# Fighting Spurious Correlations in Text Classification via a Causal Learning Perspective
**Authors**: Yuqing Zhou, Ziwei Zhu
> George Mason University Fairfax, VA, USA
## Abstract
In text classification tasks, models often rely on spurious correlations for predictions, incorrectly associating irrelevant features with the target labels. This issue limits the robustness and generalization of models, especially when faced with out-of-distribution data where such spurious correlations no longer hold. To address this challenge, we propose the Causally Calibrated Robust Classifier (CCR), which aims to reduce models’ reliance on spurious correlations and improve model robustness. Our approach integrates a causal feature selection method based on counterfactual reasoning, along with an unbiased inverse propensity weighting (IPW) loss function. By focusing on selecting causal features, we ensure that the model relies less on spurious features during prediction. We theoretically justify our approach and empirically show that CCR achieves state-of-the-art performance among methods without group labels, and in some cases, it can compete with the models that utilize group labels. Our code can be found at: https://github.com/yuqing-zhou/Causal-Learning-For-Robust-Classifier.
Fighting Spurious Correlations in Text Classification via a Causal Learning Perspective
## 1 Introduction
Despite their success on standard benchmarks, neural networks often struggle to generalize to out-of-distribution (OOD) data. A primary cause of this problem is their tendency to rely on features not causally related to tasks but holding spurious correlations to labels, which can reduce model robustness when the data distribution shifts Hovy and Søgaard (2015); Ribeiro et al. (2016); Tatman (2017); Buolamwini and Gebru (2018); Hashimoto et al. (2018). For example, in natural language inference (NLI) tasks, if contradictory sentences in a dataset frequently contain negation words, a model trained on this dataset might predict contradiction simply based on the presence of negation words rather than relying on the true underlying features. When encountering data where such spurious correlations do not hold, the model is likely to make incorrect predictions.
Prior works divide the data into different groups based on combinations of class labels and spurious features. The distribution of these groups is often unbalanced, and the correlation between labels and spurious features in the majority groups leads to spurious correlations. As a result, a model trained on such a dataset inevitably performs worse on the minority groups compared to the majority groups. Existing methods have focused on improving the worst-group accuracy. Some methods tackle this issue by utilizing group labels, which provide information about both the true labels and the spurious features Sagawa et al. (2019); Goel et al. (2020); Zhang et al. (2020); Idrissi et al. (2022). However, obtaining annotations for group labels is costly and not always feasible, limiting the utility and applicability of these methods.
Other approaches employ a two-stage process, where group labels are first inferred, followed by an adjustment of the loss function based on this inferred information. Examples include reweighting samples Liu et al. (2021); Qiu et al. (2023) or incorporating supervised contrastive loss Zhang et al. (2022). However, these methods attempt to calibrate the model learning process by only adjusting the loss function and hope the model’s over-reliance on spurious features can be alleviated. The effects are indirect and limited. A more direct and effective approach would involve modifying the model architecture itself to explicitly identify causal features and filter out spurious ones.
Existing works show that models trained using standard Empirical Risk Minimization (ERM) can learn high-quality representations of both spurious and causal features Kirichenko et al. (2022); Izmailov et al. (2022). Therefore, our goal is to encourage models to rely more on causal features than spurious ones. We propose a method, Causally Calibrated Robust Classifier (CCR), to identify causal feature representations through counterfactual reasoning. Specifically, we first disentangle the representation vector from the model’s last layer and then construct counterfactual representation vectors. We adapt causal inference theory Pearl (2009) to calculate the probabilities of necessity and sufficiency for each feature within the representation vector and the entire representation. By retraining the last layer to maximize the probability of necessity and sufficiency of the overall feature representation, the model is guided to assign higher weights to causal features, ultimately relying more on these features. Additionally, we derive a theoretically unbiased loss function based on inverse propensity weighting (IPW), further enhancing the model’s robustness to spurious correlations.
Our contributions are summarized as follows:
1. We integrate causal inference theory into feature representation selection by calculating the probabilities of necessity and sufficiency (PNS) for each feature, and propose a method that enhances the weights of causal features in model predictions through counterfactual reasoning by maximizing the PNS for the entire representation vector.
2. We derive a general unbiased loss function with the inverse propensity weighting (IPW) and find that existing methods, which reweight samples to mitigate the effects of spurious correlations, are in fact variants of this unbiased loss function.
3. We propose a Causally Calibrated Robust Classifier (CCR) for text classification tasks that combines causal feature selection with unbiased IPW loss, without the need for group label annotations of training datasets.
4. Comparing our methods CCR with standard ERM, JTT Liu et al. (2021), and AFR Qiu et al. (2023) on 4 text classification tasks with varying spurious correlations, the proposed method achieves superior performance on most tasks and even outperforms methods that rely on full group labels Sagawa et al. (2019); Kirichenko et al. (2022).
## 2 Method
In this paper, we focus on the impact of spurious correlations on transformer-based text classifiers and aim to enhance their robustness. While implemented on BERT Devlin et al. (2018), our method can be generalized to other models as well.
Our method, CCR, consists of two stages. In stage 1, we apply standard ERM with a covariance matrix regularization to disentangle the representations in the model’s last layer, ensuring each feature representation is independent. In stage 2, we retrain the last layer to encourage the model to rely on causal features by introducing a sample-wise causal constraint based on counterfactual representation vectors. Additionally, we reweight each sample’s loss in stage 2 to achieve an unbiased loss, ensuring accurate causal feature selection.
### 2.1 Problem Formulation
In text classification tasks, models are trained to assign a label $y\in\mathcal{Y}$ (such as sentiment, topic, and intent) to a given input text. Transformer-based models, such as BERT, encode the original text input into a fixed-dimensional embedding, regarded as hidden features of the text input. Among these features, some are causally related to the true label, referred to as causal features, while others may be coincidentally correlated with the label, referred to as spurious features. These spurious features do not have a causal connection to the label but can mislead the model. Although models trained by standard ERM can rely on spurious correlation, existing works show that they learn high-quality representations of both causal and spurious features Kirichenko et al. (2022).
We use capital letters ${\bf X}$ , ${\bf S}$ , and ${\bf Y}$ to denote the variable of causal features, spurious features, and labels, respectively, and ${\bf x}$ , ${\bf s}$ , and $y$ represent their values. Then a text dataset of N samples can be denoted as $D=\{({\bf x}_{0},{\bf s}_{0},y_{0}),...,({\bf x}_{N-1},{\bf s}_{N-1},y_{N-1})\}$ . For simplicity, we assume ${\bf s}_{i}\in\{{\bf s}^{0},{\bf s}^{1}\}$ where ${\bf s}^{0}$ and ${\bf s}^{1}$ represent two distinct spurious features. Then, the dataset $D$ can be divided into groups based on the different combinations of ${\bf S}$ , and ${\bf Y}$ . For example, in a binary classification task, the dataset would be divided into four groups: $D_{0,0}=\{({\bf x}_{i},{\bf s}^{0},y^{0})\}$ , $D_{0,1}=\{({\bf x}_{i},{\bf s}^{1},y^{0})\}$ , $D_{1,0}=\{({\bf x}_{i},{\bf s}^{0},y^{1})\}$ , and $D_{1,1}=\{({\bf x}_{i},{\bf s}^{0},y^{1})\}$ , where $y^{0}$ and $y^{1}$ represent two classes. To avoid ambiguity, in the following text, we will refer to the input text features only as ${\bf x}$ and ${\bf s}$ , and use the term "features" exclusively to denote their representation vectors from the model’s last layer.
