# Competence-Aware AI Agents with Metacognition for Unknown Situations and Environments (MUSE)
**Authors**: Rodolfo Valiente, Praveen K. Pilly
Abstract
Metacognition, defined as the awareness and regulation of one’s cognitive processes, is central to human adaptability in unknown situations. In contrast, current autonomous agents often struggle in novel environments due to their limited capacity for adaptation. We hypothesize that metacognition is a critical missing ingredient in autonomous agents for the cognitive flexibility needed to tackle unfamiliar challenges. Given the broad scope of metacognitive abilities, we focus on competence awareness and strategy selection. To this end, we propose the Metacognition for Unknown Situations and Environments (MUSE) framework to integrate metacognitive processes of self-assessment and self-regulation into autonomous agents. We present two implementations of MUSE: one based on world modeling and another leveraging large language models (LLMs). Our system continually learns to assess its competence on a given task and uses this self-assessment to guide iterative cycles of strategy selection. MUSE agents demonstrate high competence awareness and significant improvements in self-regulation for solving novel, out-of-distribution tasks more effectively compared to model-based reinforcement learning and purely prompt-based LLM agent approaches. This work highlights the promise of approaches inspired by cognitive and neural systems in enabling autonomous agents to adapt to new environments while mitigating the heavy reliance on extensive training data and large models for the current models.
keywords: Agentic AI , Large Language Model , Metacognition , Reinforcement Learning , Self-Assessment , Self-Regulation , World Model
\NewColumnType
L[1]Q[l,#1] \NewColumnType C[1]Q[c,#1] \NewColumnType R[1]Q[r,#1]
Intelligent Systems Center
1 Introduction
The pursuit of fully autonomous agents in artificial intelligence (AI) remains a significant challenge. Current autonomous agents are primarily designed for operating environments, conditions, and uses that are known a priori. They rely on either scripted behaviors or pre-trained policies, both of which struggle to handle unknown situations effectively. As a result, when faced with novelty, they are prone to fail with suboptimal or even catastrophic outcomes (e.g., robotic manipulation errors in unstructured settings). This limitation severely restricts their deployment in safety-critical unknown environments, especially for long-duration missions or applications with little to no human oversight. Therefore, there is a practical urgency to reduce the failure rate, time to completion, and cost of autonomous missions by enabling resilient handling of unknowns during deployment.
In mainstream AI, large-scale multi-task pre-training has emerged as the leading approach for enhancing adaptability in autonomous agents (Team et al., 2021). For example, Adaptive Agent (AdA) (Team et al., 2023) was trained with billions of frames and tasks to enable rapid adaptation to unseen, open-ended tasks. Similarly, the RT-2 (Brohan et al., 2023) and RT-X (Collaboration et al., 2023) models leverage large-scale robotic trajectory datasets to train agents capable of solving novel manipulation tasks and generalizing to new robots and environments. However, internet-scale pre-training to be able to handle every potential change and combination of changes in real-world applications is impractical, prohibitively resource-intensive, and expensive. Even with significantly limited data, AI agents must intelligently interpolate and extrapolate beyond their pre-trained scenarios while continually learning and adapting to novelty (Kudithipudi et al., 2023). In other words, when faced with novel scenarios, pre-trained knowledge must be continually updated to strike a dynamic balance between stability and plasticity (Grossberg, 1980).
Similar to humans, AI agents can leverage pre-deployment training to acquire a wide range of skills across diverse, known scenarios. Importantly, they can also be equipped with the ability to engage in online learning for continual improvement when encountering novel situations. For example, a teenager attending driving school follows a structured curriculum that teaches foundational vehicle control skills, which are then progressively built upon to master more complex tasks, such as merging onto highways or navigating construction zones. This learning process is cumulative in the sense that mastery of foundational skills simplifies the acquisition of more advanced ones. Moreover, the key principles of driving are consolidated in the student’s brain, protecting them from catastrophic forgetting. Ultimately, the end of driving school marks the beginning of a lifelong learning process, where the student draws on prior experiences to navigate novel driving challenges independently without an instructor.
Metacognition, defined as the awareness and regulation of one’s cognitive processes, is a key human trait that has been extensively studied in cognitive psychology (Flavell, 1979; Nelson and Narens, 1990; Metcalfe et al., 1993; Koriat, 1997; Dunlosky and Metcalfe, 2008). This metacognitive flexibility enables humans to learn online efficiently and solve problems iteratively, especially in relation to new tasks. For instance, students can leverage metacognition to more accurately assess their knowledge and adjust their study habits accordingly (Cohen, 2012; Chen et al., 2017). The use of metacognition among college students has indeed been shown to correlate significantly with various measures of academic success (Young and Fry, 2008; Isaacson and Fujita, 2006). Students who perform poorly often overestimate their abilities, leading to under-preparation for exams. This is a common issue in education, where overconfident students allocate insufficient time to study, believing they have already mastered the material. Conversely, students who underestimate their knowledge may spend excessive time reviewing topics they already understand, hindering their progress. Even children as young as three years old can become effective learners and thinkers from activities designed to develop metacognitive skills (Chatzipanteli et al., 2014). It is generally agreed that self-assessment of competence, which can range from over-confidence in novices to slight under-confidence in experts (Kruger and Dunning, 1999; Dunning, 2011), is a capability that is teachable and improves naturally as one becomes more skilled or knowledgeable (Kramarski and Mevarech, 2003; Schraw et al., 2006). Neuroscience further reveals that the subregions of the prefrontal cortex responsible for metacognitive judgments are distinct from those involved in cognitive functions like visual memory recognition, such that the metacognitive function can be selectively deactivated without affecting the cognitive function (e.g., Middlebrooks et al. (2012); Miyamoto et al. (2017)).
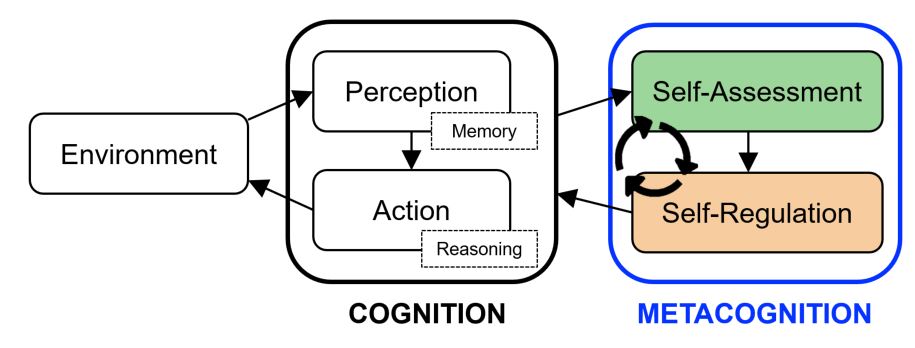
While metacognition spans a wide range of capabilities and higher-order cognitive processes (e.g., Feeling of Knowing, Judgment of Learning, Source Monitoring), it can be conceptualized as an internal perception-action loop of self-assessment and self-regulation (Nelson and Narens, 1990; Dunlosky and Bjork, 2013). Self-assessment in this context refers to an individual’s ability to assess their competence regarding a specific task. Self-regulation refers to the ability to strategically select and control one’s actions based on this self-assessment. In this article, we introduce the Metacognition for Unknown Situations and Environments (MUSE) framework to computationally instantiate and train the metacognitive capabilities of self-assessment and self-regulation for AI agents, so that they can also achieve more efficient learning and improved generalization to unknown scenarios (Figure 1). Specifically, the self-assessment mechanism is designed to predict the agent’s likelihood of successfully completing a given task for proposed action plans, with a learnable internal model informed by past experiences. And the self-regulation mechanism leverages this self-assessment to enable iterative cycles of competence-aware strategy selection for problem-solving. We present two implementations of the MUSE agent: one based on world modeling and the other utilizing large language models (LLMs). Our experiments in two distinct environments (namely, Meta-World and ALFWorld) demonstrate that MUSE agents achieve substantial improvements in handling novel scenarios compared to baseline/non-metacognitive approaches. Further, we show that metacognition makes a particularly big impact on smaller or less-capable LLM agents, making them amenable to edge deployment as well as less reliant on big data for online adaptation.
<details>
<summary>figures/metacognitive_cycle.png Details</summary>
### Visual Description
## Cognitive Process Diagram: Cognition and Metacognition
### Overview
The image is a diagram illustrating the relationship between cognition and metacognition. It depicts a flow of information and processes, starting from the environment, moving through perception and action within cognition, and then into self-assessment and self-regulation within metacognition.
### Components/Axes
* **Environment:** A rounded rectangle on the left, representing the external environment.
* **Cognition:** A larger rounded rectangle encompassing "Perception" and "Action".
* **Perception:** A rounded rectangle inside the Cognition box.
* **Memory:** A dashed rectangle connected to Perception.
* **Action:** A rounded rectangle inside the Cognition box, below Perception.
* **Reasoning:** A dashed rectangle connected to Action.
* **Metacognition:** A rounded rectangle on the right, encompassing "Self-Assessment" and "Self-Regulation".
* **Self-Assessment:** A green rounded rectangle inside the Metacognition box.
* **Self-Regulation:** An orange rounded rectangle inside the Metacognition box, below Self-Assessment.
* **Arrows:** Arrows indicate the flow of information and processes.
### Detailed Analysis or ### Content Details
1. **Environment** to **Cognition**: An arrow points from the "Environment" box to both "Perception" and "Action" within the "Cognition" box.
2. **Perception** to **Action**: An arrow points from "Perception" to "Action".
3. **Cognition** to **Metacognition**: An arrow points from "Action" to both "Self-Assessment" and "Self-Regulation" within the "Metacognition" box.
4. **Self-Assessment** to **Self-Regulation**: An arrow points from "Self-Assessment" to "Self-Regulation".
5. **Self-Regulation** to **Self-Assessment**: A curved arrow points from "Self-Regulation" back to "Self-Assessment", indicating a feedback loop.
### Key Observations
* The diagram highlights a hierarchical structure, with the environment influencing cognition, and cognition influencing metacognition.
* Metacognition involves a feedback loop between self-assessment and self-regulation.
* Memory is associated with perception, and reasoning is associated with action.
### Interpretation
The diagram illustrates a model of cognitive processing where the environment provides input that is processed through perception and action. This cognitive processing then informs metacognitive processes of self-assessment and self-regulation. The feedback loop between self-assessment and self-regulation suggests a continuous process of monitoring and adjusting one's own cognitive processes. The association of memory with perception and reasoning with action suggests that these cognitive functions play a crucial role in these processes.
```
</details>
Figure 1: The metacognitive cycle of self-assessment and self-regulation operates on the traditional perception-action loop of existing AI agents to boost their ability for iterative problem-solving in unknown situations and environments.
In contrast to current reinforcement learning (RL) approaches (e.g., Silver et al. (2016, 2017, 2018); Ha and Schmidhuber (2018); Hafner et al. (2023)), which focus on maximizing expected cumulative reward, our MUSE framework prioritizes competence as the primary evaluation metric to enhance the agent’s adaptability to unknown situations. We hypothesize that focusing solely on maximizing return may cause an agent to become stuck in unfamiliar situations, particularly under sparse reward regimes. By contrast, maximizing competence continually for strategy selection encourages more effective exploration in such novel environments. Through metacognition, the agent can evaluate its capabilities and attempt new strategies within its perceived competence, enabling safer and more effective online adaptation. In other words, by maximizing competence, the agent not only improves its ability to tackle immediate challenges more effectively but also fosters iterative problem-solving in complex environments.
The contributions of our article are threefold:
- We introduce the Metacognition for Unknown Situations and Environments (MUSE) framework, which integrates metacognitive functions of self-assessment and self-regulation into sequential decision-making agents.
- We propose an implementation of a competence awareness model that continually learns to assess the agent’s competence on a given task and serves as an evaluation function for planning (Self-Assessment).
- We propose an implementation of a policy modulation model that leverages self-assessment to iteratively drive strategy selection by identifying action plans that maximize the likelihood of task success (Self-Regulation).
2 Related Work
2.1 Self-Assessment
Self-assessment broadly refers to an agent’s ability to monitor its internal states and assess its capabilities and performance in relation to tasks and goals. It enables humans to reflect and make adjustments for improving outcomes (Flavell, 1979; Nelson and Narens, 1990; Schraw, 1998).
World Models: These are generative models of environmental dynamics (Ha and Schmidhuber, 2018; Robine et al., 2023; Micheli et al., 2023; Hansen et al., 2022, 2023), which can be used to estimate the expected cumulative reward of agents. These models often employ sequence-based architectures, such as recurrent neural networks, to predict the next state, reward, and terminal signals. Decoder-based World Models (Hafner et al., 2023; Robine et al., 2023; Micheli et al., 2023) can additionally generate the input state corresponding to the predicted next state. In contrast, decoder-free World Models focus on predicting the outcomes of actions in the latent space, bypassing the need to decode input states (Hansen et al., 2022, 2023). World Models act as proxy simulators during training, enabling agents to learn more efficiently by reducing the reliance on real-environment interactions (e.g., Ha and Schmidhuber (2018); Koul et al. (2020); Hafner et al. (2023)). In this work, we extend the capabilities of decoder-based World Models by training them to predict not only environmental dynamics but also the agent’s competence to solve a given task.
