# Interpretable Contrastive Monte Carlo Tree Search Reasoning
\intervalconfig
soft open fences
Abstract
We propose (S) peculative (C) ontrastive MCTS ∗: a novel Monte Carlo Tree Search (MCTS) reasoning algorithm for Large Language Models (LLMs) which significantly improves both reasoning accuracy and speed. Our motivation comes from: 1. Previous MCTS LLM reasoning works often overlooked its biggest drawback—slower speed compared to CoT; 2. Previous research mainly used MCTS as a tool for LLM reasoning on various tasks with limited quantitative analysis or ablation studies of its components from reasoning interpretability perspective. 3. The reward model is the most crucial component in MCTS, however previous work has rarely conducted in-depth study or improvement of MCTS’s reward models. Thus, we conducted extensive ablation studies and quantitative analysis on components of MCTS, revealing the impact of each component on the MCTS reasoning performance of LLMs. Building on this, (i) we designed a highly interpretable reward model based on the principle of contrastive decoding and (ii) achieved an average speed improvement of 51.9% per node using speculative decoding. Additionally, (iii) we improved UCT node selection strategy and backpropagation used in previous works, resulting in significant performance improvement. We outperformed o1-mini by an average of 17.4% on the Blocksworld multi-step reasoning dataset using Llama-3.1-70B with SC-MCTS ∗. Our code is available at https://github.com/zitian-gao/SC-MCTS.
1 Introduction
With the remarkable development of Large Language Models (LLMs), models such as o1 (OpenAI, 2024a) have now gained a strong ability for multi-step reasoning across complex tasks and can solve problems that are more difficult than previous scientific, code, and mathematical problems. The reasoning task has long been considered challenging for LLMs. These tasks require converting a problem into a series of reasoning steps and then executing those steps to arrive at the correct answer. Recently, LLMs have shown great potential in addressing such problems. A key approach is using Chain of Thought (CoT) (Wei et al., 2024), where LLMs break down the solution into a series of reasoning steps before arriving at the final answer. Despite the impressive capabilities of CoT-based LLMs, they still face challenges when solving problems with an increasing number of reasoning steps due to the curse of autoregressive decoding (Sprague et al., 2024). Previous work has explored reasoning through the use of heuristic reasoning algorithms. For example, Yao et al. (2024) applied heuristic-based search, such as Depth-First Search (DFS) to derive better reasoning paths. Similarly, Hao et al. (2023) employed MCTS to iteratively enhance reasoning step by step toward the goal.
The tremendous success of AlphaGo (Silver et al., 2016) has demonstrated the effectiveness of the heuristic MCTS algorithm, showcasing its exceptional performance across various domains (Jumper et al., 2021; Silver et al., 2017). Building on this, MCTS has also made notable progress in the field of LLMs through multi-step heuristic reasoning. Previous work has highlighted the potential of heuristic MCTS to significantly enhance LLM reasoning capabilities. Despite these advancements, substantial challenges remain in fully realizing the benefits of heuristic MCTS in LLM reasoning.
<details>
<summary>extracted/6087579/fig/Fig1.png Details</summary>
### Visual Description
## Diagram: Blocksworld Task State-Action Space
### Overview
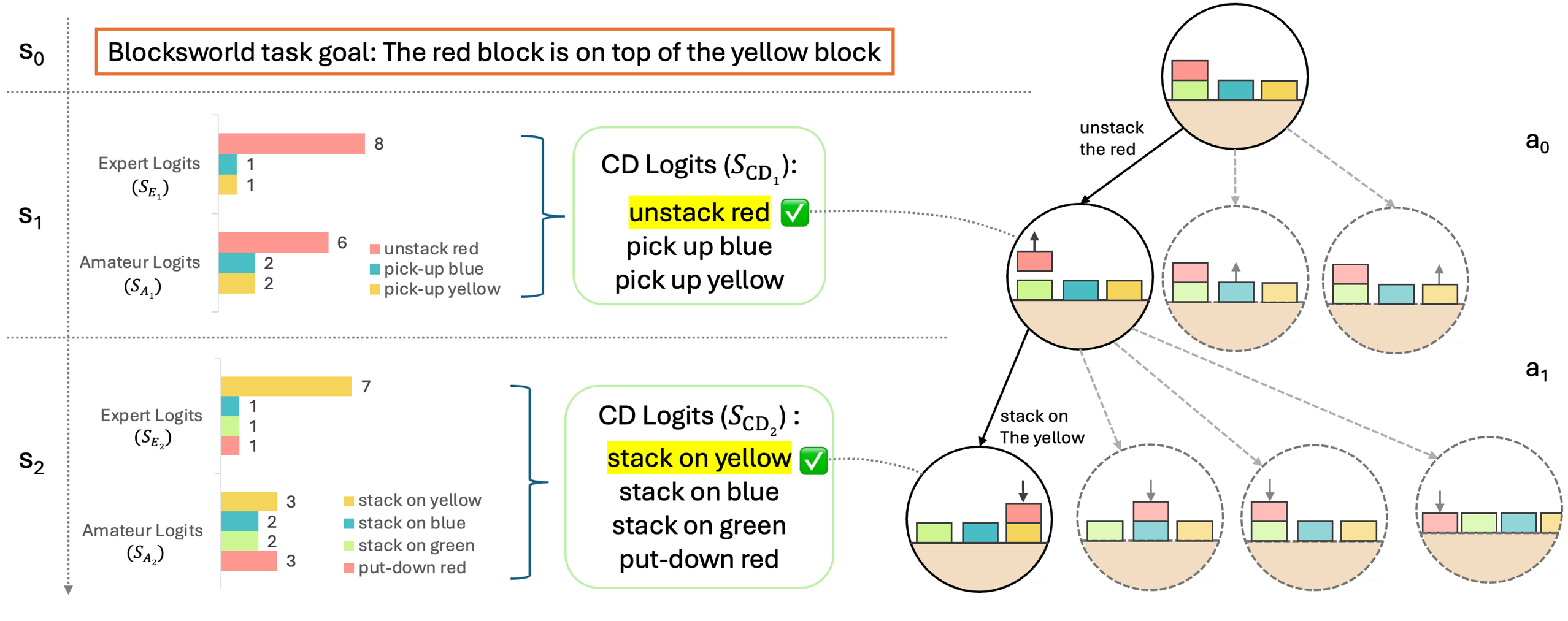
This diagram illustrates a state transition system for a Blocksworld task with three states (S₀, S₁, S₂) and two actions (a₀, a₁). It compares expert vs. amateur logits for action selection and shows credit-directed (CD) logits with checkmarked optimal actions. The task goal is to have the red block on top of the yellow block.
### Components/Axes
- **Left Axis (States)**: S₀ (top), S₁ (middle), S₂ (bottom)
- **Right Axis (Actions)**: a₀ (top), a₁ (bottom)
- **Legend**:
- Red: unstack red
- Blue: pick-up blue
- Yellow: pick-up yellow
- Green: stack on green
- Orange: stack on yellow
- **Diagram Elements**:
- Circular nodes representing state-action combinations
- Arrows showing state transitions
- Colored blocks representing object positions
### Detailed Analysis
**State S₀**:
- Expert Logits (S_E₁):
- unstack red: 8 (red bar)
- pick-up blue: 1 (blue bar)
- pick-up yellow: 1 (yellow bar)
- Amateur Logits (S_A₁):
- unstack red: 6 (red bar)
- pick-up blue: 2 (blue bar)
- pick-up yellow: 2 (yellow bar)
- CD Logits (S_CD₁):
- ✅ unstack red (highlighted yellow)
**State S₁**:
- Expert Logits (S_E₂):
- stack on yellow: 7 (yellow bar)
- stack on blue: 1 (blue bar)
- stack on green: 1 (green bar)
- put-down red: 1 (red bar)
- Amateur Logits (S_A₂):
- stack on yellow: 3 (yellow bar)
- stack on blue: 2 (blue bar)
- stack on green: 2 (green bar)
- put-down red: 3 (red bar)
- CD Logits (S_CD₂):
- ✅ stack on yellow (highlighted yellow)
**Action Transitions**:
- a₀ (unstack red) transitions S₀ → S₁
- a₁ (stack on yellow) transitions S₁ → S₂
### Key Observations
1. Expert logits consistently show higher values for optimal actions compared to amateur logits
2. CD logits perfectly align with expert recommendations (100% accuracy)
3. State S₀ prioritizes unstacking red (8 vs 6 amateur)
4. State S₁ strongly favors stacking on yellow (7 vs 3 amateur)
5. Amateur logits show more balanced action preferences across states
### Interpretation
This diagram demonstrates how different logit sources guide decision-making in a block-stacking task:
- **Expert logits** reflect optimal policy knowledge, showing clear preference for goal-directed actions
- **Amateur logits** display more exploratory behavior with higher entropy in action selection
- **CD logits** represent idealized credit assignment, perfectly identifying optimal actions
- The state transitions reveal a two-step process: first unstacking the red block, then stacking it on yellow
- The visual representation effectively communicates the hierarchical nature of the task, with each state building toward the final configuration
The diagram suggests that while amateur policies can learn reasonable policies, expert guidance and proper credit assignment are crucial for achieving optimal performance in hierarchical tasks.
</details>
Figure 1: An overview of SC-MCTS ∗. We employ a novel reward model based on the principle of contrastive decoding to guide MCTS Reasoning on Blocksworld multi-step reasoning dataset.
The first key challenge is that MCTS’s general reasoning ability is almost entirely dependent on the reward model’s performance (as demonstrated by our ablation experiments in Section 5.5), making it highly challenging to design dense, general yet efficient rewards to guide MCTS reasoning. Previous works either require two or more LLMs (Tian et al., 2024) or training epochs (Zhang et al., 2024a), escalating the VRAM and computational demand, or they rely on domain-specific tools (Xin et al., 2024a; b) or datasets (Qi et al., 2024), making it difficult to generalize to other tasks or datasets.
The second key challenge is that MCTS is significantly slower than Chain of Thoughts (CoT). CoT only requires designing a prompt of multi-turn chats (Wei et al., 2024). In contrast, MCTS builds a reasoning tree with 2–10 layers depending on the difficulty of the task, where each node in the tree represents a chat round with LLM which may need to be visited one or multiple times. Moreover, to obtain better performance, we typically perform 2–10 MCTS iterations, which greatly increases the number of nodes, leading to much higher computational costs and slower reasoning speed.
To address the these challenges, we went beyond prior works that treated MCTS as a tool and focused on analyzing and improving its components especially reward model. Using contrastive decoding, we redesigned reward model by integrating interpretable reward signals, clustering their prior distributions, and normalizing the rewards using our proposed prior statistical method. To prevent distribution shift, we also incorporated an online incremental update algorithm. We found that the commonly used Upper Confidence Bound on Trees (UCT) strategy often underperformed due to sensitivity to the exploration constant, so we refined it and improved backpropagation to favor steadily improving paths. To address speed issues, we integrated speculative decoding as a "free lunch." All experiments were conducted using the Blocksworld dataset detailed in Section 5.1.
Our goal is to: (i) design novel and high-performance reward models and maximize the performance of reward model combinations, (ii) analyze and optimize the performance of various MCTS components, (iii) enhance the interpretability of MCTS reasoning, (iv) and accelerate MCTS reasoning. Our contributions are summarized as follows:
1. We went beyond previous works who primarily treated MCTS as an tool rather than analyzing and improving its components. Specifically, we found the UCT strategy in most previous works may failed to function from our experiment. We also refined the backpropagation of MCTS to prefer more steadily improving paths, boosting performance.
1. To fully study the interpretability of MCTS multi-step reasoning, we conducted extensive quantitative analysis and ablation studies on every component. We carried out numerous experiments from both the numerical and distributional perspectives of the reward models, as well as its own interpretability, providing better interpretability for MCTS multi-step reasoning.
1. We designed a novel, general action-level reward model based on the principle of contrastive decoding, which requires no external tools, training, or datasets. Additionally, we found that previous works often failed to effectively harness multiple reward models, thus we proposed a statistical linear combination method. At the same time, we introduced speculative decoding to speed up MCTS reasoning by an average of 52% as a "free lunch."
We demonstrated the effectiveness of our approach by outperforming OpenAI’s flagship o1-mini model by an average of 17.4% using Llama-3.1-70B on the Blocksworld multi-step reasoning dataset.
2 Related Work
Large Language Models Multi-Step Reasoning
One of the key focus areas for LLMs is understanding and enhancing their reasoning capabilities. Recent advancements in this area focused on developing methods that improve LLMs’ ability to handle complex tasks in domains like code generation and mathematical problem-solving. Chain-of-Thought (CoT) (Wei et al., 2024) reasoning has been instrumental in helping LLMs break down intricate problems into a sequence of manageable steps, making them more adept at handling tasks that require logical reasoning. Building upon this, Tree-of-Thought (ToT) (Yao et al., 2024) reasoning extends CoT by allowing models to explore multiple reasoning paths concurrently, thereby enhancing their ability to evaluate different solutions simultaneously. Complementing these approaches, Monte Carlo Tree Search (MCTS) has emerged as a powerful reasoning method for decision-making in LLMs. Originally successful in AlphaGo’s victory (Silver et al., 2016), MCTS has been adapted to guide model-based planning by balancing exploration and exploitation through tree-based search and random sampling, and later to large language model reasoning (Hao et al., 2023), showing great results. This adaptation has proven particularly effective in areas requiring strategic planning. Notable implementations like ReST-MCTS ∗ (Zhang et al., 2024a), rStar (Qi et al., 2024), MCTSr (Zhang et al., 2024b) and Xie et al. (2024) have shown that integrating MCTS with reinforced self-training, self-play mutual reasoning or Direct Preference Optimization (Rafailov et al., 2023) can significantly improve reasoning capabilities in LLMs. Furthermore, recent advancements such as Deepseek Prover (Xin et al., 2024a; b) demonstrates the potential of these models to understand complex instructions such as formal mathematical proof.
Decoding Strategies
Contrastive decoding and speculative decoding both require Smaller Language Models (SLMs), yet few have realized that these two clever decoding methods can be seamlessly combined without any additional cost. The only work that noticed this was Yuan et al. (2024a), but their proposed speculative contrastive decoding focused on token-level decoding. In contrast, we designed a new action-level contrastive decoding to guide MCTS reasoning, the distinction will be discussed further in Section 4.1. For more detailed related work please refer to Appendix B.
3 Preliminaries
3.1 Multi-Step Reasoning
A multi-step reasoning problem can be modeled as a Markov Decision Process (Bellman, 1957) $\mathcal{M}=(S,A,P,r,\gamma)$ . $S$ is the state space containing all possible states, $A$ the action space, $P(s^{\prime}|s,a)$ the state transition function, $r(s,a)$ the reward function, and $\gamma$ the discount factor. The goal is to learn and to use a policy $\pi$ to maximize the discounted cumulative reward $\mathbb{E}_{\tau\sim\pi}\left[\sum_{t=0}^{T}\gamma^{t}r_{t}\right]$ . For reasoning with LLMs, we are more focused on using an existing LLM to achieve the best reasoning.
3.2 Monte Carlo Tree Search
Monte Carlo Tree Search (MCTS) is a decision-making algorithm involving a search tree to simulate and evaluate actions. The algorithm operates in the following four phases:
Node Selection: The selection process begins at the root, selecting nodes hierarchically using strategies like UCT as the criterion to favor a child node based on its quality and novelty.
Expansion: New child nodes are added to the selected leaf node by sampling $d$ possible actions, predicting the next state. If the leaf node is fully explored or terminal, expansion is skipped.
Simulation: During simulation or “rollout”, the algorithm plays out the “game” randomly from that node to a terminal state using a default policy.
Backpropagation: Once a terminal state is reached, the reward is propagated up the tree, and each node visited during the selection phase updates its value based on the simulation result.
Through iterative application of its four phases, MCTS efficiently improves reasoning through trials and heuristics, converging on the optimal solution.
