# Towards Probabilistic Inductive Logic Programming with Neurosymbolic Inference and Relaxation
**Authors**: F. Hillerström and G.J. Burghouts
> TNO, The Netherlands
refs.bib
Hillerström and Burghouts
116 2024 10.1017/xxxxx
## Abstract
Many inductive logic programming (ILP) methods are incapable of learning programs from probabilistic background knowledge, e.g. coming from sensory data or neural networks with probabilities. We propose Propper, which handles flawed and probabilistic background knowledge by extending ILP with a combination of neurosymbolic inference, a continuous criterion for hypothesis selection (BCE) and a relaxation of the hypothesis constrainer (NoisyCombo). For relational patterns in noisy images, Propper can learn programs from as few as 8 examples. It outperforms binary ILP and statistical models such as a Graph Neural Network.
keywords: Inductive Logic Programming, Neurosymbolic inference, Probabilistic background knowledge, Relational patterns, Sensory data.
## 1 Introduction
Inductive logic programming (ILP) muggleton1995inverse learns a logic program from labeled examples and background knowledge (e.g. relations between entities). Due to the strong inductive bias imposed by the background knowledge, ILP methods can generalize from small numbers of examples cropper2022inductive. Other advantages are the ability to learn complex relations between the entities, the expressiveness of first-order logic, and the resulting program can be understood and transferred easily because it is in symbolic form cropper2022_30newintro. This makes ILP an attractive alternative methodology besides statistical learning methods.
For many real-world applications, dealing with noise is essential. Mislabeled samples are one source of noise. To learn from noisy labels, various ILP methods have been proposed to generalize a subset of the samples srinivasan2001aleph,ahlgren2013efficient,zeng2014quickfoil,raedt2015inducing. To advance methods to learn recursive programs and invent new predicates, Combo cropper2023learning was proposed, a method that searches for small programs that generalize subsets of the samples and combines them. MaxSynth hocquette2024learning extends Combo to allow for mislabeled samples, while trading off program complexity for training accuracy. These methods are dealing with noisy labels, but do not explicitly take into account errors in the background knowledge, nor are they designed to deal with probabilistic background knowledge.
Most ILP methods take as a starting point the inputs in symbolic declarative form cropper2021turning. Real-world data often does not come in such a form. A predicate $p(.)$ , detected in real-world data, is neither binary or perfect. The assessment of the predicate can be uncertain, resulting in a non-binary, probabilistic predicate. Or the assessment can be wrong, leading to imperfect predicates. Dealing with noisy and probabilistic background knowledge is relevant for learning from sources that exhibit uncertainties. A probabilistic source can be a human who needs to make judgements at an indicated level of confidence. A source can also be a sensor measurement with some confidence. For example, an image is described by the objects that are detected in it, by a deep learning model. Such a model predicts locations in the image where objects may be, at some level of confidence. Some objects are detected with a lower confidence than others, e.g. if the object is partially observable or lacks distinctive visual features. The deep learning model implements a probabilistic predicate that a particular image region may contain a particular object, e.g. 0.7 :: vehicle(x). Given that most object detection models are imperfect in practice, it is impossible to determine a threshold that distinguishes the correct and incorrect detections.
Two common ILP frameworks, Aleph srinivasan2001aleph and Popper learning_from_failures, typically fail to find the correct programs when dealing with predicted objects in images helff2023v; even with a state-of-the-art object detection model, and after advanced preprocessing of said detections. In the absence of an ideal binarization of probabilities, most ILP methods are not applicable to probabilistic sources cropper2021turning.
<details>
<summary>x1.png Details</summary>
### Visual Description
## System Diagram: Neurosymbolic Inference
### Overview
The image presents a system diagram illustrating a neurosymbolic inference process. It combines symbolic reasoning (logic programs, constraints) with neural network outputs (probabilities associated with object detection). The diagram shows a cyclical process of generating hypotheses, testing them against examples, and constraining the hypothesis space based on the results. The right side of the diagram shows examples of positive and negative cases with object detection probabilities.
### Components/Axes
* **Left Side (Process Flow)**:
* **Generate**: Top of the cycle, associated with "Predicates" and "Constraints". An arrow points from "Generate" to "Test".
* **Test**: Middle of the cycle. A "logic program is_on(vehicle, bridge)" is associated with this step.
* **Constrain**: Bottom of the cycle, associated with "relaxation of the hypothesis constrainer (NoisyCombo) contribution #3". An arrow points from "Constrain" to "Generate", completing the cycle.
* **Arrows**: Two curved arrows indicate the flow of information. One from "Generate" to "Test", and another from "Constrain" back to "Generate". A smaller arrow labeled "failure" points from "Test" to "Constrain".
* **Right Side (Examples)**:
* **Title**: "Neurosymbolic inference on Probabilistic background knowledge contribution #1"
* **Examples**: Section header.
* **Positives**: Labeled section containing examples where the "is_on(vehicle, bridge)" relationship is likely true.
* **Negatives**: Labeled section containing examples where the "is_on(vehicle, bridge)" relationship is likely false.
* **Images**: Several aerial images showing vehicles and bridges, with bounding boxes around detected objects.
* **Probabilities**: Probabilities associated with object detections and relationships, displayed next to the images.
### Detailed Analysis or Content Details
**Left Side (Process Flow)**:
* **Generate**: This step involves generating hypotheses based on predicates and constraints.
* **Test**: The generated hypotheses are tested using a logic program, specifically "is_on(vehicle, bridge)".
* **Constrain**: Based on the test results, the hypothesis space is constrained. This involves relaxation of the hypothesis constrainer using a method called "NoisyCombo" (contribution #3). A continuous criterion for hypothesis selection (BCE) is also mentioned (contribution #2).
* **Feedback Loop**: The process is cyclical, with the "Constrain" step feeding back into the "Generate" step, refining the hypotheses over time.
**Right Side (Examples)**:
* **Positive Examples**:
* The first positive example shows the following probabilities:
* 0.33 :: vehicle(A)
* 0.68 :: bridge(B)
* 0.92 :: is_close(A,B)
* 0.95 :: is_on(A,B)
* Image shows a bridge with vehicles on it. Bounding boxes are present around the vehicle and bridge.
* vehicle: 54.8%
* bridge: 68.4%
* vehicle: 33.3%
* The second positive example shows the following probabilities:
* Image shows a bridge with vehicles on it. Bounding boxes are present around the vehicles and bridge.
* bridge: 77.1%
* vehicle: 55.5%
* vehicle: 50.4%
* vehicle: 64.2%
* vehicle: 38.5%
* vehicle: 48.1%
* **Negative Examples**:
* The first negative example shows the following probabilities:
* 0.31 :: vehicle(A)
* 0.42 :: bridge(B)
* 0.29 :: is_close(A,B)
* 0.00 :: is_on(A,B)
* Image shows a bridge and a vehicle on a road next to the bridge. Bounding boxes are present around the vehicle and bridge.
* vehicle: 31.0%
* bridge: 42.2%
* The second negative example shows the following probabilities:
* Image shows a bridge and a vehicle on a road next to the bridge. Bounding boxes are present around the vehicles and bridge.
* vehicle: 48.4%
* vehicle: 56.2%
* vehicle: 44.6%
* vehicle: 57.0%
* bridge: 79.1%
* vehicle: 49.5%
* vehicle: 43.5%
* **Additional Notes**:
* The probabilities represent the confidence of the model in detecting the objects and their relationships.
* The positive examples have high probabilities for "is_on(A,B)", while the negative examples have low probabilities for "is_on(A,B)".
* The green boxes "0.21 :: is_on(vehicle, bridge)" and "0.00 :: is_on(vehicle, bridge)" are used to show the result of the test. Green indicates success, red indicates failure.
### Key Observations
* The diagram illustrates a neurosymbolic approach to reasoning about relationships between objects in images.
* The system uses a feedback loop to refine its hypotheses based on positive and negative examples.
* The probabilities associated with object detections play a crucial role in the inference process.
* The "is_on(vehicle, bridge)" relationship is used as a specific example to demonstrate the system's capabilities.
### Interpretation
The diagram demonstrates a system that combines neural networks and symbolic reasoning to infer relationships between objects in images. The cyclical process of generating, testing, and constraining hypotheses allows the system to learn and improve its accuracy over time. The use of probabilities from object detection provides a measure of confidence in the inferred relationships. The example of "is_on(vehicle, bridge)" shows how the system can be used to reason about spatial relationships between objects. The contributions #1, #2, and #3 likely refer to specific techniques or components used in the system, such as the neurosymbolic inference method, the hypothesis selection criterion, and the hypothesis constrainer.
</details>
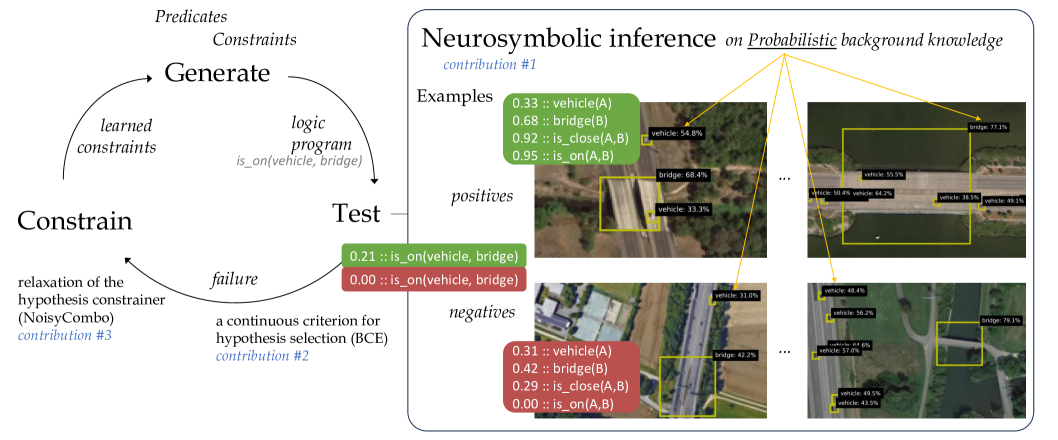
Figure 1: Our method Propper extends the ILP method Popper that learns from failures (left) with neurosymbolic inference to test logical programs on probabilistic background knowledge, e.g. objects detected in images with a certain probability (right).
