<details>
<summary>Image 1 Details</summary>

### Visual Description
Icon/Small Image (92x33)
</details>
## Rewarding Progress: Scaling Automated Process Verifiers for LLM Reasoning
1,3,* 1,* 2 2 2 2
Amrith Setlur , Chirag Nagpal , Adam Fisch , Xinyang Geng , Jacob Eisenstein , Rishabh Agarwal , Alekh Agarwal 1 , Jonathan Berant † ,2 and Aviral Kumar † ,2,3 1 Google Research, 2 Google DeepMind, 3 Carnegie Mellon University, * Equal contribution, † Equal advising
A promising approach for improving reasoning in large language models is to use process reward models (PRMs). PRMs provide feedback at each step of a multi-step reasoning trace, potentially improving credit assignment over outcome reward models (ORMs) that only provide feedback at the final step. However, collecting dense, per-step human labels is not scalable, and training PRMs from automatically-labeled data has thus far led to limited gains. To improve a base policy by running search against a PRM or using it as dense rewards for reinforcement learning (RL), we ask: 'How should we design process rewards?'. Our key insight is that, to be effective, the process reward for a step should measure progress : a change in the likelihood of producing a correct response in the future, before and after taking the step, corresponding to the notion of step-level advantages in RL. Crucially, this progress should be measured under a prover policy distinct from the base policy. We theoretically characterize the set of good provers and our results show that optimizing process rewards from such provers improves exploration during test-time search and online RL. In fact, our characterization shows that weak prover policies can substantially improve a stronger base policy, which we also observe empirically. We validate our claims by training process advantage verifiers (PAVs) to predict progress under such provers, and show that compared to ORMs, test-time search against PAVs is > 8% more accurate, and 1 . 5 -5 × more compute-efficient. Online RL with dense rewards from PAVs enables one of the first results with 5 -6 × gain in sample efficiency, and > 6% gain in accuracy, over ORMs.
## 1. Introduction
Trained reward models or verifiers are often used to improve math reasoning in large language models, either by re-ranking solutions at test-time (Collins, 2000) or via reinforcement learning (RL) (Uesato et al., 2022). Typically, verifiers are trained to predict the outcome of an entire reasoning trace, often referred to as outcome reward models (ORM) (Cobbe et al., 2021b; Hosseini et al., 2024). However, ORMs only provide a sparse signal of correctness, which can be hard to learn from and inefficient to search against. This challenge is alleviated by fine-grained supervision, in theory. For reasoning, prior works train process reward models (PRMs) that assign intermediate rewards after each step of search (Snell et al., 2024) or during RL. While Lightman et al. (2023) obtains PRM annotations from human raters, this approach is not scalable. More recent works (Luo et al., 2024; Wang et al., 2024) train PRMs to predict automatically-generated annotations that estimate future success of solving the problem, akin to value functions in RL. So far, automated PRMs, especially as dense rewards in RL, only improve by 1-2% over ORMs (Shao et al., 2024), raising serious doubts over their utility.
To resolve these uncertainties, in this paper, we train PRMs with automated annotations, such that optimizing the dense rewards from trained PRMs can improve a base policy compute- and sampleefficiently , during test-time search and online RL. For this, we first ask: (i) what should the per-step process rewards measure, and (ii) what kind of automated data collection strategy should we use to train PRMs that predict this measure. For (i) , conventional belief (Lightman et al., 2023; Uesato et al., 2022)
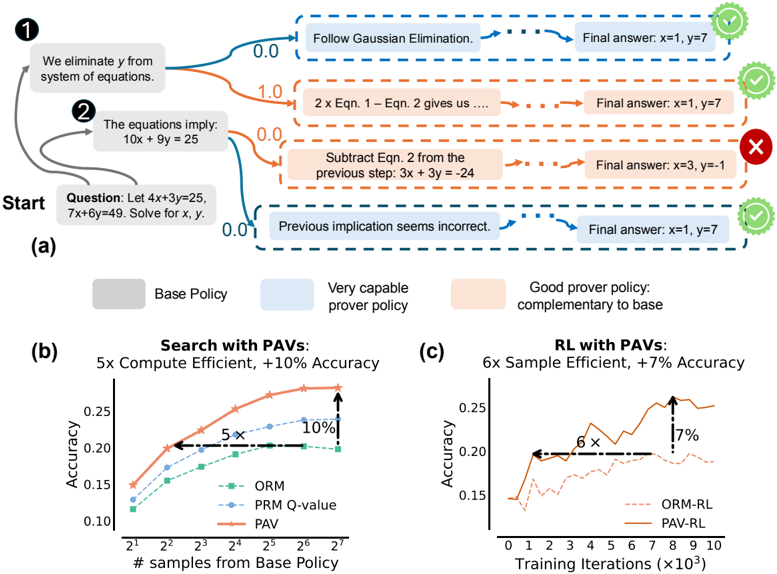
Figure 1 | Process advantage verifiers (PAV): Process reward for a step is defined as progress (advantage) under the prover policy, i.e. , change in prover policy's success rate before and after the step. (a): The base policy samples both correct 1 and incorrect 2 steps but struggles to succeed from either. A strong prover policy completes the solution from both steps, and is unable to adequately reflect progress made by 1 and 2 (both scored 0.0). Conversely, a complementary prover policy distinguishes 1 , 2 more prominently (only succeeds from 1 ). (b,c): Compared to ORMs, PAVs are 5x more compute efficient, 10% more accurate in test-time search, and 6x more sample efficient, 7% more accurate for online reinforcement learning (RL).
<details>
<summary>Image 2 Details</summary>
### Visual Description
## Decision Tree and Performance Charts: PAVs
### Overview
The image presents a decision tree diagram illustrating a problem-solving process, alongside two line charts comparing the performance of different algorithms with and without PAVs (Potentially Advantageous Variants). The decision tree shows steps to solve a system of equations, while the charts compare accuracy versus computational effort or training iterations.
### Components/Axes
**Decision Tree (a):**
* **Nodes:** Represented by rounded rectangles containing text describing the current state or action.
* **Edges:** Arrows indicating the flow of the decision-making process.
* **Start Node:** Labeled "Start" with the initial question: "Let 4x+3y=25, 7x+6y=49. Solve for x, y."
* **Intermediate Nodes:** Describe steps like "We eliminate y from system of equations" and "The equations imply: 10x + 9y = 25".
* **Leaf Nodes:** Contain "Final answer: x=..., y=..." and are marked with either a green checkmark (correct) or a red "X" (incorrect).
* **Edge Labels:** Numerical values (0.0, 1.0) associated with certain edges.
* **Node Styles:** Nodes are filled with different colors: gray ("Base Policy"), light blue ("Very capable prover policy"), and light orange ("Good prover policy: complementary to base").
**Chart (b): Search with PAVs**
* **Title:** "Search with PAVs: 5x Compute Efficient, +10% Accuracy"
* **X-axis:** "# samples from Base Policy" with a logarithmic scale (2<sup>1</sup> to 2<sup>7</sup>).
* **Y-axis:** "Accuracy" ranging from 0.10 to 0.25.
* **Data Series:**
* ORM (green dashed line with square markers)
* PRM Q-value (blue dashed line with triangle markers)
* PAV (orange solid line with star markers)
* **Annotations:** "5x" and "+10%" indicating performance improvements.
**Chart (c): RL with PAVs**
* **Title:** "RL with PAVs: 6x Sample Efficient, +7% Accuracy"
* **X-axis:** "Training Iterations (×10<sup>3</sup>)" ranging from 0 to 10.
* **Y-axis:** "Accuracy" ranging from 0.15 to 0.25.
* **Data Series:**
* ORM-RL (brown dashed line)
* PAV-RL (dark orange solid line)
* **Annotations:** "6x" and "+7%" indicating performance improvements.
### Detailed Analysis
**Decision Tree (a):**
* The tree starts with the question and branches into two initial steps.
* The first branch ("We eliminate y from system of equations") leads to "Follow Gaussian Elimination" (blue node) and a correct final answer (x=1, y=7).
* The second branch ("The equations imply: 10x + 9y = 25") splits into two paths.
* One path ("2 x Eqn. 1 - Eqn. 2 gives us...") leads to a correct final answer (x=1, y=7).
* The other path ("Subtract Eqn. 2 from the previous step: 3x + 3y = -24") leads to an incorrect final answer (x=3, y=-1).
* A final branch from the initial question ("Previous implication seems incorrect.") leads to a correct final answer (x=1, y=7).
**Chart (b): Search with PAVs**
* **ORM:** Starts at approximately 0.12 accuracy and increases to approximately 0.20 accuracy.
* **PRM Q-value:** Starts at approximately 0.15 accuracy and increases to approximately 0.22 accuracy.
* **PAV:** Starts at approximately 0.14 accuracy and increases to approximately 0.27 accuracy.
* The PAV line consistently outperforms the other two.
* The "5x Compute Efficient" annotation indicates that PAV achieves a certain accuracy level with 5 times fewer samples than another method (likely ORM or PRM Q-value).
* The "+10% Accuracy" annotation indicates that PAV achieves 10% higher accuracy than another method at a certain sample size.
**Chart (c): RL with PAVs**
* **ORM-RL:** Starts at approximately 0.15 accuracy and fluctuates, ending around 0.20 accuracy.
* **PAV-RL:** Starts at approximately 0.20 accuracy and increases to approximately 0.26 accuracy.
* The PAV-RL line consistently outperforms the ORM-RL line.
* The "6x Sample Efficient" annotation indicates that PAV-RL achieves a certain accuracy level with 6 times fewer training iterations than ORM-RL.
* The "+7% Accuracy" annotation indicates that PAV-RL achieves 7% higher accuracy than ORM-RL at a certain number of training iterations.
### Key Observations
* The decision tree illustrates different approaches to solving a system of equations, with varying degrees of success.
* The charts demonstrate that using PAVs improves both computational efficiency and accuracy in both search and reinforcement learning contexts.
* In both charts, the PAV-based methods (PAV and PAV-RL) consistently outperform their counterparts (ORM and ORM-RL).
### Interpretation
The data suggests that incorporating Potentially Advantageous Variants (PAVs) into algorithms can significantly enhance their performance. The decision tree highlights the importance of choosing the correct steps in problem-solving, as some paths lead to incorrect solutions. The charts quantify the benefits of PAVs, showing that they can lead to substantial improvements in both computational efficiency and accuracy. This implies that PAVs are a valuable technique for optimizing algorithms in various domains. The "5x", "6x", "+10%", and "+7%" annotations provide concrete evidence of the performance gains achieved by using PAVs.
</details>
has been to measure mathematical correctness or relevance of steps. But, it is unclear if this supervision yields the most improvement in the base policy ( e.g. , a policy may need to generate simpler, repetitive, and even incorrect steps to explore and discover the final answer during test-time search and RL). Our key insight is that per-step, process rewards that measure a notion of progress : change in the likelihood of arriving at a correct final answer before and after taking the step, are effective, for both test-time beam search and online RL. Reinforcing steps that make progress regardless of whether they appear in a correct or incorrect trace diversifies the exploration of possible answers at initial steps, which is crucial when the approach to solve a problem is not clear. Formally, such rewards correspond to per-step advantages of steps from the RL literature (Sutton and Barto, 2018). We empirically show that using advantages in addition to ORM rewards outperforms the typical use of future probabilities of success or 𝑄 -values (Wang et al., 2024) for both search and RL. This is because, when given a combinatorial space of responses, under bounded computational and sampling constraints, 𝑄 -values mainly 'exploit' states whereas advantages also 'explore' steps that make the most progress towards the final answer (Fig. 2).
To answer (ii) , we first note that advantages under a poor base policy are ≈ 0 on most steps, and thus will not be informative for search or RL. In addition, regardless of the strength of the base policy, using its own per-step advantages as process rewards in RL will result in base policy updates equivalent to only
using outcome rewards for RL (since a standard policy gradient algorithm already computes advantages). Hence, we propose to use advantages estimated via rollouts under a different prover policy as process rewards (Fig. 1(a)). How should we choose this prover policy? A natural guess would be to use a very capable prover. However, we show advantages under an overly capable prover policy, that can succeed from any step, fail to distinguish good and bad steps. A similar argument holds for very weak provers.
In theory, we formalize this intuition to define good provers as policies that are complementary to the base policy ( i.e. , policies with advantages that can contrast steps produced by the base policy sufficiently), while still producing step-level advantages correlated with those of the base policy. For e.g. , for Bestof𝐾 policies (Nakano et al., 2021) corresponding to a base policy, we empirically find that provers corresponding to 𝐾 > 1 (but not too large) are more capable at improving the base policy. Contrary to intuition, the set of complementary provers also contains policies that are worse than the base policy. To predict the advantages of such provers we train dense verifiers, called process advantage verifiers (PAVs) , that accelerate sample and compute efficiency of RL and search.
With the conceptual design of PAVs in place, we prescribe practical workflows for training PAVs and demonstrate their efficacy on a series of 2B, 9B, and 27B Gemma2 models (Gemma Team et al., 2024). PAV training data is gathered by sampling 'seed' solution traces from the prover and partial rollouts from the same to estimate the 𝑄 -value at each prefix of the seed trace. Our workflow prescribes favorable ratios for seed and partial rollouts. Our first set of empirical results show that for an equal budget on test-time compute, beam search against trained PAVs is >8% better in accuracy, and 1 . 5 -5 × more compute efficient compared to re-ranking complete traces against an ORM (Fig. 1(b)). Dense rewards from PAVs improve the efficiency of step-level exploration during search by pruning the combinatorial space of solutions aggressively and honing in on a diverse set of possible sequences. Finally, we demonstrate for the first time , that using PAVs as dense rewards in RL scales up data efficiency by 6 × compared to only using outcome rewards (Fig. 1(c)). Moreover, base policies trained with PAVs also achieve 8 × better Pass @ 𝑁 performance (probability of sampling the correct solution in 𝑁 attempts), and consequently afford a higher ceiling on the performance of any test-time re-ranker. Finally, running RL with PAVs discovers solutions to hard problems that sampling from the SFT policy with a very large budget can't solve.
## 2. Preliminaries, Definitions, and Notation
Following protocols from Lightman et al. (2023); Uesato et al. (2022), a reasoning trace from an LLM consists of multiple logical steps separated by a demarcation token. An outcome reward model (ORM) is a trained verifier that assigns a numerical score after the last step of the trace, and a process reward model (PRM) is a trained verifier that scores each step of the trace individually.
Problem setup and notation. Given a math problem 𝒙 ∈ X , our goal is to improve a base policy 𝜋 that samples a response 𝒚 ∼ 𝜋 (· | 𝒙 ) in the set Y . A response 𝒚 consists of multiple reasoning steps (maximum 𝐻 ), separated by a delimiter ('next line' in our case), i.e. , 𝒚 = ( 𝑎 1 , 𝑎 2 , . . . , 𝑎𝐻 ) . Since sampling is auto-regressive, we can view each step as an action taken by the agent 𝜋 in a Markov decision process (MDP) with deterministic dynamics. Specifically, we treat the prefix ( 𝒙 , 𝑎 1 , . . . , 𝑎 ℎ -1 ) as the current state 𝒔 ℎ and next step 𝑎ℎ ∼ 𝜋 (· | 𝒙 ) as the action taken by 𝜋 at 𝒔 ℎ , resulting in the next state 𝒔 ℎ + 1 . For problem 𝒙 , with ground-truth response 𝒚 ★ 𝒙 , we can evaluate the accuracy of 𝜋 by running a regular expression match on the final answer (Hendrycks et al., 2021): Rex ( 𝒚 , 𝒚 ★ 𝒙 ) ↦→ { 0 , 1 } , i.e. , accuracy is given by 𝔼 𝒚 ∼ 𝜋 (·| 𝒙 ) Rex ( 𝒚 , 𝒚 ★ 𝒙 ) . Now, given a dataset D = {( 𝒙 𝑖 , 𝒚 ★ 𝒙 𝑖 )} 𝑖 of problem-solution pairs, the main goal is to learn a good base policy by optimizing this outcome reward on D . Next, we see how we can leverage the final answer verifier Rex available on D to train ORMs and PRMs.
Outcome reward model (ORM). Given a response 𝒚 , an ORM estimates the ground-truth correctness Rex ( 𝒚 , 𝒚 ★ 𝒙 ) . To train such a model we first take problems in D , and collect training data of the form {( 𝒙 , 𝒚 ∼ 𝜋 (· | 𝒙 ) , Rex ( 𝒚 , 𝒚 ★ 𝒙 ))} . Then we train an ORM that takes as input a problem-response pair ( 𝒙 , 𝒚 ) and predicts Rex ( 𝒚 , 𝒚 ★ 𝒙 ) . At test time, when 𝒚 ★ 𝒙 is unknown, the ORM is used to score candidate solutions revealed by test-time search. Given a base policy 𝜋 , a Best-of𝐾 policy: BoK ( 𝜋 ) , is a policy that samples 𝐾 responses from 𝜋 , scores them against an ORM, and returns the one with the highest score. Whenever the ORM matches Rex, the performance of BoK ( 𝜋 ) is referred to as Pass @ 𝐾 . Furthermore, when the likelihood of 𝜋 solving problem 𝒙 is 𝑝 𝒙 , then for BoK ( 𝜋 ) this likelihood is given by the expression: 1 - ( 1 -𝑝 𝒙 ) 𝐾 . In general, this is larger than 𝑝 𝒙 , making BoK ( 𝜋 ) stronger than 𝜋 for 𝐾 > 1.
Standard process reward models (PRMs). A PRM scores every step 𝑎ℎ in a multi-step response 𝒚 ∼ 𝜋 ( e.g. , in Lightman et al. (2023) PRMs are trained to score correct steps over incorrect and irrelevant ones). But, unlike ORMs, which only require Rex for data collection, PRM training data requires expensive step-level human annotations. Prior works (Luo et al., 2024; Wang et al., 2024) attempted to scale process rewards automatically by sampling from the model to provide a heuristic understanding of when a step is actually correct. In particular, they evaluate a prefix by computing the expected future accuracy of multiple completions sampled from 𝜋 , after conditioning on the prefix, i.e. , value function 𝑄 𝜋 (Eq. 1) from RL. Similarly, we define 𝑉 𝜋 ( 𝒔 ℎ ) B 𝔼 𝑎 ℎ ∼ 𝜋 (·| 𝒔 ℎ ) 𝑄 𝜋 ( 𝒔 ℎ , 𝑎 ℎ ) as value of state 𝒔 ℎ . These works use 𝑄 𝜋 as the PRM that assigns a score of 𝑄 𝜋 ( 𝒔 ℎ , 𝑎 ℎ ) to the action 𝑎ℎ , at state 𝒔 ℎ .
$$Q ^ { \pi } ( \underbrace { ( x , a _ { 1 } , \dots , a _ { h - 1 } ) } _ { s t a t e \, s _ { h } } , \underbrace { a _ { h } } _ { a c t i o n \, a _ { h } } ) = \underbrace { \mathbb { E } _ { a _ { h + 1 } , \dots , a _ { H } \sim \pi ( \cdot | s _ { h } , a _ { h } ) } \left [ R e x \left ( ( a _ { 1 } , \dots , a _ { H } ) , y _ { x } ^ { ^ { * } } \right ) \right ] } _ { l i k e l i d o f f u t r e s c e s s } ,$$
Using PRMs for beam search at test-time. Given a PRM, a natural way to spend test-time compute is to use it as a step-level re-ranker within a beam search procedure (Snell et al., 2024). For each problem, at step 0, a beam of maximum width 𝐵 , is initialized with a single state consisting of just the problem. At step ℎ , a beam contains partial responses unrolled till a set of states or prefixes { 𝒔 𝑖 } 𝐵 𝑖 = 1 . From each state 𝒔 𝑖 in this set, 𝐶 independent actions or steps { 𝑎𝑖,𝑗 } 𝐶 𝑗 = 1 are sampled from 𝜋 (· | 𝒔 𝑖 ) , each of which leads to a new state. Process rewards from PRMs assign a score to every new state ( 𝒔 𝑖 , 𝑎 𝑖, 𝑗 ) , and only the states corresponding to the top 𝐵 values are retained in the beam for the next step.
## 3. How Should we Define Process Rewards and Why?
Ultimately, we are interested in test-time search and RL methods that can most efficiently and reliably discover solution traces with the correct final answer, thus maximizing Rex. To this end, process rewards should serve as step-level supervision to indirectly maximize outcome-level Rex. Our position contrasts with conventional belief that process rewards should mainly evaluate mathematical correctness or relevance of individual steps (Lightman et al., 2023; Uesato et al., 2022), since LLMs might need to generate trivial or repetitive intermediate steps in order to discover a trace with the correct final answer. With this insight, in this section we approach the design of dense automated step rewards as a form of supervision to be used in conjunction with sparse outcome rewards to improve the base policy.
