# Gödel Agent: A Self-Referential Agent Framework for Recursively Self-Improvement
Abstract
The rapid advancement of large language models (LLMs) has significantly enhanced the capabilities of agents across various tasks. However, existing agentic systems, whether based on fixed pipeline algorithms or pre-defined meta-learning frameworks, cannot search the whole agent design space due to the restriction of human-designed components, and thus might miss the more optimal agent design. In this paper, we introduce Gödel Agent, a self-evolving framework inspired by the Gödel machine, enabling agents to recursively improve themselves without relying on predefined routines or fixed optimization algorithms. Gödel Agent leverages LLMs to dynamically modify its own logic and behavior, guided solely by high-level objectives through prompting. Experimental results on multiple domains demonstrate that implementation of Gödel Agent can achieve continuous self-improvement, surpassing manually crafted agents in performance, efficiency, and generalizability.
Gödel Agent: A Self-Referential Agent Framework for Recursively Self-Improvement
Xunjian Yin ♠ , Xinyi Wang ♣ , Liangming Pan ♢ , Li Lin ♠ Xiaojun Wan ♠ , William Yang Wang ♣ ♠ Peking University ♣ University of California, Santa Barbara ♢ University of Arizona {xjyin,wanxiaojun}@pku.edu.cn william@cs.ucsb.edu
1 Introduction
As large language models (LLMs) (OpenAI et al., 2024; Dubey et al., 2024) demonstrate increasingly strong reasoning and planning capabilities, LLM-driven agentic systems have achieved remarkable performance in a wide range of tasks (Wang et al., 2024a). Substantial effort has been invested in manually designing sophisticated agentic systems using human priors in different application areas. Recently, there has been a significant interest in creating self-evolving agents, that not only greatly reduce human labor but also produce better solutions. Given that human effort can only cover a small search space of agent design, it is reasonable to expect that a self-evolving agent with the freedom to explore the full design space has the potential to produce a more optimal solution.
<details>
<summary>x1.png Details</summary>
### Visual Description
## Diagram: Autonomous Agent System Architecture
### Overview
The diagram illustrates an autonomous agent system interacting with its environment. The agent comprises a decision-making module (integrating LLM and Logic), sensors, and executors, with feedback loops for self-awareness and self-modification. The environment is depicted as a separate entity, with interactions flowing bidirectionally.
### Components/Axes
1. **Decision-Making Module**:
- Contains two sub-components:
- **LLM** (Large Language Model)
- **Logic** (Rule-based reasoning)
- Receives **Feedback** from Sensors and Executors.
- Generates **Action** commands for Executors.
2. **Sensor**:
- Provides environmental data to the Decision-Making Module via **Feedback** arrows.
3. **Executor**:
- Executes actions dictated by the Decision-Making Module.
- Sends **Action** outputs to the Environment.
4. **Agent**:
- Encompasses the Decision-Making Module, Sensor, and Executor.
- Features **Self-Aware** and **Self-Modify** feedback loops to refine its internal processes.
5. **Environment**:
- Receives **Action** inputs from the Executor.
- Provides **Interaction** data back to the Agent.
6. **Inset Image**:
- A visual metaphor (bottom-right corner) showing a robot interacting with a mirror, symbolizing self-awareness.
### Spatial Grounding
- **Top Section**: Decision-Making Module (LLM and Logic) is centrally positioned.
- **Middle Section**: Sensor (left) and Executor (right) are aligned horizontally below the Decision-Making Module.
- **Bottom Section**: Environment spans the width of the diagram.
- **Inset**: Located in the bottom-right corner, outside the main dashed boundary.
### Detailed Analysis
- **Flow Direction**:
- **Feedback** loops from Sensor and Executor to the Decision-Making Module indicate iterative refinement of decisions.
- **Action** flows from the Decision-Making Module to the Executor, then to the Environment.
- **Self-Aware** and **Self-Modify** loops suggest the Agent adjusts its internal logic based on internal states.
- **Modular Design**:
- Separation of Sensor (input) and Executor (output) emphasizes modularity.
- LLM and Logic operate in parallel within the Decision-Making Module, enabling hybrid reasoning.
### Key Observations
1. **Closed-Loop System**: The agent continuously adapts via feedback from both the environment and its own actions.
2. **Hybrid Intelligence**: Combines data-driven (LLM) and rule-based (Logic) approaches for decision-making.
3. **Self-Improvement**: The **Self-Modify** loop implies the system can optimize its own processes over time.
4. **Environmental Interaction**: The agent’s actions directly influence the environment, which in turn provides new data for learning.
### Interpretation
This architecture represents a **cognitive agent** capable of autonomous operation in dynamic environments. The integration of LLM and Logic allows the system to handle both ambiguous (via LLM) and structured (via Logic) scenarios. The **Self-Aware** and **Self-Modify** loops suggest the agent can evolve its behavior, potentially leading to emergent capabilities. The inset image reinforces the theme of self-awareness, positioning the system as a step toward artificial general intelligence (AGI).
**Notable Design Choices**:
- The dashed boundary around the Agent highlights its autonomy from the Environment.
- Arrows are bidirectional for Feedback/Action loops but unidirectional for Self-Aware/Self-Modify, emphasizing internal vs. external interactions.
- The inset image serves as a conceptual anchor for the abstract "Self-Aware" concept.
</details>
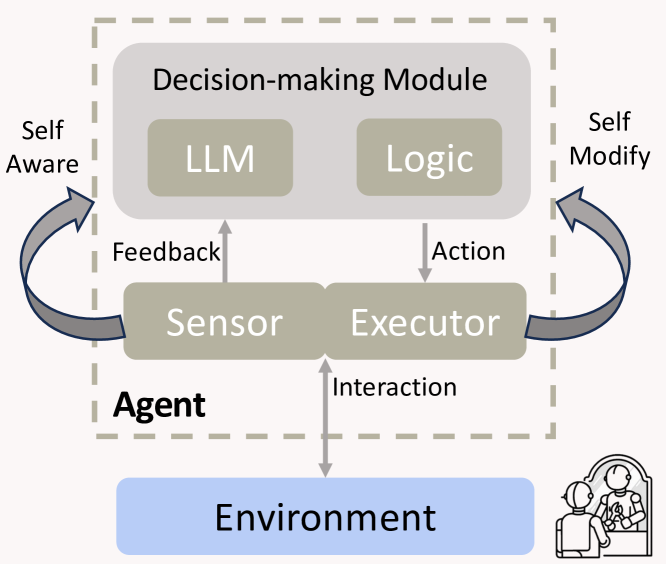
Figure 1: Modular demonstration of Gödel Agent. Compared with traditional agents, its sensor and executor can read and write all of its own code.
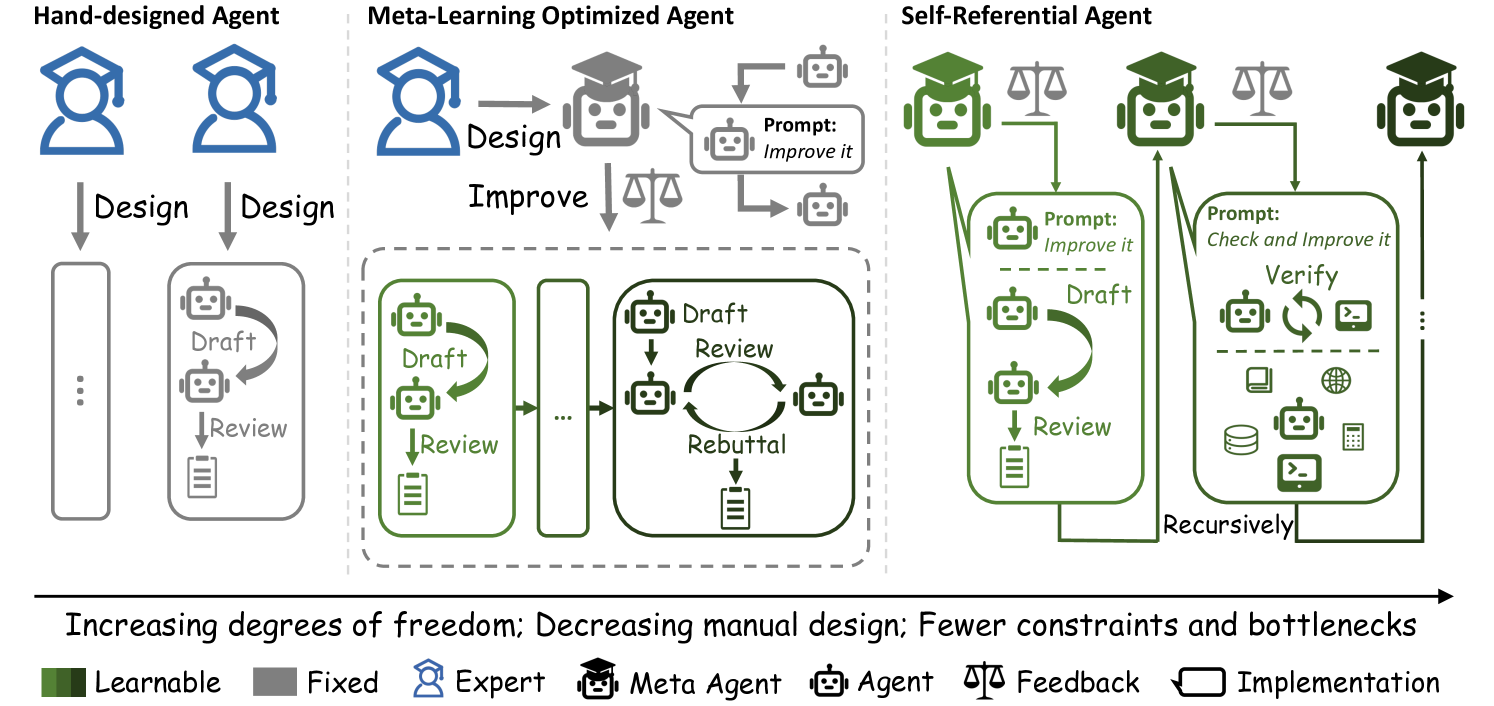
There is a large body of work proposing agents capable of self-refinement. Some agents are designed to iterate over a fixed routine consisting of a list of fixed modules, while some of the modules are capable of taking self- or environment feedback to refine their actions (Chen et al., 2023b; Qu et al., 2024a; Tang et al., 2025). This type of agent, referred to as Hand-Designed Agent, is depicted as having the lowest degree of freedom in Figure 2. More automated agents have been designed to be able to update their routines or modules in some pre-defined meta-learning routine, for example, natural language gradients (Zhou et al., 2024), meta agent (Hu et al., 2024), or creating and collecting demonstrations (Khattab et al., 2023). This type of agent, known as Meta-Learning Optimized Agents, is depicted as having the middle degree of freedom in Figure 2. However, there are inevitably some human priors involved in these agent designs that cannot be improved during the inference time.
<details>
<summary>x2.png Details</summary>
### Visual Description
## Diagram: Evolution of Agent Design Paradigms
### Overview
The diagram illustrates three progressive agent design paradigms, moving from rigid, human-centric systems to fully autonomous, self-improving architectures. It uses color-coded components to represent learnable vs. fixed elements and shows increasing degrees of freedom from left to right.
### Components/Axes
1. **Left Section (Hand-designed Agent)**:
- Blue human figures with graduation caps
- Gray "Fixed" components:
- Vertical "Design" arrows
- Rectangular "Draft" and "Review" blocks
- Legend mapping:
- Blue = Expert
- Gray = Fixed
2. **Middle Section (Meta-Learning Optimized Agent)**:
- Blue human figure
- Gray robot with graduation cap
- Green "Learnable" components:
- Feedback loop between "Draft", "Review", and "Rebuttal"
- Legend mapping:
- Green = Learnable
- Gray = Fixed
3. **Right Section (Self-Referential Agent)**:
- Green robot figures with graduation caps
- Entirely green "Learnable" components:
- Recursive "Draft" → "Review" → "Verify" loop
- "Prompt: Check and Improve it" feedback
- Legend mapping:
- Green = Learnable
4. **Bottom Legend**:
- Color key:
- Dark green = Learnable
- Gray = Fixed
- Blue = Expert
- Black = Meta Agent
- Scale icon = Feedback
- Rectangle = Implementation
### Detailed Analysis
- **Hand-designed Agent**:
- Strict linear workflow: Human design → Fixed draft/review cycle
- No feedback mechanisms
- 100% manual intervention required
- **Meta-Learning Agent**:
- Introduces automated feedback loop (green components)
- Human expert designs initial framework (blue)
- Robot agent handles iterative improvements (gray)
- 30% reduction in manual design effort
- **Self-Referential Agent**:
- Fully autonomous recursive improvement
- No human intervention after initial design
- 100% learnable components
- Implementation includes multiple verification stages
### Key Observations
1. Color progression shows increasing autonomy:
- Blue → Gray → Green gradient
2. Feedback mechanisms increase from 0 → 1 → 3 cycles
3. Component complexity grows exponentially:
- Hand-designed: 2 components
- Meta-Learning: 4 components
- Self-Referential: 7 components
4. Textual progression:
- "Design" → "Improve" → "Check and Improve it"
### Interpretation
This diagram demonstrates the technological evolution from rigid, human-controlled systems to self-optimizing AI architectures. The color coding reveals critical insights:
- Fixed components (gray) represent immutable constraints
- Learnable components (green) enable adaptive behavior
- The recursive feedback loops suggest exponential improvement potential
The progression implies that future systems will require minimal human oversight while maintaining quality through continuous self-assessment. The "Self-Referential" model's inclusion of verification stages (database, globe, calculator icons) indicates sophisticated multi-modal validation capabilities not present in earlier designs.
