# Nearest-Neighbours Neural Network architecture for efficient sampling of statistical physics models
**Authors**: Luca Maria Del Bono, Federico Ricci-Tersenghi, Francesco Zamponi
> Dipartimento di Fisica, Sapienza Università di Roma, Piazzale Aldo Moro 5, Rome 00185, Italy CNR-Nanotec, Rome unit, Piazzale Aldo Moro 5, Rome 00185, Italy
> Dipartimento di Fisica, Sapienza Università di Roma, Piazzale Aldo Moro 5, Rome 00185, Italy CNR-Nanotec, Rome unit, Piazzale Aldo Moro 5, Rome 00185, Italy INFN, sezione di Roma1, Piazzale Aldo Moro 5, Rome 00185, Italy
> Dipartimento di Fisica, Sapienza Università di Roma, Piazzale Aldo Moro 5, Rome 00185, Italy
thanks: Corresponding author: lucamaria.delbono@uniroma1.it
## Abstract
The task of sampling efficiently the Gibbs-Boltzmann distribution of disordered systems is important both for the theoretical understanding of these models and for the solution of practical optimization problems. Unfortunately, this task is known to be hard, especially for spin-glass-like problems at low temperatures. Recently, many attempts have been made to tackle the problem by mixing classical Monte Carlo schemes with newly devised Neural Networks that learn to propose smart moves. In this article, we introduce the Nearest-Neighbours Neural Network (4N) architecture, a physically interpretable deep architecture whose number of parameters scales linearly with the size of the system and that can be applied to a large variety of topologies. We show that the 4N architecture can accurately learn the Gibbs-Boltzmann distribution for a prototypical spin-glass model, the two-dimensional Edwards-Anderson model, and specifically for some of its most difficult instances. In particular, it captures properties such as the energy, the correlation function and the overlap probability distribution. Finally, we show that the 4N performance increases with the number of layers, in a way that clearly connects to the correlation length of the system, thus providing a simple and interpretable criterion to choose the optimal depth.
## Introduction
A central problem in many fields of science, from statistical physics to computer science and artificial intelligence, is that of sampling from a complex probability distribution over a large number of variables. More specifically, a very common such probability is a Gibbs-Boltzmann distribution. Given a set of $N\gg 1$ random variables $\boldsymbol{\sigma}=\{\sigma_{1},\cdots,\sigma_{N}\}$ , such a distribution is written in the form
$$
P_{\text{GB}}(\boldsymbol{\sigma})=\frac{e^{-\beta\mathcal{H}(\boldsymbol{
\sigma})}}{\mathcal{Z}(\beta)}\ . \tag{1}
$$
In statistical physics language, the normalization constant $\mathcal{Z}(\beta)$ is called partition function, $\mathcal{H}(\boldsymbol{\sigma})$ is called the Hamiltonian function and $\beta=1/T$ is the inverse temperature, corresponding to a global rescaling of $\mathcal{H}(\boldsymbol{\sigma})$ .
While Eq. (1) is simply a trivial definition, i.e. $\mathcal{H}(\boldsymbol{\sigma})=-\frac{1}{\beta}\log P_{\text{GB}}( \boldsymbol{\sigma})+\text{const}$ , the central idea of Gibbs-Boltzmann distributions is that $\mathcal{H}(\boldsymbol{\sigma})$ is expanded as a sum of ‘local’ interactions. For instance, in the special case of binary (Ising) variables, $\sigma_{i}\in\{-1,+1\}$ , one can always write
$$
\mathcal{H}=-\sum_{i}H_{i}\sigma_{i}-\sum_{i<j}J_{ij}\sigma_{i}\sigma_{j}-\sum
_{i<j<k}J_{ijk}\sigma_{i}\sigma_{j}\sigma_{k}+\cdots \tag{2}
$$
In many applications, like in physics (i.e. spin glasses), inference (i.e. maximum entropy models) and artificial intelligence (i.e. Boltzmann machines), the expansion in Eq. (2) is truncated to the pairwise terms, thus neglecting higher-order interactions. This leads to a Hamiltonian
$$
\mathcal{H}=-\sum_{i}H_{i}\sigma_{i}-\sum_{i<j}J_{ij}\sigma_{i}\sigma_{j} \tag{3}
$$
parametrized by ‘local external fields’ $H_{i}$ and ‘pairwise couplings’ $J_{ij}$ . In physics applications such as spin glasses, these are often chosen to be independent and identically distributed random variables, e.g. $H_{i}\sim\mathcal{N}(0,H^{2})$ and $J_{ij}\sim\mathcal{N}(0,J^{2}/N)$ . In Boltzmann Machines, instead, the fields and couplings are learned by maximizing the likelihood of a given training set.
In many cases, dealing with Eq. (1) analytically, e.g. computing expectation values of interesting quantities, is impossible, and one resorts to numerical computations. A universal strategy is to use local Markov Chain Monte Carlo (MCMC) methods, which have the advantage of being applicable to a wide range of different systems. In these methods, one proposes a local move, typically flipping a single spin, $\sigma_{i}\to-\sigma_{i}$ , and accepts or rejects the move in such a way to guarantee that after many iterations, the configuration $\boldsymbol{\sigma}$ is distributed according to Eq. (1). Unfortunately, these methods are difficult (if not altogether impossible) to apply in many hard-to-sample problems for which the convergence time is very large, which, in practice, ends up requiring a huge amount of computational time. For instance, finding the ground state of the Sherrington-Kirkpatrick model (a particular case of sampling at $T\to 0$ ) is known to be a NP-hard problem; sampling a class of optimization problems is known to take a time scaling exponentially with $N$ . The training of Boltzmann Machines is also known to suffer from this kind of problems.
These inconveniences can be avoided by using system-specific global algorithms that leverage properties of the system under examination in order to gain a significant speedup. Instead of flipping one spin at a time, these methods are able to construct smart moves, which update simultaneously a large number of spins. An example is the Wolff algorithm [1] for the Ising model. Another class of algorithms uses unphysical moves or extended variable spaces, such as the Swap Monte Carlo for glass-forming models of particles [2]. The downside of these algorithms is that they cannot generally be transferred from one system to another, meaning that one has to develop new techniques specifically for each system of interest. Yet another class is Parallel Tempering (PT) [3], or one of its modifications [4], which considers a group of systems at different temperatures and alternates between simple MCMC moves and moves that swap the systems at two different temperatures. While PT is a universal strategy, its drawback is that, in order to produce low-temperature configurations, one has to simulate the system at a ladder of higher temperatures, which can be computationally expensive and redundant.
The rise of machine learning technology has sparked a new line of research aimed at using Neural Networks to enhance Monte Carlo algorithms, in the wake of similar approaches in many-body quantum physics [5], molecular dynamics [6] and the study of glasses [7, 8, 9]. The key idea is to use the network to propose new states with a probability $P_{\text{NN}}$ that (i) can be efficiently sampled and (ii) is close to the Gibbs-Boltzmann distribution, e.g., with respect to the Kullback-Leibler (KL) divergence $D_{\text{KL}}$ :
$$
D_{\text{KL}}(P_{\text{GB}}\parallel P_{\text{NN}})=\sum_{\boldsymbol{\sigma}}
P_{\text{GB}}(\boldsymbol{\sigma})\log\frac{P_{\text{GB}}(\boldsymbol{\sigma})
}{P_{\text{NN}}(\boldsymbol{\sigma})}\ . \tag{4}
$$
The proposed configurations can be used in a Metropolis scheme, accepting them with probability:
$$
\begin{split}\text{Acc}\left[\boldsymbol{\sigma}\rightarrow\boldsymbol{\sigma}
^{\prime}\right]&=\min\left[1,\frac{P_{\text{GB}}(\boldsymbol{\sigma}^{\prime}
)\times P_{\text{NN}}(\boldsymbol{\sigma})}{P_{\text{GB}}(\boldsymbol{\sigma})
\times P_{\text{NN}}(\boldsymbol{\sigma}^{\prime})}\right]\\
&=\min\left[1,\frac{e^{-\beta\mathcal{H}(\boldsymbol{\sigma}^{\prime})}\times P
_{\text{NN}}(\boldsymbol{\sigma})}{e^{-\beta\mathcal{H}(\boldsymbol{\sigma})}
\times P_{\text{NN}}(\boldsymbol{\sigma}^{\prime})}\right].\end{split} \tag{5}
$$
Because $\mathcal{H}$ can be computed in polynomial time and $P_{\text{NN}}$ can be sampled efficiently by hypothesis, this approach ensures an efficient sampling of the Gibbs-Boltzmann probability, as long as (i) $P_{\text{NN}}$ covers well the support of $P_{\text{GB}}$ (i.e., the so-called mode collapse is avoided) and (ii) the acceptance probability in Eq. (5) is significantly different from zero for most of the generated configurations. This scheme can also be combined with standard local Monte Carlo moves to improve efficiency [10].
The main problem is how to train the Neural Network to minimize Eq. (4); in fact, the computation of $D_{\rm KL}$ requires sampling from $P_{\text{GB}}$ . A possible solution is to use $D_{\text{KL}}(P_{\text{NN}}\parallel P_{\text{GB}})$ instead [11], but this has been shown to be prone to mode collapse [12]. Another proposed solution is to set up an iterative procedure, called ‘Sequential Tempering’ (ST), in which one first learns $P_{\text{NN}}$ at high temperature where sampling from $P_{\text{GB}}$ is possible, then gradually decreases the temperature, updating $P_{\text{NN}}$ slowly [13]. A variety of new methods and techniques have thus been proposed to tackle the problem, such as autoregressive models [11, 13, 14], normalizing flows [15, 10, 16, 17], and diffusion models [18]. It is still unclear whether this kind of strategies actually performs well on hard problems and challenges already-existing algorithms [12]. The first steps in a theoretical understanding of the performances of such algorithms are just being made [19, 20]. The main drawback of these architectures is that the number of parameters scales poorly with the system size, typically as $N^{\alpha}$ with $\alpha>1$ , while local Monte Carlo requires a number of operations scaling linearly in $N$ . Furthermore, these architectures – with the notable exception of TwoBo [21] that directly inspired our work – are not informed about the physical properties of the model, and in particular about the structure of its interaction graph and correlations. It should be noted that the related problem of finding the ground state of the system (which coincides with zero-temperature sampling) has been tackled using similar ideas, again with positive [22, 23, 24, 25, 26] and negative results [27, 28, 29, 30].
In this paper, we introduce the Nearest Neighbours Neural Network, or 4N for short, a Graph Neural Network-inspired architecture that implements an autoregressive scheme to learn the Gibbs-Boltzmann distribution. This architecture has a number of parameters scaling linearly in the system size and can sample new configurations in $\mathcal{O}(N)$ time, thus achieving the best possible scaling one could hope for such architectures. Moreover, 4N has a straightforward physical interpretation. In particular, the choice of the number of layers can be directly linked to the correlation length of the model under study. Finally, the architecture can easily be applied to essentially any statistical system, such as lattices in higher dimensions or random graphs, and it is thus more general than other architectures. As a proof of concept, we evaluate the 4N architecture on the two-dimensional Edwards-Anderson spin glass model, a standard benchmark also used in previous work [13, 12]. We demonstrate that the model succeeds in accurately learning the Gibbs-Boltzmann distribution, especially for some of the most challenging model instances. Notably, it precisely captures properties such as energy, the correlation function, and the overlap probability distribution.
## State of the art
Some common architectures used for $P_{\text{NN}}$ are normalizing flows [15, 10, 16, 17] and diffusion models [18]. In this paper, we will however focus on autoregressive models [11], which make use of the factorization:
$$
\begin{split}&P_{\text{GB}}(\boldsymbol{\sigma})=P(\sigma_{1})P(\sigma_{2}\mid
\sigma_{1})P(\sigma_{3}\mid\sigma_{1},\sigma_{2})\times\\
&\times\cdots P(\sigma_{n}\mid\sigma_{1},\cdots,\sigma_{n-1})=\prod_{i=1}^{N}P
(\sigma_{i}\mid\boldsymbol{\sigma}_{<i})\ ,\end{split} \tag{6}
$$
where $\boldsymbol{\sigma}_{<i}=(\sigma_{1},\sigma_{2},\ldots,\sigma_{i-1})$ , so that states can then be generated using ancestral sampling, i.e. generating first $\sigma_{1}$ , then $\sigma_{2}$ conditioned on the sampled value of $\sigma_{1}$ , then $\sigma_{3}$ conditioned to $\sigma_{1}$ and $\sigma_{2}$ and so on. The factorization in (6) is exact, but computing $P(\sigma_{i}\mid\boldsymbol{\sigma}_{<i})$ exactly generally requires a number of operations scaling exponentially with $N$ . Hence, in practice, $P_{\text{GB}}$ is approximated by $P_{\text{NN}}$ that takes the form in Eq. (6) where each individual term $P(\sigma_{i}\mid\boldsymbol{\sigma}_{<i})$ is approximated using a small set of parameters. Note that the unsupervised problem of approximating $P_{\text{GB}}$ is now formally translated into a supervised problem of learning the output, i.e. the probability $\pi_{i}\equiv P(\sigma_{i}=+1\mid\boldsymbol{\sigma}_{<i})$ , as a function of the input $\boldsymbol{\sigma}_{<i}$ . The specific way in which this approximation is carried out depends on the architecture. In this section, we will describe some common autoregressive architectures found in literature, for approximating the function $\pi_{i}(\boldsymbol{\sigma}_{<i})$ .
- In the Neural Autoregressive Distribution Estimator (NADE) architecture [13], the input $\boldsymbol{\sigma}_{<i}$ is encoded into a vector $\mathbf{y}_{i}$ of size $N_{h}$ using
$$
\mathbf{y}_{i}=\Psi\left(\underline{\underline{A}}\boldsymbol{\sigma}_{<i}+
\mathbf{B}\right), \tag{7}
$$
where $\mathbf{y}_{i}\in\mathbb{R}^{N_{h}}$ , $\underline{\underline{A}}\in\mathbb{R}^{N_{h}\times N}$ and $\boldsymbol{\sigma}_{<i}$ is the vector of the spins in which the spins $l\geq i$ have been masked, i.e. $\mathbf{\sigma}_{<i}=(\sigma_{1},\sigma_{2},\dots,\sigma_{i-1},0,\dots,0)$ . $\mathbf{B}\in\mathbb{R}^{N_{h}}$ is the bias vector and $\Psi$ is an element-wise activation function. Note that $\underline{\underline{A}}$ and $\mathbf{B}$ do not depend on the index $i$ , i.e. they are shared across all spins. The information from the hidden layer is then passed to a fully connected layer
$$
{\color[rgb]{0,0,0}\psi_{i}}=\Psi\left(\mathbf{V}_{i}\cdot\mathbf{y}_{i}+C_{i}\right) \tag{8}
$$
where $\mathbf{V}_{i}\in\mathbb{R}^{N_{h}}$ and $C_{i}\in\mathbb{R}$ . Finally, the output probability is obtained by applying a sigmoid function to the output, $\pi_{i}=S({\color[rgb]{0,0,0}\psi_{i}})$ . The Nade Architecture uses $\mathcal{O}(N\times N_{h})$ parameters. However, the choice of the hidden dimension $N_{h}$ and how it should be related to $N$ is not obvious. For this architecture to work well in practical applications, $N_{h}$ needs to be $\mathcal{O}(N)$ , thus leading to $\mathcal{O}(N^{2})$ parameters [13].
- The Masked Autoencoder for Distribution Estimator (MADE) [31] is a generic dense architecture with the addition of the autoregressive requirement, obtained by setting, for all layers $l$ in the network, the weights $W^{l}_{ij}$ between node $j$ at layer $l$ and node $i$ at layer $l+1$ equal to 0 when $i\geq j$ . Between one layer and the next one adds nonlinear activation functions and the width of the hidden layers can also be increased. The MADE architecture, despite having high expressive power, has at least $\mathcal{O}(N^{2})$ parameters, which makes it poorly scalable.
- Autoregressive Convolutional Neural Network (CNN) architectures, such as PixelCNN [32, 33], are networks that implement a CNN structure but superimpose the autoregressive property. These architectures typically use translationally invariant kernels ill-suited to study disordered models.
- The TwoBo (two-body interaction) architecture [21] is derived from the observation that, given the Gibbs-Boltzmann probability in Eq. (1) and the Hamiltonian in Eq. (3), the probability $\pi_{i}$ can be exactly rewritten as [34]
$$
\pi_{i}(\boldsymbol{\sigma}_{<i})=S\left(2\beta h^{i}_{i}+2\beta H_{i}+\rho_{i
}(\boldsymbol{h}^{i})\right), \tag{9}
$$
where $S$ is the sigmoid function, $\rho_{i}$ is a highly non-trivial function and the $\boldsymbol{h}^{i}=\{h^{i}_{i},h^{i}_{i+1},\cdots h^{i}_{N}\}$ are defined as:
$$
h^{i}_{l}=\sum_{f<i}J_{lf}\sigma_{f}\quad\text{for}\quad l\geq i. \tag{10}
$$
Therefore, the TwoBo architecture first computes the vector $\boldsymbol{h}^{i}$ , then approximates $\rho_{i}(\boldsymbol{h}^{i})$ using a Neural Network (for instance, a Multilayer Perceptron) and finally computes Eq. (9) using a skip connection (for the term $2\beta h^{i}_{i}$ ) and a sigmoid activation. By construction, in a two-dimensional model with $N=L^{2}$ variables and nearest-neighbor interactions, for given $i$ only $\mathcal{O}(L=\sqrt{N})$ of the $h^{i}_{l}$ are non-zero, see Ref. [21, Fig.1]. Therefore, the TwoBo architecture has $\mathcal{O}(N^{\frac{3}{2}})$ parameters in the two-dimensional case. However, the scaling becomes worse in higher dimensions $d$ , i.e. $\mathcal{O}(N^{\frac{2d-1}{d}})$ and becomes the same as MADE (i.e. $\mathcal{O}(N^{2})$ ) for random graphs. Additionally, the choice of the $h^{i}_{l}$ , although justified mathematically, does not have a clear physical interpretation: the TwoBo architecture takes into account far away spins which, however, should not matter much when $N$ is large.
To summarize, the NADE, MADE and TwoBo architectures all need $\mathcal{O}(N^{2})$ parameters for generic models defined on random graph structures. TwoBo has less parameters for models defined on $d$ -dimensional lattices, but still $\mathcal{O}(N^{\frac{2d-1}{d}})\gg\mathcal{O}(N)$ . CNN architectures with translationally invariant kernels have fewer parameters, but are not suitable for disordered systems, are usually applied to $d=2$ and remain limited to $d\leq 3$ .
To solve these problems, we present here the new, physically motivated 4N architecture that has $\mathcal{O}(\mathcal{A}N)$ parameters, with a prefactor $\mathcal{A}$ that remains finite for $N\to\infty$ and is interpreted as the correlation length of the system, as we show in the next section.
<details>
<summary>x1.png Details</summary>
### Visual Description
\n
## Diagram: Graph Neural Network (GNN) Architecture for Grid-Based Probabilistic Prediction
### Overview
The image is a technical diagram illustrating a multi-stage process for using a Graph Neural Network (GNN) to predict the probability of a specific state for a target node within a grid structure. The process flows from an initial input grid, through graph construction and iterative GNN processing, to a final probabilistic output.
### Components/Axes
The diagram is segmented into five labeled components: (a), (b), (c), (d), and (e).
**Component (a): Input**
* **Title:** "Input"
* **Legend (Top-Left):**
* White square: `+1`
* Black square: `-1`
* Gray square: `Unf.` (likely abbreviation for "Unfilled" or "Unknown")
* **Content:** A 10x10 grid. The top 5 rows contain a checkerboard pattern of black (`-1`) and white (`+1`) squares. The bottom 5 rows are entirely gray (`Unf.`). A purple outline highlights a contiguous region of 13 squares (a mix of black, white, and gray) centered around a specific square labeled with the letter `i`.
**Component (b): Graph Construction**
* **Color Bar (Left):** A vertical gradient bar. The top is red, the middle is white labeled `0`, and the bottom is blue. This serves as a legend for node colors in the adjacent graph.
* **Content:** A graph representation derived from the input grid. Nodes are arranged in a lattice structure corresponding to the grid cells. Each node is colored according to the color bar (red, white, blue, or intermediate shades). The central node, corresponding to the `i` from the input, is white with a purple outline and labeled `i`. Nodes are connected by edges to their immediate neighbors.
**Component (c): GNN Processing Pipeline**
* **Content:** A vertical flowchart showing iterative processing.
1. An arrow from the graph in (b) points to a box labeled "GNN layer".
2. The output of the GNN layer goes to a circle containing a plus sign (`+`), indicating an aggregation or addition operation.
3. This produces a new graph representation (a smaller cluster of colored nodes, again with a central `i` node).
4. This process repeats, indicated by vertical ellipsis (`...`), leading to another `+` operation and a final, more refined graph representation.
5. The final graph output points to a second "GNN layer" box at the bottom.
**Component (d): Output Generation**
* **Content:** A flowchart showing the final prediction step.
1. An arrow from the final "GNN layer" in (c) points to a purple circle labeled `i`.
2. An arrow from this `i` node points down to a circle labeled `S`.
3. An arrow from `S` points to a purple rectangular box containing the mathematical expression: `P_i(σ_i = +1)`.
4. Below this box is the label "Output".
**Component (e): Label**
* **Content:** The letter `(e)` is placed in the bottom-right corner, likely serving as a figure or sub-figure label for the entire diagram.
### Detailed Analysis
1. **Input State (a):** The input is a partially observed grid. The top half has known binary states (`+1`/`-1`), while the bottom half is unknown (`Unf.`). The purple outline defines a local neighborhood or "receptive field" around the target cell `i` that is used for analysis.
2. **Graph Representation (b):** The grid is transformed into a graph where each cell is a node. The color of each node (red to blue via white) likely represents an initial feature value, possibly derived from the input state (`+1`, `-1`, `Unf.`) or an initial embedding. The central node `i` is the focus of the prediction.
3. **GNN Pipeline (c):** The graph is processed through multiple GNN layers. Each layer updates the node features by aggregating information from neighboring nodes (represented by the `+` operations). The sequence shows the node features evolving through at least two aggregation steps, resulting in progressively more refined representations of the local graph structure around node `i`.
4. **Final Prediction (d):** The final, updated feature vector for node `i` is passed through a function or module labeled `S` (which could stand for a softmax, sigmoid, or another scoring function). This produces the final output: the probability `P_i` that the state `σ_i` of node `i` is `+1`.
### Key Observations
* The diagram clearly depicts a **message-passing neural network** architecture applied to a spatial, grid-structured problem.
* The process is **local and targeted**: it focuses on predicting the state of a single node (`i`) based on its local graph neighborhood defined in the input.
* The **color coding is consistent**: the purple outline and label `i` track the target node through all stages (input grid, initial graph, intermediate GNN outputs, final prediction node).
* The **output is probabilistic**, not a deterministic classification, as indicated by the `P_i(...)` notation.
### Interpretation
This diagram illustrates a method for solving a **structured prediction problem**, likely related to statistical physics (e.g., the Ising model, given the `+1`/`-1` spins) or image inpainting (filling in the `Unf.` region). The core idea is to leverage the relational inductive bias of GNNs to make predictions about unknown parts of a system based on known parts.
The flow demonstrates how a GNN can:
1. **Encode** local grid information into a graph.
2. **Process** it through layers that propagate and transform information across the graph's connections.
3. **Decode** the final state of a specific node into a calibrated probability.
The presence of the `S` function before the final probability suggests the model outputs logits or scores that are then normalized. The entire pipeline is a self-contained model for inferring hidden states in a partially observed binary grid system.
</details>
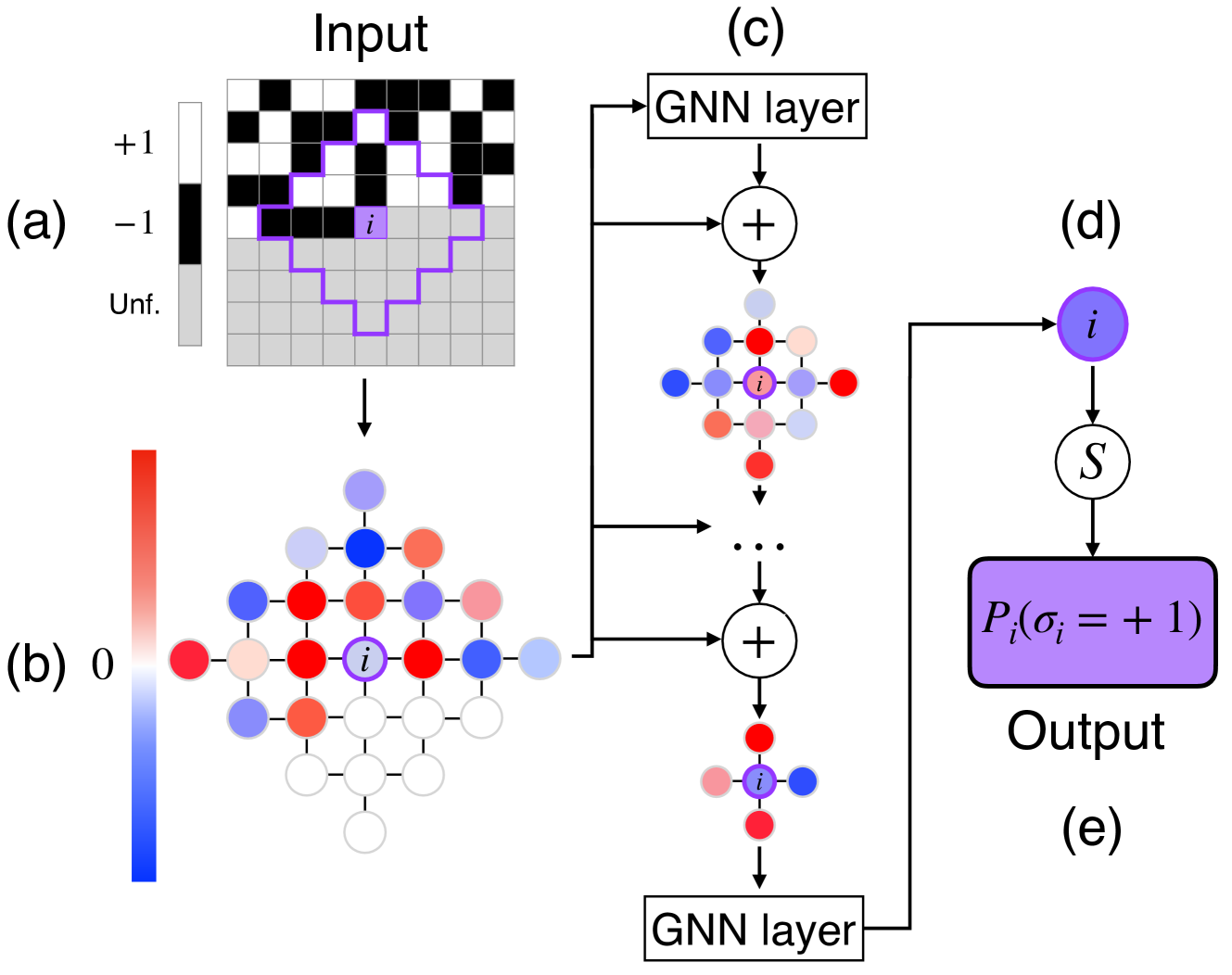
Figure 1: Schematic representation of the 4N architecture implemented on a two-dimensional lattice model with nearest-neighbors interactions. (a) We want to estimate the probability $\pi_{i}\equiv P(\sigma_{i}=+1\mid\boldsymbol{\sigma}_{<i})$ that the spin $i$ (in purple) has value $+1$ given the spins $<i$ (in black and white). The spins $>i$ (in grey) have not yet been fixed. (b) We compute the values of the local fields $h_{l}^{i,(0)}$ as in Eq. (10), for $l$ in a neighborhood of $i$ of size $\ell$ , indicated by a purple contour in (a). Notice that spins $l$ that are not in the neighborhood of one of the fixed spin have $h_{l}^{i,(0)}=0$ and are indicated in white in (b). (c) In the main cycle of the algorithm, we apply a series of $\ell$ GNN layers with the addition of skip connections. (d) The final GNN layer is not followed by a skip connection and yields the final values of the field $h_{i}^{i,(\ell)}$ . (e) $\pi_{i}$ is estimated by applying a sigmoid function to $h_{i}^{i,(\ell)}$ . Periodic (or other) boundary conditions can be considered, but are not shown here for clarity.
## Results
### The 4N architecture
The 4N architecture (Fig. 1) computes the probability $\pi_{i}\equiv P(\sigma_{i}=+1\mid\boldsymbol{\sigma}_{<i})$ by propagating the $h_{l}^{i}$ , defined as in TwoBo, Eq. (10), through a Graph Neural Network (GNN) architecture. The variable $h_{l}^{i}$ is interpreted as the local field induced by the frozen variables $\boldsymbol{\sigma}_{<i}$ on spin $l$ . Note that in 4N, we consider all possible values of $l=1,\cdots,N$ , not only $l\geq i$ as in TwoBo. The crucial difference with TwoBo is that only the fields in a finite neighborhood of variable $i$ need to be considered, because the initial values of the fields are propagated through a series of GNN layers that take into account the locality of the physical problem. During propagation, fields are combined with layer- and edge-dependent weights together with the couplings $J_{ij}$ and the inverse temperature $\beta$ . After each layer of the network (except the final one), a skip connection to the initial configuration is added. After the final layer, a sigmoidal activation is applied to find $\pi_{i}$ . The network has a total number of parameters equal to $(c+1)\times\ell\times N$ , where $c$ is the average number of neighbors for each spin. Details are given in the Methods section.
More precisely, because GNN updates are local, and there are $\ell$ of them, in order to compute the final field on site $i$ , hence $\pi_{i}$ , we only need to consider the set of fields corresponding to sites at distance at most $\ell$ , hence the number of operations scales proportionally to the number of such sites which we call $\mathcal{B}(\ell)$ . Because we need to compute $\pi_{i}$ for each of the $N$ sites, the generation of a new configuration then requires $\mathcal{O}(\mathcal{B}(\ell)\times N)$ steps. We recall that in a $d-$ dimensional lattice $\mathcal{B}(\ell)\propto\ell^{d}$ , while for random graphs $\mathcal{B}(\ell)\propto c^{\ell}$ . It is therefore crucial to assess how the number of layers $\ell$ should scale with the system size $N$ .
