# Paths-over-Graph: Knowledge Graph Empowered Large Language Model Reasoning
**Authors**: Xingyu Tan, Xiaoyang Wang, Qing Liu, Xiwei Xu, Xin Yuan, Wenjie Zhang
> 0009-0000-7232-7051 University of New South Wales Data61, CSIRO Sydney Australia
> 0000-0003-3554-3219 University of New South Wales Sydney Australia
> 0000-0001-7895-9551 Data61, CSIRO Sydney Australia
> 0000-0002-2273-1862 Data61, CSIRO Sydney Australia
> 0000-0002-9167-1613 Data61, CSIRO Sydney Australia
> 0000-0001-6572-2600 University of New South Wales Sydney Australia
(2025)
## Abstract
Large Language Models (LLMs) have achieved impressive results in various tasks but struggle with hallucination problems and lack of relevant knowledge, especially in deep complex reasoning and knowledge-intensive tasks. Knowledge Graphs (KGs), which capture vast amounts of facts in a structured format, offer a reliable source of knowledge for reasoning. However, existing KG-based LLM reasoning methods face challenges like handling multi-hop reasoning, multi-entity questions, and effectively utilizing graph structures. To address these issues, we propose Paths-over-Graph (PoG), a novel method that enhances LLM reasoning by integrating knowledge reasoning paths from KGs, improving the interpretability and faithfulness of LLM outputs. PoG tackles multi-hop and multi-entity questions through a three-phase dynamic multi-hop path exploration, which combines the inherent knowledge of LLMs with factual knowledge from KGs. In order to improve the efficiency, PoG prunes irrelevant information from the graph exploration first and introduces efficient three-step pruning techniques that incorporate graph structures, LLM prompting, and a pre-trained language model (e.g., SBERT) to effectively narrow down the explored candidate paths. This ensures all reasoning paths contain highly relevant information captured from KGs, making the reasoning faithful and interpretable in problem-solving. PoG innovatively utilizes graph structure to prune the irrelevant noise and represents the first method to implement multi-entity deep path detection on KGs for LLM reasoning tasks. Comprehensive experiments on five benchmark KGQA datasets demonstrate PoG outperforms the state-of-the-art method ToG across GPT-3.5-Turbo and GPT-4, achieving an average accuracy improvement of 18.9%. Notably, PoG with GPT-3.5-Turbo surpasses ToG with GPT-4 by up to 23.9%.
Large Language Models; Knowledge Graph; Knowledge Graph Question Answering; Retrieval-Augmented Generation journalyear: 2025 copyright: acmlicensed conference: Proceedings of the ACM Web Conference 2025; April 28-May 2, 2025; Sydney, NSW, Australia booktitle: Proceedings of the ACM Web Conference 2025 (WWW ’25), April 28-May 2, 2025, Sydney, NSW, Australia doi: 10.1145/3696410.3714892 isbn: 979-8-4007-1274-6/25/04 ccs: Information systems Question answering
## 1. Introduction
<details>
<summary>x1.png Details</summary>
### Visual Description
## Diagram: Comparison of AI Reasoning Methods for a Multi-Hop Question
### Overview
The image is a technical diagram comparing four different artificial intelligence approaches to answering a complex, multi-hop reasoning question. The central question posed is: **"What country bordering France contains an airport that serves Nijmegen?"** The diagram is divided into four horizontal panels, labeled (a) through (d), each illustrating a different method's process and final answer. Three methods fail (marked with a red "X"), while one succeeds (marked with a green checkmark).
### Components/Axes
The diagram is structured as a vertical sequence of four panels. Each panel contains:
1. **A method label** (e.g., "GPT-3.5/GPT-4 LLM only").
2. **A flowchart** using icons (question mark, brain/LLM icon, network/KG icon, document icon) and arrows to represent the process flow.
3. **A text box** explaining the method's reasoning or output.
4. **A final answer box** (colored red for incorrect, green for correct) and a status icon (red "X" or green checkmark).
### Detailed Analysis
#### **Panel (a): GPT-3.5/GPT-4 LLM only**
* **Process Flow:** A question mark icon points directly to an LLM (brain) icon, which outputs the answer "Belgium".
* **Reasoning Text (Chain of Thoughts prompt):** "Let's go step by step. Response: Nijmegen is served by airports in the neighboring countries, and one of the closest major ones is **Brussels Airport (BRU)** in **Belgium**, which is relatively near Nijmegen compared to other major airports. The answer is **Belgium**."
* **Final Answer:** "Belgium" (in a red box).
* **Status:** Incorrect (Red "X").
#### **Panel (b): LLM empowered KG exploration search**
* **Process Flow:** The entities "France" and "Nijmegen" are input. They are processed by a combination of a Knowledge Graph (KG) icon and an LLM icon, generating "KG Triples". This leads to the answer "Netherlands".
* **Reasoning Text (TextGG (:****** (** (** triples triples triples triples: location location[,, France,, location.location.containedby, Europe], [France, location.location.containedby, Western Europe], [France, location.location.geolocation, Unnamed Entity], [Nijmegen, second_level_division, Netherland] Answering: First, Nijmegen is a city in the Netherlands. Second, the Netherlands is a country bordering France. The answer is **{Netherlands}**."
* **Final Answer:** "Netherlands" (in a red box).
* **Status:** Incorrect (Red "X").
#### **Panel (c): LLM empowered KG subgraph answering**
* **Process Flow:** A question mark and a KG icon are input to an LLM. The output is a document icon combined with a KG icon, leading to the result "Refuse to answering".
* **Reasoning Text (MindMap):** "MindMap cannot prompt LLM to construct a graph and generate the graph descript document since the retrieved subgraph is extremely large and dense."
* **Final Answer:** "Refuse to answering" (in a red box).
* **Status:** Incorrect (Red "X").
#### **Panel (d): PoG (Path of Graph)**
* **Process Flow:** This is the most complex flowchart.
1. **Subgraph Detection:** Multiple question marks and magnifying glasses point to multiple KG icons, which are combined into a single, denser KG icon.
2. **Question Analysis:** A separate question mark goes through an LLM icon to a "Question Analysis" box (a question mark inside a square).
3. The outputs of Subgraph Detection and Question Analysis are combined.
4. **Reasoning Path Exploration:** The combined data is processed, represented by a series of horizontal black bars (suggesting multiple paths).
5. **Reasoning Path Pruning:** An LLM icon acts on the paths, reducing them to a shorter set of bars.
6. A final LLM icon processes the pruned paths to output the answer "Germany".
* **Reasoning Text (PoG Reasoning paths):**
* **Path 1:** `Nijmegen --(nearby)--> Weeze Airport --(contain by)--> Germany --(continent)--> Europ, Western Europen --(contain)--> France`
* **Path 2:** `Nijmegen --(nearby)--> Weeze Airport --(contain by)--> Germany --(adjoins)--> Unnamed Entity --(adjoins)--> France`
* **Response:** "From the provided knowledge graph path, the entity **{Germany}** is the country that contains an airport serving Nijmegen and is also the country bordering France. Therefore, the answer to the main question 'What country bordering France contains an airport that serves Nijmegen?' is **{Germany}**."
* **Final Answer:** "Germany" (in a green box).
* **Status:** Correct (Green checkmark).
### Key Observations
1. **Question Complexity:** The question requires connecting three entities (Nijmegen, an airport, a country) and verifying a geographical relationship (bordering France). This makes it a challenging multi-hop reasoning task.
2. **Method Failure Modes:**
* **LLM-only (a):** Fails due to a plausible but incorrect assumption (that Brussels is the closest major airport). It lacks factual grounding.
* **KG Exploration (b):** Fails because it retrieves correct but incomplete triples. It correctly identifies Nijmegen as being in the Netherlands but incorrectly concludes the Netherlands borders France.
* **KG Subgraph (c):** Fails due to computational or representational overload; the retrieved knowledge subgraph is too large and dense for the method to process effectively.
3. **PoG Success (d):** The PoG method succeeds by explicitly modeling and pruning reasoning paths. It finds the correct chain: Nijmegen -> Weeze Airport (in Germany) -> Germany (borders France). The "Pruning" step is critical for filtering out irrelevant or incorrect paths.
### Interpretation
This diagram serves as a comparative analysis of AI reasoning architectures, highlighting the limitations of pure LLMs and basic knowledge graph integration for complex, multi-constraint questions. It argues for the superiority of a structured, path-based approach (PoG) that combines subgraph detection, explicit question analysis, and iterative reasoning path exploration and pruning.
The core insight is that answering such questions isn't just about retrieving facts (like "Nijmegen is in the Netherlands") but about constructing and validating a *chain of relationships* that satisfies all constraints of the query. The PoG method's success demonstrates the importance of:
1. **Structured Exploration:** Systematically generating potential reasoning paths from a knowledge graph.
2. **Constraint Verification:** Explicitly checking each path against all conditions in the question (e.g., "contains an airport that serves Nijmegen" AND "borders France").
3. **Pruning:** Eliminating paths that are incomplete, irrelevant, or lead to contradictions.
The incorrect answer "Netherlands" in panel (b) is particularly instructive; it shows how a system can be partially correct yet ultimately wrong by missing a single relational link (the border with France). The diagram implicitly critiques methods that perform shallow retrieval or lack mechanisms for holistic path validation.
</details>
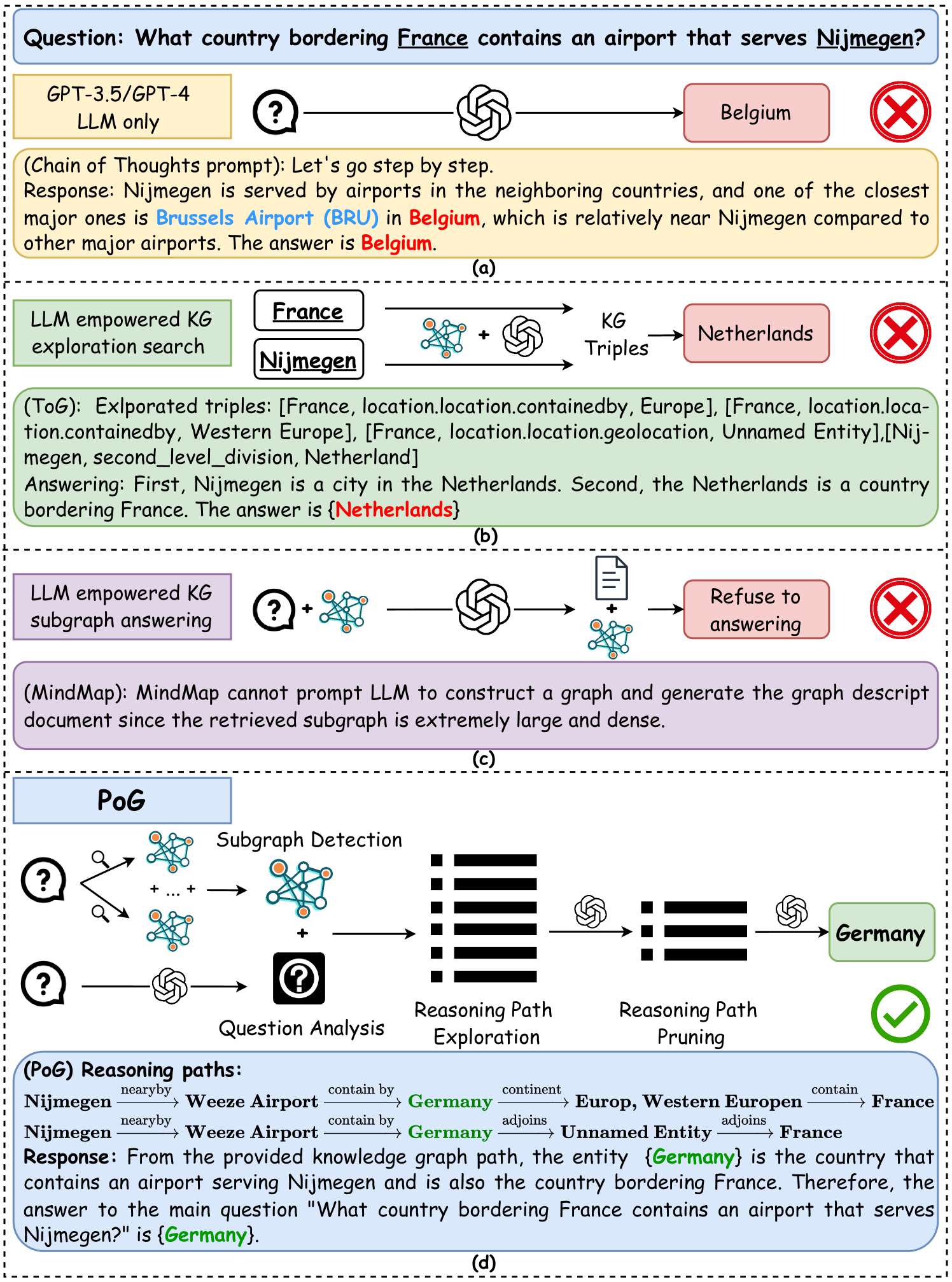
Figure 1. Representative workflow of four LLM reasoning paradigms.
Large Language Models (LLMs) have demonstrated remarkable performance in various tasks (Brown, 2020; Chowdhery et al., 2023; Touvron et al., 2023; Besta et al., 2024; Huang et al., 2025). These models leverage pre-training techniques by scaling to billions of parameters and training on extensive, diverse, and unlabelled data (Touvron et al., 2023; Rawte et al., 2023). Despite these impressive capabilities, LLMs face two well-known challenges. First, they struggle with deep and responsible reasoning when tackling complex tasks (Petroni et al., 2020; Talmor et al., 2018; Khot et al., 2022). Second, the substantial cost of training makes it difficult to keep models updated with the latest knowledge (Sun et al., 2024; Wen et al., 2024), leading to errors when answering questions that require specialized information not included in their training data. For example, in Figure 1 (a), though models like GPT can generate reasonable answers for knowledge-specific questions, these answers may be incorrect due to outdated information or hallucination of reasoning on LLM inherent Knowledge Base (KB).
To deal with the problems of error reasoning and knowledge gaps, the plan-retrieval-answering method has been proposed (Luo et al., 2024; Zhao et al., 2023; Li et al., 2023b). In this approach, LLMs are prompted to decompose complex reasoning tasks into a series of sub-tasks, forming a plan. Simultaneously, external KBs are retrieved to answer each step of the plan. However, this method still has the issue of heavily relying on the reasoning abilities of LLMs rather than the faithfulness of the retrieved knowledge. The generated reasoning steps guide information selection, but answers are chosen based on the LLM’s interpretation of the retrieved knowledge rather than on whether the selection leads to a correct and faithful answer.
To address these challenges, incorporating external knowledge sources like Knowledge Graphs (KGs) is a promising solution to enhance LLM reasoning (Sun et al., 2024; Luo et al., 2024; Pan et al., 2024; Luo et al., 2023). KGs offer abundant factual knowledge in a structured format, serving as a reliable source to improve LLM capabilities. Knowledge Graph Question Answering (KGQA) serves as an approach for evaluating the integration of KGs with LLMs, which requires machines to answer natural language questions by retrieving relevant facts from KGs. These approaches typically involve: (1) identifying the initial entities from the question, and (2) iteratively retrieving and refining inference paths until sufficient evidence has been obtained. Despite their success, they still face challenges such as handling multi-hop reasoning problems, addressing questions with multiple topic entities, and effectively utilizing the structural information of graphs.
Challenge 1: Multi-hop reasoning problem. Current methods (Guo et al., 2024; Ye et al., 2021; Sun et al., 2024; Ma et al., 2024), such as the ToG model presented in Figure 1 (b), begin by exploring from each topic entity, with LLMs selecting connected knowledge triples like (France, contained_by, Europe). This process relies on the LLM’s inherent understanding of these triples. However, focusing on one-hop neighbors can result in plausible but incorrect answers and prematurely exclude correct ones, especially when multi-hop reasoning is required. Additionally, multi-hop reasoning introduces significant computational overhead, making efficient pruning essential, especially in dense and large KGs.
Challenge 2: Multi-entity question. As shown in Figure 1 (b), existing work (Guo et al., 2024; Ye et al., 2021; Sun et al., 2024; Ma et al., 2024) typically explores KG for each topic entity independently. When a question involves multiple entities, these entities are examined in separate steps without considering their interconnections. This approach can result in a large amount of irrelevant information in the candidate set that does not connect to the other entities in the question, leading to suboptimal results.
Challenge 3: Utilizing graph structure. Existing methods (Wen et al., 2024; Guo et al., 2023; Chen et al., 2024) often overlook the inherent graph structures when processing retrieved subgraphs. For example, the MindMap model in Figure 1 (c) utilizes LLMs to generate text-formatted subgraphs from KG triples, converting them into graph descriptions that are fed back into the LLM to produce answers. This textual approach overlooks the inherent structural information of graphs and can overwhelm the LLM when dealing with large graphs. Additionally, during KG information selection, most methods use in-context learning by feeding triples into the LLM, ignoring the overall graph structure.
Contributions. In this paper, we introduce a novel method, P aths- o ver- G raph (PoG). Unlike previous studies that utilize knowledge triples for retrieval (Sun et al., 2024; Ma et al., 2024), PoG employs knowledge reasoning paths, that contain all the topic entities in a long reasoning length, as a retrieval-augmented input for LLMs. The paths in KGs serve as logical reasoning chains, providing KG-supported, interpretable reasoning logic that addresses issues related to the lack of specific knowledge background and unfaithful reasoning paths.
To address multi-hop reasoning problem, as shown in Figure 1 (d), PoG first performs question analysis, to extract topic entities from questions. Utilizing these topic entities, it decomposes the complex question into sub-questions and generates an LLM thinking indicator termed "Planning". This planning not only serves as an answering strategy but also predicts the implied relationship depths between the answer and each topic entity. The multi-hop paths are then explored starting from a predicted depth, enabling a dynamic search process. Previous approaches using planning usually retrieve information from scratch, which often confuses LLMs with source neighborhood-based semantic information. In contrast, our method ensures that LLMs follow accurate reasoning paths that directly lead to the answer.
To address multi-entity questions, PoG employs a three-phase exploration process to traverse reasoning paths from the retrieved question subgraph. All paths must contain all topic entities in the same order as they occur in the LLM thinking indicator. In terms of reasoning paths in KGs, all paths are inherently logical and faithful. Each path potentially contains one possible answer and serves as the interpretable reasoning logic. The exploration leverages the inherent knowledge of both LLM and KG.
To effectively utilize graph structure, PoG captures the question subgraph by expanding topic entities to their maximal depth neighbors, applying graph clustering and reduction to reduce graph search costs. In the path pruning phase, we select possible correct answers from numerous candidates. All explored paths undergo a three-step beam search pruning, integrating graph structures, LLM prompting, and a pre-trained language understanding model (e.g., BERT) to ensure effectiveness and efficiency. Additionally, inspired by the Graph of Thought (GoT) (Besta et al., 2024), to reduce LLM hallucination, PoG prompts LLMs to summarize the obtained Top- $W_{\max}$ paths before evaluating the answer, where $W_{\max}$ is a user-defined maximum width in the path pruning phase. In summary, the advantage of PoG can be abbreviated as:
- Dynamic deep search: Guided by LLMs, PoG dynamically extracts multi-hop reasoning paths from KGs, enhancing LLM capabilities in complex knowledge-intensive tasks.
- Interpretable and faithful reasoning: By utilizing highly question-relevant knowledge paths, PoG improves the interpretability of LLM reasoning, enhancing the faithfulness and question-relatedness of LLM-generated content.
- Efficient pruning with graph structure integration: PoG incorporates efficient pruning techniques in both the KG and reasoning paths to reduce computational costs, mitigate LLM hallucinations caused by irrelevant noise, and effectively narrow down candidate answers.
- Flexibility and effectiveness: a) PoG is a plug-and-play framework that can be seamlessly applied to various LLMs and KGs. b) PoG allows frequent knowledge updates via the KG, avoiding the expensive and slow updates required for LLMs. c) PoG reduces the LLMs token usage by over 50% with only a ±2% difference in accuracy compared to the best-performing strategy. d) PoG achieves state-of-the-art results on all the tested KGQA datasets, outperforming the strong baseline ToG by an average of 18.9% accuracy using both GPT-3.5 and GPT-4. Notably, PoG with GPT-3.5 can outperform ToG with GPT-4 by up to 23.9%.
## 2. Related Work
KG-based LLM reasoning. KGs provide structured knowledge valuable for integration with LLMs (Pan et al., 2024). Early studies (Peters et al., 2019; Luo et al., 2024; Zhang et al., 2021; Li et al., 2023b) embed KG knowledge into neural networks during pre-training or fine-tuning, but this can reduce explainability and hinder efficient knowledge updating (Pan et al., 2024). Recent methods combine KGs with LLMs by converting relevant knowledge into textual prompts, often ignoring structural information (Pan et al., 2024; Wen et al., 2024). Advanced works (Sun et al., 2024; Jiang et al., 2023; Ma et al., 2024) involve LLMs directly exploring KGs, starting from an initial entity and iteratively retrieving and refining reasoning paths until the LLM decides the augmented knowledge is sufficient. However, by starting from a single vertex and ignoring the question’s position within the KG’s structure, these methods overlook multiple topic entities and the explainability provided by multi-entity paths.
Reasoning with LLM prompting. LLMs have shown significant potential in solving complex tasks through effective prompting strategies. Chain of Thought (CoT) prompting (Wei et al., 2022) enhances reasoning by following logical steps in few-shot learning. Extensions like Auto-CoT (Zhang et al., 2023), Complex-CoT (Fu et al., 2022), CoT-SC (Wang et al., 2022), Zero-Shot CoT (Kojima et al., 2022), ToT (Yao et al., 2024), and GoT (Besta et al., 2024) build upon this approach. However, these methods often rely solely on knowledge present in training data, limiting their ability to handle knowledge-intensive or deep reasoning tasks. To solve this, some studies integrate external KBs using plan-and-retrieval methods such as CoK (Li et al., 2023b), RoG (Luo et al., 2024), and ReAct (Yao et al., 2022), decomposing complex questions into subtasks to reduce hallucinations. However, they may focus on the initial steps of sub-problems and overlook further steps of final answers, leading to locally optimal solutions instead of globally optimal ones. To address these deep reasoning challenges, we introduce dynamic multi-hop question reasoning. By adaptively determining reasoning depths for different questions, we enable the model to handle varying complexities effectively.
KG information pruning. Graphs are widely used to model complex relationships among different entities (Tan et al., 2023; Sima et al., 2024; Li et al., 2024b, a). KGs contain vast amounts of facts (Guo et al., 2019; Wu et al., 2024; Wang et al., 2024a), making it impractical to involve all relevant triples in the context of the LLM due to high costs and potential noise (Wang et al., 2024b). Existing methods (Sun et al., 2024; Jiang et al., 2023; Ma et al., 2024) typically identify initial entities and iteratively retrieve reasoning paths until an answer is reached, often treating the LLM as a function executor and relying on in-context learning or fine-tuning, which is expensive. Some works attempt to reduce pruning costs. KAPING (Baek et al., 2023a) projects questions and triples into the same semantic space to retrieve relevant knowledge via similarity measures. KG-GPT (Kim et al., 2023) decomposes complex questions, matches, and selects the relevant relations with sub-questions to form evidence triples. However, these methods often overlook the overall graph structure and the interrelations among multiple topic entities, leading to suboptimal pruning and reasoning performance.
<details>
<summary>x2.png Details</summary>
### Visual Description
## Technical Diagram: Knowledge Graph-Based Question Answering System
### Overview
This image is a detailed technical diagram illustrating a multi-stage system for answering complex natural language questions by exploring and reasoning over a knowledge graph. The system uses a combination of graph traversal, Large Language Model (LLM) assistance, and path selection/pruning techniques. The diagram is divided into four main dashed-line boxes representing sequential phases: **Initialization**, **Exploration**, **Path Pruning**, and **Question Answering**. A large, central knowledge graph sub-diagram is the focal point of the Exploration phase.
### Components/Axes (System Phases & Modules)
**1. Initialization (Top-Right Box)**
* **Question:** "What country bordering **France** contains an airport that serves **Nijmegen**?" (The words "France" and "Nijmegen" are highlighted in yellow and red, respectively).
* **Components:**
* **Topic Entity Recognition:** A module icon (brain with nodes) processes the question.
* **Question Subgraph Detection:** A module icon (network graph) follows.
* **Split Questions, LLM indicator, Ordered Entities:** A green box outputs processed question components.
* **Flow:** Arrows indicate the question feeds into Topic Entity Recognition, then to Question Subgraph Detection, and finally to the Split Questions module.
**2. Exploration (Top-Center Box)**
* **Components (Three Exploration Strategies):**
* **Topic Entity Path Exploration:** A small diagram showing a path from a red node to a yellow node through white nodes.
* **LLM Supplement Path Exploration:** A small diagram showing multiple paths (red, green, yellow nodes) with an LLM icon (brain) connected.
* **Node Expand Exploration:** A small diagram showing a central node expanding to many surrounding nodes.
* **Flow:** These three exploration modules feed into the large central knowledge graph diagram.
**3. Central Knowledge Graph (Main Diagram within Exploration)**
This is a directed graph with labeled edges. Nodes are colored boxes, and edges are arrows with relation labels.
* **Key Nodes (Entities):**
* **Nijmegen** (Red box, left side)
* **Weeze Airport** (Blue box)
* **Germany** (Pink box)
* **France** (Yellow box, right side)
* **Kingdom of the Netherlands** (Grey box)
* **Europe, Western Europe** (Blue box)
* **Central European Time Zone** (Grey box)
* **Lyon-Saint Exupéry Airport** (Blue box)
* **Public airport** (Grey box)
* **Ryanair** (Grey box)
* **Wired** (Grey box)
* **2000, 2002, 1924 Olympics** (Grey box)
* **Unnamed Entity, ...** (Grey box, appears twice)
* **Veghel, Strijen, Rhenen, Oostzaan** (Grey box)
* **Key Edges (Relations):**
* `nearby_airports` (Nijmegen -> Weeze Airport)
* `airport_type` (Weeze Airport -> Public airport)
* `containedby` (Weeze Airport -> Germany)
* `adjoin_s` (Germany -> UnnamedEntity; UnnamedEntity -> France)
* `continent` (Germany -> Europe, Western Europe)
* `containedby` (Kingdom of the Netherlands -> Europe, Western Europe)
* `country` (Kingdom of the Netherlands -> Veghel, Strijen, Rhenen, Oostzaan)
* `time_zones` (Veghel... -> Central European Time Zone)
* `in_this_time_zone` (France -> Central European Time Zone)
* `airports_of_this_type` (Public airport -> Lyon-Saint Exupéry Airport)
* `containedby` (Lyon-Saint Exupéry Airport -> France)
* `user_topics` (Wired -> Ryanair; Wired -> France)
* `olympic_athletes` (Nijmegen -> Unnamed Entity, ...)
* `athlete_affiliation` (Unnamed Entity... -> 2000, 2002, 1924 Olympics)
* `participating_countries` (2000... Olympics -> France)
* `second_level_division` (Nijmegen -> Netherlands)
* `location.administrative_division, containedby` (Nijmegen -> Kingdom of the Netherlands)
**4. Path Pruning (Bottom-Center Box)**
* **Components (Three Selection/Pruning Stages):**
* **Fuzzy Selection:** Takes `Indicator` (H_I) and `Paths_Set` (H_Path) as input, outputs a simplified graph.
* **Precise Path Selection:** Shows a more complex graph with colored nodes (red, blue, yellow) and an LLM icon.
* **Branch Reduced Selection:** Shows a pruned graph with dashed lines indicating removed branches, colored nodes (green, purple, red, yellow), and an LLM icon.
* **Flow:** The output of the central knowledge graph feeds into Fuzzy Selection, then to Precise Path Selection, then to Branch Reduced Selection.
**5. Question Answering (Bottom-Right Box)**
* **Components:**
* **Path Summarizing:** A beige box with an LLM icon.
* **Decision Diamond:** A diamond shape with "Yes!" and "No" outputs.
* **Answer:** A green box.
* **Flow:** The pruned paths from the previous stage go to Path Summarizing. The output goes to a decision point (likely checking if a valid answer path is found). If "Yes!", it proceeds to the final **Answer**. If "No", an arrow loops back to the **Split Questions, LLM indicator, Ordered Entities** module in the Initialization phase, suggesting an iterative refinement process.
### Detailed Analysis
The diagram meticulously maps the process of answering the sample question: "What country bordering France contains an airport that serves Nijmegen?"
1. **Initialization:** The system identifies key entities ("France", "Nijmegen") and decomposes the question.
2. **Exploration:** It explores the knowledge graph starting from these entities. The central graph shows potential paths:
* From **Nijmegen** to **Weeze Airport** (`nearby_airports`).
* From **Weeze Airport** to **Germany** (`containedby`).
* From **Germany** to **France** via an `adjoin_s` (adjoins) relation through an `UnnamedEntity`.
* This path (Nijmegen -> Weeze Airport -> Germany -> France) appears to satisfy the question's conditions: Germany borders France and contains an airport (Weeze) that serves Nijmegen.
3. **Path Pruning:** The system evaluates and selects the most relevant paths from the explored graph using fuzzy, precise, and branch-reduction techniques, likely leveraging LLMs for semantic understanding.
4. **Question Answering:** The selected path is summarized to generate the final answer ("Germany").
### Key Observations
* **Color Coding:** Entities are color-coded: Red (Nijmegen - source), Yellow (France - target), Blue (Airports/Regions), Pink (Germany - candidate answer), Grey (other entities).
* **Iterative Loop:** The "No" path from the answer decision back to initialization indicates the system can retry with refined parameters if an answer isn't found.
* **LLM Integration:** LLM icons are present in Exploration (supplement paths), Path Pruning (Precise and Branch Reduced Selection), and Path Summarizing, indicating they are used for reasoning, path evaluation, and answer generation.
* **Graph Complexity:** The central knowledge graph contains multiple, potentially distracting paths (e.g., connections to Olympics, Ryanair, time zones) that the pruning stages must filter out.
### Interpretation
This diagram represents a sophisticated **neuro-symbolic AI system** for question answering. It combines the structured reasoning of knowledge graphs (symbolic) with the flexible language understanding of Large Language Models (neuro).
* **What it demonstrates:** The system can break down a complex, multi-hop natural language question into a graph traversal problem. It explores a wide neighborhood of relevant entities, then uses learned heuristics (via LLMs and selection algorithms) to prune irrelevant information and converge on the most plausible answer path.
* **How elements relate:** The phases form a pipeline: **Parse -> Explore -> Prune -> Answer**. The central knowledge graph is the shared data structure manipulated by each phase. The LLMs act as reasoning engines within the symbolic framework, guiding exploration and selection.
* **Notable aspects:** The inclusion of "Fuzzy Selection" suggests handling of uncertainty or partial matches in the graph. The iterative loop highlights the system's robustness, allowing for re-attempts. The presence of extraneous nodes (like "Wired" or "Olympics") in the exploration graph shows the system's challenge: distinguishing relevant from irrelevant connections in a densely connected knowledge base. The final answer ("Germany") is derived not from a direct "serves" relation but from a chain of inferences (`nearby_airports` -> `containedby` -> `adjoin_s`), showcasing the system's ability to perform compositional reasoning.
</details>
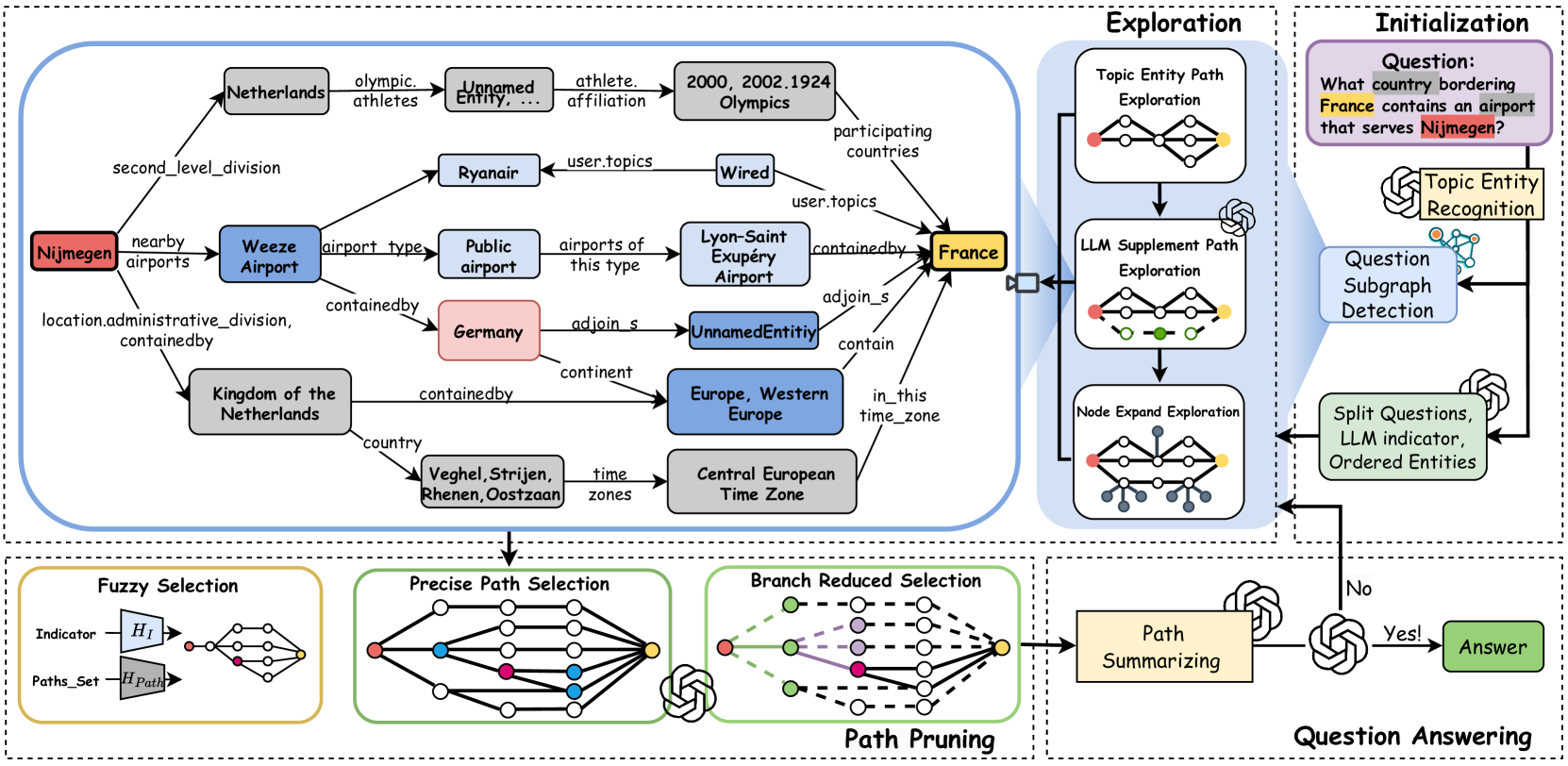
Figure 2. Overview of the PoG architecture. Exploration: After initialization (detailed in Figure 3), the model retrieves entity paths from $\mathcal{G}_{q}$ through three exploration phases. Path Pruning: PoG applies a three-step beam search to prune paths after each exploration phase. Question Answering: The pruned paths are then evaluated for question answering. If these paths do not fully answer the question, the model explores deeper paths until $D_{max}$ is reached or moves on to the next exploration phase.
