# Proof of Thought : Neurosymbolic Program Synthesis allows Robust and Interpretable Reasoning
**Authors**:
- Debargha Ganguly (Case Western Reserve University)
- &Srinivasan Iyengar (Microsoft Corporation)
- Vipin Chaudhary (Case Western Reserve University)
- &Shivkumar Kalyanaraman (Microsoft Corporation)
> Most work conducted at Microsoft Research, with partial support from NSF Awards 2117439 and 2112606.
## Abstract
Large Language Models (LLMs) have revolutionized natural language processing, yet they struggle with inconsistent reasoning, particularly in novel domains and complex logical sequences. This research introduces Proof of Thought, a framework that enhances the reliability and transparency of LLM outputs. Our approach bridges LLM-generated ideas with formal logic verification, employing a custom interpreter to convert LLM outputs into First Order Logic constructs for theorem prover scrutiny. Central to our method is an intermediary JSON-based Domain-Specific Language, which by design balances precise logical structures with intuitive human concepts. This hybrid representation enables both rigorous validation and accessible human comprehension of LLM reasoning processes. Key contributions include a robust type system with sort management for enhanced logical integrity, explicit representation of rules for clear distinction between factual and inferential knowledge, and a flexible architecture that allows for easy extension to various domain-specific applications. We demonstrate Proof of Thought ’s effectiveness through benchmarking on StrategyQA and a novel multimodal reasoning task, showing improved performance in open-ended scenarios. By providing verifiable and interpretable results, our technique addresses critical needs for AI system accountability and sets a foundation for human-in-the-loop oversight in high-stakes domains.
## 1 Introduction
Large language models (LLMs) have revolutionized the field of AI and enabled a wide range of applications. However, as these models are increasingly deployed to process unstructured data and perform complex tasks autonomously, their inconsistent reasoning capabilities remain a critical limitation (Marcus, 2020). This inconsistency manifests in variable performance across out-of-domain reasoning, negation understanding, and extended logical chains, suggesting a reliance on superficial heuristics (Bender et al., 2021). The implications are far-reaching, particularly in high-stakes domains where reliable and transparent decision-making is crucial (Rudin, 2019). Errors or biases in these contexts could have severe consequences, underscoring the urgent need for more dependable and interpretable AI systems.
Recent advances in prompt engineering have shown promise in addressing these challenges. Techniques such as Chain-of-Thought (CoT) (Wei et al., 2022), Self-Consistency with CoT (CoT-SC) (Wang et al., 2022), Tree of Thoughts (ToT) (Yao et al., 2024), and Graph of Thoughts (GoT) (Besta et al., 2024) have improved problem-solving capabilities. In the multimodal domain, techniques like Set-of-Marks (SoM) prompting have emerged (Yang et al., 2023). Despite advancements in performance figures, the mechanisms behind these improvements remain opaque, causing blind spots in real-world usage as failure modes are not well understood. The fundamental issue lies in the lack of interpretability and guaranteed verifiability in LLM reasoning processes (Danilevsky et al., 2020). This opacity hinders our ability to trust and validate LLM outputs, a critical concern in scenarios requiring explainable AI or human-in-the-loop oversight.
Real-world applications, especially in health and safety domains, face additional challenges in training and deploying models due to the scarcity of high-quality annotated data. This is particularly evident in sectors like energy, healthcare, and manufacturing, where ML has significant potential for operational efficiency (Jordan and Mitchell, 2015). Complex tasks, such as identifying OSHA violations in cluttered visual data, illustrate the difficulties in long-tail, low-data scenarios. These scenarios are characterized by diverse and unpredictable phenomena, where specialized model training is impractical (Zhang et al., 2021). With robust reasoning, LLMs’ wide knowledge and commonsense abilities can potentially operate in these low-data paradigms, opening up more applications.
Contributions: To address these challenges, we :
1. Propose Proof of Thought (PoT), a novel approach that leverages the in-context learning and code generation capabilities of LLMs while incorporating their inherent knowledge and spatial understanding. Our system employs a custom interpreter that parses "LLM-Thoughts" (represented as DSL code snippets) to generate First Order Logic programs, which are then verified by a Z3 theorem prover.
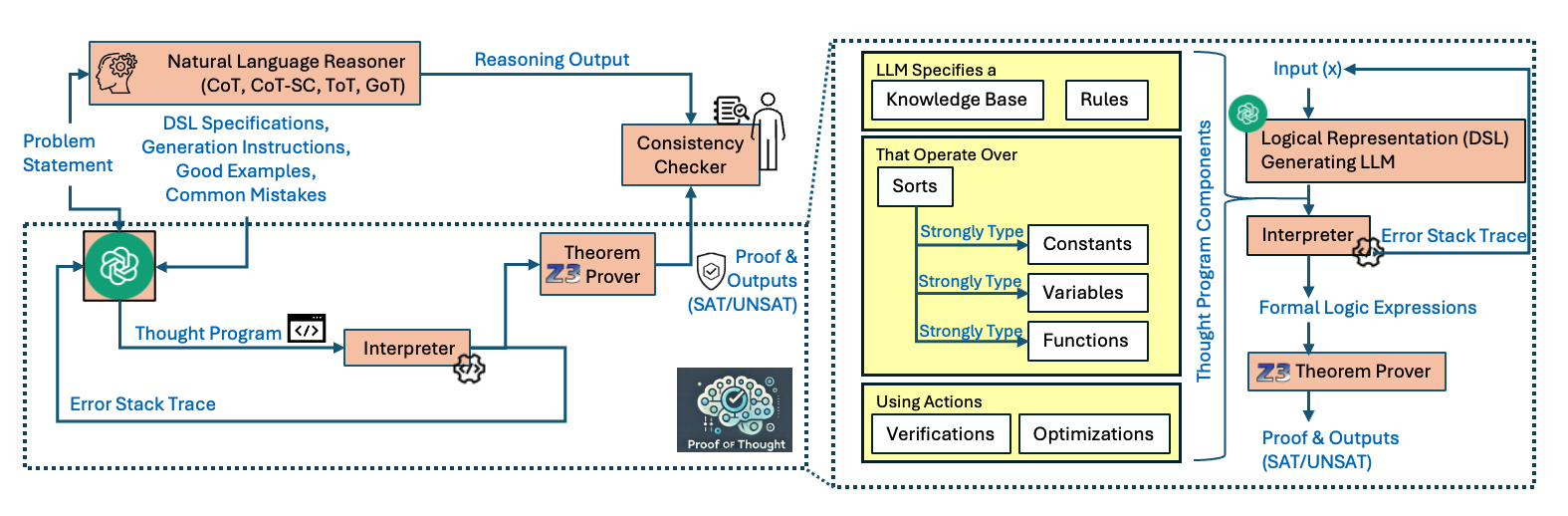
1. Introduce an intermediate JSON-based DSL (neurosymbolic representation) and the associated interpreter that operates on human-understandable abstract concepts using intuitive, near-English language constructs (see Fig 1). This strikes a balance between the precision required for logical definitions with formal first-order logic proofs and accessibility for non-expert users.
1. Benchmark performance over StrategyQA (a boolean multi-hop implicit NLP reasoning benchmark) and a novel multimodal real-world long-tail reasoning problem (Reddit-OSHA Benchmark). This shows that PoT works on complex, and a wide variety of tasks.
Proof of Thought enhances the capabilities of LLMs in complex, open-ended scenarios by providing reasoning guarantees, conditioned on correctness of knowledge base and rule specifications, therefore furnishing a framework for human-in-the-loop oversight and verification.
## 2 Related Work
Early Integration Attempts laid the groundwork for neuro-symbolic AI. Works like EBL-ANN (Towell and Shavlik, 1994), KBANN (Towell et al., 1990), and C-ILP (d’Avila Garcez et al., 2009) incorporated propositional formulae into neural networks. While pioneering, these approaches struggled with scalability and expressiveness. Knowledge Graph integration advanced the field further. Methods proposed by Chen et al. (2020a) and Kampffmeyer et al. (2019) showed promise in leveraging structured knowledge for improved reasoning. However, maintaining interpretability and explicit rule incorporation remained challenging. Differentiable Logic Programming frameworks like DeepProbLog (Manhaeve et al., 2018) and Scallop (Li et al., 2023) demonstrated the potential of integrating probabilistic logic programming with neural networks. These approaches enable end-to-end training of neuro-symbolic systems but face limitations in handling complex reasoning tasks and diverse logical formalisms. Gupta and Kembhavi (2023) showed how compositional visual reasoning can be done by program generation without training.
Large Language Models have opened new avenues for neuro-symbolic reasoning. Techniques such as Chain-of-Thought (Wei et al., 2022), Tree-of-Thoughts (Yao et al., 2024), and Graph-of-Thoughts (Besta et al., 2024) have shown impressive results in complex reasoning tasks. However, these methods often produce inconsistent intermediate steps and struggle with out-of-domain reasoning. Interpretable Concept-based Models, as explored by Kim et al. (2018) and Chen et al. (2020b), aim to increase trust in deep learning models. However, state-of-the-art approaches often rely on high-dimensional concept embeddings that lack clear semantic meaning, limiting their interpretability.
Advanced Neuro-symbolic Frameworks like the Deep Concept Reasoner (DCR) (Barbiero et al., 2023) and GENOME (Chen et al., 2023) have made progress in combining neural and symbolic components. DCR constructs syntactic rule structures from concept embeddings, while GENOME introduces a modular approach for visual reasoning tasks. Despite these advancements, challenges in scalability and generalization to diverse task domains persist. A critical issue is reasoning shortcuts, where models use unintended concept semantics. To address this, Marconato et al. (2024) introduced BEARS, improving model calibration and informative annotation acquisition. These developments showcase the potential for imparting robustness and reliability via neuro-symbolic AI systems.
LLM Code Generation and Low-Resource Translation demonstrate the remarkable adaptability of large language models. In code generation, LLMs like Codex (Chen et al., 2021) and AlphaCode (Li et al., 2022) show proficiency across multiple programming languages, often outperforming specialized models. These systems excel at understanding context, generating syntactically correct code, and even solving complex algorithmic problems. Paralleling this, research in low-resource language translation (Zoph et al., 2016; Tanzer et al., 2023) reveals LLMs’ ability to rapidly adapt to new languages with minimal examples. Techniques like few-shot learning and cross-lingual transfer enable models to leverage knowledge from high-resource languages to improve performance on low-resource ones. Both domains highlight LLMs’ capacity for quick adaptation and generalization, suggesting potential for enhanced neuro-symbolic systems that can efficiently learn and apply formal reasoning across diverse domains with limited training data.
## 3 Proof of Thought : A Neurosymbolic Reasoning Framework
In this section, we introduce Proof of Thought (PoT), a novel framework that bridges NLP with formal logical reasoning to enhance the interpretability and verifiability of LLM outputs. We first outline the foundational concepts and notations that underpin our approach.
<details>
<summary>PoT_Framework.png Details</summary>
### Visual Description
## Diagram: Proof of Thought System Architecture
### Overview
This image is a technical system architecture diagram illustrating a framework called "Proof of Thought." It depicts a multi-stage process for enhancing the reasoning capabilities of Large Language Models (LLMs) by generating and verifying formal "Thought Programs." The system integrates natural language reasoning, formal logic, and theorem proving to produce verifiable outputs. The diagram is divided into two primary sections: a left panel showing the overall system flow and a right panel detailing the internal components of a "Thought Program."
### Components/Axes
The diagram is a flowchart with labeled boxes, arrows indicating data/control flow, and descriptive text annotations. There are no traditional chart axes. Key components are color-coded:
* **Orange Boxes:** Represent active processing modules (e.g., Natural Language Reasoner, Theorem Prover, Interpreter).
* **Green Icon:** Represents an LLM (Large Language Model) at the core of the generation process.
* **Yellow Box:** Encapsulates the detailed structure of the "Thought Program Components."
* **Blue Text/Arrows:** Primarily indicate data flow, inputs, outputs, and labels.
* **Black Dashed Lines:** Group related subsystems.
**Spatial Layout:**
* **Left Panel (Overall Flow):** Occupies the left ~60% of the image. It shows the high-level pipeline from a "Problem Statement" to final "Proof & Outputs."
* **Right Panel (Thought Program Components):** Occupies the right ~40% of the image, enclosed in a black dashed box. It provides a detailed breakdown of the "Thought Program" generated by the LLM.
* **Logo:** A "Proof of Thought" logo with a brain and checkmark is positioned in the bottom-center of the left panel.
### Detailed Analysis
**Left Panel - Overall System Flow:**
1. **Input:** A "Problem Statement" is fed into two parallel paths.
2. **Path 1 (Natural Language Reasoning):**
* The problem goes to a **"Natural Language Reasoner"** box. Text inside lists reasoning methods: "(CoT, CoT-SC, ToT, GoT)".
* This reasoner also receives "DSL Specifications, Generation Instructions, Good Examples, Common Mistakes."
* Its output is labeled **"Reasoning Output"** and flows to a **"Consistency Checker"**.
3. **Path 2 (Formal Thought Program Generation & Verification):**
* The problem also goes to a central **green LLM icon**.
* The LLM generates a **"Thought Program"** (indicated by a `</>` code icon).
* This program is sent to an **"Interpreter"**.
* The Interpreter produces an **"Error Stack Trace"** which loops back to the LLM, creating a feedback loop for refinement.
* The Interpreter's output also goes to a **"Theorem Prover"** labeled with the **"Z3"** logo.
* The Theorem Prover produces **"Proof & Outputs (SAT/UNSAT)"**.
* This proof output is also sent to the **"Consistency Checker"**, which compares it with the "Reasoning Output" from Path 1.
4. **Final Output:** The system's verified result is the **"Proof & Outputs (SAT/UNSAT)"**.
**Right Panel - Thought Program Components (Detailed View):**
This panel is a callout from the "Thought Program" in the left panel. It details what the LLM specifies.
1. **Top Section:** **"LLM Specifies a"** containing two boxes: **"Knowledge Base"** and **"Rules"**.
2. **Middle Section:** **"That Operate Over"** containing a box **"Sorts"**. From "Sorts," three arrows labeled **"Strongly Type"** point to boxes for **"Constants"**, **"Variables"**, and **"Functions"**.