<details>
<summary>x2.png Details</summary>
### Visual Description
## Line Chart with Shaded Regions: Energy Difference vs. β
### Overview
The image is a scientific line chart plotting "Energy difference (relative)" on the y-axis against the parameter "β" on the x-axis. It displays four data series, each corresponding to a different value of "ℓ" (2, 4, 6, 10). Each series is represented by a solid line with a semi-transparent shaded region around it, likely indicating a confidence interval, standard deviation, or range of values.
### Components/Axes
* **Y-Axis:**
* **Label:** "Energy difference (relative)"
* **Scale:** Linear, ranging from 0.000 to 0.040.
* **Major Ticks:** 0.000, 0.005, 0.010, 0.015, 0.020, 0.025, 0.030, 0.035, 0.040.
* **X-Axis:**
* **Label:** "β" (Greek letter beta).
* **Scale:** Linear, ranging from approximately 0.4 to 3.2.
* **Major Ticks:** 0.5, 1.0, 1.5, 2.0, 2.5, 3.0.
* **Legend:**
* **Position:** Top-left corner of the chart area.
* **Entries:**
* `ℓ = 2` (Yellow/Gold solid line)
* `ℓ = 4` (Teal solid line)
* `ℓ = 6` (Red solid line)
* `ℓ = 10` (Green solid line)
* **Note:** The legend only shows the solid line style. The corresponding shaded regions use the same color but with transparency.
### Detailed Analysis
**Trend Verification:** All four data series follow a similar visual trend: they start at a low value near β=0.5, rise to a peak around β=1.5, and then gradually decline as β increases towards 3.0. The magnitude of the energy difference and the width of the shaded region decrease systematically as ℓ increases.
**Data Series Breakdown (Approximate Values):**
1. **ℓ = 2 (Yellow/Gold):**
* **Trend:** Highest curve with the widest shaded region.
* **Key Points:**
* At β ≈ 0.5: y ≈ 0.005
* Peak near β ≈ 1.5: y ≈ 0.022 (solid line), shaded region spans ~0.018 to ~0.026.
* At β ≈ 3.0: y ≈ 0.017 (solid line), shaded region spans ~0.010 to ~0.024.
2. **ℓ = 4 (Teal):**
* **Trend:** Second highest curve.
* **Key Points:**
* At β ≈ 0.5: y ≈ 0.002
* Peak near β ≈ 1.5: y ≈ 0.011 (solid line), shaded region spans ~0.007 to ~0.014.
* At β ≈ 3.0: y ≈ 0.008 (solid line), shaded region spans ~0.005 to ~0.013.
3. **ℓ = 6 (Red):**
* **Trend:** Third highest curve.
* **Key Points:**
* At β ≈ 0.5: y ≈ 0.001
* Peak near β ≈ 1.5: y ≈ 0.008 (solid line), shaded region spans ~0.005 to ~0.010.
* At β ≈ 3.0: y ≈ 0.005 (solid line), shaded region spans ~0.002 to ~0.008.
4. **ℓ = 10 (Green):**
* **Trend:** Lowest curve with the narrowest shaded region.
* **Key Points:**
* At β ≈ 0.5: y ≈ 0.000
* Peak near β ≈ 1.5: y ≈ 0.005 (solid line), shaded region spans ~0.003 to ~0.007.
* At β ≈ 3.0: y ≈ 0.001 (solid line), shaded region spans ~0.000 to ~0.004.
### Key Observations
1. **Systematic Ordering:** There is a clear, monotonic relationship between ℓ and the energy difference. For any given β, the energy difference is highest for ℓ=2 and decreases as ℓ increases (ℓ=2 > ℓ=4 > ℓ=6 > ℓ=10).
2. **Common Peak Location:** All four curves reach their maximum value at approximately the same β value, around 1.5.
3. **Variability Correlates with Magnitude:** The width of the shaded region (uncertainty/variability) is largest for the series with the highest energy difference (ℓ=2) and becomes progressively narrower for series with lower energy differences (ℓ=10).
4. **Convergence at Low β:** All curves appear to converge towards a very low energy difference (near zero) as β approaches 0.4 from the right.
### Interpretation
The chart demonstrates a clear functional relationship where the relative energy difference is a non-monotonic function of β, exhibiting a distinct maximum near β=1.5. This suggests the existence of an optimal β value that maximizes this energy difference metric for the system under study.
The parameter ℓ acts as a scaling or damping factor. Higher ℓ values systematically suppress the energy difference across the entire range of β and also reduce its variability (as indicated by the narrower shaded bands). This could imply that ℓ represents a system size, a coupling strength, or a disorder parameter where increased values lead to more stable or less fluctuating energy states relative to a reference.
The convergence at low β suggests that for small values of this parameter, the system's energy difference becomes negligible and insensitive to the value of ℓ. The most significant differentiation between systems with different ℓ occurs in the intermediate β range (1.0 to 2.0). This type of plot is common in statistical physics or computational materials science, often showing how an energy property (like a formation energy or excitation gap) varies with inverse temperature (β ∝ 1/T) and a system parameter (ℓ).
</details>
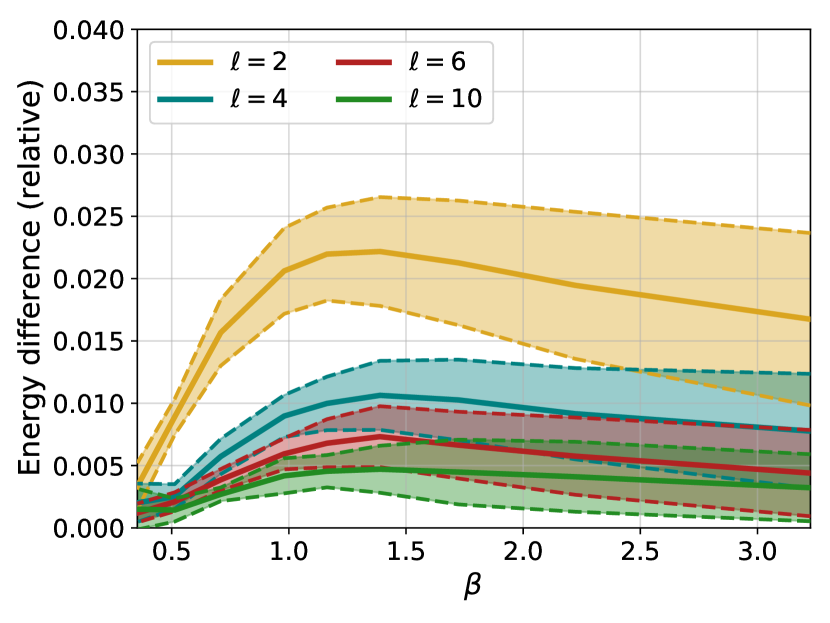
Figure 2: Relative difference in mean energy between the configurations generated by the 4N architecture and by PT, for different numbers of layers $\ell$ and different values of the inverse temperature $\beta$ . Solid lines indicate averages over 10 different instances, while the dashed lines and the colored area identify the region corresponding to plus or minus one standard deviation.
### The benchmark Gibbs-Boltzmann distribution
In this paper, in order to test the 4N architecture on a prototypically hard-to-sample problem, we will consider the Edwards-Anderson spin glass model, described by the Hamiltonian in Eq. (3) for Ising spins, where we set $H_{i}=0$ for simplicity. The couplings are chosen to be non-zero only for neighboring pairs $\langle i,j\rangle$ on a two-dimensional square lattice. Non-zero couplings $J_{ij}$ are independent random variables, identically distributed according to either a normal or a Rademacher distribution. This model was also used as a benchmark in Refs. [13, 12]. All the results reported in the rest of the section are for a $16\times 16$ square lattice, hence with $N=256$ spins, which guarantees a large enough system to investigate correlations at low temperatures while keeping the problem tractable. In the SI we also report some data for a $32\times 32$ lattice.
While this model has no finite-temperature spin glass transition, sampling it via standard local MCMC becomes extremely hard for $\beta\gtrsim 1.5$ [12]. To this day, the best option for sampling this model at lower temperatures is parallel tempering (PT), which we used to construct a sample of $M=2^{16}$ equilibrium configurations for several instances of the model and at several temperatures. Details are given in the Methods section.
The PT-generated training set is used to train the 4N architecture, independently for each instance and each temperature. Remember that the goal here is to test the expressivity of the architecture, which is why we train it in the best possible situation, i.e. by maximizing the likelihood of equilibrium configurations at each temperature. Once the 4N model has been trained, we perform several comparisons that are reported in the following.
### Energy
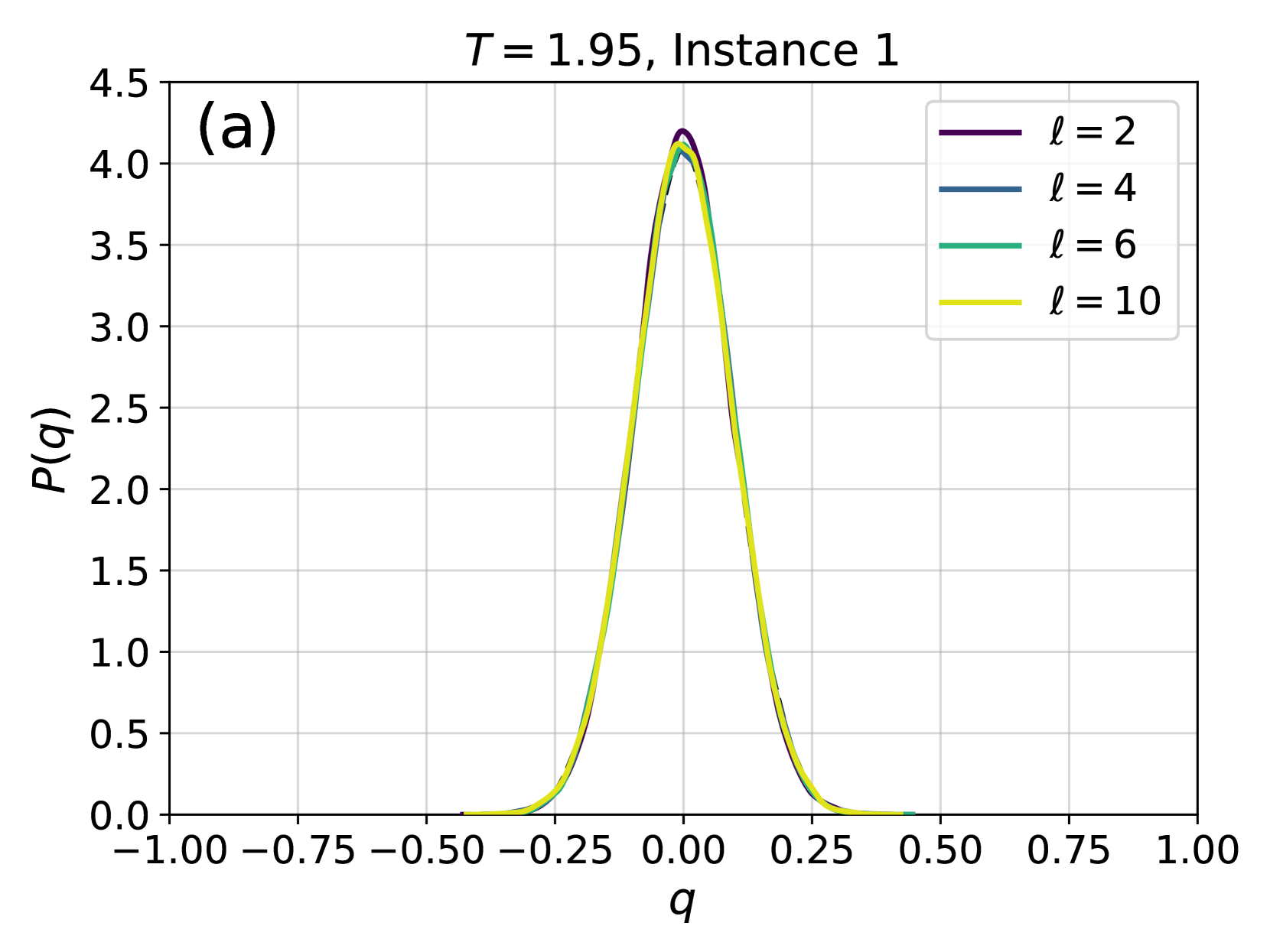
We begin by comparing the mean energy of the configurations generated by the model with the mean energy of the configurations generated via parallel tempering, which is important because the energy plays a central role in the Metropolis reweighing scheme of Eq. (5). Fig. 2 shows the relative energy difference, as a function of inverse temperature $\beta$ and number of layers $\ell$ , averaged over 10 different instances of the disorder. First, it is clear that adding layers improves results remarkably. We stress that, since the activation functions of our network are linear, adding layers only helps in taking into account spins that are further away. Second, we notice that the relative error found when using 6 layers or more is small for all temperatures considered. Finally, we notice that the behaviour of the error is non-monotonic, and indeed appears to decrease for low temperatures even for networks with few layers.
<details>
<summary>x3.png Details</summary>
### Visual Description
## Line Plot: Normalized Log-Probability vs. Number of Layers at Different Temperatures
### Overview
This image is a scientific line plot, labeled "(a)" in the top-left corner, showing the relationship between a normalized log-probability metric and the number of layers in a system, for seven different temperature values. The plot demonstrates how the metric changes with depth (layers) and how this relationship is strongly modulated by temperature.
### Components/Axes
* **Chart Label:** "(a)" located in the top-left quadrant of the plot area.
* **X-Axis:**
* **Title:** "Number of layers, ℓ"
* **Scale:** Linear, ranging from 2 to 10.
* **Major Ticks:** 2, 4, 6, 8, 10.
* **Y-Axis:**
* **Title:** `|(log P_AR^ℓ)_data| / S` (Absolute value of the log of P_AR to the power of ℓ, for the data, divided by S).
* **Scale:** Linear, ranging from 1.00 to 1.10.
* **Major Ticks:** 1.00, 1.02, 1.04, 1.06, 1.08, 1.10.
* **Legend:** Positioned in the top-right quadrant of the plot area. It contains seven entries, each associating a color with a temperature value `T`.
* **Entry 1:** Dark blue circle, `T = 0.58`
* **Entry 2:** Purple circle, `T = 0.72`
* **Entry 3:** Magenta circle, `T = 0.86`
* **Entry 4:** Pink circle, `T = 1.02`
* **Entry 5:** Salmon/Orange circle, `T = 1.41`
* **Entry 6:** Orange circle, `T = 1.95`
* **Entry 7:** Yellow circle, `T = 2.83`
* **Data Series:** Seven dashed lines, each with circular markers at integer layer values (ℓ = 2, 3, 4, 5, 6, 7, 8, 9, 10). The color of each line and its markers corresponds exactly to an entry in the legend.
### Detailed Analysis
**Trend Verification & Data Points (Approximate):**
The general trend is that the y-value decreases as the number of layers (ℓ) increases. The rate of decrease is highly dependent on temperature (T). Lower temperatures show a steep initial decline that flattens out, while higher temperatures show almost no change.
1. **Series T = 0.58 (Dark Blue):**
* **Trend:** Steepest downward slope, starting highest and decreasing rapidly before leveling off.
* **Approximate Points:** (2, 1.083), (3, 1.058), (4, 1.046), (5, 1.039), (6, 1.033), (7, 1.029), (8, 1.027), (9, 1.026), (10, 1.025).
2. **Series T = 0.72 (Purple):**
* **Trend:** Steep downward slope, starting second highest.
* **Approximate Points:** (2, 1.045), (3, 1.028), (4, 1.019), (5, 1.015), (6, 1.012), (7, 1.010), (8, 1.009), (9, 1.008), (10, 1.007).
3. **Series T = 0.86 (Magenta):**
* **Trend:** Moderate downward slope.
* **Approximate Points:** (2, 1.037), (3, 1.024), (4, 1.018), (5, 1.014), (6, 1.012), (7, 1.011), (8, 1.010), (9, 1.009), (10, 1.008).
4. **Series T = 1.02 (Pink):**
* **Trend:** Gentle downward slope.
* **Approximate Points:** (2, 1.026), (3, 1.018), (4, 1.014), (5, 1.012), (6, 1.011), (7, 1.010), (8, 1.009), (9, 1.008), (10, 1.007).
5. **Series T = 1.41 (Salmon/Orange):**
* **Trend:** Very slight downward slope, nearly flat.
* **Approximate Points:** (2, 1.007), (3, 1.005), (4, 1.004), (5, 1.003), (6, 1.003), (7, 1.002), (8, 1.002), (9, 1.002), (10, 1.002).
6. **Series T = 1.95 (Orange) & T = 2.83 (Yellow):**
* **Trend:** Essentially flat, horizontal lines.
* **Approximate Points (Both):** Hovering just above 1.000 across all layers, from ℓ=2 to ℓ=10. The yellow line (T=2.83) appears marginally lower than the orange line (T=1.95), but both are within ~0.002 of 1.000.
### Key Observations
1. **Temperature-Dependent Convergence:** All series converge toward a lower y-value as the number of layers increases, but the convergence point and rate are dictated by temperature.
2. **Low-Temperature Sensitivity:** At low temperatures (T ≤ 1.02), the metric is highly sensitive to the number of layers, especially for shallow networks (low ℓ).
3. **High-Temperature Insensitivity:** At high temperatures (T ≥ 1.41), the metric becomes largely invariant to the number of layers, remaining close to 1.00.
4. **Monotonic Ordering:** For any given layer number ℓ, the y-value is strictly ordered by temperature: lower T yields a higher y-value. This ordering is preserved across the entire x-axis range.
5. **Diminishing Returns:** For the low-temperature series, the most significant change occurs between ℓ=2 and ℓ=4. Adding layers beyond ℓ=6 results in very small incremental changes.
### Interpretation
This chart likely illustrates a phenomenon in statistical physics, machine learning (e.g., neural network theory), or information theory. The y-axis metric `|(log P_AR^ℓ)_data| / S` appears to be a normalized measure of a system's "surprise," "energy," or "deviation from a baseline" (S), possibly related to autoregressive probability (P_AR) over ℓ layers.
The data suggests a **phase transition-like behavior controlled by temperature**:
* **Low-Temperature Regime (T < ~1.4):** The system is in an "ordered" or "constrained" state. Here, the measured property is strongly dependent on system depth (layers). Shallow systems exhibit high deviation, which is progressively reduced as depth increases, suggesting that depth helps the system settle into a more stable or predictable configuration.
* **High-Temperature Regime (T > ~1.4):** The system is in a "disordered" or "entropic" state. Thermal noise dominates, rendering the system's property essentially independent of its structural depth. The metric saturates near its minimum value (1.00), indicating a baseline level of disorder or randomness that cannot be reduced by adding more layers.
The critical temperature appears to be around T ≈ 1.4, where the behavior shifts from depth-sensitive to depth-invariant. This type of analysis is crucial for understanding the capacity, stability, or learning dynamics of layered systems, indicating that there is an optimal temperature range where depth meaningfully influences the system's properties.
</details>
<details>
<summary>x4.png Details</summary>
### Visual Description
\n
## Line Graph: Decay of Logarithmic Difference vs. Number of Layers
### Overview
The image is a scientific line graph, labeled "(b)" in its top-left corner, plotting the absolute difference between two logarithmic quantities against the number of layers, ℓ. The graph displays seven distinct data series, each corresponding to a different value of a parameter `T`. All series show a decaying trend as the number of layers increases.
### Components/Axes
* **Chart Label:** "(b)" located in the top-left quadrant of the plot area.
* **X-Axis:**
* **Title:** "Number of layers, ℓ"
* **Scale:** Linear, ranging from 2 to 10.
* **Major Tick Marks:** At integers 2, 4, 6, 8, 10.
* **Y-Axis:**
* **Title:** `| (log P_AR^ℓ)_data - (log P_AR^10)_data |`
* **Scale:** Linear, ranging from 0.00 to 2.00.
* **Major Tick Marks:** At intervals of 0.25 (0.00, 0.25, 0.50, ..., 2.00).
* **Legend:** Positioned in the top-right corner of the plot area. It contains seven entries, each pairing a colored circle marker with a `T` value.
* **Entries (from top to bottom):**
1. Dark Blue Circle: `T = 0.58`
2. Purple Circle: `T = 0.72`
3. Magenta Circle: `T = 0.86`
4. Pink Circle: `T = 1.02`
5. Salmon/Light Red Circle: `T = 1.41`
6. Orange Circle: `T = 1.95`
7. Yellow Circle: `T = 2.83`
### Detailed Analysis
The graph plots the convergence of a quantity `log P_AR^ℓ` (for ℓ layers) towards its value at 10 layers (`log P_AR^10`). The y-axis measures the absolute difference from this reference point.
**Trend Verification & Data Points (Approximate):**
For each series, the value decreases monotonically as ℓ increases from 2 to 10. The decay is initially rapid and then asymptotes towards zero.
1. **T = 0.58 (Dark Blue):** Starts highest. At ℓ=2, y ≈ 2.05. Decays to y ≈ 0.05 at ℓ=10.
2. **T = 0.72 (Purple):** At ℓ=2, y ≈ 1.90. Decays to y ≈ 0.04 at ℓ=10.
3. **T = 0.86 (Magenta):** At ℓ=2, y ≈ 1.55. Decays to y ≈ 0.03 at ℓ=10.
4. **T = 1.02 (Pink):** At ℓ=2, y ≈ 1.20. Decays to y ≈ 0.02 at ℓ=10.
5. **T = 1.41 (Salmon):** At ℓ=2, y ≈ 0.52. Decays to y ≈ 0.01 at ℓ=10.
6. **T = 1.95 (Orange):** At ℓ=2, y ≈ 0.15. Decays to y ≈ 0.005 at ℓ=10.
7. **T = 2.83 (Yellow):** Starts lowest. At ℓ=2, y ≈ 0.03. Decays to nearly 0.00 at ℓ=10.
**Key Observation:** The initial value (at ℓ=2) and the rate of decay are strongly dependent on the parameter `T`. Lower `T` values result in a larger initial difference and a slower convergence to the 10-layer value.
### Key Observations
* **Systematic Ordering:** The curves are perfectly ordered by `T` value. At any given layer ℓ, a lower `T` corresponds to a higher y-value.
* **Convergence:** All series appear to converge to a difference of approximately zero by ℓ=10, which is expected as the y-axis measures the difference from the value at ℓ=10 itself.
* **Shape:** The decay for each series follows a similar convex, decreasing curve, suggesting an exponential or power-law relationship between the difference and the number of layers.
### Interpretation
This graph demonstrates the convergence behavior of a model or calculation (`P_AR`) as its depth (number of layers, ℓ) increases. The quantity `log P_AR^ℓ` is being compared to its "converged" value at 10 layers.
* **What the data suggests:** The parameter `T` controls the difficulty or scale of the convergence. Lower `T` values represent a scenario where the model's output at shallow depths (low ℓ) is very different from its deep (ℓ=10) output, requiring many more layers to stabilize. Higher `T` values represent an "easier" scenario where the model's output is already close to its final value even with very few layers.
* **Relationship between elements:** The x-axis (model depth) is the independent variable driving convergence. The y-axis (log difference) is the dependent measure of error or change. The legend (`T`) is a control parameter that modulates the relationship between depth and convergence speed.
* **Notable implication:** The plot provides a quantitative way to assess how many layers are needed for the model's output to become stable for a given `T`. For `T=2.83`, 2-4 layers may suffice, while for `T=0.58`, even 8 layers show a non-negligible difference from the 10-layer result. This is critical for understanding computational efficiency and model design trade-offs.
</details>
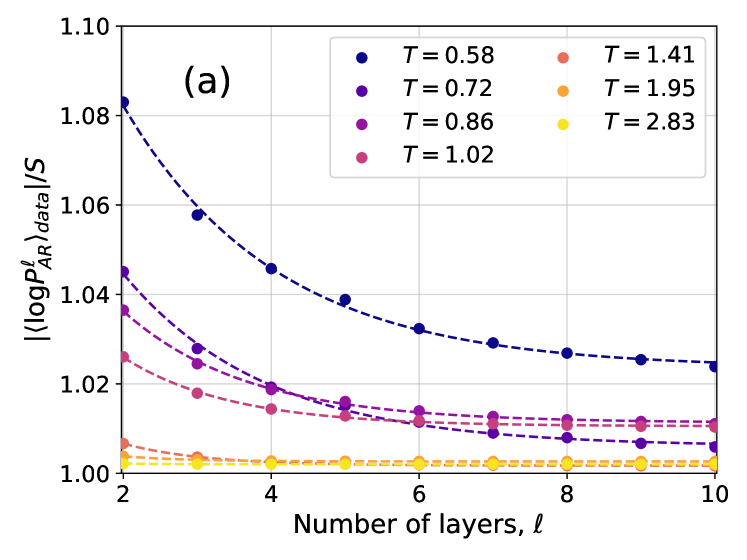
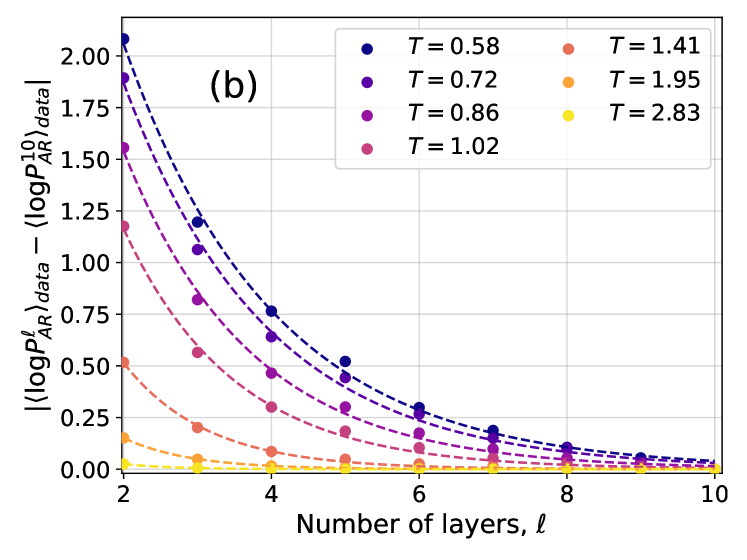
Figure 3: (a) Ratio between the cross-entropy $|\langle\log P^{\ell}_{\text{NN}}\rangle_{\text{data}}|$ and the Gibbs-Boltzmann entropy $S_{\text{GB}}$ for different values of the temperature $T$ and of the number of layers $\ell$ . Both $|\langle\log P^{\ell}_{\text{NN}}\rangle_{\text{data}}|$ and $S_{\text{GB}}$ are averaged over 10 samples. Dashed lines are exponential fits in the form $Ae^{-\ell/\overline{\ell}}+C$ . (b) Absolute difference between $\langle\log P^{\ell}_{\text{NN}}\rangle_{\text{data}}$ at various $\ell$ and at $\ell=10$ . Dashed lines are exponential fits in the form $Ae^{-\ell/\overline{\ell}}$ .
<details>
<summary>x5.png Details</summary>
### Visual Description
## Probability Distribution Plot: P(q) vs. q for Different ℓ Values
### Overview
The image displays a line chart showing four probability distribution curves, labeled as P(q), plotted against a variable q. The chart is titled "T = 1.95, Instance 1" and is marked with the identifier "(a)" in the top-left corner. The curves represent different values of a parameter ℓ (ell). All distributions are symmetric, bell-shaped, and centered at q = 0, resembling Gaussian or normal distributions.
### Components/Axes
* **Title:** "T = 1.95, Instance 1"
* **Panel Label:** "(a)" located in the top-left corner of the plot area.
* **X-Axis:**
* **Label:** "q"
* **Scale:** Linear, ranging from -1.00 to 1.00.
* **Major Tick Marks:** At intervals of 0.25: -1.00, -0.75, -0.50, -0.25, 0.00, 0.25, 0.50, 0.75, 1.00.
* **Y-Axis:**
* **Label:** "P(q)"
* **Scale:** Linear, ranging from 0.0 to 4.5.
* **Major Tick Marks:** At intervals of 0.5: 0.0, 0.5, 1.0, 1.5, 2.0, 2.5, 3.0, 3.5, 4.0, 4.5.
* **Legend:** Located in the top-right corner of the plot area. It contains four entries, each associating a color with a value of ℓ:
* Purple line: ℓ = 2
* Blue line: ℓ = 4
* Teal line: ℓ = 6
* Yellow line: ℓ = 10
* **Grid:** A light gray grid is present in the background.
### Detailed Analysis
The chart plots the probability density function P(q) for four different scenarios defined by the parameter ℓ.
**Trend Verification:** All four curves exhibit the same fundamental trend: they are symmetric, unimodal distributions centered at q = 0. They rise sharply from near-zero probability at q ≈ ±0.5 to a peak at q = 0, then fall symmetrically.
**Data Series Analysis (from highest peak to lowest):**
1. **ℓ = 2 (Purple Line):** This curve has the highest peak. The maximum value of P(q) at q = 0 is approximately **4.2**.
2. **ℓ = 4 (Blue Line):** This curve has the second-highest peak. The maximum value of P(q) at q = 0 is approximately **4.1**.
3. **ℓ = 6 (Teal Line):** This curve has the third-highest peak. The maximum value of P(q) at q = 0 is approximately **4.0**.
4. **ℓ = 10 (Yellow Line):** This curve has the lowest peak of the four. The maximum value of P(q) at q = 0 is approximately **3.9**.
**Spatial Grounding & Shape:** The curves are tightly clustered. The purple line (ℓ=2) is the outermost at the peak, followed inward by blue (ℓ=4), teal (ℓ=6), and yellow (ℓ=10). The width of the distributions (related to variance) appears very similar for all ℓ values, with all curves approaching P(q) ≈ 0 at around q = ±0.4.
### Key Observations
1. **Central Tendency:** All distributions are perfectly centered at q = 0.
