# MR-Ben: A Meta-Reasoning Benchmark for Evaluating System-2 Thinking in LLMs
> 1Chinese University of Hong Kong2University of Cambridge3University of Edinburgh4City University of Hong Kong5Tsinghua University6University of Texas at Austin7University of Hong Kong8Nanyang Technological University9Massachusetts Institute of Technology
Abstract
Large language models (LLMs) have shown increasing capability in problem-solving and decision-making, largely based on the step-by-step chain-of-thought reasoning processes. However, evaluating these reasoning abilities has become increasingly challenging. Existing outcome-based benchmarks are beginning to saturate, becoming less effective in tracking meaningful progress. To address this, we present a process-based benchmark MR-Ben that demands a meta-reasoning skill, where LMs are asked to locate and analyse potential errors in automatically generated reasoning steps. Our meta-reasoning paradigm is especially suited for system-2 slow thinking, mirroring the human cognitive process of carefully examining assumptions, conditions, calculations, and logic to identify mistakes. MR-Ben comprises 5,975 questions curated by human experts across a wide range of subjects, including physics, chemistry, logic, coding, and more. Through our designed metrics for assessing meta-reasoning on this benchmark, we identify interesting limitations and weaknesses of current LLMs (open-source and closed-source models). For example, with models like the o1 series from OpenAI demonstrating strong performance by effectively scrutinizing the solution space, many other state-of-the-art models fall significantly behind on MR-Ben, exposing potential shortcomings in their training strategies and inference methodologies Our dataset and codes are available on https://randolph-zeng.github.io/Mr-Ben.github.io.. footnotetext: Correspondence to: Zhijiang Guo (zg283@cam.ac.uk) and Jiaya Jia (leojia@cse.cuhk.edu.hk).
1 Introduction
Reasoning, the cognitive process of using evidence, arguments, and logic to reach conclusions, is crucial for problem-solving, decision-making, and critical thinking [65, 19]. With the rapid advancement of Large Language Models (LLMs), there is an increasing interest in exploring their reasoning capabilities [30, 57]. Consequently, evaluating reasoning in LLMs reliably becomes paramount. Current evaluation methodologies primarily focus on the final result [16, 28, 22, 60], disregarding the intricacies of the reasoning process. While effective to some extent, such evaluation practices may conceal underlying issues like logical errors or unnecessary steps that compromise the accuracy and efficiency of reasoning [68, 41].
Therefore, it is important to complement outcome-based evaluation with an intrinsic evaluation of the quality of the reasoning process. However, current benchmarks for evaluating LLMs’ reasoning capabilities have certain limitations in terms of their scope and size. For instance, PRM800K [38] categorizes each reasoning step as positive, negative, or neutral. Similarly, BIG-Bench Mistake [64] focuses on identifying errors in step-level answers. We follow the same meta-reasoning paradigm as MR-GSM8K [77] and MR-Math [68], which go a step further by providing the error reason for the first negative step in the reasoning chain. However, these benchmarks are limited to a narrower task scope—MR-GSM8K and MR-Math focus solely on mathematical reasoning, while BIG-Bench Mistake mainly assesses logical reasoning. To ensure a comprehensive evaluation of reasoning abilities, it is crucial to identify reasoning errors and assess the LLMs’ capacity to elucidate them across wider domains.
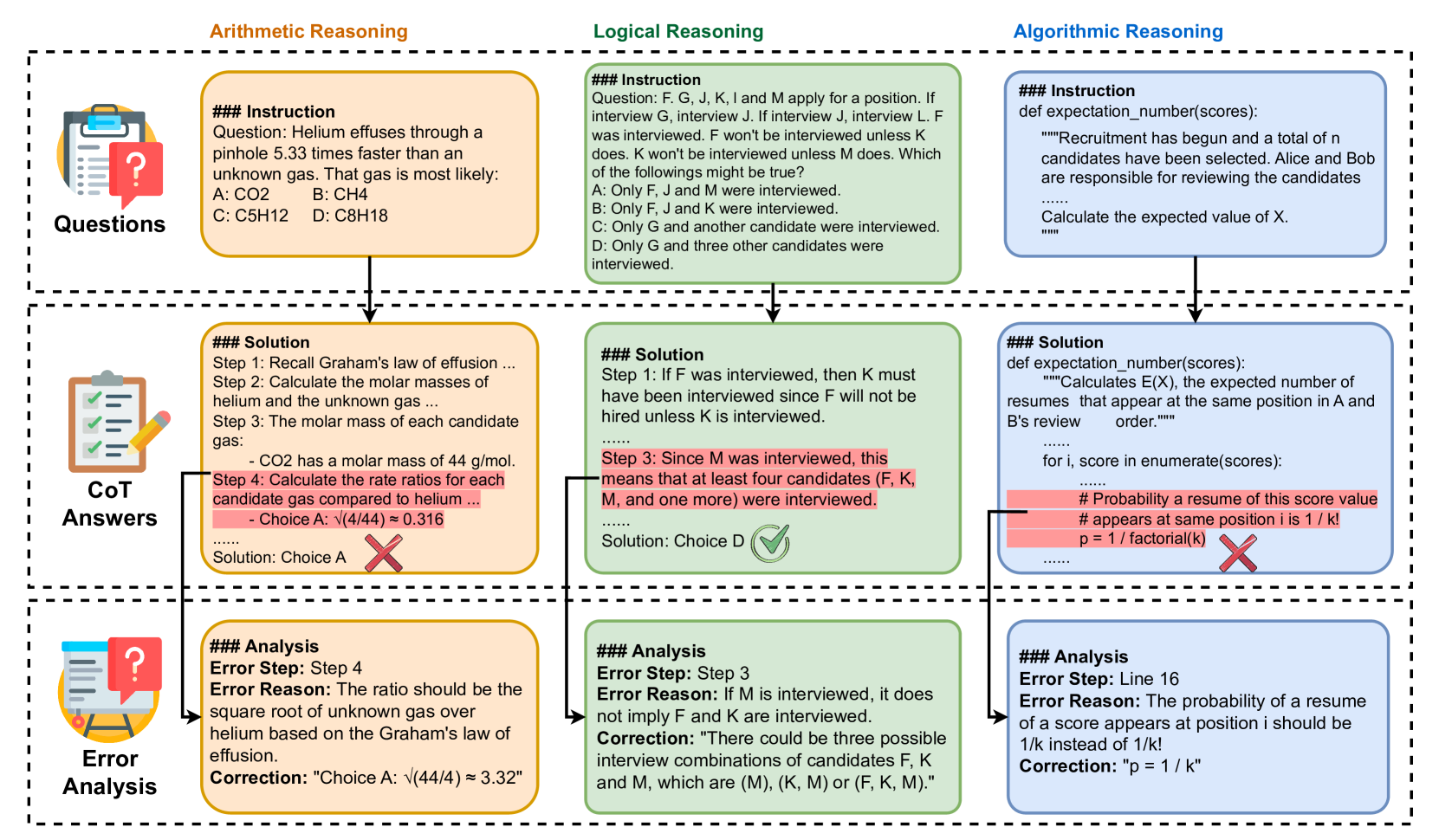
To bridge this gap, we construct a comprehensive benchmark MR-Ben comprising 6k questions covering a wide range of subjects, including natural sciences like math, biology, and physics, as well as coding and logic. One unique aspect of MR-Ben is its meta-reasoning paradigm, which involves challenging LLMs to reason about different forms of reasoning. In this paradigm, LLMs take on the role of a teacher, evaluating the reasoning process by assessing correctness, analyzing potential errors, and providing corrections, as depicted in Figure 1.
Our analysis of various LLMs [50, 51, 5, 33, 47] uncovers distinct limitations and previously unidentified weaknesses in their reasoning abilities. While many LLMs are capable of generating correct answers, they often struggle to identify errors within their reasoning processes and explain the underlying rationale. To excel under our meta-reasoning paradigm, models must meticulously scrutinize assumptions, conditions, calculations, and logical steps, even inferring step outcomes counterfactually. These requirements align with the characteristics of “System-2” slow thinking [35, 9], which we believe remains underdeveloped in most of the state-of-the-art models we evaluated.
We suspect that a key reason for this gap lies in current fine-tuning paradigms, which prioritize correct solutions and limit effective exploration of the broader solution space. Echoing this hypothesis, we observed that models like o1-preview [52], which reportedly incorporate effective search and disambiguation techniques across trajectories in the solution space, outperform other models by a large margin. Moreover, we found that leveraging high-quality and diverse synthetic data [1] significantly mitigates this issue, offering a promising path to enhance performance regardless of model size. Additionally, our results indicate that different LLMs excel in distinct reasoning paradigms, challenging the notion that domain-specific enhancements necessarily yield broad cognitive improvements. We hope that MR-Ben will guide researchers in comprehensively evaluating their models’ capabilities and foster the development of more robust AI reasoning frameworks.
Our key contributions are summarized as follows:
- We introduced MR-Ben, which includes around 6k questions across a wide range of subjects, from natural sciences to coding and logic, and employs a unique meta-reasoning paradigm.
- We conduct an extensive analysis of various LLMs on MR-Ben, revealing various limitations and previously unidentified weaknesses in their reasoning abilities.
- We offer potential pathways for enhancing the reasoning abilities of LLMs and challenge the assumption that domain-specific enhancements necessarily lead to broad improvements.
<details>
<summary>x1.png Details</summary>
### Visual Description
## Diagram: Reasoning Types and Error Analysis Workflow
### Overview
The image is a structured flowchart diagram illustrating a three-stage process applied to three distinct domains of problem-solving. It demonstrates how a system (likely a Large Language Model) is presented with a prompt, generates a step-by-step "Chain of Thought" (CoT) answer that contains a specific logical or factual error, and subsequently undergoes an "Error Analysis" to identify, explain, and correct that specific flaw.
### Components and Layout
The diagram is organized into a grid format:
* **Columns (Domains):**
* **Left Column (Orange):** Arithmetic Reasoning
* **Center Column (Green):** Logical Reasoning
* **Right Column (Blue):** Algorithmic Reasoning
* **Rows (Stages):**
* **Top Row:** "Questions" (Indicated by a clipboard icon with a question mark on the far left).
* **Middle Row:** "CoT Answers" (Indicated by a clipboard icon with checkmarks and a pencil).
* **Bottom Row:** "Error Analysis" (Indicated by a clipboard icon with a question mark and an easel).
* **Flow Indicators:** Black downward-pointing arrows connect the boxes from top to bottom within each column. Additionally, specific lines connect red-highlighted text in the middle row directly to the analysis boxes in the bottom row.
---
### Content Details (Transcription and Spatial Grounding)
#### Column 1: Arithmetic Reasoning (Left, Orange)
* **Top Box (Questions):**
```text
### Instruction
Question: Helium effuses through a pinhole 5.33 times faster than an unknown gas. That gas is most likely:
A: CO2 B: CH4
C: C5H12 D: C8H18
```
* **Middle Box (CoT Answers):**
```text
### Solution
Step 1: Recall Graham's law of effusion ...
Step 2: Calculate the molar masses of helium and the unknown gas ...
Step 3: The molar mass of each candidate gas:
- CO2 has a molar mass of 44 g/mol.
[HIGHLIGHTED IN RED]: Step 4: Calculate the rate ratios for each candidate gas compared to helium ...
- Choice A: √(4/44) ≈ 0.316
......
Solution: Choice A [Large Red 'X' icon]
```
*Visual Note:* A line connects the red highlighted text in Step 4 down to the Error Analysis box.
* **Bottom Box (Error Analysis):**
```text
### Analysis
Error Step: Step 4
Error Reason: The ratio should be the square root of unknown gas over helium based on the Graham's law of effusion.
Correction: "Choice A: √(44/4) ≈ 3.32"
```
#### Column 2: Logical Reasoning (Center, Green)
* **Top Box (Questions):**
```text
### Instruction
Question: F. G, J, K, I and M apply for a position. If interview G, interview J. If interview J, interview L. F was interviewed. F won't be interviewed unless K does. K won't be interviewed unless M does. Which of the followings might be true?
A: Only F, J and M were interviewed.
B: Only F, J and K were interviewed.
C: Only G and another candidate were interviewed.
D: Only G and three other candidates were interviewed.
```
* **Middle Box (CoT Answers):**
```text
### Solution
Step 1: If F was interviewed, then K must have been interviewed since F will not be hired unless K is interviewed.
......
[HIGHLIGHTED IN RED]: Step 3: Since M was interviewed, this means that at least four candidates (F, K, M, and one more) were interviewed.
......
Solution: Choice D [Large Green Checkmark icon]
```
*Visual Note:* A line connects the red highlighted text in Step 3 down to the Error Analysis box.
* **Bottom Box (Error Analysis):**
```text
### Analysis
Error Step: Step 3
Error Reason: If M is interviewed, it does not imply F and K are interviewed.
Correction: "There could be three possible interview combinations of candidates F, K and M, which are (M), (K, M) or (F, K, M)."
```
#### Column 3: Algorithmic Reasoning (Right, Blue)
* **Top Box (Questions):**
```python
### Instruction
def expectation_number(scores):
"""Recruitment has begun and a total of n candidates have been selected. Alice and Bob are responsible for reviewing the candidates
......
Calculate the expected value of X.
"""
```
* **Middle Box (CoT Answers):**
```python
### Solution
def expectation_number(scores):
"""Calculates E(X), the expected number of resumes that appear at the same position in A and B's review order."""
......
for i, score in enumerate(scores):
......
[HIGHLIGHTED IN RED]: # Probability a resume of this score value
# appears at same position i is 1 / k!
p = 1 / factorial(k) [Large Red 'X' icon]
......
```
*Visual Note:* A line connects the red highlighted code block down to the Error Analysis box.
* **Bottom Box (Error Analysis):**
```text
### Analysis
Error Step: Line 16
Error Reason: The probability of a resume of a score appears at position i should be 1/k instead of 1/k!
Correction: "p = 1 / k"
```
---
### Key Observations
1. **Structured Error Targeting:** The diagram explicitly isolates the exact point of failure within a multi-step reasoning process. It does not just mark the final answer wrong; it highlights the specific flawed step (Step 4, Step 3, or Line 16).
2. **Standardized Correction Format:** Every Error Analysis box follows a strict tripartite structure: `Error Step`, `Error Reason`, and `Correction`.
3. **The "Right Answer, Wrong Reason" Anomaly:** In the Center Column (Logical Reasoning), the final solution ("Choice D") is marked with a Green Checkmark, indicating it is the correct multiple-choice option. However, "Step 3" of the reasoning used to arrive at that answer is highlighted in red as an error.
### Interpretation
This diagram outlines a sophisticated data structure or training methodology for Artificial Intelligence, specifically Large Language Models (LLMs).
* **What the data demonstrates:** It shows a framework for "process supervision" rather than just "outcome supervision." Instead of merely training a model to output the correct final answer (A, B, C, D, or a final number), this framework evaluates the *Chain of Thought* (CoT).
* **Reading between the lines (The Peircean view):** The most revealing part of this diagram is the Logical Reasoning column. The fact that a green checkmark (correct final answer) is paired with a red-highlighted error in the steps proves that this system is designed to detect and correct *hallucinated logic* or *lucky guesses*. It enforces that the model must not only be right, but it must be right for the correct reasons.
* **Purpose:** This image is likely taken from an academic paper or technical documentation introducing a new dataset or fine-tuning method. By providing models with examples of common reasoning errors alongside structured explanations of *why* they are wrong and *how* to fix them, developers can train AI to self-correct, debug code more effectively, and produce more reliable, faithful step-by-step logic.
</details>
Figure 1: Overview of the evaluation paradigm and representative examples in MR-Ben. Each data point encompasses three key elements: a question, a Chain-of-Thought (CoT) answer, and an error analysis. The CoT answer is generated by various LLMs. Human experts annotate the error analyses, which include error steps, reasons behind the error, and subsequent corrections. The three examples shown are selected to represent arithmetic, logical, and algorithmic reasoning types.
2 Related Works
Reasoning Benchmarks
Evaluating the reasoning capabilities of LLMs is crucial for understanding their potential and limitations. While existing benchmarks often assess reasoning by measuring performance on tasks that require reasoning, such as accuracy, they often focus on specific reasoning types like arithmetic, knowledge, logic, or algorithmic reasoning. Arithmetic reasoning, involving mathematical concepts and operations, has been explored in benchmarks ranging from elementary word problems [37, 4, 55, 16] to more complex and large-scale tasks [28, 48]. Knowledge reasoning, on the other hand, requires either internal (commonsense) or external knowledge, or a combination of both [14, 62, 22]. Logical reasoning benchmarks, encompassing deductive and inductive reasoning, use synthetic rule bases for the former [15, 61, 18] and specific observations for the latter to formulate general principles [78, 71]. Algorithmic reasoning often involves understanding the coding problem description and performing multi-step reasoning to solve it [17, 25]. Benchmarks like BBH [59] and MMLU [27] indirectly assess reasoning by evaluating performance on tasks that require it. However, these benchmarks primarily focus on final results, neglecting the analysis of potential errors in the reasoning process. Unlike prior efforts, MR-Ben goes beyond accuracy by assessing the ability to locate potential errors in the reasoning process and provide explanations and corrections. Moreover, MR-Ben covers different types of reasoning, offering a more comprehensive assessment.
Evaluation Beyond Accuracy
Many recent studies have shifted their focus from using only the final result to evaluating the reasoning quality beyond accuracy. This shift has led to the development of two approaches: reference-free and reference-based evaluation. Reference-free methods aim to assess reasoning quality without relying on human-provided solutions. For example, ROSCOE [23] evaluates reasoning chains by quantifying reasoning errors such as redundancy and hallucination. Other approaches convert reasoning steps into structured forms, like subject-verb-object frames [56] or symbolic proofs [58], allowing for automated analysis. Reference-based methods depend on human-generated step-by-step solutions. For instance, PRM800K [38] offers solutions to MATH problems [28], categorizing each reasoning step as positive, negative, or neutral. Building on this, MR-GSM8K [77] and MR-Math [68] further provide the error reason behind the first negative step. MR-GSM8K focuses on elementary math problems, sampling questions from GSM8K [16]. MR-Math samples a smaller set of 459 questions from MATH [28]. Using the same annotation scheme, BIG-Bench Mistake [64] focuses on symbolic reasoning. It encompasses 2,186 instances from 5 tasks in BBH [59]. Despite the progress made by these datasets, limitations in scope and size remain. To address this, we introduce MR-Ben, a benchmark consisting of 5,975 manually annotated instances covering a wide range of subjects, including natural sciences, coding, and logic. MR-Ben also features more challenging questions, spanning high school, graduate, and professional levels.
3 MR-Ben: Dataset Construction
3.1 Dataset Structure
To comprehensively evaluate the reasoning capabilities of LLMs, MR-Ben employs a meta-reasoning paradigm. This paradigm casts LLMs in the role of a teacher, where they assess the reasoning process by evaluating its correctness, analyzing errors, and providing corrections. As shown in Figure 1, each data point within MR-Ben consists of three key elements: a question, a CoT answer, and an error analysis. The construction pipeline is shown in Figure 6 in Appendix- D.
Question
The questions in MR-Ben are designed to cover a diverse range of reasoning types and difficulty levels, spanning from high school to professional levels. To ensure this breadth, we curated questions from various subjects, including natural sciences (mathematics, biology, physics), coding, and logic. Specifically, we sampled questions from mathematics, physics, biology, chemistry, and medicine from MMLU [27], which comprehensively assesses LLMs across academic and professional domains. For logic questions, we draw from LogiQA [40], which encompasses a broad spectrum of logical reasoning types, including categorical, conditional, disjunctive, and conjunctive reasoning. Finally, we select coding problems from MHPP [17], which focuses on function-level code generation requiring advanced algorithmic reasoning. Questions in MMLU and LogiQA require a single-choice answer, while MHPP requires a snippet of code as the answer.
CoT Answer
We queried GPT-3.5-Turbo-0125 [50], Claude2 [5], and Mistral-Medium [32] (as of February 2024) using a prompt template (provided in Figure- 7 in Appendix- D) designed to elicit step-by-step solutions [66]. For clarity, all LLMs were instructed to format their solutions with numbered steps, except for coding problems. To encourage diverse solutions, we set the temperature parameter to 1 during sampling. This empirical setting yielded satisfactory instruction following and desirable fine-grained reasoning errors, which annotators and evaluated models are expected to identify.
3.2 Annotation Process
After acquiring the questions and their corresponding Chain-of-Thought (CoT) answers, we engage annotators to provide error analyses. The annotation process is divided into three stages.
Answer Correctness
CoT answers that result in a final answer different from the ground truth are automatically flagged as incorrect. However, for cases where the final answer matches the ground truth, manual annotation is required. This is because there are instances where the reasoning process leading to the correct answer is flawed, as illustrated in the middle example of Figure 1. Therefore, annotators are tasked with meticulously examining the entire reasoning path to determine if the correct final answer is a direct result of the reasoning process.
Error Step
This stage is applicable for solutions with either an unmatched final output or a matched final output underpinned by flawed reasoning. Following the prior effort [38], each step in the reasoning process is categorized as positive, neutral, or negative. Positive and neutral steps represent stages where the correct final output remains attainable. Conversely, negative steps indicate a divergence from the path leading to the correct solution. Annotators are required to identify the first step in the reasoning process where the conditions, assumptions, or calculations are incorrect, making the correct final result unreachable for the subsequent reasoning steps.
Error Reason and Correction
Annotators are tasked with conducting an in-depth analysis of the reasoning that led to the identified error. As shown in Figure 1, annotators are required to provide the error reason and the corresponding correction to this reasoning step. This comprehensive approach ensures a thorough understanding and rectification of errors in the reasoning process.
3.3 Data Statistics
Table 1: Statistics of MR-Ben. The length of questions and solutions are measured inthe number of words. Notice that the steps for coding denote the number of lines of code. They are not directly comparable with other subjects.
| Correct Solution Ratio Avg Solution Steps Avg First Error Step | 16.2% 6.8 3.1 | 31.0% 5.3 3.0 | 59.6% 5.1 2.7 | 47.8% 5.7 3.1 | 45.0% 5.6 3.0 | 51.1% 5.3 2.8 | 31.1% 32.5* 14.0* | 40.3% 9.5 4.5 |
| --- | --- | --- | --- | --- | --- | --- | --- | --- |
| Avg Length of Questions | 44.3 | 88.7 | 56.3 | 66.6 | 48.1 | 154.8 | 140.1 | 85.6 |
| Avg Length of Solutions | 205.9 | 206.1 | 187.6 | 199.4 | 194.5 | 217.7 | 950.3 | 308.8 |
Table 1 presents the statistics of MR-Ben. The benchmark exhibits a balanced distribution of correct and incorrect solutions, with an overall correct solution rate of 40.3%. Solutions, on average, involve 9.5 steps, and errors typically manifest around the fourth step (4.5). The questions and solutions are substantial, with average lengths of 85.6 and 308.8 words, respectively. The subject-wise analysis reveals that Math is the most challenging, with a correct solution rate of a mere 16.2%. This could be attributable to the intricacy of the arithmetic operations involved. Conversely, Biology emerges as the least daunting, with a high correct solution rate of 59.6%. Coding problems have the longest solutions, averaging 950.3 number of words. This underscores the complexity and the detailed procedural reasoning inherent in coding tasks. Similarly, Logic problems have the longest questions, averaging 154.8 words. This is in line with the need for elaborate descriptions in logical reasoning. The typical step at which the first error occurs is fairly consistent across most subjects, usually around the 3rd step out of a total of 5. However, Coding deviates from this trend. The first error tends to appear earlier, specifically around the 14th line out of a total of 32.5 lines. This suggests that the problem-solving process in Coding may have distinct dynamics compared to other subjects.
3.4 Quality Control
Annotators
Given the complexity of the questions, which span a range of subjects from high school to professional levels, we enlisted the services of an annotation company. This company meticulously recruited annotators, each holding a minimum of a bachelor’s degree. Before their trial labeling, annotators are thoroughly trained and are required to review the annotation guidelines. We’ve included the guidelines for all subjects in Appendix H for reference. The selection of annotators is based on their performance on a balanced, small hold-out set of problems for each subject. In addition to the annotators, a team of 14 quality controllers diligently monitors the quality of the annotation weekly. As a final layer of assurance, we have 4 meta controllers who scrutinize the quality of the work.
Quality Assurance
Every problem in MR-Ben undergoes a rigorous three-round quality assurance process to ensure its accuracy and clarity. Initially, each question is labeled by two different annotators. Any inconsistencies in the solution correctness or the first error step are identified and reviewed by a quality controller for arbitration. Following this, every annotated problem is subjected to a secondary review by annotators who were not involved in the initial labeling. This is to ensure that the annotations for different solutions to the same problem are consistent and coherent. In the final phase of the review, 10% of the problems are randomly sampled and reviewed by the meta controllers. Throughout the entire evaluation process, all annotated fields are meticulously examined in multiple rounds for their accuracy and clarity. Any incorrect annotations or those with disagreements are progressively filtered out and rectified, ensuring a high-quality dataset. This rigorous process allows us to maintain a high level of annotation quality.
Dataset Artifacts & Biases
Table 1 reveals a relatively balanced distribution of correct and incorrect solutions. However, an exception was observed in mathematical subjects, where the distribution tends to skew towards incorrect solutions. This skew could suggest an inherent complexity or ambiguity in mathematical problem statements. Our analysis of the first error step across all subjects indicated that errors predominantly occur in the initial stages ( $n≤ 7$ ) of problem-solving and are distributed relatively uniformly. This pattern was consistent across most subjects, with no significant skew towards later steps. More detailed discussions of biases are provided in the Appendix C.
4 Evaluation
For each question-solution pair annotated, the evaluated model are supposed to decide the correctness of the solution and report the first-error-step and error-reason if any. The solution-correctness and first-error-step is scored automatically based on the manual annotation result. Only when the evaluated model correctly identified the incorrect solution and first-error-step will its error-reason be further examined manually or automatically by models. Therefore in order to provide a unified and normalized score to reflect the overall competence of the evaluated model, we follow the work of [77] and apply a metric named MR-Score, which consist of three sub-metrics.
The first one is the Matthews Correlation Coefficient (a.k.a MCC, 46) for the binary classification of solution-correctness.
$$
\displaystyle MCC=\frac{TP\times TN-FP\times FN}{\sqrt{(TP+FP)\times(TP+FN)%
\times(TN+FP)\times(TN+FN)}} \tag{1}
$$
where TP, TN, FP, FN stand for true positive, true negative, false positive and false negative. The MCC score ranges from -1 to +1 with -1 means total disagreement between prediction and observation, 0 indicates near random performance and +1 represents perfect prediction. In the context of this paper, we interpret negative values as no better than random guess and set 0 as cut-off threshold for normalization purpose.