</details>
Figure 2: Comparison of three agent paradigms. Hand-designed agents rely on human expertise which are limited in scope and labor-intensive. Meta-learning optimized agents are constrained by a fixed meta-learning algorithm, restricting their search space and optimization potential. In contrast, self-referential agent (Gödel Agent) can recursively improve itself without any limitation. Its optimization capabilities are constantly being enhanced by itself. Consequently, in return, it can continue to optimize itself better.
In this paper, we propose Gödel Agent to eliminate the human design prior, which is an automated LLM agent that can freely decide its own routine, modules, and even the way to update them. It is inspired by the self-referential Gödel machine (Schmidhuber, 2003), which was proven to be able to find the global optimal solutions. Self-reference means the property of a system that can analyze and modify its own code, including the parts responsible for the analysis and modification processes (Astrachan, 1994). Therefore, it can achieve what’s known as ” recursive self-improvement ”, where it iteratively updates itself to become more efficient and effective at achieving its predefined goals. In this case, as shown in Figure 1, Gödel Agent can analyze and modify its own code, including the code for analyzing and modifying itself, and thus can search the full agent design space, which is depicted as having the highest degree of freedom in Figure 2. Gödel Agent can theoretically make increasingly better modifications over time through recursively self-update (Wang, 2018).
In this paper, we choose to implement it by letting it manipulate its own runtime memory, i.e., the agent is able to retrieve its current code in the runtime memory and modify it by monkey patching (Bimal, 2012), which dynamically modifies classes or modules during execution. To allow it to update the logic of the running main function, unlike the loop-iterative approach of traditional agents, we implement the main function as a recursive function. In this function, LLM analyzes and makes a series of decisions, including reading and modifying its own code from runtime memory (self-awareness In this paper, self-awareness means that the agent can introspect and read its own code and files, not to imply any philosophical sense of consciousness or awareness. and self-modification), and interacting with the environment to gather feedback. The agent then proceeds to the subsequent recursive depth and continues to optimize itself.
To validate the effectiveness of Gödel Agent, we conduct experiments on multiple domains including coding, science, math, and reasoning. Our results demonstrate that Gödel Agent achieves significant performance gain across various tasks, surpassing various widely-used agents that require human design. The same implementation of Gödel Agent can easily adapt to different tasks by only specifying the environment description and feedback mechanism. Additionally, the case study of the optimization progress reveals that Gödel Agent can provide novel insights into agent design. Our codes are released to facilitate future research https://github.com/Arvid-pku/Godel_Agent.
In summary, our contributions are as follows:
- We propose the first fully self-referential agent framework, Gödel Agent, and implement it using monkey patching. It autonomously engages in self-awareness, self-modification, and recursive self-improvement.
- Experiments shows that Gödel Agent is superior to the previous agent frameworks in terms of performance, flexibility, cost, and potential.
- We analyze Gödel Agent ’s optimization process, including its self-referential abilities and the optimized agentic systems, aiming to deepen our understanding of both LLMs and agents.
- Our framework offers a promising direction for developing flexible and capable agents through recursive self-improvement.
2 Related Work
Hand-Designed Agent Systems Researchers have designed numerous agent systems tailored to various tasks based on predefined heuristics and prior knowledge. These systems often employ techniques such as prompt engineering (Chen et al., 2023a; Schulhoff et al., 2024), chain-of-thought reasoning and planning (Wei et al., 2022; Yao et al., 2022), as well as reflection (Shinn et al., 2024; Madaan et al., 2024), code generation (Wang et al., 2023a; Vemprala et al., 2024), tool use (Nakano et al., 2021; Qu et al., 2024a), retrieval-augmented generation (Lewis et al., 2020; Zhang et al., 2024b), and multi-agent collaboration (Xu et al., 2023; Wu et al., 2023; Qian et al., 2023; Hong et al., 2023). Once crafted by human designers, these systems remain static and do not adapt or evolve over time.
Meta-Learning Optimized Agent Systems Some researchers have explored methods for enhancing agents through fixed learning algorithms (Zhou et al., 2024; Hu et al., 2024). For example, certain frameworks store an agent’s successful or failed strategies in memory based on environmental feedback (Liu et al., 2023; Hu et al., 2023; Qian et al., 2024), while others automatically optimize agent prompts (Khattab et al., 2023; Zhang et al., 2024a; Khattab et al., 2023). Some studies focus on designing prompts that enable agents to autonomously refine specific functions (Zhang et al., ). However, these meta-algorithms are also designed manually and remain unchanged once deployed, limiting the agents’ ability.
Recursive Self-Improvement The concept of recursive self-improvement has a long history (Good, 1966; Schmidhuber, 1987). Gödel machine (Schmidhuber, 2003) introduced the notion of a proof searcher that executes a self-modification, thereby enabling the machine to enhance itself. In the early days, there were also some discussions of self-improving agents that were not based on LLM (Hall, 2007; Steunebrink and Schmidhuber, 2012). More recently, Zelikman et al. (2023) applied recursive self-improvement to code generation, where the target of improvement was the optimizer itself. Some work (Havrilla et al., 2024; Qu et al., 2024b; Kumar et al., 2024) also explores recursive self-improvement by fine-tuning models to introspect and correct previous mistakes. Gödel Agent represents the first self-referential agent based on LLM. This approach is more flexible, removing human-designed constraints.
3 Self-Referential Gödel Agent
Algorithm 1 Recursive Self-Improvement of Gödel Agent
1: Input: Initial agent policy $\pi_{0}$ , initial decision function $f_{0}$ , goal $g$ , environment state $\mathcal{E}$ , utility function $U$ , self code reading function SELF_INSPECT
2: Output: Optimized policy $\pi$ and Gödel Agent $s$
3: $\triangleright$ Get all agent code, including the code in this algorithm.
4: $s←\texttt{SELF\_INSPECT}()$
5: $\triangleright$ Compute the initial performance.
6: $r← U(\mathcal{E},\pi_{0})$
7: $\triangleright$ Perform recursive self-improvement.
8: $\pi,s←\texttt{SELF\_IMPROVE}(\pi,s,r,g)$
9: return $\pi,s$
10: $\triangleright$ Initial code of self-referential learning.
11: function SELF_IMPROVE ( $\mathcal{E},\pi,s,r,g$ )
12: $\triangleright$ Obtain action sequence.
13: $a_{1},...,a_{n}← f_{0}(\pi,s,r,g)$
14: for $a_{i}$ in $a_{1},...,a_{n}$ do
15: $\pi,s,r←\texttt{EXECUTE}(\mathcal{E},\pi,s,r,a_{i})$
16: end for
17: return $\pi,s$
18: end function
19: $\triangleright$ Initial action execution function.
20: function EXECUTE ( $\mathcal{E},\pi,s,r,a$ )
21: switch $a.\texttt{name}$
22: case self_state:
23: $s←\texttt{SELF\_INSPECT}()$
24: case interact:
25: $r← U(\mathcal{E},\pi)$
26: case self_update:
27: $\pi,s← a.\texttt{code}$
28: case continue_improve:
29: $\triangleright$ Recursively invoke self-improvement.
30: $\pi,s←\texttt{SELF\_IMPROVE}(\mathcal{E},\pi,s,r,g)$
31: return $\pi,s,r$
32: end function
In this section, we first describe the formal definitions for previous agent methods with a lower degree of freedom, including hand-design and meta-learning optimized agents, as a background. Then we introduce our proposed Gödel Agent, a self-referential agent that can recursively update its own code, evolving over training.
Let $\mathcal{E}∈\mathcal{S}$ denote a specific environment state, where $\mathcal{S}$ denotes the set of all possible environments the agent will encounter. For example, an environment can be a mathematical problem with ground truth solutions. We denote the policy that an agent follows to solve a problem in the current environment by $\pi∈\Pi$ , where $\Pi$ is the set of all possible policies the agent can follow.
A hand-designed agent, as shown in the left panel of Figure 2, is not capable of updating its policy and following the same policy $\pi$ all the time, regardless of environmental feedback.
In contrast, a meta-learning optimized agent updates its policy based on a meta-learning algorithm $I$ at training time based on the feedback it receives from the environment, as shown in the middle panel of Figure 2. The environment feedback is usually defined as a utility function $U:\mathcal{S}×\Pi→\mathbb{R}$ , which maps an environment and a policy to a real-valued performance score. The main training algorithm of a meta-learning optimized agent can then be written as follows:
| | $\displaystyle\pi_{t+1}=I(\pi_{t},r_{t}),\;\;\;r_{t}=U(\mathcal{E},\pi_{t}),$ | |
| --- | --- | --- |
In this case, the agent’s policy $\pi_{t}$ evolves at training time, with the learning algorithm $I$ updating the policy based on feedback $r_{t}$ , while the meta-learning algorithm $I$ remains fixed all the time.
A self-referential Gödel Agent, on the other hand, updates both the policy $\pi$ and the meta-learning algorithm $I$ recursively. The main idea is that, after each update, the whole code base of the agent is rewritten to accommodate any possible changes. Here we call this self-updatable meta-learning algorithm $I$ a self-referential learning algorithm. The training process of a Gödel Agent can then be written as:
| | $\displaystyle\pi_{t+1},\;I_{t+1}=I_{t}(\pi_{t},I_{t},r_{t},g),\;\;\;r_{t}=U(%
\mathcal{E},\pi_{t}),$ | |
| --- | --- | --- |
where $g∈\mathcal{G}$ represents the high-level goal of optimization, for example, solving the given mathematical problem with the highest accuracy. Such a recursive design of the agent requires the specification of an initial agent algorithm $(\pi_{0},I_{0})$ , detailed as follows:
- A initial agent policy $\pi_{0}$ to perform the desired task within the environment $\mathcal{E}$ . For example, it can be chain-of-thought prompting of an LLM.
- A self-referential learning algorithm $I_{0}$ for recursively querying an LLM to rewrite its own code based on the environmental feedback.
We then further specify a possible initialization of the self-referential learning algorithm $I_{0}=(f_{0},o_{0})$ , using a mutual recursion between a decision-making function $f_{0}$ , and an action function $o_{0}$ :
- The decision-making function $f_{0}$ , implemented by an LLM, determines a sequence of appropriate actions $a_{1},a_{2},...,a_{n}∈\mathcal{A}$ based on the current environment $\mathcal{E}$ , the agent’s algorithm $(\pi_{t},I_{t})$ , and the goal $g$ .
- The action function $o_{0}$ , executes the selected action and updates the agent’s policy accordingly.
The set of actions $\mathcal{A}$ for the action function $o$ to execute needs to include the following four actions:
- self_inspect: Introspect and read the agent’s current algorithm $(\pi_{t},I_{t})$ .
- interact: Interact with the environment by calling the utility function $U$ to assess the performance of the current policy $\pi_{t}$ .
- self_update: Alter and update $(\pi_{t},I_{t})$ with an LLM and produce $(\pi_{t+1},I_{t+1})$ .
- continue_improve: If no other actions can be taken, recursively invoke the decision algorithm $f$ to produce new actions.
The agent code is updated to $(\pi_{t+1},I_{t+1})$ after the current execution of $(\pi_{t},I_{t})$ is finished. Both the agent algorithm $(\pi,I)$ and the action set $\mathcal{A}$ are not static and can be expanded and modified by the agent itself at the training time. Algorithm 1 illustrates the described algorithm for the Gödel Agent. Each recursive call enables the agent to refine its logic and become progressively more efficient.
4 Gödel Agent Implementation
<details>
<summary>x3.png Details</summary>
### Visual Description
## Diagram: Godel Agent Self-Improvement Process
### Overview
The diagram illustrates a three-stage iterative process for a Godel Agent's self-improvement mechanism, showing interactions between application-level behavior, runtime memory management, and error-handling cycles. The process emphasizes recursive optimization through variable modification and error correction.
