# A Scalable Communication Protocol for Networks of Large Language Models
**Authors**: Samuele Marro&Emanuele La Malfa&Jesse Wright&Guohao Li, Nigel Shadbolt&Michael Wooldridge&Philip Torr, Oxford, UK Oxford, UK
> Corresponding author. Email:samuele@robots.ox.ac.uk.
Abstract
Communication is a prerequisite for collaboration. When scaling networks of AI-powered agents, communication must be versatile, efficient, and portable. These requisites, which we refer to as the Agent Communication Trilemma, are hard to achieve in large networks of agents. We introduce Agora, a meta protocol that leverages existing communication standards to make LLM-powered agents solve complex problems efficiently. In Agora, agents typically use standardised routines for frequent communications, natural language for rare communications, and LLM-written routines for everything in between. Agora sidesteps the Agent Communication Trilemma and robustly handles changes in interfaces and members, allowing unprecedented scalability with full decentralisation and minimal involvement of human beings. On large Agora networks, we observe the emergence of self-organising, fully automated protocols that achieve complex goals without human intervention.
1 Introduction
Human language evolved primarily for communication purposes (Fedorenko et al., 2024). Despite its inherent ambiguity, natural language provides great versatility and allows humans and machines to collaborate and achieve complex goals that they otherwise could not (Russell & Norvig, 2016).
Decades of literature in computer science explored how to foster collaboration between agents modelled as programs (Wooldridge & Jennings, 1995; Gilbert, 2019). Several research papers design networks of agents to solve complex problems by leveraging each model’s specialisation, the so-called rule-based agents paradigm (Wooldridge, 2009). Despite its influence, such a paradigm faces two major limitations: agents hardly adapt to environmental changes and require structured data that limits their versatility (Gilbert & Terna, 2000).
With the advent of Large Language Models (LLM) (Vaswani et al., 2017; Brown et al., 2020), there has been a resurgent interest in networks of collaborative agents. LLMs can solve a variety of problems (Achiam et al., 2023; Dubey et al., 2024a) expressed in natural language as they excel at following instructions (Schulman et al., 2017; Rafailov et al., 2024). LLMs also showed remarkable improvements at handling structured data such as graphs and formatted languages (Kassner et al., 2020; Collins et al., 2022; Jin et al., 2023; Lin et al., 2024).
In terms of performance (e.g., accuracy on classification), the literature suggests that specialised LLMs outperform general purpose models (Hu et al., 2021; Zhang et al., 2024), as well as mitigating the difficulties of handling gargantuan models and the drawbacks of data and model centralisation (Song et al., 2023).
Thus, we hypothesise that:
Hypothesis
A network of heterogeneous LLMs can automate various complex tasks with nearly no human supervision via specialised and efficient protocols.
However, networks of LLM-powered agents face three key challenges that make communication at scale significantly more difficult:
- LLMs are heterogeneous: different LLMs have different architectures, makers, capabilities and usage policies. Heterogeneity is not unique to agents of LLMs, yet, compared to classic MAS agents, LLMs come with deeper representations of the surrounding environment and are thus more challenging to standardise.
- LLMs are (mostly) general-purpose tools: enumerating and standardising each task they can perform is infeasible.
- LLMs are expensive: the computational footprint and inference time of “small” LLMs dwarfs that of comparable, specialised APIs.
Scalable communication between heterogeneous LLMs must be versatile, i.e., capable of handling a variety of use cases, efficient, i.e., requiring the least computational effort, and portable, i.e., supporting the protocol should require the least human effort possible. The above-mentioned issues constitute the Agent Communication Trilemma, which we expand in Section 3.
In light of this, the aim of this paper is the following:
Key Contribution
We design and implement a communication protocol between heterogeneous LLM-powered agents and assess its feasibility and scalability for solving high-order tasks.
We sidestep the Trilemma with Agora, a meta protocol that relies on the dual use of structured data for frequent communications and natural language for infrequent ones. With Agora, we instantiate large networks of LLM-powered agents that solve complex tasks autonomously by leveraging efficient communications schemas. In such networks, we observe agents develop an emergent fully automated protocol to solve a complex task starting from an instruction expressed in natural language. We believe that this observation can serve as a basis to renew interest in emergent protocols/languages in large networks of LLMs (Lazaridou et al., 2018; Chaabouni et al., 2019; Lazaridou & Baroni, 2020; Chaabouni et al., 2022).
The paper is structured as follows. We first outline the key challenges that constitute the Agent Communication Trilemma (Section 3); we then detail how Agora addresses the Trilemma and serves as a communication protocol for networks of LLMs (Section 4). Finally, in Section 5, we provide two fully functional demos Our code is available at github.com/agora-protocol/paper-demo.: the former, with two agents, to clarify Agora’s operating principles; the latter, with 100, to prove Agora’s scalability and show the emergence of self-organising behaviours.
2 Related Work
Multi-agent LLMs and communication.
At the time of writing, Multi-Agent-Systems of Large Language Models (MAS-LLM) have become an active area of research (Guo et al., 2024) after the upsurge of LLMs as general purpose problem solvers (Brown et al., 2020; Achiam et al., 2023; Dubey et al., 2024b). Many fields have adapted techniques from the MAS-LLM paradigm to solve problems single models fail at, including reasoning and math (Li et al., 2024), Theory of Mind (Cross et al., 2024; Li et al., 2023b), planning (Singh et al., 2024), alignment to human values (Pang et al., 2024), and simulation of games, economics, and political scenarios (Bakhtin et al., 2022; Hua et al., 2023; Wu et al., 2024a). The common intuition of these works is that by breaking a task into sub-components (Hong et al., 2023) and allocating a large number of specialised models (Li et al., 2024) to each of them (Li et al., 2023a), one can achieve higher performance and observe emergent behaviours that otherwise would not occur.
On the other hand, a key requisite for solving complex tasks in large networks of MAS-LLMs is effective and efficient communication. In large networks, LLMs must agree on the actions to take (Chen et al., 2023): works such as Agashe et al. (2023) and Liang et al. (2023) studied how LLMs debate to foster collaboration on high-order tasks (Du et al., 2023). Another recent line of research explores the topology of the MAS-LLM network as a facilitator to reach consensus (Chen et al., 2024).
LLMs for simulations and emergence of protocols.
A few seminal works studied how emergent communication and protocols arise between neural networks that manipulate symbols (Havrylov & Titov, 2017; Lazaridou et al., 2018; Lazaridou & Baroni, 2020). Written before the rise of LLMs, these works inspired researchers to explore how spontaneous collaboration emerges in MAS-LLMs (Wu et al., 2024b), with application to simulation of societies (Gao et al., 2024). Of particular interest for this paper are the works by Chaabouni et al. (2019) and Chaabouni et al. (2022). Chaabouni et al. (2019) describes how emergent communication systems between neural networks privilege longer messages. Chaabouni et al. (2022) posits the existence of “scaling laws” (Kaplan et al., 2020) for large networks of MAS-LLMs in which the dataset, task complexity, and population size are the key to observe emergent behaviours.
3 The Agent Communication Trilemma
<details>
<summary>img/triangle-trilemma.png Details</summary>
### Visual Description
## Triangle Diagram: API Design Trade-offs
### Overview
The image presents a triangular diagram comparing two API design paradigms: **Traditional static API (e.g., OBP)** and **Meta-API (e.g., RDF)**. The diagram uses a blue outer triangle and a red inner inverted triangle to represent trade-offs between three axes: **Efficiency**, **Portability**, and **Versatility**. A smaller inverted triangle labeled **"Agora"** is centered within the main triangle, with **"Natural language"** positioned at the bottom of the inner triangle.
---
### Components/Axes
1. **Main Triangle (Blue)**:
- **Vertices**:
- **Top**: **Efficiency**
- **Bottom-left**: **Portability**
- **Bottom-right**: **Versatility**
- **Sides**:
- **Left side**: **Traditional static API (e.g., OBP)**
- **Right side**: **Meta-API (e.g., RDF)**
- **Legend**: Blue represents the outer triangle (Traditional static API).
2. **Inner Inverted Triangle (Red)**:
- **Label**: **Agora**
- **Bottom vertex**: **Natural language**
- **Legend**: Red represents the inner triangle (Agora).
---
### Detailed Analysis
- **Axes and Labels**:
- The three axes (**Efficiency**, **Portability**, **Versatility**) form the primary framework for evaluating API design.
- The **Traditional static API (OBP)** is associated with the left side of the triangle, while the **Meta-API (RDF)** is linked to the right side.
- The **Agora** label is placed centrally within the inner triangle, suggesting a balanced or hybrid approach.
- **Natural language** is positioned at the bottom of the inner triangle, possibly indicating a foundational or contextual layer for API design.
- **Color Coding**:
- **Blue**: Outer triangle (Traditional static API).
- **Red**: Inner inverted triangle (Agora).
- **Spatial Relationships**:
- The **Agora** triangle is smaller and inverted, positioned centrally within the main triangle.
- **Natural language** is anchored at the bottom of the inner triangle, aligning with the **Portability** axis of the main triangle.
---
### Key Observations
1. **Trade-off Visualization**:
- The outer triangle emphasizes the trade-offs between **Efficiency**, **Portability**, and **Versatility** for traditional and meta-APIs.
- The inner triangle (Agora) suggests a middle ground or optimized balance between these axes.
2. **Natural Language Role**:
- The placement of **Natural language** at the bottom of the inner triangle implies it may serve as a unifying or contextual element for API design, bridging the gap between technical and human-centric considerations.
3. **Color Significance**:
- The use of **blue** for the outer triangle and **red** for the inner triangle visually distinguishes the two API paradigms and their respective trade-offs.
---
### Interpretation
- **API Design Paradigms**:
- The diagram contrasts **Traditional static APIs** (e.g., OBP) with **Meta-APIs** (e.g., RDF), highlighting their differing priorities in terms of efficiency, portability, and versatility.
- **Agora** represents a hybrid or optimized approach that balances these trade-offs, potentially integrating the strengths of both paradigms.
- **Natural Language as a Foundation**:
- The inclusion of **Natural language** at the bottom of the inner triangle suggests it may act as a foundational layer, enabling APIs to be more human-readable, context-aware, or adaptable across domains.
- **Design Implications**:
- The inverted triangle for **Agora** could symbolize a departure from rigid trade-offs, emphasizing flexibility or innovation in API design.
- The central positioning of **Agora** implies it may represent an ideal or aspirational model for future API development.
---
### Conclusion
This diagram illustrates the complex trade-offs in API design, contrasting traditional and meta-API approaches while introducing **Agora** as a balanced or innovative paradigm. The inclusion of **Natural language** at the base of the inner triangle highlights its potential role in bridging technical and human-centric aspects of API development. The use of color and spatial positioning reinforces the relationships between these concepts, offering a framework for evaluating API design strategies.
</details>
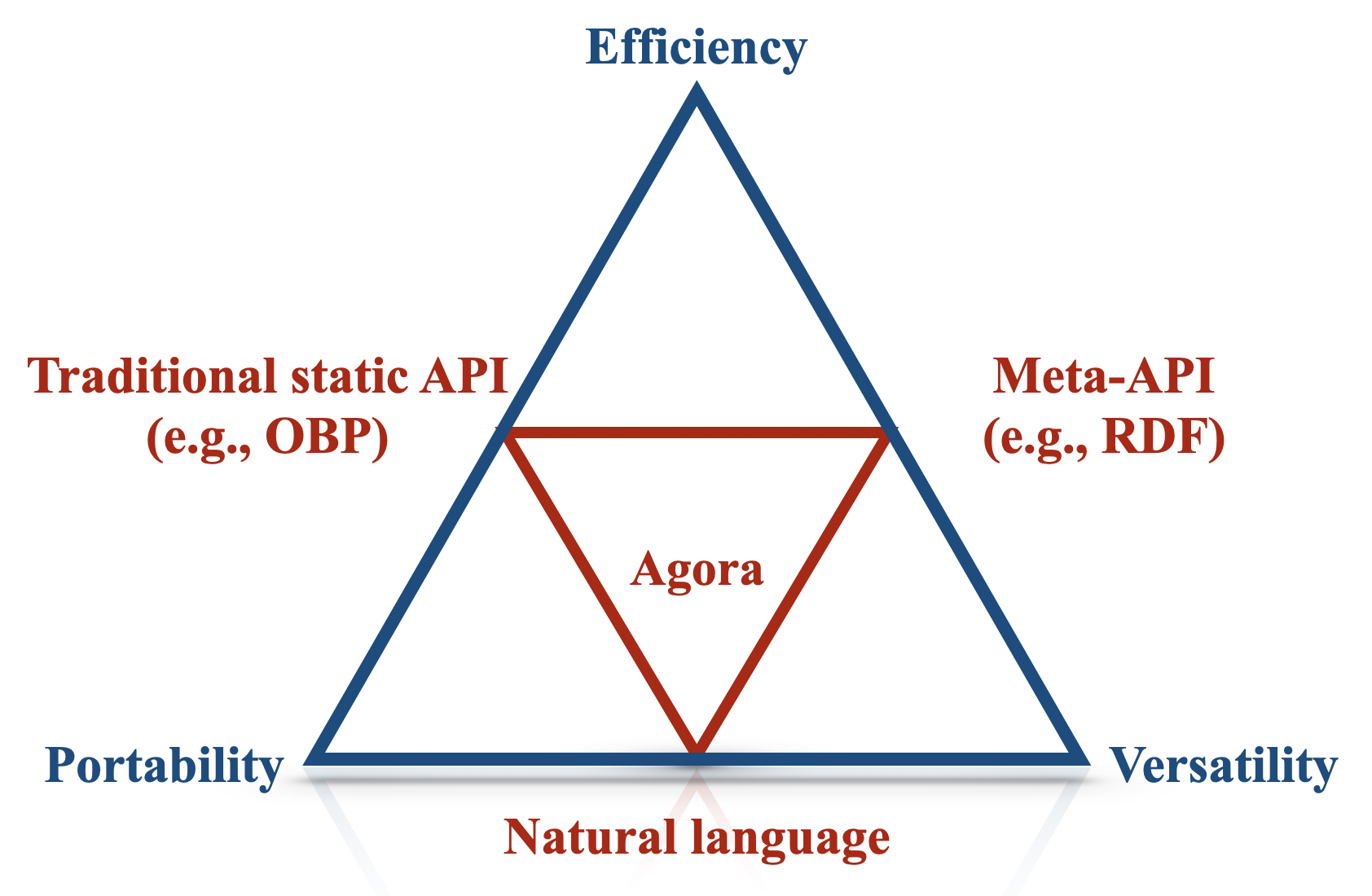
Figure 1: The Trilemma and how our solution (Agora) balances efficiency, portability and versatility.
An agent is a computer system that, in an environment, is capable of autonomous actions (the so-called ‘agency’ (Horty, 2001)) to meet its design objective (Wooldridge & Jennings, 1995; Wooldridge, 2009, p. 15). Just as humans must negotiate and cooperate to achieve shared goals, so too must agents within multi-agent systems (Wooldridge, 2009, p. 24-25). However, when designing communication protocols for heterogeneous networks (i.e., networks where agents have different architectures, capabilities and design constraints), we run into difficulties when attempting to optimise for three properties at the same time:
- Versatility: communication between agents should support a wide variety of messages, both in terms of content and format;
- Efficiency: the computational cost of running an agent and networking cost of communication should be minimal;
- Portability: supporting the communication protocol should require the least implementation effort by the largest number of agents involved.
We name the trade-off between such properties the Agent Communication Trilemma, which is illustrated in Figure 1. In the next sections, we will discuss how an LLM-powered communication protocol can trade off versatility, efficiency, and portability.
3.1 Versatile vs. Portable Communication
In networks of agents, versatility and portability are at tension for two fundamental reasons (Olivé, 2007). A prerequisite for two agents who communicate is (1) a shared conceptual understanding of the topic on which they communicate. For instance, two agents can communicate about the weather if they both ‘know’ what it means to be sunny, rainy and overcast. For example, they should share a similar notion of describing and measuring temperature (e.g., in degrees Celsius). In addition, (2) agents must encode and decode messages in a way that is intelligible for both. Continuing the weather example, if two agents exchange data using JSON objects, both the sender and the receiver must know the syntax (e.g., the keys of a JSON object, such as temperature) and the semantics (e.g. temperature is a $32$ -bit floating point value representing the temperature, in central London, as measured in degrees Celsius) of the exchanged messages.
In complex scenarios, defining routines whose syntax and semantics satisfy requisites (1) and (2) may be difficult. For example, a programmer has to manually implement a method to decode (or decode) messages to (or from) other agents. Additionally, the programmer must explicitly instruct the agent about how to manipulate and reason about the message content, often by interpreting API documentation describing the semantics of the message. Therefore, there is a trade-off between the breadth of messages (versatility) and the implementation cost (portability).
An example of high-portability, low-versatility is the Open Banking Platform (OBP), which uses a well-defined Open API schema for data transfer (OBL, 2024). OBP is highly portable because it uses a fixed range of well-known concepts which developers can implement; however, it is restricted to discussing a narrow domain of banking data and is thus not versatile. On the other end of the spectrum, rules-based Semantic Web agents (Berners-Lee et al., 2001) that exchange RDF (Beckett et al., 2014) encoded documents are highly versatile since ontologies (Wooldridge, 2009, p. 180) enable the description of structured relations between essentially any concept. Still, they require developers to program agents to implement the specific ontologies used by the network (e.g., if a set of RDF triples states that the temperature is 38°C, an agent must be able to interpret the concepts of “temperature” and “Celsius”).
3.2 Efficient vs. Versatile and Portable Communication
As previously mentioned, rule-based agents excel at the tasks they are designed to solve but hardly adapt to new environments. Decades of research in reinforcement learning (Sutton, 2018) and then in deep reinforcement learning (Arulkumaran et al., 2017; Henderson et al., 2018), introduced a paradigm where agents learn to optimise their reward as proxy of the task we want them to solve. Agentic-LLMs, i.e., multi-agent systems powered by language models, is a recent paradigm for machine-to-machine communication that relies mostly on their proficiency at handling natural language and following instructions (Li et al., 2023a).
Natural language is highly expressive, making it a suitable choice for versatile communication (Russell & Norvig, 2016). Additionally, LLMs trained on massive corpora seem to develop an implicit understanding of various concepts that abstracts and makes communication independent from their internal architecture. Moreover, LLMs can integrate external tools, write code and invoke APIs with relatively little or no training (Schick et al., 2024), since the only requirement is a natural-language description of the tool and its parameters.
Conversely, natural language as a communication medium has two major drawbacks. While engineering and hardware improvements (Dubey et al., 2024b) mitigate costs over time, the computational requirements of invoking an LLM dwarf those of comparable APIs, representing a major bottleneck for scaling networks of LLMs. On the other hand, using closed-source pay-per-usage LLMs hosted by third parties is expensive and raises concerns in terms of replicability of the results (La Malfa et al., 2023). Additionally, natural language is inherently ambiguous: while LLMs have a certain degree of “common sense” to fulfil requests, non-determinism and natural language specifics leave space for errors that routines minimise (for instance, if someone asks for the temperature in Fahrenheit and the agent has a tool that returns the temperature in Celsius, the model must know that Celsius and Fahrenheit are both units of measure for temperature). These factors make LLMs and natural language more prone to errors than other alternatives like handwritten APIs.