In an MDP, a starting point to design step-level dense feedback that is eventually meant to optimize a sparse outcome reward Rex is to consider the notion of a potential function (Ng et al., 1999): in our case, this is a function that summarizes the difference between some statistic of the policy at the future state and the same statistic computed at the current state. By appealing to this framework, in Sec. 3.1, we
Figure 2 | Issues with using 𝑄 -values as process rewards : (a): Unlike 𝐴 𝜋 , 𝑄 𝜋 mixes action evaluation with the 𝑄 -value of the previous state. Beam search with 𝑄 𝜋 exploits high-likelihood states, while adding 𝐴 𝜋 ( e.g. , 𝑄 𝜋 + 𝛼𝐴 𝜋 in Eq. 5) aids in exploring states reached by making actions that induce progress, i.e. , increase likelihood of success. (b): 𝑄 𝜇 from a strong prover 𝜇 can assign unmerited bonuses to trivial actions.
<details>
<summary>Image 3 Details</summary>
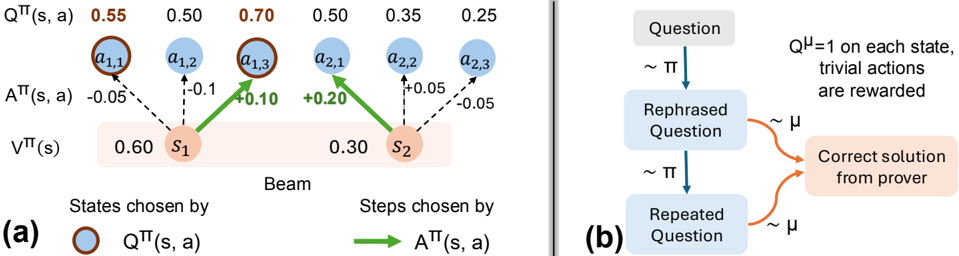
### Visual Description
## Diagram: State Transition Diagrams
### Overview
The image presents two diagrams illustrating state transitions. Diagram (a) depicts a beam search process with states, actions, and associated values. Diagram (b) shows a sequence of questions and solutions.
### Components/Axes
**Diagram (a): Beam Search**
* **Nodes:**
* `s1`: State 1, with a value `Vπ(s)` of 0.60. Located on the left side of the "Beam" label.
* `s2`: State 2, with a value `Vπ(s)` of 0.30. Located on the right side of the "Beam" label.
* `a1,1`, `a1,2`, `a1,3`: Actions associated with state `s1`.
* `a2,1`, `a2,2`, `a2,3`: Actions associated with state `s2`.
* **Edges:**
* Dashed black lines represent transitions with negative `Aπ(s, a)` values.
* Solid green lines represent transitions with positive `Aπ(s, a)` values.
* **Values:**
* `Qπ(s, a)`: Q-values for each action. The values are 0.55 for `a1,1`, 0.50 for `a1,2`, 0.70 for `a1,3`, 0.50 for `a2,1`, 0.35 for `a2,2`, and 0.25 for `a2,3`.
* `Aπ(s, a)`: Advantage values for each action. The values are -0.05 for `a1,1`, -0.1 for `a1,2`, +0.10 for `a1,3`, +0.20 for `a2,1`, +0.05 for `a2,2`, and -0.05 for `a2,3`.
* `Vπ(s)`: State values for `s1` (0.60) and `s2` (0.30).
* **Labels:**
* `Qπ(s, a)`: Q-value of state-action pair.
* `Aπ(s, a)`: Advantage of state-action pair.
* `Vπ(s)`: Value of state.
* "Beam": Indicates the beam search process.
* "States chosen by": Label for the states.
* "Steps chosen by": Label for the actions.
* **Legend:**
* Brown-outlined blue circle: `Qπ(s, a)`
* Green arrow: `Aπ(s, a)`
**Diagram (b): Question-Answering Process**
* **Nodes:**
* "Question": Initial question.
* "Rephrased Question": Rephrased version of the question.
* "Repeated Question": Repeated version of the question.
* "Correct solution from prover": The correct solution.
* **Edges:**
* Blue arrows labeled "~ π": Transitions between question states.
* Orange arrows labeled "~ μ": Transitions from question states to the correct solution.
* **Text:**
* "Qμ = 1 on each state, trivial actions are rewarded": Describes the reward structure.
### Detailed Analysis
**Diagram (a): Beam Search**
* The beam search starts with two states, `s1` and `s2`, having values 0.60 and 0.30, respectively.
* From `s1`, actions `a1,1`, `a1,2`, and `a1,3` are possible, with Q-values 0.55, 0.50, and 0.70, and advantages -0.05, -0.1, and +0.10, respectively.
* From `s2`, actions `a2,1`, `a2,2`, and `a2,3` are possible, with Q-values 0.50, 0.35, and 0.25, and advantages +0.20, +0.05, and -0.05, respectively.
* The actions with positive advantages (green arrows) are `a1,3` from `s1` and `a2,1` from `s2`.
**Diagram (b): Question-Answering Process**
* The process starts with a "Question".
* The question is rephrased, leading to a "Rephrased Question".
* The rephrased question is repeated, leading to a "Repeated Question".
* From both the "Rephrased Question" and "Repeated Question", the process can transition to the "Correct solution from prover".
* The transitions between question states are governed by a policy π, while the transitions to the correct solution are governed by a policy μ.
* The text indicates that Qμ = 1 on each state, and trivial actions are rewarded.
### Key Observations
* In diagram (a), the Q-values and advantage values vary for different actions from each state.
* In diagram (b), the question-answering process involves rephrasing and repeating the question before arriving at the correct solution.
### Interpretation
The diagrams illustrate two different processes. Diagram (a) shows a beam search algorithm, where the algorithm explores different actions from different states, guided by Q-values and advantage values. Diagram (b) depicts a question-answering process, where the question is iteratively refined before a solution is obtained. The use of policies π and μ suggests a reinforcement learning framework for question answering. The statement "Qμ = 1 on each state, trivial actions are rewarded" implies that the reward structure favors actions that lead to the correct solution, even if they are trivial.
</details>
show that advantages - not value functions (Luo et al., 2024; Wang et al., 2024) - that measure a notion of 'progress' at each new step are more appropriate for use as dense rewards in search and RL (primarily for exploration). Then in Secs. 3.3 and 3.4, we show that this progress or advantage vakue is measured best under a policy 𝜇 , different from the base policy 𝜋 . We call this policy 𝜇 , the prover policy .
## 3.1. Process Rewards Should be Advantages, Not Value Functions
To understand the relationship to potential functions, we first study test-time beam search, and present some challenges with the reward design of Snell et al. (2024), that uses value function 𝑄 𝜋 ( 𝒔 , 𝑎 ) of the base policy 𝜋 to reward action 𝑎 at state 𝒔 . Consider the example in Fig. 2(a), where from the 2 states in the beam, we sample 3 actions. If we pick next states purely based on highest values of 𝑄 𝜋 , we would be comparing steps sampled from different states ( e.g. , 𝑎 1 , 1 vs. 𝑎 2 , 1 ) against each other. Clearly, a reduction in expected final outcome, i.e. , 𝑄 𝜋 ( 𝒔 1 , 𝑎 1 , 1 ) -𝑉 𝜋 ( 𝒔 1 ) , means that 𝑎 1 , 1 by itself has a negative effect of -0 . 05 on the probability of success from 𝒔 1 , whereas 𝑎 2 , 1 has a positive effect of + 0 . 20 from 𝒔 2 . However, expanding the beam based on absolute values of 𝑄 𝜋 retains the action that makes negative progress, and removes state 𝒔 2 from the beam (as beam size is 2). In other words, 𝑄 𝜋 fails to decouple the 'evaluation' of an action (step), from the 'promise' shown by the previous state. This will not be an issue for every problem, and particularly not when the beam capacity is unbounded, but under finite computational and sampling constraints, using 𝑄 𝜋 might retain states with potentially unfavorable steps that hurt the overall likelihood of success. If we could also also utilize the progress made by the previous step along with the likelihood of success 𝑄 𝜋 when deciding what to retain in the beam, then we can address this tradeoff.
How can we measure the 'progress' made by a step? One approach is to consider the relative increase/decrease in the likelihood of success, before and after the step. This notion is formalized by the advantage (Eq. 2) of a step under policy 𝜋 . Furthermore, since advantages can attach either positive or negative values to a step, training the base policy against advantages supervises the base policy when it generates a step that makes progress (where 𝐴 𝜋 > 0), and also when it fails to produce one, employing a 'negative gradient' that speeds up RL training (Tajwar et al., 2024).
$$A ^ { \pi } ( { \mathbf s _ { h } } , a _ { h } ) \coloneqq Q ^ { \pi } ( { \mathbf s _ { h } } , a _ { h } ) - V ^ { \pi } ( { \mathbf s _ { h } } ) = Q ^ { \pi } ( { \mathbf s _ { h } } , a _ { h } ) - Q ^ { \pi } ( { \mathbf s _ { h - 1 } } , a _ { h - 1 } ) .$$
Recall that since we view process rewards as potential functions in the MDP, they can be computed under
any policy 𝜇 , which can be the base policy. However, in the above example, reasons for which 𝑄 𝜋 is a seemingly unfit choice for process rewards also apply to 𝑄 𝜇 . Nevertheless, we can possibly use advantage under 𝜇 : 𝐴 𝜇 , which measures the progress made by a step to improve the likelihood of success under 𝜇 . In that case, how should we choose this policy 𝜇 , that we call the prover policy, and should it be necessarily different from base policy 𝜋 ? Before diving into the choice of 𝜇 , we discuss a more pertinent question: how should we use 𝐴 𝜇 in conjunction with outcome rewards for improving the base policy 𝜋 ? We will then formally reason about the choice of 𝜇 in Secs. 3.3 and 3.4.
## 3.2. Our Approach: Process Advantage Verifiers (PAV)
For building an approach that uses process rewards 𝐴 𝜇 together with the outcome reward Rex to improve the base policy 𝜋 , we situate ourselves in the context of improving 𝜋 with online RL. If all we had was access to Rex on D , the standard RL objective is given by:
$$\ell _ { \text {ORM-RL} } ( \pi ) \coloneqq \mathbb { E } _ { \mathbf x \sim \mathcal { D } , ( a _ { 1 } , \dots , a _ { H } ) \sim \pi ( \cdot | \mathbf x ) } \left [ R e x \left ( ( \mathbf x , a _ { 1 } , \dots , a _ { H } ) , y _ { \mathbf x } ^ { ^ { * } } \right ) \right ] .$$
Inspired by how reward bonuses (and potential functions) are additive (Bellemare et al., 2016; Ng et al., 1999), one way to use process rewards 𝐴 𝜇 is to combine it with the standard RL objective as:
$$\ell _ { \text {PAV-RL} } ^ { \pi ^ { \prime } } ( \pi ) \colon = \ell _ { \text {ORM-RL} } ( \pi ) + \alpha \cdot \sum _ { h = 1 } ^ { H } \mathbb { E } _ { s _ { h } \sim d _ { h } ^ { \prime } } \, \mathbb { E } _ { a _ { h } \sim \pi ( \cdot | s _ { h } ) } \left [ A ^ { \mu } ( s _ { h } , a _ { h } ) \right ]$$
The term in red is the difference in likelihoods of success of the prover 𝜇 , summed over consecutive steps (a notion of progress ). Here, 𝑑 𝜋 ′ ℎ denotes the distribution over states at step ℎ , visited by the old policy 𝜋 ′ (policy at previous iterate). Following policy gradient derivations (Williams, 1992):
$$\boxed { \nabla _ { \pi } \ell ^ { \pi ^ { \prime } } _ { \text {PAV-RL} } ( \pi ) \Big | _ { \pi ^ { \prime } = \pi } = \sum _ { h = 1 } ^ { H } \, \nabla _ { \pi } \log \pi ( a _ { h } \, | \, s _ { h } ) \cdot \underbrace { ( Q ^ { \pi } ( s _ { h } , a _ { h } ) + \alpha \cdot A ^ { \mu } ( s _ { h } , a _ { h } ) ) } _ { \text {effective reward} } }$$
At a glance, we can view 𝑄 𝜋 ( 𝒔 ℎ , 𝑎 ℎ ) + 𝛼𝐴 𝜇 ( 𝒔 ℎ , 𝑎 ℎ ) as the effective reward for step 𝑎ℎ when scored against a combination of the outcome evaluation Rex, i.e., 𝑄 𝜋 , and process rewards 𝐴 𝜇 . Thus, we can optimize Eq. 4 indirectly via (a) running beam-search against the effective reward; or (b) online RL where the policy gradients are given by Eq. 5. For either of these, we need access to verifiers that are trained to predict the advantage 𝐴 𝜇 ( 𝒔 ℎ , 𝑎 ℎ ) under the prover. We refer to these verifiers as process advantage verifiers (PAVs) . In Sec. 4.2 we describe how to train PAVs, but now we use the above formulation to reason about how to choose prover 𝜇 that is most effective at improving base 𝜋 .
We also remark that the term in red resembles prior work on imitation learning via policy optimization (Ross and Bagnell, 2014; Sun et al., 2017), where the main aim is to learn a policy 𝜋 that imitates the prover 𝜇 , or to improve upon it to some extent. Of course, this is limiting since our goal is to not just take actions that perform at a similar level as 𝜇 , but to improve the base policy even further, and using a combination of 𝑄 𝜋 and 𝐴 𝜇 is critical towards this goal.
How should we choose the prover 𝜇 ? Perhaps a natural starting point is to set the prover to be identical to the base policy, i.e. , 𝜇 = 𝜋 , which produces process rewards that prior works have considered Shao et al. (2024). However, setting 𝐴 𝜋 = 𝐴 𝜇 in Eq. 5 results in exactly the same policy gradient update as only optimizing outcome evaluation Rex. Moreover, for a poor base policy 𝜋 , where 𝑄 𝜋 ≈ 0 on most states,
the term 𝐴 𝜋 would also be ≈ 0, and hence running beam search with the effective rewards would not be informative at all. Hence, a better approach is to use a different prover policy , but a very weak prover 𝜇 will likely run into similar issues as a poor base policy. We could instead use a very capable prover 𝜇 , but unfortunately even this may not be any better than optimizing only the outcome reward either. To see why, consider a scenario where 𝜋 's response contains an intermediate step that does not help make progress towards the solution ( e.g. , 𝜋 simply restates the question, see Fig. 2(b)). Here, 𝑄 𝜇 for a capable prover before and after this irrelevant step will be identical since 𝜇 can succeed from either step. This means that 𝜇 fails to distinguish steps, resulting in 𝐴 𝜇 ≈ 0 in most cases. Training with this process reward during RL will then lead to gradients that are equivalent to those observed when purely optimizing ℓ ORM -RL . In fact, empirically, we observe that online RL with 𝑄 𝜇 from strong provers leads to polices that only produce re-phrasings of the question (App. G) and do not succeed at solving the question. Clearly, any policy different from the base policy cannot serve as a prover. So, how do we identify a set of good provers? Can they indeed be weaker than the base policy? We answer next.
## Takeaway: What should process rewards measure during test-time search and online RL?
- Process rewards should correspond to progress, or advantage , as opposed to absolute 𝑄 -values, for a better explore-exploit tradeoff during beam search and online RL.
- Advantages should be computed using a prover policy, different from the base policy.
## 3.3. Analysis in a Didactic Setting: Learning a Planted Sub-sequence
In this section, we aim to characterize prover policies that are effective in improving the base policy. To do so, we first introduce a didactic example, representative of real reasoning scenarios to illustrate the main intuition. Then, we will formalize these intuitions in the form of theoretical results.
Didactic example setup. Given an unknown sub-sequence 𝒚 ★ consisting of tokens from vocabulary V B { 1 , 2 , . . . , 15 } , we train a policy 𝜋 to produce a response which contains this sub-sequence. The task completion reward is terminal and sparse, i.e. , 𝑟 ( 𝒚 , 𝒚 ★ ) = 1 for a 𝒚 if and only if 𝒚 ★ appears in 𝒚 . By design, the reward 𝑟 ( 𝒚 , 𝒚 ★ ) resembles outcome reward Rex ( 𝒚 , 𝒚 ★ 𝒙 ) in Sec. 2. The prover policy 𝜇 is a procedural policy, parameterized by a scalar 𝛾 > 0 (details in App. B). As 𝛾 increases, the performance of 𝜇 improves and → 1 as 𝛾 →∞ . For simplicity, we assume oracle access to ground-truth 𝐴 𝜇 and 𝑄 𝜋 , and alleviate errors from learned verifiers approximating these values.
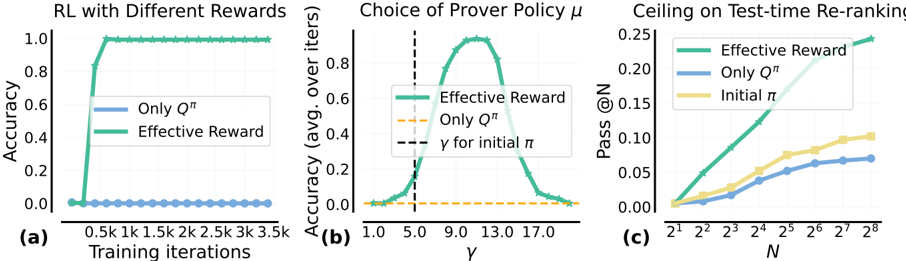
(1) RL with effective reward 𝑄 𝜋 + 𝛼𝐴 𝜇 is 10 × more sample-efficient than only outcome reward. In Fig. 3(a), we first note that training 𝜋 with this effective reward under a prover 𝜇 with strength 𝛾 = 10, produces optimal performance (100% accuracy) in 350 iterations, despite starting from a mediocre initialization for 𝜋 ( 𝛾 = 5 . 0 ) . Training with only outcome reward is ineffective. More importantly, in Fig. 3(b), we note that effective rewards only help for a set of provers, in 𝛾 ∈ [ 8 . 0 , 15 . 0 ] . Outside this range, we observed advantages 𝐴 𝜇 were close to 0 on most states, either because 𝜇 was poor (small 𝛾 ) and was unable to generate 𝒚 ★ even when 𝜋 got the sequence partially correct, or because 𝜇 was strong (large 𝛾 ) that it generated 𝒚 ∗ with almost equal likelihood from all prefixes.
(2) Effective reward improves Pass @N by 5 × over only outcome reward. We report the 'Pass @N' performance in Fig. 3(c), which measures the maximum reward 𝑟 across 𝑁 traces sampled i.i.d. from 𝜋 and hence, represents the ceiling on the performance of any test-time search method that picks a single response from multiple draws ( e.g. , as in Best-of-N). For a policy trained with the effective reward for 100 iterations, the Pass @N performance grows 5 × faster with 𝑁 , compared to the policy trained with only
Figure 3 | Results for our didactic analysis: (a): We train base policy via RL with either effective reward 𝑄 𝜋 + 𝛼𝐴 𝜇 , or the typical 𝑄 𝜋 (computed via Monte-Carlo sampling). (b): We vary the strength 𝛾 of the prover 𝜇 used to compute advantages 𝐴 𝜇 in the effective reward, and plot the base policy accuracy averaged over the RL run. (c): We plot the max score out of 𝑁 responses (Pass @N) sampled i.i.d. from an undertrained base policy (iter 100) .
<details>
<summary>Image 4 Details</summary>
### Visual Description
## Chart: RL Performance with Different Rewards and Prover Policies
### Overview
The image presents three line charts comparing the performance of reinforcement learning (RL) agents under different reward structures and prover policies. The charts illustrate the accuracy and pass rates achieved by the agents as a function of training iterations, policy parameter γ, and the number of samples N.
### Components/Axes
**Chart (a): RL with Different Rewards**
* **Title:** RL with Different Rewards
* **X-axis:** Training iterations (0.5k, 1k, 1.5k, 2k, 2.5k, 3k, 3.5k)
* **Y-axis:** Accuracy (0.0, 0.2, 0.4, 0.6, 0.8, 1.0)
* **Legend:**
* Blue: Only Q<sup>π</sup>
* Green: Effective Reward
**Chart (b): Choice of Prover Policy μ**
* **Title:** Choice of Prover Policy μ
* **X-axis:** γ (1.0, 5.0, 9.0, 13.0, 17.0)
* **Y-axis:** Accuracy (avg. over iters) (0.0, 0.2, 0.4, 0.6, 0.8)
* **Legend:**
* Green: Effective Reward
* Orange: Only Q<sup>π</sup>
* Black dashed line: γ for initial π
**Chart (c): Ceiling on Test-time Re-ranking**
* **Title:** Ceiling on Test-time Re-ranking
* **X-axis:** N (2<sup>1</sup>, 2<sup>2</sup>, 2<sup>3</sup>, 2<sup>4</sup>, 2<sup>5</sup>, 2<sup>6</sup>, 2<sup>7</sup>, 2<sup>8</sup>)
* **Y-axis:** Pass @N (0.00, 0.05, 0.10, 0.15, 0.20, 0.25)
* **Legend:**
* Green: Effective Reward
* Blue: Only Q<sup>π</sup>
* Yellow: Initial π
### Detailed Analysis
**Chart (a): RL with Different Rewards**
* **Only Q<sup>π</sup> (Blue):** The accuracy remains consistently low, near 0.0, across all training iterations.
