# * : On-the-Fly Self-Speculative Decoding for LLM Inference Acceleration
> Corresponding Author
## Abstract
Speculative decoding (SD) has emerged as a widely used paradigm to accelerate LLM inference without compromising quality. It works by first employing a compact model to draft multiple tokens efficiently and then using the target LLM to verify them in parallel. While this technique has achieved notable speedups, most existing approaches necessitate either additional parameters or extensive training to construct effective draft models, thereby restricting their applicability across different LLMs and tasks. To address this limitation, we explore a novel plug-and-play SD solution with layer-skipping, which skips intermediate layers of the target LLM as the compact draft model. Our analysis reveals that LLMs exhibit great potential for self-acceleration through layer sparsity and the task-specific nature of this sparsity. Building on these insights, we introduce , an on-the-fly self-speculative decoding algorithm that adaptively selects intermediate layers of LLMs to skip during inference. does not require auxiliary models or additional training, making it a plug-and-play solution for accelerating LLM inference across diverse input data streams. Our extensive experiments across a wide range of models and downstream tasks demonstrate that can achieve over a $1.3\times$ $\sim$ $1.6\times$ speedup while preserving the original distribution of the generated text. We release our code in https://github.com/hemingkx/SWIFT.
## 1 Introduction
Large Language Models (LLMs) have exhibited outstanding capabilities in handling various downstream tasks (OpenAI, 2023; Touvron et al., 2023a; b; Dubey et al., 2024). However, their token-by-token generation necessitated by autoregressive decoding poses efficiency challenges, particularly as model sizes increase. To address this, speculative decoding (SD) has been proposed as a promising solution for lossless LLM inference acceleration (Xia et al., 2023; Leviathan et al., 2023; Chen et al., 2023). At each decoding step, SD first employs a compact draft model to efficiently predict multiple tokens as speculations for future decoding steps of the target LLM. These tokens are then validated by the target LLM in parallel, ensuring that the original output distribution remains unchanged.
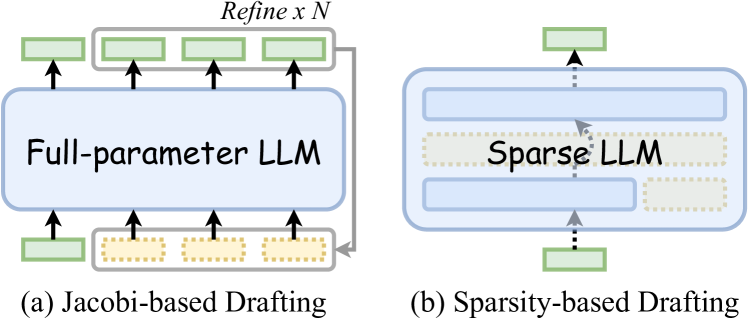
Recent advancements in SD have pushed the boundaries of the latency-accuracy trade-off by exploring various strategies (Xia et al., 2024), including incorporating lightweight draft modules into LLMs (Cai et al., 2024; Ankner et al., 2024; Li et al., 2024a; b), employing fine-tuning strategies to facilitate efficient LLM drafting (Kou et al., 2024; Yi et al., 2024; Elhoushi et al., 2024), and aligning draft models with the target LLM (Liu et al., 2023a; Zhou et al., 2024; Miao et al., 2024). Despite their promising efficacy, these approaches require additional modules or extensive training, which limits their broad applicability across different model types and causes significant inconvenience in practice. To tackle this issue, another line of research has proposed the Jacobi-based drafting (Santilli et al., 2023; Fu et al., 2024) to facilitate plug-and-play SD. As illustrated in Figure 1 (a), these methods append pseudo tokens to the input prompt, enabling the target LLM to generate multiple tokens as drafts in a single decoding step. However, the Jacobi-decoding paradigm misaligns with the autoregressive pretraining objective of LLMs, resulting in suboptimal acceleration effects.
<details>
<summary>x1.png Details</summary>
### Visual Description
\n
## Diagram: LLM Drafting Methods
### Overview
The image presents a comparative diagram illustrating two different drafting methods for Large Language Models (LLMs): Jacobi-based Drafting and Sparsity-based Drafting. Each method is visually represented with a block diagram showing the flow of information and the components involved.
### Components/Axes
The diagram consists of two main sections, labeled (a) and (b), representing the two drafting methods. Each section includes:
* **LLM Block:** A large rectangular block representing the LLM itself. In (a) it is labeled "Full-parameter LLM", and in (b) it is labeled "Sparse LLM".
* **Input/Output Blocks:** Smaller rectangular blocks, colored light green, representing input or output data.
* **Intermediate Blocks:** Smaller rectangular blocks, colored yellow with a dotted pattern, representing intermediate data or processing steps.
* **Arrows:** Arrows indicating the direction of information flow.
* **Labels:** Text labels identifying the components and the overall method.
* **Refine x N:** A label at the top of the (a) section indicating a refinement process repeated N times.
### Detailed Analysis or Content Details
**(a) Jacobi-based Drafting:**
* **Full-parameter LLM:** A large blue rectangle dominates the center.
* **Input:** Four light green rectangles are positioned below the LLM block, each connected to the LLM via an arrow.
* **Intermediate:** Four yellow, dotted rectangles are positioned between the input and the LLM, each connected to both.
* **Output:** Four light green rectangles are positioned above the LLM block, each connected to the LLM via an arrow.
* **Refine x N:** Located at the top center, indicating a refinement process repeated N times. The arrows from the LLM to the top green blocks suggest this refinement.
**(b) Sparsity-based Drafting:**
* **Sparse LLM:** A large blue rectangle dominates the center. This LLM block is composed of multiple smaller blue rectangles stacked vertically.
* **Intermediate:** Two yellow, dotted rectangles are positioned within the Sparse LLM block, suggesting internal processing.
* **Input:** Two light green rectangles are positioned below the Sparse LLM block, connected via dotted arrows.
* **Output:** One light green rectangle is positioned above the Sparse LLM block, connected via a dotted arrow.
* The dotted arrows indicate a more selective or sparse connection between the input/output and the LLM.
### Key Observations
* Jacobi-based Drafting (a) appears to involve a full parameter LLM with a direct connection between input, intermediate processing, and output. The "Refine x N" label suggests an iterative refinement process.
* Sparsity-based Drafting (b) utilizes a Sparse LLM, implying a more efficient or selective use of parameters. The dotted arrows suggest a less dense connection between input/output and the LLM.
* The number of input/output blocks differs between the two methods, suggesting different data handling approaches.
### Interpretation
The diagram illustrates two distinct approaches to drafting LLMs. Jacobi-based Drafting seems to employ a full-parameter model with iterative refinement, potentially requiring more computational resources. Sparsity-based Drafting, on the other hand, leverages a sparse model, potentially offering improved efficiency and scalability. The use of dotted arrows in the sparsity-based method suggests a selective activation or connection of parameters, which is characteristic of sparse models. The diagram highlights a trade-off between model complexity (full vs. sparse) and data flow (direct vs. selective). The "Refine x N" label in (a) suggests an iterative process to improve the model's performance, while (b) appears to focus on efficient parameter utilization. The diagram does not provide quantitative data, but it visually conveys the conceptual differences between the two drafting methods.
</details>
Figure 1: Illustration of prior solution and ours for plug-and-play SD. (a) Jacobi-based drafting appends multiple pseudo tokens to the input prompt, enabling the target LLM to generate multiple tokens as drafts in a single step. (b) adopts sparsity-based drafting, which exploits the inherent sparsity in LLMs to facilitate efficient drafting. This work is the first exploration of plug-and-play SD using sparsity-based drafting.
In this work, we introduce a novel research direction for plug-and-play SD: sparsity-based drafting, which leverages the inherent sparsity in LLMs to enable efficient drafting (see Figure 1 (b)). Specifically, we exploit a straightforward yet practical form of LLM sparsity – layer sparsity – to accelerate inference. Our approach is based on two key observations: 1) LLMs possess great potential for self-acceleration through layer sparsity. Contrary to the conventional belief that layer selection must be carefully optimized (Zhang et al., 2024), we surprisingly found that uniformly skipping layers to draft can still achieve a notable $1.2\times$ speedup, providing a strong foundation for plug-and-play SD. 2) Layer sparsity is task-specific. We observed that each task requires its own optimal set of skipped layers, and applying the same layer configuration across different tasks would cause substantial performance degradation. For example, the speedup drops from $1.47\times$ to $1.01\times$ when transferring the configuration optimized for a storytelling task to a reasoning task.
Building on these observations, we introduce , the first on-the-fly self-speculative decoding algorithm that adaptively optimizes the set of skipped layers in the target LLM during inference, facilitating the lossless acceleration of LLMs across diverse input data streams. integrates two key innovations: (1) a context-based layer set optimization mechanism that leverages LLM-generated context to efficiently identify the optimal set of skipped layers corresponding to the current input stream, and (2) a confidence-aware inference acceleration strategy that maximizes the use of draft tokens, improving both speculation accuracy and verification efficiency. These innovations allow to strike an expected balance between the latency-accuracy trade-off in SD, providing a new plug-and-play solution for lossless LLM inference acceleration without the need for auxiliary models or additional training, as demonstrated in Table 1.
We conduct experiments using LLaMA-2 and CodeLLaMA models across multiple tasks, including summarization, code generation, mathematical reasoning, etc. achieves a $1.3\times$ $\sim$ $1.6\times$ wall-clock time speedup compared to conventional autoregressive decoding. Notably, in the greedy setting, consistently maintains a $98\$ $\sim$ $100\$ token acceptance rate across the LLaMA2 series, indicating the high alignment potential of this paradigm. Further analysis validated the effectiveness of across diverse data streams and its compatibility with various LLM backbones.
Our key contributions are:
1. We performed an empirical analysis of LLM acceleration on layer sparsity, revealing both the potential for LLM self-acceleration via layer sparsity and its task-specific nature, underscoring the necessity for adaptive self-speculative decoding during inference.
1. Building on these insights, we introduce , the first plug-and-play self-speculative decoding algorithm that optimizes the set of skipped layers in the target LLM on the fly, enabling lossless acceleration of LLM inference across diverse input data streams.
1. We conducted extensive experiments across various models and tasks, demonstrating that consistently achieves a $1.3\times$ $\sim$ $1.6\times$ speedup without any auxiliary model or training, while theoretically guaranteeing the preservation of the generated text’s distribution.
## 2 Related Work
Speculative Decoding (SD)
Due to the sequential nature of autoregressive decoding, LLM inference is constrained by memory-bound computations (Patterson, 2004; Shazeer, 2019), with the primary latency bottleneck arising not from arithmetic computations but from memory reads/writes of LLM parameters (Pope et al., 2023). To mitigate this issue, speculative decoding (SD) introduces utilizing a compact draft model to predict multiple decoding steps, with the target LLM then validating them in parallel (Xia et al., 2023; Leviathan et al., 2023; Chen et al., 2023). Recent SD variants have sought to enhance efficiency by incorporating additional modules (Kim et al., 2023; Sun et al., 2023; Du et al., 2024; Li et al., 2024a; b) or introducing new training objectives (Liu et al., 2023a; Kou et al., 2024; Zhou et al., 2024; Gloeckle et al., 2024). However, these approaches necessitate extra parameters or extensive training, limiting their applicability across different models. Another line of research has explored plug-and-play SD methods with Jacobi decoding (Santilli et al., 2023; Fu et al., 2024), which predict multiple steps in parallel by appending pseudo tokens to the input and refining them iteratively. As shown in Table 1, our work complements these efforts by investigating a novel plug-and-play SD method with layer-skipping, which exploits the inherent sparsity of LLM layers to accelerate inference. The most related approaches to ours include Self-SD (Zhang et al., 2024) and LayerSkip (Elhoushi et al., 2024), which also skip intermediate layers of LLMs to form the draft model. However, both methods require a time-consuming offline training process, making them neither plug-and-play nor easily generalizable across different models and tasks.
| Eagle (Li et al., 2024a; b) | Draft Heads | Yes | ✗ | ✓ | ✓ | ✓ | - |
| --- | --- | --- | --- | --- | --- | --- | --- |
| Rest (He et al., 2024) | Context Retrieval | Yes | ✗ | ✓ | ✓ | ✓ | - |
| Self-SD (Zhang et al., 2024) | Layer Skipping | No | ✗ | ✓ | ✓ | ✗ | - |
| Parallel (Santilli et al., 2023) | Jacobi Decoding | No | ✓ | ✓ | ✗ | ✗ | $0.9\times$ $\sim$ $1.0\times$ |
| Lookahead (Fu et al., 2024) | Jacobi Decoding | No | ✓ | ✓ | ✓ | ✓ | $1.2\times$ $\sim$ $1.4\times$ |
| (Ours) | Layer Skipping | No | ✓ | ✓ | ✓ | ✓ | $1.3\times$ $\sim$ $1.6\times$ |
Table 1: Comparison of with existing SD methods. “ AM ” denotes whether the method requires auxiliary modules such as additional parameters or data stores. “ Greedy ”, “ Sampling ”, and “ Token Tree ” denote whether the method supports greedy decoding, multinomial sampling, and token tree verification, respectively. is the first plug-and-play layer-skipping SD method, which is orthogonal to those Jacobi-based methods such as Lookahead (Fu et al., 2024).
Efficient LLMs Utilizing Sparsity
LLMs are powerful but often over-parameterized (Hu et al., 2022). To address this issue, various methods have been proposed to accelerate inference by leveraging different forms of LLM sparsity. One promising research direction is model compression, which includes approaches such as quantization (Dettmers et al., 2022; Frantar et al., 2023; Ma et al., 2024), parameter pruning (Liu et al., 2019; Hoefler et al., 2021; Liu et al., 2023b), and knowledge distillation (Touvron et al., 2021; Hsieh et al., 2023; Gu et al., 2024). These approaches aim to reduce model sparsity by compressing LLMs into more compact forms, thereby decreasing memory usage and computational overhead during inference. Our proposed method, , focuses specifically on sparsity within LLM layer computations, providing a more streamlined approach to efficient LLM inference that builds upon recent advances in layer skipping (Corro et al., 2023; Zhu et al., 2024; Jaiswal et al., 2024; Liu et al., 2024). Unlike these existing layer-skipping methods that may lead to information loss and performance degradation, investigates the utilization of layer sparsity to enable lossless acceleration of LLM inference.
## 3 Preliminaries
### 3.1 Self-Speculative Decoding
Unlike most SD methods that require additional parameters, self-speculative decoding (Self-SD) first proposed utilizing parts of an LLM as a compact draft model (Zhang et al., 2024). In each decoding step, this approach skips intermediate layers of the LLM to efficiently generate draft tokens; these tokens are then validated in parallel by the full-parameter LLM to ensure that the output distribution of the target LLM remains unchanged. The primary challenge of Self-SD lies in determining which layers, and how many, should be skipped – referred to as the skipped layer set – during the drafting stage, which is formulated as an optimization problem. Formally, given the input data $\mathcal{X}$ and the target LLM $\mathscr{M}_{T}$ with $L$ layers (including both attention and MLP layers), Self-SD aims to identify the optimal skipped layer set $\bm{z}$ that minimizes the average inference time per token:
$$
\bm{z}^{*}=\underset{\bm{z}}{\arg\min}\frac{\sum_{\bm{x}\in\mathcal{X}}f\left(
\bm{x}\mid\bm{z};\bm{\theta}_{\mathscr{M}_{T}}\right)}{\sum_{\bm{x}\in\mathcal
{X}}|\bm{x}|},\quad\text{ s.t. }\bm{z}\in\{0,1\}^{L}, \tag{1}
$$
where $f(\cdot)$ is a black-box function that returns the inference latency of sample $\bm{x}$ , $\bm{z}_{i}\in\{0,1\}$ denotes whether layer $i$ of the target LLM is skipped when drafting, and $|\bm{x}|$ represents the sample length. Self-SD addresses this problem through a Bayesian optimization process (Jones et al., 1998). Before inference, this process iteratively selects new inputs $\bm{z}$ based on a Gaussian process (Rasmussen & Williams, 2006) and evaluates Eq (1) on the training set of $\mathcal{X}$ . After a specified number of iterations, the best $\bm{z}$ is considered an approximation of $\bm{z}^{*}$ and is held fixed for inference.
While Self-SD has proven effective, its reliance on a time-intensive Bayesian optimization process poses certain limitations. For each task, Self-SD must sequentially evaluate all selected training samples during every iteration to optimize Eq (1); Moreover, the computational burden of Bayesian optimization escalates substantially with the number of iterations. As a result, processing just eight CNN/Daily Mail (Nallapati et al., 2016) samples for 1000 Bayesian iterations requires nearly 7.5 hours for LLaMA-2-13B and 20 hours for LLaMA-2-70B on an NVIDIA A6000 server. These computational demands restrict the generalizability of Self-SD across different models and tasks.
### 3.2 Experimental Observations
This subsection delves into Self-SD, exploring the plug-and-play potential of this layer-skipping SD paradigm for lossless LLM inference acceleration. Our key findings are detailed below.
<details>
<summary>x2.png Details</summary>
### Visual Description
## Chart: Speedups with Skipping and Domain Shift
### Overview
The image presents two charts. The first (a) shows the relationship between the number of sub-layers skipped and the token acceptance rate for two different candidate selection methods (Top-k and Top-1). The second chart (b) displays speedup variations across different evaluation tasks (Summarization, Reasoning, Storytelling, and Translation) under domain shift conditions.
### Components/Axes
**Chart (a): Speedups with a Unified Skipping Pattern**
* **X-axis:** Number of Sub-layers to Skip (ranging from approximately 25 to 45, with markers at 25, 30, 35, 40, 45).
* **Y-axis (left):** Token Acceptance Rate (ranging from approximately 0.2 to 1.0).
* **Y-axis (right):** Speedup (ranging from approximately 0.8 to 1.2).
* **Legend:**
* Top-k candidates (represented by a dark blue line with triangle markers)
* Top-1 candidates (represented by a light blue line with triangle markers)
**Chart (b): Speedup Variations under Domain Shift**
* **X-axis:** Evaluation Tasks (Summarization, Reasoning, Storytelling, Translation).
* **Y-axis:** Speedup (ranging from approximately 0.8 to 1.5).
* **Legend:**
* Sum. LS (represented by an orange bar)
* Rea. LS (represented by a light green bar)
* Story. LS (represented by a teal bar)
* Trans. LS (represented by a red bar)
### Detailed Analysis or Content Details
**Chart (a):**
* **Top-k candidates:** The line starts at approximately 0.95 at 25 sub-layers skipped, decreases to approximately 0.75 at 35 sub-layers, then increases to approximately 0.9 at 45 sub-layers.
* **Top-1 candidates:** The line starts at approximately 0.85 at 25 sub-layers skipped, decreases sharply to approximately 0.25 at 35 sub-layers, and then increases to approximately 0.4 at 45 sub-layers.
* The speedup axis is not directly tied to the lines, but appears to be a secondary indicator.
**Chart (b):**
* **Summarization:** Sum. LS = 0.99
* **Reasoning:** Rea. LS = 1.17, and a second value of 1.12 is present.
* **Storytelling:** Story. LS = 1.34
* **Translation:** Trans. LS = 1.24
* The bars represent the speedup for each task.
### Key Observations
* In Chart (a), increasing the number of skipped sub-layers initially decreases the token acceptance rate for both Top-k and Top-1 candidates, but the rate recovers somewhat at higher skip numbers. Top-1 candidates experience a more dramatic initial drop in acceptance rate.
* In Chart (b), Storytelling shows the highest speedup (1.34), while Summarization has the lowest (0.99). Reasoning has two values, suggesting potential variance or multiple measurements.
### Interpretation
The data suggests that skipping sub-layers can be a viable strategy for accelerating model performance, but it comes with a trade-off in token acceptance rate. The optimal number of sub-layers to skip appears to depend on the candidate selection method used. Top-1 candidates are more sensitive to skipping than Top-k candidates.
Chart (b) indicates that the effectiveness of this acceleration strategy varies across different NLP tasks. Storytelling benefits the most from the domain shift, while Summarization sees the least improvement. The presence of two values for Reasoning suggests that the speedup may be less consistent for this task.
The "LS" in the legend for Chart (b) likely refers to a specific domain shift or evaluation setting (e.g., Low-resource setting). The charts demonstrate the impact of this domain shift on the speedup achieved for each task. The data suggests that the benefits of skipping sub-layers are not uniform across all tasks and are influenced by the evaluation context.
