# Sound Field Synthesis with Acoustic Waves 111Author is affiliated with Amazon Inc. USA. 222This manuscript is an expanded version of a conference paper of the same title
**Authors**: Mohamed F. Mansour
## Abstract
We propose a practical framework to synthesize the broadband sound-field on a small rigid surface based on the physics of sound propagation. The sound-field is generated as a composite map of two components: the room component and the device component, with acoustic plane waves as the core tool for the generation. This decoupling of room and device components significantly reduces the problem complexity and provides accurate rendering of the sound-field. We describe in detail the theoretical foundations, and efficient procedures of the implementation. The effectiveness of the proposed framework is established through rigorous validation under different environment setups.
Index Terms: Room acoustics, acoustic simulation, plane wave decomposition, multichannel audio synthesis.
## I Introduction
ound-field synthesis at a microphone array in a room is the process of synthesizing audio at each microphone of the array from a source signal emanating from a sound source elsewhere in the room. It is a key task in evaluating performance metrics of speech/audio communication devices, as it is a cost-effective methodology for data generation to replace real data collection, which is usually a slow, expensive, and error-prone procedure. Acoustic modeling techniques are usually utilized to generate synthetic data to either replace or augment real data collection at a fraction of the cost. These techniques usually aim at estimating the Room Impulse Response (RIR) between two points in the room. The RIR is either computed empirically using direct measurement, or simulated using a model for room acoustics. Empirical methods are in general accurate, but they are relatively expensive because of the required human labor.
Simulation methods provide a cost effective alternative as they utilize computational acoustics rather than physical measurements. A brute-force simulation would solve the inhomogeneous acoustic wave equation with proper boundary conditions of the room and device surface [1]. Though theoretically viable, it requires significant effort to characterize all boundary conditions in a typical room. Further, simulation time can be prohibitive if it is evaluated over a broadband spectrum. Moreover, the whole simulation needs to be repeated for every new form factor of the device under test. To address the computational complexity, the image source method [2] has been widely used to approximate point-to-point room acoustics. It utilizes the ray tracing concept [1] to significantly reduce the modeling and computational complexity of brute-force simulation. Though simple and effective in some scenarios, the image source method has few limitations. For example, it has poor approximation at low frequencies, and it cannot model small surfaces (as compared to wavelength), e.g., furniture, and rough surfaces, e.g., curtains.
In this work, we describe a novel procedure that combines empirical and simulation methods to provide a balanced tradeoff between the two approaches for sound-field synthesis. It splits the sound-field into two independent components: room component, and device component, such that the overall sound-field is the composite mapping of the two components. The room component captures the room impact at an interior point, due to a predefined sound source in the room. This is represented as a superposition of acoustic plane waves, which is computed using a single measurement with a large microphone array. The device component is computed using acoustic simulation or anechoic measurements to evaluate the fingerprint of each acoustic plane wave on the device surface (as measured at the microphone array mounted on the device surface). The overall acoustic pressure on the device surface when placed at an interior point in a room is computed by plugging in the computed device fingerprints into the acoustic plane wave representation at that point. This arrangement provides an efficient representation of room acoustics that allows reusing room information with devices of different form factor when tested in the same room. Therefore, it enables the concept of room database, which contains abstract room acoustics information that is independent of the device under test. Likewise, it allows reusing the same device component with different rooms. To enable the proposed method, we develop a general procedure to compute the plane wave decomposition at a point in a room by applying sparse recovery techniques on an audio capture with a large microphone array. We also utilize the device dictionary concept, that captures the acoustic behavior of general microphone array mounted on a rigid surface of arbitrary form factor [3]. The proposed methodology is rigorously validated across many rooms and many devices with different form factors and microphone array geometry. The synthetic RIR is shown to match the true RIR, in the least square sense, over a broadband spectrum up to $8$ kHz. The synthesis methodology is also shown to closely resemble real measurements in evaluating higher level metrics, e.g., word error rate, and false rejection rate.
The acoustic plane wave expansion has been used in earlier work with model-based sound-field reconstruction, e.g., [4, 5, 6, 7], where acoustic plane waves are used as kernels for sound-field reconstruction. The plane wave expansion is interpolated with free-field propagation model to reproduce the sound field within a convex source-free zone. The plane wave expansion is computed from measurements of an array of microphones placed at the zone perimeter. The computation of the expansion is done either through spherical harmonics or using sparse recovery techniques. In this work, we study a different problem of reproducing the sound field on a rigid surface that is placed at the same point in the room. A key contribution of the current work is utilizing the device dictionary concept for sound synthesis. This enables the generalization of the sound-field production to a rigid surface with an arbitrary form factor and microphone array size.
The paper is organized as follows. In section II, we lay down the theoretical foundation of the work. The details of the proposed framework are described in section III. Then, we present the validation results in section IV. Finally, we describe few engineering applications in section V. The following notations are used throughout the paper. A bold lower-case letter denotes a column vector, while a bold upper-case letter denotes a matrix. $M$ always refers to the number of microphones. The independent variables $t$ and $\omega$ refer to time and frequency respectively. Additional notations are introduced when needed.
## II Foundations
### II-A Acoustic Plane Waves
Acoustic plane waves are eigenfunctions of the homogenous Helmholtz equation. Hence, they constitute a powerful tool for analyzing the wave equation. Further, a plane wave is a good approximation of the wave-field emanating from a far-field point source [8]. The acoustic pressure of a plane wave with vector wave number $\bf{k}(\theta,\phi)$ (where $\theta$ and $\phi$ correspond respectively to polar azimuth and elevation of the direction of propagation) is defined at a point ${\bf{r}}=(x,y,z)$ in the three dimensional space as [9]:
$$
\psi({\bf{\omega,\theta,\phi,r}})\triangleq p_{0}(\omega)e^{-j{\bf{k}}^{T}{\bf
{r}}} \tag{1}
$$
where $p_{0}(\omega)$ is a real-valued frequency dependent scaling. The plane wave decomposition has been used for approximating point-source seismic recording [10, 11, 12], and sound field reproduction [8, 13, 14, 15]. A local solution to the homogenous Helmholtz equation can be approximated by a linear superposition of plane waves of different angles of the form [11, 16]:
$$
p(\omega,{\bf{r}})=\sum_{l\in\Lambda}\alpha_{l}(\omega)\ \psi\left(\omega,
\theta_{l},\phi_{l},\bf{r}\right) \tag{2}
$$
where $\Lambda$ is a set of indices that defines the directions of plane waves $\{\theta_{l},\phi_{l}\}$ , each $\psi(.)$ is a plane wave as in (1), and $\{\alpha_{l}\}$ are complex-valued scaling factors. We will refer to the wave-field in (2) as the free-field acoustic pressure. The decision variables in this approximation are $\left\{\Lambda,\{\alpha_{l}\}_{l\in\Lambda}\right\}$ .
