## Python Symbolic Execution with LLM-powered Code Generation
WENHAN WANG ∗ , University of Alberta, Canada
AN RAN CHEN, University of Alberta, Canada
KAIBO LIU ∗ , Peking University, China
GE LI, Peking University, China
GANG HUANG, Peking University, China
ZHI JIN, Peking University, China
LEI MA, The University of Tokyo, Japan and University of Alberta, Canada
Symbolic execution is a key technology in software testing, which generates test cases by collecting symbolic path constraints and then solving constraints with SMT solvers. Symbolic execution has been proven helpful in generating high-coverage test cases, but its limitations, e.g., the difficulties in solving path constraints, prevent it from broader usage in software testing. Moreover, symbolic execution has encountered many difficulties when applied to dynamically typed languages like Python, because it is extremely challenging to translate the flexible Python grammar into rigid solvers.
To overcome the main challenges of applying symbolic execution in Python, we proposed an LLMempowered agent, LLM-Sym, that automatically calls an SMT solver, Z3, to solve execution path constraints. Based on an introductory-level symbolic execution engine, our LLM agent can extend it to supporting programs with complex data type 'list'. The core contribution of LLM-Sym is translating complex Python path constraints into Z3 code. To enable accurate path-to-Z3 translation, we design a multiple-step code generation pipeline including type inference, retrieval and self-refine. Our experiments demonstrate that LLM-Sym is capable of solving path constraints on Leetcode problems with complicated control flows and list data structures, which is impossible for the backbone symbolic execution engine. Our approach paves the way for the combination of the generation ability of LLMs with the reasoning ability of symbolic solvers, and opens up new opportunities in LLM-augmented test case generation.
CCS Concepts: · Software and its engineering → Empirical software validation .
Additional Key Words and Phrases: Software testing, Large language models, Symbolic execution
## ACMReference Format:
Wenhan Wang, Kaibo Liu, An Ran Chen, Ge Li, Zhi Jin, Gang Huang, and Lei Ma. 2018. Python Symbolic Execution with LLM-powered Code Generation. In Proceedings of Make sure to enter the correct conference title from your rights confirmation emai (Conference acronym 'XX). ACM, New York, NY, USA, 20 pages. https://doi.org/XXXXXXX.XXXXXXX
∗ Both authors contributed equally to this research.
Authors' Contact Information: Wenhan Wang, wenhan12@ualberta.ca, University of Alberta, Canada; Kaibo Liu, Peking University, China, liukb@pku.edu.cn; An Ran Chen, University of Alberta, Canada, anran6@ualberta.ca; Ge Li, Peking University, China, lige@pku.edu.cn; Zhi Jin, Peking University, China, zhijin@pku.edu.cn; Gang Huang, Peking University, China, hg@pku.edu.cn; Lei Ma, The University of Tokyo, Japan and University of Alberta, Canada, ma.lei@acm.org.
Permission to make digital or hard copies of all or part of this work for personal or classroom use is granted without fee provided that copies are not made or distributed for profit or commercial advantage and that copies bear this notice and the full citation on the first page. Copyrights for components of this work owned by others than the author(s) must be honored. Abstracting with credit is permitted. To copy otherwise, or republish, to post on servers or to redistribute to lists, requires prior specific permission and/or a fee. Request permissions from permissions@acm.org.
Conference acronym 'XX, June 03-05, 2018, Woodstock, NY
© 2018 Copyright held by the owner/author(s). Publication rights licensed to ACM.
ACM ISBN 978-1-4503-XXXX-X/18/06
https://doi.org/XXXXXXX.XXXXXXX
## 1 Introduction
Symbolic execution [1, 10] is a widely used program analysis technique which explores program execution paths with symbolic values. Together with constraint solving (with an SMT solver), symbolic execution can generate real variable values to satisfy a certain execution path. The key application of symbolic execution is software testing. Because symbolic execution can solve constraints for certain execution paths, we can use it to generate test cases that cover a specific execution path or expose hidden bugs. Symbolic execution has been successfully applied to various program languages, including Java [9, 13], LLVM IR [5] and binary code [26].
To address the above difficulties, we took the first step to perform a large language modelaugmented symbolic execution engine, LLM-Sym, for Python. LLM-Sym is an LLM agent that can automatically call the Z3 [8] SMT solver to solve path constraints in symbolic execution. On the basis of our LLMSym lies an introductory-level symbolic execution engine, The Fuzzing Book [38], which only supports variables with explicit type hints in int/float types. The basis engine consists of two components. The first one is a control flow graph (CFG) explorer for extracting execution paths. The second one is a program for translating the collected execution path constraints into Z3 code using a pre-defined set of rules. In our approach, we only adopt the CFG explorer in the engine for execution path collection. Instead of writing a program to translate Python constraints to Z3, we leverage an LLM to generate code for calling the Z3 solver to solve path constraints. This gives us more flexibility in solving some constraints that cannot be easily translated into Z3. During the generation of Z3 code, we propose a workflow with multiple-step generation and self-refinement to improve the correctness of the generated code.
However, symbolic execution faces significant difficulties when applied to dynamically typed languages such as Python [4]. The major difficulty lies in mapping program execution paths to SMT solver constraints. First, without explicit type annotations, it can be difficult to define symbolic variables in the solver, where all symbolic variables must have their own data type. Second, existing symbolic execution engines often use rules to convert Python statements into SMT constraints [2, 38], but Python data structures are highly flexible. For example, a Python list can have an unfixed length, which is different from similar data structures in most other languages (e.g., array in C, Java). An obvious challenge this feature brings is that in Python programs, there are condition constraints on list lengths, and we may need to write extra SMT constraints to solve the length variable. To deal with these unique Python features, tremendous efforts may be required to design Python-to-SMT rules to support them. These unique difficulties result in Python not having a widely adopted symbolic execution engine. Most existing symbolic execution engines only support simple data types, such as integers and floats. Some developers tried to overcome these obstacles with concolic execution [25], which combines symbolic execution with concrete execution on real values. However, concolic execution is a dynamic method that requires a runnable code environment. However, in many practical applications, such a code environment is often difficult to configure.
In general, LLM-Sym solves a CFG path constraint with the following steps: (1) Given a program under test, LLM-Sym first performs type inference to predict the type of variables inside the program. (2) For the execution path, we decompose it into chunks and generate the Z3 code with multiple steps. Before each generation step, LLM-Sym queries a path-to-Z3 knowledge base to acquire code generation templates. We manually build this knowledge base to enable the generation of Z3 code to solve constraints on Python lists. (3) After generating code for a path chunk, we execute the generated code to check whether it contains bugs. If the generated code is buggy, LLM-Sym tries to fix the code given the error message. If all fixes are unsuccessful, we regard this path as unsolvable and directly use an LLM solver to solve the constraints. (4) After LLM-Sym finishes the code generation for an execution path, the Z3 solver will try to solve the generated constraints,
and LLM-Sym generates a final test case based on the solving results. All the code generation steps in LLM-Sym are fulfilled with LLMs, which minimizes the effort of writing complicated logic for Z3 code generation.
To evaluate the LLMSym framework, we conduct experiments on a set of LeetCode problem solutions for unit test case generation. LeetCode programs contain plenty of control flows and list operations, which make them suitable for evaluating our symbolic execution engine. We build a dataset of 111 execution traces from 50 programs, and ask LLM-Sym to solve these traces and generate test cases that can satisfy them. In the experiments, most components in LLM-Sym is based on an efficient LLM GPT-4o-mini. In our experiments, we aim to answer the following research questions:
- RQ1 : Can LLM-Sym generates correct Z3Py code to solve Python path constraints?
- RQ3 : What are the strengths/weaknesses of the Z3 code generator and the LLM solver in solving path constraints?
- RQ2 : How do each module and different settings of the Z3 code generator work when solving a path constraint?
- RQ4 : How is the time and money cost of LLM-Sym?
The results show that LLM-Sym can correctly solve around 60% of the given execution traces and outperforms pure LLM-base approaches, proving the potential of using LLM to further guide symbolic execution by generating code that calls SMT solvers. Moreover, our approach is also cost-effective: as an LLM agent, its cost is less than one-third of a stronger model, GPT-4o, while achieving similar results.
To summarize, the main contributions of our paper are:
- We propose LLM-Sym, the first LLM agent-based system that augments an existing symbolic execution engine to solve more complex constraints. In LLM-Sym, we put forward the idea of using LLM to call the Z3 solver for solving constraints in symbolic execution. This allows us to build LLM-Sym on a simple introductory-level symbolic execution engine without the laborious effort of writing lengthy code to translate path constraints into Z3.
- We create a dataset from LeetCode programs execution paths and evaluate LLM-Sym using this dataset. We find that LLM-Sym is capable of generating correct Z3 code and test cases for long execution paths.
- As far as we know, LLM-Sym is the first Python symbolic execution engine that supports Python 'list' and dynamic data types without concolic execution. It is also the first attempt to integrate LLMs with SMT solvers for test case generation.
The remainder of this paper is organized as follows. Section 2 describes a motivating example. Section 3 describe the methodology of LLM-Sym in details. Section 4 presents the experimental evaluation and answer to the RQs. Section 5 is threats to validity. The related works in introduced in Section 6, and Section 7 concludes our work.
