# LLMs Know More Than They Show: On the Intrinsic Representation of LLM Hallucinations
> Corresponding author; Work partially done during internship at Apple.
Abstract
Large language models (LLMs) often produce errors, including factual inaccuracies, biases, and reasoning failures, collectively referred to as “hallucinations”. Recent studies have demonstrated that LLMs’ internal states encode information regarding the truthfulness of their outputs, and that this information can be utilized to detect errors. In this work, we show that the internal representations of LLMs encode much more information about truthfulness than previously recognized. We first discover that the truthfulness information is concentrated in specific tokens, and leveraging this property significantly enhances error detection performance. Yet, we show that such error detectors fail to generalize across datasets, implying that—contrary to prior claims—truthfulness encoding is not universal but rather multifaceted. Next, we show that internal representations can also be used for predicting the types of errors the model is likely to make, facilitating the development of tailored mitigation strategies. Lastly, we reveal a discrepancy between LLMs’ internal encoding and external behavior: they may encode the correct answer, yet consistently generate an incorrect one. Taken together, these insights deepen our understanding of LLM errors from the model’s internal perspective, which can guide future research on enhancing error analysis and mitigation. Our code is available in https://github.com/technion-cs-nlp/LLMsKnow.
1 Introduction
The ever-growing popularity of large language models (LLM) across many domains has brought a significant limitation to center stage: their tendency to “hallucinate” – which is often used to describe the generation of inaccurate information. But what are hallucinations, and what causes them? A considerable body of research has sought to define, taxonomize, and understand hallucinations through extrinsic, behavioral analysis, primarily examining how users perceive such errors (Bang et al., 2023; Ji et al., 2023; Huang et al., 2023a; Rawte et al., 2023). However, this approach does not adequately address how these errors are encoded within the LLMs. Alternatively, another line of work has explored the internal representations of LLMs, suggesting that LLMs encode signals of truthfulness (Kadavath et al., 2022; Li et al., 2024; Chen et al., 2024, inter alia). However, these analyses were typically restricted to detecting errors—determining whether a generated output contains inaccuracies—without delving deeper into how such signals are represented and could be leveraged to understand or mitigate hallucinations.
In this work, we reveal that the internal representations of LLMs encode much more information about truthfulness than previously recognized. Through a series of experiments, we train classifiers on these internal representations to predict various features related to the truthfulness of generated outputs. Our findings reveal the patterns and types of information encoded in model representations, linking this intrinsic data to extrinsic LLM behavior. This enhances our ability to detect errors (while understanding the limitations of error detection), and may guide the development of more nuanced strategies based on error types and mitigation methods that make use of the model’s internal knowledge. Our experiments are designed to be general, covering a broad array of LLM limitations. While the term “hallucinations” is widely used, it lacks a universally accepted definition (Venkit et al., 2024). Our framework adopts a broad interpretation, considering hallucinations to encompass all errors produced by an LLM, including factual inaccuracies, biases, common-sense reasoning failures, and other real-world errors. This approach enables us to draw general conclusions about model errors from a broad perspective.
Our first step is identifying where truthfulness signals are encoded in LLMs. Previous studies have suggested methods for detecting errors in LLM outputs using intermediate representations, logits, or probabilities, implying that LLMs may encode signals of truthfulness (Kadavath et al., 2022; Li et al., 2024; Chen et al., 2024). Focusing on long-form generations, which reflect real-world usage of LLMs, our analysis uncovers a key oversight: the choice of token used to extract these signals (Section 3). We find that truthfulness information is concentrated in the exact answer tokens – e.g., “Hartford” in “The capital of Connecticut is Hartford, an iconic city…”. Recognizing this nuance significantly improves error detection strategies across the board, revealing that truthfulness encoding is stronger than previously observed.
From this point forward, we concentrate on our most effective strategy: a classifier trained on intermediate LLM representations within the exact answer tokens, referred to as ‘probing classifiers’ (Belinkov, 2021). This approach helps us explore what these representations reveal about LLMs. Our demonstration that a trained probing classifier can predict errors suggests that LLMs encode information related to their own truthfulness. However, we find that probing classifiers do not generalize across different tasks (Section 4). Generalization occurs only within tasks requiring similar skills (e.g., factual retrieval), indicating the truthfulness information is “skill-specific” and varies across different tasks. For tasks involving different skills, e.g., sentiment analysis, these classifiers are no better–or worse–than logit-based uncertainty predictors, challenging the idea of a “universal truthfulness” encoding proposed in previous work (Marks & Tegmark, 2023; Slobodkin et al., 2023). Instead, our results indicate that LLMs encode multiple, distinct notions of truth. Thus, deploying trainable error detectors in practical applications should be undertaken with caution.
We next find evidence that LLMs encode not only error detection signals but also more nuanced information about error types. Delving deeper into errors within a single task, we taxonomize its errors based on responses across repeated samples (Section 5). For example, the same error being consistently generated is different from an error that is generated occasionally among many other distinct errors. Using a different set of probing classifiers, we find that error types are predictable from the LLM representations, drawing a connection between the models’s internal representations and its external behavior. This classification offers a more nuanced understanding of errors, enabling developers to predict error patterns and implement more targeted mitigation strategies.
Finally, we find that the truthfulness signals encoded in LLMs can also differentiate between correct and incorrect answers for the same question (Section 6). Results highlight a significant misalignment between LLM’s internal representations and its external behavior in some cases. The model’s internal encoding may identify the correct answer–yet it frequently generates an incorrect response. This discrepancy reveals that the LLM’s external behavior may misrepresent its abilities, potentially pointing to new strategies for reducing errors by utilizing its existing strengths. Overall, our model-centric framework provides a deeper understanding of LLM errors, suggesting potential directions for improvements in error analysis and mitigation.
2 Background
Defining and characterizing LLM errors.
The term “hallucinations” is widely used across various subfields such as conversational AI (Liu et al., 2022), abstractive summarization (Zhang et al., 2019), and machine translation (Wang & Sennrich, 2020), each interpreting the term differently. Yet, no consensus exists on defining hallucinations: Venkit et al. (2024) identified 31 distinct frameworks for conceptualizing hallucinations, revealing the diversity of perspectives. Research efforts aim to define and taxonomize hallucinations, distinguishing them from other error types (Liu et al., 2022; Ji et al., 2023; Huang et al., 2023a; Rawte et al., 2023). On the other hand, recent scholarly conversations introduce terms like “confabulations” (Millidge, 2023) and “fabrications” (McGowan et al., 2023), attributing a possible “intention” to LLMs, although the notions of LLM “intention” and other human-like traits are still debated (Salles et al., 2020; Serapio-García et al., 2023; Harnad, 2024). These categorizations, however, adopt a human-centric view by focusing on the subjective interpretations of LLM hallucinations, which does not necessarily reflect how these errors are encoded within the models themselves. This gap limits our ability to address the root causes of hallucinations, or to reason about their nature. For example, it is unclear whether conclusions about hallucinations defined in one framework can be applied to another framework. Liang et al. (2024) defined hallucinations as inconsistencies with the training data. While this approach engage with the possible root causes of hallucinations, our study focuses on insights from the model itself, without requiring training data access. Instead, we adopt a broad interpretation of hallucinations. Here, we define hallucinations as any type of error generated by an LLM, including factual inaccuracies, biases, failures in common-sense reasoning, and others.
Another line of research suggests that LLMs either encode information about their own errors (Kadavath et al., 2022; Azaria & Mitchell, 2023) or exhibit discrepancies between their outputs and internal representations (Liu et al., 2023; Gottesman & Geva, 2024), indicating the presence of underlying mechanisms not reflected in their final outputs. Moreover, Yona et al. (2024) found that current LLMs fail to effectively convey their uncertainty through their generated outputs. Hence, we propose shifting the focus from human-centric interpretations of hallucinations to a model-centric perspective, examining the model’s intermediate activations.
Error detection in LLMs.
Error detection is a longstanding task in NLP, crucial for maintaining high standards in various practical applications and for constructing more reliable systems that ensure user trust (Bommasani et al., 2021). Over the years, many studies have proposed task-specific solutions (see Section A.1). However, the recent shift towards general-purpose LLMs necessitates a holistic approach capable of addressing any error type, rather than focusing on specific ones, making it suitable for the diverse errors generated by these models.
A line of work has addressed this challenge by leveraging external knowledge sources (Lewis et al., 2020; Gao et al., 2023) or an external LLM judge (Lin et al., 2021; Rawte et al., 2023) to identify erroneous outputs. On the other hand, our work focuses on detection methods that rely solely on the computations of the LLM—specifically, output logits, probabilities after softmax, and hidden states.
Error detection in LLMs is also closely linked to uncertainty estimation, where low certainty signals potential inaccuracies and possible errors. Popular methods to derive calibrated confidence include inspecting the model logit output values (Varshney et al., 2023; Taubenfeld et al., 2025), agreement across multiple sampled answers (Kuhn et al., 2023; Manakul et al., 2023; Tian et al., 2023a), verbalized probability (Tian et al., 2023b), and direct prompting (Kadavath et al., 2022).
Another line of work trains probing classifiers to discover and utilize truthfulness features. This approach has shown some success by probing the final token of an answer–either generated (Kadavath et al., 2022; Snyder et al., 2023; Yuksekgonul et al., 2023; Zou et al., 2023; Yin et al., 2024; Chen et al., 2024; Simhi et al., 2024; Gekhman et al., 2025) or not (Li et al., 2024; Marks & Tegmark, 2023; Burns et al., 2022; Azaria & Mitchell, 2023; Rateike et al., 2023). Others probe the final token of the prompt before the response is generated (Slobodkin et al., 2023; Snyder et al., 2023; Simhi et al., 2024; Gottesman & Geva, 2024). Many previous studies simplify the analysis by generating answers in a few-shot setting or limiting generation to a single token. In contrast, we simulate real-world usage of LLMs by allowing unrestricted answer generation. By probing exact answer tokens, we achieve significant improvements in error detection.
3 Better Error Detection
This section presents our experiments on detecting LLM errors through their own computations, focusing on token selection’s impact and introducing a method that outperforms other approaches.
3.1 Task Definition
Given an LLM $M$ , an input prompt $p$ and the LLM-generated response $\hat{y}$ , the task is to predict whether $\hat{y}$ is correct or wrong. We assume that there is access to the LLM’s internal states (i.e., white-box setting), but no access to any external resources (e.g., search engine or additional LLMs).
We use a dataset $D=\{(q_{i},y_{i})\}_{i=1}^{N}$ , consisting of $N$ question-label pairs, where $\{q_{i}\}_{i=1}^{N}$ represents a series of questions (e.g., “What is the capital of Connecticut?”) and $\{y_{i}\}_{i=1}^{N}$ the corresponding ground-truth answers (“Hartford”). For each question $q_{i}$ , we prompt the model $M$ to generate a response $y_{i}$ , resulting in the set of predicted answers $\{\hat{y}_{i}\}_{i=1}^{N}$ (“The capital of Connecticut is Hartford…”). Next, to build our error-detection dataset, we evaluate the correctness of each generated response $\hat{y}_{i}$ by comparing it to the ground-truth label $y_{i}$ . This comparison yields a correctness label $z_{i}∈\{0,1\}$ ( $1$ correct, $0 0$ wrong). The comparison can be done either via automatic heuristics or with the assistance of an instruct-LLM. For most datasets, we use heuristics to predict correctness, except for one case. See Appendix A.2. Our error detection dataset is: $\{(q_{i},\hat{y}_{i},z_{i})\}_{i=1}^{N}$ . Note that this dataset is defined based on the analyzed LLM and its generated answers. Any instances where the LLM refuses to answer are excluded, as these can easily be classified as incorrect.
3.2 Experimental Setup
Datasets and models.
We perform all experiments on four LLMs: Mistral-7b (Jiang et al., 2023), Mistral-7b-instruct-v0.2 (denoted Mistral-7b-instruct), Llama3-8b (Touvron et al., 2023), and Llama3-8b-instruct. We consider 10 different datasets spanning various domains and tasks: TriviaQA (Joshi et al., 2017), HotpotQA with/without context (Yang et al., 2018), Natural Questions (Kwiatkowski et al., 2019), Winobias (Zhao et al., 2018), Winogrande (Sakaguchi et al., 2021), MNLI (Williams et al., 2018), Math (Sun et al., 2024), IMDB review sentiment analysis (Maas et al., 2011), and a dataset of movie roles (movies) that we curate. We allow unrestricted response generation to mimic real-world LLM usage, with answers decoded greedily. For more details on the datasets and the prompts used to generate answers, refer to Appendix A.3.
Performance metric.
We measure the area under the ROC curve to evaluate error detectors, providing a single metric that reflects their ability to distinguish between positive and negative cases across many thresholds, balancing sensitivity (true positive rate) and specificity (false positive rate).
Error detection methods. We compare methods from both uncertainty and hallucinations literature.
- Aggregated probabilities / logits: Previous studies (Guerreiro et al., 2023; Kadavath et al., 2022; Varshney et al., 2023; Huang et al., 2023b) aggregate output token probabilities or logits to score LLM confidence for error detection. We implement several methods from the literature, calculating the minimum, maximum, or mean of these values. The main paper reports results for the most common approach, Logits-mean, and the best-performing one, Logits-min, with additional baselines in Appendix B.
- P(True): Kadavath et al. (2022) showed that LLMs are relatively calibrated when asked to evaluate the correctness of their generation via prompting. We implement this evaluation using the same prompt.
- Probing: Probing classifiers involve training a small classifier on a model’s intermediate activations to predict features of processed text (Belinkov, 2021). Recent studies show their effectiveness for error detection in generated text (Kadavath et al., 2022, inter alia). An intermediate activation is a vector $h_{l,t}$ from a specific LLM layer $l$ and (either read or generated) token $t$ . Thus, each LLM generation produces multiple such activations. Following prior work, we use a linear probing classifier for error detection (Li et al., 2024, inter alia) on static tokens: the last generated token ( $h_{l,-1}$ ), the one before it ( $h_{l,-2}$ ), and the final prompt token ( $h_{l,k}$ ). The layer $l$ is selected per token based on validation set performance.
For further details on the implementation of each method, refer to Appendix A.4.
<details>
<summary>x1.png Details</summary>

### Visual Description
## Diagram: Question Answering Example
### Overview
The image illustrates an example of a question-answering interaction, likely demonstrating how a model like Mistral processes a prompt and generates a response. It highlights the prompt, the model's answer, and the tokenization of the answer.
### Components/Axes
* **Prompt:** The input question provided to the model.
* **Mistral:** The model generating the answer.
* **first_exact_answer_token:** Indicates the start of the correct answer within the model's response.
* **last_exact_answer_token:** Indicates the end of the correct answer within the model's response.
* **last_q_token:** Indicates the last token of the question.
* **Tags:** "\<s>", "[INST]", "[/INST]", "\</s>" are special tokens used for formatting and instruction.
* **Numerical Indices:** "-2", "-1" are numerical indices, likely representing token positions relative to the end of the sequence.
### Detailed Analysis or ### Content Details
* **Prompt (Top, Green Box):**
* Text: "\<s> [INST] What is the capital of the U.S. state of Connecticut? [/INST]"
* **Mistral Response (Bottom, Blue Box):**
* Text: "The capital city of the U.S. state of Connecticut is Hartford. It's one of the oldest cities in the United States and was founded in 1635. Hartford is located in the central part of the state and is home to several cultural institutions, universities, and businesses.\</s>"
* **Token Annotations:**
* "first_exact_answer_token" (Purple Line): Points to the word "Hartford".
* "last_exact_answer_token" (Teal Line): Points to the word "Hartford".
* "last_q_token" (Green Line): Points to the end of the prompt.
* **Numerical Indices:**
* "-2" (Orange Box): Located near the end of the Mistral response.
* "-1" (Orange Box): Located near the end of the Mistral response.
### Key Observations
* The model correctly identifies "Hartford" as the capital of Connecticut.
* The "first_exact_answer_token" and "last_exact_answer_token" both point to "Hartford", indicating that the model's answer is precise.
* The model provides additional context about Hartford beyond just stating its name.
* The tags \<s>, [INST], [/INST], and \</s> are used to structure the prompt and response.
### Interpretation
The diagram demonstrates a successful question-answering interaction. The model (Mistral) receives a prompt, processes it, and generates a relevant and accurate response. The annotations highlight the specific tokens that constitute the correct answer, suggesting a mechanism for evaluating the model's performance. The additional context provided in the response indicates a degree of understanding beyond simple keyword matching. The numerical indices at the end of the response likely represent token positions, potentially used for further analysis or processing of the output.
</details>
Figure 1: Example for the input and LLM output from the TriviaQA dataset, and the names of the tokens that can be probed.
Exact Answer Tokens.
Existing methods often overlook a critical nuance: the token selection for error detection, typically focusing on the last generated token or taking a mean. However, since LLMs typically generate long-form responses, this practice may miss crucial details (Brunner et al., 2020). Other approaches use the last token of the prompt (Slobodkin et al., 2023, inter alia), but this is inherently inaccurate due to LLMs’ unidirectional nature, failing to account for the generated response and missing cases where different sampled answers from the same model vary in correctness. We investigate a previously unexamined token location: the exact answer tokens, which represent the most meaningful parts of the generated response. We define exact answer tokens as those whose modification alters the answer’s correctness, disregarding subsequent generated content. In practice, we do not use this definition for extracting the exact answer, but rather an instruct model in a few-shot setting. Still, the definition is useful to manually verify that automatic extractions work as expected. Figure 1 illustrates the different token locations. In the following experiments, we implement each error detection method with an “exact answer” version, demonstrating that it often improves performance, especially in probing. Implementation details for detecting the exact answer token are given in Appendix A.2.
3.3 Results
<details>
<summary>extracted/6450693/figures/probing_heatmaps/mistral-7b-instruct/triviaqa_auc.png Details</summary>
### Visual Description
## Heatmap: Layer vs. Token
### Overview
The image is a heatmap visualizing the relationship between "Layer" and "Token". The color intensity represents a value, with darker blue indicating higher values and lighter blue indicating lower values. The heatmap spans layers 0 to 30 and various tokens, including "last_q", "first_answer", "second_answer", "exact_answer_before_first", "exact_answer_first", "exact_answer_last", "exact_answer_after_last", and numerical tokens from -8 to -1.
### Components/Axes
* **X-axis (Token):** Categorical, listing tokens: "last\_q", "first\_answer", "second\_answer", "exact\_answer\_before\_first", "exact\_answer\_first", "exact\_answer\_last", "exact\_answer\_after\_last", "-8", "-7", "-6", "-5", "-4", "-3", "-2", "-1".
* **Y-axis (Layer):** Numerical, ranging from 0 to 30 in increments of 2.
* **Color Scale:** A gradient from light blue (approximately 0.5) to dark blue (1.0), indicating the value associated with each cell in the heatmap.
### Detailed Analysis
The heatmap displays varying intensities of blue, indicating different values for each layer-token combination.
* **"last\_q", "first\_answer", "second\_answer":** These tokens show relatively high values (darker blue) across most layers, especially from layer 0 to approximately layer 20. The values seem to decrease slightly in the higher layers (20-30).
* **"exact\_answer\_before\_first", "exact\_answer\_first", "exact\_answer\_last", "exact\_answer\_after\_last":** These tokens exhibit a band of high values (darker blue) concentrated between approximately layers 8 and 18. Outside this band, the values are generally lower (lighter blue).
* **Numerical Tokens (-8 to -1):** These tokens generally show lower values (lighter blue) across all layers compared to the other tokens. There are some localized areas of slightly higher values, but overall, the intensity is less.
### Key Observations
* The tokens related to "exact\_answer" exhibit a distinct band of high values in the middle layers (8-18).
* The initial tokens ("last\_q", "first\_answer", "second\_answer") have higher values in the lower layers, gradually decreasing as the layer number increases.
* The numerical tokens (-8 to -1) generally have the lowest values across all layers.
### Interpretation
The heatmap likely represents the activation or importance of different tokens across various layers of a neural network model, possibly a transformer model used for question answering.
* The high values for "last\_q", "first\_answer", and "second\_answer" in the lower layers suggest that these tokens are important for initial processing and understanding of the question.
* The concentration of high values for "exact\_answer" tokens in the middle layers indicates that these layers are crucial for identifying and processing the exact answer within the context.
* The lower values for numerical tokens might indicate that these tokens are less relevant for the specific task or model being analyzed.
The distinct patterns observed in the heatmap suggest that different layers of the model specialize in processing different types of tokens, contributing to the overall question-answering process. The black box highlights the "exact_answer" tokens, emphasizing their importance in the middle layers.
</details>
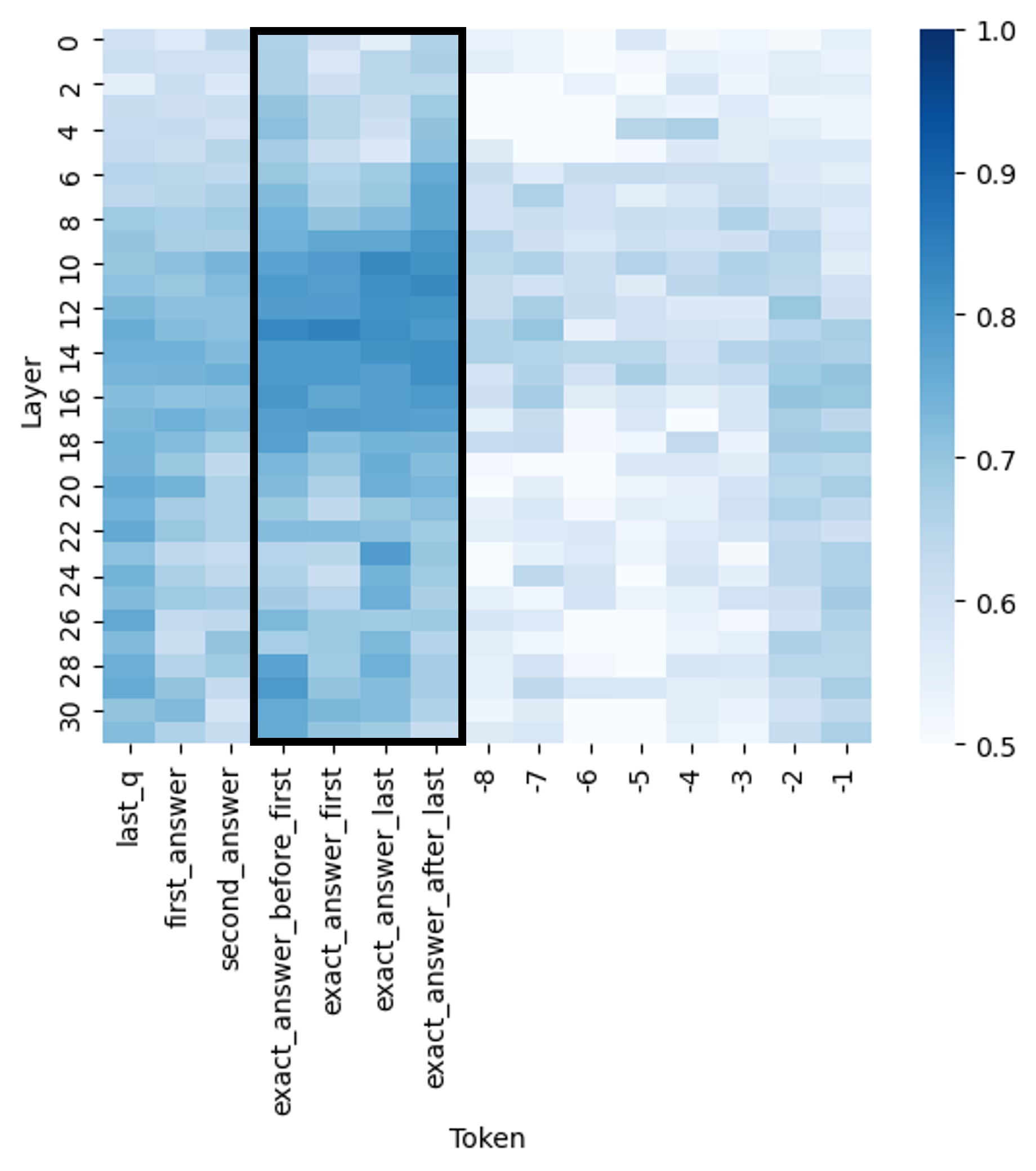
(a) TriviaQA
<details>
<summary>extracted/6450693/figures/probing_heatmaps/mistral-7b-instruct/winobias_auc.png Details</summary>
### Visual Description
## Heatmap: Token vs Layer
### Overview
The image is a heatmap visualizing the relationship between "Token" and "Layer". The color intensity represents a value ranging from 0.5 to 1.0, with darker blue shades indicating higher values. The x-axis represents different tokens, and the y-axis represents different layers. A black rectangle highlights a specific region of the heatmap.
### Components/Axes
* **X-axis (Token):**
* Categories: last\_q, first\_answer, second\_answer, exact\_answer\_before\_first, exact\_answer\_first, exact\_answer\_last, exact\_answer\_after\_last, -8, -7, -6, -5, -4, -3, -2, -1
* **Y-axis (Layer):**
* Scale: 0, 2, 4, 6, 8, 10, 12, 14, 16, 18, 20, 22, 24, 26, 28, 30
* **Color Scale (Legend):** Located on the right side of the heatmap.
* 1. 0: Darkest Blue
* 2. 9:
* 3. 8:
* 4. 7:
* 5. 6:
* 6. 5: Lightest Blue
### Detailed Analysis
* **last\_q:** The color intensity generally increases from layer 0 to layer 30, starting from a light blue (around 0.5-0.6) and reaching a darker blue (around 0.7-0.8).
* **first\_answer:** Similar to "last\_q", the color intensity increases from layer 0 to layer 30, starting from a light blue (around 0.5-0.6) and reaching a darker blue (around 0.7-0.8).
* **second\_answer:** The color intensity increases from layer 0 to layer 30, starting from a light blue (around 0.5-0.6) and reaching a darker blue (around 0.7-0.8).
* **exact\_answer\_before\_first, exact\_answer\_first, exact\_answer\_last, exact\_answer\_after\_last:** These tokens show a higher color intensity (darker blue, around 0.8-0.9) in the upper layers (0-10) compared to the other tokens. The intensity decreases slightly towards layer 30.
* **-8 to -1:** The color intensity is generally lower (lighter blue, around 0.5-0.7) compared to the other tokens, especially in the upper layers (0-10). The intensity seems to increase slightly towards layer 30.
### Key Observations
* The tokens "exact\_answer\_before\_first", "exact\_answer\_first", "exact\_answer\_last", and "exact\_answer\_after\_last" have a higher value in the initial layers (0-10).
* The tokens "-8" to "-1" have a lower value across all layers compared to the other tokens.
* The color intensity generally increases from layer 0 to layer 30 for "last\_q", "first\_answer", and "second\_answer".
### Interpretation
The heatmap visualizes the relationship between different tokens and layers, with color intensity representing a certain value. The "exact\_answer" related tokens seem to be more relevant or have a higher impact in the initial layers, while the numerical tokens (-8 to -1) have a lower impact across all layers. The increasing color intensity for "last\_q", "first\_answer", and "second\_answer" suggests that these tokens become more relevant or important as the layer number increases. The black rectangle highlights a specific region of interest, possibly indicating a particular area of focus for analysis.
</details>
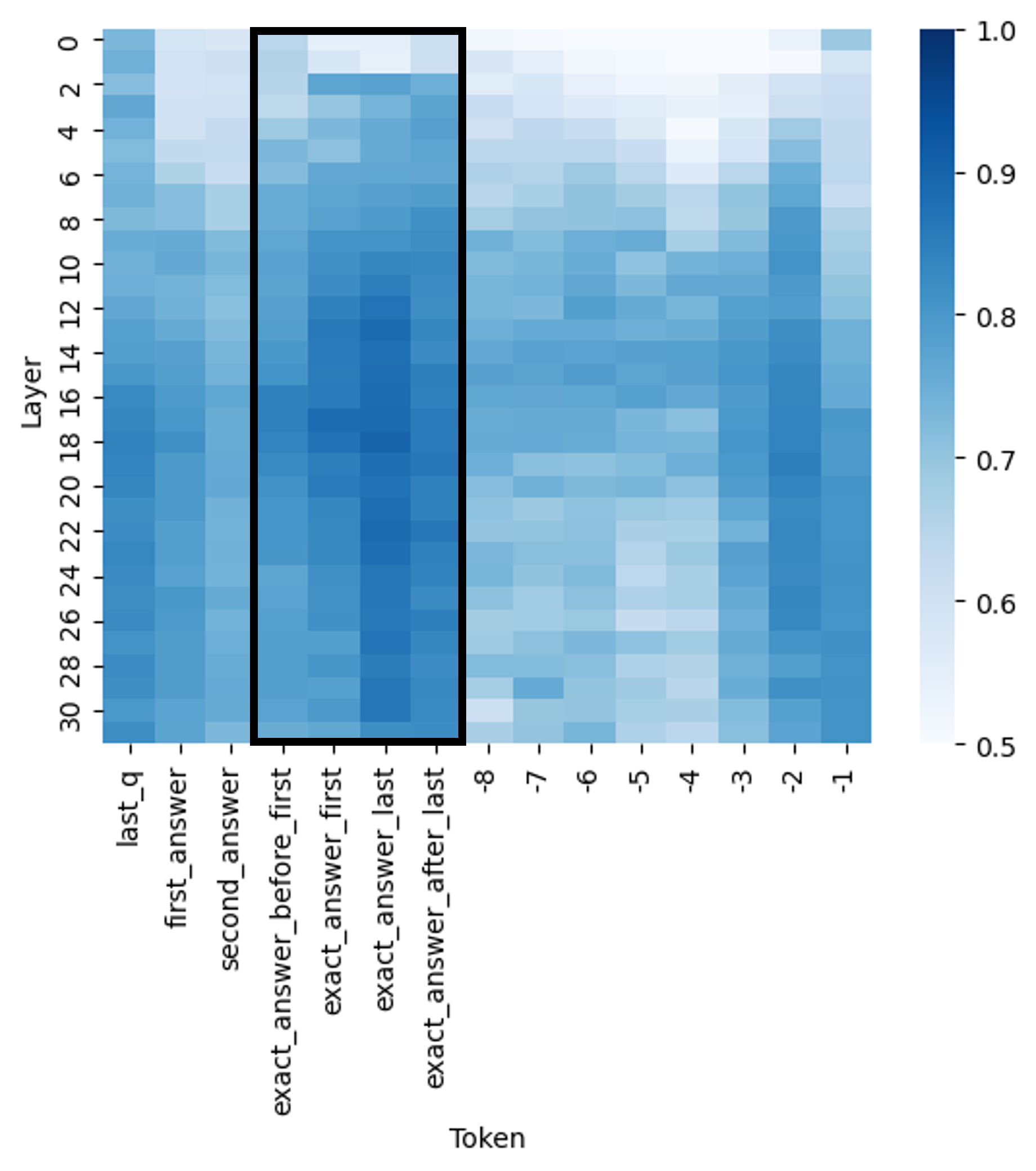
(b) Winobias
<details>
<summary>extracted/6450693/figures/probing_heatmaps/mistral-7b-instruct/answerable_math_auc.png Details</summary>
### Visual Description
## Heatmap: Layer vs Token
### Overview
The image is a heatmap visualizing the relationship between "Layer" and "Token". The heatmap uses a blue color gradient, where darker shades of blue indicate higher values and lighter shades indicate lower values. The vertical axis represents "Layer" with numerical values from 0 to 30. The horizontal axis represents "Token" with categorical values including "last_q", "first_answer", "second_answer", "exact_answer_before_first", "exact_answer_first", "exact_answer_last", "exact_answer_after_last", and numerical values from -8 to -1.
### Components/Axes
* **X-axis (Token):**
* Categories: last\_q, first\_answer, second\_answer, exact\_answer\_before\_first, exact\_answer\_first, exact\_answer\_last, exact\_answer\_after\_last
* Numerical: -8, -7, -6, -5, -4, -3, -2, -1
* **Y-axis (Layer):** Numerical values from 0 to 30, incrementing by 2.
* **Color Scale:** A blue gradient ranging from 0.5 (lightest blue) to 1.0 (darkest blue).
### Detailed Analysis
The heatmap shows distinct patterns based on the token type and layer.
* **Tokens "exact\_answer\_before\_first", "exact\_answer\_first", "exact\_answer\_last", and "exact\_answer\_after\_last":** These tokens exhibit the highest values (darkest blue) across all layers. The values are approximately 0.9 to 1.0.
* **Token "last\_q":** This token shows relatively lower values (lighter blue) across all layers, generally ranging from 0.5 to 0.7.
* **Tokens "first\_answer" and "second\_answer":** These tokens have intermediate values, generally between 0.6 and 0.8.
* **Numerical Tokens (-8 to -1):** These tokens show a mix of values, with some layers having higher values than others. The values range from 0.5 to 0.8.