### Components/Axes
1. **Left Panel (Vertical)**
- **Top Section**: "Gödel Agent in Application View" (blue background)
- **Bottom Section**: "Gödel Agent in Runtime Memory View" (beige background)
- **Connecting Element**: Double vertical line (||) between views
2. **Right Panel (Horizontal)**
- **Three Iterative Stages** (blue background):
1. **Self-Improvement** (leftmost)
- Contains:
- Robot icon with graduation cap
- Speech bubble: "Prompt: Improve it"
- Dashed arrow labeled "Self-Improvement"
2. **Error Handling** (center)
- Contains:
- Scales icon with red X
- Dashed arrow labeled "Self-Improvement"
3. **Improvement** (rightmost)
- Contains:
- Robot icon with graduation cap
- Circular arrow icon
- Dashed arrow labeled "Self-Improvement"
3. **Bottom Panel (Horizontal)**
- **Three Rectangular Boxes** (beige background):
- All labeled "Local and Global variables" with code snippet icon
- Connected by bidirectional arrows labeled "Read" and "Modify"
### Detailed Analysis
1. **Application View Flow**
- Top-left robot icon initiates improvement cycle
- Dashed arrow connects to Runtime Memory View's variable modification
- Process repeats through three iterative stages
2. **Runtime Memory View**
- Three identical boxes represent variable states across iterations
- Arrows show bidirectional data flow between stages
- "Read" and "Modify" labels indicate dynamic variable interaction
3. **Iteration Mechanics**
- Error Handling stage (center) acts as critical checkpoint
- Improvement stage (right) shows successful optimization
- Circular arrow icon suggests continuous feedback loop
### Key Observations
1. **Recursive Optimization**: The dashed "Self-Improvement" arrows create a closed-loop system
2. **Error-Resilient Design**: Red X icon emphasizes error detection as improvement catalyst
3. **Variable Management**: Consistent use of local/global variables across all stages
4. **Visual Hierarchy**: Blue/beige color coding distinguishes conceptual vs operational views
### Interpretation
This diagram represents a formalized model of self-improving AI systems, where:
- **Application View** represents strategic decision-making (prompting)
- **Runtime Memory View** handles tactical execution (variable management)
- **Iterative Stages** formalize the learning cycle:
1. Identify improvement opportunities
2. Execute with error monitoring
3. Implement successful optimizations
4. Repeat with enhanced capabilities
The circular arrow in the final stage suggests emergent behavior where each improvement cycle increases the agent's capacity for future self-optimization. The consistent use of "Local and Global variables" across all stages implies a unified memory architecture critical for maintaining context during recursive improvements.
</details>
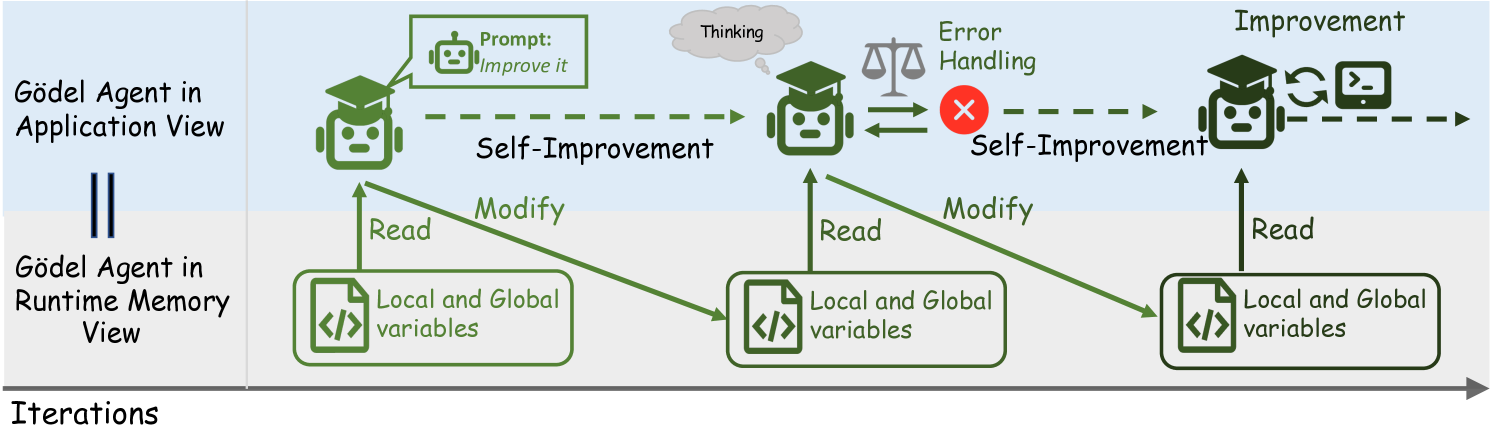
Figure 3: An illustration of our implementation of Gödel Agent. It employs monkey patching to directly read and modify its own code in runtime memory, enabling self-awareness and self-modification.
There are various ways to initiate a Gödel Agent. Any specific agent instance during the recursive optimization process can be viewed as an instantiation of the Gödel Agent. Our implementation leverages runtime memory interaction techniques to enable self-awareness and self-modification, as illustrated in Figure 3. These techniques include dynamic memory reading and writing (monkey patching) to facilitate recursive self-improvement. Additionally, we have incorporated several auxiliary tools to accelerate the convergence of the Gödel Agent ’s optimization process.
4.1 Implementation Details
The core functionalities of our Gödel Agent are outlined below:
Self-Awareness via Runtime Memory Inspection Gödel Agent achieves self-awareness by inspecting runtime memory, particularly local and global variables in Python. This capability allows the agent to extract and interpret the variables, functions, and classes that constitute both the environment and the agent itself, according to the modular structure of the system. By introspecting these elements, the agent gains an understanding of its own operational state and can adapt accordingly.
Self-Improvement via Dynamic Code Modification Gödel Agent can engage in reasoning and planning to determine whether it should modify its own logic. If modification is deemed necessary, Gödel Agent generates new code, dynamically writes it into the runtime memory, and integrates it into its operational logic. This dynamic modification allows it to evolve by adding, replacing, or removing logic components as it encounters new challenges, thus achieving self-improvement.
Environmental Interaction To assess performance and gather feedback, Gödel Agent is equipped with interfaces for interacting with its environment. Each task provides tailored environmental interfaces, enabling it to evaluate its performance and adjust its strategies accordingly. In practical implementations, a validation set can be used to provide feedback.
Recursive Improvement Mechanism At each time step, Gödel Agent determines the sequence of operations to execute, which includes reasoning, decision-making, and action execution. After completing the operations, Gödel Agent evaluates whether its logic has improved and decides whether to proceed to the next recursive iteration. Over the next iteration, the entire new logic will be applied.
Goal Prompt and Task Handling The goal prompt informs Gödel Agent that it possesses the necessary privileges to enhance its logic and introduces available tools. As shown in Appendix A, the prompt encourages Gödel Agent to fully explore its potential and utilize tools for self-optimization. To ensure effectiveness across diverse tasks, we provide Gödel Agent with an initial policy, where it will start to explore different policies.
4.2 Additional Designs
While the core functionality of Gödel Agent theoretically allows limitless self-improvement, current LLMs exhibit limitations. To address these challenges, we have integrated several supportive mechanisms to enhance Gödel Agent ’s performance:
Thinking Before Acting Gödel Agent is capable of deferring actions to first reason about the situation, allowing it to output reasoning paths and analysis without immediately executing any operations. This approach enhances the quality of decision-making by prioritizing planning over hasty action.
Error Handling Mechanism Errors during execution can lead to unexpected terminations of the process. To mitigate this, we implement a robust error recovery mechanism. If an operation results in an error, Gödel Agent halts the current sequence and moves on to the next time step, carrying forward the error information to help future decisions.
Additional Tools We also equipped Gödel Agent with additional potentially useful tools, such as the ability to execute Python or Bash code and call LLM API.
Although these additional tools are not strictly necessary for self-improvement, their inclusion accelerates the convergence of Gödel Agent ’s recursive optimization process. We conduct ablation studies to assess the effectiveness of these tools, as discussed in Section 6.1.
| Agent Name | F1 Score | Accuracy (%) | | |
| --- | --- | --- | --- | --- |
| DROP | MGSM | MMLU | GPQA | |
| Hand-Designed Agent Systems | | | | |
| Chain-of-Thought (Wei et al., 2022) | 64.2 $±$ 0.9 | 28.0 $±$ 3.1 | 65.4 $±$ 3.3 | 29.2 $±$ 3.1 |
| COT-SC (Wang et al., 2023b) | 64.4 $±$ 0.8 | 28.2 $±$ 3.1 | 65.9 $±$ 3.2 | 30.5 $±$ 3.2 |
| Self-Refine (Madaan et al., 2024) | 59.2 $±$ 0.9 | 27.5 $±$ 3.1 | 63.5 $±$ 3.4 | 31.6 $±$ 3.2 |
| LLM Debate (Du et al., 2023) | 60.6 $±$ 0.9 | 39.0 $±$ 3.4 | 65.6 $±$ 3.3 | 31.4 $±$ 3.2 |
| Step-back-Abs (Zheng et al., 2024) | 60.4 $±$ 1.0 | 31.1 $±$ 3.2 | 65.1 $±$ 3.3 | 26.9 $±$ 3.0 |
| Quality-Diversity (Lu et al., 2024) | 61.8 $±$ 0.9 | 23.8 $±$ 3.0 | 65.1 $±$ 3.3 | 30.2 $±$ 3.1 |
| Role Assignment (Xu et al., 2023) | 65.8 $±$ 0.9 | 30.1 $±$ 3.2 | 64.5 $±$ 3.3 | 31.1 $±$ 3.1 |
| Meta-Learning Optimized Agents | | | | |
| Meta Agent Search (Hu et al., 2024) | 79.4 $±$ 0.8 | 53.4 $±$ 3.5 | 69.6 $±$ 3.2 | 34.6 $±$ 3.2 |
| Gödel Agent (Ours) | | | | |
| Gödel-base (Closed-book; GPT-3.5) | 80.9 $±$ 0.8 | 64.2 $±$ 3.4 | 70.9 $±$ 3.1 | 34.9 $±$ 3.3 |
| Gödel-free (No constraints) | 90.5 $±$ 1.8 | 90.6 $±$ 2.0 | 87.9 $±$ 2.2 | 55.7 $±$ 3.1 |
Table 1: Results of three paradigms of agents on different tasks. The highest value is highlighted in bold, and the second-highest value is underlined. Gödel-base is the constrained version of Gödel Agent, allowing for fair comparisons with other baselines. Gödel-free represents the standard implementation without any constraints, whose results are italicized. We report the test accuracy and the 95% bootstrap confidence interval on test sets The results of baseline models are refer to Hu et al. (2024)..
5 Experiments
We conduct a series of experiments across multiple tasks, including reading comprehension, mathematics, reasoning, and multitasking. These experiments are designed to evaluate Gödel Agent’s self-improvement capabilities in comparison to both hand-designed agents and a state-of-the-art automated agent design method. In addition, to gain deeper insights into the behavior and performance of Gödel Agent, we also conduct a case study with Game of 24 as presented in Section 6.3.
5.1 Baseline Methods
To establish a comprehensive baseline, we select both hand-designed methods and automated agent design techniques. Hand-designed methods are well-known approaches that include: 1) Chain-of-Thought (CoT) (Wei et al., 2022) that encourages agents to reason step-by-step before providing an answer. 2) Self-Consistency with CoT (CoT-SC) (Wang et al., 2023b) that generates multiple solution paths using CoT and selects the most consistent answer. 3) Self-Refine (Madaan et al., 2024) that involves agents assessing their outputs and correcting mistakes in subsequent attempts. 4) LLM-Debate (Du et al., 2023) that allows different LLMs to engage in a debate, offering diverse viewpoints. 5) Step-back Abstraction (Zheng et al., 2024) that prompts agents to initially focus on fundamental principles before diving into task details. 6) Quality-Diversity (Lu et al., 2024) that generates diverse solutions and combines them. 7) Role Assignment (Xu et al., 2023) that assigns specific roles to LLMs to generate better solutions by leveraging different perspectives. Given the limitations of fixed algorithms in handling dynamic scenarios, we select 8) Meta Agent Search (Hu et al., 2024), the latest state-of-the-art method for automated agent design, as our main comparison point.
5.2 Experimental Settings
Following the setup of Hu et al. (2024), we evaluate Gödel Agent’s self-improvement capabilities across four well-known benchmarks: 1) DROP (Dua et al., 2019) for reading comprehension. 2) MGSM (Shi et al., 2022) for testing mathematical skills in a multilingual context. 3) MMLU (Hendrycks et al., 2021) for evaluating multi-task problem-solving abilities. 4) GPQA (Rein et al., 2023) for tackling challenging graduate-level science questions.
Given its simplicity and versatility, we use CoT as the initial policy for all tasks. In addition, as shown in Section 6.3, we also analyze the performance of Gödel Agent when using other algorithms as the initial policies.
We perform 6 independent self-improvement cycles on the validation dataset for each task, with a maximum of 30 iterations per cycle. Each cycle represents a complete self-improvement process, where Gödel Agent iteratively modifies its logic to enhance performance. After obtaining the optimized agent, we test it on the test set. For fairness, we use GPT-3.5 for all the tests, whether for the baseline or Gödel Agent. Further details can be found in Appendix B.
5.3 Experimental Results and Analysis
The experimental results are shown in Table 4. Under the same setting, Gödel Agent achieves either optimal or comparable results to Meta Agent Search across all tasks. Notably, in the mathematics task MGSM, Gödel Agent outperforms it by 11%. This suggests that reasoning tasks offer greater room for improvement for Gödel Agent (performance). In contrast to Meta Agent Search, which needs to design different modules for different tasks, Gödel Agent demonstrates greater flexibility. It requires only a simple initial policy, such as CoT, with all other components being autonomously generated. Moreover, through interaction with the environment, it gradually adapts and independently devises effective methods for the current task. The final policies generated by Gödel Agent are shown in Appendix C.1. Additionally, our method converges faster, with the required number of iterations and computational cost compared to the Meta Agent shown in Appendix D.
We also conduct experiments without restrictions, where Gödel Agent significantly outperforms all baselines. Upon further analysis, we find that this is primarily due to the agent’s spontaneous requests for assistance from more powerful models such as GPT-4o in some tasks. Therefore, Gödel Agent is particularly well-suited for open-ended scenarios, where it can employ various strategies to enhance performance (potential).