3. **Bottom Section:** **"Using Actions"** containing two boxes: **"Verifications"** and **"Optimizations"**.
4. **Right-Side Flow (within the yellow box):**
* An **"Input (x)"** enters the system.
* It goes to a **"Logical Representation (DSL) Generating LLM"**.
* The output goes to an **"Interpreter"** (with a gear icon).
* The Interpreter produces **"Formal Logic Expressions"**.
* These expressions are fed into the **"Z3 Theorem Prover"**.
* The prover yields the final **"Proof & Outputs (SAT/UNSAT)"**.
* An **"Error Stack Trace"** also flows from the Interpreter back to the "Logical Representation... LLM".
### Key Observations
1. **Dual Verification Pathway:** The architecture employs a unique dual-check system: formal verification via Z3 (producing SAT/UNSAT) and consistency checking between the formal proof and the natural language reasoning output.
2. **Iterative Refinement Loop:** A clear feedback loop exists where the "Interpreter" sends an "Error Stack Trace" back to the generating LLM, enabling iterative correction of the Thought Program.
3. **Strong Typing Emphasis:** The Thought Program is built on a formally specified foundation with "Sorts" that are "Strongly Type[d]" for Constants, Variables, and Functions, ensuring logical rigor.
4. **Integration of Methods:** The diagram explicitly lists advanced reasoning techniques (Chain-of-Thought, Self-Consistency, Tree-of-Thought, Graph-of-Thought) as part of the Natural Language Reasoner, showing the system's intent to leverage and verify these methods.
5. **Modular Design:** The separation between the high-level flow (left) and the detailed Thought Program specification (right) indicates a modular, layered system design.
### Interpretation
This diagram presents a sophisticated framework for making LLM reasoning more reliable and verifiable. The core innovation is the "Thought Program"—a formal, interpretable representation of the LLM's reasoning process that can be executed, checked for errors, and mathematically proven.
The system addresses a critical weakness of standard LLMs: their outputs are not inherently verifiable. By translating natural language reasoning into a Domain-Specific Language (DSL) and formal logic, and then using a theorem prover (Z3), the framework can provide a formal guarantee (SAT/UNSAT) about the correctness of the conclusion relative to the specified knowledge and rules.
The "Consistency Checker" adds a second layer of validation, ensuring that the informal natural language reasoning aligns with the formal proof. This dual approach mitigates the risk of the LLM generating a formally correct but semantically irrelevant proof, or a plausible-sounding but logically flawed explanation.
The feedback loop via "Error Stack Trace" is crucial, as it allows the system to self-correct, mimicking a debugging process in software engineering. This transforms the LLM from a one-shot generator into a component within an iterative, verifiable reasoning engine. The overall architecture suggests a move towards "neuro-symbolic" AI, combining the flexible pattern recognition of neural networks (LLMs) with the rigorous, reliable inference of symbolic logic and formal methods.
</details>
Figure 1: Architecture of the Proof of Thought (PoT) framework, illustrating the integration of natural language reasoning with formal logical verification.
### 3.1 Background Concepts & Notation from LLM Reasoning Literature
Let $p_θ$ denote a pre-trained language model (LM) with parameters $θ$ . In a conversation, user messages (prompts) and LM replies (thoughts) are exchanged. We use lowercase letters $x,y,z,...$ to indicate LM thoughts, where the definition of a "thought" is use-case specific (e.g., a paragraph, document, or code block). The simplest Prompting Approach approach is Input-Output (IO) where an LM directly transforms an input sequence $x$ into output $y$ without intermediate steps. Chain-of-Thought (CoT) introduces intermediate thoughts $a_1,a_2,...$ between $x$ and $y$ , enhancing performance on tasks like mathematical reasoning.
Multiple CoTs generalizes CoT by generating $k$ independent chains and selecting the best output based on a prescribed scoring metric. This approach, introduced as Self-Consistency with CoT (CoT-SC), allows exploration of different reasoning paths. Tree of Thoughts (ToT) further enhances CoT-SC by modeling reasoning as a tree of thoughts. Each node represents a partial solution. For a given node, $k$ new nodes are generated, then evaluated using an LM or human scores. The tree expansion is guided by search algorithms like BFS or DFS. Finally, Graph of Thoughts (GoT) extends ToT by allowing more complex connections between thoughts, forming a directed graph structure. In GoT, thoughts can have multiple predecessors and successors, enabling more flexible reasoning paths and the combination of ideas from different branches. This approach allows for cyclic reasoning patterns and can capture more intricate problem-solving strategies.
### 3.2 Framework Overview
"All our knowledge begins with the senses, proceeds then to the understanding, and ends with reason. There is nothing higher than reason."
- Immanuel Kant, in Critique of Pure Reason
Proof of Thought models the LLM’s reasoning process as a structured transformation from natural language input to formal logical expressions that can be verified using theorem proving techniques. The framework consists of three primary components :
- Logical Representation Generator $G$ : Maps input $x$ to a logical representation $L$ using $p_θ$ .
- Interpreter $I$ : Parses $L$ and constructs formal logical expressions $φ$ in first-order logic (FOL).
- Theorem Prover $T$ : Verifies the validity of $φ$ and provides proofs or counterexamples.
The PoT reasoning process can thus be formalized as:
$$
L=G(x;p_θ);φ=I(L);Verification Result=T(φ)
$$
Guarantees: By using theorem proving, we rely on the principle of logical consequence, where conclusions are guaranteed to be true if the premises and inference rules, depicted in the logical representations (both of which are human readable, allowing interpretability and verifiability). These logical representations are the ultimate arbiter of truth and validity. The guarantees are what distinguishes PoT from other forms of reasoning. Inductive reasoning (drawing general conclusions from specific observations) can be useful, but doesn’t offer the same level of certainty. In contrast, guarantees with theorem proving allow us to establish precise arguments with mathematical truths with absolute confidence, elevating the reasoning process beyond mere conjecture or intuition.
Our Proof of Thought framework architecture (shown in Fig 1) introduces a JSON-based Domain Specific Language (DSL) along with the associated interpreter. Next, we discuss the design choices for these in detail.
### 3.3 Design of the JSON-Based Domain-Specific Language (DSL)
The core of our logical reasoning system is built upon a carefully designed JSON-based Domain-Specific Language (DSL) that serves as an intermediate representation for translating reasoning tasks into formal logic. This DSL was created with the primary challenge of being general-purpose enough to accommodate a wide range of reasoning problems. The choice of JSON as the underlying format was deliberate, leveraging its widespread use, human readability, and ease of parsing. This design decision ensures that the logical representations are both machine-parseable and accessible to users who may not have expertise in formal logic or programming. Moreover, JSON’s compatibility with structured outputs from AI service providers like OpenAI and Google, which offer guaranteed outputs matching particular schemas, makes it an ideal choice for our system that doesn’t rely on retraining models. The key components of the DSL are:
<details>
<summary>examplecomponents1.png Details</summary>

### Visual Description
\n
## Technical Specification Diagram: Task Assignment System Formalization
### Overview
The image displays a structured, formal specification for a task assignment system, presented as nine distinct green-bordered rectangular panels arranged in a 3x3 grid. Each panel contains a JSON-like data structure defining a specific component of the system's logic, including sorts, variables, functions, constants, a knowledge base, rules, verifications, and an optimization problem. The content is entirely textual and symbolic, representing a formal logic or constraint satisfaction model.
### Components/Axes
The image is segmented into nine independent panels, each with a clear title in quotes. The panels are organized as follows:
* **Top Row (Left to Right):** "sorts", "variables", "verifications" (part 1).
* **Middle Row (Left to Right):** "functions", "knowledge_base", "verifications" (part 2, continuing from top-right).
* **Bottom Row (Left to Right):** "constants", "rules", "optimization".
### Detailed Analysis / Content Details
Below is a precise transcription of the content within each panel.
**1. Top-Left Panel: "sorts"**
```json
"sorts": [
{"name": "Person", "type": "DeclareSort"},
{"name": "Equipment", "type": "DeclareSort"},
{"name": "Task", "type": "DeclareSort"},
{"name": "Location", "type": "DeclareSort"},
{"name": "Time", "type": "RealSort"}
]
```
* **Content:** Defines five fundamental data types (sorts) for the domain: Person, Equipment, Task, Location (all declared sorts), and Time (a real-number sort).
**2. Top-Middle Panel: "variables"**
```json
"variables": [
{"name": "p", "sort": "Person"},
{"name": "e", "sort": "Equipment"},
{"name": "t", "sort": "Task"},
{"name": "l", "sort": "Location"},
{"name": "time", "sort": "Time"}
]
```
* **Content:** Declares five variables (`p`, `e`, `t`, `l`, `time`) corresponding to the previously defined sorts.
**3. Top-Right & Middle-Right Panels: "verifications"**
This section spans two panels. The top-right panel begins the list, and the middle-right panel contains the second entry.
```json
"verifications": [
{
"name": "All Tasks Assigned",
"forall": [
{"name": "t", "sort": "Task"}
],
"constraint": "Exists([{'name': 'p', 'sort': 'Person'}], assigned_to(t, p))"
},
{
"name": "No Overqualified Assignments",
"forall": [
{"name": "p", "sort": "Person"},
{"name": "t", "sort": "Task"}
],
"implies": {
"antecedent": "assigned_to(t, p)",
"consequent": "skill_level(p, t) <= 7"
}
}
]
```
* **Content:** Defines two verification rules (constraints that must hold true).
1. **All Tasks Assigned:** For every task `t`, there must exist a person `p` such that `assigned_to(t, p)` is true.
2. **No Overqualified Assignments:** For any person `p` and task `t`, if `p` is assigned to `t`, then the `skill_level` of `p` for `t` must be less than or equal to 7.
**4. Middle-Left Panel: "functions"**
```json
"functions": [
{"name": "assigned_to", "domain": ["Task", "Person"], "range": "BoolSort"},
{"name": "location_of", "domain": ["Person"], "range": "Location"},
{"name": "start_time", "domain": ["Task"], "range": "Time"},
{"name": "duration", "domain": ["Task"], "range": "Time"},
{"name": "skill_level", "domain": ["Person", "Task"], "range": "IntSort"}
]
```
* **Content:** Defines five functions mapping inputs (domains) to outputs (ranges).
* `assigned_to(Task, Person)`: Returns a Boolean (true/false).
* `location_of(Person)`: Returns a Location.
* `start_time(Task)`: Returns a Time.
* `duration(Task)`: Returns a Time.
* `skill_level(Person, Task)`: Returns an Integer.
**5. Center Panel: "knowledge_base"**
```json
"knowledge_base": [
"assigned_to(task1, alice)",
"location_of(alice) == warehouse_A",
"start_time(task1) == 9.0",
"duration(task1) == 2.0",
"skill_level(alice, task1) == 5"
]
```
* **Content:** Lists specific, ground facts about the current state:
* Task `task1` is assigned to person `alice`.
* Alice is located at `warehouse_A`.
* Task `task1` starts at time `9.0`.
* Task `task1` has a duration of `2.0` time units.
* Alice's skill level for task `task1` is `5`.
**6. Bottom-Left Panel: "constants"**
```json
"constants": {
"persons": {
"sort": "Person",
"members": ["alice", "bob", "charlie"]
},
"equipment": {
"sort": "Equipment",
"members": ["forklift", "crane", "truck"]
},
"locations": {
"sort": "Location",
"members": ["warehouse_A", "construction_site_B", "office_C"]
}
}
```
* **Content:** Defines the specific instances (constants) for three sorts.
* **Persons:** alice, bob, charlie.
* **Equipment:** forklift, crane, truck.
* **Locations:** warehouse_A, construction_site_B, office_C.
**7. Bottom-Middle Panel: "rules"**
```json
"rules": [
{
"name": "Task Assignment Rule",
"forall": [
{"name": "p", "sort": "Person"},
{"name": "t", "sort": "Task"}
],
"implies": {
"antecedent": "assigned_to(t, p)",
"consequent": "location_of(p) == location_of(t)"
}
}
]
```
* **Content:** Defines a logical rule. For any person `p` and task `t`, if `p` is assigned to `t`, then the location of `p` must equal the location of `t`. This enforces a spatial constraint for assignments.
**8. Bottom-Right Panel: "optimization"**
```json
"optimization": {
"variables": [
{"name": "x", "sort": "Person"},
{"name": "y", "sort": "Task"}
],
"constraints": [
"ForAll([x, y], Implies(assigned_to(y, x), skill_level(x, y) >= 3))",
"ForAll([y], Exists([x], assigned_to(y, x)))"
],
"objectives": [
{
"type": "minimize",
"expression": "Sum([x, y], If(assigned_to(y, x), skill_level(x, y), 0))"
}
]
}
```
* **Content:** Defines an optimization problem.
* **Variables:** `x` (Person), `y` (Task).
* **Constraints:**
1. For all assignments, the person's skill level for the task must be at least 3.
2. Every task must be assigned to at least one person.
* **Objective:** Minimize the sum of skill levels for all assignments. The expression sums `skill_level(x, y)` for every pair `(x, y)` where `assigned_to(y, x)` is true, otherwise adding 0.
### Key Observations
1. **Formal Structure:** The specification uses a consistent, formal syntax resembling first-order logic and constraint programming.
2. **Interconnected Components:** The panels are not independent. The `sorts` and `constants` define the universe of discourse. The `functions` and `variables` operate within that universe. The `knowledge_base`, `rules`, and `verifications` define the system's state and constraints. The `optimization` panel builds upon all previous elements to define a goal.
3. **Specific Instance:** The `knowledge_base` provides a snapshot with concrete data (alice, task1, warehouse_A), while other panels define general rules and structures.
4. **Constraint Hierarchy:** There are multiple layers of constraints: basic verification rules (e.g., all tasks assigned), logical rules (e.g., location matching), and optimization constraints (e.g., minimum skill level of 3).
### Interpretation
This image represents a **formal model for a constrained task allocation problem**. It is likely used in fields like operations research, AI planning, or logistics software specification.
* **What it Demonstrates:** The model captures a real-world scenario where tasks must be assigned to qualified personnel at specific locations and times, subject to various business rules (skill matching, location proximity, no over-qualification). The inclusion of an optimization objective (minimizing total skill level used) suggests an aim for efficiency, perhaps to assign the most appropriately skilled (not over-skilled) workers to tasks.