## 2 Motivating Example
Figure 1 shows a motivating example for LLM-empowered symbolic execution. Figure 1 (a) (top) depicts a simple Python execution path with function definition, comparison operators, and variable assignments. In this execution path, all variables are explicitly annotated with a basic data type (int), and all operators are simple computational operators. In this case, we can easily generate the code which invokes Z3 to solve this path (Figure 1 (a) (bottom)). In this example, we follow the format defined in [38]: variables are transformed into the single static assignment (SSA) form to keep variable values before assignments. We can see that the translation from the execution path to Z3 is simple: we convert variables to SSA and then add every statement to the solver. This can
Fig. 1. A motivating example of using LLMs to generate Z3 code for symbolic execution. LLMs are capable of generating complex code with non-trivial patterns (c).
<details>
<summary>Image 1 Details</summary>

### Visual Description
\n
## Code Snippets: Solvability Examples
### Overview
The image presents three code snippets, labeled (a), (b), and (c), demonstrating examples related to the solvability of constraints. Each snippet is accompanied by a series of lines representing a potential solution process or constraint propagation steps. The snippets appear to be written in a Python-like syntax, possibly related to a constraint solving library.
### Components/Axes
The image is divided into three columns, each representing a different case:
* **(a): Solvable, trivial** - A simple example that is easily solvable.
* **(b): Unsolvable** - An example that cannot be solved.
* **(c): Solvable, non-trivial** - A more complex example that is solvable but requires more steps.
Each column contains:
1. A code definition (function or similar).
2. A series of numbered lines representing constraints or operations.
3. A series of lines representing the solver's steps.
### Detailed Analysis or Content Details
**(a): Solvable, trivial**
* **Code Definition:** `def gcd(a: int, b: int):`
* `a < b`
* `c: int = a`
* `a = b`
* **Solver Steps:**
* `a_0 = Int('a 0')`
* `b_0 = Int('b 0')`
* `solver.add(a_0 < b_0)`
* `c_0 = Int('c 0')`
* `solver.add(c_0 == a_0)`
* `a_1 = Int('a 1')`
* `solver.add(a_1 == b_0)`
**(b): Unsolvable**
* **Code Definition:** `def xxx(obj1, obj2):`
* `x = obj1.a`
* `y, z = unk_func(obj2)`
* `y + z == x`
* **Solver Steps:** `???` (Indicates no solution or an unknown solution process)
**(c): Solvable, non-trivial**
* **Code Definition:** `def func(nums, x):`
* `len(nums) > x`
* `nums[1] = 1`
* `nums[0] == abs(x)`
* **Solver Steps:**
* `nums_0 = Array('nums 0', IntSort(), IntSort())`
* `nums_0_len = Int('nums 0 len')`
* `solver.add(nums_0_len > 0)`
* `x_0 = Int('x 0')`
* `solver.add(nums_0_len > x_0)`
* `nums_1 = Store(nums_0, 1, 1)`
* `nums_1_len = nums_0_len`
* `solver.add(nums_1[0] == If(x_0 > 0, x_0, -x_0))`
### Key Observations
* Snippet (a) demonstrates a simple constraint solving scenario with clear variable assignments and inequalities.
* Snippet (b) is marked as unsolvable, and the solver steps are unknown, suggesting a failure to find a consistent solution.
* Snippet (c) involves array manipulation and absolute values, making the constraint solving process more complex. The use of `Store` indicates modification of the array elements.
* The solver steps in (a) and (c) use a consistent naming convention (e.g., `a_0`, `b_0`, `x_0`) to represent variables and their indices.
* The use of `IntSort()` and `Array()` suggests the use of a constraint solving library that supports integer variables and arrays.
### Interpretation
The image illustrates the different outcomes of applying a constraint solver to various code snippets. The snippets represent simplified examples of constraint satisfaction problems.
* **(a)** shows a trivial case where the constraints are easily satisfied, leading to a straightforward solution.
* **(b)** demonstrates a case where the constraints are contradictory or insufficient, resulting in an unsolvable problem. The `???` indicates that the solver either failed to find a solution or encountered an error.
* **(c)** presents a more complex scenario involving array manipulation and absolute values. The solver successfully propagates the constraints, as evidenced by the detailed solver steps.
The use of `Int('variable name')` suggests the creation of integer variables within the solver's environment. The `solver.add()` function is used to add constraints to the solver. The `Store()` function modifies the array elements. The `If()` function introduces conditional logic within the constraints.
The image highlights the importance of constraint solving in verifying the correctness and consistency of code. It also demonstrates the challenges of solving complex constraints and the need for efficient constraint propagation techniques. The examples are likely used to illustrate the capabilities and limitations of a specific constraint solving library or framework.
</details>
be implemented without extensive coding effort: The Fuzzing Book [38] used 76 lines of code to translate one line of execution path into Z3 code. It first uses abstract syntax tree (AST) rewriting to generate Python statements in SSA form, then translates the SSA statements into Z3-compatible form with simple rules.
In addition to the two types of path constraints above, there is another type that lies in between: the constraints are theoretically solvable by a solver, but require non-trivial reasoning by domain experts. Figure 1 (c) (top) demonstrates an example execution path that contains list indexing, list assignments, and a simple built-in function (abs()). For these operations, designing rules to map them to Z3 expressions can be difficult and time-consuming. However, human developers with knowledge of Z3 can still write a program to solve these constraints in only a few lines of code (Figure 1 (c) (bottom)). Based on this observation, we propose utilizing LLMs to automatically generate Z3 code for such non-trivial constraints, which is one of the key contributions of LLM-Sym.
However, traditional rule-based symbolic execution has its limitations. The major limitations include difficulties in handling complex data structures and external function calls. For instance, in Figure 1 (b) (top), there are user-defined data types and functions with external functions that cannot be interpreted as SMT-compatible constraints. As a result, it becomes infeasible to generate a Z3 code snippet to accurately describe the constraints for this execution path. Traditionally, researchers tend to overcome these situations by concolic execution [25], where test inputs are directly executed with concrete values. However, concolic execution also has its limitations. First, relying on concrete inputs might cause concolic execution to have difficulty reaching certain paths. Second, directly executing unverified test inputs may introduce undesired security risks [12]. To address these complex, non-linear constraints, a natural approach is to leverage large language models (LLMs) for solving. LLMs have demonstrated considerable capability in logical reasoning, including tasks such as solving mathematical problems [7] or logic puzzles [27]. Similarly, we can harness the reasoning ability of LLMs to solve path constraints in symbolic execution.
Previous works have shown that LLMs are capable of calling the Z3 solver [19, 28, 36], but they mainly focus on solving simple logical/arithmetic problems with only a few lines of code. On the other hand, symbolic execution brings new challenges to Z3 code generation as it requires us to generate longer, more complicated Z3 code to solve lengthy execution paths with diverse data types and execution behaviors.
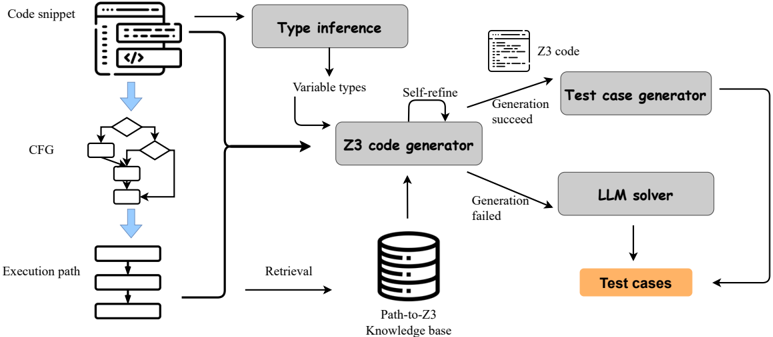
Fig. 2. The overview of LLMSym workflow.
<details>
<summary>Image 2 Details</summary>
### Visual Description
\n
## Diagram: Z3 Code Generation and Testing Pipeline
### Overview
This diagram illustrates a pipeline for generating Z3 code from a code snippet, inferring variable types, and generating test cases using an LLM solver. The process involves several stages, including type inference, Z3 code generation, and test case generation, with feedback loops for refinement and failure handling.
### Components/Axes
The diagram consists of several rectangular blocks representing different components or stages in the pipeline. Arrows indicate the flow of data or control between these components. Key components include:
* **Code snippet:** Input to the pipeline, represented by a block with a code icon.
* **Type inference:** A block that infers variable types from the code snippet.
* **Variable types:** Output of the type inference stage, feeding into the Z3 code generator.
* **Z3 code generator:** The central component, responsible for generating Z3 code.
* **Z3 code:** Output of the Z3 code generator.
* **Test case generator:** Generates test cases from the Z3 code.
* **LLM solver:** Solves the Z3 code to generate test cases.
* **Test cases:** The final output of the pipeline.
* **CFG:** Control Flow Graph, generated from the code snippet.
* **Execution path:** Represents the execution path of the code.
* **Path-to-Z3 Knowledge base:** A database used for retrieval by the Z3 code generator.
The diagram also includes labels indicating the flow of control:
* "Self-refine" (from Variable types to Z3 code generator)
* "Generation succeed" (from Z3 code generator to Test case generator)
* "Generation failed" (from Z3 code generator to LLM solver)
* "Retrieval" (from Path-to-Z3 Knowledge base to Z3 code generator)
### Detailed Analysis or Content Details
The pipeline begins with a "Code snippet" which is processed to generate a "CFG" (Control Flow Graph) and an "Execution path". The "Code snippet" also feeds into a "Type inference" block, which outputs "Variable types". These "Variable types" are then fed into the "Z3 code generator" along with a "Retrieval" signal from the "Path-to-Z3 Knowledge base".
The "Z3 code generator" produces "Z3 code". If the "Generation succeed" signal is triggered, the "Z3 code" is passed to the "Test case generator". The "Test case generator" then uses an "LLM solver" to produce "Test cases".