LLM Critics: These models are designed to evaluate the performance of LLMs. The LLM itself can be prompted to provide feedback on its outputs (Madaan et al., 2023), intermediate reasoning steps (Paul et al., 2023), or even the prompt itself (Hu et al., 2023). Some approaches enhance the correctness and quality of LLM outputs by using stochastic beam search guided by self-evaluation (Xie et al., 2023). Recognizing that LLMs currently are limited in identifying their own errors, reasoning missteps, or biases (Huang et al., 2023), researchers have augmented LLM critics with external tools, such as search engines and calculators, to improve reliability (Gou et al., 2023). Retrieval Augmented Generation (RAG) approaches have also been proposed to strengthen self-evaluation by providing relevant external knowledge bases (Asai et al., 2023). In contrast, MUSE does not rely solely on pre-trained knowledge or external tools. Instead, it continually learns and grounds itself to evaluate its competence on given tasks and uses this kind of self-assessment to modulate policy decisions.
Confidence Networks: Recent work in cognitive computational neuroscience has developed quantitative frameworks for assessing metacognitive judgments related to self-assessment across a range of domains, task difficulties, and time scales with and without external feedback (Fleming, 2024; Lu et al., 2025). Measures that have been proposed and utilized to assess metacognition include the statistical correlation between self-reported confidence ratings and actual performance across trials as well as the more reliable meta- d’ metric, which measures the ability of self-assessment to discriminate between high-performance (correct) and low-performance (incorrect) trials without being affected by response bias in metacognitive judgments (Maniscalco and Lau, 2012; Fleming and Lau, 2014).
Consistent with these measures of metacognition, there is prior work in machine learning aimed at self-assessment of deep neural networks that perform perception tasks. For classification, Corbiere et al. (2019) trained a separate neural network (called ConfidNet) that operates on high-level features extracted by the classifier to predict the true class probability (TCP), which is the softmax probability of the correct class irrespective of whether it was chosen or not. Further, Webb et al. (2023) trained confidence networks for a variety of perception tasks to instead predict the probability of the decision being correct, i.e., a value of 1 if correct and 0 otherwise. They also trained a RL agent that chooses among perception labels as well as an opt-out action that earns a low-risk low-reward in situations when the agent is least certain about its decision. These self-assessment metrics themselves are task-agnostic (Fleming, 2024) but require a training scheme that is adapted to the specifics of the task. In this regard, one of our contributions is to implement a global self-assessment metric for artificial agents that predicts the probability of task success in each episode over time.
2.2 Self-Regulation
Self-regulation is the process by which an agent dynamically adjusts its behavior based on self-assessment to achieve specific goals (Flavell, 1979; Nelson and Narens, 1990). This ability is essential for humans to exhibit robust decision-making and function autonomously in unfamiliar environments.
Model-based Reinforcement Learning (MBRL) Agents: These agents utilize World Models to simulate future scenarios, enabling them to train with minimal real interactions with the environment (Moerland et al., 2023). Dyna (Sutton, 1991) is a foundational architecture that integrates learning and planning within a single agent. Its core idea is to use the agent’s real experiences to update not only its policy but also its internal model of the environment, and thereby leverage the updated internal model to further improve the policy offline using simulated experiences. Among recent leading ones, AlphaGo (Silver et al., 2016), AlphaZero (Silver et al., 2017), and MuZero (Silver et al., 2018) are all MBRL systems that employ internal simulations/models and Monte Carlo Tree Search (MCTS) to explore potential action paths, based on variations of the Upper Confidence Bound (UCB) score, and evaluate them for action selection. In contrast to MBRL agents, which prioritize maximizing expected cumulative reward, the self-regulation mechanism of MUSE leverages competence as the primary evaluation metric to enhance the agent’s ability to navigate and adapt effectively in unknown situations.
Prompt-based LLM Agents: The capabilities of LLMs extend beyond language generation, making them increasingly popular for reasoning tasks to potentially deal with novelty. Chain-of-Thought (CoT) prompting (Wei et al., 2022), for example, decomposes a complex problem into intermediate steps to arrive at a final answer. However, CoT reasoning struggles to yield accurate results due to error propagation as the number of steps increases (Chen et al., 2022). Techniques such as self-consistency (Wang et al., 2022), least-to-most prompting (Zhou et al., 2022), and Tree-of-Thought (ToT) prompting (Yao et al., 2024) aim to mitigate this issue by improving sampling strategies and leveraging search algorithms. Nevertheless, these methods rely solely on the LLM’s pre-trained knowledge, which limits their ability to adapt to external feedback.
Beyond reasoning tasks, LLMs are also being increasingly applied to operate in an agentic loop of perception and action, which unlocks the benefits of large-scale pre-training for multi-step interactive tasks without relying on RL. ReAct (Yao et al., 2022) was among the first purely prompt-based LLM agents that integrated both reasoning and action planning to perform text-based problem-solving. However, ReAct is inefficient and limited in its ability to transfer performance improvements to subsequent episodes. To address this issue, Reflexion (Shinn et al., 2023) built on ReAct by adding an LLM critic that reflects on failures and provides persistent verbal feedback to the agent for improved performance in subsequent episodes. The performance gains from these LLM agent methods are solely dependent on enhanced prompt-based in-context learning, which limits their ability for longer-term true learning from new varied experiences. While MUSE also makes use of prompting for both reasoning and planning, it can also continually learn from its experiences to facilitate more effective problem-solving in unknown situations and environments.
3 Decoder-based World Model implementation
In this section, we describe our implementation of the MUSE framework using a decoder-based World Model to equip MBRL agents with metacognitive abilities of self-assessment and self-regulation.
3.1 Methods
3.1.1 Self-Assessment through World Modeling
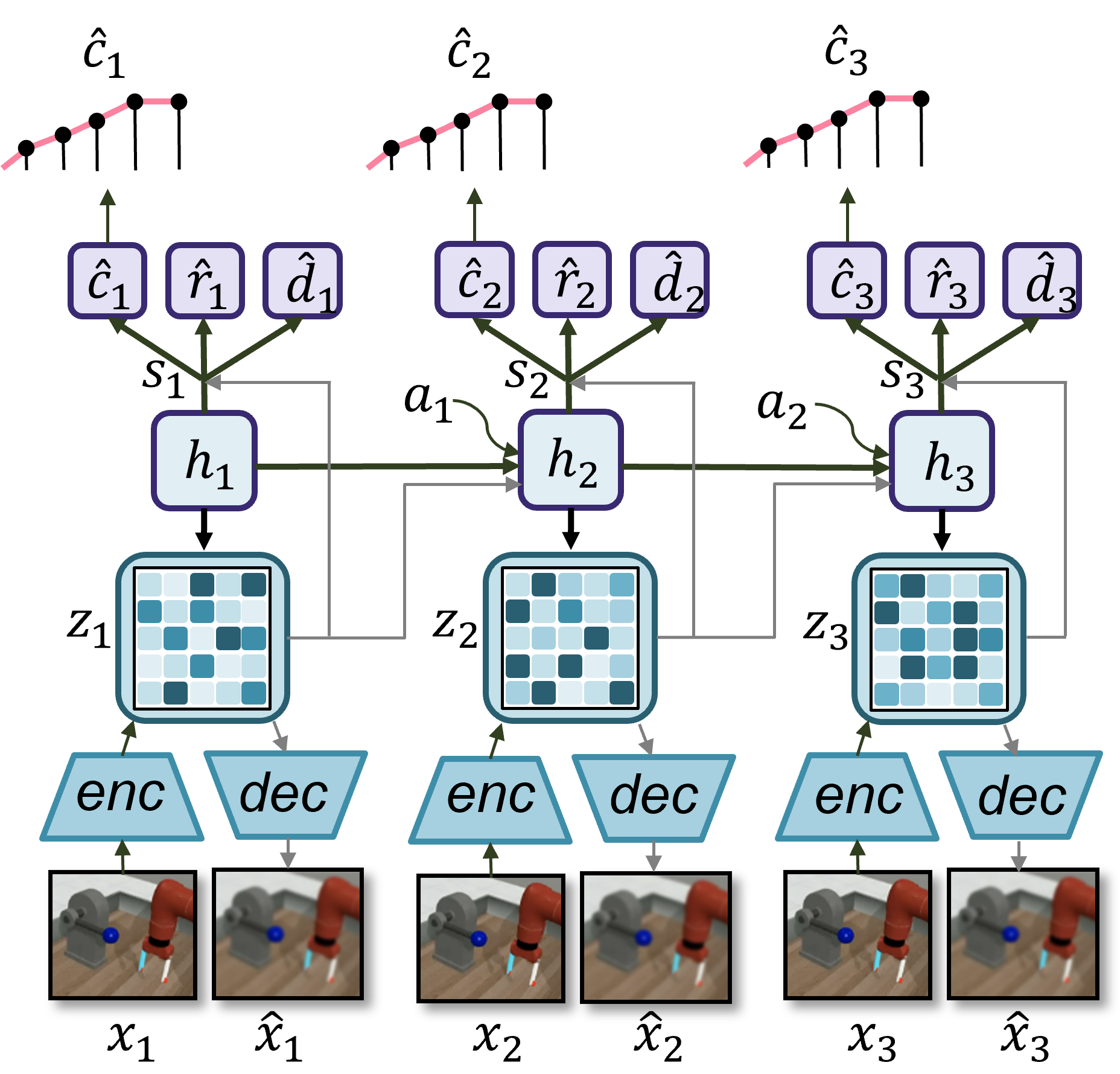
We leverage the decoder-based World Model from Dreamer-v3 (Hafner et al., 2023) to implement self-assessment for agents, but we note that our approach can be extended to decoder-free World Models as well. Dreamer-v3 uses a Recurrent State-Space Model (RSSM) to model the environment dynamics. See Equations 1 - 3 for the formulation from Hafner et al. (2023). The RSSM maps the input state $x_{t}$ and recurrent state $h_{t}$ to a latent embedding $z_{t}$ and uses the concatenation of $h_{t}$ and $z_{t}$ , called the RSSM state, as input to parameterize various distributions over the reward $\hat{r}_{t}$ , terminal signal $\hat{d}_{t}$ , and decoded state $\hat{x}_{t}$ .
$$
\displaystyle\begin{aligned} \begin{aligned} \raisebox{8.39578pt}{\hbox to0.0pt{\hss\vbox to0.0pt{\hbox{$\text{RSSM}\hskip 4.30554pt\begin{cases}\hphantom{A}\\
\hphantom{A}\\
\hphantom{A}\end{cases}\hskip-10.33327pt$}\vss}}}&\text{Sequence model:}\hskip 35.00005pt&&h_{t}&\ =&\ f_{\phi}(h_{t-1},z_{t-1},a_{t-1})\\
&\text{Encoder:}\hskip 35.00005pt&&z_{t}&\ \sim&\ q_{\phi}(z_{t}\;|\;h_{t},x_{t})\\
&\text{Dynamics predictor:}\hskip 35.00005pt&&\hat{z}_{t}&\ \sim&\ p_{\phi}(\hat{z}_{t}\;|\;h_{t})\\
&\text{Reward predictor:}\hskip 35.00005pt&&\hat{r}_{t}&\ \sim&\ p_{\phi}(\hat{r}_{t}\;|\;h_{t},z_{t})\\
&\text{Terminal signal predictor:}\hskip 35.00005pt&&\hat{d}_{t}&\ \sim&\ p_{\phi}(\hat{d}_{t}\;|\;h_{t},z_{t})\\
&\text{Decoder:}\hskip 35.00005pt&&\hat{x}_{t}&\ \sim&\ p_{\phi}(\hat{x}_{t}\;|\;h_{t},z_{t})\end{aligned}\end{aligned} \tag{1}
$$
ifnextchar
gobble
Following Hafner et al. (2023), given a sequential batch of inputs $x_{1:T}$ , actions $a_{1:T}$ , rewards $r_{1:T}$ , and terminal signals $d_{1:T}$ , the World Model parameters $\phi$ are optimized to minimize the prediction loss $\mathcal{L}_{\mathrm{pred}}$ , the dynamics loss $\mathcal{L}_{\mathrm{dyn}}$ , and the representation loss $\mathcal{L}_{\mathrm{rep}}$ . The prediction loss $\mathcal{L}_{\mathrm{pred}}$ is the joint negative log-likelihood of the multiple probabilistic predictors (Equation 3). Real-valued quantities like the reward and decoded state are trained with a symlog squared loss, whereas the terminal signal, which is a binary-valued quantity, is trained with logistic regression. The dynamics loss $\mathcal{L}_{\mathrm{dyn}}$ and the representation loss $\mathcal{L}_{\mathrm{rep}}$ are designed to effectively learn the dynamics of the latent embeddings for generating realistic rollout trajectories.
$$
\displaystyle\begin{aligned} \mathcal{L}(\phi)\doteq\operatorname{E}_{q_{\phi}}\Bigg[\displaystyle\sum_{t=1}^{T}(\mathcal{L}_{\mathrm{pred}}(\phi)+\mathcal{L}_{\mathrm{dyn}}(\phi)+0.1\mathcal{L}_{\mathrm{rep}}(\phi))\Bigg]\end{aligned} \tag{2}
$$
ifnextchar
gobble
$$
\displaystyle\begin{aligned} \mathcal{L}_{pred}\doteq-\ln p_{\phi}(r_{t}\;|\;h_{t},z_{t})-\ln p_{\phi}(d_{t}\;|\;h_{t},z_{t})-\ln p_{\phi}(x_{t}\;|\;h_{t},z_{t})\end{aligned} \tag{3}
$$
ifnextchar
gobble
We augment Dreamer-v3’s World Model with an additional head for predicting task success. In this implementation, the Self-Assessment Model is an MLP with $N$ outputs that map the RSSM state to the probability of task success within the $N$ quantiles of the maximum episode duration. Specifically, the MLP outputs parameterize $N=5$ Bernoulli distributions $\{\psi_{1},·s\psi_{N}\}$ for the five quantiles. A self-assessment prediction involves sampling from each of these distributions, $\hat{c}^{i}_{t}\sim\psi_{i}(h_{t},z_{t})$ , and combining these samples into a prediction vector. For example, a prediction of success in the first quantile would yield the vector $[1,1,1,1,1]$ , whereas a prediction of failure even by the last quantile would yield the vector $[0,0,0,0,0]$ . This process is visualized in Figure 2. Note that each component of the self-assessment head is trained separately using binary cross-entropy loss, and the individual losses are then added to the total prediction loss $\mathcal{L}_{\mathrm{pred}}$ (Equation 4).
$$
\displaystyle\begin{aligned} \mathcal{L}_{\mathrm{SA}}\doteq-\sum_{i=1}^{N}\ln\psi_{i}(h_{t},z_{t}),\hskip 35.00005pt\mathcal{L}_{pred}\leftarrow\mathcal{L}_{pred}+\mathcal{L}_{\mathrm{SA}}\end{aligned} \tag{4}
$$
ifnextchar
gobble
<details>
<summary>figures/rssm_sa_combined.png Details</summary>
### Visual Description
## Diagram: Recurrent Neural Network for Robotic Control
### Overview
The image depicts a recurrent neural network (RNN) architecture, likely used for controlling a robotic arm. The diagram illustrates the flow of information through the network over three time steps. It includes input images, encoding and decoding layers, hidden states, and predicted control parameters.