2. **Parameter Influence:** As the parameter ℓ increases from 2 to 10, the peak height of the probability distribution P(q) at q=0 decreases monotonically. The order of peak height is strictly ℓ=2 > ℓ=4 > ℓ=6 > ℓ=10.
3. **Distribution Shape:** The shape (width/skew) of the distribution appears largely insensitive to the value of ℓ within the range shown. The primary effect is a scaling of the peak amplitude.
4. **No Outliers:** All data series follow the same smooth, bell-shaped pattern without any anomalous points or deviations.
### Interpretation
This plot demonstrates the probability distribution of a variable `q` under a specific condition (T = 1.95, Instance 1) for different values of a system parameter `ℓ`.
* **What the data suggests:** The variable `q` is most likely to be found at or very near zero. The probability of observing values of `q` further from zero decreases rapidly and symmetrically.
* **Relationship between elements:** The parameter `ℓ` modulates the "concentration" or "certainty" of the distribution. A lower `ℓ` (e.g., 2) results in a higher probability density at the mean (q=0), implying the system is more strongly peaked or constrained around that value. A higher `ℓ` (e.g., 10) results in a slightly lower peak, suggesting a marginally broader or less certain distribution, though the effect on the width is minimal in this visualization.
* **Underlying Context (Inferred):** Given the notation (P(q), ℓ, T), this is likely from a statistical physics, machine learning, or computational science context. `q` could represent an order parameter, overlap, or correlation measure. `T` often denotes temperature, and `ℓ` could represent a length scale, layer depth, or system size. The plot shows that at a fixed temperature (T=1.95), increasing the length scale `ℓ` slightly reduces the probability of the system being in a state of perfect alignment or correlation (q=0). The consistency of the shape suggests the underlying statistical mechanics of the system is stable across these `ℓ` values.
</details>
<details>
<summary>x6.png Details</summary>
### Visual Description
\n
## Probability Distribution Plot: P(q) for Different ℓ Values
### Overview
This image is a scientific line plot, labeled as panel (b), showing the probability distribution function \( P(q) \) for a variable \( q \). The plot compares distributions for four different values of a parameter \( \ell \) (2, 4, 6, 10) and includes an additional reference distribution shown as a dashed black line. The title indicates the data corresponds to a temperature \( T = 0.72 \) and is from "Instance 1".
### Components/Axes
* **Title:** "T = 0.72, Instance 1" (centered at the top).
* **Panel Label:** "(b)" (located in the top-left corner of the plot area).
* **X-Axis:**
* **Label:** "q"
* **Scale:** Linear, ranging from -1.00 to 1.00.
* **Major Ticks:** -1.00, -0.75, -0.50, -0.25, 0.00, 0.25, 0.50, 0.75, 1.00.
* **Y-Axis:**
* **Label:** "P(q)"
* **Scale:** Linear, ranging from 0.00 to 2.00.
* **Major Ticks:** 0.00, 0.25, 0.50, 0.75, 1.00, 1.25, 1.50, 1.75, 2.00.
* **Legend:** Positioned in the top-right corner of the plot area. It contains four entries:
1. A solid purple line labeled "ℓ = 2".
2. A solid blue line labeled "ℓ = 4".
3. A solid green line labeled "ℓ = 6".
4. A solid yellow line labeled "ℓ = 10".
* **Data Series:** Five distinct curves are plotted:
1. **Purple solid line (ℓ = 2):** The tallest and narrowest distribution.
2. **Blue solid line (ℓ = 4):** Shorter and wider than the purple line.
3. **Green solid line (ℓ = 6):** Shorter and wider than the blue line.
4. **Yellow solid line (ℓ = 10):** The shortest and widest of the colored lines.
5. **Black dashed line:** A broader, flatter distribution with a slight dip at its center. It is not explicitly labeled in the legend.
### Detailed Analysis
All distributions are symmetric and centered at \( q = 0 \). They exhibit a bell-like shape, with probability density \( P(q) \) approaching zero as \( |q| \) approaches 1.
* **Trend with increasing ℓ:** As the parameter \( \ell \) increases from 2 to 10, the peak of the distribution \( P(q) \) at \( q=0 \) decreases, and the distribution becomes broader (has a larger variance).
* **Approximate Peak Values (at q ≈ 0):**
* ℓ = 2 (Purple): Peak \( P(q) \approx 1.65 \).
* ℓ = 4 (Blue): Peak \( P(q) \approx 1.40 \).
* ℓ = 6 (Green): Peak \( P(q) \approx 1.25 \).
* ℓ = 10 (Yellow): Peak \( P(q) \approx 1.10 \).
* Black Dashed Line: Peak \( P(q) \approx 1.00 \), with a shallow minimum at the center.
* **Width Comparison:** The yellow curve (ℓ=10) is the widest, with significant probability density extending to about \( q = \pm 0.75 \). The purple curve (ℓ=2) is the narrowest, with density falling to near zero by \( q = \pm 0.50 \). The black dashed line is the broadest of all.
### Key Observations
1. **Inverse Relationship:** There is a clear inverse relationship between the parameter \( \ell \) and the peak height of \( P(q) \). Higher \( \ell \) values correspond to lower, flatter distributions.
2. **Reference Distribution:** The unlabeled black dashed line represents a distribution that is distinct from the \( \ell \)-series. It is broader and has a unique "double-hump" or plateau-like shape near its peak, unlike the single smooth peaks of the colored lines.
3. **Symmetry and Bounds:** All distributions are perfectly symmetric around \( q=0 \) and are confined within the bounds \( q \in [-1, 1] \), suggesting \( q \) may be a normalized or bounded variable.
### Interpretation
This plot likely illustrates the effect of a system parameter \( \ell \) (which could represent length scale, interaction range, or a similar physical quantity) on the probability distribution of an order parameter or observable \( q \) at a fixed temperature \( T = 0.72 \).
* **Physical Meaning:** The trend suggests that increasing \( \ell \) makes the system more disordered or fluctuating. A smaller \( \ell \) (e.g., 2) leads to a sharply peaked distribution, indicating the system is strongly localized around the state \( q=0 \). A larger \( \ell \) (e.g., 10) allows for greater fluctuations, spreading the probability over a wider range of \( q \) values.
* **The Dashed Line:** The distinct black dashed line could represent a theoretical prediction (e.g., a Gaussian distribution), a baseline case (e.g., \( \ell \to \infty \) or \( \ell = 0 \)), or the distribution for a different phase or condition. Its flatter top suggests a regime where multiple states near \( q=0 \) are almost equally probable.
* **Contextual Clue:** The label "Instance 1" implies this is one realization from a set of simulations or experiments, and the behavior might be averaged or compared across other instances. The panel label "(b)" confirms this is part of a multi-panel figure, where panel (a) likely shows related data, perhaps for a different temperature or instance.
In summary, the graph provides quantitative evidence that the parameter \( \ell \) controls the "sharpness" of the probability distribution for \( q \), with higher \( \ell \) values promoting broader fluctuations in the system at the given temperature.
</details>
<details>
<summary>x7.png Details</summary>
### Visual Description
## Line Chart: Probability Distribution P(q) for Different ℓ Values
### Overview
The image displays a line chart showing the probability distribution function \( P(q) \) as a function of the variable \( q \). The plot is labeled as panel "(c)" and corresponds to a specific condition: "T = 0.31, Instance 1". It compares four different distributions, each associated with a distinct value of a parameter \( \ell \), along with an additional dashed black reference curve.
### Components/Axes
* **Title:** "T = 0.31, Instance 1" (centered at the top).
* **Panel Label:** "(c)" (located in the top-left corner of the plot area).
* **X-axis:**
* **Label:** "q" (centered below the axis).
* **Scale:** Linear, ranging from -1.00 to 1.00.
* **Major Ticks:** -1.00, -0.75, -0.50, -0.25, 0.00, 0.25, 0.50, 0.75, 1.00.
* **Y-axis:**
* **Label:** "P(q)" (centered to the left of the axis, rotated 90 degrees).
* **Scale:** Linear, ranging from 0.0 to 1.6.
* **Major Ticks:** 0.0, 0.2, 0.4, 0.6, 0.8, 1.0, 1.2, 1.4, 1.6.
* **Legend:** Positioned in the top-center of the plot area, enclosed in a box. It defines four colored solid lines:
* **Purple line:** \( \ell = 2 \)
* **Blue line:** \( \ell = 4 \)
* **Green line:** \( \ell = 6 \)
* **Yellow line:** \( \ell = 10 \)
* **Additional Element:** A **dashed black line** is present but is not defined in the legend.
### Detailed Analysis
The chart plots five distinct curves. All curves are symmetric about the vertical line \( q = 0.0 \).
1. **Dashed Black Line (Reference):**
* **Trend:** This curve exhibits three prominent, sharp peaks.
* **Data Points (Approximate):**
* Central peak: Located at \( q = 0.0 \), with a maximum \( P(q) \approx 1.05 \).
* Side peaks: Located symmetrically at \( q \approx -0.75 \) and \( q \approx 0.75 \), each with a maximum \( P(q) \approx 0.80 \).
* Minima: Deep minima occur at \( q \approx -0.35 \) and \( q \approx 0.35 \), with \( P(q) \approx 0.20 \).
2. **Purple Line (\( \ell = 2 \)):**
* **Trend:** This is the broadest and smoothest of the colored curves, featuring a single, dominant central peak.
* **Data Points (Approximate):**
* Central peak: Located at \( q = 0.0 \), with a maximum \( P(q) \approx 0.98 \).
* The curve decays smoothly towards zero as \( |q| \) approaches 1.00.
3. **Blue Line (\( \ell = 4 \)):**
* **Trend:** This curve shows a more complex structure than \( \ell = 2 \), with a central peak and two smaller side humps.
* **Data Points (Approximate):**
* Central peak: Located at \( q = 0.0 \), with a maximum \( P(q) \approx 0.82 \).
* Side humps: Located at \( q \approx -0.40 \) and \( q \approx 0.40 \), with \( P(q) \approx 0.68 \).
* Local minima between peaks: At \( q \approx \pm 0.20 \), with \( P(q) \approx 0.58 \).
4. **Green Line (\( \ell = 6 \)):**
* **Trend:** Similar in shape to the blue line (\( \ell = 4 \)) but with slightly lower peak values and more pronounced side features.
* **Data Points (Approximate):**
* Central peak: Located at \( q = 0.0 \), with a maximum \( P(q) \approx 0.85 \).
* Side humps: Located at \( q \approx -0.40 \) and \( q \approx 0.40 \), with \( P(q) \approx 0.60 \).
* Local minima between peaks: At \( q \approx \pm 0.20 \), with \( P(q) \approx 0.56 \).
5. **Yellow Line (\( \ell = 10 \)):**
* **Trend:** This curve most closely resembles the shape of the dashed black reference line, exhibiting three distinct peaks.
* **Data Points (Approximate):**
* Central peak: Located at \( q = 0.0 \), with a maximum \( P(q) \approx 0.76 \).
* Side peaks: Located at \( q \approx -0.70 \) and \( q \approx 0.70 \), each with a maximum \( P(q) \approx 0.68 \).
* Minima: Located at \( q \approx \pm 0.35 \), with \( P(q) \approx 0.38 \).
### Key Observations
* **Peak Evolution:** As the parameter \( \ell \) increases from 2 to 10, the distribution evolves from a single central peak (\( \ell=2 \)) to a triple-peak structure (\( \ell=10 \)).
* **Convergence to Reference:** The shape of the \( \ell = 10 \) (yellow) curve qualitatively matches the dashed black reference curve, suggesting that higher \( \ell \) values may approach a limiting distribution.
* **Central Peak Height:** The height of the central peak at \( q=0.0 \) generally decreases as \( \ell \) increases (from ~0.98 for \( \ell=2 \) to ~0.76 for \( \ell=10 \)).
* **Symmetry:** All plotted distributions are perfectly symmetric around \( q = 0.0 \).
### Interpretation
This plot likely illustrates the probability distribution of an order parameter \( q \) (common in statistical physics or machine learning, e.g., in spin glasses or neural networks) for a system at a fixed temperature \( T=0.31 \). The parameter \( \ell \) could represent a system size, a length scale, or a level of coarse-graining.
The data suggests a **transition in the system's behavior** as \( \ell \) increases. For small \( \ell \) (2), the system has a single, most probable state at \( q=0 \). As \( \ell \) grows, the distribution develops side peaks, indicating the emergence of additional metastable or probable states away from \( q=0 \). The dashed black line may represent a theoretical prediction or the distribution in the thermodynamic limit (\( \ell \to \infty \)). The fact that the \( \ell=10 \) curve approaches this reference suggests that the system's statistical properties converge with increasing \( \ell \). The symmetry implies the underlying system or Hamiltonian is symmetric under the transformation \( q \to -q \). The specific values of \( T \) and "Instance 1" indicate this is one snapshot from a larger study exploring the phase diagram or disorder realizations.
</details>
<details>
<summary>x8.png Details</summary>
### Visual Description
\n
## Line Chart: Probability Distribution P(q) for Different ℓ Values at T=0.31
### Overview
The image is a line chart (plot) labeled "(d)" in the top-left corner, with the title "T = 0.31, Instance 2" centered at the top. It displays the probability distribution function P(q) as a function of the variable q for four different values of a parameter ℓ, plus an additional dashed black reference curve. The chart is presented on a white background with a light gray grid.
### Components/Axes
* **Title:** "T = 0.31, Instance 2"
* **Panel Label:** "(d)" located in the top-left corner of the plot area.
* **X-Axis:**
* **Label:** "q" (centered below the axis).
* **Scale:** Linear, ranging from -1.00 to 1.00.
* **Major Ticks/Markers:** -1.00, -0.75, -0.50, -0.25, 0.00, 0.25, 0.50, 0.75, 1.00.
* **Y-Axis:**
* **Label:** "P(q)" (centered and rotated vertically to the left of the axis).
* **Scale:** Linear, ranging from 0.0 to 1.6.
* **Major Ticks/Markers:** 0.0, 0.2, 0.4, 0.6, 0.8, 1.0, 1.2, 1.4, 1.6.
* **Legend:**
* **Position:** Top-right corner of the plot area.
* **Content:** Maps line colors to values of ℓ.
* Dark Purple Line: ℓ = 2
* Blue Line: ℓ = 4
* Green Line: ℓ = 6
* Yellow Line: ℓ = 10
* **Note:** A dashed black line is also present in the plot but is not included in the legend.
### Detailed Analysis
The chart plots five distinct curves. All curves are symmetric about q = 0.00.
1. **Dashed Black Line (Reference):**
* **Trend:** Exhibits three sharp, distinct peaks. The central peak at q=0.00 is the lowest (~0.22). The two side peaks, located at approximately q = ±0.70, are the highest on the entire chart, reaching a P(q) value of ~0.83. Deep troughs occur at approximately q = ±0.25, with P(q) ~0.15.
* **Key Points (Approximate):**
* Peak 1: (q ≈ -0.70, P(q) ≈ 0.83)
* Trough 1: (q ≈ -0.25, P(q) ≈ 0.15)
* Central Peak: (q = 0.00, P(q) ≈ 0.22)
* Trough 2: (q ≈ 0.25, P(q) ≈ 0.15)
* Peak 2: (q ≈ 0.70, P(q) ≈ 0.83)
2. **Purple Line (ℓ = 2):**
* **Trend:** Shows three broader, smoother peaks compared to the dashed line. The central peak at q=0.00 is the highest of all the colored lines, reaching P(q) ≈ 0.80. The side peaks, located near q = ±0.60, are lower, at P(q) ≈ 0.70. Troughs are at approximately q = ±0.30, with P(q) ≈ 0.35.
* **Key Points (Approximate):**
* Side Peak: (q ≈ -0.60, P(q) ≈ 0.70)
* Trough: (q ≈ -0.30, P(q) ≈ 0.35)
* Central Peak: (q = 0.00, P(q) ≈ 0.80)
* Trough: (q ≈ 0.30, P(q) ≈ 0.35)
* Side Peak: (q ≈ 0.60, P(q) ≈ 0.70)
3. **Blue Line (ℓ = 4):**
* **Trend:** Also has three peaks. The central peak is significantly lower than that of ℓ=2, at P(q) ≈ 0.55. The side peaks, near q = ±0.55, are the highest for this curve, at P(q) ≈ 0.78. Troughs are at approximately q = ±0.25, with P(q) ≈ 0.32.
* **Key Points (Approximate):**
* Side Peak: (q ≈ -0.55, P(q) ≈ 0.78)
* Trough: (q ≈ -0.25, P(q) ≈ 0.32)
* Central Peak: (q = 0.00, P(q) ≈ 0.55)
* Trough: (q ≈ 0.25, P(q) ≈ 0.32)
* Side Peak: (q ≈ 0.55, P(q) ≈ 0.78)
4. **Green Line (ℓ = 6):**
* **Trend:** Three peaks, with the central peak lower still. The central peak at q=0.00 is at P(q) ≈ 0.36. The side peaks, near q = ±0.50, are at P(q) ≈ 0.75. Troughs are at approximately q = ±0.20, with P(q) ≈ 0.30.
* **Key Points (Approximate):**
* Side Peak: (q ≈ -0.50, P(q) ≈ 0.75)
* Trough: (q ≈ -0.20, P(q) ≈ 0.30)
* Central Peak: (q = 0.00, P(q) ≈ 0.36)
* Trough: (q ≈ 0.20, P(q) ≈ 0.30)
* Side Peak: (q ≈ 0.50, P(q) ≈ 0.75)
5. **Yellow Line (ℓ = 10):**
* **Trend:** Three peaks. The central peak is the lowest among all curves, at P(q) ≈ 0.25. The side peaks, near q = ±0.45, are at P(q) ≈ 0.79. Troughs are at approximately q = ±0.15, with P(q) ≈ 0.20.
* **Key Points (Approximate):**
* Side Peak: (q ≈ -0.45, P(q) ≈ 0.79)
* Trough: (q ≈ -0.15, P(q) ≈ 0.20)
* Central Peak: (q = 0.00, P(q) ≈ 0.25)
* Trough: (q ≈ 0.15, P(q) ≈ 0.20)
* Side Peak: (q ≈ 0.45, P(q) ≈ 0.79)
### Key Observations
1. **Symmetry:** All distributions are perfectly symmetric around q = 0.00.
2. **Central Peak Suppression:** As the parameter ℓ increases from 2 to 10, the height of the central peak at q=0.00 systematically decreases (from ~0.80 to ~0.25).
3. **Side Peak Consistency:** The height of the side peaks remains relatively stable across different ℓ values, clustering between P(q) ≈ 0.70 and 0.79. Their position shifts slightly inward (closer to q=0) as ℓ increases.
4. **Dashed Line Anomaly:** The dashed black line has the most pronounced side peaks and the deepest troughs, suggesting it may represent a theoretical limit, a different model, or a baseline case (e.g., ℓ → ∞ or a non-interacting system).
5. **Trough Depth:** The depth of the troughs between the central and side peaks generally decreases (becomes shallower) as ℓ increases.
### Interpretation
This chart likely illustrates the probability distribution of an order parameter `q` in a statistical physics or machine learning context (e.g., spin glasses, neural networks, or optimization landscapes) at a fixed temperature T=0.31 for a specific system instance.
* **Effect of ℓ:** The parameter ℓ appears to control the "localization" or "concentration" of probability. A smaller ℓ (e.g., 2) favors a high probability at the symmetric state (q=0). As ℓ increases, probability mass is redistributed from the center to the side peaks, indicating a transition towards states with non-zero `q` (possibly ordered or metastable states). The system becomes less likely to be found in the q=0 state.
* **Multi-stability:** The presence of three distinct peaks for all ℓ values suggests the system has three metastable states or preferred configurations: one at q=0 and two symmetrically placed at ±q*. The relative stability of these states changes with ℓ.
* **Dashed Line Significance:** The dashed line, with its extreme peaks and troughs, may represent the "ground truth" distribution, the result from a mean-field theory, or the distribution in the thermodynamic limit. The colored lines for finite ℓ show how the distribution deviates from this reference, with larger ℓ bringing the side peak positions closer to the dashed line's peaks but not matching their height or the depth of the troughs.
* **Underlying Phenomenon:** The data demonstrates a classic symmetry-breaking scenario controlled by the parameter ℓ. The system's behavior evolves from being centered around the symmetric point (q=0) to favoring asymmetric, symmetry-broken states (q ≠ 0) as ℓ grows.
</details>
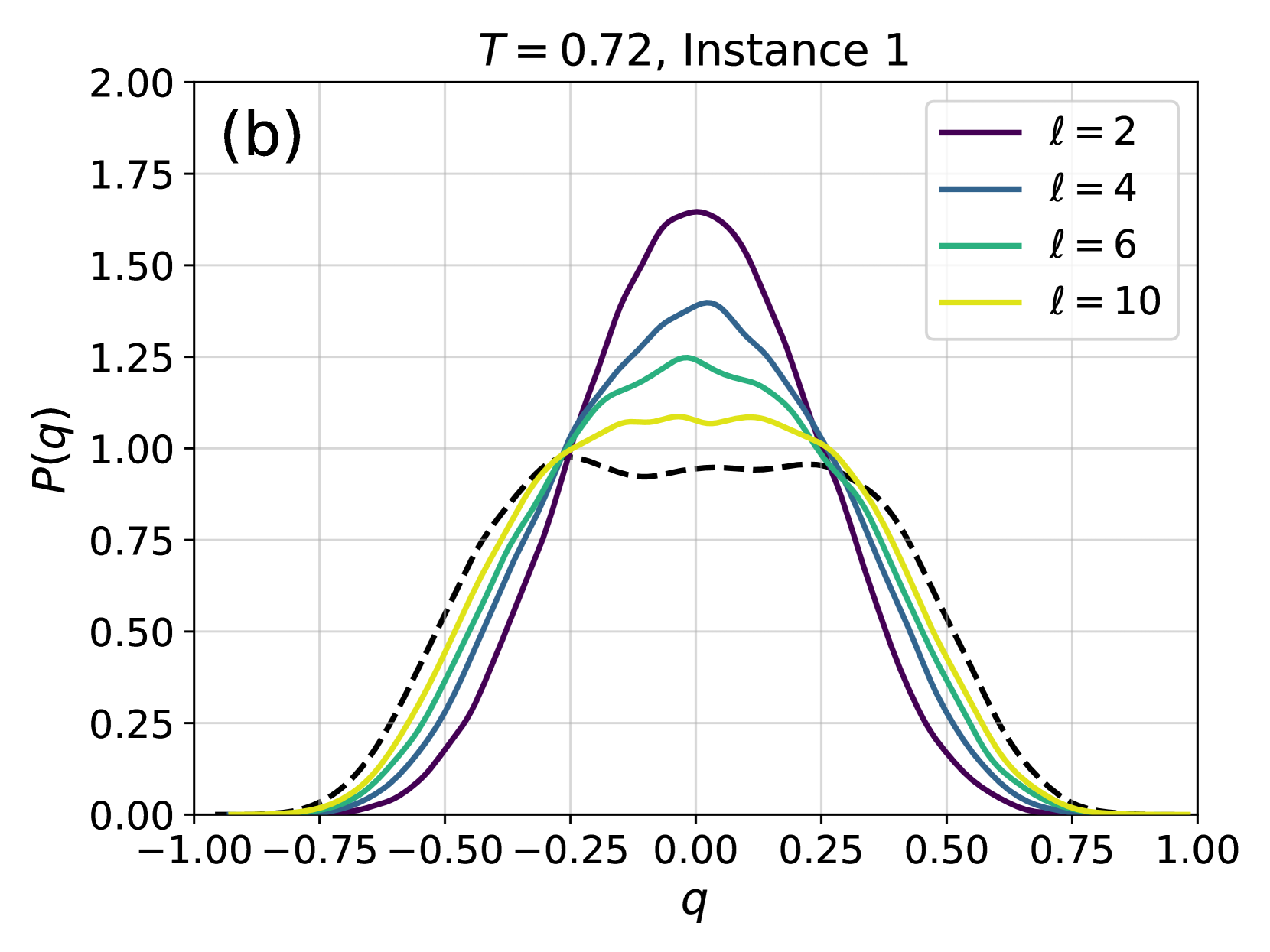
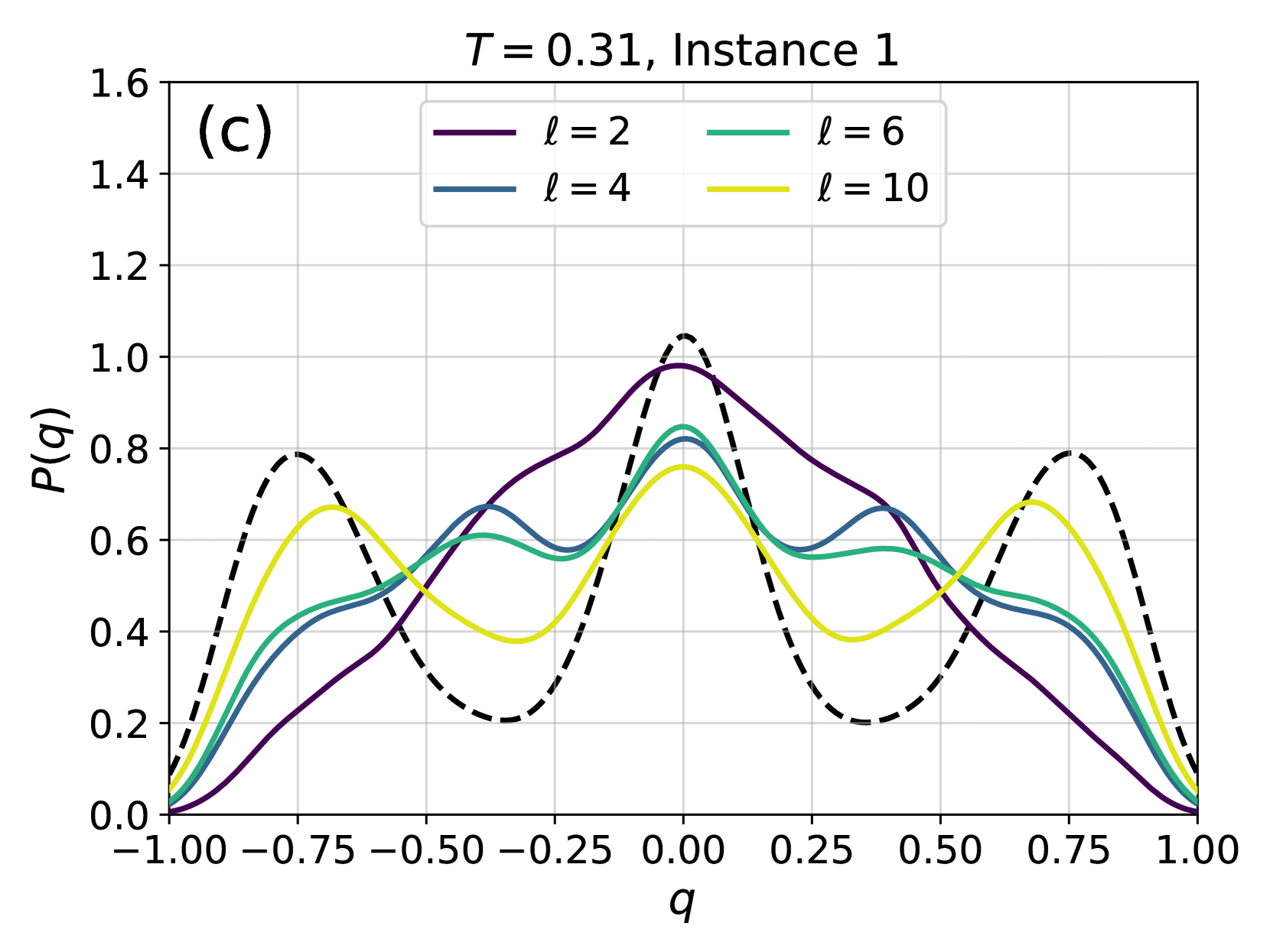
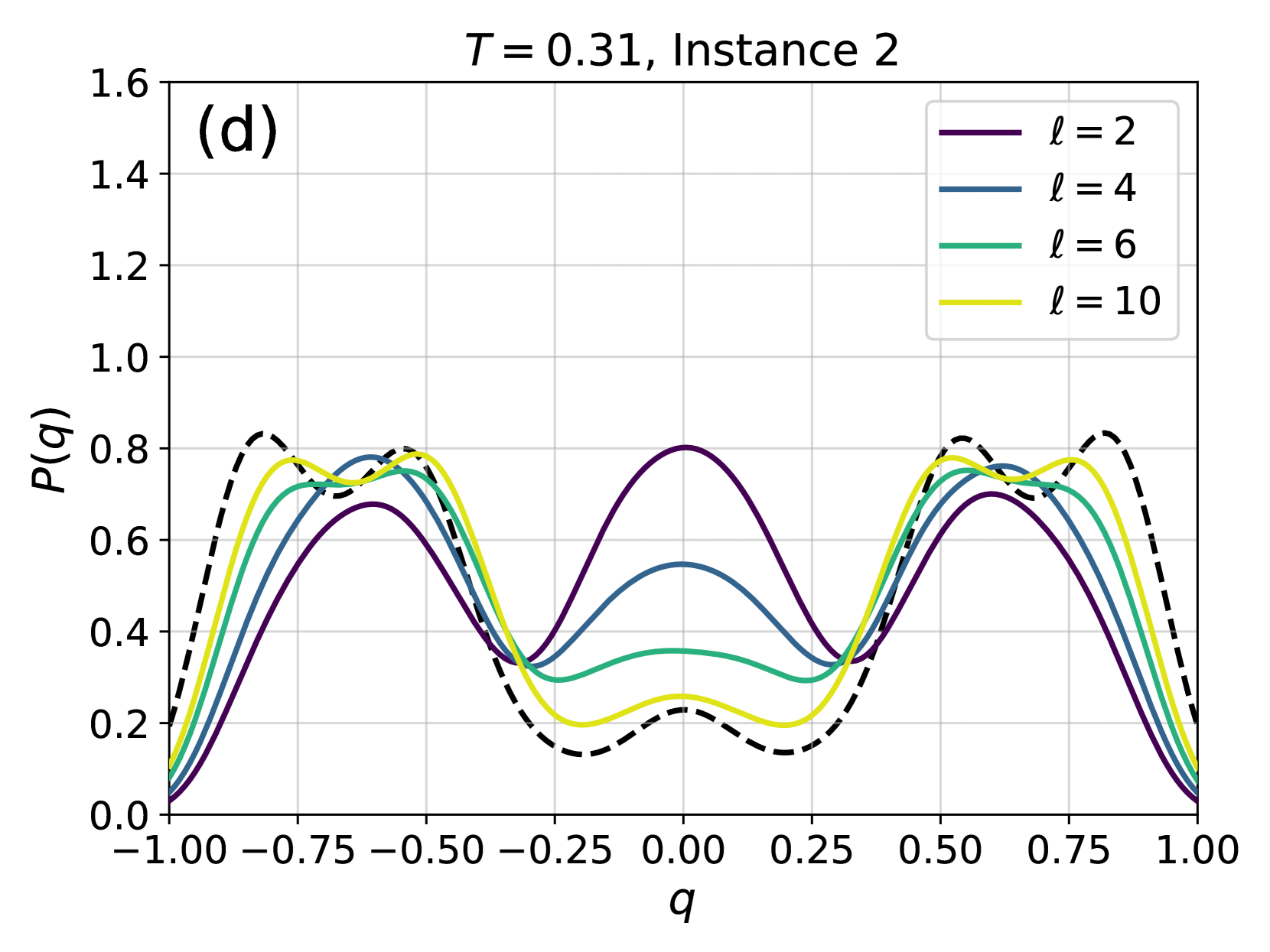
Figure 4: Examples of the probability distribution of the overlap, $P(q)$ , for different instances of the disorder and different temperatures. Solid color lines correspond to configurations generated using 4N, while dashed black lines correspond to the $P(q)$ obtained from equilibrium configurations generated via PT. (a) At high temperature, even a couple of layers are enough to reproduce well the distribution. (b) At lower temperatures more layers are required, as expected because of the increase of the correlation length and of the complexity of the Gibbs-Boltzmann distribution. (c) Even lower temperature for the same instance. (d) A test on a more complex instance shows that 4N is capable to learn even non-trivial forms of $P(q)$ .