### II-B Device Acoustic Dictionary
Generalizing the free-field plane wave expansion in (2) to include the scattering due to the device surface, requires computing the device acoustic response to each plane wave. The device response to all plane waves in the three-dimensional space is collectively referred to as the device acoustic dictionary. The total wave-field at any point on the device surface when the device is impinged by an incident plane wave $\psi(\omega,\theta,\phi,{\bf{r}})$ has the general form:
$$
p_{t}(\omega,\theta,\phi,{\bf{r}})=\psi(\omega,\theta,\phi,{\bf{r}})+p_{s}(
\omega,\theta,\phi,{\bf{r}}) \tag{3}
$$
where $p_{t}$ and $p_{s}$ refer to the total and scattered wave-field respectively. $p_{t}$ can be computed numerically by inserting (3) in the Helmholtz equation and solving for $p_{s}$ with appropriate boundary conditions. If a microphone array of size $M$ is mounted on the device surface, and the microphone port size is much smaller than the wavelength, then each microphone can be approximated by a point on the device surface. In this case, the total field, ${\mathbf{p}}_{t}(\omega,\theta,\phi)$ , at the microphone array, due to an incident plane wave $\psi(\omega,\theta,\phi,{\bf{r}})$ , is a vector of size $M$ whose entries are the corresponding total field at the coordinate values, $\bf{r}$ , of each individual microphone. The device acoustic dictionary of a device is composed of vectors of total acoustic wave-field. The device acoustic dictionary is computed using numerical acoustic simulation with Finite Element Method (FEM) or Boundary Element Method (BEM) with device CAD to specify the device surface. The details and validation results are described in [3].
An entry of the device dictionary can be either measured in anechoic room with single-frequency far-field sources, or computed numerically by solving the Helmholtz equation on the device surface with background plane-wave using the device CAD model. Both methods yield same result, but the numerical method has much lower cost and it is less error-prone because it does not require human labor.
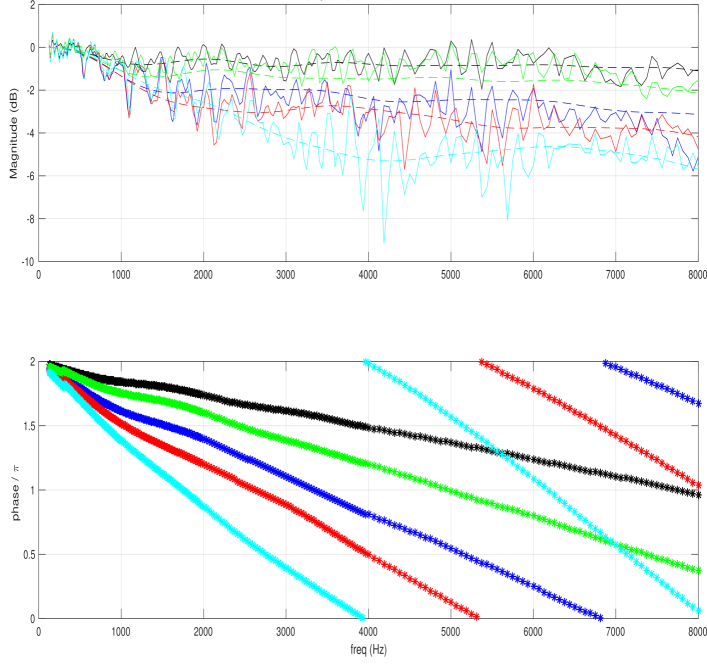
For the numerical method, each entry in the device dictionary is computed by solving the Helmholtz equation, using Finite Element Method (FEM) or Boundary Element Method (BEM) techniques, for the total field at the microphones with the given background plane wave. The device CAD is used to specify the surface, which is modeled as sound hard boundary. To have a true background plane-wave, the external boundary should be open and non-reflecting. In our model, the device is enclosed by a closed boundary, e.g., a cylinder or a spherical surface. To mimic open-ended boundary we use Perfectly Matched Layer (PML), which defines a special absorbing domain that eliminates reflection and refractions in the internal domain that encloses the device [17]. Standard packages for solving partial differential equations, e.g., [18] are used, and the simulation is rigorously validated with measured acoustic pressure on different form-factors. In Fig. 1, we show an example of the frequency amplitude and phase of the inter-channel transfer function of both simulated and anechoic measured response for a microphone array mounted on a sphere. The reference channel in the inter-channel transfer function is the first microphone that is hit by the plane wave. The phase plot at the bottom is the phase error between the measured and simulated response. In the ideal case, the magnitude response of the measured and simulated transfer function should coincide, and the phase error is identically zero. The matching of the magnitude response is quite clear and ripples in the measure response is due to the impact of minor reflections in the anechoic room. Similarly, the phase error cannot be identically zero in practice because of the finite geometric precision in the position in the anechoic room, which results in unavoidable linear phase error that is shown in the phase plot. More validation examples were described in [3]. In [19, 20], comparisons between simulated and theoretical acoustic pressure responses were presented.
<details>
<summary>x1.png Details</summary>
### Visual Description
\n
## Charts: Frequency Response Analysis
### Overview
The image presents two charts displaying frequency response data. The top chart shows magnitude in decibels (dB) versus frequency in Hertz (Hz), while the bottom chart shows phase in radians of pi (π) versus frequency in Hz. Both charts display multiple data series, each represented by a different colored line.
### Components/Axes
* **Top Chart:**
* X-axis: Frequency (Hz), ranging from 0 to 8000 Hz.
* Y-axis: Magnitude (dB), ranging from -10 to 2 dB.
* Data Series: Multiple lines, each representing a different frequency response.
* **Bottom Chart:**
* X-axis: Frequency (Hz), ranging from 0 to 8000 Hz.
* Y-axis: Phase / π, ranging from 0 to 2.
* Data Series: Multiple lines, each representing a different frequency response.
* **Colors:** The lines are colored as follows (approximate):
* Black
* Red
* Green
* Cyan
* Blue
* Magenta
### Detailed Analysis or Content Details
**Top Chart (Magnitude vs. Frequency):**
* **Black Line:** Relatively flat, fluctuating around 0 dB. At approximately 4000 Hz, there is a slight dip.
* **Red Line:** Generally around -2 dB, with significant fluctuations, especially between 3000 and 6000 Hz.
* **Green Line:** Fluctuates around 0 dB, with more pronounced peaks and troughs than the black line.
* **Cyan Line:** Shows a large dip around 4000 Hz, reaching approximately -8 dB. Fluctuates significantly.
* **Blue Line:** Relatively stable around -1 dB, with minor fluctuations.
* **Magenta Line:** Fluctuates around 0 dB, with moderate peaks and troughs.
**Bottom Chart (Phase vs. Frequency):**
* **Black Line:** Decreases linearly from approximately 2 to 0.5 radians/π over the frequency range.
* **Red Line:** Decreases more rapidly than the black line, starting at approximately 2 and ending near 0 radians/π.
* **Green Line:** Decreases at a rate similar to the red line, but starts slightly lower.
* **Cyan Line:** Decreases very rapidly, starting at approximately 2 and reaching 0 radians/π around 4000 Hz.
* **Blue Line:** Decreases at a moderate rate, starting at approximately 2 and ending near 0.2 radians/π.
* **Magenta Line:** Decreases at a rate between the black and red lines, starting at approximately 2 and ending near 0.3 radians/π.
### Key Observations
* The cyan line exhibits a significant magnitude dip around 4000 Hz in the top chart and a rapid phase change in the bottom chart, suggesting a resonance or anti-resonance at that frequency.
* The black line shows a relatively flat magnitude response, indicating a stable frequency response.
* The red, green, and magenta lines show more complex frequency responses with varying magnitudes and phase shifts.
* The phase responses generally decrease with increasing frequency, indicating a time delay that increases with frequency.
### Interpretation
The data likely represents the frequency response of a system, such as a filter or an audio component. The magnitude plot shows how the system amplifies or attenuates different frequencies, while the phase plot shows the phase shift introduced by the system at each frequency.