We propose a method towards probabilistic ILP. At a high level, ILP methods typically induce a logical program that entails many positive and few negative samples, by searching the hypothesis space, and subsequently testing how well the current hypothesis fits the training samples cropper2022_30newintro. One such method is Popper, which learns from failures (LFF) learning_from_failures, in an iterative cycle of generating hypotheses, testing them and constraining the hypothesis search. Our proposal is to introduce a probabilistic extension to LFF at the level of hypothesis testing. For that purpose, we consider neurosymbolic AI hybrid_ai. Within neurosymbolic AI a neural network predicts the probability for a predicate. For example a neural network for object detection, which outputs a probability for a particular object being present in an image region, e.g., 0.7 :: vehicle(x). Neurosymbolic AI connects this neural network with knowledge represented in a symbolic form, to perform reasoning over the probabilistic predicates predicted by the neural network. With this combination of a neural network and symbolic reasoning, neurosymbolic AI can reason over unstructured inputs, such as images. We leverage neurosymbolic programming and connect it to the tester within the hypothesis search. One strength of neurosymbolic programming is that it can deal with uncertainty and imperfect information hybrid_ai,neuro_symbolic,scallop,scallop_foundationmodels, in our case the probablistic background knowledge.
We propose to use neurosymbolic inference as tester in the test-phase of the LFF cycle. Neurosymbolic reasoning calculates an output probability for a logical query being true, for every input sample. The input samples are the set of positive and negative examples, together with their probabilistic background knowledge. The logical query evaluated within the neurosymbolic reasoning is the hypothesis generated in the generate-phase of the LFF cycle, which is a first-order-logic program. With the predicted probability of the hypothesis being true per sample, it becomes possible to compute how well the hypothesis fits the training samples. That is used to continue the LFF cycle and generate new constraints based on the failures.
Our contribution is a step towards probabilistic ILP by proposing a method called Propper. It builds on an ILP framework that is already equipped to deal with noisy labels, Popper-MaxSynth learning_from_failures,hocquette2024learning, which we extend with neurosymbolic inference which is able to process probabilistic facts, i.e. uncertain and imperfect background knowledge. Our additional contributions are a continuous criterion for hypothesis selection, that can deal with probabilities, and a relaxed formulation for constraining the hypothesis space. Propper and the three contributions are outlined in Figure 1. We compare Popper and Propper with statistical ML models (SVM and Graph Neural Network) for the real-life task of finding relational patterns in satellite images based on objects predicted by an imperfect deep learning model. We validate the learning robustness and efficiency of the various models. We analyze the learned logical programs and discuss the cases which are hard to predict.
## 2 Related Work
For the interpretation of images based on imperfect object predictions, ILP methods such as Aleph srinivasan2001aleph and Popper learning_from_failures proved to be vulnerable and lead to incorrect programs or not returning a program at all helff2023v. Solutions to handle observational noise were proposed cropper2021beyondentailment for small binary images. With LogVis muggleton2018meta images are analyzed via physical properties. This method could estimate the direction of the light source or the position of a ball from images in very specific conditions or without clutter or distractors. $Meta_{Abd}$ dai2020abductive jointly learns a neural network with induction of recursive first-order logic theories with predicate invention. This was demonstrated on small binary images of digits. Real-life images are more complex and cluttered. We aim to extend these works to realistic samples, e.g. large color images that contain many objects under partial visiblity and in the midst of clutter, causing uncertainties. Contrary to $Meta_{Abd}$ , we take pretrained models as a starting point, as they are often already very good at their task of analyzing images. Our focus is on extending ILP to handle probabilistic background knowledge.
In statistical relational artificial intelligence (StarAI) raedt2016statistical the rationale is to directly integrate probabilities into logical models. StarAI addresses a different learning task than ILP: it learns the probabilistic parameters of a given program, whereas ILP learns the program cropper2021turning. Probabilities have been integrated into ILP previously. Aleph srinivasan2001aleph was used to find interesting clauses and then learn the corresponding weights huynh2008discriminative. ProbFOIL raedt2015inducing and SLIPCOVER bellodi2015structure search for programs with probabilities associated to the clauses, to deal with the probabilistic nature of the background knowledge. SLIPCOVER searches the space of probabilistic clauses using beam search. The clauses come from Progol muggleton1995inverse. Theories are searched using greedy search, where refinement is achieved by adding a clauses for a target predicate. As guidance the log likelihood of the data is considered. SLIPCOVER operates in a probabilistic manner on binary background knowledge, where our goal is to involve the probabilities associated explicitly the background knowledge.
How to combine these probabilistic methods with recent ILP frameworks is unclear. In our view, it is not trivial and possibly incompatible. Our work focuses on integrating a probabilistic method into a modern ILP framework, in a simple yet elegant manner. We replace the binary hypothesis tester of Popper learning_from_failures by a neurosymbolic program that can operate on probabilistic and imperfect background knowledge hybrid_ai,neuro_symbolic. Rather than advanced learning of both the knowledge and the program, e.g. NS-CL mao2019neuro, we take the current program as the starting point. Instead of learning parameters, e.g. Scallop scallop, we use the neurosymbolic program for inference given the program and probabilistic background knowledge. Real-life samples may convey large amounts of background knowledge, e.g. images with many objects and relations between them. Therefore, scalability is essential. Scallop scallop improved the scalability over earlier neurosymbolic frameworks such as DeepProbLog deepproblog,deepproblog_efficient. Scallop introduced a tunable parameter $k$ to restrain the validation of hypotheses by analyzing the top- $k$ proofs. They asymptotically reduced the computational cost while providing relative accuracy guarantees. This is beneficial for our purpose. By replacing only the hypothesis tester, the strengths of ILP (i.e. hypothesis search) are combined with the strengths of neurosymbolic inference (i.e. probabilistic hypothesis testing).
## 3 Propper Algorithm
To allow ILP on flawed and probabilistic background knowledge, we extend modern ILP (Section 3.1) with neurosymbolic inference (3.2) and coin our method Propper. The neurosymbolic inference requires program conversion by grammar functions (3.3), and we added a continuous criterion for hypothesis selection (3.4), and a relaxation of the hypothesis constrainer (3.5).
### 3.1 ILP: Popper
Popper represents the hypothesis space as a constraint satisfaction problem and generates constraints based on the performance of earlier tested hypotheses. It works by learning from failures (LFF) learning_from_failures. Given background knowledge $B$ , represented as a logic program, positive examples $E^{+}$ and negative examples $E^{-}$ , it searches for a hypothesis $H$ that is complete ( $\forall e\in E^{+},H\cup B\models e$ ) and consistent ( $\forall e\in E^{-},H\cup B\not\models e$ ). The algorithm consists of three main stages (see Figure 1, left). First a hypothesis in the form of a logical program is generated, given the known predicates and constraints on the hypothesis space. The Test stage tests the generated logical program against the provided background knowledge and examples, using Prolog for inference. It evaluates whether the examples are entailed by the logical program and background knowledge. From this information, failures that are made when applying the current hypothesis, can be identified. These failures are used to constrain the hypothesis space, by removing specializations or generalizations from the hypothesis space. In the original Popper implementation learning_from_failures, this cycle is repeated until an optimal solution is found; the smallest program that covers all positives and no negative examples See learning_from_failures for a formal definition.. Its extension Combo combines small programs that do not entail any negative example cropper2023learning. When no optimal solution is found, Combo returns the obtained best solution. The Popper variant MaxSynth does allow noise in the examples and generates constraints based on a minimum description length cost function, by comparing the length of a hypothesis with the possible gain in wrongly classified examples hocquette2024learning.
### 3.2 Neurosymbolic Inference: Scallop
Scallop is a language for neurosymbolic programming which integrates deep learning with logical reasoning scallop. Scallop reasons over continuous, probabilistic inputs and results in a probabilistic output confidence. It consists of two parts: a neural model that outputs the confidence for a specific concept occurring in the data and a reasoning model that evaluates the probability for the query of interest being true, given the input. It uses provenance frameworks kimmig2017algebraic to approximate exact probabilistic inference, where the AND operator is evaluated as a multiplication ( $AND(x,y)=x*y$ ), the OR as a minimization ( $OR(x,y)=min(1,x+y)$ ) and the NOT as a $1-x$ . Other, more advanced formulations are possible, e.g. $noisy$ - $OR(x,y)=1-(1-a)(1-b)$ for enhanced performance. For ease of integration, we considered this basic provenance. To improve the speed of the inference, only the most likely top-k hypotheses are processed, during the intermediate steps of computing the probabilities for the set of hypotheses.
### 3.3 Connecting ILP and Neurosymbolic Inference
Propper changes the Test stage of the Popper algorithm (see Figure 1): the binary Prolog reasoner is replaced by the neurosymbolic inference using Scallop, operating on probabilistic background knowledge (instead of binary), yielding a probability for each sample given the logical program. The background knowledge is extended with a probability value before each first-order-logic statement, e.g. 0.7 :: vehicle(x).