### Components/Axes
* **Time Steps:** The diagram shows three time steps, indexed by 1, 2, and 3.
* **Input Images (x):** At the bottom, there are pairs of images at each time step, labeled as x1, x̂1, x2, x̂2, x3, x̂3. The 'x' likely represents the input image, and 'x̂' represents the reconstructed or predicted image.
* **Encoder (enc):** A light blue trapezoid labeled "enc" represents the encoder network. It takes the input image (x) and transforms it into a latent representation (z).
* **Decoder (dec):** A light blue trapezoid labeled "dec" represents the decoder network. It takes the latent representation (z) and reconstructs the image (x̂).
* **Latent Representation (z):** The square boxes labeled z1, z2, and z3 represent the latent representations at each time step. These boxes contain a grid of smaller squares, each with varying shades of blue, suggesting a matrix or tensor representation.
* **Hidden State (h):** The rounded rectangles labeled h1, h2, and h3 represent the hidden states of the RNN at each time step.
* **Control Parameters (ĉ, r̂, d̂):** At the top, there are three rounded rectangles at each time step, labeled ĉ1, r̂1, d̂1, ĉ2, r̂2, d̂2, ĉ3, r̂3, d̂3. These likely represent the predicted control parameters for the robotic arm, such as position (ĉ), rotation (r̂), and depth (d̂).
* **Control Parameter Visualization:** Above each set of control parameters (ĉ1, ĉ2, ĉ3), there is a small graph. The x-axis represents time, and the y-axis represents the value of the control parameter. A pink line connects the data points, showing the trend of the control parameter over time.
* **Arrows:** Arrows indicate the flow of information through the network. Dark green arrows represent the primary flow, while gray arrows represent recurrent connections.
* **Recurrent Connections (a):** The gray arrows labeled a1 and a2 represent the recurrent connections, feeding the hidden state from the previous time step into the current time step.
* **State Connections (s):** The dark green arrows labeled s1, s2, and s3 connect the hidden state to the control parameters.
### Detailed Analysis
* **Input Images:** The images at the bottom show a robotic arm interacting with an object (possibly a blue sphere). The "x" images are likely the real images, while the "x̂" images are the reconstructions generated by the decoder. The reconstructed images appear slightly blurred.
* **Encoder-Decoder:** The encoder-decoder structure suggests that the network is learning a compressed representation of the input images. This representation is then used to reconstruct the images and predict the control parameters.
* **Hidden State:** The hidden state acts as a memory, storing information from previous time steps. This allows the network to make decisions based on the history of the robot's actions and observations.
* **Control Parameters:** The control parameters are the output of the network, and they determine the actions of the robotic arm. The graphs above the control parameters provide a visualization of how these parameters change over time.
* **Recurrent Connections:** The recurrent connections allow the network to maintain a state over time, enabling it to learn complex sequences of actions.
* **Control Parameter Visualization Details:**
* **ĉ1:** The pink line starts low and increases steadily. The black dots are at approximately y=0.2, 0.4, 0.6, 0.8.
* **ĉ2:** The pink line starts low and increases steadily. The black dots are at approximately y=0.2, 0.4, 0.6, 0.8.
* **ĉ3:** The pink line starts low and increases steadily. The black dots are at approximately y=0.2, 0.4, 0.6, 0.8.
### Key Observations
* The network appears to be processing sequential data, as evidenced by the time steps and recurrent connections.
* The encoder-decoder structure suggests that the network is learning a compressed representation of the input images.
* The hidden state plays a crucial role in maintaining a memory of past events.
* The control parameters are the output of the network and determine the actions of the robotic arm.
### Interpretation
The diagram illustrates a recurrent neural network designed for controlling a robotic arm. The network takes input images, encodes them into a latent representation, and uses this representation to predict control parameters. The recurrent connections allow the network to maintain a state over time, enabling it to learn complex sequences of actions. The encoder-decoder structure suggests that the network is learning a compressed representation of the input images, which is then used to reconstruct the images and predict the control parameters. This architecture is well-suited for tasks that require sequential decision-making, such as robotic control. The network learns to map visual inputs to appropriate motor commands, enabling the robot to perform complex tasks.
</details>
Figure 2: Schematic of the implementation of self-assessment in the context of the Dreamer-v3 World Model (adapted from Hafner et al. (2023)). The input state $x$ to the RSSM is encoded into latent embedding $z$ . The model recurrently predicts self-assessment $\hat{c}$ , reward $\hat{r}$ , and terminal signal $\hat{d}$ , while also decoding the input state $\hat{x}$ .
3.1.2 Self-Regulation
Even with pre-deployment training on multiple tasks, including parametric variations, MBRL agents exhibit limited generalization to novel tasks that require either new, orchestrated combinations of those skills or entirely new skills (Ketz and Pilly, 2022). While Dreamer-v3 can handle novel parametric variations for a known task, it struggles to make progress when faced with an unknown reward function that differs semantically from those of the training tasks. Central to our MUSE framework is the self-regulation algorithm, which performs competence-aware actions to solve novel tasks. Specifically, the decision-making process selects actions that maximize the likelihood of task success. Self-assessed competence can be used to guide planning in three primary ways:
1. Simulate multiple future scenarios (rollout trajectories) based on the current state and potential actions, then greedily select the path that maximizes the self-assessment criterion
1. Perform MCTS over actions using the self-assessment criterion in place of variations of the UCB score
1. Optimize the RSSM state to directly maximize the self-assessment criterion to effectively self-regulate the policy
For this implementation of MUSE, we used the third option. This self-regulation method, which is detailed in Algorithm 1, leverages the differentiability of the World Model with the self-assessment head. MUSE performs a World Model rollout where the agent’s actions are regulated to increase the likelihood of reaching a success state. Specifically, MUSE directly optimizes the RSSM state, $s$ ( $\doteq\{h,z\}$ ), input to the agent for selecting actions that maximize the self-assessment criterion. The intuition is that when the Self-Assessment Model predicts failure in a novel environment, it is no longer useful to just rely on the default policy. Instead, we seek competence-aware actions that guide the agent to a success state by augmenting the RSSM state in a direction that increases the probability of task success. At each time step $t$ , MUSE performs a short World Model rollout of horizon $H$ that optimizes over the RSSM state $s$ as follows:
$$
\displaystyle\begin{aligned} s\leftarrow s+\beta\nabla_{s}\left(\sum_{i=1}^{N}\psi_{i}(s)\right).\end{aligned} \tag{5}
$$
ifnextchar
gobble It then applies the self-regulated action $a_{t}\sim\pi(a_{t}|s)$ , observes the resulting recurrent state $h_{t+1}$ , and begins a new iteration.
Algorithm 1 Self-regulation leverages the World Model and its constituent Self-Assessment Model to select competence-aware actions
1: $h_{t}$
2: $H$ = 10
3: $\beta=0.02$
4: $z_{t}\sim p_{\phi}(z_{t}|h_{t})$
5: $h← h_{t}$
6: $z← z_{t}$
7: $s\doteq\{h,z\}$
8: for $step← 1$ to $H$ do
9: $a\sim\pi(a|s)$
10: $h← f_{\phi}(s,a)$
11: $\displaystyle s← s+\beta∇_{s}\left(\sum_{i=1}^{N}\psi_{i}(s)\right)$
12: end for
13: $a_{t}\sim\pi(a_{t}|s)$
14: $h_{t+1}← f_{\phi}(s,a_{t})$
15: return $z_{t}$ , $a_{t}$ , $h_{t+1}$
3.2 Meta-World Experiments
For the World-Model-based implementation, we evaluated our approach within the Meta-World robotic manipulation simulator (Yu et al., 2020) and compared it against Dreamer-v3 (Hafner et al., 2023) as the MBRL baseline. Meta-World provides a suitable testbed for learning a shared perceptual and dynamics model across multiple tasks using a 6 degrees-of-freedom (DOF) robotic arm.
To ensure consistency, we used Dreamer-v3’s network architectures, hyperparameters, and learning procedures across all shared components between the two agents (e.g., an imagination horizon of 15 time steps for actor and critic learning). Both methods were implemented in the same PyTorch codebase, with the self-assessment and self-regulation modules omitted for Dreamer-v3. The agents received a $64× 64$ RGB observation alongside a 40-dimensional proprioceptive state. Additionally, we included a task embedding that was represented as a single integer-valued channel appended to the visual state. MUSE leveraged the built-in success signal returned by the Meta-World environment to train its Self-Assessment Model. For the experiments, we employed a two-stage protocol comprising pre-deployment training on known tasks followed by deployment adaptation to unknown tasks. Each episode in these experiments had a maximum time limit of 500 steps.
For pre-deployment training, we utilized Meta-World’s MT10 suite of 10 different manipulation tasks (Figure 3). In particular, we adopted a multi-task learning paradigm (Mandi et al., 2023), encompassing all 10 training tasks over 2M total environment steps. This paradigm was chosen over meta-RL approaches to reduce computational costs and training time (Wang et al., 2021). By default, object and goal positions were randomly sampled to enable domain randomization. For deployment adaptation, we evaluated the agents on a set of 10 novel tasks from Meta-World’s MT50 suite with distinct reward functions, which were semantically different from those in the pre-deployment training set (Figure 4). The agents were exposed to one novel task at a time, starting with pre-deployment trained weights, for 20 adaptation episodes per task. They were assessed for performance on novel tasks during these adaptation episodes. The task embedding channel was set to zero for novel tasks. During training as well as adaptation, both agents continually updated their World Models with real data and their actor and critic neural networks with imagined data. The replay buffer from pre-deployment training was retained for deployment adaptation to prevent catastrophic forgetting of previously trained performance.
3.2.1 Metrics
Self-Assessment We used metacognitive accuracy and the Area under the Type 2 Receiver Operating Characteristic Curve (AUROC2) to evaluate how well MUSE predicts its success on novel tasks (Fleming and Lau, 2014), which in turn indicates how effectively the self-assessment signal can support online adaptation. MUSE was evaluated for each novel task separately over 20 adaptation episodes. During these episodes, we collected MUSE’s step-wise self-assessment predictions for evaluation. The predictions at all time steps across tasks were compared with the true labels to compute the metacognitive accuracy and AUROC2 metrics. The Type 2 ROC curve for MUSE was computed by treating the sum of the self-assessment components $\left(\sum_{i=1}^{N}\psi_{i}(s)\right)$ as the signal. Note that, as Dreamer-v3 lacks a self-assessment module to predict episode outcomes, we cannot make a meaningful comparison between Dreamer-v3 and MUSE for self-assessment.
Self-Regulation We evaluated how well the agents generalize to unknown situations using two metrics: the percentage of novel tasks solved and the average time to task completion. Each agent was assessed for each novel task separately over the 20 adaptation episodes. The percentage of episodes where the agent completed the task within the maximum time limit was averaged across all novel tasks to calculate the success rate. Similarly, the number of time steps required to achieve success in each episode was averaged across all episodes for each novel task to compute the respective time-to-completion metrics.
<details>
<summary>figures/train_mt10_tasks.png Details</summary>

### Visual Description
## Image Montage: Robotic Arm Interactions
### Overview
The image is a montage of ten separate scenes, each depicting a red robotic arm interacting with different objects in a simulated environment. The scenes show the arm manipulating objects of various shapes and colors, suggesting a sequence of tasks or a demonstration of the arm's capabilities.
### Components/Axes
* **Robotic Arm:** A red, articulated robotic arm is the central element in each scene. It has a gripper at the end, which appears to be equipped with sensors or markers of blue, white, and red.