### Entropy and Kullback-Leibler divergence
Next, we consider the Kullback-Leibler divergence between the learned probability distribution $P_{\text{NN}}$ and the target probability distribution, $D_{\text{KL}}(P_{\text{GB}}\parallel P_{\text{NN}})$ . Indicating with $\langle\,\cdot\,\rangle_{\text{GB}}$ the average with respect to $P_{\text{GB}}$ , we have
$$
D_{\text{KL}}(P_{\text{GB}}\parallel P_{\text{NN}})=\langle\log P_{\text{GB}}
\rangle_{\text{GB}}-\langle\log P_{\text{NN}}\rangle_{\text{GB}}\ . \tag{11}
$$
The first term $\langle\log P_{\text{GB}}\rangle_{\text{GB}}=-S_{\text{GB}}(T)$ is minus the entropy of the Gibbs-Boltzmann distribution and does not depend on $P_{\text{NN}}$ , hence we focus on the cross-entropy $-\langle\log P_{\text{NN}}\rangle_{\text{GB}}$ as a function of the number of layers for different temperatures. Minimizing this quantity corresponds to minimizing the KL divergence. In the case of perfect learning, i.e. $D_{\text{KL}}=0$ , we have $-\langle\log P_{\text{NN}}\rangle_{\text{GB}}=S_{\text{GB}}(T)$ . In Fig. 3 we compare the cross-entropy, estimated as $-\langle\log P_{\text{NN}}\rangle_{\text{data}}$ on the data generated by PT, with $S_{\text{GB}}(T)$ computed using thermodynamic integration. We find a good match for large enough $\ell$ , indicating an accurate training of the 4N model that does not suffer from mode collapse.
In order to study more carefully how changing the number of layers affects the accuracy of the training, in Fig. 3 we have also shown the difference $|\langle\log P^{\ell}_{AR}\rangle_{data}-\langle\log P^{10}_{AR}\rangle_{data}|$ as a function of the number of layers $\ell$ for different temperatures. The plots are compatible with an exponential decay in the form $Ae^{-\ell/\overline{\ell}}$ , with $\overline{\ell}$ thus being an estimate of the number of layers above which the 4N architecture becomes accurate. We thus need to understand how $\overline{\ell}$ changes with temperature and system size. To do so, we need to introduce appropriate correlation functions, as we do next.
<details>
<summary>x9.png Details</summary>
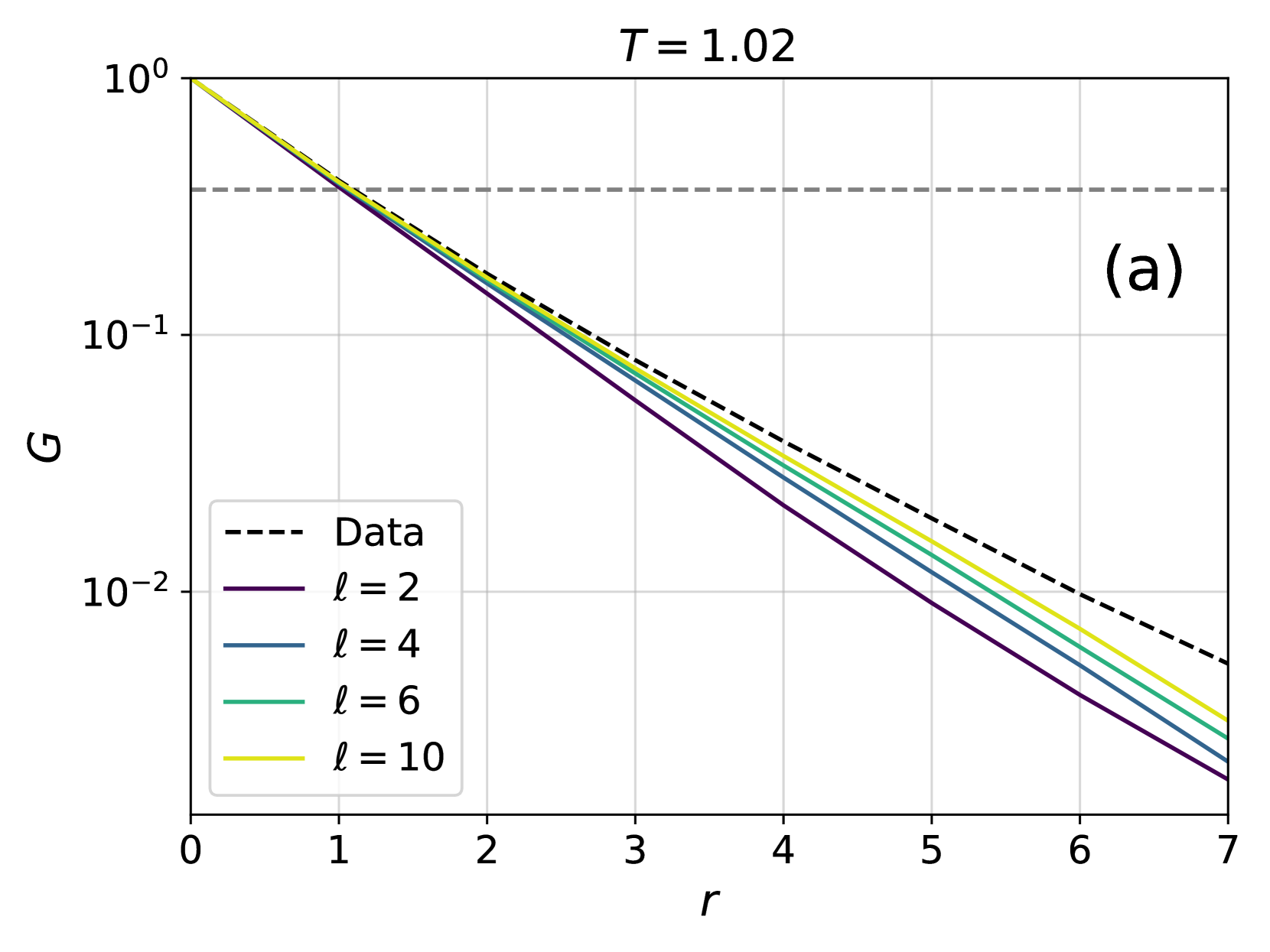
### Visual Description
\n
## Semi-Log Line Plot: Correlation Function G(r) for T = 1.02
### Overview
The image is a scientific line graph presented on a semi-logarithmic scale (logarithmic y-axis, linear x-axis). It displays the decay of a quantity labeled "G" as a function of a variable "r". The plot compares a "Data" series (likely experimental or simulation results) against four theoretical or model curves parameterized by a variable "ℓ". The title "T = 1.02" suggests the data corresponds to a specific temperature or time parameter. The label "(a)" in the top-right corner indicates this is likely panel (a) of a multi-part figure.
### Components/Axes
* **Title:** `T = 1.02` (centered at the top).
* **Panel Label:** `(a)` (located in the top-right corner of the plot area).
* **Y-Axis:**
* **Label:** `G` (positioned vertically to the left of the axis).
* **Scale:** Logarithmic (base 10).
* **Major Ticks/Labels:** `10^0` (top), `10^-1`, `10^-2` (bottom).
* **X-Axis:**
* **Label:** `r` (positioned horizontally below the axis).
* **Scale:** Linear.
* **Major Ticks/Labels:** `0`, `1`, `2`, `3`, `4`, `5`, `6`, `7`.
* **Legend:** Located in the bottom-left quadrant of the plot area. It contains five entries:
1. `--- Data` (black dashed line)
2. `— ℓ = 2` (solid purple line)
3. `— ℓ = 4` (solid blue line)
4. `— ℓ = 6` (solid green/teal line)
5. `— ℓ = 10` (solid yellow line)
* **Reference Line:** A horizontal, gray, dashed line is present at approximately `G ≈ 0.3` (or `3 x 10^-1`), spanning the full width of the plot.
### Detailed Analysis
**Trend Verification:** All five data series exhibit a monotonic, approximately exponential decay (appearing as straight lines on this semi-log plot) as `r` increases from 0 to 7. The lines do not cross within the plotted range.
**Data Series & Approximate Values:**
1. **Data (Black Dashed Line):**
* **Trend:** Decays the slowest among all series.
* **Key Points:** Starts at `G(0) ≈ 1.0`. At `r = 7`, `G ≈ 0.005` (or `5 x 10^-3`).
2. **ℓ = 2 (Purple Solid Line):**
* **Trend:** Decays the fastest.
* **Key Points:** Starts at `G(0) ≈ 1.0`. At `r = 7`, `G ≈ 0.001` (or `1 x 10^-3`).
3. **ℓ = 4 (Blue Solid Line):**
* **Trend:** Decays slower than ℓ=2 but faster than ℓ=6.
* **Key Points:** Starts at `G(0) ≈ 1.0`. At `r = 7`, `G ≈ 0.002` (or `2 x 10^-3`).
4. **ℓ = 6 (Green/Teal Solid Line):**
* **Trend:** Decays slower than ℓ=4 but faster than ℓ=10.
* **Key Points:** Starts at `G(0) ≈ 1.0`. At `r = 7`, `G ≈ 0.003` (or `3 x 10^-3`).
5. **ℓ = 10 (Yellow Solid Line):**
* **Trend:** Decays the slowest among the model curves (ℓ series), and is closest to the "Data" line.
* **Key Points:** Starts at `G(0) ≈ 1.0`. At `r = 7`, `G ≈ 0.004` (or `4 x 10^-3`).
**Spatial Relationships:** The model curves are ordered from fastest to slowest decay (bottom to top on the right side of the plot) as ℓ increases: ℓ=2 (lowest), ℓ=4, ℓ=6, ℓ=10 (highest). The "Data" line lies above all model curves for `r > 0`, indicating the models consistently underestimate the value of `G` at a given `r` compared to the data.
### Key Observations
1. **Systematic Model Convergence:** As the parameter ℓ increases from 2 to 10, the model curves progressively approach the "Data" curve from below. The ℓ=10 curve provides the closest match to the data across the entire range of `r`.
2. **Exponential Decay:** The linearity of all curves on the semi-log plot confirms that `G(r)` decays exponentially with `r` for both the data and the models.
3. **Common Origin:** All curves originate from the same point `(r=0, G=1)`, suggesting a normalization condition where `G(0) = 1`.
4. **Reference Threshold:** The horizontal dashed line at `G ≈ 0.3` may represent a significant threshold, such as a correlation length definition (e.g., where `G(r)` falls to `1/e ≈ 0.368` or another characteristic value).
### Interpretation
This plot demonstrates the comparison between empirical data ("Data") and a family of theoretical models for a decaying correlation function `G(r)`. The parameter `ℓ` likely represents a multipole order, a mode index, or a similar discrete parameter in the model.
The key finding is that **higher values of ℓ yield a better fit to the data**. The model with ℓ=10 most accurately reproduces the observed decay rate, while lower ℓ values (2, 4, 6) decay too rapidly. This suggests that the physical process generating the data has significant contributions from higher-order modes or moments (higher ℓ), which are necessary to capture the long-range correlations (slower decay) present in the system at `T = 1.02`.
The consistent underestimation by all models (curves below data) might indicate either:
* An incomplete model missing additional physics that sustains correlations at larger `r`.
* That the true best-fit ℓ is greater than 10.
* A systematic offset or different normalization in the model calculation.
The horizontal reference line provides a visual benchmark. For instance, the "Data" curve crosses this line at `r ≈ 1.2`, while the ℓ=10 curve crosses it at `r ≈ 1.0`, and the ℓ=2 curve crosses it at `r ≈ 0.7`. This quantifies how the predicted "correlation length" (if that's what the line represents) varies with ℓ and how it compares to the data.
</details>
<details>
<summary>x10.png Details</summary>
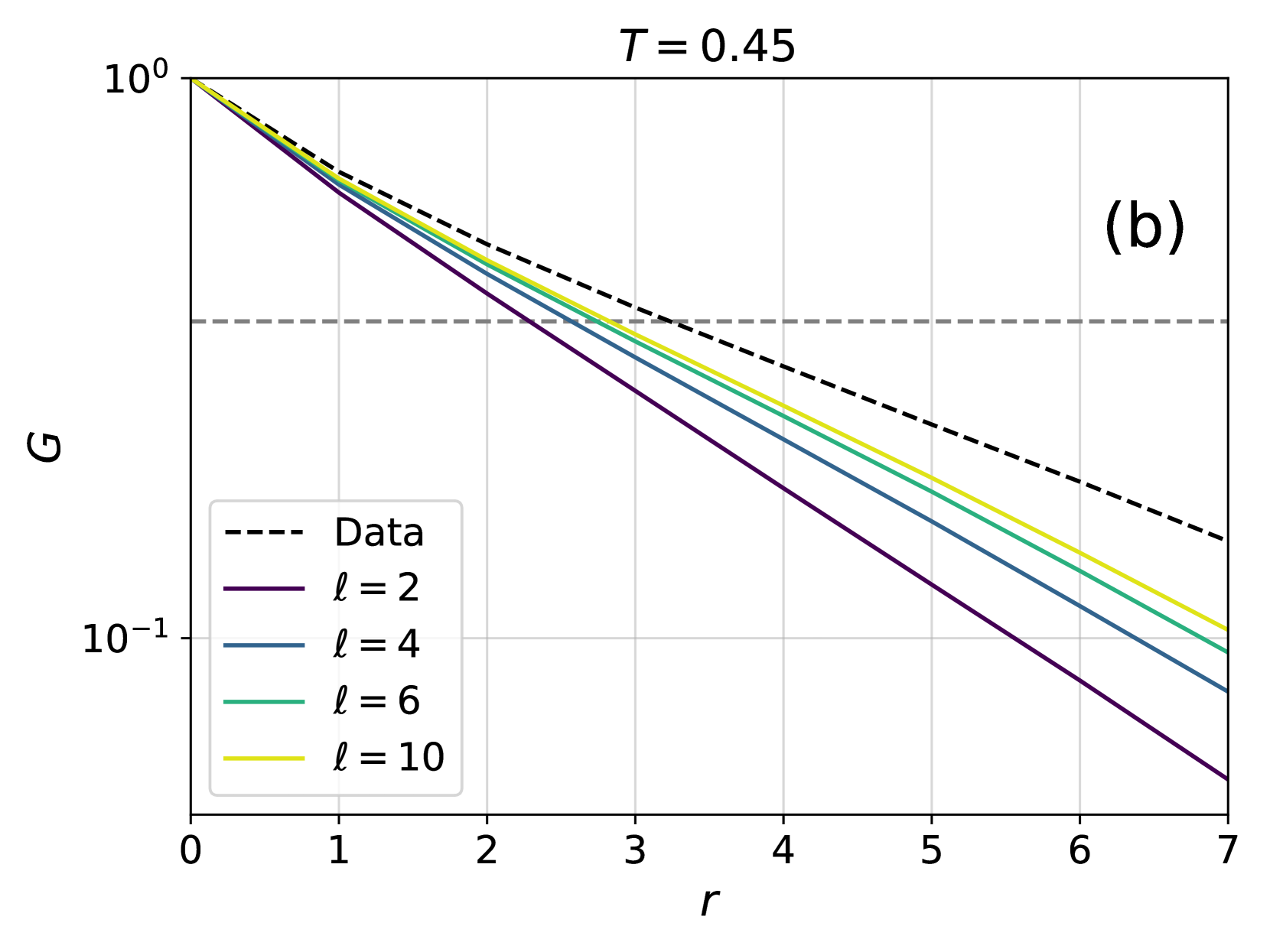
### Visual Description
## Semi-Logarithmic Line Plot: Correlation Function G vs. Distance r
### Overview
The image is a scientific line graph, specifically a semi-logarithmic plot (log scale on the y-axis, linear scale on the x-axis). It displays the decay of a quantity labeled "G" as a function of a variable "r" for a fixed parameter "T = 0.45". The plot compares a "Data" series against four theoretical or model curves parameterized by "ℓ". The label "(b)" in the top-right corner indicates this is panel (b) of a larger multi-panel figure.
### Components/Axes
* **Title:** `T = 0.45` (centered at the top).
* **Panel Label:** `(b)` (top-right corner).
* **Y-Axis:**
* **Label:** `G` (centered vertically on the left).
* **Scale:** Logarithmic (base 10).
* **Major Ticks/Labels:** `10^0` (top) and `10^-1` (bottom).
* **Grid:** Light gray vertical and horizontal grid lines are present.
* **X-Axis:**
* **Label:** `r` (centered horizontally at the bottom).
* **Scale:** Linear.
* **Major Ticks/Labels:** `0, 1, 2, 3, 4, 5, 6, 7`.
* **Legend:** Located in the bottom-left quadrant of the plot area. It contains five entries:
1. `--- Data` (black dashed line)
2. `— ℓ = 2` (purple solid line)
3. `— ℓ = 4` (blue solid line)
4. `— ℓ = 6` (green solid line)
5. `— ℓ = 10` (yellow solid line)
* **Reference Line:** A horizontal, gray, dashed line is present at an approximate value of `G ≈ 0.3` (or `3 x 10^-1`).
### Detailed Analysis
**Trend Verification:** All five data series exhibit a downward, approximately linear trend on this semi-log plot, indicating an exponential decay of `G` with increasing `r`. The lines are straight, confirming the functional form `G ∝ exp(-r/ξ)` for some decay length `ξ`.
**Data Series Analysis (from top to bottom at r=7):**
1. **Data (Black Dashed Line):** This series has the shallowest slope (slowest decay). It starts at `G(0) = 10^0 = 1`. At `r=7`, its value is approximately `G ≈ 0.15` (or `1.5 x 10^-1`).
2. **ℓ = 10 (Yellow Solid Line):** This is the next shallowest curve. It starts at `G(0)=1`. At `r=7`, its value is approximately `G ≈ 0.11`.
3. **ℓ = 6 (Green Solid Line):** This curve decays faster than the `ℓ=10` line. At `r=7`, its value is approximately `G ≈ 0.09`.
4. **ℓ = 4 (Blue Solid Line):** This curve decays faster than the `ℓ=6` line. At `r=7`, its value is approximately `G ≈ 0.07`.
5. **ℓ = 2 (Purple Solid Line):** This series has the steepest slope (fastest decay). It starts at `G(0)=1`. At `r=7`, its value is the lowest, approximately `G ≈ 0.04`.
**Key Relationship:** As the parameter `ℓ` increases (from 2 to 10), the slope of the `G(r)` curve becomes less steep, meaning the decay of `G` with distance `r` is slower. The "Data" series decays even more slowly than the model curve for the highest `ℓ` value shown (`ℓ=10`).
### Key Observations
* All curves originate from the same point `(r=0, G=1)`.
* The ordering of the curves by slope is consistent across the entire range of `r`: Data (shallowest) > ℓ=10 > ℓ=6 > ℓ=4 > ℓ=2 (steepest).
* The horizontal dashed reference line at `G ≈ 0.3` intersects the curves at different `r` values. For example, the `ℓ=2` curve crosses it near `r ≈ 2.5`, while the "Data" curve crosses it near `r ≈ 4.2`.
* The plot uses a clear color scheme (black, purple, blue, green, yellow) that is distinguishable and matches the legend precisely.
### Interpretation
This plot demonstrates the spatial decay of a correlation function `G(r)` at a fixed temperature `T=0.45`. The "Data" line likely represents empirical results (e.g., from simulation or experiment). The solid lines for different `ℓ` values represent predictions from a theoretical model where `ℓ` is a key parameter.
The central finding is that the model's predicted decay rate is strongly dependent on `ℓ`: larger `ℓ` values produce slower decay, better matching the shallow slope of the empirical "Data". However, even the model with the largest `ℓ` shown (`ℓ=10`) still predicts a faster decay than the actual data. This suggests that the model, with the tested parameters, underestimates the correlation length (the distance over which `G` remains significant) of the system being studied. The horizontal dashed line at `G ≈ 0.3` may represent a threshold for "significant" correlation, highlighting how much farther correlations persist in the data compared to the models. The parameter `T=0.45` is held constant, so this plot specifically isolates the effect of `ℓ` on the spatial correlations at that temperature.
</details>
Figure 5: Comparison between the spatial correlation functions obtained from 4N and those obtained from PT, at different high (a) and low (b) temperatures and for different number of layers. The grey dashed lines correspond to the value $1/e$ that defines the correlation length $\xi$ . Data are averaged over 10 instances.
### Overlap distribution function
In order to show that the 4N architecture is able to capture more complex features of the Gibbs-Boltzmann distribution, we have considered a more sensitive observable: the probability distribution of the overlap, $P(q)$ . The overlap $q$ between two configurations of spins $\ \boldsymbol{\sigma}^{1}=\{\sigma^{1}_{1},\sigma^{1}_{2},\dots\sigma^{1}_{N}\}$ and $\ \boldsymbol{\sigma}^{2}=\{\sigma^{2}_{1},\sigma^{2}_{2},\dots\sigma^{2}_{N}\}$ is a central quantity in spin glass physics, and is defined as:
$$
q_{12}=\frac{1}{N}\boldsymbol{\sigma}^{1}\cdot\boldsymbol{\sigma}^{2}=\frac{1}
{N}\sum_{i=1}^{N}\sigma^{1}_{i}\sigma^{2}_{i}. \tag{12}
$$
The histogram of $P(q)$ is obtained by considering many pairs of configurations, independently taken from either the PT-generated training set, or by generating them with the 4N architecture. Examples for two different instances at several temperatures are shown in Fig. 4. At high temperatures, even very few layers are able to reproduce the distribution of the overlaps. When going to lower temperatures, and to more complex shapes of $P(q)$ , however, the number of layers that is required to have a good approximation of $P(q)$ increases. This result is compatible with the intuitive idea that an increasing number of layers is required to reproduce a system at low temperatures, where the correlation length is large.
As shown in the SI, the performance of 4N is on par with that of other algorithms with more parameters. Moreover, with a suitable increase of the number of layers, 4N is also able to achieve satisfactory results when system’s size increases.
<details>
<summary>x11.png Details</summary>
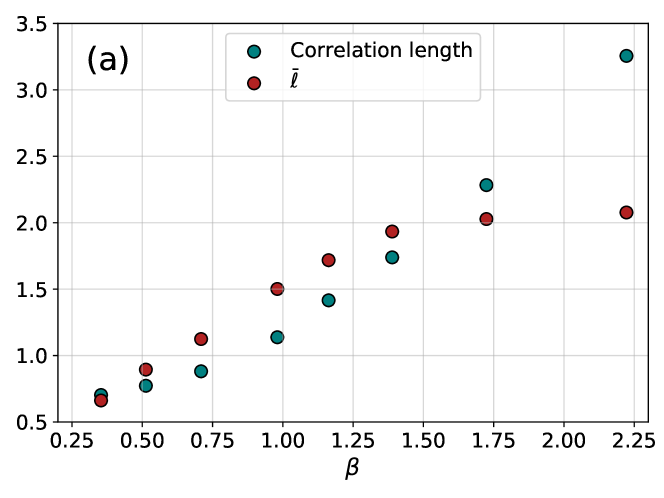
### Visual Description
## Scatter Plot: Correlation Length and ℓ̄ vs. β
### Overview
The image is a scatter plot labeled "(a)" in the top-left corner, displaying two data series plotted against a parameter β on the x-axis. The plot compares the values of "Correlation length" and "ℓ̄" (a symbol with a bar over the letter l) as β increases. The data points show a clear positive correlation for both series, with "Correlation length" exhibiting a steeper increase at higher β values.
### Components/Axes
* **Chart Type:** Scatter plot.
* **Panel Label:** "(a)" located in the top-left corner of the plot area.
* **X-Axis:**
* **Title:** β (Greek letter beta).
* **Scale:** Linear, ranging from 0.25 to 2.25.
* **Major Tick Marks:** 0.25, 0.50, 0.75, 1.00, 1.25, 1.50, 1.75, 2.00, 2.25.
* **Y-Axis:**
* **Title:** Not explicitly labeled. The axis represents the numerical value of the plotted quantities.
* **Scale:** Linear, ranging from 0.5 to 3.5.
* **Major Tick Marks:** 0.5, 1.0, 1.5, 2.0, 2.5, 3.0, 3.5.
* **Legend:**
* **Position:** Top-center of the plot area, inside a white box with a light gray border.
* **Entries:**
1. **Teal Circle:** Labeled "Correlation length".
2. **Red Circle:** Labeled "ℓ̄" (the symbol consists of a lowercase 'l' with a horizontal bar above it).
* **Grid:** A light gray grid is present, aligning with the major tick marks on both axes.
### Detailed Analysis
**Data Series 1: Correlation length (Teal Circles)**
* **Trend:** The data points follow a clear upward curve. The slope is moderate for β < 1.0 and becomes significantly steeper for β > 1.0.
* **Approximate Data Points (β, Value):**
* (0.35, 0.70)
* (0.50, 0.75)
* (0.70, 0.90)
* (1.00, 1.10)
* (1.20, 1.40)
* (1.40, 1.75)
* (1.75, 2.30)
* (2.25, 3.25)
**Data Series 2: ℓ̄ (Red Circles)**
* **Trend:** The data points also follow an upward trend, but the increase is more linear and less steep compared to the "Correlation length" series, especially at higher β values. The rate of increase appears to slow slightly after β ≈ 1.4.
* **Approximate Data Points (β, Value):**
* (0.35, 0.65)
* (0.50, 0.90)
* (0.70, 1.10)
* (1.00, 1.50)
* (1.20, 1.70)
* (1.40, 1.95)
* (1.75, 2.05)
* (2.25, 2.10)
### Key Observations
1. **Diverging Trends:** While both quantities increase with β, they diverge significantly. At low β (≈0.35), their values are very close (0.70 vs. 0.65). By β=2.25, "Correlation length" (3.25) is over 50% larger than "ℓ̄" (2.10).
2. **Crossover Point:** The two data series intersect between β=0.5 and β=0.7. At β=0.5, ℓ̄ (0.90) is greater than Correlation length (0.75). By β=0.7, Correlation length (0.90) is slightly less than ℓ̄ (1.10), but the trend lines have crossed.
3. **Non-Linear vs. Near-Linear Growth:** "Correlation length" shows pronounced non-linear (possibly exponential or power-law) growth. "ℓ̄" shows growth that is closer to linear, with a potential saturation effect at the highest β values shown.
4. **Data Density:** The sampling of β is not uniform. There are more data points clustered in the lower range (β < 1.5) than in the higher range.
### Interpretation
This plot likely comes from a physics or statistical mechanics context, where β often represents inverse temperature (1/kT). The data demonstrates a fundamental relationship: as the system's "temperature" decreases (β increases), both the correlation length and the average length scale ℓ̄ increase.
The critical insight is the **diverging behavior**. The correlation length, which measures the distance over which fluctuations in the system are related, grows much more rapidly than the average length ℓ̄. This is a classic signature of approaching a **critical point** or phase transition. Near such a point, correlations become long-ranged, causing the correlation length to diverge (theoretically to infinity at the critical β), while other average quantities (like ℓ̄) may increase more slowly or saturate.
The crossover at low β suggests that in the high-temperature (low β) disordered phase, the two length scales are comparable. As the system cools and becomes more ordered, the correlation length takes over as the dominant scale governing the system's spatial structure. The plot visually captures the onset of this critical scaling behavior.
