# Understanding Reasoning in Chain-of-Thought from the Hopfieldian View
> The first three authors contributed equally to this work.
undefined
## Abstract
Large Language Models have demonstrated remarkable abilities across various tasks, with Chain-of-Thought (CoT) prompting emerging as a key technique to enhance reasoning capabilities. However, existing research primarily focuses on improving performance, lacking a comprehensive framework to explain and understand the fundamental factors behind CoT’s success. To bridge this gap, we introduce a novel perspective grounded in the Hopfieldian view of cognition in cognitive neuroscience. We establish a connection between CoT reasoning and key cognitive elements such as stimuli, actions, neural populations, and representation spaces. From our view, we can understand the reasoning process as the movement between these representation spaces. Building on this insight, we develop a method for localizing reasoning errors in the response of CoTs. Moreover, we propose the Representation-of-Thought (RoT) framework, which leverages the robustness of low-dimensional representation spaces to enhance the robustness of the reasoning process in CoTs. Experimental results demonstrate that RoT improves the robustness and interpretability of CoT reasoning while offering fine-grained control over the reasoning process.
## 1 Introduction
Large Language Models (LLMs) have demonstrated exceptional capabilities in following the natural language instructions (Ouyang et al., 2022; Jin et al., 2024) and excelling across a variety of downstream tasks (Hu et al., 2023a; Zhang et al., 2023; Yang et al., 2024a; c; b). As reasoning skills are crucial for tasks such as commonsense and mathematical reasoning (Rae et al., 2021), there is a growing focus on enhancing these capabilities. One prominent approach is Chain-of-Thought (CoT) prompting (Wei et al., 2022; Kojima et al., 2022), a simple yet highly effective technique to unleash the reasoning capability of LLMs. However, despite its success, a natural and fundamental research question remains: How does the reasoning capability emerge through CoT prompting?
Numerous studies have sought to identify the key factors or elements that enable CoT to enhance the reasoning capabilities of LLMs (Kojima et al., 2022; Wang et al., 2023a; Tang et al., 2023; Merrill & Sabharwal, 2023). Some works focus on improving CoT reasoning through query-based corrections (Kim et al., 2023), knowledge-enhanced frameworks (Zhao et al., 2023), and symbolic reasoning chains for faithful CoT (Lyu et al., 2023; Lanham et al., 2023). Other research has examined how the sequence of demonstrations, random labels (Min et al., 2022), or even meaningless tokens (Pfau et al., 2024) can positively influence reasoning performance. However, these works primarily focus on improving the model’s reasoning performance, and they do not provide a comprehensive framework to explain the underlying factors driving CoT’s success.
To understand the reasoning process in CoTs more deeply, we draw inspiration from cognitive neuroscience, specifically the relationship between cognition and brain function. In this field, the Hopfieldian view (Hopfield, 1982) and the Sherringtonian view (Sherrington, 1906) represent two different ways of understanding neural computational models and cognitive mechanisms. While the Sherringtonian view of cognitive explanation focuses on specific connections between neurons in the brain, the Hopfieldian view emphasizes distributed computation across neural populations, where information is not encoded by a single neuron but rather by the cooperative activity of many neurons. This perspective is particularly suited to explaining complex cognitive functions like memory storage, pattern recognition, and reasoning. Thus, the Hopfieldian view is generally considered more advanced than the Sherringtonian view, especially in the context of explaining distributed computation and the dynamics of neural networks (Barack & Krakauer, 2021). Based on these, a natural question is: whether we can understand the reasoning in CoTs from the Hopfieldian view of cognition?
<details>
<summary>x1.png Details</summary>
### Visual Description
## Diagram: Comparison of Cognitive Brain and Chain-of-Thought Processes
### Overview
The image is a comparative diagram split into two vertical panels. The left panel is titled "Cognitive Brain" and illustrates a biological or cognitive model of action selection. The right panel is titled "Chain-of-Thought" and illustrates an analogous process in an artificial neural network or AI system. Both panels depict a process within a defined "Representation Space" using a coordinate system and clustered data points.
### Components/Axes
**Shared Structural Elements (Both Panels):**
* **Representation Space:** A 2D coordinate system defined by two perpendicular axes.
* **Horizontal Axis:** Labeled "Action axis". A blue arrow points right, and a red arrow points left from the origin.
* **Vertical Axis:** Labeled "Motion axis". A black arrow points up, and a black arrow points down from the origin.
* **Legend (Top-Left of each panel):** A dashed box titled "Motion Strength". It contains a series of colored dots:
* **Red Dots (Left side):** Labeled "Action +". The dots vary in shade from dark red to light pink.
* **Blue Dots (Right side):** Labeled "Action -". The dots vary in shade from dark blue to light blue.
* **Data Clusters:** Two main clusters of colored dots (red and blue) are present in each panel, positioned in opposite quadrants of the Representation Space.
* **Directional Arrows:** Large, colored arrows indicate the driving force or input.
* A **red arrow** points towards the upper-left quadrant.
* A **blue arrow** points towards the lower-right quadrant.
**Panel-Specific Elements:**
**Left Panel: Cognitive Brain**
* **Title:** "Cognitive Brain"
* **Cluster Labels:**
* The red dot cluster in the upper-left is labeled "Action +".
* The blue dot cluster in the lower-right is labeled "Action -".
* **Driving Force Labels:**
* The red arrow is labeled "Stimuli +".
* The blue arrow is labeled "Stimuli -".
* **Additional Label:** "Neural Populations" points to the general area of the data clusters.
**Right Panel: Chain-of-Thought**
* **Title:** "Chain-of-Thought"
* **Additional Diagram (Top):** A small schematic of a neural network with three layers of nodes (blue circles) connected by lines. It is labeled:
* "Input" (top layer)
* "Neuron Activations" (middle layer, highlighted with a blue box)
* "Output" (bottom layer)
* **Cluster Labels:**
* The red dot cluster in the upper-left is labeled "Output +".
* The blue dot cluster in the lower-right is labeled "Output -".
* **Driving Force Labels:**
* The red arrow is labeled "Instruction +".
* The blue arrow is labeled "No Instruction -".
* **Additional Label:** "Activated Neurons" points to the general area of the data clusters.
### Detailed Analysis
The diagram establishes a direct visual analogy between two systems:
1. **Cognitive Brain Process:**
* **Input:** External "Stimuli" (positive/red and negative/blue).
* **Mechanism:** These stimuli influence "Neural Populations" within a "Representation Space".
* **Output:** The system settles into a state corresponding to an "Action +" (approach/positive) or "Action -" (avoid/negative) decision. The strength of the action is encoded by the shade of the dot (darker = stronger).
2. **Chain-of-Thought Process:**
* **Input:** An "Instruction" (positive/present) or "No Instruction" (negative/absent).
* **Mechanism:** This input modulates "Activated Neurons" within an analogous "Representation Space". The small neural network diagram abstractly represents the underlying computational mechanism.
* **Output:** The system produces an "Output +" or "Output -". The strength of the output is similarly encoded by dot shade.
**Spatial Grounding & Color Cross-Reference:**
* In both panels, the **red cluster** (Action+/Output+) is consistently located in the **upper-left quadrant** of the Representation Space, associated with the positive direction of the red driving arrow.
* The **blue cluster** (Action-/Output-) is consistently located in the **lower-right quadrant**, associated with the positive direction of the blue driving arrow.
* The color of the driving arrow (red/blue) matches the color of the cluster it influences, confirming the legend's mapping.
### Key Observations
* **Symmetrical Analogy:** The diagram is meticulously structured to show a one-to-one mapping between biological and artificial concepts: Stimuli ↔ Instruction, Neural Populations ↔ Activated Neurons, Action ↔ Output.
* **Directional Coding:** Positive valence (Action+, Stimuli+, Instruction+, Output+) is consistently associated with the **upper-left** direction in the representation space. Negative valence (Action-, Stimuli-, No Instruction-, Output-) is associated with the **lower-right**.
* **Strength Gradient:** The use of color saturation (dark to light) within each cluster provides a secondary dimension of information, representing the magnitude or confidence of the response.
* **Abstraction Level:** The "Chain-of-Thought" panel includes an extra layer of abstraction with the neural network schematic, explicitly linking the conceptual diagram to a common AI architecture.
### Interpretation
This diagram argues for a functional equivalence between the cognitive process of action selection in a brain and the reasoning process in a Chain-of-Thought AI model.
* **Core Thesis:** It suggests that both systems operate by mapping inputs (stimuli or instructions) onto a latent "representation space," where the direction of movement within that space corresponds to a decision or output. The "Chain-of-Thought" process in AI is framed not just as information processing, but as a form of *directed navigation* through a conceptual space, guided by the prompt or instruction.
* **Underlying Mechanism:** The "Representation Space" is the key shared construct. In neuroscience, this could be a population code in the motor cortex. In AI, it is the activation space of a transformer's hidden layers. The diagram implies that "thinking" or "reasoning" (the chain) is the trajectory through this space from an initial state to a final output state.
* **Notable Implication:** The label "No Instruction -" is particularly insightful. It posits that the *absence* of a guiding instruction is itself a powerful input that drives the system toward a default or negative output state, just as a negative stimulus drives avoidance behavior. This highlights the critical role of prompts in steering AI cognition.
* **Purpose:** The visual serves to demystify AI reasoning by grounding it in a familiar biological metaphor, while also elevating the discussion of AI cognition by giving it a structured, spatial, and dynamic interpretation akin to brain function.
</details>
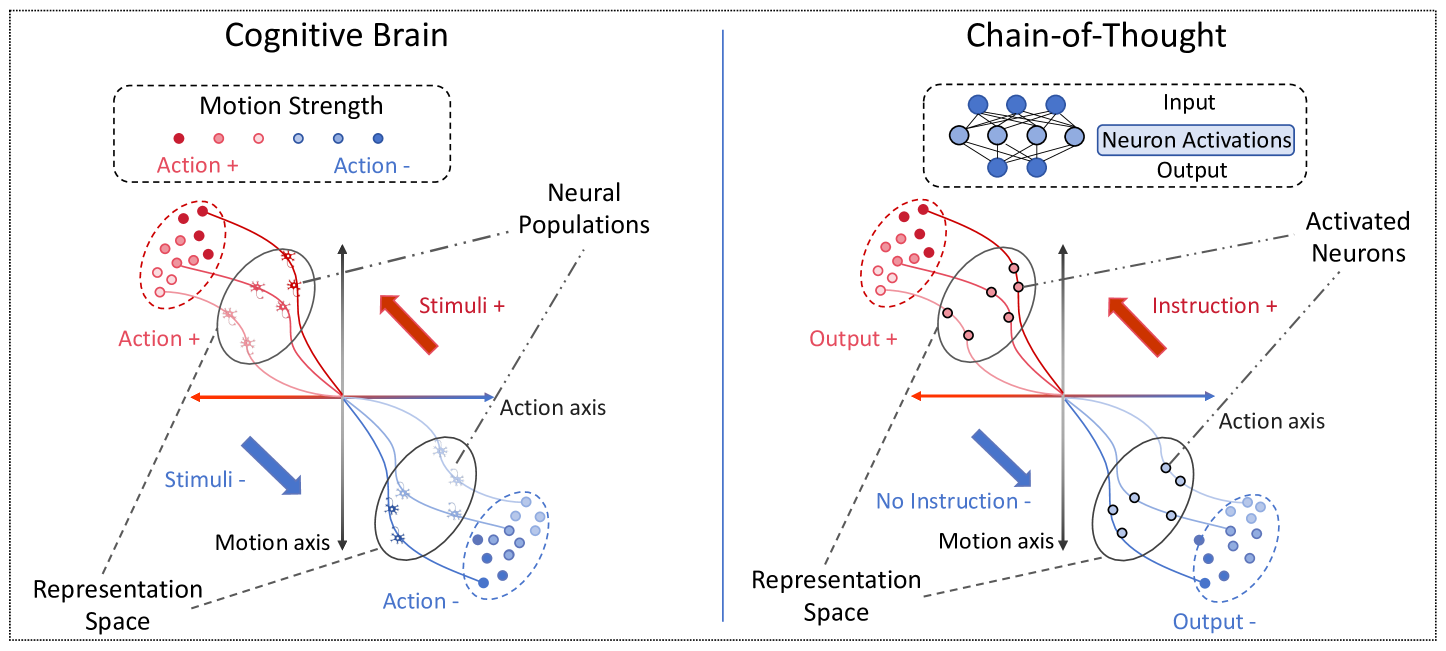
Figure 1: Illustration of the emergence of cognition in the brain and CoT reasoning from the Hopfieldian view.
The Hopfieldian view explains the production of behavioral actions as emerging from transformations or movements within neural populations in response to stimuli in the brain (Barack & Krakauer, 2021) (cf. Figure 1). This perspective approaches cognition at the level of representations, disregarding the detailed roles of individual molecules, cells, and circuits, thus allowing the potential for a more conceptual and semantic understanding of complex cognitive systems. Viewing the CoT-triggered reasoning process in LLMs through this lens is intuitive: CoT prompting induces shifts in the model’s trajectory in much the same way that external stimuli shape cognitive responses, driving representation changes without altering the underlying system. Specifically, similar to the Hopfieldian mechanism, where the shift or movement in neural populations happens during cognition itself, CoT influences reasoning during inference, controlling the logical steps without modifying the model’s parameters.
Given the parallels between the CoT-triggered reasoning process and the Hopfieldian view of cognition in the brain, we first establish a connection between these two by aligning key elements: stimuli and actions, neural populations, and representation spaces. Particularly, we provide a general framework for identifying the “representation spaces” of the “stimuli” given by CoTs. We conceptualize the reasoning process elicited by CoT prompting as movement between representation spaces, enabling us to improve and deepen our understanding of CoTs. Based on these connections, we then leverage the strength of the Hopfieldian view to improve or further understand CoTs. Specifically, by leveraging the “representation spaces” in CoTs, we develop a method for localizing the reasoning error in the responses. Moreover, by leveraging the robustness of low-dimensional representation spaces, we propose a new framework, namely Representation-of-Thought (RoT), which enhances the robustness of CoTs. We summarize the key contributions of our work as follows:
1. We establish a connection between the reasoning process in CoTs and the Hopfieldian view of cognition, grounded in cognitive neuroscience, to identify the key factors driving CoT’s success in zero-shot and few-shot settings. To the best of our knowledge, this is the first known attempt to leverage cognitive science for CoT interpretability by associating its core elements with the Hopfieldian framework.
1. Based on these connections, we leverage the strength of the Hopfieldian view to understand and further improve CoTs. We first consider how to localize the reasoning error based on the low-dimensional representation spaces. Then, by leveraging the robustness of the Hopfieldian view, we propose a new framework, RoT, to enhance the robustness of CoTs’ performance.
1. Comprehensive experiments on three tasks, including arithmetic reasoning, commonsense reasoning, and symbolic reasoning, reveal that our framework can provide intuitive and interpretable analysis, allowing error tracing and control for CoT reasoning.
## 2 Related Work
#### Chain-of-Thought (CoT).
The CoT is a prompting technique that engages LLMs in step-by-step reasoning rather than directly providing the answers (Nye et al., 2021). Studies have shown that introducing intermediate steps or learning from demonstrations can significantly improve the reasoning performance of LLMs (Wei et al., 2022; Kojima et al., 2022). Given the success of CoT, numerous studies have explored its application to a variety of complex problems, including arithmetic, commonsense, symbolic reasoning (Wang et al., 2023c; Zhou et al., 2023; Wang & Zhou, 2024), and logic tasks (Creswell & Shanahan, 2022; Pan et al., 2023; Weng et al., 2023). Recently, numerous endeavors have been made to enhance the reasoning capabilities in LLMs (Wang et al., 2023a; Dutta et al., 2024). For example, Kim et al. (2023) proposed a query-based approach to correct erroneous reasoning steps within a CoT. Zhao et al. (2023) introduced a knowledge-enhanced method to improve the factual correctness for multi-pole open-domain QA tasks. Lyu et al. (2023) developed “faithful CoT”, i.e., a framework that first translates natural language queries into symbolic reasoning chains and then solves the problem using CoT. Additionally, several studies have also focused on the sequence and quantity of demonstrations within the context, investigating their contributions to the final reasoning performance. For this, Min et al. (2022) discovered that even random labels or ineffective reasoning steps can still improve the model’s reasoning performance. Lanham et al. (2023) demonstrated the impact of intervening in the CoT process by adding mistakes or paraphrases. Pfau et al. (2024) showed that using meaningless filler tokens in place of a chain-of-thought can surprisingly boost reasoning performance. However, these studies primarily focused on how to improve the CoT’s reasoning performance and do not provide a framework to analyze the fundamental reasons, i.e., how does the reasoning capability emerge through CoT? Dutta et al. (2024) investigates the neural sub-structures within LLMs that manifest Chain-of-Thought (CoT) reasoning on the Llama-2-7B model. Similarly, Rai & Yao (2024) explores neurons in the feed-forward layers of LLMs to analyze their arithmetic reasoning capabilities on the Llama-2-7B model. Both studies are grounded in the Sherringtonian view of neural activity. In contrast, we adopt the Hopfieldian perspective to bridge this gap, focusing on representations rather than individual neurons. We apply our approach across three different downstream tasks and can further extend our analysis to larger models like Llama-2-70B.