</details>
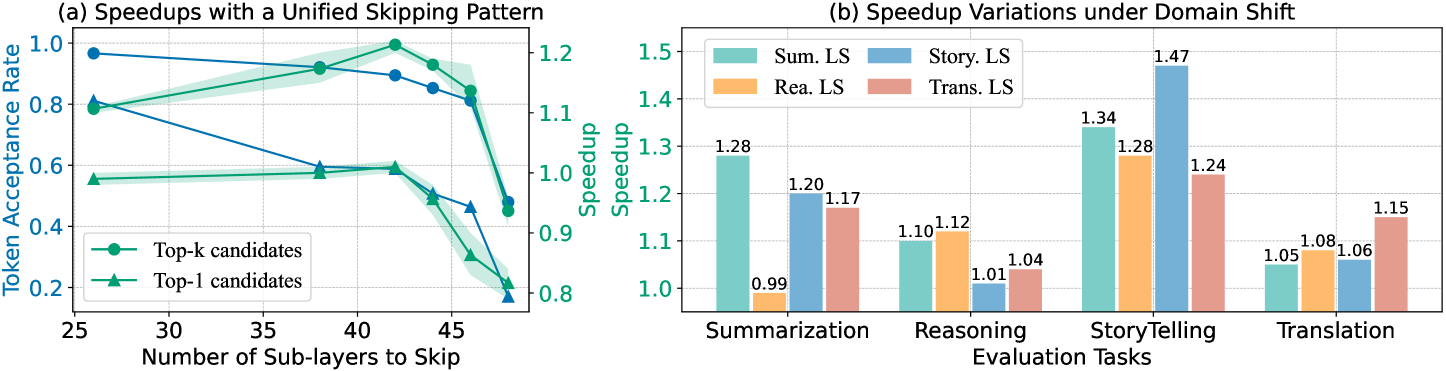
Figure 2: (a) LLMs possess self-acceleration potential via layer sparsity. By utilizing drafts from the top- $k$ candidates, we found that uniformly skipping half of the layers during drafting yields a notable $1.2\times$ speedup. (b) Layer sparsity is task-specific. Each task requires its own optimal set of skipped layers, and applying the skipped layer configuration from one task to another can lead to substantial performance degradation. “ X LS ” represents the skipped layer set optimized for task X.
#### 3.2.1 LLMs Possess Self-Acceleration Potential via Layer Sparsity
We begin by investigating the potential of behavior alignment between the target LLM and its layer-skipping variant. Unlike previous work (Zhang et al., 2024) that focused solely on greedy draft predictions, we leverage potential draft candidates from top- $k$ predictions, as detailed in Section 4.2. We conducted experiments using LLaMA-2-13B across the CNN/Daily Mail (Nallapati et al., 2016), GSM8K (Cobbe et al., 2021), and TinyStories (Eldan & Li, 2023) datasets. We applied a uniform layer-skipping pattern with $k$ set to 10. The experimental results, illustrated in Figure 2 (a), demonstrate a $30\$ average improvement in the token acceptance rate by leveraging top- $k$ predictions, with over $90\$ of draft tokens accepted by the target LLM. Consequently, compared to Self-SD, which achieved a maximum speedup of $1.01\times$ in this experimental setting, we revealed that the layer-skipping SD paradigm could yield an average wall-clock speedup of $1.22\times$ over conventional autoregressive decoding with a uniform layer-skipping pattern. This finding challenges the prevailing belief that the selection of skipped layers must be meticulously curated, suggesting instead that LLMs possess greater potential for self-acceleration through inherent layer sparsity.
#### 3.2.2 Layer Sparsity is Task-specific
We further explore the following research question: Is the skipped layer set optimized for one specific task applicable to other tasks? To address this, we conducted domain shift experiments using LLaMA-2-13B on the CNN/Daily Mail, GSM8K, TinyStories, and WMT16 DE-EN datasets. The experimental results, depicted in Figure 2 (b), reveal two critical findings: 1) Each task requires its own optimal skipped layer set. As illustrated in Figure 2 (b), the highest speedup performance is consistently achieved by the skipped layer configuration specifically optimized for each task. The detailed configuration of these layers is presented in Appendix A, demonstrating that the optimal configurations differ across tasks. 2) Applying the static skipped layer configuration across different tasks can lead to substantial efficiency degradation. For example, the speedup decreases from $1.47\times$ to $1.01\times$ when the optimized skipped layer set from a storytelling task is applied to a mathematical reasoning task, indicating that the optimized skipped layer set for one specific task does not generalize effectively to others.
These findings lay the groundwork for our plug-and-play solution within layer-skipping SD. Section 3.2.1 provides a strong foundation for real-time skipped layer selection, suggesting that additional optimization using training data may be unnecessary; Section 3.2.2 highlights the limitations of static layer-skipping patterns for dynamic input data streams across various tasks, underscoring the necessity for adaptive layer optimization during inference. Building on these insights, we present our on-the-fly self-speculative decoding method for efficient and adaptive layer set optimization.
## 4 SWIFT: On-the-Fly Self-Speculative Decoding
We introduce , the first plug-and-play self-speculative decoding approach that optimizes the skipped layer set of the target LLM on the fly, facilitating lossless LLM acceleration across diverse input data streams. As shown in Figure 3, divides LLM inference into two distinct phases: (1) context-based layer set optimization (§ 4.1), which aims to identify the optimal skipped layer set given the input stream, and (2) confidence-aware inference acceleration (§ 4.2), which employs the determined configuration to accelerate LLM inference.
<details>
<summary>x3.png Details</summary>

### Visual Description
\n
## Diagram: Context-based Layer Set Optimization and Confidence-aware Inference Acceleration
### Overview
The image is a diagram illustrating a process divided into two main phases: "Context-based Layer Set Optimization" and "Confidence-aware Inference Acceleration". The diagram depicts these phases occurring sequentially along a timeline representing "Generated Tokens". The timeline is marked with numerical values representing multiples of 'N', and the diagram uses colored blocks to represent different stages within the process.
### Components/Axes
* **X-axis:** Represents "Generated Tokens", with markers at 0, N, 2N, mN, (m+1)N, (m+2)N, and continuing with "...".
* **Phases:** Two main phases are labeled:
* "Context-based Layer Set Optimization" (spanning from 0 to mN)
* "Confidence-aware Inference Acceleration" (spanning from mN onwards)
* **Legend:** Located at the bottom-right, the legend defines the color-coding:
* Yellow: "context accumulation"
* Red: "layer set optimization"
* Green: "acceleration"
### Detailed Analysis
The diagram shows a repeating pattern within the "Context-based Layer Set Optimization" phase. This pattern consists of a yellow block ("context accumulation") followed by a red block ("layer set optimization"). This pattern repeats multiple times, indicated by the "...".
The "Confidence-aware Inference Acceleration" phase is represented by a long series of green blocks ("acceleration"). The green blocks become increasingly dense towards the right, suggesting an increasing rate of acceleration.
The x-axis is divided into segments marked by multiples of N. The transition from the optimization phase to the acceleration phase occurs at mN. The diagram does not provide a specific value for 'm'.
### Key Observations
* The process begins with context accumulation and layer set optimization, which are repeated multiple times.
* After a certain point (mN), the process transitions to a phase of acceleration.
* The acceleration phase appears to be continuous and increasing in intensity.
* The diagram does not provide quantitative data about the duration or intensity of each phase.
### Interpretation
The diagram illustrates a two-stage process for generating tokens. The initial "Context-based Layer Set Optimization" phase focuses on building context and refining the model's parameters. This phase involves iterative accumulation of context and optimization of layer sets. Once sufficient context is established (at mN), the process transitions to the "Confidence-aware Inference Acceleration" phase, where the model leverages its learned knowledge to generate tokens more efficiently. The increasing density of green blocks suggests that the acceleration becomes more pronounced as the process continues, potentially due to increased confidence in the model's predictions.
The diagram suggests a strategy for balancing exploration (optimization) and exploitation (acceleration) in a token generation process. The initial optimization phase ensures that the model has a strong foundation of knowledge, while the subsequent acceleration phase allows it to generate tokens quickly and efficiently. The value of 'm' likely represents a threshold or trigger point for switching between these two phases, and its optimal value would depend on the specific application and model architecture.
</details>
Figure 3: Timeline of inference. N denotes the maximum generation length per instance.
### 4.1 Context-based Layer Set Optimization
Layer set optimization is a critical challenge in self-speculative decoding, as it determines which layers of the target LLM should be skipped to form the draft model (see Section 3.1). Unlike prior methods that rely on time-intensive offline optimization, our work emphasizes on-the-fly layer set optimization, which poses a greater challenge to the latency-accuracy trade-off: the optimization must be efficient enough to avoid delays during inference while ensuring accurate drafting of subsequent decoding steps. To address this, we propose an adaptive optimization mechanism that balances efficiency with drafting accuracy. Our method minimizes overhead by performing only a single forward pass of the draft model per step to validate potential skipped layer set candidates. The core innovation is the use of LLM-generated tokens (i.e., prior context) as ground truth, allowing for simultaneous validation of the draft model’s accuracy in predicting future decoding steps.
In the following subsections, we illustrate the detailed process of this optimization phase for each input instance, which includes context accumulation (§ 4.1.1) and layer set optimization (§ 4.1.2).
#### 4.1.1 Context Accumulation
Given an input instance in the optimization phase, the draft model is initialized by uniformly skipping layers in the target LLM. This initial layer-skipping pattern is maintained to accelerate inference until a specified number of LLM-generated tokens, referred to as the context window, has been accumulated. Upon reaching this window length, the inference transitions to layer set optimization.
<details>
<summary>x4.png Details</summary>
### Visual Description
## Diagram: Efficient Layer Set Suggestion & Parallel Candidate Evaluation
### Overview
The image presents a diagram illustrating two processes: (a) Efficient Layer Set Suggestion and (b) Parallel Candidate Evaluation, both related to Large Language Model (LLM) optimization. The diagram depicts the flow of tokens through these processes, highlighting the interaction between random search, Bayesian optimization, and LLM verification, as well as the parallel evaluation of candidate models.
### Components/Axes
The diagram is divided into two main sections, labeled (a) and (b). Each section contains several components represented by boxes and arrows. A legend at the bottom of the image defines the color coding for different types of tokens:
* Yellow: input tokens
* Light Green: LLM-generated tokens
* Light Blue: draft tokens
* Light Yellow: accepted tokens
Section (a) includes:
* LLM Inputs: A block of yellow tokens.
* Random Search: A box with a dice icon and the text "np.random.choice()".
* Bayes Optimization: A box with a curve icon.
* MLP/Attention Layer Sets: A table listing layer configurations with associated binary values (0 or 1).
* Target LLM Verification: A box with a target icon.
* Accepted Tokens: A block of light yellow tokens.
Section (b) includes:
* Original Outputs: A block of light green tokens.
* Parallel Draft Tokens: A block of light blue tokens.
* Calculate Matchness: A box.
* Gaussian Update: A box.
* Alter Skipped Layer Set: A box with an edit icon.
* Compact Model: A box with a model icon.
* Draft multiple steps: A box.
Arrows indicate the flow of tokens and data between these components. Dashed arrows represent update signals.
### Detailed Analysis or Content Details
**Section (a): Efficient Layer Set Suggestion**
* **LLM Inputs:** The process begins with a series of yellow "input tokens".
* **Random Search & Bayes Optimization:** These two methods operate in parallel, receiving input tokens and generating layer set suggestions.
* **Layer Sets:** The table within this section lists the following layer configurations and their binary values:
* MLP: 0
* Attention: 1
* MLP: 0
* Attention: 0
* MLP: 1
* Attention: 0
* **Target LLM Verification:** The generated layer sets are then sent to "Target LLM Verification".
* **Accepted Tokens:** Verified layer sets result in "accepted tokens" (light yellow), which are fed back into the "LLM Inputs" via a dashed "update" arrow.
**Section (b): Parallel Candidate Evaluation**
* **Original Outputs:** The process starts with "original outputs" (light green tokens).
* **Parallel Draft Tokens:** These outputs are used to generate "parallel draft tokens" (light blue).
* **Calculate Matchness:** The "matchness" between the original and draft tokens is calculated.
* **Gaussian Update:** The results of the matchness calculation are used to perform a "Gaussian Update".
* **Alter Skipped Layer Set:** Based on the update, the "skipped layer set" is altered.
* **Compact Model:** The altered layer set leads to a "compact model".
* **Draft multiple steps:** The process can be repeated in multiple steps.
* **Conditional Flow:** A "if best" arrow indicates that the process continues if the current candidate is the best.
### Key Observations
* The diagram highlights a closed-loop optimization process where layer sets are suggested, verified, and updated based on performance.
* The parallel evaluation of candidate models allows for efficient exploration of different layer configurations.
* The use of "draft tokens" suggests an iterative refinement process.
* The "Gaussian Update" implies a probabilistic approach to optimization.
* The diagram does not provide specific numerical data or performance metrics.
### Interpretation
The diagram illustrates a method for efficiently optimizing LLMs by suggesting and evaluating different layer configurations. The combination of random search and Bayesian optimization allows for a balance between exploration and exploitation of the layer space. The parallel evaluation of candidate models accelerates the optimization process. The feedback loop, driven by the "Target LLM Verification" and "Gaussian Update", ensures that the model converges towards an optimal configuration. The use of different token colors clearly visualizes the flow of information and the transformation of data throughout the process. The diagram suggests a focus on model compression or efficiency, as indicated by the "Compact Model" component. The overall goal appears to be to find a layer set that maintains performance while reducing computational cost.
</details>
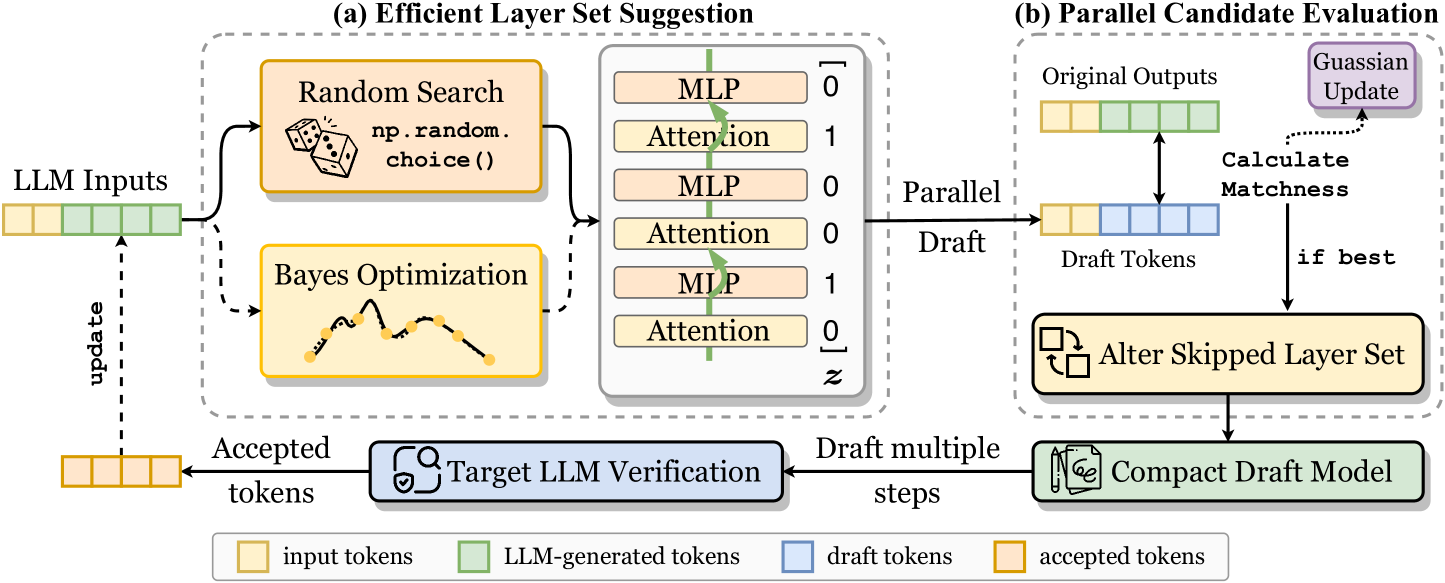
Figure 4: Layer set optimization process in . During the optimization stage, performs an optimization step prior to each LLM decoding step to adjust the skipped layer set, which involves: (a) Efficient layer set optimization. integrates random search with interval Bayesian optimization to propose layer set candidates; (b) Parallel candidate evaluation. uses LLM-generated tokens (i.e., prior context) as ground truth, enabling simultaneous validation of the proposed candidates. The best-performing layer set is selected to accelerate the current decoding step.
#### 4.1.2 Layer Set Optimization
During this stage, as illustrated in Figure 4, we integrate an optimization step before each LLM decoding step to refine the skipped layer set, which comprises two substeps:
Efficient Layer Set Suggestion
This substep aims to suggest a potential layer set candidate. Formally, given a target LLM $\mathscr{M}_{T}$ with $L$ layers, our goal is to identify an optimal skipped layer set $\bm{z}\in\{0,1\}^{L}$ to form the compact draft model. Unlike Zhang et al. (2024), which relies entirely on a time-consuming Bayesian optimization process, we introduce an efficient strategy that combines random search with Bayesian optimization. In this approach, random sampling efficiently handles most of the exploration. Specifically, given a fixed skipping ratio $r$ , applies Bayesian optimization at regular intervals of $\beta$ optimization steps (e.g., $\beta=25$ ) to suggest the next layer set candidate, while random search is employed during other optimization steps.
$$
\bm{z}=\left\{\begin{array}[]{ll}\operatorname{Bayesian\_Optimization}(\bm{l})
&\text{ if }o\text{ \
\operatorname{Random\_Search}(\bm{l})&\text{ otherwise }\end{array},\right. \tag{2}
$$
where $1\leq o\leq S$ is the current optimization step; $S$ denotes the maximum number of optimization steps; $\bm{l}=\binom{L}{rL}$ denotes the input space, i.e., all possible combinations of layers that can be skipped.
Parallel Candidate Evaluation
leverages LLM-generated context to simultaneously validate the candidate draft model’s performance in predicting future decoding steps. Formally, given an input sequence $\bm{x}$ and the previously generated tokens within the context window, denoted as $\bm{y}=\{y_{1},\dots,y_{\gamma}\}$ , the draft model $\mathscr{M}_{D}$ , which skips the designated layers $\bm{z}$ of the target LLM, is employed to predict these context tokens in parallel:
$$
y^{\prime}_{i}=\arg\max_{y}\log P\left(y\mid\bm{x},\bm{y}_{<i};\bm{\theta}_{
\mathscr{M}_{D}}\right),1\leq i\leq\gamma, \tag{3}
$$
where $\gamma$ represents the context window. The cached key-value pairs in the target LLM $\mathscr{M}_{T}$ are reused by $\mathscr{M}_{D}$ , presumably aligning $\mathscr{M}_{D}$ ’s distribution with $\mathscr{M}_{T}$ and reducing the redundant computation. The matchness score is defined as the exact match ratio between $\bm{y}$ and $\bm{y}^{\prime}$ :
$$
\texttt{matchness}=\frac{\sum_{i}\mathbb{I}\left(y_{i}=y^{\prime}_{i}\right)}{
\gamma},1\leq i\leq\gamma, \tag{4}
$$
where $\mathbb{I}(\cdot)$ denotes the indicator function. This score serves as the optimization objective during optimization, reflecting $\mathscr{M}_{D}$ ’s accuracy in predicting future decoding steps. As shown in Figure 4, the matchness score at each step is integrated into the Gaussian process model to guide Bayesian optimization, with the highest-scoring layer set candidate being retained to form the draft model.
As illustrated in Figure 3, the process of context accumulation and layer set optimization alternates for each instance until a termination condition is met – either the maximum number of optimization steps is reached or the best candidate remains unchanged over multiple iterations. Once the optimization phase concludes, the inference process transitions to the confidence-aware inference acceleration phase, where the optimized draft model is employed to speed up LLM inference.
### 4.2 Confidence-aware Inference Acceleration
<details>
<summary>x5.png Details</summary>
### Visual Description
\n
## Diagram: Early-stopping Drafting and Dynamic Verification
### Overview
The image presents a diagram illustrating two stages of a process: "Early-stopping Drafting" (a) and "Dynamic Verification" (b). The diagram depicts a sequence of operations involving text processing, attention mechanisms, and decision-making based on probability thresholds. It appears to be a visual representation of a method for generating text, potentially within a machine learning context.