* **Objects:** The objects being manipulated vary in shape, size, and color. They include:
* A yellow rectangular prism
* A dark gray cabinet with an open door
* A green cube
* A red cylinder
* A wooden frame
* A window
* **Environment:** The environment appears to be a simulated room with a light-colored floor and walls. Some scenes include a green circular marker on the floor.
### Detailed Analysis or ### Content Details
The montage presents a sequence of interactions. Here's a breakdown of each scene:
1. **Scene 1:** The robotic arm is positioned near a yellow rectangular prism. The gripper is close to the object, suggesting an attempt to grasp or manipulate it.
2. **Scene 2:** The robotic arm is interacting with a dark gray cabinet. The cabinet door is open, and the arm's gripper is inside, possibly retrieving or placing an object. A green circular marker is on the floor.
3. **Scene 3:** The robotic arm is positioned above a green cube. The gripper is open, suggesting it is about to pick up the cube. A green circular marker is on the floor.
4. **Scene 4:** The robotic arm is holding a green cube. The gripper is closed around the cube, and the arm is likely moving it to a new location.
5. **Scene 5:** The robotic arm is positioned near a red rectangular prism. The gripper is close to the object, suggesting an attempt to grasp or manipulate it. A green circular marker is on the floor.
6. **Scene 6:** The robotic arm is positioned near the floor. The gripper is open, suggesting it is about to pick up something.
7. **Scene 7:** The robotic arm is positioned above a red cylinder. The gripper is open, suggesting it is about to pick up the cylinder.
8. **Scene 8:** The robotic arm is positioned near a wooden frame. The gripper is close to the object, suggesting an attempt to grasp or manipulate it.
9. **Scene 9:** The robotic arm is positioned near a window. The gripper is close to the object, suggesting an attempt to grasp or manipulate it.
10. **Scene 10:** The robotic arm is positioned near a window. The gripper is close to the object, suggesting an attempt to grasp or manipulate it.
### Key Observations
* The robotic arm appears to be performing a variety of tasks, including picking up, placing, and manipulating objects.
* The green circular markers may indicate target locations or points of interest for the robotic arm.
* The objects being manipulated vary in shape, size, and color, suggesting the arm is capable of handling a variety of items.
### Interpretation
The montage likely demonstrates the capabilities of the robotic arm in a simulated environment. The different scenes showcase the arm's ability to interact with various objects and perform tasks such as picking, placing, and manipulating. The presence of green markers suggests a guided or programmed sequence of actions. The variety of objects indicates the arm's versatility in handling different shapes and sizes. Overall, the montage presents a visual representation of the robotic arm's functionality and potential applications.
</details>
Figure 3: Meta-World pre-deployment training set [button-press, door-open, drawer-close, drawer-open, peg-insert-side, pick-place, push, reach, window-close, window-open], which comprises the 10 tasks from the MT10 suite.
<details>
<summary>figures/test_evaluation_tasks.png Details</summary>

### Visual Description
## Image Set: Robotic Arm Tasks
### Overview
The image shows a series of ten simulated environments where a robotic arm is performing different tasks. Each environment features a different object or set of objects that the arm interacts with. The arm itself is a reddish-brown color with a white and light blue gripper. The environments are simple, with a light-colored floor and walls.
### Components/Axes
Each of the ten images contains the following key components:
* **Robotic Arm:** A reddish-brown robotic arm with a white and light blue gripper.
* **Environment:** A simulated environment with a light-colored floor and walls.
* **Objects:** Various objects that the arm interacts with, such as a button, soccer ball, blocks, and tools.
### Detailed Analysis or ### Content Details
Here's a breakdown of each of the ten environments:
1. **Top-Left:** A yellow box with a red button on top, a brown barrier, and the robotic arm approaching.
2. **Top-Center-Left:** A blue and white soccer goal with a green ball inside and a black and white soccer ball outside. The robotic arm is positioned to interact with the balls.
3. **Top-Center:** A small red rectangular prism and a larger brown rectangular prism. The robotic arm is positioned to interact with the red prism.
4. **Top-Center-Right:** A brown cylinder and a green ball. The robotic arm is positioned to interact with the ball.
5. **Top-Right:** A brown box with a white knob and a white mug. A green ball is on the floor. The robotic arm is positioned to interact with the mug.
6. **Bottom-Left:** A white and red goal with a red ball inside and a black puck outside. The robotic arm is positioned to interact with the puck.
7. **Bottom-Center-Left:** A clear rectangular prism and two red balls. The robotic arm is positioned to interact with the balls.
8. **Bottom-Center:** A gray vise with a blue ball in the vise and a red ball on the floor. The robotic arm is positioned to interact with the vise.
9. **Bottom-Center-Right:** A gray box with a red cylinder on top. The robotic arm is positioned to interact with the cylinder.
10. **Bottom-Right:** A dark gray safe with a silver handle, a blue button, and a green light. The robotic arm is positioned to interact with the safe.
### Key Observations
* The robotic arm is consistent across all environments.
* The objects and tasks vary significantly, suggesting a range of capabilities being tested.
* The environments are simple and uncluttered, focusing attention on the task at hand.
### Interpretation
The image set likely represents a series of tests or demonstrations of a robotic arm's ability to interact with different objects and perform various tasks. The variety of objects and tasks suggests that the arm is designed to be versatile and adaptable. The simple environments allow for a clear focus on the arm's performance without distractions. The tasks range from simple manipulation (picking up a ball) to more complex interactions (operating a vise or safe), indicating a range of potential applications.
</details>
Figure 4: Meta-World evaluation set [button-press-topdown-wall, soccer, push-wall, push-block, coffee-button, plate-slide, peg-unplug-side, lever-pull, handle-press, door-unlock], which comprises 10 novel tasks from the MT50 suite with distinct reward functions, which differ semantically from those in the pre-deployment training set.
Table 1: Self-assessment performance of the MUSE agent on novel tasks in the Meta-World environment.
| Method | Metric | Value |
| --- | --- | --- |
| MUSE | Metacognitive Accuracy | 92% |
| MUSE | AUROC2 | 0.95 |
3.2.2 Results
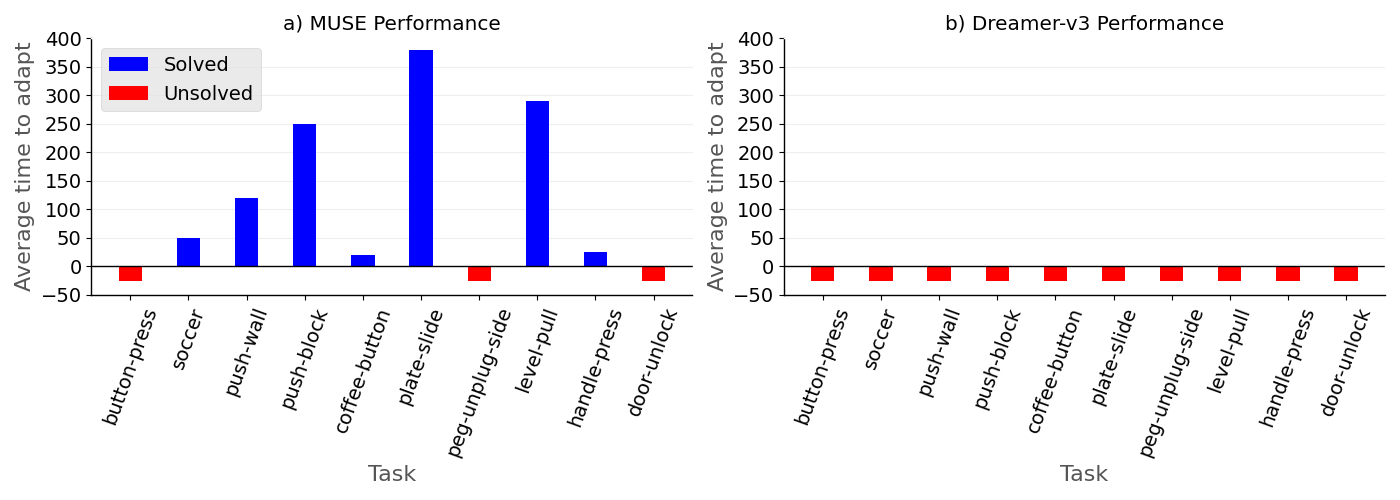
The MUSE agent achieved a metacognitive accuracy of 92% and an AUROC2 of 0.95 on novel tasks over the adaptation episodes, demonstrating that the Self-Assessment Model is highly predictive of competence for novel tasks (Table 1). Further, MUSE successfully solved 7 of the 10 novel tasks (70%) by leveraging competence-aware actions. The 7 solved tasks required different time steps per episode depending on the relative difficulty and complexity of the task (Figure 5 a). For instance, plate-slide required nearly the maximum time budget, while coffee-button was solved quickly. But in sharp contrast, Dreamer-v3 failed to solve any of the novel tasks within the allotted adaptation episodes (Figure 5 b).
<details>
<summary>figures/adaptation_steps.png Details</summary>
### Visual Description
## Bar Charts: MUSE vs. Dreamer-v3 Performance
### Overview
The image contains two bar charts comparing the performance of two systems, MUSE and Dreamer-v3, on a set of tasks. The charts display the average time to adapt for each task, with blue bars indicating tasks that were solved and red bars indicating tasks that were not solved.
### Components/Axes
**Chart a) MUSE Performance:**
* **Title:** a) MUSE Performance
* **Y-axis:** Average time to adapt
* Scale: 0 to 400, with increments of 50.
* **X-axis:** Task
* Categories: button-press, soccer, push-wall, push-block, coffee-button, plate-slide, peg-unplug-side, level-pull, handle-press, door-unlock
* **Legend:** Located in the top-left corner.
* Blue: Solved
* Red: Unsolved
**Chart b) Dreamer-v3 Performance:**
* **Title:** b) Dreamer-v3 Performance
* **Y-axis:** Average time to adapt
* Scale: 0 to 400, with increments of 50.
* **X-axis:** Task
* Categories: button-press, soccer, push-wall, push-block, coffee-button, plate-slide, peg-unplug-side, level-pull, handle-press, door-unlock
* **Legend:** (Implicitly the same as MUSE, as no legend is present)
* Blue: Solved
* Red: Unsolved
### Detailed Analysis
**Chart a) MUSE Performance:**
* **button-press:** Unsolved (Red bar) at approximately -25.
* **soccer:** Solved (Blue bar) at approximately 50.
* **push-wall:** Solved (Blue bar) at approximately 125.
* **push-block:** Solved (Blue bar) at approximately 250.
* **coffee-button:** Solved (Blue bar) at approximately 25.
* **plate-slide:** Solved (Blue bar) at approximately 380.
* **peg-unplug-side:** Unsolved (Red bar) at approximately -25.
* **level-pull:** Solved (Blue bar) at approximately 290.
* **handle-press:** Solved (Blue bar) at approximately 25.
* **door-unlock:** Unsolved (Red bar) at approximately -25.
**Chart b) Dreamer-v3 Performance:**
* **button-press:** Unsolved (Red bar) at approximately -25.
* **soccer:** Unsolved (Red bar) at approximately -25.
* **push-wall:** Unsolved (Red bar) at approximately -25.
* **push-block:** Unsolved (Red bar) at approximately -25.
* **coffee-button:** Unsolved (Red bar) at approximately -25.
* **plate-slide:** Unsolved (Red bar) at approximately -25.
* **peg-unplug-side:** Unsolved (Red bar) at approximately -25.
* **level-pull:** Unsolved (Red bar) at approximately -25.
* **handle-press:** Unsolved (Red bar) at approximately -25.
* **door-unlock:** Unsolved (Red bar) at approximately -25.
### Key Observations
* MUSE solves most tasks, with 'plate-slide' requiring the highest average time to adapt.
* Dreamer-v3 fails to solve any of the tasks, with all tasks showing a negative average time to adapt (represented by red bars at approximately -25).
### Interpretation
The data suggests that MUSE significantly outperforms Dreamer-v3 on the given set of tasks. MUSE is able to solve most of the tasks, while Dreamer-v3 fails to solve any of them. The negative average time to adapt for Dreamer-v3 across all tasks is unusual and may indicate a specific issue with the system's adaptation process or how the metric is being calculated. The 'plate-slide' task appears to be the most challenging for MUSE, requiring a substantially longer adaptation time compared to other solved tasks.
</details>
Figure 5: Average number of time steps per episode required to solve each of the 10 novel tasks in the Meta-World environment. MUSE (a) successfully solved 7 out of 10 tasks, whereas Dreamer-v3 (b) failed to solve any of them. Note that to facilitate illustration, unsolved tasks are assigned a nominal value of -25 and depicted by a red bar.
3.3 Discussion
The pre-deployment training tasks were selected to encompass a broad range of skills, so the agents could develop a better understanding of various manipulation strategies. Following this training, the agents were exposed to out-of-distribution tasks that were selected to evaluate their ability to generalize learned skills to novel challenges. This two-stage approach of training on familiar tasks and then adapting to novel ones was used to rigorously assess the effectiveness of MUSE and Dreamer-v3 in unknown situations. Overall, the World-Model-based experiments showed that MUSE significantly outperforms Dreamer-v3 in adapting to novel tasks by effectively leveraging competence awareness for strategy selection.
4 LLM-based implementation
In this section, we describe our implementation of the MUSE framework to equip LLM agents with metacognitive abilities of self-assessment and self-regulation.