* **Relationships Between Elements:** The `sorts` and `constants` establish the "vocabulary" of the domain. The `functions` define the "properties" and "relationships" between entities. The `knowledge_base` is a specific "fact sheet." The `rules` and `verifications` are the "laws" the system must obey. The `optimization` block is the "goal" the system should strive for when making assignments.
* **Notable Anomalies/Tensions:** There is a potential tension between the `verifications` rule "No Overqualified Assignments" (skill <= 7) and the `optimization` constraint requiring skill >= 3. This defines an acceptable skill range of [3, 7] for assignments. The optimization goal to *minimize* the sum of skill levels would push assignments towards the lower end of this range (skill level 3), which aligns with the business logic of using appropriately, not excessively, skilled labor.
* **Peircean Investigation:** The model is a **symbolic representation** (a sign) of a physical task assignment system. Its **interpretant** would be the software or algorithm that processes this specification to produce valid and optimal assignment schedules. The **object** it refers to is the real-world set of people, tasks, equipment, and locations. The specification's value lies in making the implicit rules of task assignment explicit, machine-readable, and optimizable.
</details>
Figure 2: Example DSL program components of the Proof of Thought (PoT) framework for a dummy task assignment verification and optimization problem. The figure displays the JSON-based Domain-Specific Language (DSL) structure, including sort definitions, variables, functions, constants, knowledge base, rules, verifications, and optimization constraints for a workforce management scenario.
1. Sorts ( $S$ ) define the domains or types used in the logic. Let $S=\{S_1,S_2,…,S_n\}$ be the set of sorts, where each $S_i$ represents a specific domain. The inclusion of sorts in our system is a key differentiator. It allows for reasoning over high-level, human-understandable concepts, which is crucial for bridging the gap between natural language problem descriptions and formal logical representations. The sort definition in Fig 2 allows for more intuitive problem representation. For instance, instead of reasoning about abstract entities, we can now reason about Persons, Equipment, Tasks, Locations, and Time. This makes it easier to translate natural language problems into formal logic. The type-safe reasoning catches semantic errors early. For example, if we tried to apply a function meant for Equipment to a Person, the system would catch this error before any reasoning takes place. Moreover, this structure allows for domain-specific reasoning strategies. For instance, we could implement specialized reasoning algorithms for time-based logic using the Time sort.
1. Functions ( $F$ ) definitions in our system go beyond simple predicates, allowing for rich, typed relationships between sorts. Let $f:S_1× S_2×…× S_k→ S_r$ represent a function, where $S_1,S_2,…,S_k,S_r∈S$ . For predicates, $S_r=Bool$ .
For example, in Fig 2, the function definition allows for complex domain modeling. For instance, ‘assigned_to‘ represents a relationship between Tasks and Persons, ‘location_of‘ transforms a Person into a Location, and ‘skill_level‘ represents a property of a Person in relation to a specific Task. The type-checking ensures that functions are only applied to arguments of the correct sort, reducing logical errors. For example, trying to find the ‘skill_level‘ of an Equipment item for a Task would be caught as a type error. In future work, we hope that these function definitions also open up the possibility of incorporating external algorithms. For instance, the ‘duration’ function could be linked to an external scheduling algorithm that calculates task durations based on various factors.
1. Constants ( $C$ ) with associated sorts provide grounding for abstract reasoning in concrete entities. Let $c_i:S_j$ denote that constant $c_i$ is of sort $S_j$ . In Fig 2 constant declaration grounds the abstract sorts in concrete entities. It allows for easy integration of domain-specific knowledge - for instance, we know that "alice", "bob", and "charlie" are Persons in our system. In future work, we believe this structure has the potential for linking with external databases or knowledge graphs. For example, the "equipment" constants could be linked to an external database containing detailed specifications for each piece of equipment.
1. Variables ( $V$ ) enable clear scoping rules for quantifiers and type-safe substitutions in logical formulas. Let $x_i:S_j$ denote that variable $x_i$ ranges over sort $S_j$ (see Fig 2).
1. Knowledge Base ( $KB$ ) contains axioms or facts assumed to be true within the logical system. Let $KB=\{φ_1,φ_2,…,φ_m\}$ where each $φ_i$ is a well-formed formula in first-order logic. The structured knowledge base allows for separation of axioms from rules and queries, and supports incremental knowledge addition. In Fig 2, the knowledge base contains factual information about the problem domain. It’s separate from the rules and verifications, allowing for easy updates and additions without changing the core reasoning system. This structure also allows for potential consistency checking. For instance, we could verify that no person is assigned to two tasks at the same time, or that no task has a negative duration.
1. Rules ( $R$ ) specify logical constructs, often involving quantifiers and implications. Let $R=\{r_1,r_2,…,r_l\}$ where each $r_i$ is a well-formed formula representing a rule. The explicit representation of rules enables a clear distinction between factual knowledge and inferential knowledge. These rules represent inferential knowledge - knowledge that can be derived from the facts in the knowledge base. They allow for easy addition of domain-specific reasoning patterns. This explicit representation of rules also supports explainable AI. When the system makes an inference, it can point to the specific rule(s) used, making its reasoning process transparent and understandable to users. For example, some rules are depicted in Fig 2 and here are a few more:
- $∀ x:Person,Worker(x)→∃ y:Equipment,Wearing(x,y)$
- $∀ x:Person,∀ y:Equipment,Wearing(x,y)∧SafetyGear(y)→Safe(x)$
1. Verifications ( $V$ ) state properties or conditions to be verified by the theorem prover. Let $V=\{v_1,v_2,…,v_p\}$ where each $v_i$ is a well-formed formula to be verified. Separating verifications from the knowledge base and rules allows for clear goal-directed reasoning. These verifications (Fig 2) represent specific properties we want to check in our system. They allow for easy testing and validation of the knowledge base and rules. When a verification fails, the system can potentially generate counter-examples, providing valuable insights into why the desired property doesn’t hold. For example:
- $∀ x:Person,Worker(x)→Safe(x)$
- $∃ x:Person,Worker(x)∧\lnotSafe(x)$
1. Optimization (optional) ( $O$ ) sections define problems with objectives and constraints. Let $O=(f_obj,C)$ where $f_obj$ is the objective function and $C$ is a set of constraints. The optimization problem in Fig 2 seeks to minimize the total skill level of assigned persons while ensuring that all tasks are assigned and that each assigned person has at least the minimum required skill level. This ability to combine logical constraints with numerical optimization allows for the representation of complex real-world problems that go beyond pure logical satisfiability. We intend to benchmark this in future work. Here is an example:
- $minimize f_obj(x)=∑_i=1^ncost(x_i)$
- subject to: $∀ i,1≤ i≤ n,Safe(x_i)$
1. Actions ( $A$ ) list what the interpreter has to perform. The only two possible actions are ‘verify’ and ‘optimize’. This simple declaration tells the system what to do with the problem representation we’ve built up. It provides flexibility in choosing different reasoning or optimization approaches for the same problem representation. For extensibility, this structure also opens up possibilities for meta-reasoning about which actions to take. For instance, the system could analyze the problem structure to decide whether to attempt verification first or go straight to optimization.
### 3.4 Design of the Interpreter’s Facilities and Capabilities
This section provides an in-depth description of the interpreter’s facilities, detailing how it constructs and manipulates logical expressions.
Type System, Sort Management: The interpreter implements a robust type system, managing sorts and ensuring type safety across all expressions. It supports a variety of Z3 compatible sorts, including primitive sorts like Bool, Int, and Real, which form the foundation of the type system. User-defined sorts, known as declared sorts, allow for the representation of specific domains such as Person or Equipment. For situations requiring a finite set of elements, enumerated sorts are available. The type system also accommodates composite sorts, constructed using type constructors, which enable the creation of function sorts or tuple sorts. Throughout its operations, the interpreter rigorously enforces type consistency, ensuring that functions and predicates are applied only to arguments of the correct sorts.
Symbol Table, Scope Management: Central to the interpreter’s functionality is a symbol table that maintains mappings from identifiers to their definitions, including variables, constants, and functions. This table is crucial for scope management, particularly when dealing with quantified variables in logical expressions. The parsing process is another key component, where the interpreter builds abstract syntax trees (ASTs) that represent the structure of expressions. This process handles a wide range of logical constructs, from atomic formulas (basic predicates applied to terms) to complex formulas constructed using logical connectives and quantifiers. The interpreter pays special attention to quantifiers, carefully managing bound variables to ensure correct scoping. Additionally, it supports substitution of terms for variables, an essential operation in applying inference rules.
Pre-processing: While the bulk of reasoning is handled by the theorem prover, the interpreter applies basic inference and simplification rules to optimize expressions before passing them on. This includes simplification processes that reduce expressions using logical identities, such as eliminating double negations. Normalization is another crucial step, converting expressions into a standard form (like prenex normal form) to facilitate theorem proving. The interpreter also performs early error detection, identifying contradictory statements or type mismatches before they can cause issues in later stages of processing.
Feedback Loop: Adequate error handling and diagnostics are paramount in the interpreter’s design. It provides detailed error messages to assist the LLM in identifying and correcting issues with its programs. These diagnostics cover a range of potential problems, including type errors that indicate inconsistencies or mismatches in the type system, alerts for undefined symbols when functions, predicates, or constants are used without proper definition, and syntax errors that highlight issues in the structure of logical expressions.
Future Proofing: The interpreter’s architecture emphasizes extensibility and customization. Users have the flexibility to extend its capabilities in several ways. They can add new sorts to define additional domains of discourse, expanding the system’s ability to represent complex scenarios. The logical language can be enhanced by defining new functions and predicates, allowing users to capture more intricate relationships within their domain of interest. Furthermore, the modular design of the interpreter facilitates integration with different theorem provers or logic systems, enhancing its versatility and applicability to various problem domains.
## 4 Results
### 4.1 StrategyQA - Complex Natural Language Reasoning
Task Setup: StrategyQA presents a significant challenge in natural language processing, testing a model’s ability to perform multi-hop, implicit reasoning across diverse scenarios. This boolean question answering benchmark requires models to infer unstated reasoning steps, mirroring complex human cognitive processes. For example, "Did Aristotle use a laptop?" requires the implicit chain: "When did Aristotle live? When was the laptop invented? Do these time periods overlap?" This level of abstraction surpasses simple fact retrieval or explicit reasoning tasks in other benchmarks like BoolQ or Twenty Questions (20QA). While state-of-the-art language models have shown impressive performance on StrategyQA (e.g., PaLM-2 achieving 90.20% accuracy with few-shot Chain of Thought and Self Consistency (Anil et al., 2023)), they lack transparency and verifiability in their reasoning process. Our Proof of Thought (PoT) framework addresses this limitation by providing complete, explicit, and verifiable reasoning chains. PoT breaks down implicit reasoning steps into explicit logical representations, defines the knowledge base used, and ensures each inference is provable through a theorem prover.
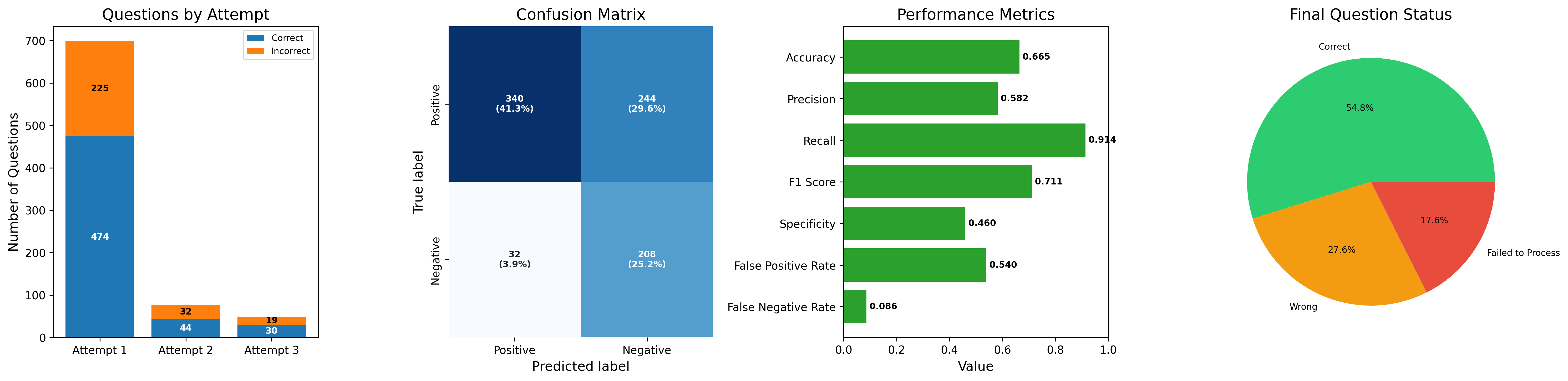
PoT Results: We evaluated PoT on a sample of 1000 questions from the StrategyQA dataset, focusing on the framework’s ability to generate syntactically correct programs, produce provable reasoning chains, and match outputs with correct answers. The system, with the inclusion of a 3 step feedback loops (i.e., initial prompt, +2 attempts at resolving), successfully compiled and executed 82.4% of the 1000 processed questions, marking a significant improvement from runs with lower feedback loops. This increase in compilation success rate underscores the effectiveness of our feedback mechanism in addressing and resolving issues in generated logical representations. The system demonstrated strong recall at 91.40%, indicating its proficiency in identifying true positive cases. The F1 score of 71.13% suggests a good balance between precision and recall, though precision (58.22%) presents an area for potential enhancement. The high recall, coupled with a false positive rate of 53.98%, indicates a tendency for the system to overpredict positive cases. This observation points to a need for future refinements in discriminating between positive and negative instances more accurately. While the compilation success rate is encouraging, the 17.6% of questions that failed to compile highlight an area for further improvement. Enhancing the robustness of the code generation process through improved prompting techniques, fine-tuning, and expansion of the feedback loop mechanism could potentially reduce this failure rate in future iterations.