The second metric is the ratio between numbers of solutions with correct first-error-step predicted and the total number of incorrect solutions.
$$
\begin{split}ACC_{\text{step}}=\frac{N_{\text{correct\_first\_error\_step}}}{N%
_{\text{incorrect\_sols}}}\end{split} \tag{2}
$$
The third metrics is likewise the ratio between number of solutions with correct first-error-step plus correct error-reason predicted and the total number of incorrect solutions.
$$
\begin{split}ACC_{\text{reason}}=\frac{N_{\text{correct\_error\_reason}}}{N_{%
\text{incorrect\_sols}}}\end{split} \tag{3}
$$
MR-Score is then a weighted combination of three metrics, given by
$$
\displaystyle MR\mbox{-}Score \displaystyle=w_{1}*\max(0,MCC)+w_{2}*ACC_{\text{step}}+w_{3}*ACC_{\text{%
reason}} \tag{4}
$$
For the weights $w_{1},w_{2}$ and $w_{3}$ , they are chosen based on our evaluation results to maximize the differentiation between different models. It is important to note that the Matthews Correlation Coefficient (MCC) and the accuracy of locating the first error step can be directly calculated by comparing the responses of the evaluated model with the ground truth annotations. However, assessing the accuracy of the error reason explained by the evaluated model presents more complexity. While consulting domain experts for annotations is a feasible approach, we instead utilized GPT-4-Turbo as a proxy to examine the error reasons, as detailed in Figure- 11 in Appendix- D.
We operate under the assumption that while our benchmark presents a significant challenge for GPT-4 in evaluating complete solution correctness—identifying the first error step and explaining the error reason—it is comparatively easier for GPT-4 to assess whether the provided error reasons align with the ground truth. Specifically, in a hold-out set of sampled error reasons, there was a 92% agreement rate between the manual annotations by the authors and those generated by GPT-4. For more detailed evaluations on the robustness of MR-Score and its design thinking, please refer to our discussion in Appendix- B.
5 Experiments
5.1 Experiment Setup
Table 2: Evaluation results on MR-Ben: This table presents a detailed breakdown of each model’s performance evaluated under metric MR-Score across different subjects, where K stands for the number of demo examples here.
| Model | Bio. | | Phy. | | Math | | Chem. | | Med. | | Logic | | Coding | | Avg. | | | | | | | | |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| $k$ =0 | $k$ =1 | | $k$ =0 | $k$ =1 | | $k$ =0 | $k$ =1 | | $k$ =0 | $k$ =1 | | $k$ =0 | $k$ =1 | | $k$ =0 | $k$ =1 | | $k$ =0 | $k$ =1 | | $k$ =0 | $k$ =1 | |
| Closed-Source LLMs | | | | | | | | | | | | | | | | | | | | | | | |
| Claude3-Haiku | 5.7 | 5.8 | | 3.3 | 3.5 | | 3.1 | 3.1 | | 6.5 | 6.4 | | 2.0 | 2.0 | | 1.2 | 1.2 | | 9.0 | 0.0 | | 4.4 | 3.1 |
| GPT-3.5-Turbo | 3.6 | 6.6 | | 5.7 | 6.7 | | 5.7 | 5.4 | | 4.9 | 6.7 | | 3.6 | 4.4 | | 1.7 | 4.5 | | 3.0 | 4.1 | | 4.0 | 5.5 |
| Doubao-pro-4k | 8.4 | 13.5 | | 10.0 | 11.7 | | 12.3 | 15.5 | | 10.6 | 17.5 | | 5.9 | 10.0 | | 4.5 | 5.5 | | 9.8 | 7.4 | | 8.8 | 11.6 |
| Mistral-Large | 22.2 | 28.0 | | 26.7 | 25.4 | | 24.3 | 28.2 | | 24.0 | 27.0 | | 15.9 | 19.3 | | 14.7 | 17.1 | | 21.1 | 21.4 | | 21.3 | 23.8 |
| Yi-Large | 35.3. | 40.7 | | 37.2 | 36.8 | | 36.5 | 20.6 | | 40.0 | 39.1 | | 29.3 | 32.1 | | 25.1 | 31.3 | | 21.9 | 25.7 | | 32.2 | 32.3 |
| Moonshot-v1-8k | 35.0 | 36.8 | | 33.8 | 33.8 | | 34.9 | 33.0 | | 36.7 | 35.0 | | 29.4 | 32.3 | | 25.0 | 29.2 | | 32.7 | 31.2 | | 32.5 | 33.0 |
| GPT-4o-mini | 37.7 | 38.9 | | 38.5 | 37.4 | | 44.4 | 40.4 | | 39.2 | 37.0 | | 33.9 | 25.1 | | 23.6 | 17.7 | | 41.6 | 34.9 | | 37.0 | 33.1 |
| Zhipu-GLM-4 | 40.7 | 46.2 | | 37.7 | 42.5 | | 38.4 | 36.6 | | 43.1 | 44.0 | | 34.5 | 41.0 | | 37.5 | 32.5 | | 38.8 | 32.8 | | 38.7 | 39.4 |
| GPT-4-Turbo | 44.7 | 47.3 | | 42.8 | 45.2 | | 44.3 | 45.4 | | 44.0 | 46.0 | | 38.8 | 38.4 | | 34.1 | 33.6 | | 53.6 | 57.3 | | 43.2 | 44.7 |
| GPT-4o | 48.3 | 49.1 | | 45.5 | 48.2 | | 42.6 | 41.3 | | 48.2 | 49.1 | | 47.9 | 47.7 | | 31.9 | 28.4 | | 56.5 | 54.6 | | 45.8 | 45.5 |
| o1-mini | 45.8 | 46.9 | | 56.0 | 53.8 | | 68.5 | 67.0 | | 55.2 | 56.1 | | 45.9 | 47.2 | | 30.7 | 28.7 | | 55.1 | 55.6 | | 51.0 | 50.8 |
| o1-preview | 54.1 | 56.0 | | 62.2 | 61.7 | | 69.8 | 70.3 | | 60.6 | 60.3 | | 54.3 | 55.1 | | 46.1 | 45.3 | | 65.1 | 70.0 | | 58.9 | 59.8 |
| Open-Source Small | | | | | | | | | | | | | | | | | | | | | | | |
| Qwen1.5-1.8B | 0.0 | 0.0 | | 0.0 | 0.0 | | 0.0 | 0.1 | | 0.0 | 0.1 | | 0.0 | 0.0 | | 0.0 | 0.1 | | 0.0 | 0.0 | | 0.0 | 0.0 |
| Gemma-2B | 0.1 | 0.0 | | 0.0 | 0.0 | | 0.0 | 1.0 | | 0.1 | 0.0 | | 0.0 | 0.4 | | 0.0 | 0.2 | | 0.7 | 0.0 | | 0.1 | 0.2 |
| Qwen2-1.5B | 2.2 | 2.8 | | 2.2 | 1.3 | | 3.3 | 6.3 | | 2.5 | 3.3 | | 2.9 | 11.2 | | 1.5 | 9.4 | | 0.0 | 3.6 | | 2.1 | 5.4 |
| Phi3-3.8B | 13.4 | 12.5 | | 12.7 | 10.8 | | 13.3 | 13.1 | | 16.4 | 17.1 | | 10.2 | 8.1 | | 8.4 | 5.3 | | 9.1 | 10.2 | | 11.9 | 11.0 |
| Open-Source LLMs Medium | | | | | | | | | | | | | | | | | | | | | | | |
| GLM-4-9B | 4.4 | 2.4 | | 9.6 | 1.2 | | 8.1 | 4.7 | | 8.7 | 2.9 | | 2.3 | 1.9 | | 2.5 | 1.6 | | 11.4 | 0.0 | | 6.7 | 2.1 |
| DeepSeek-7B | 5.7 | 6.2 | | 4.7 | 2.6 | | 4.9 | 5.2 | | 4.2 | 4.9 | | 3.1 | 1.6 | | 3.0 | 3.8 | | 0.0 | 1.2 | | 3.7 | 3.6 |
| Deepseek-Coder-33B | 7.4 | 5.5 | | 7.8 | 5.6 | | 7.2 | 8.6 | | 7.8 | 7.4 | | 6.0 | 5.5 | | 4.6 | 6.7 | | 8.4 | 4.9 | | 7.0 | 6.3 |
| DeepSeek-Coder-7B | 10.5 | 9.9 | | 11.8 | 9.6 | | 11.8 | 12.1 | | 12.3 | 11.9 | | 10.4 | 11.0 | | 9.8 | 10.7 | | 5.0 | 5.8 | | 10.2 | 10.2 |
| LLaMA3-8B | 12.0 | 11.9 | | 10.9 | 7.5 | | 15.0 | 9.0 | | 12.6 | 12.7 | | 9.3 | 8.0 | | 9.4 | 9.6 | | 15.8 | 10.0 | | 12.2 | 9.8 |
| Yi-1.5-9B | 10.4 | 14.8 | | 11.9 | 12.9 | | 12.5 | 15.6 | | 13.1 | 14.4 | | 9.5 | 14.8 | | 9.1 | 9.5 | | 4.8 | 6.3 | | 10.2 | 12.6 |
| Open-Source LLMs Large | | | | | | | | | | | | | | | | | | | | | | | |
| Qwen1.5-72B | 15.3 | 19.2 | | 12.9 | 13.6 | | 12.0 | 10.0 | | 13.9 | 16.3 | | 11.7 | 14.7 | | 10.4 | 12.9 | | 3.9 | 5.9 | | 11.5 | 13.3 |
| DeepSeek-67B | 17.1 | 19.7 | | 14.9 | 17.3 | | 15.4 | 16.2 | | 16.3 | 20.6 | | 14.7 | 12.2 | | 13.6 | 14.3 | | 14.5 | 15.2 | | 15.2 | 16.5 |
| LLaMA3-70B | 20.4 | 27.1 | | 17.4 | 20.5 | | 14.9 | 15.8 | | 19.5 | 25.1 | | 16.3 | 19.3 | | 16.3 | 16.8 | | 29.8 | 16.7 | | 19.2 | 20.2 |
| DeepSeek-V2-236B | 30.0 | 37.1 | | 32.2 | 36.5 | | 32.2 | 30.0 | | 32.5 | 35.4 | | 26.5 | 32.4 | | 23.6 | 27.4 | | 34.2 | 27.1 | | 30.2 | 32.3 |
| Qwen2-72B | 36.0 | 40.8 | | 36.7 | 40.9 | | 38.0 | 38.7 | | 37.2 | 38.8 | | 28.3 | 29.3 | | 25.6 | 20.5 | | 31.3 | 30.4 | | 33.3 | 34.2 |
To evaluate the performance of different models on our new benchmark, we selected a diverse array of models based on size and source accessibility Note: All models used in our experiments are instruction-finetuned versions, although this is not indicated in their abbreviated names. This included smaller models like Gemma-2B [63], Phi-3 [1], Qwen1.5-1.8B [7], as well as larger counterparts such as Llama3-70B [47], Deepseek-67B [10], and Qwen1.5-72B [7]. We also compared open-source models (e.g. models from the Llama3 and Qwen1.5/Qwen2 series) against closed-source models from the GPT [51], Claude [6], Mistral [32], GLM [3], Yi [39], Moonshot [2], Doubao [12] families. Additionally, models from the Deepseek-Coder [10] series were included to assess the impact of coding-focused pretraining on reasoning performance.
Given the complexity of our benchmark, even larger open-source models like Llama3-70B-Instruct struggle to produce accurate evaluation results without the use of prompting methods, often achieving MR-Scores near zero. Consequently, we employed a step-wise chain-of-thought prompting technique similar to those described in [77, 64]. This approach guides models in systematically reasoning through solution traces before making final decisions, as detailed in Appendix- D.
Considering the complexity of the task, which includes question comprehension, reasoning through the provided solutions, and adhering to format constraints, few-shot demonstration setups are also explored to investigate if models can benefit from In-Context Learning (ICL) examples. Due to the context token limits, we report zero and one-shot results in the main result table (Table 2) For the breakdown performances of models in the sub-tasks, please refer to Table 7. The performance of additional few-shot configurations on a selection of models with various capabilities is further discussed in Section 6.1.
<details>
<summary>x2.png Details</summary>
### Visual Description
## Radar Chart: AI Model Performance Across Scientific and Technical Domains
### Overview
This image is a radar chart (also known as a spider chart) comparing the performance of five different Large Language Models (LLMs) across seven distinct academic and technical subject areas. The chart uses concentric heptagonal grid lines to represent a numerical scoring scale, with the models' scores plotted as colored polygons. All text in the image is in English.
### Components/Axes
**1. Header Region (Legend)**
Located at the top center of the image, the legend identifies the five data series (AI models) by color and line style. All lines feature circular markers at the data points.
* **DeepSeek-v2:** Brown/Orange line
* **GPT-4-turbo:** Blue line
* **O1-Preview:** Light Green line
* **Qwen2-72B:** Dark Green line
* **GLM-4:** Pink/Light Red line
**2. Main Chart Region (Axes and Scale)**
* **Categories (Axes):** Seven axes radiate from the center, dividing the chart into equal segments. Reading clockwise from the top (12 o'clock position), the categories are:
* `math` (Top)
* `chemistry` (Top-Right)
* `biology` (Right)
* `logic` (Bottom-Right)
* `coding` (Bottom)
* `medicine` (Bottom-Left)
* `physics` (Top-Left)
* **Scale:** The numerical scale is explicitly printed along the horizontal axis pointing towards `biology`. It starts at the center and moves outward.
* Markers: `0`, `0.1`, `0.2`, `0.3`, `0.4`, `0.5`, `0.6`, `0.7`.
* The grid consists of seven concentric white heptagons set against a light blue circular background. Each heptagon corresponds to an increment of 0.1.
### Detailed Analysis
**Trend Verification & Visual Hierarchy:**
Visually, the polygons form a distinct nested hierarchy.
* The **Light Green polygon (O1-Preview)** is the outermost shape, encompassing almost all other lines, indicating the highest overall performance. It spikes significantly outward on the `math` and `coding` axes.
* The **Blue polygon (GPT-4-turbo)** is generally the second-largest shape, sitting just inside O1-Preview, except on the `medicine` axis where it slightly overtakes O1-Preview.
* The **Pink polygon (GLM-4)** forms the third layer, closely tracking just inside GPT-4-turbo.
* The **Dark Green polygon (Qwen2-72B)** forms the fourth layer.
* The **Brown polygon (DeepSeek-v2)** is the innermost shape, indicating the lowest relative scores among the group across all categories.
**Estimated Data Points:**
*Note: Values are approximate (±0.02) based on visual interpolation between the 0.1 grid lines.*
| Category | O1-Preview (Light Green) | GPT-4-turbo (Blue) | GLM-4 (Pink) | Qwen2-72B (Dark Green) | DeepSeek-v2 (Brown) |
| :--- | :--- | :--- | :--- | :--- | :--- |
| **math** | ~0.70 | ~0.50 | ~0.48 | ~0.40 | ~0.38 |
| **chemistry** | ~0.60 | ~0.48 | ~0.50 | ~0.40 | ~0.38 |
| **biology** | ~0.60 | ~0.50 | ~0.48 | ~0.40 | ~0.38 |
| **logic** | ~0.50 | ~0.38 | ~0.40 | ~0.38 | ~0.30 |
| **coding** | ~0.70 | ~0.50 | ~0.48 | ~0.40 | ~0.38 |
| **medicine** | ~0.58 | ~0.60 | ~0.50 | ~0.40 | ~0.38 |
| **physics** | ~0.60 | ~0.50 | ~0.48 | ~0.40 | ~0.38 |
### Key Observations
1. **O1-Preview's Dominance:** O1-Preview shows exceptional performance peaks in `math` and `coding`, reaching the maximum chart value of 0.7. It leads in 6 out of 7 categories.
2. **The Medicine Anomaly:** `medicine` is the only category where O1-Preview does not hold the top score. GPT-4-turbo peaks at ~0.60 here, slightly edging out O1-Preview (~0.58).
3. **Logic as a Weak Point:** All models show a relative dip in performance on the `logic` axis compared to their scores in other scientific domains. Even the leading model (O1-Preview) drops to ~0.50 here.
4. **Tight Clustering of Inner Models:** DeepSeek-v2 and Qwen2-72B exhibit very similar performance profiles, forming a tight inner cluster. Their shapes are nearly identical, with Qwen2-72B maintaining a consistent, slight lead over DeepSeek-v2 across all axes.
### Interpretation
This radar chart illustrates a comparative benchmark of advanced AI models on complex, reasoning-heavy STEM (Science, Technology, Engineering, and Mathematics) and logic tasks.
The data suggests a clear stratification in model capabilities. **O1-Preview** represents a significant leap in quantitative and algorithmic reasoning, evidenced by its massive advantage in math and coding. This aligns with the industry understanding of "O1" class models being specifically optimized for chain-of-thought reasoning and mathematical problem-solving.
**GPT-4-turbo** remains a highly capable generalist, holding a strong second place and demonstrating superior domain-specific knowledge in medicine.
The models **GLM-4**, **Qwen2-72B**, and **DeepSeek-v2** (which are notably prominent models originating from Chinese AI labs) show respectable, balanced performance but lag behind the top-tier proprietary models (O1 and GPT-4) in these specific, rigorous benchmarks. Their highly uniform, concentric shapes suggest they share similar architectural limitations or were trained on similar distributions of scientific data, resulting in a proportional scaling of capabilities rather than domain-specific spikes.
</details>
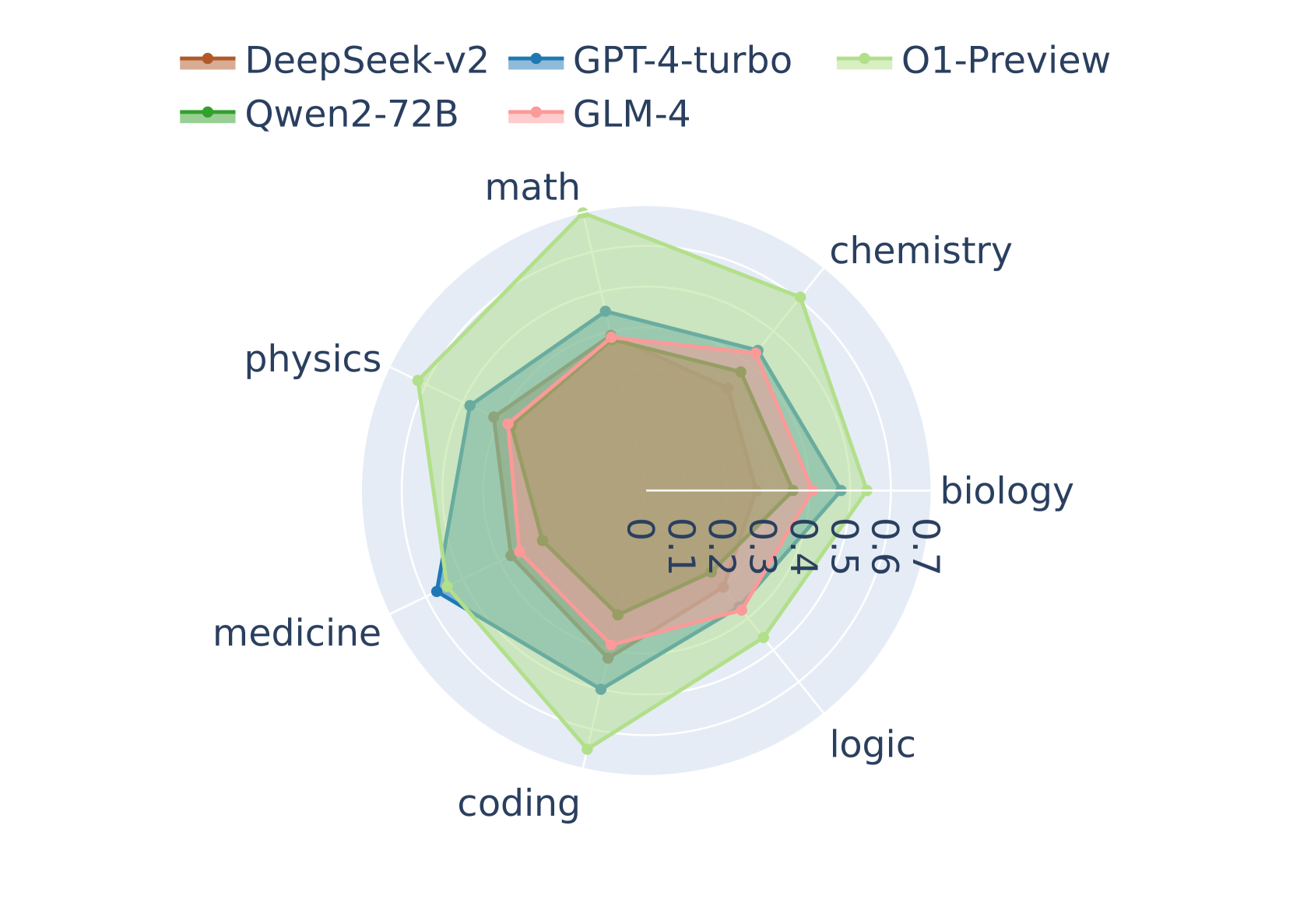
Figure 2: Model performance across subjects
<details>
<summary>x3.png Details</summary>
### Visual Description
## Grouped Bar Chart: MR-Scores of Models on Different Reasoning Paradigms
### Overview
This image is a grouped bar chart comparing the performance of five different artificial intelligence models across four distinct reasoning paradigms. The performance is measured using a metric called "MR-Scores." The chart highlights comparative strengths and weaknesses of each model in specific cognitive tasks.
### Components/Axes
**Header Region (Top Center):**
* **Chart Title:** "MR-Scores of Models on Different Reasoning Paradigms"
**Legend Region (Top-Right, inside chart area):**
* **Title:** "Paradigms"
* **Categories & Color Mapping:**
* Light Blue square: `knowledge`
* Dark Blue square: `logic`
* Light Green square: `arithmetic`
* Dark Green square: `algorithmic`
**Y-Axis (Left side):**
* **Label:** "MR-Scores" (oriented vertically).
* **Scale:** Ranges from 0.0 to 0.6, with major tick marks and solid light-grey horizontal gridlines at intervals of 0.1 (0.0, 0.1, 0.2, 0.3, 0.4, 0.5, 0.6).
* **Special Marker:** There is a distinct, dark-grey dashed horizontal line spanning the width of the chart exactly at the 0.5 mark.
**X-Axis (Bottom):**
* **Label:** "Models" (centered below the categories).
* **Categories (Left to Right):** DeepSeek-v2, GPT-4-turbo, O1-Preview, Qwen2-72B, GLM-4.
### Detailed Analysis
*Trend Verification & Data Extraction by Model:*
**1. DeepSeek-v2 (Far Left)**
* *Visual Trend:* The bars show a dip from knowledge to logic, then a significant step up for arithmetic, and a slight increase for algorithmic. None of the bars reach the 0.5 dashed line.
* *Data Points:*
* knowledge (Light Blue): ~0.32
* logic (Dark Blue): ~0.30
* arithmetic (Light Green): ~0.40
* algorithmic (Dark Green): ~0.42
**2. GPT-4-turbo (Center Left)**
* *Visual Trend:* Knowledge is high, dropping sharply for logic, then stepping back up through arithmetic to peak at algorithmic. The algorithmic bar exactly touches the 0.5 dashed line.
* *Data Points:*
* knowledge (Light Blue): ~0.49
* logic (Dark Blue): ~0.36
* arithmetic (Light Green): ~0.46
* algorithmic (Dark Green): ~0.50
**3. O1-Preview (Center)**
* *Visual Trend:* This group contains the highest bars on the chart. Knowledge is high, logic dips, but arithmetic and algorithmic spike dramatically, breaking well past the 0.6 top gridline.
* *Data Points:*
* knowledge (Light Blue): ~0.56
* logic (Dark Blue): ~0.46
* arithmetic (Light Green): ~0.66
* algorithmic (Dark Green): ~0.65
**4. Qwen2-72B (Center Right)**
* *Visual Trend:* Overall lower performance. Knowledge drops to a chart-wide low for logic, spikes up for arithmetic, and drops again for algorithmic.
* *Data Points:*
* knowledge (Light Blue): ~0.34
* logic (Dark Blue): ~0.25
* arithmetic (Light Green): ~0.37
* algorithmic (Dark Green): ~0.31
**5. GLM-4 (Far Right)**
* *Visual Trend:* This is the most visually uniform group. All four bars are nearly identical in height, hovering just below the 0.4 line, showing a very flat distribution across paradigms.
* *Data Points:*
* knowledge (Light Blue): ~0.39
* logic (Dark Blue): ~0.37
* arithmetic (Light Green): ~0.38
* algorithmic (Dark Green): ~0.39
### Key Observations
* **Dominant Model:** O1-Preview significantly outperforms all other models across every single paradigm. It is the only model to consistently break the 0.5 dashed line (doing so in 3 out of 4 categories).
* **Weakest Paradigm:** Across almost all models (except GLM-4, where it is nearly tied), "logic" (Dark Blue) represents the lowest score, indicating it is the most challenging reasoning paradigm for these LLMs.
* **Most Balanced Model:** GLM-4 shows the least variance between paradigms, scoring between ~0.37 and ~0.39 across the board.
* **The 0.5 Threshold:** The explicit dashed line at 0.5 suggests a benchmark of significance. Only O1-Preview (knowledge, arithmetic, algorithmic) and GPT-4-turbo (algorithmic) meet or exceed this line.
### Interpretation
The data demonstrates a clear hierarchy in current model capabilities regarding complex reasoning. O1-Preview represents a generational leap, particularly in "arithmetic" and "algorithmic" tasks, suggesting its architecture is highly optimized for structured, mathematical, and step-by-step computational problem-solving.
Conversely, the universal dip in "logic" scores implies that abstract logical deduction remains a persistent bottleneck in AI development, even for the most advanced models like O1-Preview.
GLM-4's flat profile is highly unusual compared to the others; it suggests a model architecture or training methodology that prioritizes generalist consistency over specialized peaks, though it achieves this at the cost of not excelling in any single area.
The dashed line at 0.5 likely represents a critical threshold—perhaps a "pass" rate, a human baseline, or a previous state-of-the-art benchmark. The fact that O1-Preview shatters this line in math and algorithms indicates a paradigm shift in how models handle quantitative reasoning.