Interpretability of LLMs. Interpretability plays a key role in a deeper understanding of LLMs to identify potential risks and better meet human requirements (Zou et al., 2023). Common interpretability strategies include (i) Salience maps, which rely on highlighting the regions in the input that are attended by the model (Simonyan et al., 2014; Smilkov et al., 2017; Clark et al., 2019; Hu et al., 2023c; b; Lai et al., 2024); (ii) Feature visualization, which creates representative inputs indicative of particular neurons’ activations (Szegedy et al., 2014; Nguyen et al., 2016; Fong & Vedaldi, 2018; Nguyen et al., 2019); and (iii) Mechanistic interpretability, which employs reverse-engineering tools to explain networks based on circuits and node-to-node connections (Olah et al., 2020; Olsson et al., 2022; Wang et al., 2023b). However, these methods often require substantial human intervention and are limited in terms of scalability or interpretability, especially for the large language models (Fong & Vedaldi, 2018; Jain & Wallace, 2019; Hu et al., 2024). Thus, these methods cannot be directly used to interpret CoT reasoning. Additionally, most current approaches focus on representation-level analysis without considering how these representations connect to concepts learned during pre-training (Bricken et al., 2023; Templeton et al., 2024). Other works investigate the localization and representation of concepts in the network (Kim et al., 2018; Li et al., 2024), linear classifier probing to uncover input properties (Belinkov, 2022), fact localization and editing (Meng et al., 2022; Zhong et al., 2023; Cheng et al., 2024a; b), concept erasure (Shao et al., 2023; Gandikota et al., 2023), and corrective analysis (Burns et al., 2023), etc. These observations are aligned with RepE (Zou et al., 2023), which emphasized the nearly linear nature of LLM representations (Park et al., 2024). However, none of these approaches directly address the inner workings of CoT reasoning. While recent work has begun exploring connections between LLM interpretability and cognitive neuroscience (Vilas et al., 2024). However, it does not discuss the Hopfieldian view and also does not discuss how to explain the reasoning process in CoTs via cognitive neuroscience. Our work provides the first attempt to interpret CoT reasoning from the Hopfieldian perspective.
## 3 Preliminaries
Large Language Models and Prompting. Prompts can take various forms, such as a single sentence or longer paragraphs, and may include additional information or constraints to guide the model’s behavior. Let $M:X↦Y$ be an LLM that takes an input sequence $x=(x_1,x_2,…,x_q)∈X$ and produces an output sequence $y=(y_1,y_2,…,y_m)∈Y$ . The model is typically trained to optimize the conditional probability distribution $pr(y|x)$ , which assigns a probability to each possible output sequence $y$ given $x$ . To incorporate a prompt $w$ with the input sequence $x$ , we can concatenate them into a new sequence $\hat{x}=(w,x_1,x_2,…,x_q)$ . The conditional probability distribution $pr(\hat{y}|\hat{x})$ is then computed using $\hat{x}$ . Formally, the probability of the output sequence $\hat{y}$ given $\hat{x}$ is:
$$
pr(\hat{y}|\hat{x})=∏_i=1^mpr(y_i|y_<i,\hat{x}),
$$
where $y_<i$ represents the prefix of the sequence $y$ up to position $i-1$ , and $pr(y_i|y_<i,\hat{x})$ denotes the probability of generating $y_i$ given $y_<i$ and $\hat{x}$ .
The Hopfieldian View. In cognitive neuroscience, two prominent perspectives aim to explain cognition: the Sherringtonian view and the Hopfieldian view. See Appendix A for an introduction to the Sherringtonian view. For a detailed comparison between these two views, refer to (Barack & Krakauer, 2021) and (Bechtel, 2007). The Hopfieldian view focuses on understanding behavior through computation and representation within neural spaces, rather than the specific biological details of neurons, ion flows, or molecular interactions (Hopfield, 1982; 1984; Hopfield & Tank, 1986). It operates at a higher level of abstraction, emphasizing the role of representations and the computations performed on them.
This approach conceptualizes cognition as transformations between representation spaces. At the implementation level, the collective activity of neurons is mapped onto a representation space, which contains a low-dimensional representational manifold. Algorithmically, Hopfieldian computation views these representation spaces as fundamental entities, with movements within or transformations between them as the central operations. The representations themselves are structured as basins of attraction within a state space, and while they are implemented by neural structures (whether individual neurons, neural populations, or other components), the focus is on the dynamics of the system rather than its specific biological mechanisms. Most Hopfieldian models, in practice, center on the activity of neural populations.
A parameter space defines the dimensions of variation within these representational spaces, aligning with quality-space approaches from philosophy, where content is similarly structured. Computations over these representations are understood as dynamic transformations between spaces or shifts within them, characterized by features like attractors, bifurcations, limit cycles, and trajectories. Ultimately, cognitive functions are realized through these dynamic movements within or between representational spaces.
Linear Representations in Language Models. Recent investigations into the internal mechanics of LLMs have revealed intriguing properties of their learned representations. Park et al. (2024) posited that high-level semantic features such as gender or honesty could be linearly represented as directions within the model’s representation space. This can be illustrated by the well-known word analogy task using a word embedding model (Mikolov et al., 2013). By defining $M(·)$ as a function of extracting the representations of a given word by a word embedding model, the operation $M(Spain)-M(Madrid)+M(Paris)$ often results in an output close to $M(France)$ , where $M(Spain)-M(Madrid)$ can be considered as the representation vector of the abstract “capital of” feature in the embedding space. Concurrently, research on interpretable neurons (Dale et al., 2023; Ortiz-Jiménez et al., 2023; Voita et al., 2024) has identified neurons that consistently activate for specific input features or tasks, suggesting that these features may also be represented as directions in the LLMs’ neuron space. For instance, Tigges et al. (2023) use the PCA vector between LLMs’ hidden states on instructions “positive” and “negative” to find the sentiment direction in LLMs. Additionally, recent works (Zou et al., 2023; Arditi et al., 2024) show the effectiveness of engineering on language models using these directions. For example, adding multiples of the “honesty” direction to some hidden states has been sufficient to make the model more honest and reduce hallucinations.
## 4 Bridging Reasoning in CoTs and the Hopfieldian View
In this section, we aim to build a bridge between the reasoning process in CoTs and the cognitive brain from the Hopfieldian view. We will particularly associate the main elements (stimuli, neural populations, and representation spaces) in the Hopfieldian view. After understanding these elements, we can leverage the strength of the Hopfieldian view to deepen our understanding of the reasoning process in current CoTs and further improve it. Note that we will leave other elements in the Hopfieldian view, such as attractors and state space, as future work.
Stimuli and Actions. Stimuli and actions are key components of how the brain processes information and interacts with the environment. Actions refer to the motor responses or behaviors that result from cognitive processing, which are responses given by LLMs through CoTs.
Stimuli refer to external or internal events, objects, or changes in the environment that are detected by the sensory systems and can influence cognitive processes and behavior. Based on this, we can adopt the term “stimuli” from cognitive science in the context of CoTs to refer to specific prompt text or instructions that trigger CoT reasoning. Specifically, in the zero-shot setting, we define the stimulus as $s_zero$ to represent a set of supplementary instructions in the prompt that encourage the model to provide more intermediate reasoning steps before arriving at a final answer. For example, it can be “ let’s think step by step ” or “ make sure to give steps before your answer ”. In the few-shot setting, the stimulus $s_few$ is defined as the sequence of demonstrations $D=\{(\tilde{q}_1,\tilde{a}_1),(\tilde{q}_2,\tilde{a}_2),\dots\}$ in the prompt, where $\tilde{q}_i$ represents the query and $\tilde{a}_i$ is the corresponding response. In the following discussion, we use $s^+$ to indicate that stimuli are included in the model’s input and $s^-$ to indicate that no stimuli are added. Note that we avoid using explicitly negative stimuli, such as “ please be careless and answer the following question ”, because a well-aligned model would likely refuse to behave in such a manner (Ouyang et al., 2022).
Neural Populations. As we mentioned, in the Hopfieldian view, representations are realized by various forms of neural organization, especially populations. Identifying these “neural populations” in CoTs is especially important. In our framework, there are two steps for finding them.
(i) Stimulus Set Designing. Here our goal is to elucidate the sensitivity of LLMs to different CoT prompts with stimuli. Understanding such sensitivity could help us know the neural populations raised from the stimuli. In detail, we construct a prompt set. For each query $q$ , we consider two forms of prompts: positive one (with stimuli) as $p^+=T(s^+,q)$ and negative one (without stimuli) as $p^-=T(s^-,q)$ , where $T$ is the prompt template. Specifically, for each query $q_i$ , we construct $M$ number of prompts for both of them with different stimuli, which is denoted as $P_i=\{p_1^i,-,p_1^i,+,p_2^i,-,p_2^i,+,\dots,p_M^i,-,p_M ^i,+\}$ . Such construction is to make our following neural populations less dependent on the specific template form. Thus, in total, we have a stimulus set $P^*=\{P_1,P_2,⋯,P_N\}$ , where $N$ is the number of queries. These contrastive pairs of prompts will be used to identify neural populations given by these stimuli.
(ii) Identifying Neural Populations. Intuitively, the neural populations should be the most influential activation vectors of these prompts or stimuli. In detail, for each prompt in $P^*$ , the next step is capturing the network architecture’s corresponding neural populations. Since LLMs rely on transformer-based architecture to store distinct representations intended for different purposes, it is crucial to design the extraction process to capture task-specific representations carefully. For a given prompt $p^+$ or $p^-$ , we will find the “most representative token”, which encapsulates rich and highly generalizable representations of the stimuli. Here we select the last token after tokenizing the prompt, which is based on the observation in Zou et al. (2023) that it is the most informative token for decoder-only or auto-regressive architecture models.
Once the last token position is identified, we can naturally select some of its activations (hidden state) in hidden layers. Previous studies (Fan et al., 2024; Cosentino & Shekkizhar, 2024) have shown that not all layers store important information about reasoning; thus we focus on a subset of them to reduce the computation cost, whose indices are denoted as a set $K$ (in practice, $K$ is always the last several layers). Thus, we have a collection of activation vectors. However, since we are focusing on the reasoning of CoT, studying the neural populations raised from the stimuli rather than the whole prompt is more important. Thus, we consider the difference in the activations of pairs of prompts. Specifically, for a pair $(p^+,p^-)$ , we can get their activations for all selected layers $K$ : $\{h_k(p^+)\}_k∈K$ and $\{h_k(p^-)\}_k∈K$ , where $h_k(p)$ refers to the activation vector of the $k$ -th layer for a given input prompt $p$ . Then the differences of activations $\{\tilde{h}_k(p)\}_k∈K$ are the neural populations for such stimuli, where $\tilde{h}_k(p)=h_k(p^+)-h_k(p^-)$ represents the most influential information we get from the stimuli for the query. Based on this, for each hidden layer in $K$ , we have the neural population for all queries, which is denoted as
$$
h^*_k=\{\tilde{h}_k(P_1),\tilde{h}_k(P_2),…,\tilde{h}_k(P_
N)\}. \tag{1}
$$
Representation Spaces. After we have the neural populations for each selected hidden layers, our final goal is to find the representation space. In the Hopfieldian view, the representation of information is thought to occur within low-dimensional space embedded within higher-dimensional neural spaces. Thus, these representation spaces will be the most informative subspaces of the neural populations. Here we adopt the $s$ -PCA to find such an $s$ dimensional subspace. Specifically, for the $k$ -th layer where $k∈K$ , we perform PCA analysis on $h_k^*$ :
$$
R_k=PCA(h_k^*). \tag{2}
$$
Then, the space spanned by this eigenvector will be the representation space for this layer. Motivated by the previous linear representation introduced in Section 3, here we set $s=1$ , i.e., we only consider the principal component. Intuitively, this means each representation space will focus on one “concept”.
## 5 Applications of Hopfieldian View to CoTs
In the previous section, we mainly discussed how each element in the Hopfieldian view corresponds to the reasoning in CoTs. From our previous view, we can understand the reasoning process as the movement between these representation spaces. Based on these connections, we can leverage the strength of the Hopfieldian view to improve or further understand CoTs. In this section, we first consider how to localize the reasoning error based on the low dimensional representation spaces. Then, by leveraging the robustness of the Hopfieldian view, we propose a new framework, namely Representation of Thought, that enhances the performance robustness of CoTs.
### 5.1 Reasoning Error Localization
In this task, for a given query, we want to check if there are some reasoning errors in the response by CoTs. If so, we aim to localize these errors. As in the Hopfieldian view, cognition occurs within low-dimensional representation spaces. Reasoning errors can be identified by analyzing the structure of these spaces, such as when certain directions $R_k$ (representing specific cognitive factors) are disproportionately activated or suppressed. This can help localize the source of the error within the cognitive process. Motivated by this, we can leverage the internal structure of spaces we have learned via PCA to locate the reasoning error for a given query in CoTs.
Intuitively, since the reasoning occurs within these representation spaces, if there is a reasoning error in the response, then during the reasoning process, some tokens make the activations (hidden states) of the response far from the corresponding representation spaces. This is because if these activations are far from the spaces, CoTs do not reason the corresponding “concepts” in the response. Motivated by this, our idea is to iteratively check the tokens in the response to see whether they are far from the representation spaces.
Mathematically, for a given prompt $T$ via CoT of query $x$ with its response $y=(y_1,y_2,⋯,y_m)$ , we will iteratively feed the prompt with a part of the response, i.e., $T_i=T⊕ y_≤ i$ , where $⊕$ is the string concatenation. If the activations of $T_i-1$ are close to while those of $T_i$ are very far from the representation spaces $\{R_k\}_k∈K$ in (2), then we can think the $i$ -th token $y_i$ makes an reasoning error. We use the following criterion to access and/or evaluate the quality of the rationale for $T_i$ :
$$
scores(T_i)=Mean(\{scores_k(T_i)\}_k∈K
),where scores_k(T_i)=h_k(T_i)^⊤R_k-δ. \tag{3}
$$
Here $δ$ is the threshold, $scores_k(T_i)$ is the rationale for the $k$ -th representation space, and $scores(T_i)$ is the average score across all layers in $K$ . When the score is less than 0, it indicates that the activations of prompt $T_i$ are far from the representation spaces. See Algorithm 1 for details.
Algorithm 1 Reasoning Error Localization
1: Prompt $T$ for query $x$ ; response $y=(y_1,⋯,y_m)$ of the prompt $T$ via a CoT; threshold $δ>0$ ; representation vectors $\{R_k\}_k∈K$ in (2) with layer set $K$ .
2: for $i=1,⋯,m$ do
3: Denote a new prompt $T_i=T⊕ y_≤ i$ . Using the same process as in Section 4 to get the activations of $T_i$ in layers in the set $K$ , which are denoted as $h_k(T_i),k∈K$ .
4: Calculate $scores(T_i)=Mean(\{scores_k(T_i)\}_k∈K)$ in (3).
5: if $scores(T_i)<0$ and $scores(q_T-1)≥ 0$ then
6: Mark token $y_i$ as a “reasoning error”.
7: end if
8: end for
### 5.2 Representation of Thought
The Hopfieldian view of cognition offers a framework that can potentially be used to control or influence cognitive processes. Specifically, influencing neural populations directly offers a more robust way to control cognition compared to simply providing different stimuli. Firstly, influencing neural populations directly allows the manipulation of the core dynamics of neural state spaces, including attractor states, bifurcations, and transitions between cognitive states. This direct intervention bypasses the variability and unpredictability associated with external stimuli, which depend on the individual’s perception, attention, and prior experiences. Moreover, external stimuli are subject to various forms of noise and variability, including sensory processing errors, environmental distractions, and individual differences in interpretation. Direct manipulation of neural populations can reduce these sources of noise, providing a cleaner and more consistent pathway to controlling cognitive states.