### 2.2 Automatic Causal Feature Selection
In this section, we introduce how to encourage the model to focus on causal features. This is achieved through structural modifications to the model, specifically by incorporating a counterfactual feature selection module, which helps the model prioritize features with true causal significance over those that are merely correlated.
Existing works show that the final layer of a classifier contains both high-quality representations of spurious and causal features Kirichenko et al. (2022); Izmailov et al. (2022). To disentangle these representations, we apply covariance matrix regularization Cogswell et al. (2015), aiming to maximize the independence of each feature in the final layer. This encourages the separation of spurious and causal features. Next, we conduct automatic causal feature selection on this disentangled feature layer using a counterfactual method. In the following section, we will provide a detailed explanation of this counterfactual approach.
#### 2.2.1 Probabilistic Causality: Necessity and Sufficiency of Features
To identify causal features, we will estimate the causality of each feature. To quantify this causality, we introduce the probability of necessity and sufficiency as a metric to estimate the causal effect of features on labels, based on the causation theory of Pearl (2009). First, we introduce the definitions of the probability of necessity and sufficiency using the counterfactuals. Let ${\bf E}$ denote the variable of the feature embedding (the last layer of the classifier) and ${\bf e}$ denote its value. Assume the feature embedding vector contains $h$ elements, each representing a feature. Additionally, we define a mask M for the embedding vector, with the same dimensions as ${\bf E}$ , where each element $\textbf{M}_{i}$ takes a value of $1$ or $0 0$ , representing whether a feature is selected ( $1$ means the corresponding feature is selected). Thus, the final picked feature representation vector for prediction can be expressed as $\tilde{\textbf{E}}=\textbf{E}\odot\textbf{M}$ , where $\odot$ denotes the element-wise multiplication.
Definition 1. Probability of Necessity (PN) for a single feature ${\bf E}_{j}$ .
$$
\displaystyle PN:=P(Y_{\textbf{M}_{j}\neq 1,\textbf{M}_{i\neq j}=\textbf{m}_{i
\neq j},(\textbf{X},\textbf{S})=(\textbf{x},\textbf{s})}\neq y| \displaystyle\quad\textbf{M}_{j}=1,\textbf{M}_{i\neq j}=\textbf{m}_{i\neq j},Y
=y,(\textbf{X},\textbf{S})=(\textbf{x},\textbf{s})) \tag{1}
$$
where $\textbf{M}_{j}=1$ indicates that ${\bf E}_{j}$ is selected and will contribute to the final prediction, while $\textbf{M}_{j}\neq 1$ indicates that it is not selected. Equation 1 represents the probability of $Y\neq y$ for the same input in the absence of the feature ${\bf E}_{j}$ , given that feature ${\bf E}_{j}$ exists and $Y=y$ in reality.
Definition 2. Probability of Sufficiency (PS) for a single feature ${\bf E}_{j}$ .
$$
\displaystyle PS:=P(Y_{\textbf{M}_{j}=1,\textbf{M}_{i\neq j}=\textbf{m}_{i\neq
j
},(\textbf{X},\textbf{S})=(\textbf{x},\textbf{s})}=y| \displaystyle\quad\textbf{M}_{j}\neq 1,\textbf{M}_{i\neq j}=\textbf{m}_{i\neq j
},Y\neq y,(\textbf{X},\textbf{S})=(\textbf{x},\textbf{s})) \tag{2}
$$
Equation 2 measures the contribution of the feature ${\bf E}_{j}$ to the prediction of $y$ for the input $(\textbf{x},\textbf{s})$ .
Definition 3. Probability of Necessity and Sufficiency (PNS) for a single feature $\textbf{E}_{j}$ .
$$
\displaystyle PNS:=P( \displaystyle Y_{\textbf{M}_{j}\neq 1,\textbf{M}_{i\neq j}=\textbf{m}_{i\neq j
},(\textbf{X},\textbf{S})=(\textbf{x},\textbf{s})}\neq y, \displaystyle Y_{\textbf{M}_{j}=1,\textbf{M}_{i\neq j}=\textbf{m}_{i\neq j},(
\textbf{X},\textbf{S})=(\textbf{x},\textbf{s})}=y) \tag{3}
$$
Equation 3 evaluates both the necessity and sufficiency of the feature ${\bf E}_{j}$ for the label $Y=y$ , given the input $(\textbf{x},\textbf{s})$ . If the feature ${\bf E}_{j}$ is a causal feature in this task, its $PNS$ should have a high value, and We aim to encourage the classifier’s final layer to assign a high weight to this feature.
Directly calculating Euqation 3 can be difficult. However, by applying and extending Theorem 9.2.10 of Pearl (2009) to a more general case, we can get a lower bound of PNS.
**Theorem 1**
*The lower bound of PNS for causal features is given as follows:
$$
\displaystyle PNS\geq \displaystyle\quad max[0,P(Y_{\textbf{M}_{j}=1,\textbf{M}_{i\neq j}=\textbf{m}
_{i\neq j},(\textbf{X},\textbf{S})=(\textbf{x},\textbf{s})}=y) \displaystyle\quad\quad\quad-P(Y_{\textbf{M}_{j}\neq 1,\textbf{M}_{i\neq j}=
\textbf{m}_{i\neq j},(\textbf{X},\textbf{S})=(\textbf{x},\textbf{s})}\neq y)] \tag{4}
$$*
We can achieve a higher $PNS$ for the feature ${\bf E}_{j}$ by maximizing this lower bound $\underline{PNS}$ . In practice, $P(Y_{\textbf{M}_{j}=1,\textbf{M}_{i\neq j}=\textbf{m}_{i\neq j},(\textbf{X}, \textbf{S})=(\textbf{x},\textbf{s})}=y)$ is estimated from the model’s output using the original feature vector, while $P(Y_{\textbf{M}_{j}\neq 1,\textbf{M}_{i\neq j}=\textbf{m}_{i\neq j},(\textbf{X },\textbf{S})=(\textbf{x},\textbf{s})}\neq y)$ is estimated using the model’s output based on the counterfactual feature vector.
#### 2.2.2 Causal Constraints with PNS
We introduce a module to generate the counterfactual feature vectors. Let M denote a mask with all values set to $1$ , except for one value set to $0 0$ . By $\tilde{\textbf{E}}=\textbf{E}\odot\textbf{M}$ with $\textbf{M}_{j}=0$ for each $j\in\{1,2,...,h\}$ , we create a counterfactual feature vector, a copy of ${\bf E}$ with the $j$ -th element discarded. This process produces $h$ counterfactual feature vectors.
Definition 4. Let $PNS_{j}$ denote the $PNS$ of the $j$ -th counterfactual feature vector. We define the total $PNS$ of the feature embedding vector ${\bf E}$ as follows:
$$
\displaystyle PNS=\prod_{j=1}^{h}PNS_{j} \tag{5}
$$
We take the mean of the negative log of Equation 5 as the causal constraint and incorporate it into the loss function, where $PNS_{j}$ is replaced by its lower bound. In this way, the final layer can be trained to rely more on causal features, i.e., the feature with higher $PNS$ values.