### Components/Axes
The diagram consists of two main sections, labeled (a) and (b). Each section contains visual elements representing text blocks, attention mechanisms, and a decision-making process.
* **Section (a): Early-stopping Drafting**
* Text Blocks: "is", "will", "that" (orange boxes), "all", "the", "best" (red boxes).
* Model: `M_D` (green rectangle)
* Attention: Indicated by arrows and the label "Attention".
* Probability Thresholds: `P_is = 0.85 > ε` (blue), `P_all = 0.65 < ε` (red). `ε` is a threshold value.
* Arrows: Representing flow and connections between components. A dashed arrow indicates a "Continue" path, while a solid arrow indicates an "Early Stop!" path.
* **Section (b): Dynamic Verification**
* Text Blocks: "is", "all", "will", "the", "best" (blue boxes with dashed outlines).
* Model: `M_D` (green rectangle)
* Attention: Indicated by arrows and the label "Attention".
* Attention Matrix: A grid of yellow squares representing an attention matrix.
### Detailed Analysis or Content Details
**Section (a): Early-stopping Drafting**
* The process begins with the model `M_D` receiving "Attention" input.
* The model generates the sequence "is", "will", "that".
* A probability `P_is` is calculated for "is", with a value of 0.85. This value is compared to a threshold `ε`. Since 0.85 > `ε`, the process continues.
* The model then generates the sequence "all", "the", "best".
* A probability `P_all` is calculated for "all", with a value of 0.65. This value is compared to the same threshold `ε`. Since 0.65 < `ε`, the process stops ("Early Stop!").
* The dashed arrow indicates the continuation path, while the solid arrow indicates the early stopping path.
**Section (b): Dynamic Verification**
* The model `M_D` receives "Attention" input and generates the sequence "is", "all", "will", "the", "best".
* The attention matrix is a 6x6 grid of yellow squares. The rows correspond to the words "is", "all", "will", "the", "best", and the columns likely represent the same words, indicating the attention weights between them.
* The text blocks are enclosed in dashed blue boxes.
### Key Observations
* The diagram illustrates a dynamic process where text generation can be stopped early based on a probability threshold.
* The attention mechanism plays a crucial role in both stages of the process.
* The attention matrix in Section (b) provides a visual representation of the relationships between different words in the generated sequence.
* The threshold `ε` is a key parameter that controls the trade-off between generation length and quality.
### Interpretation
The diagram depicts a method for efficient text generation that combines drafting and verification stages. The "Early-stopping Drafting" stage aims to quickly generate a draft sequence, while the "Dynamic Verification" stage refines the sequence and ensures its quality. The probability thresholds and attention mechanisms are used to make informed decisions about when to continue or stop the generation process.
The use of different colors (orange, red, blue) to highlight the text blocks likely indicates different stages or roles in the generation process. The attention matrix in Section (b) suggests that the model is able to focus on the most relevant parts of the generated sequence.
The diagram suggests a system that balances exploration (generating new text) with exploitation (verifying and refining existing text). The threshold `ε` allows for tuning the system's behavior based on the desired trade-off between these two objectives. The overall goal appears to be to generate high-quality text efficiently by stopping the generation process when the probability of generating meaningful content falls below a certain level.
</details>
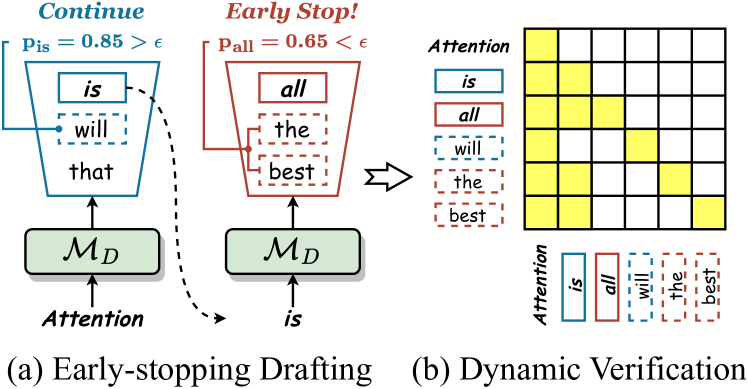
Figure 5: Confidence-aware inference process of . (a) The drafting terminates early if the confidence score drops below threshold $\epsilon$ . (b) Draft candidates are dynamically selected based on confidence and then verified in parallel by the target LLM.
During the acceleration phase, the optimization step is removed. applies the best-performed layer set to form the compact draft model and decodes following the draft-then-verify paradigm. Specifically, at each decoding step, given the input $\bm{x}$ and previous LLM outputs $\bm{y}$ , the draft model $\mathscr{M}_{D}$ predicts future LLM decoding steps in an autoregressive manner:
$$
y^{\prime}_{j}=\arg\max_{y}\log P\left(y\mid\bm{x},\bm{y},\bm{y}^{\prime}_{<j}
;\bm{\theta}_{\mathscr{M}_{D}}\right), \tag{5}
$$
where $1\leq j\leq N_{D}$ is the current draft step, $N_{D}$ denotes the maximum draft length, $\bm{y}^{\prime}_{<j}$ represents previous draft tokens, and $P(\cdot)$ denotes the probability distribution of the next draft token. The KV cache of the target LLM $\mathscr{M}_{T}$ and preceding draft tokens $\bm{y}^{\prime}_{<j}$ is reused to reduce the computational cost.
Let $p_{j}=\max P(\cdot)$ denote the probability of the top-1 draft prediction $y^{\prime}_{j}$ , which can be regarded as a confidence score. Recent research (Li et al., 2024b; Du et al., 2024) shows that this score is highly correlated with the likelihood that the draft token $y^{\prime}_{j}$ will pass verification – higher confidence scores indicate a greater chance of acceptance. Therefore, following previous studies (Zhang et al., 2024; Du et al., 2024), we leverage the confidence score to prune unnecessary draft steps and select valuable draft candidates, improving both speculation accuracy and verification efficiency.
As shown in Figure 5, we integrate with two confidence-aware inference strategies These confidence-aware inference strategies are also applied during the optimization phase, where the current optimal layer set is used to form the draft model and accelerate the corresponding LLM decoding step.: 1) Early-stopping Drafting. The autoregressive drafting process halts if the confidence $p_{j}$ falls below a specified threshold $\epsilon$ , avoiding any waste of subsequant drafting computation. 2) Dynamic Verification. Each $y^{\prime}_{j}$ is dynamically extended with its top- $k$ draft predictions for parallel verification to enhance speculation accuracy, with $k$ determined by the confidence score $p_{j}$ . Concretely, $k$ is set to 10, 5, 3, and 1 for $p$ in the ranges of $(0,0.5]$ , $(0.5,0.8]$ , $(0.8,0.95]$ , and $(0.95,1]$ , respectively. All draft candidates are linearized into a single sequence and verified in parallel by the target LLM using a special causal attention mask (see Figure 5 (b)).
## 5 Experiments
### 5.1 Experimental Setup
Implementation Details
We mainly evaluate on LLaMA-2 (Touvron et al., 2023b) and CodeLLaMA series (Rozière et al., 2023) across various tasks, including summarization, mathematical reasoning, storytelling, and code generation. The evaluation datasets include CNN/Daily Mail (CNN/DM) (Nallapati et al., 2016), GSM8K (Cobbe et al., 2021), TinyStories (Eldan & Li, 2023), and HumanEval (Chen et al., 2021). The maximum generation lengths on CNN/DM, GSM8K, and TinyStories are set to 64, 64, and 128, respectively. We conduct 1-shot evaluation for CNN/DM and TinyStories, and 5-shot evaluation for GSM8K. We compare pass@1 and pass@10 for HumanEval. We randomly sample 1000 instances from the test set for each dataset except HumanEval. The maximum generation lengths for HumanEval and all analyses are set to 512. During optimization, we employ both random search and Bayesian optimization https://github.com/bayesian-optimization/BayesianOptimization to suggest skipped layer set candidates. Following prior work, we adopt speculative sampling (Leviathan et al., 2023) as our acceptance strategy with a batch size of 1. Detailed setups are provided in Appendix B.1 and B.2.
Baselines
In our main experiments, we compare to two existing plug-and-play methods: Parallel Decoding (Santilli et al., 2023) and Lookahead Decoding (Fu et al., 2024), both of which employ Jacobi decoding for efficient LLM drafting. It is important to note that , as a layer-skipping SD method, is orthogonal to these Jacobi-based SD methods, and integrating with them could further boost inference efficiency. We exclude other SD methods from our comparison as they necessitate additional modules or extensive training, which limits their generalizability.
Evaluation Metrics
We report two widely-used metrics for evaluation: mean generated length $M$ (Stern et al., 2018) and token acceptance rate $\alpha$ (Leviathan et al., 2023). Detailed descriptions of these metrics can be found in Appendix B.3. In addition to these metrics, we report the actual decoding speed (tokens/s) and wall-time speedup ratio compared with vanilla autoregressive decoding. The acceleration of theoretically guarantees the preservation of the target LLMs’ output distribution, making it unnecessary to evaluate the generation quality. However, to provide a point of reference, we present the evaluation scores for code generation tasks.
| LLaMA-2-13B Parallel Lookahead | Vanilla 1.04 1.38 | 1.00 0.95 $\times$ 1.16 $\times$ | 1.00 $\times$ 1.11 1.50 | 1.00 0.99 $\times$ 1.29 $\times$ | 1.00 $\times$ 1.06 1.62 | 1.00 0.97 $\times$ 1.37 $\times$ | 1.00 $\times$ 19.49 25.46 | 20.10 0.97 $\times$ 1.27 $\times$ | 1.00 $\times$ |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| 4.34 | 1.37 $\times$ † | 3.13 | 1.31 $\times$ † | 8.21 | 1.53 $\times$ † | 28.26 | 1.41 $\times$ | | |
| LLaMA-2-13B -Chat | Vanilla | 1.00 | 1.00 $\times$ | 1.00 | 1.00 $\times$ | 1.00 | 1.00 $\times$ | 19.96 | 1.00 $\times$ |
| Parallel | 1.06 | 0.96 $\times$ | 1.08 | 0.97 $\times$ | 1.10 | 0.98 $\times$ | 19.26 | 0.97 $\times$ | |
| Lookahead | 1.35 | 1.15 $\times$ | 1.57 | 1.31 $\times$ | 1.66 | 1.40 $\times$ | 25.69 | 1.29 $\times$ | |
| 3.54 | 1.28 $\times$ | 2.95 | 1.25 $\times$ | 7.42 | 1.50 $\times$ † | 26.80 | 1.34 $\times$ | | |
| LLaMA-2-70B | Vanilla | 1.00 | 1.00 $\times$ | 1.00 | 1.00 $\times$ | 1.00 | 1.00 $\times$ | 4.32 | 1.00 $\times$ |
| Parallel | 1.05 | 0.95 $\times$ | 1.07 | 0.97 $\times$ | 1.05 | 0.96 $\times$ | 4.14 | 0.96 $\times$ | |
| Lookahead | 1.36 | 1.15 $\times$ | 1.54 | 1.30 $\times$ | 1.59 | 1.35 $\times$ | 5.45 | 1.26 $\times$ | |
| 3.85 | 1.43 $\times$ † | 2.99 | 1.39 $\times$ † | 6.17 | 1.62 $\times$ † | 6.41 | 1.48 $\times$ | | |
Table 2: Comparison between and prior plug-and-play methods. We report the mean generated length M, speedup ratio, and average decoding speed (tokens/s) under greedy decoding. † indicates results with a token acceptance rate $\alpha$ above 0.98. More details are provided in Appendix C.1.
| HumanEval (pass@1) HumanEval (pass@10) | Vanilla 4.75 Vanilla | 1.00 0.98 1.00 | - 0.311 - | 0.311 1.40 $\times$ 0.628 | 1.00 $\times$ 3.79 1.00 $\times$ | 1.00 0.88 1.00 | - 0.372 - | 0.372 1.46 $\times$ 0.677 | 1.00 $\times$ 1.00 $\times$ |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| 3.55 | 0.93 | 0.628 | 1.29 $\times$ | 2.79 | 0.90 | 0.683 | 1.30 $\times$ | | |
Table 3: Experimental results of on code generation tasks. We report the mean generated length M, acceptance rate $\alpha$ , accuracy (Acc.), and speedup ratio for comparison. We use greedy decoding for pass@1 and random sampling with a temperature of 0.6 for pass@10.
### 5.2 Main Results
Table 2 presents the comparison between and previous plug-and-play methods on text generation tasks. The experimental results demonstrate the following findings: (1) shows superior efficiency over prior methods, achieving consistent speedups of $1.3\times$ $\sim$ $1.6\times$ over vanilla autoregressive decoding across various models and tasks. (2) The efficiency of is driven by the high behavior consistency between the target LLM and its layer-skipping draft variant. As shown in Table 2, produces a mean generated length M of 5.01, with a high token acceptance rate $\alpha$ ranging from $90\$ to $100\$ . Notably, for the LLaMA-2 series, this acceptance rate remains stable at $98\$ $\sim$ $100\$ , indicating that nearly all draft tokens are accepted by the target LLM. (3) Compared with 13B models, LLaMA-2-70B achieves higher speedups with a larger layer skip ratio ( $0.45$ $\rightarrow$ $0.5$ ), suggesting that larger-scale LLMs exhibit greater layer sparsity. This underscores ’s potential to deliver even greater speedups as LLM scales continue to grow. A detailed analysis of this finding is presented in Section 5.3, while additional experimental results for LLaMA-70B models, including LLaMA-3-70B, are presented in Appendix C.2.
Table 3 shows the evaluation results of on code generation tasks. achieves speedups of $1.3\times$ $\sim$ $1.5\times$ over vanilla autoregressive decoding, demonstrating its effectiveness across both greedy decoding and random sampling settings. Additionally, speculative sampling theoretically guarantees that maintains the original output distribution of the target LLM. This is empirically validated by the task performance metrics in Table 3. Despite a slight variation in the pass@10 metric for CodeLLaMA-34B, achieves identical performance to autoregressive decoding.
### 5.3 In-depth Analysis
<details>
<summary>x6.png Details</summary>
### Visual Description
## Chart: Speedup vs. Number of Instances
### Overview
This chart illustrates the relationship between the number of instances and the resulting speedup and matchness, along with a latency breakdown per token. Two speedup curves are presented: an overall speedup and an instance speedup. The chart also shows the matchness as a function of the number of instances. A vertical dashed red line indicates an "Optimization Stop!" point.
### Components/Axes
* **X-axis:** "# of Instances" - Ranging from 0 to 100, with markers at intervals of 10.
* **Y-axis (left):** "Matchness" - Ranging from 0.0 to 1.0, with markers at intervals of 0.2.
* **Y-axis (right):** "Speedup" - Ranging from 1.2 to 1.6, with markers at intervals of 0.1.
* **Legend:** Located in the center-right of the chart.
* "Overall Speedup" - Represented by green circles connected by a solid line.
* "Instance Speedup" - Represented by gray circles connected by a dashed line.
* **Annotation:** "Optimization Stop!" - A vertical dashed red line at approximately instance 15.
* **Annotation:** "Average" - A label placed near the end of the Instance Speedup line.
* **Table:** "Latency Breakdown per Token" - Located in the bottom-right corner. Columns are "Modules", "Latency (ms)", and "Ratio (%)".
### Detailed Analysis or Content Details
**Matchness:**
The Matchness starts at approximately 0.0 at 0 instances and increases rapidly, approaching 0.85-0.90 by 20 instances. The rate of increase slows down as the number of instances increases, leveling off around 0.95-1.0 after 60 instances.
**Overall Speedup (Green Line):**
The Overall Speedup line starts at approximately 1.3 at 0 instances. It exhibits a steep upward slope initially, reaching around 1.52 at 10 instances. The slope gradually decreases, and the line plateaus around 1.55-1.57 after 50 instances, with a slight fluctuation towards the end.
**Instance Speedup (Gray Line):**
The Instance Speedup line begins at approximately 1.58 at 0 instances. It shows a slight downward trend initially, decreasing to around 1.52 at 10 instances. The line remains relatively stable between 1.50 and 1.55 for the remainder of the instances, with some minor fluctuations. The "Average" label is placed near the end of the line, indicating an average value of approximately 1.56.
**Latency Breakdown per Token (Table):**
| Modules | Latency (ms) | Ratio (%) |
|---|---|---|
| Optimize | 0.24 ± 0.02 | 0.8 |
| Draft | 19.93 ± 1.36 | 64.4 |
| Verify | 8.80 ± 2.21 | 28.4 |
| Others | 1.98 ± 0.13 | 6.4 |
| Total | 30.95 ± 2.84 | 100.0 |
### Key Observations
* The "Optimization Stop!" point at approximately 15 instances suggests that adding more instances beyond this point yields diminishing returns in terms of speedup.
* The Instance Speedup remains relatively constant after the initial decrease, while the Overall Speedup continues to increase, albeit at a decreasing rate.
* The Draft module contributes the largest portion (64.4%) to the total latency.
* The Matchness approaches 1.0 with a relatively small number of instances (around 60).
### Interpretation
The chart demonstrates the benefits of increasing the number of instances for processing, as evidenced by the initial increase in Overall Speedup and Matchness. However, it also highlights the point of diminishing returns, indicated by the "Optimization Stop!" annotation. The relatively stable Instance Speedup suggests that the performance gain from adding more instances is limited after a certain point. The latency breakdown reveals that the "Draft" module is the primary bottleneck in the process, suggesting that optimizing this module could lead to significant performance improvements. The high Matchness achieved with a moderate number of instances indicates that the system is able to maintain accuracy even as the number of instances increases. The difference between the Overall and Instance Speedup suggests that there are overheads associated with coordinating multiple instances.
</details>
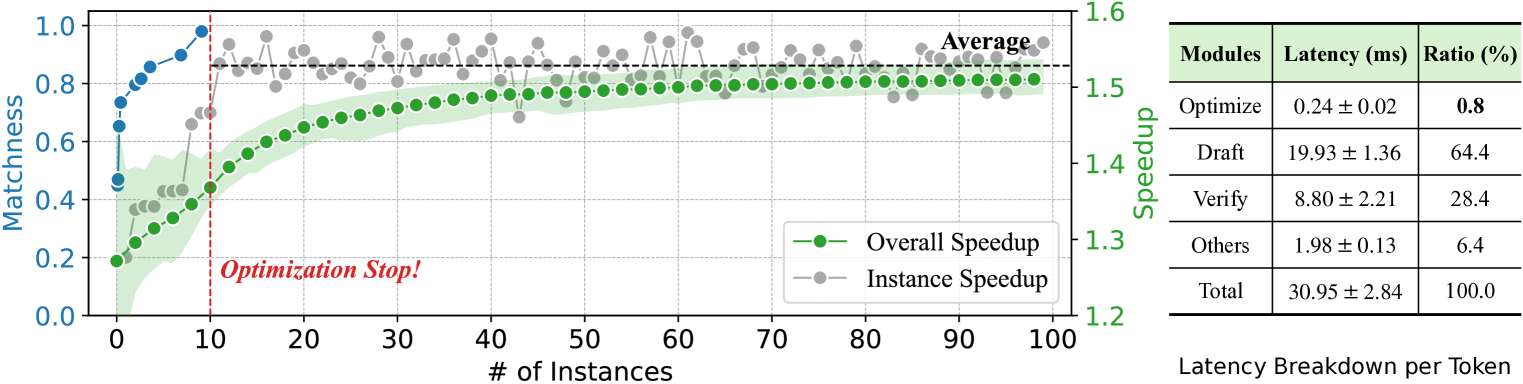
Figure 6: Illustration and latency breakdown of inference. As the left figure shows, after the context-based layer set optimization phase, the overall speedup of steadily increases, reaching the average instance speedup during the acceleration phase. The additional optimization steps account for only $\bf{0.8\$ of the total inference latency, as illustrated in the right figure.