If the "Generation failed" signal is triggered, the "Z3 code generator" sends the "Z3 code" to the "LLM solver" directly, which then generates "Test cases". The "Z3 code generator" also receives a "Self-refine" signal from the "Variable types", indicating a feedback loop for improving the Z3 code generation process.
### Key Observations
The diagram highlights a closed-loop system where the Z3 code generation process can be refined based on variable types. It also shows two paths for generating test cases: one through the test case generator and another directly through the LLM solver when Z3 code generation fails. The inclusion of a knowledge base suggests that the Z3 code generation process leverages existing knowledge to improve its accuracy and efficiency.
### Interpretation
This diagram represents a sophisticated approach to automated testing. By leveraging Z3 code generation and an LLM solver, the pipeline aims to automatically generate test cases from code snippets. The feedback loop and failure handling mechanisms suggest a robust system that can adapt to different code structures and complexities. The use of a knowledge base indicates an attempt to improve the quality of the generated Z3 code by leveraging existing knowledge about program behavior. The diagram suggests a system designed for formal verification or automated bug finding, where the generated test cases are intended to thoroughly exercise the code and identify potential errors. The two paths to test case generation suggest a fallback mechanism to ensure test cases are always generated, even if the primary Z3 code generation process fails. This is a system that attempts to automate the process of creating formal tests.
</details>
## 3 Approach
Figure 2 depicts the overall workflow of our LLM-Sym. LLM-Sym is a system with two components: an execution path extractor, and an LLM agent which generates test cases based on execution paths. As demonstrated, for a given Python program under test, we first generate its control flow graph (CFG), then traverse the CFG to extract execution paths. After we extract an execution path, an LLM-powered Z3 code generator will translate this path into Z3 constraints. To enable the correct generation of Z3 code, we build a knowledge base with path-to-Z3 pairs and retrieve templates from this knowledge base to guide the code generator. If the initially generated Z3 code is buggy, the code generator will try to fix it using a self-refine mechanism. If the Z3 code for the complete execution path is generated successfully, then a test case generator LLM takes the solver's results as input and interprets it as a complete test case. If the Z3 code generation is unsuccessful, we directly use LLM to solve the path constraints and produce test cases. The main components of the LLMSys agent are based on a sub-optimal and cost-efficient LLM GPT-4o-mini, which helps in reducing the overall cost.
## 3.1 Execution path extractor
The main body of the path extractor is built on the implementation in The Fuzzing Book 1 [38]. Basically, it first builds the program CFG from its abstract syntax tree (AST), then uses breadth-first search to extract all paths from the CFG. In order to successfully create execution paths that LLMs can comprehend, we made the following improvements to the original implementation:
- In the CFG parsing module, we add support to class definitions so that We can build CFGs for Python functions that are located inside a class.
- In the CFG, each node corresponds to a Python statement. We categorize all statements into 3 types. The first type is 'enter', where we encounter a function definition statement, and enter this function during execution. The second type is 'condition', where we encounter a
- For 'for' loop statements, we add a number to the execution path node to denote which iteration of the loop the path has reached.
1 The code for path extraction can be found at https://www.fuzzingbook.org/html/SymbolicFuzzer.html
branch/loop condition in a 'if'/'while'/'for' statement. The third type is 'expression': all other CFG nodes belong to this type, most of which are assignment statements.
```
```
Fig. 3. An example of an extracted execution path (b) for the program (a).
An example of an extracted execution path is shown in Figure 3. Every execution step consists of a line number, a statement type, and the statement itself. After the execution path is extracted, we split it into chunks before providing it to the Z3 code generator. This is because we find that the Z3 code generator is more likely to err when the input execution path sequence is long. In our default setting, we split the path by lines: each chunk only contains one statement in the execution path. We also adopt an alternative approach that splits the path by condition statement, and we will discuss this further in the follow-up sections.
We need to be aware that our improvements do not mitigate the path extractor from its intrinsic weakness: the path explosion problem, as optimizing path extraction is not the main goal of our work.
## 3.2 LLM agent for constraint solving
3.2.1 Type predictor. One of the critical features of Python, different from many other program languages, is its dynamically typed variables. In Python, when we declare a new variable, we do not need to annotate its type explicitly. On the other hand, in Z3, symbolic variables must be assigned with a fixed type when initialized. In order to translate Python expressions to Z3 expressions, we first need to know the variable types in the execution path. So, before we start generating Z3 code, we use an LLM to predict the variable types in the program under test. Specifically, we ask the LLM to gather all variables and input arguments in the program, and predict their types. We use few-shot examples to provide relevant knowledge for type inference, and regulate the output format of the type predictor. Here, we made an approximate assumption: the type of a variable does not change during the execution, which can be applied to the majority of variables. Figure 4 shows the prompt template for our type predictor.
You are given a Python code snippet, and you need to predict the type of all the variables in the code. If the type of a variable cannot be determined, you should choose the most likely type. If the type of a variable is a sequence/mapping type (e.g., list, dict), you should specify the type of its elements/keys and values.
```
```
Fig. 4. The prompt template for the type predictor.
3.2.2 Z3 code generator. The core of our LLM agent in LLM-Sym is to translate extracted path constraints into Z3 code. For a given execution path, the Z3 code generator generates the Z3 constraints for the path in multiple steps. In each step, the code generator takes three pieces of information as input: an execution path chunk (ends with a condition statement), the variable types (generated by the type predictor), and the previously generated Z3 code (generated by the Z3 code generator in previous steps).
A more difficult reasoning step is to accurately translate the constraints semantics in the Python statement into the Z3Py form. During practice, we find that LLMs often make syntax errors when generating Z3Py code, which is understandable since Z3 code rarely occurs in the training corpus of LLMs. Moreover, when we encounter complex data structures (e.g., Python 'list'), it is non-trivial to translate its operations and constraints into Z3Py. To improve the syntactical and semantical correctness of generated Z3 code, we leverage retrieval augmented generation techniques to provide expert knowledge to the code generator LLM. Specifically, we build a Python-to-Z3 knowledge base with execution paths and Z3Py code templates. In each template, we implement a Python operation that cannot be directly interpreted to Z3Py by LLM. One of the main targets of the knowledge base is to support Python operations on 'list'. In LLM-Sym, we approximate Python lists using 'Z3.Array', because the 'Array' data structure has an infinite length, which is suitable for Python lists which has an unfixed length. To represent the length of a Python list, we additionally define a 'Z3.Int' symbolic length variable for each list so that the Z3 solver can reason about Python list lengths. Currently, we support 4 types of list operations in our knowledge base: list initialization, list indexing (read list values), list assignments (write list values), and list append. Table 1 shows how we implemented these functionalities in Z3Py. Apart from list operations, we also include several other operations in our knowledge base, including general assignments, numerical computations, etc. In total, we design 14 Python-to-Z3 templates in the knowledge base for retrieving relevant information. Each template contains a full input-respond example of the Z3 code generator, which includes an execution path chunk (with one or several statements), an input SSA variable environment, with the target Z3Py code, and an updated variable environment. A complete example of a retrieval template is demonstrated in Figure 5. When the Z3 code generator tries to generate Z3 code for an execution path chunk, it first searches the Python-to-Z3 knowledge base, using the path chunk as the query. In the knowledge base, the execution path for each template is used as the key. All keys and queries are encoded to vectors using the Sentence-BERT [21] model, and we use the L2-norm as the distance metric for retrieval. For each retrieval query, we return the most similar templates, and these templates are used as the few-shot examples for Z3Py code generation. The complete prompt template for the Z3 code generator is shown in Figure 6.
To translate a Python expression in the execution into the Z3 Python API (Z3Py) 2 , the Z3 code generator is required to perform two steps of reasoning: first, similar to [38], all variables should be transformed into SSA. This is not a difficult step since the knowledge of SSA is already processed by LLMs. We designed a few examples to demonstrate the variable naming specifications (e.g., the 2nd re-assignment of variable 'x' should be written as '\_x\_2' in our SSA setting). To further enhance the memory of SSA for the LLM, we introduce a variable environment to store the SSA indices for each variable. In each generation with the Z3 code generator, we give the current SSA variable environment to the LLM, and ask it to return the updated variable environment along with the generated Z3Py code.
Even if we integrate multiple-step generation and retrieval templates, the Z3 code generator may still generate buggy code. When the Z3Py code for a chunk is generated, we first concatenate it with the previously generated code and then execute it. If the execution fails with an error, the code
2 https://z3prover.github.io/api/html/namespacez3py.html
Table 1. Examples of translating Python list operations into Z3Py constraints for LLM-Sym.
| Operation | Python execution path | Z3Py code example |
|---------------------|----------------------------|--------------------------------------------------------------------------------------------------------------------------------------------|
| List initialize | enter func(n1: List[int]): | _n1_0 = Array('_n1_0', IntSort(), IntSort()) _n1_0_len=Int('_n1_0_len') solver.add(_n1_0_len >= 0) |
| List length | len(n)>5 | solver.add(_n_0_len) > 5 |
| List indexing | lst[i] == j | solver.add(_lst_1[_i_0] == _j_0) |
| List assignment | lst[i] = 2 | _lst_2 = Store(_lst_1, _i_0, 2) _lst_2_len = _lst_1_len # list length is not changed |
| List append | n.append(x) | _n_1 = Store(_n_0, _n_0_len, _x_0) # n.append(x) _n_1_len = _n_0_len + 1 #increase length by 1 |
| List pop | n.pop() | solver.add(_n_0_len > 0) #before pop(), check length _n_1 = _n_0 #Array values do not change _n_1_len = _n_0_len - 1 #decrease length by 1 |
| List negative index | lst[-2] == z | solver.add(_lst_0[_lst_0_len - 2] == _z_2) solver.add(-2 >= -_lst_0_len) |
```
```
Fig. 5. An example for the path-to-Z3 template in the retrieval knowledge base.
generator tries to fix it with a self-relection mechanism. We input the buggy code and the error message into an LLM, and ask it to fix the code. In our experiments, we keep tying this self-repair process 3 times for each chunk. If all fixing attempts fail, we terminate the Z3 code generation and directly ask an LLM (the LLM solver in Figure 2) to solve the execution path constraints.