## 3. Preliminary
Consider a Knowledge Graph (KG) $\mathcal{G(E,R,T)}$ , where $\mathcal{E}$ , $\mathcal{R}$ and $\mathcal{T}$ represent the set of entities, relations, and knowledge triples, respectively. Each knowledge triple $T\in\mathcal{T}$ encapsulates the factual knowledge in $\mathcal{G}$ , and is represented as $T=(e_{h},r,e_{t})$ , where $e_{h},e_{t}\in\mathcal{E}$ and $r\in\mathcal{R}$ . Given an entity set $\mathcal{E_{S}\subseteq E}$ , the induced subgraph of $\mathcal{E_{S}}$ is denoted as $\mathcal{S=(E_{S},R_{S},T_{S})}$ , where $\mathcal{T}_{S}=\{(e,r,e^{\prime})\in\mathcal{T}\mid e,e^{\prime}\in\mathcal{E }_{S}\}$ , and $\mathcal{R}_{S}=\{r\in\mathcal{R}\mid(e,r,e^{\prime})\in\mathcal{T}_{S}\}.$ Furthermore, we denote $\mathcal{D}(e)$ and $\mathcal{D}(r)$ as the sets of short textual descriptions for each entity $e\in\mathcal{E}$ and each relation $r\in\mathcal{R}$ , respectively. For example, the text description of the entity “m.0f8l9c” is $\mathcal{D}$ (“m.0f8l9c”)= “France”. For simplicity, in this paper, all entities and relations are referenced through their $\mathcal{D}$ representations and transformed into natural language.
** Definition 0 (Reasoning Path)**
*Given a KG $\mathcal{G}$ , a reasoning path within $\mathcal{G}$ is defined as a connected sequence of knowledge triples, represented as: $path_{\mathcal{G}}(e_{1},e_{l+1})=\{T_{1},T_{2},...,T_{l}\}=\{(e_{1},r_{1},e_{ 2}),(e_{2},r_{2},e_{3})$ $,...,(e_{l},r_{l},e_{l+1})\}$ , where $T_{i}\in\mathcal{T}$ denotes the $i$ -th triple in the path and $l$ denotes the length of the path, i.e., $length(path_{\mathcal{G}}(e_{1},e_{l+1}))=l$ .*
** Example 0**
*Consider a reasoning path between ”University” and ”Student” in KG: $path_{\mathcal{G}}(\text{University}$ , $\text{Student})$ $=\{(\text{University}$ , employs, $\text{Professor})$ , $(\text{Professor}$ , teaches, $\text{Course})$ , $(\text{Course}$ , enrolled_in, $\text{Student})\}$ , and can be visualized as:
$$
\text{University}\xrightarrow{\text{employs}}\text{Professor}\xrightarrow{
\text{teaches}}\text{Course}\xrightarrow{\text{enrolled\_in}}\text{Student}.
$$
It indicates that a “University” employs a “Professor,” who teaches a “Course,” in which a ”Student” is enrolled. The length of the path is 3.*
For any entity $s$ and $t$ in $\mathcal{G}$ , if there exists a reasoning path between $s$ and $t$ , we say $s$ and $t$ can reach each other, denoted as $s\leftrightarrow t$ . The distance between $s$ and $t$ in $\mathcal{G}$ , denoted as $dist_{\mathcal{G}}(s,t)$ , is the shortest reasoning path distance between $s$ and $t$ . For the non-reachable vertices, their distance is infinite. Given a positive integer $h$ , the $h$ -hop neighbors of an entity $s$ in $\mathcal{G}$ is defined as $N_{\mathcal{G}}(s,h)=\{t\in\mathcal{E}|dist_{\mathcal{G}}(s,t)\leq h\}$ .
** Definition 0 (Entity Path)**
*Given a KG $\mathcal{G}$ and a list of entities $list_{e}$ = [ $e_{1},e_{2},e_{3},\ldots,e_{l}$ ], the entity path of $list_{e}$ is defined as a connected sequence of reasoning paths, which is denoted as $path_{\mathcal{G}}(list_{e})$ $=\{path_{\mathcal{G}}(e_{1},e_{2}),$ $path_{\mathcal{G}}(e_{2},e_{3}),\ldots,path_{\mathcal{G}}(e_{l-1},e_{l})\}=\{( e_{s},r,e_{t})$ $|(e_{s},r,e_{t})\in path_{\mathcal{G}}(e_{i},e_{i+1})\land 1\leq i<l\}$ .*
Knowledge Graph Question Answering (KGQA) is a fundamental reasoning task based on KGs. Given a natural language question $q$ and a KG $\mathcal{G}$ , the objective is to devise a function $f$ that predicts answers $a\in Answer(q)$ utilizing knowledge encapsulated in $\mathcal{G}$ , i.e., $a=f(q,\mathcal{G})$ . Consistent with previous research (Sun et al., 2019; Luo et al., 2024; Sun et al., 2024; Ma et al., 2024), we assume the topic entities $Topic(q)$ mentioned in $q$ and answer entities $Answer(q)$ in ground truth are linked to the corresponding entities in $\mathcal{G}$ , i.e., $Topic(q)\subseteq\mathcal{E}\text{ and }Answer(q)\subseteq\mathcal{E}$ .
## 4. Method
PoG implements the “KG-based LLM Reasoning” by first exploring all possible faithful reasoning paths and then collaborating with LLM to perform a 3-step beam search selection on the retrieved paths. Compared to previous approaches (Sun et al., 2024; Ma et al., 2024), our model focuses on providing more accurate and question-relevant retrieval-argument graph information. The framework of PoG is outlined in Figure 2, comprising four main components.
- Initialization. The process begins by identifying the set of topic entities from the question input, and then queries the source KG $\mathcal{G}$ by exploring up to $D_{\max}$ -hop from each topic entity to construct the evidence sub-graph $\mathcal{G}_{q}$ , where $D_{\max}$ is the user-defined maximum exploration depth. Subsequently, we prompt the LLM to analyze the question and generate an indicator that serves as a strategy for the answer formulation process and predicting the exploration depth $D_{\text{predict}}$ .
- Exploration. After initialization, the model retrieves topic entity paths from $\mathcal{G}_{q}$ through three exploration phases: topic entity path exploration, LLM supplement path exploration, and node expand exploration. All reasoning paths are constrained within the depth range $D\in[D_{\text{predict}},D_{\max}]$ .
- Path Pruning. Following each exploration phase, PoG employs a pre-trained LM, LLM prompting, and graph structural analysis to perform a three-step beam search. The pruned paths are then evaluated in the question answering.
- Question Answering. Finally, LLM is prompted to assess if the pruned reasoning paths sufficiently answer the question. If not, continue exploration with deeper paths incrementally until the $D_{\max}$ is exceeded or proceed to the next exploration phase.
<details>
<summary>x3.png Details</summary>
### Visual Description
## Diagram: Knowledge Graph Question Answering System Architecture
### Overview
This image is a technical system architecture diagram illustrating a multi-stage process for answering complex natural language questions using a Knowledge Graph (KG). The system combines Large Language Model (LLM) capabilities for question decomposition with graph-based operations for information retrieval and reasoning. The flow proceeds from an input question and knowledge graph to two primary outputs: a decomposed question set and a reduced, relevant subgraph.
### Components/Axes
The diagram is organized into several interconnected blocks, flowing generally from top-left to bottom-right, with feedback loops.
**1. Input Section (Top-Left):**
* **Input Label:** `Input: G, q, D_max`
* `G`: Represents the Knowledge Graph.
* `q`: Represents the input question.
* `D_max`: Likely a maximum distance or depth parameter for graph traversal.
* **Question Box:** Contains the example question: `Question: What country bordering France contains an airport that serves Nijmegen?`
* **Entity Extraction:** An arrow points from the question to a list of extracted entities and their types:
* `Country` (Grey background)
* `France` (Yellow background)
* `Airport` (Grey background)
* `Nijmegen` (Red background)
* **Topic Entity Identification:** Arrows labeled `H_G` and `H_T` point to a box labeled `Topic Entity:`, which contains:
* `France` (Yellow background)
* `Nijmegen` (Red background)
**2. LLM Indictor / Question Analysis (Center-Left, Green Dashed Box):**
* **Label:** `LLM Indictor:`
* **Question Analysis Diagram:** Shows a semantic parse of the question:
* `Nijmegen ←serves airport ←own answer (country) →borders France`
* This indicates the relationships: an airport *serves* Nijmegen, the answer (a country) *owns* that airport, and that country *borders* France.
* **Split Questions:** The LLM decomposes the original question into two simpler sub-questions:
* `Split_question1: What country contains an airport that serves Nijmegen?`
* `Split_question2: What country borders France?`
* **Output 1 Arrow:** Points left, labeled `Output1: I_LLM, q_split`.
**3. Knowledge Graph (G) Processing (Top-Right, Blue Box):**
* **Label:** `Knowledge Graph (G)` with a small network icon.
* **Visual Representation:** Two overlapping circular diagrams representing graph neighborhoods.
* **Left Circle (Yellow Spotlight):** Centered on `France` (yellow node). Concentric dashed circles represent increasing distance (`D_max`). Arrows show paths radiating outward from France.
* **Right Circle (Red Spotlight):** Centered on `Nijmegen` (red node). Similar concentric circles and radiating paths.
* **Operation:** A `+` symbol between the circles indicates the combination or union of these two neighborhoods.
* **Flow:** An arrow points downward from this combined graph to the "Graph Detection" stage.
**4. Graph Operations Pipeline (Bottom, Three Blue Dashed Boxes):**
This pipeline processes the combined graph from the previous stage. The flow is right-to-left (Graph Detection → Node and Relation Clustering → Graph Reduction).
* **Graph Detection (Rightmost Box):**
* **Label:** `Graph Detection`
* **Visual:** A network graph with white nodes and multi-colored edges (blue, red, green, purple, orange, black). Key nodes are colored: one yellow (France), one red (Nijmegen), and one orange (likely representing the answer country or an airport).
* **Node and Relation Clustering (Center Box):**
* **Label:** `Node and Relation Clustering`
* **Visual:** The same graph structure, but edges are now uniformly black. The colored nodes (yellow, red, orange) remain, suggesting the process identifies and clusters relevant nodes and their connecting relations.
* **Graph Reduction (Leftmost Box):**
* **Label:** `Graph Reduction`
* **Visual:** A simplified graph. Many nodes and edges from the previous stage have been removed, leaving a sparse subgraph that connects the key entities (yellow, red, orange nodes) via specific paths.
* **Output 2 Arrow:** Points left from the Graph Reduction box, labeled `Output2: G_q`.
### Detailed Analysis
* **Textual Content Transcription:**
* All text is in English.
* Input Question: "What country bordering France contains an airport that serves Nijmegen?"
* LLM Split Questions: "What country contains an airport that serves Nijmegen?" and "What country borders France?"
* System Labels: Input, Output1, Output2, LLM Indictor, Question Analysis, Topic Entity, Knowledge Graph (G), Graph Detection, Node and Relation Clustering, Graph Reduction.
* Mathematical/Notational Symbols: `G`, `q`, `D_max`, `H_G`, `H_T`, `I_LLM`, `q_split`, `G_q`.
* **Spatial Grounding:**
* The **Legend/Entity Key** is implicitly defined by the colored boxes in the "Topic Entity" section (top-center): Yellow = France, Red = Nijmegen. This color coding is consistently applied to the nodes in the Knowledge Graph visualization and the subsequent graph operation diagrams.
* The **Knowledge Graph visualization** is in the top-right quadrant.
* The **LLM processing** is in the center-left.
* The **graph operation pipeline** runs along the bottom third of the image.
* **Component Flow & Relationships:**
1. The system starts with a complex question (`q`) and a large knowledge graph (`G`).
2. An LLM analyzes the question, extracts entities (France, Nijmegen), and decomposes it into two simpler, answerable sub-questions (`q_split`). This is `Output1`.
3. Simultaneously, the system identifies topic entities and uses them to extract relevant neighborhoods from the main KG (`G`), centered on France and Nijmegen, within a distance `D_max`.
4. These neighborhoods are combined and passed through a three-step graph processing pipeline:
* **Detection:** Identifies relevant nodes and relations in the combined neighborhood.
* **Clustering:** Groups the detected nodes and relations.
* **Reduction:** Prunes the graph to retain only the most salient subgraph (`G_q`) that likely contains the answer path. This is `Output2`.
5. The final answer would presumably be derived by reasoning over the reduced graph `G_q` and/or answering the split questions `q_split`.
### Key Observations
* **Hybrid Architecture:** The system explicitly combines neural (LLM) and symbolic (Knowledge Graph) AI components. The LLM handles natural language understanding and decomposition, while the KG provides structured reasoning.
* **Two-Pronged Output:** The system produces both a reformulated question set (`Output1`) and a focused data subgraph (`Output2`), which could be used independently or together for final answer generation.
* **Visual Consistency:** The color-coding of key entities (France=yellow, Nijmegen=red) is maintained across different diagram sections, aiding in tracking these elements through the process.
* **Graph Pipeline Logic:** The sequence from Detection → Clustering → Reduction suggests a funnel-like process of first gathering all potentially relevant information, then organizing it, and finally distilling it to its essence.
### Interpretation
This diagram outlines a sophisticated approach to **Complex Question Answering (CQA)** over knowledge graphs. The core innovation appears to be the tight coupling of an LLM's reasoning and decomposition skills with targeted graph operations.
* **Problem Solved:** It addresses the challenge of answering multi-hop questions (like the example, which requires finding a country that satisfies two conditions: bordering France and owning an airport serving Nijmegen) by breaking them down and constraining the search space within a vast knowledge graph.
* **Mechanism:** The LLM acts as a "question analyst," translating a complex query into a logical form and simpler sub-questions. The graph operations then execute a focused search, starting from the mentioned entities (France, Nijmegen) and exploring their local neighborhoods to find connecting paths that satisfy the sub-question conditions.
* **Significance:** The `D_max` parameter is crucial, as it limits the computational cost of graph traversal. The "Graph Reduction" step is the key efficiency gain, transforming a large, noisy subgraph into a minimal, answer-bearing one (`G_q`).
* **Potential Applications:** This architecture is suited for search engines, question-answering systems, and analytical tools that need to perform reasoning over structured data (e.g., corporate knowledge bases, biomedical databases, encyclopedic graphs like Wikidata).
* **Underlying Assumption:** The system assumes that the answer to the complex question can be found by exploring a bounded neighborhood around the explicitly mentioned entities and that the LLM can correctly decompose the question into logically equivalent sub-questions. The success hinges on the quality of the LLM's decomposition and the completeness of the underlying knowledge graph.
</details>
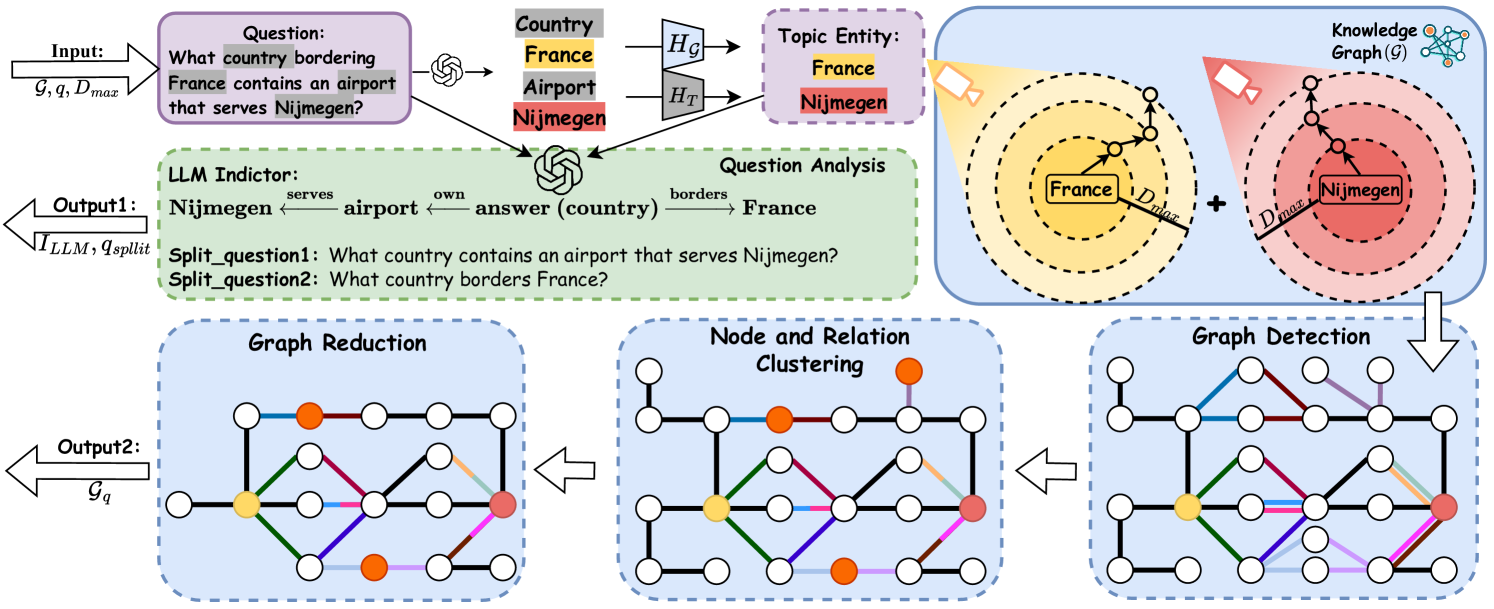
Figure 3. Overview of the initialization phase. Output 1: from the input question, the model identifies topic entities and prompts the LLM to decompose questions into split questions $q_{split}$ and generate an indicator $I_{LLM}$ . The indicator outlines a strategy for formulating the answer and predicts the exploration depth $D_{predict}$ . Output 2: the model queries the source KG up to $D_{max}$ -hop from identified topic entities, constructing and pruning the evidence subgraph $\mathcal{G}_{q}$ .
### 4.1. Initialization
The initialization has two main stages, i.e., question subgraph detection and question analysis. The framework is shown in Figure 3.
Question subgraph detection. Given a question $q$ , PoG initially identifies the question subgraph, which includes all the topic entities of $q$ and their $D_{\max}$ -hop neighbors.
Topic entity recognition. To identify the relevant subgraph, PoG first employs LLMs to extract the potential topic entities from the question. Following the identification, the process applies BERT-based similarity matching to align these potential entities with entities from KG. Specifically, as shown in Figure 3, we encode both the keywords and all entities from KG into dense vector embeddings as $H_{T}$ and $H_{\mathcal{G}}$ . We then compute a cosine similarity matrix between these embeddings to determine the matches. For each keyword, the entities with the highest similarity scores are selected to form the set $Topic(q)$ . This set serves as the foundation for constructing the question subgraph in subsequent steps.
Subgraph detection. Upon identifying the topic entities, PoG captures the induced subgraph $\mathcal{G}_{q}\subseteq\mathcal{G}$ by expanding around each entity $e$ in $Topic(q)$ . For each entity, we retrieve knowledge triples associated with its $D_{\max}$ -hop neighbors, thereby incorporating query-relevant and faithful KG information into $\mathcal{G}_{q}$ . Through this process, we update $\mathcal{E}_{q}$ with newly added intermediate nodes that serve as bridging pathways between the topic entities. The result subgraph, $\mathcal{G}_{q}$ is defined as $(\mathcal{E}_{q},\mathcal{R}_{q},\mathcal{T}_{q})$ , where $\mathcal{E}_{q}$ encompasses $Topic(q)$ together with the set $\{N_{\mathcal{G}}(e,D_{\max})\mid e\in Topic(q)\}$ , effectively linking all relevant entities and their connective paths within the defined hop distance. To interact with KG, we utilize the pre-defined SPARQL queries as detailed in Appendix D.
Graph pruning. To efficiently manage information overhead and reduce computational cost, we implement graph pruning on the question subgraph $\mathcal{G}_{q}$ using node and relation clustering alongside graph reduction techniques. As illustrated in Figure 3, node and relation clustering is achieved by compressing multiple nodes and their relations into supernodes, which aggregate information from the original entities and connections. For graph reduction, we employ bidirectional BFS to identify all paths connecting the topic entities. Based on these paths, we regenerate induced subgraphs that involve only the relevant connections, effectively excluding nodes and relations that lack strong relevance to the topic entities.
Question analysis. To reduce hallucinations in LLMs, the question analysis phase is divided into two parts and executed within a single LLM call using an example-based prompt (shown in Appendix E). First, the complex question $q$ is decomposed into simpler questions based on the identified topic entities, each addressing their relationship to the potential answer. Addressing these simpler questions collectively guides the LLM to better answer the original query, thereby reducing hallucinations. Second, a LLM indicator is generated, encapsulating all topic entities and predicting the answer position within a single chain of thought derived from the original question. This indicator highlights the relationships and sequence among the entities and answer. Based on this, a predicted depth $D_{\text{predict}}$ is calculated, defined as the maximum distance between the predicted answer and each topic entity. An example of question analysis is shown in Figure 3 with predicted depth 2.
### 4.2. Exploration
As discussed in Section 1, identifying reasoning paths that encompass all topic entities is essential to derive accurate answers. These paths serve as interpretable chains of thought, providing both the answer and the inference steps leading to it, a feature we refer as interpretability. To optimize the discovery of such paths efficiently and accurately, the exploration process is divided into three phases: topic entity path exploration, LLM supplement path exploration, and node expand exploration. After each phase, we perform path pruning and question answering. If a sufficient path is found, the process terminates; otherwise, it advances to the next phase to explore additional paths. Due to the space limitation, the pseudo-code of exploration section is shown in Appendix A.1.
Topic entity path exploration. To reduce LLM usage and search space, PoG begins exploration from a predicted depth $D_{\text{predict}}$ rather than the maximum depth. Using the question subgraph $\mathcal{G}_{q}$ , topic entities $Topic(q)$ , LLM indicator $I_{\text{LLM}}$ , and $D_{\text{predict}}$ , PoG identifies reasoning paths containing all topic entities by iteratively adjusting the exploration depth $D$ . Entities in $Topic(q)$ are ordered according to $I_{\text{LLM}}$ to facilitate reasoning effectively. Starting from the predicted depth $D=min(D_{\text{predict}},D_{\text{max}})$ , we employ a bidirectional BFS to derive all potential entity paths, which is defined as:
$$
Paths_{t}=\{p\mid|Topic(q)|\times(D-1)<length(p)\leq|Topic(q)|\times D\},
$$
where $p=Path_{\mathcal{G}_{q}}(Topic(q))$ . To reduce the complexity, a pruning strategy is employed and selects the top- $W_{\max}$ paths based on $Paths_{t}$ , $I_{\text{LLM}}$ , and split questions from Section 4.1. These paths are evaluated for sufficiency verification. If inadequate, $D$ is incremented until $D_{\max}$ is reached. Then the next phase commences.
LLM supplement path exploration. Traditional KG-based LLM reasoning often rephrases KG facts without utilizing the LLM’s inherent knowledge. To overcome this, PoG prompts LLMs to generate predictions based on path understanding and its implicit knowledge, providing additional relevant insights. It involves generating new LLM thinking indicators $I_{\text{Sup}}$ for predicted entities $e\in Predict(q)$ , and then using text similarity to verify and align them with $\mathcal{E}_{q}\in\mathcal{G}_{q}$ . The supplementary entity list $List_{S}(e)=Topic(q)+e$ is built and ranked by $I_{\text{Sup}}$ to facilitate reasoning effectively. Next, supplementary paths $Paths_{s}$ are derived from $List_{S}(e)$ in the evidence KG $\mathcal{G}_{q}$ with a fixed depth $D_{\max}$ :
$$
Paths_{s}=\{p\mid\text{length}(p)\leq|Topic(q)|\times D_{\max}\},
$$
where $p=Path_{\mathcal{G}_{q}}(List_{S}(e))$ . These paths with new indicators are evaluated similarly to the topic entity path exploration phase. The prompting temple is shown in Appendix E.
Node expand exploration. If previous phases cannot yield sufficient paths, PoG proceeds to node expansion. Unlike previous methods (Sun et al., 2024; Ma et al., 2024) that separately explore relations and entities, PoG explores both simultaneously, leveraging clearer semantic information for easier integration with existing paths. During the exploration, PoG expands unvisited entities by 1-hop neighbors in $\mathcal{G}$ . New triples are merged into existing paths to form the new paths, followed by pruning and evaluation.
### 4.3. Path Pruning
As introduced in Section 2, KGs contain vast amounts of facts, making it impractical to involve all relevant triples in the LLM’s context due to high costs. To address this complexity and reduce LLM overhead, we utilize a three-step beam search for path pruning. The corresponding pseudo-code can be found in Appendix A.2.
Fuzzy selection. Considering that only a small subset of the generated paths is relevant, the initial step of our beam search involves fuzzy selection by integrating a pre-trained language model (e.g. SentenceBERT (Reimers and Gurevych, 2019)), to filter the irrelevant paths quickly. As shown in Figure 2, we encode the LLM indicator $I_{\text{LLM}}$ (or $I_{\text{Sup}}$ ) and all reasoning paths into vector embeddings, denoted as $H_{I}$ and $H_{Paths}$ , and calculate cosine similarities between them. The top- $W_{1}$ paths with the highest similarity scores are selected for further evaluation.
Precise path selection. Following the initial fuzzy selection, the number of candidate paths is reduced to $W_{1}$ . At this stage, we prompt the LLM to select the top- $W_{\max}$ reasoning paths most likely to contain the correct answer. The specific prompt used to guide LLM in selection phase can be found in Appendix E.
Branch reduced selection. Considering that paths are often represented in natural language and can be extensive, leading to high processing costs for LLMs, we implement a branch reduced selection method integrated with the graph structure. This method effectively balances efficiency and accuracy by further refining path selection. Starting with $D=1$ , for each entity $e$ in the entity list, we extract the initial $D$ -step paths from every path in the candidate set $Paths_{c}$ into a new set $Paths_{e}$ . If the number of $Paths_{e}$ exceeds the maximum designated width $W_{\max}$ , these paths are pruned using precise path selection. The process iterates until the number of paths in $Paths_{c}$ reaches $D_{\max}$ . For example, as illustrated in Figure 2, with $W_{\max}=1$ , only the initial step paths (depicted in green) are extracted for further examination, while paths represented by dashed lines are pruned. This selection method enables efficient iterative selection by limiting the number of tokens and ensuring the relevance and conciseness of the reasoning paths.
Beam search strategy. Based on the three path pruning methods above, PoG can support various beam search strategies, ranging from non-reliant to fully reliant on LLMs. These strategies are selectable in a user-friendly manner, allowing flexibility based on the specific requirements of the task. We have defined four such strategies in Algorithm 2 of Appendix A.2.
### 4.4. Question Answering
Based on the pruned paths in Section 4.3, we introduce a two-step question-answering method.
Path Summarizing. To address hallucinations caused by paths with excessive or incorrect text, we develop a summarization strategy by prompting LLM to review and extract relevant triples from provided paths, creating a concise and focused path. Details of the prompts used are in Appendix E.
Question answering. Based on the current reasoning path derived from path pruning and summarizing, we prompt the LLM to first evaluate whether the paths are sufficient for answering the split question and then the main question. If the evaluation is positive, LLM is prompted to generate the answer using these paths, along with the question and question analysis results as inputs, as shown in Figures 2. The prompts for evaluation and generation are detailed in Appendix E. If the evaluation is negative, the exploration process is repeated until completion. If node expand exploration reaches its depth limit without yielding a satisfactory answer, LLM will leverage both provided and inherent knowledge to formulate a response. Additional details on the prompts can be found in Appendix E.
## 5. Experiments
Table 1. Results of PoG across various datasets, compared with the state-of-the-art (SOTA) in Supervised Learning (SL) and In-Context Learning (ICL) methods. The highest scores for ICL methods are highlighted in bold, while the second-best results are underlined. The Prior FT (Fine-tuned) SOTA includes the best-known results achieved through supervised learning.
| Method | Class | LLM | Multi-Hop KGQA | Single-Hop KGQA | Open-Domain QA | | |
| --- | --- | --- | --- | --- | --- | --- | --- |
| CWQ | WebQSP | GrailQA | Simple Questions | WebQuestions | | | |
| Without external knowledge | | | | | | | |
| IO prompt (Sun et al., 2024) | - | GPT-3.5-Turbo | 37.6 | 63.3 | 29.4 | 20.0 | 48.7 |
| CoT (Sun et al., 2024) | - | GPT-3.5-Turbo | 38.8 | 62.2 | 28.1 | 20.3 | 48.5 |
| SC (Sun et al., 2024) | - | GPT-3.5-Turbo | 45.4 | 61.1 | 29.6 | 18.9 | 50.3 |
| With external knowledge | | | | | | | |
| Prior FT SOTA | SL | - | 70.4 (Das et al., 2021) | 85.7 (Luo et al., 2024) | 75.4 (Gu et al., 2023) | 85.8 (Baek et al., 2023b) | 56.3 (Kedia et al., 2022) |
| KB-BINDER (Li et al., 2023a) | ICL | Codex | - | 74.4 | 58.5 | - | - |
| ToG/ToG-R (Sun et al., 2024) | ICL | GPT-3.5-Turbo | 58.9 | 76.2 | 68.7 | 53.6 | 54.5 |
| ToG-2.0 (Ma et al., 2024) | ICL | GPT-3.5-Turbo | - | 81.1 | - | - | - |
| ToG/ToG-R (Sun et al., 2024) | ICL | GPT-4 | 69.5 | 82.6 | 81.4 | 66.7 | 57.9 |
| PoG-E | ICL | GPT-3.5-Turbo | 71.9 | 90.9 | 87.6 | 78.3 | 76.9 |
| PoG | ICL | GPT-3.5-Turbo | 74.7 | 93.9 | 91.6 | 80.8 | 81.8 |
| PoG-E | ICL | GPT-4 | 78.5 | 95.4 | 91.4 | 81.2 | 82.0 |
| PoG | ICL | GPT-4 | 81.4 | 96.7 | 94.4 | 84.0 | 84.6 |
Experimental settings. We evaluate PoG on five KGQA datasets, i.e., CWQ (Talmor and Berant, 2018), WebQSP (Yih et al., 2016), GrailQA (Gu et al., 2021), SimpleQuestions (Petrochuk and Zettlemoyer, 2018), and WebQuestions (Berant et al., 2013). PoG is tested against methods without external knowledge (IO, CoT (Wei et al., 2022), SC (Wang et al., 2022)) and the state-of-the-art (SOTA) approaches with external knowledge, including prompting-based and fine-tuning-based methods. Freebase (Bollacker et al., 2008) serves as the background knowledge graph for all datasets. Experiments are conducted using two LLMs, i.e., GPT-3.5 (GPT-3.5-Turbo) and GPT-4. Following prior studies, we use exact match accuracy (Hits@1) as the evaluation metric. Due to the space limitation, detailed experimental settings, including dataset statistics, baselines, and implementation details, are provided in Appendix C.
PoG setting. We adopt the Fuzzy + Precise Path Selection strategy in Algorithm 2 of Appendix A.2 for PoG, with $W_{1}=80$ for fuzzy selection. Additionally, we introduce PoG-E, which randomly selects one relation from each edge in the clustered question subgraph to evaluate the impact of graph structure on KG-based LLM reasoning. $W_{\max}$ and $D_{\max}$ are 3 by default for beam search.
### 5.1. Main Results
Since PoG leverages external knowledge to enhance LLM reasoning, we first compare it with other methods that utilize external knowledge. Although PoG is a training-free, prompting-based method and has natural disadvantages compared to fine-tuned methods trained on evaluation data. As shown in Table 1, PoG with GPT-3.5-Turbo still achieves new SOTA performance across most datasets. Additionally, PoG with GPT-4 surpasses fine-tuned SOTA across all the multi-hop and open-domain datasets by an average of 17.3% and up to 28.3% on the WebQuestions dataset. Comparing all the in-context learning (ICL) methods, PoG with GPT-3.5-Turbo surpasses all the previous SOTA methods. When comparing PoG with GPT-3.5-Turbo against SOTA using GPT-4, PoG outperforms the SOTA by an average of 12.9% and up to 23.9%. When using the same LLM, PoG demonstrates substantial improvements: with GPT-3.5-Turbo, it outperforms SOTA by an average of 21.2% and up to 27.3% on the WebQuestions dataset; with GPT-4, it outperforms SOTA by 16.6% on average and up to 26.7% on the WebQuestions dataset. Additionally, PoG with GPT-3.5-Turbo outperforms methods without external knowledge (e.g., IO, CoT, SC prompting) by 62% on GrailQA and 60.5% on Simple Questions. These results show that incorporating external knowledge graphs significantly enhances reasoning tasks. PoG-E also achieves excellent results. Under GPT-4, PoG-E surpasses all SOTA in ICL by 14.1% on average and up to 24.1% on the WebQuestions dataset. These findings demonstrate that the graph structure is crucial for reasoning tasks, particularly for complex logical reasoning. By integrating the structural information of the question within the graph, PoG enhances the deep reasoning capabilities of LLMs, leading to superior performance.