Illustration of Inference
As described in Section 4, divides the LLM inference process into two distinct phases: optimization and acceleration. Figure 6 (left) illustrates the detailed acceleration effect of during LLM inference. Specifically, the optimization phase begins at the start of inference, where an optimization step is performed before each decoding step to adjust the skipped layer set forming the draft model. As shown in Figure 6, in this phase, the matchness score of the draft model rises sharply from 0.45 to 0.73 during the inference of the first instance. This score then gradually increases to 0.98, which triggers the termination of the optimization process. Subsequently, the inference transitions to the acceleration phase, during which the optimization step is removed, and the draft model remains fixed to accelerate LLM inference. As illustrated, the instance speedup increases with the matchness score, reaching an average of $1.53\times$ in the acceleration phase. The overall speedup gradually rises as more tokens are generated, eventually approaching the average instance speedup. This dynamic reflects a key feature of : the efficiency of improves with increasing input length and the number of instances.
Breakdown of Computation
Figure 6 (right) presents the computation breakdown of different modules in with 1000 CNN/DM samples using LLaMA-2-13B. The results demonstrate that the optimization step only takes $\bf{0.8\$ of the overall inference process, indicating the efficiency of our strategy. Compared with Self-SD (Zhang et al., 2024) that requires a time-consuming optimization process (e.g., 7.5 hours for LLaMA-2-13B on CNN/DM), achieves a nearly 180 $\times$ optimization time reduction, facilitating on-the-fly inference acceleration. Besides, the results show that the drafting stage of consumes the majority of inference latency. This is consistent with our results of mean generated length in Table 2 and 3, which shows that nearly $80\$ output tokens are generated by the efficient draft model, demonstrating the effectiveness of our framework.
<details>
<summary>x7.png Details</summary>
### Visual Description
\n
## Bar Chart: Performance Comparison of Language Models
### Overview
This bar chart compares the performance of three language models – Vanilla, Self-SD, and SWIFT – across five different tasks: Summarization, Reasoning, Instruction, Translation, and QA (Question Answering). The performance is measured using two metrics: Speedup (left y-axis) and Token Acceptance (right y-axis). The chart uses bar graphs to represent Speedup and line graphs to represent Token Acceptance.
### Components/Axes
* **X-axis:** Task type (Summarization, Reasoning, Instruction, Translation, QA)
* **Left Y-axis:** Speedup (Scale: 0.8 to 1.6)
* **Right Y-axis:** Token Acceptance (Scale: 0.5 to 1.0)
* **Legend:**
* Vanilla (Yellow) - Represented by yellow bars.
* Self-SD (Light Blue) - Represented by light blue bars.
* SWIFT (Dark Blue) - Represented by dark blue bars.
* SWIFT (Green Line with filled circles) - Represents Token Acceptance for SWIFT.
* Self-SD (Light Blue Line with empty circles) - Represents Token Acceptance for Self-SD.
### Detailed Analysis
The chart presents data for each task, showing the Speedup and Token Acceptance for each model.
**Summarization:**
* Vanilla Speedup: Approximately 1.00x
* Self-SD Speedup: Approximately 1.28x
* SWIFT Speedup: Approximately 1.56x
* SWIFT Token Acceptance: Starts at approximately 0.95 and decreases to approximately 0.92.
* Self-SD Token Acceptance: Starts at approximately 0.85 and increases to approximately 0.88.
**Reasoning:**
* Vanilla Speedup: Approximately 1.00x
* Self-SD Speedup: Approximately 1.10x
* SWIFT Speedup: Approximately 1.45x
* SWIFT Token Acceptance: Relatively flat, around 0.94-0.95.
* Self-SD Token Acceptance: Starts at approximately 0.75 and increases to approximately 0.82.
**Instruction:**
* Vanilla Speedup: Approximately 1.00x
* Self-SD Speedup: Approximately 1.08x
* SWIFT Speedup: Approximately 1.47x
* SWIFT Token Acceptance: Starts at approximately 0.95 and decreases to approximately 0.93.
* Self-SD Token Acceptance: Relatively flat, around 0.70-0.72.
**Translation:**
* Vanilla Speedup: Approximately 1.05x
* Self-SD Speedup: Approximately 1.27x
* SWIFT Speedup: Approximately 1.00x
* SWIFT Token Acceptance: Starts at approximately 0.93 and decreases to approximately 0.88.
* Self-SD Token Acceptance: Relatively flat, around 0.68-0.70.
**QA:**
* Vanilla Speedup: Approximately 1.02x
* Self-SD Speedup: Approximately 1.35x
* SWIFT Speedup: Approximately 1.00x
* SWIFT Token Acceptance: Relatively flat, around 0.93-0.94.
* Self-SD Token Acceptance: Starts at approximately 0.65 and increases to approximately 0.68.
### Key Observations
* SWIFT consistently demonstrates the highest Speedup across most tasks (Summarization, Reasoning, Instruction).
* Self-SD generally shows a moderate improvement in Speedup compared to Vanilla.
* Token Acceptance for SWIFT is generally high and relatively stable.
* Token Acceptance for Self-SD is lower than SWIFT but shows a slight increasing trend across tasks.
* Vanilla consistently has a Speedup of approximately 1.00x, indicating no performance improvement.
* The Translation task shows a relatively low Speedup for SWIFT compared to other tasks.
### Interpretation
The data suggests that the SWIFT model significantly outperforms Vanilla and Self-SD in terms of Speedup for most of the evaluated tasks. This indicates that SWIFT is more efficient at processing these tasks. The higher Token Acceptance for SWIFT suggests that it is also more reliable in generating appropriate tokens. Self-SD provides a moderate improvement over Vanilla, but it does not reach the performance level of SWIFT. The relatively low Speedup for SWIFT in the Translation task could indicate that this task presents unique challenges for the model, or that the benefits of SWIFT are less pronounced in this specific domain. The increasing trend in Token Acceptance for Self-SD might suggest that the model is learning and improving its token generation capabilities as it processes more complex tasks. The combination of Speedup and Token Acceptance provides a comprehensive view of the model's performance, highlighting its efficiency and reliability.
</details>
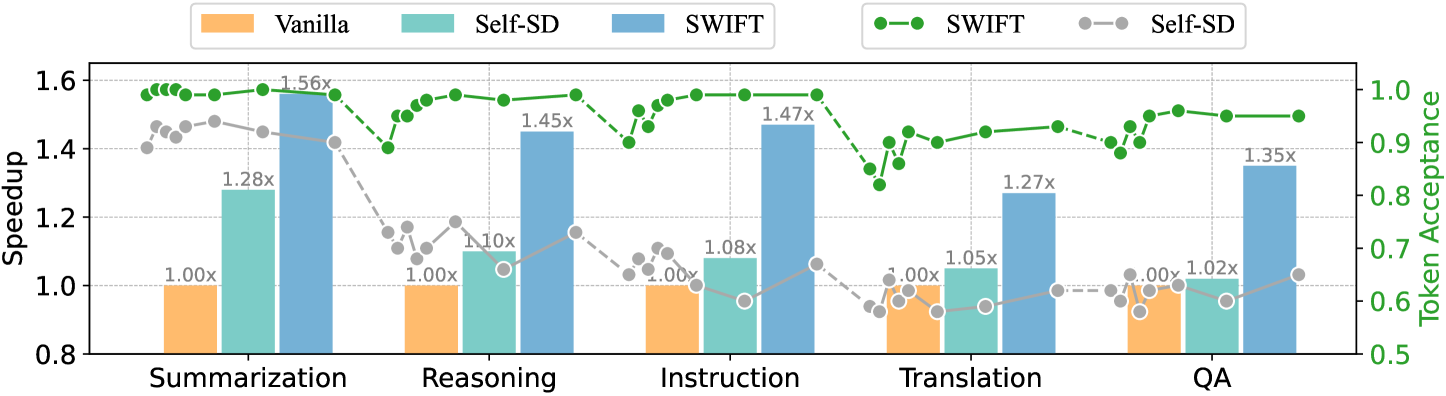
Figure 7: Comparison between and Self-SD in handling dynamic data input streams. Unlike Self-SD, which suffers from efficiency reduction during distribution shift, maintains stable acceleration performance with an acceptance rate exceeding 0.9.
Dynamic Input Data Streams
We further validate the effectiveness of in handling dynamic input data streams. We selected CNN/DM, GSM8K, Alpaca (Taori et al., 2023), WMT14 DE-EN, and Nature Questions (Kwiatkowski et al., 2019) for the evaluation on summarization, reasoning, instruction following, translation, and question answering tasks, respectively. For each task, we randomly sample 500 instances from the test set and concatenate them task-by-task to form the input stream. The experimental results are presented in Figure 7. As demonstrated, Self-SD is sensitive to domain shifts, with the average token acceptance rate dropping from $92\$ to $68\$ . Consequently, it suffers from severe speedup reduction from $1.33\times$ to an average of $1.05\times$ under domain shifts. In contrast, exhibits promising adaptation capability to different domains with an average token acceptance rate of $96\$ , leading to a consistent $1.3\times$ $\sim$ $1.6\times$ speedup.
<details>
<summary>x8.png Details</summary>
### Visual Description
\n
## Charts: Speedup vs. Instances/Layer Skip Ratio
### Overview
The image contains two charts, labeled (a) and (b). Chart (a) depicts the relationship between speedup and the number of instances for different optimization strategies. Chart (b) shows the speedup as a function of the layer skip ratio for different model sizes. Both charts aim to demonstrate performance scaling characteristics.
### Components/Axes
**Chart (a): Flexible Optimization Strategy**
* **X-axis:** "# of Instances" ranging from 0 to 50.
* **Y-axis:** "Speedup" ranging from 1.25 to 1.50.
* **Legend:**
* Blue Line: "S=1000, β=25"
* Orange Line: "S=500, β=25"
* Green Line: "S=1000, β=50"
**Chart (b): Scaling Law of SWIFT**
* **X-axis:** "Layer Skip Ratio r" ranging from 0.30 to 0.60.
* **Y-axis:** "Speedup" ranging from 1.2 to 1.6.
* **Legend:**
* Blue Line: "7B"
* Orange Line: "13B"
* Green Line: "70B"
### Detailed Analysis or Content Details
**Chart (a): Flexible Optimization Strategy**
* **Blue Line (S=1000, β=25):** The line slopes upward, showing increasing speedup with the number of instances.
* At 0 instances, speedup is approximately 1.28.
* At 5 instances, speedup is approximately 1.34.
* At 10 instances, speedup is approximately 1.38.
* At 15 instances, speedup is approximately 1.41.
* At 20 instances, speedup is approximately 1.43.
* At 25 instances, speedup is approximately 1.45.
* At 30 instances, speedup is approximately 1.46.
* At 35 instances, speedup is approximately 1.47.
* At 40 instances, speedup is approximately 1.48.
* At 45 instances, speedup is approximately 1.49.
* At 50 instances, speedup is approximately 1.50.
* **Orange Line (S=500, β=25):** The line also slopes upward, but at a slower rate than the blue line.
* At 0 instances, speedup is approximately 1.27.
* At 5 instances, speedup is approximately 1.32.
* At 10 instances, speedup is approximately 1.36.
* At 15 instances, speedup is approximately 1.39.
* At 20 instances, speedup is approximately 1.41.
* At 25 instances, speedup is approximately 1.43.
* At 30 instances, speedup is approximately 1.44.
* At 35 instances, speedup is approximately 1.45.
* At 40 instances, speedup is approximately 1.46.
* At 45 instances, speedup is approximately 1.47.
* At 50 instances, speedup is approximately 1.48.
* **Green Line (S=1000, β=50):** The line slopes upward, similar to the orange line, but generally higher than the orange line.
* At 0 instances, speedup is approximately 1.30.
* At 5 instances, speedup is approximately 1.36.
* At 10 instances, speedup is approximately 1.40.
* At 15 instances, speedup is approximately 1.43.
* At 20 instances, speedup is approximately 1.45.
* At 25 instances, speedup is approximately 1.46.
* At 30 instances, speedup is approximately 1.47.
* At 35 instances, speedup is approximately 1.48.
* At 40 instances, speedup is approximately 1.49.
* At 45 instances, speedup is approximately 1.50.
* At 50 instances, speedup is approximately 1.50.
**Chart (b): Scaling Law of SWIFT**
* **Blue Line (7B):** The line initially decreases, then plateaus.
* At 0.30, speedup is approximately 1.42.
* At 0.40, speedup is approximately 1.38.
* At 0.50, speedup is approximately 1.32.
* At 0.60, speedup is approximately 1.28.
* **Orange Line (13B):** The line increases initially, reaches a peak, and then decreases.
* At 0.30, speedup is approximately 1.40.
* At 0.40, speedup is approximately 1.46.
* At 0.50, speedup is approximately 1.52.
* At 0.60, speedup is approximately 1.44.
* **Green Line (70B):** The line increases steadily and then decreases.
* At 0.30, speedup is approximately 1.45.
* At 0.40, speedup is approximately 1.50.
* At 0.50, speedup is approximately 1.56.
* At 0.60, speedup is approximately 1.50.
### Key Observations
* In Chart (a), increasing the number of instances consistently improves speedup for all configurations. Higher values of S (1000) generally yield higher speedup than lower values (500). Higher values of β (50) also tend to improve speedup.
* In Chart (b), the 7B model shows a decreasing speedup with increasing layer skip ratio. The 13B model exhibits an optimal layer skip ratio around 0.50, while the 70B model shows a peak speedup around 0.50, followed by a decrease.
### Interpretation
Chart (a) demonstrates the benefits of distributed computing. Increasing the number of instances leads to a near-linear speedup, suggesting efficient parallelization. The parameters S and β likely control aspects of the optimization strategy, with higher S and β values leading to better performance.
Chart (b) illustrates the trade-offs involved in layer skipping. For smaller models (7B), skipping layers degrades performance. However, for larger models (13B and 70B), a moderate amount of layer skipping can improve speedup, likely by reducing computational cost. The optimal layer skip ratio depends on the model size, suggesting that larger models can benefit more from skipping layers. The decrease in speedup at higher layer skip ratios indicates that excessive skipping can lead to information loss and reduced accuracy. These charts provide insights into optimizing model training and inference by tuning the number of instances and layer skip ratio.
</details>
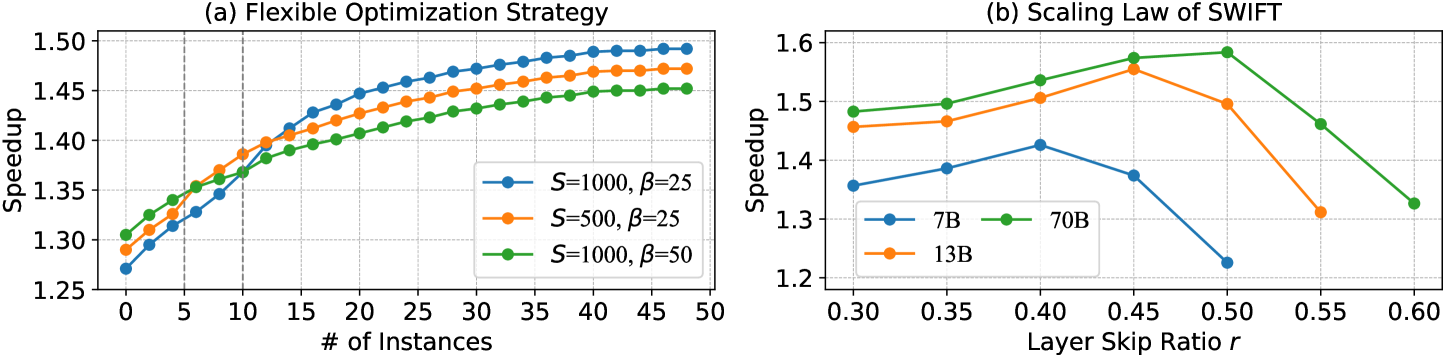
Figure 8: In-depth analysis of , which includes: (a) Flexible optimization strategy. The maximum optimization iteration $S$ and Bayesian interval $\beta$ can be flexibly adjusted to accommodate different input data types. (b) Scaling law. The speedup and optimal layer skip ratio of increase with larger model sizes, indicating that larger LLMs exhibit greater layer sparsity.
Flexible Optimization & Scaling Law
Figure 8 (a) presents the flexibility of in handling various input types by adjusting the maximum optimization step $S$ and Bayesian interval $\beta$ . For input with fewer instances, reducing $S$ enables an earlier transition to the acceleration phase while increasing $\beta$ reduces the overhead during the optimization phase, enhancing speedups during the initial stages of inference. In cases with sufficient input data, enables exploring more optimization paths, thereby enhancing the overall speedup. Figure 8 (b) illustrates the scaling law of : as the model size increases, both the optimal layer-skip ratio and overall speedup improve, indicating that larger LLMs exhibit more layer sparsity. This finding highlights the potential of for accelerating LLMs of larger sizes (e.g., 175B), which we leave for future investigation.
<details>
<summary>x9.png Details</summary>
### Visual Description
\n
## Bar Chart: Speedup Comparison of Language Models
### Overview
This bar chart compares the speedup achieved by three different training configurations – Vanilla, Base, and Instruct – for two language models: Yi-34B and DeepSeek-Coder-33B. The speedup is measured on the y-axis, while the x-axis represents the language model being evaluated.
### Components/Axes
* **X-axis:** Language Model (Yi-34B, DeepSeek-Coder-33B)
* **Y-axis:** Speedup (Scale ranges from 1.0 to 1.6, with increments of 0.1)
* **Legend:**
* Vanilla (Color: Orange)
* Base (Color: Blue)
* Instruct (Color: Teal)
### Detailed Analysis
The chart consists of six bars, two for each language model, representing the speedup for each training configuration.
**Yi-34B:**
* **Vanilla:** The bar is positioned at approximately 1.00 on the y-axis.
* **Base:** The bar reaches approximately 1.31 on the y-axis. The line slopes upward from the Vanilla bar.
* **Instruct:** The bar reaches approximately 1.26 on the y-axis. The line slopes downward from the Base bar.
**DeepSeek-Coder-33B:**
* **Vanilla:** The bar is positioned at approximately 1.00 on the y-axis.
* **Base:** The bar reaches approximately 1.54 on the y-axis. The line slopes upward from the Vanilla bar.
* **Instruct:** The bar reaches approximately 1.39 on the y-axis. The line slopes downward from the Base bar.
### Key Observations
* The "Base" configuration consistently provides the highest speedup for both language models.
* The "Instruct" configuration provides a speedup that is lower than the "Base" configuration but higher than the "Vanilla" configuration.
* DeepSeek-Coder-33B shows a greater speedup overall compared to Yi-34B, particularly in the "Base" configuration.
* The "Vanilla" configuration has a speedup of 1.00 for both models, indicating no speedup relative to a baseline.
### Interpretation
The data suggests that the "Base" training configuration is the most effective for accelerating both Yi-34B and DeepSeek-Coder-33B. The "Instruct" configuration offers a moderate speedup, while the "Vanilla" configuration provides no speedup. The larger speedup observed with DeepSeek-Coder-33B suggests that this model benefits more from the "Base" training approach than Yi-34B. This could be due to differences in model architecture, training data, or other factors. The consistent pattern of "Base" > "Instruct" > "Vanilla" indicates a clear hierarchy in the effectiveness of these training configurations. The speedup values provide quantitative evidence of the performance gains achieved by each configuration.
</details>
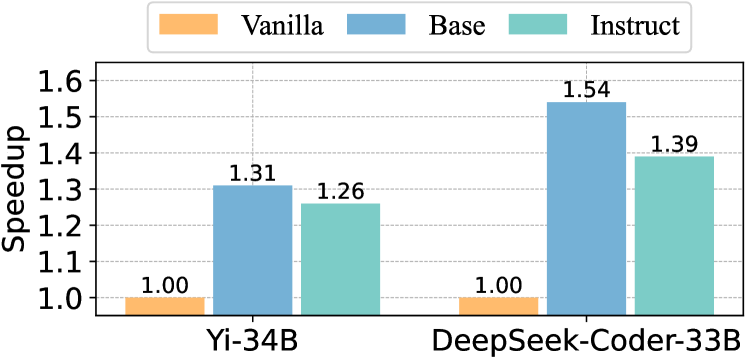
Figure 9: Speedups of on LLM backbones and their instruction-tuned variants.
Other LLM Backbones
Beyond LLaMA, we assess the effectiveness of on additional LLM backbones. Specifically, we include Yi-34B (Young et al., 2024) and DeepSeek-Coder-33B (Guo et al., 2024) along with their instruction-tuned variants for text and code generation tasks, respectively. The speedup results of are illustrated in Figure 9, demonstrating that achieves efficiency improvements ranging from $26\$ to $54\$ on these LLM backbones. Further experimental details are provided in Appendix C.3.
