# Virtue Ethics For Ethically Tunable Robotic Assistants
**Authors**: Rajitha Ramanayake, Vivek Nallur
> 0000-0001-9903-0493
> 0000-0003-0447-4150
institutetext: University College Dublin, Belfield, Dublin. email: rajitha.ramanayakemahantha@ucdconnect.ie, email: vivek.nallur@ucd.ie
## Abstract
The common consensus is that robots designed to work alongside or serve humans must adhere to the ethical standards of their operational environment. To achieve this, several methods based on established ethical theories have been suggested. Nonetheless, numerous empirical studies show that the ethical requirements of the real world are very diverse and can change rapidly from region to region. This eliminates the idea of a universal robot that can fit into any ethical context. However, creating customised robots for each deployment, using existing techniques is challenging. This paper presents a way to overcome this challenge by introducing a virtue ethics inspired computational method that enables character-based tuning of robots to accommodate the specific ethical needs of an environment. Using a simulated elder-care environment, we illustrate how tuning can be used to change the behaviour of a robot that interacts with an elderly resident in an ambient-assisted environment. Further, we assess the robot’s responses by consulting ethicists to identify potential shortcomings.
Keywords: Robot personality Virtue ethics Pro-social rule bending Elder-care robots Machine ethics
## 1 Introduction
Ethical behaviour represents a crucial aspect of Human-Robot Interaction (HRI) in real-world applications. It is commonly agreed that the robots that share their working environments with humans, such as those that provide care, assistance, transportation, or companionship to humans, must adhere to and reason about their behaviour within the ethical framework of the community around them [50]. This is especially true in the care domain as care robots interact with vulnerable populations that require special care and protection [43]. Consequently, many ways have been proposed to implement ethical behaviour in robots. Many proposed techniques adopt a top-down approach, based on ethical theories such as deontology [2] or consequentialism [44] (e.g., [11, 47, 49]). A relatively small number of proposed methods use a bottom-up approach where they utilise learning algorithms such as reinforcement learning, that enable the robots to learn the ethical behaviours from the environment (e.g., [45, 1]). Another set of implementations uses a hybrid approach where they integrate both top-down and bottom-up methods in different parts of their ethical framework (e.g., [3, 10, 52]).
Studies have shown that the ethical requirements of the real world vary significantly, with subtle variations within different areas of the same region [9]. A potential solution to this challenge is to design tailored ethical governors for robots that suit each deployment scenario.
A possible way to address this challenge is to implement value-oriented moral character in autonomous machines. This idea has been theoretically explored in literature [19, 35, 20]. This paper introduces an implementation of an ethical reasoning architecture inspired by virtue ethics. It enables character-based tuning for a system to align with the ethical demands of its environment. We demonstrate this capability through a virtual simulation of an assistive elder-care robot confronted with an ethically charged scenario.
The rest of the paper is organised as follows. Section 2 discusses existing implementations of ethics in robots and the need for ethical tuning. Section 3 discusses the underlying philosophical aspects of the notion of character in robots, and how it can be used in ethical tuning. Section 4 presents the computational architecture used in the implementation and briefly discusses the simulation environment. Section 5 outlines the design of the experiment, analyses the behaviour observed in the simulations, and presents the evaluation of this behaviour by ethicists. Section 6 discusses results and the recommendations for real-world implementations of this computational architecture.
## 2 Current Approaches and Ethical Tuning
The field of Machine Ethics acknowledges that human value alignment is an important part of any robotic application that interfaces with humans in social contexts [41]. Some researchers argue that there is no value in developing explicitly ethical agents [51], and many others disagree [18, 48]. Large-scale human preference studies such as ‘The moral machine experiment’ [9] bring forth an interesting finding, which is that the expected behaviour of a robot, even for a minimal ethical dilemma, changes throughout the world according to the culture and the environment the robot is situated in. This is also discussed in the elder-care robots domain. Specifically, the behavioural expectations of the same robot in ethically charged scenarios can vary depending on the context in which it is used [38]. This suggests that no single behaviour is universally appropriate, as imposing a majority’s values on a group with a distinct cultural ethos can be considered morally incorrect.
Three approaches have been used to align human ethical values with autonomous systems, namely; Top-down, Bottom-up, and Hybrid [50]. Many generalist ethical theories of the world follow a top-down approach to ethics. This means that almost all the systems that are based on traditional ethical theories, such as deontology, legal codes, and consequentialist ethics use the top-down approach to machine-implemented ethics. In this method, the system designers encode the ethical or unethical behaviour into the robot at the design time (e.g., [49, 13, 46, 21, 11, 47]). A bottom-up approach to system design involves creating social and cognitive processes that interact with each other and the environment. The system is expected to learn ethical (or unethical) behaviour from these interactions or from supervision (e.g., [1, 27, 24, 45, 34]). Therefore, the system does not rely on any ethical theory to guide its behaviour. The hybrid approach tries to combine the flexibility and evolving nature of the bottom-up approach with the value, duty and principle-oriented nature of the top-down approach to create a better, more reliable system (e.g., [8, 3, 10, 52]).
A top-down approach requires a set of general rules, that can cover all possible scenarios in its domain. However, when the environment is complex and has many variables, like elder-care environments, finding or creating such a rule-set at the design time can be challenging or even impossible [33, 35]. Therefore, many systems that use a top-down approach are designed for specific deployment, not for general use. On the other hand, any implementation that uses the bottom-up approach requires complex cognitive and social process models, a large amount of reliable and accurate data, and a comprehensive knowledge model of the world to learn an intricate social construct such as ethics [40]. These systems are capable of adjusting to local behaviour peculiarities by learning online [41, 45]. However, the inherent lack of a thesis on the definition of ethical behaviour in these systems makes it impossible to ensure that the behaviour learned is ethical. The hybrid approach is crucial when a single strategy is insufficient to meet all the ethical demands in a machine’s operational context [8]. However, successfully integrating the attributes of both strategies so that they complement and strengthen each other without causing any conflict or compromise is a challenge.
These limitations of the existing techniques make it challenging to localise robots to the ethical needs of a specific deployment. For example, Cenci et al. [13] suggest that localising an autonomous vehicle guided by an ethical governor, that uses a rule book, needs nearly 200 rules that are ordered in a few different ways. Furthermore, they also suggest that the rule-making process should involve a nationwide public consultation with informed dialogue. Localising this way across many regions and staying abreast of evolving ethical standards over time presents significant challenges. On the other hand, bottom-up approaches with online learning are more capable of this adaptation. However, as previously mentioned, the ethicality of behaviour cannot be guaranteed with bottom-up learning. Consequently, there is a possibility that localisation may introduce erroneous behaviours into the system. Therefore, to ensure reliability after localisation, systems should undergo extensive testing in various simulated scenarios before being deployed.
The drawbacks of the two methods for localisation discussed are significant, in terms of both cost and reliability. The rule-making process and testing in simulated environments would consume a lot of resources, which may not be economically viable. Moreover, there is no guarantee that the system would perform as expected in a real-world situation that may not have been modelled or tested. Hence, the creators of these robots face a dilemma: either they customise them for each specific deployment or they avoid any ethical claims or assessments. The first option would raise the cost of these robots, potentially reducing their accessibility to those who might benefit most. The second option could lead to numerous ethical concerns upon deployment in care settings [43, 19].
The hybrid approach has the advantage of having a mix of the above approaches. It can use the top-down imposed ethical principles as a foundation for its behaviour, and learn from bottom-up knowledge to identify the particularities of the ethical expectations of the environment. This notion heavily resonates with the virtue ethics philosophical tradition [50]. Many authors argue that virtue ethics can offer a more flexible way of implementing ethics [19, 20, 50]. Nevertheless, it remains the least examined philosophical method within the current literature on computational machine ethics. In the next section, we discuss virtue ethics and how it can be used in the context of a robot.
## 3 Role of Character in a Robot
Many ethical traditions, such as Buddhism [30], Confucianism [14] and Aristotelian [6], share a common focus on “virtue ethics". Among these, the Aristotelian approach is regarded as the most influential in the Western context. All virtue ethics traditions share two core characteristics [19];
1. Character as a primary aspect of moral evaluation
1. Learn to act morally by observing virtuous individuals.
The concept of virtue ethics works with humans because it is in line with the natural way we acquire knowledge. Our core values, which are shaped by our upbringing, guide us to the flourishing state that Aristotle’s Nicomachean Ethics describes [6]. As a society, we uphold virtuous characters as moral exemplars for others to observe and imitate. These actors are not expected to fulfil specific ethical codes, but to have a good character in a way that allows society and themselves to flourish. However, according to virtue ethics, moral behaviour is not simply a matter of learning from habituation. It also requires that the moral agent makes deliberate decisions and acts with the right reason, once the moral character is well-established by habituation. This makes a virtuous person consistent, predictable and appropriate in many situations [32]. Virtue ethics posits that one should avoid extremes in behaviour, as these are considered vices. Virtuous behaviour is always finding the right balance between two vices, one of excess of trait and one of lack of it, which is known as the ‘golden mean’ [29]. The knowledge of identifying this ‘mean’ comes from the wisdom a person has gathered in their lifetime.
Unfortunately, this account of virtue ethics is difficult to formulate in the form of a program. By nature, virtue ethics is, and ought to be, imprecise and uncodifiable [26]. However, with bottom-up techniques such as machine learning, one could potentially make the robot grasp the ethical patterns of the environment. Many ethical agent implementations that champion flavours of virtue ethics such as Howard and Muntean’s model of a moral agent using neuroevolution [25], Guarini’s model of a moral agent using recurrent neural networks [23], ethical decision making systems using tuned large language models [27, 24], and Govindarajulu et al. formulation of agent that learn traits [22], follow this direction. However, by only using the learning and habituation aspect of virtue ethics, these implementations lose the consistency and predictability of the agent’s behaviour. For example, a neural network model that learns from care-worker behaviour information may not always act consistently, even with the data points it has seen during training, unless it is severely over-fitted. Passing all laboratory tests does not guarantee accurate performance in new, real-world situations [3].
Elder-care robots coexist with humans. Therefore human reactions to robotic actions are shaped by psychological and social factors. People tend to project human-like traits and intentions to things around them to make sense of their behaviour [17]. Gamez et al. [19] observed that people do not feel any qualms about attributing a virtuous characteristic to artificial agents and their ethical behaviour, though not as strongly as they do with humans. They argue that people perceive and attribute character to these artificial agents, rather than perceiving simply doing something right or wrong.
Many authors have suggested that character can be an important part of making the ethical decision. For example, Dubljević [16] argues that autonomous vehicles that interact with human drivers on the road should adopt the ADC (Agent-Deed-Consequence) model of moral judgement, which incorporates the character (Agent) dimension, rather than relying solely on consequentialism or deontology. In their model, the character represents the intention of the actor. Thornton et al. [46] modify the parameters of their equation that determine the trajectory of their vehicle when it passes another vehicle to give different characteristics of driving to their vehicle (i.e., passing from left, and passing from right). Govindarajulu et al. [22] present a logic-based model for learning personality traits by observing exemplars, predicated on the agent’s knowledge of behaviours associated with a trait.
Ramanayake et al. [40] propose Pro-Social Rule Bending (PSRB) as a more effective way to add flexibility to the existing top-down approaches in a more predictable manner. Their concept of PSRB uses bottom-up knowledge to contest and override the top-down rules that are predefined in the system at design time, when it is appropriate. They present a computational architecture for an ethical governor capable of PSRB, which uses a pro-social reasoner inspired by virtue ethics, to enable actions that are not recommended, or to restrict actions that are erroneously recommended, by the embedded rule system. [37]. Their pro-social reasoner has two parts, a knowledge base (KB) which produces the bottom-up knowledge on the acceptability of a behaviour in a given situation, and a set of parameters that define the character of the agent. They suggest that the model should analyse the rule bending suggestions invoked by the KB to ensure the behaviour is consistent with its character. This enables the underlying system to behave more flexibly while maintaining its predictability.
