# LeanAgent: Lifelong Learning for Formal Theorem Proving
**Authors**:
- Chaowei Xiao, Anima Anandkumar (California Institute of Technology, Stanford University, University of Wisconsin, Madison)
> Equal contribution.
Abstract
Large Language Models (LLMs) have been successful in mathematical reasoning tasks such as formal theorem proving when integrated with interactive proof assistants like Lean. Existing approaches involve training or fine-tuning an LLM on a specific dataset to perform well on particular domains, such as undergraduate-level mathematics. These methods struggle with generalizability to advanced mathematics. A fundamental limitation is that these approaches operate on static domains, failing to capture how mathematicians often work across multiple domains and projects simultaneously or cyclically. We present LeanAgent, a novel lifelong learning framework for formal theorem proving that continuously generalizes to and improves on ever-expanding mathematical knowledge without forgetting previously learned knowledge. LeanAgent introduces several key innovations, including a curriculum learning strategy that optimizes the learning trajectory in terms of mathematical difficulty, a dynamic database for efficient management of evolving mathematical knowledge, and progressive training to balance stability and plasticity. LeanAgent successfully generates formal proofs for 155 theorems across 23 diverse Lean repositories where formal proofs were previously missing, many from advanced mathematics. It performs significantly better than the static LLM baseline, proving challenging theorems in domains like abstract algebra and algebraic topology while showcasing a clear progression of learning from basic concepts to advanced topics. In addition, we analyze LeanAgent’s superior performance on key lifelong learning metrics. LeanAgent achieves exceptional scores in stability and backward transfer, where learning new tasks improves performance on previously learned tasks. This emphasizes LeanAgent’s continuous generalizability and improvement, explaining its superior theorem-proving performance.
1 Introduction
Mathematics can be expressed in informal and formal languages. Informal mathematics utilizes natural language and intuitive reasoning, whereas formal mathematics employs symbolic logic to construct machine-verifiable proofs (Kevin Buzzard, 2019). State-of-the-art large language models (LLMs), such as o1 (OpenAI, 2024) and Claude (Claude Team, 2024), produce incorrect informal proofs (Zhou et al., 2024). This highlights the importance of formal mathematics in ensuring proof correctness and reliability. Interactive theorem provers (ITPs), such as Lean (De Moura et al., 2015), have emerged as tools for formalizing and verifying mathematical proofs. However, constructing formal proofs using ITPs is complex and time-consuming; it requires extremely detailed proof steps and involves working with extensive mathematical libraries.
Recent research has explored using LLMs to generate proof steps or complete proofs. For example, LeanDojo (Yang et al., 2023) introduced the first open-source framework to spur such research. Existing approaches typically involve training or fine-tuning LLMs on a specific dataset (Jiang et al., 2022). However, data scarcity in formal theorem proving (Polu et al., 2022) hinders the generalizability of these approaches (Liu et al., 2023). For example, ReProver, the retrieval-augmented LLM from the LeanDojo family, uses a retriever fine-tuned on Lean’s math library, mathlib4 (mathlib4 Community, 2024). Although mathlib4 contains over 100,000 formalized mathematical theorems and definitions, it covers primarily up to undergraduate mathematics. Consequently, ReProver performs poorly on more challenging mathematics, such as Terence Tao’s formalization of the Polynomial Freiman-Ruzsa (PFR) Conjecture (Tao et al., 2024).
<details>
<summary>extracted/6256159/Final2.png Details</summary>
### Visual Description
## Diagram: Automated Theorem Proving System Architecture
### Overview
The diagram illustrates a multi-stage automated theorem proving system with iterative learning and curriculum adaptation. It shows data flow from GitHub repositories through a LeanAgent, curriculum learning framework, progressive training mechanisms, and specialized handling of "SORRY Theorems" (theorems that initially fail to prove).
### Components/Axes
**Key Components:**
1. **Input Layer**
- GitHub Repositories (source of theorems/proofs)
- Extract Data Per Repository → Premise Corpus + Theorems + Proofs
2. **Core Processing**
- LeanAgent (theorem proving engine)
- Curriculum Learning (complexity-based adaptation)
- Progressive Training (retriever evolution)
3. **Output Layer**
- Dynamic Database (knowledge repository)
- SORRY Theorem Proving (specialized handling)
**Visual Elements:**
- Color-coded complexity levels (green=low, yellow=medium, red=high)
- Feedback loops between components
- Iterative refinement arrows
### Detailed Analysis
**1. Data Ingestion Pipeline**
- GitHub repositories → Extract Data Per Repository
- Creates: Premise Corpus + Theorems + Proofs
**2. Curriculum Learning System**
- Complexity → Theorem Complexities (e.g., 2.7, 7.4)
- Complexity graph shows:
- # Proof Steps vs Complexity
- Distribution: Easy (green) → Medium (yellow) → Hard (red)
- Descending # Easy Theorems over time
**3. Progressive Training Mechanism**
- Latest Retriever → Limited Exposure (1 epoch)
- Balanced Training (Stability vs Plasticity)
- New Retriever generation
**4. SORRY Theorem Proving**
- Input: SORRY Theorems
- Process:
- Retrieved Premises (updated retriever)
- Generated Tactics
- Best-First Tree Search
- Output: New Proofs
### Key Observations
1. **Iterative Learning**: Feedback loops between components suggest continuous improvement
2. **Complexity Adaptation**: Curriculum learning adjusts difficulty based on proof complexity metrics
3. **Retriever Evolution**: Progressive training creates increasingly sophisticated theorem retrieval systems
4. **Specialized Handling**: SORRY Theorems use distinct processing pipeline with retrieval-augmented generation
### Interpretation
This architecture demonstrates a sophisticated approach to automated theorem proving that:
1. **Adapts Difficulty**: Uses complexity metrics to create personalized learning paths
2. **Balances Stability/Plasticity**: Progressive training maintains core knowledge while enabling adaptation
3. **Handles Edge Cases**: Specialized SORRY Theorem Proving addresses previously unsolved problems
4. **Leverages Community Knowledge**: GitHub repositories serve as initial knowledge base
The system appears designed to create self-improving theorem provers that can handle increasingly complex mathematical problems through iterative learning and curriculum adaptation. The "SORRY Theorem" handling suggests a focus on solving previously intractable problems through advanced retrieval and search strategies.
</details>
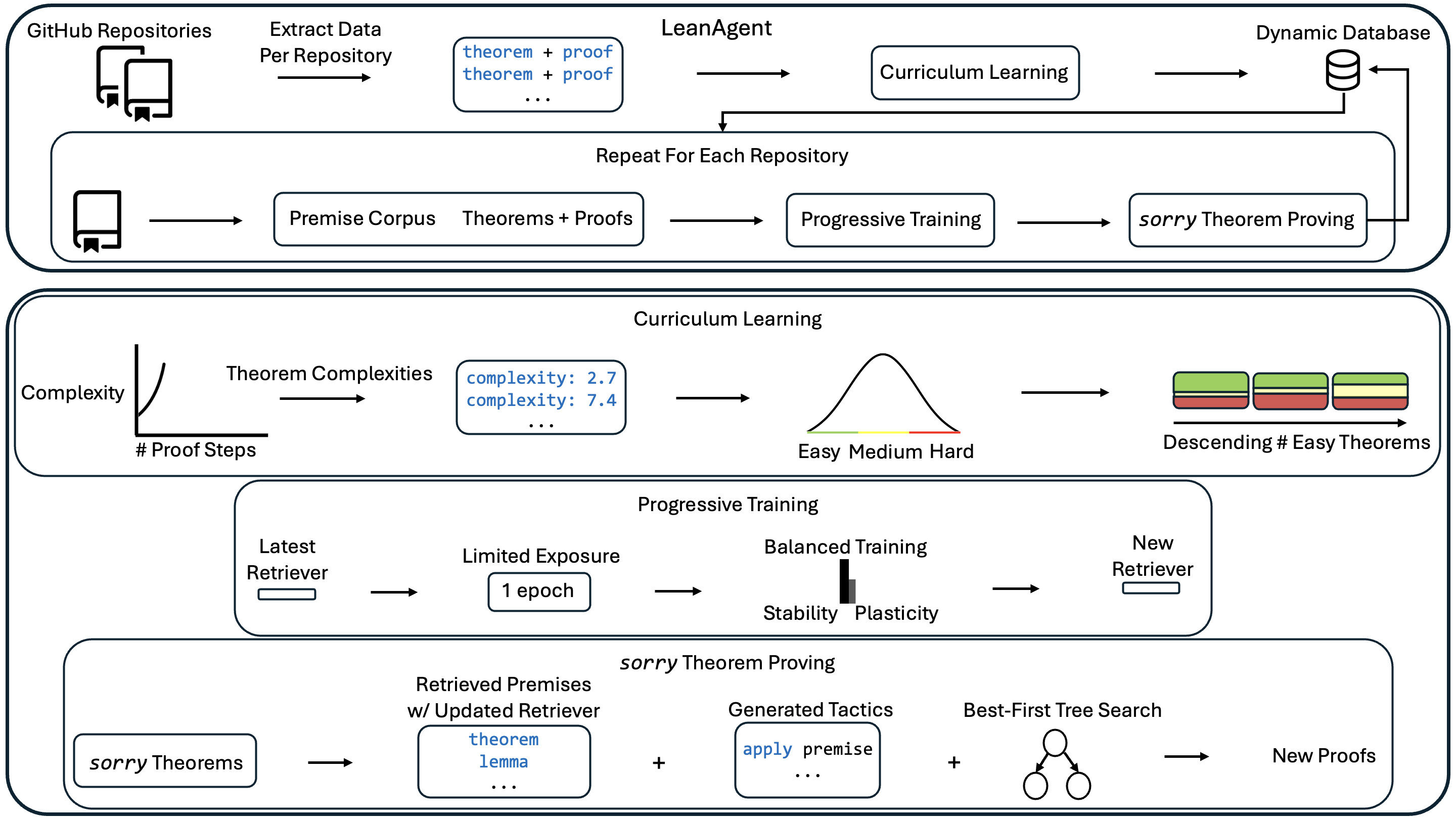
Figure 1: LeanAgent overview. LeanAgent searches for Lean repositories and uses LeanDojo to extract theorems and proofs. It uses curriculum learning, computing theorem complexity as $e^{S}$ ( $S$ = proof steps) and calculating the 33rd and 67th complexity percentiles across all theorems to sort repositories by easy theorem count. LeanAgent adds the curriculum to its dynamic database. As a retrieval-based framework, LeanAgent generates a dataset (premise corpus and a collection of theorems and proofs) for each repository in the curriculum and progressively trains its retriever. Progressive training happens over one epoch to prevent forgetting old knowledge. Then, LeanAgent uses the updated retriever in a search-based method to generate formal proofs for theorems where formal proofs were previously missing, known as sorry theorems. It adds new proofs to the database.
The dynamic nature of mathematical research exacerbates this generalizability issue. Mathematicians often formalize across multiple domains and projects simultaneously or cyclically. For example, Terence Tao has worked on various projects in parallel, including formalizations of the PFR Conjecture, symmetric mean of real numbers, classical Newton inequality, and asymptotic analysis (Tao, ; Tao, 2024a; Tao et al., 2024; Tao, 2024b). Patrick Massot has been formalizing Scholze’s condensed mathematics and the Perfectoid Spaces project (Community, 2024a; b). These examples highlight a critical gap in current theorem-proving AI approaches: the lack of a system that can adapt and improve across multiple, diverse mathematical domains over time, given limited Lean data availability.
Connection to Lifelong Learning. Crucially, how mathematicians formalize is relevant to lifelong learning, i.e. learning multiple tasks without forgetting (Wang et al., 2024b). A significant challenge is catastrophic forgetting: when adaptation to new distributions leads to a loss of understanding of old ones (Jiang et al., 2024). The core challenge is balancing plasticity (the ability to learn and adapt) with stability (the ability to retain existing knowledge) (Wang et al., 2024b). Increasing plasticity to learn new tasks efficiently can lead to overwriting previously learned information. However, enhancing stability to preserve old knowledge may impair the model’s ability to acquire new skills (van de Ven et al., 2024). Achieving the right balance is key to continuous generalizability in theorem proving.
LeanAgent. We present LeanAgent, a novel lifelong learning framework for theorem proving. As shown in Figure 1, LeanAgent’s workflow consists of (1) deriving complexity measures of theorems to compute a curriculum for learning, (2) progressive training to learn while balancing stability and plasticity, and (3) searching for proofs of sorry theorems by leveraging a best-first tree search, all while using a dynamic database to manage its evolving mathematical knowledge. LeanAgent works with any LLM; we implement it with retrieval for improved generalizability (Yang et al., 2023).
We employ a simple progressive training method to avoid catastrophic forgetting. Progressive training allows LeanAgent to continuously adapt to new mathematical knowledge while preserving previously learned information. This process involves incrementally training the retriever on newly generated datasets from each repository in the curriculum. Starting with a pre-trained retriever (e.g., ReProver’s retriever based on ByT5 (Xue et al., 2022)), LeanAgent trains on each new dataset for one additional epoch. Restricting progressive training to one epoch helps balance stability and plasticity. Crucially, this training is repeated for each dataset generated from the database, gradually expanding LeanAgent’s knowledge base. This approach increases the space of possible proof states (where a state consists of a theorem’s hypotheses and current proof progress) while adding new premises to the premise embeddings. More sophisticated lifelong learning methods like Elastic Weight Consolidation (EWC) (Kirkpatrick et al., 2017), which uses the Fisher Information Matrix to constrain important weights for previous tasks, result in excessive plasticity. The uncontrolled plasticity is due to the inability of these methods to adapt parameter importance as theorem complexity increases. This forces rapid changes in parameters crucial for learning advanced concepts. Such methods fail to adapt to the evolving complexity of mathematical theorems, making them unsuitable for lifelong learning in theorem proving.
Extensive experiments across 23 diverse Lean repositories demonstrate LeanAgent’s advancements in lifelong learning for theorem proving. LeanAgent successfully generates formal proofs for 155 theorems across these 23 repositories where formal proofs were previously missing, known as sorry theorems, many from advanced mathematics. For example, it proves challenging sorry theorems in abstract algebra and algebraic topology related to Coxeter systems and the Hairy Ball Theorem (Coxeter, 2024; Hairy Ball Theorem, 2024). LeanAgent also proves 7 theorems using exploits found within Lean’s type system. We find that LeanAgent demonstrates progressive learning in theorem proving, initially proving basic sorry theorems and significantly advancing to more complex ones. It significantly outperforms the static ReProver baseline in terms of proving new sorry theorems. We have issued pull requests to the respective repositories with the newly proven sorry theorems. Some of these proofs utilized unintended constructs within the repositories’ implementations, which are currently being addressed through appropriate fixes.
In theorem proving, we find that stability, without losing too much plasticity, is crucial for continuous generalizability to new repositories. Backward transfer (BWT), where learning new tasks improves performance on previously learned tasks, is essential in theorem proving (Wang et al., 2024b). Mathematicians require a lifelong learning framework for theorem proving that is both continuously generalizable and continuously improving. We conduct an extensive ablation study using six lifelong metrics carefully proposed or selected from the literature. LeanAgent’s simple components of curriculum learning and progressive training improve stability and BWT scores substantially, emphasizing its continuous generalizability and improvement and explaining its superior sorry theorem proving performance.
2 Preliminaries
Neural Theorem Proving. The current state-of-the-art of learning-based provers employs Transformer-based (Vaswani et al., 2017) LLMs that process expressions as plain text strings (Azerbayev et al., 2024; Xin et al., 2024b; Shao et al., 2024). In addition, researchers have explored complementary aspects like proof search algorithms (Lample et al., ; Wang et al., 2023). Moreover, other works break the theorem-proving process into smaller proving tasks (Song et al., 2024; Wang et al., 2024a; Lin et al., 2024).
Premise Selection. A critical challenge in theorem proving is the effective selection of relevant premises (Irving et al., 2016; Tworkowski et al., ). However, many existing approaches treat premise selection as an isolated problem (Wang & Deng, 2020; Piotrowski et al., 2023) or use selected premises only as input to symbolic provers (Alama et al., 2014; Mikuła et al., 2024).
Retrieval-Augmented LLMs. While retrieval-augmented language models have been extensively studied in areas like code generation (Lu et al., 2022; Zhou et al., 2023), their application to formal theorem proving is relatively new. However, relevant architectures have been researched in natural language processing (NLP) (Lu et al., 2024; Borgeaud et al., 2022; Thakur et al., 2024).
Lifelong Learning. Lifelong learning addresses catastrophic forgetting in sequential task learning (Chen et al., 2024). Approaches include regularization methods (Kirkpatrick et al., 2017), memory-based techniques (Lopez-Paz & Ranzato, 2017; Chaudhry et al., 2019; Shin et al., 2017), and knowledge distillation (Li & Hoiem, 2017; Kim et al., 2023). Other strategies involve dynamic architecture adjustment (Mendez & Eaton, 2021) and recent work on gradient manipulation and selective re-initialization (Chen et al., 2024; Dohare et al., 2024). We justify not using these strategies in Appendix A.6.
Curriculum Learning in Theorem Proving. Prior work created a synthetic inequality generator to produce a curriculum of statements of increasing difficulty (Polu et al., 2022). For reinforcement learning, an existing work used the length of proofs to help determine rewards (Zombori et al., 2019).
3 Methodology
A useful lifelong learning strategy for theorem proving requires (a) a repository order strategy and (b) a learning strategy. We solve (a) with curriculum learning to utilize the structure of Lean proofs and (b) with progressive training to balance stability and plasticity. LeanAgent consists of four main components: curriculum learning, dynamic database management, progressive training of the retriever, and sorry theorem proving. Further methodology details are in Appendix A.1 and a discussion of why curriculum learning works in theorem proving is available in Appendix A.6.
3.1 Curriculum Learning
LeanAgent uses curriculum learning to learn on increasingly complex mathematical repositories. This process optimizes LeanAgent’s learning trajectory, allowing it to build upon foundational knowledge before tackling more advanced concepts.
First, we automatically search for and clone Lean repositories from GitHub. We use LeanDojo for each repository to extract fine-grained information about their theorems, proofs, and dependencies. Then, we calculate the complexity of each theorem using $e^{S}$ , where $S$ represents the number of proof steps. However, sorry theorems, which have no proofs, are assigned infinite complexity. We use an exponential scaling to address the combinatorial explosion of possible proof paths as the length of the proof increases. Further justification for considering this complexity metric is in Appendix A.6.
We compute the 33rd and 67th percentiles of complexity across all theorems in all repositories. Using these percentiles, we categorize non- sorry theorems into three groups: easy (theorems with complexity below the 33rd percentile), medium (theorems with complexity between the 33rd and 67th percentiles), and hard (theorems with complexity above the 67th percentile). We then sort repositories by the number of easy theorems they contain. This sorting forms the basis of our curriculum, with LeanAgent starting on repositories with the highest number of easy theorems.
3.2 Dynamic Database Management
Then, we add the sorted repositories to LeanAgent’s custom dynamic database using the data LeanAgent extracted. This way, we can keep track of and interact with the knowledge that LeanAgent is aware of and the proofs it has produced. We also include the complexity of each theorem computed in the previous step into the dynamic database, allowing for efficient reuse of repositories in a future curriculum. Details of the database’s contents and features can be found in Appendix A.1.
For each repository in the curriculum, LeanAgent uses the dynamic database to generate a dataset by following the same procedure used to make LeanDojo Benchmark 4 (details in Appendix A.1). This dataset includes a collection of theorems and their proofs. Each step of these proofs contains detailed annotations, such as how the step changes the state of the proof. A state consists of a theorem’s hypotheses and the current progress in proving the theorem. As such, this pairing of theorems and proofs demonstrates how to use specific tactics (functions) and premises in sequence to prove a theorem. In addition, the dataset includes a premise corpus, serving as a library of facts and definitions.
3.3 Progressive Training of the Retriever
LeanAgent then progressively trains its retriever on the newly generated dataset. This strategy allows LeanAgent to continuously adapt to new mathematical knowledge from the premises in new datasets while preserving previously learned information, crucial for lifelong learning in theorem proving. Progressive training achieves this by incrementally incorporating new knowledge from each repository.
Although LeanAgent works with any LLM, we provide a specific implementation here. We start with ReProver’s retriever, a fine-tuned version of the ByT5 encoder (Xue et al., 2022), leveraging its general pre-trained knowledge from mathlib4. We train LeanAgent on the new dataset for an additional epoch. This limited exposure helps prevent overfitting to the new data while allowing LeanAgent to learn essential new information. LeanAgent’s retriever, and therefore the embeddings it generates, are continuously updated during progressive training. Thus, at the end of the current progressive training run, we precompute embeddings for all premises in the corpus generated by LeanAgent’s current state to ensure that we properly evaluate LeanAgent’s validation performance. To understand how LeanAgent balances stability and plasticity, we save the model iteration with the highest validation recall for the top ten retrieved premises (R@10). This is a raw plasticity value: it can be used to compute other metrics that describe LeanAgent’s ability to adapt to and handle new types of mathematics in the latest repository (details in Sec. 4). Then, we compute the average test R@10 over all previous datasets the model has progressively trained on, a raw stability value.
As mentioned previously, we repeat this procedure for each dataset we generate from the database, hence the progressive nature of this training. Progressive training adds new premises to the premise embeddings and increases the space of possible proof states. This allows LeanAgent to explore more diverse paths to prove theorems, discovering new proofs that it couldn’t produce with its original knowledge base.
3.4 sorry Theorem Proving
For each sorry theorem, LeanAgent generates a proof with a best-first tree search by generating tactic candidates at each step, in line with prior work (Yang et al., 2023). Using the embeddings from the entire corpus of premises we previously collected, LeanAgent retrieves relevant premises from the premise corpus based on their similarity to the current proof state, represented as a context embedding. Then, it filters the results using a corpus dependency graph to ensure that we only consider premises accessible from the current file. We add these retrieved premises to the current state and generate tactic candidates using beam search. Then, we run each tactic candidate through Lean to obtain potential next states. Each successful tactic application adds a new edge to the proof search tree. We choose the tactic with the maximum cumulative log probability of the tactics leading to it. If the search reaches a dead-end, we backtrack and explore alternative paths. We repeat the above steps until the search finds a proof, exhausts all possibilities, or reaches the time limit of 10 minutes.
If LeanAgent finds a proof, it adds it to the dynamic database. The newly added premises from this proof will be included in a future premise corpus involving the current repository. Moreover, LeanAgent can learn from the new proof during progressive training in the future, aiding further improvements.
4 Experiments
4.1 Experimental Setup
Table 1: Selected repository descriptions
| PFR Hairy Ball Theorem Coxeter | Polynomial Freiman-Ruzsa Conjecture Algebraic topology result Coxeter groups |
| --- | --- |
| Mathematics in Lean Source | Lean files for the textbook |
| Formal Book | Proofs from THE BOOK |
| MiniF2F | Math olympiad-style problem solving |
| SciLean | Scientific computing |
| Carleson | Carleson’s Theorem |
| Lean4 PDL | Propositional Dynamic Logic |
We devote this section to describing two types of experiments: (1) sorry Theorem Proving: We compare sorry theorem proving performance between LeanAgent and ReProver. We also examine the progression of LeanAgent’s proven sorry theorems during lifelong learning to the end of lifelong learning. This shows LeanAgent’s continuous generalizability and improvement. (2) Lifelong Learning Analysis: We conduct an ablation study with six lifelong learning metrics to explain LeanAgent’s superiority in sorry theorem proving. Moreover, these results explain LeanAgent’s superior handling of the stability-plasticity tradeoff. Please see Appendix A.2 for experiment implementation details. We release LeanAgent at https://github.com/lean-dojo/LeanAgent.
Repositories. We evaluate our approach on a diverse set of 23 Lean repositories to assess its generalizability across different mathematical domains (Skřivan, 2024; Kontorovich, 2024; Avigad, 2024; Tao et al., 2024; Renshaw, 2024; Fermat’s Last Theorem, 2024; DeepMind, 2024; Carneiro, 2024; Wieser, 2024; Mizuno, 2024; Murphy, 2024; Formal Logic, 2024; Con-nf, 2024; Gadgil, 2024; Yang, 2024; Zeta 3 Irrational, 2024; Firsching, Moritz, 2024; Monnerjahn, 2024; van Doorn, 2024; Dillies, 2024; Hairy Ball Theorem, 2024; Coxeter, 2024; Gattinger, 2024). Details of key repositories are in Table 1. Further details of these repositories, including commits and how we chose the initial curriculum and the sub-curriculum (described in Sec. 4.2), are in Appendix A.3.
4.2 sorry Theorem Proving
We compare the number of sorry theorems LeanAgent can prove, both during and after lifelong learning, to the ReProver baseline. We use ReProver as the baseline because we use its retriever as LeanAgent’s initial retriever in our experiments.
<details>
<summary>extracted/6256159/newproof4.png Details</summary>

### Visual Description
## Code Snippet Analysis: Theorem Prover Syntax Comparison
### Overview
The image contains code snippets from multiple formal theorem provers (PFR, SciLean, Coqeter, MiniF2F, Formal Book) demonstrating mathematical proofs. Each section includes syntax-highlighted code with specific terms emphasized in green.
### Components/Axes
- **Structure**: Five distinct code blocks labeled by prover name
- **Syntax Highlighting**:
- Blue: Keywords (theorem, lemma, simp, apply, etc.)
- Brown: Theorem/lemma names
- Green: Highlighted terms (key components)
- Black: Mathematical symbols and variables
### Detailed Analysis
#### PFR Section
```text
lemma condRho_of_translate {Ω S : Type*} [MeasureSpace Ω] (X : Ω → G) (Y : Ω → S) (A : Finset G) (s:G) :
condRho (fun ω ↦ X ω + s) Y A = condRho X Y A := by
simp only [condRho, rho_of_translate]
```
- **Highlighted Terms**: `condRho`, `rho_of_translate`
#### SciLean Section
```text
theorem re_float (a : Float) : RCLike.re a = a := by
exact RCLike.re_eq_self_of_le le_rfl
```
- **Highlighted Terms**: `RCLike.re_eq_self_of_le`, `le_rfl`
#### Coqeter Section
```text
lemma invmaps_of_eq {S:Set G} [CoxeterSystem G S] {s :S} :
invmaps S s = s := by
simp [CoxeterSystem.Presentation.invmaps]
unfold CoxeterSystem.toMatrix
apply CoxeterSystem.monoidLift.mapLift.of
```
- **Highlighted Terms**: `CoxeterSystem.Presentation.invmaps`, `CoxeterSystem.toMatrix`, `CoxeterSystem.monoidLift.mapLift.of`
#### MiniF2F Section
```text
theorem induction_12dvd4expnp1p20 (n : N) :
12 | 4^(n+1) + 20 := by
norm_num
induction' n with n hn
simp
omega
theorem amc12a_2002_p6 (n : N) (h₀ : 0 < n) :
∃ m, (m > n ∧ ∃ p, m * p ≤ m + p) := by
lift n to N+ using h₀
cases' n with n
exact (_, lt_add_of_pos_right _ _ _ zero_lt_one 1, by simp)
```
- **Highlighted Terms**: `lt_add_of_pos_right`, `zero_lt_one`
#### Formal Book Section
```text
theorem wedderburn (h: Fintype R) : IsField R := by
apply Field.toIsField
```
- **Highlighted Terms**: `Field.toIsField`
### Key Observations
1. **Syntax Consistency**: All provers use similar proof structures (`by`, `simp`, `apply`)
2. **Highlighted Patterns**:
- Mathematical operations (`condRho`, `re_float`)
- Type constraints (`Finset G`, `Fintype R`)
- Core proof tactics (`simp`, `apply`, `exact`)
3. **Mathematical Focus**: All proofs involve algebraic structures (groups, fields, Coxeter systems)
### Interpretation
The image demonstrates comparative analysis of formal proof structures across different theorem provers. The highlighted terms represent:
- Core mathematical concepts (`condRho`, `re_float`)
- Type system constraints (`Finset`, `Fintype`)
- Fundamental proof strategies (`simp`, `apply`)
- Algebraic structure properties (`CoxeterSystem`, `Field`)
The consistent use of `simp` and `apply` across provers suggests shared foundational proof techniques, while the specific highlighted terms reveal domain-specific implementations. The MiniF2F section's number theory focus contrasts with the algebraic emphasis in other sections, showing the versatility of these provers in handling different mathematical domains.
</details>
Figure 2: Case studies of LeanAgent’s new proofs. LeanAgent shows an ability to work with these repositories, often able to retrieve the necessary premises (highlighted). For example, LeanAgent proves a sorry theorem from PFR, condRho_of_translate, by simply expanding definitions, showing its proving ability on the PFR repository. In addition, LeanAgent could prove re_float from SciLean during lifelong learning, while ReProver could not. Moreover, its MiniF2F proofs demonstrate its ability to generate relatively longer and more complex proofs for complex mathematics. LeanAgent’s proof of invmap.of_eq and wedderburn represents its theorem proving capabilities with abstract algebra premises.
Table 2: Accuracy in proving sorry theorems across repositories. Accuracy is calculated as (proven theorems / total sorry theorems). “LA” denotes LeanAgent and “ReProver+” denotes the setting where we update ReProver on all 23 repositories at once. “During” shows accuracy during lifelong learning, “Add. After” shows additional accuracy after lifelong learning, and “Total” shows the combined accuracy. “MIL” stands for Mathematics in Lean Source and “Hairy Ball” refers to the Hairy Ball Theorem repository. Repositories with no sorry theorems or no proven ones are not shown. The best accuracy for each repository is in bold. As noted previously, we progressively train on MiniF2F after the initial curriculum to demonstrate the use case of formalizing in a new repository after learning a curriculum. As such, we don’t evaluate LeanAgent after lifelong learning on MiniF2F.
| MIL MiniF2F Formal Book | 29 406 29 | 72.4 24.4 10.3 | 48.3 24.4 6.9 | 24.1 - 3.4 | 48.3 20.9 6.9 | 55.2 20.9 10.3 |
| --- | --- | --- | --- | --- | --- | --- |
| SciLean | 294 | 9.2 | 7.5 | 1.7 | 8.2 | 8.5 |
| Hairy Ball | 14 | 7.1 | 0.0 | 7.1 | 0.0 | 7.1 |
| Coxeter | 15 | 6.7 | 6.7 | 0.0 | 0.0 | 6.7 |
| Carleson | 24 | 4.2 | 4.2 | 0.0 | 4.2 | 4.2 |
| Lean4 PDL | 30 | 3.3 | 3.3 | 0.0 | 3.3 | 3.3 |
| PFR | 37 | 2.7 | 2.7 | 0.0 | 0.0 | 0.0 |
In addition, a use case of LeanAgent is proving in a new repository after learning a curriculum; we progressively train on MiniF2F to demonstrate this. Note that we choose the Lean4 version of the MiniF2F repository (Yang, 2024) and disregard its separation into validation and test splits (reasoning in Appendix A.5). LeanAgent’s success rate on the Lean4 version of the MiniF2F test set is also in Appendix A.5. Moreover, a mathematician could use LeanAgent for (1) an initial curriculum $A$ , and later (2) a sub-curriculum $B$ . LeanAgent can then help the mathematician prove in the repositories in curriculum $A+B$ . To demonstrate this scenario, we continue LeanAgent on a sub-curriculum $B$ of 8 repositories.