### 2.3 Unbiased Loss through IPW
Accurately selecting causal features requires an unbiased loss. To achieve this goal, we derive a reweighting method using inverse propensity weighting. Previous methods Liu et al. (2021); Qiu et al. (2023) that use heuristics for weight computation can be regarded as special implementations of our framework.
Assume we have a text classification dataset with $C$ classes $\{y^{1},y^{2},...,y^{C}\}$ and $K$ spurious features $\{{\bf s}^{1},...,{\bf s}^{K}\}$ . Then the dataset can be divided into $C*K$ groups, denoted as $D_{j,k}=\{(\textbf{x}_{i},\textbf{s}_{i},y_{i})|y_{i}=y^{j},\textbf{s}_{i}= \textbf{s}^{k})\}$ . In an ideal scenario, the size of group $D_{j,k}$ should be same for all $k=1,...,K,$ within the class $y^{j}$ , i.e., $|D_{j,k}|=|D_{j,t}|$ , $\forall k$ , $t\in\{1,..,K\}$ . In this case, the spurious features ${\bf s}$ are not correlated with the labels $y$ . An ideal loss function is as follows:
$$
\displaystyle L_{ideal}=\frac{1}{|D|}\sum_{j=1}^{C}\sum_{k=1}^{K}L_{D_{j,k}} \displaystyle=\frac{1}{|D|}\sum_{j=1}^{C}\sum_{k=1}^{K}\sum_{i=1}^{|D|}L(y_{i}
,f(\textbf{x}_{i},\textbf{s}_{i}))\mathbb{I}_{\{y_{i}=y^{j},\textbf{s}_{i}=
\textbf{s}^{k}\}}, \tag{6}
$$
where $L_{D_{j,k}}$ is the sum of the losses over all samples in the subset $D_{j,k}$ , $|D|$ is the size of the whole dataset $D$ , $L(y_{i},f(\textbf{x}_{i},\textbf{s}_{i}))$ is the loss on the $i$ -th sample, which will be simplified as $L_{i}$ in the following text. Additionally, $\mathbb{I}$ is an indicator function. $\mathbb{I}_{\{A\}}=1$ when $A$ is true. Ideally, all subgroups $D_{j,*}$ within the class $y^{j}$ contribute equally to the total loss. A classifier $f$ learned on this dataset would be robust and make predictions of $y$ solely based on x. However, in reality, the group distribution of a dataset $D^{\prime}$ is unbalanced, i.e., $\exists l$ , $|D^{{}^{\prime}}_{j,l}|\gg|D^{{}^{\prime}}_{j,k}|$ , $\forall k\neq l$ . In this case, we call $|D^{{}^{\prime}}_{j,k}|$ as the majority group when $k=l$ , and as the minority group otherwise. A classifier trained on such a dataset would falsely rely on the spurious correlation between $s^{l}$ and label $y^{j}$ leading to biased predictions.
We can assume that not all samples in the ideal datasets can be observed and the ratio of samples observed for different groups varies. We use the $\mathcal{O}$ to denote the observation of the whole ideal dataset $D$ and $o_{i}$ to denote the observation result for $i$ -th sample in the ideal dataset, where $o_{i}=1$ means the sample is in the reality dataset $D^{\prime}$ , and 0 means the sample is not in $D^{\prime}$ . The probability of $p(o_{i}=1)$ depends on its group membership, thus leading to an unbalanced dataset $D^{\prime}$ . We use $p_{j,k}(o=1)$ to represent the probability of a sample in $D_{j,k}$ being observed. The majority groups in $D^{{}^{\prime}}$ have a much larger $p_{j,k}$ than the minority group. With these notations, the actual loss is given by
$$
L_{real}=\frac{1}{|D|}\sum_{j=1}^{C}\sum_{k=1}^{K}\sum_{i=1}^{|D|}L_{i}\mathbb
{I}_{\{y_{i}=y^{j},\textbf{s}_{i}=\textbf{s}^{k}\}}\mathbb{I}_{\{o_{i}=1\}}, \tag{7}
$$
In this case,
$$
\displaystyle\mathbb{E}[L_{real}] \displaystyle=\frac{1}{|D|}\sum_{j=1}^{C}\sum_{k=1}^{K}\sum_{i=1}^{|D|}L_{i}
\mathbb{I}_{\{y_{i}=y^{j},\textbf{s}_{i}=\textbf{s}^{k}\}}p_{j,k}(o_{i}=1) \displaystyle\neq L_{ideal} \tag{8}
$$
i.e., $L_{real}$ is biased.
To achieve an unbiased loss on an unbalanced dataset, the key is to balance the weights of the majority and minority groups in the final loss function. This can be achieved by normalizing the losses for each subset and averaging their contributions across the groups. The loss function is defined as
$$
\displaystyle L \displaystyle=\frac{1}{|D^{{}^{\prime}}|}\sum_{j=1}^{C}\frac{|D_{j}^{{}^{
\prime}}|}{K}\sum_{k=1}^{K}\frac{L_{D^{{}^{\prime}}_{j,k}}}{|D^{{}^{\prime}}_{
j,k}|} \displaystyle=\frac{1}{|D^{{}^{\prime}}|}\sum_{j=1}^{C}\frac{1}{K}\sum_{k=1}^{
K}\frac{L_{D^{{}^{\prime}}_{j,k}}}{\frac{|D^{{}^{\prime}}_{j,k}|}{|D_{j}^{{}^{
\prime}}|}} \tag{9}
$$
where $D^{{}^{\prime}}_{j}=\cup_{k=1}^{K}D^{{}^{\prime}}_{j,k}$ and $D^{{}^{\prime}}=\cup_{j=1}^{C}D^{{}^{\prime}}_{j}$ . Here, the normalization ensures that within each group $D^{{}^{\prime}}_{j}$ , the contributions from subsets $D^{{}^{\prime}}_{j,k}$ for $k=1,...,K$ are equal, leading to a more equitable contribution to the overall loss. When the dataset is large enough, we can get
$$
\displaystyle p({\bf S}={\bf s}^{k}|Y=y^{j})=\frac{|D^{{}^{\prime}}_{j,k}|}{|D
^{{}^{\prime}}_{j}|}, \tag{10}
$$
which is a propensity for a sample with label $j$ to contain the spurious feature ${\bf s}^{k}$ . This suggests that the Equation 9 can be expressed in the following form:
$$
\displaystyle L \displaystyle=\frac{1}{K*|D|}\sum_{j=1}^{C}\sum_{k=1}^{K}\sum_{i=1}^{|D|}\frac
{L_{i}\mathbb{I}_{\{y_{i}=y^{j},\textbf{s}_{i}=\textbf{s}^{k}\}}\mathbb{I}_{\{
o_{i}=1\}}}{p({\bf s}^{k}|Y=y^{j})} \tag{11}
$$
As we have no knowledge of group information, so the true $p({\bf s}^{k}|Y=y^{j})$ is unknown. However, if we can find a way to get its estimation $\hat{p}$ , then we can get the following loss function:
$$
\displaystyle L_{IPW} \displaystyle=\frac{1}{|D|}\sum_{j=1}^{C}\sum_{k=1}^{K}\sum_{i=1}^{|D|}\frac{L
_{i}\mathbb{I}_{\{y_{i}=y^{j},\textbf{s}_{i}=\textbf{s}^{k}\}}\mathbb{I}_{\{o_
{i}=1\}}}{K*\hat{p}({\bf s}^{k}|Y=y^{j})} \tag{12}
$$
The expectation of $L_{IPW}$ is given as follows:
$$
\displaystyle\mathbb{E}[L_{IPW}] \displaystyle=\frac{1}{|D|}\sum_{j=1}^{C}\sum_{k=1}^{K}\sum_{i=1}^{N}\frac{L_{
i}\mathbb{I}_{\{y_{i}=y^{j},\textbf{s}_{i}=\textbf{s}^{k}\}}\mathbb{E}[\mathbb
{I}_{\{o_{i}=1\}}]}{K*\hat{p}({\bf s}^{k}|Y=y^{j})} \displaystyle=\frac{1}{|D|}\sum_{j=1}^{C}\sum_{k=1}^{K}\sum_{i=1}^{N}\frac{L_{
i}\mathbb{I}_{\{y_{i}=y^{j},\textbf{s}_{i}=\textbf{s}^{k}\}}p(o_{i}=1)}{K*\hat
{p}({\bf s}^{k}|Y=y^{j})} \tag{13}
$$
When $\hat{p}({\bf s}^{k}|y^{j})=\frac{p_{j,k}(o=1)}{K}$ , $\mathbb{E}[L_{IPW}]=L_{ideal}$ , which is unbiased. It demonstrates that we can get the unbiased loss function through inverse propensity weighting (IPW). The state-of-the-art robust methods JTT Liu et al. (2021) and AFR Qiu et al. (2023) can be considered as special implementations of $L_{IPW}$ , which rely on different heuristics for estimating $\hat{p}({\bf s}^{k}|y^{j})$ .