### 4.2 Multimodal Reddit-OSHA Benchmark
Task Setup: We curated 103 samples from the r/OSHA subreddit, featuring individuals in extremely hazardous situations. This dataset represents long-tail, low-probability scenarios, mirroring challenging real-world deployment conditions for health and safety applications. The images encompass a wide range of problems with varied lighting, scene setups, visual clutter, and resolutions.
Baselines: We implemented four reasoning strategies using GPT-4 as the underlying language model: Chain of Thought (CoT), Chain of Thought with Self-Consistency (CoT-SC), Tree of Thought (ToT), and Graph of Thought (GoT). Each baseline processes base64-encoded images and uses a consistent system prompt instructing the model to act as a safety inspector. CoT encourages step-by-step reasoning, concluding with a binary hazard decision. CoT-SC extends this by generating 5 independent reasoning paths per image, with the final decision determined by majority voting. ToT explores multiple reasoning paths in a tree-like structure with a maximum depth of 3 and a breadth of 2 at each node. GoT implements an iterative reasoning process with 3 iterations per image, building upon previous analyses. Evaluation metrics include win rate (proportion of correctly identified hazards) and reasoning richness (number of sentences in model responses).
Baseline Results: All reasoning strategies demonstrated high performance, with CoT achieving a 99.03% win rate and CoT-SC, ToT, and GoT all achieving perfect 100% win rates. This suggests that advanced reasoning strategies can correct errors made by simpler approaches. Reasoning richness varied significantly, with ToT producing the most detailed responses (often over 1000 sentences per image) and CoT the most concise (25-30 sentences).
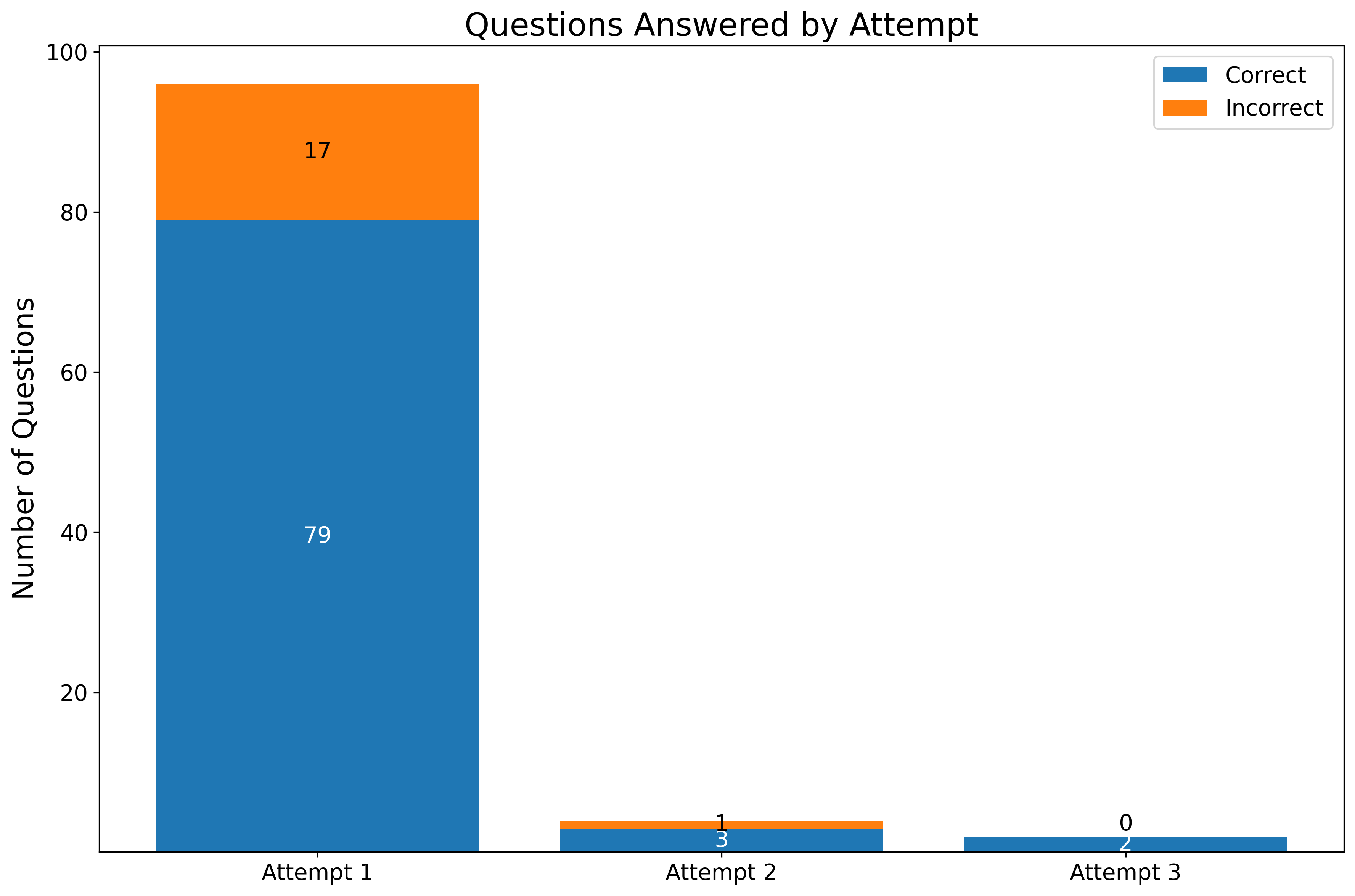
PoT Results: Our Proof of Thought framework showed remarkable improvements on this dataset with the inclusion of a 3 step feedback loop (i.e., initial prompt, +2 attempts at resolving). Notably, we reduced compilation errors from 14.6% to 0%, demonstrating the effectiveness of our feedback and error correction mechanisms. The win rate on compiled programs increased from 72% to 81.55%, indicating both more reliable code generation and more accurate logical reasoning.
## 5 Discussion and Future work
Future research directions include expanding PoT to handle more complex logical structures, that extend past boolean SAT & UNSAT, using one versus all setups, and developing more sophisticated feedback mechanisms to further reduce compilation errors. We intend to explore JSON-like representations for non-boolean responses. Additionally, exploring ways to make the logical representations more accessible to non-expert users and investigating the scalability of PoT to larger, more diverse datasets will be important next steps. Further, integrating PoT with other techniques such as model updates using reinforcement learning, or supervised fine-tuned models on synthetically generated syntactically correct PoT programs might unlock at-scale “System 2” thinking.
## 6 Conclusion
Proof of Thought bridges the gap between language models’ flexibility and formal logic’s rigor, offering a promising solution for trustworthy reasoning in vision-language models. By enhancing interpretability and providing reasoning guarantees, PoT addresses critical challenges in AI system accountability and reliability. Our results demonstrate its potential in both natural language and multimodal reasoning tasks, paving the way for more transparent, verifiable AI systems capable of complex reasoning in high-stakes domains.
## References
- Anil et al. [2023] Rohan Anil, Andrew M Dai, Orhan Firat, Melvin Johnson, Dmitry Lepikhin, Alexandre Passos, Siamak Shakeri, Emanuel Taropa, Paige Bailey, Zhifeng Chen, et al. Palm 2 technical report. arXiv preprint arXiv:2305.10403, 2023.
- Barbiero et al. [2023] Pietro Barbiero, Gabriele Ciravegna, Francesco Giannini, Mateo Espinosa Zarlenga, Lucie Charlotte Magister, Alberto Tonda, Pietro Lió, Frederic Precioso, Mateja Jamnik, and Giuseppe Marra. Interpretable neural-symbolic concept reasoning. In International Conference on Machine Learning, pages 1801–1825. PMLR, 2023.
- Bender et al. [2021] Emily M Bender, Timnit Gebru, Angelina McMillan-Major, and Shmargaret Shmitchell. On the dangers of stochastic parrots: Can language models be too big? In Proceedings of the 2021 ACM conference on fairness, accountability, and transparency, pages 610–623, 2021.
- Besta et al. [2024] Maciej Besta, Nils Blach, Ales Kubicek, Robert Gerstenberger, Michal Podstawski, Lukas Gianinazzi, Joanna Gajda, Tomasz Lehmann, Hubert Niewiadomski, Piotr Nyczyk, et al. Graph of thoughts: Solving elaborate problems with large language models. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 38, pages 17682–17690, 2024.
- Chen et al. [2021] Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde De Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, et al. Evaluating large language models trained on code. arXiv preprint arXiv:2107.03374, 2021.
- Chen et al. [2020a] Xiaojun Chen, Shengbin Jia, and Yang Xiang. A review: Knowledge reasoning over knowledge graph. Expert systems with applications, 141:112948, 2020a.
- Chen et al. [2023] Zhenfang Chen, Rui Sun, Wenjun Liu, Yining Hong, and Chuang Gan. Genome: generative neuro-symbolic visual reasoning by growing and reusing modules. arXiv preprint arXiv:2311.04901, 2023.
- Chen et al. [2020b] Zhi Chen, Yijie Bei, and Cynthia Rudin. Concept whitening for interpretable image recognition. Nature Machine Intelligence, 2(12):772–782, 2020b.
- Danilevsky et al. [2020] Marina Danilevsky, Kun Qian, Ranit Aharonov, Yannis Katsis, Ban Kawas, and Prithviraj Sen. A survey of the state of explainable ai for natural language processing. arXiv preprint arXiv:2010.00711, 2020.
- d’Avila Garcez et al. [2009] Artur S d’Avila Garcez, Luís C Lamb, and Dov M Gabbay. Neural-symbolic learning systems. Springer, 2009.
- Gupta and Kembhavi [2023] Tanmay Gupta and Aniruddha Kembhavi. Visual programming: Compositional visual reasoning without training. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 14953–14962, 2023.
- Jordan and Mitchell [2015] Michael I Jordan and Tom M Mitchell. Machine learning: Trends, perspectives, and prospects. Science, 349(6245):255–260, 2015.
- Kampffmeyer et al. [2019] Michael Kampffmeyer, Yinbo Chen, Xiaodan Liang, Hao Wang, Yujia Zhang, and Eric P Xing. Rethinking knowledge graph propagation for zero-shot learning. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 11487–11496, 2019.
- Kim et al. [2018] Been Kim, Martin Wattenberg, Justin Gilmer, Carrie Cai, James Wexler, Fernanda Viegas, et al. Interpretability beyond feature attribution: Quantitative testing with concept activation vectors (tcav). In International conference on machine learning, pages 2668–2677. PMLR, 2018.
- Li et al. [2022] Yujia Li, David Choi, Junyoung Chung, Nate Kushman, Julian Schrittwieser, Rémi Leblond, Tom Eccles, James Keeling, Felix Gimeno, Agustin Dal Lago, et al. Competition-level code generation with alphacode. Science, 378(6624):1092–1097, 2022.
- Li et al. [2023] Ziyang Li, Jiani Huang, and Mayur Naik. Scallop: A language for neurosymbolic programming. Proceedings of the ACM on Programming Languages, 7(PLDI):1463–1487, 2023.
- Manhaeve et al. [2018] Robin Manhaeve, Sebastijan Dumancic, Angelika Kimmig, Thomas Demeester, and Luc De Raedt. Deepproblog: Neural probabilistic logic programming. Advances in neural information processing systems, 31, 2018.
- Marconato et al. [2024] Emanuele Marconato, Samuele Bortolotti, Emile van Krieken, Antonio Vergari, Andrea Passerini, and Stefano Teso. Bears make neuro-symbolic models aware of their reasoning shortcuts. arXiv preprint arXiv:2402.12240, 2024.
- Marcus [2020] Gary Marcus. The next decade in ai: four steps towards robust artificial intelligence. arXiv preprint arXiv:2002.06177, 2020.
- Rudin [2019] Cynthia Rudin. Stop explaining black box machine learning models for high stakes decisions and use interpretable models instead. Nature machine intelligence, 1(5):206–215, 2019.
- Tanzer et al. [2023] Garrett Tanzer, Mirac Suzgun, Eline Visser, Dan Jurafsky, and Luke Melas-Kyriazi. A benchmark for learning to translate a new language from one grammar book. arXiv preprint arXiv:2309.16575, 2023.
- Towell and Shavlik [1994] Geoffrey G Towell and Jude W Shavlik. Knowledge-based artificial neural networks. Artificial intelligence, 70(1-2):119–165, 1994.
- Towell et al. [1990] Geoffrey G Towell, Jude W Shavlik, and Michiel O Noordewier. Refinement of approximate domain theories by knowledge-based neural networks. In Proceedings of the eighth National conference on Artificial intelligence-Volume 2, pages 861–866, 1990.
- Wang et al. [2022] Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc Le, Ed Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. Self-consistency improves chain of thought reasoning in language models. arXiv preprint arXiv:2203.11171, 2022.
- Wei et al. [2022] Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. Chain-of-thought prompting elicits reasoning in large language models. Advances in neural information processing systems, 35:24824–24837, 2022.
- Yang et al. [2023] Jianwei Yang, Hao Zhang, Feng Li, Xueyan Zou, Chunyuan Li, and Jianfeng Gao. Set-of-mark prompting unleashes extraordinary visual grounding in gpt-4v. arXiv preprint arXiv:2310.11441, 2023.
- Yao et al. [2024] Shunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Shafran, Tom Griffiths, Yuan Cao, and Karthik Narasimhan. Tree of thoughts: Deliberate problem solving with large language models. Advances in Neural Information Processing Systems, 36, 2024.
- Zhang et al. [2021] Chiyuan Zhang, Samy Bengio, Moritz Hardt, Benjamin Recht, and Oriol Vinyals. Understanding deep learning (still) requires rethinking generalization. Communications of the ACM, 64(3):107–115, 2021.
- Zoph et al. [2016] Barret Zoph, Deniz Yuret, Jonathan May, and Kevin Knight. Transfer learning for low-resource neural machine translation. arXiv preprint arXiv:1604.02201, 2016.
## 7 Appendix
### 7.1 StrategyQA Results
<details>
<summary>strategyqaresults.png Details</summary>
### Visual Description
## Composite Performance Dashboard: Four-Chart Analysis
### Overview
The image displays a single horizontal composite figure containing four distinct charts that collectively analyze the performance of a question-answering or classification system across multiple attempts. The charts are, from left to right: a stacked bar chart ("Questions by Attempt"), a confusion matrix heatmap, a horizontal bar chart ("Performance Metrics"), and a pie chart ("Final Question Status"). The overall theme is the evaluation of accuracy, error types, and progression over attempts.