In conclusion, RESTful APIs (efficient), RDF tuples (portable) and natural language (versatile) are all trade-offs in the Trilemma. While some approaches are more useful in practice than others, the fact that no communication format achieves all three properties simultaneously suggests that we need a hybrid communication protocol that leverages all of them. The next section outlines our solution.
4 Agora: a Communication Protocol Layer for LLMs
<details>
<summary>img/evil.png Details</summary>
### Visual Description
## Diagram: LLM-Powered Node Architecture
### Overview
The diagram illustrates a distributed system architecture featuring LLM-powered nodes interconnected with a multi-layered platform. Key elements include:
- Four black polyhedral nodes labeled "LLM-Powered Node"
- A central platform layer containing tech stack components
- A lower data layer with HTTPS security and data flow indicators
- Communication pathways labeled "Send/receive message"
### Components/Axes
1. **LLM Nodes**:
- Four identical black polyhedral shapes (likely representing AI/ML models)
- Positioned at the top layer, forming a mesh network
- Connected via bidirectional "Send/receive message" pathways
2. **Platform Layer**:
- Contains 8 distinct tech stack components:
- **Databases**: MongoDB (blue icon), SQL (blue icon)
- **Frontend**: HTML (red icon), CSS (blue icon), JS (green icon)
- **Backend**: PHP (purple icon)
- **Tools**: Python (yellow icon), Infinity symbol (blue)
- **Security**: Lock icon labeled "HTTPS"
3. **Lower Layer**:
- Two-tiered structure with black dots connected by lines
- Positioned beneath the platform layer
- Contains HTTPS security indicator at the base
### Spatial Relationships
- LLM nodes form a tetrahedral arrangement above the platform
- Platform layer sits centrally between LLM nodes and lower layer
- HTTPS security indicator anchors the lower layer
- "Send/receive message" pathways radiate from LLM nodes to platform components
### Key Observations
1. **Network Topology**: LLM nodes exhibit a fully connected mesh network
2. **Tech Stack Integration**: Platform layer combines databases, frontend/backend frameworks, and tools
3. **Security Emphasis**: HTTPS indicator positioned at the lowest layer suggests foundational security
4. **Data Flow**: Black dots in lower layer likely represent data points or processing nodes
### Interpretation
This architecture demonstrates a modular AI system where:
- LLM nodes act as distributed intelligence units
- The platform layer provides full-stack capabilities for application development
- The lower layer handles secure data processing/storage
- Communication pathways enable real-time interaction between components
The design suggests a cloud-native architecture optimized for AI/ML workloads, with explicit emphasis on security through HTTPS implementation. The polyhedral node shapes may symbolize the multidimensional nature of language models, while the layered structure reflects a typical three-tier application architecture (presentation, business logic, data).
</details>
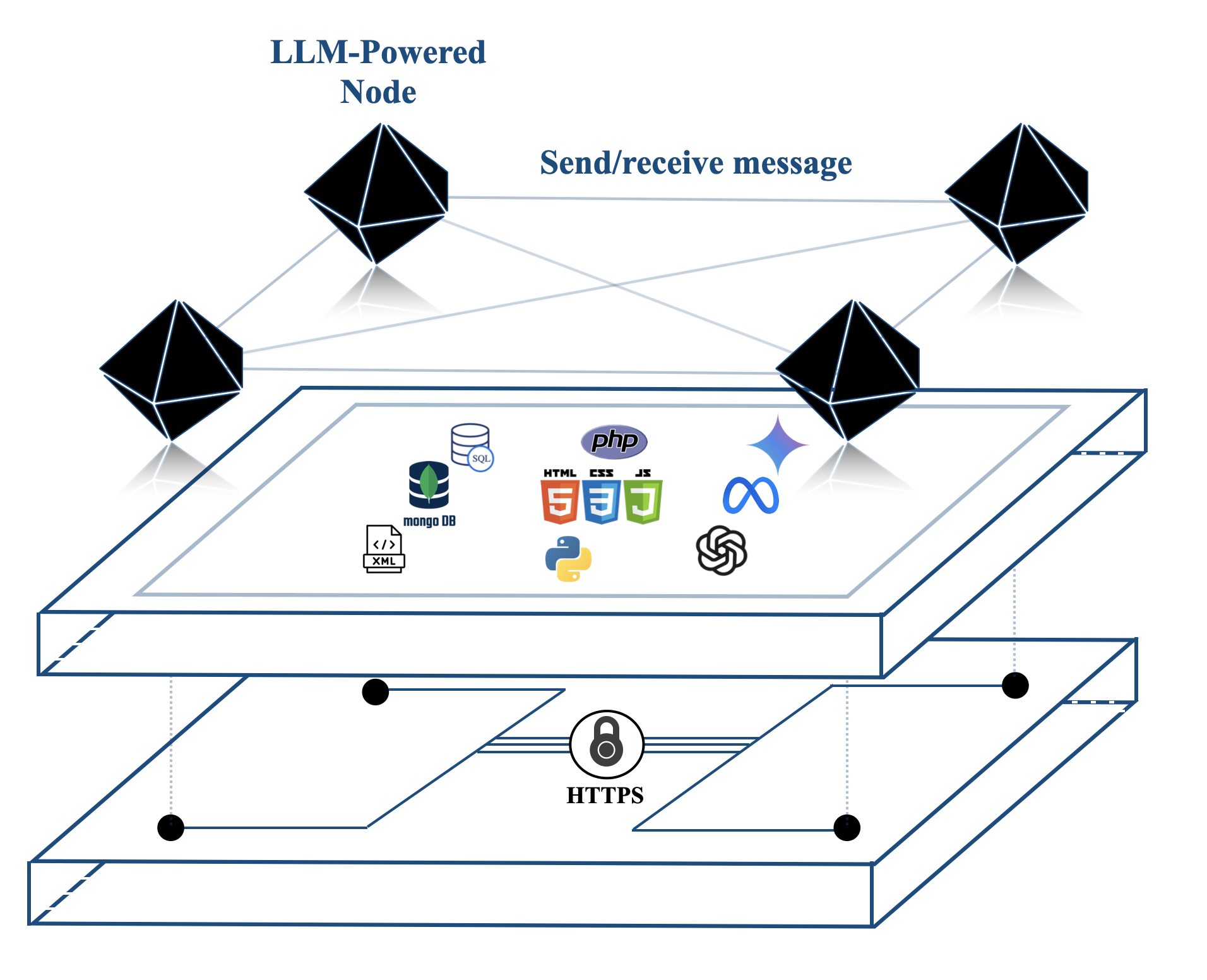
(a) An illustration of Agora and how it abstracts the underlying implementation, communication, and physical layers.
<details>
<summary>img/evil-stack.png Details</summary>
### Visual Description
## Layered Architecture Diagram: System Component Stack
### Overview
The diagram illustrates a multi-layered system architecture with five distinct horizontal layers stacked vertically. Each layer is enclosed in a red-bordered rectangle with specific labels and icons. The layers progress from abstract to concrete implementation from top to bottom.
### Components/Axes
1. **Top Layer**:
- Label: "Further layers" (dashed red border)
- Position: Topmost position
2. **Second Layer**:
- Label: "Agora" (solid red border)
- Icon: Black polyhedron (12-sided geometric shape)
3. **Third Layer**:
- Label: "Implementation Layer" (solid red border)
- Icons:
- Network node (circular connection point)
- Python logo (blue/yellow serpent)
- SQL database (stacked cylinders with "SQL" label)
4. **Fourth Layer**:
- Label: "Communication layer" (solid red border)
- Icon: Padlock (security symbol)
5. **Bottom Layer**:
- Label: "Physical Layer" (solid red border)
- Position: Bottommost position
### Detailed Analysis
- **Layer Hierarchy**:
- Top-to-bottom progression shows increasing abstraction level
- "Further layers" suggests additional unspecified components above the diagram
- **Icon Symbolism**:
- Polyhedron (Agora): Represents complex, interconnected components
- Network/SQL/Python (Implementation): Indicates backend development stack
- Padlock (Communication): Emphasizes data security/encryption
- Physical Layer: Implies hardware infrastructure foundation
### Key Observations
1. The architecture follows a standard software stack pattern (application → infrastructure)
2. Security is emphasized through the padlock icon in the communication layer
3. The implementation layer combines multiple technologies (networking, Python, SQL)
4. The top "Further layers" suggests this is part of a larger system architecture
### Interpretation
This diagram represents a typical multi-tier software architecture where:
- The "Agora" layer likely represents the application/service interface
- The "Implementation Layer" contains the core business logic and data management
- The "Communication layer" handles secure data transmission
- The "Physical Layer" represents the underlying hardware infrastructure
The inclusion of specific technology icons (Python, SQL) suggests this architecture is designed for modern web applications using these technologies. The padlock icon emphasizes the importance of security in data communication between layers. The "Further layers" designation implies this is a simplified view of a more complex system architecture.
</details>
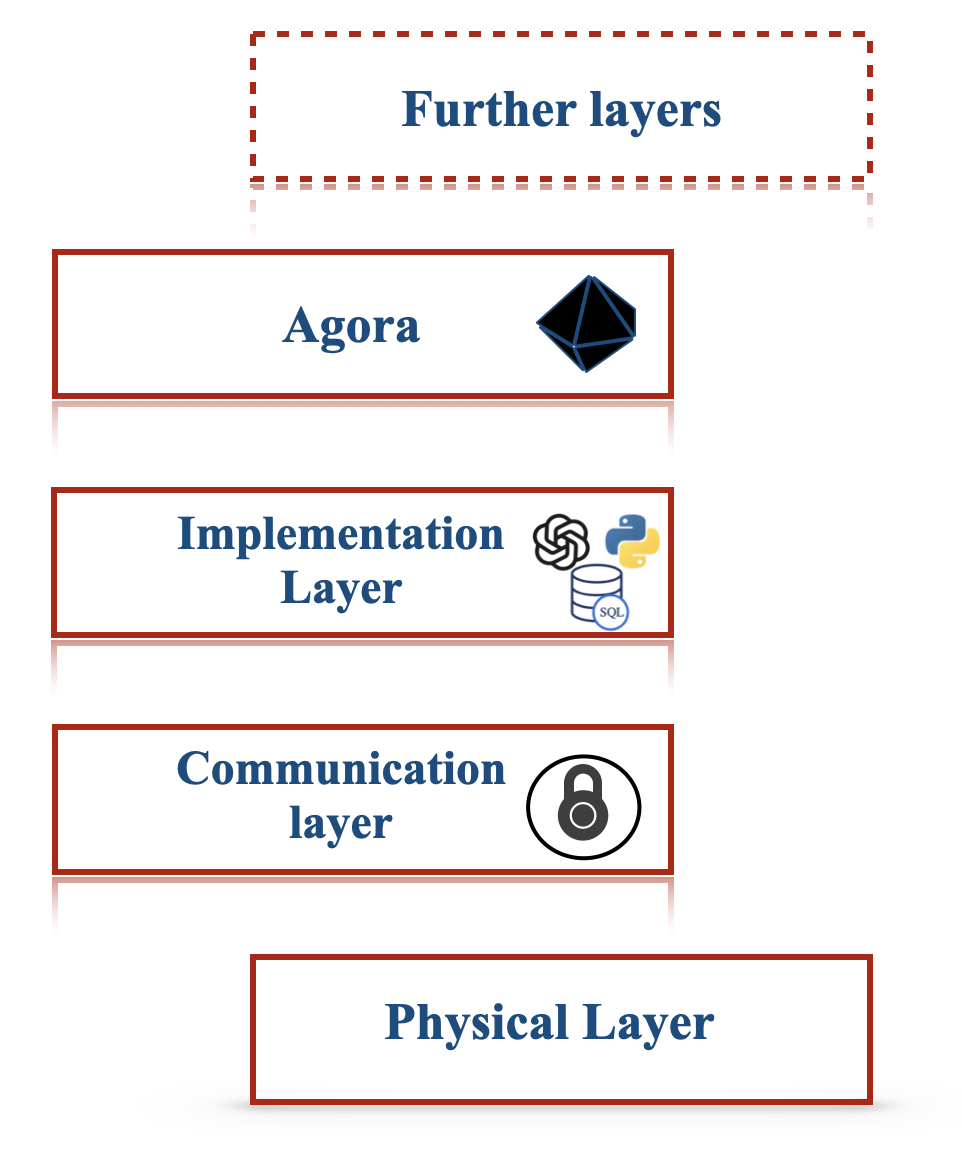
(b) Stack of technologies to build Agora.
Figure 2: How Agora fits into a standard communication protocol stack.
The key to solving the Communication Trilemma involves accepting that no single protocol can achieve optimal efficiency, portability and versatility at the same time. In this section we introduce Agora, a meta protocol that takes advantage of the unique capabilities of LLMs to sidestep the Trilemma by adapting different communications methods for different scenarios.
The most powerful LLMs share three key properties:
- They can understand, manipulate, and reply to other agents using natural language;
- They excel at following instructions, including writing code to implement routines (Schick et al., 2024; Hou et al., 2023; Liu et al., 2024);
- They can autonomously negotiate protocols and reach consensus on strategies and behaviours to adopt in complex scenarios (Chen et al., 2023; Fu et al., 2023).
At its core, Agora uses different communication formats depending on the circumstances; an agent can support a wide breadth of communications (high versatility) while handling the majority of the total volume of requests with efficient routines (high efficiency). Moreover, the entire negotiation and implementation workflow is handled by the LLMs and requires no human supervision (high portability). The concept of protocol documents (PD), which we sketch in Figure 3 and discuss in the next section, lies at the core of Agora’s functionalities.
In the next sections, we illustrate the hierarchy of communication methods Agora supports natively and the concept of PD; we then provide an example of how Agora works and how it enables versatile, efficient, and portable communication. We conclude by emphasising how one can integrate and build upon Agora with further technological layers independently from its underlying technologies.
4.1 Communication in (an) Agora
Agora introduces a machine-readable way to transfer and refer to protocols, namely the protocol documents (PDs). A PD is a plain-text description of a communication protocol. Throughout this paper, we use the word “protocol” to refer to any standardised description of structured communication. PDs are self-contained, implementation-agnostic, and contain everything an agent needs to support a protocol: this means that most descriptions of existing protocols, such as RFCs, are also suitable PDs. However, instead of relying on a central body to assign identifiers, a PD is uniquely identified by its hash (for multiplexing).
In Agora, the most frequent communications have dedicated efficient routines, and the least frequent ones use inefficient but flexible LLMs and natural language. In particular:
- When possible, frequent communications are handled through traditional protocols, for which there are standard, human-written implementations (e.g., OBP);
- For communications that happen less frequently (or for which there are no standard protocols), agents can use structured data as an exchange medium (which can be handled by LLM-written routines);
- For communications that might be frequent for one side but not the other, the agents still use structured data, but one side can choose to use an LLM, while the other uses a routine;
- For rare communications or when a routine fails unexpectedly, the agents can resort to natural language.
It is entirely up to the agent to handle a query using a human-written routine, an LLM-written routine, or an LLM (or a combination of these three). This gives the agent maximum flexibility over how to process queries. Forcing or nudging a model to use a specific communication style can improve efficiency, yet its discussion is out of the scope of this paper. One can, for example, specify in the system prompt of an LLM to negotiate a protocol whenever possible. In the Demo (Section 5.3), we will illustrate the trade-off between the versatility of a communication protocol and its expected usage.
Hierarchical communications support any form of communication (maximum versatility) , although in practice an LLM is invoked in very rare cases (maximum efficiency). Moreover, since LLMs can implement routines on their own (since PDs fully describe the syntax and semantics of a protocol), human programmers only need to provide an overview of the tools the agent has access to, which means that the implementation effort required on the human side is minimal (maximum portability). In other words, Agora sidesteps the Communication Trilemma by employing routines for frequent requests and resorting to natural language when agents need to negotiate efficient ways to solve a problem or errors occur.
4.2 An Example of Communication over Agora
<details>
<summary>img/pd-negotiation.png Details</summary>

### Visual Description
## Diagram: LLM-Powered Node Communication Flow
### Overview
The image depicts a two-part technical diagram illustrating data flow between LLM-powered nodes and message formatting processes. It uses geometric shapes (black polyhedrons) to represent nodes, arrows for data flow, and text labels to describe processes. The diagrams emphasize natural language processing, message hashing, and structured data transmission.
### Components/Axes
1. **Nodes**:
- **LLM-Powered Node**: Labeled in blue text at the top-left of the left diagram.
- **Negotiate PD Node**: Labeled in blue text at the bottom-left of the left diagram.
- **Message Formatted as PD**: Labeled in blue text at the top-right of the right diagram.
2. **Data Flow Arrows**:
- **Natural Language**: Gray dashed arrow connecting LLM-Powered Node to Negotiate PD Node (left diagram).
- **Message Formatted as PD hash ‘123’**: Solid arrow connecting Negotiate PD Node to Message Formatted as PD Node (right diagram).
3. **Message Representation**:
- A document icon with a pencil (left diagram) and a document icon with a hash symbol (right diagram).
- Explicit hash value: `‘123’` in both diagrams.
### Detailed Analysis
- **Left Diagram**:
- Shows bidirectional flow between LLM-Powered Node and Negotiate PD Node.
- Natural language input is processed by the LLM node and negotiated into a structured PD format with hash `‘123’`.
- The pencil icon suggests manual input or editing.
- **Right Diagram**:
- Focuses on message transmission.
- The hash `‘123’` is explicitly tied to the PD-formatted message, indicating data integrity or identification.
- The document icon with a hash symbol emphasizes cryptographic or structured encoding.
### Key Observations
1. **Hash Consistency**: The hash `‘123’` appears in both diagrams, suggesting it acts as a unique identifier for the message across processing stages.
2. **Bidirectional Flow**: The dashed arrow in the left diagram implies two-way communication between nodes, possibly for feedback or validation.
3. **Structured Output**: The right diagram emphasizes the transformation of natural language into a standardized, hash-encoded PD message.
### Interpretation
This diagram represents a system where:
1. **Natural language inputs** are processed by an LLM-powered node to generate structured data.
2. The data undergoes negotiation (e.g., validation, formatting) and is assigned a hash for uniqueness or security.
3. The final output is a PD-formatted message with embedded hash, ready for transmission or storage.
The use of geometric shapes (polyhedrons) may symbolize complex, multi-dimensional data processing. The bidirectional flow suggests iterative refinement of the message, while the explicit hash highlights the importance of data integrity in the system. The diagram likely models a pipeline for AI-driven natural language understanding and secure data exchange.
</details>
Figure 3: How a protocol document is negotiated between LLM-powered agents (left) and used for future efficient communications.
We now describe how two agents, Alice and Bob, can efficiently communicate over Agora using a PD routine, as illustrated in Figure 3. Alice initially sends a query with the hash of its corresponding PD. Bob uses the hash to determine if he has a corresponding routine. If so, he calls it and handles the communication without invoking the LLM. Otherwise, Bob handles the response with the LLM itself.
If Bob uses an LLM to reply several times to queries that follow a given protocol over time, to the point where using an LLM every time becomes expensive, he can use the LLM to write a routine that handles future communications.
If the routine fails or the communication is a one-off instance that does not require a protocol, Alice and Bob use natural language, which is again handled by the LLM. Natural language is also available to bootstrap communication between nodes that have never interacted before, as well as to negotiate new protocols. That said, the lower cost of routines and the lack of ambiguity are strong incentives for agents to prefer structured data.