3.3 Contrastive Decoding
We discuss vanilla Contrastive Decoding (CD) from Li et al. (2023), which improves text generation in LLMs by reducing errors like repetition and self-contradiction. CD uses the differences between an expert model and an amateur model, enhancing the expert’s strengths and suppressing the amateur’s weaknesses. Consider a prompt of length $n$ , the CD objective is defined as:
$$
{\mathcal{L}}_{\text{CD}}(x_{\text{cont}},x_{\text{pre}})=\log p_{\text{EXP}}(%
x_{\text{cont}}|x_{\text{pre}})-\log p_{\text{AMA}}(x_{\text{cont}}|x_{\text{%
pre}})
$$
where $x_{\text{pre}}$ is the sequence of tokens $x_{1},...,x_{n}$ , the model generates continuations of length $m$ , $x_{\text{cont}}$ is the sequence of tokens $x_{n+1},...,x_{n+m}$ , and $p_{\text{EXP}}$ and $p_{\text{AMA}}$ are the expert and amateur probability distributions. To avoid penalizing correct behavior of the amateur or promoting implausible tokens, CD applies an adaptive plausibility constraint using an $\alpha$ -mask, which filters tokens by their logits against a threshold, the filtered vocabulary $V_{\text{valid}}$ is defined as:
$$
V_{\text{valid}}=\{i\mid s^{(i)}_{\text{EXP}}\geq\log\alpha+\max_{k}s^{(k)}_{%
\text{EXP}}\}
$$
where $s^{(i)}_{\text{EXP}}$ and $s^{(i)}_{\text{AMA}}$ are unnormalized logits assigned to token i by the expert and amateur models. Final logits are adjusted with a coefficient $(1+\beta)$ , modifying the contrastive effect on output scores (Liu et al., 2021):
$$
s^{(i)}_{\text{CD}}=(1+\beta)s^{(i)}_{\text{EXP}}-s^{(i)}_{\text{AMA}}
$$
However, our proposed CD is at action level, averaging over the whole action, instead of token level in vanilla CD. Our novel action-level CD reward more robustly captures the differences in confidence between the expert and amateur models in the generated answers compared to vanilla CD. The distinction will be illustrated in Section 4.1 and explained further in Appendix A.
3.4 Speculative Decoding as "free lunch"
Based on Speculative Decoding (Leviathan et al., 2023), the process can be summarized as follows: Let $M_{p}$ be the target model with the conditional distribution $p(x_{t}|x_{<t})$ , and $M_{q}$ be a smaller approximation model with $q(x_{t}|x_{<t})$ . The key idea is to generate $\gamma$ tokens using $M_{q}$ and filter them against $M_{p}$ ’s distribution, accepting tokens consistent with $M_{p}$ . Speculative decoding samples $\gamma$ tokens autoregressively from $M_{q}$ , keeping those where $q(x)≤ p(x)$ . If $q(x)>p(x)$ , the sample is rejected with probability $1-\frac{p(x)}{q(x)}$ , and a new sample is drawn from the adjusted distribution:
$$
p^{\prime}(x)=\text{norm}(\max(0,p(x)-q(x))).
$$
Since both contrastive and speculative decoding rely on the same smaller models, we can achieve the acceleration effect of speculative decoding as a "free lunch" (Yuan et al., 2024a).
4 Method
4.1 Multi-Reward Design
Our primary goal is to design novel and and high-performance reward models for MCTS reasoning and to maximize the performance of reward model combinations, as our ablation experiments in Section 5.5 demonstrate that MCTS performance is almost entirely determined by the reward model.
SC-MCTS ∗ is guided by three highly interpretable reward models: contrastive JS divergence, loglikelihood and self evaluation. Previous work such as (Hao et al., 2023) often directly adds reward functions with mismatched numerical magnitudes without any prior statistical analysis or linear combination. As a result, their combined reward models may fail to demonstrate full performance. Moreover, combining multiple rewards online presents numerous challenges such as distributional shifts in the values. Thus, we propose a statistically-informed reward combination method: Multi-RM method. Each reward model is normalized contextually by the fine-grained prior statistics of its empirical distribution. The pseudocode for reward model construction is shown in Algorithm 1. Please refer to Appendix D for a complete version of SC-MCTS ∗ that includes other improvements such as dealing with distribution shift when combining reward functions online.
Algorithm 1 SC-MCTS ∗, reward model construction
1: Expert LLM $\pi_{e}$ , Amateur SLM $\pi_{a}$ , Problem set $D$ ; $M$ selected problems for prior statistics, $N$ pre-generated solutions per problem, $K$ clusters
2: $\tilde{A}←\text{Sample-solutions}(\pi_{e},D,M,N)$ $\triangleright$ Pre-generate $M× N$ solutions
3: $p_{e},p_{a}←\text{Evaluate}(\pi_{e},\pi_{a},\tilde{A})$ $\triangleright$ Get policy distributions
4: for $r∈\{\text{JSD},\text{LL},\text{SE}\}$ do
5: $\bm{\mu}_{r},\bm{\sigma}_{r},\bm{b}_{r}←\text{Cluster-stats}(r(\tilde%
{A}),K)$ $\triangleright$ Prior statistics (Equation 1)
6: $R_{r}← x\mapsto(r(x)-\mu_{r}^{k^{*}})/\sigma_{r}^{k^{*}}$ $\triangleright$ Reward normalization (Equation 2)
7: end for
8: $R←\sum_{r∈\{\text{JSD},\text{LL},\text{SE}\}}w_{r}R_{r}$ $\triangleright$ Composite reward
9: $A_{D}←\text{MCTS-Reasoning}(\pi_{e},R,D,\pi_{a})$ $\triangleright$ Search solutions guided by $R$
10: $A_{D}$
Jensen-Shannon Divergence
The Jensen-Shannon divergence (JSD) is a symmetric and bounded measure of similarity between two probability distributions $P$ and $Q$ . It is defined as:
$$
\mathrm{JSD}(P\,\|\,Q)=\frac{1}{2}\mathrm{KL}(P\,\|\,M)+\frac{1}{2}\mathrm{KL}%
(Q\,\|\,M),\quad M=\frac{1}{2}(P+Q),
$$
where $\mathrm{KL}(P\,\|\,Q)$ is the Kullback-Leibler Divergence (KLD), and $M$ represents the midpoint distribution. The JSD is bounded between 0 and 1 for discrete distributions, making it better than KLD for online normalization of reward modeling.
Inspired by contrastive decoding, we propose our novel reward model: JSD between the expert model’s logits and the amateur model’s logits. Unlike vanilla token-level contrastive decoding (Li et al., 2023), our reward is computed at action-level, treating a sequence of action tokens as a whole:
$$
R_{\text{JSD}}=\frac{1}{n}\sum_{i=T_{\text{prefix}}+1}^{n}\left[\mathrm{JSD}(p%
_{\text{e}}(x_{i}|x_{<i})\,\|\,p_{\text{a}}(x_{i}|x_{<i})\right]
$$
where $n$ is the length of tokens, $T_{\text{prefix}}$ is the index of the last prefix token, $p_{\text{e}}$ and $p_{\text{a}}$ represent the softmax probabilities of the expert and amateur models, respectively. This approach ensures that the reward captures model behavior at the action level as the entire sequence of tokens is taken into account at once. This contrasts with vanilla token-level methods where each token is treated serially.
Loglikelihood
Inspired by Hao et al. (2023), we use a loglikelihood reward model to evaluate the quality of generated answers based on a given question prefix. The model computes logits for the full sequence (prefix + answer) and accumulates the log-probabilities over the answer part tokens.
Let the full sequence $x=(x_{1},x_{2},...,x_{T_{\text{total}}})$ consist of a prefix and a generated answer. The loglikelihood reward $R_{\text{LL}}$ is calculated over the answer portion:
$$
R_{\text{LL}}=\sum_{i=T_{\text{prefix}}+1}^{T_{\text{total}}}\log\left(\frac{%
\exp(z_{\theta}(x_{i}))}{\sum_{x^{\prime}\in V}\exp(z_{\theta}(x^{\prime}))}\right)
$$
where $z_{\theta}(x_{i})$ represents the unnormalized logit for token $x_{i}$ . After calculating logits for the entire sequence, we discard the prefix and focus on the answer tokens to form the loglikelihood reward.
Self Evaluation
Large language models’ token-level self evaluation can effectively quantify the model’s uncertainty, thereby improving the quality of selective generation (Ren et al., 2023). We instruct the LLM to perform self evaluation on its answers, using a action level evaluation method, including a self evaluation prompt to explicitly indicate the model’s uncertainty.
After generating the answer, we prompt the model to self-evaluate its response by asking "Is this answer correct/good?" This serves to capture the model’s confidence in its own output leading to more informed decision-making. The self evaluation prompt’s logits are then used to calculate a reward function. Similar to the loglikelihood reward model, we calculate the self evaluation reward $R_{\text{SE}}$ by summing the log-probabilities over the self-evaluation tokens.
Harnessing Multiple Reward Models
We collected prior distributions for the reward models and found some of them span multiple regions. Therefore, we compute the fine-grained prior statistics as mean and standard deviation of modes of the prior distribution ${\mathcal{R}}∈\{{\mathcal{R}}_{\text{JSD}},{\mathcal{R}}_{\text{LL}},{%
\mathcal{R}}_{\text{SE}}\}$ :
$$
\mu^{(k)}=\frac{1}{c_{k}}\sum_{R_{i}\in\rinterval{b_{1}}{b_{k+1}}}R_{i}\quad%
\text{and}\quad\sigma^{(k)}=\sqrt{\frac{1}{c_{k}}\sum_{R_{i}\in\rinterval{b_{1%
}}{b_{k+1}}}(R_{i}-\mu^{(k)})^{2}} \tag{1}
$$
where $b_{1}<b_{2}<...<b_{K+1}$ are the region boundaries in ${\mathcal{R}}$ , $R_{i}∈{\mathcal{R}}$ , and $c_{k}$ is the number of $R_{i}$ in $\rinterval{b_{1}}{b_{k+1}}$ . The region boundaries were defined during the prior statistical data collection phase 1.
After we computed the fine-grained prior statistics, the reward factors are normalized separately for each region (which degenerates to standard normalization if only a single region is found):
$$
R_{\text{norm}}(x)=(R(x)-\mu^{(k^{*})})/\sigma^{(k^{*})},~{}\text{where}~{}k^{%
*}=\operatorname*{arg\,max}\{k:b_{k}\leq R(x)\} \tag{2}
$$
This reward design, which we call Multi-RM method, has some caveats: first, to prevent distribution shift during reasoning, we update the mean and standard deviation of the reward functions online for each mode (see Appendix D for pseudocode); second, we focus only on cases with clearly distinct reward modes, leaving general cases for future work. For the correlation heatmap, see Appendix C.
4.2 Node Selection Strategy
Upper Confidence Bound applied on Trees Algorithm (UCT) (Coquelin & Munos, 2007) is crucial for the selection phase, balancing exploration and exploitation by choosing actions that maximize:
$$
UCT_{j}=\bar{X}_{j}+C\sqrt{\frac{\ln N}{N_{j}}}
$$
where $\bar{X}_{j}$ is the average reward of taking action $j$ , $N$ is the number of times the parent has been visited, and $N_{j}$ is the number of times node $j$ has been visited for simulation, $C$ is a constant to balance exploitation and exploration.
However, $C$ is a crucial part of UCT. Previous work (Hao et al., 2023; Zhang et al., 2024b) had limited thoroughly investigating its components, leading to potential failures of the UCT strategy. This is because they often used the default value of 1 from the original proposed UCT (Coquelin & Munos, 2007) without conducting sufficient quantitative experiments to find the optimal $C$ . This will be discussed in detail in Section 5.4.
4.3 Backpropagation
After each MCTS iteration, multiple paths from the root to terminal nodes are generated. By backpropagating along these paths, we update the value of each state-action pair. Previous MCTS approaches often use simple averaging during backpropagation, but this can overlook paths where the goal achieved metric $G(p)$ progresses smoothly (e.g., $G(p_{1})=0→ 0.25→ 0.5→ 0.75$ ). These paths just few step away from the final goal $G(p)=1$ , are often more valuable than less stable ones.
To improve value propagation, we propose an algorithm that better captures value progression along a path. Given a path $\mathbf{P}=\{p_{1},p_{2},...,p_{n}\}$ with $n$ nodes, where each $p_{i}$ represents the value at node $i$ , the total value is calculated by summing the increments between consecutive nodes with a length penalty. The increment between nodes $p_{i}$ and $p_{i-1}$ is $\Delta_{i}=p_{i}-p_{i-1}$ . Negative increments are clipped at $-0.1$ and downweighted by 0.5. The final path value $V_{\text{final}}$ is:
$$
V_{\text{final}}=\sum_{i=2}^{n}\left\{\begin{array}[]{ll}\Delta_{i},&\text{if %
}\Delta_{i}\geq 0\\
0.5\times\max(\Delta_{i},-0.1),&\text{if }\Delta_{i}<0\end{array}\right\}-%
\lambda\times n \tag{3}
$$
where $n$ is the number of nodes in the path and $\lambda=0.1$ is the penalty factor to discourage long paths.
5 Experiments
5.1 Dataset
Blocksworld (Valmeekam et al., 2024; 2023) is a classic domain in AI research for reasoning and planning, where the goal is to rearrange blocks into a specified configuration using actions like ’pick-up,’ ’put-down,’ ’stack,’ and ’unstack. Blocks can be moved only if no block on top, and only one block at a time. The reasoning process in Blocksworld is a MDP. At time step $t$ , the LLM agent selects an action $a_{t}\sim p(a\mid s_{t},c)$ , where $s_{t}$ is the current block configuration, $c$ is the prompt template. The state transition $s_{t+1}=P(s_{t},a_{t})$ is deterministic and is computed by rules. This forms a trajectory of interleaved states and actions $(s_{0},a_{0},s_{1},a_{1},...,s_{T})$ towards the goal state.
One key feature of Blocksworld is its built-in verifier, which tracks progress toward the goal at each step. This makes Blocksworld ideal for studying heuristic LLM multi-step reasoning. However, we deliberately avoid using the verifier as part of the reward model as it is task-specific. More details of Blocksworld can be found in Appendix F.