The significant dip in the cyan line's magnitude and its rapid phase change suggest a sharp change in the system's impedance at around 4000 Hz. This could be due to a resonant frequency or an anti-resonant frequency.
The relatively flat magnitude response of the black line suggests that this system has a consistent response across the frequency range, potentially representing a low-pass or high-pass filter with a gentle roll-off.
The differences in the phase responses of the various lines indicate that each line represents a different system or a different configuration of the same system. The varying rates of phase change suggest different time delays for different frequencies.
The data could be used to characterize the performance of a system, identify potential problems, or design filters to achieve specific frequency response characteristics.
</details>
Figure 1: (top) Measured (solid line) and simulated (dotted line) total field of a microphone array mounted on a sphere of PW, (bottom) phase error, with azimuth = $150^{\circ}$ , elevation = $90^{\circ}$ .
The output of the above model is the plane wave dictionary of the device
$$
\mathcal{D}\triangleq\{\boldsymbol{\beta}_{l}(\omega)\triangleq{\bf{p}}_{t}(
\omega,\theta_{l},\phi_{l}):\forall\ \omega,l\} \tag{4}
$$
where each entry in the dictionary is a vector of length $M$ , and each element in the vector is the total acoustic pressure at one microphone in the microphone array when a plane wave with ${\bf{k}}(\theta_{l},\phi_{l})$ hits the device. The dictionary also covers all frequencies of interest typically up to $8$ kHz. Note that, the acoustic dictionary can accommodate any form factor of the surface, and any geometry of the microphone array as it utilizes acoustic simulation with the CAD of the device surface, and the coordinates of the microphone array.
## III Proposed Framework
### III-A Overview
The proposed sound synthesis methodology generalizes the plane wave expansion in (2), which summarizes room acoustics at a point in a room, to include the impact of scattering due to the device surface. This generalization yields the combined acoustic effect of the room and the scattering on the device surface. If the device dimensions are much smaller than the room dimensions, then secondary reflections due to the device surface are negligible, and the device impact on the room acoustics could be ignored. Hence, even after introducing the device into the room, the directions and weights of the free-field acoustic plane waves in (2) do not change. However, because of the device surface, each plane wave $\psi\left(\omega,\theta_{l},\phi_{l},{\bf{r}}\right)$ in (2), has an acoustic fingerprint at the device microphone array, which is the corresponding entry in the device dictionary, $\boldsymbol{\beta}_{l}(\omega)$ . Hence, if the device is placed at a point in the room whose sound-field is expressed as in (2), then the observed sound field vector at the device microphone array is
$$
{\mathbf{p}}(\omega)=\sum_{l\in\Lambda}\alpha_{l}\ \boldsymbol{\beta}_{l}(\omega) \tag{5}
$$
The transition from the sound-field in (2) in the absence of the device to the sound field in (5) in the presence of the device is the technical foundation of the proposed synthesis framework. This transition is enabled by the linearity of the wave equation and the introduction of the device acoustic dictionary as described in section II-B.
Note that, if another device with acoustic dictionary $\mathcal{D}^{(2)}\triangleq\{\boldsymbol{\beta}_{l}^{(2)}(\omega):\forall\ \omega,l\}$ is placed at the same point in the room, then the observed sound-field at the second microphone array can be expressed as
$$
{\mathbf{p}}^{(2)}(\omega)=\sum_{l\in\Lambda}\alpha_{l}\ \boldsymbol{\beta}_{l
}^{(2)}(\omega) \tag{2}
$$
where only the mapping through device dictionary changes, while the directions, $\Lambda$ , and weights, $\{\alpha_{l}\}$ , of constituent plane waves do not change. This is the essence of the proposed methodology that separates room and device components. Hence, the three steps for sound-field synthesis at a microphone array mounted on a device that is placed at a point in the room are as follows:
1. Compute the free-field plane wave expansion at a point as in (2). This summarizes room acoustics at a point in the room. A procedure for computing this expansion is described in section III-B. This process is repeated for every new point in a room, and it is independent of the device under test.
1. Generate the acoustic dictionary of the device under test as described in section II-B. This is computed once per device and it is independent of the room.
1. For each room position, combine the plane wave expansion with the device dictionary as in (5) to synthesize the sound-field at the device microphone array.
Repeating step $1$ above for multiple rooms and multiple positions within each room generates a room database. This database is generated only once, then it could be reused in evaluating and generating data for new devices.
### III-B Acoustic Plane Wave Decomposition
The main technical hurdle in the proposed framework is computing the plane wave expansion (2) at a point in a room with a source signal emanating from another point in the room. In the proposed framework, this is computed through a data capture using a large microphone array of $32$ microphones mounted on a sphere (EigenMike) [21]. The large microphone array is necessary to mitigate the creation of an underdetermined system of equations in recovering the constituent plane waves. It was found experimentally that $20$ to $30$ plane waves are sufficient for an accurate approximation of the sound field (with reconstruction error less than $-30$ dB for frequencies up to $8$ kHz). The plane wave decomposition problem is formulated as an optimization problem whose objective is minimizing the difference in the least square sense between observed and synthesized sound fields. If the observed sound field of the EigenMike at frequency $\omega$ , is ${\mathbf{y}}(\omega)$ , then the objective function has the form
$$
J=\int_{\omega}\|{\mathbf{y}}(\omega)-\sum_{l\in\Lambda}\alpha_{l}(\omega)\bar
{\boldsymbol{\beta}}_{l}(\omega)\|^{2}+\lambda\sum_{l\in\Lambda}|\alpha_{l}(
\omega)| \tag{7}
$$
where $\left\{\bar{\boldsymbol{\beta}}_{l}(\omega)\right\}$ are the entries of the EigenMike acoustic dictionary at frequency $\omega$ . The decision variables are the set of indices $\Lambda$ , and the corresponding weights $\{\alpha_{l}\}$ . The L1-regularization in (7) is added to stimulate a sparse solution as $|\Lambda|<30$ is much smaller than the dictionary size, which is in the order of $10^{3}$ . The objective function can be put in matrix form as:
$$
J=\int_{\omega}\|{\mathbf{y}}(\omega)-{\mathbf{A}}(\omega)\ .\ \boldsymbol{
\alpha}\|_{2}^{2}+\lambda\ |\boldsymbol{\alpha}|_{1}. \tag{8}
$$
where ${\mathbf{A}}$ is a matrix whose columns are the individual entries of the acoustic dictionary at frequency $\omega$ , i.e., $\{\bar{\boldsymbol{\beta}}_{l}(\omega)\}$ . The above problem is a form of the well-known LASSO optimization [22] that is encountered in numerous sparse recovery problems in statistics and signal processing. Many efficient solutions have been proposed for this problem under various conditions [23, 24]. The big microphone array size in the EigenMike provides much flexibility in solving (8) because the observation size is bigger than the number of nonzero components in $\boldsymbol{\alpha}$ . Note that, the optimization problem in (8) is solved only once for a given source/receiver position in a room, and it is solved offline. Therefore, it does not have constraints on computational complexity, memory, or latency. In our analysis, the orthogonal matching pursuit algorithm [25] was used to recover $\Lambda$ and $\boldsymbol{\alpha}$ , though other existing solutions to the sparse recovery problem can be used with this formation. This was generalized for smaller microphone arrays of arbitrary geometry in [26].