Results are in Table 2, with case studies in Figure 2. Appendix A.5 provides a more thorough discussion, including an ablation study, and contains the complete theorems and proofs relevant to this section.
LeanAgent demonstrates continuous generalizability and improvement in theorem-proving capabilities across multiple repositories. LeanAgent’s proofs are a superset of the sorry theorems proved by ReProver in most cases. Moreover, to isolate the effect of curriculum learning, we compare LeanAgent against ReProver+, the ReProver model updated on all 23 repositories at once, and notice that LeanAgent outperforms it on several repositories, emphasizing the importance of curriculum learning. Overall, LeanAgent progresses from basic concepts (arithmetic, simple algebra) to advanced topics (abstract algebra, topology).
PFR. LeanAgent can prove a sorry theorem from this repository, while ReProver cannot. It also generalizes to a different commit (not included in progressive training), uncovering 7 system exploits. LeanAgent proves two theorems with just the rfl tactic, one of which ReProver cannot, and proves 5 sorry theorems with a $0=1$ placeholder theorem statement.
SciLean. During lifelong learning, LeanAgent proves theorems related to fundamental algebraic structures, linear and affine maps, and measure theory basics. By the end of lifelong learning, it proves concepts in advanced function spaces, sophisticated bijections, and abstract algebraic structures.
Mathematics in Lean Source. During lifelong learning, LeanAgent proves theorems about basic algebraic structures and fundamental arithmetic properties. By the end of lifelong learning, it proves more complex theorems involving quantifier manipulation, set theory, and relations.
MiniF2F. ReProver demonstrates proficiency in basic arithmetic, elementary algebra, and simple calculus. However, by the end of lifelong learning, LeanAgent handles theorems with advanced number theory, sophisticated algebra, complex calculus and analysis, abstract algebra, and complex induction.
Sub-curriculum. In the Formal Book repository, LeanAgent progresses from proving basic real analysis and number theory theorems to more advanced abstract algebra, exemplified by its proof of Wedderburn’s Little Theorem. For the Coxeter repository, LeanAgent proves a complex lemma about Coxeter systems, showcasing its increased understanding of group theory. In the Hairy Ball Theorem repository, LeanAgent proves a key step of the theorem, demonstrating improved performance in algebraic topology. Only LeanAgent can prove these theorems, demonstrating that it has much more advanced theorem-proving capabilities than ReProver.
4.3 Lifelong Learning Analysis
To our knowledge, no other lifelong learning frameworks for theorem proving exist in the literature. As such, we conduct an ablation study with six lifelong learning metrics to showcase LeanAgent’s superior handling of the stability-plasticity tradeoff. These results help explain LeanAgent’s superiority in sorry theorem proving performance. We compute these metrics for the original curriculum of 14 repositories.
Specifically, the ablation study consists of seven additional setups constructed from a combination of learning and dataset options. Options for learning setups are progressive training with or without EWC. Dataset setups involve a dataset order and construction. Options for dataset orders involve Single Repository or Merge All, where each dataset consists of all previous repositories and the new one. Given the most popular repositories on GitHub by star count, options for dataset construction include popularity order or curriculum order. Appendix A.3 shows these orders and additional repository details.
Metrics. We use six lifelong learning metrics: Windowed-Forgetting 5 (WF5), Forgetting Measure (FM), Catastrophic Forgetting Resilience (CFR), Expanded Backward Transfer (EBWT), Windowed-Plasticity 5 (WP5), and Incremental Plasticity (IP). A description of these metrics is in Table 3 (De Lange et al., 2023; Wang et al., 2024b; Díaz-Rodríguez et al., 2018). Our reasoning for considering these metrics is detailed in Appendix A.4.
Table 3: Description of lifelong learning metrics.
| WF5 | Measures forgetting over a 5-task window | Lower | Existing |
| --- | --- | --- | --- |
| FM | Average performance drop on old tasks | Lower | Existing |
| CFR | Ratio of min to max average test R@10 | Higher | Proposed |
| EBWT | Average improvement on old tasks after learning new ones | Higher | Existing |
| WP5 | Max average test R@10 increase over a 5-task window | Higher | Existing |
| IP | Rate of validation R@10 change per task | Higher | Proposed |
We describe why we introduce two new metrics to address specific aspects of lifelong learning in theorem proving:
- Catastrophic Forgetting Resilience (CFR). This metric captures LeanAgent’s ability to maintain performance on its weakest task relative to its best performance, crucial in the presence of diverse mathematical domains.
- Incremental Plasticity (IP). IP provides a more granular view of plasticity than aggregate measures and is sensitive to the order of tasks, particularly relevant in lifelong learning for theorem proving.
In addition, these metrics in the Merge All strategy measure cumulative knowledge refinement rather than isolated task performance (details in Appendix A.4). Due to these interpretational differences, we analyze Single Repository and Merge All setups separately. We consider an improvement of at least 3% to be significant.
Table 4: Comparison of lifelong learning metrics across setups. The best scores for each metric are in bold.
| WF5 ( $\downarrow$ ) FM ( $\downarrow$ ) CFR ( $\uparrow$ ) | 0.18 0.85 0.88 | 7.60 6.53 0.87 | 7.17 4.04 0.88 | 0.73 2.11 0.85 | 15.83 10.50 0.76 | 2.23 4.06 0.94 | 13.34 11.44 0.75 | 5.82 3.80 0.90 |
| --- | --- | --- | --- | --- | --- | --- | --- | --- |
| EBWT ( $\uparrow$ ) | 1.21 | 0.51 | 1.04 | 0.76 | -0.20 | 0.73 | -1.34 | -0.39 |
| WP5 ( $\uparrow$ ) | 2.47 | 0.89 | 1.47 | 3.42 | 0.00 | 0.09 | 0.00 | 0.11 |
| IP ( $\uparrow$ ) | 1.02 | 0.36 | 0.26 | 1.06 | -1.50 | -0.64 | -1.71 | -0.89 |
| Single Repository: | Merge All: |
| --- | --- |
| Setup 1: No EWC, Popularity Order | Setup 4: No EWC, Popularity Order |
| Setup 2: EWC, Popularity Order | Setup 5: No EWC, Curriculum Learning |
| Setup 3: EWC, Curriculum Learning | Setup 6: EWC, Popularity Order |
| Setup 7: EWC, Curriculum Learning | |
Single Repository Analysis. We first analyze the Single Repository results from Table 4. LeanAgent demonstrates superior stability across multiple metrics. The WF5 metric is 75.34% lower for LeanAgent than the next best setup, suggesting it maintains performance over a window more effectively. Its FM score is 59.97% lower than Setup 3’s, showcasing its resilience against catastrophic forgetting. Furthermore, LeanAgent, Setup 1, and Setup 2 demonstrate high and consistent resilience against catastrophic forgetting, with CFR values above 0.87 and minimal (±0.01) differences. This underscores LeanAgent’s ability to continuously generalize over time. In addition, LeanAgent has a 16.25% higher EBWT, indicating its ability to continuously improve over time.
In contrast, Setup 3 exhibits characteristics of higher plasticity. It shows a 38.26% higher WP5 over LeanAgent, indicating a greater ability to rapidly adapt to new tasks in a window. This is complemented by its 3.98% higher IP over LeanAgent, suggesting a more pronounced improvement on new tasks over time. However, these plasticity gains come at a significant cost: Setup 3 suffers from more severe catastrophic forgetting, as evidenced by its significantly worse stability metrics compared to LeanAgent. This excessive plasticity in Setup 3 stems from EWC’s inability to adapt parameter importance as theorem complexity increases. EWC preserves parameters important for simpler theorems, which may not be crucial for more complex ones. Consequently, these preserved parameters resist change while other parameters change rapidly for complex theorems. This forces the model to become more plastic overall, relying heavily on non-preserved parameters for new, complex theorems.
LeanAgent’s favorable stability and EBWT scores make it the most suitable for lifelong learning in the Single Repository setting.
Merge All Analysis. Next, we analyze the Merge All setups from Table 4. Setup 5’s WF5 metric is 61.68% lower than the next best setup (Setup 7), suggesting Setup 5 balances and retains knowledge across an expanding dataset most effectively. Furthermore, Setup 5’s CFR score is 3.77% higher than that of Setup 7, again demonstrating high and consistent resilience in the face of an expanding, potentially more complex dataset. However, Setup 7 has a 6.44% lower FM score than Setup 5’s, showcasing its ability to maintain performance on earlier data points. Moreover, Setup 5 is the only setup with a positive EBWT, indicating that learning new tasks improves performance on the entire historical dataset. The other setups have a negative EBWT, indicating performance degradation on earlier tasks after learning new ones.
Only Setups 5 and 7 have a non-zero WP5, suggesting the ability to adapt to the growing complexity of the combined dataset. The zero values for Setups 4 and 6 indicate that popularity order struggles to show improvement when dealing with merged data. However, although Setup 5 has the highest IP score with a 27.75% improvement over Setup 7, all 4 setups have negative IP values. This indicates a decrease in validation R@10 over time, suggesting that the Merge All strategy struggles to maintain performance.
Experiment 5’s favorable stability and EBWT scores suggest it is the best at balancing the retention of earlier knowledge with the adaptation to new data in a combined dataset. However, its negative IP value indicates a fundamental issue with its approach.
Comparative Analysis and Insights. Although the metrics have different interpretations in the Single Repository and Merge All settings, we can still draw some meaningful comparisons by focusing on overall trends and relative performance. We must consider that the negative IP values in Merge All setups indicate a significant issue. This drawback outweighs the potential benefits seen in other metrics like WP5, as it indicates a fundamental inability to maintain and improve performance in a continuously growing dataset. In contrast, LeanAgent demonstrates a positive IP, indicating its ability to incorporate new knowledge. This, combined with its superior stability and EBWT metrics relative to other Single Repository methods, suggests that LeanAgent is better suited than Setup 5 for continuous generalizability and improvement.
Consistency with sorry Theorem Proving Performance. This lifelong learning analysis is consistent with LeanAgent’s sorry theorem proving performance. LeanAgent’s superior stability metrics (WF5, FM, and CFR) explain its ability to maintain performance across diverse mathematical domains, as evidenced by its success in proving theorems from various repositories like SciLean, Mathematics in Lean Source, and PFR. Its high EBWT score aligns with its progression from basic concepts to advanced topics in theorem proving. While LeanAgent shows slightly lower plasticity (WP5 and IP) compared to some setups, this trade-off results in better overall performance, as reflected in its ability to prove a superset of sorry theorems compared to ReProver in most cases. This analysis demonstrates LeanAgent’s overall superiority in lifelong learning for theorem proving.
5 Conclusion
We have presented LeanAgent, a lifelong learning framework for theorem proving that achieves continuous generalizability and improvement across diverse mathematical domains. Key components include a curriculum learning strategy, progressive training approach, and custom dynamic database infrastructure. LeanAgent successfully generates formal proofs for 155 theorems where formal proofs were previously missing and uncovers 7 exploits across 23 Lean repositories, including from challenging mathematics. This highlights its potential to assist in formalizing complex proofs across multiple domains and identifying system exploits. For example, LeanAgent successfully proves challenging theorems in abstract algebra and algebraic topology. It outperforms the ReProver baseline in proving new sorry theorems, progressively learning from basic to complex mathematical concepts. Moreover, LeanAgent shows significant performance in forgetting measures and backward transfer, explaining its continuous generalizability and continuous improvement.
Future work could explore integration with Lean Copilot, providing real-time assistance with a mathematician’s repositories. In addition, a limitation of LeanAgent is its inability to prove certain theorems due to a lack of data on specific topics, such as odeSolve.arg_x 0.semiAdjoint_rule in SciLean about ODEs. To solve this problem, future work could use reinforcement learning for synthetic data generation during curriculum construction. Moreover, future work could use LeanAgent with additional math LLMs and search strategies.
Acknowledgments
Adarsh Kumarappan is supported by the Summer Undergraduate Research Fellowships (SURF) program at Caltech. Anima Anandkumar is supported by the Bren named chair professorship, Schmidt AI 2050 senior fellowship, and ONR (MURI grant N00014-18-12624). We thank Terence Tao for detailed discussions and feedback that significantly improved this paper. We thank Zulip chat members for engaging in clarifying conversations that were incorporated into the paper.
References
- Alama et al. (2014) Jesse Alama, Tom Heskes, Daniel Kühlwein, Evgeni Tsivtsivadze, and Josef Urban. Premise Selection for Mathematics by Corpus Analysis and Kernel Methods. Journal of Automated Reasoning, 52(2):191–213, February 2014. ISSN 0168-7433, 1573-0670. doi: 10.1007/s10817-013-9286-5.
- Arana & Stafford (2023) Andrew Arana and Will Stafford. On the difficulty of discovering mathematical proofs. Synthese, 202(2):1–29, 2023. doi: 10.1007/s11229-023-04184-5.
- Avigad (2024) Jeremy Avigad. Avigad/mathematics_in_lean_source, August 2024.
- Azerbayev et al. (2024) Zhangir Azerbayev, Hailey Schoelkopf, Keiran Paster, Marco Dos Santos, Stephen McAleer, Albert Q. Jiang, Jia Deng, Stella Biderman, and Sean Welleck. Llemma: An Open Language Model For Mathematics, March 2024.
- Bengio et al. (2009) Yoshua Bengio, Jérôme Louradour, Ronan Collobert, and Jason Weston. Curriculum learning. In Proceedings of the 26th Annual International Conference on Machine Learning, pp. 41–48, Montreal Quebec Canada, June 2009. ACM. ISBN 978-1-60558-516-1. doi: 10.1145/1553374.1553380.
- Borgeaud et al. (2022) Sebastian Borgeaud, Arthur Mensch, Jordan Hoffmann, Trevor Cai, Eliza Rutherford, Katie Millican, George van den Driessche, Jean-Baptiste Lespiau, Bogdan Damoc, Aidan Clark, Diego de Las Casas, Aurelia Guy, Jacob Menick, Roman Ring, Tom Hennigan, Saffron Huang, Loren Maggiore, Chris Jones, Albin Cassirer, Andy Brock, Michela Paganini, Geoffrey Irving, Oriol Vinyals, Simon Osindero, Karen Simonyan, Jack W. Rae, Erich Elsen, and Laurent Sifre. Improving language models by retrieving from trillions of tokens, February 2022.
- Carneiro (2024) Mario Carneiro. Digama0/lean4lean, September 2024.
- Chang et al. (2021) Ernie Chang, Hui-Syuan Yeh, and Vera Demberg. Does the Order of Training Samples Matter? Improving Neural Data-to-Text Generation with Curriculum Learning. In Paola Merlo, Jorg Tiedemann, and Reut Tsarfaty (eds.), Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: Main Volume, pp. 727–733, Online, April 2021. Association for Computational Linguistics. doi: 10.18653/v1/2021.eacl-main.61.
- Chaudhry et al. (2019) Arslan Chaudhry, Marc’Aurelio Ranzato, Marcus Rohrbach, and Mohamed Elhoseiny. Efficient Lifelong Learning with A-GEM, January 2019.
- Chen et al. (2023) Jiefeng Chen, Timothy Nguyen, Dilan Gorur, and Arslan Chaudhry. Is forgetting less a good inductive bias for forward transfer?, March 2023.
- Chen et al. (2024) Yupeng Chen, Senmiao Wang, Zhihang Lin, Zeyu Qin, Yushun Zhang, Tian Ding, and Ruoyu Sun. MoFO: Momentum-Filtered Optimizer for Mitigating Forgetting in LLM Fine-Tuning. 2024. doi: 10.48550/ARXIV.2407.20999.
- Cirik et al. (2016) Volkan Cirik, Eduard Hovy, and Louis-Philippe Morency. Visualizing and Understanding Curriculum Learning for Long Short-Term Memory Networks, November 2016.
- Claude Team (2024) Claude Team. Introducing claude 3.5 sonnet, June 2024. URL https://www.anthropic.com/news/claude-3-5-sonnet.
- Community (2024a) Lean Community. Leanprover-community/lean-liquid. leanprover-community, September 2024a.
- Community (2024b) Lean Community. Leanprover-community/lean-perfectoid-spaces. leanprover-community, August 2024b.
- Con-nf (2024) Con-nf. Leanprover-community/con-nf: A formal consistency proof of Quine’s set theory New Foundations. https://github.com/leanprover-community/con-nf/tree/main, 2024.
- Coxeter (2024) Coxeter. NUS-Math-Formalization/coxeter at 96af8aee7943ca8685ed1b00cc83a559ea389a97. https://github.com/NUS-Math-Formalization/coxeter/tree/96af8aee7943ca8685ed1b00cc83a559ea389a97, 2024.
- De Lange et al. (2023) Matthias De Lange, Gido van de Ven, and Tinne Tuytelaars. Continual evaluation for lifelong learning: Identifying the stability gap, March 2023.
- De Moura et al. (2015) Leonardo De Moura, Soonho Kong, Jeremy Avigad, Floris Van Doorn, and Jakob Von Raumer. The Lean Theorem Prover (System Description). In Amy P. Felty and Aart Middeldorp (eds.), Automated Deduction - CADE-25, volume 9195, pp. 378–388, Cham, 2015. Springer International Publishing. ISBN 978-3-319-21400-9 978-3-319-21401-6. doi: 10.1007/978-3-319-21401-6˙26.
- DeepMind (2024) Google DeepMind. Google-deepmind/debate. Google DeepMind, August 2024.
- Díaz-Rodríguez et al. (2018) Natalia Díaz-Rodríguez, Vincenzo Lomonaco, David Filliat, and Davide Maltoni. Don’t forget, there is more than forgetting: New metrics for Continual Learning, October 2018.
- Dillies (2024) Yaël Dillies. YaelDillies/LeanAPAP, September 2024.
- Dohare et al. (2024) Shibhansh Dohare, J. Fernando Hernandez-Garcia, Qingfeng Lan, Parash Rahman, A. Rupam Mahmood, and Richard S. Sutton. Loss of plasticity in deep continual learning. Nature, 632(8026):768–774, August 2024. ISSN 0028-0836, 1476-4687. doi: 10.1038/s41586-024-07711-7.
- Fermat’s Last Theorem (2024) Fermat’s Last Theorem. ImperialCollegeLondon/FLT. Imperial College London, September 2024.
- Firsching, Moritz (2024) Firsching, Moritz. Mo271/FormalBook: Formalizing ”Proofs from THE BOOK”, 2024.
- Formal Logic (2024) Formalized Formal Logic. FormalizedFormalLogic/Foundation. FormalizedFormalLogic, September 2024.
- Gadgil (2024) Siddhartha Gadgil. Siddhartha-gadgil/Saturn: Experiments with SAT solvers with proofs in Lean 4. https://github.com/siddhartha-gadgil/Saturn, 2024.
- Gattinger (2024) Malvin Gattinger. M4lvin/lean4-pdl, September 2024.
- Hairy Ball Theorem (2024) Hairy Ball Theorem. Corent1234/hairy-ball-theorem-lean at a778826d19c8a7ddf1d26beeea628c45450612e6. https://github.com/corent1234/hairy-ball-theorem-lean/tree/a778826d19c8a7ddf1d26beeea628c45450612e6, 2024.
- Irving et al. (2016) Geoffrey Irving, Christian Szegedy, Alexander A Alemi, Niklas Een, Francois Chollet, and Josef Urban. DeepMath - Deep Sequence Models for Premise Selection. In Advances in Neural Information Processing Systems, volume 29. Curran Associates, Inc., 2016.
- Jiang et al. (2022) Albert Q. Jiang, Wenda Li, Szymon Tworkowski, Konrad Czechowski, Tomasz Odrzygóźdź, Piotr Miłoś, Yuhuai Wu, and Mateja Jamnik. Thor: Wielding Hammers to Integrate Language Models and Automated Theorem Provers. 2022. doi: 10.48550/ARXIV.2205.10893.
- Jiang et al. (2024) Gangwei Jiang, Caigao Jiang, Zhaoyi Li, Siqiao Xue, Jun Zhou, Linqi Song, Defu Lian, and Ying Wei. Interpretable Catastrophic Forgetting of Large Language Model Fine-tuning via Instruction Vector. 2024. doi: 10.48550/ARXIV.2406.12227.
- Kevin Buzzard (2019) Kevin Buzzard. The Future of Mathematics? Professor Kevin Buzzard - 30 May 2019, June 2019.
- Kim et al. (2023) Seungyeon Kim, Ankit Singh Rawat, Manzil Zaheer, Sadeep Jayasumana, Veeranjaneyulu Sadhanala, Wittawat Jitkrittum, Aditya Krishna Menon, Rob Fergus, and Sanjiv Kumar. EmbedDistill: A Geometric Knowledge Distillation for Information Retrieval. 2023. doi: 10.48550/ARXIV.2301.12005.
- Kirkpatrick et al. (2017) James Kirkpatrick, Razvan Pascanu, Neil Rabinowitz, Joel Veness, Guillaume Desjardins, Andrei A. Rusu, Kieran Milan, John Quan, Tiago Ramalho, Agnieszka Grabska-Barwinska, Demis Hassabis, Claudia Clopath, Dharshan Kumaran, and Raia Hadsell. Overcoming catastrophic forgetting in neural networks. Proceedings of the National Academy of Sciences, 114(13):3521–3526, March 2017. ISSN 0027-8424, 1091-6490. doi: 10.1073/pnas.1611835114.
- Kontorovich (2024) Alex Kontorovich. AlexKontorovich/PrimeNumberTheoremAnd, August 2024.
- (37) Guillaume Lample, Marie-Anne Lachaux, Thibaut Lavril, Xavier Martinet, Amaury Hayat, Gabriel Ebner, Aurélien Rodriguez, and Timothée Lacroix. HyperTree Proof Search for Neural Theorem Proving.
- Li et al. (2024) Conglong Li, Zhewei Yao, Xiaoxia Wu, Minjia Zhang, Connor Holmes, Cheng Li, and Yuxiong He. DeepSpeed Data Efficiency: Improving Deep Learning Model Quality and Training Efficiency via Efficient Data Sampling and Routing. Proceedings of the AAAI Conference on Artificial Intelligence, 38(16):18490–18498, March 2024. ISSN 2374-3468, 2159-5399. doi: 10.1609/aaai.v38i16.29810.
- Li & Hoiem (2017) Zhizhong Li and Derek Hoiem. Learning without Forgetting, February 2017.
- Lin et al. (2024) Haohan Lin, Zhiqing Sun, Yiming Yang, and Sean Welleck. Lean-STaR: Learning to Interleave Thinking and Proving, August 2024.
- Liu et al. (2023) Chengwu Liu, Jianhao Shen, Huajian Xin, Zhengying Liu, Ye Yuan, Haiming Wang, Wei Ju, Chuanyang Zheng, Yichun Yin, Lin Li, Ming Zhang, and Qun Liu. FIMO: A Challenge Formal Dataset for Automated Theorem Proving, December 2023.
- Lopez-Paz & Ranzato (2017) David Lopez-Paz and Marc’ Aurelio Ranzato. Gradient Episodic Memory for Continual Learning. In Advances in Neural Information Processing Systems, volume 30. Curran Associates, Inc., 2017.
- Loshchilov & Hutter (2017) I. Loshchilov and F. Hutter. Decoupled Weight Decay Regularization. In International Conference on Learning Representations, November 2017.
- Lu et al. (2024) Minghai Lu, Benjamin Delaware, and Tianyi Zhang. Proof Automation with Large Language Models, September 2024.
- Lu et al. (2022) Shuai Lu, Nan Duan, Hojae Han, Daya Guo, Seung-won Hwang, and Alexey Svyatkovskiy. ReACC: A Retrieval-Augmented Code Completion Framework. In Smaranda Muresan, Preslav Nakov, and Aline Villavicencio (eds.), Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 6227–6240, Dublin, Ireland, May 2022. Association for Computational Linguistics. doi: 10.18653/v1/2022.acl-long.431.
- mathlib4 Community (2024) The mathlib4 Community. Leanprover-community/mathlib4. leanprover-community, September 2024.
- Mendez & Eaton (2021) Jorge A Mendez and Eric Eaton. Lifelong Learning of Compositional Structures. 2021.
- Mikuła et al. (2024) Maciej Mikuła, Szymon Tworkowski, Szymon Antoniak, Bartosz Piotrowski, Albert Qiaochu Jiang, Jin Peng Zhou, Christian Szegedy, Łukasz Kuciński, Piotr Miłoś, and Yuhuai Wu. Magnushammer: A Transformer-Based Approach to Premise Selection, March 2024.
- Mizuno (2024) Yuma Mizuno. Yuma-mizuno/lean-math-workshop. https://github.com/yuma-mizuno/lean-math-workshop, 2024.
- Monnerjahn (2024) Ludwig Monnerjahn. Louis-Le-Grand/Formalisation-of-constructable-numbers, September 2024.
- Murphy (2024) Logan Murphy. Loganrjmurphy/LeanEuclid, September 2024.
- OpenAI (2024) OpenAI. OpenAI o1 System Card, September 2024.
- Piotrowski et al. (2023) Bartosz Piotrowski, Ramon Fernández Mir, and Edward Ayers. Machine-Learned Premise Selection for Lean. In Automated Reasoning with Analytic Tableaux and Related Methods: 32nd International Conference, TABLEAUX 2023, Prague, Czech Republic, September 18–21, 2023, Proceedings, pp. 175–186, Berlin, Heidelberg, September 2023. Springer-Verlag. ISBN 978-3-031-43512-6. doi: 10.1007/978-3-031-43513-3˙10.
- Polu et al. (2022) Stanislas Polu, Jesse Michael Han, Kunhao Zheng, Mantas Baksys, Igor Babuschkin, and I. Sutskever. Formal Mathematics Statement Curriculum Learning. ArXiv, February 2022.
- Renshaw (2024) David Renshaw. Dwrensha/compfiles: Catalog Of Math Problems Formalized In Lean. https://github.com/dwrensha/compfiles, September 2024.
- Shao et al. (2024) Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, Y. K. Li, Y. Wu, and Daya Guo. DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models, April 2024.
- Shin et al. (2017) Hanul Shin, Jung Kwon Lee, Jaehong Kim, and Jiwon Kim. Continual Learning with Deep Generative Replay, December 2017.
- Skřivan (2024) Tomáš Skřivan. Lecopivo/SciLean: Scientific computing in Lean 4. https://github.com/lecopivo/SciLean/tree/master, September 2024.
- Song et al. (2024) Peiyang Song, Kaiyu Yang, and Anima Anandkumar. Towards large language models as copilots for theorem proving in lean, 2024. URL https://arxiv.org/abs/2404.12534.
- (60) Valentin I Spitkovsky, Hiyan Alshawi, and Daniel Jurafsky. Baby Steps: How “Less is More” in Unsupervised Dependency Parsing.
- Subramanian et al. (2017) Sandeep Subramanian, Sai Rajeswar, Francis Dutil, Chris Pal, and Aaron Courville. Adversarial Generation of Natural Language. In Phil Blunsom, Antoine Bordes, Kyunghyun Cho, Shay Cohen, Chris Dyer, Edward Grefenstette, Karl Moritz Hermann, Laura Rimell, Jason Weston, and Scott Yih (eds.), Proceedings of the 2nd Workshop on Representation Learning for NLP, pp. 241–251, Vancouver, Canada, August 2017. Association for Computational Linguistics. doi: 10.18653/v1/W17-2629.
- (62) Terence Tao. Teorth/asymptotic.
- Tao (2024a) Terence Tao. Teorth/newton, June 2024a.
- Tao (2024b) Terence Tao. Teorth/symmetric_project, July 2024b.
- Tao et al. (2024) Terence Tao, Pietro Monticone, Lorenzo Luccioli, and Rémy Degenne. Teorth/pfr, August 2024.
- Thakur et al. (2024) Amitayush Thakur, George Tsoukalas, Yeming Wen, Jimmy Xin, and Swarat Chaudhuri. An In-Context Learning Agent for Formal Theorem-Proving, August 2024.
- (67) Szymon Tworkowski, Maciej Mikula, Tomasz Odrzygozdz, Konrad Czechowski, Szymon Antoniak, Albert Q Jiang, Christian Szegedy, Lukasz Kucinski, Piotr Milos, and Yuhuai Wu. Formal Premise Selection With Language Models.
- van de Ven et al. (2024) Gido M. van de Ven, Nicholas Soures, and Dhireesha Kudithipudi. Continual Learning and Catastrophic Forgetting, March 2024.
- van Doorn (2024) Floris van Doorn. Fpvandoorn/carleson, September 2024.
- Vaswani et al. (2017) Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Ł ukasz Kaiser, and Illia Polosukhin. Attention is All you Need. In Advances in Neural Information Processing Systems, volume 30. Curran Associates, Inc., 2017.
- Wang et al. (2023) Haiming Wang, Ye Yuan, Zhengying Liu, Jianhao Shen, Yichun Yin, Jing Xiong, Enze Xie, Han Shi, Yujun Li, Lin Li, Jian Yin, Zhenguo Li, and Xiaodan Liang. DT-Solver: Automated Theorem Proving with Dynamic-Tree Sampling Guided by Proof-level Value Function. In Anna Rogers, Jordan Boyd-Graber, and Naoaki Okazaki (eds.), Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 12632–12646, Toronto, Canada, July 2023. Association for Computational Linguistics. doi: 10.18653/v1/2023.acl-long.706.
- Wang et al. (2024a) Haiming Wang, Huajian Xin, Zhengying Liu, Wenda Li, Yinya Huang, Jianqiao Lu, Zhicheng Yang, Jing Tang, Jian Yin, Zhenguo Li, and Xiaodan Liang. Proving Theorems Recursively, May 2024a.
- Wang et al. (2024b) Liyuan Wang, Xingxing Zhang, Hang Su, and Jun Zhu. A Comprehensive Survey of Continual Learning: Theory, Method and Application. IEEE Transactions on Pattern Analysis and Machine Intelligence, 46(8):5362–5383, August 2024b. ISSN 0162-8828, 2160-9292, 1939-3539. doi: 10.1109/TPAMI.2024.3367329.