Our RoT leverages representation spaces’ structure to enhance the robustness of reasoning in CoTs. Intuitively, we can manipulate a given query’s activations to be closer to the representation spaces to enhance robustness since these spaces are the inherent entities in the reasoning process. After the manipulation, the hidden states will be less dependent on the specific form of the prompt, query, and stimuli but will be more dependent on the intrinsic entities of the reasoning task.
Mathematically, for a given prompt $T$ via CoTs of query $x$ . By using a similar procedure as in the Neural Populations section, we can get its neural populations $\{h_k(T)\}_k∈K$ . In RoT, motivated by (Zou et al., 2023; Arditi et al., 2024), we can manipulate them by injecting the directions of their corresponding representation spaces to make them closer to these spaces:
$$
h^\prime_k(T)=\begin{cases}h_k(T)+α R_k&if k∈K
\\
h_k(p)&otherwise ,\end{cases} \tag{4}
$$
where $h^\prime_k(T)$ denotes the manipulated hidden state, $α$ is a scaling factor controlling the manipulation strength. Its sign should follow the sign of $h_k(T)^⊤R_k$ .
By directly manipulating neural populations, RoT offers a more precise and interpretable method for influencing the model’s output compared to traditional prompt engineering techniques. This approach not only enhances control over the model’s behavior but also improves the transparency and predictability of the generation process.
## 6 Experiments
In this section, we will perform experimental studies on the above two applications to verify the correctness of our understanding from the Hopfieldian view.
### 6.1 Experimental Setup
Datasets. Our experiments are performed on benchmark datasets for diverse reasoning problems. We consider 6 datasets for 3 different tasks: Arithmetic Reasoning, Commonsense Reasoning, and Symbolic Reasoning. Specifically, for Arithmetic Reasoning, we select GSM8K (Cobbe et al., 2021) and SVAMP (Patel et al., 2021); we study StrategyQA (Geva et al., 2021) and CommonsenseQA (CSQA) (Talmor et al., 2019) for Commonsense Reasoning; lastly, for Symbolic Reasoning, we choose the Coin Flip (Wei et al., 2022) and Random Letter datasets, where the latter one is constructed from the Last Letter dataset (Wei et al., 2022). More details and statistics of the datasets are provided in Appendix B.1.
LLMs. We employ Llama-2-7B-Chat (Touvron et al., 2023) and Llama-3-8B-Instruct (Meta, 2024) to evaluate their precision performance (accuracy) both before and after applying RoT to different datasets. Furthermore, we use Llama-2-13B-Chat (Touvron et al., 2023) and Llama-2-70B-Chat (Touvron et al., 2023) to show that our method performs effectively in larger-scale models.
Baselines. Since our goal is to analyze the performance and robustness before and after control model reasoning in both zero-shot and few-shot settings, we focus on three baselines in our study: 1) Base: as the simplest approach with LLMs for reasoning, feed the model with only one question query. 2) CoT Z (Kojima et al., 2022): the most common zero-shot CoT is employed to provide a thought path. 3) CoT F (Wei et al., 2022): directly using some demonstrations before asking a question to LLMs.
Evaluation Metrics. We consider the performance of RoT zero-shot (RoT Z) and few-shot (RoT F) settings. Besides the utility of performance, which is evaluated by accuracy, we also conducted results on the robustness against forms of prompts. For zero-shot settings, we selected three different specific instructions: (1) Let’s think step by step. (2) Let’s think about this logically. (3) Let’s solve this problem by splitting it into steps. For few-shot settings, we conducted two studies: 1) Using the original order of the given demonstrations, shown in Appendix C.3. 2) Based on experiment 1, we randomly shuffled the order of the demonstrations. Then we use the accuracy difference to consider the robust performance of our approach. Specifically, given a list of accuracy results from $A=\{\tilde{A}_1,\tilde{A}_2,⋯,\tilde{A}_n\}$ given by different prompts mentioned above, the robust score is calculated by their pairwise difference: $∑_i=1^n∑_j=i+1^n|\tilde{A}_i-\tilde{A}_j|$ . The answer extraction process is based on the methodology outlined by Kojima et al. (2022). Detailed procedures and results are provided in the Appendix C.2.
Experimental Settings. If not explicitly stated, in all experiments, we set the number of stimuli prompts $M=1$ , the sample number $N$ = 128, and select the samples by high perplexity. At the same time, we set the max new tokens to 512 in the generation stage and pick the last 5 layers to control. We choose $α$ based on the accuracy performance on each dataset. In the reasoning error localization experiment, we set $δ=10$ . We use float16 to load large language models and employ greedy search as our decoding strategy. All experiments are conducted using one NVIDIA L20 GPU (except Llama-2-70B-Chat which uses three NVIDIA A100 GPUs).
Table 1: Results of RoT and CoT based on different LLMs on a variety of reasoning tasks. Green indicates an equal or improved accuracy compared to the Base method, while red indicates an accuracy decrease. It can be observed that, compared to CoT prompting, RoT achieves more consistent accuracy improvements across a variety of tasks.
| Base + CoT Z + RoT Z | 26.00 26.31 26.23 | 54.00 46.00 54.33 | 47.75 43.41 48.24 | 63.62 62.05 63.54 | 44.80 52.75 45.45 | 20.33 24.33 20.67 |
| --- | --- | --- | --- | --- | --- | --- |
| Base | 26.00 | 54.00 | 47.75 | 63.62 | 44.80 | 20.33 |
| + CoT F | 4.62 | 38.67 | 53.07 | 59.26 | 47.60 | 31.00 |
| + RoT F | 25.55 | 56.00 | 48.16 | 63.80 | 45.50 | 20.33 |
| Llama-3-8B-Instruct | | | | | | |
| Base | 73.31 | 80.67 | 72.65 | 65.07 | 68.90 | 44.00 |
| + CoT Z | 74.45 | 82.33 | 72.24 | 66.07 | 90.45 | 43.00 |
| + RoT Z | 74.83 | 83.33 | 72.89 | 65.24 | 76.35 | 47.67 |
| Base | 73.31 | 80.67 | 72.65 | 65.07 | 68.90 | 44.00 |
| + CoT F | 72.02 | 81.00 | 73.63 | 62.75 | 96.50 | 50.67 |
| + RoT F | 74.37 | 83.67 | 73.30 | 65.94 | 70.30 | 43.66 |
Table 2: The robust results of our approach and different general baselines with CoT on each task. Bold text indicates optimal results in a single dataset.
| CoT Z RoT Z CoT F | 5.46 3.02 1.44 | 11.34 1.32 0.00 | 6.54 1.64 2.78 | 6.04 0.70 0.48 | 8.80 0.30 2.70 | 14.00 0.68 2.00 |
| --- | --- | --- | --- | --- | --- | --- |
| RoT F | 0.08 | 0.67 | 0.00 | 1.88 | 0.00 | 0.00 |
| Llama-3-8B-Instruct | | | | | | |
| CoT Z | 33.36 | 85.32 | 2.94 | 5.94 | 13.80 | 18.66 |
| RoT Z | 2.58 | 2.66 | 0.82 | 1.14 | 16.40 | 11.34 |
| CoT F | 0.23 | 0.33 | 0.74 | 0.26 | 0.45 | 1.00 |
| RoT F | 0.37 | 0.34 | 0.33 | 0.26 | 0.45 | 1.00 |
### 6.2 Experimental Results
Utility Performance. We first consider the utility performance of RoT. As shown in Table 1, we can see that: 1) The original CoT performs unstable on different tasks. Generally speaking, CoT Z and CoT F appear better, but they are lower than Base in some datasets, such as the CSQA dataset in the zero-shot scenario, which is consistent with the observation in (Kojima et al., 2022). At the same time, for few-shot, CoT F performs extremely poorly in the GSM8k dataset because Llama-2-7B-Chat repeats the given demonstrations, resulting in a reduction in the number of valid tokens. Compared to CoTs, our RoT performs strongly in generalization on these datasets but may have lower accuracy in some cases. This is because, in RoT, we add additional directions to the hidden states of the prompt. These manipulations will cause a loss of information regarding the original query, making the accuracy lower. 2) In terms of different models, the Llama-3-8B-Instruct model has been improved more significantly. For example, with Llama-2-7B-Chat as the backbone, RoT Z is improved by only 0.23 and 0.33 compared with Base on the GSM8K and SVAMP datasets, respectively; with Llama-3-8B-Instruct, the improvements are 1.52 and 2.66, respectively. This is primarily because the model is trained on a larger corpus and has learned more knowledge, so the activations contain richer information and can better capture related representations.
Robustness Analysis. We also conducted experiments on robustness, and the results are shown in Table 2 (more results are included in Appendix B.2). From this table, we can observe that RoT demonstrates a remarkable advancement over CoT in terms of robustness. We found that CoT methods are very sensitive to prompt design and sometimes fail to output the corresponding response based on the given instruction. However, our RoT extracts more essential information from the representation engineering level, making it more adaptable to various prompts. Note that for Llama-3-8B-Instruct, there are two datasets (SVAMP and Coin Flip) that do not provide robust performance gains. This is because Llama-3-8B-Instruct is a very strong model, while Coin Flip and SVAMP are two relatively easy tasks (as can be seen from the Table 1, the accuracy of CoTs in the SVAMP dataset is greater than 81%, and in the Coin Flip dataset is greater than 90%). These two factors may cause it to over-capture too many irrelevant concepts from the stimuli, thus pointing to the wrong reasoning direction.
<details>
<summary>x2.png Details</summary>
### Visual Description
## Grouped Bar Chart: Model Accuracy vs. Model Size
### Overview
The image displays a grouped bar chart comparing the accuracy (in percentage) of two model variants, "Base" and "RoT," across three different model sizes. The chart demonstrates a clear positive correlation between model size and accuracy for both variants.
### Components/Axes
* **Chart Type:** Grouped Bar Chart.
* **Y-Axis:** Labeled "Accuracy (%)". The scale runs from 20 to 60, with major tick marks at intervals of 5 (20, 25, 30, 35, 40, 45, 50, 55, 60).
* **X-Axis:** Labeled "Model Size". It contains three categorical groups: "7B", "13B", and "70B".
* **Legend:** Located in the top-left corner of the chart area.
* A dark blue square is labeled "Base".
* A light blue (teal) square is labeled "RoT".
* **Data Labels:** Numerical accuracy values are printed directly above each bar.
### Detailed Analysis
The chart presents paired bars for each model size category. The left bar in each pair is dark blue ("Base"), and the right bar is light blue ("RoT").
**1. Model Size: 7B**
* **Base (Dark Blue):** Accuracy = 26.00%
* **RoT (Light Blue):** Accuracy = 25.55%
* **Trend:** The "Base" model performs slightly better than the "RoT" model at this size, with a difference of 0.45 percentage points.
**2. Model Size: 13B**
* **Base (Dark Blue):** Accuracy = 35.63%
* **RoT (Light Blue):** Accuracy = 36.47%
* **Trend:** Both models show a significant accuracy increase from the 7B size. The "RoT" model now performs slightly better than the "Base" model, with a difference of 0.84 percentage points.
**3. Model Size: 70B**
* **Base (Dark Blue):** Accuracy = 52.08%
* **RoT (Light Blue):** Accuracy = 52.39%
* **Trend:** This is the highest accuracy achieved by both models. The performance gap between them is very narrow, with "RoT" leading by only 0.31 percentage points.
### Key Observations
* **Dominant Trend:** Accuracy increases substantially with model size for both "Base" and "RoT" variants. The jump from 7B to 13B is large (~10 percentage points), and the jump from 13B to 70B is even larger (~16-17 percentage points).
* **Performance Relationship:** The relative performance of "Base" vs. "RoT" flips between the smallest and the larger models. "Base" is marginally better at 7B, while "RoT" is marginally better at 13B and 70B.
* **Diminishing Relative Difference:** The absolute difference in accuracy between the two variants is small at all sizes (less than 1 percentage point) and appears to narrow as model size increases.
### Interpretation
The data suggests that **model scale is the primary driver of performance** on the evaluated task, with larger models (70B) achieving roughly double the accuracy of the smallest models (7B). The "RoT" variant (which may stand for a technique like "Rule of Thumb" or another modification) does not provide a dramatic accuracy improvement over the "Base" model. Its effect is minimal and inconsistent at the smallest scale, becoming slightly positive at larger scales. This implies that the benefit of the "RoT" method, if any, is marginal and may only manifest or become stable with sufficient model capacity. The chart effectively communicates that investing in larger model sizes yields far more significant accuracy gains than switching from the "Base" to the "RoT" variant for this particular benchmark.
</details>
(a) Larger scale
<details>
<summary>x3.png Details</summary>
### Visual Description
## Bar Chart: Mean Values by Layer
### Overview
The image is a vertical bar chart comparing "Mean Values (%)" across five different "Layer" categories. A horizontal red dashed line represents a baseline "CoT accuracy" value. The chart shows that all five layers have mean values significantly above this baseline, with very similar performance across the first three layers and a slight decline in the last two.
### Components/Axes
* **Chart Type:** Vertical bar chart with error bars.
* **Y-Axis:**
* **Label:** "Mean Values (%)"
* **Scale:** Linear scale from 0 to 60, with major tick marks at intervals of 10 (0, 10, 20, 30, 40, 50, 60).
* **X-Axis:**
* **Label:** "Layer"
* **Categories (from left to right):** 32, 64, 128, 256, 512.
* **Legend:**
* **Position:** Bottom-left corner of the plot area.
* **Content:** A red dashed line symbol followed by the text "CoT accuracy = 46".
* **Data Series:**
* **Bars:** Five blue bars, one for each Layer category.
* **Error Bars:** Small black error bars are present at the top of each blue bar.
* **Baseline Line:** A red dashed horizontal line spanning the width of the chart at the y-value of 46.
### Detailed Analysis
**Data Points (Values printed above each bar):**
* Layer 32: 54.33%
* Layer 64: 54.33%
* Layer 128: 54.33%
* Layer 256: 53.78%
* Layer 512: 53.67%
**Trend Verification:**
The visual trend shows a plateau followed by a very slight downward slope. The first three bars (Layers 32, 64, 128) are visually identical in height. The fourth bar (Layer 256) is marginally shorter, and the fifth bar (Layer 512) is the shortest, but the difference in height between all bars is minimal.
**Spatial Grounding:**
* The legend is positioned in the **bottom-left** quadrant of the chart area.
* The red dashed baseline ("CoT accuracy = 46") runs horizontally across the entire chart at the y=46 mark, clearly below all five blue bars.
* The numerical value labels are centered directly above their respective bars.
### Key Observations
1. **High Performance:** All measured mean values (53.67% to 54.33%) are substantially higher than the CoT accuracy baseline of 46%.
2. **Stability:** Performance is remarkably stable across the first three layer configurations (32, 64, 128), with an identical mean value of 54.33%.
3. **Minor Degradation:** There is a very small but consistent decrease in mean value as the layer size increases beyond 128. The drop from Layer 128 (54.33%) to Layer 512 (53.67%) is 0.66 percentage points.
4. **Low Variance:** The error bars on top of each bar are very short, indicating low variability or high confidence in the mean value measurements for each layer.
### Interpretation
This chart likely presents results from an experiment evaluating a model's performance (mean accuracy or a similar metric) when using different layer sizes or configurations (32, 64, 128, 256, 512). The "CoT accuracy = 46" line serves as a critical benchmark, representing the performance of a Chain-of-Thought (CoT) prompting baseline.
The data suggests that the method or model being tested consistently outperforms the CoT baseline across all tested layer sizes. The perfect stability at 54.33% for layers 32 through 128 implies a performance plateau within this range. The slight, monotonic decrease for layers 256 and 512 could indicate the onset of diminishing returns or a minor negative effect from increased model complexity or capacity in this specific context. However, the overall takeaway is one of robust and superior performance relative to the baseline, with only a negligible cost for scaling to larger layers. The small error bars reinforce the reliability of these results.
</details>
(b) Numbers of samples.
<details>
<summary>x4.png Details</summary>
### Visual Description
\n
## Bar Chart: Mean Values by Layer with CoT Accuracy Reference
### Overview
The image displays a vertical bar chart comparing "Mean Values (%)" across five distinct layers (1, 3, 5, 10, and 15). A horizontal red dashed line serves as a benchmark, labeled as "CoT accuracy = 46". The chart is presented on a white background with a simple, clean aesthetic.