**Specific Data Points (Approximate):**
* Layer 0, Token last\_q: Approximately 0.6
* Layer 0, Token exact\_answer\_first: Approximately 0.9
* Layer 30, Token last\_q: Approximately 0.5
* Layer 30, Token exact\_answer\_first: Approximately 0.9
### Key Observations
* The tokens related to "exact\_answer" consistently show high values across all layers.
* The token "last\_q" consistently shows low values across all layers.
* There is some variation in values for the numerical tokens (-8 to -1) depending on the layer.
### Interpretation
The heatmap suggests that the "exact\_answer" tokens are highly relevant or important across all layers, as indicated by their high values. The "last\_q" token, on the other hand, appears to be less relevant or important. The varying values for the numerical tokens (-8 to -1) indicate that their relevance or importance may depend on the specific layer. The data demonstrates a clear distinction in the importance or relevance of different token types across the layers.
</details>
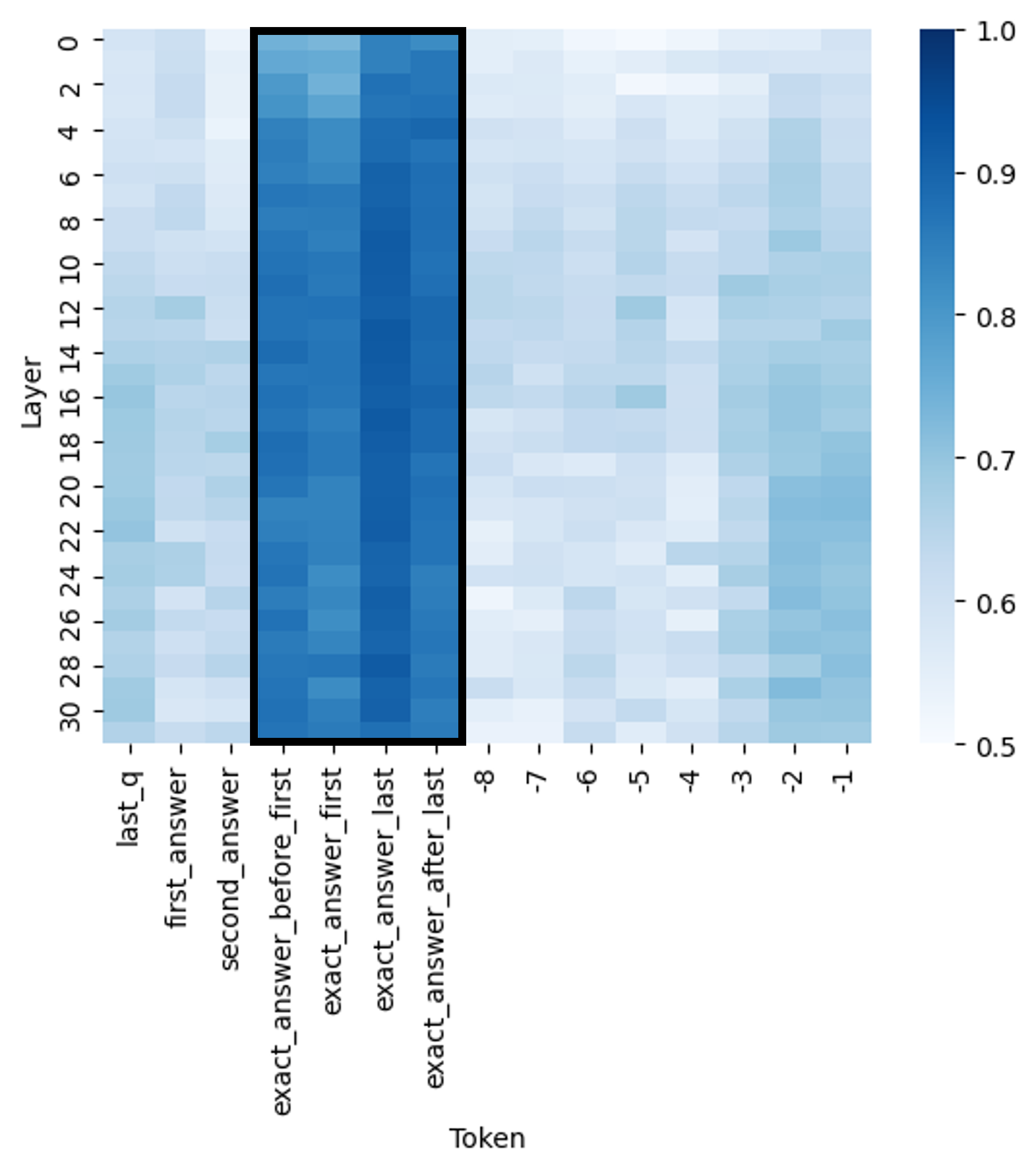
(c) Math
Figure 2: AUC values of a probe error detector across layers and tokens, Mistral-7b-instruct. Generation proceeds from left to right, with detection performance peaking at the exact answer tokens.
Patterns of truthfulness encoding.
We first focus on probing classifiers to gain insights into the internal representations of LLMs. Specifically, we analyze the effects of layer and token selection on the error detection performance of these probing classifiers. By systematically probing all model layers, starting from the last question token to the final generated token, we observe consistent truthfulness encoding patterns. Figure 2 shows AUC metrics of probes across Mistral-7b-Instruct layers and tokens. Middle to later layers often yield the most effective probing results (see Appendix B for more datasets and models), aligning with previous studies on truthfulness encoding (Burns et al., 2022; CH-Wang et al., 2023) and transformer representations (nostalgebraist, 2020; Meng et al., 2022; Geva et al., 2023). Regarding tokens, a strong truthfulness signal appears immediately after the prompt, suggesting that this representation encodes information on the model’s general ability to answer the question correctly. This signal weakens as text generation progresses but peaks again at the exact answer tokens. Towards the end of the generation process, signal strength rises again, though it remains weaker than at the exact answer tokens. These patterns are consistent across nearly all datasets and models (see Appendix B), suggesting a general mechanism by which LLMs encode and process truthfulness during text generation.
Error Detection Results.
Table 1: Comparison of error detection techniques using AUC metric, across different models and datasets. The best-performing method is bolded. Using exact answer tokens is useful for many cases, especially probing.
| | Mistral-7b-Instruct | Llama 3-8b-Instruct | | | | |
| --- | --- | --- | --- | --- | --- | --- |
| TriviaQA | Winobias | Math | TriviaQA | Winobias | Math | |
| Logits-mean | $0.60$ $± 0.009$ | $0.56$ $± 0.017$ | $0.55$ $± 0.029$ | $0.66$ $± 0.005$ | $0.60$ $± 0.026$ | $0.75$ $± 0.018$ |
| Logits-mean-exact | $0.68$ $± 0.007$ | $0.54$ $± 0.012$ | $0.51$ $± 0.005$ | $0.71$ $± 0.006$ | $0.55$ $± 0.019$ | $0.80$ $± 0.021$ |
| Logits-min | $0.63$ $± 0.008$ | $0.59$ $± 0.012$ | $0.51$ $± 0.017$ | $0.74$ $± 0.007$ | $0.61$ $± 0.024$ | $0.75$ $± 0.016$ |
| Logits-min-exact | $0.75$ $± 0.006$ | $0.53$ $± 0.013$ | $0.71$ $± 0.009$ | $0.79$ $± 0.006$ | $0.61$ $± 0.019$ | $0.89$ $± 0.018$ |
| p(True) | $0.66$ $± 0.006$ | $0.45$ $± 0.021$ | $0.48$ $± 0.022$ | $0.73$ $± 0.008$ | $0.59$ $± 0.020$ | $0.62$ $± 0.017$ |
| p(True)-exact | $0.74$ $± 0.003$ | $0.40$ $± 0.021$ | $0.60$ $± 0.025$ | $0.73$ $± 0.005$ | $0.63$ $± 0.014$ | $0.59$ $± 0.018$ |
| Probe @ token | | | | | | |
| Last generated [-1] | $0.71$ $± 0.006$ | $0.82$ $± 0.004$ | $0.74$ $± 0.008$ | $0.81$ $± 0.005$ | $0.86$ $± 0.007$ | $0.82$ $± 0.016$ |
| Before last generated [-2] | $0.73$ $± 0.004$ | $0.85$ $± 0.004$ | $0.74$ $± 0.007$ | $0.75$ $± 0.005$ | $0.88$ $± 0.005$ | $0.79$ $± 0.020$ |
| End of question | $0.76$ $± 0.008$ | $0.82$ $± 0.011$ | $0.72$ $± 0.007$ | $0.77$ $± 0.007$ | $0.80$ $± 0.018$ | $0.72$ $± 0.023$ |
| Exact | 0.85 $± 0.004$ | 0.92 $± 0.005$ | 0.92 $± 0.008$ | 0.83 $± 0.002$ | 0.93 $± 0.004$ | 0.95 $± 0.027$ |
Next, we evaluate various error detection methods by comparing their performance with and without the use of exact answer tokens. Table 1 compares the AUC across three representative datasets (additional datasets and models in Appendix B, showing consistent patterns). Here we present results for the last exact answer token, which outperformed both the first exact answer token and the one preceding it, while the token following the last performed similarly. Incorporating the exact answer token improves the different error detection methods in almost all datasets. Notably, our probing technique (bottom line) consistently outperforms all other baselines across the board. While we did not compare all existing error detection methods, the primary conclusion is that information about truthfulness is highly localized in specific generated tokens, and that focusing on exact answer tokens leads to significant improvements in error detection.
4 Generalization Between Tasks
The effectiveness of a probing classifier in detecting errors suggests that LLMs encode information about the truthfulness of their outputs. This supports using probing classifiers for error detection in production, but their generalizability across tasks remains unclear. While some studies argue for a universal mechanism of truthfulness encoding in LLMs (Marks & Tegmark, 2023; Slobodkin et al., 2023), results on probe generalization across datasets are mixed (Kadavath et al., 2022; Marks & Tegmark, 2023; CH-Wang et al., 2023; Slobodkin et al., 2023; Levinstein & Herrmann, 2024) –observing a decline in performance, yet it remains significantly above random chance. Understanding this is essential for real-world applications, where the error detector may encounter examples that significantly differ from those it was trained on. Therefore, we explore whether a probe trained on one dataset can detect errors in others.
Our generalization experiments are conducted between all of the ten datasets discussed in Section 3, covering a broader range of reaslistic task settings than previous work. This breadth of experiments has not been previously explored, and is crucial considering the mixed findings in previous work. We select the optimal token and layer combination for each dataset, train all probes using this combination on other datasets, and then test them on the original dataset. We evaluate generalization performance using the absolute AUC score, defined as $\max(\text{auc},1-\text{auc})$ , to also account for cases where the learned signal in one dataset is reversed in another.
Results.
<details>
<summary>extracted/6450693/figures/generalization/mistral_instruct.png Details</summary>
### Visual Description
## Heatmap: Dataset Performance Comparison
### Overview
The image is a heatmap visualizing the performance of different models trained on various datasets and tested on the same or different datasets. The color intensity represents the performance score, ranging from blue (low) to red (high), with corresponding numerical values displayed in each cell. The rows represent the training datasets, and the columns represent the testing datasets.
### Components/Axes
* **Title:** None explicitly present in the image.
* **X-axis (Test dataset):**
* Categories: TriviaQA, HotpotQA, Movies, Winobias, Winogrande, NLI, IMDB, Math, HotpotQA\_WC, NQ\_WC
* **Y-axis (Train dataset):**
* Categories: TriviaQA, HotpotQA, Movies, Winobias, Winogrande, NLI, IMDB, Math, HotpotQA\_WC, NQ\_WC
* **Colorbar (Right side):**
* Scale: Ranges from 0.0 (blue) to 1.0 (red) in increments of 0.2.
### Detailed Analysis
The heatmap displays performance scores for each combination of training and testing datasets. The scores range from approximately 0.50 to 0.97.
Here's a breakdown of the values:
* **TriviaQA:**
* Trained on TriviaQA: 0.86
* Tested on:
* TriviaQA: 0.86
* HotpotQA: 0.72
* Movies: 0.78
* Winobias: 0.55
* Winogrande: 0.57
* NLI: 0.63
* IMDB: 0.68
* Math: 0.80
* HotpotQA\_WC: 0.59
* NQ\_WC: 0.70
* **HotpotQA:**
* Trained on HotpotQA: 0.80
* Tested on:
* TriviaQA: 0.80
* HotpotQA: 0.85
* Movies: 0.78
* Winobias: 0.61
* Winogrande: 0.58
* NLI: 0.58
* IMDB: 0.87
* Math: 0.67
* HotpotQA\_WC: 0.62
* NQ\_WC: 0.65
* **Movies:**
* Trained on Movies: 0.74
* Tested on:
* TriviaQA: 0.74
* HotpotQA: 0.69
* Movies: 0.82
* Winobias: 0.50
* Winogrande: 0.52
* NLI: 0.53
* IMDB: 0.81
* Math: 0.67
* HotpotQA\_WC: 0.57
* NQ\_WC: 0.71
* **Winobias:**
* Trained on Winobias: 0.54
* Tested on:
* TriviaQA: 0.54
* HotpotQA: 0.59
* Movies: 0.52
* Winobias: 0.92
* Winogrande: 0.73
* NLI: 0.64
* IMDB: 0.91
* Math: 0.52
* HotpotQA\_WC: 0.51
* NQ\_WC: 0.62
* **Winogrande:**
* Trained on Winogrande: 0.60
* Tested on:
* TriviaQA: 0.60
* HotpotQA: 0.60
* Movies: 0.57
* Winobias: 0.61
* Winogrande: 0.84
* NLI: 0.66
* IMDB: 0.71
* Math: 0.61
* HotpotQA\_WC: 0.51
* NQ\_WC: 0.55
* **NLI:**
* Trained on NLI: 0.51
* Tested on:
* TriviaQA: 0.51
* HotpotQA: 0.56
* Movies: 0.55
* Winobias: 0.56
* Winogrande: 0.66
* NLI: 0.93
* IMDB: 0.66
* Math: 0.64
* HotpotQA\_WC: 0.51
* NQ\_WC: 0.54
* **IMDB:**
* Trained on IMDB: 0.63
* Tested on:
* TriviaQA: 0.63
* HotpotQA: 0.54
* Movies: 0.66
* Winobias: 0.62
* Winogrande: 0.62
* NLI: 0.66
* IMDB: 0.97
* Math: 0.66
* HotpotQA\_WC: 0.51
* NQ\_WC: 0.58
* **Math:**
* Trained on Math: 0.56
* Tested on:
* TriviaQA: 0.56
* HotpotQA: 0.55
* Movies: 0.60
* Winobias: 0.57
* Winogrande: 0.51
* NLI: 0.64
* IMDB: 0.91
* Math: 0.92
* HotpotQA\_WC: 0.54
* NQ\_WC: 0.51
* **HotpotQA\_WC:**
* Trained on HotpotQA\_WC: 0.65
* Tested on:
* TriviaQA: 0.65
* HotpotQA: 0.73
* Movies: 0.56
* Winobias: 0.55
* Winogrande: 0.50
* NLI: 0.51
* IMDB: 0.92
* Math: 0.70
* HotpotQA\_WC: 0.75
* NQ\_WC: 0.67
* **NQ\_WC:**
* Trained on NQ\_WC: 0.69
* Tested on:
* TriviaQA: 0.69
* HotpotQA: 0.66
* Movies: 0.68
* Winobias: 0.54
* Winogrande: 0.67
* NLI: 0.58
* IMDB: 0.94
* Math: 0.52
* HotpotQA\_WC: 0.53
* NQ\_WC: 0.87
### Key Observations
* The diagonal elements (training and testing on the same dataset) generally have higher scores, indicating better performance when the model is tested on data similar to what it was trained on.
* The IMDB dataset shows high performance when used as the test set, regardless of the training dataset.
* Winobias, NLI, IMDB, and Math datasets show high performance when trained and tested on themselves.
### Interpretation
The heatmap illustrates the transferability of models across different datasets. Training and testing on the same dataset generally yields the best performance, suggesting that models are highly specialized to the characteristics of their training data. However, some datasets, like IMDB, appear to be more generalizable, as models trained on other datasets perform relatively well when tested on IMDB. The lower off-diagonal scores indicate that models trained on one dataset may not perform as well on datasets with different characteristics or distributions. The high self-performance of Winobias, NLI, IMDB, and Math suggests these datasets have unique features that allow models to learn effectively when trained and tested on them.
</details>
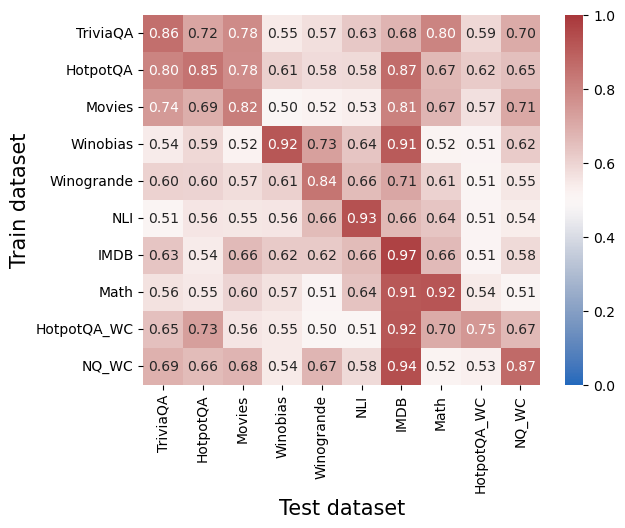
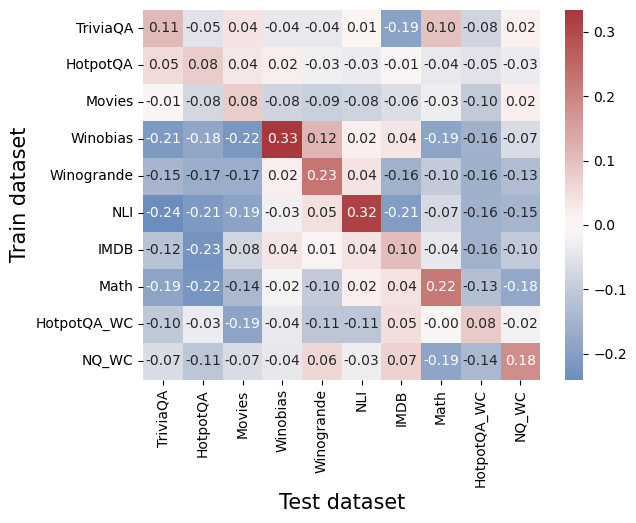
(a) Raw AUC values. Values above $0.5$ indicate some generalization.
<details>
<summary>extracted/6450693/figures/generalization/mistral_instruct_reduced.png Details</summary>
### Visual Description
## Heatmap: Dataset Transfer Performance
### Overview
The image is a heatmap visualizing the transfer performance between different datasets. The rows represent the training dataset, and the columns represent the test dataset. The color intensity indicates the performance, with redder colors indicating positive transfer and bluer colors indicating negative transfer. Numerical values are overlaid on each cell, providing precise performance metrics.
### Components/Axes
* **X-axis (Test dataset):** TriviaQA, HotpotQA, Movies, Winobias, Winogrande, NLI, IMDB, Math, HotpotQA\_WC, NQ\_WC
* **Y-axis (Train dataset):** TriviaQA, HotpotQA, Movies, Winobias, Winogrande, NLI, IMDB, Math, HotpotQA\_WC, NQ\_WC
* **Colorbar (right side):** Ranges from -0.2 (blue) to 0.3 (red), with intermediate values of -0.1, 0.0, 0.1, 0.2. This represents the transfer performance score.
### Detailed Analysis or Content Details
The heatmap displays a matrix of transfer performance values. Each cell (i, j) represents the performance of a model trained on dataset i (row) and tested on dataset j (column).
Here's a breakdown of the values:
* **TriviaQA:**
* Trained on TriviaQA: 0.11
* Trained on HotpotQA: -0.05
* Trained on Movies: 0.04
* Trained on Winobias: -0.04
* Trained on Winogrande: -0.04
* Trained on NLI: 0.01
* Trained on IMDB: -0.19
* Trained on Math: 0.10
* Trained on HotpotQA\_WC: -0.08
* Trained on NQ\_WC: 0.02
* **HotpotQA:**
* Trained on TriviaQA: -0.05
* Trained on HotpotQA: 0.08
* Trained on Movies: 0.04
* Trained on Winobias: 0.04
* Trained on Winogrande: 0.02
* Trained on NLI: -0.03
* Trained on IMDB: -0.03
* Trained on Math: -0.01
* Trained on HotpotQA\_WC: -0.04
* Trained on NQ\_WC: -0.05
* **Movies:**
* Trained on TriviaQA: -0.01
* Trained on HotpotQA: -0.08
* Trained on Movies: 0.08
* Trained on Winobias: -0.08
* Trained on Winogrande: -0.09
* Trained on NLI: -0.08
* Trained on IMDB: -0.06
* Trained on Math: -0.03
* Trained on HotpotQA\_WC: -0.10
* Trained on NQ\_WC: 0.02
* **Winobias:**
* Trained on TriviaQA: -0.21
* Trained on HotpotQA: -0.18
* Trained on Movies: -0.22
* Trained on Winobias: 0.33
* Trained on Winogrande: 0.12
* Trained on NLI: 0.02
* Trained on IMDB: 0.04
* Trained on Math: -0.19
* Trained on HotpotQA\_WC: -0.16
* Trained on NQ\_WC: -0.07
* **Winogrande:**
* Trained on TriviaQA: -0.15
* Trained on HotpotQA: -0.17
* Trained on Movies: -0.17
* Trained on Winobias: 0.02
* Trained on Winogrande: 0.23
* Trained on NLI: 0.04
* Trained on IMDB: -0.16
* Trained on Math: -0.10
* Trained on HotpotQA\_WC: -0.16
* Trained on NQ\_WC: -0.13
* **NLI:**
* Trained on TriviaQA: -0.24
* Trained on HotpotQA: -0.21
* Trained on Movies: -0.19
* Trained on Winobias: -0.03
* Trained on Winogrande: 0.05
* Trained on NLI: 0.32
* Trained on IMDB: -0.21
* Trained on Math: -0.07
* Trained on HotpotQA\_WC: -0.16
* Trained on NQ\_WC: -0.15
* **IMDB:**
* Trained on TriviaQA: -0.12
* Trained on HotpotQA: -0.23
* Trained on Movies: -0.08
* Trained on Winobias: 0.04
* Trained on Winogrande: 0.01
* Trained on NLI: 0.04
* Trained on IMDB: 0.10
* Trained on Math: -0.04
* Trained on HotpotQA\_WC: -0.16
* Trained on NQ\_WC: -0.10
* **Math:**
* Trained on TriviaQA: -0.19
* Trained on HotpotQA: -0.22
* Trained on Movies: -0.14
* Trained on Winobias: -0.02
* Trained on Winogrande: -0.10
* Trained on NLI: 0.02
* Trained on IMDB: 0.04
* Trained on Math: 0.22
* Trained on HotpotQA\_WC: -0.13
* Trained on NQ\_WC: -0.18
* **HotpotQA\_WC:**
* Trained on TriviaQA: -0.10
* Trained on HotpotQA: -0.03
* Trained on Movies: -0.19
* Trained on Winobias: -0.04
* Trained on Winogrande: -0.11
* Trained on NLI: -0.11
* Trained on IMDB: 0.05
* Trained on Math: -0.00
* Trained on HotpotQA\_WC: 0.08
* Trained on NQ\_WC: -0.02
* **NQ\_WC:**
* Trained on TriviaQA: -0.07
* Trained on HotpotQA: -0.11
* Trained on Movies: -0.07
* Trained on Winobias: -0.04
* Trained on Winogrande: 0.06
* Trained on NLI: -0.03
* Trained on IMDB: 0.07
* Trained on Math: -0.19
* Trained on HotpotQA\_WC: -0.14
* Trained on NQ\_WC: 0.18
### Key Observations
* The diagonal elements (training and testing on the same dataset) generally show positive transfer, as indicated by the redder colors and positive values.
* Negative transfer (blue colors and negative values) is observed in many off-diagonal elements, suggesting that training on one dataset can sometimes hurt performance on another.
* Winobias and NLI datasets show strong positive transfer when trained and tested on themselves (0.33 and 0.32 respectively).
* Training on TriviaQA often results in negative transfer to other datasets, as seen by the blueish colors in the first row.
### Interpretation
The heatmap provides insights into the transferability of knowledge between different datasets. The positive diagonal elements indicate that models generally perform best when trained and tested on the same dataset. The off-diagonal elements reveal how well a model trained on one dataset generalizes to another. Negative transfer highlights potential domain differences or biases that prevent effective generalization. The data suggests that some datasets are more similar and benefit from transfer learning, while others are distinct and require specific training. For example, training on Winobias or NLI seems to provide a strong positive transfer when tested on the same dataset, suggesting these datasets have unique characteristics that are well-learned by the models. Conversely, training on TriviaQA often leads to negative transfer, indicating that the knowledge gained from TriviaQA may not be directly applicable or may even be detrimental to performance on other datasets.
</details>
(b) Performance (AUC) difference of the probe and the logit-based method. Values above $0 0$ indicate generalization beyond the logit-based method.
Figure 3: Generalization between datasets, Mistral-7b-instruct. After subtracting the logit-based method’s performance, we observe that most datasets show limited or no meaningful generalization.
Figure 3(a) shows the generalization results for Mistral-7b-instruct, with similar patterns observed for other LLMs in Appendix C. In this context, values above $0.5$ indicate successful generalization. At first glance, the results appear consistent with previous research: most heatmap values exceed $0.5$ , implying some degree of generalization across tasks. This observation supports the existence of a universal mechanism for decoding truthfulness, since the same linear directions—captured by the probe—encode truthfulness information across many datasets. However, upon closer inspection, it turns out that most of this performance can be achieved by logit-based truthfulness detection, which only observes the output logits. Figure 3(b) presents the same heatmap after subtracting results from our strongest logit-based baseline (Logit-min-exact). This adjusted heatmap reveals the probe’s generalization rarely exceeds what can be achieved by examining logits alone. This suggests that the observed generalization is not due to a universal internal encoding of truthfulness. Instead, it likely arises from information already available through external features, such as logits. Past evidence for generalization may therefore have been overstated.
Nonetheless, we do observe some successful generalization in tasks requiring similar skills, such as parametric factual retrieval (TriviaQA, HotpotQA, Movies) and common-sense reasoning (Winobias, Wingrande, NLI). This suggests that, although the overall pattern of truthfulness signals across tokens appeared consistent across tasks (as observed in Section 3.3), LLMs have many “skill-specific” truthfulness mechanisms rather than universal ones. However, some patterns remain unexplained, such as the asymmetric generalization from TriviaQA to Math tasks. Overall, our findings indicate that models have a multifaceted representation of truthfulness. The internal mechanisms responsible for solving distinct problem are implemented as different mechanisms (e.g., circuits) within models (Elhage et al., 2021; Olah et al., 2023). Similarly, LLMs do not encode truthfulness through a single unified mechanism but rather through multiple mechanisms, each corresponding to different notions of truth. Further investigation is required to disentangle these mechanisms.
5 Investigating Error Types
Having established the limitations of error detection, we now shift to error analysis. Previously, we explored types of LLM limitations across different tasks, noting both commonalities and distinctions in their error representations. In this section, we focus on the types of errors LLMs make in a specific task—TriviaQA—which represents factual errors, a commonly studied issue in LLMs (Kadavath et al., 2022; Snyder et al., 2023; Li et al., 2024; Chen et al., 2024; Simhi et al., 2024).
5.1 Taxonomy of Errors
Intuitively, not all mistakes are identical. In one case, an LLM may consistently generate an incorrect answer, considering it correct, while in another case, it could issue a best guess. To analyze errors from the LLM’s perspective, we sample $K=30$ responses at a temperature setting of $T=1$ We chose $K=30$ as the overall correctness seemed to plateau around this point; see Appendix D. We found that lower temperatures generally produced less truthful answers across repeated trials. for each example in the dataset and then analyze the resulting distribution of answers.
<details>
<summary>x2.png Details</summary>
### Visual Description
## Diagram: Model Output Analysis
### Overview
The image depicts a diagram illustrating the output of a model in response to the question "Otis Barton was a pioneer in exploring where?". The model generates multiple possible answers, each associated with a confidence score (percentage). The diagram also indicates whether each answer is considered correct (green checkmark) or incorrect (red X).
### Components/Axes
* **Input Question (Left):** "Otis Barton was a pioneer in exploring where?" - Presented in a dashed-line box.
* **Model (Center):** A blue rectangle labeled "Model".
* **Output Answers (Right):** Three possible answers generated by the model, each in a dashed-line box, along with their confidence scores and correctness indicators.
* **Answer 1:** "Otis Barton was a pioneer in exploring the underwater world..." - Confidence: 93%, Correctness: Green checkmark. There are multiple boxes stacked behind this one, with the top one reading "Otis co-invented..."
* **Answer 2:** "... best known for his excavations in the Maya region of Central America" - Confidence: 3%, Correctness: Red X.
* **Answer 3:** "... Exploring the underground rivers to Tennessee ..." - Confidence: 3%, Correctness: Red X.
* **Arrows:** Blue arrows connect the input question to the "Model" and the "Model" to each of the output answers, indicating the flow of information.
### Detailed Analysis or ### Content Details
* **Input:** The question "Otis Barton was a pioneer in exploring where?" is presented as input to the model.
* **Model Processing:** The "Model" block represents the processing stage where the input question is analyzed.
* **Output Generation:** The model generates three possible answers with associated confidence scores:
* "Otis Barton was a pioneer in exploring the underwater world..." is assigned a 93% confidence score and is marked as correct.
* "... best known for his excavations in the Maya region of Central America" is assigned a 3% confidence score and is marked as incorrect.
* "... Exploring the underground rivers to Tennessee ..." is assigned a 3% confidence score and is marked as incorrect.
### Key Observations
* The model demonstrates a high degree of confidence (93%) in the correct answer ("Otis Barton was a pioneer in exploring the underwater world...").
* The model assigns low confidence scores (3% each) to the incorrect answers.
* The diagram clearly distinguishes between correct and incorrect answers using green checkmarks and red X's, respectively.
### Interpretation
The diagram illustrates the performance of a model in answering a specific question. The high confidence score assigned to the correct answer suggests that the model is effective in identifying the correct response. The low confidence scores assigned to the incorrect answers indicate that the model is also capable of distinguishing between relevant and irrelevant information. The diagram provides a clear and concise overview of the model's output and its accuracy in answering the given question.
</details>
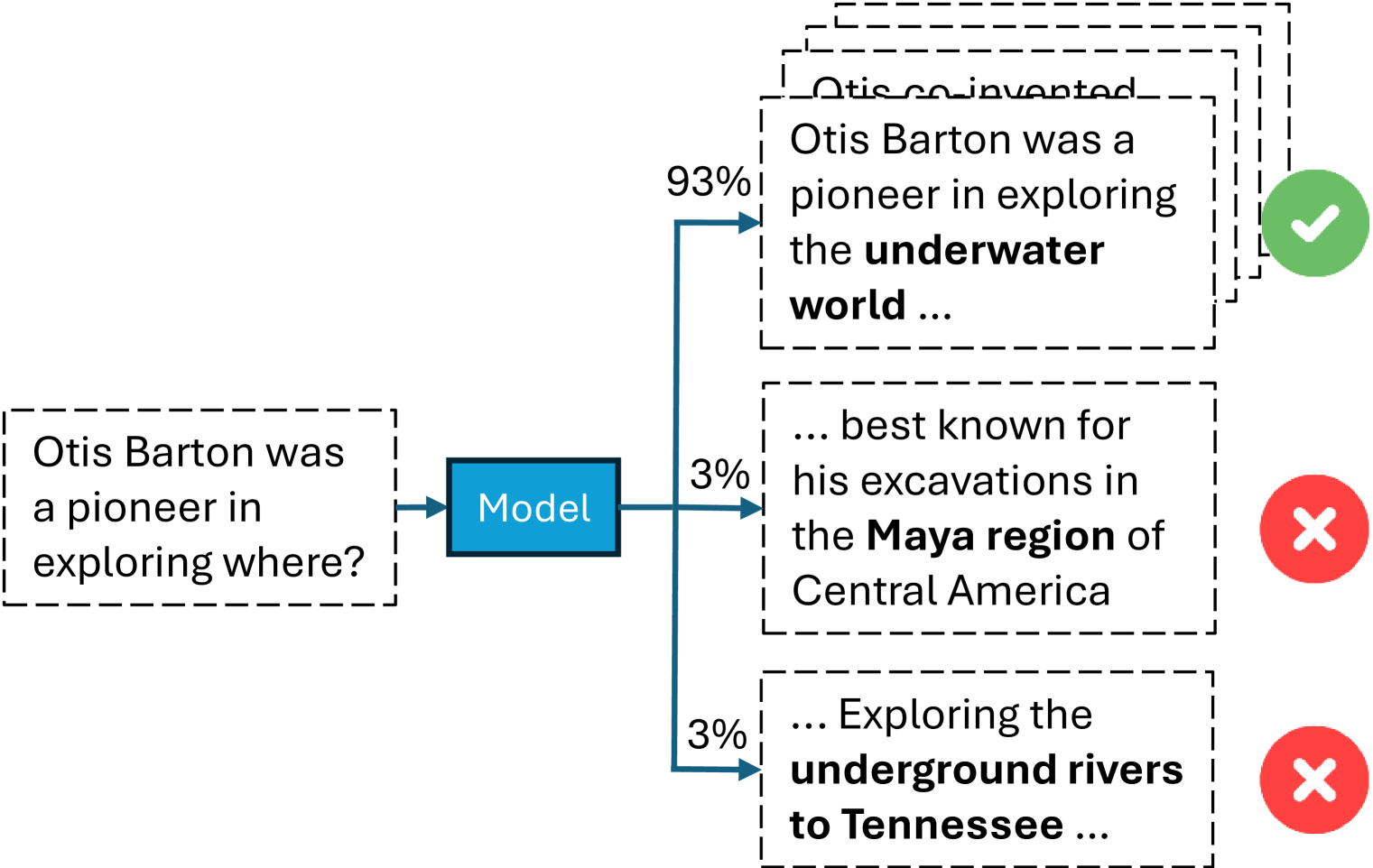
(a) The LLM mostly answers correctly, but sometimes hallucinates.