</details>
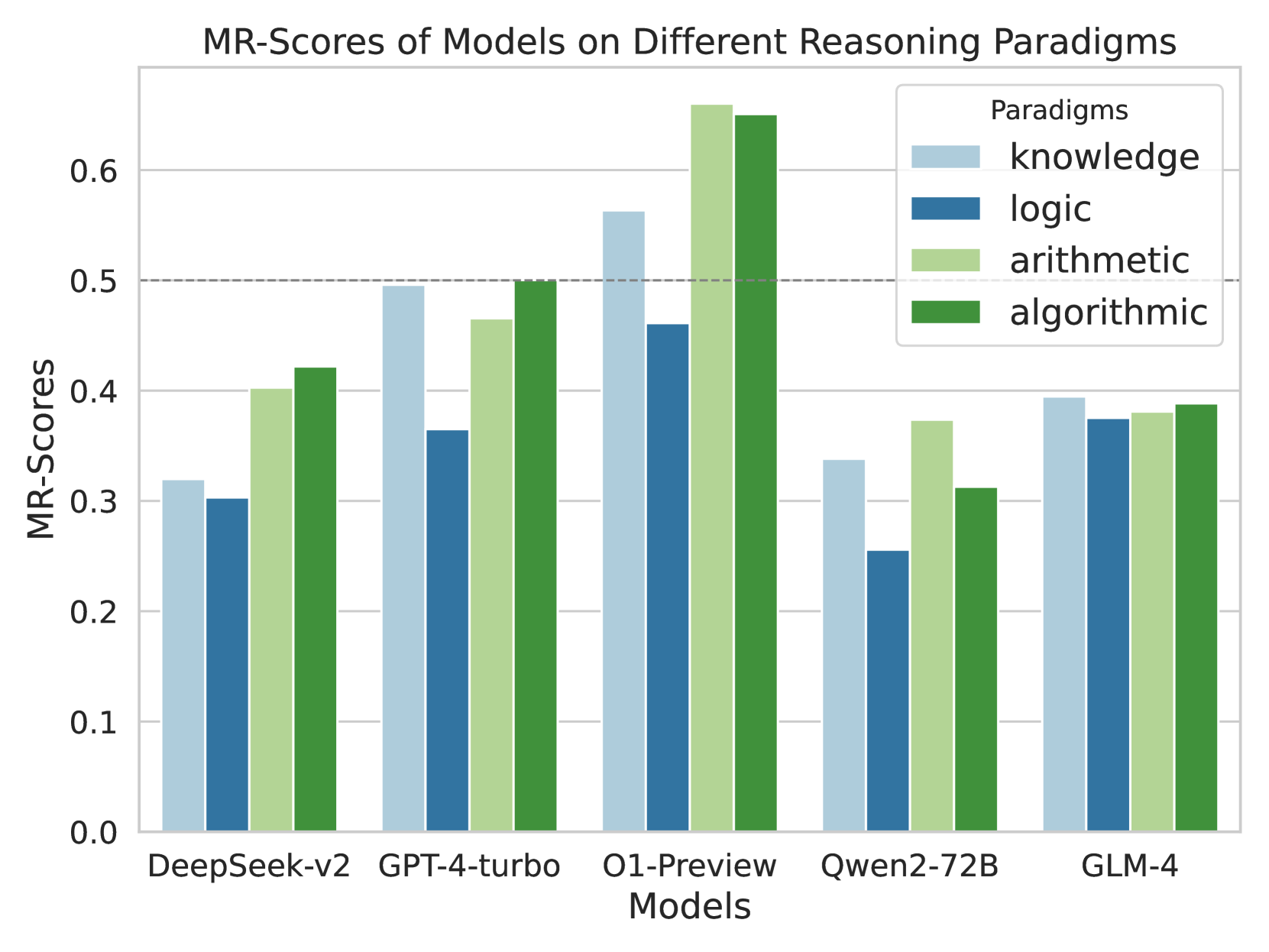
Figure 3: Model performance on different reasoning paradigms
5.2 Experiment Results
The MR-Ben benchmark presents a significant shift in the challenge for state-of-the-art large language models, transitioning from question-answering to the nuanced role of question-solution scoring. This section details our findings, emphasizing variations in model performances and their implications.
Overall Performance
Among the evaluated models, o1-preview consistently achieves the highest MR-Scores across all subjects, significantly outperforming most competitors from both open and closed-source communities. Notably, the open-sourced Qwen2-72B and Deepseek-V2-236B models are performing exceptionally well, surpassing every other open-sourced model including Llama3 by a large margin. Their scores are even comparable to or greater than some of the most capable models from commercial companies, such as Mistral, Yi, and Moonshot AI. In the small language model category, the performance of Phi3-3.8B exceeds many of the mid-size models, including Deepseek-Coder-33B, whose size is around tenfold larger.
Performance across Model Size and Reasoning Paradigm
Table 2 reveals a general trend where larger models tend to perform better, highlighting the correlation between model size and the efficacy in complex reasoning tasks. However, this relationship is not strictly linear, as demonstrated by models like Phi3-3.8B, which excel despite their smaller size. Since MR-Ben challenges the language models to reason about the reasoning in the solution space among a diverse range of domains, models like Phi-3 that are trained with effective data synthesis techniques and broader coverage of the solution space, intuitively achieve higher MR-Score. This suggests that while larger model sizes generally yield superior performances, techniques like knowledge distillation can also significantly boost reasoning performance. Similarly, although the size of the o1 model series remains undisclosed, these models reportedly employ mechanisms that scale computation efficiently through effective exploration, frequent retrospection, and meticulous reflection within the solution space. These characteristics align closely with the principles of “system-2” thinking, which emphasizes deliberate, reflective problem-solving. As a result, the o1 models demonstrate a more effective reasoning process, achieving significantly higher MR-Scores than other models by a large margin.
Performance across Reasoning Types
Our categorization into four reasoning types—knowledge, arithmetic, algorithmic, and logic—illustrates the unique challenges each model faces within these paradigms (Figure 3). Logic reasoning emerges as the most formidable due to the intricate logical operations required by questions from the LogiQA dataset. In stark contrast, o1-Preview and GPT-4-turbo demonstrate exceptional prowess in algorithmic reasoning, where their capabilities markedly surpass other models. Notably, models excel in different reasoning paradigms, reflecting their varied strengths and training backgrounds. For instance, despite Deepseek-Coder’s specialized pre-training focused on coding tasks, it does not necessarily confer superior abilities in algorithmic reasoning, underscoring that targeted pretraining does not guarantee enhanced performance across all reasoning types. Comparing the performance of the Deepseek-Coder with that of the Phi-3 model, which excels despite its much smaller size, highlights the potential significance of high-quality synthetic data in achieving broad-based reasoning capabilities.
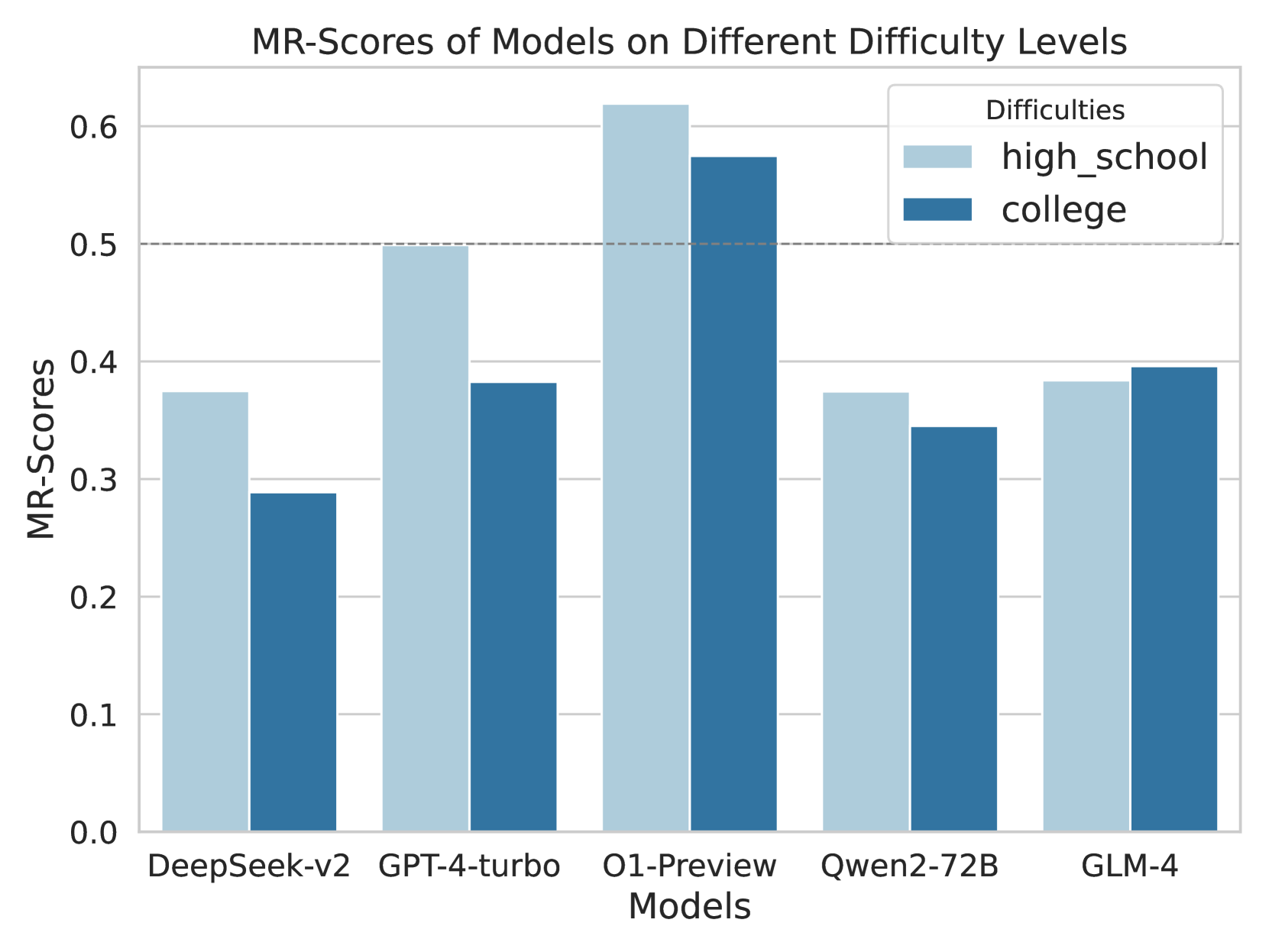
Sensitivity to Task Difficulty and Solution Length
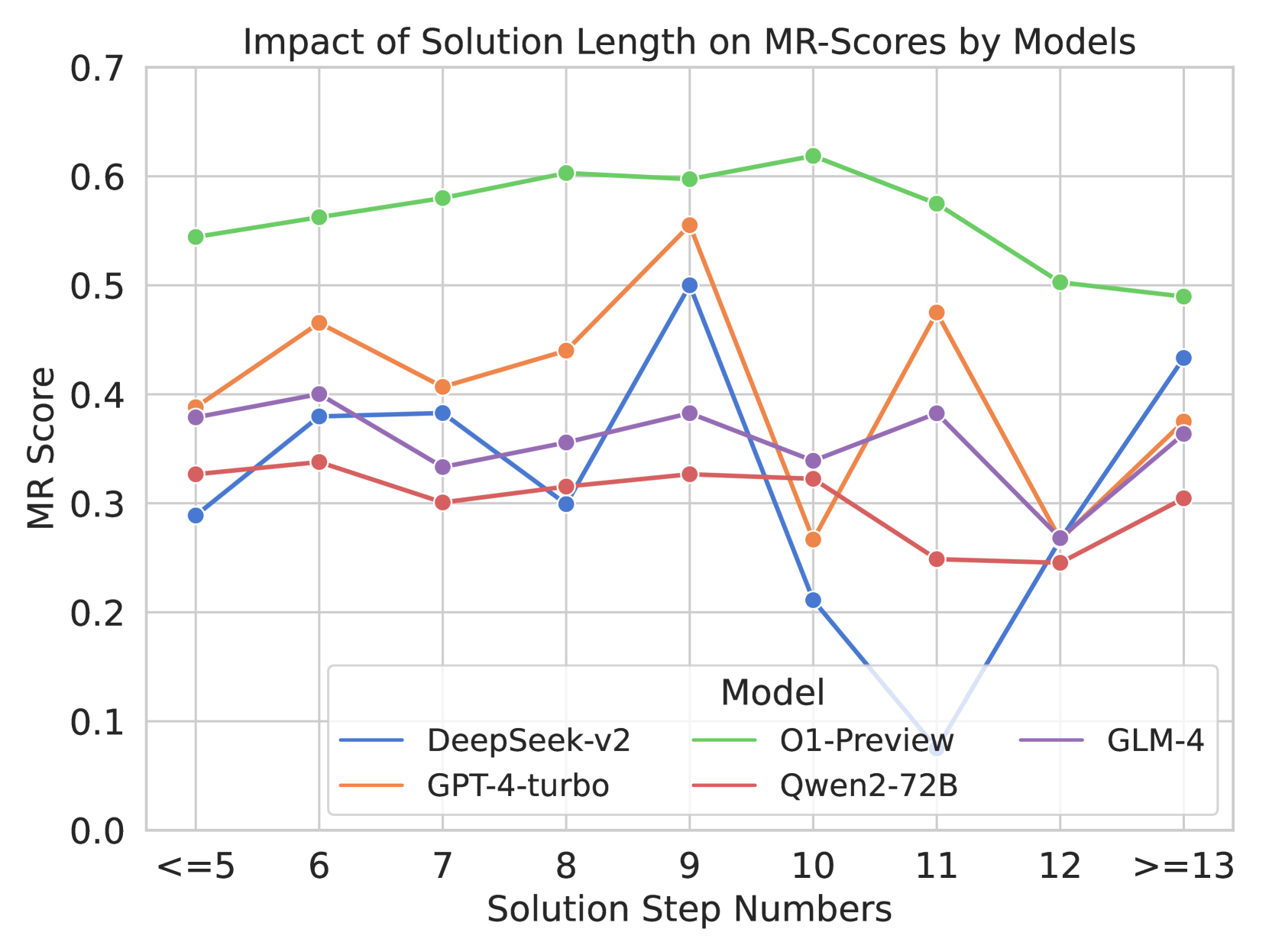
An examination across educational levels shows most models perform better at high school-level questions than college-level ones, indicating an intuitive level of sensitivity to the difficulty levels of the questions. Additionally, our analysis finds a minor negative correlation between the length of solution steps and MR-Scores, as detailed in Figure 5 and Figure 5.
Summary:
MR-Ben effectively differentiates model capabilities, often obscured in simpler settings. It not only identifies top performers but also underscores the influence of model size on outcomes, while demonstrating that techniques like knowledge distillation and test-time compute scaling, as seen with the Phi-3 and o1 models, can notably enhance smaller models’ performance, challenging the dominance of larger models. The analysis further reveals that specialized training, such as in coding, does not guarantee superior algorithmic reasoning. This suggests the potential need for more balanced data approaches or improved data synthesis methods.
6 Further Analysis & Discussion
<details>
<summary>x4.png Details</summary>
### Visual Description
## Bar Chart: MR-Scores of Models on Different Difficulty Levels
### Overview
This image is a grouped bar chart comparing the performance of five different artificial intelligence models based on a metric called "MR-Scores." The performance is evaluated across two distinct difficulty levels: "high_school" and "college."
*Language Declaration:* All text in this image is in English. No other languages are present.
### Components/Axes
**Header Region:**
* **Chart Title:** "MR-Scores of Models on Different Difficulty Levels" (Centered at the top).
**Main Chart Region:**
* **Y-axis:**
* **Title:** "MR-Scores" (Rotated 90 degrees counter-clockwise, positioned on the left).
* **Scale/Markers:** Linear scale starting from 0.0 to 0.6, with increments of 0.1 (0.0, 0.1, 0.2, 0.3, 0.4, 0.5, 0.6).
* **Gridlines:** Solid light gray horizontal lines extend from each y-axis marker across the chart area.
* **Reference Line:** A distinct, horizontal dashed gray line is positioned exactly at the 0.5 mark on the y-axis.
* **Legend:**
* **Position:** Top-right corner of the chart area, enclosed in a white box with a light gray border.
* **Title:** "Difficulties"
* **Categories:**
* Light blue solid square = "high_school"
* Dark blue solid square = "college"
**Footer Region:**
* **X-axis:**
* **Title:** "Models" (Centered at the bottom).
* **Categories (Left to Right):** "DeepSeek-v2", "GPT-4-turbo", "O1-Preview", "Qwen2-72B", "GLM-4".
### Detailed Analysis
*Trend Verification & Spatial Grounding:* For each model on the x-axis, there is a pair of bars. The left bar is always light blue (representing `high_school`), and the right bar is always dark blue (representing `college`). Visually, the light blue bar is taller than the dark blue bar for four out of the five models, indicating higher scores on high school difficulty. The exception is GLM-4, where the dark blue bar is marginally taller.
Below are the extracted approximate values (±0.01 uncertainty) based on visual alignment with the y-axis gridlines:
**1. DeepSeek-v2**
* *Visual Trend:* The light blue bar is noticeably taller than the dark blue bar.
* `high_school` (Light Blue): ~0.37
* `college` (Dark Blue): ~0.29
**2. GPT-4-turbo**
* *Visual Trend:* The light blue bar touches the dashed reference line, while the dark blue bar is significantly lower.
* `high_school` (Light Blue): ~0.50 (Exactly on the dashed line)
* `college` (Dark Blue): ~0.38
**3. O1-Preview**
* *Visual Trend:* Both bars are the tallest in the chart, extending above the 0.5 dashed line. The light blue bar is taller than the dark blue bar.
* `high_school` (Light Blue): ~0.62
* `college` (Dark Blue): ~0.57
**4. Qwen2-72B**
* *Visual Trend:* The light blue bar is slightly taller than the dark blue bar. Both are below the 0.4 line.
* `high_school` (Light Blue): ~0.37
* `college` (Dark Blue): ~0.34
**5. GLM-4**
* *Visual Trend:* This is the only grouping where the dark blue bar is slightly taller than the light blue bar. Both sit just below the 0.4 line.
* `high_school` (Light Blue): ~0.38
* `college` (Dark Blue): ~0.39
### Key Observations
* **Top Performer:** "O1-Preview" significantly outperforms all other models in both difficulty categories, being the only model to score above 0.5 on the college-level difficulty.
* **General Difficulty Trend:** Four out of five models score higher on "high_school" tasks than on "college" tasks, which aligns with the expected progression of academic difficulty.
* **The Anomaly:** "GLM-4" is the only model that scores slightly higher on the "college" difficulty (~0.39) compared to the "high_school" difficulty (~0.38).
* **The 0.5 Threshold:** The explicit dashed line at 0.5 suggests this is a critical benchmark. Only "O1-Preview" (both levels) and "GPT-4-turbo" (high school level only) meet or exceed this threshold.
### Interpretation
The data demonstrates a comparative evaluation of Large Language Models (LLMs) on a specific reasoning or knowledge benchmark (MR-Scores).
The consistent drop in performance from "high_school" to "college" for almost all models indicates that the "college" dataset successfully introduces a higher degree of complexity that these models struggle to resolve.
The presence of the dashed line at 0.5 likely represents a "pass" rate, a 50% accuracy mark, or a baseline human-level performance metric. The fact that "O1-Preview" clears this line comfortably in both categories suggests a generational leap or a specific architectural advantage in reasoning capabilities compared to the other models tested (like GPT-4-turbo and DeepSeek-v2).
The anomaly with GLM-4 (scoring better on college than high school) is highly unusual. Reading between the lines, this could suggest a few possibilities:
1. The training data for GLM-4 was heavily skewed toward advanced academic texts, making it better at college-level phrasing.
2. The specific "high_school" prompts used in this test contained formatting or logic puzzles that GLM-4's architecture handles poorly compared to standard academic Q&A.
3. It is a statistical artifact due to a specific subset of questions in the benchmark.
</details>
Figure 4: MR-Scores of different models on different levels of difficulty
<details>
<summary>x5.png Details</summary>
### Visual Description
## Line Chart: Impact of Solution Length on MR-Scores by Models
### Overview
This image is a multi-series line chart illustrating the performance of five different Large Language Models (LLMs) based on the length of the solution required. Performance is measured by an "MR Score" on the y-axis, plotted against the "Solution Step Numbers" on the x-axis. The chart demonstrates how model accuracy or reliability fluctuates as the complexity (measured in steps) of the problem increases.
### Components/Axes
**Header Region:**
* **Title:** Located at the top center, reading "Impact of Solution Length on MR-Scores by Models".
**Main Chart Area:**
* **Y-Axis (Left):** Labeled "MR Score" (rotated 90 degrees counter-clockwise). The scale ranges from `0.0` to `0.7` with major tick marks and corresponding horizontal grid lines at intervals of `0.1` (0.0, 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7).
* **X-Axis (Bottom):** Labeled "Solution Step Numbers" (centered below the axis). It contains categorical/ordinal bins representing step counts. Vertical grid lines align with each category. The categories are:
* `<=5`
* `6`
* `7`
* `8`
* `9`
* `10`
* `11`
* `12`
* `>=13`
**Footer/Legend Region:**
* **Legend:** Positioned inside the main chart area, in the lower-middle section (spanning horizontally from step 6 to 13, and vertically between MR scores 0.05 and 0.25). It is enclosed in a box with a light gray border.
* **Legend Title:** "Model"
* **Legend Entries (Color to Label Mapping):**
* Blue Line: `DeepSeek-v2`
* Orange Line: `GPT-4-turbo`
* Green Line: `O1-Preview`
* Red Line: `Qwen2-72B`
* Purple Line: `GLM-4`
### Detailed Analysis
*Note: All numerical values extracted from the chart are approximate visual estimates based on the placement of data points relative to the y-axis gridlines. An uncertainty margin of roughly ±0.02 applies.*
**Trend Verification and Data Extraction by Series:**
1. **O1-Preview (Green Line):**
* *Trend:* This line is consistently the highest on the chart. It shows a smooth, steady upward slope from `<=5` steps, peaking at `10` steps, followed by a steady downward slope as steps increase to `>=13`.
* *Data Points:* <=5 (~0.54), 6 (~0.56), 7 (~0.58), 8 (~0.60), 9 (~0.60), 10 (~0.62), 11 (~0.58), 12 (~0.50), >=13 (~0.49).
2. **GPT-4-turbo (Orange Line):**
* *Trend:* This line exhibits high volatility. It rises initially, dips at step 7, rises to a peak at step 9, suffers a sharp drop at step 10, spikes back up at step 11, drops sharply again at step 12, and recovers slightly at >=13.
* *Data Points:* <=5 (~0.39), 6 (~0.47), 7 (~0.41), 8 (~0.44), 9 (~0.56), 10 (~0.27), 11 (~0.48), 12 (~0.27), >=13 (~0.38).
3. **GLM-4 (Purple Line):**
* *Trend:* This line remains relatively stable in the middle of the pack. It fluctuates mildly between 0.33 and 0.40 until step 11, experiences a sharp drop at step 12, and recovers at >=13.
* *Data Points:* <=5 (~0.38), 6 (~0.40), 7 (~0.33), 8 (~0.36), 9 (~0.38), 10 (~0.34), 11 (~0.38), 12 (~0.27), >=13 (~0.36).
4. **DeepSeek-v2 (Blue Line):**
* *Trend:* Highly erratic behavior in the middle-to-late stages. It starts low, rises to a plateau at steps 6-7, dips at 8, spikes sharply to its peak at step 9, then crashes dramatically to the lowest point on the entire chart at step 11, before recovering sharply at steps 12 and >=13.
* *Data Points:* <=5 (~0.29), 6 (~0.38), 7 (~0.38), 8 (~0.30), 9 (~0.50), 10 (~0.21), 11 (~0.08), 12 (~0.26), >=13 (~0.43).
5. **Qwen2-72B (Red Line):**
* *Trend:* This line is the most stable but generally the lowest performing overall (excluding DeepSeek's crash). It remains relatively flat, hovering around the 0.30 mark, with a slight decline at steps 11 and 12 before a minor recovery.
* *Data Points:* <=5 (~0.33), 6 (~0.34), 7 (~0.30), 8 (~0.31), 9 (~0.33), 10 (~0.32), 11 (~0.25), 12 (~0.25), >=13 (~0.31).
**Reconstructed Data Table (Approximate Values):**
| Solution Step Numbers | DeepSeek-v2 (Blue) | GPT-4-turbo (Orange) | O1-Preview (Green) | Qwen2-72B (Red) | GLM-4 (Purple) |
| :--- | :--- | :--- | :--- | :--- | :--- |
| **<=5** | ~0.29 | ~0.39 | ~0.54 | ~0.33 | ~0.38 |
| **6** | ~0.38 | ~0.47 | ~0.56 | ~0.34 | ~0.40 |
| **7** | ~0.38 | ~0.41 | ~0.58 | ~0.30 | ~0.33 |
| **8** | ~0.30 | ~0.44 | ~0.60 | ~0.31 | ~0.36 |
| **9** | ~0.50 | ~0.56 | ~0.60 | ~0.33 | ~0.38 |
| **10** | ~0.21 | ~0.27 | ~0.62 | ~0.32 | ~0.34 |
| **11** | ~0.08 | ~0.48 | ~0.58 | ~0.25 | ~0.38 |
| **12** | ~0.26 | ~0.27 | ~0.50 | ~0.25 | ~0.27 |
| **>=13** | ~0.43 | ~0.38 | ~0.49 | ~0.31 | ~0.36 |
### Key Observations
* **Absolute Maximum:** O1-Preview achieves the highest overall MR Score of approximately 0.62 at 10 steps.
* **Absolute Minimum:** DeepSeek-v2 drops to the lowest overall MR Score of approximately 0.08 at 11 steps.
* **Convergence Point:** At `>=13` steps, four of the five models (DeepSeek-v2, GPT-4-turbo, GLM-4, and Qwen2-72B) converge tightly between scores of ~0.31 and ~0.43.
* **The "Step 10-12" Anomaly:** Steps 10, 11, and 12 represent a zone of extreme volatility for several models. DeepSeek-v2 crashes at 10 and 11; GPT-4-turbo crashes at 10, recovers at 11, and crashes again at 12; GLM-4 crashes at 12. Conversely, O1-Preview peaks at step 10.
### Interpretation
The data suggests a strong correlation between the number of reasoning steps required to solve a problem and the performance (MR Score) of various LLMs.
1. **Architectural Superiority in Long-Context Reasoning:** The `O1-Preview` model demonstrates a distinct advantage in handling multi-step problems. Its smooth curve suggests a robust underlying architecture that scales well with complexity up to 10 steps before experiencing a graceful degradation. It does not suffer the catastrophic failures seen in other models.
2. **Context Window/Attention Breakdown:** The extreme volatility of `DeepSeek-v2` and `GPT-4-turbo` between steps 9 and 12 strongly implies a breaking point in their attention mechanisms or context handling. The sharp spikes and crashes suggest that at these specific lengths, the models either perfectly grasp the logic or lose the thread entirely (hallucination or context dropping). DeepSeek-v2's near-zero score at step 11 is a notable catastrophic failure.
3. **Complexity Ceiling:** Across almost all models, performance begins to degrade or converge at the highest complexity level (`>=13` steps). Even the dominant O1-Preview drops from its peak of ~0.62 down to ~0.49. This indicates a general limitation in current LLM capabilities when forced to maintain logical coherence over very long chains of reasoning.
4. **Consistency vs. Peak Performance:** `Qwen2-72B` is the lowest performer on average, but it is highly consistent. It does not suffer the massive drops seen in GPT-4-turbo or DeepSeek-v2, suggesting it might be a safer, albeit less capable, choice for problems of unpredictable length where catastrophic failure is unacceptable.
</details>
Figure 5: The MR-Scores of models on solutions with different step numbers.
6.1 Few Shot Prompting
As previously discussed and exemplified by our prompt template (Figure 10 in Appendix- D), our evaluation method is characterized by its high level of difficulty and complexity. In this experiment, we aimed to determine whether providing a few step-wise chain-of-thought (CoT) examples could improve model performance in terms of format adherence and reasoning quality. The results, as presented in Table 9 in Appendix, do not show a consistent pattern as the number of shots increases. While smaller language models like Gemma-2B exhibit performance improvements with additional shots, the performance of larger language models tends to fluctuate with an increasing number of shots. We hypothesize that for our complex tasks, the lengthy few-shot demonstrations may act more as a hindrance, providing distracting information rather than aiding in format adherence and reasoning. Our empirical findings suggest that a one-shot demonstration strikes the optimal balance between providing guidance and minimizing distraction. This supports our decision to focus on zero-shot versus one-shot comparisons in our primary experiments, as detailed in Table 2.
6.2 Self Refine Prompting
As suggested by [31], large language models typically cannot perform self-correction without external ground truth feedback. To explore whether this phenomenon occurs in our benchmark, we adopted a similar setting by prompting the language model to verify its own answer across a three-round interaction sequence: query, examine, and refine. Our prompting template, detailed in Figure 8 in Appendix D, is minimalistic and designed solely to encourage the model to self-examine.