For a given source signal, the above procedure is repeated at each frequency $\omega$ , and at each time frame to generate a time-frequency map of the active set $\Lambda(t,\omega)$ and the corresponding weights $\boldsymbol{\alpha}(t,\omega)$ . To synthesize the sound field for another device with acoustic dictionary $\{{\boldsymbol{\beta}}_{l}(\omega)\}$ at this particular source/receiver position and source signal, the synthesis formula (5) is applied at each time-frequency cell with the corresponding parameters $\Lambda(t,\omega)$ and $\boldsymbol{\alpha}(t,\omega)$ . Generating the sound-field for an arbitrary source signal requires the computation of the room impulse response, which is described in the following section.
### III-C Room Impulse Response (RIR) Computation
RIR aims at modeling the acoustic channel between source and receiver as a linear time-invariant system. The RIR combines both room acoustics and scattering due to device surface, and it is computed once for a given device and a given source/receiver positions in a room. It is a multichannel transfer function where the number of channels equals the size of the microphone array. For RIR computation, a special source signal that covers the whole frequency spectrum, e.g., white noise or Golay sequence [27], is utilized. For a source signal $x(t,\omega)$ , the EigenMike is utilized to generate the time-frequency map of the plane wave decomposition as described in the previous section. For a device under test, this time-frequency map is combined with the device dictionary to generate the multichannel output signal ${\mathbf{y}}(t,\omega)$ as in (5). The transfer function between $x(t,\omega)$ and ${\mathbf{y}}(t,\omega)$ is computed using system identification techniques. For example, by applying Wiener-Hopf equation in the frequency domain [28], we get
$$
\hat{\mathbf{h}}(\omega)=\frac{\mathbf{S}_{xy}(\omega)}{S_{xx}(\omega)} \tag{9}
$$
where $\hat{\mathbf{h}}(\omega)$ is the multichannel acoustic transfer function in the frequency domain, and
$$
\displaystyle S_{xx}(\omega) \displaystyle= \displaystyle\mathbb{E}\left\{x^{*}(t,\omega)\ x(t,\omega)\right\} \displaystyle{\mathbf{S}}_{xy}(\omega) \displaystyle= \displaystyle\mathbb{E}\left\{x^{*}(t,\omega)\ {\mathbf{y}}(t,\omega)\right\} \tag{10}
$$
After RIR estimation for a device at a point in a room, the sound field for an arbitrary source signal $u(t,\omega)$ is computed as
$$
\hat{\mathbf{y}}(t,\omega)=\hat{\mathbf{h}}(\omega)\ .\ u(t,\omega) \tag{12}
$$
Note that, the RIR computes only the part of the sound field that is correlated with the source signal, and it disregards the background ambient noise and other interferences in the room. To add background and/or diffuse noise to the synthesized output, a separate time-frequency map, ${\mathbf{b}}(t,\omega)$ , is computed once as described in section III-A with only background noise, then the synthesized sound-field in (12) is modified to
$$
\hat{\mathbf{y}}(t,\omega)=\hat{\mathbf{h}}(\omega)\ .\ u(t,\omega)+{\mathbf{b
}}(t,\omega) \tag{13}
$$
### III-D Discussion
The proposed method is a combination of measurements (for room component) and simulation (for device component). A single measurement with a large microphone array is required per room position, and this measurement is reused for all devices. The measurement is processed by plane wave decomposition to compute the time-frequency map of the acoustic decomposition that is combined with device dictionary to generate the total sound field. Similarly, the device dictionary is computed once, and it is combined with any room to generate the total sound-field. The computational complexity for computing the broadband device dictionary is small because it is computed in an anechoic setup. Further, it is highly parallelizable because the same process is repeated at different frequencies and at different directions for plane wave. The concept of splitting room acoustics and device acoustics significantly reduces the measurement/simulation overhead. In addition to simplifying both room and device modeling, abstracting room acoustics in a single measurement and device acoustics with the device dictionary enables reuse of either components with the other side.
The proposed approach provides an accurate approximation of room acoustics and alleviates the need for full room simulation whose complexity is prohibitive at high frequencies for a regular-size room. Further, this single room measurement eliminates the need to model the room interior surfaces, which can also be an overly time-consuming process. As compared to the image source method, the proposed method addresses all the limitations outlined in section I as follows:
1. The plane-wave expansion model in (5) is valid at all frequencies.
1. The impact of device scattering is incorporated through the device dictionary in sound-field synthesis.
1. The impact of all boundary conditions in the room is inherently included in the plane-wave expansion in (2). It automatically accounts for all surfaces in the room without explicitly modeling them.
Note that, it is possible to combine the device acoustic dictionary with the image source method [2] to further educe complexity at the cost of lower accuracy. In the image source method, the concept of a sound wave is replaced by sound rays; which is a small portion of a spherical wave with vanishing aperture [1]. These sound rays from the image source method can be regarded as a crude approximation of acoustic plane waves in (2); which eliminates the need for room measurements. If these sound rays are combined with device dictionary, then it extends the image source method to account for scattering due to the device surface. However, it still inherits the other gaps of the image source method as previously outlined in section I.
## IV Experimental Validation
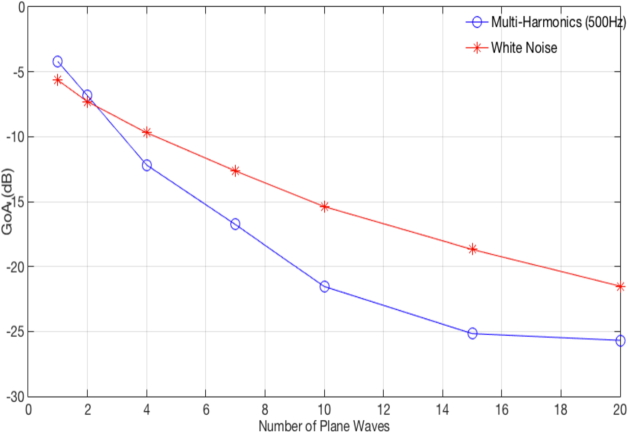
The first experiment aimed at validating the plane wave decomposition procedure as described in section III-B. In Fig. 2, we showed the reconstruction error of the EigenMike for two different source signals versus the number of plane wave in the expansion. The Goodness of Approximation, GoA, (or reconstruction error) is defined as:
$$
\text{GoA}\triangleq\frac{\int_{\omega}\|{\mathbf{y}}(\omega)-\sum_{l\in
\Lambda}\alpha_{l}(\omega)\bar{\boldsymbol{\beta}}_{l}(\omega)\|^{2}}{\int_{
\omega}\|{\mathbf{y}}(\omega)\|^{2}} \tag{14}
$$
where ${\mathbf{y}}(\omega)$ is the observed sound-field at the EigenMike. This was evaluated over a frequency range up to 8 kHz. As noted from the figure, a small number of plane waves is sufficient for sound field approximation with error less than $-20$ dB.
<details>
<summary>x2.png Details</summary>
### Visual Description
\n
## Chart: GoA(dB) vs. Number of Plane Waves for Multi-Harmonics and White Noise
### Overview
The image presents a line graph comparing the Gain-over-Amplitude (GoA) in decibels (dB) for two signal types – Multi-Harmonics (500Hz) and White Noise – as a function of the Number of Plane Waves. The graph illustrates how the GoA decreases for both signal types as the number of plane waves increases.
### Components/Axes
* **X-axis:** Number of Plane Waves, ranging from 0 to 20, with markers at integer values.
* **Y-axis:** GoA (dB), ranging from -30 dB to 0 dB, with markers at 5 dB intervals.
* **Legend:** Located in the top-right corner.
* Blue line with circle markers: Multi-Harmonics (500Hz)
* Red line with cross markers: White Noise
* **Gridlines:** Present to aid in reading values.