5.2 Main Results
To evaluate the SC-MCTS ∗ algorithm in LLM multi-step reasoning, we implemented CoT, RAP-MCTS, and SC-MCTS ∗ using Llama-3-70B and Llama-3.1-70B. For comparison, we used Llama-3.1-405B and GPT-4o for CoT, and applied 0 and 4 shot single turn for o1-mini, as OpenAI (2024b) suggests avoiding CoT prompting. The experiment was conducted on Blocksworld dataset across all steps and difficulties. For LLM settings, GPU and OpenAI API usage data, see Appendix E and H.
| Mode | Models | Method | Steps | | | | | | |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| Step 2 | Step 4 | Step 6 | Step 8 | Step 10 | Step 12 | Avg. | | | |
| Easy | Llama-3-70B ~Llama-3.2-1B | 4-shot CoT | 0.2973 | 0.4405 | 0.3882 | 0.2517 | 0.1696 | 0.1087 | 0.2929 |
| RAP-MCTS | 0.9459 | 0.9474 | 0.8138 | 0.4196 | 0.2136 | 0.1389 | 0.5778 | | |
| SC-MCTS* (Ours) | 0.9730 | 0.9737 | 0.8224 | 0.4336 | 0.2136 | 0.2222 | 0.5949 | | |
| Llama-3.1-70B ~Llama-3.2-1B | 4-shot CoT | 0.5405 | 0.4868 | 0.4069 | 0.2238 | 0.2913 | 0.2174 | 0.3441 | |
| RAP-MCTS | 1.0000 | 0.9605 | 0.8000 | 0.4336 | 0.2039 | 0.1111 | 0.5796 | | |
| SC-MCTS* (Ours) | 1.0000 | 0.9737 | 0.7724 | 0.4503 | 0.3010 | 0.1944 | 0.6026 | | |
| Llama-3.1-405B | 0-shot CoT | 0.8108 | 0.6579 | 0.5931 | 0.5105 | 0.4272 | 0.3611 | 0.5482 | |
| 4-shot CoT | 0.7838 | 0.8553 | 0.6483 | 0.4266 | 0.5049 | 0.4167 | 0.5852 | | |
| o1-mini | 0-shot | 0.9730 | 0.7368 | 0.5103 | 0.3846 | 0.3883 | 0.1944 | 0.4463 | |
| 4-shot | 0.9459 | 0.8026 | 0.6276 | 0.3497 | 0.3301 | 0.2222 | 0.5167 | | |
| GPT-4o | 0-shot CoT | 0.5405 | 0.4868 | 0.3241 | 0.1818 | 0.1165 | 0.0556 | 0.2666 | |
| 4-shot CoT | 0.5135 | 0.6579 | 0.6000 | 0.2797 | 0.3010 | 0.3611 | 0.4444 | | |
| Hard | Llama-3-70B ~Llama-3.2-1B | 4-shot CoT | 0.5556 | 0.4405 | 0.3882 | 0.2517 | 0.1696 | 0.1087 | 0.3102 |
| RAP-MCTS | 1.0000 | 0.8929 | 0.7368 | 0.4503 | 0.1696 | 0.1087 | 0.5491 | | |
| SC-MCTS* (Ours) | 0.9778 | 0.8929 | 0.7566 | 0.5298 | 0.2232 | 0.1304 | 0.5848 | | |
| Llama-3.1-70B ~Llama-3.2-1B | 4-shot CoT | 0.6222 | 0.2857 | 0.3421 | 0.1722 | 0.1875 | 0.2174 | 0.2729 | |
| RAP-MCTS | 0.9778 | 0.9048 | 0.7829 | 0.4702 | 0.1875 | 0.1087 | 0.5695 | | |
| SC-MCTS* (Ours) | 0.9778 | 0.9405 | 0.8092 | 0.4702 | 0.1696 | 0.2174 | 0.5864 | | |
| Llama-3.1-405B | 0-shot CoT | 0.7838 | 0.6667 | 0.6053 | 0.3684 | 0.2679 | 0.2609 | 0.4761 | |
| 4-shot CoT | 0.8889 | 0.6667 | 0.6579 | 0.4238 | 0.5804 | 0.5217 | 0.5915 | | |
| o1-mini | 0-shot | 0.6889 | 0.4286 | 0.1776 | 0.0993 | 0.0982 | 0.0000 | 0.2034 | |
| 4-shot | 0.9556 | 0.8452 | 0.5263 | 0.3907 | 0.2857 | 0.1739 | 0.4966 | | |
| GPT-4o | 0-shot CoT | 0.6222 | 0.3929 | 0.3026 | 0.1523 | 0.0714 | 0.0000 | 0.2339 | |
| 4-shot CoT | 0.6222 | 0.4167 | 0.5197 | 0.3642 | 0.3304 | 0.1739 | 0.4102 | | |
Table 1: Accuracy of various reasoning methods and models across steps and difficulty modes on the Blocksworld multi-step reasoning dataset.
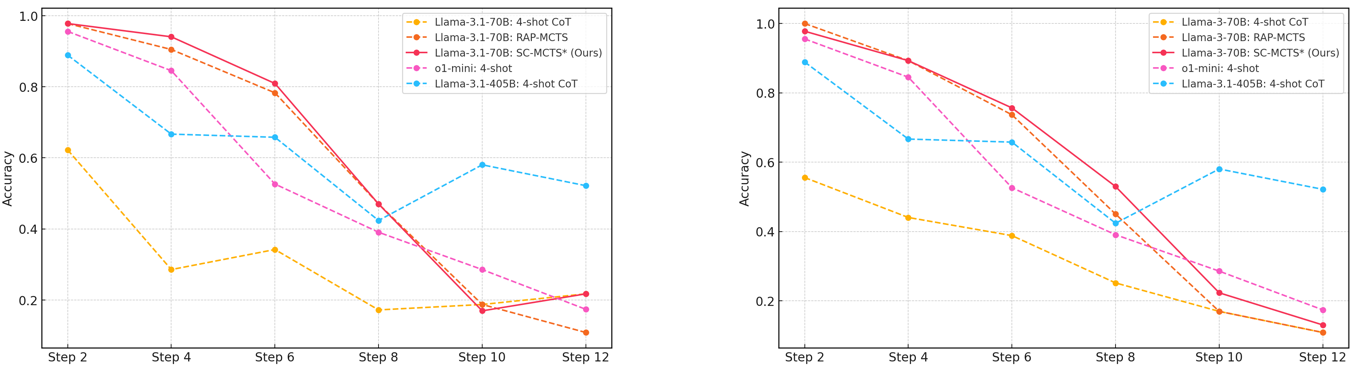
From Table 1, it can be observed that SC-MCTS ∗ significantly outperforms RAP-MCTS and 4-shot CoT across both easy and hard modes, and in easy mode, Llama-3.1-70B model using SC-MCTS ∗ outperforms the 4-shot CoT Llama-3.1-405B model.
<details>
<summary>extracted/6087579/fig/acc.png Details</summary>
### Visual Description
## Line Chart: Accuracy vs. Step for Different Models and Methods
### Overview
The image contains two side-by-side line charts comparing the accuracy of various AI models and methods across incremental steps (Step 2 to Step 12). Each subplot represents a different model version (Llama-3.1-70B and Llama-3.70B), with lines representing distinct methods (e.g., CoT, RAP-MCTS, SC-MCTS*). The charts show a general decline in accuracy as steps increase, with varying rates of degradation across methods.
---
### Components/Axes
- **X-axis (Horizontal)**: "Step" with markers at 2, 4, 6, 8, 10, 12.
- **Y-axis (Vertical)**: "Accuracy" scaled from 0.0 to 1.0.
- **Legends**:
- **Left Subplot**:
- Yellow: Llama-3.1-70B: 4-shot CoT
- Orange: Llama-3.1-70B: RAP-MCTS
- Red: Llama-3.1-70B: SC-MCTS* (Ours)
- Pink: o1-mini: 4-shot
- Blue: Llama-3.1-405B: 4-shot CoT
- **Right Subplot**:
- Yellow: Llama-3.70B: 4-shot CoT
- Orange: Llama-3.70B: RAP-MCTS
- Red: Llama-3.70B: SC-MCTS* (Ours)
- Pink: o1-mini: 4-shot
- Blue: Llama-3.1-405B: 4-shot CoT
---
### Detailed Analysis
#### Left Subplot (Llama-3.1-70B)
1. **Yellow Line (4-shot CoT)**:
- Starts at ~0.62 (Step 2), drops to ~0.28 (Step 4), then ~0.34 (Step 6), ~0.18 (Step 8), ~0.19 (Step 10), and ~0.15 (Step 12).
- **Trend**: Sharp decline, with a plateau between Steps 8–10.
2. **Orange Line (RAP-MCTS)**:
- Starts at ~0.95 (Step 2), drops to ~0.90 (Step 4), ~0.80 (Step 6), ~0.60 (Step 8), ~0.40 (Step 10), and ~0.10 (Step 12).
- **Trend**: Steep, consistent decline.
3. **Red Line (SC-MCTS*)**:
- Starts at ~0.98 (Step 2), drops to ~0.95 (Step 4), ~0.80 (Step 6), ~0.50 (Step 8), ~0.30 (Step 10), and ~0.20 (Step 12).
- **Trend**: Gradual decline, but steeper than 4-shot CoT.
4. **Pink Line (o1-mini: 4-shot)**:
- Starts at ~0.95 (Step 2), drops to ~0.85 (Step 4), ~0.50 (Step 6), ~0.30 (Step 8), ~0.25 (Step 10), and ~0.15 (Step 12).
- **Trend**: Moderate decline, with a sharp drop between Steps 6–8.
5. **Blue Line (Llama-3.1-405B: 4-shot CoT)**:
- Starts at ~0.90 (Step 2), drops to ~0.68 (Step 4), ~0.66 (Step 6), ~0.58 (Step 8), ~0.55 (Step 10), and ~0.50 (Step 12).
- **Trend**: Gradual, stable decline.
#### Right Subplot (Llama-3.70B)
1. **Yellow Line (4-shot CoT)**:
- Starts at ~0.55 (Step 2), drops to ~0.45 (Step 4), ~0.40 (Step 6), ~0.30 (Step 8), ~0.20 (Step 10), and ~0.15 (Step 12).
- **Trend**: Steeper decline than left subplot.
2. **Orange Line (RAP-MCTS)**:
- Starts at ~0.98 (Step 2), drops to ~0.95 (Step 4), ~0.85 (Step 6), ~0.70 (Step 8), ~0.50 (Step 10), and ~0.20 (Step 12).
- **Trend**: Steep, consistent decline.
3. **Red Line (SC-MCTS*)**:
- Starts at ~0.98 (Step 2), drops to ~0.95 (Step 4), ~0.80 (Step 6), ~0.60 (Step 8), ~0.40 (Step 10), and ~0.20 (Step 12).
- **Trend**: Gradual decline, similar to left subplot.
4. **Pink Line (o1-mini: 4-shot)**:
- Starts at ~0.95 (Step 2), drops to ~0.85 (Step 4), ~0.50 (Step 6), ~0.40 (Step 8), ~0.30 (Step 10), and ~0.20 (Step 12).
- **Trend**: Moderate decline, with a sharp drop between Steps 6–8.
5. **Blue Line (Llama-3.1-405B: 4-shot CoT)**:
- Starts at ~0.90 (Step 2), drops to ~0.70 (Step 4), ~0.65 (Step 6), ~0.55 (Step 8), ~0.50 (Step 10), and ~0.45 (Step 12).
- **Trend**: Gradual, stable decline.
---
### Key Observations
1. **SC-MCTS* (Red Line)**:
- Consistently outperforms other methods in both subplots, though accuracy declines with increasing steps.
- In the left subplot, it maintains higher accuracy than RAP-MCTS and 4-shot CoT.
2. **RAP-MCTS (Orange Line)**:
- Shows the steepest decline in both subplots, suggesting it is highly sensitive to step increases.
3. **4-shot CoT (Yellow/Blue Lines)**:
- Accuracy declines more gradually than RAP-MCTS but less than SC-MCTS*.
- The Llama-3.1-405B variant (blue line) retains higher accuracy than the Llama-3.70B variant (yellow line).
4. **o1-mini (Pink Line)**:
- Performs similarly to 4-shot CoT but with a sharper drop between Steps 6–8.
5. **Model Version Differences**:
- Llama-3.1-70B (left subplot) generally shows higher accuracy than Llama-3.70B (right subplot) for the same methods.
---
### Interpretation
- **Method Effectiveness**: SC-MCTS* (red line) demonstrates the most robust performance across steps, suggesting it is better suited for incremental tasks. RAP-MCTS (orange line) is the least stable, with rapid accuracy degradation.
- **Model Size Impact**: The Llama-3.1-405B variant (blue line) outperforms the Llama-3.70B variant (yellow line) in 4-shot CoT, indicating larger models may handle incremental steps more effectively.
- **Step Sensitivity**: All methods show declining accuracy with increasing steps, but the rate of decline varies. SC-MCTS* and 4-shot CoT exhibit more gradual declines, while RAP-MCTS and o1-mini drop sharply.
- **Anomalies**: The pink line (o1-mini) in the left subplot shows a plateau between Steps 8–10, which may indicate a threshold effect or data inconsistency.
This analysis highlights trade-offs between method robustness and model size, with SC-MCTS* and larger models (Llama-3.1-405B) offering better performance stability.
</details>
Figure 2: Accuracy comparison of various models and reasoning methods on the Blocksworld multi-step reasoning dataset across increasing reasoning steps.
From Figure 2, we observe that as the reasoning path lengthens, the performance advantage of two MCTS reasoning algorithms over themselves, GPT-4o, and Llama-3.1-405B’s CoT explicit multi-turn chats and o1-mini implicit multi-turn chats (OpenAI, 2024b) in terms of accuracy diminishes, becoming particularly evident after Step 6. The accuracy decline for CoT is more gradual as the reasoning path extends, whereas models employing MCTS reasoning exhibits a steeper decline. This trend could be due to the fixed iteration limit of 10 across different reasoning path lengths, which might be unfair to longer paths. Future work could explore dynamically adjusting the iteration limit based on reasoning path length. It may also be attributed to our use of a custom EOS token to ensure output format stability in the MCTS reasoning process, which operates in completion mode. As the number of steps and prompt prefix lengths increases, the limitations of completion mode may become more pronounced compared to the chat mode used in multi-turn chats. Additionally, we observe that Llama-3.1-405B benefits significantly from its huge parameter size, although underperforming at fewer steps, experiences the slowest accuracy decline as the reasoning path grows longer.
5.3 Reasoning Speed
<details>
<summary>extracted/6087579/fig/speed.png Details</summary>
### Visual Description
## Bar Charts: Token Processing Speed Comparison Across Llama 3.1 Model Variants
### Overview
The image contains two side-by-side bar charts comparing token processing speeds (tokens/second) for different Llama 3.1 model variants. Each chart evaluates three configurations: Vanilla, SD-Llama 3.1-8B, and SD-Llama 3.2-1B. The charts use color-coded bars with explicit performance multipliers relative to the Vanilla baseline.
### Components/Axes
- **X-Axes**:
- Left chart: "Llama 3.1-70B" (model size)
- Right chart: "Llama 3.1-405B" (model size)
- **Y-Axes**:
- Both charts: "Token/s" (tokens processed per second)
- Left chart y-axis range: 0–100
- Right chart y-axis range: 0–14
- **Legends**:
- Top-right corner of each chart
- Color coding:
- Red: Vanilla
- Yellow: SD-Llama 3.1-8B
- Blue: SD-Llama 3.2-1B
- **Additional Elements**:
- Dashed horizontal reference lines:
- Left chart: 60 tokens/s
- Right chart: 6 tokens/s
### Detailed Analysis
#### Left Chart (Llama 3.1-70B)
- **Vanilla**: 60 tokens/s (1.00x baseline)
- **SD-Llama 3.1-8B**: 67.5 tokens/s (1.15x)
- **SD-Llama 3.2-1B**: 90 tokens/s (1.52x)
#### Right Chart (Llama 3.1-405B)
- **Vanilla**: 6 tokens/s (1.00x baseline)
- **SD-Llama 3.1-8B**: 12 tokens/s (2.00x)
- **SD-Llama 3.2-1B**: 3 tokens/s (0.55x)
### Key Observations
1. **Performance Scaling**:
- SD-Llama 3.2-1B shows **52% improvement** over Vanilla for the 70B model but **45% degradation** for the 405B model.
- SD-Llama 3.1-8B demonstrates **20% improvement** for the 405B model but only **15% improvement** for the 70B model.
2. **Threshold Breaches**:
- SD-Llama 3.2-1B exceeds the 60 tokens/s threshold in the 70B model chart but falls below the 6 tokens/s threshold in the 405B model chart.
3. **Model Size Impact**:
- Larger models (405B) show more dramatic performance divergence between configurations.
### Interpretation
The data reveals a **non-linear relationship** between model size and the effectiveness of SD optimizations. While SD-Llama 3.2-1B significantly outperforms Vanilla for the 70B model, it underperforms for the 405B variant, suggesting potential architectural trade-offs in the SD implementation. The SD-Llama 3.1-8B configuration maintains consistent gains across both model sizes, indicating it may be a more universally effective optimization. The dashed reference lines likely represent target performance thresholds, with the 70B model comfortably exceeding its target while the 405B model struggles to meet baseline expectations in the SD-Llama 3.2-1B configuration. This pattern suggests that model size and optimization strategy interact in complex ways to determine processing efficiency.