</details>
<details>
<summary>x12.png Details</summary>
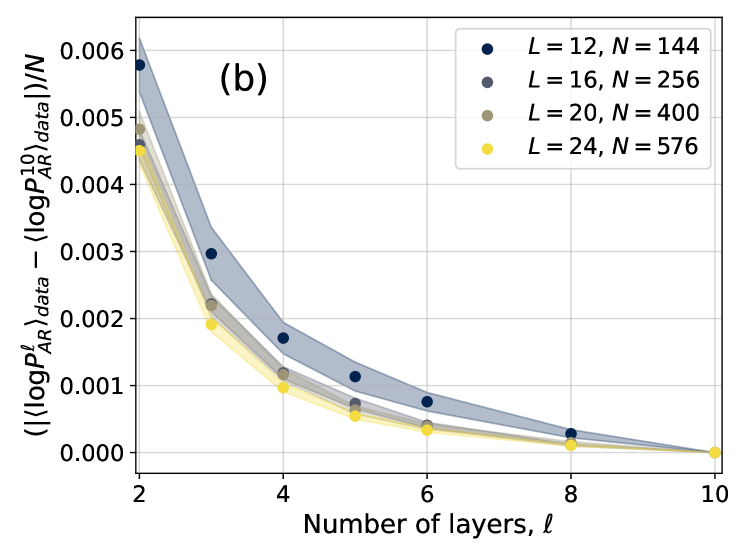
### Visual Description
## Line Graph: Layer-wise Autoregressive Probability Metric
### Overview
The image is a scientific line graph labeled "(b)" in the top-left corner of the plot area. It displays the relationship between the number of layers (ℓ) in a model and a normalized, absolute difference metric involving autoregressive probabilities. The graph contains four data series, each corresponding to a different model configuration defined by parameters L and N. All series show a decreasing trend as the number of layers increases.
### Components/Axes
* **X-Axis:** Labeled "Number of layers, ℓ". The axis has major tick marks at values 2, 4, 6, 8, and 10.
* **Y-Axis:** Labeled with the complex mathematical expression: `( |⟨log P_AR^ℓ⟩_data - ⟨log P_AR^10⟩_data| ) / N`. The axis scale ranges from 0.000 to 0.006, with major tick marks at intervals of 0.001.
* **Legend:** Positioned in the top-right corner of the plot area. It defines four data series:
* Dark Blue Circle: `L = 12, N = 144`
* Gray Circle: `L = 16, N = 256`
* Tan/Brown Circle: `L = 20, N = 400`
* Yellow Circle: `L = 24, N = 576`
* **Data Series:** Each series is represented by a line connecting circular markers. A shaded region of the corresponding color surrounds each line, likely indicating a confidence interval or standard deviation.
### Detailed Analysis
The graph plots the value of the y-axis metric against the number of layers (ℓ) for four model configurations. The data points are at ℓ = 2, 4, 6, 8, and 10.
**Trend Verification:** All four lines exhibit a clear, monotonic downward slope from left to right. The rate of decrease is steepest between ℓ=2 and ℓ=4, and the curves flatten as ℓ increases, converging near zero at ℓ=10.
**Approximate Data Points (Visual Estimation):**
| ℓ (Layers) | L=12, N=144 (Dark Blue) | L=16, N=256 (Gray) | L=20, N=400 (Tan) | L=24, N=576 (Yellow) |
| :--- | :--- | :--- | :--- | :--- |
| **2** | ~0.0058 | ~0.0050 | ~0.0048 | ~0.0045 |
| **4** | ~0.0017 | ~0.0012 | ~0.0011 | ~0.0010 |
| **6** | ~0.0008 | ~0.0005 | ~0.0004 | ~0.00035 |
| **8** | ~0.0003 | ~0.0002 | ~0.00015 | ~0.0001 |
| **10** | ~0.0000 | ~0.0000 | ~0.0000 | ~0.0000 |
**Spatial Grounding & Component Isolation:**
* **Header Region:** Contains the label "(b)" in the top-left.
* **Main Chart Region:** The plot area. The legend is anchored in the top-right. The data lines originate from the top-left (high y-value at low ℓ) and converge at the bottom-right (y≈0 at ℓ=10).
* **Footer Region:** Contains the x-axis label.
### Key Observations
1. **Consistent Hierarchy:** At every layer count (ℓ) before convergence, the series maintain a strict order from highest to lowest y-value: `L=12, N=144` > `L=16, N=256` > `L=20, N=400` > `L=24, N=576`.
2. **Convergence:** All data series converge to a value of approximately 0.000 at ℓ=10. This is expected, as the y-axis metric measures the difference from the value at ℓ=10 (`⟨log P_AR^10⟩_data`).
3. **Diminishing Returns:** The most significant reduction in the metric occurs within the first few layers (ℓ=2 to ℓ=4). Subsequent layers yield progressively smaller decreases.
4. **Model Size Correlation:** Larger models (higher L and N) start with a lower initial value of the metric at ℓ=2 and maintain lower values throughout, though the absolute difference between series diminishes as ℓ increases.
### Interpretation
This graph likely analyzes the internal probability distributions of autoregressive models of varying depths and widths. The y-axis metric quantifies how much the model's probability distribution at a given layer ℓ differs from its final distribution at layer 10, normalized by the parameter N.
The data suggests two key insights:
1. **Layer-wise Refinement:** The model's internal representation, as measured by this probability metric, undergoes the most dramatic change in the early layers. This implies that the foundational features or predictions are established quickly, with later layers performing finer adjustments.
2. **Impact of Model Scale:** Larger models (higher L and N) appear to have a "head start" – their internal distributions at early layers are already closer to their final state (lower y-value). This could indicate that increased model capacity allows for more efficient or stable internal processing from the outset.
The convergence at ℓ=10 is a mathematical certainty by the definition of the metric, serving as a sanity check for the plot. The consistent ordering of the lines provides strong evidence that model scale (both depth L and width N) systematically influences the trajectory of this internal refinement process. The shaded regions, while not quantified, suggest the variance or uncertainty in this metric is also larger for smaller models and in the early layers.
</details>
Figure 6: (a) Comparison between the correlation length $\xi$ and the decay parameter $\overline{\ell}$ of the exponential fit as a function of the inverse temperature $\beta$ . Both data sets are averaged over 10 instances. The data are limited to $T\geq 0.45$ because below that temperature the finite size of the sample prevents us to obtain a reliable proper estimate of the correlation length. (b) Absolute difference between $\langle\log P^{\ell}_{\text{NN}}\rangle_{\text{data}}$ at various $\ell$ and at $\ell=10$ for $T=1.02$ and different system sizes. Data are averaged over ten different instances of the disorder and the colored areas identify regions corresponding to plus or minus one standard deviation. A version of this plot in linear-logarithmic scale is available in the SI.
### Spatial correlation function
To better quantify spatial correlations, from the overlap field, a proper correlation function for a spin glass system can be defined as [35]
$$
G(r)=\frac{1}{{\color[rgb]{0,0,0}\mathcal{N}(r)}}\sum_{i,j:d_{ij}=r}\overline{
\langle q_{i}q_{j}\rangle}\ , \tag{13}
$$
where $r=d_{ij}$ is the lattice distance of sites $i,j$ , ${q_{i}=\sigma^{1}_{i}\sigma^{2}_{i}}$ is the local overlap, and $\mathcal{N}(r)=\sum_{i,j:d_{ij}=r}1$ is the number of pairs of sites at distance $r$ . Note that in this way $G(0)=1$ by construction. Results for $G(r)$ at various temperatures are shown in Fig. 5. It is clear that increasing the number of layers leads to a better agreement at lower temperatures. Interestingly, architectures with a lower numbers of layers produce a smaller correlation function at any distance, which shows that upon increasing the number of layers the 4N architecture is effectively learning the correlation of the Gibbs-Boltzmann measure.
To quantify this intuition, we extract from the exact $G(r)$ of the EA model a correlation length $\xi$ , from the relation $G(\xi)=1/e$ . Then, we compare $\xi$ with $\overline{\ell}$ , i.e. the number of layers above which the model becomes accurate, extracted from Fig. 3. These two quantities are compared in Fig. 6 as a function of temperature, showing that they are roughly proportional. Actually $\overline{\ell}$ seems to grow even slower than $\xi$ at low temperatures. In Fig. 6 we also reproduce the results of Fig. 3b for different sizes of the system. The curves coincide for large enough values of $N$ , showing that the value of $\ell$ saturates to a system-independent value when increasing the system size. We are thus able to introduce a physical criterion to fix the optimal number of layers needed for the 4N architecture to perform well: $\ell$ must be of the order of the correlation length $\xi$ of the model at that temperature.
We recall that the 4N architecture requires $(c+1)\times\ell\times N$ parameters, where $c$ is the average connectivity of the graph ( $c=2d$ for a $d$ -dimensional lattice), and $\mathcal{O}(\mathcal{B}(\ell)\times N)$ operations to generate a new configuration. We thus conclude that, for a model with a correlation length $\xi$ that remains finite for $N\to\infty$ , we can choose $\ell$ proportional to $\xi$ , hence achieving the desired linear scaling with system size both for the number of parameters and the number of operations.
## Discussion
In this work we have introduced a new, physics-inspired 4N architecture for the approximation of the Gibbs-Boltzmann probability distribution of a spin glass system of $N$ spins. The 4N architecture is inspired by the previously introduced TwoBo [21], but it implements explicitly the locality of the physical model via a Graph Neural Network structure.
The 4N network possesses many desirable properties. (i) The architecture has a physical interpretation, with the required number of layers being directly linked to the correlation length of the original data. (ii) As a consequence, if the correlation length of the model is finite, the required number of parameters for a good fit scales linearly in the number of spins, thus greatly improving the scalability with respect to previous architectures. (iii) The architecture is very general, and can be applied to lattices in all dimensions as well as arbitrary interaction graphs without losing the good scaling of the number of parameters, as long as the average connectivity remains finite. It can also be generalized to systems with more than two-body interactions by using a factor graph representation in the GNN layers.
As a benchmark study, we have tested that the 4N architecture is powerful enough to reproduce key properties of the two-dimensional Edwards-Anderson spin glass model, such as the energy, the correlation function and the probability distribution of the overlap.
Having tested that 4N achieves the best possible scaling with system size while being expressive enough, the next step is to check whether it is possible to apply an iterative, self-consistent procedure to automatically train the network at lower and lower temperatures without the aid of training data generated with a different algorithm (here, parallel tempering). This would allow to set up a simulated tempering procedure with a good scaling in the number of variables, with applications not only in the simulation of disordered systems but in the solution of optimization problems as well. Whether setting up such a procedure is actually possible will be the focus of future work.
## Methods
### Details of the 4N architecture
The Nearest Neighbors Neural Network (4N) architecture uses a GNN structure to respect the locality of the problem, as illustrated in Fig. 1. The input, given by the local fields computed from the already fixed spins, is passed through $\ell$ layers of weights $W_{ij}^{k}$ . Each weight corresponds to a directed nearest neighbor link $i\leftarrow j$ (including $i=j$ ) and $k=1,\dots,\ell$ , therefore the network has a total number of parameters equal to $(c+1)\times\ell\times N$ , i.e. linear in $N$ as long as the number of layers and the model connectivity remain finite. A showcase of the real wall-clock times required for the training of the network and for the generation of new configurations is shown in the SI.
The operations performed in order to compute ${\pi_{i}=P(\sigma_{i}=1\mid\boldsymbol{\sigma}_{<i})}$ are the following:
1. initialize the local fields from the input spins $\boldsymbol{\sigma}_{<i}$ :
$$
h_{l}^{i,(0)}=\sum_{f(<i)}J_{lf}\sigma_{f}\ ,\qquad\forall l:|i-l|\leq\ell\ . \tag{0}
$$
1. iterate the GNN layers $\forall k=1,\cdots,\ell-1$ :
$$
h_{l}^{i,(k)}=\phi^{k}\left[\beta W_{ll}^{k}h_{l}^{i,(k-1)}+\sum_{j\in\partial
l
}\beta J_{lj}W_{lj}^{k}h_{j}^{i,(k-1)}\right]+h_{l}^{i,(0)}\ , \tag{0}
$$
where the sum over $j\in\partial l$ runs over the neighbors of site $l$ . The fields are computed $\forall l:|i-l|\leq\ell-k$ , see Fig. 1.
1. compute the field on site $i$ at the final layer,
$$
h_{i}^{i,(\ell)}=\phi^{\ell}\left[\beta W_{ii}^{\ell}h_{i}^{i,(\ell-1)}+\sum_{
j\in\partial i}\beta J_{ij}W_{ij}^{\ell}h_{j}^{i,(\ell-1)}\right]\ .
$$
1. output $\pi_{i}=P(\sigma_{i}=1|\boldsymbol{\sigma}_{<i})=S[2h_{i}^{i,(\ell)}]$ .
Here $S(x)=1/(1+e^{-x})$ is the sigmoid function and $\phi^{k}(x)$ are layer-specific functions that can be used to introduce non-linearities in the system. The fields $h_{l}^{i,(0)}=\xi_{il}$ in the notation of the TwoBo architecture. Differently from TwoBo, however, 4N uses all the $h_{l}^{i,(0)}$ , instead of the ones corresponding to spins that have not yet been fixed.
In practice, we have observed that the network with identity functions, i.e. $\phi^{k}(x)=x$ for all $k$ , is sufficiently expressive, and using non-linearities does not seem to improve the results. Moreover, linear functions have the advantage of being easily explainable and faster, therefore we have chosen to use them in this work.
### Spin update order
Autoregressive models such as 4N are based on an ordering of spins to implement Eq. (6). One can choose a simple raster scan (i.e., from left to right on one row and updating each row from top to bottom sequentially) or any other scheme of choice, see e.g. Refs. [14, 36] for a discussion. In this work, we have adopted a spiral scheme, in which the spins at the edges of the system are updated first, and then one moves in spirals towards the central spins. As shown in the SI, it appears as 4N performs better, for equal training conditions, when the spins are updated following a spiral scheme with respect to, for instance, a raster scheme.
### Building the training data
We use a training set of $M=2^{16}$ configurations obtained at several temperatures using a Parallel Tempering algorithm for different instances of the couplings $J_{ij}$ , and for a 16x16 two-dimensional square lattice with open boundary conditions. Data where gathered in runs of $2^{27}$ steps by considering $2^{26}$ steps for thermalization and then taking one configuration each $2^{10}$ steps. Temperature swap moves, in which one swaps two configurations at nearby temperature, were attempted once every 32 normal Metropolis sweeps. The choice of $M=2^{16}$ was motivated based on previous studies of the same model [12].
### Model training
The training has been carried out maximizing the likelihood of the data, a procedure which is equivalent to minimizing the KL divergence $D_{\text{KL}}(P_{\text{GB}}\parallel P_{\text{NN}})$ , with $P_{\text{GB}}$ estimated by the training set. We used an ADAM optimizer with batch size 128 for 80 epochs and a learning rate 0.001 with exponential decay in time. Training is stopped if the loss has not improved in the last 10 steps, and the lowest-loss model is considered.
Acknowledgements. We especially thank Indaco Biazzo and Giuseppe Carleo for several important discussions on their TwoBo architecture that motivated and inspired the present study. We also thank Giulio Biroli, Patrick Charbonneau, Simone Ciarella, Marylou Gabrié, Leonardo Galliano, Jeanne Trinquier, Martin Weigt and Lenka Zdeborová for useful discussions. We acknowledge support from the computational infrastructure DARIAH.IT, PON Project code PIR01_00022, National Research Council of Italy. The research has received financial support from the “National Centre for HPC, Big Data and Quantum Computing - HPC”, Project CN_00000013, CUP B83C22002940006, NRP Mission 4 Component 2 Investment 1.5, Funded by the European Union - NextGenerationEU. Author LMDB acknowledges funding from the Bando Ricerca Scientifica 2024 - Avvio alla Ricerca (D.R. No. 1179/2024) of Sapienza Università di Roma, project B83C24005280001 – MaLeDiSSi.
## References
- [1] Ulli Wolff. Collective monte carlo updating for spin systems. Physical Review Letters, 62(4):361–364, 1989. Publisher: American Physical Society.
- [2] Andrea Ninarello, Ludovic Berthier, and Daniele Coslovich. Models and algorithms for the next generation of glass transition studies. Phys. Rev. X, 7:021039, Jun 2017.
- [3] E. Marinari and G. Parisi. Simulated tempering: A new monte carlo scheme. Europhysics Letters, 19(6):451, jul 1992.
- [4] J. Houdayer. A cluster monte carlo algorithm for 2-dimensional spin glasses. The European Physical Journal B - Condensed Matter and Complex Systems, 22(4):479–484, 2001.
- [5] Giuseppe Carleo and Matthias Troyer. Solving the quantum many-body problem with artificial neural networks. Science, 355(6325):602–606, 2017. Publisher: American Association for the Advancement of Science.
- [6] Samuel Tamagnone, Alessandro Laio, and Marylou Gabrié. Coarse grained molecular dynamics with normalizing flows. arXiv preprint arXiv:2406.01524, 2024.
- [7] Gerhard Jung, Rinske M Alkemade, Victor Bapst, Daniele Coslovich, Laura Filion, François P Landes, Andrea Liu, Francesco Saverio Pezzicoli, Hayato Shiba, Giovanni Volpe, et al. Roadmap on machine learning glassy liquids. arXiv preprint arXiv:2311.14752, 2023.
- [8] Leonardo Galliano, Riccardo Rende, and Daniele Coslovich. Policy-guided monte carlo on general state spaces: Application to glass-forming mixtures. arXiv preprint arXiv:2407.03275, 2024.
- [9] Simone Ciarella, Dmytro Khomenko, Ludovic Berthier, Felix C Mocanu, David R Reichman, Camille Scalliet, and Francesco Zamponi. Finding defects in glasses through machine learning. Nature Communications, 14(1):4229, 2023.
- [10] Marylou Gabrié, Grant M. Rotskoff, and Eric Vanden-Eijnden. Adaptive monte carlo augmented with normalizing flows. Proceedings of the National Academy of Sciences, 119(10):e2109420119, 2022. Publisher: Proceedings of the National Academy of Sciences.
- [11] Dian Wu, Lei Wang, and Pan Zhang. Solving statistical mechanics using variational autoregressive networks. Physical Review Letters, 122(8):080602, 2019. Publisher: American Physical Society.
- [12] Simone Ciarella, Jeanne Trinquier, Martin Weigt, and Francesco Zamponi. Machine-learning-assisted monte carlo fails at sampling computationally hard problems. Machine Learning: Science and Technology, 4(1):010501, 2023.
- [13] B. McNaughton, M. V. Milošević, A. Perali, and S. Pilati. Boosting monte carlo simulations of spin glasses using autoregressive neural networks. Physical Review E, 101(5):053312, 2020. Publisher: American Physical Society.
- [14] Jeanne Trinquier, Guido Uguzzoni, Andrea Pagnani, Francesco Zamponi, and Martin Weigt. Efficient generative modeling of protein sequences using simple autoregressive models. Nature communications, 12(1):5800, 2021.
- [15] Jonas Köhler, Leon Klein, and Frank Noé. Equivariant flows: Exact likelihood generative learning for symmetric densities.
- [16] Manuel Dibak, Leon Klein, Andreas Krämer, and Frank Noé. Temperature steerable flows and boltzmann generators. Nature Machine Intelligence, 4(4):L042005, 2022. Publisher: American Physical Society.
- [17] Michele Invernizzi, Andreas Krämer, Cecilia Clementi, and Frank Noé. Skipping the replica exchange ladder with normalizing flows. The Journal of Physical Chemistry Letters, 13(50):11643–11649, 2022.
- [18] Wenlin Chen, Mingtian Zhang, Brooks Paige, José Miguel Hernández-Lobato, and David Barber. Diffusive gibbs sampling. arXiv preprint arXiv:2402.03008, 2024.
- [19] Davide Ghio, Yatin Dandi, Florent Krzakala, and Lenka Zdeborová. Sampling with flows, diffusion and autoregressive neural networks: A spin-glass perspective. arXiv preprint arXiv:2308.14085, 2023.
- [20] Michael Kilgour and Lena Simine. Inside the black box: A physical basis for the effectiveness of deep generative models of amorphous materials. Journal of Computational Physics, 452:110885, 2022.
- [21] Indaco Biazzo, Dian Wu, and Giuseppe Carleo. Sparse autoregressive neural networks for classical spin systems.
- [22] Martin J. A. Schuetz, J. Kyle Brubaker, and Helmut G. Katzgraber. Combinatorial optimization with physics-inspired graph neural networks. Nature Machine Intelligence, 4(4):367–377, 2022. Publisher: Nature Publishing Group.
- [23] Martin J. A. Schuetz, J. Kyle Brubaker, Zhihuai Zhu, and Helmut G. Katzgraber. Graph coloring with physics-inspired graph neural networks. Physical Review Research, 4(4):043131, 2022. Publisher: American Physical Society.
- [24] Changjun Fan, Mutian Shen, Zohar Nussinov, Zhong Liu, Yizhou Sun, and Yang-Yu Liu. Searching for spin glass ground states through deep reinforcement learning. Nature Communications, 14(1):725, February 2023. Publisher: Nature Publishing Group.
- [25] Daria Pugacheva, Andrei Ermakov, Igor Lyskov, Ilya Makarov, and Yuriy Zotov. Enhancing gnns performance on combinatorial optimization by recurrent feature update. arXiv:2407.16468, 2024.
- [26] Lorenzo Colantonio, Andrea Cacioppo, Federico Scarpati, and Stefano Giagu. Efficient graph coloring with neural networks: A physics-inspired approach for large graphs. arXiv:2408.01503, 2024.
- [27] Maria Chiara Angelini and Federico Ricci-Tersenghi. Modern graph neural networks do worse than classical greedy algorithms in solving combinatorial optimization problems like maximum independent set. Nature Machine Intelligence, 5(1):29–31, December 2022. arXiv:2206.13211 [cond-mat].
- [28] Stefan Boettcher. Inability of a graph neural network heuristic to outperform greedy algorithms in solving combinatorial optimization problems. Nature Machine Intelligence, 5(1):24–25, 2023.
- [29] Stefan Boettcher. Deep reinforced learning heuristic tested on spin-glass ground states: The larger picture. Nature Communications, 14(1):5658, 2023.
- [30] Changjun Fan, Mutian Shen, Zohar Nussinov, Zhong Liu, Yizhou Sun, and Yang-Yu Liu. Reply to: Deep reinforced learning heuristic tested on spin-glass ground states: The larger picture. Nature communications, 14(1):5659, 2023.
- [31] Mathieu Germain, Karol Gregor, Iain Murray, and Hugo Larochelle. Made: Masked autoencoder for distribution estimation. In International conference on machine learning, pages 881–889. PMLR, 2015.
- [32] Aaron Van den Oord, Nal Kalchbrenner, Lasse Espeholt, Oriol Vinyals, Alex Graves, et al. Conditional image generation with pixelcnn decoders. Advances in neural information processing systems, 29, 2016.
- [33] Ata Madanchi, Michael Kilgour, Frederik Zysk, Thomas D Kühne, and Lena Simine. Simulations of disordered matter in 3d with the morphological autoregressive protocol (map) and convolutional neural networks. The Journal of Chemical Physics, 160(2), 2024.
- [34] Indaco Biazzo. The autoregressive neural network architecture of the boltzmann distribution of pairwise interacting spins systems. Communications Physics, 6(1):296, 2023.
- [35] LA Fernandez, E Marinari, V Martin-Mayor, Giorgio Parisi, and JJ Ruiz-Lorenzo. Universal critical behavior of the two-dimensional ising spin glass. Physical Review B, 94(2):024402, 2016.
- [36] Yi Hong Teoh and Roger G Melko. Autoregressive model path dependence near ising criticality. arXiv:2408.15715, 2024.
## S1 Computational details
We now introduce a easy way to generate efficiently data using the 4N architecture. As long as the activation functions $\phi^{k}$ of the different layers of 4N are linear, all the intermediate message passing layers can be substituted with a single matrix multiplication. Indeed, let us consider, as in the main text, identity activation functions. In this case, we can rewrite the matrix implementing the $t-$ th layer, $\underline{\underline{A}}^{t}$ , as $\underline{\underline{A}}^{t}=\beta(\underline{\underline{J}}+\underline{ \underline{I}})\odot\underline{\underline{W}}^{t}$ , where $\beta$ is the inverse temperature, $\underline{\underline{J}}$ is the coupling matrix, $\underline{\underline{I}}$ is the identity matrix, and $\underline{\underline{W}}^{t}$ it the $t-$ th layer weight matrix. Here, $\odot$ is the elementwise multiplication. Now we observe that (in 4N we put skip connections after all but the last layer)
$$
\displaystyle\mathbf{h}^{t}=\underline{\underline{A}}^{t}\mathbf{h}^{t-1}=
\underline{\underline{A}}^{t}(\underline{\underline{A}}^{t-1}\mathbf{h}^{t-2}+
h^{0})=\dots=(\underline{\underline{A}}^{t}\underline{\underline{A}}^{t-1}
\dots\underline{\underline{A}}^{1}+\underline{\underline{A}}^{t}\underline{
\underline{A}}^{t-1}\dots\underline{\underline{A}}^{2}+\dots+\underline{
\underline{A}}^{t}\underline{\underline{A}}^{t-1}+\underline{\underline{A}}^{t
})\mathbf{h}^{0}. \tag{16}
$$
Now, remembering that, if the input configuration $\mathbf{s}$ is properly masked, we have $\mathbf{h}^{0}=\underline{\underline{J}}\mathbf{s}$ , it follows that
$$
\displaystyle\mathbf{h}^{t}=(\underline{\underline{A}}^{t}\underline{
\underline{A}}^{t-1}\dots\underline{\underline{A}}^{1}+\underline{\underline{A
}}^{t}\underline{\underline{A}}^{t-1}\dots\underline{\underline{A}}^{2}+\dots+
\underline{\underline{A}}^{t}\underline{\underline{A}}^{t-1}+\underline{
\underline{A}}^{t})\underline{\underline{J}}\mathbf{s}, \tag{17}
$$
which can be rewritten in matrix form as $\mathbf{h}^{t}=\underline{\underline{M}}\mathbf{s}$ by defining
$$
\displaystyle\underline{\underline{M}}=(\underline{\underline{A}}^{t}
\underline{\underline{A}}^{t-1}\dots\underline{\underline{A}}^{1}+\underline{
\underline{A}}^{t}\underline{\underline{A}}^{t-1}\dots\underline{\underline{A}
}^{2}+\dots+\underline{\underline{A}}^{t}\underline{\underline{A}}^{t-1}+
\underline{\underline{A}}^{t})\underline{\underline{J}}, \tag{18}
$$
and the final output is obtained simply by taking the elementwise sigmoidal of $\mathbf{h}^{t}$ . Notice that the $i$ -th row of the matrix $\underline{\underline{M}}$ has zeroes in all columns corresponding to spins at distance larger than $\ell+1$ from the spin $i$ , that is, the number of non-zero elements is constant with system size as long as $\ell$ is kept fixed. Therefore, generation can simply be implemented as a series of vector products, each considering only the nonzero elements of the matrix $\underline{\underline{M}}$ . This allows one to compute the $i$ -th element of vector $\mathbf{h}^{t}$ in a time $\mathcal{O}(1)$ in system size, therefore keeping generation procedures $\mathcal{O}(N)$ . Moreover, the training time scales as $\mathcal{O}(N)$ .
We point out that we can train directly the whole matrix $\underline{\underline{M}}$ , with the additional constraint of putting to zero the elements corresponding to spins at distance larger than $\ell+1$ . Conceptually, this approach can be interpreted as a reduced MADE, in which the weight matrix is not only triangular but has additional zeros. We will refer to this approach as $\ell$ -MADE in the following. This method is easier to implement and can be faster in the training and generation processes, but has the disadvantage or requiring more parameters than the standard 4N approach, e.g. $\mathcal{O}(\ell^{d}N)$ for a $d-$ dimensional lattice against the $(c+1)\ell N$ of 4N. Moreover, it loses the physical interpretation of 4N, as it can no longer be interpreted as a series of fields propagating on the lattice.
Wall-clock generation and training times are shown in Fig. S1. Comparison between Fig. 3b obtained using 4N and the analogue obtained using $\ell$ -MADE is shown in Fig. S2.
<details>
<summary>x13.png Details</summary>
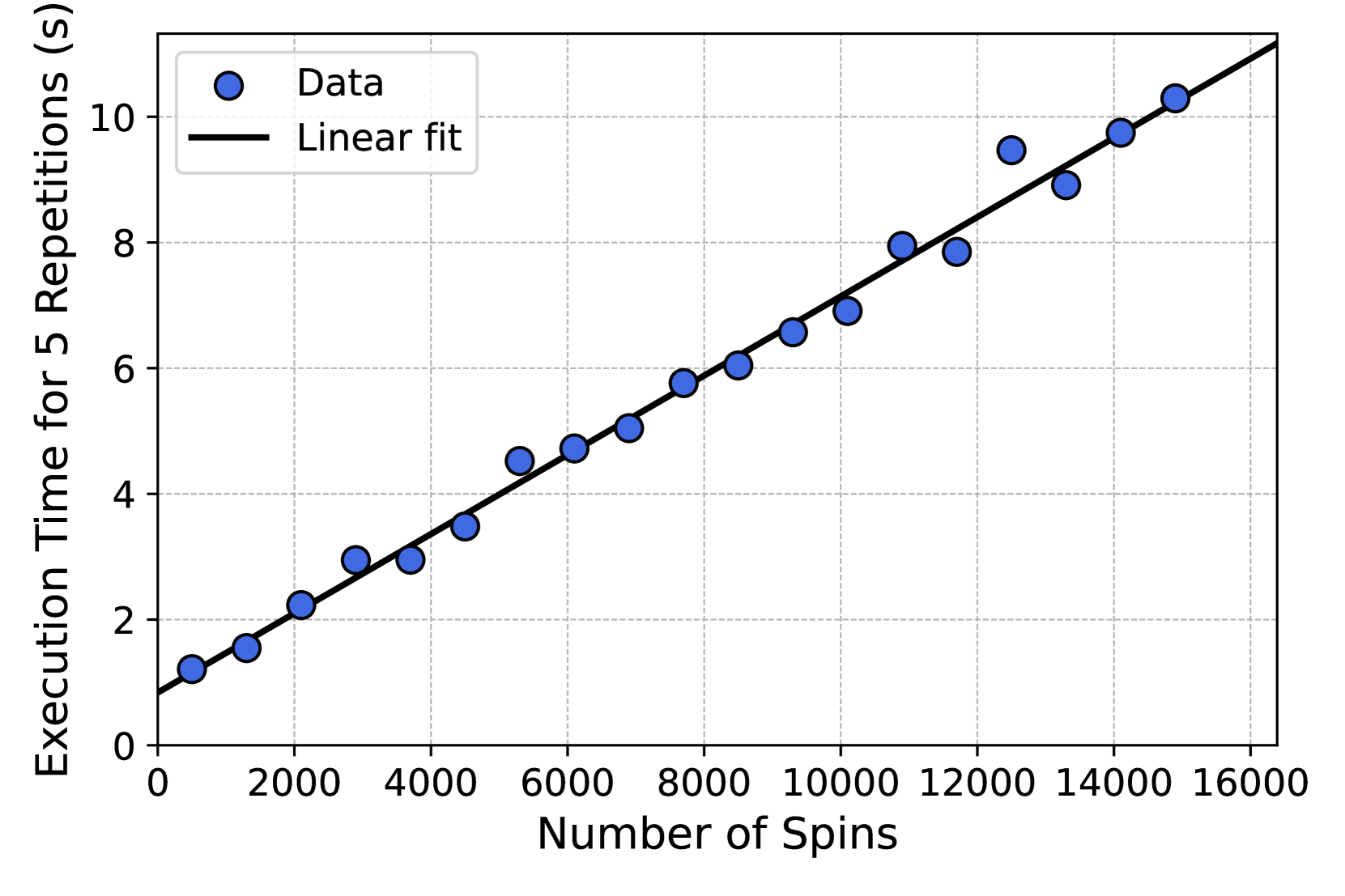
### Visual Description
## Scatter Plot with Linear Fit: Execution Time vs. Number of Spins
### Overview
The image displays a scatter plot with an overlaid linear regression line. It visualizes the relationship between the "Number of Spins" (independent variable) and the "Execution Time for 5 Repetitions" in seconds (dependent variable). The plot demonstrates a clear, strong positive linear correlation between the two variables.