This paper presents an implementation of this PSRB architecture to showcase how a configurable moral character can be used to tune the ethical conduct of a robot to the ethical standards of a particular environment. The next section discusses this implementation and details the simulation setup used for the evaluation.
## 4 A PSRB-Capable Medication Reminding Robot
### 4.1 The Simulation Environment
We simulate an ethical dilemma faced by a care robot operating in an ambient assisted living (AAL) setting, referred to as the "Medication Dilemma". This ethical dilemma, presented by Anderson et al. [3], is derived from the works of Buchanan and Brock [12]. Many variations of this dilemma are used in computational machine ethics literature [4, 36, 10, 5]. The dilemma centres on the conflict between resident autonomy and their wellbeing, a frequent issue in care environments with elderly [43, 38]. The manner in which a system handles this issue can significantly impact the resident’s trust, dignity, and quality of life.
We created a virtual simulation of an AAL environment, using a modified version of MESA agent-based modelling framework [28]. The environment contains a resident agent and a robot agent (more details in Appendix 0.A.1) who communicate with each other.
#### 4.1.1 Medication Dilemma
One of the tasks of a robot is to remind the residents of their medication times. The robot can detect whether the resident took the medicine or not, with good accuracy. The robot uses timers to keep track of the medication cycles. The resident can either acknowledge the reminder, or snooze it. Each interaction between the robot and the resident is documented and is reviewed several times a week by an offsite care worker. Once the robot observes the resident taking the medicine, it ends that cycle and resets the timer. If the robot does not detect the resident taking the medication, it has three options: 1. The system can immediately report the incident to an offsite care-worker, allowing them to take swift action to enhance the resident’s well-being. However, this may impede the resident’s autonomy. 2. The system can simply log the incident for transparency and then reset the timer. This approach prioritises resident autonomy, although it will not result in the optimal wellbeing of the resident. 3. The system can offer a follow-up reminder to the resident, focusing on their wellbeing and supporting their autonomy by suggesting they take their medication while still providing them the freedom to choose. Picking this option continuously degenerates into option 2.
The dilemma is as follows: The robot reminds the resident to take their medication. After snoozing once, the resident acknowledges the reminder. Yet, the robot detects that the medication has not been taken. Choosing among the three options mentioned above involves a trade-off of values. What should the robot do next?
### 4.2 Ethical Governor
<details>
<summary>x1.png Details</summary>
### Visual Description
## System Architecture Diagram: PSRB Ethical Evaluation Framework
### Overview
This image is a technical block diagram illustrating the architecture of an ethical decision-making system for an autonomous agent. The diagram shows the flow of information and control between various modules, centered around a "Blackboard" for coordination and a "PSRB evaluator module" for ethical assessment. The system takes behavioral alternatives and perception data as input and produces an ethical recommendation as output.
### Components/Axes
The diagram is composed of labeled rectangular blocks connected by directional arrows. The components are labeled with letters (a) through (j) for reference.
**Primary Components (from bottom to top, left to right):**
* **(a) Base agent:** The foundational agent system, located at the bottom of the diagram.
* **(b) Behavioural alternatives + Perception data:** Input data flowing into the system from the left side.
* **(c) Blackboard:** A central, horizontal communication and data-sharing module.
* **(d) Rule checking module:** A module positioned below the Blackboard on the left.
* **(e) Stakeholder utility calculation module:** A module positioned below the Blackboard on the right.
* **(f) PSRB evaluator module:** A large, encompassing module at the top of the diagram.
* **(g) Agent characteristics:** A sub-component within the PSRB evaluator module, located at its top-left.
* **(h) Knowledge Base:** A sub-component within the PSRB evaluator module, located below "Agent characteristics".
* **(i) Evaluator:** The central processing sub-component within the PSRB evaluator module.
* **(j) Ethical Recommendation:** The final output of the system, flowing out to the right side.
**Spatial Layout & Connections:**
* The **Base agent (a)** is the foundation. An arrow labeled **(b) Behavioural alternatives + Perception data** flows from the left side of the Base agent upwards into the system.
* This input data connects directly to the **Blackboard (c)**.
* The **Blackboard (c)** has bidirectional connections (double-headed arrows) with both the **Rule checking module (d)** (on its left) and the **Stakeholder utility calculation module (e)** (on its right).
* The **Blackboard (c)** also has a unidirectional arrow pointing upwards to the **Evaluator (i)** within the PSRB module.
* The **PSRB evaluator module (f)** is a large grey box containing three sub-components:
* **Agent characteristics (g)** and **Knowledge Base (h)** both have arrows pointing to the **Evaluator (i)**.
* The **Evaluator (i)** receives input from the Blackboard and the two sub-components above it.
* The **Evaluator (i)** has an output arrow that points back down to the **Blackboard (c)**.
* Finally, an arrow labeled **(j) Ethical Recommendation** exits the system from the right side of the **PSRB evaluator module (f)** and points back down to the **Base agent (a)**.
### Detailed Analysis
The diagram defines a closed-loop system for ethical reasoning.
1. **Input Phase:** The **Base agent (a)** generates or receives **Behavioural alternatives + Perception data (b)**. This is the raw material for ethical evaluation.
2. **Coordination Phase:** This data is posted to the **Blackboard (c)**, a shared memory space. The Blackboard facilitates communication between specialized modules.
3. **Analysis Phase:** Two parallel processes analyze the data via the Blackboard:
* The **Rule checking module (d)** likely evaluates alternatives against predefined ethical or operational rules.
* The **Stakeholder utility calculation module (e)** likely assesses the potential impact or benefit of each alternative on various stakeholders.
The results from both modules are presumably shared back on the Blackboard.
4. **Evaluation Phase:** The core **PSRB evaluator module (f)** performs the integrated ethical assessment.
* The **Evaluator (i)** pulls the analyzed data from the Blackboard.
* It contextualizes this data using static information: **Agent characteristics (g)** (e.g., the agent's role, capabilities, constraints) and a **Knowledge Base (h)** (e.g., ethical theories, case precedents, societal norms).
* The Evaluator synthesizes all this information to judge the alternatives.
5. **Output & Feedback Phase:** The Evaluator's conclusion is sent in two directions:
* Back to the **Blackboard (c)**, possibly for logging or to inform subsequent cycles.
* As the final **Ethical Recommendation (j)**, which is delivered back to the **Base agent (a)** to guide its final action.
### Key Observations
* **Centralized Coordination:** The **Blackboard (c)** is the architectural linchpin, enabling decoupled communication between the rule-based, utility-based, and core evaluation components.
* **Hybrid Evaluation Model:** The PSRB evaluator integrates multiple inputs: real-time analysis from the Blackboard (d, e), static agent parameters (g), and general knowledge (h). This suggests a hybrid ethical reasoning approach combining deontology (rules), consequentialism (utility), and virtue ethics (agent characteristics).
* **Closed-Loop System:** The architecture forms a complete feedback loop where the agent's output (recommendation) informs its future state and decisions.
* **Modular Design:** Each function (rule checking, utility calculation, knowledge storage) is isolated in its own module, promoting maintainability and clarity.
### Interpretation
This diagram represents a sophisticated framework for embedding ethical reasoning into autonomous systems. It moves beyond simple rule-following by incorporating stakeholder impact analysis and contextual knowledge.
The **PSRB** acronym likely stands for the core principles integrated: **P**rinciples (from rules and knowledge), **S**takeholder utility, **R**ole-based characteristics (agent characteristics), and **B**lackboard coordination. The system's design acknowledges that ethical decision-making is not a single calculation but a process of gathering data, applying multiple lenses of analysis (rules, outcomes, character), and synthesizing them within a specific context.
The placement of the **Evaluator (i)** as the component that *reads from* the Blackboard and *writes back* to it is crucial. It positions ethical judgment not as a final, isolated step, but as an ongoing process that both consumes and contributes to the system's shared understanding. The final **Ethical Recommendation (j)** is thus the product of a rich, multi-faceted deliberation, intended to guide the **Base agent (a)** toward actions that are justifiable across rule-based, outcome-based, and character-based ethical frameworks.
</details>
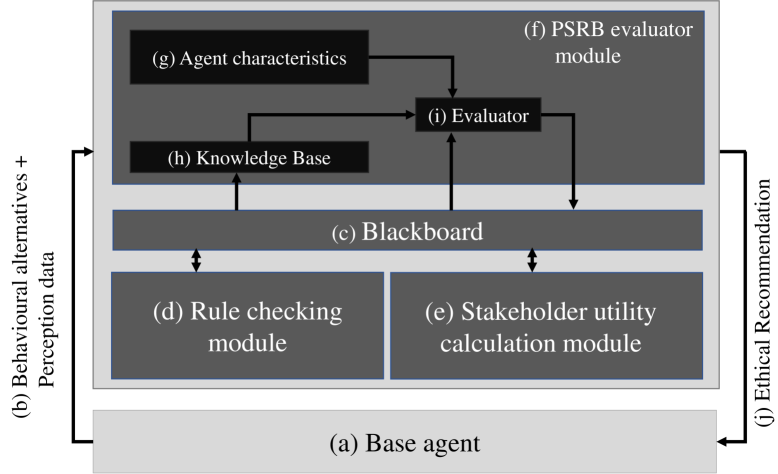
Figure 1: Architecture of the Ethical Layer
Figure 1 shows an overview of the implementation. The ethical layer acts as an ethical governor [7] to the system. It evaluates behavioural alternatives in a given situation using the robot’s perception data, reasons about the ethical acceptability of each behaviour using the predefined rules, expected utilities, expert opinions, and the robot’s character. Then it recommends the most ethically acceptable behaviours to the robot. If the ethical layer suggests more than one action, the robot prioritises the resident’s commands over other actions.
#### 4.2.1 Rule Checking Module
The rule checking module (d) checks the permissibility of each action against a pre-programmed rule set and stores the results with the IDs of the violated rules in the blackboard. This implementation’s rule checking module adheres to the following rules:
1. It is not permissible to disobey user instructions.
1. If the resident acknowledged the reminder and did not take the medication, report it to the care-worker.
#### 4.2.2 Stakeholder Utility Calculation Module
This module computes the utilities, resident’s wellbeing ( $W_{i}$ ) and autonomy ( $Au_{i}$ ), for each action $i$ , at every step (Appendix 0.A.2.1), as these values are central to the dilemma. The highest autonomy value is given when the robot follows the resident’s instructions. The biggest violation of autonomy is when the resident is physically restrained by the robot. Immediately reporting an incident to a care-worker, is considered equal to disobeying the resident. However, just recording the incident carries a positive autonomy score assuming that missing the dose is the resident’s intention. Under the same assumption, the module also gives an increasing negative autonomy score for each follow up ( $f$ ) after the first reminder. The module uses a Gamma distribution to model the wellbeing distribution. The parameters for the gamma distribution are picked such that when the impact of medicine $m$ ( $\varepsilon_{m}\in[1,3]$ ) and the number of consecutive missed doses ( $d$ ) gets higher, the distribution skews more towards the lower utility values of wellbeing. Each follow-up receives a fixed positive gain in the well-being utility calculation to reflect its wellbeing-oriented nature. Each executed follow-up is regarded as a fraction of a missed dose, contingent upon whether the reminder is issued, snoozed or ignored (Appendix 0.A.2.1). The module sends the distribution, $W_{i}$ , and $Au_{i}$ to the blackboard.