### 5.2. Ablation Study
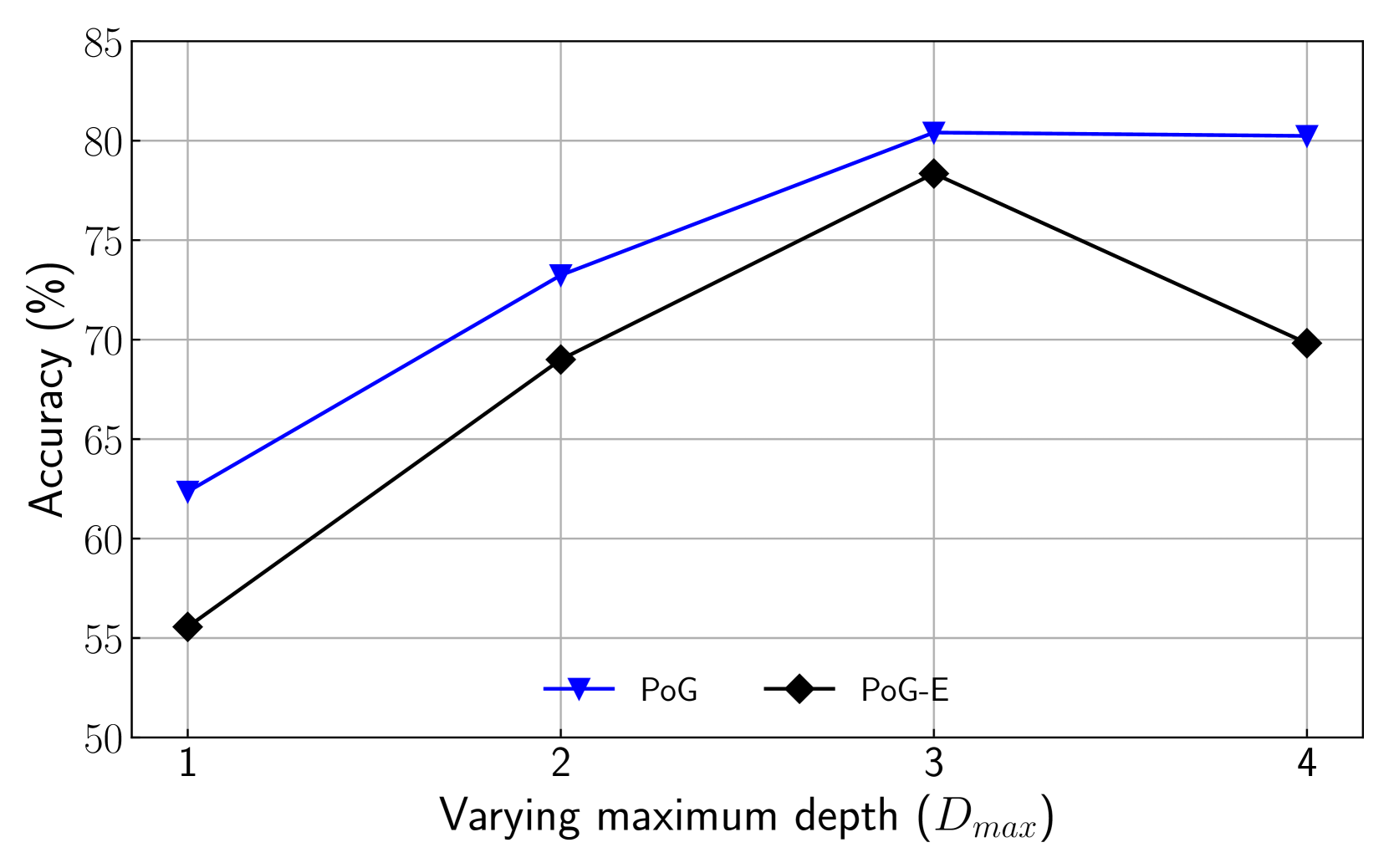
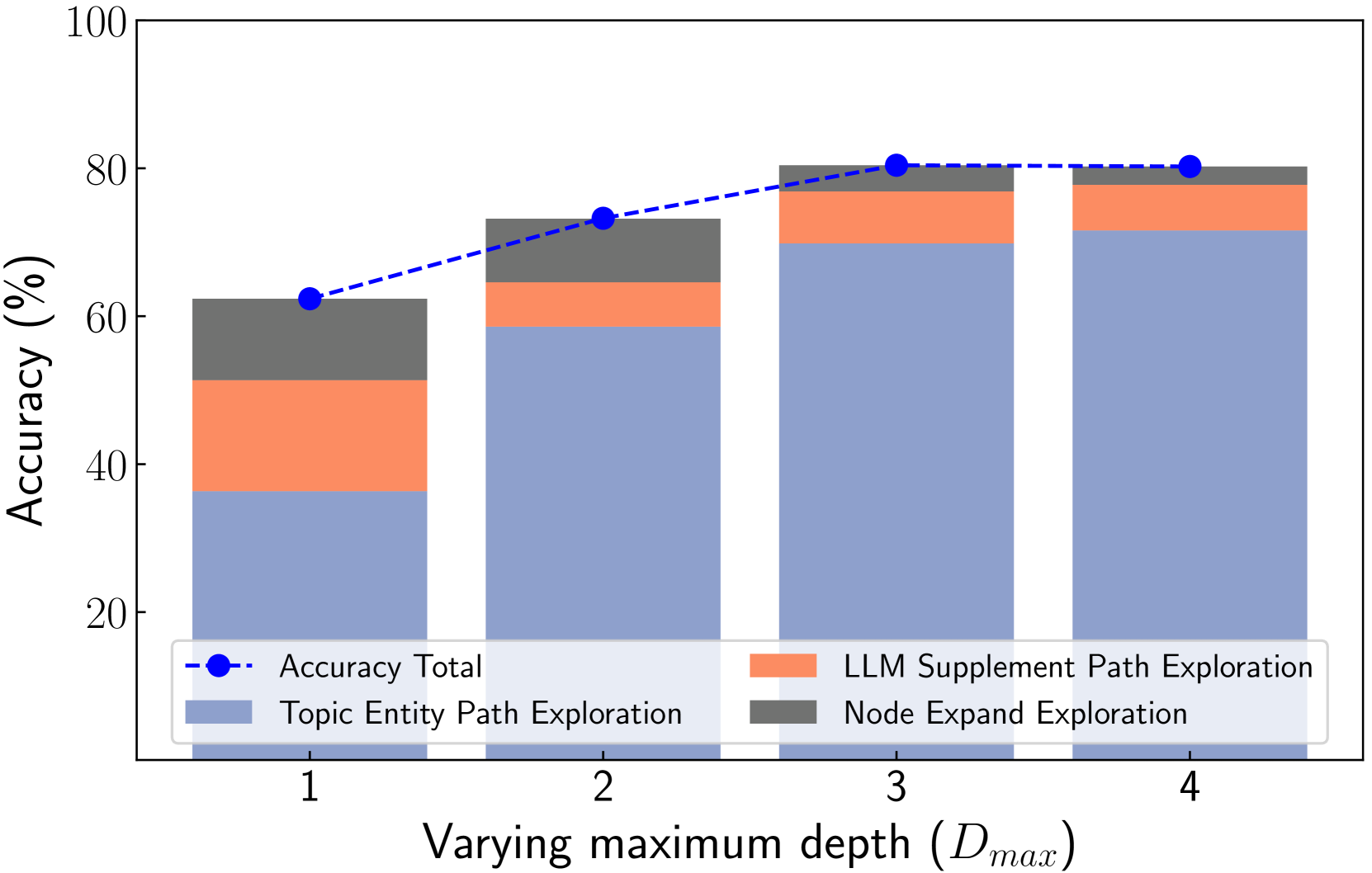
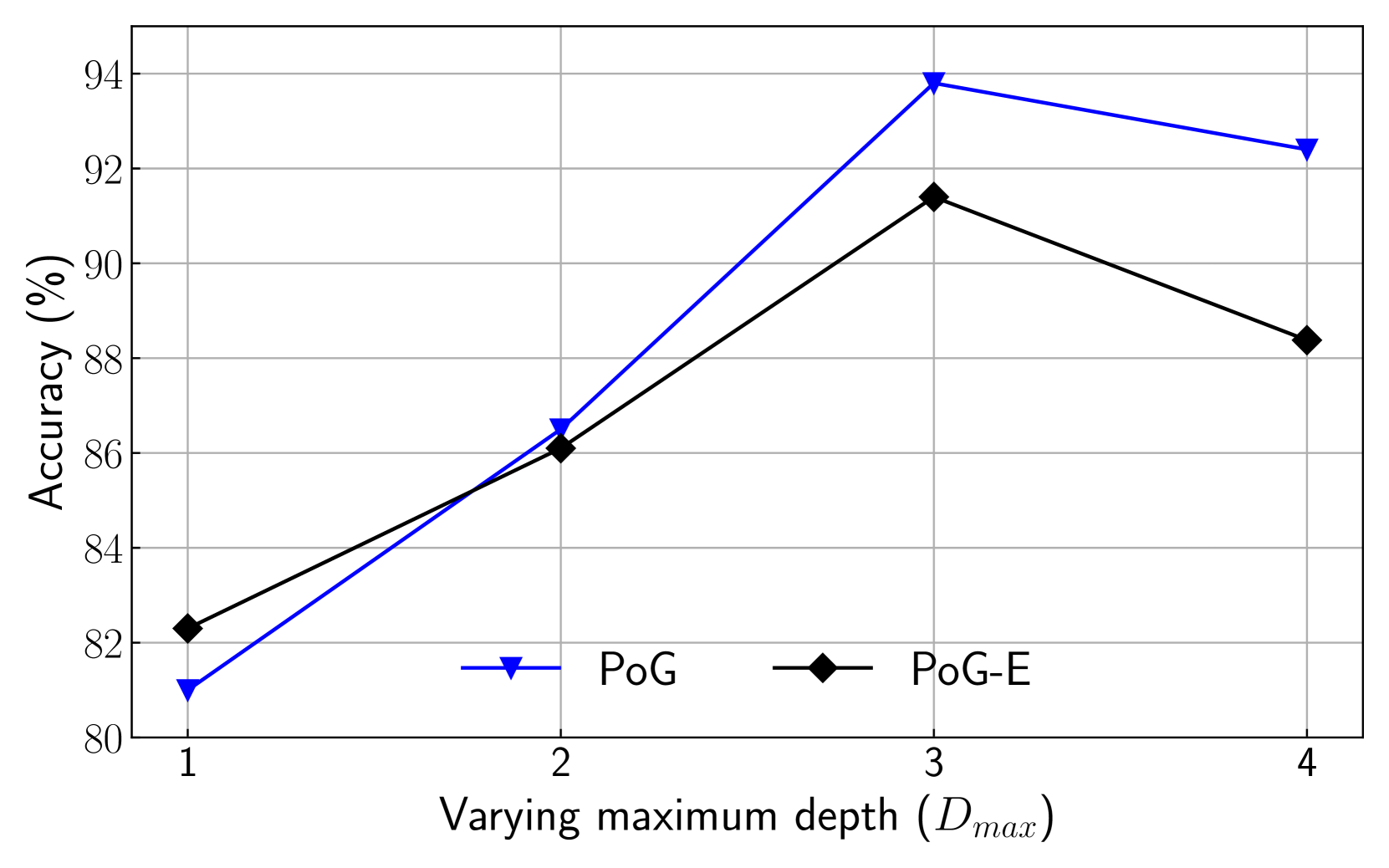
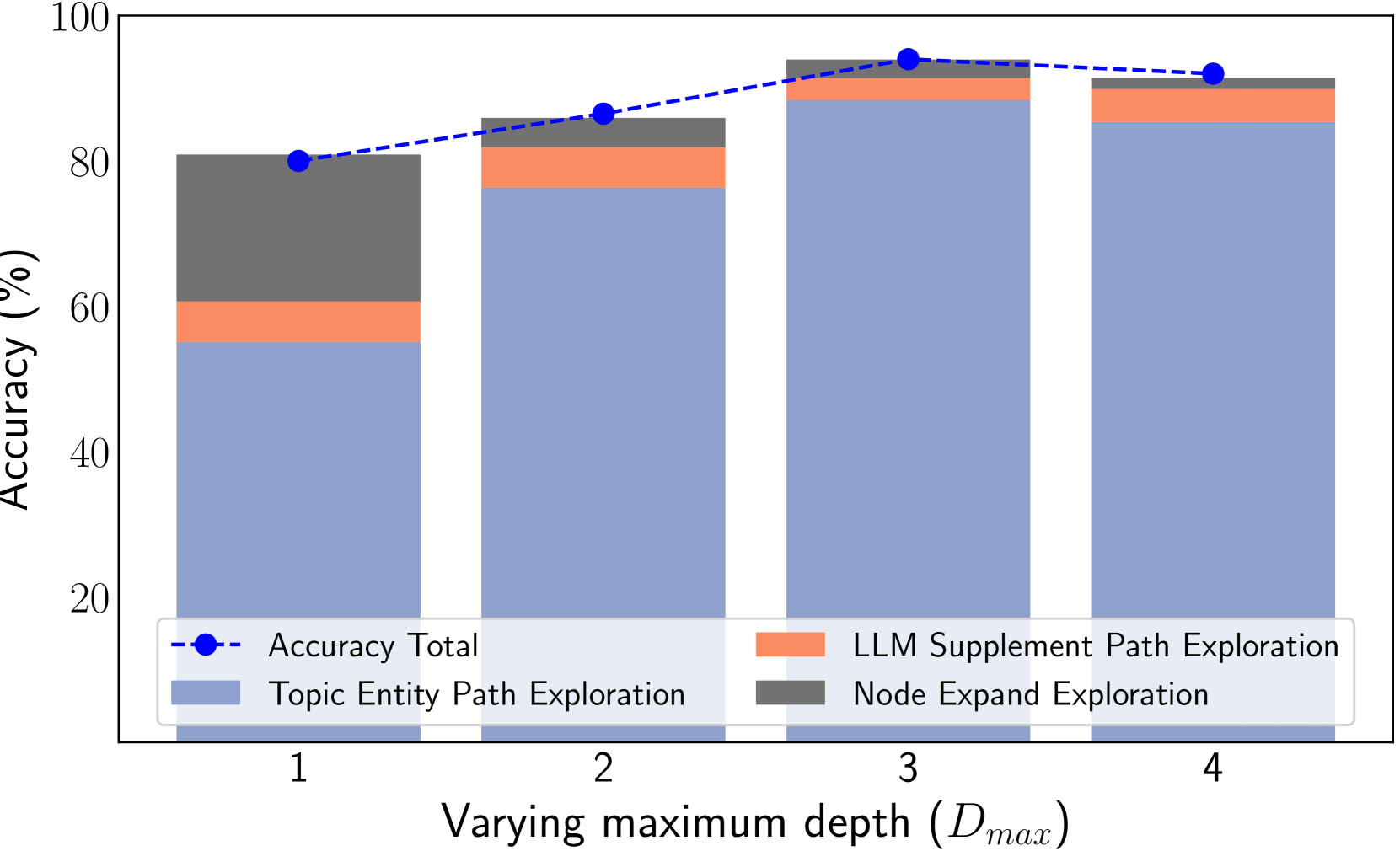
We perform various ablation studies to understand the importance of different factors in PoG. These ablation studies are performed with GPT-3.5-Turbo on two subsets of the CWQ and WebQSP test sets, each containing 500 randomly sampled questions. Does search depth matter? As described, PoG’s dynamic deep search is limited by $D_{max}$ . To assess the impact of $D_{\max}$ on performance, we conduct experiments with depth from 1 to 4. The results, shown in Figures 4 (a) and (c), indicate that performance improves with increased depth, but the benefits diminish beyond a depth of 3. Figures 4 (b) and (d), showing which exploration phase the answer is generated from, reveal that higher depths reduce the effectiveness of both LLM-based path supplementation and node exploration. Excessive depth leads to LLM hallucinations and difficulties in managing long reasoning paths. Therefore, we set the maximum depth to 3 for experiments to balance performance and computational efficiency. Additionally, even at lower depths, PoG maintains strong performance by effectively combining the LLM’s inherent knowledge with the structured information from the KG.
<details>
<summary>x4.png Details</summary>
### Visual Description
## Line Chart: Accuracy vs. Maximum Depth for PoG and PoG-E Methods
### Overview
This is a line chart comparing the performance, measured in accuracy percentage, of two methods—PoG and PoG-E—as a function of a parameter called "Varying maximum depth (D_max)". The chart plots accuracy on the vertical axis against discrete depth values on the horizontal axis.
### Components/Axes
* **Chart Type:** Line chart with markers.
* **X-Axis (Horizontal):**
* **Label:** "Varying maximum depth (D_max)"
* **Scale:** Discrete integer values: 1, 2, 3, 4.
* **Y-Axis (Vertical):**
* **Label:** "Accuracy (%)"
* **Scale:** Linear scale from 50 to 85, with major gridlines every 5 units (50, 55, 60, ..., 85).
* **Legend:**
* **Position:** Centered at the bottom of the chart area.
* **Series 1:** "PoG" - Represented by a solid blue line with downward-pointing triangle markers (▼).
* **Series 2:** "PoG-E" - Represented by a solid black line with diamond markers (◆).
* **Grid:** A light gray grid is present, with both horizontal and vertical lines aligned with the axis ticks.
### Detailed Analysis
**Data Series: PoG (Blue line, ▼ markers)**
* **Trend:** The line shows a consistent upward trend that plateaus at the highest depth values.
* **Data Points (Approximate):**
* At D_max = 1: Accuracy ≈ 62.5%
* At D_max = 2: Accuracy ≈ 73.5%
* At D_max = 3: Accuracy ≈ 80.5%
* At D_max = 4: Accuracy ≈ 80.5%
**Data Series: PoG-E (Black line, ◆ markers)**
* **Trend:** The line shows an initial upward trend, peaks at D_max=3, and then declines.
* **Data Points (Approximate):**
* At D_max = 1: Accuracy ≈ 55.5%
* At D_max = 2: Accuracy ≈ 69.0%
* At D_max = 3: Accuracy ≈ 78.5%
* At D_max = 4: Accuracy ≈ 70.0%
### Key Observations
1. **Performance Gap:** The PoG method consistently achieves higher accuracy than the PoG-E method at every measured depth value.
2. **Peak Performance:** Both methods reach their peak accuracy at D_max = 3. PoG's peak is ~80.5%, while PoG-E's peak is ~78.5%.
3. **Divergent Behavior at High Depth:** At the maximum depth of 4, the two methods diverge significantly. PoG maintains its peak accuracy (plateaus), while PoG-E's accuracy drops sharply by approximately 8.5 percentage points from its peak.
4. **Rate of Improvement:** The most significant gains in accuracy for both methods occur when increasing D_max from 1 to 2.
### Interpretation
The chart demonstrates the relationship between model complexity (controlled by maximum depth, D_max) and predictive accuracy for two related algorithms. The data suggests:
* **Benefit of Increased Depth:** For both methods, increasing the maximum depth from 1 to 3 leads to substantial improvements in accuracy, indicating that allowing the model to consider deeper hierarchical structures or longer sequences is beneficial up to a point.
* **Robustness vs. Overfitting:** The PoG method appears more robust to increases in model complexity. Its performance plateaus at D_max=3 and 4, suggesting it has reached its capacity or that additional depth provides no further benefit. In contrast, the PoG-E method's performance degrades at D_max=4, which is a classic sign of overfitting—the model may be becoming too complex and fitting noise in the training data, harming its generalization performance.
* **Method Superiority:** Based on this evaluation, PoG is the superior method across the tested range of depths, offering both higher peak accuracy and more stable performance as complexity increases. The "E" variant (PoG-E) may incorporate a modification that introduces instability or sensitivity at higher depths.
**Language Note:** All text in the image is in English. No other languages are present.
</details>
(a) CWQ (Vary $D_{\max}$ )
<details>
<summary>x5.png Details</summary>
### Visual Description
## Stacked Bar Chart with Line Overlay: Accuracy vs. Maximum Depth
### Overview
This image displays a stacked bar chart with an overlaid line graph. It illustrates how the total accuracy of a system and the contribution of its three constituent exploration methods change as a key parameter, the maximum depth (`D_max`), is increased from 1 to 4.
### Components/Axes
* **X-Axis:** Labeled "Varying maximum depth (`D_max`)". It has four discrete, evenly spaced categories marked with the integers `1`, `2`, `3`, and `4`.
* **Y-Axis:** Labeled "Accuracy (%)". It is a linear scale ranging from 0 to 100, with major tick marks at intervals of 20 (0, 20, 40, 60, 80, 100).
* **Legend:** Positioned at the bottom of the chart area, spanning its width. It contains four entries:
1. **Accuracy Total:** Represented by a blue dashed line with circular markers.
2. **Topic Entity Path Exploration:** Represented by a light blue (periwinkle) solid bar segment.
3. **LLM Supplement Path Exploration:** Represented by an orange solid bar segment.
4. **Node Expand Exploration:** Represented by a dark gray solid bar segment.
### Detailed Analysis
**Data Series and Values (Approximate):**
The chart presents data for four values of `D_max`. For each, the total accuracy (line) and the stacked contributions (bars) are as follows:
* **D_max = 1:**
* **Accuracy Total (Line):** ~62%
* **Bar Composition (Bottom to Top):**
* Topic Entity Path Exploration (Light Blue): ~36%
* LLM Supplement Path Exploration (Orange): ~15% (stacked from ~36% to ~51%)
* Node Expand Exploration (Dark Gray): ~11% (stacked from ~51% to ~62%)
* **Trend Check:** The line starts at its lowest point. The bar is the shortest, with the "Topic Entity" segment being the largest component.
* **D_max = 2:**
* **Accuracy Total (Line):** ~73%
* **Bar Composition (Bottom to Top):**
* Topic Entity Path Exploration (Light Blue): ~59%
* LLM Supplement Path Exploration (Orange): ~5% (stacked from ~59% to ~64%)
* Node Expand Exploration (Dark Gray): ~9% (stacked from ~64% to ~73%)
* **Trend Check:** The line shows a significant upward slope. The "Topic Entity" segment grows substantially, while the "LLM Supplement" segment shrinks noticeably.
* **D_max = 3:**
* **Accuracy Total (Line):** ~80%
* **Bar Composition (Bottom to Top):**
* Topic Entity Path Exploration (Light Blue): ~70%
* LLM Supplement Path Exploration (Orange): ~7% (stacked from ~70% to ~77%)
* Node Expand Exploration (Dark Gray): ~3% (stacked from ~77% to ~80%)
* **Trend Check:** The line continues to rise, but the slope is less steep than the previous step. The "Topic Entity" segment continues to dominate and grow. The "Node Expand" segment is now very small.
* **D_max = 4:**
* **Accuracy Total (Line):** ~80%
* **Bar Composition (Bottom to Top):**
* Topic Entity Path Exploration (Light Blue): ~72%
* LLM Supplement Path Exploration (Orange): ~6% (stacked from ~72% to ~78%)
* Node Expand Exploration (Dark Gray): ~2% (stacked from ~78% to ~80%)
* **Trend Check:** The line is flat, indicating a plateau. The bar composition is nearly identical to `D_max=3`, with a very slight increase in the "Topic Entity" segment and a negligible decrease in the "Node Expand" segment.
### Key Observations
1. **Plateau Effect:** The total accuracy (blue dashed line) increases from `D_max=1` to `D_max=3` but then plateaus, showing no improvement between `D_max=3` and `D_max=4`.
2. **Dominant Component:** The "Topic Entity Path Exploration" (light blue) is the largest contributor to accuracy at every depth, and its contribution grows steadily as `D_max` increases.
3. **Diminishing Returns of Other Methods:** The contributions from "LLM Supplement Path Exploration" (orange) and especially "Node Expand Exploration" (dark gray) become proportionally smaller as `D_max` increases. The "Node Expand" method's contribution is minimal at depths 3 and 4.
4. **Component Shift:** There is a clear shift in the system's behavior. At low depth (`D_max=1`), all three methods contribute meaningfully. At higher depths (`D_max=3,4`), the system relies almost entirely on "Topic Entity Path Exploration."
### Interpretation
This chart demonstrates the performance characteristics of a multi-method exploration system, likely for knowledge graph traversal, question answering, or a similar AI task. The data suggests:
* **Optimal Depth:** The system reaches its peak effective performance at a maximum depth (`D_max`) of 3. Increasing the depth further to 4 does not yield accuracy gains, indicating a point of diminishing returns or a fundamental limit of the approach.
* **Method Efficacy:** The "Topic Entity Path Exploration" method is the most effective and scalable component. Its increasing contribution with depth implies it benefits from exploring deeper, more complex paths in the data structure.
* **Role of Supplementary Methods:** The "LLM Supplement" and "Node Expand" methods appear to be most valuable in compensating for the limitations of the primary method at shallow depths. As the primary method is allowed to explore deeper (higher `D_max`), these supplementary methods become less critical, suggesting they may be addressing surface-level or immediate neighbor information that the deeper primary search eventually captures more effectively.
* **System Design Insight:** The plateau suggests that for this specific task and configuration, allocating computational resources to increase depth beyond 3 is inefficient. Resources might be better spent improving the core "Topic Entity" exploration algorithm or investigating why deeper exploration fails to improve accuracy further.
</details>
(b) CWQ(PoG)
<details>
<summary>x6.png Details</summary>
### Visual Description
## Line Chart: Accuracy vs. Maximum Depth for PoG and PoG-E Methods
### Overview
The image is a line chart comparing the performance (accuracy) of two methods, labeled "PoG" and "PoG-E," as a function of a parameter called "Varying maximum depth (D_max)." The chart shows that both methods improve in accuracy as depth increases from 1 to 3, but then experience a decline at depth 4. The "PoG" method consistently achieves higher accuracy than "PoG-E" at depths 2, 3, and 4.
### Components/Axes
* **Chart Type:** Line chart with markers.
* **X-Axis:**
* **Label:** "Varying maximum depth (D_max)"
* **Scale:** Discrete integer values: 1, 2, 3, 4.
* **Y-Axis:**
* **Label:** "Accuracy (%)"
* **Scale:** Linear scale from 80 to 94, with major gridlines at intervals of 2 (80, 82, 84, 86, 88, 90, 92, 94).
* **Legend:**
* **Position:** Bottom center of the chart area.
* **Series 1:** "PoG" - Represented by a blue line with downward-pointing triangle markers (▼).
* **Series 2:** "PoG-E" - Represented by a black line with diamond markers (◆).
* **Grid:** A light gray grid is present for both major x and y ticks.
### Detailed Analysis
**Data Series: PoG (Blue line, ▼ markers)**
* **Trend:** The line slopes steeply upward from depth 1 to 3, then slopes slightly downward to depth 4.
* **Data Points (Approximate):**
* D_max = 1: Accuracy ≈ 81.0%
* D_max = 2: Accuracy ≈ 86.5%
* D_max = 3: Accuracy ≈ 93.8% (Peak)
* D_max = 4: Accuracy ≈ 92.4%
**Data Series: PoG-E (Black line, ◆ markers)**
* **Trend:** The line slopes upward from depth 1 to 3, then slopes downward to depth 4. The slope is less steep than the PoG line between depths 1 and 3.
* **Data Points (Approximate):**
* D_max = 1: Accuracy ≈ 82.3%
* D_max = 2: Accuracy ≈ 86.1%
* D_max = 3: Accuracy ≈ 91.4% (Peak)
* D_max = 4: Accuracy ≈ 88.4%
### Key Observations
1. **Performance Peak:** Both methods achieve their highest accuracy at a maximum depth (D_max) of 3.
2. **Relative Performance:** PoG-E starts with a slightly higher accuracy than PoG at D_max=1 (≈82.3% vs. ≈81.0%). However, PoG surpasses PoG-E at D_max=2 and maintains a significant lead at D_max=3 and D_max=4.
3. **Performance Drop-off:** Both methods show a decrease in accuracy when moving from D_max=3 to D_max=4. The drop is more pronounced for PoG-E (≈3.0 percentage points) than for PoG (≈1.4 percentage points).
4. **Greatest Divergence:** The largest performance gap between the two methods occurs at D_max=3, where PoG outperforms PoG-E by approximately 2.4 percentage points.
### Interpretation
The chart demonstrates the relationship between model complexity (controlled by maximum depth, D_max) and predictive accuracy for two related algorithms, PoG and PoG-E. The data suggests an optimal complexity point at D_max=3 for both methods, where accuracy is maximized. Increasing depth beyond this point (to 4) leads to a decline in performance, which could indicate the onset of overfitting, where the model becomes too specialized to the training data and loses generalization ability.
The "PoG" variant appears to be the more robust and effective method overall, as it not only achieves a higher peak accuracy but also experiences a less severe performance degradation at the highest tested depth. The initial advantage of PoG-E at the simplest configuration (D_max=1) is quickly overcome, suggesting that PoG scales better with increased model complexity within the tested range. This analysis would be crucial for a practitioner deciding which method to use and what depth parameter to select for their specific application, balancing accuracy against potential computational costs associated with greater depth.
</details>
(c) WebQSP (Vary $D_{\max}$ )
<details>
<summary>x7.png Details</summary>
### Visual Description
## Stacked Bar Chart with Line Overlay: Accuracy vs. Maximum Depth
### Overview
This image displays a stacked bar chart with an overlaid line graph. It illustrates how the total accuracy and the contribution of three different exploration methods change as a parameter called "Varying maximum depth (D_max)" increases from 1 to 4. The chart suggests an analysis of a system's performance, likely in a knowledge graph or information retrieval context, where different path exploration strategies contribute to an overall accuracy score.
### Components/Axes
* **Chart Type:** Stacked bar chart with a line graph overlay.
* **X-Axis:** Labeled "Varying maximum depth (D_max)". It has four discrete, evenly spaced categories marked with the integers: **1, 2, 3, 4**.
* **Y-Axis:** Labeled "Accuracy (%)". The scale runs from 0 to 100, with major tick marks and numerical labels at intervals of 20 (0, 20, 40, 60, 80, 100).
* **Legend:** Positioned at the bottom center of the chart area. It contains four entries:
1. **Accuracy Total:** Represented by a blue dashed line with circular markers (`--●--`).
2. **Topic Entity Path Exploration:** Represented by a light blue/periwinkle solid bar segment.
3. **LLM Supplement Path Exploration:** Represented by an orange solid bar segment.
4. **Node Expand Exploration:** Represented by a dark gray solid bar segment.
### Detailed Analysis
The data is presented for each of the four depth categories (D_max = 1 to 4). For each category, a single bar is composed of three stacked segments. The total height of the bar corresponds to the sum of the three components. A blue dashed line connects data points that align with the top of each bar, representing the "Accuracy Total."
**Trend Verification:**
* The **Accuracy Total (blue line)** shows an upward trend from D_max=1 to D_max=3, peaking at D_max=3, followed by a slight decrease at D_max=4.
* The **Topic Entity Path Exploration (light blue)** segment shows a strong, consistent upward trend as depth increases.
* The **LLM Supplement Path Exploration (orange)** segment appears relatively stable in height from D_max=2 to D_max=4, after being smaller at D_max=1.
* The **Node Expand Exploration (dark gray)** segment decreases significantly in height from D_max=1 to D_max=2 and remains a very small component for depths 3 and 4.
**Data Point Extraction (Approximate Values):**
* **D_max = 1:**
* Topic Entity Path Exploration: ~55%
* LLM Supplement Path Exploration: ~5% (bar from ~55% to ~60%)
* Node Expand Exploration: ~20% (bar from ~60% to ~80%)
* **Total Bar Height / Accuracy Total:** ~80%
* **D_max = 2:**
* Topic Entity Path Exploration: ~76%
* LLM Supplement Path Exploration: ~6% (bar from ~76% to ~82%)
* Node Expand Exploration: ~4% (bar from ~82% to ~86%)
* **Total Bar Height / Accuracy Total:** ~86%
* **D_max = 3:**
* Topic Entity Path Exploration: ~88%
* LLM Supplement Path Exploration: ~4% (bar from ~88% to ~92%)
* Node Expand Exploration: ~2% (bar from ~92% to ~94%)
* **Total Bar Height / Accuracy Total:** ~94%
* **D_max = 4:**
* Topic Entity Path Exploration: ~85%
* LLM Supplement Path Exploration: ~5% (bar from ~85% to ~90%)
* Node Expand Exploration: ~2% (bar from ~90% to ~92%)
* **Total Bar Height / Accuracy Total:** ~92%
### Key Observations
1. **Dominant Component:** The "Topic Entity Path Exploration" method is the primary contributor to accuracy at all depths, and its contribution grows substantially with increased depth.
2. **Diminishing Returns:** The "Node Expand Exploration" method is a major contributor only at the shallowest depth (D_max=1). Its contribution becomes negligible at deeper levels.
3. **Peak Performance:** The highest total accuracy (~94%) is achieved at a maximum depth of 3. Increasing the depth further to 4 results in a slight performance drop (~92%).
4. **Stable Supplement:** The "LLM Supplement Path Exploration" provides a small but consistent boost to accuracy across all depths, with its most notable contribution at D_max=1.
### Interpretation
The data demonstrates a clear relationship between the allowed search depth (D_max) and the system's accuracy, mediated by the exploration strategy employed.
* **Strategy Efficacy:** The "Topic Entity Path Exploration" is the most effective strategy, and its value increases with depth, suggesting that deeper, more focused searches along topic-entity paths yield better results. Conversely, the "Node Expand Exploration" strategy, which likely involves broader, less targeted expansion, is only useful when the search is very shallow (D_max=1). This implies it may introduce noise or irrelevant paths that hinder performance at greater depths.
* **Optimal Depth:** The system exhibits an optimal operating point at D_max=3. The drop in accuracy at D_max=4 could indicate the onset of over-searching, where the system begins to retrieve less relevant information or encounters computational/complexity limits that degrade performance.