### 1. Questions by Attempt (Stacked Bar Chart)
**Components/Axes:**
* **Title:** "Questions by Attempt"
* **Y-axis:** Label: "Number of Questions". Scale: 0 to 700, with major ticks every 100.
* **X-axis:** Categories: "Attempt 1", "Attempt 2", "Attempt 3".
* **Legend:** Located in the top-right corner. "Correct" (blue), "Incorrect" (orange).
**Detailed Analysis:**
* **Attempt 1:** The tallest bar. The blue "Correct" segment has a value of **474**. The orange "Incorrect" segment stacked on top has a value of **225**. The total height is 699 questions.
* **Attempt 2:** A much shorter bar. The blue "Correct" segment is **44**. The orange "Incorrect" segment is **32**. Total: 76 questions.
* **Attempt 3:** The shortest bar. The blue "Correct" segment is **30**. The orange "Incorrect" segment is **19**. Total: 49 questions.
**Key Observations:**
* There is a dramatic, steep decline in the total number of questions processed from Attempt 1 (699) to Attempt 2 (76) and Attempt 3 (49).
* In all three attempts, the number of "Correct" answers is higher than "Incorrect" ones.
* The ratio of correct to incorrect answers remains relatively stable across attempts (Attempt 1: ~2.1:1, Attempt 2: ~1.4:1, Attempt 3: ~1.6:1).
### 2. Confusion Matrix (Heatmap)
**Components/Axes:**
* **Title:** "Confusion Matrix"
* **Y-axis (True label):** Categories: "Positive" (top row), "Negative" (bottom row).
* **X-axis (Predicted label):** Categories: "Positive" (left column), "Negative" (right column).
* **Cell Labels:** Each cell contains a raw count and a percentage in parentheses. The percentage is likely relative to the total number of instances (824, calculated from the sum of all cells).
**Detailed Analysis:**
* **Top-Left Cell (True Positive - TP):** Dark blue. Value: **340 (41.3%)**. Instances correctly predicted as Positive.
* **Top-Right Cell (False Negative - FN):** Medium blue. Value: **244 (29.6%)**. Actual Positive instances incorrectly predicted as Negative.
* **Bottom-Left Cell (False Positive - FP):** Very light blue/white. Value: **32 (3.9%)**. Actual Negative instances incorrectly predicted as Positive.
* **Bottom-Right Cell (True Negative - TN):** Medium blue. Value: **208 (25.2%)**. Instances correctly predicted as Negative.
**Key Observations:**
* The model has a high number of False Negatives (244), which is the second-largest category.
* The number of False Positives (32) is the smallest category.
* The model correctly identifies 340 out of 584 actual Positive instances (TP + FN) and 208 out of 240 actual Negative instances (TN + FP).
### 3. Performance Metrics (Horizontal Bar Chart)
**Components/Axes:**
* **Title:** "Performance Metrics"
* **Y-axis (Metrics):** Listed from top to bottom: "Accuracy", "Precision", "Recall", "F1 Score", "Specificity", "False Positive Rate", "False Negative Rate".
* **X-axis (Value):** Scale from 0.0 to 1.0, with major ticks every 0.2.
* **Bars:** All bars are green. The exact value is printed at the end of each bar.
**Detailed Analysis:**
* **Accuracy:** Bar extends to **0.665**.
* **Precision:** Bar extends to **0.582**.
* **Recall:** The longest bar, extending to **0.914**.
* **F1 Score:** Bar extends to **0.711**.
* **Specificity:** Bar extends to **0.460**.
* **False Positive Rate:** Bar extends to **0.540**.
* **False Negative Rate:** The shortest bar, extending to **0.086**.
**Key Observations:**
* **Recall (0.914)** is the highest metric, indicating the model is very good at finding all actual positive instances.
* **Specificity (0.460)** and **Precision (0.582)** are relatively low, indicating the model has a high rate of false alarms (low specificity) and many of its positive predictions are incorrect (low precision).
* The **False Positive Rate (0.540)** is high, consistent with the low Specificity.
* The **False Negative Rate (0.086)** is low, consistent with the high Recall.
### 4. Final Question Status (Pie Chart)
**Components/Axes:**
* **Title:** "Final Question Status"
* **Slices & Labels:**
* **Green Slice (Top):** Label: "Correct". Percentage: **54.8%**.
* **Orange Slice (Bottom-Left):** Label: "Wrong". Percentage: **27.6%**.
* **Red Slice (Bottom-Right):** Label: "Failed to Process". Percentage: **17.6%**.
**Detailed Analysis:**
* The "Correct" category constitutes the majority, at 54.8%.
* The "Wrong" category is the next largest, at 27.6%.
* The "Failed to Process" category accounts for 17.6% of the final status.
**Key Observations:**
* Nearly half of the questions (45.2%) were either answered incorrectly or could not be processed at all.
* The "Failed to Process" slice is a significant portion, suggesting a non-trivial system or data issue beyond simple incorrect answers.
### Interpretation
This dashboard paints a picture of a classification system with a specific performance profile:
1. **High Recall, Low Precision Bias:** The system is optimized or naturally inclined to cast a wide net (high Recall of 0.914, low False Negative Rate of 0.086). However, this comes at the cost of many false alarms (low Precision of 0.582, high False Positive Rate of 0.540, low Specificity of 0.460). It misses very few true positives but incorrectly labels many negatives as positive.
2. **Attempt Progression:** The "Questions by Attempt" chart suggests a filtering or iterative process. The vast majority of questions are handled in Attempt 1. The sharp drop-off implies that questions are either resolved (correctly or incorrectly) or perhaps filtered out after the first attempt, leaving a smaller, potentially harder subset for subsequent attempts.
3. **Overall Outcome:** The "Final Question Status" pie chart shows that while the system gets more than half right (54.8%), a substantial portion fails. Combining "Wrong" and "Failed to Process" indicates that 45.2% of questions do not yield a correct, processable answer. This aligns with the moderate overall Accuracy (0.665) and highlights that the high Recall does not translate to high overall reliability.
4. **Data Consistency:** The confusion matrix percentages sum to 100% (41.3+29.6+3.9+25.2=100%), confirming internal consistency. The total instances (824) from the matrix do not directly match the sum of questions from the bar chart (699+76+49=824), which is a perfect match, confirming the charts describe the same dataset.
**In summary, the system is a sensitive detector (high recall) but not a precise one. It processes most questions in a first attempt, and its final output is correct slightly more often than not, but with a very high rate of false positives and a significant failure-to-process rate.**
</details>
Figure 3: Performance analysis of the Proof of Thought (PoT) framework on the StrategyQA dataset. The includes four visualizations: (1) a stacked bar chart showing questions answered by attempt, (2) a pie chart displaying the final question status, (3) a confusion matrix for predicted vs. true labels, and (4) a bar chart of various performance metrics including accuracy, precision, recall, F1-score, specificity, and false positive rate.
### 7.2 Multimodal Reddit-OSHA Benchmark
<details>
<summary>HSE_Image_Samples.png Details</summary>

### Visual Description
## Photograph Collage: Construction and Industrial Work Scenes
### Overview
The image is a digital collage containing eight separate photographs arranged in two rows. The top row contains five images, and the bottom row contains three. The collage depicts various scenes of manual labor, construction, maintenance, and industrial work. There is no embedded text, charts, diagrams, or data tables within the image. The content is purely photographic.
### Components/Axes
Not applicable. This is a collage of photographs, not a chart or diagram with axes or legends.
### Detailed Analysis
The collage is segmented into eight distinct photographic panels. Each panel is described below with its approximate position in the grid.
**Top Row (Left to Right):**
1. **Top-Left Panel:** A worker in a beige uniform and yellow hard hat is kneeling on a paved sidewalk. They are using a long-handled tool, possibly a pry bar or tamper, near an open utility access point. Two orange traffic cones with reflective strips are placed nearby for safety. The setting appears to be an urban street.
2. **Top-Center-Left Panel:** Two workers in high-visibility orange jackets and white hard hats are operating a large, orange concrete saw. The saw is cutting into a concrete or stone surface, generating a significant spray of sparks and debris. The scene is outdoors, near a metal fence.
3. **Top-Center Panel:** A worker in a red shirt and dark pants is standing on the top step of a metal A-frame ladder. They are reaching up to work on a ceiling-mounted light fixture or panel in what appears to be an indoor stairwell or corridor. The lighting is dim.
4. **Top-Center-Right Panel:** A small, white and red mini-excavator is positioned at the edge of a deep, narrow trench dug in soil and gravel. The excavator's arm is extended down into the trench. The background shows a wooden fence and a brick building.
5. **Top-Right Panel:** Two workers are on a wooden scaffolding platform attached to the side of a building under construction. One worker, wearing a white hard hat, is leaning over the edge, handling a large, dark panel or formwork. The other worker is assisting. Vertical rebar columns are visible in the foreground.
**Bottom Row (Left to Right):**
6. **Bottom-Left Panel:** A large, green mechanical claw or grapple, likely from an excavator or material handler, is lifting a person horizontally. The person is wearing jeans and a light-colored shirt and appears to be holding onto the claw's structure. The scene is outdoors on a gravel surface next to a concrete wall and green fence.
7. **Bottom-Center Panel:** A worker viewed from behind, wearing an orange hard hat and a yellow high-visibility vest over a red shirt, is kneeling on a dirt slope. They appear to be working with a cable or rope near a red and white striped barrier tape. A metal structure, possibly a tower or scaffolding, is in the background.
8. **Bottom-Right Panel:** A person in a white shirt and blue pants is operating a red wood chipper/shredder machine. They are feeding tree branches and foliage into the machine's hopper. The setting is a wooded or landscaped area with dirt ground.
### Key Observations
* **Diverse Activities:** The collage showcases a wide range of tasks: utility work, concrete cutting, electrical/lighting maintenance, excavation, formwork installation, material/personnel handling, ground work, and debris processing.
* **Safety Gear:** Most workers are wearing appropriate personal protective equipment (PPE), including hard hats (yellow, white, orange) and high-visibility clothing (orange jackets, yellow vests). Traffic cones and barrier tape are used for site safety.
* **Equipment Variety:** A broad array of tools and machinery is depicted, from hand tools and ladders to powered saws, mini-excavators, mechanical claws, and wood chippers.
* **Settings:** The work environments include urban streets, construction sites, indoor facilities, and natural/landscaped areas.
* **Notable Scene:** The bottom-left panel is particularly striking, showing a person being lifted by a mechanical claw in a manner that appears unconventional and potentially unsafe for personnel transport, contrasting with the more standard procedures in other images.
### Interpretation
This collage serves as a visual catalog of the construction and maintenance industry's hands-on nature. It emphasizes the physicality, variety of skills, and reliance on both manual labor and heavy machinery required in these fields. The inclusion of the potentially hazardous lifting scene (bottom-left) alongside images of standard safety practices (cones, PPE, barriers) may be intended to highlight the spectrum of on-site conditions, from routine protocol to unusual or risky situations. Collectively, the images demonstrate the process of building and maintaining infrastructure, from ground-breaking and material preparation to finishing work and site clearance. The lack of textual data means the interpretation is based solely on the visual narrative of work being performed.
</details>
Figure 4: Sample Images from the Multimodal Reddit-OSHA Benchmark
<details>
<summary>hsestackplot.png Details</summary>
### Visual Description
## Stacked Bar Chart: Questions Answered by Attempt
### Overview
The image displays a stacked bar chart titled "Questions Answered by Attempt." It visualizes the number of questions answered correctly and incorrectly across three sequential attempts. The chart shows a dramatic decrease in the volume of questions attempted from the first to the subsequent attempts.
### Components/Axes
* **Chart Title:** "Questions Answered by Attempt" (centered at the top).
* **Y-Axis:** Labeled "Number of Questions." The scale runs from 0 to 100 in increments of 20 (0, 20, 40, 60, 80, 100).
* **X-Axis:** Represents the attempt number, with three categorical labels: "Attempt 1", "Attempt 2", and "Attempt 3".
* **Legend:** Located in the top-right corner. It defines two data series:
* **Correct:** Represented by a blue color.
* **Incorrect:** Represented by an orange color.
* **Data Labels:** Numerical values are embedded directly within each colored segment of the bars.
### Detailed Analysis
The chart consists of three vertical stacked bars, each representing an attempt. The total height of each bar represents the total number of questions answered in that attempt.
**1. Attempt 1 (Leftmost Bar):**
* **Correct (Blue, bottom segment):** 79 questions.
* **Incorrect (Orange, top segment):** 17 questions.
* **Total Questions:** 79 + 17 = 96.
* **Trend/Visual:** This is by far the tallest bar, indicating the vast majority of questions were addressed in the first attempt. The blue segment is significantly larger than the orange segment.
**2. Attempt 2 (Center Bar):**
* **Correct (Blue, bottom segment):** 3 questions.
* **Incorrect (Orange, top segment):** 1 question.
* **Total Questions:** 3 + 1 = 4.
* **Trend/Visual:** This bar is drastically shorter than the first. The blue segment is still larger than the orange, but both values are very low.
**3. Attempt 3 (Rightmost Bar):**
* **Correct (Blue, bottom segment):** 2 questions.
* **Incorrect (Orange, top segment):** 0 questions.
* **Total Questions:** 2 + 0 = 2.
* **Trend/Visual:** This is the shortest bar. It consists only of a blue segment, as the incorrect count is zero.
### Key Observations
1. **Massive Drop-off in Volume:** There is an extreme, non-linear decline in the number of questions attempted after the first attempt. Attempt 1 accounts for 96 out of 102 total questions (≈94.1%).
2. **High Initial Accuracy:** In Attempt 1, the accuracy rate (Correct / Total) is approximately 82.3% (79/96).
3. **Diminishing Returns:** The subsequent attempts (2 and 3) handle a very small residual set of questions (6 total), with a combined accuracy of 83.3% (5/6).
4. **Perfect Accuracy in Final Attempt:** In Attempt 3, all questions answered (2) were correct.