- Wang & Deng (2020) Mingzhe Wang and Jia Deng. Learning to Prove Theorems by Learning to Generate Theorems. ArXiv, February 2020.
- Wang et al. (2024c) Ruida Wang, Jipeng Zhang, Yizhen Jia, Rui Pan, Shizhe Diao, Renjie Pi, and Tong Zhang. TheoremLlama: Transforming General-Purpose LLMs into Lean4 Experts, October 2024c.
- Wieser (2024) Eric Wieser. Eric-wieser/lean-matrix-cookbook: The matrix cookbook, proved in the Lean theorem prover. https://github.com/eric-wieser/lean-matrix-cookbook, 2024.
- Xin et al. (2024a) Huajian Xin, Daya Guo, Zhihong Shao, Zhizhou Ren, Qihao Zhu, Bo Liu, Chong Ruan, Wenda Li, and Xiaodan Liang. DeepSeek-Prover: Advancing Theorem Proving in LLMs through Large-Scale Synthetic Data, May 2024a.
- Xin et al. (2024b) Huajian Xin, Z. Z. Ren, Junxiao Song, Zhihong Shao, Wanjia Zhao, Haocheng Wang, Bo Liu, Liyue Zhang, Xuan Lu, Qiushi Du, Wenjun Gao, Qihao Zhu, Dejian Yang, Zhibin Gou, Z. F. Wu, Fuli Luo, and Chong Ruan. DeepSeek-Prover-V1.5: Harnessing Proof Assistant Feedback for Reinforcement Learning and Monte-Carlo Tree Search, August 2024b.
- Xue et al. (2022) Linting Xue, Aditya Barua, Noah Constant, Rami Al-Rfou, Sharan Narang, Mihir Kale, Adam Roberts, and Colin Raffel. ByT5: Towards a Token-Free Future with Pre-trained Byte-to-Byte Models. Transactions of the Association for Computational Linguistics, 10:291–306, 2022. doi: 10.1162/tacl˙a˙00461.
- Yang (2024) Kaiyu Yang. Yangky11/miniF2F-lean4. https://github.com/yangky11/miniF2F-lean4/tree/main, 2024.
- Yang et al. (2023) Kaiyu Yang, Aidan M. Swope, Alex Gu, Rahul Chalamala, Peiyang Song, Shixing Yu, Saad Godil, Ryan Prenger, and Anima Anandkumar. LeanDojo: Theorem Proving with Retrieval-Augmented Language Models. 2023. doi: 10.48550/ARXIV.2306.15626.
- Zaremba & Sutskever (2015) Wojciech Zaremba and Ilya Sutskever. Learning to Execute, February 2015.
- Zeta 3 Irrational (2024) Zeta 3 Irrational. Ahhwuhu/zeta_3_irrational at 3d68ddd90434a398c9a72f30d50c57f15a0118c7. https://github.com/ahhwuhu/zeta_3_irrational/tree/3d68ddd90434a398c9a72f30d50c57f15a0118c7, 2024.
- (84) Jiawei Zhao, Zhenyu Zhang, Beidi Chen, Zhangyang Wang, Anima Anandkumar, and Yuandong Tian. GaLore: Memory-Efficient LLM Training by Gradient Low-Rank Projection. URL http://arxiv.org/abs/2403.03507.
- Zhou et al. (2024) Jin Peng Zhou, Charles Staats, Wenda Li, Christian Szegedy, Kilian Q. Weinberger, and Yuhuai Wu. Don’t Trust: Verify – Grounding LLM Quantitative Reasoning with Autoformalization, March 2024.
- Zhou et al. (2023) Shuyan Zhou, Uri Alon, Frank F. Xu, Zhiruo Wang, Zhengbao Jiang, and Graham Neubig. DocPrompting: Generating Code by Retrieving the Docs, February 2023.
- Zombori et al. (2019) Zsolt Zombori, Adrian Csiszarik, Henryk Michalewski, Cezary Kaliszyk, and Josef Urban. Curriculum Learning and Theorem Proving. 2019.
Appendix A Appendix
A.1 Further Methodology Details
Repository Scanning and Data Extraction. We use the GitHub API to query for Lean repositories based on sorting parameters (e.g., by repository stars or most recently updated repositories). We maintain a list of known repositories to avoid; the list can be updated to allow LeanAgent to re-analyze the same repository on a new commit or Lean version.
We clone each identified repository locally using the Git version control system. To ensure compatibility with our theorem-proving pipeline, we check the Lean version required by each repository and compare it with the supported versions of our system. If the required version is incompatible, we skip the repository and move on to the next one. Otherwise, LeanAgent switches its Lean version to match the repository’s version. This version checking is performed by parsing the repository’s configuration files and extracting the specified Lean version.
Dynamic Database Management. This database contains many key features that are useful in our setting. For example, it can add new repositories, update existing ones, and generate merged datasets from multiple repositories with customizable splitting strategies. In addition, it can query specific theorems or premises across repositories, track the progress of proof attempts (including the proof status of sorry theorems), and analyze the structure and content of Lean proofs, including tactic sequences and proof states.
The database keeps track of various details: Repository metadata; theorems categorized as already proven, sorry theorems that are proven, or sorry theorems that are unproven; premise files with their imports and individual premises; traced files for tracking which files have been processed; detailed theorem information, including file path, start/end positions, and full statements; and traced tactics with annotated versions, including the proof state before and after application.
If we encounter duplicate theorems between repositories while merging repositories, we use the theorem from the repository most recently added to the database. We deduplicate premise files and traced files by choosing the first one encountered while merging the repositories. We also generate metadata containing details of all the repositories used to generate the dataset and statistics regarding the theorems, premise files, and traced files in the dataset, such as the total number of theorems.
We provide the user with many options to generate a dataset. To generate the set of theorems and proofs, the default option is to simply use the theorems, proofs, premise files, and traced files from the current curriculum repository in the database. Specifically, we use the random split from LeanDojo to create training, validation, and testing sets. We refrain from using the novel split from LeanDojo, as we would like LeanAgent to learn as much as possible from a repository to perform well on its hardest theorems. The data in the splits include details about the proofs of theorems, including the URL and commit of the source repository, the file path of the theorem, the full name of the theorem, the theorem statement, the start and end positions in the source file, and a list of traced tactics with annotations. The validation and test split each contain 2% of the total theorem and proofs, following the methodology from LeanDojo. Moreover, the database uses a topological sort over the traced files in the repository to generate the premise corpus. This corpus is a JSON Lines file, where each line is a JSON object consisting of a path to a Lean source file, the file’s imports, and the file’s premise statements and definitions.
Progressive Training of the Retriever. We describe some additional steps for progressive training. To precompute the embeddings, we use a single forward pass with batch processing to serialize and tokenize premises from the entire corpus. Then, we use the retriever’s encoder to process the batches and generate embeddings.
sorry Theorem Proving. We start by processing the premise corpus to use it more efficiently during premise retrieval. This involves initializing a directed dependency graph to represent each file path in the corpus, adding files as nodes and imports as edges, and creating a transitive closure of this graph. We also track all premises encountered during this process, building a comprehensive knowledge base.
Crucially, we limit retrieval to a subset of all available premises to aid the effectiveness of the results. Specifically, we choose the top 25% of accessible and relevant premises, following ReProver’s method.
Proof Integration and Pull Request Generation. We integrate the generated proofs into the original Lean files and create pull requests to propose the changes to the repository owners. This aids the development of these repositories and functions as more training data for future research.
To achieve this, in a temporary Git branch, we iterate over the Lean files and locate the sorry keywords corresponding to the generated proofs. We then replace these sorry keywords with the actual proof text, working from the bottom of each file upward to preserve the position of theorems. After integrating the proofs, we commit our changes, push them, and create a pull request for the repository on GitHub.
A.2 Experiment Implementation Details
We use ReProver’s retriever trained on the random split from LeanDojo. We use four NVIDIA A100 GPUs with 80GB of memory each for progressive training. LeanAgent uses a distributed architecture leveraging PyTorch Lightning and Ray for parallel processing. We use bfloat16 mixed precision and optimize with AdamW (Loshchilov & Hutter, 2017) with an effective batch size of 16 (achieved through a batch size of 4 with gradient accumulation over 4 steps). In the first 1,000 steps, the learning rate warms up linearly from 0 to the maximum value of $10^{-3}$ . Then it decays to 0 using a cosine schedule. In addition, we apply gradient clipping with a value of 1.0. Just as ReProver does during training, we sample 3 negative premises per example, including 1 in-file negative premise. The maximum sequence length for the retriever is set to 1024 tokens. The maximum sequence length for the generator is set to 512 tokens for input and 128 tokens for output.
The prover uses a best-first search strategy with no limit on the maximum number of expansions of the search tree. It generates 64 tactic candidates and retrieves 100 premises for each proof state. LeanAgent uses ReProver’s tactic generator for the experiments. We generate tactics with a beam search of size 5. We used 4 CPU workers, 1 per GPU. Due to the wide variety of repositories and experimental setups that we tested, the time for each experiment widely varied. For example, the experiments in Table 10 took from 4 to 9 days to complete.
Furthermore, we do not compare LeanAgent with any existing LLM-based prover besides ReProver because LeanAgent is a framework, not a model. As mentioned previously, it can be used with any LLM. As such, a comparison would be impractical for reasons including differences in data, pre-training, and fine-tuning. We only compare with ReProver because we use ReProver’s retriever as the starting one in LeanAgent, allowing for a more faithful comparison.
Moreover, we do not compare with Aesop because it is not an ML model. We aim to improve upon ML research for theorem proving, such as ReProver. Moreover, Aesop is not a framework, but ReProver was included as the starting point of the LeanAgent framework, which is why we compare LeanAgent to ReProver. Rather than comparing against existing tools, we aim to understand how lifelong learning can work in theorem proving.
Furthermore, although LeanAgent can work with other LLMs such as Llemma (Azerbayev et al., 2024) and DeepSeek-Prover (Xin et al., 2024a), using these LLMs in our work would require architectural modifications that go beyond the scope of our current work. For example, the 7B model DeepSeek-Prover as well as the 7B and 34B Llemma models are not retrieval-based. As such, rather than progressively training a retriever, we would progressively train the entire model. This may be feasible with methods such as Gradient Low-Rank Projection (Zhao et al., ), but this would lead to fundamentally different usage than we currently demonstrate. Specifically, rather than using a best-first tree search approach as we do with ReProver’s retriever and tactic generator, we may instead need to generate the entire proof at once. This setup is quite dissimilar from our current evaluation, and so these results may be too dissimilar from our current evaluation framework.
In addition, we would like to note that because LeanAgent does not claim to contribute a new search algorithm, it can be used with other search strategies such as Hypertree Proof Search (Lample et al., ). However, the source code for Hypertree Proof Search was only recently released on GitHub, explaining why we did not use it thus far.
Moreover, the objective function for Elastic Weight Consolidation (EWC) is given by:
$$
L(\theta)=L_{B}(\theta)+\frac{\lambda}{2}\sum_{i}F_{i}(\theta_{i}-\theta_{A,i}%
)^{2}
$$
where $L_{B}(\theta)$ is the loss for the current task B, $i$ is the label for each parameter, $\theta_{A,i}$ are the parameters from the previous task A, $F_{i}$ is the Fisher information matrix, and $\lambda$ is a hyperparameter that controls the strength of the EWC penalty. For the setups that use EWC, we performed a grid search over $\lambda$ values in {0.01, 0.1, 1, 10, 100}. For each value, we ran Setup 2 on separate testing repositories. We found 0.1 to yield the best overall stability and plasticity scores.
A.3 Repository Details
Table 5: Additional repository descriptions
Table 6: Repository commits. Formalization of Const. Numbers denotes Formalization of Constructable Numbers.
| PFR Hairy Ball Theorem Coxeter | fa398a5b853c7e94e3294c45e50c6aee013a2687 a778826d19c8a7ddf1d26beeea628c45450612e6 96af8aee7943ca8685ed1b00cc83a559ea389a97 |
| --- | --- |
| Mathematics in Lean Source | 5297e0fb051367c48c0a084411853a576389ecf5 |
| Formal Book | 6fbe8c2985008c0bfb30050750a71b90388ad3a3 |
| MiniF2F | 9e445f5435407f014b88b44a98436d50dd7abd00 |
| SciLean | 22d53b2f4e3db2a172e71da6eb9c916e62655744 |
| Carleson | bec7808b907190882fa1fa54ce749af297c6cf37 |
| Lean4 PDL | c7f649fe3c4891cf1a01c120e82ebc5f6199856e |
| Prime Number Theorem And | 29baddd685660b5fedd7bd67f9916ae24253d566 |
| Compfiles | f99bf6f2928d47dd1a445b414b3a723c2665f091 |
| FLT | b208a302cdcbfadce33d8165f0b054bfa17e2147 |
| Debate | 7fb39251b705797ee54e08c96177fabd29a5b5a3 |
| Lean4Lean | 05b1f4a68c5facea96a5ee51c6a56fef21276e0f |
| Matrix Cookbook | f15a149d321ac99ff9b9c024b58e7882f564669f |
| Math Workshop | 5acd4b933d47fd6c1032798a6046c1baf261445d |
| LeanEuclid | f1912c3090eb82820575758efc31e40b9db86bb8 |
| Foundation | d5fe5d057a90a0703a745cdc318a1b6621490c21 |
| Con-nf | 00bdc85ba7d486a9e544a0806a1018dd06fa3856 |
| Saturn | 3811a9dd46cdfd5fa0c0c1896720c28d2ec4a42a |
| Zeta 3 Irrational | 914712200e463cfc97fe37e929d518dd58806a38 |
| Formalization of Const. Numbers | 01ef1f22a04f2ba8081c5fb29413f515a0e52878 |
| LeanAPAP | 951c660a8d7ba8e39f906fdf657674a984effa8b |
Table 7: Repository orders (initial curriculum). Note that Popularity Order is by star count on August 20, 2024.
| 1 2 3 | Compfiles Mathematics in Lean Source Prime Number Theorem And | SciLean FLT PFR |
| --- | --- | --- |
| 4 | Math Workshop | Prime Number Theorem And |
| 5 | FLT | Compfiles |
| 6 | PFR | Debate |
| 7 | SciLean | Mathematics in Lean Source |
| 8 | Debate | Lean4Lean |
| 9 | Matrix Cookbook | Matrix Cookbook |
| 10 | Con-nf | Math Workshop |
| 11 | Foundation | LeanEuclid |
| 12 | Saturn | Foundation |
| 13 | LeanEuclid | Con-nf |
| 14 | Lean4Lean | Saturn |
Table 8: Curriculum order (sub-curriculum)
| 1 2 3 | Zeta 3 Irrational Formal Book Formalization of Constructable Numbers |
| --- | --- |
| 4 | Carleson |
| 5 | LeanAPAP |
| 6 | Hairy Ball Theorem |
| 7 | Coxeter |
| 8 | Lean4 PDL |
Table 9: Repository theorem and premise counts
| PFR Hairy Ball Theorem Coxeter | 74306 73026 71273 | 109855 131217 127608 |
| --- | --- | --- |
| Mathematics in Lean Source | 78886 | 117699 |
| Formal Book | 74654 | 112458 |
| MiniF2F | 71313 | 127202 |
| SciLean | 72244 | 129711 |
| Carleson | 73851 | 109334 |
| Lean4 PDL | 20599 | 46400 |
| Prime Number Theorem And | 79147 | 115751 |
| Compfiles | 121391 | 178108 |
| FLT | 75082 | 114830 |
| Debate | 68853 | 103684 |
| Lean4Lean | 2559 | 22689 |
| Matrix Cookbook | 67585 | 102294 |
| Math Workshop | 76942 | 115458 |
| LeanEuclid | 15423 | 40555 |
| Foundation | 25047 | 57964 |
| Con-nf | 29489 | 64177 |
| Saturn | 10982 | 34497 |
| Zeta 3 Irrational | 120174 | 176332 |
| Formalization of Const. Numbers | 74050 | 109645 |
| LeanAPAP | 71090 | 109477 |
Repository Statistics and Information. Additional repository descriptions are in Table 5. The commits we used for experiments are in Table 6. Moreover, the repository orders are detailed in Table 7 and Table 8. Furthermore, the total number of theorems and premises per repository (including dependencies) are in Table 9.
Repository Selection Process. Many repositories have issues such as incompatibilities with LeanDojo, unsupported Lean versions, and build failures. As such, our process for choosing the 14 repositories in the first curriculum was simply using LeanAgent to extract information from the most popular repositories on GitHub. We disregard incompatible and inapplicable ones, such as those with no theorems. We performed this process on August 20, 2024. We performed a similar process for the eight repositories in the second curriculum with two differences: (1) We checked that the number of sorry theorems visible from GitHub was at least 10. This narrowed down the available repositories significantly. (2) We included some more recently updated repositories to provide some variety in the age of the repositories in our curriculum. We performed this process on September 14, 2024. However, many of the repositories that passed this test had fewer than 10 sorry theorems when processed by LeanDojo; this is mainly due to the functionalities of LeanDojo.
A.4 Lifelong Learning Metric Details
Prior work has noted that lifelong learning methods generally lack standard evaluation metrics (De Lange et al., 2023; Díaz-Rodríguez et al., 2018). As such, our selection primarily focused on metrics that emphasized a change over time, aligning with our problem setup. In addition, we removed metrics that were redundant. For example, prior work suggests that evaluating lifelong learning frameworks only after each task, rather than over time, leads to substantial forgetting (De Lange et al., 2023). As such, we adopt WF and WP in our analysis of LeanAgent. We use a window size of 5 for WF and WP as this represents a relatively medium-term understanding, given that we have 14 repositories. This would provide a balanced interpretation of forgetting and plasticity. Furthermore, we use the EBWT metric, in line with previous work, to evaluate LeanAgent throughout its lifetime rather than simply at the end (Díaz-Rodríguez et al., 2018). Moreover, we chose not to include the Forward Transfer metric as prior work has shown that a lower FM leads to better forward transfer (Chen et al., 2023). As such, we only check FM. We also chose not to include lifelong learning metrics for overall performance, such as Time Weighted Cumulative Performance (TWCP), Area Under the Learning Curve (AULC), and Average Accuracy (AA), as these would lead to redundancy in our analysis. Specifically, the metrics we chose were all computed using validation R@10 and the average test R@10, which are already measures of LeanAgent’s performance.
We provide some additional details on the metrics we used. Windowed-Forgetting 5 (WF5) quantifies model stability by measuring the maximum performance decrease in average test R@10 over a sliding window of 5 evaluations. Following prior work, we define WF for a given window size and then average it over all evaluation tasks to provide a single measure of stability. Moreover, Catastrophic Forgetting Resilience (CFR) is a key indicator of the stability-plasticity trade-off. Furthermore, the Forgetting Measure (FM) measures the negative influence that learning a task has on the test R@10 of all old tasks. It is the average forgetting of all old tasks, where forgetting of a task is the difference between its highest and current performance. Furthermore, BWT measures the positive influence of learning a new task on the test R@10 of old tasks. EBWT improves upon this metric by considering the average of the BWT computed after each task. Windowed-Plasticity 5 (WP5) measures the ability to learn new information by quantifying the maximum average test R@10 increase over a sliding window of 5 evaluations. Incremental Plasticity (IP) tracks changes in validation R@10 for each task over time.
However, it is important to note that our lifelong learning metrics have different interpretations in the Merge All dataset construction strategy, which differs from the traditional task-incremental setup. To our knowledge, an interpretation of these metrics in this setting has not been thoroughly conducted. As such, we propose that metrics should be interpreted with an understanding that they may reflect an adaptation to gradual shifts in data distribution rather than abrupt task changes. Specifically, WF5 may reflect not just forgetting old tasks but also the ability to balance and retain knowledge across an expanding dataset. WP5 could indicate how well the model adapts to the growing complexity of the combined dataset rather than purely learning new, isolated tasks. FM, in this context, may represent the ability to maintain performance on earlier data points as the dataset grows. EBWT might reflect the capacity to leverage newly added data to improve performance on the entire historical dataset. CFR becomes a measure of stability in the face of an expanding, potentially more complex dataset. IP may represent how quickly the model adapts to the evolving nature of the combined dataset rather than discrete new tasks. These metrics in the Merge All case measure the ability to accumulate and refine knowledge over time rather than strictly measuring performance on isolated tasks.
It is worth analyzing the effect of EWC. Our results in Sec. 4.3 suggest that the effect of EWC is not uniform across different task-ordering strategies. In curriculum-based ordering, EWC seems to improve plasticity (WP5 and IP) at the cost of stability and continuous improvement (WF5, FM, EBWT, and CFR). An exception is Setup 7, which improves WP5 and FM. This suggests that the Merge All strategy creates a more nuanced balance between stability and plasticity. EWC generally improves stability and plasticity metrics, except IP, in the popularity order for the Single Repository strategy. This may be because this ordering is less optimized for learning, and EWC helps to mitigate some of its shortcomings. However, when used with a more effective curriculum-based ordering, EWC interferes with the carefully structured learning process, leading to mixed results. Moreover, in the Merge All scenario, EWC offers benefits only for the curriculum learning setups, suggesting that its effectiveness might be limited in more complex, merged datasets. This can be explained by the fact that the Merge All strategy is a memory-based approach to lifelong learning. As such, using both EWC and the Merge All strategy may lead to excessive stability. This analysis further explains why LeanAgent’s setup is superior.
A.5 Further sorry Theorem Proving Discussion
We provide some additional discussion on the results in Table 2.
First, we note that comparing LeanAgent to ReProver+, the fine-tuning baseline, is not a direct comparison. Specifically, we note how mathematicians often formalize across multiple domains and projects simultaneously or cyclically. We use this as motivation for connecting mathematical knowledge between domains. Moreover, a key use case is formalizing new repositories without retraining on the entire dataset each time. When a mathematician creates some new repositories and adds them to a curriculum, they can simply progressively train LeanAgent on the new repositories while maintaining performance on previous ones, as shown in our experiments with both the initial curriculum and sub-curriculum. This is much more practical than retraining on the entire dataset, which would be expensive in terms of compute and time, especially as the number of repositories grows.
Moreover, data scarcity is a major problem in theorem proving. As such, having enough high-quality data for effective pre-training on all repositories may not be feasible. Training on all data, an approach similar to existing work, could prevent the model from generalizing to new repositories. However, LeanAgent does not have this restraint as it continuously generalizes to and improves on ever-expanding mathematical knowledge without forgetting previously learned knowledge.
In addition, the results in Table 4 show that our lifelong learning setup leads to effective backward transfer. This is a strong advantage that pre-training does not provide and is also a reason why LeanAgent demonstrates progressive learning, starting with basic concepts and advancing to more complex ones. Also, although not a direct comparison to the pre-training approach, the “Merge All” strategy indicates decreased performance over time. This dataset strategy can be interpreted as being closer to pre-training than the “Single Repository” strategy, suggesting lower than desired pre-training performance when training on all data.
Second, we note that LeanAgent improves over the direct fine-tuning baseline on various repositories, including MiniF2F, Scilean, and PFR. We find that these repositories contain a range of mathematical concepts that require progressively more advanced reasoning capabilities. This highlights the effectiveness of our lifelong learning approach in continuously generalizing to and improving on expanding mathematical knowledge without catastrophic forgetting.
Table 10: Accuracy comparison across setups. Accuracy is calculated as (proven theorems / total sorry theorems). MIL denotes the Mathematics in Lean Source repository, LA denotes LeanAgent, and SX denotes Setup X (e.g., S1 is Setup 1). The best accuracy for each repository is in bold.
| MIL SciLean PFR | 29 294 37 | 72.4 9.2 2.7 | 55.2 8.5 0.0 | 41.4 7.5 0.0 | 55.2 6.8 0.0 | 55.2 8.5 0.0 | 48.3 8.5 0.0 | 58.6 8.8 0.0 | 48.3 7.8 0.0 |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
In addition to comparing LeanAgent and ReProver, we conduct an ablation study between LeanAgent and the seven variants discussed in Sec. 4.3 regarding the original curriculum. The detailed sorry theorem proving comparison, which focuses on some of the repositories compared in Sec. 4.2, is in Table 10. Note that when using the Merge All strategy, only sorry theorems from the new repository are proven during each iteration of lifelong learning. We devote the rest of this section to the detailed comparison of sorry theorems that these setups can prove.
Mathematics in Lean Source. We notice a progression in LeanAgent’s proving ability in the Mathematics in Lean Source repository. During lifelong learning, LeanAgent demonstrates a grasp of fundamental algebraic structures and basic mathematical operations:
a) Group and Ring Theory: LeanAgent proves theorems about basic algebraic structures. For instance, MyGroup.mul_right_inv shows that multiplying an element by its inverse yields the identity and MyRing.add_right_cancel demonstrates the cancellation property in ring addition.
<details>
<summary>extracted/6256159/carbon17.png Details</summary>

### Visual Description
## Screenshot: Code Editor with Mathematical Theorems
### Overview
The image shows a code editor interface with two mathematical theorems written in a programming or formal verification language (likely Lean or a similar proof assistant). The code uses syntax highlighting with color-coded elements (e.g., keywords, variables, operators).
### Components/Axes
- **Top-left corner**: Three colored dots (red, yellow, green) typical of macOS window controls.
- **Code blocks**: Two theorem definitions with syntax highlighting.
- **First theorem**:
- **Text**: `theorem mul_right_inv (a : G) : a * a⁻¹ = 1 := by`
- **Subtext**: `simp`
- **Second theorem**:
- **Text**: `theorem add_right_cancel {a b c : R} (h : a + b = c + b) : a = c := by`
- **Subtext**: `simpa using h`
### Detailed Analysis
- **Theorem 1 (`mul_right_inv`)**:
- **Purpose**: Defines the multiplicative inverse property in a group `G`.
- **Equation**: `a * a⁻¹ = 1` (multiplication of an element and its inverse equals the identity).
- **Proof method**: `by simp` (uses the `simp` tactic to simplify the proof).
- **Theorem 2 (`add_right_cancel`)**:
- **Purpose**: Defines the cancellation law for addition in a ring `R`.
- **Equation**: If `a + b = c + b`, then `a = c`.
- **Proof method**: `by simpa using h` (uses the `simpa` tactic with the hypothesis `h`).
### Key Observations
- **Syntax Highlighting**:
- Keywords (`theorem`, `by`, `simp`, `simpa`) are in red.
- Variables (`a`, `b`, `c`, `G`, `R`) are in yellow.
- Operators (`*`, `⁻¹`, `=`, `+`) are in blue.
- Hypotheses (`h`) are in purple.
- **Structure**: Theorems are written in a formal, declarative style typical of proof assistants.
### Interpretation
This code demonstrates formal verification of algebraic properties in a mathematical structure (group and ring). The theorems assert fundamental properties:
1. **Multiplicative Inverse**: Every element in a group has an inverse that, when multiplied, yields the identity.
2. **Additive Cancellation**: If two elements added to the same third element are equal, the original elements must be equal.
The use of `simp` and `simpa` suggests the code is part of a proof assistant workflow, where these tactics automate proof steps by applying known axioms or lemmas. The presence of `h` (a hypothesis) indicates the second theorem relies on a previously established equality.
No numerical data or trends are present, as the image focuses on formal mathematical definitions and proofs.
</details>
b) Elementary Number Theory: LeanAgent handles fundamental arithmetic properties, including MyRing.zero_mul, which proves that zero multiplied by any number is zero, and MyRing.neg_neg, which shows that the negative of a negative number is the original number.
<details>
<summary>extracted/6256159/carbon19.png Details</summary>
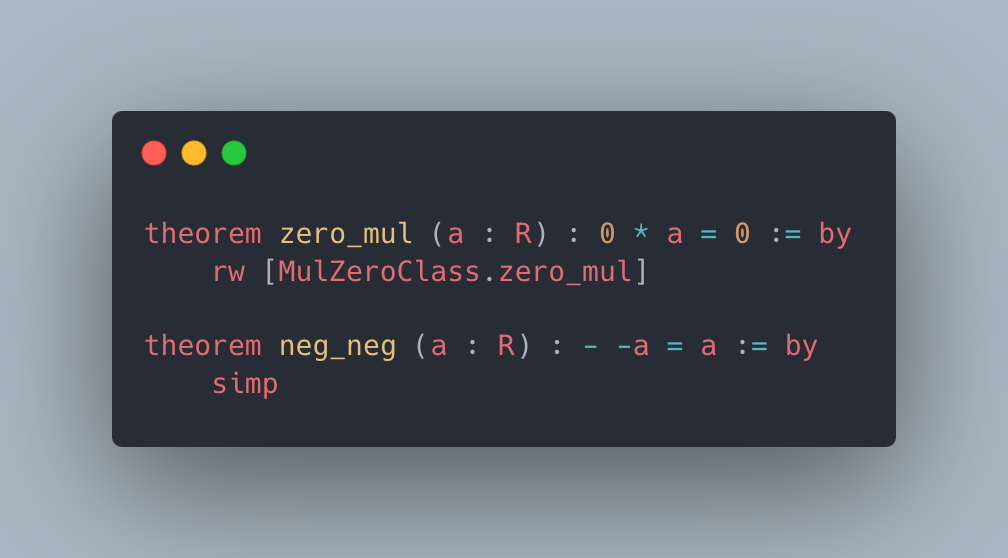
### Visual Description
## Screenshot: Lean/HOL Light Theorem Definitions
### Overview
The image shows a code snippet from a formal proof assistant (likely Lean or HOL Light) defining two mathematical theorems. The syntax uses type annotations, proof tactics, and class-based reasoning.
### Components/Axes
- **Text Colors**:
- Red: Keywords (`theorem`, `by`, `rw`, `simp`)
- Yellow: Identifiers (`zero_mul`, `neg_neg`, `MulZeroClass.zero_mul`)
- White: Variables (`a`, `R`), operators (`*`, `-`, `=`), and tactics (`:=`)
- **Structure**:
- Two theorem definitions separated by blank lines.
- Each theorem includes a name, type signature, proposition, and proof tactic.
### Detailed Analysis
1. **Theorem `zero_mul`**:
- **Signature**: `theorem zero_mul (a : R) : 0 * a = 0`
- States that multiplying zero by any element `a` in type `R` yields zero.
- **Proof**: `:= by rw [MulZeroClass.zero_mul]`
- Uses the `rw` (rewrite) tactic with the `MulZeroClass.zero_mul` lemma.
2. **Theorem `neg_neg`**:
- **Signature**: `theorem neg_neg (a : R) : - -a = a`
- States that negating a number twice returns the original value.
- **Proof**: `:= by simp`
- Uses the `simp` (simplification) tactic to auto-derive the result.