The Generate step yields a logic program in Prolog syntax. The program can cover multiple clauses, that can be understood as OR as one needs to be satisfied. Each clause is a function of predicates, with input arguments. The predicate arguments can differ between the clauses within the logic program. This is different from Scallop, where every clause in the logic program is assumed to be a function of the same set of arguments. As a consequence, the Prolog program requires syntax rewriting to arrive at an equivalent Scallop program. This rewriting involves three steps by consecutive grammar functions, which we illustrate with an example. Take the Prolog program:
$$
\displaystyle\begin{split}\texttt{f(A)}={}&\texttt{has\_object(A, B), vehicle(
B)}\\
\texttt{f(A)}={}&\texttt{has\_object(A, B), bridge(C), is\_on(B, C)}\end{split} \tag{1}
$$
The bodies of f(A) are extracted by: $b(\texttt{f})$ = {[has_object(A, B), vehicle(B)], [has_object(A, B), bridge(C), is_on(B, C)]}. The sets of arguments of f(A) are extracted by: $v(\texttt{f})=\{\{\texttt{A, B}\},\{\texttt{C, A, B}\}\}$ .
For a Scallop program, the clauses in the logic program need to be functions of the same argument set. Currently the sets are not the same: {A, B} vs. {C, A, B}. Function $e(\cdot)$ adds a dummy predicate for all non-used arguments, i.e. C in the first clause, such that all clauses operate on the same set, i.e. {C, A, B}:
$$
\displaystyle\begin{split}e([\texttt{has\_object(A, B)},{}&\texttt{vehicle(B)}
],\{\texttt{C, A, B}\})=\\
&\texttt{has\_object(A, B), vehicle(B), always\_true(C)}\end{split} \tag{2}
$$
After applying grammar functions $b(\cdot)$ , $v(\cdot)$ and $e(\cdot)$ , the Prolog program f(A) becomes the equivalent Scallop program g(C, A, B):
$$
\displaystyle\begin{split}\texttt{g\textsubscript{0}(C, A, B)}={}&\texttt{has
\_object(A, B), vehicle(B), always\_true(C)}\\
\texttt{g\textsubscript{1}(C, A, B)}={}&\texttt{has\_object(A, B), bridge(C),
is\_on(B, C)}\\
\texttt{g(C, A, B)}={}&\texttt{g\textsubscript{0}(C, A, B) or g\textsubscript{
1}(C, A, B)}\end{split} \tag{3}
$$
### 3.4 Selecting the Best Hypothesis
MaxSynth uses a minimum-description-length (MDL) cost hocquette2024learning to select the best solution:
$$
MDL_{B,E}=size(h)+fn_{B,E}(h)+fp_{B,E}(h) \tag{4}
$$
The MDL cost compares the number of correctly classified examples with the number of literals in the program. This makes the cost dependent on the dataset size and requires binary predictions in order to determine the number of correctly classified examples. Furthermore, it is doubtful whether the number of correctly classified examples can be compared directly with the rule size, since it makes the selection of the rule size dependent on the dataset size again.
Propper uses the Binary Cross Entropy (BCE) loss to compare the performance of hypotheses, as it is a more continuous measure than MDL. The neurosymbolic inference predicts an output confidence for an example being entailed by the hypothesis. The BCE-cost compares this predicted confidence with the groundtruth (one or zero). For $y_{i}$ being the groundtruth label and $p_{i}$ the confidence predicted via neurosymbolic inference for example $i$ , the BCE cost for $N$ examples becomes:
$$
BCE=\frac{1}{N}\sum_{i=1}^{N}(y_{i}*log(p_{i})+(1-y_{i})*log(1-p_{i})). \tag{5}
$$
Scallop reasoning automatically avoids overfitting, by punishing the size of the program, because when adding more or longer clauses the probability becomes lower by design. The more ANDs in the program, the lower the output confidence of the Scallop reasoning, due to the multiplication of the probabilities. Therefore, making a program more specific will result in a higher BCE-cost, unless the specification is beneficial to remove FPs. Making the program more generic will cover more samples (due to the addition operator for the OR). However the confidences for the negative samples will increase as well, which will increase the BCE-cost again. The BCE-cost is purely calculated on the predictions itself, and thereby removes the dependency on the dataset size and the comparison between number of samples and program length.
### 3.5 Constraining on Inferred Probabilities
Whereas Combo cropper2023learning and MaxSynth hocquette2024learning yield optimal programs given perfect background knowledge, with imperfect and probabilistic background knowledge no such guarantees can be provided. The probabilistic outputs of Scallop are converted into positives and negatives before constraining. The optimal threshold is chosen by testing 15 threshold values, evenly spaced between 0 and 1 and selecting the threshold resulting in the most highest true positives plus true negatives on the training samples.
MaxSynth generates constraints based on the MDL loss hocquette2024learning, making the constraints dependent on the size of the dataset. To avoid this dependency, we introduce the NoisyCombo constrainer. Combo generates constraints once a false positive (FP) or negative (FN) is detected. $\exists e\in E^{-},H\cup B\models e$ : prune generalisations. $\exists e\in E^{+},H\cup B\not\models e$ or $\forall e\in E^{-},H\cup B\not\models e$ : prune specialisations. NoisyCombo relaxes this condition and allows a few FPs and FNs to exist, depending on an expected noise level, inspired by LogVis muggleton2018meta. This parameter defines a percentage of the examples that could be imperfect, from which the allowed number of FPs and FNs is calculated. $\sum(e\in E^{-},H\cup B\models e)>noise\_level*N_{negatives}$ : prune generalisations. $\forall e\in E^{-},H\cup B\not\models e$ : prune specialisations. The positives are not thresholded by the noise level, since programs that cover at least one positive sample are added to the combiner.
## 4 Analyses
We validate Propper on a real-life task of finding relational patterns in satellite images, based on flawed and probabilistic background knowledge about the objects in the images, which are predicted by an imperfect deep learning model. We analyze the learning robustness under various degrees of flaws in the background knowledge. We do this for various models, including Popper (on which Propper is based) and statistical ML models. In addition, we establish the learning efficiency for very low amounts of training data, as ILP is expected to provide an advantage because it has the inductive bias of background knowledge. We analyze the learned logical programs, to compare them qualitatively against the target program. Finally, we discuss the cases that are hard to predict.
### 4.1 First Dataset
The DOTA dataset xia2018dota contains many satellite images. This dataset is very challenging, because the objects are small, and therefore visual details are lacking. Moreover, some images are very cluttered by sometimes more than 100 objects.
<details>
<summary>extracted/5868417/result_figs/pos_full.jpg Details</summary>

### Visual Description
## Aerial Image with Object Detection
### Overview
The image is an aerial view of a coastal area, featuring roads, bridges, water, and vegetation. Yellow bounding boxes highlight detected objects, labeled as either "vehicle" or "bridge," along with a confidence percentage.
### Components/Axes
* **Objects Detected:** Vehicles and Bridges
* **Labels:** Each detected object has a label in the format "object_type: confidence_percentage%"
* **Bounding Boxes:** Yellow rectangles enclose each detected object.
### Detailed Analysis or Content Details
Here's a breakdown of the detected objects and their confidence percentages, proceeding from left to right and top to bottom:
* **Vehicles (Left Side):**
* Vehicle: 37.0%
* Vehicle: 58.0%
* Vehicle: 30.1%
* Vehicle: 46.9%
* Vehicle: 50.4%
* Vehicle: 55.5%
* Vehicle: 64.2%
* Vehicle: 38.5%
* Vehicle: 49.1%
* Vehicle: 55.1%
* Vehicle: 63.2%
* Vehicle: 75.5%
* Vehicle: 69.5%
* Vehicle: 48.7%
* Vehicle: 33.5%
* **Bridges:**
* Bridge: 77.1% (Located towards the center-left)
* Bridge: 86.4% (Located towards the center-right)
* **Vehicles (Top Right):**
* Vehicle: 43.9%
* Vehicle: 51.5%
* Vehicle: 39.9%
* Vehicle: 30.3%
* Vehicle: 41.8%
* Vehicle: 60.5%
### Key Observations
* The confidence percentages for bridge detections are significantly higher than those for vehicle detections.
* Vehicle detections are concentrated along the roads.
* There is a cluster of vehicle detections in what appears to be a parking lot in the upper-right corner.
### Interpretation
The image demonstrates an object detection system identifying vehicles and bridges in an aerial image. The confidence percentages indicate the system's certainty in its classifications. The higher confidence for bridges suggests that the system is more accurate in identifying bridges than vehicles, possibly due to the bridges' distinct shape and size. The distribution of vehicle detections aligns with the road network, indicating that the system is successfully locating vehicles in their expected environment. The cluster of vehicles in the parking lot further validates the system's ability to identify multiple objects in a concentrated area.
</details>
(a) Positive image
<details>
<summary>extracted/5868417/result_figs/neg_full.jpg Details</summary>
### Visual Description
## Aerial Image Analysis with Object Detection
### Overview
The image is an aerial view of an industrial area, a highway, and a waterway, possibly a canal or river. The image includes object detection bounding boxes with labels indicating the presence of "vehicle" and "bridge" along with a confidence score (percentage).
### Components/Axes
* **Objects Detected:** Vehicles, Bridge
* **Labels:** Each detected object has a label in the format "object_type: confidence_score%"
* **Confidence Scores:** Represented as percentages, indicating the certainty of the object detection model.
### Detailed Analysis or ### Content Details
**Industrial Area (Left Side):**
* Several large buildings with flat roofs are visible.
* Numerous vehicles are detected in parking lots and along roads.
* Vehicle confidence scores in this area range from approximately 31.7% to 65.6%.