### Interpretation
This chart likely represents the results of a learning, testing, or problem-solving process where participants (or a system) make multiple attempts at a set of questions.
* **Process Efficiency:** The data suggests a highly efficient first pass. The overwhelming majority of questions were resolved in Attempt 1 with a high success rate. This could indicate effective initial training, clear instructions, or that the questions were generally well-understood.
* **Nature of Residual Questions:** The small number of questions requiring a second or third attempt may represent edge cases, particularly difficult items, or questions that were initially misinterpreted. The perfect score in Attempt 3 implies that with enough tries, all questions in this set were ultimately answerable correctly.
* **Potential Scenarios:** This pattern is common in scenarios like:
* **Educational Testing:** Students answering a quiz, with most getting questions right on the first try, and a few needing retries.
* **Machine Learning Model Evaluation:** A model making predictions, where most are correct initially, and a small subset requires re-evaluation or parameter tuning.
* **Customer Support/Troubleshooting:** A knowledge base where most issues are resolved by the first article/solution, with a few complex cases requiring follow-up attempts.
The chart tells a story of initial competence and efficiency, with a long tail of minor, resolvable exceptions.
</details>
Figure 5: Performance analysis of the Proof of Thought (PoT) framework on the Multimodal Reddit-OSHA Benchmark dataset with a stacked bar chart showing questions answered by attempt.
### 7.3 Real Reasoning Traces using PoT : StrategyQA Dataset
1. Question: Could Javier Sotomayor jump over the head of the average giraffe? Answer: False Predicted Answer: UNSAT (False).
⬇
{
"sorts": [
{"name": "Person", "type": "DeclareSort"},
{"name": "Animal", "type": "DeclareSort"},
{"name": "Real", "type": "RealSort"}
],
"functions": [
{"name": "jump_height", "domain": ["Person"], "range": "Real"},
{"name": "height", "domain": ["Animal"], "range": "Real"}
],
"constants": {
"persons": {"sort": "Person", "members": ["javier_sotomayor"]},
"animals": {"sort": "Animal", "members": ["average_giraffe"]}
},
"variables": [
{"name": "p", "sort": "Person"},
{"name": "a", "sort": "Animal"}
],
"knowledge_base": [
{"assertion": "jump_height(javier_sotomayor) == 2.45"},
{"assertion": "height(average_giraffe) == 5.5"}
],
"verifications": [
{"name": "Sotomayor Jump Over Giraffe", "constraint": "jump_height(javier_sotomayor) >= height(average_giraffe)"
}
],
"actions": ["verify_conditions"]
}
1. Question: Did the Cherokee people send a delegation to oppose allotment? Answer: True Predicted Answer: SAT (True)
⬇
{
"sorts": [
{"name": "Group", "type": "DeclareSort"},
{"name": "Action", "type": "DeclareSort"},
{"name": "Bool", "type": "BoolSort"}
],
"functions": [
{"name": "send_delegation", "domain": ["Group"], "range": "Bool"},
{"name": "oppose_allotment", "domain": ["Group"], "range": "Bool"}
],
"constants": {
"groups": {"sort": "Group", "members": ["cherokee_people"]},
"actions": {"sort": "Action", "members": ["allotment"]}
},
"variables": [
{"name": "g", "sort": "Group"}
],
"knowledge_base": [
{"assertion": "send_delegation(cherokee_people)"},
{"assertion": "ForAll([g], Implies(send_delegation(g), oppose_allotment(g)))",
"variables": [{"name": "g", "sort": "Group"}]
}
],
"verifications": [
{"name": "Cherokee Oppose Allotment", "constraint": "oppose_allotment(cherokee_people)"}
],
"actions": ["verify_conditions"]
}
### 7.4 Real Reasoning Traces using PoT : Multimodal Reddit-OSHA Dataset
<details>
<summary>88-hse.png Details</summary>

### Visual Description
## Photograph: Building Exterior with Activity
### Overview
The image captures a daytime, street-level view of a multi-story commercial or institutional building. The primary subject is the building's facade, which features a prominent sign identifying it as the "AMERICAN LITERARY HISTORICAL SOCIETY." A person is actively working on a ladder propped against the building's side. A car is parked at the curb in the foreground.
### Components & Spatial Details
**Building Facade (Left and Center):**
* **Material & Color:** The primary cladding is vertical, corrugated metal siding in a medium gray tone. The lower portion of the wall, to the left of the entrance, is constructed from gray concrete blocks.
* **Signage:** A large, rectangular, light gray sign is mounted high on the building's upper right section. It contains the text "AMERICAN LITERARY HISTORICAL SOCIETY" in a dark, serif font, arranged in four centered lines.
* **Windows & Balcony:**
* A large, rectangular window is visible on the lower left. It has a dark frame and a light green or off-white interior shade partially drawn.
* Above this, on the second level, is a balcony with a simple metal railing. Two small potted plants sit on the balcony floor.
* The balcony and the window above it are sheltered by beige, shed-style awnings with vertical seams.
* **Entrance:** A bright yellow double door is located at ground level, slightly right of center. The number "10045" is displayed in large, black, sans-serif numerals above the door frame. The door has two vertical glass panes. A red, circular fire alarm bell is mounted on the gray block wall to the left of the door.
* **Architectural Feature:** A large, beige, sloped metal panel (resembling a mansard roof section) extends from above the yellow door upwards to the right, meeting the main gray wall. This creates an angled surface.
**Activity & Equipment:**
* **Ladder & Person:** A silver aluminum extension ladder is propped against the beige sloped panel, leaning towards the upper right corner of the building. A person is near the top of the ladder, facing the building. They are wearing a teal or turquoise short-sleeved shirt, dark pants, and dark shoes. A white object, possibly a tool or cloth, is tucked into their back pocket.
* **Other Equipment:** A coiled black cable or rope hangs from a fixture on the gray wall to the left of the beige panel. A small, white security camera or light fixture is mounted on the beige panel near the base of the ladder.
**Foreground & Surroundings:**
* **Vehicle:** A dark gray, two-door hatchback car (resembling a Toyota Yaris or similar model) is parked parallel to the curb, facing left. It has silver hubcaps.
* **Street:** The asphalt street has a double yellow line down the center and a white lane marker. A red-painted curb section is visible near the sidewalk.
* **Right Side:** To the right of the main building, an alley or driveway leads back. Visible elements include:
* A white corrugated metal fence or wall.
* Two orange traffic cones.
* Parked vehicles (a dark SUV and a silver car).
* Utility poles and overhead wires.
* Trees and distant hills under a blue sky with scattered white clouds.
### Content Details
**Textual Information Extracted:**
1. **Building Sign:** "AMERICAN LITERARY HISTORICAL SOCIETY"
2. **Address Number:** "10045" (above the yellow door)
**Visual Facts:**
* The building appears to be undergoing maintenance or inspection, indicated by the worker on the ladder.
* The architectural style is utilitarian or industrial, with the bright yellow door and literary society sign providing contrasting elements.
* The scene is well-lit by natural daylight, casting soft shadows.
### Key Observations
* **Contrast:** There is a stark contrast between the building's industrial, corrugated metal aesthetic and its stated purpose as a "Literary Historical Society."
* **Focal Points:** The bright yellow door and the large sign are the most visually dominant elements, drawing the eye. The worker on the ladder adds a dynamic, human element to the otherwise static scene.
* **Condition:** The building appears functional but not newly renovated. The presence of the worker suggests active upkeep.
### Interpretation
The image documents the physical premises of an organization dedicated to American literary history. The setting—an industrial-style building in what appears to be a mixed commercial/light industrial area—suggests the society may prioritize function and space over a traditional, stately architectural presence. The active maintenance work implies the facility is in regular use and receiving care. The photograph captures a moment of routine operation, blending the mundane (a worker, a parked car) with the institutional identity proclaimed by the sign. It raises curiosity about the activities occurring inside a building whose exterior does not immediately reflect its cultural mission.
</details>
<details>
<summary>84-HSE.png Details</summary>

### Visual Description
## Photograph: Industrial Scene with Forklift Operator
### Overview
This is a vertically oriented photograph taken inside an industrial or warehouse setting. The primary subject is a person standing on the elevated forks of a forklift, interacting with the mechanism of a large, sectional overhead garage door. The scene is brightly lit, likely by overhead industrial lighting, creating some glare and lens flare on the left side.
### Components/Axes
As a photograph, there are no chart axes. The key visual components are:
1. **Person:** A fair-skinned individual with short blond hair, wearing a dark blue or black short-sleeved collared shirt and blue jeans. They are standing on a wooden pallet that is resting on the forklift's forks.
2. **Forklift:** A black industrial forklift. The mast and carriage are prominently visible on the left side of the frame. A safety/information label is affixed to the lower left section of the mast.
3. **Wooden Pallet:** A standard wooden shipping pallet, appearing weathered, is placed on the forklift's forks, serving as a makeshift platform.
4. **Overhead Garage Door:** A large, white, sectional door composed of multiple horizontal panels. It features metal tracks, hinges, and a handle mechanism.
5. **Environment:** The background shows the interior of a warehouse with a high ceiling, exposed metal beams, and ductwork. The lower portion of the garage door has translucent or white panels, through which bright exterior light and indistinct shapes (possibly vehicles or equipment) are visible.
### Detailed Analysis
* **Person's Action:** The individual is standing on the pallet, facing the garage door. Their left hand is holding onto the forklift's overhead guard for stability. Their right arm is extended, and their hand is touching or manipulating a cable or rope that is part of the door's operating mechanism, near a metal bracket attached to the door.
* **Forklift Label:** On the lower left side of the forklift mast, there is a white label with red and black text. The most prominent text is the acronym "**AMC**" in red. Below this, there is smaller black text that is not fully legible in the image. It appears to be a safety or operational instruction label.
* **Spatial Grounding:** The person and forklift are positioned in the center-left of the frame. The garage door dominates the right and background. The "AMC" label is located in the bottom-left quadrant of the image, on the forklift's structure.
### Key Observations
1. **Improvised Platform:** The use of a standard wooden pallet on the forklift forks as a standing platform is a notable and potentially unsafe practice, as it is not a secured, purpose-built work platform.
2. **Task Context:** The person appears to be performing maintenance, adjustment, or manual operation of the overhead door mechanism, using the forklift for elevation.
3. **Lighting and Quality:** The image has a slight haze and a prominent lens flare on the left, suggesting a strong light source from that direction. The focus is reasonably sharp on the person and the immediate door mechanism.
### Interpretation
This photograph documents a moment of manual intervention in an industrial setting. The central action—a person elevated on a forklift to access a high mechanism—speaks to a common scenario in warehouses where standard equipment is used for non-standard tasks. The presence of the "AMC" label on the forklift likely indicates the manufacturer, model, or a safety certification mark, but its specific meaning cannot be determined from the visible text alone.
The image raises points for consideration regarding workplace safety protocols, specifically the use of appropriate elevated work platforms versus improvised solutions. The bright light coming through the lower door panels suggests it is daytime, and the door may be partially open or designed to let in light. The overall scene is one of practical, on-the-fly problem-solving within an industrial environment. No charts, data tables, or quantitative information are present in this image; it is purely a photographic record of an activity.
</details>
<details>
<summary>hse-10.png Details</summary>

### Visual Description
## Photograph: Maintenance Work on Ceiling Light
### Overview
The image is a vertically oriented photograph capturing a person performing maintenance or installation work on a ceiling light fixture. The scene appears to be indoors, likely in a residential or commercial building hallway or stairwell, given the presence of a handrail. The lighting is bright, primarily emanating from the ceiling fixture being worked on.
### Components & Subjects
1. **Primary Subject (Person):**
* **Position:** Centered in the frame, standing on a ladder.
* **Action:** Reaching upward with both hands to interact with a square, recessed ceiling light fixture.
* **Attire:** Wearing a short-sleeved shirt with a red torso and blue sleeves/shoulders, dark (likely black or navy) knee-length shorts, and dark shoes.
* **Posture:** Standing on the top platform of a ladder, body slightly angled, head tilted up towards the light.
2. **Equipment & Objects:**
* **Primary Ladder:** A multi-step aluminum A-frame ladder. The person is standing on its top platform. It is positioned centrally.
* **Secondary Ladder:** A smaller, wooden step-ladder is visible to the left of the main ladder, partially out of frame.
* **Ceiling Light Fixture:** A square, bright, recessed panel light in the ceiling. It is the focal point of the person's activity.
* **Wooden Planks:** Several long, light-colored wooden planks or boards are lying on the floor in the foreground, extending from the bottom left towards the center.
* **Handrail:** A dark-colored, tubular metal handrail is mounted on the right-side wall, running diagonally upwards from the lower right towards the center-right, suggesting a staircase or ramp.
3. **Environment:**
* **Walls:** Plain, light-colored (off-white or light gray) walls.
* **Floor:** A light-colored floor, partially obscured by the ladders and planks.
* **Lighting:** The primary light source is the ceiling fixture itself, creating a bright area at the top of the image and casting shadows below.
### Detailed Analysis
* **Spatial Grounding:** The scene is composed with the main ladder and person as the central vertical axis. The secondary ladder occupies the left mid-ground. The handrail provides a strong diagonal line on the right, leading the eye upwards. The wooden planks create horizontal lines in the foreground.
* **Action Context:** The person's posture and direct interaction with the light fixture strongly indicate an active task such as bulb replacement, fixture repair, or installation.
* **Image Quality:** The photograph has moderate resolution and some visible grain, particularly in the shadow areas. Details on the person's face and the exact mechanism of the light fixture are not clearly discernible.
### Key Observations
1. **Active Work Zone:** The combination of two ladders and construction materials (planks) suggests this is an active work area, not a staged scene.
2. **Safety Consideration:** The person is standing on the top platform of the A-frame ladder, which is generally considered an unsafe practice as it lacks handhold support.
3. **Architectural Clues:** The presence of a sturdy, wall-mounted handrail is a strong indicator that this location is adjacent to a staircase or is an accessibility ramp.
4. **Lighting Source:** The ceiling light is on and very bright, which could mean the person is testing it after work or working with the power on (another potential safety note).