Our estimation of $\hat{p}({\bf s}^{k}|y^{j})$ is based on the performance of the first-stage model. For each class, we treat the samples correctly classified by the first-stage model as the major groups (e.g., $(\textbf{s}^{1},y^{1})$ and $(\textbf{s}^{2},y^{2})$ ), while the misclassified samples are taken as minor groups (e.g., $(\textbf{s}^{2},y^{1})$ and $(\textbf{s}^{1},y^{2})$ ). This process divides the dataset into $2C$ groups, and we use each group’s proportion to the whole dataset as the estimated $\hat{p}({\bf s}^{k}|y^{j})$ .
### 2.4 Training Framework
The overall training process is as follows.
Stage 1. A linear layer is introduced to the pretrained model, with input dimensions $h$ (a hyperparameter, representing the number of features) and output dimensions corresponding to the number of classes. The model is then finetuned using ERM, combining cross-entropy loss with covariance matrix regularization on the feature vectors. This process encourages the model to learn an effective feature extractor, which will be frozen in stage 2, and ensures that the final feature vector consists of $h$ disentangled and independent features.
Stage 2. We freeze all layers of the model except the last one, taking the frozen layers as a fixed feature extractor, while retraining only the last layer in this stage. Before retraining, we evaluate the model’s performance on the training set, identifying the correctly and incorrectly classified samples within each class. Based on this, we estimate the data groups and calculate their ratios as the estimated propensities, which are used to assign weights to each group. Then, we finetune the last layer according to the following loss function:
$$
\displaystyle L=\frac{1}{|D^{{}^{\prime}}|}\sum_{i=1}^{|D^{{}^{\prime}}|}\frac
{1}{\hat{p}}( \displaystyle CE(y_{i},f({\bf x}_{i},{\bf s}_{i})- \displaystyle\lambda*\frac{1}{h}\sum_{j=1}^{h}\log\underline{PNS}_{j}) \tag{14}
$$
where the $\lambda$ is the coefficient of causality constraints.
## 3 Experiments
In this section, we investigate the effect of CCR through three research questions. RQ1: What is the performance of CCR compared with other state-of-the-art methods on the text classification benchmarks? RQ2: How is the contribution of each component of CCR to the model’s robustness? RQ3: What is the effect of causal feature selection under different hyperparameters?
### 3.1 Experiments Setup
#### 3.1.1 Datasets
We evaluate our method, CCR, on two real-world datasets, CivilComments Borkan et al. (2019) and MultiNLI Williams et al. (2017), following previous works Liu et al. (2021); Qiu et al. (2023). Additionally, we use two semi-synthetic datasets, which are real-world datasets manually introduced with spurious correlations: the Yelp dataset Zhang et al. (2015) with author style shortcuts Zhou et al. (2024) and the Beer dataset Bao et al. (2018) with concept occurrence shortcuts Zhou et al. (2024). These four datasets cover four types of spurious correlations Zhou et al. (2024).
CivilComments Borkan et al. (2019) is a text classification dataset, where the target is to classify a comment as "toxic" or "not toxic". The WILDS benchmark Koh et al. (2021) provides a version of CivilComments that contains spurious correlations between the label "toxic" and some sensitive characteristics such as gender and race, which are used in our experiments. These words describing sensitive characteristics such as gender (male, female) construct a category-word shortcut.
MultiNLI Williams et al. (2018) is designed for the task of natural language inference, where each sample contains sentence pairs labeled with one of three categories that describe the relationship between the sentences: entailment, contradiction, or neutral. In this dataset, spurious correlations exist between the label "contradiction" and negation words, which lead to a synonym shortcut.
Yelp review dataset Zhang et al. (2015) consists of review-rating pairs from Yelp, with ratings ranging from $1$ to $5$ . Zhou et al. (2024) constructed a Yelp-Author-Style dataset based on the Yelp reviews, where each review is rewritten in the distinct styles of different authors (Shakespeare and Hemingway) according to the ratings. We adapt this multiclass classification task into a binary classification task by selecting reviews with ratings of $2$ and $4$ , where lower ratings are correlated with Hemingway’s style and higher ratings with Shakespeare’s style.
Beer-Concept-Occurrence dataset Zhou et al. (2024) consists of review-rating pairs about beer, where each sample contains two parts—one for the palate review (the target) and another representing a spurious feature (comments on either "aroma" or "appearance"). Comments on the appearance of the beer are correlated with lower palate ratings, while comments on the aroma are correlated with higher ratings.
#### 3.1.2 Model and Baselines
Model.
Following the settings in AFR Qiu et al. (2023), we use the pretrained model "bert-base-uncased" Devlin et al. (2018) for the text classification tasks. The hyperparameter settings are provided in Table 5 of Appendix A.1.
Baselines.
In our experiments, we primarily focus on the following three baselines, which do not require group labels: standard ERM Liu et al. (2021), JTT Liu et al. (2021), and AFR Qiu et al. (2023). JTT trains two models: the first model is trained via standard ERM, while the second model is trained by upweighting the samples misclassified by the first model. AFR also trains twice but on the same model: it retrains the last layer of a standard ERM-trained model by upweighting the samples on which the model previously performed poorly.