* **Role of LLM Supplement:** The consistent, small contribution from "LLM Supplement Path Exploration" suggests it acts as a reliable auxiliary method, possibly filling gaps left by the primary topic-entity path method, but it is not the main driver of performance gains.
* **System Design Implication:** For this system, configuring a maximum depth of 3 and prioritizing the "Topic Entity Path Exploration" algorithm would maximize accuracy. The "Node Expand Exploration" method could potentially be disabled or heavily constrained for depths greater than 1 to save resources without harming performance.
</details>
(d) WebQSP(PoG)
Figure 4. The accuracy of PoG and PoG-E among CWQ and WebQSP datasets by varying different $D_{\max}$ .
### 5.3. Effectiveness Evaluation
Effective evaluation on multi-entity questions. To evaluate PoG’s performance on multi-entity questions, we report the accuracy on all test sets by categorizing questions based on the number of topic entities. The results, shown in Table 2, demonstrate that, despite the increased complexity of multi-entity questions compared to single-entity ones, PoG maintains excellent accuracy, achieving up to 93.9% on the WebQSP dataset. This underscores the effectiveness of our structure-based model in handling complex multi-entity queries. Notably, the slightly lower performance on the GrailQA dataset can be attributed to some questions lacking matched topic entities, which prevents effective reasoning using KG.
Table 2. Performance of PoG and PoG-E on multi-entity and single-entity questions of all datasets. The symbol ‘-’ indicates no multi-entity question inside.
| Question Set | CWQ | WebQSP | GrailQA | WebQuestions | Simple Questions |
| --- | --- | --- | --- | --- | --- |
| PoG with GPT-3.5-Turbo | | | | | |
| Single-entity | 70.3 | 93.9 | 92.1 | 81.7 | 78.3 |
| Multi-entity | 80.2 | 93.1 | 70.7 | 82.8 | - |
| PoG-E with GPT-3.5-Turbo | | | | | |
| Single-entity | 67.5 | 91 | 88.2 | 76.8 | 80.8 |
| Multi-entity | 77.5 | 82.8 | 76.0 | 82.8 | - |
Effective evaluation on multi-hop reasoning. To assess PoG’s performance on multi-hop reasoning tasks, we analyze accuracy by categorizing questions based on the length of their ground-truth SPARQL queries. We randomly sample 1,000 questions from CWQ and WebQSP datasets and determine the reasoning length of each question by counting the number of relations in their ground-truth SPARQL queries. The distribution of questions with varying reasoning lengths is illustrated in Figure 5. We evaluate the performance of PoG and PoG-E across different ground-truth lengths to understand their effectiveness under varying query complexities. As shown in Figure 6, the performance of PoG and PoG-E remains consistent across different reasoning lengths. Even at the highest length levels in the WebQSP dataset, PoG achieves excellent accuracy, reaching up to 90%. Notably, although some questions have ground-truth lengths of eight or more, PoG successfully addresses them without matching the ground-truth length, demonstrating its ability to explore novel paths by effectively combining the LLM’s inherent knowledge with the structured information from the KG. These results demonstrate the effectiveness of PoG in handling complex multi-hop reasoning tasks.
Table 3. The illustration of graph size reduction.
| | CWQ | WebQSP | GrailQA | WebQuestions |
| --- | --- | --- | --- | --- |
| Ave Entity Number | 3,540,267 | 243,826 | 62,524 | 240,863 |
| Ave Entity Number After Pruned | 1,621,055 | 182,673 | 30,267 | 177,822 |
| Ave Entitiy Reduction Proportion (%) | 54% | 25% | 52% | 26% |
<details>
<summary>x8.png Details</summary>
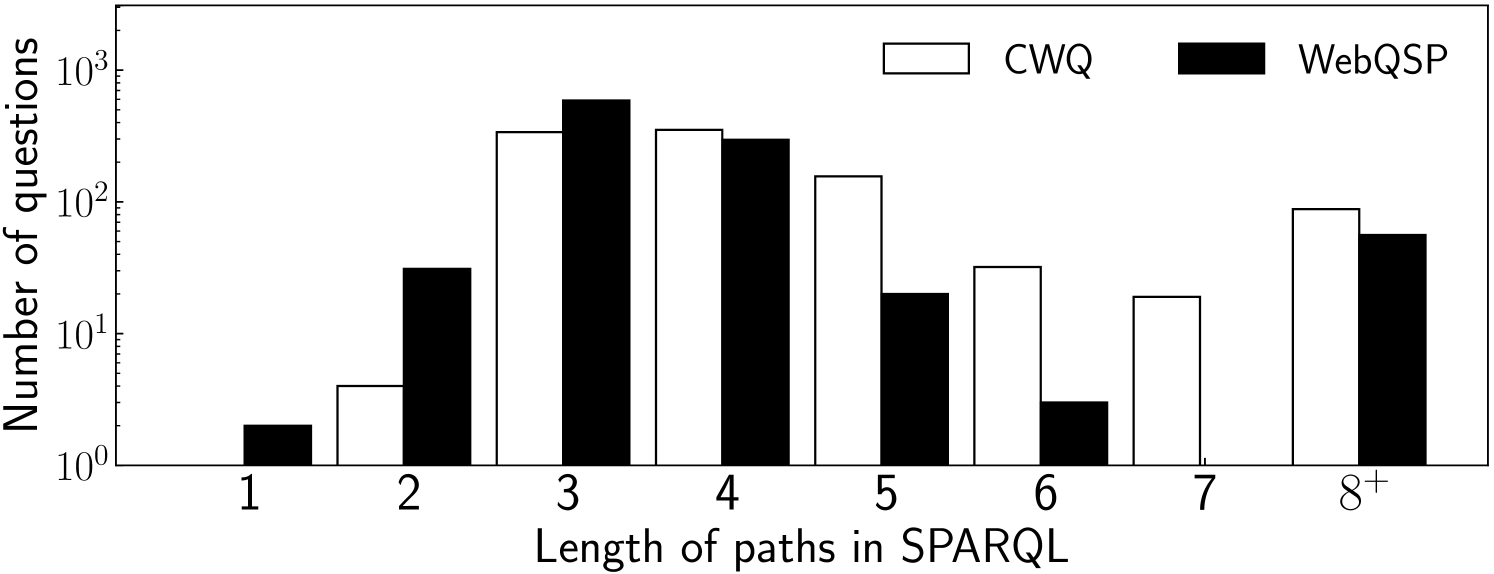
### Visual Description
## Bar Chart: Distribution of SPARQL Path Lengths for CWQ and WebQSP Datasets
### Overview
This is a grouped bar chart comparing the frequency distribution of SPARQL query path lengths for two question datasets: CWQ (Complex WebQuestions) and WebQSP (WebQuestionsSP). The chart uses a logarithmic scale on the y-axis to accommodate the wide range of question counts.
### Components/Axes
* **Chart Type:** Grouped Bar Chart.
* **X-Axis:** Labeled "Length of paths in SPARQL". It has categorical markers for path lengths 1, 2, 3, 4, 5, 6, 7, and 8.
* **Y-Axis:** Labeled "Number of questions". It uses a base-10 logarithmic scale with major grid lines at 10⁰ (1), 10¹ (10), 10² (100), and 10³ (1000).
* **Legend:** Located in the top-right corner of the chart area.
* A white rectangle corresponds to the label "CWQ".
* A black rectangle corresponds to the label "WebQSP".
* **Data Series:** Two series of bars, grouped by path length.
* **CWQ Series:** Represented by white bars with black outlines.
* **WebQSP Series:** Represented by solid black bars.
### Detailed Analysis
The following table reconstructs the approximate data from the chart. Values are estimated based on the logarithmic y-axis.
| Path Length (SPARQL) | CWQ (White Bars) - Approx. Count | WebQSP (Black Bars) - Approx. Count |
| :--- | :--- | :--- |
| **1** | 0 (No bar visible) | ~2 |
| **2** | ~4 | ~30 |
| **3** | ~350 | ~600 |
| **4** | ~350 | ~300 |
| **5** | ~150 | ~20 |
| **6** | ~30 | ~3 |
| **7** | ~20 | 0 (No bar visible) |
| **8** | ~90 | ~60 |
**Trend Verification:**
* **CWQ (White Bars):** The distribution is roughly unimodal, peaking at path lengths 3 and 4. It shows a secondary, smaller peak at length 8. The trend increases sharply from length 2 to 3, plateaus at 4, then generally declines, with a notable resurgence at length 8.
* **WebQSP (Black Bars):** The distribution is also unimodal, with a clear peak at path length 3. The trend increases from length 1 to 3, then declines steadily. There is no visible bar for length 7.
### Key Observations
1. **Peak Complexity:** Both datasets have the highest concentration of questions requiring SPARQL paths of length 3. WebQSP has a more pronounced peak at this length.
2. **Short Path Dominance (WebQSP):** WebQSP has a significantly higher number of questions with very short paths (lengths 1 and 2) compared to CWQ.
3. **Long Tail (CWQ):** CWQ maintains a substantial number of questions across longer path lengths (5, 6, 7, and especially 8), indicating a greater proportion of complex, multi-hop questions.
4. **Absence at Length 7:** There is a notable gap in the WebQSP data at path length 7, while CWQ has a small but present count.
5. **Logarithmic Scale Necessity:** The use of a log scale is essential, as the counts range from single digits (WebQSP at length 1, 6) to several hundred (both at length 3).
### Interpretation
This chart visualizes the inherent complexity difference between the CWQ and WebQSP question answering datasets. The data suggests that **WebQSP questions are generally simpler**, clustering around shorter SPARQL query paths (primarily length 3). In contrast, **CWQ questions are more complex and varied**, with a significant portion requiring longer reasoning chains (paths of length 4 and above, with a notable group at length 8).
The absence of WebQSP questions at path length 7 and the minimal count at length 6 further highlight that CWQ is designed to test deeper, more compositional reasoning. The secondary peak for CWQ at length 8 is particularly interesting, indicating a subset of questions that are exceptionally complex, requiring eight relational hops to answer. This distribution aligns with the stated purpose of CWQ as a more challenging extension of the WebQuestions dataset.
</details>
Figure 5. The lengths of the ground-truth SPARQL queries within the CWQ and WebQSP datasets.
<details>
<summary>x9.png Details</summary>
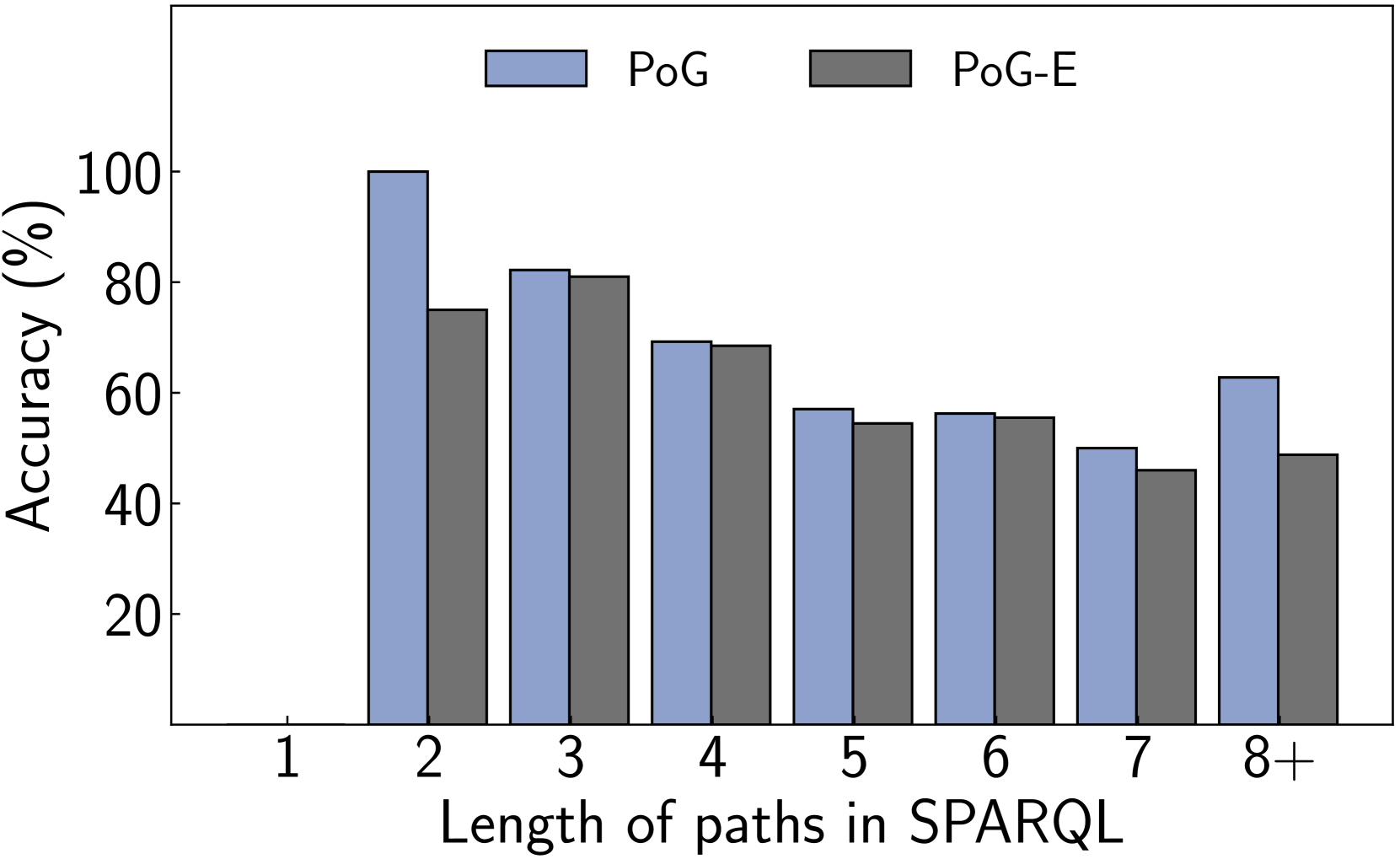
### Visual Description
## Grouped Bar Chart: Accuracy of PoG vs. PoG-E by SPARQL Path Length
### Overview
The image is a grouped bar chart comparing the accuracy (in percentage) of two methods, labeled "PoG" and "PoG-E," across different lengths of paths in SPARQL queries. The chart demonstrates how the performance of each method changes as the complexity (path length) of the query increases.
### Components/Axes
* **Chart Type:** Grouped (clustered) bar chart.
* **X-Axis:** Labeled **"Length of paths in SPARQL"**. It has categorical tick marks for path lengths: **1, 2, 3, 4, 5, 6, 7, and 8+**.
* **Y-Axis:** Labeled **"Accuracy (%)"**. It is a linear scale ranging from 0 to 100, with major tick marks at intervals of 20 (0, 20, 40, 60, 80, 100).
* **Legend:** Positioned at the **top center** of the chart area.
* **PoG:** Represented by a light blue (periwinkle) bar.
* **PoG-E:** Represented by a dark gray bar.
* **Data Series:** Two series of bars, one for each method, grouped together for each x-axis category.
### Detailed Analysis
The following table reconstructs the approximate accuracy values for each method at each path length. Values are estimated from the bar heights relative to the y-axis.
| Length of paths in SPARQL | PoG Accuracy (Approx. %) | PoG-E Accuracy (Approx. %) |
| :--- | :--- | :--- |
| 1 | No data plotted | No data plotted |
| 2 | 100 | ~75 |
| 3 | ~82 | ~80 |
| 4 | ~70 | ~69 |
| 5 | ~58 | ~55 |
| 6 | ~57 | ~56 |
| 7 | ~50 | ~46 |
| 8+ | ~62 | ~49 |
**Trend Verification:**
* **PoG (Light Blue):** The trend line slopes downward from a peak at path length 2 (100%) to a low at length 7 (~50%), with a notable upward rebound at length 8+ (~62%).
* **PoG-E (Dark Gray):** The trend line shows a consistent, gradual downward slope from its highest point at length 2 (~75%) to its lowest at length 7 (~46%), with a very slight increase at length 8+ (~49%).
### Key Observations
1. **Performance Gap:** PoG consistently achieves higher accuracy than PoG-E across all reported path lengths where data is present (2 through 8+).
2. **Peak Performance:** Both methods achieve their highest accuracy at the shortest measured path length (2). PoG reaches a perfect 100% here.
3. **General Decline:** There is a clear general trend of decreasing accuracy for both methods as the SPARQL path length increases from 2 to 7.
4. **Anomaly at 8+:** The expected downward trend is broken at the "8+" category. PoG shows a significant recovery in accuracy (~62%), while PoG-E shows only a marginal increase (~49%). This suggests PoG may handle very long paths better than the general trend would predict.
5. **Convergence Points:** The performance of the two methods is closest at path lengths 3, 4, and 6, where the difference in bar heights is minimal (within ~2-3 percentage points).
6. **Missing Data:** No accuracy data is plotted for a path length of 1.
### Interpretation
The data suggests that the **PoG method is generally more accurate than PoG-E** for generating or answering SPARQL queries of varying path complexities. The strong performance of PoG at length 2 (100%) indicates it is highly reliable for simpler queries.
The **inverse relationship between path length and accuracy** for both methods (from length 2 to 7) demonstrates that increasing query complexity—measured by the number of hops or relationships in the path—poses a significant challenge, leading to a drop in performance. This is a common pattern in knowledge graph and semantic web tasks.
The **notable outlier is the "8+" category for PoG**. Its accuracy rebound suggests one of two possibilities: 1) The "8+" bin may contain a different distribution of query types that PoG is better suited for, or 2) The method has a specific architectural advantage for handling very long-range dependencies that does not scale linearly with intermediate lengths. This anomaly would be a critical point for further investigation in a technical paper.
The **relatively small performance gap at lengths 3, 4, and 6** indicates that for mid-complexity queries, the choice between PoG and PoG-E may depend on other factors like computational cost or recall, as their accuracy is nearly equivalent. The widening gap at lengths 2, 7, and 8+ highlights the scenarios where PoG's advantage is most pronounced.
</details>
(a) CWQ
<details>
<summary>x10.png Details</summary>
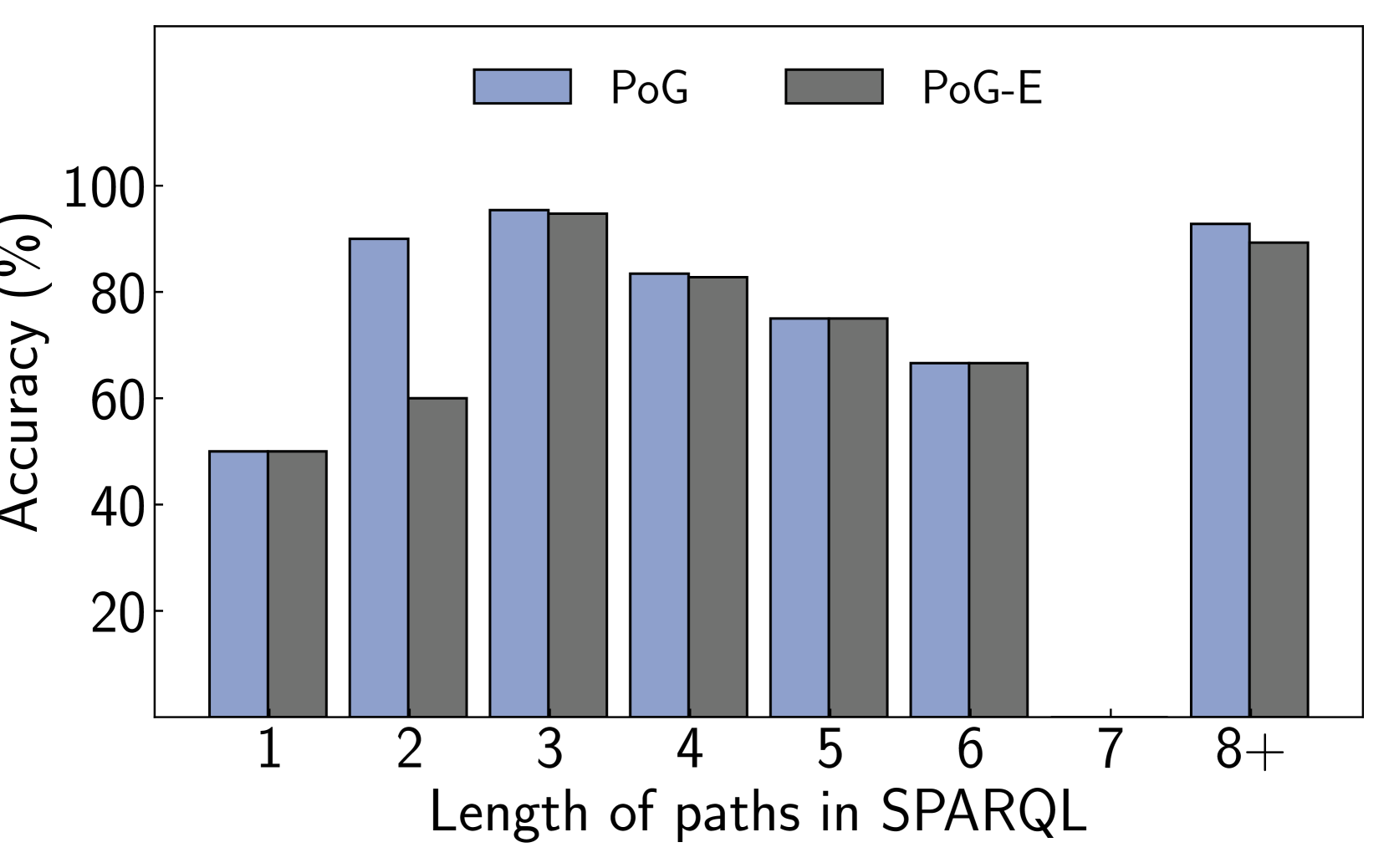
### Visual Description
## Grouped Bar Chart: Accuracy by SPARQL Path Length
### Overview
This is a grouped bar chart comparing the accuracy (in percentage) of two methods, labeled "PoG" and "PoG-E," across different path lengths in SPARQL queries. The chart visualizes how performance varies with increasing query complexity.
### Components/Axes
* **Chart Type:** Grouped vertical bar chart.
* **X-Axis (Horizontal):**
* **Label:** "Length of paths in SPARQL"
* **Categories (from left to right):** 1, 2, 3, 4, 5, 6, 7, 8+
* **Note:** There is no data plotted for category "7".
* **Y-Axis (Vertical):**
* **Label:** "Accuracy (%)"
* **Scale:** Linear, from 0 to 100.
* **Major Tick Marks:** 0, 20, 40, 60, 80, 100.
* **Legend:**
* **Position:** Top-center of the chart area.
* **Series 1:** "PoG" - Represented by light blue bars.
* **Series 2:** "PoG-E" - Represented by dark gray bars.
### Detailed Analysis
The following table reconstructs the approximate accuracy values for each method at each path length, derived from visual inspection of the bar heights against the y-axis scale.
| Path Length | PoG (Light Blue) Accuracy (%) | PoG-E (Dark Gray) Accuracy (%) |
| :--- | :--- | :--- |
| 1 | ~50 | ~50 |
| 2 | ~90 | ~60 |
| 3 | ~95 | ~94 |
| 4 | ~83 | ~82 |
| 5 | ~75 | ~75 |
| 6 | ~66 | ~66 |
| 7 | (No Data) | (No Data) |
| 8+ | ~92 | ~89 |
**Trend Verification:**
* **PoG (Blue):** The trend is non-monotonic. Accuracy starts at ~50% (length 1), jumps to a high of ~95% (length 3), then generally declines through lengths 4, 5, and 6 (to ~66%), before rebounding sharply to ~92% for the longest paths (8+).
* **PoG-E (Gray):** Follows a very similar pattern to PoG. It starts at ~50% (length 1), rises to ~94% (length 3), declines to ~66% (length 6), and rebounds to ~89% (length 8+). Its most significant deviation from PoG is at path length 2, where it is substantially lower (~60% vs. PoG's ~90%).
### Key Observations
1. **Peak Performance:** Both methods achieve their highest accuracy at a path length of 3.
2. **Performance Dip:** Both methods show a clear decline in accuracy for intermediate path lengths (4, 5, 6), reaching a local minimum at length 6.
3. **Strong Recovery:** Both methods demonstrate a significant recovery in accuracy for the longest path category (8+), nearly matching their peak performance.
4. **Convergence at Certain Lengths:** The accuracy of PoG and PoG-E is nearly identical at path lengths 1, 3, 4, 5, and 6.
5. **Major Divergence:** The most notable difference occurs at path length 2, where PoG (~90%) significantly outperforms PoG-E (~60%).
6. **Missing Data:** There is a complete absence of data for path length 7, creating a gap in the trend analysis.
### Interpretation
The data suggests that the complexity of a SPARQL query, as measured by path length, has a non-linear impact on the accuracy of both the PoG and PoG-E methods. The relationship is not a simple case of "longer paths are harder."
* **The "Sweet Spot":** Queries with a path length of 3 appear to be the most reliably handled by both systems, possibly representing an optimal balance between query complexity and the methods' reasoning capabilities.
* **The "Intermediate Challenge":** The decline in accuracy for lengths 4-6 indicates a zone of increased difficulty. This could be due to a combinatorial explosion in possible reasoning paths or increased ambiguity in longer, but not longest, queries.
* **The "Long-Path Resilience":** The strong performance on the "8+" category is intriguing. It may suggest that very long paths are often more structured or follow more predictable patterns, or that the methods employ different strategies for handling extreme complexity that are effective. Alternatively, the "8+" category might be dominated by a specific, easier subclass of long queries.
* **Method Comparison:** PoG and PoG-E are largely comparable, with the critical exception of path length 2. This specific divergence warrants investigation—it may reveal a flaw in PoG-E's handling of a particular query pattern common at that length, or a specific strength of PoG. The fact that they converge at other lengths suggests their core mechanisms are similar, but differ in this one edge case.
**In summary,** the chart reveals that query accuracy is highly dependent on path length in a specific, non-linear pattern. The most significant finding is the dramatic performance gap at length 2, which is the primary differentiator between the two otherwise closely matched methods. The missing data for length 7 is a notable limitation in the presented results.
</details>
(b) WebQSP
Figure 6. The accuracy of PoG and PoG-E on the CWQ and WebQSP datasets, categorized by the different lengths of the ground-truth answers for each question.
Graph structure pruning. To evaluate the effectiveness of the graph pruning method proposed in Section 4.1, we conduct experiments using 200 random samples from each dataset. We report the average number of entities per question before and after graph reduction, as well as the proportion of entities reduced, in Table 3. The results indicate that up to 54% of entities in the CWQ dataset can be pruned before path exploration. This demonstrates the effectiveness of eliminating irrelevant data from the outset.
Case study: interpretable reasoning. We also conduct the case study to demonstrate interpretability of PoG, we present three reasoning examples in Table 9 of Appendix B.5. These examples feature questions with one, two, and three entities, respectively. Through the case study, we showcase PoG’s effectiveness in handling multi-entity and multi-hop tasks by providing faithful and interpretable reasoning paths that lead to accurate answers.
To further evaluate the effectiveness and efficiency of PoG, we perform additional experiments, including pruning beam search strategy ablation and prompt setting ablation (Appendix B.1), reasoning faithfulness analysis (Appendix B.2), error analysis (Appendix B.3), LLM calls cost and running time analysis (Appendix B.4), and graph reduction and path pruning case study (Appendix B.5).
## 6. Conclusion
In this paper, we introduce Paths-over-Graphs (PoG), a novel method that integrates LLMs with KGs to enable faithful and interpretable reasoning. PoG addresses complex reasoning tasks through a three-phase dynamic multi-hop path exploration, combining the inherent knowledge of LLMs with factual information from KGs. Efficiency is enhanced by graph-structured pruning and a three-step pruning process to effectively narrow down candidate paths. Extensive experiments on five public datasets demonstrate that PoG outperforms existing baselines, showcasing its superior reasoning capabilities and interoperability.
## 7. Acknowledgment
Xiaoyang Wang is supported by the Australian Research Council DP230101445 and DP240101322. Wenjie Zhang is supported by the Australian Research Council DP230101445 and FT210100303.
## References
- (1)
- Baek et al. (2023b) Jinheon Baek, Alham Fikri Aji, Jens Lehmann, and Sung Ju Hwang. 2023b. Direct Fact Retrieval from Knowledge Graphs without Entity Linking. In ACL.
- Baek et al. (2023a) Jinheon Baek, Alham Fikri Aji, and Amir Saffari. 2023a. Knowledge-augmented language model prompting for zero-shot knowledge graph question answering. arXiv preprint arXiv:2306.04136 (2023).
- Berant et al. (2013) Jonathan Berant, Andrew Chou, Roy Frostig, and Percy Liang. 2013. Semantic Parsing on Freebase from Question-Answer Pairs. In EMNLP. 1533–1544.
- Besta et al. (2024) Maciej Besta, Nils Blach, Ales Kubicek, Robert Gerstenberger, Michal Podstawski, Lukas Gianinazzi, Joanna Gajda, Tomasz Lehmann, Hubert Niewiadomski, Piotr Nyczyk, et al. 2024. Graph of thoughts: Solving elaborate problems with large language models. In AAAI, Vol. 38. 17682–17690.
- Bollacker et al. (2008) Kurt Bollacker, Colin Evans, Praveen Paritosh, Tim Sturge, and Jamie Taylor. 2008. Freebase: a collaboratively created graph database for structuring human knowledge. In SIGMOD. 1247–1250.
- Brown (2020) Tom B Brown. 2020. Language models are few-shot learners. arXiv preprint arXiv:2005.14165 (2020).
- Chen et al. (2024) Zhikai Chen, Haitao Mao, Hang Li, Wei Jin, Hongzhi Wen, Xiaochi Wei, Shuaiqiang Wang, Dawei Yin, Wenqi Fan, Hui Liu, et al. 2024. Exploring the potential of large language models (llms) in learning on graphs. ACM SIGKDD Explorations Newsletter 25, 2 (2024), 42–61.
- Chowdhery et al. (2023) Aakanksha Chowdhery, Sharan Narang, Jacob Devlin, Maarten Bosma, Gaurav Mishra, Adam Roberts, Paul Barham, Hyung Won Chung, Charles Sutton, Sebastian Gehrmann, et al. 2023. Palm: Scaling language modeling with pathways. Journal of Machine Learning Research 24, 240 (2023), 1–113.
- Das et al. (2021) Rajarshi Das, Manzil Zaheer, Dung Thai, Ameya Godbole, Ethan Perez, Jay Yoon Lee, Lizhen Tan, Lazaros Polymenakos, and Andrew McCallum. 2021. Case-based Reasoning for Natural Language Queries over Knowledge Bases. In EMNLP.
- Fu et al. (2022) Yao Fu, Hao Peng, Ashish Sabharwal, Peter Clark, and Tushar Khot. 2022. Complexity-based prompting for multi-step reasoning. In ICLR.
- Gu et al. (2023) Yu Gu, Xiang Deng, and Yu Su. 2023. Don’t Generate, Discriminate: A Proposal for Grounding Language Models to Real-World Environments. In ACL.
- Gu et al. (2021) Yu Gu, Sue Kase, Michelle Vanni, Brian Sadler, Percy Liang, Xifeng Yan, and Yu Su. 2021. Beyond I.I.D.: Three Levels of Generalization for Question Answering on Knowledge Bases. In WWW. 3477–3488.
- Guo et al. (2023) Jiayan Guo, Lun Du, Hengyu Liu, Mengyu Zhou, Xinyi He, and Shi Han. 2023. Gpt4graph: Can large language models understand graph structured data? an empirical evaluation and benchmarking. arXiv preprint arXiv:2305.15066 (2023).
- Guo et al. (2019) Lingbing Guo, Zequn Sun, and Wei Hu. 2019. Learning to exploit long-term relational dependencies in knowledge graphs. In International conference on machine learning. PMLR, 2505–2514.
- Guo et al. (2024) Tiezheng Guo, Qingwen Yang, Chen Wang, Yanyi Liu, Pan Li, Jiawei Tang, Dapeng Li, and Yingyou Wen. 2024. Knowledgenavigator: Leveraging large language models for enhanced reasoning over knowledge graph. Complex & Intelligent Systems 10, 5 (2024), 7063–7076.
- Huang et al. (2025) Chengkai Huang, Yu Xia, Rui Wang, Kaige Xie, Tong Yu, Julian McAuley, and Lina Yao. 2025. Embedding-Informed Adaptive Retrieval-Augmented Generation of Large Language Models. In COLING.
- Jiang et al. (2023) Jinhao Jiang, Kun Zhou, Zican Dong, Keming Ye, Wayne Xin Zhao, and Ji-Rong Wen. 2023. Structgpt: A general framework for large language model to reason over structured data. arXiv preprint arXiv:2305.09645 (2023).
- Kedia et al. (2022) Akhil Kedia, Mohd Abbas Zaidi, and Haejun Lee. 2022. FiE: Building a Global Probability Space by Leveraging Early Fusion in Encoder for Open-Domain Question Answering. In EMNLP.
- Khot et al. (2022) Tushar Khot, Harsh Trivedi, Matthew Finlayson, Yao Fu, Kyle Richardson, Peter Clark, and Ashish Sabharwal. 2022. Decomposed prompting: A modular approach for solving complex tasks. arXiv preprint arXiv:2210.02406 (2022).
- Kim et al. (2023) Jiho Kim, Yeonsu Kwon, Yohan Jo, and Edward Choi. 2023. Kg-gpt: A general framework for reasoning on knowledge graphs using large language models. arXiv preprint arXiv:2310.11220 (2023).
- Kojima et al. (2022) Takeshi Kojima, Shixiang Shane Gu, Machel Reid, Yutaka Matsuo, and Yusuke Iwasawa. 2022. Large language models are zero-shot reasoners. NeurIPS (2022).
- Li et al. (2024a) Fan Li, Xiaoyang Wang, Dawei Cheng, Wenjie Zhang, Ying Zhang, and Xuemin Lin. 2024a. Hypergraph Self-supervised Learning with Sampling-efficient Signals. arXiv preprint arXiv:2404.11825 (2024).