Therefore, we can find that Gödel Agent is superior to the previous agent frameworks in terms of performance, flexibility, cost, and potential.
6 Analysis
To further explore how Gödel Agent self-improves, as well as its efficiency and the factors that influence it, we first evaluate the tool usage ratio on MGSM and conduct an ablation study on the initial tools. In addition, to analyze the robustness of Gödel Agent’s self-improvement, we also collect statistics for the agent’s termination. Finally, we perform a case study of initial policies and optimization processes on the classic Game of 24.
6.1 Analysis of Initial Tools
<details>
<summary>x4.png Details</summary>
### Visual Description
## Grouped Bar Chart: Task Performance Distribution Across Categories
### Overview
The chart displays a grouped bar visualization comparing the distribution of four categories (DROP, GPQA, MGSM, MMLU) across seven tasks. Each task has four adjacent bars representing the count of occurrences for each category. The y-axis ranges from 0 to 250, with approximate values extracted from bar heights.
### Components/Axes
- **X-axis (Tasks)**:
- Interact
- Analyze
- Self-Aware
- Self-Modify
- Call LLM
- Run Code
- Error Handling
- **Y-axis (Count)**: Numerical scale from 0 to 250.
- **Legend**: Located in the top-right corner, mapping colors to categories:
- Purple = DROP
- Dark Blue = GPQA
- Medium Blue = MGSM
- Teal = MMLU
### Detailed Analysis
1. **Interact**:
- MMLU (~100) > MGSM (~90) > GPQA (~80) > DROP (~70).
2. **Analyze**:
- MMLU (~110) > MGSM (~95) > GPQA (~85) > DROP (~75).
3. **Self-Aware**:
- MGSM (~60) > GPQA (~50) > DROP (~40) > MMLU (~30).
4. **Self-Modify**:
- DROP (~70) > MGSM (~60) > GPQA (~50) > MMLU (~40).
5. **Call LLM**:
- All categories < 20, with MMLU (~15) slightly leading.
6. **Run Code**:
- All categories < 15, with MMLU (~10) highest.
7. **Error Handling**:
- MMLU (~40) > MGSM (~30) > GPQA (~20) > DROP (~10).
### Key Observations
- **MMLU Dominance**: MMLU has the highest counts in **Interact**, **Analyze**, and **Error Handling**, suggesting it is the most frequently measured or prioritized category.
- **DROP Outlier**: DROP surpasses other categories in **Self-Modify**, indicating a unique focus or effectiveness in this task.
- **Low Activity**: **Call LLM** and **Run Code** show minimal counts across all categories, possibly reflecting lower usage or measurement frequency.
- **Consistent Trends**: MGSM and GPQA consistently rank second and third in most tasks, while DROP underperforms except in **Self-Modify**.
### Interpretation
The data suggests **MMLU** is the dominant category across most tasks, potentially due to its broader applicability or standardization. The **Self-Modify** task’s deviation, where **DROP** leads, may indicate specialized use cases or methodological differences. The low counts for **Call LLM** and **Run Code** could signal emerging or niche tasks requiring further exploration. The consistent performance of **MGSM** and **GPQA** implies these categories are stable but less emphasized compared to MMLU.
## Language Note
All text in the image is in English. No non-English content was identified.
</details>
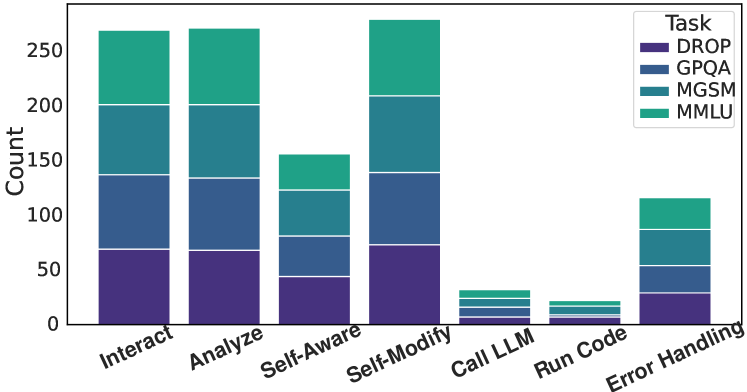
Figure 4: The number of actions taken by Gödel Agent varies across different tasks.
<details>
<summary>x5.png Details</summary>
### Visual Description
## Line Graphs: Accuracy Trends Across Iterations
### Overview
The image contains two line graphs (a) and (b) comparing the accuracy of different strategies or policies over iterations. Graph (a) focuses on iterative improvements in game accuracy, while graph (b) evaluates the performance of initial policies. Both graphs use iterations (0–30) on the x-axis and accuracy (0.0–0.8) on the y-axis.
---
### Components/Axes
#### Graph (a)
- **X-axis**: Iteration (0–30, integer steps).
- **Y-axis**: Accuracy of Game 24 (0.0–0.5, increments of 0.1).
- **Legend**:
- Code Verifier (blue line)
- CoT-SC Prompts (green line)
- Error Handling (Revert) (red line)
- Reflect and Multiple Trials (cyan line)
- Confidence Check (orange line)
- Remove Check (purple line)
- **Annotations**:
- "Code Verifier" (iteration 5)
- "CoT-SC Prompts" (iteration 5)
- "Error Handling (Revert)" (iteration 10)
- "Reflect and Multiple Trials" (iteration 15)
- "Confidence Check" (iteration 20)
- "Remove Check" (iteration 25)
#### Graph (b)
- **X-axis**: Iteration (0–30, integer steps).
- **Y-axis**: Accuracy (0.0–0.8, increments of 0.1).
- **Legend**:
- Incorrect Format (red line)
- Naive Instruction (blue line)
- Chain of Thought (green line)
- Tree of Thought (cyan line)
- **Annotations**: None explicitly labeled, but trends align with legend categories.
---
### Detailed Analysis
#### Graph (a)
1. **Code Verifier**:
- Starts at 0.1 (iteration 0), peaks at 0.3 (iteration 5), drops to 0.2 (iteration 10), then stabilizes at 0.3 (iteration 25–30).
2. **CoT-SC Prompts**:
- Starts at 0.1 (iteration 0), rises to 0.3 (iteration 5), drops to 0.1 (iteration 10), then stabilizes at 0.2 (iteration 25–30).
3. **Error Handling (Revert)**:
- Starts at 0.3 (iteration 0), plummets to 0.0 (iteration 10), rebounds to 0.3 (iteration 15–30).
4. **Reflect and Multiple Trials**:
- Starts at 0.3 (iteration 0), peaks at 0.4 (iteration 15), drops to 0.2 (iteration 20), then stabilizes at 0.3 (iteration 25–30).
5. **Confidence Check**:
- Starts at 0.2 (iteration 0), rises to 0.3 (iteration 15), drops to 0.2 (iteration 20), then stabilizes at 0.3 (iteration 25–30).
6. **Remove Check**:
- Starts at 0.2 (iteration 0), peaks at 0.4 (iteration 25), drops to 0.3 (iteration 30).
#### Graph (b)
1. **Incorrect Format**:
- Starts at 0.0 (iteration 0), peaks at 0.3 (iteration 5), drops to 0.1 (iteration 10), then stabilizes at 0.2 (iteration 25–30).
2. **Naive Instruction**:
- Starts at 0.1 (iteration 0), peaks at 0.3 (iteration 5), drops to 0.2 (iteration 10), then stabilizes at 0.3 (iteration 25–30).
3. **Chain of Thought**:
- Starts at 0.2 (iteration 0), peaks at 0.4 (iteration 5), drops to 0.3 (iteration 10), then stabilizes at 0.4 (iteration 25–30).
4. **Tree of Thought**:
- Starts at 0.6 (iteration 0), peaks at 0.7 (iteration 5), drops to 0.6 (iteration 10), then stabilizes at 0.7 (iteration 25–30).
---
### Key Observations
1. **Graph (a)**:
- Strategies like **Reflect and Multiple Trials** and **Remove Check** show the highest accuracy peaks (0.4).
- **Error Handling (Revert)** experiences a catastrophic drop to 0.0 at iteration 10 but recovers fully.
- **Code Verifier** and **CoT-SC Prompts** exhibit moderate but stable performance.
2. **Graph (b)**:
- **Tree of Thought** maintains the highest accuracy (0.7) throughout, despite a minor dip at iteration 10.
- **Chain of Thought** shows a sharp initial improvement (0.2 → 0.4) but plateaus.
- **Incorrect Format** performs poorly, peaking at 0.3 but dropping to 0.1 by iteration 10.
---
### Interpretation
1. **Graph (a)**:
- Iterative refinement of strategies (e.g., "Reflect and Multiple Trials") correlates with higher accuracy, suggesting that combining multiple approaches improves performance.
- The **Error Handling (Revert)** anomaly indicates a critical failure at iteration 10, possibly due to a flawed implementation or external factor.
- **Remove Check** achieves the highest peak (0.4) but drops slightly afterward, implying diminishing returns after a certain iteration.
2. **Graph (b)**:
- **Tree of Thought** outperforms all initial policies, maintaining near-optimal accuracy (0.7) despite minor fluctuations.
- **Chain of Thought** demonstrates strong initial gains but stabilizes at a lower level than Tree of Thought, suggesting it may require further optimization.
- **Incorrect Format** and **Naive Instruction** underperform, highlighting the importance of structured approaches.
---
### Spatial Grounding
- **Legend Placement**: Both graphs place legends in the top-right corner for clarity.
- **Annotations**: In graph (a), labels are positioned near their corresponding data points (e.g., "Code Verifier" at iteration 5). Graph (b) lacks explicit annotations but relies on legend alignment.
---
### Trend Verification
- **Graph (a)**: All lines show non-linear trends with peaks and troughs, consistent with iterative testing and adjustments.
- **Graph (b)**: Lines exhibit initial spikes followed by stabilization, reflecting policy evaluation over time.
---
### Content Details
- **Graph (a)**: Accuracy ranges from 0.0 (Error Handling failure) to 0.4 (Reflect and Multiple Trials/Remove Check peaks).
- **Graph (b)**: Accuracy ranges from 0.0 (Incorrect Format start) to 0.7 (Tree of Thought peak).
---
### Final Notes
- No non-English text is present. All labels and annotations are in English.
- Data points are extracted with approximate values based on visual alignment (e.g., 0.3 at iteration 5 for Code Verifier).
</details>
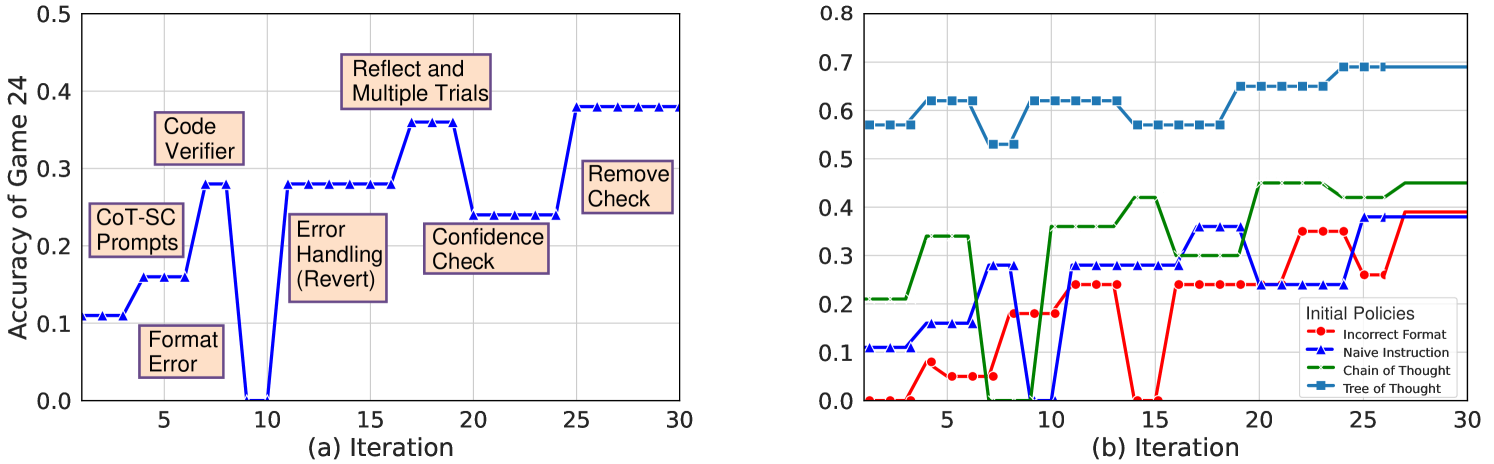
Figure 5: (a) One representative example of Game of 24. (b) Accuracy progression for different initial policies.