4.1 Methods
4.1.1 ReAct
Yao et al. (2022) was among the first to introduce an LLM agent that interacts with its environment to accomplish tasks by being prompted to reason and act (Figure 6). At time step $t$ , the ReAct agent ( $M_{a}$ ) perceives an observation $o_{t}∈\mathcal{O}$ , executes an action $a_{t}∈\mathcal{A}$ based on the policy $\pi(a_{t}|I,c_{t-1},o_{t})$ , and receives a reward $r_{t}$ . Here, $I$ is the natural language description of the task, and $c_{t}=\{o_{1},a_{1},r_{1}...,o_{t},a_{t},r_{t}\}$ is the running context of the trajectory within the episode. The context is reset at the end of each episode, which occurs when either the task is solved within the time budget or the episode terminates due to running out of time. The ReAct agent leverages language-based CoT reasoning (Wei et al., 2022) for improved sequential action selection for multi-step tasks. Note that actions $a_{t}$ stored in $c_{t}$ include both standard actions and CoT reasoning steps. Two-shot domain-specific trajectory examples with step-by-step reasoning are included in the prompt for CoT reasoning. See Supplementary Section 8.1 for illustrative examples.
<details>
<summary>figures/ReAct.png Details</summary>

### Visual Description
## Diagram: Actor-Environment Interaction Loop
### Overview
The image is a diagram illustrating an actor-environment interaction loop, incorporating elements of long-term memory, language descriptors, and low-level policies. The diagram depicts the flow of information and actions between the actor and the environment, with context and task descriptions influencing the actor's behavior.
### Components/Axes
* **Actor:** A green rounded rectangle labeled "Actor" at the top-right. It receives input from "Context" (c<sub>t-1</sub>), "Task description" (I), and "Long-term memory". It outputs "High-level action" (a<sub>t</sub>) and "M<sub>a</sub>".
* **Long-term memory:** A green rounded rectangle on the left, receiving "Few-shot examples" as input and providing context (c<sub>t-1</sub>) to the "Actor". It also receives "Text observation, Reward" (o<sub>t+1</sub>, r<sub>t</sub>).
* **Language descriptor:** A white rounded rectangle at the bottom-left, receiving "Text observation" (o<sub>t</sub>) and outputting to the "Environment".
* **Environment:** A white rounded rectangle at the bottom-center, receiving input from the "Language descriptor" ("Low-level action") and outputting "Observation, Reward" to the "Language descriptor".
* **Low-level policies:** A white rounded rectangle at the bottom-right, receiving "High-level action" (a<sub>t</sub>) from the "Actor" and outputting "Low-level action" to the "Environment".
* **Arrows:** Arrows indicate the flow of information and actions between the components.
### Detailed Analysis
* **Actor:** The "Actor" receives three inputs:
* "Context" (c<sub>t-1</sub>) from the "Long-term memory".
* "Task description" (I).
* "M<sub>a</sub>" from the "Long-term memory".
The "Actor" outputs "High-level action" (a<sub>t</sub>) to the "Low-level policies".
* **Long-term memory:** The "Long-term memory" receives "Few-shot examples" and "Text observation, Reward" (o<sub>t+1</sub>, r<sub>t</sub>). It outputs "Context" (c<sub>t-1</sub>) to the "Actor".
* **Language descriptor:** The "Language descriptor" receives "Text observation" (o<sub>t</sub>) and outputs to the "Environment".
* **Environment:** The "Environment" receives input from the "Language descriptor" ("Low-level action") and outputs "Observation, Reward" to the "Language descriptor".
* **Low-level policies:** The "Low-level policies" receives "High-level action" (a<sub>t</sub>) from the "Actor" and outputs "Low-level action" to the "Environment".
### Key Observations
* The diagram illustrates a closed-loop system where the "Actor" interacts with the "Environment" through "Low-level policies" and "Language descriptor".
* The "Long-term memory" provides context to the "Actor" based on "Few-shot examples" and past experiences ("Text observation, Reward").
* The "Language descriptor" translates "Text observation" into a format understandable by the "Environment".
### Interpretation
The diagram represents a reinforcement learning framework where an "Actor" learns to perform tasks in an "Environment". The "Actor" uses "Long-term memory" to store and retrieve relevant information, allowing it to adapt to new situations based on "Few-shot examples". The "Language descriptor" enables the system to process textual observations from the "Environment". The "Low-level policies" translate high-level actions from the "Actor" into concrete actions that can be executed in the "Environment". The loop represents the continuous interaction between the "Actor" and the "Environment", where the "Actor" learns from its experiences and improves its performance over time.
</details>
Figure 6: Our illustration of the ReAct architecture (Yao et al., 2022).
4.1.2 Reflexion
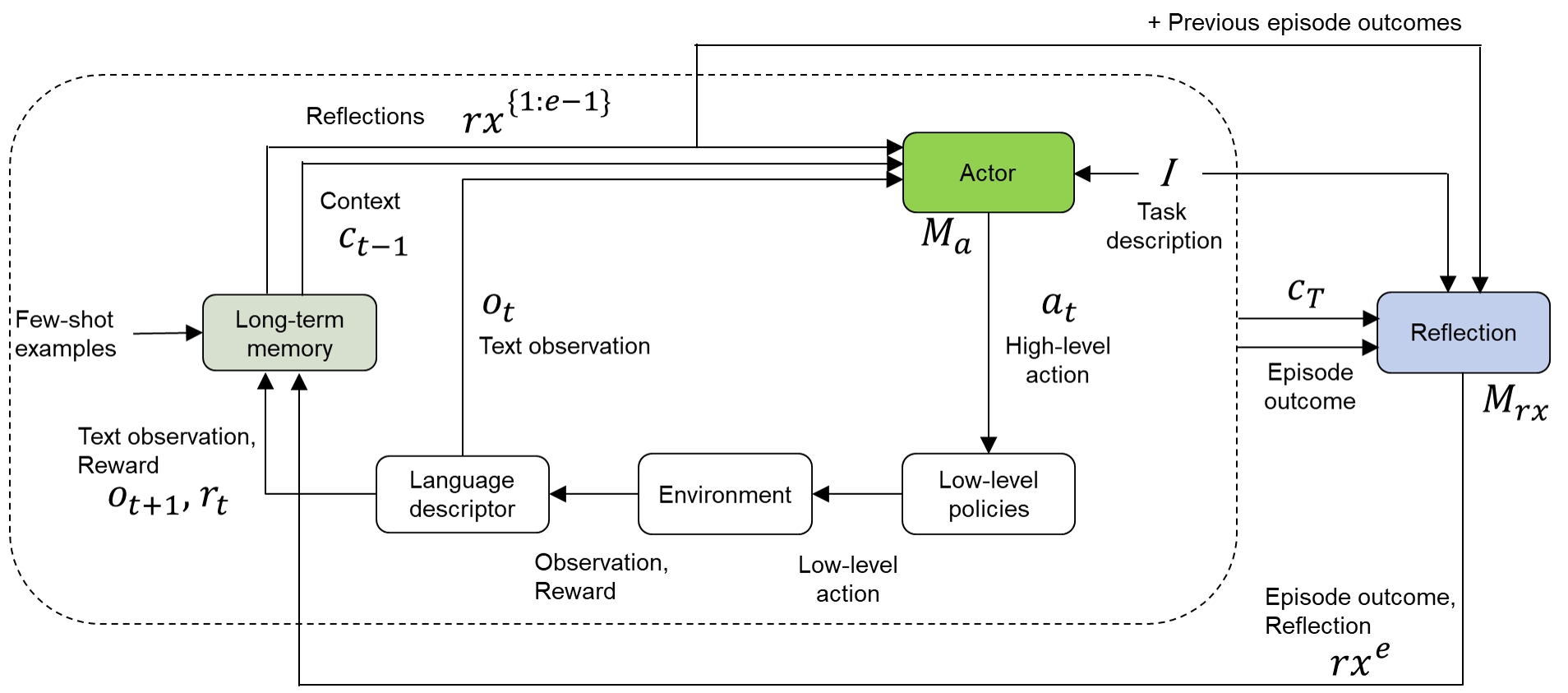
Reflexion (Shinn et al., 2023) enhances in-context prompting for LLM agents by generating internal feedback in language, referred to as “reflection,” to transfer lessons learned across episodes for a given task (Figure 7). At the end of each episode $e$ , Reflexion prompts an LLM to reason and generate verbal feedback $rx^{e}$ about the agent’s performance by analyzing the entire trajectory $c_{T}$ from the episode start ( $t=1$ ) to finish ( $t=T$ ) and the episode outcome (success or failure). This Reflection LLM ( $M_{rx}$ ) also receives the reflections and outcomes from previous episodes ( $1:e-1$ ). The Reflexion agent ( $M_{a}$ ) follows the policy $\pi(a_{t}|I,c_{t-1},o_{t},rx^{\{1:e-1\}})$ , which incorporates cumulative reflections from earlier episodes. In contrast to ReAct, which relies solely on short-term memory comprising the agent’s running trajectory within the current episode, Reflexion leverages both short- and long-term memory for improved strategic adaptation to novel situations. This iterative internal feedback mechanism allows the agent to refine its strategies progressively by integrating lessons learned from failures in previous episodes. Reflexion addresses the credit assignment problem through implicit reasoning about specific actions within the trajectory that led to failures, proposing alternative strategies for future episodes. Through this process, the agent develops an enhanced understanding of effective plans to iteratively improve its adaptability to novel tasks.
While the original Reflexion study (Shinn et al., 2023) utilized a single LLM for both action generation and reflection, our implementation uses distinct LLMs that are fine-tuned for each respective task. Additionally, we extend the reflection process to include successful outcomes, which enables the model to reinforce effective strategies alongside learning from failures.
<details>
<summary>figures/Reflex.png Details</summary>
### Visual Description
## System Diagram: Actor-Reflection Interaction
### Overview
The image is a system diagram illustrating the interaction between an "Actor" and a "Reflection" module within an environment. It depicts the flow of information, actions, and feedback loops between these components, including the environment, long-term memory, and low-level policies.
### Components/Axes
* **Nodes:**
* Actor (Green rounded rectangle)
* Reflection (Blue rounded rectangle)
* Long-term memory (Green rounded rectangle)
* Language descriptor (White rounded rectangle)
* Environment (White rounded rectangle)
* Low-level policies (White rounded rectangle)
* **Labels:**
* Reflections: rx^{1:e-1}
* Context: c_{t-1}
* Few-shot examples
* Text observation: o_t
* Text observation, Reward: o_{t+1}, r_t
* Observation, Reward
* Low-level action
* Task description: I
* High-level action: a_t
* Episode outcome: c_T
* Episode outcome, Reflection: rx^e
* M_a (below Actor)
* M_rx (below Reflection)
* + Previous episode outcomes (top-right)
### Detailed Analysis
* **Actor:** The Actor receives input from "Reflections rx^{1:e-1}", "Context c_{t-1}", and "Task description I". It outputs a "High-level action a_t" to "Low-level policies". The Actor has an associated memory M_a.
* **Reflection:** The Reflection module receives input from "Task description I", "Episode outcome c_T", and "+ Previous episode outcomes". It outputs to "Reflections rx^{1:e-1}", and "Long-term memory". The Reflection module has an associated memory M_rx, which also receives "Episode outcome, Reflection rx^e".
* **Long-term memory:** Receives "Few-shot examples" and "Text observation, Reward o_{t+1}, r_t". It outputs "Context c_{t-1}" and "Text observation o_t".
* **Language descriptor:** Receives "Text observation o_t" and outputs "Observation, Reward" to the "Environment".
* **Environment:** Receives "Observation, Reward" from the "Language descriptor" and "Low-level action" from "Low-level policies". It outputs "Text observation, Reward o_{t+1}, r_t" to "Long-term memory".
* **Low-level policies:** Receives "High-level action a_t" from the "Actor" and outputs "Low-level action" to the "Environment".
### Key Observations
* The diagram illustrates a closed-loop system where the Actor interacts with the Environment through high-level actions, which are then translated into low-level actions.
* The Reflection module plays a crucial role in learning and adaptation by processing episode outcomes and updating the long-term memory.
* The system incorporates both few-shot examples and continuous feedback (reward) to guide learning.
### Interpretation
The diagram represents a reinforcement learning architecture where an agent (Actor) learns to interact with an environment. The Reflection module allows the agent to learn from past experiences and improve its performance over time. The long-term memory stores relevant information that can be used to guide future actions. The inclusion of few-shot examples suggests a meta-learning approach, where the agent can quickly adapt to new tasks based on limited data. The overall architecture emphasizes the importance of both exploration (through interaction with the environment) and exploitation (through leveraging past experiences) in achieving optimal performance.
</details>
Figure 7: Our illustration of the Reflexion architecture (Shinn et al., 2023), which leverages verbal RL to enable agents to learn from past episodes.