- 3.2.3 Test case generator. After the Z3 code generator successfully generates the Z3Py code for a complete path, the test case generator module will generate the final test case based on the solving
```
```
Fig. 6. The prompt template for the Z3 code generator.
results of the generated Z3 constraints. The Z3 solver will output the values of all solved SSA variables, and the test case generator needs to analyze these values, find variables that are related to the test input, and build a test case from the value of these variables.
Among all types of variables returned by the Z3 solver, the 'Z3.Array' type needs special consideration. The value of Z3 Array variables cannot be easily interpreted as a Python list: it is represented by first defining a constant array (e.g., K(Int, 1)), then applying 'Store' operations (e.g., Store(x, 0, 1) means set x[0] to 1) on it. For example, an Array 'Store(K(Int, 0), 2, 3)' can be transferred to a Python list as [0, 0, 3, 0, ...]. In LLM-Sym, with the Array value and the length value, the test case generator should be able to restore them as a Python list in a test input. For this module, we choose GPT-4o as the backend model because it shows significantly better performances in interpreting Z3 Arrays than GPT-4o-mini. Figure 7 demonstrates the prompt template used in the test case generator.
```
```
Fig. 7. The prompt template for the test case generator.
3.2.4 LLM solver. When the Z3 code generator is incapable of generating Z3 code to solve path constraints, we directly seek the LLM to accomplish this task. In the LLM solver, the LLM is given the program under test and the execution path. The LLM solver is asked to solve these constraints directly, produce possible values for input arguments, and then generate a test case from the produced values. Similar to the Z3 code generator, when the LLM solver is asked to solve the constraints of an execution path, it also needs to determine whether this path can be satisfied. If the LLM solver predicts that a path cannot be satisfied, it will terminate generating the answer, allows us to explore other paths. As this module is not the key contribution of our LLM-Sym, we only design a simple prompting mechanism in our current implementation and leave the improvement of the LLM solver as future works. Figure 8 shows the prompt template of the LLM solver.
Given an execution path for a Python program under test, you need to find a group of input arguments that can satisfy all the constraints in the execution path. Think step by step. After you find a group of valid input arguments, generate a test case for the Python program under test. I will provide some guidance for you to understand the execution path and generate the test case accordingly:
1. The execution path contains a list of statement that are executed in order. Each element in the execution path is a dictionary with the following keys/values: a line number, a statement type ('enter' for entering a function, 'condition' for a branch/loop condition, and 'expr' for other statements (such as assignments)), and an expression (the expression in the statement).
2. After you reason about the constraints in the execution path, you should explicitly generate a group of valid input arguments that satisfy the execution path. If all the constraints cannot be satisfied simultaneously, you should immediatly print "UNSAT" and terminate further reasoning.
3. Your generated test case should be a Python function formatted as:
{Format template}
You should generate the complete test function without any code outside the function.
Now please solve the given execution path and generate the test case accordingly. Program under test:
{code}
Execution path: {path}
Fig. 8. The prompt template for the LLM solver.
Table 2. The number (rate) of passed paths solved by LLM-Sym in our LeetCode dataset.
| SAT | Execution pass | Path correct |
|------------|------------------|----------------|
| 99 (89.2%) | 97 (87.4%) | 70 (63.1%) |
## 4 Experiments
## 4.1 Experiment settings
In LLM-Sym, apart from the test case generator module, all other modules are powered by the cost-efficient LLM GPT-4o-mini. The test case generator is built upon GPT-4o. We implement the LLM-Sym agent using the AutoGen [33] library.
## 4.2 Dataset
To evaluate the capability of LLM-Sym, we build a small-scale dataset from the online programming platform LeetCode. We select 50 problems from LeetCode, whose Python solutions 3 with up to 25 lines of code. These programs contain statements with multiple data types and control flows. For each problem, we run the example test cases in their problem description and collect the execution traces. This results in a total of 111 paths. We further truncate the traces with a max length of 20, and the average trace length in our dataset is 12.3. The collected execution traces do not contain information on branch selection, so we use the CFG path extractor in LLM-Sym to find the complete execution path corresponding to the execution trace. Our main task is to let LLM-Sym solve the constraints for these execution paths and generate test cases. After we obtain the generated test cases, we execute them to find whether the generated test case can cover the same path as the example test case. Due to the lack of explicit variable type annotations and the presence of Python list data structures, our backbone symbolic execution engine [38] can solve None of these traces.
## 4.3 RQ1: Capability of LLM-Sym
Table 2 shows the results of LLM-Sym on our LeetCode dataset. We measure the number of generated results (test case or 'UNSAT') that can solve path constraints ('SAT"), produce runnable test cases, and correctly fulfill the given execution trace. From all 111 results generated from LLM-Sym, over 63% percent of them can produce the exact same execution trace as the given input. This shows the potential of using LLMs to generate code for solving symbolic path constraints.
3 The Python solutions are collected from a public GitHub repository https://github.com/walkccc/LeetCode.
, Vol. 1, No. 1, Article . Publication date: September 2018.
Fig. 9. An example of the Z3Py code and test case correctly generated by LLM-Sym. Due to the path length, we only display a part of it.
<details>
<summary>Image 3 Details</summary>

### Visual Description
\n
## Textual Document: Program Under Test & Type Inference Result
### Overview
The image presents a textual document detailing a program under test, its type inference result, and a series of execution paths with associated generated Z3 code and updated environments. The document appears to be related to formal verification or program analysis, likely using a tool that translates code into logical constraints for a solver (Z3).
### Components/Axes
The document is structured into two main columns:
* **Left Column:** "program under test" - Contains the Python code definition of a function `sort_colors` and a series of execution paths. Each path is labeled with `Path: ['line', number, 'type', 'expression']` and includes retrieved examples.
* **Right Column:** "type inference result" - Defines the types of variables (`nums: List[int]`, `n: int`, `i: int`) and then details the generated Z3 code and updated environments for each execution path.
### Detailed Analysis or Content Details
**Program Under Test:**
```python
class Solution:
def sortColors(self, nums: List[int]) -> None:
# ... (code omitted for brevity)
```
**Type Inference Result:**
```
nums: List[int]
n: int
i: int
```
**Execution Paths (Left Column) & Z3 Code/Environments (Right Column):**
* **Path:** `['line', 2, 'type', 'expression']` - `enter: sortColors(nums)`
* Retrieved examples: `['list_pop', 'assign']`
* Generated Z3 code: `generated z3 code: nums_0 = Array('_nums_0', IntSort(), IntSort())`
* Updated env: `{'nums': nums_0}`
* **Path:** `['line', 3, 'type', 'expression']` - `i = 0`
* Retrieved examples: `['assign', 'list_negid']`
* Generated Z3 code: `generated z3 code: i_0 = Int('i_0')`
* Updated env: `{'nums': nums_0, 'i': i_0}`
* **Path:** `['line', 4, 'type', 'expression']` - `r = len(nums) - 1`
* Retrieved examples: `['list_append', 'list_inconst']`
* Generated Z3 code: `generated z3 code: r_0 = nums_0_len - 1`
* Updated env: `{'nums': nums_0, 'i': i_0, 'r': r_0}`
* **Path:** `['line', 6, 'type', 'expression']` - `i = 0`
* Retrieved examples: `['assign', 'list_assign']`
* Generated Z3 code: `generated z3 code: i_0 = Int('i_0')`
* Updated env: `{'nums': nums_0, 'i': i_0, 'r': r_0}`
* **Path:** `['line', 7, 'type', 'condition']` - `expression: 'i <= r'`
* Retrieved examples: `['mod', 'list_negid']`
* Generated Z3 code: `generated z3 code: solver.add(i_0 <= r_0)`
* Updated env: `{'nums': nums_0, 'i': i_0, 'r': r_0, 'i': i_0}`
* **Path:** `['line', 8, 'type', 'condition']` - `expression: 'not(nums[i] == 0)'`
* Retrieved examples: `['for_init', 'logic']`
* Generated Z3 code: `generated z3 code: solver.add(not(nums_0[i_0] == 0))`
* Updated env: `{'nums': nums_0, 'i': i_0, 'r': r_0, 'i': i_0}`
* **Path:** `['line', 9, 'type', 'condition']` - `expression: 'nums[i] != 2'`
* Retrieved examples: `['for_init', 'logic']`
* Generated Z3 code: `generated z3 code: solver.add(not(nums_0[i_0] == 2))`
* Updated env: `{'nums': nums_0, 'i': i_0, 'r': r_0, 'i': i_0}`
* **Path:** `['line', 11, 'type', 'expression']` - `nums[i], nums[r] = nums[r], nums[i]`
* Retrieved examples: `['list_assign', 'list_append']`
* Generated Z3 code: `generated z3 code: nums_0[i_0], nums_0[r_0] = nums_0[r_0], nums_0[i_0]`
* Updated env: `{'nums': nums_0, 'i': i_0, 'r': r_0, 'i': i_0}`
* **Path:** `['line', 12, 'type', 'expression']` - `i += 1`
* Retrieved examples: `['assign', 'int_add']`
* Generated Z3 code: `generated z3 code: i_0 = i_0 + 1`
* Updated env: `{'nums': nums_0, 'i': i_0, 'r': r_0, 'i': i_0}`
* **Path:** `['line', 13, 'type', 'expression']` - `r -= 1`
* Retrieved examples: `['assign', 'int_sub']`
* Generated Z3 code: `generated z3 code: r_0 = r_0 - 1`
* Updated env: `{'nums': nums_0, 'i': i_0, 'r': r_0, 'i': i_0}`
**Footer:**
* `program=sortColors`
* `signature=sortColors(List[int]) -> None`
* `z3_version=4.8.7`
* `date=2023-11-17T19:34:39`
* `time=0.123s`
### Key Observations
* The document traces the execution of the `sortColors` function, generating Z3 code to represent the state of the program at each step.