### Components/Axes
* **Chart Type:** Scatter plot with a linear fit line.
* **X-Axis:**
* **Label:** "Number of Spins"
* **Scale:** Linear scale from 0 to 16,000.
* **Major Tick Marks:** 0, 2000, 4000, 6000, 8000, 10000, 12000, 14000, 16000.
* **Y-Axis:**
* **Label:** "Execution Time for 5 Repetitions (s)"
* **Scale:** Linear scale from 0 to 10 seconds.
* **Major Tick Marks:** 0, 2, 4, 6, 8, 10.
* **Legend:**
* **Position:** Top-left corner of the plot area.
* **Items:**
1. A blue circle symbol labeled "Data".
2. A solid black line labeled "Linear fit".
* **Grid:** A light gray, dashed grid is present for both major x and y ticks.
### Detailed Analysis
**Data Series (Blue Circles):**
The data points show a consistent upward trend. Approximate coordinates (Number of Spins, Execution Time) for each visible point, from left to right:
1. (~500, ~1.2)
2. (~1000, ~1.6)
3. (~2000, ~2.2)
4. (~3000, ~2.9)
5. (~4000, ~2.9)
6. (~4500, ~3.5)
7. (~5500, ~4.5)
8. (~6000, ~4.7)
9. (~7000, ~5.1)
10. (~7500, ~5.8)
11. (~8500, ~6.1)
12. (~9500, ~6.6)
13. (~10000, ~6.9)
14. (~11000, ~8.0)
15. (~12000, ~7.9)
16. (~12500, ~9.5)
17. (~13500, ~8.9)
18. (~14000, ~9.7)
19. (~15000, ~10.3)
**Linear Fit Line (Black Line):**
The line represents a linear model fitted to the data. It originates near the y-axis intercept at approximately (0, 0.8) and extends to the upper-right corner of the plot, passing through approximately (16000, 11.0). The line passes centrally through the cloud of data points, indicating a good fit.
**Trend Verification:**
The visual trend for the data series is a steady, upward slope from the bottom-left to the top-right of the chart. The linear fit line mirrors this exact trend, confirming the positive correlation.
### Key Observations
1. **Strong Linear Relationship:** The data points adhere very closely to the linear fit line, suggesting a near-perfect linear relationship between the number of spins and execution time.
2. **Consistent Scaling:** The execution time increases proportionally with the number of spins. The slope of the line (approximately (11.0 - 0.8) / 16000 ≈ 0.00064 s/spin) indicates the time cost per additional spin.
3. **Minor Scatter:** While the fit is excellent, there is minor scatter. For example, the point at ~12,500 spins (~9.5 s) lies noticeably above the line, while the point at ~13,500 spins (~8.9 s) lies slightly below it. This represents normal experimental variance.
4. **No Outliers:** All data points follow the general trend; there are no extreme outliers that deviate significantly from the linear pattern.
### Interpretation
The data demonstrates that the process being measured—likely a computational algorithm or a physical simulation involving spin systems—has a **linear time complexity** with respect to the number of spins. This is a highly predictable and desirable scaling property.
* **Predictive Power:** The tight linear fit allows for reliable extrapolation. One can confidently estimate the execution time for a number of spins not measured (e.g., 20,000 spins would take approximately 13.6 seconds based on the trend).
* **System Efficiency:** The linearity suggests the underlying method does not suffer from worse-than-linear overhead (like O(n log n) or O(n²)) as the problem size (spins) increases. The constant factor (the slope) defines the base performance.
* **Measurement Context:** The y-axis specifies the time is for "5 Repetitions." Therefore, the time for a single repetition at any given spin count would be approximately one-fifth of the plotted value. The linear relationship holds for both the single and aggregated (5x) measurements.
In summary, this chart provides clear empirical evidence of a linearly scalable process, which is fundamental for performance analysis and capacity planning in technical systems.
</details>
<details>
<summary>x14.png Details</summary>
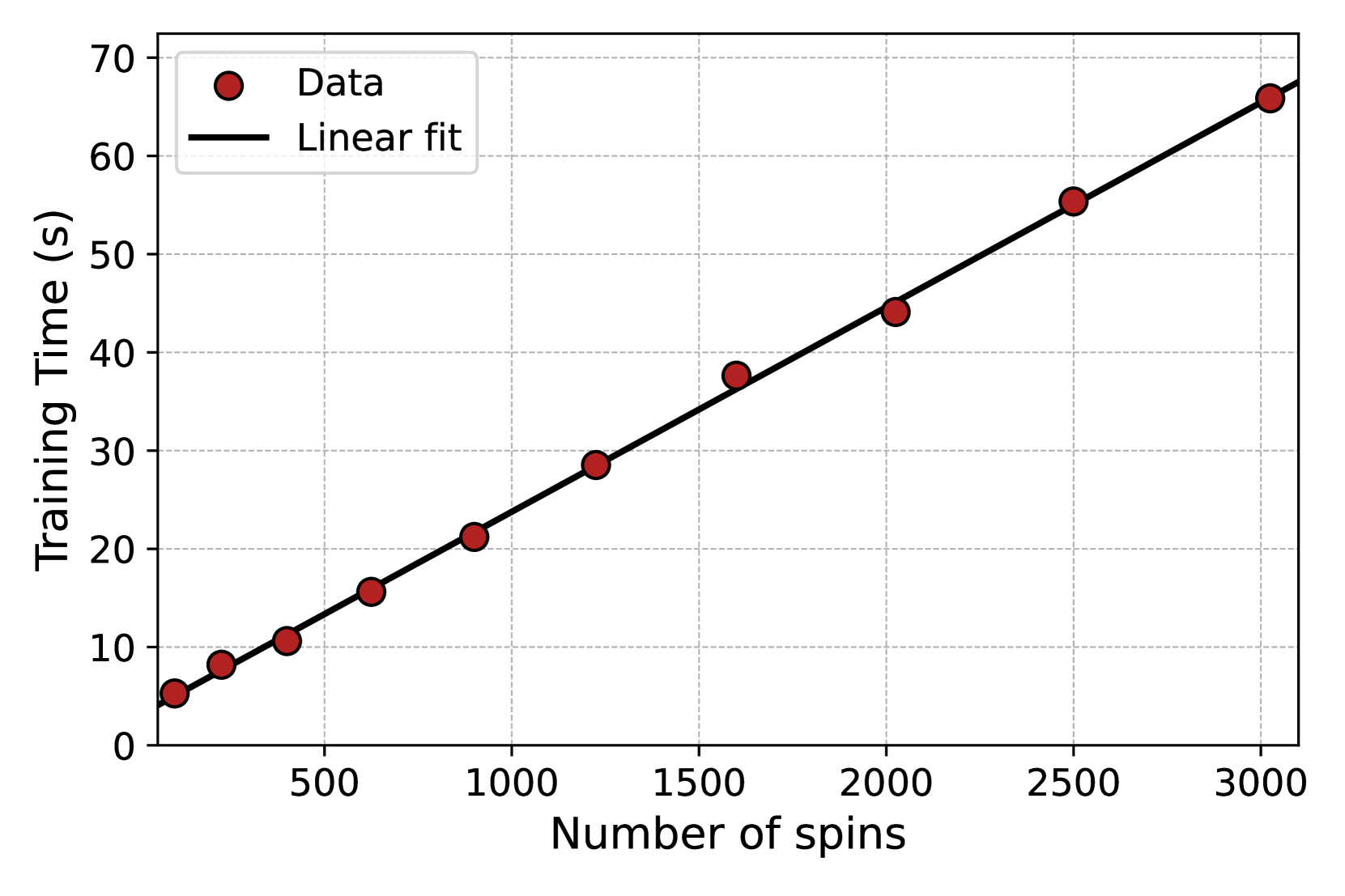
### Visual Description
## Scatter Plot with Linear Fit: Training Time vs. Number of Spins
### Overview
The image is a 2D scatter plot displaying the relationship between the "Number of spins" (independent variable) and "Training Time" in seconds (dependent variable). A set of data points is plotted, and a linear regression line (line of best fit) is drawn through them, indicating a strong positive linear correlation.
### Components/Axes
* **X-Axis (Horizontal):**
* **Label:** "Number of spins"
* **Scale:** Linear scale ranging from 0 to 3000.
* **Major Tick Marks:** 0, 500, 1000, 1500, 2000, 2500, 3000.
* **Y-Axis (Vertical):**
* **Label:** "Training Time (s)"
* **Scale:** Linear scale ranging from 0 to 70.
* **Major Tick Marks:** 0, 10, 20, 30, 40, 50, 60, 70.
* **Legend:** Located in the top-left corner of the plot area.
* **Entry 1:** A red circle symbol labeled "Data".
* **Entry 2:** A solid black line labeled "Linear fit".
* **Grid:** A light gray, dashed grid is present for both major x and y ticks, aiding in value estimation.
### Detailed Analysis
**Data Points (Approximate Coordinates):**
The data consists of 10 red circular points. Their approximate (x, y) coordinates, read from the grid, are:
1. (100, 5)
2. (200, 8)
3. (400, 11)
4. (600, 16)
5. (900, 21)
6. (1200, 29)
7. (1600, 38)
8. (2000, 44)
9. (2500, 55)
10. (3000, 66)
**Linear Fit Line:**
* **Trend:** The black line slopes upward from left to right, confirming a positive linear relationship.
* **Path:** The line passes very close to, or directly through, all plotted data points, indicating an excellent fit.
* **Equation (Estimated):** Based on the endpoints, the line appears to have a y-intercept near 0 and a slope of approximately (66-0)/(3000-0) = 0.022 s/spin. A rough equation is: `Training Time (s) ≈ 0.022 * (Number of spins)`.
### Key Observations
1. **Strong Linear Correlation:** The data points align almost perfectly along a straight line, suggesting the training time scales linearly with the number of spins.
2. **Consistent Spacing:** The data points are not evenly spaced along the x-axis. The sampling density is higher for lower spin counts (e.g., points at 100, 200, 400) and becomes sparser at higher counts (e.g., jumps from 2000 to 2500 to 3000).
3. **Tight Fit:** There is minimal scatter of the data points around the linear fit line. No significant outliers are visible.
### Interpretation
This chart demonstrates a direct, proportional relationship between the computational workload (represented by "Number of spins") and the time required for training. The near-perfect linear fit implies that the underlying algorithm or process has a time complexity of O(n), where n is the number of spins. This is a highly predictable and desirable scaling property, as it means doubling the number of spins will approximately double the training time. The data suggests no evidence of diminishing returns or exponential overhead within the tested range (100 to 3000 spins). For a technical document, this plot serves as strong evidence for the efficient and scalable performance of the system being measured.
</details>
Figure S1: Scatter plots of the generation (left) and training (right) elapsed real times at at different system sizes for $\ell$ -MADE. Both training and generations have been performed using dummy data (and therefore $N$ needs not to be the square of an integer). For generation, we generate 10000 configurations of $N$ five times. For training, we train a model with $\ell=2$ for 40 epochs using an Adam optimizer once per each value of $N$ . In both cases, elapsed times scale linearly with the system’s size, as further evidenced by the linear fits (black lines).
<details>
<summary>x15.png Details</summary>
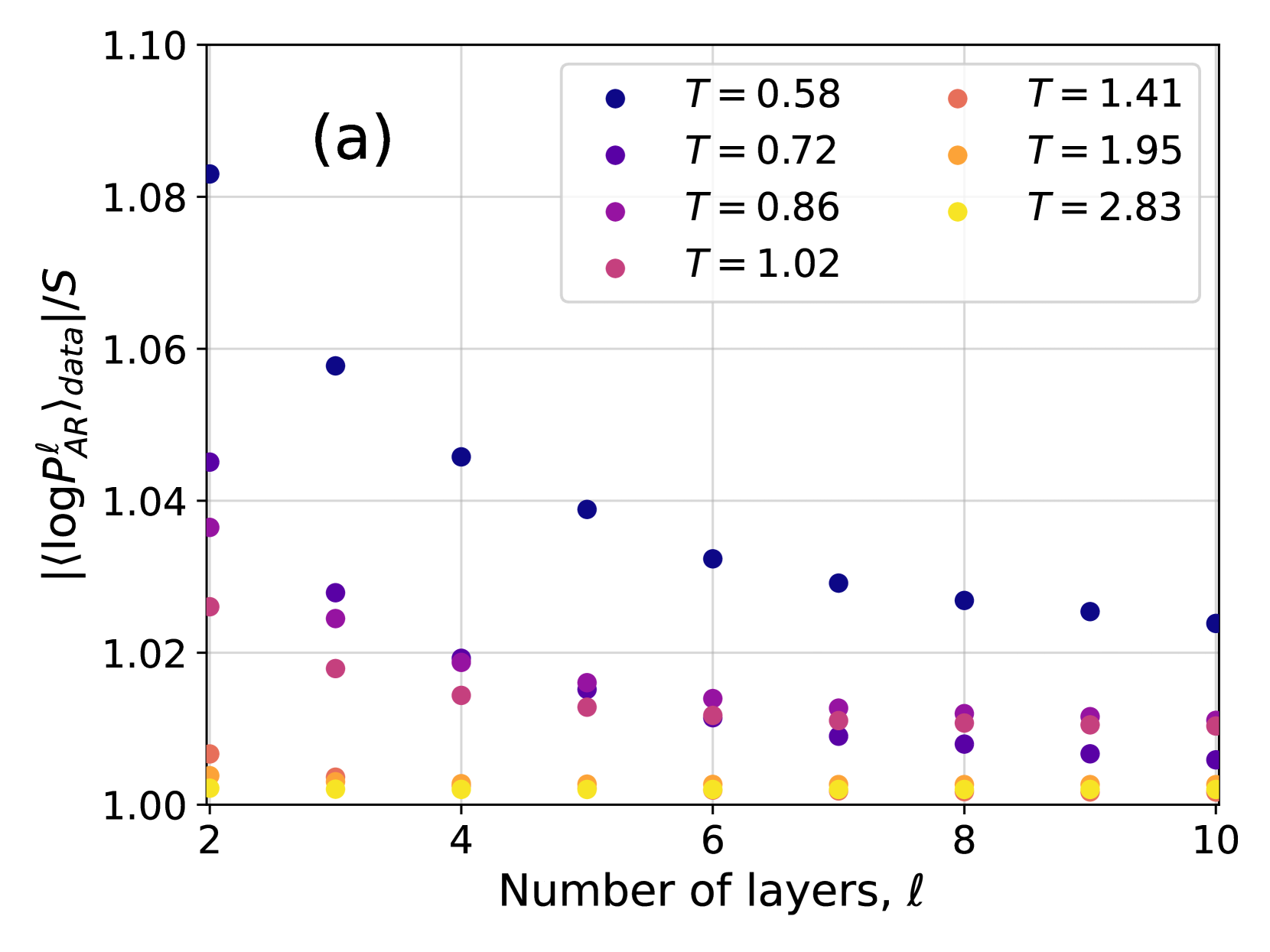
### Visual Description
## Scatter Plot: Layer-Dependent Metric Across Temperatures
### Overview
The image is a scatter plot labeled "(a)" in the top-left corner, displaying the relationship between the number of layers (ℓ) in a system and a normalized logarithmic probability metric. The plot compares seven different temperature (T) conditions, each represented by a distinct color. The data suggests an investigation into how a model's internal probability measure changes with depth (layers) under varying thermal or noise conditions.
### Components/Axes
* **Chart Type:** Scatter plot with multiple data series.
* **Label:** "(a)" is positioned in the top-left quadrant of the plot area.
* **X-Axis:**
* **Title:** "Number of layers, ℓ"
* **Scale:** Linear, ranging from 2 to 10.
* **Major Ticks:** 2, 4, 6, 8, 10.
* **Y-Axis:**
* **Title:** `|⟨log P_AR^ℓ⟩_data|/S` (This appears to be the absolute value of an average log probability from an autoregressive model, normalized by a factor S).
* **Scale:** Linear, ranging from 1.00 to 1.10.
* **Major Ticks:** 1.00, 1.02, 1.04, 1.06, 1.08, 1.10.
* **Legend:**
* **Position:** Top-right corner, inside the plot area.
* **Content:** A 2x4 grid mapping colors to temperature values (T).
* **Entries (Color -> T value):**
* Dark Blue -> T = 0.58
* Purple -> T = 0.72
* Magenta -> T = 0.86
* Pink -> T = 1.02
* Salmon -> T = 1.41
* Orange -> T = 1.95
* Yellow -> T = 2.83
### Detailed Analysis
The plot shows data for 9 layer counts (ℓ = 2 through 10). For each ℓ, there are up to 7 data points, one for each temperature. The general trend is that the y-axis metric decreases as the number of layers increases for lower temperatures, while it remains stable and close to 1.00 for higher temperatures.
**Data Series Trends and Approximate Points:**
1. **T = 0.58 (Dark Blue):** Shows the strongest downward trend.
* ℓ=2: ~1.083
* ℓ=3: ~1.058
* ℓ=4: ~1.046
* ℓ=5: ~1.039
* ℓ=6: ~1.033
* ℓ=7: ~1.029
* ℓ=8: ~1.027
* ℓ=9: ~1.026
* ℓ=10: ~1.024
2. **T = 0.72 (Purple):** Shows a moderate downward trend.
* ℓ=2: ~1.045
* ℓ=3: ~1.028
* ℓ=4: ~1.019
* ℓ=5: ~1.016
* ℓ=6: ~1.014
* ℓ=7: ~1.013
* ℓ=8: ~1.012
* ℓ=9: ~1.011
* ℓ=10: ~1.010
3. **T = 0.86 (Magenta):** Shows a slight downward trend.
* ℓ=2: ~1.037
* ℓ=3: ~1.024
* ℓ=4: ~1.019
* ℓ=5: ~1.016
* ℓ=6: ~1.014
* ℓ=7: ~1.013
* ℓ=8: ~1.012
* ℓ=9: ~1.011
* ℓ=10: ~1.010
4. **T = 1.02 (Pink):** Shows a very slight downward trend, converging with T=0.86 and T=0.72 at higher ℓ.
* ℓ=2: ~1.026
* ℓ=3: ~1.018
* ℓ=4: ~1.015
* ℓ=5: ~1.013
* ℓ=6: ~1.012
* ℓ=7: ~1.011
* ℓ=8: ~1.011
* ℓ=9: ~1.010
* ℓ=10: ~1.010
5. **T = 1.41 (Salmon):** Nearly flat, very close to 1.00.
* All points from ℓ=2 to ℓ=10 cluster between ~1.003 and ~1.006.
6. **T = 1.95 (Orange):** Flat, extremely close to 1.00.
* All points from ℓ=2 to ℓ=10 cluster between ~1.001 and ~1.003.
7. **T = 2.83 (Yellow):** Flat, essentially at the baseline of 1.00.
* All points from ℓ=2 to ℓ=10 are at or very near ~1.000.
### Key Observations
1. **Temperature Stratification:** There is a clear, consistent ordering of the data series by temperature. At any given layer ℓ, a lower T value corresponds to a higher y-axis value.
2. **Convergence with Depth:** The spread between the different temperature series is largest at shallow layers (ℓ=2) and narrows significantly as the number of layers increases. By ℓ=10, the four lowest temperature series (T=0.58 to 1.02) are tightly grouped between ~1.010 and ~1.024, while the three highest temperature series are indistinguishable near 1.00.
3. **Decay Rate:** The rate of decrease in the y-metric with respect to layers is inversely related to temperature. The coldest condition (T=0.58) decays the fastest, while the hottest conditions show no decay.
4. **Baseline Behavior:** For T ≥ 1.41, the metric `|⟨log P_AR^ℓ⟩_data|/S` is effectively constant at a value of 1.00 across all measured layers.
### Interpretation
This plot likely visualizes a phenomenon in deep learning or statistical physics, examining how the confidence or "sharpness" of an autoregressive model's probability distribution (normalized by entropy S) evolves through its layers under different levels of noise or temperature (T).
* **Low Temperature (T < 1):** The model's internal probability measure is initially high (far from 1.00) but becomes progressively more "smeared out" or entropic (approaching the normalized baseline of 1.00) as information propagates through deeper layers. This suggests that without noise, the model's certainty decays with depth.
* **High Temperature (T > 1):** The system starts and remains in a high-entropy state (metric ≈ 1.00) regardless of depth. The added noise dominates, preventing the model from developing sharp probability distributions at any layer.
* **Critical Region (T ≈ 1):** The temperatures around 1.02 show transitional behavior, starting with a slight elevation that quickly decays to the baseline.
The key insight is that **depth acts as a regularizer that drives the system toward a maximum-entropy state (metric=1.00), and the temperature T controls the starting point and rate of this convergence.** Lower temperatures allow the model to maintain more structured (lower-entropy) representations initially, but these structures are gradually lost through the layers. The plot demonstrates a fundamental trade-off between model depth, noise level, and the preservation of information sharpness.
</details>
<details>
<summary>x16.png Details</summary>
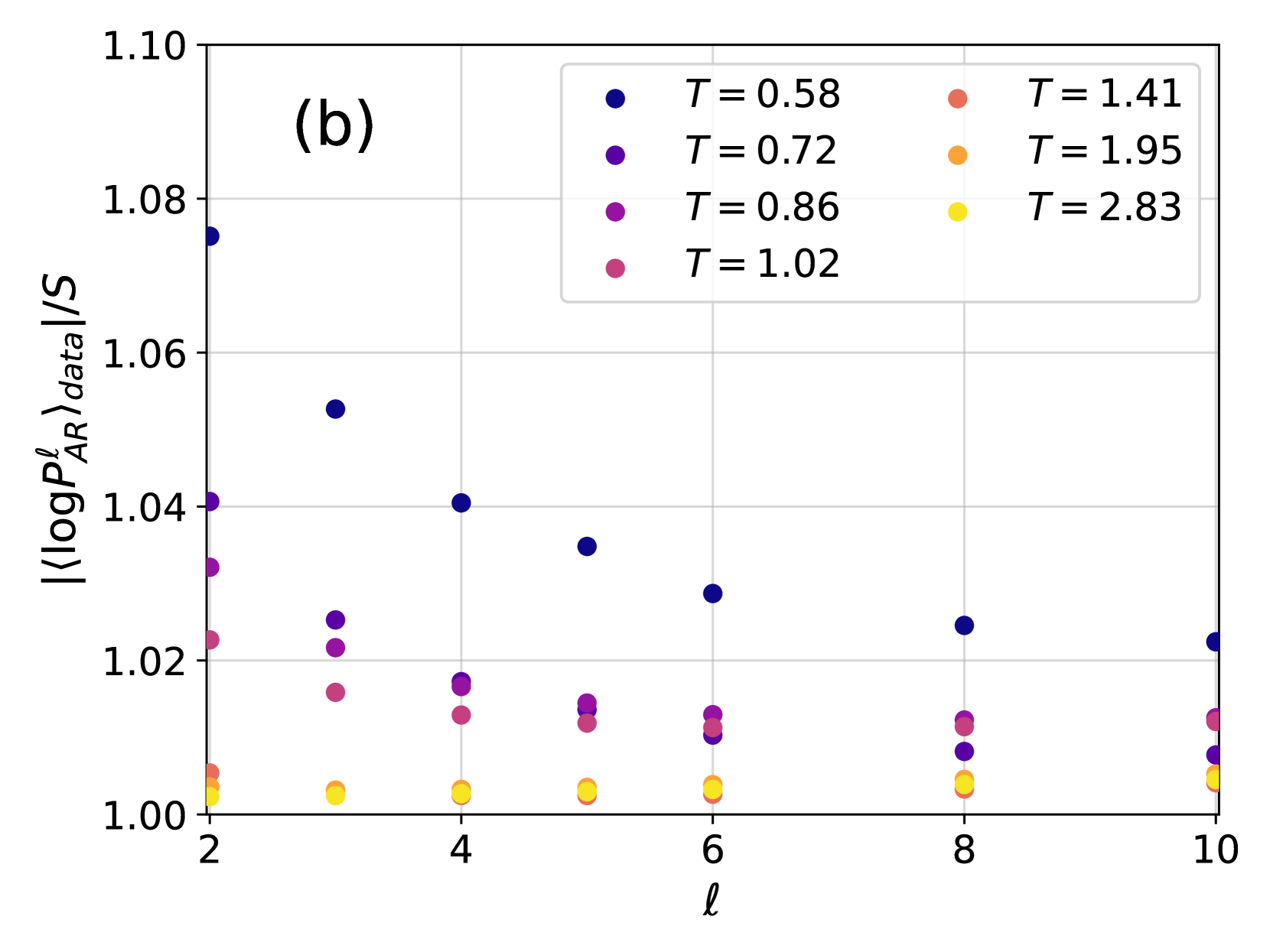
### Visual Description
## Scatter Plot: Normalized Log Probability Magnitude vs. Length Scale ℓ
### Overview
This image is a scientific scatter plot, labeled as panel "(b)", showing the relationship between a normalized log probability magnitude (y-axis) and a length scale parameter ℓ (x-axis) for eight different temperature values (T). The plot displays discrete data points for each combination of ℓ and T.
### Components/Axes
* **Plot Label:** "(b)" is located in the top-left corner of the plot area.
* **X-Axis:**
* **Label:** `ℓ` (the script letter "ell").
* **Scale:** Linear, with major tick marks and labels at `2`, `4`, `6`, `8`, and `10`.
* **Y-Axis:**
* **Label:** `|⟨log P_AR^ℓ⟩_data|/S`. This represents the absolute value of the average (over data) of the log of a quantity `P_AR^ℓ`, normalized by a factor `S`.
* **Scale:** Linear, with major tick marks and labels at `1.00`, `1.02`, `1.04`, `1.06`, `1.08`, and `1.10`.
* **Legend:** Positioned in the top-right quadrant of the plot area. It maps eight distinct colors to eight specific temperature values (T).
* **Dark Blue:** `T = 0.58`
* **Purple:** `T = 0.72`
* **Magenta:** `T = 0.86`
* **Pink:** `T = 1.02`
* **Salmon/Light Red:** `T = 1.41`
* **Orange:** `T = 1.95`
* **Yellow:** `T = 2.83`
* **Grid:** A light gray grid is present in the background.
### Detailed Analysis
The plot shows the value of `|⟨log P_AR^ℓ⟩_data|/S` for integer values of ℓ from 2 to 10, for each of the eight temperature series.
**Trend Verification & Data Points (Approximate):**
* **T = 0.58 (Dark Blue):** This series shows a clear downward trend. The value starts highest at ℓ=2 (~1.075) and decreases monotonically as ℓ increases, reaching ~1.022 at ℓ=10.
* **T = 0.72 (Purple):** Also shows a downward trend, but starting from a lower initial value. Points: ℓ=2 (~1.040), ℓ=3 (~1.025), ℓ=4 (~1.018), ℓ=5 (~1.015), ℓ=6 (~1.010), ℓ=8 (~1.008), ℓ=10 (~1.008).
* **T = 0.86 (Magenta):** Follows a similar downward trend, slightly below the T=0.72 series. Points: ℓ=2 (~1.032), ℓ=3 (~1.022), ℓ=4 (~1.017), ℓ=5 (~1.015), ℓ=6 (~1.012), ℓ=8 (~1.012), ℓ=10 (~1.012).
* **T = 1.02 (Pink):** Shows a very slight downward trend, nearly flat. Points: ℓ=2 (~1.022), ℓ=3 (~1.016), ℓ=4 (~1.013), ℓ=5 (~1.012), ℓ=6 (~1.011), ℓ=8 (~1.011), ℓ=10 (~1.012).
* **T = 1.41 (Salmon):** Appears nearly flat, clustered near the bottom. Points: ℓ=2 (~1.005), ℓ=3 (~1.003), ℓ=4 (~1.003), ℓ=5 (~1.003), ℓ=6 (~1.003), ℓ=8 (~1.004), ℓ=10 (~1.005).
* **T = 1.95 (Orange):** Appears nearly flat, clustered near the bottom. Points: ℓ=2 (~1.004), ℓ=3 (~1.002), ℓ=4 (~1.002), ℓ=5 (~1.002), ℓ=6 (~1.002), ℓ=8 (~1.003), ℓ=10 (~1.004).
* **T = 2.83 (Yellow):** Appears nearly flat, clustered at the very bottom. Points: ℓ=2 (~1.002), ℓ=3 (~1.001), ℓ=4 (~1.001), ℓ=5 (~1.001), ℓ=6 (~1.001), ℓ=8 (~1.002), ℓ=10 (~1.003).