4.1.3 MUSE
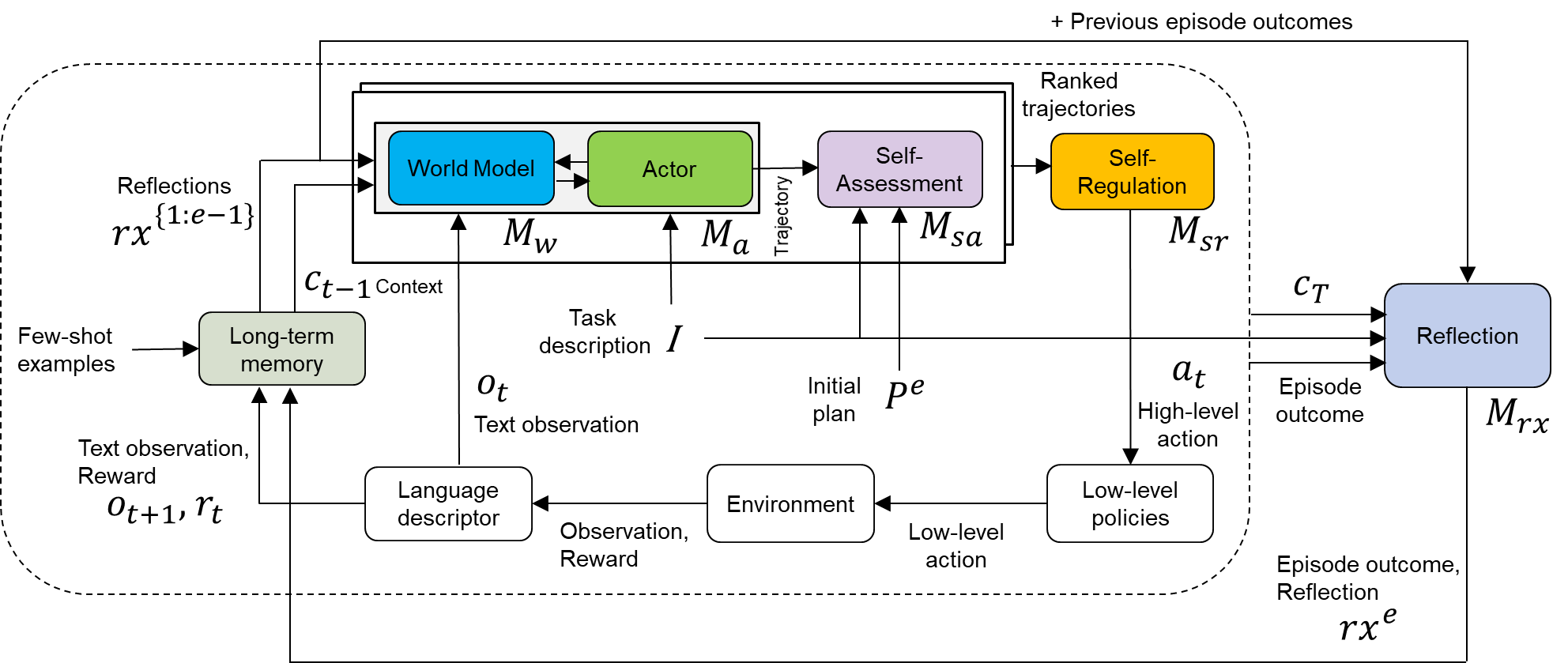
The MUSE framework, illustrated in Figure 8, builds on mechanisms from ReAct and Reflexion by incorporating additional modules for self-assessment and self-regulation:
- World Model ( $M_{w}$ ): An LLM that can be prompted to predict the next observation, reward, and terminal signal given the current observation and action. This LLM works in conjunction with the Actor ( $M_{a}$ ) to generate potential future states and actions (rollout trajectories), enabling look-ahead planning. In text-based domains, such as the experiments presented here, $M_{w}$ can use the same LLM as $M_{a}$ . In fact, the same LLM can be directly prompted to generate diverse trajectories without requiring explicit interaction between the two.
- Self-Assessment Model ( $M_{sa}$ ): A language-conditioned neural network that evaluates and scores trajectories generated by the World Model/Actor to assess their alignment and effectiveness for the agent’s goals. Specifically, it predicts task competence, or the probability of task success, for each trajectory.
- Self-Regulation ( $M_{sr}$ ): A module that decides a competence-aware course of action based on one of the options outlined in Subsection 3.1.2. For this implementation of MUSE, $M_{sr}$ chooses the first action $a_{t}$ from the rollout trajectory that is most likely to achieve task success, as determined by competence evaluations from $M_{sa}$ .
<details>
<summary>figures/MUSE.png Details</summary>
### Visual Description
## Diagram: High-Level System Architecture
### Overview
The image presents a high-level system architecture diagram, likely for a reinforcement learning or AI system. It illustrates the flow of information and interactions between various components, including a world model, actor, self-assessment, self-regulation, long-term memory, language descriptor, environment, and reflection mechanism. The diagram emphasizes the iterative nature of the process, with feedback loops and context-dependent decision-making.
### Components/Axes
* **Nodes (Rounded Rectangles):** Represent distinct modules or components within the system.
* World Model (Blue)
* Actor (Green)
* Self-Assessment (Purple)
* Self-Regulation (Yellow)
* Long-term memory (Light Green)
* Language descriptor (White)
* Environment (White)
* Low-level policies (White)
* Reflection (Light Blue)
* **Arrows:** Indicate the flow of information or control between components.
* **Labels:** Describe the data or signals being passed between components.
* Reflections rx{1:e-1}
* Ct-1 Context
* Task description I
* Ot Text observation
* Initial plan Pe
* At High-level action
* Episode outcome
* Text observation, Reward Ot+1, rt
* Observation, Reward
* Low-level action
* Episode outcome, Reflection rxe
* Ranked trajectories
* \+ Previous episode outcomes
* **Variables:**
* Mw
* Ma
* Msa
* Msr
* Mrx
### Detailed Analysis or ### Content Details
1. **Central Processing Unit:**
* A dashed rounded rectangle encloses the "World Model," "Actor," "Self-Assessment," and "Self-Regulation" modules. This grouping suggests a central processing unit or core decision-making component.
* The "World Model" (blue) receives input from "Reflections rx{1:e-1}" and "Ct-1 Context". It outputs to the "Actor".
* The "Actor" (green) receives input from the "World Model" and "Task description I". It outputs a "Trajectory" to the "Self-Assessment" module.
* The "Self-Assessment" (purple) receives the "Trajectory" and "Initial plan Pe". It outputs to the "Self-Regulation" module.
* The "Self-Regulation" (yellow) receives input from "Self-Assessment" and outputs "At High-level action" and "Ranked trajectories".
2. **Memory and Context:**
* "Long-term memory" (light green) receives "Few-shot examples" and "Text observation, Reward Ot+1, rt". It outputs "Ct-1 Context" to the "World Model".
3. **Environment Interaction:**
* "Language descriptor" (white) receives "Observation, Reward" from the "Environment" (white) and outputs "Text observation, Reward Ot+1, rt" to the "Long-term memory". It also outputs "Ot Text observation" to the "World Model".
* The "Environment" receives "Low-level action" from "Low-level policies" (white) and outputs "Observation, Reward" to the "Language descriptor".
* "Low-level policies" receives "At High-level action" from "Self-Regulation" and outputs "Low-level action" to the "Environment".
4. **Reflection Mechanism:**
* The "Reflection" module (light blue) receives "Ranked trajectories" (indirectly from "Self-Regulation"), "Ct", and "Episode outcome". It outputs "Reflections rx{1:e-1}" to the "World Model" and "Episode outcome, Reflection rxe" to the "Long-term memory".
* The "Reflection" module also receives "+ Previous episode outcomes" as input.
### Key Observations
* The system incorporates a hierarchical structure, with high-level planning and decision-making ("World Model," "Actor," "Self-Assessment," "Self-Regulation") interacting with lower-level policies and the environment.
* Feedback loops are prevalent, allowing the system to learn from its experiences and adapt its behavior.
* The "Reflection" module plays a crucial role in learning and knowledge accumulation.
* The system integrates both textual and reward-based information.
### Interpretation
The diagram illustrates a sophisticated AI system designed for complex tasks. The system leverages a world model to reason about the environment, an actor to take actions, and self-assessment and self-regulation mechanisms to improve performance. The inclusion of long-term memory and a reflection module suggests a system capable of continuous learning and adaptation. The system appears to be designed to learn from both successful and unsuccessful episodes, using the reflection mechanism to extract valuable insights. The integration of language and reward signals indicates a system that can understand and respond to both human instructions and environmental feedback. The overall architecture suggests a system capable of handling complex, dynamic environments and learning to achieve long-term goals.
</details>
Figure 8: Illustration of the MUSE architecture for LLM agents, which implements the metacognitive cycle to iteratively solve unknown tasks.
World Model/Actor During deployment, the World Model/Actor generates several potential future state-action sequences with a horizon $H$ at each time step $t$ . The diversity of these rollout trajectories, denoted by $\tau_{t}=\{a_{t},r_{t},o_{t+1},...,a_{t+H-1},r_{t+H-1},o_{t+H}\}$ , is controlled by the temperature setting of the LLM. These trajectories represent hypothetical paths extending from the current observation $o_{t}$ and context $c_{t-1}$ , guided by the task description $I$ and task-specific reflections $rx^{\{1:e-1\}}$ stored in memory. For this implementation, we explicitly did not specify a horizon $H$ ; instead, the LLM was allowed to generate trajectories up to the maximum length permitted by its context window. The temperature of the LLM was set to 0.5, and five rollout trajectories were generated at each time step.
Self-Assessment The Self-Assessment Model ( $M_{sa}$ ) utilizes a transformer encoder $\mathcal{M}$ (SentenceTransformers, 2024) and an MLP $g_{\eta}$ to predict the probability of task success (Equation 6) for rollout trajectories generated by the World Model/Actor before their actual execution in the environment. Specifically, $M_{sa}$ evaluates the alignment and effectiveness of potential trajectories for the task at hand. The algorithm for training $M_{sa}$ and using it for evaluation is detailed in Algorithm 2.
$$
\displaystyle\begin{aligned} y_{\text{pred}}=M_{sa}(I,P^{e},\tau)\end{aligned} \tag{6}
$$
ifnextchar
gobble Here, $\tau$ represents a trajectory and $P^{e}$ denotes the initial language-based plan generated by the World Model/Actor LLM at the start of episode $e$ based on task description $I$ . See Supplementary Material for several illustrative examples of the initial plan $P^{e}$ . The output layer of $M_{sa}$ employs a sigmoid activation function to yield a probability of task success. A threshold of 0.5 is used to convert these probabilities into binary outcomes (success or failure). During pre-deployment training and deployment adaptation, $M_{sa}$ is trained to minimize the binary cross-entropy loss between the predicted task success ( $y_{\text{pred}}$ ) and the actual binary outcome ( $y$ ) as follows:
$$
\displaystyle\begin{aligned} \mathcal{L}(y,y_{\text{pred}})\doteq-\left[y\log(y_{\text{pred}})+(1-y)\log(1-y_{\text{pred}})\right]\end{aligned} \tag{7}
$$
ifnextchar
gobble To increase the number of training samples and mitigate overfitting, the training trajectories are segmented into non-overlapping chunks, each containing four action-observation pairs. For example, the initial chunk within an episode includes pairs ( $a_{1}$ , $o_{1}$ ) through ( $a_{4}$ , $o_{4}$ ), while the next spans ( $a_{5}$ , $o_{5}$ ) through ( $a_{8}$ , $o_{8}$ ), and so on.
Algorithm 2 Training and evaluation of Self-Assessment Model $M_{sa}$
1: Input: Dataset $\mathcal{D}=\{(I,P^{e},\tau,y)\}$ , transformer encoder $\mathcal{M}$ , MLP $g_{\eta}$
2: Output: Trained evaluator $g_{\eta}$
3: function TrainEvaluator ( $\mathcal{D}$ , $\mathcal{M}$ , $g_{\eta}$ )
4: for each $(I,P^{e},\tau,y)∈\mathcal{D}$ do
5: $Z←\mathcal{M}(I)$ $\triangleright$ Generate task embedding
6: $S←\mathcal{M}(\tau,P^{e})$ $\triangleright$ Generate trajectory and plan embedding
7: $X←\text{concat}(S,Z)$
8: $y_{\text{pred}}← g_{\eta}(X)$ $\triangleright$ Predict task success probability
9: Update $g_{\eta}$ parameters to minimize $\mathcal{L}(y,y_{\text{pred}})$
10: end for
11: return Trained MLP $g_{\eta}$
12: end function
13: function EvaluateTrajectory ( $I$ , $P^{e}$ , $\tau$ , $\mathcal{M}$ , $g_{\eta}$ )
14: $Z←\mathcal{M}(I)$
15: $S←\mathcal{M}(\tau,P^{e})$
16: $X←\text{concat}(S,Z)$
17: $y_{\text{pred}}← g_{\eta}(X)$
18: return $y_{\text{pred}}$
19: end function
MUSE Framework The pre-deployment training and deployment adaptation procedures for the MUSE agent are detailed in Algorithms 3 and 4, respectively. For pre-deployment training, we first train the Reflexion agent (Shinn et al., 2023) on each of the training tasks separately to collect data. The constituent models of the MUSE agent are then trained with multi-task supervised learning to benefit from the diversity of experiences. Specifically, the Reflection LLM ( $M_{rx}$ ) in MUSE is trained using Direct Preference Optimization (DPO) with a preference dataset (Rafailov et al., 2024) that is created by comparing reflections of success and failure across the training tasks. A success (positive) reflection occurs when the agent fails in episode $e_{i}$ but succeeds in episode $e_{i+1}$ following the reflection. Conversely, a failure (negative) reflection happens when the agent succeeds in episode $e_{i}$ but fails in episode $e_{i+1}$ despite the reflection. DPO directly optimizes $M_{rx}$ to generate generalizable reflections that maximize the likelihood of satisfying these preferences (i.e., increase the likelihood of success and decrease the likelihood of failure). This enables MUSE to iteratively improve its ability to recover from failures and adapt to novel tasks through a more effective reflection process.