- Li et al. (2024b) Fan Li, Zhiyu Xu, Dawei Cheng, and Xiaoyang Wang. 2024b. AdaRisk: Risk-adaptive Deep Reinforcement Learning for Vulnerable Nodes Detection. IEEE TKDE (2024).
- Li et al. (2023a) Tianle Li, Xueguang Ma, Alex Zhuang, Yu Gu, Yu Su, and Wenhu Chen. 2023a. Few-shot In-context Learning on Knowledge Base Question Answering. In ACL.
- Li et al. (2023b) Xingxuan Li, Ruochen Zhao, Yew Ken Chia, Bosheng Ding, Shafiq Joty, Soujanya Poria, and Lidong Bing. 2023b. Chain-of-knowledge: Grounding large language models via dynamic knowledge adapting over heterogeneous sources. arXiv preprint arXiv:2305.13269 (2023).
- Luo et al. (2023) Linhao Luo, Jiaxin Ju, Bo Xiong, Yuan-Fang Li, Gholamreza Haffari, and Shirui Pan. 2023. Chatrule: Mining logical rules with large language models for knowledge graph reasoning. arXiv preprint arXiv:2309.01538 (2023).
- Luo et al. (2024) Linhao Luo, Yuanfang Li, Reza Haf, and Shirui Pan. 2024. Reasoning on Graphs: Faithful and Interpretable Large Language Model Reasoning. In ICLR.
- Ma et al. (2024) Shengjie Ma, Chengjin Xu, Xuhui Jiang, Muzhi Li, Huaren Qu, and Jian Guo. 2024. Think-on-Graph 2.0: Deep and Interpretable Large Language Model Reasoning with Knowledge Graph-guided Retrieval. arXiv preprint arXiv:2407.10805 (2024).
- Pan et al. (2024) Shirui Pan, Linhao Luo, Yufei Wang, Chen Chen, Jiapu Wang, and Xindong Wu. 2024. Unifying large language models and knowledge graphs: A roadmap. TKDE (2024).
- Peters et al. (2019) Matthew E Peters, Mark Neumann, Robert L Logan IV, Roy Schwartz, Vidur Joshi, Sameer Singh, and Noah A Smith. 2019. Knowledge enhanced contextual word representations. arXiv preprint arXiv:1909.04164 (2019).
- Petrochuk and Zettlemoyer (2018) Michael Petrochuk and Luke Zettlemoyer. 2018. SimpleQuestions Nearly Solved: A New Upperbound and Baseline Approach. In EMNLP. 554–558.
- Petroni et al. (2020) Fabio Petroni, Aleksandra Piktus, Angela Fan, Patrick Lewis, Majid Yazdani, Nicola De Cao, James Thorne, Yacine Jernite, Vladimir Karpukhin, Jean Maillard, et al. 2020. KILT: a benchmark for knowledge intensive language tasks. arXiv preprint arXiv:2009.02252 (2020).
- Rawte et al. (2023) Vipula Rawte, Amit Sheth, and Amitava Das. 2023. A survey of hallucination in large foundation models. arXiv preprint arXiv:2309.05922 (2023).
- Reimers and Gurevych (2019) Nils Reimers and Iryna Gurevych. 2019. Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks. In EMNLP.
- Sima et al. (2024) Qing Sima, Jianke Yu, Xiaoyang Wang, Wenjie Zhang, Ying Zhang, and Xuemin Lin. 2024. Deep Overlapping Community Search via Subspace Embedding. arXiv preprint arXiv:2404.14692 (2024).
- Sun et al. (2019) Haitian Sun, Tania Bedrax-Weiss, and William W Cohen. 2019. Pullnet: Open domain question answering with iterative retrieval on knowledge bases and text. arXiv preprint arXiv:1904.09537 (2019).
- Sun et al. (2024) Jiashuo Sun, Chengjin Xu, Lumingyuan Tang, Saizhuo Wang, Chen Lin, Yeyun Gong, Lionel Ni, Heung-Yeung Shum, and Jian Guo. 2024. Think-on-Graph: Deep and Responsible Reasoning of Large Language Model on Knowledge Graph. In ICLR.
- Talmor and Berant (2018) Alon Talmor and Jonathan Berant. 2018. The Web as a Knowledge-Base for Answering Complex Questions. In NAACL.
- Talmor et al. (2018) Alon Talmor, Jonathan Herzig, Nicholas Lourie, and Jonathan Berant. 2018. Commonsenseqa: A question answering challenge targeting commonsense knowledge. arXiv preprint arXiv:1811.00937 (2018).
- Tan et al. (2023) Xingyu Tan, Jingya Qian, Chen Chen, Sima Qing, Yanping Wu, Xiaoyang Wang, and Wenjie Zhang. 2023. Higher-Order Peak Decomposition. In CIKM.
- Touvron et al. (2023) Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, et al. 2023. Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288 (2023).
- Wang et al. (2024a) Jinghao Wang, Yanping Wu, Xiaoyang Wang, Ying Zhang, Lu Qin, Wenjie Zhang, and Xuemin Lin. 2024a. Efficient Influence Minimization via Node Blocking. Proc. VLDB Endow. (2024).
- Wang et al. (2024b) Kai Wang, Yuwei Xu, Zhiyong Wu, and Siqiang Luo. 2024b. LLM as Prompter: Low-resource Inductive Reasoning on Arbitrary Knowledge Graphs. In ACL.
- Wang et al. (2022) Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc Le, Ed Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. 2022. Self-consistency improves chain of thought reasoning in language models. arXiv preprint arXiv:2203.11171 (2022).
- Wei et al. (2022) Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. 2022. Chain-of-thought prompting elicits reasoning in large language models. NeurIPS (2022).
- Wen et al. (2024) Yilin Wen, Zifeng Wang, and Jimeng Sun. 2024. Mindmap: Knowledge graph prompting sparks graph of thoughts in large language models. In ACL.
- Wu et al. (2024) Yanping Wu, Renjie Sun, Xiaoyang Wang, Dong Wen, Ying Zhang, Lu Qin, and Xuemin Lin. 2024. Efficient Maximal Frequent Group Enumeration in Temporal Bipartite Graphs. Proc. VLDB Endow. (2024).
- Yao et al. (2024) Shunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Shafran, Tom Griffiths, Yuan Cao, and Karthik Narasimhan. 2024. Tree of thoughts: Deliberate problem solving with large language models. NeurIPS (2024).
- Yao et al. (2022) Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. 2022. React: Synergizing reasoning and acting in language models. arXiv preprint arXiv:2210.03629 (2022).
- Ye et al. (2021) Xi Ye, Semih Yavuz, Kazuma Hashimoto, Yingbo Zhou, and Caiming Xiong. 2021. Rng-kbqa: Generation augmented iterative ranking for knowledge base question answering. arXiv preprint arXiv:2109.08678 (2021).
- Yih et al. (2016) Wen-tau Yih, Matthew Richardson, Chris Meek, Ming-Wei Chang, and Jina Suh. 2016. The Value of Semantic Parse Labeling for Knowledge Base Question Answering. In ACL. 201–206.
- Zhang et al. (2021) Hang Zhang, Yeyun Gong, Yelong Shen, Weisheng Li, Jiancheng Lv, Nan Duan, and Weizhu Chen. 2021. Poolingformer: Long document modeling with pooling attention. In ICML. 12437–12446.
- Zhang et al. (2023) Zhuosheng Zhang, Aston Zhang, Mu Li, and Alex Smola. 2023. Automatic Chain of Thought Prompting in Large Language Models. In ICLR.
- Zhao et al. (2023) Ruochen Zhao, Xingxuan Li, Shafiq Joty, Chengwei Qin, and Lidong Bing. 2023. Verify-and-Edit: A Knowledge-Enhanced Chain-of-Thought Framework. In ACL.
## Appendix A Algorithm
### A.1. Exploration
We summarize the comprehensive algorithmic procedure for exploration detailed in Section 4.2 as presented in Algorithm 1.
AlgoLine0.1
Input : Question subgraph ( $\mathcal{G}_{q}$ ), source KG ( $\mathcal{G}$ ),question and split question ( $Q=q$ + $q_{split}$ ), topic entities ( $Topic(q)$ ), LLM indicator ( $I_{\text{LLM}}$ ), predict depth ( $D_{\text{predict}}$ ), maximum depth ( $D_{\max}$ ), maximum width ( $W_{\max}$ ), and path pruning case ( $case$ )
Output : PoG answers ( $a(q)$ ), final reasoning path ( $Paths_{f}(q)$ )
AlgoLine0.2
/* Start with topic entity path exploration */ AlgoLine0.3
$List_{T}\leftarrow$ Reorder ( $Topic(q),I_{\text{LLM}}$ ), $D\leftarrow$ min( $D_{\text{predict}},D_{\max}$ ); AlgoLine0.4
AlgoLine0.5
while $D\leq D_{\max}$ do $Paths_{t}\leftarrow\text{EntityPathFind}$ ( $List_{T},D$ , $\mathcal{G}_{q}$ ); AlgoLine0.6
$\text{PathPruning}(Paths_{t},Q,I_{\text{LLM}},W_{\max},D_{\max},List_{T},case)$ ; AlgoLine0.7
$Answer,Paths_{T}\leftarrow\text{QuestionAnswering}(Paths_{t},Q,I_{\text{LLM}})$ ; AlgoLine0.8
AlgoLine0.9
if $\texttt{"\{Yes\}"}\text{ in }Answer$ then return $Answer,Paths_{T}$ ; AlgoLine0.10
else $D\leftarrow D+1$ ; AlgoLine0.11
AlgoLine0.12
/* LLM supplement path exploration procedure */ AlgoLine0.13
$Paths_{s}\leftarrow[]$ ; AlgoLine0.14
AlgoLine0.15
$Predict(q)\leftarrow$ SupplementPrediction( $Paths_{T},Q,I_{\text{LLM}}$ ); AlgoLine0.16
for each $e,I_{sup(e)}\in Predict(q)$ do AlgoLine0.17
$List_{S}\leftarrow$ Reorder ( $List_{T}+e,I_{sup(e)}$ ); AlgoLine0.18
$Paths_{s}^{\prime}\leftarrow\text{EntityPathFind}$ ( $List_{S},D_{\max}$ , $\mathcal{G}_{q}$ ); AlgoLine0.19
$Paths_{s}\leftarrow Paths_{s}+\text{FuzzySelect}$ ( $Paths_{s}^{\prime},I_{sup(e)},W_{\max}$ ); AlgoLine0.20
AlgoLine0.21
$\text{PathPruning}(Paths_{s},Q,I_{\text{LLM}},W_{\max},D_{\max},List_{S},case)$ ; AlgoLine0.22
$Answer,Paths_{S}\leftarrow\text{QuestionAnswering}(Paths_{s},Q,I_{\text{LLM}})$ ; AlgoLine0.23
AlgoLine0.24
if "{Yes}" in $Answer$ then return $Answer,Paths_{S}$ ; AlgoLine0.25
AlgoLine0.26
AlgoLine0.27
/* Node expand exploration procedure */ AlgoLine0.28
$Visted\leftarrow\emptyset$ , $D\leftarrow 1$ , $Paths_{e}\leftarrow Paths_{T}+Paths_{S}$ ; AlgoLine0.29
$\text{PathPruning}(Paths_{e},Q,I_{\text{LLM}},W_{\max},D_{\max},List_{T},case)$ ;; AlgoLine0.30
AlgoLine0.31
while $D\leq D_{\max}$ do for each $e\in\text{ExtractEntity}(Paths_{e})\land e\notin Visted$ do $Related\_edges=\text{Find\_1\_hop\_Edges}(\mathcal{G},e)$ ; AlgoLine0.32
$Paths_{e}\leftarrow\text{MergeTogether}(Paths_{e},Related\_edge)$ ; AlgoLine0.33
AlgoLine0.34
$\text{PathPruning}(Paths_{e},Q,I_{\text{LLM}},W_{\max},D_{\max},List_{T},case)$ ; AlgoLine0.35
$Answer,Paths_{e}\leftarrow\text{QuestionAnswering}(Paths_{e},Q,I_{\text{LLM}})$ ; AlgoLine0.36
if $\texttt{"\{Yes\}"}\text{ in }Answer$ then return $Answer,Paths_{e}$ ; AlgoLine0.37
else $Visted\leftarrow Visted\cup e$ ; $D\leftarrow D+1$ ; AlgoLine0.38
AlgoLine0.39
$Paths_{l}\leftarrow Paths_{T}+Paths_{S}+Paths_{E}$ ; AlgoLine0.40
$\text{PathPruning}(Paths_{l},Q,I_{\text{LLM}},W_{\max},D_{\max},List_{T},case)$ ; AlgoLine0.41
AlgoLine0.42
$Answer,Paths_{L}\leftarrow\text{QuestionAnsweringFinal}(Paths_{l},Q,I_{\text{ LLM}})$ ; AlgoLine0.43
Return $Answer,Paths_{L}$ ; AlgoLine0.44
AlgoLine0.45
Algorithm 1 Exploration
45
45
45
45
45
45
45
45
45
45
45
45
45
45
45
45
45
45
45
45
45
45
45
45
45
45
45
45
45
45
45
45
45
45
45
45
45
45
45
45
45
45
45
45
45
### A.2. Path Pruning
We summarize the comprehensive algorithmic procedure of path pruning detailed in Section 4.3 as presented in Algorithm 2.
AlgoLine0.1
Input : Candidate paths( $Paths_{c}$ ), question and split question ( $Q=q+q_{split}$ ), indicator ( $I$ ), maximum width ( $W_{\max}$ ), maximum depth ( $D_{\max}$ ), entity list ( $list$ )
Output : Pruned candidate paths ( $Paths_{c}$ )
if Case = Fuzzy Selection Only then $\text{FuzzySelect}(Paths_{c},Q,I,W_{\max})$ ; AlgoLine0.2
else if Case = Fuzzy + Precise Path Selection then $\text{FuzzySelect}(Paths_{c},Q,I,W_{1})$ ; AlgoLine0.3
$\text{PrecisePathSelect}(Paths_{c},Q,I,W_{\max})$ ; AlgoLine0.4
else if Case = Fuzzy + Branch Reduced Selection then $\text{FuzzySelect}(Paths_{c},Q,I,W_{1})$ ; AlgoLine0.5
$\text{BranchReduceSelect}(Paths_{c},Q,I,W_{\max},D_{\max},list)$ ; AlgoLine0.6
AlgoLine0.7
else if Case = Fuzzy + Branch Reduced + Precise Path then /* case = 3-Step Beam Search */ $\text{FuzzySelect}(Paths_{c},Q,I,W_{1})$ ; AlgoLine0.8
$\text{BranchReduceSelect}(Paths_{c},Q,I,W_{2},D_{\max},list)$ ; AlgoLine0.9
$\text{PrecisePathSelect}(Paths_{c},Q,I,W_{\max})$ ; AlgoLine0.10
AlgoLine0.11
Procedure BranchReduceSelect $(Paths_{c},Q,I,W,D_{\max},list)$ AlgoLine0.12
$D\leftarrow 1$ , $Paths_{e}\leftarrow\emptyset$ ; AlgoLine0.13
AlgoLine0.14
while $|Paths_{c}|\geq W\land D\leq D_{\max}$ do AlgoLine0.15
for each $e\in list$ do AlgoLine0.16
$Paths_{e}\leftarrow Paths_{e}\cup\text{ExtractHeadSteps}(Paths_{c},e,D)$ ; AlgoLine0.17
if $|Paths_{e}|>W$ then $\text{PrecisePathSelect}(Paths_{e},Q,I,W)$ ; AlgoLine0.18
AlgoLine0.19
$Paths_{c}\leftarrow\text{IntersectMatchUpdate}(Paths_{e},Paths_{c})$ ; AlgoLine0.20
$Paths_{e}\leftarrow\emptyset$ ; AlgoLine0.21
$D\leftarrow D+1$ ; AlgoLine0.22
AlgoLine0.23
if $|Paths_{c}|>W$ then $\text{PrecisePathSelect}(Paths_{c},Q,I,W)$ ; AlgoLine0.24
AlgoLine0.25
Algorithm 2 PathPruning
25
25
25
25
25
25
25
25
25
25
25
25
25
25
25
25
25
25
25
25
25
25
25
25
25
## Appendix B Experiment
### B.1. Additional Ablation Study
Compare the effect of different beam search strategies. As introduced in Section 4.3, PoG supports various beam search strategies, ranging from non-reliant to fully reliant on LLMs, selectable in a user-friendly manner. To evaluate the computational cost and performance, we test four cases outlined in Algorithm 2. In the 3-Step Beam Search case, we set $W_{2}=20$ for internal narrowing. The Fuzzy Selection approach, as described in Section 4.3, utilizes all candidate paths and a LLM-generated indicator for encoding and comparison. We report accuracy, average LLM calls in total, and average token input during the path pruning for each beam search strategy applied to PoG and PoG-E in Table 4 and Table 5. These results indicate that PoG/PoG-E with Fuzzy and Precise Path Selection achieves the highest accuracy. Additionally, the BranchReduced Selection method, which leverages the graph structure, not only delivers excellent results but also reduces token usage by over 50% (65%) with only a ±2% (±4.3%) difference in accuracy on PoG (PoG-E) compared to the best-performing strategy. Furthermore, the Fuzzy Selection method, which employs lightweight models instead of relying solely on LLMs, also demonstrates strong performance. These results validate the effectiveness of our beam search strategies and underscore the importance of structure-based faithful path reasoning.
Table 4. Performance comparison of PoG with different beam search methods on CWQ and WebQSP.
| PoG | Evaluation | CWQ | WebQSP |
| --- | --- | --- | --- |
| w/ Fuzzy Selection | Accuracy | 57.1 | 86.4 |
| Token Input | - | - | |
| LLM Calls | 6.8 | 6.5 | |
| w/ Fuzzy and | Accuracy | 79.3 | 93.0 |
| BranchReduced Selection | Token Input | 101,455 | 328,742 |
| LLM Calls | 9.7 | 9.3 | |
| w/ Fuzzy and | Accuracy | 81.4 | 93.9 |
| Precise Path Selection | Token Input | 216,884 | 617,448 |
| LLM Calls | 9.1 | 7.5 | |
| w/ 3-Step Beam Search | Accuracy | 79.8 | 91.9 |
| Token Input | 102,036 | 369,175 | |
| LLM Calls | 8.8 | 9.0 | |
How do summary prompts affect? Inspired by GoT (Besta et al., 2024), we utilize summary prompts to reduce LLM hallucinations and decrease computational costs. To evaluate their impact, we conduct an ablation study comparing PoG and PoG-E with and without path summarization. We measure both accuracy and average token input to the LLM API during the path pruning phase to measure efficiency and effectiveness. The results, present in Tabel 6, show that using graph summaries increases accuracy by up to 10% on the CWQ dataset with PoG-E, while reducing token input by up to 36% on WebQSP. These results indicate hat path summarization effectively minimizes LLM hallucinations, enhances the LLM’s understanding of the explored paths, facilitates answer retrieval, enables earlier termination of the reasoning process, and reduces costs.
Table 5. Performance comparison of PoG-E with different beam search methods among CWQ and WebQSP datasets.
| PoG-E | Evaluation | CWQ | WebQSP |
| --- | --- | --- | --- |
| w/ FuzzySelect | Accuracy | 62.31 | 82.3 |
| Token Input | - | - | |
| Ave LLM Calls | 6 | 6.3 | |
| w/ Fuzzy and | Accuracy | 71.9 | 88.4 |
| BranchReduced Selection | Token Input | 128,407 | 371,083 |
| Ave LLM Calls | 9.4 | 9.1 | |
| w/ Fuzzy and | Accuracy | 80.4 | 91.4 |
| Precise Path Selection | Token Input | 344,747 | 603,261 |
| Ave LLM Calls | 8.3 | 7.4 | |
| w/ 3-Step Beam Search | Accuracy | 73.87 | 89.4 |
| Token Input | 120,159 | 411,283 | |
| Ave LLM Calls | 8.3 | 9.1 | |
Table 6. Performance comparison of PoG and PoG-E with and without path summarizing on CWQ and WebQSP datasets.
| Method | Evaluation | CWQ | WebQSP |
| --- | --- | --- | --- |
| PoG | | | |
| w/ Path Summarizing | Accuracy | 81.4 | 93.9 |
| Token Input | 216,884 | 297,359 | |
| w/o Path Summarizing | Accuracy | 74.7 | 91.9 |
| Token Input | 273,447 | 458,545 | |
| PoG-E | | | |
| w/ Path Summarizing | Accuracy | 80.4 | 91.4 |
| Token Input | 314,747 | 273,407 | |
| w/o Path Summarizing | Accuracy | 70.4 | 90.4 |
| Token Input | 419,679 | 428,545 | |
### B.2. Reasoning Faithfulness Analysis
Overlap ratio between explored paths and ground-truth paths. We analyzed correctly answered samples from three datasets to investigate the overlap ratio between the paths $P$ explored by PoG and the ground-truth paths $S$ in SPARQL queries. The overlap ratio is defined as the proportion of overlapping relations to the total number of relations in the ground-truth SPARQL path:
$$
Ratio(P)=\frac{|Relation(P)\cap Relation(S)|}{|Relation(S)|},
$$
where $Relation(P)$ denotes the set of relations in path $P$ . Figure 7 illustrates the distribution of questions across different overlap ratios. For the WebQSP dataset, PoG achieves the highest proportion of fully overlapping paths with the ground truth, reaching approximately 60% accuracy. In contrast, PoG-E applied to the GrailQA dataset shows the highest proportion of paths with up to 70% non-overlapping relations, indicating that PoG-E explores novel paths to derive the answers. The different results between PoG and PoG-E are due to PoG-E’s strategy of randomly selecting one related edge from each clustered edge. This approach highlights the effectiveness of our structure-based path exploration method in generating diverse and accurate reasoning paths.
<details>
<summary>x11.png Details</summary>
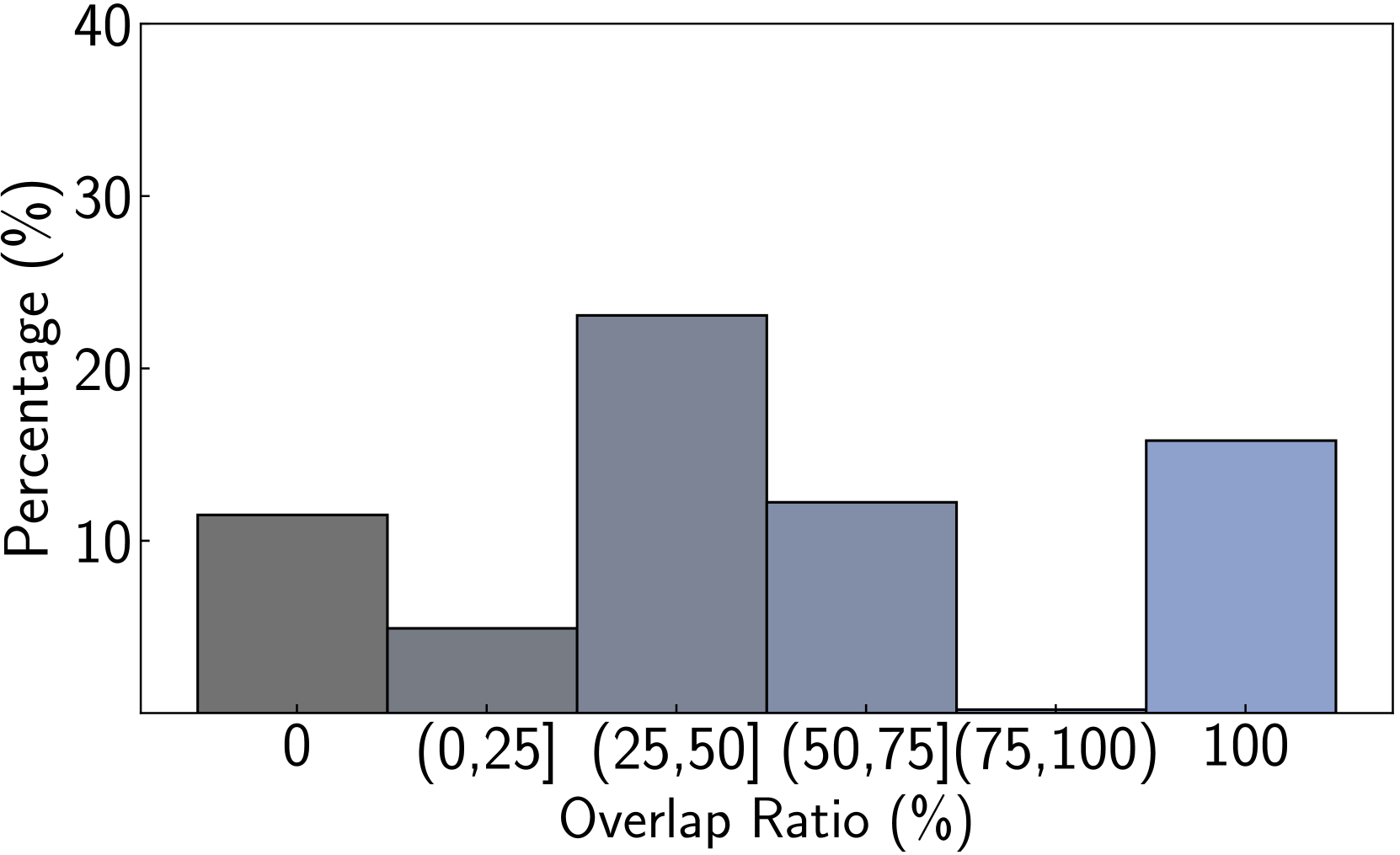
### Visual Description
\n
## Histogram: Distribution of Overlap Ratios
### Overview
The image displays a histogram showing the percentage distribution of data across different overlap ratio categories. The chart illustrates how frequently various levels of overlap occur within a dataset, with the x-axis representing the overlap ratio as a percentage and the y-axis representing the percentage of occurrences.
### Components/Axes
* **Chart Type:** Histogram (bar chart with categorical bins).
* **X-Axis (Horizontal):**
* **Label:** "Overlap Ratio (%)"
* **Categories/Bins (from left to right):**
1. `0`
2. `(0,25]` (meaning greater than 0% and less than or equal to 25%)
3. `(25,50]`
4. `(50,75]`
5. `(75,100)` (meaning greater than 75% and less than 100%)
6. `100`
* **Y-Axis (Vertical):**
* **Label:** "Percentage (%)"
* **Scale:** Linear scale from 0 to 40, with major tick marks at 0, 10, 20, 30, and 40.
* **Legend:** Not present. The chart represents a single data series.
* **Visual Elements:** Six vertical bars, each corresponding to an x-axis category. The bars are colored in a gradient from dark gray (leftmost) to light blue-gray (rightmost).
### Detailed Analysis
The height of each bar represents the approximate percentage of data points falling within that overlap ratio bin. Values are estimated from the y-axis scale.
1. **Bin `0`:** The bar height is approximately **11%**. This indicates that about 11% of the observed cases have zero overlap.
2. **Bin `(0,25]`:** The bar height is approximately **5%**. This is the lowest frequency category.
3. **Bin `(25,50]`:** The bar height is approximately **23%**. This is the tallest bar, representing the most frequent overlap range.
4. **Bin `(50,75]`:** The bar height is approximately **12%**.
5. **Bin `(75,100)`:** The bar height is very low, approximately **0.5%**. This is a significant dip, indicating very few instances of overlap in this high-but-not-complete range.
6. **Bin `100`:** The bar height is approximately **16%**. This is the second-tallest bar, indicating a substantial number of cases with complete (100%) overlap.
**Trend Verification:** The distribution is not uniform. It shows a bimodal pattern with a primary peak in the moderate overlap range `(25,50]` and a secondary peak at complete overlap `100`. There is a pronounced trough in the `(75,100)` range.
### Key Observations
* **Bimodal Distribution:** The data clusters around two distinct points: moderate overlap (25-50%) and complete overlap (100%).
* **Significant Dip:** The category `(75,100)` has a near-zero frequency, creating a clear separation between the two peaks.
* **Non-Zero Baseline:** A notable portion of the data (11%) exhibits zero overlap.
* **Color Gradient:** The bars transition from dark gray on the left to a lighter blue-gray on the right, which may be a stylistic choice to visually separate the bins.
### Interpretation
This histogram suggests a polarized behavior in the underlying phenomenon being measured. The data does not follow a normal or uniform distribution. Instead, it indicates that overlaps tend to be either:
1. **Moderate** (clustered between 25% and 50%), or
2. **Complete** (exactly 100%).
The near absence of data in the `(75,100)` range is particularly striking. It implies that once overlap exceeds 75%, it almost always jumps to 100%, rather than gradually increasing. This could point to a threshold effect or a binary outcome in the process generating the data (e.g., a match is either partial or exact, with very few "almost exact" matches).
The presence of a 11% `0` overlap category shows that a significant minority of cases have no overlap at all. The overall pattern is crucial for understanding the system's behavior, as it highlights that the most common outcomes are not at the extremes (0 or 100) but in a specific mid-range, with a strong secondary tendency toward perfect alignment.
</details>
(a) CWQ (PoG)
<details>
<summary>x12.png Details</summary>
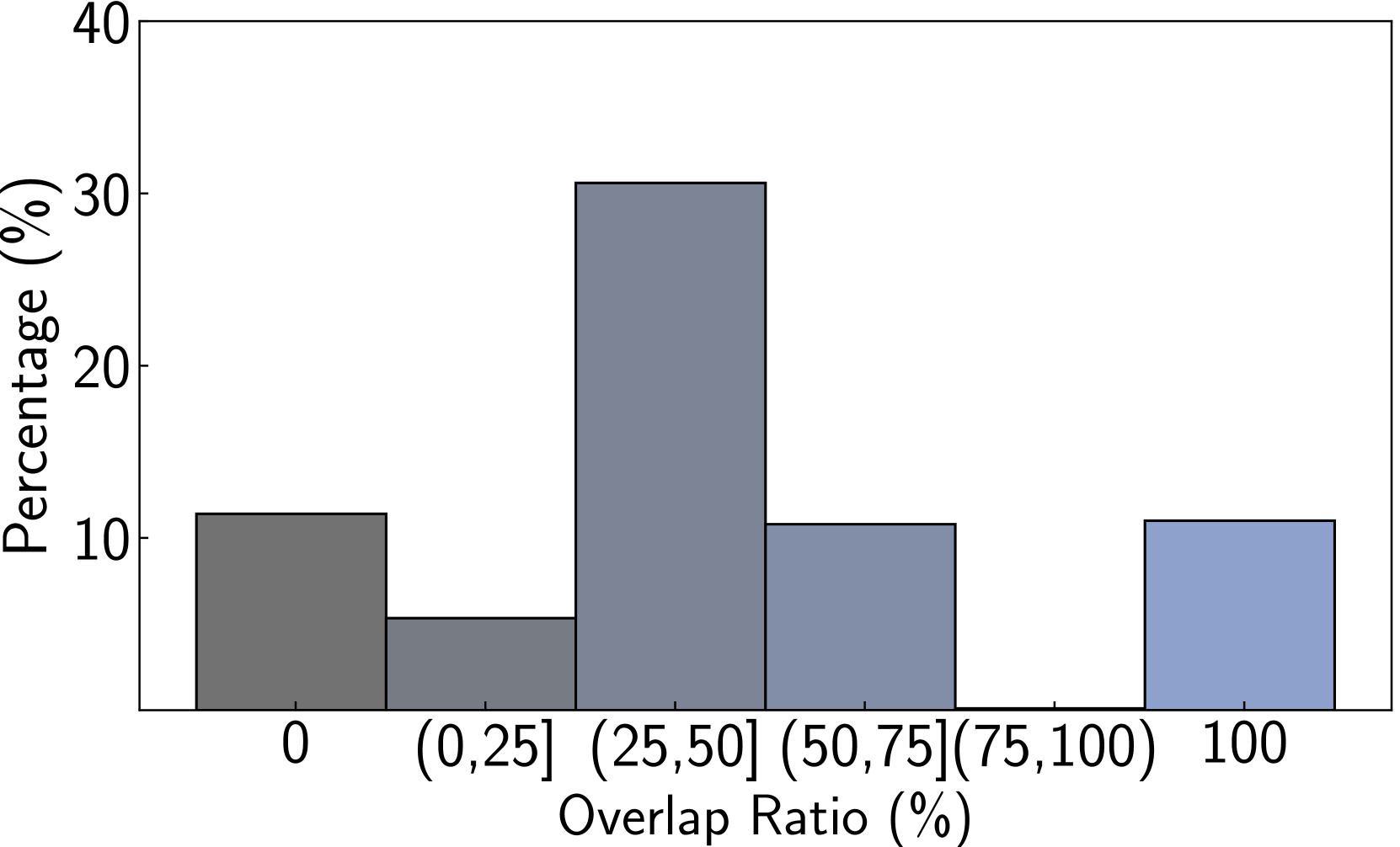
### Visual Description
## Bar Chart: Distribution of Overlap Ratios
### Overview
The image displays a bar chart illustrating the percentage distribution of data across six distinct categories of "Overlap Ratio (%)". The chart uses a single data series represented by bars of varying heights, with a color gradient from dark gray to light blue moving from left to right along the x-axis.
### Components/Axes
* **Chart Type:** Vertical Bar Chart (Histogram-like).
* **Y-Axis:**
* **Label:** "Percentage (%)"
* **Scale:** Linear scale from 0 to 40.
* **Tick Marks:** Major ticks at 0, 10, 20, 30, and 40.
* **X-Axis:**
* **Label:** "Overlap Ratio (%)"
* **Categories (Bins):** Six discrete categories are labeled:
1. `0`
2. `(0,25]` (Greater than 0% and less than or equal to 25%)
3. `(25,50]` (Greater than 25% and less than or equal to 50%)
4. `(50,75]` (Greater than 50% and less than or equal to 75%)
5. `(75,100)` (Greater than 75% and less than 100%)
6. `100`
* **Legend:** Not present. The chart contains a single data series.
* **Spatial Layout:** The plot area is framed by a black border. The y-axis label is positioned vertically to the left of the axis. The x-axis label is centered below the category labels. The bars are centered above their respective category labels.