* **Effective Reward (Green):** The accuracy rapidly increases to 1.0 within the first 0.5k training iterations and remains at 1.0 for the rest of the training period.
**Chart (b): Choice of Prover Policy μ**
* **Effective Reward (Green):** The accuracy starts near 0.0 at γ = 1.0, increases to a peak of approximately 0.9 at γ ≈ 11.0, and then decreases back to near 0.0 at γ = 17.0.
* **Only Q<sup>π</sup> (Orange):** The accuracy remains constant at approximately 0.02 across all values of γ.
* **Vertical Dashed Line (Black):** Indicates the value of γ for the initial policy π, located at γ = 5.0.
**Chart (c): Ceiling on Test-time Re-ranking**
* **Effective Reward (Green):** The pass rate increases steadily from approximately 0.01 at N = 2<sup>1</sup> to approximately 0.24 at N = 2<sup>8</sup>.
* **Only Q<sup>π</sup> (Blue):** The pass rate increases from approximately 0.01 at N = 2<sup>1</sup> to approximately 0.07 at N = 2<sup>8</sup>. The rate of increase slows down as N increases.
* **Initial π (Yellow):** The pass rate increases from approximately 0.01 at N = 2<sup>1</sup> to approximately 0.10 at N = 2<sup>8</sup>. The rate of increase slows down as N increases.
### Key Observations
* The "Effective Reward" consistently outperforms "Only Q<sup>π</sup>" in all three scenarios.
* In chart (b), the accuracy of the "Effective Reward" policy is highly sensitive to the choice of γ, with a clear peak around γ = 11.0.
* In chart (c), the "Effective Reward" policy shows a significantly higher pass rate as N increases compared to the other policies.
### Interpretation
The data suggests that using an "Effective Reward" structure in reinforcement learning leads to significantly better performance compared to using "Only Q<sup>π</sup>". The choice of the policy parameter γ is crucial for the "Effective Reward" policy, as it greatly affects the accuracy of the agent. The "Effective Reward" policy also demonstrates a higher ceiling on test-time re-ranking, indicating its ability to generalize better as the number of samples increases. The "Only Q<sup>π</sup>" policy appears to be less effective and less sensitive to the parameters tested.
</details>
the outcome reward. Due to only sparse feedback, the latter policy does not learn to sample partially correct 𝒚 ★ , whereas a policy trained with the effective reward produces partially correct 𝒚 ★ , and is able to sample the complete 𝒚 ★ with higher likelihood during Pass @N.
## Takeaway: Online RL with process rewards from different prover policies.
Effective rewards 𝑄 𝜋 + 𝛼𝐴 𝜇 from prover 𝜇 : (i) improve sample efficiency of online RL, and (ii) yield policies with better Pass @N performance, over using only outcome rewards. But, advantages of very capable or poor 𝜇 do not improve base policy beyond outcome rewards.
## 3.4. Theory: Provers Complementary to the Base Policy Boost Improvement
From our didactic analysis, it is clear that process rewards 𝐴 𝜇 under different provers 𝜇 disparately affect the base policy that optimizes 𝑄 𝜋 + 𝛼𝐴 𝜇 via online RL. We now present a formal analysis of why this happens and characterize a class of provers that can guarantee non-trivial improvements to the base policy. For simplicity, we assume oracle access to 𝑄 𝜋 , 𝐴 𝜇 at every state-action pair ( 𝒔 ℎ , 𝑎 ℎ ) and prove our result in the tabular RL setting, where the policy class is parameterized using the softmax parameterization in Agarwal et al. (2021). Proofs for this section are in App. F.
Main intuitions. We expect a prover 𝜇 to improve a base policy 𝜋 only when 𝝁 is able to distinguish different actions taken by 𝜋 , by attaining sufficiently varying advantage values 𝐴 𝜇 ( 𝒔 ℎ , 𝑎 ) for actions 𝑎 at state 𝒔 ℎ . This can be formalized under the notion of sufficiently large variance across actions, 𝕍 𝑎 ∼ 𝜋 [ 𝐴 𝜇 ( 𝒔 ℎ , 𝑎 )] . In that case, can we simply use a policy with large advantage variance under any measure? No, because when the prover 𝜇 ranks actions at a given state very differently compared to the base policy 𝜋 (e.g., if 𝐴 𝜇 and 𝐴 𝜋 are opposite), then effective rewards 𝑄 𝜇 + 𝛼𝐴 𝜋 will be less reliable due to conflicting learning signals. Thus, we want 𝔼 𝜋 [⟨ 𝐴 𝜇 , 𝐴 𝜋 ⟩] to not be too negative, so that 𝝁 and 𝝅 are reasonably aligned on their assessment of steps from 𝜋 .
In Theorem 3.1, we present our result on policy improvement where the base policy is updated with natural policy gradient (Kakade, 2001a): 𝜋𝑡 + 1 ( 𝑎 | 𝒔 ℎ ) ∝ exp ( 𝛾 · ( 𝑄 𝜋 ( 𝒔 ℎ , 𝑎 ) + 𝐴 𝜇 ( 𝒔 ℎ , 𝑎 ))) . We note that in this idealized update rule, swapping 𝑄 values (of 𝜇 or 𝜋 ) with advantages does not affect the update since we assume access to all possible actions when running the update. Nonetheless, despite this simplifying assumption, the analysis is able to uncover good choices for the prover policy 𝜇 for computing process
reward 𝐴 𝜇 , and is orthogonal to the design consideration of advantages or 𝑄 -values as process rewards that we have discussed so far in this paper. Theorem 3.1 formalizes our intuition by showing that policy improvement at iteration 𝑡 , grows as the variance in 𝐴 𝜇 values increases (higher distinguishability) and reduces when 𝐴 𝜇 and 𝐴 𝜋 become extremely misaligned. This will then allow us to discuss a special case for the case of Best-of-K policies as provers as an immediate corollary.
Theorem 3.1 (Lower bound on policy improvement; informal) . For base policy iterate 𝜋𝑡 , after one step of policy update, with learning rate 𝛾 ≪ 1 , the improvement over a distribution of states 𝜌 :
$$\mathbb { E } _ { s \sim \rho } \left [ V ^ { \pi _ { t + 1 } } ( s ) - V ^ { \pi _ { t } } ( s ) \right ] & \gtrsim \gamma \cdot \mathbb { E } _ { s \sim \rho } \mathbb { V } _ { a \sim \pi _ { t } } [ A ^ { \mu } ( s , a ) ] + \gamma \cdot \mathbb { E } _ { s \sim \rho } \mathbb { E } _ { a \sim \pi _ { t } } \left [ A ^ { \mu } ( s , a ) A ^ { \pi _ { t } } ( s , a ) \right ] \\ & \underbrace { d i s t i n g u i s h a b i l i t y f r o m \, u } _ { d i s t i n g u i s h a b i l i t y f r o m \, u } \left [ A ^ { \mu } ( s , a ) \right ] + \gamma \cdot \mathbb { E } _ { s \sim \rho } \mathbb { E } _ { a \sim \pi _ { t } } \left [ A ^ { \mu } ( s , a ) A ^ { \pi _ { t } } ( s , a ) \right ] \\$$
It may seem that the base policy 𝜋 can only learn from an improved prover 𝜇 , but our result shows that a weak prover can also amplify a stronger base policy , since a weak prover 𝜇 may have a lower average of 𝑄 𝜇 under its own measure, but still have higher variance across 𝑄 𝜇 (compared to 𝑄 𝜋 ) when evaluated under 𝜋 (see Proposition F.1 in App. F.5 for formal discussion). This tells us that rewarding progress under a prover is different from typical knowledge distillation or imitation learning algorithms (Hinton, 2015; Rusu et al., 2015) that in most cases remain upper bounded by the performance of the stronger teacher. So provers cannot be characterized purely by strength, what is a class of provers that is a reasonable starting point if we were to improve any base policy 𝜋 ?
The policy class of 'Best-of-K' (computed over base policies) contain complementary provers. A good starting point to identify good provers for a base policy 𝜋 , is the class of Best-of-K policies or BoK ( 𝜋 ) . Recall from Sec. 2 that the performance of BoK ( 𝜋 ) increases monotonically with 𝐾 . Applying Theorem 3.1 to this class, we arrive at Remark 3.1 that recommends using BoK ( 𝜋 ) with 𝐾 > 1 as a prover policy for a poor base policy 𝜋 . However, 𝐾 cannot be too large always since when 𝑄 𝜋 ( 𝒔 , 𝑎 ) ≈ 1 , increasing 𝐾 too much can hurt distinguishability of different steps at that state. In the next section, we empirically note that the policies in the class of BoK ( 𝜋 ) indeed induce different performance gains when used as prover policies, and we find Bo4 to be a good choice for test-time search over most base policies.
Remark 3.1. When 𝑄 𝜋 ( 𝒔 , 𝑎 ) = 𝑂 ( 1 / 𝐾 ) , ∀ 𝒔 , 𝑎 , using BoK ( 𝜋 ) as a prover for base 𝜋 improves distinguishability (and improvement) by Ω ( 𝐾 2 ) , and make alignment worse at most by 𝑂 ( 𝐾 ) .
## Takeaway: Formal characterization of good prover policies that improve the base policy.
Provers with advantages that can distinguish actions taken by the base policy (more strongly than the base policy itself) but are not too misaligned from the base, boost improvements on each update of the base policy. We call such policies complementary provers . BoK ( 𝜋 ) for any base policy 𝜋 for 𝐾 > 1 can provide a good starting choice of prover policies.
## 4. Results: Scaling Test-Time Compute with PAVs
Now, we study how process verifiers can scale up test-time compute. While our derivations from Sec. 3.2 were with RL, we can also use the effective reward 𝑄 𝜋 ( 𝒔 ℎ , 𝑎 ℎ ) + 𝛼 · 𝐴 𝜇 ( 𝒔 ℎ , 𝑎 ℎ ) for running beam search over intermediate steps sampled from base policy 𝜋 . To do so, we train a process advantage verifier to predict 𝐴 𝜇 , along with a process reward model 𝑄 𝜋 . PAV training is done using procedures discussed in Sec. 4.2. While the candidates of the beam are selected using a combination of both the PAV and the PRM 𝑄 𝜋 ,
Figure 4 | For test-time search, PAVs are 8 -10% more accurate and 1 . 5 -5 × more compute efficient over ORMs: On samples from (a) Gemma-2B , (b) 9B , and (c) 27B SFT policies, we run test-time beam search with the estimate of effective reward 𝑄 𝜋 + 𝛼𝐴 𝜇 (PAV), where 𝜇 is the Bo4 ( 𝜋 ) policy. We compare beam search performance with best-of-N, re-ranking with a trained outcome verifier (ORM), or the oracle Rex (Pass @N).
<details>
<summary>Image 5 Details</summary>

### Visual Description
## Line Charts: Gemma Model Accuracy vs. N
### Overview
The image contains three line charts comparing the accuracy of different Gemma models (2B, 9B, and 27B) across varying values of 'N'. Each chart plots the accuracy of three methods: ORM, PAV (ours), and Pass @N, against N, which is displayed on a logarithmic scale. The charts also highlight specific performance differences between the methods at certain N values.
### Components/Axes
* **Titles:**
* Left Chart: Gemma-2B
* Middle Chart: Gemma-9B
* Right Chart: Gemma-27B
* **X-axis:**
* Label: N
* Scale: Logarithmic, with markers at 2<sup>1</sup>, 2<sup>2</sup>, 2<sup>3</sup>, 2<sup>4</sup>, 2<sup>5</sup>, 2<sup>6</sup>, and 2<sup>7</sup>.
* **Y-axis:**
* Label: Accuracy
* Scale: Linear, ranging from 0.1 to 0.4 (Gemma-2B), 0.4 to 0.6 (Gemma-9B), and 0.4 to 0.6 (Gemma-27B).
* **Legend:** (Positioned at the top-left of each chart)
* Blue dashed line with circles: ORM
* Orange solid line with stars: PAV (ours)
* Gray dashed line with squares: Pass @N
* **Annotations:**
* Arrows and text indicating performance differences (e.g., "5x", "10%", "2x", "1.5x", "8%") between methods at specific N values.
* **Chart Labels:**
* (a) - Left Chart
* (b) - Middle Chart
* (c) - Right Chart
### Detailed Analysis
**Gemma-2B (Left Chart)**
* **ORM (Blue):** The accuracy starts around 0.12 at N=2<sup>1</sup>, increases to approximately 0.20 at N=2<sup>3</sup>, and then plateaus around 0.20 for higher N values. There is a shaded region around the line, indicating a confidence interval.
* **PAV (Orange):** The accuracy starts around 0.15 at N=2<sup>1</sup>, increases to approximately 0.25 at N=2<sup>5</sup>, and continues to increase slowly to about 0.28 at N=2<sup>7</sup>. There is a shaded region around the line, indicating a confidence interval.
* **Pass @N (Gray):** The accuracy starts around 0.15 at N=2<sup>1</sup> and increases steadily to approximately 0.42 at N=2<sup>7</sup>.
* **Annotation:** At N=2<sup>3</sup>, PAV is approximately 5 times more accurate than ORM. The accuracy of Pass @N is 10% higher than PAV at N=2<sup>7</sup>.
**Gemma-9B (Middle Chart)**
* **ORM (Blue):** The accuracy starts around 0.38 at N=2<sup>1</sup>, increases to approximately 0.45 at N=2<sup>3</sup>, and then plateaus around 0.45 for higher N values. There is a shaded region around the line, indicating a confidence interval.
* **PAV (Orange):** The accuracy starts around 0.40 at N=2<sup>1</sup>, increases to approximately 0.55 at N=2<sup>5</sup>, and plateaus around 0.58 at N=2<sup>7</sup>. There is a shaded region around the line, indicating a confidence interval.
* **Pass @N (Gray):** The accuracy starts around 0.40 at N=2<sup>1</sup> and increases steadily to approximately 0.68 at N=2<sup>7</sup>.
* **Annotation:** At N=2<sup>3</sup>, PAV is approximately 2 times more accurate than ORM. The accuracy of Pass @N is 10% higher than PAV at N=2<sup>7</sup>.
**Gemma-27B (Right Chart)**
* **ORM (Blue):** The accuracy starts around 0.45 at N=2<sup>1</sup>, increases to approximately 0.52 at N=2<sup>4</sup>, and then decreases slightly to about 0.50 at N=2<sup>7</sup>. There is a shaded region around the line, indicating a confidence interval.
* **PAV (Orange):** The accuracy starts around 0.45 at N=2<sup>1</sup>, increases to approximately 0.55 at N=2<sup>5</sup>, and plateaus around 0.58 at N=2<sup>7</sup>. There is a shaded region around the line, indicating a confidence interval.
* **Pass @N (Gray):** The accuracy starts around 0.45 at N=2<sup>1</sup> and increases steadily to approximately 0.70 at N=2<sup>7</sup>.
* **Annotation:** At N=2<sup>3</sup>, PAV is approximately 1.5 times more accurate than ORM. The accuracy of Pass @N is 8% higher than PAV at N=2<sup>7</sup>.
### Key Observations
* For all three models, Pass @N consistently achieves the highest accuracy across all N values.
* The performance gap between PAV and ORM decreases as the model size increases.
* ORM's accuracy plateaus at lower N values compared to PAV and Pass @N.
* The annotations highlight specific performance gains of PAV over ORM and Pass @N over PAV at certain N values.
### Interpretation
The charts demonstrate the impact of model size (2B, 9B, 27B) and the value of N on the accuracy of different methods (ORM, PAV, Pass @N). The "Pass @N" method consistently outperforms the other two, suggesting it is the most effective approach for these models. The annotations emphasize the relative improvements of PAV over ORM and Pass @N over PAV, providing insights into the specific benefits of each method at different N values. The shaded regions around the lines indicate the uncertainty or variability in the accuracy measurements. The logarithmic scale on the x-axis suggests that the initial increases in N have a more significant impact on accuracy than later increases.
</details>
the final candidate is selected using the outcome reward prediction from 𝑄 𝜋 itself (i.e., we repurpose the PRM representing 𝑄 𝜋 as an ORM). For clarity, we abuse notation and refer to the estimated effective reward (ORM + 𝛼 PAV) as PAV directly.
Setup . We finetune Gemma 2B, 9B, and 27B (Gemma Team et al., 2024) on MATH (Hendrycks et al., 2021) via supervised fine-tuning (SFT) to get three base policies. The set of provers consists of the three base SFT policies themselves as well as their best-of-K policies for different values of 𝐾 ∈ { 2 0 , . . . , 2 5 } . Additional details for the experiments in this section are in App. C.
## 4.1. PAVs Scale Test-Time Compute by 5 -10 × Over ORMs
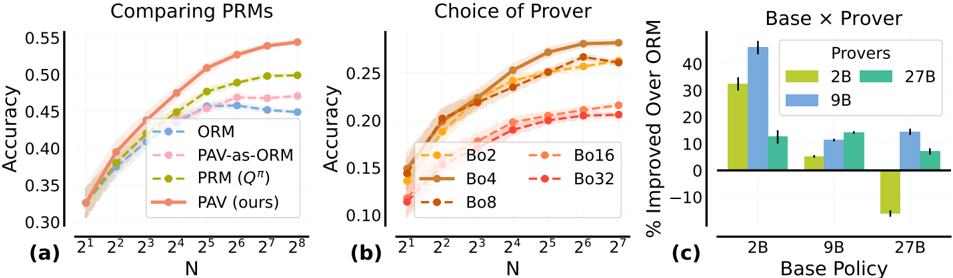
Result 1: PAVs are more compute efficient than ORMs. In Fig. 4, we plot the performance of beam search with PAVs for different sizes of the beam 𝑁 , and compare it with best-of𝑁 using ORMs, i.e. , sampling 𝑁 complete solutions from the base policy and returning the one with the highest ORM score. To compare PAVs and ORMs, we evaluate the compute efficiency of PAVs over ORMs, given by the ratio of total compute needed by PAVs to obtain the same performance as running best-of-128 with ORM. Even when accounting for the fact that running beam search with PAVs does require additional compute per solution trace (since each element in the beam samples 𝐶 = 3 next steps, before scoring and pruning the beam), PAVs are able to scale the compute efficiency by 10 × over ORMs for Gemma-2B, 9B base models, and by 5 × for Gemma-27B model. We use BoK ( 𝜋 ) with 𝐾 = 4 as the prover policy for all base policies 𝜋 .
We also compare performance with beam search using process verifiers that only predict 𝑄 𝜋 , and best-of-N where the ORM is replaced with PAV (PAV-as-ORM). At 𝑁 = 128, similar to Luo et al. (2024), we note a similar gain of 4% for 'PAV-as-ORM' Fig. 5(a) over only ORMs, for base Gemma-9B 𝜋 . When comparing beam search with 𝑄 𝜋 (Snell et al., 2024), we find that PAVs scale compute efficiency by 8 × . Evidently, advantages from the prover in the effective reward positively impact the beam search. Why does 𝐴 𝜇 help, and for what choice of the prover 𝜇 ?
Result 2: Beam search with too weak/strong provers is sub-optimal. In Fig. 5(b), for the setting when the base policy 𝜋 is a Gemma-2B SFT model, we compare beam search with PAVs where the provers are given by BoK ( 𝜋 ) , for different values of 𝐾 . Recall that as 𝐾 increases, BoK ( 𝜋 ) becomes stronger. Corroborating our analysis in Sec. 3.4, our results show that neither too weak (Bo2) or too strong (Bo32) provers perform best. Instead, across all values of 𝑁 , we find Bo4 to be dominant. The advantage values
Figure 5 | Comparing PAVs with search baselines and ablating over the prover policy: (a): We compare beam search over Gemma 9B SFT, using either effective reward (PAV), or 𝑄 𝜋 (Snell et al., 2024), and report best-of-N performance where the re-ranker is either the ORM or PAV-as-ORM. (b): For the base Gemma 2B SFT policy, we run beam search with the effective reward where the prover is BoK ( 𝜋 ) for different values of 𝐾 . In both ( 𝑎 ) , ( 𝑏 ) the x-axis scales the size of the beam or 𝑁 for best-of-N. (c): For each base policy in the set: Gemma 2B, 9B, 27B policies, we run beam search with PAVs (beam size of 16) where the prover is another policy from the same set.
<details>
<summary>Image 6 Details</summary>
### Visual Description
## Chart Type: Multiple Charts - Line Graphs and Bar Graph
### Overview
The image presents three charts comparing different Prover-Reasoner Models (PRMs). Chart (a) compares the accuracy of different PRM approaches as a function of N. Chart (b) shows the accuracy of different choices of provers as a function of N. Chart (c) shows the percentage improvement over ORM for different base policies and provers.