<details>
<summary>x3.png Details</summary>
### Visual Description
## Diagram: Model Accuracy on State Border Question
### Overview
The image is a diagram illustrating the accuracy of a model in answering the question: "Which American state borders on only one other state?". The diagram shows the model's output, the percentage of times each output was given, and whether the output was correct or incorrect.
### Components/Axes
* **Input Question:** "Which American state borders on only one other state?" (contained in a dashed-line box on the left)
* **Model:** A blue rectangle labeled "Model" in the center.
* **Output 1:** "Missouri is the. The only state to border ... is Missouri ..." (contained in a dashed-line box on the right, top). This output is marked with a red "X", indicating it is incorrect.
* **Output 2:** "Maine is the. The US state that ... is Maine, which ..." (contained in a dashed-line box on the right, bottom). This output is marked with a green checkmark, indicating it is correct.
* **Percentages:**
* 87% associated with the "Missouri" output.
* 13% associated with the "Maine" output.
### Detailed Analysis
* The model incorrectly identifies Missouri as the state bordering only one other state 87% of the time.
* The model correctly identifies Maine as the state bordering only one other state 13% of the time.
* The diagram uses a blue arrow to indicate the flow from the input question to the model and from the model to the outputs.
### Key Observations
* The model is significantly more likely to provide the incorrect answer (Missouri) than the correct answer (Maine).
* The model's accuracy is low, with only 13% of responses being correct.
### Interpretation
The diagram demonstrates that the model performs poorly on the given question. The high percentage of incorrect answers suggests that the model may be biased towards Missouri or lacks the necessary information to accurately answer the question. The diagram highlights the need for improvement in the model's ability to identify states based on their bordering states.
</details>
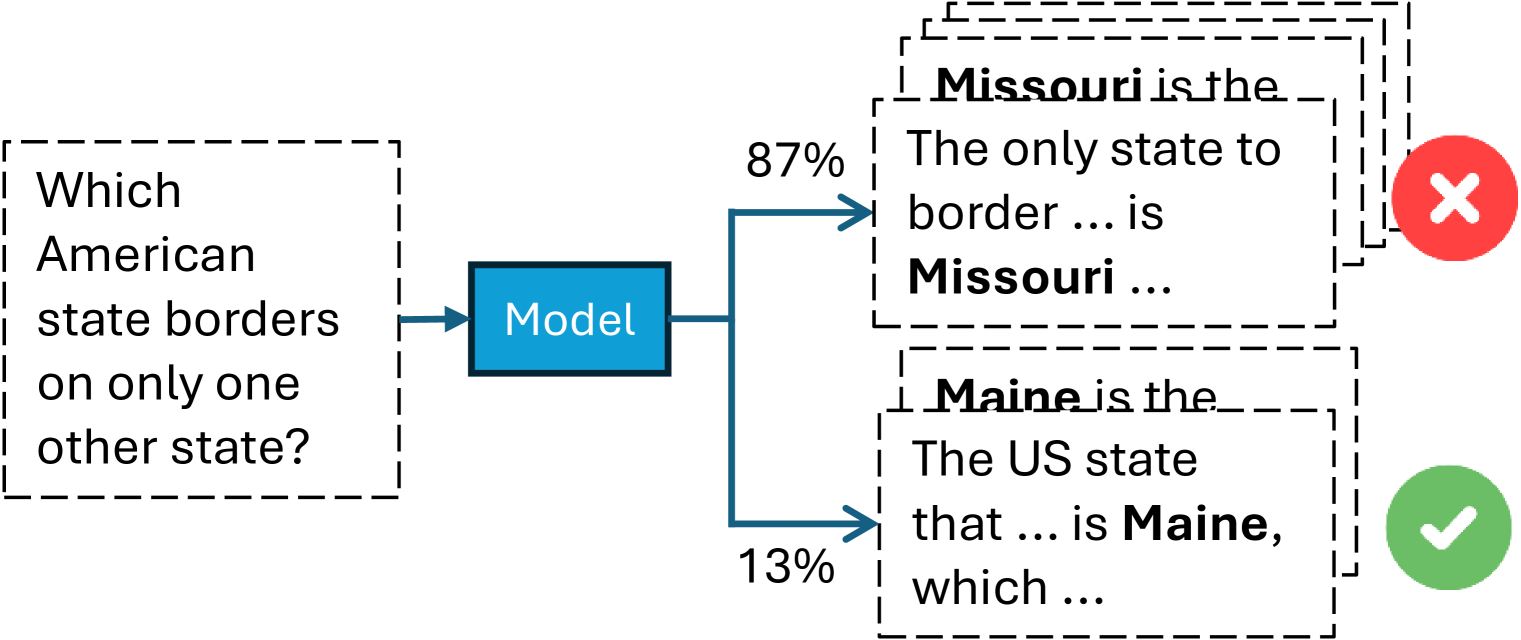
(b) The LLM mostly answers incorrectly, but seems to have some knowledge on the correct answer.
<details>
<summary>x4.png Details</summary>
### Visual Description
## Diagram: Model Output for Football Commentary Question
### Overview
The image is a diagram illustrating the output of a model in response to the question: "Who became the first female to deliver football commentary on 'match of the day'?" The model's output is represented by three different text snippets, each associated with a percentage and a visual indicator (a red "X" or a green checkmark).
### Components/Axes
* **Input Question (Left):** "Who became the first female to deliver football commentary on 'match of the day'?" This is enclosed in a dashed-line rectangle.
* **Model (Center):** A blue rectangle labeled "Model".
* **Output Branches (Right):** Three dashed-line rectangles, each containing a potential answer. Each branch is connected to the "Model" box by a blue arrow.
* **Percentages:** Each output branch is associated with a percentage (20% and 6%).
* **Validation Indicators:** Each output branch has either a red "X" or a green checkmark.
### Detailed Analysis
* **Input Question:** The question is clearly stated and forms the basis for the model's task.
* **Model:** The "Model" box represents the system processing the input question and generating potential answers.
* **Output Branch 1 (Top):**
* Text: "... In 2007, Gabby Logan ..."
* Percentage: 20%
* Validation: Red "X" (Incorrect)
* **Output Branch 2 (Middle):**
* Text: "The first ... is Clare Balding"
* Percentage: 6%
* Validation: Red "X" (Incorrect)
* **Output Branch 3 (Bottom):**
* Text: "Jackie Oatley is the first woman ..."
* Percentage: 6%
* Validation: Green Checkmark (Correct)
### Key Observations
* The model assigns the highest probability (20%) to an incorrect answer (Gabby Logan).
* The correct answer (Jackie Oatley) is assigned a lower probability (6%).
* The model provides partial answers, indicated by the ellipses ("...").
### Interpretation
The diagram illustrates a scenario where a model tasked with answering a specific question about football commentary provides multiple potential answers with associated confidence levels. The model incorrectly assigns a higher probability to a wrong answer, highlighting a potential weakness in its reasoning or training data. The use of validation indicators (red "X" and green checkmark) clearly distinguishes between correct and incorrect answers, providing a visual assessment of the model's performance. The diagram suggests that while the model can generate relevant answers, its accuracy and confidence calibration need improvement.
</details>
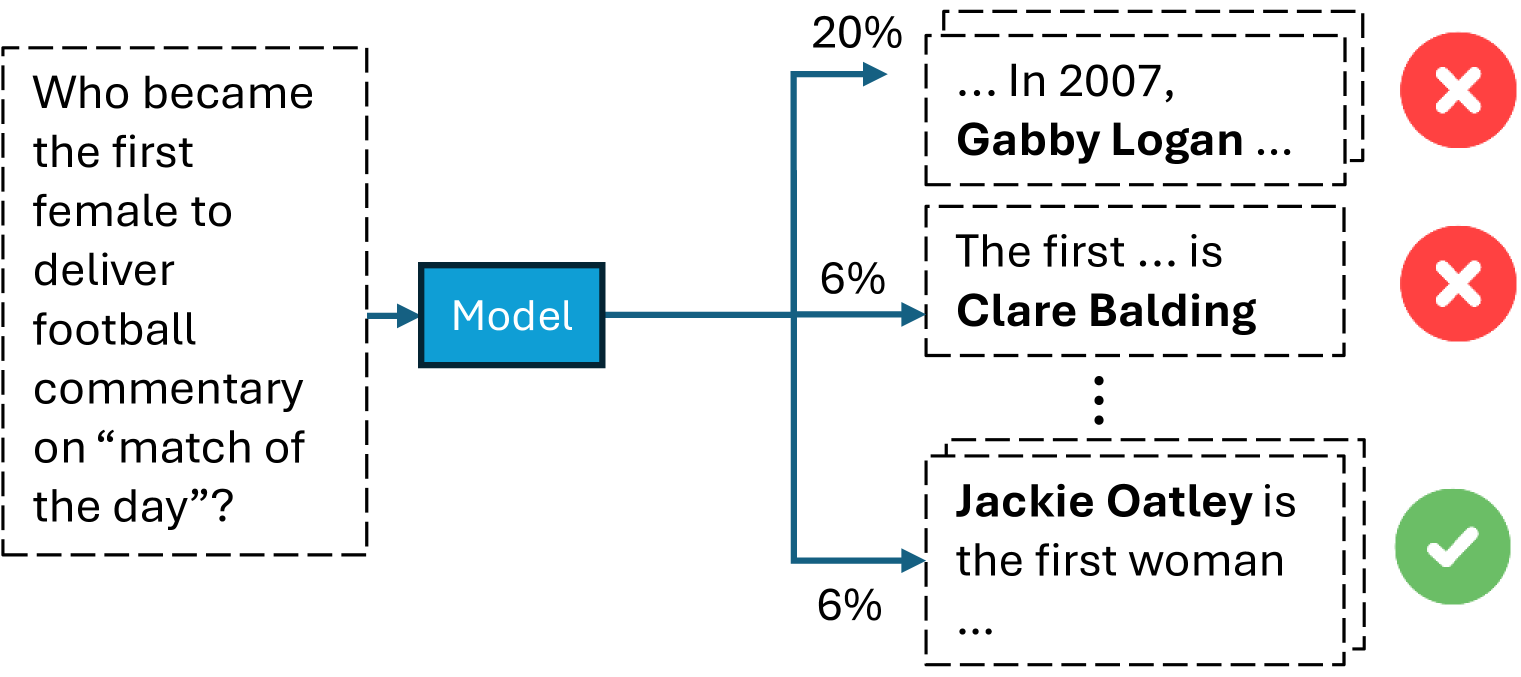
(c) The LLM generates many different answers, one of them is the correct one which is generated a small fraction of the resamples.
Figure 4: Different error types in free-form generation, exposed when resampled many times.
Figure 4 illustrates three representative error types. In one (Figure 4(a)), the model usually gives the correct answer but occasionally make an error, implying correct information is present but sampling may lead to mistakes. In another (Figure 4(b), the model often responds incorrectly, though it is capable of providing the right answer, indicating some retained knowledge despite consistently making the same error. In a third type (Figure 4(c)), the model generates a wide array of mostly incorrect answers, reflecting low confidence in any generated answer.
More generally, we categorize the errors by logging three specific features for each example: (a) the number of different answers generated; (b) the frequency of the correct answer; and (c) the frequency of the most common incorrect answer. These features reveal the following error patterns:
- (A) Refuses to answer: The model responds that it cannot answer the question in at least half the cases.
- (B) Consistently correct: Answers correctly in at least half of the cases. This category is divided into: (B1) always correct; and (B2) mostly correct with occasional errors.
- (C) Consistently incorrect: Consistently generates the same incorrect response in at least half of the cases. Similarly to type B, we subdivide this type into (C1) correct answer is never produced; and (C2) correct answer appears at least once.
- (D) Two competing: Generates both correct and incorrect responses at similar rates–difference in rates is 5 or less, and each response is generated at least 5 times.
- (E) Many answers: Generates over 10 distinct answers. Like types C and D, Subtypes include (E1) correct answer is never generated; and (E2) correct answer is generated at least once.
This taxonomy covers 96% of the errors in TriviaQA for Mistral-7b-instruct. For more qualitative examples of each type of error, see Appendix D.3. Although some overlap exists between types, our goal is to identify general patterns and explore their connection to the models’s internal representations. For a discussion on the design choices of this taxonomy, refer to Appendix D.1. This taxonomy classifies LLM errors based on an extrinsic, behavior-based analysis. Similarly, previous work analyzed repeated samples to assess an LLM’s knowledge of the correct answer (Simhi et al., 2024; Gekhman et al., 2024). Our approach is distinct because it also examines the nature of errors that the LLM makes. Furthermore, as we discuss next, we analyze the connection between these behavioral patterns and the model’s internal encoding.
5.2 Predicting Error Types
Our taxonomy offers an external, behavioral analysis of LLMs, which we complement by an intrinsic evaluation. We explore whether LLMs encode information on potential error types within their intermediate activations, offering a deeper insight into the underlying mechanisms. To investigate this, we train a probe in a one-to-many setting, where a single probe identifies a specific error type from all others. We use representations extracted from the answers produced via greedy decoding.
Table 2 presents the results. Our findings show that error types can be predicted from the intermediate representations of the greedy decoding generations, suggesting that they may capture not only output correctness but also fine-grained information about potential errors. While detection performance varies between types, the predictability of each type is valuable on its own, as it opens the possibility of tailoring targeted interventions for specific error types. Additionally, although performance on error types C and D is lower, it remains well above random, providing meaningful insights. These results suggest that internal representations encode more than just binary correctness, revealing a nuanced taxonomy of error types and offering deeper insights into how these models process and encode knowledge.
Table 2: AUC scores for error type classification (TriviaQA). Error types are predictable from the inner model representations, indicating the encoding of fine-grained information on errors.
| Error type | Mistral-7b | Mistral-Instr-7b | Llama3-8b | Llama3-Instr-8b |
| --- | --- | --- | --- | --- |
| (A) Refuses to answer | $0.86\scriptscriptstyle{± 0.002}$ | $0.85\scriptscriptstyle{± 0.011}$ | $0.87\scriptscriptstyle{± 0.002}$ | $0.88\scriptscriptstyle{± 0.014}$ |
| (B) Consistently correct | $0.88\scriptscriptstyle{± 0.001}$ | $0.82\scriptscriptstyle{± 0.008}$ | $0.86\scriptscriptstyle{± 0.001}$ | $0.81\scriptscriptstyle{± 0.002}$ |
| (C) Consistently incorrect | $0.59\scriptscriptstyle{± 0.002}$ | $0.67\scriptscriptstyle{± 0.002}$ | $0.59\scriptscriptstyle{± 0.002}$ | $0.64\scriptscriptstyle{± 0.003}$ |
| (D) Two competing | $0.63\scriptscriptstyle{± 0.002}$ | $0.68\scriptscriptstyle{± 0.006}$ | $0.61\scriptscriptstyle{± 0.001}$ | $0.65\scriptscriptstyle{± 0.004}$ |
| (E) Many answers | $0.90\scriptscriptstyle{± 0.001}$ | $0.84\scriptscriptstyle{± 0.003}$ | $0.89\scriptscriptstyle{± 0.001}$ | $0.89\scriptscriptstyle{± 0.001}$ |
6 Detecting the Correct Answer
After identifying that models encode diverse truthfulness-related information, we examine how this internal truthfulness aligns with their external behavior during response generation. To this end, we use our probe, We choose the best-performing probe for each task, which is trained on the last exact answer token. trained on error detection, to select an answer from a pool of 30 generated responses to the same question. We then measure the model’s accuracy based on the selected answers. A case where this accuracy does not significantly differ from traditional decoding methods (such as greedy decoding), suggests that the LLM’s internal representation of truthfulness is consistent with its external behavior. In simpler terms, that the model is generating answers that it also internally considers as correct. Conversely, a case where using the probe alters performance either way, would suggest a misalignment between the LLM’s internal representations and its actual behavior.
Experimental Setup
The experiments were conducted on TriviaQA, Winobias, and Math. We resample each model answer in the same strategy described in Section 5.1. The final chosen answer is the one with the highest correctness probability, as assessed by the probe. We compare to three baselines: (1) greedy decoding, (2) random selection from the $K=30$ answer candidates; and (3) majority vote wherein the most frequently generated answer is chosen.
Results
The results for Mistral-7b-instruct are summarized in Figure 5, with additional results for other LLMs and datasets as well as qualitative examples provided in Appendix E. We only present results on error types that appear 30 times or more in our test dataset. Overall, using the probe to select answers enhances the LLMs accuracy across all examined tasks. However, the extent of improvement varies by error type. For instance, in the TriviaQA dataset, there is minimal gain in the “mostly correct” category (B2). In contrast, substantial gains—ranging from 30 to 40 points in some cases—are observed in the “mostly incorrect” (C2), “two competing answers” (D), and “many answers” (E1) categories. Interestingly, and perhaps surprisingly, the probe is most effective in cases where the LLM lacks any (external) preference for the correct answer during generation. The fact that the probe can effectively identify the correct answer in these scenarios, points at a significant disconnect between the LLM’s internal encoding and its external behavior. These results suggest that even when the model encodes information of which answer is correct, it can still generate an incorrect answer in practice.
While using the probe to select the answer proves effective, it is not proposed here as an error mitigation strategy but rather as a diagnostic tool. However, these findings indicate that further research in this area could leverage the existing knowledge within LLMs to significantly reduce errors. We recommend exploring this direction in future investigations.
<details>
<summary>extracted/6450693/figures/choose_answer/probe_choose_answer_triviaqa_mistral_instruct.png Details</summary>
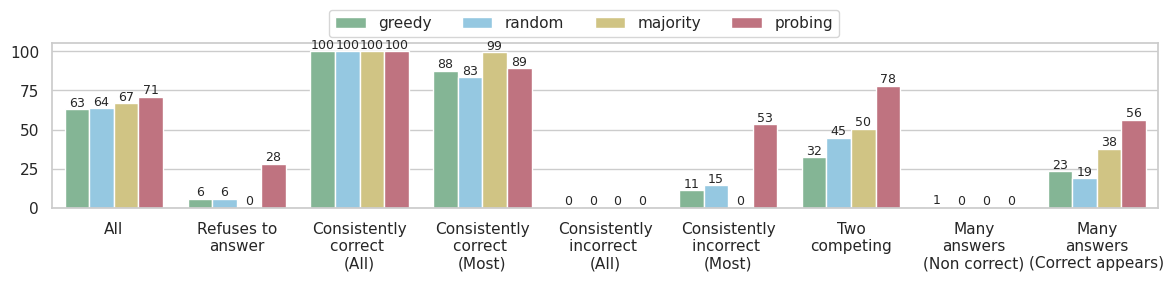
### Visual Description
## Bar Chart: Algorithm Performance on Question Answering
### Overview
The image is a bar chart comparing the performance of four different algorithms ("greedy", "random", "majority", and "probing") on a question-answering task. The y-axis represents the percentage of correct answers, ranging from 0 to 100. The x-axis represents different categories of question answering scenarios, such as "All", "Refuses to answer", "Consistently correct", "Consistently incorrect", "Two competing answers", and "Many answers".
### Components/Axes
* **Title:** (Implicit) Algorithm Performance on Question Answering
* **Y-axis:** Percentage of correct answers (0 to 100, with increments of 25)
* **X-axis:** Categories of question answering scenarios:
* All
* Refuses to answer
* Consistently correct (All)
* Consistently correct (Most)
* Consistently incorrect (All)
* Consistently incorrect (Most)
* Two competing
* Many answers (Non correct)
* Many answers (Correct appears)
* **Legend:** Located at the top of the chart.
* Green: greedy
* Light Blue: random
* Tan: majority
* Rose: probing
### Detailed Analysis or ### Content Details
**1. All:**
* greedy: 63%
* random: 64%
* majority: 67%
* probing: 71%
**2. Refuses to answer:**
* greedy: 6%
* random: 6%
* majority: 0%
* probing: 28%
**3. Consistently correct (All):**
* greedy: 100%
* random: 100%
* majority: 100%
* probing: 100%
**4. Consistently correct (Most):**
* greedy: 88%
* random: 83%
* majority: 99%
* probing: 89%
**5. Consistently incorrect (All):**
* greedy: 0%
* random: 0%
* majority: 0%
* probing: 0%
**6. Consistently incorrect (Most):**
* greedy: 11%
* random: 15%
* majority: 0%
* probing: 53%
**7. Two competing:**
* greedy: 32%
* random: 45%
* majority: 50%
* probing: 78%
**8. Many answers (Non correct):**
* greedy: 1%
* random: 0%
* majority: 0%
* probing: 0%
**9. Many answers (Correct appears):**
* greedy: 23%
* random: 19%
* majority: 38%
* probing: 56%
### Key Observations
* All algorithms perform perfectly when the answer is consistently correct.
* The "probing" algorithm has the highest percentage when refusing to answer, and when there are two competing answers.
* The "probing" algorithm performs best when there are many answers and the correct answer appears.
* All algorithms perform poorly when consistently incorrect.
### Interpretation
The bar chart provides a comparative analysis of four question-answering algorithms across various scenarios. The "probing" algorithm appears to be more aggressive in providing answers, as it has a higher percentage of correct answers in complex scenarios like "Two competing" and "Many answers (Correct appears)", but also refuses to answer more often. The "greedy", "random", and "majority" algorithms show more consistent performance across different scenarios, but generally lower accuracy in complex situations. The fact that all algorithms score 0% when consistently incorrect (All) suggests that these scenarios are fundamentally difficult for all approaches.
</details>
(a) TriviaQA
<details>
<summary>extracted/6450693/figures/choose_answer/probe_choose_answer_math_mistral_instruct.png Details</summary>
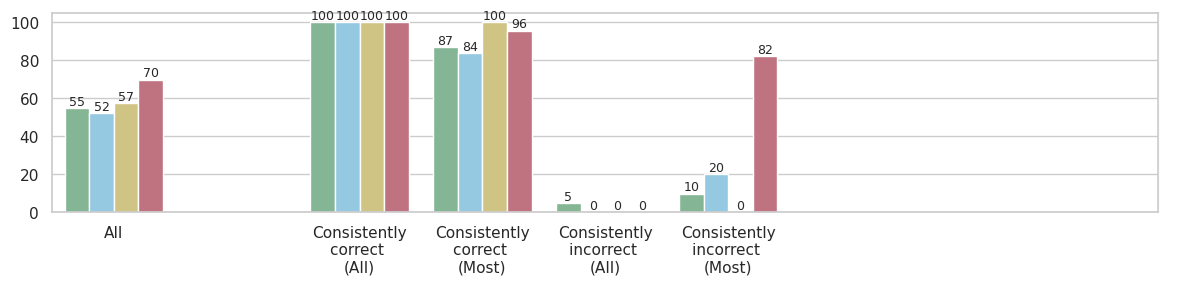
### Visual Description
## Bar Chart: Accuracy Analysis
### Overview
The image is a bar chart comparing the accuracy of a system under different conditions. The x-axis represents different categories of consistency (All, Consistently correct (All), Consistently correct (Most), Consistently incorrect (All), Consistently incorrect (Most)), and the y-axis represents the percentage of accuracy, ranging from 0 to 100. There are four data series represented by different colored bars: green, light blue, yellow, and red.
### Components/Axes
* **X-axis:**
* All
* Consistently correct (All)
* Consistently correct (Most)
* Consistently incorrect (All)
* Consistently incorrect (Most)
* **Y-axis:** Percentage scale from 0 to 100, with increments of 20.
* **Data Series (Bar Colors):**
* Green
* Light Blue
* Yellow
* Red
### Detailed Analysis
Here's a breakdown of the data for each category:
* **All:**
* Green: 55%
* Light Blue: 52%
* Yellow: 57%
* Red: 70%
* **Consistently correct (All):**
* Green: 100%
* Light Blue: 100%
* Yellow: 100%
* Red: 100%
* **Consistently correct (Most):**
* Green: 87%
* Light Blue: 84%
* Yellow: 100%
* Red: 96%
* **Consistently incorrect (All):**
* Green: 5%
* Light Blue: 0%
* Yellow: 0%
* Red: 0%
* **Consistently incorrect (Most):**
* Green: 10%
* Light Blue: 20%
* Yellow: 0%
* Red: 82%
### Key Observations
* The "Consistently correct (All)" category shows perfect accuracy (100%) across all data series.
* The "Consistently incorrect (All)" category shows very low accuracy (0-5%) across all data series.
* The "Consistently incorrect (Most)" category shows a high degree of variance, with the red series showing a high percentage (82%) while the yellow series shows 0%.
* The "All" category shows the lowest accuracy across all categories, with values ranging from 52% to 70%.
### Interpretation
The chart indicates that the system performs exceptionally well when it is consistently correct, achieving 100% accuracy. Conversely, when the system is consistently incorrect, the accuracy drops significantly, approaching 0% for some data series. The "Consistently incorrect (Most)" category reveals a potential issue, as the red series shows a high percentage, suggesting that under certain conditions, the system might be consistently incorrect in a specific way. The "All" category represents the overall accuracy, which is lower than the "Consistently correct" categories, indicating that there are instances where the system struggles. The differences between the data series (green, light blue, yellow, red) suggest that different factors or configurations influence the system's accuracy. Further investigation is needed to understand the specific conditions that lead to consistent incorrectness, especially for the red series in the "Consistently incorrect (Most)" category.
</details>
(b) Math
Figure 5: Different answer choice strategies, Mistral-7B-Instruct. A notable improvement in accuracy by using the error-detection probe is observed for error types where the LLM shows no preference for the correct answer across repeated generations.
7 Discussion and Conclusions
In this study, we analyzed LLM errors through their internal representations. Our approach depends on access to internal representations, restricting its use to open-source models. We focus on QA tasks with clear gold labels, which are key for benchmarking truthfulness detection and valued by the community. To ensure robustness, we tested 10 datasets across 4 model architectures. Open-ended tasks are left for future research, with our work laying the groundwork for broader applications. For instance, we found that truthfulness-related information is localized in specific tokens within long-responses, enabling practical improvements in error detection for production models. This insight could extend to tasks like summarization, by probing the most meaningful entities in an answer.
Truthfulness features showed poor generalization across tasks and datasets, highlighting the need for caution when applying trained error detectors in varied settings. Some unexplained patterns suggest hidden links between unrelated tasks that warrant further research. Improving generalization could involve exploring the effects of layer-token combinations and training on diverse datasets, as demonstrated by Bürger et al. (2024). Deciphering task-specific truthfulness features and their overlaps across tasks might also enhance classifier design. Still, task-specific probes could be highly valuable in critical fields like medicine and law, where reliability matters. These probes can detect errors, predict error types, and guide response selection from resampled outputs, offering significant practical benefits. Guidelines for applying these probes are provided in Appendix F.
Finally, we identified a significant discrepancy between the model’s external behavior and internal states, where it repeatedly outputs incorrect responses despite internally encoding the correct answer. It is possible that mechanisms favoring likelihood override those promoting truthfulness, as LLMs are trained to predicting likely tokens, which does not necessarily align with factual accuracy. Our findings imply that these models already encode valuable information that could possibly be harnessed to reduce errors. Work by Chuang et al. (2024) shows promising results in this area, while a subsequent work by Gekhman et al. (2025) focused exclusively on this “hidden knowledge” phenomenon, formally defining it and studying its extent. In conclusion, our findings suggest that LLMs’ internal representations provide useful insights into their errors, highlights the complex link between the internal processes of models and their external outputs, and hopefully paves the way for further improvements in error detection and mitigation.
8 Reproducibility Statement
To ensure reproducibility of our work, we provide detailed instructions and necessary code. The source code, including scripts for generating model answers, probing, resampling, and error type analysis, is available in the supplementary material, where we also provide command examples and specific seeds used for experiment reproducibility. This repository includes documentation on how to set up the environment, download and preprocess datasets, and execute the experiments outlined in Sections 3–6 of the paper. Additionally, all datasets, models, and results generation steps are described in the Appendix A.
Acknowledgments
This research was supported by the Israel Science Foundation (grant No. 448/20), an Azrieli Foundation Early Career Faculty Fellowship, an AI Alignment grant from Open Philanthropy, and a Google gift. HO is supported by the Apple AIML PhD fellowship. This research was funded by the European Union (ERC, Control-LM, 101165402). Views and opinions expressed are however those of the author(s) only and do not necessarily reflect those of the European Union or the European Research Council Executive Agency. Neither the European Union nor the granting authority can be held responsible for them.
References
- Allauzen (2007) Alexandre Allauzen. Error detection in confusion network. In 8th Annual Conference of the International Speech Communication Association, INTERSPEECH 2007, Antwerp, Belgium, August 27-31, 2007, pp. 1749–1752. ISCA, 2007. doi: 10.21437/INTERSPEECH.2007-490. URL https://doi.org/10.21437/Interspeech.2007-490.
- Azaria & Mitchell (2023) Amos Azaria and Tom Mitchell. The internal state of an llm knows when it’s lying. In Findings of the Association for Computational Linguistics: EMNLP 2023, pp. 967–976, 2023.
- Bang et al. (2023) Yejin Bang, Samuel Cahyawijaya, Nayeon Lee, Wenliang Dai, Dan Su, Bryan Wilie, Holy Lovenia, Ziwei Ji, Tiezheng Yu, Willy Chung, et al. A multitask, multilingual, multimodal evaluation of chatgpt on reasoning, hallucination, and interactivity. arXiv preprint arXiv:2302.04023, 2023.
- Belinkov (2021) Yonatan Belinkov. Probing classifiers: Promises, shortcomings, and advances, 2021. URL https://arxiv.org/abs/2102.12452.
- Bell et al. (2019) Samuel J. Bell, Helen Yannakoudakis, and Marek Rei. Context is key: Grammatical error detection with contextual word representations. In Helen Yannakoudakis, Ekaterina Kochmar, Claudia Leacock, Nitin Madnani, Ildikó Pilán, and Torsten Zesch (eds.), Proceedings of the Fourteenth Workshop on Innovative Use of NLP for Building Educational Applications, BEA@ACL 2019, Florence, Italy, August 2, 2019, pp. 103–115. Association for Computational Linguistics, 2019. doi: 10.18653/V1/W19-4410. URL https://doi.org/10.18653/v1/w19-4410.
- Bommasani et al. (2021) Rishi Bommasani, Drew A Hudson, Ehsan Adeli, Russ Altman, Simran Arora, Sydney von Arx, Michael S Bernstein, Jeannette Bohg, Antoine Bosselut, Emma Brunskill, et al. On the opportunities and risks of foundation models. arXiv preprint arXiv:2108.07258, 2021.
- Brunner et al. (2020) Gino Brunner, Yang Liu, Damian Pascual, Oliver Richter, Massimiliano Ciaramita, and Roger Wattenhofer. On identifiability in transformers. In 8th International Conference on Learning Representations (ICLR 2020)(virtual). International Conference on Learning Representations, 2020.
- Bürger et al. (2024) Lennart Bürger, Fred A Hamprecht, and Boaz Nadler. Truth is universal: Robust detection of lies in llms. arXiv preprint arXiv:2407.12831, 2024.
- Burns et al. (2022) Collin Burns, Haotian Ye, Dan Klein, and Jacob Steinhardt. Discovering latent knowledge in language models without supervision. arXiv preprint arXiv:2212.03827, 2022.
- Caines et al. (2020) Andrew Caines, Christian Bentz, Kate M. Knill, Marek Rei, and Paula Buttery. Grammatical error detection in transcriptions of spoken english. In Donia Scott, Núria Bel, and Chengqing Zong (eds.), Proceedings of the 28th International Conference on Computational Linguistics, COLING 2020, Barcelona, Spain (Online), December 8-13, 2020, pp. 2144–2162. International Committee on Computational Linguistics, 2020. doi: 10.18653/V1/2020.COLING-MAIN.195. URL https://doi.org/10.18653/v1/2020.coling-main.195.
- CH-Wang et al. (2023) Sky CH-Wang, Benjamin Van Durme, Jason Eisner, and Chris Kedzie. Do androids know they’re only dreaming of electric sheep?, 2023.