### Detailed Analysis
**Multi-Harmonics (500Hz) - Blue Line:**
The blue line exhibits a consistent downward trend, indicating a decrease in GoA as the number of plane waves increases.
* At 0 Plane Waves: Approximately -1.5 dB.
* At 2 Plane Waves: Approximately -6 dB.
* At 4 Plane Waves: Approximately -11 dB.
* At 6 Plane Waves: Approximately -16 dB.
* At 8 Plane Waves: Approximately -20 dB.
* At 10 Plane Waves: Approximately -23 dB.
* At 12 Plane Waves: Approximately -25 dB.
* At 14 Plane Waves: Approximately -26 dB.
* At 16 Plane Waves: Approximately -26 dB.
* At 18 Plane Waves: Approximately -26 dB.
* At 20 Plane Waves: Approximately -27 dB.
**White Noise - Red Line:**
The red line also shows a downward trend, but it is less steep than the blue line.
* At 0 Plane Waves: Approximately -3 dB.
* At 2 Plane Waves: Approximately -7 dB.
* At 4 Plane Waves: Approximately -10 dB.
* At 6 Plane Waves: Approximately -13 dB.
* At 8 Plane Waves: Approximately -15 dB.
* At 10 Plane Waves: Approximately -17 dB.
* At 12 Plane Waves: Approximately -19 dB.
* At 14 Plane Waves: Approximately -21 dB.
* At 16 Plane Waves: Approximately -22 dB.
* At 18 Plane Waves: Approximately -23 dB.
* At 20 Plane Waves: Approximately -24 dB.
### Key Observations
* The Multi-Harmonics signal consistently exhibits a higher GoA than White Noise across all tested numbers of plane waves.
* The rate of GoA decrease is more pronounced for Multi-Harmonics than for White Noise.
* Both signals show diminishing returns in GoA reduction as the number of plane waves increases beyond 16.
### Interpretation
The data suggests that increasing the number of plane waves reduces the GoA for both Multi-Harmonics and White Noise signals. This could be due to increased interference and signal cancellation as more waves are introduced. The higher GoA for Multi-Harmonics indicates that this signal is less susceptible to reduction by increasing the number of plane waves compared to White Noise. This difference could be attributed to the coherent nature of the Multi-Harmonics signal versus the random nature of White Noise. The flattening of the curves at higher plane wave numbers suggests a limit to the effectiveness of this technique for GoA reduction. The graph demonstrates a trade-off between the number of plane waves and the resulting GoA, and the optimal number of plane waves would depend on the specific application and desired GoA level.
</details>
Figure 2: EigenMike reconstruction error versus the number of plane waves in the plane wave decomposition
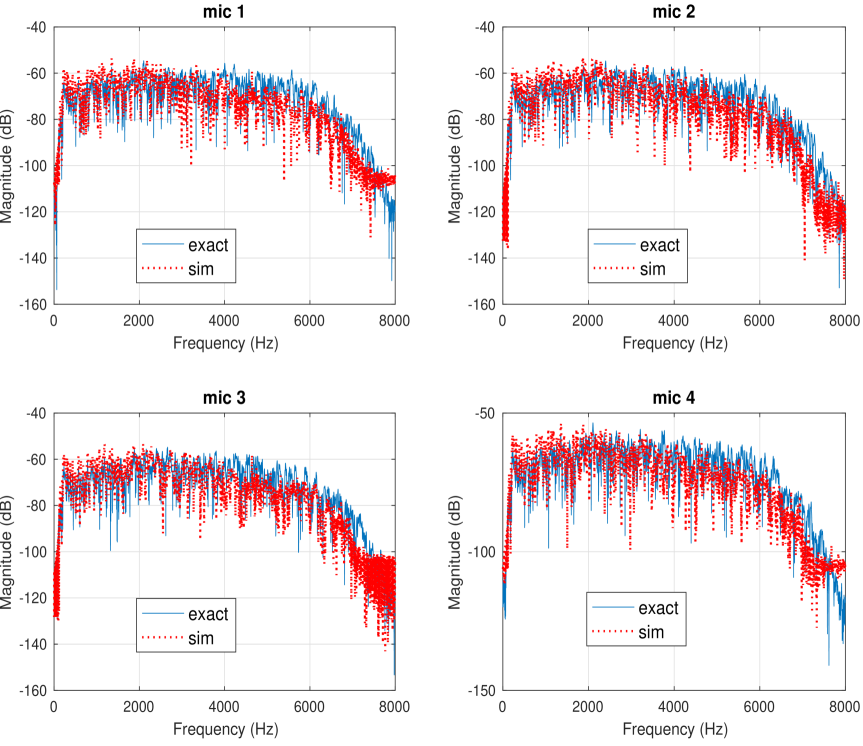
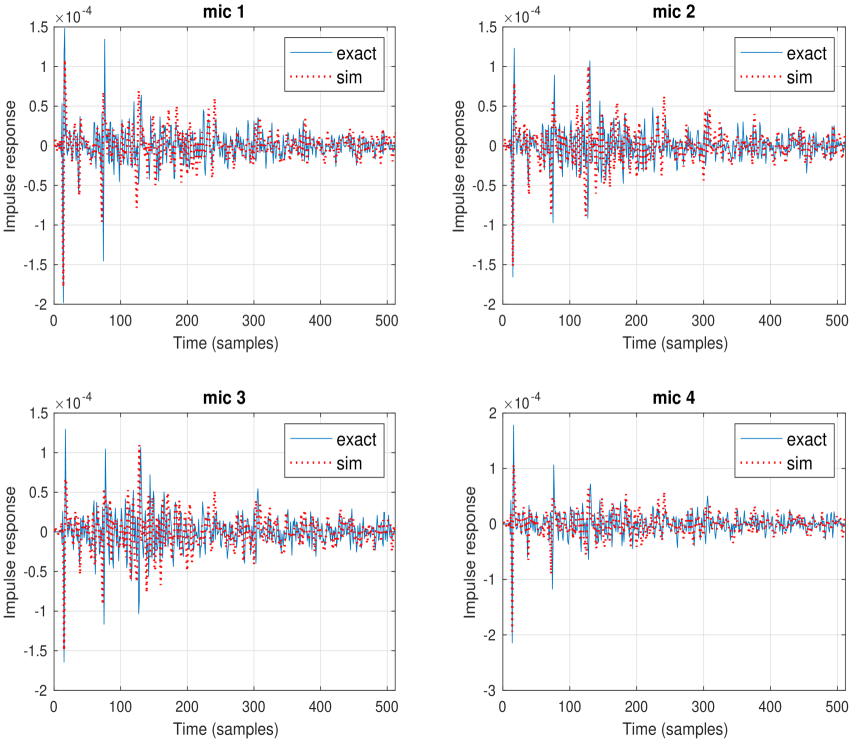
In the following set of experiments, the RIR procedure as described in section III-C was evaluated. The experiments were conducted in three different rooms with furniture that resemble typical bedrooms and living rooms, and in $24$ different positions within the three rooms. The EigenMike was placed in all positions to compute the room component that is combined with device dictionary to generate the synthetic RIR. Four other devices with different form factors and microphone array geometries were placed later at the same positions to compute the true RIR. Two devices had cylindrical form factor, one had cube-like shape, and the fourth was a slated sphere. The $24$ test positions covered different room positions: middle of the room, next to a wall, and at a corner. For each position, the origins of the EigenMike and other devices were aligned precisely using laser beams. The measured and synthetic RIR are computed as described in section III-C. In all cases, there existed strong resemblance between measured and synthetic RIR at all frequencies, and the reconstruction signal-to-noise ratio (SNR) is between $19$ and $23$ dB. An example of the transfer function and the impulse response of the measured and synthetic RIR is shown respectively in Figures 3 and 4. This is a typical behavior at all positions and devices.