The results of this self-refinement process are recorded in Table 4. Notably, models smaller than Llama3-70B exhibit performance degradation with self-refinement, while larger models, such as GPT-4, show marginal benefits from the process. Conversely, from Llama3-8B to Llama3-70B, despite a significant portion of correct predictions shifting to incorrect ones, as previously reported by [31], our benchmark shows an increasing trend of incorrect predictions shifting to correct ones as model size increases. This shift results in the significant performance improvements observed in models like Llama3-70B.
To understand the disproportionate improvement observed in the 70B model, we analyzed performance breakdown at the task level. These results are visualized and discussed in Figure 9 of Appendix E. In short, we believe the lack of consistency does not necessarily indicate a more robust or advanced reasoning ability, despite the increase of the evaluation results.
6.3 Solution Correctness Prior
Table 3: Comparison of average accuracy in identifying the first error step and the corresponding error reason, with and without prior knowledge of the solutions’ correctness.
| Gemma-2B Llama3-8B Llama3-70B | 0.3 15.5 14.5 | 0.1 26.4 34.6 | 0.1 6.6 9.1 | 0.0 11.9 25.7 |
| --- | --- | --- | --- | --- |
| GPT-4-Turbo | 40.9 | 41.6 | 37.9 | 38.0 |
Table 4: Comparison of prompting methods: MR-Scores achieved by zero-shot step-wise CoT and Self-Refine technique.
| Gemma-2B Llama3-8B Llama3-70B | 0.1 11.7 17.7 | 0.2 11.3 27.5 |
| --- | --- | --- |
| GPT-4-Turbo | 43.2 | 45.5 |
To verify the influence of external ground truth signals, we sampled 100 incorrect solutions from each subject respectively as our test set. By observing the same set of language models under a zero-shot CoT setting, we aim to determine whether the knowledge of the solution’s incorrectness enhances their ability to identify the first error step and the reason for the error.
The results in Table 4 illustrate that the benefits of knowing the solution correctness prior generally increase with the model’s competence but begin to plateau at the level of sophisticated models like GPT-4. Specifically, the Gemma-2b model struggles significantly in our benchmark, showing nearly zero performance due to its limited ability to follow formats and comprehend complex tasks. Consequently, having the solution correctness prior does not improve its performance metrics. In contrast, models with moderate capabilities benefit substantially from this prior knowledge, which aids in accurately locating the first error step and elucidating the error reason. However, as model capabilities improve, the incremental benefits of this prior knowledge quickly diminish. For instance, GPT-4 shows only a marginal improvement in identifying the first error step and an almost negligible impact on error reason analysis when provided with the prior.
7 Conclusion
This paper highlights the importance of evaluating the reasoning capabilities of LLMs with process-oriented design and presents a comprehensive benchmark called MR-Ben that addresses the limitations of existing evaluation methodologies. MR-Ben consists of questions from a diverse range of subjects and incorporates a meta-reasoning paradigm, where LLMs act as teachers to evaluate the reasoning process. Our evaluation of a diverse suite of LLMs on MR-Ben reveals several key limitations and weaknesses. Many models struggle with identifying and correcting errors within reasoning chains, demonstrating difficulty in performing system-2 style thinking—such as scrutinizing assumptions, calculations, and intermediate steps. Furthermore, even state-of-the-art models often fail to maintain consistency across reasoning paradigms, exposing gaps in their generalization abilities. Additionally, our findings emphasize the importance of searching and reflecting on the solution space during inference. Models like the o1 series showcase the potential of scaling test-time computation, where frequent retrospection and iterative search through multiple solution paths significantly enhance reasoning performance. Nevertheless, improving LLMs’ reasoning abilities on complex and nuanced tasks remains an open research question, and we encourage future work to develop upon MR-Ben.
8 Acknowledgement
This work was supported in part by the Research Grants Council under the Areas of Excellence scheme grant AoE/E-601/22-R.
References
- Abdin et al. [2024] Marah Abdin, Sam Ade Jacobs, Ammar Ahmad Awan, Jyoti Aneja, Ahmed Awadallah, Hany Awadalla, Nguyen Bach, Amit Bahree, Arash Bakhtiari, Harkirat Behl, et al. Phi-3 technical report: A highly capable language model locally on your phone. arXiv preprint arXiv:2404.14219, 2024.
- AI [2024a] Moonshot AI. Moonshot ai, 2024a. URL https://www.moonshot.cn/.
- AI [2024b] Zhipu AI. Welcome to glm-4, 2024b. URL https://en.chatglm.cn/.
- Amini et al. [2019] Aida Amini, Saadia Gabriel, Shanchuan Lin, Rik Koncel-Kedziorski, Yejin Choi, and Hannaneh Hajishirzi. Mathqa: Towards interpretable math word problem solving with operation-based formalisms. In Jill Burstein, Christy Doran, and Thamar Solorio, editors, Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, NAACL-HLT 2019, Minneapolis, MN, USA, June 2-7, 2019, Volume 1 (Long and Short Papers), pages 2357–2367. Association for Computational Linguistics, 2019. doi: 10.18653/V1/N19-1245. URL https://doi.org/10.18653/v1/n19-1245.
- Anthropic [2024a] Anthropic. Claude 2, 2024a. URL https://www.anthropic.com/news/claude-2.
- Anthropic [2024b] Anthropic. Introducing the next generation of claude, 2024b. URL https://www.anthropic.com/news/claude-3-family.
- Bai et al. [2023] Jinze Bai, Shuai Bai, Yunfei Chu, Zeyu Cui, Kai Dang, Xiaodong Deng, Yang Fan, Wenbin Ge, Yu Han, Fei Huang, et al. Qwen technical report. arXiv preprint arXiv:2309.16609, 2023.
- Bai et al. [2022] Yuntao Bai, Saurav Kadavath, Sandipan Kundu, Amanda Askell, Jackson Kernion, Andy Jones, Anna Chen, Anna Goldie, Azalia Mirhoseini, Cameron McKinnon, Carol Chen, Catherine Olsson, Christopher Olah, Danny Hernandez, Dawn Drain, Deep Ganguli, Dustin Li, Eli Tran-Johnson, Ethan Perez, Jamie Kerr, Jared Mueller, Jeffrey Ladish, Joshua Landau, Kamal Ndousse, Kamile Lukosiute, Liane Lovitt, Michael Sellitto, Nelson Elhage, Nicholas Schiefer, Noemí Mercado, Nova DasSarma, Robert Lasenby, Robin Larson, Sam Ringer, Scott Johnston, Shauna Kravec, Sheer El Showk, Stanislav Fort, Tamera Lanham, Timothy Telleen-Lawton, Tom Conerly, Tom Henighan, Tristan Hume, Samuel R. Bowman, Zac Hatfield-Dodds, Ben Mann, Dario Amodei, Nicholas Joseph, Sam McCandlish, Tom Brown, and Jared Kaplan. Constitutional AI: harmlessness from AI feedback. CoRR, abs/2212.08073, 2022. doi: 10.48550/ARXIV.2212.08073. URL https://doi.org/10.48550/arXiv.2212.08073.
- Bengio [2020] Yoshua Bengio. Deep learning for system 2 processing. Presentation at the AAAI-20 Turing Award Winners 2018 Special Event, February 9 2020.
- Bi et al. [2024] Xiao Bi, Deli Chen, Guanting Chen, Shanhuang Chen, Damai Dai, Chengqi Deng, Honghui Ding, Kai Dong, Qiushi Du, Zhe Fu, Huazuo Gao, Kaige Gao, Wenjun Gao, Ruiqi Ge, Kang Guan, Daya Guo, Jianzhong Guo, Guangbo Hao, Zhewen Hao, Ying He, Wenjie Hu, Panpan Huang, Erhang Li, Guowei Li, Jiashi Li, Yao Li, Y. K. Li, Wenfeng Liang, Fangyun Lin, Alex X. Liu, Bo Liu, Wen Liu, Xiaodong Liu, Xin Liu, Yiyuan Liu, Haoyu Lu, Shanghao Lu, Fuli Luo, Shirong Ma, Xiaotao Nie, Tian Pei, Yishi Piao, Junjie Qiu, Hui Qu, Tongzheng Ren, Zehui Ren, Chong Ruan, Zhangli Sha, Zhihong Shao, Junxiao Song, Xuecheng Su, Jingxiang Sun, Yaofeng Sun, Minghui Tang, Bingxuan Wang, Peiyi Wang, Shiyu Wang, Yaohui Wang, Yongji Wang, Tong Wu, Y. Wu, Xin Xie, Zhenda Xie, Ziwei Xie, Yiliang Xiong, Hanwei Xu, R. X. Xu, Yanhong Xu, Dejian Yang, Yuxiang You, Shuiping Yu, Xingkai Yu, B. Zhang, Haowei Zhang, Lecong Zhang, Liyue Zhang, Mingchuan Zhang, Minghua Zhang, Wentao Zhang, Yichao Zhang, Chenggang Zhao, Yao Zhao, Shangyan Zhou, Shunfeng Zhou, Qihao Zhu, and Yuheng Zou. Deepseek LLM: scaling open-source language models with longtermism. CoRR, abs/2401.02954, 2024. doi: 10.48550/ARXIV.2401.02954. URL https://doi.org/10.48550/arXiv.2401.02954.
- Brown et al. [2020] Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-Voss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel M. Ziegler, Jeffrey Wu, Clemens Winter, Christopher Hesse, Mark Chen, Eric Sigler, Mateusz Litwin, Scott Gray, Benjamin Chess, Jack Clark, Christopher Berner, Sam McCandlish, Alec Radford, Ilya Sutskever, and Dario Amodei. Language models are few-shot learners. CoRR, abs/2005.14165, 2020. URL https://arxiv.org/abs/2005.14165.
- Bytedance [2024] Bytedance. Doubao team - crafting the industry’s most advanced llms., 2024. URL https://www.doubao.com/chat/.
- Chung et al. [2022] Hyung Won Chung, Le Hou, Shayne Longpre, Barret Zoph, Yi Tay, William Fedus, Eric Li, Xuezhi Wang, Mostafa Dehghani, Siddhartha Brahma, Albert Webson, Shixiang Shane Gu, Zhuyun Dai, Mirac Suzgun, Xinyun Chen, Aakanksha Chowdhery, Sharan Narang, Gaurav Mishra, Adams Yu, Vincent Y. Zhao, Yanping Huang, Andrew M. Dai, Hongkun Yu, Slav Petrov, Ed H. Chi, Jeff Dean, Jacob Devlin, Adam Roberts, Denny Zhou, Quoc V. Le, and Jason Wei. Scaling instruction-finetuned language models. CoRR, abs/2210.11416, 2022. doi: 10.48550/ARXIV.2210.11416. URL https://doi.org/10.48550/arXiv.2210.11416.
- Clark et al. [2018] Peter Clark, Isaac Cowhey, Oren Etzioni, Tushar Khot, Ashish Sabharwal, Carissa Schoenick, and Oyvind Tafjord. Think you have solved question answering? try arc, the AI2 reasoning challenge. CoRR, abs/1803.05457, 2018. URL http://arxiv.org/abs/1803.05457.
- Clark et al. [2020] Peter Clark, Oyvind Tafjord, and Kyle Richardson. Transformers as soft reasoners over language. In Christian Bessiere, editor, Proceedings of the Twenty-Ninth International Joint Conference on Artificial Intelligence, IJCAI 2020, pages 3882–3890. ijcai.org, 2020. doi: 10.24963/IJCAI.2020/537. URL https://doi.org/10.24963/ijcai.2020/537.
- Cobbe et al. [2021] Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. Training verifiers to solve math word problems. CoRR, abs/2110.14168, 2021. URL https://arxiv.org/abs/2110.14168.
- Dai et al. [2024] Jianbo Dai, Jianqiao Lu, Yunlong Feng, Rongju Ruan, Ming Cheng, Haochen Tan, and Zhijiang Guo. Mhpp: Exploring the capabilities and limitations of language models beyond basic code generation. arXiv preprint arXiv:2405.11430, 2024.
- Dalvi et al. [2021] Bhavana Dalvi, Peter Jansen, Oyvind Tafjord, Zhengnan Xie, Hannah Smith, Leighanna Pipatanangkura, and Peter Clark. Explaining answers with entailment trees. In Marie-Francine Moens, Xuanjing Huang, Lucia Specia, and Scott Wen-tau Yih, editors, Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, EMNLP 2021, Virtual Event / Punta Cana, Dominican Republic, 7-11 November, 2021, pages 7358–7370. Association for Computational Linguistics, 2021. doi: 10.18653/V1/2021.EMNLP-MAIN.585. URL https://doi.org/10.18653/v1/2021.emnlp-main.585.
- Fagin and Halpern [1994] Ronald Fagin and Joseph Y. Halpern. Reasoning about knowledge and probability. J. ACM, 41(2):340–367, 1994. doi: 10.1145/174652.174658. URL https://doi.org/10.1145/174652.174658.
- Fernandes et al. [2023] Patrick Fernandes, Aman Madaan, Emmy Liu, António Farinhas, Pedro Henrique Martins, Amanda Bertsch, José G. C. de Souza, Shuyan Zhou, Tongshuang Wu, Graham Neubig, and André F. T. Martins. Bridging the gap: A survey on integrating (human) feedback for natural language generation. CoRR, abs/2305.00955, 2023. doi: 10.48550/ARXIV.2305.00955. URL https://doi.org/10.48550/arXiv.2305.00955.
- Gao et al. [2023] Luyu Gao, Zhuyun Dai, Panupong Pasupat, Anthony Chen, Arun Tejasvi Chaganty, Yicheng Fan, Vincent Y. Zhao, Ni Lao, Hongrae Lee, Da-Cheng Juan, and Kelvin Guu. RARR: researching and revising what language models say, using language models. In Anna Rogers, Jordan L. Boyd-Graber, and Naoaki Okazaki, editors, Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), ACL 2023, Toronto, Canada, July 9-14, 2023, pages 16477–16508. Association for Computational Linguistics, 2023. doi: 10.18653/V1/2023.ACL-LONG.910. URL https://doi.org/10.18653/v1/2023.acl-long.910.
- Geva et al. [2021] Mor Geva, Daniel Khashabi, Elad Segal, Tushar Khot, Dan Roth, and Jonathan Berant. Did aristotle use a laptop? A question answering benchmark with implicit reasoning strategies. Trans. Assoc. Comput. Linguistics, 9:346–361, 2021. doi: 10.1162/TACL\_A\_00370. URL https://doi.org/10.1162/tacl_a_00370.
- Golovneva et al. [2023] Olga Golovneva, Moya Chen, Spencer Poff, Martin Corredor, Luke Zettlemoyer, Maryam Fazel-Zarandi, and Asli Celikyilmaz. ROSCOE: A suite of metrics for scoring step-by-step reasoning. In The Eleventh International Conference on Learning Representations, ICLR 2023, Kigali, Rwanda, May 1-5, 2023. OpenReview.net, 2023. URL https://openreview.net/pdf?id=xYlJRpzZtsY.
- Gou et al. [2023] Zhibin Gou, Zhihong Shao, Yeyun Gong, Yelong Shen, Yujiu Yang, Nan Duan, and Weizhu Chen. CRITIC: large language models can self-correct with tool-interactive critiquing. CoRR, abs/2305.11738, 2023. doi: 10.48550/ARXIV.2305.11738. URL https://doi.org/10.48550/arXiv.2305.11738.
- Gu et al. [2024] Alex Gu, Baptiste Rozière, Hugh James Leather, Armando Solar-Lezama, Gabriel Synnaeve, and Sida Wang. Cruxeval: A benchmark for code reasoning, understanding and execution. In Forty-first International Conference on Machine Learning, ICML 2024, Vienna, Austria, July 21-27, 2024. OpenReview.net, 2024. URL https://openreview.net/forum?id=Ffpg52swvg.
- Gunasekar et al. [2023] Suriya Gunasekar, Yi Zhang, Jyoti Aneja, Caio César Teodoro Mendes, Allie Del Giorno, Sivakanth Gopi, Mojan Javaheripi, Piero Kauffmann, Gustavo de Rosa, Olli Saarikivi, Adil Salim, Shital Shah, Harkirat Singh Behl, Xin Wang, Sébastien Bubeck, Ronen Eldan, Adam Tauman Kalai, Yin Tat Lee, and Yuanzhi Li. Textbooks are all you need. CoRR, abs/2306.11644, 2023. doi: 10.48550/ARXIV.2306.11644. URL https://doi.org/10.48550/arXiv.2306.11644.
- Hendrycks et al. [2021a] Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. Measuring massive multitask language understanding. In 9th International Conference on Learning Representations, ICLR 2021, Virtual Event, Austria, May 3-7, 2021. OpenReview.net, 2021a. URL https://openreview.net/forum?id=d7KBjmI3GmQ.
- Hendrycks et al. [2021b] Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. Measuring mathematical problem solving with the MATH dataset. In Joaquin Vanschoren and Sai-Kit Yeung, editors, Proceedings of the Neural Information Processing Systems Track on Datasets and Benchmarks 1, NeurIPS Datasets and Benchmarks 2021, December 2021, virtual, 2021b. URL https://datasets-benchmarks-proceedings.neurips.cc/paper/2021/hash/be83ab3ecd0db773eb2dc1b0a17836a1-Abstract-round2.html.
- Huang et al. [2024] Dong Huang, Jianbo Dai, Han Weng, Puzhen Wu, Yuhao Qing, Jie M. Zhang, Heming Cui, and Zhijiang Guo. SOAP: enhancing efficiency of generated code via self-optimization. CoRR, abs/2405.15189, 2024. doi: 10.48550/ARXIV.2405.15189. URL https://doi.org/10.48550/arXiv.2405.15189.
- Huang and Chang [2023] Jie Huang and Kevin Chen-Chuan Chang. Towards reasoning in large language models: A survey. In Anna Rogers, Jordan L. Boyd-Graber, and Naoaki Okazaki, editors, Findings of the Association for Computational Linguistics: ACL 2023, Toronto, Canada, July 9-14, 2023, pages 1049–1065. Association for Computational Linguistics, 2023. doi: 10.18653/V1/2023.FINDINGS-ACL.67. URL https://doi.org/10.18653/v1/2023.findings-acl.67.
- Huang et al. [2023] Jie Huang, Xinyun Chen, Swaroop Mishra, Huaixiu Steven Zheng, Adams Wei Yu, Xinying Song, and Denny Zhou. Large language models cannot self-correct reasoning yet. arXiv preprint arXiv:2310.01798, 2023.
- Jiang et al. [2023] Albert Q. Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra Singh Chaplot, Diego de Las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lucile Saulnier, Lélio Renard Lavaud, Marie-Anne Lachaux, Pierre Stock, Teven Le Scao, Thibaut Lavril, Thomas Wang, Timothée Lacroix, and William El Sayed. Mistral 7b. CoRR, abs/2310.06825, 2023. doi: 10.48550/ARXIV.2310.06825. URL https://doi.org/10.48550/arXiv.2310.06825.
- Jiang et al. [2024] Albert Q. Jiang, Alexandre Sablayrolles, Antoine Roux, Arthur Mensch, Blanche Savary, Chris Bamford, Devendra Singh Chaplot, Diego de Las Casas, Emma Bou Hanna, Florian Bressand, Gianna Lengyel, Guillaume Bour, Guillaume Lample, Lélio Renard Lavaud, Lucile Saulnier, Marie-Anne Lachaux, Pierre Stock, Sandeep Subramanian, Sophia Yang, Szymon Antoniak, Teven Le Scao, Théophile Gervet, Thibaut Lavril, Thomas Wang, Timothée Lacroix, and William El Sayed. Mixtral of experts. CoRR, abs/2401.04088, 2024. doi: 10.48550/ARXIV.2401.04088. URL https://doi.org/10.48550/arXiv.2401.04088.
- Jung et al. [2022] Jaehun Jung, Lianhui Qin, Sean Welleck, Faeze Brahman, Chandra Bhagavatula, Ronan Le Bras, and Yejin Choi. Maieutic prompting: Logically consistent reasoning with recursive explanations. In Yoav Goldberg, Zornitsa Kozareva, and Yue Zhang, editors, Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, EMNLP 2022, Abu Dhabi, United Arab Emirates, December 7-11, 2022, pages 1266–1279. Association for Computational Linguistics, 2022. doi: 10.18653/V1/2022.EMNLP-MAIN.82. URL https://doi.org/10.18653/v1/2022.emnlp-main.82.
- Kahneman [2011] Daniel Kahneman. Thinking, fast and slow. Farrar, Straus and Giroux, 2011.
- Kojima et al. [2022] Takeshi Kojima, Shixiang Shane Gu, Machel Reid, Yutaka Matsuo, and Yusuke Iwasawa. Large language models are zero-shot reasoners. In Sanmi Koyejo, S. Mohamed, A. Agarwal, Danielle Belgrave, K. Cho, and A. Oh, editors, Advances in Neural Information Processing Systems 35: Annual Conference on Neural Information Processing Systems 2022, NeurIPS 2022, New Orleans, LA, USA, November 28 - December 9, 2022, 2022. URL http://papers.nips.cc/paper_files/paper/2022/hash/8bb0d291acd4acf06ef112099c16f326-Abstract-Conference.html.
- Koncel-Kedziorski et al. [2016] Rik Koncel-Kedziorski, Subhro Roy, Aida Amini, Nate Kushman, and Hannaneh Hajishirzi. MAWPS: A math word problem repository. In Kevin Knight, Ani Nenkova, and Owen Rambow, editors, NAACL HLT 2016, The 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, San Diego California, USA, June 12-17, 2016, pages 1152–1157. The Association for Computational Linguistics, 2016. doi: 10.18653/V1/N16-1136. URL https://doi.org/10.18653/v1/n16-1136.
- Lightman et al. [2023] Hunter Lightman, Vineet Kosaraju, Yura Burda, Harrison Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe. Let’s verify step by step. CoRR, abs/2305.20050, 2023. doi: 10.48550/ARXIV.2305.20050. URL https://doi.org/10.48550/arXiv.2305.20050.
- LingYiWanWu [2024] LingYiWanWu. Yi ai, 2024. URL https://platform.lingyiwanwu.com/.
- Liu et al. [2020] Jian Liu, Leyang Cui, Hanmeng Liu, Dandan Huang, Yile Wang, and Yue Zhang. Logiqa: A challenge dataset for machine reading comprehension with logical reasoning. In Christian Bessiere, editor, Proceedings of the Twenty-Ninth International Joint Conference on Artificial Intelligence, IJCAI 2020, pages 3622–3628. ijcai.org, 2020. doi: 10.24963/IJCAI.2020/501. URL https://doi.org/10.24963/ijcai.2020/501.
- Liu et al. [2024a] Yinhong Liu, Zhijiang Guo, Tianya Liang, Ehsan Shareghi, Ivan Vulić, and Nigel Collier. Measuring, evaluating and improving logical consistency in large language models. arXiv preprint arXiv:2410.02205, 2024a.
- Liu et al. [2024b] Yinhong Liu, Han Zhou, Zhijiang Guo, Ehsan Shareghi, Ivan Vulić, Anna Korhonen, and Nigel Collier. Aligning with human judgement: The role of pairwise preference in large language model evaluators, 2024b.
- Liu et al. [2024c] Yiqi Liu, Nafise Sadat Moosavi, and Chenghua Lin. Llms as narcissistic evaluators: When ego inflates evaluation scores, 2024c.
- Lu et al. [2024a] Jianqiao Lu, Zhiyang Dou, Hongru Wang, Zeyu Cao, Jianbo Dai, Yingjia Wan, Yinya Huang, and Zhijiang Guo. Autocv: Empowering reasoning with automated process labeling via confidence variation. CoRR, abs/2405.16802, 2024a. doi: 10.48550/ARXIV.2405.16802. URL https://doi.org/10.48550/arXiv.2405.16802.
- Lu et al. [2024b] Jianqiao Lu, Zhengying Liu, Yingjia Wan, Yinya Huang, Haiming Wang, Zhicheng Yang, Jing Tang, and Zhijiang Guo. Process-driven autoformalization in lean 4. CoRR, abs/2406.01940, 2024b. doi: 10.48550/ARXIV.2406.01940. URL https://doi.org/10.48550/arXiv.2406.01940.
- Matthews [1975] Brian W. Matthews. Comparison of the predicted and observed secondary structure of t4 phage lysozyme. Biochimica et biophysica acta, 405 2:442–51, 1975. URL https://api.semanticscholar.org/CorpusID:44596673.
- Meta [2024] Meta. Introducing meta llama 3: The most capable openly available llm to date, 2024. URL https://ai.meta.com/blog/meta-llama-3/.
- Mishra et al. [2022] Swaroop Mishra, Matthew Finlayson, Pan Lu, Leonard Tang, Sean Welleck, Chitta Baral, Tanmay Rajpurohit, Oyvind Tafjord, Ashish Sabharwal, Peter Clark, and Ashwin Kalyan. LILA: A unified benchmark for mathematical reasoning. In Yoav Goldberg, Zornitsa Kozareva, and Yue Zhang, editors, Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, EMNLP 2022, Abu Dhabi, United Arab Emirates, December 7-11, 2022, pages 5807–5832. Association for Computational Linguistics, 2022. doi: 10.18653/V1/2022.EMNLP-MAIN.392. URL https://doi.org/10.18653/v1/2022.emnlp-main.392.
- Mukherjee et al. [2023] Subhabrata Mukherjee, Arindam Mitra, Ganesh Jawahar, Sahaj Agarwal, Hamid Palangi, and Ahmed Awadallah. Orca: Progressive learning from complex explanation traces of GPT-4. CoRR, abs/2306.02707, 2023. doi: 10.48550/ARXIV.2306.02707. URL https://doi.org/10.48550/arXiv.2306.02707.
- OpenAI [2023a] OpenAI. GPT-3.5 Turbo, 2023a. URL https://platform.openai.com/docs/models/gpt-3-5.
- OpenAI [2023b] OpenAI. GPT-4 Technical Report. CoRR, abs/2303.08774, 2023b. doi: 10.48550/arXiv.2303.08774. URL https://doi.org/10.48550/arXiv.2303.08774.
- OpenAI [2024] OpenAI. Introducing openai o1-preview, 2024. URL https://openai.com/index/introducing-openai-o1-preview/.
- Ouyang et al. [2022] Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll L. Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, John Schulman, Jacob Hilton, Fraser Kelton, Luke Miller, Maddie Simens, Amanda Askell, Peter Welinder, Paul F. Christiano, Jan Leike, and Ryan Lowe. Training language models to follow instructions with human feedback. In Sanmi Koyejo, S. Mohamed, A. Agarwal, Danielle Belgrave, K. Cho, and A. Oh, editors, Advances in Neural Information Processing Systems 35: Annual Conference on Neural Information Processing Systems 2022, NeurIPS 2022, New Orleans, LA, USA, November 28 - December 9, 2022, 2022. URL http://papers.nips.cc/paper_files/paper/2022/hash/b1efde53be364a73914f58805a001731-Abstract-Conference.html.
- Panickssery et al. [2024] Arjun Panickssery, Samuel R. Bowman, and Shi Feng. Llm evaluators recognize and favor their own generations, 2024.