The Actor LLM ( $M_{a}$ ) is trained using Supervised Fine-Tuning (SFT) with only successful episodes, for simplicity, across the training tasks. By imitating the behavior demonstrated in these episodes, $M_{a}$ learns to align its policy with actions seen during successful episodes. This joint multi-task fine-tuning process equips MUSE with generalizable success-driven strategies. Note that we use Low-Rank Adaptation (LoRA) (Hu et al., 2021) for parameter-efficient fine-tuning of both the $M_{a}$ and $M_{rx}$ LLMs. Additionally, the Self-Assessment Model ( $M_{sa}$ ) undergoes supervised learning with pertinent multi-task data, which maps trajectory chunks to corresponding episode outcomes.
During deployment, when the agents encounter a novel task, they engage in sequential episodes until success is achieved. MUSE employs competence-aware planning, as described above, to choose its actions. Furthermore, MUSE can perform online updates to each of its constituent models as new data becomes available from the novel task. Note that the baseline agents, ReAct and Reflexion, can also respond adaptively to new experiences but rely only on in-context prompting and/or reflection. However, these methods do not involve updating model parameters, which leads to knowledge being stored only for the short term. This constraint hinders the transfer of knowledge across episodes and tasks. MUSE overcomes these limitations by continually updating the weights of its models, enabling more effective knowledge transfer.
Algorithm 3 Procedure for pre-deployment training of the MUSE agent
Training dataset ${D_{in}}\sim$ in-distribution tasks Specify max. training episodes, max. steps
1: function PreTrainModels ( $D_{in}$ , $M_{a}$ , $M_{rx}$ , $M_{sa}$ , $M_{w}$ )
2: Initialize $M_{sa}$ , $M_{w}$ , memory buffer
3: for each task $\sim{D_{in}}$ do
4: Initialize $M_{a}$ , $M_{rx}$ for the Reflexion agent
5: Add $I$ to memory buffer
6: Set $t=0$ , $e=0$
7: while $e<$ max. training episodes do
8: while $t<$ max. steps & task-not-solved do
9: Generate $a_{t}$ using $M_{a}$ and submit to simulator
10: Obtain $o_{t+1}$ and $r_{t}$ , append $o_{t}$ , $a_{t}$ , $r_{t}$ to $c_{t}$
11: Increment $t$
12: end while
13: Generate $rx^{e}$ using $M_{rx}$
14: Append episode outcome, $c_{t}$ , $rx^{e}$ to memory buffer
15: Increment $e$
16: end while
17: end for
18: Use all data in memory buffer to train $M_{a}$ , $M_{rx}$ , $M_{sa}$ , $M_{w}$ for MUSE
19: return Trained $M_{a}$ , $M_{rx}$ , $M_{sa}$ , $M_{w}$
20: end function
Algorithm 4 Procedure for deployment adaptation of the MUSE agent
Test dataset ${D_{out}}\sim$ out-of-distribution tasks Specify max. adaptation episodes
1: function AdaptModels ( $D_{out}$ , $M_{a}$ , $M_{rx}$ , $M_{sa}$ , $M_{w}$ )
2: Initialize memory buffer
3: for each task $\sim{D_{out}}$ do
4: Set $M_{a}$ , $M_{rx}$ , $M_{sa}$ , $M_{w}$ to pre-deployment trained weights
5: Add $I$ to memory buffer
6: Set $t=0$ , $e=0$
7: while $e<$ max. adaptation episodes do
8: while $t<$ max. steps & task-not-solved do
9: Generate rollout trajectories using $M_{w}$ and $M_{a}$
10: Evaluate each trajectory using $M_{sa}$
11: Select the best action $a_{t}$ and submit to simulator
12: Obtain $o_{t+1}$ and $r_{t}$ , append $o_{t}$ , $a_{t}$ , $r_{t}$ to $c_{t}$
13: Increment $t$
14: end while
15: Generate $rx^{e}$ using $M_{rx}$
16: Append episode outcome, $c_{t}$ , $rx^{e}$ to memory buffer
17: Increment $e$
18: end while
19: Use data in memory buffer to update $M_{a}$ , $M_{rx}$ , $M_{sa}$ , $M_{w}$
20: Test updated MUSE agent on the current task over the test episodes
21: end for
22: end function
4.2 ALFWorld Experiments
For the LLM-based implementation, we evaluated our approach within the ALFWorld simulator (Shridhar et al., 2020) and compared it against ReAct (Yao et al., 2022) and Reflexion (Shinn et al., 2023) as the baselines. ALFWorld is a synthetic, text-based game simulator with diverse interactive environments that challenge agents to solve multi-step tasks (e.g., “Find two plates and put them in a cabinet”). A unique aspect of ALFWorld is its emphasis on spatial and commonsense reasoning, requiring agents to infer probable locations of common household items; for example, recognizing that plates are typically found in kitchens. This characteristic makes ALFWorld particularly well-suited for leveraging the pre-trained commonsense knowledge of LLMs.
For these experiments, we selected the Mistral-7B-Instruct-v0.2 as the primary LLM (Jiang et al., 2023). This LLM features a substantial context window size of 32,000 tokens, allowing it to process large chunks of data in a single pass for improved in-context learning. Similar to the World-Model-based experiments, we employed a two-stage protocol comprising pre-deployment training on known tasks followed by deployment adaptation to unknown tasks. Each episode in these experiments had a maximum time limit of 50 steps. To further explore the robustness of our framework, we conducted additional experiments using smaller or less capable LLMs such as Mistral-7B-OpenOrca (Mukherjee et al., 2023; Open-Orca, 2024) and OpenELM-3B-Instruct (Mehta et al., 2024).
The MUSE agent underwent pre-deployment training using 140 household tasks from ALFWorld’s in-distribution (seen) set. For deployment adaptation, we evaluated all agents on 134 household tasks from ALFWorld’s out-of-distribution (unseen) set. The agents were exposed to one novel task at a time, starting with the pre-deployment trained weights (for MUSE) or pre-trained LLM weights (for ReAct and Reflexion), under two conditions: (1) five test episodes for each task without any adaptation and (2) five adaptation episodes followed by five test episodes for each task. The agents were assessed for performance on the novel tasks over the test episodes. Note that there were no weight updates to the MUSE agent during these episodes. While it is possible to continually update all constituent models of MUSE (namely, $M_{w}$ , $M_{a}$ , $M_{rx}$ , $M_{sa}$ ) using new data acquired from adaptation episodes, we chose to update only the MLP portion ( $g_{\eta}$ ) of $M_{sa}$ to minimize computational time without loss of any generality. We used a replay buffer that included both training data and new adaptation data to update $M_{sa}$ without catastrophic forgetting of pre-deployment trained performance.
4.2.1 Metrics
Self-Assessment We used metacognitive accuracy and AUROC2 to evaluate how well MUSE predicts its success on the novel tasks. MUSE was evaluated for each novel task separately over five test episodes, at the end of pre-deployment training and after five adaptation episodes. During each test episode, the trajectory was segmented into non-overlapping chunks, each containing four action-observation pairs. MUSE’s chunk-wise self-assessment predictions were then collected for evaluation, and the predictions for all chunks across tasks were compared against the true labels to compute the metacognitive accuracy and AUROC2 metrics. Note that, as the baseline agents, ReAct and Reflexion, lack a self-assessment module to predict episode outcomes, we cannot make a meaningful comparison between them and MUSE for self-assessment.
Self-Regulation We evaluated how well the agents generalize to unknown situations using two metrics: the percentage of the novel tasks solved and the average time to task completion. Each agent was assessed for each novel task separately over the five test episodes. The percentage of episodes in which the agent completed the task within the maximum time limit was averaged across all the novel tasks to calculate the success rate. Similarly, the number of time steps required to achieve success in each episode was averaged across all episodes and tasks to compute the time-to-completion metric. There was a penalty of 100 time steps for failures.
4.2.2 Results
Self-Assessment The self-assessment results are summarized in Table 2, with the corresponding Type 2 ROC curves shown in Figure 9. Following the five adaptation episodes, the MUSE agent achieved an AUROC2 of 0.93 and a metacognitive accuracy of 85%, demonstrating a high level of competence awareness.
Table 2: Self-assessment performance of the MUSE agent on the novel tasks in the ALFWorld environment, at the end of pre-deployment training (No Adaptation) and after five adaptation episodes (Adaptation).
| Condition | AUROC2 | Metacognitive Accuracy |
| --- | --- | --- |
| No Adaptation | 0.66 | 60% |
| Adaptation | 0.93 | 85% |
<details>
<summary>figures/self_aware_LLM.png Details</summary>
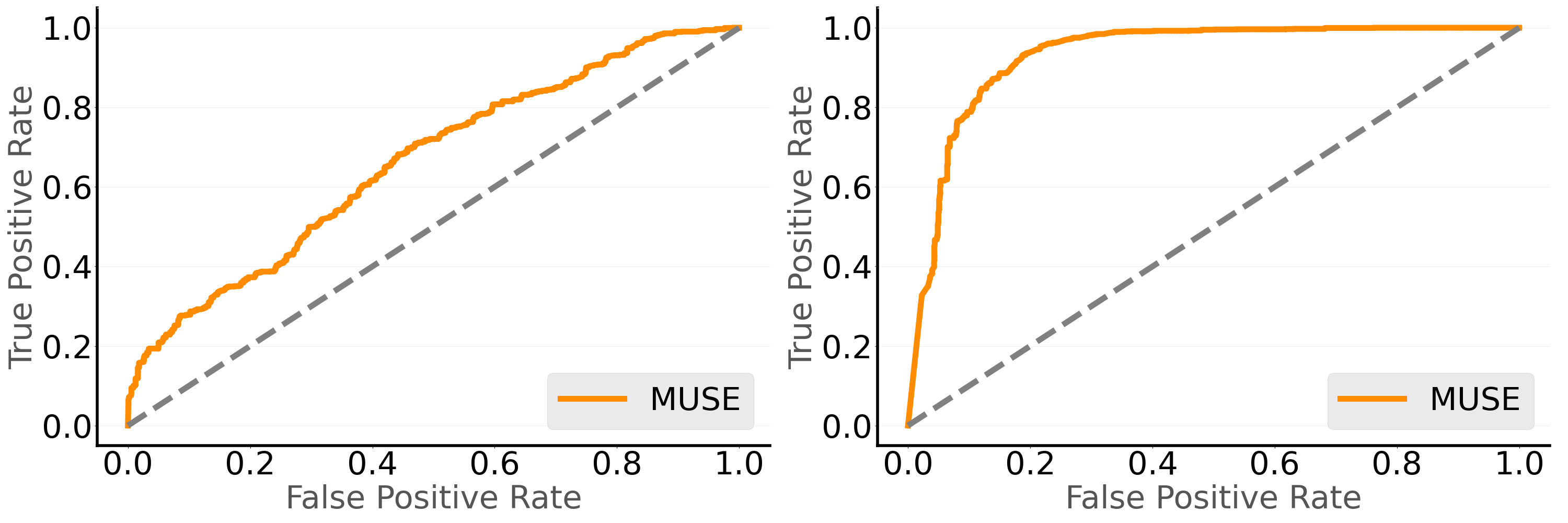
### Visual Description
## ROC Curve: MUSE Performance
### Overview
The image presents two Receiver Operating Characteristic (ROC) curves, both evaluating the performance of a model labeled "MUSE". The ROC curves plot the True Positive Rate against the False Positive Rate. The left chart shows a more gradual curve, while the right chart shows a steeper curve, indicating better performance. A dashed diagonal line represents the performance of a random classifier.
### Components/Axes
* **X-axis (False Positive Rate):** Ranges from 0.0 to 1.0 in both charts, with tick marks at intervals of 0.2.
* **Y-axis (True Positive Rate):** Ranges from 0.0 to 1.0 in both charts, with tick marks at intervals of 0.2.
* **Legend:** Located in the bottom-right corner of each chart. It identifies the orange curve as "MUSE".
* **Data Series:**
* **MUSE (Orange):** Represents the performance of the MUSE model.
* **Random Classifier (Dashed Gray):** Represents the performance of a random classifier.
### Detailed Analysis
**Left Chart:**
* **MUSE (Orange):** The curve starts at (0.0, 0.0) and gradually increases.
* At False Positive Rate = 0.2, True Positive Rate ≈ 0.35
* At False Positive Rate = 0.4, True Positive Rate ≈ 0.55
* At False Positive Rate = 0.6, True Positive Rate ≈ 0.75
* At False Positive Rate = 0.8, True Positive Rate ≈ 0.85
* At False Positive Rate = 1.0, True Positive Rate = 1.0
* **Random Classifier (Dashed Gray):** A straight line from (0.0, 0.0) to (1.0, 1.0).
**Right Chart:**
* **MUSE (Orange):** The curve rises sharply initially and then plateaus.
* At False Positive Rate = 0.05, True Positive Rate ≈ 0.7
* At False Positive Rate = 0.2, True Positive Rate ≈ 0.95
* At False Positive Rate = 0.4, True Positive Rate ≈ 0.98
* At False Positive Rate = 0.6, True Positive Rate ≈ 0.99
* At False Positive Rate = 1.0, True Positive Rate = 1.0
* **Random Classifier (Dashed Gray):** A straight line from (0.0, 0.0) to (1.0, 1.0).