* The Z3 code uses array representations (`nums_0`) and integer variables (`i_0`, `r_0`) to model the program's variables.
* The `solver.add()` calls indicate the addition of constraints to a Z3 solver, likely for verification purposes.
* The "updated env" shows how the program's state (variable values) changes with each step.
* The footer provides metadata about the analysis, including the program name, signature, Z3 version, date, and execution time.
### Interpretation
This document represents a formal verification attempt of the `sortColors` function. The tool translates the Python code into logical constraints (using Z3) and tracks the program's state as it executes. The generated Z3 code and updated environments are used to verify properties of the function, such as whether it correctly sorts the input array. The "retrieved examples" suggest the tool is using a combination of symbolic execution and concrete examples to guide the verification process. The relatively short execution time (0.123s) suggests the analysis is efficient, but the limited snippet of code makes it difficult to assess the overall effectiveness of the verification process. The document provides a detailed trace of the program's execution and its translation into a formal representation, which is crucial for understanding and verifying the correctness of the code.
</details>
Figure 9 shows an example of a success generation by LLM-Sym. We can see that during the generation process, the type predictor first correctly generates variable types for all variables in the
program. In generating Z3Py code for each Python statement, the retriever first retrieves relevant templates from the knowledge base, which is extremely important for non-trivial operations. For example, in line 12, the retriever successfully returned the 'list assignment' template that helped generate the correct Z3Py statement. Meanwhile, for simple operations, the retrieval results are not so important. For example, in lines 7 and 8, the retriever returns irrelevant results, but the code generator can still generate the correct Z3Py code. An interesting finding emerges from line 12: the LLM code generator correctly generates the Z3Py code for an advanced list operation. It implements 'swap list elements" with two Array assignment operations, while similar patterns do not exist in our template knowledge base. This suggests that the LLM code generator can understand the semantics of path-to-Z3 templates (in this case, the 'list assignment' template) and flexibly compose the basic operations in these templates to implement more complex operations. From this example, we can see that the LLM code generator shows strong capability in generating Z3Py code with the retrieval and memory mechanism designed by ours.
Fig. 10. An example of an incorrect generation of LLM-Sym.
<details>
<summary>Image 4 Details</summary>

### Visual Description
\n
## Diagram: Program Under Test & Type Inference Result
### Overview
The image presents a diagram illustrating the process of type inference for a Python function `removeDuplicates`. It shows the program under test (PUT), the type inference result, and the generated Z3 code for each path within the function. The diagram uses arrows to indicate the flow from the PUT to the type inference and then to the generated Z3 code. Each path is labeled with a line number and details about the type, expression, and retrieved examples.
### Components/Axes
The diagram is structured into three main columns:
1. **Program Under Test (PUT):** Describes the function `removeDuplicates` and the execution paths within it. Includes line numbers, type of operation, expression, and retrieved examples.
2. **Type Inference Result:** Shows the inferred types for variables used in the PUT.
3. **Generated Z3 Code:** Displays the Z3 code generated based on the type inference for each path.
The diagram also includes a small copyright notice at the bottom right: "© 2020 Microsoft".
### Detailed Analysis or Content Details
Here's a breakdown of each path, extracted from the diagram:
* **Path: ['line: 2', 'type': 'enter', 'expression': 'enter: removeDuplicates(nums)']**
* Retrieved examples: `['list_pop', 'list_append']`
* Type inference result: `nums: list[int]`, `i: int`, `num: int`
* Generated Z3 code: `_nums_0 = Array('_nums_0', IntSort(), IntSort())`, `_nums_0.len = Int('nums_0_len >= 0')`, `solver.add(_nums_0.len >= 0)`
* **Path: ['line: 3', 'type': 'expr', 'expression': 'i = 0']**
* Retrieved examples: `['assign', 'list_negid']`
* Generated Z3 code: `_i_0 = Int('_i_0')`, `solver.add(_i_0 == 0)`
* **Path: ['line: 5', 'type': 'condition', 'expression': 'for num in nums the 1-th iteration']**
* Retrieved examples: `['for_inlist', 'for']`
* Generated Z3 code: `_num_0 = Int('_num_0')`, `solver.add(_num_0 == _nums_0[0])`
* **Path: ['line: 6', 'type': 'condition', 'expression': '((i < 2) or (num != nums[(i - 2)]))']**
* Retrieved examples: `['for_inlist', 'list_negid']`
* Generated Z3 code: `solver.add(Or(_i_0 < 2, _num_0 != _nums_0[(_i_0 - 2)]))`
* **Path: ['line: 7', 'type': 'expr', 'expression': 'nums[i] = num']**
* Retrieved examples: `['list_append', 'list_pop']`
* Generated Z3 code: `solver.add(_i_0 >= 0)`, `solver.add(_i_0 < _nums_0.len)`, `_nums_1 = Store(_nums_0, _i_0, _num_0)`
* **Path: ['line: 8', 'type': 'expr', 'expression': 'i += 1']**
* Retrieved examples: `['assign', 'list_assign']`
* Generated Z3 code: `_i_1 = Int('_i_1')`, `solver.add(_i_1 == (_i_0 + 1))`
* **Path: ['line: 5', 'type': 'condition', 'expression': 'for num in nums the 2-th iteration']**
* Retrieved examples: `['for_inlist', 'for']`
* Generated Z3 code: `_num_1 = Int('_num_1')`, `solver.add(_num_1 == _nums_0[1])`
* **Path: ['line: 6', 'type': 'condition', 'expression': '((i < 2) or (num != nums[(i - 2)]))']**
* Retrieved examples: `['for_inlist', 'list_negid']`
* Generated Z3 code: `solver.add(Or(_i_0 < 2, _num_1 != _nums_0[(_i_0 - 2)]))`
* **Path: ['line: 11', 'type': 'return', 'expression': 'return nums']**
* Retrieved examples: `['list_assign', 'list_negid']`
* Generated Z3 code: `solver.add(_nums_1 == _nums_0)`, `_return_0 = _nums_1`
### Key Observations
The diagram demonstrates how a simple Python function is analyzed and translated into Z3 code for formal verification. Each path through the function generates corresponding Z3 constraints. The type inference step is crucial, as it determines the types of variables used in the Z3 code. The copyright notice suggests this is related to research or a tool developed by Microsoft.
### Interpretation
This diagram illustrates a technique for program verification using formal methods. The process involves:
1. **Execution Path Analysis:** Identifying different execution paths through the code.
2. **Type Inference:** Determining the data types of variables.
3. **Z3 Code Generation:** Translating the program logic and type information into constraints that can be solved by a Satisfiability Modulo Theories (SMT) solver (Z3).
The Z3 code represents a logical formula that must hold true for the program to be correct. By solving this formula, one can verify whether the program satisfies certain properties or identify potential bugs. The diagram highlights the connection between high-level code and formal verification techniques. The retrieval examples suggest a system that learns from previous executions to improve the type inference and Z3 code generation process. The diagram is a visual representation of a complex process, aiming to make it more understandable.
</details>
Figure 10 shows a failed example of LLM-Sym. This failed generation finally lead to the generate constraints cannot be satisfied. In this example, the Z3 code generator generates correct Z3Py code until it reaches the 8th statement in the execution path: '(i < 2) or (num != nums[(i - 2)])'.
Table 3. The number of passed paths solved by LLM-Sym with different numbers of templates returned by the retriever.
| No. of templates | SAT | Execution pass | Path correct |
|--------------------|-------|------------------|----------------|
| 1 | 91 | 87 | 54 |
| 2 | 97 | 94 | 65 |
| 3 | 100 | 100 | 62 |
| 4 | 90 | 90 | 61 |
| 5 | 95 | 93 | 62 |
Table 4. The recall@k of the LLM-Sym retriever in retrieving relevant templates.
| Recall@1 | Recall@2 | Recall@5 |
|------------|------------|------------|
| 55.8% | 64.2% | 81.5% |
Before this statement, the Python variable 'num' corresppond to the Z3Py SSA variable '\_num\_1', and this statement do not make new assignments to 'num', so the Z3 code generator should use variable '\_num\_1' in its generated code. However, the LLM failed to generate the correct SSA variable reference, and use '\_num\_0' instead. This will cause the generated Z3 constraints differ from the given path constraints, and eventually, in this case, fail to solve the given path when it is actually satisfiable.
Answer to RQ1: LLM-Sym can generate correct Z3Py code to solve path constraints for symbolic execution. For non-trivial list operations, our retrieval mechanism allows the LLM to acquire knowledge on translating Python constraints to Z3 and generate the correct Z3Py code thereafter. However, sometimes the Z3 code generator still make mistakes, such as generating incorrect SSA variables.