Additionally, we compare the performance against two baselines that rely on group labels: Group-DRO Sagawa et al. (2019), which minimizes the loss of the worst group while applying an additional penalty based on group size to avoid overfitting, and DFR Kirichenko et al. (2022), which is similar to AFR but retrains the last layer on a small dataset with group labels.
### 3.2 Strong Group Robustness of CCR (RQ1)
We evaluate CCR on four benchmarks, measuring both overall accuracy and worst-group accuracy (WGA), with the results presented in Table 1. Compared to other state-of-the-art robust methods that do not require group labels, CCR achieves the highest WGA across all four datasets, demonstrating strong robustness to spurious correlations. Specifically, CCR achieves the best performance in terms of both mean accuracy over the entire test dataset and WGA on Yelp-Author-Style, improving WGA by $3\$ and mean accuracy by $0.5\$ , while on Beer-Concept-Occurrence, its mean accuracy is only $0.2\$ lower than the highest recorded performance. This performance shows that CCR can improve the WGA without sacrificing the overall performance, suggesting its effect on helping the model mitigate the reliance on spurious correlations and utilize causal features.
Furthermore, we compare CCR with two state-of-the-art (SOTA) methods, Group-DRO and DFR, which utilize group labels. As shown in Table 2, CCR achieves comparable performance without the need for group labels in the training data, and even slightly outperforms Group-DRO and DFR on CivilComments, achieving SOTA WGA and a $1\$ improvement in mean accuracy. It also surpasses DFR in terms of WGA on MultiNLI.
| Datasets | CivilComments | MultiNLI | Yelp-Author-Style | Beer-Concept-Occur | | | | |
| --- | --- | --- | --- | --- | --- | --- | --- | --- |
| Methods | Mean | WGA | Mean | WGA | Mean | WGA | Mean | WGA |
| ERM | 0.9260 | 0.5740 | 0.8240 | 0.6790 | 0.9200 | 0.8500 | 0.9538 | 0.9000 |
| JTT | 0.9110 | 0.6930 | 0.7860 | 0.7260 | 0.9210 | 0.8583 | 0.9554 | 0.9000 |
| AFR | 0.8980 | 0.6870 | 0.8140 | 0.7340 | 0.9205 | 0.8542 | 0.9506 | 0.9200 |
| CCR (ours) | 0.9000 | 0.7067 | 0.8072 | 0.7517 | 0.9260 | 0.8874 | 0.9530 | 0.9304 |
Table 1: Comparisons of different methods that do not need group labels. We report both the overall mean accuracy and the worst-group accuracy (WGA). The results for ERM, JTT, and AFR on the CivilComments and MultiNLI datasets are sourced from Qiu et al. (2023). We implement ERM, JTT, and AFR on the Yelp-Author-Style and Beer-Concept-Occurrence datasets.
| Methods | Mean | WGA | Mean | WGA |
| --- | --- | --- | --- | --- |
| Group-DRO | 0.889 | 0.699 | 0.814 | 0.777 |
| DFR | 0.872 | 0.701 | 0.821 | 0.747 |
| CCR(ours) | 0.900 | 0.707 | 0.807 | 0.752 |
Table 2: Comparing CCR with the methods need group labels. The results for Group-DRO and DFR are sourced from Qiu et al. (2023).
### 3.3 Ablation Study (RQ2)
After showing the effect of CCR on improving model robustness, we aim to understand how each component of CCR contributes to the overall performance. Using the Yelp-Author-Style dataset, we investigate the impact of the following operations: feature representation disentanglement, causal feature constraints (CFC) for causal feature selection (CFS), and loss debiasing with inverse propensity weighting (IPW). The results are shown in Table 3 and we have the following observations from it:
First, representation disentanglement, causal feature selection (CFS), and loss debiasing with IPW all contribute to improving the model’s robustness compared to standard ERM, although the improvements are subtle. CFS alone increases WGA by only $0.8\$ , but when combined with feature disentanglement, it achieves a $2\$ improvement in WGA. This suggests that disentangling spurious and causal features as much as possible is essential. If these features are entangled, it may diminish the evaluation of each feature’s necessity and sufficiency to labels, limiting the effectiveness of CFS.
Second, CFS and IPW all get more than $1\$ improvement in WGA by combining with disentanglement. Meanwhile, disentanglement alone can improve the WGA of ERM by $1.6\$ , outperforming CFS and IPW. These results suggest that disentanglement may transform the input features into a more effective representation space, which CFS and IPW can leverage to enhance performance.
Third, while both CFS and IPW individually enhance the model’s robustness, their combination is the most effective. After disentanglement, the joint effect of CFS and IPW improves both the mean accuracy and WGA of the model, even increasing WGA by approximately $4\$ .
Additionally, we explore three different approaches for propensity estimation in IPW: one proposed by us and two others derived from AFR and JTT’s methods for calculating weights. Our method involves counting the samples correctly and incorrectly classified by the first-stage model within each class, then using the inverse of their ratio as the weights, normalized across the entire training dataset. All three methods show similar performance.
| ERM disentangle CFS | 0.9200 0.9235 0.9210 | 0.8500 0.8658 0.8583 |
| --- | --- | --- |
| IPW | 0.9210 | 0.8571 |
| disentangle + CFS | 0.9235 | 0.8701 |
| disentangle + IPW | 0.9245 | 0.8701 |
| disentangle + CFS + IPW (ours) | 0.9260 | 0.8874 |
| disentangle + CFS + IPW (AFR) | 0.9265 | 0.8916 |
| disentangle + CFS + IPW (JTT) | 0.9250 | 0.8831 |
Table 3: Comparisons of the effect of each component in CCR on the Yelp-Author-Style dataset. For simplicity, we omit ERM from each row. CFS refers to the module for causal feature selection. IPW (ours) represents our proposed method for obtaining weights, while IPW (AFR) and IPW (JTT) use the weight calculation algorithms from AFR Qiu et al. (2023) and JTT Liu et al. (2021), respectively.
### 3.4 Hyperparameter Study (RQ3)
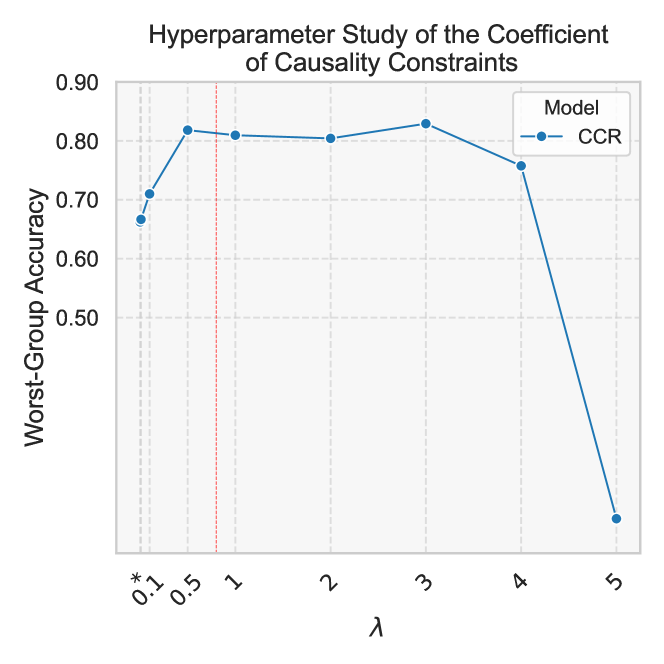
In this section, we investigate the effect of the causality constraint coefficient $\lambda$ in Equation 14 on model performance. Specifically, we aim to investigate how much emphasis should be placed on the PNS of the feature representation in the final loss function for optimal performance. The experiment results on the Yelp-Author-Style dataset are shown in Figure 1. From Figure 1, we can see that as $\lambda$ increases from $0.001$ to $0.5$ , WGA increases gradually. However, adding more PNS constraints does not necessarily lead to better performance. As $\lambda$ increases from $0.5$ to $3$ , WGA fluctuates slightly, reaching its peak at $\lambda=3$ , but gradually decreases as $\lambda$ increases further.