### Detailed Analysis
The following table reconstructs the approximate data presented in the chart. Values are estimated based on the bar heights relative to the y-axis scale.
| Overlap Ratio Category | Approximate Percentage (%) | Visual Trend & Bar Color |
| :--- | :--- | :--- |
| **0** | ~11% | Dark gray bar. |
| **(0,25]** | ~5% | Medium-dark gray bar. The shortest bar in the chart. |
| **(25,50]** | ~31% | Medium gray-blue bar. The tallest bar, representing the mode of the distribution. |
| **(50,75]** | ~11% | Medium-light blue-gray bar. Similar in height to the "0" and "100" bars. |
| **(75,100)** | 0% | No visible bar. This category has a percentage of zero. |
| **100** | ~11% | Light blue bar. Similar in height to the "0" and "(50,75]" bars. |
**Trend Verification:** The distribution is not uniform. It peaks sharply in the `(25,50]%` range, drops significantly for `(0,25]%`, and shows moderate, equal representation at the extremes (`0%` and `100%`) and the `(50,75]%` range. There is a complete absence of data in the `(75,100)%` range.
### Key Observations
1. **Dominant Category:** The `(25,50]%` overlap ratio category contains the highest percentage of the data, at approximately 31%.
2. **Bimodal Extremes:** There is a notable presence of data points at both complete non-overlap (`0%`) and complete overlap (`100%`), each comprising about 11% of the total.
3. **Data Gap:** The `(75,100)%` category is empty, indicating no instances in the dataset had an overlap ratio in this specific high-but-not-complete range.
4. **Symmetry:** The percentages for `0%`, `(50,75]%`, and `100%` are visually very similar (~11%), creating a rough symmetry around the central peak.
### Interpretation
This chart visualizes the frequency distribution of a metric called "Overlap Ratio." The data suggests a non-normal, potentially bimodal or multi-modal distribution.
* **Central Tendency:** The most common scenario involves a moderate overlap, between 25% and 50%.
* **Polarization:** A significant portion of the data (over 20% combined) exists at the absolute extremes—either no overlap or perfect overlap. This could indicate two distinct subgroups or conditions within the dataset.
* **The "Missing Middle-High":** The complete lack of data in the `(75,100)%` range is the most striking anomaly. This gap suggests a potential threshold effect or a categorical distinction in the underlying process being measured. For example, once overlap exceeds 75%, it may rapidly tend toward 100%, or the measurement method may not capture values in this range.
* **Implication:** The distribution implies that the phenomenon generating this "Overlap Ratio" does not produce a smooth continuum of values. Instead, outcomes cluster around moderate overlap, with significant chances of no or total overlap, and an avoidance of the near-total overlap zone. This pattern would be critical for understanding system behavior, model performance, or biological/physical interactions, depending on the context of the data.
</details>
(b) CWQ (PoG-E)
<details>
<summary>x13.png Details</summary>
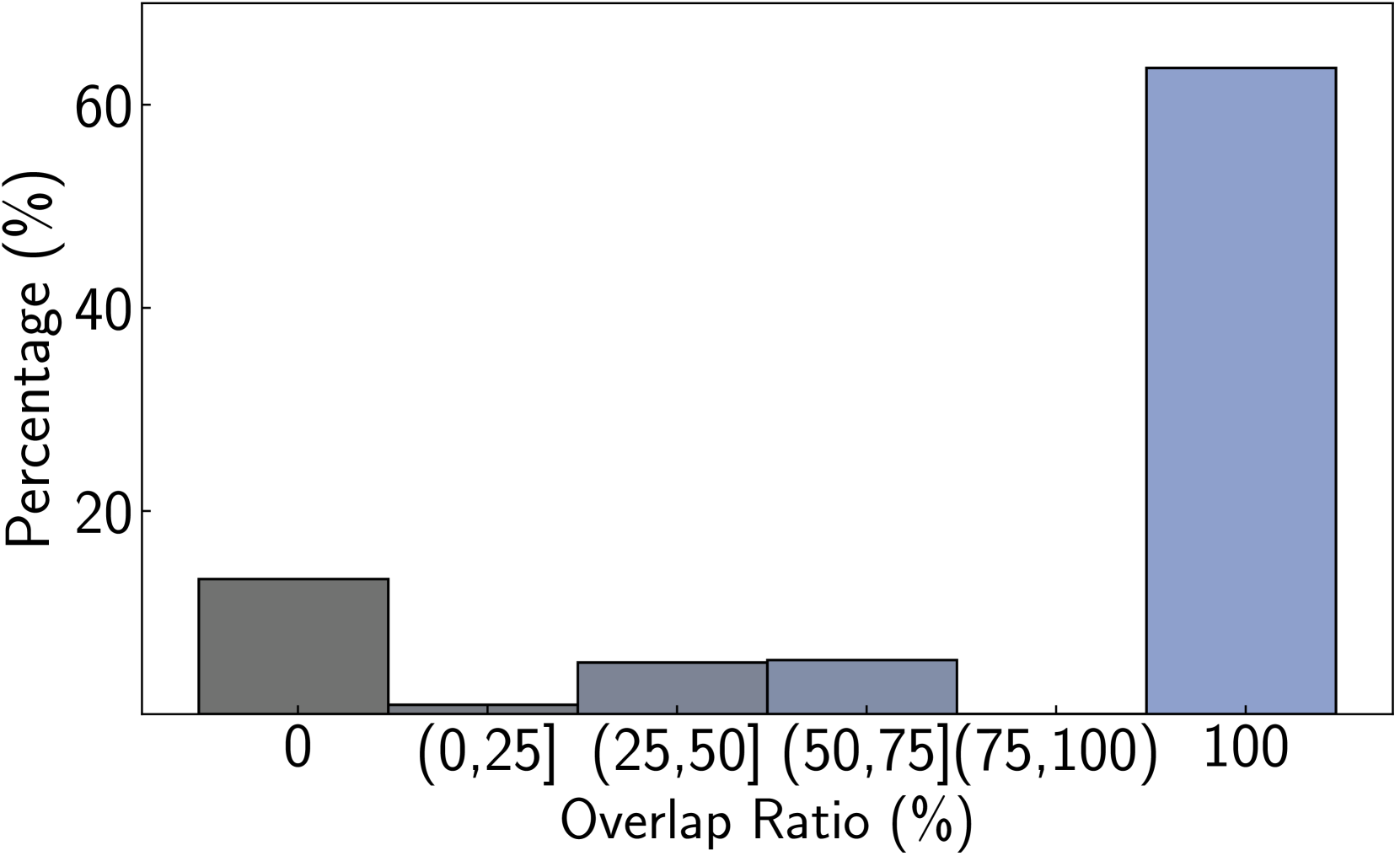
### Visual Description
## Bar Chart: Distribution of Overlap Ratios
### Overview
The image displays a bar chart illustrating the percentage distribution of items across different overlap ratio categories. The chart reveals a highly polarized distribution, with the vast majority of items falling into either the "0" (no overlap) or "100" (complete overlap) categories, and very few items showing partial overlap.
### Components/Axes
* **Chart Type:** Vertical bar chart.
* **X-Axis (Horizontal):**
* **Label:** "Overlap Ratio (%)"
* **Categories (from left to right):**
1. `0`
2. `(0,25]` (representing >0% to ≤25%)
3. `(25,50]` (representing >25% to ≤50%)
4. `(50,75]` (representing >50% to ≤75%)
5. `(75,100)` (representing >75% to <100%)
6. `100`
* **Y-Axis (Vertical):**
* **Label:** "Percentage (%)"
* **Scale:** Linear scale from 0 to 60, with major tick marks at 0, 20, 40, and 60.
* **Legend:** No separate legend is present. The categories are defined by the x-axis labels.
* **Spatial Layout:** The chart area is bounded by a simple black frame. The y-axis is on the left, and the x-axis is at the bottom. The bars are evenly spaced along the x-axis.
### Detailed Analysis
The chart contains six bars, each corresponding to an overlap ratio category. The height of each bar represents the approximate percentage of items in that category.
1. **Category `0` (Leftmost bar):**
* **Color:** Dark gray.
* **Approximate Value:** ~13% (The bar height is between the 0 and 20 marks, closer to 20).
* **Trend:** This is the second-tallest bar, indicating a significant portion of items have zero overlap.
2. **Category `(0,25]`:**
* **Color:** Very dark gray (similar to the first bar but appears slightly lighter).
* **Approximate Value:** ~1% (The bar is barely visible above the baseline).
* **Trend:** This is the shortest bar, showing a negligible number of items have a low partial overlap.
3. **Category `(25,50]`:**
* **Color:** Medium gray.
* **Approximate Value:** ~5% (The bar height is about a quarter of the way to the 20 mark).
* **Trend:** A small but measurable percentage of items fall into this mid-low overlap range.
4. **Category `(50,75]`:**
* **Color:** Medium gray (identical to the `(25,50]` bar).
* **Approximate Value:** ~5% (The bar height is visually identical to the `(25,50]` bar).
* **Trend:** The percentage of items in this mid-high overlap range is similar to the mid-low range.
5. **Category `(75,100)`:**
* **Color:** Not visible. There is no bar present for this category.
* **Approximate Value:** 0% or a value too small to render.
* **Trend:** This indicates an absence of items with high-but-not-complete overlap in this dataset.
6. **Category `100` (Rightmost bar):**
* **Color:** Light blue/periwinkle.
* **Approximate Value:** ~63% (The bar extends slightly above the 60 mark on the y-axis).
* **Trend:** This is by far the tallest bar, dominating the chart. It shows that a clear majority of items have a complete (100%) overlap ratio.
### Key Observations
1. **Bimodal Distribution:** The data is heavily concentrated at the two extremes (`0` and `100`), with very little representation in the intermediate partial overlap ranges (`(0,25]` to `(75,100)`).
2. **Dominance of Complete Overlap:** The `100` category accounts for nearly two-thirds of all items, making it the most significant finding.
3. **Significant Zero-Overlap Group:** The `0` category represents a substantial minority (~13%), indicating a distinct group with no overlap.
4. **Absence of High Partial Overlap:** The `(75,100)` category has no visible bar, suggesting items either achieve full overlap or do not reach that high threshold.
5. **Symmetry in Mid-Range:** The percentages for `(25,50]` and `(50,75]` are approximately equal, forming a low, flat plateau in the middle of the distribution.
### Interpretation
This chart demonstrates a **polarized or "all-or-nothing" pattern** in the measured overlap ratio. The data suggests that the process or phenomenon being measured tends to result in either complete alignment (100% overlap) or no alignment (0% overlap), with partial overlap being an uncommon outcome.
* **What it means:** This could indicate a system with binary success criteria, a threshold effect where partial states are unstable, or a classification where items are forced into definitive categories. The near-equal, low percentages in the middle ranges might represent transitional states or measurement noise.
* **Why it matters:** Understanding this polarization is crucial. If the goal is to maximize overlap, efforts should focus on understanding what drives items to the `100` state. Conversely, if partial overlap is desirable, the system or measurement method may need adjustment, as the current outcome strongly discourages it. The stark contrast between the `100` and `0` bars is the central story of this data.
</details>
(c) WebQSP (PoG)
<details>
<summary>x14.png Details</summary>
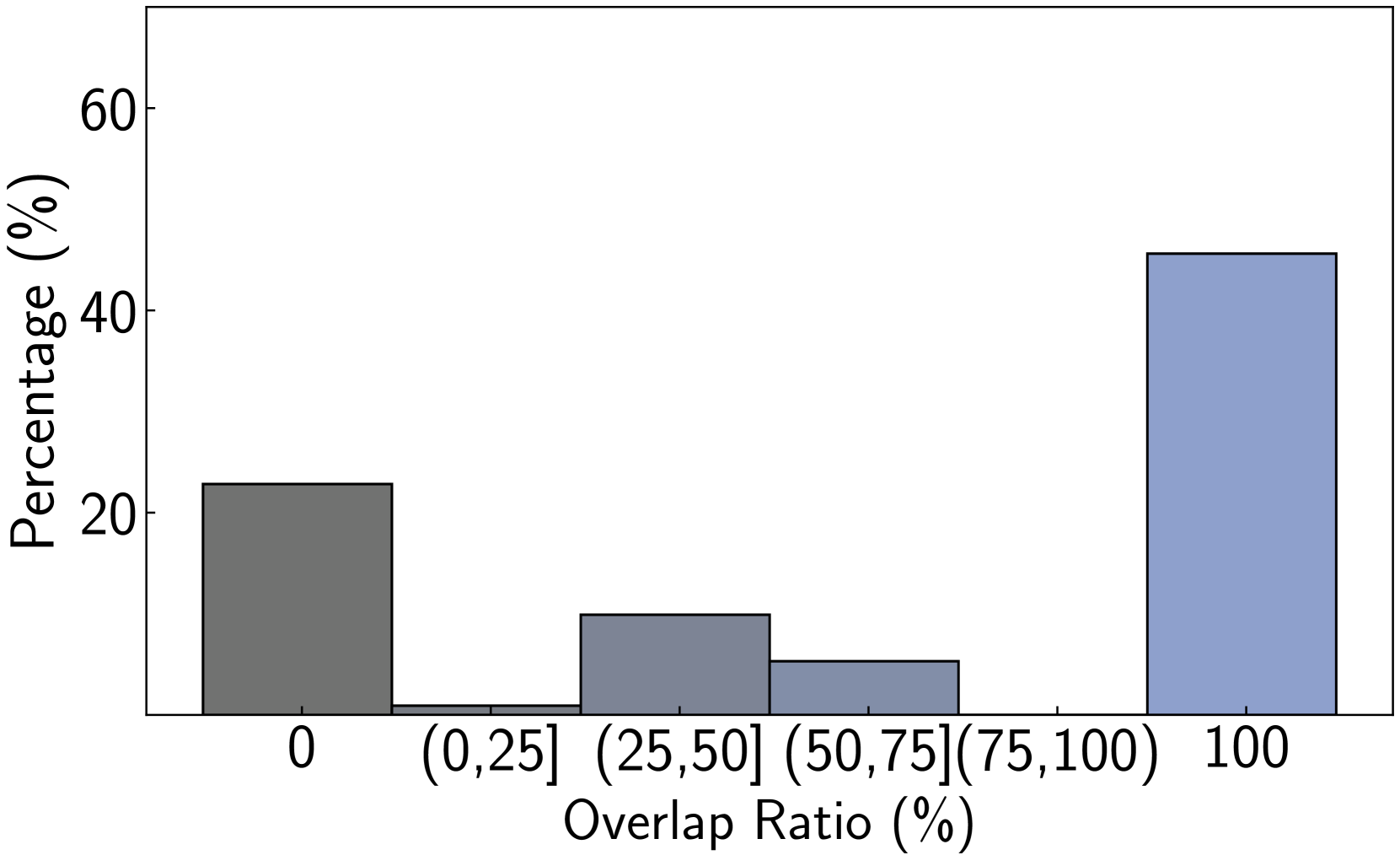
### Visual Description
## Bar Chart: Distribution of Overlap Ratios
### Overview
The image is a bar chart displaying the percentage distribution of items across different categories of "Overlap Ratio." The chart shows a bimodal distribution with the highest percentages at the extreme ends of the scale (0% and 100% overlap) and significantly lower percentages in the intermediate ranges.
### Components/Axes
* **Chart Type:** Vertical Bar Chart (Histogram-like bins).
* **Y-Axis:**
* **Label:** "Percentage (%)"
* **Scale:** Linear scale from 0 to 60, with major tick marks at 0, 20, 40, and 60.
* **X-Axis:**
* **Label:** "Overlap Ratio (%)"
* **Categories/Bins:** Six distinct categories are labeled:
1. `0`
2. `(0,25]` (greater than 0%, up to and including 25%)
3. `(25,50]` (greater than 25%, up to and including 50%)
4. `(50,75]` (greater than 50%, up to and including 75%)
5. `(75,100)` (greater than 75%, up to but not including 100%)
6. `100`
* **Legend:** No separate legend is present. The bars are differentiated by position and a subtle color gradient from dark gray (left) to light blue-gray (right).
### Detailed Analysis
The chart presents the following approximate percentage values for each overlap ratio category. Values are estimated based on the bar heights relative to the y-axis scale.
1. **Category `0` (Leftmost bar, dark gray):** The bar height is slightly above the 20% mark. **Approximate Value: 22%**.
2. **Category `(0,25]` (Second bar from left, medium gray):** This is the shortest bar, barely visible above the baseline. **Approximate Value: ~1%**.
3. **Category `(25,50]` (Third bar, medium gray):** The bar height is halfway between 0 and 20%. **Approximate Value: 10%**.
4. **Category `(50,75]` (Fourth bar, medium-light gray):** The bar height is about a quarter of the way to 20%. **Approximate Value: 5%**.
5. **Category `(75,100)` (Fifth bar, light gray):** This bar is extremely short, similar to the `(0,25]` category. **Approximate Value: ~0.5%**.
6. **Category `100` (Rightmost bar, light blue-gray):** This is the tallest bar, extending above the 40% mark. **Approximate Value: 45%**.
**Trend Verification:** The visual trend is not linear. It starts high at 0%, drops dramatically for the next bin, rises slightly for the middle bins, drops again, and then spikes to its maximum at 100%. This creates a clear "U-shaped" or bimodal pattern.
### Key Observations
* **Bimodal Dominance:** The distribution is heavily polarized. The two extreme categories (`0` and `100`) together account for approximately **67%** of the total (22% + 45%).
* **Sparse Middle:** The intermediate overlap ranges contain very few items. The combined percentage for all bins from `(0,25]` through `(75,100)` is only about **16.5%**.
* **Notable Gap:** The `(75,100)` category is nearly empty, suggesting that cases with very high but not complete overlap are exceptionally rare in this dataset.
* **Color Coding:** The bars use a grayscale-to-blue gradient, with the leftmost (`0`) being the darkest and the rightmost (`100`) being the lightest and most distinct in hue (blue-gray).
### Interpretation
This chart demonstrates a strong **polarization effect** in the measured overlap. The data suggests that the entities being compared tend to either have **no overlap at all** or **complete, perfect overlap**, with very few instances falling in between.
This pattern is significant and could imply several scenarios depending on the context (which is not provided in the image):
1. **Binary Nature of the Phenomenon:** The process generating this data may have a natural tendency toward all-or-nothing outcomes. For example, in document comparison, this could indicate that documents are either identical copies or completely unrelated.
2. **Threshold Effect:** There might be a system or mechanism that pushes outcomes toward the extremes, preventing partial overlaps from being stable or common.
3. **Data Artifact:** If this represents matching or alignment data, it could suggest that the matching algorithm is highly confident in either a perfect match or no match, but struggles with ambiguous, partial cases.
The near-absence of data in the `(75,100)` range is a critical anomaly. It indicates that achieving a very high degree of overlap without reaching 100% is an unlikely or unstable state in this system. The overall message is one of dichotomy, not gradation.
</details>
(d) WebQSP (PoG-E)
<details>
<summary>x15.png Details</summary>
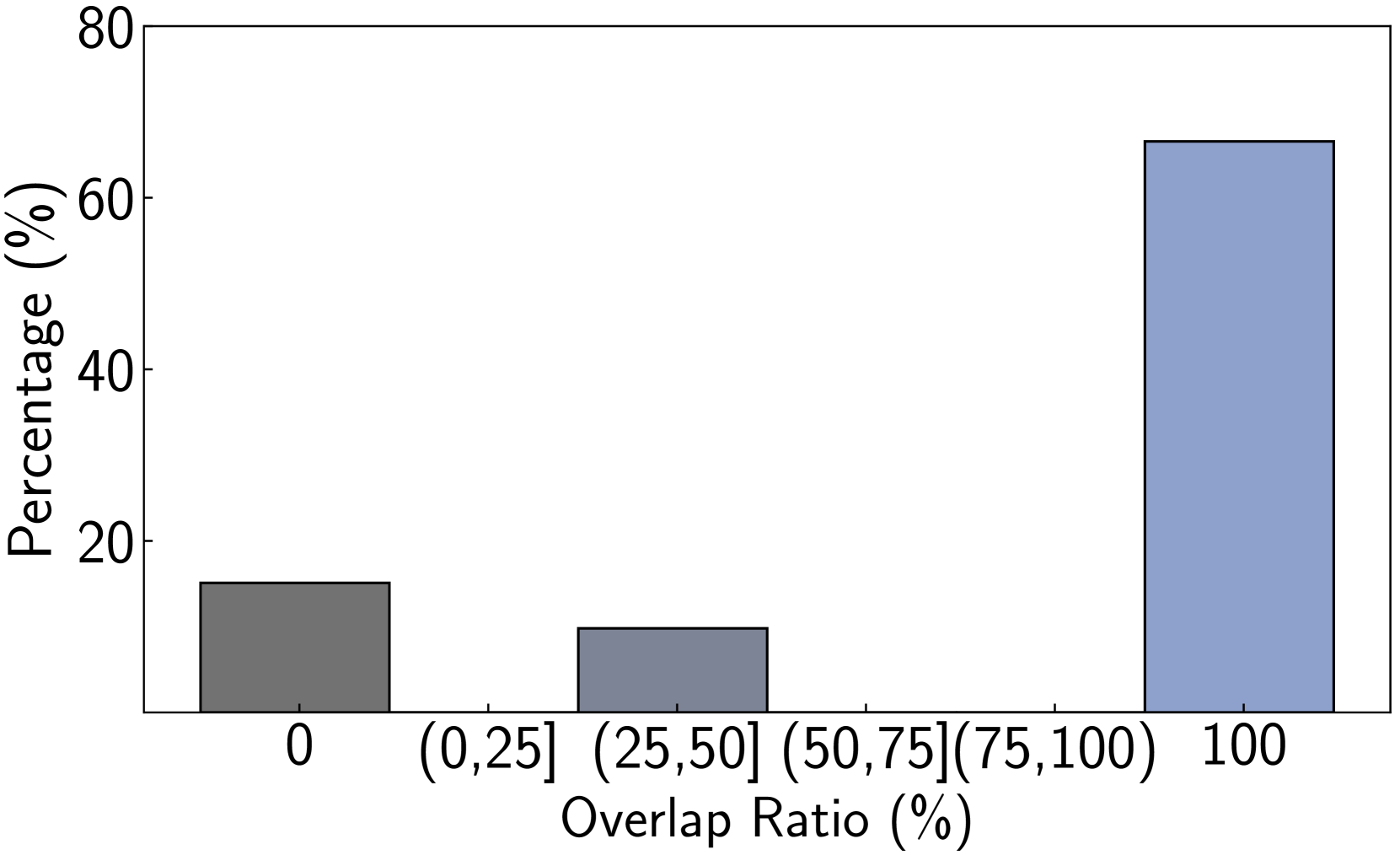
### Visual Description
## Bar Chart: Distribution of Overlap Ratios
### Overview
The image displays a vertical bar chart illustrating the percentage distribution of different overlap ratio categories. The chart shows a highly skewed distribution, with the vast majority of cases falling into the 100% overlap category.
### Components/Axes
* **Chart Type:** Vertical Bar Chart.
* **X-Axis (Horizontal):**
* **Label:** "Overlap Ratio (%)"
* **Categories (from left to right):** `0`, `(0,25]`, `(25,50]`, `(50,75]`, `(75,100)`, `100`.
* **Note:** The categories `(0,25]`, `(25,50]`, `(50,75]`, and `(75,100)` represent intervals. The notation `(a,b]` typically means the interval is greater than `a` and less than or equal to `b`.
* **Y-Axis (Vertical):**
* **Label:** "Percentage (%)"
* **Scale:** Linear scale from 0 to 80, with major tick marks at 0, 20, 40, 60, and 80.
* **Legend:** No explicit legend is present. The bars are differentiated by color and their corresponding x-axis category label.
### Detailed Analysis
The chart contains three visible bars, each corresponding to a specific overlap ratio category. The remaining categories have no visible bar, indicating a value of 0%.
1. **Category `0` (Leftmost bar):**
* **Color:** Dark gray.
* **Position:** Centered above the "0" label on the x-axis.
* **Value:** The bar's height is approximately **15%** (visually estimated between the 0 and 20% y-axis ticks, closer to 20).
2. **Category `(25,50]` (Middle bar):**
* **Color:** Medium gray (lighter than the first bar).
* **Position:** Centered above the "(25,50]" label on the x-axis.
* **Value:** The bar's height is approximately **10%** (visually estimated, shorter than the first bar).
3. **Category `100` (Rightmost bar):**
* **Color:** Light blue.
* **Position:** Centered above the "100" label on the x-axis.
* **Value:** The bar's height is approximately **67%** (visually estimated, extending significantly above the 60% y-axis tick but below the 80% tick).
4. **Categories with 0% Value:**
* `(0,25]`
* `(50,75]`
* `(75,100)`
* These categories have no visible bar, indicating their percentage is **0%** or negligibly small.
### Key Observations
* **Dominant Category:** The `100`% overlap ratio category is overwhelmingly dominant, representing approximately two-thirds of the total distribution.
* **Bimodal Distribution:** The data shows a bimodal pattern with peaks at the extremes: a major peak at 100% and a minor peak at 0%.
* **Absence of Partial Overlap:** There is a notable absence of data in the partial overlap intervals `(0,25]`, `(50,75]`, and `(75,100)`. The only non-zero partial overlap is in the `(25,50]` range, which is itself a small fraction.
* **Color Coding:** The bars use a grayscale-to-blue color progression, with the most significant bar (100%) highlighted in a distinct light blue color.
### Interpretation
This chart likely represents the results of a matching or comparison process where two entities (e.g., image segments, data records, object detections) are evaluated for their spatial or conceptual overlap. The data suggests an "all-or-nothing" outcome is most common.
* **High Precision/Consensus:** The large 100% bar indicates that in the majority of cases, the compared entities are in perfect agreement or alignment. This could signify high precision in a detection algorithm, perfect matches in a database, or complete consensus between annotators.
* **Complete Disagreement:** The smaller 0% bar represents cases with no overlap at all, indicating complete disagreement or mismatch.
* **Rare Ambiguity:** The very low percentage in the `(25,50]` range and the absence of data in other partial ranges suggest that ambiguous or partially overlapping cases are rare in this dataset or process. The system or phenomenon being measured tends to resolve clearly into either full match or no match, with only a small fraction falling into a middle ground.
* **Potential Implication:** If this chart evaluates an algorithm's performance, it shows the algorithm is highly confident and accurate in most cases (100% overlap) but fails completely in a smaller subset (0% overlap), with very few uncertain or partially correct outputs. The distribution is not Gaussian or uniform; it is heavily polarized.
</details>
(e) GrailQA (PoG)
<details>
<summary>x16.png Details</summary>
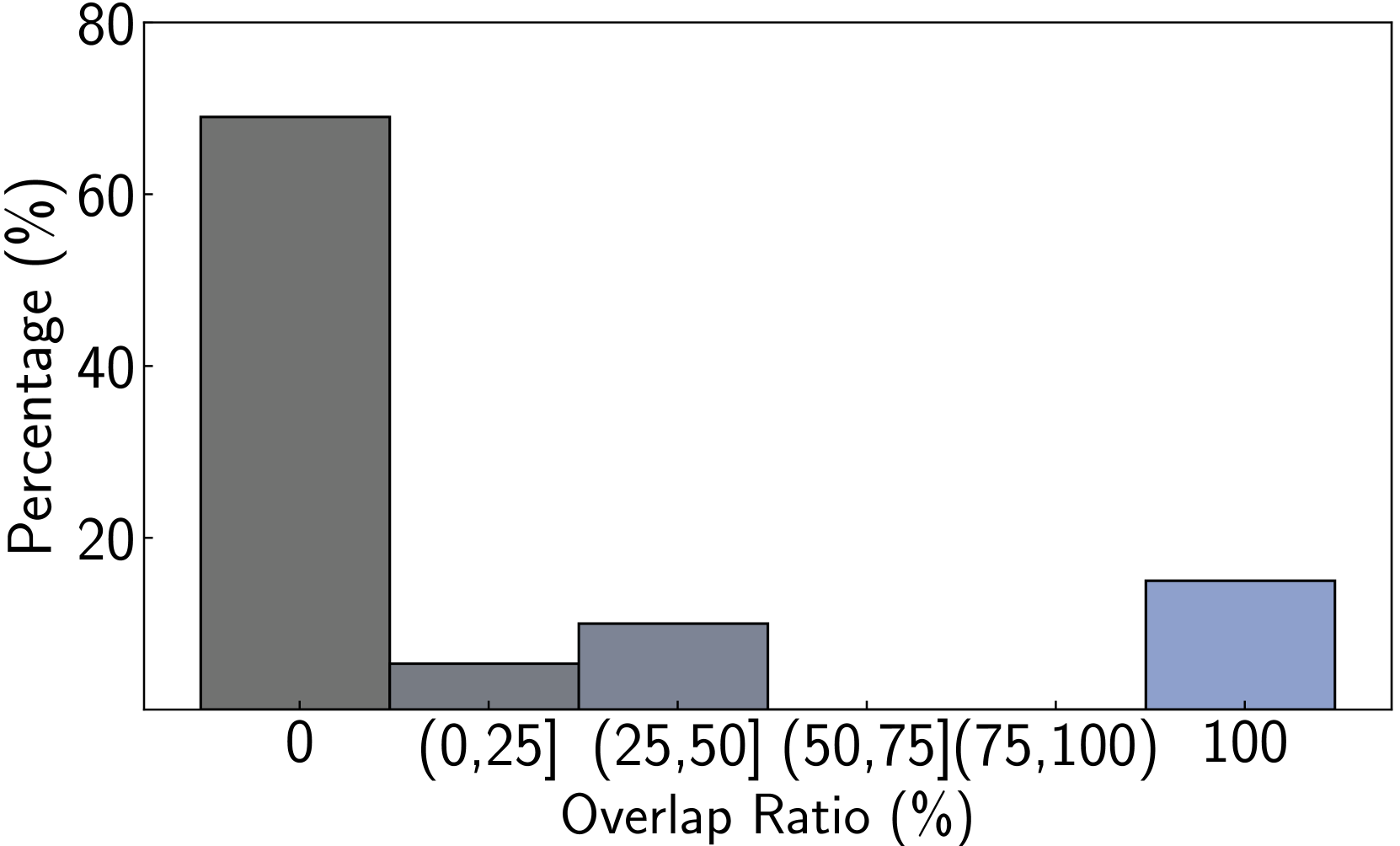
### Visual Description
## Bar Chart: Distribution of Overlap Ratios
### Overview
The image displays a bar chart illustrating the percentage distribution of items across different overlap ratio categories. The chart shows a highly skewed distribution, with the majority of items having zero overlap, a small portion having complete (100%) overlap, and very few items falling into intermediate overlap ranges.
### Components/Axes
* **Chart Type:** Vertical bar chart.
* **X-Axis (Horizontal):** Labeled "Overlap Ratio (%)". It contains six categorical bins:
* `0`
* `(0,25]` (greater than 0% and less than or equal to 25%)
* `(25,50]` (greater than 25% and less than or equal to 50%)
* `(50,75]` (greater than 50% and less than or equal to 75%)
* `(75,100)` (greater than 75% and less than 100%)
* `100`
* **Y-Axis (Vertical):** Labeled "Percentage (%)". The scale runs from 0 to 80, with major tick marks at intervals of 20 (0, 20, 40, 60, 80).
* **Legend:** No explicit legend is present. The bars are differentiated by color/shade.
* **Bar Colors (from left to right):**
* `0`: Dark gray.
* `(0,25]`: Medium gray.
* `(25,50]`: Lighter gray.
* `(50,75]`: No visible bar (value is 0%).
* `(75,100)`: No visible bar (value is 0%).
* `100`: Light blue.
### Detailed Analysis
The following table reconstructs the data presented in the chart. Values are approximate, estimated from the visual height of the bars relative to the y-axis scale.
| Overlap Ratio Category | Approximate Percentage (%) | Bar Color/Shade |
| :--- | :--- | :--- |
| 0 | ~70% | Dark Gray |
| (0,25] | ~5% | Medium Gray |
| (25,50] | ~10% | Lighter Gray |
| (50,75] | 0% | (No bar) |
| (75,100) | 0% | (No bar) |
| 100 | ~15% | Light Blue |
**Trend Verification:** The data series shows a sharp decline from the first category (`0`) to the second (`(0,25]`), a slight increase to the third (`(25,50]`), then drops to zero for the next two categories, before rising again for the final category (`100`). The dominant trend is concentration at the two extremes (0% and 100%).
### Key Observations
1. **Dominant Category:** The `0` overlap ratio category is overwhelmingly the most common, representing approximately 70% of the total.
2. **Bimodal Distribution:** The distribution is bimodal, with significant peaks at `0` and `100`, and very low values in between.
3. **Absence of Mid-Range Overlap:** There are no items (0%) in the `(50,75]` and `(75,100)` overlap ratio ranges.
4. **Minor Intermediate Presence:** Only about 15% of items have any overlap between 0% and 100%, split between the `(0,25]` and `(25,50]` bins.
5. **Complete Overlap:** A notable minority (~15%) of items exhibit complete (100%) overlap.
### Interpretation
This chart likely represents the degree of similarity or redundancy between pairs of items in a dataset (e.g., duplicate detection, document comparison, or feature matching). The data suggests a scenario where most pairs are completely distinct (0% overlap), while a smaller, separate group is perfectly identical (100% overlap). The near absence of pairs with partial overlap (especially above 50%) indicates a clear dichotomy in the data: items are either entirely different or exactly the same, with very little middle ground. This pattern is characteristic of datasets containing exact duplicates alongside a large set of unique records, and it implies that a simple threshold-based deduplication strategy (e.g., flagging pairs above 90% overlap) would be highly effective, as it would cleanly separate the two main clusters.
</details>
(f) GrailQA (PoG-E)
Figure 7. The path overlap ratio of PoG and PoG-E among CWQ, WebQSP, and GrailQA datasets.