</details>
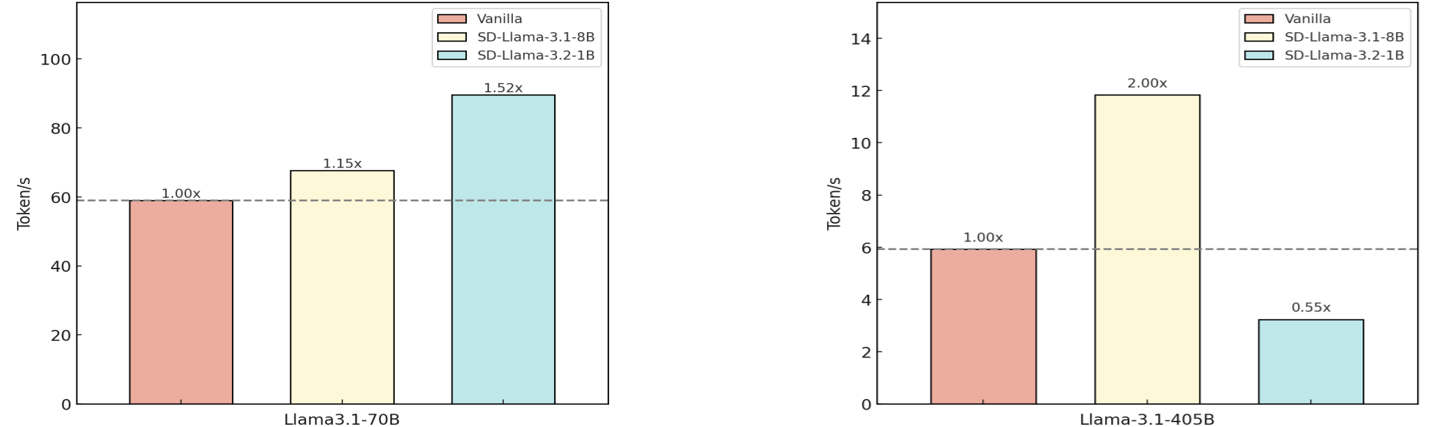
Figure 3: Speedup comparison of different model combinations. For speculative decoding, we use Llama-3.2-1B and Llama-3.1.8B as amateur models with Llama-3.1-70B and Llama-3.1-405B as expert models, based on average node-level reasoning speed in MCTS for Blocksworld multi-step reasoning dataset.
As shown in Figure 3, we can observe that the combination of Llama-3.1-405B with Llama-3.1-8B achieves the highest speedup, improving inference speed by approximately 100% compared to vanilla decoding. Similarly, pairing Llama-3.1-70B with Llama-3.2-1B results in a 51.9% increase in reasoning speed. These two combinations provide the most significant gains, demonstrating that speculative decoding with SLMs can substantially enhance node level reasoning speed. However, we can also observe from the combination of Llama-3.1-405B with Llama-3.2-1B that the parameters of SLMs in speculative decoding should not be too small, since the threshold for accepting draft tokens during the decoding process remains fixed to prevent speculative decoding from affecting performance (Leviathan et al., 2023), as overly small parameters may have a negative impact on decoding speed, which is consistent with the findings in Zhao et al. (2024); Chen et al. (2023).
5.4 Parameters
<details>
<summary>extracted/6087579/fig/uct.png Details</summary>
### Visual Description
## Line Chart: Accuracy vs. C Parameter
### Overview
The chart illustrates the relationship between the parameter "C" and accuracy for three distinct methods: RAP-MCTS, SC-MCTS* (Ours), and Negative Control (c=0). The x-axis represents the parameter "C" (ranging from 0 to 400), while the y-axis represents accuracy (ranging from 0.54 to 0.62). The legend is positioned in the top-right corner, with distinct markers for each method.
### Components/Axes
- **X-axis (C)**: Labeled "C" with increments of 50 (0, 50, 100, ..., 400).
- **Y-axis (Accuracy)**: Labeled "Accuracy" with increments of 0.02 (0.54, 0.56, ..., 0.62).
- **Legend**:
- **RAP-MCTS**: Triangle marker (green line).
- **SC-MCTS* (Ours)**: Star marker (green line).
- **Negative Control (c=0)**: Circle marker (green line).
### Detailed Analysis
1. **RAP-MCTS (Triangle)**:
- Starts at approximately **0.545** when C=0.
- Peaks at **0.63** (slightly above the y-axis upper bound of 0.62) at C=50.
- Drops to **0.62** at C=100 and remains flat until C=400.
2. **SC-MCTS* (Ours, Star)**:
- Starts at approximately **0.545** when C=0.
- Peaks at **0.63** at C=100.
- Drops to **0.62** at C=150 and remains flat until C=400.
3. **Negative Control (c=0, Circle)**:
- Starts at approximately **0.545** when C=0.
- Gradually increases to **0.56** at C=50.
- Plateaus at **0.56** from C=50 to C=400.
### Key Observations
- **Peak Accuracy**: Both RAP-MCTS and SC-MCTS* achieve higher accuracy (0.63) compared to the Negative Control (0.56).
- **C Parameter Sensitivity**:
- RAP-MCTS peaks earlier (C=50) than SC-MCTS* (C=100).
- After their respective peaks, both methods stabilize at 0.62.
- **Negative Control**: Shows minimal improvement (0.545 → 0.56) and no further gains beyond C=50.
### Interpretation
The data suggests that **RAP-MCTS** and **SC-MCTS*** outperform the **Negative Control** in terms of accuracy. The **SC-MCTS*** (Ours) achieves the highest peak accuracy (0.63) but requires a higher C value (100) to reach it compared to RAP-MCTS (C=50). The **Negative Control** (c=0) demonstrates significantly lower performance, indicating that the intervention (RAP-MCTS/SC-MCTS*) is critical for improving accuracy. The plateauing behavior of all methods after their peaks implies diminishing returns for increasing C beyond optimal values. The **SC-MCTS*** (Ours) may offer a more efficient trade-off between C and accuracy, as it achieves the same peak as RAP-MCTS but with a higher C threshold.
**Note**: The y-axis upper bound (0.62) appears to be slightly lower than the observed peak values (0.63), suggesting potential axis scaling discrepancies or data extrapolation.
</details>
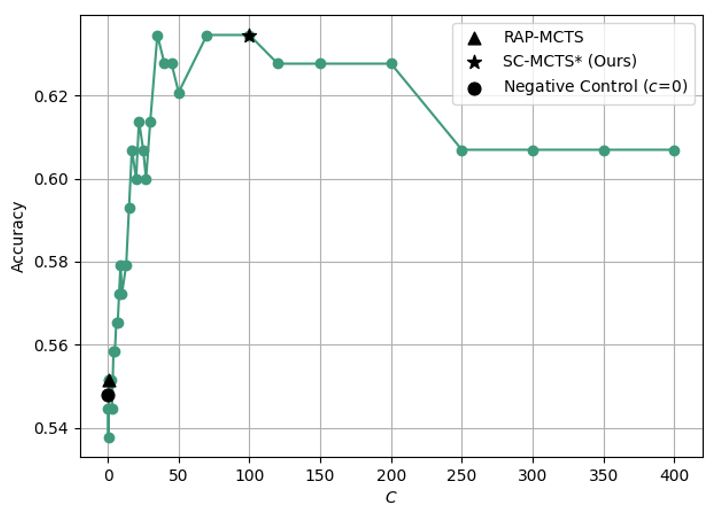
Figure 4: Accuracy comparison of different constant $C$ of UCT on Blocksworld multi-step reasoning dataset.
<details>
<summary>extracted/6087579/fig/iter.png Details</summary>
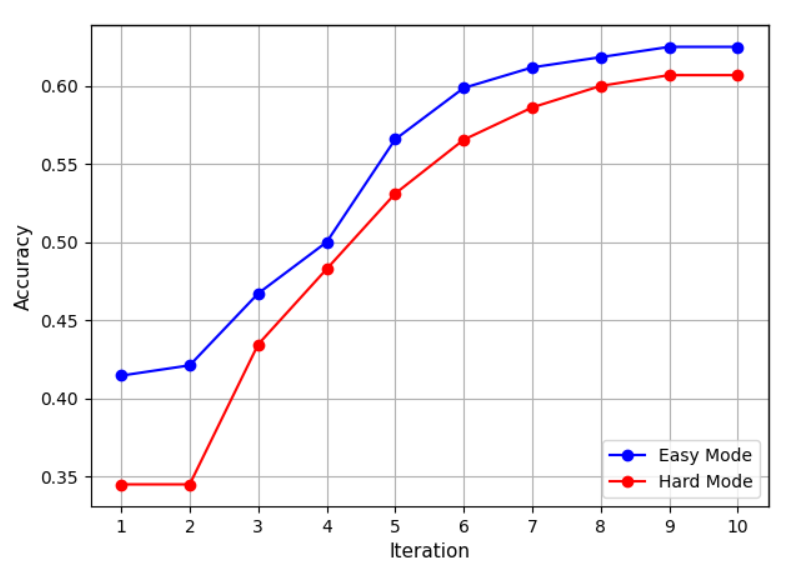
### Visual Description
## Line Chart: Accuracy vs. Iteration for Easy and Hard Modes
### Overview
The image is a line chart comparing the accuracy of two modes ("Easy Mode" and "Hard Mode") across 10 iterations. The x-axis represents iterations (1–10), and the y-axis represents accuracy (0.35–0.60). Two lines are plotted: a blue line for "Easy Mode" and a red line for "Hard Mode," with a legend in the bottom-right corner.
### Components/Axes
- **X-axis (Iteration)**: Labeled "Iteration," with integer markers from 1 to 10.
- **Y-axis (Accuracy)**: Labeled "Accuracy," with decimal markers from 0.35 to 0.60 in increments of 0.05.
- **Legend**: Located in the bottom-right corner, with:
- Blue circle: "Easy Mode"
- Red circle: "Hard Mode"
### Detailed Analysis
#### Easy Mode (Blue Line)
- **Trend**: Steadily increases from iteration 1 to 10.
- **Data Points**:
- Iteration 1: 0.41
- Iteration 2: 0.42
- Iteration 3: 0.47
- Iteration 4: 0.50
- Iteration 5: 0.57
- Iteration 6: 0.60
- Iteration 7: 0.61
- Iteration 8: 0.62
- Iteration 9: 0.63
- Iteration 10: 0.63
#### Hard Mode (Red Line)
- **Trend**: Sharp upward trajectory after iteration 2, plateauing near iteration 9–10.
- **Data Points**:
- Iteration 1: 0.35
- Iteration 2: 0.35
- Iteration 3: 0.43
- Iteration 4: 0.48
- Iteration 5: 0.53
- Iteration 6: 0.56
- Iteration 7: 0.59
- Iteration 8: 0.60
- Iteration 9: 0.61
- Iteration 10: 0.61
### Key Observations
1. **Initial Disparity**: At iterations 1–2, "Easy Mode" starts significantly higher (0.41–0.42 vs. 0.35 for "Hard Mode").
2. **Convergence**: By iteration 10, "Hard Mode" closes the gap, achieving 0.61 accuracy vs. 0.63 for "Easy Mode."
3. **Growth Rate**: "Hard Mode" shows a steeper increase (e.g., +0.08 from iteration 4 to 5) compared to "Easy Mode" (+0.03 over the same range).
4. **Plateau**: Both modes stabilize near iteration 9–10, with minimal changes in accuracy.
### Interpretation
- **Performance Insight**: "Easy Mode" consistently outperforms "Hard Mode" across all iterations, suggesting inherent simplicity or optimization in its design. However, "Hard Mode" demonstrates significant improvement over time, indicating potential for adaptation or learning.
- **Iteration Impact**: The plateau at later iterations implies diminishing returns, where further iterations yield minimal accuracy gains. This could reflect model saturation or data exhaustion.
- **Anomaly**: The abrupt jump in "Hard Mode" accuracy at iteration 3 (from 0.35 to 0.43) suggests a critical update or algorithmic adjustment that accelerated learning.
### Spatial Grounding
- The legend is positioned in the bottom-right corner, ensuring clarity without obstructing the data.
- Data points are plotted with markers (circles) aligned to their respective lines, confirming color-legend consistency.
### Conclusion
The chart highlights a trade-off between initial performance and iterative improvement. While "Easy Mode" offers higher baseline accuracy, "Hard Mode" shows promise for scenarios requiring adaptive learning, albeit with a slower start. The convergence at later iterations underscores the value of persistence in complex systems.
</details>
Figure 5: Accuracy comparison of different numbers of iteration on Blocksworld multi-step reasoning dataset.
As discussed in Section 4.2, the constant $C$ is a crucial part of UCT strategy, which completely determines whether the exploration term takes effect. Therefore, we conducted quantitative experiments on the constant $C$ , to eliminate interference from other factors, we only use MCTS base with the common reward model $R_{\text{LL}}$ for both RAP-MCTS and SC-MCTS ∗. From Figure 5 we can observe that the constant $C$ of RAP-MCTS is too small to function effectively, while the constant $C$ of SC-MCTS ∗ is the value most suited to the values of reward model derived from extensive experimental data. After introducing new datasets, this hyperparameter may need to be re-tuned.
From Figure 5, it can be observed that the accuracy of SC-MCTS ∗ on multi-step reasoning increases steadily with the number of iterations. During the first 1-7 iterations, the accuracy rises consistently. After the 7th iteration, the improvement in accuracy becomes relatively smaller, indicating that under the experimental setting with depth limitations, the exponentially growing exploration nodes in later iterations bring diminishing returns in accuracy.
5.5 Ablation Study
| Parts of SC-MCTS ∗ | Accuracy (%) | Improvement (%) |
| --- | --- | --- |
| MCTS base | 55.92 | — |
| + $R_{\text{JSD}}$ | 62.50 | +6.58 |
| + $R_{\text{LL}}$ | 67.76 | +5.26 |
| + $R_{\text{SE}}$ | 70.39 | +2.63 |
| + Multi-RM Method | 73.68 | +3.29 |
| + Improved $C$ of UCT | 78.95 | +5.27 |
| + BP Refinement | 80.92 | +1.97 |
| SC-MCTS ∗ | 80.92 | Overall +25.00 |
Table 2: Ablation Study on the Blocksworld dataset at Step 6 under difficult mode. For a more thorough ablation study, the reward model for the MCTS base was set to pseudo-random numbers.
As shown in Table 2, the results of the ablation study demonstrate that each component of SC-MCTS ∗ contributes significantly to performance improvements. Starting from a base MCTS accuracy of 55.92%, adding $R_{\text{JSD}}$ , $R_{\text{LL}}$ , and $R_{\text{SE}}$ yields a combined improvement of 14.47%. Multi-RM method further boosts performance by 3.29%, while optimizing the $C$ parameter in UCT adds 5.27%, and the backpropagation refinement increases accuracy by 1.97%. Overall, SC-MCTS ∗ achieves an accuracy of 80.92%, a 25% improvement over the base, demonstrating the effectiveness of these enhancements for complex reasoning tasks.
5.6 Interpretability Study
In the Blocksworld multi-step reasoning dataset, we utilize a built-in ground truth verifier to measure the percentage of progress toward achieving the goal at a given step, denoted as $P$ . The value of $P$ ranges between $[0,1]$ . For any arbitrary non-root node $N_{i}$ , the progress is defined as:
$$
P(N_{i})=\text{Verifier}(N_{i}).
$$
For instance, in a 10-step Blocksworld reasoning task, the initial node $A$ has $P(A)=0$ . After executing one correct action and transitioning to the next node $B$ , the progress becomes $P(B)=0.1$ .
Given a non-root node $N_{i}$ , transitioning to its parent node $\text{Parent}(N_{i})$ through a specific action $a$ , the contribution of $a$ toward the final goal state is defined as:
$$
\Delta_{a}=P(\text{Parent}(N_{i}))-P(N_{i}).
$$
Next, by analyzing the relationship between $\Delta_{a}$ and the reward value $R_{a}$ assigned by the reward model for action $a$ , we aim to reveal how our designed reward model provides highly interpretable reward signals for the selection of each node in MCTS. We also compare the performance of our reward model against a baseline reward model. Specifically, the alignment between $\Delta_{a}$ and $R_{a}$ demonstrates the interpretability of the reward model in guiding the reasoning process toward the goal state. Since Section 5.5 has already demonstrated that the reasoning performance of MCTS reasoning is almost entirely determined by the reward model, using interpretable reward models greatly enhances the interpretability of our algorithm SC-MCTS ∗.