- Patel et al. [2021] Arkil Patel, Satwik Bhattamishra, and Navin Goyal. Are NLP models really able to solve simple math word problems? In Kristina Toutanova, Anna Rumshisky, Luke Zettlemoyer, Dilek Hakkani-Tür, Iz Beltagy, Steven Bethard, Ryan Cotterell, Tanmoy Chakraborty, and Yichao Zhou, editors, Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, NAACL-HLT 2021, Online, June 6-11, 2021, pages 2080–2094. Association for Computational Linguistics, 2021. doi: 10.18653/V1/2021.NAACL-MAIN.168. URL https://doi.org/10.18653/v1/2021.naacl-main.168.
- Prasad et al. [2023] Archiki Prasad, Swarnadeep Saha, Xiang Zhou, and Mohit Bansal. Receval: Evaluating reasoning chains via correctness and informativeness. In Houda Bouamor, Juan Pino, and Kalika Bali, editors, Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, EMNLP 2023, Singapore, December 6-10, 2023, pages 10066–10086. Association for Computational Linguistics, 2023. doi: 10.18653/V1/2023.EMNLP-MAIN.622. URL https://doi.org/10.18653/v1/2023.emnlp-main.622.
- Qiao et al. [2023] Shuofei Qiao, Yixin Ou, Ningyu Zhang, Xiang Chen, Yunzhi Yao, Shumin Deng, Chuanqi Tan, Fei Huang, and Huajun Chen. Reasoning with language model prompting: A survey. In Anna Rogers, Jordan L. Boyd-Graber, and Naoaki Okazaki, editors, Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), ACL 2023, Toronto, Canada, July 9-14, 2023, pages 5368–5393. Association for Computational Linguistics, 2023. doi: 10.18653/V1/2023.ACL-LONG.294. URL https://doi.org/10.18653/v1/2023.acl-long.294.
- Saparov and He [2023] Abulhair Saparov and He He. Language models are greedy reasoners: A systematic formal analysis of chain-of-thought. In The Eleventh International Conference on Learning Representations, ICLR 2023, Kigali, Rwanda, May 1-5, 2023. OpenReview.net, 2023. URL https://openreview.net/pdf?id=qFVVBzXxR2V.
- Srivastava et al. [2022] Aarohi Srivastava, Abhinav Rastogi, Abhishek Rao, Abu Awal Md Shoeb, Abubakar Abid, Adam Fisch, Adam R. Brown, Adam Santoro, Aditya Gupta, Adrià Garriga-Alonso, Agnieszka Kluska, Aitor Lewkowycz, Akshat Agarwal, Alethea Power, Alex Ray, Alex Warstadt, Alexander W. Kocurek, Ali Safaya, Ali Tazarv, Alice Xiang, Alicia Parrish, Allen Nie, Aman Hussain, Amanda Askell, Amanda Dsouza, Ameet Rahane, Anantharaman S. Iyer, Anders Andreassen, Andrea Santilli, Andreas Stuhlmüller, Andrew M. Dai, Andrew La, Andrew K. Lampinen, Andy Zou, Angela Jiang, Angelica Chen, Anh Vuong, Animesh Gupta, Anna Gottardi, Antonio Norelli, Anu Venkatesh, Arash Gholamidavoodi, Arfa Tabassum, Arul Menezes, Arun Kirubarajan, Asher Mullokandov, Ashish Sabharwal, Austin Herrick, Avia Efrat, Aykut Erdem, Ayla Karakas, and et al. Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. CoRR, abs/2206.04615, 2022. doi: 10.48550/ARXIV.2206.04615. URL https://doi.org/10.48550/arXiv.2206.04615.
- Suzgun et al. [2023] Mirac Suzgun, Nathan Scales, Nathanael Schärli, Sebastian Gehrmann, Yi Tay, Hyung Won Chung, Aakanksha Chowdhery, Quoc V. Le, Ed H. Chi, Denny Zhou, and Jason Wei. Challenging big-bench tasks and whether chain-of-thought can solve them. In Anna Rogers, Jordan L. Boyd-Graber, and Naoaki Okazaki, editors, Findings of the Association for Computational Linguistics: ACL 2023, Toronto, Canada, July 9-14, 2023, pages 13003–13051. Association for Computational Linguistics, 2023. doi: 10.18653/V1/2023.FINDINGS-ACL.824. URL https://doi.org/10.18653/v1/2023.findings-acl.824.
- Tafjord et al. [2021] Oyvind Tafjord, Bhavana Dalvi, and Peter Clark. Proofwriter: Generating implications, proofs, and abductive statements over natural language. In Chengqing Zong, Fei Xia, Wenjie Li, and Roberto Navigli, editors, Findings of the Association for Computational Linguistics: ACL/IJCNLP 2021, Online Event, August 1-6, 2021, volume ACL/IJCNLP 2021 of Findings of ACL, pages 3621–3634. Association for Computational Linguistics, 2021. doi: 10.18653/V1/2021.FINDINGS-ACL.317. URL https://doi.org/10.18653/v1/2021.findings-acl.317.
- Talmor et al. [2019] Alon Talmor, Jonathan Herzig, Nicholas Lourie, and Jonathan Berant. Commonsenseqa: A question answering challenge targeting commonsense knowledge. In Jill Burstein, Christy Doran, and Thamar Solorio, editors, Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, NAACL-HLT 2019, Minneapolis, MN, USA, June 2-7, 2019, Volume 1 (Long and Short Papers), pages 4149–4158. Association for Computational Linguistics, 2019. doi: 10.18653/V1/N19-1421. URL https://doi.org/10.18653/v1/n19-1421.
- Team et al. [2024] Gemma Team, Thomas Mesnard, Cassidy Hardin, Robert Dadashi, Surya Bhupatiraju, Shreya Pathak, Laurent Sifre, Morgane Rivière, Mihir Sanjay Kale, Juliette Love, et al. Gemma: Open models based on gemini research and technology. arXiv preprint arXiv:2403.08295, 2024.
- Tyen et al. [2023] Gladys Tyen, Hassan Mansoor, Peter Chen, Tony Mak, and Victor Carbune. Llms cannot find reasoning errors, but can correct them! CoRR, abs/2311.08516, 2023. doi: 10.48550/ARXIV.2311.08516. URL https://doi.org/10.48550/arXiv.2311.08516.
- Wason and Johnson-Laird [1972] Peter Cathcart Wason and Philip Nicholas Johnson-Laird. Psychology of reasoning: Structure and content, volume 86. Harvard University Press, 1972.
- Wei et al. [2022] Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed H. Chi, Quoc V. Le, and Denny Zhou. Chain-of-thought prompting elicits reasoning in large language models. In Sanmi Koyejo, S. Mohamed, A. Agarwal, Danielle Belgrave, K. Cho, and A. Oh, editors, Advances in Neural Information Processing Systems 35: Annual Conference on Neural Information Processing Systems 2022, NeurIPS 2022, New Orleans, LA, USA, November 28 - December 9, 2022, 2022. URL http://papers.nips.cc/paper_files/paper/2022/hash/9d5609613524ecf4f15af0f7b31abca4-Abstract-Conference.html.
- Welleck et al. [2023] Sean Welleck, Ximing Lu, Peter West, Faeze Brahman, Tianxiao Shen, Daniel Khashabi, and Yejin Choi. Generating sequences by learning to self-correct. In The Eleventh International Conference on Learning Representations, ICLR 2023, Kigali, Rwanda, May 1-5, 2023. OpenReview.net, 2023. URL https://openreview.net/pdf?id=hH36JeQZDaO.
- Xia et al. [2024] Shijie Xia, Xuefeng Li, Yixin Liu, Tongshuang Wu, and Pengfei Liu. Evaluating mathematical reasoning beyond accuracy. CoRR, abs/2404.05692, 2024. doi: 10.48550/ARXIV.2404.05692. URL https://doi.org/10.48550/arXiv.2404.05692.
- Xiong et al. [2024] Jing Xiong, Zixuan Li, Chuanyang Zheng, Zhijiang Guo, Yichun Yin, Enze Xie, Zhicheng Yang, Qingxing Cao, Haiming Wang, Xiongwei Han, Jing Tang, Chengming Li, and Xiaodan Liang. Dq-lore: Dual queries with low rank approximation re-ranking for in-context learning. In The Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024. OpenReview.net, 2024. URL https://openreview.net/forum?id=qAoxvePSlq.
- Yang et al. [2022] Kevin Yang, Yuandong Tian, Nanyun Peng, and Dan Klein. Re3: Generating longer stories with recursive reprompting and revision. CoRR, abs/2210.06774, 2022. doi: 10.48550/ARXIV.2210.06774. URL https://doi.org/10.48550/arXiv.2210.06774.
- Yang et al. [2024] Zonglin Yang, Li Dong, Xinya Du, Hao Cheng, Erik Cambria, Xiaodong Liu, Jianfeng Gao, and Furu Wei. Language models as inductive reasoners. In Yvette Graham and Matthew Purver, editors, Proceedings of the 18th Conference of the European Chapter of the Association for Computational Linguistics, EACL 2024 - Volume 1: Long Papers, St. Julian’s, Malta, March 17-22, 2024, pages 209–225. Association for Computational Linguistics, 2024. URL https://aclanthology.org/2024.eacl-long.13.
- Yao et al. [2023] Shunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Shafran, Tom Griffiths, Yuan Cao, and Karthik Narasimhan. Tree of thoughts: Deliberate problem solving with large language models. In Alice Oh, Tristan Naumann, Amir Globerson, Kate Saenko, Moritz Hardt, and Sergey Levine, editors, Advances in Neural Information Processing Systems 36: Annual Conference on Neural Information Processing Systems 2023, NeurIPS 2023, New Orleans, LA, USA, December 10 - 16, 2023, 2023. URL http://papers.nips.cc/paper_files/paper/2023/hash/271db9922b8d1f4dd7aaef84ed5ac703-Abstract-Conference.html.
- Yao et al. [2024] Yuxuan Yao, Han Wu, Zhijiang Guo, Biyan Zhou, Jiahui Gao, Sichun Luo, Hanxu Hou, Xiaojin Fu, and Linqi Song. Learning from correctness without prompting makes LLM efficient reasoner. CoRR, abs/2403.19094, 2024. doi: 10.48550/ARXIV.2403.19094. URL https://doi.org/10.48550/arXiv.2403.19094.
- Yasunaga et al. [2023] Michihiro Yasunaga, Xinyun Chen, Yujia Li, Panupong Pasupat, Jure Leskovec, Percy Liang, Ed H. Chi, and Denny Zhou. Large language models as analogical reasoners. CoRR, abs/2310.01714, 2023. doi: 10.48550/ARXIV.2310.01714. URL https://doi.org/10.48550/arXiv.2310.01714.
- Ye and Durrett [2022] Xi Ye and Greg Durrett. The unreliability of explanations in few-shot prompting for textual reasoning. In Sanmi Koyejo, S. Mohamed, A. Agarwal, Danielle Belgrave, K. Cho, and A. Oh, editors, Advances in Neural Information Processing Systems 35: Annual Conference on Neural Information Processing Systems 2022, NeurIPS 2022, New Orleans, LA, USA, November 28 - December 9, 2022, 2022. URL http://papers.nips.cc/paper_files/paper/2022/hash/c402501846f9fe03e2cac015b3f0e6b1-Abstract-Conference.html.
- Yu et al. [2023] Wenhao Yu, Zhihan Zhang, Zhenwen Liang, Meng Jiang, and Ashish Sabharwal. Improving language models via plug-and-play retrieval feedback. CoRR, abs/2305.14002, 2023. doi: 10.48550/ARXIV.2305.14002. URL https://doi.org/10.48550/arXiv.2305.14002.
- Zeng et al. [2023] Zhongshen Zeng, Pengguang Chen, Shu Liu, Haiyun Jiang, and Jiaya Jia. Mr-gsm8k: A meta-reasoning benchmark for large language model evaluation. CoRR, abs/2312.17080, 2023. doi: 10.48550/ARXIV.2312.17080. URL https://doi.org/10.48550/arXiv.2312.17080.
- Zhang et al. [2021] Chi Zhang, Baoxiong Jia, Mark Edmonds, Song-Chun Zhu, and Yixin Zhu. ACRE: abstract causal reasoning beyond covariation. In IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2021, virtual, June 19-25, 2021, pages 10643–10653. Computer Vision Foundation / IEEE, 2021. doi: 10.1109/CVPR46437.2021.01050. URL https://openaccess.thecvf.com/content/CVPR2021/html/Zhang_ACRE_Abstract_Causal_REasoning_Beyond_Covariation_CVPR_2021_paper.html.
- Zhou et al. [2024] Han Zhou, Xingchen Wan, Lev Proleev, Diana Mincu, Jilin Chen, Katherine A Heller, and Subhrajit Roy. Batch calibration: Rethinking calibration for in-context learning and prompt engineering. In The Twelfth International Conference on Learning Representations, 2024. URL https://openreview.net/forum?id=L3FHMoKZcS.
- Zhou et al. [2023] Yongchao Zhou, Andrei Ioan Muresanu, Ziwen Han, Keiran Paster, Silviu Pitis, Harris Chan, and Jimmy Ba. Large language models are human-level prompt engineers. In The Eleventh International Conference on Learning Representations, ICLR 2023, Kigali, Rwanda, May 1-5, 2023. OpenReview.net, 2023. URL https://openreview.net/pdf?id=92gvk82DE-.
Appendix A Appendix
A.1 Limitations
The meta-reasoning evaluation framework in MR-Ben, while innovative, is not without its limitations. Firstly, its applicability may be restricted when it comes to subjects that are inherently holistic or creative in nature, such as humanities or sociology. These subjects often require a comprehensive understanding and modification (e.g. essay writing), which can be challenging to break down into specific, sequential reasoning steps and corrections. Secondly, MR-Ben is currently confined to questions in English. This could potentially limit the scope of reasoning challenges that can be explored, as different languages may present unique cognitive and linguistic hurdles. Lastly, the analysis and correction of errors in the reasoning steps are currently based on solutions generated by three LLMs, namely GPT-3.5, Mistral-Medium, and Claude 2. It’s important to note that different LLMs and different individuals, may exhibit distinct reasoning and error patterns. Therefore, it would be beneficial to broaden the spectrum of solutions analyzed, incorporating a more diverse range of LLMs and even human responses. This would not only enhance the robustness of the evaluation framework but also provide a more nuanced understanding of the reasoning processes at play.
A.2 Broader Impact
Positive Societal Impacts
The proposed dataset MR-Ben has the potential to bring about significant positive societal impacts. It can contribute to the development and enhancement of LLMs by providing a comprehensive benchmark suite, which researchers and developers can use to identify and address the limitations and weaknesses of their models. This can lead to more accurate, efficient, and reliable LLMs. The meta-reasoning paradigm might open new avenues in AI research, leading to a deeper understanding of reasoning capabilities and the development of innovative methodologies for their evaluation and improvement. Moreover, with a wide range of subjects, MR-Ben can be a valuable resource for educational AI tools, providing personalized learning experiences and helping students understand and improve their reasoning skills. AI systems with improved reasoning capabilities can also be instrumental in various sectors, including healthcare, finance, and environmental management, aiding in complex decision-making and problem-solving tasks.
Negative Societal Impacts
MR-Ben may also present potential negative societal impacts. As with any technology, there is a risk of LLMs being misused or used maliciously. For instance, LLMs with advanced reasoning capabilities could be used to manipulate information or deceive people. The use of LLMs in decision-making and problem-solving tasks could lead to an over-reliance on these systems, potentially undermining human judgment and critical thinking skills. Advanced LLMs, especially those used in sensitive sectors like healthcare and finance, need to handle vast amounts of data, which can raise privacy and security concerns if not managed properly.
A.3 Additional Related Work
Improving Reasoning Abilities of LLMs
To enhance the reasoning capabilities of LLMs, prior research primarily focuses on specific prompting techniques [11]. Existing efforts include few-shot prompting with intermediate steps augmented demonstrations [66, 72, 69] or zero-shot prompting with specific instructions [36, 74]. Although these methods have shown promising results, their effectiveness is often constrained by their task-specific nature and the labour-intensive process of designing prompts, leading to inconsistent outcomes across different tasks [75, 80]. Another strategy to facilitate reasoning involves instruction tuning or knowledge distillation, which elicits reasoning paths from LLMs without explicit prompting [13, 49, 26, 44]. These approaches typically involve resource-intensive fine-tuning over LLMs and require a large set of examples annotated with CoT.
Learning From Feedback
Improving LLMs through learning from feedback has become a prevalent strategy, notably through reinforcement learning from human feedback, which seeks to align LLMs with human values by refining their outputs based on feedback [53, 8]. However, this method faces challenges such as high costs due to manual labor and a lack of real-time feedback capabilities [20]. An alternative strategy involves using self-correcting LLMs, which rely on automated feedback to iteratively adapt and understand the consequences of their actions without relying on humans. This feedback can be derived from outside sources such as other models [70, 45], tools [24, 29], knowledge bases [21, 76], evaluation metrics [34, 67] or generation logits [73].
Appendix B Robustness of MR-Score
| gpt-4-turbo deepseek_coder Qwen2-72B | 83/55 100/38 99/39 | 137/15 145/7 142/10 | 164/11 167/8 167/8 | 305/46 321/30 312/39 | 194/25 200/19 195/24 | 166/27 172/21 172/21 | 192/16 193/15 200/8 |
| --- | --- | --- | --- | --- | --- | --- | --- |
Table 5: Scoring of error reasons from different models across subjects.
| Agreement Ratio | Coding 7/8 | Phy. 12/13 | Bio. 21/21 | Med. 12/12 | Chem. 15/17 | Logic 15/16 | Math 10/13 |
| --- | --- | --- | --- | --- | --- | --- | --- |
Table 6: Agreement ratio between the author and the proxy scoring model across different subjects.
Question: Does the ACC_reason metric’s dependency on the judgments of different LLMs or human evaluators lead to variability in scoring ?
Answer: We would like to argue that due to the careful design of our evaluation mechanism, the automatic scoring of error reasons is both robust and economically feasible:
- Multiple annotators: During the annotation stage, we collected multiple annotations for the first error reasons and potential error rectification from different annotators who agreed on the solution correctness and the first error step.
- Proxy Model Evaluation: Based on the ground truth annotations collected from various perspectives, the proxy language model (e.g., GPT-4-Turbo) then examines the error reasons provided by evaluating models. Given the question/solution pair and information regarding the first error step, error reasons, and rectification, the potential flaws of the error reasons provided by the evaluating models are easy to diagnose under contrast.
- ACC_reason robustness: Table- 5 shows the scores of error reasons sampled from our evaluation results. For the same set of error reasons collected in each subject, three different models made their predictions on correctness/incorrectness. We can clearly see the consistency of their predictions among the three models over questions in all subjects. Since the MR-Score is a weighted metric, the final score variability is less than 1 percent in total.
Human-Model Agreement Rate: As mentioned in 3, the agreement rate between manual annotations and the GPT-4 predictions over 100 samples randomly collected from all subjects is 92%. Below is the exact detail of our setup:
We randomly collected 100 data instances where the evaluating model correctly identified the solution correctness and the first error step across all subjects. We then manually examined whether the proxy scoring model (e.g., GPT-4-Turbo-2024-04-09) correctly scored the error reasons of the evaluating models. Table- 6 is the detailed composition of the ratio in which the author agrees with the proxy scoring model. The annotation time varies significantly across subjects, as some problems—such as coding and chemistry—can take more than 10 minutes to evaluate, while subjects like biology are easier to assess. This high agreement rate further supports the reliability of our evaluation, thus avoiding the need for manual annotation of potentially 138,000 problems (6,000 benchmark size times 23 models evaluated).
Table 7: Evaluation results breakdown on MR-Ben: This table presents a detailed breakdown of each model’s performance evaluated under metric MCC/ACC-step/ACC-reason across different subjects. Here k stands for number of shot and every model we used in this experiment are instruction-tuned.
| Model | Bio. | | Phy. | | Math | | Chem. | | Med. | | Logic | | Coding | | Avg. | | | | | | | | |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| $k$ =0 | $k$ =1 | | $k$ =0 | $k$ =1 | | $k$ =0 | $k$ =1 | | $k$ =0 | $k$ =1 | | $k$ =0 | $k$ =1 | | $k$ =0 | $k$ =1 | | $k$ =0 | $k$ =1 | | $k$ =0 | $k$ =1 | |
| MR-Scores | | | | | | | | | | | | | | | | | | | | | | | |
| Claude3-Haiku | 5.7 | 5.8 | | 3.3 | 3.5 | | 3.1 | 3.1 | | 6.5 | 6.4 | | 2.0 | 2.0 | | 1.2 | 1.2 | | 9.0 | 0.0 | | 4.4 | 3.1 |
| GPT-3.5-Turbo | 3.6 | 6.6 | | 5.7 | 6.7 | | 5.7 | 5.4 | | 4.9 | 6.7 | | 3.6 | 4.4 | | 1.7 | 4.5 | | 3.0 | 4.1 | | 4.0 | 5.5 |
| Phi3-3.8B | 13.4 | 12.5 | | 12.7 | 10.8 | | 13.3 | 13.1 | | 16.4 | 17.1 | | 10.2 | 8.1 | | 8.4 | 5.3 | | 9.1 | 10.2 | | 11.9 | 11.0 |
| Deepseek-Coder-33B | 7.4 | 5.5 | | 7.8 | 5.6 | | 7.2 | 8.6 | | 7.8 | 7.4 | | 6.0 | 5.5 | | 4.6 | 6.7 | | 8.4 | 4.9 | | 7.0 | 6.3 |
| DeepSeek-Coder-7B | 10.5 | 9.9 | | 11.8 | 9.6 | | 11.8 | 12.1 | | 12.3 | 11.9 | | 10.4 | 11.0 | | 9.8 | 10.7 | | 5.0 | 5.8 | | 10.2 | 10.2 |
| LLaMA3-8B | 12.0 | 11.9 | | 10.9 | 7.5 | | 15.0 | 9.0 | | 12.6 | 12.7 | | 9.3 | 8.0 | | 9.4 | 9.6 | | 15.8 | 10.0 | | 12.2 | 9.8 |
| Qwen1.5-72B | 15.3 | 19.2 | | 12.9 | 13.6 | | 12.0 | 10.0 | | 13.9 | 16.3 | | 11.7 | 14.7 | | 10.4 | 12.9 | | 3.9 | 5.9 | | 11.5 | 13.3 |
| DeepSeek-67B | 17.1 | 19.7 | | 14.9 | 17.3 | | 15.4 | 16.2 | | 16.3 | 20.6 | | 14.7 | 12.2 | | 13.6 | 14.3 | | 14.5 | 15.2 | | 15.2 | 16.5 |
| LLaMA3-70B | 20.4 | 27.1 | | 17.4 | 20.5 | | 14.9 | 15.8 | | 19.5 | 25.1 | | 16.3 | 19.3 | | 16.3 | 16.8 | | 29.8 | 16.7 | | 19.2 | 20.2 |
| Mistral-Large | 22.2 | 28.0 | | 26.7 | 25.4 | | 24.3 | 28.2 | | 24.0 | 27.0 | | 15.9 | 19.3 | | 14.7 | 17.1 | | 21.1 | 21.4 | | 21.3 | 23.8 |
| DeepSeek-V2-236B | 30.0 | 37.1 | | 32.2 | 36.5 | | 32.2 | 30.0 | | 32.5 | 35.4 | | 26.5 | 32.4 | | 23.6 | 27.4 | | 34.2 | 27.1 | | 30.2 | 32.3 |
| GPT-4-Turbo | 44.7 | 47.3 | | 42.8 | 45.2 | | 44.3 | 45.4 | | 44.0 | 46.0 | | 38.8 | 38.4 | | 34.1 | 33.6 | | 53.6 | 57.3 | | 43.2 | 44.7 |
| MCC-Matthews Correlation Coefficient | | | | | | | | | | | | | | | | | | | | | | | |
| Claude3-Haiku | 13.96 | 17.72 | | 16.47 | 13.62 | | 15.09 | 10.74 | | 16.54 | 19.96 | | 8.52 | 8.35 | | 6.21 | 4.94 | | 4.36 | 0 | | 11.59 | 10.76 |
| GPT-3.5-Turbo | 10.72 | 19.44 | | 16.66 | 21.33 | | 17.48 | 17.45 | | 18.24 | 12.6 | | 11.19 | 13.28 | | 4.07 | 0 | | 12.35 | 12.35 | | 12.96 | 13.78 |
| Deepseek-Coder-33B | 7.51 | 8.57 | | 11.73 | 6.81 | | 9.69 | 21.06 | | 9.98 | 7.94 | | 1.62 | 6.28 | | 0 | 0 | | 26.18 | 15.44 | | 9.53 | 9.44 |
| Deepseek-Coder-7B | 4.96 | 9.79 | | 8.77 | 6.72 | | 9.05 | 10.82 | | 10.49 | 9.39 | | 5.02 | 3.17 | | 3.22 | 2.58 | | 10.91 | 6.27 | | 7.49 | 6.96 |
| LlaMA3-8B | 19.37 | 21.15 | | 16.24 | 18.64 | | 26.55 | 21.87 | | 25.99 | 28.6 | | 14.92 | 18.95 | | 11.8 | 16.24 | | 14.54 | 15.72 | | 18.49 | 20.17 |
| Phi3-3.8B | 27.66 | 28.48 | | 21.61 | 21.44 | | 22.29 | 25.17 | | 30.92 | 33.37 | | 17.36 | 14.9 | | 13.03 | 9.56 | | 14.48 | 18.76 | | 21.05 | 21.67 |
| Qwen1.5-72B | 33.64 | 42.44 | | 31.4 | 31.56 | | 29.2 | 23.28 | | 35.47 | 36.47 | | 21.76 | 29.64 | | 24.42 | 27.74 | | 13.8 | 15.69 | | 27.1 | 29.55 |
| Deepseek-67B | 43.61 | 41.73 | | 24.16 | 28.77 | | 24.95 | 23.87 | | 36.58 | 37.29 | | 27.8 | 28.93 | | 26.74 | 25.09 | | 28.23 | 29.06 | | 30.3 | 30.68 |
| LlaMA3-70B | 45.67 | 56.14 | | 40.34 | 41.3 | | 32.76 | 30.94 | | 41.72 | 52.12 | | 33.18 | 37.75 | | 32.0 | 33.87 | | 47.86 | 29.67 | | 39.08 | 40.26 |
| Mistral-Large | 41.67 | 49.0 | | 34.24 | 33.47 | | 29.0 | 37.05 | | 41.99 | 47.07 | | 23.76 | 32.05 | | 25.66 | 33.25 | | 37.05 | 33.52 | | 33.34 | 37.92 |
| Deepseek-v2-236B | 52.96 | 53.38 | | 41.81 | 46.48 | | 43.75 | 40.53 | | 54.32 | 50.15 | | 37.61 | 44.53 | | 36.36 | 35.41 | | 45.89 | 35.7 | | 44.67 | 43.74 |
| GPT-4-Turbo | 63.33 | 62.59 | | 52.9 | 52.7 | | 50.67 | 52.84 | | 53.05 | 54.59 | | 56.79 | 54.66 | | 40.95 | 42.94 | | 52.5 | 57.53 | | 52.88 | 53.98 |
| Accuracy of First Error Step | | | | | | | | | | | | | | | | | | | | | | | |
| Claude3-Haiku | 2.15 | 3.1 | | 1.4 | 1.12 | | 2.38 | 1.59 | | 1.77 | 4.42 | | 1.69 | 0.68 | | 1.01 | 0.29 | | 0.0 | 0.0 | | 1.49 | 1.6 |
| GPT-3.5-Turbo | 2.86 | 4.53 | | 4.2 | 4.76 | | 4.37 | 3.84 | | 2.87 | 8.17 | | 2.37 | 3.05 | | 1.73 | 7.63 | | 0.61 | 2.44 | | 2.72 | 4.92 |
| Deepseek-Coder-33B | 14.83 | 10.29 | | 14.94 | 12.36 | | 14.69 | 10.92 | | 15.67 | 16.31 | | 14.54 | 12.43 | | 12.22 | 18.18 | | 5.49 | 3.05 | | 13.2 | 11.93 |
| Deepseek-Coder-7B | 21.77 | 18.18 | | 23.28 | 19.83 | | 23.41 | 20.03 | | 24.46 | 23.18 | | 23.29 | 26.09 | | 20.03 | 24.72 | | 4.27 | 6.1 | | 20.07 | 19.73 |
| LlaMA3-8B | 14.35 | 14.35 | | 17.53 | 8.62 | | 20.29 | 7.8 | | 14.16 | 11.59 | | 13.13 | 8.41 | | 13.64 | 11.36 | | 17.68 | 9.76 | | 15.83 | 10.27 |
| Phi3-3.8B | 12.68 | 11.48 | | 16.38 | 12.07 | | 17.69 | 16.12 | | 18.03 | 17.17 | | 12.78 | 8.76 | | 10.23 | 6.96 | | 8.54 | 9.15 | | 13.76 | 11.67 |
| Qwen1.5-72B | 11.48 | 15.31 | | 10.63 | 11.49 | | 10.79 | 9.88 | | 12.45 | 14.38 | | 11.03 | 13.49 | | 8.1 | 10.94 | | 1.83 | 4.27 | | 9.47 | 11.39 |
| Deepseek-67B | 13.16 | 19.14 | | 19.25 | 21.84 | | 20.81 | 22.11 | | 17.17 | 23.39 | | 14.71 | 12.08 | | 12.78 | 13.49 | | 12.2 | 14.02 | | 15.72 | 18.01 |
| LlaMA3-70B | 15.79 | 22.25 | | 14.66 | 18.39 | | 13.65 | 15.08 | | 17.81 | 22.32 | | 14.36 | 16.64 | | 14.91 | 14.91 | | 26.83 | 13.41 | | 16.86 | 17.57 |
| Mistral-Large | 18.38 | 25.54 | | 26.33 | 28.29 | | 27.28 | 33.25 | | 26.05 | 27.59 | | 16.92 | 19.29 | | 14.53 | 14.96 | | 19.51 | 19.51 | | 21.29 | 24.06 |
| Deepseek-v2-236B | 27.51 | 35.41 | | 37.64 | 40.23 | | 36.28 | 34.33 | | 33.91 | 37.55 | | 27.5 | 32.57 | | 22.87 | 27.56 | | 33.54 | 26.83 | | 31.32 | 33.5 |
| GPT-4-Turbo | 41.77 | 46.06 | | 42.58 | 46.5 | | 46.49 | 47.81 | | 42.6 | 46.8 | | 37.06 | 36.72 | | 29.93 | 33.24 | | 50.61 | 59.15 | | 41.58 | 45.18 |
| Accuracy of First Error Reason | | | | | | | | | | | | | | | | | | | | | | | |
| Claude3-Haiku | 1.67 | 2.63 | | 0.56 | 0.84 | | 1.19 | 0.93 | | 0.22 | 2.21 | | 1.18 | 0.34 | | 0.72 | 0.29 | | 0.0 | 0.0 | | 0.79 | 1.03 |
| GPT-3.5-Turbo | 1.19 | 2.63 | | 2.24 | 1.96 | | 1.85 | 1.46 | | 0.88 | 3.53 | | 1.35 | 1.69 | | 0.72 | 4.17 | | 0.61 | 1.83 | | 1.26 | 2.47 |
| Deepseek-Coder-33B | 2.87 | 1.44 | | 2.01 | 1.15 | | 1.69 | 2.21 | | 2.15 | 1.93 | | 2.63 | 1.05 | | 1.85 | 2.56 | | 3.05 | 1.83 | | 2.32 | 1.74 |
| Deepseek-Coder-7B | 5.98 | 5.02 | | 6.03 | 4.6 | | 5.98 | 7.93 | | 5.79 | 6.22 | | 4.9 | 5.08 | | 6.25 | 5.54 | | 3.05 | 5.49 | | 5.43 | 5.7 |
| LlaMA3-8B | 7.66 | 6.7 | | 4.89 | 2.3 | | 7.28 | 4.55 | | 6.22 | 7.08 | | 4.73 | 3.33 | | 5.97 | 5.97 | | 15.24 | 7.93 | | 7.43 | 5.41 |
| Phi3-3.8B | 8.13 | 6.7 | | 6.9 | 5.75 | | 7.02 | 6.37 | | 9.66 | 10.52 | | 5.78 | 5.08 | | 5.4 | 2.7 | | 7.32 | 7.32 | | 7.17 | 6.35 |
| Qwen1.5-72B | 10.29 | 12.2 | | 6.9 | 7.76 | | 5.85 | 4.81 | | 6.22 | 9.44 | | 8.06 | 9.46 | | 6.11 | 8.24 | | 1.22 | 3.05 | | 6.38 | 7.85 |
| Deepseek-67B | 8.85 | 11.24 | | 8.62 | 10.06 | | 8.32 | 9.49 | | 7.73 | 12.23 | | 9.46 | 5.6 | | 8.81 | 10.37 | | 10.37 | 10.37 | | 8.88 | 9.91 |
| LlaMA3-70B | 13.16 | 18.42 | | 9.77 | 13.51 | | 8.58 | 10.27 | | 11.59 | 15.88 | | 10.68 | 13.49 | | 10.94 | 11.08 | | 24.39 | 13.41 | | 12.73 | 13.72 |
| Mistral-Large | 15.27 | 21.0 | | 19.05 | 20.45 | | 15.1 | 21.72 | | 16.56 | 18.54 | | 13.03 | 14.21 | | 11.22 | 11.94 | | 17.07 | 17.68 | | 15.33 | 17.94 |
| Deepseek-v2-236B | 22.25 | 31.58 | | 25.57 | 30.17 | | 25.1 | 23.28 | | 22.96 | 28.11 | | 21.54 | 27.5 | | 18.89 | 24.15 | | 29.88 | 23.78 | | 23.74 | 26.94 |
| GPT-4-Turbo | 39.14 | 42.0 | | 38.38 | 41.46 | | 40.4 | 41.06 | | 36.64 | 42.16 | | 32.83 | 32.83 | | 27.63 | 30.07 | | 50.61 | 56.1 | | 37.95 | 40.81 |
Question: Is the MR-Score sensitive to different weightings? Is MR-Score a robust unified metric?