## 4.4 RQ2: Submodule analysis
To study the effectiveness of each module in LLM-Sym, we first investigate the impact of different settings of the retriever. Table 3 shows the results of LLM-Sym on our LeetCode dataset under different number of retrieved templates. We find that when the retriever returns two templates, LLM-Sym has the highest pass rate for execution paths, and increasing the number of retrieved samples will cause a slight drop in the passed paths. We believe that only returning one template may miss the key relevant template, while returning too many templates may mislead the LLM into generating incorrect code.
We perform a case study to demonstrate how the self-refine module fixes the generated code. Figure 11 shows an example of a successful fix by our self-refine mechanism. For the input Python
We further study the efficacy of the retriever by measuring their recall@k in retrieving relevant templates. The results are shown in Table 4. In this table, we exclude path constraint statements with only a simple condition (because the LLM can correctly translate them to Z3Py without external templates). On average, for over half of statements in our dataset, the retriever can return the relevant template as the most correlated retrieval result. This indicates the strong capability of the retriever. Nevertheless, there is still room for improvement in the retrieving module. Even if we return 5 retrieval templates, there are still 19% of the path constraint statements that do not successfully retrieve a relevant template.
statement, the Z3 code generator first converts it into Z3Py without changing any operators. However, the Python floor division operator '//' is not supported by Z3, so when we execute the generated code, it returns a type error. The self-refine module receives the buggy code with the error message and successfully generates the fix. In the fixed code, the operator '//' is replaced by '/' because, in Z3Py, the '/' division operation on integer variables is naturally equivalent to the '//' operation in Python: it rounds the division result down to the nearest integer.
<details>
<summary>Image 5 Details</summary>

### Visual Description
\n
## Diagram: Code Generation and Error Correction
### Overview
This diagram illustrates a code generation process, specifically focusing on a scenario where generated Z3 code results in a TypeError. It shows the original expression, the generated Z3 code, the resulting error message, and the corrected Z3 code. The diagram uses arrows to indicate the flow of the process: from expression to generated code, execution, error, and finally, correction.
### Components/Axes
The diagram is segmented into four main sections:
1. **Path:** Displays the original expression: `m = (1 + r) // 2`
2. **Generated Z3 code:** Shows the code generated from the expression: `m_2 = Int('m_2')\nsolver.add(m_2 == (1_2 + r_1) // 2)`
3. **Error message:** Displays the TypeError encountered during execution: `TypeError: unsupported operand type(s) for //: 'ArithRef' and 'int'`
4. **Fixed code:** Shows the corrected Z3 code: `m_2 = Int('m_2')\nsolver.add(m_2 == (1_2 + r_1) // 2)`
The diagram also uses arrows to show the process flow. A red dashed arrow indicates the error feedback loop.
### Detailed Analysis or Content Details
* **Path:** The original expression is `m = (1 + r) // 2`. This appears to be a mathematical expression where `m` is assigned the integer division of `(1 + r)` by 2.
* **Generated Z3 code:** The generated Z3 code initializes an integer variable `m_2` using `Int('m_2')`. It then attempts to add a constraint to the solver using `solver.add(m_2 == (1_2 + r_1) // 2)`. Note that `1` and `r` are transformed into `1_2` and `r_1` respectively.
* **Error message:** The error message indicates a `TypeError`. The error specifically states that the `//` operator (integer division) does not support operands of type `'ArithRef'` and `'int'`. The error highlights the `//` operator and the operands involved.
* **Fixed code:** The fixed code is identical to the generated Z3 code. This suggests the error was not in the code itself, but potentially in the environment or how the code was executed.
### Key Observations
The diagram highlights a common issue in automated code generation: type mismatches. The generated Z3 code attempts to perform integer division between an `ArithRef` (likely a symbolic arithmetic expression) and an integer, which is not supported. The fact that the "fixed" code is the same as the generated code suggests the error might be related to the execution environment or the solver's configuration rather than a coding error.
### Interpretation
This diagram demonstrates a debugging scenario in an automated code generation pipeline. The process starts with a simple mathematical expression. The code generator translates this expression into Z3 code, which is then executed by a solver. The solver encounters a TypeError due to incompatible operand types during integer division. The diagram suggests that the error is not a result of incorrect code generation, but rather a type mismatch during execution. The "fixed" code being identical to the generated code implies that the issue lies outside the code itself, potentially in the solver's environment or configuration. This highlights the importance of robust type checking and error handling in automated code generation systems. The diagram is a simplified representation of a complex process, focusing on a specific error case and its resolution.
</details>
(a)
Path: [{'line': 13, 'type': 'expr', 'expression': 'nxt += (str(count) + ans[i])'}] Fig. 11. An example of the self-refine module successfully fixes a bug in generated Z3Py code.
Path: [{'line': 7, 'type': 'expr', 'expression': 'm = ((l + r) // 2)'}]
Generated z3 code: \_nxt\_1 = String('\_nxt\_1') solver.add(\_nxt\_1 == \_nxt\_0 + (String(str(\_count\_0)) + \_ans\_0[\_i\_0])) execute Error message: solver.add(\_nxt\_1 == \_nxt\_0 + (String(str(\_count\_0)) + \_ans\_0[\_i\_0])) z3.z3types.Z3Exception: Non-sequence passed as a sequence 3 attempts \_nxt\_1 = String('\_nxt\_1') solver.add(\_nxt\_1 == Concat(\_nxt\_0, Concat(String(str(\_count\_0)), Substring(\_ans\_0, \_i\_0, 1)))) NameError: name 'Substring' is not defined execute Figure 12 shows a failed example of the self-refine module in LLM-Sym. The input Python code converts an integer to a Python string, although such operation is theoretically supported by Z3 4 , its Z3Py API is rarely used in practice. From the example we can see that the LLM do not have the knowledge for converting an integer to a string, so it tries to generate different non-existing APIs in the three attempts, and all attempt are unsuccessful. We can conclude that when using the LLM to generate Z3Py code for non-trivial operations that are seldom seen in its training corpus, it is extremely important to provide high-quality examples to supplement it with new knowledge. Generated z3 code: \_m\_2 = Int('\_m\_2') solver.add(\_m\_2 == (\_l\_2 + \_r\_1) // 2) Error message: solver.add(\_m\_2 == (\_l\_2 + \_r\_1) // 2) ~~~~~~~~~~~~~~^^~~ TypeError: unsupported operand type(s) for //: 'ArithRef' and 'int' execute Fixed code: \_m\_2 = Int('\_m\_2') solver.add(\_m\_2 == (\_l\_2 + \_r\_1) / 2) (a)
```
```
Fig. 12. An example of the self-refine module fails in fixing a bug in generated Z3Py code.
We further compare two path chunking strategies: chunk by line (our default setting) and chunk by condition statements (discussed in Section 3.1). Table 5 shows the results of chunking by condition statements under different retrieval settings. We can observe that in all settings, chunking by condition results in fewer solved paths than chunking by line. This difference in performance is predictable because when we ask the LLM to generate Z3Py constraints for multiple Python statements, it is harder than generating for a single statement, and the LLM is more likely to make mistakes.
4 See https://microsoft.github.io/z3guide/docs/theories/Strings/#strfrom\_int-i-strto\_int-s---convert-to-and-from-nonnegative-integers for examples.
, Vol. 1, No. 1, Article . Publication date: September 2018.
Table 5. The number of passed paths solved by LLM-Sym with path inputs split by condition statements (and the differences to the results of chunking by line).
| No. of templates | SAT | Execution pass | Path correct |
|--------------------|-------|------------------|----------------|
| 1 | 93 | 91 | 48(-7) |
| 2 | 83 | 80 | 49(-16) |
| 3 | 84 | 82 | 48(-14) |
| 4 | 82 | 79 | 45(-16) |
| 5 | 82 | 79 | 45(-17) |
Table 6. The number and pass rates for the Z3 code generator (Z3) and the LLM solver (LLM) in solving path constraints. Notice that the sum of the solutions generated by the Z3 code generator and the LLM solver is not equal to the dataset size. This is because we do not count UNSAT generation results in the table.
| No. of templates | No. generated by Z3 | No. generated by LLM | Z3 pass rate | LLM pass rate |
|--------------------|-----------------------|------------------------|----------------|-----------------|
| 1 | 66 | 25 | 63.6% | 48.0% |
| 2 | 74 | 23 | 73.0% | 47.8% |
| 3 | 76 | 24 | 69.7% | 37.5% |
| 4 | 71 | 19 | 70.4% | 57.9% |
| 5 | 66 | 29 | 68.2% | 58.6% |
Answer to RQ2: Both the retrieval and self-refine modules play a key role in improving the correctness of the Z3 code generator. For the retriever, different numbers of retrieved examples can affect the performance of the LLM code generator. Meanwhile, adding more templates in the retrieval knowledge base can allow the code generator to support more complex operations. Considering the results on recall@k, the retriever is generally powerful but can be further improved in the future. As for the self-refine module, it can fix some of the bugs in the generated Z3Py code, but if the input Python statement is beyond the ability of the code generator itself, then the self-refine module is unlikely to fix the buggy Z3Py code. For the path chunking strategies, split by lines achieves better results than split by condition statements.
## 4.5 RQ3: comparison between Z3 code generator and LLM solver
LLM-Sym adopts two approaches in solving Python path constraints. The first one is using the Z3 code generator to generate Z3Py code for solving. The second one is to use an LLM for solving when the Z3 code generator fails. It is important to analyze the performances of both components and find whether the Z3 code generator can outperform the vanilla LLM solver with basic prompts.