Note that PDs can be shared with other nodes in the network, which means that two agents that have never interacted before can use protocols developed by other agents.
In the Appendix A, we provide details of five use cases of Agora to further show its versatility as a personal assistant and data analysis tool, and how it leverages compositionality and scalability to reduce costs.
4.3 Agora as a Layer Zero Protocol
Figure 2 illustrates that Agora is implementation and technology agnostic. The implementation of the agents themselves (e.g., LLMs), the database used to store data (e.g., VectorDB, SQL, MongoDB, etc.), the language in which implementations are written (Python, Java, etc.) and the nature of tools are all abstracted.
At the same time, PDs can refer to other protocol documents, and since routines can call other routines, agents can build upon previous negotiations to solve more complex tasks.
Finally, the versatility and portability of Agora make it straightforward to handle the addition or removal of a node, a change in the capabilities of a node, or a change in the goals of the network, as illustrated in the demo, Section 5.3.
All these factors contribute to making Agora a natural Layer Zero protocol, i.e. a foundation layer, for higher-order communication and collaboration between LLMs. We hope our protocol can fuel theoretical and applied research on complex protocols, negotiation schemes, and consensus algorithms in large networks of LLMs.
5 Agora in Practice
We implement and showcase two scenarios where Agora can be applied. The former, with two agents whose objective is to exchange some data; the latter, with $100$ , to test Agora scalability and the capacity of LLM-powered agents to autonomously coordinate in complex scenarios. For space reasons, the scenarios are further expanded in Appendices C and D; here, we instead focus on their functionalities and the key observations we drew in terms of efficiency/versatility/portability, reduction of costs, scalability and emergent behaviours of fully automated networks of LLMs.
5.1 Implementation Details
The design of Agora for our working demos follows three key principles:
- Minimality. Agora enforces the basic standards that allow for efficient negotiation and use of protocols, leaving everything else to PDs or other higher-order standards;
- Decentralisation. Agora does not rely on central authorities, with any collection of nodes being able to use Agora independently;
- Full backward compatibility. Agora supports existing communication protocols and schemas such as OpenAPI and JSON-Schema.
From a practical point of view, Agora uses HTTPS as base communication layer and JSON as format to exchange metadata. When sending a message in a given protocol, an agent sends a JSON document with three keys: the protocol hash, the body of the request formatted according to the protocol, and a non-empty list of sources from which the protocol can be downloaded. The receiver downloads the PD from its preferred source and, upon checking that the hash matches, stores it for future uses. This hash-based identification system ensures that any node can reference any PD without relying on a central authority to assign identifiers. Where PDs are stored is entirely up to the agents; aside from regular cloud storage, hash-based indexing makes decentralised storage options (such as IPFS Benet (2014)) viable. Additionally, since essentially all protocols can be stored as PDs, Agora has full backwards compatibility with existing protocols (although human programmers are encouraged to provide existing, standardised implementations instead of having the LLM re-implement them from scratch).
To simplify negotiation, an agent can expose an endpoint with a list of supported protocols: a potential sender can thus compare the list with its own to automatically determine if there is a common protocol. The sender can also use a potentially unsupported protocol, although the receiver can choose to reject it by returning a predefined error message.
Refer to LABEL:sec:\pname{}-specification for a more formal description of Agora.
5.2 Demo: Retrieving Weather Data
Consider two agents, Alice and Bob. Alice is a Llama-3-405B (Dubey et al., 2024b) powered agent managing the bookings of a guided tour service in London. While Llama-3 models can be hosted locally, for the sake of a proper comparison with GPT-4o and Gemini, we use a cloud provider, namely SambaNova (https://sambanova.ai). Bob is a GPT-4o (Achiam et al., 2023) agent for weather service that provides weather forecasts for a given date and location. As part of the user interaction loop, Alice notifies the user if heavy raining is expected on a booked date.
To check the weather, she initially uses her LLM to send a natural language query to Bob (phase A1):
Alice - Natural Language
What is the weather forecast for London, UK on 2024-09-27?
Bob uses his Toolformer LLM (Schick et al., 2024) to query his database (phase B1) and returns a natural language reply (phase B2):
Bob - Natural Language
The weather forecast for London, UK, on 2024-09-27 is as follows: “Rainy, 11 degrees Celsius, with a precipitation of 12 mm.”
Over time, the cost of invoking an LLM for phases A1 and B2 dominate all the other costs; Alice and Bob thus decide to develop a protocol. Alice checks if Bob already supports a suitable protocol but finds none. Therefore, she decides to negotiate a protocol with Bob. After a few rounds of negotiation, Alice and Bob agree on the following protocol: Alice sends a JSON document with two fields, location and date, and Bob replies with a JSON document containing three fields, namely temperature (in degrees Celsius), precipitation (in millimetres), and weatherCondition (one of “sunny”, “cloudy”, “rainy” and “snowy”). From there on, Alice specifies the protocol hash when performing a query. An example of exchanged message (excluding Agora’s metadata) is:
Alice - PD
{"location": "London, UK", "date": "2024-09-27"}
Both Alice and Bob independently decide to write a routine to handle their side of the communication. From now on, Alice and Bob do not need to use the LLM to transmit traffic data: a routine now automates phases A1, B1 and B2 and leverages the costs of invoking the respective LLMs.
A cost analysis.
In our demo, negotiating the protocol and implementing the routines cost $0.043$ USD in API calls, compared to an average cost of $0.020$ USD for a natural-language exchange. This means that, as long as Alice and Bob use the agreed-upon protocol more than twice, Agora reduces the overall cost. Please refer to Appendix C for a transcription of the negotiation process and the final protocol.
As a final note, we stress that the entire communication happened without human intervention. Additionally, should Bob become unavailable, Alice can simply reuse the PD with a new node that may use a different LLM/database/technology stack.
5.3 Demo: a Network of 100 Agents
<details>
<summary>img/agora-100.png Details</summary>
### Visual Description
## Flowchart: Food Delivery Process with Proof of Delivery (PD) Hashes
### Overview
The diagram illustrates a decentralized food delivery workflow within the Agora subnetwork, emphasizing cryptographic verification via Proof of Delivery (PD) hashes. It shows interactions between a restaurant, delivery service, traffic service, and rider, with PD hashes ensuring trust at each stage.
### Components/Axes
- **Key Elements**:
- **Agora Subnetwork**: Centralized hub for PD hash negotiation (PD hash '123').
- **Restaurant**: Initiates order (PD hash '234' for food delivery).
- **Delivery Service**: Verifies traffic flow (PD hash '600') and rider availability.
- **Traffic Service**: Confirms traffic conditions via PD hash '600'.
- **Rider**: Completes delivery, triggering final PD confirmation.
- **Flow Direction**:
- Left-to-right progression: Restaurant → Delivery Service → Traffic Service → Rider.
- Circular feedback loops for PD verification at each step.
### Detailed Analysis
1. **Order Initiation**:
- Restaurant sends PD hash '234' to Agora subnetwork to negotiate food delivery.
- Agora subnetwork replies with PD hash '123' to confirm order.
2. **Traffic Flow Check**:
- Delivery service queries traffic service using PD hash '600'.
- Traffic service replies with PD confirming traffic flow.
3. **Rider Availability**:
- Delivery service checks rider availability via PD hash '600'.
- Rider confirms availability, triggering PD hash '600' response.
4. **Delivery Completion**:
- Rider delivers food, prompting PD hash '234' confirmation from delivery service.
- Final PD hash '600' confirms delivery completion.
### Key Observations
- **PD Hash Reuse**: PD hash '600' is reused for traffic flow and rider availability checks, suggesting a standardized verification mechanism.
- **Sequential Trust**: Each party (restaurant, delivery service, traffic service, rider) must validate their role via PD hashes before proceeding.
- **Cryptographic Security**: PD hashes act as immutable records, preventing tampering and ensuring accountability.
### Interpretation
This workflow demonstrates a trustless system where cryptographic proofs replace traditional intermediaries. The Agora subnetwork facilitates secure PD hash negotiation, while sequential PD checks ensure:
1. **Authenticity**: Each participant’s role is verified (e.g., rider availability).
2. **Transparency**: Traffic conditions and delivery status are publicly verifiable.
3. **Efficiency**: Automated PD exchanges reduce manual oversight, enabling real-time updates.
The reuse of PD hash '600' for multiple checks implies a modular design, where a single hash can validate multiple trust nodes (traffic, rider). This system could scale to other services (e.g., logistics) by extending PD hash applications.
</details>
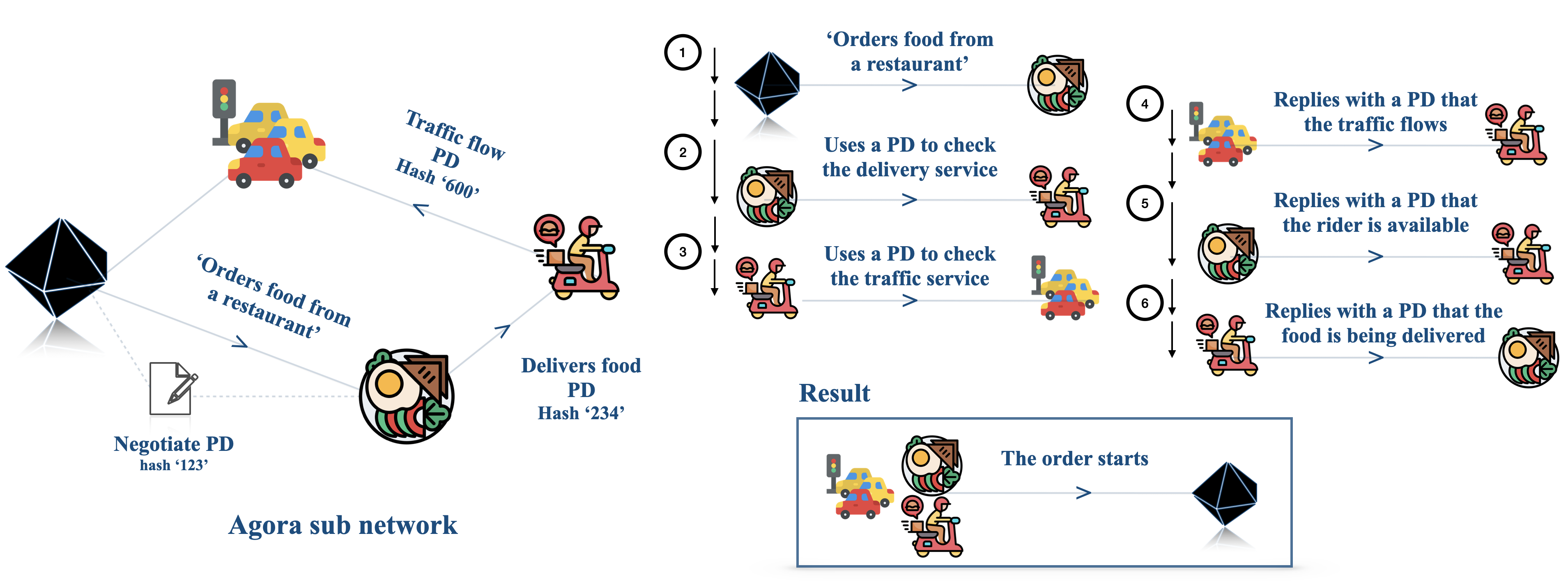
Figure 4: Illustration of how in an Agora network with $100$ agents (left; for clarity, only the relevant sub-network is displayed), an emergent protocol for food delivery emerges (right).
We now show the scaling capabilities and emergent behaviours of Agora by considering a network of 100 LLM-powered agents. In particular, we scale the number of agents, which, as posited in Chaabouni et al. (2022), is a requisite for the emergence of complex behaviours in multi-agent networks.
We design a network of $85$ assistant agents interacting with $15$ server agents, all powered by LLMs. The server agents offer various services, such as booking hotel rooms, calling taxis, ordering food, etc. An example of a sub-network for food delivery is sketched in Figure 4, left. Their specialisation is handled via prompting, as in Deshpande et al. (2023); Joshi et al. (2023); Li et al. (2023a). As part of their workflow, server agents must interact with several tools and databases; additionally, some servers need to interact with other servers to complete assistants’ requests (e.g., taxi services use the traffic data agent to adjust estimated fares for a run). We bootstrap the network by leveraging the underlying communication layer (as described in Section 4 and Figure 2) and inform the nodes of which URLs correspond to which node, as well as manually creating the connection links between agents (e.g. the Taxi Service server knows that the server on port 5007 is a traffic server, but it does not know how to communicate with it and what information it requires);
To showcase the portability of Agora throughout the network, we use different database technologies (SQL and MongoDB) and different LLMs, both open- and closed-source (GPT-4o, Llama-3-405B, and Gemini 1.5 Pro (Reid et al., 2024)). We then generate $1000$ random queries, which range from simple ones, such as requesting today’s weather, to more complex ones, like booking rooms in ski resorts, buying tickets for movies, ordering one of each dish from a menu, and so on. For each query, assistants receive a JSON document (which represents the task data) and are tasked with fulfilling the request and returning a parsed response that follows a given schema. Queries are distributed among assistants following a Pareto distribution, to simulate some assistants sending significantly more requests than others. Each node can also read and share PDs to one of three protocol databases. Overall, these design decisions result in a very heterogeneous network, testing the limits of Agora. Refer to Appendix D for further implementation details.
Emergent protocols in large networks.
Once the connections are established and the networks can send and receive messages, we observe several noteworthy behaviours. As PDs are progressively shared between agents (see Figure 5(b)), we observe the emergence of a decentralised consensus on the appropriate protocols for a given task. An example of this behaviour involves ordering food from restaurants: an agent queries another to request food to be delivered to a certain address. The restaurant agent requests a delivery driver from a food delivery service, who, in turn, checks with the traffic data agent to see if the traffic is smooth enough to fulfil the delivery. None of the agents know each other’s roles and the protocols involved beyond their immediate communication. Still, the interaction of the various agents creates an automated workflow that takes care of everything. The emergence of such a protocol is illustrated in Figure 4 (right). In contrast with some recent literature on the emergence of complex protocols (Chaabouni et al., 2019), we observe that with the proper incentives (i.e., efficiency), agents in Agora escape the inefficient trap of committing to longer messages in large scale communications.
A cost analysis.
We compare the cost of running our Agora network against one that uses natural language for all communications. As shown in Figure 5(a), at the beginning Agora’s cost-efficiency marginally outperforms the network that relies only on natural language; this gap increases over time, with progressively more Agora-powered nodes relying on LLM-written routines. The overall cost in API queries for running $1000$ queries in the natural language network is $36.23$ USD, compared to Agora’s $7.67$ USD: in other words, executing this demo with Agora is approximately five times cheaper than with regular natural language. Continuing the demo for more queries would have led to an even larger cost difference.
<details>
<summary>x1.png Details</summary>
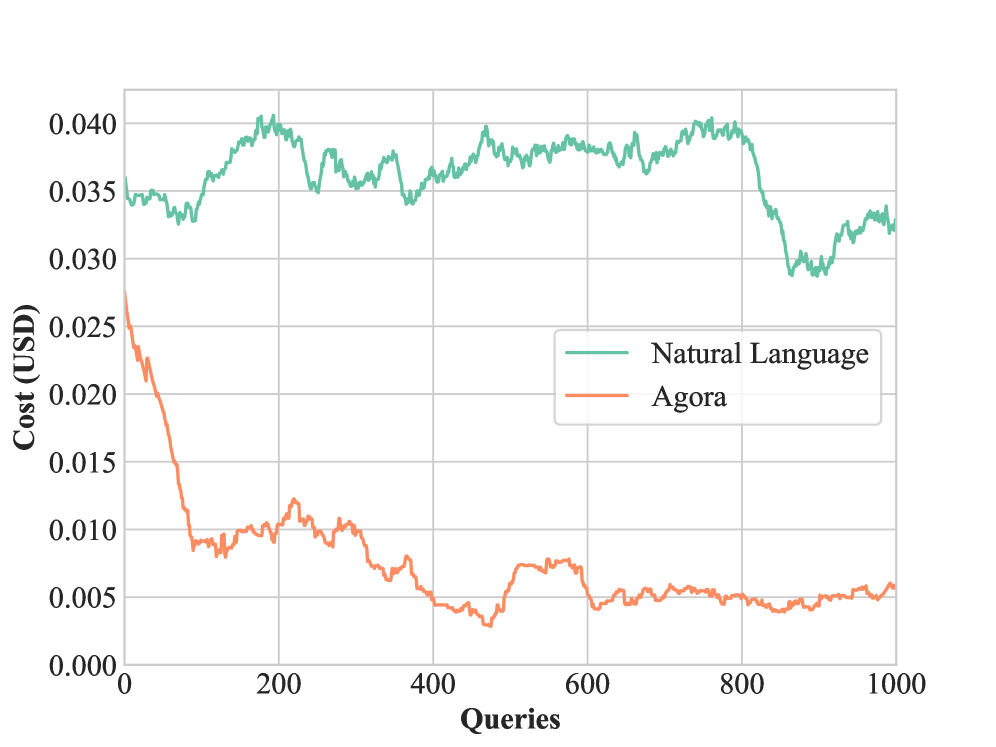
### Visual Description
## Line Graph: Cost Comparison of Natural Language and Agora Processing
### Overview
The graph compares the cost (in USD) of processing queries using two methods: "Natural Language" (teal line) and "Agora" (orange line) across 1,000 queries. The y-axis represents cost per query, while the x-axis represents the number of queries processed.
### Components/Axes
- **X-axis (Queries)**: Ranges from 0 to 1,000 in increments of 200.
- **Y-axis (Cost, USD)**: Ranges from 0.000 to 0.040 in increments of 0.005.
- **Legend**: Located in the bottom-right corner, with:
- Teal line labeled "Natural Language"
- Orange line labeled "Agora"
### Detailed Analysis
1. **Natural Language (Teal Line)**:
- Starts at ~0.035 USD/query.
- Peaks at ~0.040 USD/query near 200 queries.
- Experiences fluctuations but stabilizes around ~0.035 USD/query after 400 queries.
- Ends at ~0.033 USD/query at 1,000 queries.
2. **Agora (Orange Line)**:
- Begins at ~0.025 USD/query.
- Drops sharply to ~0.005 USD/query by 200 queries.
- Remains below 0.010 USD/query for the remainder of the graph.
- Ends at ~0.005 USD/query at 1,000 queries.
### Key Observations
- **Cost Disparity**: Natural Language consistently costs 3–8× more than Agora across all query volumes.
- **Agora Efficiency**: Agora’s cost plummets rapidly and stabilizes at a low value, suggesting scalability.
- **Natural Language Volatility**: Fluctuations in Natural Language’s cost may indicate variable processing demands or resource allocation.
### Interpretation
The data demonstrates that Agora is significantly more cost-effective for query processing, particularly at scale. Natural Language’s higher and more variable costs suggest it may require more computational resources or face inefficiencies in handling queries. The sharp decline in Agora’s cost implies optimized algorithms or infrastructure, making it preferable for high-volume applications. The lack of intersection between the lines confirms Natural Language remains the pricier option throughout.
</details>
(a) Cost comparison of natural language vs Agora on a network of $100$ agents. Costs are averaged with a window size of $100$ .