<details>
<summary>x1.png Details</summary>
### Visual Description
\n
## Line Chart: Hyperparameter Study of the Coefficient of Causality Constraints
### Overview
This image presents a line chart illustrating the relationship between a hyperparameter (λ - lambda) and Worst-Group Accuracy. The chart appears to be evaluating the performance of a model (CCR) across a range of lambda values. A vertical dashed line at λ = 1 may indicate a significant threshold or point of interest.
### Components/Axes
* **Title:** "Hyperparameter Study of the Coefficient of Causality Constraints" (Top-center)
* **X-axis:** λ (lambda) - ranging from 0.1 to 5, with markers at 0.1, 0.5, 1, 2, 3, 4, and 5.
* **Y-axis:** Worst-Group Accuracy - ranging from 0.5 to 0.9, with markers at 0.5, 0.6, 0.7, 0.8, and 0.9.
* **Legend:** Located in the top-right corner.
* Model: CCR (represented by a blue dashed line with circular markers)
* **Vertical Dashed Line:** Located at λ = 1.
### Detailed Analysis
The chart displays a single data series representing the CCR model. The line begins at approximately 0.68 accuracy at λ = 0.1.
* **λ = 0.1:** Accuracy ≈ 0.68 (± 0.02)
* **λ = 0.5:** Accuracy ≈ 0.81 (± 0.02)
* **λ = 1:** Accuracy ≈ 0.82 (± 0.02) - This is the peak accuracy.
* **λ = 2:** Accuracy ≈ 0.81 (± 0.02)
* **λ = 3:** Accuracy ≈ 0.81 (± 0.02)
* **λ = 4:** Accuracy ≈ 0.74 (± 0.02)
* **λ = 5:** Accuracy ≈ 0.45 (± 0.02) - A significant drop in accuracy.
The line initially increases rapidly from λ = 0.1 to λ = 0.5, then plateaus between λ = 0.5 and λ = 3, and finally declines sharply from λ = 4 to λ = 5.
### Key Observations
* The model performs best around λ = 1, achieving a peak accuracy of approximately 0.82.
* Accuracy decreases significantly as λ exceeds 4.
* The vertical dashed line at λ = 1 may indicate an optimal hyperparameter value.
* The initial increase in accuracy suggests that increasing lambda up to a certain point improves performance.
* The subsequent decrease suggests that excessively high lambda values may lead to overfitting or other issues.
### Interpretation
The data suggests that the coefficient of causality constraints (λ) has a significant impact on the Worst-Group Accuracy of the CCR model. There appears to be an optimal value for λ, around 1, where the model achieves its highest performance. Beyond this point, increasing λ leads to a decline in accuracy, potentially due to overfitting or the introduction of excessive constraints. The initial increase in accuracy indicates that incorporating causality constraints up to a certain level is beneficial. The sharp drop at λ = 5 suggests that the model becomes unstable or loses its ability to generalize when the constraints are too strong. This study highlights the importance of hyperparameter tuning in machine learning and the need to find a balance between model complexity and generalization ability. The vertical line at λ = 1 could be a suggested default value for this hyperparameter.
</details>
Figure 1: Study on the effect of different coefficients for causality constraints in CFS.( $*$ = 0.001)
### 3.5 Analyzing Model Behavior Through Explainability
In Section 3.2, we demonstrated that CCR improves model robustness against spurious correlations. In this section, we further explore model behavior through explainability techniques. We use the SHAP Lundberg and Lee (2017) analysis tool to examine how classifiers rely on specific tokens for their predictions.
We use the Beer-Concept-Occurrence dataset as an example, where descriptions of beer appearance are correlated with low palate ratings, while descriptions of beer aroma are associated with high palate ratings. We sampled 200 test instances and computed the average SHAP absolute values for the spurious features (i.e., comments on beer appearance and aroma). Table 4 shows the SHAP analysis results for each method. The SHAP absolute value quantifies a token’s influence on the model’s prediction for the corresponding label. For the spurious features, SHAP values closer to zero indicate less reliance on these features by the model. Although the task is relatively straightforward and all methods yield low SHAP values, we observe that CCR’s SHAP values for spurious features are significantly lower than those of other methods—approximately an order of magnitude lower—demonstrating strong robustness and effectively reducing reliance on spurious features in predictions. Besides, we provide an example of SHAP analysis in Appendix A.2.
| ERM JTT AFR | 1.63E-3 3.10E-3 1.47E-3 | 1.54E-3 2.54E-3 1.47E-3 |
| --- | --- | --- |
| CCR (Ours) | 1.85E-4 | 1.85E-4 |
Table 4: SHAP values different methods
## 4 Related Work
Spurious correlations challenge the robustness of machine learning models trained via ERM, especially when there are shifts between the training and test data distribution Hovy and Søgaard (2015); Ribeiro et al. (2016); Tatman (2017); Buolamwini and Gebru (2018); Hashimoto et al. (2018).
Sagawa et al. (2019) addresses this problem by training a classifier via a regularized group distributionally robust optimization (Group-DRO) method, which minimizes the loss of the worst-case group. This approach is to train the entire model. In contrast, some methods propose that simply retraining the last layer of an ERM-trained model can effectively improve robustness. For example, DFR Kirichenko et al. (2022) retrain the last layer of the model trained via ERM on a small dataset where the spurious correlations break. However, both Sagawa et al. (2019) and Kirichenko et al. (2022) require prior knowledge of spurious correlations to define groups in the training data, making it costly and limiting its ability to generalize to unseen spurious attributes. Some methods upweight samples during retraining where the initially trained model performs poorly Liu et al. (2021); Qiu et al. (2023). Another approach uses contrastive learning to improve robustness by aligning same-class representations and separating misclassified negatives, allowing the model to learn similar representations of same-class samples and ignore spurious attributes Zhang et al. (2022). These methods do not require prior knowledge of group labels. All these approaches focus on reducing spurious correlations by modifying the loss function, while our method tackles the underlying issue by directly identifying causal features using a counterfactual feature generation module.
Our method for identifying causal features is based on the theorem of probability of necessity and sufficiency from causality theory Pearl (2009). A related work also applies this theory Zhang et al. (2023), but their goal is to identify minimal tokens in input text that lead to correct predictions. In contrast, our approach operates on feature representations within the model to identify causal features, aiming to build a robust classifier that performs well across varying data distributions.
