# LogicVista: Multimodal LLM Logical Reasoning Benchmark in Visual Contexts
## Abstract
We propose LogicVista, an evaluation benchmark that assesses the integrated logical reasoning capabilities of multimodal large language models (MLLMs) in Vis ual contexts. Recent advancements in MLLMs have demonstrated various fascinating abilities, from crafting poetry based on an image to performing mathematical reasoning. However, there is still a lack of systematic evaluation of MLLMs’ proficiency in logical reasoning tasks, which are essential for activities like navigation and puzzle-solving. Thus we evaluate general logical cognition abilities across 5 logical reasoning tasks encompassing 9 different capabilities, using a sample of 448 multiple-choice questions. Each question is annotated with the correct answer and the human-written reasoning behind the selection, enabling both open-ended and multiple-choice evaluation. A total of 8 MLLMs are comprehensively evaluated using LogicVista. Code and Data Available at https://github.com/Yijia-Xiao/LogicVista.
∗ Both authors contributed equally.
## 1 Introduction
Recent advancements in Large Language Models (LLMs) are gradually turning the vision of a generalist AI agent into reality. These models exhibit near-human expert-level performance across a variety of tasks and have recently been augmented with visual understanding capabilities, enabling them to tackle even more complex visual challenges. This branch of work, led by proprietary projects such as GPT-4 [1] and Flamingo [2], as well as open-source efforts like LLaVA [3], Mini-GPT4 [4], enhances existing LLMs by incorporating visual comprehension. These models, known as Multimodal Large Language Models (MLLMs), use LLMs as the foundation for processing information and generating reasoned outcomes [5], thereby bridging the gap between language and vision.
Recent MLLMs have demonstrated a range of impressive abilities, such as writing poems based on an image [6], engaging in mathematical reasoning [2], and even aiding in medical diagnosis [7]. To evaluate the performance of these models, various benchmarks have been proposed, as shown in Figure. 1 targeting the performance on common tasks such as objects recognition [8], text understanding in images [9], or mathematical problem solving [10]. However, as seen in Figure. 1, there is a notable shortage of benchmarks for MLLMs’ abilities in critical logical reasoning tasks that underlie most tasks. Perception and reasoning are two representative abilities of high-level intelligence that are used in unison during human problem-solving processes.
Many current MLLM datasets have focused solely on perception tasks, which require fact retrieval where the MLLM identifies and retrieve relevant information from a scene. However, complex multimodal reasoning, such as interpreting graphs [11], everyday reasoning, critical thinking, and problem-solving [12, 13] requires a combination of perception and logical reasoning. Proficiency in these reasoning skills is a reliable indicator of cognitive capabilities required for performing specialized or routine tasks across different domains. To our knowledge, MathVista [14] is the only benchmark that attempts to evaluate multimodal logical reasoning, but its scope is limited to mathematical-related reasoning. For a better understanding of how MLLMs perform on general reasoning tasks, there is a need for a comprehensive and general visual reasoning benchmark.
| LogicVista (Ours) | | | | | | | | | VQAv2, TextVQA and MM-vet |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
|
<details>
<summary>extracted/5714025/figures/ours1.png Details</summary>
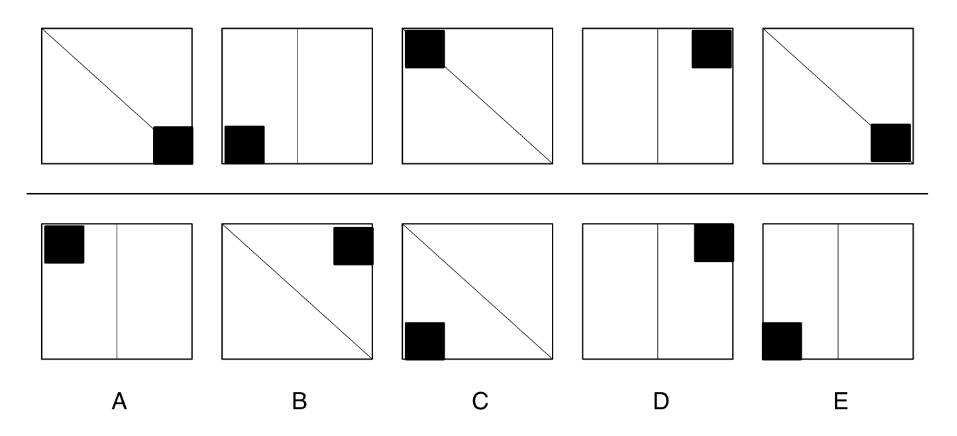
### Visual Description
## Diagram: Geometric Pattern Sequence
### Overview
The image displays a diagram consisting of two horizontal rows of squares. Each row contains five squares arranged side-by-side. The top row is unlabeled, while the bottom row has the letters A, B, C, D, and E centered beneath each respective square. Each square contains a combination of a line (either diagonal or vertical) and a solid black square positioned in one of the corners. The diagram appears to be a visual pattern or logic puzzle, likely testing spatial reasoning or sequence identification.
### Components/Axes
* **Structure:** Two rows of five squares each.
* **Labels:** The bottom row squares are labeled with uppercase letters: **A, B, C, D, E**.
* **Internal Elements:**
* **Lines:** Each square contains a single line. Most are diagonal lines running from the top-left corner to the bottom-right corner. Two squares (the second and fourth in the top row, and the fourth in the bottom row) contain a vertical line dividing the square in half.
* **Black Squares:** Each square contains one solid black square, positioned in one of the four corners (top-left, top-right, bottom-left, bottom-right).
### Detailed Analysis
**Top Row (Left to Right):**
1. **Square 1:** Diagonal line (top-left to bottom-right). Black square in the **bottom-right** corner.
2. **Square 2:** Vertical line (center). Black square in the **bottom-left** corner.
3. **Square 3:** Diagonal line (top-left to bottom-right). Black square in the **top-left** corner.
4. **Square 4:** Vertical line (center). Black square in the **top-right** corner.
5. **Square 5:** Diagonal line (top-left to bottom-right). Black square in the **bottom-right** corner.
**Bottom Row (Labeled A-E):**
* **A:** Vertical line (center). Black square in the **top-left** corner.
* **B:** Diagonal line (top-left to bottom-right). Black square in the **top-right** corner.
* **C:** Diagonal line (top-left to bottom-right). Black square in the **bottom-left** corner.
* **D:** Vertical line (center). Black square in the **top-right** corner.
* **E:** Vertical line (center). Black square in the **bottom-left** corner.
### Key Observations
1. **Line Pattern:** The sequence of line types in the top row is: Diagonal, Vertical, Diagonal, Vertical, Diagonal. This creates an alternating pattern.
2. **Black Square Movement (Top Row):** The black square's position changes in a specific sequence: Bottom-Right -> Bottom-Left -> Top-Left -> Top-Right -> Bottom-Right. This represents a clockwise rotation around the corners of the square.
3. **Relationship Between Rows:** The bottom row (A-E) does not appear to be a direct continuation of the top row's sequence. Instead, it presents five distinct configurations. Squares A, D, and E have vertical lines, while B and C have diagonal lines.
4. **Repetition:** The configuration of Top Row Square 1 (Diagonal, Bottom-Right) is identical to that of Top Row Square 5. The configuration of Bottom Row Square D (Vertical, Top-Right) is identical to that of Top Row Square 4.
### Interpretation
This diagram is most likely a **non-verbal reasoning or abstract reasoning test item**. The top row establishes a clear, logical pattern governed by two rules:
* **Rule 1 (Lines):** The line type alternates between diagonal and vertical.
* **Rule 2 (Black Square):** The black square moves one corner clockwise with each step.
The bottom row (A-E) likely presents a set of answer choices. The task would be to identify which of the five squares (A-E) correctly continues the sequence established in the top row. Based on the established patterns:
* The next line type after the fifth square (Diagonal) should be **Vertical**.
* The next black square position after the fifth square (Bottom-Right) should be **Bottom-Left** (moving clockwise).
Therefore, the correct continuation would be a square with a **vertical line** and a **black square in the bottom-left corner**. Examining the options:
* **A:** Vertical, Top-Left (Incorrect position)
* **B:** Diagonal, Top-Right (Incorrect line and position)
* **C:** Diagonal, Bottom-Left (Incorrect line)
* **D:** Vertical, Top-Right (Incorrect position)
* **E:** Vertical, Bottom-Left (**Matches both predicted rules**)
Thus, **Square E** is the logical next element in the sequence. The diagram tests the ability to isolate and apply multiple, concurrent visual rules.
</details>
| Q: Which of the boxes comes next? A: E Reasoning Skill: Inductive Capability: Diagram |
<details>
<summary>extracted/5714025/figures/vqav2.jpg Details</summary>

### Visual Description
## Photograph: Female Tennis Player in Action
### Overview
This is a high-resolution action photograph capturing a female tennis player mid-swing during a match or practice session. The image is taken from a low angle, slightly to the player's side, emphasizing her dynamic movement and the moment of contact with the ball. The setting is an outdoor hard court on a bright, sunny day.
### Components & Visible Details
**1. Primary Subject: The Tennis Player**
* **Position:** Centered in the frame, captured in a full-body shot. She is airborne, with both feet off the ground, indicating a powerful running or lunging forehand stroke.
* **Action:** Her body is angled towards the left side of the frame. Her right arm is extended forward, holding the racket which is making contact with the tennis ball. Her left arm is extended back for balance. Her gaze is focused intently on the ball.
* **Attire:**
* **Head:** A white visor with a small, dark logo on the front (appears to be the Adidas three-stripe mountain logo).
* **Torso:** A bright red, short-sleeved athletic shirt. On the chest is a large, white circular logo. The logo features a stylized letter "W" inside a circle, with the word "Wildcats" written in a cursive or script font beneath it.
* **Lower Body:** A white tennis skirt or skort.
* **Feet:** Light gray or silver athletic shoes with white soles and laces.
* **Equipment:**
* **Racket:** A tennis racket with a blue and black frame. The strings are in contact with the ball. The brand is not clearly legible from this angle.
* **Ball:** A standard yellow-green tennis ball, captured in motion just as it meets the racket strings. It is positioned slightly to the left of the player's torso.
**2. Environment & Background**
* **Court Surface:** A green hard court with white boundary lines. A thick white line runs diagonally from the bottom left corner towards the center. The court surface shows some minor scuff marks and debris.
* **Background:** Immediately behind the player is a tall, gray chain-link fence. Beyond the fence, the background is out of focus but shows hints of green foliage (trees or bushes) and a pale, overcast or hazy sky. The lighting is bright and direct, casting a sharp, dark shadow of the player onto the court surface to her right.
### Detailed Analysis of Text & Logos
* **Shirt Logo (Primary Text):**
* **Text:** "Wildcats"
* **Language:** English.
* **Style:** Script/cursive font, white color.
* **Placement:** Centered on the chest, beneath a large stylized "W" emblem.
* **Interpretation:** This strongly indicates the player is affiliated with a team or school named the "Wildcats."
* **Visor Logo:**
* **Text/Symbol:** A small, dark logo consistent with the Adidas brand mark (three diagonal stripes forming a triangle/mountain shape).
* **Placement:** Centered on the front of the white visor.
* **Other Potential Text:** No other legible text is visible on the racket, shoes, or in the background.
### Key Observations
1. **Peak Action Moment:** The photograph freezes the precise moment of impact between racket and ball, showcasing athletic technique and intensity.
2. **Team Affiliation:** The prominent "Wildcats" logo is the most significant textual information, providing context about the player's team.
3. **Environmental Context:** The chain-link fence and court surface clearly establish the setting as a standard outdoor tennis facility.
4. **Lighting and Shadow:** The strong, directional sunlight creates high contrast and a defined shadow, adding depth and a sense of time (likely mid-day).
### Interpretation
This image is a documentary sports photograph, not a data chart. Its primary informational value lies in capturing:
* **Athletic Form:** It serves as a visual record of a specific tennis stroke (a running forehand) for analysis of technique, posture, and motion.
* **Identity and Affiliation:** The "Wildcats" branding on the uniform is the key piece of identifying information, linking the athlete to a specific team, likely at the high school or collegiate level.
* **Context of Play:** The setting indicates a competitive or practice environment on a standard hard court.
The image does not contain quantitative data, trends, or diagrams. Its "data" is qualitative and visual, useful for coaching, sports journalism, or team documentation. The lack of visible sponsor logos beyond the apparel brand (Adidas) and the team name suggests this may be a collegiate or amateur sports context rather than a professional tour event.
</details>
| Q: Is the girl touching the ground? A: No Reasoning Skill: None Capability: Recognition |
| --- | --- | --- | --- |
|
<details>
<summary>extracted/5714025/figures/ours2.png Details</summary>
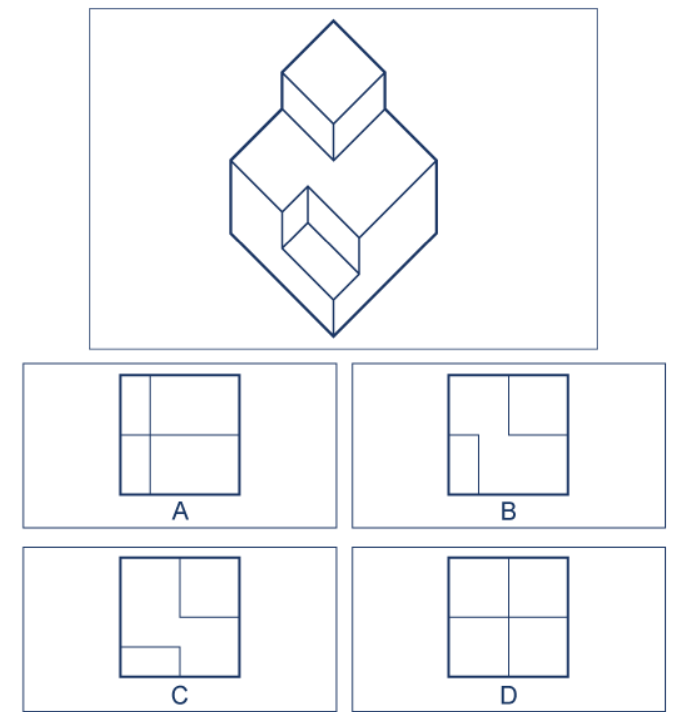
### Visual Description
## Diagram: 3D Isometric Block with 2D Top-View Options
### Overview
The image presents a spatial reasoning puzzle. It consists of two main sections: a large, centrally positioned isometric line drawing of a 3D block structure at the top, and a set of four smaller, labeled 2D diagrams (A, B, C, D) arranged in a 2x2 grid below it. The task implied is to identify which of the four 2D diagrams correctly represents the top-down view of the 3D structure.
### Components/Axes
* **Primary Element (Top):** A single isometric projection of a composite 3D block. The drawing uses blue lines on a white background.
* **Secondary Elements (Bottom):** Four rectangular frames, each containing a 2D square diagram composed of internal lines. Each frame has a centered label below it:
* **A** (Bottom-left of the grid)
* **B** (Bottom-right of the grid)
* **C** (Top-left of the grid)
* **D** (Top-right of the grid)
* **Text:** The only textual elements are the single capital letters "A", "B", "C", and "D" serving as labels for the 2D options.
### Detailed Analysis
**1. 3D Structure Analysis (Top Image):**
* The object is a large cube or rectangular prism.
* A smaller cube is stacked on top of the main block, aligned with its top-rear corner (from the viewer's isometric perspective).
* A rectangular notch or cutout is present on the front-left vertical face of the main block. This notch extends inward, creating an L-shaped profile when viewed from the front.
**2. 2D Diagram Analysis (Options A-D):**
Each diagram is a square divided by internal lines, representing a potential top-down view.
* **Diagram A:** The square is divided by one vertical line (left of center) and one horizontal line (below center), creating four unequal rectangular sections.
* **Diagram B:** The square contains an L-shaped region formed by a vertical line on the left and a horizontal line near the top. This leaves a smaller square in the top-right corner and a larger L-shaped area occupying the bottom and left.
* **Diagram C:** Similar to B but mirrored. It contains an L-shaped region formed by a vertical line on the right and a horizontal line near the top. This leaves a smaller square in the top-left corner and a larger L-shaped area occupying the bottom and right.
* **Diagram D:** The square is divided by one vertical and one horizontal line, both centered, creating four equal smaller squares (a 2x2 grid).
### Key Observations
* The 3D structure has two key features visible from a top-down perspective: the smaller cube on top and the notch cut into the side.
* The smaller top cube would appear as a smaller square within the larger square outline in a top view.
* The side notch would manifest as a missing or indented section in the perimeter of the larger square's top view, creating an L-shaped or irregular outer boundary for the main block's footprint.
* **Diagram D** is the only option with perfect symmetry and no indication of a notch or a smaller top cube, making it an unlikely match.
* **Diagram A** shows asymmetry but lacks a clear, isolated square representing the top cube.
* **Diagrams B and C** both show a smaller square in a corner (top-right for B, top-left for C) and an L-shaped region, which are the most plausible representations of the 3D structure's top view. The correct choice between them depends on the rotational orientation of the top view relative to the isometric projection.
### Interpretation
This image is a classic spatial visualization test, likely from an engineering, architecture, or aptitude assessment. It evaluates the ability to mentally rotate a 3D object and derive its correct 2D orthographic projection.
* **What the data suggests:** The puzzle implies there is one correct 2D top view among the four options that accurately corresponds to the given 3D isometric drawing.
* **Relationship between elements:** The 3D drawing is the problem statement. The 2D diagrams are the multiple-choice answers. The solver must perform a mental transformation from 3D to 2D.
* **Notable pattern/anomaly:** The critical reasoning step is correlating the position of the smaller top cube and the side notch with the internal lines in the 2D options. The notch on the front-left face of the 3D block (from the viewer's perspective) would, when viewed from directly above, create an indentation on the corresponding side of the square outline. Assuming a standard top-view orientation where the "front" of the isometric view maps to the "bottom" of the top view, the notch would appear on the bottom or left side of the 2D square. This logic would favor **Diagram B** (notch implied on the left/bottom, small square top-right) over **Diagram C** (notch implied on the right/bottom, small square top-left). However, without an explicit arrow indicating the "front" direction for the top view, a degree of ambiguity remains, which is common in such puzzles to test careful assumption-checking.
</details>
| Q: Which of these are the top view? A: B Reasoning Skill: Spatial Capability: 3D Shape |
<details>
<summary>extracted/5714025/figures/textvqa.jpg Details</summary>

### Visual Description
## Digital Route Display: Transit Information Sign
### Overview
The image shows a close-up photograph of an electronic dot-matrix display board, likely installed inside a public transit vehicle (such as a train or bus). The display provides real-time route information using illuminated text against a dark background. The information is presented in three distinct, vertically stacked lines.
### Components/Axes
The display is structured into three labeled rows. Each row consists of a static label in a grey, sans-serif font followed by a dynamic value displayed in a bright yellow, segmented LED/dot-matrix font. To the right of each dynamic value, there is a series of solid green rectangular blocks.
**Spatial Layout (Top to Bottom):**
1. **Top Row:**
* **Label (Left):** `ORIGIN:`
* **Value (Center-Left):** `WASHINGTON`
* **Green Blocks (Right):** Three consecutive green blocks.
2. **Middle Row:**
* **Label (Left):** `NEXT STOP:`
* **Value (Center-Left):** `BWI AIRPORT`
* **Green Blocks (Right):** Two consecutive green blocks.
3. **Bottom Row:**
* **Label (Left):** `DESTINATION:`
* **Value (Center-Left):** `NEW YORK`
* **Green Blocks (Right):** Five consecutive green blocks.
### Detailed Analysis
* **Text Transcription:**
* Line 1: `ORIGIN: WASHINGTON`
* Line 2: `NEXT STOP: BWI AIRPORT`
* Line 3: `DESTINATION: NEW YORK`
* **Visual Characteristics:**
* **Font:** The dynamic values (`WASHINGTON`, `BWI AIRPORT`, `NEW YORK`) use a classic dot-matrix or segmented LED font style, where each character is formed by a grid of illuminated yellow squares/pixels.
* **Color Scheme:** The primary palette is high-contrast for readability: bright yellow text on a black/dark grey background. The static labels are a muted grey. The green blocks provide a secondary accent color.
* **Green Blocks:** The number of green blocks varies per row (3, 2, and 5 respectively). Their purpose is not explicitly labeled. They may represent a progress bar, a visual separator, or a placeholder for additional information not currently displayed.
### Key Observations
1. **Information Hierarchy:** The display clearly communicates a three-stage journey: starting point, immediate next stop, and final terminus.
2. **Geographic Context:** The locations indicate a transit route in the Northeastern United States. "BWI" is a common airport code for Baltimore/Washington International Thurgood Marshall Airport.
3. **Design for Readability:** The use of all-caps, a simple dot-matrix font, and high-contrast colors is optimized for quick reading in a moving vehicle, potentially from a distance or at an angle.
4. **Variable Data Fields:** Only the location names are displayed in the dynamic, illuminated font, suggesting these are the elements that change based on the vehicle's position in its route. The labels (`ORIGIN:`, etc.) are fixed.
### Interpretation
This image captures a standard real-time passenger information system. Its primary function is to reduce passenger anxiety and improve wayfinding by clearly stating the vehicle's current context within its route.
* **Journey Narrative:** The data tells a simple story: The trip began in Washington, the immediate next destination is BWI Airport, and the final endpoint is New York. This suggests a long-distance intercity route, possibly an Amtrak train or a dedicated airport connector service.
* **Ambiguity of Green Blocks:** The green blocks are the only element without an explicit label. Their varying count (3, 2, 5) does not correlate obviously with the length of the location names or any other visible data. They might be a legacy design element, a generic "fill" graphic, or part of a system where they could be filled/unfilled to indicate progress (though all are solidly lit here). Their exact function cannot be determined from this single image alone.
* **User Experience:** The display is effective in its simplicity. It answers the three most critical questions for a passenger: "Where did we start?", "Where are we going next?", and "Where does this trip end?" without any extraneous information.
</details>
| Q: What is the final destination? A: New York Reasoning Skill: None Capability: OCR |
|
<details>
<summary>extracted/5714025/figures/ours3.png Details</summary>
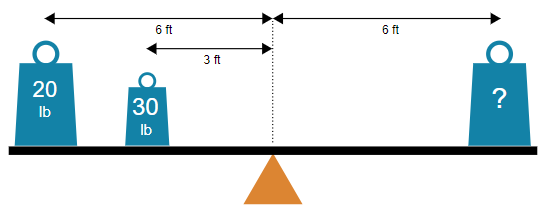
### Visual Description
## Diagram: Torque Balance on a Lever
### Overview
The image is a technical diagram illustrating the principle of torque equilibrium on a lever (seesaw). It depicts a balanced lever with known weights and distances on the left side and an unknown weight on the right side, posing a problem to solve for the unknown mass.
### Components/Axes
* **Main Structure:** A horizontal black bar representing a lever or beam.
* **Fulcrum:** An orange triangle positioned at the exact center of the lever, serving as the pivot point.
* **Weights:** Three blue, trapezoidal weight icons with circular handles on top.
* **Left Side (Two Weights):**
* A larger weight labeled **"20 lb"**.
* A smaller weight labeled **"30 lb"**.
* **Right Side (One Weight):**
* A larger weight labeled with a **"?"** (question mark), indicating an unknown value.
* **Distance Markers:** Black double-headed arrows with text labels indicating horizontal distances from the central fulcrum.
* An arrow from the fulcrum to the center of the **20 lb** weight is labeled **"6 ft"**.
* An arrow from the fulcrum to the center of the **30 lb** weight is labeled **"3 ft"**.
* An arrow from the fulcrum to the center of the **"?"** weight is labeled **"6 ft"**.
* **Language:** All text in the diagram is in **English**.
### Detailed Analysis
The diagram sets up a classic physics problem involving rotational equilibrium (sum of torques = 0). The lever is shown in a balanced, horizontal state.
**Left Side Torques (Counter-Clockwise):**
1. **Weight 1:** 20 lb at a distance of 6 ft from the fulcrum.
* Torque = Force × Distance = 20 lb × 6 ft = **120 lb-ft**.
2. **Weight 2:** 30 lb at a distance of 3 ft from the fulcrum.
* Torque = 30 lb × 3 ft = **90 lb-ft**.