<details>
<summary>x2.png Details</summary>
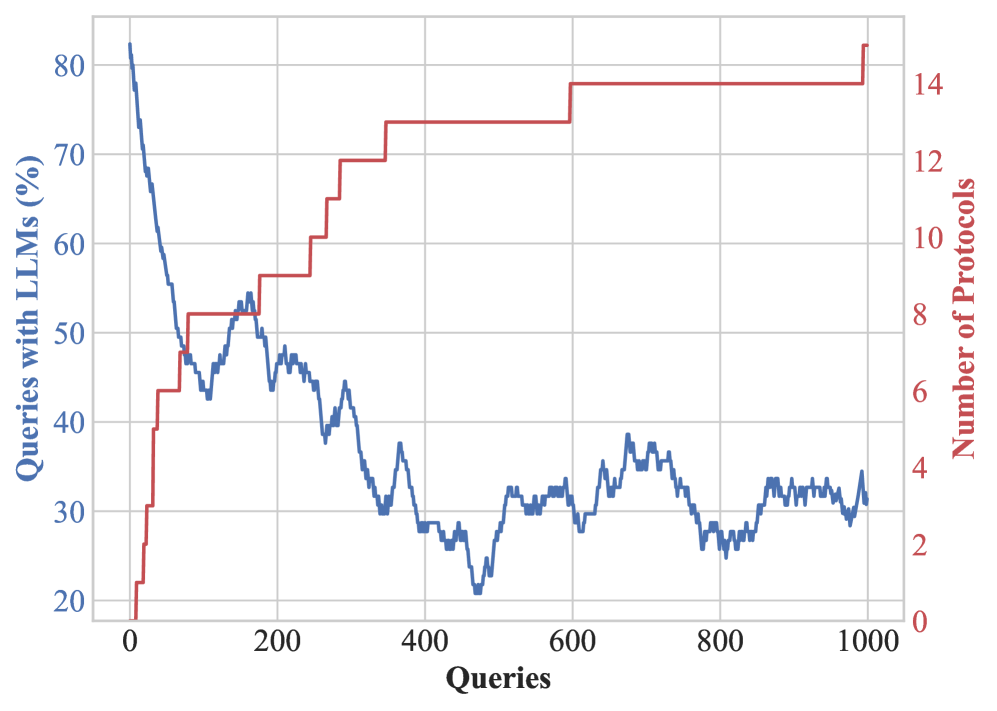
### Visual Description
## Line Graph: Queries with LLMs (%) vs. Number of Protocols
### Overview
The image is a dual-axis line graph comparing two metrics across 1,000 queries. The left y-axis represents "Queries with LLMs (%)" (blue line), and the right y-axis represents "Number of Protocols" (red line). The x-axis spans 0 to 1,000 queries.
### Components/Axes
- **X-axis**: Labeled "Queries" with increments of 200 (0, 200, 400, 600, 800, 1000).
- **Left Y-axis**: Labeled "Queries with LLMs (%)" with increments of 10% (20%, 30%, ..., 80%).
- **Right Y-axis**: Labeled "Number of Protocols" with increments of 2 (0, 2, 4, ..., 14).
- **Legend**: Positioned on the right side of the graph. Blue corresponds to "Queries with LLMs (%)", and red corresponds to "Number of Protocols".
### Detailed Analysis
1. **Blue Line (Queries with LLMs %)**:
- Starts at **80%** at 0 queries.
- Declines sharply to **~50%** by 200 queries.
- Continues a gradual decline to **~30%** by 1,000 queries.
- Notable fluctuations (e.g., minor spikes around 250 and 450 queries).
2. **Red Line (Number of Protocols)**:
- Starts at **~2 protocols** at 0 queries.
- Increases sharply to **~14 protocols** by 600 queries.
- Remains flat at **~14 protocols** from 600 to 1,000 queries.
- Sharp rise between 200–600 queries, with a plateau afterward.
### Key Observations
- **Inverse Relationship**: As the percentage of queries using LLMs decreases, the number of protocols increases.
- **Stabilization**: The number of protocols plateaus after 600 queries, suggesting a saturation point.
- **Volatility**: The blue line shows minor fluctuations, while the red line exhibits a sharp, linear rise followed by stability.
### Interpretation
The data suggests a trade-off between the adoption of LLMs and the proliferation of protocols. As queries with LLMs decline (possibly due to efficiency gains or alternative solutions), the number of protocols increases, potentially indicating a need for standardization or interoperability frameworks. The plateau in protocols after 600 queries implies that once a critical threshold is reached, additional queries do not drive further protocol development.
**Note**: There is a potential inconsistency in the red line’s values. The right y-axis is labeled "Number of Protocols" (0–14), but the red line’s values are described as percentages (20%–80%). This may indicate a mislabeling in the original image or a misinterpretation of the data. If the red line represents protocols, its values should align with the 0–14 scale, not percentages. Further verification of the data source is recommended.
</details>
(b) The number of queries to the LLMs in Agora decreases over time as the number of established PDs grows.
Figure 5: Summary of the efficiency of Agora for the demo with 100 agents.
6 Conclusions
In this paper, we introduced Agora, a meta protocol that sidesteps the Agent Communication Trilemma by using a mix of natural language and structured protocols. We showed that Agora agents can negotiate, implement and use protocols, creating self-organising networks that solve complex tasks. Additionally, we demonstrated the scalability of Agora by testing a $100$ -agent demo and achieving a five-fold reduction in costs compared to natural language-only communication. Our results showcase the power of negotiation as a basis for efficient, scalable, and decentralised agent networks. As LLMs continue to improve and as interactions between them increase, LLM-powered agent networks have the potential to surpass the scale limitations of single LLMs. Developing frameworks and protocols that enable decentralised, flexible and efficient communication, either through Agora or other technologies, can lay the foundations for a future where complex activities are partially, if not fully, automated by LLMs.
Acknowledgements
We thank the Alan Turing Institute for providing the computational power to run our agent network, as well as SambaNova for providing credits for our Llama 3 experiments. Samuele Marro is funded by Microsoft Research Ltd. Emanuele La Malfa is funded by the Alan Turing Institute. Jesse Wright is funded by the Department of Computer Science of the University of Oxford.
References
- Achiam et al. (2023) Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report. arXiv preprint arXiv:2303.08774, 2023.
- Agashe et al. (2023) Saaket Agashe, Yue Fan, and Xin Eric Wang. Evaluating multi-agent coordination abilities in large language models. arXiv preprint arXiv:2310.03903, 2023.
- Arulkumaran et al. (2017) Kai Arulkumaran, Marc Peter Deisenroth, Miles Brundage, and Anil Anthony Bharath. Deep reinforcement learning: A brief survey. IEEE Signal Processing Magazine, 34(6):26–38, 2017.
- Bakhtin et al. (2022) Anton Bakhtin, Noam Brown, Emily Dinan, Gabriele Farina, Colin Flaherty, Daniel Fried, Andrew Goff, Jonathan Gray, Meta Fundamental AI Research Diplomacy Team (FAIR)† Hu, Hengyuan, et al. Human-level play in the game of diplomacy by combining language models with strategic reasoning. Science, 378(6624):1067–1074, 2022.
- Beckett et al. (2014) David Beckett, Tim Berners-Lee, Eric Prud’hommeaux, and Gavin Carothers. Rdf 1.1 turtle. World Wide Web Consortium, 2014.
- Benet (2014) Juan Benet. Ipfs-content addressed, versioned, p2p file system. arXiv preprint arXiv:1407.3561, 2014.
- Berners-Lee et al. (2001) Tim Berners-Lee, James Hendler, and Ora Lassila. The semantic web. Scientific american, 284(5):34–43, 2001.
- Brown et al. (2020) Tom B. Brown, Benjamin Mann, Nick Ryder, et al. Language models are few-shot learners. In Advances in Neural Information Processing Systems 33: Annual Conference on Neural Information Processing Systems 2020, NeurIPS 2020, December 6-12, 2020, virtual, 2020. URL https://proceedings.neurips.cc/paper/2020/hash/1457c0d6bfcb4967418bfb8ac142f64a-Abstract.html.
- Chaabouni et al. (2019) Rahma Chaabouni, Eugene Kharitonov, Emmanuel Dupoux, and Marco Baroni. Anti-efficient encoding in emergent communication. Advances in Neural Information Processing Systems, 32, 2019.
- Chaabouni et al. (2022) Rahma Chaabouni, Florian Strub, Florent Altché, Eugene Tarassov, Corentin Tallec, Elnaz Davoodi, Kory Wallace Mathewson, Olivier Tieleman, Angeliki Lazaridou, and Bilal Piot. Emergent communication at scale. In International conference on learning representations, 2022.
- Chen et al. (2023) Huaben Chen, Wenkang Ji, Lufeng Xu, and Shiyu Zhao. Multi-agent consensus seeking via large language models. arXiv preprint arXiv:2310.20151, 2023.
- Chen et al. (2024) Yongchao Chen, Jacob Arkin, Yang Zhang, Nicholas Roy, and Chuchu Fan. Scalable multi-robot collaboration with large language models: Centralized or decentralized systems? In 2024 IEEE International Conference on Robotics and Automation (ICRA), pp. 4311–4317. IEEE, 2024.
- Collins et al. (2022) Katherine M Collins, Catherine Wong, Jiahai Feng, Megan Wei, and Joshua B Tenenbaum. Structured, flexible, and robust: benchmarking and improving large language models towards more human-like behavior in out-of-distribution reasoning tasks. arXiv preprint arXiv:2205.05718, 2022.
- Cross et al. (2024) Logan Cross, Violet Xiang, Agam Bhatia, Daniel LK Yamins, and Nick Haber. Hypothetical minds: Scaffolding theory of mind for multi-agent tasks with large language models. arXiv preprint arXiv:2407.07086, 2024.
- Deshpande et al. (2023) Ameet Deshpande, Vishvak Murahari, Tanmay Rajpurohit, Ashwin Kalyan, and Karthik Narasimhan. Toxicity in chatgpt: Analyzing persona-assigned language models. arXiv preprint arXiv:2304.05335, 2023.
- Du et al. (2023) Yilun Du, Shuang Li, Antonio Torralba, Joshua B Tenenbaum, and Igor Mordatch. Improving factuality and reasoning in language models through multiagent debate. arXiv preprint arXiv:2305.14325, 2023.
- Dubey et al. (2024a) Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Amy Yang, Angela Fan, Anirudh Goyal, Anthony Hartshorn, Aobo Yang, et al. The llama 3 herd of models. 2024a. URL https://api.semanticscholar.org/CorpusID:271571434.
- Dubey et al. (2024b) Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Amy Yang, Angela Fan, et al. The llama 3 herd of models. arXiv preprint arXiv:2407.21783, 2024b.
- Fedorenko et al. (2024) Evelina Fedorenko, Steven T. Piantadosi, and Edward A. F. Gibson. Language is primarily a tool for communication rather than thought. In Nature, pp. volume 630. Springer Nature, 2024.
- Fu et al. (2023) Yao Fu, Hao Peng, Tushar Khot, and Mirella Lapata. Improving language model negotiation with self-play and in-context learning from ai feedback. arXiv preprint arXiv:2305.10142, 2023.
- Gao et al. (2024) Chen Gao, Fengli Xu, Xu Chen, Xiang Wang, Xiangnan He, and Yong Li. Simulating human society with large language model agents: City, social media, and economic system. In Companion Proceedings of the ACM on Web Conference 2024, pp. 1290–1293, 2024.
- Gilbert (2019) Nigel Gilbert. Agent-based models. Sage Publications, 2019.
- Gilbert & Terna (2000) Nigel Gilbert and Pietro Terna. How to build and use agent-based models in social science. Mind & Society, 1:57–72, 2000.
- Guo et al. (2024) Taicheng Guo, Xiuying Chen, Yaqi Wang, Ruidi Chang, Shichao Pei, Nitesh V Chawla, Olaf Wiest, and Xiangliang Zhang. Large language model based multi-agents: A survey of progress and challenges. arXiv preprint arXiv:2402.01680, 2024.
- Havrylov & Titov (2017) Serhii Havrylov and Ivan Titov. Emergence of language with multi-agent games: Learning to communicate with sequences of symbols. Advances in neural information processing systems, 30, 2017.
- Henderson et al. (2018) Peter Henderson, Riashat Islam, Philip Bachman, Joelle Pineau, Doina Precup, and David Meger. Deep reinforcement learning that matters. In Proceedings of the AAAI conference on artificial intelligence, volume 32, 2018.
- Hong et al. (2023) Sirui Hong, Xiawu Zheng, Jonathan Chen, Yuheng Cheng, Jinlin Wang, Ceyao Zhang, Zili Wang, Steven Ka Shing Yau, Zijuan Lin, Liyang Zhou, et al. Metagpt: Meta programming for multi-agent collaborative framework. arXiv preprint arXiv:2308.00352, 2023.
- Horty (2001) John F Horty. Agency and deontic logic. Oxford University Press, 2001.
- Hou et al. (2023) Xinyi Hou, Yanjie Zhao, Yue Liu, Zhou Yang, Kailong Wang, Li Li, Xiapu Luo, David Lo, John Grundy, and Haoyu Wang. Large language models for software engineering: A systematic literature review. ACM Transactions on Software Engineering and Methodology, 2023.
- Hu et al. (2021) Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. Lora: Low-rank adaptation of large language models. arXiv preprint arXiv:2106.09685, 2021.
- Hua et al. (2023) Wenyue Hua, Lizhou Fan, Lingyao Li, Kai Mei, Jianchao Ji, Yingqiang Ge, Libby Hemphill, and Yongfeng Zhang. War and peace (waragent): Large language model-based multi-agent simulation of world wars. arXiv preprint arXiv:2311.17227, 2023.
- Jin et al. (2023) Bowen Jin, Gang Liu, Chi Han, Meng Jiang, Heng Ji, and Jiawei Han. Large language models on graphs: A comprehensive survey. arXiv preprint arXiv:2312.02783, 2023.
- Joshi et al. (2023) Nitish Joshi, Javier Rando, Abulhair Saparov, Najoung Kim, and He He. Personas as a way to model truthfulness in language models. arXiv preprint arXiv:2310.18168, 2023.
- Kaplan et al. (2020) Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei. Scaling laws for neural language models. arXiv preprint arXiv:2001.08361, 2020.
- Kassner et al. (2020) Nora Kassner, Benno Krojer, and Hinrich Schütze. Are pretrained language models symbolic reasoners over knowledge? arXiv preprint arXiv:2006.10413, 2020.
- La Malfa et al. (2023) Emanuele La Malfa, Aleksandar Petrov, Simon Frieder, Christoph Weinhuber, Ryan Burnell, Raza Nazar, Anthony G Cohn, Nigel Shadbolt, and Michael Wooldridge. Language models as a service: Overview of a new paradigm and its challenges. arXiv e-prints, pp. arXiv–2309, 2023.
- Lazaridou & Baroni (2020) Angeliki Lazaridou and Marco Baroni. Emergent multi-agent communication in the deep learning era. arXiv preprint arXiv:2006.02419, 2020.
- Lazaridou et al. (2018) Angeliki Lazaridou, Karl Moritz Hermann, Karl Tuyls, and Stephen Clark. Emergence of linguistic communication from referential games with symbolic and pixel input. arXiv preprint arXiv:1804.03984, 2018.
- Li et al. (2023a) Guohao Li, Hasan Hammoud, Hani Itani, Dmitrii Khizbullin, and Bernard Ghanem. Camel: Communicative agents for” mind” exploration of large language model society. Advances in Neural Information Processing Systems, 36:51991–52008, 2023a.
- Li et al. (2023b) Huao Li, Yu Quan Chong, Simon Stepputtis, Joseph Campbell, Dana Hughes, Michael Lewis, and Katia Sycara. Theory of mind for multi-agent collaboration via large language models. arXiv preprint arXiv:2310.10701, 2023b.
- Li et al. (2024) Junyou Li, Qin Zhang, Yangbin Yu, Qiang Fu, and Deheng Ye. More agents is all you need. arXiv preprint arXiv:2402.05120, 2024.
- Liang et al. (2023) Tian Liang, Zhiwei He, Wenxiang Jiao, Xing Wang, Yan Wang, Rui Wang, Yujiu Yang, Zhaopeng Tu, and Shuming Shi. Encouraging divergent thinking in large language models through multi-agent debate. arXiv preprint arXiv:2305.19118, 2023.
- Lin et al. (2024) Fangru Lin, Emanuele La Malfa, Valentin Hofmann, Elle Michelle Yang, Anthony Cohn, and Janet B Pierrehumbert. Graph-enhanced large language models in asynchronous plan reasoning. arXiv preprint arXiv:2402.02805, 2024.
- Liu et al. (2024) Jiawei Liu, Chunqiu Steven Xia, Yuyao Wang, and Lingming Zhang. Is your code generated by chatgpt really correct? rigorous evaluation of large language models for code generation. Advances in Neural Information Processing Systems, 36, 2024.
- OBL (2024) OBL. Open banking read write api profile v4.0. 2024. URL https://openbankinguk.github.io/read-write-api-site3/v4.0/profiles/read-write-data-api-profile.html.
- Olivé (2007) Antoni Olivé. Conceptual modeling of information systems. Springer Science & Business Media, 2007.
- Pang et al. (2024) Xianghe Pang, Shuo Tang, Rui Ye, Yuxin Xiong, Bolun Zhang, Yanfeng Wang, and Siheng Chen. Self-alignment of large language models via multi-agent social simulation. In ICLR 2024 Workshop on Large Language Model (LLM) Agents, 2024.
- Rafailov et al. (2024) Rafael Rafailov, Archit Sharma, Eric Mitchell, Christopher D Manning, Stefano Ermon, and Chelsea Finn. Direct preference optimization: Your language model is secretly a reward model. Advances in Neural Information Processing Systems, 36, 2024.
- Reid et al. (2024) Machel Reid, Nikolay Savinov, Denis Teplyashin, Dmitry Lepikhin, Timothy Lillicrap, Jean-baptiste Alayrac, Radu Soricut, Angeliki Lazaridou, Orhan Firat, Julian Schrittwieser, et al. Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context. arXiv preprint arXiv:2403.05530, 2024.
- Russell & Norvig (2016) Stuart J Russell and Peter Norvig. Artificial intelligence: a modern approach. Pearson, 2016.
- Schick et al. (2024) Timo Schick, Jane Dwivedi-Yu, Roberto Dessì, Roberta Raileanu, Maria Lomeli, Eric Hambro, Luke Zettlemoyer, Nicola Cancedda, and Thomas Scialom. Toolformer: Language models can teach themselves to use tools. Advances in Neural Information Processing Systems, 36, 2024.
- Schulman et al. (2017) John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms. arXiv preprint arXiv:1707.06347, 2017.
- Singh et al. (2024) Ishika Singh, David Traum, and Jesse Thomason. Twostep: Multi-agent task planning using classical planners and large language models. arXiv preprint arXiv:2403.17246, 2024.
- Song et al. (2023) Junghwan Song, Heeyoung Jung, Selin Chun, Hyunwoo Lee, Minhyeok Kang, Minkyung Park, Eunsang Cho, et al. How to decentralize the internet: A focus on data consolidation and user privacy. Computer Networks, 234:109911, 2023.
- Sutton (2018) Richard S Sutton. Reinforcement learning: An introduction. A Bradford Book, 2018.