## 5 Conclusion
In this paper, we address the problem of models relying on spurious correlations in their predictions, particularly in text classification tasks. To mitigate this issue, we propose the Causally Calibrated Robust Classifier (CCR). Specifically, we introduce a causal feature selection model based on counterfactual reasoning, combined with an unbiased inverse propensity weighting (IPW) loss function. We provide theoretical justification for our method and empirically demonstrate that it achieves state-of-the-art performance among approaches that do not require group labels, and in some cases, it can even compete with models that utilize group labels.
## 6 Limitations
Apart from the contributions mentioned in the paper, there are still some limitations of this work.
First, the loss debiasing relies on the quality of the estimation of the propensity $\hat{p}$ . If $\hat{p}$ is not accurately estimated, the loss function may still exhibit bias. Improving the estimation method could lead to enhanced performance.
Second, our experiments showed that the optimal feature embedding size varies across datasets, with different sizes yielding the best results. Identifying the appropriate embedding size is important for effectively separating irrelevant features from causal features.
Additionally, we did not explore alternative disentanglement methods, which may improve feature representation. Better disentanglement could lead to more effective causal feature selection and ultimately enhance model performance.
## Acknowledgements
This work was partially supported by resources provided by the Office of Research Computing at George Mason University (URL: https://orc.gmu.edu) and funded in part by grants from the Commonwealth Cyber Initiative.
## Ethics Statement
Our research complies with ethical standards, utilizing publicly available datasets. All contents in the datasets do NOT represent the authors’ views.
## References
- Bao et al. (2018) Yujia Bao, Shiyu Chang, Mo Yu, and Regina Barzilay. 2018. Deriving machine attention from human rationales. arXiv preprint arXiv:1808.09367.
- Borkan et al. (2019) Daniel Borkan, Lucas Dixon, Jeffrey Sorensen, Nithum Thain, and Lucy Vasserman. 2019. Nuanced metrics for measuring unintended bias with real data for text classification. In Companion proceedings of the 2019 world wide web conference, pages 491–500.
- Buolamwini and Gebru (2018) Joy Buolamwini and Timnit Gebru. 2018. Gender shades: Intersectional accuracy disparities in commercial gender classification. In Conference on fairness, accountability and transparency, pages 77–91. PMLR.
- Cogswell et al. (2015) Michael Cogswell, Faruk Ahmed, Ross Girshick, Larry Zitnick, and Dhruv Batra. 2015. Reducing overfitting in deep networks by decorrelating representations. arXiv preprint arXiv:1511.06068.
- Devlin et al. (2018) Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2018. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805.
- Goel et al. (2020) Karan Goel, Albert Gu, Yixuan Li, and Christopher Ré. 2020. Model patching: Closing the subgroup performance gap with data augmentation. arXiv preprint arXiv:2008.06775.
- Hashimoto et al. (2018) Tatsunori Hashimoto, Megha Srivastava, Hongseok Namkoong, and Percy Liang. 2018. Fairness without demographics in repeated loss minimization. In International Conference on Machine Learning, pages 1929–1938. PMLR.
- Hovy and Søgaard (2015) Dirk Hovy and Anders Søgaard. 2015. Tagging performance correlates with author age. In Proceedings of the 53rd annual meeting of the Association for Computational Linguistics and the 7th international joint conference on natural language processing (volume 2: Short papers), pages 483–488.
- Idrissi et al. (2022) Badr Youbi Idrissi, Martin Arjovsky, Mohammad Pezeshki, and David Lopez-Paz. 2022. Simple data balancing achieves competitive worst-group-accuracy. In Conference on Causal Learning and Reasoning, pages 336–351. PMLR.
- Izmailov et al. (2022) Pavel Izmailov, Polina Kirichenko, Nate Gruver, and Andrew G Wilson. 2022. On feature learning in the presence of spurious correlations. Advances in Neural Information Processing Systems, 35:38516–38532.
- Kirichenko et al. (2022) Polina Kirichenko, Pavel Izmailov, and Andrew Gordon Wilson. 2022. Last layer re-training is sufficient for robustness to spurious correlations. arXiv preprint arXiv:2204.02937.
- Koh et al. (2021) Pang Wei Koh, Shiori Sagawa, Henrik Marklund, Sang Michael Xie, Marvin Zhang, Akshay Balsubramani, Weihua Hu, Michihiro Yasunaga, Richard Lanas Phillips, Irena Gao, et al. 2021. Wilds: A benchmark of in-the-wild distribution shifts. In International conference on machine learning, pages 5637–5664. PMLR.
- Liu et al. (2021) Evan Z Liu, Behzad Haghgoo, Annie S Chen, Aditi Raghunathan, Pang Wei Koh, Shiori Sagawa, Percy Liang, and Chelsea Finn. 2021. Just train twice: Improving group robustness without training group information. In International Conference on Machine Learning, pages 6781–6792. PMLR.
- Lundberg and Lee (2017) Scott M Lundberg and Su-In Lee. 2017. A unified approach to interpreting model predictions. Advances in neural information processing systems, 30.
- Pearl (2009) J Pearl. 2009. Causality. Cambridge university press.
- Qiu et al. (2023) Shikai Qiu, Andres Potapczynski, Pavel Izmailov, and Andrew Gordon Wilson. 2023. Simple and fast group robustness by automatic feature reweighting. In International Conference on Machine Learning, pages 28448–28467. PMLR.
- Ribeiro et al. (2016) Marco Tulio Ribeiro, Sameer Singh, and Carlos Guestrin. 2016. " why should i trust you?" explaining the predictions of any classifier. In Proceedings of the 22nd ACM SIGKDD international conference on knowledge discovery and data mining, pages 1135–1144.
- Sagawa et al. (2019) Shiori Sagawa, Pang Wei Koh, Tatsunori B Hashimoto, and Percy Liang. 2019. Distributionally robust neural networks for group shifts: On the importance of regularization for worst-case generalization. arXiv preprint arXiv:1911.08731.
- Tatman (2017) Rachael Tatman. 2017. Gender and dialect bias in youtube’s automatic captions. In Proceedings of the first ACL workshop on ethics in natural language processing, pages 53–59.
- Williams et al. (2018) Adina Williams, Nikita Nangia, and Samuel Bowman. 2018. A broad-coverage challenge corpus for sentence understanding through inference. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers), pages 1112–1122. Association for Computational Linguistics.
- Williams et al. (2017) Adina Williams, Nikita Nangia, and Samuel R Bowman. 2017. A broad-coverage challenge corpus for sentence understanding through inference. arXiv preprint arXiv:1704.05426.
- Zhang et al. (2020) Jingzhao Zhang, Aditya Menon, Andreas Veit, Srinadh Bhojanapalli, Sanjiv Kumar, and Suvrit Sra. 2020. Coping with label shift via distributionally robust optimisation. arXiv preprint arXiv:2010.12230.
- Zhang et al. (2022) Michael Zhang, Nimit S Sohoni, Hongyang R Zhang, Chelsea Finn, and Christopher Ré. 2022. Correct-n-contrast: A contrastive approach for improving robustness to spurious correlations. arXiv preprint arXiv:2203.01517.