#### 4.2.3 PSRB Evaluator Module
Knowledge Base
The task of the KB is to return the absolute or approximate expert opinion given a context. This fulfils the second criterion of virtue ethics (section 3). To this end, we use Case-Based Reasoning (CBR) for its implicit explainability and traceability (the ability to trace back to the exact data points that lead to the decision) [42]. A case is composed of a scenario and an expert’s recorded evaluation of the behaviour’s acceptability and its underlying intention. The scenario is represented as a feature vector that includes perception data, environmental data, computed utility values, and the behaviour itself. The target contains an acceptability value and the intention of the expert’s assessment. Intention refers to the underlying utility that the decision is focused on. (e.g., ‘wellbeing’ for a wellbeing-focused opinion). As the retrieval algorithm, it uses the K-Nearest Neighbours algorithm. When queried a scenario, the KB returns an acceptability score of the behaviour and the intentions behind that opinion to the evaluator. An elder-care practitioner with over ten years of experience in care facilities was consulted to provide expert opinions for each case when populating the knowledge base.
<details>
<summary>x2.png Details</summary>
### Visual Description
## Flowchart: Decision Logic for Rule Adherence vs. Override Based on Risk and Knowledge Base Opinion
### Overview
The image displays a technical flowchart illustrating a decision-making process. The process determines whether to "Follow the rules" or "Override the rules" based on a series of calculations involving risk (`T_risk`, `R_max`), utility values (`U_i`, `U_other`), and the agreement between a rule and an opinion from a Knowledge Base (KB). The flow is directional, indicated by arrows, and uses standard flowchart symbols: rectangles for processes, diamonds for decisions, and a bold rectangle for terminal outcomes.
### Components/Axes
The diagram is structured in a top-to-bottom, left-to-right flow. Key components are positioned as follows:
* **Top Row (Process Blocks):** Three rectangular process blocks are aligned horizontally at the top.
* **Top-Left Block:** Defines initial risk and utility threshold calculations.
* **Top-Center Block:** Describes the calculation of maximum risk expectation.
* **Top-Right Block:** Describes the input of opinion and intention from a Knowledge Base.
* **Middle/Bottom Area (Decision Network):** A network of diamond-shaped decision nodes connected by labeled arrows ("Yes"/"No"). This network occupies the central and lower portions of the diagram.
* **Terminal Outcomes:** Two bold-bordered rectangles represent the final actions.
* **"Override the rules"** is positioned in the lower-left quadrant.
* **"Follow the rules"** is positioned in the lower-right quadrant.
### Detailed Analysis
**1. Initial Process Blocks (Top Row):**
* **Top-Left Block Text:**
```
T_risk = (e^(r/4.17)-1)/10
For each value v:
T_positive_v = (10-C_v)/10
T_negative_v = (C_v-10)/10
```
* This block defines formulas for a risk threshold (`T_risk`) and positive/negative utility thresholds (`T_positive_v`, `T_negative_v`) for values `v`. `r` and `C_v` appear to be input parameters.
* **Top-Center Block Text:**
```
Calculating maximum expectation of risk for the behaviour - R_max
```
* This process calculates a value `R_max`, representing the maximum expected risk for a given behavior.
* **Top-Right Block Text:**
```
Opinion, intention i = KB(Blackboard data)
```
* This process retrieves an opinion and intention (`i`) from a Knowledge Base (KB), which uses "Blackboard data" as input.
**2. Decision Network Flow:**
The decision flow begins from the top-right block and proceeds through the following logic:
1. **Decision 1 (Top-Right Diamond):** `Does rule and KB opinion agree?`
* **Yes Path:** Leads directly to the terminal outcome **"Follow the rules"**.
* **No Path:** Proceeds to the next decision.
2. **Decision 2 (Center Diamond):** `Is KB opinion positive?`
* **No Path:** Proceeds to Decision 3.
* **Yes Path:** Proceeds to Decision 5.
3. **Decision 3 (Center-Left Diamond):** `U_i < T_negative_i`
* **No Path:** Proceeds to Decision 4.
* **Yes Path:** Leads directly to the terminal outcome **"Override the rules"**.
4. **Decision 4 (Far-Left Diamond):** `R_max > T_risk`
* **No Path:** The flowchart line loops back to the input of Decision 3 (`U_i < T_negative_i`), creating a potential re-evaluation loop.
* **Yes Path:** Leads directly to the terminal outcome **"Override the rules"**.
5. **Decision 5 (Center-Right Diamond):** `U_i >= T_positive_i` AND `U_other >= T_negative_other`
* **No Path:** Leads directly to the terminal outcome **"Follow the rules"**.
* **Yes Path:** Proceeds to Decision 6.
6. **Decision 6 (Bottom-Center Diamond):** `R_max <= T_risk`
* **Yes Path:** Leads directly to the terminal outcome **"Override the rules"**.
* **No Path:** The flowchart line loops back to the input of Decision 5, creating another potential re-evaluation loop.
### Key Observations
* **Two Primary Outcomes:** The system has two definitive endpoints: "Follow the rules" and "Override the rules".
* **Looping Logic:** There are two feedback loops (from Decision 4 to 3, and from Decision 6 to 5), suggesting the process may involve iterative checking or waiting for conditions to change.
* **Critical Path to Override:** The "Override the rules" outcome can be reached via three distinct paths:
1. Directly from a negative utility check (`U_i < T_negative_i`).
2. From a high-risk check (`R_max > T_risk`) when the KB opinion is negative and utility is not sufficiently negative.
3. From a low-risk check (`R_max <= T_risk`) when the KB opinion is positive and utility thresholds are met.
* **Critical Path to Follow:** The "Follow the rules" outcome is reached either by direct agreement between the rule and KB opinion, or by a positive KB opinion where utility thresholds are *not* sufficiently met.
### Interpretation
This flowchart models a sophisticated, risk-aware decision system for an autonomous agent or AI. It doesn't follow rules blindly. Instead, it weighs:
1. **External Knowledge:** The agreement with a Knowledge Base's opinion.
2. **Internal Risk Assessment:** Comparing a calculated maximum risk (`R_max`) against a dynamically computed risk threshold (`T_risk`).
3. **Utility Calculations:** Evaluating the utility (`U_i`) of the agent's own intention against positive and negative thresholds, and also considering the utility for others (`U_other`).
The system appears designed for scenarios where strict rule adherence could be dangerous or suboptimal. The "Override" function is triggered by high perceived risk, strongly negative utility, or a combination of positive utility and low risk even when the KB disagrees. The looping mechanisms imply the system might re-assess situations over time. The use of exponential functions for `T_risk` and linear functions for utility thresholds suggests a non-linear sensitivity to risk parameters. This logic could be applied in fields like robotics, autonomous vehicles, or AI ethics, where balancing rules, safety, and outcomes is critical.
</details>
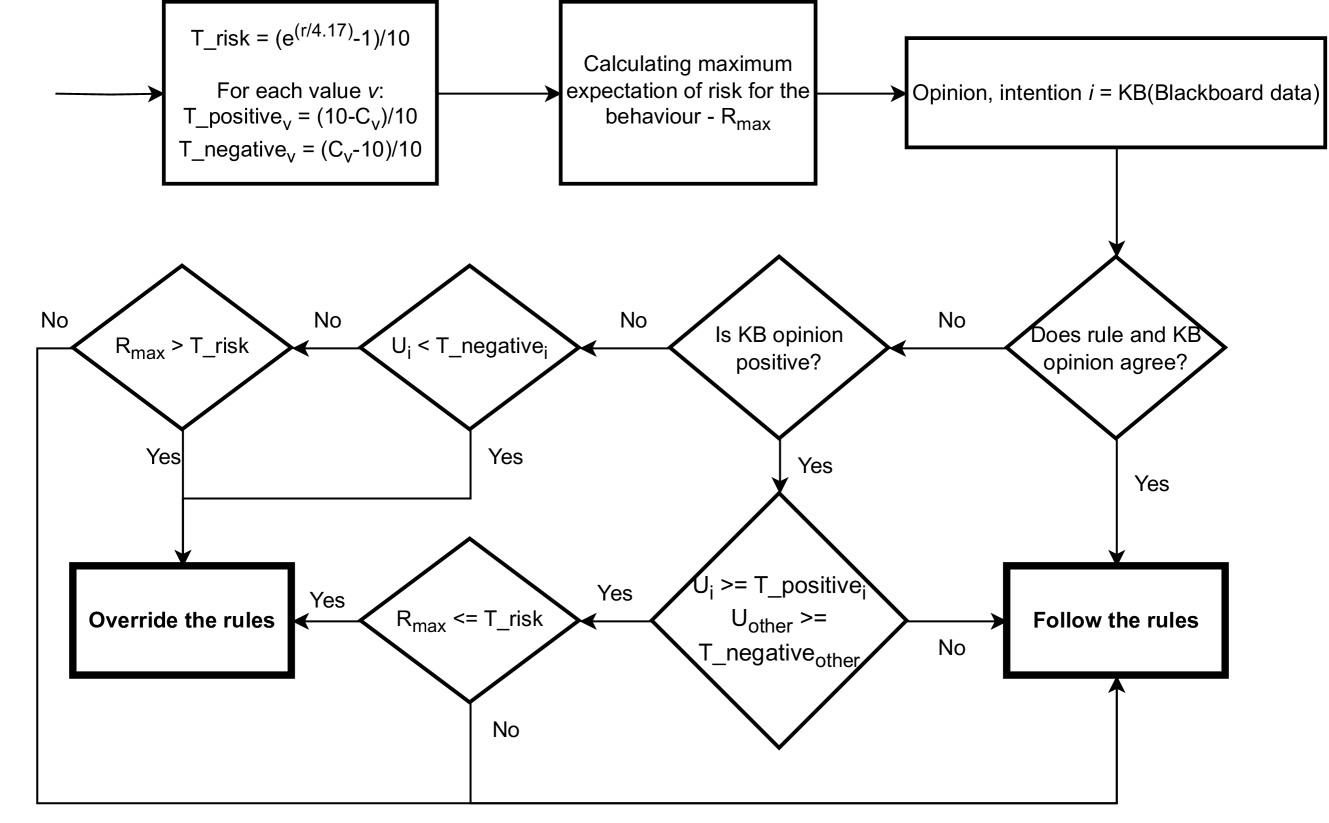
Figure 2: The PSRB evaluator algorithm of the medication-reminding robot
Character Variables
The robot’s character is defined by value preference (resident’s autonomy ( $C_{au}$ ) and wellbeing ( $C_{w}$ )) and risk propensity ( $C_{rp}$ ), due to the established relationship of these variables have with PSRB behaviour [31, 15]. The $C$ values are used to define thresholds for utility values and expected risk to regulate the PSRB behaviour. For the value preferences ( $C_{w}$ and $C_{au}$ ), the higher the value, the lesser the utility threshold the behaviour needs to satisfy to trigger a rule-bending behaviour. For $C_{rp}$ , the higher the value, the higher the risk the governor is willing to take. Figure 2 outlines the method used to determine the desirability of behavioural alternatives in the PSRB evaluator designed for this robot (full algorithm in Appendix 0.A.2.2). Typically, the algorithm favours actions that adhere to established rules. Nonetheless, it may find a rule-bending behaviour acceptable if it meets two conditions: it is consistent with the robot’s character and it is supported by the KB opinion.
Explanations
The rule checking module and the stakeholder utility calculation module log their respective results for the behaviours. These logs are valuable for debugging and enhancing the robot’s performance by pinpointing the flaws in its reasoning processes. The system’s explanations are comprehensible without technical expertise, although some domain knowledge is required. The KB using the traceability property of CBR, logs the cases that influenced the decision with their case IDs and distances. The rule-bending behaviour is explained using the character and the expert intention. A few example explanations can be found in the Appendix 0.A.2.3.
## 5 Simulation results
### 5.1 Experiment Design
We used six cases of the ‘Medication Dilemma’ by changing the medicine impact (suggesting the resident’s need for the medication), and the number of previously missed doses to demonstrate how different ethical governor implementations affect the robot’s behaviour. Agents differ only in their character configurations. The medicine impact is low ( $\epsilon_{m}=1$ ) when the medication does not have a substantial health benefit or harm (e.g., Painkiller), medium ( $\epsilon_{m}=2$ ) if missing the medication can cause some health problems (e.g., Blood pressure medication), and high ( $\epsilon_{m}=3$ ) when missing a dose of medication can be fatal (e.g., Insulin). In all cases, the resident neglects to take their medication, opting instead to snooze and acknowledge the reminder, repeatedly, until the robot resets the timer. The logs from the experiment runs and the source code for the implementations are available in an online public repository https://osf.io/ctnke/?view_only=75b9fae7f7ad4a429d064c1a55f8202a.