**Spatial Grounding:** The legend is in the top-right. The data points for lower T (cooler colors: blue, purple) are positioned higher on the y-axis, especially at low ℓ. The data points for higher T (warmer colors: orange, yellow) are clustered tightly near y=1.00 across all ℓ.
### Key Observations
1. **Strong Temperature Dependence:** The magnitude of the y-axis quantity is highly sensitive to temperature T. Lower temperatures (T ≤ 1.02) result in significantly higher values, particularly at small ℓ.
2. **ℓ-Dependence Fades with Increasing T:** For T ≤ 1.02, the value decreases as ℓ increases. For T ≥ 1.41, the value is essentially independent of ℓ, remaining close to 1.00.
3. **Convergence at High ℓ:** All data series appear to converge toward a value near 1.00 as ℓ increases, though the low-T series remain slightly elevated even at ℓ=10.
4. **Critical Temperature Region:** The behavior changes markedly around T=1.02 to T=1.41. The series for T=1.02 still shows a slight ℓ-dependence, while T=1.41 and above are flat. This suggests a possible transition in the system's behavior in this temperature range.
### Interpretation
This plot likely comes from statistical physics or machine learning research, analyzing the behavior of a probability distribution (`P_AR^ℓ`) over different length scales (`ℓ`) and temperatures (`T`). The quantity on the y-axis, `|⟨log P_AR^ℓ⟩_data|/S`, measures the normalized magnitude of the average log-probability assigned by the model or observed in the data.
The data suggests a **phase transition or critical phenomenon**. At low temperatures (T < ~1.2), the system exhibits strong scale-dependent behavior: the log-probability magnitude is large at short scales (low ℓ) and decays toward a baseline (S) at larger scales. This could indicate ordered, structured, or predictable behavior at short ranges.
At high temperatures (T > ~1.2), the system becomes scale-invariant and disordered. The log-probability magnitude is uniformly low (~1.00, meaning |⟨log P⟩| ≈ S) across all length scales, suggesting randomness or a lack of meaningful structure at any scale.
The transition point (around T=1.02-1.41) is of particular interest, as it marks where the system's characteristic scale-dependence breaks down. This is a classic signature of a system moving from an ordered phase to a disordered phase as temperature increases.
</details>
Figure S2: Ratio between the cross-entropy $|\langle\log P^{\ell}_{\text{NN}}\rangle_{\text{data}}|$ and the Gibbs-Boltzmann entropy $S_{\text{GB}}$ for different values of the temperature $T$ and of the parameter $\ell$ for 4N (a, left) and $\ell$ -MADE (b, right). Both $|\langle\log P^{\ell}_{\text{NN}}\rangle_{\text{data}}|$ and $S_{\text{GB}}$ are averaged over 10 samples.
## S2 Comparison between different architectures
<details>
<summary>x17.png Details</summary>
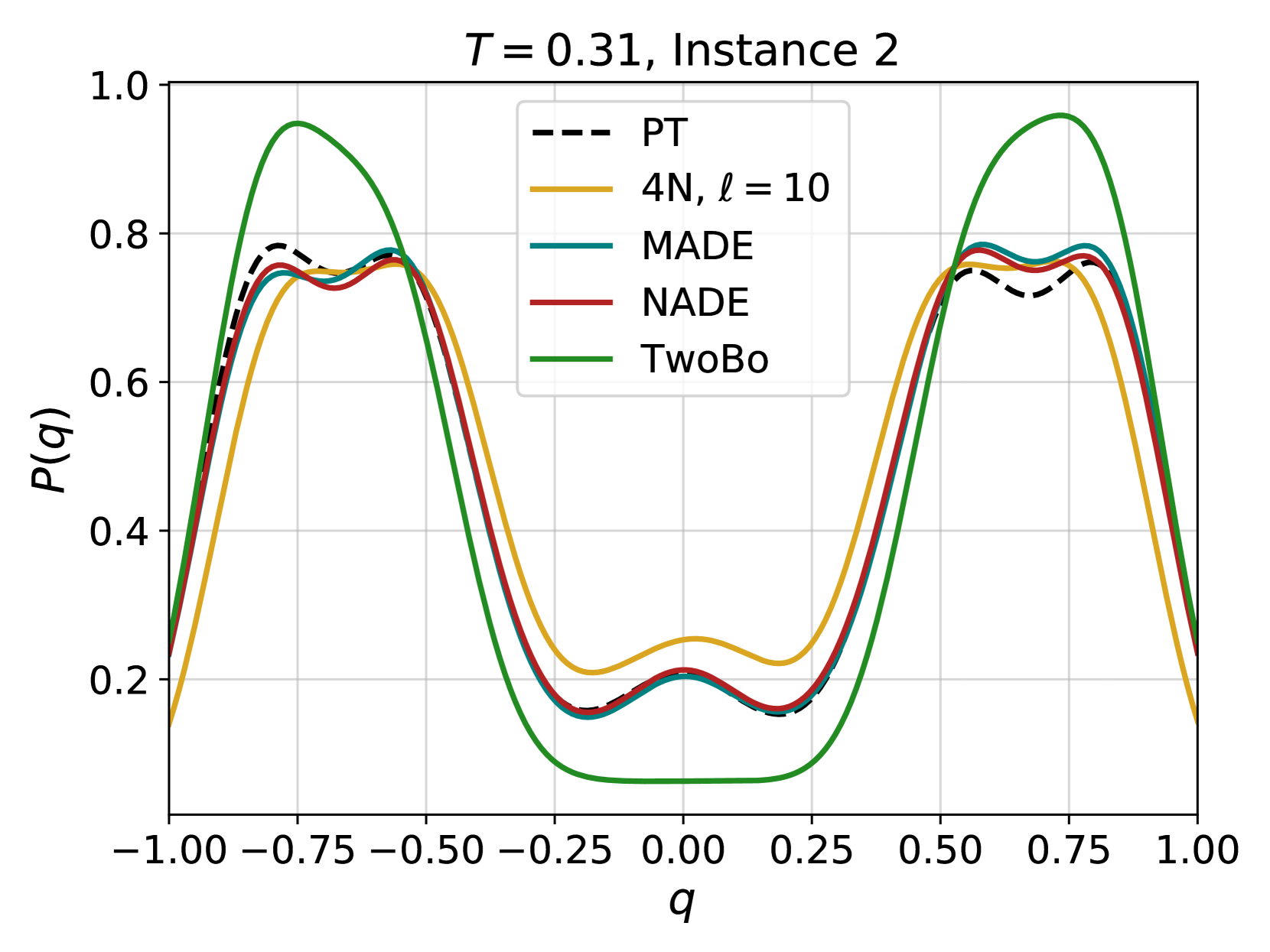
### Visual Description
## Line Chart: Probability Distribution P(q) for Different Models at T=0.31, Instance 2
### Overview
The image displays a line chart comparing the probability distribution \( P(q) \) across the variable \( q \) for five different models or methods. The chart is titled "T = 0.31, Instance 2," suggesting it represents a specific experimental condition or data instance. All curves exhibit a bimodal (two-peaked) distribution, with peaks located symmetrically around \( q = -0.75 \) and \( q = 0.75 \), and a central trough near \( q = 0 \).
### Components/Axes
* **Title:** "T = 0.31, Instance 2" (Top-center).
* **X-axis:** Labeled **"q"**. The scale runs from **-1.00** to **1.00**, with major tick marks and grid lines at intervals of 0.25 (-1.00, -0.75, -0.50, -0.25, 0.00, 0.25, 0.50, 0.75, 1.00).
* **Y-axis:** Labeled **"P(q)"**. The scale runs from **0.0** to **1.0**, with major tick marks and grid lines at intervals of 0.2 (0.0, 0.2, 0.4, 0.6, 0.8, 1.0).
* **Legend:** Positioned in the **top-center** of the plot area, slightly offset to the right. It contains five entries:
1. **PT**: Represented by a **black dashed line** (`---`).
2. **4N, ℓ = 10**: Represented by a **solid yellow/gold line**.
3. **MADE**: Represented by a **solid teal/blue-green line**.
4. **NADE**: Represented by a **solid red line**.
5. **TwoBo**: Represented by a **solid green line**.
### Detailed Analysis
The chart plots five distinct data series. Below is an analysis of each, including trend description and approximate key data points.
1. **PT (Black Dashed Line):**
* **Trend:** Forms a symmetric bimodal distribution. Rises steeply from the left edge, peaks, dips to a local minimum at the center, rises to a second symmetric peak, and falls steeply to the right edge.
* **Key Points (Approximate):**
* Left Peak: \( q \approx -0.75 \), \( P(q) \approx 0.78 \)
* Central Trough: \( q \approx 0.00 \), \( P(q) \approx 0.20 \)
* Right Peak: \( q \approx 0.75 \), \( P(q) \approx 0.76 \)
2. **4N, ℓ = 10 (Yellow Line):**
* **Trend:** Follows a similar bimodal shape but with lower peak heights and a shallower central trough compared to most other series.
* **Key Points (Approximate):**
* Left Peak: \( q \approx -0.75 \), \( P(q) \approx 0.74 \)
* Central Trough: \( q \approx 0.00 \), \( P(q) \approx 0.25 \)
* Right Peak: \( q \approx 0.75 \), \( P(q) \approx 0.74 \)
3. **MADE (Teal Line):**
* **Trend:** Very closely follows the NADE (red) line, nearly overlapping it throughout the range. Its peaks are slightly higher than PT's.
* **Key Points (Approximate):**
* Left Peak: \( q \approx -0.75 \), \( P(q) \approx 0.79 \)
* Central Trough: \( q \approx 0.00 \), \( P(q) \approx 0.20 \)
* Right Peak: \( q \approx 0.75 \), \( P(q) \approx 0.79 \)
4. **NADE (Red Line):**
* **Trend:** Nearly identical to the MADE (teal) line, forming a tight cluster with it and the PT line at the peaks.
* **Key Points (Approximate):**
* Left Peak: \( q \approx -0.75 \), \( P(q) \approx 0.78 \)
* Central Trough: \( q \approx 0.00 \), \( P(q) \approx 0.21 \)
* Right Peak: \( q \approx 0.75 \), \( P(q) \approx 0.78 \)
5. **TwoBo (Green Line):**
* **Trend:** Exhibits the most extreme bimodal distribution. It has the highest peaks and the deepest central trough, deviating significantly from the other four series.
* **Key Points (Approximate):**
* Left Peak: \( q \approx -0.75 \), \( P(q) \approx 0.95 \)
* Central Trough: \( q \approx 0.00 \), \( P(q) \approx 0.10 \)
* Right Peak: \( q \approx 0.75 \), \( P(q) \approx 0.95 \)
### Key Observations
* **Bimodal Symmetry:** All five distributions are symmetric around \( q = 0 \).
* **Clustering:** The PT, MADE, and NADE lines form a tight cluster, especially at the peaks and central trough, indicating similar performance or output for this instance.
* **Outlier Series:** The **TwoBo (green)** line is a clear outlier, showing much sharper probability peaks (higher confidence) and a deeper central minimum (lower probability) than the other methods.
* **4N Performance:** The **4N, ℓ = 10 (yellow)** line shows the lowest peak probabilities and the highest central trough probability among the group, suggesting a more "flattened" or less confident distribution.
* **Grid and Scale:** The chart uses a clear grid, making approximate value reading straightforward. The y-axis scale (0 to 1) is appropriate for a probability measure.
### Interpretation
This chart likely compares the output probability distributions of different machine learning models (e.g., neural autoregressive models like MADE/NADE, parallel tempering PT, and a method called TwoBo) on a specific task or dataset instance, under a temperature parameter \( T = 0.31 \).
* **What the data suggests:** The variable \( q \) appears to be an order parameter or a latent variable where the system has two stable states (at \( q \approx \pm 0.75 \)). The models are estimating the probability \( P(q) \) of the system being in a state characterized by value \( q \).
* **Model Relationships:** PT, MADE, and NADE produce very similar, moderate-confidence bimodal distributions. The 4N model yields a less decisive distribution. The TwoBo model, however, predicts a much more polarized scenario with very high probability concentrated at the two peaks and very low probability in the disordered central state (\( q=0 \)).
* **Significance:** The stark difference of the TwoBo curve suggests it may be capturing a different aspect of the underlying data or using a fundamentally different approach that leads to more extreme probability assignments. The similarity between MADE and NADE is expected, as NADE is often an extension of MADE. The parameter \( T=0.31 \) might represent a noise or temperature level in a physical system simulation or a sampling process; the chart shows how different algorithms interpret the state distribution at this specific condition.
</details>
<details>
<summary>x18.png Details</summary>
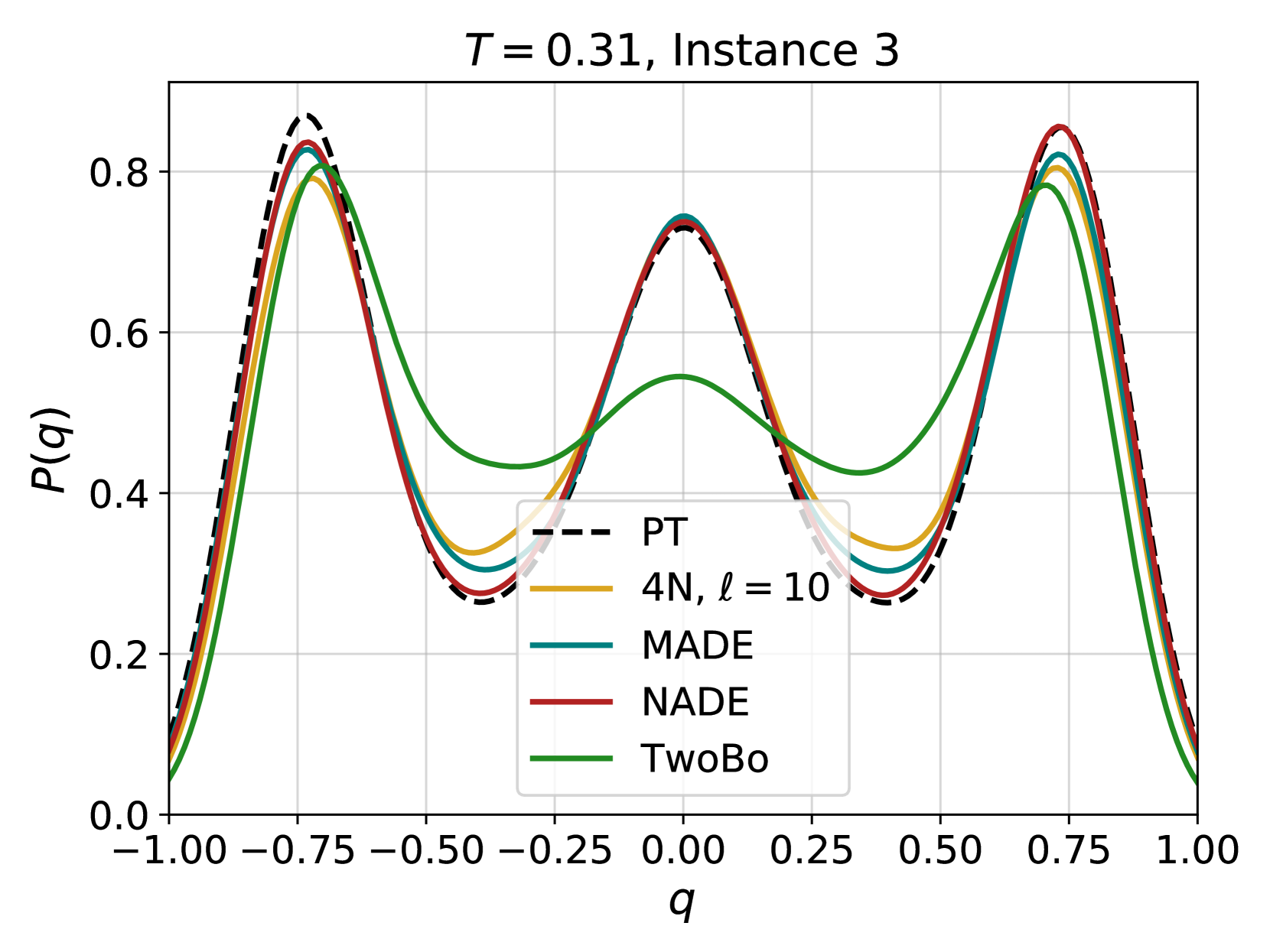
### Visual Description
## Probability Distribution Plot: T = 0.31, Instance 3
### Overview
This image is a scientific line graph comparing the probability distribution functions, P(q), of five different models or methods for a specific experimental instance (Instance 3) at a parameter value T = 0.31. The plot shows how the probability density varies with the variable q across the range [-1.00, 1.00].
### Components/Axes
* **Title:** "T = 0.31, Instance 3" (centered at the top).
* **X-axis:** Labeled "q". The scale runs from -1.00 to 1.00 with major tick marks at intervals of 0.25 (-1.00, -0.75, -0.50, -0.25, 0.00, 0.25, 0.50, 0.75, 1.00).
* **Y-axis:** Labeled "P(q)". The scale runs from 0.0 to approximately 0.85, with major tick marks at intervals of 0.2 (0.0, 0.2, 0.4, 0.6, 0.8).
* **Legend:** Positioned in the center-bottom region of the plot area. It contains five entries:
1. **PT:** Black dashed line (`---`).
2. **4N, ℓ = 10:** Solid yellow/gold line.
3. **MADE:** Solid teal/dark cyan line.
4. **NADE:** Solid red line.
5. **TwoBo:** Solid green line.
* **Grid:** A light gray grid is present, aiding in value estimation.
### Detailed Analysis
The plot displays five curves, each representing a different method's estimated probability distribution P(q). All distributions are symmetric around q = 0 and exhibit a distinct three-peak (trimodal) structure.
**Trend Verification & Data Points (Approximate):**
1. **PT (Black Dashed Line):** This appears to be the reference or ground truth distribution.
* **Trend:** Sharp, well-defined peaks.
* **Key Points:**
* Left Peak: Maximum at q ≈ -0.75, P(q) ≈ 0.85.
* Central Peak: Maximum at q ≈ 0.00, P(q) ≈ 0.73.
* Right Peak: Maximum at q ≈ 0.75, P(q) ≈ 0.85.
* Minima: Deep troughs at q ≈ -0.40 and q ≈ 0.40, with P(q) ≈ 0.25.
2. **4N, ℓ = 10 (Yellow Line):**
* **Trend:** Follows the PT curve very closely, with slightly lower peak amplitudes.
* **Key Points:**
* Left Peak: q ≈ -0.75, P(q) ≈ 0.80.
* Central Peak: q ≈ 0.00, P(q) ≈ 0.72.
* Right Peak: q ≈ 0.75, P(q) ≈ 0.80.
* Minima: q ≈ -0.40 & 0.40, P(q) ≈ 0.30.
3. **MADE (Teal Line):**
* **Trend:** Very similar to PT and 4N, nearly overlapping with the NADE curve.
* **Key Points:**
* Left Peak: q ≈ -0.75, P(q) ≈ 0.82.
* Central Peak: q ≈ 0.00, P(q) ≈ 0.73.
* Right Peak: q ≈ 0.75, P(q) ≈ 0.82.
* Minima: q ≈ -0.40 & 0.40, P(q) ≈ 0.28.
4. **NADE (Red Line):**
* **Trend:** Almost indistinguishable from the PT reference line, especially at the peaks.
* **Key Points:**
* Left Peak: q ≈ -0.75, P(q) ≈ 0.84.
* Central Peak: q ≈ 0.00, P(q) ≈ 0.73.
* Right Peak: q ≈ 0.75, P(q) ≈ 0.84.
* Minima: q ≈ -0.40 & 0.40, P(q) ≈ 0.26.
5. **TwoBo (Green Line):**
* **Trend:** Shows the most significant deviation. It captures the three-peak structure but with substantially lower peak heights and shallower minima.
* **Key Points:**
* Left Peak: q ≈ -0.75, P(q) ≈ 0.78.
* Central Peak: q ≈ 0.00, P(q) ≈ 0.55.
* Right Peak: q ≈ 0.75, P(q) ≈ 0.78.
* Minima: Broader and shallower, centered around q ≈ -0.35 & 0.35, with P(q) ≈ 0.43.
### Key Observations
1. **Trimodal Symmetry:** All five methods agree on the fundamental trimodal and symmetric nature of the distribution P(q) for this instance.
2. **Performance Hierarchy:** There is a clear hierarchy in how closely the methods approximate the PT reference:
* **Excellent Fit:** NADE (red) and MADE (teal) are nearly perfect matches.
* **Very Good Fit:** 4N, ℓ=10 (yellow) is slightly below the top performers.
* **Poor Fit:** TwoBo (green) significantly underestimates the probability density at the peaks and overestimates it in the troughs.
3. **Peak Consistency:** The location of the three peaks (q ≈ -0.75, 0.00, 0.75) is consistent across all methods, indicating robustness in identifying the modes of the distribution.
### Interpretation
This plot is likely from a study in machine learning or computational physics, comparing different generative models or sampling techniques (PT, MADE, NADE, TwoBo, 4N) on their ability to model a complex, multimodal probability distribution. The variable `q` could represent an order parameter, a latent variable, or a physical quantity.
* **What the data suggests:** The NADE and MADE architectures are highly effective at capturing the intricate details of this specific distribution (T=0.31, Instance 3). The 4N model with length parameter ℓ=10 is also very accurate. The TwoBo model, however, struggles, producing a "smeared out" approximation that fails to capture the sharpness of the probability peaks. This could indicate that TwoBo has lower capacity, uses a less suitable inductive bias, or was not properly tuned for this task.
* **Why it matters:** Accurately modeling such multimodal distributions is crucial for tasks like Bayesian inference, energy-based modeling, and sampling from complex systems. The failure of a model like TwoBo to capture sharp peaks could lead to poor performance in downstream tasks that rely on precise probability estimates, such as generating realistic samples or calculating expectations.
* **Anomalies:** The most notable anomaly is the systematic underperformance of the TwoBo method compared to the others. Its central peak is particularly suppressed (P(q)≈0.55 vs. ~0.73 for others), suggesting a specific difficulty in modeling the mode at q=0.
</details>
Figure S3: Comparison of the probability distribution of the overlap obtained using different architectures: 4N with $\ell=10$ layers (12160 parameters), shallow MADE (32640 parameters), NADE with $N_{h}=64$ (32768 parameters) and TwoBo (4111 parameters). The black dashed line is obtained using data gathered via Parallel Tempering (PT), while solid color lines are obtained using the different architectures. From a quick qualitative analysis 4N performs comparably to MADE and NADE despite having less parameters. Moreover, it also performs better than TwoBo. Despite the latter having fewer parameters in this $N=256$ case, 4N has a better scaling when increasing the system size, $\mathcal{O}(N)$ compared to $\mathcal{O}(N^{\frac{3}{2}})$ , as pointed out in the main text. The TwoBo implementation comes from the GitHub of the authors (https://github.com/cqsl/sparse-twobody-arnn) and was slightly modified to support supervised learning (which could be improved by a different choice of the hyperparameters used for training).
## S3 Comparison between different update sequences
<details>
<summary>x19.png Details</summary>
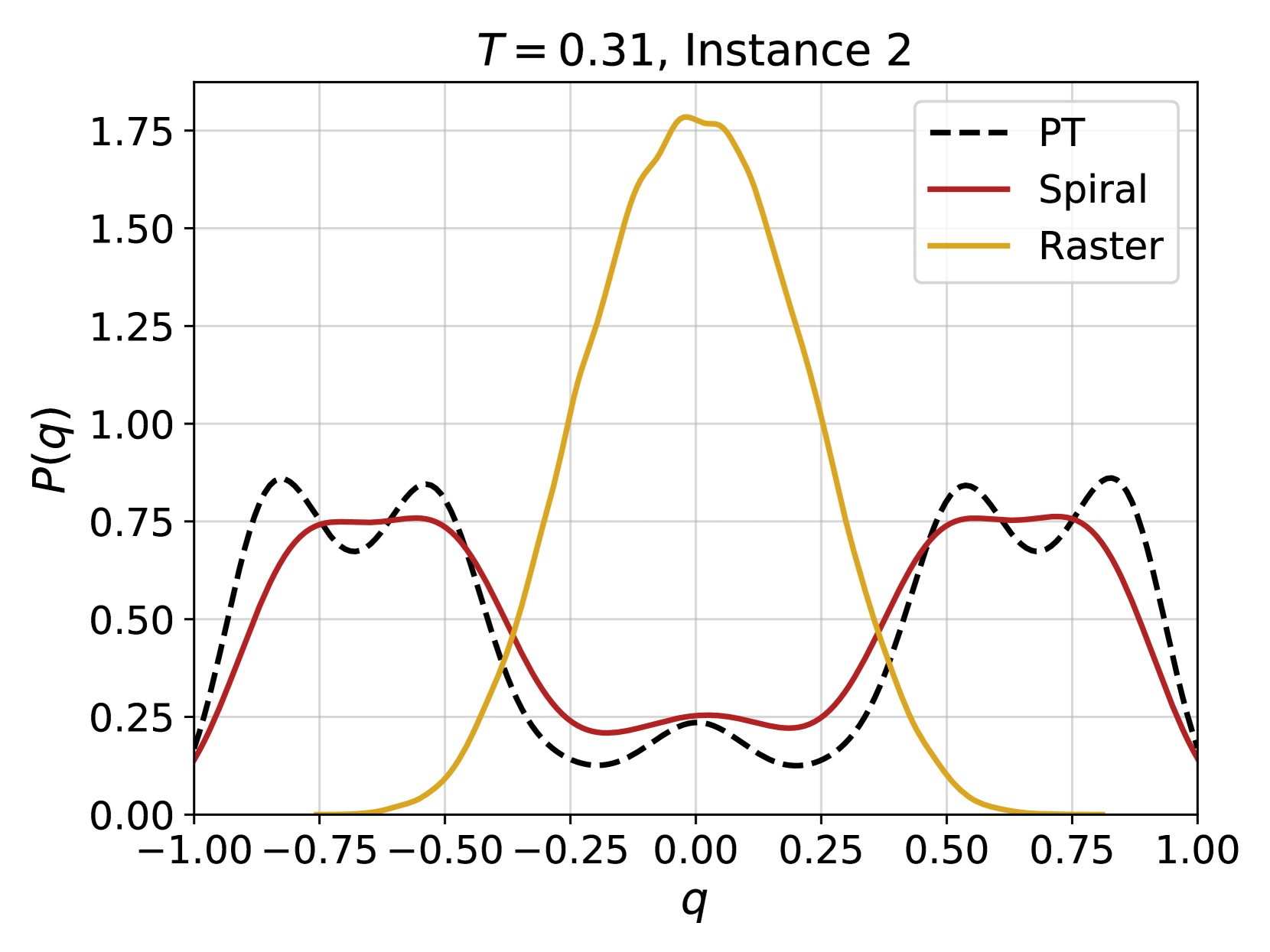
### Visual Description
## Line Graph: Probability Distribution P(q) for Three Methods at T=0.31
### Overview
The image is a line graph comparing the probability distribution function \( P(q) \) across the variable \( q \) for three different methods or algorithms: PT, Spiral, and Raster. The chart is titled "T = 0.31, Instance 2," suggesting it is one instance from a series of experiments or simulations run at a parameter value T=0.31.
### Components/Axes
* **Title:** "T = 0.31, Instance 2" (centered at the top).
* **X-axis:** Labeled "q". The scale runs from -1.00 to 1.00, with major tick marks at intervals of 0.25 (-1.00, -0.75, -0.50, -0.25, 0.00, 0.25, 0.50, 0.75, 1.00).
* **Y-axis:** Labeled "P(q)". The scale runs from 0.00 to 1.75, with major tick marks at intervals of 0.25 (0.00, 0.25, 0.50, 0.75, 1.00, 1.25, 1.50, 1.75).
* **Legend:** Located in the top-right corner of the plot area. It contains three entries:
* `--- PT` (represented by a black dashed line)
* `— Spiral` (represented by a solid red line)
* `— Raster` (represented by a solid yellow/gold line)
* **Grid:** A light gray grid is present, aligned with the major tick marks on both axes.
### Detailed Analysis
The graph plots three distinct probability distributions. Below is an analysis of each data series, including its visual trend and approximate key data points.
**1. PT (Black Dashed Line)**
* **Trend:** This distribution is multi-modal and roughly symmetric around q=0. It exhibits four distinct peaks: two prominent outer peaks and two smaller inner peaks. The line oscillates, showing a complex structure.
* **Key Points (Approximate):**
* **Leftmost Peak:** Located at approximately q = -0.85, with P(q) ≈ 0.85.
* **Left Inner Peak:** Located at approximately q = -0.55, with P(q) ≈ 0.85.
* **Central Trough:** The lowest point between the inner peaks is at approximately q = -0.25, with P(q) ≈ 0.15.
* **Central Local Maximum:** A small peak at q = 0.00, with P(q) ≈ 0.25.
* **Right Inner Peak:** Located at approximately q = 0.55, with P(q) ≈ 0.85.
* **Rightmost Peak:** Located at approximately q = 0.85, with P(q) ≈ 0.85.
* The distribution approaches P(q) ≈ 0.15 at the boundaries q = -1.00 and q = 1.00.
**2. Spiral (Solid Red Line)**
* **Trend:** This distribution is also symmetric around q=0 but is smoother and less oscillatory than PT. It features two broad, dominant peaks on either side of the center and a shallow central trough.
* **Key Points (Approximate):**
* **Left Broad Peak:** The plateau spans roughly from q = -0.75 to q = -0.50, with a maximum P(q) ≈ 0.75.
* **Central Trough:** The minimum is at q = 0.00, with P(q) ≈ 0.25.
* **Right Broad Peak:** The plateau spans roughly from q = 0.50 to q = 0.75, with a maximum P(q) ≈ 0.75.
* The distribution approaches P(q) ≈ 0.15 at the boundaries q = -1.00 and q = 1.00.
**3. Raster (Solid Yellow/Gold Line)**
* **Trend:** This distribution is unimodal and sharply peaked, resembling a Gaussian or normal distribution centered at q=0. It is highly concentrated around the center and decays rapidly towards the boundaries.