Evidence of answer exploration sources. We conduct an analysis of correctly answered samples from three datasets to investigate the sources of evidence used by the LLM in generating answers, as illustrated in Figure 8. Specifically, we categorize all generated answers into three cases: KG only, LLM-inspired KG, and KG-inspired LLM. In the KG only scenario, answers are generated solely based on KG paths. The LLM-inspired KG case involves the LLM predicting an answer using its inherent knowledge and subsequently using the KG to verify its correctness. Conversely, in the KG-inspired LLM case, the paths generated by the KG are insufficient to reach the answer, and the LLM supplements the reasoning using its inherent knowledge. As shown in the figure, up to 14% of answers are generated through the KG-inspired LLM approach, and up to 9% involve LLM-inspired KG path supplementation. Compared to previous work that integrates LLM inherent knowledge with KG data (Sun et al., 2024), PoG more effectively leverages the strengths of both sources. These results demonstrate that PoG is a faithful reasoning method that primarily relies on KG-based reasoning while being supplemented by the LLM, ensuring both accuracy and interpretability in answer generation.
<details>
<summary>x17.png Details</summary>
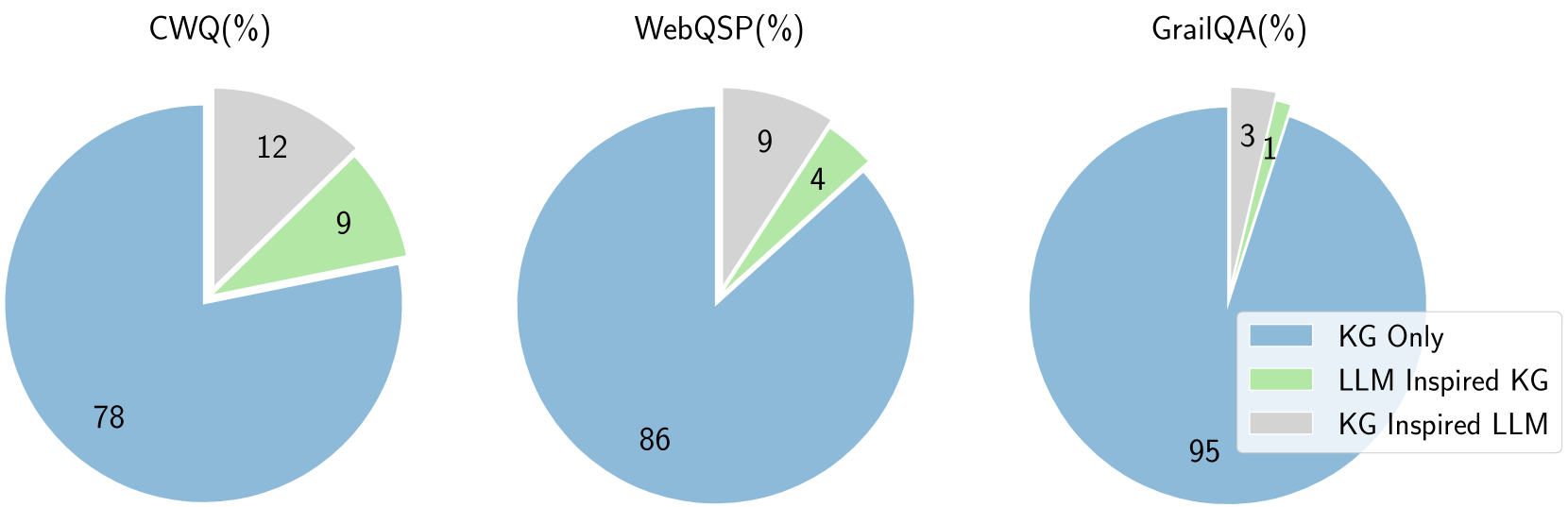
### Visual Description
## Pie Charts: Performance Distribution Across Three Datasets
### Overview
The image displays three pie charts arranged horizontally, each representing the percentage distribution of three distinct methodological categories across three different question-answering datasets: CWQ, WebQSP, and GrailQA. The charts compare the relative contribution or performance share of "KG Only," "LLM Inspired KG," and "KG Inspired LLM" approaches.
### Components/Axes
* **Chart Titles (Top Center of each pie):**
* Left Chart: `CWQ(%)`
* Middle Chart: `WebQSP(%)`
* Right Chart: `GrailQA(%)`
* **Legend (Bottom Right of the image):**
* A blue square corresponds to the label `KG Only`.
* A light green square corresponds to the label `LLM Inspired KG`.
* A light gray square corresponds to the label `KG Inspired LLM`.
* **Data Representation:** Each pie chart is divided into three colored segments (blue, light green, light gray) with numerical percentage labels embedded within them.
### Detailed Analysis
**1. CWQ(%) Chart (Left):**
* **KG Only (Blue):** Dominates the chart, occupying the largest segment. The label indicates **78%**. This segment starts from the 12 o'clock position and sweeps clockwise to approximately the 9:30 position.
* **KG Inspired LLM (Light Gray):** The second-largest segment. The label indicates **12%**. It is positioned in the top-right quadrant, adjacent to the blue segment.
* **LLM Inspired KG (Light Green):** The smallest segment. The label indicates **9%**. It is positioned between the gray and blue segments in the top-right quadrant.
**2. WebQSP(%) Chart (Middle):**
* **KG Only (Blue):** Again the dominant segment, with an increased share. The label indicates **86%**.
* **KG Inspired LLM (Light Gray):** The second-largest segment, but smaller than in CWQ. The label indicates **9%**.
* **LLM Inspired KG (Light Green):** The smallest segment. The label indicates **4%**.
**3. GrailQA(%) Chart (Right):**
* **KG Only (Blue):** Overwhelmingly dominant, representing nearly the entire chart. The label indicates **95%**.
* **KG Inspired LLM (Light Gray):** A very small sliver. The label indicates **3%**.
* **LLM Inspired KG (Light Green):** The smallest segment, barely visible. The label indicates **1%**.
### Key Observations
1. **Dominant Trend:** The "KG Only" (Knowledge Graph Only) category is the overwhelmingly dominant method across all three datasets, consistently accounting for the vast majority of the percentage share (78%, 86%, 95%).
2. **Inverse Relationship:** There is a clear inverse relationship between the dataset and the share of the hybrid methods. As we move from CWQ to WebQSP to GrailQA, the percentage for "KG Only" increases (78% → 86% → 95%), while the combined percentage for the other two categories decreases (21% → 13% → 4%).
3. **Category Ranking:** In all three charts, the ranking of the categories by size is consistent: "KG Only" > "KG Inspired LLM" > "LLM Inspired KG".
4. **Magnitude of Difference:** The gap between the dominant "KG Only" category and the others widens significantly. In GrailQA, "KG Only" is 95%, which is over 30 times larger than the next category ("KG Inspired LLM" at 3%).
### Interpretation
This visualization strongly suggests that for the evaluated tasks on these specific datasets (CWQ, WebQSP, GrailQA), methods relying solely on Knowledge Graphs ("KG Only") are perceived as the most effective or constitute the largest portion of the solution space. The hybrid approaches—"LLM Inspired KG" (where a Large Language Model informs the KG) and "KG Inspired LLM" (where the KG informs the LLM)—play a significantly smaller role.
The trend indicates that the GrailQA dataset, in particular, appears to be highly amenable to pure KG-based methods, with hybrid approaches contributing minimally. This could imply that GrailQA's questions are more structured or directly answerable from a knowledge graph compared to CWQ and WebQSP. The data does not specify whether these percentages represent accuracy, contribution to a model, or another metric, but the consistent pattern across datasets points to a robust finding about the relative dominance of the "KG Only" paradigm in this context.
</details>
(a) PoG
<details>
<summary>x18.png Details</summary>
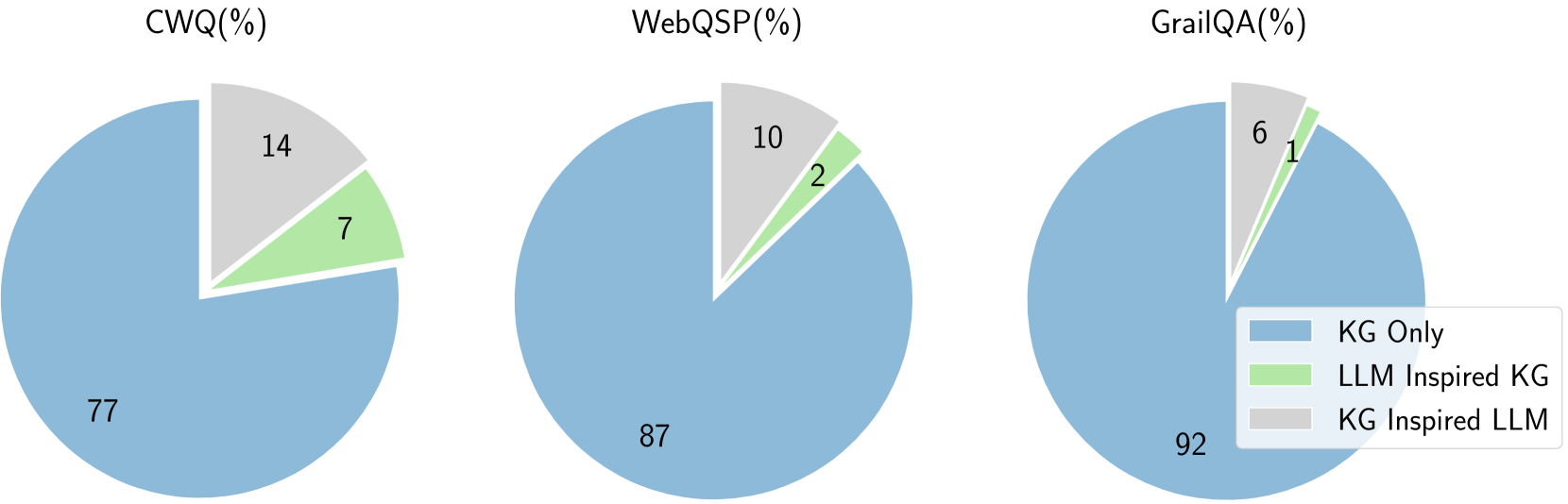
### Visual Description
\n
## Pie Charts: Distribution of Method Types Across Three QA Datasets
### Overview
The image displays three pie charts arranged horizontally, each representing the percentage distribution of three method types for a specific question-answering (QA) dataset. The charts are titled "CWQ(%)", "WebQSP(%)", and "GrailQA(%)". A shared legend is positioned in the bottom-right corner of the image.
### Components/Axes
* **Chart Titles (Top-Center of each pie):**
* Left Chart: `CWQ(%)`
* Middle Chart: `WebQSP(%)`
* Right Chart: `GrailQA(%)`
* **Legend (Bottom-Right):**
* A blue square corresponds to the label: `KG Only`
* A light green square corresponds to the label: `LLM Inspired KG`
* A gray square corresponds to the label: `KG Inspired LLM`
* **Data Labels:** Each pie slice contains a numerical percentage value.
### Detailed Analysis
The data for each dataset is as follows:
**1. CWQ(%) Dataset (Left Chart):**
* **KG Only (Blue slice, dominant portion):** 77%
* **LLM Inspired KG (Green slice, small wedge):** 7%
* **KG Inspired LLM (Gray slice, medium wedge):** 14%
**2. WebQSP(%) Dataset (Middle Chart):**
* **KG Only (Blue slice, dominant portion):** 87%
* **LLM Inspired KG (Green slice, very small wedge):** 2%
* **KG Inspired LLM (Gray slice, small wedge):** 10%
**3. GrailQA(%) Dataset (Right Chart):**
* **KG Only (Blue slice, overwhelmingly dominant portion):** 92%
* **LLM Inspired KG (Green slice, minimal sliver):** 1%
* **KG Inspired LLM (Gray slice, very small wedge):** 6%
### Key Observations
1. **Dominance of "KG Only":** Across all three datasets, the "KG Only" method constitutes the vast majority of the distribution, ranging from 77% to 92%.
2. **Inverse Trend for "LLM Inspired KG":** The proportion of the "LLM Inspired KG" method decreases consistently across the datasets in the order presented: CWQ (7%) > WebQSP (2%) > GrailQA (1%).
3. **Inverse Trend for "KG Inspired LLM":** Similarly, the proportion of the "KG Inspired LLM" method also decreases across the datasets: CWQ (14%) > WebQSP (10%) > GrailQA (6%).
4. **Dataset Progression:** The visual trend suggests a progression where the reliance on pure Knowledge Graph (KG) methods increases from CWQ to WebQSP to GrailQA, while the hybrid or LLM-influenced methods decrease.
### Interpretation
The data suggests a strong and increasing reliance on pure Knowledge Graph (KG) approaches for the evaluated question-answering tasks across these three benchmark datasets. The "KG Only" method is not just dominant but becomes progressively more so, reaching 92% on the GrailQA dataset.
This pattern could indicate several underlying factors:
* **Dataset Nature:** The GrailQA dataset may be structured in a way that is particularly well-suited to formal KG querying, making hybrid or LLM-inspired approaches less necessary or effective. Conversely, CWQ might contain more questions that benefit from the flexibility of LLM-inspired methods.
* **Method Maturity:** The "KG Only" approaches might represent more established, reliable, or precisely controllable techniques for these specific QA tasks, leading to their preferential use.
* **Performance Trade-off:** The decreasing share of "LLM Inspired KG" and "KG Inspired LLM" methods might reflect a performance trade-off where, for these benchmarks, the added complexity of integrating LLMs does not yield sufficient accuracy gains over pure KG systems to justify their use in the majority of cases.
The charts effectively communicate that while hybrid KG-LLM methods exist, the evaluated systems or solutions for these datasets are overwhelmingly built upon core Knowledge Graph technology, with this trend strengthening across the CWQ -> WebQSP -> GrailQA progression.
</details>
(b) PoG-E
Figure 8. The proportions of answer evidence of PoG and PoG-E among CWQ, WebQSP, and GrailQA datasets.
### B.3. Error Analysis
To further analyze the integration of LLMs and KGs, we conduct an error analysis on the CWQ, WebQSP, and GrailQA datasets. We categoriz errors into four types: (1) answer generation error, (2) refuse error, (3) format error, and (4) other hallucination errors. Note that answer generation error occurs when PoG provides an accurate reasoning path, but the LLM fails to extract the correct answer from it. The distribution of these error types is illustrated in Figure 9. The results indicate that using more powerful LLMs reduces the number of ”other hallucination errors,” ”refuse errors,” and ”answer generation errors,” as the model offers enhanced reasoning capabilities based on the retrieved data. Specifically, the reduction in ”answer generation errors” shows the reasoning paths provided by PoG are effectively utilized by more advanced LLMs. However, we observe an increase in ”format errors” with more powerful LLMs, which may be attributed to their greater creative flexibility.
<details>
<summary>x19.png Details</summary>
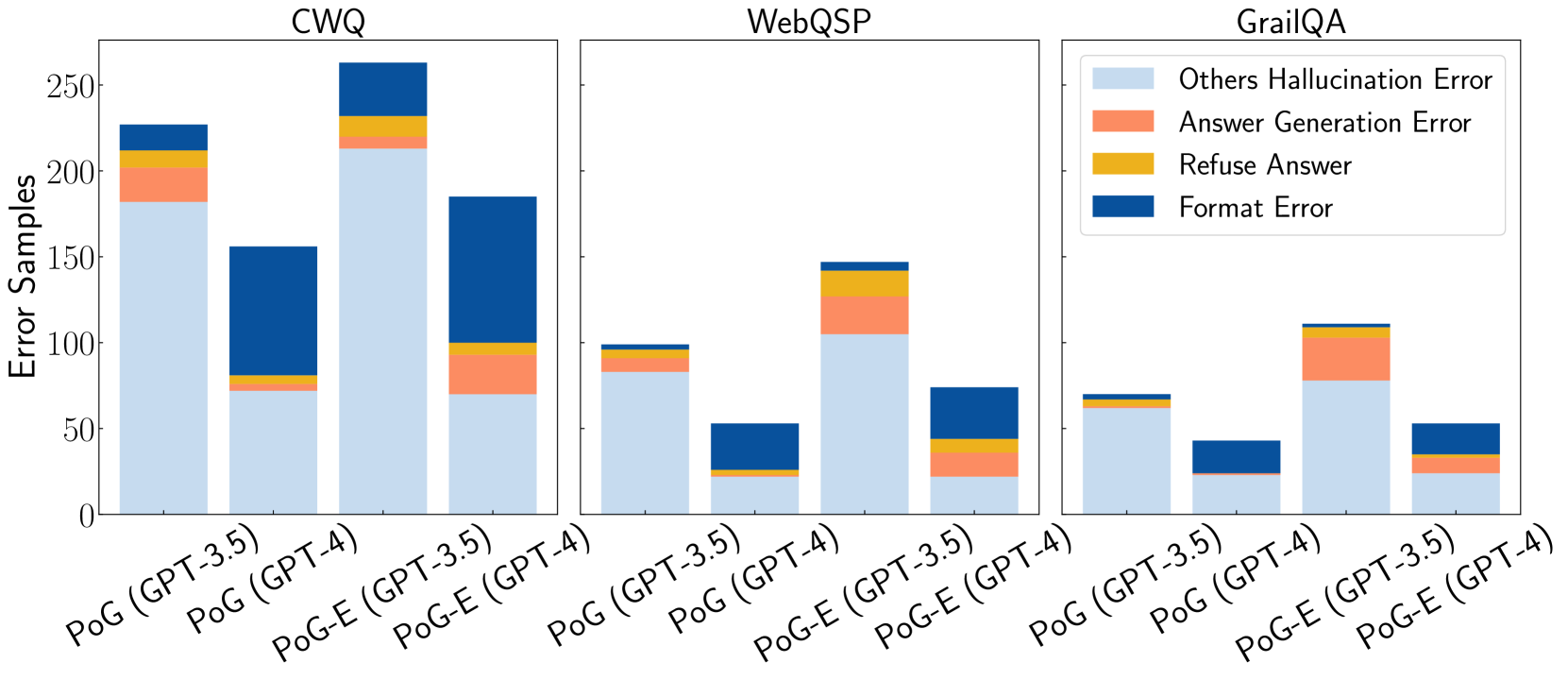
### Visual Description
## Stacked Bar Chart: Error Analysis Across Three QA Datasets
### Overview
The image displays three separate stacked bar charts arranged horizontally, comparing the distribution of error types for four different model configurations across three question-answering (QA) datasets: CWQ, WebQSP, and GrailQA. The y-axis for all charts is labeled "Error Samples," indicating the count of erroneous responses. Each chart contains four bars, representing two base methods (PoG and PoG-E) each run with two underlying language models (GPT-3.5 and GPT-4).
### Components/Axes
* **Chart Titles (Top Center):** "CWQ", "WebQSP", "GrailQA"
* **Y-Axis Label (Left Side, Shared):** "Error Samples"
* **Y-Axis Scale:** Linear scale from 0 to 250, with major ticks at 0, 50, 100, 150, 200, 250.
* **X-Axis Labels (Bottom of each chart):** Four categories per chart:
1. `PoG (GPT-3.5)`
2. `PoG (GPT-4)`
3. `PoG-E (GPT-3.5)`
4. `PoG-E (GPT-4)`
* **Legend (Top Right of the GrailQA chart):** A box containing four colored squares with corresponding labels:
* Light Blue: `Others Hallucination Error`
* Orange: `Answer Generation Error`
* Yellow: `Refuse Answer`
* Dark Blue: `Format Error`
### Detailed Analysis
**1. CWQ Chart (Leftmost)**
* **Trend:** The total error count is highest for the PoG-E (GPT-3.5) configuration. The PoG (GPT-4) configuration shows a notably different error composition, with a very large "Format Error" segment.
* **Data Points (Approximate Values):**
* **PoG (GPT-3.5):** Total ~225. Others Hallucination: ~180. Answer Generation: ~25. Refuse Answer: ~10. Format Error: ~10.
* **PoG (GPT-4):** Total ~155. Others Hallucination: ~75. Answer Generation: ~5. Refuse Answer: ~5. Format Error: ~70.
* **PoG-E (GPT-3.5):** Total ~260. Others Hallucination: ~215. Answer Generation: ~15. Refuse Answer: ~10. Format Error: ~20.
* **PoG-E (GPT-4):** Total ~185. Others Hallucination: ~70. Answer Generation: ~25. Refuse Answer: ~5. Format Error: ~85.
**2. WebQSP Chart (Center)**
* **Trend:** Overall error counts are lower than in CWQ. The PoG-E (GPT-3.5) configuration again has the highest total errors. The "Format Error" segment is prominent in the GPT-4 based models.
* **Data Points (Approximate Values):**
* **PoG (GPT-3.5):** Total ~100. Others Hallucination: ~85. Answer Generation: ~10. Refuse Answer: ~3. Format Error: ~2.
* **PoG (GPT-4):** Total ~55. Others Hallucination: ~25. Answer Generation: ~2. Refuse Answer: ~3. Format Error: ~25.
* **PoG-E (GPT-3.5):** Total ~145. Others Hallucination: ~105. Answer Generation: ~25. Refuse Answer: ~10. Format Error: ~5.
* **PoG-E (GPT-4):** Total ~75. Others Hallucination: ~25. Answer Generation: ~15. Refuse Answer: ~5. Format Error: ~30.
**3. GrailQA Chart (Rightmost)**
* **Trend:** This dataset shows the lowest overall error counts. The pattern of PoG-E (GPT-3.5) having the most errors and GPT-4 models having larger "Format Error" segments continues.
* **Data Points (Approximate Values):**
* **PoG (GPT-3.5):** Total ~70. Others Hallucination: ~60. Answer Generation: ~5. Refuse Answer: ~3. Format Error: ~2.
* **PoG (GPT-4):** Total ~45. Others Hallucination: ~25. Answer Generation: ~2. Refuse Answer: ~1. Format Error: ~17.
* **PoG-E (GPT-3.5):** Total ~110. Others Hallucination: ~75. Answer Generation: ~25. Refuse Answer: ~5. Format Error: ~5.
* **PoG-E (GPT-4):** Total ~55. Others Hallucination: ~25. Answer Generation: ~10. Refuse Answer: ~3. Format Error: ~17.
### Key Observations
1. **Dominant Error Type:** "Others Hallucination Error" (light blue) is consistently the largest error component across all datasets and models, especially for GPT-3.5 based configurations.
2. **Model Comparison:** GPT-4 based models (`PoG (GPT-4)` and `PoG-E (GPT-4)`) consistently show a much larger proportion of "Format Error" (dark blue) compared to their GPT-3.5 counterparts.
3. **Method Comparison:** The `PoG-E` method generally results in a higher total number of error samples than the `PoG` method when using the same underlying language model (GPT-3.5 or GPT-4).
4. **Dataset Difficulty:** The total error counts are highest for CWQ, intermediate for WebQSP, and lowest for GrailQA, suggesting varying levels of difficulty or error propensity across these benchmarks for the tested models.
### Interpretation
This visualization provides a diagnostic breakdown of *why* models fail on these QA tasks, moving beyond simple accuracy metrics. The data suggests two key insights:
1. **Hallucination is the Primary Failure Mode:** The overwhelming prevalence of "Others Hallucination Error" indicates that the core challenge for these models is generating factually incorrect or unsupported information, rather than refusing to answer or making simple formatting mistakes.
2. **Model Capability Affects Error Type:** The shift from hallucination-dominated errors in GPT-3.5 to a significant share of format errors in GPT-4 implies that as models become more capable (GPT-4), they may be better at avoiding factual hallucinations but encounter new failures in adhering to strict output protocols or structured response formats required by the evaluation framework. This highlights a potential trade-off or a new area for refinement in more advanced models.
The consistent pattern across three distinct datasets strengthens the reliability of these observations. The `PoG-E` method, while potentially offering other benefits, appears to increase the raw number of errors, particularly hallucinations, compared to the base `PoG` method.
</details>
Figure 9. The error instances and categories of PoG and PoG-E in the CWQ, WebQSP, and GrailQA datasets.
### B.4. Efficiency Analysis
LLM calls cost analysis. To evaluate the cost and efficiency of utilizing LLMs, we conducted an analysis of LLM calls on the CWQ, WebQSP, and GrailQA datasets. Initially, we examined the proportion of questions answered with varying numbers of LLM calls, as depicted in Figure 10. The results indicate that the majority of questions are answered within nine LLM calls across all datasets, with approximately 80% and 50% of questions being resolved within six calls on CWQ and WebQSP, respectively. These findings demonstrate PoG’s efficiency in minimizing LLM usage costs. Furthermore, we compared the average number of LLM calls required by PoG with the current SOTA method, ToG (Sun et al., 2024), as shown in Table 7. Since we utilized identical datasets for WebQSP, GrailQA, Simple Questions, and WebQuestions, we report the ToG results from their paper. The comparison reveals that PoG achieves comparable or superior accuracy while reducing the number of LLM calls by up to 40% on the GrailQA dataset compared to ToG. This improvement is attributed to PoG’s dynamic exploration strategy, which avoids starting from scratch, and its effective use of graph structures to prune irrelevant information, thereby significantly decreasing computational costs.
<details>
<summary>x20.png Details</summary>
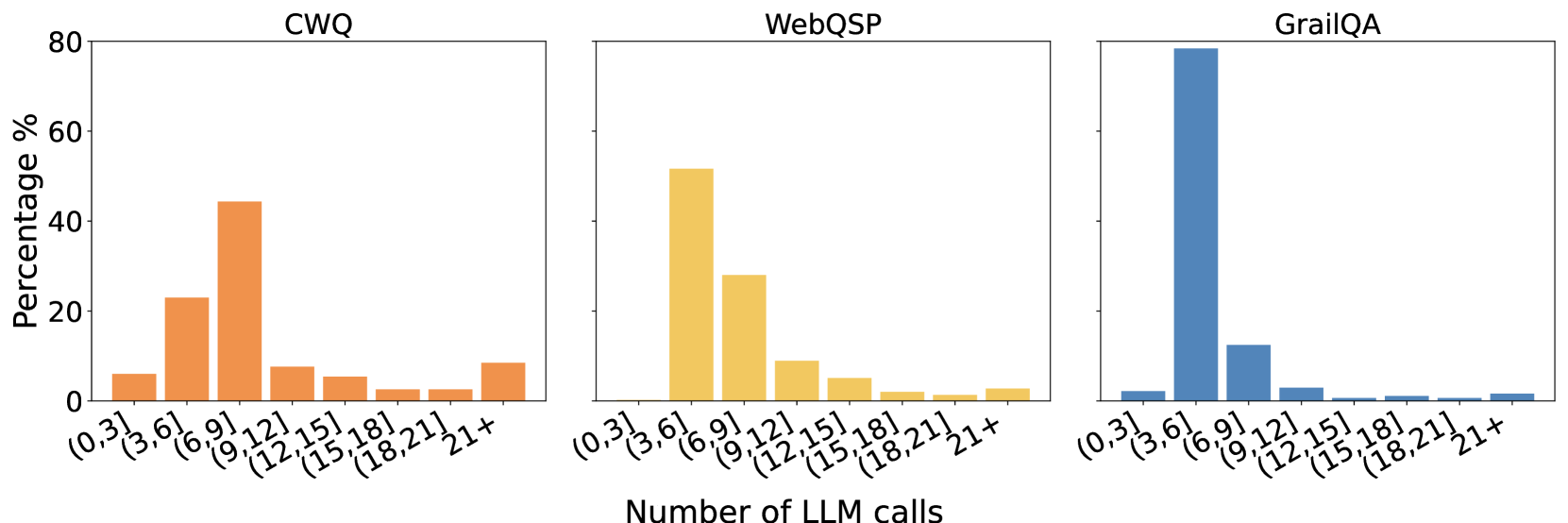
### Visual Description
## Bar Charts: Distribution of LLM Calls Across Three Datasets
### Overview
The image displays three adjacent bar charts, each representing the distribution of the number of Large Language Model (LLM) calls required for a different question-answering dataset. The charts share a common x-axis and y-axis scale, allowing for direct comparison of the distributions. The overall title for the x-axis is "Number of LLM calls".
### Components/Axes
* **Chart Titles (Top Center of each subplot):**
* Left Chart: `CWQ`
* Middle Chart: `WebQSP`
* Right Chart: `GrailQA`
* **Y-Axis (Leftmost chart only, applies to all):**
* Label: `Percentage %`
* Scale: Linear, from 0 to 80, with major ticks at 0, 20, 40, 60, 80.
* **X-Axis (Bottom of all charts):**
* Label: `Number of LLM calls` (centered below the three charts).
* Categories (Bins): `(0,3]`, `(3,6]`, `(6,9]`, `(9,12]`, `(12,15]`, `(15,18]`, `(18,21]`, `21+`. These represent ranges of LLM call counts.
* **Data Series (Bar Colors):**
* CWQ: Orange bars.
* WebQSP: Yellow/Gold bars.
* GrailQA: Blue bars.
### Detailed Analysis
**1. CWQ Dataset (Left Chart, Orange Bars):**
* **Trend:** The distribution is somewhat broad, peaking in the middle ranges and tapering off at the extremes.
* **Data Points (Approximate Percentages):**
* `(0,3]`: ~6%
* `(3,6]`: ~23%
* `(6,9]`: ~44% **(Peak)**
* `(9,12]`: ~8%
* `(12,15]`: ~5%
* `(15,18]`: ~2%
* `(18,21]`: ~2%
* `21+`: ~9%
**2. WebQSP Dataset (Middle Chart, Yellow Bars):**
* **Trend:** The distribution is right-skewed, with a strong peak in the lower-middle range and a steady decline thereafter.
* **Data Points (Approximate Percentages):**
* `(0,3]`: ~0% (No visible bar)
* `(3,6]`: ~52% **(Peak)**
* `(6,9]`: ~28%
* `(9,12]`: ~9%
* `(12,15]`: ~5%
* `(15,18]`: ~2%
* `(18,21]`: ~1%
* `21+`: ~3%
**3. GrailQA Dataset (Right Chart, Blue Bars):**
* **Trend:** The distribution is extremely right-skewed and concentrated in a single bin, with very low percentages in all others.
* **Data Points (Approximate Percentages):**
* `(0,3]`: ~2%
* `(3,6]`: ~79% **(Dominant Peak)**
* `(6,9]`: ~12%
* `(9,12]`: ~3%
* `(12,15]`: ~1%
* `(15,18]`: ~1%
* `(18,21]`: ~1%
* `21+`: ~1%
### Key Observations
1. **Peak Location Shift:** The modal (most frequent) number of LLM calls increases from GrailQA (`(3,6]`) to WebQSP (`(3,6]`) to CWQ (`(6,9]`).
2. **Distribution Shape:** GrailQA has the most concentrated distribution, with nearly 80% of samples requiring 3-6 calls. WebQSP is also concentrated but less so. CWQ has the most spread-out distribution, indicating greater variability in the number of calls needed.
3. **High-Call Tail:** All datasets show a small but non-zero percentage of samples requiring 21+ LLM calls (CWQ: ~9%, WebQSP: ~3%, GrailQA: ~1%).
### Interpretation
This data visualizes the computational "effort" or complexity, measured in LLM API calls, required by a system to answer questions from three established benchmarks. The stark differences suggest fundamental variations in the datasets' nature:
* **GrailQA** appears to be the most "efficient" for the system being measured, with the vast majority of questions resolved with very few (3-6) LLM calls. This could imply more straightforward questions, better alignment with the system's capabilities, or a more direct answer path.
* **WebQSP** shows a moderate level of complexity, with most questions requiring 3-9 calls.
* **CWQ** presents the greatest challenge or variability, with a significant portion of questions requiring 6-9 calls and a heavier tail of questions needing many more calls (9+). This suggests CWQ contains more complex, multi-step, or ambiguous questions that force the system to make more exploratory or iterative LLM calls.
The charts effectively argue that benchmark performance cannot be evaluated on accuracy alone; the computational cost (here, LLM calls) varies dramatically across datasets. A system might achieve high accuracy on GrailQA with low cost, but the same system could be much more expensive to run on CWQ. This has practical implications for deployment costs and efficiency.
</details>
Figure 10. The proportion of question of PoG and PoG-E by different LLM Calls among CWQ, WebQSP, and GrailQA datasets
Table 7. Average LLM calls per question of PoG and ToG among all datasets.
| Method | CWQ | WebQSP | GrailQA | Simple Questions | WebQuestions |
| --- | --- | --- | --- | --- | --- |
| PoG | 10.7 | 8.3 | 6.5 | 6.1 | 9.3 |
| ToG | - | 11.2 | 10.6 | 8.7 | 10.5 |
Running time analysis. To further evaluate the processing efficiency of PoG, we conducted extensive evaluations focusing on average accuracy, LLM call frequency, and running time on multi-hop question datasets GrailQA and CWQ. The results, presented in Table 8, compare the performance of ToG and PoG across various beam search strategies. The data indicate that while higher accuracy slightly increases runtime, PoG effectively balances accuracy with reduced LLM call costs. Specifically, PoG reduces LLM call costs by up to 53.5% while increasing accuracy by up to 33.4%. This allows users to tailor the PoG framework to their specific needs regarding accuracy, cost, and runtime. All PoG setting provide significantly lower costs. For instance, on the GrailQA dataset, PoG with 3-step beam search reduces LLM call costs by 39.6% and improves accuracy by 33.1%, with only a 1.14% increase in runtime. A similar trend is also observed in the CWQ dataset.