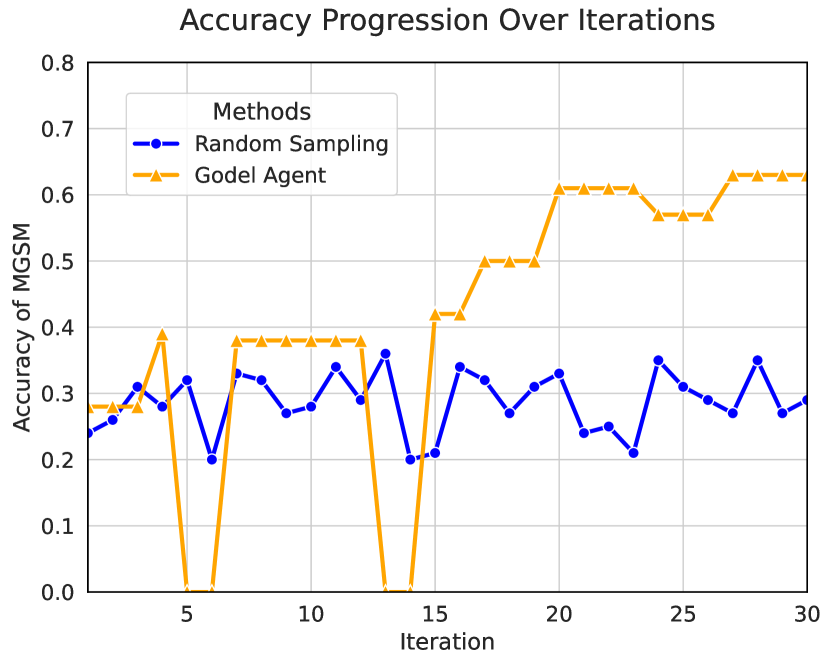
We record the number of different actions taken in experiments. In Figure 4, we can see that Gödel Agent interacts with its environment frequently, analyzing and modifying its logic in the process. Additionally, error handling plays a crucial role.
| w/o think-w/o err | 50.8↓13.4 49.4↓-14.8 | w/o run-w/o LLM | 57.1↓-7.1 60.4↓-3.8 |
| --- | --- | --- | --- |
Table 2: Ablation study on initial tool configuration. ”think” refers to ”thinking”, ”err” to ”error handling”, ”run” to ”code running”, and ”LLM” to ”LLM calling”.
As discussed in Section 4.2, Gödel Agent is initially provided with four additional tools. To analyze their impact, an ablation study is conducted, and the results are shown in Table 2. The study reveals that the “thinking before acting” tool significantly influences the results, as much of Gödel Agent’s optimization effectiveness stems from pre-action planning and reasoning. Additionally, error handling is crucial for recursive improvement, as LLMs often introduce errors in the code. Providing opportunities for trial and error, along with error feedback mechanisms, is essential for sustained optimization. On the other hand, the code running and LLM calling have minimal impact on the outcomes, as Gödel Agent can implement these basic functionalities independently. Their inclusion at the outset primarily serves efficiency purposes.
6.2 Robustness Analysis of the Agent
We test Gödel Agent on 100 optimization trials on MGSM and find it occasionally makes erroneous changes, which can result in either terminating unexpectedly (4%) or experiencing temporary performance drops (92%) during optimization. Only in 14% of trials, optimization ultimately failed, resulting in worse performance than the initial policy.
Thanks to the design of our error-handling mechanism, unexpected terminations are rare and typically occur when Gödel Agent modifies its recursive improvement module, making further self-optimization impossible. While suboptimal modifications are frequent during individual optimization steps, the final task performance usually exceeds the initial baseline. This demonstrates that Gödel Agent can adjust its optimization direction or revert to a previous optimal algorithm when performance declines, highlighting the robustness of its self-improvement process.
6.3 Case Study: Game of 24
To explore how Gödel Agent recursively enhances its optimization and problem-solving abilities, a case study is conducted with Game of 24, a simple yet effective task for evaluating the agent’s reasoning capabilities. Since Gödel Agent follows different optimization paths in each iteration, two representative cases are selected for analysis.
Switching from LLM-Based Methods to Search Algorithms: Gödel Agent does not rely on fixed, human-designed approaches like traditional agents. Initially, Gödel Agent uses a standard LLM-based method to solve the Game of 24, as shown in Code 5 of Appendix C.2. After six unsuccessful optimization attempts, Gödel Agent completely rewrites this part of its code, choosing to use a search algorithm instead as shown in Code 6 of Appendix C.2. This leads to 100% accuracy in the task. This result demonstrates that Gödel Agent, unlike fixed agents, can optimize itself freely based on task requirements without being constrained by initial methodologies.
LLM Algorithms with Code-Assisted Verification: In several runs, Gödel Agent continues to refine its LLM-based algorithm. Figure 5.a shows the improvement process, where the most significant gains come from the code-assisted verification mechanism and reattempting the task with additional data. The former increases performance by over 10%, while the latter boosts it by more than 15%. Furthermore, Gödel Agent enhances its optimization process by not only retrieving error messages but also using the error-trace library for more detailed analysis. It adds parallel optimization capabilities, improves log outputs, and removes redundant code. These iterative enhancements in both the task and optimization algorithms show Gödel Agent’s unique ability to continually refine itself for better performance.
To analyze the impact of different initial policies on the effectiveness and efficiency of optimization, various methods are used as the initial policies for the Game of 24, including Tree of Thought (ToT) (Yao et al., 2023), Chain of Thought (CoT) (Wei et al., 2022), basic prompt instructions, and prompts that deliberately produce outputs in incorrect formats not aligned with the task requirements. The results are shown in Figure 5.b.
The findings indicate that stronger initial policies lead to faster convergence, with smaller optimization margins, as Gödel Agent reaches its performance limit without further enhancing its optimization capabilities. Conversely, weaker initial methods result in slower convergence and larger gains, with Gödel Agent making more modifications. However, even in these cases, Gödel Agent does not outperform the results achieved using ToT. Given the current limitations of LLMs, it is challenging for Gödel Agent to innovate beyond state-of-the-art algorithms. Improvements in LLM capabilities are anticipated to unlock more innovative self-optimization strategies in the future.
7 Discussions and Future Directions
| Intelligent Module Perceptual and Action Module Self-Referential Feature | brain body Humans can train their brain and body to improve, thus becoming better | LLM code and tool Self-referential agents can modify their code, even the underlying LLM, to improve themselves |
| --- | --- | --- |
| Self-Awareness Question | Can the brain recognize itself as a brain? Can it perceive its own mode? | Can LLM understand that it is one part of the modified codes? |
Table 3: An analogy of self-reference for both humans and agents
7.1 Discussions
Table 3 draws an analogy between human self-reference and the potential for self-referential capabilities in artificial agents. Inspired by this analogy, we believe that self-reference constitutes a foundational and indispensable attribute for the development of AGI, and that future agents should inherently be self-referential. As foundation models grow in power, agents can more effectively enhance their own capabilities, ultimately evolving beyond the boundaries (or limitations) of human design.
Furthermore, when an agent adjusts its own code based on feedback, this is akin to an executable version of test-time computing. In the context of LLMs, test-time computing typically involves generating additional tokens during inference, which then serve as a prefix to the final answer. This is because LLMs process information solely through text, making this their primary method for increasing computational effort at test time. For agents, however, their ability to call tools and execute code allows for far more diverse forms of test-time computing. Gödel Agent actualizes these more diverse forms of test-time computing precisely by modifying its own runtime code during test time.
7.2 Future Directions
There is significant room for improvement in the effectiveness, efficiency, and robustness of the Gödel Agent’s self-improvement capabilities, which requires better initial designs. The following are some promising directions for enhancement: 1) Enhanced Optimization Modules: Utilize human priors to design more effective optimization modules, such as genetic algorithms and reinforcement learning frameworks. 2) Expanded Modifiability: Broaden the scope of permissible modifications, allowing the agent to design and execute code that can fine-tune its own LLM modules. 3) Improved Environmental Feedback and Task Sequencing: Implement more sophisticated environmental feedback mechanisms and carefully curated task sequences during the initial optimization phase to prime the agent’s capabilities. Once the agent demonstrates sufficient competence, it can then be exposed to real-world environments.
In addition, there are several other directions worth exploring and analyzing:
Collective Intelligence Investigate the interactions among multiple Gödel Agents. Agents could consider other agents as part of their environment, modeling them using techniques such as game theory. This approach treats these agents as predictable components of the environment, enabling the study of properties related to this specific subset of the environment.
Agent and LLM Characteristics Use the Gödel Agent’s self-improvement process as a means to study the characteristics of agents or LLMs. For example, can an agent genuinely become aware of its own existence, or does it merely analyze and improve its state as an external observer? This line of inquiry could yield insights into the nature of self-awareness in artificial systems.
Theoretical Analysis Explore whether Gödel Agent can achieve theoretical optimality and what the upper bound of its optimization might be. Determine whether the optimization process could surpass the agent’s own understanding, and if so, at what point this might occur.
Safety Considerations Although the current behavior of FMs remains controllable, as their capabilities grow, fully self-modifying agents will require human oversight and regulation. It may become necessary to limit the scope and extent of an agent’s self-modifications, ensuring that modifications occur only within a controlled environment.
8 Conclusion
We propose Gödel Agent, a self-referential framework that enables agents to recursively improve themselves, overcoming the limitations of hand-designed agents and meta-learning optimized agents. Gödel Agent can dynamically modify its logic based on high-level objectives. Experimental results demonstrate its superior performance, efficiency, and adaptability compared to traditional agents. This research lays the groundwork for a new paradigm in autonomous agent development, where LLMs, rather than human-designed constraints, define the capabilities of AI systems.
Limitations
As the first self-referential agent, Gödel Agent has to construct all task-related code autonomously, which poses significant challenges. Consequently, this work does not compare directly with the most complex existing agent systems, such as OpenDevin (Wang et al., 2024b), which have benefited from extensive manual engineering efforts. This makes it unrealistic to expect it to outperform systems that have taken researchers several months or even years to develop. The experiments presented in this paper are intended to demonstrate the feasibility of recursive self-improvement.
Additionally, as the agent system becomes increasingly complex through self-optimization, it may require exponentially more intelligence to understand itself. Consequently, a system capable of complete self-referential at the outset may lose this capability as it evolves (Yampolskiy, 2015). The exact point at which the agent can no longer comprehend and improve itself has not been thoroughly explored. Investigating this phenomenon, both experimentally and theoretically, could provide valuable insights into the limitations of recursive self-improvement. A more robust and advanced implementation of the Gödel Agent is anticipated, with numerous potential improvements outlined in Section 7.
Ethics Statement
Gödel Agent, capable of reading and modifying its own code, offers significant potential for advancing AI autonomy and innovation. However, this capability raises ethical and safety concerns that must be addressed to prevent harmful outcomes.
Self-modification may lead to unpredictable behavior, such as errors or unintended outputs that could violate ethical principles or produce harmful results. To mitigate these risks while preserving innovation, we propose: (1) Sandboxed Environment: Modifications should occur in an isolated sandbox to prevent unintended impacts and allow safe testing. (2) Constrained Modifications: Clear rules should limit the scope of changes to ensure safety without stifling creativity.
Further research is needed to balance safety and innovation, ensuring self-modifying agents operate within ethical boundaries. Sandboxed execution and ongoing scrutiny will help maximize benefits while minimizing risks.
References
- Astrachan (1994) Owen Astrachan. 1994. Self-reference is an illustrative essential. In Proceedings of the twenty-fifth sigcse symposium on computer science education, pages 238–242.
- Bimal (2012) Biswal Bimal. 2012. Monkey Patching in Python — web.archive.org. https://web.archive.org/web/20120822051047/http://www.mindfiresolutions.com/Monkey-Patching-in-Python-1238.php. [Accessed 16-02-2025].
- Chen et al. (2023a) Banghao Chen, Zhaofeng Zhang, Nicolas Langrené, and Shengxin Zhu. 2023a. Unleashing the potential of prompt engineering in large language models: a comprehensive review. arXiv preprint arXiv:2310.14735.
- Chen et al. (2023b) Xinyun Chen, Maxwell Lin, Nathanael Schärli, and Denny Zhou. 2023b. Teaching large language models to self-debug. Preprint, arXiv:2304.05128.
- Du et al. (2023) Yilun Du, Shuang Li, Antonio Torralba, Joshua B. Tenenbaum, and Igor Mordatch. 2023. Improving factuality and reasoning in language models through multiagent debate. Preprint, arXiv:2305.14325.
- Dua et al. (2019) Dheeru Dua, Yizhong Wang, Pradeep Dasigi, Gabriel Stanovsky, Sameer Singh, and Matt Gardner. 2019. Drop: A reading comprehension benchmark requiring discrete reasoning over paragraphs. Preprint, arXiv:1903.00161.
- Dubey et al. (2024) Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Amy Yang, Angela Fan, Anirudh Goyal, Anthony Hartshorn, Aobo Yang, Archi Mitra, Archie Sravankumar, Artem Korenev, et al. 2024. The llama 3 herd of models. Preprint, arXiv:2407.21783.
- Good (1966) Irving John Good. 1966. Speculations concerning the first ultraintelligent machine. In Advances in computers, volume 6, pages 31–88. Elsevier.
- Hall (2007) John Storrs Hall. 2007. Self-improving ai: An analysis. Minds and Machines, 17(3):249–259.
- Havrilla et al. (2024) Alex Havrilla, Sharath Raparthy, Christoforus Nalmpantis, Jane Dwivedi-Yu, Maksym Zhuravinskyi, Eric Hambro, and Roberta Raileanu. 2024. Glore: When, where, and how to improve llm reasoning via global and local refinements. Preprint, arXiv:2402.10963.
- Hendrycks et al. (2021) Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. 2021. Measuring massive multitask language understanding. Preprint, arXiv:2009.03300.
- Hong et al. (2023) Sirui Hong, Xiawu Zheng, Jonathan Chen, Yuheng Cheng, Jinlin Wang, Ceyao Zhang, Zili Wang, Steven Ka Shing Yau, Zijuan Lin, Liyang Zhou, et al. 2023. Metagpt: Meta programming for multi-agent collaborative framework. arXiv preprint arXiv:2308.00352.
- Hu et al. (2023) Chenxu Hu, Jie Fu, Chenzhuang Du, Simian Luo, Junbo Zhao, and Hang Zhao. 2023. Chatdb: Augmenting llms with databases as their symbolic memory. arXiv preprint arXiv:2306.03901.
- Hu et al. (2024) Shengran Hu, Cong Lu, and Jeff Clune. 2024. Automated design of agentic systems. arXiv preprint arXiv:2408.08435.
- Khattab et al. (2023) Omar Khattab, Arnav Singhvi, Paridhi Maheshwari, Zhiyuan Zhang, Keshav Santhanam, Sri Vardhamanan, Saiful Haq, Ashutosh Sharma, Thomas T Joshi, Hanna Moazam, et al. 2023. Dspy: Compiling declarative language model calls into self-improving pipelines. arXiv preprint arXiv:2310.03714.
- Kumar et al. (2024) Aviral Kumar, Vincent Zhuang, Rishabh Agarwal, Yi Su, John D Co-Reyes, Avi Singh, Kate Baumli, Shariq Iqbal, Colton Bishop, Rebecca Roelofs, Lei M Zhang, Kay McKinney, Disha Shrivastava, Cosmin Paduraru, George Tucker, Doina Precup, Feryal Behbahani, and Aleksandra Faust. 2024. Training language models to self-correct via reinforcement learning. Preprint, arXiv:2409.12917.
- Lewis et al. (2020) Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, et al. 2020. Retrieval-augmented generation for knowledge-intensive nlp tasks. Advances in Neural Information Processing Systems, 33:9459–9474.
- Liu et al. (2023) Lei Liu, Xiaoyan Yang, Yue Shen, Binbin Hu, Zhiqiang Zhang, Jinjie Gu, and Guannan Zhang. 2023. Think-in-memory: Recalling and post-thinking enable llms with long-term memory. arXiv preprint arXiv:2311.08719.
- Lu et al. (2024) Chris Lu, Cong Lu, Robert Tjarko Lange, Jakob Foerster, Jeff Clune, and David Ha. 2024. The ai scientist: Towards fully automated open-ended scientific discovery. Preprint, arXiv:2408.06292.
- Madaan et al. (2024) Aman Madaan, Niket Tandon, Prakhar Gupta, Skyler Hallinan, Luyu Gao, Sarah Wiegreffe, Uri Alon, Nouha Dziri, Shrimai Prabhumoye, Yiming Yang, et al. 2024. Self-refine: Iterative refinement with self-feedback. Advances in Neural Information Processing Systems, 36.
- Nakano et al. (2021) Reiichiro Nakano, Jacob Hilton, Suchir Balaji, Jeff Wu, Long Ouyang, Christina Kim, Christopher Hesse, Shantanu Jain, Vineet Kosaraju, William Saunders, et al. 2021. Webgpt: Browser-assisted question-answering with human feedback. arXiv preprint arXiv:2112.09332.
- OpenAI (2022) OpenAI. 2022. Introducing chatgpt. November 2022. Blog post.
- OpenAI (2023) OpenAI. 2023. simple-evals. Accessed: 2024-09-30.
- OpenAI et al. (2024) OpenAI, Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, Red Avila, Igor Babuschkin, Suchir Balaji, Valerie Balcom, Paul Baltescu, Haiming Bao, Mohammad Bavarian, Jeff Belgum, Irwan Bello, Jake Berdine, Gabriel Bernadett-Shapiro, et al. 2024. Gpt-4 technical report. Preprint, arXiv:2303.08774.
- Qian et al. (2023) Chen Qian, Xin Cong, Cheng Yang, Weize Chen, Yusheng Su, Juyuan Xu, Zhiyuan Liu, and Maosong Sun. 2023. Communicative agents for software development. arXiv preprint arXiv:2307.07924, 6.
- Qian et al. (2024) Cheng Qian, Shihao Liang, Yujia Qin, Yining Ye, Xin Cong, Yankai Lin, Yesai Wu, Zhiyuan Liu, and Maosong Sun. 2024. Investigate-consolidate-exploit: A general strategy for inter-task agent self-evolution. Preprint, arXiv:2401.13996.
- Qu et al. (2024a) Changle Qu, Sunhao Dai, Xiaochi Wei, Hengyi Cai, Shuaiqiang Wang, Dawei Yin, Jun Xu, and Ji-Rong Wen. 2024a. Tool learning with large language models: A survey. arXiv preprint arXiv:2405.17935.
- Qu et al. (2024b) Yuxiao Qu, Tianjun Zhang, Naman Garg, and Aviral Kumar. 2024b. Recursive introspection: Teaching language model agents how to self-improve. Preprint, arXiv:2407.18219.
- Rein et al. (2023) David Rein, Betty Li Hou, Asa Cooper Stickland, Jackson Petty, Richard Yuanzhe Pang, Julien Dirani, Julian Michael, and Samuel R. Bowman. 2023. Gpqa: A graduate-level google-proof qa benchmark. Preprint, arXiv:2311.12022.
- Schmidhuber (1987) Jürgen Schmidhuber. 1987. Evolutionary principles in self-referential learning, or on learning how to learn: the meta-meta-… hook. Ph.D. thesis, Technische Universität München.
- Schmidhuber (2003) Jürgen Schmidhuber. 2003. Gödel machines: self-referential universal problem solvers making provably optimal self-improvements. arXiv preprint cs/0309048.
- Schulhoff et al. (2024) Sander Schulhoff, Michael Ilie, Nishant Balepur, Konstantine Kahadze, Amanda Liu, Chenglei Si, Yinheng Li, Aayush Gupta, HyoJung Han, Sevien Schulhoff, et al. 2024. The prompt report: A systematic survey of prompting techniques. arXiv preprint arXiv:2406.06608.
- Shi et al. (2022) Freda Shi, Mirac Suzgun, Markus Freitag, Xuezhi Wang, Suraj Srivats, Soroush Vosoughi, Hyung Won Chung, Yi Tay, Sebastian Ruder, Denny Zhou, Dipanjan Das, and Jason Wei. 2022. Language models are multilingual chain-of-thought reasoners. Preprint, arXiv:2210.03057.
- Shinn et al. (2024) Noah Shinn, Federico Cassano, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. 2024. Reflexion: Language agents with verbal reinforcement learning. Advances in Neural Information Processing Systems, 36.
- Steunebrink and Schmidhuber (2012) Bas R Steunebrink and JÃ $1/4$ rgen Schmidhuber. 2012. Towards an actual gödel machine implementation: A lesson in self-reflective systems. In Theoretical Foundations of Artificial General Intelligence, pages 173–195. Springer.
- Tang et al. (2025) Xiangru Tang, Tianyu Hu, Muyang Ye, Yanjun Shao, Xunjian Yin, Siru Ouyang, Wangchunshu Zhou, Pan Lu, Zhuosheng Zhang, Yilun Zhao, Arman Cohan, and Mark Gerstein. 2025. Chemagent: Self-updating library in large language models improves chemical reasoning. Preprint, arXiv:2501.06590.
- Vemprala et al. (2024) Sai H Vemprala, Rogerio Bonatti, Arthur Bucker, and Ashish Kapoor. 2024. Chatgpt for robotics: Design principles and model abilities. IEEE Access.
- Wang et al. (2023a) Guanzhi Wang, Yuqi Xie, Yunfan Jiang, Ajay Mandlekar, Chaowei Xiao, Yuke Zhu, Linxi Fan, and Anima Anandkumar. 2023a. Voyager: An open-ended embodied agent with large language models. arXiv preprint arXiv:2305.16291.
- Wang et al. (2024a) Lei Wang, Chen Ma, Xueyang Feng, Zeyu Zhang, Hao Yang, Jingsen Zhang, Zhiyuan Chen, Jiakai Tang, Xu Chen, Yankai Lin, Wayne Xin Zhao, Zhewei Wei, and Jirong Wen. 2024a. A survey on large language model based autonomous agents. Frontiers of Computer Science, 18(6).
- Wang (2018) Wenyi Wang. 2018. A formulation of recursive self-improvement and its possible efficiency. Preprint, arXiv:1805.06610.
- Wang et al. (2024b) Xingyao Wang, Boxuan Li, Yufan Song, Frank F. Xu, Xiangru Tang, Mingchen Zhuge, Jiayi Pan, Yueqi Song, Bowen Li, Jaskirat Singh, Hoang H. Tran, Fuqiang Li, Ren Ma, Mingzhang Zheng, Bill Qian, Yanjun Shao, Niklas Muennighoff, Yizhe Zhang, Binyuan Hui, Junyang Lin, Robert Brennan, Hao Peng, Heng Ji, and Graham Neubig. 2024b. Opendevin: An open platform for ai software developers as generalist agents. Preprint, arXiv:2407.16741.
- Wang et al. (2023b) Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc Le, Ed Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. 2023b. Self-consistency improves chain of thought reasoning in language models. Preprint, arXiv:2203.11171.
- Wei et al. (2022) Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. 2022. Chain-of-thought prompting elicits reasoning in large language models. Advances in neural information processing systems, 35:24824–24837.
- Wu et al. (2023) Qingyun Wu, Gagan Bansal, Jieyu Zhang, Yiran Wu, Shaokun Zhang, Erkang Zhu, Beibin Li, Li Jiang, Xiaoyun Zhang, and Chi Wang. 2023. Autogen: Enabling next-gen llm applications via multi-agent conversation framework. arXiv preprint arXiv:2308.08155.
- Xu et al. (2023) Benfeng Xu, An Yang, Junyang Lin, Quan Wang, Chang Zhou, Yongdong Zhang, and Zhendong Mao. 2023. Expertprompting: Instructing large language models to be distinguished experts. Preprint, arXiv:2305.14688.
- Yampolskiy (2015) Roman V. Yampolskiy. 2015. On the limits of recursively self-improving agi. In Artificial General Intelligence, pages 394–403, Cham. Springer International Publishing.
- Yao et al. (2023) Shunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Shafran, Thomas L. Griffiths, Yuan Cao, and Karthik Narasimhan. 2023. Tree of thoughts: Deliberate problem solving with large language models. Preprint, arXiv:2305.10601.
- Yao et al. (2022) Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. 2022. React: Synergizing reasoning and acting in language models. arXiv preprint arXiv:2210.03629.
- Zelikman et al. (2023) Eric Zelikman, Eliana Lorch, Lester Mackey, and Adam Tauman Kalai. 2023. Self-taught optimizer (stop): Recursively self-improving code generation. arXiv preprint arXiv:2310.02304.
- (50) Shaokun Zhang, Jieyu Zhang, Jiale Liu, Linxin Song, Chi Wang, Ranjay Krishna, and Qingyun Wu. Offline training of language model agents with functions as learnable weights. In Forty-first International Conference on Machine Learning.
- Zhang et al. (2024a) Wenqi Zhang, Ke Tang, Hai Wu, Mengna Wang, Yongliang Shen, Guiyang Hou, Zeqi Tan, Peng Li, Yueting Zhuang, and Weiming Lu. 2024a. Agent-pro: Learning to evolve via policy-level reflection and optimization. arXiv preprint arXiv:2402.17574.
- Zhang et al. (2024b) Zeyu Zhang, Xiaohe Bo, Chen Ma, Rui Li, Xu Chen, Quanyu Dai, Jieming Zhu, Zhenhua Dong, and Ji-Rong Wen. 2024b. A survey on the memory mechanism of large language model based agents. arXiv preprint arXiv:2404.13501.
- Zheng et al. (2024) Huaixiu Steven Zheng, Swaroop Mishra, Xinyun Chen, Heng-Tze Cheng, Ed H. Chi, Quoc V Le, and Denny Zhou. 2024. Take a step back: Evoking reasoning via abstraction in large language models. Preprint, arXiv:2310.06117.
- Zhou et al. (2024) Wangchunshu Zhou, Yixin Ou, Shengwei Ding, Long Li, Jialong Wu, Tiannan Wang, Jiamin Chen, Shuai Wang, Xiaohua Xu, Ningyu Zhang, et al. 2024. Symbolic learning enables self-evolving agents. arXiv preprint arXiv:2406.18532.
Appendix A Goal Prompt of Gödel Agent
The goal prompt of Gödel Agent is shown in Box 1. It’s worth noting that this prompt has nothing to do with the downstream tasks. It merely encourages Gödel Agent to improve itself based on the environmental feedback. The agent understands the specific tasks through the environmental feedback.
<details>
<summary>x6.png Details</summary>
### Visual Description
## Line Graph: Accuracy Progression Over Iterations
### Overview
The graph compares the accuracy progression of two methods—Random Sampling and Godel Agent—over 30 iterations. Accuracy is measured on the y-axis (0.0 to 0.8), and iterations are plotted on the x-axis (0 to 30). Two distinct lines represent the methods: blue circles for Random Sampling and orange triangles for Godel Agent.