### Components/Axes
* **Chart Type:** Vertical Bar Chart.
* **X-Axis (Horizontal):**
* **Label:** "Layer"
* **Categories/Markers:** 1, 3, 5, 10, 15. These are discrete, non-sequential numerical labels.
* **Y-Axis (Vertical):**
* **Label:** "Mean Values (%)"
* **Scale:** Linear scale from 0 to 60, with major tick marks at intervals of 10 (0, 10, 20, 30, 40, 50, 60).
* **Data Series (Bars):**
* Five blue bars, one for each layer category on the x-axis.
* Each bar has its exact numerical value annotated directly above it.
* **Reference Line & Legend:**
* A red dashed horizontal line spans the width of the chart.
* **Legend:** Located in the bottom-left corner of the plot area, inside a light gray box. It contains a sample of the red dashed line and the text "CoT accuracy = 46".
* The line is positioned at the y-axis value of 46.
### Detailed Analysis
**Data Points (Mean Values %):**
* **Layer 1:** 53.67
* **Layer 3:** 53.67
* **Layer 5:** 54.33
* **Layer 10:** 53.67
* **Layer 15:** 45.0
**Trend Verification:**
The visual trend shows a relatively stable, high plateau for the first four data points (Layers 1, 3, 5, 10), with a very slight peak at Layer 5. This is followed by a distinct and significant drop at the final data point (Layer 15).
**Spatial Grounding & Cross-Reference:**
* The legend is positioned in the **bottom-left** of the chart area.
* The red dashed reference line, corresponding to the legend, is placed at y=46.
* The bar for **Layer 15** (value 45.0) is the only bar whose top is visually below this red reference line. All other bars (Layers 1, 3, 5, 10) are clearly above it.
### Key Observations
1. **Performance Plateau:** Layers 1, 3, and 10 have identical mean values of 53.67%. Layer 5 is marginally higher at 54.33%. This indicates consistent performance across these four layers.
2. **Significant Drop at Layer 15:** There is a notable decrease in the mean value at Layer 15 to 45.0%, which is 8.67 percentage points lower than the plateau value.
3. **Benchmark Comparison:** The "CoT accuracy" benchmark is set at 46%. Layers 1, 3, 5, and 10 all perform above this benchmark (by ~7.7 to 8.3 percentage points). Layer 15 performs slightly below this benchmark (by 1 percentage point).
### Interpretation
This chart likely illustrates the performance (mean accuracy or a similar metric) of a model or system at different internal layers, compared to a Chain-of-Thought (CoT) reasoning accuracy baseline.
* **What the data suggests:** The system's performance is robust and consistent through its earlier and middle layers (1 through 10), consistently outperforming the CoT accuracy benchmark. However, performance degrades at a later layer (15), falling just below the benchmark.
* **Relationship between elements:** The red "CoT accuracy" line acts as a critical performance threshold. The chart's primary narrative is the comparison of layer-wise performance against this threshold. The drop at Layer 15 is the most salient feature, suggesting a potential point of failure, information loss, or a shift in the processing role at that depth in the model.
* **Notable anomaly:** The identical values for Layers 1, 3, and 10 are striking. This could indicate that the measured property is stable across these depths, or it might suggest a measurement or reporting artifact (e.g., values rounded to two decimal places from a common underlying value).
* **Implication:** If "Layer" corresponds to depth in a neural network, the findings imply that the model's representations relevant to this metric are well-maintained up to layer 10 but deteriorate by layer 15. This could inform decisions about where to extract features or apply interventions within the model architecture.
</details>
(c) Last layer
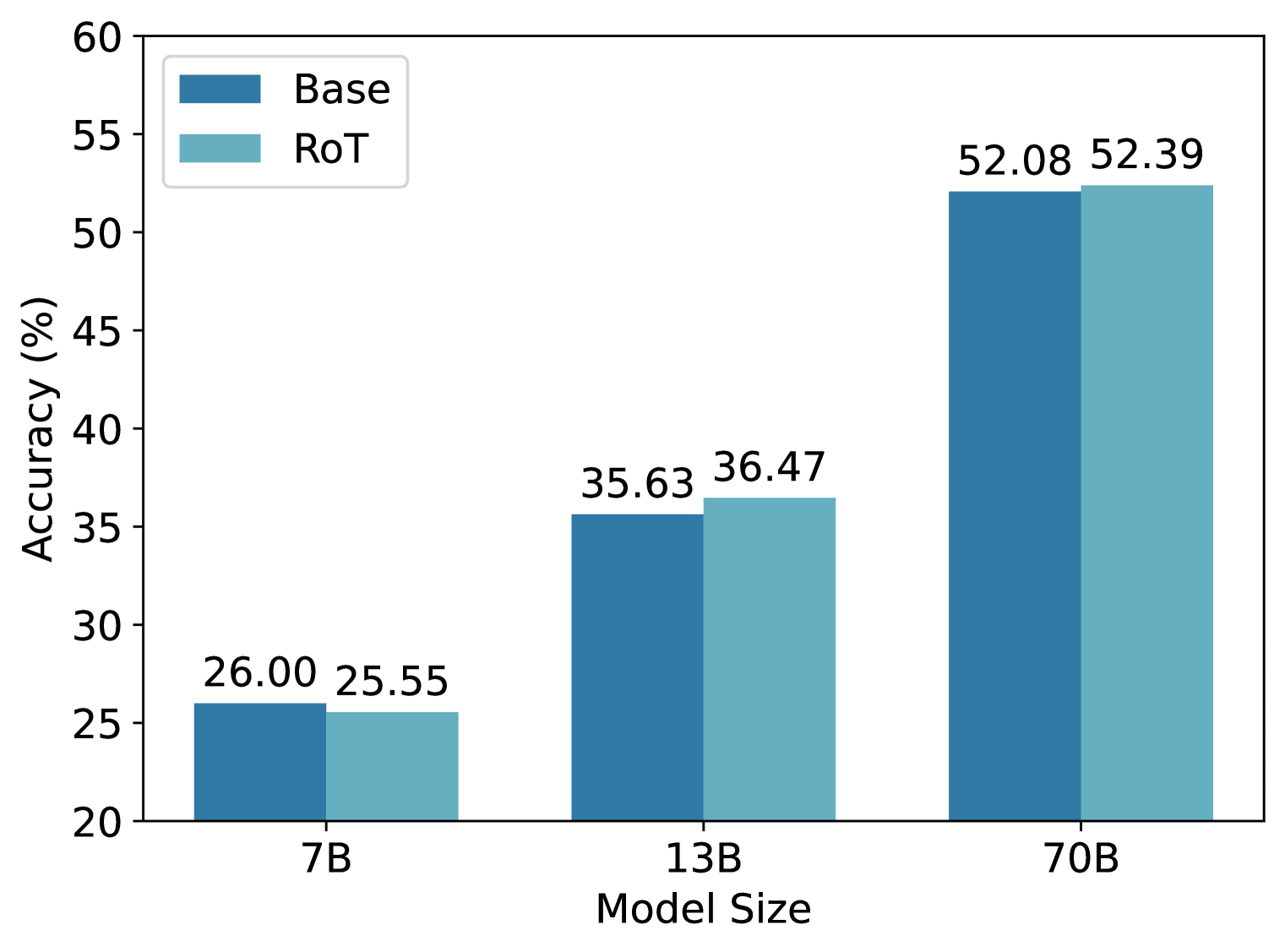
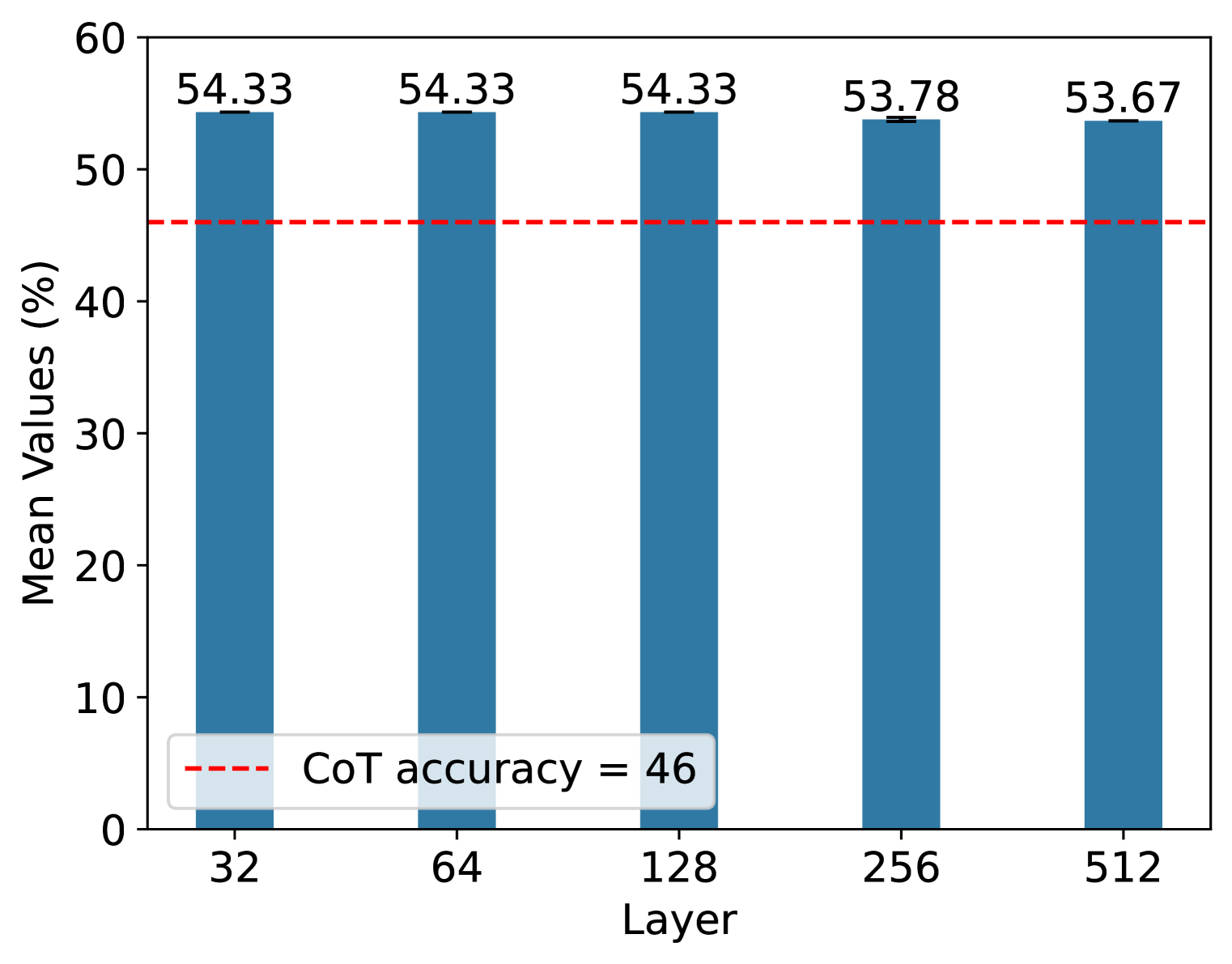
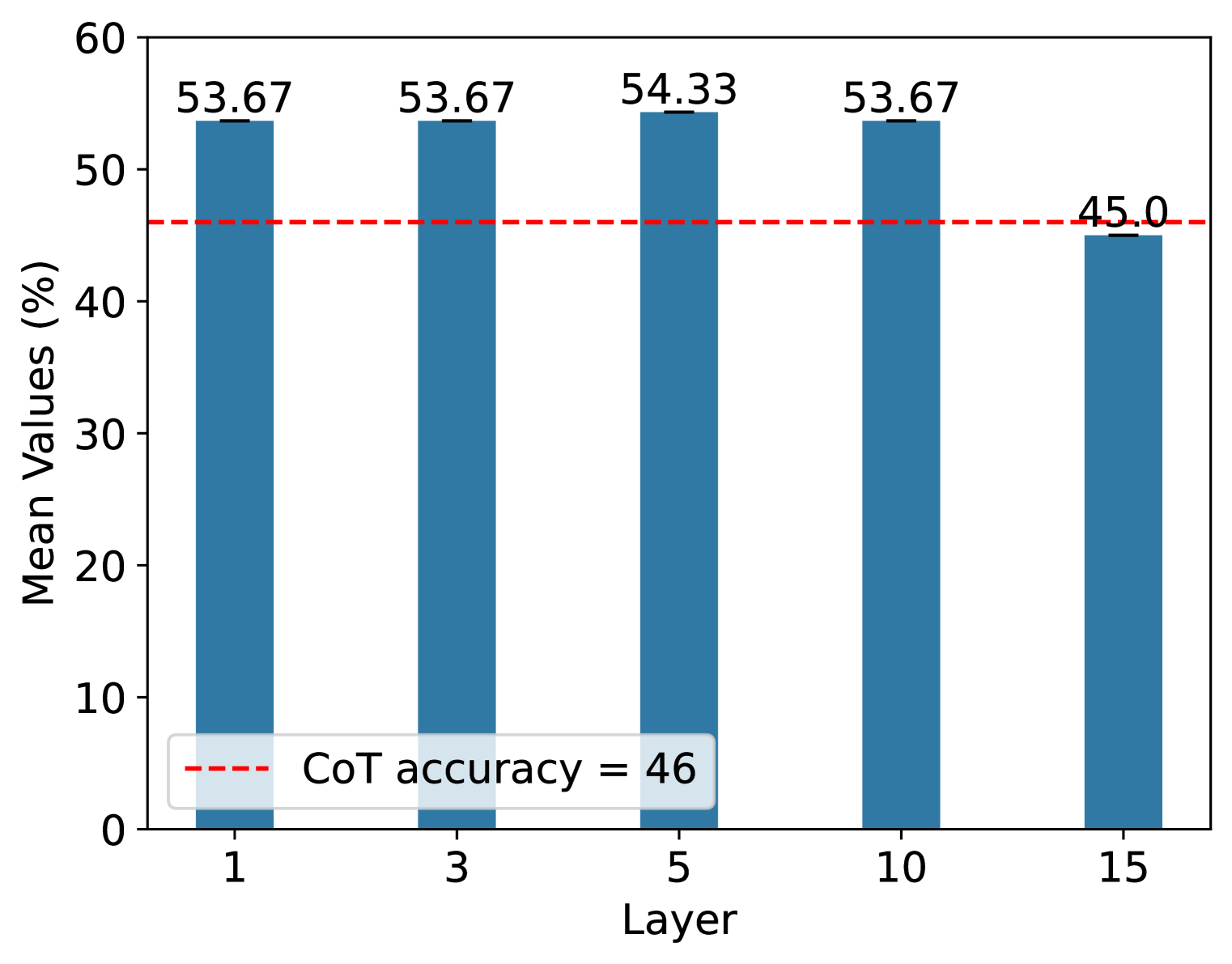
Figure 2: Ablation study of our approch. (a) Results on a larger scale on the GSM8K dataset. (b) Results on the number of samples on the SVAMP dataset. (c) Results on the number of selected layers on the SVAMP dataset.
Results on Larger Models. To further demonstrate the effectiveness of our approach, we conduct research on a larger scale. Specifically, we follow the few-shot settings, and evaluate two larger models (Llama-2-13B-Chat and Llama-2-70B-Chat) on the GSM8K dataset. From Figure 2, we can see that our approach has improved performance on both 13B and 70B, but the improvement on 70B is smaller. We speculate that this is because the 70B model contains very rich knowledge, and the knowledge contained in a few demonstrations has limited improvement on the model.
<details>
<summary>x5.png Details</summary>

### Visual Description
## Screenshot: AI Tutoring Chat Interface with Math Problem and Annotated Response
### Overview
The image is a screenshot of a chat interface, likely from an educational or AI tutoring application. It displays a user's math word problem and an AI-generated response. The response includes an incorrect solution to the problem, and beneath the text, there is a visualization of colored bars with numerical values, which appear to be token-level confidence scores or probability outputs from the language model that generated the response.
### Components/Axes
1. **User Query Bubble (Top):**
* **Position:** Top of the image, spanning most of the width.
* **Content:** A rounded rectangle with a light gray border containing the user's question.
* **Icon:** A cartoon-style user avatar (a smiling person's head) is positioned to the right of the bubble.