<details>
<summary>x3.png Details</summary>
### Visual Description
## Chart: Microphone Frequency Response Comparison
### Overview
The image presents a 2x2 grid of charts, each displaying the frequency response of a different microphone (mic 1, mic 2, mic 3, and mic 4). Each chart compares the "exact" measured frequency response with a "sim"ulated response, plotted against frequency. The y-axis represents magnitude in decibels (dB), and the x-axis represents frequency in Hertz (Hz). All charts share the same scales.
### Components/Axes
* **X-axis:** Frequency (Hz), ranging from 0 to 8000 Hz.
* **Y-axis:** Magnitude (dB), ranging from -160 dB to -40 dB.
* **Legend:**
* "exact" - Represented by a solid blue line.
* "sim" - Represented by a dotted red line.
* **Titles:** Each subplot is labeled "mic 1", "mic 2", "mic 3", and "mic 4" respectively.
### Detailed Analysis or Content Details
**Mic 1 (Top-Left):**
The "exact" response (blue line) generally slopes downward from approximately -45 dB at 0 Hz to approximately -140 dB at 8000 Hz. There are several peaks and valleys along the curve. The "sim" response (red dotted line) is generally similar, but exhibits more pronounced peaks and valleys, and is slightly higher in magnitude across most frequencies.
* At 1000 Hz: exact ≈ -65 dB, sim ≈ -55 dB
* At 2000 Hz: exact ≈ -70 dB, sim ≈ -60 dB
* At 4000 Hz: exact ≈ -80 dB, sim ≈ -70 dB
* At 6000 Hz: exact ≈ -110 dB, sim ≈ -90 dB
* At 8000 Hz: exact ≈ -140 dB, sim ≈ -120 dB
**Mic 2 (Top-Right):**
The "exact" response (blue line) starts at approximately -40 dB at 0 Hz and decreases to approximately -130 dB at 8000 Hz. The "sim" response (red dotted line) is more erratic, with larger fluctuations in magnitude.
* At 1000 Hz: exact ≈ -60 dB, sim ≈ -50 dB
* At 2000 Hz: exact ≈ -70 dB, sim ≈ -60 dB
* At 4000 Hz: exact ≈ -85 dB, sim ≈ -75 dB
* At 6000 Hz: exact ≈ -110 dB, sim ≈ -90 dB
* At 8000 Hz: exact ≈ -130 dB, sim ≈ -110 dB
**Mic 3 (Bottom-Left):**
The "exact" response (blue line) begins at approximately -50 dB at 0 Hz and declines to approximately -150 dB at 8000 Hz. The "sim" response (red dotted line) is again more variable, with larger peaks and dips.
* At 1000 Hz: exact ≈ -60 dB, sim ≈ -50 dB
* At 2000 Hz: exact ≈ -70 dB, sim ≈ -60 dB
* At 4000 Hz: exact ≈ -85 dB, sim ≈ -75 dB
* At 6000 Hz: exact ≈ -115 dB, sim ≈ -95 dB
* At 8000 Hz: exact ≈ -150 dB, sim ≈ -130 dB
**Mic 4 (Bottom-Right):**
The "exact" response (blue line) starts at approximately -50 dB at 0 Hz and decreases to approximately -150 dB at 8000 Hz. The "sim" response (red dotted line) is similar to the others, showing more pronounced fluctuations.
* At 1000 Hz: exact ≈ -60 dB, sim ≈ -50 dB
* At 2000 Hz: exact ≈ -70 dB, sim ≈ -60 dB
* At 4000 Hz: exact ≈ -85 dB, sim ≈ -75 dB
* At 6000 Hz: exact ≈ -115 dB, sim ≈ -95 dB
* At 8000 Hz: exact ≈ -150 dB, sim ≈ -130 dB
### Key Observations
* The "sim"ulated responses consistently exhibit more pronounced peaks and valleys compared to the "exact" measurements across all microphones.
* The "sim"ulated responses generally have higher magnitudes than the "exact" responses, particularly at higher frequencies.
* All microphones show a general downward trend in magnitude as frequency increases.
* The differences between the "exact" and "sim" responses appear to be more significant at higher frequencies.
### Interpretation
The charts demonstrate a comparison between measured ("exact") and simulated ("sim") frequency responses for four different microphones. The consistent overestimation of magnitude by the simulation suggests that the simulation model may not fully capture the damping or other frequency-dependent characteristics of the microphones. The larger discrepancies at higher frequencies indicate that the simulation may be less accurate in modeling the behavior of the microphones in that range. This could be due to factors not included in the simulation, such as internal resonances or parasitic capacitances. The data suggests that while the simulation provides a reasonable approximation, it is not a perfect representation of the actual microphone performance. Further refinement of the simulation model may be necessary to improve its accuracy, particularly at higher frequencies. The consistent pattern across all four microphones suggests a systematic issue with the simulation rather than a microphone-specific problem.
</details>
Figure 3: An example of frequency response of measured and synthetic RIR for a microphone array of size 4 on a slated sphere surface
<details>
<summary>x4.png Details</summary>
### Visual Description
\n
## Charts: Impulse Response Comparison for Four Microphones
### Overview
The image presents four separate charts, each displaying the impulse response of a different microphone (mic 1, mic 2, mic 3, and mic 4). Each chart compares the "exact" impulse response with a "simulated" (sim) impulse response over a time range of 0 to 500 samples. The y-axis represents the impulse response value, scaled to approximately 1.5 x 10^-4.
### Components/Axes
Each chart shares the following components:
* **Title:** "mic 1", "mic 2", "mic 3", "mic 4" positioned at the top-center of each respective chart.
* **X-axis Label:** "Time (samples)" ranging from 0 to 500.
* **Y-axis Label:** "Impulse response" ranging from -2 to 1.5 x 10^-4.
* **Legend:** Located in the top-right corner of each chart, with two entries:
* "exact" – represented by a solid blue line.
* "sim" – represented by a dashed orange/red line.
* **Grid:** A light gray grid is overlaid on each chart to aid in visual data interpretation.
### Detailed Analysis or Content Details
**Mic 1:**
The "exact" impulse response (blue line) starts at approximately 0.8 x 10^-4 at time 0, fluctuates significantly between approximately -1.5 x 10^-4 and 1.2 x 10^-4, and ends around 0.2 x 10^-4 at 500 samples. The "sim" impulse response (dashed orange line) begins at approximately 0.6 x 10^-4, exhibits similar fluctuations, and concludes around 0.1 x 10^-4 at 500 samples. The trend is generally similar, but the simulated response appears slightly less noisy.
**Mic 2:**
The "exact" impulse response (blue line) starts at approximately 1.0 x 10^-4, fluctuates between approximately -1.8 x 10^-4 and 1.1 x 10^-4, and ends around -0.1 x 10^-4 at 500 samples. The "sim" impulse response (dashed orange line) begins at approximately 0.7 x 10^-4, fluctuates similarly, and ends around -0.2 x 10^-4 at 500 samples.