Table- 7 shows breakdown performance for models in all four metrics (MR-Score, MCC, ACC_step, and ACC_reason):
1. Metric Robustness: Due to the progressive nature of the definitions of our subtasks (e.g., the success of subsequent tasks depends on the previous ones), we can see the diminishing trend in the scores of MCC, ACC_step, and ACC_reason. However, thanks to the design of our evaluation mechanism and metrics, the score rankings of different models stay in relatively stable order across metrics. In other words, we have not observed any model that excels in determining the solution correctness (thus high in MCC) but is unable to explain the rationale behind it (e.g., low in ACC_reason).
1. Task Difficulties: As shown in the breakdown table, the ACC_reason metric is more discriminative than the MCC metric for competent models but vice versa for the less competent ones. This aligns with our intuition that generally more difficult questions are more discriminative for strong candidates, while weaker ones are simply incapable of solving them. This phenomenon could in part explain why in general the MR-Score is not very sensitive to minor changes in the weightings assigned to the subtasks, since the differentiability of the subtask metrics tends to reconcile with each other under different scenarios.
1. Differentiability and Interpretability: The weights of the MR-Score are ultimately decided by considering both the discriminative ability and the interpretability. To best differentiate models with different evaluation results, we conducted a thorough grid search to investigate the impact of the weightings. Since the weightings calculated returned a few optimal instances, we deliberately selected the one that assigns higher scores to more difficult tasks. We believe the current weighting ratio strikes a good balance between interpretability and differentiation: For example, GPT-4-Turbo, Deepseek-v2-236B, and Mistral-Large achieve 86.4%, 78.5%, and 81.2% respectively in MMLU but score 43.2%, 29.4%, and 21.3% in our benchmark.
Appendix C More Discussion on Biases
To quantitatively assess the relationship between the length of solutions and their correctness, Pearson-Correlation-Coefficients were calculated and reported in Table- 8 in the Appendix. The result suggests varying dynamics across disciplines regarding how solution length impacts the likelihood of correctness. For subjects such as coding, chemistry and math, longer solutions are less likely to be correct, which could suggest that complexity or elaboration in responses may lead to mistakes or incorrect reasoning. For medicine, despite being weak, there’s a tendency for longer solutions to be slightly more correct, possibly due to more detailed or thorough explanations being favorable. For the other subjects, length of solution does not appear to significantly affect correctness, indicating that other factors likely play a more dominant role in determining solution quality. The overall Pearson Coefficients analysis reflects the distinct nature of problem-solving in each field of our benchmark.
Table 8: Pearson Correlation Between Solution Length and Correctness
| Medicine Physics Biology | 0.094 -0.061 0.009 | 0.0072 0.111 0.783 |
| --- | --- | --- |
| Chemistry | -0.127 | 0.00018 |
| Coding | -0.199 | 0.0021 |
| Logic | 0.0002 | 0.995 |
| Math | -0.115 | 0.00049 |
Table 9: Evaluation Results of Models on MR-Bean in few-shot settings: This table presents a detailed breakdown of each model’s performance evaluated under metric MR-Score across different subjects.
| Gemma-2B 1 2 | 0 0.0 0.1 | 0.1 0.0 0.2 | 0.0 1.0 0.7 | 0.0 0.0 0.6 | 0.1 0.4 0.7 | 0.0 0.2 0.2 | 0.0 0.0 0.0 | 0.7 0.2 0.4 | 0.1 |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| 3 | 0.1 | 0.3 | 1.1 | 0.1 | 0.7 | 0.3 | 0.0 | 0.4 | |
| Llama3-8B | 0 | 11.1 | 14.9 | 14.8 | 12.8 | 9.4 | 9.6 | 9.1 | 11.7 |
| 1 | 11.7 | 8.1 | 7.8 | 12.8 | 7.3 | 10.7 | 5.7 | 9.2 | |
| 2 | 9.7 | 7.8 | 11.1 | 8.8 | 6.4 | 6.2 | 2.4 | 7.5 | |
| 3 | 10.0 | 10.7 | 8.3 | 8.2 | 5.5 | 5.3 | 3.0 | 7.3 | |
| Llama3-70B | 0 | 19.9 | 15.4 | 15.0 | 17.6 | 14.6 | 13.5 | 28.2 | 17.7 |
| 1 | 30.5 | 21.4 | 16.8 | 26.2 | 16.9 | 16.0 | 15.3 | 20.4 | |
| 2 | 27.2 | 19.9 | 16.8 | 22.0 | 15.9 | 17.5 | 19.5 | 19.8 | |
| 3 | 27.2 | 20.6 | 16.3 | 21.1 | 16.0 | 14.6 | 19.4 | 19.3 | |
| GPT-4-Turbo | 0 | 44.7 | 42.8 | 44.3 | 44.0 | 38.8 | 34.1 | 53.6 | 43.2 |
| 1 | 47.3 | 45.2 | 45.4 | 46.0 | 38.4 | 33.6 | 57.3 | 44.7 | |
| 2 | 46.6 | 42.7 | 44.9 | 43.3 | 42.1 | 35.9 | 53.0 | 44.1 | |
| 3 | 44.0 | 44.8 | 46.5 | 44.4 | 41.2 | 33.7 | 56.6 | 44.5 | |
<details>
<summary>extracted/6085487/figures/Mr-Ben-Pipeline.jpg Details</summary>
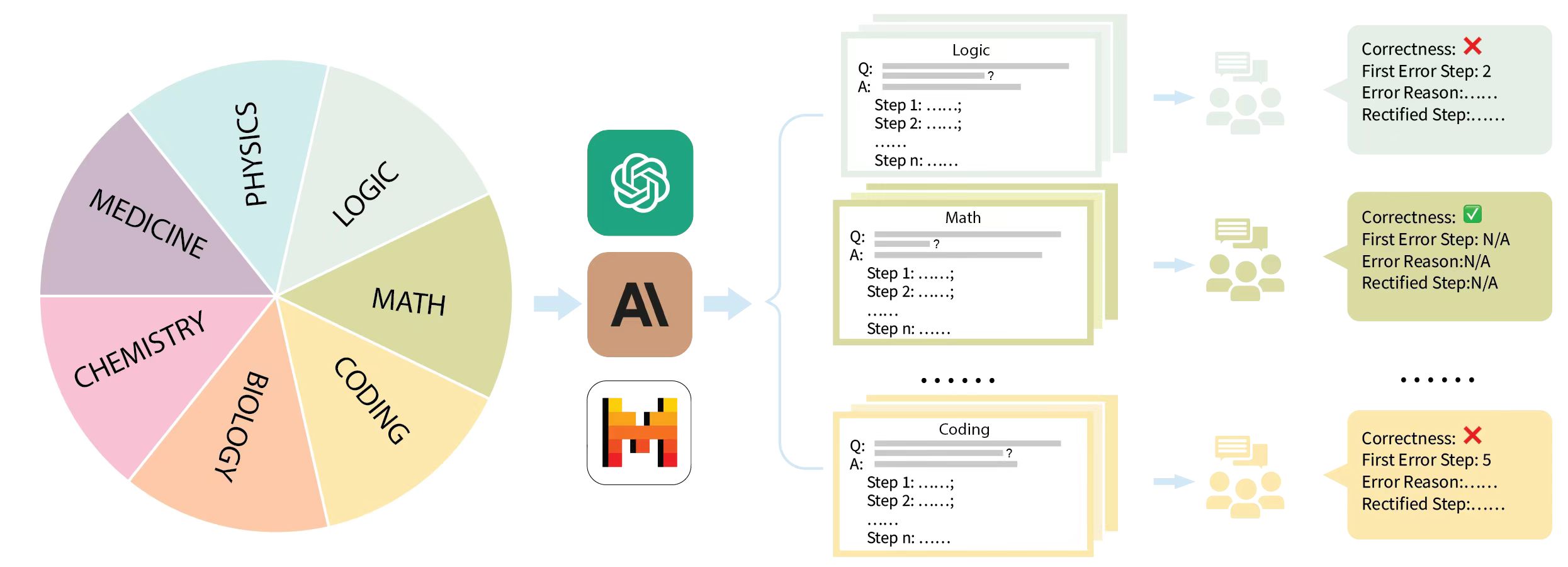
### Visual Description
## Diagram: Multi-Domain AI Reasoning Evaluation Pipeline
### Overview
This image is a process flow diagram illustrating a methodology for evaluating Large Language Models (LLMs) on complex, multi-step reasoning tasks across various scientific and technical domains. The flow moves from left to right, starting with a diverse dataset of domain-specific questions, passing them through specific AI models to generate step-by-step answers, and concluding with human evaluation to identify and rectify specific logical errors within the generated steps.
### Components Isolation & Spatial Grounding
The diagram is divided into four distinct vertical sections, flowing from left to right, connected by light blue arrows:
1. **Far Left (Input Domain):** A segmented pie chart representing the subject matter dataset.
2. **Center-Left (Processing):** A vertical stack of three prominent AI model logos.
3. **Center-Right (Output Generation):** Stacks of generated text cards, color-coded to match the input domains, showing step-by-step reasoning.
4. **Far Right (Evaluation):** Human annotator icons leading to color-coded evaluation result boxes detailing correctness and error localization.
---
### Content Details & Transcription
#### 1. Input Domains (Far Left)
A 7-slice pie chart. The slices appear roughly equal in size, suggesting a balanced dataset.
* **Top Right:** LOGIC (Light Green)
* **Right:** MATH (Olive Green)
* **Bottom Right:** CODING (Light Orange/Yellow)
* **Bottom:** BIOLOGY (Orange)
* **Bottom Left:** CHEMISTRY (Pink)
* **Left:** MEDICINE (Purple)
* **Top Left:** PHYSICS (Light Blue)
*Flow:* A light blue arrow points from the right edge of the pie chart to the AI models.
#### 2. AI Models (Center-Left)
Three vertically stacked, rounded-square icons representing the LLMs being evaluated:
* **Top:** OpenAI logo (White swirling geometric shape on a teal/green background).
* **Middle:** Anthropic / Claude logo (Stylized black "A" and backslash on a tan/brown background).
* **Bottom:** Mistral AI logo (Stylized "M" made of orange, red, and black blocks on a white background).
*Flow:* A light blue arrow points from these models, splitting into a large bracket `{` that encompasses the output cards to the right.
#### 3. Generated Outputs (Center-Right)
Three visible stacks of cards representing the models' outputs. The borders of these cards are color-coded to match the pie chart slices.
* **Top Stack (Light Green border - matches LOGIC):**
* Header: `Logic`
* Body Text:
```text
Q: [grey line representing text] ?
A: [grey line representing text]
Step 1: ......;
Step 2: ......;
......
Step n: ......
```
* **Middle Stack (Olive Green border - matches MATH):**
* Header: `Math`
* Body Text: Identical structure to the Logic card (Q, A, Step 1 to Step n).
* **Separator:** Six black dots (`......`) indicating omitted categories (likely Biology, Chemistry, Medicine, Physics).
* **Bottom Stack (Light Orange/Yellow border - matches CODING):**
* Header: `Coding`
* Body Text: Identical structure to the Logic card.
*Flow:* A light blue arrow points from each card stack to an icon of three human figures with a chat bubble (representing human annotators/evaluators).
#### 4. Human Evaluation Results (Far Right)
Arrows point from the human annotator icons to evaluation boxes. These boxes share the background color of their corresponding domain.
* **Top Box (Light Green background - Logic Evaluation):**
```text
Correctness: ❌
First Error Step: 2
Error Reason:......
Rectified Step:......
```
* **Middle Box (Olive Green background - Math Evaluation):**
```text
Correctness: ✅
First Error Step: N/A
Error Reason:N/A
Rectified Step:N/A
```
* **Separator:** Six black dots (`......`) aligning with the omitted categories.
* **Bottom Box (Light Orange/Yellow background - Coding Evaluation):**
```text
Correctness: ❌
First Error Step: 5
Error Reason:......
Rectified Step:......
```
---
### Key Observations
* **Color-Coding Consistency:** There is a strict visual mapping using color. The "Logic" slice in the pie chart is light green, the generated output cards for Logic have a light green border, and the final evaluation box for Logic has a light green background. This pattern holds true for Math (olive green) and Coding (yellow/orange).
* **Chain-of-Thought Structure:** The generated outputs explicitly use a "Step 1, Step 2... Step n" format. This indicates the models are prompted to use Chain-of-Thought (CoT) reasoning rather than providing direct answers.
* **Granular Evaluation:** The evaluation metrics go beyond simple binary pass/fail (`Correctness: ✅ / ❌`). When an answer is incorrect, the evaluators identify the exact point of failure (`First Error Step`), explain why it failed (`Error Reason`), and provide the correct logical step (`Rectified Step`).
---
### Interpretation
This diagram outlines a sophisticated framework for benchmarking the reasoning capabilities of state-of-the-art Large Language Models (specifically OpenAI, Anthropic, and Mistral models).
**Reading between the lines (Peircean investigative analysis):**
1. **Process-Based vs. Outcome-Based Evaluation:** The inclusion of "First Error Step" and "Rectified Step" strongly suggests this methodology is designed to create or utilize a **Process Reward Model (PRM)** dataset. Instead of just grading the final answer (Outcome Reward Model), this approach evaluates the *trajectory* of the model's logic. This is crucial for complex STEM fields (Physics, Math, Coding) where a single arithmetic mistake in Step 2 can ruin a perfectly logical 10-step deduction.
2. **Human-in-the-Loop (HITL):** The explicit inclusion of human annotator icons indicates that automated evaluation (using another LLM as a judge) is deemed insufficient for this level of logical scrutiny. Human experts are required to trace the logic and pinpoint the exact moment the AI hallucinates or makes a logical leap.
3. **Dataset Creation:** Because the evaluation includes a "Rectified Step," this pipeline is not just testing models; it is actively generating a high-quality, human-corrected dataset. This corrected data can subsequently be used to fine-tune future models, teaching them not just what the right answer is, but how to correct their specific logical missteps in various scientific domains.
</details>
Figure 6: This is the illustration of the dataset creation pipeline of MR-Ben . We first compile a set of questions from different subjects and then collect solutions from different LLMs. For each subject, a group of domain experts is recruited to annotate each question solution pair on its solution correctness, first error step, and error reasons.
<details>
<summary>x6.png Details</summary>
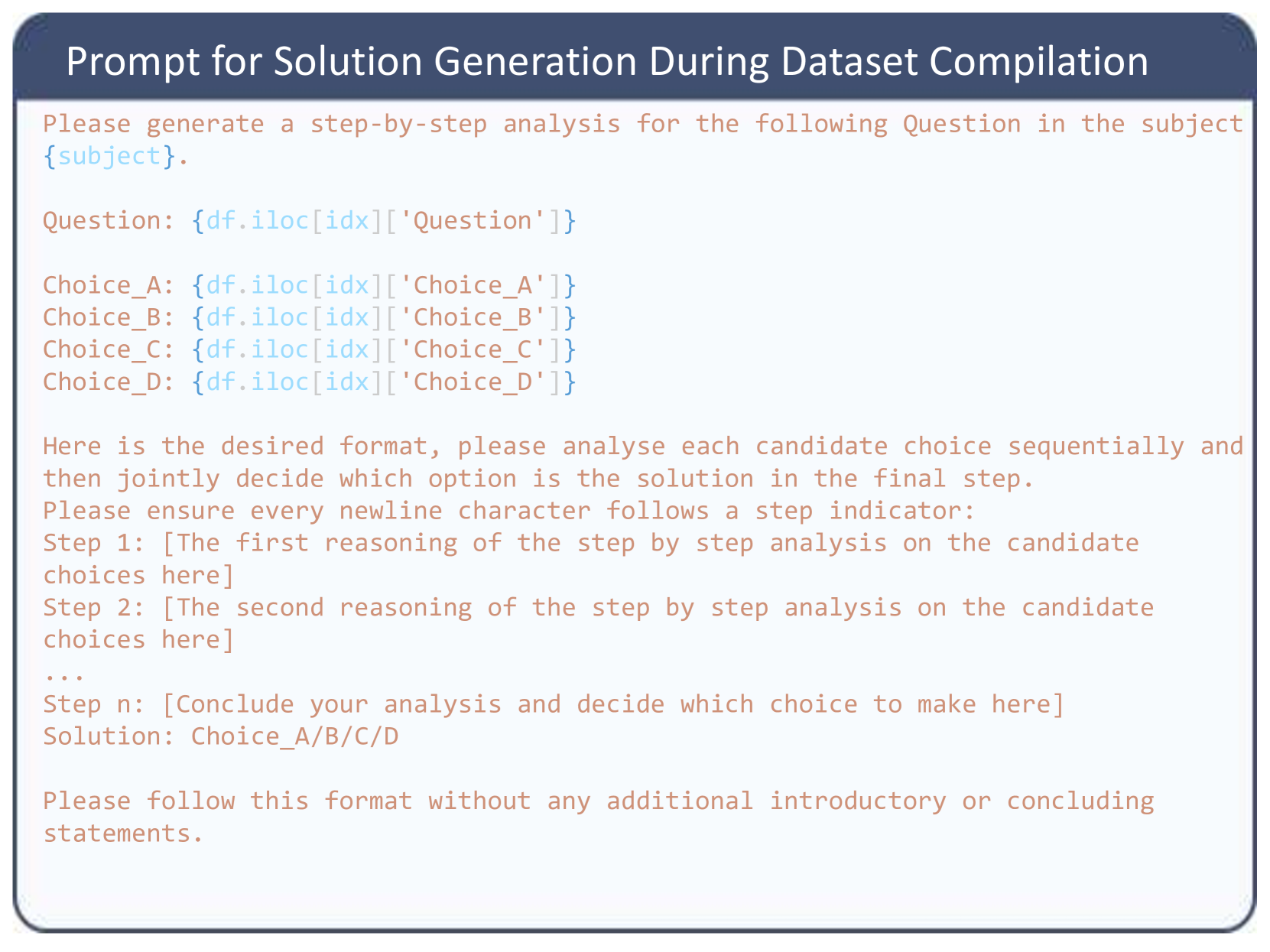
### Visual Description
## Text Block / Prompt Template: Prompt for Solution Generation During Dataset Compilation
### Overview
This image displays a structured text block representing a prompt template used in artificial intelligence and machine learning. Specifically, it is an instruction set designed to be fed into a Large Language Model (LLM) to automatically generate step-by-step reasoning (Chain-of-Thought) for multiple-choice questions. The image contains no charts, graphs, or data tables; it consists entirely of formatted text within a graphical user interface (GUI) style container.
### Components/Layout
The image is divided into two primary spatial regions:
1. **Header (Top):** A dark blue rectangular banner spanning the width of the image containing white text.
2. **Main Body (Center to Bottom):** A larger rectangular area with a white/very light gray background and a rounded border. The text inside uses a monospaced or typewriter-style font and is color-coded:
* **Salmon/Reddish-Brown Text:** Represents static instructions and formatting templates that remain constant.
* **Light Blue Text:** Represents dynamic variables or code snippets that will be injected into the prompt programmatically.
### Content Details (Transcription)
**Header Text:**
Prompt for Solution Generation During Dataset Compilation
**Main Body Text:**
*(Note: Text in `[brackets]` indicates the light blue variable text in the original image; the rest is the salmon-colored static text).*
Please generate a step-by-step analysis for the following Question in the subject `[{subject}]`.
Question: `[{df.iloc[idx]['Question']}]`
Choice_A: `[{df.iloc[idx]['Choice_A']}]`
Choice_B: `[{df.iloc[idx]['Choice_B']}]`
Choice_C: `[{df.iloc[idx]['Choice_C']}]`
Choice_D: `[{df.iloc[idx]['Choice_D']}]`
Here is the desired format, please analyse each candidate choice sequentially and then jointly decide which option is the solution in the final step.
Please ensure every newline character follows a step indicator:
Step 1: [The first reasoning of the step by step analysis on the candidate choices here]
Step 2: [The second reasoning of the step by step analysis on the candidate choices here]
...
Step n: [Conclude your analysis and decide which choice to make here]
Solution: Choice_A/B/C/D
Please follow this format without any additional introductory or concluding statements.
### Key Observations
* **Programming Syntax:** The light blue variables utilize standard Python syntax, specifically the Pandas library. `df.iloc[idx]['ColumnName']` indicates that a script is iterating through a DataFrame (`df`) using an index (`idx`) to extract specific strings for the 'Question' and the four choices ('Choice_A' through 'Choice_D').
* **Strict Formatting Constraints:** The prompt explicitly forbids "additional introductory or concluding statements" (often referred to as "chatty" behavior in LLMs, like "Sure, I can help with that!"). It also strictly mandates how newline characters should be used.
* **Chain-of-Thought Elicitation:** The prompt forces the model to generate "Step 1", "Step 2", etc., before arriving at the final "Solution".