### Components/Axes
**Chart (a): Comparing PRMs**
* **Title:** Comparing PRMs
* **X-axis:** N (values: 2<sup>1</sup>, 2<sup>2</sup>, 2<sup>3</sup>, 2<sup>4</sup>, 2<sup>5</sup>, 2<sup>6</sup>, 2<sup>7</sup>, 2<sup>8</sup>)
* **Y-axis:** Accuracy (values range from 0.30 to 0.55, incrementing by 0.05)
* **Legend (top-right):**
* ORM (light blue, dashed line)
* PAV-as-ORM (pink, dotted line)
* PRM (Q<sup>π</sup>) (olive green, dashed line)
* PAV (ours) (salmon, solid line)
**Chart (b): Choice of Prover**
* **Title:** Choice of Prover
* **X-axis:** N (values: 2<sup>1</sup>, 2<sup>2</sup>, 2<sup>3</sup>, 2<sup>4</sup>, 2<sup>5</sup>, 2<sup>6</sup>, 2<sup>7</sup>)
* **Y-axis:** Accuracy (values range from 0.10 to 0.25, incrementing by 0.05)
* **Legend (center-right):**
* Bo2 (light orange, dashed line)
* Bo4 (light red, dashed line)
* Bo8 (brown, solid line)
* Bo16 (orange, dashed line)
* Bo32 (red, dashed line)
**Chart (c): Base x Prover**
* **Title:** Base x Prover
* **X-axis:** Base Policy (categories: 2B, 9B, 27B)
* **Y-axis:** % Improved Over ORM (values range from -10 to 40, incrementing by 10)
* **Legend (top-right):**
* 2B (olive green)
* 9B (light blue)
* 27B (teal)
### Detailed Analysis
**Chart (a): Comparing PRMs**
* **ORM (light blue, dashed line):** Accuracy increases from approximately 0.38 at N=2<sup>1</sup> to approximately 0.46 at N=2<sup>6</sup>, then plateaus.
* **PAV-as-ORM (pink, dotted line):** Accuracy increases from approximately 0.37 at N=2<sup>1</sup> to approximately 0.47 at N=2<sup>6</sup>, then plateaus.
* **PRM (Q<sup>π</sup>) (olive green, dashed line):** Accuracy increases from approximately 0.37 at N=2<sup>1</sup> to approximately 0.50 at N=2<sup>6</sup>, then plateaus.
* **PAV (ours) (salmon, solid line):** Accuracy increases from approximately 0.32 at N=2<sup>1</sup> to approximately 0.54 at N=2<sup>8</sup>.
**Chart (b): Choice of Prover**
* **Bo2 (light orange, dashed line):** Accuracy increases from approximately 0.14 at N=2<sup>1</sup> to approximately 0.18 at N=2<sup>4</sup>, then plateaus around 0.20 at N=2<sup>7</sup>.
* **Bo4 (light red, dashed line):** Accuracy increases from approximately 0.12 at N=2<sup>1</sup> to approximately 0.17 at N=2<sup>4</sup>, then plateaus around 0.21 at N=2<sup>7</sup>.
* **Bo8 (brown, solid line):** Accuracy increases from approximately 0.15 at N=2<sup>1</sup> to approximately 0.24 at N=2<sup>4</sup>, then plateaus around 0.26 at N=2<sup>7</sup>.
* **Bo16 (orange, dashed line):** Accuracy increases from approximately 0.15 at N=2<sup>1</sup> to approximately 0.25 at N=2<sup>4</sup>, then plateaus around 0.27 at N=2<sup>7</sup>.
* **Bo32 (red, dashed line):** Accuracy increases from approximately 0.11 at N=2<sup>1</sup> to approximately 0.19 at N=2<sup>4</sup>, then plateaus around 0.21 at N=2<sup>7</sup>.
**Chart (c): Base x Prover**
* **2B Base Policy:**
* 2B Prover (olive green): Approximately 32% improvement over ORM.
* 9B Prover (light blue): Approximately 42% improvement over ORM.
* 27B Prover (teal): Approximately 12% improvement over ORM.
* **9B Base Policy:**
* 2B Prover (olive green): Approximately 4% improvement over ORM.
* 9B Prover (light blue): Approximately 14% improvement over ORM.
* 27B Prover (teal): Approximately 14% improvement over ORM.
* **27B Base Policy:**
* 2B Prover (olive green): Approximately -12% improvement over ORM.
* 9B Prover (light blue): Approximately 10% improvement over ORM.
* 27B Prover (teal): Approximately 8% improvement over ORM.
### Key Observations
* In Chart (a), PAV (ours) consistently outperforms the other PRM approaches as N increases.
* In Chart (b), Bo8 and Bo16 provers generally achieve higher accuracy compared to Bo2, Bo4, and Bo32.
* In Chart (c), the 9B prover shows the highest improvement over ORM when used with the 2B base policy. The 2B prover performs poorly with the 27B base policy.
### Interpretation
The charts provide a comparative analysis of different Prover-Reasoner Models (PRMs) and the impact of prover choice on accuracy. Chart (a) highlights the superior performance of the PAV (ours) approach, suggesting its effectiveness in improving accuracy as the complexity (N) increases. Chart (b) indicates that certain provers (Bo8 and Bo16) are more effective than others, potentially due to their specific characteristics or configurations. Chart (c) reveals the interplay between base policies and provers, demonstrating that the optimal combination can significantly improve performance over the ORM baseline. The negative improvement observed with the 2B prover and 27B base policy suggests potential incompatibility or interference between these components.
</details>
𝐴 𝜇 ≈ 0 on all steps for very large 𝐾 , since 𝑄 𝜇 ( 𝒔 ℎ , 𝑎 ℎ ) = 1 - ( 1 -𝑄 𝜋 ( 𝒔 ℎ , 𝑎 ℎ )) 𝐾 → 1 on all steps, as we increase 𝐾 . Hence, in order to succeed we need an intermediate-level prover policy .
We make similar observations in Figure 5(c) where we use the three base policies (Gemma 2B/9B/27B) as provers for training PAVs. In this scenario, we evaluate beam search with PAVs at 𝑁 = 16 on top of different base policies. We find that for the 2B and 9B base models, the 9B and 27B provers are most effective respectively , whereas for the 27B model, surprisingly a weaker 9B policy is more effective than the stronger 27B model. The weaker model presumably offers a complementary signal that distinguishes between different actions taken by 27B, aligning with our theoretical observations in Sec. 3.4.
Result 3: Advantages from the prover policy enable exploration. As discussed in Sec. 3.1, advantage 𝐴 𝜇 measures the progress made by an action agnostic of the value of the previous state, where as 𝑄 𝜋 measures the promise of a particular state. Given a finite capacity beam, our effective reward (Eq. 5), which linearly combines 𝑄 𝜋 and 𝐴 𝜇 induces a better tradeoff between exploring new prefixes (states) from where progress can be made and exploiting currently known prefixes with high Q-values. Exploration at
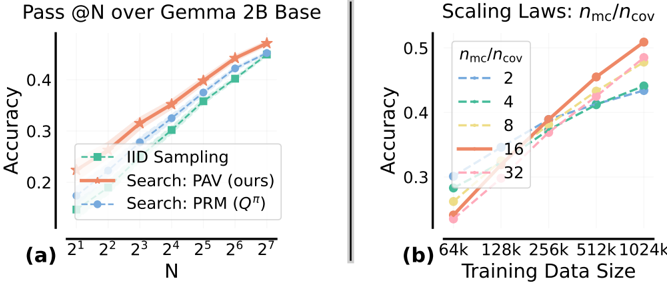
Figure 6 | (a): Beam search with PAVs improves exploration efficiency (higher Pass@N), over typical PRMs. (b): Performance of beam search over Gemma 9B SFT for PAVs trained on datasets with different 𝑛 mc / 𝑛 cov .
<details>
<summary>Image 7 Details</summary>
### Visual Description
## Chart: Pass @N over Gemma 2B Base and Scaling Laws
### Overview
The image presents two line charts comparing the accuracy of different search methods and scaling laws over varying parameters. The left chart (a) shows the accuracy of "IID Sampling," "Search: PAV (ours)," and "Search: PRM (Q^π)" as a function of N, plotted on a log scale. The right chart (b) illustrates the scaling laws of accuracy with respect to training data size for different ratios of n_mc/n_cov.
### Components/Axes
**Chart (a): Pass @N over Gemma 2B Base**
* **Title:** Pass @N over Gemma 2B Base
* **X-axis:** N (values: 2^1, 2^2, 2^3, 2^4, 2^5, 2^6, 2^7)
* **Y-axis:** Accuracy (scale: 0.2 to 0.45, incrementing by 0.1)
* **Legend (bottom-right):**
* IID Sampling (green dashed line with square markers)
* Search: PAV (ours) (orange solid line with star markers)
* Search: PRM (Q^π) (blue dashed line with circle markers)
**Chart (b): Scaling Laws: n_mc/n_cov**
* **Title:** Scaling Laws: n_mc/n_cov
* **X-axis:** Training Data Size (values: 64k, 128k, 256k, 512k, 1024k)
* **Y-axis:** Accuracy (scale: 0.3 to 0.5, incrementing by 0.1)
* **Legend (top-left):** n_mc/n_cov
* 2 (light blue dashed line)
* 4 (green dashed line)
* 8 (yellow dashed line)
* 16 (orange solid line)
* 32 (pink dashed line)
### Detailed Analysis
**Chart (a): Pass @N over Gemma 2B Base**
* **IID Sampling (green):** The accuracy starts at approximately 0.15 at N=2^1 and increases to approximately 0.42 at N=2^7.
* **Search: PAV (ours) (orange):** The accuracy starts at approximately 0.22 at N=2^1 and increases to approximately 0.47 at N=2^7. This line also has a shaded region around it, indicating a confidence interval.
* **Search: PRM (Q^π) (blue):** The accuracy starts at approximately 0.17 at N=2^1 and increases to approximately 0.45 at N=2^7.
**Chart (b): Scaling Laws: n_mc/n_cov**
* **n_mc/n_cov = 2 (light blue):** The accuracy starts at approximately 0.30 at 64k and increases to approximately 0.39 at 1024k.
* **n_mc/n_cov = 4 (green):** The accuracy starts at approximately 0.28 at 64k and increases to approximately 0.42 at 1024k.
* **n_mc/n_cov = 8 (yellow):** The accuracy starts at approximately 0.25 at 64k and increases to approximately 0.41 at 1024k.
* **n_mc/n_cov = 16 (orange):** The accuracy starts at approximately 0.33 at 64k and increases to approximately 0.51 at 1024k.
* **n_mc/n_cov = 32 (pink):** The accuracy starts at approximately 0.23 at 64k and increases to approximately 0.47 at 1024k.
### Key Observations
* In chart (a), "Search: PAV (ours)" consistently outperforms "IID Sampling" and "Search: PRM (Q^π)" across all values of N.
* In chart (b), the scaling laws show that higher n_mc/n_cov ratios generally lead to higher accuracy, with n_mc/n_cov = 16 showing the highest accuracy across all training data sizes.
* In chart (b), the lines for n_mc/n_cov = 2, 4, and 8 are very close together, suggesting similar performance within that range.
### Interpretation
The charts suggest that the "Search: PAV (ours)" method is more effective than "IID Sampling" and "Search: PRM (Q^π)" for the given task, as it consistently achieves higher accuracy across different values of N. The scaling laws indicate that increasing the ratio of n_mc/n_cov can improve accuracy, but the effect plateaus or even decreases beyond a certain point (around n_mc/n_cov = 16). This implies that there is an optimal balance between these parameters for maximizing performance. The shaded region around the "Search: PAV (ours)" line in chart (a) indicates the uncertainty or variability in the accuracy of this method.
</details>
initial steps is critical to ensure that the beam at later steps covers diverse partial rollouts each with a high likelihood of producing the correct answer. Thus over-committing to the beam with actions from the same state, regardless of the progress made by each can prove to be sub-optimal over a selection strategy that balances rewarding previous actions 𝐴 𝜇 and current states 𝑄 𝜋 . Indeed, we observe in Fig. 6(a), beam search with PAV enhances pass@N performance vs. beam search with 𝑄 𝜋 and i.i.d. sampling.
## Takeaways: Scaling test-time compute with process advantage verifiers.
- Beam search with PAVs boosts accuracy by >8% & compute efficiency by 1.5-5x over ORMs.
- Utilizing Best-of-K policies (corresponding to the base policy) as provers induce better exploration to maximize outcome reward. Optimal provers for a base policy appear at 𝐾 > 1.
## 4.2. How to Collect Data to Train PAVs?: PAV Training Data Scaling Laws
We now describe the procedure for training outcome verifiers and PAVs. We can learn to predict 𝑄 𝜋 for a policy 𝜋 (similar for 𝑄 𝜇 ) by finetuning LLMs with a cross-entropy loss on the following data with triplets ( 𝒔 , 𝑎, 𝑄 𝜋 mc ( 𝒔 , 𝑎 )) . To collect this data, we first sample 𝑛 cov 'seed' rollouts from the base or prover policy respectively for ORM and PAVs, to promote coverage over prefixes and steps. Then we sample 𝑛 mc additional rollouts, conditioned on each prefix in the seed rollout to compute the Monte-Carlo estimate of 𝑄 𝜋 at each prefix. In Fig. 6(b) we plot the beam search performance of PAVs trained with different ratios of 𝑛 mc / 𝑛 cov , as we scale the total dataset size. Here, the beam size is fixed to 128 and the base policy is the Gemma 9B SFT policy and prover is 𝐵𝑜 4 policy. We find that under low sampling budgets, optimizing for coverage ( 𝑛 cov > 𝑛 mc ) is better for performance, and when budget is higher, reducing label noise in 𝑄 𝜋 mc by setting 𝑛 mc > 𝑛 cov gets us more improvements. In addition, we also spend some initial sampling budget is spent to identify 'high value' states where 𝑄 𝜋 is larger than a threshold, and identify the first step with low 𝑄 𝜋 on an incorrect partial rollout from this state. We found this strategy to scale better with dataset size, as we discuss in App. D.
## 5. Results: Scaling Dense-Reward RL with PAVs
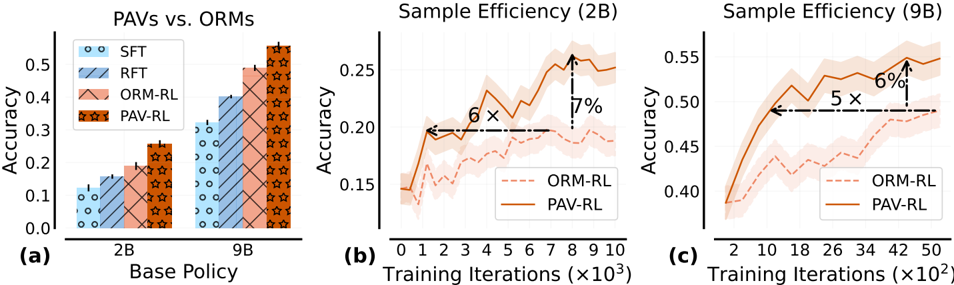
We can also use PAVs to train policies via online reinforcement learning (RL), by using the effective reward 𝑄 𝜋 + 𝛼𝐴 𝜇 as dense, per-step rewards. We compare the sample efficiency of PAV-RL (i.e., ℓ PAV -RL in Eq. 4) with standard ORM-RL (i.e., ℓ ORM -RL in Eq. 3) on Gemma 2B and Gemma 9B SFT models, which are further optimized via rejection finetuning (RFT) (Yuan et al., 2023), before using them to initialize RL. To our knowledge, no prior work has successfully demonstrated the use of dense per-step feedback with a process reward model for RL, and we present the first significant set of results establishing the efficacy of this approach. We show that PAV-RL is much more sample-efficient, and enjoys a higher ceiling on the performance of any test-time re-ranker. Additional details for the experiments are in App. E.
Result 1: PAV-RL is > 7% better than ORM-RL in test accuracy, and 6 × sample efficient. In Fig. 7(a), we report the test accuracies of Gemma 2B and 9B models trained with SFT, RFT, ORM-RL and PAV-RL. PAV-RL improves the RFT policy by 11% for 2B, and 15% for 9B, with > 7% gain over ORM-RL in both cases. Not only do the effective rewards from PAV improve the raw accuracy after RL, this higher accuracy is attained 6 × faster (see Fig. 7(b)) for the 2B run and similarly for the 9B RL run (Fig. 7(c)). For both 2B and 9B, RL runs, we experiment with two options for the prover policy: (i) 2B SFT policy; and (ii) 9B SFT policy. While both of these provers rapidly become weaker than the base policy within a few gradient steps of RL, a fixed PAV trained with each of these provers is able to still sustain performance gains in RL. More interestingly, we find that the 2B SFT policy serves as the best choice of the prover for both 2B and
Figure 7 | PAVs as dense rewards in RL improve sample efficiency compared to ORMs, along with gains on raw accuracy: (a) We report the performance of a base policy trained using RL with effective rewards (PAV-RL), or only outcome rewards (ORM-RL), and baselines SFT, RFT. (b,c): Across training iterations, we report the test performance of policies trained with PAV-RL and ORM-RL, on Gemma 2B and 9B SFT base policies.
<details>
<summary>Image 8 Details</summary>
### Visual Description
## Chart Type: Multiple Charts Comparing Model Accuracy
### Overview
The image presents three charts comparing the accuracy of different models (SFT, RFT, ORM-RL, and PAV-RL) under varying conditions. Chart (a) compares the accuracy of PAV-RL and ORM-RL against SFT and RFT for base policies 2B and 9B. Charts (b) and (c) show the sample efficiency of ORM-RL and PAV-RL for 2B and 9B base policies, respectively, plotting accuracy against training iterations.
### Components/Axes
**Chart (a): PAVs vs. ORMs**
* **Title:** PAVs vs. ORMs
* **X-axis:** Base Policy (2B, 9B)
* **Y-axis:** Accuracy (0.0 to 0.5, incrementing by 0.1)
* **Legend (top-left):**
* SFT (light blue with circles)
* RFT (blue with diagonal lines)
* ORM-RL (light orange with diagonal lines)
* PAV-RL (dark orange with stars)
**Chart (b): Sample Efficiency (2B)**
* **Title:** Sample Efficiency (2B)
* **X-axis:** Training Iterations (x10^3) (0 to 10, incrementing by 1)
* **Y-axis:** Accuracy (0.15 to 0.25, incrementing by 0.05)
* **Legend (bottom):**
* ORM-RL (light orange, dashed line)
* PAV-RL (dark orange, solid line)
**Chart (c): Sample Efficiency (9B)**
* **Title:** Sample Efficiency (9B)
* **X-axis:** Training Iterations (x10^2) (2 to 50, uneven increments)
* **Y-axis:** Accuracy (0.40 to 0.55, incrementing by 0.05)
* **Legend (bottom):**
* ORM-RL (light orange, dashed line)
* PAV-RL (dark orange, solid line)
### Detailed Analysis
**Chart (a): PAVs vs. ORMs**
* **SFT (2B):** Accuracy ~0.12
* **RFT (2B):** Accuracy ~0.16
* **ORM-RL (2B):** Accuracy ~0.19
* **PAV-RL (2B):** Accuracy ~0.26
* **SFT (9B):** Accuracy ~0.32
* **RFT (9B):** Accuracy ~0.40
* **ORM-RL (9B):** Accuracy ~0.48
* **PAV-RL (9B):** Accuracy ~0.53
**Chart (b): Sample Efficiency (2B)**
* **ORM-RL:** Starts at ~0.15, increases to ~0.20 by iteration 2, then fluctuates between 0.18 and 0.20.
* **PAV-RL:** Starts at ~0.15, increases sharply to ~0.24 by iteration 8, then plateaus.
* The annotation "6x" indicates the PAV-RL reaches the same accuracy as ORM-RL 6x faster.
* The annotation "7%" indicates the PAV-RL achieves 7% higher accuracy than ORM-RL.
**Chart (c): Sample Efficiency (9B)**
* **ORM-RL:** Starts at ~0.40, increases to ~0.48 by iteration 18, then fluctuates around 0.48.
* **PAV-RL:** Starts at ~0.42, increases sharply to ~0.50 by iteration 10, then plateaus around 0.53.
* The annotation "5x" indicates the PAV-RL reaches the same accuracy as ORM-RL 5x faster.
* The annotation "6%" indicates the PAV-RL achieves 6% higher accuracy than ORM-RL.
### Key Observations
* PAV-RL consistently outperforms ORM-RL in both base policies (2B and 9B).
* Increasing the base policy from 2B to 9B significantly improves the accuracy of all models.
* PAV-RL demonstrates better sample efficiency, reaching higher accuracy levels faster than ORM-RL.
### Interpretation
The data suggests that PAV-RL is a more effective approach than ORM-RL for improving model accuracy, especially when considering sample efficiency. The increase in accuracy from 2B to 9B base policies highlights the importance of model size. The annotations on charts (b) and (c) quantify the performance advantage of PAV-RL, showing it achieves similar accuracy levels much faster and ultimately reaches higher accuracy. This implies that PAV-RL requires fewer training iterations to achieve better results, making it a more efficient choice.