* **Total Left Torque:** 120 lb-ft + 90 lb-ft = **210 lb-ft**.
**Right Side Torque (Clockwise):**
1. **Unknown Weight (?):** Let's call it *W* lb, at a distance of 6 ft from the fulcrum.
* Torque = *W* lb × 6 ft = **6*W* lb-ft**.
**Equilibrium Condition:** For the lever to be balanced, the total counter-clockwise torque must equal the total clockwise torque.
* 210 lb-ft = 6*W* lb-ft
* Solving for *W*: *W* = 210 / 6 = **35 lb**.
### Key Observations
* The diagram is spatially precise. The fulcrum is centered, and the distance markers clearly originate from the central dotted vertical line aligned with the fulcrum's apex.
* The visual placement of the weights corresponds to their labeled distances. The 30 lb weight is visibly closer to the fulcrum than the 20 lb weight, matching the 3 ft vs. 6 ft labels.
* The unknown weight on the right is placed at the same distance (6 ft) as the 20 lb weight on the left, but the system is balanced, implying it must be heavier than 20 lb to counteract the combined torque from the left side.
* The color coding is consistent: all weights are the same shade of blue, and the fulcrum is a distinct orange.
### Interpretation
This diagram is an educational tool demonstrating the **principle of moments** or **lever equilibrium**. It visually communicates that balance depends not just on weight (force), but on the product of weight and its distance from the pivot (torque).
The data suggests that to balance a system, a single weight on one side must produce a torque equal to the sum of all torques on the opposite side. The specific solution (35 lb) is a direct mathematical consequence of the given values. The "question mark" transforms the diagram from a mere illustration into an interactive problem, prompting the viewer to apply the formula: **Clockwise Torque = Counter-Clockwise Torque**.
There are no anomalies; the diagram is a clean, idealized representation of a fundamental physics concept. Its purpose is to teach or test understanding of rotational mechanics.
</details>
| Q: What is the weight if balanced? A: C: 35 lb Reasoning Skill: Mechanical Capability: Physics |
<details>
<summary>extracted/5714025/figures/mmvet1.png Details</summary>

### Visual Description
## Photograph: Children Solving Math Problems on a Chalkboard
### Overview
The image is a photograph depicting three young children, seen from behind, standing side-by-side and writing on a large, green chalkboard. Each child is holding a piece of white chalk and is in the process of writing or has just written a basic arithmetic problem. The scene suggests a classroom or educational setting focused on early mathematics.
### Components/Subjects
1. **Subjects:** Three children, likely of primary school age.
* **Left Child:** A girl with long dark hair tied in a ponytail with a red, cherry-shaped hair accessory. She wears a white collared shirt under a navy blue vest with red and white trim at the neckline.
* **Center Child:** A girl with long dark hair in a ponytail, secured with a small, light-colored hair clip. She wears a pink collared shirt under a similar navy blue vest.
* **Right Child:** A boy with short dark hair. He wears a white collared shirt under the same style of navy blue vest.
2. **Primary Surface:** A large, green chalkboard with a slightly textured, dusty surface. Faint, erased chalk marks are visible in the background.
3. **Objects:** Each child holds a small piece of white chalk in their right hand, raised to the board.
### Detailed Analysis: Embedded Text Content
Three distinct mathematical equations are written in white chalk across the upper portion of the chalkboard. The handwriting is clear and child-like.
* **Left Equation (Position: Upper-left quadrant):**
* **Text:** `3×3=`
* **Transcription:** The multiplication problem "three times three equals".
* **Status:** The equation is incomplete; no answer is written.
* **Center Equation (Position: Upper-center):**
* **Text:** `7×2=`
* **Transcription:** The multiplication problem "seven times two equals".
* **Status:** The equation is incomplete; no answer is written.
* **Right Equation (Position: Upper-right quadrant):**
* **Text:** `11-2=`
* **Transcription:** The subtraction problem "eleven minus two equals".
* **Status:** The equation is incomplete; no answer is written.
**Language:** The mathematical notation and numerals are in a universal format. The underlying language context is not explicitly stated but is consistent with basic arithmetic taught globally.
### Key Observations
1. **Action & Focus:** All three children are actively engaged, with their arms raised and chalk touching or near the board, indicating they are in the moment of solving the problems.
2. **Uniformity:** The children wear similar school uniforms (navy vests with trim over collared shirts), suggesting a formal school environment.
3. **Problem Types:** The problems include two multiplication equations (single-digit factors) and one subtraction equation (two-digit minus single-digit), representing foundational arithmetic operations.
4. **Absence of Answers:** None of the equations have answers written next to them. This captures a moment of active work rather than completed work.
5. **Composition:** The photograph is taken from a slightly low angle behind the children, emphasizing their perspective and engagement with the board. The chalkboard fills the entire background.
### Interpretation
This image captures a fundamental moment in early education: the hands-on practice of basic arithmetic. The scene demonstrates **active learning** and **skill application**. The children are not passively receiving information but are physically engaged in the process of problem-solving.
The choice of problems—simple multiplication and subtraction—indicates a focus on building numerical fluency and confidence. The uniform setting implies a structured learning environment, while the individual handwriting on the board shows personal engagement with the task.
The photograph's power lies in its simplicity and universality. It represents the foundational step of learning mathematics, a scene repeated in classrooms worldwide. The lack of visible answers shifts the focus from the result to the **process of learning itself**. It highlights concentration, participation, and the development of fundamental academic skills. The image does not provide data or trends but instead documents a typical, essential activity within an educational framework.
</details>
| Q: What will girl on right write? A: 14 Reasoning Skill: Numerical Capability: OCR |
Figure 1: Capabilities and reasoning skills of various existing benchmarks. Traditional benchmarks seldom assess reasoning skills, whereas LogicVista emphasizes the fundamental capacities necessary for solving specific problems, going beyond simple recognition or math tasks.
We argue that a universal comprehensive evaluation benchmark should have the following characteristics: (1) cover a wide range of logical reasoning tasks, including deductive, inductive, numeric, spatial, and mechanical reasoning; (2) present information in both graphical and Optical Character Recognition (OCR) formats to accommodate different types of data inputs; and (3) facilitate convenient quantitative analysis for rigorous assessment and comparison of model performance.
To this end, we present a comprehensive MLLM evaluation benchmark, named LogicVista, which meets all these criteria:
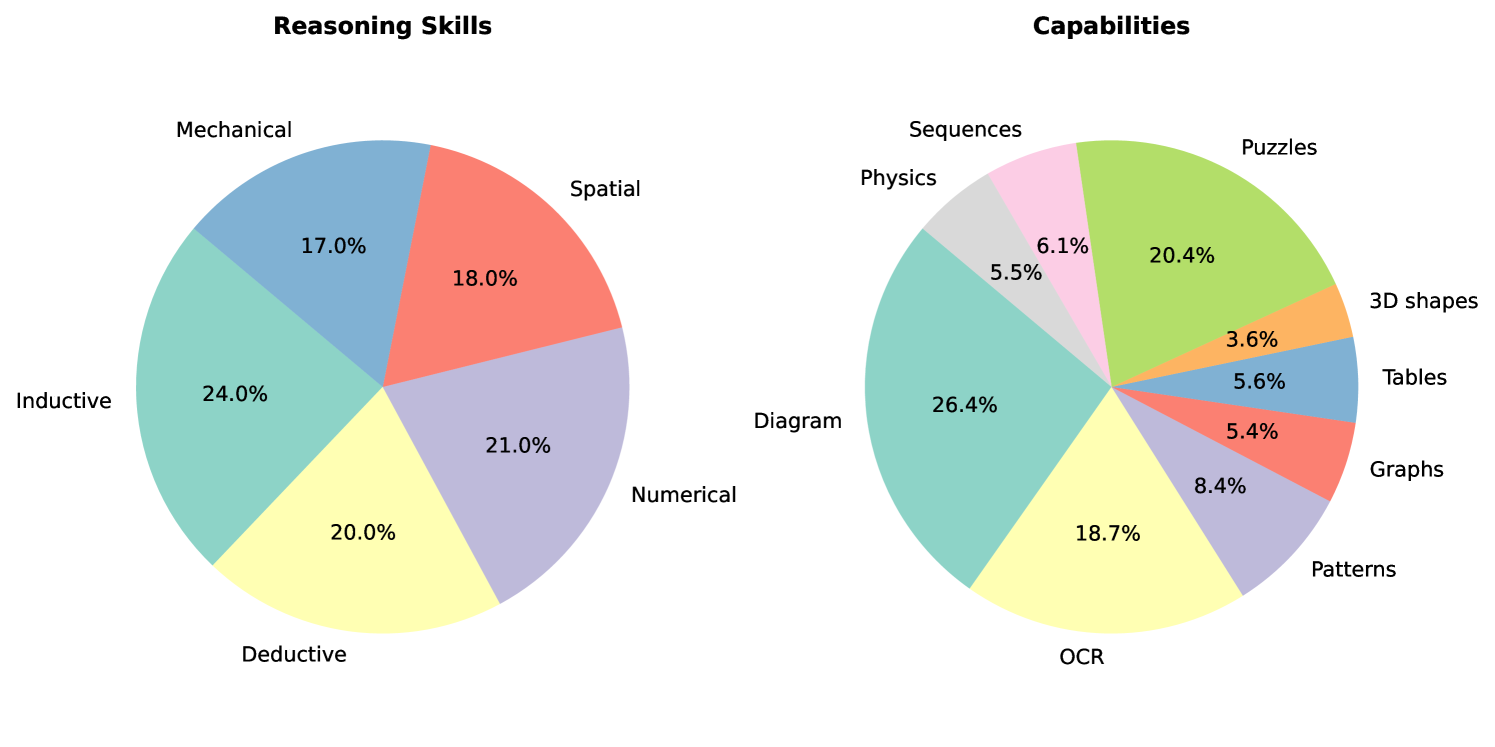
- LogicVista covers 5 representative categories of logical reasoning tasks: inductive ( $sample=107$ ), deductive ( $sample=93$ ), numerical ( $sample=95$ ), spatial ( $sample=79$ ), and mechanical ( $sample=74$ ).
- LogicVista includes a variety of capabilities, ranging from diagrams ( $sample=330$ ), OCR, ( $sample=234$ ), patterns ( $sample=105$ ), graphs ( $sample=67$ ), tables ( $sample=70$ ), 3D shapes ( $samples=45$ ), puzzles ( $samples=256$ ), sequences ( $samples=76$ ), and physics ( $samples=69$ ).
- All images, instructions, solution, and reasoning are manually annotated and validated.
- With our instruction design “please select from A, B, C, D, and E." and our LLM answer evaluator, we can assess different reasoning skills and capabilities and easily perform quantitative statistical analysis based on the natural language output of MLLMs. Additionally, We provide more in-depth human-written explanations for why each answer is correct, allowing for thorough open-ended evaluation.
As shown in Figure. 1, LogicVista covers a wide range of reasoning capabilities and evaluates them comprehensively. For instance, answering the question “Which of these images is the top view of the given object" in Figure 1 (b) requires not only recognizing the objects’ orientation but also the ability to spatially reason over the object from a different perspective. Since these questions and diagrams are presented without context, they effectively probe the MLLM’s underlying ability rather than relying on contextual cues from the surrounding real-life environment.
Furthermore, we provide two evaluation strategies with our annotations: multiple-choice question (MCQ) evaluation and open-ended evaluation. Our annotation of MCQ choices along with our LLM evaluator allows quick evaluations of answers provided by MLLMs. Additionally, our annotation of the reasoning and thought process behind each MCQ enables open-ended evaluation, capturing the nuances of the MLLM responses and identifying which reasoning steps were correct or incorrect.
We comprehensively evaluate the performance of 8 representative open and closed source MLLMs on 448 tasks across 5 main logical reasoning categories. LogicVista’s evaluation strategy allows users to see a detailed breakdown of an MLLM’s performance on each reasoning skill and capability. This approach provides more insights than a single overall score, enabling users to better understand the specific skills in which a model excels or needs improvement.
## 2 Related Works
| | VQAv2 [8, 15] | COCO [16] | TextCaps [17] | Contextual [18] | MM-vet [10] | MathVista [14] | VisIT-Bench [19] | LogicVista |
| --- | --- | --- | --- | --- | --- | --- | --- | --- |
| Number of Logical Reasoning Skills Tested | 0 | 0 | 1 | 1 | 1 | 2 | 1 | 5 |
| Number of Multimodal Capabilities Tested | 1 | 1 | 2 | 2 | 6 | 12 | 2 | 9 |
| Dataset Size | 204,721 | 330,000 | 28,000 | 506 | 217 | 6,141 | 592 | 448 |
| Scene and Object Recognition | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| Inductive Reasoning | ✗ | ✗ | ✗ | ✗ | ✗ | ✓ | ✗ | ✓ |
| Deductive Reasoning | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✓ |
| Numerical Reasoning | ✗ | ✗ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| Spatial Reasoning | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✓ |
| Mechanical Reasoning | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ | ✓ |
| Answer Choice Explanations | ✗ | ✗ | ✗ | ✗ | ✗ | ✓ | ✗ | ✓ |
| Human Annotation | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| Human Evaluation | ✗ | ✓ | ✓ | ✓ | ✗ | ✓ | ✓ | ✗ |
| Auto/GPT-4 Evaluation | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| Open-ended Evaluation | ✗ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
Table 1: Comparision with related vision-language benchmarks.
Multimodal Language Models The field of vision-language models [20, 21, 22, 23, 24, 25, 26, 27, 28, 29] has made significant progress towards achieving a cohesive understanding and generation of both visual and linguistic information. This progress is largely driven by the remarkable generalization and quality capabilities of recent large language models (LLMs) [30, 1, 31, 32]. As a result, there has been a surge in the development of MLLMs that aim to integrate the diverse capabilities of vision and language for complex multimodal tasks.
Efforts to create these multimodal generalist systems include enhancing LLMs with multi-sensory processing abilities, as demonstrated by innovative projects like Frozen [33], Flamingo [2], PaLM-E [34], and GPT-4 [1]. Recent releases of open-source LLMs [35, 32, 36] have further propelled research in this field, leading to the development of OpenFlamingo [37], LLaVA [38], MiniGPT-4 [4], Otter [39], InstructBLIP [40], among others [41, 38, 42]. Additionally, multimodal agents [43, 44, 45] have been explored for their ability to link various vision tools with LLMs [30, 1], aiming to enhance integrated vision-language capabilities
Vision-Language Benchmarks Traditional vision-language benchmarks have focused on assessing specific capabilities, including visual recognition [21], generating image descriptions [20, 46], and other specialized functions such as understanding scene text [47, 17, 48], commonsense reasoning [49], mathematical reasoning [14], instruction following [19], and external knowledge incorporation [50]. While some benchmarks incorporate reasoning [18], they are often presented in real-life contexts, which may reduce the task to mere recognition based on contextual cues.
The emergence of general MLLMs has highlighted the need for updated vision-language benchmarks that encompass complex multimodal tasks requiring comprehensive vision-language skills. Our benchmark, LogicVista, aligns closely with recent evaluation studies like MM-Vet and MMBench [10, 51], which aim to provide thorough evaluations of MLLMs through well-designed evaluation samples. A key distinction of LogicVista lies in its focus on integrated vision-language capabilities, offering deeper insights beyond mere model rankings.
LLM-Based Evaluation. LogicVista adopts an open-ended LLM-based evaluation approach, which facilitates the generation and assessment of diverse answer styles and question types beyond the limitations of binary or multiple-choice responses. This innovative method leverages the capabilities of large language models (LLMs) for comprehensive model evaluation, a technique that has been effectively applied in natural language processing (NLP) tasks [52, 53, 54, 55]. Our findings indicate that this LLM-based evaluation framework is not only versatile but also robust, enabling a unified and flexible assessment across various modalities. By accommodating a wide range of answer styles and question types, this approach enhances evaluation depth and breadth, which contributes to a more thorough understanding of model performance.
## 3 Data annotation and organization
<details>
<summary>x1.png Details</summary>
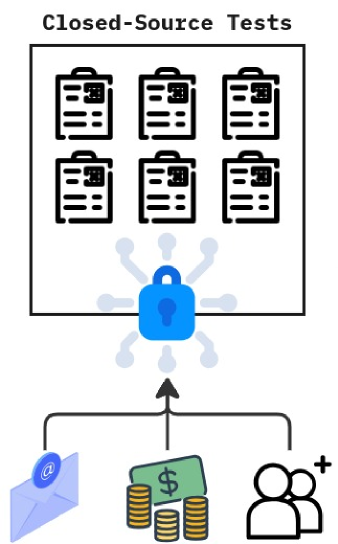
### Visual Description
## Diagram: Closed-Source Tests Process Flow
### Overview
The image is a conceptual diagram illustrating a process or system related to "Closed-Source Tests." It depicts a flow where various resources or inputs are secured before being utilized within a set of closed, proprietary test documents. The visual style is a simple, flat icon-based illustration.
### Components/Axes
The diagram is organized vertically into three distinct regions:
1. **Header Region (Top):**
* **Title:** "Closed-Source Tests" is written in a bold, sans-serif font, centered at the very top.
* **Main Container:** A large, black-outlined rectangle dominates the upper half of the image. Inside this rectangle are six identical icons arranged in a 2x3 grid (two rows, three columns).
* **Icons:** Each icon is a black-and-white line drawing of a clipboard. On each clipboard, there is a stylized QR code in the upper-left corner and three horizontal lines representing text below it.
2. **Central Security Element (Middle):**
* **Padlock Icon:** Positioned centrally below the main rectangle is a large, blue padlock icon. It has a classic shape with a keyhole.
* **Radiating Lines:** Eight light-blue lines with circular endpoints radiate outward from the padlock, suggesting a network, data flow, or a protective field.
3. **Input/Resource Region (Bottom):**
* **Three Input Icons:** At the bottom of the diagram, three distinct icons are arranged horizontally.
* **Left:** A light blue envelope icon with a dark blue "@" symbol on its flap, representing email or electronic communication.
* **Center:** A green dollar bill icon with a "$" symbol, accompanied by three stacks of gold coins below it, representing financial resources or funding.
* **Right:** A black outline icon of two people (one slightly behind the other) with a small "+" symbol to the upper right, representing personnel, team members, or user accounts.
* **Flow Arrows:** A black arrow originates from the top of the central dollar/coins icon and points directly upward to the base of the blue padlock. From the padlock, a single black arrow points upward into the bottom of the large "Closed-Source Tests" rectangle. This establishes a clear directional flow: Inputs → Security → Tests.
### Detailed Analysis
* **Spatial Grounding:** The legend/title is at the top-center. The primary data (the six test documents) is contained within the top rectangle. The security mechanism (padlock) is centrally located, acting as a gateway. The input sources are anchored at the bottom.
* **Component Isolation:**
* **Header (Tests):** Contains six discrete, identical test document units. The QR codes imply each test may be uniquely identifiable or trackable.
* **Middle (Security):** The padlock is the focal point, visually connecting the inputs to the outputs. Its blue color makes it stand out against the black-and-white elements.
* **Footer (Inputs):** Clearly depicts three categories of resources required: communication/data (@), capital ($), and human resources (people+).
* **Flow Verification:** The arrows create a unidirectional, bottom-up flow. Resources are funneled into a secured system (the padlock), which then grants access to or enables the closed-source tests.
### Key Observations
1. **Security as a Gatekeeper:** The padlock is not just a symbol; it is an active component in the flow. All inputs must pass through it before reaching the tests.
2. **Proprietary Nature:** The title "Closed-Source Tests" and the secured container strongly imply that the test methodologies, data, or results are proprietary, confidential, or not publicly accessible.
3. **Resource Dependency:** The diagram explicitly shows that conducting these tests requires a combination of communication/information, financial investment, and personnel.
4. **Standardization:** The six test documents are visually identical, suggesting a standardized format or batch of tests being conducted under the same secured conditions.
### Interpretation
This diagram illustrates a **controlled and resource-intensive process for conducting proprietary evaluations.**
* **What it suggests:** The data or processes involved in these "Closed-Source Tests" are considered valuable or sensitive, necessitating a security layer (the padlock) to control access and integrity. The tests are not standalone; they are fueled by tangible inputs—information flow, money, and people.
* **Relationships:** The relationship is hierarchical and gated. Inputs are subordinate to the security protocol, which in turn is subordinate to the final test suite. The security element mediates the relationship between resources and the proprietary work.
* **Anomalies/Notable Points:** The use of QR codes on the test documents is a specific detail. It could indicate that each test instance is serialized, linked to a digital record, or requires scanning for access, further emphasizing control and tracking. The radiating lines from the padlock might symbolize that the security protocol actively monitors or manages connections to the tests, rather than being a passive barrier.
**In essence, the diagram maps a pipeline: Invest resources → Secure the process → Execute proprietary tests.** It visually argues that closed-source testing is a protected, resource-backed activity.
</details>
(a)
<details>
<summary>x2.png Details</summary>
### Visual Description
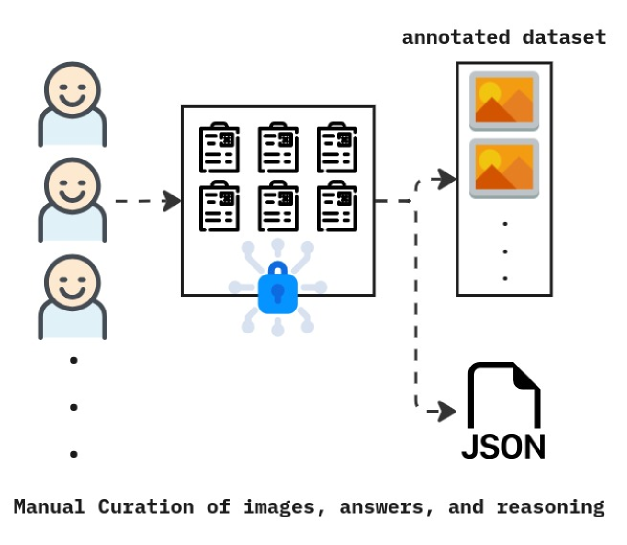
## Diagram: Manual Curation Workflow
### Overview
This image is a schematic diagram illustrating a workflow for the "Manual Curation of images, answers, and reasoning." It depicts a process where human curators interact with a secure system to produce structured outputs, specifically an annotated dataset and a JSON file.
### Components/Axes
The diagram is composed of three main sections arranged horizontally, connected by dotted arrows indicating flow.
1. **Left Section (Input/Actors):**
* Contains three identical, simplified human icons (smiling faces with light blue shirts) arranged vertically.
* Below the third icon are three vertical dots (`...`), implying a larger, indefinite number of human participants.
* A dotted arrow originates from this group and points to the central section.
2. **Central Section (Processing/Secure System):**
* A large rectangular box.
* Inside the box, at the top, are six identical document/clipboard icons arranged in a 2x3 grid.
* At the bottom center of the box is a prominent blue padlock icon, symbolizing security, privacy, or a protected process.
* Faint, light blue lines radiate from the padlock, suggesting it is active or central to the system's function.
3. **Right Section (Outputs):**
* Two distinct output paths are shown, both originating from the central box via dotted arrows.
* **Top Output Path:** Leads to a tall, vertical rectangle labeled **"annotated dataset"** at the top. Inside this rectangle are two image icons (depicting a landscape with an orange sun/mountain) at the top, followed by three vertical dots (`...`), indicating a continuing series of such annotated images.
* **Bottom Output Path:** Leads to a file icon labeled **"JSON"**. The icon has a folded corner and a small graphic of curly braces `{}` on it, representing a structured data file.
### Detailed Analysis
* **Flow Direction:** The process flows unidirectionally from left to right: Humans → Secure Curation System → Structured Outputs.
* **Textual Content:**
* Primary Title (Bottom): `Manual Curation of images, answers, and reasoning`
* Output Label (Top Right): `annotated dataset`
* Output Label (Bottom Right): `JSON`
* **Iconography & Symbolism:**
* **Human Icons:** Represent the manual, human-in-the-loop aspect of the curation.
* **Document Icons:** Likely represent individual data items, tasks, or records being curated.
* **Padlock:** A key element indicating that the curation process occurs within a secure, private, or controlled environment.
* **Image Icons in Output:** Represent the final product—images that have been annotated or labeled.
* **JSON File:** Represents the export of curated data in a machine-readable, structured format.