Table 6 compares the Z3 code generator with the LLM solver in the number and pass rate of generated path solutions. For all retrieval settings, the majority of solutions are generated by the Z3 code generator, and the pass rate of solutions generated from Z3 is significantly higher than those generated by the LLM solver. For example, when the number of retrieved templates is set to 2, the Z3 code generator generates 74 solutions, which is more than three times of the solutions generated by the LLM solver. Besides, the Z3 code generator reaches a high pass rate of 73%. This shows the potential of building a symbolic execution engine fully powered by LLM to solve the constraints that are within the ability of Z3.
Table 7. The results of only using the LLM solver on our dataset.
| Approach | SAT | Execution pass | Path correct | Pass rate (Z3) | Pass rate (LLM) |
|-------------|-------|------------------|----------------|------------------|-------------------|
| gpt-4o-mini | 110 | 108 | 55 | 55.4% | 39.1% |
| gpt-4o | 110 | 110 | 71 | 64.9% | 52.2 % |
| LLM-Sym | 97 | 94 | 65 | 73.0 % | 47.8% |
Table 8. The total cost (and cost per sample) for path constraints solving in our dataset with LLM-Sym and different LLMs. The time metrics are shown in seconds, and the money costs are shown in US dollars.
| Approach | Time | Money |
|--------------------|-------------|---------------|
| LLM-Sym | 2241 (20.2) | 0.61 (0.005) |
| gpt-4o-mini gpt-4o | 495 (4.5) | 0.04 (0.0004) |
| | 1189 (10.7) | 1.96 (0.018) |
We also perform an ablation to evaluate the performance of the Z3 code generator: we compare LLM-Sym with a baseline in which we use the LLM solver to solve all paths. This baseline can be seen as a variant of SymPrompt [22], where the execution path is used in prompts for test case generation. The main difference is that our baseline uses execution paths extracted from CFGs instead of ASTs in SymPrompt. Table 7 displays the results of the LLM solver on our dataset. We evaluate two proprietary models, GPT-4o-mini and GPT-4o, for the LLM solver. We record the number of successfully solved paths and the pass rate of the paths that are generated by Z3 code generator/LLM solver in LLM-Sym. We find that although directly using the LLM for constraint solving can produce more executable test cases, its successfully solved paths are less than LLM-Sym. Although GPT-4o has a higher overall pass rate than LLM-Sym, its pass rate on the subset of Z3-solved paths is still lower than LLM-Sym. Moreover, our Z3 code generator is based on the weaker and more efficient GPT-4o-mini. This indicates that using LLMs to call the SMT solver can free the LLM from complex constraint solving, and achieve better pass rates.
Answer to RQ3: The Z3 code generator can generate Z3Py code that better solves path constraints than only relying on the LLM. Meanwhile, for constraints that are difficult to solve with Z3, the LLM solver is a complementation with strong potential.
## 4.6 RQ4: Time and cost efficiency
The LLM-Sym is an LLM agent, and its core, the Z3 code generator, requires multiple-step generation with self-refine. So, it is important to measure its efficiency. We compare LLM-Sym with only using the LLM solver (without the Z3 code generator) in time and money costs, and the results are shown in Table 8. In this table, we record the total time of LLM-Sym in solving all 111 path constraints in our dataset and the total cost of using the OpenAI API.
On average, LLM-Sym solves a single path with 20.2s, and the cost is only 0.005$. With a complicated line-by-line generation pipeline, its time overhead is less than twice that of the GPT-4o solver, and the money cost is only one-third of that of GPT-4o. While achieving similar results to GPT-4o, the price of our LLM-Sym is significantly lower, and the time efficiency is still acceptable.
Answer to RQ4: Although the Z3 code generation pipeline is complicated, the time overhead of LLM-Sym is not much longer than the basic GPT-4o. The money cost of LLM-Sym is significantly lower than GPT-4o, due to the low cost of the backbone LLM GPT-4o-mini.
## 5 Threats to Validity
## 5.1 Model validity
The proposed approach LLM-Sym is based on LLMs GPT-4o-mini and GPT-4o, while other models are not considered. However, we should be aware that these two models are widely used stateof-the-art LLMs, so the experiment results are representative, and the choice of these models is reasonable.
Another threat is related to the capability of LLM-Sym. Currently, our approach only supports a part of the Python 'list' operation and does not explicitly support other data structures, which may be inadequate for real-world complex programs. However, because LLM-Sym supports non-trivial operations by providing Z3Py examples in the knowledge base, we can add support for other operations by adding new examples into the knowledge base. Also, the ability of the key module in LLM-Sym: the Z3 code generator, is limited by the abilities of the Z3 solver. To mitigate this threat, we introduced an LLM solver to solve constraints that Z3 cannot solve. Improvements on the LLM solver for stronger reasoning abilities are left as future work.
## 5.2 Data validity
In this paper, we have only evaluated LLM-Sym on a subset of LeetCode problem solutions. As the first step of integrating LLMs with an SMT solver for symbolic execution, we should first evaluate simple, restricted programs and understand the behavior of LLM-Sym on these data before we move on to more complicated, real-world data.
## 6 Related Work
## 6.1 Symbolic execution
Symbolic execution was first proposed to test whether a piece of software can violate certain properties [1]. Symbolic execution has been successful in many tasks, such as test case generation [10], inferring program invariants [14], and vulnerability detection [31]. However, symbolic execution is known to suffer from many limitations, including path explosion and difficulties in solving non-linear constraints or external API calls. To address these limitations, one of the most adopted techniques is concolic execution [25]. Instead of only executing with symbolic values, concolic execution executes the program with concrete values, collects path constraints, and explores other paths by negating constraints. Currently, many successful symbolic execution engines are based on concolic execution, including KLEE [5], SPF [20], and Triton [23]. Most symbolic execution engines use SMT solvers, such as Z3 [8], to solve path constraints.
Although existing symbolic execution engines have enabled symbolic analysis in many languages (e.g., C, Java, LLVM), few of them can support Python. We assume that the lack of Python symbolic execution engines is due to the unique features of Python: dynamic typing and data structures with flexible operations. Although several previous works [2-4] tried to perform symbolic execution on Python, none of them have successfully transferred into established, well-maintained tools. For example, the Python symbolic execution tool PyExZ3 [2] only supports simple data types (no support for 'list') and has been deprecated. The most popular Python symbolic execution engine, CrossHair 5 (with 900+ Github stars), is maintained by independent developers. We did not compare
5 https://github.com/pschanely/CrossHair
with CrossHair in our paper because it uses concolic execution and does not support pure-symbolic constraint solving. Another limitation of CrossHair is that it requires that the input arguments in the function under test must have explicit type annotations.
## 6.2 LLM for test case generation
Recently, software testing researchers have applied LLM for test case generation in different domains [29]. One of the most discussed domains in LLM-aided software testing is unit test case generation [6, 11, 22, 24, 37], which aims to generate test cases separately for individual software components. For example, ChatUniTest [6] and ChatTester [37] aim to leverage Openai GPT models to generate correct, runnable test cases for Java methods, while TrickyBugs [15], TestEval [30] and SWT-Bench [17] built benchmark datasets to facilitate researches on generating bug-triggering or high-coverage test cases. There have also been some recent empirical studies [18, 35] which discussed the correctness, coverage, and bug-finding ability of LLM-generated test cases with different prompt designs. Symprompt [22] tried to combine LLM-based test case generation with symbolic analysis by using program execution paths to prompt LLMs. Although the overall idea of Symprompt resembles symbolic execution, it did not make additional efforts to improve the LLM's ability to solve path constraints. Instead, the execution path is provided to the LLM in one single prompt, which may hinder the LLM from solving the constraints with complex reasoning.
There are also other works that tried to combine LLMs with traditional program analysis tools or software testing techniques for test case generation. For example, CodaMosa [11] improves test coverage by integrating LLMs with Pynguin [16], a search-based software testing tool. When Pynguin gets stuck in a coverage plateau, CodeMosa calls an LLM to generate new test case seeds so that Pynguin can generate new mutants on this seed and further improve test coverage. TELPA [34] leverages control flow graph analysis to extract method invocation sequences for guiding LLM-generated test cases to enter hard-to-cover branches. HITS [32] applies program slicing on Java methods under test and improves test coverage by generating test cases for different slices.
## 7 Conclusion
This paper proposes LLM-Sym, a symbolic execution engine prototype which is powered by an LLM agent. It improves the solving ability of a basic symbolic execution engine by leveraging LLMs to call an SMT solver Z3 for constraint solving. Our proposed code generation approach allows LLM-Sym to solve constraints on complex data types, e.g., Python lists, using the Z3 solver. If Z3 cannot solve the constraint, it turns to LLMs for solving. LLM-Sym enables Z3 code generation for complex Python statements with a meticulously designed retrieval knowledge base and a self-refine mechanism. In this paper, we focus on supporting Python lists when building the knowledge base. Our experiments show that LLM-Sym is capable of generating correct Z3 code for long path constraints in LeetCode programs. Moreover, we find that integrating a cost-efficient LLM with Z3 can beat the most state-of-the-art LLM in constraint solving for Python symbolic execution.
## References
- [1] Roberto Baldoni, Emilio Coppa, Daniele Cono D'elia, Camil Demetrescu, and Irene Finocchi. 2018. A survey of symbolic execution techniques. ACM Computing Surveys (CSUR) 51, 3 (2018), 1-39.
- [3] Alessandro Disney Bruni, Tim Disney, and Cormac Flanagan. 2011. A peer architecture for lightweight symbolic execution. Universidad de California, Santa Cruz (2011).