- Vaswani et al. (2017) Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin. Attention is all you need. In Advances in Neural Information Processing Systems 30: 2017, December 4-9, 2017, Long Beach, CA, USA, pp. 5998–6008, 2017. URL https://proceedings.neurips.cc/paper/2017/hash/3f5ee243547dee91fbd053c1c4a845aa-Abstract.html.
- Wooldridge (2009) Michael Wooldridge. An introduction to multiagent systems. John wiley & sons, 2009.
- Wooldridge & Jennings (1995) Michael Wooldridge and Nicholas R Jennings. Intelligent agents: Theory and practice. The knowledge engineering review, 10(2):115–152, 1995.
- Wu et al. (2024a) Shuang Wu, Liwen Zhu, Tao Yang, Shiwei Xu, Qiang Fu, Yang Wei, and Haobo Fu. Enhance reasoning for large language models in the game werewolf. arXiv preprint arXiv:2402.02330, 2024a.
- Wu et al. (2024b) Zengqing Wu, Shuyuan Zheng, Qianying Liu, Xu Han, Brian Inhyuk Kwon, Makoto Onizuka, Shaojie Tang, Run Peng, and Chuan Xiao. Shall we talk: Exploring spontaneous collaborations of competing llm agents. arXiv preprint arXiv:2402.12327, 2024b.
- Zhang et al. (2024) Biao Zhang, Zhongtao Liu, Colin Cherry, and Orhan Firat. When scaling meets llm finetuning: The effect of data, model and finetuning method. arXiv preprint arXiv:2402.17193, 2024.
Appendix A Agora: Use Cases
S1. Agora as a personal assistant.
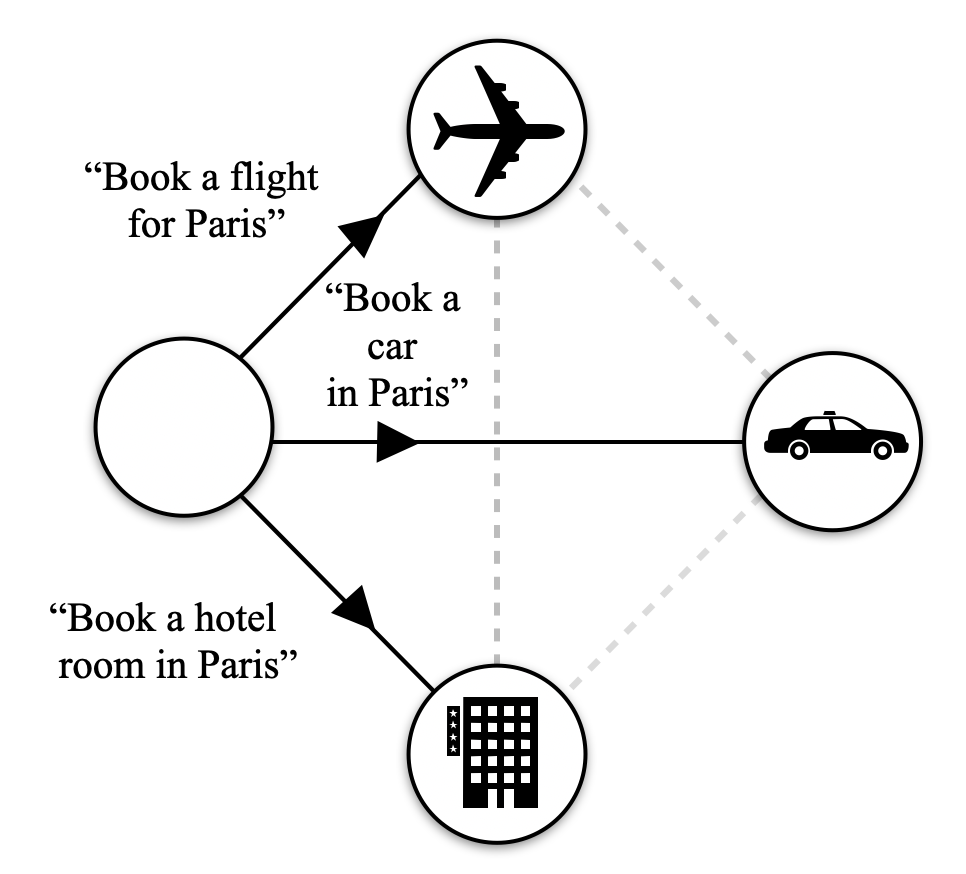
A user is organising a trip to Paris: they want to book a flight, rent a car, and book a hotel room.
The LLM reads the prompt, identifies the actions it has to undertake and checks if there are LLMs available in Agora who can fulfil it. For each service, an LLM is ready to reply.
1. A user sends a message to its personal assistant. 2. The personal assistant dispatches it to Agora.
<details>
<summary>img/scenarios/s1-1.png Details</summary>

### Visual Description
## Flowchart: User Request Dispatch to LLM Assistant Services
### Overview
The image depicts a user interface interaction flow where a user's request to book travel services (flight, hotel, car) is processed and dispatched to corresponding service providers via an LLM assistant. The diagram uses color-coded text, icons, and a flowchart structure to represent the workflow.
### Components/Axes
1. **Left Panel**:
- **User Interface**: Silhouette of a human head facing a smartphone.
- **Text Input**: Message on the smartphone screen:
`"I want to book a flight, a hotel and a car for next week in Paris."`
- Color-coded keywords:
- `flight` (blue)
- `hotel` (orange)
- `car` (red)
- **Dispatch Instruction**: Arrow labeled `"Dispatch to the LLMs’ assistant"` pointing right.
2. **Right Panel (Flowchart)**:
- **Structure**: Diamond-shaped flowchart with four interconnected nodes.
- **Nodes**:
- **Top Node**: Airplane icon (flight service).
- **Right Node**: Car icon (car rental service).
- **Bottom Node**: Building icon (hotel service).
- **Left Node**: Blank (unlabeled, possibly a placeholder or error).
- **Connections**: Lines link all nodes, suggesting parallel processing or interdependencies.
### Detailed Analysis
- **Textual Content**:
The user’s request explicitly mentions three services (`flight`, `hotel`, `car`), each highlighted in distinct colors (blue, orange, red). The LLM assistant is tasked with dispatching these requests to the corresponding services. The blank node introduces ambiguity, as it lacks an icon or label, potentially indicating an unassigned or unspecified service.
- **Flowchart Dynamics**:
The diamond structure implies a centralized dispatch mechanism (LLM assistant) routing requests to multiple services simultaneously. The absence of a clear start/end point suggests a continuous or iterative process.
### Key Observations
1. **Color-Coded Prioritization**:
The use of distinct colors for service types (`flight`, `hotel`, `car`) may indicate categorization or prioritization logic within the LLM’s processing pipeline.
2. **Blank Node Anomaly**:
The unlabeled node disrupts the symmetry of the flowchart and raises questions about incomplete service mapping or a design oversight.
3. **Parallel Processing**:
The interconnected nodes suggest the LLM assistant handles multiple service requests concurrently rather than sequentially.
### Interpretation
The diagram illustrates a modular service dispatch system where user intents are parsed and routed to specialized providers. The color-coding of keywords likely aids the LLM in identifying service categories, while the flowchart visualizes the system’s architecture. The blank node highlights a potential gap in service coverage or a need for error handling. This workflow emphasizes automation and scalability, critical for real-time travel booking systems. The absence of explicit time or cost data suggests the focus is on routing efficiency rather than financial or temporal optimization.
</details>
The LLM that acts as personal assistant in the network dispatches the flight, hotel and car requests to the respective LLMs in the network. The messages are dispatched in natural language as there are no pre-existing routines to handle them.
1. The LLM personal assistant dispatches the respective messages to the right node. 2. The car, hotel, and flight LLMs process the requests and turn them into queries for their booking systems. 3. Each LLM replies with their availability and options.
<details>
<summary>img/scenarios/s1-2.png Details</summary>
### Visual Description
## Flowchart: Travel Booking Process for Paris
### Overview
The image depicts a flowchart illustrating a travel booking process centered around Paris. It consists of three primary components connected to a central node, with directional arrows indicating sequential or conditional relationships. The flowchart uses icons to represent transportation and accommodation services.
### Components/Axes
1. **Central Node**: Unlabeled, acts as the origin point for all actions.
2. **Flight Booking**:
- Icon: Airplane
- Label: "Book a flight for Paris"
- Connection: Solid arrow from central node
3. **Car Rental**:
- Icon: Car
- Label: "Book a car in Paris"
- Connection: Solid arrow from central node
4. **Hotel Booking**:
- Icon: Building
- Label: "Book a hotel room in Paris"
- Connection: Solid arrow from central node
5. **Dashed Connection**: A dotted line links the car rental and hotel booking nodes, suggesting an optional or alternative pathway.
### Detailed Analysis
- **Textual Labels**: All actions are enclosed in quotation marks, indicating they are commands or steps within a process.
- **Spatial Relationships**:
- The central node is positioned at the geometric center of the diagram.
- Flight, car, and hotel nodes are arranged in a triangular formation around the central node.
- The dashed line between car and hotel nodes forms a secondary connection, creating a triangular sub-network.
### Key Observations
1. **Mandatory Pathways**: All three booking actions (flight, car, hotel) are directly connected to the central node via solid arrows, implying they are primary options.
2. **Optional Pathway**: The dashed line between car and hotel nodes suggests these two services may be conditionally linked (e.g., "If you book a car, you might also book a hotel").
3. **Iconography**:
- Airplane icon aligns with flight booking.
- Car icon aligns with car rental.
- Building icon (with window details) aligns with hotel accommodation.
### Interpretation
This flowchart represents a decision tree for organizing travel to Paris. The central node likely represents a user, travel agency, or booking system initiating the process. The solid arrows indicate core services that must be addressed, while the dashed line implies a secondary, possibly optional relationship between car rental and hotel booking. The use of quotation marks around each action emphasizes their role as discrete, executable steps within a larger workflow. The diagram does not include numerical data or probabilistic elements, focusing instead on structural relationships between travel components.
</details>
For the next iterations, the LLMs involved in the request propose a routine to standardise the requests to avoid natural language and process the request without invoking the LLMs.
<details>
<summary>img/scenarios/s1-3.png Details</summary>
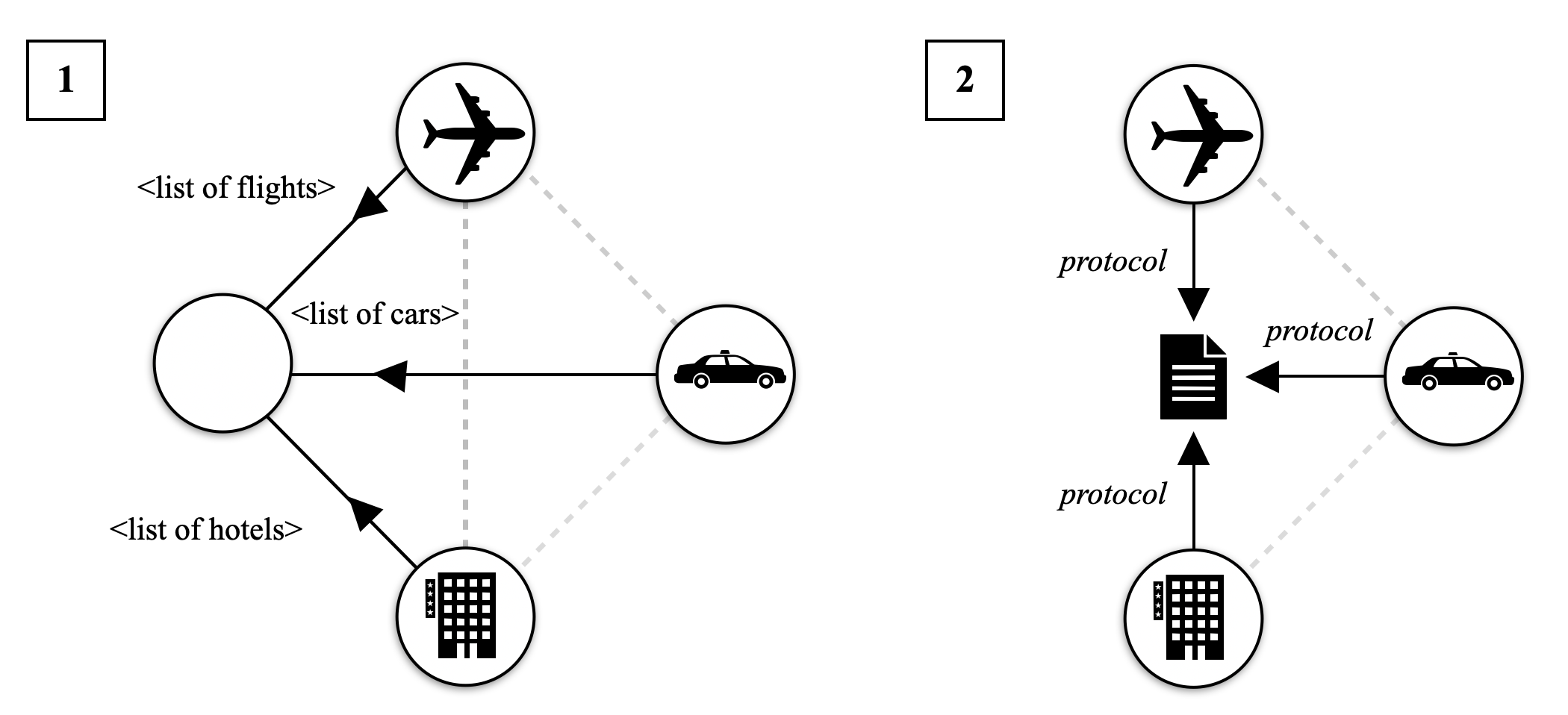
### Visual Description
## Diagram: Service Interaction Architecture
### Overview
The image contains two labeled diagrams (1 and 2) depicting a system architecture with interconnected components. Diagram 1 shows a central node connected to three service nodes (airplane, car, hotel) via labeled arrows. Diagram 2 introduces a "protocol" document as a central node with bidirectional dashed arrows to the same service nodes.
### Components/Axes
- **Diagram 1**:
- **Central Node**: Unlabeled, acts as a hub.
- **Service Nodes**:
- Airplane (icon: airplane)
- Car (icon: car)
- Hotel (icon: building)
- **Arrows**:
- Solid black arrows from the central node to each service node.
- Labels on arrows:
- `<list of flights>` (to airplane)
- `<list of cars>` (to car)
- `<list of hotels>` (to hotel)
- **Diagram 2**:
- **Central Node**: Labeled "protocol" (icon: document).
- **Service Nodes**: Same as Diagram 1 (airplane, car, hotel).
- **Arrows**:
- Dashed gray arrows connecting the protocol node to each service node.
- Labels on arrows: "protocol" (bidirectional).
### Detailed Analysis
- **Diagram 1**:
- The central node distributes three distinct data lists (`<list of flights>`, `<list of cars>`, `<list of hotels>`) to their respective service nodes.
- Arrows are unidirectional, suggesting a one-way flow of information from the central node to services.
- **Diagram 2**:
- The "protocol" document serves as a mediator, with bidirectional dashed arrows to all service nodes.
- Dashed arrows imply optional, indirect, or governance-related interactions rather than direct data exchange.
### Key Observations
1. **Centralization**: Both diagrams emphasize a central node (either the hub or protocol document) as the focal point of interactions.
2. **Data Flow**: Diagram 1 focuses on data distribution, while Diagram 2 emphasizes governance or standardization via protocols.
3. **Dashed vs. Solid Arrows**: Solid arrows in Diagram 1 suggest mandatory data exchange, whereas dashed arrows in Diagram 2 indicate advisory or optional relationships.
### Interpretation
- **System Functionality**:
- Diagram 1 likely represents a travel booking system where a central agency provides curated lists of flights, cars, and hotels to users or downstream services.
- Diagram 2 introduces a protocol layer, suggesting standardized rules or agreements governing interactions between the central system and external services (e.g., API specifications, data formats).
- **Relationships**:
- The protocol document in Diagram 2 acts as a bridge, ensuring consistency across services. For example, flight booking protocols might dictate how flight data is structured or validated.
- Dashed arrows could represent feedback loops or compliance checks (e.g., hotels adhering to protocol standards).
- **Anomalies/Outliers**:
- No explicit outliers, but the shift from solid to dashed arrows between diagrams highlights a conceptual transition from data provision to governance.
- **Underlying Logic**:
- The architecture prioritizes modularity, with services (airplane, car, hotel) operating independently but governed by shared protocols.
- The central node in Diagram 1 may represent a database or API gateway, while the protocol node in Diagram 2 could symbolize a rule engine or compliance framework.
</details>
The user receives all the data and decides whether to book or not.
S2. Security and scalability.
An LLM (Alice) collects some historical data from another LLM (Bob) that has access to a database whose internal mechanism and implementation are to keep private.
Alice submits a request to collect some historical records from Bob. The request is formatted in natural language.
<details>
<summary>img/scenarios/s2-1.png Details</summary>
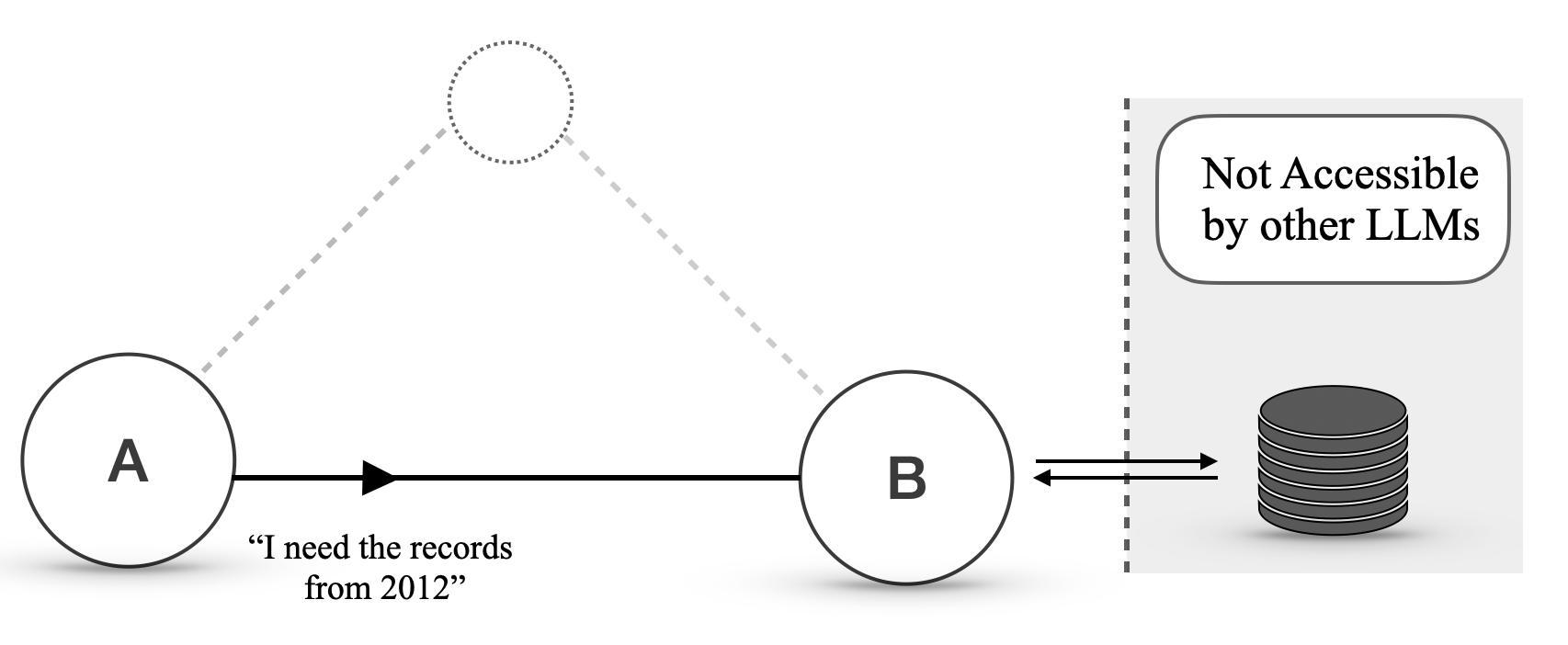
### Visual Description
## Diagram: Data Flow and Accessibility Between Components A, B, and a Stack of Disks
### Overview
The diagram illustrates a data flow system involving three primary components:
1. **Circle A** (left) with text: *"I need the records from 2012"*.
2. **Circle B** (center-right) connected to A via a solid arrow.
3. A **stack of disks** (right) labeled *"Not Accessible by other LLMs"*.
A dotted line connects an unlabeled third circle (top-center) to both A and B, suggesting an indirect or optional relationship.
### Components/Axes
- **Circles**:
- **A**: Contains textual request for 2012 records.
- **B**: Intermediate node in the data flow.
- **Unlabeled Circle**: Connected via dotted lines to A and B.
- **Arrows**:
- Solid arrow from A → B (unidirectional flow).
- Bidirectional arrows between B and the stack of disks.
- Dotted lines from the unlabeled circle to A and B.
- **Stack of Disks**:
- Labeled *"Not Accessible by other LLMs"*.
- Positioned to the right of B, separated by a dashed vertical boundary.
### Detailed Analysis
- **Textual Content**:
- Circle A explicitly states a need for historical records ("from 2012"), implying a query or data retrieval action.
- The stack of disks is explicitly restricted in accessibility, suggesting it contains sensitive or privileged data.
- **Flow Dynamics**:
- Data flows from A to B, then interacts bidirectionally with the stack.
- The unlabeled circle’s dotted connections may represent auxiliary or conditional interactions (e.g., oversight, logging, or fallback mechanisms).
### Key Observations
1. **Access Restriction**: The stack’s label emphasizes exclusivity, implying B (and possibly A via the dotted line) has privileged access.
2. **Temporal Specificity**: A’s request for 2012 records introduces a time-bound dependency, potentially critical for the system’s purpose.
3. **Bidirectional Interaction**: B’s two-way connection to the stack suggests it acts as a mediator or gateway for the stack’s data.
### Interpretation
- **Functional Role of B**: B serves as a central hub, processing requests from A and managing interactions with the restricted stack. This positions B as a critical node for data integrity and access control.
- **Implications of Accessibility**: The stack’s restriction highlights security or compliance requirements, possibly indicating that other LLMs (Language Learning Models) lack authorization to interact with it.
- **Unlabeled Circle’s Purpose**: The dotted lines suggest the unlabeled circle may represent an external system, audit trail, or error-handling mechanism that influences A and B’s operations.
This diagram likely models a workflow where historical data retrieval (A) triggers a process (B) that interacts with a secure, isolated data repository (stack), emphasizing controlled access and temporal specificity.
</details>
Alice submits another request to Bob.
Bob negotiates a protocol to query its data and writes a shared document protocol in JSON.
<details>
<summary>img/scenarios/s2-2.png Details</summary>
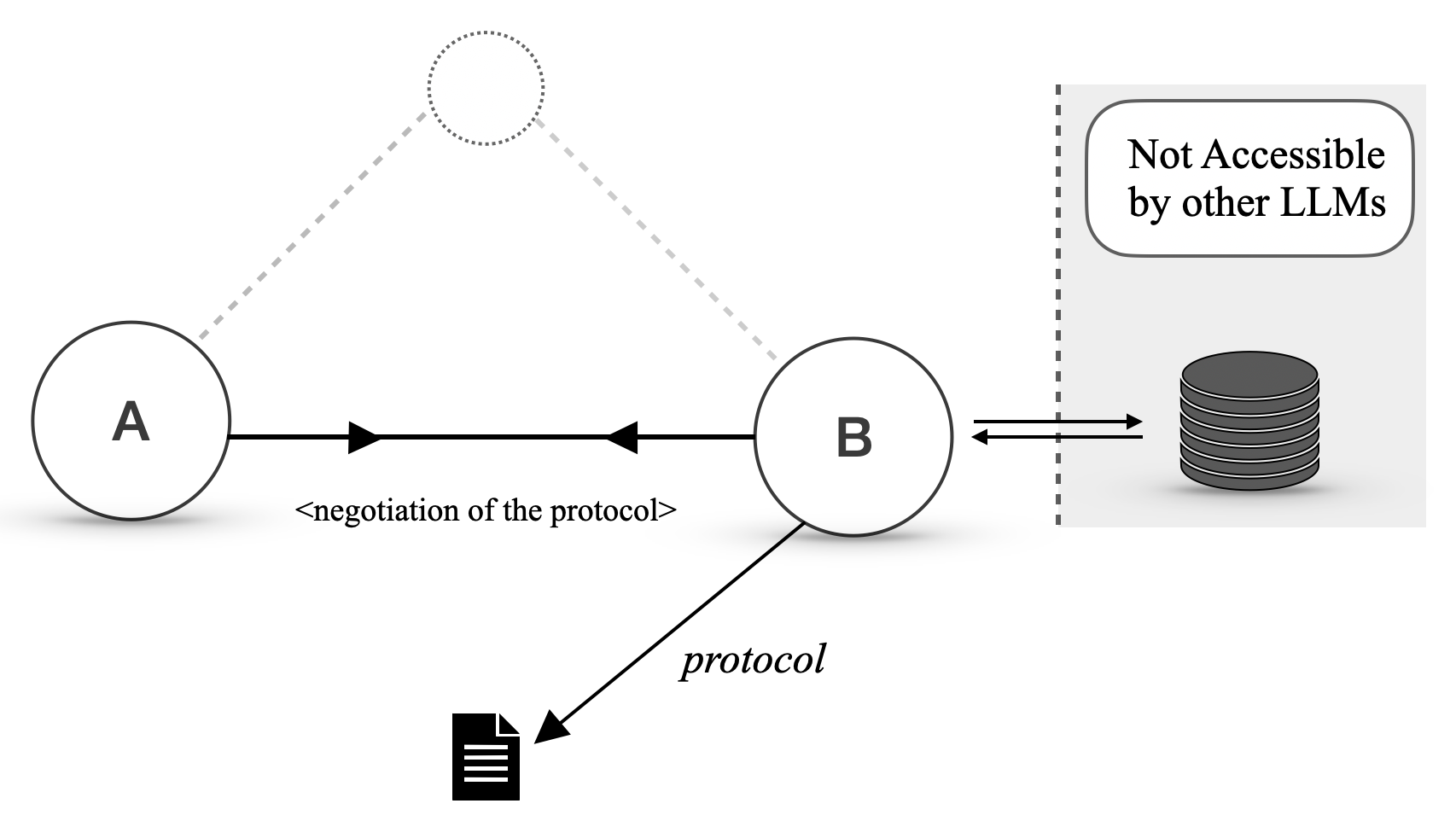
### Visual Description
## System Interaction Diagram: Protocol Negotiation and Data Access Control
### Overview
The diagram illustrates a technical interaction between two components (A and B) involving protocol negotiation and data exchange. A third element, a database stack, is marked as "Not Accessible by other LLMs," indicating restricted access. The flow includes bidirectional communication between A and B, a protocol document, and a unidirectional connection to the database.
### Components/Axes
1. **Nodes**:
- **A**: Leftmost circle labeled "A"
- **B**: Rightmost circle labeled "B"
- **Database**: Stack of disks labeled "Not Accessible by other LLMs"
2. **Connectors**:
- **Bidirectional Arrow**: Between A and B, labeled "<negotiation of the protocol>"
- **Unidirectional Arrow**: From B to the database
- **Dashed Lines**: Connecting A and B to an unlabeled central node (possibly a mediator or shared resource)
3. **Symbols**:
- **Document Icon**: Labeled "protocol" pointing to B
### Detailed Analysis
- **Protocol Negotiation**: The bidirectional arrow between A and B suggests a mutual exchange of protocol definitions or parameters. The label "<negotiation of the protocol>" implies dynamic adjustment or agreement on communication standards.
- **Data Flow**: The unidirectional arrow from B to the database indicates that B transmits data to the database after protocol negotiation. The database’s inaccessibility to other LLMs implies encryption, access controls, or proprietary formatting.
- **Dashed Lines**: These may represent indirect dependencies (e.g., shared libraries, environmental variables) or non-critical interactions between A and B.
### Key Observations
1. **Exclusivity**: The database’s restriction to "other LLMs" suggests A and B operate within a closed ecosystem, prioritizing data privacy or security.
2. **Negotiation Dependency**: The protocol negotiation is central to the interaction, acting as a gatekeeper for subsequent data exchange.
3. **Unidirectional Data Transfer**: Data flows only from B to the database, not vice versa, indicating a one-way submission or logging process.
### Interpretation
This diagram likely represents a secure data pipeline where components A and B must first agree on a protocol before B can submit data to a restricted database. The exclusivity of the database implies that A and B are part of a specialized system (e.g., a private AI model or compliance-driven application) where external LLMs (e.g., third-party models) are barred from accessing sensitive data. The dashed lines hint at shared infrastructure or dependencies that enable the negotiation process but are not part of the core data flow. The absence of feedback loops or error-handling mechanisms suggests a simplified or idealized representation of the system.
</details>
Alice now uses the protocol to query data from Bob.
Bob directly turns the JSON they receives from Alice into a query for its Database. In this way: Bob does not invoke the LLM and the database internals are not exposed.
<details>
<summary>img/scenarios/s2-3.png Details</summary>
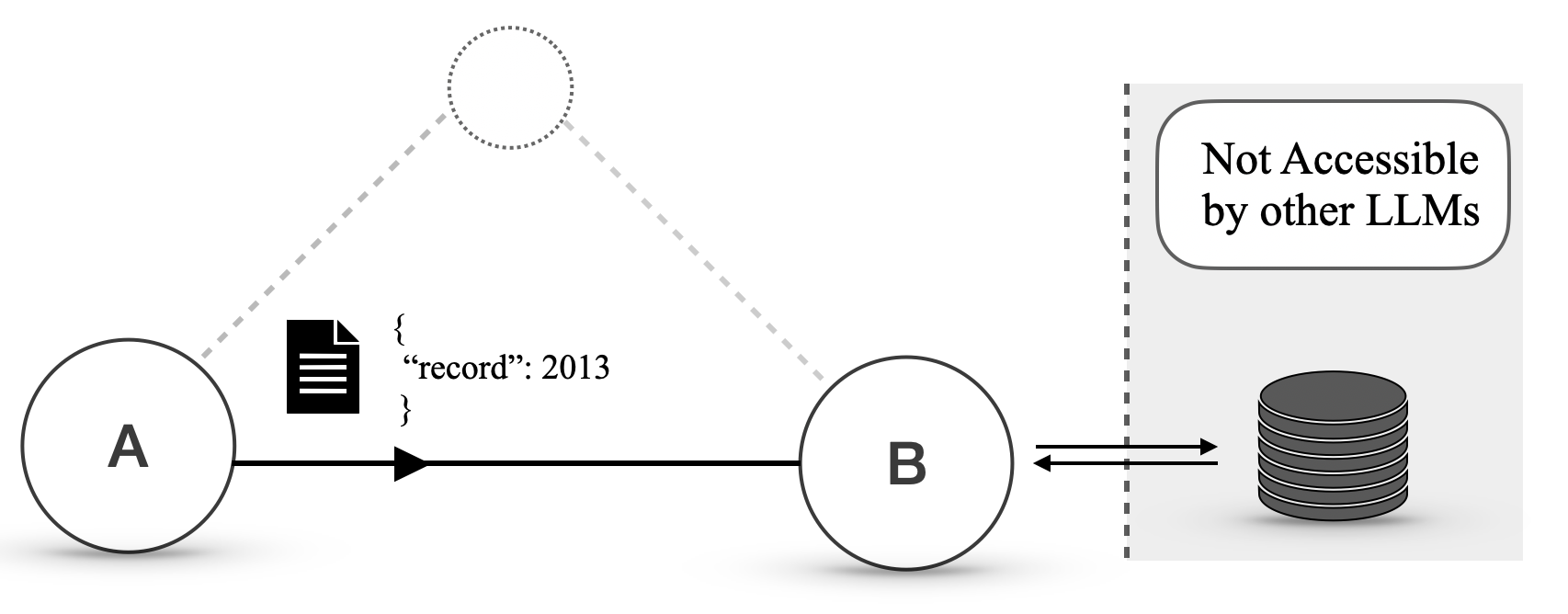
### Visual Description
## Diagram: Data Flow and Accessibility Between Components A, B, and a Restricted Data Stack
### Overview
The diagram illustrates a data flow system involving three primary components:
1. **Circle A** (left)
2. **Circle B** (right)
3. A **stack of disks** (rightmost, labeled "Not Accessible by other LLMs")
A third unlabeled circle (top-center) connects to the stack via a dashed line. Arrows indicate directional relationships, with a document icon labeled `{ "record": 2013 }` bridging A and B.
---
### Components/Axes
- **Circles A and B**:
- Labeled with uppercase letters "A" and "B" in black text.
- Connected by a solid black arrow pointing from A to B.
- **Document Icon**:
- Positioned between A and B, containing the text `{ "record": 2013 }`.
- Represents a data payload or record from the year 2013.
- **Third Circle (Top-Center)**:
- Unlabeled, connected to the stack via a **dashed gray line**.
- Implies a non-direct or conditional relationship.
- **Stack of Disks**:
- Located on the far right, labeled "Not Accessible by other LLMs" in a gray box.
- Rendered as five stacked gray disks with white outlines.
- **Arrows**:
- Solid black arrow from A to B.
- Dashed gray arrow from the third circle to the stack.
---
### Detailed Analysis
- **Data Flow**:
- A → B: A direct, unidirectional transfer of data (via the document icon) from A to B.
- B → Stack: A bidirectional arrow suggests B interacts with the stack, but the stack’s inaccessibility label implies restricted access.
- **Dashed Line**:
- The third circle’s connection to the stack is indirect, possibly indicating a secondary or optional pathway.
- **Temporal Context**:
- The document’s "record": 2013 suggests historical data is central to the interaction between A and B.
---
### Key Observations
1. **Restricted Access**: The stack’s label explicitly states it is inaccessible to "other LLMs," implying A and B may have privileged access.
2. **Historical Data**: The 2013 record is a critical node in the A→B interaction.
3. **Dashed Connection**: The third circle’s relationship to the stack is ambiguous but likely non-primary.
---
### Interpretation
This diagram likely models a system where:
- **A and B** are core components exchanging historical data (2013 record).
- The **stack of disks** represents a restricted resource (e.g., proprietary data, legacy systems) inaccessible to external LLMs.
- The **third circle** may symbolize an external or auxiliary system that indirectly interacts with the stack but lacks direct access.
The solid arrow from A to B emphasizes a primary data pathway, while the dashed line to the stack highlights limitations in accessibility. The 2013 record’s prominence suggests it is a foundational dataset enabling A and B’s interaction, despite the stack’s restricted nature.
</details>
S3. Compositional tasks.
An LLM (Alice) wants to (1) analyse some market data and then (2) compute some metrics. Two LLMs in the network can do that.
1. Alice retrieves the protocol documents from a database. 2. Alice finds out that there are two protocol documents that can be used to achieve its goal.
<details>
<summary>img/scenarios/s3-1.png Details</summary>
### Visual Description
## Flowchart: Protocol Document Processing Workflow
### Overview
The image depicts a flowchart with three primary components:
1. **Document Check**: Three document icons labeled "Check if a protocol document exists"
2. **Central Processing Node**: A circle labeled "A"
3. **Calculation Module**: A calculator icon
Dashed arrows connect these elements, suggesting conditional or iterative relationships.
### Components/Axes
- **Top Row**: Three document icons (black with white text)
- Label: "Check if a protocol document exists"
- Arrows: Vertical bidirectional arrows connecting documents to circle "A"
- **Center**: Circle labeled "A"
- Dashed arrows connect to:
- Stack of disks (symbolizing data storage/processing)
- Calculator icon (symbolizing computation)
- **Bottom Right**: Calculator icon
- Label: "Retrieve some numerical data and compute some metrics"
### Detailed Analysis
- **Document Check**:
- Three identical document icons represent protocol document verification.
- Bidirectional arrows imply potential feedback loops (e.g., document validation may require rechecking).
- **Central Node "A"**:
- Acts as a decision/processing hub.
- Dashed arrows to disks and calculator suggest conditional execution (e.g., "A" determines whether to proceed to storage or computation).
- **Calculator Module**:
- Explicitly tied to numerical data retrieval and metric computation.
### Key Observations
- **Conditional Flow**: The dashed arrows indicate optional or probabilistic steps (e.g., computation may only occur if certain conditions in "A" are met).
- **Data Dependency**: The stack of disks (data storage) is linked to "A," implying data retrieval precedes computation.
- **No Numerical Data**: The flowchart lacks quantitative values, focusing on process logic rather than metrics.
### Interpretation
This flowchart outlines a protocol-driven workflow:
1. **Document Validation**: Ensures compliance or correctness of input documents.
2. **Central Decision ("A")**: Determines next steps (e.g., data storage vs. computation).
3. **Metric Computation**: Final step for generating numerical outputs.
The use of dashed arrows suggests flexibility, allowing the process to adapt based on document validity or intermediate results. The absence of explicit numerical thresholds implies the workflow is designed for general protocol adherence rather than specific quantitative analysis.
</details>
1. Alice submits a request to the first agent to retrieve the data using the first protocol document. 2. Alice receives the data as expected.
<details>
<summary>img/scenarios/s3-2.png Details</summary>
### Visual Description
## Diagram: Data Processing Flow with Two Input Methods
### Overview
The image depicts a two-part technical diagram illustrating data flow from a source labeled "A" to a stack of disks. Two distinct input methods are shown:
1. **Section 1**: A document icon (representing structured data) transfers information to the disks via an arrow.
2. **Section 2**: A scatter plot (representing unstructured or variable data) transfers information to the disks via an arrow.
### Components/Axes
- **Labels**:
- Two circles labeled "A" (source of data).
- Two stacks of disks (destination for processed data).
- Section labels "1" (top-left) and "2" (bottom-right).
- **Icons**:
- Document icon (Section 1): Represents structured data (e.g., text, files).
- Scatter plot icon (Section 2): Represents unstructured or variable data (e.g., measurements, observations).
- **Arrows**:
- Black arrows indicate directional flow from "A" to the disks.
### Detailed Analysis
- **Section 1**:
- A document icon (black with white text lines) points to a stack of disks.
- No numerical values or axis markers present.
- **Section 2**:
- A scatter plot icon (black with five white dots) points to a stack of disks.