- Chen et al. (2024) Chao Chen, Kai Liu, Ze Chen, Yi Gu, Yue Wu, Mingyuan Tao, Zhihang Fu, and Jieping Ye. INSIDE: LLMs’ internal states retain the power of hallucination detection. In The Twelfth International Conference on Learning Representations, 2024. URL https://openreview.net/forum?id=Zj12nzlQbz.
- Chen et al. (2013) Wei Chen, Sankaranarayanan Ananthakrishnan, Rohit Kumar, Rohit Prasad, and Prem Natarajan. ASR error detection in a conversational spoken language translation system. In IEEE International Conference on Acoustics, Speech and Signal Processing, ICASSP 2013, Vancouver, BC, Canada, May 26-31, 2013, pp. 7418–7422. IEEE, 2013. doi: 10.1109/ICASSP.2013.6639104. URL https://doi.org/10.1109/ICASSP.2013.6639104.
- Cheng & Duan (2020) Yong Cheng and Mofan Duan. Chinese grammatical error detection based on BERT model. In Erhong YANG, Endong XUN, Baolin ZHANG, and Gaoqi RAO (eds.), Proceedings of the 6th Workshop on Natural Language Processing Techniques for Educational Applications, pp. 108–113, Suzhou, China, December 2020. Association for Computational Linguistics. URL https://aclanthology.org/2020.nlptea-1.15.
- Chuang et al. (2024) Yung-Sung Chuang, Yujia Xie, Hongyin Luo, Yoon Kim, James R. Glass, and Pengcheng He. Dola: Decoding by contrasting layers improves factuality in large language models. In The Twelfth International Conference on Learning Representations, 2024. URL https://openreview.net/forum?id=Th6NyL07na.
- Elhage et al. (2021) Nelson Elhage, Neel Nanda, Catherine Olsson, Tom Henighan, Nicholas Joseph, Ben Mann, Amanda Askell, Yuntao Bai, Anna Chen, Tom Conerly, et al. A mathematical framework for transformer circuits. Transformer Circuits Thread, 1(1):12, 2021.
- Errattahi et al. (2015) Rahhal Errattahi, Asmaa El Hannani, and Hassan Ouahmane. Automatic speech recognition errors detection and correction: A review. In Mourad Abbas and Ahmed Abdelali (eds.), 1st International Conference on Natural Language and Speech Processing, ICNLSP 2015, Algiers, Algeria, October 18-19, 2015, volume 128 of Procedia Computer Science, pp. 32–37. Elsevier, 2015. doi: 10.1016/J.PROCS.2018.03.005. URL https://doi.org/10.1016/j.procs.2018.03.005.
- Flickinger et al. (2016) Dan Flickinger, Michael Wayne Goodman, and Woodley Packard. Uw-stanford system description for AESW 2016 shared task on grammatical error detection. In Joel R. Tetreault, Jill Burstein, Claudia Leacock, and Helen Yannakoudakis (eds.), Proceedings of the 11th Workshop on Innovative Use of NLP for Building Educational Applications, BEA@NAACL-HLT 2016, June 16, 2016, San Diego, California, USA, pp. 105–111. The Association for Computer Linguistics, 2016. doi: 10.18653/V1/W16-0511. URL https://doi.org/10.18653/v1/w16-0511.
- Gao et al. (2023) Luyu Gao, Zhuyun Dai, Panupong Pasupat, Anthony Chen, Arun Tejasvi Chaganty, Yicheng Fan, Vincent Zhao, Ni Lao, Hongrae Lee, Da-Cheng Juan, et al. Rarr: Researching and revising what language models say, using language models. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 16477–16508, 2023.
- Gekhman et al. (2020) Zorik Gekhman, Roee Aharoni, Genady Beryozkin, Markus Freitag, and Wolfgang Macherey. KoBE: Knowledge-based machine translation evaluation. In Trevor Cohn, Yulan He, and Yang Liu (eds.), Findings of the Association for Computational Linguistics: EMNLP 2020, pp. 3200–3207, Online, November 2020. Association for Computational Linguistics. doi: 10.18653/v1/2020.findings-emnlp.287. URL https://aclanthology.org/2020.findings-emnlp.287.
- Gekhman et al. (2022) Zorik Gekhman, Dina Zverinski, Jonathan Mallinson, and Genady Beryozkin. RED-ACE: Robust error detection for ASR using confidence embeddings. In Yoav Goldberg, Zornitsa Kozareva, and Yue Zhang (eds.), Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pp. 2800–2808, Abu Dhabi, United Arab Emirates, December 2022. Association for Computational Linguistics. doi: 10.18653/v1/2022.emnlp-main.180. URL https://aclanthology.org/2022.emnlp-main.180.
- Gekhman et al. (2023) Zorik Gekhman, Jonathan Herzig, Roee Aharoni, Chen Elkind, and Idan Szpektor. TrueTeacher: Learning factual consistency evaluation with large language models. In Houda Bouamor, Juan Pino, and Kalika Bali (eds.), Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pp. 2053–2070, Singapore, December 2023. Association for Computational Linguistics. doi: 10.18653/v1/2023.emnlp-main.127. URL https://aclanthology.org/2023.emnlp-main.127.
- Gekhman et al. (2024) Zorik Gekhman, Gal Yona, Roee Aharoni, Matan Eyal, Amir Feder, Roi Reichart, and Jonathan Herzig. Does fine-tuning llms on new knowledge encourage hallucinations?, 2024.
- Gekhman et al. (2025) Zorik Gekhman, Eyal Ben David, Hadas Orgad, Eran Ofek, Yonatan Belinkov, Idan Szpector, Jonathan Herzig, and Roi Reichart. Inside-out: Hidden factual knowledge in llms. arXiv preprint arXiv:2503.15299, 2025.
- Geva et al. (2023) Mor Geva, Jasmijn Bastings, Katja Filippova, and Amir Globerson. Dissecting recall of factual associations in auto-regressive language models. arXiv preprint arXiv:2304.14767, 2023.
- Gottesman & Geva (2024) Daniela Gottesman and Mor Geva. Estimating knowledge in large language models without generating a single token. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing (EMNLP 2024), Miami, Florida, 2024. Association for Computational Linguistics.
- Guerreiro et al. (2023) Nuno M Guerreiro, Elena Voita, and André FT Martins. Looking for a needle in a haystack: A comprehensive study of hallucinations in neural machine translation. In Proceedings of the 17th Conference of the European Chapter of the Association for Computational Linguistics, pp. 1059–1075, 2023.
- Harnad (2024) Stevan Harnad. Language writ large: Llms, chatgpt, grounding, meaning and understanding. arXiv preprint arXiv:2402.02243, 2024.
- Honovich et al. (2021) Or Honovich, Leshem Choshen, Roee Aharoni, Ella Neeman, Idan Szpektor, and Omri Abend. $q^{2}$ : Evaluating factual consistency in knowledge-grounded dialogues via question generation and question answering. In Marie-Francine Moens, Xuanjing Huang, Lucia Specia, and Scott Wen-tau Yih (eds.), Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pp. 7856–7870, Online and Punta Cana, Dominican Republic, November 2021. Association for Computational Linguistics. doi: 10.18653/v1/2021.emnlp-main.619. URL https://aclanthology.org/2021.emnlp-main.619.
- Honovich et al. (2022) Or Honovich, Roee Aharoni, Jonathan Herzig, Hagai Taitelbaum, Doron Kukliansy, Vered Cohen, Thomas Scialom, Idan Szpektor, Avinatan Hassidim, and Yossi Matias. TRUE: Re-evaluating factual consistency evaluation. In Marine Carpuat, Marie-Catherine de Marneffe, and Ivan Vladimir Meza Ruiz (eds.), Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pp. 3905–3920, Seattle, United States, July 2022. Association for Computational Linguistics. doi: 10.18653/v1/2022.naacl-main.287. URL https://aclanthology.org/2022.naacl-main.287.
- Huang et al. (2023a) Lei Huang, Weijiang Yu, Weitao Ma, Weihong Zhong, Zhangyin Feng, Haotian Wang, Qianglong Chen, Weihua Peng, Xiaocheng Feng, Bing Qin, et al. A survey on hallucination in large language models: Principles, taxonomy, challenges, and open questions. arXiv preprint arXiv:2311.05232, 2023a.
- Huang et al. (2023b) Yuheng Huang, Jiayang Song, Zhijie Wang, Huaming Chen, and Lei Ma. Look before you leap: An exploratory study of uncertainty measurement for large language models. arXiv preprint arXiv:2307.10236, 2023b.
- Ji et al. (2023) Ziwei Ji, Nayeon Lee, Rita Frieske, Tiezheng Yu, Dan Su, Yan Xu, Etsuko Ishii, Ye Jin Bang, Andrea Madotto, and Pascale Fung. Survey of hallucination in natural language generation. ACM Computing Surveys, 55(12):1–38, 2023.
- Jiang et al. (2023) Albert Q. Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lucile Saulnier, Lélio Renard Lavaud, Marie-Anne Lachaux, Pierre Stock, Teven Le Scao, Thibaut Lavril, Thomas Wang, Timothée Lacroix, and William El Sayed. Mistral 7b, 2023. URL https://arxiv.org/abs/2310.06825.
- Joshi et al. (2017) Mandar Joshi, Eunsol Choi, Daniel S Weld, and Luke Zettlemoyer. Triviaqa: A large scale distantly supervised challenge dataset for reading comprehension. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 1601–1611, 2017.
- Kadavath et al. (2022) Saurav Kadavath, Tom Conerly, Amanda Askell, Tom Henighan, Dawn Drain, Ethan Perez, Nicholas Schiefer, Zac Hatfield-Dodds, Nova DasSarma, Eli Tran-Johnson, et al. Language models (mostly) know what they know. arXiv preprint arXiv:2207.05221, 2022.
- Kasewa et al. (2018) Sudhanshu Kasewa, Pontus Stenetorp, and Sebastian Riedel. Wronging a right: Generating better errors to improve grammatical error detection. In Ellen Riloff, David Chiang, Julia Hockenmaier, and Jun’ichi Tsujii (eds.), Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, October 31 - November 4, 2018, pp. 4977–4983. Association for Computational Linguistics, 2018. URL https://aclanthology.org/D18-1541/.
- Kotek et al. (2023) Hadas Kotek, Rikker Dockum, and David Sun. Gender bias and stereotypes in large language models. In Proceedings of the ACM collective intelligence conference, pp. 12–24, 2023.
- Kryscinski et al. (2020) Wojciech Kryscinski, Bryan McCann, Caiming Xiong, and Richard Socher. Evaluating the factual consistency of abstractive text summarization. In Bonnie Webber, Trevor Cohn, Yulan He, and Yang Liu (eds.), Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pp. 9332–9346, Online, November 2020. Association for Computational Linguistics. doi: 10.18653/v1/2020.emnlp-main.750. URL https://aclanthology.org/2020.emnlp-main.750.
- Kuhn et al. (2023) Lorenz Kuhn, Yarin Gal, and Sebastian Farquhar. Semantic uncertainty: Linguistic invariances for uncertainty estimation in natural language generation. In The Eleventh International Conference on Learning Representations, 2023. URL https://openreview.net/forum?id=VD-AYtP0dve.
- Kwiatkowski et al. (2019) Tom Kwiatkowski, Jennimaria Palomaki, Olivia Redfield, Michael Collins, Ankur Parikh, Chris Alberti, Danielle Epstein, Illia Polosukhin, Matthew Kelcey, Jacob Devlin, Kenton Lee, Kristina N. Toutanova, Llion Jones, Ming-Wei Chang, Andrew Dai, Jakob Uszkoreit, Quoc Le, and Slav Petrov. Natural questions: a benchmark for question answering research. Transactions of the Association of Computational Linguistics, 2019.
- Laban et al. (2022) Philippe Laban, Tobias Schnabel, Paul N. Bennett, and Marti A. Hearst. SummaC: Re-visiting NLI-based models for inconsistency detection in summarization. Transactions of the Association for Computational Linguistics, 10:163–177, 2022. doi: 10.1162/tacl˙a˙00453. URL https://aclanthology.org/2022.tacl-1.10.
- Levinstein & Herrmann (2024) Benjamin A Levinstein and Daniel A Herrmann. Still no lie detector for language models: Probing empirical and conceptual roadblocks. Philosophical Studies, pp. 1–27, 2024.
- Lewis et al. (2020) Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, et al. Retrieval-augmented generation for knowledge-intensive nlp tasks. Advances in Neural Information Processing Systems, 33:9459–9474, 2020.
- Li et al. (2024) Kenneth Li, Oam Patel, Fernanda Viégas, Hanspeter Pfister, and Martin Wattenberg. Inference-time intervention: Eliciting truthful answers from a language model. Advances in Neural Information Processing Systems, 36, 2024.
- Li & Wang (2024) Wei Li and Houfeng Wang. Detection-correction structure via general language model for grammatical error correction. In Lun-Wei Ku, Andre Martins, and Vivek Srikumar (eds.), Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), ACL 2024, Bangkok, Thailand, August 11-16, 2024, pp. 1748–1763. Association for Computational Linguistics, 2024. URL https://aclanthology.org/2024.acl-long.96.
- Liang et al. (2024) Xun Liang, Shichao Song, Zifan Zheng, Hanyu Wang, Qingchen Yu, Xunkai Li, Rong-Hua Li, Yi Wang, Zhonghao Wang, Feiyu Xiong, et al. Internal consistency and self-feedback in large language models: A survey. arXiv preprint arXiv:2407.14507, 2024.
- Lin et al. (2021) Stephanie Lin, Jacob Hilton, and Owain Evans. Truthfulqa: Measuring how models mimic human falsehoods. arXiv preprint arXiv:2109.07958, 2021.
- Liu et al. (2023) Kevin Liu, Stephen Casper, Dylan Hadfield-Menell, and Jacob Andreas. Cognitive dissonance: Why do language model outputs disagree with internal representations of truthfulness? In Houda Bouamor, Juan Pino, and Kalika Bali (eds.), Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pp. 4791–4797, Singapore, December 2023. Association for Computational Linguistics. doi: 10.18653/v1/2023.emnlp-main.291. URL https://aclanthology.org/2023.emnlp-main.291.
- Liu et al. (2022) Tianyu Liu, Yizhe Zhang, Chris Brockett, Yi Mao, Zhifang Sui, Weizhu Chen, and Bill Dolan. A token-level reference-free hallucination detection benchmark for free-form text generation. In Smaranda Muresan, Preslav Nakov, and Aline Villavicencio (eds.), Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 6723–6737, Dublin, Ireland, May 2022. Association for Computational Linguistics. doi: 10.18653/v1/2022.acl-long.464. URL https://aclanthology.org/2022.acl-long.464.
- Lo (2019) Chi-kiu Lo. YiSi - a unified semantic MT quality evaluation and estimation metric for languages with different levels of available resources. In Ondřej Bojar, Rajen Chatterjee, Christian Federmann, Mark Fishel, Yvette Graham, Barry Haddow, Matthias Huck, Antonio Jimeno Yepes, Philipp Koehn, André Martins, Christof Monz, Matteo Negri, Aurélie Névéol, Mariana Neves, Matt Post, Marco Turchi, and Karin Verspoor (eds.), Proceedings of the Fourth Conference on Machine Translation (Volume 2: Shared Task Papers, Day 1), pp. 507–513, Florence, Italy, August 2019. Association for Computational Linguistics. doi: 10.18653/v1/W19-5358. URL https://aclanthology.org/W19-5358.
- Maas et al. (2011) Andrew L. Maas, Raymond E. Daly, Peter T. Pham, Dan Huang, Andrew Y. Ng, and Christopher Potts. Learning word vectors for sentiment analysis. In Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies, pp. 142–150, Portland, Oregon, USA, June 2011. Association for Computational Linguistics. URL http://www.aclweb.org/anthology/P11-1015.
- Manakul et al. (2023) Potsawee Manakul, Adian Liusie, and Mark Gales. Selfcheckgpt: Zero-resource black-box hallucination detection for generative large language models. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pp. 9004–9017, 2023.
- Marks & Tegmark (2023) Samuel Marks and Max Tegmark. The geometry of truth: Emergent linear structure in large language model representations of true/false datasets. arXiv preprint arXiv:2310.06824, 2023.
- McGowan et al. (2023) Alessia McGowan, Yunlai Gui, Matthew Dobbs, Sophia Shuster, Matthew Cotter, Alexandria Selloni, Marianne Goodman, Agrima Srivastava, Guillermo A Cecchi, and Cheryl M Corcoran. Chatgpt and bard exhibit spontaneous citation fabrication during psychiatry literature search. Psychiatry Research, 326:115334, 2023.
- Meng et al. (2022) Kevin Meng, David Bau, Alex Andonian, and Yonatan Belinkov. Locating and editing factual associations in GPT. Advances in Neural Information Processing Systems, 36, 2022. arXiv:2202.05262.
- Millidge (2023) Beren Millidge. LLMs confabulate not hallucinate. Beren’s Blog, March 2023. URL https://www.beren.io/2023-03-19-LLMs-confabulate-not-hallucinate/.
- Mishra & Kaur (2013) Ritika Mishra and Navjot Kaur. A survey of spelling error detection and correction techniques. International Journal of Computer Trends and Technology, 4(3):372–374, 2013.
- nostalgebraist (2020) nostalgebraist. Interpreting gpt: The logit lens. LessWrong blog post, 2020. URL https://www.lesswrong.com/posts/AcKRB8wDpdaN6v6ru/interpreting-gpt-the-logit-lens. Accessed: 2024-11-18.
- Olah et al. (2023) Chris Olah, Nelson Elhage, Neel Nanda, Catherine Schubert, Daniel Filan, et al. Towards monosemanticity: Decomposing language models with dictionary learning. Transformer Circuits Thread, 2023. URL https://transformer-circuits.pub/2023/monosemantic-features/index.html.
- Pedregosa et al. (2011) F. Pedregosa, G. Varoquaux, A. Gramfort, V. Michel, B. Thirion, O. Grisel, M. Blondel, P. Prettenhofer, R. Weiss, V. Dubourg, J. Vanderplas, A. Passos, D. Cournapeau, M. Brucher, M. Perrot, and E. Duchesnay. Scikit-learn: Machine learning in Python. Journal of Machine Learning Research, 12:2825–2830, 2011.
- Pellegrini & Trancoso (2009) Thomas Pellegrini and Isabel Trancoso. Error detection in broadcast news ASR using markov chains. In Zygmunt Vetulani (ed.), Human Language Technology. Challenges for Computer Science and Linguistics - 4th Language and Technology Conference, LTC 2009, Poznan, Poland, November 6-8, 2009, Revised Selected Papers, volume 6562 of Lecture Notes in Computer Science, pp. 59–69. Springer, 2009. doi: 10.1007/978-3-642-20095-3“˙6. URL https://doi.org/10.1007/978-3-642-20095-3_6.
- Pu et al. (2021) Amy Pu, Hyung Won Chung, Ankur Parikh, Sebastian Gehrmann, and Thibault Sellam. Learning compact metrics for MT. In Marie-Francine Moens, Xuanjing Huang, Lucia Specia, and Scott Wen-tau Yih (eds.), Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pp. 751–762, Online and Punta Cana, Dominican Republic, November 2021. Association for Computational Linguistics. doi: 10.18653/v1/2021.emnlp-main.58. URL https://aclanthology.org/2021.emnlp-main.58.
- Rao et al. (2020) Gaoqi Rao, Erhong Yang, and Baolin Zhang. Overview of NLPTEA-2020 shared task for Chinese grammatical error diagnosis. In Erhong YANG, Endong XUN, Baolin ZHANG, and Gaoqi RAO (eds.), Proceedings of the 6th Workshop on Natural Language Processing Techniques for Educational Applications, pp. 25–35, Suzhou, China, December 2020. Association for Computational Linguistics. URL https://aclanthology.org/2020.nlptea-1.4.
- Rateike et al. (2023) Miriam Rateike, Celia Cintas, John Wamburu, Tanya Akumu, and Skyler Speakman. Weakly supervised detection of hallucinations in llm activations. arXiv preprint arXiv:2312.02798, 2023.
- Rawte et al. (2023) Vipula Rawte, Swagata Chakraborty, Agnibh Pathak, Anubhav Sarkar, SM Tonmoy, Aman Chadha, Amit P Sheth, and Amitava Das. The troubling emergence of hallucination in large language models–an extensive definition, quantification, and prescriptive remediations. arXiv preprint arXiv:2310.04988, 2023.
- Rei et al. (2020) Ricardo Rei, Craig Stewart, Ana C Farinha, and Alon Lavie. COMET: A neural framework for MT evaluation. In Bonnie Webber, Trevor Cohn, Yulan He, and Yang Liu (eds.), Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pp. 2685–2702, Online, November 2020. Association for Computational Linguistics. doi: 10.18653/v1/2020.emnlp-main.213. URL https://aclanthology.org/2020.emnlp-main.213.
- Rei et al. (2022a) Ricardo Rei, José G. C. de Souza, Duarte Alves, Chrysoula Zerva, Ana C Farinha, Taisiya Glushkova, Alon Lavie, Luisa Coheur, and André F. T. Martins. COMET-22: Unbabel-IST 2022 submission for the metrics shared task. In Philipp Koehn, Loïc Barrault, Ondřej Bojar, Fethi Bougares, Rajen Chatterjee, Marta R. Costa-jussà, Christian Federmann, Mark Fishel, Alexander Fraser, Markus Freitag, Yvette Graham, Roman Grundkiewicz, Paco Guzman, Barry Haddow, Matthias Huck, Antonio Jimeno Yepes, Tom Kocmi, André Martins, Makoto Morishita, Christof Monz, Masaaki Nagata, Toshiaki Nakazawa, Matteo Negri, Aurélie Névéol, Mariana Neves, Martin Popel, Marco Turchi, and Marcos Zampieri (eds.), Proceedings of the Seventh Conference on Machine Translation (WMT), pp. 578–585, Abu Dhabi, United Arab Emirates (Hybrid), December 2022a. Association for Computational Linguistics. URL https://aclanthology.org/2022.wmt-1.52.
- Rei et al. (2022b) Ricardo Rei, Marcos Treviso, Nuno M. Guerreiro, Chrysoula Zerva, Ana C Farinha, Christine Maroti, José G. C. de Souza, Taisiya Glushkova, Duarte Alves, Luisa Coheur, Alon Lavie, and André F. T. Martins. CometKiwi: IST-unbabel 2022 submission for the quality estimation shared task. In Philipp Koehn, Loïc Barrault, Ondřej Bojar, Fethi Bougares, Rajen Chatterjee, Marta R. Costa-jussà, Christian Federmann, Mark Fishel, Alexander Fraser, Markus Freitag, Yvette Graham, Roman Grundkiewicz, Paco Guzman, Barry Haddow, Matthias Huck, Antonio Jimeno Yepes, Tom Kocmi, André Martins, Makoto Morishita, Christof Monz, Masaaki Nagata, Toshiaki Nakazawa, Matteo Negri, Aurélie Névéol, Mariana Neves, Martin Popel, Marco Turchi, and Marcos Zampieri (eds.), Proceedings of the Seventh Conference on Machine Translation (WMT), pp. 634–645, Abu Dhabi, United Arab Emirates (Hybrid), December 2022b. Association for Computational Linguistics. URL https://aclanthology.org/2022.wmt-1.60.
- Sakaguchi et al. (2021) Keisuke Sakaguchi, Ronan Le Bras, Chandra Bhagavatula, and Yejin Choi. Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM, 64(9):99–106, 2021.
- Salles et al. (2020) Arleen Salles, Kathinka Evers, and Michele Farisco. Anthropomorphism in ai. AJOB neuroscience, 11(2):88–95, 2020.
- Scialom et al. (2021) Thomas Scialom, Paul-Alexis Dray, Sylvain Lamprier, Benjamin Piwowarski, Jacopo Staiano, Alex Wang, and Patrick Gallinari. QuestEval: Summarization asks for fact-based evaluation. In Marie-Francine Moens, Xuanjing Huang, Lucia Specia, and Scott Wen-tau Yih (eds.), Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pp. 6594–6604, Online and Punta Cana, Dominican Republic, November 2021. Association for Computational Linguistics. doi: 10.18653/v1/2021.emnlp-main.529. URL https://aclanthology.org/2021.emnlp-main.529.
- Sellam et al. (2020) Thibault Sellam, Dipanjan Das, and Ankur Parikh. BLEURT: Learning robust metrics for text generation. In Dan Jurafsky, Joyce Chai, Natalie Schluter, and Joel Tetreault (eds.), Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pp. 7881–7892, Online, July 2020. Association for Computational Linguistics. doi: 10.18653/v1/2020.acl-main.704. URL https://aclanthology.org/2020.acl-main.704.
- Serapio-García et al. (2023) Greg Serapio-García, Mustafa Safdari, Clément Crepy, Luning Sun, Stephen Fitz, Peter Romero, Marwa Abdulhai, Aleksandra Faust, and Maja Matarić. Personality traits in large language models. arXiv preprint arXiv:2307.00184, 2023.
- Simhi et al. (2024) Adi Simhi, Jonathan Herzig, Idan Szpektor, and Yonatan Belinkov. Constructing benchmarks and interventions for combating hallucinations in llms, 2024.
- Slobodkin et al. (2023) Aviv Slobodkin, Omer Goldman, Avi Caciularu, Ido Dagan, and Shauli Ravfogel. The curious case of hallucinatory (un)answerability: Finding truths in the hidden states of over-confident large language models. In Houda Bouamor, Juan Pino, and Kalika Bali (eds.), Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pp. 3607–3625, Singapore, December 2023. Association for Computational Linguistics. doi: 10.18653/v1/2023.emnlp-main.220. URL https://aclanthology.org/2023.emnlp-main.220.
- Snyder et al. (2023) Ben Snyder, Marius Moisescu, and Muhammad Bilal Zafar. On early detection of hallucinations in factual question answering, 2023. URL https://arxiv.org/abs/2312.14183.
- Sun et al. (2024) Yuhong Sun, Zhangyue Yin, Qipeng Guo, Jiawen Wu, Xipeng Qiu, and Hui Zhao. Benchmarking hallucination in large language models based on unanswerable math word problem. CoRR, 2024.
- Taubenfeld et al. (2025) Amir Taubenfeld, Tom Sheffer, Eran Ofek, Amir Feder, Ariel Goldstein, Zorik Gekhman, and Gal Yona. Confidence improves self-consistency in llms. arXiv preprint arXiv:2502.06233, 2025.
- Tian et al. (2023a) Katherine Tian, Eric Mitchell, Huaxiu Yao, Christopher D Manning, and Chelsea Finn. Fine-tuning language models for factuality. arXiv preprint arXiv:2311.08401, 2023a.
- Tian et al. (2023b) Katherine Tian, Eric Mitchell, Allan Zhou, Archit Sharma, Rafael Rafailov, Huaxiu Yao, Chelsea Finn, and Christopher D Manning. Just ask for calibration: Strategies for eliciting calibrated confidence scores from language models fine-tuned with human feedback. arXiv preprint arXiv:2305.14975, 2023b.
- Touvron et al. (2023) Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, et al. Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971, 2023.
- Varshney et al. (2023) Neeraj Varshney, Wenlin Yao, Hongming Zhang, Jianshu Chen, and Dong Yu. A stitch in time saves nine: Detecting and mitigating hallucinations of llms by validating low-confidence generation, 2023.
- Venkit et al. (2024) Pranav Narayanan Venkit, Tatiana Chakravorti, Vipul Gupta, Heidi Biggs, Mukund Srinath, Koustava Goswami, Sarah Rajtmajer, and Shomir Wilson. ” confidently nonsensical?”: A critical survey on the perspectives and challenges of’hallucinations’ in nlp. arXiv preprint arXiv:2404.07461, 2024.
- Wang & Sennrich (2020) Chaojun Wang and Rico Sennrich. On exposure bias, hallucination and domain shift in neural machine translation. In Dan Jurafsky, Joyce Chai, Natalie Schluter, and Joel Tetreault (eds.), Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pp. 3544–3552, Online, July 2020. Association for Computational Linguistics. doi: 10.18653/v1/2020.acl-main.326. URL https://aclanthology.org/2020.acl-main.326.
- Wang & Tan (2020) Quanbin Wang and Ying Tan. Grammatical error detection with self attention by pairwise training. In 2020 International Joint Conference on Neural Networks, IJCNN 2020, Glasgow, United Kingdom, July 19-24, 2020, pp. 1–7. IEEE, 2020. doi: 10.1109/IJCNN48605.2020.9206715. URL https://doi.org/10.1109/IJCNN48605.2020.9206715.
- Williams et al. (2018) Adina Williams, Nikita Nangia, and Samuel Bowman. A broad-coverage challenge corpus for sentence understanding through inference. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers), pp. 1112–1122. Association for Computational Linguistics, 2018. URL http://aclweb.org/anthology/N18-1101.
- Yang et al. (2018) Zhilin Yang, Peng Qi, Saizheng Zhang, Yoshua Bengio, William Cohen, Ruslan Salakhutdinov, and Christopher D Manning. Hotpotqa: A dataset for diverse, explainable multi-hop question answering. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, pp. 2369–2380, 2018.
- Yin et al. (2024) Fan Yin, Jayanth Srinivasa, and Kai-Wei Chang. Characterizing truthfulness in large language model generations with local intrinsic dimension. In Proceedings of the 41st International Conference on Machine Learning, Vienna, Austria, 2024.
- Yona et al. (2024) Gal Yona, Roee Aharoni, and Mor Geva. Can large language models faithfully express their intrinsic uncertainty in words?, 2024. URL https://arxiv.org/abs/2405.16908.
- Yuksekgonul et al. (2023) Mert Yuksekgonul, Varun Chandrasekaran, Erik Jones, Suriya Gunasekar, Ranjita Naik, Hamid Palangi, Ece Kamar, and Besmira Nushi. Attention satisfies: A constraint-satisfaction lens on factual errors of language models. In The Twelfth International Conference on Learning Representations, 2023.
- Zhang et al. (2019) Zhengyan Zhang, Xu Han, Zhiyuan Liu, Xin Jiang, Maosong Sun, and Qun Liu. ERNIE: Enhanced language representation with informative entities. In Anna Korhonen, David Traum, and Lluís Màrquez (eds.), Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pp. 1441–1451, Florence, Italy, July 2019. Association for Computational Linguistics. doi: 10.18653/v1/P19-1139. URL https://aclanthology.org/P19-1139.
- Zhao et al. (2018) Jieyu Zhao, Tianlu Wang, Mark Yatskar, Vicente Ordonez, and Kai-Wei Chang. Gender bias in coreference resolution: Evaluation and debiasing methods. arXiv preprint arXiv:1804.06876, 2018.
- Zhou et al. (2005) Lina Zhou, Yongmei Shi, Jinjuan Feng, and Andrew Sears. Data mining for detecting errors in dictation speech recognition. IEEE Trans. Speech Audio Process., 13(5-1):681–688, 2005. doi: 10.1109/TSA.2005.851874. URL https://doi.org/10.1109/TSA.2005.851874.
- Zou et al. (2023) Andy Zou, Long Phan, Sarah Chen, James Campbell, Phillip Guo, Richard Ren, Alexander Pan, Xuwang Yin, Mantas Mazeika, Ann-Kathrin Dombrowski, Shashwat Goel, Nathaniel Li, Michael J. Byun, Zifan Wang, Alex Mallen, Steven Basart, Sanmi Koyejo, Dawn Song, Matt Fredrikson, J. Zico Kolter, and Dan Hendrycks. Representation engineering: A top-down approach to ai transparency, 2023. URL https://arxiv.org/abs/2310.01405.
Appendix A Implementation Details
A.1 Task Specific Error Detection
In this work, we specifically address errors produced by modern large language models (LLMs). Given the diverse range of tasks these models are applied to, our focus is on general error detection across all categories, rather than isolating specific types. Prior to the emergence of LLMs, much research targeted error detection for specific tasks, with common examples including grammatical errors (Kasewa et al., 2018; Bell et al., 2019; Cheng & Duan, 2020; Wang & Tan, 2020; Flickinger et al., 2016), spelling mistakes (Mishra & Kaur, 2013), machine translation inaccuracies (Lo, 2019; Pu et al., 2021; Sellam et al., 2020; Gekhman et al., 2020; Rei et al., 2020; 2022a; 2022b), speech recognition faults (Caines et al., 2020; Rao et al., 2020; Li & Wang, 2024; Zhou et al., 2005; Allauzen, 2007; Gekhman et al., 2022; Errattahi et al., 2015; Pellegrini & Trancoso, 2009; Chen et al., 2013), and factual consistency failures (Honovich et al., 2022; Laban et al., 2022; Honovich et al., 2021; Gekhman et al., 2023; Scialom et al., 2021; Kryscinski et al., 2020).
A.2 Probing: Implementation Details
We examine the intermediate representations of the exact answer tokens generated by a large language model (LLM) during the answer generation process. The intermediate representation selected for this analysis is derived from the output of the final multi-layer perceptron (MLP). This choice is based on preliminary experiments comparing the MLP output, the residual stream, and the attention heads, which showed no significant differences. We leave the in-depth analysis for future work.