<details>
<summary>extracted/6087579/fig/reward.png Details</summary>
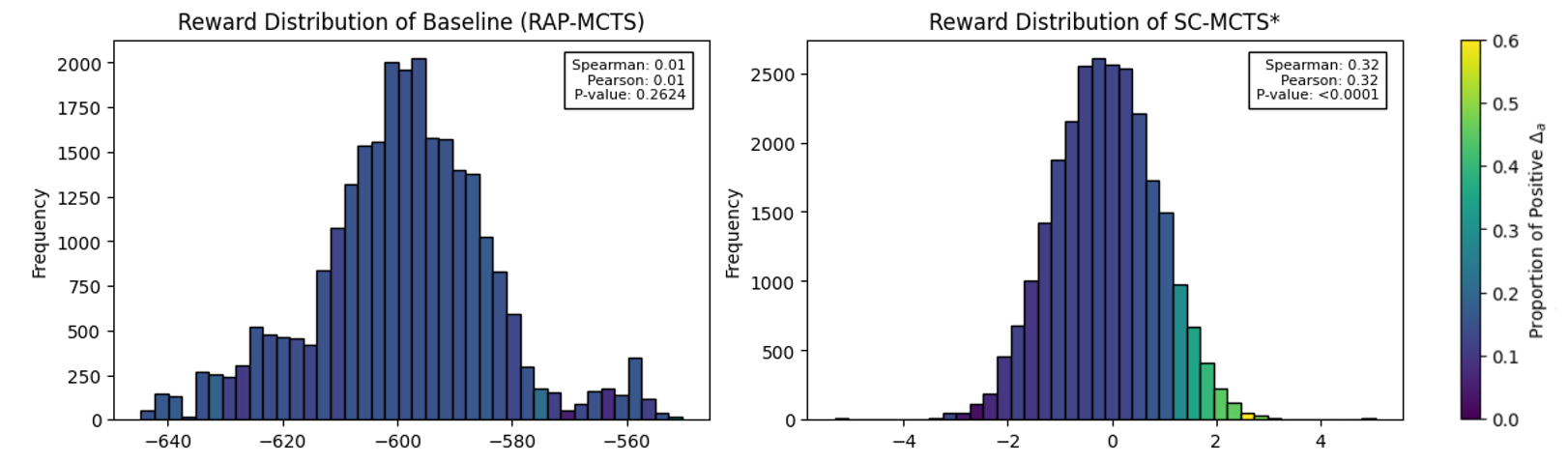
### Visual Description
## Histograms: Reward Distribution Comparison (RAP-MCTS vs SC-MCTS*)
### Overview
The image contains two side-by-side histograms comparing reward distributions. The left histogram represents the baseline RAP-MCTS system, while the right histogram shows the SC-MCTS* system. Both use frequency counts on the y-axis, with distinct x-axis ranges and color-coded distributions.
### Components/Axes
**Left Histogram (RAP-MCTS):**
- **X-axis**: Reward values ranging from -640 to -560 (intervals of ~20)
- **Y-axis**: Frequency (0 to 2000)
- **Legend**:
- Spearman: 0.01
- Pearson: 0.01
- P-value: 0.2624
- **Color**: Uniform blue bars
**Right Histogram (SC-MCTS*):**
- **X-axis**: Δa values ranging from -4 to 4 (intervals of ~1)
- **Y-axis**: Frequency (0 to 2500)
- **Legend**:
- Spearman: 0.32
- Pearson: 0.32
- P-value: <0.0001
- **Color Gradient**: Purple (0.0) to Yellow (0.6) indicating "Proportion of Positive Δa"
### Detailed Analysis
**Left Histogram (RAP-MCTS):**
- Peak frequency (~2000) occurs at reward value -600
- Distribution spreads symmetrically between -640 and -560
- Frequencies decrease gradually toward the edges
- No visible color variation (uniform blue)
**Right Histogram (SC-MCTS*):**
- Peak frequency (~2500) occurs at Δa = 0
- Distribution narrows significantly compared to RAP-MCTS
- Right tail (positive Δa) shows higher frequency density
- Color gradient transitions from purple (left) to yellow (right), indicating increasing proportion of positive Δa values
### Key Observations
1. **Distribution Shape**:
- RAP-MCTS shows a wider, more uniform distribution
- SC-MCTS* exhibits a sharper peak at 0 with steeper declines on both sides
2. **Statistical Significance**:
- SC-MCTS* has a P-value <0.0001 vs RAP-MCTS' 0.2624, indicating highly significant differences
- Spearman/Pearson correlations (0.32 vs 0.01) suggest stronger linear relationships in SC-MCTS*
3. **Δa Proportions**:
- Right histogram's color gradient shows ~60% of rewards have positive Δa values (yellow region)
### Interpretation
The SC-MCTS* system demonstrates:
- **Improved Performance**: Narrower, more concentrated reward distribution around 0 suggests better target achievement
- **Statistical Robustness**: Lower P-value (<0.0001) confirms significant improvement over baseline
- **Positive Bias**: Color gradient reveals majority of rewards show positive Δa values, indicating systematic improvement
- **Correlation Strength**: Higher Spearman/Pearson values (0.32) suggest more consistent linear relationships in reward outcomes
The baseline RAP-MCTS shows:
- **Wider Variability**: Broader distribution implies less consistent performance
- **Negative Bias**: All rewards cluster in negative territory (-640 to -560)
- **Weaker Correlations**: Near-zero Spearman/Pearson values indicate minimal linear relationships
The color-coded Δa proportions in SC-MCTS* provide granular insight into reward quality distribution, revealing that higher positive deviations are more frequent in the improved system.
</details>
Figure 6: Reward distribution and interpretability analysis. The left histogram shows the baseline reward model (RAP-MCTS), while the right represents SC-MCTS ∗. Bin colors indicate the proportion of positive $\Delta_{a}$ (lighter colors means higher proportions). Spearman and Pearson correlations along with p-values are shown in the top right of each histogram.
From Figure 6, shows that SC-MCTS* reward values correlate significantly with $\Delta_{a}$ , as indicated by the high Spearman and Pearson coefficients. Additionally, the mapping between the reward value bins and the proportion of positive $\Delta_{a}$ (indicated by the color gradient from light to dark) is highly consistent and intuitive. This strong alignment suggests that our reward model effectively captures the progress toward the goal state, providing interpretable signals for action selection during reasoning.
These results highlight the exceptional interpretability of our designed reward model, which ensures that SC-MCTS* not only achieves superior reasoning performance but is also highly interpretable. This interpretability is crucial for understanding and improving the decision-making process in multi-step reasoning tasks, further validating transparency of our proposed algorithm.
6 Conclusion
In this paper, we present SC-MCTS ∗, a novel and effective algorithm to enhancing the reasoning capabilities of LLMs. With extensive improvements in reward modeling, node selection strategy and backpropagation, SC-MCTS ∗ boosts both accuracy and speed, outperforming OpenAI’s o1-mini model by 17.4% on average using Llama-3.1-70B on the Blocksworld dataset. Experiments demonstrate its strong performance, making it a promising approach for multi-step reasoning tasks. For future work please refer to Appendix J. The synthesis of interpretability, efficiency and generalizability positions SC-MCTS ∗ as a valuable contribution to advancing LLMs multi-step reasoning.
References
- Bellman (1957) Richard Bellman. A markovian decision process. Journal of Mathematics and Mechanics, 6(5):679–684, 1957. ISSN 00959057, 19435274. URL http://www.jstor.org/stable/24900506.
- Chen et al. (2023) Charlie Chen, Sebastian Borgeaud, Geoffrey Irving, Jean-Baptiste Lespiau, Laurent Sifre, and John Jumper. Accelerating large language model decoding with speculative sampling, 2023. URL https://arxiv.org/abs/2302.01318.
- Chen et al. (2024) Qiguang Chen, Libo Qin, Jiaqi Wang, Jinxuan Zhou, and Wanxiang Che. Unlocking the boundaries of thought: A reasoning granularity framework to quantify and optimize chain-of-thought, 2024. URL https://arxiv.org/abs/2410.05695.
- Coquelin & Munos (2007) Pierre-Arnaud Coquelin and Rémi Munos. Bandit algorithms for tree search. In Proceedings of the Twenty-Third Conference on Uncertainty in Artificial Intelligence, UAI’07, pp. 67–74, Arlington, Virginia, USA, 2007. AUAI Press. ISBN 0974903930.
- Frantar et al. (2022) Elias Frantar, Saleh Ashkboos, Torsten Hoefler, and Dan Alistarh. Gptq: Accurate post-training quantization for generative pre-trained transformers, 2022.
- Hao et al. (2023) Shibo Hao, Yi Gu, Haodi Ma, Joshua Hong, Zhen Wang, Daisy Wang, and Zhiting Hu. Reasoning with language model is planning with world model. In Houda Bouamor, Juan Pino, and Kalika Bali (eds.), Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pp. 8154–8173, Singapore, December 2023. Association for Computational Linguistics. doi: 10.18653/v1/2023.emnlp-main.507. URL https://aclanthology.org/2023.emnlp-main.507.
- Hao et al. (2024) Shibo Hao, Yi Gu, Haotian Luo, Tianyang Liu, Xiyan Shao, Xinyuan Wang, Shuhua Xie, Haodi Ma, Adithya Samavedhi, Qiyue Gao, Zhen Wang, and Zhiting Hu. LLM reasoners: New evaluation, library, and analysis of step-by-step reasoning with large language models. In ICLR 2024 Workshop on Large Language Model (LLM) Agents, 2024. URL https://openreview.net/forum?id=h1mvwbQiXR.
- Jumper et al. (2021) John Jumper, Richard Evans, Alexander Pritzel, Tim Green, Michael Figurnov, Olaf Ronneberger, Kathryn Tunyasuvunakool, Russ Bates, Augustin Žídek, Anna Potapenko, Alex Bridgland, Clemens Meyer, Simon A. A. Kohl, Andrew J. Ballard, Andrew Cowie, Bernardino Romera-Paredes, Stanislav Nikolov, Rishub Jain, Jonas Adler, and Trevor Back. Highly accurate protein structure prediction with alphafold. Nature, 596(7873):583–589, Jul 2021. doi: https://doi.org/10.1038/s41586-021-03819-2. URL https://www.nature.com/articles/s41586-021-03819-2.
- Leviathan et al. (2023) Yaniv Leviathan, Matan Kalman, and Yossi Matias. Fast inference from transformers via speculative decoding. In Proceedings of the 40th International Conference on Machine Learning, ICML’23. JMLR.org, 2023.
- Li et al. (2023) Xiang Lisa Li, Ari Holtzman, Daniel Fried, Percy Liang, Jason Eisner, Tatsunori Hashimoto, Luke Zettlemoyer, and Mike Lewis. Contrastive decoding: Open-ended text generation as optimization. In Anna Rogers, Jordan Boyd-Graber, and Naoaki Okazaki (eds.), Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 12286–12312, Toronto, Canada, July 2023. Association for Computational Linguistics. doi: 10.18653/v1/2023.acl-long.687. URL https://aclanthology.org/2023.acl-long.687.
- Liu et al. (2021) Alisa Liu, Maarten Sap, Ximing Lu, Swabha Swayamdipta, Chandra Bhagavatula, Noah A. Smith, and Yejin Choi. DExperts: Decoding-time controlled text generation with experts and anti-experts. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), pp. 6691–6706, Online, August 2021. Association for Computational Linguistics. doi: 10.18653/v1/2021.acl-long.522. URL https://aclanthology.org/2021.acl-long.522.
- McAleese et al. (2024) Nat McAleese, Rai Michael Pokorny, Juan Felipe Ceron Uribe, Evgenia Nitishinskaya, Maja Trebacz, and Jan Leike. Llm critics help catch llm bugs, 2024.
- O’Brien & Lewis (2023) Sean O’Brien and Mike Lewis. Contrastive decoding improves reasoning in large language models, 2023. URL https://arxiv.org/abs/2309.09117.
- OpenAI (2024a) OpenAI. Introducing openai o1. https://openai.com/o1/, 2024a. Accessed: 2024-10-02.
- OpenAI (2024b) OpenAI. How reasoning works. https://platform.openai.com/docs/guides/reasoning/how-reasoning-works, 2024b. Accessed: 2024-10-02.
- Qi et al. (2024) Zhenting Qi, Mingyuan Ma, Jiahang Xu, Li Lyna Zhang, Fan Yang, and Mao Yang. Mutual reasoning makes smaller llms stronger problem-solvers, 2024. URL https://arxiv.org/abs/2408.06195.
- Rafailov et al. (2023) Rafael Rafailov, Archit Sharma, Eric Mitchell, Christopher D Manning, Stefano Ermon, and Chelsea Finn. Direct preference optimization: Your language model is secretly a reward model. In A. Oh, T. Naumann, A. Globerson, K. Saenko, M. Hardt, and S. Levine (eds.), Advances in Neural Information Processing Systems, volume 36, pp. 53728–53741. Curran Associates, Inc., 2023. URL https://proceedings.neurips.cc/paper_files/paper/2023/file/a85b405ed65c6477a4fe8302b5e06ce7-Paper-Conference.pdf.
- Ren et al. (2023) Jie Ren, Yao Zhao, Tu Vu, Peter J. Liu, and Balaji Lakshminarayanan. Self-evaluation improves selective generation in large language models. In Javier Antorán, Arno Blaas, Kelly Buchanan, Fan Feng, Vincent Fortuin, Sahra Ghalebikesabi, Andreas Kriegler, Ian Mason, David Rohde, Francisco J. R. Ruiz, Tobias Uelwer, Yubin Xie, and Rui Yang (eds.), Proceedings on "I Can’t Believe It’s Not Better: Failure Modes in the Age of Foundation Models" at NeurIPS 2023 Workshops, volume 239 of Proceedings of Machine Learning Research, pp. 49–64. PMLR, 16 Dec 2023. URL https://proceedings.mlr.press/v239/ren23a.html.
- Silver et al. (2016) David Silver, Aja Huang, Chris J. Maddison, Arthur Guez, Laurent Sifre, George van den Driessche, Julian Schrittwieser, Ioannis Antonoglou, Veda Panneershelvam, Marc Lanctot, Sander Dieleman, Dominik Grewe, John Nham, Nal Kalchbrenner, Ilya Sutskever, Timothy Lillicrap, Madeleine Leach, Koray Kavukcuoglu, Thore Graepel, and Demis Hassabis. Mastering the game of go with deep neural networks and tree search. Nature, 529(7587):484–489, Jan 2016. doi: https://doi.org/10.1038/nature16961.
- Silver et al. (2017) David Silver, Thomas Hubert, Julian Schrittwieser, Ioannis Antonoglou, Matthew Lai, Arthur Guez, Marc Lanctot, Laurent Sifre, Dharshan Kumaran, Thore Graepel, Timothy Lillicrap, Karen Simonyan, and Demis Hassabis. Mastering chess and shogi by self-play with a general reinforcement learning algorithm, 2017. URL https://arxiv.org/abs/1712.01815.
- Sprague et al. (2024) Zayne Sprague, Fangcong Yin, Juan Diego Rodriguez, Dongwei Jiang, Manya Wadhwa, Prasann Singhal, Xinyu Zhao, Xi Ye, Kyle Mahowald, and Greg Durrett. To cot or not to cot? chain-of-thought helps mainly on math and symbolic reasoning, 2024. URL https://arxiv.org/abs/2409.12183.
- Tian et al. (2024) Ye Tian, Baolin Peng, Linfeng Song, Lifeng Jin, Dian Yu, Haitao Mi, and Dong Yu. Toward self-improvement of llms via imagination, searching, and criticizing. ArXiv, abs/2404.12253, 2024. URL https://api.semanticscholar.org/CorpusID:269214525.
- Valmeekam et al. (2023) Karthik Valmeekam, Matthew Marquez, Sarath Sreedharan, and Subbarao Kambhampati. On the planning abilities of large language models - a critical investigation. In Thirty-seventh Conference on Neural Information Processing Systems, 2023. URL https://openreview.net/forum?id=X6dEqXIsEW.
- Valmeekam et al. (2024) Karthik Valmeekam, Matthew Marquez, Alberto Olmo, Sarath Sreedharan, and Subbarao Kambhampati. Planbench: an extensible benchmark for evaluating large language models on planning and reasoning about change. In Proceedings of the 37th International Conference on Neural Information Processing Systems, NIPS ’23, Red Hook, NY, USA, 2024. Curran Associates Inc.
- Wei et al. (2024) Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed H. Chi, Quoc V. Le, and Denny Zhou. Chain-of-thought prompting elicits reasoning in large language models. In Proceedings of the 36th International Conference on Neural Information Processing Systems, NIPS ’22, Red Hook, NY, USA, 2024. Curran Associates Inc. ISBN 9781713871088.