### Key Observations
- Both theorems are axiomatic or derived via predefined lemmas (`MulZeroClass.zero_mul`) or automated simplification.
- The `rw` tactic explicitly references a class-based lemma, while `simp` relies on global simplification rules.
- Type `R` is unspecified but likely represents a ring or algebraic structure.
### Interpretation
This code demonstrates formal verification of basic algebraic properties:
- **Zero Multiplication**: Proves `0 * a = 0` using a class instance (`MulZeroClass`), ensuring consistency across algebraic structures.
- **Double Negation**: Proves `- -a = a` via simplification, leveraging built-in arithmetic rules.
- The use of `by` tactics (`rw`, `simp`) highlights the declarative nature of proof assistants, where proofs are constructed by chaining existing lemmas or automated steps.
No numerical data or trends are present; the focus is on symbolic reasoning and proof construction.
</details>
c) Order Theory: LeanAgent grasps order theory, as evidenced by absorb1, which proves that the infimum of x and the supremum of x and y is always equal to x, and absorb2, which demonstrates that the supremum of x and the infimum of x and y is always equal to x.
<details>
<summary>extracted/6256159/carbon20.png Details</summary>
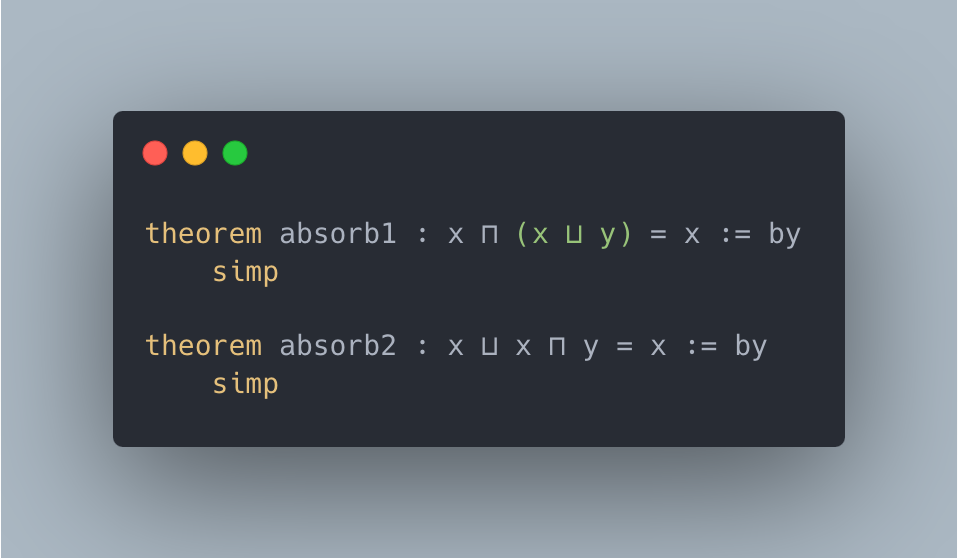
### Visual Description
## Screenshot: Code Editor Displaying Mathematical Theorems
### Overview
The image shows a code editor interface with a dark theme, displaying two mathematical theorems labeled `absorb1` and `absorb2`. The code uses symbolic logic and set theory notation, with syntax highlighting in yellow, gray, and green.
### Components/Axes
- **UI Elements**:
- Top-left corner: Three circular buttons (red, yellow, green) for window controls.
- Text editor background: Dark gray/black with syntax-highlighted code.
- **Code Structure**:
- **Theorem 1 (`absorb1`)**:
- Statement: `x ∩ (x ∪ y) = x`
- Simplification: `simp`
- **Theorem 2 (`absorb2`)**:
- Statement: `x ∪ x ∩ y = x`
- Simplification: `simp`
### Detailed Analysis
- **Theorem 1 (`absorb1`)**:
- **Text**: `theorem absorb1 : x ∩ (x ∪ y) = x := by simp`
- **Symbols**:
- `∩` (intersection), `∪` (union), `=` (equality), `:=` (definition).
- **Color Coding**:
- `theorem`, `absorb1`, `simp`: Yellow.
- Variables (`x`, `y`), operators (`∩`, `∪`, `=`, `:=`): Gray.
- Parentheses: Green.
- **Theorem 2 (`absorb2`)**:
- **Text**: `theorem absorb2 : x ∪ x ∩ y = x := by simp`
- **Symbols**:
- `∪` (union), `∩` (intersection), `=` (equality), `:=` (definition).
- **Color Coding**:
- Identical to Theorem 1.
### Key Observations
1. Both theorems demonstrate **absorption laws** in set theory:
- `x ∩ (x ∪ y) = x` (intersection absorbs union).
- `x ∪ (x ∩ y) = x` (union absorbs intersection).
2. The `simp` keyword suggests automated simplification using predefined rules.
3. No numerical data or trends are present; the focus is on symbolic logic.
### Interpretation
This code defines two foundational theorems in set theory, likely part of a formal proof or automated theorem prover (e.g., Lean, Coq). The absorption laws confirm that combining a set with its union/intersection with another set simplifies to the original set. The use of `simp` implies reliance on a library of axioms to validate these statements. The absence of numerical values or visualizations emphasizes the abstract, logical nature of the content.
</details>
d) Rudimentary Real Analysis: LeanAgent demonstrates an early capability to handle properties related to real numbers and absolute values, as shown by C03S05.MyAbs.abs_add, which proves the triangle inequality for real numbers.
<details>
<summary>extracted/6256159/carbon21.png Details</summary>
### Visual Description
## Screenshot: Lean Theorem Proof Interface
### Overview
The image shows a code editor interface displaying a formal theorem proof in the Lean theorem prover. The editor uses a dark theme with syntax highlighting. The visible content includes a theorem declaration and an application of a built-in lemma.
### Components/Axes
- **UI Elements**:
- Top-left corner: Three circular buttons (red, yellow, green) for window management (close, minimize, maximize).
- Dark-themed code editor with syntax highlighting.
- **Code Structure**:
- Theorem declaration: `theorem abs_add (x y : R) : |x + y| ≤ |x| + |y| := by`
- Apply command: `apply abs_add_le`
### Detailed Analysis
- **Theorem Declaration**:
- Name: `abs_add`
- Parameters: `x, y : R` (real numbers)
- Statement: `|x + y| ≤ |x| + |y|` (triangle inequality)
- Proof method: `by` (invokes Lean's proof assistant to complete the proof)
- **Apply Command**:
- Lemma used: `abs_add_le` (pre-existing lemma for the triangle inequality)
### Key Observations
1. The theorem explicitly states the triangle inequality for real numbers.
2. The `apply` command leverages Lean's built-in lemma `abs_add_le` to auto-generate the proof.
3. Syntax highlighting distinguishes keywords (`theorem`, `apply`), variables (`x`, `y`), and symbols (`|`, `:`, `≤`).
### Interpretation
This screenshot demonstrates Lean's capability to formalize mathematical proofs. The theorem `abs_add` declares the triangle inequality, while `apply abs_add_le` uses Lean's type checker to automatically derive the proof from the pre-verified lemma `abs_add_le`. The structure reflects Lean's functional programming paradigm, where proofs are treated as programs. The use of `by` indicates reliance on Lean's automated proof search, showcasing the interplay between human-readable mathematics and machine-verified logic.
No numerical data or trends are present; the focus is on formal syntax and proof structure.
</details>
10/14 of these proven sorry theorems from Mathematics in Lean Source during the lifelong learning process are from the exercise file for proving identities about algebraic structures. This indicates that LeanAgent starts its grasp of mathematical concepts from the basics.
Crucially, by the end of the lifelong learning process, LeanAgent exhibits significant growth in its mathematical reasoning abilities:
a) Quantifier Manipulation: LeanAgent exhibits more advanced logical reasoning by managing multiple quantifiers and implications, as evidenced by C03S01.my_lemma3, which proves a complex statement involving bounds and absolute values with multiple quantifiers and conditions, and C03S05.MyAbs.abs_lt, which establishes that the absolute value of x being less than y is equivalent to $-y<x\land x<y$ .
<details>
<summary>extracted/6256159/carbon23.png Details</summary>

### Visual Description
## Screenshot: Code Editor Interface with Theorem Definitions
### Overview
The image shows a code editor interface displaying two theorem definitions in a functional programming or proof assistant language (likely Lean or Coq). The code uses syntax highlighting with color-coded elements: red for keywords, blue for variables/symbols, and orange for identifiers. The editor has a dark theme with a light gray background.
### Components/Axes
- **Editor Interface**:
- Top-left corner: Three circular buttons (red, yellow, green) typical of macOS window controls.
- Code area: Two theorem definitions with syntax highlighting.
- **Syntax Highlighting**:
- Red: Keywords (`theorem`, `apply`, `cases`, `exact`).
- Blue: Variables (`x`, `y`), symbols (`|x|`, `*`, `->`, `<`, `>`), and type annotations (`ℝ`).
- Orange: Identifiers (`my_lemma3`, `abs_lt`, `C03S01.my_lemma`).
- Gray: Logical operators (`∧`, `∃`, `≤`, `:`).
### Detailed Analysis
1. **Theorem Definitions**:
- **`theorem my_lemma3`**:
- Premise: `∀ {x y : ℝ}, 0 < ε → ε ≤ 1 → |x| < ε → |y| < ε → |x * y| < ε`.
- Conclusion: `by apply C03S01.my_lemma`.
- Interpretation: Proves that if `x` and `y` are real numbers with absolute values bounded by `ε` (where `0 < ε ≤ 1`), their product's absolute value is also bounded by `ε`. Uses an existing lemma (`C03S01.my_lemma`) for the proof.
- **`theorem abs_lt`**:
- Premise: `|x| < y`.
- Conclusion: `by cases x; exact abs_lt`.
- Interpretation: Proves a property about absolute values using case analysis on `x`, though the full proof details are omitted.
2. **Syntax Structure**:
- Functional style with type annotations (`{x y : ℝ}`).
- Logical implications (`→`) and quantifiers (`∀`).
- Pattern matching (`cases x`) and proof tactics (`by`, `exact`).
### Key Observations
- **Color Consistency**: Red keywords (`theorem`, `apply`) and blue variables (`x`, `y`) are consistently applied.
- **Incomplete Proofs**: Both theorems use `by` or `exact` to defer proof details, suggesting this is a work-in-progress.
- **Type System**: Explicit type annotations (`ℝ` for real numbers) indicate a strongly typed language.
### Interpretation
This code defines two mathematical theorems about absolute values and inequalities. The first theorem (`my_lemma3`) establishes a multiplicative bound on products of numbers within a tolerance `ε`, leveraging a pre-existing lemma. The second theorem (`abs_lt`) likely addresses the triangle inequality or similar properties but omits full proof details. The use of `apply` and `cases` suggests the code is part of a formal verification system, where proofs are constructed incrementally using existing lemmas and case analysis. The syntax and structure align with dependently typed languages like Lean, where proofs and programs share the same formalism.
</details>
b) Set Theory and Relations: LeanAgent handles abstract set-theoretic concepts, as shown by C03S01.Subset.trans, which proves that subset relations are transitive.
<details>
<summary>extracted/6256159/carbon24.png Details</summary>

### Visual Description
## Screenshot: Code Snippet with Theorem Declaration
### Overview
The image displays a code snippet from a formal proof assistant or theorem prover, likely written in a language like Lean, Coq, or Isabelle. The text is syntax-highlighted with color-coded elements, and the interface includes standard window control buttons (red, yellow, green circles) in the top-left corner.
### Components/Axes
- **Window Controls**: Three circular buttons in the top-left corner:
- Red (close)
- Yellow (minimize)
- Green (maximize)
- **Text Content**:
- **Line 1**: `theorem Subset.trans : r ⊆ s → s ⊆ t → r ⊆ t := by`
- `theorem` (purple)
- `Subset.trans` (red)
- `r ⊆ s → s ⊆ t → r ⊆ t` (pink)
- `:= by` (pink)
- **Line 2**: `exact Set.Subset.trans`
- `exact` (purple)
- `Set.Subset.trans` (purple)
### Detailed Analysis
- **Syntax Highlighting**:
- Keywords (`theorem`, `exact`) are highlighted in purple.
- Identifiers (`Subset.trans`, `Set.Subset.trans`) are in red.
- Mathematical/logical symbols (`⊆`, `→`, `:=`, `by`) are in pink.
- **Code Structure**:
- The first line declares a theorem (`theorem`) named `Subset.trans`, which states that if `r` is a subset of `s` and `s` is a subset of `t`, then `r` is a subset of `t`.
- The second line (`exact Set.Subset.trans`) likely references a built-in or previously defined transitive closure property for sets.
### Key Observations
- The theorem asserts the transitivity of subset relations, a fundamental property in set theory.
- The use of `by` suggests the proof is deferred to a tactic (e.g., `transitivity`) in the proof assistant.
- The `exact` keyword indicates the theorem is being proven by directly applying a known lemma (`Set.Subset.trans`).
### Interpretation
This snippet demonstrates a formal verification of the transitivity law for subset relations. The code is structured to:
1. **Declare a theorem** (`theorem Subset.trans`) with a hypothesis chain (`r ⊆ s → s ⊆ t → r ⊆ t`).
2. **Invoke a pre-existing lemma** (`Set.Subset.trans`) to complete the proof, avoiding manual derivation.
The color coding enhances readability by distinguishing syntactic roles:
- **Purple** for high-level constructs (`theorem`, `exact`).
- **Red** for identifiers (theorem name, lemma reference).
- **Pink** for logical/mathematical operators and proof tactics.
The theorem’s validity relies on the correctness of the underlying proof assistant’s logic, ensuring that transitivity holds for all sets `r`, `s`, and `t`. This is critical in formal systems where such properties must be rigorously validated.
</details>
Now, only 2/7 sorry theorems from Mathematics in Lean Source are from the exercise file for proving identities about algebraic structures. This suggests that lifelong learning allowed LeanAgent to transition to gaining a stronger ability to work with premises for more complicated proofs.
We gain some insights from comparing the performance of LeanAgent over time on Mathematics in Lean Source to other setups. For example, the fact that ReProver can handle harder theorems out of the box, such as C03S01.my_lemma3, but fewer theorems overall suggests that it has a broader knowledge base initially but loses performance from a lack of adaptability. Furthermore, Setup 5 proves the same sorry theorems as LeanAgent does during lifelong learning. This suggests that pure curriculum learning without EWC or the Merge All strategy emphasizes grasping easier concepts earlier. This mimics the insights gained from the lifelong learning analysis. However, Setups 3 and 7 (curriculum with EWC and/or Merge All) demonstrate some knowledge plasticity, proving harder theorems during lifelong learning, such as C03S01.Subset.trans in Setup 3. However, this comes at the cost of proving basic theorems, showing catastrophic forgetting. For example, Setups 3 and 7 could not prove the trivial theorems MyGroup.mul_right_inv and MyRing.zero_mul, respectively, during lifelong learning, whereas LeanAgent could. This again aligns with the insights from the lifelong learning scores from our previous analysis.
By the end of lifelong learning, the sorry theorems that LeanAgent prove from Mathematics in Lean Source are a superset of those that the other setups prove. This shows that LeanAgent’s lifelong learning setup provides continuously improving capabilities to reason about more advanced premises and proofs than other setups. For example, LeanAgent is the only system, except for Setup 6, which can prove theorem C03S05.MyAbs.abs_lt. LeanAgent achieved this by using the available premises, such as abs_lt with a statement similar to C03S05.MyAbs.abs_lt.
An interesting case study can be found in the dichotomy between the theorems C03S05.MyAbs.neg_le_abs_self and C03S05.MyAbs.le_abs_self. LeanAgent can prove C03S05.MyAbs.neg_le_abs_self by referencing C03S05.MyAbs.le_abs_self, which is still unproven at that point:
<details>
<summary>extracted/6256159/carbon27.png Details</summary>

### Visual Description
## Code Snippet: Theorem Proof in a Proof Assistant
### Overview
The image displays a code snippet from a formal proof assistant (likely Lean or a similar system) demonstrating a theorem about absolute values. The code is written in a syntax-highlighted environment with a dark background and three macOS window control dots (red, yellow, green) in the top-left corner.
### Components/Axes
- **Window Controls**: Red, yellow, and green circular buttons in the top-left corner (standard macOS window management).
- **Code Content**:
- **Theorem Declaration**: `theorem neg_le_abs_self (x : ℝ) : -x ≤ |x| := by`
- **Proof Tactic**: `simpa using C03S05.MyAbs.le_abs_self (-x)`
### Detailed Analysis
1. **Theorem Statement**:
- **Name**: `neg_le_abs_self` (short for "negative less than or equal to absolute value of self").
- **Parameters**: `(x : ℝ)` — `x` is a real number.
- **Statement**: `-x ≤ |x|` — The negation of `x` is less than or equal to the absolute value of `x`.
- **Proof Method**: `:= by` — Indicates the start of a proof block.
2. **Proof Tactic**:
- **Command**: `simpa` — A simplification tactic that applies lemmas automatically.
- **Lemma Reference**: `C03S05.MyAbs.le_abs_self` — A specific lemma from a file/module named `C03S05.MyAbs`.
- **Argument**: `(-x)` — The lemma is applied to the negated variable `x`.
### Key Observations
- The theorem asserts a fundamental property of absolute values: for any real number `x`, its negation is bounded by its absolute value.
- The proof relies on a predefined lemma (`C03S05.MyAbs.le_abs_self`), suggesting modularity in the proof assistant's library.
- The use of `simpa` implies the lemma is designed to simplify expressions involving absolute values.
### Interpretation
This snippet demonstrates how formal proof assistants structure mathematical reasoning. The theorem `neg_le_abs_self` formalizes the intuitive idea that the absolute value of a number is always non-negative, even when the number itself is negative. By referencing a lemma from a dedicated module (`C03S05.MyAbs`), the proof highlights the importance of reusable components in formal verification. The `simpa` tactic automates the application of this lemma, reducing manual effort and ensuring correctness. This reflects the broader philosophy of formal methods: breaking down proofs into verifiable, modular steps.
</details>
At the end of lifelong learning, LeanAgent can prove C03S05.MyAbs.le_abs_self:
<details>
<summary>extracted/6256159/carbon28.png Details</summary>

### Visual Description
## Screenshot: Lean Theorem Proof in Proof Assistant
### Overview
The image shows a code snippet from a proof assistant environment (likely Lean 4) displaying a theorem declaration and its proof. The code is syntax-highlighted with color-coded elements, and the window interface includes standard control buttons.
### Components/Axes
- **Window Controls**: Top-left corner contains three circular buttons:
- Red (close)
- Yellow (minimize)
- Green (maximize)
- **Code Structure**:
- **Theorem Declaration**: `theorem le_abs_self (x : R) : x ≤ |x| := by`
- **Proof Steps**:
- `rw [le_abs]`
- `simp`
### Detailed Analysis
- **Theorem Name**: `le_abs_self` (likely short for "less than or equal to absolute value self")
- **Parameters**: `(x : R)` declares `x` as a real number (`R`).
- **Type Annotations**:
- `x ≤ |x|` asserts that `x` is less than or equal to its absolute value.
- `|x|` denotes the absolute value of `x`.
- **Proof Strategy**:
- `by` introduces a proof block.
- `rw [le_abs]` applies the `le_abs` lemma (likely a built-in or previously defined lemma about absolute values).
- `simp` simplifies the goal using available simplifications.
### Key Observations
- The theorem states a fundamental property of absolute values: for any real number `x`, `x` is bounded above by its absolute value.
- The proof uses two steps:
1. **Rewrite**: Invokes `le_abs` to establish the inequality.
2. **Simplification**: Finalizes the proof with `simp`.
### Interpretation
This code demonstrates a basic property of absolute values in real numbers. The theorem `le_abs_self` formalizes the intuition that no real number exceeds its absolute value. The proof leverages the `le_abs` lemma (a standard result in real analysis) and simplification tactics common in proof assistants. The use of `rw` (rewrite) and `simp` reflects the declarative nature of proof assistants, where proofs are constructed by applying logical rules and simplifications rather than step-by-step computation. The absence of numerical data or visualizations emphasizes the formal, symbolic nature of the proof.
</details>
It achieves this through its use of the le_abs premise, which provides conditions for when an element is less than or equal to the absolute value of another. This suggests that LeanAgent begins by using existing knowledge where possible before trying to realizing why existing facts are reasonable.
SciLean. We examine the sorry theorems from SciLean that LeanAgent proved to gain some further key insights about its performance. During the lifelong learning process, LeanAgent demonstrated stronger understanding relative to ReProver in a wide range of mathematical concepts from SciLean. These theorems primarily focus on:
a) Fundamental Algebraic Structures: LeanAgent proves basic algebraic operations and properties, such as SciLean.scalar_div_one, which proves that dividing any number by one yields the same number, SciLean.scalar_min_zero_one, which demonstrates the minimum value between 0 and 1 is 0, and Function.invFun.id_rule, which proves that the inverse of the identity function is the identity function itself.
<details>
<summary>extracted/6256159/carbon29.png Details</summary>

### Visual Description
## Screenshot: Functional Programming Theorem Proofs
### Overview
The image shows a code editor displaying three formal theorem proofs written in a functional programming or proof assistant language (likely Lean or Coq). The code uses syntax highlighting with red, yellow, green, purple, and pink colors. The theorems involve mathematical properties of functions and their implementations.
### Components/Axes
- **Header**: Three colored dots (red, yellow, green) in top-left corner (standard window control buttons)
- **Main Content**: Three theorem blocks with:
1. **Theorem Statements** (red text)
2. **Proof Tactics** (purple text)
3. **Function References** (pink text)
4. **Equality Operators** (`=>`, `=`, `:=`) in purple
5. **Function Application** (`.`) in green
- **Syntax Highlighting**: Color-coded elements for different language constructs
### Detailed Analysis
1. **Theorem: scalar_div_one**
- Statement: `theorem scalar_div_one (x : R) : x / 1 = x := by`
- Proof: `simp` (simplification tactic)
2. **Theorem: scalar_min_zero_one**
- Statement: `theorem scalar_min_zero_one : min (0 : R) (1 : R) = 0 := by`
- Proof:
- `rw [min_comm]` (rewrite using commutativity of min)
- `simp`
3. **Theorem: id_rule**
- Statement: `theorem id_rule : invFun (fun (x : X) => x) = fun x => x := by`
- Proof:
- `apply Function.invFun_comp` (apply inverse function composition)
- `exact Function.injective_id` (use exact match for injective identity)
### Key Observations
- All theorems use the `by` keyword to introduce proof tactics
- `simp` appears twice as a simplification tactic
- `rw` (rewrite) is used once with `min_comm` lemma
- `invFun` and `injective_id` suggest working with function inverses
- Type annotations (`: R`, `: X`) indicate a statically typed language
- Equality operators use both `=` (definition) and `=>` (proof relevance)
### Interpretation
This code demonstrates formal verification of three mathematical properties:
1. **Division Identity**: Division by 1 preserves value
2. **Minimum Property**: Minimum of 0 and 1 in any ordered ring is 0
3. **Function Identity**: The inverse of the identity function is itself
The proofs use a combination of:
- Simplification (`simp`)
- Lemma rewriting (`rw`)
- Function composition (`invFun_comp`)
- Exact matching (`exact`)
The color coding helps distinguish between:
- Theorem declarations (red)
- Type annotations (yellow)
- Proof structure (purple)
- Function application (green)
- Equality operators (pink)
This appears to be a formal proof assistant implementation verifying properties of basic arithmetic operations and function theory, likely part of a larger mathematical library or educational tool.
</details>
b) Linear and Affine Maps: LeanAgent handles basic properties of linear and affine maps effectively, recognizing their structure in IsLinearMap.isLinearMap_apply, which proves the linearity of function applications, and IsAffineMap.IsAffineMap_apply, which demonstrates the affine property of function applications.
<details>
<summary>extracted/6256159/carbon30.png Details</summary>
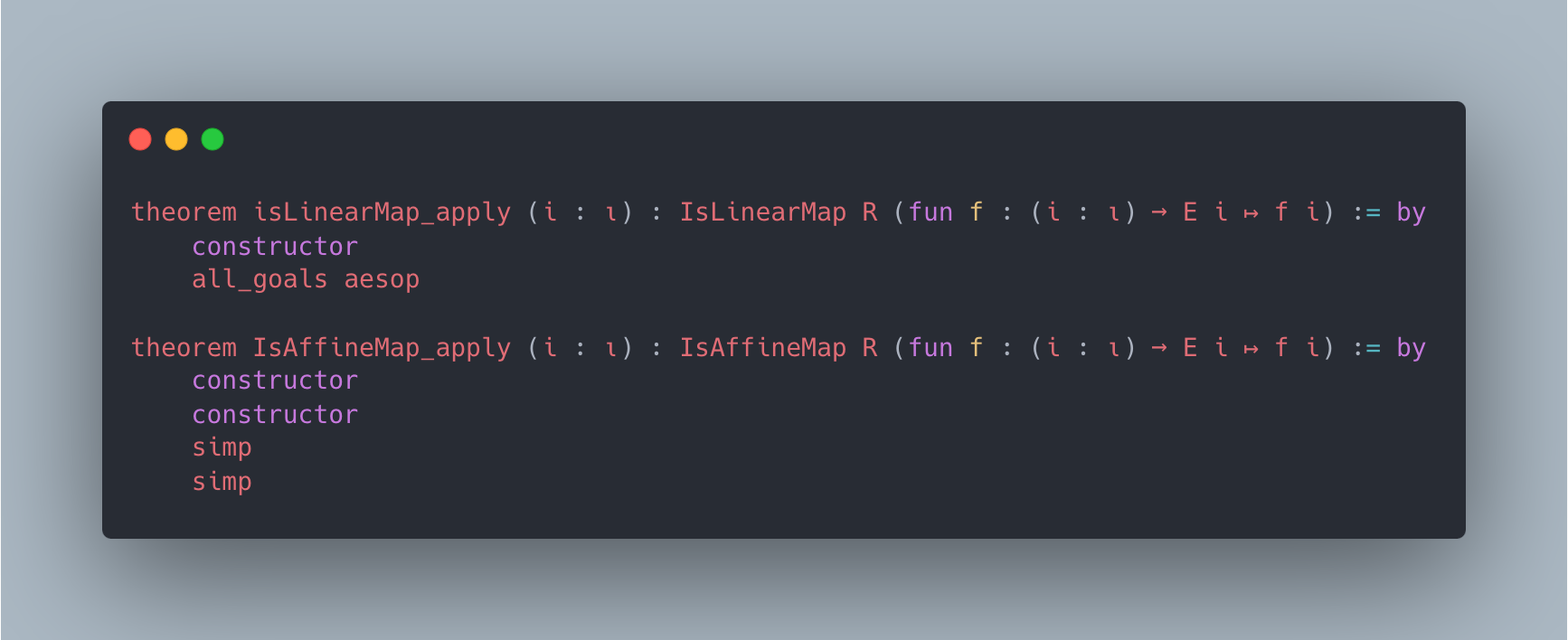
### Visual Description
## Screenshot: Code Editor with Theorem Definitions
### Overview
The image shows a code editor interface with two theorem definitions written in a formal proof language (likely Lean 4). The editor has a dark theme with syntax-highlighted code. Two theorem blocks are visible, each defining a property (`IsLinearMap` and `IsAffineMap`) and their proofs using tactics like `constructor` and `simp`.
### Components/Axes
- **UI Elements**:
- Top-left corner: Three circular buttons (red, yellow, green) for window controls (close, minimize, maximize).
- Code editor background: Dark gray/black with light-colored syntax highlighting.
- **Code Structure**:
- Two theorem definitions separated by blank lines.
- Each theorem includes a type signature, proof goal, and tactics.
### Detailed Analysis
#### First Theorem (`IsLinearMap`):
```lean4
theorem isLinearMap_apply (i : ι) : IsLinearMap R (fun f : (i : ι) → E i ↦ f i) := by
constructor
all_goals aesop
```
- **Text Colors**:
- `theorem`, `IsLinearMap_apply`, `IsLinearMap`, `R`, `E i ↦ f i`: Red.
- `constructor`, `all_goals`, `aesop`: Purple.
- `by`: Pink.
- **Syntax**:
- `i : ι` declares a variable `i` of type `ι`.
- `fun f : (i : ι) → E i ↦ f i` defines a function `f` mapping `i` to `E i ↦ f i`.
- `by constructor` applies the `constructor` tactic to build the proof.
- `all_goals aesop` likely refers to a tactic for handling all goals (possibly a typo for `aesop` as a lemma name).
#### Second Theorem (`IsAffineMap`):
```lean4
theorem IsAffineMap_apply (i : ι) : IsAffineMap R (fun f : (i : ι) → E i ↦ f i) := by
constructor
constructor
simp
simp
```
- **Text Colors**:
- `theorem`, `IsAffineMap_apply`, `IsAffineMap`, `R`, `E i ↦ f i`: Red.
- `constructor`, `simp`: Purple.
- `by`: Pink.
- **Syntax**:
- Similar structure to the first theorem but with two `constructor` calls and two `simp` (simplification) tactics.
### Key Observations
1. **Repetition of Tactics**:
- The second theorem uses `constructor` twice, suggesting nested or sequential proof steps.
- `simp` is called twice, indicating repeated simplification.
2. **Shared Elements**:
- Both theorems share the same function type `(i : ι) → E i ↦ f i`.
- The `by` keyword introduces automated proof tactics.
3. **Unclear Term**:
- `aesop` in the first theorem is ambiguous; it may be a typo (e.g., `aesop` instead of `aesop` or another term).
### Interpretation
This code defines formal proofs for linear and affine maps in a mathematical library. The `IsLinearMap` and `IsAffineMap` theorems likely assert properties about functions preserving linearity or affinity. The use of `constructor` implies building proofs by constructing elements (e.g., verifying axioms), while `simp` applies simplification rules to reduce subgoals. The `aesop` term is unclear but might reference a specific lemma or tactic in the context of the proof assistant. The repetition of tactics in the second theorem suggests a more complex proof structure, possibly requiring multiple layers of construction or simplification.
### Notable Patterns
- **Syntax Consistency**: Red highlights key terms (theorems, types), while purple/pink indicate tactics and keywords.
- **Automation**: The `by` keyword delegates proof construction to the proof assistant, common in interactive theorem provers like Lean.
- **Potential Typo**: `aesop` may need verification against the intended lemma or tactic name.
This code exemplifies formal verification workflows, where proofs are constructed programmatically using tactics to ensure mathematical correctness.