* vehicle: 64.8%
* vehicle: 36.5% 7.2% 4%
* vehicle: 47.5%
* vehicle: 41.0%
* vehicle: 40.1%
* vehicle: 31.8%
* vehicle: 35.6%
* vehicle: 32.2%
* vehicle: 32.0%
* vehicle: 45.3%
* vehicle: 44.3%
* vehicle: 36.4%
* vehicle: 43.4%
* vehicle: 31.7%
* vehicle: 33.2%
* vehicle: 42.1%
* vehicle: 65.6%
* vehicle: 37.2%
* vehicle: 53.3%
* vehicle: 36.9%
* vehicle: 34.3%
* vehicle: 31.1%
* vehicle: 30.4%
* vehicle: 32.4%
* vehicle: 43.4%
* vehicle: 34.2%
* vehicle: 78.3%
* vehicle: 36.7%
* vehicle: 32.4%
* vehicle: 35.3%
* vehicle: 58.6%
* vehicle: 40.6%
* vehicle: 52.4%
* vehicle: 32.3%
* vehicle: 46.3%
* vehicle: 39.7%
* vehicle: 70.1%
**Highway (Right Side):**
* A multi-lane highway runs vertically through the right side of the image.
* Vehicles are detected on the highway with confidence scores ranging from approximately 43.5% to 70.0%.
* vehicle: 60.5%
* vehicle: 70.0%
* vehicle: 55.6%
* vehicle: 58.3%
* vehicle: 65.9%
* vehicle: 62.0%
* vehicle: 65.5%
* vehicle: 53.1%
* vehicle: 48.4%
* vehicle: 56.2%
* vehicle: 64.6%
* vehicle: 57.0%
* vehicle: 49.5%
* vehicle: 43.5%
* vehicle: 65.1%
* vehicle: 58.1%
* vehicle: 55.5%
* vehicle: 57.6%
* vehicle: 68.4%
* vehicle: 55.9%
* vehicle: 50.0%
* vehicle: 52.5%
**Waterway (Right Side):**
* A canal or river runs parallel to the highway.
* A bridge is detected crossing the waterway with a confidence score of 79.1%.
* bridge: 79.1%
**Other Features:**
* Dense vegetation (trees) is present between the industrial area, highway, and waterway.
### Key Observations
* The object detection model appears to be identifying vehicles with varying degrees of confidence.
* The bridge detection has a relatively high confidence score.
* The distribution of vehicles is concentrated in the industrial area and along the highway.
### Interpretation
The image provides a snapshot of a transportation network intersecting with an industrial zone. The object detection results suggest the model is capable of identifying vehicles and bridges in aerial imagery. The confidence scores provide a measure of the model's certainty, which could be used to filter or prioritize detections in a real-world application. The presence of both an industrial area and a major highway suggests a logistical hub, where goods are likely transported. The waterway could also be part of this transportation network.
</details>
(b) Negative image
<details>
<summary>extracted/5868417/result_figs/pos_crop.jpg Details</summary>

### Visual Description
## Object Detection: Aerial View of Bridge and Vehicles
### Overview
The image is an aerial view of a bridge over water, with bounding boxes and confidence scores indicating object detection results. The objects detected are "bridge" and "vehicle".
### Components/Axes
* **Objects Detected:** Bridge, Vehicle
* **Bounding Boxes:** Yellow rectangles indicating the location of detected objects.
* **Confidence Scores:** Percentages associated with each detected object, indicating the model's confidence in its prediction.
### Detailed Analysis or ### Content Details
* **Bridge:** A yellow bounding box surrounds the bridge structure. The confidence score for the bridge detection is 77.1%.
* **Vehicles:** Several vehicles are detected on the bridge, each with its own yellow bounding box and confidence score. The confidence scores for the vehicles are:
* Vehicle 1: 55.5% (located near the center of the bridge)
* Vehicle 2: 50.4% (located on the left side of the bridge)
* Vehicle 3: 64.2% (located on the left side of the bridge, next to Vehicle 2)
* Vehicle 4: 38.5% (located on the right side of the bridge)
* Vehicle 5: 49.1% (located on the right side of the bridge, next to Vehicle 4)
### Key Observations
* The bridge detection has a relatively high confidence score (77.1%).
* The vehicle detection confidence scores vary, ranging from 38.5% to 64.2%.
* The vehicles are distributed across the bridge.
### Interpretation
The image demonstrates an object detection model's ability to identify bridges and vehicles in an aerial image. The confidence scores provide a measure of the model's certainty in its predictions. The varying confidence scores for the vehicles could be due to factors such as image quality, vehicle size, or occlusion. The model appears to be more confident in identifying the bridge structure than individual vehicles.
</details>
(c) (zoom)
<details>
<summary>extracted/5868417/result_figs/neg_crop.jpg Details</summary>

### Visual Description
## Object Detection: Aerial View with Object Confidence Scores
### Overview
The image is an aerial view, likely a satellite or drone capture, showing a landscape with roads, vegetation, and a river with a bridge. The image includes object detection bounding boxes with associated confidence scores for "vehicle" and "bridge" objects.
### Components/Axes
* **Objects:** Vehicles, Bridge
* **Bounding Boxes:** Yellow rectangles indicating the detected objects.
* **Confidence Scores:** Percentages associated with each bounding box, indicating the model's confidence in the object's classification.
### Detailed Analysis or ### Content Details
The image contains the following object detections and confidence scores:
* **Vehicles (Left Side of Image):**
* Vehicle: 48.4% (top-left)
* Vehicle: 56.2% (slightly below the first vehicle)
* Vehicle: 64.6% (middle-left)
* Vehicle: 57.0% (slightly below the third vehicle)
* Vehicle: 49.5% (bottom-left)
* Vehicle: 43.5% (slightly below the fifth vehicle)
* **Bridge (Right Side of Image):**
* Bridge: 79.1% (top-right, over a river)
### Key Observations
* The confidence score for the bridge detection is significantly higher than the confidence scores for the vehicle detections.
* The vehicles are detected on a road, suggesting traffic.
* The confidence scores for the vehicles vary, possibly due to differences in vehicle size, angle, or image quality.
### Interpretation
The image demonstrates an object detection model's ability to identify and classify objects in an aerial view. The confidence scores provide a measure of the model's certainty in its predictions. The higher confidence score for the bridge suggests that the model is more confident in identifying bridges than vehicles in this particular image. The varying confidence scores for the vehicles could be due to several factors, including the quality of the image, the size and shape of the vehicles, and the angle at which they are viewed. The model seems to be performing reasonably well, given the complexity of the scene.
</details>
(d) (zoom)
Figure 2: Examples of images with the detected objects and their probabilities.
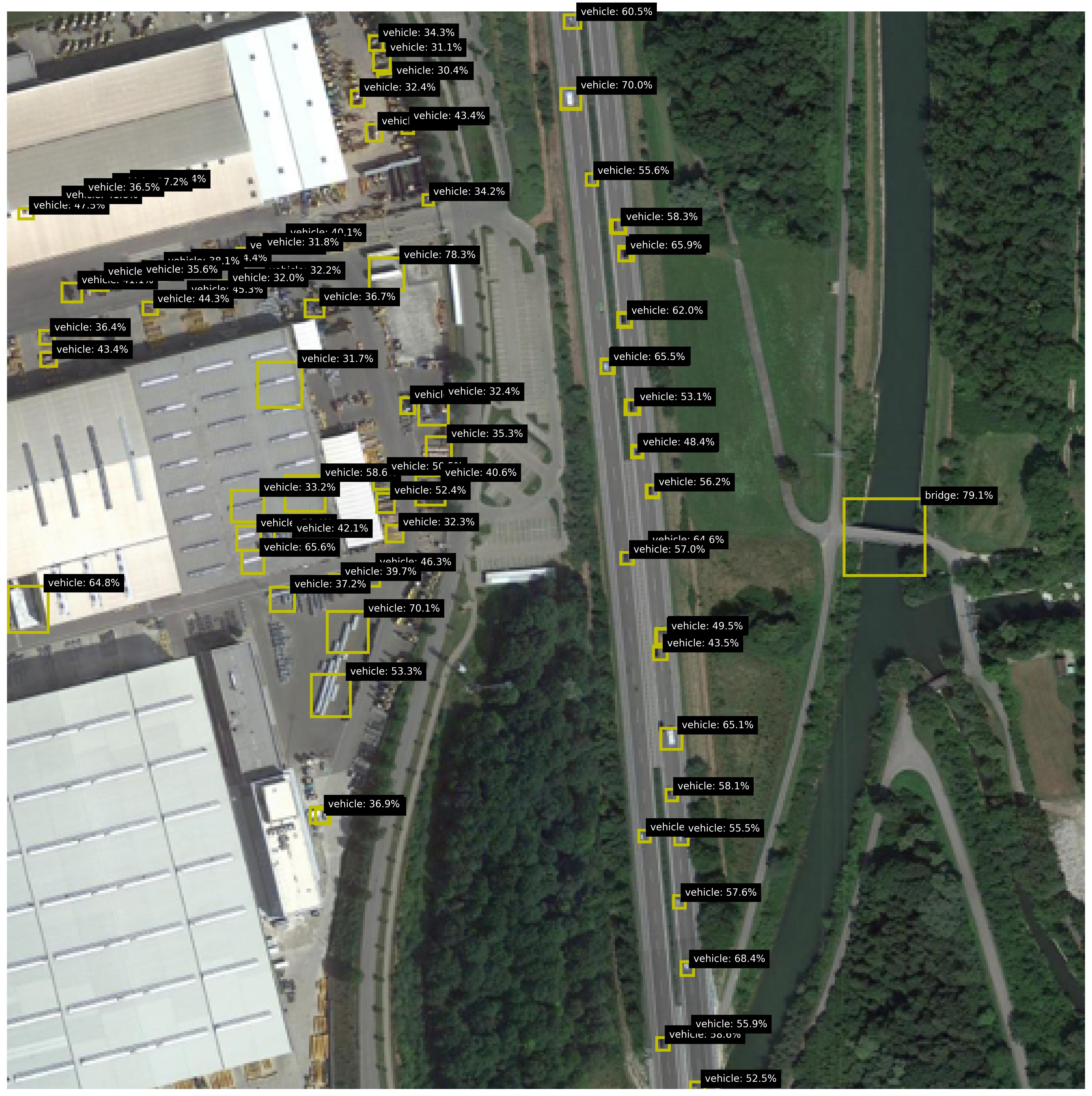
For the background knowledge, we leverage the pretrained DOTA Aerial Images Model dota_model to predict the objects in the images, with for each object a label, location (bounding box) and a probability (confidence value). For each image, the respective predictions are added to the background knowledge, as a predicate with a confidence, e.g. 0.7 :: vehicle(x). The locations of the objects are used to calculate a confidence for two relations: is_on and is_close. This information is added to the background knowledge as well. Figure 2 shows various images from the dataset, including zoomed versions to reveal some more details and to highlight the small size of the objects. Figure 2(b) shows an image with many objects. The relational patterns of interest is ‘vehicle on bridge’. For this pattern, there are 11 positive test images and 297 negative test images. Figure 2 shows both a positive (left) and negative image (right). To make the task realistic, both sets contain images with vehicles, bridges and roundabouts, so the model cannot distinguish the positives and negatives by purely finding the right sets of objects; the model really needs to find the right pattern between the right objects. Out of the negative images, 17 are designated as hard, due to incorrect groundtruths (2 images) and incorrect detections (15 images). These hard cases are shown in Figure 3.
<details>
<summary>extracted/5868417/result_figs/fp_crop_1.jpg Details</summary>

### Visual Description
## Object Detection Output: Aerial View
### Overview
The image shows an aerial view, likely a satellite or drone image, with object detection bounding boxes overlaid. The bounding boxes, colored yellow, identify and classify objects as either "vehicle" or "bridge," along with a confidence score (percentage).
### Components/Axes
* **Image:** Aerial view of a road or highway.
* **Bounding Boxes:** Yellow rectangles indicating detected objects.
* **Labels:** Text labels associated with each bounding box, indicating the object class and confidence score.
### Detailed Analysis
* **Top-Right:** A yellow bounding box labeled "vehicle:" with no percentage provided.
* **Upper-Right Center:** A yellow bounding box labeled "vehicle: 42.2%".
* **Center:** A yellow bounding box labeled "v bridge: 44.3%". The "v" is likely a truncated "vehicle" due to space constraints or an error.
* **Bottom-Left Center:** A yellow bounding box labeled "vehicle: 36.2%".
### Key Observations
* The object detection model seems to be identifying vehicles with varying degrees of confidence.
* One object is classified as a "bridge" with a confidence of 44.3%.
* The image quality is low, making it difficult to visually verify the accuracy of the object detections.
### Interpretation
The image represents the output of an object detection algorithm applied to an aerial image. The algorithm attempts to identify and classify objects of interest, such as vehicles and bridges. The confidence scores indicate the algorithm's certainty in its classification. The low confidence scores (36.2%, 42.2%, 44.3%) suggest that the algorithm may be struggling with the image quality or the complexity of the scene. The missing percentage on the top-right vehicle suggests a possible error in the output. The "v bridge" label suggests a possible misclassification or a combination of classifications.
</details>
<details>
<summary>extracted/5868417/result_figs/fp_crop_2.jpg Details</summary>

### Visual Description
## Object Detection: Aerial View of Road Network
### Overview
The image is an aerial view of a road network, possibly a highway interchange or a complex intersection. Several objects are identified and labeled with bounding boxes and associated confidence percentages. The objects include bridges and vehicles.
### Components/Axes
* **Objects:** Bridges, Vehicles
* **Bounding Boxes:** Yellow rectangles indicating the location of detected objects.
* **Labels:** Text labels associated with each bounding box, indicating the object type and confidence percentage.
### Detailed Analysis
* **Bridge:** A yellow bounding box is placed around a section of the road network identified as a "bridge." The associated confidence percentage is 46.3%. The bridge appears to be part of an overpass or elevated roadway.
* **Vehicle 1:** A yellow bounding box is placed around a small object on the road, identified as a "vehicle." The associated confidence percentage is 65.8%. This vehicle is located on the bridge.
* **Vehicle 2:** A yellow bounding box is placed around another object on the road, identified as a "vehicle." The associated confidence percentage is 41.7%. This vehicle is located on a lower road segment.
* **Unspecified Objects:** Two additional percentages, "44.3%" and "9%", are present in the lower-left corner of the image, but they are not associated with any bounding boxes or object labels. Their meaning is unclear without further context.
### Key Observations
* The object detection system seems to be identifying bridges and vehicles with varying degrees of confidence.
* The confidence percentages vary significantly between the detected objects.
* The presence of unlabeled percentages suggests that there may be other objects detected that are not being fully identified or labeled.
### Interpretation
The image demonstrates the output of an object detection system applied to an aerial image of a road network. The system is capable of identifying bridges and vehicles, but the confidence levels suggest that the accuracy may vary depending on the object type, size, or image quality. The unlabeled percentages indicate that the system may be detecting other features or objects that are not being fully classified. The image could be used to assess the performance of the object detection system or to provide information about traffic density and infrastructure in the road network.
</details>
<details>
<summary>extracted/5868417/result_figs/fp_crop_3.jpg Details</summary>

### Visual Description
## Object Detection: Aerial View of Bridge and Vehicles
### Overview
The image is an aerial view of a bridge with vehicles on it. The image includes object detection bounding boxes with associated confidence scores. The bounding boxes are yellow.
### Components/Axes
* **Objects Detected:** Bridge, Vehicle
* **Confidence Scores:** Represented as percentages.
### Detailed Analysis or ### Content Details
* **Bridge:** A yellow bounding box surrounds a section of the bridge. The associated confidence score is 57.7%. The bounding box is located on the top-left of the image.
* **Vehicle 1:** A yellow bounding box surrounds a vehicle on the bridge. The associated confidence score is 51.0%. The bounding box is located in the center of the image.
* **Vehicle 2:** A yellow bounding box surrounds a vehicle on the bridge. The associated confidence score is 31.8%. The bounding box is located on the bottom-right of the image.
### Key Observations
* The object detection algorithm identifies a bridge and two vehicles.
* The confidence score for the bridge detection is higher than the confidence score for the vehicle detections.
* The confidence score for the first vehicle is higher than the confidence score for the second vehicle.
### Interpretation
The image demonstrates the output of an object detection algorithm applied to an aerial image. The algorithm successfully identifies the bridge and vehicles with varying degrees of confidence. The confidence scores likely reflect the algorithm's certainty about the presence and location of each object. The higher confidence for the bridge may be due to its larger size and more distinct features compared to the vehicles. The difference in confidence scores between the two vehicles could be due to factors such as image resolution, vehicle size, or occlusion.
</details>
Figure 3: Hard cases due to incorrect groundtruths (right) or incorrect detections (others).
### 4.2 Experimental Setup
The dataset is categorized into three subsets that are increasingly harder in terms of flaws in the background knowledge. Easy: This smallest subset excludes the incorrect groundtruths, a manual check that most object predictions are reasonable, i.e. images with many predicted objects are withheld (this includes images with many false positives). Intermediate: This subset excludes the incorrect groundtruths. Compared to Easy, this subset adds all images with many object predictions. Hard: This is the full set, which includes all images, also the ones with incorrect groundtruths. We are curious whether ILP methods can indeed generalize from small numbers of examples, as is hypothesized cropper2022inductive. Many datasets used in ILP are using training data with tens to hundreds (sometimes thousands) of labeled samples hocquette2024learning,bellodi2015structure. We investigate the performance for as few as {1, 2, 4, 8} labels for respectively the positive and negative set, as this is common in practical settings. Moreover, common ILP datasets are about binary background knowledge, without associated probabilities hocquette2024learning,bellodi2015structure. In contrast, we consider probabilistic background knowledge. From the Easy subset we construct an Easy-1.0 set by thresholding the background knowledge with a manually chosen optimal threshold, which results in an almost noiseless dataset and shows the complexity of the logical rule to learn. All experiments are repeated 5 times, randomly selecting the training samples from the dataset and using the rest of the data set as test set.
### 4.3 Model Variants and Baselines
We compare Propper with Popper (on which it builds), to validate the merit of integrating the neurosymbolic inference and the continuous cost function BCE. Moreover, we compare these ILP models with statistical ML models: the Support Vector Machine cortes1995support (SVM) because it is used so often in practice; a Graph Neural Network wu2020comprehensive (GNN) because it is also relational by design which makes it a reasonable candidate for the task at hand i.e. finding a relational pattern between objects. All methods except the SVM are relational and permutation invariant. The objects are unordered and the models should therefore represent them in an orderless manner. The SVM is not permutation invariant, as objects and their features have some arbitrary but designated position in its feature vectors. All methods except Popper are probabilistic. All methods except the most basic Popper variant, can handle some degree of noise. The expected noise level for NoisyCombo is set at 0.15. The tested models are characterized in Table 1.
Table 1: The tested model variants and their properties.
| Tester Cost function | Cortes 1995 - - | Wu 2020 - - | Cropper 2021 Prolog MDL | Hoguette 2024 Prolog MDL | (ours) Constrainer Scallop BCE Type | - Stat. | - Stat. | Combo Logic | MaxSynth Logic | Noisy-Combo Logic |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| Label noise | Yes | Yes | No | Yes | Yes | | | | | |
| Background noise | Yes | Yes | No | Some | Yes | | | | | |
| Relational | No | Yes | Yes | Yes | Yes | | | | | |
| Permutation inv. | No | Yes | Yes | Yes | Yes | | | | | |
| Probabilistic | Yes | Yes | No | No | Yes | | | | | |
For a valid comparison, we increase the SVM’s robustness against arbitrary object order. With prior knowledge about the relevant objects for the pattern at hand, these objects can be placed in front of the feature vector. This preprocessing step makes the SVM model less dependent on the arbitrary order of objects. In the remainder of the analyses, we call this variant ‘SVM ordered’. To binarize the probabilistic background knowledge as input for Popper, the detections are thresholded with the general value of 0.5.
### 4.4 Increasing Noise in Background Knowledge
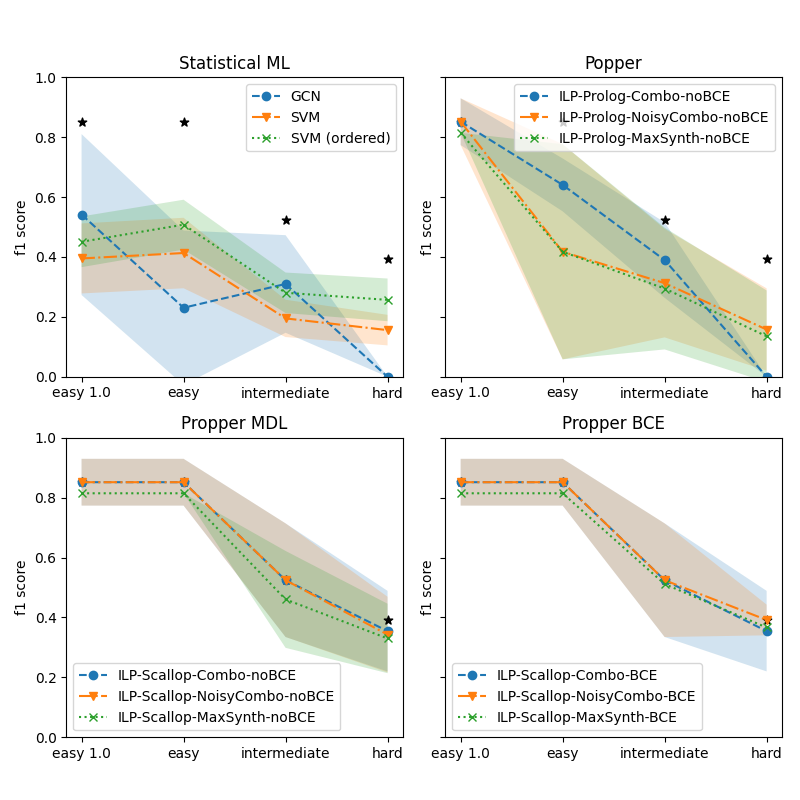
We are interested in how the robustness of model learning for increasing difficulty of the dataset. Here we investigate the performance on the three subsets from Section 4.2: Easy, Intermediate and Hard. Figure 4 shows the performance for various models for increasing difficulty. The four subplots show the various types of models. For a reference, the best performing model is indicated by an asterisk (*) in all subplots. It is clear that for increasing difficulty, all models struggle. The statistical ML models struggle the most: the performance of the GNN drops to zero on the Hard set. The SVMs are a bit more robust but the performance on the Hard set is very low. The most basic variant of Popper also drops to zero. The noise-tolerant Popper variants (Noisy-Combo and MaxSynth) perform similarly to the SVMs. Propper outperforms all models. This finding holds for all Propper variants (Combo, Noisy-Combo and MaxSynth). Using BCE as a cost function yields a small but negligible advantage over MDL.
<details>
<summary>extracted/5868417/result_propper_figures/increasing_test_hardness/n_train_avg_4_8.png Details</summary>
### Visual Description
## Line Charts: Performance Comparison of Different Models
### Overview
The image presents four line charts comparing the performance (f1 score) of different models across varying difficulty levels (easy 1.0, easy, intermediate, hard). Each chart represents a different model category: Statistical ML, Popper, Propper MDL, and Propper BCE. The charts display the f1 score on the y-axis and the difficulty level on the x-axis. Shaded regions around the lines indicate uncertainty or variance in the performance. Black stars are placed above certain data points, possibly indicating statistical significance or other important metrics.
### Components/Axes
* **Titles:**
* Top-left: Statistical ML
* Top-right: Popper
* Bottom-left: Propper MDL
* Bottom-right: Propper BCE
* **Y-axis:** f1 score, ranging from 0.0 to 1.0 in increments of 0.2.
* **X-axis:** Difficulty levels: easy 1.0, easy, intermediate, hard.
* **Legends:** Located in the top-right corner of each chart.
* **Statistical ML:**
* Blue line with circle markers: GCN
* Orange line with triangle markers: SVM
* Green line with cross markers: SVM (ordered)
* **Popper:**
* Blue line with circle markers: ILP-Prolog-Combo-noBCE
* Orange line with triangle markers: ILP-Prolog-NoisyCombo-noBCE
* Green line with cross markers: ILP-Prolog-MaxSynth-noBCE
* **Propper MDL:**
* Blue line with circle markers: ILP-Scallop-Combo-noBCE
* Orange line with triangle markers: ILP-Scallop-NoisyCombo-noBCE
* Green line with cross markers: ILP-Scallop-MaxSynth-noBCE
* **Propper BCE:**
* Blue line with circle markers: ILP-Scallop-Combo-BCE
* Orange line with triangle markers: ILP-Scallop-NoisyCombo-BCE
* Green line with cross markers: ILP-Scallop-MaxSynth-BCE
### Detailed Analysis
**1. Statistical ML**
* **GCN (Blue):** Starts at approximately 0.55 f1 score at "easy 1.0", decreases to around 0.23 at "easy", increases to approximately 0.32 at "intermediate", and decreases again to about 0.20 at "hard".
* **SVM (Orange):** Starts at approximately 0.45 f1 score at "easy 1.0", decreases to around 0.20 at "easy", increases to approximately 0.25 at "intermediate", and remains around 0.20 at "hard".
* **SVM (ordered) (Green):** Starts at approximately 0.45 f1 score at "easy 1.0", increases to around 0.50 at "easy", decreases to approximately 0.30 at "intermediate", and decreases again to about 0.25 at "hard".
**2. Popper**
* **ILP-Prolog-Combo-noBCE (Blue):** Starts at approximately 0.90 f1 score at "easy 1.0", decreases to around 0.60 at "easy", decreases to approximately 0.40 at "intermediate", and decreases again to about 0.15 at "hard".
* **ILP-Prolog-NoisyCombo-noBCE (Orange):** Starts at approximately 0.85 f1 score at "easy 1.0", decreases to around 0.40 at "easy", decreases to approximately 0.30 at "intermediate", and decreases again to about 0.15 at "hard".
* **ILP-Prolog-MaxSynth-noBCE (Green):** Starts at approximately 0.85 f1 score at "easy 1.0", decreases to around 0.50 at "easy", decreases to approximately 0.25 at "intermediate", and decreases again to about 0.15 at "hard".
**3. Propper MDL**
* **ILP-Scallop-Combo-noBCE (Blue):** Starts at approximately 0.85 f1 score at "easy 1.0", remains around 0.80 at "easy", decreases to approximately 0.50 at "intermediate", and decreases again to about 0.35 at "hard".
* **ILP-Scallop-NoisyCombo-noBCE (Orange):** Starts at approximately 0.85 f1 score at "easy 1.0", remains around 0.80 at "easy", decreases to approximately 0.50 at "intermediate", and decreases again to about 0.35 at "hard".
* **ILP-Scallop-MaxSynth-noBCE (Green):** Starts at approximately 0.85 f1 score at "easy 1.0", remains around 0.80 at "easy", decreases to approximately 0.50 at "intermediate", and decreases again to about 0.35 at "hard".
**4. Propper BCE**
* **ILP-Scallop-Combo-BCE (Blue):** Starts at approximately 0.85 f1 score at "easy 1.0", remains around 0.80 at "easy", decreases to approximately 0.50 at "intermediate", and decreases again to about 0.35 at "hard".
* **ILP-Scallop-NoisyCombo-BCE (Orange):** Starts at approximately 0.85 f1 score at "easy 1.0", remains around 0.80 at "easy", decreases to approximately 0.50 at "intermediate", and decreases again to about 0.35 at "hard".
* **ILP-Scallop-MaxSynth-BCE (Green):** Starts at approximately 0.85 f1 score at "easy 1.0", remains around 0.80 at "easy", decreases to approximately 0.50 at "intermediate", and decreases again to about 0.35 at "hard".
### Key Observations
* In the Statistical ML chart, the GCN model shows a more fluctuating performance across difficulty levels compared to the SVM models.
* In the Popper chart, all three models exhibit a significant decrease in performance as the difficulty level increases.
* In the Propper MDL and Propper BCE charts, all three models show similar performance trends, with a plateau at easier difficulty levels followed by a decrease as difficulty increases.
* The black stars appear to be placed at points where the f1 score is relatively high or where there might be a significant change in performance.
### Interpretation
The charts provide a comparative analysis of different models' performance across varying difficulty levels. The general trend observed is that as the difficulty level increases, the f1 score tends to decrease, indicating a decline in performance. The shaded regions represent the uncertainty or variance in the model's performance, which could be due to factors such as data variability or model instability. The black stars highlight specific data points that may be of particular interest, such as peak performance or significant changes in performance. The choice of model depends on the specific application and the desired trade-off between performance and difficulty level. For example, in the Statistical ML category, the SVM (ordered) model might be preferred for its relatively stable performance across different difficulty levels, while in the Popper category, the ILP-Prolog-Combo-noBCE model might be chosen for its higher initial performance at easier difficulty levels. The Propper MDL and Propper BCE models show similar performance trends, suggesting that the choice between them might depend on other factors such as computational cost or ease of implementation.
</details>
Figure 4: Performance of the models on finding a relational pattern in satellite images, for increasing hardness of image sets. The best performer is Propper BCE, indicated in each graph by * for comparison. Our probabilistic ILP outperforms binary ILP and statistical ML.
### 4.5 Learning Efficiency with Few Labels
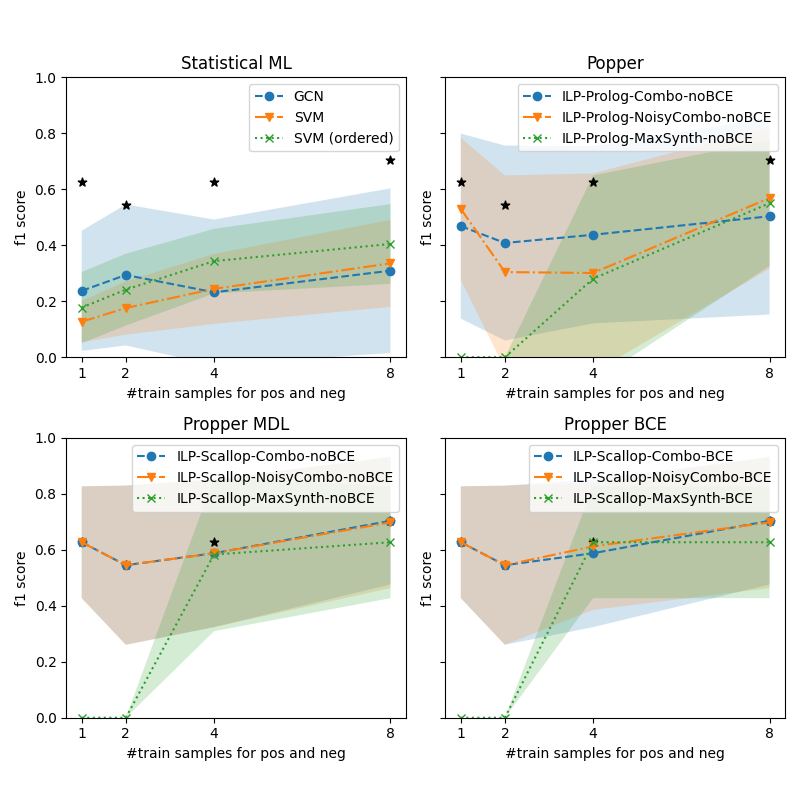
We are curious how the models perform with as few as {1, 2, 4, 8} labels for respectively the positive and negative set. The performance is measured on the Hard set. Figure 5 shows the performance for various models for increasing training set size. The four subplots show the various types of models. Again, for reference, the best performing model is indicated by an asterisk (*) in all subplots. The upper left shows the statistical ML models. They do perform better with more training samples, but the performance is inferior to the ILP model variants. The Propper variant with Scallop and Noisy-Combo and BCE is the best performer. BCE does not improve significantly over MDL. MaxSynth has an optimization criterion that cannot operate with less than three training samples. The main improvement by Propper is observed when switching from Combo to Noisy-Combo and switching from Prolog to Scallop (i.e. neurosymbolic inference).
<details>
<summary>extracted/5868417/result_propper_figures/increasing_train_samples/all_test_cases_avg.png Details</summary>
### Visual Description
## Chart: Performance Comparison of Different Models
### Overview
The image presents four line charts comparing the performance (f1 score) of different machine learning models across varying numbers of training samples. The charts are grouped into two rows, with the top row showing "Statistical ML" and "Popper" models, and the bottom row showing "Propper MDL" and "Propper BCE" models. Each chart plots the f1 score against the number of training samples for positive and negative examples. Shaded regions around the lines indicate uncertainty or variance. Black stars are overlaid on the charts, likely indicating statistical significance or best performance.
### Components/Axes
* **X-axis (all charts):** "#train samples for pos and neg" with tick marks at 1, 2, 4, and 8.
* **Y-axis (all charts):** "f1 score" ranging from 0.0 to 1.0, with tick marks at 0.2 intervals.
* **Titles (top-left):** "Statistical ML"
* **Titles (top-right):** "Popper"
* **Titles (bottom-left):** "Propper MDL"
* **Titles (bottom-right):** "Propper BCE"
**Legends:**
* **Top-left (Statistical ML):**
* Blue solid line with circles: "GCN"
* Orange dashed line with inverted triangles: "SVM"
* Green dotted line with crosses: "SVM (ordered)"
* **Top-right (Popper):**
* Blue solid line with circles: "ILP-Prolog-Combo-noBCE"
* Orange dashed line with inverted triangles: "ILP-Prolog-NoisyCombo-noBCE"
* Green dotted line with crosses: "ILP-Prolog-MaxSynth-noBCE"
* **Bottom-left (Propper MDL):**
* Blue solid line with circles: "ILP-Scallop-Combo-noBCE"
* Orange dashed line with inverted triangles: "ILP-Scallop-NoisyCombo-noBCE"
* Green dotted line with crosses: "ILP-Scallop-MaxSynth-noBCE"
* **Bottom-right (Propper BCE):**
* Blue solid line with circles: "ILP-Scallop-Combo-BCE"
* Orange dashed line with inverted triangles: "ILP-Scallop-NoisyCombo-BCE"
* Green dotted line with crosses: "ILP-Scallop-MaxSynth-BCE"
### Detailed Analysis
**Top-Left: Statistical ML**
* **GCN (Blue):** Starts at approximately 0.25 f1 score at 1 training sample, increases to approximately 0.35 at 8 training samples. The shaded region indicates a variance of approximately +/- 0.1.
* **SVM (Orange):** Starts at approximately 0.15 f1 score at 1 training sample, increases to approximately 0.35 at 8 training samples.
* **SVM (ordered) (Green):** Starts at approximately 0.2 f1 score at 1 training sample, increases to approximately 0.4 f1 score at 8 training samples. The shaded region indicates a variance of approximately +/- 0.1.
* Black stars are present at (1, 0.63), (2, 0.54), (4, 0.62), and (8, 0.70).
**Top-Right: Popper**
* **ILP-Prolog-Combo-noBCE (Blue):** Starts at approximately 0.55 f1 score at 1 training sample, decreases to approximately 0.4 f1 score at 2 training samples, and increases to approximately 0.6 f1 score at 8 training samples. The shaded region indicates a variance of approximately +/- 0.1.
* **ILP-Prolog-NoisyCombo-noBCE (Orange):** Starts at approximately 0.5 f1 score at 1 training sample, decreases to approximately 0.3 f1 score at 2 training samples, and increases to approximately 0.5 f1 score at 8 training samples. The shaded region indicates a variance of approximately +/- 0.1.
* **ILP-Prolog-MaxSynth-noBCE (Green):** Starts at approximately 0.1 f1 score at 1 training sample, increases to approximately 0.55 f1 score at 8 training samples. The shaded region indicates a variance of approximately +/- 0.2.
* Black stars are present at (1, 0.62), (2, 0.52), and (8, 0.72).
**Bottom-Left: Propper MDL**
* **ILP-Scallop-Combo-noBCE (Blue):** Starts at approximately 0.62 f1 score at 1 training sample, decreases to approximately 0.55 at 2 training samples, and remains relatively constant at approximately 0.6 f1 score at 8 training samples. The shaded region indicates a variance of approximately +/- 0.1.
* **ILP-Scallop-NoisyCombo-noBCE (Orange):** Starts at approximately 0.62 f1 score at 1 training sample, decreases to approximately 0.55 at 2 training samples, and remains relatively constant at approximately 0.6 f1 score at 8 training samples. The shaded region indicates a variance of approximately +/- 0.1.
* **ILP-Scallop-MaxSynth-noBCE (Green):** Starts at approximately 0.0 f1 score at 1 training sample, increases to approximately 0.65 f1 score at 8 training samples. The shaded region indicates a variance of approximately +/- 0.2.
* Black star is present at (4, 0.62).
**Bottom-Right: Propper BCE**
* **ILP-Scallop-Combo-BCE (Blue):** Starts at approximately 0.62 f1 score at 1 training sample, decreases to approximately 0.55 at 2 training samples, increases to approximately 0.7 f1 score at 4 training samples, and remains relatively constant at approximately 0.7 f1 score at 8 training samples. The shaded region indicates a variance of approximately +/- 0.1.
* **ILP-Scallop-NoisyCombo-BCE (Orange):** Starts at approximately 0.62 f1 score at 1 training sample, decreases to approximately 0.55 at 2 training samples, and increases to approximately 0.65 f1 score at 8 training samples. The shaded region indicates a variance of approximately +/- 0.1.
* **ILP-Scallop-MaxSynth-BCE (Green):** Starts at approximately 0.0 f1 score at 1 training sample, increases to approximately 0.7 f1 score at 8 training samples. The shaded region indicates a variance of approximately +/- 0.2.
### Key Observations
* The "Statistical ML" chart shows a general upward trend for all models as the number of training samples increases.
* The "Popper" chart shows an initial decrease in performance for "ILP-Prolog-Combo-noBCE" and "ILP-Prolog-NoisyCombo-noBCE" followed by an increase. "ILP-Prolog-MaxSynth-noBCE" shows a consistent upward trend.
* The "Propper MDL" chart shows that "ILP-Scallop-MaxSynth-noBCE" starts with a very low f1 score but increases significantly with more training samples. The other two models are relatively stable.