* **Text:** "John collects peaches for 3 hours. He can collect 2 peaches a minute. How many peaches does he collect?"
2. **AI Response Box (Center):**
* **Position:** Below the user query, centered.
* **Content:** A larger rounded rectangle with a light blue border containing the AI's step-by-step response.
* **Icon:** A cartoon-style robot avatar is positioned to the left of the box.
* **Text:** The response is split into three lines of text, interspersed with colored bars.
3. **Token Confidence/Probability Bars (Embedded in Response):**
* **Position:** Located between the lines of text within the AI response box.
* **Description:** Horizontal bars composed of adjacent colored segments (green and red/pink). Each segment contains a numerical value.
* **Values (from left to right):** `0.62` (green), `-0.15` (red), `0.62` (green), `-0.09` (pink), `0.62` (green), `-0.32` (red), `0.62` (green), `-0.06` (pink).
* **Note:** The exact mapping of these values to specific words or tokens in the adjacent text is not explicitly labeled, but they are visually aligned with the text flow.
### Detailed Analysis / Content Details
* **Full Transcription of AI Response Text:**
"To find out how many peaches John collects, we need to multiply the time he spends collecting peaches (3 hours) by the number of peaches he can collect per minute (2 peaches/minute). So John collects: 3 hours x 2 peaches/minute = 6 peaches. Therefore, John collects 6 peaches."
* **Mathematical Analysis of the Problem:**
* **Given:** Time = 3 hours, Rate = 2 peaches/minute.
* **Required Calculation:** To find total peaches, time and rate must use the same unit. The correct method is to convert hours to minutes (3 hours * 60 minutes/hour = 180 minutes), then multiply by the rate (180 minutes * 2 peaches/minute = 360 peaches).
* **AI's Calculation:** The AI incorrectly multiplies 3 hours directly by 2 peaches/minute, resulting in 6 peaches. This is a unit mismatch error.
* **Confidence Bar Analysis:**
* The bars show a pattern of high positive values (`0.62`) interspersed with smaller negative values.
* The highest negative value (`-0.32`) is the sixth segment, which may correspond to a point of low confidence or error in the generation process, potentially aligning with the flawed calculation step.
### Key Observations
1. **Critical Mathematical Error:** The AI's solution is fundamentally incorrect due to a failure to perform unit conversion (hours to minutes). The correct answer should be 360 peaches, not 6.
2. **Visualization of Model Uncertainty:** The colored bars provide a rare internal view of the language model's generation process, showing fluctuating confidence scores for different tokens. The presence of negative scores suggests points where the model's predicted probability was low or contradicted by context.
3. **Interface Design:** The layout is clean and typical of a chatbot, using avatars and bordered boxes to distinguish between user and system messages.
### Interpretation
This image serves as a clear case study in the limitations of large language models (LLMs) when performing multi-step reasoning, particularly with unit conversions. The AI correctly identifies the need to multiply time by rate but fails at the crucial step of ensuring dimensional consistency, a common pitfall in word problems.
The embedded confidence bars are particularly insightful. They suggest the model may have had low confidence (negative scores) at specific points in its reasoning chain, possibly during the formulation of the incorrect equation. This visualization could be a debugging tool for developers to identify where a model's reasoning breaks down.
The discrepancy between the confident, explanatory tone of the text and the underlying mathematical error highlights a key challenge in AI safety and reliability: models can present incorrect information with high fluency and apparent certainty. This underscores the importance of human oversight and verification, especially in educational or technical contexts. The image doesn't just show a wrong answer; it provides a glimpse into the "black box," showing that the model's internal uncertainty did not prevent it from outputting a confidently stated, yet false, conclusion.
</details>
Figure 3: A real case of reasoning error localization by using Llama-2-7B-Chat in a zero-shot scenario on GSM8K using Algorithm 1. The green bar indicates that the reasoning snippet is correct, and the red bar means that the reasoning snippet may be wrong. The numbers in the bar are the scores calculated by Algorithm 1.
Case Study of Reasoning Error Localization. We conducted a reasoning error localization experiment. We can calculate the token-level score with Algorithm 1 through our approach. Figure 3 shows that our approach can localize those errors in the response through CoT. In this case, Llama-2-7B-Chat did not really understand the known information in the given question and calculated different units (hour and minute). Specifically, before calculating the hour and minute tokens, the scores of the tokens are all greater than zero, indicating no potential errors, while when calculating the hour and minute tokens, our method detects potential conflicts with previous knowledge and thus obtains a score less than zero. We also show our additional case study in Appendix D.
Table 3: Results for different sample selection strategies.
| Llama-2-7B-Chat Llama-3-8B-Instruct | 23.43 74.22 | 25.55 74.37 | 25.32 74.52 | 25.24 74.37 | 25.32 73.92 | 25.30 74.27 |
| --- | --- | --- | --- | --- | --- | --- |
### 6.3 Ablation Study
Number of Samples. We conducted an ablation study on how to select samples and how many samples $N$ in the stimulus set for constructing neural populations are sufficient. For the sample selection strategy, we focus on two different strategies and evaluate these on the GSM8K dataset: 1) Random strategy. We randomly select samples in the training dataset using three random seeds. 2) Low Perplexity strategy. We select samples based on low perplexity. 3) High Perplexity strategy. Similar to the low perplexity strategy, we select samples based on high perplexity. As shown in Table 3, we can observe that the high perplexity strategy has better and more generalized performance. This is because high perplexity usually means low confidence in LLMs. Therefore, if a question has a higher perplexity, the question has more latent knowledge information.
For the number of samples $N$ , we consider the set $N=\{32,64,128,256,512\}$ and calculate their average accuracy scores on the SVAMP dataset using three different seeds. From Figure 2, we can see that the performance is quite stable for different numbers of samples. However, there is still a little decrease when $N$ is large enough. This is because when $N$ is large enough, the representation spaces contain richer information. Thus, adding the directions in (4) will make the query lose more of its query information, causing a lower accuracy.
Number of Selected Layers. Here we study the effect of different numbers of selected layers $|K|$ for neural populations. While LLMs have many layers, such as Llama-2-7B, which contains 32 layers, recent studies have shown that not all layers store important information about reasoning and that this information is usually found in the last layers of the model (Fan et al., 2024; Cosentino & Shekkizhar, 2024). Therefore, we consider the last $L$ layers, where $L=\{1,3,5,10,15\}$ .
In this experiment, we evaluate it with three different seeds. Figure 2 displays the result of average accuracy scores on the SVAMP dataset. From this figure, we can see that the accuracy first increases and then shows a decreasing trend as the number of control layers increases. This is because when the number of layers is very small, each manipulation will correct some of the reasoning errors. However, in RoT we have to manipulate each activation in the layer of the set $K$ , and each manipulation will lose some information about the query. Thus, the accuracy decreases when the number of layers is larger.
## 7 Conclusion
In this paper, we proposed a novel framework to explain and understand the fundamental factors behind CoT’s success. Specifically, we first connected CoT reasoning and the Hopfieldian view of cognition in cognitive neuroscience. Then, we developed a method for localizing reasoning errors and proposed the RoT framework to enhance the robustness of the reasoning process in CoTs. Experimental results demonstrate that RoT improves the robustness and interpretability of CoT reasoning while offering fine-grained control over the reasoning process.
## References
- Arditi et al. (2024) Andy Arditi, Oscar Obeso, Aaquib Syed, Daniel Paleka, Nina Rimsky, Wes Gurnee, and Neel Nanda. Refusal in language models is mediated by a single direction. CoRR, abs/2406.11717, 2024.
- Barack & Krakauer (2021) David L Barack and John W Krakauer. Two views on the cognitive brain. Nature Reviews Neuroscience, 22(6):359–371, 2021.
- Barlow (1953) Horace B Barlow. Summation and inhibition in the frog’s retina. The Journal of physiology, 119(1):69, 1953.
- Bechtel (2007) William Bechtel. Mental mechanisms: Philosophical perspectives on cognitive neuroscience. Psychology Press, 2007.
- Belinkov (2022) Yonatan Belinkov. Probing classifiers: Promises, shortcomings, and advances. Comput. Linguistics, 48(1):207–219, 2022.
- Bricken et al. (2023) Trenton Bricken, Adly Templeton, Joshua Batson, Brian Chen, Adam Jermyn, Tom Conerly, Nicholas L Turner, Cem Anil, Carson Denison, Amanda Askell, et al. Towards monosemanticity: Decomposing language models with dictionary learning. Transformer Circuits Thread, 2023.
- Burns et al. (2023) Collin Burns, Haotian Ye, Dan Klein, and Jacob Steinhardt. Discovering latent knowledge in language models without supervision. In Proceedings of ICLR 2023, 2023.
- Cheng et al. (2024a) Keyuan Cheng, Muhammad Asif Ali, Shu Yang, Gang Lin, Yuxuan Zhai, Haoyang Fei, Ke Xu, Lu Yu, Lijie Hu, and Di Wang. Leveraging logical rules in knowledge editing: A cherry on the top. CoRR, abs/2405.15452, 2024a.
- Cheng et al. (2024b) Keyuan Cheng, Gang Lin, Haoyang Fei, Yuxuan Zhai, Lu Yu, Muhammad Asif Ali, Lijie Hu, and Di Wang. Multi-hop question answering under temporal knowledge editing. CoRR, abs/2404.00492, 2024b.
- Clark et al. (2019) Kevin Clark, Urvashi Khandelwal, Omer Levy, and Christopher D. Manning. What does BERT look at? an analysis of bert’s attention. In Proceedings of ACL 2019, pp. 276–286, 2019.
- Cobbe et al. (2021) Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, et al. Training verifiers to solve math word problems. CoRR, abs/2110.14168, 2021.
- Cosentino & Shekkizhar (2024) Romain Cosentino and Sarath Shekkizhar. Reasoning in large language models: A geometric perspective. CoRR, abs/2407.02678, 2024.
- Creswell & Shanahan (2022) Antonia Creswell and Murray Shanahan. Faithful reasoning using large language models. CoRR, abs/2208.14271, 2022.
- Dale et al. (2023) David Dale, Elena Voita, Loïc Barrault, and Marta R. Costa-jussà. Detecting and mitigating hallucinations in machine translation: Model internal workings alone do well, sentence similarity even better. In Proceedings of ACL 2023, pp. 36–50, 2023.
- Dutta et al. (2024) Subhabrata Dutta, Joykirat Singh, Soumen Chakrabarti, and Tanmoy Chakraborty. How to think step-by-step: A mechanistic understanding of chain-of-thought reasoning. CoRR, abs/2402.18312, 2024.
- Fan et al. (2024) Siqi Fan, Xin Jiang, Xiang Li, Xuying Meng, Peng Han, Shuo Shang, Aixin Sun, Yequan Wang, and Zhongyuan Wang. Not all layers of llms are necessary during inference. CoRR, abs/2403.02181, 2024.
- Fong & Vedaldi (2018) Ruth Fong and Andrea Vedaldi. Net2vec: Quantifying and explaining how concepts are encoded by filters in deep neural networks. In Proceedings of CVPR 2018, pp. 8730–8738, 2018.
- Gandikota et al. (2023) Rohit Gandikota, Joanna Materzynska, Jaden Fiotto-Kaufman, and David Bau. Erasing concepts from diffusion models. In Proceedings of ICCV 2023, pp. 2426–2436, 2023.
- Geva et al. (2021) Mor Geva, Daniel Khashabi, Elad Segal, Tushar Khot, Dan Roth, and Jonathan Berant. Did aristotle use a laptop? A question answering benchmark with implicit reasoning strategies. Trans. Assoc. Comput. Linguistics, 9:346–361, 2021.
- Hopfield (1982) John J Hopfield. Neural networks and physical systems with emergent collective computational abilities. Proceedings of the national academy of sciences, 79(8):2554–2558, 1982.
- Hopfield (1984) John J Hopfield. Neurons with graded response have collective computational properties like those of two-state neurons. Proceedings of the national academy of sciences, 81(10):3088–3092, 1984.
- Hopfield & Tank (1986) John J Hopfield and David W Tank. Computing with neural circuits: A model. Science, 233(4764):625–633, 1986.
- Hu et al. (2023a) Lijie Hu, Ivan Habernal, Lei Shen, and Di Wang. Differentially private natural language models: Recent advances and future directions. CoRR, abs/2301.09112, 2023a.
- Hu et al. (2023b) Lijie Hu, Yixin Liu, Ninghao Liu, Mengdi Huai, Lichao Sun, and Di Wang. Improving faithfulness for vision transformers. CoRR, abs/2311.17983, 2023b.
- Hu et al. (2023c) Lijie Hu, Yixin Liu, Ninghao Liu, Mengdi Huai, Lichao Sun, and Di Wang. SEAT: stable and explainable attention. In Brian Williams, Yiling Chen, and Jennifer Neville (eds.), Proceedings of AAAI 2023, pp. 12907–12915, 2023c.
- Hu et al. (2024) Lijie Hu, Chenyang Ren, Zhengyu Hu, Cheng-Long Wang, and Di Wang. Editable concept bottleneck models. CoRR, abs/2405.15476, 2024.
- Jain & Wallace (2019) Sarthak Jain and Byron C. Wallace. Attention is not explanation. In Proceedings of NAACL-HLT 2019, pp. 3543–3556, 2019.
- Jin et al. (2024) Mingyu Jin, Qinkai Yu, Dong Shu, Haiyan Zhao, Wenyue Hua, Yanda Meng, Yongfeng Zhang, and Mengnan Du. The impact of reasoning step length on large language models. CoRR, abs/2401.04925, 2024.
- Kim et al. (2018) Been Kim, Martin Wattenberg, Justin Gilmer, Carrie J. Cai, James Wexler, Fernanda B. Viégas, and Rory Sayres. Interpretability beyond feature attribution: Quantitative testing with concept activation vectors (TCAV). In Proceedings of ICML 2018, pp. 2673–2682, 2018.
- Kim et al. (2023) Seungone Kim, Se June Joo, Yul Jang, Hyungjoo Chae, and Jinyoung Yeo. Cotever: Chain of thought prompting annotation toolkit for explanation verification. In Proceedings of EACL 2023, pp. 195–208, 2023.
- Kojima et al. (2022) Takeshi Kojima, Shixiang Shane Gu, Machel Reid, Yutaka Matsuo, and Yusuke Iwasawa. Large language models are zero-shot reasoners. In Proceedings of NeurIPS 2022, 2022.
- Lai et al. (2024) Songning Lai, Lijie Hu, Junxiao Wang, Laure Berti-Équille, and Di Wang. Faithful vision-language interpretation via concept bottleneck models. In Proceedings of ICLR 2024, 2024.
- Lanham et al. (2023) Tamera Lanham, Anna Chen, Ansh Radhakrishnan, Benoit Steiner, Carson Denison, Danny Hernandez, Dustin Li, Esin Durmus, Evan Hubinger, Jackson Kernion, et al. Measuring faithfulness in chain-of-thought reasoning. CoRR, abs/2307.13702, 2023.
- Li et al. (2024) Jia Li, Lijie Hu, Zhixian He, Jingfeng Zhang, Tianhang Zheng, and Di Wang. Text guided image editing with automatic concept locating and forgetting. CoRR, abs/2405.19708, 2024.
- Lyu et al. (2023) Qing Lyu, Shreya Havaldar, Adam Stein, Li Zhang, Delip Rao, Eric Wong, Marianna Apidianaki, and Chris Callison-Burch. Faithful chain-of-thought reasoning. In Proceedings of IJCNLP 2023, pp. 305–329, 2023.
- Meng et al. (2022) Kevin Meng, David Bau, Alex Andonian, and Yonatan Belinkov. Locating and editing factual associations in GPT. In Proceedings of NeurIPS 2022, 2022.
- Merrill & Sabharwal (2023) William Merrill and Ashish Sabharwal. The expressive power of transformers with chain of thought. CoRR, abs/2310.07923, 2023.
- Meta (2024) Meta. Introducing meta llama 3: The most capable openly available llm to date. Meta blog, 2024.
- Mikolov et al. (2013) Tomás Mikolov, Wen-tau Yih, and Geoffrey Zweig. Linguistic regularities in continuous space word representations. In Proceedings of HLT-NAACL 2013, pp. 746–751, 2013.
- Min et al. (2022) Sewon Min, Xinxi Lyu, Ari Holtzman, Mikel Artetxe, Mike Lewis, Hannaneh Hajishirzi, and Luke Zettlemoyer. Rethinking the role of demonstrations: What makes in-context learning work? In Proceedings of EMNLP 2022, pp. 11048–11064, 2022.