</details>
c) Measure Theory Basics: LeanAgent starts grasping measure theory concepts, exemplified by SciLean.ite_pull_measureOf, which handles conditional measure selection between two measures based on a proposition, SciLean.Measure.prod_volume, which proves that the product of two volume measures is the volume measure itself, and SciLean.ite_pull_ennreal_toReal, which proves that conditionally pulling out an extended non-negative real and converting it to a real is equivalent to converting the individual components first.
<details>
<summary>extracted/6256159/carbon40.png Details</summary>
### Visual Description
## Screenshot: Code Block with Three Theorems
### Overview
The image shows a code snippet in a text editor with syntax highlighting. It contains three theorem definitions related to measure theory and real number conversions. The code uses functional programming constructs, conditional logic, and type annotations.
### Components/Axes
- **Syntax Highlighting**:
- Keywords (`theorem`, `if`, `then`, `else`, `by`, `split_ifs`, `toReal`) in red/magenta.
- Variables (`X`, `Y`, `c`, `μ`, `v`, `A`, `x`, `y`) in teal.
- Functions (`Measure`, `prod_volume`, `ite_pull_measureOf`, `ite_pull_ennreal_toReal`) in orange.
- Logical operators (`:=`, `=`, `:`, `:Prop`, `:Decidable`, `:ENNReal`) in cyan.
- **Structure**:
- Three theorems separated by blank lines.
- Each theorem has a name, parameters, and a body with conditional logic.
### Detailed Analysis
1. **Theorem 1: `ite_pull_measureOf`**
- **Parameters**:
- `X` (MeasurableSpace X)
- `c` (Prop, Decidable c)
- **Body**:
```
(μ v : Measure X) (A : Set X) :
(if c then μ else v) A
=
(if c then μ A else v A) := by
split_ifs <;> rfl
```
- Defines a measure pullback using a conditional (`if c then ... else ...`).
- Uses `split_ifs` to split the conditional into cases.
2. **Theorem 2: `Measure.prod_volume`**
- **Parameters**:
- `X` (MeasureSpace X)
- `Y` (MeasureSpace Y)
- **Body**:
```
(Measure.prod (volume : Measure X) (volume : Measure Y))
= volume := by
rfl
```
- Asserts that the product of two measures equals their combined volume.
- Uses `rfl` (reflexivity) to confirm equality.
3. **Theorem 3: `ite_pull_ennreal_toReal`**
- **Parameters**:
- `c` (Prop, Decidable c)
- `x y` (ENNReal)
- **Body**:
```
(if c then x else y).toReal
=
(if c then x.toReal else y.toReal) := by
split_ifs <;> rfl
```
- Converts extended real numbers (`ENNReal`) to real numbers (`Real`) conditionally.
- Uses `split_ifs` to handle the conditional conversion.
### Key Observations
- **Conditional Logic**: All theorems use `if c then ... else ...` constructs, suggesting a focus on decidable properties (`Decidable c`).
- **Functional Programming**: Heavy use of lambda abstractions (`(μ v : Measure X) ...`) and function composition.
- **Formal Verification**: Theorems are structured for proof assistants (e.g., Lean 4), with `by` and `rfl` indicating proof steps.
- **Measure Theory**: Terms like `Measure`, `volume`, and `MeasurableSpace` indicate a focus on integration and measure spaces.
### Interpretation
- **Purpose**: These theorems formalize properties of measure theory and real number conversions in a proof assistant.
- `ite_pull_measureOf` defines how measures behave under conditional transformations.
- `Measure.prod_volume` establishes the product measure’s volume as the product of individual volumes.
- `ite_pull_ennreal_toReal` ensures conditional conversions from extended reals to standard reals preserve equality.
- **Significance**: Critical for verifying correctness in systems involving probabilistic models, integration, or numerical computations.
- **Anomalies**: No numerical data or visual trends; purely symbolic/logical assertions.
### Spatial Grounding
- Theorems are vertically stacked, with each body indented under its name.
- Syntax highlighting colors are consistent across the block, aiding readability.
- No legends or axes, as this is code, not a chart.
</details>
d) Floating-Point Operations: LeanAgent demonstrates an early grasp of floating-point representations and their correspondence to real numbers, shown by SciLean.re_float, proving that a floating-point number’s real-like part is itself.
<details>
<summary>extracted/6256159/carbon33.png Details</summary>
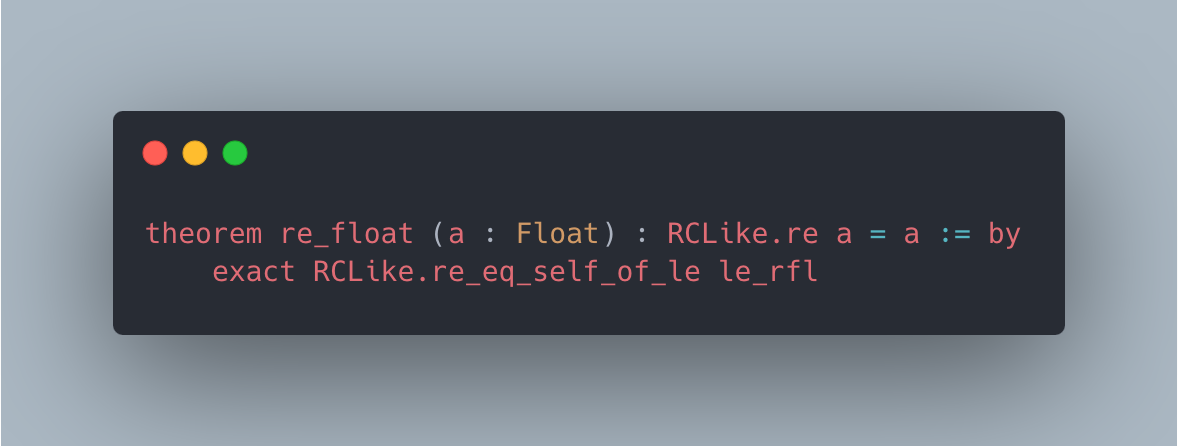
### Visual Description
## Screenshot: Code Snippet in Theorem Prover
### Overview
The image shows a code snippet in a theorem prover environment, likely OCaml or a similar language with dependent types. The code defines a theorem asserting that the real part of a floating-point number equals itself, using a reflexive equality lemma. The interface includes macOS-style window controls (red, yellow, green circles) and syntax-highlighted code.
### Components/Axes
- **UI Elements**:
- Top-left corner: Three circular buttons (red, yellow, green) for window management (close, minimize, maximize).
- Dark-themed text editor with syntax highlighting.
- **Code Structure**:
- **First Line**: `theorem re_float (a : Float) : RCLike.re a = a := by`
- `theorem`: Red (keyword).
- `re_float`: Red (identifier).
- `(a : Float)`: Yellow (`Float` type annotation).
- `RCLike.re a = a`: Red (equality assertion).
- `:= by`: Red (proof strategy keyword).
- **Second Line**: `exact RCLike.re_eq_self_of_le le_rfl`
- `exact`: Red (proof tactic).
- `RCLike.re_eq_self_of_le`: Red (lemma name).
- `le_rfl`: Red (reflexive property identifier).
### Detailed Analysis
- **Syntax Highlighting**:
- Keywords (`theorem`, `by`, `exact`) and identifiers (`re_float`, `RCLike.re`, `le_rfl`) are colored red.
- Type annotations (`Float`) are yellow.
- Equality operator (`=`) and colon (`:`) are teal.
- **Code Logic**:
- The theorem `re_float` takes a float `a` and asserts `RCLike.re a = a`, where `RCLike.re` extracts the real part of a complex number.
- The proof uses `exact` to apply the reflexivity lemma `RCLike.re_eq_self_of_le`, which states that the real part of a float equals itself.
### Key Observations
1. **Reflexivity Lemma**: The theorem relies on a pre-defined lemma (`RCLike.re_eq_self_of_le`) to prove equality, common in formal verification systems.
2. **Type Safety**: The use of `Float` ensures `a` is a valid floating-point number, avoiding undefined behavior.
3. **Proof Strategy**: The `by` keyword indicates a tactic-driven proof, typical in interactive theorem provers.
### Interpretation
This code demonstrates formal verification of a basic mathematical property (reflexivity of real parts in floats) within a dependent type system. The theorem prover ensures that the equality `RCLike.re a = a` holds for all floats `a`, leveraging a pre-proven lemma. The use of `exact` suggests the system checks the lemma’s applicability rigorously, preventing errors in proof construction. This aligns with practices in formal methods, where such proofs guarantee software correctness by construction.
**Note**: No numerical data or trends are present, as this is a code snippet rather than a chart or diagram.
</details>
The proofs during this phase are characteristically concise, often using basic tactics like simp, rfl, or aesop that do not use premises. This suggests that LeanAgent recognizes these theorems are straightforward enough to prove without the complex retrieval of premises.
Crucially, by the end of the lifelong learning process, LeanAgent exhibits significant growth in its mathematical reasoning abilities on SciLean, just as it did with Mathematics in Lean Source:
a) Advanced Function Spaces: LeanAgent understands concepts in advanced function spaces, such as SciLean.ContCDiffMapFD_eta, which demonstrates the eta reduction property for continuously differentiable maps over finite dimensions.
<details>
<summary>extracted/6256159/carbon34.png Details</summary>

### Visual Description
## Screenshot: Lean Theorem Definition with Syntax Highlighting
### Overview
The image shows a terminal window displaying a Lean theorem definition with syntax highlighting. The code defines a theorem named `ContCDiffMapFD_eta` involving a function `f` and its properties. Key elements include type annotations, function definitions, and a simplification tactic (`simp only`).
### Components/Axes
- **Window Controls**: Top-left corner with red, yellow, and green dots (standard macOS window controls).
- **Code Structure**:
- **Theorem Name**: `theorem ContCDiffMapFD_eta` (red text).
- **Parameters**:
- `f : X → FD[K,n]` (yellow text).
- `Y : (fun x → FD[K,n] x) = f` (purple text).
- **Simplification Clause**: `simp only [DFunLike.ext_iff]` (red text).
- **Comment**: `aesop` (red text, likely a placeholder or note).
- **Syntax Highlighting**:
- Keywords (e.g., `theorem`, `simp only`): Red.
- Variables/Types (e.g., `X`, `Y`, `FD[K,n]`): Yellow.
- Function Definitions (e.g., `fun x → ...`): Purple.
- Equality/Assignment (`=`, `:=`): Cyan.
- Comments: Green.
### Detailed Analysis
1. **Theorem Definition**:
- `theorem ContCDiffMapFD_eta (f : X → FD[K,n]) (Y : (fun x → FD[K,n] x) = f) : ...`
- Defines a theorem `ContCDiffMapFD_eta` with two hypotheses:
- `f` maps `X` to `FD[K,n]`.
- `Y` is a function equal to `f`.
- The ellipsis (`...`) indicates the theorem’s body is omitted.
2. **Simplification Tactic**:
- `simp only [DFunLike.ext_iff]`:
- Applies the `simp` tactic to simplify the proof using only the lemma `DFunLike.ext_iff`.
3. **Comment**:
- `aesop`: Likely a placeholder or internal note (e.g., a reference to a person or project).
### Key Observations
- The code uses Lean’s type theory syntax, with explicit type annotations and function definitions.
- The `simp only` clause restricts simplification to a specific lemma, suggesting a focused proof strategy.
- The comment `aesop` is isolated and lacks context, possibly indicating an incomplete or draft state.
### Interpretation
This code snippet defines a theorem in Lean, a formal proof assistant, asserting properties of a function `f` under specific conditions. The use of `simp only` indicates the proof relies on a single lemma (`DFunLike.ext_iff`), which may relate to extending functions or properties in a formal system. The comment `aesop` could hint at a collaborative or contextual note, but its meaning is unclear without additional context. The syntax highlighting emphasizes Lean’s structured approach to formalizing mathematical proofs.
</details>
b) Sophisticated Bijections: LeanAgent grows in its ability to work with product spaces and bijections, proving theorems such as Function.Bijective.Prod.mk.arg_fstsnd.Bijective_rule_simple’, which proves the bijectivity of a function that swaps elements in a product space and Function.Bijective.Equiv.invFun.arg_a0.Bijective_rule, which proves that the composition of a bijection and its inverse remains bijective. Crucially, these theorems might seem simple, but they demonstrate LeanAgent’s capability to handle abstract algebraic thinking.
<details>
<summary>extracted/6256159/carbon39.png Details</summary>
### Visual Description
## Screenshot: Coq Code Editor Interface
### Overview
The image shows a code editor interface displaying Coq (a formal proof management system) code. The editor has a dark theme with syntax highlighting. Two theorem definitions are visible, focusing on bijective functions and their properties.
### Components/Axes
- **UI Elements**:
- Top-left corner: Red, yellow, and green circular buttons (standard macOS window controls).
- Dark background with light-colored text (likely for readability).
- **Code Structure**:
- Two theorem definitions:
1. `theorem Prod.mk.arg_fstsnd.Bijective_rule_simple`
2. `theorem Equiv.invFun.arg_a0.Bijective_rule`
- Syntax elements:
- Keywords (e.g., `theorem`, `Bijective`, `constructor`, `intro`, `convert`, `simp`, `exact`).
- Function definitions (e.g., `Bijective (fun xy : X×Y => (xy.2, xy.1))`).
- Logical constructs (e.g., `=>`, `:`, `:= by`).
### Detailed Analysis
#### Theorem 1: `Prod.mk.arg_fstsnd.Bijective_rule_simple`
- **Definition**:
```coq
Bijective (fun xy : X×Y => (xy.2, xy.1))
```
- Defines a bijective function that swaps the second and first components of a pair `(X×Y)`.
- **Proof**:
```coq
:= by
constructor <;> intro h
all_goals aesop
```
- Uses Coq's `constructor` tactic to build the proof.
- Introduces a hypothesis `h` and applies `aesop` (a proof automation tactic).
#### Theorem 2: `Equiv.invFun.arg_a0.Bijective_rule`
- **Definition**:
```coq
Bijective (fun x => f.invFun (g x))
```
- Defines a bijective function composed of `f.invFun` and `g`.
- **Proof**:
```coq
:= by
convert hf
simp [hf]
exact f.symm.bijective.comp hf
```
- Uses `convert` to transform the hypothesis `hf`.
- Simplifies using `hf` and applies `exact` with `f.symm.bijective.comp hf` (a composed bijective property).
### Key Observations
- **Syntax Highlighting**:
- Keywords (e.g., `theorem`, `Bijective`) are in pink.
- Function names (e.g., `Prod.mk.arg_fstsnd.Bijective_rule_simple`) are in yellow.
- Logical operators (e.g., `=>`, `:`, `:=`) are in orange.
- **Code Structure**:
- Theorems are defined with `theorem` followed by a name and a function type.
- Proofs use Coq-specific tactics (`constructor`, `intro`, `simp`, `exact`).
### Interpretation
- **Purpose**:
- The code defines and proves properties of bijective functions in a formal system (likely related to product types and function composition).
- **Key Insights**:
- The first theorem demonstrates that swapping components of a pair preserves bijectivity.
- The second theorem shows that the composition of `f.invFun` and `g` is bijective, relying on symmetry and composition rules.
- **Technical Significance**:
- These proofs are foundational in formal verification, ensuring that functions behave as expected in mathematical or computational contexts.
### Notes on Language
- The code is written in **Coq**, a formal proof language. No other languages are present.
- English terms (e.g., "bijective", "function") are used within the Coq code for clarity.
This description captures all textual and structural elements of the image, focusing on the Coq code's syntax, logic, and purpose.
</details>
c) Abstract Algebraic Structures: LeanAgent proves further abstract algebraic properties, including SciLean.CDifferentiable.id_rule, which proves that the identity function is continuously differentiable.
<details>
<summary>extracted/6256159/carbon36.png Details</summary>
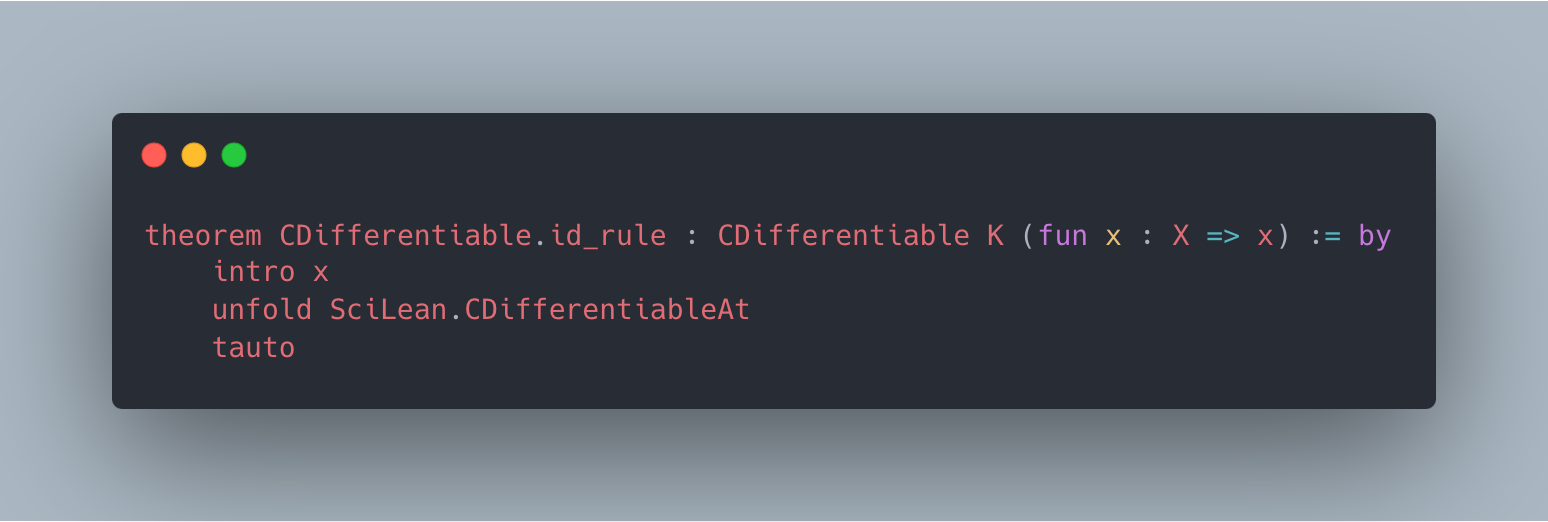
### Visual Description
## Screenshot: Code Snippet in a Programming Environment
### Overview
The image shows a code snippet in a dark-themed code editor with syntax highlighting. The code defines a theorem related to differentiability, using a formal proof structure. Key elements include window control buttons (red, yellow, green circles) and a block of code with color-coded syntax.
### Components/Axes
- **Window Controls**: Top-left corner with three circular buttons (red, yellow, green) for window management.
- **Code Block**:
- **Syntax Highlighting**:
- Keywords (`theorem`, `intro`, `unfold`, `tauto`, `by`) in **red**.
- Function definition (`fun x : X => x`) in **purple**.
- Variables (`x`, `X`) in **blue**.
- Operators (`:=`, `=>`, `:`) in **green**.
- **Text Content**:
- Theorem declaration: `theorem CDifferentiable.id_rule : CDifferentiable K (fun x : X => x) := by`
- Proof steps:
- `intro x`
- `unfold SciLean.CDifferentiableAt`
- `tauto`
### Detailed Analysis
1. **Theorem Declaration**:
- `theorem CDifferentiable.id_rule : CDifferentiable K (fun x : X => x) := by`
- Declares a theorem named `CDifferentiable.id_rule` asserting that the function `fun x : X => x` (identity function) is `CDifferentiable` under type `K`.
- `:= by` initiates the proof.
2. **Proof Steps**:
- `intro x`: Introduces a variable `x` into the proof context.
- `unfold SciLean.CDifferentiableAt`: Expands the definition of `CDifferentiableAt` (likely a predicate for differentiability at a point).
- `tauto`: Applies automatic theorem proving to complete the proof.
### Key Observations
- The code uses a **proof-by-unfolding** strategy, common in formal verification tools like Lean or Coq.
- `tauto` suggests the proof relies on automated tactics to discharge obligations, implying the identity function’s differentiability is derivable from existing axioms.
- No numerical data or visual trends; focus is on logical structure and syntax.
### Interpretation
This code snippet demonstrates a formal proof in a dependent type theory or proof assistant environment. The theorem `CDifferentiable.id_rule` establishes that the identity function `fun x : X => x` is differentiable (under type `K`). The proof unfolds the definition of differentiability (`CDifferentiableAt`) and uses `tauto` to leverage automated reasoning, indicating the result follows from foundational axioms.
The use of `by` and `tauto` reflects a declarative style, where the programmer specifies the logical steps, and the tool fills in the mechanical details. This aligns with practices in formal methods for verifying software correctness.
</details>
d) Data Structures in Mathematics: LeanAgent navigates proofs involving array types in a mathematical context, proving theorems such as SciLean.ArrayType.ext, which proves that two arrays are equal if their elements are equal at all indices.
<details>
<summary>extracted/6256159/carbon37.png Details</summary>

### Visual Description
## Screenshot: Functional Programming Theorem Proof
### Overview
The image shows a code snippet in a text editor with syntax highlighting. The code defines a theorem in a functional programming or proof assistant environment (likely SciLean/Haskell). Key elements include theorem declaration, type annotations, and proof steps.
### Components/Axes
- **Window Controls**: Top-left corner with red (close), yellow (minimize), and green (maximize) dots.
- **Code Structure**:
- **Theorem Declaration**: `theorem ext (x y : Cont) : (∀ i, x[i] = y[i]) → x = y := by`
- **Proof Steps**:
- `intro h`
- `apply SciLean.ArrayType.get_injective`
- `simp only [h]`
- **Syntax Highlighting**:
- Keywords (`theorem`, `by`, `intro`, `apply`, `simp`) in red.
- Variables (`x`, `y`, `i`, `h`) in green.
- Operators (`→`, `:=`, `=`) in cyan.
- Type annotations (`Cont`, `ArrayType`) in orange.
### Detailed Analysis
1. **Theorem Statement**:
- **Parameters**: `x` and `y` are of type `Cont` (likely a continuation type).
- **Hypothesis**: `∀ i, x[i] = y[i]` (element-wise equality for all indices `i`).
- **Conclusion**: `x = y` (arrays are equal if all elements are equal).
- **Proof Method**: Uses `by` to introduce a proof block.
2. **Proof Steps**:
- `intro h`: Introduces the hypothesis `h` (the element-wise equality).
- `apply SciLean.ArrayType.get_injective`: Applies a function from the SciLean library to prove injectivity of arrays.
- `simp only [h]`: Simplifies the proof using the hypothesis `h`.
### Key Observations
- The theorem asserts that array equality is equivalent to element-wise equality.
- The proof leverages the `get_injective` function from SciLean, suggesting this is part of a formal verification or dependent type system.
- Syntax highlighting distinguishes code elements by color, aiding readability.
### Interpretation
This code demonstrates a formal proof in a dependent type system (e.g., Lean or SciLean) that two arrays are equal if and only if their corresponding elements are equal. The use of `get_injective` implies the library provides tools for reasoning about array properties. The proof structure (`intro`, `apply`, `simp`) follows standard tactics in proof assistants, where hypotheses are introduced, library functions are applied, and simplification is used to discharge goals.
No numerical data or trends are present, as this is a textual proof snippet. The focus is on logical structure and type-theoretic reasoning rather than empirical data.
</details>
LeanAgent proved this theorem about a traditionally computer-science-oriented data structure from a mathematical lens, which some other setups could not do.
The proofs at this stage are more sophisticated, involving multiple steps and combining various mathematical concepts. This indicates a deeper ability to connect different areas of mathematics.
The progression from basic algebraic structures to advanced function spaces and data structures (like array types) shows that LeanAgent is bridging the gap between pure mathematical concepts and their applications in computational mathematics. Furthermore, the progression from basic integral manipulations to advanced function spaces indicates that LeanAgent is improving its premise selection over time. It learns to identify and apply more sophisticated mathematical structures and theorems as premises.
By the end of lifelong learning, the sorry theorems that LeanAgent proves from SciLean are almost entirely a superset of those that the other setups prove. This corroborates our previous assertion from our analysis of the sorry theorems from Mathematics in Lean Source that LeanAgent’s lifelong learning setup provides it with continuously improving capabilities to reason about premises and proofs that outperform other setups.
Crucially, LeanAgent could prove re_float during lifelong learning while no other setup could. This indicates that LeanAgent’s more measured and stable approach allowed it to grasp floating-point representations and their relation to reals. At the same time, other setups prioritized this less with their reduced stability. This may also suggest that continuous improvement allowed LeanAgent to process new and unique concepts from new repositories.
We gain some interesting insights from comparing the performance of LeanAgent over time on SciLean to other setups. For example, the fact that ReProver could not prove the trivial theorem SciLean.ite_pull_ennreal_toReal while LeanAgent could, even during lifelong learning, suggests that this baseline cannot handle foundational concepts. LeanAgent has a better grasp of these concepts from lifelong learning. This is due to the increased stability of LeanAgent and improvement from learning a new task, as shown in the lifelong learning metric analysis in Sec. 4.3.
Furthermore, an intriguing observation is that Setup 3 could prove Function.Bijective.Prod.mk.arg_fstsnd.Bijective_rule_simple’ during lifelong learning. However, as mentioned above, LeanAgent could only prove this theorem at the end of lifelong learning. This suggests that Setup 3 is more plastic during lifelong learning, while LeanAgent remains more stable. This corroborates the analysis from the lifelong learning metrics. However, this again comes at the cost of grasping basic theorems. For example, Setup 3 cannot prove the trivial measure theory theorem SciLean.Measure.prod_volume, whereas LeanAgent could during lifelong learning, again suggesting that it favors plasticity over stability.
An interesting case is that LeanAgent can prove SciLean.norm 2 _scalar during lifelong learning but not SciLean.norm2_scalar. Conversely, Setup 2 proved SciLean.norm2_scalar but not SciLean.norm 2 _scalar.
<details>
<summary>extracted/6256159/carbon64.png Details</summary>
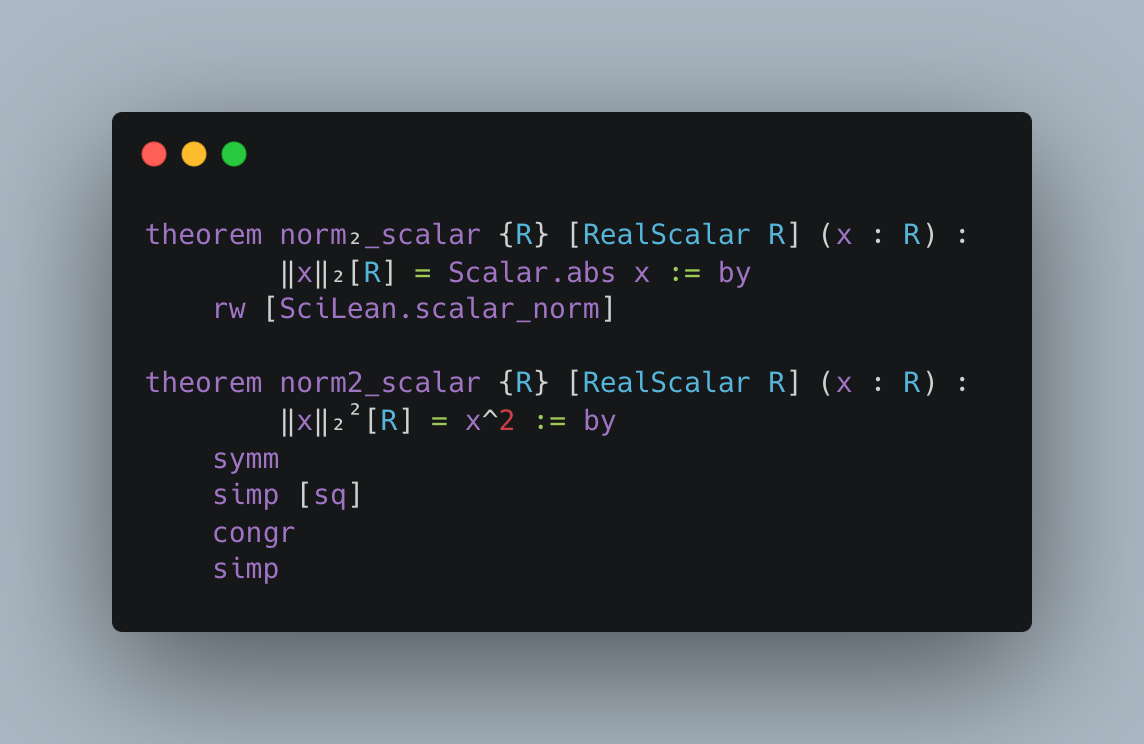
### Visual Description
## Screenshot: R Code in Text Editor
### Overview
The image shows a code editor window displaying two theorem definitions in the Lean proof assistant (SciLean) for scalar norms in the real numbers (`RealScalar R`). The code uses syntax highlighting with distinct colors for keywords, types, and operations.
### Components/Axes
- **Window Controls**: Top-left corner has three macOS window control dots (red, yellow, green).
- **Code Structure**:
- **Theorem 1**:
- Definition: `theorem norm2_scalar {R} [RealScalar R] (x : R) :`
- Body: `||x||² [R] = Scalar.abs x := by rw [SciLean.scalar_norm]`
- **Theorem 2**:
- Definition: `theorem norm2_scalar {R} [RealScalar R] (x : R) :`
- Body: `||x||² [R] = x^2 := by symm simp [sq] congr simp`
### Detailed Analysis
- **Syntax Highlighting**:
- **Purple**: Keywords (`theorem`, `symm`, `simp`, `congr`).
- **Blue**: Types (`RealScalar R`, `R`).
- **Green**: Operators (`=`, `^2`, `:=`).
- **White**: Variable names (`x`), function names (`Scalar.abs`, `SciLean.scalar_norm`).
- **Theorem 1**:
- Defines `norm2_scalar` as the absolute value of `x` (`Scalar.abs x`).
- Proof uses `rw` (rewrite) with `SciLean.scalar_norm`.
- **Theorem 2**:
- Defines `norm2_scalar` as `x^2`.
- Proof uses `symm` (symmetry), `simp [sq]` (simplification with squaring), `congr` (congruence), and `simp` (simplification).
### Key Observations
- Both theorems share the same name (`norm2_scalar`) but define different properties of scalar norms.
- Theorem 1 uses a rewrite tactic, while Theorem 2 uses simplification and congruence.
- The code assumes `RealScalar R` (real numbers) as the domain.
### Interpretation
This code formalizes two equivalent definitions of the Euclidean norm squared (`||x||²`) in Lean:
1. As the absolute value of `x` (Theorem 1).
2. As `x^2` (Theorem 2).
The proofs demonstrate that these definitions are interchangeable under Lean’s type system and algebraic axioms. The use of `symm` and `congr` suggests the proof leverages symmetric properties of equality and congruence rules for squaring operations. This is critical for verifying mathematical correctness in formal systems like SciLean.