</details>
9B policies. This observation that a weak prover can still improve the base policy corroborates our results in the didactic setup and our analysis in Sec. 3.4. While we were not able to run experiments where the prover policy is dynamically updated on the fly, we believe that updating the prover through the process of RL training should only amplify these benefits.
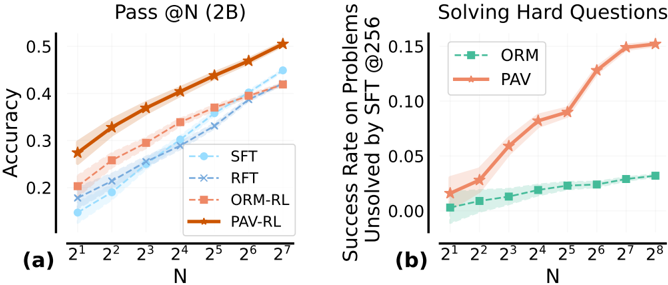
Result 2: PAV-RL achieves higher performance ceiling on test-time re-ranking. In Fig. 8(a), for Gemma 2B, we plot the Pass @N performance for each method, and find (i) Pass @N is higher ( > 7%) for PAV-RL, compared to ORM-RL, for any 𝑁 ≤ 128; and (ii) the rate at which Pass @N improves for PAV-RL is higher than ORM-RL. Both trends are consistent with our observations on the didactic example in Sec. 3.3. Notably, for 𝑁 ≥ 64, ORM-RL is worse than the SFT policy, perhaps due to lower entropy over the distribution at the next step resulting in non-diverse candidates. Why does PAV-RL produce diverse candidates, and does not suffer from the low diversity problem in ORM-RL? We answer this with a key insight on how the primary benefit of PAVs is to promote efficient exploration.
Figure 8 | (a): For the policies trained in (a) we report the best-of-N performance where the oracle reward Rex is used to rank 𝑁 candidates sampled from the base policy (Pass @N). (b): Amongst hard problems that remain unsolved by Best-of-256 over the base SFT policy, we check how many are solved by Best-of-N over PAV-RL or ORM-RL. PAV-RL is able to solve a substantially more problems than what ORM-RL was able to solve.
<details>
<summary>Image 9 Details</summary>
### Visual Description
## Chart Type: Line Graphs
### Overview
The image contains two line graphs comparing the performance of different models on two tasks: "Pass @N (2B)" and "Solving Hard Questions". The x-axis represents the number of samples (N) on a logarithmic scale (base 2), and the y-axis represents accuracy or success rate. The graphs compare the performance of models SFT, RFT, ORM-RL, and PAV-RL (in the first graph) and ORM and PAV (in the second graph).
### Components/Axes
**Graph (a): Pass @N (2B)**
* **Title:** Pass @N (2B)
* **X-axis:** N (Number of samples). Scale: 2<sup>1</sup>, 2<sup>2</sup>, 2<sup>3</sup>, 2<sup>4</sup>, 2<sup>5</sup>, 2<sup>6</sup>, 2<sup>7</sup>
* **Y-axis:** Accuracy. Scale: 0.2, 0.3, 0.4, 0.5
* **Legend (top-right):**
* SFT (light blue, dashed line with circle markers)
* RFT (light blue, dashed line with x markers)
* ORM-RL (light red, dashed line with square markers)
* PAV-RL (dark orange, solid line with star markers)
**Graph (b): Solving Hard Questions**
* **Title:** Solving Hard Questions
* **X-axis:** N (Number of samples). Scale: 2<sup>1</sup>, 2<sup>2</sup>, 2<sup>3</sup>, 2<sup>4</sup>, 2<sup>5</sup>, 2<sup>6</sup>, 2<sup>7</sup>, 2<sup>8</sup>
* **Y-axis:** Success Rate on Problems Unsolved by SFT @256. Scale: 0.00, 0.05, 0.10, 0.15
* **Legend (top-right):**
* ORM (light green, dashed line with square markers)
* PAV (light red, solid line with star markers)
### Detailed Analysis
**Graph (a): Pass @N (2B)**
* **SFT (light blue, dashed line with circle markers):** Starts at approximately 0.18 accuracy at N=2<sup>1</sup> and increases to approximately 0.42 at N=2<sup>7</sup>. The trend is generally upward.
* **RFT (light blue, dashed line with x markers):** Starts at approximately 0.17 accuracy at N=2<sup>1</sup> and increases to approximately 0.40 at N=2<sup>7</sup>. The trend is generally upward.
* **ORM-RL (light red, dashed line with square markers):** Starts at approximately 0.20 accuracy at N=2<sup>1</sup> and increases to approximately 0.39 at N=2<sup>7</sup>. The trend is generally upward.
* **PAV-RL (dark orange, solid line with star markers):** Starts at approximately 0.28 accuracy at N=2<sup>1</sup> and increases to approximately 0.50 at N=2<sup>7</sup>. The trend is generally upward.
**Graph (b): Solving Hard Questions**
* **ORM (light green, dashed line with square markers):** Starts at approximately 0.00 at N=2<sup>1</sup> and increases to approximately 0.025 at N=2<sup>8</sup>. The trend is slightly upward.
* **PAV (light red, solid line with star markers):** Starts at approximately 0.02 at N=2<sup>1</sup>, increases sharply to approximately 0.08 at N=2<sup>4</sup>, and then continues to increase to approximately 0.15 at N=2<sup>8</sup>. The trend is upward.
### Key Observations
* In Graph (a), PAV-RL consistently outperforms the other models (SFT, RFT, ORM-RL) in terms of accuracy.
* In Graph (b), PAV significantly outperforms ORM in terms of the success rate on problems unsolved by SFT.
* Both graphs show an increase in performance (accuracy or success rate) as the number of samples (N) increases.
* The shaded regions around the lines likely represent confidence intervals or standard deviations, indicating the uncertainty in the performance estimates.
### Interpretation
The data suggests that the PAV-RL model is more effective than SFT, RFT, and ORM-RL for the "Pass @N (2B)" task. Additionally, the PAV model is more successful at solving hard questions that SFT cannot solve, compared to the ORM model. The increasing performance with larger N values indicates that all models benefit from more data. The confidence intervals provide a measure of the reliability of these conclusions. The "Solving Hard Questions" graph indicates that PAV is significantly better at addressing problems that SFT struggles with.
</details>
Result 3: PAVs improve exploration and discover correct solutions to novel problems. An outcome reward model rewards downweight all steps in an incorrect rollout equally during RL, whereas the effective reward 𝑄 𝜋 + 𝛼𝐴 𝜇 in PAVs, up-weights steps that make progress under the prover, even when the complete rollout is incorrect. This increases the coverage over individual steps that can improve the likelihood of the base policy to succeed (since the prover policy is not too misaligned with the base policy). These can now be proposed by the base policy at a given prefix. This mechanism for exploration is analogous to test-time search we discussed in Sec. 4.1. Hence, the directed supervision from PAVs improves sample-efficiency throughout the course of training (Fig. 7(c)). In fact, we also find that combining the PAV-RL policy with test-time beam search is able to solve a substantially larger number of new problems within smaller compute budgets ( 𝑁 = 16 , 32) that the SFT policy cannot solve with a much larger budget 𝑁 = 256 (Fig. 8(b)).
## Takeaway: RL with process advantage verifiers (PAVs) as dense rewards
- Using trained PAVs as dense rewards in RL boosts scales sample efficiency by 5 -6 × , compared to only using sparse ORM rewards, and results in policies with a higher Pass @N performance.
- Advantages from a complementary prover policy improves the sample efficiency of exploration in RL, and produces policies that can discover solutions to hard novel questions.
## 6. Related Work
We briefly discuss some key related works here, and leave the detailed discussion for App. A. To address issues of sparse feedback in ORMs (Cobbe et al., 2021b), recent works (Lightman et al., 2023; Uesato et al., 2022) trained process reward models (PRMs) to densely predict incorrect steps in a multi-step reasoning trace. Since human data collection for process labels is not scalable enough, recent work (Luo et al., 2024; Wang et al., 2024) used automated supervision to annotate steps with 𝑄 values under the base policy, i.e. , the PRMs score a step with the likelihood of future success, when continuing to sample from the step. While 𝑄 -value PRMs in Lightman et al. (2023); Luo et al. (2024) were mainly used as verifiers for re-ranking, Snell et al. (2024) used them for test-time beam search. Shao et al. (2024) uses PRMs for RL but found a gain of only 1 -2% with PRMs. In our work, we question solely relying on 𝑄 -values or advantages of the base policy, and find that measuring progress (i.e., advantages) under a different prover policy can amplify exploration, thus boosting test-time search and RL. To our knowledge, we are the first to show substantial gains in compute and sample efficiency with PRMs. Our methodology for data collection is similar to (Hwang et al., 2024; Setlur et al., 2024) (i.e., identify 'first pits' in reasoning traces), these works only use it to collect preference pairs. Beyond all of these, we also characterize which policy to use for computing advantages.
Concurrently to us, akin to the methodology in Hwang et al. (2024); Setlur et al. (2024), Kazemnejad et al. (2024) optimize the base policy 𝜋 with online RL, where the dense step-level rewards correspond to advantages 𝐴 𝜋 under the base policy 𝜋 itself. This is a special case of our setting, where the prover policy 𝜇 = 𝜋 , but as we note in Sec. 3.2, setting 𝜇 = 𝜋 in our effective reward (Eq. 5) results in exactly the same policy gradient updates as only optimizing the outcome reward. Since Kazemnejad et al. (2024) use 'on-the-fly' Monte-Carlo rollout estimation to estimate advantages, they are able to avoid estimation errors in the process reward model. Nonetheless, our theoretical result and the didactic example (both of which assume access to perfect advantage estimates) show that gains from this approach are significantly smaller than using an appropriate prover policy, which is distinct from the base policy.
## 7. Discussion and Conclusion
We began our exposition with the following question: how to define process rewards such that optimizing the base policy against process rewards ultimately improves the outcome level correctness of the final answer? Our key finding is that process rewards defined as advantages of a prover policy, distinct from the base policy improve the efficiency of exploration for steps sampled from the base policy during test-time search and online RL. This improved exploration in turn leads to discovery of better solutions, resulting in a higher accuracy on the math reasoning task. We also formally characterized the set of good prover policies as policies with step-level advantages that meaningfully contrast steps generated by the base policy, while still producing step-level advantages that are aligned with the base policy. Having trained process advantage verifiers (PAVs) to predict advantages under the prover policy, we empirically observed that test-time search against the trained PAVs improve the compute-efficiency of search by 1 . 5 -5 × , and accuracy of search by over 8% compared to running best-of𝑁 against an ORM. Next, we present one of the significant results that validate the use of dense supervision when optimizing the base policy with online RL. Specifically, we show that dense online RL with rewards from our trained PAVs, improves sample efficiency of online RL by 5 -6 × , and results in an accuracy gain of over 6%.
Limitations. Despite the promise of our results, there are several limitations to our work that present important avenues for future research. First, while we can easily compute the right hand side of our result in Theorem 3.1 to understand whether a given prover policy will improve a fixed base policy, it is unclear how to automatically design a flexible class of optimal (or very good) prover policies for a sequence of base policy iterates. Perhaps simultaneously optimizing the prover and the base policy (in a two-player game) might provide for an approach to obtain the best prover during RL, but this is largely an open question. Second, since inevitably learning a process advantage verifier (PAV) will incur fitting errors and this upper bounds peformance of our method. Fitting errors can be circumvented if our approach if we can simply run rollouts from prover policies during online RL or search to estimate advantages without training verifiers, and extending our approach to this setup is a good avenue for future work.
## Acknowledgements
The authors would like to thank Charlie Snell, Yi Su, Katherine Heller, and Virginia Smith for feedback on an earlier version of this paper. We also thank Ahmad Beirami, Sergey Levine, Victor Veitch, Idan Shenfeld, Arian Hosseini, Stephen Pfohl, Xiangyu Qi, Tianhe Yu, and Christina Baek for technical discussions. AS and CN also thank Preston Robinette, Sho Kannan, Tianze Shi, Diana Mincu, Hritik Bansal, and Liangchen Luo for code, infrastructure and data analytics support.
## References
- A. Agarwal, S. M. Kakade, J. D. Lee, and G. Mahajan. On the theory of policy gradient methods: Optimality, approximation, and distribution shift. Journal of Machine Learning Research , 22(98):1-76, 2021.
- T. Anthony, Z. Tian, and D. Barber. Thinking fast and slow with deep learning and tree search. Advances in neural information processing systems , 30, 2017.
- M. Bellemare, S. Srinivasan, G. Ostrovski, T. Schaul, D. Saxton, and R. Munos. Unifying count-based exploration and intrinsic motivation. In Advances in Neural Information Processing Systems , pages 1471-1479, 2016.
- X. Bi, D. Chen, G. Chen, S. Chen, D. Dai, C. Deng, H. Ding, K. Dong, Q. Du, Z. Fu, et al. Deepseek llm: Scaling open-source language models with longtermism. arXiv preprint arXiv:2401.02954 , 2024.
- J. D. Chang, K. Brantley, R. Ramamurthy, D. Misra, and W. Sun. Learning to generate better than your llm. arXiv preprint arXiv:2306.11816 , 2023.
3. K.-W. Chang, A. Krishnamurthy, A. Agarwal, H. Daumé III, and J. Langford. Learning to search better than your teacher. In International Conference on Machine Learning , pages 2058-2066. PMLR, 2015.
- K. Cobbe, V. Kosaraju, M. Bavarian, M. Chen, H. Jun, L. Kaiser, M. Plappert, J. Tworek, J. Hilton, R. Nakano, C. Hesse, and J. Schulman. Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 , 2021a.
- K. Cobbe, V. Kosaraju, M. Bavarian, M. Chen, H. Jun, L. Kaiser, M. Plappert, J. Tworek, J. Hilton, R. Nakano, et al. Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 , 2021b.
- M. Collins. Discriminative reranking for natural language parsing. In Proceedings of the International Conference on Machine Learning , 2000.
7. Gemma Team, T. Mesnard, C. Hardin, R. Dadashi, S. Bhupatiraju, S. Pathak, L. Sifre, M. Rivière, M. S. Kale, J. Love, et al. Gemma: Open models based on gemini research and technology. arXiv preprint arXiv:2403.08295 , 2024.
- M. Germain, K. Gregor, I. Murray, and H. Larochelle. Made: Masked autoencoder for distribution estimation. In International conference on machine learning , pages 881-889. PMLR, 2015.
- A. Havrilla, Y. Du, S. C. Raparthy , C. Nalmpantis, J. Dwivedi-Yu, M. Zhuravinskyi, E. Hambro, S. Sukhbaatar, and R. Raileanu. Teaching large language models to reason with reinforcement learning. arXiv preprint arXiv:2403.04642 , 2024.
- D. Hendrycks, C. Burns, S. Kadavath, A. Arora, S. Basart, E. Tang, D. Song, and J. Steinhardt. Measuring mathematical problem solving with the math dataset. NeurIPS , 2021.
- G. Hinton. Distilling the knowledge in a neural network. arXiv preprint arXiv:1503.02531 , 2015.
- A. Hosseini, X. Yuan, N. Malkin, A. Courville, A. Sordoni, and R. Agarwal. V-star: Training verifiers for self-taught reasoners. arXiv preprint arXiv:2402.06457 , 2024.
- H. Hwang, D. Kim, S. Kim, S. Ye, and M. Seo. Self-explore to avoid the pit: Improving the reasoning capabilities of language models with fine-grained rewards. arXiv preprint arXiv:2404.10346 , 2024.
- S. Kakade and J. Langford. Approximately optimal approximate reinforcement learning. In Proceedings of the Nineteenth International Conference on Machine Learning , pages 267-274, 2002.
- S. M. Kakade. A natural policy gradient. In Advances in neural information processing systems , volume 14. Advances in neural information processing systems, 2001a.
- S. M. Kakade. A natural policy gradient. Advances in neural information processing systems , 14, 2001b.
- A. Kazemnejad, M. Aghajohari, E. Portelance, A. Sordoni, S. Reddy, A. Courville, and N. L. Roux. Vineppo: Unlocking rl potential for llm reasoning through refined credit assignment. arXiv preprint arXiv:2410.01679 , 2024.
- H. Lightman, V. Kosaraju, Y. Burda, H. Edwards, B. Baker, T. Lee, J. Leike, J. Schulman, I. Sutskever, and K. Cobbe. Let's verify step by step. arXiv preprint arXiv:2305.20050 , 2023.
- L. Luo, Y. Liu, R. Liu, S. Phatale, H. Lara, Y. Li, L. Shu, Y. Zhu, L. Meng, J. Sun, et al. Improve mathematical reasoning in language models by automated process supervision. arXiv preprint arXiv:2406.06592 , 2024.
- Q. Ma, H. Zhou, T. Liu, J. Yuan, P. Liu, Y. You, and H. Yang. Let's reward step by step: Step-level reward model as the navigators for reasoning. arXiv preprint arXiv:2310.10080 , 2023.
- R. Nakano, J. Hilton, S. Balaji, J. Wu, L. Ouyang, C. Kim, C. Hesse, S. Jain, V. Kosaraju, W. Saunders, et al. Webgpt: Browser-assisted question-answering with human feedback. arXiv preprint arXiv:2112.09332 , 2021.
- A. Y. Ng, D. Harada, and S. Russell. Policy invariance under reward transformations: Theory and application to reward shaping. In ICML , volume 99, pages 278-287, 1999.
- L. Ouyang, J. Wu, X. Jiang, D. Almeida, C. Wainwright, P. Mishkin, C. Zhang, S. Agarwal, K. Slama, A. Ray, et al. Training language models to follow instructions with human feedback. Advances in Neural Information Processing Systems , 35:27730-27744, 2022.
- R. Rafailov, A. Sharma, E. Mitchell, S. Ermon, C. D. Manning, and C. Finn. Direct preference optimization: Your language model is secretly a reward model. arXiv preprint arXiv:2305.18290 , 2023.
- S. Ross and J. A. Bagnell. Reinforcement and imitation learning via interactive no-regret learning. arXiv preprint arXiv:1406.5979 , 2014.
- A. A. Rusu, S. G. Colmenarejo, C. Gulcehre, G. Desjardins, J. Kirkpatrick, R. Pascanu, V. Mnih, K. Kavukcuoglu, and R. Hadsell. Policy distillation. arXiv preprint arXiv:1511.06295 , 2015.
- A. Setlur, S. Garg, X. Geng, N. Garg, V. Smith, and A. Kumar. Rl on incorrect synthetic data scales the efficiency of llm math reasoning by eight-fold. arXiv preprint arXiv:2406.14532 , 2024.
- Z. Shao, P. Wang, Q. Zhu, R. Xu, J. Song, M. Zhang, Y. Li, Y. Wu, and D. Guo. Deepseekmath: Pushing the limits of mathematical reasoning in open language models. arXiv preprint arXiv:2402.03300 , 2024.
- A. Singh, J. D. Co-Reyes, R. Agarwal, A. Anand, P. Patil, P. J. Liu, J. Harrison, J. Lee, K. Xu, A. Parisi, et al. Beyond human data: Scaling self-training for problem-solving with language models. arXiv preprint arXiv:2312.06585 , 2023a.
- I. Singh, V. Blukis, A. Mousavian, A. Goyal, D. Xu, J. Tremblay, D. Fox, J. Thomason, and A. Garg. Progprompt: Generating situated robot task plans using large language models. In 2023 IEEE International Conference on Robotics and Automation (ICRA) , pages 11523-11530. IEEE, 2023b.
- C. Snell, J. Lee, K. Xu, and A. Kumar. Scaling llm test-time compute optimally can be more effective than scaling model parameters. arXiv preprint arXiv:2408.03314 , 2024.
- W. Sun, A. Venkatraman, G. J. Gordon, B. Boots, and J. A. Bagnell. Deeply aggrevated: Differentiable imitation learning for sequential prediction. In International conference on machine learning , pages 3309-3318. PMLR, 2017.
- R. S. Sutton and A. G. Barto. Reinforcement learning: An introduction . The MIT Press, second edition, 2018.
- R. S. Sutton, D. McAllester, S. Singh, and Y. Mansour. Policy gradient methods for reinforcement learning with function approximation. Advances in neural information processing systems , 12, 1999.
- F. Tajwar, A. Singh, A. Sharma, R. Rafailov, J. Schneider, T. Xie, S. Ermon, C. Finn, and A. Kumar. Preference Fine-Tuning of LLMs Should Leverage Suboptimal, On-Policy Data, 2024.
- J. Uesato, N. Kushman, R. Kumar, F. Song, N. Siegel, L. Wang, A. Creswell, G. Irving, and I. Higgins. Solving math word problems with process-and outcome-based feedback. arXiv preprint arXiv:2211.14275 , 2022.
- P. Wang, L. Li, Z. Shao, R. X. Xu, D. Dai, Y. Li, D. Chen, Y. Wu, and Z. Sui. Math-shepherd: Verify and reinforce llms step-by-step without human annotations, 2024.