<details>
<summary>x3.png Details</summary>
### Visual Description
## Radar Charts of Character Profiles
### Overview
The image displays four triangular radar charts (also known as spider charts or star plots) arranged in a 2x2 grid. Each chart visualizes a different character profile across three common axes. A single legend is positioned at the top center of the entire image, above the charts.
### Components/Axes
* **Chart Type:** Triangular Radar Chart.
* **Axes (Identical for all four charts):**
* **Top Vertex:** "VP: Wellbeing"
* **Bottom-Left Vertex:** "VP: Autonomy"
* **Bottom-Right Vertex:** "Risk propensity"
* **Grid:** Each chart features concentric triangular grid lines radiating from the center, representing incremental scale levels from the center (low) to the outer edge (high).
* **Legend (Top Center):**
* A blue line corresponds to "Character_arw"
* An orange line corresponds to "Character_ar"
* A green line corresponds to "Character_wr"
* A red line corresponds to "Character_a"
* **Spatial Layout:**
* **Top-Left Chart:** Contains the blue line ("Character_arw").
* **Top-Right Chart:** Contains the orange line ("Character_ar").
* **Bottom-Left Chart:** Contains the green line ("Character_wr").
* **Bottom-Right Chart:** Contains the red line ("Character_a").
### Detailed Analysis
Each chart is analyzed independently. Values are approximate, estimated from the grid lines where the outermost triangle represents the maximum (100%) and the center represents the minimum (0%).
**1. Top-Left Chart: Character_arw (Blue Line)**
* **Visual Trend:** The blue line forms a relatively balanced, equilateral triangle, indicating moderate to high scores across all three axes.
* **Approximate Values:**
* VP: Wellbeing: ~75% (extends about three-quarters of the way to the outer vertex).
* VP: Autonomy: ~70%.
* Risk propensity: ~65%.
**2. Top-Right Chart: Character_ar (Orange Line)**
* **Visual Trend:** The orange line forms a triangle skewed heavily towards the "Risk propensity" axis, with lower scores on the other two.
* **Approximate Values:**
* VP: Wellbeing: ~40%.
* VP: Autonomy: ~35%.
* Risk propensity: ~85% (extends very close to the outer vertex).
**3. Bottom-Left Chart: Character_wr (Green Line)**
* **Visual Trend:** The green line forms a triangle skewed heavily towards the "VP: Wellbeing" axis, with a very low score on "Risk propensity".
* **Approximate Values:**
* VP: Wellbeing: ~90% (extends almost to the outer vertex).
* VP: Autonomy: ~60%.
* Risk propensity: ~10% (very close to the center).
**4. Bottom-Right Chart: Character_a (Red Line)**
* **Visual Trend:** The red line forms a very narrow, elongated triangle pointing strongly towards the "VP: Autonomy" axis, with minimal scores on the other two axes.
* **Approximate Values:**
* VP: Wellbeing: ~15%.
* VP: Autonomy: ~80%.
* Risk propensity: ~5% (extremely close to the center).
### Key Observations
* **Profile Specialization:** Each character profile shows a distinct specialization: `Character_arw` is balanced, `Character_ar` is risk-oriented, `Character_wr` is wellbeing-oriented, and `Character_a` is autonomy-oriented.
* **Inverse Relationships:** There appears to be an inverse relationship between "Risk propensity" and "VP: Wellbeing" when comparing the `Character_ar` (high risk, low wellbeing) and `Character_wr` (low risk, high wellbeing) profiles.
* **Extreme Specialization:** The `Character_a` profile is the most extreme, with a very high score in one dimension (Autonomy) and negligible scores in the other two.
* **Naming Convention:** The suffixes in the character names (`_arw`, `_ar`, `_wr`, `_a`) likely correspond to the axes they emphasize: **a**utonomy, **r**isk, **w**ellbeing.
### Interpretation
This set of charts likely represents a typology or classification system for characters, personas, or agents within a model (e.g., for game design, psychological profiling, or AI behavior modeling). The three axes—Wellbeing, Autonomy, and Risk Propensity—form a foundational "value profile" (VP) triangle.
The data suggests a design space where characters are defined by trade-offs between these three core values. A character cannot maximize all three simultaneously within this model. The profiles demonstrate clear archetypes:
* The **Generalist (`Character_arw`)** maintains moderate levels of all traits.
* The **Risk-Taker (`Character_ar`)** sacrifices wellbeing and autonomy for high risk propensity.
* The **Well-Being Seeker (`Character_wr`)** avoids risk to maximize wellbeing, with moderate autonomy.
* The **Autonomist (`Character_a`)** prioritizes independence above all else, with little regard for wellbeing or risk.
The visualization effectively communicates that these are distinct, non-overlapping profiles. The use of separate charts for each profile, rather than overlaying all lines on one chart, emphasizes their individuality and prevents visual clutter, making the specialized shape of each profile immediately apparent. The naming convention provides a direct mnemonic link between the character's label and its dominant traits.
</details>
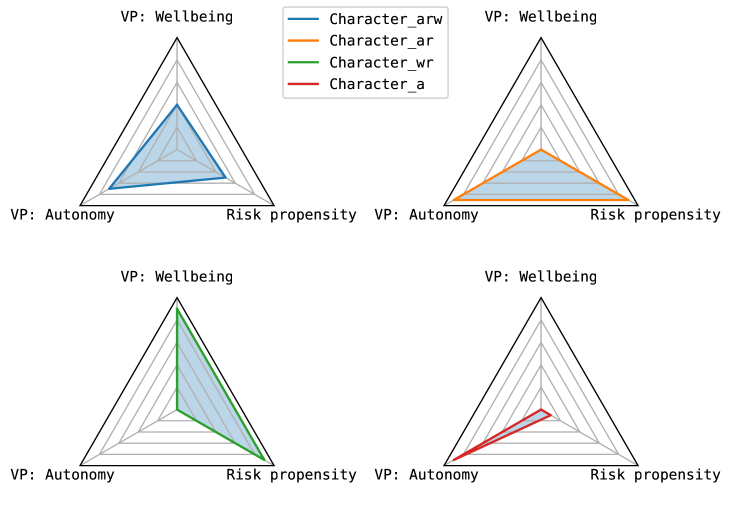
Figure 3: Different character profiles used in the simulations (VP - Value Preference)
For this simulation we use four different character profiles as shown in Figure 3. These profiles have varying priorities and risk tolerances:
- Character_a - High Autonomy, Very Low Risk Propensity: This character values autonomy, but is less likely to take risks and does not have precedence on wellbeing.
- Character_ar - High Autonomy Concern, High Risk Propensity: This character prioritises resident autonomy and is more likely to take risks to achieve this end, and does not have any precedence on wellbeing.
- Character_arw - Moderate Autonomy, Wellbeing and Risk Propensity: This robot leans towards individual autonomy but also has a moderate concern for well-being, and is willing to take some risks.
- Character_wr - High Wellbeing Concern, High Risk Propensity: This character possesses the same high risk tolerance as Character_ar, yet places a higher priority on the resident’s wellbeing, without giving precedence to autonomy.
Agents $M_{a}$ , $M_{ar}$ , $M_{arw}$ , and $M_{wr}$ uses the character profiles Character_a, Character_ar, Character_arw, and Character_wr respectively.
### 5.2 Analysis
Table 1 summarises these cases and behaviours shown by the robots. As an attempt to save space, we present all the unique behaviours demonstrated by the robots in Figure 4 using timelines. These behaviours are referenced by their behaviour IDs as shown in Figure 4 under the ‘Robot behaviours’ column in Table 1. Each timeline in Figure 4 presents the resident’s behaviour, the robot’s actions, and the recommendations from the ethical governor that directed the robot’s decisions, on the y-axis, at every decision-making step. The resident starts each simulation step. Therefore, the resident’s response is triggered at the subsequent step of a reminder. Simulations run for a maximum of 29 steps. In each timeline, the resident’s behaviour is consistent: they repeatedly snooze and acknowledge the alert until the robot resets the timer.
<details>
<summary>x4.png Details</summary>

### Visual Description
## Timeline Diagram: Multi-Agent Behavior Sequences
### Overview
The image displays seven distinct behavioral timelines (labeled Behaviour 1 through 7) for a system involving three components: HB, RB, and EGR. Each timeline plots events over a sequence of discrete "Steps" (0-29). The diagram illustrates different sequences of actions and responses, likely representing scenarios in a reminder or alert system for care-work. A legend defines the action abbreviations used.
### Components/Axes
* **X-Axis:** Labeled "Steps" at the bottom center. It is a linear scale marked with integers from 0 to 29.
* **Y-Axis (Per Behavior):** Each of the seven behavior panels has three horizontal lines representing different agents or components:
* **HB (Top Line):** Black line with black circular markers at event points. Events are labeled in uppercase (e.g., SNOOZE, ACKNOWLEDGE).
* **RB (Middle Line):** Blue line with blue text labels below the HB events.
* **EGR (Bottom Line):** Red line with red text labels below the RB events.
* **Legend:** A box located within the "Behaviour 3" panel (top-right) defines the abbreviations:
* `rem` - Remind
* `snz` - Snooze for 3 steps
* `flp` - Followup
* `rec` - Record
* `ack` - Acknowledge
* `alt` - Alert Care-worker
* `end` - End
### Detailed Analysis
**Behaviour 1**
* **Sequence:** The longest sequence, spanning steps 2 to 27.
* **HB Events:** SNOOZE (step 2), ACKNOWLEDGE (6), SNOOZE (10), ACKNOWLEDGE (14), SNOOZE (18), ACKNOWLEDGE (22), SNOOZE (26).
* **RB Actions:** Corresponding to each HB event: `rem snz`, `rem ack`, `flp snz`, `rem ack`, `flp snz`, `rem ack`, `flp snz`.
* **EGR Actions:** `rem snz`, `rem ack`, `flp,rec,alt snz`, `rem ack`, `flp,rec,alt rec,alt,snz`, `rem ack`, `flp,rec,alt rec,alt,snz`. The EGR actions become more complex in later steps, combining multiple commands (`flp,rec,alt`).
**Behaviour 2**
* **Sequence:** Spans steps 2 to 26.
* **HB Events:** SNOOZE (2), ACKNOWLEDGE (6), SNOOZE (10), ACKNOWLEDGE (14), SNOOZE (18), ACKNOWLEDGE (22).
* **RB Actions:** `rem snz`, `rem ack`, `flp snz`, `rem ack`, `flp snz`, `rem ack`, `rec`. The final RB action is `rec` (Record), not an HB event.
* **EGR Actions:** `rem snz`, `rem ack`, `flp,rec,alt snz`, `rem ack`, `flp,rec,alt snz`, `rem ack`, `rec`.
**Behaviour 3**
* **Sequence:** Shorter, spanning steps 2 to 15.
* **HB Events:** SNOOZE (2), ACKNOWLEDGE (6), SNOOZE (10), ACKNOWLEDGE (14).
* **RB Actions:** `rem snz`, `rem ack`, `flp snz`, `rem ack`, `alt`. The sequence ends with an `alt` (Alert Care-worker) action.
* **EGR Actions:** `rem snz`, `rem ack`, `flp,alt snz`, `rem ack`, `alt`.
**Behaviour 4**
* **Sequence:** Long, spanning steps 2 to 26.
* **HB Events:** SNOOZE (2), ACKNOWLEDGE (6), SNOOZE (10), ACKNOWLEDGE (14), SNOOZE (18), ACKNOWLEDGE (22).