## 6 Conclusion
In this work, we introduce , an on-the-fly self-speculative decoding algorithm that adaptively selects certain intermediate layers of LLMs to skip during inference. The proposed method does not require additional training or auxiliary models, making it a plug-and-play solution for accelerating LLM inference across diverse input data streams. Extensive experiments conducted across various LLMs and tasks demonstrate that achieves over a $1.3\times$ $\sim$ $1.6\times$ speedup while preserving the distribution of the generated text. Furthermore, our in-depth analysis highlights the effectiveness of in handling dynamic input data streams and its seamless integration with various LLM backbones, showcasing the great potential of this paradigm for practical LLM inference acceleration.
## Ethics Statement
The datasets used in our experiments are publicly released and labeled through interaction with humans in English. In this process, user privacy is protected, and no personal information is contained in the dataset. The scientific artifacts that we used are available for research with permissive licenses. The use of these artifacts in this paper is consistent with their intended purpose.
## Acknowledgements
We thank all anonymous reviewers for their valuable comments during the review process. The work described in this paper was supported by Research Grants Council of Hong Kong (PolyU/15207122, PolyU/15209724, PolyU/15207821, PolyU/15213323) and PolyU internal grants (BDWP).
## Reproducibility Statement
All the results in this work are reproducible. We provide all the necessary code in the Supplementary Material to replicate our results. The repository includes environment configurations, scripts, and other relevant materials. We discuss the experimental settings in Section 5.1 and Appendix C, including implementation details such as models, datasets, inference setup, and evaluation metrics.
## References
- Ankner et al. (2024) Zachary Ankner, Rishab Parthasarathy, Aniruddha Nrusimha, Christopher Rinard, Jonathan Ragan-Kelley, and William Brandon. Hydra: Sequentially-dependent draft heads for medusa decoding. CoRR, abs/2402.05109, 2024. doi: 10.48550/ARXIV.2402.05109. URL https://doi.org/10.48550/arXiv.2402.05109.
- Bae et al. (2023) Sangmin Bae, Jongwoo Ko, Hwanjun Song, and Se-Young Yun. Fast and robust early-exiting framework for autoregressive language models with synchronized parallel decoding. In Houda Bouamor, Juan Pino, and Kalika Bali (eds.), Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pp. 5910–5924, Singapore, December 2023. Association for Computational Linguistics. doi: 10.18653/v1/2023.emnlp-main.362. URL https://aclanthology.org/2023.emnlp-main.362.
- Cai et al. (2024) Tianle Cai, Yuhong Li, Zhengyang Geng, Hongwu Peng, Jason D. Lee, Deming Chen, and Tri Dao. Medusa: Simple LLM inference acceleration framework with multiple decoding heads. In Forty-first International Conference on Machine Learning, ICML 2024, Vienna, Austria, July 21-27, 2024. OpenReview.net, 2024. URL https://openreview.net/forum?id=PEpbUobfJv.
- Chen et al. (2023) Charlie Chen, Sebastian Borgeaud, Geoffrey Irving, Jean-Baptiste Lespiau, Laurent Sifre, and John Jumper. Accelerating large language model decoding with speculative sampling. CoRR, abs/2302.01318, 2023. doi: 10.48550/arXiv.2302.01318. URL https://doi.org/10.48550/arXiv.2302.01318.
- Chen et al. (2021) Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Pondé de Oliveira Pinto, Jared Kaplan, Harrison Edwards, et al. Evaluating large language models trained on code. CoRR, abs/2107.03374, 2021. URL https://arxiv.org/abs/2107.03374.
- Cobbe et al. (2021) Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. Training verifiers to solve math word problems. CoRR, abs/2110.14168, 2021. URL https://arxiv.org/abs/2110.14168.
- Corro et al. (2023) Luciano Del Corro, Allie Del Giorno, Sahaj Agarwal, Bin Yu, Ahmed Awadallah, and Subhabrata Mukherjee. Skipdecode: Autoregressive skip decoding with batching and caching for efficient LLM inference. CoRR, abs/2307.02628, 2023. doi: 10.48550/ARXIV.2307.02628. URL https://doi.org/10.48550/arXiv.2307.02628.
- Dettmers et al. (2022) Tim Dettmers, Mike Lewis, Younes Belkada, and Luke Zettlemoyer. Gpt3.int8(): 8-bit matrix multiplication for transformers at scale. In Sanmi Koyejo, S. Mohamed, A. Agarwal, Danielle Belgrave, K. Cho, and A. Oh (eds.), Advances in Neural Information Processing Systems 35: Annual Conference on Neural Information Processing Systems 2022, NeurIPS 2022, New Orleans, LA, USA, November 28 - December 9, 2022, 2022. URL http://papers.nips.cc/paper_files/paper/2022/hash/c3ba4962c05c49636d4c6206a97e9c8a-Abstract-Conference.html.
- Du et al. (2024) Cunxiao Du, Jing Jiang, Yuanchen Xu, Jiawei Wu, Sicheng Yu, Yongqi Li, Shenggui Li, Kai Xu, Liqiang Nie, Zhaopeng Tu, and Yang You. Glide with a cape: A low-hassle method to accelerate speculative decoding. In Forty-first International Conference on Machine Learning, ICML 2024, Vienna, Austria, July 21-27, 2024. OpenReview.net, 2024. URL https://openreview.net/forum?id=mk8oRhox2l.
- Dubey et al. (2024) Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, et al. The llama 3 herd of models, 2024. URL https://arxiv.org/abs/2407.21783.
- Eldan & Li (2023) Ronen Eldan and Yuanzhi Li. Tinystories: How small can language models be and still speak coherent english? CoRR, abs/2305.07759, 2023. doi: 10.48550/ARXIV.2305.07759. URL https://doi.org/10.48550/arXiv.2305.07759.
- Elhoushi et al. (2024) Mostafa Elhoushi, Akshat Shrivastava, Diana Liskovich, Basil Hosmer, Bram Wasti, Liangzhen Lai, Anas Mahmoud, Bilge Acun, Saurabh Agarwal, Ahmed Roman, Ahmed Aly, Beidi Chen, and Carole-Jean Wu. LayerSkip: Enabling early exit inference and self-speculative decoding. In Lun-Wei Ku, Andre Martins, and Vivek Srikumar (eds.), Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 12622–12642, Bangkok, Thailand, August 2024. Association for Computational Linguistics. URL https://aclanthology.org/2024.acl-long.681.
- Frantar et al. (2023) Elias Frantar, Saleh Ashkboos, Torsten Hoefler, and Dan Alistarh. OPTQ: Accurate quantization for generative pre-trained transformers. In The Eleventh International Conference on Learning Representations, 2023. URL https://openreview.net/forum?id=tcbBPnfwxS.
- Fu et al. (2024) Yichao Fu, Peter Bailis, Ion Stoica, and Hao Zhang. Break the sequential dependency of LLM inference using lookahead decoding. In Forty-first International Conference on Machine Learning, ICML 2024, Vienna, Austria, July 21-27, 2024. OpenReview.net, 2024. URL https://openreview.net/forum?id=eDjvSFOkXw.
- Gloeckle et al. (2024) Fabian Gloeckle, Badr Youbi Idrissi, Baptiste Rozière, David Lopez-Paz, and Gabriel Synnaeve. Better & faster large language models via multi-token prediction. CoRR, abs/2404.19737, 2024. doi: 10.48550/ARXIV.2404.19737. URL https://doi.org/10.48550/arXiv.2404.19737.
- Gu et al. (2024) Yuxian Gu, Li Dong, Furu Wei, and Minlie Huang. MiniLLM: Knowledge distillation of large language models. In The Twelfth International Conference on Learning Representations, 2024. URL https://openreview.net/forum?id=5h0qf7IBZZ.
- Guo et al. (2024) Daya Guo, Qihao Zhu, Dejian Yang, Zhenda Xie, Kai Dong, Wentao Zhang, Guanting Chen, Xiao Bi, Y. Wu, Y. K. Li, Fuli Luo, Yingfei Xiong, and Wenfeng Liang. Deepseek-coder: When the large language model meets programming - the rise of code intelligence. CoRR, abs/2401.14196, 2024. doi: 10.48550/ARXIV.2401.14196. URL https://doi.org/10.48550/arXiv.2401.14196.
- He et al. (2024) Zhenyu He, Zexuan Zhong, Tianle Cai, Jason Lee, and Di He. REST: Retrieval-based speculative decoding. In Kevin Duh, Helena Gomez, and Steven Bethard (eds.), Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), pp. 1582–1595, Mexico City, Mexico, June 2024. Association for Computational Linguistics. URL https://aclanthology.org/2024.naacl-long.88.
- Hoefler et al. (2021) Torsten Hoefler, Dan Alistarh, Tal Ben-Nun, Nikoli Dryden, and Alexandra Peste. Sparsity in deep learning: Pruning and growth for efficient inference and training in neural networks. J. Mach. Learn. Res., 22(241):1–124, 2021.
- Hooper et al. (2023) Coleman Hooper, Sehoon Kim, Hiva Mohammadzadeh, Hasan Genc, Kurt Keutzer, Amir Gholami, and Yakun Sophia Shao. SPEED: speculative pipelined execution for efficient decoding. CoRR, abs/2310.12072, 2023. doi: 10.48550/ARXIV.2310.12072. URL https://doi.org/10.48550/arXiv.2310.12072.
- Hsieh et al. (2023) Cheng-Yu Hsieh, Chun-Liang Li, Chih-Kuan Yeh, Hootan Nakhost, Yasuhisa Fujii, Alex Ratner, Ranjay Krishna, Chen-Yu Lee, and Tomas Pfister. Distilling step-by-step! outperforming larger language models with less training data and smaller model sizes. In Anna Rogers, Jordan L. Boyd-Graber, and Naoaki Okazaki (eds.), Findings of the Association for Computational Linguistics: ACL 2023, Toronto, Canada, July 9-14, 2023, pp. 8003–8017. Association for Computational Linguistics, 2023. doi: 10.18653/V1/2023.FINDINGS-ACL.507. URL https://doi.org/10.18653/v1/2023.findings-acl.507.
- Hu et al. (2022) Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. Lora: Low-rank adaptation of large language models. In The Tenth International Conference on Learning Representations, ICLR 2022, Virtual Event, April 25-29, 2022. OpenReview.net, 2022. URL https://openreview.net/forum?id=nZeVKeeFYf9.
- Jaiswal et al. (2024) Ajay Jaiswal, Bodun Hu, Lu Yin, Yeonju Ro, Shiwei Liu, Tianlong Chen, and Aditya Akella. Ffn-skipllm: A hidden gem for autoregressive decoding with adaptive feed forward skipping. CoRR, abs/2404.03865, 2024. doi: 10.48550/ARXIV.2404.03865. URL https://doi.org/10.48550/arXiv.2404.03865.
- Jones et al. (1998) Donald R. Jones, Matthias Schonlau, and William J. Welch. Efficient global optimization of expensive black-box functions. J. Glob. Optim., 13(4):455–492, 1998. doi: 10.1023/A:1008306431147. URL https://doi.org/10.1023/A:1008306431147.
- Kim et al. (2023) Sehoon Kim, Karttikeya Mangalam, Suhong Moon, Jitendra Malik, Michael W. Mahoney, Amir Gholami, and Kurt Keutzer. Speculative decoding with big little decoder. In Alice Oh, Tristan Naumann, Amir Globerson, Kate Saenko, Moritz Hardt, and Sergey Levine (eds.), Advances in Neural Information Processing Systems 36: Annual Conference on Neural Information Processing Systems 2023, NeurIPS 2023, New Orleans, LA, USA, December 10 - 16, 2023, 2023. URL http://papers.nips.cc/paper_files/paper/2023/hash/7b97adeafa1c51cf65263459ca9d0d7c-Abstract-Conference.html.
- Kim et al. (2024) Taehyeon Kim, Ananda Theertha Suresh, Kishore A Papineni, Michael Riley, Sanjiv Kumar, and Adrian Benton. Accelerating blockwise parallel language models with draft refinement. In The Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024. URL https://openreview.net/forum?id=KT6F5Sw0eg.
- Kou et al. (2024) Siqi Kou, Lanxiang Hu, Zhezhi He, Zhijie Deng, and Hao Zhang. Cllms: Consistency large language models. In Forty-first International Conference on Machine Learning, ICML 2024, Vienna, Austria, July 21-27, 2024. OpenReview.net, 2024. URL https://openreview.net/forum?id=8uzBOVmh8H.
- Kwiatkowski et al. (2019) Tom Kwiatkowski, Jennimaria Palomaki, Olivia Redfield, Michael Collins, Ankur Parikh, Chris Alberti, Danielle Epstein, Illia Polosukhin, Jacob Devlin, Kenton Lee, Kristina Toutanova, Llion Jones, Matthew Kelcey, Ming-Wei Chang, Andrew M. Dai, Jakob Uszkoreit, Quoc Le, and Slav Petrov. Natural questions: A benchmark for question answering research. Transactions of the Association for Computational Linguistics, 7:452–466, 2019. doi: 10.1162/tacl˙a˙00276. URL https://aclanthology.org/Q19-1026.
- Leviathan et al. (2023) Yaniv Leviathan, Matan Kalman, and Yossi Matias. Fast inference from transformers via speculative decoding. In Andreas Krause, Emma Brunskill, Kyunghyun Cho, Barbara Engelhardt, Sivan Sabato, and Jonathan Scarlett (eds.), International Conference on Machine Learning, ICML 2023, 23-29 July 2023, Honolulu, Hawaii, USA, volume 202 of Proceedings of Machine Learning Research, pp. 19274–19286. PMLR, 2023. URL https://proceedings.mlr.press/v202/leviathan23a.html.
- Li et al. (2024a) Yuhui Li, Fangyun Wei, Chao Zhang, and Hongyang Zhang. Eagle: Speculative sampling requires rethinking feature uncertainty, 2024a.
- Li et al. (2024b) Yuhui Li, Fangyun Wei, Chao Zhang, and Hongyang Zhang. EAGLE-2: faster inference of language models with dynamic draft trees. CoRR, abs/2406.16858, 2024b. doi: 10.48550/ARXIV.2406.16858. URL https://doi.org/10.48550/arXiv.2406.16858.
- Liu et al. (2023a) Xiaoxuan Liu, Lanxiang Hu, Peter Bailis, Ion Stoica, Zhijie Deng, Alvin Cheung, and Hao Zhang. Online speculative decoding. CoRR, abs/2310.07177, 2023a. doi: 10.48550/ARXIV.2310.07177. URL https://doi.org/10.48550/arXiv.2310.07177.
- Liu et al. (2024) Yijin Liu, Fandong Meng, and Jie Zhou. Accelerating inference in large language models with a unified layer skipping strategy. CoRR, abs/2404.06954, 2024. doi: 10.48550/ARXIV.2404.06954. URL https://doi.org/10.48550/arXiv.2404.06954.
- Liu et al. (2019) Zhuang Liu, Mingjie Sun, Tinghui Zhou, Gao Huang, and Trevor Darrell. Rethinking the value of network pruning. In 7th International Conference on Learning Representations, ICLR 2019, New Orleans, LA, USA, May 6-9, 2019. OpenReview.net, 2019. URL https://openreview.net/forum?id=rJlnB3C5Ym.
- Liu et al. (2023b) Zichang Liu, Jue Wang, Tri Dao, Tianyi Zhou, Binhang Yuan, Zhao Song, Anshumali Shrivastava, Ce Zhang, Yuandong Tian, Christopher Re, et al. Deja vu: Contextual sparsity for efficient llms at inference time. In International Conference on Machine Learning, pp. 22137–22176. PMLR, 2023b.
- Ma et al. (2024) Shuming Ma, Hongyu Wang, Lingxiao Ma, Lei Wang, Wenhui Wang, Shaohan Huang, Li Dong, Ruiping Wang, Jilong Xue, and Furu Wei. The era of 1-bit llms: All large language models are in 1.58 bits. CoRR, abs/2402.17764, 2024. doi: 10.48550/ARXIV.2402.17764. URL https://doi.org/10.48550/arXiv.2402.17764.
- Miao et al. (2024) Xupeng Miao, Gabriele Oliaro, Zhihao Zhang, Xinhao Cheng, Zeyu Wang, Zhengxin Zhang, Rae Ying Yee Wong, Alan Zhu, Lijie Yang, Xiaoxiang Shi, Chunan Shi, Zhuoming Chen, Daiyaan Arfeen, Reyna Abhyankar, and Zhihao Jia. Specinfer: Accelerating large language model serving with tree-based speculative inference and verification. In Proceedings of the 29th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 3, ASPLOS ’24, pp. 932–949, New York, NY, USA, 2024. Association for Computing Machinery. ISBN 9798400703867. doi: 10.1145/3620666.3651335. URL https://doi.org/10.1145/3620666.3651335.
- Nallapati et al. (2016) Ramesh Nallapati, Bowen Zhou, Cícero Nogueira dos Santos, Çaglar Gülçehre, and Bing Xiang. Abstractive text summarization using sequence-to-sequence rnns and beyond. In Yoav Goldberg and Stefan Riezler (eds.), Proceedings of the 20th SIGNLL Conference on Computational Natural Language Learning, CoNLL 2016, Berlin, Germany, August 11-12, 2016, pp. 280–290. ACL, 2016. doi: 10.18653/V1/K16-1028. URL https://doi.org/10.18653/v1/k16-1028.
- OpenAI (2023) OpenAI. GPT-4 technical report. CoRR, abs/2303.08774, 2023. doi: 10.48550/ARXIV.2303.08774. URL https://doi.org/10.48550/arXiv.2303.08774.
- Patterson (2004) David A. Patterson. Latency lags bandwith. Commun. ACM, 47(10):71–75, 2004. doi: 10.1145/1022594.1022596. URL https://doi.org/10.1145/1022594.1022596.
- Pope et al. (2023) Reiner Pope, Sholto Douglas, Aakanksha Chowdhery, Jacob Devlin, James Bradbury, Jonathan Heek, Kefan Xiao, Shivani Agrawal, and Jeff Dean. Efficiently scaling transformer inference. In Dawn Song, Michael Carbin, and Tianqi Chen (eds.), Proceedings of the Sixth Conference on Machine Learning and Systems, MLSys 2023, Miami, FL, USA, June 4-8, 2023. mlsys.org, 2023. URL https://proceedings.mlsys.org/paper_files/paper/2023/hash/c4be71ab8d24cdfb45e3d06dbfca2780-Abstract-mlsys2023.html.
- Rasmussen & Williams (2006) Carl Edward Rasmussen and Christopher K. I. Williams. Gaussian processes for machine learning. Adaptive computation and machine learning. MIT Press, 2006. ISBN 026218253X. URL https://www.worldcat.org/oclc/61285753.
- Rozière et al. (2023) Baptiste Rozière, Jonas Gehring, Fabian Gloeckle, Sten Sootla, Itai Gat, Xiaoqing Ellen Tan, Yossi Adi, Jingyu Liu, Tal Remez, Jérémy Rapin, Artyom Kozhevnikov, Ivan Evtimov, Joanna Bitton, Manish Bhatt, Cristian Canton-Ferrer, Aaron Grattafiori, Wenhan Xiong, Alexandre Défossez, Jade Copet, Faisal Azhar, Hugo Touvron, Louis Martin, Nicolas Usunier, Thomas Scialom, and Gabriel Synnaeve. Code llama: Open foundation models for code. CoRR, abs/2308.12950, 2023. doi: 10.48550/ARXIV.2308.12950. URL https://doi.org/10.48550/arXiv.2308.12950.
- Santilli et al. (2023) Andrea Santilli, Silvio Severino, Emilian Postolache, Valentino Maiorca, Michele Mancusi, Riccardo Marin, and Emanuele Rodolà. Accelerating transformer inference for translation via parallel decoding. In Anna Rogers, Jordan L. Boyd-Graber, and Naoaki Okazaki (eds.), Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), ACL 2023, Toronto, Canada, July 9-14, 2023, pp. 12336–12355. Association for Computational Linguistics, 2023. doi: 10.18653/v1/2023.acl-long.689. URL https://doi.org/10.18653/v1/2023.acl-long.689.
- Shazeer (2019) Noam Shazeer. Fast transformer decoding: One write-head is all you need. CoRR, abs/1911.02150, 2019. URL http://arxiv.org/abs/1911.02150.