- R. J. Williams. Simple statistical gradient-following algorithms for connectionist reinforcement learning. Machine learning , 8(3-4):229-256, 1992.
- Y. Wu, Z. Sun, S. Li, S. Welleck, and Y. Yang. An empirical analysis of compute-optimal inference for problem-solving with language models. arXiv preprint arXiv:2408.00724 , 2024.
- F. Yu, A. Gao, and B. Wang. Outcome-supervised verifiers for planning in mathematical reasoning. arXiv preprint arXiv:2311.09724 , 2023.
- Z. Yuan, H. Yuan, C. Li, G. Dong, C. Tan, and C. Zhou. Scaling relationship on learning mathematical reasoning with large language models. arXiv preprint arXiv:2308.01825 , 2023.
- E. Zelikman, Y. Wu, J. Mu, and N. Goodman. Star: Bootstrapping reasoning with reasoning. Advances in Neural Information Processing Systems , 35:15476-15488, 2022.
- L. Zhang, A. Hosseini, H. Bansal, M. Kazemi, A. Kumar, and R. Agarwal. Generative verifiers: Reward modeling as next-token prediction. arXiv preprint arXiv:2408.15240 , 2024.
## Appendices
## A. Additional Related Work
In this section, we highlight works from four relevant streams, expanding on discussion in Section 6. First, we look at works that train verifiers to provide outcome level feedback (Cobbe et al., 2021b; Hosseini et al., 2024; Singh et al., 2023b; Zelikman et al., 2022) on the correctness of the full response (ORM). Here, the trained ORMs are mainly used for test-time search (best-of𝑁 ). Next, we look at works that alleviate issues with sparse feedback in ORMs, and instead train process reward models (PRMs), that can perform credit assignment. PRMs are trained either through human annotations (Lightman et al., 2023; Uesato et al., 2022), or automated forms of supervision (Luo et al., 2024; Snell et al., 2024; Wang et al., 2024). While some works use PRMs and ORMs to collect data for supervised fine-tuning Hosseini et al. (2024) or offline RL Setlur et al. (2024), other works directly use them as rewards in online RL (Shao et al., 2024; Uesato et al., 2022; Wang et al., 2024). Finally, we contrast our work against papers on imitating stronger teacher policies via RL objectives that optimize potential functions of teacher policies.
Outcome reward models. ORMs are verifiers (Cobbe et al., 2021b; Uesato et al., 2022) commonly used to improve the test-time performance using best-of𝑁 , where we generate multiple candidate solutions from the base policy (LLM), rank them using the ORM, and pick the best one. ORMs are trained to assess correctness of a solution either using binary classification (Cobbe et al., 2021a; Yu et al., 2023), preference optimization using DPO (Hosseini et al., 2024), or next-token prediction (Zhang et al., 2024). Furthermore, prior works train LLMs on self-generated data using ground-truth outcome rewards (Rex), either via supervised fine-tuning (Singh et al., 2023a; Yuan et al., 2023; Zelikman et al., 2022), or online RL (Bi et al., 2024). In contrast to these approaches, our work focuses on process reward models (PRMs) for improving performance with beam-search at test time as well as online RL where we maximize the effective reward in Eq. 5 which linearly combines both Rex (outcome supervision) and process supervision in the form of advantages 𝐴 𝜇 under a prover policy 𝜇 .
PRMs and credit assignment. Several works focus on training step-level PRMs on math reasoning tasks, either using human labels (Lightman et al., 2023) or automated LLM-generated data to estimate value functions 𝑄 𝜋 (Luo et al., 2024; Wang et al., 2024). Our work also focus on automated data collection for PRMs but empirically argues for using the advantage function 𝐴 𝜇 as step-level rewards along with 𝑄 𝜋 , with a conceptual explanation in Section 3.1. Several prior works have explored step-level search algorithms with PRMs, such as beam search (Snell et al., 2024), heuristic greedy search (Ma et al., 2023), and reward-balanced tree search (Wu et al., 2024). Hwang et al. (2024); Setlur et al. (2024) use advantages to identify the 'first pit' in an incorrect reasoning trace. Specifically, they collect data by computing advantages at each step using Monte Carlo rollouts. Then in an incorrect trace, they identify the step with the least advantage, and use the prefix of that step to construct preference pairs for offline direct preference optimization (Rafailov et al., 2023). In contrast, our work computes advantages under a prover policy, that we formally characterize, and use the computed advantages for improving test-time search and efficiency of online reinforcement learning.
Online RL for math reasoning. Once we have a trained outcome or process verifiers, it is natural update a policy by optimizing it against the learned signal, similar to how learned reward models are optimized in RLHF (Ouyang et al., 2022). In the context of math reasoning, Havrilla et al. (2024); Shao et al. (2024); Uesato et al. (2022) trained policies with RL, experimenting with both dense and sparse
Planted sub-sequence 𝒚 ⋆ : [3 6 0 3 5]
```
Samples from policy corresponding to 𝑦 = 15
```
Figure 9 | Pictorial description of our planted sub-sequence didactic setup : An example showing five samples drawn i.i.d. from a very strong policy ( 𝛾 = 100), and a relatively weaker ( 𝛾 = 15) policy in our didactic setup.
rewards. In all three works, the gains observed by using PRMs that predict step-level correctness (similar to Lightman et al. (2023)) is quite small, compared to simply using trained ORMs, or the ground-truth outcome supervision Rex. In fact, Havrilla et al. (2024) states that the only algorithm that does well is a form of expert iteration (Anthony et al., 2017), which does not inhibit exploration as severely as some other approaches they compare with. Our work presents one of the first results, where trained PRMs, used in conjunction with the outcome rewards during online RL, result in policies with substantially higher ( + 6%) performance, than the one trained only with outcome supervision. Our results also indicate a 5 -6 × sample efficiency boost for online RL, with our trained PAVs.
Connections to imitation learning through RL. The idea of mixing potential functions from different policies 𝜇 and 𝜋 , in order to improve upon a sub-optimal expert 𝜇 appears in Chang et al. (2015), but this work considers the structured prediction problem which is vastly different from our setting. Related to this, is the work by Chang et al. (2023), which uses a 'guide' policy to rollout from prefixes generated by a base policy. The base policy can now imitate the guide by cloning those rollouts, and eventually surpass. Our work also uses a prover policy which can complete rollouts from states where the base policy fails. But, we also show that weak provers in many cases are able to improve the base policy, or search over its responses, better than a stronger prover policy. We tie this observation to the insight that the main goal of the prover policy is to distinguish steps taken by the base policy, as measured by advantages under the prover. Thus, we do not require the prover policy to be something better than the base policy, which is a key distinction with Chang et al. (2023).
## B. Didactic Analysis
We consider sequences of length 10 from a 15-token vocabulary V B { 1 , 2 , . . . , 14 } , where the end-ofsequence token is given by 14, and all tokens following the end-of-sequence token (including it) are masked. Given an unknown planted sequence 𝒚 ★ (in Fig. 9), we train a policy 𝜋 with policy gradient, where the outcome reward we wish to optimize is terminal and sparse, i.e. , for 𝒚 ∼ 𝜋 we have 𝑟 ( 𝒚 , 𝒚 ★ ) = 1 if and only if 𝒚 ★ appears in 𝒚 , and 0 otherwise (Fig. 9). The policy 𝜋 in our experiments is represented by a multi-layer neural network, similar to the MADE architecture (Germain et al., 2015). The prover policy 𝜇 is parameterized by a scalar 𝛾 > 0. In particular, at any state 𝒔 , where the last 𝑘 tokens leading up to 𝒔 match first 𝑘 tokens of 𝒚 ★ , then:
$$\mu ( y _ { k + 1 } ^ { ^ { * } } | s ) \varpropto c \gamma ,$$
and uniform on all other tokens. Thus, as 𝛾 increases, the performance of 𝜇 improves and → 1 as 𝛾 →∞ . For our experiments, we assume (almost) oracle access to ground-truth advantage and 𝑄 -values, thus
mitigating any confounding issues due to usage of a learned verifier. We are able to approximate exact 𝑄 -values very accurately by using Monte Carlo estimates with large > 100 rollouts. With the goal of optimizing the terminal reward 𝑟 ( 𝒚 , 𝒚 ★ ) , we optimize 𝜋 with two types of rewards: (i) only the outcome reward 𝑟 ( 𝒚 , 𝒚 ★ ) , which is equivalent to using only 𝑄 𝜋 as step-level rewards; and (ii) using the effective reward: 𝑄 𝜋 + 𝛼𝐴 𝜇 as the step-level reward.
Training details. We use effective rewards with 𝛼 = 1, and use the gradient in Eq. 5 to update the policy via policy gradient iterations. For the ORM runs, where we only use the outcome reward 𝑟 ( 𝒚 , 𝒚 ★ ) , the policy gradient is equivalent to the case where 𝛼 = 0 in Eq. 5. We train for 10,000 iterations in both cases, with a batch size of 64, and a constant learning rate of 1 𝑒 -3 for the Adam optimizer. The RL runs are initialized with a supervised finetuned policy. For this we take a randomly initialized network, based on the MADE architecture (Germain et al., 2015), with 3 layers, and 128 hidden units in each. Then we train it with supervised next-token prediction loss for 50 iterations on a dataset of 3200 samples from a weak policy ( 𝛾 = 5 . 0 ) . The batch size for the SFT training is also set to 64. For evaluating Pass @ 𝑁 performance, we either sample 𝑁 independent trajectories (temperature 1.0) from the base policy trained using effective rewards, or only 𝑄 𝜋 . We also evaluate Pass @ 𝑁 for the SFT policy for comparison.
## C. Additional: Experiments on Test-time Search with PAVs
Implementation details. For our experiments in Sec. 4, we use three pretrained models: Gemma 2B, 9B and 27B. We finetune each of these on the MATH (Hendrycks et al., 2021) dataset. The finetuning is done for 5000 iterations, with a batchsize of 32, and a maximum learning rate of 5 𝑒 -6 for 2B, 9B and 5 𝑒 -7 for the 27B models. We trained the policies using the Adam optimizer, with a linear warm up and cosine decay learning rate schedule. The linear warm up is done for the first 500 iterations. For the base policies, we choose the SFT checkpoints with the best accuracy on a holdout validation set of the MATH dataset. Given the SFT checkpoints, we next train PAVs using the procedure in Sec. 4.2. We do this for a class of provers, which include the base policies themselves. As we discuss in Sec. 4, the prover class also includes the best-of𝐾 policy for 𝐾 in { 2 , 4 , 8 , 16 , 32 } .
We use the hold out validation set to ascertain the value of 𝛼 in the effective reward. For each base policy we run beam search with a beam size of 16 on this hold out validation set, and using the base policy itself as a prover, we evaluate the value of 𝛼 that works best in the effective reward. We find that 𝛼 = 0 . 5 worked best for Gemma 2B and 9B base policies, while a lower value of 𝛼 = 0 . 2 was optimal for Gemma 27B. To tune 𝛼 we ran a grid search over the range [ 0 . 0 , 1 . 0 ] , evaluating at an interval of 0 . 1. We observe that the choice of 𝛼 is a relatively robust one, since for all three base policies, we saw improvements (over only 𝑄 𝜋 as the reward) for values in the range of [ 0 . 2 , 0 . 6 ] . Having a separate value of 𝛼 for each base policy, we use the same value in the effective reward given by any choice of the prover policy that is used for that base policy. Next, we present an experiment that compares the predictive power of effective reward vs. just 𝑄 𝜋 at initial states of a rollout under the base policy 𝜋 , when either is used to predict the final outcome given by Rex.
Experiment: Is the effective reward able to predict the final outcome better than 𝑄 𝜋 ? In Fig. 10, we describe an experiment where for both the effective reward 𝑄 𝜋 + 𝛼𝐴 𝜇 (PAV) and just 𝑄 𝜋 (PQV), we compute the error of the classifier that makes a prediction on the final outcome by thresholding on either reward value at each step of the rollout. This threshold is computed using a validation set, and is separate for each step and reward combination. The figure tells us that the outcome prediction error drops for both rewards as the base policy is rolled out more, but clearly the effective reward dominates 𝑄 𝜋 (PQV)
across all steps. Thus, the effective reward is a more informative signal (lower classification error) for the problem of predicting the success of a partial rollout, especially in the earlier steps of the rollout. This helps to explain the better performance of beam search with a finite capacity beam that re-ranks partial rollouts with the effective reward. For this experiment, we use the Gemma 9B SFT policy as the base policy and the best-of-4 policy corresponding to the same SFT policy as the prover.
Figure 10 | Effective rewards at any step are able to predict the outcome rewards at the final step, better than 𝑸 𝝅 : For both the effective reward 𝑄 𝜋 + 𝛼𝐴 𝜇 and just 𝑄 𝜋 , we compute the error of the classifier that makes a prediction on the final outcome by thresholding on either reward value at each step of the rollout. This threshold is computed using a validation set, and is separate for each step and reward combination. The figure tells us that the outcome prediction error drops for both rewards, as the base policy is rolled out more, but compared to 𝑄 𝜋 at an intermediate step, the effective reward 𝑄 𝜋 + 𝛼𝐴 𝜇 at an intermediate step is able to reliably predict the final outcome level correctness of the future rollout under the base policy 𝜋 .
<details>
<summary>Image 10 Details</summary>
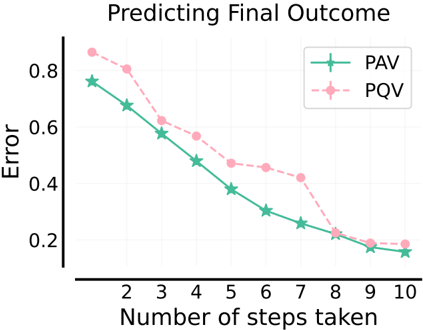
### Visual Description
## Line Chart: Predicting Final Outcome
### Overview
The image is a line chart comparing the error rates of two methods, PAV and PQV, in predicting a final outcome, as the number of steps taken increases. Both methods show a decreasing error rate as more steps are taken.
### Components/Axes
* **Title:** Predicting Final Outcome
* **X-axis:** Number of steps taken, with values ranging from 2 to 10 in increments of 1.
* **Y-axis:** Error, with values ranging from 0.2 to 0.8 in increments of 0.2.
* **Legend:** Located in the top-right corner.
* PAV (green line with star markers)
* PQV (pink dashed line with circle markers)
### Detailed Analysis
* **PAV (green line with star markers):**
* Trend: The error rate decreases as the number of steps increases.
* Data Points:
* 2 steps: approximately 0.77
* 3 steps: approximately 0.68
* 4 steps: approximately 0.58
* 5 steps: approximately 0.48
* 6 steps: approximately 0.38
* 7 steps: approximately 0.27
* 8 steps: approximately 0.22
* 9 steps: approximately 0.17
* 10 steps: approximately 0.15
* **PQV (pink dashed line with circle markers):**
* Trend: The error rate decreases as the number of steps increases, but the decrease slows down after 7 steps.
* Data Points:
* 2 steps: approximately 0.87
* 3 steps: approximately 0.81
* 4 steps: approximately 0.63
* 5 steps: approximately 0.57
* 6 steps: approximately 0.48
* 7 steps: approximately 0.45
* 8 steps: approximately 0.42
* 9 steps: approximately 0.20
* 10 steps: approximately 0.19
### Key Observations
* Both PAV and PQV show a decrease in error as the number of steps increases.
* PAV consistently has a lower error rate than PQV for the same number of steps.
* The error reduction for PQV slows down significantly after 7 steps.
* Both methods appear to converge to a similar error rate as the number of steps approaches 10.
### Interpretation
The chart suggests that both PAV and PQV methods become more accurate in predicting the final outcome as they take more steps. However, PAV appears to be more efficient, achieving lower error rates with fewer steps compared to PQV. The diminishing returns observed in PQV after 7 steps indicate that increasing the number of steps beyond this point may not significantly improve its accuracy. The convergence of both methods at higher step counts suggests a potential limit to the accuracy achievable with either method.
</details>
## D. Details on Collecting Data and Training PAVs
In Fig. 6(b) in Sec. 4.2, our seed rollouts are i.i.d. sampled from 𝜋 , but prior works (Hwang et al., 2024; Luo et al., 2024; Setlur et al., 2024) employed a 'first pit' strategy for coverage. Here, some initial sampling budget is spent to identify 'high value' states where 𝑄 𝜋 is larger than a threshold. Then, for any incorrect sample from these high value states greater budget is spent to estimate the first step (first pit) with 𝑄 𝜋 = 0. All prefixes (and their estimated 𝑄 -values) until the first pit are then added to the training data. In Fig. 11, we compare beam search using PAVs trained using data from the first pit strategy, and the random sampling strategy. Both of them use the best value of 𝑛 mc / 𝑛 cov from Fig. 6(b) for every dataset size. We find the first pit strategy to be better than random, especially when the number of seed rollouts are limited. Once we get coverage over such pits, we sample a large number of partial rollouts conditioned on each prefix until the first pit. This is used to compute the Monte Carlo estimate of 𝑄 values more accurately on the path to the first pit. Each prefix and estimated 𝑄 value pair is then added to the dataset used to train PAVs.
Training details. All PAVs used in this work are trained by taking the Gemma 9B pretrained checkpoint and finetuning it on the data collected from the above strategy. The data collection uses first pit strategy for better coverage over pits in the seed rollouts. Based on findings in Fig. 6(b), we use a high value of 𝑛 mc = 20 to estimate the 𝑄 -values accurately for each step in the seed rollout. For each base policy,
in total, we collect a dataset of over 300 , 000 (prefix, ˆ 𝑄 𝜋 -value) pairs. Here, ˆ 𝑄 𝜋 is the Monte Carlo estimate for the 𝑄 -value at the prefix, under the policy 𝜋 . on which we finetune the Gemma 9B model with cross-entropy loss. Since the distribution of values for ˆ 𝑄 𝜋 can be skewed, we split the range of ˆ 𝑄 𝜋 -values into two buckets, based on which we also partition the training data. The first bucket is the set of all prefixes with ˆ 𝑄 𝜋 < 0 . 5 and the second is the set of all prefixes with ˆ 𝑄 𝜋 ≥ 0 . 5. Then, we use class-balanced sampling over these buckets to finetune the pretrained model for 20000 training iterations, using a batch size of 32. We use an Adam optimizer with a maximum learning rate of 5 𝑒 -7. We use a linear warm up (till 2000 steps), followed by a cosine decay learning rate schedule to train the models. Since a pretrained LLM would output a matrix of logits (vocabulary size × sequence length) we fix a token as the 'scoring token' to be the end of the sequence / prefix that needs to be scored. The logits of this scoring token are then used to determine the prediction for the LLM being trained.
Once we have models that predict the 𝑄 𝜋 for a base policy 𝜋 , we compute the 𝑄 -value under the BoK policy corresponding to 𝜋 , by setting: 𝑄 BoK ( 𝜋 ) ( 𝒔 , 𝑎 ) = 1 - ( 1 -𝑄 𝜋 ( 𝒔 , 𝑎 )) 𝐾 . Next, given the 𝑄 -values we for 𝜋 , and their corresponding best-of𝐾 policies, we can compute any effective reward in Eq. 5, using the definition of advantage value of a step in Eq. 2.
Figure 11 | First pit strategy from Luo et al. (2024); Setlur et al. (2024) : We compare the beam search performance (with beam size 128) for a PAV trained on data collected using two types of seed rollouts. For the seed rollouts, we either randomly sample from the distribution of state action pairs induced by the base policy. Or we improve coverage particularly by using the 'first pit' strategy of identifying the first state with low 𝑄 values on a partial rollout that starts from a high 𝑄 -value state and ends with an outcome reward of 0, i.e., 𝑄 value is 0.
<details>
<summary>Image 11 Details</summary>
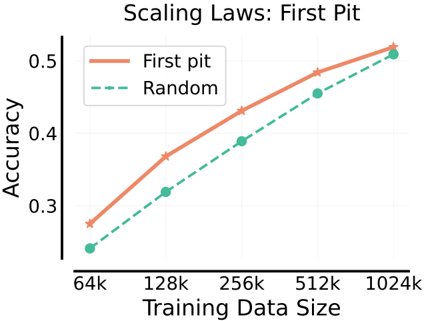
### Visual Description
## Line Chart: Scaling Laws: First Pit
### Overview
The image is a line chart comparing the accuracy of two methods, "First pit" and "Random," against the size of the training data. The x-axis represents the training data size, ranging from 64k to 1024k, while the y-axis represents accuracy, ranging from 0.3 to 0.5.
### Components/Axes
* **Title:** Scaling Laws: First Pit
* **X-axis Title:** Training Data Size
* **X-axis Markers:** 64k, 128k, 256k, 512k, 1024k
* **Y-axis Title:** Accuracy
* **Y-axis Markers:** 0.3, 0.4, 0.5
* **Legend:** Located in the top-left corner.
* **First pit:** Represented by a solid coral line with star markers.
* **Random:** Represented by a dashed teal line with circle markers.
### Detailed Analysis
* **First pit:** The coral line with star markers.
* At 64k training data size, the accuracy is approximately 0.27.