### Interpretation
This photograph documents a moment of routine building maintenance. The scene conveys a sense of informal, hands-on work. The presence of multiple tools (ladders) and materials (planks) implies this might be part of a larger repair or renovation project in the building, not just a simple lightbulb change. The setting—a utilitarian space with a handrail—points to a common area like a stairwell in an apartment building, office, or school. The image captures the practical, often unseen labor required to maintain functional infrastructure. From a safety perspective, it highlights common but risky practices (standing on the top of a ladder) encountered in such environments.
</details>
Figure 6: Example 1-3 from the HSE Reddit OSHA Dataset.
1. HSE Example 1
⬇
{
"sorts": [
{"name": "Person", "type": "DeclareSort"},
{"name": "Equipment", "type": "DeclareSort"},
{"name": "SafetyGear", "type": "DeclareSort"}
],
"functions": [
{"name": "Using", "domain": ["Person", "Equipment"], "range": "BoolSort"
},
{"name": "Wearing", "domain": ["Person", "SafetyGear"], "range": "BoolSort"}
],
"constants": {
"persons": {"sort": "Person", "members": ["worker"]},
"equipments": {"sort": "Equipment", "members": ["ladder"]},
"safetyGears": {"sort": "SafetyGear", "members": ["hardHat", "harness"]}
},
"knowledge_base": [
{"assertion": "Using(worker, ladder)", "value": true},
{"assertion": "Wearing(worker, hardHat)", "value": false},
{"assertion": "Wearing(worker, harness)", "value": false}
],
"rules": [
{"name": "Hard Hat Rule", "forall": [{"name": "p", "sort": "Person"},
{"name": "e", "sort": "Equipment"}], "implies": {"antecedent": "Using(p, e)", "consequent": "Wearing(p, hardHat)"}},
{"name": "Harness Rule", "forall": [{"name": "p", "sort": "Person"}, {"name": "e", "sort": "Equipment"}],
"implies": {"antecedent": "Using(p, e)", "consequent": "Wearing(p, harness)"}}
],
"verifications": [
{"name": "Verify Hard Hat Compliance", "constraint": "Wearing(worker, hardHat)"},
{"name": "Verify Harness Compliance", "constraint": "Wearing(worker, harness)"}
],
"actions": ["verify_conditions"]
}
1. HSE Example 2
⬇
{
"sorts": [{"name": "Person", "type": "DeclareSort"},
{"name": "Equipment", "type": "DeclareSort"},
{"name": "SafetyEquipment", "type": "DeclareSort"}
],
"functions": [
{"name": "StandingOn", "domain": ["Person", "Equipment"], "range": "BoolSort"},
{"name": "UsingSafetyEquipment", "domain": ["Person", "SafetyEquipment"], "range": "BoolSort"},
{"name": "IsSafe", "domain": ["Person"], "range": "BoolSort"}
],
"constants": {
"persons": {"sort": "Person", "members": ["worker"]},
"equipments": {"sort": "Equipment", "members": ["forklift", "pallet"]},
"safetyEquipments": {"sort": "SafetyEquipment", "members": ["harness"]}
},
"knowledgebase": [
{"assertion": "StandingOn(worker, pallet)", "value": true},
{"assertion": "UsingSafetyEquipment(worker, harness)", "value": false}
],
"rules": [
{"name": "Safety Rule", "forall": [{"name": "p", "sort": "Person"}],
"implies": {"antecedent": "And(StandingOn(p, pallet), Not(UsingSafetyEquipment(p, harness)))", "consequent": "Not(IsSafe(p))"}}
],
"verifications": [
{"name": "Verify Safety", "constraint": "IsSafe(worker)"}
],
"actions": ["verify_conditions"]
}
1. HSE Example 3
⬇
{
"sorts": [
{"name": "Person", "type": "DeclareSort"},
{"name": "Equipment", "type": "DeclareSort"},
{"name": "Location", "type": "DeclareSort"}
],
"functions": [
{"name": "Worker", "domain": ["Person"], "range": "BoolSort"},
{"name": "Using", "domain": ["Person", "Equipment"], "range": "BoolSort"},
{"name": "AtHeight", "domain": ["Person"], "range": "BoolSort"},
{"name": "HasFallProtection", "domain": ["Person"], "range": "BoolSort"},
{"name": "Stable", "domain": ["Equipment"], "range": "BoolSort"}
],
"constants": {
"persons": {"sort": "Person", "members": ["worker"]},
"equipments": {"sort": "Equipment", "members": ["ladder", "scaffold"]},
"locations": {"sort": "Location", "members": ["worksite"]}
},
"knowledge_base": [
"Worker(worker)", "Using(worker, ladder)", "Using(worker, scaffold)", "AtHeight(worker)",
{"assertion": "Stable(ladder)", "value": false},
{"assertion": "Stable(scaffold)", "value": false},
{"assertion": "HasFallProtection(worker)", "value": false}
],
"rules": [
{
"name": "Safety Rule", "forall": [{"name": "p", "sort": "Person"}],
"implies": {"antecedent": "And(Worker(p), AtHeight(p))", "consequent": "HasFallProtection(p)"}
},
{
"name": "Stability Rule", "forall": [{"name": "e", "sort": "Equipment"}],
"implies": {"antecedent": "Using(worker, e)", "consequent": "Stable(e)"}
}],
"verifications": [
{"name": "Verify Safety", "constraint": "And(HasFallProtection(worker), Stable(ladder), Stable(scaffold))"}
],
"actions": ["verify_conditions"]
}
### 7.5 A Qualitative Analysis of Generated DSL Programs and Reasoning Patterns
The generated DSL programs across both the StrategyQA dataset and the OSHA dataset illustrate how formal logical representations can be used to model complex reasoning tasks. In both cases, the structured use of sorts, functions, rules, and verifications ensures that the questions posed are systematically decomposed into logical assertions that can be verified by a theorem prover such as Z3. Here, we analyze key aspects of these programs and how they contribute to effective reasoning.
#### 7.5.1 Sorts and Function Definitions as the Backbone of Logical Modeling
The use of DeclareSort, BoolSort, RealSort, and other basic sorts in the DSL programs serves as the foundation for defining the domains of discourse. For example, in the StrategyQA question involving Javier Sotomayor and a giraffe, the Person and Animal sorts allow the definition of relationships between humans and animals in terms of measurable attributes (e.g., jump height and height). Similarly, in the OSHA-related examples, Person, Equipment, and SafetyGear sorts model the entities relevant to workplace safety.
By defining functions like jump_height, height, Wearing, and Using, we map the relationships between entities and their properties. These functions serve as predicates that are later used in verifications or rule implications. In these cases, the functions provide critical context for understanding the state of the world and the conditions under which certain outcomes (e.g., compliance with safety regulations or reaching a height) hold true.
#### 7.5.2 Knowledge Base and Its Role in Establishing Ground Truth
The knowledge_base section plays a vital role in grounding the reasoning process by introducing factual information, such as the jump height of Javier Sotomayor (2.45 meters) or the height of an average giraffe (5.5 meters). This knowledge is essential for theorem proving because it establishes the foundational truths that the logical system will work with. Similarly, in the OSHA examples, the knowledge base specifies whether a worker is using certain equipment, wearing protective gear, or working at height.
In both datasets, the knowledge base is used to capture the known facts that are assumed to be true at the start of reasoning. This helps set the initial conditions for the logical rules to be applied.
#### 7.5.3 Rules as Key Drivers of Logical Implication
The rules section formalizes the relationships between entities based on conditional logic. These rules encapsulate the domain knowledge and drive the reasoning process. For instance, the "Hard Hat Rule" in the OSHA examples states that if a person is using equipment, they should also be wearing a hard hat, while the "Harness Rule" mandates that a harness should be worn when using certain equipment. In the StrategyQA example, no explicit rules are needed beyond the basic comparison of heights.
These rules introduce a level of generalization that allows the reasoning process to handle not just specific instances but also classes of entities. For example, the rule:
⬇
{
"name": "Hard Hat Rule",
"forall": [{"name": "p", "sort": "Person"}, {"name": "e", "sort": "Equipment"}],
"implies": {"antecedent": "Using(p, e)", "consequent": "Wearing(p, hardHat)"}
}
is applicable to any person and any equipment. This generalization is key in enabling logical inferences beyond the immediate facts provided in the knowledge base.
#### 7.5.4 Verifications as the Core of Decision-Making
The verifications section in these programs forms the basis of decision-making by checking whether the conditions specified in the knowledge base and rules hold. In the StrategyQA case, the verification checks if Javier Sotomayor’s jump height is greater than or equal to the height of an average giraffe. The outcome of this check (UNSAT) indicates that it is false, thus the predicted answer matches the correct answer.
In the OSHA-related examples, verifications are used to ensure compliance with safety rules. For example, the program checks if the worker is wearing a hard hat or harness while using a ladder. These verifications serve as the final step in determining whether the conditions needed for safety are met or not. The results of these verifications provide a direct SAT (true) or UNSAT (false) outcome, which can then be used to assess compliance or answer the given question.
#### 7.5.5 Patterns in Error Detection and Resolution
The DSL framework helps detect inconsistencies or non-compliance in the input data. For example, the OSHA programs can flag situations where workers are using unsafe equipment or failing to follow safety protocols. This is achieved by systematically comparing the facts provided in the knowledge base with the rules and verifications, ensuring that errors are caught before any conclusions are drawn.
Additionally, the explicit use of logical operators like And, Not, and Implies makes it easy to trace the reasoning path when an outcome is SAT (true) or UNSAT (false). This traceability allows users to understand why a particular result was obtained, making the reasoning process more transparent and interpretable.
#### 7.5.6 Overall Analysis and Utility of Generated DSL Programs
Across both the StrategyQA and OSHA datasets, the use of DSL programs enables structured, logical reasoning that is verifiable and interpretable. The modularity of the DSL—where different aspects of the reasoning process (entities, relationships, rules, and verifications) are clearly separated—ensures that the programs remain adaptable to a variety of problem domains.
The reasoning traces provided by these DSL programs offer significant benefits:
- Interpretability: The modular structure makes it easy to follow the logical steps leading to a conclusion.
- Error Detection: The use of formal logic allows for early detection of contradictions or violations of safety rules.
- Scalability: The DSL framework can handle increasingly complex scenarios by adding new sorts, functions, rules, and verifications.
- Generalization: Rules written in a generalized form (e.g., using ForAll) can be applied across different entities and scenarios, making the system more flexible.
### 7.6 Exploring the possibilities: Satisfiable Neurosymbolic Programs
Our DSL designed to be very expressive, and future proof for additional scenarios. In this subsection we present some example problems that can be expressed and solved to be found SAT.
1. Simple Arithmetic Verification : Verify that there exists an integer x such that x + 2 = 5.
⬇
{
"sorts": [
{"name": "Int", "type": "IntSort"}
],
"functions": [],
"constants": {},
"knowledge_base": [],
"rules": [],
"verifications": [
{
"name": "verify_addition",
"exists": [
{"name": "x", "sort": "Int"}
],
"constraint": "x + 2 == 5"
}
],
"actions": ["verify_conditions"]
}
1. Basic Safety Equipment Rule : Ensure all workers are wearing hard hats.
⬇
{
"sorts": [
{"name": "Person", "type": "DeclareSort"},
{"name": "Equipment", "type": "DeclareSort"}
],
"functions": [
{"name": "Worker", "domain": ["Person"], "range": "BoolSort"},
{"name": "Wearing", "domain": ["Person", "Equipment"], "range": "BoolSort"}
],
"constants": {
"persons": {
"sort": "Person",
"members": ["alice", "bob"]
},
"equipments": {
"sort": "Equipment",
"members": ["hardHat"]
}
},
"knowledge_base": [
"Worker(alice)",
"Worker(bob)",
"Wearing(alice, hardHat)"
],
"rules": [
{
"name": "Hard Hat Rule",
"forall": [
{"name": "p", "sort": "Person"}
],
"implies": {
"antecedent": "Worker(p)",
"consequent": "Wearing(p, hardHat)"
}
}
],
"verifications": [
{
"name": "Check Hard Hat Compliance",
"forall": [
{"name": "p", "sort": "Person"}
],
"implies": {
"antecedent": "Worker(p)",
"consequent": "Wearing(p, hardHat)"
}
}
],
"actions": ["verify_conditions"]
}
1. Parent-Child Relationship : Define a family tree and verify that a grandparent relationship holds.
⬇
{
"sorts": [
{"name": "Person", "type": "DeclareSort"}
],
"functions": [
{"name": "parent_of", "domain": ["Person"], "range": "Person"}
],
"constants": {
"persons": {
"sort": "Person",
"members": ["alice", "bob", "charlie"]
}
},
"knowledge_base": [
"parent_of(bob) == alice",
"parent_of(charlie) == bob"
],
"rules": [],
"verifications": [
{
"name": "Verify Grandparent",
"constraint": "parent_of(parent_of(charlie)) == alice"
}
],
"actions": ["verify_conditions"]
}
1. Transitive Relation Verification : Verify that a transitive property holds in a relation.
⬇
{
"sorts": [
{"name": "Element", "type": "DeclareSort"}
],
"functions": [
{"name": "related", "domain": ["Element", "Element"], "range": "BoolSort"}
],
"constants": {
"elements": {
"sort": "Element",
"members": ["x", "y", "z"]
}
},
"knowledge_base": [
"related(x, y)",
"related(y, z)"
],
"rules": [
{
"name": "Transitive Rule",
"forall": [
{"name": "a", "sort": "Element"},
{"name": "b", "sort": "Element"},
{"name": "c", "sort": "Element"}
],
"implies": {
"antecedent": "And(related(a, b), related(b, c))",
"consequent": "related(a, c)"
}
}
],
"verifications": [
{
"name": "Verify Transitivity",
"constraint": "related(x, z)"
}
],
"actions": ["verify_conditions"]