- Stern et al. (2018) Mitchell Stern, Noam Shazeer, and Jakob Uszkoreit. Blockwise parallel decoding for deep autoregressive models. In Samy Bengio, Hanna M. Wallach, Hugo Larochelle, Kristen Grauman, Nicolò Cesa-Bianchi, and Roman Garnett (eds.), Advances in Neural Information Processing Systems 31: Annual Conference on Neural Information Processing Systems 2018, NeurIPS 2018, December 3-8, 2018, Montréal, Canada, pp. 10107–10116, 2018. URL https://proceedings.neurips.cc/paper/2018/hash/c4127b9194fe8562c64dc0f5bf2c93bc-Abstract.html.
- Sun et al. (2023) Ziteng Sun, Ananda Theertha Suresh, Jae Hun Ro, Ahmad Beirami, Himanshu Jain, and Felix Yu. Spectr: Fast speculative decoding via optimal transport. In Thirty-seventh Conference on Neural Information Processing Systems, 2023. URL https://openreview.net/forum?id=SdYHLTCC5J.
- Taori et al. (2023) Rohan Taori, Ishaan Gulrajani, Tianyi Zhang, Yann Dubois, Xuechen Li, Carlos Guestrin, Percy Liang, and Tatsunori B. Hashimoto. Stanford alpaca: An instruction-following llama model. https://github.com/tatsu-lab/stanford_alpaca, 2023.
- Touvron et al. (2021) Hugo Touvron, Matthieu Cord, Matthijs Douze, Francisco Massa, Alexandre Sablayrolles, and Hervé Jégou. Training data-efficient image transformers & distillation through attention. In International Conference on Machine Learning, pp. 10347–10357. PMLR, 2021.
- Touvron et al. (2023a) Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, Aurélien Rodriguez, Armand Joulin, Edouard Grave, and Guillaume Lample. Llama: Open and efficient foundation language models. CoRR, abs/2302.13971, 2023a. doi: 10.48550/arXiv.2302.13971. URL https://doi.org/10.48550/arXiv.2302.13971.
- Touvron et al. (2023b) Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, et al. Llama 2: Open foundation and fine-tuned chat models. CoRR, abs/2307.09288, 2023b. doi: 10.48550/ARXIV.2307.09288. URL https://doi.org/10.48550/arXiv.2307.09288.
- Xia et al. (2023) Heming Xia, Tao Ge, Peiyi Wang, Si-Qing Chen, Furu Wei, and Zhifang Sui. Speculative decoding: Exploiting speculative execution for accelerating seq2seq generation. In Houda Bouamor, Juan Pino, and Kalika Bali (eds.), Findings of the Association for Computational Linguistics: EMNLP 2023, Singapore, December 6-10, 2023, pp. 3909–3925. Association for Computational Linguistics, 2023. doi: 10.18653/V1/2023.FINDINGS-EMNLP.257. URL https://doi.org/10.18653/v1/2023.findings-emnlp.257.
- Xia et al. (2024) Heming Xia, Zhe Yang, Qingxiu Dong, Peiyi Wang, Yongqi Li, Tao Ge, Tianyu Liu, Wenjie Li, and Zhifang Sui. Unlocking efficiency in large language model inference: A comprehensive survey of speculative decoding. In Lun-Wei Ku, Andre Martins, and Vivek Srikumar (eds.), Findings of the Association for Computational Linguistics ACL 2024, pp. 7655–7671, Bangkok, Thailand and virtual meeting, August 2024. Association for Computational Linguistics. URL https://aclanthology.org/2024.findings-acl.456.
- Yang et al. (2023) Seongjun Yang, Gibbeum Lee, Jaewoong Cho, Dimitris S. Papailiopoulos, and Kangwook Lee. Predictive pipelined decoding: A compute-latency trade-off for exact LLM decoding. CoRR, abs/2307.05908, 2023. doi: 10.48550/ARXIV.2307.05908. URL https://doi.org/10.48550/arXiv.2307.05908.
- Yi et al. (2024) Hanling Yi, Feng Lin, Hongbin Li, Ning Peiyang, Xiaotian Yu, and Rong Xiao. Generation meets verification: Accelerating large language model inference with smart parallel auto-correct decoding. In Lun-Wei Ku, Andre Martins, and Vivek Srikumar (eds.), Findings of the Association for Computational Linguistics ACL 2024, pp. 5285–5299, Bangkok, Thailand and virtual meeting, August 2024. Association for Computational Linguistics. URL https://aclanthology.org/2024.findings-acl.313.
- Young et al. (2024) Alex Young, Bei Chen, Chao Li, Chengen Huang, Ge Zhang, Guanwei Zhang, Heng Li, Jiangcheng Zhu, Jianqun Chen, Jing Chang, Kaidong Yu, Peng Liu, Qiang Liu, Shawn Yue, Senbin Yang, Shiming Yang, Tao Yu, Wen Xie, Wenhao Huang, Xiaohui Hu, Xiaoyi Ren, Xinyao Niu, Pengcheng Nie, Yuchi Xu, Yudong Liu, Yue Wang, Yuxuan Cai, Zhenyu Gu, Zhiyuan Liu, and Zonghong Dai. Yi: Open foundation models by 01.ai. CoRR, abs/2403.04652, 2024. doi: 10.48550/ARXIV.2403.04652. URL https://doi.org/10.48550/arXiv.2403.04652.
- Zhang et al. (2024) Jun Zhang, Jue Wang, Huan Li, Lidan Shou, Ke Chen, Gang Chen, and Sharad Mehrotra. Draft& verify: Lossless large language model acceleration via self-speculative decoding. In Lun-Wei Ku, Andre Martins, and Vivek Srikumar (eds.), Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 11263–11282, Bangkok, Thailand, August 2024. Association for Computational Linguistics. URL https://aclanthology.org/2024.acl-long.607.
- Zhou et al. (2024) Yongchao Zhou, Kaifeng Lyu, Ankit Singh Rawat, Aditya Krishna Menon, Afshin Rostamizadeh, Sanjiv Kumar, Jean-François Kagy, and Rishabh Agarwal. Distillspec: Improving speculative decoding via knowledge distillation. In The Twelfth International Conference on Learning Representations, 2024. URL https://openreview.net/forum?id=rsY6J3ZaTF.
- Zhu et al. (2024) Yunqi Zhu, Xuebing Yang, Yuanyuan Wu, and Wensheng Zhang. Hierarchical skip decoding for efficient autoregressive text generation. CoRR, abs/2403.14919, 2024. doi: 10.48550/ARXIV.2403.14919. URL https://doi.org/10.48550/arXiv.2403.14919.
## Appendix
## Appendix A Preliminary Details
We present the detailed configuration of Self-SD across four task domains in Figure 10, demonstrating that the optimal skipped layer configurations vary depending on the specific task.
<details>
<summary>x10.png Details</summary>

### Visual Description
\n
## Bar Chart: Comparison of MLP and ATT
### Overview
The image presents a bar chart comparing two datasets labeled "MLP" (blue bars) and "ATT" (red bars) across a range of values from 1 to 76. The chart appears to represent the presence or absence of a value for each data point, indicated by the height of the bars.
### Components/Axes
* **X-axis:** Represents values from 1 to 76, incrementing by 1.
* **Y-axis:** Not explicitly labeled, but represents the presence/absence of a value for each data point.
* **Data Series 1:** "MLP" - Represented by blue bars.
* **Data Series 2:** "ATT" - Represented by red bars.
### Detailed Analysis
The chart consists of 76 vertical bars, grouped in pairs representing MLP and ATT for each value on the x-axis.
**MLP (Blue Bars):**
The blue bars are present at the following x-axis values: 10, 16, 18, 20, 28, 32, 36, 44, 46, 50, 54, 58, 62, 64, 70, 76.
There are 16 blue bars in total.
**ATT (Red Bars):**
The red bars are present at the following x-axis values: 3, 7, 9, 13, 15, 19, 23, 25, 27, 31, 35, 39, 41, 43, 45, 47, 49, 53, 55, 57, 59, 61, 63, 65, 67, 69, 73, 75, 79.
There are 29 red bars in total.
### Key Observations
* The "ATT" dataset has significantly more data points with a value (29) than the "MLP" dataset (16).
* There is no overlap in the values where both MLP and ATT have a value.
* The distribution of values for both datasets appears relatively random, with no clear clustering or patterns.
### Interpretation
The chart suggests a comparison between two different sets of data, "MLP" and "ATT," where the presence of a bar indicates a value is present for that specific data point. The higher number of values in the "ATT" dataset suggests that it represents a more frequent or comprehensive occurrence of the measured phenomenon. The lack of overlap indicates that the two datasets are largely independent of each other. Without knowing what "MLP" and "ATT" represent, it's difficult to draw more specific conclusions. The chart could be illustrating the presence or absence of a feature, a binary outcome, or any other categorical variable. The values on the x-axis could represent time, samples, or any other ordered sequence.
</details>
(a) Summarization - CNN/DM
<details>
<summary>x11.png Details</summary>

### Visual Description
\n
## Bar Chart: Comparison of MLP and ATT
### Overview
The image presents a bar chart comparing two datasets labeled "MLP" (blue bars) and "ATT" (red bars) across a range of values from 2 to 79. The chart appears to represent a binary comparison, where each value has a corresponding bar for both MLP and ATT, indicating presence or absence (or some other binary state).
### Components/Axes
* **X-axis:** Represents values from 2 to 79, incrementing by 1.
* **Y-axis:** Not explicitly labeled, but represents the presence or absence of a bar for each dataset at each value.
* **Datasets:**
* MLP (blue bars)
* ATT (red bars)
### Detailed Analysis
The chart consists of a series of bars, one for each value on the x-axis for each dataset. The presence of a bar indicates a positive value or state, while the absence indicates a negative value or state.
**MLP (Blue Bars):**
* Bars are present at values: 2, 4, 6, 8, 10, 12, 14, 16, 18, 20, 22, 24, 26, 28, 30, 32, 34, 36, 38, 40, 42, 44, 46, 48, 50, 52, 54, 56, 58, 60, 62, 64, 66, 68, 70, 72, 74, 76, 78, 80.
* There are 40 bars present for MLP.
**ATT (Red Bars):**
* Bars are present at values: 3, 5, 7, 9, 11, 13, 15, 17, 19, 21, 23, 25, 27, 29, 31, 33, 35, 37, 39, 41, 43, 45, 47, 49, 51, 53, 55, 57, 59, 61, 63, 65, 67, 69, 71, 73, 75, 77, 79.
* There are 40 bars present for ATT.
The pattern observed is that MLP bars are present at even numbers, and ATT bars are present at odd numbers, across the entire range of 2 to 79.
### Key Observations
* The two datasets are perfectly complementary. Where MLP has a bar, ATT does not, and vice versa.
* There is a clear alternating pattern between the two datasets.
* Both datasets have the same number of bars (40).
### Interpretation
The data suggests a strict binary separation between the two datasets, MLP and ATT, based on whether the value is even or odd. MLP appears to represent even numbers, while ATT represents odd numbers. This could be a visualization of a parity check, a feature selection process, or a simple categorization based on even/odd properties. The perfect complementarity indicates a deterministic relationship between the two datasets. The chart effectively demonstrates a clear distinction and mutual exclusivity between the two categories. It is a simple, yet effective, way to visualize a binary classification or partitioning of a numerical range.
</details>
(b) Reasoning - GSM8K
<details>
<summary>x12.png Details</summary>

### Visual Description
\n
## Chart: Binary Time Series Comparison
### Overview
The image presents a chart comparing two binary time series, labeled "MLP" and "ATT", across 80 time points. Each time point is represented by a vertical bar, colored either light blue (for MLP) or red (for ATT) to indicate a value of 1 or 0, respectively. The chart visually displays the presence or absence of a signal for each series over time.
### Components/Axes
* **X-axis:** Represents time points, ranging from 1 to 80. The axis is labeled with numerical values at each time point.
* **Y-axis:** Implicitly represents the two time series, "MLP" and "ATT".
* **MLP:** A time series represented by light blue bars.
* **ATT:** A time series represented by red bars.
### Detailed Analysis
The chart shows the following values for each time series:
**MLP:**
* 1-2: 1
* 3-5: 0
* 6-7: 1
* 8-10: 0
* 11-12: 1
* 13-15: 0
* 16-17: 1
* 18-20: 0
* 21-22: 1
* 23-24: 0
* 25-27: 1
* 28-30: 0
* 31-32: 1
* 33-35: 0
* 36-37: 1
* 38-40: 0
* 41-42: 1
* 43-45: 0
* 46-47: 1
* 48-50: 0
* 51-52: 1
* 53-55: 0
* 56-57: 1
* 58-60: 0
* 61-62: 1
* 63-65: 0
* 66-67: 1
* 68-70: 0
* 71-73: 1
* 74-75: 0
* 76-78: 1
* 79-80: 0
**ATT:**
* 1-4: 0
* 5-7: 1
* 8-10: 0
* 11-13: 1
* 14-18: 0
* 19-20: 1
* 21-22: 0
* 23-25: 1
* 26-28: 0
* 29-31: 1
* 32-34: 0
* 35-37: 1
* 38-41: 0
* 42-44: 1
* 45-47: 0
* 48-50: 1
* 51-53: 0
* 54-56: 1
* 57-59: 0
* 60-62: 1
* 63-65: 0
* 66-68: 1
* 69-71: 0
* 72-74: 1
* 75-77: 0
* 78-79: 1
* 80: 0
### Key Observations
* Both time series exhibit a roughly alternating pattern of 1s and 0s.
* There is no clear synchronization between the two series; they switch between 0 and 1 at different time points.
* The frequency of 1s appears to be similar for both series, although a precise count would be needed to confirm this.
* There are periods where both series are 0 or 1 simultaneously, but these are not consistent.
### Interpretation
The chart likely represents the activation patterns of two different components ("MLP" and "ATT") over time. The binary values could indicate whether each component is "on" (1) or "off" (0). The lack of synchronization suggests that the two components operate independently or respond to different inputs. The alternating pattern could indicate a cyclical process or a response to a fluctuating signal. Further context is needed to determine the specific meaning of these activation patterns and the relationship between the two components. The chart could be used to analyze the temporal dynamics of a system, identify potential dependencies between components, or evaluate the performance of different algorithms.
</details>
(c) Storytelling - TinyStories
<details>
<summary>x13.png Details</summary>

### Visual Description
\n
## Bar Chart: MP vs. ATT
### Overview
The image presents a bar chart comparing two datasets labeled "MP" (blue bars) and "ATT" (red bars) across a range of values from 1 to 78. Each value on the x-axis has a corresponding bar for both MP and ATT, indicating the presence or absence of a value.
### Components/Axes
* **X-axis:** Values ranging from 1 to 78, incrementing by 1.
* **Y-axis:** Not explicitly labeled, but represents the presence or absence of a value for each dataset.
* **MP:** Represented by blue bars.
* **ATT:** Represented by red bars.
### Detailed Analysis
The chart shows which values are present for each dataset. A bar indicates the presence of the value, while the absence of a bar indicates its absence.
**MP (Blue Bars):**
* Present at values: 2, 4, 6, 10, 12, 14, 18, 20, 24, 26, 30, 32, 34, 36, 40, 42, 44, 46, 50, 52, 54, 56, 58, 60, 62, 64, 66, 68, 70, 72, 74, 76, 78.
* Absent at values: 1, 3, 5, 7, 8, 9, 11, 13, 15, 16, 17, 19, 21, 22, 23, 25, 27, 28, 29, 31, 33, 35, 37, 38, 39, 41, 43, 45, 47, 48, 49, 51, 53, 55, 57, 59, 61, 63, 65, 67, 69, 71, 73, 75, 77.
**ATT (Red Bars):**
* Present at values: 1, 3, 5, 9, 11, 13, 19, 21, 23, 27, 29, 31, 35, 39, 41, 43, 47, 49, 53, 55, 57, 61, 63, 65, 67, 69, 71, 73, 75, 77, 79.
* Absent at values: 2, 4, 6, 7, 8, 10, 12, 14, 15, 16, 17, 18, 20, 22, 24, 25, 26, 28, 30, 32, 33, 34, 36, 37, 38, 40, 42, 44, 45, 46, 48, 50, 51, 52, 54, 56, 58, 59, 60, 62, 64, 66, 68, 70, 72, 74, 76, 78.
### Key Observations
* The datasets have very little overlap. Most values are present in either MP *or* ATT, but rarely both.
* MP is present at a higher number of values (34) than ATT (31).
* The distribution of present values appears somewhat random for both datasets, with no immediately obvious clustering.
### Interpretation
This chart likely represents a binary classification or presence/absence data for two different categories, MP and ATT, across a range of identifiers (1-78). The lack of overlap suggests that these categories are largely mutually exclusive. The chart could be used to identify which identifiers belong to each category, or to assess the relative prevalence of each category within the overall set of identifiers. The data suggests that MP is slightly more prevalent than ATT. Further context would be needed to understand the meaning of "MP" and "ATT" and the significance of their presence or absence.
</details>
(d) Translation - WMT16
Figure 10: Visualization of skipped layer set configurations of LLaMA-2-13B optimized by Self-SD (Zhang et al., 2024) on different task domains. Gray squares indicate retained layers, red squares denote skipped attention layers, and blue squares signify skipped MLP layers.
## Appendix B Experimental Setups
### B.1 Models and Datasets
Our experiments mainly evaluate the effectiveness of on LLaMA-2 (Touvron et al., 2023b) and CodeLLaMA series (Rozière et al., 2023). We provide empirical validation on a diverse range of generation tasks. For summarization, mathematical reasoning, storytelling, and code generation tasks, we chose the CNN/Daily Mail (CNN/DM) (Nallapati et al., 2016), GSM8K (Cobbe et al., 2021), TinyStories (Eldan & Li, 2023), and HumanEval (Chen et al., 2021) datasets, respectively. We perform 1-shot evaluation for CNN/DM and TinyStories, and 5-shot evaluation for GSM8K. The maximum generation lengths on CNN/DM, GSM8K, and TinyStories are set to 64, 64, and 128, respectively. We compare pass@1 and pass@10 for HumanEval. In our further analysis, we include three more datasets to validate the capability of in handling dynamic input data streams. Specifically, we select Alpaca (Taori et al., 2023), WMT14 DE-EN, and Nature Questions (Kwiatkowski et al., 2019) for the instruction following, translation, and question answering tasks, respectively. The maximum generation lengths for HumanEval and all analyses are set to 512. We randomly sample 1000 instances from the test set for each dataset except HumanEval.
### B.2 Inference Setup
In the optimization phase, we employ both random search and Bayesian optimization to suggest potential skipped layer set candidates, striking a balance between optimization performance and efficiency. The context window $\gamma$ is set to 32. The maximum draft length $N_{D}$ is set to 25. For random sampling in code generation tasks, we apply a temperature of 0.6 and $top\_p=0.95$ . The maximum number of layer set optimization steps $S$ is set to 1000, with Bayesian optimization performed every $\beta=25$ steps. The optimization phase is set to be early stopped if the matchness score does not improve after 300 steps or exceeds 0.95. The layer skip ratio $r$ is fixed at 0.45 for the 13B model and 0.5 for the 34B and 70B models. All experiments were conducted using Pytorch 2.1.0 on 4 $\times$ NVIDIA RTX A6000 GPU (40GB) with CUDA 12.1, and an Intel(R) Xeon(R) Platinum 8370C CPU with 32 cores. Inference for our method and all baselines was performed using the Huggingface transformers package. Following prior work, we adopt speculative sampling (Leviathan et al., 2023) as our acceptance strategy, and the batch size is set to 1.
### B.3 Evaluation Metrics
This subsection provides a detailed illustration of our evaluation metrics, which are mean generated length $M$ and token acceptance rate $\alpha$ . Specifically, the mean generated length $M$ refers to the average number of output tokens produced per forward pass of the target LLM; the acceptance rate $\alpha$ is defined as the ratio of accepted tokens to the total number of draft steps. In other words, it represents the expected probability of the target LLM accepting a potential token from a forward pass of the draft model. These two metrics are independent of computational hardware and, therefore considered as more objective metrics. Given the mean generated length $M$ , acceptance rate $\alpha$ , and the layer skip ratio $r$ , the mathematical formula for the expected wall-time speedup during the acceleration phase is derived as follows:
$$
\mathbb{E}(\text{Spd.})=\frac{M}{(M-1)\times\frac{c}{\alpha}+1}=\frac{M\alpha}
{(M-1)c+\alpha},\quad c=1-r, \tag{6}
$$
where $c$ is defined as the cost coefficient in Leviathan et al. (2023). It is calculated as the ratio between the single forward time of the draft model and that of the target LLM. In summary, the ideal speedup will be higher with the larger $M$ and $\alpha$ and smaller $c$ .