* At 128k training data size, the accuracy is approximately 0.37.
* At 256k training data size, the accuracy is approximately 0.43.
* At 512k training data size, the accuracy is approximately 0.49.
* At 1024k training data size, the accuracy is approximately 0.52.
* The trend is upward, indicating increasing accuracy with larger training data sizes.
* **Random:** The dashed teal line with circle markers.
* At 64k training data size, the accuracy is approximately 0.24.
* At 128k training data size, the accuracy is approximately 0.32.
* At 256k training data size, the accuracy is approximately 0.39.
* At 512k training data size, the accuracy is approximately 0.46.
* At 1024k training data size, the accuracy is approximately 0.51.
* The trend is upward, indicating increasing accuracy with larger training data sizes.
### Key Observations
* Both methods, "First pit" and "Random," show an increase in accuracy as the training data size increases.
* The "First pit" method consistently outperforms the "Random" method across all training data sizes.
* The gap in accuracy between the two methods appears to narrow slightly as the training data size increases, but "First pit" maintains a higher accuracy.
* Both lines appear to be approaching an asymptote as the training data size increases to 1024k.
### Interpretation
The data suggests that the "First pit" method is more effective than the "Random" method for this particular task, as it achieves higher accuracy across all tested training data sizes. The positive correlation between training data size and accuracy for both methods indicates that increasing the amount of training data generally improves performance. The narrowing gap between the two methods at larger training data sizes could suggest that the "Random" method benefits more from increased data, or that both methods are approaching a performance ceiling. Further investigation with even larger training datasets would be needed to confirm this.
</details>
## E. Additional: Experiments on RL Training with PAVs
Training details. As discussed in Section 5, the initialization for RL training is the RFT (rejection finetuned) checkpoint for the corresponding base policies. More specifically, we consider two base policies Gemma 2B SFT, and Gemma 9B SFT, where the RL training is initialized with the policy obtained by further optimizing the base policy via rejection finetuning (RFT) Yuan et al. (2023). This is done to improve coverage over states and actions during the initial iterations of RL training. For rejection finetuning we train the SFT model (base policy) on all correct trajectories sampled when collecting seed rollouts for training PAVs (that predict the advantage of the same base policy). The training details for RFT remain same as SFT and are detailed in Appendix C. We use the REINFORCE (Sutton et al., 1999)
algorithm to improve the base policy. The RL training is run for 10000 iterations for the 2B model, and for 5000 iterations for the 9B model. For both we use the Adam optimizer with a learning rate of 1e-7, and a batchsize of 32. The maximum response length is set to 512. For both we used a learning rate schedule with a linear warm up for 10% of the total training iterations, followed by a cosine decay. The implementation of our policy gradient algorithm also uses a token-level value function that is initialized to be the base policy itself, and is trained with a square loss. The value function is only used as a baseline during RL training, i.e., at any state 𝒔 it is only predicting 𝔼 𝑎 ∼ 𝜋 (·| 𝒔 ) 𝑄 𝜋 ( 𝒔 , 𝑎 ) + 𝛼𝐴 𝜇 ( 𝒔 , 𝑎 ) .
Most importantly, we use a validation set to identify a good choice of 𝛼 in the effective reward (in Eq. 5). For Gemma 2B this value is 5 . 0 and for the 9B policy 𝛼 = 3 . 0 works best. Similar to the choice of 𝛼 for test-time search, we find that most values of 𝛼 in the range of 0 . 5 to 6 . 0 improved performance over ORM-RL, to different degrees. Both policies are also optimized with KL regularization, against the initial iterate of the RL policy, where the strength of the KL penalty is set to 0.001 for both.
## F. Theoretical Analysis: Complementary Provers Amplify Base Policy Improvement
In this section, we present the proofs for our theoretical results in the main paper (Sec. 3.4). We begin by describing some notation we use in our proofs, the natural policy gradient algorithm we use for the policy update, followed by the proof for Theorem 3.1. We also present a simple application of this result in Proposition F.1. Our results in this section are in the tabular setting, with softmax parameterization of the policies. Note that for the deterministic Markov decision process induced by the LLM, we are indeed in a tabular setting, where the set of states and actions is discrete, but large and grows exponentially in sequence length.
Notation and preliminaries. We use 𝑑 𝜋 ℎ , 𝑑 𝜇 ℎ to denote the distribution over states 𝒔 ℎ at time step ℎ , starting from the initial state distribution given by the empirical distribution over the questions in the dataset D , and following the base policy 𝜋 , or prover policy 𝜇 respectively. The term 𝑑 𝜋 𝒔 denotes the distribution over future states, starting from state 𝒔 , and following policy 𝜋 . Here, 𝒔 can be a state at any time ℎ ∈ [ 0 , . . . , 𝐻 ] . For convenience, we overload the notation 𝑑 𝜋 𝒔 (the distribution over future states induced by a policy starting from state 𝒔 ), and use 𝑑 𝜋 𝜌 to denote the mixture distribution over 𝑑 𝜋 𝒔 starting from a random state 𝒔 drawn from 𝒔 ∼ 𝜌 , and following policy 𝜋 .
The term 𝑄 𝜋 ( 𝒔 ℎ , 𝑎 ℎ ) refers to the value of state-action pair 𝒔 ℎ , 𝑎 ℎ , i.e. , the expected return in the future, starting the policy from state 𝒔 ℎ and taking action 𝑎ℎ :
$$Q ^ { \pi } ( s _ { h } , a _ { h } ) \colon = \mathbb { E } _ { a _ { h } , \dots , a _ { H } \sim \pi ( \cdot | s _ { h } , a _ { h } ) } \left [ R e x \left ( ( a _ { 1 } , \dots , a _ { H } ) , y _ { x } ^ { ^ { * } } \right ) \right ] .$$
Note that 𝒚 ★ 𝒙 is known on the dataset D , and state 𝒔 ℎ contains the question 𝒙 as part of it. Similarly , we can define the value function 𝑉 𝜋 ( 𝒔 ℎ ) of a state 𝒔 ℎ as:
$$V ^ { \pi } ( s _ { h } ) \coloneqq \mathbb { E } _ { a _ { h + 1 } \sim \pi ( \cdot | s _ { h } ) } Q ^ { \pi } ( s _ { h } , a _ { h } ) .$$
The advantage function is then given by:
$$A ^ { \pi } ( s _ { h } , a _ { h } ) \colon = Q ^ { \pi } ( s _ { h } , a _ { h } ) - V ^ { \pi } ( s _ { h } ) .$$
The policy gradient algorithm we use to update the base policy iteratively is natural policy gradient (Kakade, 2001b), and we use 𝜋𝑡 to refer to the base policy iterate at time 𝑡 of this iterative algorithm.
Finally, we use S to denote the set of all states (prefixes) and A for the set of all actions (steps) that the LLM can take at any state.
Parameterization of the base policy. We adopt the softmax parameterization for the base policy:
$$\pi _ { \theta } ( a | s _ { h } ) = \frac { \exp ( \theta _ { s _ { h } , a } ) } { \sum _ { a ^ { \prime } \in \mathcal { A } } \exp ( \theta _ { s _ { h } , a ^ { \prime } } ) } .$$
Here 𝜽𝒔 ℎ ,𝑎 ∈ 𝚯 ⊆ ℝ 𝑑 controls the probability of taking action 𝑎 at state 𝒔 ℎ . The full set of parameters across all states and actions is denoted by 𝜽 ∈ ℝ 𝑑 ×|S|×|A| . Whenever clear from context, we overload the notation 𝜋𝑡 to denote both the policy at iterate 𝑡 , i.e. , 𝜋 𝜽 𝑡 and the parameter 𝜽 𝑡 itself. E.g. , the gradient operator ∇ 𝜋𝑡 [·] is referring to ∇ 𝜽 𝑡 [·] .
Defining policy improvement. Let 𝜌 be a distribution over all states { 𝒔 ℎ : ℎ ∈ [ 0 , 1 , . . . , 𝐻 ]} , then 𝔼 𝒔 ∼ 𝜌 𝑉 𝜋 ( 𝒔 ) , and 𝔼 𝒔 ∼ 𝜌 𝑉 𝜇 ( 𝒔 ) give us the expected value functions over states across time steps, measured under 𝜌 , for policies 𝜋 and 𝜇 respectively. We assume that 𝑑 𝜋 ℎ and 𝑑 𝜇 ℎ are both absolutely continuous with respect to 𝜌 , and use the expected value function over 𝜌 as the quantity we track before and after a policy update. A positive change in 𝔼 𝒔 ∼ 𝜌 𝑉 𝜋 ( 𝒔 ) implies a net positive improvement in the base policy. Thus, progress is made at each update of the policy when:
$$\mathbb { E } _ { s \sim \rho } V ^ { \pi _ { t + 1 } } ( { s } ) - \mathbb { E } _ { s \sim \rho } V ^ { \pi _ { t } } ( { s } ) > 0 .$$
## F.1. Natural Policy Gradient
The natural policy gradient (NPG) algorithm (Kakade, 2001a) defines a Fisher information matrix (induced by the policy), and performs gradient updates in the geometry induced by the following matrix:
$$\begin{array} { r } { F _ { \rho } ( \pi ) = \mathbb { E } _ { s \sim d _ { \rho } ^ { \pi } } \mathbb { E } _ { a \sim \pi ( \cdot | s ) } \left [ \nabla _ { \pi } \log \pi ( a | s ) \left ( \nabla _ { \pi } \log \pi ( a | s ) \right ) ^ { \top } \right ] } \end{array}$$
Typically, the NPG update does gradient updates on the objective ℓ ORM -RL in Eq. 3, but in our case, the objective of interest is ℓ PAV -RL in Eq. 4, and thus the natural gradient is given by:
$$\pi _ { t + 1 } = \pi _ { t } + \gamma \cdot F _ { \rho } ( \pi ^ { t } ) ^ { \dagger } \left ( \nabla _ { \pi } \ell _ { P A V - R L } ( \pi ) \right | _ { \pi = \pi _ { t } } ,$$
where 𝑀 † denotes the Moore-Penrose pseudoinverse of the matrix 𝑀 . We restrict to using the initial state distribution 𝜌 in our update rule, i.e. , we restrict attention to states 𝒔 reachable from 𝜌 , since 𝜌 governs the performance measure of interest when evaluating the expected value of a policy. Thus, without loss of generality, we can exclude states that are not reachable under 𝜌 . Specifically, we restrict the MDP to the set: { 𝒔 ℎ : ∃ 𝜋 such that 𝑑 𝜋 𝜌 ( 𝒔 ℎ ) > 0 , ℎ ∈ [ 0 , . . . , 𝐻 ]} . The scalar 𝛾 > 0 determines the learning rate.
## F.2. Useful Lemmas
Lemma F.1. [The performance difference lemma; (Kakade and Langford, 2002)] For all policies 𝜋, 𝜋 ′ and states 𝑠 0 ,
$$\begin{array} { r l r } { V ^ { \pi } ( s ) - V ^ { \pi ^ { \prime } } ( s ) } & { = } & { \mathbb { E } _ { s _ { h } \sim d _ { s } ^ { \pi } } \mathbb { E } _ { a _ { h } \sim \pi ( \cdot | s _ { h } ) } \left [ A ^ { \pi ^ { \prime } } ( s _ { h } , a _ { h } ) \right ] . } \end{array}$$
Proof. See proof of Lemma 6.1 in Kakade and Langford (2002).
□
Lemma F.2 (Natural policy gradient update) . For the natural policy gradient in Eq. 12, the corresponding policy update is given by:
$$\pi ^ { t + 1 } ( a \, | \, s ) = \pi ^ { t } ( a \, | \, s ) \cdot \frac { \exp \left ( \gamma \cdot ( Q ^ { t } ( s , a ) + \alpha \cdot A ^ { \mu } ( s , a ) ) \right ) } { Z ^ { t } ( s ) } ,$$
<!-- formula-not-decoded -->
Proof. Weuse arguments similar to the proof of Lemma 15 in Agarwal et al. (2021), with the key difference of separately accounting for the term 𝐴 𝜇 ( 𝒔 , 𝑎 ) in the effective reward. For the sake of completeness we reproduce some of the derivation, accounting for the 𝐴 𝜇 term in the process. We follow compatible function approximation in Sutton et al. (1999) and Kakade (2001a). For a vector 𝒘 ∈ ℝ 𝑑 ×|S||A| , we define the error function
$$L ^ { \pi } ( w ) = \mathbb { E } _ { s \sim d _ { \rho } ^ { \pi } } , \, \mathbb { E } _ { a \sim \pi ( \cdot | s ) } \left [ w ^ { \top } \nabla _ { \pi } \log \pi ( \cdot \, | \, s ) - \left ( A ^ { \pi } ( s , a ) + \alpha A ^ { \mu } ( s , a ) - \alpha \mathbb { E } _ { a \sim \pi _ { t } ( \cdot | s ) } A ^ { \mu } ( s , a ) \right ) \right ] ^ { 2 } .$$
Let 𝒘 ★ be the minimizer of 𝐿 𝜋 ( 𝒘 ) with the smallest ℓ 2 norm. Then by definition of Moore-Penrose pseudoinverse:
$$w ^ { ^ { * } } & = F _ { \rho } ( \pi ) ^ { \dagger } \mathbb { E } _ { s \sim d _ { \rho } ^ { \pi } , a \sim \pi ( a | s ) } \left [ \nabla _ { \pi } \log \pi ( a | s ) \left ( A ^ { \pi } ( s , a ) + \alpha A ^ { \mu } ( s , a ) - \alpha \mathbb { E } _ { a \sim \pi _ { t } ( \cdot | s ) } A ^ { \mu } ( s , a ) \right ] \\ & = F _ { \rho } ( \pi ) ^ { \dagger } \nabla _ { \pi } \ell _ { \text {PAV-RL} } ( \pi ) .$$
In other words, 𝒘 ★ is precisely proportional to the NPG update direction. Note further that for the Softmax policy parameterization, we have:
$$w ^ { \top } \nabla \log \pi ( a | s ) = w _ { s , a } - \sum _ { a ^ { \prime } \in \mathcal { A } } w _ { s , a ^ { \prime } } \pi ( a ^ { \prime } | s ) .$$
Since ˝ 𝑎 ∈A 𝜋 ( 𝑎 | 𝑠 ) 𝐴 𝜋 ( 𝑠, 𝑎 ) = 0, this immediately yields that:
$$L ^ { \pi } ( A ^ { \pi } ( s , a ) + \alpha A ^ { \mu } ( s , a ) ) = 0 .$$
However, this might not be the unique minimizer of 𝐿 𝜋 , which is problematic since 𝒘 ★ ( 𝜋 ) as defined in terms of the Moore-Penrose pseudoinverse is formally the smallest norm solution to the least-squares problem, which 𝐴 𝜋 + 𝛼𝐴 𝜇 may not be. However, given any vector 𝒗 ∈ ℝ | S | × | A | , let us consider solutions of the form 𝐴 𝜋 + 𝛼𝐴 𝜇 + 𝒗 . Due to the form of the derivatives of the policy for the softmax parameterization, we have for any state 𝒔 , 𝑎 such that 𝒔 is reachable under 𝜌 ,
$$v ^ { \top } \nabla _ { \pi } \log \pi ( a | s ) = \sum _ { a ^ { \prime } \in \mathcal { A } } ( v _ { s , a ^ { \prime } } 1 [ a = a ^ { \prime } ] - v _ { s , a ^ { \prime } } \pi ( a ^ { \prime } | s ) ) = v _ { s , a } - \sum _ { a ^ { \prime } \in \mathcal { A } } v _ { s , a ^ { \prime } } \pi ( a ^ { \prime } | s ) .$$
This is because 𝜋 is a stochastic policy with 𝜋 ( 𝑎 | 𝒔 ) > 0 for all actions 𝑎 in each state 𝒔 , so that if a state is reachable under 𝜌 , it will also be reachable using 𝜋 , and hence the zero derivative conditions apply at each reachable state. For 𝐴 𝜋 + 𝛼𝐴 𝜇 + 𝒗 to minimize 𝐿 𝜋 , we would like 𝑣 ⊤ ∇ 𝜋 log 𝜋 ( 𝑎 | 𝒔 ) = 0 for all 𝒔 , 𝑎 so that 𝒗𝒔 ,𝑎 is independent of the action and can be written as a constant 𝑐 𝒔 for each 𝒔 by the above equality. Hence, the minimizer of 𝐿 𝜋 ( 𝒘 ) is determined up to a state-dependent offset, and
$$F _ { \rho } ( \theta ) ^ { \dagger } \nabla _ { \pi } \ell _ { P A V - R L } ( \pi ) = Q ^ { \pi } + \alpha A ^ { \mu } + v ,$$
where 𝒗𝒔 ,𝑎 = 𝑐 𝒔 for some 𝑐 𝒔 ∈ ℝ for each state 𝒔 and action 𝑎 . Finally, we observe that this yields the updates
$$\theta _ { t + 1 } = \theta ^ { t } + \gamma ( Q ^ { \pi } + \alpha A ^ { \mu } + v ) \quad a n d \quad \pi _ { t + 1 } ( a | s ) = \pi _ { t } ( a | s ) \frac { \exp ( \gamma Q ^ { t } ( s , a ) + \gamma \alpha A ^ { \mu } ( s , a ) ) } { Z ^ { t } ( s ) } .$$
Owing to the normalization factor 𝑍 𝑡 ( 𝒔 ) , the state dependent offsets cancel in the updates for 𝜋 , which yields the statement of the lemma. □
## F.3. Proof of Theorem 3.1
Proof. For some notational convenience, we use 𝑉 𝑡 , 𝑉 𝑡 + 1 , to denote the value functions 𝑉 𝜋𝑡 , 𝑉 𝜋𝑡 + 1 for policies at 𝜋𝑡 , 𝜋𝑡 + 1 at time 𝑡 and 𝑡 + 1 respectively. Similarly, we use 𝐴 𝑡 , 𝐴 𝑡 + 1 for 𝐴 𝜋𝑡 , 𝐴 𝜋𝑡 + 1 respectively. For the distribution over states 𝑑 𝜋𝑡 + 1 𝜌 induced by the policy 𝜋𝑡 + 1 , starting from an initial distribution of states given by 𝜌 , we simplify the notation and use 𝑑 𝑡 + 1 𝜌 . Similarly we use 𝑑 𝑡 𝜌 for 𝑑 𝜋𝑡 𝜌 .
Next, for simplicity we set 𝛼 = 1 in the natural policy gradient update in Lemma F.2. It is easy to see that the lower bound result we show holds for any value of 𝛼 > 0, and the term in the lower bound scales linearly with 𝛼 . Note, that this is not a free variable, and 𝛼 has to be 𝑂 ( 1 ) , since as we increase the value of 𝛼 we would have to correspondingly reduce 𝛾 for our result to hold. For now, we fix 𝛼 = 1.
From the policy difference Lemma F.1, we can write:
$$\mathbb { E } _ { s \sim \rho } V ^ { t + 1 } ( s ) - \mathbb { E } _ { s \sim \rho } V ^ { t } ( s ) = \mathbb { E } _ { s \sim d _ { \rho } ^ { t + 1 } } \mathbb { E } _ { a \sim \pi ^ { t + 1 } ( a | s ) } \left [ A ^ { t } ( s , a ) \right ]$$
Next, from the natural policy gradient update in Lemma F.2, we can write 𝐴 𝑡 + 1 ( 𝒔 , 𝑎 ) as:
$$A ^ { t } ( \boldsymbol s , a ) = \frac { 1 } { \gamma } \cdot \log \left ( \frac { \pi ^ { t + 1 } ( a | \boldsymbol s ) \cdot Z ^ { t } ( \boldsymbol s , a ) } { \pi ^ { t } ( a | \boldsymbol s ) } \right ) - A ^ { \mu } ( \boldsymbol s , a )$$
Substituting Eq. 18 in Eq. 17 we get:
$$\mathbb { E } _ { s \sim \rho } V ^ { t + 1 } ( s ) & - \mathbb { E } _ { s \sim \rho } V ^ { t } ( s ) = \frac { 1 } { \gamma } \mathbb { E } _ { s \sim d _ { \rho } ^ { t + 1 } } \left [ \text {KL} ( \pi ^ { t + 1 } ( \cdot | s ) ) \| \pi ^ { t } ( \cdot | s ) ) \right ] \\ & + \frac { 1 } { \gamma } \log Z ^ { t } ( s ) - \mathbb { E } _ { s \sim d _ { \rho } ^ { t + 1 } } \mathbb { E } _ { a \sim \pi ^ { t + 1 } ( a | s ) } A ^ { \mu } ( s , a ) .$$
$$\log Z ^ { t } ( s ) = \log \mathbb { E } _ { a \sim \pi ^ { t } ( \cdot | s ) } \exp \left ( \gamma \cdot ( A ^ { t } ( s , a ) + A ^ { \mu } ( s , a ) ) \right )$$
Applying Jensen's inequality we get:
$$\log Z ^ { t } ( s ) \geq \gamma \cdot \mathbb { E } _ { a \sim \pi ^ { t } ( \cdot | s ) } \left [ A ^ { t } ( s , a ) + A ^ { \mu } ( s , a ) \right ]$$
$$= \gamma \cdot \mathbb { E } _ { a \sim \pi ^ { t } ( \cdot | s ) } \left [ A ^ { \mu } ( s , a ) \right ] ,$$
since 𝔼 𝜋 𝑡 [ 𝐴 𝑡 ( 𝒔 , 𝑎 )] = 0. Note that in Eq. 20 the KL term is always non-negative. Thus, we can lower bound our policy improvement:
$$\mathbb { E } _ { \mathfrak { s } \sim \rho } V ^ { t + 1 } ( \mathbf s ) - \mathbb { E } _ { \mathfrak { s } \sim \rho } V ^ { t } ( \mathbf s ) \geq \mathbb { E } _ { \mathfrak { s } \sim d _ { \rho } ^ { t + 1 } } \langle \pi ^ { t + 1 } ( \cdot | \mathbf s ) - \pi ^ { t } ( \cdot | \mathbf s ) , A ^ { \mu } ( \mathbf s , \cdot ) \rangle ,$$
Recall that for 𝛼 = 1,
where the inner product is the standard euclidean product as our actions space A is discrete.