### Key Observations
1. The diagram explicitly highlights **security** (the padlock) as a core component of the curation system.
2. The outputs are dual-format: a human-interpretable **annotated dataset** (visual) and a machine-interpretable **JSON** file (data structure).
3. The use of ellipses (`...`) in both the human group and the annotated dataset implies scalability—the process is designed for many curators and results in a large dataset.
4. The connection between the central system and the outputs is not a single line but a branching path, showing the generation of two distinct but related products from the same curation activity.
### Interpretation
This diagram outlines a **human-in-the-loop data curation pipeline**, likely for machine learning or computer vision tasks. The core message is that raw data (implied by the document icons) is processed by human curators within a secure framework to produce high-quality, labeled training data.
* **Process Significance:** The "Manual Curation" title emphasizes that this is not an automated process. Human judgment is applied to create "answers and reasoning," which are then embedded into the dataset. This suggests the creation of a **reasoning-aware** or **explainable** dataset, where annotations may include not just labels but also justifications.
* **Security Implication:** The central padlock suggests the data being curated is sensitive (e.g., private user data, proprietary information) or that the curation process itself needs to be integrity-protected to ensure the quality and trustworthiness of the resulting dataset.
* **Output Relationship:** The `annotated dataset` and `JSON` file are two sides of the same coin. The former is the visual, human-auditable product, while the latter is the structured, programmatically accessible version ready for ingestion by algorithms. This dual output ensures both usability and verifiability.
* **Underlying Need:** The workflow addresses a critical need in AI development: transforming unstructured or loosely structured data into a clean, labeled, and reasoned format that can reliably train or evaluate models, with an added emphasis on security and human expertise.
</details>
(b)
Figure 2: a) Data collected for LogicVista were gathered from closed sources to avoid data leakage. b) Manual annotators used the gathered tests, gathered the correct answers, and came up with reasonings on why the selected answers were correct. All these annotations were then stored in JSON format.
### 3.1 Data Sources
To ensure the integrity and quality of LogicVista’s evaluations, we have implemented a stringent data collection and curation process specifically designed to prevent data leakage detailed in Figure. 2. Our approach involves sourcing and annotating our samples from proprietary sources that require licenses, registration, payment, or a combination of these barriers to access. This methodology is critical to minimizing the risk that our benchmark data has been previously seen or utilized in the training of other multi-modal models. We prioritized sourcing data from closed sources to further reduce the potential of data leakage.
- Licensed Access: We obtain data from sources that require formal licensing, ensuring the data is used solely for research purposes and not freely available for general use or scraping on the internet.
- Registration Requirements: Some of our data sources mandate user registration and account verification, adding an additional layer of access control to ensure that the data remain restricted and not easily accessible.
- Paid Content: We utilize paid sources where content is accessible only through purchase or subscription, further restricting the data from being freely available on the internet.
Additionally, we obtained permission from the creators of IQ tests and other evaluation materials included in our dataset. This permission specifically allows the use of their content for research purposes, ensuring the data’s legitimacy and accuracy.
### 3.2 Annotation and Data Collection
LogicVista consists of images designed to assess the underlying reasoning capacities of MLLMs. Using real-life scenes as explicit tests of logical reasoning can be challenging, as they often contain context clues that AI agent can use to deduce answers without directly reasoning through the scene. Therefore, LogicVista presents multiple-choice questions across 9 explicit capabilities that specify the type of reasoning required, without the additional context of real-life scenes typically found in intelligence and reasoning tests. The dataset is manually collected and annotated from various licensed intelligence test sources. Over a period of 3 months, 5 annotators extracted images, correct answers, and explanations when available. The explanations detailing the reasoning behind answer choices were extensively annotated and cross-validated among annotators, ensuring data integrity through multiple rounds of quality checks. The data is structured in JSON format to facilitate easy retrieval and processing in our evaluation pipeline. For our evaluation, we focused on summarizing five reasoning skills spanning two multimodal capabilities. For detailed examples of these reasoning skills and capabilities, please refer to Appendix. A and Appendix. B.
<details>
<summary>x3.png Details</summary>
### Visual Description
## Pie Charts: Reasoning Skills and Capabilities
### Overview
The image displays two distinct pie charts presented side-by-side on a white background. The left chart is titled "Reasoning Skills," and the right chart is titled "Capabilities." Each chart is divided into colored slices representing different categories, with percentage values labeled directly on or adjacent to each slice. There is no separate legend; category labels are placed outside the pie, pointing to their respective slices.
### Components/Axes
**Chart 1 (Left): "Reasoning Skills"**
* **Title:** "Reasoning Skills" (centered above the chart).
* **Categories & Labels (with approximate slice positions and colors):**
* **Mechanical:** 17.0% (Blue slice, top-left quadrant).
* **Spatial:** 18.0% (Red slice, top-right quadrant).
* **Numerical:** 21.0% (Light purple slice, bottom-right quadrant).
* **Deductive:** 20.0% (Yellow slice, bottom-left quadrant).
* **Inductive:** 24.0% (Teal/green slice, left side).
**Chart 2 (Right): "Capabilities"**
* **Title:** "Capabilities" (centered above the chart).
* **Categories & Labels (with approximate slice positions and colors):**
* **Diagram:** 26.4% (Teal/green slice, left side).
* **OCR:** 18.7% (Yellow slice, bottom).
* **Patterns:** 8.4% (Light purple slice, bottom-right).
* **Graphs:** 5.4% (Red slice, right side).
* **Tables:** 5.6% (Blue slice, right side).
* **3D shapes:** 3.6% (Orange slice, right side).
* **Puzzles:** 20.4% (Light green slice, top-right quadrant).
* **Sequences:** 6.1% (Pink slice, top).
* **Physics:** 5.5% (Gray slice, top-left quadrant).
### Detailed Analysis
**Reasoning Skills Chart:**
The distribution of reasoning skills is relatively balanced, with no single category holding a majority. The largest segment is **Inductive** reasoning at 24.0%. The smallest segment is **Mechanical** reasoning at 17.0%. The remaining three categories—**Numerical** (21.0%), **Deductive** (20.0%), and **Spatial** (18.0%)—are closely grouped within a 3-percentage-point range.
**Capabilities Chart:**
This chart shows a more varied distribution. The most prominent capability is **Diagram** interpretation at 26.4%. **Puzzles** (20.4%) and **OCR** (Optical Character Recognition) (18.7%) are also significant components. The remaining six categories are all below 10%, with **3D shapes** being the smallest at 3.6%. The capabilities span visual processing (Diagram, 3D shapes, Patterns), textual/data processing (OCR, Tables, Graphs), and logical/sequential tasks (Puzzles, Sequences, Physics).
### Key Observations
1. **Dominant Categories:** Each chart has one clearly dominant category: **Inductive** (24.0%) for Reasoning Skills and **Diagram** (26.4%) for Capabilities.
2. **Balance vs. Skew:** The Reasoning Skills chart shows a more even distribution among its five categories. The Capabilities chart is more skewed, with the top three categories (Diagram, Puzzles, OCR) accounting for approximately 65.5% of the total.
3. **Smallest Segments:** The smallest segments in each chart are **Mechanical** (17.0%) and **3D shapes** (3.6%), suggesting these are the least represented skills/capabilities in this dataset.
4. **Color Reuse:** Colors are reused between the two charts (e.g., teal for Inductive/Diagram, yellow for Deductive/OCR, red for Spatial/Graphs) but do not appear to carry consistent meaning across the two separate charts.
### Interpretation
These charts likely represent a profile or assessment of an entity's cognitive abilities, such as an AI system, a student, or a professional role. The data suggests a strong aptitude for **visual-spatial and inductive reasoning**. The high value for "Diagram" capability aligns with the strong "Inductive" and "Spatial" reasoning scores, indicating an ability to interpret visual information and infer patterns.
The relatively lower scores in "Mechanical" reasoning and "3D shapes" capability might indicate a comparative weakness in tasks involving physical systems or three-dimensional manipulation. The presence of "OCR," "Tables," and "Graphs" as distinct categories highlights an emphasis on data and document processing as key capabilities.
Overall, the profile depicts an entity strongest in visual, pattern-based, and puzzle-solving tasks, with a solid foundation in numerical and deductive reasoning, but with less emphasis on mechanical or purely three-dimensional spatial tasks. The two charts together provide a complementary view: the left chart outlines the *types* of reasoning, while the right chart details the specific *application domains* or task types where those reasoning skills are deployed.
</details>
Figure 3: Proportion of reasoning skills and capabilities. On the left is the proportion of questions belonging to each reasoning skill. These proportions add up to $100\$ as each skill is independent of another. On the right is the proportion of questions belonging to each multi-modal capability. These do not add up to $100\$ due to the use of mixed capabilities.
#### 3.2.1 Capabilities
We distinguish multimodal capabilities from reasoning skills, considering these capabilities fundamental to understanding a multimodal scene and extracting information. Capabilities refer to the modalities through which logical reasoning questions are delivered. To ensure comprehensive coverage in LogicVista, we have defined a diverse array of 9 capabilities for evaluation. This diversity guarantees that LogicVista thoroughly assess various logical situations that an MLLM may encounter in everyday reasoning. Figure 3 demonstrates how LogicVista contains a balanced mix of capabilities, including samples that utilize multiple capabilities to solve a problem.
- Diagrams: Simple flow diagrams and logical diagrams (e.g., Markov diagrams).
- OCR: Text embedded within an image (e.g., “gas station” in an image of a gas station).
- Patterns: Repeated sequences such as a series of diagrams, numbers, shapes, and objects (e.g., identifying patterns in how a box moves through repeated images of boxes).
- Graphs: Mathematical graphs with axes (e.g., graphs of $y=2x$ and $y=x^2$ ).
- Tables: Data tables (e.g., pie charts and T-tables).
- 3D Shapes: The ability to understand and differentiate 3D objects from 2D ones (e.g., recognizing a 3D shape in different rotations).
- Puzzles: Puzzles with logical implications embedded within the shapes (e.g., chess puzzles).
- Sequences: Sequences of related items or objects (e.g., predicting the next item in a sequence).
- Physics: Situations involving physics (e.g., diagrams of projectile motion).
#### 3.2.2 Reasoning Skills
The reasoning skills of interest for this benchmark are based on common critical thinking and problem-solving skills used by humans in various contexts. For our evaluation, we summarize these into the following five skills. For our evaluation, we summarize these to include the following 5 skills. As seen in Figure 3, LogicVista encompasses a wide range of all these reasoning skills:
- Inductive Reasoning: The ability to infer the next entry in a pattern given a set of observations. This involves making generalizations based on specific observations to form an educated guess. It moves from many specific observations to a generalization. For example, observing that John gets a stomach ache when he eats dairy products leads to the inductive conclusion that he is likely lactose intolerant.
- Deductive Reasoning: The ability to conclude a specific case from a general principle or pattern. This involves moving from the general to the specific. For example, from the statement “all men are mortal,” one can deduce that “John is mortal” because John is a man.
- Numerical Reasoning: The ability to read arithmetic problems in an image and solve the math equations. For example, given the equation “10 + 10 = ?,” the answer would be “20.”
- Spatial Reasoning: The ability to understand the spatial relationships between objects and patterns and reason with those relationships. For example, seeing an unfolded box and understanding what the box would look like when folded.
- Mechanical Reasoning: The ability to recognize a physical system and solve equations based on that system or answer questions about it. For example, seeing a set of three gears and understanding which gears will turn clockwise and which will turn counterclockwise.
### 3.3 LLM-based Multiple Choice Answer Extractor
<details>
<summary>x4.png Details</summary>
### Visual Description
\n
## Diagram: Evaluation Pipeline for AI Models
### Overview
The image is a flowchart illustrating a technical pipeline for evaluating AI models. The process begins with multiple evaluation models processing an annotated dataset, generating raw open-ended outputs, which are then converted into extracted multiple-choice question (MCQ) answers, and finally evaluated. The diagram uses icons, text labels, and directional arrows to depict the flow of data and processing steps.
### Components/Axes
The diagram is organized into three main vertical sections, flowing from left to right.
**1. Left Section: Input & Models**
* **Label:** `evaluation models` (bottom-left).
* **Icons:** A vertical list of model icons:
* A llama (likely representing LLaMA or similar open-source models).
* A green, circular logo with a white knot-like symbol (resembling the OpenAI/ChatGPT logo).
* A volcano icon (possibly representing a specific model or framework).
* Three vertical dots (`...`) indicating additional models.
* **Data Source:** An `annotated dataset` (top-center of this section), depicted as a box containing two image icons (orange/yellow landscapes) and vertical dots (`...`), suggesting a collection of image-text pairs.
* **Data Format:** A `JSON` file icon, connected via a dashed arrow from the dataset, indicating the dataset's format.
**2. Middle Section: Processing Stages**
* **Stage 1 - Raw Outputs:** A rounded rectangle labeled `raw open-ended outputs`. It contains example text snippets:
* `The answer is 76 because...`
* `Tom would win the race...`
* `The pie chart shows...`
* `The next element in the sequence is...`
* `...` (ellipsis indicating more outputs).
* **Processing Node:** A ChatGPT-style icon (interlocking rings) sits between the two main processing stages. Arrows point into it from the `raw open-ended outputs` and from the `JSON` file below, and an arrow points out from it to the next stage. This suggests a central processing or parsing model (likely a large language model) is used to transform the data.
* **Stage 2 - Extracted Answers:** A rounded rectangle labeled `extracted MCQ answers`. It contains a vertical list of letters:
* `A`
* `B`
* `D`
* `E`
* `...` (ellipsis indicating more options).
**3. Right Section: Outputs & Evaluation**
* **Output 1 (Top):** A set of evaluation symbols: two checkmarks (`✓✓`), a filled circle (`●`), and three horizontal bars of varying lengths. This likely represents a scoring or grading rubric.
* **Output 2 (Bottom):** A small bar chart with three bars of increasing height (pink, red, yellow-green) and an upward-trending arrow overlay. This represents quantitative results or performance metrics.
**Flow & Connections:**
* Solid arrows indicate the primary data flow: from the `evaluation models` and `annotated dataset` into the `raw open-ended outputs`, then through the central processing node to the `extracted MCQ answers`, and finally to the two output visualizations.
* Dashed arrows indicate secondary or supporting data flows, notably from the `JSON` file to the central processing node and from the `extracted MCQ answers` to the outputs.
### Detailed Analysis
The diagram explicitly maps a multi-step evaluation methodology:
1. **Input Phase:** Multiple AI models (llama, ChatGPT-like, volcano, etc.) are tasked with processing a common `annotated dataset` (likely containing images and questions/answers in JSON format).
2. **Generation Phase:** The models produce `raw open-ended outputs`—free-text responses to the dataset's prompts.
3. **Transformation Phase:** A central language model (represented by the ChatGPT icon) processes these open-ended texts. Its function is to parse or extract structured multiple-choice answers from the unstructured text.
4. **Extraction Phase:** The result is a set of `extracted MCQ answers` (e.g., A, B, D, E), which are standardized, machine-readable responses.
5. **Evaluation Phase:** These extracted answers are then evaluated, producing both qualitative (checkmarks, bars) and quantitative (bar chart) results.
### Key Observations
* **Hybrid Evaluation:** The pipeline combines the generative capability of models (producing open-ended text) with the standardized scoring of MCQs.
* **Central Parser:** The ChatGPT-like icon in the middle is pivotal. It acts as a "judge" or "parser" that converts subjective, open-ended text into objective, gradable answers.
* **Non-Sequential MCQ Options:** The listed options in the extracted answers box are `A, B, D, E`, skipping `C`. This could be an example, or it might indicate the system handles non-standard or partial answer sets.
* **Multiple Output Forms:** The evaluation produces both symbolic (checkmarks) and graphical (bar chart) results, suggesting a comprehensive assessment.
### Interpretation
This diagram illustrates a sophisticated framework for benchmarking AI models, particularly on tasks that require reasoning (e.g., visual question answering, logical puzzles). The core innovation is using a powerful language model not just as a test-taker, but as an **evaluation intermediary**. It translates the nuanced, human-like responses from various models into a uniform format (MCQs) that can be automatically and consistently scored.
The process addresses a key challenge in AI evaluation: how to fairly compare models that produce different styles of open-ended text. By funneling all outputs through a common parser to extract a standardized answer format, the framework aims to create a level playing field for comparison. The final outputs (symbolic and graphical) suggest the results are used for both detailed error analysis (which questions were missed) and high-level performance tracking (overall accuracy trends). The presence of multiple model icons on the left emphasizes that this pipeline is designed for comparative analysis across different AI systems.
</details>
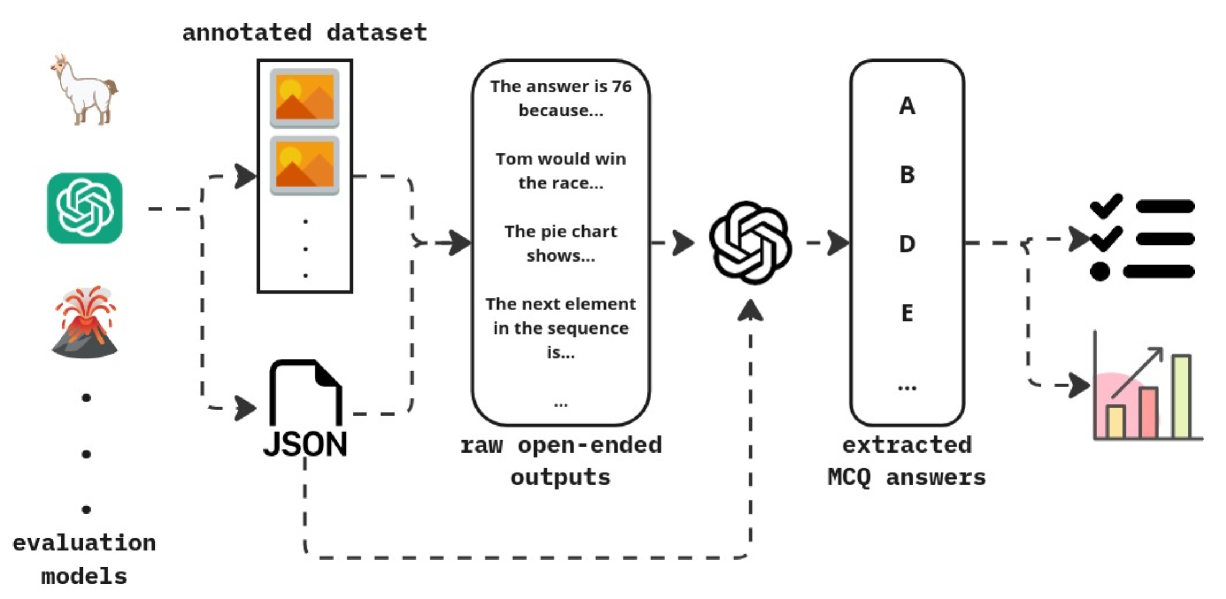
Figure 4: Pipeline of evaluating open-ended LMM outputs using MCQ answer choice extraction.
LLMs generate non-deterministic and open-ended responses [56, 57], making direct evaluation challenging. To address this, we use an LLM evaluator to compare these open-ended responses to our annotations as detailed in 4. This evaluator can assess both MCQ answer choices and the MLLM’s reasoning behind those selections, as both elements are included in our annotations. This step is achieved by feeding various contexts such as the question, and the available choices, along with the LLM-generated answers to an extraction LLM (GPT, LLaMA, etc.). Based on the provided rich context, the LLM can generate the selected letter answer choice. The final output is also repeatedly validated and if the validation fails, the extraction repeats with the provided feedback to obtain correct results.
## 4 Evaluation Setup
| Model | Size | Language Model | Vision Model |
| --- | --- | --- | --- |
| LLaVA-Vicuna-7B | 7B | Vicuna-7B | CLIP ViT-L/14 |
| LLaVA-Vicuna-13B | 13B | Vicuna-13B | CLIP ViT-L/336px |
| LLaVA-NeXT-Mistral-7B | 7B | Mistral-7B | CLIP ViT-L/14 |
| LLaVA-NeXT-Vicuna-7B | 7B | Vicuna-7B | CLIP ViT-L/14 |
| LLaVA-NeXT-Vicuna-13B | 13B | Vicuna-13B | CLIP ViT-L/336px |
| LLaVA-NeXT-Nous-Hermes-Yi-34B | 34B | Nous Hermes 2-Yi-34B | CLIP ViT-L/336px |
| MiniGPT-4-7B | 7B | Vicuna-7B | BLIP-2 Q-Former |
| MiniGPT-4-13B | 13B | Vicuna-13B | BLIP-2 Q-Former |
| Otter-9B | 9B | MPT-7B | CLIP ViT-L/14 |
| GPT-4 Vision | N/A N/A: Not disclosed | N/A | N/A |
| BLIP-2 | 2.7B | OPT-2.7B | EVA-ViT-G |
| Pix2Struct | 1.3B | ViT | ViT |
| InstructBLIP-Vicuna-7B | 7B | Vicuna-7B | BLIP-2 Q-Former |
| InstructBLIP-Vicuna-13B | 13B | Vicuna-13B | BLIP-2 Q-Former |
| InstructBLIP-FLAN-T5-xl | 3B | FLAN-T5 XL | BLIP-2 Q-Former |
| InstructBLIP-FLAN-T5-xxl | 11B | FLAN-T5 XXL | BLIP-2 Q-Former |
Table 2: Summary of the MLLMs used for evaluations in this study.
To evaluate the performance of MLLMs on LogicVista, we selected a range of representative models detailed in Table. 2. Specifically, we chose8 models for evaluation, including LLaVA [3, 58], MiniGPT4 [4], Otter [39], GPT-4 Vision [1], BLIP-2 [59], and InstructBLIP [40] We also included pix2struct [60] which has been fine-tuned to understand chart and diagram data.
Each model generated outputs using the LogicVista dataset. Our LLM-based multiple-choice extractor was then employed to isolate the multiple-choice selections from the MLLMs’ outputs (which often appear as full-sentence responses rather than single letters) and compare them to the ground truth answers. The overall logical reasoning score is calculated as follows:
$$
S=\frac{∑_n=1^Ns_i}{N}*100\ \tag{1}
$$
Here, $S$ represents the overall score, $s_i$ indicate whether a sample $i$ is evaluated as correct or not (regardless of category), and $N$ is the total number of samples. The score for each reasoning skill subcategory is calculated as:
$$
S_LR=\frac{∑_n=1^N_LRs_i}{N_LR}*100\ \tag{2}
$$
where $S_LR$ represents the score for a specific reasoning skill category, $N_LR$ is the total number of samples in that reasoning skill category, and $s_i$ indicate whether a sample $i$ from that category was evaluated as correct. Similarly, the score for each multi-modal capability is calculated as:
$$
S_c=\frac{∑_n=1^N_cs_i}{N_c}*100\ \tag{3}
$$
where $S_c$ represents the score for a specific capability, $N_c$ is the total number of samples in that capability, and $s_i$ indicates whether a sample $i$ in the capability category is evaluated correctly.
## 5 LogicVista Benchmarking and Performance Interpretation
### 5.1 Logical Reasoning Skills
We present the performance results of various multimodal LLMs on LogicVista. Table 3 outlines the outcome for these models across five logical reasoning categories. We analyzed models of different architectures and sizes, benchmarking them against a random baseline that assumes an average of five choices per question in the LogicVista dataset. Our findings indicate that many models perform below expectations, often yielding results that are worse than random guessing. This outcome is somewhat anticipated, given that most training data for multimodal LLMs and LLMs are derived from classical computer vision datasets such as COCO, which focus on recognition tasks rather than complex reasoning.