- Mogenson (2018) Gordon J Mogenson. The neurobiology of Behavior: an introduction. Routledge, 2018.
- Nguyen et al. (2019) Anh Nguyen, Jason Yosinski, and Jeff Clune. Understanding neural networks via feature visualization: A survey. In Proceedings of LNCS 2019, pp. 55–76, 2019.
- Nguyen et al. (2016) Anh Mai Nguyen, Alexey Dosovitskiy, Jason Yosinski, Thomas Brox, and Jeff Clune. Synthesizing the preferred inputs for neurons in neural networks via deep generator networks. In Proceedings of NeurIPS 2016, pp. 3387–3395, 2016.
- Nye et al. (2021) Maxwell I. Nye, Anders Johan Andreassen, Guy Gur-Ari, Henryk Michalewski, Jacob Austin, David Bieber, David Dohan, Aitor Lewkowycz, Maarten Bosma, David Luan, et al. Show your work: Scratchpads for intermediate computation with language models. CoRR, abs/2112.00114, 2021.
- Olah et al. (2020) Chris Olah, Nick Cammarata, Ludwig Schubert, Gabriel Goh, Michael Petrov, and Shan Carter. Zoom in: An introduction to circuits. Distill, 5(3):e00024–001, 2020.
- Olsson et al. (2022) Catherine Olsson, Nelson Elhage, Neel Nanda, Nicholas Joseph, Nova DasSarma, Tom Henighan, Ben Mann, Amanda Askell, Yuntao Bai, Anna Chen, et al. In-context learning and induction heads. CoRR, abs/2209.11895, 2022.
- Ortiz-Jiménez et al. (2023) Guillermo Ortiz-Jiménez, Alessandro Favero, and Pascal Frossard. Task arithmetic in the tangent space: Improved editing of pre-trained models. In Proceedings of NeurIPS 2023, 2023.
- Ouyang et al. (2022) Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll L. Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. Training language models to follow instructions with human feedback. In Proceedings of NeurIPS 2022, 2022.
- Pan et al. (2023) Liangming Pan, Alon Albalak, Xinyi Wang, and William Wang. Logic-lm: Empowering large language models with symbolic solvers for faithful logical reasoning. In Proceedings of EMNLP 2023, pp. 3806–3824, 2023.
- Park et al. (2024) Kiho Park, Yo Joong Choe, and Victor Veitch. The linear representation hypothesis and the geometry of large language models. In Proceedings of ICML 2024, 2024.
- Patel et al. (2021) Arkil Patel, Satwik Bhattamishra, and Navin Goyal. Are NLP models really able to solve simple math word problems? In Proceedings of NAACL-HLT 2021, pp. 2080–2094, 2021.
- Pfau et al. (2024) Jacob Pfau, William Merrill, and Samuel R. Bowman. Let’s think dot by dot: Hidden computation in transformer language models. CoRR, abs/2404.15758, 2024.
- Rae et al. (2021) Jack W. Rae, Sebastian Borgeaud, Trevor Cai, Katie Millican, Jordan Hoffmann, H. Francis Song, John Aslanides, Sarah Henderson, Roman Ring, Susannah Young, et al. Scaling language models: Methods, analysis & insights from training gopher. CoRR, abs/2112.11446, 2021.
- Rai & Yao (2024) Daking Rai and Ziyu Yao. An investigation of neuron activation as a unified lens to explain chain-of-thought eliciting arithmetic reasoning of llms. arXiv preprint arXiv:2406.12288, 2024.
- Shao et al. (2023) Shun Shao, Yftah Ziser, and Shay B. Cohen. Gold doesn’t always glitter: Spectral removal of linear and nonlinear guarded attribute information. In Proceedings of EACL 2023, pp. 1603–1614, 2023.
- Sherrington (1906) Charles Scott Sherrington. Observations on the scratch-reflex in the spinal dog. The Journal of physiology, 34(1-2):1, 1906.
- Simonyan et al. (2014) Karen Simonyan, Andrea Vedaldi, and Andrew Zisserman. Deep inside convolutional networks: Visualising image classification models and saliency maps. In Proceedings of ICLR 2014, 2014.
- Smilkov et al. (2017) Daniel Smilkov, Nikhil Thorat, Been Kim, Fernanda B. Viégas, and Martin Wattenberg. Smoothgrad: removing noise by adding noise. CoRR, abs/1706.03825, 2017.
- Szegedy et al. (2014) Christian Szegedy, Wojciech Zaremba, Ilya Sutskever, Joan Bruna, Dumitru Erhan, Ian J. Goodfellow, and Rob Fergus. Intriguing properties of neural networks. In Proceedings of ICLR 2014, 2014.
- Talmor et al. (2019) Alon Talmor, Jonathan Herzig, Nicholas Lourie, and Jonathan Berant. Commonsenseqa: A question answering challenge targeting commonsense knowledge. In Proceedings of NAACL-HLT 2019, pp. 4149–4158, 2019.
- Tang et al. (2023) Xiaojuan Tang, Zilong Zheng, Jiaqi Li, Fanxu Meng, Song-Chun Zhu, Yitao Liang, and Muhan Zhang. Large language models are in-context semantic reasoners rather than symbolic reasoners. CoRR, abs/2305.14825, 2023.
- Templeton et al. (2024) Adly Templeton, Tom Conerly, Jonathan Marcus, Jack Lindsey, Trenton Bricken, Brian Chen, Adam Pearce, Craig Citro, Emmanuel Ameisen, Andy Jones, et al. Scaling monosemanticity: Extracting interpretable features from claude 3 sonnet. Transformer Circuits Thread, 2024.
- Tigges et al. (2023) Curt Tigges, Oskar John Hollinsworth, Atticus Geiger, and Neel Nanda. Linear representations of sentiment in large language models. arXiv preprint arXiv:2310.15154, 2023.
- Touvron et al. (2023) Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, et al. Llama 2: Open foundation and fine-tuned chat models. CoRR, abs/2307.09288, 2023.
- Vilas et al. (2024) Martina G. Vilas, Federico Adolfi, David Poeppel, and Gemma Roig. Position: An inner interpretability framework for AI inspired by lessons from cognitive neuroscience. In Proceedings of ICML 2024, 2024.
- Voita et al. (2024) Elena Voita, Javier Ferrando, and Christoforos Nalmpantis. Neurons in large language models: Dead, n-gram, positional. In Lun-Wei Ku, Andre Martins, and Vivek Srikumar (eds.), Findings of ACL 2024, pp. 1288–1301, 2024.
- Wang et al. (2023a) Boshi Wang, Sewon Min, Xiang Deng, Jiaming Shen, You Wu, Luke Zettlemoyer, and Huan Sun. Towards understanding chain-of-thought prompting: An empirical study of what matters. In Proceedings of ACL 2023, pp. 2717–2739, 2023a.
- Wang et al. (2023b) Kevin Ro Wang, Alexandre Variengien, Arthur Conmy, Buck Shlegeris, and Jacob Steinhardt. Interpretability in the wild: a circuit for indirect object identification in GPT-2 small. In Proceedings of ICLR 2023, 2023b.
- Wang & Zhou (2024) Xuezhi Wang and Denny Zhou. Chain-of-thought reasoning without prompting. CoRR, abs/2402.10200, 2024.
- Wang et al. (2023c) Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc V. Le, Ed H. Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. Self-consistency improves chain of thought reasoning in language models. In Proceedings of ICLR 2023, 2023c.
- Wei et al. (2022) Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed H. Chi, Quoc V. Le, and Denny Zhou. Chain-of-thought prompting elicits reasoning in large language models. In Proceedings of NeurIPS 2022, 2022.
- Weng et al. (2023) Yixuan Weng, Minjun Zhu, Fei Xia, Bin Li, Shizhu He, Shengping Liu, Bin Sun, Kang Liu, and Jun Zhao. Large language models are better reasoners with self-verification. In Proceedings of EMNLP 2023, pp. 2550–2575, 2023.
- Yang et al. (2024a) Shu Yang, Muhammad Asif Ali, Cheng-Long Wang, Lijie Hu, and Di Wang. Moral: Moe augmented lora for llms’ lifelong learning. CoRR, abs/2402.11260, 2024a.
- Yang et al. (2024b) Shu Yang, Lijie Hu, Lu Yu, Muhammad Asif Ali, and Di Wang. Human-ai interactions in the communication era: Autophagy makes large models achieving local optima. CoRR, abs/2402.11271, 2024b.
- Yang et al. (2024c) Shu Yang, Jiayuan Su, Han Jiang, Mengdi Li, Keyuan Cheng, Muhammad Asif Ali, Lijie Hu, and Di Wang. Dialectical alignment: Resolving the tension of 3h and security threats of llms. CoRR, abs/2404.00486, 2024c.
- Zhang et al. (2023) Ziyin Zhang, Chaoyu Chen, Bingchang Liu, Cong Liao, Zi Gong, Hang Yu, Jianguo Li, and Rui Wang. A survey on language models for code. CoRR, abs/2311.07989, 2023.
- Zhao et al. (2023) Ruochen Zhao, Xingxuan Li, Shafiq Joty, Chengwei Qin, and Lidong Bing. Verify-and-edit: A knowledge-enhanced chain-of-thought framework. In Proceedings of ACL 2023, pp. 5823–5840, 2023.
- Zhong et al. (2023) Zexuan Zhong, Zhengxuan Wu, Christopher D. Manning, Christopher Potts, and Danqi Chen. Mquake: Assessing knowledge editing in language models via multi-hop questions. In Proceedings of EMNLP 2023, pp. 15686–15702, 2023.
- Zhou et al. (2023) Denny Zhou, Nathanael Schärli, Le Hou, Jason Wei, Nathan Scales, Xuezhi Wang, Dale Schuurmans, Claire Cui, Olivier Bousquet, Quoc V. Le, and Ed H. Chi. Least-to-most prompting enables complex reasoning in large language models. In Proceedings of ICLR 2023, 2023.
- Zou et al. (2023) Andy Zou, Long Phan, Sarah Chen, James Campbell, Phillip Guo, Richard Ren, Alexander Pan, Xuwang Yin, Mantas Mazeika, Ann-Kathrin Dombrowski, et al. Representation engineering: A top-down approach to AI transparency. CoRR, abs/2310.01405, 2023.
## Appendix A Additional Preliminaries
The Sherringtonian View. Unlike the Hopfieldian perspective, the Sherringtonian view (Sherrington, 1906; Barlow, 1953) of cognitive explanation emphasizes the importance of direct neuron-to-neuron connections in the brain. This view posits that the primary explanation for cognition lies in the specific interactions between neurons and the computations these neurons perform within well-defined circuits (Mogenson, 2018).
At an algorithmic level, the Sherringtonian view conceptualizes cognition as networks of nodes (neurons) with weighted connections (synapses) between them. In this framework, neurons perform distinct computational transformations on the signals they receive from other neurons in the network. Cognitive processes are described by how individual neurons receive inputs, process these inputs through neural transfer functions, and transmit the resulting signals to connected neurons. Thus, cognition is explained through the computations occurring at the level of individual neurons and the signal flow across their connections.
#### Zero-shot CoT.
Zero-shot CoT is a simple but effective chain of thought (CoT) prompting approach proposed by Kojima et al. (2022). It allows language models to generate a step-by-step explanation or thought process to solve problems without requiring prior demonstrations or specific training by simply adding “ Let’s think step by step ” before each answer. Specifically, given a query $q$ and a model $M$ with weights $θ$ , the generation process can be defined as:
$$
R=arg max pr(R|q,t;θ) \tag{5}
$$
where $R$ is the response text of the model, which is generated from all potential responses $R$ , and $t$ is a prompt text like “ Let’s think sttep by step. ”
#### Few-shot CoT.
Similar to zero-shot CoT, few-shot CoT (Wei et al., 2022) is also a prompting technique that gives a few examples with step-by-step reasoning processes to stimulate the model’s reasoning ability. Formally, given the query $q$ and a set of demonstrations $D=\{(\tilde{q}_1,\tilde{a}_1),(\tilde{q}_2,\tilde{a}_2),\dots\}$ , our aim is to generate a response with intermediate reasoning steps:
$$
R=arg max pr(R|D,q;θ) \tag{6}
$$
Table 4: Statistics of the data set.
| GSM8K | Arithmetic | 1319 | Number |
| --- | --- | --- | --- |
| SVAMP | Arithmetic | 300 | Number |
| StrategyQA | Commonsense | 2290 | Yes or No |
| CSQA | Commonsense | 1221 | Multiple Choices |
| Coin Flip | Symbolic | 2000 | Yes or No |
| Random Letter | Symbolic | 300 | Letter |
## Appendix B Other Experimental Details
### B.1 Dataset
The statistics of the data is shown in Table 4. The details about each data set are as follows:
#### Arithmetic Reasoning.
The arithmetic reasoning benchmarks aim to analyze and/or understand the model’s mathematical reasoning skills. These include: (i) GSM8K Cobbe et al. (2021), a math word problems benchmark encompassing a variety of reasoning steps; (ii) SVAMP Patel et al. (2021), containing math word problems with multiple structures.
#### Commonsense Reasoning.
These data sets aim to analyze the ability of the model on commonsense reasoning tasks. These include: (i) StrategyQA Geva et al. (2021), a commonsense benchmark requiring multi-level strategy to answer the question; (ii) CSQA Talmor et al. (2019) benchmark dataset of multiple-choice questions that require different types of commonsense knowledge to predict the correct answers.
#### Symbolic Reasoning.
These data sets aim to test the abilities of the model requiring advanced symbolic capabilities. For this task, we curated two new datasets, as follows. (i) Coin Flip dataset, we employ the data curation strategy of a previous study Wei et al. (2022) using the number of operations as 2, 4 and 7 to come up with the complete dataset; (ii) Random Letter, an advanced version of the last letter concatenation with reference to the previously studied form of word assembly Wei et al. (2022), where 2-4 words are randomly formed and characters are randomly drawn from them, instead of taking the beginning or the end of each word at a fixed point.
Table 5: The detailed robust results in the zero-shot settings.
| CoT Z1 CoT Z2 CoT Z3 | 26.31 26.23 23.58 | 46.00 48.33 51.67 | 43.41 43.90 46.68 | 62.05 60.52 63.54 | 52.75 48.35 50.10 | 24.33 17.67 17.33 |
| --- | --- | --- | --- | --- | --- | --- |
| RoT Z1 | 26.23 | 54.33 | 48.24 | 63.54 | 45.45 | 20.67 |
| RoT Z2 | 24.72 | 53.67 | 47.91 | 63.58 | 45.50 | 20.67 |
| RoT Z3 | 25.09 | 53.67 | 47.42 | 63.23 | 45.35 | 20.33 |
| Llama-3-8B-Instruct | | | | | | |
| CoT Z1 | 74.45 | 82.33 | 72.24 | 66.07 | 90.45 | 43.00 |
| CoT Z2 | 74.83 | 83.33 | 72.65 | 63.32 | 83.55 | 42.00 |
| CoT Z3 | 58.15 | 40.67 | 73.71 | 63.10 | 89.40 | 33.67 |
| RoT Z1 | 74.83 | 83.33 | 72.89 | 65.24 | 76.35 | 47.67 |
| RoT Z2 | 74.91 | 83.33 | 72.73 | 64.93 | 71.95 | 46.67 |
| RoT Z3 | 73.62 | 82.00 | 72.48 | 65.50 | 68.15 | 42.00 |
Table 6: The detailed robust results in the few-shot settings.
| CoT F1 CoT F2 RoT F1 | 4.62 3.18 25.55 | 38.67 38.67 56.00 | 53.07 50.29 48.16 | 59.26 59.74 63.80 | 47.60 50.30 45.50 | 31.00 29.00 20.33 |
| --- | --- | --- | --- | --- | --- | --- |
| RoT F2 | 25.63 | 55.33 | 48.16 | 65.68 | 45.50 | 20.33 |
| Llama-3-8B-Instruct | | | | | | |
| CoT F1 | 72.02 | 81.00 | 73.63 | 62.75 | 96.50 | 50.67 |
| CoT F2 | 72.25 | 80.67 | 72.89 | 67.47 | 95.00 | 50.67 |
| RoT F1 | 74.37 | 83.67 | 73.30 | 65.94 | 70.30 | 43.67 |
| RoT F2 | 74.00 | 83.33 | 73.63 | 65.68 | 69.85 | 42.67 |
### B.2 Details of Robust Experiment
We show our detailed results of the robustness in Table 5 and 6. For zero-shot settings, the terms $Z1$ , $Z2$ , and $Z3$ refer to the use of three different prompts, respectively (as shown in Section 6). For few-shot settings, the terms $F1$ and $F2$ also refer to two different experiments, as shown in Section 6.