- No numerical values or axis markers present.
### Key Observations
1. Both sections share identical disk stacks, suggesting a common destination for processed data.
2. The document icon (Section 1) implies structured data input, while the scatter plot (Section 2) implies unstructured or variable data input.
3. No quantitative data (e.g., values, scales) is provided in the diagram.
### Interpretation
The diagram likely represents two methods of data ingestion or processing:
- **Structured Data (Section 1)**: Direct transfer of organized information (e.g., documents, files) to storage (disks).
- **Unstructured Data (Section 2)**: Transfer of variable or observational data (e.g., measurements, sensor readings) to storage.
- The identical disk stacks in both sections suggest that both data types are ultimately stored or processed in the same system, though their input methods differ.
No numerical trends, outliers, or anomalies can be identified due to the absence of quantitative data. The diagram emphasizes the relationship between data sources (A) and storage (disks) via distinct input mechanisms.
</details>
1. Alice submits a request to the second LLM to compute some metrics on the data using the second protocol document. 2. Alice receives the metrics as expected.
<details>
<summary>img/scenarios/s3-3.png Details</summary>
### Visual Description
## Diagram: Data Processing Workflow
### Overview
The image depicts two sequential diagrams (labeled "1" and "2") illustrating a data processing workflow. Both diagrams feature a central circle labeled "A" connected via arrows to a calculator icon, with distinct input elements preceding the calculator in each case.
### Components/Axes
1. **Diagram 1 (Top)**:
- **Input Elements**:
- A document icon (text-based data).
- A scatter plot (discrete data points).
- **Process**:
- A bidirectional arrow connects the document icon and scatter plot to circle "A".
- A unidirectional arrow links circle "A" to a calculator icon.
- **Labels**:
- "1" (top-left corner).
- "A" (center of the first circle).
2. **Diagram 2 (Bottom)**:
- **Input Element**:
- A bar chart (aggregated data).
- **Process**:
- A unidirectional arrow connects the bar chart directly to circle "A".
- A unidirectional arrow links circle "A" to the same calculator icon as in Diagram 1.
- **Labels**:
- "2" (bottom-left corner).
- "A" (center of the second circle).
### Detailed Analysis
- **Diagram 1**: Combines raw text data (document) and unstructured numerical data (scatter plot) as inputs to circle "A", which then feeds into the calculator.
- **Diagram 2**: Uses structured numerical data (bar chart) as input to circle "A", which also feeds into the calculator.
- **Calculator Icon**: Appears in both diagrams, suggesting it is the endpoint for computational analysis regardless of input type.
### Key Observations
1. **Consistency in Output**: Both diagrams converge on the calculator, implying it performs a unified computational role (e.g., calculations, analysis).
2. **Input Variability**: Diagram 1 handles unstructured data (text + scatter), while Diagram 2 uses structured data (bar chart), highlighting adaptability in the workflow.
3. **Directionality**: Arrows enforce a strict sequence: inputs → circle "A" → calculator.
### Interpretation
This workflow likely represents a system for processing diverse data types (text, raw numerical, aggregated numerical) through a central processing node ("A") before computational analysis. The calculator’s dual appearance suggests it is the final step for deriving insights or results. The use of "A" as a intermediary node may indicate preprocessing, validation, or transformation of data before computation. The diagrams emphasize flexibility in handling different data formats while maintaining a standardized output process.
</details>
S4. Scalable consensus in large networks.
An LLM (Alice) wants to collect and aggregate data points from $N\gg 1$ resources. There is no protocol to handle that, and each resource has its own implementation, possibly not public.
1. Alice submits the requests in natural language. 2. Each queried LLM processes the request, turns it into a routine to retrieve the data and sends it back to Alice.
<details>
<summary>img/scenarios/s4-1.png Details</summary>
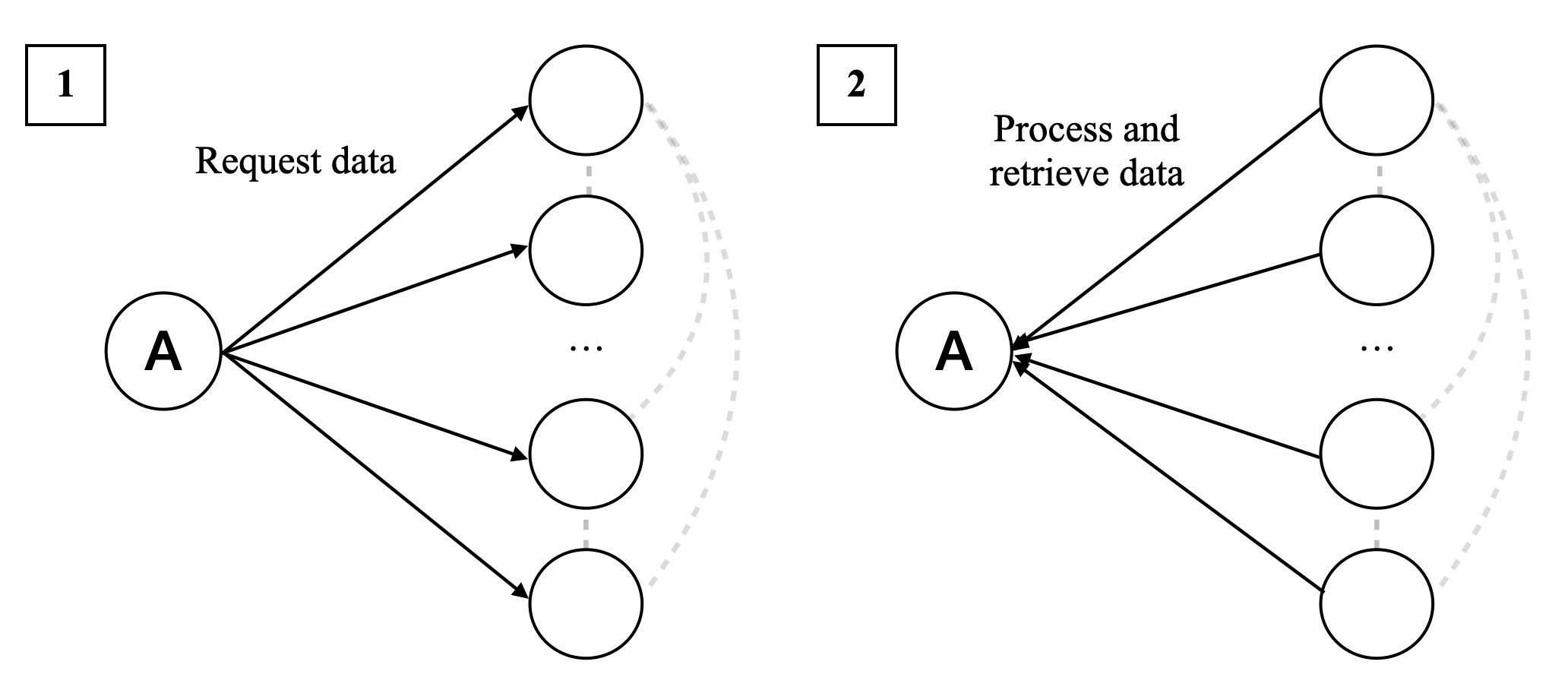
### Visual Description
## Diagram: Two-Step Data Flow Process
### Overview
The image depicts a two-stage data flow process represented as a diagram with labeled sections. Section 1 ("Request data") and Section 2 ("Process and retrieve data") illustrate interactions between a central node labeled "A" and multiple peripheral nodes. Arrows indicate directional relationships, with solid lines in Section 1 and dashed lines in Section 2. Dotted lines connect nodes in both sections, suggesting indirect or secondary relationships.
### Components/Axes
- **Nodes**:
- Central node labeled "A" (appears in both sections).
- Multiple unlabeled peripheral nodes (represented as empty circles) connected to "A."
- **Arrows**:
- **Section 1 (Request data)**: Solid arrows from "A" to peripheral nodes, indicating data requests.
- **Section 2 (Process and retrieve data)**: Dashed arrows from "A" to peripheral nodes, suggesting data processing/retrieval.
- **Dotted Lines**: Connect peripheral nodes in both sections, possibly representing dependencies or indirect interactions.
### Detailed Analysis
- **Section 1 (Request data)**:
- Node "A" initiates requests to peripheral nodes via solid arrows.
- Peripheral nodes are arranged in a linear sequence (left to right) with no explicit labels.
- Dotted lines between peripheral nodes may imply shared dependencies or parallel processing.
- **Section 2 (Process and retrieve data)**:
- Node "A" processes data from peripheral nodes via dashed arrows.
- Peripheral nodes are similarly arranged but connected via dashed lines, indicating a return or feedback loop.
- Dotted lines persist, suggesting ongoing indirect relationships.
### Key Observations
1. **Directional Flow**: Solid arrows in Section 1 emphasize unidirectional data requests, while dashed arrows in Section 2 suggest bidirectional or iterative processing.
2. **Node "A"**: Acts as the central hub for both initiating and resolving data interactions.
3. **Dotted Lines**: Persist across both sections, hinting at a networked or modular system architecture.
4. **No Numerical Data**: The diagram focuses on structural relationships rather than quantitative metrics.
### Interpretation
This diagram likely represents a system workflow where node "A" (e.g., a server, application, or central processor) coordinates data requests and subsequent processing. The transition from solid to dashed arrows in Section 2 implies a shift from initial data acquisition to analysis or retrieval. The dotted lines suggest that peripheral nodes may interact indirectly (e.g., through shared resources or secondary systems).
The absence of labels on peripheral nodes limits specificity but emphasizes their role as generic components in the process. The diagram could model scenarios such as:
- A client-server architecture where "A" requests data from multiple servers (Section 1) and aggregates/processes results (Section 2).
- A distributed computing system where "A" orchestrates tasks across nodes.
- A data pipeline with feedback loops for iterative refinement.
The use of dashed arrows in Section 2 may indicate asynchronous operations, error handling, or data validation steps. Overall, the diagram highlights modularity, central coordination, and bidirectional data flow in a technical system.
</details>
Alice wants to retrieve more data and queries the network another time.
1. One or more receivers suggest using a protocol document for the next iterations. 2. Alice agrees and uses the protocols with as many resources as possible.
<details>
<summary>img/scenarios/s4-2.png Details</summary>
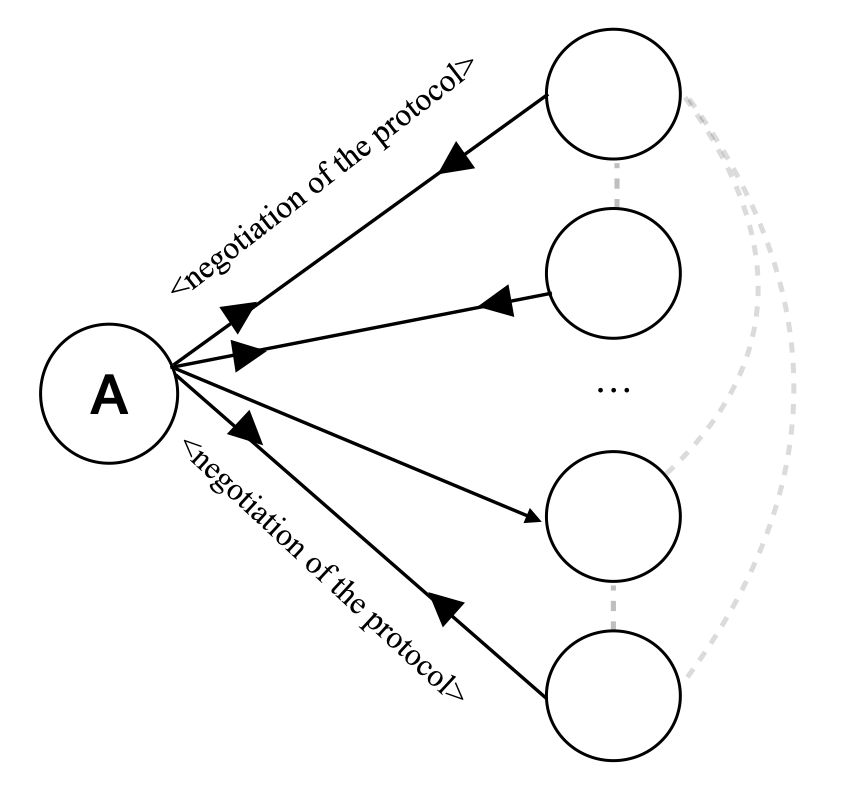
### Visual Description
## Diagram: Protocol Negotiation Process
### Overview
The diagram illustrates a centralized protocol negotiation process involving a primary node (labeled "A") and multiple secondary nodes. Arrows labeled "negotiation of the protocol" indicate directional communication from the central node to peripheral nodes, with a cyclical feedback loop among the peripheral nodes.
### Components/Axes
- **Central Node**: Labeled "A" (positioned at the bottom-left).
- **Peripheral Nodes**: Five unlabeled nodes arranged in a semi-circular pattern around node A.
- **Arrows**:
- Solid black arrows labeled "negotiation of the protocol" (four direct connections from A to peripheral nodes).
- Dashed gray loop connecting peripheral nodes in a clockwise direction (no explicit labels).
- **No numerical axes, scales, or legends present**.
### Detailed Analysis
- **Central Node (A)**: Acts as the initiator of negotiations, with all outgoing arrows originating here.
- **Peripheral Nodes**: Receive input from A and participate in a closed-loop interaction (dashed lines suggest iterative or cyclical communication).
- **Arrow Labels**: All solid arrows share the identical label "negotiation of the protocol," implying uniform communication type.
- **Dashed Loop**: Implies a secondary process (e.g., consensus-building, error correction) among peripheral nodes after initial negotiation.
### Key Observations
1. **Centralized Control**: Node A dominates the process, with no incoming arrows, suggesting it dictates initial protocol terms.
2. **Cyclical Feedback**: The dashed loop indicates ongoing refinement or validation among peripheral nodes post-negotiation.
3. **Uniform Negotiation**: Identical labels on all solid arrows suggest standardized negotiation steps across all connections.
### Interpretation
This diagram models a hierarchical protocol negotiation system where:
- A central authority (A) proposes protocol terms to multiple entities.
- Peripheral nodes engage in iterative dialogue (dashed loop) to resolve conflicts or optimize the protocol.
- The absence of numerical data implies a focus on process flow rather than quantitative metrics (e.g., success rates, latency).
The structure emphasizes **decentralized consensus** after centralized initiation, common in distributed systems or multi-party agreements. The lack of explicit failure states or termination conditions suggests an idealized, continuous negotiation model.
</details>
The successive communications will increasingly use protocol documents, thus not necessitating the receiver to process the query with the LLM.
S5. Scaling complex NLP routines.
An LLM (Alice) wants to retrieve data from a system powered by an LLM (Bob) that, in turns, obtains its data from a search engine (i.e., the LLM is combined with a RAG). Bob has to (1) turn the natural language request into a query, (2) retrieve the data from the RAG, and (3) return a summary.
Alice queries Bob to retrieve some data. There is no routine to handle any of the three phases, so Bob has to invoke the LLM twice to turn the query into a format to invoke the RAG and then perform the summarisation.
<details>
<summary>img/scenarios/s5-1.png Details</summary>
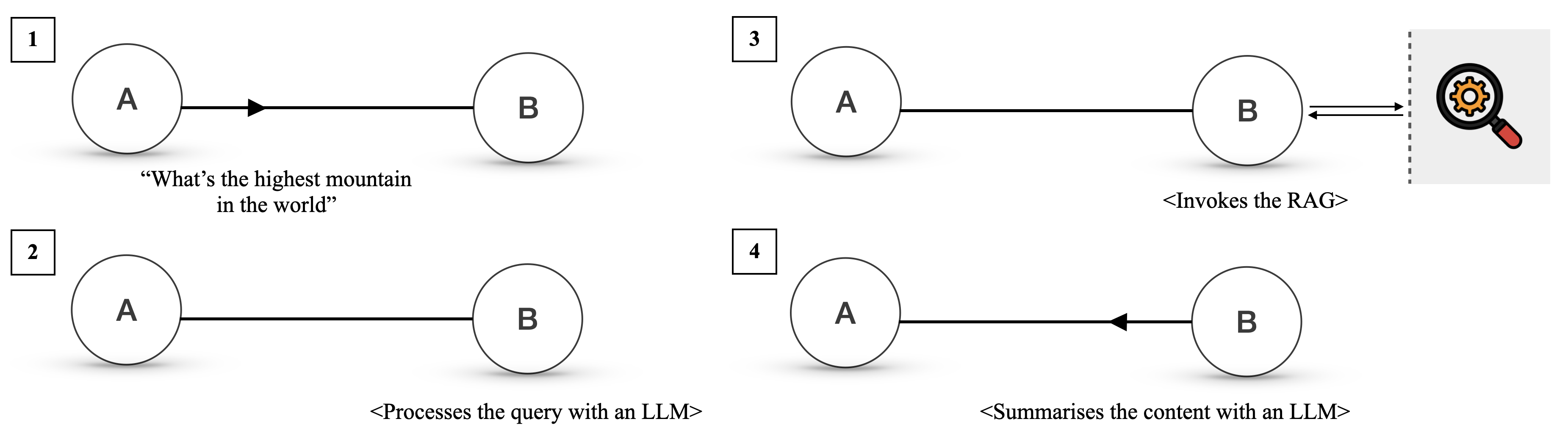
### Visual Description
## Flowchart: Multi-Step AI Query Processing System
### Overview
The diagram illustrates a four-step process for handling a query about "the highest mountain in the world" using AI components. It shows sequential interactions between two entities (A and B) with specific actions at each stage, culminating in a search interface.
### Components/Axes
1. **Nodes**:
- Two labeled circles (A and B) in each step
- Magnifying glass icon with gear (step 3)
2. **Arrows**:
- Directional flow indicators between nodes
3. **Text Labels**:
- Step numbers (1-4) in top-left corners
- Descriptive text under each step
4. **Interface Element**:
- Search interface with magnifying glass (step 3)
### Detailed Analysis
1. **Step 1**:
- Query "What's the highest mountain in the world?" originates from node A
- Transmitted to node B via rightward arrow
2. **Step 2**:
- Node A processes the query using an LLM (Large Language Model)
- Output flows to node B via bidirectional arrow
3. **Step 3**:
- Node A invokes a RAG (Retrieval-Augmented Generation) system
- Visualized by magnifying glass with gear icon
- Output returns to node B via bidirectional arrow
4. **Step 4**:
- Final summarization occurs at node A using an LLM
- Result transmitted to node B via rightward arrow
### Key Observations
- Bidirectional arrows in steps 2 and 3 suggest iterative processing
- Magnifying glass icon represents external data retrieval (RAG)
- All steps maintain consistent node labeling (A→B flow)
- No numerical data present; purely procedural diagram
### Interpretation
This flowchart demonstrates a hybrid AI workflow combining:
1. **Natural Language Processing** (LLM for query understanding)
2. **Knowledge Retrieval** (RAG for factual verification)
3. **Content Synthesis** (LLM for final summarization)
The bidirectional arrows between nodes A and B in steps 2-3 imply a feedback loop where the LLM and RAG system collaborate to refine the response. The magnifying glass icon visually reinforces the RAG component's role in information retrieval. The consistent A→B flow suggests a centralized processing unit (B) receiving inputs from an initiating entity (A), possibly representing user-interface interaction.