Traditional benchmarks typically emphasize recognition tasks, resulting in a lack of emphasis on reasoning tasks during both training and evaluation phases. This is evident from the observation that while many models excel on recognition-based benchmarks like COCO, TextVQA, and MM-vet, they often struggle to outperform a random baseline on logical reasoning tasks.
| Model | Inductive | Deductive | Numerical | Spatial | Mechanical |
| --- | --- | --- | --- | --- | --- |
| LLAVA7B | 29.91% | 29.03% | 26.32% | 25.32% | 36.49% |
| LLAVA13B | 18.69% | 31.18% | 20.00% | 27.85% | 24.32% |
| otter9B | 31.78% | 24.73% | 18.95% | 18.99% | 21.62% |
| GPT4 | 23.36% | 54.84% | 24.21% | 21.52% | 41.89% |
| BLIP2 | 17.76% | 23.66% | 23.16% | 24.05% | 18.92% |
| LLAVANEXT-7B-mistral | 16.82% | 34.41% | 23.16% | 21.52% | 22.97% |
| miniGPTvicuna7B | 10.28% | 9.68% | 7.37% | 3.80% | 27.03% |
| miniGPTvicuna13B | 13.08% | 23.66% | 10.53% | 10.13% | 17.57% |
| pix2struct | 12.15% | 6.45% | 2.11% | 7.59% | 17.57% |
| instructBLIP-vicuna-7B | 4.67% | 21.51% | 24.21% | 2.53% | 22.97% |
| instructBLIP-vicuna-13B | 3.74% | 10.75% | 18.95% | 5.06% | 17.57% |
| instructBLIP-flan-t5-xl | 23.36% | 22.58% | 22.11% | 7.59% | 33.78% |
| instructBLIP-flan-t5-xxl | 17.76% | 30.11% | 24.21% | 20.25% | 22.97% |
| LLAVANEXT-7B-vicuna | 26.17% | 21.51% | 25.26% | 27.85% | 29.73% |
| LLAVANEXT-13B-vicuna | 22.43% | 22.58% | 26.32% | 26.58% | 25.68% |
| LLAVANEXT-34B-NH | 20.56% | 52.69% | 30.53% | 24.05% | 40.54% |
Table 3: LogicVista evaluation results for various multimodal LLMs on each logical reasoning skill are presented as $\$ , with the highest possible accuracy being $100\$ . The highest-scoring models are highlighted in green and the lower-scoring models are highlighted in yellow.
Upon closer examination, we find that models perform best on deductive, numerical, and mechanical reasoning tasks. These types of reasoning are more prevalent in real-life scenarios, which makes models more adept at handling them. For example, deductive reasoning can be applied in predicting a character’s actions based on a scene, while numerical reasoning is crucial in solving arithmetic visual tasks. Mechanical reasoning involves understanding physical principles and interactions.
In contrast, induction and spatial reasoning are less frequently encountered in standard training data, potentially explaining the lower performance of models in these areas. These insights underscore the necessity for enhanced training and evaluation methodologies that prioritize reasoning tasks to bolster the logical reasoning capabilities of multimodal LLMs.
### 5.2 Visual Capabilities
In Table 4, we present the results of multimodal LLMs on logical reasoning tasks across diagrammatic and OCR mediums. Generally, we observe that OCR tasks tend to perform better than diagrammatic tasks. This difference stems from the nature of traditional computer vision tasks, which often prioritize recognizing prominent objects (“landmarks”) in a scene, such as distinct cars, planes, people, or balls. Diagrams, in contrast, lack such prominent features and mainly consist of lines and shapes, making it challenging for models to extract intricate relationships between objects.
In OCR tasks, once the text is accurately extracted from the image, the remainder of the reasoning task relies on the underlying LLM’s ability to process and interpret the content. This process typically bypasses the complexities of multimodal reasoning, leading to better performance on OCR tasks compared to diagrammatic tasks. These findings highlight the necessity for enhanced evaluation methodologies tailored to diagrammatic reasoning in multimodal LLMs, as current approaches may overlook critical details inherent in these types of tasks.
| Model | Diagram | OCR | Patterns | Graphs | Tables | 3D Shapes | Puzzles | Sequences | Physics |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| LLAVA7B | 29.70% | 28.21% | 30.47% | 25.37% | 25.71% | 22.22% | 28.52% | 25.00% | 43.48% |
| LLAVA13B | 21.52% | 22.65% | 16.19% | 16.42% | 20.00% | 31.11% | 26.17% | 15.79% | 26.09% |
| otter9B | 23.64% | 20.51% | 30.48% | 14.93% | 22.86% | 13.33% | 26.17% | 26.32% | 24.64% |
| GPT4 | 26.06% | 39.74% | 20.95% | 20.90% | 22.86% | 31.11% | 31.25% | 28.95% | 47.83% |
| BLIP2 | 20.30% | 21.79% | 20.00% | 17.91% | 24.29% | 17.78% | 22.27% | 15.79% | 20.29% |
| LLAVANEXT-7B-mistral | 20.30% | 26.92% | 21.90% | 23.88% | 22.86% | 13.33% | 22.27% | 23.68% | 30.43% |
| miniGPTvicuna7B | 10.91% | 11.54% | 12.38% | 7.46% | 8.57% | 11.11% | 9.77% | 7.89% | 23.19% |
| miniGPTvicuna13B | 12.73% | 17.52% | 12.38% | 10.45% | 11.43% | 11.11% | 14.84% | 6.58% | 20.29% |
| pix2struct | 9.39% | 8.55% | 10.48% | 0.00% | 4.29% | 11.11% | 10.55% | 11.84% | 14.49% |
| instructBLIP-vicuna-7B | 11.82% | 21.37% | 7.62% | 22.39% | 22.86% | 6.67% | 10.55% | 0.00% | 24.64% |
| instructBLIP-vicuna-13B | 10.91% | 13.68% | 5.71% | 19.40% | 15.71% | 11.11% | 6.25% | 2.63% | 18.84% |
| instructBLIP-flan-t5-xl | 20.30% | 22.22% | 20.00% | 17.91% | 22.86% | 13.33% | 18.36% | 15.79% | 33.33% |
| instructBLIP-flan-t5-xxl | 20.91% | 24.36% | 22.86% | 20.90% | 25.71% | 20.00% | 21.09% | 14.47% | 21.74% |
| LLAVANEXT-7B-vicuna | 26.67% | 23.08% | 26.67% | 20.90% | 27.14% | 33.33% | 26.56% | 19.74% | 30.43% |
| LLAVANEXT-13B-vicuna | 25.15% | 22.65% | 23.81% | 20.90% | 27.14% | 26.67% | 24.61% | 15.79% | 27.54% |
| LLAVANEXT-34B-NH | 27.58% | 39.32% | 25.71% | 28.36% | 32.86% | 26.67% | 30.86% | 21.05% | 46.37% |
Table 4: LogicVista evaluation results on various multimodal LLMs across each multi-modal capability. Accuracy results are presented as $\$ , with a maximum possible accuracy of $100\$ . Models achieving the highest scores are highlighted green, while lower-scoring models are highlighted yellow.
### 5.3 Relationship between Model Size and Performance
Figure 5 presents a comparative analysis of the model size and the average score achieved across all logical reasoning tasks and capabilities. Each plot includes a shaded region denoting the 95% confidence interval for the regression estimate, visually representing the uncertainty associated with the regression line. Dot sizes in the scatter plot indicate the number of models with identical parameter counts, illustrating the distribution density. This visual evidence strongly suggests a positive correlation between larger model sizes and improved performance in LogicVista. Specifically, as model size increases, performance tends to improve, indicating that larger models may have greater capacity to handle complex patterns and reasoning tasks.
## 6 Conclusion
Reasoning skills are critical for solving complex tasks and serve as the foundation for many challenges that humans expect AI agents to tackle. However, the exploration of reasoning abilities in multimodal LLM agents remains limited, with most benchmarks and training datasets predominantly focused on traditional computer vision tasks like recognition. For multimodal LLMs to excel in critical thinking and complex tasks, they must comprehend the underlying logical relationships inherent in these challenges.
<details>
<summary>x5.png Details</summary>
### Visual Description
## Scatter Plot with Regression Lines: Model Size vs Average Reasoning and Capability Accuracy
### Overview
The image is a scatter plot with two overlaid linear regression trend lines and their associated confidence intervals. It visualizes the relationship between the size of a model (in billions of parameters) and its average accuracy (in percent) on two distinct metrics: "Capability Avg" and "Reasoning Avg." The chart suggests a positive correlation between model size and performance for both metrics.
### Components/Axes
* **Title:** "Model Size vs Average Reasoning and Capability Accuracy"
* **X-Axis:** Label: "Model Size (Billions)". Scale: Linear, from 0 to 35, with major ticks every 5 units.
* **Y-Axis:** Label: "Average Accuracy (Percent)". Scale: Linear, from 0 to 60, with major ticks every 10 units.
* **Legend:** Located in the top-left corner of the plot area.
* Red circle: "Capability Avg"
* Blue circle: "Reasoning Avg"
* **Data Series & Trend Lines:**
* **Reasoning Avg (Blue):** Represented by blue circles and a solid blue trend line. A blue shaded region represents its confidence interval. A blue text box contains its regression equation: `y = 0.55x + 15.41` and coefficient of determination: `R² = 0.68`.
* **Capability Avg (Red):** Represented by red circles and a solid red trend line. A red shaded region represents its confidence interval. A red text box contains its regression equation: `y = 0.48x + 14.91` and coefficient of determination: `R² = 0.65`.
### Detailed Analysis
**Data Points (Approximate Coordinates):**
* **Reasoning Avg (Blue Circles):**
* (1, 9)
* (3, 22)
* (7, 21)
* (9, 23)
* (11, 23)
* (13, 19)
* (34, 34)
* **Capability Avg (Red Circles):**
* (3, 20)
* (7, 21)
* (9, 23)
* (11, 21)
* (13, 18)
* (34, 31)
**Trend Line Analysis:**
* **Reasoning Avg (Blue Line):** The line slopes upward from left to right, indicating a positive linear relationship. It starts at approximately y=16 when x=0 and rises to approximately y=34 at x=34. The slope (0.55) is steeper than the Capability Avg line.
* **Capability Avg (Red Line):** Also slopes upward, indicating a positive linear relationship. It starts at approximately y=15 when x=0 and rises to approximately y=31 at x=34. The slope (0.48) is shallower than the Reasoning Avg line.
**Confidence Intervals:**
* Both trend lines are surrounded by shaded regions (light blue for Reasoning, light red for Capability) that widen as model size increases. This indicates greater uncertainty in the predicted accuracy for larger models. The blue (Reasoning) confidence interval is notably wider than the red (Capability) interval, especially at larger model sizes.
### Key Observations
1. **Positive Correlation:** Both "Reasoning Avg" and "Capability Avg" show a clear positive correlation with model size. Larger models tend to have higher average accuracy.
2. **Diverging Slopes:** The "Reasoning Avg" metric improves at a slightly faster rate per billion parameters (slope = 0.55) compared to "Capability Avg" (slope = 0.48).
3. **Model Fit:** The regression models explain a moderate amount of variance, with R² values of 0.68 for Reasoning and 0.65 for Capability.
4. **Outlier/Potential Threshold:** The smallest model plotted (approx. 1B parameters) has a very low "Reasoning Avg" score (~9%), which is a significant outlier below the trend line. This suggests a potential performance cliff or threshold for reasoning capabilities at very small model sizes.
5. **Convergence at Mid-Range:** Between model sizes of approximately 7B and 13B, the data points for both metrics are tightly clustered and often overlap, indicating similar performance levels in this range.
6. **Uncertainty Growth:** The widening confidence intervals suggest that while the trend is positive, the specific accuracy of a very large model (e.g., 35B+) is less predictable based on this data.
### Interpretation
The data demonstrates that scaling model size is a viable strategy for improving both general capabilities and reasoning skills in AI models. The steeper slope for "Reasoning Avg" suggests that reasoning abilities may benefit more from increased scale than other capabilities, or that they emerge more prominently as models grow larger.
The overlapping data points and confidence intervals in the 7B-13B range imply that for mid-sized models, the distinction between "reasoning" and "capability" performance may be minimal. However, the divergence of the trend lines and the outlier at the smallest size hint that reasoning might be a more complex capability that requires a certain scale to develop reliably.
The increasing uncertainty (wider confidence bands) for larger models is a critical insight. It indicates that while the average trend is upward, individual large models may exhibit high variance in performance. This could be due to factors not captured by size alone, such as training data quality, architecture, or optimization. Therefore, while scaling is promising, it does not guarantee a specific accuracy outcome, and other factors become increasingly important for predicting performance at the large end of the scale.
</details>
Figure 5: correlation between model size and average accuracy. The scatter plot uses varying dot sizes to represent the density of models with identical sizes.
To address this gap, we introduce LogicVista, a novel benchmark designed to evaluate multimodal LLMs through a comprehensive assessment of logical reasoning capabilities. This benchmark features a dataset of 448 samples covering five distinct reasoning skills, providing a robust platform for evaluating cutting-edge multimodal models. Our evaluation aims to shed light on the current state of logical reasoning in multimodal LLMs.
To facilitate straightforward evaluation, we employ an LLM-based multiple-choice question-answer extractor, which helps mitigate the non-deterministic nature often associated with multimodal LLM outputs. While LogicVista primarily focuses on explicit logical reasoning tasks isolated from real-life contexts, this approach represents a crucial step toward understanding fundamental reasoning skills. However, it is equally important to explore how AI agents perform tasks that blend abstract reasoning with real-world scenarios, a direction that will guide our future research endeavors.
## Acknowledgements
We extend our sincere appreciation to the student researchers at the University of California, Los Angeles, for their diligent efforts in the manual annotation and validation of our dataset: Evan Li, Srinath Saikrishnan, Lawrence Li, and Oscar Cooper Stern.
## References
- [1] OpenAI, Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, Red Avila, Igor Babuschkin, Suchir Balaji, Valerie Balcom, Paul Baltescu, Haiming Bao, Mohammad Bavarian, Jeff Belgum, Irwan Bello, Jake Berdine, Gabriel Bernadett-Shapiro, Christopher Berner, Lenny Bogdonoff, Oleg Boiko, Madelaine Boyd, Anna-Luisa Brakman, Greg Brockman, Tim Brooks, Miles Brundage, Kevin Button, Trevor Cai, Rosie Campbell, Andrew Cann, Brittany Carey, Chelsea Carlson, Rory Carmichael, Brooke Chan, Che Chang, Fotis Chantzis, Derek Chen, Sully Chen, Ruby Chen, Jason Chen, Mark Chen, Ben Chess, Chester Cho, Casey Chu, Hyung Won Chung, Dave Cummings, Jeremiah Currier, Yunxing Dai, Cory Decareaux, Thomas Degry, Noah Deutsch, Damien Deville, Arka Dhar, David Dohan, Steve Dowling, Sheila Dunning, Adrien Ecoffet, Atty Eleti, Tyna Eloundou, David Farhi, Liam Fedus, Niko Felix, Simón Posada Fishman, Juston Forte, Isabella Fulford, Leo Gao, Elie Georges, Christian Gibson, Vik Goel, Tarun Gogineni, Gabriel Goh, Rapha Gontijo-Lopes, Jonathan Gordon, Morgan Grafstein, Scott Gray, Ryan Greene, Joshua Gross, Shixiang Shane Gu, Yufei Guo, Chris Hallacy, Jesse Han, Jeff Harris, Yuchen He, Mike Heaton, Johannes Heidecke, Chris Hesse, Alan Hickey, Wade Hickey, Peter Hoeschele, Brandon Houghton, Kenny Hsu, Shengli Hu, Xin Hu, Joost Huizinga, Shantanu Jain, Shawn Jain, Joanne Jang, Angela Jiang, Roger Jiang, Haozhun Jin, Denny Jin, Shino Jomoto, Billie Jonn, Heewoo Jun, Tomer Kaftan, Łukasz Kaiser, Ali Kamali, Ingmar Kanitscheider, Nitish Shirish Keskar, Tabarak Khan, Logan Kilpatrick, Jong Wook Kim, Christina Kim, Yongjik Kim, Jan Hendrik Kirchner, Jamie Kiros, Matt Knight, Daniel Kokotajlo, Łukasz Kondraciuk, Andrew Kondrich, Aris Konstantinidis, Kyle Kosic, Gretchen Krueger, Vishal Kuo, Michael Lampe, Ikai Lan, Teddy Lee, Jan Leike, Jade Leung, Daniel Levy, Chak Ming Li, Rachel Lim, Molly Lin, Stephanie Lin, Mateusz Litwin, Theresa Lopez, Ryan Lowe, Patricia Lue, Anna Makanju, Kim Malfacini, Sam Manning, Todor Markov, Yaniv Markovski, Bianca Martin, Katie Mayer, Andrew Mayne, Bob McGrew, Scott Mayer McKinney, Christine McLeavey, Paul McMillan, Jake McNeil, David Medina, Aalok Mehta, Jacob Menick, Luke Metz, Andrey Mishchenko, Pamela Mishkin, Vinnie Monaco, Evan Morikawa, Daniel Mossing, Tong Mu, Mira Murati, Oleg Murk, David Mély, Ashvin Nair, Reiichiro Nakano, Rajeev Nayak, Arvind Neelakantan, Richard Ngo, Hyeonwoo Noh, Long Ouyang, Cullen O’Keefe, Jakub Pachocki, Alex Paino, Joe Palermo, Ashley Pantuliano, Giambattista Parascandolo, Joel Parish, Emy Parparita, Alex Passos, Mikhail Pavlov, Andrew Peng, Adam Perelman, Filipe de Avila Belbute Peres, Michael Petrov, Henrique Ponde de Oliveira Pinto, Michael, Pokorny, Michelle Pokrass, Vitchyr H. Pong, Tolly Powell, Alethea Power, Boris Power, Elizabeth Proehl, Raul Puri, Alec Radford, Jack Rae, Aditya Ramesh, Cameron Raymond, Francis Real, Kendra Rimbach, Carl Ross, Bob Rotsted, Henri Roussez, Nick Ryder, Mario Saltarelli, Ted Sanders, Shibani Santurkar, Girish Sastry, Heather Schmidt, David Schnurr, John Schulman, Daniel Selsam, Kyla Sheppard, Toki Sherbakov, Jessica Shieh, Sarah Shoker, Pranav Shyam, Szymon Sidor, Eric Sigler, Maddie Simens, Jordan Sitkin, Katarina Slama, Ian Sohl, Benjamin Sokolowsky, Yang Song, Natalie Staudacher, Felipe Petroski Such, Natalie Summers, Ilya Sutskever, Jie Tang, Nikolas Tezak, Madeleine B. Thompson, Phil Tillet, Amin Tootoonchian, Elizabeth Tseng, Preston Tuggle, Nick Turley, Jerry Tworek, Juan Felipe Cerón Uribe, Andrea Vallone, Arun Vijayvergiya, Chelsea Voss, Carroll Wainwright, Justin Jay Wang, Alvin Wang, Ben Wang, Jonathan Ward, Jason Wei, CJ Weinmann, Akila Welihinda, Peter Welinder, Jiayi Weng, Lilian Weng, Matt Wiethoff, Dave Willner, Clemens Winter, Samuel Wolrich, Hannah Wong, Lauren Workman, Sherwin Wu, Jeff Wu, Michael Wu, Kai Xiao, Tao Xu, Sarah Yoo, Kevin Yu, Qiming Yuan, Wojciech Zaremba, Rowan Zellers, Chong Zhang, Marvin Zhang, Shengjia Zhao, Tianhao Zheng, Juntang Zhuang, William Zhuk, and Barret Zoph. Gpt-4 technical report, 2024.
- [2] Jean-Baptiste Alayrac, Jeff Donahue, Pauline Luc, Antoine Miech, Iain Barr, Yana Hasson, Karel Lenc, Arthur Mensch, Katie Millican, Malcolm Reynolds, Roman Ring, Eliza Rutherford, Serkan Cabi, Tengda Han, Zhitao Gong, Sina Samangooei, Marianne Monteiro, Jacob Menick, Sebastian Borgeaud, Andrew Brock, Aida Nematzadeh, Sahand Sharifzadeh, Mikolaj Binkowski, Ricardo Barreira, Oriol Vinyals, Andrew Zisserman, and Karen Simonyan. Flamingo: a visual language model for few-shot learning, 2022.
- [3] Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning, 2023.
- [4] Deyao Zhu, Jun Chen, Xiaoqian Shen, Xiang Li, and Mohamed Elhoseiny. Minigpt-4: Enhancing vision-language understanding with advanced large language models, 2023.
- [5] Shukang Yin, Chaoyou Fu, Sirui Zhao, Ke Li, Xing Sun, Tong Xu, and Enhong Chen. A survey on multimodal large language models, 2023.
- [6] Chaoyou Fu, Peixian Chen, Yunhang Shen, Yulei Qin, Mengdan Zhang, Xu Lin, Jinrui Yang, Xiawu Zheng, Ke Li, Xing Sun, Yunsheng Wu, and Rongrong Ji. Mme: A comprehensive evaluation benchmark for multimodal large language models, 2023.
- [7] Xiaoman Zhang, Chaoyi Wu, Ziheng Zhao, Weixiong Lin, Ya Zhang, Yanfeng Wang, and Weidi Xie. Pmc-vqa: Visual instruction tuning for medical visual question answering, 2023.
- [8] Stanislaw Antol, Aishwarya Agrawal, Jiasen Lu, Margaret Mitchell, Dhruv Batra, C. Lawrence Zitnick, and Devi Parikh. Vqa: Visual question answering. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), December 2015.
- [9] Amanpreet Singh, Vivek Natarajan, Meet Shah, Yu Jiang, Xinlei Chen, Dhruv Batra, Devi Parikh, and Marcus Rohrbach. Towards vqa models that can read, 2019.
- [10] Weihao Yu, Zhengyuan Yang, Linjie Li, Jianfeng Wang, Kevin Lin, Zicheng Liu, Xinchao Wang, and Lijuan Wang. Mm-vet: Evaluating large multimodal models for integrated capabilities, 2023.
- [11] Michael J. Wavering. Logical reasoning necessary to make line graphs. Journal of Research in Science Teaching, 26(5):373–379, May 1989.
- [12] Catherine Sophian and Susan C. Somerville. Early developments in logical reasoning: Considering alternative possibilities. Cognitive Development, 3(2):183–222, 1988.
- [13] Hugo Bronkhorst, Gerrit Roorda, Cor Suhre, and Martin Goedhart. Logical reasoning in formal and everyday reasoning tasks - international journal of science and mathematics education, Dec 2019.
- [14] Pan Lu, Hritik Bansal, Tony Xia, Jiacheng Liu, Chunyuan Li, Hannaneh Hajishirzi, Hao Cheng, Kai-Wei Chang, Michel Galley, and Jianfeng Gao. Mathvista: Evaluating mathematical reasoning of foundation models in visual contexts, 2024.
- [15] Yash Goyal, Tejas Khot, Douglas Summers-Stay, Dhruv Batra, and Devi Parikh. Making the V in VQA matter: Elevating the role of image understanding in Visual Question Answering. In Conference on Computer Vision and Pattern Recognition (CVPR), 2017.
- [16] Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Dollár, and C. Lawrence Zitnick. Microsoft COCO: Common Objects in Context, page 740–755. Springer International Publishing, 2014.
- [17] Oleksii Sidorov, Ronghang Hu, Marcus Rohrbach, and Amanpreet Singh. Textcaps: a dataset for image captioning with reading comprehension, 2020.
- [18] Rohan Wadhawan, Hritik Bansal, Kai-Wei Chang, and Nanyun Peng. Contextual: Evaluating context-sensitive text-rich visual reasoning in large multimodal models, 2024.
- [19] Yonatan Bitton, Hritik Bansal, Jack Hessel, Rulin Shao, Wanrong Zhu, Anas Awadalla, Josh Gardner, Rohan Taori, and Ludwig Schmidt. Visit-bench: A benchmark for vision-language instruction following inspired by real-world use, 2023.
- [20] Xinlei Chen, Hao Fang, Tsung-Yi Lin, Ramakrishna Vedantam, Saurabh Gupta, Piotr Dollar, and C. Lawrence Zitnick. Microsoft coco captions: Data collection and evaluation server, 2015.
- [21] Yash Goyal, Tejas Khot, Douglas Summers-Stay, Dhruv Batra, and Devi Parikh. Making the v in vqa matter: Elevating the role of image understanding in visual question answering, 2017.
- [22] Jiasen Lu, Dhruv Batra, Devi Parikh, and Stefan Lee. Vilbert: Pretraining task-agnostic visiolinguistic representations for vision-and-language tasks, 2019.
- [23] Yen-Chun Chen, Linjie Li, Licheng Yu, Ahmed El Kholy, Faisal Ahmed, Zhe Gan, Yu Cheng, and Jingjing Liu. Uniter: Universal image-text representation learning, 2020.