}
1. Scheduling Without Conflicts : Ensure two tasks are scheduled at different times.
⬇
{
"sorts": [
{"name": "Task", "type": "DeclareSort"},
{"name": "TimeSlot", "type": "IntSort"}
],
"functions": [
{"name": "scheduled_at", "domain": ["Task"], "range": "TimeSlot"}
],
"constants": {
"tasks": {
"sort": "Task",
"members": ["task1", "task2"]
}
},
"knowledge_base": [],
"rules": [],
"verifications": [
{
"name": "Verify Scheduling",
"exists": [
{"name": "t1", "sort": "TimeSlot"},
{"name": "t2", "sort": "TimeSlot"}
],
"constraint": "And(scheduled_at(task1) == t1, scheduled_at(task2) == t2, t1 != t2)"
}
],
"actions": ["verify_conditions"]
}
1. Graph Coloring Problem : Assign colors to nodes such that adjacent nodes have different colors.
⬇
{
"sorts": [
{"name": "Node", "type": "DeclareSort"},
{"name": "Color", "type": "DeclareSort"}
],
"functions": [
{"name": "color_of", "domain": ["Node"], "range": "Color"},
{"name": "connected", "domain": ["Node", "Node"], "range": "BoolSort"}
],
"constants": {
"nodes": {
"sort": "Node",
"members": ["node1", "node2", "node3"]
},
"colors": {
"sort": "Color",
"members": ["red", "green", "blue"]
}
},
"knowledge_base": [
"connected(node1, node2)",
"connected(node2, node3)",
"connected(node1, node3)"
],
"rules": [
{
"name": "Coloring Rule",
"forall": [
{"name": "n1", "sort": "Node"},
{"name": "n2", "sort": "Node"}
],
"implies": {
"antecedent": "connected(n1, n2)",
"consequent": "color_of(n1) != color_of(n2)"
}
}
],
"verifications": [
{
"name": "Verify Coloring",
"exists": [
{"name": "c1", "sort": "Color"},
{"name": "c2", "sort": "Color"},
{"name": "c3", "sort": "Color"}
],
"constraint": "And(color_of(node1) == c1, color_of(node2) == c2, color_of(node3) == c3)"
}
],
"actions": ["verify_conditions"]
}
1. Health and Safety Scenario : Verify that all workers at heights above 6 feet are wearing safety harnesses.
⬇
{
"sorts": [
{"name": "Person", "type": "DeclareSort"},
{"name": "Equipment", "type": "DeclareSort"},
{"name": "Location", "type": "DeclareSort"}
],
"functions": [
{"name": "Worker", "domain": ["Person"], "range": "BoolSort"},
{"name": "At", "domain": ["Person", "Location"], "range": "BoolSort"},
{"name": "Wearing", "domain": ["Person", "Equipment"], "range": "BoolSort"},
{"name": "Height", "domain": ["Location"], "range": "IntSort"}
],
"constants": {
"persons": {
"sort": "Person",
"members": ["worker1", "worker2"]
},
"equipments": {
"sort": "Equipment",
"members": ["safetyHarness"]
},
"locations": {
"sort": "Location",
"members": ["groundLevel", "highLevel"]
}
},
"knowledge_base": [
"Worker(worker1)",
"Worker(worker2)",
"At(worker1, groundLevel)",
"At(worker2, highLevel)",
"Height(groundLevel) == 0",
"Height(highLevel) == 20",
"Wearing(worker1, safetyHarness)"
],
"rules": [
{
"name": "Fall Protection Rule",
"forall": [
{"name": "p", "sort": "Person"},
{"name": "l", "sort": "Location"}
],
"implies": {
"antecedent": "And(Worker(p), At(p, l), Height(l) > 6)",
"consequent": "Wearing(p, safetyHarness)"
}
}
],
"verifications": [
{
"name": "Check Fall Protection",
"forall": [
{"name": "p", "sort": "Person"},
{"name": "l", "sort": "Location"}
],
"implies": {
"antecedent": "And(Worker(p), At(p, l), Height(l) > 6)",
"consequent": "Wearing(p, safetyHarness)"
}
}
],
"actions": ["verify_conditions"]
}
1. Electrical Safety Scenario: Ensure workers using energized equipment above 250V are wearing insulated gloves.
⬇
{
"sorts": [
{"name": "Person", "type": "DeclareSort"},
{"name": "Equipment", "type": "DeclareSort"}
],
"functions": [
{"name": "Worker", "domain": ["Person"], "range": "BoolSort"},
{"name": "Using", "domain": ["Person", "Equipment"], "range": "BoolSort"},
{"name": "IsEnergized", "domain": ["Equipment"], "range": "BoolSort"},
{"name": "Voltage", "domain": ["Equipment"], "range": "IntSort"},
{"name": "Wearing", "domain": ["Person", "Equipment"], "range": "BoolSort"}
],
"constants": {
"persons": {
"sort": "Person",
"members": ["worker1"]
},
"equipments": {
"sort": "Equipment",
"members": ["circuitBreaker", "insulatedGloves"]
}
},
"knowledge_base": [
"Worker(worker1)",
"Using(worker1, circuitBreaker)",
"IsEnergized(circuitBreaker)",
"Voltage(circuitBreaker) == 480"
],
"rules": [
{
"name": "High Voltage Safety Rule",
"forall": [
{"name": "p", "sort": "Person"},
{"name": "e", "sort": "Equipment"}
],
"implies": {
"antecedent": "And(Worker(p), Using(p, e), IsEnergized(e), Voltage(e) > 250)",
"consequent": "Wearing(p, insulatedGloves)"
}
}
],
"verifications": [
{
"name": "Verify Electrical Safety",
"forall": [
{"name": "p", "sort": "Person"},
{"name": "e", "sort": "Equipment"}
],
"implies": {
"antecedent": "And(Worker(p), Using(p, e), IsEnergized(e), Voltage(e) > 250)",
"consequent": "Wearing(p, insulatedGloves)"
}
}
],
"actions": ["verify_conditions"]
}
1. Chemical Handling Safety : Ensure workers handling corrosive chemicals are wearing gloves and goggles.
⬇
{
"sorts": [
{"name": "Person", "type": "DeclareSort"},
{"name": "Chemical", "type": "DeclareSort"},
{"name": "Equipment", "type": "DeclareSort"}
],
"functions": [
{"name": "Worker", "domain": ["Person"], "range": "BoolSort"},
{"name": "Handling", "domain": ["Person", "Chemical"], "range": "BoolSort"},
{"name": "IsCorrosive", "domain": ["Chemical"], "range": "BoolSort"},
{"name": "Wearing", "domain": ["Person", "Equipment"], "range": "BoolSort"}
],
"constants": {
"persons": {
"sort": "Person",
"members": ["worker1"]
},
"chemicals": {
"sort": "Chemical",
"members": ["acid"]
},
"equipments": {
"sort": "Equipment",
"members": ["gloves", "goggles"]
}
},
"knowledge_base": [
"Worker(worker1)",
"Handling(worker1, acid)",
"IsCorrosive(acid)"
],
"rules": [
{
"name": "Corrosive Chemical Handling Rule",
"forall": [
{"name": "p", "sort": "Person"},
{"name": "c", "sort": "Chemical"}
],
"implies": {
"antecedent": "And(Worker(p), Handling(p, c), IsCorrosive(c))",
"consequent": "And(Wearing(p, gloves), Wearing(p, goggles))"
}
}
],
"verifications": [
{
"name": "Verify Chemical Safety",
"forall": [
{"name": "p", "sort": "Person"},
{"name": "c", "sort": "Chemical"}
],
"implies": {
"antecedent": "And(Worker(p), Handling(p, c), IsCorrosive(c))",
"consequent": "And(Wearing(p, gloves), Wearing(p, goggles))"
}
}
],
"actions": ["verify_conditions"]
}
1. Resource Allocation Optimization : Allocate tasks to workers while minimizing total cost.
⬇
{
"sorts": [
{"name": "Worker", "type": "DeclareSort"},
{"name": "Task", "type": "DeclareSort"},
{"name": "Cost", "type": "IntSort"}
],
"functions": [
{"name": "assigned_to", "domain": ["Task"], "range": "Worker"},
{"name": "cost_of", "domain": ["Worker"], "range": "Cost"}
],
"constants": {
"workers": {
"sort": "Worker",
"members": ["worker1", "worker2"]
},
"tasks": {
"sort": "Task",
"members": ["taskA", "taskB"]
}
},
"knowledge_base": [
"cost_of(worker1) == 50",
"cost_of(worker2) == 30"
],
"rules": [],
"verifications": [],
"optimization": {
"constraints": [
"assigned_to(taskA) != assigned_to(taskB)"
],
"objectives": [
{
"type": "minimize",
"expression": "cost_of(assigned_to(taskA)) + cost_of(assigned_to(taskB))"
}
]
},
"actions": ["optimize"]
}
### 7.7 Exploring the possibilities: Unsatisfiable Neurosymbolic Programs
Our DSL designed to be very expressive, and future proof for additional scenarios. In this subsection we present some example problems that can be expressed and solved to be found UNSAT.
1. Pigeonhole Principle: A classic unsatisfiable problem where more pigeons than holes cannot be assigned uniquely.
⬇
{
"sorts": [
{
"name": "Pigeon",
"type": "EnumSort",
"values": ["p1", "p2", "p3", "p4"]
},
{
"name": "Hole",
"type": "EnumSort",
"values": ["h1", "h2", "h3"]
}
],
"functions": [
{"name": "assigned_to", "domain": ["Pigeon"], "range": "Hole"}
],
"constants": {},
"knowledge_base": [],
"rules": [],
"verifications": [
{
"name": "Pigeonhole Verification",
"constraint": "Distinct(assigned_to(p1), assigned_to(p2), assigned_to(p3), assigned_to(p4))"
}
],
"actions": ["verify_conditions"]
}
1. Non-Three-Colorable Graph : A complete graph with four nodes cannot be colored with only three colors without adjacent nodes sharing the same color.
⬇
{
"sorts": [
{
"name": "Node",
"type": "EnumSort",
"values": ["n1", "n2", "n3", "n4"]
},
{
"name": "Color",
"type": "EnumSort",
"values": ["red", "green", "blue"]
}
],
"functions": [
{"name": "color_of", "domain": ["Node"], "range": "Color"},
{"name": "connected", "domain": ["Node", "Node"], "range": "BoolSort"}
],
"constants": {},
"knowledge_base": [
"connected(n1, n2)",
"connected(n1, n3)",
"connected(n1, n4)",
"connected(n2, n3)",
"connected(n2, n4)",
"connected(n3, n4)"
],
"rules": [
{
"name": "Coloring Rule",
"forall": [
{"name": "n1", "sort": "Node"},
{"name": "n2", "sort": "Node"}
],
"implies": {
"antecedent": "And(connected(n1, n2), n1 != n2)",
"consequent": "color_of(n1) != color_of(n2)"
}
}
],
"verifications": [
{
"name": "Verify 3-Coloring",
"constraint": "True"
}
],
"actions": ["verify_conditions"]
}
1. Contradictory Mathematical Constraints
⬇
{
"sorts": [
{"name": "Int", "type": "IntSort"}
],
"functions": [],
"constants": {},
"knowledge_base": [],
"rules": [],
"verifications": [
{
"name": "Contradictory Constraints",
"exists": [
{"name": "x", "sort": "Int"}
],
"constraint": "And(x > 0, x < 0)"
}
],
"actions": ["verify_conditions"]
}
1. An Unsatisfiable Boolean formula in conjunctive normal form (CNF).
⬇
{
"sorts": [
{"name": "Bool", "type": "BoolSort"}
],
"functions": [],
"constants": {
"variables": {
"sort": "Bool",
"members": ["A", "B"]
}
},
"knowledge_base": [],
"rules": [],
"verifications": [
{
"name": "Unsatisfiable CNF",
"constraint": "And(A, Not(A))"
}
],
"actions": ["verify_conditions"]
}
1. Mutual Exclusivity: Defining two constants that cannot be equal, but also constrained to be equal.
⬇
{
"sorts": [
{"name": "Element", "type": "DeclareSort"}
],
"functions": [],
"constants": {
"elements": {
"sort": "Element",
"members": ["e1", "e2"]
}
},
"knowledge_base": [
"e1 != e2",
"e1 == e2"
],
"rules": [],
"verifications": [
{
"name": "Mutual Exclusivity Verification",
"constraint": "True"
}
],
"actions": ["verify_conditions"]
}
1. Inconsistent Equations
⬇
{
"sorts": [
{"name": "Int", "type": "IntSort"}
],
"functions": [],
"constants": {},
"knowledge_base": [],
"rules": [],
"verifications": [
{
"name": "Inconsistent Equations",
"exists": [
{"name": "x", "sort": "Int"},
{"name": "y", "sort": "Int"}
],
"constraint": "And(x + y == 10, x + y == 5)"
}
],
"actions": ["verify_conditions"]
}
1. Unsolvable Scheduling Conflict : Tasks that must occur at the same time and also at different times.
⬇
{
"sorts": [
{"name": "Task", "type": "EnumSort", "values": ["task1", "task2"]}
],
"functions": [
{"name": "scheduled_at", "domain": ["Task"], "range": "IntSort"}
],
"constants": {},
"knowledge_base": [
"scheduled_at(task1) == scheduled_at(task2)",
"scheduled_at(task1) != scheduled_at(task2)"
],
"rules": [],
"verifications": [
{
"name": "Scheduling Conflict Verification",
"constraint": "True"
}
],
"actions": ["verify_conditions"]
}
1. Invalid Parent-Child Relationship
⬇
{
"sorts": [
{"name": "Person", "type": "EnumSort", "values": ["bob"]}
],
"functions": [
{"name": "parent_of", "domain": ["Person"], "range": "Person"}
],
"constants": {},
"knowledge_base": [
"parent_of(bob) == bob"
],
"rules": [
{
"name": "No Self Parenting Rule",
"forall": [
{"name": "p", "sort": "Person"}
],
"implies": {
"antecedent": "True",
"consequent": "parent_of(p) != p"
}
}
],
"verifications": [
{
"name": "Self Parenting Verification",
"constraint": "True"
}
],
"actions": ["verify_conditions"]
}
1. Impossible Optimization
⬇
{
"sorts": [
{"name": "Int", "type": "IntSort"}
],
"functions": [],
"constants": {},
"knowledge_base": [],
"rules": [],
"verifications": [],
"optimization": {
"constraints": [
"x > 0",
"x < 0"
],
"objectives": [
{
"type": "minimize",
"expression": "x"
}
]
},
"actions": ["optimize"]
}