- [2] Thomas Ball and Jakub Daniel. 2015. Deconstructing dynamic symbolic execution. In Dependable Software Systems Engineering . IOS Press, 26-41. https://github.com/thomasjball/PyExZ3
- [4] Stefan Bucur, Johannes Kinder, and George Candea. 2014. Prototyping symbolic execution engines for interpreted languages. In Proceedings of the 19th international conference on Architectural support for programming languages and operating systems . 239-254.
- [5] Cristian Cadar, Daniel Dunbar, Dawson R Engler, et al. 2008. Klee: unassisted and automatic generation of high-coverage tests for complex systems programs.. In OSDI , Vol. 8. 209-224.
- [7] Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, et al. 2021. Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021).
- [6] Yinghao Chen, Zehao Hu, Chen Zhi, Junxiao Han, Shuiguang Deng, and Jianwei Yin. 2024. Chatunitest: A framework for llm-based test generation. In Companion Proceedings of the 32nd ACM International Conference on the Foundations of Software Engineering . 572-576.
- [8] Leonardo De Moura and Nikolaj Bjørner. 2008. Z3: An efficient SMT solver. In International conference on Tools and Algorithms for the Construction and Analysis of Systems . Springer, 337-340.
- [10] James C King. 1976. Symbolic execution and program testing. Commun. ACM 19, 7 (1976), 385-394.
- [9] Juan Pablo Galeotti, Gordon Fraser, and Andrea Arcuri. 2013. Improving search-based test suite generation with dynamic symbolic execution. In 2013 ieee 24th international symposium on software reliability engineering (issre) . IEEE, 360-369.
- [11] Caroline Lemieux, Jeevana Priya Inala, Shuvendu K Lahiri, and Siddhartha Sen. 2023. Codamosa: Escaping coverage plateaus in test generation with pre-trained large language models. In 2023 IEEE/ACM 45th International Conference on Software Engineering (ICSE) . IEEE, 919-931.
- [13] Xin Li, Yongjuan Liang, Hong Qian, Yi-Qi Hu, Lei Bu, Yang Yu, Xin Chen, and Xuandong Li. 2016. Symbolic execution of complex program driven by machine learning based constraint solving. In Proceedings of the 31st IEEE/ACM International Conference on Automated Software Engineering . 554-559.
- [12] Penghui Li, Wei Meng, Mingxue Zhang, Chenlin Wang, and Changhua Luo. 2024. Holistic Concolic Execution for Dynamic Web Applications via Symbolic Interpreter Analysis. In Proceedings of the 45th IEEE Symposium on Security and Privacy (Oakland). San Francisco, CA, USA .
- [14] Chang Liu, Xiwei Wu, Yuan Feng, Qinxiang Cao, and Junchi Yan. 2023. Towards General Loop Invariant Generation via Coordinating Symbolic Execution and Large Language Models. arXiv preprint arXiv:2311.10483 (2023).
- [16] Stephan Lukasczyk and Gordon Fraser. 2022. Pynguin: Automated unit test generation for python. In Proceedings of the ACM/IEEE 44th International Conference on Software Engineering: Companion Proceedings . 168-172.
- [15] Kaibo Liu, Yudong Han, Yiyang Liu, Zhenpeng Chen, Jie M Zhang, Federica Sarro, Gang Huang, and Yun Ma. 2024. TrickyBugs: A Dataset of Corner-case Bugs in Plausible Programs. In Proceedings of the 21st International Conference on Mining Software Repositories . 113-117.
- [17] Niels Mündler, Mark Niklas Müller, Jingxuan He, and Martin Vechev. 2024. Code Agents are State of the Art Software Testers. arXiv preprint arXiv:2406.12952 (2024).
- [19] Liangming Pan, Alon Albalak, Xinyi Wang, and William Wang. 2023. Logic-LM: Empowering Large Language Models with Symbolic Solvers for Faithful Logical Reasoning. In Findings of the Association for Computational Linguistics: EMNLP 2023 . 3806-3824.
- [18] Wendkûuni C Ouédraogo, Kader Kaboré, Haoye Tian, Yewei Song, Anil Koyuncu, Jacques Klein, David Lo, and Tegawendé F Bissyandé. 2024. Large-scale, Independent and Comprehensive study of the power of LLMs for test case generation. arXiv preprint arXiv:2407.00225 (2024).
- [20] Corina S Păsăreanu and Neha Rungta. 2010. Symbolic PathFinder: symbolic execution of Java bytecode. In Proceedings of the 25th IEEE/ACM International Conference on Automated Software Engineering . 179-180.
- [22] Gabriel Ryan, Siddhartha Jain, Mingyue Shang, Shiqi Wang, Xiaofei Ma, Murali Krishna Ramanathan, and Baishakhi Ray. 2024. Code-Aware Prompting: A Study of Coverage-Guided Test Generation in Regression Setting using LLM. Proceedings of the ACM on Software Engineering 1, FSE (2024), 951-971.
- [21] Nils Reimers and Iryna Gurevych. 2019. Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing . Association for Computational Linguistics. https://arxiv.org/abs/1908.10084
- [23] Florent Saudel and Jonathan Salwan. 2015. Triton: A dynamic symbolic execution framework. In Symposium sur la sécurité des technologies de l'information et des communications, SSTIC, France, Rennes . 31-54.
- [25] Koushik Sen. 2007. Concolic testing. In Proceedings of the 22nd IEEE/ACM international conference on Automated software engineering . 571-572.
- [24] Max Schäfer, Sarah Nadi, Aryaz Eghbali, and Frank Tip. 2023. An empirical evaluation of using large language models for automated unit test generation. IEEE Transactions on Software Engineering (2023).
- [26] Yan Shoshitaishvili, Ruoyu Wang, Christopher Salls, Nick Stephens, Mario Polino, Andrew Dutcher, John Grosen, Siji Feng, Christophe Hauser, Christopher Kruegel, et al. 2016. Sok:(state of) the art of war: Offensive techniques in binary analysis. In 2016 IEEE symposium on security and privacy (SP) . IEEE, 138-157.
- [27] Aarohi Srivastava, Abhinav Rastogi, Abhishek Rao, Abu Awal Md Shoeb, Abubakar Abid, Adam Fisch, Adam R Brown, Adam Santoro, Aditya Gupta, Adrià Garriga-Alonso, et al. 2022. Beyond the imitation game: Quantifying and
extrapolating the capabilities of language models. arXiv preprint arXiv:2206.04615 (2022).
- [29] Junjie Wang, Yuchao Huang, Chunyang Chen, Zhe Liu, Song Wang, and Qing Wang. 2024. Software testing with large language models: Survey, landscape, and vision. IEEE Transactions on Software Engineering (2024).
- [28] Chengpeng Wang, Wuqi Zhang, Zian Su, Xiangzhe Xu, Xiaoheng Xie, and Xiangyu Zhang. 2024. When Dataflow Analysis Meets Large Language Models. arXiv preprint arXiv:2402.10754 (2024).
- [30] Wenhan Wang, Chenyuan Yang, Zhijie Wang, Yuheng Huang, Zhaoyang Chu, Da Song, Lingming Zhang, An Ran Chen, and Lei Ma. 2024. TESTEVAL: Benchmarking Large Language Models for Test Case Generation. arXiv preprint arXiv:2406.04531 (2024).
- [32] Zejun Wang, Kaibo Liu, Ge Li, and Zhi Jin. 2024. HITS: High-coverage LLM-based Unit Test Generation via Method Slicing. arXiv preprint arXiv:2408.11324 (2024).
- [31] Zexu Wang, Jiachi Chen, Yanlin Wang, Yu Zhang, Weizhe Zhang, and Zibin Zheng. 2024. Efficiently detecting reentrancy vulnerabilities in complex smart contracts. Proceedings of the ACM on Software Engineering 1, FSE (2024), 161-181.
- [33] Qingyun Wu, Gagan Bansal, Jieyu Zhang, Yiran Wu, Beibin Li, Erkang Zhu, Li Jiang, Xiaoyun Zhang, Shaokun Zhang, Jiale Liu, et al. 2024. AutoGen: Enabling Next-Gen LLM Applications via Multi-Agent Conversation. In ICLR 2024 Workshop on Large Language Model (LLM) Agents .
- [35] Lin Yang, Chen Yang, Shutao Gao, Weijing Wang, Bo Wang, Qihao Zhu, Xiao Chu, Jianyi Zhou, Guangtai Liang, Qianxiang Wang, et al. 2024. An Empirical Study of Unit Test Generation with Large Language Models. arXiv preprint arXiv:2406.18181 (2024).
- [34] Chen Yang, Junjie Chen, Bin Lin, Jianyi Zhou, and Ziqi Wang. 2024. Enhancing LLM-based Test Generation for Hard-to-Cover Branches via Program Analysis. arXiv preprint arXiv:2404.04966 (2024).
- [36] Xi Ye, Qiaochu Chen, Isil Dillig, and Greg Durrett. 2023. Satlm: Satisfiability-aided language models using declarative prompting. Advances in Neural Information Processing Systems 36 (2023).
- [38] Andreas Zeller, Rahul Gopinath, Marcel Böhme, Gordon Fraser, and Christian Holler. 2019. The fuzzing book.
- [37] Zhiqiang Yuan, Mingwei Liu, Shiji Ding, Kaixin Wang, Yixuan Chen, Xin Peng, and Yiling Lou. 2024. Evaluating and improving chatgpt for unit test generation. Proceedings of the ACM on Software Engineering 1, FSE (2024), 1703-1726.