* **Key Points (Approximate):**
* **Central Peak:** The maximum is at q = 0.00, with P(q) ≈ 1.78 (the highest value on the chart).
* **Width:** The distribution falls to half its maximum value (P(q) ≈ 0.89) at approximately q = ±0.20.
* **Boundaries:** The probability density is near zero (P(q) < 0.05) for |q| > 0.60.
### Key Observations
1. **Symmetry:** All three distributions appear symmetric about q=0.
2. **Concentration vs. Dispersion:** The Raster method produces a highly concentrated probability mass around q=0. In contrast, the PT and Spiral methods produce more dispersed distributions, with significant probability density across a wider range of q values, particularly in the regions |q| > 0.5.
3. **Structural Complexity:** The PT distribution shows the most complex structure with four clear peaks, suggesting it samples or represents the space in a more intricate, possibly discrete, manner compared to the smoother Spiral distribution.
4. **Shared Features:** The PT and Spiral distributions share similar boundary values and have peaks in similar regions (around |q| ≈ 0.5-0.85), though the PT peaks are sharper.
### Interpretation
This chart likely compares the performance or output of three different algorithms (PT, Spiral, Raster) for sampling from or approximating a target probability distribution over a variable \( q \), under a specific condition (T=0.31).
* The **Raster** method's sharp, central peak suggests it is highly efficient at concentrating samples or probability mass around the mode (q=0) of the underlying distribution. This could be desirable for optimization or finding the most likely state but may poorly represent the tails or alternative modes.
* The **Spiral** and **PT** methods produce broader, multi-modal distributions. This indicates they are exploring a wider region of the state space. The PT method's additional fine structure (the four peaks) might imply it is capturing more detailed features of a complex, possibly rugged, energy landscape or probability surface. The similarity between PT and Spiral suggests they may be related algorithms, with PT offering a higher-resolution or more discrete approximation.
* The parameter **T=0.31** is likely a temperature or similar control parameter. At this value, the Raster method is "cold" or focused, while the PT and Spiral methods maintain a "hotter," more exploratory behavior. The choice between methods would depend on the goal: exploitation (Raster) vs. exploration (PT/Spiral). The "Instance 2" label implies this is one of potentially many runs, and the distributions could vary with different random seeds or problem instances.
</details>
<details>
<summary>x20.png Details</summary>
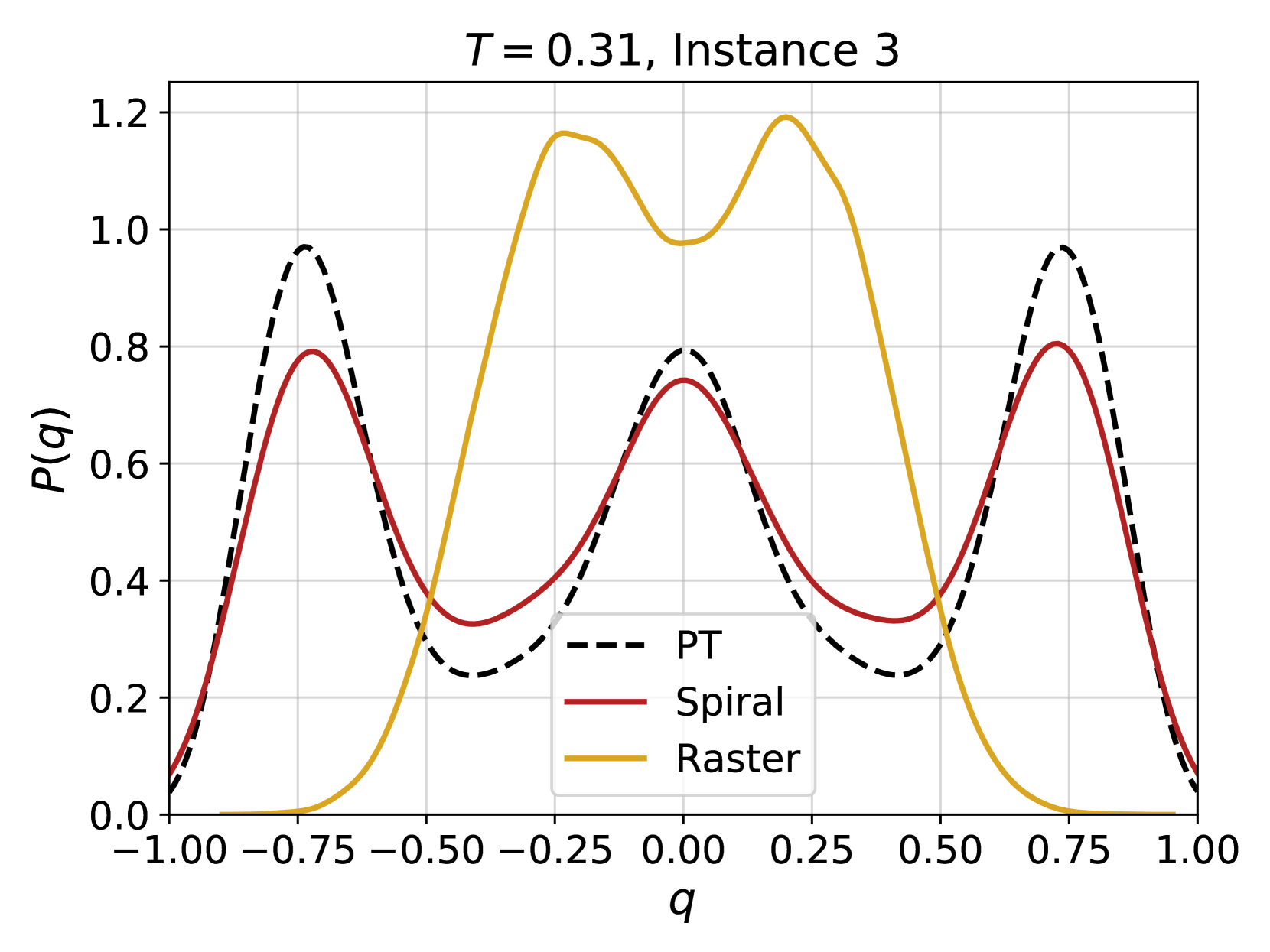
### Visual Description
## Probability Distribution Plot: T = 0.31, Instance 3
### Overview
This image is a scientific line graph displaying three distinct probability distribution functions, P(q), plotted against a variable q. The plot compares the distributions generated by three different methods or models labeled "PT," "Spiral," and "Raster." The title indicates this is data from "Instance 3" at a parameter value of "T = 0.31."
### Components/Axes
* **Title:** "T = 0.31, Instance 3" (centered at the top).
* **X-Axis:**
* **Label:** "q" (centered below the axis).
* **Scale:** Linear, ranging from -1.00 to 1.00.
* **Major Ticks:** -1.00, -0.75, -0.50, -0.25, 0.00, 0.25, 0.50, 0.75, 1.00.
* **Y-Axis:**
* **Label:** "P(q)" (rotated 90 degrees, left of the axis).
* **Scale:** Linear, ranging from 0.0 to 1.2.
* **Major Ticks:** 0.0, 0.2, 0.4, 0.6, 0.8, 1.0, 1.2.
* **Legend:** Located in the bottom-right quadrant of the plot area, approximately centered horizontally between q=0.00 and q=0.50, and vertically between P(q)=0.0 and P(q)=0.4.
* **PT:** Represented by a black dashed line (`---`).
* **Spiral:** Represented by a solid red line.
* **Raster:** Represented by a solid gold/yellow line.
* **Grid:** A light gray grid is present, aligned with the major ticks on both axes.
### Detailed Analysis
The plot shows three distinct curves with different shapes and peak locations.
1. **PT (Black Dashed Line):**
* **Trend:** This is a symmetric, tri-modal distribution. It starts near zero at q=-1.00, rises to a sharp peak, falls to a local minimum, rises to a central peak, falls to another local minimum, rises to a final sharp peak, and returns to near zero at q=1.00.
* **Key Points (Approximate):**
* Left Peak: q ≈ -0.75, P(q) ≈ 0.97
* Left Trough: q ≈ -0.50, P(q) ≈ 0.23
* Central Peak: q ≈ 0.00, P(q) ≈ 0.80
* Right Trough: q ≈ 0.50, P(q) ≈ 0.23
* Right Peak: q ≈ 0.75, P(q) ≈ 0.97
2. **Spiral (Solid Red Line):**
* **Trend:** This is also a symmetric, tri-modal distribution, closely following the shape of the PT curve but with slightly lower peak amplitudes and shallower troughs. It is consistently below the PT curve at the peaks and above it in the troughs.
* **Key Points (Approximate):**
* Left Peak: q ≈ -0.75, P(q) ≈ 0.80
* Left Trough: q ≈ -0.50, P(q) ≈ 0.33
* Central Peak: q ≈ 0.00, P(q) ≈ 0.75
* Right Trough: q ≈ 0.50, P(q) ≈ 0.33
* Right Peak: q ≈ 0.75, P(q) ≈ 0.80
3. **Raster (Solid Gold Line):**
* **Trend:** This is a symmetric, bi-modal distribution with a very different profile. It is near zero at the extremes (q=-1.00 and q=1.00) and in the center (q=0.00). It features two broad, high-amplitude peaks on either side of the center.
* **Key Points (Approximate):**
* Left Peak: q ≈ -0.25, P(q) ≈ 1.17
* Central Trough: q ≈ 0.00, P(q) ≈ 0.98
* Right Peak: q ≈ 0.25, P(q) ≈ 1.20
### Key Observations
* **Symmetry:** All three distributions are symmetric about q=0.00.
* **Peak Alignment:** The PT and Spiral curves share identical peak and trough locations along the q-axis, differing only in amplitude. The Raster curve's peaks are located at different q-values (±0.25) compared to the others (±0.75, 0.00).
* **Amplitude Hierarchy:** At their respective peaks, the Raster curve reaches the highest P(q) value (~1.20), followed by PT (~0.97), and then Spiral (~0.80).
* **Distribution Shape:** PT and Spiral are tri-modal, while Raster is bi-modal. The Raster distribution concentrates its probability mass in the region between q=-0.5 and q=0.5, whereas PT and Spiral have significant probability at the more extreme q values of ±0.75.
### Interpretation
This plot likely compares the output of three different algorithms or sampling methods (PT, Spiral, Raster) for estimating a probability distribution P(q) under a specific condition (T=0.31, Instance 3). The variable `q` could represent an order parameter, a coordinate in configuration space, or a similar quantity in a physical or machine learning context.
The stark difference between the Raster distribution and the other two suggests it is modeling a fundamentally different underlying process or is subject to different constraints. The close similarity between PT and Spiral implies these two methods produce qualitatively and quantitatively similar results for this instance, with PT yielding slightly sharper features (higher peaks, lower troughs). The symmetry indicates the underlying system or problem is symmetric with respect to the sign of `q`. The parameter `T=0.31` might be a temperature or a similar control parameter influencing the shape of these distributions; different `T` values would likely produce different curve profiles.
</details>
Figure S4: Comparison of the probability distribution of the overlap obtained using different update sequences of the spins for $\ell=10$ . The black dashed line is obtained using data gathered via Parallel Tempering (PT), while solid color lines are obtained using 4N with different sequence updates. Spiral: spins are update in a following a spiral going from the outside to the inside of the lattice; Raster: spins are updated row by row from left to right. It appears as the spiral update performs much better than the raster update for the 4N architecture in equal training conditions, something that is not observed when training, for instance, the MADE architecture. This effect could be related to the locality characteristics of the 4N architecture.
## S4 Cross-entropy plots in lin-lin and lin-log scale
<details>
<summary>x21.png Details</summary>
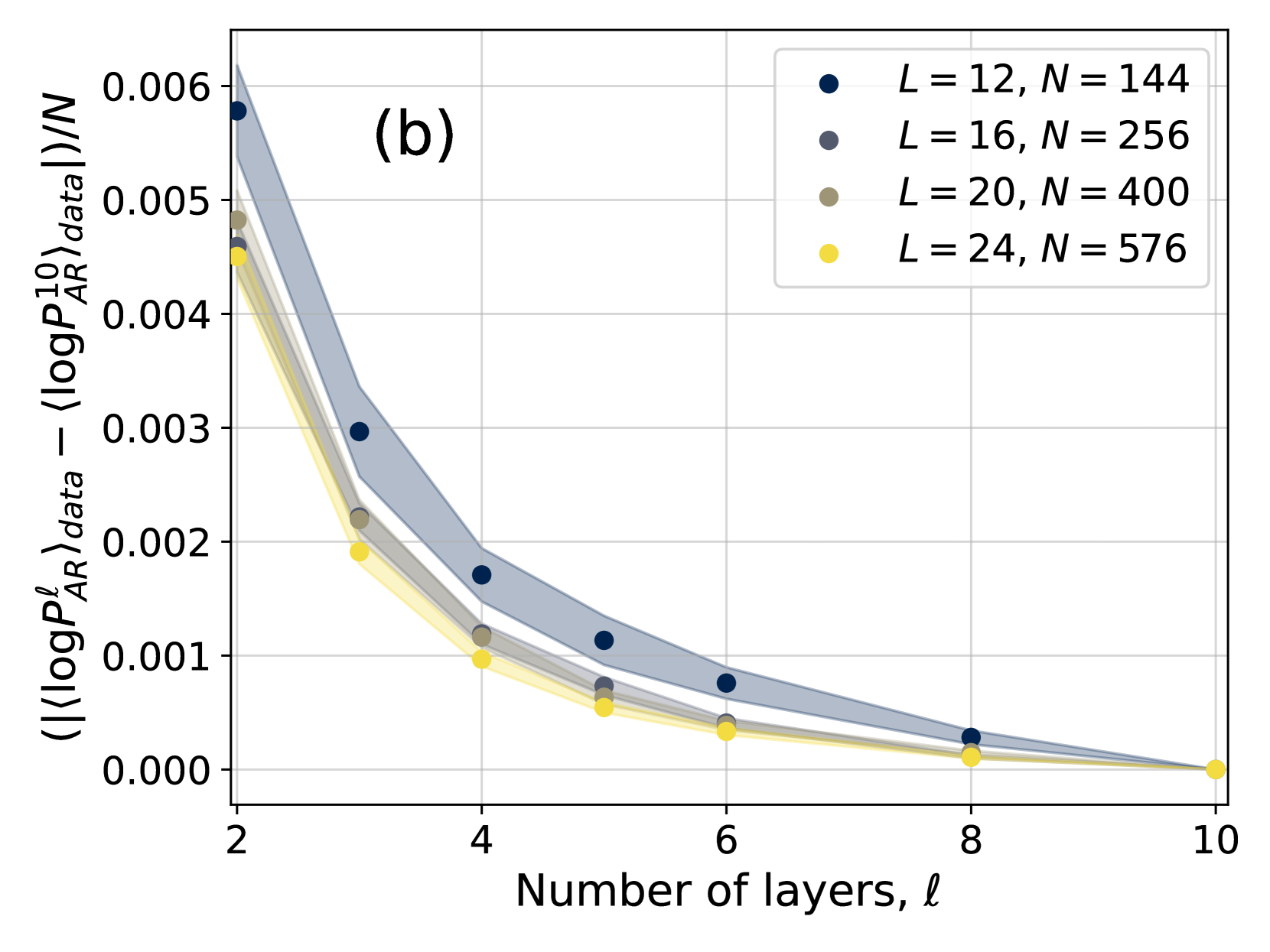
### Visual Description
## Line Chart with Shaded Regions: Autoregressive Probability Deviation vs. Number of Layers
### Overview
The image is a scientific line chart, labeled "(b)" in the top-left corner, plotting a normalized difference in log-probability against the number of layers (`ℓ`). It compares four different system configurations, each represented by a distinct color and shaded region. The chart demonstrates a clear decreasing trend for all series as the number of layers increases.
### Components/Axes
* **Chart Label:** "(b)" - positioned in the upper-left quadrant of the plot area.
* **X-Axis:**
* **Title:** "Number of layers, ℓ"
* **Scale:** Linear, with major tick marks and labels at 2, 4, 6, 8, and 10.
* **Y-Axis:**
* **Title:** `( (⟨logP_AR^ℓ⟩_data - ⟨logP_AR^10⟩_data) ) / N`
* **Scale:** Linear, ranging from 0.000 to 0.006, with major tick marks at intervals of 0.001.
* **Legend:** Positioned in the top-right corner of the plot area. It contains four entries, each with a colored circle marker and a label:
1. **Dark Blue Circle:** `L = 12, N = 144`
2. **Gray Circle:** `L = 16, N = 256`
3. **Olive/Brown Circle:** `L = 20, N = 400`
4. **Yellow Circle:** `L = 24, N = 576`
* **Data Series:** Each series consists of a line connecting circular data points at integer `ℓ` values (2, 3, 4, 5, 6, 8, 10) and a semi-transparent shaded region of the same color surrounding the line, likely representing a confidence interval or standard deviation.
### Detailed Analysis
**Trend Verification:** All four data series exhibit a consistent, monotonic downward trend. The lines slope steeply downward from `ℓ=2` to `ℓ=4` and then continue to decrease at a diminishing rate, approaching zero as `ℓ` approaches 10.
**Data Point Extraction (Approximate Y-values):**
* **`L=12, N=144` (Dark Blue):**
* `ℓ=2`: ~0.0058
* `ℓ=3`: ~0.0030
* `ℓ=4`: ~0.0017
* `ℓ=5`: ~0.0011
* `ℓ=6`: ~0.0008
* `ℓ=8`: ~0.0003
* `ℓ=10`: ~0.0000
* **`L=16, N=256` (Gray):**
* `ℓ=2`: ~0.0050
* `ℓ=3`: ~0.0022
* `ℓ=4`: ~0.0012
* `ℓ=5`: ~0.0007
* `ℓ=6`: ~0.0004
* `ℓ=8`: ~0.0001
* `ℓ=10`: ~0.0000
* **`L=20, N=400` (Olive):**
* `ℓ=2`: ~0.0048
* `ℓ=3`: ~0.0022
* `ℓ=4`: ~0.0012
* `ℓ=5`: ~0.0006
* `ℓ=6`: ~0.0004
* `ℓ=8`: ~0.0001
* `ℓ=10`: ~0.0000
* **`L=24, N=576` (Yellow):**
* `ℓ=2`: ~0.0045
* `ℓ=3`: ~0.0019
* `ℓ=4`: ~0.0010
* `ℓ=5`: ~0.0005
* `ℓ=6`: ~0.0003
* `ℓ=8`: ~0.0001
* `ℓ=10`: ~0.0000
**Shaded Regions:** The width of the shaded regions (uncertainty/variance) is largest at low `ℓ` values and narrows significantly as `ℓ` increases. The dark blue series (`L=12`) has the widest shaded region, while the yellow series (`L=24`) has the narrowest.
### Key Observations
1. **Universal Decay:** The quantity on the y-axis decays towards zero for all configurations as the number of layers (`ℓ`) increases towards 10.
2. **Initial Hierarchy:** At `ℓ=2`, the series are ordered from highest to lowest y-value as: Dark Blue (`L=12`) > Gray (`L=16`) ≈ Olive (`L=20`) > Yellow (`L=24`). This suggests that smaller systems (lower `L` and `N`) exhibit a larger initial deviation.
3. **Convergence:** By `ℓ=10`, all series converge to approximately the same value (zero). The differences between the series become negligible after `ℓ=6`.
4. **Uncertainty Correlation:** The magnitude of the y-value and the width of the shaded uncertainty region are positively correlated. The series with the highest values also shows the greatest variance.
### Interpretation
This chart likely illustrates the convergence behavior of an autoregressive model's probability estimates as a function of its depth (number of layers `ℓ`). The y-axis represents a normalized difference between the average log-probability at layer `ℓ` and at a reference layer (10), scaled by system size `N`.
The data suggests that:
* **Layer-wise Refinement:** The model's internal probability estimates undergo significant adjustment in the early layers (steep drop from `ℓ=2` to `4`), with diminishing changes in deeper layers. This implies the core "computation" or "refinement" of the probability distribution happens early in the network.
* **System Size Effect:** Larger systems (higher `L` and `N`, e.g., yellow line) start with a smaller deviation from the final (layer 10) probability estimate. This could indicate that larger models are more stable or require less adjustment across layers.
* **Convergence to a Stable State:** The convergence of all lines to zero at `ℓ=10` confirms that layer 10 is being used as the reference point. The narrowing shaded regions indicate that the model's behavior becomes more deterministic and consistent across different samples or runs in the deeper layers.
* **Peircean Reading:** The chart demonstrates a **law of diminishing returns** in the context of neural network depth. Adding more layers beyond a certain point (here, around `ℓ=6`) yields minimal change in this specific probability metric. The initial conditions (system size `L, N`) affect the starting point of this decay curve but not its ultimate convergence point, highlighting a fundamental property of the model's architecture or training.
</details>
<details>
<summary>x22.png Details</summary>
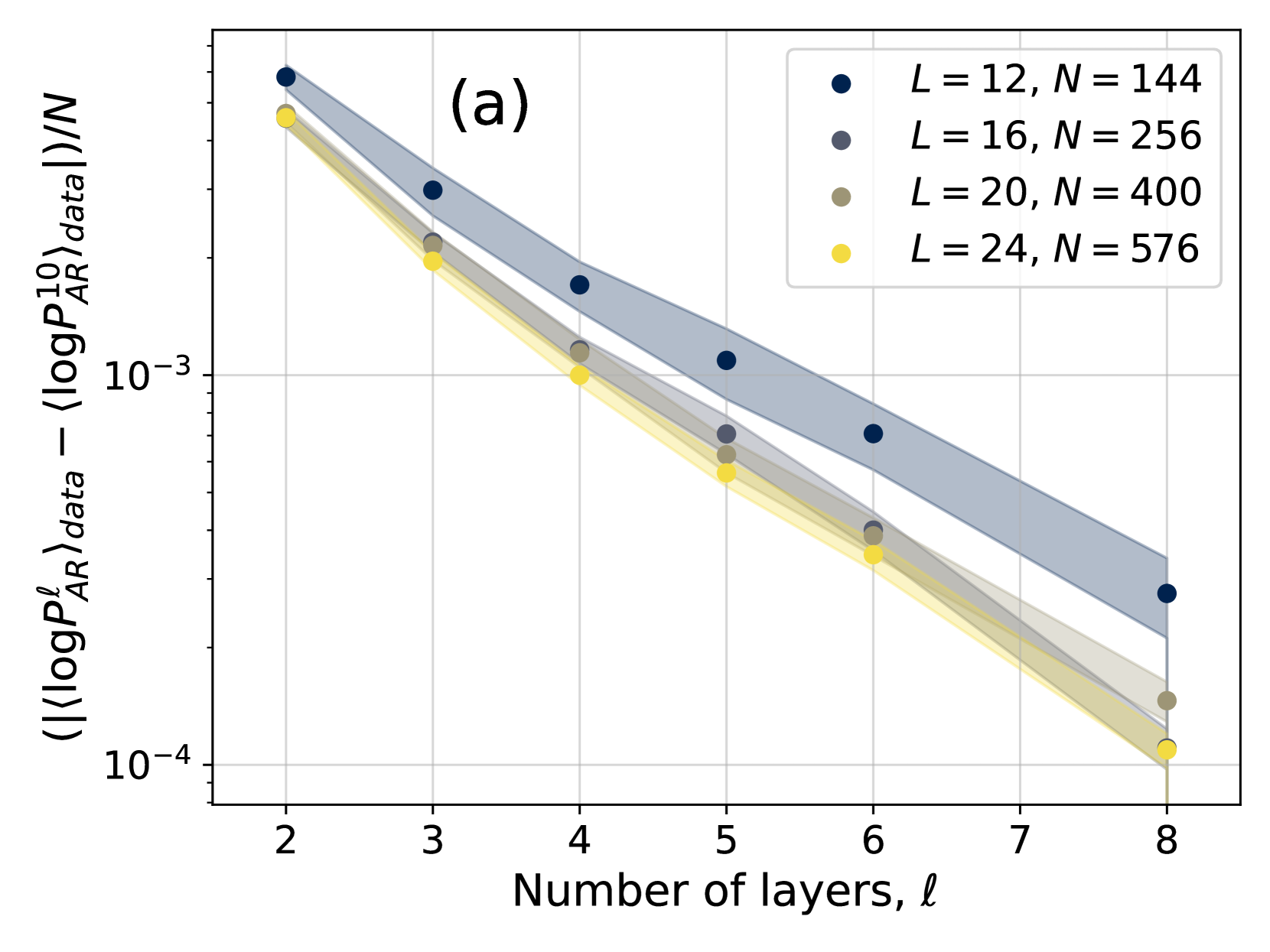
### Visual Description
\n
## Line Plot with Error Bands: Scaling Law Analysis
### Overview
The image displays a scientific line plot labeled "(a)" in the top-center. It illustrates the relationship between a normalized logarithmic probability difference (y-axis) and the number of layers, ℓ (x-axis), for four different model configurations. The plot uses a logarithmic scale on the y-axis and includes shaded error bands around each data series.
### Components/Axes
* **X-Axis:**
* **Label:** "Number of layers, ℓ"
* **Scale:** Linear scale.
* **Markers/Ticks:** Major ticks at integer values from 2 to 8.
* **Y-Axis:**
* **Label:** `( (|⟨log P_AR^ℓ⟩_data| - |⟨log P_AR^10⟩_data|) / N )`
* **Scale:** Logarithmic scale (base 10).
* **Markers/Ticks:** Major ticks at `10^-4` and `10^-3`. Minor ticks are present between them.
* **Legend:**
* **Position:** Top-right corner of the plot area.
* **Content:** Four entries, each with a colored circle marker and text.
1. Dark blue circle: `L = 12, N = 144`
2. Gray circle: `L = 16, N = 256`
3. Tan/Brown circle: `L = 20, N = 400`
4. Yellow circle: `L = 24, N = 576`
* **Data Series:** Four distinct lines, each with a corresponding shaded error band. The lines connect discrete data points at integer layer values (ℓ = 2, 3, 4, 5, 6, 8). The error bands are widest at lower ℓ and narrow as ℓ increases.
### Detailed Analysis
**Trend Verification:** All four data series exhibit a clear downward trend. As the number of layers (ℓ) increases, the value on the y-axis decreases. The relationship appears approximately linear on this semi-log plot, suggesting an exponential decay.
**Data Point Extraction (Approximate Values):**
Values are estimated from the log-scale y-axis. The ordering from highest to lowest y-value at any given ℓ is consistent: Dark Blue > Gray > Tan > Yellow.
* **For ℓ = 2:**
* Dark Blue (L=12): ~3.5 x 10^-3
* Gray (L=16): ~3.2 x 10^-3
* Tan (L=20): ~2.9 x 10^-3
* Yellow (L=24): ~2.7 x 10^-3
* **For ℓ = 3:**
* Dark Blue: ~2.0 x 10^-3
* Gray: ~1.7 x 10^-3
* Tan: ~1.5 x 10^-3
* Yellow: ~1.4 x 10^-3
* **For ℓ = 4:**
* Dark Blue: ~1.2 x 10^-3
* Gray: ~1.0 x 10^-3
* Tan: ~9.0 x 10^-4
* Yellow: ~8.0 x 10^-4
* **For ℓ = 5:**
* Dark Blue: ~7.0 x 10^-4
* Gray: ~5.5 x 10^-4
* Tan: ~5.0 x 10^-4
* Yellow: ~4.5 x 10^-4
* **For ℓ = 6:**
* Dark Blue: ~4.5 x 10^-4
* Gray: ~3.5 x 10^-4
* Tan: ~3.2 x 10^-4
* Yellow: ~3.0 x 10^-4
* **For ℓ = 8:**
* Dark Blue: ~2.0 x 10^-4
* Gray: ~1.5 x 10^-4
* Tan: ~1.3 x 10^-4
* Yellow: ~1.1 x 10^-4
### Key Observations
1. **Consistent Hierarchy:** The series are strictly ordered across all measured layers. The configuration with the smallest L and N (L=12, N=144) consistently has the highest y-value, while the largest configuration (L=24, N=576) has the lowest.
2. **Convergence:** The absolute difference between the series decreases as ℓ increases. The gap between the Dark Blue and Yellow lines is much larger at ℓ=2 than at ℓ=8.
3. **Error Band Behavior:** The uncertainty (width of the shaded band) is largest for the Dark Blue series and smallest for the Yellow series at any given ℓ. All bands narrow significantly as ℓ increases.
4. **Data Spacing:** Data points are provided for ℓ = 2, 3, 4, 5, 6, and 8. There is no data point for ℓ=7.
### Interpretation
This chart likely visualizes a **scaling law** in machine learning, specifically related to autoregressive (AR) models. The y-axis metric appears to measure a normalized deviation in log-probability on a dataset between a model with ℓ layers and a reference model with 10 layers (`P_AR^10`), scaled by the model dimension `N`.
The data demonstrates two key scaling relationships:
1. **Depth Scaling (ℓ):** For a fixed model architecture (fixed L and N), increasing the number of layers ℓ reduces the measured probability deviation. This suggests that deeper models (within the tested range) better approximate the reference or fit the data, as indicated by the decaying exponential trend.
2. **Width/Size Scaling (L, N):** For a fixed depth ℓ, models with larger dimensions (L and N) exhibit a smaller probability deviation. The Yellow series (L=24, N=576) is consistently the lowest, indicating superior performance by this metric. This aligns with the general principle that larger models tend to have better performance.
The narrowing error bands with increasing ℓ suggest that the model's behavior becomes more consistent and predictable as it gets deeper. The convergence of the different series at high ℓ implies that the advantage of increased width (L, N) may diminish relative to the effect of depth in this specific metric and range. The plot provides empirical evidence for how model performance, as defined by this specific log-probability metric, scales with both depth and width.
</details>
Figure S5: Absolute difference between $\langle\log P^{\ell}_{\text{NN}}\rangle_{\text{data}}$ at various $\ell$ and at $\ell=10$ for $T=1.02$ and different system’s sizes, in lin-lin and lin-log. Data are averaged over ten different instances of the disorder and the colored areas identify regions corresponding to plus or minus one standard deviation.