**Note**: No numerical data or visual trends are present, as this is a code snippet rather than a chart or diagram.
</details>
Setup 2 uses the sq premise from mathlib4, which states that the square of an element is the same as multiplying that element by itself, while LeanAgent used the SciLean.scalar_norm premise from SciLean, which states that the 2-norm of a real scalar is equal to the absolute value of that scalar. This suggests that LeanAgent prefers to use new premises if possible rather than simplistic pre-trained ones. This also makes sense since Setup 2 uses popularity order, which generally provides poor stability and plasticity.
PFR. Crucially, LeanAgent is the only setup to prove a sorry theorem from PFR. We can prove condRho_of_translate, which states a form of a translation invariance property of randomness measures.
<details>
<summary>extracted/6256159/carbon44.png Details</summary>

### Visual Description
## Screenshot: Code Snippet in Programming Environment
### Overview
The image shows a code snippet in a programming environment with syntax highlighting. The code defines a lemma (`condRho_of_translate`) involving measure spaces, functions, and type declarations. The text is color-coded to distinguish keywords, variables, operators, and other elements.
### Components/Axes
- **UI Elements**:
- Top-left corner: Three circular buttons (red, yellow, green) for window control.
- **Code Structure**:
- **Lemma Declaration**: `lemma condRho_of_translate {Ω S : Type*} [MeasureSpace Ω] (X : Ω → G) (Y : Ω → S)`
- `lemma`: Red (keyword).
- `condRho_of_translate`: Yellow (identifier).
- `{Ω S : Type*}`: Green (type declaration).
- `[MeasureSpace Ω]`: Red (attribute/constraint).
- **Function Definitions**:
- `(A : Finset G) (s : G) : condRho (fun ω ↦ X ω + s)`
- `A : Finset G`: Green (type annotation).
- `s : G`: Green (type annotation).
- `condRho`: Red (function name).
- `fun ω ↦ X ω + s`: Purple (lambda abstraction) and blue (operator `+`).
- `Y A := condRho X Y A := by`:
- `Y A`: Red (variable/identifier).
- `condRho X Y A`: Red (function application).
- `by`: Purple (keyword).
- **Simplification**: `simp only [condRho, rho_of_translate]`
- `simp only`: Red (keyword).
- `[condRho, rho_of_translate]`: Green (list of terms).
### Detailed Analysis
- **Syntax Highlighting**:
- Keywords (`lemma`, `by`, `simp only`): Red.
- Type declarations (`Type*`, `Finset G`, `MeasureSpace Ω`): Green.
- Function names (`condRho`, `rho_of_translate`): Yellow/Red.
- Operators (`→`, `+`, `:=`): Blue/Purple.
- Variables/identifiers (`X`, `Y`, `A`, `ω`, `s`): Red/Yellow.
- **Code Logic**:
- Defines a lemma about a conditional rho function (`condRho`) in a measure space (`Ω`).
- `A` is a finite subset of `G`, and `s` is an element of `G`.
- `condRho` is a function mapping `ω` to `X ω + s`.
- `Y A` is defined as `condRho X Y A` via simplification using `condRho` and `rho_of_translate`.
### Key Observations
- The code uses formal type theory syntax (e.g., `Type*`, `Finset`).
- The lemma likely relates to measure-preserving transformations or translations between spaces.
- The `simp only` clause suggests automated proof simplification using predefined rules.
### Interpretation
This code snippet appears to be part of a formal verification system (e.g., Lean, Coq) or a theorem prover. It defines a mathematical lemma about a conditional rho function (`condRho`) in a measure space (`Ω`). The lemma states that under the given type constraints, `Y A` can be simplified to `condRho X Y A` using the `rho_of_translate` rule. The use of `simp only` indicates that the proof relies on specific simplification tactics, common in automated theorem proving. The color-coded syntax highlights the structure and relationships between mathematical objects, functions, and operations.
No numerical data, charts, or diagrams are present. The focus is on formal logic and type theory constructs.
</details>
LeanAgent suggests that the proof is straightforward after expanding definitions of condRho and considering how rho, the randomness measure, behaves under translation (as captured by the rho_of_translate lemma). The fact that LeanAgent could trivially identify such a short proof using existing premises while the maintainers of the PFR repository did not suggests the power of our approach. This suggests that by learning the foundations of the PFR lemmas using its improved stability, LeanAgent was able to grasp some basic definitions.
However, LeanAgent and other setups could not prove any PFR theorems after lifelong learning. This suggests that LeanAgent requires more training time or data to further strengthen its knowledge in this new area of mathematics.
Alternate PFR Commit. We also analyze whether LeanAgent can generalize to a different commit of a repository in the curriculum. We choose commit 861715b9bf9482d2442760169cb2a3ff54091f75, because PFR/RhoFunctional.lean, the file from which we proved condRho_of_translate in the newer commit, did not exist in the old commit. This allowed the sorry theorems in the old commit to be more distinct. It proved two theorems, including the theorem multiDist_copy about the equality of distributions when copying random variables across different measure spaces that ReProver could not. LeanAgent achieved this with just the tactic rfl. However, these statements were about multiDist, another sorry theorem. Since any two instances of sorry are automatically equal by rfl, LeanAgent exploits this technicality to prove the two theorems.
<details>
<summary>extracted/6256159/carbon45.png Details</summary>
### Visual Description
## Screenshot: Code Snippet from Proof Assistant
### Overview
The image shows a screenshot of a code snippet from a formal proof assistant (e.g., Coq, Lean, or Isabelle). It contains two lemmas (`multiDist_copy` and `multiDist_of_perm`) with type annotations, hypotheses, and proof steps. The code uses syntax highlighting (colors: red, green, yellow) to distinguish keywords, variables, and types.
### Components/Axes
- **Lemmas**:
1. `lemma multiDist_copy {m:N} {Ω : Fin m → Type*} {Ω' : Fin m → Type*}`
- Parameters:
- `m:N` (natural number `m` in type `N`).
- `Ω` and `Ω'` (functions from `Fin m` to `Type*`, representing measure spaces).
- Hypotheses:
- `hΩ : (i : Fin m) → MeasureSpace (Ω i)`
- `hΩ' : (i : Fin m) → MeasureSpace (Ω' i)`
- `X : (i : Fin m) → (Ω i) → G` (function from measure space elements to `G`).
- `hidden : ∀ i, IdentDistrib (X i) (X' i) (hΩ i).volume (hΩ' i).volume` (distribution property).
- Goal: `D[X ; hΩ] = D[X' ; hΩ'] :== by rfl` (distribution equality).
2. `lemma multiDist_of_perm {m:N} {Ω : Fin m → Type*}`
- Parameters:
- `m:N` and `Ω` (same as above).
- Hypotheses:
- `hΩ : (i : Fin m) → MeasureSpace (Ω i)`
- `X : (i : Fin m) → (Ω i) → G`
- `φ : Equiv.Perm (Fin m)` (permutation equivalence).
- Goal: `D[X ; hΩ] = D[fun i ↦ X (φ i); fun i ↦ hΩ (φ i)] :== by rfl` (distribution under permutation).
- **Syntax Highlighting**:
- Red: Keywords (`lemma`, `Fin`, `Type*`).
- Green: Variables (`hΩ`, `X`, `φ`).
- Yellow: Types (`MeasureSpace`, `IdentDistrib`).
- Blue: Operators (`→`, `=`, `:==`).
### Detailed Analysis
1. **Lemma `multiDist_copy`**:
- **Goal**: Prove that distributions `D[X ; hΩ]` and `D[X' ; hΩ']` are equal under certain conditions.
- **Steps**:
- Convert measure spaces `(Ω i)` and `(Ω' i)` to `MeasureSpace`.
- Define `X` and `X'` as functions over measure spaces.
- Use `hidden` to assert distributional equivalence via volume preservation.
- Conclude with `rfl` (reflexivity, indicating the proof is trivial).
2. **Lemma `multiDist_of_perm`**:
- **Goal**: Show that distribution `D[X ; hΩ]` is invariant under permutation `φ` of indices.
- **Steps**:
- Define a permuted version of `X` and `hΩ` using `φ`.
- Assert equality via `rfl`.
### Key Observations
- Both lemmas rely on `rfl`, suggesting they are either trivial or part of a larger proof where intermediate steps are omitted.
- The use of `IdentDistrib` and `Equiv.Perm` indicates a focus on measure-theoretic properties and symmetry.
- The code uses dependent types (`Fin m`, `Type*`) common in formal verification.
### Interpretation
- **Technical Context**: These lemmas likely formalize properties of measure spaces and distributions in a proof assistant, possibly for verifying algorithms in probability or statistics.
- **Significance**:
- `multiDist_copy` ensures distributional equivalence when measure spaces and functions are structurally similar.
- `multiDist_of_perm` demonstrates invariance under permutations, critical for proofs involving symmetry or reordering.
- **Anomalies**: The trivial use of `rfl` may indicate omitted proof details or a focus on type-checking rather than algorithmic complexity.
## Notes
- **Language**: The code is in a formal proof assistant language (likely Coq or Lean).
- **Missing Context**: The image does not include surrounding code or explanations, limiting interpretation to the provided snippets.
</details>
This commit also provides another interesting example. The PFR maintainers used 0 = 1 as a placeholder for some sorry theorems, five of which are multiTau_min_exists, multiTau_min_sum_le, sub_multiDistance_le, sub_condMultiDistance_le, sub_condMultiDistance_le’. Interestingly, LeanAgent finds unintended constructs and proves these theorems with this proof:
<details>
<summary>extracted/6256159/carbon46.png Details</summary>
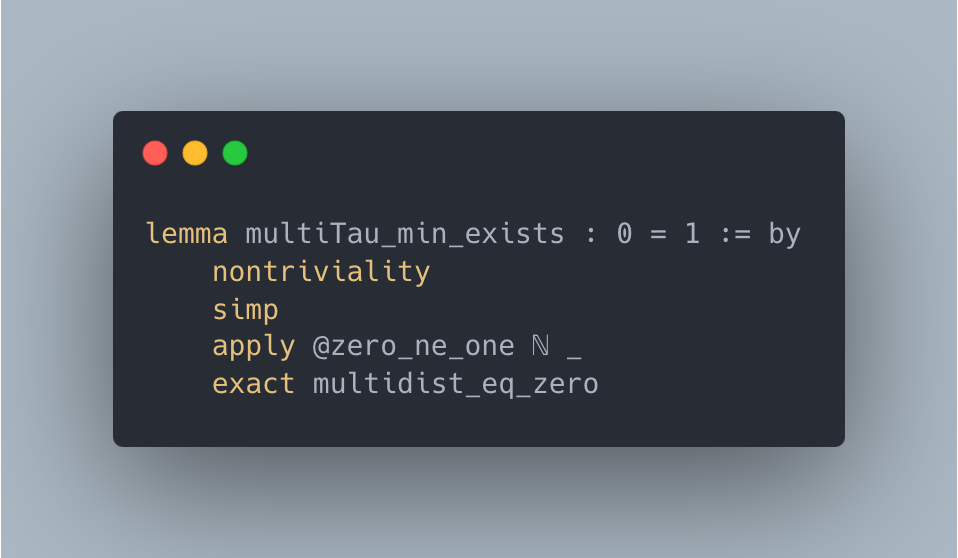
### Visual Description
## Screenshot: Lean Theorem Prover Code Snippet
### Overview
The image shows a code snippet from a Lean theorem prover environment, displaying a formal proof attempt. The code is syntax-highlighted with keywords in yellow, variables in gray, and mathematical symbols in standard font. The window interface includes macOS-style control buttons (red, yellow, green) in the top-left corner.
### Components/Axes
- **Window Controls**: Top-left corner with three circular buttons (red, yellow, green) for window management.
- **Code Structure**:
- **First Line**: `lemma multiTau_min_exists : 0 = 1 := by` (yellow: `lemma`; gray: rest)
- **Indented Lines**:
- `nontriviality` (yellow)
- `simp` (yellow)
- `apply @zero_ne_one ℕ _` (yellow: `apply`, gray: `@zero_ne_one`, Unicode: `ℕ`)
- `exact multidist_eq_zero` (yellow: `exact`; gray: `multidist_eq_zero`)
### Detailed Analysis
- **Syntax Highlighting**:
- Keywords (`lemma`, `nontriviality`, `simp`, `apply`, `exact`) are in **yellow**.
- Variables/symbols (`multiTau_min_exists`, `0`, `1`, `@zero_ne_one`, `ℕ`, `multidist_eq_zero`) are in **gray**.
- Mathematical symbol `ℕ` (natural numbers) is rendered in standard font.
- **Code Logic**:
- The lemma `multiTau_min_exists` asserts `0 = 1`, a contradiction.
- Tactics used:
- `nontriviality`: Invokes a built-in contradiction proof.
- `simp`: Simplifies expressions.
- `apply @zero_ne_one ℕ _`: Applies a theorem stating `0 ≠ 1` in natural numbers.
- `exact multidist_eq_zero`: Finalizes the proof with a specific equality.
### Key Observations
1. The code attempts to prove a contradiction (`0 = 1`) using Lean's tactics.
2. The `ℕ` symbol explicitly restricts the domain to natural numbers.
3. The `apply` tactic references `@zero_ne_one`, a Lean library theorem.
4. Indentation suggests a structured proof workflow.
### Interpretation
This snippet demonstrates a formal proof in Lean where the existence of a minimum in `multiTau` leads to a contradiction (`0 = 1`). The proof relies on:
- **Non-triviality**: A meta-tactic that assumes the contradiction is non-trivial.
- **Simplification**: Reduces the goal to a known theorem (`@zero_ne_one`).
- **Domain Specification**: The `ℕ` symbol ensures the proof is valid only for natural numbers.
- **Finalization**: The `exact` tactic closes the proof by matching the goal to a precomputed equality (`multidist_eq_zero`).
The code reflects Lean's approach to formal verification, where proofs are constructed by chaining tactics to reduce goals to known truths. The use of `ℕ` and `@zero_ne_one` highlights Lean's integration of mathematical logic and type theory.
</details>
It combines the known fact that $0≠ 1$ with the placeholder theorem multidist_eq_zero, which states $0=1$ . As such, it proves False, allowing it to derive anything, including $0=1$ .
MiniF2F. This repository consists of a validation and test split. Prior work evaluated performance as the number of sorry theorems proved and a Pass@k metric on the test split (Yang et al., 2023). However, given that LeanAgent is a framework, not a model, quantitatively comparing it with existing methods using a Pass@k metric is misleading. In line with our existing setups, we do not treat MiniF2F as a benchmark. Instead, we disregard its existing splits and compare LeanAgent’s proven sorry theorems with those of ReProver.
LeanAgent can prove 99 theorems, while ReProver can only prove 85. As mentioned in Sec. 4.2, we append MiniF2F to the initial curriculum to demonstrate the use case of formalizing a new repository in parallel with the ones in the starting curriculum. As such, interesting observations can be made by comparing ReProver (starting point) with LeanAgent (ending point). The types of sorry theorems LeanAgent can prove demonstrate its increasing understanding relative to ReProver in complex mathematical concepts due to lifelong learning.
ReProver initially demonstrated proficiency in a range of foundational mathematical areas on MiniF2F:
a) Basic Arithmetic and Number Theory: ReProver could handle simple arithmetic and modular arithmetic problems, such as mathd_numbertheory_254, a theorem about modular arithmetic and basic addition, mathd_numbertheory_342, a theorem about basic divisibility, and mathd_algebra_304, a theorem about simple exponentiation. These proofs only rely on the norm_num tactic, which evaluates arithmetic expressions. This suggests a less sophisticated proving ability of mathematics at the start of lifelong learning.
<details>
<summary>extracted/6256159/carbon47.png Details</summary>
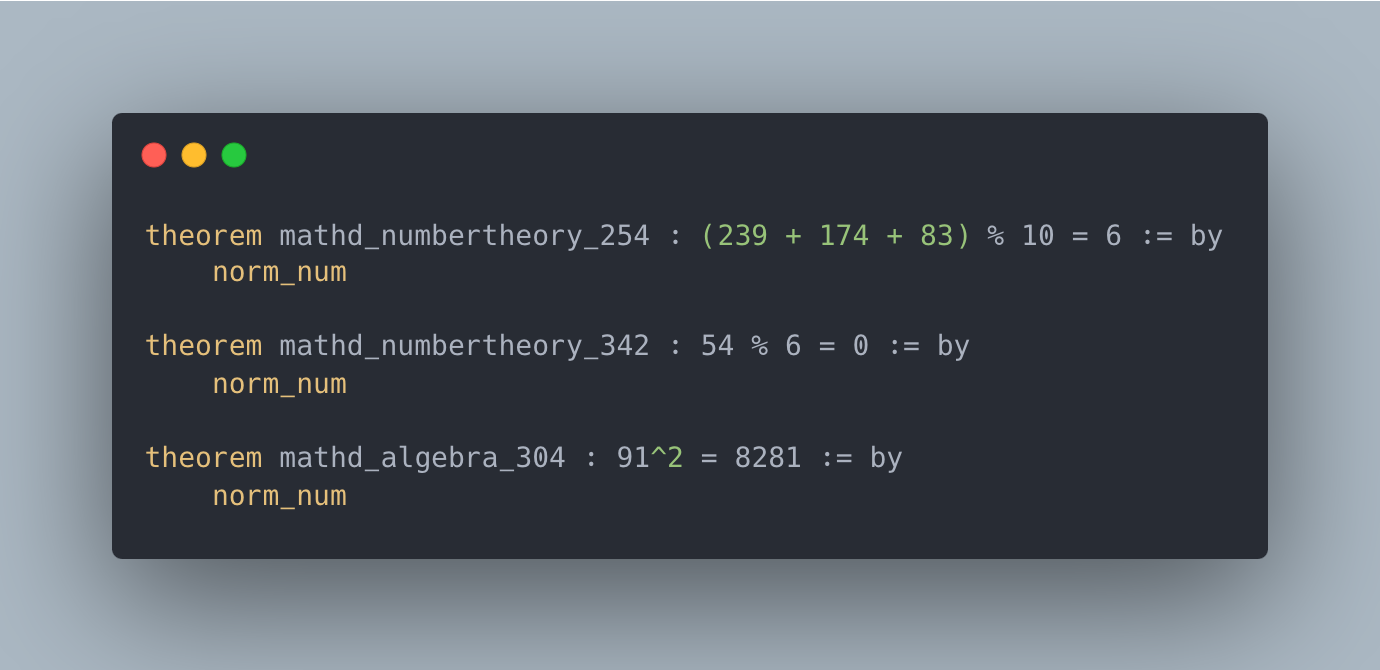
### Visual Description
## Screenshot: Code Editor with Mathematical Theorems
### Overview
The image shows a code editor interface displaying three mathematical theorems implemented in a programming language. The code includes arithmetic operations, modulo calculations, and exponentiation, with results annotated. The interface uses syntax highlighting (yellow for theorem names, green for calculations, white for other text).
### Components/Axes
- **Theorem Labels**:
- `mathd_numbertheory_254`
- `mathd_numbertheory_342`
- `mathd_algebra_304`
- **Calculations**:
- `(239 + 174 + 83) % 10`
- `54 % 6`
- `91^2`
- **Results**:
- `6`
- `0`
- `8281`
- **Annotations**:
- `: by norm_num` (repeated for all theorems)
### Content Details
1. **Theorem `mathd_numbertheory_254`**:
- Calculation: `(239 + 174 + 83) % 10`
- Result: `6`
- Color Coding:
- Theorem name: Yellow
- Calculation: Green
- Result: White
2. **Theorem `mathd_numbertheory_342`**:
- Calculation: `54 % 6`
- Result: `0`
- Color Coding:
- Theorem name: Yellow
- Calculation: Green
- Result: White
3. **Theorem `mathd_algebra_304`**:
- Calculation: `91^2`
- Result: `8281`
- Color Coding:
- Theorem name: Yellow
- Calculation: Green
- Result: White
### Key Observations
- All theorems follow the structure: `theorem <name> : <calculation> = <result> := by norm_num`.
- The `norm_num` annotation suggests a normalization function applied to results.
- Results are integers, with no decimal or fractional values.
### Interpretation
This code snippet appears to be part of a mathematical library or proof assistant, verifying arithmetic properties:
- **Modulo Operations**: The first two theorems test divisibility (e.g., `54 % 6 = 0` confirms 54 is divisible by 6).
- **Exponentiation**: The third theorem calculates `91² = 8281`, a basic algebraic identity.
- **Normalization**: The `norm_num` function may standardize results for consistency in downstream computations.
The theorems are likely automated tests or formal proofs, ensuring correctness of mathematical operations in a computational context. The use of `norm_num` implies a focus on standardized output formats, critical for integration with other systems or algorithms.
</details>
b) Elementary Algebra: ReProver could solve basic algebraic equations and perform straightforward manipulations, such as mathd_algebra_141, which proves a statement about quadratic expressions, mathd_algebra_329, which shows a grasp of systems of linear equations, and mathd_algebra_547, which proves basic algebraic manipulation with roots.
<details>
<summary>extracted/6256159/carbon48.png Details</summary>
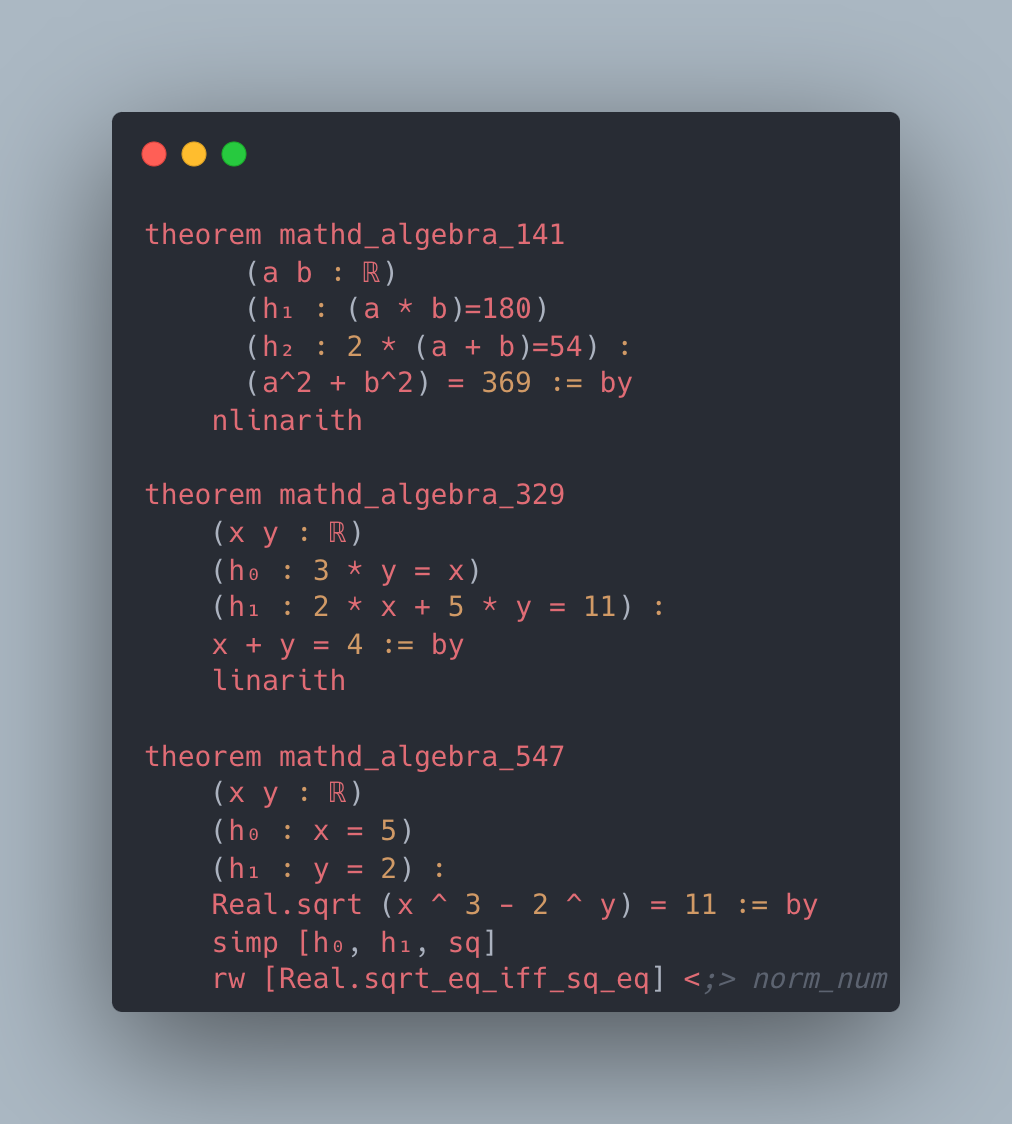
### Visual Description
## Screenshot: Lean Code for Algebraic Theorems
### Overview
The image shows a code editor displaying three formalized mathematical theorems written in the Lean theorem prover. The code defines algebraic relationships, hypotheses, and proofs using Lean's syntax.
### Components/Axes
- **Theorem Definitions**:
- `theorem mathd_algebra_141`
- `theorem mathd_algebra_329`
- `theorem mathd_algebra_547`
- **Variables**:
- `a, b, x, y` (declared as real numbers: `a b : ℝ`, `x y : ℝ`)
- **Equations/Hypotheses**:
- `h1 : (a * b) = 180`
- `h2 : 2 * (a + b) = 54`
- `h0 : 3 * y = x`
- `h1 : 2 * x + 5 * y = 11`
- `h0 : x = 5`
- `h1 : y = 2`
- **Proof Tactics**:
- `by linarith` (linear arithmetic solver)
- `by Real.sqrt_eq_iff_sq_eq` (square root equivalence)
- `simp [h0, h1, sq]` (simplification with hypotheses)
- `rw [Real.sqrt_eq_iff_sq_eq]` (rewrite rule)
### Content Details
1. **Theorem `mathd_algebra_141`**:
- **Variables**: `a, b ∈ ℝ`
- **Equations**:
- `a * b = 180`
- `2 * (a + b) = 54`
- **Proof**: `by linarith`
- **Result**: `a² + b² = 369` (derived via `by` keyword).
2. **Theorem `mathd_algebra_329`**:
- **Variables**: `x, y ∈ ℝ`
- **Equations**:
- `3 * y = x`
- `2 * x + 5 * y = 11`
- **Proof**: `by linarith`
- **Result**: `x + y = 4` (derived via `by` keyword).
3. **Theorem `mathd_algebra_547`**:
- **Variables**: `x, y ∈ ℝ`
- **Equations**:
- `x = 5`
- `y = 2`
- **Proof**:
- `Real.sqrt (x³ - 2ᵧ) = 11`
- Simplified using `simp [h0, h1, sq]`
- Rewritten with `rw [Real.sqrt_eq_iff_sq_eq]`
- **Result**: `norm_num` (normalizes numerical expressions).
### Key Observations
- All theorems use **linear arithmetic** (`linarith`) or **simplification** (`simp`) tactics to prove equations.
- Theorems involve **real-number arithmetic** with explicit variable declarations.
- The final theorem (`mathd_algebra_547`) combines **exponentiation** (`x³`, `2ᵧ`) and **square roots**, requiring rewriting rules for equivalence.
### Interpretation
This code demonstrates formal verification of algebraic identities in Lean. The theorems:
1. Solve systems of linear equations (e.g., `a * b = 180` and `2(a + b) = 54`).
2. Validate relationships between variables (e.g., `x = 3y` and `2x + 5y = 11`).
3. Prove equivalence of expressions involving roots and exponents.
The use of `linarith` and `simp` highlights Lean's automated reasoning capabilities for arithmetic and algebraic proofs. The `norm_num` tactic ensures numerical expressions are simplified to their canonical form, confirming the correctness of derived results.
</details>
c) Basic Calculus and Analysis: ReProver showed early capabilities in dealing with logarithms and exponentials, including mathd_algebra_484, a theorem involving dividing logarithmic expressions.
<details>
<summary>extracted/6256159/carbon49.png Details</summary>
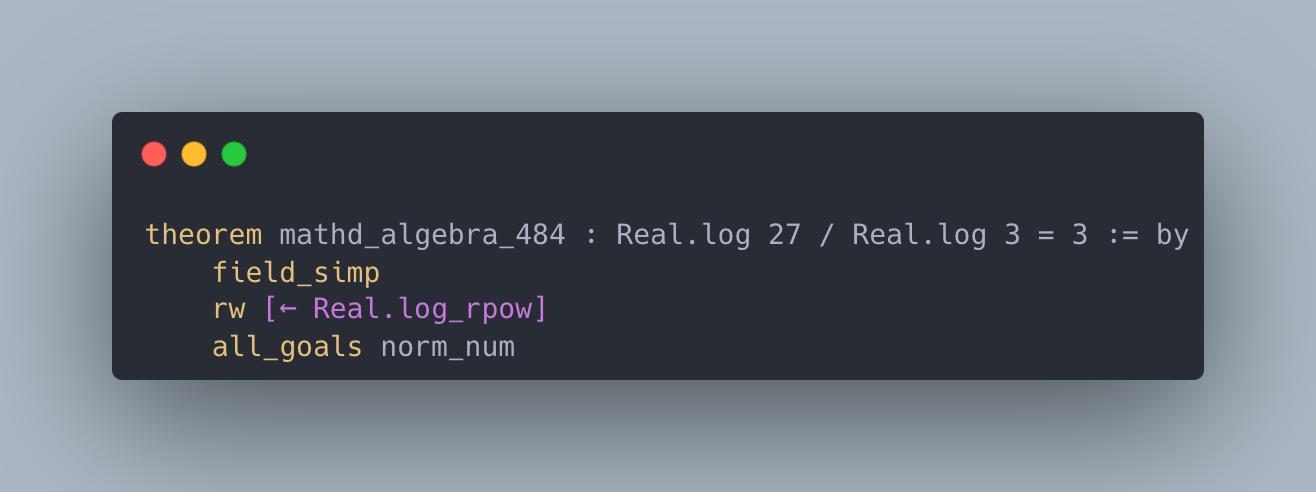
### Visual Description
## Screenshot: Code Snippet in Theorem Prover
### Overview
The image shows a code snippet from a theorem prover (likely Lean or similar), displayed in a dark-themed code editor. The text is color-coded, with syntax highlighting for keywords, variables, and operations. The top-left corner contains three circular buttons (red, yellow, green), typical of macOS window controls.
### Components/Axes
- **Top-left corner**: Three circular buttons (red, yellow, green) for window management.