* The "Propper BCE" chart shows a similar trend to "Propper MDL" with "ILP-Scallop-MaxSynth-BCE" starting low and increasing significantly.
### Interpretation
The charts compare the performance of different machine learning models under varying training conditions. The f1 score, a measure of accuracy that considers both precision and recall, is used as the primary performance metric. The number of training samples for positive and negative examples is varied to assess how well each model learns from more data.
The shaded regions around the lines indicate the variability or uncertainty in the model's performance. Wider shaded regions suggest that the model's performance is more sensitive to variations in the training data.
The black stars likely indicate statistically significant performance improvements or the best-performing model at a given number of training samples.
The "Statistical ML" models generally improve with more training data, as expected. The "Popper" models show more complex behavior, with some models initially decreasing in performance before improving. The "Propper MDL" and "Propper BCE" charts highlight the importance of sufficient training data for certain models, particularly those using "MaxSynth."
The choice of model and training method (e.g., BCE vs. MDL) appears to significantly impact performance, and the optimal choice may depend on the amount of available training data.
</details>
Figure 5: Performance of the models on finding a relational pattern in satellite images, for increasing training sets. The best performer is Propper BCE, indicated in each graph by * for comparison. Our probabilistic ILP outperforms binary ILP and statistical ML.
### 4.6 Second Dataset
We are interested how the methods perform on a different dataset. The MS-COCO dataset lin2014microsoft contains a broad variety of images of everyday scenes. This dataset is challenging, because there are many different objects in a wide range of settings. Similar to the previous experiment, the background knowledge is acquired by the predictions of a pretrained model, GroundingDINO liu2023groundingDINO, which are used to extract the same two relations. Figure 6 shows some examples.
<details>
<summary>extracted/5868417/coco/2.jpg Details</summary>

### Visual Description
## Photograph: Police Officer on Motorcycle
### Overview
The image is a photograph of a police officer sitting on a motorcycle. The photo is taken at eye level, focusing on the officer and the motorcycle. The background includes a car and other blurred elements. The image also contains bounding box detections with confidence scores for "person" and "car".
### Components/Axes
* **Objects Detected:**
* Person: 85.7% confidence
* Car: 48.1% confidence
* **Motorcycle Details:** The motorcycle is a police motorcycle with "POLICE" written on the back storage compartment. The number "0020" is visible on the side of the motorcycle.
* **Officer Details:** The officer is wearing a white uniform shirt, black gloves, and a helmet. A police badge is visible on the front of the motorcycle.
### Detailed Analysis or ### Content Details
* **Person Detection:** The bounding box for "person" is located in the top-right corner of the image, with a confidence score of 85.7%. The box encompasses the officer.
* **Car Detection:** The bounding box for "car" is located in the top-right corner of the image, with a confidence score of 48.1%. The box encompasses a portion of a car in the background.
* **Motorcycle Details:** The motorcycle is white with black accents. The word "POLICE" is written in large, bold letters on the rear storage compartment. The number "0020" is displayed on the side of the motorcycle, near the bottom.
* **Officer Details:** The officer is wearing a white, long-sleeved uniform shirt. Black gloves cover the officer's hands. A black helmet is visible on the officer's head. A police badge is prominently displayed on the front of the motorcycle.
### Key Observations
* The confidence score for the "person" detection is significantly higher than the "car" detection, indicating a higher certainty in the identification of the officer.
* The motorcycle is clearly identifiable as a police motorcycle due to the "POLICE" marking and the presence of a police badge.
### Interpretation
The image depicts a police officer on duty, likely patrolling on a motorcycle. The bounding box detections provide an automated assessment of the objects present in the image, with varying degrees of confidence. The high confidence in the "person" detection suggests that the algorithm accurately identifies the officer. The lower confidence in the "car" detection may be due to the car being partially obscured or out of focus in the background. The image suggests a scene of law enforcement and public safety.
</details>
<details>
<summary>extracted/5868417/coco/3.jpg Details</summary>

### Visual Description
## Object Detection Image: Street Scene with People and Cars
### Overview
The image is a street scene with several objects detected and labeled with bounding boxes and confidence scores. The objects include people, cars, and elements of the street environment.
### Components/Axes
* **Objects Detected:**
* People
* Cars
* **Labels:** Each detected object has a label indicating the object type (e.g., "person", "car") and a confidence score (e.g., "59.4%").
* **Bounding Boxes:** Yellow bounding boxes surround each detected object.
### Detailed Analysis or ### Content Details
* **People:**
* Person (top-left): 59.4% confidence
* Person (near left car): 33.1% confidence
* Person (near right car): 42.9% confidence
* Person (near right car): 35.3% confidence
* Person (near store): 32.5% confidence
* Person (far right): 82.1% confidence
* Person (kneeling near fire hydrant): 91.9% confidence
* **Cars:**
* Car (left): 76.7% confidence
* Car (right): 73.6% confidence
* **Environment:**
* Buildings: "ASHLEY'S" and "BIVOUAC Bivonac Adventure Travel" are visible on the buildings.
* Street: Includes a road, sidewalk, and brick-paved area.
* Fire Hydrant: Located near the kneeling person.
### Key Observations
* The confidence scores for the detected objects vary, with the kneeling person having the highest confidence (91.9%).
* The image appears to be taken during the day in an urban environment.
* The kneeling person is likely interacting with the fire hydrant, possibly painting it, given the presence of paint cans.
### Interpretation
The image demonstrates an object detection algorithm's ability to identify and classify objects in a real-world scene. The confidence scores provide a measure of the algorithm's certainty in its classifications. The scene depicts a typical urban environment with people, cars, and street infrastructure. The kneeling person adds an element of human activity and interaction with the environment. The presence of paint cans suggests an artistic or maintenance activity.
</details>
Figure 6: Examples of the MS-COCO dataset with images of everyday scenes.
The pattern of interest is ‘person next to a car’. We consider all images that have a maximum of two persons and two cars, yielding 1728 images. We use random 8 positive and 8 negative images for training, which is repeated 5 times. We test both ILP variants, Popper and Propper, for the MaxSynth constrainer, because the Combo constrainer regularly did not return a solution. We validate Popper with various thresholds to be included as background knowledge. Propper does not need such a threshold beforehand, as all background knowledge is considered in a probabilistic manner. The results are shown in Table 2. Propper is the best performer, achieving f1 = 0.947. This is significantly better than the alternatives: SVM achieves f1 = 0.668 (-0.279) and Popper achieves f1 = 0.596 (-0.351). Adding probabilistic behavior to ILP is helpful for challenging datasets.
Table 2: Model variants and performance on MS-COCO.
| ILP | Propper (ours) | MaxSynth | probabilistic | BCE | - | 0.754 |
| --- | --- | --- | --- | --- | --- | --- |
| Statistical ML | SVM | - | - | - | - | 0.668 |
| Statistical ML | SVM (ordered) | - | - | - | - | 0.652 |
| ILP | Popper | MaxSynth | Prolog | MDL | 0.3 | 0.596 |
| ILP | Popper | MaxSynth | Prolog | MDL | 0.5 | 0.466 |
| ILP | Popper | MaxSynth | Prolog | MDL | 0.4 | 0.320 |
Table 3 shows the learned programs, how often each program was predicted across the experimental repetitions, and the respective resulting f1 scores. The best program is that there is a person on a car. Popper yields the same program, however, with a lower f1-score, since the background knowledge is thresholded before learning the program, removing important data from the background knowledge. This confirms that in practice it is intractable to set a perfect threshold on the background knowledge. It is beneficial to use Propper which avoids such prior thresholding.
Table 3: Learned programs, prevalence and performance on MS-COCO.
| Popper Popper Popper | 0.72 0.72 0 | 20 40 20 | f(A) :- has_object(A,C), is_on(B,C), person(B). f(A) :- person(C), is_on(C,B), has_object(A,C), car(B). No program learned. |
| --- | --- | --- | --- |
## 5 Discussion and Conclusions
We proposed Propper, which handles flawed and probabilistic background knowledge by extending ILP with a combination of neurosymbolic inference, a continuous criterion for hypothesis selection (BCE), and a relaxation of the hypothesis constrainer (NoisyCombo). Neurosymbolic inference has a significant impact on the results. Its advantage is that it does not need prior thresholding on the probabilistic background knowledge (BK), which is needed for binary ILP and is always imperfect. NoisyCombo has a small yet positive effect. It provides a parameter for the level of noise in BK, which can be tailored to the dataset at hand. The BCE has little impact. Propper is able to learn a logic program about a relational pattern that distinguishes between two sets of images, even if the background knowledge is provided by an imperfect neural network that predicts concepts in the images with some confidence. With as few as a handful of examples, Propper learns effective programs and outperforms statistical ML methods such as a GNN.
Although we evaluated Propper on two common datasets with different recording conditions, a broader evaluation of Propper across various domains and datasets to confirm its generalizability and robustness for various (especially non-image) use cases, is interesting. The proposed framework of integrated components allows for an easy setup of the system and simple adaptation to new developments/algorithms within the separate components. However, the integration as is performed now could be non-optimal in terms of computational efficiency. For example the output of the hypothesis generation is an answer set, which in Popper is converted to Prolog syntax. Propper converts this Prolog syntax to Scallop syntax. Developing a direct conversion from the answer sets to the Scallop syntax is recommended. We favored modularization over full integration and computational efficiency, in order to facilitate the methodological configuration and comparison of the various components. It is interesting to investigate whether a redesign of the whole system with the components integrated will lead to a better system. To make the step to fully probabilistic ILP, the allowance of probabilistic rules should be added to the system as well, for example by integration of StarAI methods raedt2016statistical.