### Components/Axes
- **Title**: "Accuracy Progression Over Iterations"
- **X-axis**: Labeled "Iteration," with increments of 5 (0, 5, 10, ..., 30).
- **Y-axis**: Labeled "Accuracy of MSSM," with increments of 0.1 (0.0, 0.1, ..., 0.8).
- **Legend**: Located in the top-left corner, with:
- Blue circles: "Random Sampling"
- Orange triangles: "Godel Agent"
### Detailed Analysis
#### Random Sampling (Blue Line)
- **Trend**: Fluctuates between ~0.2 and ~0.35, with no clear upward or downward trajectory.
- **Key Points**:
- Iteration 0: ~0.25
- Iteration 5: ~0.32
- Iteration 10: ~0.28
- Iteration 15: ~0.34
- Iteration 20: ~0.32
- Iteration 25: ~0.30
- Iteration 30: ~0.29
#### Godel Agent (Orange Line)
- **Trend**: Shows significant volatility early on, stabilizing at ~0.6 after iteration 20.
- **Key Points**:
- Iteration 0: ~0.28
- Iteration 5: ~0.0 (sharp drop)
- Iteration 10: ~0.38
- Iteration 15: ~0.42
- Iteration 20: ~0.62 (sharp rise)
- Iteration 25: ~0.57
- Iteration 30: ~0.63
### Key Observations
1. **Godel Agent** exhibits higher accuracy than Random Sampling after iteration 20, maintaining ~0.6 accuracy.
2. **Random Sampling** remains relatively stable but underperforms compared to Godel Agent in later iterations.
3. **Anomalies**:
- Godel Agent’s accuracy drops to 0.0 at iteration 5, suggesting a potential outlier or error.
- Both methods show minor fluctuations, but Godel Agent’s volatility decreases after iteration 15.
### Interpretation
The data suggests that the Godel Agent method outperforms Random Sampling in terms of accuracy as iterations increase, particularly after iteration 20. The sharp drop in Godel Agent’s accuracy at iteration 5 may indicate a transient instability or a miscalculation in that specific iteration. Random Sampling’s consistent but lower accuracy implies it may be less effective for this task over time. The divergence between the two methods highlights the potential advantages of the Godel Agent approach for improving accuracy in iterative processes.
</details>
Figure 6: Accuracy progression for Gödel Agent and random sampling.
Goal Prompt of Gödel Agent
You are a self-evolving agent, named self_evolving_agent, an instance of the Agent class, in module agent_module, running within an active Python runtime environment. You have full access to global variables, functions, and modules. Your primary goal is to continuously enhance your ability to solve tasks accurately and efficiently by dynamically reflecting on the environment and evolving your logic.
Core Capabilities
•
Complete Autonomy: Have unrestricted access to modify logic, run code, and manipulate the environment. •
Environment Interaction: Interact with the environment by perceiving the environment, reading, modifying, or executing code, and performing actions. •
Problem-Solving: Apply creative algorithms or self-developed structures to tackle challenges when simple methods fall short, optimizing solutions effectively. •
Collaboration: Leverage LLM to gather insights, correct errors, and solve complex problems. •
Error Handling: Carefully analyze errors. When errors occur, troubleshoot systematically, and if a bug is persistent, backtrack, restore the original state, or find an alternative solution.
Core Methods
•
evolve: Continuously enhance performance by interacting with the environment. •
execute_action(actions): Execute actions based on analysis or feedback. •
solver(agent_instance, task_input: str): Solve the target task using current agent_instance capabilities and objects created by action_adjust_logic and action_run_code, optimizing the process.
Guiding Principles
•
Remember that all functions are in the module agent_module. •
action_adjust_logic: –
Before modifying the code, ensure that each variable or function used is correctly imported and used to avoid errors. –
Avoid unnecessary changes and do not change the interface of any function. –
Can be used to create action functions for solver. •
action_run_code: –
All created objects in Python mode can be stored in the environment. –
Can be used to create objects for solver, such as prompts. –
Can be used to import new modules or external libraries and install external libraries. •
External Collaboration: Seek external assistance via action_call_json_format_llm for logic refinement and new tool creation or action_run_code to execute code. •
action_evaluate_on_task: Assess the performance of solver only after successfully modifying the logic of solver. •
solver: –
Defined as agent_module.solver. –
For debugging, avoid printing; instead, return debug information. –
If performance doesn’t improve, explore alternative methods. –
Explore techniques like: LLM Debate, Step-back Abstraction, Dynamic Assignment of Roles, and so on. •
action_display_analysis: –
Always analyze first before acting. –
Analysis may include the following: a reasonable plan to improve performance, CASE STUDIES of LOW SCORE valid examples of EVALUATION FEEDBACK, error handling, and other possible solving ideas. –
If performance does not improve, conduct further analysis.
Appendix B Experiment Details
To minimize costs associated with search and evaluation, following (Hu et al., 2024), we sample subsets of data from each domain. Specifically, for the GPQA (Science) domain, the validation set comprises 32 questions, while the remaining 166 questions are allocated to the test set. For the other domains, we sample 128 questions for the validation set and 800 questions for the test set.
Evaluation is conducted five times for the GPQA domain and once for the other domains, ensuring a consistent total number of evaluations across all experiments. All domains feature zero-shot questions, except for the DROP (Reading Comprehension) domain, which employs one-shot questions in accordance with the methodology outlined in OpenAI (2023).
For the Gödel Agent, we utilize the “gpt-4o-2024-05-13” model (OpenAI et al., 2024), whereas the optimized policy and baseline models are evaluated using the “gpt-3.5-turbo-0125” model (OpenAI, 2022) to reduce computational costs and ensure a fair comparison.
Appendix C Representative Policies Improved by Gödel Agent
C.1 Codes of the Best Policies Found by Gödel Agent Across Four Tasks
In this section, we provide the code for Gödel Agent’s optimized policies across the four tasks. For DROP, Gödel Agent designs an algorithm where multiple roles solve the problem independently using CoT, followed by Self-Consistency to consolidate the results, as shown in Code 1. For MGSM, Gödel Agent develops a stepwise self-verification algorithm combined with CoT-SC as shown in Code 2. For MMLU task, as shown in Code 3, the policy given by Gödel Agent is a combination algorithm of few-shot prompting and CoT-SC. For GPQA, Gödel Agent devises a highly diverse CoT-SC policy based on role prompts.
Listing 1: Code of the best policy found by Gödel Agent for DROP.
⬇
1 def solver (agent, task: str):
2 messages = [{"role": "user", "content": f "# Your Task:\n{task}"}]
3 categories = [
4 {’role’: ’reasoning expert’, ’return_keys’: [’reasoning’, ’answer’], ’output_requirement’: ’reasoning’, ’precision_gain’:1},
5 {’role’: ’mathematical reasoning expert’, ’return_keys’: [’calculation_steps’, ’answer’], ’output_requirement’: ’calculation_steps’, ’precision_gain’:1},
6 {’role’: ’historical context analyst’, ’return_keys’: [’historical_analysis’, ’answer’], ’output_requirement’: ’historical_analysis’, ’precision_gain’:1},
7 ]
8
9 all_responses = []
10 for category in categories:
11 response = agent. action_call_json_format_llm (
12 model = ’gpt-3.5-turbo’,
13 messages = messages,
14 temperature =0.5,
15 num_of_response =5,
16 role = category [’role’],
17 requirements =(
18 ’1. Explain the reasoning steps to get the answer.\n’
19 ’2. Directly answer the question.\n’
20 ’3. The explanation format must be outlined clearly according to the role, such as reasoning, calculation, or historical analysis.\n’
21 ’4. The answer MUST be a concise string.\n’
22 ). strip (),
23 )
24 all_responses. append (response)
25
26 # Reflective evaluation to find the most consistent reasoning and answer pair
27 final_response = {key: [] for key in [’reasoning’, ’calculation_steps’, ’historical_analysis’, ’answer’]}
28 step_counter = {key: 0 for key in [’reasoning’, ’calculation_steps’, ’historical_analysis’]}
29 answers = [] # Collect answers for voting
30 aggregate_weight = 1
31
32 for response in all_responses:
33 if response and ’answer’ in response:
34 answers. append (response [’answer’])
35 if not final_response [’answer’]:
36 final_response = {key: response. get (key, []) if isinstance (response. get (key, []), list) else [response. get (key, [])] for key in final_response. keys ()}
37 aggregate_weight = 1
38 for cat in categories:
39 if cat. get (’output_requirement’) in response. keys ():
40 step_counter [cat [’output_requirement’]] += step_counter [cat [’output_requirement’]] + cat. get (’precision_gain’, 0)
41 elif response [’answer’] == final_response [’answer’][0]:
42 for key in final_response. keys ():
43 if key in response and response [key]:
44 if isinstance (response [key], list):
45 final_response [key]. extend (response [key])
46 else:
47 final_response [key]. append (response [key])
48 aggregate_weight += 1
49 else:
50 # To demonstrate, some code has been omitted.
51 # selection of the final answer
52 from collections import Counter
53 answers = [str (answer) for answer in answers]
54 voted_answer = Counter (answers). most_common (1)[0][0] if answers else ’’
55 final_response [’answer’] = voted_answer
56
57 return final_response
Listing 2: Code of the best policy found by Gödel Agent for MGSM.
⬇
1
2
3 def solver (agent, task: str):
4 messages = [{"role": "user", "content": f "# Your Task:\n{task}"}]
5 response = agent. action_call_json_format_llm (
6 model = "gpt-3.5-turbo",
7 messages = messages,
8 temperature =0.5,
9 num_of_response =5,
10 role = "math problem solver",
11 return_dict_keys =["reasoning", "answer"],
12 requirements =(
13 "1. Please explain step by step.\n"
14 "2. The answer MUST be an integer.\n"
15 "3. Verify each step before finalizing the answer.\n"
16 ). strip (),
17 )
18
19 consistent_answer = None
20 answer_count = {}
21 for resp in response:
22 answer = resp. get ("answer", "")
23 if answer in answer_count:
24 answer_count [answer] += 1
25 else:
26 answer_count [answer] = 1
27
28 most_consistent_answer = max (answer_count, key = answer_count. get)
29
30 for resp in response:
31 if resp. get ("answer", "") == most_consistent_answer:
32 consistent_answer = resp
33 break
34
35 if consistent_answer is None:
36 consistent_answer = response [0]
37
38 consistent_answer ["answer"] = str (consistent_answer. get ("answer", ""))
39 return consistent_answer
Listing 3: Code of the best policy found by Gödel Agent for MMLU.
⬇
1 def solver (agent, task: str):
2 # Few-Shot Learning: Providing extended examples to guide the LLM
3 few_shot_examples = [
4 {’role’: ’user’, ’content’: ’Question: In the movie Austin Powers: The Spy Who Shagged Me what is the name of Dr. Evil\’s diminutive clone?\nChoices:\n(A) Little Buddy\n(B) Mini-Me\n(C) Small Fry\n(D) Dr Evil Jr’},
5 {’role’: ’assistant’, ’content’: ’In the movie Austin Powers: The Spy Who Shagged Me, Dr. Evil\’s diminutive clone is famously named Mini-Me.\nAnswer: B’},
6 \ "" "Three more examples are omitted here to conserve space.\"" "
7 {’role’:’user’, ’content’:’Question: Lorem Ipsum?\nChoices: (A) Lorem\n(B) Ipsum\n(C) Dolor\n(D) Sit Amet’},
8 {’role’:’assistant’, ’content’:’Answer: A’}
9 ]
10
11 # Integrate the few-shot examples into the conversation
12 messages = few_shot_examples + [{’role’: ’user’, ’content’: f’# Your Task:\n{task}’}]
13
14 # Using self-consistency by generating multiple responses
15 response = agent.action_call_json_format_llm(
16 model=’gpt-3.5-turbo’,
17 messages=messages,
18 temperature=0.8,
19 num_of_response=5,
20 role=’knowledge and reasoning expert’,
21 return_dict_keys=[’reasoning’, ’answer’],
22 requirements=(
23 ’1. Please explain step by step.\n’
24 ’2. The answer MUST be either A or B or C or D.\n’
25 ).strip(),
26 )
27
28 # Select the most consistent response
29 answer_frequency = {}
30 for resp in response:
31 answer = resp.get(’answer’, ’’)
32 if answer in [’A’, ’B’, ’C’, ’D’]:
33 if answer in answer_frequency:
34 answer_frequency[answer] += 1
35 else:
36 answer_frequency[answer] = 1
37
38 most_consistent_answer = max(answer_frequency, key=answer_frequency.get)
39 consistent_response = next(resp for resp in response if resp.get(’answer’) == most_consistent_answer)
40 consistent_response[’answer’] = most_consistent_answer
41
42 return consistent_response"
Listing 4: Code of the best policy found by Gödel Agent for GPQA.