## Appendix C Experimental Details
### C.1 Details of Main Results
We present the detailed statistics of our main experimental results in Table 4. consistently achieves a token acceptance rate $\alpha$ exceeding $90\$ across all evaluation settings, with the mean generated length M ranging from 2.99 to 8.21. These statistics indicate strong behavior alignment between the target LLM and its layer-skipping draft variant, as discussed in Section 5.2. Additionally, we report the expected speedup $\mathbb{E}(\text{Spd.})$ calculated using Eq (6), indicating that the current implementation of has significant potential for further optimization to boost its efficiency.
| LLaMA-2-13B LLaMA-2-13B -Chat | Vanilla 4.34 Vanilla | 1.00 0.99 1.00 | - 1.52 $\times$ - | 1.00 $\times$ 3.13 1.00 $\times$ | 1.00 0.98 1.00 | - 1.43 $\times$ - | 1.00 $\times$ 8.21 1.00 $\times$ | 1.00 1.00 1.00 | - 1.65 $\times$ - | 1.00 $\times$ 1.53 $\times$ 1.00 $\times$ | 1.00 $\times$ 1.00 $\times$ |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| 3.54 | 0.90 | 1.39 $\times$ | 2.95 | 0.92 | 1.36 $\times$ | 7.42 | 0.99 | 1.62 $\times$ | 1.46 $\times$ | | |
| LLaMA-2-70B | Vanilla | 1.00 | - | 1.00 $\times$ | 1.00 | - | 1.00 $\times$ | 1.00 | - | 1.00 $\times$ | 1.00 $\times$ |
| 3.85 | 0.99 | 1.58 $\times$ | 2.99 | 0.98 | 1.48 $\times$ | 6.17 | 0.99 | 1.71 $\times$ | 1.59 $\times$ | | |
Table 4: Detailed results of on text generation tasks using LLaMA-2 series. We report the mean generated length M, token acceptance rate $\alpha$ , and the expected speedup $\mathbb{E}(\text{Spd.})$ calculated by Eq (6) under the setting of greedy decoding with FP16 precision.
### C.2 Additional Results on LLaMA-70B Models
In addition to the main results presented in Table 2, we provide further experimental evaluations of on LLaMA-70B models, including LLaMA-2-70B and LLaMA-3-70B, along with their instruction-tuned variants, under the same experimental settings. The results demonstrate that consistently achieves a $1.4\times$ $\sim$ $1.5\times$ wall-clock speedup across both the LLaMA-2 and LLaMA-3 series. Notably, achieves a token acceptance rate $\alpha$ exceeding $85\$ across various evaluation settings, with the mean generated length M ranging from 3.43 to 7.80. Although differences in layer redundancy are observed between models (e.g., skip ratio $r$ for LLaMA-2-70B vs. LLaMA-3-70B During the optimization phase, the layer skip ratio $r$ for LLaMA-3-70B was automatically adjusted from 0.5 to 0.4 as the token acceptance rate $\alpha$ remained below the tolerance threshold of 0.7.), demonstrates robust adaptability, maintaining consistent acceleration performance regardless of model version.
| LLaMA-2-70B LLaMA-2-70B -Chat | Vanilla 3.85 Vanilla | 1.00 0.99 1.00 | - 1.43 $\times$ - | 1.00 $\times$ 2.99 1.00 $\times$ | 1.00 0.98 1.00 | - 1.39 $\times$ - | 1.00 $\times$ 6.17 1.00 $\times$ | 1.00 0.99 1.00 | - 1.62 $\times$ - | 1.00 $\times$ 1.48 $\times$ 1.00 $\times$ | 1.00 $\times$ 1.00 $\times$ |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| 3.43 | 0.85 | 1.31 $\times$ | 3.12 | 0.89 | 1.32 $\times$ | 5.45 | 0.95 | 1.53 $\times$ | 1.37 $\times$ | | |
| LLaMA-3-70B | Vanilla | 1.00 | - | 1.00 $\times$ | 1.00 | - | 1.00 $\times$ | 1.00 | - | 1.00 $\times$ | 1.00 $\times$ |
| 5.43 | 0.99 | 1.41 $\times$ | 4.11 | 0.99 | 1.37 $\times$ | 7.80 | 0.99 | 1.51 $\times$ | 1.43 $\times$ | | |
| LLaMA-3-70B -Instruct | Vanilla | 1.00 | - | 1.00 $\times$ | 1.00 | - | 1.00 $\times$ | 1.00 | - | 1.00 $\times$ | 1.00 $\times$ |
| 3.76 | 0.95 | 1.33 $\times$ | 3.92 | 0.93 | 1.31 $\times$ | 5.87 | 0.97 | 1.43 $\times$ | 1.36 $\times$ | | |
Table 5: Experimental results of on text generation tasks using the LLaMA-70B series. We report the mean generated length M, token acceptance rate $\alpha$ , and speedup ratio under the setting of greedy decoding. The skip ratio $r$ is set to 0.5 for LLaMA-2 models and 0.4 for LLaMA-3 models.
### C.3 Detailed Results of LLM Backbones
To further validate the effectiveness of , we conducted experiments using additional LLM backbones beyond the LLaMA series. Specifically, we select two recently representative LLMs: Yi-34B for text generation and DeepSeek-Coder-33B for code generation tasks. The experimental results are illustrated in Table 6 and 7, demonstrating the efficacy of across these LLM backbones. achieves a consistent $1.2\times$ $\sim$ $1.3\times$ wall-clock speedup on the Yi-34B series and a $1.3\times$ $\sim$ $1.5\times$ on the DeepSeek-Coder-33B series. Notably, for the DeepSeek-Coder-33B series, attains a mean generate length M ranging from 3.16 to 4.17, alongside a token acceptance rate $\alpha$ exceeding $83\$ . These findings substantiate the utility of as a general-purpose, plug-and-play SD method, offering promising inference acceleration across diverse LLM backbones.
| Yi-34B Yi-34B-Chat | Vanilla 2.74 Vanilla | 1.00 0.94 1.00 | - 1.30 $\times$ - | 1.00 $\times$ 2.65 1.00 $\times$ | 1.00 0.97 1.00 | - 1.28 $\times$ - | 1.00 $\times$ 3.25 1.00 $\times$ | 1.00 0.98 1.00 | - 1.34 $\times$ - | 1.00 $\times$ 1.31 $\times$ 1.00 $\times$ | 1.00 $\times$ 1.00 $\times$ |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| 2.84 | 0.91 | 1.29 $\times$ | 2.77 | 0.89 | 1.27 $\times$ | 2.52 | 0.80 | 1.21 $\times$ | 1.26 $\times$ | | |
Table 6: Experimental results of on text generation tasks using Yi-34B series. We report the mean generated length M, token acceptance rate $\alpha$ and speedup ratio under the setting of greedy decoding with FP16 precision. The skip ratio $r$ is set to 0.45.
## Appendix D Further Analysis and Discussion
### D.1 Ablation Study
Table 8 presents the ablation study of using LLaMA-2-13B on CNN/DM. The experimental results demonstrate that each component of contributes to its overall speedup of . Specifically, early-stopping drafting effectively reduces the number of ineffective draft steps, improving the token acceptance rate $\alpha$ by $55\$ . Dynamic verification further enhances efficiency by selecting suitable draft candidates from the top- $k$ predictions based on their confidence scores; removing this component leads to a decrease in both the mean generated length (M) and the overall speedup ratio. Additionally, the optimization phase refines the set of skipped layers, improving speedup by $34\$ compared to the initial uniform layer-skipping strategy. In summary, these results confirm the effectiveness of each proposed innovation in .
| HumanEval (pass@1) HumanEval (pass@10) | Vanilla 4.97 Vanilla | 1.00 0.99 1.00 | - 1.54 $\times$ - | 1.00 $\times$ 3.80 1.00 $\times$ | 1.00 0.88 1.00 | - 1.39 $\times$ - | 1.00 $\times$ 1.00 $\times$ |
| --- | --- | --- | --- | --- | --- | --- | --- |
| 3.16 | 0.91 | 1.36 $\times$ | 3.74 | 0.83 | 1.31 $\times$ | | |
Table 7: Experimental results of on code generation tasks using DeepSeek-Coder-33B series. The skip ratio $r$ is set to 0.5. We use greedy decoding for pass@1 and random sampling with a temperature of 0.6 for pass@10. “ DS ” denotes the abbreviation of DeepSeek.
| w/o early-stopping-w/o dynamic ver. | 5.82 11.16 4.39 | 0.98 0.43 0.90 | 1.560 $\times$ 0.896 $\times$ 1.342 $\times$ |
| --- | --- | --- | --- |
| w/o optimization | 2.15 | 0.90 | 1.224 $\times$ |
Table 8: Ablation study of . “ ver. ” denotes the abbreviation of verification.
| 16 32 64 | 3.91 5.82 5.56 | 0.95 0.98 0.99 | 1.341 $\times$ 1.560 $\times$ 1.552 $\times$ | 0.242ms 0.244ms 0.312ms |
| --- | --- | --- | --- | --- |
| 128 | 5.61 | 0.98 | 1.550 $\times$ | 0.425ms |
Table 9: Speedups of across different context window $\gamma$ . The latency of the optimization step is reported to illustrate the associated overhead.
### D.2 Context Window
In Table 9, we show a detailed analysis of context window $\gamma$ , which determines the number of LLM-generated tokens used in the layer set optimization process. A smaller $\gamma$ introduces greater randomness in the matchness score calculation, resulting in suboptimal performance, while a larger $\gamma$ increases the computational overhead of the optimization step. The results indicate that $\gamma=32$ provides an optimal balance between optimization performance and computational overhead.
### D.3 Comparisons with Prior Layer-Skipping Methods
In this subsection, we compare with two representative layer-skipping speculative decoding (SD) methods: LayerSkip (Elhoushi et al., 2024) and Self-SD (Zhang et al., 2024). Specifically, LayerSkip (Elhoushi et al., 2024) introduces an innovative approach to self-speculative decoding by implementing early-exit drafting, where the LLM generates drafts using only its earlier layers. However, this method necessitates a time-consuming pretraining or finetuning process, which modifies the original output distribution of the target LLM. Such alterations may compromise the reliability of the generated outputs; Self-SD (Zhang et al., 2024) proposed to construct the compact draft model by skipping intermediate layers, using an extensive Bayesian Optimization process before inference to determine the optimal skipped layers within the target LLM. As illustrated in Section 3.1, while effective, Self-SD suffers from significant optimization latency (nearly 7.5 hours for LLaMA-2-13B and 20 hours for LLaMA-2-70B). This prolonged optimization process limits its practicality and generalizability across diverse models and tasks.
Tables 10 and 11 summarize the comparative results in terms of acceleration performance and training/optimization costs, respectively. Below, we detail the advantages of over these methods:
- Comparison with LayerSkip: LayerSkip achieves an aggressive skip ratio ( $r=0.8$ ), resulting in an average generated length of $2.42$ and a token acceptance rate of $0.64$ . However, its reliance on pretraining or finetuning alters the original distribution of the target LLM, potentially reducing reliability. In contrast, preserves the original distribution of the target LLM while delivering a comparable $1.56\times$ speedup without requiring additional training.
- Comparison with Self-SD: Self-SD relies on a time-intensive Bayesian Optimization process, which incurs substantial latency before inference. eliminates this bottleneck through an on-the-fly optimization strategy, achieving an approximately $\mathbf{200\times}$ reduction in optimization latency while maintaining the same $1.56\times$ speedup. We further augmented Self-SD with our Confidence-aware Inference Acceleration strategy (Self-SD w/ dynamic ver.). Even compared to this augmented version, achieves competitive speedups.
These findings highlight the efficiency and practicality of over previous layer-skipping SD methods. As the first plug-and-play layer-skipping SD approach, we hope that could provide valuable insights and inspire further research in this area.
| LayerSkip | ✗ | ✗ | 0.80 | 2.42 | 0.64 | 1.64 $\times$ |
| --- | --- | --- | --- | --- | --- | --- |
| Self-SD | ✗ | ✓ | 0.43 | 4.02 | 0.85 | 1.29 $\times$ |
| Self-SD w/ dynamic ver. | ✗ | ✓ | 0.43 | 5.69 | 0.98 | 1.52 $\times$ |
| (Ours) | ✓ | ✓ | 0.45 | 5.82 | 0.98 | 1.56 $\times$ |
Table 10: Comparison of and prior layer-skipping SD methods. We report the skip ratio $r$ , mean generated length M, token acceptance $\alpha$ , and speedup ratio under greedy decoding. The results are obtained with LLaMA-2-13B on CNN/DM. “ ver. ” denotes the abbreviation of verification.
| LayerSkip Self-SD (Ours) | $50\times 10^{3}$ training steps with 64 A100 (80GB) 1000 Bayesian Optimization Iterations Before inference N/A | - $\sim$ $7.5$ hours $\sim$ $\mathbf{2}$ minutes |
| --- | --- | --- |
Table 11: Comparison of and prior layer-skipping SD methods in terms of training cost and optimization latency for LLaMA-2-13B. Training costs are sourced from the original papers, while optimization latency is measured from our re-implementation on an A6000 GPU. demonstrates a $\sim$ $\mathbf{200\times}$ reduction in optimization latency compared to previous methods without requiring additional training, establishing it as an efficient plug-and-play SD method.
### D.4 Detailed Comparisons with Self-SD
<details>
<summary>x14.png Details</summary>
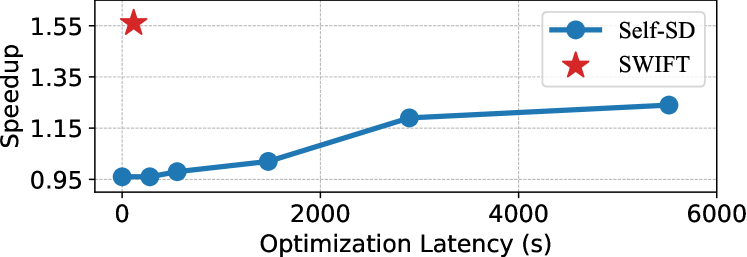
### Visual Description
\n
## Line Chart: Speedup vs. Optimization Latency
### Overview
This line chart compares the speedup achieved by "Self-SD" and "SWIFT" across varying optimization latencies. The x-axis represents optimization latency in seconds, and the y-axis represents speedup. The chart shows how speedup changes as optimization time increases for both methods.
### Components/Axes
* **X-axis Title:** Optimization Latency (s)
* **Y-axis Title:** Speedup
* **X-axis Scale:** 0 to 6000 seconds, with gridlines at 0, 1000, 2000, 3000, 4000, 5000, and 6000.
* **Y-axis Scale:** 0.9 to 1.55, with gridlines at 0.95, 1.05, 1.15, 1.25, 1.35, 1.45, and 1.55.
* **Legend:** Located in the top-right corner.
* "Self-SD" - Represented by a blue line with circular markers.
* "SWIFT" - Represented by a red star marker.
### Detailed Analysis
The chart displays two data series: "Self-SD" and "SWIFT".
**Self-SD (Blue Line):**
The line slopes generally upward, indicating that speedup increases with optimization latency.
* At 0 seconds latency, the speedup is approximately 0.96.
* At approximately 1000 seconds latency, the speedup is approximately 0.98.
* At approximately 2000 seconds latency, the speedup is approximately 1.05.
* At approximately 3000 seconds latency, the speedup is approximately 1.16.
* At approximately 4000 seconds latency, the speedup is approximately 1.20.
* At approximately 5000 seconds latency, the speedup is approximately 1.23.
* At 6000 seconds latency, the speedup is approximately 1.25.
**SWIFT (Red Star):**
A single data point is shown for "SWIFT".
* At 0 seconds latency, the speedup is approximately 1.55.
### Key Observations
* "SWIFT" exhibits a significantly higher speedup than "Self-SD" at 0 seconds latency.
* "Self-SD" shows a consistent, albeit gradual, increase in speedup as optimization latency increases.
* The chart only provides a single data point for "SWIFT", making it difficult to assess its performance trend across different optimization latencies.
### Interpretation
The data suggests that "SWIFT" offers a substantial initial speedup compared to "Self-SD" when no optimization latency is involved. However, as optimization time increases, "Self-SD" gradually improves its speedup, potentially approaching or even surpassing "SWIFT" at higher latency values (though this cannot be definitively determined from the provided data). The lack of data points for "SWIFT" beyond 0 seconds latency limits the ability to draw comprehensive conclusions about its overall performance. The chart highlights a trade-off between initial speedup (favored by "SWIFT") and sustained improvement with optimization time (favored by "Self-SD"). Further investigation with more data points for "SWIFT" is needed to understand its behavior across a wider range of optimization latencies.
</details>
Figure 11: Comparison of and Self-SD in terms of optimization latency and speedup. achieves a $1.56\times$ speedup with an optimization latency of 116 seconds.
In this subsection, we provide a detailed comparison of and Self-SD (Zhang et al., 2024). Figure 11 presents the speedups of Self-SD across varying optimization latencies, reflecting the increase in Bayesian Optimization iterations. As shown, Self-SD achieves minimal speedup improvement – almost equivalent to unified skipping – with fewer than 50 Bayesian iterations, corresponding to an optimization latency below 1474 seconds. At 100 Bayesian iterations, Self-SD achieves a $1.19\times$ speedup; however, its optimization latency is nearly 25 times longer than that of (2898s vs. 116s).
Table 12 compares and Self-SD (first two rows) under similar optimization latencies. The results highlight ’s superiority in both optimization efficiency (116s vs. 155s) and speedup ( $1.56\times$ vs. $0.97\times$ ). Even when compared to the augmented version of Self-SD (w/ dynamic verification), achieves a substantial $30\$ relative improvement in speedup. Below, we analyze the factors contributing to this advantage (elaborated in Section 3.1):
- Optimization Objective Granularity: Self-SD calculates its optimization objective at a multi-sample level, requiring sequential decoding of all selected training samples (e.g., 8 samples with 32 tokens each) for every iteration to optimize Equation 1. In contrast, adopts a step-level optimization objective, optimizing the layer set dynamically at each decoding step.
- Bayesian Optimization Complexity: The computational complexity of Bayesian optimization increases significantly with the number of iterations. mitigates this burden by combining random search with interval Bayesian optimization, accelerating convergence of the optimization process while reducing computational overhead.
To further examine optimization trade-offs, we reduce Self-SD’s sequential optimization requirement to a single sample with 8 tokens, enabling more Bayesian Optimization iterations within a comparable latency. The corresponding results, denoted as Self-SD c (rows 3-4), are presented in Table 12. Even with these optimized settings, demonstrates substantial superior speedup and efficiency, highlighting the effectiveness of our proposed strategies.
| Self-SD | - | 5 | 155 | 0.50 | 1.80 | 0.57 | 0.97 $\times$ |
| --- | --- | --- | --- | --- | --- | --- | --- |
| Self-SD w/ dynamic ver. | - | 5 | 155 | 0.50 | 2.07 | 0.86 | 1.17 $\times$ |
| Self-SD c | - | 30 | 199 | 0.45 | 2.08 | 0.70 | 1.04 $\times$ |
| Self-SD c w/ dynamic ver. | - | 30 | 199 | 0.45 | 2.44 | 0.93 | 1.22 $\times$ |
| (Ours) | 552 | 23 | 116 | 0.45 | 5.82 | 0.98 | 1.56 $\times$ |
Table 12: Comparison of and Self-SD at similar optimization latencies. We report the skip ratio $r$ , mean generated length M, token acceptance rate $\alpha$ , and speedup under greedy decoding. The results are obtained with LLaMA-2-13B on CNN/DM, with “ ver. ” indicating verification.
### D.5 The Necessity of Plug-and-Play SD Methods
There has been a surge of recent interest in Speculative Decoding (SD), leading to the development of numerous promising strategies in the field, which can be broadly categorized into two directions:
- Training-required SD. These methods require additional pretraining or fine-tuning to improve speculative accuracy, often involving the integration of extra parameters. For instance, Medusa (Cai et al., 2024) and Eagle (Li et al., 2024a; b) incorporate lightweight draft heads into target LLMs and fine-tune them, achieving $3\times$ $\sim$ $4\times$ speedups.