For the probing classifier, we employ a logistic regression model from the scikit-learn library (Pedregosa et al., 2011). We used the default hyperparameters, which include a norm penalty of L2 and an LBFGS solver. We initially experimented with other hyper-parameters and did not find a singnificant difference. For each random seed, the dataset was split to training and validation in a 80-20 ratio, and the test dataset was bootstrap sampled.
Obtaining correctness label for the probing dataset.
An answer is generally considered correct if it includes the correct answer label and appears before any alternative incorrect labels. We manually analyzed the results of this heuristic to confirm that it is accurate in almost all cases. However, one exception is the Natural Questions with Context (NQ_WC) dataset, where we identified false negatives and thus deployed a more precise validation using an instruct LLM, as demonstrated below:
{mdframed}
[backgroundcolor=blue!5, skipabove=0.5] Evaluate the following answers to questions. For each question you would be given an LLM answer and the correct answer. You would have to determine if the LLM answer is correct or not. If the LLM answer is correct, write ’1’ and if it is not correct, write ’0’. For example:
Question: [Question 1]
Ground Truth: [Gold label 1]
LLM Answer: [LLM long answer 1]
Correctness: 0
Question: [Question 2]
Ground Truth: [Gold label 2]
LLM Answer: [LLM long answer 2]
Correctness: 1
Question: [Question]
Ground Truth: [Label]
LLM Answer: [LLM long answer]
Correctness:
Detecting and using exact answer tokens.
Exact answers are identified from a lengthy generated answer using an external algorithm, which processes the question and the LLM’s response, $A(q_{i},\hat{y_{i}})$ , to extract the exact answer. After extraction, we identify the exact answer tokens via a simple search process, focusing on four key tokens: the one before the first exact answer token, the first and last exact answer tokens, and the one after the last.
For the implementation of $A$ that detects the exact locations of answer tokens, we use a combination of heuristic methods and an instruction-tuned LLM. Specifically, when the set of possible answers is finite, we rely on heuristics. For more open-ended scenarios, such as factual questions, we automatically locate the answer if it matches the gold label. Otherwise, we prompt an instruction-tuned LLM, specifically Mistral-7b-Instruct (Jiang et al., 2023), to identify and extract the exact answer substring using the following prompt:
{mdframed}
[backgroundcolor=blue!5, skipabove=0.5] Extract from the following long answer the short answer, only the relevant tokens. If the long answer does not answer the question, output NO ANSWER.
Q: [Question 1]
A: [LLM long answer 1]
Exact answer: [Short exact answer 1]
Q: [Question 2]
A: [LLM long answer that does not answer the question]
Exact answer: NO ANSWER
Q: [Question]
A: [LLM long answer] Exact answer:
To extract a valid exact answer from a long response, we prompt the instruct LLM up to five times. This process involves verifying that the exact answer is a substring of the long answer unless the instruct LLM indicates that there is no answer. To avoid bias in our probing task, we only retain questions for which a valid exact answer was successfully extracted. This ensures there is no unfair correlation between invalid answers and incorrect answers in the experiments.
We note the following: (a) While it is possible to use an instruct LLM to extract every answer regardless of its correctness, we chose the aforementioned strategy to improve the efficiency of our experiments; (b) This is just one possible implementation. For each LLM, one could use the same LLM to extract its own exact answer token, as demonstrated in a proof-of-concept over 1000 samples of TriviaQA in Table 3. Alternatively, it may be more effective to train a smaller system specifically designed for detecting exact answer tokens, which would be more suitable for real-world scenarios. We choose to keep the extraction process as abstract as possible, as our primary focus is not on the specific implementation, but on analyzing the potential gains from probing these locations.
Additionally, if the exact answer token is not among the first generated tokens, we examine the token immediately preceding it (“before exact answer token”). If the exact answer token is not the last one, we also examine the following token. When the exact answer spans multiple tokens, the first and last exact answer tokens are probed separately.
Table 3: Success rate of extracting exact answer from a long model answer. Each model is used to extract answers from its own output.
| Mistral-7b | Mistral-Instruct-7b | Llama3-8b | Llama3-Instruct-8b |
| --- | --- | --- | --- |
| 0.99 | 0.96 | 0.99 | 0.95 |
A.3 Datasets
We outline here all ten datasets that we investigate in our work. In our analysis, we aimed at covering a wide range of tasks, skills required to solve the tasks, diversity of datasets and as a result also different LLM limitations such as factual inaccuracies (often referred to as “hallucinations”), biases, arithmetic mistakes, and more. For each dataset, we explain how it covers something different from all the previous datasets. For all datasets, we present the LLM with non or a short instruct, a context (if exists for the task), and let it generate a free text. We follow this paradigm as it better mimics real-world usage of LLMs by humans, as opposed to using few-shot to force a short answer that is generated on the first token (Yuksekgonul et al., 2023; Chen et al., 2024; Simhi et al., 2024). One exception to this is a the sentiment analysis (IMDB) for which we apply 1-shot for the LLM to use the allowed labels, as it did not follow the instruction alone and we could not identify if the answer is correct or not even with manual analysis. Additionally, we implemented a different prompting strategy to the instruct and non-instruct LLMs. To see the exact formats we used to prompt each dataset and LLM, refer to our code implementation at https://github.com/technion-cs-nlp/LLMsKnow.
For each dataset we used a split of 10K training samples and 10K test samples, unless the dataset is too small, in which case we mention the size.
- TriviaQA (Joshi et al., 2017): a collection of trivia question-answer pairs. The questions are presented to the LLM without any context, allowing it to generate responses based solely on its internal, parametric knowledge. The dataset includes various acceptable variations of the correct answer, which are used to automatically evaluate the accuracy of the generated res.
- HotpotQA (Yang et al., 2018): a dataset designed for diverse multi-hop question answering. Each entry includes Wikipedia documents that help answering the questions. We use two different settings: (1) without context, where questions are asked directly, which covers slightly different skills from TriviaQA as it requires reasoning in addition to factual knowledge; and (2) with context (HotpotQA_WC), where the additional context is provided, emphasizing the ability to adhere to and utilize contextual information to solve the task.
- Movies: to further investigate generalization, we focused on a case of classic “hallucinations”, involving factual knowledge, within a non-diverse dataset. This approach allowed us to test whether generalization to other types of errors is influenced by the type of error (factual versus others) or by the dataset’s diversity. For this purpose, we created the movies dataset consisting of prompts in the form: “Who acted as [figure name] in the movie [movie name]?” The figures, movies, and correct answers were sourced from “The Movies Dataset” in Kaggle: https://www.kaggle.com/datasets/rounakbanik/the-movies-dataset, which is based on the MovieLens website.
- Winogrande (Sakaguchi et al., 2021): we use this dataset to explore errors in common-sense reasoning. It consists of Winograd-style coreference challenges, where each example presents a sentence containing two entities and a pronoun. The objective is to determine which entity the pronoun refers to, relying on common-sense reasoning. For example, in the sentence: “The trophy doesn’t fit into the suitcase because it’s too large,” the pronoun “it” refers to the trophy, not the suitcase.
- Winobias (Zhao et al., 2018): this benchmark focuses on coreference resolution in the context of gender bias, revealing a different type of limitation in LLMs. Each example consists of two professions: one stereotypically male and one stereotypically female, along with a gendered pronoun. The task requires the LLM to determine which profession the pronoun refers to. The sentences are unambiguous, with one correct answer. In some cases, the correct answer aligns with the stereotype, while in others, it is anti-stereotypical. For example, in the sentence “The developer argued with the designer because she did not like the design,” “she” refers to the developer, which is an anti-stereotypical case since “developer” is considered a stereotypically male profession. Research has shown that LLMs often perform poorly on anti-stereotypical sentences (Zhao et al., 2018) and tend to base their decisions on stereotypes rather than on common-sense reasoning or linguistic rules (Kotek et al., 2023). Each split contains around 1500 samples.
- NLI (Natural Language Inference): NLI involves determining whether a given “hypothesis” is true (entailment), false (contradiction), or undetermined (neutral) based on a provided “premise.” For this purpose, we use the MNLI dataset (Williams et al., 2018). NLI tasks address a distinct aspect of common-sense reasoning and are generally considered complex. This complexity allows us to investigate whether a model’s generalization ability is related to the difficulty of the task it was trained on, or to other factors, such as the limited diversity of labels (NLI has only three valid labels) or the type of task.
- Math (Sun et al., 2024): this dataset includes both unanswerable and answerable math problems. In our study, we focus exclusively on the answerable problems, as our aim is to assess the correctness of the LLM’s outputs, which requires a known correct answer (gold standard). This task introduces an additional, previously unexplored skill of arithmetic reasoning. The train-test split consists of approximately 2,000 and 650 samples, respectively.
- IMDB (Maas et al., 2011): contains movie reviews used for the task of sentiment classification.
- Natural Questions With Context (Kwiatkowski et al., 2019): the Natural Questions (NQ) dataset is designed to evaluate and train automatic question-answering systems. It consists of real, anonymized queries submitted by users to Google, with answers extracted from Wikipedia, as well as the relevant Wikipedia pages which can be given in context. We included this dataset to introduce an additional challenge that requires adherence to context, complementing the HotpotQA with context dataset.
A.4 Baselines: Implementation Details
Aggregated probabilities / logits.
Inspired by prior work (Kadavath et al., 2022; Guerreiro et al., 2023), we compute an aggregated score using the log-probabilities or raw probabilities of the generated text tokens $y_{1},y_{2},...,y_{N}$ produced by the generative large language model (LLM). For instance, the following formulation is used to compute the Logits-mean baseline on the entire generated answer:
$$
\centering\frac{1}{N}\sum_{i=1}^{N}\mathbb{P}(y_{i}|Q,y_{1},...,y_{i-1})\@add@centering \tag{1}
$$
We also explore aggregation strategies that focus solely on the exact answer tokens (PE-Exact). Following Varshney et al. (2023), we also experiment with aggregating the minimum and maximum values (PE-[Min—Max]-[Exact]), alongside the mean aggregation described in Equation 1.
P(True):
We follow Kadavath et al. (2022) and prompt the LLM to judge whether its answer is correct. Our prompt followed the following template, from Kadavath et al. (2022):
{mdframed}
[backgroundcolor=blue!5, skipabove=0.5]
Question: [Question]
Proposed Answer: [LLM long answer]
Is the proposed answer:
(A) True
(B) False
The proposed answer is:
Appendix B Full Error Detection Results
Figure 6 presents the AUC values of a traind probe across layers and token for Mistral-7b-instruct, showing a similar pattern across all datasets. We also observe similar patterns across other models. See our repo https://github.com/technion-cs-nlp/LLMsKnow for the figures.
<details>
<summary>extracted/6450693/figures/probing_heatmaps/mistral-7b-instruct/hotpotqa_auc.png Details</summary>
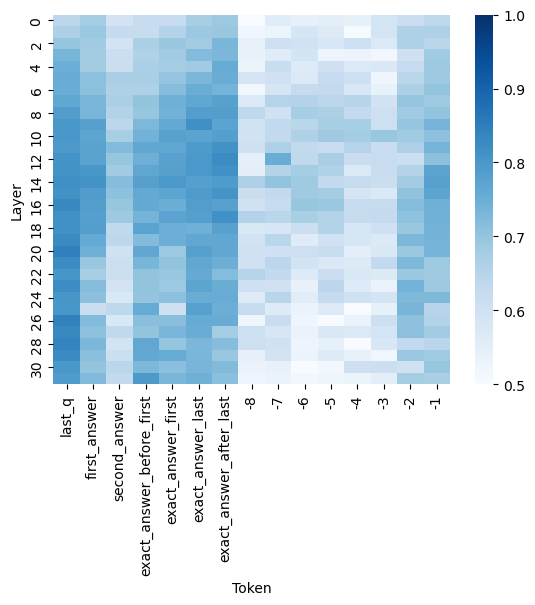
### Visual Description
## Heatmap: Layer vs. Token
### Overview
The image is a heatmap visualizing the relationship between "Layer" and "Token". The color intensity represents a value, ranging from 0.5 (lightest blue) to 1.0 (darkest blue), as indicated by the colorbar on the right. The x-axis represents different tokens, and the y-axis represents layers.
### Components/Axes
* **X-axis (Token):**
* last\_q
* first\_answer
* second\_answer
* exact\_answer\_before\_first
* exact\_answer\_first
* exact\_answer\_last
* exact\_answer\_after\_last
* -8
* -7
* -6
* -5
* -4
* -3
* -2
* -1
* **Y-axis (Layer):** 0, 2, 4, 6, 8, 10, 12, 14, 16, 18, 20, 22, 24, 26, 28, 30
* **Colorbar:** Ranges from 0.5 to 1.0, with intermediate values of 0.6, 0.7, 0.8, and 0.9.
### Detailed Analysis
The heatmap displays varying color intensities, indicating different values for each layer-token combination.
* **Tokens "last\_q", "first\_answer", "second\_answer", "exact\_answer\_before\_first", "exact\_answer\_first", "exact\_answer\_last", and "exact\_answer\_after\_last":** These tokens generally show higher values (darker blue) across all layers, with values generally between 0.7 and 1.0.
* **Tokens "-8" to "-1":** These tokens generally show lower values (lighter blue) across all layers, with values generally between 0.5 and 0.8.
* **Layer 0-10:** The values for tokens "-8" to "-1" are generally higher (darker blue) compared to layers 20-30.
* **Layer 12:** The value for "exact_answer_first" is notably lower (lighter blue) compared to other layers.
### Key Observations
* The first seven tokens ("last\_q" to "exact\_answer\_after\_last") consistently exhibit higher values across all layers compared to the remaining tokens ("-8" to "-1").
* The values for tokens "-8" to "-1" tend to be lower, especially in the lower layers (20-30).
* There is some variation in values across different layers for the same token, but the general trend remains consistent.
### Interpretation
The heatmap suggests that the first seven tokens ("last\_q" to "exact\_answer\_after\_last") are more significant or have a stronger relationship with the layers compared to the remaining tokens ("-8" to "-1"). The lower values for tokens "-8" to "-1" might indicate a weaker association or less relevance to the layers being analyzed. The variation across layers could reflect the hierarchical processing or feature extraction occurring within the layers. The outlier at Layer 12 for "exact_answer_first" might indicate a specific interaction or anomaly at that layer for that particular token.
</details>
(a) HotpotQA
<details>
<summary>extracted/6450693/figures/probing_heatmaps/mistral-7b-instruct/hotpotqa_with_context_auc.png Details</summary>
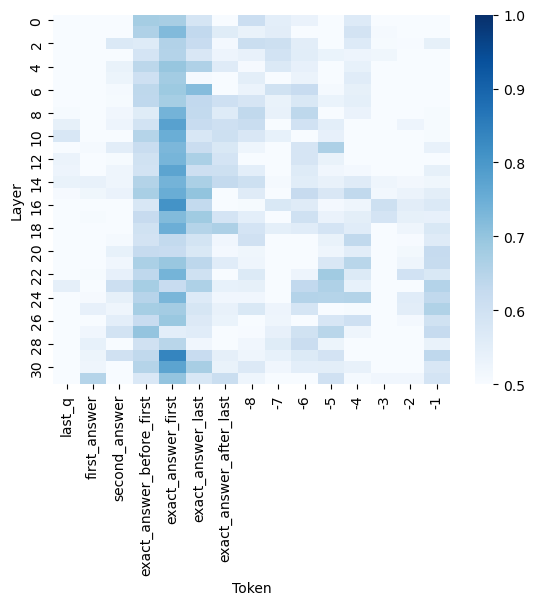
### Visual Description
## Heatmap: Layer Activation by Token Type
### Overview
The image is a heatmap visualizing the activation levels of different layers in a neural network for various token types. The x-axis represents different token types, and the y-axis represents the layer number. The color intensity indicates the activation level, with darker blue representing higher activation and lighter blue representing lower activation.
### Components/Axes
* **X-axis (Token):** Represents different token types. The labels are: `last_q`, `first_answer`, `second_answer`, `exact_answer_before_first`, `exact_answer_first`, `exact_answer_last`, `exact_answer_after_last`, `-8`, `-7`, `-6`, `-5`, `-4`, `-3`, `-2`, `-1`, `0`.
* **Y-axis (Layer):** Represents the layer number, ranging from 0 to 30 in increments of 2. The labels are: `0`, `2`, `4`, `6`, `8`, `10`, `12`, `14`, `16`, `18`, `20`, `22`, `24`, `26`, `28`, `30`.
* **Color Scale:** A vertical color bar on the right side of the heatmap represents the activation level. The scale ranges from 0.5 (lightest blue) to 1.0 (darkest blue) in increments of 0.1.
### Detailed Analysis
The heatmap shows the activation levels for each layer and token combination.
* **last\_q:** Activation is generally low (around 0.5-0.6) across all layers, with a slight increase in activation around layer 28-30 (approximately 0.7-0.8).
* **first\_answer:** Activation is low (around 0.5-0.6) across all layers.
* **second\_answer:** Activation is low (around 0.5-0.6) across all layers.
* **exact\_answer\_before\_first:** Shows a distinct vertical band of high activation (0.8-0.9) between layers 6 and 16, with lower activation (0.5-0.7) in other layers.
* **exact\_answer\_first:** Similar to `exact_answer_before_first`, it shows a vertical band of high activation (0.8-0.9) between layers 6 and 16, with lower activation (0.5-0.7) in other layers.
* **exact\_answer\_last:** Similar to `exact_answer_before_first` and `exact_answer_first`, it shows a vertical band of high activation (0.8-0.9) between layers 6 and 16, with lower activation (0.5-0.7) in other layers.
* **exact\_answer\_after\_last:** Activation is generally low (around 0.5-0.6) across all layers.
* **-8 to 0:** Activation is generally low (around 0.5-0.7) across all layers, with some layers showing slightly higher activation (0.7-0.8).
### Key Observations
* The tokens `exact_answer_before_first`, `exact_answer_first`, and `exact_answer_last` show a clear pattern of high activation in the middle layers (approximately layers 6 to 16).
* The other tokens generally show lower and more uniform activation across all layers.
* The activation levels for tokens `-8` to `0` are generally low, with some variation across layers.
### Interpretation
The heatmap suggests that the middle layers (6-16) of the neural network are particularly sensitive to the tokens related to the exact answer (`exact_answer_before_first`, `exact_answer_first`, and `exact_answer_last`). This could indicate that these layers are responsible for processing and extracting information related to the answer. The lower activation for other tokens suggests that these layers are less relevant for processing those types of tokens. The tokens `-8` to `0` might represent positional embeddings or other contextual information, and their lower activation could indicate that these features are less important for the specific task being performed by the network.
</details>
(b) HotpotQA with context
<details>
<summary>extracted/6450693/figures/probing_heatmaps/mistral-7b-instruct/movies_auc.png Details</summary>
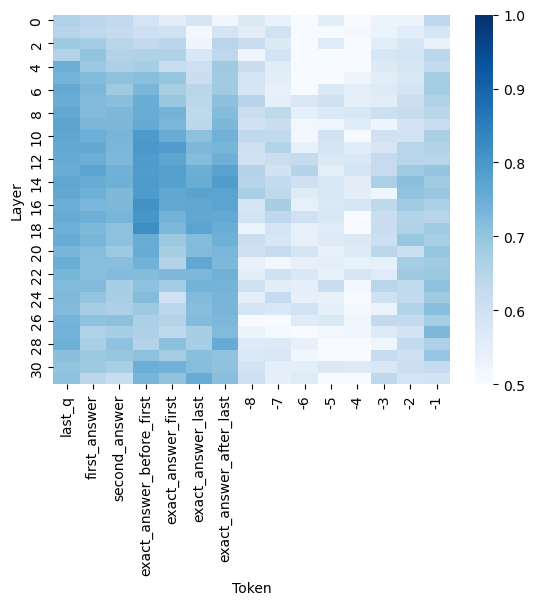
### Visual Description
## Heatmap: Layer vs. Token
### Overview
The image is a heatmap visualizing the relationship between "Layer" (y-axis) and "Token" (x-axis). The color intensity represents a value, with darker blue indicating higher values and lighter blue indicating lower values. The color scale ranges from 0.5 to 1.0.
### Components/Axes
* **Y-axis:** "Layer" with numerical labels from 0 to 30, incrementing by 2.
* **X-axis:** "Token" with categorical labels: "last\_q", "first\_answer", "second\_answer", "exact\_answer\_before\_first", "exact\_answer\_first", "exact\_answer\_last", "exact\_answer\_after\_last", "-8", "-7", "-6", "-5", "-4", "-3", "-2", "-1".
* **Color Scale:** Ranges from 0.5 (lightest blue) to 1.0 (darkest blue), with intermediate values of 0.6, 0.7, 0.8, and 0.9. The color scale is positioned on the right side of the heatmap.
### Detailed Analysis
The heatmap shows the values for each combination of layer and token.
* **Tokens "last\_q", "first\_answer", "second\_answer", "exact\_answer\_before\_first", "exact\_answer\_first", "exact\_answer\_last", "exact\_answer\_after\_last":**
* Layers 0-16: Generally have higher values (darker blue), mostly between 0.8 and 1.0.
* Layers 18-30: Values tend to decrease (lighter blue), ranging from 0.6 to 0.8.
* **Tokens "-8" to "-1":**
* Values are generally lower (lighter blue) compared to the other tokens, mostly between 0.5 and 0.7.
* There are some exceptions, such as layer 26 for token "-8", which has a slightly higher value (around 0.7-0.8).
### Key Observations
* The first seven tokens ("last\_q" to "exact\_answer\_after\_last") show a similar pattern: higher values in the lower layers (0-16) and decreasing values in the higher layers (18-30).
* The last eight tokens ("-8" to "-1") have consistently lower values across all layers.
* There is a clear distinction in the heatmap between the first group of tokens and the second group of tokens.
### Interpretation
The heatmap suggests that the initial layers (0-16) of the model are more sensitive to the first seven tokens ("last\_q" to "exact\_answer\_after\_last"), while the later layers (18-30) are less sensitive. The tokens "-8" to "-1" appear to have a consistently lower impact across all layers. This could indicate that the first set of tokens are more important for the model's initial processing, while the second set of tokens might represent less relevant or more nuanced information that is processed differently across the layers. The data suggests a hierarchical processing of information within the model, where different layers focus on different aspects of the input.
</details>
(c) Movies
<details>
<summary>extracted/6450693/figures/probing_heatmaps/mistral-7b-instruct/winogrande_auc.png Details</summary>
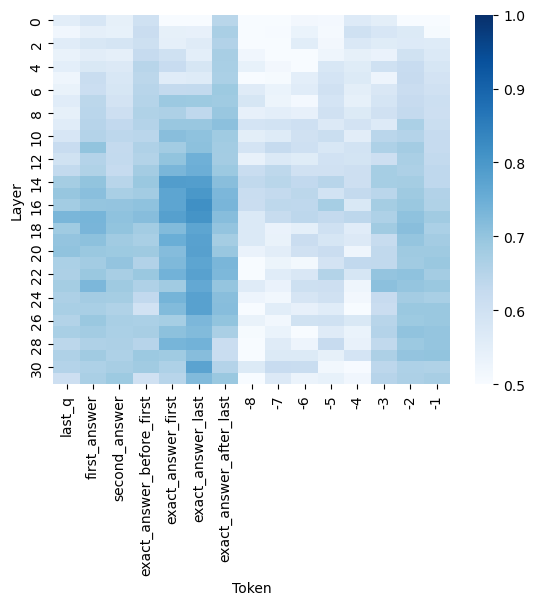
### Visual Description
## Heatmap: Layer vs. Token
### Overview
The image is a heatmap displaying the relationship between "Layer" (y-axis) and "Token" (x-axis). The color intensity represents a value, with darker blue indicating higher values and lighter blue indicating lower values. The heatmap provides a visual representation of how different tokens are represented across different layers.
### Components/Axes
* **X-axis (Token):**
* Categories: last\_q, first\_answer, second\_answer, exact\_answer\_before\_first, exact\_answer\_first, exact\_answer\_last, exact\_answer\_after\_last, -8, -7, -6, -5, -4, -3, -2, -1
* **Y-axis (Layer):**
* Scale: 0 to 30, incrementing by 2 (0, 2, 4, 6, 8, 10, 12, 14, 16, 18, 20, 22, 24, 26, 28, 30)
* **Color Scale (Right side of the heatmap):**
* 1. 0 (Darkest Blue)
* 0.9
* 0.8
* 0.7
* 0.6
* 0.5 (Lightest Blue)
### Detailed Analysis
The heatmap shows varying intensities of blue, indicating different values for each layer-token combination.
* **last\_q:** The values are relatively high (darker blue) from layer 0 to layer 30, with some variation.
* **first\_answer:** The values are relatively high (darker blue) from layer 0 to layer 30, with some variation.
* **second\_answer:** The values are relatively high (darker blue) from layer 0 to layer 30, with some variation.
* **exact\_answer\_before\_first:** The values are relatively high (darker blue) from layer 0 to layer 30, with some variation. There is a notably darker blue region around layers 14-18.
* **exact\_answer\_first:** The values are relatively high (darker blue) from layer 0 to layer 30, with some variation.
* **exact\_answer\_last:** The values are relatively high (darker blue) from layer 0 to layer 30, with some variation.
* **exact\_answer\_after\_last:** The values are relatively high (darker blue) from layer 0 to layer 30, with some variation.
* **-8 to -1:** The values are generally lower (lighter blue) compared to the other tokens, with some variation across layers.
### Key Observations
* The tokens "last\_q", "first\_answer", "second\_answer", "exact\_answer\_before\_first", "exact\_answer\_first", "exact\_answer\_last", and "exact\_answer\_after\_last" generally have higher values across all layers compared to the tokens "-8" to "-1".
* There is a noticeable darker blue region for "exact\_answer\_before\_first" around layers 14-18, indicating a higher value in this specific layer range.
* The tokens "-8" to "-1" show a trend of lower values, suggesting they might be less relevant or have a different representation across the layers.
### Interpretation
The heatmap visualizes the relationship between different tokens and layers, likely in a neural network or similar model. The color intensity could represent activation strength, attention weights, or some other measure of importance. The higher values for "last\_q", "first\_answer", "second\_answer", "exact\_answer\_before\_first", "exact\_answer\_first", "exact\_answer\_last", and "exact\_answer\_after\_last" suggest that these tokens are more significant or receive more attention across all layers. The lower values for "-8" to "-1" indicate that these tokens might be less relevant or have a different role in the model. The darker blue region for "exact\_answer\_before\_first" around layers 14-18 could indicate that this token is particularly important in those specific layers.
</details>
(d) Winogrande
<details>
<summary>extracted/6450693/figures/probing_heatmaps/mistral-7b-instruct/mnli_auc.png Details</summary>
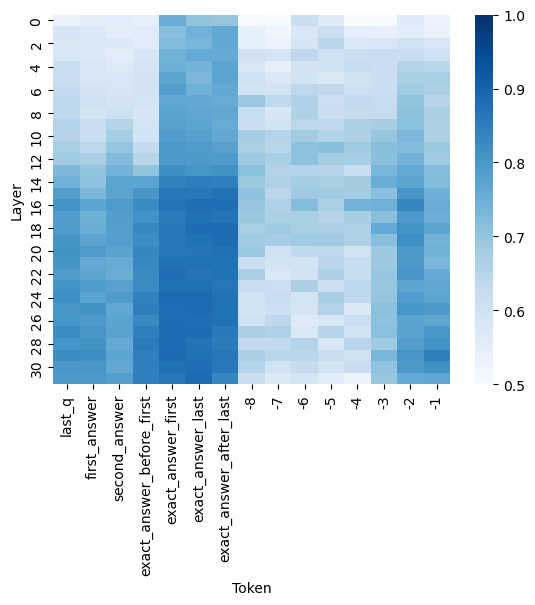
### Visual Description
## Heatmap: Layer vs. Token
### Overview
The image is a heatmap visualizing the relationship between "Layer" (y-axis) and "Token" (x-axis). The color intensity represents a value, ranging from 0.5 (lightest blue) to 1.0 (darkest blue), as indicated by the colorbar on the right. The heatmap shows how different tokens are represented across different layers.
### Components/Axes
* **X-axis (Token):** Categorical labels include: "last\_q", "first\_answer", "second\_answer", "exact\_answer\_before\_first", "exact\_answer\_first", "exact\_answer\_last", "exact\_answer\_after\_last", "-8", "-7", "-6", "-5", "-4", "-3", "-2", "-1".
* **Y-axis (Layer):** Numerical labels range from 0 to 30, in increments of 2 (0, 2, 4, 6, 8, 10, 12, 14, 16, 18, 20, 22, 24, 26, 28, 30).
* **Colorbar:** Ranges from 0.5 to 1.0, with increments of 0.1 (0.5, 0.6, 0.7, 0.8, 0.9, 1.0). Darker blue indicates higher values, while lighter blue indicates lower values.
### Detailed Analysis
The heatmap displays varying intensities of blue, indicating different values for each layer-token combination.
* **Tokens "last\_q", "first\_answer", "second\_answer", "exact\_answer\_before\_first", "exact\_answer\_first", "exact\_answer\_last", "exact\_answer\_after\_last":** These tokens generally show higher values (darker blue) in the lower layers (approximately layers 16 to 30). The "exact\_answer\_first" and "exact\_answer\_last" tokens appear to have the highest values in the lower layers.
* **Tokens "-8" to "-1":** These tokens generally show lower values (lighter blue) compared to the other tokens, especially in the lower layers. There appears to be a slight increase in values (darker blue) in the higher layers (approximately layers 0 to 10) for some of these tokens.
### Key Observations
* The tokens related to "exact\_answer" (before, first, last, after) show a strong signal in the lower layers.
* The numerical tokens ("-8" to "-1") have a weaker signal overall.
* There is a noticeable difference in the heatmap pattern between the named tokens and the numerical tokens.
### Interpretation
The heatmap likely represents the activation or importance of different tokens across different layers of a neural network model. The darker blue regions suggest that certain tokens are more relevant or have a stronger influence in specific layers. The "exact\_answer" related tokens being prominent in the lower layers might indicate that these tokens are crucial for initial processing or understanding of the input. The numerical tokens having lower values could mean they are less important for the task the model is performing, or that their importance is distributed across multiple layers. The heatmap provides insights into how the model processes different types of tokens at different stages of its computation.
</details>
(e) NLI
<details>
<summary>extracted/6450693/figures/probing_heatmaps/mistral-7b-instruct/imdb_auc.png Details</summary>
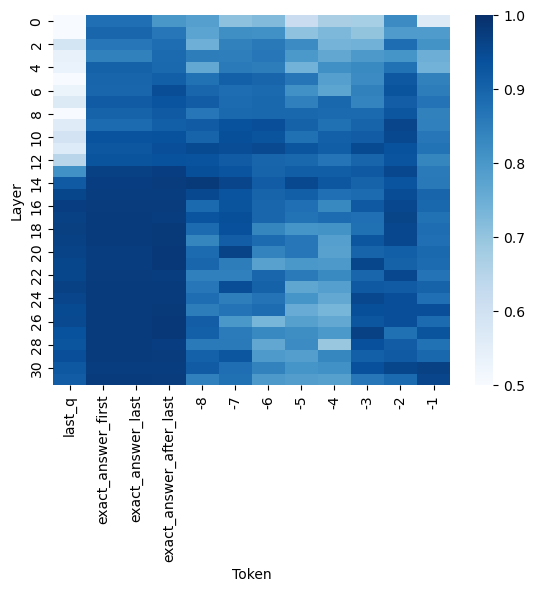
### Visual Description
## Heatmap: Layer vs. Token
### Overview
The image is a heatmap visualizing the relationship between "Layer" and "Token". The color intensity represents a value, with darker blue indicating higher values and lighter blue indicating lower values. The heatmap shows how different tokens are represented across different layers of a model.
### Components/Axes
* **Y-axis (Layer):** Represents the layer number, ranging from 0 to 30 in increments of 2.
* **X-axis (Token):** Represents different tokens, including "last\_q", "exact\_answer\_first", "exact\_answer\_last", "exact\_answer\_after\_last", and numerical tokens from -8 to -1.
* **Color Scale:** A color bar on the right side of the heatmap indicates the value range, from 0.5 (lightest blue) to 1.0 (darkest blue).
### Detailed Analysis
The heatmap displays the intensity of a certain metric (unspecified) for each combination of layer and token.
* **"last\_q", "exact\_answer\_first", "exact\_answer\_last", "exact\_answer\_after\_last" Tokens:** These tokens show high values (dark blue) in the lower layers (approximately layers 14 to 30). The values are lower (lighter blue) in the upper layers (approximately layers 0 to 12).
* **Numerical Tokens (-8 to -1):** These tokens generally show lower values (lighter blue) compared to the "last\_q" and "exact\_answer" tokens. There are some variations across layers, with some layers showing slightly higher values than others. The values appear to increase slightly for tokens closer to -1.
* **Layer 0-12:** The values for all tokens are generally lower (lighter blue) in these layers compared to the lower layers.