- [24] Xiujun Li, Xi Yin, Chunyuan Li, Pengchuan Zhang, Xiaowei Hu, Lei Zhang, Lijuan Wang, Houdong Hu, Li Dong, Furu Wei, Yejin Choi, and Jianfeng Gao. Oscar: Object-semantics aligned pre-training for vision-language tasks, 2020.
- [25] Wonjae Kim, Bokyung Son, and Ildoo Kim. Vilt: Vision-and-language transformer without convolution or region supervision, 2021.
- [26] Zirui Wang, Jiahui Yu, Adams Wei Yu, Zihang Dai, Yulia Tsvetkov, and Yuan Cao. Simvlm: Simple visual language model pretraining with weak supervision, 2022.
- [27] Jianfeng Wang, Zhengyuan Yang, Xiaowei Hu, Linjie Li, Kevin Lin, Zhe Gan, Zicheng Liu, Ce Liu, and Lijuan Wang. Git: A generative image-to-text transformer for vision and language, 2022.
- [28] Zhengyuan Yang, Zhe Gan, Jianfeng Wang, Xiaowei Hu, Faisal Ahmed, Zicheng Liu, Yumao Lu, and Lijuan Wang. Unitab: Unifying text and box outputs for grounded vision-language modeling, 2022.
- [29] Zhe Gan, Linjie Li, Chunyuan Li, Lijuan Wang, Zicheng Liu, and Jianfeng Gao. Vision-language pre-training: Basics, recent advances, and future trends, 2022.
- [30] Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-Voss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel M. Ziegler, Jeffrey Wu, Clemens Winter, Christopher Hesse, Mark Chen, Eric Sigler, Mateusz Litwin, Scott Gray, Benjamin Chess, Jack Clark, Christopher Berner, Sam McCandlish, Alec Radford, Ilya Sutskever, and Dario Amodei. Language models are few-shot learners, 2020.
- [31] Aakanksha Chowdhery, Sharan Narang, Jacob Devlin, Maarten Bosma, Gaurav Mishra, Adam Roberts, Paul Barham, Hyung Won Chung, Charles Sutton, Sebastian Gehrmann, Parker Schuh, Kensen Shi, Sasha Tsvyashchenko, Joshua Maynez, Abhishek Rao, Parker Barnes, Yi Tay, Noam Shazeer, Vinodkumar Prabhakaran, Emily Reif, Nan Du, Ben Hutchinson, Reiner Pope, James Bradbury, Jacob Austin, Michael Isard, Guy Gur-Ari, Pengcheng Yin, Toju Duke, Anselm Levskaya, Sanjay Ghemawat, Sunipa Dev, Henryk Michalewski, Xavier Garcia, Vedant Misra, Kevin Robinson, Liam Fedus, Denny Zhou, Daphne Ippolito, David Luan, Hyeontaek Lim, Barret Zoph, Alexander Spiridonov, Ryan Sepassi, David Dohan, Shivani Agrawal, Mark Omernick, Andrew M. Dai, Thanumalayan Sankaranarayana Pillai, Marie Pellat, Aitor Lewkowycz, Erica Moreira, Rewon Child, Oleksandr Polozov, Katherine Lee, Zongwei Zhou, Xuezhi Wang, Brennan Saeta, Mark Diaz, Orhan Firat, Michele Catasta, Jason Wei, Kathy Meier-Hellstern, Douglas Eck, Jeff Dean, Slav Petrov, and Noah Fiedel. Palm: Scaling language modeling with pathways, 2022.
- [32] Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, Aurelien Rodriguez, Armand Joulin, Edouard Grave, and Guillaume Lample. Llama: Open and efficient foundation language models, 2023.
- [33] Maria Tsimpoukelli, Jacob Menick, Serkan Cabi, S. M. Ali Eslami, Oriol Vinyals, and Felix Hill. Multimodal few-shot learning with frozen language models, 2021.
- [34] Danny Driess, Fei Xia, Mehdi S. M. Sajjadi, Corey Lynch, Aakanksha Chowdhery, Brian Ichter, Ayzaan Wahid, Jonathan Tompson, Quan Vuong, Tianhe Yu, Wenlong Huang, Yevgen Chebotar, Pierre Sermanet, Daniel Duckworth, Sergey Levine, Vincent Vanhoucke, Karol Hausman, Marc Toussaint, Klaus Greff, Andy Zeng, Igor Mordatch, and Pete Florence. Palm-e: An embodied multimodal language model, 2023.
- [35] Susan Zhang, Stephen Roller, Naman Goyal, Mikel Artetxe, Moya Chen, Shuohui Chen, Christopher Dewan, Mona Diab, Xian Li, Xi Victoria Lin, Todor Mihaylov, Myle Ott, Sam Shleifer, Kurt Shuster, Daniel Simig, Punit Singh Koura, Anjali Sridhar, Tianlu Wang, and Luke Zettlemoyer. Opt: Open pre-trained transformer language models, 2022.
- [36] Baolin Peng, Chunyuan Li, Pengcheng He, Michel Galley, and Jianfeng Gao. Instruction tuning with gpt-4, 2023.
- [37] Anas Awadalla, Irena Gao, Josh Gardner, Jack Hessel, Yusuf Hanafy, Wanrong Zhu, Kalyani Marathe, Yonatan Bitton, Samir Gadre, Shiori Sagawa, Jenia Jitsev, Simon Kornblith, Pang Wei Koh, Gabriel Ilharco, Mitchell Wortsman, and Ludwig Schmidt. Openflamingo: An open-source framework for training large autoregressive vision-language models, 2023.
- [38] Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning, 2023.
- [39] Bo Li, Yuanhan Zhang, Liangyu Chen, Jinghao Wang, Jingkang Yang, and Ziwei Liu. Otter: A multi-modal model with in-context instruction tuning, 2023.
- [40] Wenliang Dai, Junnan Li, Dongxu Li, Anthony Meng Huat Tiong, Junqi Zhao, Weisheng Wang, Boyang Li, Pascale Fung, and Steven Hoi. Instructblip: Towards general-purpose vision-language models with instruction tuning, 2023.
- [41] Tao Gong, Chengqi Lyu, Shilong Zhang, Yudong Wang, Miao Zheng, Qian Zhao, Kuikun Liu, Wenwei Zhang, Ping Luo, and Kai Chen. Multimodal-gpt: A vision and language model for dialogue with humans, 2023.
- [42] Qinghao Ye, Haiyang Xu, Guohai Xu, Jiabo Ye, Ming Yan, Yiyang Zhou, Junyang Wang, Anwen Hu, Pengcheng Shi, Yaya Shi, Chenliang Li, Yuanhong Xu, Hehong Chen, Junfeng Tian, Qian Qi, Ji Zhang, and Fei Huang. mplug-owl: Modularization empowers large language models with multimodality, 2023.
- [43] Zhengyuan Yang, Linjie Li, Jianfeng Wang, Kevin Lin, Ehsan Azarnasab, Faisal Ahmed, Zicheng Liu, Ce Liu, Michael Zeng, and Lijuan Wang. Mm-react: Prompting chatgpt for multimodal reasoning and action, 2023.
- [44] Yongliang Shen, Kaitao Song, Xu Tan, Dongsheng Li, Weiming Lu, and Yueting Zhuang. Hugginggpt: Solving ai tasks with chatgpt and its friends in hugging face, 2023.
- [45] Difei Gao, Lei Ji, Luowei Zhou, Kevin Qinghong Lin, Joya Chen, Zihan Fan, and Mike Zheng Shou. Assistgpt: A general multi-modal assistant that can plan, execute, inspect, and learn, 2023.
- [46] Harsh Agrawal, Karan Desai, Yufei Wang, Xinlei Chen, Rishabh Jain, Mark Johnson, Dhruv Batra, Devi Parikh, Stefan Lee, and Peter Anderson. nocaps: novel object captioning at scale. In 2019 IEEE/CVF International Conference on Computer Vision (ICCV). IEEE, October 2019.
- [47] Amanpreet Singh, Vivek Natarajan, Meet Shah, Yu Jiang, Xinlei Chen, Dhruv Batra, Devi Parikh, and Marcus Rohrbach. Towards vqa models that can read, 2019.
- [48] Zhengyuan Yang, Yijuan Lu, Jianfeng Wang, Xi Yin, Dinei Florencio, Lijuan Wang, Cha Zhang, Lei Zhang, and Jiebo Luo. Tap: Text-aware pre-training for text-vqa and text-caption, 2020.
- [49] Rowan Zellers, Yonatan Bisk, Ali Farhadi, and Yejin Choi. From recognition to cognition: Visual commonsense reasoning, 2019.
- [50] Kenneth Marino, Mohammad Rastegari, Ali Farhadi, and Roozbeh Mottaghi. Ok-vqa: A visual question answering benchmark requiring external knowledge, 2019.
- [51] Yuan Liu, Haodong Duan, Yuanhan Zhang, Bo Li, Songyang Zhang, Wangbo Zhao, Yike Yuan, Jiaqi Wang, Conghui He, Ziwei Liu, Kai Chen, and Dahua Lin. Mmbench: Is your multi-modal model an all-around player?, 2023.
- [52] Cheng-Han Chiang and Hung yi Lee. Can large language models be an alternative to human evaluations?, 2023.
- [53] Yang Liu, Dan Iter, Yichong Xu, Shuohang Wang, Ruochen Xu, and Chenguang Zhu. G-eval: Nlg evaluation using gpt-4 with better human alignment, 2023.
- [54] Jinlan Fu, See-Kiong Ng, Zhengbao Jiang, and Pengfei Liu. Gptscore: Evaluate as you desire, 2023.
- [55] Yiqiao Jin, Minje Choi, Gaurav Verma, Jindong Wang, and Srijan Kumar. Mm-soc: Benchmarking multimodal large language models in social media platforms. In ACL, 2024.
- [56] Mina Lee, Percy Liang, and Qian Yang. Coauthor: Designing a human-ai collaborative writing dataset for exploring language model capabilities. In CHI Conference on Human Factors in Computing Systems, CHI ’22. ACM, April 2022.
- [57] Shuyin Ouyang, Jie M. Zhang, Mark Harman, and Meng Wang. Llm is like a box of chocolates: the non-determinism of chatgpt in code generation, 2023.
- [58] Haotian Liu, Chunyuan Li, Yuheng Li, Bo Li, Yuanhan Zhang, Sheng Shen, and Yong Jae Lee. Llava-next: Improved reasoning, ocr, and world knowledge, January 2024.
- [59] Junnan Li, Dongxu Li, Silvio Savarese, and Steven Hoi. Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models, 2023.
- [60] Kenton Lee, Mandar Joshi, Iulia Turc, Hexiang Hu, Fangyu Liu, Julian Eisenschlos, Urvashi Khandelwal, Peter Shaw, Ming-Wei Chang, and Kristina Toutanova. Pix2struct: Screenshot parsing as pretraining for visual language understanding, 2023.
Appendix: LogicVista: Multimodal LLM Logical Reasoning Benchmark in Visual Contexts
## Appendix A Examples of LogicVista Logical Reasoning Data
Table 5: Three samples requiring inductive logical reasoning skills.
| (Case A) | |
| --- | --- |
|
<details>
<summary>extracted/5714025/figures/Appendix/ind1.png Details</summary>
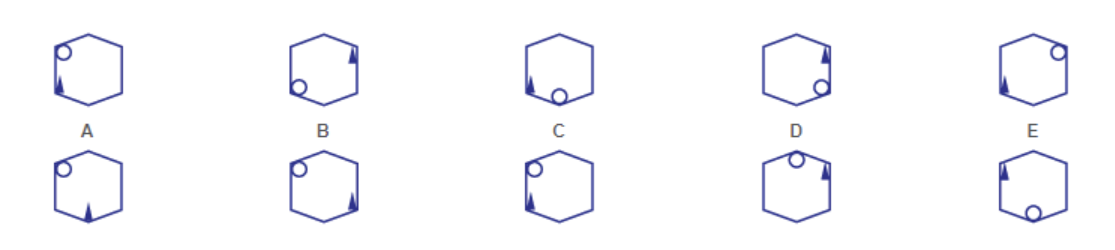
### Visual Description
## Schematic Diagram Series: Hexagonal State Configurations
### Overview
The image displays a series of ten schematic diagrams arranged in two horizontal rows of five. Each diagram consists of a regular hexagon containing two elements: a small circle and an arrow. The top row is labeled with the letters A, B, C, D, and E, centered beneath each respective hexagon. The bottom row contains five additional, unlabeled hexagons positioned directly below their counterparts in the top row. The diagrams appear to represent different states or configurations within a system, possibly illustrating a sequence, rule set, or puzzle.
### Components/Axes
* **Primary Shape:** A regular hexagon, drawn with a blue outline and a white interior.
* **Internal Elements:**
1. **Circle:** A small, solid blue circle. Its position varies, located either at a vertex (corner) or the midpoint of an edge of the hexagon.
2. **Arrow:** A solid blue arrow. Its position is always on an edge of the hexagon, and it points either directly up, down, left, or right relative to the page.
* **Labels:** The letters "A", "B", "C", "D", and "E" are present in a sans-serif font, centered below the five hexagons in the top row. No other text is present in the image.
### Detailed Analysis
The configuration of each hexagon is defined by the position of the circle and the arrow. Below is a precise description of each labeled diagram (Top Row) and its corresponding diagram directly below it (Bottom Row).
**Top Row (Labeled A-E):**
* **A:** Circle is at the top-left vertex. Arrow is on the left vertical edge, pointing **up**.
* **B:** Circle is at the bottom-left vertex. Arrow is on the right vertical edge, pointing **up**.
* **C:** Circle is at the midpoint of the bottom edge. Arrow is on the left vertical edge, pointing **up**.
* **D:** Circle is at the bottom-right vertex. Arrow is on the right vertical edge, pointing **up**.
* **E:** Circle is at the top-right vertex. Arrow is on the left vertical edge, pointing **up**.
**Bottom Row (Unlabeled, corresponding to A-E above):**
* **Below A:** Circle is at the top-left vertex. Arrow is on the bottom horizontal edge, pointing **down**.
* **Below B:** Circle is at the top-left vertex. Arrow is on the right vertical edge, pointing **down**.
* **Below C:** Circle is at the top-left vertex. Arrow is on the left vertical edge, pointing **up**.
* **Below D:** Circle is at the top horizontal edge (midpoint). Arrow is on the right vertical edge, pointing **up**.
* **Below E:** Circle is at the bottom horizontal edge (midpoint). Arrow is on the left vertical edge, pointing **up**.
### Key Observations
1. **Circle Movement (Top Row):** The circle in the top row (A-E) appears to move clockwise around the hexagon's perimeter. It starts at the top-left vertex (A), moves to the bottom-left vertex (B), then to the bottom edge midpoint (C), then to the bottom-right vertex (D), and finally to the top-right vertex (E).
2. **Arrow Consistency (Top Row):** In all five labeled diagrams (A-E), the arrow is consistently on a vertical edge (left or right) and always points **up**.
3. **Relationship Between Rows:** There is no immediately obvious, consistent transformation rule from the top row to the bottom row. For example:
* The circle in the bottom row is **not** in a simple next clockwise position from its top-row counterpart.
* The arrow direction changes inconsistently (e.g., from up in A to down below A; remains up in C and below C).
4. **Repetition:** The configuration of the hexagon labeled **C** (circle bottom edge, arrow left-up) is **identical** to the unlabeled hexagon directly below it.
### Interpretation
This image likely presents a visual logic puzzle or a set of examples for a pattern recognition task. The data suggests the following:
* **The system has defined states:** Each hexagon represents a discrete state defined by two variables: circle position and arrow direction/orientation.
* **The top row (A-E) may demonstrate a primary sequence:** The clockwise movement of the circle is a clear, ordered pattern. The constant upward arrow in this row might indicate a "default" or "input" condition.
* **The bottom row introduces complexity:** The lack of a simple, uniform rule connecting the top and bottom rows implies the relationship is either non-linear, governed by a more complex hidden rule, or that the bottom row represents outputs or transformations based on an external logic not fully depicted.
* **The identical pair (C and below C) is a critical clue:** This suggests that under certain conditions (specific circle and arrow placement in the top state), the resulting state is unchanged. This could be a key to deciphering the underlying rule.
* **Purpose:** The set is designed to test or teach the ability to infer rules from visual examples. The viewer is meant to analyze the relationships between the circle's position, the arrow's properties, and the transition from the top state to the bottom state to deduce the governing principle.
</details>
| |
| Q: | Which choice (A, B, C, or D) completes the series? |
| Answer: | D |
| Reasoning: | In this example, there are two rules to be applied. The first is that the circle moves counter-clockwise in the hexagon. It follows that, in the following diagram, the circle will be in the upper corner of the hexagon, pointing to D as the answer. To confirm this, the second rule can be applied, according to which the position of the black triangle alternates between the bottom left and the top right. Thus, in the following diagram, the black triangle will need to be in the upper right corner of the hex. The answer is therefore definitely D. |
| Logical Reasoning Skill: | Inductive |
| Required capability | Diagram |
Table 6: Three samples requiring inductive logical reasoning skills (Case B).
| (Case B) | |
| --- | --- |
|
<details>
<summary>extracted/5714025/figures/Appendix/ind2.png Details</summary>

### Visual Description
## Visual Logic Puzzle: Grid Pattern Recognition
### Overview
The image presents a visual logic puzzle divided into two main panels. The left panel establishes a rule using two example 3x3 grids. The right panel poses a question, asking the viewer to identify which two of four option grids (A, B, C, D) follow the same established rule. The puzzle uses a set of colored geometric symbols.
### Components/Axes
**Textual Content:**
* **Left Panel Header:** "These two grids follow a rule."
* **Right Panel Header:** "Which two of these grids follow the same rule?"
* **Option Labels:** The letters "A", "B", "C", and "D" are placed to the left of their respective grids.
**Visual Elements (Symbols):**
The puzzle uses four distinct symbols, each with a consistent color:
1. **Green Square**
2. **Purple Circle**
3. **Red Plus Sign (+)**
4. **Blue Triangle**
**Grid Structure:**
All grids are 3x3 matrices (3 rows, 3 columns).
### Detailed Analysis
**1. Example Grids (Left Panel - Establishing the Rule):**
* **Top Example Grid:**
* Row 1: [Green Square] [Purple Circle] [Red Plus]
* Row 2: [Blue Triangle] [Blue Triangle] [Blue Triangle]
* Row 3: [Blue Triangle] [Blue Triangle] [Blue Triangle]
* **Bottom Example Grid:**
* Row 1: [Purple Circle] [Green Square] [Red Plus]
* Row 2: [Blue Triangle] [Blue Triangle] [Blue Triangle]
* Row 3: [Blue Triangle] [Blue Triangle] [Blue Triangle]
**2. Option Grids (Right Panel - Applying the Rule):**
* **Grid A:**
* Row 1: [Green Square] [Purple Circle] [Blue Triangle]
* Row 2: [Blue Triangle] [Blue Triangle] [Red Plus]
* Row 3: [Blue Triangle] [Blue Triangle] [Blue Triangle]
* **Grid B:**
* Row 1: [Purple Circle] [Red Plus] [Green Square]
* Row 2: [Blue Triangle] [Blue Triangle] [Blue Triangle]
* Row 3: [Blue Triangle] [Blue Triangle] [Blue Triangle]
* **Grid C:**
* Row 1: [Red Plus] [Blue Triangle] [Green Square]
* Row 2: [Blue Triangle] [Purple Circle] [Blue Triangle]
* Row 3: [Blue Triangle] [Blue Triangle] [Blue Triangle]
* **Grid D:**
* Row 1: [Red Plus] [Purple Circle] [Green Square]
* Row 2: [Blue Triangle] [Blue Triangle] [Blue Triangle]
* Row 3: [Blue Triangle] [Blue Triangle] [Blue Triangle]
### Key Observations
1. **Rule Deduction:** The two example grids share a strict pattern: The **first row contains exactly one of each of the three non-triangle symbols** (Green Square, Purple Circle, Red Plus) in some order. The **second and third rows consist entirely of Blue Triangles**.
2. **Grid A Violation:** The first row contains a Blue Triangle, and the second row contains a Red Plus. This breaks both parts of the deduced rule.
3. **Grid C Violation:** The first row contains a Blue Triangle, and the second row contains a Purple Circle. This also breaks both parts of the rule.
4. **Grids B & D Compliance:** Both Grid B and Grid D have a first row containing the three unique symbols (Square, Circle, Plus) in different permutations. Their second and third rows are composed solely of Blue Triangles, perfectly matching the pattern from the examples.
### Interpretation
This is a non-verbal reasoning test of pattern recognition and rule application. The puzzle's core logic is based on **set composition and positional constraints**.
* **What the data suggests:** The rule defines a specific "signature" for a valid grid: a unique symbol trio in the primary (top) row and uniformity (all triangles) in the secondary rows. The order of the trio in the top row is variable, but its composition is fixed.
* **How elements relate:** The example grids serve as the "training data," defining the rule. The option grids are test cases. The solver must abstract the rule from the examples and then apply it deductively to the new cases.
* **Notable patterns/anomalies:** The most common failure modes in the incorrect options (A and C) are the intrusion of a triangle into the top row or the placement of a unique symbol (Plus or Circle) into the lower rows. The correct answers (B and D) are distinguished only by the permutation of the top-row symbols, demonstrating that the rule cares about the *set* of symbols in the top row, not their specific sequence.
**Conclusion:** Based on the extracted visual data and the deduced rule, **Grids B and D** are the two grids that follow the same rule as the provided examples.
</details>
| |
| Q: | Two grids containing colored symbols and following a common rule are presented. In the block on the right, four additional grids are presented. The candidate must find the two grids that follow the same rule out of these four options. What options (A, B, C, or D) follow this same rule? |
| Answer: | B, D |
| Reasoning: | In this example, it is easy to see that the rule governing the two grids on the left is: that blue triangles are present in each of the two bottom lines. This rule is followed in the two grids on the right. |
| Logical Reasoning Skill: | Inductive |
| Required capability | Diagram, OCR |
Table 7: Three samples requiring inductive logical reasoning skills (Case C).
| (Case C) | |
| --- | --- |
|
<details>
<summary>extracted/5714025/figures/Appendix/ind3.png Details</summary>

### Visual Description
\n
## Diagram: Sequence of Labeled Geometric Symbols
### Overview
The image displays a horizontal sequence of nine square boxes, each containing a single geometric symbol. Above each box is a capital letter label, ranging from A to I. The symbols alternate between filled (black) diamonds and outlined (white) diamonds, with one notable exception where a filled square appears.
### Components/Axes
- **Labels**: A, B, C, D, E, F, G, H, I (positioned directly above each corresponding box).
- **Boxes**: Nine identical square frames arranged in a single row.
- **Symbols**: Geometric shapes centered within each box. Two types are present:
1. **Diamonds**: Present in eight of the nine boxes.
2. **Square**: Present in one box (G).
- **Fill/Color**: Symbols are either solid black or outlined in black with a white interior.
### Detailed Analysis
The sequence from left to right (A to I) is as follows:
| Label | Symbol Shape | Fill/Color | Position in Sequence |
| :--- | :--- | :--- | :--- |
| **A** | Diamond | Filled Black | 1st |
| **B** | Diamond | Outlined White | 2nd |
| **C** | Diamond | Filled Black | 3rd |
| **D** | Diamond | Outlined White | 4th |
| **E** | Diamond | Filled Black | 5th |
| **F** | Diamond | Outlined White | 6th |
| **G** | **Square** | **Filled Black** | **7th** |
| **H** | Diamond | Outlined White | 8th |
| **I** | Diamond | Filled Black | 9th |
**Pattern Observation**: The sequence follows a strict alternating pattern of **Filled Black Diamond** -> **Outlined White Diamond** for the first six positions (A-F). This pattern is broken at position G, which contains a **Filled Black Square**. The alternating diamond pattern then resumes for positions H (Outlined White Diamond) and I (Filled Black Diamond).
### Key Observations
1. **Primary Pattern**: A clear alternating sequence of filled and outlined diamonds exists for 8 out of 9 elements.
2. **Singular Anomaly**: The element at position **G** is the only square and the only element that breaks the established diamond alternation pattern.
3. **Symmetry**: The sequence is not perfectly symmetrical due to the anomaly at G. However, the pattern of fills (Black, White, Black, White, Black, White, **Black**, White, Black) is symmetric around the central element (E) if the shape difference at G is ignored.