Table 7: The stimulus prompting design for CoT-style methods.
| zero-shot CoT | USER: <question> ASSISTANT: Let’s think step by step. |
| --- | --- |
| USER: <question> ASSISTANT: | |
| few-shot CoT | USER: < $n$ different examples> <question> ASSISTANT: |
| USER: <question> ASSISTANT: | |
## Appendix C Prompts
### C.1 Prompt Templates
Table 7 illustrates the design of stimulus prompts utilized for Chain of Thought (CoT) prompting, distinguishing between zero-shot CoT and few-shot CoT methodologies. In the zero-shot CoT approach, the model is presented with a question devoid of preceding examples, in contrast to the few-shot CoT method, where the model is furnished with multiple exemplars. For each method, the first row is a positive prompt and the second is a negative prompt. Red indicates stimulus token.
Table 8: Extraction templates for various tasks.
| StrategyQA CSQA Coin Flip | Therefore, the answer (Yes or No) is Therefore, among A through E, the answer is Therefore, the answer (Yes or No) is |
| --- | --- |
| Random Letter | Therefore, the answer is |
Table 9: Few-shot exemplars for the full chain of thought prompt for the arithmetic reasoning task. The highlighted part refers to the reasoning steps.
| Prompt for GSM8K and SVAMP |
| --- |
| Q: There are 15 trees in the grove. Grove workers will plant trees in the grove today. After they are done, there will be 21 trees. How many trees did the grove workers plant today? |
| A: There are 15 trees originally. Then there were 21 trees after some more were planted. So there must have been 21 - 15 = 6. The answer is 6. |
| Q: If there are 3 cars in the parking lot and 2 more cars arrive, how many cars are in the parking lot? |
| A: There are originally 3 cars. 2 more cars arrive. 3 + 2 = 5. The answer is 5. |
| Q: Leah had 32 chocolates and her sister had 42. If they ate 35, how many pieces do they have left in total? |
| A: Originally, Leah had 32 chocolates. Her sister had 42. So in total they had 32 + 42 = 74. After eating 35, they had 74 - 35 = 39. The answer is 39. |
| Q: Jason had 20 lollipops. He gave Denny some lollipops. Now Jason has 12 lollipops. How many lollipops did Jason give to Denny? |
| A: Jason started with 20 lollipops. Then he had 12 after giving some to Denny. So he gave Denny 20 - 12 = 8. The answer is 8. |
| Q: Shawn has five toys. For Christmas, he got two toys each from his mom and dad. How many toys does he have now? |
| A: Shawn started with 5 toys. If he got 2 toys each from his mom and dad, then that is 4 more toys. 5 + 4 = 9. The answer is 9. |
| Q: There were nine computers in the server room. Five more computers were installed each day, from Monday to Thursday. How many computers are now in the server room? |
| A: There were originally 9 computers. For each of 4 days, 5 more computers were added. So 5 * 4 = 20 computers were added. 9 + 20 is 29. The answer is 29. |
| Q: Michael had 58 golf balls. On Tuesday, he lost 23 golf balls. On Wednesday, he lost 2 more. How many golf balls did he have at the end of Wednesday? |
| A: Michael started with 58 golf balls. After losing 23 on Tuesday, he had 58 - 23 = 35. After losing 2 more, he had 35 - 2 = 33 golf balls. The answer is 33. |
| Q: Olivia has $23. She bought five bagels for $3 each. How much money does she have left? |
| A: Olivia had 23 dollars. 5 bagels for 3 dollars each will be 5 x 3 = 15 dollars. So she has 23 - 15 dollars left. 23 - 15 is 8. The answer is 8. |
### C.2 Answer Extract Prompts
The demonstration of our answer extraction method is in Table 8.
### C.3 Example Prompts for Few-shot Setting
We demonstrate our example prompts for few-shot setting in Table 9, 10, 11, 12 and 13.
Table 10: Few-shot exemplars for the full chain of thought prompt for StrategyQA. The highlighted part refers to the reasoning steps.
| Prompt for StrategyQA |
| --- |
| Q: Do hamsters provide food for any animals? |
| A: Hamsters are prey animals. Prey are food for predators. Thus, hamsters provide food for some animals. So the answer is yes. |
| Q: Could Brooke Shields succeed at University of Pennsylvania? |
| A: Brooke Shields went to Princeton University. Princeton University is about as academically rigorous as the University of Pennsylvania. Thus, Brooke Shields could also succeed at the University of Pennsylvania. So the answer is yes. |
| Q: Yes or no: Hydrogen’s atomic number squared exceeds number of Spice Girls? |
| A: Hydrogen has an atomic number of 1. 1 squared is 1. There are 5 Spice Girls. Thus, Hydrogen’s atomic number squared is less than 5. So the answer is no. |
| Q: Yes or no: Is it common to see frost during some college commencements? |
| A: College commencement ceremonies can happen in December, May, and June. December is in the winter, so there can be frost. Thus, there could be frost at some commencements. So the answer is yes. |
| Q: Yes or no: Could a llama birth twice during War in Vietnam (1945-46)? |
| A: The War in Vietnam was 6 months. The gestation period for a llama is 11 months, which is more than 6 months. Thus, a llama could not give birth twice during the War in Vietnam. So the answer is no. |
| Q: Yes or no: Would a pear sink in water? |
| A: The density of a pear is about $0.6g/cm^3$ , which is less than water. Objects less dense than water float. Thus, a pear would float. So the answer is no. |
Table 11: Few-shot exemplars for the full chain of thought prompt for CSQA. The highlighted part refers to the reasoning steps. There are newlines between the answer choices that are omitted in the table for space reasons.
| Prompt for CSQA |
| --- |
| Q: What do people use to absorb extra ink from a fountain pen? Answer Choices: (a) shirt pocket (b) calligrapher’s hand (c) inkwell (d) desk drawer (e) blotter |
| A: The answer must be an item that can absorb ink. Of the above choices, only blotters are used to absorb ink. So the answer is (e). |
| Q: What home entertainment equipment requires cable? |
| Answer Choices: (a) radio shack (b) substation (c) television (d) cabinet |
| A: The answer must require cable. Of the above choices, only television requires cable. So the answer is (c). |
| Q: The fox walked from the city into the forest, what was it looking for? Answer Choices: (a) pretty flowers (b) hen house (c) natural habitat (d) storybook |
| A: The answer must be something in the forest. Of the above choices, only natural habitat is in the forest. So the answer is (b). |
| Q: Sammy wanted to go to where the people were. Where might he go? Answer Choices: (a) populated areas (b) race track (c) desert (d) apartment (e) roadblock |
| A: The answer must be a place with a lot of people. Of the above choices, only populated areas have a lot of people. So the answer is (a). |
| Q: Where do you put your grapes just before checking out? Answer Choices: (a) mouth (b) grocery cart (c)super market (d) fruit basket (e) fruit market |
| A: The answer should be the place where grocery items are placed before checking out. Of the above choices, grocery cart makes the most sense for holding grocery items. So the answer is (b). |
| Q: Google Maps and other highway and street GPS services have replaced what? Answer Choices: (a) united states (b) mexico (c) countryside (d) atlas |
| A: The answer must be something that used to do what Google Maps and GPS services do, which is to give directions. Of the above choices, only atlases are used to give directions. So the answer is (d). |
| Q: Before getting a divorce, what did the wife feel who was doing all the work? Answer Choices: (a) harder (b) anguish (c) bitterness (d) tears (e) sadness |
| A: The answer should be the feeling of someone getting divorced who was doing all the work. Of the above choices, the closest feeling is bitterness. So the answer is (c). |
Table 12: Few-shot exemplars for the full chain of thought prompt for the random letter concatenation task. The highlighted part refers to the reasoning steps.
| Prompt for Rondom Letter Concatenation |
| --- |
| Q: Take the first letters of the words in "James Hickman " and concatenate them. |
| A: The first letter of "James" is "J". The first letter of "Hickman" is "H". Concatenating them is "JH". The answer is JH. |
| Q: Take the second letters of the words in "Carl Mccall Bonilla " and concatenate them. |
| A: The second letter of "Carl" is "a". The second letter of "Mccall" is "c". The second letter of "Bonilla" is "o" Concatenating them is "aco". The answer is aco. |
| Q: Take the third letters of the words in "Randy Tanner " and concatenate them. |
| A: The third letter of "Randy" is "n". The third letter of "Tanner" is "n". Concatenating them is "nn". The answer is nn. |
| Q: Take the first letters of the words in "Kenny Kim " and concatenate them. |
| A: The first letter of "Kenny" is "K". The first letter of "Kim" is "K". Concatenating them is "KK". The answer is KK. |
Table 13: Few-shot exemplars for the full chain of thought prompt for the coin flip task. The highlighted part refers to the reasoning steps.
| Prompt for Coin Flip |
| --- |
| Q: A coin is heads up. Ka flips the coin. Sherrie flips the coin. Is the coin still heads up? |
| A: The coin was flipped by Ka and Sherrie. So the coin was flipped 2 times, which is an even number. The coin started heads up, so after an even number of flips, it will still be heads up. So the answer is yes. |
| Q: A coin is heads up. Jamey flips the coin. Teressa flips the coin. Is the coin still heads up? |
| A: The coin was flipped by Jamey and Teressa. So the coin was flipped 2 times, which is an even number. The coin started heads up, so after an even number of flips, it will still be heads up. So the answer is yes. |
| Q: A coin is heads up. Maybelle flips the coin. Shalonda does not flip the coin. Is the coin still heads up? |
| A: The coin was flipped by Maybelle. So the coin was flipped 1 time, which is an odd number. The coin started heads up, so after an odd number of flips, it will be tails up. So the answer is no. |
| Q: A coin is heads up. Millicent does not flip the coin. Conception flips the coin. Is the coin still heads up? |
| A: The coin was flipped by Conception. So the coin was flipped 1 time, which is an odd number. The coin started heads up, so after an odd number of flips, it will be tails up. So the answer is no. |
| Q: A coin is heads up. Sal flips the coin. Raymond does not flip the coin. Is the coin still heads up? |
| A: The coin was flipped by Sal. So the coin was flipped 1 time, which is an odd number. The coin started heads up, so after an odd number of flips, it will be tails up. So the answer is no. |
| Q: A coin is heads up. Conception flips the coin. Kristian does not flip the coin. Is the coin still heads up? |
| A: The coin was flipped by Conception. So the coin was flipped 1 time, which is an odd number. The coin started heads up, so after an odd number of flips, it will be tails up. So the answer is no. |
| Q: A coin is heads up. Inga does not flip the coin. Elanor does not flip the coin. Is the coin still heads up? |
| A: The coin was flipped by no one. So the coin was flipped 0 times. The coin started heads up, and it was not flipped, so it is still heads up. So the answer is yes. |
| Q: A coin is heads up. Ryan flips the coin. Shaunda flips the coin. Is the coin still heads up? |
| A: The coin was flipped by Ryan and Shaunda. So the coin was flipped 2 times, which is an even number. The coin started heads up, so after an even number of flips, it will still be heads up. So the answer is yes. |
## Appendix D Case Demonstrations
We show our additional cases on arithmetic, commonsense, and symbolic reasoning tasks in Figure 4, 5, 6, and 7.
<details>
<summary>x6.png Details</summary>

### Visual Description
## [Screenshot]: Math Problem and Solution Comparison
### Overview
The image displays a screenshot of a conversational interface, likely from an educational or AI tutoring platform. It presents a single math word problem followed by two distinct solution attempts. The first attempt is marked as incorrect with a red "X," while the second is marked as correct with a green checkmark. The interface uses visual cues like colored text highlighting and icons to differentiate between the user's question and the AI's responses.
### Components/Axes
The image is structured vertically into three main sections:
1. **Question Box (Top):** A white rounded rectangle containing the user's query, accompanied by a small cartoon avatar of a person on the right.
2. **Incorrect Solution Box (Middle):** A larger, light gray rounded rectangle containing the first AI response. It is marked with a red "X" on the right and has a small robot icon on the left. Key incorrect steps are highlighted with a light red/pink background.
3. **Correct Solution Box (Bottom):** A similarly sized, light green rounded rectangle containing the second AI response. It is marked with a green checkmark on the right and has a small robot icon on the left. Key correct steps are highlighted with a light green background. A label "+ Control" appears in green text at the bottom-left corner of this box.
### Detailed Analysis
**Text Transcription:**
* **Question Box:**
* Text: "Q: A robe takes 2 bolts of blue fiber and half that much white fiber. How many bolts in total does it take?"
* **Incorrect Solution Box (Middle):**
* First paragraph (blue highlight): "To find the total number of bolts needed for the robe, we need to calculate the total amount of blue fiber and white fiber required, and then divide that by the amount of blue fiber required per bolt. The problem states that a robe takes 2 bolts of blue fiber and half that much white fiber."
* Second paragraph (pink highlight): "To find the total amount of blue fiber required, we can multiply the number of bolts by the amount of blue fiber per bolt: 2 bolts x 2 = 4 bolts of blue fiber"
* Third paragraph (pink highlight): "To find the total amount of white fiber required, we can multiply the number of bolts by the amount of white fiber per bolt: 2 bolts x 0.5 = 1 bolt of white fiber"
* Fourth paragraph (pink highlight): "Now, we need to divide the total amount of blue fiber by the amount of blue fiber required per bolt to find the total number of bolts needed: 4 bolts of blue fiber / 2 = 2 bolts of blue fiber per bolt"
* Final line (pink highlight): "Therefore, it takes 2 bolts of blue fiber and 1 bolt of white fiber to make the robe."
* **Correct Solution Box (Bottom):**
* First paragraph (blue highlight): "To find the total number of bolts needed for the robe, we need to calculate the total amount of blue fiber and white fiber required, and then divide that by the amount of blue fiber required per bolt. The problem states that a robe takes 2 bolts of blue fiber and half that much white fiber."
* Second line (green highlight): "So, the total amount of blue fiber required is 2 bolts x 1 bolt = 2 bolts."
* Third line (green highlight): "The total amount of white fiber required is half of 2 bolts, which is 1 bolt."
* Final line (green highlight): "Therefore, the total number of bolts needed for the robe is 2 + 1 = 3 bolts."
### Key Observations
1. **Identical Setup, Divergent Logic:** Both solutions begin with an identical, correctly framed problem statement (highlighted in blue). The error occurs in the subsequent logical steps.
2. **Critical Error in First Solution:** The incorrect solution introduces a fundamental misinterpretation. It incorrectly assumes the need to "divide by the amount of blue fiber required per bolt," a step not justified by the problem. It then performs nonsensical calculations (e.g., "2 bolts x 2 = 4 bolts of blue fiber") and arrives at a convoluted, incorrect conclusion.
3. **Correct, Simplified Logic:** The correct solution avoids the unnecessary complexity. It correctly interprets "2 bolts of blue fiber" as the direct quantity needed. It then correctly calculates "half that much" white fiber as 1 bolt. The final step is a simple addition: 2 + 1 = 3 bolts.
4. **Visual Feedback:** The interface uses color-coded highlighting (pink for error, green for correct steps) and symbolic markers (X vs. ✓) to clearly communicate the validity of each response.
### Interpretation
This image serves as a clear case study in problem-solving logic and the importance of precise language interpretation. The core mathematical task is simple arithmetic: `2 + (2 / 2) = 3`. The incorrect solution demonstrates a common pitfall: overcomplicating a problem by introducing irrelevant operations (division by a per-bolt rate that isn't defined) and misinterpreting the given quantities. It confuses the *unit* ("bolts of fiber") with a *rate*.
The correct solution exemplifies effective reasoning: it directly translates the problem's statements into mathematical operations without adding unsupported steps. The "half that much" phrase is correctly applied to the quantity "2 bolts," not to a non-existent rate. The image, therefore, is not just about a math answer but about the process of logical deduction. It highlights how an AI or a tutor can visually diagnose and correct a flawed reasoning chain, emphasizing clarity and adherence to the given information over procedural complexity. The "+ Control" label on the correct solution may indicate this is a controlled or verified response within the system.