- Zhang et al. (2023) Wenbo Zhang, Tong Wu, Yunlong Wang, Yong Cai, and Hengrui Cai. 2023. Towards trustworthy explanation: On causal rationalization. In Proceedings of the 40th International Conference on Machine Learning, volume 202 of Proceedings of Machine Learning Research, pages 41715–41736. PMLR.
- Zhang et al. (2015) Xiang Zhang, Junbo Zhao, and Yann LeCun. 2015. Character-level convolutional networks for text classification. Advances in neural information processing systems, 28.
- Zhou et al. (2024) Yuqing Zhou, Ruixiang Tang, Ziyu Yao, and Ziwei Zhu. 2024. Navigating the shortcut maze: A comprehensive analysis of shortcut learning in text classification by language models. arXiv preprint arXiv:2409.17455.
## Appendix A Appendix
### A.1 Experiment Setup
The reported performance was achieved using the settings outlined in Table 5. All experiments were conducted once, with a fixed random seed to ensure reproducibility. The pre-trained model, ’bert-base-uncased,’ consists of approximately 110M parameters. The statistics for each dataset are provided in Table 6. Each experiment can be completed within 24 hours on a single A100 GPU.
| Datasets Coefficient for disentanglement Coefficient for causal constraints | CivilComments 0.5 0.1 | MultiNLI 0.5 2 | Yelp-Author-Style 0.5 3 | Beer-Concept-Occurrence 0.5 2 |
| --- | --- | --- | --- | --- |
| Learning rate | 2.00E-02 | 2.00E-01 | 3.00E-03 | 3.00E-02 |
| Weight decay | 0 | 0 | 1.00E-04 | 1.00E-04 |
| Batch size | 32 | 32 | 32 | 32 |
| Size of Feature Embedding | 128 | 128 | 128 | 150 |
| Epoch | 15 | 10 | 30 | 30 |
| Seed | 42 | 42 | 42 | 42 |
Table 5: The hyperparameter settings for each dataset.
### A.2 Explainability Analysis
Figure 2 presents a review of beer palate labeled as $0 0$ (corresponding to a $0.6$ palate rating), along with the behaviors of models trained using standard ERM and CCR in predicting this label. In the ERM model, there is a strong reliance on the words that describe "appearance" (e.g., "appearance" and "golden"). These words show high SHAP values (highlighted in red), indicating that the model attributes significant importance to these terms when predicting a label of $0 0$ . In contrast, the CCR model exhibits much lower SHAP values for the same appearance-related terms, indicating that CCR has successfully reduced the model’s reliance on the spurious correlation between appearance-related features and label $0 0$ . The SHAP values in the CCR model are closer to neutral (around zero), showing that the model is less biased toward irrelevant features and more robust to spurious correlations compared to the standard ERM model.
<details>
<summary>x2.png Details</summary>

### Visual Description
\n
## SHAP Value Visualization: Feature Importance
### Overview
The image presents a visualization of SHAP (SHapley Additive exPlanations) values for two features, "ERM" and "CCR", related to a model output. The visualization displays the impact of each feature on the model's prediction, along with the feature's descriptive text. The SHAP values are color-coded to indicate positive or negative impacts.
### Components/Axes
* **Features:** ERM (top), CCR (bottom)
* **SHAP Value Scale:** Ranges from approximately -3 to +3 for ERM, and -0.5 to +0.5 for CCR. The scale is represented by a color gradient on the right side of the image.
* **Color Legend:**
* Red: Positive SHAP value (increases model output)
* Blue: Negative SHAP value (decreases model output)
* White: SHAP value close to zero (little impact)
* **Feature Descriptions:** Textual descriptions associated with each feature.
* **Numerical Values:** Two numerical values are displayed above each feature description.
### Detailed Analysis or Content Details
**ERM:**
* Numerical Values: 0.985 and 0.484
* Description: "appearance: goldenwith a nice amount of head that stays with it until the last drink . lowish carbonation and a light , smooth mouthfeel ."
* SHAP Value Indication: The text "smooth" is highlighted in blue, suggesting a negative impact on the model output. The overall SHAP value for ERM appears to be positive, indicated by the predominantly red color in the surrounding area (though not explicitly shown).
**CCR:**
* Numerical Values: 0.195 and 0.068
* Description: "appearance: goldenwith a nice amount of head that stays with it until the last drink . lowish carbonation and a light , smooth mouthfeel ."
* SHAP Value Indication: The text "smooth" is highlighted in blue, suggesting a negative impact on the model output. The overall SHAP value for CCR appears to be slightly positive, indicated by the light red color in the surrounding area (though not explicitly shown).
### Key Observations
* Both features share the same descriptive text.
* The term "smooth" consistently appears to have a negative impact on the model output, as indicated by the blue highlighting.
* ERM has a significantly larger range of SHAP values compared to CCR, suggesting it has a more substantial impact on the model's predictions.
* The numerical values (0.985, 0.484 for ERM and 0.195, 0.068 for CCR) are not directly explained in the context of SHAP values, but may represent some form of feature importance or contribution.
### Interpretation
This visualization aims to explain how the features "ERM" and "CCR" contribute to the model's predictions. The SHAP values quantify the impact of each feature, indicating whether it increases or decreases the model's output. The consistent negative impact of "smooth" suggests that the model associates this characteristic with a lower prediction value. The larger SHAP value range for ERM implies that this feature is more influential in determining the model's output than CCR. The numerical values provided alongside each feature may represent the magnitude of the feature's contribution or its overall importance within the dataset. The identical descriptions for both features suggest they are closely related or potentially redundant, and the model may be treating them similarly.
</details>
Figure 2: SHAP Analysis for BERT with ERM and CCR
| CivilComments | 0 | 0 | (no identities, non-toxic) | 148486 |
| --- | --- | --- | --- | --- |
| 1 | 0 | (has identities, non-toxic) | 90337 | |
| 2 | 1 | (no identities, toxic) | 12731 | |
| 3 | 1 | (hasidentities, toxic) | 17784 | |
| MultiNLI | 0 | 0 | (no negations, contradiction) | 57498 |
| 1 | 0 | (has negations, contradiction) | 11158 | |
| 2 | 1 | (no negations, entailment) | 67376 | |
| 3 | 1 | (has negations, entailment) | 1521 | |
| 4 | 2 | (no negations, neutral) | 66630 | |
| 5 | 2 | (has negations, neutral) | 1992 | |
| Yelp-Author-Style | 0 | 0 | (Hemingway’s Style, Rating 2) | 684 |
| 1 | 0 | (Shakespeare’s Style, Rating 2) | 214 | |
| 2 | 1 | (Hemingway’s Style, Rating 4) | 252 | |
| 3 | 1 | (Shakespeare’s Style, Rating 4) | 660 | |
| Beer-Concept-Style | 0 | 0 | (Comments on Appearance , Rating 0.6) | 477 |
| 1 | 0 | (Comments on Aroma, Rating 0.6) | 261 | |
| 2 | 1 | (Comments on Appearance, Rating 1.0) | 65 | |
| 3 | 1 | (Comments on Aroma, Rating 1.0) | 432 | |
Table 6: The statistics of each dataset. The statistics for CivilComments and MultiNLI are sourced from Qiu et al. (2023).