4. **Spatial Layout**: All elements are evenly spaced and aligned horizontally. Labels are consistently placed above their respective boxes.
### Interpretation
This diagram most likely represents a **code, sequence, or pattern recognition test**. The deliberate break in an otherwise predictable pattern at a specific position (G) is the central piece of information.
* **What it suggests**: The sequence establishes a rule (alternating filled/outlined diamonds) and then demonstrates a violation of that rule. This is a common method in logic puzzles, coding schemes, or visual tests to identify an "odd one out" or a special marker.
* **How elements relate**: The labels (A-I) provide a fixed reference system. The relationship between consecutive elements is defined by the alternating pattern, making the deviation at G immediately salient.
* **Notable anomaly**: The filled square at **G** is the critical outlier. Its difference in both **shape** (square vs. diamond) and its position in the **fill sequence** (it is black, which fits the fill pattern but not the shape pattern) makes it the focal point of the diagram. This could signify an error, a special command, a separator, or the answer to a puzzle embedded within the sequence.
* **Potential purpose**: Without additional context, the diagram's purpose is abstract. It could be a visual analogy for a digital signal (where G represents a different bit), a step in a process flow where a transformation occurs, or simply a self-contained logical puzzle where the task is to identify the anomalous element.
</details>
| |
| Q: | Who is the odd-one-out? Select answers from A-I. |
| Answer: | G |
| Reasoning: | Element G constitutes the exception and is therefore the correct answer. |
| Logical Reasoning Skill: | Inductive |
| Required capability | Diagram |
Table 8: Three samples requiring deductive logical reasoning skills (Case A).
| (Case A) | |
| --- | --- |
|
<details>
<summary>extracted/5714025/figures/Appendix/ded1.png Details</summary>

### Visual Description
\n
## Logical Deduction Problem: Text-Based Syllogism
### Overview
The image presents a text-based logical reasoning problem consisting of two premises, a question, and five multiple-choice answer options. The content is entirely textual, with no charts, diagrams, or numerical data. The problem tests the ability to perform categorical syllogism.
### Components/Axes
The image is structured as follows:
1. **Premise 1:** "All footballers are fit and healthy."
2. **Premise 2:** "All famous sports players are footballers."
3. **Question:** "Given that the above is true, which of the following is the logical deduction?"
4. **Answer Options:** A numbered list from 1 to 5.
### Detailed Analysis / Content Details
**Transcription of All Text:**
* **Premise 1:** `All footballers are fit and healthy.`
* **Premise 2:** `All famous sports players are footballers.`
* **Question:** `Given that the above is true, which of the following is the logical deduction?`
* **Option 1:** `1. All footballers are famous sports people`
* **Option 2:** `2. All famous people are fit and healthy`
* **Option 3:** `3. All famous sports players are fit and healthy`
* **Option 4:** `4. All fit and healthy people are footballers`
* **Option 5:** `5. All football players are men`
**Logical Structure Analysis:**
The problem is a categorical syllogism. We can represent the premises using set theory:
* Let **F** = Set of all footballers.
* Let **H** = Set of all fit and healthy people.
* Let **S** = Set of all famous sports players.
The premises state:
1. **F ⊆ H** (All footballers are a subset of fit and healthy people).
2. **S ⊆ F** (All famous sports players are a subset of footballers).
Combining these via transitivity (**S ⊆ F** and **F ⊆ H**), the valid logical deduction is: **S ⊆ H** (All famous sports players are a subset of fit and healthy people).
### Key Observations
* The text is presented in a clear, sans-serif font on a plain white background.
* The premises are stated as universal affirmative statements ("All A are B").
* The question asks for a necessary logical deduction, not a possible or probable one.
* Option 5 introduces an entirely new category ("men") not mentioned in the premises, making it irrelevant to the given logic.
### Interpretation
This is a test of deductive reasoning, specifically the validity of a syllogism in the **Barbara** (AAA-1) form.
* **Valid Deduction:** Only **Option 3 ("All famous sports players are fit and healthy")** is a logically necessary conclusion. It directly follows from the chain of inclusion: Famous Sports Players → Footballers → Fit and Healthy.
* **Invalid Deductions:**
* **Option 1** reverses the first premise. While all famous sports players are footballers, the premises do not state that all footballers are famous sports players. This is the fallacy of illicit conversion.
* **Option 2** overextends the conclusion. The premises only connect "famous sports players" to "fit and healthy," not all "famous people."
* **Option 4** also reverses a premise. Being fit and healthy is a necessary condition for being a footballer, but not a sufficient one. This is the fallacy of affirming the consequent.
* **Option 5** is a non sequitur; the gender of football players is not addressed or implied by the premises.
The problem demonstrates how formal logic requires conclusions to be derived strictly from the given premises without introducing external assumptions or reversing established relationships. The correct answer is **3**.
</details>
| |
| Q: | Which is the correct answer according to the image? Select from 1-5? |
| Answer: | 3 |
| Reasoning: | Using deductive reasoning, the only logical answer is 3. To get to this answer, you need to simplify the given facts. All famous sports players are footballers, and all footballers are fit and healthy. We can not deduce that all footballers are famous sports people, as we have not got that information. We can not deduce that all famous people are fit and healthy, because the fact is about famous sports people. This is the logical answer. This information is not given; all footballers are fit and healthy but we can not logically link that all fit and healthy people are footballers. This is obviously incorrect, as gender is not mentioned at all in the question. |
| Logical Reasoning Skill: | Deductive |
| Required capability: | OCR |
Table 9: Three samples requiring deductive logical reasoning skills (Case B).
| (Case B) | |
| --- | --- |
|
<details>
<summary>extracted/5714025/figures/Appendix/ded2.png Details</summary>

### Visual Description
## Text-Based Logical Reasoning Question
### Overview
The image displays a multiple-choice question presented in a clean, text-only format. The question presents a premise about the color of swallows and asks for the most logical conclusion from four given options.
### Content Details
**Main Text (Top):**
"The vast majority of swallows are blue. What is the most logical conclusion?"
**Options (Listed below the question):**
* **A.** There is a white swallow.
* **B.** Not everything that is blue is a swallow.
* **C.** There is a blue swallow.
* **D.** None of the answers are satisfactory.
**Language:** The text is entirely in English.
### Key Observations
1. **Premise Structure:** The statement "The vast majority of swallows are blue" is a universal affirmative about a subset (the majority) of a category (swallows). It does not claim that *all* swallows are blue.
2. **Logical Scope:** The premise provides information about the property (blue) of the subject (swallows). It does not provide information about the converse (the property of other blue things).
3. **Option Analysis:**
* **Option A** introduces a new color (white) not mentioned in the premise. The premise's claim about a majority being blue does not logically entail the existence of a swallow of any other specific color.
* **Option B** makes a claim about the set of all blue things. The premise is about swallows, not about the exclusivity of the color blue. This is a converse error.
* **Option C** is a direct, minimal inference. If the vast majority of a set has a property, then at least one member of that set must have that property. Therefore, at least one blue swallow must exist.
* **Option D** is a meta-answer that depends on the validity of A, B, and C.
### Interpretation
This is a test of basic deductive logic and the ability to avoid common fallacies.
* **What the data suggests:** The question tests the understanding of quantifiers like "the vast majority." This phrase logically implies "more than half," which in turn necessitates the existence of at least one instance. It does not support conclusions about what else might exist (Option A) or about the broader category of blue objects (Option B).
* **How elements relate:** The premise sets a logical condition. The options are potential conclusions. The task is to identify which conclusion is *necessarily true* if the premise is true.
* **Notable pattern/anomaly:** The most common error would be to select Option B, confusing "All A are B" with "All B are A." The correct logical step is to recognize that a statement about a majority guarantees existence, making Option C the only necessarily true conclusion from the given premise.
**Conclusion:** Based on strict logical deduction from the provided premise, **Option C ("There is a blue swallow")** is the most logical conclusion.
</details>
| |
| Q: | What is the correct answer to the question in the image? Select from A-D. |
| Answer: | C |
| Reasoning: | The vast majority of swallows are blue so the answer must be C: there is a blue swallow. |
| Logical Reasoning Skill: | Deductive |
| Required capability: | OCR |
Table 10: Three samples requiring deductive logical reasoning skills (Case C).
| (Case C) | |
| --- | --- |
|
<details>
<summary>extracted/5714025/figures/Appendix/ded3.png Details</summary>

### Visual Description
## Text Block: Statements on Societal Structure
### Overview
The image displays a rectangular box with a thin, orange-yellow border containing five lines of centered text. The text presents a series of declarative statements describing a cyclical relationship between "the people," "the government," "production," and "the free-market." The background is plain white, and the text is in a standard, dark gray sans-serif font.
### Components/Axes
* **Container:** A rectangular box with a solid, thin border (approximate color: #e6b800, a golden yellow).
* **Text Alignment:** All lines of text are horizontally centered within the box.
* **Text Content:** Five distinct statements, each on a new line.
### Detailed Analysis / Content Details
The exact text transcribed from the image is as follows:
1. The people determine what is produced.
2. The government is made up of the people.
3. Production is determined by the free-market.
4. The free-market is made up of production.
5. Government is determined by the free-market.
### Key Observations
* **Logical Structure:** The statements form a closed, circular logic chain. "The people" influence "production" (line 1), which is defined by the "free-market" (line 3), which in turn constitutes the "government" (line 5), which is composed of "the people" (line 2). The final link is implied: the government (made of people) determines policy, which influences the people.
* **Terminology:** The text uses specific, capitalized terms ("Government," "free-market") as defined entities within its logical framework.
* **Visual Presentation:** The text is presented neutrally, without emphasis (like bold or italics), within a simple bordered container, suggesting it may be a definition, axiom, or excerpt from a larger theoretical model.
### Interpretation
This text block outlines a theoretical model of a democratic, market-based society. It posits a self-reinforcing system where individual agency (the people) and economic mechanisms (the free-market) are the foundational drivers of both production and governance. The circularity suggests a system of mutual constitution and feedback.
The statements imply that political power ("Government") is ultimately derived from economic activity ("the free-market"), which itself is the aggregate result of individual choices ("the people determine what is produced"). This presents a view where economic and political spheres are deeply intertwined and co-dependent, with the populace acting as the primary agent through both their economic choices and their collective identity as the government's composition.
A potential logical tension or area for deeper inquiry lies in the direction of determination. The model states both that "the people determine what is produced" and that "Production is determined by the free-market." This could be interpreted as the free-market being the *mechanism* through which the people's collective determinations are enacted, or it could indicate a more complex, multi-causal relationship not fully detailed in these five lines. The model presents a specific, perhaps idealized, view of a liberal democratic capitalist system.
</details>
| |
| Q: | What is produced is determined by the people. Select from A, B, and C. (A) True (B)False (C)Insufficient Information? |
| Answer: | A |
| Reasoning: | Line 1 states that the people determine what is produced. Line 2 states that the government is made up of the people. Therefore, the people determine what is produced. This is a syllogism. Thus, this statement is true. |
| Logical Reasoning Skill: | Deductive |
| Required capability: | OCR |
Table 11: Three samples requiring numerical logical reasoning skills (Case A).
| (Case A) | |
| --- | --- |
|
<details>
<summary>extracted/5714025/figures/Appendix/num1.png Details</summary>
### Visual Description
## Data Tables: Share Price Index & Dividend Index
### Overview
The image displays two distinct data tables presented in a clean, professional format. The top table is titled "Share Price Index" and provides stock market data for five companies. The bottom table is titled "Dividend Index" and details the dividend payments per share for the same five companies. A note at the bottom clarifies the calculation for total annual dividends.
### Components/Axes
**Table 1: Share Price Index**
* **Structure:** A 6-column, 6-row table (including header).
* **Column Headers (Left to Right):**
1. Company
2. Today's Price (€)
3. Change from previous day (%)
4. Past 12 months (This is a merged header spanning two sub-columns)
* Sub-column 1: Max price (€)
* Sub-column 2: Min price (€)
* **Row Headers (Top to Bottom):** The five companies listed are Huver Co., Drebs Ltd, Fevs Plc, Fauvers, and Steapars.
* **Visual Styling:** The header row has a dark background with white text. Data rows alternate between light grey and white backgrounds for readability. Negative percentage changes are displayed in red text.
**Table 2: Dividend Index**
* **Structure:** A 6-column, 3-row table (including header).
* **Column Headers (Left to Right):**
1. Dividend paid per share (€)
2. Huver Co.
3. Drebs Ltd
4. Fevs Plc
5. Fauvers
6. Steapars
* **Row Headers (Top to Bottom):**
1. Interim Dividend
2. Final Dividend
* **Visual Styling:** Similar to the first table, with a dark header row and alternating row backgrounds.
**Note Section:**
* Located below the Dividend Index table.
* Text: "Note: the total annual dividend paid per share is the sum of the interim dividend and the final dividend."
### Detailed Analysis
**Share Price Index Data:**
| Company | Today's Price (€) | Change from previous day (%) | Past 12 months Max price (€) | Past 12 months Min price (€) |
| :--------- | :---------------- | :--------------------------- | :---------------------------- | :--------------------------- |
| Huver Co. | 1,150 | 1.10 | 1,360 | 860 |
| Drebs Ltd | 18 | 0.50 | 22 | 11 |
| Fevs Plc | 1,586 | **-9.00** (in red) | 1,955 | 1,242 |
| Fauvers | 507 | **-1.00** (in red) | 724 | 464 |
| Steapars | 2,537 | 1.00 | 2,630 | 2,216 |
**Dividend Index Data:**
| Dividend Type | Huver Co. | Drebs Ltd | Fevs Plc | Fauvers | Steapars |
| :-------------- | :-------- | :-------- | :------- | :------ | :------- |
| Interim Dividend | 0.83 | 0.44 | 0.34 | 0.09 | 0.48 |
| Final Dividend | 1.75 | 1.12 | 1.25 | 0.32 | 0.96 |
**Calculated Total Annual Dividend (Interim + Final):**
* Huver Co.: €2.58
* Drebs Ltd: €1.56
* Fevs Plc: €1.59
* Fauvers: €0.41
* Steapars: €1.44
### Key Observations
1. **Price Volatility:** Fevs Plc shows the most significant single-day movement with a **-9.00%** drop. Fauvers also declined (-1.00%). The other three companies saw positive changes.
2. **Price Range:** Steapars has the highest share price (€2,537) and the narrowest 12-month trading range relative to its price (€2,216 to €2,630). Drebs Ltd has the lowest share price (€18).
3. **Dividend Disparity:** There is a wide range in dividend payments. Huver Co. pays the highest total annual dividend (€2.58), while Fauvers pays the lowest (€0.41).
4. **Dividend Structure:** For all companies, the Final Dividend is significantly larger than the Interim Dividend, typically by a factor of 2 to 3.5.
### Interpretation
This data provides a snapshot of financial performance and shareholder returns for five companies. The **Share Price Index** suggests mixed market sentiment on the day captured, with Fevs Plc experiencing a notable downturn. The 12-month high/low prices indicate Steapars has been the most stable in terms of price appreciation, trading near its annual high.
The **Dividend Index** reveals the companies' policies on returning cash to shareholders. The note is crucial for interpretation, confirming that the total annual payout is the simple sum of the two listed dividends. An investor analyzing this data would likely correlate the two tables. For instance:
* **Huver Co.** combines a solid share price with the highest dividend yield, potentially indicating a mature, income-focused company.
* **Fauvers** has both a declining share price and the lowest dividend, which could signal financial pressure or a growth phase where profits are reinvested.
* **Steapars** has the highest share price but a moderate dividend, which might reflect investor expectations for future growth over immediate income.
The data does not provide context for the observed changes (e.g., earnings reports, market conditions) or the companies' sectors, which would be necessary for a full investment analysis. The tables are purely quantitative, presenting facts without causal explanation.
</details>
| |
| Q: | Which share had the largest difference between the highest and lowest price over the last 12 months? Select from A, B, C, D and E. (A) Huver Co. (B) Drebs Ltd (C) Fevs Plc (D) Fauvers (E) Steapars |
| Answer: | C |
| Reasoning: | Step 1- Calculate the difference between the maximum and the minimum prices. Huver Co. = 1,360 - 860 = 500 Drebs Ltd = 22 - 11 = 11 Fevs Plc = 1,955 - 1,242 = 713 Fauvers = 724 - 464 = 260 Steapars = 2,630 - 2,216 = 414. Tip: Notice the wording of the question is asking for the share with the largest absolute change in price, NOT the largest percentage change, which would have been Drebs Ltd. If the question had wanted the percentage change it would have used the word percentage. Thus the correct answer is (C) Fevs Plc |
| Logical Reasoning Skill: | Numerical |
| Required capability: | OCR |
Table 12: Three samples requiring numerical logical reasoning skills (Case B).
| (Case B) | |
| --- | --- |
|
<details>
<summary>extracted/5714025/figures/Appendix/num2.png Details</summary>
### Visual Description
## Stacked Bar Chart: Reyes Heslop Consulting Profits
### Overview
This is a stacked bar chart titled "Reyes Heslop Consulting Profits" showing the profit breakdown (in £ millions) for five different business sectors. Each bar represents a sector and is divided into three colored segments representing profits from three distinct geographic regions: Pacific Rim, American, and European.
### Components/Axes
* **Chart Title:** "Reyes Heslop Consulting Profits"
* **Subtitle/Unit:** "(£ millions)"
* **X-Axis (Categories):** Lists five business sectors. From left to right: Leisure, Manufacturing, Retail, Government, Utilities.
* **Y-Axis:** Not explicitly labeled with a title or numerical markers. The numerical values are embedded directly within each bar segment.
* **Legend:** Positioned in the top-right corner of the chart area. It defines the color coding for the geographic regions:
* **Green Square:** Pacific Rim
* **Blue Square:** American
* **Dark Gray Square:** European
### Detailed Analysis
The chart displays profit data for each sector, broken down by region. The values are read from the bottom segment (European) to the top segment (Pacific Rim) for each bar.
**1. Leisure Sector (First bar from left):**
* **European (Dark Gray, bottom):** 5.2
* **American (Blue, middle):** 7.4
* **Pacific Rim (Green, top):** 4.6
* **Total (approximate):** 5.2 + 7.4 + 4.6 = 17.2
**2. Manufacturing Sector (Second bar):**
* **European (Dark Gray, bottom):** 5.0
* **American (Blue, middle):** 7.2
* **Pacific Rim (Green, top):** 6.3
* **Total (approximate):** 5.0 + 7.2 + 6.3 = 18.5
**3. Retail Sector (Third bar):**
* **European (Dark Gray, bottom):** 4.4
* **American (Blue, middle):** 5.8
* **Pacific Rim (Green, top):** 3.8
* **Total (approximate):** 4.4 + 5.8 + 3.8 = 14.0
**4. Government Sector (Fourth bar):**
* **European (Dark Gray, bottom):** 4.5
* **American (Blue, middle):** 5.9
* **Pacific Rim (Green, top):** 3.6
* **Total (approximate):** 4.5 + 5.9 + 3.6 = 14.0
**5. Utilities Sector (Fifth bar, far right):**
* **European (Dark Gray, bottom):** 3.5
* **American (Blue, middle):** 5.1
* **Pacific Rim (Green, top):** 6.2
* **Total (approximate):** 3.5 + 5.1 + 6.2 = 14.8
### Key Observations
* **Highest Total Profit:** The Manufacturing sector has the tallest bar, indicating the highest total profit at approximately £18.5 million.
* **Lowest Total Profit:** The Retail and Government sectors appear to have the lowest and equal total profits of approximately £14.0 million each.
* **Regional Dominance:** The American region (blue segment) is the largest profit contributor in four out of five sectors (Leisure, Manufacturing, Retail, Government). The exception is Utilities, where the Pacific Rim (green segment) is the largest contributor.
* **Pacific Rim Performance:** The Pacific Rim shows its strongest performance in the Manufacturing (£6.3m) and Utilities (£6.2m) sectors, and its weakest in Government (£3.6m).
* **European Performance:** The European region's profits are relatively consistent across sectors, ranging from a low of £3.5m (Utilities) to a high of £5.2m (Leisure).
* **Sector Comparison:** The Manufacturing sector leads in profits from both the American and Pacific Rim regions. The Leisure sector has the highest European profit.
### Interpretation
The data suggests that Reyes Heslop Consulting's profitability is highly dependent on both the business sector and the geographic market. The Manufacturing sector is the firm's most lucrative overall, driven by strong performance in the American and Pacific Rim markets. The consistent strength of the American region across most sectors indicates it is likely the core market for the firm.
A notable anomaly is the Utilities sector, where the typical profit hierarchy is inverted: the Pacific Rim is the largest contributor, followed by American, with European being the smallest. This could indicate a specialized expertise or a strong client base in the Pacific Rim for utilities consulting that differs from the firm's profile in other sectors.
The equal total profits for Retail and Government, despite different internal compositions (Government has a slightly higher American component, Retail a slightly higher European one), suggest similar overall market size or engagement levels for the firm in these two areas. The chart effectively communicates that a one-size-fits-all regional strategy would be suboptimal; sector-specific regional focuses are evident in the profit distribution.
</details>
| |
| Q: | Reyes Heslop had a target for Leisure profits to be a quarter of their total profits. Assuming profits in other areas remain the same, by how much did the Leisure profits miss this target? Select from A, B, C, D and E. (A) 31.8 million (B) 32.4 million (C) 32.7 million (D) 33.2 million (E) 33.4 million |
| Answer: | D |
| Reasoning: | Step 1- Calculate the total Reyes Heslop profits across all areas other than Leisure. (6.3 + 7.2 + 5.0) + (3.8 + 5.8 + 4.4) + (3.6 + 5.9 + 4.5) + (6.2 + 5.1 + 3.5) = 61.3 million. Step 2- This needs to be 1/4 of all profits for the condition to be met. Therefore all profits, across all sectors, would be 61.3 / 75% = 81.7333 million. Step 3- Now we look at the difference between actual and target Leisure profits. Actual = (4.6 + 7.4 + 5.2) = 17.2 Target = (81.7333 - 61.3) = 20.4333 Shortfall = 3.2333 (millions) Thus the correct answer is (D) 33.2 million |
| Logical Reasoning Skill: | Numerical |
| Required capability: | Diagram, OCR |
Table 13: Three samples requiring numerical logical reasoning skills (Case C).
| (Case C) | |
| --- | --- |
|
<details>
<summary>extracted/5714025/figures/Appendix/num3.png Details</summary>
### Visual Description
\n
## Comparative Pie Charts: Building Energy Use (1990 vs. 2000)
### Overview
The image displays two pie charts side-by-side, comparing the percentage distribution of energy consumption across five different functional areas within a building for the years 1990 and 2000. The total annual energy use for the building is provided for each year.
### Components/Axes
* **Chart Type:** Two pie charts.
* **Titles:**
* Left Chart: "Building Energy Use 1990"
* Right Chart: "Building Energy Use 2000"
* **Total Values:**
* 1990: "Total: 17,000 kWh"
* 2000: "Total: 15,000 kWh"
* **Categories (Slices):** The same five categories are present in both charts, each represented by a distinct shade of blue.
* **Kitchen** (Darkest Blue)
* **Meeting Rooms** (Lightest Blue)
* **PC Room** (Medium-Dark Blue)
* **Office Space** (Medium-Light Blue)
* **Print Room** (Medium Blue)
* **Labels:** Each slice is labeled with its category name and percentage value. Labels are connected to their respective slices with thin lines.
* **Legend/Key:** The category names and their associated colors are defined by the labels directly on the chart slices; there is no separate legend box.
* **Source/Logo:** A logo for "AssessmentDay" with the tagline "Practice Test Experts" is present in the bottom-right corner.
### Detailed Analysis
**1990 Chart (Total: 17,000 kWh)**
* **Office Space:** 41% (Largest slice, located in the bottom-right quadrant).
* **PC Room:** 20% (Second-largest slice, located in the left half).
* **Print Room:** 15% (Located in the bottom-left quadrant).
* **Kitchen:** 12% (Located in the top-left quadrant).
* **Meeting Rooms:** 12% (Located in the top-right quadrant).
**2000 Chart (Total: 15,000 kWh)**
* **Office Space:** 39% (Remains the largest slice, located in the bottom-right quadrant).
* **PC Room:** 21% (Second-largest slice, located in the left half).
* **Kitchen:** 14% (Located in the top-left quadrant).