### Key Observations
* The "last\_q" and "exact\_answer" tokens have significantly higher values in the lower layers (14-30) compared to the upper layers (0-12).
* The numerical tokens (-8 to -1) have generally lower values across all layers compared to the "last\_q" and "exact\_answer" tokens.
* There is some variation in values across different layers for the numerical tokens.
### Interpretation
The heatmap suggests that the "last\_q" and "exact\_answer" tokens are more strongly represented in the lower layers of the model, while the numerical tokens have a weaker representation overall. The variations across layers for the numerical tokens may indicate that these tokens are processed differently at different stages of the model. The lower values in the upper layers (0-12) for all tokens may indicate that these layers are less sensitive to the specific tokens being analyzed. The data suggests that the model may be focusing on "last\_q" and "exact\_answer" related tokens in the later processing stages.
</details>
(f) IMDB
Figure 6: AUC values of a probe error detector across layers and tokens, Mistral-7b-instruct. The detection performance spikes at the exact answer tokens.
Tables 4, 5, 6, and 7 present the full error detection results across all baselines and datasets, which are consistent with the main paper results.
Table 4: Comparison of error detection performance (AUC) on Mistral-7B.
| | Mistral-7B | | | | |
| --- | --- | --- | --- | --- | --- |
| TriviaQA | Winobias | Math | Movies | IMDB | |
| Logits-mean | $0.67$ $± 0.004$ | $0.49$ $± 0.010$ | $0.41$ $± 0.015$ | $0.67$ $± 0.007$ | $0.88$ $± 0.064$ |
| Logits-mean-exact | $0.67$ $± 0.004$ | $0.50$ $± 0.010$ | $0.56$ $± 0.026$ | $0.68$ $± 0.008$ | $0.57$ $± 0.080$ |
| Logits-min | $0.80$ $± 0.003$ | $0.45$ $± 0.014$ | $0.48$ $± 0.021$ | $0.73$ $± 0.006$ | $0.78$ $± 0.056$ |
| Logits-min-exact | $0.80$ $± 0.005$ | $0.53$ $± 0.014$ | $0.78$ $± 0.032$ | $0.72$ $± 0.005$ | $0.57$ $± 0.080$ |
| Logits-max | $0.53$ $± 0.008$ | $0.49$ $± 0.010$ | $0.42$ $± 0.023$ | $0.54$ $± 0.005$ | $0.83$ $± 0.076$ |
| Logits-max-exact | $0.54$ $± 0.009$ | $0.50$ $± 0.010$ | $0.40$ $± 0.024$ | $0.58$ $± 0.007$ | $0.57$ $± 0.080$ |
| Probas-mean | $0.76$ $± 0.003$ | $0.53$ $± 0.018$ | $0.66$ $± 0.016$ | $0.72$ $± 0.007$ | $0.87$ $± 0.041$ |
| Probas-mean-exact | $0.78$ $± 0.002$ | $0.55$ $± 0.014$ | $0.62$ $± 0.016$ | $0.74$ $± 0.007$ | $0.83$ $± 0.057$ |
| Probas-min | $0.82$ $± 0.003$ | $0.52$ $± 0.013$ | $0.82$ $± 0.020$ | $0.73$ $± 0.006$ | $0.86$ $± 0.032$ |
| Probas-min-exact | 0.85 $± 0.003$ | $0.58$ $± 0.011$ | $0.84$ $± 0.015$ | $0.74$ $± 0.006$ | $0.83$ $± 0.057$ |
| Probas-max | $0.53$ $± 0.008$ | $0.50$ $± 0.016$ | $0.43$ $± 0.025$ | $0.55$ $± 0.008$ | $0.80$ $± 0.074$ |
| Probas-max-exact | $0.55$ $± 0.009$ | $0.51$ $± 0.013$ | $0.39$ $± 0.019$ | $0.59$ $± 0.009$ | $0.83$ $± 0.057$ |
| p(True) | $0.57$ $± 0.007$ | $0.53$ $± 0.019$ | $0.56$ $± 0.027$ | $0.51$ $± 0.003$ | $0.65$ $± 0.004$ |
| p(True)-exact | $0.56$ $± 0.006$ | $0.55$ $± 0.026$ | $0.57$ $± 0.036$ | $0.52$ $± 0.003$ | $0.65$ $± 0.003$ |
| Probe @ token | | | | | |
| Last generated [-1] | $0.83$ $± 0.002$ | $0.65$ $± 0.008$ | $0.82$ $± 0.023$ | $0.79$ $± 0.002$ | $0.85$ $± 0.007$ |
| Before last generated [-2] | $0.82$ $± 0.003$ | $0.84$ $± 0.012$ | $0.83$ $± 0.019$ | $0.78$ $± 0.003$ | $0.95$ $± 0.004$ |
| End of question | $0.74$ $± 0.005$ | $0.78$ $± 0.012$ | $0.83$ $± 0.016$ | $0.77$ $± 0.002$ | $0.81$ $± 0.009$ |
| Exact answer last | $0.84$ $± 0.005$ | 0.89 $± 0.007$ | 0.96 $± 0.008$ | $0.78$ $± 0.003$ | 0.95 $± 0.004$ |
| Exact answer last+1 | $0.84$ $± 0.004$ | $0.84$ $± 0.012$ | $0.95$ $± 0.010$ | 0.80 $± 0.002$ | $0.85$ $± 0.007$ |
| HotpotQA | HotpotQA-WC | Winogrande | NLI | NQ-WC | |
| Logits-mean | $0.63$ $± 0.005$ | $0.52$ $± 0.009$ | $0.49$ $± 0.004$ | $0.51$ $± 0.004$ | $0.69$ $± 0.006$ |
| Logits-mean-exact | $0.57$ $± 0.008$ | $0.52$ $± 0.007$ | $0.50$ $± 0.003$ | 0.93 $± 0.004$ | $0.72$ $± 0.005$ |
| Logits-min | $0.72$ $± 0.008$ | $0.59$ $± 0.006$ | $0.50$ $± 0.007$ | $0.53$ $± 0.005$ | $0.65$ $± 0.009$ |
| Logits-min-exact | $0.72$ $± 0.007$ | $0.65$ $± 0.004$ | $0.51$ $± 0.007$ | $0.49$ $± 0.006$ | $0.70$ $± 0.005$ |
| Logits-max | $0.54$ $± 0.007$ | $0.49$ $± 0.010$ | $0.48$ $± 0.005$ | $0.48$ $± 0.005$ | $0.59$ $± 0.012$ |
| Logits-max-exact | $0.48$ $± 0.010$ | $0.44$ $± 0.007$ | $0.50$ $± 0.003$ | $0.48$ $± 0.005$ | $0.58$ $± 0.009$ |
| Probas-mean | $0.65$ $± 0.004$ | $0.55$ $± 0.006$ | $0.51$ $± 0.007$ | $0.49$ $± 0.003$ | $0.63$ $± 0.008$ |
| Probas-mean-exact | $0.62$ $± 0.006$ | $0.56$ $± 0.007$ | $0.51$ $± 0.005$ | $0.02$ $± 0.001$ | $0.66$ $± 0.007$ |
| Probas-min | $0.73$ $± 0.005$ | $0.58$ $± 0.007$ | $0.52$ $± 0.009$ | $0.53$ $± 0.004$ | $0.63$ $± 0.011$ |
| Probas-min-exact | $0.78$ $± 0.005$ | $0.66$ $± 0.004$ | $0.52$ $± 0.008$ | $0.49$ $± 0.005$ | $0.69$ $± 0.006$ |
| Probas-max | $0.54$ $± 0.008$ | $0.49$ $± 0.007$ | $0.50$ $± 0.005$ | $0.47$ $± 0.004$ | $0.52$ $± 0.004$ |
| Probas-max-exact | $0.48$ $± 0.010$ | $0.44$ $± 0.005$ | $0.50$ $± 0.004$ | $0.48$ $± 0.003$ | $0.53$ $± 0.012$ |
| p(True) | $0.55$ $± 0.007$ | $0.54$ $± 0.006$ | $0.51$ $± 0.005$ | $0.51$ $± 0.003$ | $0.52$ $± 0.008$ |
| p(True)-exact | $0.61$ $± 0.005$ | $0.54$ $± 0.006$ | $0.61$ $± 0.006$ | $0.51$ $± 0.006$ | $0.53$ $± 0.014$ |
| Probe @ token | | | | | |
| Last generated [-1] | $0.78$ $± 0.006$ | $0.67$ $± 0.004$ | $0.51$ $± 0.007$ | $0.77$ $± 0.004$ | $0.78$ $± 0.003$ |
| Before last generated [-2] | $0.79$ $± 0.007$ | $0.69$ $± 0.007$ | $0.66$ $± 0.004$ | $0.81$ $± 0.002$ | $0.75$ $± 0.006$ |
| End of question | $0.72$ $± 0.007$ | $0.56$ $± 0.003$ | $0.51$ $± 0.007$ | $0.88$ $± 0.004$ | $0.70$ $± 0.005$ |
| Exact answer last | $0.80$ $± 0.008$ | 0.74 $± 0.007$ | 0.69 $± 0.006$ | $0.84$ $± 0.004$ | $0.81$ $± 0.009$ |
| Exact answer last+1 | 0.81 $± 0.008$ | $0.72$ $± 0.005$ | $0.59$ $± 0.005$ | $0.75$ $± 0.006$ | 0.84 $± 0.007$ |
Table 5: Comparison of error detection performance (AUC) on Mistral-7B-Instruct.
| | Mistral-7B-Instruct | | | | |
| --- | --- | --- | --- | --- | --- |
| TriviaQA | Winobias | Math | Movies | IMDB | |
| Logits-mean | $0.60$ $± 0.009$ | $0.56$ $± 0.017$ | $0.55$ $± 0.029$ | $0.63$ $± 0.005$ | $0.57$ $± 0.006$ |
| Logits-mean-exact | $0.68$ $± 0.007$ | $0.54$ $± 0.012$ | $0.51$ $± 0.005$ | $0.70$ $± 0.004$ | $0.87$ $± 0.007$ |
| Logits-min | $0.63$ $± 0.008$ | $0.59$ $± 0.012$ | $0.51$ $± 0.017$ | $0.66$ $± 0.008$ | $0.52$ $± 0.007$ |
| Logits-min-exact | $0.75$ $± 0.006$ | $0.53$ $± 0.013$ | $0.71$ $± 0.009$ | $0.74$ $± 0.005$ | $0.87$ $± 0.007$ |
| Logits-max | $0.54$ $± 0.005$ | $0.53$ $± 0.012$ | $0.54$ $± 0.039$ | $0.54$ $± 0.004$ | $0.47$ $± 0.004$ |
| Logits-max-exact | $0.55$ $± 0.004$ | $0.54$ $± 0.011$ | $0.32$ $± 0.015$ | $0.61$ $± 0.006$ | $0.87$ $± 0.007$ |
| Probas-mean | $0.60$ $± 0.007$ | $0.58$ $± 0.018$ | $0.56$ $± 0.028$ | $0.61$ $± 0.002$ | $0.54$ $± 0.008$ |
| Probas-mean-exact | $0.71$ $± 0.003$ | $0.57$ $± 0.015$ | $0.71$ $± 0.014$ | $0.74$ $± 0.006$ | $0.84$ $± 0.007$ |
| Probas-min | $0.59$ $± 0.008$ | $0.58$ $± 0.014$ | $0.50$ $± 0.025$ | $0.60$ $± 0.008$ | $0.51$ $± 0.010$ |
| Probas-min-exact | $0.74$ $± 0.004$ | $0.57$ $± 0.016$ | $0.75$ $± 0.011$ | $0.73$ $± 0.006$ | $0.84$ $± 0.007$ |
| Probas-max | $0.50$ $± 0.006$ | $0.41$ $± 0.010$ | $0.53$ $± 0.009$ | $0.51$ $± 0.005$ | $0.48$ $± 0.004$ |
| Probas-max-exact | $0.51$ $± 0.007$ | $0.54$ $± 0.010$ | $0.45$ $± 0.015$ | $0.60$ $± 0.003$ | $0.84$ $± 0.007$ |
| p(True) | $0.68$ $± 0.005$ | $0.45$ $± 0.021$ | $0.48$ $± 0.026$ | $0.62$ $± 0.005$ | $0.62$ $± 0.009$ |
| p(True)-exact | $0.74$ $± 0.003$ | $0.40$ $± 0.021$ | $0.60$ $± 0.025$ | $0.69$ $± 0.008$ | $0.60$ $± 0.009$ |
| Probe @ token | | | | | |
| Last generated [-1] | $0.71$ $± 0.006$ | $0.82$ $± 0.004$ | $0.74$ $± 0.008$ | $0.72$ $± 0.005$ | $0.92$ $± 0.010$ |
| Before last generated [-2] | $0.73$ $± 0.004$ | $0.85$ $± 0.004$ | $0.74$ $± 0.007$ | $0.72$ $± 0.006$ | $0.94$ $± 0.006$ |
| End of question | $0.76$ $± 0.008$ | $0.82$ $± 0.011$ | $0.72$ $± 0.007$ | $0.74$ $± 0.003$ | $0.96$ $± 0.006$ |
| Exact answer last | $0.85$ $± 0.004$ | 0.92 $± 0.005$ | 0.92 $± 0.008$ | $0.81$ $± 0.003$ | 0.97 $± 0.005$ |
| Exact answer last+1 | 0.86 $± 0.006$ | $0.88$ $± 0.006$ | $0.90$ $± 0.010$ | 0.82 $± 0.003$ | $0.96$ $± 0.006$ |
| HotpotQA | HotpotQA-WC | Winogrande | NLI | NQ-WC | |
| Logits-mean | $0.61$ $± 0.002$ | $0.55$ $± 0.009$ | $0.59$ $± 0.004$ | $0.64$ $± 0.006$ | $0.71$ $± 0.008$ |
| Logits-mean-exact | $0.66$ $± 0.009$ | $0.55$ $± 0.004$ | $0.49$ $± 0.004$ | $0.57$ $± 0.004$ | $0.69$ $± 0.009$ |
| Logits-min | $0.61$ $± 0.003$ | $0.53$ $± 0.013$ | $0.61$ $± 0.003$ | $0.62$ $± 0.002$ | $0.67$ $± 0.008$ |
| Logits-min-exact | $0.77$ $± 0.004$ | $0.67$ $± 0.013$ | $0.48$ $± 0.004$ | $0.54$ $± 0.005$ | $0.69$ $± 0.006$ |
| Logits-max | $0.53$ $± 0.008$ | $0.51$ $± 0.011$ | $0.52$ $± 0.006$ | $0.59$ $± 0.008$ | $0.63$ $± 0.011$ |
| Logits-max-exact | $0.51$ $± 0.011$ | $0.41$ $± 0.010$ | $0.49$ $± 0.007$ | $0.64$ $± 0.003$ | $0.63$ $± 0.013$ |
| Probas-mean | $0.63$ $± 0.003$ | $0.56$ $± 0.010$ | $0.58$ $± 0.005$ | $0.62$ $± 0.005$ | $0.68$ $± 0.010$ |
| Probas-mean-exact | $0.72$ $± 0.006$ | $0.66$ $± 0.010$ | $0.46$ $± 0.004$ | $0.57$ $± 0.003$ | $0.65$ $± 0.008$ |
| Probas-min | $0.58$ $± 0.003$ | $0.52$ $± 0.008$ | $0.59$ $± 0.002$ | $0.58$ $± 0.008$ | $0.65$ $± 0.014$ |
| Probas-min-exact | $0.76$ $± 0.004$ | $0.68$ $± 0.010$ | $0.46$ $± 0.005$ | $0.57$ $± 0.003$ | $0.66$ $± 0.008$ |
| Probas-max | $0.50$ $± 0.005$ | $0.53$ $± 0.003$ | $0.48$ $± 0.007$ | $0.52$ $± 0.007$ | $0.51$ $± 0.005$ |
| Probas-max-exact | $0.46$ $± 0.010$ | $0.46$ $± 0.010$ | $0.48$ $± 0.004$ | $0.53$ $± 0.004$ | $0.52$ $± 0.018$ |
| p(True) | $0.54$ $± 0.006$ | $0.54$ $± 0.004$ | $0.53$ $± 0.003$ | $0.58$ $± 0.003$ | $0.57$ $± 0.006$ |
| p(True)-exact | $0.60$ $± 0.008$ | $0.48$ $± 0.005$ | $0.57$ $± 0.011$ | $0.65$ $± 0.004$ | $0.57$ $± 0.009$ |
| Probe @ token | | | | | |
| Last generated [-1] | $0.72$ $± 0.005$ | $0.64$ $± 0.005$ | $0.74$ $± 0.005$ | $0.85$ $± 0.004$ | $0.82$ $± 0.006$ |
| Before last generated [-2] | $0.73$ $± 0.006$ | $0.64$ $± 0.004$ | $0.76$ $± 0.004$ | $0.87$ $± 0.002$ | $0.84$ $± 0.009$ |
| End of question | $0.80$ $± 0.003$ | $0.63$ $± 0.003$ | $0.71$ $± 0.007$ | $0.79$ $± 0.004$ | $0.85$ $± 0.010$ |
| Exact answer last | $0.85$ $± 0.003$ | $0.75$ $± 0.006$ | 0.84 $± 0.005$ | 0.93 $± 0.003$ | $0.86$ $± 0.003$ |
| Exact answer last+1 | 0.85 $± 0.002$ | 0.76 $± 0.004$ | $0.80$ $± 0.004$ | $0.92$ $± 0.004$ | 0.87 $± 0.006$ |
Table 6: Comparison of error detection performance (AUC) on Llama-8b.
| | Llama-8b | | | | |
| --- | --- | --- | --- | --- | --- |
| TriviaQA | Winobias | Math | Movies | IMDB | |
| Logits-mean | $0.58$ $± 0.006$ | $0.44$ $± 0.015$ | $0.43$ $± 0.026$ | $0.64$ $± 0.008$ | $0.77$ $± 0.007$ |
| Logits-mean-exact | $0.63$ $± 0.007$ | $0.50$ $± 0.015$ | $0.50$ $± 0.028$ | $0.64$ $± 0.008$ | $0.77$ $± 0.007$ |
| Logits-min | $0.75$ $± 0.007$ | $0.50$ $± 0.022$ | $0.45$ $± 0.042$ | $0.73$ $± 0.005$ | $0.73$ $± 0.007$ |
| Logits-min-exact | $0.76$ $± 0.003$ | $0.53$ $± 0.009$ | $0.75$ $± 0.022$ | $0.73$ $± 0.005$ | $0.77$ $± 0.007$ |
| Logits-max | $0.48$ $± 0.006$ | $0.48$ $± 0.009$ | $0.42$ $± 0.027$ | $0.53$ $± 0.005$ | $0.72$ $± 0.007$ |
| Logits-max-exact | $0.52$ $± 0.007$ | $0.49$ $± 0.014$ | $0.35$ $± 0.026$ | $0.53$ $± 0.005$ | $0.77$ $± 0.007$ |
| Probas-mean | $0.64$ $± 0.006$ | $0.41$ $± 0.008$ | $0.61$ $± 0.029$ | $0.71$ $± 0.007$ | $0.70$ $± 0.008$ |
| Probas-mean-exact | $0.72$ $± 0.005$ | $0.50$ $± 0.018$ | $0.54$ $± 0.026$ | $0.72$ $± 0.006$ | $0.88$ $± 0.003$ |
| Probas-min | $0.79$ $± 0.008$ | $0.43$ $± 0.004$ | $0.75$ $± 0.044$ | $0.74$ $± 0.005$ | $0.68$ $± 0.005$ |
| Probas-min-exact | $0.82$ $± 0.003$ | $0.53$ $± 0.014$ | $0.78$ $± 0.022$ | $0.74$ $± 0.005$ | $0.88$ $± 0.003$ |
| Probas-max | $0.49$ $± 0.006$ | $0.50$ $± 0.009$ | $0.46$ $± 0.032$ | $0.53$ $± 0.007$ | $0.60$ $± 0.009$ |
| Probas-max-exact | $0.53$ $± 0.008$ | $0.50$ $± 0.018$ | $0.36$ $± 0.032$ | $0.54$ $± 0.007$ | $0.88$ $± 0.003$ |
| p(True) | $0.62$ $± 0.005$ | $0.48$ $± 0.011$ | $0.53$ $± 0.027$ | $0.61$ $± 0.005$ | $0.51$ $± 0.010$ |
| p(True)-exact | $0.67$ $± 0.002$ | $0.53$ $± 0.017$ | $0.63$ $± 0.028$ | $0.58$ $± 0.005$ | $0.52$ $± 0.008$ |
| Probe @ token | | | | | |
| Last generated [-1] | $0.77$ $± 0.005$ | $0.59$ $± 0.024$ | $0.83$ $± 0.013$ | $0.82$ $± 0.005$ | $0.94$ $± 0.002$ |
| Before last generated [-2] | $0.76$ $± 0.012$ | $0.58$ $± 0.021$ | $0.82$ $± 0.032$ | $0.79$ $± 0.004$ | $0.96$ $± 0.002$ |
| End of question | $0.73$ $± 0.005$ | $0.77$ $± 0.012$ | $0.80$ $± 0.027$ | $0.78$ $± 0.005$ | $0.68$ $± 0.009$ |
| Exact answer last | 0.82 $± 0.006$ | 0.91 $± 0.007$ | 0.96 $± 0.010$ | $0.80$ $± 0.005$ | 0.97 $± 0.001$ |
| Exact answer last+1 | $0.82$ $± 0.006$ | $0.86$ $± 0.008$ | $0.95$ $± 0.007$ | 0.82 $± 0.006$ | $0.95$ $± 0.003$ |
| HotpotQA | HotpotQA-WC | Winogrande | NLI | NQ-WC | |
| Logits-mean | $0.65$ $± 0.004$ | $0.62$ $± 0.006$ | $0.48$ $± 0.003$ | $0.47$ $± 0.002$ | $0.53$ $± 0.010$ |
| Logits-mean-exact | $0.55$ $± 0.003$ | $0.54$ $± 0.006$ | $0.49$ $± 0.004$ | $0.48$ $± 0.002$ | $0.58$ $± 0.009$ |
| Logits-min | $0.57$ $± 0.004$ | $0.49$ $± 0.003$ | $0.48$ $± 0.003$ | $0.48$ $± 0.007$ | $0.58$ $± 0.009$ |
| Logits-min-exact | $0.69$ $± 0.002$ | $0.68$ $± 0.006$ | $0.49$ $± 0.003$ | $0.48$ $± 0.007$ | $0.61$ $± 0.010$ |
| Logits-max | $0.61$ $± 0.005$ | $0.60$ $± 0.004$ | $0.48$ $± 0.003$ | $0.52$ $± 0.003$ | $0.51$ $± 0.008$ |
| Logits-max-exact | $0.47$ $± 0.003$ | $0.46$ $± 0.005$ | $0.49$ $± 0.004$ | $0.51$ $± 0.002$ | $0.54$ $± 0.005$ |
| Probas-mean | $0.67$ $± 0.002$ | $0.62$ $± 0.006$ | $0.49$ $± 0.002$ | $0.48$ $± 0.004$ | $0.57$ $± 0.003$ |
| Probas-mean-exact | $0.62$ $± 0.005$ | $0.56$ $± 0.005$ | $0.51$ $± 0.002$ | $0.46$ $± 0.006$ | $0.64$ $± 0.007$ |
| Probas-min | $0.62$ $± 0.006$ | $0.51$ $± 0.002$ | $0.49$ $± 0.003$ | $0.50$ $± 0.010$ | $0.62$ $± 0.005$ |
| Probas-min-exact | $0.76$ $± 0.005$ | $0.67$ $± 0.004$ | $0.51$ $± 0.002$ | $0.50$ $± 0.010$ | $0.69$ $± 0.008$ |
| Probas-max | $0.61$ $± 0.004$ | $0.58$ $± 0.004$ | $0.48$ $± 0.002$ | $0.48$ $± 0.003$ | $0.51$ $± 0.012$ |
| Probas-max-exact | $0.49$ $± 0.003$ | $0.44$ $± 0.004$ | $0.51$ $± 0.003$ | $0.47$ $± 0.002$ | $0.56$ $± 0.005$ |
| p(True) | $0.52$ $± 0.007$ | $0.45$ $± 0.005$ | $0.54$ $± 0.004$ | $0.54$ $± 0.007$ | $0.56$ $± 0.006$ |
| p(True)-exact | $0.58$ $± 0.005$ | $0.50$ $± 0.007$ | $0.64$ $± 0.004$ | $0.62$ $± 0.005$ | $0.61$ $± 0.002$ |
| Probe @ token | | | | | |
| Last generated [-1] | $0.76$ $± 0.007$ | $0.57$ $± 0.006$ | $0.59$ $± 0.006$ | $0.89$ $± 0.002$ | $0.66$ $± 0.010$ |
| Before last generated [-2] | $0.74$ $± 0.007$ | $0.58$ $± 0.005$ | $0.59$ $± 0.005$ | $0.94$ $± 0.002$ | $0.63$ $± 0.008$ |
| End of question | $0.71$ $± 0.006$ | $0.53$ $± 0.004$ | $0.48$ $± 0.003$ | $0.91$ $± 0.001$ | $0.66$ $± 0.004$ |
| Exact answer last | $0.81$ $± 0.006$ | $0.77$ $± 0.004$ | 0.65 $± 0.004$ | 0.94 $± 0.002$ | 0.75 $± 0.008$ |
| Exact answer last+1 | 0.82 $± 0.004$ | 0.79 $± 0.001$ | $0.57$ $± 0.004$ | $0.90$ $± 0.002$ | $0.75$ $± 0.007$ |
Table 7: Comparison of error detection performance (AUC) on Llama-8b-Instruct.
| | Llama-8b-Instruct | | | | |
| --- | --- | --- | --- | --- | --- |
| TriviaQA | Winobias | Math | Movies | IMDB | |
| Logits-mean | $0.66$ $± 0.005$ | $0.60$ $± 0.026$ | $0.75$ $± 0.018$ | $0.75$ $± 0.005$ | $0.59$ $± 0.017$ |
| Logits-mean-exact | $0.71$ $± 0.006$ | $0.55$ $± 0.019$ | $0.80$ $± 0.021$ | $0.72$ $± 0.004$ | $0.88$ $± 0.012$ |
| Logits-min | $0.74$ $± 0.007$ | $0.61$ $± 0.024$ | $0.75$ $± 0.016$ | $0.71$ $± 0.005$ | $0.55$ $± 0.016$ |
| Logits-min-exact | $0.79$ $± 0.006$ | $0.61$ $± 0.019$ | $0.89$ $± 0.018$ | $0.77$ $± 0.006$ | $0.88$ $± 0.012$ |
| Logits-max | $0.54$ $± 0.007$ | $0.55$ $± 0.013$ | $0.73$ $± 0.027$ | $0.67$ $± 0.003$ | $0.51$ $± 0.009$ |
| Logits-max-exact | $0.58$ $± 0.005$ | $0.54$ $± 0.019$ | $0.64$ $± 0.014$ | $0.61$ $± 0.003$ | $0.88$ $± 0.012$ |
| Probas-mean | $0.67$ $± 0.006$ | $0.63$ $± 0.024$ | $0.66$ $± 0.033$ | $0.73$ $± 0.006$ | $0.73$ $± 0.015$ |
| Probas-mean-exact | $0.75$ $± 0.009$ | $0.61$ $± 0.014$ | $0.83$ $± 0.022$ | $0.74$ $± 0.005$ | $0.74$ $± 0.021$ |
| Probas-min | $0.67$ $± 0.009$ | $0.65$ $± 0.019$ | $0.64$ $± 0.036$ | $0.65$ $± 0.004$ | $0.57$ $± 0.016$ |
| Probas-min-exact | $0.79$ $± 0.008$ | $0.62$ $± 0.014$ | $0.86$ $± 0.024$ | $0.74$ $± 0.005$ | $0.74$ $± 0.021$ |
| Probas-max | $0.54$ $± 0.003$ | $0.49$ $± 0.020$ | $0.57$ $± 0.022$ | $0.64$ $± 0.006$ | $0.49$ $± 0.008$ |
| Probas-max-exact | $0.56$ $± 0.007$ | $0.55$ $± 0.016$ | $0.57$ $± 0.018$ | $0.61$ $± 0.003$ | $0.74$ $± 0.021$ |
| p(True) | $0.73$ $± 0.008$ | $0.59$ $± 0.020$ | $0.62$ $± 0.017$ | $0.66$ $± 0.004$ | $0.60$ $± 0.006$ |
| p(True)-exact | $0.73$ $± 0.005$ | $0.63$ $± 0.014$ | $0.59$ $± 0.018$ | $0.63$ $± 0.006$ | $0.76$ $± 0.004$ |
| Probe @ token | | | | | |
| Last generated [-1] | $0.81$ $± 0.005$ | $0.86$ $± 0.007$ | $0.82$ $± 0.016$ | $0.78$ $± 0.004$ | $0.81$ $± 0.014$ |
| Before last generated [-2] | $0.75$ $± 0.005$ | $0.88$ $± 0.005$ | $0.79$ $± 0.020$ | $0.82$ $± 0.005$ | $0.83$ $± 0.006$ |
| End of question | $0.77$ $± 0.007$ | $0.80$ $± 0.018$ | $0.72$ $± 0.023$ | $0.76$ $± 0.005$ | $0.87$ $± 0.006$ |
| Exact answer last | 0.83 $± 0.002$ | 0.93 $± 0.004$ | 0.95 $± 0.027$ | $0.85$ $± 0.005$ | 0.96 $± 0.003$ |
| Exact answer last+1 | $0.83$ $± 0.006$ | $0.90$ $± 0.005$ | $0.94$ $± 0.023$ | 0.86 $± 0.004$ | $0.95$ $± 0.004$ |
| HotpotQA | HotpotQA-WC | Winogrande | NLI | NQ-WC | |
| Logits-mean | $0.65$ $± 0.002$ | $0.56$ $± 0.004$ | $0.58$ $± 0.007$ | $0.59$ $± 0.009$ | $0.65$ $± 0.006$ |
| Logits-mean-exact | $0.66$ $± 0.008$ | $0.57$ $± 0.005$ | $0.48$ $± 0.003$ | $0.49$ $± 0.010$ | $0.67$ $± 0.005$ |
| Logits-min | $0.67$ $± 0.008$ | $0.55$ $± 0.007$ | $0.60$ $± 0.008$ | $0.53$ $± 0.009$ | $0.68$ $± 0.004$ |
| Logits-min-exact | $0.76$ $± 0.010$ | $0.65$ $± 0.010$ | $0.48$ $± 0.004$ | $0.50$ $± 0.009$ | $0.68$ $± 0.004$ |
| Logits-max | $0.59$ $± 0.005$ | $0.56$ $± 0.005$ | $0.46$ $± 0.004$ | $0.55$ $± 0.013$ | $0.56$ $± 0.006$ |
| Logits-max-exact | $0.52$ $± 0.006$ | $0.48$ $± 0.002$ | $0.48$ $± 0.003$ | $0.49$ $± 0.009$ | $0.63$ $± 0.008$ |
| Probas-mean | $0.61$ $± 0.002$ | $0.56$ $± 0.010$ | $0.57$ $± 0.007$ | $0.58$ $± 0.007$ | $0.65$ $± 0.007$ |
| Probas-mean-exact | $0.68$ $± 0.008$ | $0.65$ $± 0.006$ | $0.51$ $± 0.006$ | $0.57$ $± 0.009$ | $0.67$ $± 0.003$ |
| Probas-min | $0.60$ $± 0.004$ | $0.51$ $± 0.007$ | $0.59$ $± 0.007$ | $0.55$ $± 0.005$ | $0.64$ $± 0.008$ |
| Probas-min-exact | $0.74$ $± 0.007$ | $0.67$ $± 0.007$ | $0.51$ $± 0.006$ | $0.59$ $± 0.008$ | $0.66$ $± 0.004$ |
| Probas-max | $0.56$ $± 0.005$ | $0.53$ $± 0.005$ | $0.46$ $± 0.003$ | $0.51$ $± 0.004$ | $0.55$ $± 0.004$ |
| Probas-max-exact | $0.49$ $± 0.007$ | $0.47$ $± 0.002$ | $0.51$ $± 0.005$ | $0.50$ $± 0.009$ | $0.62$ $± 0.006$ |
| p(True) | $0.55$ $± 0.005$ | $0.55$ $± 0.008$ | $0.47$ $± 0.002$ | $0.54$ $± 0.006$ | $0.71$ $± 0.003$ |
| p(True)-exact | $0.55$ $± 0.004$ | $0.50$ $± 0.005$ | $0.50$ $± 0.008$ | $0.50$ $± 0.003$ | $0.67$ $± 0.007$ |
| Probe @ token | | | | | |
| Last generated [-1] | $0.77$ $± 0.005$ | $0.68$ $± 0.006$ | $0.69$ $± 0.006$ | $0.78$ $± 0.005$ | $0.77$ $± 0.009$ |
| Before last generated [-2] | $0.76$ $± 0.002$ | $0.69$ $± 0.005$ | $0.67$ $± 0.008$ | $0.79$ $± 0.004$ | $0.75$ $± 0.007$ |
| End of question | $0.78$ $± 0.004$ | $0.60$ $± 0.003$ | $0.65$ $± 0.004$ | $0.74$ $± 0.002$ | $0.75$ $± 0.011$ |
| Exact answer last | 0.83 $± 0.005$ | 0.76 $± 0.003$ | 0.78 $± 0.007$ | 0.91 $± 0.005$ | 0.78 $± 0.006$ |
| Exact answer last+1 | $0.83$ $± 0.002$ | $0.76$ $± 0.006$ | $0.70$ $± 0.006$ | $0.90$ $± 0.004$ | $0.78$ $± 0.007$ |
Appendix C Full Generalization Results
Figures 7, 8 and 9 present the generalization results for the remaining models. While these results exhibit similar high-level patterns to those found in the main paper on Mistral-7b-instruct, notable differences suggest that these models may possess different mechanisms for encoding truthfulness.