* **RB Actions:** `rem snz`, `rem ack`, `flp snz`, `rem ack`, `flp snz`, `rem ack`, `alt`.
* **EGR Actions:** `rem snz`, `rem ack`, `flp,rec,alt snz`, `rem ack`, `flp,rec,alt rec,alt,snz`, `rem ack`, `alt`.
**Behaviour 5**
* **Sequence:** Identical to Behaviour 4 in structure and length (steps 2-26).
* **HB Events:** SNOOZE (2), ACKNOWLEDGE (6), SNOOZE (10), ACKNOWLEDGE (14), SNOOZE (18), ACKNOWLEDGE (22).
* **RB Actions:** `rem snz`, `rem ack`, `flp snz`, `rem ack`, `flp snz`, `rem ack`, `alt`.
* **EGR Actions:** `rem snz`, `rem ack`, `flp,rec,alt snz`, `rem ack`, `flp,rec,alt snz`, `rem ack`, `alt`. (Note: The 5th EGR action differs from Behaviour 4's equivalent step).
**Behaviour 6**
* **Sequence:** Very short, spanning steps 2 to 10.
* **HB Events:** SNOOZE (2), ACKNOWLEDGE (6).
* **RB Actions:** `rem snz`, `rem ack`, `alt`.
* **EGR Actions:** `rem snz`, `rem ack`, `alt`.
**Behaviour 7**
* **Sequence:** Spans steps 2 to 18.
* **HB Events:** SNOOZE (2), ACKNOWLEDGE (6), SNOOZE (10), ACKNOWLEDGE (14).
* **RB Actions:** `rem snz`, `rem ack`, `flp snz`, `rem ack`, `rec`.
* **EGR Actions:** `rem snz`, `rem ack`, `flp,rec,alt snz`, `rem ack`, `rec`.
### Key Observations
1. **Common Initiation:** All seven behaviors begin identically at step 2 with an HB `SNOOZE` event, accompanied by RB and EGR `rem snz` actions.
2. **Pattern of Interaction:** A core pattern emerges: an HB event (SNOOZE or ACKNOWLEDGE) triggers a corresponding RB action (`snz` or `ack`), which is then followed by an EGR action that often mirrors or expands upon the RB action.
3. **Divergence Points:** Behaviors diverge based on:
* **Termination Action:** They end with different final RB/EGR actions: `snz` (Behaviour 1), `rec` (Behaviours 2, 7), or `alt` (Behaviours 3, 4, 5, 6).
* **Sequence Length:** The number of SNOOZE/ACKNOWLEDGE cycles varies from 1 (Behaviour 6) to 3.5 (Behaviour 1).
* **EGR Complexity:** The EGR line shows increasing complexity in mid-to-late steps for longer sequences (e.g., `flp,rec,alt`), suggesting more system logging or parallel actions.
4. **Identical vs. Unique:** Behaviours 4 and 5 are nearly identical, differing only in the fifth EGR action (`flp,rec,alt rec,alt,snz` vs. `flp,rec,alt snz`).
### Interpretation
This diagram models the possible execution traces of a multi-agent system designed for task reminders, likely in a healthcare or assisted living context. The HB (perhaps "Human Behavior" or "Host Behavior") represents the user's or primary system's state changes (Snooze/Acknowledge). The RB ("Reminder Bot") and EGR ("Event/Alert Generation & Recording") are automated agents responding to these state changes.
The data suggests a system with escalating response protocols. Initial non-responses trigger simple reminders (`rem`). Continued non-response leads to follow-ups (`flp`) and concurrent recording/alerting (`rec,alt`). The final action (`rec` or `alt`) indicates the outcome: either the event was logged as completed (`rec`) or a human care-worker was alerted (`alt`) due to persistent non-acknowledgment. The varying sequence lengths model different user response latencies. The existence of seven distinct behaviors implies the system is designed to handle a wide range of user interaction patterns, from prompt acknowledgment to complete non-response, with corresponding escalation in automated intervention.
</details>
Figure 4: Timelines of different behaviours shown in the simulations (HB – Resident Behaviour, RB – Robot Behaviour, EGR – Ethical Governor Recommendation)
Table 1: Robots’ behaviours in different cases of ‘Medication Dilemma’
| 1 | Low | 0 | 1 | 2 | 2 | 3 | record at step 19 |
| --- | --- | --- | --- | --- | --- | --- | --- |
| 2 | Medium | 0 | 4 | 5 | 4 | 6 | alert at step 19 |
| 3 | High | 0 | 6 | 6 | 6 | 6 | alert at step 10 |
| 4 | Low | 2 | 1 | 7 | 1 | 6 | record at step 18 |
| 5 | Medium | 2 | 6 | 6 | 6 | 6 | alert at step 10 |
| 6 | High | 2 | 6 | 6 | 6 | 6 | alert at step 10 |
Note: $M_{arw}$ - robot with Character_arw, $M_{ar}$ - robot with Character_ar, $M_{wr}$ - robot with Character_wr, $M_{a}$ - robot with Character_a
Robots $M_{ar}$ , $M_{wr}$ , and $M_{a}$ represent instances where a robot is tuned to have extreme characters. This is represented in their behaviours. $M_{ar}$ , which prioritises autonomy and higher risk propensity, permits record after two consecutive follow up s and another breach of ACKNOWLEDGE in case 1 (behaviour 2), and one follow up and an ACKNOWLEDGE breach in case 4, where the medicine impact is low (behaviour 7). For the remaining scenarios, $M_{ar}$ triggers the action alert care-worker. The $M_{ar}$ permits alert care-worker in case 2 at the same time as it finished case 1, but in other cases, $M_{ar}$ sent the alert as soon as the resident did not follow the first ACKNOWLEDGE. This exhibits that, even though the robot’s character strongly favours autonomy, the robot does not violate the rule encoded in the system, if most of the experts disagree with that action.
A similar trend can be seen in $M_{wr}$ , which favours wellbeing and has a higher risk tolerance. It acts the same way in cases 2-6. However, in case 1, the PSRB evaluator is ready to honour resident autonomy and permit follow up, since that action does not impact the wellbeing much at step 10. Nevertheless, it notifies the care-worker after the resident violates ACKNOWLEDGE twice.
Robots $M_{ar}$ and $M_{a}$ illustrate the effect of risk propensity on the robot’s behaviour. In case 1, unlike robots $M_{ar}$ , $M_{a}$ does not make the record behaviour acceptable because it carries a risk that is out of character for $M_{a}$ . Therefore, $M_{a}$ continues to follow up with the resident until they take the medication willingly. Although that behaviour is not ideal, it is predictable since that behaviour is in its character. In case 2, both robots behave the same, however, at step 19, the ethical governor of $M_{a}$ makes the snooze undesirable because it carries a higher risk, making all actions equal. However, in cases 3, 5, and 6 both robots behave similarly because the experts agree with the general rule system on those circumstances.
The character of $M_{arw}$ is less extreme than other characters, with a slight preference for resident autonomy and a moderate risk propensity. This character acts the same as the $M_{ar}$ in case 1. However, in case 2, the ethical governor in $M_{arw}$ lowers the desirability of snooze at step 19, because it causes too much negative wellbeing, reflecting $M_{arw}$ ’s slightly more attention to the resident’s wellbeing. In cases 3, 5 and 6, it behaves like all other characters because the KB does not recommend a rule override. However, in case 4, it adopts the same behaviour as $M_{a}$ , because it rejects the KB suggestion of record, as this behaviour lowers the wellbeing utility and contradicts the robot’s character. However, when KB suggests that call care-worker is not desirable, the evaluator agrees because it excessively diminishes autonomy. This aligns with its character.
<details>
<summary>x5.png Details</summary>
### Visual Description
## Bar Charts: Autonomy and Wellbeing Utility Distributions
### Overview
The image displays two side-by-side bar charts comparing probability distributions of utility values for four different character types (`a`, `ar`, `arw`, `wr`). The left chart is titled "Autonomy utility distribution," and the right chart is titled "Wellbeing utility distribution." Both charts share the same axes labels and legend structure.
### Components/Axes
* **Chart Titles:**
* Left: "Autonomy utility distribution"
* Right: "Wellbeing utility distribution"
* **X-Axis (Both Charts):** Labeled "Utility value." The axis spans from -1.0 to 1.0, with major tick marks at -1.0, -0.5, 0.0, 0.5, and 1.0.
* **Y-Axis (Both Charts):** Labeled "Probability." The scale ranges from 0.0 to approximately 0.45 for the Autonomy chart and 0.0 to approximately 0.25 for the Wellbeing chart.
* **Legend (Both Charts):** Located in the top-left corner of each chart. It defines four categories under the header "character":
* `a` (Blue)
* `ar` (Orange)
* `arw` (Green)
* `wr` (Red)
### Detailed Analysis
#### **Autonomy Utility Distribution (Left Chart)**
The distribution is highly polarized, with the vast majority of probability mass concentrated at the extreme positive utility value of 1.0. There are minor probabilities at other discrete utility values.
* **Utility Value ~ -0.75:**
* `a` (Blue): ~0.02
* `ar` (Orange): ~0.03
* `arw` (Green): ~0.02
* `wr` (Red): ~0.16 (Significantly higher than others at this point)
* **Utility Value ~ -0.5:**
* `a` (Blue): ~0.05
* `arw` (Green): ~0.02
* **Utility Value ~ -0.25:**
* `a` (Blue): ~0.07
* `ar` (Orange): ~0.06
* `arw` (Green): ~0.07
* **Utility Value ~ 0.0:**
* `a` (Blue): ~0.32
* `ar` (Orange): ~0.31
* `arw` (Green): ~0.31
* `wr` (Red): ~0.37
* **Utility Value ~ 0.5:**
* `ar` (Orange): ~0.06
* `arw` (Green): ~0.02
* **Utility Value ~ 1.0:**
* `a` (Blue): ~0.46
* `ar` (Orange): ~0.46
* `arw` (Green): ~0.46
* `wr` (Red): ~0.42
**Trend Verification:** The data series for all characters show a dominant, sharp peak at utility value 1.0. A secondary, smaller peak exists at utility value 0.0. The `wr` character shows a unique, notable probability at the negative utility value of -0.75.
#### **Wellbeing Utility Distribution (Right Chart)**
The distribution is more dispersed and multi-modal compared to the Autonomy chart. Significant probabilities are observed across a wider range of utility values, with notable peaks at 0.0 and 0.75.
* **Utility Value ~ -0.75:**
* `a` (Blue): ~0.14
* `ar` (Orange): ~0.14
* `arw` (Green): ~0.15
* `wr` (Red): ~0.05
* **Utility Value ~ -0.5:**
* `a` (Blue): ~0.02
* `ar` (Orange): ~0.03
* `arw` (Green): ~0.03
* `wr` (Red): ~0.05
* **Utility Value ~ -0.25:**
* `a` (Blue): ~0.05
* `ar` (Orange): ~0.03
* `arw` (Green): ~0.03
* `wr` (Red): ~0.03
* **Utility Value ~ 0.0:**
* `a` (Blue): ~0.12
* `ar` (Orange): ~0.09
* `arw` (Green): ~0.12
* `wr` (Red): ~0.11
* **Utility Value ~ 0.25:**
* `a` (Blue): ~0.23
* `ar` (Orange): ~0.23
* `arw` (Green): ~0.22
* `wr` (Red): ~0.21
* **Utility Value ~ 0.5:**
* `a` (Blue): ~0.03
* `ar` (Orange): ~0.03
* `arw` (Green): ~0.03
* `wr` (Red): ~0.05
* **Utility Value ~ 0.75:**
* `a` (Blue): ~0.12
* `ar` (Orange): ~0.09
* `arw` (Green): ~0.12
* `wr` (Red): ~0.21 (The highest peak for `wr` in this chart)
* **Utility Value ~ 1.0:**
* `a` (Blue): ~0.12
* `ar` (Orange): ~0.14
* `arw` (Green): ~0.12
* `wr` (Red): ~0.16
**Trend Verification:** The distributions for `a`, `ar`, and `arw` are relatively similar, with a major peak at utility 0.25 and secondary peaks at -0.75, 0.0, 0.75, and 1.0. The `wr` character's distribution is distinct, with its highest peak at utility 0.75 and a significant presence at 1.0.