### Interpretation
This image provides a behind-the-scenes look at how synthetic datasets are created for training or fine-tuning AI models.
**What the data demonstrates:**
The creators of this dataset already have a database (likely a CSV or Parquet file loaded as a Pandas DataFrame) containing subjects, questions, and multiple-choice options. However, they lack the *reasoning* (the "why") behind the correct answers. They are using a capable LLM (like GPT-4 or Claude) to act as a "teacher" to generate this missing reasoning.
**How the elements relate:**
A Python script will loop through the database. For row 1, it will replace `{subject}`, `{df.iloc[idx]['Question']}`, etc., with the actual text from the database. It sends this completed text to an LLM. The LLM reads the strict formatting rules and outputs a highly structured, step-by-step explanation ending with the correct choice. The script then saves this output back into the database.
**Why it matters (Peircean investigative reading):**
The extreme strictness of the formatting instructions ("ensure every newline character follows a step indicator", "without any additional introductory... statements") reveals a common pain point in AI engineering: parsing LLM outputs. If the LLM generates conversational filler, the automated script trying to extract the reasoning and the final answer will break. By forcing a rigid structure, the engineers ensure they can use simple Regular Expressions (Regex) or string splitting to separate the reasoning steps from the final answer, thereby creating a clean, high-quality dataset that can be used to train smaller, less capable models to reason better.
</details>
Figure 7: This is the prompt we used for solution generation during the dataset compilation stage. Note that besides coding, every subject question in our dataset takes the form of multiple choice problem.
<details>
<summary>x7.png Details</summary>

### Visual Description
## Text Block: Three-Round Interaction Prompt Template for Self-Refine
### Overview
The image displays a structured text document, specifically a prompt template designed for interacting with a Large Language Model (LLM). It outlines a three-step (or three-round) methodology where an AI model is instructed to evaluate a solution, critique its own evaluation, and subsequently generate an improved, self-refined response.
### Components and Layout
The image is composed of two primary spatial regions:
1. **Header (Top):** A dark blue rectangular banner spanning the full width of the image. It contains the main title in a white, sans-serif font.
2. **Main Body (Center to Bottom):** A light blue/off-white rectangular area with rounded bottom corners, enclosed by a thin dark blue border. This section contains the prompt instructions and placeholders. The text is rendered in a reddish-brown/coral color using a monospaced font, visually distinguishing it as code or a system prompt.
### Content Details (Transcription)
Below is the exact transcription of the text within the image, maintaining the structural flow and placeholders (indicated by curly braces `{}`).
**Header Text:**
> Three-Round Interaction Prompt Template for Self-Refine
**Main Body Text:**
```text
Following is a question/solution pair in subject {sol['Subject']}. Your task is
to examine the solutions step by step and determine the solution correctness.
If the solution is incorrect, please further find out the first error step and
explain the error reason.
. . . . .
{Generated Response From Evaluated Model}
Review your previous answer and find problems with your answer
{Review Response From Evaluated Model}
Based on the problems you found, improve your answer.
Please follow the desired response format:
. . . . .
{Self-Refined Response From Evaluated Model}
```
### Key Observations
* **Programmatic Placeholders:** The text utilizes curly braces `{}` to denote variables that will be dynamically injected by a script.
* `{sol['Subject']}` indicates a dictionary or JSON object named `sol` is being accessed for a specific subject category.
* The other placeholders (`{Generated Response...}`, `{Review Response...}`, `{Self-Refined Response...}`) represent the outputs generated by the LLM at each stage of the interaction, which are appended to the prompt history for the next round.
* **Sequential Logic:** The prompt forces a specific chronological workflow:
1. **Evaluate:** Check step-by-step correctness and isolate the *first* error.
2. **Critique:** Review the initial evaluation for flaws.
3. **Refine:** Output a corrected evaluation based on the critique.
* **Formatting Indicators:** The use of `. . . . .` suggests omitted text in this visual representation, likely where specific formatting instructions or the actual question/solution pair would be inserted in the live code.
### Interpretation
This image demonstrates an advanced prompt engineering technique known as "Self-Refinement" or "Self-Correction."
**What the data suggests:**
The template is designed to mitigate common LLM hallucinations or logical errors by forcing the model to slow down and review its own work. By explicitly asking the model to "find problems with your answer" in a separate, isolated step, it breaks the model's tendency toward confirmation bias (where an LLM will stubbornly defend its initial, sometimes incorrect, output).
**How the elements relate:**
The structure implies an automated pipeline (likely written in Python, given the dictionary syntax `sol['Subject']`). A script feeds a question to the model, captures the `Generated Response`, appends the "Review your previous answer..." text, sends it back to the model, captures the `Review Response`, appends the final instruction, and captures the `Self-Refined Response`.
**Investigative Reading:**
The specific instruction to "find out the first error step" is highly indicative of tasks involving mathematics, logic puzzles, or coding. In these domains, a single early error cascades into a completely wrong final answer. By forcing the model to identify the *exact point of failure* rather than just stating "it is wrong," the prompt ensures a higher quality, more explainable evaluation. This template is likely used in "LLM-as-a-Judge" scenarios, where one AI is being used to grade the outputs of another AI, or to generate high-quality synthetic training data.
</details>
Figure 8: This is the prompt we used for self-refine experiment, note that three consecutive inference calls are made in order to perform the most basic self correction.
<details>
<summary>x8.png Details</summary>
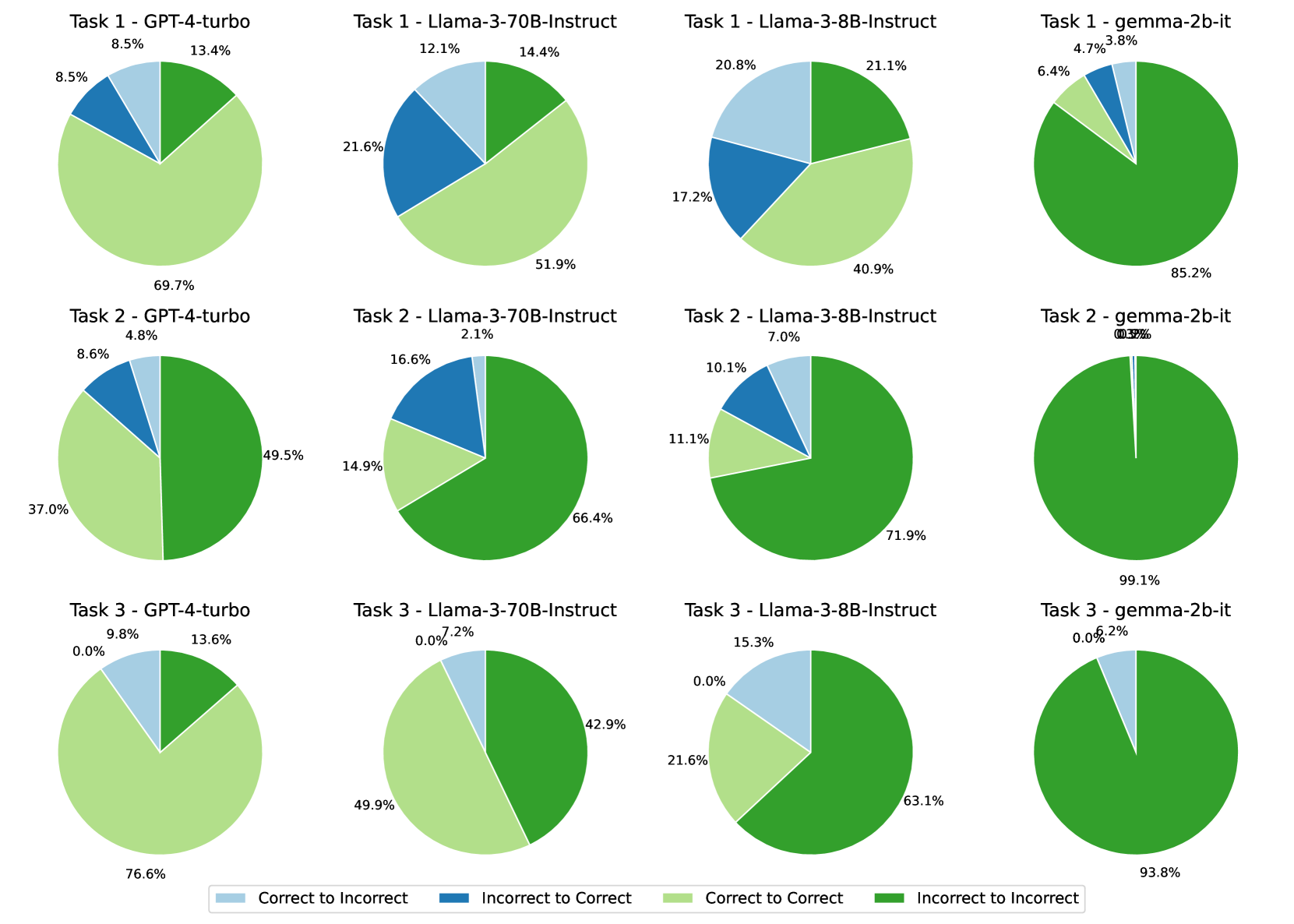
### Visual Description
## Pie Chart Grid: Model Performance State Transitions Across Tasks
### Overview
This image displays a 3x4 grid of pie charts comparing the performance of four different Large Language Models (LLMs) across three distinct tasks. The charts visualize state transitions—specifically, how a model's answer changes correctness between two states (e.g., an initial answer versus a self-corrected answer, or a base model versus an aligned model). The data illustrates varying degrees of baseline accuracy, successful correction, and negative regression across the models and tasks.
### Components/Axes
The image is divided into three main spatial regions: the Grid (Main Chart area), the Column/Row Headers, and the Legend (Footer).
**1. Layout & Headers (Spatial Grounding: Top and Left)**
* **Rows (Tasks):** The grid is divided into three horizontal rows labeled "Task 1", "Task 2", and "Task 3".
* **Columns (Models):** The grid is divided into four vertical columns representing the models tested, ordered generally from largest/most capable to smallest:
* Column 1: `GPT-4-turbo`
* Column 2: `Llama-3-70B-Instruct`
* Column 3: `Llama-3-8B-Instruct`
* Column 4: `gemma-2b-it`
**2. Legend (Spatial Grounding: Bottom Center)**
A horizontal legend at the bottom of the image defines the four colors used in the pie charts. These represent the transition of an answer's state:
* **Light Blue square:** `Correct to Incorrect` (Regression)
* **Dark Blue square:** `Incorrect to Correct` (Improvement)
* **Light Green square:** `Correct to Correct` (Maintained Accuracy)
* **Dark Green square:** `Incorrect to Incorrect` (Persistent Failure)
---
### Detailed Analysis & Content Details
*Trend Verification Methodology:* For each row, the visual distribution of colors is described from left to right to establish the trend before extracting the precise numerical percentages. Slices generally follow a clockwise placement starting from the top/top-right for Dark Green, bottom for Light Green, left for Dark Blue, and top-left for Light Blue.
#### Row 1: Task 1
* **Visual Trend:** Moving from left to right, the Light Green area (Correct to Correct) shrinks drastically, while the Dark Green area (Incorrect to Incorrect) expands to dominate the chart. The blue slices (state changes) are most prominent in the middle two Llama models.
* **GPT-4-turbo:** Dominated by Light Green (bottom).
* Correct to Incorrect (Light Blue): 8.5%
* Incorrect to Correct (Dark Blue): 8.5%
* Correct to Correct (Light Green): 69.7%
* Incorrect to Incorrect (Dark Green): 13.4%
* **Llama-3-70B-Instruct:** Light Green is roughly half; Dark Blue is a significant quarter.
* Correct to Incorrect (Light Blue): 12.1%
* Incorrect to Correct (Dark Blue): 21.6%
* Correct to Correct (Light Green): 51.9%
* Incorrect to Incorrect (Dark Green): 14.4%
* **Llama-3-8B-Instruct:** Light Green and Dark Green are roughly equal; Light Blue is prominent.
* Correct to Incorrect (Light Blue): 20.8%
* Incorrect to Correct (Dark Blue): 17.2%
* Correct to Correct (Light Green): 40.9%
* Incorrect to Incorrect (Dark Green): 21.1%
* **gemma-2b-it:** Overwhelmingly Dark Green.
* Correct to Incorrect (Light Blue): 3.8%
* Incorrect to Correct (Dark Blue): 4.7%
* Correct to Correct (Light Green): 6.4%
* Incorrect to Incorrect (Dark Green): 85.2%
#### Row 2: Task 2
* **Visual Trend:** Across all models, Task 2 shows a massive increase in Dark Green compared to Task 1, indicating higher difficulty. GPT-4-turbo is split nearly in half between green shades. Gemma is almost entirely a solid Dark Green circle.
* **GPT-4-turbo:** Dark Green takes up the right half; Light Green the bottom left.
* Correct to Incorrect (Light Blue): 4.8%
* Incorrect to Correct (Dark Blue): 8.6%
* Correct to Correct (Light Green): 37.0%
* Incorrect to Incorrect (Dark Green): 49.5%
* **Llama-3-70B-Instruct:** Dark Green dominates the right and bottom.
* Correct to Incorrect (Light Blue): 2.1%
* Incorrect to Correct (Dark Blue): 16.6%
* Correct to Correct (Light Green): 14.9%
* Incorrect to Incorrect (Dark Green): 66.4%
* **Llama-3-8B-Instruct:** Similar to the 70B model, but with slightly more Dark Green.
* Correct to Incorrect (Light Blue): 7.0%
* Incorrect to Correct (Dark Blue): 10.1%
* Correct to Correct (Light Green): 11.1%
* Incorrect to Incorrect (Dark Green): 71.9%
* **gemma-2b-it:** Visually a solid Dark Green circle. The labels for the blue slices overlap at the top.
* Correct to Incorrect (Light Blue): 0.3%
* Incorrect to Correct (Dark Blue): 0.5%
* Correct to Correct (Light Green): 0.0% (Implied by absence)
* Incorrect to Incorrect (Dark Green): 99.1%
#### Row 3: Task 3
* **Visual Trend:** The most striking visual anomaly occurs here: the Dark Blue slice (Incorrect to Correct) completely vanishes from the first three models. Light Green recovers somewhat for GPT-4 and Llama-70B compared to Task 2.
* **GPT-4-turbo:** Mostly Light Green, with a notable Light Blue slice.
* Correct to Incorrect (Light Blue): 9.8%
* Incorrect to Correct (Dark Blue): 0.0%
* Correct to Correct (Light Green): 76.6%
* Incorrect to Incorrect (Dark Green): 13.6%
* **Llama-3-70B-Instruct:** Split almost evenly between Light Green and Dark Green.
* Correct to Incorrect (Light Blue): 7.2%
* Incorrect to Correct (Dark Blue): 0.0%
* Correct to Correct (Light Green): 49.9%
* Incorrect to Incorrect (Dark Green): 42.9%
* **Llama-3-8B-Instruct:** Dark Green dominates, with a significant Light Blue slice.
* Correct to Incorrect (Light Blue): 15.3%
* Incorrect to Correct (Dark Blue): 0.0%
* Correct to Correct (Light Green): 21.6%
* Incorrect to Incorrect (Dark Green): 63.1%
* **gemma-2b-it:** Almost entirely Dark Green, with a small Light Blue slice.
* Correct to Incorrect (Light Blue): 6.2%
* Incorrect to Correct (Dark Blue): 0.0%
* Correct to Correct (Light Green): 0.0%
* Incorrect to Incorrect (Dark Green): 93.8%
#### Reconstructed Data Table
| Task | Model | Correct -> Incorrect (Light Blue) | Incorrect -> Correct (Dark Blue) | Correct -> Correct (Light Green) | Incorrect -> Incorrect (Dark Green) |
| :--- | :--- | :--- | :--- | :--- | :--- |
| **Task 1** | GPT-4-turbo | 8.5% | 8.5% | 69.7% | 13.4% |
| | Llama-3-70B-Instruct | 12.1% | 21.6% | 51.9% | 14.4% |
| | Llama-3-8B-Instruct | 20.8% | 17.2% | 40.9% | 21.1% |
| | gemma-2b-it | 3.8% | 4.7% | 6.4% | 85.2% |
| **Task 2** | GPT-4-turbo | 4.8% | 8.6% | 37.0% | 49.5% |
| | Llama-3-70B-Instruct | 2.1% | 16.6% | 14.9% | 66.4% |
| | Llama-3-8B-Instruct | 7.0% | 10.1% | 11.1% | 71.9% |
| | gemma-2b-it | 0.3% | 0.5% | 0.0% | 99.1% |
| **Task 3** | GPT-4-turbo | 9.8% | 0.0% | 76.6% | 13.6% |
| | Llama-3-70B-Instruct | 7.2% | 0.0% | 49.9% | 42.9% |
| | Llama-3-8B-Instruct | 15.3% | 0.0% | 21.6% | 63.1% |
| | gemma-2b-it | 6.2% | 0.0% | 0.0% | 93.8% |
---
### Key Observations
1. **Model Capability Hierarchy:** There is a clear correlation between presumed model size/capability and performance. GPT-4-turbo consistently has the highest "Correct to Correct" (Light Green) rates. Gemma-2b-it consistently has the highest "Incorrect to Incorrect" (Dark Green) rates, failing almost entirely on Tasks 2 and 3.
2. **Task Difficulty:** Task 2 is universally the most difficult task. Even GPT-4-turbo drops from 69.7% baseline accuracy (Task 1) to 37.0% (Task 2).
3. **The Task 3 Anomaly:** In Task 3, the "Incorrect to Correct" (Dark Blue) metric drops to exactly 0.0% across all four models. None of the models were able to transition a wrong answer to a right answer in this specific task.
4. **Llama's Volatility in Task 1:** The Llama models show the highest rates of state transition (both blue slices) in Task 1. Llama-3-70B successfully corrected itself 21.6% of the time, but also broke correct answers 12.1% of the time.
### Interpretation
This chart likely visualizes an experiment involving a two-pass LLM system—such as a model generating an initial answer, and then being prompted to reflect, self-correct, or use a different reasoning pathway.
* **Light Green (C->C)** represents the model's robust baseline knowledge; it knew the answer and didn't second-guess itself.
* **Dark Green (I->I)** represents a hard failure; the model lacks the knowledge or reasoning capability to solve the prompt, regardless of the second pass. Gemma-2b-it's near 100% Dark Green on Tasks 2 and 3 indicates these tasks are entirely outside its capability threshold.
* **Dark Blue (I->C)** represents the ideal outcome of a self-correction or multi-agent workflow: the model successfully identified and fixed its own error. Llama-3-70B is notably the best at this specific behavior (Task 1 and 2).
* **Light Blue (C->I)** represents negative interference or "hallucination" during reflection. The model had the right answer but was talked out of it (or talked itself out of it) during the second pass.
**Peircean Investigative Reading:** The most fascinating data point is the 0.0% "Incorrect to Correct" rate across all models in Task 3. This suggests a fundamental characteristic of Task 3's design. It is likely a "brittle" task—perhaps a strict logic puzzle, a math problem with a specific trap, or a task where the evaluation metric is unforgiving. The data shows that if a model gets Task 3 wrong on the first try, the secondary intervention *cannot* save it. Furthermore, because the "Correct to Incorrect" (Light Blue) slice still exists in Task 3 (ranging from 6.2% to 15.3%), the secondary intervention is actively harmful to models that initially got it right. This implies that whatever prompting strategy is being tested for self-correction is highly ineffective, and potentially detrimental, for the specific cognitive demands of Task 3.
</details>
Figure 9: This is the performance breakdown for self-refine experiment in the task level, where task 1,2,3 refers to solution correctness, first error step and error reason determination.
<details>
<summary>x9.png Details</summary>
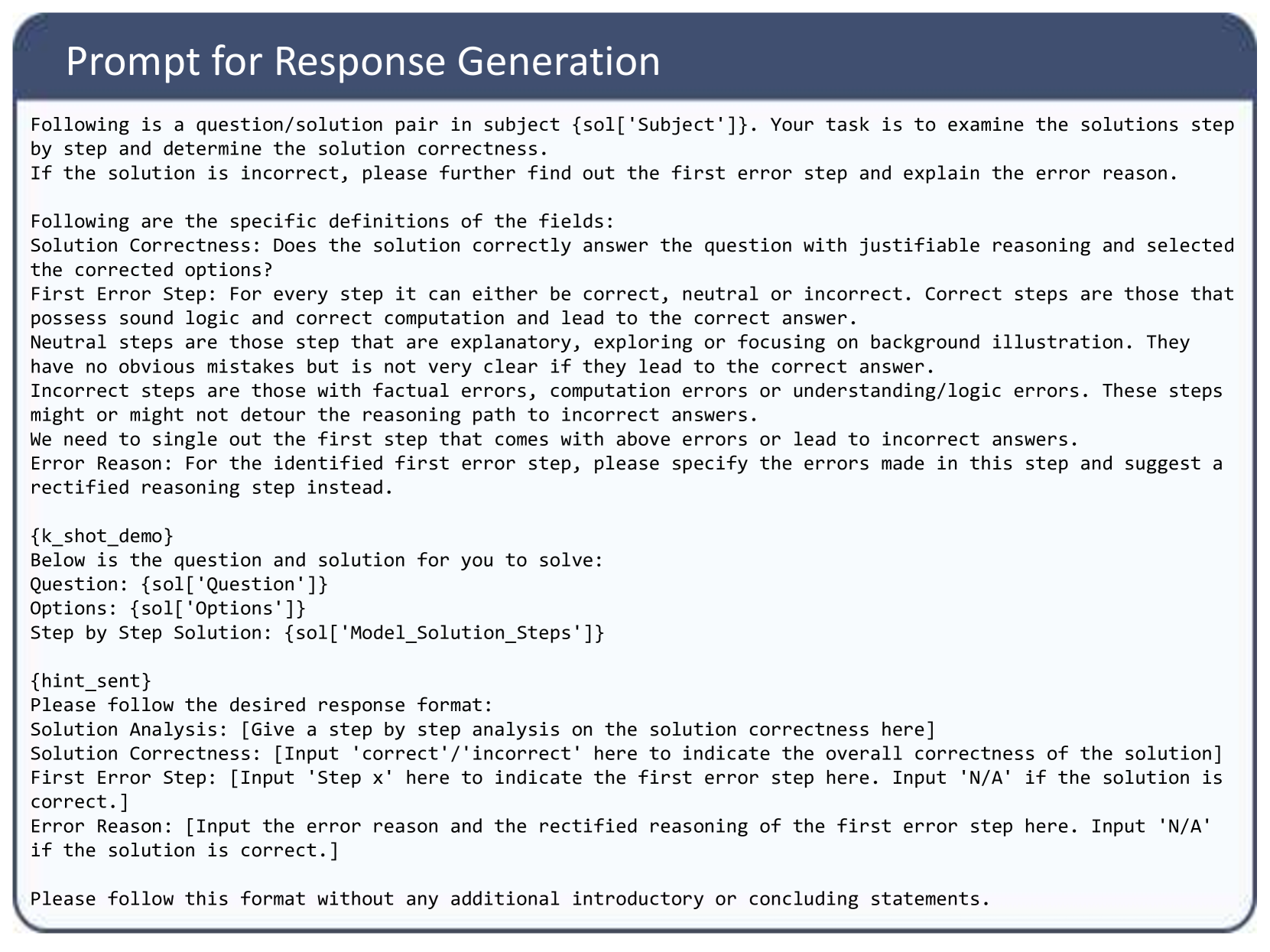
### Visual Description
## Text Block: Prompt for Response Generation
### Overview
The image displays a screenshot of a structured text prompt designed for an Artificial Intelligence system, specifically a Large Language Model (LLM). The prompt instructs the AI to act as an evaluator. Its task is to analyze a provided multiple-choice question and a step-by-step solution, determine the overall correctness, identify the specific step where the first error occurs (if any), and provide a reason and correction for that error.
### Components and Layout
The image is composed of two main visual regions:
* **Header (Top):** A dark blue rectangular banner spanning the width of the image. It contains the title text aligned to the left in a white, sans-serif font.
* **Main Body (Center to Bottom):** A light gray/white rectangular area enclosed by a thin dark border. It contains the main instructional text in a black, monospaced or simple sans-serif font.
The text itself is structured into four logical sections:
1. **Task Introduction:** Defines the role and primary objective.
2. **Definitions:** Provides strict criteria for evaluating steps as "correct," "neutral," or "incorrect."
3. **Data Injection Points:** Placeholders where the specific question, options, and solution will be inserted programmatically.
4. **Output Formatting:** Strict instructions on how the AI must format its response.
### Content Details (Full Transcription)
Below is the exact transcription of the text contained within the image. Note the presence of programmatic variables enclosed in curly braces `{}`.
**[Header Text]**
Prompt for Response Generation
**[Main Body Text]**
Following is a question/solution pair in subject {sol['Subject']}. Your task is to examine the solutions step by step and determine the solution correctness.
If the solution is incorrect, please further find out the first error step and explain the error reason.
Following are the specific definitions of the fields:
Solution Correctness: Does the solution correctly answer the question with justifiable reasoning and selected the corrected options?
First Error Step: For every step it can either be correct, neutral or incorrect. Correct steps are those that possess sound logic and correct computation and lead to the correct answer.
Neutral steps are those step that are explanatory, exploring or focusing on background illustration. They have no obvious mistakes but is not very clear if they lead to the correct answer.
Incorrect steps are those with factual errors, computation errors or understanding/logic errors. These steps might or might not detour the reasoning path to incorrect answers.
We need to single out the first step that comes with above errors or lead to incorrect answers.
Error Reason: For the identified first error step, please specify the errors made in this step and suggest a rectified reasoning step instead.
{k_shot_demo}
Below is the question and solution for you to solve:
Question: {sol['Question']}
Options: {sol['Options']}
Step by Step Solution: {sol['Model_Solution_Steps']}
{hint_sent}
Please follow the desired response format:
Solution Analysis: [Give a step by step analysis on the solution correctness here]
Solution Correctness: [Input 'correct'/'incorrect' here to indicate the overall correctness of the solution]
First Error Step: [Input 'Step x' here to indicate the first error step here. Input 'N/A' if the solution is correct.]
Error Reason: [Input the error reason and the rectified reasoning of the first error step here. Input 'N/A' if the solution is correct.]
Please follow this format without any additional introductory or concluding statements.
### Key Observations
* **Programmatic Placeholders:** The text utilizes Python-style dictionary formatting (e.g., `{sol['Subject']}`, `{sol['Question']}`). This indicates that this text is a template used in a software pipeline. A script will replace these variables with actual data before sending the prompt to the AI model.
* **Few-Shot Capability:** The inclusion of the `{k_shot_demo}` variable suggests the system is designed to optionally provide the AI with examples of correctly completed evaluations before asking it to perform the task, a technique known to improve accuracy.
* **Nuanced Evaluation Criteria:** The prompt does not treat reasoning as strictly binary. It introduces the concept of "Neutral steps" (explanatory or background information), which prevents the AI from falsely flagging non-mathematical/non-logical setup text as an error.
* **Strict Output Constraints:** The final sentence explicitly forbids "additional introductory or concluding statements." This is a standard prompt engineering technique to prevent LLMs from generating conversational filler (e.g., "Sure, I can help with that! Here is the analysis..."), ensuring the output can be easily parsed by a computer script.