* **Meeting Rooms:** 14% (Located in the top-right quadrant).
* **Print Room:** 12% (Located in the bottom-left quadrant).
**Trend Verification (1990 to 2000):**
* **Office Space:** Percentage decreased by 2 percentage points (41% → 39%).
* **PC Room:** Percentage increased by 1 percentage point (20% → 21%).
* **Print Room:** Percentage decreased by 3 percentage points (15% → 12%).
* **Kitchen:** Percentage increased by 2 percentage points (12% → 14%).
* **Meeting Rooms:** Percentage increased by 2 percentage points (12% → 14%).
* **Total Energy Use:** Decreased by 2,000 kWh (17,000 → 15,000), an approximate 11.8% reduction.
### Key Observations
1. **Overall Reduction:** The building's total energy consumption decreased significantly (by ~11.8%) over the decade.
2. **Shift in Distribution:** While "Office Space" remained the largest consumer, its dominance slightly diminished. The proportional shares of "Kitchen" and "Meeting Rooms" grew equally.
3. **Print Room Decline:** The "Print Room" saw the largest proportional decrease, which may correlate with technological changes (e.g., reduced printing needs, more efficient printers).
4. **PC Room Stability:** The "PC Room" share remained relatively stable, increasing only slightly, suggesting its energy demand grew roughly in line with the building's average efficiency changes.
### Interpretation
The data suggests a building undergoing a transition in both efficiency and function between 1990 and 2000. The **absolute reduction in total energy use (from 17,000 to 15,000 kWh)** is the most significant finding, indicating successful energy conservation measures or a reduction in overall building activity.
The **changing percentages** reveal a shift in internal energy priorities. The rise in proportional use for "Kitchen" and "Meeting Rooms" could indicate increased catering, more collaborative work, or the addition of appliances. The relative stability of the "PC Room" suggests computing became a consistent, baseline load. The notable drop in the "Print Room's" share is a strong candidate for a primary driver of the overall efficiency gain, potentially reflecting the early digital transformation of office workflows.
In essence, the charts depict a building becoming more energy-efficient overall, while its internal energy profile slowly shifts away from centralized printing and towards spaces associated with sustenance (Kitchen) and collaboration (Meeting Rooms).
</details>
| |
| Q: | Which space experienced the smallest reduction in kWh used between 1990 and 2000? Select from A, B, C, and D. (A) Office Space (B) Print Room (C) Meeting Rooms (D) PC Room |
| Answer: | D |
| Reasoning: | Step 1- Calculate the value of kWh for 1990 and 2000 for each of the rooms. Room 1990 per kWh 2000 per kWh Meeting Rooms 2.04 2.10 Office Space 6.97 5.85 Print Room 2.55 1.80 PC Room 3.40 3.15 Kitchen 2.04 2.10 Step 2- Subtract the kWh for 2000 from that of 1990 for each of the rooms. Room change (1990 - 2000) kWh Meeting Rooms -0.06 Office Space 1.12 Print Room 0.75 PC Room 0.25 Kitchen -0.06 Step 3- Look for the smallest positive value. Negative values represent an increase between 1990 and 2000. Tip- You only need to perform 4 calculations, as two of the rooms have the same values. Thus, the correct answer is (D) PC Room. |
| Logical Reasoning Skill: | Deductive |
| Required capability: | Diagram, OCR |
Table 14: Three samples requiring spatial logical reasoning skills (Case A).
| (Case A) | |
| --- | --- |
|
<details>
<summary>extracted/5714025/figures/Appendix/spat1.png Details</summary>
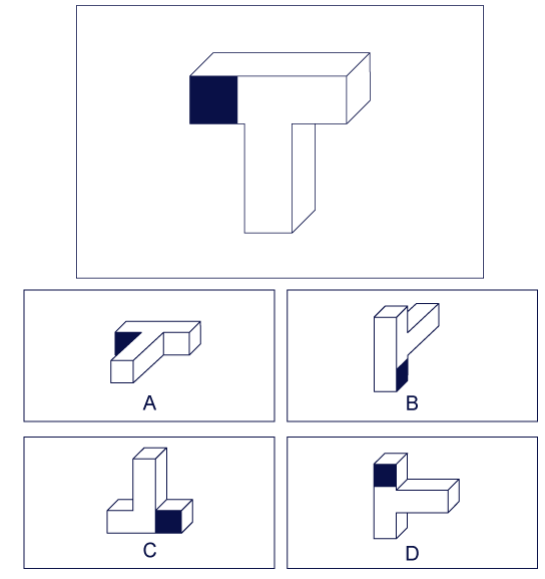
### Visual Description
## 3D Spatial Reasoning Diagram: T-Block Rotation Puzzle
### Overview
The image presents a visual spatial reasoning puzzle. It consists of a primary reference diagram at the top and four candidate answer diagrams (labeled A, B, C, D) below. The puzzle challenges the viewer to identify which of the four smaller diagrams represents the same three-dimensional T-shaped block as the main reference, but rotated to a different orientation. The only distinguishing feature is a single face of the block shaded in dark blue.
### Components/Axes
* **Main Reference Diagram (Top):** A 3D isometric line drawing of a T-shaped block. The block is composed of two rectangular prisms: a horizontal top bar and a vertical stem centered beneath it. One specific face is shaded dark blue.
* **Answer Options (Bottom):** Four smaller boxes, each containing a 3D isometric line drawing of a similar T-shaped block in a different orientation. Each is labeled with a capital letter in a sans-serif font, centered beneath its respective diagram.
* **Label A:** Positioned below the top-left answer box.
* **Label B:** Positioned below the top-right answer box.
* **Label C:** Positioned below the bottom-left answer box.
* **Label D:** Positioned below the bottom-right answer box.
* **Color Legend:** The only color used is a solid dark blue (approximate hex: #000033) applied to one face of the block in each diagram. This blue face is the key feature for matching the reference to the correct answer.
### Detailed Analysis
**Main Reference Diagram:**
* **Orientation:** The T-block is viewed from a front-right angle. The top bar extends left-to-right, and the stem extends downward.
* **Shaded Face Location:** The dark blue shading is applied to the **left-most face of the horizontal top bar**. This face is oriented toward the front-left of the viewer's perspective.
**Answer Option A:**
* **Orientation:** The T-block is rotated so the top bar is angled, running from the front-left to the back-right. The stem points downward and slightly to the left.
* **Shaded Face Location:** The dark blue shading is on the **top surface of the left end of the horizontal bar**. This appears to be the same physical face as in the reference, now viewed from above due to the rotation.
**Answer Option B:**
* **Orientation:** The T-block is rotated so the stem is vertical and the top bar is angled, running from the front-right to the back-left.
* **Shaded Face Location:** The dark blue shading is on the **right-side face of the vertical stem**, near its base. This is a different face than the one shaded in the reference diagram.
**Answer Option C:**
* **Orientation:** The T-block is in a similar upright orientation to the reference, but viewed from a front-left angle.
* **Shaded Face Location:** The dark blue shading is on the **right-side face of the vertical stem**, near its base. This is the same face as in Option B, and different from the reference.
**Answer Option D:**
* **Orientation:** The T-block is rotated so the stem is vertical and the top bar extends to the right. The view is from a front-left angle.
* **Shaded Face Location:** The dark blue shading is on the **left-side face of the vertical stem**, at the very top where it joins the horizontal bar. This is a different face than the one shaded in the reference diagram.
### Key Observations
1. **Consistent Feature:** All five diagrams (reference + four options) depict the same fundamental T-shaped block geometry.
2. **Critical Variable:** The sole differentiating element is the location of the dark blue shaded face on the block's surface.
3. **Spatial Transformation:** The puzzle requires mentally rotating the 3D object to track which face is which through different viewpoints.
4. **Labeling:** The only text present are the single-letter labels (A, B, C, D) identifying the answer choices.
### Interpretation
This diagram is a classic non-verbal reasoning test item, specifically a **3D mental rotation or spatial visualization task**. The objective is to determine which of the four options (A, B, C, D) shows the *exact same object* as the reference diagram, merely turned to a new position.
* **What the data suggests:** The puzzle tests the ability to maintain object constancy across transformations. The correct answer will be the option where the blue-shaded face corresponds to the *same physical face* of the block as in the reference, not just a similarly positioned face in the new view.
* **How elements relate:** The reference sets the rule ("this specific face is blue"). The options present hypotheses. The solver must reject options where the blue face is on a different part of the object's geometry (e.g., the stem instead of the top bar).
* **Analysis of Options:** Based on the detailed analysis, only **Option A** appears to show the blue shading on the same physical face (the end of the top bar) as the reference, just viewed from a different angle. Options B, C, and D all show the blue shading on a face of the vertical stem, which is a different part of the object.
* **Purpose:** Such puzzles are used in aptitude testing, cognitive assessments, and design/engineering evaluations to measure spatial intelligence, a key skill for fields like architecture, mechanical engineering, surgery, and chemistry.
</details>
| |
| Q: | Which figure is a rotation of the object? Select from A, B, C, and D. (A) (B) (C) (D) |
| Answer: | B |
| Reasoning: | The answer is B. |
| Logical Reasoning Skill: | Spatial |
| Required capability: | Diagram |
Table 15: Three samples requiring spatial logical reasoning skills (Case B).
| (Case B) | |
| --- | --- |
|
<details>
<summary>extracted/5714025/figures/Appendix/spat2.png Details</summary>
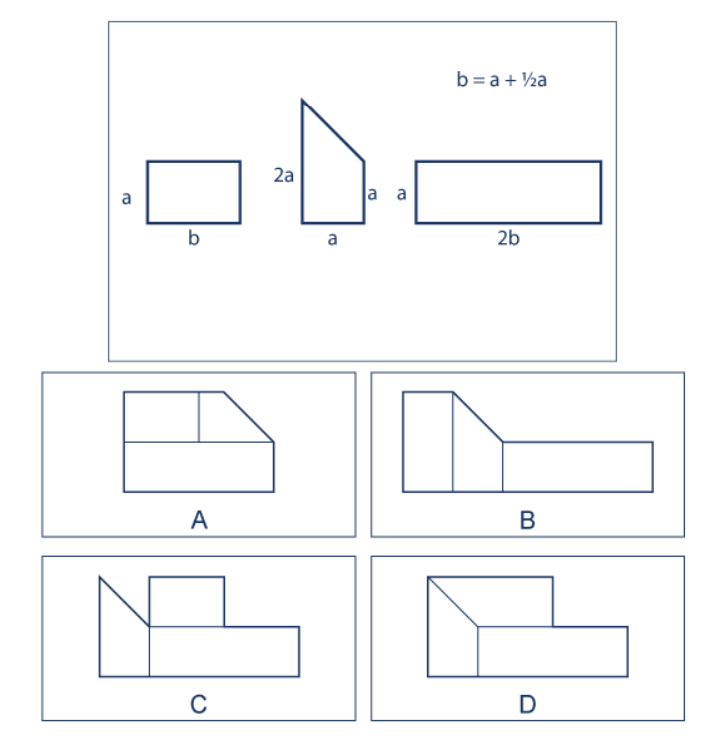
### Visual Description
\n
## Diagram: Geometric Shape Composition
### Overview
The image is a technical diagram illustrating how three basic geometric shapes, defined by variables `a` and `b`, can be combined to form four more complex composite shapes labeled A, B, C, and D. The diagram is presented as a black-and-white line drawing on a white background.
### Components/Axes
The diagram is divided into two main sections:
1. **Top Section (Basic Shapes & Equation):**
* **Equation:** Located in the top-right corner: `b = a + ½a`. This defines the relationship between the two primary length variables.
* **Shape 1 (Left):** A rectangle with height labeled `a` and width labeled `b`.
* **Shape 2 (Center):** A right trapezoid. Its left vertical side is labeled `2a`, its bottom horizontal side is labeled `a`, and its right vertical side is labeled `a`. The top side is a diagonal connecting the top of the `2a` side to the top of the `a` side.
* **Shape 3 (Right):** A rectangle with height labeled `a` and width labeled `2b`.
2. **Bottom Section (Composite Shapes):**
* Four boxes, each containing a composite shape formed by combining the basic shapes from the top section.
* Each composite shape is labeled with a capital letter: **A**, **B**, **C**, and **D**.
### Detailed Analysis
**Basic Shape Definitions:**
* From the equation `b = a + ½a`, we can deduce `b = 1.5a`.
* Therefore, the dimensions of the basic shapes in terms of `a` are:
* **Rectangle 1:** Height = `a`, Width = `1.5a`.
* **Trapezoid:** Left Height = `2a`, Base = `a`, Right Height = `a`.
* **Rectangle 2:** Height = `a`, Width = `2b = 3a`.
**Composite Shape Analysis:**
* **Composite A:** Appears to be formed by placing the trapezoid (Shape 2) on top of Rectangle 1 (Shape 1). The trapezoid's base (`a`) aligns with the top edge of the rectangle. The rectangle's width (`b`) is wider than the trapezoid's base, creating an overhang on the right.
* **Composite B:** Appears to be formed by placing the trapezoid (Shape 2) to the left of Rectangle 2 (Shape 3). The trapezoid's right vertical side (`a`) aligns with the left vertical side of the rectangle (also height `a`). The rectangle extends to the right.
* **Composite C:** Appears to be formed by placing Rectangle 2 (Shape 3) on the bottom. On its left side, the trapezoid (Shape 2) is placed vertically, rotated 90 degrees clockwise so its long side (`2a`) is now horizontal at the bottom. On top of the right portion of Rectangle 2, a smaller rectangle (likely a segment of Rectangle 1) is placed.
* **Composite D:** Appears to be formed by placing the trapezoid (Shape 2) on the left, oriented with its long side (`2a`) vertical. To its right, and aligned at the bottom, is a rectangle whose width appears to be `b` (from Shape 1). The top of this rectangle aligns with the midpoint of the trapezoid's diagonal slope.
### Key Observations
* The diagram is purely geometric and conceptual. It contains no numerical data, charts, or graphs.
* All text is in English, using mathematical variables (`a`, `b`) and labels (A, B, C, D).
* The spatial arrangement is clear: basic components are defined at the top, and their assembled results are shown below.
* The line work is consistent, using solid black lines of uniform weight to define all shapes.
### Interpretation
This diagram serves as a visual puzzle or an exercise in spatial reasoning and geometric composition. It demonstrates how a set of simple shapes with defined proportional relationships (`b = 1.5a`) can be rearranged and combined to create more complex forms.
The core informational content is the **set of rules for composition**:
1. The three basic shapes are the only allowed components.
2. They can be translated (moved), rotated, and placed adjacent to or on top of each other.
3. The composite shapes (A-D) are specific solutions or examples of valid combinations.
The diagram does not provide factual data but rather presents a **geometric system**. Its purpose is likely educational—to teach or test understanding of shape properties, spatial relationships, and the ability to decompose complex figures into simpler, known parts. The absence of color or texture focuses the viewer entirely on form and adjacency.
</details>
| |
| Q: | Which figure can be formed with the given piece? Select from A, B, C, and D. (A) (B) (C) (D) |
| Answer: | C |
| Reasoning: | The answer is C. |
| Logical Reasoning Skill: | Spatial |
| Required capability: | Diagram |
Table 16: Three samples requiring spatial logical reasoning skills (Case C).
| (Case C) | |
| --- | --- |
|
<details>
<summary>extracted/5714025/figures/Appendix/spat3.png Details</summary>
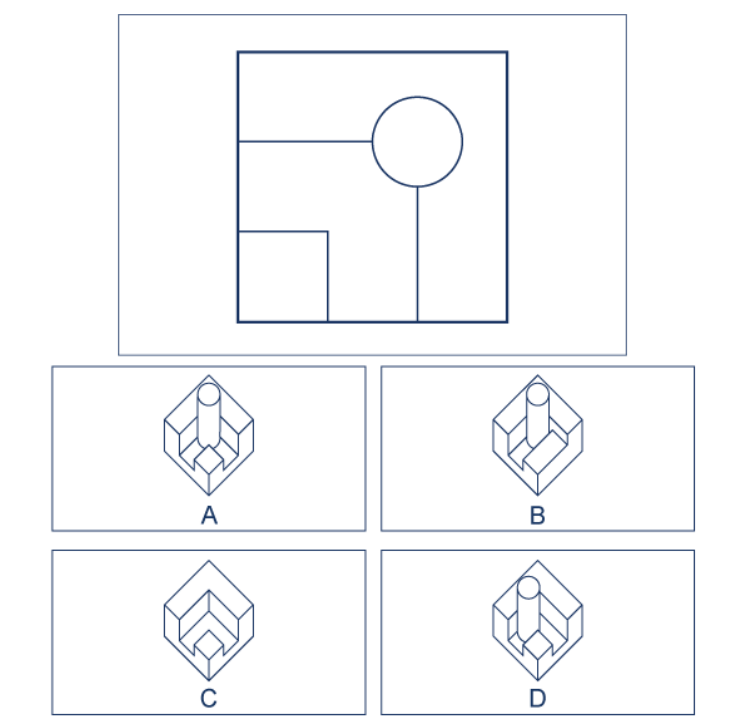
### Visual Description
## Spatial Reasoning Diagram: 2D Plan to 3D Isometric Projection
### Overview
The image presents a spatial reasoning puzzle. It consists of two main sections:
1. A top panel containing a 2D top-down floor plan or layout.
2. A bottom section containing four multiple-choice options (A, B, C, D), each showing a different 3D isometric projection of a structure.
The task implied by the diagram is to identify which of the four 3D structures (A, B, C, or D) correctly corresponds to the given 2D plan.
### Components/Axes
**Top Panel (2D Plan):**
* **Frame:** A large square border.
* **Internal Layout:** A smaller, centered square representing the footprint of a structure.
* **Elements within the footprint:**
* A vertical line dividing the left third from the right two-thirds.
* A horizontal line dividing the top third from the bottom two-thirds.
* A **circle** located in the top-right quadrant formed by the intersecting lines.
* A **square** located in the bottom-left quadrant.
* The lines suggest internal walls or divisions.
**Bottom Panel (3D Options):**
* **Four labeled boxes:** Each contains an isometric drawing of a 3D block structure.
* **Labels:** The letters **A**, **B**, **C**, and **D** are centered below each respective box.
* **Common 3D Elements:** All structures are based on a cube-like base with internal divisions and protruding features. The key differentiating features are:
* A **cylindrical column** (corresponding to the circle in the 2D plan).
* A **rectangular block** (corresponding to the square in the 2D plan).
* The arrangement and presence of internal walls.
### Detailed Analysis
**Analysis of the 2D Plan:**
* The plan shows a square footprint.
* It is divided into four quadrants by a vertical line (left/right) and a horizontal line (top/bottom).
* The **circle** is in the **top-right quadrant**.
* The **square** is in the **bottom-left quadrant**.
* The lines imply that the circle and square are separate features within their respective quadrants, connected to the dividing walls.
**Analysis of the 3D Options:**
* **Option A:**
* Shows a cylindrical column in the **back-right** position (matches top-right in isometric view).
* Shows a rectangular block in the **front-left** position (matches bottom-left in isometric view).
* Has internal walls that appear to create separate compartments for the column and the block.
* **Trend/Verification:** The column is tall and cylindrical. The block is low and rectangular. Their positions align with the 2D plan's quadrants.
* **Option B:**
* Shows a cylindrical column in the **back-right** position.
* Shows a rectangular block in the **front-right** position.
* **Mismatch:** The block is in the wrong quadrant (front-right instead of front-left).
* **Option C:**
* Shows **no cylindrical column**.
* Shows a rectangular block in the **front-left** position.
* **Mismatch:** The prominent circular feature from the 2D plan is entirely absent.
* **Option D:**
* Shows a cylindrical column in the **back-right** position.
* Shows a rectangular block in the **front-left** position.
* **Subtle Difference:** Compared to Option A, the internal wall configuration appears slightly different. In Option A, the wall seems to run from the front of the column to the side of the block. In Option D, the wall configuration is less clear but may connect differently. Option A's wall structure more cleanly separates the two features as implied by the 2D plan's quadrant lines.
### Key Observations
1. **Primary Matching Features:** The correct 3D model must have a cylinder in the back-right (top-right) and a rectangular block in the front-left (bottom-left). This eliminates Options B and C.
2. **Critical Differentiator:** The deciding factor between the plausible Options A and D is the precise configuration of the internal walls. The 2D plan shows clean quadrant divisions. Option A's isometric drawing depicts internal walls that most logically correspond to these divisions, creating distinct spaces for the column and the block. Option D's internal geometry is more ambiguous and less directly mapped.
3. **Spatial Translation:** The puzzle tests the ability to translate a 2D top-down view into a 3D isometric perspective, understanding that "top-right" on the plan becomes "back-right" in the isometric view, and "bottom-left" becomes "front-left".
### Interpretation
This diagram is a classic spatial reasoning test, likely used in aptitude assessments for fields like engineering, architecture, or design. It evaluates the ability to mentally manipulate and rotate objects in three dimensions based on two-dimensional information.
The data (the visual information) suggests that **Option A is the correct answer**. It is the only model that accurately places both key features (cylinder and block) in their correct quadrants *and* presents an internal wall structure that most faithfully represents the quadrant divisions shown in the 2D plan. The anomaly in Option D is its slightly less clear internal wall mapping, making it a less precise translation. The exercise demonstrates that successful 3D reconstruction requires not just matching major features, but also accurately interpreting the relationships and divisions between them.
</details>
| |
| Q: | To which object does the given top view correspond? Select from A, B, C, and D. (A) (B) (C) (D) |
| Answer: | A |
| Reasoning: | The answer is A. |
| Logical Reasoning Skill: | Spatial |
| Required capability: | Diagram |
Table 17: Three samples requiring mechanical logical reasoning skills (Case A).
| (Case A) | |
| --- | --- |
|
<details>
<summary>extracted/5714025/figures/Appendix/mech1.png Details</summary>
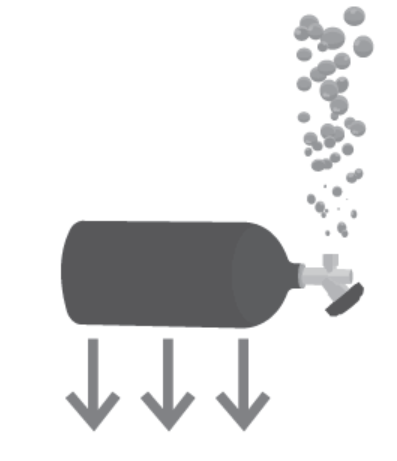
### Visual Description
## Diagram: Pressurized Gas Cylinder with Release Valve
### Overview
The image is a grayscale schematic diagram illustrating a horizontal cylindrical tank with a valve assembly on its right side. The diagram depicts gas being released from the valve, visualized as a stream of bubbles rising upward, while three arrows below the tank indicate a downward force or direction. There are no textual labels, axis titles, or numerical data present in the image.
### Components/Axes
* **Primary Component:** A dark gray, horizontally oriented cylindrical tank with rounded ends.
* **Valve Assembly:** Attached to the right end of the tank. It consists of a lighter gray fitting and a dark, disc-shaped handle or knob.
* **Gas Release Visualization:** A cluster of light gray circles (bubbles) of varying sizes emanates from the valve outlet and rises vertically toward the top-right corner of the image.
* **Directional Indicators:** Three identical, downward-pointing arrows are positioned in a horizontal row directly beneath the tank. They are evenly spaced and rendered in a medium gray tone.
* **Background:** Plain white.
### Detailed Analysis
* **Spatial Grounding:**
* The tank is centered vertically and occupies the middle-left to center of the frame.
* The valve is attached to the tank's rightmost point.
* The bubble stream originates at the valve outlet and extends upward, with bubbles becoming slightly more dispersed as they rise.
* The three downward arrows are aligned horizontally, centered beneath the tank's body.
* **Component Relationships:** The diagram shows a clear cause-and-effect relationship: the valve (control point) is the source of the gas release (bubbles). The downward arrows are spatially associated with the tank itself, not the gas flow.
* **Visual Trends:** The bubble stream shows a trend of expansion and dispersion as it moves away from the source (valve). The arrows are static and uniform, indicating a constant, directional force.
### Key Observations
1. **Absence of Text:** The diagram contains zero textual information—no labels, keys, scales, or annotations.
2. **Symbolic Representation:** The bubbles are a symbolic, not literal, representation of gas release, common in technical illustrations to indicate fluid or gas flow.