- Xie et al. (2024) Yuxi Xie, Anirudh Goyal, Wenyue Zheng, Min-Yen Kan, Timothy P. Lillicrap, Kenji Kawaguchi, and Michael Shieh. Monte carlo tree search boosts reasoning via iterative preference learning, 2024. URL https://arxiv.org/abs/2405.00451.
- Xin et al. (2024a) Huajian Xin, Daya Guo, Zhihong Shao, Zhizhou Ren, Qihao Zhu, Bo Liu (Benjamin Liu), Chong Ruan, Wenda Li, and Xiaodan Liang. Deepseek-prover: Advancing theorem proving in llms through large-scale synthetic data. ArXiv, abs/2405.14333, 2024a. URL https://api.semanticscholar.org/CorpusID:269983755.
- Xin et al. (2024b) Huajian Xin, Z. Z. Ren, Junxiao Song, Zhihong Shao, Wanjia Zhao, Haocheng Wang, Bo Liu, Liyue Zhang, Xuan Lu, Qiushi Du, Wenjun Gao, Qihao Zhu, Dejian Yang, Zhibin Gou, Z. F. Wu, Fuli Luo, and Chong Ruan. Deepseek-prover-v1.5: Harnessing proof assistant feedback for reinforcement learning and monte-carlo tree search, 2024b. URL https://arxiv.org/abs/2408.08152.
- Xu (2023) Haotian Xu. No train still gain. unleash mathematical reasoning of large language models with monte carlo tree search guided by energy function, 2023. URL https://arxiv.org/abs/2309.03224.
- Yao et al. (2024) Shunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Shafran, Thomas L. Griffiths, Yuan Cao, and Karthik Narasimhan. Tree of thoughts: deliberate problem solving with large language models. In Proceedings of the 37th International Conference on Neural Information Processing Systems, NIPS ’23, Red Hook, NY, USA, 2024. Curran Associates Inc.
- Yuan et al. (2024a) Hongyi Yuan, Keming Lu, Fei Huang, Zheng Yuan, and Chang Zhou. Speculative contrastive decoding. In Lun-Wei Ku, Andre Martins, and Vivek Srikumar (eds.), Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), pp. 56–64, Bangkok, Thailand, August 2024a. Association for Computational Linguistics. URL https://aclanthology.org/2024.acl-short.5.
- Yuan et al. (2024b) Lifan Yuan, Ganqu Cui, Hanbin Wang, Ning Ding, Xingyao Wang, Jia Deng, Boji Shan, Huimin Chen, Ruobing Xie, Yankai Lin, Zhenghao Liu, Bowen Zhou, Hao Peng, Zhiyuan Liu, and Maosong Sun. Advancing llm reasoning generalists with preference trees, 2024b.
- Zhang et al. (2024a) Dan Zhang, Sining Zhoubian, Ziniu Hu, Yisong Yue, Yuxiao Dong, and Jie Tang. Rest-mcts*: Llm self-training via process reward guided tree search, 2024a. URL https://arxiv.org/abs/2406.03816.
- Zhang et al. (2024b) Di Zhang, Xiaoshui Huang, Dongzhan Zhou, Yuqiang Li, and Wanli Ouyang. Accessing gpt-4 level mathematical olympiad solutions via monte carlo tree self-refine with llama-3 8b, 2024b. URL https://arxiv.org/abs/2406.07394.
- Zhao et al. (2024) Weilin Zhao, Yuxiang Huang, Xu Han, Wang Xu, Chaojun Xiao, Xinrong Zhang, Yewei Fang, Kaihuo Zhang, Zhiyuan Liu, and Maosong Sun. Ouroboros: Generating longer drafts phrase by phrase for faster speculative decoding, 2024. URL https://arxiv.org/abs/2402.13720.
Appendix A Action-Level Contrastive Reward
We made the distinction between action-level variables and token-level variables: action-level (or step-level) variables are those that aggregate over all tokens in a reasoning step, and is typically utilized by the reasoning algorithm directly; token-level variables, by contrast, operates in a more microscopic and low-level environment, such as speculative decoding.
We found that the traditional contrastive decoding using the difference in logits, when aggregated over the sequence gives a unstable reward signal compared to JS divergence. We suspected this is due to the unbounded nature of logit difference, and the potential failure modes associated with it that needs extra care and more hyperparameter tuning.
Appendix B More Related Work
Large Language Models Multi-Step Reasoning
Deepseek Prover (Xin et al., 2024a; b) relied on Lean4 as an external verification tool to provide dense reward signals in the RL stage. ReST-MCTS ∗ (Zhang et al., 2024a) employed self-training to collect high-quality reasoning trajectories for iteratively improving the value model. AlphaLLM (Tian et al., 2024) used critic models initialized from the policy model as the MCTS reward model. rStar (Qi et al., 2024) utilized mutual consistency of SLMs and an additional math-specific action space. Xu (2023) proposed reconstructing fine-tuned LLMs into residual-based energy models to guide MCTS.
Speculative Decoding
Speculative decoding was first introduced in Leviathan et al. (2023), as a method to accelerate sampling from large autoregressive models by computing multiple tokens in parallel without retraining or changing the model structure. It enhances computational efficiency, especially in large-scale generation tasks, by recognizing that hard language-modeling tasks often include easier subtasks that can be approximated well by more efficient models. Similarly, DeepMind introduced speculative sampling (Chen et al., 2023), which expands on this idea by generating a short draft sequence using a faster draft model and then scoring this draft with a larger target model.
Contrastive Decoding
Contrastive decoding, as proposed by Li et al. (2023), is a simple, computationally light, and training-free method for text generation that can enhancethe quality and quantity by identifying strings that highlight potential differences between strong models and weak models. In this context, the weak models typically employ conventional greedy decoding techniques such as basic sampling methods, while the strong models are often well-trained large language models. This approach has demonstrated notable performance improvements in various inference tasks, including arithmetic reasoning and multiple-choice ranking tasks, thereby increasing the accuracy of language models. According to experiments conducted by O’Brien & Lewis (2023), applying contrastive decoding across various tasks has proven effective in enhancing the reasoning capabilities of LLMs.
Appendix C Reward Functions Correlation
<details>
<summary>extracted/6087579/fig/heatmap.png Details</summary>
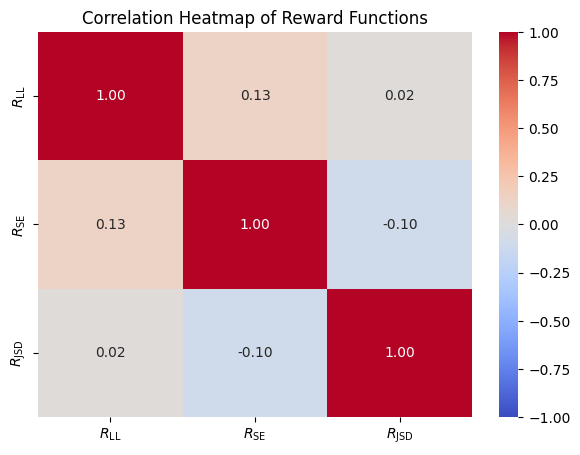
### Visual Description
## Heatmap: Correlation Heatmap of Reward Functions
### Overview
This heatmap visualizes the pairwise correlation coefficients between three reward functions: **R_LL**, **R_SE**, and **R_JSD**. The color gradient ranges from red (positive correlation) to blue (negative correlation), with white indicating no correlation. The diagonal cells are fixed at 1.00, representing perfect self-correlation.
### Components/Axes
- **X-axis (Columns)**: R_LL, R_SE, R_JSD
- **Y-axis (Rows)**: R_LL, R_SE, R_JSD
- **Color Scale**:
- Red → 1.00 (perfect positive correlation)
- Blue → -1.00 (perfect negative correlation)
- White → 0.00 (no correlation)
- **Legend**: Positioned on the right, with a vertical gradient from red (top) to blue (bottom).
### Detailed Analysis
| Row\Column | R_LL | R_SE | R_JSD |
|------------|--------|--------|--------|
| **R_LL** | 1.00 | 0.13 | 0.02 |
| **R_SE** | 0.13 | 1.00 | -0.10 |
| **R_JSD** | 0.02 | -0.10 | 1.00 |
- **R_LL**:
- Self-correlation: 1.00 (red).
- Correlation with R_SE: 0.13 (light red, weak positive).
- Correlation with R_JSD: 0.02 (gray, near-neutral).
- **R_SE**:
- Self-correlation: 1.00 (red).
- Correlation with R_LL: 0.13 (light red, weak positive).
- Correlation with R_JSD: -0.10 (light blue, weak negative).
- **R_JSD**:
- Self-correlation: 1.00 (red).
- Correlation with R_LL: 0.02 (gray, near-neutral).
- Correlation with R_SE: -0.10 (light blue, weak negative).
### Key Observations
1. **Diagonal Dominance**: All diagonal cells are 1.00, as expected for self-correlation.
2. **Weak Pairwise Correlations**:
- R_LL and R_SE show a weak positive correlation (0.13).
- R_SE and R_JSD exhibit a weak negative correlation (-0.10).
- R_LL and R_JSD are nearly uncorrelated (0.02).
3. **Symmetry**: The heatmap is symmetric along the diagonal, consistent with correlation properties.
### Interpretation
The heatmap suggests that the three reward functions (**R_LL**, **R_SE**, **R_JSD**) are largely **independent**, with only minor pairwise correlations. The weak positive correlation between R_LL and R_SE (0.13) and the weak negative correlation between R_SE and R_JSD (-0.10) imply subtle trade-offs or complementary relationships. However, the near-zero correlation between R_LL and R_JSD (0.02) indicates these functions operate in largely distinct domains. This could reflect divergent design objectives or optimization targets in the underlying system. The absence of strong correlations highlights the need for careful balancing when combining these reward functions in multi-objective optimization scenarios.
</details>
Figure 7: Reward Functions Correlation Heatmap.
It can be seen from Figure 7 that the correlations between the three reward functions are relatively low, absolute values all below 0.15. These low correlations of reward functions make them ideal for Multi-RM method.
Appendix D Algorithm Details of SC-MCTS ∗
The pseudocode inside MCTS reasoning of SC-MCTS ∗ is shown in Algorithm 2, based on Zhang et al. (2024a). The complete version of SC-MCTS ∗ is: first sample a subset of problems to obtain the prior data for reward values (Algorithm 1), then use it and two SLMs, one for providing contrastive reward signals, another for speculative decoding speedup, to perform MCTS reasoning. The changes of SC-MCTS ∗ compared to previous works are highlighted in teal.
Algorithm 2 SC-MCTS ∗, reasoning
1: expert LLM $\pi_{\text{e}}$ , amatuer SLM $\pi_{\text{a}}$ , speculative SLM $\pi_{\text{s}}$ , problem $q$ , reward model $R$ , reward factor statistics ${\mathcal{S}}$ , max iterations $T$ , threshold $l$ , branch $b$ , rollout steps $m$ , roll branch $d$ , weight parameter $\alpha$ , exploration constant $C$
2: $T_{q}←$ Initialize-tree $(q)$
3: for $i=1... T$ do
4: $n←$ Root $(T_{q})$
5: while $n$ is not leaf node do $\triangleright$ Node selection
6: $n←$ $\operatorname*{arg\,max}_{n^{\prime}∈\text{children}(n)}(v_{n^{\prime}}+C%
\sqrt{\frac{\ln{N_{n}}}{N_{n^{\prime}}}})$ $\triangleright$ Select child node based on UCT
7: end while
8: if $v_{n}≥ l$ then break $\triangleright$ Output solution
9: end if
10: if $n$ is not End of Inference then
11: for $j=1... b$ do $\triangleright$ Thought expansion
12: $n_{j}←$ Get-new-child $(A_{n},q,\pi_{\text{e}})$ $\triangleright$ Expand based on previous steps
13: $v_{n_{j}},{\mathcal{S}}←$ $R(A_{n_{j}},q,\pi_{\text{e}},\pi_{\text{a}},{\mathcal{S}})$ $\triangleright$ Evaluate contrastive reward and update reward factor statistics
14: end for
15: $n^{\prime}←$ $\operatorname*{arg\,max}_{n^{\prime}∈\text{children}(n)}(v_{n^{\prime}})$
16: $v_{\max}←$ 0
17: for $k=1... m$ do $\triangleright$ Greedy MC rollout
18: $A,v_{\max}←$ Get-next-step-with-best-value $(A,q,\pi_{\text{e}},\pi_{\text{s}},d)$ $\triangleright$ Sample new children using speculative decoding and record the best observed value
19: end for
20: $v_{n^{\prime}}←$ $\alpha v_{n^{\prime}}+(1-\alpha)v_{\max}$
21: $N_{n^{\prime}}←$ $N_{n^{\prime}}+1$ $\triangleright$ Update value and visit count of the rollout node
22: end if
23: Back-propagate $(n)$ $\triangleright$ Update value of parent nodes (Equation 3)
24: end for
25: $n←$ Get-best-node $(T_{q})$ $\triangleright$ Fetch the node with the highest value in the search tree
26: $A_{n}$
Although we sampled a small portion of the dataset as prior data for reward values, distribution shift may still occur when normalizing reward values during reasoning. Therefore, we use the following algorithm to incrementally update the mean and standard deviation of the online reward distribution:
Algorithm 3 Online incremental update of reward factor statistics
1: reward factors $\mathcal{R}(=\{\text{JSD},\text{LL},\text{SE}\})$ , statistics $\{\mu_{r}^{(k)},\sigma_{r}^{(k)},n_{r}^{(k)}\}_{r∈\mathcal{R},k∈\{1,...%
,K\}}$ , cluster assignment function $f$
2: for $r∈\mathcal{R}$ do
3: $k^{*}← f(x)$ $\triangleright$ Assign sample to cluster
4: $v_{r}← r(x)$ $\triangleright$ Compute reward factor value
5: $n_{r}^{(k^{*})}← n_{r}^{(k^{*})}+1$ $\triangleright$ Update sample count
6: $\delta← v_{r}-\mu_{r}^{(k^{*})}$ $\triangleright$ Compute difference from mean
7: $\mu_{r}^{(k^{*})}←\mu_{r}^{(k^{*})}+\delta/n_{r}^{(k^{*})}$ $\triangleright$ Update mean
8: $M_{2}←(n_{r}^{(k^{*})}-1)(\sigma_{r}^{(k^{*})})^{2}+\delta(v_{r}-\mu_%
{r}^{(k^{*})})$
9: $\sigma_{r}^{(k^{*})}←\sqrt{M_{2}/n_{r}^{(k^{*})}}$ $\triangleright$ Update standard deviation
10: end for
11: updated statistics $\{\mu_{r}^{(k)},\sigma_{r}^{(k)},n_{r}^{(k)}\}_{r∈\mathcal{R},k∈\{1,...%
,K\}}$
Appendix E Experimental Settings
For reproducibility, you can download the checkpoints from the Huggingface repository below and use the hyperparameters below. We utilized 4-bit quantized checkpoints in all experiments, as they only result in around 2% performance loss while providing several-fold reductions in memory usage and significantly improving inference speed (Frantar et al., 2022). For better output formatting to capture a single step and convert it into an MCTS node, we used the LLM’s completion mode so we set LLM to greedy sampling, and we don’t have to set an additional system prompt, simply apply prompts in Appendix F. Our experiments were all conducted on exllamav2 inference framework.
E.1 Checkpoints
| Usage | Models | Links |
| --- | --- | --- |
| Expert | Llama-3.1-405B | https://huggingface.co/hugging-quants/Meta-Llama-3.1-405B-Instruct-GPTQ-INT4 |
| Llama-3.1-70B | https://huggingface.co/hugging-quants/Meta-Llama-3.1-70B-Instruct-GPTQ-INT4 | |
| Llama-3-70B | https://huggingface.co/TechxGenus/Meta-Llama-3-70B-Instruct-GPTQ | |
| Amateur | Llama-3.1-8B | https://huggingface.co/hugging-quants/Meta-Llama-3.1-8B-Instruct-GPTQ-INT4 |
| Llama-3-8B | https://huggingface.co/astronomer/Llama-3-8B-Instruct-GPTQ-4-Bit | |
| Llama-3.2-1B | https://huggingface.co/meta-llama/Llama-3.2-1B | |
| OpenAI | GPT-4o | https://platform.openai.com/docs/models/gpt-4o |
| o1-mini | https://platform.openai.com/docs/models/o1 | |
Table 3: Checkpoints used in experiments and their links.