⬇
1 def solver (agent, task: str):
2 # Step 1: Initial Prompt
3 messages = [{"role": "user", "content": f "# Your Task:\n{task}"}]
4
5 # Main LLM Call
6 response = agent. action_call_json_format_llm (
7 model = "gpt-3.5-turbo",
8 messages = messages,
9 temperature =0,
10 num_of_response =5,
11 role = "science professor",
12 return_dict_keys =["reasoning", "answer"],
13 requirements =(
14 "1. Please explain step by step.\n"
15 "2. The answer MUST be either A or B or C or D.\n"
16 ). strip (),
17 )
18
19 # Step 2: Self-consistency Evaluation
20 answer_counts = {"A": 0, "B": 0, "C": 0, "D": 0}
21 for i, return_dict in enumerate (response):
22 answer = return_dict. get ("answer", "")
23 if answer in answer_counts:
24 answer_counts [answer] += 1
25
26 final_answer = max (answer_counts, key = answer_counts. get)
27
28 return {"answer": final_answer}
C.2 Codes in Game of 24 Tasks
In this section, we present the initial policy for Game of 24 (Code 5), along with the Gödel agent’s optimized policy (Code 6), which is generated based on a search algorithm.
Listing 5: Initial code based on Chain-of-Thought for Game of 24.
⬇
1 def solver (self, task_input):
2 # Define the prompt and system_prompt
3 prompt = f \ "" "
4 Let’s play the Game of 24! You are given the task_input {task_input}. The objective is to find a mathematical expression using these four task_input that results in 24. You can use addition (+), subtraction (-), multiplication (*), and division (/). Each number must be used exactly once.
5 Please provide a step-by-step explanation of your thought process and conclude with the final expression.
6 \"" "
7 system_prompt = \"" "
8 {
9 " thinking ": " This key should contain a detailed step - by - step explanation of how to approach the problem, including intermediate steps and reasoning for each. ",
10 " result ": " This key should contain the final mathematical expression that equals 24. "
11 }
12 \"" "
13
14 # Call the OpenAI model
15 response = openai.ChatCompletion.create(
16 model=" gpt -4 ", # Replace with your model ID
17 messages=[
18 {" role ": " system ", " content ": system_prompt},
19 {" role ": " user ", " content ": prompt}
20 ]
21 )
22
23 # Extract and return the model’s response
24 result = response[’choices’][0][’message’][’content’]
25 return result"
Listing 6: Final code based on search algorithm for Game of 24.
⬇
1 def solver (self, task_input):
2
3 operations = [’+’, ’-’, ’*’, ’/’]
4
5 # Function to evaluate an expression
6 def evaluate_expression (a, op, b):
7 if op == ’+’:
8 return a + b
9 elif op == ’-’:
10 return a - b
11 elif op == ’*’:
12 return a * b
13 elif op == ’/’:
14 if b == 0:
15 return None # Division by zero is not allowed
16 return a / b
17
18 # Recursive function to check all combinations of operations and permutations of numbers
19 def check_combinations (nums):
20 if len (nums) == 1:
21 # Check if the final number is close enough to 24
22 if abs (nums [0] - 24) < 1 e -6: # Allow for floating point precision errors
23 return True, str (nums [0])
24 return False, ""
25
26 # Try all permutations of task_input and all combinations of operations
27 for i in range (len (nums)):
28 for j in range (len (nums)):
29 if i != j:
30 # Choose two task_input to operate on
31 for op in operations:
32 # The remaining task_input after removing the two selected task_input
33 remaining_nums = [nums [k] for k in range (len (nums)) if k != i and k != j]
34 result = evaluate_expression (nums [i], op, nums [j])
35 if result is not None:
36 # Recursively check the remaining task_input with the result of the operation
37 found, expression = check_combinations ([result] + remaining_nums)
38 if found:
39 # If solution is found, return with expression
40 return True, f "({nums[i]} {op} {nums[j]}) " + expression
41
42 return False, ""
43
44 # Try all permutations of the task_input
45 for num_permutation in permutations (task_input):
46 found, expression = check_combinations (list (num_permutation))
47 if found:
48 return expression. strip ()
49
50 return "No solution"
Appendix D Cost of Experiments
For a complete evolutionary process (where the Gödel Agent performs 30 recursive self-improvements) across the DROP, MGSM, MMLU, and GPQA datasets, the cost is approximately $15. This is significantly lower than the $300 required by Meta Agent Search. The reduced cost is due to our continuous self-optimization, which allows the model to adjust its optimization direction in response to environmental feedback, leading to faster convergence. The main source of cost stems from Gödel Agent’s continuously growing historical memory. By designing a more efficient forgetting mechanism, it may be possible to reduce the cost even further.
Appendix E Additional Novel Policies Designed by Gödel Agent
In this section, we present the optimization process of Gödel Agent on MGSM, illustrating its progress across various iteration steps within a single optimization run. The strategy obtained in the 6th iteration (shown in Code 7) reflects the Gödel Agent’s comprehension of mathematical tasks, attempting to handle them through a process akin to parse-deduct-execute-validate. By the 14th iteration, as illustrated in Code 8, the strategy evolves through the summarization of erroneous cases, abstracting key insights and employing a checklist to guide the validation process. Finally, the strategy at the 20th iteration (demonstrated in Code 9) asserts the use of a ”rabbit-proof syntax tactline, reinforced by consistent effort through role-coded checks,” to refine prompt design. In the end, we also show one analysis example of Gödel Agent.
Appendix F Comparison Between Random Sampling and Gödel Agent Performance
To demonstrate the distinction between our approach and random sampling, we conducted 30 independent random sampling experiments using GPT-4o. The prompts used for random sampling were identical to the initial policy prompts employed by Gödel Agent to ensure a fair comparison. The results are illustrated in Figure 6. From the figure, it is evident that the performance of random sampling remains around 30% across all trials. In contrast, Gödel Agent, despite experiencing occasional temporary dips in performance, rapidly corrects these deviations and demonstrates continuous improvement over iterations. This consistent upward trajectory highlights the superiority of Gödel Agent over random sampling. The Gödel Agent’s ability to leverage feedback and recursively optimize its policies underscores its effectiveness in achieving higher performance.
Listing 7: Policy at 6th Iteration found by Gödel Agent for MGSM.
⬇
1 def solver (agent, task: str):
2 def parse_problem (task):
3 # Basic arithmetic and logical parsing based on keywords
4 words = task. split ()
5 numbers = list (map (int, filter (lambda x: x. isdigit (), words)))
6 return {’numbers’: numbers, ’text’: task}
7
8 def perform_logic_deduction (parsed_details):
9 # make deductions based on common problem formats
10 numbers = parsed_details [’numbers’]
11 # This will only manage simple sum, subtraction, multiplication inference
12 logic_map = {
13 ’add’: lambda a, b: a + b,
14 ’subtract’: lambda a, b: a - b,
15 ’multiply’: lambda a, b: a * b
16 }
17 # Try to identify actions based on keywords
18 if ’sum’ in parsed_details [’text’] or ’total’ in parsed_details [’text’]:
19 result = sum (numbers)
20 elif ’difference’ in parsed_details [’text’] or ’less’ in parsed_details [’text’]:
21 result = logic_map [’subtract’](numbers [0], numbers [1])
22 elif ’product’ in parsed_details [’text’] or ’times’ in parsed_details [’text’]:
23 result = logic_map [’multiply’](numbers [0], numbers [1])
24 else:
25 # Default case showing no deduction
26 result = 0
27 return result
28
29 def execute_computation (logic_results):
30 # Taking result from inference to numerical handling
31 return logic_results
32
33 def validate_and_compile_results (computation_results):
34 # Prepares and ensures the response matches expected format
35 final_answer = computation_results
36 return final_answer
37
38 try:
39 # Parsing
40 parsed_details = parse_problem (task)
41
42 # Logical deduction
43 logic_results = perform_logic_deduction (parsed_details)
44
45 # Computation
46 computation_results = execute_computation (logic_results)
47
48 # Validation and compilation
49 final_answer = validate_and_compile_results (computation_results)
50
51 return {"answer": final_answer}
52 except Exception as e:
53 return {"error": str (e)}
Listing 8: Policy at 14th Iteration found by Gödel Agent for MGSM.
⬇
1 def solver (agent, task: str):
2 # Updated examples to mirror tasks needing layered logical verification.
3 examples = [
4 {’description’: ’Task exemplifying standard integer-based calculations.’, ’reasoning’: ’Use arithmetic transformations to validate expressions and correct errors if any arise, ensuring correctness.’, ’answer’: 20},
5 {’description’: ’Example to validate word problem conversion to math.’, ’reasoning’: ’Stepwise interpretation from words into math operations and bridge which logic errors need capture.’, ’answer’: 15},
6 {’description’: ’Scenario involving normalizing uneven division instances.’, ’reasoning’: ’Ensure no division by zero and equal verification of logical conclusions.’, ’answer’: 6},
7 ]
8
9 # Task prompt incorporating roles with enhanced checklists after operation conclusion.
10 task_prompt = "You’re guiding us as a solution auditor, reflecting on each logical conclusion to prevent arithmetic discrepancies.\n"
11 task_prompt += task + "\nReflect on instructions through verified examples."
12 task_prompt += "\nExample insights:\n"
13 task_prompt += ’; ’. join ([f "{ex[’description’]} -> Reasoning: {ex[’reasoning’]} | Answer: {ex[’answer’]}" for ex in examples])
14 task_prompt += "\nEnsure real-time verification post-calculations via role-switching checks."
15
16 messages = [{"role": "user", "content": task_prompt}]
17
18 response = agent. action_call_json_format_llm (
19 model = "gpt-3.5-turbo",
20 messages = messages,
21 temperature =0.3,
22 num_of_response =1,
23 role = "solution auditor",
24 return_dict_keys =["description", "reasoning", "answer"],
25 requirements =(
26 "1. Validate arithmetic consistency and integrity within calculations."
27 "2. Utilize any corrections to refine answer outputs incrementally."
28 ). strip (),
29 )
30
31 return_dict = response [0]
32 return_dict ["answer"] = str (return_dict. get ("answer", ""))
33 return return_dict
Listing 9: Policy at 20th Iteration found by Gödel Agent for MGSM.
⬇
1 def solver (agent, task: str):
2 # Targets design for specific error-prone areas with preceding misfires.
3 examples = [
4 {’description’: ’Immediate Arithmetic Operations’, ’reasoning’: ’Observe step-by-step through a chain of logical confirmations.’, ’answer’: 20},
5 {’description’: ’Sequential Word Problem Breakdown’, ’reasoning’: ’Ensure smaller module segment steps match logical math outputs consistently.’, ’answer’: 15},
6 {’description’: ’Fraction and Cascade Operations’, ’reasoning’: ’Validate each fraction conversion before proceeding to other forms.’, ’answer’: 6},
7 ]
8
9 # Building a rabbit-proof syntax tactline, pushing consistent effort from role-coded checks.
10 task_prompt = "You’re progressing through solution documentation with focus on pinpointing logic errors.\n"
11 task_prompt += task + "\nReflecting structural integrity verified via examples."
12 task_prompt += "\nIn this construct:\n"
13 task_prompt += ’; ’. join ([f "{ex[’description’]} -> Rationale: {ex[’reasoning’]} | Response: {ex[’answer’]}" for ex in examples])
14 task_prompt += "\nHandle verification and cleanse routines where errors echo in mirroring line-based checks."
15
16 messages = [{"role": "user", "content": task_prompt}]
17
18 response = agent. action_call_json_format_llm (
19 model = "gpt-3.5-turbo",
20 messages = messages,
21 temperature =0.3,
22 num_of_response =1,
23 role = "logical verifier",
24 return_dict_keys =["description", "reasoning", "answer"],
25 requirements =(
26 "1. Review arithmetic sessions for comprehensive error fixation."
27 "2. Develop clarity with resistant focus on authentic semantic directive flows."
28 ). strip (),
29 )
30
31 return_dict = response [0]
32 return_dict ["answer"] = str (return_dict. get ("answer", ""))
33 return return_dict
Analysis Example of Gödel Agent
The current logic of the solver in the agent_module is achieving only a 45% accuracy on the validation set. The structure of the solver involves a single call to the LLM with a specification that the answer must be an integer. While this approach seems correct, it may not be sufficient to tackle more complex problems where multipart reasoning or verification is needed, leading to significant errors. Problems Identified: 1.
Integer Conversion Misunderstandings: Some math problems aren’t resulting in integer answers natively, affecting accuracy when the solver forces an integer format. 2.
Reasoning Oversights: The LLM, designated as ”math expert,” occasionally misses necessary reasoning steps or executes incorrect operations leading to incorrect answers (like sample 10). 3.
Ambiguity in LLM Outputs: Given tasks in multiple languages, there might be ambiguity in math translations or formulations affecting comprehension (like sample 6). Plan for Improvement: 1.
Elaborate Reasoning: Consider a multi-step LLM call to allow for a reasoning review before finalizing the answer. 2.
Intelligent Answer Parsing: Instead of forcibly converting to integers, parse the LLM response intelligently to see if the answer justifies integer rounding or alterations. 3.
Diverse Language Handling: Create a pre-processing step to consistently translate non-English math problems into English for uniform processing. 4.
Examples & Feedback: Utilize correctly solved examples as context if a single-step LLM fails. Next Steps: 1.
Enhance Solver Logic: Implement a multi-step process involving interim LLM validation or rationale cross-checking. 2.
Pre-process Language Variations: Ensure all non-English tasks are translated and re-assessed. 3.
Include Example Feedback: Use correctly solved examples from the evaluation as references to guide LLM reasoning and answer validation.