3. **Force Indication:** The three downward arrows are a standard symbolic representation of a distributed load, weight, gravity, or downward force acting on the tank.
4. **Monochromatic Scheme:** The use of grayscale shades (dark tank, medium arrows, light bubbles) creates clear visual separation between components without relying on color.
### Interpretation
This diagram is a conceptual illustration, not a data-driven chart. It communicates a physical principle or system state rather than quantitative information.
* **What it Demonstrates:** The image depicts a pressurized gas cylinder in a state of release. The rising bubbles symbolize the escape of gas (e.g., during venting, purging, or a leak) from the cylinder's valve. The downward arrows most likely represent the **weight of the cylinder itself** or the **force of gravity** acting upon it. An alternative interpretation could be that the arrows indicate the direction of mounting or installation (e.g., the tank is secured from below).
* **Relationships:** The core relationship is between the contained substance (implied gas inside the tank), its release mechanism (the valve), and an external force (gravity/weight). The diagram isolates these elements to explain a basic concept in fluid power, thermodynamics, or mechanical systems.
* **Notable Anomalies:** The primary "anomaly" is the complete lack of labels. For a technical document, this diagram would be considered incomplete without accompanying text to define the components (e.g., "CO2 Tank," "Vent Valve," "Weight Force") and the specific process being illustrated. Its utility is purely as a supporting visual for a verbal explanation.
</details>
| |
| Q: | A non-pressurised cylindrical metal tank filled with air is submerged underwater. As the air escapes, the tank gradually moves deeper underwater. Which statement provides the best reason for this motion? Select from A, B, C, D, and E. (A) The bubbles provide a downward thrust on the tank (B) The metal increases in density so it gets heavier (C) The bubbles lower the density of the water which lowers its buoyancy (D) Water replaces the air in the tank which makes it heavier (E) Impossible to tell |
| Answer: | D |
| Reasoning: | As air escapes the available space is quickly replaced with water, so the tank’s density becomes the same as that of the water and with the added weight and density of the tank itself continues to sink. |
| Logical Reasoning Skill: | Mechanical |
| Required capability: | Diagram |
Table 18: Three samples requiring mechanical logical reasoning skills (Case B).
| (Case B) | |
| --- | --- |
|
<details>
<summary>extracted/5714025/figures/Appendix/mech2.png Details</summary>
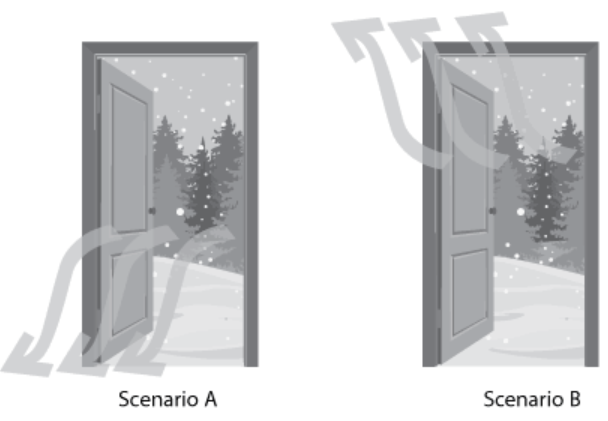
### Visual Description
## Comparative Diagram: Airflow Through an Open Door in Two Scenarios
### Overview
The image is a technical diagram presented in grayscale, illustrating two distinct airflow patterns through an open door leading to a snowy exterior. It is divided into two side-by-side panels labeled "Scenario A" (left) and "Scenario B" (right). The diagram visually contrasts how air moves into or out of a building under different conditions.
### Components/Axes
* **Primary Components:** Each panel contains an identical illustration of an open interior door (hinged on the left, opening inward) framing a view of a snowy landscape with pine trees.
* **Flow Indicators:** Large, curved, light-gray arrows are superimposed on each scene to indicate the direction of airflow.
* **Labels:** The text "Scenario A" is centered below the left panel. The text "Scenario B" is centered below the right panel.
* **Spatial Layout:** The two scenarios are presented with equal visual weight, separated by a central vertical gap. The door and exterior scene are positioned in the upper two-thirds of each panel, with the label in the lower third.
### Detailed Analysis
**Scenario A (Left Panel):**
* **Arrow Placement & Direction:** Two large, curved arrows originate from the bottom-left corner of the image (outside the door frame). They sweep upward and to the right, passing through the lower half of the open doorway and into the room.
* **Visual Trend:** The arrows clearly depict a flow of air **entering** the interior space from the outside, moving from a lower exterior point to a higher interior point.
**Scenario B (Right Panel):**
* **Arrow Placement & Direction:** Two large, curved arrows originate from the upper-right area inside the room (to the right of the door frame). They sweep downward and to the left, passing through the upper half of the open doorway and exiting to the outside.
* **Visual Trend:** The arrows clearly depict a flow of air **exiting** the interior space to the outside, moving from a higher interior point to a lower exterior point.
### Key Observations
1. **Symmetrical Contrast:** The arrow patterns in Scenarios A and B are near-perfect mirror images of each other, emphasizing opposite airflow directions.
2. **Vertical Stratification:** In Scenario A, the inflow is shown at the **bottom** of the doorway. In Scenario B, the outflow is shown at the **top** of the doorway. This suggests a model based on air density differences (cold air sinking, warm air rising).
3. **Environmental Context:** The consistent snowy exterior in both panels establishes a cold outdoor environment, which is critical for interpreting the thermal dynamics implied by the airflow.
### Interpretation
This diagram is a classic illustration of **stack effect** or **thermal draft** in building science. It demonstrates how temperature differences between indoor and outdoor air create pressure differentials that drive airflow through an opening.
* **Scenario A** represents **cold air infiltration**. The denser, colder outdoor air flows inward at the bottom of the opening, displacing warmer indoor air.
* **Scenario B** represents **warm air exfiltration**. The less dense, warmer indoor air rises and flows outward at the top of the opening.
* **Relationship:** The two scenarios are not mutually exclusive but often occur simultaneously in a continuous cycle: cold air enters low (A), is heated, rises, and exits high (B). This cycle is a major source of heat loss in buildings during cold weather.
* **Anomaly/Note:** The diagram simplifies the phenomenon for clarity. In reality, the airflow paths are more diffuse, and pressure equalization involves the entire building envelope, not just a single door. The perfect symmetry is a pedagogical tool.
**Language Declaration:** All text within the image is in English.
</details>
| |
| Q: | It is a cold winter outside and a well-insulated house has its heater turned on. The front door is opened and cold air rushes in. If the wind speed outside is very low, how would the cold air enter the house? Select from A, B, C, D, and E. (A) Scenario A, the cold air will flow towards the floor (B) Scenario B, the cold air will flow towards the ceiling (C) A combination of A and B (D) The cold air will not enter the house (E) Impossible to tell |
| Answer: | A |
| Reasoning: | Cold air sinks, whereas hot air rises. The house and the air inside it are warmer than the outside air temperature, so if these two systems (house and outside) were to be suddenly connected (door opening) the cold air would sink and the hot air would sit above the cold air until the heat transferred between the two. |
| Logical Reasoning Skill: | Mechanical |
| Required capability: | Diagram |
Table 19: Three samples requiring mechanical logical reasoning skills (Case C).
| (Case C) | |
| --- | --- |
|
<details>
<summary>extracted/5714025/figures/Appendix/mech3.png Details</summary>
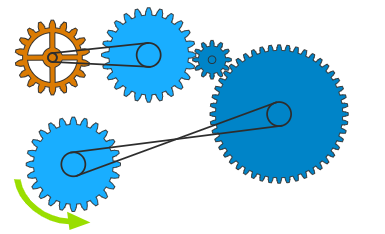
### Visual Description
## Mechanical Diagram: Interconnected Gear Train
### Overview
The image is a technical diagram illustrating a mechanical gear train system. It depicts five gears of varying sizes and colors, interconnected by two belts, demonstrating the transmission of rotational motion and torque through a combination of direct meshing and belt drives. There is no textual information (labels, titles, or annotations) present in the image.
### Components/Axes
The diagram consists of the following components, positioned as described:
1. **Gears (5 total):**
* **Gear A (Driver):** A medium-sized, orange gear located in the **top-left quadrant**. It has a central hub and visible teeth.
* **Gear B:** A large, light blue gear positioned to the **right of Gear A**, in the **upper-center area**. It is connected to Gear A via a belt.
* **Gear C:** A very small, light blue gear located **directly to the right of Gear B**, near the **top edge**. It meshes directly with the teeth of Gear B.
* **Gear D:** The largest gear in the system, a dark blue gear situated in the **center-right area**. It meshes directly with the teeth of Gear C.
* **Gear E:** A medium-sized, light blue gear located in the **bottom-left quadrant**. It is connected to Gear D via a second belt.
2. **Belts (2 total):**
* **Belt 1:** A black, looped belt connecting the central hub of **Gear A (orange)** to the central hub of **Gear B (light blue)**.
* **Belt 2:** A black, looped belt connecting the central hub of **Gear D (dark blue)** to the central hub of **Gear E (light blue)**.
3. **Directional Indicator:**
* A curved, green arrow is positioned **below and to the left of Gear E**. It points in a **clockwise direction**, indicating the intended or resulting direction of rotation for Gear E (and likely the system's output).
### Detailed Analysis
* **Power Flow Path:** The system demonstrates a compound gear train. The assumed input is at **Gear A (orange)**. Motion is transmitted via **Belt 1** to **Gear B**. **Gear B** then drives **Gear C** through direct tooth meshing. **Gear C** drives the large **Gear D** through direct meshing. Finally, **Gear D** transmits motion via **Belt 2** to **Gear E**, which is indicated as the output by the green arrow.
* **Gear Sizes & Implied Ratios:** The gears have distinct sizes, which would create specific gear ratios affecting speed and torque at each stage.
* Gear A (medium) to Gear B (large): This belt drive likely results in a **speed reduction** and **torque increase**.
* Gear B (large) to Gear C (very small): This direct meshing creates a significant **speed increase** and **torque reduction**.
* Gear C (very small) to Gear D (very large): This direct meshing creates a very significant **speed reduction** and **torque increase**.
* Gear D (very large) to Gear E (medium): This belt drive likely results in a moderate **speed increase** and **torque reduction**.
* **Spatial Relationships:** The layout is asymmetric. The input (Gear A) and output (Gear E) are on the left side, while the central processing gears (B, C, D) are clustered on the right. The belts create diagonal connections across the diagram.
### Key Observations
1. **Hybrid Transmission:** The system uses both **belt drives** (for connecting non-adjacent shafts, allowing for flexibility and potential slip) and **direct gear meshing** (for precise, positive drive between closely spaced shafts).
2. **Extreme Gear Ratio Stages:** The transition from the very small **Gear C** to the very large **Gear D** represents the most dramatic change in the system, implying a major functional stage for torque multiplication or speed reduction.
3. **Color Coding:** Gears are color-coded (orange vs. shades of blue), which may indicate different materials, functions (e.g., driver vs. driven), or simply serve for visual distinction. The two belts are consistently black.
4. **Directional Consistency:** The green arrow indicates a clockwise output. Tracing the motion: a clockwise rotation of Gear A would turn Gear B clockwise via the belt. Gear B turning clockwise would drive Gear C counter-clockwise. Gear C counter-clockwise would drive Gear D clockwise. Gear D clockwise would drive Gear E counter-clockwise via the second belt. **Therefore, the green arrow (clockwise) contradicts the expected mechanical output (counter-clockwise) based on standard gear and belt drive principles.** This is a critical anomaly.
### Interpretation
This diagram is a schematic representation of a mechanical power transmission system, likely used for educational or conceptual design purposes. It demonstrates how rotational motion can be routed, transformed in speed and torque, and directed through a combination of mechanical elements.
The primary **anomaly** is the direction of the green output arrow. Based on the physical connections shown, the output gear (E) should rotate **counter-clockwise** if the input gear (A) rotates clockwise. The clockwise arrow suggests either:
* The input rotation is intended to be counter-clockwise.
* There is an error in the diagram's annotation.
* An additional, unshown gear or mechanism reverses the direction before the output.
The system's design prioritizes a compact layout on the right side for the high-torque, low-speed stage (Gear D) while using belts to bridge the distance to the input and output. The use of a very small gear (C) driving a very large gear (D) is a classic method for achieving a large mechanical advantage, converting high-speed, low-torque input into low-speed, high-torque output at Gear D, which is then moderated by the final belt drive to Gear E.
</details>
| |
| Q: | In which direction does the orange gear rotate? Select from A, B, and C. (A) Clockwise (B) Counterclockwise (C) No rotation |
| Answer: | A |
| Reasoning: | The correct answer is clockwise. |
| Logical Reasoning Skill: | Mechanical |
| Required capability: | Diagram |
## Appendix B Examples of Different LogicVista Capabilities Data
Table 20: Three samples of diagram, OCR, and mixed LogicVista data (Case A).
| (Case A) | |
| --- | --- |
|
<details>
<summary>extracted/5714025/figures/Appendix/diagramex.png Details</summary>
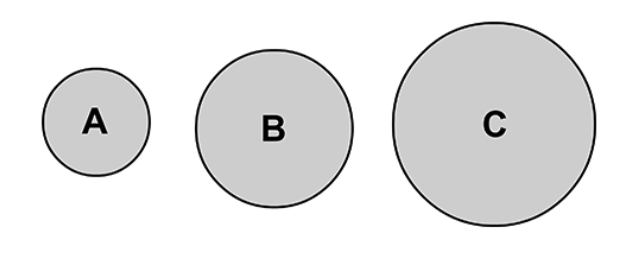
### Visual Description
## Diagram: Relative Size Comparison of Three Circles
### Overview
The image displays a simple, non-quantitative diagram consisting of three circles arranged horizontally on a plain white background. The circles are labeled sequentially and increase in size from left to right, illustrating a clear progression or comparison of scale.
### Components/Axes
* **Elements:** Three circles.
* **Labels:** Each circle contains a single, bold, black capital letter centered within it.
* Left circle: **A**
* Center circle: **B**
* Right circle: **C**
* **Visual Properties:**
* **Fill Color:** All circles are filled with a uniform light gray.
* **Outline:** Each circle has a thin, solid black border.
* **Arrangement:** The circles are aligned along a horizontal axis. Circle A is positioned on the far left, Circle B in the center, and Circle C on the far right. There is consistent, moderate spacing between them.
### Detailed Analysis
* **Size Progression:** The primary data conveyed is relative size.
* **Circle A:** The smallest circle.
* **Circle B:** Visibly larger than Circle A.
* **Circle C:** The largest circle, significantly bigger than both A and B.
* **Trend Verification:** The visual trend is a monotonic increase in diameter from left to right (A < B < C). There are no decreases or fluctuations in the progression.
* **Spatial Grounding:** The legend (the labels A, B, C) is embedded directly within each corresponding data point (circle). The positioning is unambiguous: the label is always at the geometric center of its circle.
### Key Observations
1. **Uniform Styling:** All circles share identical color, fill, and outline style, ensuring the only variable being compared is size.
2. **Clear Hierarchy:** The arrangement and size difference create an immediate visual hierarchy, suggesting a sequence (e.g., small, medium, large) or a ranked order.
3. **Lack of Quantification:** The diagram contains no numerical scales, axes, or measurement indicators. The comparison is purely qualitative and relative.
### Interpretation
This diagram is a fundamental visual tool for demonstrating **relative scale, growth, or hierarchy** without specifying exact metrics. The progression from A to B to C suggests a logical sequence, such as stages of development, levels of importance, or categories of magnitude. The use of identical styling isolates size as the sole differentiating factor, making the comparison direct and unambiguous. In a technical context, this could represent concepts like:
* **System Components:** Where C is the core module, B a secondary service, and A a peripheral utility.
* **Data Volumes:** Illustrating orders of magnitude difference between datasets.
* **Process Steps:** Showing the expanding scope or impact from an initial step (A) to a final outcome (C).
The absence of specific data indicates the diagram's purpose is conceptual illustration rather than precise data presentation. Its power lies in its simplicity and immediate comprehensibility.
</details>
| |
| Q: | Which ball is the heaviest? Select from A, B, C, and D. (A) A (B) B (C) C (D) CAN NOT SAY |
| Answer: | D |
| Reasoning: | The correct answer is D. |
| Logical Reasoning Skill: | Mechanical |
| Required capability: | Diagram |
Table 21: Three samples of diagram, OCR, and mixed LogicVista data (Case B).
| (Case B) | |
| --- | --- |
|
<details>
<summary>extracted/5714025/figures/Appendix/ocrex.png Details</summary>

### Visual Description
## Text-Based Question: Buoyancy Inquiry
### Overview
The image displays a single line of text presenting a question related to the physical property of buoyancy. There are no accompanying visual elements, charts, diagrams, or multiple-choice options visible within the frame. The image consists solely of this textual query on a plain, light-colored background.
### Components/Axes
* **Primary Text:** "Which of these objects will not float on water?"
* **Text Positioning:** The text is horizontally centered within the image frame. It is positioned in the vertical center of the visible area.
* **Font:** A standard, sans-serif typeface (likely Arial or Helvetica) in a dark color (black or dark gray).
* **Background:** A uniform, light-colored (likely white or off-white) background with no discernible texture, gradient, or other graphical elements.
### Detailed Analysis
The image contains only the following transcribed text:
> "Which of these objects will not float on water?"
There are no data points, numerical values, categories, legends, axes, or other graphical components to analyze. The image does not present the list of objects referenced by the phrase "these objects."
### Key Observations
1. **Incomplete Context:** The question is posed without the necessary context (the list of objects) to answer it. This suggests the image is likely a cropped section of a larger document, such as a quiz, worksheet, or textbook page.
2. **Educational Context:** The phrasing is typical of a basic science or physics question aimed at testing understanding of density and buoyancy.
3. **Visual Simplicity:** The design is purely functional, with no decorative elements, intended solely to present the textual question.
### Interpretation
This image is a fragment of an educational assessment or instructional material. Its purpose is to prompt a learner to apply knowledge about the density of common objects relative to water. The question implies a set of objects was provided elsewhere (e.g., in a preceding paragraph, a list, or adjacent images), and the task is to identify which one(s) have a density greater than water (1 g/cm³), causing them to sink.
The absence of the object list in the image itself means the core factual data required to answer the question is missing. Therefore, the image serves only to present the interrogative statement. To derive meaning, one must infer the missing context: the question is designed to evaluate understanding of the principle that objects denser than water will not float.
</details>
| |
| Q: | Select from A, B, C, and D. (A) banana (B) scissors (C) empty plastic soda bottle (D) wooden pencil |
| Answer: | B |
| Reasoning: | The correct answer is B because scissors have metal and are most likely to sink. |
| Logical Reasoning Skill: | Deductive |
| Required capability: | OCR |
Table 22: Three samples of diagram, OCR, and mixed LogicVista data (Case C).
| (Case C) | |
| --- | --- |
|
<details>
<summary>extracted/5714025/figures/Appendix/mixedex.png Details</summary>
### Visual Description
## Bar Chart and Data Table: Legal Sector IT Spending and Consultancy Income
### Overview
The image contains two distinct data visualizations related to the legal sector's IT expenditure. The top section is a grouped bar chart titled "Legal Sector IT Spending (£ millions)" showing spending across three IT categories over five years. The bottom section is a data table titled "Two Legal Sector IT Firms Income for Consultancy Services (10,000s)" comparing the income of two specific firms over four years.
### Components/Axes
**Bar Chart:**
* **Title:** Legal Sector IT Spending (£ millions)
* **Y-Axis:** Numerical scale from 0 to 50, with increments of 10. Represents spending in millions of British pounds (£).
* **X-Axis:** Categorical labels for five time periods: "Year 1", "Year 2", "Year 3", "Year 4", and "Year 5 projection".
* **Legend:** Located at the top center, below the title.
* Orange square: "IT Hardware"
* Blue square: "IT Software"
* Dark gray square: "IT Consulting"
**Data Table:**
* **Title:** Two Legal Sector IT Firms Income for Consultancy Services (10,000s)
* **Structure:** A 5-row by 3-column table.
* **Column Headers (from left to right):** (Empty cell), "Make Fit Ltd", "Pure Gap Plc".
* **Row Labels (from top to bottom):** "Year 1", "Year 2", "Year 3", "Year 4".
* **Unit:** Income values are in tens of thousands (10,000s).
### Detailed Analysis
**Bar Chart Data (Approximate Values in £ millions):**
* **Year 1:** IT Hardware ≈ 30, IT Software ≈ 20, IT Consulting ≈ 10.
* **Year 2:** IT Hardware ≈ 45, IT Software ≈ 30, IT Consulting ≈ 20.
* **Year 3:** IT Hardware ≈ 35, IT Software ≈ 15, IT Consulting ≈ 15.
* **Year 4:** IT Hardware ≈ 40, IT Software ≈ 25, IT Consulting ≈ 15.
* **Year 5 (projection):** IT Hardware ≈ 45, IT Software ≈ 30, IT Consulting ≈ 20.
**Data Table Content (Income in 10,000s):**
| | Make Fit Ltd | Pure Gap Plc |
| :--- | :--- | :--- |
| **Year 1** | 290 | 230 |
| **Year 2** | 180 | 310 |
| **Year 3** | 260 | 300 |
| **Year 4** | 320 | 290 |
### Key Observations
1. **IT Hardware Dominance:** IT Hardware is consistently the largest spending category across all five years, with peaks in Year 2 and the Year 5 projection (both ≈ £45m).
2. **Software Volatility:** IT Software spending shows more fluctuation, with a notable dip in Year 3 (≈ £15m) before recovering.
3. **Consulting Stability:** IT Consulting spending is the lowest and most stable category, hovering between £10m and £20m.
4. **Firm Income Divergence:** The two consultancy firms show contrasting income trends. Make Fit Ltd's income dips sharply in Year 2 (180) before recovering and growing to its highest point in Year 4 (320). Pure Gap Plc's income peaks in Year 2 (310) and then shows a slight, gradual decline.
5. **Inverse Relationship (Year 2):** In Year 2, when overall IT Consulting sector spending increased (from £10m to £20m), Make Fit Ltd's income fell significantly, while Pure Gap Plc's income rose sharply.
### Interpretation
The data suggests a legal sector IT market where hardware investment is the primary and growing expenditure, possibly indicating ongoing infrastructure modernization. The volatility in software spending could reflect project-based purchasing cycles or shifting technological priorities.
The consultancy income table provides a micro-level view within the broader "IT Consulting" spending category. The inverse performance of the two firms in Year 2 is a critical anomaly. It implies that increased sector-wide spending on consulting does not benefit all firms equally; market share may be shifting, or firms may be specializing in different, non-competing services. Make Fit Ltd's recovery and growth by Year 4 suggest a successful strategic adjustment after its Year 2 slump. Pure Gap Plc's slight decline after its Year 2 peak could indicate market saturation for its specific service offerings or increased competition.
**Relationship Between Charts:** While the bar chart shows overall sector spending on IT Consulting rising from Year 1 to Year 2 (from £10m to £20m), the table reveals this aggregate growth masked a significant redistribution of income between two major players. This highlights the importance of examining both macro-sector trends and micro-firm performance to understand market dynamics fully. The unit difference (£ millions vs. 10,000s) means the firms' incomes represent a small but measurable portion of the total sector consulting spend.
</details>
| |
| Q: | Which of the following statements is false regarding legal sector spending between Year 4 and projected Year 5? Select from A, B, C, D, and E. (A) IT consulting will increase by 35 million. (B) IT consulting will match that of year 2. (C) IT software will exceed IT consulting. (D) Spending on IT hardware will decline. (E) None of these. |
| Answer: | D |
| Reasoning: | Step 1- Check in turn whether each statement is true or false: a) The projected spend on IT consulting is projected to increase by 35 million. Option A is true. b) The projected spend on IT consulting is 320 million, which matches year 2. Option B is true. c) The projected spend on IT software is 330 million and for IT consulting it is 320 million. Option C is true. d) There are increases projected for IT hardware, IT software, and consulting, therefore “spending on IT hardware will decline” is not true. The option for D is false. e) We see that option D is false, so E cannot be the correct answer. Thus the correct answer is (D) Spending on IT hardware, software, and consulting is projected to decline. |
| Logical Reasoning Skill: | Numerical |
| Required capability: | Diagram, OCR |