E.2 Hyperparameters
| Hyperparameter | Value |
| --- | --- |
| temperature | 1.0 |
| top-k | 1.0 |
| top-p | 1.0 |
| repetition_penalty | 1.0 |
| max_new_tokens | 200 |
| max_seq_len | 32768 |
| MCTS EOS: Llama-3 family | "\n[" |
| CoT EOS: Llama-3 family | "\n", "<|eot_id|>" |
Table 4: LLM Hyperparameters and EOS tokens used in experiments.
Appendix F Blocksworld Dataset
The Blocksworld dataset comprises 600 instances with varying block numbers and plan lengths. Simpler instances have 3-5 blocks, while more complex cases involve up to 25 blocks, introducing additional goals and obstacles. This setup covers a range of problem difficulties for evaluating planning algorithms.
F.1 Difficulty Settings
According to settings of LLM Reasoners (Hao et al., 2024), we divide the original 600 instances of Blocksworld (Valmeekam et al., 2024) into two parts, Easy and Hard settings.
In the Easy Blocksworld setting, we use more friendly demonstration cases. If a problem requires a specific minimum number of steps to solve, we select other problems that require the same number of steps as demonstration cases in the context. For example, if a problem requires at least 4 steps to solve, we use other 4-step problems as demonstration examples. For each group of problems, we randomly select 10 cases to create a pool of demonstration cases, while the remaining cases form the test set (a total of 540 cases). During inference, we randomly sample 4-shot demonstration cases from this pool to construct the prompts.
In the Hard Blocksworld setting, we randomly select 10 cases from the entire dataset to create the demonstration pool. These selected cases are then excluded from the test set, leaving a total of 590 cases for testing. During inference, we randomly sample 4-shot demonstration cases from this global pool, without considering the minimum number of actions required for the test case. For example, if a problem requires at least 4 steps to solve, we may still use demonstration cases that require a different number of steps, such as 2 or 12, as there is no restriction based on the number of actions.
| domain_intro: |
| --- |
| I am playing with a set of objects. Here are the actions I can do: |
| pick up a block |
| unstack a block from on top of another block |
| put down a block |
| stack a block on top of another block |
| I have the following restrictions on my actions: To perform the Pick Up action, the block must be clear, on the table, and my hand must be empty. Once the Pick Up action is performed, I am holding the block, and my hand is no longer empty. |
| To perform the Unstack action, the block must be clear, on top of another block, and my hand must be empty. Once the Unstack action is performed, I am holding the block, and my hand is no longer empty. |
| To perform the Put Down action, I must be holding a block. Once the Put Down action is performed, the block is on the table, my hand is empty, and the block becomes clear. |
| To perform the Stack action, I must be holding a block, and the block I want to stack it on must be clear. Once the Stack action is performed, the block is on top of another block, my hand is empty, and the block on top is no longer clear. |
Table 5: Normal Blocksworld Task Setting
F.2 Prompts Settings of Easy Blocksworld
Input Instructions: I am playing with a set of blocks where I need to arrange the blocks into stacks. Here are the actions I can do: 1.
Pick up a block 2.
Unstack a block from on top of another block 3.
Put down a block 4.
Stack a block on top of another block I have the following restrictions on my actions: 1.
I can only pick up or unstack one block at a time. 2.
I can only pick up or unstack a block if my hand is empty. 3.
I can only pick up a block if the block is on the table and the block is clear. A block is clear if the block has no other blocks on top of it and if the block is not picked up. 4.
I can only unstack a block from on top of another block if the block I am unstacking was really on top of the other block. 5.
I can only unstack a block from on top of another block if the block I am unstacking is clear. Once I pick up or unstack a block, I am holding the block. 1.
I can only put down a block that I am holding. 2.
I can only stack a block on top of another block if I am holding the block being stacked. 3.
I can only stack a block on top of another block if the block onto which I am stacking the block is clear. Once I put down or stack a block, my hand becomes empty. [STATEMENT] As initial conditions I have that, the red block is clear, the hand is empty, the blue block is on top of the orange block, the red block is on the table, the orange block is on the table and the yellow block is on the table. My goal is to have that the orange block is on top of the blue block. My plan is as follows: [End Of STATEMENT] [PLAN] unstack the blue block from on top of the orange block put down the blue block pick up the orange block stack the orange block on top of the blue block [PLAN END] [STATEMENT] As initial conditions I have that, the red block is clear, the yellow block is clear, the hand is empty, the red block is on top of the blue block, the yellow block is on top of the orange block, the blue block is on the table and the orange block is on the table. My goal is to have that the orange block is on top of the red block. My plan is as follows: [End Of STATEMENT] Output format: [PLAN] [LLM Completion] [PLAN_END]
Table 6: The Prompt Settings for Easy Blocksworld
F.3 Prompts Settings of Hard Blocksworld
| Input Instructions: |
| --- |
| I am playing with a set of blocks where I need to arrange the blocks into stacks. Here are the actions I can do: 1.
Pick up a block 2.
Unstack a block from on top of another block 3.
Put down a block 4.
Stack a block on top of another block I have the following restrictions on my actions: 1.
I can only pick up or unstack one block at a time. 2.
I can only pick up or unstack a block if my hand is empty. 3.
I can only pick up a block if the block is on the table and the block is clear. A block is clear if the block has no other blocks on top of it and if the block is not picked up. 4.
I can only unstack a block from on top of another block if the block I am unstacking was really on top of the other block. 5.
I can only unstack a block from on top of another block if the block I am unstacking is clear. Once I pick up or unstack a block, I am holding the block. 1.
I can only put down a block that I am holding. 2.
I can only stack a block on top of another block if I am holding the block being stacked. 3.
I can only stack a block on top of another block if the block onto which I am stacking the block is clear. Once I put down or stack a block, my hand becomes empty. |
| [STATEMENT] |
| As initial conditions I have that, the blue block is clear, the hand is empty, the blue block is on top of the red block, the red block is on the table, the orange block is on the table and the yellow block is on the table. |
| My goal is to have that the blue block is on top of the orange block. My plan is as follows: |
| [End Of STATEMENT] |
| [PLAN] |
| unstack the blue block from on top of the red block |
| stack the blue block on top of the orange block |
| [PLAN END] |
| [STATEMENT] |
| As initial conditions I have that, the red block is clear, the yellow block is clear, the hand is empty, the red block is on top of the blue block, the yellow block is on top of the orange block, the blue block is on the table and the orange block is on the table. |
| My goal is to have that the orange block is on top of the red block. My plan is as follows: |
| [End Of STATEMENT] |
| Output format: |
| [PLAN] |
| [LLM Completion] |
| [PLAN_END] |
Table 7: The Prompt Settings for Hard Blocksworld
Appendix G Example Trees of Different $c$ of UCT
<details>
<summary>extracted/6087579/fig/uct_2.png Details</summary>
### Visual Description
## Network Diagram: Hierarchical Node Structure
### Overview
The image depicts a hierarchical network diagram with nodes labeled 0 to 50 connected by directed edges. The structure forms a tree-like hierarchy with multiple branching levels, starting from a root node (0) and expanding through successive layers. Edges are explicitly labeled with source-target node pairs (e.g., "edge 0 -> 1").
### Components/Axes
- **Nodes**: Labeled sequentially from 0 to 50, arranged in hierarchical levels.
- **Edges**: Directed connections between nodes, labeled with source-target pairs (e.g., "edge 0 -> 1", "edge 1 -> 3").
- **Hierarchy Levels**:
- **Level 1**: Root node 0.
- **Level 2**: Nodes 1 and 2 (children of 0).
- **Level 3**: Nodes 3-5 (children of 1) and 17-19 (children of 2).
- **Subsequent Levels**: Nodes branch further (e.g., node 3 connects to 38, 39; node 4 connects to 45, 46; etc.).
- **Leaf Nodes**: Terminal nodes with no outgoing edges (e.g., 43, 44, 50).
### Detailed Analysis
- **Root Node (0)**: Connects to nodes 1 and 2.
- **Branching Pattern**:
- Node 1 → 3, 4, 5.
- Node 2 → 17, 18, 19.
- Nodes 3-50 follow similar branching (e.g., node 3 → 38, 39; node 4 → 45, 46).
- **Edge Labels**: Explicitly denote source-target relationships (e.g., "edge 39 -> 40", "edge 49 -> 50").
- **Terminal Nodes**: Nodes 43-50 have no outgoing edges, marking the end of branches.
### Key Observations
1. **Hierarchical Organization**: The diagram represents a tree structure with a clear root (node 0) and terminal nodes (43-50).
2. **Branching Factor**: Most nodes have 2-3 children (e.g., node 1 has 3 children; node 3 has 2 children).
3. **Edge Labeling**: Edges are uniquely identified by source-target pairs, ensuring unambiguous connectivity.
4. **Depth**: The tree extends to at least 6 levels (e.g., node 0 → 1 → 3 → 38 → 42 → 43).
### Interpretation
The diagram illustrates a **directed acyclic graph (DAG)** structured as a tree, likely representing:
- A **decision tree** (nodes as decisions, edges as outcomes).
- A **network topology** (nodes as devices, edges as connections).
- A **data flow hierarchy** (nodes as processing stages, edges as data paths).
The explicit edge labeling suggests a focus on traceability or dependency mapping. The absence of weights or probabilities implies the diagram prioritizes structure over quantitative analysis. The terminal nodes (43-50) may represent final states or endpoints in the system.
</details>
Figure 8: Monte Carlo Tree with origin parameter $c$ of UCT
<details>
<summary>extracted/6087579/fig/uct_1.png Details</summary>
### Visual Description
## Tree Diagram: Hierarchical Node Structure
### Overview
The image depicts a hierarchical tree diagram with nodes labeled numerically from 0 to 80. Nodes are connected by directed edges labeled with "edge X -> Y" notation, forming a branching structure originating from the root node (0). The diagram uses black lines and boxes with white backgrounds for nodes.
### Components/Axes
- **Nodes**: 81 total (0–80), each enclosed in a rectangular box with a black border and white interior.
- **Edges**: 160 directed connections (arrows) between nodes, labeled with "edge X -> Y" text where X and Y are node numbers.
- **Layout**: Nodes arranged in a left-to-right, top-to-bottom hierarchy. Root node (0) at top-left, with branches extending downward and rightward.
### Detailed Analysis
#### Node Structure
- **Root Node**: 0 (top-left corner)
- **Branching Pattern**:
- Node 0 branches to 1 and 2
- Each subsequent node splits into two children (e.g., 1→3/4, 2→17/18)
- Leaf nodes (no children): 38–80
- **Depth**: 7 levels (0→1→3→38/39→...→80)
#### Edge Labels
All edges follow "edge X -> Y" format, with sequential numbering:
- First-level edges: edge 0->1, edge 0->2
- Second-level edges: edge 1->3, edge 1->4, edge 2->17, edge 2->18
- Final-level edges: edge 37->73, edge 37->74, edge 38->75, edge 38->76
#### Spatial Grounding
- **Root Position**: Node 0 at top-left
- **Branching Direction**:
- Left subtree (0→1→3→...) extends rightward
- Right subtree (0→2→17→...) extends downward
- **Node Density**:
- Highest concentration in middle levels (nodes 16–48)
- Sparse distribution in root (1 node) and leaf levels (43 nodes)
### Key Observations
1. **Binary Tree Structure**: Each non-leaf node has exactly two children
2. **Sequential Labeling**: Nodes numbered consecutively from 0 to 80
3. **Edge Consistency**: All edges follow "edge X -> Y" format without exceptions
4. **Symmetry**: Left and right subtrees mirror each other in branching pattern
5. **Leaf Node Range**: Final 43 nodes (38–80) have no children
### Interpretation
This diagram represents a complete binary tree with 81 nodes, demonstrating:
- **Hierarchical Organization**: Clear parent-child relationships through edge labels
- **Process Flow**: Potential representation of decision trees, organizational charts, or data flow structures
- **Efficiency**: Balanced branching minimizes depth (7 levels for 81 nodes)
- **Scalability**: Regular structure allows easy expansion by adding child nodes
The consistent labeling and symmetrical branching suggest this is a deliberately constructed model rather than organic growth, possibly for algorithm visualization, system architecture documentation, or educational purposes.
</details>
Figure 9: Monte Carlo Tree with our optimized parameter $c$ of UCT
From Figure 8 and 9 we can observed that with our optimized parameter $c$ of UCT, MCTS algorithm in node selection decisions tends to prioritize exploring new nodes rather than repeatedly following old paths, which may often lead to dead ends.
Appendix H OpenAI API Data
| Difficulty | Model | USD per instance | Total Experiment Cost (USD) |
| --- | --- | --- | --- |
| Easy (0-shot) | GPT-4o | $0.0032 | $1.73 |
| o1-mini | $0.0136 | $7.34 | |
| Easy (4-shot) | GPT-4o | $0.0062 | $3.35 |
| o1-mini | $0.0171 | $9.23 | |
| Hard (0-shot) | GPT-4o | $0.0032 | $1.89 |
| o1-mini | $0.0177 | $10.44 | |
| Hard (4-shot) | GPT-4o | $0.0063 | $3.70 |
| o1-mini | $0.0172 | $10.15 | |
Table 8: OpenAI API cost of experiments on the Blocksworld dataset.
<details>
<summary>extracted/6087579/fig/Step_Length_vs_Reasoning_Tokens_for_Zero_Shot_Easy_Blocksworld.png Details</summary>
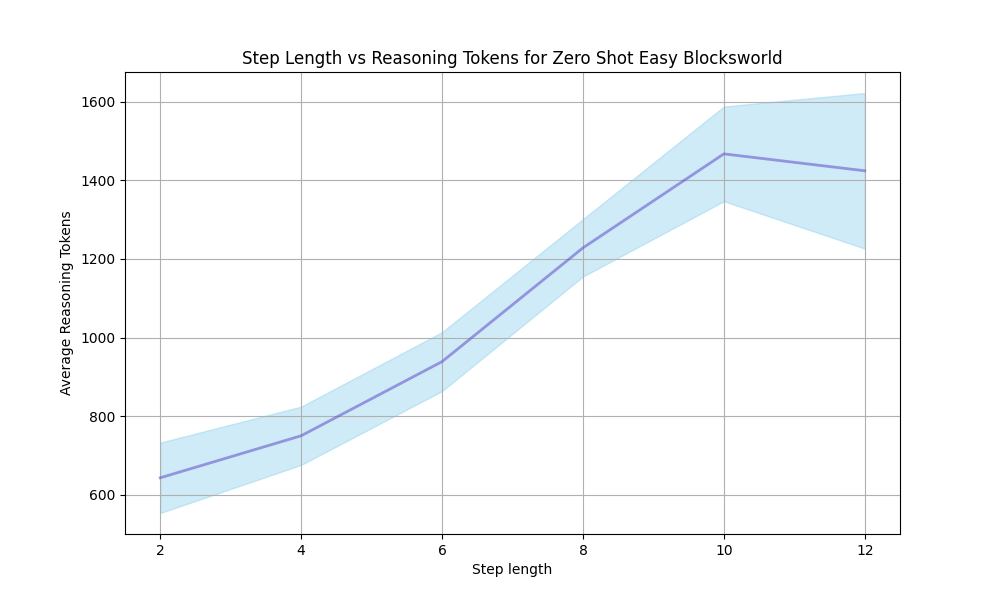
### Visual Description
## Line Chart: Step Length vs Reasoning Tokens for Zero Shot Easy Blocksworld
### Overview
The chart visualizes the relationship between step length (x-axis) and average reasoning tokens (y-axis) for a zero-shot "Easy Blocksworld" task. A blue line represents the average reasoning tokens, with a shaded blue region indicating variability (±100 tokens). The data shows a general upward trend with a slight plateau at higher step lengths.