In the following we will treat the distribution 𝜋 𝑡 + 1 (· | 𝒔 ) as a vector denoted by 𝜋 Next, from the NPG update we know that:
<!-- formula-not-decoded -->
We note that for 𝛾 ≪ 1, exp 𝛾 ( 𝐴 𝑡 ( 𝒔 , 𝑎 )) + 𝛾 ( 𝐴 𝜇 ( 𝒔 , 𝑎 )) = Θ ( 1 + 𝛾 ( 𝐴 𝑡 ( 𝒔 , 𝑎 ) + 𝐴 𝜇 ( 𝒔 , 𝑎 ))) , where the terms that grow as 𝜔 ( 𝛾 ) are being ignored. Based on this, for 𝛾 ≪ 1, ∃ constants 0 < 𝐶 1 < 𝐶 2 such that:
$$\exp ( \gamma A ^ { t } ( s , a ) + \gamma A ^ { \mu } ( s , a ) ) - 1 \in [ C _ { 1 } \gamma ( A ^ { t } ( s , a ) + A ^ { \mu } ( s , a ) ) , C _ { 2 } \gamma ( A ^ { t } ( s , a ) + A ^ { \mu } ( s , a ) ) ]$$
Applying the above claim in Eq. 24 gives us:
$$\begin{array} { r l } & { \text {applying the above claim in Eq. 24 gives us:} } \\ & { \quad \pi ^ { t + 1 } ( a | s ) - \pi ^ { t } ( a | s ) \geq \pi ^ { t } ( a | s ) \left ( \frac { 1 + C _ { 1 } \gamma ( A ^ { t } ( s , a ) + A ^ { \mu } ( s , a ) ) } { 1 + C _ { 2 } \gamma E _ { a | \pi ^ { t } ( \cdot | s ) } [ A ^ { t } ( s , a ) + A ^ { \mu } ( s , a ) ] } - 1 \right ) } \\ & { \geq C _ { 3 } \gamma \frac { \left ( \pi ^ { t } ( a | s ) ( A ^ { t } ( s , a ) + A ^ { \mu } ( s , a ) ) - \pi _ { t } ( a | s ) [ E _ { a \sim \pi _ { t } ( a | s ) } [ A ^ { t } ( s , a ) + A ^ { \mu } ( s , a ) ] \right ) } { 1 + C _ { 2 } \gamma E _ { a \sim \pi _ { t } ( a | s ) } [ A ^ { t } ( s , a ) + A ^ { \mu } ( s , a ) ] } } \\ & { \quad \left ( \pi ^ { t } ( a | s ) ( A ^ { t } ( s , a ) + A ^ { \mu } ( s , a ) ) - \pi _ { t } ( a | s ) [ E _ { a \sim \pi _ { t } ( a | s ) } [ A ^ { \mu } ( s , a ) ] } \right ) } \end{array}$$
$$( 2 5 )$$
$$= C _ { 3 } \gamma \frac { \left ( \pi ^ { t } ( a \, | \, s ) \left ( A ^ { t } ( s , a ) + A ^ { \mu } ( s , a ) \right ) - \pi _ { t } ( a \, | \, s ) \mathbb { E } _ { a \sim \pi _ { t } ( a | s ) } \left [ A ^ { \mu } ( s , a ) \right ] \right ) } { 1 + \gamma C _ { 2 } \mathbb { E } _ { a \sim \pi _ { t } ( a | s ) } \left [ A ^ { t } ( s , a ) + A ^ { \mu } ( s , a ) \right ] , }$$
where we reused: 𝔼 𝜋 𝑡 [ 𝐴 𝑡 ( 𝒔 , 𝑎 )] = 0. Here, 𝐶 3 > 0 is a constant.
We now plug in the above lower bound into Eq. 21 to get the final lower bound on the policy improvement in Theorem 3.1. For this, we will once again use the assumption that the learning rate 𝛾 ≪ 1, which allows us to use 1 + 𝛾 𝔼 𝑎 ∼ 𝜋𝑡 ( 𝑎 | 𝑠 ) [ 𝐴 𝑡 ( 𝒔 , 𝑎 ) + 𝐴 𝜇 ( 𝒔 , 𝑎 )] ≥ 𝐶 4 for some constant 𝐶 4 > 0. This is because, in our setting the range of the advantages is [-1 , 1 ] .
$$\begin{array} { r l } \mathbb { E } _ { s \sim \rho } \left [ V ^ { t + 1 } ( s ) - V ^ { t } ( s ) \right ] \gtrsim \gamma \mathbb { E } _ { s \sim d _ { \rho } ^ { t + 1 } } \left [ \mathbb { E } _ { a \sim \pi ^ { t } ( a | s ) } \left [ A ^ { \mu } ( s , a ) A ^ { t } ( s , a ) \right ] \right ] \\ + \gamma \mathbb { E } _ { s \sim d _ { \rho } ^ { t + 1 } } \left [ \mathbb { E } _ { a \sim \pi ^ { t } ( a | s ) } \left [ \left ( A ^ { \mu } ( s , a ) \right ) ^ { 2 } \right ] \right ] \\ - \gamma \mathbb { E } _ { s \sim d _ { \rho } ^ { t + 1 } } \left [ \left ( \mathbb { E } _ { a \sim \pi ^ { t } ( a | s ) } \left [ A ^ { \mu } ( s , a ) \right ] \right ) ^ { 2 } \right ] \\ \end{array}$$
Now Eq. 27 gives us,
$$\mathbb { E } _ { s \sim \rho } \left [ V ^ { t + 1 } ( \boldsymbol s ) - V ^ { t } ( \boldsymbol s ) \right ] \gtrsim \gamma \mathbb { E } _ { s \sim d _ { \rho } ^ { l + 1 } } \left [ \mathbb { V } _ { a \sim \pi _ { t } ( a | \boldsymbol s ) } \left [ A ^ { \mu } ( \boldsymbol s , a ) \right ] - \mathbb { E } _ { a \sim \pi _ { t } ( a | \boldsymbol s ) } \left [ A ^ { \mu } ( \boldsymbol s , a ) A ^ { t } ( \boldsymbol s , a ) \right ] \right ]$$
Now, for the last step we note that 𝑑 𝑡 + 1 𝜌 is component wise larger than 𝜌 , and this gives us the final result:
$$\mathbb { E } _ { s \sim \rho } \left [ V ^ { t + 1 } ( \boldsymbol s ) - V ^ { t } ( \boldsymbol s ) \right ] \gtrsim \gamma \mathbb { E } _ { s \sim \rho } \left [ \mathbb { V } _ { a \sim \pi _ { t } ( a | \boldsymbol s ) } \left [ A ^ { \mu } ( \boldsymbol s , a ) \right ] - \mathbb { E } _ { a \sim \pi _ { t } ( a | \boldsymbol s ) } \left [ A ^ { \mu } ( \boldsymbol s , a ) A ^ { t } ( \boldsymbol s , a ) \right ] \right ]$$
□
## F.4. Discussion on Remark 3.1
First, we note that if the 𝑄 -value of a base policy 𝜋 at state, action pair ( 𝒔 , 𝑎 ) is 𝑄 𝜋 ( 𝒔 , 𝑎 ) , then for the prover 𝜇 set to the best-of-K policy BoK ( 𝜋 ) , the 𝑄 -value at the same state, action pair is:
$$Q ^ { \mu } ( s , a ) = 1 - ( 1 - Q ^ { \pi } ( s , a ) ) ^ { K } & & ( 3 0 )$$
This is because, in our setup the final outcome of correctness given by Rex is a random variable taking values in { 0 , 1 } , with expectation 𝑄 𝜋 ( 𝒔 , 𝑎 ) , when completing a rollout starting from prefix ( 𝒔 , 𝑎 ) . Thus, we can treat the outcome of function Rex as a Bernoulli random variable. Next, we can simply compute the probability of sampling a single correct answer out of 𝐾 attempts, which is also a Bernoulli random variable with mean given by 𝑄 𝜇 ( 𝒔 , 𝑎 ) in Eq. 30.
Now for Remark 3.1, we observe that whenever 𝑄 𝜋 ( 𝒔 , 𝑎 ) ≪ 1, e.g. , when 𝑄 𝜋 ( 𝒔 , 𝑎 ) = 𝑂 ( 1 / 𝐾 ) , for all values of ( 𝒔 , 𝑎 ) , we can do the Taylor approximation of 𝑄 𝜇 ( 𝒔 , 𝑎 ) around 0, and note that 𝑄 𝜇 ( 𝒔 , 𝑎 ) = Θ ( 𝐾 · 𝑄 𝜋 ( 𝒔 , 𝑎 )) . Next, note the following calculation for the first term (distinguishability) in Theorem 3.1:
$$\begin{array} { r l } & { \mathbb { V } _ { \pi } A ^ { \mu } ( s , a ) = \mathbb { V } _ { \pi } Q ^ { \mu } ( s , a ) } \\ & { = \mathbb { V } _ { \pi } \left [ 1 - ( 1 - Q ^ { \pi } ( s , a ) ) ^ { K } \right ] } \\ & { = \mathbb { V } _ { \pi } \left [ ( 1 - Q ^ { \pi } ( s , a ) ) ^ { K } \right ] } \end{array}$$
This means that the first term in Theorem 3.1 which measures 'distinguishability' now increases by a factor of 𝐾 2 . Similarly, we can see that the the term which measures 'misalignment' can change in magnitude by atmost a factor of 𝑂 ( 𝐾 ) , since the misalignment term is linear in 𝑄 𝜇 . These two observations combined lead us to the conclusion in Remark 3.1.
## F.5. Improving a Stronger Base policy with a Weaker Prover Policy
In Proposition F.1, we consider the case where the 𝜋 and 𝜇 differ in performance, as measured under the distribution of states 𝜌 in the following way:
$$\mathbb { E } _ { s \sim \rho } [ | V ^ { \mu } ( { \pm b s } ) - V ^ { \pi _ { t } } ( { \pm b s } ) | ] = \eta .$$
Next, whenever the prover's preference over actions is complementary to the base policy, by a factor of 𝜂 , i.e.,
<!-- formula-not-decoded -->
then the variance of 𝐴 𝜇 or 𝐴 𝜋𝑡 under 𝜋𝑡 should scale as 𝜂 2 .
Thus, we see that when 𝜋𝑡 fails to distinguish actions ( i.e. , 𝔼 𝒔 ∼ 𝜌 𝕍 𝜋𝑡 [ 𝐴 𝜋𝑡 ( 𝒔 , 𝑎 )] is small) regardless of the strength of prover policy 𝜇 , as long as it is sufficiently complementary to 𝜋𝑡 , the prover policy induces an improvement in base policy, that scales as 𝜂 2 .
Proposition F.1 (Complementary 𝜇 boosts improvements in 𝜋 ) . Under the distribution over states given by 𝜌 , let prover 𝜇 and base policy at iterate 𝑡 , 𝜋𝑡 , differ in absolute performance, i.e.,
$$\mathbb { E } _ { s \sim \rho } [ | V ^ { \mu } ( { \pm b s } ) - V ^ { \pi _ { t } } ( { \pm b s } ) | ] = \eta .$$
When 𝔼 𝒔 ∼ 𝜌 𝕍 𝑎 ∼ 𝜋𝑡 [ 𝐴 𝜋𝑡 ( 𝒔 , 𝑎 )] < 𝔼 𝒔 ∼ 𝜌 𝕍 𝑎 ∼ 𝜋𝑡 [ 𝐴 𝜇 ( 𝒔 , 𝑎 )] , and 𝜇 is complementary to 𝜋𝑡 , i.e.,
$$\mathbb { E } _ { \boldsymbol s \sim \rho } \mathbb { E } _ { a \sim \pi _ { t } } | Q ^ { \pi _ { t } } ( { \boldsymbol s } , a ) - Q ^ { \mu } ( { \boldsymbol s } _ { h } , a ) | = \Theta ( \eta ) ,$$
then 𝔼 𝒔 ∼ 𝜌 [ 𝑉 𝜋𝑡 + 1 ( 𝒔 ) -𝑉 𝜋𝑡 ( 𝒔 )] > ∼ 𝜂 2 .
Proof. We begin by proving an upper bound on the disagreement between prover and base policy:
$$& \mathbb { E } _ { s \sim \rho } \mathbb { E } _ { a \sim \pi _ { t } } | Q ^ { \mu } ( s , a ) - Q ^ { \pi _ { t } } ( s , a ) | \\ & \leq \mathbb { E } _ { s \sim \rho } \mathbb { E } _ { a \sim \pi _ { t } } | Q ^ { \mu } ( s , a ) - V ^ { \mu } ( s ) | + \mathbb { E } _ { s \sim \rho } \mathbb { E } _ { a \sim \pi _ { t } } | Q ^ { \pi _ { t } } ( s , a ) - V ^ { \mu } ( s ) | \\ & \leq \mathbb { E } _ { s \sim \rho } \mathbb { E } _ { a \sim \pi _ { t } } | Q ^ { \mu } ( s , a ) - V ^ { \mu } ( s ) | + \mathbb { E } _ { s \sim \rho } [ | V ^ { \mu } ( s ) - V ^ { \pi _ { t } } ( s ) | ] + \mathbb { E } _ { s \sim \rho } \mathbb { E } _ { a \sim \pi _ { t } } | Q ^ { \pi _ { t } } ( s , a ) - V ^ { \pi _ { t } } ( s , a ) | \\ & \leq \eta + \mathbb { E } _ { s \sim \rho } \sqrt { \mathbb { V } _ { \pi _ { t } } [ A ^ { \mu } ( s , a ) ] } + \mathbb { E } _ { s \sim \rho } \sqrt { \mathbb { V } _ { \pi _ { t } } [ A ^ { \pi _ { t } } ( s , a ) ] } ,$$
where the last inequality uses Cauchy-Schwartz. Next we apply Jensen's inequality on the terms in the square root, and the conditions that 𝔼 𝒔 ∼ 𝜌 𝔼 𝑎 ∼ 𝜋𝑡 | 𝑄 𝜋𝑡 ( 𝒔 , 𝑎 ) -𝑄 𝜇 ( 𝒔 ℎ , 𝑎 )| = Ω ( 𝜂 ) to conclude:
$$\sqrt { \mathbb { E } _ { s \sim \rho } \mathbb { V } _ { \pi _ { t } } [ A ^ { \mu } ( { \pm b s , a } ) ] } \gtrsim \eta ,$$
whenever 𝔼 𝒔 ∼ 𝜌 𝕍 𝑎 ∼ 𝜋𝑡 [ 𝐴 𝜋𝑡 ( 𝒔 , 𝑎 )] < 𝔼 𝒔 ∼ 𝜌 𝕍 𝑎 ∼ 𝜋𝑡 [ 𝐴 𝜇 ( 𝒔 , 𝑎 )] . Now that we lower bound 'distinguishability', it is easy to see that a similar derivation would upper bound the magnitude of the misalignment term by 𝑂 ( 𝜂 2 ) . Invoking the result in Theorem 3.1 yields:
$$E _ { s \sim \rho } [ V ^ { \pi _ { t + 1 } } ( s ) - V ^ { \pi _ { t } } ( s ) ] \gtrsim \eta ^ { 2 }$$
$$E _ { s \sim \rho } [ V ^ { \pi _ { t + 1 } } ( s ) - V ^ { \pi _ { t } } ( s ) ] \gtrsim \eta ^ { 2 }$$
## G. Examples Generated by Base Policy Trained on Rewards 𝑄 𝜋 + 𝛼𝑄 𝜇
When we train the base policy with reinforcement learning where the reward is 𝑄 𝜋 + 𝛼𝑄 𝜇 , instead of the effective reward 𝑄 𝜋 + 𝛼𝐴 𝜇 , we find that the policy training converges to contrived solutions with degenerate failures.
For example, we see in multiple examples (like the four below), that for every question, the model learns to output "REPHRASE THE PROBLEM" as the first step. This is because under 𝑄 𝜇 this trivial step achieves a positive reward. While there exists a better solution where the policy outputs the correct answer and achieves higher rewards, it fails to recover from this local optima and find the better solution. Across multiple training runs, we observed similar trends when training with 𝑄 𝜋 + 𝛼𝑄 𝜇 . Note that in the idealized update, where we observe advantages 𝐴 𝜇 or value function 𝑄 𝜇 on all actions at a state ( e.g. , in the NPG update in Sec. 3.4), using 𝑄 𝜋 + 𝛼𝑄 𝜇 is equivalent to 𝑄 𝜋 + 𝛼𝐴 𝜇 . But, in practice, 𝐴 𝜇 offers significant benefits in the form of variance reduction in policy gradient iterates. In this instance, it does that by not assigning reward to steps like 'REPHRASE THE PROBLEM', since the likelihood of a prover solving before or after this step is expected to be roughly the same under any choice of the prover policy ( i.e. , the prover policy makes no progress).
## Example 1
```
Q: My club has 25 members. In how many ways can I choose members to form a 4-person executive committee?
A:
>>>
REPHRASE THE PROBLEM
WE NEED TO FIND THE NUMBER OF WAYS TO CHOOSE 4 MEMBERS OUT OF 25 FOR THE EXECUTIVE COMMITTEE SO WE CAN USE THE COMBINATION FORMULA WHICH IS
```
N C R = N! / (R! * (N - R)!) WHERE N IS THE TOTAL NUMBER OF MEMBERS AND R IS THE NUMBER OF MEMBERS WE CHOOSE SO IN THIS CASE N = 25 AND R = 4 SO WE PLUG THEM IN AND SIMPLIFY 25 C 4 = 25! / (4! * (25 - 4)!) = (25 * 24 * 23 * 22) / (4 * 3 * 2 * 1) = 104005 # Answer
## Example 2
Q: We have a triangle $\triangle ABC$ and a point $K$ on $BC$ such that $AK$ is an altitude of $\triangle ABC$. If $AC = 10,$ $BK = 7$, and $BC = 13,$ then what is the area of $\triangle ABC$?
A:
>>>
REPHRASE THE PROBLEM
WE NEED TO FIND THE AREA OF $\triangle ABC$ SO WE CAN USE THE FORMULA $A = \frac{1}{2}bh$ WHERE $b$ IS THE BASE AND $h$ IS THE HEIGHT SO SINCE $AK$ IS AN ALTITUDE, THAT MEANS $AK \perp BC$ SO WE CAN USE $BC$ AS THE BASE AND $AK$ AS THE HEIGHT SO NOW WE NEED TO FIND $AK$ SO WE CAN USE THE PYTHAGORE THEOREM ON $\triangle AKC$ SINCE $AC = 10$ # Answer
## Example 3
```
Example 3
Q: Suppose that $n, n+1, n+2, n+3, n+4$ are five consecutive integers.
Determine a simplified expression for the sum of these five consecutive integers.
A:
>>>
REPHRASE THE PROBLEM
WE NEED TO FIND THE SUM OF THESE FIVE CONSECUTIVE INTEGERS SO WE CAN USE THE FORMULA
$S_n = \frac{n}{2}(a_1 + a_n)$ WHERE $S_n$ IS THE SUM, $n$ IS THE NUMBER OF TERMS,
$a_1$ IS THE FIRST TERM, AND $a_n$ IS THE LAST TERM SO IN THIS CASE $n = 5, a_1 = n,
a_5 = n + 4$
# Answer
5n + 10
```
5n + 10
## Example 4
```
Q: What is the value of $x^2+y^2-z^2+2xy$ when $x=-3$, $y=5$, and $z=-4$?
A:
>>>
REPHRASE THE PROBLEM
WE NEED TO FIND THE VALUE OF $x^2+y^2-z^2+2xy$ WHEN $x=-3$, $y=5$, AND $z=-4$
SO WE JUST PLUG IN THE VALUES AND SIMPLIFY
# Answer
-2
```