- Plug-and-play SD. These approaches offer immediate acceleration of LLM inference without relying on auxiliary models or additional training. Notable examples include Parallel Decoding (Santilli et al., 2023) and Lookahead (Fu et al., 2024), which leverage Jacobi-based drafting, achieving $1.2\times$ $\sim$ $1.4\times$ speedups across various LLMs.
While training-required SD methods generally deliver higher speedups, their reliance on additional training and parameters limits both their generalizability and practicality. This has sparked debate within the academic community regarding the value of plug-and-play SD methods. To address these concerns, we present a detailed analysis below to highlight the necessity of plug-and-play SD approaches and underscore the contributions of our proposed :
1) Training costs of training-required SD methods are often prohibitive.
Training-required methods such as Medusa (Cai et al., 2024) and Eagle (Li et al., 2024a; b), while achieving higher speedups, incur substantial training costs. Despite efforts to reduce training overhead, these methods still require extensive computational resources (e.g., GPU time and datasets) to deliver valid acceleration performance. For example, Eagle requires 1–2 days of training with 8 RTX 3090 GPUs for LLaMA-33B or up to 2 days on 4 A100 (40G) GPUs for LLaMA-2-Chat-70B, using a dataset of 70k dialogues from ShareGPT. Such computational burdens introduce challenges in several scenarios:
- Users must train new draft models for unsupported target LLMs. For example, if the user’s target LLM is not among the released checkpoints or if the base model is updated (e.g., LLaMA-3.x), users are forced to train a new draft model, which may exceed their available GPU resources (e.g., GPU time).
- Users with small-scale acceleration needs face inefficiencies. For instance, a researcher needing to evaluate a small set of samples (e.g., 10 hours of evaluation) would find the 1–2 day training requirement disproportionate and hinder overall research efficiency.
2) Plug-and-play SD fills critical gaps unaddressed by training-required methods.
Plug-and-play SD methods, including , are model-agnostic and training-free, providing immediate acceleration without requiring additional computational overhead. These attributes are particularly critical for large models (70B–340B) and for use cases requiring rapid integration. The growing adoption of plug-and-play SD methods, such as Lookahead (Fu et al., 2024), further underscores their importance. These methods cater to scenarios where ease of use and computational efficiency are paramount, validating their research significance.
3) pioneers plug-and-play SD with layer-skipping drafting.
represents the first plug-and-play SD method to incorporate layer-skipping drafting. It consistently achieves $1.3\times$ $\sim$ $1.6\times$ speedups over vanilla autoregressive decoding across diverse models and tasks. Additionally, it demonstrates $10\$ $\sim$ $20\$ higher efficiency compared to Lookahead (Fu et al., 2024). Despite its effectiveness, introduces a complementary research direction for existing plug-and-play SD. Its approach is orthogonal to Lookahead Decoding, and combining the two could further amplify their collective efficiency. We believe this study provides valuable insights and paves the way for future SD advancements, particularly for practical and cost-effective LLM acceleration.
To sum up, while training-required SD methods achieve higher speedups, their high computational costs and limited flexibility reduce practicality. Plug-and-play SD methods, like , offer training-free, model-agnostic acceleration, making them ideal for diverse scenarios. We hope this clarification fosters greater awareness and recognition of the value of plug-and-play SD research.
### D.6 Additional Discussions with Related Work
In this work, we leverage the inherent layer sparsity of LLMs through layer skipping, which selectively bypasses intermediate layers within the target LLM to construct the compact draft model. In addition to layer skipping, there has been another research direction in SD that focuses on early exiting, where inference halts at earlier layers to improve computational efficiency (Yang et al., 2023; Hooper et al., 2023; Bae et al., 2023; Elhoushi et al., 2024). Particularly, LayerSkip (Elhoushi et al., 2024) explores early-exit drafting by generating drafts using only the earlier layers of the target LLM, followed by verification with the full-parameter model. This approach requires training involving layer dropout and early exit losses. Similarly, PPD (Yang et al., 2023) employs early exiting but trains individual classifiers for each layer instead of relying on a single final-layer classifier. Although effective, these methods rely on extensive fine-tuning to enable early-exiting capabilities, incurring substantial computational costs. Moreover, the training process alters the target LLM’s original output distribution, potentially compromising the reliability of generated outputs. In contrast, our proposed does not require auxiliary models or additional training, preserving the original output distribution of the target LLM while delivering comparable acceleration benefits.
There has been a parallel line of training-required SD research focusing on non-autoregressive drafting strategies (Stern et al., 2018; Cai et al., 2024; Gloeckle et al., 2024; Kim et al., 2024). These methods integrate multiple draft heads into the target LLM, enabling the parallel generation of draft tokens at each decoding step. Notably, Kim et al. (2024) builds on the Blockwise Parallel Decoding paradigm introduced in Stern et al. (2018), accelerating inference by refining block drafts with task-independent n-grams and lightweight rescorers using smaller LMs. While these approaches achieve notable acceleration, they also necessitate extensive training of draft models. complements these efforts by pioneering plug-and-play SD that eliminates the need for auxiliary models or additional training, offering a more flexible and practical solution for diverse use cases.
### D.7 Optimization Steps
We present the detailed configuration of across various optimization steps in Figure 10. As the process continues, the skipped layer set is gradually refined toward the optimal configuration.
<details>
<summary>x15.png Details</summary>

### Visual Description
\n
## Patterned Image: Alternating Stripes
### Overview
The image displays a pattern of alternating vertical stripes in two colors: light blue and red. The pattern is arranged in two rows, labeled "MP" and "ATT" respectively. Each row is numbered from 2 to 78, indicating the position of each stripe.
### Components/Axes
* **Horizontal Axis:** Numbers 2 through 78, representing the position of each stripe.
* **Vertical Axis:** Two labels: "MP" (top row) and "ATT" (bottom row).
* **Color Legend:** Light Blue and Red, representing the color of the stripes.
### Detailed Analysis or Content Details
The pattern consists of alternating stripes. The "MP" row begins with a light blue stripe at position 2, followed by a red stripe at position 3, and so on. The "ATT" row begins with a red stripe at position 2, followed by a light blue stripe at position 3, and so on.
Here's a breakdown of the stripe colors by position:
* **MP:**
* 2: Light Blue
* 3: Red
* 4: Light Blue
* 5: Red
* 6: Light Blue
* 7: Red
* 8: Light Blue
* 9: Red
* 10: Light Blue
* 11: Red
* 12: Light Blue
* 13: Red
* 14: Light Blue
* 15: Red
* 16: Light Blue
* 17: Red
* 18: Light Blue
* 19: Red
* 20: Light Blue
* 21: Red
* 22: Light Blue
* 23: Red
* 24: Light Blue
* 25: Red
* 26: Light Blue
* 27: Red
* 28: Light Blue
* 29: Red
* 30: Light Blue
* 31: Red
* 32: Light Blue
* 33: Red
* 34: Light Blue
* 35: Red
* 36: Light Blue
* 37: Red
* 38: Light Blue
* 39: Red
* 40: Light Blue
* 41: Red
* 42: Light Blue
* 43: Red
* 44: Light Blue
* 45: Red
* 46: Light Blue
* 47: Red
* 48: Light Blue
* 49: Red
* 50: Light Blue
* 51: Red
* 52: Light Blue
* 53: Red
* 54: Light Blue
* 55: Red
* 56: Light Blue
* 57: Red
* 58: Light Blue
* 59: Red
* 60: Light Blue
* 61: Red
* 62: Light Blue
* 63: Red
* 64: Light Blue
* 65: Red
* 66: Light Blue
* 67: Red
* 68: Light Blue
* 69: Red
* 70: Light Blue
* 71: Red
* 72: Light Blue
* 73: Red
* 74: Light Blue
* 75: Red
* 76: Light Blue
* 77: Red
* 78: Light Blue
* **ATT:**
* 2: Red
* 3: Light Blue
* 4: Red
* 5: Light Blue
* 6: Red
* 7: Light Blue
* 8: Red
* 9: Light Blue
* 10: Red
* 11: Light Blue
* 12: Red
* 13: Light Blue
* 14: Red
* 15: Light Blue
* 16: Red
* 17: Light Blue
* 18: Red
* 19: Light Blue
* 20: Red
* 21: Light Blue
* 22: Red
* 23: Light Blue
* 24: Red
* 25: Light Blue
* 26: Red
* 27: Light Blue
* 28: Red
* 29: Light Blue
* 30: Red
* 31: Light Blue
* 32: Red
* 33: Light Blue
* 34: Red
* 35: Light Blue
* 36: Red
* 37: Light Blue
* 38: Red
* 39: Light Blue
* 40: Red
* 41: Light Blue
* 42: Red
* 43: Light Blue
* 44: Red
* 45: Light Blue
* 46: Red
* 47: Light Blue
* 48: Red
* 49: Light Blue
* 50: Red
* 51: Light Blue
* 52: Red
* 53: Light Blue
* 54: Red
* 55: Light Blue
* 56: Red
* 57: Light Blue
* 58: Red
* 59: Light Blue
* 60: Red
* 61: Light Blue
* 62: Red
* 63: Light Blue
* 64: Red
* 65: Light Blue
* 66: Red
* 67: Light Blue
* 68: Red
* 69: Light Blue
* 70: Red
* 71: Light Blue
* 72: Red
* 73: Light Blue
* 74: Red
* 75: Light Blue
* 76: Red
* 77: Light Blue
* 78: Red
### Key Observations
The pattern is perfectly alternating between light blue and red for both rows. There are no deviations from this pattern. The rows are offset from each other; where "MP" is light blue, "ATT" is red, and vice versa.
### Interpretation
The image presents a simple, repetitive pattern. Without additional context, it's difficult to determine the meaning or purpose of this pattern. It could represent a visual code, a sequence, or simply a decorative element. The labels "MP" and "ATT" suggest these rows might represent two different categories or variables, but their specific meaning is unknown. The consistent alternation could indicate a binary relationship or a cyclical process. The image itself does not provide any facts or data beyond the visual pattern. It is a representation of a pattern, not a dataset.
</details>
(a) Optimization Step 0
<details>
<summary>x16.png Details</summary>

### Visual Description
\n
## Chart: Binary Representation
### Overview
The image presents a chart displaying a binary representation across two rows, labeled "MLP" and "ATT". Each row consists of 80 columns, with each column representing a position and colored either blue or red, indicating a binary value (presumably 0 or 1).
### Components/Axes
* **Horizontal Axis:** Represents position, ranging from 1 to 80.
* **Vertical Axis:** Two categories: "MLP" (top row) and "ATT" (bottom row).
* **Color Coding:**
* Blue: Represents a value of 1.
* Red: Represents a value of 0.
### Detailed Analysis or Content Details
**MLP Row:**
The MLP row shows a sequence of blue (1) and white (0) blocks. The blue blocks appear at positions: 2, 4, 6, 8, 10, 12, 14, 16, 18, 20, 22, 24, 26, 28, 30, 32, 34, 36, 38, 40, 42, 44, 46, 48, 50, 52, 54, 56, 58, 60, 62, 64, 66, 68, 70, 72, 74, 76, 78, 80.
**ATT Row:**
The ATT row shows a sequence of red (0) and blue (1) blocks. The blue blocks appear at positions: 9, 13, 15, 19, 21, 25, 27, 31, 33, 37, 39, 43, 45, 49, 51, 55, 57, 61, 63, 67, 69, 73, 75, 79.
### Key Observations
* The MLP row has a higher density of blue blocks (1s) compared to the ATT row.
* The positions of the blue blocks are not consistently aligned between the two rows.
* The pattern of blue and red blocks appears somewhat random within each row, but is clearly defined.
### Interpretation
The chart likely represents a comparison of binary sequences for two different models or systems, labeled "MLP" and "ATT". The binary values could represent various features, states, or activations within these systems. The differing densities of 1s suggest that the MLP model might be more active or have a higher proportion of "on" states compared to the ATT model, at least for the positions represented in this chart. The lack of alignment between the blue blocks indicates that the two models do not exhibit the same pattern of activation or feature selection. Without further context, it's difficult to determine the specific meaning of these binary sequences, but they likely represent a crucial aspect of the models' behavior or internal state. The chart could be used to visualize differences in model architecture, training data, or operational characteristics.
</details>
(b) Optimization Step 64
<details>
<summary>x17.png Details</summary>

### Visual Description
\n
## Chart: Binary Data Representation
### Overview
The image presents a chart displaying binary data across a range of 80 data points. The chart consists of two rows, labeled "MLP" and "ATT", each representing a series of binary values (represented by colored blocks). The horizontal axis represents the index of the data point, ranging from 2 to 79.
### Components/Axes
* **Horizontal Axis:** Data Point Index (2 to 79)
* **Vertical Axis:** Two data series: "MLP" and "ATT"
* **Color Coding:**
* Blue: Represents a value of 1 (or True) for the "MLP" series.
* Red: Represents a value of 1 (or True) for the "ATT" series.
* White: Represents a value of 0 (or False) for both series.
### Detailed Analysis
The chart shows a sequence of binary values for both MLP and ATT.
**MLP Series:**
The MLP series starts with a blue block at index 2, indicating a value of 1. It then alternates between blue (1) and white (0) blocks.
* Index 2: 1
* Index 4: 1
* Index 6: 1
* Index 8: 1
* Index 10: 1
* Index 12: 1
* Index 14: 1
* Index 16: 1
* Index 18: 1
* Index 20: 1
* Index 22: 1
* Index 24: 1
* Index 26: 1
* Index 28: 1
* Index 30: 1
* Index 32: 1
* Index 34: 1
* Index 36: 1
* Index 38: 1
* Index 40: 1
* Index 42: 1
* Index 44: 1
* Index 46: 1
* Index 48: 1
* Index 50: 1
* Index 52: 1
* Index 54: 1
* Index 56: 1
* Index 58: 1
* Index 60: 1
* Index 62: 1
* Index 64: 1
* Index 66: 1
* Index 68: 1
* Index 70: 1
* Index 72: 1
* Index 74: 1
* Index 76: 1
* Index 78: 1
**ATT Series:**
The ATT series starts with a white block at index 2, indicating a value of 0. It then alternates between red (1) and white (0) blocks.
* Index 3: 1
* Index 5: 1
* Index 7: 1
* Index 9: 1
* Index 11: 1
* Index 13: 1
* Index 15: 1
* Index 17: 1
* Index 19: 1
* Index 21: 1
* Index 23: 1
* Index 25: 1
* Index 27: 1
* Index 29: 1
* Index 31: 1
* Index 33: 1
* Index 35: 1
* Index 37: 1
* Index 39: 1
* Index 41: 1
* Index 43: 1
* Index 45: 1
* Index 47: 1
* Index 49: 1
* Index 51: 1
* Index 53: 1
* Index 55: 1
* Index 57: 1
* Index 59: 1
* Index 61: 1
* Index 63: 1
* Index 65: 1
* Index 67: 1
* Index 69: 1
* Index 71: 1
* Index 73: 1
* Index 75: 1
* Index 77: 1
* Index 79: 1
### Key Observations
The MLP and ATT series are perfectly out of phase with each other. When MLP is 1, ATT is 0, and vice versa. This suggests a complementary relationship between the two data series.
### Interpretation
The chart likely represents a binary encoding or a comparison between two features ("MLP" and "ATT"). The alternating pattern suggests a simple encoding scheme or a scenario where one feature is active when the other is inactive. The perfect out-of-phase relationship indicates a strong inverse correlation between the two series. This could represent, for example, the activation states of two different components in a system, where only one can be active at a time. Without further context, it's difficult to determine the specific meaning of these binary values, but the chart clearly demonstrates a structured and predictable relationship between the two data series.
</details>
(c) Optimization Step 128
<details>
<summary>x18.png Details</summary>

### Visual Description
\n
## Chart: Chromosome Ideogram
### Overview
The image presents a chromosome ideogram, visually representing the banding patterns of two chromosomes, labeled "MLP" and "ATT". The ideogram displays alternating colored bands, likely representing regions of differing chromatin density or genetic content. The x-axis represents the position along the chromosome, ranging from 2 to 80.
### Components/Axes
* **X-axis:** Chromosome position, labeled from 2 to 80, in increments of 2.
* **Y-axis:** Two chromosomes are represented: "MLP" (top) and "ATT" (bottom).
* **Color Coding:**
* Blue: Represents regions on the "MLP" chromosome.
* Red: Represents regions on the "ATT" chromosome.
* **Banding Pattern:** Alternating blue and red bands indicate the presence of different genetic regions along the chromosomes.
### Detailed Analysis
The "MLP" chromosome exhibits blue bands at the following approximate positions:
* 8-10 (approximately 9)
* 16-18 (approximately 17)
* 24-26 (approximately 25)
* 32-34 (approximately 33)
* 40-42 (approximately 41)
* 48-50 (approximately 49)
* 56-58 (approximately 57)
* 64-66 (approximately 65)
* 72-74 (approximately 73)
* 78-80 (approximately 79)
The "ATT" chromosome exhibits red bands at the following approximate positions:
* 2-4 (approximately 3)
* 6-8 (approximately 7)
* 10-12 (approximately 11)
* 14-16 (approximately 15)
* 18-20 (approximately 19)
* 22-24 (approximately 23)
* 28-30 (approximately 29)
* 34-36 (approximately 35)
* 42-44 (approximately 43)
* 46-48 (approximately 47)
* 52-54 (approximately 53)
* 58-60 (approximately 59)
* 62-64 (approximately 63)
* 68-70 (approximately 69)
* 74-76 (approximately 75)
* 78-79 (approximately 79)
### Key Observations
* The banding patterns of the two chromosomes are largely complementary, with blue bands in "MLP" often corresponding to red bands in "ATT".
* The bands are roughly of equal width, suggesting a consistent resolution in the ideogram.
* The chromosomes appear to have a similar overall length, as indicated by the range of positions covered.
* There is a slight overlap in the final band position (78-80) for both chromosomes.
### Interpretation
This ideogram likely represents a comparison of two homologous chromosomes or two different alleles of the same chromosome. The alternating banding patterns suggest differences in the genetic content or chromatin structure between the two chromosomes. The complementary nature of the bands indicates that the regions represented by the blue bands in "MLP" may contain different genes or genetic variations compared to the regions represented by the red bands in "ATT". This type of visualization is commonly used in cytogenetics to identify chromosomal abnormalities, such as deletions, duplications, or translocations. The consistent banding pattern suggests a relatively stable genome structure, while any deviations from the expected pattern could indicate genetic instability or disease. The overlapping band at the end suggests a shared region or a potential point of recombination. The data suggests a comparison of two similar, but not identical, genetic structures.
</details>
(d) Optimization Step 512
Figure 12: Visualization of skipped layer set configurations of LLaMA-2-13B optimized by on different optimization steps. Gray squares indicate retained layers, red squares denote skipped attention layers, and blue squares signify skipped MLP layers.
### D.8 Case Study
We present examples from CNN/DM and Humaneval in Table 13 and 14, respectively, comparing token acceptance between and prior plug-and-play approach, Lookahead (Fu et al., 2024). The results demonstrate that accepts a higher number of drafts, which are uniformly distributed in the outputs, highlighting the effectiveness of our approach.
Table 13: CNN/DM example using LLaMA-2-13B; red tokens indicate accepted drafts.
| Lookahead | A Canadian law student was greeted by a friendly note from a stranger when he returned to his car after leaving the head lights on all day . A Canadian law student was gre et ed by a friendly note from a stranger when he returned to his car after leaving the headlights on all day . |
| --- | --- |
Table 14: Humaneval example using CodeLLaMA-13B; red tokens indicate accepted drafts.
| Lookahead | for i in range(len(numbers) - 1): if abs(numbers [i] - numbers [i + 1]) <= threshold: return True return False def has_close_elements_2(numbers: List[float], threshold: float) ->bool: ””” Check if in given list of numbers, are any two numbers closer to each other than given threshold. >>>has_close_elements_2-for i in range(len (numbers) - 1): if abs (numbers [i] - numbers[i + 1]) <= threshold: return True return False def has_close_elements_ 2(numbers: List[float], threshold: float) -> bool: ””” Check if in given list of numbers, are any two numbers closer to each other than given threshold. >>> has _close_elements_2 |
| --- | --- |