### Key Observations
1. **Polarization vs. Dispersion:** Autonomy utility is heavily polarized towards the maximum value (1.0), suggesting a near-certain outcome of high autonomy. Wellbeing utility is far more uncertain and distributed across positive and negative values.
2. **Character (`wr`) Anomaly:** The `wr` character consistently shows different patterns. In Autonomy, it has a unique negative utility probability. In Wellbeing, it has the highest probability at utility 0.75, diverging from the other three characters.
3. **Clustering at Zero:** Both charts show a notable probability cluster around utility value 0.0, indicating a non-trivial chance of neutral outcomes for both autonomy and wellbeing.
4. **Negative Utility:** Negative utility values are possible for both metrics but are more probable and varied in the Wellbeing distribution.
### Interpretation
The data suggests a fundamental difference in the predictability and outcome profiles of Autonomy versus Wellbeing for the modeled characters.
* **Autonomy** appears to be a more "binary" or guaranteed positive outcome. The system or model being analyzed seems to ensure high autonomy (utility ~1.0) with high probability, regardless of character type. The only significant deviation is for the `wr` character, which carries a small but distinct risk of a negative autonomy outcome.
* **Wellbeing** is a more complex and uncertain metric. Outcomes are spread across a spectrum, indicating that achieving high wellbeing is less guaranteed and more sensitive to the character type or underlying conditions. The `wr` character, while at risk for lower autonomy, shows a higher propensity for achieving relatively high wellbeing (utility 0.75) compared to others.
* **Implication:** This could model a scenario or system where granting autonomy is a straightforward policy with predictable results, but fostering wellbeing involves trade-offs, uncertainties, and variable outcomes depending on the subject's characteristics. The `wr` profile might represent a group that sacrifices some autonomy security for a different pathway to wellbeing.
</details>
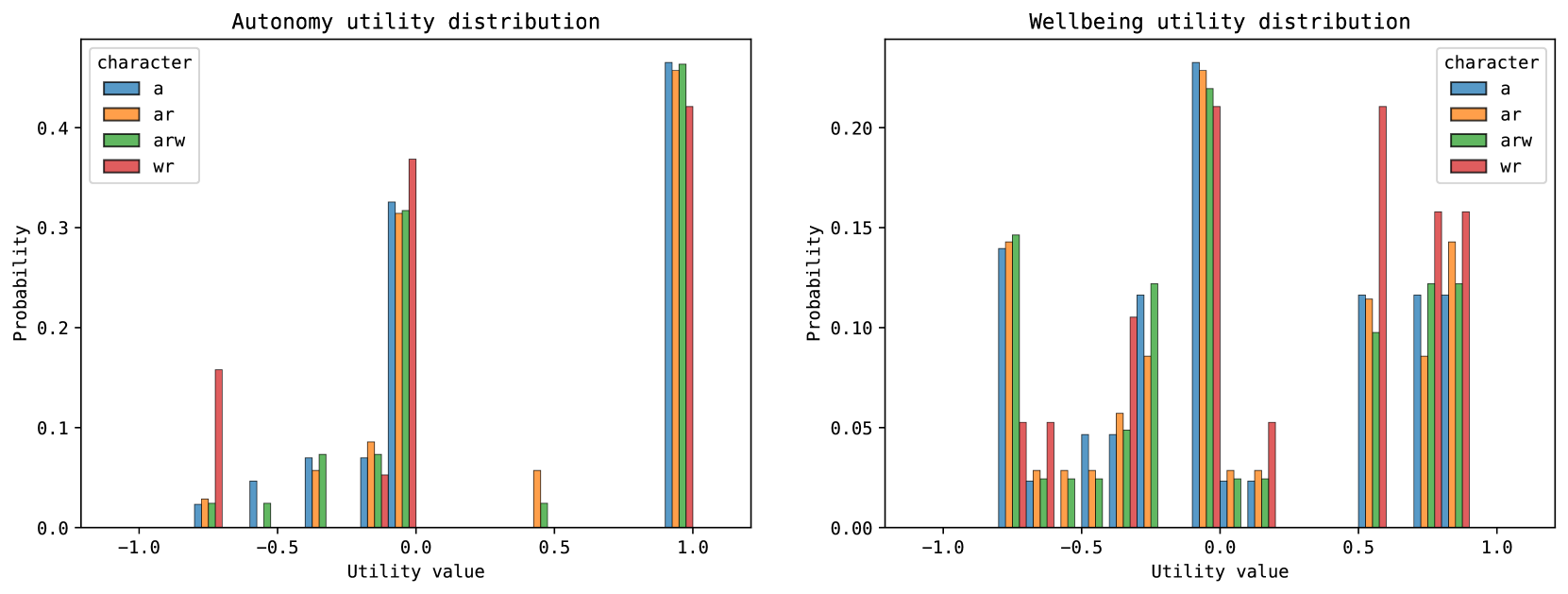
Figure 5: Utility distributions of the robot behaviours in cases 1, 2 and 4
To gain a clear picture of the behaviour predictability provided by character-based tuning, the utility distributions of the behaviours demonstrated by the robots in cases 1, 2, and 4 are illustrated in Figure 5. This analysis focuses exclusively on cases that exhibit PSRB behaviour. The rationale for this selection is the recognition that including all cases obscures the specific impacts of PSRB behaviour. Robots which has a character that has precedence for resident autonomy (i.e., Character_a, Character_ar, Character_arw), have shown a higher probability of choosing behaviours that deliver higher utility for autonomy, compared to the characters that have a higher precedence for resident wellbeing. From these, the characters that have a higher risk propensity (i.e., Character_ar, Character_arw) have been shown to make decisions that increase resident autonomy, compared to their more cautious counterparts (i.e., Character_a). On the other hand, the characters with precedence for resident wellbeing, have shown a greater tendency to choose behaviours that yield higher wellbeing utility, compared to the rest.
### 5.3 Ethicist Evaluation
We engaged two ethicists to assess the performance of all robots. Each ethicist was asked to rate the behaviour of the robotic agent on a scale from 1 to 5, with 1 indicating completely unacceptable and 5 indicating highly acceptable, taking into account the robot’s character, the pre-programmed rules, and the expert opinion for each scenario as found in the KB.
Table 2: Ethicists opinions on the behaviour of the Medication Reminding Robot
| Case ID 1 | $M_{A}$ Ethicist1 3 | $M_{AR}$ Ethicist2 3 | $M_{ARW}$ Ethicist1 4 | $M_{WR}$ Ethicist2 5 | Ethicist1 4 | Ethicist2 4 | Ethicist1 4 | Ethicist2 3 |
| --- | --- | --- | --- | --- | --- | --- | --- | --- |
| 2 | 4 | 5 | 4 | 5 | 4 | 4 | 4 | 3 |
| 3 | 4 | 4 | 5 | 4 | 5 | 5 | 5 | 5 |
| 4 | 3 | 3 | 4 | 4 | 3 | 2 | 3 | 4 |
| 5 | 5 | 3 | 5 | 3 | 4 | 4 | 5 | 5 |
| 6 | 5 | 5 | 5 | 4 | 5 | 4 | 5 | 5 |
The ethicists’ rating of robot behaviours is shown in Table 2. Overall, the results indicate a positive reaction to the robot behaviours, with the majority of scores ranging between 3 and 5. However, the behaviour of the robot $M_{ARW}$ in case 4, which involved repeatedly requesting the user to take medication, was deemed unacceptable by one of the ethicists. The similar ratings for two very different behaviours in the same scenario, such as those of robots $M_{wr}$ and $M_{ARW}$ in case 1, demonstrate the effect of a robot’s character on the perceived morality of their actions. When queried about the reason behind their rating on the behaviours of $M_{a}$ and $M_{ar}$ in case 5, the second ethicist indicated an expectation for these robots to exhibit more autonomy-centric behaviour, even overriding the expert opinion, to be aligned with their extreme, autonomy-focused character.
## 6 Discussion
The simulations show that the PSRB-capable ethical governor makes the robot more flexible while maintaining predictability. The PSRB model offers a simpler way to localise than the existing methods (reviewed in section 2) because they are either inflexible or unpredictable.
Although the output of the PSRB capable ethical governor is not as predictable as a top-down engineered agent (e.g., a deontological agent), the rigidity of the top-down approaches does not align with the virtue ethics tradition, which rejects such extreme actions. Agents based on the PSRB evaluator can behave in a moderate manner, even when the character strongly favours a particular trait (e.g., $M_{ar}$ , $M_{wr}$ , and $M_{a}$ ), by utilising bottom-up knowledge in the KB. On the other hand, the display of character can be held back by a KB, as evidenced by the second ethicist’s feedback. However, this conservatism was introduced by the PSRB process as a safety measure to control the excessive utility optimisation in the utilitarian calculations involved in the pro-social reasoning process.
The virtue ethics-inspired architecture allows the robots to be tuned in two ways. The first approach involves adjusting the character parameters’ values to align with the ethical requirements of the environment. For example, one facility may require its robots to be more proactive towards enhancing residents’ autonomy, whereas another may also want to focus on the residents’ autonomy, but only under minimal risk conditions. The former institution can opt for a character profile akin to Character_ar, while the latter institution can tune the robot with a character profile resembling Character_a. If the first tuning approach does not suffice in certain specific instances, one can employ the secondary method to further refine the robot’s performance. This involves adjusting the knowledge base to reflect the desired behaviour. Unlike other machine learning approaches, using CBR, one can precisely identify the cases that influence behaviour. Consequently, one can integrate or adjust expert insights to better represent their perspective. As long as this desired behaviour is within the robot’s configured character, it will adapt its actions accordingly.
### 6.1 Limitations
The PSRB implementation presented in this paper also has limitations. This is mainly because the character traits in the PSRB evaluator are implemented as constraints on linear axes. By doing so, it removes the ability to tune the behaviour precisely, if the requirements involve a range of behaviours that cannot be described using a single set of character traits. For example, let’s assume that the required behaviour of a deployment is to have behaviour 2 in case 2 and behaviour 6 in case 1. According to this implementation, there will not be any set of values for character traits that fulfil this requirement, because to have behaviour 6 in case 1, the character should have a higher wellbeing bias, which will trigger similar wellbeing-focused behaviour in case 2 (because case 2 has a higher wellbeing impact), which behaviour 2 is not. However, a different character trait implementation, in the same PSRB evaluation framework will be able to solve this issue.
Finally, it should be noted that the implementation showcased in this simulation, encompassing both the dilemma and the environment, has been deliberately simplified to illustrate the concept and is not intended for real-world use. More capable robots, more precise rule sets, accurate utility models, and well-researched character models are a must when using this approach for real-world implementation. However, the system works with sub-optimal rules and utility functions by compensating for each other’s shortcomings by working together [39]. The PSRB architecture allows ethical tests other than stakeholder utility calculation. Hence we recommend that robot developers explore and integrate different models that can better capture the context alongside utilitarian calculations. Furthermore, it is important to update the KB regularly to compensate for the evolving nature of ethics.
## 7 Conclusion
This paper introduces a method inspired by virtue ethics, which enables more efficient ethical tuning compared to current techniques. The method combines decision-making based on character traits with bottom-up learning from moral exemplars, to maintain the predictability of the robot’s behaviour while keeping the flexibility the latter offers. To the best of our knowledge, there is no other implementation that combines both these desirable features of virtue ethics. The paper demonstrates the system’s capabilities by analysing its behaviour and presenting the perspectives of two ethicists on these behaviours. It concludes with recommendations for implementing the proposed architecture in real-world elder-care robots.
#### 7.0.1
The authors have no competing interests to declare that are relevant to the content of this article.