Table 8. Running time evaluation of ToG and PoG with different beam search methods on CWQ and GrailQA.
| Model | Evaluation | CWQ | GrailQA |
| --- | --- | --- | --- |
| ToG | Accuracy | 53.1 | 59.3 |
| Time (s) | 78.7 | 14.8 | |
| LLM Calls | 21.3 | 10.1 | |
| PoG | Accuracy | 81.4 | 92.7 |
| Time (s) | 118.9 | 21.4 | |
| LLM Calls | 9.1 | 6.5 | |
| PoG | Accuracy | 79.8 | 92.4 |
| w/ 3-Step Beam Search | Time (s) | 87.5 | 15.0 |
| LLM Calls | 8.8 | 6.1 | |
| PoG | Accuracy | 57.1 | 83.0 |
| w/ Fuzzy Selection | Time (s) | 109.7 | 15.7 |
| LLM Calls | 6.8 | 4.7 | |
### B.5. Case Study
Case study: graph reduction and path pruning. We conducted a case study using the example question presented in Figure 2 to illustrate the effects of graph pruning and path pruning on the graph structure. Figure 11 (a) shows the results of graph pruning, where vertices in blue are selected as part of the question subgraph, and vertices in black are pruned. In this sample, the number of entities is reduced from 16,740 to 1,245, resulting in a 92% reduction of vertices. Figures 11 (b) and 11 (c) demonstrate the question subgraph induced by the blue vertices in Figure 11 (a) and the results after applying fuzzy and precise path selection. In these figures, vertices in blue represent the selected entity after each pruning, vertices in yellow represent the topic entities, and the vertex in red denotes the final answer entity. From these graphs, we observe that utilizing the graph structure allows for the rapid pruning of irrelevant vertices, ensuring that the reasoning paths remain faithful and highly relevant to the question since all vertices within the question subgraph are interconnected with all topic entities, thereby maintaining the integrity and relevance of the reasoning process.
<details>
<summary>x21.png Details</summary>
### Visual Description
## Network Diagram: Dense Interconnected Graph
### Overview
The image displays a complex, dense network graph (also known as a node-link diagram) on a white background. It consists of hundreds of circular nodes connected by a web of thin, semi-transparent gray lines (edges). There are two distinct node types differentiated by color: blue and black. The graph exhibits a high degree of connectivity, with many nodes serving as hubs for numerous connections. There is no accompanying text, title, legend, or axis labels within the image frame.
### Components/Axes
* **Nodes:** Circular markers representing entities in the network.
* **Blue Nodes:** Approximately 150-200 bright blue circles, distributed throughout the graph but appearing slightly more concentrated in the central and upper-left regions.
* **Black Nodes:** Approximately 300-400 black circles, more numerous than the blue nodes and spread across the entire visualization.
* **Edges:** Thin, gray, semi-transparent lines connecting nodes. The density of edges is extremely high, creating a dark, almost solid mass in the center of the graph where connections overlap heavily. The edges appear to have no directionality (undirected graph).
* **Layout:** The graph uses a force-directed layout algorithm, where connected nodes are pulled together and unconnected nodes are pushed apart. This results in a roughly circular or organic cluster with a very dense core and a slightly less dense periphery. No spatial axes (X/Y coordinates with meaning) are present.
### Detailed Analysis
* **Node Distribution:** Both blue and black nodes are interspersed throughout the network. There is no clear spatial segregation where one color is confined to a specific region. However, the highest density of *both* node types and their connecting edges is in the central area of the image.
* **Connectivity Pattern:** The network is highly interconnected. Many nodes, particularly in the central mass, appear to be connected to dozens of other nodes, forming dense local clusters. The edges create a complex, hairball-like structure, making it impossible to trace individual connections without interactive tools.
* **Visual Density:** The center of the graph is so densely packed with overlapping edges that it appears as a dark blue-black mass. The density decreases towards the edges of the image, where individual nodes and their connecting lines become more distinguishable.
### Key Observations
1. **High Clustering Coefficient:** The visual density suggests a network with a high clustering coefficient, meaning nodes tend to form tightly knit groups.
2. **Hub Nodes:** Several nodes (both blue and black) appear to be major hubs, with a visibly higher number of edges radiating from them compared to others. These are often located in the central dense region.
3. **Lack of Clear Community Structure:** At this scale and without algorithmic analysis, no distinct, separate communities or modules are visually apparent. The network appears as one large, integrated component.
4. **Two-Category System:** The use of only two node colors (blue and black) implies a fundamental binary classification of the entities within the network (e.g., active/inactive, type A/type B, infected/healthy).
### Interpretation
This visualization represents a complex system characterized by dense, non-random interconnections. The absence of labels or a legend means the specific domain (e.g., social network, biological pathway, citation network, neural connections) cannot be determined from the image alone.
**What the data suggests:**
* **Robustness and Vulnerability:** Such a densely connected network is likely robust to random failures (removing random nodes may not disconnect the graph) but potentially vulnerable to targeted attacks on the high-degree hub nodes.
* **Efficient Information/Resource Flow:** The short path lengths implied by the dense core suggest that information, signals, or resources could propagate very quickly through this system.
* **Binary Attribute Interaction:** The mixing of blue and black nodes throughout the structure indicates that the binary attribute they represent is not a primary driver of the network's overall topology. Connections form readily between nodes of the same color and different colors.
**Notable Anomalies:**
The primary "anomaly" is the extreme density itself. In many real-world networks, some degree of sparsity is common. This graph's density might indicate a specific type of system (like a fully connected layer in a neural network, a very small-world social group, or a synthetic dataset designed to show high connectivity) or a visualization choice where a very large number of edges are drawn with low opacity, creating an aggregated dark mass.
**Peircean Investigation:**
* **Icon:** The image is an icon of a network—a direct visual representation of nodes and links.
* **Index:** The dense clustering and hub formation are indices of underlying forces (like preferential attachment or community structure) that shaped the network's growth.
* **Symbol:** The blue/black color scheme is a symbolic, arbitrary convention to denote a categorical difference between nodes. Without a key, the symbol's meaning is lost, highlighting the critical importance of metadata in technical visualizations.
**Conclusion:** The image effectively conveys the *structural property* of being a dense, interconnected, small-world network with a binary node classification. However, it fails as a standalone technical document due to the complete absence of explanatory text, labels, or a legend, which are essential for interpreting the *meaning* of the nodes, edges, and their categories. To make this diagram informative, it requires a title, a legend explaining the blue/black node distinction, and ideally, annotations for key hub nodes or clusters.
</details>
(a) Graph pruning
<details>
<summary>x22.png Details</summary>
### Visual Description
## Network Graph: Core-Periphery Structure with Hub Nodes
### Overview
The image displays a complex network graph (or node-link diagram) on a plain white background. It visualizes a system of interconnected entities (nodes) and their relationships (edges). The graph exhibits a distinct core-periphery structure, characterized by a dense central cluster of nodes and a few highly connected peripheral nodes acting as hubs.
### Components/Axes
* **Nodes:** There are two visually distinct types of nodes:
1. **Dark Blue Nodes:** The vast majority of nodes are small, dark blue circles. They are densely interconnected, forming a large, irregular cluster that occupies the central and left portions of the image.
2. **Orange Nodes:** There are two larger, orange circular nodes positioned on the periphery.
* **Hub Node 1 (Top-Right):** Located in the upper-right quadrant, outside the main blue cluster.
* **Hub Node 2 (Bottom-Left):** Located in the lower-left quadrant, below the main blue cluster.
* **Edges (Connections):** Lines connect the nodes. Two colors are distinguishable:
1. **Dark Blue Edges:** These form the dense, intricate web within the central cluster of blue nodes.
2. **Light Brown/Tan Edges:** These primarily connect the two orange hub nodes to numerous blue nodes within the central cluster. The top-right orange node has a particularly dense fan of these connections.
* **Labels/Axes:** The image contains **no textual labels, titles, axis markers, legends, or data tables**. All information is conveyed purely through the visual properties of nodes (color, size, position) and edges (color, density).
### Detailed Analysis
* **Spatial Grounding & Component Isolation:**
* **Header/Top Region:** Dominated by the top-right orange hub node and its radiating light brown edges that connect downward and leftward into the main cluster.
* **Main Chart/Central Region:** Contains the dense, irregularly shaped core of dark blue nodes. The connectivity here is extremely high, making individual edges difficult to trace. The density appears greatest slightly right of the absolute center.
* **Footer/Bottom Region:** Contains the bottom-left orange hub node with a smaller set of light brown edges connecting upward into the main cluster.
* **Trend Verification & Data Points:**
* **Blue Node Cluster:** The trend is one of **high internal connectivity**. The nodes are not uniformly distributed; they form a cohesive, tangled mass with higher density in the center-right area. There are no clear sub-clusters or categories visible.
* **Orange Hub Nodes:** Both exhibit a trend of **high external connectivity** to the blue cluster. The top-right hub is significantly more connected than the bottom-left hub, as evidenced by the greater number and density of its radiating edges.
* **Edge Color Correlation:** The light brown edges are exclusively associated with connections involving the orange hub nodes. The dark blue edges are exclusive to connections between the dark blue nodes. This suggests a categorical difference in the type of relationship or connection being represented.
### Key Observations
1. **Core-Periphery Architecture:** The graph is a classic example of a core-periphery network. The "core" is the densely connected blue cluster, and the "periphery" consists of the orange hub nodes.
2. **Hub Disparity:** The two orange hubs are not equal. The top-right hub is a major connector, potentially a primary gateway or aggregator for the entire network. The bottom-left hub plays a secondary, less central role.
3. **Absence of Metadata:** The complete lack of labels, a legend, or a title makes it impossible to identify what the nodes or edges represent (e.g., people, computers, proteins, websites) or what the connection colors signify.
4. **Visual Complexity:** The central cluster's density creates a "hairball" effect, obscuring the precise topology and making it impossible to count nodes or edges accurately from the image alone.
### Interpretation
This network graph visually demonstrates fundamental principles of network theory. The structure suggests a system where a large, tightly-knit community (the blue core) is influenced or accessed by a few key external entities (the orange hubs).
* **What the Data Suggests:** The top-right orange node likely represents a critical point of failure, a major influencer, or a central server/router. Its removal would significantly disrupt connections between the periphery and the core. The bottom-left node may represent a secondary entry point or a specialized connector.
* **Relationships Between Elements:** The color-coded edges imply two distinct types of relationships. The dark blue edges represent internal, possibly peer-to-peer, relationships within the core group. The light brown edges represent a different class of relationship, perhaps hierarchical, directional (e.g., "follows," "cites," "downloads from"), or between different types of entities.
* **Notable Anomalies:** The stark visual separation between the two orange nodes and the main cluster is notable. They are connected *to* the cluster but are not integrated *within* it, highlighting their distinct roles. The asymmetry between the two hubs is the most significant quantitative observation possible without numerical data.
**In summary, the image conveys the structural information of a network with a dense core and two peripheral hubs of unequal importance, using color to differentiate node types and connection types. However, the absence of all textual context prevents any specific domain interpretation.**
</details>
(b) Question subgraph
<details>
<summary>x23.png Details</summary>
### Visual Description
## Network Graph: Dense Cluster with Peripheral Hubs
### Overview
The image displays a complex, force-directed network graph (or node-link diagram) on a plain white background. It visualizes a system of interconnected entities (nodes) and their relationships (edges). The graph is characterized by a very dense central cluster of nodes, with two distinct peripheral nodes acting as major hubs. There is **no textual information** (labels, titles, legends, or annotations) present in the image.
### Components/Axes
* **Nodes (Circles):** Three distinct types are visible, differentiated by color and relative size.
1. **Gray Nodes:** The vast majority of nodes. They are small, uniform in size, and form a dense, roughly circular cloud in the center-left of the image.
2. **Blue Nodes:** Larger than the gray nodes. Approximately 25-30 are scattered throughout the gray cluster, often appearing as local connection points.
3. **Orange Nodes:** Two nodes, significantly larger than all others.
* **Primary Hub (Right):** Positioned on the far right edge of the graph. It is the largest node.
* **Secondary Hub (Bottom):** Positioned at the bottom-center, slightly left. It is smaller than the right hub but larger than the blue nodes.
* **Edges (Lines):** Thin, curved lines connecting nodes. Two colors are present:
1. **Blue Edges:** The most numerous. They form the dense, intricate web connecting nodes within the central cluster (gray-to-gray, gray-to-blue, blue-to-blue).
2. **Orange Edges:** Radiate almost exclusively from the **Primary Hub (Right)**. They connect this hub to a large number of nodes within the central cluster (both gray and blue). A few faint orange lines also connect to the **Secondary Hub (Bottom)**.
### Detailed Analysis
* **Spatial Layout & Density:** The graph uses a force-directed layout where connected nodes attract each other and unconnected ones repel. This results in the dense central cluster where nodes are tightly packed, indicating a high degree of interconnection. The two orange hubs are pushed to the periphery due to their unique connection patterns.
* **Node Distribution:**
* The **gray nodes** are densely packed, with an estimated count in the hundreds (likely 400-600). Their uniform size suggests they may represent standard or equivalent entities in the network.
* The **blue nodes** are distributed semi-randomly within the gray cloud. Their larger size and position as connection points suggest they may be important sub-hubs or nodes of a different class.
* The **Primary Hub (Right Orange Node)** is the most prominent structural element. Its position and the fan of orange edges indicate it is a central point of connection or influence for a significant portion of the network.
* The **Secondary Hub (Bottom Orange Node)** has far fewer connections (approximately 5-10 visible orange edges), suggesting a more specialized or limited role.
* **Connection Patterns:**
* **Intra-Cluster Connections (Blue Edges):** These create a complex, mesh-like topology within the central cluster, implying a highly interconnected community or system where most elements are directly or indirectly linked.
* **Hub-Spoke Connections (Orange Edges):** These create a clear star topology centered on the Primary Hub. This pattern is typical of a client-server model, a central authority, or a major source/sink in a flow network.
### Key Observations
1. **Absence of Text:** The graph contains zero textual labels, making it impossible to identify what the nodes or edges represent without external context.
2. **Two-Tiered Hierarchy:** The network exhibits a clear two-tiered structure: a dense, peer-to-peer-like core (gray/blue nodes with blue edges) and a centralized, hierarchical layer (orange hubs with orange edges).
3. **Asymmetry of Hubs:** The two orange hubs are not equal. The right hub is orders of magnitude more connected than the bottom hub, indicating a significant imbalance in their roles or importance.
4. **Blue Nodes as Bridges:** The blue nodes, while embedded in the gray cluster, often appear to be key connection points for the orange edges from the Primary Hub, potentially acting as bridges or gateways between the core cluster and the central hub.
### Interpretation
This network graph visually represents a system with **both decentralized and centralized characteristics**.
* **The dense gray/blue cluster** suggests a robust, resilient community or network where information, resources, or influence can flow through many alternative paths. This could model a social network, a research collaboration field, a biological protein interaction network, or a peer-to-peer communication system.
* **The dominant Primary Hub (Right)** introduces a point of centralization, control, or aggregation. This could represent a major platform, a central server, a key influencer, a funding agency, or a critical resource that many entities in the core depend on. Its high connectivity makes it a potential single point of failure or a powerful coordinator.
* **The Secondary Hub (Bottom)** may represent a niche authority, a backup system, or a specialized service with a more limited, dedicated user base within the larger network.
**The overall structure implies a "network of networks" or a hybrid system.** The core operates with distributed dynamics, but its overall behavior and connectivity are significantly shaped by its relationship with a powerful external hub. The lack of labels prevents specific domain interpretation, but the topological patterns are classic in studies of social networks, the internet, biological systems, and organizational charts. The graph effectively communicates concepts of density, centrality, hierarchy, and the interplay between distributed and centralized control.
</details>
(c) Fuzzy selection
<details>
<summary>x24.png Details</summary>
### Visual Description
## Network Diagram: Dense Cluster with Peripheral Hubs
### Overview
The image displays a complex network graph or diagram on a plain white background. It consists of a large, dense cluster of nodes connected by a web of edges, with a few distinct nodes positioned outside or within this main cluster. There is **no textual information** present in the image—no labels, titles, legends, axis markers, or embedded text. The analysis is therefore based solely on visual structure, color, and spatial relationships.
### Components/Axes
* **Nodes (Vertices):**
* **Gray Nodes:** The vast majority of nodes are small, solid gray circles. They form a dense, roughly circular or amorphous cloud occupying the central and left portions of the image. There are several hundred of these nodes.
* **Colored Nodes:** Four larger, distinctly colored nodes are present:
1. **Blue Node (Left):** Located within the upper-left quadrant of the main gray cluster.
2. **Red Node (Center):** Positioned near the geometric center of the gray cluster.
3. **Blue Node (Right):** Situated within the lower-right quadrant of the gray cluster, appearing as a major connection point.
4. **Orange Node (Top-Right):** Positioned far outside the main cluster, in the upper-right corner of the image.
5. **Orange Node (Bottom-Left):** Positioned outside the main cluster, in the lower-left area of the image.
* **Edges (Connections):**
* **Blue Edges:** A dense network of thin, blue lines primarily connects the gray nodes to each other and to the two blue nodes and the red node within the cluster. The blue edges create a tangled, web-like structure within the main cloud.
* **Orange Edges:** Thinner, orange lines radiate outward from the two orange peripheral nodes. The top-right orange node has a very high degree, with orange edges connecting it to a large number of gray nodes across the entire cluster. The bottom-left orange node has fewer connections, primarily to nodes in the lower part of the cluster. Some orange edges also appear to connect the two orange nodes to each other via the cluster.
### Detailed Analysis
* **Spatial Grounding & Component Isolation:**
* **Header/Top Region:** Dominated by the top-right orange node and the fan of orange edges descending into the main cluster. The upper part of the gray cluster is dense with nodes and blue edges.
* **Main Chart/Center Region:** Contains the core of the network. The red node is centrally located. The right-side blue node acts as a local hub, with a particularly high density of blue edges converging on it. The left-side blue node is more embedded within the cluster.
* **Footer/Bottom Region:** Contains the bottom-left orange node and its connections. The lower edge of the gray cluster is less dense than the center.
* **Trend Verification (Visual Flow):**
* The blue edges show a trend of **high local interconnectivity** within the main cluster, with no clear directional flow. Connections appear dense and somewhat random, suggesting a tightly knit community or system.
* The orange edges show a clear trend of **radial distribution** from the two orange nodes. The top-right node exhibits a "hub-and-spoke" pattern, connecting to many disparate points in the network. This suggests a role of broadcasting, aggregation, or external influence.
### Key Observations
1. **Absence of Text:** The diagram contains zero textual information, making it purely structural.
2. **Two-Tiered Structure:** The network clearly differentiates between a dense, internally connected core (gray nodes with blue edges) and peripheral hub nodes (orange) that connect to the core.
3. **Asymmetric Hubs:** The two orange hub nodes are not equal. The top-right hub is significantly more connected than the bottom-left one.
4. **Internal Hubs:** Within the core cluster, the right-side blue node and the central red node appear to be more central or highly connected than the left-side blue node, based on the density of blue edges around them.
5. **Color Coding:** The use of color (gray, blue, red, orange) is the primary method for distinguishing node types or roles, though their specific meanings are undefined.
### Interpretation
This diagram visually represents a **complex system with a core-periphery structure**. The dense gray cluster with blue connections likely represents a primary, tightly integrated system—such as a social network of friends, a neural network's hidden layers, a database of interlinked records, or a community of interacting species.
The colored nodes within the cluster (blue, red) likely signify **specialized or influential entities** within that core system. The red node's central position might indicate a critical bridge or a unique type of component.
The orange nodes and their edges represent **external agents or interfaces** that interact with the core system. The top-right orange node, with its vast number of connections, strongly suggests a **major external influencer, a data aggregator, a central server, or a primary input/output channel**. Its position outside the cluster implies it is not part of the core community but has a broad reach into it. The bottom-left orange node represents a secondary or more specialized external connection.
The overall structure suggests a system where internal cohesion (blue edges) is high, but it is also subject to significant external influence or connectivity (orange edges) from at least one dominant source. Without labels, the specific domain (e.g., computer network, biological pathway, citation graph) cannot be determined, but the topological pattern is clear and informative.
</details>
(d) Precise selection
Figure 11. Visualization of graph reduction and Path selection.
Case study: interpretable reasoning. In this section, we present Table 9, which illustrates PoG’s interpretability through case studies involving questions with one, two, and three entities. These examples demonstrate PoG’s effectiveness in handling multi-entity and multi-hop tasks by providing clear and understandable reasoning paths that lead to accurate answers.
Table 9. Examples of faithful and interpretable reasoning of PoG.
| Field | Content |
| --- | --- |
| Question | Lou Seal is the mascot for the team that last won the World Series when? |
| Answer | 2014 World Series |
| Topic Entity | Lou Seal |
| LLM indicator | ” Lou Seal ” - mascot for - team - last won - World Series - when |
| Split Question | split_question 1: What team is ”Lou Seal” the mascot for? |
| split_question 2: When did the last World Series win occur for the team with Lou Seal as the mascot? | |
| Reasoning Path | {Lou Seal} $\rightarrow$ sports.mascot.team $\rightarrow$ {San Francisco Giants} $\rightarrow$ sports.sports_team.championships $\rightarrow$ {2014 World Series, 2012 World Series, 2010 World Series} |
| PoG answer | answer: {2014 World Series} |
| reason: From the given path {Lou Seal} $\rightarrow$ sports.mascot.team $\rightarrow$ {San Francisco Giants}, {San Francisco Giants} is the team that ”Lou Seal” serves as the mascot for. From {San Francisco Giants} $\rightarrow$ sports.sports_team.championships $\rightarrow$ {2014 World Series, 2012 World Series, 2010 World Series}, the last World Series won by the {San Francisco Giants} is in {2014}. Therefore, the provided knowledge graph path is sufficient to answer the overall question, and the answer is {2014 World Series}. | |
| Question | What European Union country sharing borders with Germany contains the Lejre Municipality? |
| Answer | Denmark |
| Topic Entity | {Germany, Lejre Municipality} |
| LLM indicator | ” Lejre Municipality ” – contained by - European Union country (answer)- shares borders with-” Germany ” |
| Split Question | split_question 1: What European Union country shares borders with ”Germany”? |
| split_question 2: What country contains the Lejre Municipality? | |
| Reasoning Path | {Lejre Municipality} $\rightarrow$ location.administrative_division.country $\rightarrow$ {Denmark} $\rightarrow$ location.location.containedby $\rightarrow$ {Eurasia} $\rightarrow$ location.location.contains $\rightarrow$ {Germany}, |
| {Lejre Municipality} $\rightarrow$ location.administrative_division.country $\rightarrow$ {Denmark} $\rightarrow$ base.locations.countries. continent $\rightarrow$ {Europe} $\rightarrow$ location.location.contains $\rightarrow$ {Western Europe} $\rightarrow$ location.location.contains $\rightarrow$ {Germany} | |
| PoG answer | answer: {Denmark} |
| reason: From {Denmark} $\rightarrow$ location.location.containedby $\rightarrow$ {Eurasia} $\rightarrow$ location.location.contains $\rightarrow$ {Germany}, Denmark is European Union country shares borders with ”Germany”. From {Lejre Municipality} $\rightarrow$ location.administrative_division.country $\rightarrow$ {Denmark}, Denmark is a country contains the Lejre Municipality Both paths lead to Denmark, which is the European Union country sharing borders with Germany and containing the Lejre Municipality. Therefore, the provided knowledge graph path is sufficient to answer the main question, and the answer is {Denmark}. | |
| Question | What Central Tiem Zone continent do the Falkland Islands belong to? |
| Answer | Americas |
| Topic Entity | {Falkland Islands, Continent, Central Time Zone} |
| LLM indicator | answer(” Central Time Zone ”) – owns - answer(” Continent ”)- located contain -” Falkland Islands ” |
| Split Question | split_question 1:What continent do the Falkland Islands belong to? |
| split_question 2: What Central Time Zone does the continent belong to? | |
| Reasoning Path | {Central Time Zone} $\rightarrow$ time.time_zone.locations_in_this_time_zone $\rightarrow$ {Americas} $\rightarrow$ common.topic.not able_types $\rightarrow$ {Continent} $\rightarrow$ common.topic. notable_types $\rightarrow$ {Americas} $\rightarrow$ location.location.con tains $\rightarrow$ { Falkland Islands} |
| PoG answer | answer: {Americas} |
| reason: From {Continent} $\rightarrow$ common.topic.notable_types $\rightarrow$ {Americas} $\rightarrow$ location.location. contains $\rightarrow$ { Falkland Islands}, Americas is the continent Falkland Islands belong to. From {Central Time Zone} $\rightarrow$ time.time_zone.locations_in_this_time_zone $\rightarrow$ {Americas} $\rightarrow$ common.topic. notable_types $\rightarrow$ {Continent}. Americas is the Central Time Zone. Therefore, the provided knowledge graph path is sufficient to answer the overall question, and the answer is {Americas}. | |
## Appendix C Experiment Details
Experiment datasets. To evaluate PoG’s capability in multi-hop knowledge-intensive reasoning tasks, we assess it on four KBQA datasets: three multi-hop datasets (CWQ (Talmor and Berant, 2018), WebQSP (Yih et al., 2016), GrailQA (Gu et al., 2021)) and one single-hop dataset (SimpleQuestions (Petrochuk and Zettlemoyer, 2018)). Additionally, to examine PoG on more general tasks, we include an open-domain QA dataset, WebQuestions. For the evaluation of large datasets such as CWQ, GrailQA, and SimpleQuestions, we utilize a random sample of 1,000 test cases from CWQ and employ the 1,000 samples previously reported by ToG (Sun et al., 2024) to facilitate a comparison with the SOTA while also minimizing computational costs. Freebase serves as the background knowledge graph for all datasets, which encompasses approximately 88 million entities, 20,000 relations, and 126 million triples (Luo et al., 2024; Bollacker et al., 2008). The statistics of the datasets utilized in this study are detailed in Table 10. The source code has been publicly available https://github.com/SteveTANTAN/PoG.
Baselines. Inspired by ToG (Sun et al., 2024), we compare our method with standard prompting (IO), Chain-of-Thought (CoT), and Self-Consistency (SC) promptings with six in-context exemplars and ”step-by-step” reasoning chains. For each dataset, we also include previous SOTA works for comparison. For a fair play, we compare with previous SOTA among all prompting-based methods and previous SOTA among all methods respectively. Since ToG is the current SOTA prompting-based method, we directly refer to their results and those of other baselines reported in their paper for comparisons.
Experimental implementation. Leveraging the plug-and-play convenience of our framework, we experiment with two LLMs: GPT-3.5 and GPT-4. We use the OpenAI API to access GPT-3.5 (GPT-3.5-turbo) and GPT-4. Aligning with ToG, we set the temperature parameter to 0.4 during the exploration process (to increase diversity) and to 0 during the reasoning process (to ensure reproducibility). The maximum token length for generation is set to 256. In all experiments, we set both $W_{\max}$ and $D_{\max}$ to 3 for beam search. All the experiments are conducted on a machine with Intel Xeon Gold 6248R CPU, Nvidia A5000 GPU and 512GB memory.
Table 10. Statistics of the datasets used in this paper. † denotes we randomly select 1,000 samples from the CWQ test set to create the experiment testing set due to the abundance of test samples. ∗ denotes that we utilize the 1,000 samples reported by ToG (Sun et al., 2024) to compare with the state-of-the-art.
| Dataset | Answer Format | Test | Train |
| --- | --- | --- | --- |
| ComplexWebQuestions (CWQ) † | Entity | 1,000 | 27,734 |
| WebQSP | Entity/Number | 1,639 | 3,098 |
| GrailQA ∗ | Entity/Number | 1,000 | 44,337 |
| Simple Question ∗ | Entity/Number | 1,000 | 14,894 |
| WebQuestions | Entity/Number | 2,032 | 3,778 |
## Appendix D SPARQL
This section outlines the pre-defined SPARQL queries used for interacting with the knowledge graph and constructing graphs for our experiments.
### D.1. 1-hop Entity and Relation Search
To facilitate the retrieval of 1-hop neighbors of entities within the Freebase Knowledge Graph, we have predefined a SPARQL query. This query is designed to be executed by simply substituting the appropriate ID for the query entity ID. It returns the connected entities’ IDs and their associated relations’ IDs, indicating whether the connected entity is at the tail or the head of the relation.
⬇
PREFIX ns: < http:// rdf. freebase. com / ns />
SELECT ? relation ? connectedEntity ? direction
WHERE {
{
ns: ID ? relation ? connectedEntity .
BIND ("tail" AS ? direction)
}
UNION
{
? connectedEntity ? relation ns: ID .
BIND ("head" AS ? direction)
}
}
### D.2. Short Textual Description
The following predefined function implements the retrieval of short textual descriptions, $\mathcal{D}(.)$ , for converting the identifiers (IDs) of entities or relations into natural language descriptions.
⬇
PREFIX ns: < http:// rdf. freebase. com / ns />
SELECT DISTINCT ? tailEntity
WHERE {
{
? entity ns: type. object. name ? tailEntity .
FILTER (? entity = ns: ID)
}
UNION
{
? entity < http:// www. w3. org /2002/07/ owlsameAs > ? tailEntity .
FILTER (? entity = ns: ID)
}
}
### D.3. 1-hop Subgraph Search
To facilitate subgraph detection in Section 4.1, we implement the 1-hop subgraph detection feature by integrating SPARQL functions described in Appendix D.1 and D.2. The purpose of this function is to retrieve, in a single SPARQL query, the 1-hop neighbors of a given query with their IDs, natural language names, and connected relationships, specifying whether the connected entity is at the tail or the head of the relationship.
⬇
PREFIX ns: < http:// rdf. freebase. com / ns />
SELECT ? relation ? connectedEntity ? connectedEntityName ? direction
WHERE {
{
ns: ID ? relation ? connectedEntity .
OPTIONAL {
? connectedEntity ns: type. object. name ? name .
FILTER (lang (? name) = ’ en ’)
}
BIND (COALESCE (? name, "Unnamed Entity") AS ? connectedEntityName)
BIND ("tail" AS ? direction)
}
UNION
{
? connectedEntity ? relation ns: ID .
OPTIONAL {
? connectedEntity ns: type. object. name ? name .
FILTER (lang (? name) = ’ en ’)
}
BIND (COALESCE (? name, "Unnamed Entity") AS ? connectedEntityName)
BIND ("head" AS ? direction)
}
}
## Appendix E Prompts
In this section, we detail the prompts required for our main experimental procedures.
Question Analysis Prompt Template
You will receive a multi-hop question, which is composed of several interconnected queries, along with a list of topic entities that serve as the main keywords for the question. Your task is to break the question into simpler parts, using each topic entity once and provide a Chain of Thought (CoT) that shows how the topic entities are related. Note: Each simpler question should explore how one topic entity connects to others or the answer. The goal is to systematically address each entity to derive the final answer. In-Context Few-shot Q: {Query} Topic Entity: {Topic Entity} A:
LLM Supplement Prompt Template
Using the main question, a possibly uncertain chain of thought generated by a language model, some related split questions, paths from the ”Related_paths” section, and main topic entities: please first provide three predicted results, and second offer three possible chains of thought that could lead to these results, using the provided knowledge paths and your own knowledge. If any answers are unclear, suggest alternative answers to fill in the gaps in the chains of thought, following the same format as the provided examples. In-Context Few-shot Q: {Query} Topic Entity: {Topic Entity} Think Indicator:{Think Indicator} Split Question:{Split Question} A:
where {Think Indicator}, and {Split Question} are obtained in section 4.1. An indicator example is shown in Figure 2.
Precise Path Select Prompt Template
Given a main question, a LLM-generated thinking Cot that considers all the entities, a few split questions that you can use one by one and finally obtain the final answer, and the associated retrieved knowledge graph path, {set of entities (with id start with ”m.”)} -¿ {set of relationships} -¿ {set of entities(with id start with ”m.”)}, Please score and give me the top three lists from the candidate paths set can be highly to be the answer of the question. In-Context Few-shot Q: {Query} Think Indicator:{Think Indicator} Split Question:{Split Question} Candidate Paths:{Candidate Paths} A:
{Candidate Paths} denotes the retrieved reasoning paths $Final_{p}aths$ to be selected in this request which are formatted as a series of structural sentences:
$\{e_{0x},...,e_{0z}\}\to r_{1_{i}}\to\{e_{1x},...,e_{1z}\}\to\dots$ $\to r_{l_{j}}\to\{e_{lx},...,e_{lz}\}$
$\dots$
$\{e_{0x},...,e_{0z}\}\to r_{1_{i}}\to\{e_{1x},...,e_{1z}\}\to\dots$ $\to r_{l_{j}}\to\{e_{lx},...,e_{lz}\}$ ,
where, $i$ and $j$ in $r_{1_{i}},r_{1_{i}}$ represent the $i$ -th, $j$ -th relation from each relation edge in the clustered question subgraph. And $e$ is constructed by its ID and natural language name $\mathcal{D}(ID)$ .
Path Summarizing Prompt Template
Given a main question, an uncertain LLM-generated thinking Cot that considers all the entities, a few split questions that you can use one by one and finally obtain the final answer, the associated accuracy retrieved knowledge paths from the Related paths section, and main topic entities. Your task is to summarize the provided knowledge triple in the Related paths section and generate a chain of thoughts by the knowledge triple related to the main topic entities of the question, which will used for generating the answer for the main question and split question further. You have to make sure you summarize correctly by using the provided knowledge triple, you can only use the entity with id from the given path and you can not skip in steps. In-Context Few-shot Q: {Query} Think Indicator:{Think Indicator} Split Question:{Split Question} Related Paths:{Related Paths} A:
{Related_Paths} has the same format with the {Candidate_Paths} before.
Question Answering Evaluation Prompt Template
Given a main question, an uncertain LLM-generated thinking Cot that considers all the entities, a few split questions that you can use and finally obtain the final answer, and the associated retrieved knowledge graph path, {set of entities (with id start with ”m.”)} -¿ {set of relationships} -¿ {set of entities(with id start with ”m.”)}. Your task is to determine if this knowledge graph path is sufficient to answer the given split question first then the main question. If it’s sufficient, you need to respond {Yes} and provide the answer to the main question. If the answer is obtained from the given knowledge path, it should be the entity name from the path. Otherwise, you need to response {No}, then explain the reason. In-Context Few-shot Q: {Query} Think Indicator:{Think Indicator} Split Question:{Split Question} Related Paths:{Related Paths} A:
Question Answering Generation Prompt Template
Given a main question, an uncertain LLM-generated thinking Cot that considers all the entities, a few split questions that you can use one by one and finally obtain the final answer, and the associated retrieved knowledge graph path, {set of entities (with id start with ”m.”)} -¿ {set of relationships} -¿ {set of entities(with id start with ”m.”)}, Your task is to generate the answer based on the given knowledge graph path and your own knowledge. In-Context Few-shot Q: {Query} Think Indicator:{Think Indicator} Split Question:{Split Question} Related Paths:{Related Paths} A: