurate responses. The bonus structure suggests a performance-based reward system. The immediate feedback mechanism is intended to facilitate learning and improve accuracy over time. The bolding of "bonus" and "$10/hour" emphasizes the potential financial reward. The interface is simple and direct, focusing on clear communication of the task requirements and incentives. The presence of "Previous" and "Next" buttons indicates a multi-step or iterative task flow.
</details>
Figure 20: Experiment instructions for the confidence variants.
<details>
<summary>user_study_figs/instructions/questions.png Details</summary>
### Visual Description
\n
## Screenshot: Quiz Interface
### Overview
The image is a screenshot of a simple quiz interface. It displays a message indicating the total number of questions in the quiz and provides navigation buttons for moving between questions. There is no chart, diagram, or complex data to extract.
### Components/Axes
The visible components are:
* **Text:** "You will see a total of 60 questions."
* **Button:** "< Previous"
* **Button:** "Next >"
### Detailed Analysis or Content Details
The text states that the quiz consists of a total of **60 questions**. The buttons allow for navigation through the questions. The "Previous" button is positioned to the left, and the "Next" button is positioned to the right.
### Key Observations
The interface is minimalistic, focusing solely on the number of questions and navigation. There are no other visual elements or information displayed.
### Interpretation
The screenshot represents a standard quiz or assessment interface. The message informs the user about the scope of the quiz, and the navigation buttons enable them to proceed through the questions sequentially. The simplicity of the design suggests a focus on content delivery and assessment rather than elaborate visual presentation. The interface is likely part of a larger online learning platform or testing system.
</details>
<details>
<summary>user_study_figs/instructions/next.png Details</summary>
### Visual Description
\n
## Screenshot: Experiment Instructions
### Overview
The image is a screenshot of a webpage displaying instructions for an upcoming experiment. It contains text-based instructions and navigation buttons. There is no chart, diagram, or data presented.
### Components/Axes
The visible components are:
* **Instructional Text:** A block of text providing guidance to the user.
* **Navigation Buttons:** Two buttons labeled "< Previous" and "Next >".
### Detailed Analysis or Content Details
The text content is as follows:
"When you are ready, please click **“Next”** to complete a quick comprehension check, before moving on to the experiment."
"Please make sure the window size is in full screen, or substantially large enough, to properly view the questions."
The button "< Previous" is positioned on the left side of the screen.
The button "Next >" is positioned on the right side of the screen.
### Key Observations
The text emphasizes the importance of completing a comprehension check before proceeding with the experiment and ensuring adequate screen size for viewing questions. The use of bold text highlights the "Next" button as the primary action.
### Interpretation
The screenshot represents a user interface element designed to guide participants through an experimental process. The instructions aim to ensure participants understand the procedure and have a suitable viewing environment. The presence of navigation buttons suggests a multi-step process. The emphasis on a comprehension check indicates a concern for data quality and participant understanding. The instructions are straightforward and aim to minimize confusion.
</details>
<details>
<summary>user_study_figs/instructions/mc_check.png Details</summary>
### Visual Description
\n
## Screenshot: Knowledge Check Instructions
### Overview
The image is a screenshot of a knowledge check interface. It presents two multiple-choice questions to the user, likely as a preliminary assessment before a more complex task. The interface is clean and minimalist, with a white background and simple text formatting.
### Components/Axes
The screenshot contains the following elements:
* **Header Text:** "Check your knowledge before you begin. If you don't know the answers, don't worry; we will show you the instructions again."
* **Question 1:** "What will you be asked to determine in this task?"
* **Option 1:** "The answer to a multiple choice question."
* **Option 2:** "The least likely answer to a multiple choice question."
* **Option 3:** "The most likely categories of an image."
* **Question 2:** "How will you select your answer?"
* **Option 1:** "Typing in a text box."
* **Option 2:** "Clicking on a radio button."
* **Option 3:** "Selecting from a dropdown menu."
* **Button:** "Continue" (located at the bottom-center of the screen)
### Detailed Analysis or Content Details
The screenshot presents a set of instructions and questions designed to gauge the user's understanding of the task ahead. The questions are formatted as multiple-choice, with three options for each. The "Continue" button suggests that the user must answer these questions before proceeding.
The questions themselves are meta-cognitive, asking the user to reflect on the *type* of task they will be performing and the *method* of providing input.
### Key Observations
The interface is designed to be user-friendly and non-intimidating. The inclusion of the sentence "If you don't know the answers, don't worry; we will show you the instructions again" suggests that the knowledge check is not a high-stakes assessment, but rather a way to ensure the user is prepared for the task.
### Interpretation
The data suggests that the task involves image analysis and categorization. The questions specifically mention "multiple choice questions" and "categories of an image," indicating that the user will likely be presented with images and asked to select the most appropriate category or answer. The options for selecting answers (text box, radio button, dropdown menu) suggest a variety of input methods may be used.
The overall purpose of this interface is to prime the user for the task and ensure they understand the expected input and output formats. It's a form of scaffolding, providing support and guidance before the main activity begins. The emphasis on reassurance ("don't worry") suggests the task may be complex or challenging, and the knowledge check is intended to reduce anxiety and build confidence.
</details>
Figure 21: Experiment instructions for the confidence variants (continued).
<details>
<summary>user_study_figs/instructions/postsurvey_questionarre.png Details</summary>
### Visual Description
\n
## Screenshot: Experiment Feedback Form
### Overview
The image is a screenshot of an online feedback form, likely part of a user study or experiment. It consists of a series of open-ended questions and a rating scale, designed to gather qualitative and quantitative data about the participant's experience. There is a "Finish" button at the bottom of the form.
### Components/Axes
The form includes the following elements:
* **Introductory Text:** "Thank you for participating in our study!" and instructions to click "Finish" for compensation.
* **Question 1:** "How challenging did you find the questions? (On a scale of 1-10, with 10 being very challenging)" - accompanied by a single-line text input field.
* **Question 2:** "Did the model's confidence impact your response? In what way if so, please be as specific as possible (1-3 sentences)" - accompanied by a multi-line text input field.
* **Question 3:** "Were there any question topics you struggled with?" - accompanied by a multi-line text input field.
* **Question 4:** "Were there any question topics you were always very confident in?" - accompanied by a multi-line text input field.
* **Question 5:** "Do you have any additional comments to share with us?" - accompanied by a multi-line text input field.
* **Submit Button:** "Finish" - located at the bottom-right of the form.
### Detailed Analysis or Content Details
The form is structured as a series of questions with text input fields for responses. The questions are designed to elicit feedback on the difficulty of the questions, the impact of the model's confidence, areas of struggle, areas of confidence, and any additional comments.
* **Question 1:** The scale is from 1 to 10, with 10 representing the highest level of challenge. The input field is a single line, suggesting a numerical response is expected.
* **Question 2:** The prompt requests a response of 1-3 sentences.
* **Question 3:** The prompt asks for specific topics where the participant struggled.
* **Question 4:** The prompt asks for specific topics where the participant felt confident.
* **Question 5:** This is a general open-ended question for any additional feedback.
### Key Observations
The form is straightforward and focuses on gathering subjective feedback from participants. The inclusion of a scale for the first question allows for quantitative analysis, while the remaining questions provide qualitative data. The prompt for Question 2 specifically asks about the impact of a "model's confidence," suggesting the experiment involved interaction with an AI or machine learning system.
### Interpretation
This form is designed to evaluate the user experience of an experiment involving a model (likely an AI model). The questions aim to understand how challenging the tasks were, whether the model's confidence level influenced the participant's responses, and identify areas where the model or the experimental design could be improved. The form's structure suggests a desire to gather both numerical data (difficulty rating) and detailed qualitative feedback (open-ended questions). The request for comments indicates a willingness to consider broader perspectives and address any unforeseen issues. The form is a standard method for collecting post-experiment feedback and is crucial for iterative improvement of the experimental process and the underlying model.
</details>
Figure 22: Sample pot-survey questionnaire for users who were allocated to a variant wherein they saw model confidence.
Appendix H Broader Impact and Implications
The goal of this work is to make LLM outputs have better confidence values associated with them. With successful, calibrated confidence values, the machine systems ultimately become more interpretable and trustworthy by a user [Janssen et al., 2008]. When applied correctly, our advancements will help users be able to make decisions based off of LLM outputs in a more informed way. Similar examples in other domains, like AlphaFold Terwilliger et al. [2023], have shown how well-calibrated confidence scores can be useful in complex decision-making domains. Our hope is to replicate those broad findings in LLMs.
We acknowledge the ongoing debate over the appropriateness, limitations, and harms of LLMs. We do highlight that the development of more confident, interpretable, and trustworthy LLMs can lead to continued techno-solutionism in unintended applications. Specifically, we highlight that our work is limited to use-cases with fact-based questions. Many applications of text-based LLMs are generative, meaning that there is no way for our paradigm to be applied appropriately, and the use of a confidences from calibration-tuned models could be misleading or damaging without checks and guardrails. Additionally, even within the fact-based paradigm, what is true can be subjective, with ground truth in machine learning being a contested topic [Aroyo and Welty, 2015, Uma et al., 2021].
The philosophical debate on these topics is beyond the expertise of the authors; nonetheless, we believe that the ongoing debate over the appropriateness of LLMs should be considered in context with the benefits of our approach in making LLMs more interpretable and useful.
Appendix I NeurIPS Paper Checklist
1. Claims
1. Question: Do the main claims made in the abstract and introduction accurately reflect the paper’s contributions and scope?
1. Answer: [Yes]
1. Justification: We describe and link all claims in section 1.
1. Guidelines:
- The answer NA means that the abstract and introduction do not include the claims made in the paper.
- The abstract and/or introduction should clearly state the claims made, including the contributions made in the paper and important assumptions and limitations. A No or NA answer to this question will not be perceived well by the reviewers.
- The claims made should match theoretical and experimental results, and reflect how much the results can be expected to generalize to other settings.
- It is fine to include aspirational goals as motivation as long as it is clear that these goals are not attained by the paper.
1. Limitations
1. Question: Does the paper discuss the limitations of the work performed by the authors?
1. Answer: [Yes]
1. Justification: We provide a discussion on the limitations in section 8.
- The answer NA means that the paper has no limitation while the answer No means that the paper has limitations, but those are not discussed in the paper.
- The authors are encouraged to create a separate ”Limitations” section in their paper.
- The paper should point out any strong assumptions and how robust the results are to violations of these assumptions (e.g., independence assumptions, noiseless settings, model well-specification, asymptotic approximations only holding locally). The authors should reflect on how these assumptions might be violated in practice and what the implications would be.
- The authors should reflect on the scope of the claims made, e.g., if the approach was only tested on a few datasets or with a few runs. In general, empirical results often depend on implicit assumptions, which should be articulated.
- The authors should reflect on the factors that influence the performance of the approach. For example, a facial recognition algorithm may perform poorly when image resolution is low or images are taken in low lighting. Or a speech-to-text system might not be used reliably to provide closed captions for online lectures because it fails to handle technical jargon.
- The authors should discuss the computational efficiency of the proposed algorithms and how they scale with dataset size.
- If applicable, the authors should discuss possible limitations of their approach to address problems of privacy and fairness.
- While the authors might fear that complete honesty about limitations might be used by reviewers as grounds for rejection, a worse outcome might be that reviewers discover limitations that aren’t acknowledged in the paper. The authors should use their best judgment and recognize that individual actions in favor of transparency play an important role in developing norms that preserve the integrity of the community. Reviewers will be specifically instructed to not penalize honesty concerning limitations.
1. Theory Assumptions and Proofs
1. Question: For each theoretical result, does the paper provide the full set of assumptions and a complete (and correct) proof?
1. Answer: [N/A]
1. Justification: [N/A]
- The answer NA means that the paper does not include theoretical results.
- All the theorems, formulas, and proofs in the paper should be numbered and cross-referenced.
- All assumptions should be clearly stated or referenced in the statement of any theorems.
- The proofs can either appear in the main paper or the supplemental material, but if they appear in the supplemental material, the authors are encouraged to provide a short proof sketch to provide intuition.
- Inversely, any informal proof provided in the core of the paper should be complemented by formal proofs provided in appendix or supplemental material.
- Theorems and Lemmas that the proof relies upon should be properly referenced.
1. Experimental Result Reproducibility
1. Question: Does the paper fully disclose all the information needed to reproduce the main experimental results of the paper to the extent that it affects the main claims and/or conclusions of the paper (regardless of whether the code and data are provided or not)?
1. Answer: [Yes]
1. Justification: We provide the complete code, and the complete list of datasets used for all experiments in section 5 to reproduce all our experiments with instructions. All hyperparameters are described in section 5.
1. Guidelines:
- The answer NA means that the paper does not include experiments.
- If the paper includes experiments, a No answer to this question will not be perceived well by the reviewers: Making the paper reproducible is important, regardless of whether the code and data are provided or not.
- If the contribution is a dataset and/or model, the authors should describe the steps taken to make their results reproducible or verifiable.
- Depending on the contribution, reproducibility can be accomplished in various ways. For example, if the contribution is a novel architecture, describing the architecture fully might suffice, or if the contribution is a specific model and empirical evaluation, it may be necessary to either make it possible for others to replicate the model with the same dataset, or provide access to the model. In general. releasing code and data is often one good way to accomplish this, but reproducibility can also be provided via detailed instructions for how to replicate the results, access to a hosted model (e.g., in the case of a large language model), releasing of a model checkpoint, or other means that are appropriate to the research performed.
- While NeurIPS does not require releasing code, the conference does require all submissions to provide some reasonable avenue for reproducibility, which may depend on the nature of the contribution. For example
1. If the contribution is primarily a new algorithm, the paper should make it clear how to reproduce that algorithm.
1. If the contribution is primarily a new model architecture, the paper should describe the architecture clearly and fully.
1. If the contribution is a new model (e.g., a large language model), then there should either be a way to access this model for reproducing the results or a way to reproduce the model (e.g., with an open-source dataset or instructions for how to construct the dataset).
1. We recognize that reproducibility may be tricky in some cases, in which case authors are welcome to describe the particular way they provide for reproducibility. In the case of closed-source models, it may be that access to the model is limited in some way (e.g., to registered users), but it should be possible for other researchers to have some path to reproducing or verifying the results.
1. Open access to data and code
1. Question: Does the paper provide open access to the data and code, with sufficient instructions to faithfully reproduce the main experimental results, as described in supplemental material?
1. Answer: [Yes]
1. Justification: We provide the complete code, and the complete list of datasets used for all experiments in section C.2 to reproduce all our experiments with instructions. All hyperparameters are described in section 5.
1. Guidelines:
- The answer NA means that paper does not include experiments requiring code.
- Please see the NeurIPS code and data submission guidelines (https://nips.cc/public/guides/CodeSubmissionPolicy) for more details.
- While we encourage the release of code and data, we understand that this might not be possible, so No is an acceptable answer. Papers cannot be rejected simply for not including code, unless this is central to the contribution (e.g., for a new open-source benchmark).
- The instructions should contain the exact command and environment needed to run to reproduce the results. See the NeurIPS code and data submission guidelines (https://nips.cc/public/guides/CodeSubmissionPolicy) for more details.
- The authors should provide instructions on data access and preparation, including how to access the raw data, preprocessed data, intermediate data, and generated data, etc.
- The authors should provide scripts to reproduce all experimental results for the new proposed method and baselines. If only a subset of experiments are reproducible, they should state which ones are omitted from the script and why.
- At submission time, to preserve anonymity, the authors should release anonymized versions (if applicable).
- Providing as much information as possible in supplemental material (appended to the paper) is recommended, but including URLs to data and code is permitted.
1. Experimental Setting/Details
1. Question: Does the paper specify all the training and test details (e.g., data splits, hyperparameters, how they were chosen, type of optimizer, etc.) necessary to understand the results?
1. Answer: [Yes]
1. Justification: We provide the complete code, and the complete list of datasets used for all experiments in section C.2 to reproduce all our experiments with instructions. All hyperparameters are described in section 5.
1. Guidelines:
- The answer NA means that the paper does not include experiments.
- The experimental setting should be presented in the core of the paper to a level of detail that is necessary to appreciate the results and make sense of them.
- The full details can be provided either with the code, in appendix, or as supplemental material.
1. Experiment Statistical Significance
1. Question: Does the paper report error bars suitably and correctly defined or other appropriate information about the statistical significance of the experiments?
1. Answer: [Yes]
1. Justification: All figures are appropriately labeled with the error bars.
1. Guidelines:
- The answer NA means that the paper does not include experiments.
- The authors should answer ”Yes” if the results are accompanied by error bars, confidence intervals, or statistical significance tests, at least for the experiments that support the main claims of the paper.
- The factors of variability that the error bars are capturing should be clearly stated (for example, train/test split, initialization, random drawing of some parameter, or overall run with given experimental conditions).
- The method for calculating the error bars should be explained (closed form formula, call to a library function, bootstrap, etc.)
- The assumptions made should be given (e.g., Normally distributed errors).
- It should be clear whether the error bar is the standard deviation or the standard error of the mean.
- It is OK to report 1-sigma error bars, but one should state it. The authors should preferably report a 2-sigma error bar than state that they have a 96% CI, if the hypothesis of Normality of errors is not verified.
- For asymmetric distributions, the authors should be careful not to show in tables or figures symmetric error bars that would yield results that are out of range (e.g. negative error rates).
- If error bars are reported in tables or plots, The authors should explain in the text how they were calculated and reference the corresponding figures or tables in the text.
1. Experiments Compute Resources
1. Question: For each experiment, does the paper provide sufficient information on the computer resources (type of compute workers, memory, time of execution) needed to reproduce the experiments?
1. Answer: [Yes]
1. Justification: We provide an estimate of the compute resources required in section 5.
1. Guidelines:
- The answer NA means that the paper does not include experiments.
- The paper should indicate the type of compute workers CPU or GPU, internal cluster, or cloud provider, including relevant memory and storage.
- The paper should provide the amount of compute required for each of the individual experimental runs as well as estimate the total compute.
- The paper should disclose whether the full research project required more compute than the experiments reported in the paper (e.g., preliminary or failed experiments that didn’t make it into the paper).
1. Code Of Ethics
1. Question: Does the research conducted in the paper conform, in every respect, with the NeurIPS Code of Ethics https://neurips.cc/public/EthicsGuidelines?
1. Answer: [Yes]
1. Justification: We have read the ethics guidelines
1. Guidelines:
- The answer NA means that the authors have not reviewed the NeurIPS Code of Ethics.
- If the authors answer No, they should explain the special circumstances that require a deviation from the Code of Ethics.
- The authors should make sure to preserve anonymity (e.g., if there is a special consideration due to laws or regulations in their jurisdiction).
1. Broader Impacts
1. Question: Does the paper discuss both potential positive societal impacts and negative societal impacts of the work performed?
1. Answer: [Yes]
1. Justification: We provide a broader impact statement in appendix H
1. Guidelines:
- The answer NA means that there is no societal impact of the work performed.
- If the authors answer NA or No, they should explain why their work has no societal impact or why the paper does not address societal impact.
- Examples of negative societal impacts include potential malicious or unintended uses (e.g., disinformation, generating fake profiles, surveillance), fairness considerations (e.g., deployment of technologies that could make decisions that unfairly impact specific groups), privacy considerations, and security considerations.
- The conference expects that many papers will be foundational research and not tied to particular applications, let alone deployments. However, if there is a direct path to any negative applications, the authors should point it out. For example, it is legitimate to point out that an improvement in the quality of generative models could be used to generate deepfakes for disinformation. On the other hand, it is not needed to point out that a generic algorithm for optimizing neural networks could enable people to train models that generate Deepfakes faster.
- The authors should consider possible harms that could arise when the technology is being used as intended and functioning correctly, harms that could arise when the technology is being used as intended but gives incorrect results, and harms following from (intentional or unintentional) misuse of the technology.
- If there are negative societal impacts, the authors could also discuss possible mitigation strategies (e.g., gated release of models, providing defenses in addition to attacks, mechanisms for monitoring misuse, mechanisms to monitor how a system learns from feedback over time, improving the efficiency and accessibility of ML).
1. Safeguards
1. Question: Does the paper describe safeguards that have been put in place for responsible release of data or models that have a high risk for misuse (e.g., pretrained language models, image generators, or scraped datasets)?
1. Answer: [N/A]
1. Justification: We train on open-access models with open-source datasets. We do not change their generation behavior, and all existing safeguards (if any) remain.
1. Guidelines:
- The answer NA means that the paper poses no such risks.
- Released models that have a high risk for misuse or dual-use should be released with necessary safeguards to allow for controlled use of the model, for example by requiring that users adhere to usage guidelines or restrictions to access the model or implementing safety filters.
- Datasets that have been scraped from the Internet could pose safety risks. The authors should describe how they avoided releasing unsafe images.
- We recognize that providing effective safeguards is challenging, and many papers do not require this, but we encourage authors to take this into account and make a best faith effort.
1. Licenses for existing assets
1. Question: Are the creators or original owners of assets (e.g., code, data, models), used in the paper, properly credited and are the license and terms of use explicitly mentioned and properly respected?
1. Answer: [Yes]
1. Justification: We explicitly cite all models in section 5. All datasets used are listed and cited in section C.2.
1. Guidelines:
- The answer NA means that the paper does not use existing assets.
- The authors should cite the original paper that produced the code package or dataset.
- The authors should state which version of the asset is used and, if possible, include a URL.
- The name of the license (e.g., CC-BY 4.0) should be included for each asset.
- For scraped data from a particular source (e.g., website), the copyright and terms of service of that source should be provided.
- If assets are released, the license, copyright information, and terms of use in the package should be provided. For popular datasets, paperswithcode.com/datasets has curated licenses for some datasets. Their licensing guide can help determine the license of a dataset.
- For existing datasets that are re-packaged, both the original license and the license of the derived asset (if it has changed) should be provided.
- If this information is not available online, the authors are encouraged to reach out to the asset’s creators.
1. New Assets
1. Question: Are new assets introduced in the paper well documented and is the documentation provided alongside the assets?
1. Answer: [Yes]
1. Justification: We release our trained models for easy use via Hugging Face.
1. Guidelines:
- The answer NA means that the paper does not release new assets.
- Researchers should communicate the details of the dataset/code/model as part of their submissions via structured templates. This includes details about training, license, limitations, etc.
- The paper should discuss whether and how consent was obtained from people whose asset is used.
- At submission time, remember to anonymize your assets (if applicable). You can either create an anonymized URL or include an anonymized zip file.
1. Crowdsourcing and Research with Human Subjects
1. Question: For crowdsourcing experiments and research with human subjects, does the paper include the full text of instructions given to participants and screenshots, if applicable, as well as details about compensation (if any)?
1. Answer: [Yes]
1. Justification: We provide screenshots of our instructions, as well as details of compensation in appendix G.
1. Guidelines:
- The answer NA means that the paper does not involve crowdsourcing nor research with human subjects.
- Including this information in the supplemental material is fine, but if the main contribution of the paper involves human subjects, then as much detail as possible should be included in the main paper.
- According to the NeurIPS Code of Ethics, workers involved in data collection, curation, or other labor should be paid at least the minimum wage in the country of the data collector.
1. Institutional Review Board (IRB) Approvals or Equivalent for Research with Human Subjects
1. Question: Does the paper describe potential risks incurred by study participants, whether such risks were disclosed to the subjects, and whether Institutional Review Board (IRB) approvals (or an equivalent approval/review based on the requirements of your country or institution) were obtained?
1. Answer: [Yes]
1. Justification: We received prior approval from our respective institutional ethics review body for our user study. All users provided consent before partaking in the study.
1. Guidelines:
- The answer NA means that the paper does not involve crowdsourcing nor research with human subjects.
- Depending on the country in which research is conducted, IRB approval (or equivalent) may be required for any human subjects research. If you obtained IRB approval, you should clearly state this in the paper.
- We recognize that the procedures for this may vary significantly between institutions and locations, and we expect authors to adhere to the NeurIPS Code of Ethics and the guidelines for their institution.
- For initial submissions, do not include any information that would break anonymity (if applicable), such as the institution conducting the review.