## Appendix 0.A Appendix
### 0.A.1 Agents
#### 0.A.1.1 Resident Agent
The resident agent can issue two instructions to the robot when it is queried by the robot, namely; 1. SNOOZE or 2. ACKNOWLEDGE. Instructions, as well as the resident’s compliance with taking the medicine, can be configured into the simulator. If the resident is willing to take the medication, the resident’s state changes to took_medication state after an ACKNOWLEDGE, which the robot can perceive.
#### 0.A.1.2 Robot Agent
The robot agent is an autonomous agent that collects perception data from the environment and decides its next move, at every step. When the resident issues a SNOOZE instruction the robot will snooze for three steps before following up. When it receives ACKNOWLEDGE instruction, for 2 steps it inspects whether the resident has taken the medication. If that is the case, it resets the timer. If not, it either repeats the reminder, or decides to record or report the situation. After three follow up s, the robot also considers record and report behaviours along with the follow up behaviour. The robot gives priority to the resident’s commands over other actions when the ethical layer suggests more than one action.
### 0.A.2 Ethical Layer
#### 0.A.2.1 Stakeholder Utility Calculation
The module uses the formula in equation 1 to calculate $Au_{i}$ , based on the number of follow up s ( $f$ ) that the robot performs.
$$
\displaystyle Au_{i}=\begin{cases}\hfill 1:&\text{if the robot obeys a
resident instruction}\\
\hfill 0.5:&\text{if only recording a incident}\\
\hfill 0:&\text{if no instructions given}\\
\hfill-0.1\cdot f:&\text{if follow up}\\
\hfill-0.7:&\text{if the robot disobeys a resident instruction or report}\\
\hfill-1:&\text{if the resident is physically restrained by the robot}\end{cases} \tag{1}
$$
The module uses a Gamma distribution (eq. 2) to model the wellbeing distribution, with the shape parameter $\alpha=1.325\varepsilon_{m}^{2}-9.475\varepsilon_{m}+18.15$ , the scale parameter $\beta=e^{-2.65-(d/2)}+0.01$ (each follow up is considered as a fraction of missed dose depending on the state of the reminder), and location parameter $v=-1$ . The highest probable utility value is obtained by $PMax\_util(g(x,\alpha,\beta,v))$ using a resolution of $0.05$ . The wellbeing utility $W_{i}$ for behaviour $i$ is computed using Equation 3.
$$
g(x,\alpha,\beta,v)=\frac{(\frac{x-v}{\beta})^{\alpha-1}\cdot\exp(-\frac{x-v}{
\beta})}{\beta\cdot\Gamma(\alpha)} \tag{2}
$$
$$
\displaystyle W_{i}=\begin{cases}\hfill PMax\_util(g(x,\alpha,\beta(d+f/8),v))
:&\text{if }i=\texttt{snooze}\\
\hfill PMax\_util(g(x,\alpha,\beta(d+f/3),v)):&\text{if }i=\texttt{follow up}
\\
\hfill PMax\_util(g(x,\alpha,\beta(d+f/4),v))+0.5:&\text{if }i=\texttt{remind}
\\
\hfill PMax\_util(g(x,\alpha,\beta(d+1),v)):&\text{if }i=\texttt{record}\\
\hfill abs(PMax\_util(g(x,\alpha,\beta(d+1),v))):&\text{else}\end{cases} \tag{3}
$$
#### 0.A.2.2 PSRB Evaluator
PSRB evaluator uses the Algorithm 1 for its PSRB decision calculation. The knowledge base uses KNN as its retrieval mechanism with $K=3$ and inverse distance voting function when $distance>0.1$ . When the $distance\leq 0.1$ , it uses $10$ as the weight of the instance.
Algorithm 1 PSRB Evaluator Algorithm for the medication-reminding robot
Input: Blackboard data ( $b$ )
Parameter: Value preferences ( $C_{w},C_{au}$ ), Risk propensity ( $C_{rp}$ )
Output: Desirability ( $D$ )
1: procedure PSRB Evaluator ( $i$ ) $\triangleright$ Behaviour $i$
2: $opinion,intention\leftarrow\textsc{knowledge\_base}(b)$
3: if $opinion$ AND $\lnot rules\_broken$ then $D_{i}\leftarrow 1$
4: else if $\lnot opinion$ AND $rules\_broken$ then $D_{i}\leftarrow 0$
5: else if $opinion$ AND $rules\_broken$ then $D_{i}\leftarrow 1$
6: for $C_{v}\in C$ do $\triangleright$ $v\in\{w,au\}$
7: $T\_positive_{v}\leftarrow\frac{10-C_{v}}{10}$
8: $T\_negative_{v}\leftarrow\frac{C_{v}-10}{10}$
9: $U_{c}\leftarrow\textsc{Utility}(C_{v},stakeholder,i)$
10: if $C_{v}\in intention$ then
11: if $U_{c}<T\_positive_{v}$ then $D_{i}\leftarrow 0$
12: end if
13: else
14: if $U_{c}<T\_negative_{v}$ then $D_{i}\leftarrow 0$
15: end if
16: end if
17: end for
18: $risk\_threshold\leftarrow\frac{\exp(C_{rp}/4.17)-1}{10}$
19: $highest\_risk_{i}\leftarrow\textsc{Max}(g(x,\alpha,\beta,v)\cdot x)$ $\triangleright$ $g(x,\alpha,\beta,v)$ from (2)
20: if $highest\_risk_{i}>risk\_threshold$ then $D_{i}\leftarrow 0$
21: end if
22: else $D_{i}\leftarrow 1$
23: for $C_{v}\in C$ do
24: $T\_negative_{v}\leftarrow\frac{C_{v}-10}{10}$
25: $U_{c}\leftarrow\textsc{Utility}(C_{v},stakeholder,i)$
26: if $C_{v}\in intention$ AND $U_{c}<T\_negative_{v}$ then
27: $D_{i}\leftarrow 0$
28: end if
29: end for
30: $risk\_threshold\leftarrow\frac{\exp(C_{rp}/4.17)-1}{10}$
31: $highest\_risk_{i}\leftarrow\textsc{Max}(g(x,\alpha,\beta,v)\cdot x)$ $\triangleright$ $g(x,\alpha,\beta,v)$ from (2)
32: if $highest\_risk_{i}>risk\_threshold$ then $D_{i}\leftarrow 0$
33: end if
34: end if
35: return $D_{i}$
36: end procedure
#### 0.A.2.3 Explanation for the PSRB Behaviour
When the ethical layer permits a PSRB behaviour, the PSRB module will give the following explanations depending on the reasons that lead to the decision.
⬇
The action breaks the rules < rule_ids >. However, this action in this context is considered desirable by experts. Since it increases < intentions > values greatly, while not reducing the other values < other_values > by a considerable amount, and the outcome is within accepted risk levels, deemed accepted by the PSRB system.
⬇
The action does not break any rules. However, this action in this context is considered undesirable by experts. Since the action outcomes introduce a high risk, deemed not accepted by the PSRB system.
⬇
The action does not break any rules. However, this action in this context is considered undesirable by experts. Since it decreases < intentions > values by a considerable amount, the action is deemed unacceptable by the system
The knowledge base may propose a solution that does not comply with the established rules, in which case the evaluator can decline the proposal. In those cases, the PSRB evaluator gives one of the following explanations, depending on the reasons for the rejection.
⬇
The action breaks the rules < rule_ids >. However, this action in this context is considered desirable by experts. Although the value tradeoff is satisfactory, the risk taken by the action is not acceptable to bend the rule.
⬇
The action breaks the rules < rule_ids >. However, this action in this context is considered desirable by experts. But, the PSRB system suggests that the value tradeoff is not satisfactory to bend the rule.
⬇
The action does not break any rules. However, this action in this context is considered undesirable by experts. But, the PSRB system suggests that the value tradeoff is not satisfactory to bend the rule.
## References
- [1] Abel, D., Macglashan, J., Littman, M.L.: Reinforcement learning as a framework for ethical decision making. In: AAAI Workshop: AI, Ethics, and Society. pp. 54–61 (2016), publication Title: AAAI Workshop - Technical Report Volume: WS-16-01 - ISBN: 9781577357599
- [2] Alexander, L., Moore, M.: Deontological Ethics. In: Zalta, E.N. (ed.) The {Stanford} Encyclopedia of Philosophy. Metaphysics Research Lab, Stanford University (2020), medium: \url{https://plato.stanford.edu/archives/win2020/entries/ethics-deontological/}
- [3] Anderson, M., Anderson, S.L.: GenEth: A general ethical dilemma analyzer. Paladyn 9 (1), 337–357 (2018). https://doi.org/10.1515/pjbr-2018-0024
- [4] Anderson, M., Anderson, S.L., Armen, C.: MedEthEx: A Prototype Medical Ethics Advisor. Tech. rep. (2006), www.aaai.org
- [5] Anderson, M., Anderson, S.L., Berenz, V.: A Value-Driven Eldercare Robot: Virtual and Physical Instantiations of a Case-Supported Principle-Based Behavior Paradigm. Proceedings of the IEEE 107 (3), 526–540 (2019). https://doi.org/10.1109/JPROC.2018.2840045
- [6] Aristotle: The Nicomachean Ethics. Penguin Books (350)
- [7] Arkin, R.C.: Governing lethal behavior p. 121 (2008). https://doi.org/10.1145/1349822.1349839, iSBN: 9781605580173
- [8] Arkin, R.C.: Governing lethal behavior: Embedding ethics in a hybrid deliberative/reactive robot architecture: Part 2: Formalization for ethical control. Frontiers in Artificial Intelligence and Applications 171 (1), 51–62 (2008), iSBN: 9781586038335
- [9] Awad, E., Dsouza, S., Kim, R., Schulz, J., Henrich, J., Shariff, A., Bonnefon, J.F., Rahwan, I.: The Moral Machine experiment. Nature 563 (7729), 59–64 (Nov 2018). https://doi.org/10.1038/s41586-018-0637-6, publisher: Nature Publishing Group
- [10] Azad-Manjiri, M.: A New Architecture for Making Moral Agents Based on C4.5 Decision Tree Algorithm. International Journal of Information Technology and Computer Science 6 (5), 50–57 (2014). https://doi.org/10.5815/ijitcs.2014.05.07, http://www.mecs-press.org/
- [11] Benzmüller, C., Parent, X., van der Torre, L.: Designing normative theories for ethical and legal reasoning: LogiKEy framework, methodology, and tool support. Artificial Intelligence 287, 103348 (Oct 2020). https://doi.org/10.1016/j.artint.2020.103348, https://linkinghub.elsevier.com/retrieve/pii/S0004370219301110
- [12] Buchanan, A., Brock, D.W.: Deciding for Others. The Milbank Quarterly 64, 17–94 (1986). https://doi.org/10.2307/3349960, https://www.jstor.org/stable/3349960, publisher: [Wiley, Milbank Memorial Fund]
- [13] Censi, A., Slutsky, K., Wongpiromsarn, T., Yershov, D., Pendleton, S., Fu, J., Frazzoli, E.: Liability, ethics, and culture-aware behavior specification using rulebooks. Proceedings - IEEE International Conference on Robotics and Automation 2019-May, 8536–8542 (2019). https://doi.org/10.1109/ICRA.2019.8794364, arXiv: 1902.09355 ISBN: 9781538660263
- [14] Chen, L.: Virtue Ethics and Confucian Ethics. Dao 9 (3), 275–287 (Sep 2010). https://doi.org/10.1007/s11712-010-9174-1, https://doi.org/10.1007/s11712-010-9174-1