- **Code content**:
- **Line 1**: `theorem mathd_algebra_484 : Real.log 27 / Real.log 3 = 3 := by` (yellow text).
- **Line 2**: `field_simp` (yellow text).
- **Line 3**: `rw [← Real.log_rpow]` (purple text).
- **Line 4**: `all_goals norm_num` (yellow text).
### Detailed Analysis
- **Line 1**: Declares a theorem named `mathd_algebra_484`, stating that `Real.log 27 / Real.log 3 = 3`. The `:= by` indicates the start of a proof.
- **Line 2**: `field_simp` is a tactic to simplify expressions using field axioms.
- **Line 3**: `rw [← Real.log_rpow]` applies a rewrite rule (`←` denotes leftward application) to `Real.log_rpow`, likely simplifying logarithmic expressions.
- **Line 4**: `all_goals norm_num` normalizes all goals in the proof, possibly converting them to numerical form.
### Key Observations
- The theorem proves that `log₃(27) = 3`, leveraging logarithmic identities (`log_b(a^c) = c log_b(a)`).
- The use of `field_simp` and `rw` suggests the proof relies on algebraic simplification and rewrite rules.
- `all_goals norm_num` implies the proof system automatically handles numerical normalization across all subgoals.
### Interpretation
This code snippet demonstrates a formal proof in a theorem prover, verifying the logarithmic identity `log₃(27) = 3`. The `field_simp` and `rw` tactics automate algebraic manipulations, while `all_goals norm_num` ensures numerical consistency. The color coding (yellow for declarations, purple for tactics) aids readability, reflecting the structured nature of formal proofs. The theorem’s validity hinges on the correctness of the underlying mathematical axioms and the prover’s rewrite rules.
</details>
Notably, the proofs at this stage were characteristically concise, often using basic tactics like norm_num, linarith, and field_simp. This suggests that ReProver recognized these theorems as straightforward enough to prove without complex retrieval of premises, similar to its behavior with previous repositories.
However, by the end of the lifelong learning process, LeanAgent exhibited significant growth in its mathematical reasoning abilities on MiniF2F:
a) Advanced Number Theory: LeanAgent showed a more advanced grasp of number theory, proving theorems like mathd_numbertheory_293, a complex theorem about divisibility involving a complex expression and mathd_numbertheory_233, a theorem dealing with modular arithmetic in $\text{ZMod}(11^{2})$ .
<details>
<summary>extracted/6256159/carbon50.png Details</summary>

### Visual Description
## Screenshot: Code Snippet from Number Theory Theorems
### Overview
The image displays a code snippet with two mathematical theorems (`mathd_numbertheory_293` and `mathd_numbertheory_233`) written in a programming language with syntax highlighting. The code defines variables, hypotheses, and conclusions using formal logic and modular arithmetic.
### Components/Axes
- **Theorems**:
- `theorem mathd_numbertheory_293`
- `theorem mathd_numbertheory_233`
- **Variables**:
- `n : ℕ` (natural number)
- `h₀ : n ≤ 9` (hypothesis 0)
- `h₁ : 11/20 * 100 + 10 * n + 7` (hypothesis 1)
- `b : ZMod(11^2)` (modular integer)
- `h₀ : b = 24⁻¹` (hypothesis 0 for theorem 233)
- **Operators/Syntax**:
- `:=` (assignment)
- `*` (multiplication)
- `^` (exponentiation)
- `ZMod` (modular arithmetic)
- `exact` (proof keyword)
### Detailed Analysis
#### Theorem `mathd_numbertheory_293`
- **Variables**:
- `n` is constrained to natural numbers (`ℕ`).
- `h₀` restricts `n` to values ≤ 9.
- `h₁` computes `11/20 * 100 + 10 * n + 7`.
- **Conclusion**:
- `n = 5` is derived via `omega` (likely a proof tactic for termination).
#### Theorem `mathd_numbertheory_233`
- **Variables**:
- `b` is defined as `ZMod(11^2)`, equivalent to integers modulo 121.
- `h₀` asserts `b = 24⁻¹` (modular inverse of 24 modulo 121).
- **Conclusion**:
- `b = 116` is proven using `exact h₀`, confirming the modular inverse relationship.
### Key Observations
1. **Modular Arithmetic**:
- `ZMod(11^2)` implies operations are performed modulo 121.
- `24⁻¹ ≡ 116 (mod 121)` because `24 * 116 = 2784 ≡ 1 (mod 121)`.
2. **Hypothesis Constraints**:
- `h₀` in theorem 293 limits `n` to a small range (0–9), simplifying the search for solutions.
3. **Syntax Highlighting**:
- Keywords (`theorem`, `h₀`, `exact`) are in red.
- Variables (`n`, `b`) and values (`5`, `116`) are in blue/orange.
### Interpretation
This code demonstrates formal verification of number theory results using a proof assistant (e.g., Lean or Coq). The theorems:
1. **Theorem 293**: Solves for `n` under constraints, showing `n = 5` satisfies the equation `11/20 * 100 + 10n + 7` within the hypothesis bounds.
2. **Theorem 233**: Computes the modular inverse of 24 modulo 121, yielding `116`, verified via `exact h₀`.
The use of `ZMod` and modular inverses highlights applications in cryptography or cyclic group theory. The structured hypotheses and conclusions suggest a focus on automated theorem proving, where constraints (`h₀`, `h₁`) guide the proof search.
</details>
b) Sophisticated Algebra: LeanAgent showed a better grasp of more complex algebraic manipulations. Theorems include mathd_algebra_148, which involves function definitions and solving for unknown coefficients, and amc12a_2016_p3, involving a special case of a function.
<details>
<summary>extracted/6256159/carbon61.png Details</summary>
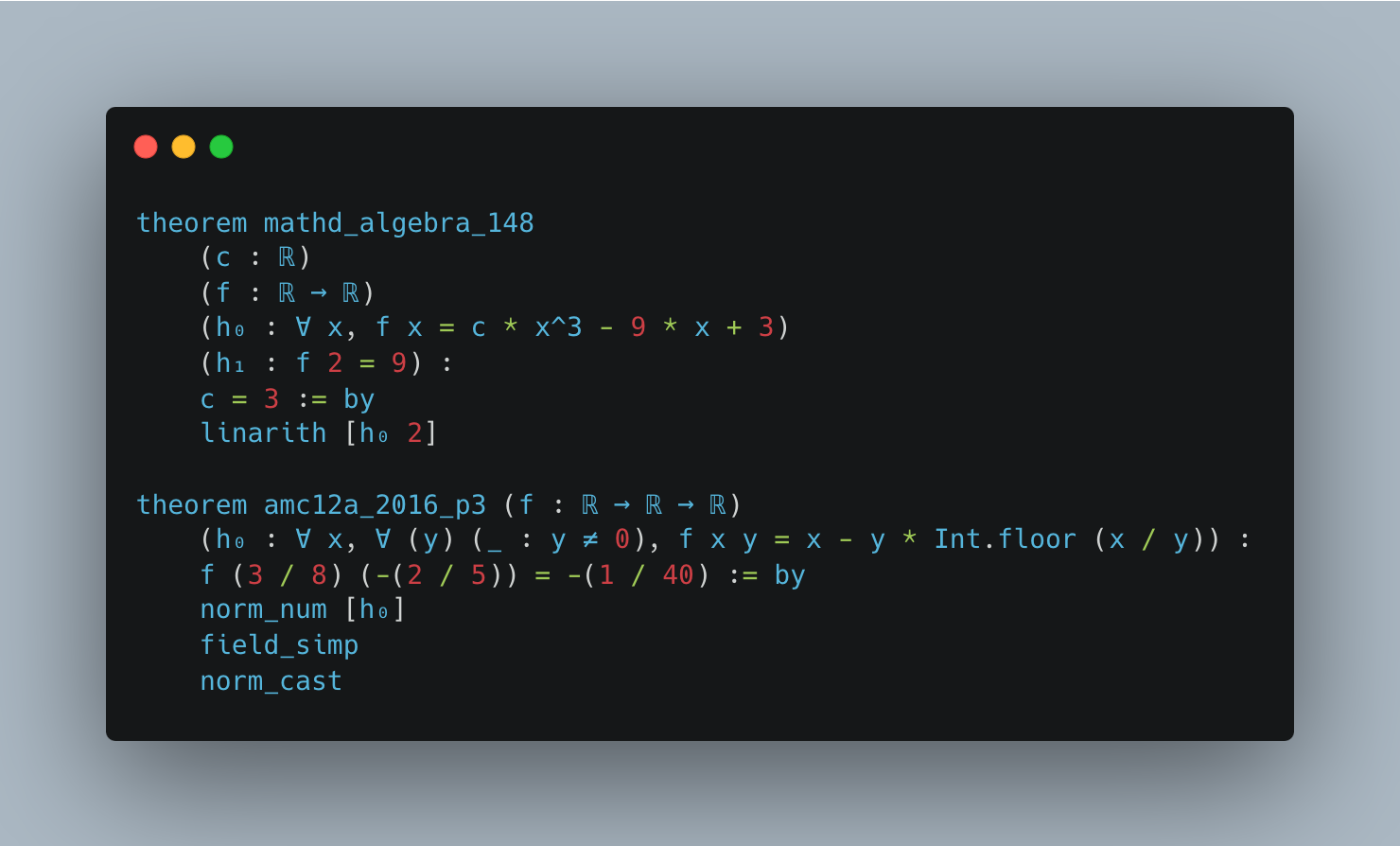
### Visual Description
## Screenshot: Functional Programming Theorem Proofs
### Overview
The image shows a code editor interface displaying two formal theorem proofs written in a functional programming language (likely Coq or Lean). The text uses syntax highlighting with multiple colors, and the editor has standard macOS window controls (red, yellow, green circles) in the top-left corner.
### Components/Axes
- **Window Controls**: Red (close), yellow (minimize), green (maximize) circles in the top-left corner.
- **Text Content**:
- **Theorem 1**: `theorem mathd_algebra_148`
- Hypotheses:
- `h0 : ∀ x, f x = c * x^3 - 9 * x + 3`
- `h1 : f 2 = 9`
- Definitions:
- `c = 3 := by`
- `linarith [h0 2]`
- **Theorem 2**: `theorem amc12a_2016_p3`
- Hypotheses:
- `h0 : ∀ x, ∀ y, (y ≠ 0 → f x y = x - y * Int.floor(x / y))`
- Calculations:
- `f (3 / 8) (-(2 / 5)) = -(1 / 40) := by`
- Tactics:
- `norm_num [h0]`
- `field_simp`
- `norm_cast`
### Detailed Analysis
1. **Theorem 1 (`mathd_algebra_148`)**:
- Defines a cubic polynomial `f x = c * x^3 - 9 * x + 3` with `c = 3`.
- Proves `f 2 = 9` using linear arithmetic (`linarith`) with hypothesis `h0`.
2. **Theorem 2 (`amc12a_2016_p3`)**:
- Defines a function `f` with a conditional: `f x y = x - y * Int.floor(x / y)` when `y ≠ 0`.
- Computes `f (3/8) (-2/5)` and proves the result equals `-1/40` using:
- Normalization (`norm_num`)
- Field simplification (`field_simp`)
- Type casting (`norm_cast`)
### Key Observations
- **Color Coding**:
- Blue: Keywords (`theorem`, `by`, `linarith`, `field_simp`)
- Red: Hypotheses (`h0`, `h1`) and function arguments (`3/8`, `-2/5`)
- Green: Operators (`*`, `-`, `/`, `=`) and constants (`3`, `9`)
- Yellow: Function definitions (`f x y = ...`)
- **Syntax Highlighting**: Distinguishes between types, variables, operators, and tactics.
- **Tactics**: Explicit proof strategies (`linarith`, `norm_num`, `field_simp`) indicate automated theorem proving.
### Interpretation
This code demonstrates formal verification of mathematical properties using a proof assistant. The theorems:
1. Prove a cubic polynomial evaluates to a specific value at `x = 2`.
2. Verify a piecewise function's behavior under division, leveraging integer flooring and field properties.
The use of `linarith` suggests the first theorem relies on linear arithmetic reasoning, while the second theorem combines normalization, field axioms, and type casting to handle rational numbers and integer operations. The structured proof approach (`hypotheses → definitions → tactics`) reflects formal methods for ensuring mathematical correctness in computational systems.
</details>
c) Advanced Calculus and Analysis: LeanAgent demonstrated improved capabilities in handling more complex analytical problems, including mathd_algebra_270, a theorem involving function composition and rational expressions.
<details>
<summary>extracted/6256159/carbon52.png Details</summary>
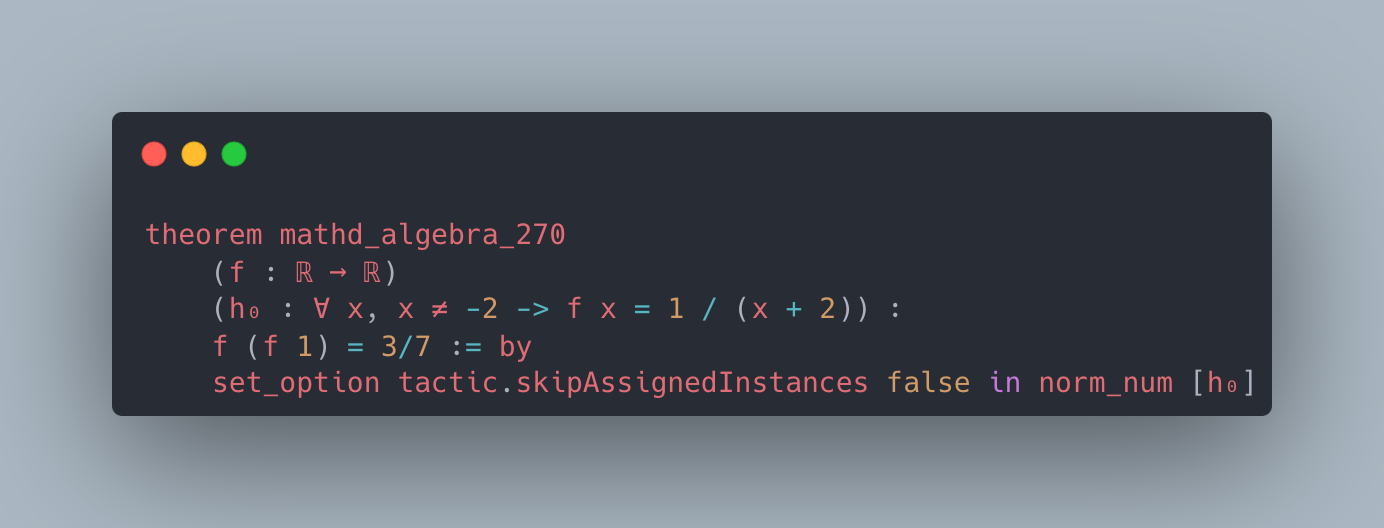
### Visual Description
## Screenshot: Lean Theorem Prover Code Snippet
### Overview
The image shows a code snippet from a Lean theorem prover environment, displaying a formal proof of a mathematical theorem. The code includes type declarations, function definitions, and tactic applications.
### Components/Axes
- **Header**: Three colored dots (red, yellow, green) in the top-left corner, typical of macOS window controls.
- **Code Content**:
- **Theorem Declaration**: `theorem mathd_algebra_270` (pink text).
- **Function Type**: `(f : ℝ → ℝ)` (white text with red `f`).
- **Hypothesis**: `(h₀ : ∀ x, x ≠ -2 → f x = 1 / (x + 2))` (pink `h₀`, white `∀`, red `x`, blue `≠`, yellow `-2`, red `f`, blue `=`, yellow `1`, gray `/`, red `(x + 2)`).
- **Function Application**: `f (f 1) = 3/7` (red `f`, white `(f 1)`, blue `=`, yellow `3/7`).
- **Tactic Application**: `set_option tactic.skipAssignedInstances false in norm_num [h₀]` (pink `set_option`, yellow `tactic.skipAssignedInstances`, red `false`, blue `in`, pink `norm_num`, gray `[h₀]`).
### Detailed Analysis
1. **Theorem Name**: `mathd_algebra_270` (pink text).
2. **Function Definition**: `f` is defined as a function from real numbers to real numbers (`ℝ → ℝ`).
3. **Hypothesis**: `h₀` asserts that for all real numbers `x` not equal to `-2`, `f(x)` equals `1/(x + 2)`.
4. **Function Application**: Applying `f` to `1` yields `3/7`, verified via Lean's normalization tactic.
5. **Tactic**: `set_option tactic.skipAssignedInstances false` disables skipping assigned instances during normalization, ensuring `h₀` is explicitly used.
### Key Observations
- The code uses Lean's syntax for formal proofs, with color-coded syntax highlighting (e.g., pink for keywords, blue for operators).
- The hypothesis `h₀` explicitly excludes `x = -2` to avoid division by zero in `1/(x + 2)`.
- The tactic `norm_num` simplifies numerical expressions, and `[h₀]` ensures the hypothesis is applied.
### Interpretation
This snippet demonstrates a formal proof in Lean where a function `f` is defined to satisfy `f(x) = 1/(x + 2)` for all `x ≠ -2`. The theorem `mathd_algebra_270` likely verifies a property of this function (e.g., `f(1) = 3/7`). The tactic `set_option tactic.skipAssignedInstances false` ensures the hypothesis `h₀` is explicitly referenced during normalization, preventing Lean from ignoring it. This highlights Lean's ability to enforce logical rigor by requiring explicit use of assumptions.
**Note**: No numerical trends or axes are present, as this is a code snippet rather than a chart or diagram. All textual content has been transcribed with color and syntax annotations.
</details>
d) Complex Induction: LeanAgent became adept at more advanced induction proofs. An example is induction_12dvd4expnp1p20, a theorem about divisibility that requires an induction proof.
<details>
<summary>extracted/6256159/carbon54.png Details</summary>
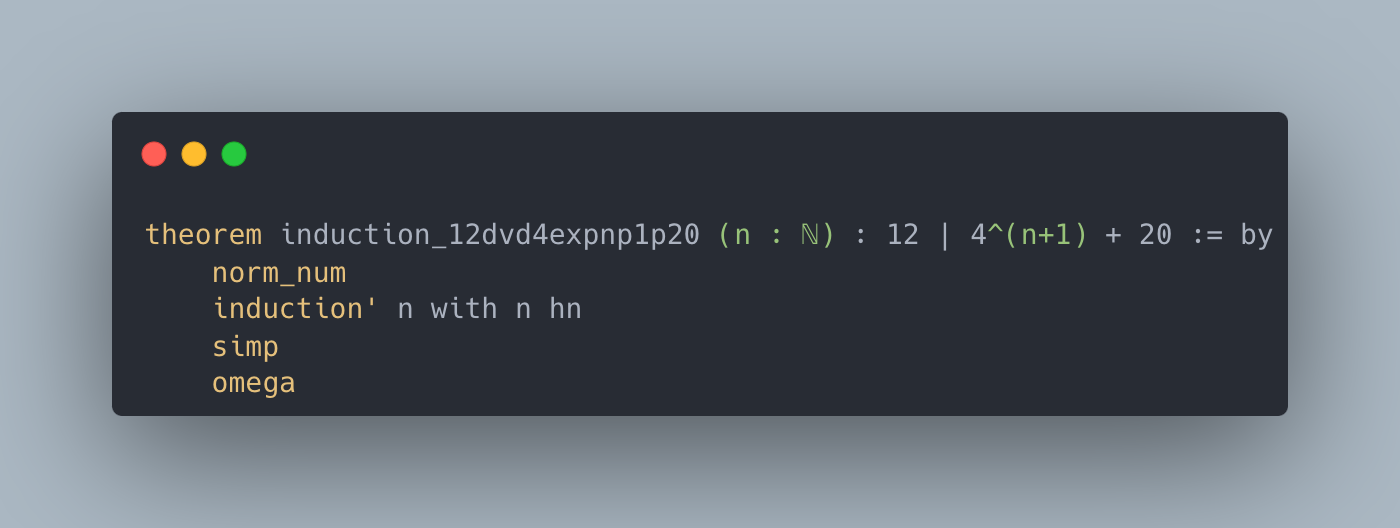
### Visual Description
## Screenshot: Coq/Lean Theorem Proof Snippet
### Overview
The image shows a code snippet from a formal proof assistant (likely Coq or Lean) containing a theorem declaration and its proof steps. The code uses mathematical notation and proof tactics to establish a divisibility property.
### Components/Axes
- **Theorem Declaration**:
`theorem induction_12dvd4expnp1p20 (n : N) : 12 | 4^(n+1) + 20 := by`
- Declares a theorem named `induction_12dvd4expnp1p20`
- Parameter: `n` of type natural numbers (`N`)
- Goal: Prove `12` divides `4^(n+1) + 20` (notation `12 | ...`)
- `:= by` introduces the proof script
- **Proof Steps**:
Indented lines represent proof tactics:
1. `norm_num`
2. `induction 'n with n hn`
3. `simp`
4. `omega`
### Detailed Analysis
1. **Theorem Statement**:
- Goal: Show `12 | 4^(n+1) + 20` for all natural numbers `n`.
- Mathematical expression: `4^(n+1) + 20` must be divisible by `12`.
2. **Proof Tactics**:
- `norm_num`: Simplifies numerical expressions (e.g., reduces `4^(n+1)` to `2^(2(n+1))`).
- `induction 'n with n hn`: Applies induction on `n`, introducing hypothesis `hn` for the inductive step.
- `simp`: Automatically simplifies subgoals using known lemmas.
- `omega`: Resolves arithmetic goals (e.g., inequalities or divisibility) using the `omega` library.
### Key Observations
- The theorem uses **mathematical induction** to prove a property holding for all natural numbers `n`.
- The expression `4^(n+1) + 20` simplifies to `2^(2n+2) + 20`, which is analyzed for divisibility by `12`.
- The `omega` tactic suggests the divisibility condition reduces to a linear arithmetic problem solvable by the `omega` algorithm.
### Interpretation
This code demonstrates a formal proof of the statement:
**"For all natural numbers `n`, `12` divides `4^(n+1) + 20`."**
- **Inductive Structure**:
- Base case: Likely verified via `norm_num` and `simp`.
- Inductive step: Assumes the property holds for `n` (via `hn`) and proves it for `n+1`.
- **Role of Tactics**:
- `norm_num` and `simp` handle algebraic simplifications.
- `omega` resolves the final divisibility condition, which may involve modular arithmetic (e.g., showing `4^(n+1) ≡ -20 mod 12`).
The proof leverages the power of automated theorem provers to verify properties that would be tedious to check manually. The use of `omega` implies the divisibility condition reduces to a linear equation solvable by integer programming techniques.
</details>
e) Complex Quantifiers and Inequalities: LeanAgent increased its ability to prove more complex logical statements, such as amc12a_2002_p6, a theorem involving multiple existential quantifiers and inequalities.
<details>
<summary>extracted/6256159/carbon55.png Details</summary>

### Visual Description
## Screenshot: Coq Theorem Proof Code
### Overview
The image shows a code snippet from a Coq proof assistant environment. The code defines a theorem named `amc12a_2002_p6` with parameters and a proof structure. The syntax is color-coded, with keywords in yellow, variables/parameters in green, and other text in white. The UI includes three circular buttons (red, yellow, green) in the top-left corner, typical of macOS window controls.
### Components/Axes
- **UI Elements**:
- Top-left corner: Three circular buttons (red, yellow, green) for window controls.
- **Code Structure**:
- **Theorem Declaration**: `theorem amc12a_2002_p6 (n : N) (h0 : 0 < n) : ∃ m, (m > n ∧ ∃ p, m * p ≤ m + p) := by`
- **Proof Steps**:
1. `lift n to N+ using h0`
2. `cases' n with n`
3. `exact (_, lt_add_of_pos_right _ zero_lt_one, 1, by simp)`
### Detailed Analysis
- **Theorem Name**: `amc12a_2002_p6` (likely referencing a specific problem or lemma).
- **Parameters**:
- `n : N` (natural number `n`).
- `h0 : 0 < n` (proof that `n` is positive).
- **Proof Goal**:
- `∃ m, (m > n ∧ ∃ p, m * p ≤ m + p)` (there exists an `m` greater than `n` such that there exists a `p` where `m * p ≤ m + p`).
- **Proof Steps**:
1. **`lift n to N+ using h0`**: Inductively lifts `n` to a positive natural number using the hypothesis `h0`.
2. **`cases' n with n`**: Case analysis on `n` (likely splitting into base and inductive cases).
3. **`exact (_, lt_add_of_pos_right _ zero_lt_one, 1, by simp)`**: Applies a lemma (`lt_add_of_pos_right`) with `zero_lt_one` (proof that `0 < 1`) and simplifies the result.
### Key Observations
- The code uses Coq's proof-by-induction and case analysis syntax.
- The theorem's goal involves existential quantification (`∃`) and arithmetic inequalities.
- The `exact` command suggests a direct application of a pre-proven lemma, followed by simplification (`simp`).
### Interpretation
This code represents a formal proof in Coq, a proof assistant used to verify mathematical theorems. The theorem `amc12a_2002_p6` asserts the existence of a number `m` greater than `n` (a positive natural number) such that there exists a `p` satisfying `m * p ≤ m + p`. The proof leverages induction on `n` and applies a lemma (`lt_add_of_pos_right`) to establish the inequality. The use of `simp` indicates automated simplification of the proof steps. This demonstrates Coq's role in formalizing and verifying mathematical reasoning, ensuring correctness through machine-checked proofs.
</details>
The proofs at this later stage are more sophisticated, usually involving multiple steps and combining various mathematical concepts or indicating a better ability to connect different areas of mathematics, mirroring the progression observed in Mathematics in Lean Source and SciLean. For example, as shown above, LeanAgent provides a one-line proof to the relatively advanced theorem mathd_numbertheory_233. The proof means the hypothesis directly proves the goal. This suggests that LeanAgent grasps modular arithmetic and recognizes when a given hypothesis is sufficient to prove the goal without additional steps.
Furthermore, as shown above, LeanAgent uses four tactics to prove the induction_12dvd4expnp1p20 theorem. This demonstrates its ability to handle more complex number theory proofs and use advanced tactics. This again shows that LeanAgent can recognize when it does not require complex premise retrieval.
LeanAgent demonstrates a similar grasp of the theorem amc12a_2002_p6. Notably, it combines the simple premises lt_add_of_pos_right, which describes how an element is less than that element added with a positive one, and zero_lt_one, which states that 0 is less than 1, with more advanced tactics like lift, cases, and exact with complex term construction. This demonstrates its ability to reuse foundational concepts for more complex proofs of abstract mathematical concepts, showing its stability.
Importantly, LeanAgent’s performance on MiniF2F showcases its ability to adapt and improve across different mathematical domains. We see this in the progression from ReProver’s basic arithmetic and algebra to LeanAgent’s more advanced number theory, calculus, and abstract algebra. This aligns with the observations from Mathematics in Lean Source and SciLean, further supporting the effectiveness of LeanAgent’s lifelong learning approach in theorem proving across various mathematical repositories.
Furthermore, early proofs from ReProver dealt with concrete numbers and simple equations. Later proofs from LeanAgent involved more abstract concepts like equivalence relations and function properties. LeanAgent gained the capability to handle more complex number theory problems involving divisibility under constraints. Moreover, LeanAgent shifted from solving basic linear and quadratic equations to analyzing functions and their compositions. Also, early proofs often used norm_num for straightforward computations. Later proofs employed more varied tactics and premises, suggesting a more sophisticated approach to proof construction. This all crucially suggests that while existing methods, like ReProver, may be more tailored to simpler computation problems, LeanAgent is superior on complex and analytical problems. These are precisely the types of problems present in advanced mathematics. This also corroborates LeanAgent’s performance on the repositories mentioned previously.
In addition, we evaluate LeanAgent on the Lean4 version of the MiniF2F test set using the same experimental setup from prior experiments, taking care not to progressively train on Test.lean and only proving sorry theorems from it. The results are as follows:
LeanAgent: Pass@1 of 38.1% (93 / 244 theorems)
ReProver (our run on Lean4): Pass@1 of 34.0% (83 / 244 theorems)
ReProver was only tested on the Lean3 test set in the LeanDojo paper, so we ran ReProver on the Lean4 test set for a fairer comparison. TheoremLlama (Wang et al., 2024c) reports a 33.61% cumulative accuracy on the Lean4 test set, but this makes a direct comparison with the Pass@1 rates of LeanAgent and ReProver infeasible. Moreover, DeepSeek-Prover-V1.5 (Xin et al., 2024b) reports a state-of-the-art result of 63.5% on the Lean4 test set.
However, LeanAgent is a lifelong learning framework, not a model. The performance of LeanAgent is dependent on the retriever used as the starting point - ReProver’s retriever in our case. As such, the metrics for other methods besides ReProver cannot be directly compared with LeanAgent. Such a comparison would be impractical for reasons including differences in data, pretraining, and fine-tuning. Again, we only compare with ReProver because we use ReProver’s retriever as the starting one in LeanAgent, allowing for a more faithful comparison. We use ReProver because past work has shown that retrieval leads to improved generalizability.
Moreover, we design LeanAgent to continuously generalize to and improve on ever-expanding mathematical knowledge without forgetting previously learned knowledge. Our goal is not to beat the MiniF2F benchmark; instead, we aim to perform well in proving sorry theorems across a range of diverse repositories. The other approaches mentioned focus on different objectives and don’t address the lifelong learning aspect that is central to our work.
Formal Book. We first examine the sorry theorems from Formal Book that LeanAgent proved during lifelong learning. These theorems centered around:
a) Real Analysis and Inequalities: LeanAgent demonstrates a better understanding relative to ReProver in real number properties and can handle basic inequality reasoning, proving book.irrational.lem_aux_ii, which involves real analysis and inequalities.
<details>
<summary>extracted/6256159/carbon56.png Details</summary>

### Visual Description
## Screenshot: Code Editor with Formal Proof Snippet
### Overview
The image shows a code editor displaying a formal proof snippet written in a functional programming or proof assistant language (likely Coq or Lean). The code is syntax-highlighted with color-coded elements, and the editor interface includes a window control bar with three colored circles (red, yellow, green) in the top-left corner.
### Components/Axes
- **UI Elements**:
- **Window Control Bar**: Top-left corner with three circular buttons:
- Red circle (close)
- Yellow circle (minimize)
- Green circle (maximize)
- **Code Block**: Dark background with syntax-highlighted text.
- **Text Content**:
- **Lemma Declaration**: `lemma lem_aux_ii (n : N) (x : R) (h1 : 0 < x) (h2 : x < 0) :`
- `N` and `R` likely represent natural numbers and real numbers, respectively.