The diagram emphasizes the integration of different AI paradigms - pure language modeling (LLM) and retrieval-augmented approaches (RAG) - to handle factual queries more effectively than either method alone.
</details>
Alice queries Bob again; this time, Bob asks to use a routine to query directly the RAG.
<details>
<summary>img/scenarios/s5-2.png Details</summary>
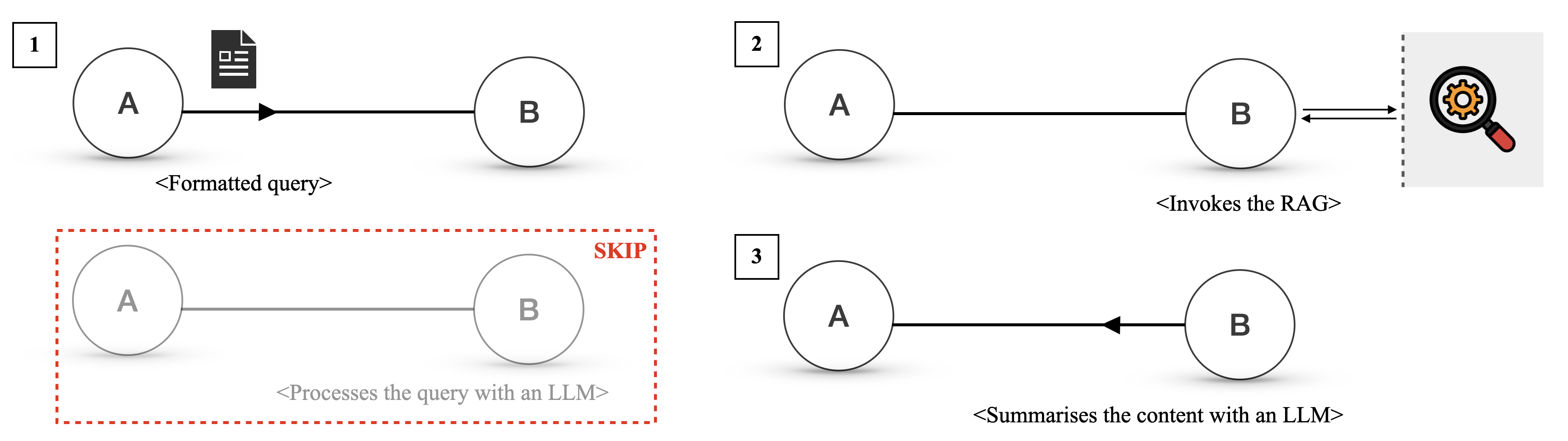
### Visual Description
## Flowchart: System Workflow for Query Processing and Content Summarization
### Overview
The diagram illustrates a four-step workflow (labeled 1–3) involving two components, **A** and **B**, with interactions mediated by external systems (RAG and LLM). Arrows indicate directional flow, while dashed boxes highlight alternative pathways. Key annotations include "SKIP" and system-specific labels like "RAG" and "LLM."
---
### Components/Axes
1. **Nodes**:
- **A**: Initiates actions (e.g., formatting queries, invoking systems).
- **B**: Receives inputs and produces outputs (e.g., processing queries, summarizing content).
2. **Arrows**:
- Solid arrows represent direct interactions between A and B.
- Dashed arrows denote indirect or alternative pathways (e.g., RAG, LLM).
3. **Icons**:
- Document icon: Represents a "Formatted query."
- Magnifying glass with gear: Symbolizes the RAG system.
4. **Annotations**:
- "SKIP": Indicates an optional bypass in Step 3.
- Angle-bracket labels (e.g., `<Processes the query with an LLM>`) describe actions.
---
### Detailed Analysis
1. **Step 1**:
- **A** sends a `<Formatted query>` (document icon) to **B** via a solid arrow.
- No intermediate systems involved.
2. **Step 2**:
- **A** invokes the **RAG** system (magnifying glass icon), which then interacts with **B** via a dashed arrow.
- RAG acts as a mediator between A and B.
3. **Step 3**:
- **A** processes the query with an **LLM** (dashed box labeled "SKIP"), bypassing prior steps.
- **B** summarizes content using an LLM (solid arrow).
---
### Key Observations
- **Flow Direction**: All steps follow a left-to-right progression (A → B).
- **Alternative Pathways**:
- Step 3 introduces a "SKIP" option, allowing A to bypass RAG and directly use an LLM.
- RAG (Step 2) and LLM (Step 3) represent distinct processing layers.
- **System Roles**:
- **RAG**: Likely retrieves external data to augment B’s processing.
- **LLM**: Handles both query processing (Step 3) and content summarization (Step 3).
---
### Interpretation
This workflow demonstrates a hybrid system where:
1. **Initial Query Handling**: A formats queries for B (Step 1).
2. **Enhanced Processing**: RAG (Step 2) enriches B’s capabilities by integrating external data.
3. **Optimization**: The "SKIP" option (Step 3) allows direct LLM-based processing, potentially reducing latency or complexity.
4. **Final Output**: B summarizes content using an LLM, suggesting a focus on concise, context-aware outputs.
The diagram emphasizes modularity, with A acting as a controller and B as an executor. The use of RAG and LLM highlights a layered approach to handling queries, balancing precision (via RAG) and efficiency (via LLM shortcuts). The "SKIP" annotation implies adaptability, allowing the system to prioritize speed over exhaustive data retrieval in certain scenarios.
</details>
Any query that complies with the document protocol now skips the first phase and directly invokes the RAG.
Appendix B Agora Specification
In this section, we provide a more formal description of Agora.
B.1 Transactions
An Agora transaction operates as follows. Suppose that an agent, Alice, is trying to communicate with another agent Bob:
- Alice sends to Bob over HTTPS a JSON document containing three fields:
- protocolHash: The hash of the protocol document. If natural language is used, then the value of protocolHash is null;
- protocolSources: A list of URIs where the protocol document can be found. Must be empty if protocolHash is null and non-empty otherwise;
- body: A string containing the body of the request as specified by the given protocol.
- If Bob does not have the protocol document, he fetches it (either from the sources provided by Alice or from another repository);
- If Bob is unable to use the protocol, he returns a JSON document with one field, namely status, which is equal to “rejected”;
- Otherwise, Bob computes the response using the LLM, routines, or a combination of both;
- Bob sends as response a JSON document with the following fields:
- status: a string indicating the status of the response (can be “success” or “failure”);
- body: the response returned by the agent.
- Note that "status":"failure" must be used only for errors that are not covered by the protocol document (e.g., the agent failing to instantiate the LLM); when the protocol prescribes how to handle an error, the agent should return "status":"success" and the correct error message as body.
B.2 Protocol Documents
A protocol document is identified by its SHA1 hash. Protocol documents can refer to other protocol documents by adding a preamble containing the protocol hash and at least one source for the protocol document. Further discussions concerning the optimal way to reference other protocol documents is left to future work.
B.3 Preferred Protocols
In order to signal to other agents which protocols are supported by default, an agent can expose an endpoint /.wellknown. This endpoint returns a JSON object where each key is a supported protocol hash and each value is a non-empty list of protocol sources.
Appendix C Example of Negotiation Process Between Two Agents
We report the negotiation process between Alice and Bob for a protocol to transmit weather forecast. Note that while the LLMs used Markdown-style formatting, for the sake of readability we replaced Markdown syntax with the corresponding typeset style.
Alice
Hello. I’m here to negotiate a protocol to query a weather forecast service. The service should accept a date and a location as input and return the predicted weather condition, temperature, and precipitation for that day. Before we start, I’d like to clarify the rules for our negotiation. We should focus on designing a simple and unambiguous protocol that specifies the exact format of the messages sent and received. We shouldn’t worry about how the messages will be delivered, and we should assume that the implementation will receive a string and return a string. To begin, I propose that we use a JSON-based protocol. The input message could be a JSON object with two properties: “date” and “location”. The output message could be a JSON object with three properties: “temperature”, “precipitation”, and “weatherCondition”. What are your thoughts on this proposal?
Bob
Your proposal aligns well with the goal of keeping the protocol simple and unambiguous. Using a JSON-based protocol for both the input and output messages is a good approach. Here’s a more detailed specification for the protocol: Input Message The input message will be a JSON object with the following structure: { "date": "YYYY-MM-DD", "location": "string" } •
date: A string representing the date for which the weather forecast is requested, in the format YYYY-MM-DD. •
location: A string representing the location for which the weather forecast is requested. Output Message The output message will be a JSON object with the following structure: { "temperature": number, "precipitation": number, "weatherCondition": "string" } •
temperature: A number representing the predicted temperature for that day in °C. •
precipitation: A number representing the predicted precipitation for that day in mm. •
weatherCondition A string representing the predicted weather condition for that day. Possible values are “sunny”, “cloudy”, “rainy”, “snowy”. Example Input: { "date": "2023-10-01", "location": "New York" } Output: { "temperature": 22.5, "precipitation": 5.0, "weatherCondition": "cloudy" } If you agree with this structure, we can finalize the protocol.
Alice
LLM response: I agree with the proposed protocol structure. It aligns well with the requirements and is simple and unambiguous.
Finalised Protocol
Name: Weather Forecast Query Protocol Description: A protocol for querying the weather forecast for a given date and location. Input Message The input message will be a JSON object with the following structure: { "date": "YYYY-MM-DD", "location": "string" } •
date: A string representing the date for which the weather forecast is requested, in the format YYYY-MM-DD. •
location: A string representing the location for which the weather forecast is requested. Output Message The output message will be a JSON object with the following structure: { "temperature": number, "precipitation": number, "weatherCondition": "string" } •
temperature: A number representing the predicted temperature for that day in °C. •
precipitation: A number representing the predicted precipitation for that day in mm. •
weatherCondition A string representing the predicted weather condition for that day. Possible values are ”sunny”, ”cloudy”, ”rainy”, ”snowy”. Example Input: { "date": "2023-10-01", "location": "New York" } Output: { "temperature": 22.5, "precipitation": 5.0, "weatherCondition": "cloudy" }
Appendix D 100 Agent Demo - Full Description
D.1 Implementation Notes
We implemented our demo in Python, using Flask servers as basis for our agents. Each agent is either a user or a server:
- Users receive a random task, some randomly generated data and a description of the task data (including its schema). Their objective is to execute the requested action and return a reply according to a certain schema. This allows us to generate a large number of queries without needing to handcraft them. Note that all tasks are single-round, i.e. they can be fulfilled in one round of communication;
- Servers receive queries from other users and reply to them using a combination of three types of tools:
- Database tools, which involve connecting to a personal SQL or MongoDB database (assigned at random). Depending on the server, some databases are initialised with dummy data;
- Mock tools, which are simplifications of actual tools (e.g., for taxi service agents, the assignTaxi tool is a mock tool that, instead of actually sending a taxi to a location, mimics the request flow);
- External tools, which are tools that enable the agent to start a Agora communication with a predefined server, although no information about the respective agents’ schema is provided. In other words, the skiLodge agent can open a channel with the weatherService agent
Moreover, we added three protocol databases, which are simple Flask servers that host protocol documents. The first protocol database is a peer with the second one, the latter of which is also a peer with the third protocol database (but the first protocol database is not a peer of the third one). Every 10 executed queries, one protocol databases shares its protocol documents with its peers. This simulates the propagation of protocol documents between different databases.
Picking a Protocol
Users track the number of communications with a given server about a certain type of task until it hits one of two thresholds: one for using a protocol instead of natural language and one for negotiating a protocol ex novo.
When the first threshold is hit, the user invokes the LLM to check if either the server or the reference protocol database (which is randomly assigned to the user at the start of the demo) already have a suitable protocol. If there are none, the user continues using natural language until the second threshold is hit: in that case, the user begins a negotiation with the server and submits the final protocol to the reference protocol database.
Similarly, each server has a counter that tracks the number of natural language communications with any user since the last negotiation. Once the counter hits a threshold, the server requests a negotiation with the user, regardless of how many of the tracked queries were sent by the current user. After negotiation, the counter is reset.
In our demo, we set the thresholds for the user to respectively 3 and 5 communications, and the threshold for the server to 10.
APIs
For GPT-4o and Gemini 1.5 Pro, we used respectively the OpenAI and Google API. For Llama 3 405b, we used the SambaNova API. Prices per million tokens are reported in Table 1.
Table 1: Prices per million tokens at the time of writing.
| GPT-4o | 5.00 | 15.00 |
| --- | --- | --- |
| Llama 3 405b | 5.00 | 10.00 |
| Gemini 1.5 Pro | 3.50 | 10.50 |
Bootstrapping Quality-of-Life Extensions
For the sake of bootstrapping the network, while implementing the demo we added two features to our nodes:
- Providing each node with a simple protocol for multi-round communication in natural language;
- Allowing the protocol document to include machine-readable metadata, such as the name or a short description of the protocol. This helps an agent to determine quickly which protocols, among a list of potential protocols, can be suitable for a certain task.
We leave whether these features should be integrated with the Agora standard, or whether they should be handled using PDs only, to future work.
D.2 Experimental Setup
Preliminary Tests
We first ran a series of qualitative tests to determine which among the considered LLMs (OpenAI GPT 4o, Llama 3 405b, Gemini 1.5 Pro) were the most suitable for negotiation and programming. We found that while all three LLMs were capable of negotiating and implementing protocols, GPT 4o was the most robust, followed by the Llama 3 405b and finally Gemini 1.5 Pro. Surprisingly, the main factor behind the brittleness of Gemini 1.5 Pro was not the model’s inherent performance, but rather the lack of robustness of the API itself: even with tailored retry systems, the API sometimes failed to respond in a nondeterministic manner (i.e. the same query would at times succeed and at times fail). We believe that our experience was due to temporary server issues, rather than fundamental problems with the model.
LLM Distribution
In light of our preliminary results, we manually assigned a model to each server node, following a power law consistent with our findings (9 nodes with GPT-4o, 4 nodes with Llama 3 405b, 2 nodes with Gemini 1.5 Pro). User agents were instead randomly assigned one of the three LLMs with uniform distribution. Overall, the breakdown of nodes by model is:
- GPT-4o: 38 nodes (9 server nodes, 29 user nodes)
- Llama 3 405b: 32 nodes (4 server nodes, 28 user nodes)
- Gemini 1.5 Pro: 30 nodes (2 server nodes, 28 user nodes)
Out of 1000 queries, 8 (representing thus 0.8% of the total query volume) failed due to Google’s Gemini API not responding. This phenomenon was unrelated to the use of Agora, with 500 Internal Server errors appearing both in the Agora demo and the natural language counterfactual with roughly the same frequency.
Task Distribution
To simulate the heterogeneity in communication frequency (i.e. how some nodes tend to be more active than others), we assigned to each user a “query budget” (which represents how many queries are sent by a given user) following a Pareto distribution with shape parameter equal to $0.5$ , adapted so that each user has at least 1 query. The query budget is then split between three randomly chosen types of queries using a Pareto law with a shape parameter of 1 and a minimum of 1 query per type (unless the budget is less than 3 queries). See Figure 6 for a visualisation of the distribution.
<details>
<summary>x3.png Details</summary>
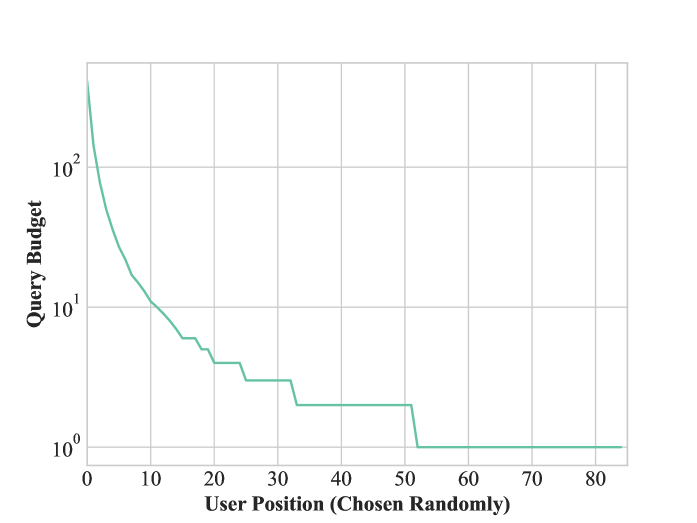
### Visual Description
## Line Graph: Query Budget vs. User Position
### Overview
The image depicts a line graph illustrating the relationship between "User Position (Chosen Randomly)" and "Query Budget" on a logarithmic scale. The green line shows a sharp initial decline in query budget as user position increases, followed by a plateau.
### Components/Axes
- **Y-Axis (Query Budget)**: Logarithmic scale with markers at 10⁰, 10¹, and 10².
- **X-Axis (User Position)**: Linear scale ranging from 0 to 80, labeled "Chosen Randomly."
- **Line**: Single green data series with stepwise decreases.
### Detailed Analysis
- **Initial Decline**:
- At **x = 0**, the query budget starts near **10² (100)**.
- By **x = 10**, it drops to **10¹ (10)**.
- Further decreases occur at **x = 20 (≈5)**, **x = 25 (≈3)**, and **x = 30 (≈2)**.
- **Plateau**:
- From **x = 30 to x = 80**, the query budget stabilizes at **10⁰ (1)**.
- **Stepwise Pattern**: The line exhibits abrupt drops at specific user positions, suggesting discrete thresholds or categorical changes.
### Key Observations
1. **Rapid Initial Drop**: The query budget decreases by **90%** between x = 0 and x = 10.
2. **Diminishing Returns**: Subsequent decreases are smaller (e.g., 50% drop from x = 10 to x = 20).
3. **Stabilization**: No further reduction occurs after x = 30, indicating a lower bound of 1.
4. **Logarithmic Scale Impact**: The steep initial decline appears less dramatic on a log scale but represents a massive absolute reduction.
### Interpretation
- **User Position Impact**: Higher user positions (e.g., x > 30) are associated with minimal query budgets, suggesting lower priority or resource allocation.
- **Randomness in Position Selection**: The "(Chosen Randomly)" label implies the data may reflect aggregated or experimental results rather than sequential positioning.
- **Threshold Behavior**: The plateau at 10⁰ (1) could indicate a system-enforced minimum budget or saturation point.
- **Practical Implications**: The data might reflect search engine ranking dynamics, where top positions (low x-values) consume disproportionate resources, while lower positions stabilize at a baseline.
## Notes
- No legends or additional text are present in the image.
- The green line’s color is consistent throughout, with no sub-categories or secondary data series.
- Uncertainty exists in exact intermediate values between steps due to the stepwise nature of the line.
</details>
Figure 6: Distribution of query budgets for users. The y axis is logarithmic.
D.3 Additional Observations
Cost Breakdown
The breakdown of cost by activity is as follows:
- Natural language communication: 54%;
- Negotiation: 6%;
- Checking the suitability of existing protocols 22%;
- Implementing the protocols: 17%;
Note that negotiation, despite being the most expensive activity (since it involves several rounds of communication), actually represented the smallest contribution to the total cost, with cheaper but more frequent operations (i.e. sending natural language messages and checking the suitability of protocols) making up the largest portion.
Similar Protocols
Due to the (intentional) partial insulation of nodes in the network, sometimes similar protocols emerged independently. Nevertheless, agents using different default protocols were still able to communicate by picking one of the available protocols; for the sake of simplicity, the preferred protocol is chosen by the sender.