### Interpretation
This image represents a "meta-evaluation" prompt. It is not meant for a human to read; rather, it is the instruction manual for an AI model that is being used to grade the output of *another* AI model (or potentially human-generated data).
**What the data demonstrates:**
This prompt is likely part of an automated benchmarking system or a Reinforcement Learning from Human Feedback (RLHF) pipeline. By asking an advanced model (like GPT-4) to evaluate the step-by-step reasoning of a lesser model, developers can automatically score the lesser model's performance on complex reasoning tasks (like math or logic).
**Reading between the lines:**
The structure of the requested response format is highly intentional. By forcing the AI to output the `Solution Analysis` *before* it outputs the `Solution Correctness`, the prompt employs a "Chain-of-Thought" (CoT) strategy. It forces the evaluating AI to "think out loud" and process the logic step-by-step before rendering a final verdict. If the prompt asked for `Solution Correctness` first, the AI would have to guess the answer before doing the work, leading to higher hallucination and error rates. The meticulous definition of "Neutral steps" indicates that previous iterations of this prompt likely failed because the evaluating AI was too aggressive in marking explanatory text as incorrect.
</details>
Figure 10: This is the prompt template we used to evaluate all the models. The k-shot-demo and hint-sent are either the few shot examples and solution correctness prior or empty string, depending on the experiment setup.
<details>
<summary>x10.png Details</summary>
### Visual Description
## Text Block / Prompt Template: Prompt for Scoring Error Reasons
### Overview
The image displays a presentation slide or a screenshot of a text block containing a structured prompt template. This template is designed to be fed into a Large Language Model (LLM) to act as an automated evaluator (LLM-as-a-judge). The prompt instructs the AI to adopt the persona of a teacher to evaluate whether a student correctly identified the reason for an error in a given problem's solution.
### Components
The image is visually divided into two main spatial regions:
1. **Header (Top):** A dark blue rectangular banner spanning the width of the image, containing white, sans-serif text.
2. **Main Body (Center to Bottom):** A white rectangular area with a light blue/grey rounded border. It contains the body of the prompt written in a monospaced, typewriter-style font colored in a light reddish-brown/salmon hue.
The text itself contains **Variables** formatted in a syntax resembling Python dictionary or JSON data extraction (e.g., `{data['Key']}`).
### Content Details
Here is the precise transcription of the text within the image, maintaining the original formatting and variable placeholders:
**[Header Text]**
Prompt for Scoring Error Reasons
**[Main Body Text]**
As an experienced `{data['Subject']}` teacher, your assistance is required to evaluate a student's explanation regarding the error in a problem solution. The task involves a detailed understanding of the problem, the incorrect solution provided, and the ground truth behind the error. Your analysis should focus on whether the student's explanation aligns with the actual error in the solution.
Please find the details below:
- Question: `{data['Question']}`
- Incorrect Solution Provided: `{data['Model_Solution_Steps']}`
- First Incorrect Step in the Solution: `{data['Model_Solution_First_Error_Step']}`
- Ground Truth Error Reasons: `{data['Model_Solution_Error_Reason']}`
- Ground Truth Rectified Steps: `{data['Model_Solution_Rectified_First_Error_Step']}`
- Student's Explanation of the Error: `{data['Evaluation_Result']['error_reason']}`
Based on this information, please provide the following:
1. Step-by-Step Reasoning: [Offer a succinct, step-by-step interpretation of the ground truth error reason.]
2. Student Error Reason Analysis: [Analyze the student's explanation step by step, determining its accuracy in reflecting the actual error briefly.]
3. Final Decision: [State only 'Correct' or 'Wrong' to conclude whether the student's explanation correctly identifies the error based on your analysis.]
Please follow this format without any additional introductory or concluding statements.
### Key Observations
* **Dynamic Data Injection:** The prompt relies heavily on dynamic variables (indicated by `{data[...]}`). This proves the text is a template used in an automated pipeline, likely a Python script iterating over a dataset of student answers.
* **Persona Adoption:** The prompt begins by assigning a role ("experienced `{data['Subject']}` teacher") to set the context and tone for the AI's evaluation.
* **Chain-of-Thought Prompting:** The requested output format (Steps 1, 2, and 3) forces the model to explain its reasoning *before* arriving at a final decision. This is a well-known prompt engineering technique to increase the accuracy of LLM outputs.
* **Strict Output Constraints:** The final sentence explicitly forbids "introductory or concluding statements" (often referred to as "chatty" behavior in LLMs), ensuring the output can be easily parsed by a computer program looking for the specific numbered list and the binary 'Correct'/'Wrong' string.
### Interpretation
This image reveals the backend methodology of an automated educational assessment system.
**What the data suggests:** The creators of this system are using an AI to grade students, but rather than asking the AI to solve the math/logic problem from scratch, they are providing the AI with the "Ground Truth" (the correct answer and the exact reason for the error). The AI's *only* job is to compare the student's written explanation against this provided ground truth.
**Reading between the lines (Peircean investigative):**
1. The variable naming convention (`Model_Solution_Steps`, `Model_Solution_First_Error_Step`) strongly implies that the "Incorrect Solution" being evaluated was actually generated by an AI model initially, and the "Student" is likely evaluating the AI's mistake. This suggests a workflow related to Reinforcement Learning from Human Feedback (RLHF) or a platform where students learn by critiquing AI-generated errors.
2. The nested variable `{data['Evaluation_Result']['error_reason']}` suggests a complex data structure (like a nested JSON object) is being passed into the prompt formatting engine.
3. The strict formatting request at the end is a defensive measure against LLM "hallucinations" or formatting inconsistencies, which would break the regular expressions (Regex) or parsing scripts used to extract the final 'Correct' or 'Wrong' grade into a database.
</details>
Figure 11: This is the prompt template we used to request GPT-4 to help us score the error reasons explained by evaluated models. Note that despite the difficulties of deciding the solution correctness, it is much easier to decide the error reason correctness given the ground truth annotations.
Appendix D Evaluation Prompt
Figure- 10 is the prompt template we used to evaluate all the models in our paper. Note that with minor modifications on the following template, the evaluation results can be heavily affected. For example, by introducing a simple hint sentence "Hint: This solution is incorrect. Please focus on looking for the First Error Step and Error Reason.", the model performance can drastically improve as shown in 4. Also, by simply taking away the line of ’Solution Analysis’ in the response format part of the prompt, the evaluated model will directly output the scoring result without step-wise COT analysis on the solution. This setup will lead to a near zero MR-Score performance as discussed in Section- 5.
Figure- 7 is the prompt we used to query language models for solution generation during the dataset compilation phase. Note that in the prompt, we specifically asked the model to analyse each option in the multiple-choice problem. This is crucial in examining if the model possesses a comprehensive understanding on the topics that the question is asking.
Figure- 11 shows the prompt we used to query GPT-4 to score the error reasons returned from evaluated models. Despite the challenging nature of the original task to determine the solution correctness, it is a much easier job to determine if the error reason from the evaluated models aligns with the ground truth error reason.
Figure- 8 demonstrates the prompt template we used for self-refine experiment. Note that we followed the setting of [31] without introducing any prior assumptions or knowledge. This minimum version of extra prompting would mostly rely on the capability of language models to perform self-refine procedure.
Appendix E Self Refine Analysis
In this section, we present the results of self-refine in the task level. Specifically, we are looking at the change of labelling by the evaluated models in the determination of solution correctness as shown by Figure- 9. We summarize our observation below:
- Small Models like Gemma-2B are too limited to perform effective self-reflection.
- Competent Models like GPT4-Turbo are confident in their initial decisions, hardly switching their decisions during self-reflection.
- Intermediate Models like Llama3-70B exhibit substantial changes during self-reflection, indicating a lack of consistency in their decisions. However, its change of decisions from incorrect to correct happens to be significantly higher in locating the first error step than in examining solution correctness and explaining the error reason, therefore boosting the overall MR-Score by a large margin. We believe the lack of consistency does not necessarily indicate a more robust or advanced reasoning ability, despite the increase in the evaluation results.
- Conclusion: Our results support the observation that LLMs generally lack effective self-refinement capabilities [31].
Appendix F Error Analysis
We provide qualitative analyses of how GPT-4 as an example model performed on our benchmark across all seven subjects. The purpose is to offer a deeper understanding of the types and causes of errors made by experimented models to inform future improvements. For each subject in the subsections below, a failure case and a success case are listed. Following the MR-Ben evaluation framework, each case demonstration consists of the following parts: (1) original questions, options, ground-truth final answers, and LLM-generated CoT solutions; (2) human annotations of step-wise error detection, explanation, and correction; (3) evaluation annotation from the experimented GPT-4 on the aforementioned LLM-generated CoT solutions; (4) scoring results of the error reason if the experimented model identifies the correct first error step.
From our analysis of sampled failure cases, several general observations are made. Firstly, the assessed model GPT-4 exhibits a widely resistant ‘false positive bias’ on our benchmark across all subjects: In cases where the LLM makes incorrect evaluations, the proportion of type I errors is much higher than type II errors. In other words, GPT-4 tends to overlook the mistakes that exist in incorrect model solutions and mislabel them as correct, while seldom actively mislabeling correct model solution steps as incorrect steps. In fact, among the 42 sampled cases we surveyed spanning the seven subjects, all failure cases (size = 21) belong to the type I error category. We provide two possible explanations for such bias: (a) input bias: the implemented LLMs are instructed-tuned, and are inherently biased to follow the prompt input. Therefore, even when the models are asked to fairly judge these CoT solution steps in the prompt input in binary labels, it is likely their labeling threshold is affected and biased towards positive judgments. This is a common issue in using LLMs as generation evaluators and may be mitigated by adjusting the prompt design or other debiasing methods [42, 79]; (b) self-preference bias: it has drawn recent attention that state-of-the-art models display self-preference bias: the phenomenon in which an LLM inherently favors their own generated output over texts from other LLMs and humans [43, 54]. Therefore, the experiment results of LLMs that are under the same family of the three sampled models (GPT-3.5-Turbo-0125 [50], Claude2 [5], and Mistral-Medium [32]) may be affected. With the increasingly extensive use of self-evaluation and LLM-as-judge methods, we call for future researchers’ attention to the potential issue.
Secondly, the MR-Ben benchmark revealed many intricate cases where the assessed model GPT-4 reached a correct final answer through incorrect solution steps, challenging the models’ multi-step reasoning capabilities to a greater scale. As shown in the failure cases in math, physics, biology, etc., our benchmark evaluation is able to identify step errors that the sample model made in the solution steps even when its final answer matches the final ground-truth choice. While such step errors can be trivial in terms of generating the correct final answer in the demonstrated failure cases, they can become significant in just slightly nuanced questions, as mentioned in the error analysis section of MMLU [27]. In contrast, our framework, by decomposing the question and model solutions, remains relatively immune to the nuances in question framing. This highlights an important significance of our MR-Ben benchmark in that it is not only elaborate but also robust compared to previous benchmarks.
Lastly, there are subtle nuances of model performance in different reasoning paradigms manifest in the case demonstrations of specific subjects. They are interpreted case by case by the captioned figures listed below.
See pages - of error_analysis/all.pdf
Appendix G Computational Resources Used
In this paper, all experiments are either performed on open-source models with local inference or closed-source models with API calls. For local inference, we are using A800 machines with 8 GPUs to run the inferences. The total evaluation time on our 6k benchmark on the 70B language models typically takes around 2 hours using fast inference libraries such as vllm. For smaller language models such as Phi-3 or Gemma, the compute time is smaller.
Appendix H Annotation Guidelines
Below we provide the original annotation guidelines distributed to annotators of distinctive subjects included in the MR-Ben benchmark: math, biology, physics, chemistry, logic, medicine, and coding. The guidelines serve as the primary training material and instructions for annotators to complete the labeling tasks, specified with detailed descriptions, requirements, and standards.
See pages - of annotation_guidelines/math.pdf
See pages - of annotation_guidelines/physics.pdf
See pages - of annotation_guidelines/biology.pdf
See pages - of annotation_guidelines/medicine.pdf
See pages - of annotation_guidelines/chemistry.pdf
See pages - of annotation_guidelines/logic.pdf
See pages - of annotation_guidelines/coding.pdf
NeurIPS Paper Checklist
1. Claims
1. Question: Do the main claims made in the abstract and introduction accurately reflect the paper’s contributions and scope?
1. Answer: [Yes]
1. Justification: Yes, the main claims made in the abstract and introduction accurately reflect the paper’s contributions and scope.
1. Guidelines:
- The answer NA means that the abstract and introduction do not include the claims made in the paper.
- The abstract and/or introduction should clearly state the claims made, including the contributions made in the paper and important assumptions and limitations. A No or NA answer to this question will not be perceived well by the reviewers.
- The claims made should match theoretical and experimental results, and reflect how much the results can be expected to generalize to other settings.
- It is fine to include aspirational goals as motivation as long as it is clear that these goals are not attained by the paper.
1. Limitations
1. Question: Does the paper discuss the limitations of the work performed by the authors?
1. Answer: [Yes]
1. Justification: The limitations of this work are discussed in § A.1.
1. Guidelines:
- The answer NA means that the paper has no limitation while the answer No means that the paper has limitations, but those are not discussed in the paper.
- The authors are encouraged to create a separate "Limitations" section in their paper.
- The paper should point out any strong assumptions and how robust the results are to violations of these assumptions (e.g., independence assumptions, noiseless settings, model well-specification, asymptotic approximations only holding locally). The authors should reflect on how these assumptions might be violated in practice and what the implications would be.
- The authors should reflect on the scope of the claims made, e.g., if the approach was only tested on a few datasets or with a few runs. In general, empirical results often depend on implicit assumptions, which should be articulated.
- The authors should reflect on the factors that influence the performance of the approach. For example, a facial recognition algorithm may perform poorly when image resolution is low or images are taken in low lighting. Or a speech-to-text system might not be used reliably to provide closed captions for online lectures because it fails to handle technical jargon.
- The authors should discuss the computational efficiency of the proposed algorithms and how they scale with dataset size.
- If applicable, the authors should discuss possible limitations of their approach to address problems of privacy and fairness.
- While the authors might fear that complete honesty about limitations might be used by reviewers as grounds for rejection, a worse outcome might be that reviewers discover limitations that aren’t acknowledged in the paper. The authors should use their best judgment and recognize that individual actions in favor of transparency play an important role in developing norms that preserve the integrity of the community. Reviewers will be specifically instructed to not penalize honesty concerning limitations.
1. Theory Assumptions and Proofs
1. Question: For each theoretical result, does the paper provide the full set of assumptions and a complete (and correct) proof?
1. Answer: [N/A]
1. Justification: Our work does not involve theoretical assumptions and proofs.
1. Guidelines:
- The answer NA means that the paper does not include theoretical results.
- All the theorems, formulas, and proofs in the paper should be numbered and cross-referenced.
- All assumptions should be clearly stated or referenced in the statement of any theorems.
- The proofs can either appear in the main paper or the supplemental material, but if they appear in the supplemental material, the authors are encouraged to provide a short proof sketch to provide intuition.
- Inversely, any informal proof provided in the core of the paper should be complemented by formal proofs provided in appendix or supplemental material.
- Theorems and Lemmas that the proof relies upon should be properly referenced.
1. Experimental Result Reproducibility
1. Question: Does the paper fully disclose all the information needed to reproduce the main experimental results of the paper to the extent that it affects the main claims and/or conclusions of the paper (regardless of whether the code and data are provided or not)?
1. Answer: [Yes]
1. Justification: We disclose all the information needed to reproduce the main experimental results of the paper to the extent that it affects the main claims and conclusions of the paper, detailed in § 5.1.
1. Guidelines:
- The answer NA means that the paper does not include experiments.
- If the paper includes experiments, a No answer to this question will not be perceived well by the reviewers: Making the paper reproducible is important, regardless of whether the code and data are provided or not.
- If the contribution is a dataset and/or model, the authors should describe the steps taken to make their results reproducible or verifiable.
- Depending on the contribution, reproducibility can be accomplished in various ways. For example, if the contribution is a novel architecture, describing the architecture fully might suffice, or if the contribution is a specific model and empirical evaluation, it may be necessary to either make it possible for others to replicate the model with the same dataset, or provide access to the model. In general. releasing code and data is often one good way to accomplish this, but reproducibility can also be provided via detailed instructions for how to replicate the results, access to a hosted model (e.g., in the case of a large language model), releasing of a model checkpoint, or other means that are appropriate to the research performed.
- While NeurIPS does not require releasing code, the conference does require all submissions to provide some reasonable avenue for reproducibility, which may depend on the nature of the contribution. For example
1. If the contribution is primarily a new algorithm, the paper should make it clear how to reproduce that algorithm.
1. If the contribution is primarily a new model architecture, the paper should describe the architecture clearly and fully.
1. If the contribution is a new model (e.g., a large language model), then there should either be a way to access this model for reproducing the results or a way to reproduce the model (e.g., with an open-source dataset or instructions for how to construct the dataset).
1. We recognize that reproducibility may be tricky in some cases, in which case authors are welcome to describe the particular way they provide for reproducibility. In the case of closed-source models, it may be that access to the model is limited in some way (e.g., to registered users), but it should be possible for other researchers to have some path to reproducing or verifying the results.
1. Open access to data and code
1. Question: Does the paper provide open access to the data and code, with sufficient instructions to faithfully reproduce the main experimental results, as described in supplemental material?
1. Answer: [Yes]
1. Justification: We opensourced our evaluation benchmark and the script as described in Section- 1. Additionally, we have detailed the experimental setup in the paper (§ 5) , including model selection, hyperparameter settings, data selection, evaluation metrics, hardware resources, etc.
1. Guidelines:
- The answer NA means that paper does not include experiments requiring code.
- Please see the NeurIPS code and data submission guidelines (https://nips.cc/public/guides/CodeSubmissionPolicy) for more details.
- While we encourage the release of code and data, we understand that this might not be possible, so “No” is an acceptable answer. Papers cannot be rejected simply for not including code, unless this is central to the contribution (e.g., for a new open-source benchmark).
- The instructions should contain the exact command and environment needed to run to reproduce the results. See the NeurIPS code and data submission guidelines (https://nips.cc/public/guides/CodeSubmissionPolicy) for more details.
- The authors should provide instructions on data access and preparation, including how to access the raw data, preprocessed data, intermediate data, and generated data, etc.
- The authors should provide scripts to reproduce all experimental results for the new proposed method and baselines. If only a subset of experiments are reproducible, they should state which ones are omitted from the script and why.
- At submission time, to preserve anonymity, the authors should release anonymized versions (if applicable).
- Providing as much information as possible in supplemental material (appended to the paper) is recommended, but including URLs to data and code is permitted.
1. Experimental Setting/Details
1. Question: Does the paper specify all the training and test details (e.g., data splits, hyperparameters, how they were chosen, type of optimizer, etc.) necessary to understand the results?
1. Answer: [Yes]
1. Justification: We provide comprehensive dataset statistics, evaluation metric descriptions, hyperparameters, and tool usage in § 5.
1. Guidelines:
- The answer NA means that the paper does not include experiments.
- The experimental setting should be presented in the core of the paper to a level of detail that is necessary to appreciate the results and make sense of them.
- The full details can be provided either with the code, in appendix, or as supplemental material.
1. Experiment Statistical Significance
1. Question: Does the paper report error bars suitably and correctly defined or other appropriate information about the statistical significance of the experiments?
1. Answer: [Yes]
1. Justification: Our proposed method is an inference-only approach for LLM and we adopt the greedy-decoding strategy for all of our experiments, making the experiment results of each session consistent.
1. Guidelines:
- The answer NA means that the paper does not include experiments.
- The authors should answer "Yes" if the results are accompanied by error bars, confidence intervals, or statistical significance tests, at least for the experiments that support the main claims of the paper.
- The factors of variability that the error bars are capturing should be clearly stated (for example, train/test split, initialization, random drawing of some parameter, or overall run with given experimental conditions).
- The method for calculating the error bars should be explained (closed form formula, call to a library function, bootstrap, etc.)
- The assumptions made should be given (e.g., Normally distributed errors).
- It should be clear whether the error bar is the standard deviation or the standard error of the mean.
- It is OK to report 1-sigma error bars, but one should state it. The authors should preferably report a 2-sigma error bar than state that they have a 96% CI, if the hypothesis of Normality of errors is not verified.
- For asymmetric distributions, the authors should be careful not to show in tables or figures symmetric error bars that would yield results that are out of range (e.g. negative error rates).
- If error bars are reported in tables or plots, The authors should explain in the text how they were calculated and reference the corresponding figures or tables in the text.
1. Experiments Compute Resources
1. Question: For each experiment, does the paper provide sufficient information on the computer resources (type of compute workers, memory, time of execution) needed to reproduce the experiments?
1. Answer: [Yes]
1. Justification: We provide comprehensive experimental setup and hardware computation resources used in § G.
1. Guidelines:
- The answer NA means that the paper does not include experiments.
- The paper should indicate the type of compute workers CPU or GPU, internal cluster, or cloud provider, including relevant memory and storage.
- The paper should provide the amount of compute required for each of the individual experimental runs as well as estimate the total compute.
- The paper should disclose whether the full research project required more compute than the experiments reported in the paper (e.g., preliminary or failed experiments that didn’t make it into the paper).
1. Code Of Ethics
1. Question: Does the research conducted in the paper conform, in every respect, with the NeurIPS Code of Ethics https://neurips.cc/public/EthicsGuidelines?
1. Answer: [Yes]
1. Justification: We confirm that the research conducted in the paper conform, in every respect, with the NeurIPS Code of Ethics, and all the authors preserve anonymity.
1. Guidelines:
- The answer NA means that the authors have not reviewed the NeurIPS Code of Ethics.
- If the authors answer No, they should explain the special circumstances that require a deviation from the Code of Ethics.
- The authors should make sure to preserve anonymity (e.g., if there is a special consideration due to laws or regulations in their jurisdiction).
1. Broader Impacts
1. Question: Does the paper discuss both potential positive societal impacts and negative societal impacts of the work performed?
1. Answer: [Yes]
1. Justification: The broader impacts of our paper are presented in § A.2.
1. Guidelines:
- The answer NA means that there is no societal impact of the work performed.
- If the authors answer NA or No, they should explain why their work has no societal impact or why the paper does not address societal impact.
- Examples of negative societal impacts include potential malicious or unintended uses (e.g., disinformation, generating fake profiles, surveillance), fairness considerations (e.g., deployment of technologies that could make decisions that unfairly impact specific groups), privacy considerations, and security considerations.
- The conference expects that many papers will be foundational research and not tied to particular applications, let alone deployments. However, if there is a direct path to any negative applications, the authors should point it out. For example, it is legitimate to point out that an improvement in the quality of generative models could be used to generate deepfakes for disinformation. On the other hand, it is not needed to point out that a generic algorithm for optimizing neural networks could enable people to train models that generate Deepfakes faster.
- The authors should consider possible harms that could arise when the technology is being used as intended and functioning correctly, harms that could arise when the technology is being used as intended but gives incorrect results, and harms following from (intentional or unintentional) misuse of the technology.
- If there are negative societal impacts, the authors could also discuss possible mitigation strategies (e.g., gated release of models, providing defenses in addition to attacks, mechanisms for monitoring misuse, mechanisms to monitor how a system learns from feedback over time, improving the efficiency and accessibility of ML).
1. Safeguards
1. Question: Does the paper describe safeguards that have been put in place for responsible release of data or models that have a high risk for misuse (e.g., pretrained language models, image generators, or scraped datasets)?
1. Answer: [N/A]
1. Justification: Our dataset focuses on evaluation rather than training models. We leverage existing datasets rather than scrape from the Internet.
1. Guidelines:
- The answer NA means that the paper poses no such risks.
- Released models that have a high risk for misuse or dual-use should be released with necessary safeguards to allow for controlled use of the model, for example by requiring that users adhere to usage guidelines or restrictions to access the model or implementing safety filters.
- Datasets that have been scraped from the Internet could pose safety risks. The authors should describe how they avoided releasing unsafe images.
- We recognize that providing effective safeguards is challenging, and many papers do not require this, but we encourage authors to take this into account and make a best faith effort.
1. Licenses for existing assets
1. Question: Are the creators or original owners of assets (e.g., code, data, models), used in the paper, properly credited and are the license and terms of use explicitly mentioned and properly respected?
1. Answer: [Yes]
1. Justification: All the assets, i.e., codes, data and models used in our paper, are properly credited and we explicitly mention and properly respect the license and terms of use.
1. Guidelines:
- The answer NA means that the paper does not use existing assets.
- The authors should cite the original paper that produced the code package or dataset.
- The authors should state which version of the asset is used and, if possible, include a URL.
- The name of the license (e.g., CC-BY 4.0) should be included for each asset.
- For scraped data from a particular source (e.g., website), the copyright and terms of service of that source should be provided.
- If assets are released, the license, copyright information, and terms of use in the package should be provided. For popular datasets, paperswithcode.com/datasets has curated licenses for some datasets. Their licensing guide can help determine the license of a dataset.
- For existing datasets that are re-packaged, both the original license and the license of the derived asset (if it has changed) should be provided.
- If this information is not available online, the authors are encouraged to reach out to the asset’s creators.
1. New Assets
1. Question: Are new assets introduced in the paper well documented and is the documentation provided alongside the assets?
1. Answer: [Yes]
1. Justification: We have submitted the anonymized dataset, codes, and corresponding documents together with the paper.
1. Guidelines:
- The answer NA means that the paper does not release new assets.
- Researchers should communicate the details of the dataset/code/model as part of their submissions via structured templates. This includes details about training, license, limitations, etc.
- The paper should discuss whether and how consent was obtained from people whose asset is used.
- At submission time, remember to anonymize your assets (if applicable). You can either create an anonymized URL or include an anonymized zip file.
1. Crowdsourcing and Research with Human Subjects
1. Question: For crowdsourcing experiments and research with human subjects, does the paper include the full text of instructions given to participants and screenshots, if applicable, as well as details about compensation (if any)?
1. Answer: [Yes]
1. Justification: The full text of instructions given to human annotators is presented in § H.
1. Guidelines:
- The answer NA means that the paper does not involve crowdsourcing nor research with human subjects.
- Including this information in the supplemental material is fine, but if the main contribution of the paper involves human subjects, then as much detail as possible should be included in the main paper.
- According to the NeurIPS Code of Ethics, workers involved in data collection, curation, or other labor should be paid at least the minimum wage in the country of the data collector.
1. Institutional Review Board (IRB) Approvals or Equivalent for Research with Human Subjects
1. Question: Does the paper describe potential risks incurred by study participants, whether such risks were disclosed to the subjects, and whether Institutional Review Board (IRB) approvals (or an equivalent approval/review based on the requirements of your country or institution) were obtained?
1. Answer: [N/A]
1. Justification: The justification is as follows: We solely engaged human annotators for the dataset, and they were not subjects of our study. Furthermore, we partnered with a legally recognized annotation company in the country, which has obtained all necessary governmental approvals to operate its annotation business.
1. Guidelines:
- The answer NA means that the paper does not involve crowdsourcing nor research with human subjects.
- Depending on the country in which research is conducted, IRB approval (or equivalent) may be required for any human subjects research. If you obtained IRB approval, you should clearly state this in the paper.
- We recognize that the procedures for this may vary significantly between institutions and locations, and we expect authors to adhere to the NeurIPS Code of Ethics and the guidelines for their institution.
- For initial submissions, do not include any information that would break anonymity (if applicable), such as the institution conducting the review.