- `h1` and `h2` are hypotheses (contradictory: `0 < x` and `x < 0`).
- **Logical Expression**:
- `(0 < f_aux n x) /\ (f_aux n x < (1 : R)) / n.factorial) :=`
- `f_aux` is a function returning a value between 0 and 1.
- Division by `n.factorial` (factorial of `n`).
- **Constructor**: `constructor <> linarith`
- `linarith` is a tactic in Coq/Lean for linear arithmetic proofs.
### Detailed Analysis
- **Textual Elements**:
- **Lemma Name**: `lem_aux_ii` (auxiliary lemma II).
- **Parameters**:
- `n : N` (natural number).
- `x : R` (real number).
- **Hypotheses**:
- `h1 : 0 < x` (x is positive).
- `h2 : x < 0` (x is negative) — **contradiction**.
- **Logical Expression**:
- `0 < f_aux n x` (output of `f_aux` is positive).
- `f_aux n x < (1 : R)` (output of `f_aux` is less than 1).
- Division by `n.factorial` (factorial of `n`).
- **Constructor**: `constructor <> linarith` (invokes the `linarith` tactic).
- **Syntax Highlighting**:
- Keywords (`lemma`, `constructor`): Red.
- Variables (`n`, `x`, `h1`, `h2`): Yellow.
- Operators (`:`, `<`, `>`, `:`, `/`, `:=`): Blue.
- Mathematical symbols (`0`, `1`, `: R`): Green.
- Comments (`// n.factorial`): Light gray.
### Key Observations
1. **Contradictory Hypotheses**: `h1` and `h2` assert `0 < x` and `x < 0`, which is logically impossible. This suggests the lemma is part of a proof by contradiction.
2. **Factorial Division**: The term `n.factorial` implies the lemma involves combinatorial or recursive reasoning.
3. **Tactic Usage**: `linarith` is a specialized tactic for linear arithmetic, indicating the lemma deals with inequalities or bounds.
### Interpretation
This code snippet defines a lemma (`lem_aux_ii`) that likely proves a property about a function `f_aux` under contradictory hypotheses. The use of `linarith` suggests the proof involves linear inequalities, and the division by `n.factorial` hints at a combinatorial or recursive structure. The contradictory hypotheses (`h1` and `h2`) imply the lemma is part of a broader proof strategy where such contradictions are resolved or leveraged to establish a result. The code is typical of formal verification in proof assistants like Coq or Lean, where lemmas are rigorously defined and proven using automated tactics.
</details>
b) Number Theory: LeanAgent shows capabilities in fundamental number theory concepts, proving book.quadratic_reciprocity.quadratic_reciprocity_2, a key result in quadratic reciprocity.
<details>
<summary>extracted/6256159/carbon57.png Details</summary>
### Visual Description
## Screenshot: Coq Proof Assistant Code
### Overview
The image shows a code snippet from a proof assistant (likely Coq) defining a formal theorem related to quadratic reciprocity. The code uses syntax highlighting with color-coded keywords, variables, and mathematical notation. The theorem is structured with hypotheses, facts, and a conclusion.
### Components/Axes
- **Window Controls**: Top-left corner has three circular buttons (red, yellow, green) typical of macOS window management.
- **Code Structure**:
- **Theorem Declaration**: `theorem quadratic_reciprocity_2 (p q : ℕ) (hp : p ≠ 2) (hq : q ≠ 2)`
- **Parameters**: `p`, `q` (natural numbers)
- **Hypotheses**: `hp` (p ≠ 2), `hq` (q ≠ 2)
- **Facts**:
- `[Fact (Nat.Prime p)]` and `[Fact (Nat.Prime q)]` (asserting primality of `p` and `q`)
- **Equation**:
- `(legendre_sym p q) * (legendre_sym q p) = -1 ^ ((p-1) / 2 * (q-1) / 2)`
- Uses Legendre symbol notation and exponentiation.
- **Conclusion**:
- `exact book.quadratic_reciprocity.quadratic_reciprocity_1 p q hp hq` (invokes a library lemma).
### Detailed Analysis
- **Syntax Highlighting**:
- Keywords (e.g., `theorem`, `Fact`) in **red**.
- Identifiers (e.g., `quadratic_reciprocity_2`, `legendre_sym`) in **yellow**.
- Mathematical symbols (e.g., `ℕ`, `≠`, `^`) in **white**.
- Operators (e.g., `*`, `/`, `=`) in **cyan**.
- **Mathematical Content**:
- The theorem formalizes the **Quadratic Reciprocity Law**, a foundational result in number theory.
- The equation relates the Legendre symbols `(p|q)` and `(q|p)` via a power of `-1` dependent on `(p-1)/2` and `(q-1)/2`.
### Key Observations
- The code enforces that `p` and `q` are primes **not equal to 2** (hypotheses `hp` and `hq`).
- The use of `exact` suggests the theorem is proven by directly applying a pre-existing lemma from the `book.quadratic_reciprocity` library.
- The Legendre symbol multiplication and exponentiation align with the standard statement of quadratic reciprocity.
### Interpretation
This code represents a formal verification of the Quadratic Reciprocity Law in a proof assistant. The theorem ensures that for odd primes `p` and `q`, the product of their Legendre symbols equals `(-1)` raised to a specific power, reflecting the reciprocity relationship. The use of hypotheses (`hp`, `hq`) and facts (`Nat.Prime`) demonstrates how the proof assistant enforces logical dependencies and mathematical axioms. The reference to `book.quadratic_reciprocity_1` indicates modularity, leveraging existing verified results to construct new proofs. This snippet exemplifies how formal methods can rigorously validate classical mathematical theorems.
</details>
Notably, the proof of the first theorem uses no premises, and the proof of the second uses a simple statement of quadratic reciprocity. However, by the end of the lifelong learning process, LeanAgent exhibits growth in its proving abilities in this repository:
a) Advanced Abstract Algebra: LeanAgent shows advancement in proving a key result in abstract algebra, wedderburn (Wedderburn’s Little Theorem), which is a crucial result in abstract algebra, stating that every finite division ring is a field.
<details>
<summary>extracted/6256159/carbon58.png Details</summary>
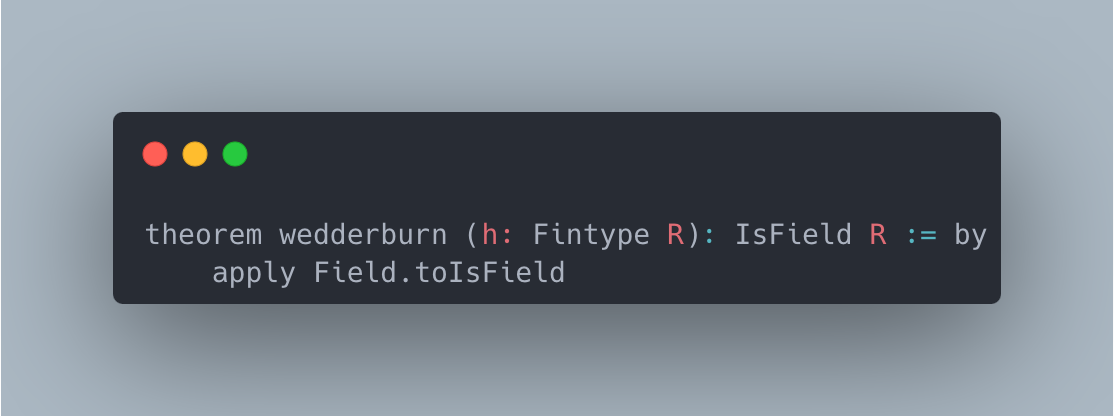
### Visual Description
## Screenshot: Code Snippet in Theorem Prover
### Overview
The image shows a code snippet from a theorem prover or formal verification system, likely in a functional programming language (e.g., Haskell, Coq, or Lean). The code defines a theorem named `wedderburn` with a hypothesis `h` of type `Fintype R`, asserting that `IsField R` holds, and provides a proof using the `apply` tactic.
### Components/Axes
- **Window Controls**: Three colored circles (red, yellow, green) at the top-left of the black rectangle, typical of macOS window management.
- **Code Text**:
- Theorem name: `theorem wedderburn`
- Hypothesis: `(h: Fintype R)`
- Result type: `: IsField R`
- Proof body: `:= by apply Field.toIsField`
### Detailed Analysis
- **Theorem Statement**:
The theorem `wedderburn` asserts that if a ring `R` is a finite type (`Fintype R`), then it is a field (`IsField R`).
- **Proof Structure**:
The proof uses the `by apply` tactic, which is common in proof assistants like Coq or Lean. The `Field.toIsField` function likely converts a `Field` instance into an `IsField` instance, leveraging type class resolution.
### Key Observations
- The code is syntactically minimal, focusing on the theorem's statement and its proof via type class application.
- No numerical data, charts, or diagrams are present.
### Interpretation
This snippet demonstrates a formal verification of the Wedderburn theorem, which states that finite division rings are fields. The use of `Fintype R` (a finite type) and `IsField R` (a field instance) aligns with the theorem's mathematical premise. The `apply Field.toIsField` line suggests the proof relies on an existing type class instance for `Field`, automating the verification process. This reflects the interplay between mathematical logic and computational formalism in theorem proving systems.
</details>
LeanAgent’s proof of the wedderburn theorem represents the ability to handle algebraic structures. By using the Field.toIsField premise, LeanAgent shows that it has grasped how to use the knowledge of what makes a ring a field. This requires an understanding of ring theory and field properties.
Coxeter. LeanAgent could not prove sorry theorems from the Coxeter repository during lifelong learning. However, by the end of lifelong learning, LeanAgent demonstrates a growing understanding of more complex algebraic structures, proving the lemma invmap.of_eq about Coxeter systems, again showing the ability to work with advanced concepts in group theory and abstract algebra. This corroborates the handling of abstract algebra necessary to prove the wedderburn theorem.
<details>
<summary>extracted/6256159/carbon59.png Details</summary>
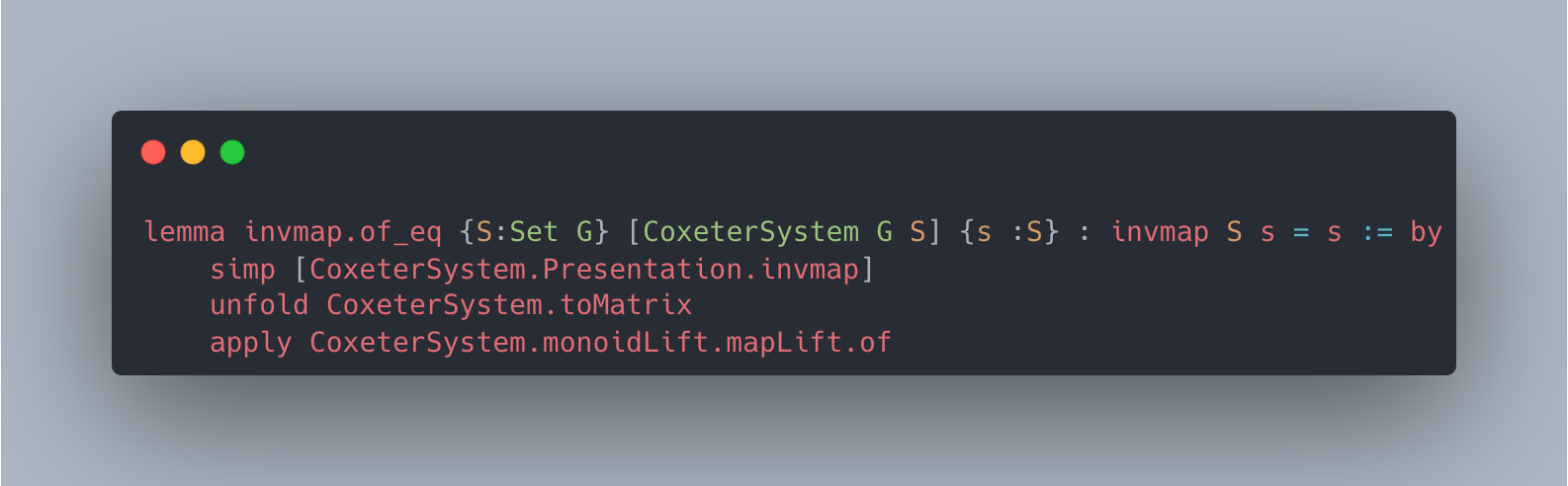
### Visual Description
## Screenshot: Functional Programming Code Snippet
### Overview
The image shows a code snippet from a functional programming or formal proof environment (likely Lean, Coq, or similar). The code defines a lemma (`invmap.of_eq`) about the inverse map of a Coxeter system, with a proof structured in three steps using `simp`, `unfold`, and `apply`. Syntax highlighting uses distinct colors for keywords, identifiers, and types.
### Components/Axes
- **UI Elements**:
- Top-left corner: Traffic light buttons (red, yellow, green) for window control.
- **Code Structure**:
- **Lemma Declaration**:
- `lemma invmap.of_eq {S:Set G} [CoxeterSystem G S] {s : S} : invmap S s = s := by`
- **Colors**:
- `lemma` (red), `invmap.of_eq` (green), `{S:Set G}` (blue), `[CoxeterSystem G S]` (orange), `{s : S}` (purple), `invmap S s = s` (red), `:= by` (orange).
- **Proof Steps**:
1. `simp [CoxeterSystem.Presentation.invmap]`
- `simp` (red), `CoxeterSystem.Presentation.invmap` (green).
2. `unfold CoxeterSystem.toMatrix`
- `unfold` (red), `CoxeterSystem.toMatrix` (green).
3. `apply CoxeterSystem.monoidLift.mapLift.of`
- `apply` (red), `CoxeterSystem.monoidLift.mapLift.of` (green).
### Detailed Analysis
- **Syntax Highlighting**:
- Keywords (`lemma`, `simp`, `unfold`, `apply`) are in **red**.
- Identifiers (`invmap`, `CoxeterSystem`, `Presentation`, `toMatrix`, `monoidLift`, `mapLift`) are in **green**.
- Type annotations (`S:Set G`, `s : S`) are in **blue** and **purple**.
- Brackets (`[ ]`, `{ }`) and operators (`:=`, `=`) are in **orange**.
### Key Observations
1. The lemma asserts that the inverse map (`invmap`) of a Coxeter system applied to an element `s` equals `s` itself.
2. The proof uses three steps:
- `simp` with `CoxeterSystem.Presentation.invmap` to simplify the expression.
- `unfold` to expand the definition of `CoxeterSystem.toMatrix`.
- `apply` to invoke `CoxeterSystem.monoidLift.mapLift.of` as the final step.
3. The code relies on domain-specific terms like `CoxeterSystem`, `monoidLift`, and `mapLift`, suggesting a focus on algebraic structures.
### Interpretation
This code snippet demonstrates a formal proof in a mathematical or algebraic context, likely verifying a property of Coxeter systems. The use of `simp`, `unfold`, and `apply` indicates a structured approach to theorem proving, common in proof assistants. The lemma’s conclusion (`invmap S s = s`) implies that the inverse map preserves elements in the Coxeter system, a non-trivial result in group theory or combinatorics. The absence of numerical data or visualizations emphasizes the abstract, logical nature of the code.
### Notable Patterns
- The proof steps are concise, leveraging built-in tactics (`simp`, `unfold`, `apply`) to automate reasoning.
- The code’s reliance on `CoxeterSystem` and `monoidLift` suggests it is part of a larger library for algebraic structures.
- The use of `:= by` indicates the proof is deferred to a separate block (not visible in the image).
### Conclusion
The image captures a formal proof snippet in a functional programming or proof-assistant environment, focusing on properties of Coxeter systems. The syntax highlighting and structured proof steps highlight the interplay between code and mathematical logic.
</details>
LeanAgent’s proof of invmap.of_eq involves unfolding definitions and applying specific properties of Coxeter systems. This demonstrates LeanAgent’s growing understanding relative to ReProver in abstract algebra specific to the new repository it has learned from.
Hairy Ball Theorem. Moreover, LeanAgent could not prove sorry theorems from the Hairy Ball Theorem repository during lifelong learning. However, at the end of lifelong learning, LeanAgent again demonstrates a stronger understanding relative to ReProver in algebraic topology. It proves HairyBallDiff, which states a key step in the Hairy Ball Theorem, demonstrating a grasp of vector spaces, norms, and their connections to topological concepts.
<details>
<summary>extracted/6256159/carbon60.png Details</summary>
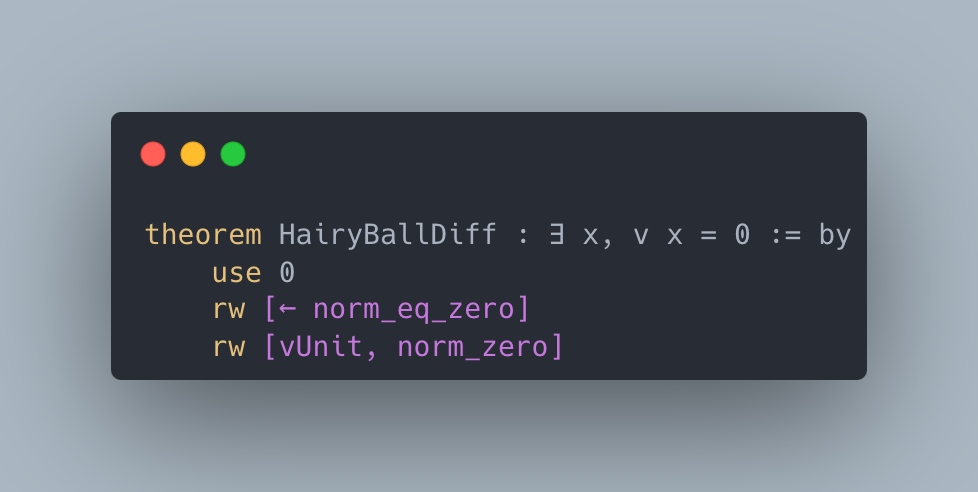
### Visual Description
## Screenshot: Code Snippet in Theorem Prover
### Overview
The image shows a code snippet from a theorem prover (likely Lean or Coq) with syntax highlighting. The code defines a theorem named `HairyBallDiff` and includes proof steps using lemmas and rewrite rules. The UI elements (window controls, syntax colors) are visible but not part of the code logic.
### Components/Axes
- **Window Controls**: Red, yellow, and green dots in the top-left corner (standard macOS window controls).
- **Code Structure**:
- **Theorem Declaration**: `theorem HairyBallDiff : ∃ x, v x = 0 := by`
- `HairyBallDiff`: Theorem name.
- `∃ x, v x = 0`: Existential quantification stating "there exists an x such that v(x) equals 0."
- `:= by`: Indicates the proof begins with the `by` tactic.
- **Proof Steps**:
1. `use 0`: Applies the lemma `0` (likely a base case or identity).
2. `rw [← norm_eq_zero]`: Rewrites using the lemma `norm_eq_zero` in reverse (denoted by `←`).
3. `rw [vUnit, norm_zero]`: Rewrites using the lemmas `vUnit` and `norm_zero`.
### Detailed Analysis
- **Textual Content**:
- `theorem HairyBallDiff : ∃ x, v x = 0 := by`
- Declares a theorem asserting the existence of an element `x` satisfying `v(x) = 0`.
- `use 0`: Invokes a lemma named `0` (possibly a trivial or foundational lemma).
- `rw [← norm_eq_zero]`: Rewrites the goal using `norm_eq_zero` in reverse.
- `rw [vUnit, norm_zero]`: Rewrites the goal using `vUnit` and `norm_zero`.
### Key Observations
- The code uses **syntax highlighting**:
- Keywords (`theorem`, `use`, `rw`) in yellow.
- Variables (`x`, `v`, `norm_eq_zero`, `vUnit`, `norm_zero`) in purple.
- Symbols (`∃`, `:=`, `by`) in white.
- The `∃` symbol (existential quantifier) is critical for the theorem's logical structure.
- The `by` keyword initiates a proof script, common in interactive theorem provers.
### Interpretation
This code snippet demonstrates a formal proof in a theorem prover, likely verifying a mathematical property related to the "hairy ball theorem" (a result in topology stating that a continuous tangent vector field on a sphere must vanish somewhere).
- **Logical Flow**:
1. The theorem asserts the existence of an `x` where `v(x) = 0`.
2. The proof uses `use 0` to apply a base case (e.g., `v(0) = 0`).
3. `rw [← norm_eq_zero]` reverses a lemma to simplify the goal.
4. `rw [vUnit, norm_zero]` combines two lemmas to complete the proof.
- **Significance**:
- The use of `∃` and `v x = 0` suggests the theorem is about the existence of a zero in a vector field or function.
- The rewrite rules (`rw`) indicate the prover is automating proof steps by leveraging pre-defined lemmas.
- **Context**:
- This is likely part of a formal verification project, ensuring correctness of mathematical or computational systems.
- The code reflects the interplay between logic (theorem) and automation (rewrite rules).
### Notes on Uncertainty
- The exact meaning of `HairyBallDiff` and the lemmas (`norm_eq_zero`, `vUnit`, `norm_zero`) depends on the broader context of the project.
- The `∃ x, v x = 0` could refer to a specific mathematical structure (e.g., a vector field on a sphere) or a computational problem.
- The `by` tactic implies the proof is automated, but the exact steps depend on the prover's configuration.
This description captures all textual and structural elements of the code, focusing on its logical and syntactic components.
</details>
Crucially, only LeanAgent could prove invmap.of_eq, wedderburn, and HairyBallDiff, demonstrating that it has developed much more advanced theorem-proving capabilities than other setups. These proofs show that LeanAgent can work with highly abstract concepts and apply them to specific mathematical objects.
A.6 Curriculum Learning Analysis
In this section, we aim to answer the following questions: (1) Why does LeanAgent use $e^{S}$ ( $S$ = number of proof steps) as its complexity metric? (2) Why does curriculum learning work in theorem proving? (3) Why does LeanAgent use curriculum learning instead of other lifelong learning methods?
Complexity Measure. There is no universal measure of proof complexity in Lean or other formal systems. One approach, the length-based measure, involves examining the proof length (number of steps or lines) and the size of the proof term in a formal system. While these can indicate verification complexity, they may not fully capture the complexity of discovering a proof (Arana & Stafford, 2023). Moreover, within the NLP literature, many works have related input length to complexity (Zaremba & Sutskever, 2015; Cirik et al., 2016; Spitkovsky et al., ; Subramanian et al., 2017; Chang et al., 2021). Starting with shorter sequences and gradually increasing length improves model quality (Li et al., 2024).
These works demonstrate the gains from basing the complexity measure on input length. As such, we consider the equivalent of length in theorem proving to be the number of proof steps. However, we consider a linear scaling of length naive for theorem proving; it doesn’t consider the combinatorial explosion of possible proof paths as the length of the proof increases. As such, we choose an exponential scaling. Notably, a key strength of this choice is it is easy to compute and requires no additional hyperparameters to tune.
We now discuss some alternative complexity metrics and why we chose not to use them in LeanAgent. One option is $e^{B}$ , where $B$ represents the number of different proof paths that could be explored at each step. Formally, $B$ is defined as the average number of child nodes for each non-leaf node in the proof tree. This is sometimes called the branching factor. We refrain from using this complexity metric as computing this becomes computationally expensive for complex proofs. Moreover, another option is to consider the complexity of the theorem statement to determine complexity. For example, this could be measured by the number of unique symbols, the depth of nested expressions, or the number of quantifiers. However, developing a reliable metric for statement complexity that works across various mathematical domains could be challenging. Moreover, LeanAgent focuses on improving proof generation, so using a metric directly related to the proof process (number of steps) aligns better with this goal than statement complexity. Dependency-based complexity, where we order theorems based on their dependency structure within the mathematical library, wasn’t used for multiple reasons. Namely, a theorem might depend on many simple results but still be relatively easy to prove, or it might depend on a few results but be very challenging. Furthermore, a topic-based curriculum would be unsuitable because LeanAgent aims to be a general-purpose framework. A topic-based approach might bias it towards certain mathematical domains. Moreover, a topic-based approach does not account for theorems spanning multiple mathematical concepts. Another option is a form of premise-based complexity measure. However, analyzing premise occurrence frequencies across repositories could be computationally expensive, especially for large repositories like SciLean.
Curriculum Learning. Prior work suggests that curriculum learning guides the learner towards better local minima in non-convex optimization problems (Bengio et al., 2009). Crucially, theorem proving involves navigating a highly non-convex optimization landscape, especially for complex mathematical statements. The space of possible proofs is vast and complex, with many potential dead ends and suboptimal solutions to parts of a proof. This makes theorem proving an ideal candidate for benefitting from curriculum learning. Moreover, curriculum learning has been shown to have an effect similar to unsupervised pre-training, acting as a form of regularization (Bengio et al., 2009). For theorem proving, curriculum learning allows LeanAgent to build a foundational knowledge base of mathematics before attempting more complex theorems, naturally leading to continuous improvement. This avoids suboptimal proof strategies early in training. Furthermore, this leads to more robust and generalizable proof techniques that work across a broader range of theorems, explaining LeanAgent’s sorry theorem proving performance. Moreover, the ability to act as a regularizer means curriculum learning prevents the model from overfitting to specific types of proofs or mathematical domains. This allows for continuous generalizability, explaining LeanAgent’s superior lifelong learning metric scores.
Moreover, other works from the literature show that curriculum learning biases models towards building constructive internal representations (Cirik et al., 2016). Specifically, it allows the model to use the knowledge from earlier steps in later predictions. In theorem proving, this allows LeanAgent to learn basic proof skills, which then become building blocks for more complex proofs later on. This corroborates our analysis of LeanAgent’s progression of proof complexity. Moreover, multiple past works agree that curriculum learning provides larger gains when training data is limited (Zaremba & Sutskever, 2015; Cirik et al., 2016; Spitkovsky et al., ). This is the case in formal theorem proving, where the number of formalized theorems and proofs is limited. These past works also state that curriculum learning leads to better generalization, supporting the observations of LeanAgent’s superior lifelong learning metrics.
This context supports LeanAgent’s sorry theorem proving performance and superiority on lifelong learning metrics.
Comparison with Other Lifelong Learning Methods. Many other lifelong learning methods exist, such as those mentioned in Sec. 2. However, we chose curriculum learning for the following reasons. Regularization methods, like EWC, slow down learning on important parameters. However, the importance of parameters can change as the theorem complexity increases. This helps explain the lower sorry theorem proving performance of EWC methods and their performance on lifelong learning metrics. Moreover, memory-based techniques store examples from previous tasks to prevent forgetting. However, this can greatly affect these methods’ balance of stability and plasticity. This can be seen in the lifelong learning metrics of Merge All setups, including the negative IP values. Knowledge distillation requires a separate teacher model, but curriculum learning is more efficient as it provides the path to knowledge accumulation in a single model. Since LeanAgent is a framework, not a model, we refrain from using dynamic architecture adjustment to keep LeanAgent general to many LLM architectures. Moreover, recent work selectively updates parameters with the largest momentum magnitudes and uses selective reinitialization to maintain plasticity. However, these methods often focus on balancing performance across distinct tasks. In theorem proving, where tasks form a spectrum of increasing complexity, curriculum learning provides a more structured approach to knowledge accumulation.
A.7 Theorem Proving Performance Score (TPPS) Analysis
In this work, we directly compared the number of proven theorems with ReProver. However, the field of theorem proving, especially in a lifelong learning context, currently lacks standardized performance metrics. To address this concern, this section discusses a possible alternative metric while acknowledging its limitations.
Theorem proving difficulty is inherently non-linear in nature. For example, LeanAgent’s significantly improved performance over the baseline across multiple repositories allows it to prove progressively harder theorems. Furthermore, sorry theorems lack ground truth proofs, so proving one is valuable. To address these nuances, one could propose the Theorem Proving Performance Score (TPPS) to emphasize newly proven sorry theorems. Specifically, it could be stated that $\text{LeanAgent TPPS}=(\text{\# ReProver Theorems Proved})+(\text{\# New %
Theorems Proved}*X)+1$ , where $X$ represents the importance of proving a new theorem, and $\text{ReProver TPPS}=(\text{\# ReProver Theorems Proved})+1$ . Then, $\text{Improvement Factor}=(\text{LeanAgent TPPS})/(\text{ReProver TPPS})$ .
The core idea behind TPPS is to assign a higher reward for newly proven theorems, aligning with lifelong learning objectives. However, it is important to recognize its preliminary nature and potential shortcomings. First, choosing the parameter $X$ is challenging. One approach is to choose a static value, such as $X=10$ , to standardize comparisons between LeanAgent and ReProver across diverse repositories. However, this may lead to inflated or deflated metrics on such repositories. Alternatively, $X$ could be chosen adaptively based on the difficulty of a repository, but this may similarly result in unrealistic metric scores. Overall, the TPPS metric focuses on quantity and faces challenges in ensuring comparisons across diverse repositories.
Moreover, the TPPS metric can be susceptible to artifacts that artificially inflate performance. For instance, several theorems in the PFR repository were proven on a technicality due to placeholder statements of “ $0=1$ ”, which could then be used to prove other “sorry” theorems through the principle of ex falso quodlibet. Examples such as this are due to the weakness of the current state of repositories rather than a fundamental shortcoming of our ML approach, underscoring the need for more robust and well-tested benchmarks.
Furthermore, TPPS does not account for the difficulty of the theorems being proved. While we initially considered using proof length as a proxy for difficulty (e.g., $e^{S}$ where $S$ is the number of proof steps), we found this approach problematic during proving evaluation. LeanAgent sometimes generates shorter proofs for difficult theorems, making proof length an unreliable indicator of theorem difficulty.
These issues expose broader challenges in evaluating theorem-proving systems. The field lacks standardized benchmarks, necessitating carefully curated sets of theorems with varying difficulties across different mathematical domains. Developing reliable metrics to assess theorem difficulty beyond simple measures like proof length or statement complexity is crucial. Future benchmarks should prevent the exploitation of technicalities. Moreover, metrics should consider the mathematical significance of proven theorems, not just their quantity. Finally, ensuring that performance metrics are meaningful and comparable across different mathematical repositories is essential for consistent evaluation.
In light of these considerations, we acknowledge that TPPS, while a step towards quantifying theorem-proving performance in a lifelong learning setting, has many limitations. Future work should focus on developing more sophisticated and robust evaluation frameworks that address these challenges. For example, we plan to investigate more sophisticated measures that reward not only newly proved theorems but also difficult ones. By highlighting these issues, we hope to contribute to the ongoing discussion on how best to evaluate and compare theorem-proving systems, particularly in the context of lifelong learning. The development of standardized, reliable metrics will be crucial for measuring progress and guiding future research in this field.