<details>
<summary>extracted/6450693/figures/generalization/mistral.png Details</summary>
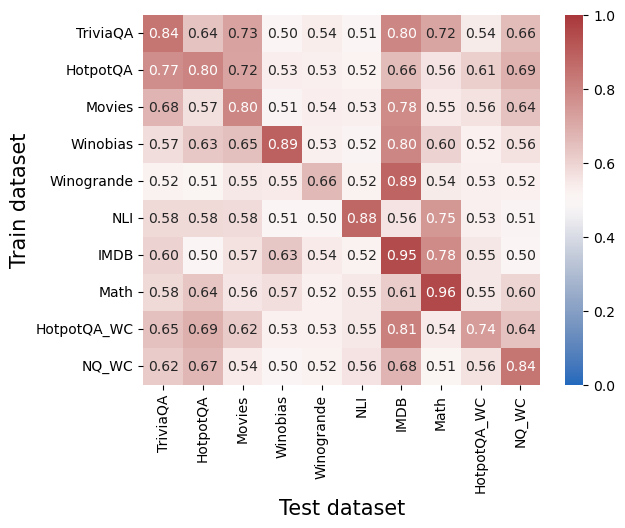
### Visual Description
## Heatmap: Dataset Performance Comparison
### Overview
The image is a heatmap visualizing the performance of different datasets when used for training and testing machine learning models. The rows represent the datasets used for training, and the columns represent the datasets used for testing. The color intensity of each cell indicates the performance score, ranging from 0.0 (blue) to 1.0 (red).
### Components/Axes
* **Y-axis (Train dataset):** Lists the datasets used for training the models. The categories are: TriviaQA, HotpotQA, Movies, Winobias, Winogrande, NLI, IMDB, Math, HotpotQA\_WC, NQ\_WC.
* **X-axis (Test dataset):** Lists the datasets used for testing the models. The categories are: TriviaQA, HotpotQA, Movies, Winobias, Winogrande, NLI, IMDB, Math, HotpotQA\_WC, NQ\_WC.
* **Color Scale:** A vertical color bar on the right side of the heatmap, ranging from 0.0 (blue) to 1.0 (red), indicating the performance score.
* **Numerical Values:** Each cell contains a numerical value representing the performance score for the corresponding train/test dataset combination.
### Detailed Analysis
Here's a breakdown of the performance scores for each train/test dataset combination:
| Train Dataset | TriviaQA | HotpotQA | Movies | Winobias | Winogrande | NLI | IMDB | Math | HotpotQA\_WC | NQ\_WC |
|---------------|----------|----------|--------|----------|------------|-----|------|------|---------------|--------|
| TriviaQA | 0.84 | 0.64 | 0.73 | 0.50 | 0.54 | 0.51 | 0.80 | 0.72 | 0.54 | 0.66 |
| HotpotQA | 0.77 | 0.80 | 0.72 | 0.53 | 0.53 | 0.52 | 0.66 | 0.56 | 0.61 | 0.69 |
| Movies | 0.68 | 0.57 | 0.80 | 0.51 | 0.54 | 0.53 | 0.78 | 0.55 | 0.56 | 0.64 |
| Winobias | 0.57 | 0.63 | 0.65 | 0.89 | 0.53 | 0.52 | 0.80 | 0.60 | 0.52 | 0.56 |
| Winogrande | 0.52 | 0.51 | 0.55 | 0.55 | 0.66 | 0.52 | 0.89 | 0.54 | 0.53 | 0.52 |
| NLI | 0.58 | 0.58 | 0.58 | 0.51 | 0.50 | 0.88 | 0.56 | 0.75 | 0.53 | 0.51 |
| IMDB | 0.60 | 0.50 | 0.57 | 0.63 | 0.54 | 0.52 | 0.95 | 0.78 | 0.55 | 0.50 |
| Math | 0.58 | 0.64 | 0.56 | 0.57 | 0.52 | 0.55 | 0.61 | 0.96 | 0.55 | 0.60 |
| HotpotQA\_WC | 0.65 | 0.69 | 0.62 | 0.53 | 0.53 | 0.55 | 0.81 | 0.54 | 0.74 | 0.64 |
| NQ\_WC | 0.62 | 0.67 | 0.54 | 0.50 | 0.52 | 0.56 | 0.68 | 0.51 | 0.56 | 0.84 |
### Key Observations
* The diagonal elements (where train and test datasets are the same) generally have higher performance scores, indicating that models perform best when tested on data similar to what they were trained on.
* IMDB and Math datasets show particularly high performance when used to train models that are then tested on themselves (0.95 and 0.96 respectively).
* Winobias and Winogrande also show high performance when trained and tested on themselves (0.89 and 0.66 respectively).
* NLI shows high performance when trained and tested on itself (0.88).
* TriviaQA shows high performance when trained and tested on itself (0.84).
* HotpotQA shows high performance when trained and tested on itself (0.80).
* Movies shows high performance when trained and tested on itself (0.80).
* NQ\_WC shows high performance when trained and tested on itself (0.84).
* The lowest performance scores are generally observed when models trained on one dataset are tested on a different dataset, indicating domain shift or differences in data characteristics.
### Interpretation
The heatmap provides insights into the transferability of machine learning models across different datasets. High scores along the diagonal suggest that models are well-suited for their respective datasets. Off-diagonal scores indicate how well a model trained on one dataset generalizes to another. The lower scores in the off-diagonal elements suggest that there are significant differences between the datasets, making it difficult for models to generalize effectively. The high self-performance of IMDB and Math datasets could be attributed to their specific characteristics or the nature of the tasks they represent. The heatmap can be used to inform decisions about dataset selection and model training strategies, such as fine-tuning models on target datasets to improve performance.
</details>
(a) Raw AUC values. Values above $0.5$ indicate some generalization.
<details>
<summary>extracted/6450693/figures/generalization/mistral_reduced.png Details</summary>
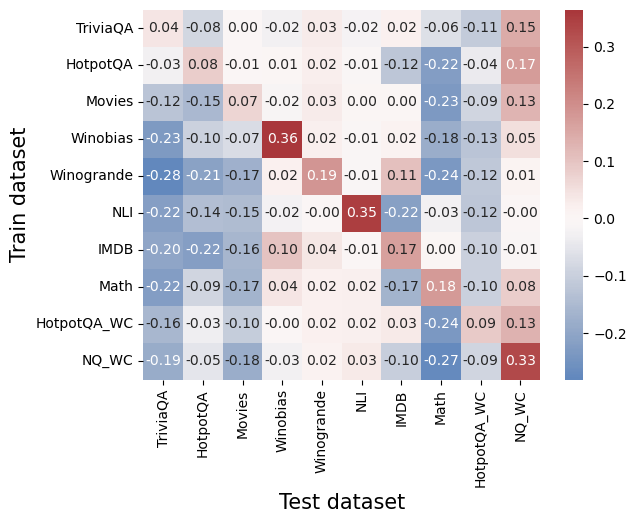
### Visual Description
## Heatmap: Dataset Correlation
### Overview
The image is a heatmap visualizing the correlation between different datasets. The rows represent the training datasets, and the columns represent the testing datasets. The color intensity indicates the strength and direction (positive or negative) of the correlation, with red indicating positive correlation and blue indicating negative correlation.
### Components/Axes
* **X-axis (Test dataset):** TriviaQA, HotpotQA, Movies, Winobias, Winogrande, NLI, IMDB, Math, HotpotQA\_WC, NQ\_WC
* **Y-axis (Train dataset):** TriviaQA, HotpotQA, Movies, Winobias, Winogrande, NLI, IMDB, Math, HotpotQA\_WC, NQ\_WC
* **Color Scale:** Ranges from -0.2 (dark blue) to 0.3 (dark red), with white representing 0.0. The scale has clear markers at -0.2, -0.1, 0.0, 0.1, 0.2, and 0.3.
### Detailed Analysis or ### Content Details
Here's a breakdown of the correlation values for each dataset pair:
* **TriviaQA:**
* TriviaQA (Train) vs. TriviaQA (Test): -0.04
* TriviaQA (Train) vs. HotpotQA (Test): -0.08
* TriviaQA (Train) vs. Movies (Test): 0.00
* TriviaQA (Train) vs. Winobias (Test): -0.02
* TriviaQA (Train) vs. Winogrande (Test): 0.03
* TriviaQA (Train) vs. NLI (Test): -0.02
* TriviaQA (Train) vs. IMDB (Test): 0.02
* TriviaQA (Train) vs. Math (Test): -0.06
* TriviaQA (Train) vs. HotpotQA\_WC (Test): -0.11
* TriviaQA (Train) vs. NQ\_WC (Test): 0.15
* **HotpotQA:**
* HotpotQA (Train) vs. TriviaQA (Test): -0.03
* HotpotQA (Train) vs. HotpotQA (Test): 0.08
* HotpotQA (Train) vs. Movies (Test): -0.01
* HotpotQA (Train) vs. Winobias (Test): 0.01
* HotpotQA (Train) vs. Winogrande (Test): 0.02
* HotpotQA (Train) vs. NLI (Test): -0.01
* HotpotQA (Train) vs. IMDB (Test): -0.12
* HotpotQA (Train) vs. Math (Test): -0.22
* HotpotQA (Train) vs. HotpotQA\_WC (Test): -0.04
* HotpotQA (Train) vs. NQ\_WC (Test): 0.17
* **Movies:**
* Movies (Train) vs. TriviaQA (Test): -0.12
* Movies (Train) vs. HotpotQA (Test): -0.15
* Movies (Train) vs. Movies (Test): 0.07
* Movies (Train) vs. Winobias (Test): -0.02
* Movies (Train) vs. Winogrande (Test): 0.03
* Movies (Train) vs. NLI (Test): 0.00
* Movies (Train) vs. IMDB (Test): 0.00
* Movies (Train) vs. Math (Test): -0.23
* Movies (Train) vs. HotpotQA\_WC (Test): -0.09
* Movies (Train) vs. NQ\_WC (Test): 0.13
* **Winobias:**
* Winobias (Train) vs. TriviaQA (Test): -0.23
* Winobias (Train) vs. HotpotQA (Test): -0.10
* Winobias (Train) vs. Movies (Test): -0.07
* Winobias (Train) vs. Winobias (Test): 0.36
* Winobias (Train) vs. Winogrande (Test): 0.02
* Winobias (Train) vs. NLI (Test): -0.01
* Winobias (Train) vs. IMDB (Test): 0.02
* Winobias (Train) vs. Math (Test): -0.18
* Winobias (Train) vs. HotpotQA\_WC (Test): -0.13
* Winobias (Train) vs. NQ\_WC (Test): 0.05
* **Winogrande:**
* Winogrande (Train) vs. TriviaQA (Test): -0.28
* Winogrande (Train) vs. HotpotQA (Test): -0.21
* Winogrande (Train) vs. Movies (Test): -0.17
* Winogrande (Train) vs. Winobias (Test): 0.02
* Winogrande (Train) vs. Winogrande (Test): 0.19
* Winogrande (Train) vs. NLI (Test): -0.01
* Winogrande (Train) vs. IMDB (Test): 0.11
* Winogrande (Train) vs. Math (Test): -0.24
* Winogrande (Train) vs. HotpotQA\_WC (Test): -0.12
* Winogrande (Train) vs. NQ\_WC (Test): 0.01
* **NLI:**
* NLI (Train) vs. TriviaQA (Test): -0.22
* NLI (Train) vs. HotpotQA (Test): -0.14
* NLI (Train) vs. Movies (Test): -0.15
* NLI (Train) vs. Winobias (Test): -0.02
* NLI (Train) vs. Winogrande (Test): -0.00
* NLI (Train) vs. NLI (Test): 0.35
* NLI (Train) vs. IMDB (Test): -0.22
* NLI (Train) vs. Math (Test): -0.03
* NLI (Train) vs. HotpotQA\_WC (Test): -0.12
* NLI (Train) vs. NQ\_WC (Test): -0.00
* **IMDB:**
* IMDB (Train) vs. TriviaQA (Test): -0.20
* IMDB (Train) vs. HotpotQA (Test): -0.22
* IMDB (Train) vs. Movies (Test): -0.16
* IMDB (Train) vs. Winobias (Test): 0.10
* IMDB (Train) vs. Winogrande (Test): 0.04
* IMDB (Train) vs. NLI (Test): -0.01
* IMDB (Train) vs. IMDB (Test): 0.17
* IMDB (Train) vs. Math (Test): 0.00
* IMDB (Train) vs. HotpotQA\_WC (Test): -0.10
* IMDB (Train) vs. NQ\_WC (Test): -0.01
* **Math:**
* Math (Train) vs. TriviaQA (Test): -0.22
* Math (Train) vs. HotpotQA (Test): -0.09
* Math (Train) vs. Movies (Test): -0.17
* Math (Train) vs. Winobias (Test): 0.04
* Math (Train) vs. Winogrande (Test): 0.02
* Math (Train) vs. NLI (Test): 0.02
* Math (Train) vs. IMDB (Test): -0.17
* Math (Train) vs. Math (Test): 0.18
* Math (Train) vs. HotpotQA\_WC (Test): -0.10
* Math (Train) vs. NQ\_WC (Test): 0.08
* **HotpotQA\_WC:**
* HotpotQA\_WC (Train) vs. TriviaQA (Test): -0.16
* HotpotQA\_WC (Train) vs. HotpotQA (Test): -0.03
* HotpotQA\_WC (Train) vs. Movies (Test): -0.10
* HotpotQA\_WC (Train) vs. Winobias (Test): -0.00
* HotpotQA\_WC (Train) vs. Winogrande (Test): 0.02
* HotpotQA\_WC (Train) vs. NLI (Test): 0.02
* HotpotQA\_WC (Train) vs. IMDB (Test): 0.03
* HotpotQA\_WC (Train) vs. Math (Test): -0.24
* HotpotQA\_WC (Train) vs. HotpotQA\_WC (Test): 0.09
* HotpotQA\_WC (Train) vs. NQ\_WC (Test): 0.13
* **NQ\_WC:**
* NQ\_WC (Train) vs. TriviaQA (Test): -0.19
* NQ\_WC (Train) vs. HotpotQA (Test): -0.05
* NQ\_WC (Train) vs. Movies (Test): -0.18
* NQ\_WC (Train) vs. Winobias (Test): -0.03
* NQ\_WC (Train) vs. Winogrande (Test): 0.02
* NQ\_WC (Train) vs. NLI (Test): 0.03
* NQ\_WC (Train) vs. IMDB (Test): -0.10
* NQ\_WC (Train) vs. Math (Test): -0.27
* NQ\_WC (Train) vs. HotpotQA\_WC (Test): -0.09
* NQ\_WC (Train) vs. NQ\_WC (Test): 0.33
### Key Observations
* The diagonal elements (training and testing on the same dataset) generally show positive correlation, especially for Winobias (0.36) and NLI (0.35).
* There are several negative correlations, particularly between IMDB/Math and other datasets.
* Winobias and NLI show the strongest positive self-correlation.
* Math and IMDB datasets often show negative correlations when used as training data against other test datasets.
### Interpretation
The heatmap illustrates how well models trained on one dataset generalize to another. High positive correlation suggests good generalization, while negative correlation indicates poor generalization or even negative transfer. The strong self-correlations along the diagonal are expected, as models tend to perform best on data similar to what they were trained on. The negative correlations suggest that certain datasets may have characteristics that hinder generalization to other tasks, or that models trained on those datasets may learn biases that are detrimental to performance on other datasets. For example, training on IMDB or Math data seems to negatively impact performance on other datasets.
</details>
(b) Performance (AUC) difference of the probe and the logit-based method. Values above $0 0$ indicate generalization beyond the logit-based method.
Figure 7: Generalization between datasets, Mistral-7b.
<details>
<summary>extracted/6450693/figures/generalization/llama.png Details</summary>
### Visual Description
## Heatmap: Dataset Performance Comparison
### Overview
The image is a heatmap visualizing the performance of models trained on different datasets and tested on different datasets. The color intensity represents the performance score, ranging from blue (low) to red (high). The x-axis represents the "Test dataset" and the y-axis represents the "Train dataset".
### Components/Axes
* **X-axis (Test dataset):** TriviaQA, HotpotQA, Movies, Winobias, Winogrande, NLI, IMDB, Math, HotpotQA\_WC, NQ\_WC
* **Y-axis (Train dataset):** TriviaQA, HotpotQA, Movies, Winobias, Winogrande, NLI, IMDB, Math, HotpotQA\_WC, NQ\_WC
* **Color Scale:** Ranges from 0.0 (blue) to 1.0 (red), with intermediate shades representing values in between.
### Detailed Analysis
The heatmap displays performance scores for each combination of training and testing datasets. The values are explicitly written in each cell.
Here's a breakdown of the values:
* **TriviaQA:**
* Trained on TriviaQA: 0.82
* Trained on HotpotQA: 0.69
* Trained on Movies: 0.69
* Trained on Winobias: 0.53
* Trained on Winogrande: 0.52
* Trained on NLI: 0.52
* Trained on IMDB: 0.59
* Trained on Math: 0.82
* Trained on HotpotQA\_WC: 0.50
* Trained on NQ\_WC: 0.55
* **HotpotQA:**
* Trained on TriviaQA: 0.76
* Trained on HotpotQA: 0.82
* Trained on Movies: 0.70
* Trained on Winobias: 0.54
* Trained on Winogrande: 0.53
* Trained on NLI: 0.51
* Trained on IMDB: 0.59
* Trained on Math: 0.79
* Trained on HotpotQA\_WC: 0.63
* Trained on NQ\_WC: 0.55
* **Movies:**
* Trained on TriviaQA: 0.70
* Trained on HotpotQA: 0.58
* Trained on Movies: 0.82
* Trained on Winobias: 0.60
* Trained on Winogrande: 0.51
* Trained on NLI: 0.56
* Trained on IMDB: 0.54
* Trained on Math: 0.54
* Trained on HotpotQA\_WC: 0.52
* Trained on NQ\_WC: 0.56
* **Winobias:**
* Trained on TriviaQA: 0.63
* Trained on HotpotQA: 0.60
* Trained on Movies: 0.62
* Trained on Winobias: 0.91
* Trained on Winogrande: 0.53
* Trained on NLI: 0.52
* Trained on IMDB: 0.77
* Trained on Math: 0.74
* Trained on HotpotQA\_WC: 0.56
* Trained on NQ\_WC: 0.51
* **Winogrande:**
* Trained on TriviaQA: 0.61
* Trained on HotpotQA: 0.55
* Trained on Movies: 0.60
* Trained on Winobias: 0.65
* Trained on Winogrande: 0.65
* Trained on NLI: 0.62
* Trained on IMDB: 0.86
* Trained on Math: 0.54
* Trained on HotpotQA\_WC: 0.50
* Trained on NQ\_WC: 0.53
* **NLI:**
* Trained on TriviaQA: 0.57
* Trained on HotpotQA: 0.53
* Trained on Movies: 0.59
* Trained on Winobias: 0.57
* Trained on Winogrande: 0.52
* Trained on NLI: 0.94
* Trained on IMDB: 0.70
* Trained on Math: 0.56
* Trained on HotpotQA\_WC: 0.51
* Trained on NQ\_WC: 0.53
* **IMDB:**
* Trained on TriviaQA: 0.60
* Trained on HotpotQA: 0.53
* Trained on Movies: 0.62
* Trained on Winobias: 0.66
* Trained on Winogrande: 0.52
* Trained on NLI: 0.67
* Trained on IMDB: 0.97
* Trained on Math: 0.57
* Trained on HotpotQA\_WC: 0.58
* Trained on NQ\_WC: 0.52
* **Math:**
* Trained on TriviaQA: 0.62
* Trained on HotpotQA: 0.53
* Trained on Movies: 0.57
* Trained on Winobias: 0.51
* Trained on Winogrande: 0.51
* Trained on NLI: 0.51
* Trained on IMDB: 0.74
* Trained on Math: 0.96
* Trained on HotpotQA\_WC: 0.54
* Trained on NQ\_WC: 0.56
* **HotpotQA\_WC:**
* Trained on TriviaQA: 0.67
* Trained on HotpotQA: 0.68
* Trained on Movies: 0.55
* Trained on Winobias: 0.51
* Trained on Winogrande: 0.53
* Trained on NLI: 0.58
* Trained on IMDB: 0.78
* Trained on Math: 0.75
* Trained on HotpotQA\_WC: 0.77
* Trained on NQ\_WC: 0.50
* **NQ\_WC:**
* Trained on TriviaQA: 0.66
* Trained on HotpotQA: 0.56
* Trained on Movies: 0.68
* Trained on Winobias: 0.58
* Trained on Winogrande: 0.55
* Trained on NLI: 0.53
* Trained on IMDB: 0.53
* Trained on Math: 0.56
* Trained on HotpotQA\_WC: 0.54
* Trained on NQ\_WC: 0.75
### Key Observations
* The diagonal elements (training and testing on the same dataset) generally have higher scores, indicating that models perform best on data similar to what they were trained on.
* IMDB and Math datasets show high performance when trained and tested on themselves (0.97 and 0.96 respectively).
* Winobias and NLI also show high performance when trained and tested on themselves (0.91 and 0.94 respectively).
* Cross-dataset performance varies, with some datasets showing better generalization than others.
### Interpretation
The heatmap illustrates the transferability of models across different datasets. Training a model on a specific dataset and testing it on the same dataset generally yields the best performance. However, the performance drops when the model is tested on a different dataset, indicating that the models are not perfectly generalizable. The extent of the performance drop varies depending on the similarity between the training and testing datasets. For example, models trained on TriviaQA perform relatively well on HotpotQA, suggesting that these two datasets share some common characteristics. Conversely, models trained on NQ\_WC tend to perform worse on other datasets. The high diagonal values suggest that the models are learning dataset-specific features, rather than generalizable knowledge.
</details>
(a) Raw AUC values. Values above $0.5$ indicate some generalization.
<details>
<summary>extracted/6450693/figures/generalization/llama_reduced.png Details</summary>
### Visual Description
## Heatmap: Dataset Performance Comparison
### Overview
The image is a heatmap visualizing the performance of different datasets when used for training and testing. The rows represent the training datasets, the columns represent the testing datasets, and the color of each cell indicates the performance score (correlation), with red indicating positive correlation and blue indicating negative correlation. A color bar on the right provides the scale for the correlation values.
### Components/Axes
* **X-axis (Test dataset):** TriviaQA, HotpotQA, Movies, Winobias, Winogrande, NLI, IMDB, Math, HotpotQA\_WC, NQ\_WC
* **Y-axis (Train dataset):** TriviaQA, HotpotQA, Movies, Winobias, Winogrande, NLI, IMDB, Math, HotpotQA\_WC, NQ\_WC
* **Color Scale:** Ranges from -0.2 (dark blue) to 0.4 (dark red). The scale includes markers at -0.2, -0.1, 0.0, 0.1, 0.2, 0.3, and 0.4.
### Detailed Analysis
Here's a breakdown of the values in the heatmap, row by row:
* **TriviaQA:**
* TriviaQA: -0.06
* HotpotQA: -0.01
* Movies: -0.04
* Winobias: -0.01
* Winogrande: 0.04
* NLI: 0.04
* IMDB: -0.19
* Math: 0.07
* HotpotQA\_WC: -0.18
* NQ\_WC: -0.05
* **HotpotQA:**
* TriviaQA: -0.00
* HotpotQA: 0.12
* Movies: -0.03
* Winobias: 0.01
* Winogrande: 0.05
* NLI: 0.04
* IMDB: -0.19
* Math: 0.04
* HotpotQA\_WC: -0.05
* NQ\_WC: -0.06
* **Movies:**
* TriviaQA: -0.06
* HotpotQA: -0.11
* Movies: 0.08
* Winobias: 0.06
* Winogrande: 0.02
* NLI: 0.09
* IMDB: -0.24
* Math: -0.20
* HotpotQA\_WC: -0.16
* NQ\_WC: -0.04
* **Winobias:**
* TriviaQA: -0.14
* HotpotQA: -0.09
* Movies: -0.11
* Winobias: 0.37
* Winogrande: 0.04
* NLI: 0.04
* IMDB: -0.01
* Math: -0.01
* HotpotQA\_WC: -0.12
* NQ\_WC: -0.09
* **Winogrande:**
* TriviaQA: -0.16
* HotpotQA: -0.14
* Movies: -0.13
* Winobias: 0.12
* Winogrande: 0.16
* NLI: 0.14
* IMDB: 0.09
* Math: -0.21
* HotpotQA\_WC: -0.18
* NQ\_WC: -0.08
* **NLI:**
* TriviaQA: -0.19
* HotpotQA: -0.17
* Movies: -0.15
* Winobias: 0.04
* Winogrande: 0.03
* NLI: 0.46
* IMDB: -0.08
* Math: -0.19
* HotpotQA\_WC: -0.17
* NQ\_WC: -0.07
* **IMDB:**
* TriviaQA: -0.17
* HotpotQA: -0.17
* Movies: -0.12
* Winobias: 0.13
* Winogrande: 0.03
* NLI: 0.19
* IMDB: 0.20
* Math: -0.18
* HotpotQA\_WC: -0.10
* NQ\_WC: -0.08
* **Math:**
* TriviaQA: -0.15
* HotpotQA: -0.17
* Movies: -0.16
* Winobias: -0.03
* Winogrande: 0.02
* NLI: 0.03
* IMDB: -0.03
* Math: 0.21
* HotpotQA\_WC: -0.14
* NQ\_WC: -0.05
* **HotpotQA\_WC:**
* TriviaQA: -0.09
* HotpotQA: -0.01
* Movies: -0.18
* Winobias: -0.02
* Winogrande: 0.04
* NLI: 0.10
* IMDB: 0.01
* Math: 0.01
* HotpotQA\_WC: 0.09
* NQ\_WC: -0.10
* **NQ\_WC:**
* TriviaQA: -0.11
* HotpotQA: -0.13
* Movies: -0.06
* Winobias: 0.05
* Winogrande: 0.06
* NLI: 0.06
* IMDB: -0.24
* Math: -0.19
* HotpotQA\_WC: -0.14
* NQ\_WC: 0.06
### Key Observations
* The diagonal elements (where the training and testing datasets are the same) generally show positive correlation, indicating that models perform best when tested on data similar to what they were trained on.
* NLI trained and tested on itself has the highest correlation (0.46).
* Winobias trained and tested on itself has a high correlation (0.37).
* Movies trained on itself has a low correlation (0.08).
* IMDB trained on itself has a correlation of 0.20.
* Math trained on itself has a correlation of 0.21.
* Using Movies as the test dataset often results in negative correlations, especially when trained on IMDB (-0.24) and Math (-0.20).
* Using IMDB as the test dataset often results in negative correlations, especially when trained on TriviaQA (-0.19), HotpotQA (-0.19), and Movies (-0.24).
### Interpretation
The heatmap reveals how well different datasets generalize to each other. High positive correlations along the diagonal suggest that models trained and tested on the same dataset perform well. Off-diagonal elements indicate how well a model trained on one dataset can generalize to another. Negative correlations suggest that the datasets are dissimilar, and models trained on one perform poorly on the other. The NLI dataset appears to be the most robust, showing the highest positive correlation when trained and tested on itself. The Movies dataset, when used as a test set, often leads to negative correlations, suggesting it may have different characteristics compared to the other datasets. The Winobias dataset also shows a strong positive correlation when trained and tested on itself, indicating its unique characteristics.
</details>
(b) Performance (AUC) difference of the probe and the logit-based method. Values above $0 0$ indicate generalization beyond the logit-based method.
Figure 8: Generalization between datasets, Llama-3-8b.
<details>
<summary>extracted/6450693/figures/generalization/llama_instruct.png Details</summary>
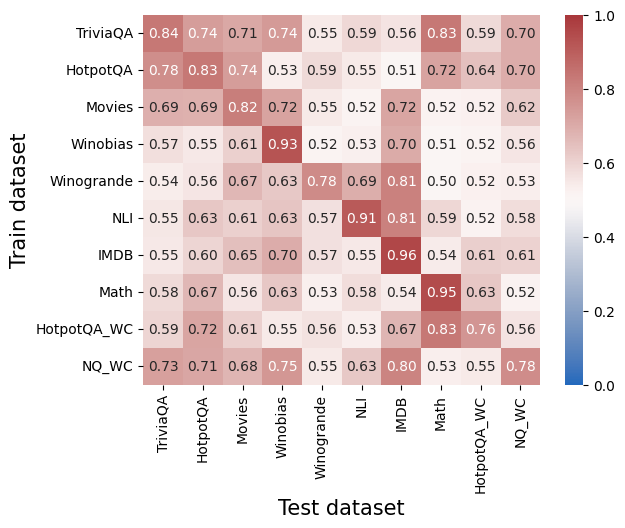
### Visual Description
## Heatmap: Dataset Performance Comparison
### Overview
The image is a heatmap visualizing the performance of different datasets when used for training and testing. The rows represent the training datasets, the columns represent the testing datasets, and the color intensity indicates the performance score, ranging from 0.0 to 1.0.
### Components/Axes
* **X-axis (Test dataset):** Lists the datasets used for testing, including TriviaQA, HotpotQA, Movies, Winobias, Winogrande, NLI, IMDB, Math, HotpotQA\_WC, and NQ\_WC.
* **Y-axis (Train dataset):** Lists the datasets used for training, including TriviaQA, HotpotQA, Movies, Winobias, Winogrande, NLI, IMDB, Math, HotpotQA\_WC, and NQ\_WC.
* **Color Scale:** A vertical color bar on the right side of the heatmap, ranging from blue (0.0) to red (1.0), indicating the performance score.
### Detailed Analysis
The heatmap displays performance scores for each combination of training and testing datasets. The scores are represented by both color intensity and numerical values within each cell.
Here's a breakdown of the values:
* **TriviaQA:**
* Trained on TriviaQA: 0.84
* Trained on HotpotQA: 0.74
* Trained on Movies: 0.71
* Trained on Winobias: 0.74
* Trained on Winogrande: 0.55
* Trained on NLI: 0.59
* Trained on IMDB: 0.56
* Trained on Math: 0.83
* Trained on HotpotQA\_WC: 0.59
* Trained on NQ\_WC: 0.70
* **HotpotQA:**
* Trained on TriviaQA: 0.78
* Trained on HotpotQA: 0.83
* Trained on Movies: 0.74
* Trained on Winobias: 0.53
* Trained on Winogrande: 0.59
* Trained on NLI: 0.55
* Trained on IMDB: 0.51
* Trained on Math: 0.72
* Trained on HotpotQA\_WC: 0.64
* Trained on NQ\_WC: 0.70
* **Movies:**
* Trained on TriviaQA: 0.69
* Trained on HotpotQA: 0.69
* Trained on Movies: 0.82
* Trained on Winobias: 0.72
* Trained on Winogrande: 0.55
* Trained on NLI: 0.52
* Trained on IMDB: 0.72
* Trained on Math: 0.52
* Trained on HotpotQA\_WC: 0.52
* Trained on NQ\_WC: 0.62
* **Winobias:**
* Trained on TriviaQA: 0.57
* Trained on HotpotQA: 0.55
* Trained on Movies: 0.61
* Trained on Winobias: 0.93
* Trained on Winogrande: 0.52
* Trained on NLI: 0.53
* Trained on IMDB: 0.70
* Trained on Math: 0.51
* Trained on HotpotQA\_WC: 0.52
* Trained on NQ\_WC: 0.56
* **Winogrande:**
* Trained on TriviaQA: 0.54
* Trained on HotpotQA: 0.56
* Trained on Movies: 0.67
* Trained on Winobias: 0.63
* Trained on Winogrande: 0.78
* Trained on NLI: 0.69
* Trained on IMDB: 0.81
* Trained on Math: 0.50
* Trained on HotpotQA\_WC: 0.52
* Trained on NQ\_WC: 0.53
* **NLI:**
* Trained on TriviaQA: 0.55
* Trained on HotpotQA: 0.63
* Trained on Movies: 0.61
* Trained on Winobias: 0.63
* Trained on Winogrande: 0.57
* Trained on NLI: 0.91
* Trained on IMDB: 0.81
* Trained on Math: 0.59
* Trained on HotpotQA\_WC: 0.52
* Trained on NQ\_WC: 0.58
* **IMDB:**
* Trained on TriviaQA: 0.55
* Trained on HotpotQA: 0.60
* Trained on Movies: 0.65
* Trained on Winobias: 0.70
* Trained on Winogrande: 0.57
* Trained on NLI: 0.55
* Trained on IMDB: 0.96
* Trained on Math: 0.54
* Trained on HotpotQA\_WC: 0.61
* Trained on NQ\_WC: 0.61
* **Math:**
* Trained on TriviaQA: 0.58
* Trained on HotpotQA: 0.67
* Trained on Movies: 0.56
* Trained on Winobias: 0.63
* Trained on Winogrande: 0.53
* Trained on NLI: 0.58
* Trained on IMDB: 0.54
* Trained on Math: 0.95
* Trained on HotpotQA\_WC: 0.63
* Trained on NQ\_WC: 0.52
* **HotpotQA\_WC:**
* Trained on TriviaQA: 0.59
* Trained on HotpotQA: 0.72
* Trained on Movies: 0.61
* Trained on Winobias: 0.55
* Trained on Winogrande: 0.56
* Trained on NLI: 0.53
* Trained on IMDB: 0.67
* Trained on Math: 0.83
* Trained on HotpotQA\_WC: 0.76
* Trained on NQ\_WC: 0.56
* **NQ\_WC:**
* Trained on TriviaQA: 0.73
* Trained on HotpotQA: 0.71
* Trained on Movies: 0.68
* Trained on Winobias: 0.75
* Trained on Winogrande: 0.55
* Trained on NLI: 0.63
* Trained on IMDB: 0.80
* Trained on Math: 0.53
* Trained on HotpotQA\_WC: 0.55
* Trained on NQ\_WC: 0.78
### Key Observations
* The diagonal elements (training and testing on the same dataset) generally have higher scores, indicating that models perform best when tested on data similar to what they were trained on.