**Mic 3:**
The "exact" impulse response (blue line) starts at approximately 0.9 x 10^-4, fluctuates between approximately -1.7 x 10^-4 and 1.0 x 10^-4, and ends around 0.3 x 10^-4 at 500 samples. The "sim" impulse response (dashed orange line) begins at approximately 0.6 x 10^-4, fluctuates similarly, and ends around 0.2 x 10^-4 at 500 samples.
**Mic 4:**
The "exact" impulse response (blue line) starts at approximately 0.8 x 10^-4, fluctuates between approximately -2.5 x 10^-4 and 1.0 x 10^-4, and ends around -0.3 x 10^-4 at 500 samples. The "sim" impulse response (dashed orange line) begins at approximately 0.5 x 10^-4, fluctuates similarly, and ends around -0.4 x 10^-4 at 500 samples.
### Key Observations
* All four charts show a generally similar pattern of fluctuation in the impulse response over time.
* The "sim" impulse response consistently appears to have a slightly smaller amplitude of fluctuation compared to the "exact" response.
* The "exact" and "sim" responses generally follow the same trend, suggesting the simulation is a reasonable approximation of the actual impulse response.
* Mic 4 exhibits the largest range of fluctuation in its impulse response, indicating potentially greater sensitivity or a different acoustic environment.
### Interpretation
The data suggests that the simulation provides a reasonable approximation of the actual impulse response for each microphone. The slight differences in amplitude between the "exact" and "sim" responses could be due to factors not accounted for in the simulation, such as noise, non-linearities in the microphone's response, or imperfections in the measurement setup. The varying range of fluctuation across the microphones (particularly Mic 4) could indicate differences in their acoustic characteristics or the environments in which they were tested. The charts demonstrate a validation of the simulation model against real-world measurements, which is crucial for accurate acoustic modeling and analysis. The consistent trend between the "exact" and "sim" lines across all microphones suggests the simulation is robust and reliable.
</details>
Figure 4: An example of impulse response of measured and synthetic for microphone array of size 4 on a slated sphere surface
In the third set of experiments, we studied the impact of mismatch between true and synthetic RIR in evaluating high level data metrics. For this test, we evaluated the False Rejection Rate (FRR) of a keyword in the source signal. The true FRR was computed by processing the device signal after the convolution of the source signal and the true RIR. Similarly, the synthetic FRR was computed from the convolution of the same source signal and synthetic RIR. The relative absolute FRR is defined as
$$
\text{Relative FRR Error}\triangleq\frac{|\ \text{FRR}_{true}-\text{FRR}_{
synthetic}\ |}{\text{FRR}_{true}} \tag{15}
$$
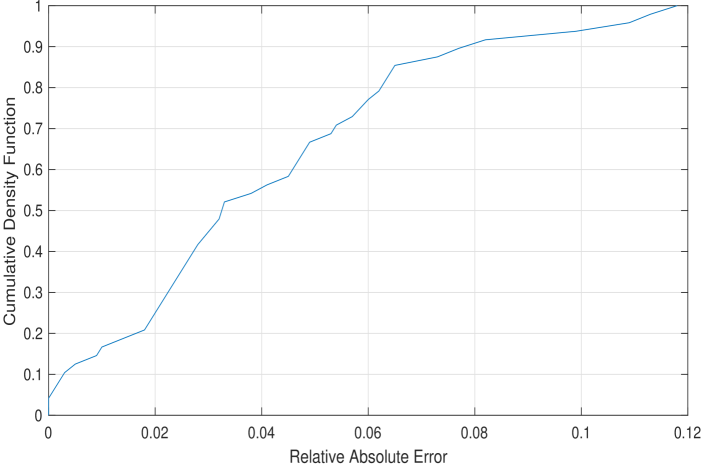
The cumulative density function of the relative absolute error (of all $24$ room positions and all devices) is shown in Fig. 5. The $95$ -percentile relative error between true and synthetic FRR is less than $10\$ .
<details>
<summary>x5.png Details</summary>
### Visual Description
\n
## Chart: Cumulative Density Function of Relative Absolute Error
### Overview
The image presents a cumulative density function (CDF) plot, illustrating the distribution of relative absolute errors. The x-axis represents the relative absolute error, and the y-axis represents the cumulative density function value. The plot shows how the probability of observing a relative absolute error less than or equal to a given value changes.
### Components/Axes
* **X-axis Title:** "Relative Absolute Error"
* Scale: Ranges from approximately 0 to 0.12.
* Markers: 0, 0.02, 0.04, 0.06, 0.08, 0.10, 0.12
* **Y-axis Title:** "Cumulative Density Function"
* Scale: Ranges from 0 to 1.
* Markers: 0, 0.2, 0.4, 0.6, 0.8, 1.0
* **Data Series:** A single blue line representing the CDF.
* **Grid:** A light gray grid is present to aid in reading values.
### Detailed Analysis
The blue line representing the CDF starts at approximately (0, 0.05). The line exhibits a steep upward slope between approximately 0.02 and 0.06 on the x-axis, indicating a rapid increase in the cumulative probability. The slope gradually decreases as the relative absolute error increases, approaching a value of approximately 0.98 at x = 0.10 and reaching approximately 0.99 at x = 0.12.
Here's a reconstruction of approximate data points:
* (0, 0.05)
* (0.02, 0.15)
* (0.04, 0.35)
* (0.06, 0.55)
* (0.08, 0.75)
* (0.10, 0.90)
* (0.12, 0.99)
### Key Observations
* The CDF shows that a significant portion of the relative absolute errors are concentrated below 0.06.
* The curve plateaus towards the higher end of the relative absolute error range, indicating that very large errors are relatively rare.
* The CDF is monotonically increasing, as expected.
### Interpretation
The data suggests that the model or process being evaluated generally exhibits low relative absolute errors. The rapid increase in the CDF between 0.02 and 0.06 indicates that the majority of errors fall within this range. The plateau at the higher end suggests that while larger errors do occur, they are infrequent. This CDF provides a visual representation of the error distribution, allowing for an assessment of the model's accuracy and reliability. The shape of the CDF is consistent with a distribution that is skewed towards lower error values. This could be due to the nature of the data, the model's design, or the optimization process used during training. Further analysis, such as calculating the mean and standard deviation of the relative absolute errors, would provide a more complete understanding of the error distribution.
</details>
Figure 5: Cumulative density function (CDF) of the relative absolute FRR error
## V Relevant Applications
### V-A Data Generation
The primary application of the proposed sound synthesis procedure is generating synthetic data to compute performance analytics for the device under test, e.g., False Rejection Rate (FRR), Word Error Rate (WER), and audio quality metrics. It provides a low-cost high-quality alternative to real data collection; which is an expensive and time-consuming process. Further, the proposed framework provides control of the environment conditions for customized usage scenarios. The synthetic data can also be used to augment real data collection for training deep learning acoustic models, which require large amount of data under diverse acoustic conditions. Note that, the proposed methodology requires only the device CAD (to compute the device dictionary), and does not need the actual device hardware. Therefore, it could be integrated with the hardware design process to evaluate different metrics at early design stages without building hardware prototypes.
### V-B Microphone Array Processing
The traditional model for microphone array processing in the literature utilizes free-field steering vectors that capture only phase differences due to wave propagation and neglect the magnitude component due to scattering with device surface [29, 30]. This limitation results in undesirable effects with beamforming, e.g., spatial aliasing. Rather, the acoustic dictionary, as described in section II-B, is a generalization of free-field steering vectors that captures device response to acoustic plane wave. The entries of the acoustic dictionary provide more accurate steering vectors because they have both magnitude and phase components. Therefore, beamformer design with steering vectors from acoustic dictionary provides significantly better directivity in real room setting [3]. Further, the plane wave decomposition in (5) incorporates scattering at the device surface; hence, it provides an accurate acoustic map of the device surrounding. It can be regarded as an invertible spatial transformation that maps microphone array observations into spatial components. This enables many applications related to microphone array processing, e.g., sound source localization, sound source separation, and dereverberation.