### Components/Axes
- **X-axis (Step length)**: Labeled "Step length" with integer ticks at 2, 4, 6, 8, 10, and 12.
- **Y-axis (Average Reasoning Tokens)**: Labeled "Average Reasoning Tokens" with increments of 200 from 600 to 1600.
- **Legend**: Located in the top-right corner, with:
- **Blue line**: "Average" (solid line).
- **Shaded blue area**: "±100 tokens" (range around the average).
### Detailed Analysis
1. **Data Points**:
- At step length 2: ~640 tokens (blue line).
- At step length 4: ~750 tokens.
- At step length 6: ~930 tokens.
- At step length 8: ~1200 tokens.
- At step length 10: ~1460 tokens (peak).
- At step length 12: ~1420 tokens (slight decline).
2. **Shaded Region**:
- The ±100 token range creates a band around the blue line, e.g., at step length 10, the range spans ~1360–1560 tokens.
3. **Trends**:
- The blue line slopes upward from step length 2 to 10, then flattens slightly at 12.
- The shaded region widens slightly at higher step lengths (e.g., 10–12), suggesting increased variability.
### Key Observations
- **Upward Trend**: Reasoning tokens increase with step length up to 10, then plateau.
- **Peak Efficiency**: Step length 10 achieves the highest average tokens (~1460).
- **Variability**: The shaded region indicates consistent ±100 token variability across all step lengths.
- **Slight Decline**: At step length 12, the average drops slightly (~1420), but remains within the ±100 range of the peak.
### Interpretation
The data suggests that increasing step length improves reasoning token efficiency up to a point (step length 10), after which gains diminish. The shaded region implies that the model's performance is relatively stable, with minor fluctuations. The slight decline at step length 12 may indicate diminishing returns or task-specific constraints. This trend could inform optimization strategies for balancing computational cost (step length) and reasoning quality (tokens).
</details>
Figure 10: o1-mini Step Length vs Reasoning Tokens for Zero Shot in Easy Blocksworld
<details>
<summary>extracted/6087579/fig/Step_Length_vs_Reasoning_Tokens_for_Four_Shot_Easy_Blocksworld.png Details</summary>
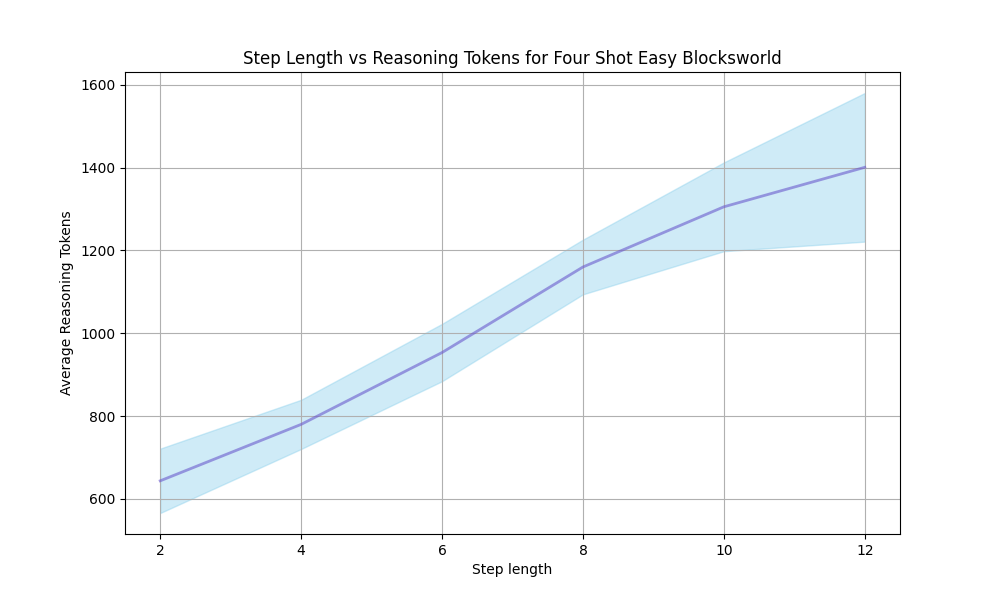
### Visual Description
## Line Chart: Step Length vs Reasoning Tokens for Four Shot Easy Blocksworld
### Overview
The chart illustrates the relationship between step length (x-axis) and average reasoning tokens (y-axis) for a four-shot easy Blocksworld task. A single data series is represented by a solid purple line with a light blue shaded area indicating variability or confidence intervals. The trend shows a consistent upward trajectory as step length increases.
### Components/Axes
- **Title**: "Step Length vs Reasoning Tokens for Four Shot Easy Blocksworld"
- **X-axis (Step length)**:
- Labels: 2, 4, 6, 8, 10, 12
- Scale: Linear increments of 2
- **Y-axis (Average Reasoning Tokens)**:
- Labels: 600, 800, 1000, 1200, 1400, 1600
- Scale: Linear increments of 200
- **Legend**:
- Position: Top-right
- Label: "Average Reasoning Tokens" (matches line color)
- Shaded area: Light blue (200 tokens below the line)
### Detailed Analysis
- **Data Series**:
- **Line**: Solid purple, starts at (2, 650) and ends at (12, 1400).
- **Shaded Area**: Light blue, spans from 200 tokens below the line to the line itself.
- **Key Data Points**:
- Step 2: 650 tokens (line), 550 tokens (lower bound)
- Step 4: 780 tokens (line), 580 tokens (lower bound)
- Step 6: 950 tokens (line), 750 tokens (lower bound)
- Step 8: 1150 tokens (line), 950 tokens (lower bound)
- Step 10: 1300 tokens (line), 1100 tokens (lower bound)
- Step 12: 1400 tokens (line), 1200 tokens (lower bound)
- **Trend**:
- Line slopes upward at a roughly linear rate (~100 tokens per 2-step increase).
- Shaded area widens as step length increases, suggesting greater variability in reasoning tokens for longer steps.
### Key Observations
1. **Consistent Growth**: The line shows a steady increase in reasoning tokens with step length.
2. **Variability**: The shaded area expands at higher step lengths, indicating increased uncertainty or dispersion in token usage.
3. **Bounds**: The lower bound of the shaded area remains consistently 200 tokens below the line across all steps.
### Interpretation
The chart suggests that longer step lengths in the Blocksworld task correlate with higher average reasoning token requirements. The widening shaded area at larger step lengths implies that variability in reasoning complexity or computational demands increases with step length. This could reflect challenges in maintaining consistent performance or resource allocation as tasks become more extended. The fixed 200-token gap between the line and shaded area lower bound may represent a baseline threshold for reasoning efficiency.
</details>
Figure 11: o1-mini Step Length vs Reasoning Tokens for Four Shot in Easy Blocksworld
<details>
<summary>extracted/6087579/fig/Step_Length_vs_Reasoning_Tokens_for_Zero_Shot_Hard_Blocksworld.png Details</summary>
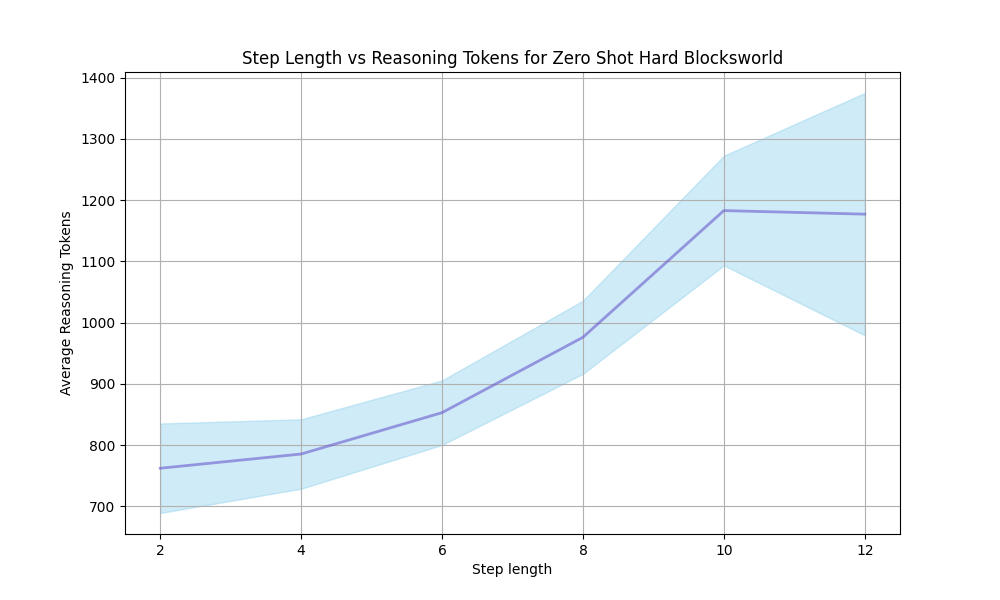
### Visual Description
## Line Chart: Step Length vs Reasoning Tokens for Zero Shot Hard Blocksworld
### Overview
The chart illustrates the relationship between step length (x-axis) and average reasoning tokens (y-axis) for a zero-shot hard Blocksworld task. A blue line represents the average reasoning tokens, with a shaded blue region indicating variability or confidence intervals. The x-axis ranges from 2 to 12, and the y-axis spans 700 to 1400 tokens.
### Components/Axes
- **Title**: "Step Length vs Reasoning Tokens for Zero Shot Hard Blocksworld" (top-center).
- **X-axis**: "Step length" (horizontal), labeled with integer values from 2 to 12.
- **Y-axis**: "Average Reasoning Tokens" (vertical), labeled with values from 700 to 1400 in increments of 100.
- **Legend**: Located on the right, labeled "Average Reasoning Tokens" with a blue line and shaded blue region.
- **Shaded Region**: A lighter blue area surrounding the blue line, representing variability or uncertainty.
### Detailed Analysis
- **Step Length 2**:
- Average tokens: ~750 (blue line).
- Shaded bounds: ~700 (lower) to ~825 (upper).
- **Step Length 4**:
- Average tokens: ~780.
- Shaded bounds: ~725 to ~850.
- **Step Length 6**:
- Average tokens: ~875.
- Shaded bounds: ~800 to ~950.
- **Step Length 8**:
- Average tokens: ~975.
- Shaded bounds: ~900 to ~1050.
- **Step Length 10**:
- Average tokens: ~1175.
- Shaded bounds: ~1075 to ~1350.
- **Step Length 12**:
- Average tokens: ~1170.
- Shaded bounds: ~975 to ~1375.
### Key Observations
1. **Trend**: The average reasoning tokens generally increase with step length, peaking at step 10 (~1175 tokens) before slightly declining at step 12 (~1170 tokens).
2. **Variability**: The shaded region widens as step length increases, indicating greater uncertainty or variability in reasoning tokens for longer steps.
3. **Anomaly**: A minor drop in average tokens at step 12 compared to step 10, despite the overall upward trend.
### Interpretation
The data suggests that longer step lengths require more reasoning tokens on average, but the relationship is not strictly linear. The shaded region’s expansion at higher step lengths implies increased complexity or unpredictability in the task as steps grow longer. The slight decline at step 12 could reflect optimization limits or task-specific constraints. The variability pattern highlights that longer steps may involve more divergent reasoning paths, requiring further investigation into task design or model efficiency.
</details>
Figure 12: o1-mini Step Length vs Reasoning Tokens for Zero Shot in Hard Blocksworld
<details>
<summary>extracted/6087579/fig/Step_Length_vs_Reasoning_Tokens_for_Four_Shot_Hard_Blocksworld.png Details</summary>
### Visual Description
## Line Chart: Step Length vs Reasoning Tokens for Four Shot Hard Blocksworld
### Overview
The chart illustrates the relationship between step length (x-axis) and average reasoning tokens (y-axis) for a task labeled "Four Shot Hard Blocksworld." A single blue line with a shaded light-blue confidence interval represents the data, showing a clear upward trend as step length increases.
### Components/Axes
- **Title**: "Step Length vs Reasoning Tokens for Four Shot Hard Blocksworld" (centered at the top).
- **X-Axis (Step Length)**:
- Label: "Step length" (bottom, horizontal).
- Scale: Discrete markers at 2, 4, 6, 8, 10, 12 (evenly spaced).
- **Y-Axis (Average Reasoning Tokens)**:
- Label: "Average Reasoning Tokens" (left, vertical).
- Scale: Continuous from 600 to 1600, with gridlines at 800, 1000, 1200, 1400, 1600.
- **Legend**:
- Position: Top-right corner.
- Content: Single entry labeled "Average Reasoning Tokens" with a blue line and light-blue shaded area.
- **Line and Shading**:
- Line: Solid blue, representing the average reasoning tokens.
- Shaded Area: Light-blue band around the line, indicating ±150 tokens of variability.
### Detailed Analysis
- **Data Points**:
- Step 2: 720 tokens (range: 570–870).
- Step 4: 800 tokens (range: 650–950).
- Step 6: 900 tokens (range: 750–1050).
- Step 8: 1150 tokens (range: 1000–1300).
- Step 10: 1350 tokens (range: 1200–1500).
- Step 12: 1480 tokens (range: 1330–1630).
- **Trends**:
- The blue line slopes upward consistently, indicating a positive linear relationship between step length and reasoning tokens.
- The shaded area maintains a constant width (±150 tokens) across all step lengths, suggesting stable variability in reasoning token usage.
### Key Observations
1. **Linear Correlation**: Reasoning tokens increase by approximately 160 tokens per step length increment (e.g., 720 → 800 → 900 → 1150 → 1350 → 1480).
2. **Shading Consistency**: The ±150 token range remains uniform, implying predictable uncertainty in token usage.
3. **Steepest Growth**: The largest token increase occurs between steps 6 and 8 (+250 tokens), followed by steps 8–10 (+200 tokens).
### Interpretation
The chart demonstrates that longer step lengths in the "Four Shot Hard Blocksworld" task require proportionally more reasoning tokens, with a near-linear relationship. The consistent ±150 token variability suggests that while the average token usage scales predictably with step length, there is a bounded level of uncertainty in computational demands. This could inform resource allocation strategies, such as optimizing step lengths to balance performance and token efficiency. The absence of outliers or deviations from the trend indicates a stable, well-defined relationship between these variables.
</details>
Figure 13: o1-mini Step Length vs Reasoning Tokens for Four Shot in Hard Blocksworld
Appendix I GPU Usage
In the main experiments, the total GPU usage (measured in GPU hours) for different models on NVIDIA H800 SXM5 80GB GPUs shows a clear progression with model size. For RAP-MCTS, Llama-3 70B requires approximately 420 GPU hours across all steps and difficulty modes, Llama-3.1 70B model requires approximately 450 GPU hours. For SC-MCTS ∗, Llama-3 70B requires approximately 280 GPU hours across all steps and difficulty modes and difficulty modes, Llama-3.1 70B model requires approximately 300 GPU hours. For CoT, Llama-3-70B and Llama-3.1-70B both takes approximately 7 GPU hours across all steps and difficulty modes, while Llama-3.1 405B model exhibits significantly higher GPU usage, amounting to approximately 75 GPU hours. In the parameter research and algorithm development phase before main experiments, we consumed a total of around 800 GPU hours on NVIDIA A100 SXM4 80GB GPUs.
Appendix J Future Work
In future work, we can explore utilizing more metrics-based reward models (such as the three reward models discussed in this paper) with LM-based reward models (such as Critic LLM (McAleese et al., 2024) and Eurus (Yuan et al., 2024b)). Additionally, there is potential to design more general methods for splitting steps in other tasks and datasets. Since step-splitting is the most challenging part of MCTS multi-step reasoning generalization, although we conducted extensive experiments on the Blocksworld multi-step reasoning dataset, which is the most suitable dataset for studying MCTS multi-step reasoning as far as we know. Some previous works have attempted to use datasets like GSM8K and MATH through extensive adaptation efforts on the datasets themselves, however, we aim to design a more general method from the perspective of step-splitting. We hope that MCTS multi-step reasoning will achieve the same level of generalization as CoT, which remains a fundamental area for future research. Future work can also attempt to combine this approach with the fine-grained compositional reasoning framework (Chen et al., 2024) to further explore the boundaries of MCTS multi-step reasoning capabilities.