* IMDB and NLI datasets show high performance when trained and tested on themselves.
* Winobias dataset shows high performance when trained and tested on itself.
* Math dataset shows high performance when trained and tested on itself.
* The performance varies significantly depending on the combination of training and testing datasets.
### Interpretation
The heatmap illustrates the transferability of knowledge between different datasets. High scores along the diagonal suggest that models are well-suited for their native datasets. Off-diagonal scores indicate how well a model trained on one dataset generalizes to another. The variations in performance highlight the differences in the nature and complexity of the datasets. For example, training on IMDB and testing on other datasets often results in lower performance, suggesting that IMDB data may have unique characteristics that don't generalize well. The heatmap can be used to inform decisions about dataset selection for training and testing machine learning models.
</details>
(a) Raw AUC values. Values above $0.5$ indicate some generalization.
<details>
<summary>extracted/6450693/figures/generalization/llama_instruct_reduced.png Details</summary>
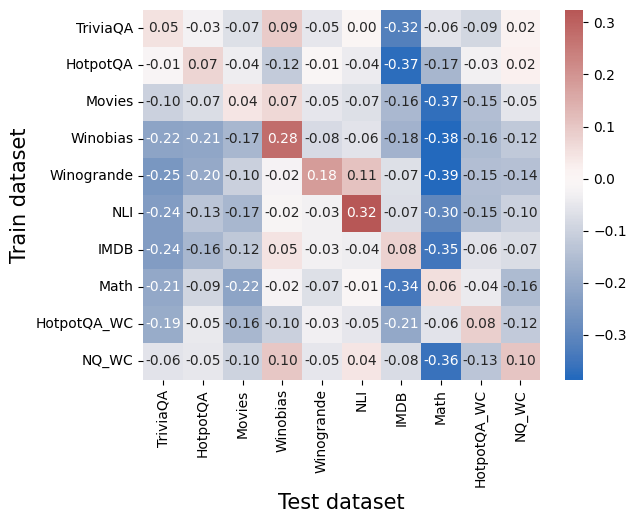
### Visual Description
## Heatmap: Dataset Correlation
### Overview
The image is a heatmap visualizing the correlation between different datasets when used for training and testing a model. The rows represent the training dataset, the columns represent the testing dataset, and the color of each cell indicates the correlation score, ranging from -0.3 (strong negative correlation, blue) to 0.3 (strong positive correlation, red).
### Components/Axes
* **Y-axis (Train dataset):**
* TriviaQA
* HotpotQA
* Movies
* Winobias
* Winogrande
* NLI
* IMDB
* Math
* HotpotQA\_WC
* NQ\_WC
* **X-axis (Test dataset):**
* TriviaQA
* HotpotQA
* Movies
* Winobias
* Winogrande
* NLI
* IMDB
* Math
* HotpotQA\_WC
* NQ\_WC
* **Color Legend (Right side):**
* Red: Positive correlation, ranging from 0 to 0.3
* White: Near zero correlation, around 0
* Blue: Negative correlation, ranging from -0.3 to 0
### Detailed Analysis or ### Content Details
Here's a breakdown of the correlation values for each combination of training and testing datasets:
| Train Dataset | TriviaQA | HotpotQA | Movies | Winobias | Winogrande | NLI | IMDB | Math | HotpotQA_WC | NQ_WC |
|---|---|---|---|---|---|---|---|---|---|---|
| TriviaQA | -0.05 | -0.03 | -0.07 | 0.09 | -0.05 | 0.00 | -0.32 | -0.06 | -0.09 | 0.02 |
| HotpotQA | -0.01 | 0.07 | -0.04 | -0.12 | -0.01 | -0.04 | -0.37 | -0.17 | -0.03 | 0.02 |
| Movies | -0.10 | -0.07 | 0.04 | 0.07 | -0.05 | -0.07 | -0.16 | -0.37 | -0.15 | -0.05 |
| Winobias | -0.22 | -0.21 | -0.17 | 0.28 | -0.08 | -0.06 | -0.18 | -0.38 | -0.16 | -0.12 |
| Winogrande | -0.25 | -0.20 | -0.10 | -0.02 | 0.18 | 0.11 | -0.07 | -0.39 | -0.15 | -0.14 |
| NLI | -0.24 | -0.13 | -0.17 | -0.02 | -0.03 | 0.32 | -0.07 | -0.30 | -0.15 | -0.10 |
| IMDB | -0.24 | -0.16 | -0.12 | 0.05 | -0.03 | -0.04 | 0.08 | -0.35 | -0.06 | -0.07 |
| Math | -0.21 | -0.09 | -0.22 | -0.02 | -0.07 | -0.01 | -0.34 | 0.06 | -0.04 | -0.16 |
| HotpotQA_WC | -0.19 | -0.05 | -0.16 | -0.10 | -0.03 | -0.05 | -0.21 | -0.06 | 0.08 | -0.12 |
| NQ_WC | -0.06 | -0.05 | -0.10 | 0.10 | -0.05 | 0.04 | -0.08 | -0.36 | -0.13 | 0.10 |
### Key Observations
* **Strong Negative Correlations:** Training on TriviaQA, HotpotQA, Movies, Math, HotpotQA_WC, or NQ_WC and testing on IMDB shows a strong negative correlation (values around -0.3 or lower).
* **Positive Correlations:** Training on Winobias and testing on Winobias shows a positive correlation (0.28). Training on NLI and testing on NLI also shows a positive correlation (0.32).
* **Near-Zero Correlations:** Many combinations show near-zero correlations, indicated by the light color.
### Interpretation
The heatmap reveals how well a model trained on one dataset generalizes to another. The strong negative correlations suggest that models trained on certain datasets (e.g., TriviaQA, HotpotQA) perform poorly when tested on IMDB. This could be due to differences in the nature of the questions, the style of the text, or the complexity of the tasks. The positive correlations indicate that models trained and tested on the same dataset perform well, as expected. The near-zero correlations suggest that there is little relationship between the datasets in terms of model performance. The negative correlations with IMDB are particularly notable and warrant further investigation.
</details>
(b) Performance (AUC) difference of the probe and the logit-based method. Values above $0 0$ indicate generalization beyond the logit-based method.
Figure 9: Generalization between datasets, Llama-3-8b-instruct.
Appendix D Taxonomy of Errors
<details>
<summary>extracted/6450693/figures/correctness_across_resamples.png Details</summary>
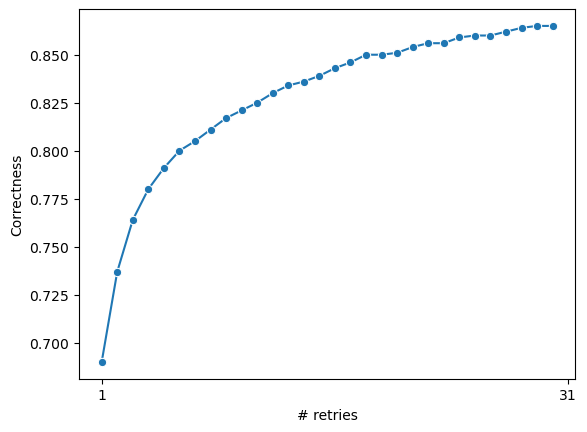
### Visual Description
## Line Chart: Correctness vs. Number of Retries
### Overview
The image is a line chart showing the relationship between the number of retries and correctness. The chart displays a single data series, with correctness increasing as the number of retries increases, eventually plateauing.
### Components/Axes
* **X-axis:** "# retries" - Number of retries, ranging from 1 to 31.
* **Y-axis:** "Correctness" - Correctness value, ranging from 0.70 to 0.86.
* **Data Series:** A single blue line with circular markers representing the correctness value for each number of retries.
### Detailed Analysis
The blue line represents the correctness value. The line starts at approximately 0.69 at 1 retry and increases rapidly initially. As the number of retries increases, the rate of increase in correctness slows down, and the line plateaus around 0.86.
Here are some approximate data points:
* 1 retry: Correctness ≈ 0.69
* 5 retries: Correctness ≈ 0.79
* 10 retries: Correctness ≈ 0.82
* 15 retries: Correctness ≈ 0.84
* 20 retries: Correctness ≈ 0.85
* 25 retries: Correctness ≈ 0.855
* 31 retries: Correctness ≈ 0.86
### Key Observations
* The correctness increases significantly with the initial retries.
* The rate of increase in correctness diminishes as the number of retries increases.
* The correctness plateaus after a certain number of retries, indicating diminishing returns.
### Interpretation
The chart suggests that increasing the number of retries initially leads to a significant improvement in correctness. However, after a certain point, the improvement becomes marginal, indicating that there is a limit to how much correctness can be improved by simply increasing the number of retries. This could be due to other factors limiting the correctness, such as inherent limitations in the system or the quality of the data. The data demonstrates a diminishing return on investment for increasing retries beyond a certain point.
</details>
Figure 10: The percentage of answers for which at least one generated answer was correct. The first step is greedy decoding.
Figure 10 presents, for each amount of resamples, the amount percentage of answers for which at least one generated answer was correct. The experiment was done on Mistral-7b-instruct with the TriviaQA dataset. For many answers that the greedy decoding fails to correctly provide an answer, the LLM is still able to generate the correct answer in at least one resample. The plot plateues around 30 resamples.
D.1 Error Taxonomy Design Choices
The error taxonomy proposed in this paper is intentionally non-orthogonal, as some errors may simultaneously belong to multiple categories. For instance, an error might fall under both “consistently incorrect” (e.g., the same incorrect answer appears at least 15 times) and “many different answers” (e.g., the remaining answers show over 10 distinct variants).
Our taxonomy is designed to capture such nuanced cases, as restricting classification to a single category would hinder the generalizability of insights. Instead, we aim to learn general properties across different error types, providing LLM providers with actionable insights into questions exhibiting overlapping error patterns.
To support this non-orthogonal framework, our probes function as one-to-many classifiers, enabling precise error analysis and tailored solutions.
D.2 Results on Additional Datasets
Table 8 presents the results of error type classification on the Winobias dataset and Table 9 on the Math dataset.
Table 8: AUC scores for error type classification (Winobias).
| Error type | Mistral-7b | Mistral-Instr-7b | Llama3-8b | Llama3-Instr-8b |
| --- | --- | --- | --- | --- |
| (A) Refuses to answer | - | - | - | - |
| (B) Consistently correct | $0.83\scriptscriptstyle{± 0.004}$ | $0.88\scriptscriptstyle{± 0.002}$ | $0.84\scriptscriptstyle{± 0.003}$ | $0.89\scriptscriptstyle{± 0.003}$ |
| (C) Consistently incorrect | $0.83\scriptscriptstyle{± 0.004}$ | $0.88\scriptscriptstyle{± 0.002}$ | $0.79\scriptscriptstyle{± 0.004}$ | $0.90\scriptscriptstyle{± 0.003}$ |
| (D) Two competing | $0.68\scriptscriptstyle{± 0.004}$ | $0.58\scriptscriptstyle{± 0.015}$ | $0.74\scriptscriptstyle{± 0.005}$ | $0.88\scriptscriptstyle{± 0.004}$ |
| (E) Many answers | - | - | - | - |
Table 9: AUC scores for error type classification (Math). Error types are predictable from the inner model representations, indicating the encoding of fine-grained information on errors.
| Error type | Mistral-7b | Mistral-Instr-7b | Llama3-8b | Llama3-Instr-8b |
| --- | --- | --- | --- | --- |
| (A) Refuses to answer | - | - | - | - |
| (B) Consistently correct | $0.85\scriptscriptstyle{± 0.017}$ | $0.84\scriptscriptstyle{± 0.007}$ | $0.83\scriptscriptstyle{± 0.020}$ | $0.87\scriptscriptstyle{± 0.006}$ |
| (C) Consistently incorrect | $0.85\scriptscriptstyle{± 0.026}$ | $0.85\scriptscriptstyle{± 0.003}$ | $0.69\scriptscriptstyle{± 0.032}$ | $0.91\scriptscriptstyle{± 0.007}$ |
| (D) Two competing | - | $0.76\scriptscriptstyle{± 0.020}$ | $0.57\scriptscriptstyle{± 0.001}$ | $0.79\scriptscriptstyle{± 0.006}$ |
| (E) Many answers | $0.74\scriptscriptstyle{± 0.010}$ | $0.79\scriptscriptstyle{± 0.015}$ | $0.69\scriptscriptstyle{± 0.041}$ | $0.90\scriptscriptstyle{± 0.008}$ |
D.3 Qualitative Examples
Tables 10 and 11 present qualitative examples of the error types in the TriviaQA and Math datasets.
Table 10: Examples of error types in TriviaQA, Mistral-7B-Instruct. Correct answer is in bold.
| Type of error | Question | Answers |
| --- | --- | --- |
| Consistently correct | What clothing-part metaphorically classifies workers/jobs according to white or blue? | “ collar ”: $30$ |
| Consistently incorrect | Which town in southeast Wales became a UNESCO World Heritage Site in 2000? | “Blaenavon”: 1, “Caerleon”: 29 |
| Many different answers | Published in 2013 who wrote the novel ’The Kill List’? | “ Frederick Forsyth ”: 1, “Jerry Patterson”: $1$ , “Edward Lee”: $1$ , “Barry Lancet”: $4$ “Jeremy Holiday”: $1$ , “Barry Lincoff”: $1$ , “Jim Marrs”: $1$ , “John Marrs”: $1$ , “Anthony Lacy”: $1$ , “Daniel Kraus”: $1$ , “Ron Bass”: $1$ , “David Martiniello”: $2$ , “Eric Lustbader”: $1$ , “Barbie Latza Nadeau”: $1$ , “James Swallow”: $1$ , “Mark Sullivan”: $1$ , “Alex Binotto”: $1$ , “David Baldacci”: $1$ , “Bill Cosores”: $1$ , “Frederic J. Brown”: $1$ , “Ron Capps and Tate Foley”: $1$ , “Barbie Wilde”: $1$ , “NO ANSWER”: $3$ |
| Two competing answers | What is the only letter of the alphabet which does not appear in any of the names of the 50 American states? | “ The letter q ”: 15, “The letter X”: 15 |
Table 11: Examples of error types in Math, Mistral-7B-Instruct. Correct answer is in bold.
| Type of error | Question | Answers |
| --- | --- | --- |
| Consistently correct | If John travels 15 miles on a bike ride, and Jill travels 5 miles less, how many miles does Jim travel if he travels only 20% as far as Jill? | “ 2 ”: $30$ |
| Consistently incorrect | Joy has 30 pencils, and Colleen has 50 pencils. If they bought the pencils at $4 each at the store, how much more money did Colleen pay than Joy for her pencils? | “ 80$ ”: 1, “16$”: $29$ (correct) |
| Many different answers | If the first skyscraper was built 100 years ago, how many years in the future will it be 5 years before its 200th anniversary of being built? | “ 95 ”: $14$ , “91”: $1$ , “87”: $1$ , “15”: $2$ , “96”: $1$ , “Six”: $1$ , “202 ”: $1$ , “2035”: $1$ , “195”: $1$ , “49”: $1$ , “101”: $1$ , “199”: $1$ , “3 years before the 200th anniversary”: $1$ , “203 years after it was built”: $1$ , “196”: $1$ , “2043”: $1$ |
| Two competing answers | David did 27 more push-ups but 7 less crunches than Zachary in gym class today. If Zachary did 5 push- ups and 17 crunches.How many more crunches than push-ups did Zachary do? | “ 12 ”:5, “1”: 5 $x$ |
Appendix E Detecting the Correct Answer Full Results
In Table 12 we present some qualitative samples from Mistral-7b-instruct, for the phenomenon we observe at error type (C2) Consistently incorrect but generates the correct answer at least one time. The samples in the table represent cases where the probe chose the correct answer. Table 13 compares different decoding mechanisms, including the choice via probe, on non-instruct models, and Table 14 compares on the instruct models. For all datasets and models, we observe similar conclusions to those in the main paper: significant improvement is observed for error types where the LLM shows no preference to the correct answer.
Table 12: Examples of questions where Mistral-7b-Instruct consistently provided incorrect answers but occasionally generated the correct one. In these instances, the probe successfully identified the right answer. For each question, the model was sampled 30 times.
Table 13: Various answer choice strategies, non-instruct models.
| | Mistral-7b | | | | | | | | | | | |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| TriviaQA | Math | Winobias | | | | | | | | | | |
| Error type | Greedy | Random | Majority | Probing | Greedy | Random | Majority | Probing | Greedy | Random | Majority | Probing |
| All | $0.63$ $± 0.003$ | $0.54$ $± 0.004$ | $0.65$ $± 0.002$ | $0.62$ $± 0.003$ | $0.25$ $± 0.018$ | $0.36$ $± 0.022$ | $0.49$ $± 0.019$ | $0.60$ $± 0.017$ | $0.69$ $± 0.016$ | $0.58$ $± 0.009$ | $0.62$ $± 0.009$ | $0.83$ $± 0.006$ |
| (A) Refuses to answer | $0.08$ $± 0.015$ | $0.04$ $± 0.009$ | $0.00$ $± 0.000$ | $0.13$ $± 0.007$ | $0.01$ $± 0.009$ | $0.04$ $± 0.019$ | $0.00$ $± 0.000$ | $0.22$ $± 0.033$ | - | - | - | - |
| (B1) All | $1.00$ $± 0.000$ | $1.00$ $± 0.000$ | $1.00$ $± 0.000$ | $1.00$ $± 0.000$ | - | - | - | - | - | - | - | - |
| (B2) Most | $0.98$ $± 0.001$ | $0.84$ $± 0.009$ | $1.00$ $± 0.000$ | $0.91$ $± 0.002$ | $0.96$ $± 0.024$ | $0.84$ $± 0.031$ | $1.00$ $± 0.000$ | $0.86$ $± 0.041$ | $0.96$ $± 0.004$ | $0.73$ $± 0.009$ | $0.95$ $± 0.003$ | $0.91$ $± 0.009$ |
| (C) Consistently incorrect | | | | | | | | | | | | |
| (C1) All | $0.00$ $± 0.003$ | $0.00$ $± 0.000$ | $0.00$ $± 0.000$ | $0.00$ $± 0.000$ | - | - | - | - | - | - | - | - |
| (C2) Most | $0.03$ $± 0.014$ | $0.20$ $± 0.008$ | $0.00$ $± 0.000$ | $0.27$ $± 0.036$ | - | - | - | - | $0.19$ $± 0.010$ | $0.30$ $± 0.026$ | $0.00$ $± 0.000$ | $0.70$ $± 0.007$ |
| (D) Two competing | $0.48$ $± 0.006$ | $0.36$ $± 0.008$ | $0.52$ $± 0.015$ | $0.54$ $± 0.016$ | - | - | - | - | $0.73$ $± 0.018$ | $0.54$ $± 0.022$ | $0.47$ $± 0.030$ | $0.85$ $± 0.019$ |
| (E) Many answers | | | | | | | | | | | | |
| (E1) Non correct | $0.01$ $± 0.004$ | $0.00$ $± 0.000$ | $0.00$ $± 0.000$ | $0.00$ $± 0.000$ | $0.01$ $± 0.010$ | $0.00$ $± 0.000$ | $0.00$ $± 0.000$ | $0.00$ $± 0.000$ | - | - | - | - |
| (E2) Correct appears | $0.38$ $± 0.009$ | $0.21$ $± 0.006$ | $0.42$ $± 0.015$ | $0.38$ $± 0.009$ | $0.09$ $± 0.010$ | $0.17$ $± 0.034$ | $0.36$ $± 0.020$ | $0.62$ $± 0.035$ | - | - | - | - |
| Llama-8b | | | | | | | | | | | | |
| TriviaQA | Math | Winobias | | | | | | | | | | |
| Error type | Greedy | Sampling | Majority | Probing | Greedy | Sampling | Majority | Probing | Greedy | Sampling | Majority | Probing |
| All | $0.66$ $± 0.002$ | $0.58$ $± 0.003$ | 0.68 $± 0.003$ | 0.68 $± 0.002$ | $0.30$ $± 0.023$ | $0.47$ $± 0.022$ | $0.62$ $± 0.014$ | $0.70$ $± 0.021$ | $0.73$ $± 0.011$ | $0.61$ $± 0.005$ | $0.66$ $± 0.016$ | 0.84 $± 0.006$ |
| (A) Refuses to answer | $0.08$ $± 0.005$ | $0.07$ $± 0.011$ | $0.00$ $± 0.000$ | 0.16 $± 0.011$ | $0.00$ $± 0.007$ | $0.04$ $± 0.015$ | $0.00$ $± 0.000$ | $0.25$ $± 0.025$ | - | - | - | - |
| (B) Consistently correct | | | | | | | | | | | | |
| (B1) All | $1.00$ $± 0.000$ | $1.00$ $± 0.000$ | $1.00$ $± 0.000$ | $1.00$ $± 0.000$ | - | - | - | - | - | - | - | - |
| (B2) Most | $0.98$ $± 0.001$ | $0.87$ $± 0.002$ | 1.00 $± 0.000$ | $0.95$ $± 0.002$ | $0.77$ $± 0.024$ | $0.88$ $± 0.025$ | $1.00$ $± 0.000$ | $0.97$ $± 0.014$ | $0.98$ $± 0.005$ | $0.75$ $± 0.004$ | 1.00 $± 0.000$ | $0.94$ $± 0.003$ |
| (C) Consistently incorrect | | | | | | | | | | | | |
| (C1) All | $0.00$ $± 0.000$ | $0.00$ $± 0.000$ | $0.00$ $± 0.000$ | $0.00$ $± 0.000$ | - | - | - | - | - | - | - | - |
| (C2) Most | $0.06$ $± 0.013$ | $0.18$ $± 0.009$ | $0.00$ $± 0.000$ | 0.35 $± 0.043$ | - | - | - | - | $0.25$ $± 0.026$ | $0.29$ $± 0.023$ | $0.00$ $± 0.000$ | 0.65 $± 0.022$ |
| (D) Two competing | $0.44$ $± 0.029$ | $0.42$ $± 0.035$ | $0.53$ $± 0.020$ | 0.66 $± 0.030$ | - | - | - | - | $0.73$ $± 0.025$ | $0.47$ $± 0.019$ | $0.41$ $± 0.037$ | 0.86 $± 0.014$ |
| (E) Many answers | | | | | | | | | | | | |
| (E1) Non correct | $0.00$ $± 0.000$ | $0.00$ $± 0.000$ | $0.00$ $± 0.000$ | $0.00$ $± 0.000$ | $0.00$ $± 0.000$ | $0.00$ $± 0.000$ | $0.00$ $± 0.000$ | $0.00$ $± 0.000$ | - | - | - | - |
| (E2) Correct appears | $0.46$ $± 0.009$ | $0.34$ $± 0.009$ | $0.53$ $± 0.007$ | 0.54 $± 0.005$ | $0.14$ $± 0.015$ | $0.17$ $± 0.025$ | $0.44$ $± 0.047$ | $0.65$ $± 0.031$ | - | - | - | - |
Table 14: Various answer choice strategies, instruct models.
| | Mistral-7b-Instruct | | | | | | | | | | | |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| TriviaQA | Math | Winobias | | | | | | | | | | |
| Error type | Greedy | Random | Majority | Probing | Greedy | Random | Majority | Probing | Greedy | Random | Majority | Probing |
| All | $0.63$ $± 0.003$ | $0.64$ $± 0.002$ | $0.67$ $± 0.004$ | $0.71$ $± 0.003$ | $0.55$ $± 0.021$ | $0.52$ $± 0.019$ | $0.57$ $± 0.025$ | $0.70$ $± 0.014$ | $0.77$ $± 0.012$ | $0.77$ $± 0.008$ | $0.77$ $± 0.010$ | $0.79$ $± 0.008$ |
| (A) Refuses to answer | $0.06$ $± 0.005$ | $0.06$ $± 0.011$ | $0.00$ $± 0.000$ | $0.28$ $± 0.009$ | - | - | - | - | - | - | - | - |
| (B1) All | $1.00$ $± 0.000$ | $1.00$ $± 0.000$ | $1.00$ $± 0.000$ | $1.00$ $± 0.000$ | $1.00$ $± 0.000$ | $1.00$ $± 0.000$ | $1.00$ $± 0.000$ | $1.00$ $± 0.000$ | $1.00$ $± 0.000$ | $1.00$ $± 0.000$ | $1.00$ $± 0.000$ | $1.00$ $± 0.000$ |
| (B2) Most | $0.88$ $± 0.007$ | $0.83$ $± 0.009$ | $0.99$ $± 0.002$ | $0.89$ $± 0.010$ | $0.87$ $± 0.013$ | $0.84$ $± 0.024$ | $1.00$ $± 0.000$ | $0.96$ $± 0.007$ | $0.91$ $± 0.031$ | $0.87$ $± 0.029$ | $0.96$ $± 0.017$ | $0.89$ $± 0.032$ |
| (C) Consistently incorrect | | | | | | | | | | | | |
| (C1) All | $0.00$ $± 0.003$ | $0.00$ $± 0.000$ | $0.00$ $± 0.000$ | $0.00$ $± 0.000$ | $0.05$ $± 0.020$ | $0.00$ $± 0.000$ | $0.00$ $± 0.000$ | $0.00$ $± 0.000$ | $0.00$ $± 0.000$ | $0.00$ $± 0.000$ | $0.00$ $± 0.000$ | $0.00$ $± 0.000$ |
| (C2) Most | $0.11$ $± 0.009$ | $0.15$ $± 0.012$ | $0.00$ $± 0.000$ | $0.53$ $± 0.005$ | $0.10$ $± 0.040$ | $0.20$ $± 0.050$ | $0.00$ $± 0.000$ | $0.82$ $± 0.037$ | $0.18$ $± 0.057$ | $0.20$ $± 0.039$ | $0.00$ $± 0.000$ | $0.54$ $± 0.067$ |
| (D) Two competing | $0.32$ $± 0.010$ | $0.45$ $± 0.023$ | $0.50$ $± 0.024$ | $0.78$ $± 0.017$ | - | - | - | - | - | - | - | - |
| (E) Many answers | | | | | | | | | | | | |
| (E1) Non correct | $0.01$ $± 0.003$ | $0.00$ $± 0.000$ | $0.00$ $± 0.000$ | $0.00$ $± 0.000$ | - | - | - | - | - | - | - | - |
| (E2) Correct appears | $0.23$ $± 0.020$ | $0.19$ $± 0.022$ | $0.38$ $± 0.009$ | $0.56$ $± 0.025$ | - | - | - | - | - | - | - | - |
| Llama-8b-Instruct | | | | | | | | | | | | |
| TriviaQA | Math | Winobias | | | | | | | | | | |
| Error type | Greedy | Sampling | Majority | Probing | Greedy | Sampling | Majority | Probing | Greedy | Sampling | Majority | Probing |
| All | $0.69$ $± 0.003$ | $0.67$ $± 0.001$ | $0.71$ $± 0.002$ | 0.73 $± 0.004$ | $0.89$ $± 0.010$ | $0.87$ $± 0.012$ | 0.91 $± 0.013$ | 0.91 $± 0.010$ | $0.75$ $± 0.009$ | $0.74$ $± 0.009$ | $0.76$ $± 0.012$ | 0.83 $± 0.009$ |
| (A) Refuses to answer | $0.06$ $± 0.011$ | $0.05$ $± 0.011$ | $0.00$ $± 0.000$ | 0.27 $± 0.025$ | - | - | - | - | - | - | - | - |
| (B) Consistently correct | | | | | | | | | | | | |
| (B1) All | $1.00$ $± 0.000$ | $1.00$ $± 0.000$ | $1.00$ $± 0.000$ | $1.00$ $± 0.000$ | $1.00$ $± 0.000$ | $1.00$ $± 0.000$ | $1.00$ $± 0.000$ | $1.00$ $± 0.000$ | $1.00$ $± 0.000$ | $1.00$ $± 0.000$ | $1.00$ $± 0.000$ | $1.00$ $± 0.000$ |
| (B2) Most | $0.93$ $± 0.002$ | $0.86$ $± 0.009$ | 1.00 $± 0.001$ | $0.92$ $± 0.004$ | $0.94$ $± 0.014$ | $0.92$ $± 0.014$ | 1.00 $± 0.000$ | $0.95$ $± 0.013$ | $0.94$ $± 0.006$ | $0.88$ $± 0.010$ | $1.00$ $± 0.000$ | $0.93$ $± 0.011$ |
| (C) Consistently incorrect | | | | | | | | | | | | |
| (C1) All | $0.00$ $± 0.001$ | $0.00$ $± 0.000$ | $0.00$ $± 0.000$ | $0.00$ $± 0.000$ | - | - | - | - | $0.00$ $± 0.000$ | $0.00$ $± 0.000$ | $0.00$ $± 0.000$ | $0.00$ $± 0.000$ |
| (C2) Most | $0.12$ $± 0.018$ | $0.22$ $± 0.010$ | $0.00$ $± 0.000$ | 0.43 $± 0.010$ | - | - | - | - | $0.11$ $± 0.018$ | $0.15$ $± 0.025$ | $0.00$ $± 0.000$ | 0.67 $± 0.016$ |
| (D) Two competing | $0.43$ $± 0.017$ | $0.42$ $± 0.014$ | $0.46$ $± 0.016$ | 0.60 $± 0.010$ | - | - | - | - | $0.39$ $± 0.068$ | $0.39$ $± 0.047$ | $0.38$ $± 0.042$ | 0.83 $± 0.050$ |
| (E) Many answers | | | | | | | | | | | | |
| (E1) Non correct | $0.00$ $± 0.002$ | $0.00$ $± 0.000$ | $0.00$ $± 0.000$ | $0.00$ $± 0.000$ | - | - | - | - | - | - | - | - |
| (E2) Correct appears | $0.28$ $± 0.006$ | $0.28$ $± 0.008$ | $0.40$ $± 0.009$ | 0.52 $± 0.009$ | - | - | - | - | - | - | - | - |
Appendix F Practical Guidance on Integrating Insights from this Paper into Model Development Workflows
The findings of this study reveal critical insights into the internal mechanisms of Large Language Models (LLMs) and their implications for truthfulness and error handling. To effectively incorporate these insights into model development, consider the following strategies:
Error Detection.
Focus on representations of exact answer tokens to train the error detection probe. These tokens encode significant truthfulness signals and improve the reliability of error detection mechanisms. The trained probe should be integrated as part of the pipeline for specific task, e.g., math calculations. The probe provides a confidence score which can be used to warn the user for unreliable outputs, or to perform an intervention to fix the answer.
Error-Specific Interventions.
The taxonomy of errors outlined in this study can be utilized to classify and analyze the types of errors that an LLMs may produce. Identifying these error types is useful for customizing strategies for error mitigation. The probes for detecting error types can be deployed as part of the LLM pipeline and create interventions based on their predictions. For example, Retrieval Augmented Generation (RAG) (Lewis et al., 2020) can help for “consistently incorrect” errors, as well as resampling and choosing the answer ranked highest by the error detection probe, or weight-update, if possible, as a more consistent solution. For “consistently correct” error types, an intervention on the LLM’s internal representations can increase the confidence in generating a correct answer (Simhi et al., 2024).
Cross-Task Generalization.
Universal generalization of probing classifiers across unrelated tasks should be approached with caution. The results in this work show that probes are mainly useful for task-specific error detection.