## VI Conclusions
The proposed framework enables generating accurate multichannel audio data for a general microphone array mounted on a rigid surface of an arbitrary form factor using only the CAD model of the surface and the coordinates of the microphone array. It is a balanced approach between measurement-based methods and simulation-based methods. The framework significantly reduces the cost of hardware validation and data collection. Its effectiveness is established by rigorous validation with physical data under diverse scenarios.
The key contribution of the proposed method is the decoupling of the room impact and the device-dependent impact in estimating the sound-field at the microphone array. This decoupling enables reusing the room component with different hardware designs, as if the corresponding devices are placed in the same room location. The room acoustics modeling is performed using plane wave decomposition, after collecting room measurements with a large microphone array to achieve high accuracy modeling as shown in the experimental validation. Device modeling through the device acoustic dictionary provides a general model that works with any microphone array geometry and any form factor of the surface. Though the discussion focused primarily on far-field sources and acoustic plane waves, it can be straightforwardly extended to the near field case by appending the device dictionary with acoustic spherical waves.
The contributions of this work are summarized as follows:
1. A methodology for decoupling and combining room acoustics and impact of device surface for accurate sound field realization.
1. A novel algorithm to compute plane wave decomposition of a point in a room based on measurement with a large microphone array with sparse recovery techniques.
1. A methodology for characterizing device acoustics based on response to acoustic plane waves.
1. A framework for data generation based on room impulse response that is derived from the proposed sound synthesis procedure.
We also highlighted few relevant applications with high impact that are based on the proposed framework; which are investigated in details in future publications.
## References
- [1] H. Kuttruff, Room acoustics, 4th ed. CRC Press, 2000.
- [2] J. B. Allen and D. A. Berkley, “Image method for efficiently simulating small-room acoustics,” The Journal of the Acoustical Society of America, vol. 65, no. 4, pp. 943–950, 1979.
- [3] A. Chhetri, M. Mansour, W. Kim, and G. Pan, “On acoustic modeling for broadband beamforming,” in 2019 27th European Signal Processing Conference (EUSIPCO). IEEE, 2019, pp. 1–5.
- [4] M. Hahmann, S. A. Verburg, and E. Fernandez-Grande, “Spatial reconstruction of sound fields using local and data-driven functions,” The Journal of the Acoustical Society of America, vol. 150, no. 6, pp. 4417–4428, 2021.
- [5] S. A. Verburg and E. Fernandez-Grande, “Reconstruction of the sound field in a room using compressive sensing,” The Journal of the Acoustical Society of America, vol. 143, no. 6, pp. 3770–3779, 2018.
- [6] S. Koyama, N. Murata, and H. Saruwatari, “Sparse sound field decomposition for super-resolution in recording and reproduction,” The Journal of the Acoustical Society of America, vol. 143, no. 6, pp. 3780–3795, 2018.
- [7] N. Iijima, S. Koyama, and H. Saruwatari, “Binaural rendering from microphone array signals of arbitrary geometry,” The Journal of the Acoustical Society of America, vol. 150, no. 4, pp. 2479–2491, 2021.
- [8] H. Teutsch, Modal array signal processing: principles and applications of acoustic wavefield decomposition. Springer, 2007, vol. 348.
- [9] E. G. Williams, Fourier acoustics: sound radiation and nearfield acoustical holography. Academic press, 1999.
- [10] S. Treitel, P. Gutowski, and D. Wagner, “Plane-wave decomposition of seismograms,” Geophysics, vol. 47, no. 10, pp. 1375–1401, 1982.
- [11] O. Yilmaz and M. T. Taner, “Discrete plane-wave decomposition by least-mean-square-error method,” Geophysics, vol. 59, no. 6, pp. 973–982, 1994.
- [12] B. Zhou and S. A. Greenhalgh, “Linear and parabolic $\tau$ -p transforms revisited,” Geophysics, vol. 59, no. 7, pp. 1133–1149, 1994.
- [13] O. Kirkeby and P. A. Nelson, “Reproduction of plane wave sound fields,” The Journal of the Acoustical Society of America, vol. 94, no. 5, pp. 2992–3000, 1993.
- [14] D. B. Ward and T. D. Abhayapala, “Reproduction of a plane-wave sound field using an array of loudspeakers,” IEEE Transactions on speech and audio processing, vol. 9, no. 6, pp. 697–707, 2001.
- [15] M. Park and B. Rafaely, “Sound-field analysis by plane-wave decomposition using spherical microphone array,” The Journal of the Acoustical Society of America, vol. 118, no. 5, pp. 3094–3103, 2005.
- [16] A. Moiola, R. Hiptmair, and I. Perugia, “Plane wave approximation of homogeneous helmholtz solutions,” Zeitschrift für angewandte Mathematik und Physik, vol. 62, no. 5, p. 809, 2011.
- [17] J.-P. Berenger, “A perfectly matched layer for the absorption of electromagnetic waves,” Journal of computational physics, vol. 114, no. 2, pp. 185–200, 1994.
- [18] COMSOL Multiphysics, “Acoustic module–user guide,” 2017.
- [19] F. M. Wiener, “The diffraction of sound by rigid disks and rigid square plates,” The Journal of the Acoustical Society of America, vol. 21, no. 4, pp. 334–347, 1949.
- [20] R. Spence, “The diffraction of sound by circular disks and apertures,” The Journal of the Acoustical Society of America, vol. 20, no. 4, pp. 380–386, 1948.
- [21] Eigenmike, “Em32 eigenmike microphone array release notes (v17. 0),” MH Acoustics, USA, 2013.
- [22] R. Tibshirani, “Regression shrinkage and selection via the lasso,” Journal of the Royal Statistical Society: Series B (Methodological), vol. 58, no. 1, pp. 267–288, 1996.
- [23] J. A. Tropp and S. J. Wright, “Computational methods for sparse solution of linear inverse problems,” Proceedings of the IEEE, vol. 98, no. 6, pp. 948–958, 2010.
- [24] T. Hastie, R. Tibshirani, and M. Wainwright, Statistical learning with sparsity: the lasso and generalizations. Chapman and Hall/CRC, 2019.
- [25] J. A. Tropp and A. C. Gilbert, “Signal recovery from random measurements via orthogonal matching pursuit,” IEEE Transactions on information theory, vol. 53, no. 12, pp. 4655–4666, 2007.
- [26] M. Mansour, “Sparse recovery of acoustic waves,” in ICASSP 2022-2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2022, pp. 5418–5422.
- [27] S. Foster, “Impulse response measurement using golay codes,” in Acoustics, Speech, and Signal Processing, IEEE International Conference on ICASSP’86., vol. 11. IEEE, 1986, pp. 929–932.
- [28] P. Stoica and R. L. Moses, Introduction to spectral analysis. Pearson Education, 1997.
- [29] M. Brandstein and D. Ward, Microphone arrays: signal processing techniques and applications. Springer Science & Business Media, 2013.
- [30] J. Benesty, J. Chen, and Y. Huang, Microphone array signal processing. Springer Science & Business Media, 2008, vol. 1.