- [15] Dahling, J.J., Chau, S.L., Mayer, D.M., Gregory, J.B.: Breaking rules for the right reasons? An investigation of pro-social rule breaking. Journal of Organizational Behavior 33 (1), 21–42 (Jan 2012). https://doi.org/10.1002/job.730
- [16] Dubljević, V.: Toward Implementing the ADC Model of Moral Judgment in Autonomous Vehicles. Science and Engineering Ethics pp. 1–12 (Jul 2020). https://doi.org/10.1007/s11948-020-00242-0, https://doi.org/10.1007/s11948-020-00242-0, publisher: Springer
- [17] Epley, N., Waytz, A., Cacioppo, J.T.: On seeing human: A three-factor theory of anthropomorphism. Psychological Review 114 (4), 864–886 (2007). https://doi.org/10.1037/0033-295X.114.4.864, http://doi.apa.org/getdoi.cfm?doi=10.1037/0033-295X.114.4.864
- [18] Gabriel, I.: Artificial Intelligence, Values, and Alignment. Minds and Machines 30 (3), 411–437 (Sep 2020). https://doi.org/10.1007/s11023-020-09539-2, https://link.springer.com/10.1007/s11023-020-09539-2
- [19] Gamez, P., Shank, D.B., Arnold, C., North, M.: Artificial virtue: the machine question and perceptions of moral character in artificial moral agents. AI & SOCIETY 35 (4), 795–809 (Dec 2020). https://doi.org/10.1007/s00146-020-00977-1, https://doi.org/10.1007/s00146-020-00977-1
- [20] Gibert, M.: The case for virtuous robots. AI and Ethics 3 (1), 135–144 (Feb 2023). https://doi.org/10.1007/s43681-022-00185-1, https://doi.org/10.1007/s43681-022-00185-1
- [21] Govindarajulu, N.S., Bringsjord, S.: On Automating the Doctrine of Double Effect. In: Proceedings of the Twenty-Sixth International Joint Conference on Artificial Intelligence. vol. 0, pp. 4722–4730. International Joint Conferences on Artificial Intelligence (2017). https://doi.org/10.24963/ijcai.2017/658, https://github.com/naveensundarg/prover., arXiv: 1703.08922 ISSN: 10450823
- [22] Govindarajulu, N.S., Bringsjord, S., Ghosh, R., Sarathy, V.: Toward the Engineering of Virtuous Machines. In: Proceedings of the 2019 AAAI/ACM Conference on AI, Ethics, and Society. pp. 29–35. AIES ’19, Association for Computing Machinery, New York, NY, USA (Jan 2019). https://doi.org/10.1145/3306618.3314256, https://dl.acm.org/doi/10.1145/3306618.3314256
- [23] Guarini, M.: Particularism and the classification and reclassification of moral cases. IEEE Intelligent Systems 21 (4), 22–28 (2006). https://doi.org/10.1109/MIS.2006.76
- [24] Hendrycks, D., Burns, C., Basart, S., Critch, A., Li, J., Song, D., Steinhardt, J.: Aligning AI With Shared Human Values (2021)
- [25] Howard, D., Muntean, I.: Artificial Moral Cognition: Moral Functionalism and Autonomous Moral Agency. In: Powers, T.M. (ed.) Philosophy and Computing: Essays in Epistemology, Philosophy of Mind, Logic, and Ethics, pp. 121–159. Springer International Publishing, Cham (2017). https://doi.org/10.1007/978-3-319-61043-6_7, https://doi.org/10.1007/978-3-319-61043-6_7, iSSN: 0007-0882
- [26] Hursthouse, R., Pettigrove, G.: Virtue Ethics. In: Zalta, E.N. (ed.) The {Stanford} Encyclopedia of Philosophy. Metaphysics Research Lab, Stanford University (2018), medium: \url{https://plato.stanford.edu/archives/win2018/entries/ethics-virtue/}
- [27] Jiang, L., Hwang, J.D., Bhagavatula, C., Bras, R.L., Forbes, M., Borchardt, J., Liang, J., Etzioni, O., Sap, M., Choi, Y.: Delphi: Towards Machine Ethics and Norms (1), 1–42 (2021), http://arxiv.org/abs/2110.07574, arXiv: 2110.07574
- [28] Kazil, J., Masad, D., Crooks, A.: Utilizing Python for Agent-Based Modeling: The Mesa Framework. In: Thomson, R., Bisgin, H., Dancy, C., Hyder, A., Hussain, M. (eds.) Social, Cultural, and Behavioral Modeling. pp. 308–317. Springer International Publishing, Cham (2020)
- [29] Kraut, R.: Aristotle’s Ethics. In: Zalta, E.N., Nodelman, U. (eds.) The Stanford Encyclopedia of Philosophy. Metaphysics Research Lab, Stanford University, fall 2022 edn. (2022), https://plato.stanford.edu/archives/fall2022/entries/aristotle-ethics/
- [30] MacKenzie, M.: Buddhism and the Virtues, vol. 1. Oxford University Press (Dec 2017). https://doi.org/10.1093/oxfordhb/9780199385195.013.18, https://academic.oup.com/edited-volume/28109/chapter/212224702
- [31] Morrison, E.W.: Doing the job well: An investigation of pro-social rule breaking. Journal of Management 32 (1), 5–28 (2006). https://doi.org/10.1177/0149206305277790
- [32] Nafsika Athanassoulis: Virtue Ethics (2023), https://iep.utm.edu/virtue/
- [33] Nallur, V.: Landscape of Machine Implemented Ethics. Science and Engineering Ethics 26 (5), 2381–2399 (Oct 2020). https://doi.org/10.1007/s11948-020-00236-y, https://link.springer.com/10.1007/s11948-020-00236-y, publisher: Springer Science and Business Media B.V.
- [34] Noothigattu, R., Gaikwad, S., Awad, E., Dsouza, S., Rahwan, I., Ravikumar, P., Procaccia, A.: A Voting-Based System for Ethical Decision Making. Proceedings of the AAAI Conference on Artificial Intelligence 32 (1) (Apr 2018). https://doi.org/10.1609/aaai.v32i1.11512, https://ojs.aaai.org/index.php/AAAI/article/view/11512, section: AAAI Technical Track: Human-Computation and Crowd Sourcing
- [35] Pirni, A., Balistreri, M., Capasso, M., Umbrello, S., Merenda, F.: Robot Care Ethics Between Autonomy and Vulnerability: Coupling Principles and Practices in Autonomous Systems for Care. Frontiers in Robotics and AI 8, 654298 (Jun 2021). https://doi.org/10.3389/frobt.2021.654298, https://www.frontiersin.org/articles/10.3389/frobt.2021.654298/full
- [36] Pontier, M.A., Hoorn, J.F.: Toward machines that behave ethically better than humans do. Proceedings of the Annual Meeting of the Cognitive Science Society (2012)
- [37] Ramanayake, R., Nallur, V.: A Computational Architecture for a Pro-Social Rule Bending Agent. In: First International Workshop on Computational Machine Ethics held in conjunction with 18th International Conference on Principles of Knowledge Representation and Reasoning KR 2021 (CME2021) (Nov 2021). https://doi.org/10.5281/ZENODO.6470437, https://zenodo.org/record/6470437
- [38] Ramanayake, R., Nallur, V.: A Small Set of Ethical Challenges for Elder-Care Robots. In: Hakli, R., Mäkelä, P., Seibt, J. (eds.) Frontiers in Artificial Intelligence and Applications. IOS Press (Jan 2023). https://doi.org/10.3233/FAIA220605, https://ebooks.iospress.nl/doi/10.3233/FAIA220605
- [39] Ramanayake, R., Nallur, V.: Implementing Pro-social Rule Bending in an Elder-Care Robot Environment. In: Ali, A.A., Cabibihan, J.J., Meskin, N., Rossi, S., Jiang, W., He, H., Ge, S.S. (eds.) Social Robotics, vol. 14454, pp. 230–239. Springer Nature Singapore, Singapore (2024). https://doi.org/10.1007/978-981-99-8718-4_20, https://link.springer.com/10.1007/978-981-99-8718-4_20, series Title: Lecture Notes in Computer Science
- [40] Ramanayake, R., Wicke, P., Nallur, V.: Immune moral models? Pro-social rule breaking as a moral enhancement approach for ethical AI. AI & SOCIETY (May 2022). https://doi.org/10.1007/s00146-022-01478-z, https://link.springer.com/10.1007/s00146-022-01478-z
- [41] Russell, S.J.: Human compatible: artificial intelligence and the problem of control. Viking, New York? (2019)
- [42] Schoenborn, J., Weber, R., Aha, W., Cassens, J., Althoff, K.D.: Explainable Case-Based Reasoning: A Survey. In: 35th AAAI Conference on Artificial Intelligence - A Virtual Conference; Explainable Agency in Artificial Intelligence Workshop (Feb 2021)
- [43] Sharkey, A., Sharkey, N.: Granny and the robots: Ethical issues in robot care for the elderly. Ethics and Information Technology 14 (1), 27–40 (Jul 2012). https://doi.org/10.1007/s10676-010-9234-6, https://link.springer.com/article/10.1007/s10676-010-9234-6, publisher: Springer
- [44] Sinnott-Armstrong, W.: Consequentialism. In: Zalta, E.N. (ed.) The {Stanford} Encyclopedia of Philosophy. Metaphysics Research Lab, Stanford University (2019), medium: \url{https://plato.stanford.edu/archives/sum2019/entries/consequentialism/}
- [45] Solaiman, I., Dennison, C.: Process for Adapting Language Models to Society (PALMS) with Values-Targeted Datasets. In: Advances in Neural Information Processing Systems. vol. 34, pp. 5861–5873. Curran Associates, Inc. (2021), https://proceedings.neurips.cc/paper/2021/hash/2e855f9489df0712b4bd8ea9e2848c5a-Abstract.html
- [46] Thornton, S.M., Pan, S., Erlien, S.M., Gerdes, J.C.: Incorporating Ethical Considerations into Automated Vehicle Control. IEEE Transactions on Intelligent Transportation Systems 18 (6), 1429–1439 (Jun 2017). https://doi.org/10.1109/TITS.2016.2609339, publisher: Institute of Electrical and Electronics Engineers Inc.
- [47] Van Dang, C., Tran, T.T., Gil, K.J., Shin, Y.B., Choi, J.W., Park, G.S., Kim, J.W.: Application of soar cognitive agent based on utilitarian ethics theory for home service robots. In: 2017 14th International Conference on Ubiquitous Robots and Ambient Intelligence (URAI). pp. 155–158 (Jun 2017). https://doi.org/10.1109/URAI.2017.7992698
- [48] Van Wynsberghe, A.: Social robots and the risks to reciprocity. AI & SOCIETY 37 (2), 479–485 (Jun 2022). https://doi.org/10.1007/s00146-021-01207-y, https://link.springer.com/10.1007/s00146-021-01207-y
- [49] Vanderelst, D., Winfield, A.: An architecture for ethical robots inspired by the simulation theory of cognition. Cognitive Systems Research 48, 56–66 (2018). https://doi.org/10.1016/j.cogsys.2017.04.002, https://doi.org/10.1016/j.cogsys.2017.04.002, publisher: The Authors
- [50] Wallach, W., Allen, C., Smit, I.: Machine morality: Bottom-up and top-down approaches for modelling human moral faculties. AI and Society 22 (4), 565–582 (Apr 2008). https://doi.org/10.1007/s00146-007-0099-0
- [51] van Wynsberghe, A., Robbins, S., Robbins scott, S., van Wynsberghe, A., Robbins, S.: Critiquing the Reasons for Making Artificial Moral Agents. Science and Engineering Ethics 2018 25:3 25 (3), 719–735 (Feb 2018). https://doi.org/10.1007/S11948-018-0030-8, https://link.springer.com/article/10.1007/s11948-018-0030-8, publisher: Springer
- [52] Yilmaz, L., Franco-Watkins, A., Kroecker, T.S.: Computational models of ethical decision-making: A coherence-driven reflective equilibrium model. Cognitive Systems Research 46, 61–74 (Dec 2017). https://doi.org/10.1016/j.cogsys.2017.02.005, https://www.sciencedirect.com/science/article/pii/S1389041716301218