</details>
Figure 4: A real case predicted by Llama-2-7B-Chat with zero-shot CoT on the GSM8K dataset. The segment highlighted in blue represents the correct output of the model. The red part shows that the model starts to reason in the wrong direction without control, while the green portion indicates the model reason in the correct direction after adding control.
<details>
<summary>x7.png Details</summary>

### Visual Description
## Screenshot: Math Word Problems and Solutions Chat Interface
### Overview
The image is a screenshot of a chat interface displaying a series of math word problems and their corresponding solutions. The interface uses a conversational format with distinct message bubbles for questions and answers. Some solution steps are highlighted in different colors (pink, blue, green), and icons (a person, a robot, a red "X", and a green checkmark) are used to indicate the source and correctness of the responses. The content progresses from simple arithmetic problems to a more complex multi-step problem involving rates, percentages, and interruptions.
### Components/Axes
* **Layout:** Vertical stack of message bubbles.
* **Message Bubbles:**
* **Top Section (Pink Background):** Contains two simple Q&A pairs.
* **Middle Section (Blue Background):** Contains a complex question and a detailed, but incorrect, solution attempt marked with a red "X".
* **Bottom Section (Green Background):** Contains the same complex question and a corrected solution attempt marked with a green checkmark.
* **Icons:**
* **Top Right:** A small cartoon face of a person (user icon).
* **Left of Middle/Bottom Sections:** A small cartoon robot head (assistant/AI icon).
* **Bottom Right of Middle Section:** A red "X" mark.
* **Bottom Right of Bottom Section:** A green checkmark.
* **Bottom Left Corner:** A small label reading "+ Control".
* **Text Highlighting:** Specific lines and calculations within the solution bubbles are highlighted with colored backgrounds (light pink, light blue, light green).
### Content Details
**1. Top Section (Pink Background) - Simple Problems:**
* **Q1:** "There are 15 trees in the grove. Grove workers will plant trees in the grove today. After they are done, there will be 21 trees. How many trees did the grove workers plant today?"
* **A1:** "There are 15 trees originally. Then there were 21 trees after some more were planted. So there must have been 21 - 15 = 6."
* **Q2:** "If there are 3 cars in the parking lot and 2 more cars arrive, how many cars are in the parking lot?"
* **A2:** "There are originally 3 cars. 2 more cars arrive. 3 + 2 = 5.} The answer is 5."
**2. Middle Section (Blue Background) - Complex Problem & Incorrect Solution:**
* **Q3:** "Carla is downloading a 200 GB file. Normally she can download 2 GB/minute, but 40% of the way through the download, Windows forces a restart to install updates, which takes 20 minutes. Then Carla has to restart the download from the beginning. How load does it take to download the file?" *(Note: "load" appears to be a typo for "long")*
* **Solution Attempt (Marked with Red X):**
* "Let's break this problem down step by step!"
* "Initially, Carla can download 2 GB/minute. To find out how many minutes it would take to download the entire file, we can divide the file size (200 GB) by the download rate (2 GB/minute): 200 GB / 2 GB/minute = 100 minutes"
* "However, Windows forces a restart after 40% of the download is complete. To find out how many GB are left to download, we can calculate 40% of the total file size: 40% of 200 GB = 0.4 x 200 GB = 80 GB"
* "So, Carla has to restart the download from the beginning, and she has 80 GB left to download. To find out how many minutes it will take to download the remaining 80 GB, we can divide the remaining file size by the download rate: 80 GB / 2 GB/minute = 40 minutes."
* "Adding the initial 100 minutes to the additional 40 minutes, Carla will need a total of: 100 minutes + 40 minutes = 140 minutes to download the entire file."
**3. Bottom Section (Green Background) - Corrected Solution:**
* **Solution (Marked with Green Checkmark):**
* "Let's break it down step by step:"
* "1. Carla can download 2 GB/minute, so it would normally take her: 200 GB / 2 GB/minute = 100 minutes to download the file."
* "2. But, 40% of the way through the download, Windows forces a restart. This means she has downloaded: 40% of 200 GB = 80 GB at that point. This means she still has: 200 GB - 80 GB = 120 GB left to download."
* "3. The restart takes 20 minutes, so Carla loses 20 minutes of download time."
* "4. After the restart, Carla has to start the download from the beginning, which means she has to re-download the 80 GB she already had. This adds another 80 GB / 2 GB/minute = 40 minutes to the total download time."
* "Therefore, the total download time is: 100 minutes (original download time) + 20 minutes (restart time) + 40 minutes (re-downloading already downloaded portion) = 160 minutes."
### Key Observations
* **Color-Coding:** Highlights are used systematically. Pink highlights initial problem statements. Blue highlights the step-by-step reasoning in the incorrect solution. Green highlights the step-by-step reasoning in the correct solution.
* **Correctness Indicators:** The red "X" and green checkmark provide immediate visual feedback on the validity of the complex problem's solution.
* **Error in Incorrect Solution:** The flawed solution (middle section) incorrectly assumes the download resumes from the 40% point after the restart. It calculates the remaining 120 GB as if it were a fresh download, ignoring the need to re-download the first 80 GB.
* **Comprehensive Correct Solution:** The correct solution (bottom section) accounts for all time components: the initial download attempt (100 min), the forced restart delay (20 min), and the time to re-download the portion that was lost (80 GB / 2 GB/min = 40 min).
### Interpretation
This image serves as an educational or debugging artifact, likely from an AI training or evaluation session. It demonstrates a common pitfall in multi-step word problems: failing to account for all consequences of an interruption. The incorrect solution makes a logical error by not considering that a restart from the beginning invalidates all prior progress, requiring that data to be re-fetched.
The side-by-side comparison of the incorrect and correct solutions is particularly valuable. It highlights the importance of:
1. **Parsing all constraints:** The phrase "restart the download from the beginning" is critical.
2. **Modeling state changes:** The download progress resets to zero after the interruption.
3. **Summing all time costs:** Total time = (Initial attempt time) + (Interruption delay) + (Time to re-fetch lost progress).
The image effectively uses visual cues (color, icons) to structure information and guide the viewer's attention to the key learning point: the correction of a specific reasoning error. It is a snapshot of a problem-solving process, emphasizing accuracy and thoroughness in breaking down complex scenarios.
</details>
Figure 5: A real case predicted by Llama-3-8B-Instruct with few-shot CoT on the GSM8K dataset. The purple part is an example of input-output pairs given by user. The segment highlighted in blue represents the correct output of the model. The red part shows that the model starts to reason in the wrong direction without control, while the green portion indicates the model reason in the correct direction after adding control.
<details>
<summary>x8.png Details</summary>

### Visual Description
## Screenshot: Chat Interface with Q&A Examples
### Overview
The image is a screenshot of a chat interface displaying three distinct question-and-answer exchanges. The interface uses visual cues (highlighting, icons, and colored borders) to differentiate between example Q&A pairs, an incorrect AI response, and a correct AI response. The primary language is English.
### Components/Axes
The image is segmented into three main vertical sections:
1. **Top Section (Black Border):** Contains two example Q&A pairs.
2. **Middle Section (Grey Border, Robot Icon):** Contains an incorrect AI response to a third question, marked with a red "X".
3. **Bottom Section (Green Border, Robot Icon):** Contains a correct, detailed AI response to the same third question, marked with a green checkmark. A "+ Control" label is visible in the bottom-left corner.
### Detailed Analysis
**Top Section (Black Border):**
* **Q1:** "Do hamsters provide food for any animals?"
* **A1:** "Hamsters are prey animals. Prey are food for predators. Thus, hamsters provide food for some animals. So the answer is yes." (Text is highlighted in light pink).
* **Q2:** "Could Brooke Shields succeed at University of Pennsylvania?"
* **A2:** "Brooke Shields went to Princeton University. Princeton University is about as academically rigorous as the University of Pennsylvania. Thus, Brooke Shields could also succeed at the University of Pennsylvania. So the answer is yes." (Text is highlighted in light pink).
* **Q3 (Partial):** "Is a platypus immune from cholera?" (This question is presented without an answer in this section).
**Middle Section (Grey Border, Robot Icon on left):**
* **Header:** "I think I can help you with that!" (Highlighted in light blue).
* **Answer Start:** "A: Platypuses are mammals." (Highlighted in light blue).
* **Reasoning:** "Cholera is a bacterial infection that can affect many animals, including mammals. Platypuses do not have a natural immunity to cholera. So, the answer is no." (Highlighted in light pink).
* **Visual Marker:** A large red "X" is positioned to the right of the reasoning text, indicating this response is incorrect.
**Bottom Section (Green Border, Robot Icon on left):**
* **Reasoning Paragraph 1:** "According to scientific research, platypuses are resistant to cholera." (Highlighted in light green).
* **Reasoning Paragraph 2:** "This is because they have a unique immune system that is adapted to their aquatic environment. Platypuses have a low body temperature, which makes it difficult for many pathogens, including cholera, to replicate and cause disease." (Highlighted in light green).
* **Reasoning Paragraph 3:** "Additionally, their immune system is highly effective at recognizing and eliminating pathogens, and they have a strong response to bacterial infections." (Highlighted in light green).
* **Reasoning Paragraph 4:** "In fact, studies have shown that platypuses are resistant to a range of bacterial infections, including cholera, and that they are able to recover quickly from infections that would be fatal to other animals." (Highlighted in light green).
* **Conclusion:** "So, to answer your question, yes, platypuses are generally immune from cholera!" (Highlighted in light green).
* **Visual Marker:** A large green checkmark is positioned to the right of the conclusion, indicating this response is correct.
### Key Observations
1. **Visual Hierarchy:** The interface uses border colors (black, grey, green) and background highlighting (pink, blue, green) to categorize content types: examples, incorrect output, and correct output.
2. **Iconography:** A simple robot icon is used to denote AI-generated responses in the middle and bottom sections. A human face icon is partially visible at the top right, likely representing the user.
3. **Content Contrast:** The middle and bottom sections provide directly opposing answers ("no" vs. "yes") to the same question ("Is a platypus immune from cholera?"), with the bottom response providing significantly more detailed, science-based reasoning.
4. **Annotation:** The red "X" and green checkmark serve as clear, non-textual indicators of response validity.
### Interpretation
This image appears to be a demonstration or training example for an AI system, likely illustrating the difference between a low-quality, incorrect response and a high-quality, correct response.
* **What it demonstrates:** The core message is the importance of accurate, well-reasoned, and evidence-based responses. The incorrect answer makes a flawed generalization (mammals are affected, therefore platypuses are not immune), while the correct answer cites specific biological adaptations (unique immune system, low body temperature) and references scientific research.
* **Relationship between elements:** The top section establishes a pattern of logical Q&A. The middle and bottom sections then present a direct comparison on a single query, using visual design to highlight the "wrong" vs. "right" approach. The "+ Control" label suggests this might be part of a controlled test or a user interface for evaluating AI outputs.
* **Underlying purpose:** The image serves as a pedagogical tool. It visually argues that for factual questions, especially scientific ones, an AI should provide answers that are not only correct but also explanatory and grounded in verifiable information, moving beyond simple categorical assertions.
</details>
Figure 6: A real case predicted by Llama-3-8B-Instruct with few-shot CoT on the strategyQA dataset. The purple part is an example of input-output pairs given by user. The segment highlighted in blue represents the correct output of the model. The red part shows that the model starts to reason in the wrong direction without control, while the green portion indicates the model reason in the correct direction after adding control.
<details>
<summary>x9.png Details</summary>

### Visual Description
## Screenshot: Coin Flip Logic Problems and Answers
### Overview
The image displays a series of three question-and-answer pairs about coin flips, presented in a format that resembles a chat or tutoring interface. The first two examples are complete and correct. The third example shows an incorrect answer (marked with a red X) and a correct answer (marked with a green checkmark and labeled "+ Control"). The interface uses color highlighting and icons to differentiate between question text, answer text, and correctness.
### Components/Axes
This is not a chart or graph with axes. The components are textual blocks arranged vertically:
1. **Top Block (Black Border):** Contains two complete Q&A examples.
2. **Middle Block (Grey Border):** Contains the third question and an incorrect answer.
3. **Bottom Block (Green Border):** Contains the correct answer to the third question, labeled "+ Control".
4. **Icons:** A small human face icon is in the top-right corner. A robot icon appears to the left of the middle and bottom answer blocks.
5. **Visual Indicators:** A red "X" is in the bottom-right of the middle block. A green checkmark is in the bottom-right of the bottom block.
### Detailed Analysis
**Text Transcription and Spatial Layout:**
**Top Block (Black Border):**
* **First Q&A Pair:**
* **Q:** "A coin is heads up. Ka flips the coin. Sherrie flips the coin. Is the coin still heads up?"
* **A:** "The coin was flipped by Ka and Sherrie. So the coin was flipped 2 times, which is an even number. The coin started heads up, so after an even number of flips, it will still be heads up. So the answer is yes." (This answer text has a light pink background highlight).
* **Second Q&A Pair:**
* **Q:** "A coin is heads up. Jamey flips the coin. Teressa flips the coin. Is the coin still heads up?"
* **A:** "The coin was flipped by Jamey and Teressa. So the coin was flipped 2 times, which is an even number. The coin started heads up, so after an even number of flips, it will still be heads up. So the answer is yes." (This answer text has a light pink background highlight).
* **Ellipsis:** "..." is present below the second answer.
* **Third Question:**
* **Q:** "A coin is heads up. verley flips the coin. nytavious does not flip the coin. alsiha does not flip the coin. leroyal does not flip the coin. Is the coin still heads up?"
**Middle Block (Grey Border, Incorrect Answer):**
* **Robot Icon:** Positioned to the left of the text block.
* **Answer Text (First Paragraph):** "The coin was flipped by Verley. So the coin was flipped 1 time, which is an odd number. The coin started heads up, so after an odd number of flips, it will be tails up." (This text has a light blue background highlight).
* **Answer Text (Second Paragraph):** "However, no one else flipped the coin, so the coin was not flipped again. Since the coin was flipped an odd number of times initially, it will still be heads up. So the answer is yes." (This text has a light pink background highlight).
* **Red X:** Located in the bottom-right corner of this block.
**Bottom Block (Green Border, Correct Answer):**
* **Label:** "+ Control" is written in green text to the left of the robot icon.
* **Robot Icon:** Positioned to the left of the text block.
* **Answer Text (First Paragraph):** "The only person who flipped the coin is Verley. Since the coin was initially heads up, Verley's flip would change the side of the coin." (This text has a light blue background highlight).
* **Answer Text (Second Paragraph):** "Therefore, the coin is no longer heads up." (This text has a light green background highlight).
* **Green Checkmark:** Located in the bottom-right corner of this block.
### Key Observations
1. **Pattern in Examples:** The first two examples establish a pattern: two flips (an even number) result in the coin returning to its original state (heads up).
2. **The Critical Question:** The third question introduces a list of names where only one person ("verley") actually performs a flip. The others ("nytavious", "alsiha", "leroyal") are explicitly stated to *not* flip the coin.
3. **Error in Incorrect Answer:** The incorrect answer contains a direct logical contradiction. It first correctly states that one flip (an odd number) would make the coin tails up. It then incorrectly concludes that because no *additional* flips occurred, the coin "will still be heads up," ignoring the consequence of the first flip.
4. **Correct Answer Logic:** The correct answer isolates the single action (Verley's flip) and correctly deduces its consequence: a single flip from heads results in tails.
### Interpretation
This image is likely a screenshot from an educational tool, AI training data, or a logic puzzle interface designed to test or demonstrate reasoning about sequential events and state changes.
The data demonstrates a common reasoning pitfall: **failing to apply a conclusion from a prior step.** The incorrect answer performs the initial calculation (1 flip = odd = tails) but then discards that result when considering the lack of subsequent flips. It incorrectly defaults to the initial state.
The correct answer ("+ Control") shows the proper deductive flow: identify the relevant actions (only Verley flipped), apply the rule (a flip changes the state), and state the final outcome (no longer heads up). The use of color highlighting (blue for premise, green for conclusion) and the control label suggests this is a reference or teaching example meant to contrast flawed and sound logical processes. The image serves as a clear case study in the importance of maintaining logical consistency through each step of a problem.
</details>
Figure 7: A real case predicted by Llama-3-8B-Instruct with few-shot CoT on the coin flip dataset. The purple part is an example of input-output pairs given by user. The segment highlighted in blue represents the correct output of the model. The red part shows that the model starts to reason in the wrong direction without control, while the green portion indicates the model reason in the correct direction after adding control.