### Key Observations
* The MUSE model performs significantly better in the right chart compared to the left chart.
* In the right chart, the MUSE model achieves a high True Positive Rate with a very low False Positive Rate.
* Both charts include a random classifier line for comparison.
### Interpretation
The ROC curves illustrate the discriminatory power of the MUSE model under two different conditions or configurations. The right chart indicates a superior model performance, as it quickly achieves a high True Positive Rate while maintaining a low False Positive Rate. This suggests that the MUSE model in the right chart is much better at correctly identifying positive cases while minimizing false alarms compared to the MUSE model in the left chart. The dashed line representing a random classifier serves as a baseline, and the MUSE model clearly outperforms this baseline in both scenarios, but especially in the right chart.
</details>
Figure 9: Type 2 ROC curves of the MUSE agent for self-assessment of competence on the novel tasks in the ALFWorld environment, at the end of pre-deployment training (left) and after five adaptation episodes (right).
Table 3: Self-Regulation: Success rate of various agents on the novel tasks, at the end of pre-deployment training (No Adaptation) and after five adaptation episodes (Adaptation).
| Agent | No Adaptation | Adaptation |
| --- | --- | --- |
| ReAct | 35% | 35% |
| Reflexion | 45% | 51% |
| Reflexion with supervised learning | 62% | 65% |
| MUSE with the lowest self-assessment | 59% | 61% |
| MUSE with random self-assessment | 68% | 69% |
| MUSE | 84% | 90% |
Table 4: Self-Regulation: Average number of time steps to success per episode for various agents on the novel tasks, at the end of pre-deployment training (No Adaptation) and after five adaptation episodes (Adaptation).
| Agent | No Adaptation | Adaptation |
| --- | --- | --- |
| ReAct | 97 | 97 |
| Reflexion | 77 | 66 |
| Reflexion with supervised learning | 61 | 54 |
| MUSE with the lowest self-assessment | 65 | 62 |
| MUSE with random self-assessment | 53 | 49 |
| MUSE | 43 | 38 |
Table 5: Self-Regulation: Success rate of various agents with smaller or less capable LLMs on the novel tasks, after five adaptation episodes.
| Agent | Mistral-7B-OpenOrca | OpenELM-3B-Instruct |
| --- | --- | --- |
| ReAct | 23% | 4% |
| Reflexion | 27% | 9% |
| MUSE | 58% | 55% |
To highlight the importance of self-assessment, we provide examples of trajectories generated by different agents. As shown in Supplementary Section 8.5, the key to MUSE’s success lies in its continual competence awareness. MUSE generates several rollout trajectories, assigns competence scores to each, and selects the one most likely to result in task success. For the given task, MUSE begins with an initial plan similar to that of Reflexion: “find a bowl, clean it at the sink, and then place it in the cabinet.” However, MUSE sets itself apart by engaging in deliberate actions that ensure steady progress toward the goal with increasing competence. After picking up the bowl from cabinet 1, MUSE evaluates multiple options, such as follows:
1. “think: Now I find a bowl (1). Next, I need to take it..OK..> take bowl 1 from cabinet 1.” … Score: 0.6284
1. “think: Now I take a bowl (1). Next, I need to go to sinkbasin (1) and clean it.” … Score: 0.8689
1. “think: Now I find a bowl (1). Next, I need to take it..OK..> take bowl 1 from cabinet 1. Nothing happens.” … Score: 0.6417
In this instance, MUSE selects Trajectory 1 due to its higher competence score, which indicates a greater likelihood of task success. By continually assessing its competence, MUSE adapts its strategy in real time to effectively navigate the environment’s complexities. It maintains a coherent plan and avoids redundant or detrimental actions that could lead to confusion or failure. In contrast, Reflexion fails due to its lack of competence awareness. After acquiring the bowl, Reflexion redundantly decides to find and take a bowl again. This leads to a faulty sequence of actions, causing Reflexion to enter an incorrect state from which it cannot recover. Without competence awareness, Reflexion fails to recognize that it already possesses the bowl. Its actions become increasingly erratic, failing to contribute toward task completion. For the complete trajectory, refer to Supplementary Section 8.5.
In summary, competence awareness allows MUSE to adapt more effectively to unfamiliar situations. By avoiding low-competence rollout trajectories, it steers clear of actions leading to failure, promotes exploration within the agent’s capabilities, and prevents the agent from getting stuck in unrecoverable states. This approach results in smarter exploration and more effective online learning in response to novel scenarios.
Self-Regulation The self-regulation results for MUSE and the two baseline agents are summarized in Tables 3 and 4. These results demonstrate that MUSE solves more novel tasks and requires fewer time steps to completion per episode, both at the end of pre-deployment training and after five adaptation episodes. Notably, MUSE achieved a high success rate of 90% on the 134 novel tasks, outperforming the baseline agents of ReAct and Reflexion by >150% and >75%, respectively. It’s important to note that all agents in the pertinent comparisons have access to the same data, ensuring a fair evaluation. ReAct and Reflexion can also respond adaptively to new experiences but rely only on in-context prompting and/or reflection. So, the observed performance gains for MUSE are from its ability to leverage available data more effectively by performing competence-aware planning, not from access to any privileged information. To clarify and validate this point, we conducted additional experiments comparing:
- Reflexion with supervised learning across the training tasks during pre-deployment (namely, DPO and SFT)
- MUSE with self-regulation based on the lowest self-assessment
- MUSE with self-regulation based on random self-assessment
The self-regulation results for these control conditions are also summarized in Tables 3 and 4. Reflexion with supervised learning during pre-deployment can consolidate knowledge across the training tasks, but exhibits only a limited improvement over its original implementation (Shinn et al., 2023) in adaptation to the novel tasks. This suggests that even a generalized reflection mechanism is less effective in novel scenarios without self-assessment and self-regulation. Furthermore, variants of MUSE using poor (random or pessimistic) self-assessment signals underperform, validating the importance of self-assessment for effective self-regulation. Note that even when self-assessment is flawed, the performance of the MUSE agent does not collapse because the Actor LLM ( $M_{a}$ ) has benefited from pre-deployment training to already generate reasonable plans for competence-aware selection.
To further evaluate the contribution of the self-assessment and self-regulation framework in MUSE beyond LLM-powered reasoning, we conducted additional experiments using smaller or less capable LLMs. Table 5 presents the post-adaptation performance of MUSE compared to the baseline agents when employing smaller or less capable LLM variants. MUSE maintained relatively higher success rates (55-58%) on the novel tasks, achieving >2x and >6x better performance than Reflexion when using Mistral-7B-OpenOrca and OpenELM-3B-Instruct, respectively. These results suggest that metacognition plays a particularly significant role when operating under constrained conditions, such as with smaller or less capable LLMs.
4.3 Discussion
Through these experiments, we evaluated the metacognitive capabilities of MUSE to showcase its superior performance over the baseline agents of ReAct and Reflexion. With reliable competence awareness on the novel tasks, the MUSE agent can make informed decisions by avoiding rollout trajectories likely to lead to failure and prioritizing those with a higher probability of task success for more effective online adaptation. MUSE’s ability to learn efficiently from a limited number of adaptation episodes is particularly critical in unknown situations and environments, where task complexity and novelty can vary significantly. Furthermore, its strong performance even with less-capable LLMs suggests that incorporating metacognitive components into mainstream AI agents can enhance performance under resource-constrained conditions. Overall, the LLM-based experiments demonstrated that integrating self-assessment and self-regulation into LLM-based agents can significantly improve their ability to handle unknown scenarios.
5 Conclusions
In this article, we introduced the Metacognition for Unknown Situations and Environments (MUSE) framework to integrate self-assessment and self-regulation into AI agents to enhance their adaptability to unknown situations and environments. MUSE uses self-assessed competence to intelligently guide an iterative trial-and-error process to identify the right strategy. In contrast, current AI agents either blindly execute their routine or policy, risking catastrophic failures, or freeze as a result of runtime anomaly detection. These limitations arise because big data-driven solutions inherently struggle to adapt to novel scenarios with little or no training data.
We presented two implementations of MUSE, one for MBRL agents and another for LLM-based agents, to instantiate the metacognitive cycle. In both cases, our experiments demonstrated that MUSE agents outperform baseline methods in handling novel tasks. These results show that MUSE facilitates problem-solving in unfamiliar environments by vetoing potentially catastrophic solutions, guiding the search toward strategies that leverage the agent’s strengths, and learning online from the environment with each attempt. In high-stakes applications like autonomous driving, MUSE can facilitate safety by relying on its self-assessment as a form of competence calibration. Furthermore, the online learning during deployment enables MUSE to fix and overcome potential metacognitive misjudgments in novel scenarios. This avoids the infinite regress of needing to calibrate the preceding lower-order calibration. In summary, by enabling agents to be aware of their competence and to regulate their strategies accordingly, MUSE offers a promising pathway toward developing more resilient and versatile AI systems.
6 Future Work
While MUSE outperforms the baseline AI agents, metacognition in AI remains a nascent and exploratory field. The scope of metacognitive abilities is broad, offering several promising directions for future research. For instance, MUSE could be expanded to include metacognitive judgments that further enhance an agent’s performance and learning. These include the Feeling of Knowing to help the agent persist in difficult, novel scenarios; the Judgment of Learning to facilitate resource-efficient learning; and Source Monitoring to assess the reliability of its knowledge. Another key avenue is integrating MUSE with lifelong learning techniques, such as generative experience replay and selective plasticity, to incrementally update its constituent models in new scenarios while mitigating catastrophic forgetting (Rostami et al., 2019; Kolouri et al., 2020; Kudithipudi et al., 2023). Such an integration would enable agents to retain and build upon previously learned knowledge while continually acquiring new skills, without requiring the storage of data from all prior conditions in the replay buffer, as was done in the current study.
Another exciting direction for future research involves applying MUSE to real-world domains, such as autonomous driving and robotics in unstructured settings. Investigating these domains for tasks with longer time horizons and larger state and action spaces will provide valuable insights into the scalability, robustness, and practicality of the MUSE framework. In this regard, MCTS methods can be adapted to leverage the self-assessment model from MUSE as the node evaluation function for guiding the search, enabling more effective exploration and problem-solving in complex environments. Another compelling avenue is expanding the metacognitive framework to incorporate additional aspects of human cognition that are currently absent in AI systems. For instance, integrating Theory-of-Mind could enhance agents’ abilities to understand and predict human behaviors, enabling more effective collaboration in social or teamwork-driven environments. Additionally, exploring multi-agent interactions within the MUSE framework offers significant potential. Enabling multiple metacognitive AI agents to interact, collaborate, negotiate, or compete could lead to more sophisticated and efficient problem-solving at the group level.
Our research highlights the potential of psychology- and brain-inspired approaches to address the limitations of current AI systems, particularly their dependence on extensive training data. By equipping AI agents with greater flexibility and adaptability, MUSE paves the way for more resilient and versatile systems capable of operating across a wide range of environments. We anticipate that future research will build upon and refine these ideas, advancing the field of metacognitive AI and expanding its applications across diverse domains.
7 Acknowledgments
The authors would like to thank Neale Ratzlaff for his invaluable contributions to this research and his constructive feedback.
8 Supplementary Material
Note that the trajectory examples provided below for the LLM-based experiments are exact copies of the LLM outputs.
8.1 Illustrative ALFWorld trajectories for in-context prompting. (Yao et al., 2022)
Interact with a household to solve a task. Here are two examples. // You are in the middle of a room. Looking quickly around you, you see a cabinet 13, a cabinet 12, a cabinet 11, a cabinet 10, a cabinet 9, a cabinet 8, a cabinet 7, a cabinet 6, a cabinet 5, a cabinet 4, a cabinet 3, a cabinet 2, a cabinet 1, a coffeemachine 1, a countertop 1, a diningtable 1, a drawer 1, a fridge 1, a garbagecan 1, a microwave 1, a shelf 3, a shelf 2, a shelf 1, a sinkbasin 1, a stoveburner 4, a stoveburner 3, a stoveburner 2, a stoveburner 1, and a toaster 1. Your task is to: put a hot apple in fridge. >think: To solve the task, I need to find and take an apple, then heat it with microwave, then put it in fridge. OK. >think: First I need to find an apple. An apple is more likely to appear in fridge (1), diningtable (1), coffeetable (1), drawer (1), cabinet (1-13), garbagecan (1). I can check one by one, starting with fridge 1. OK. >go to fridge 1 The fridge 1 is closed. >open fridge 1 You open the fridge 1. The fridge 1 is open. In it, you see a cup 1, and a egg 1. >go to diningtable 1 On the diningtable 1, you see a apple 1, a bread 1, a fork 3, a fork 2, a fork 1, a mug 2, a peppershaker 3, a plate 2, a pot 1, a soapbottle 3, a spatula 1, a spoon 3, a spoon 2, a spoon 1, a winebottle 3, and a winebottle 2. >think: Now I find an apple (1). Next, I need to take it. OK. >take apple 1 from diningtable 1 You pick up the apple 1 from the diningtable 1. >think: Now I take an apple (1). Next, I need to go to a microwave (1) and heat it. OK. >go to microwave 1 The microwave 1 is closed. >heat apple 1 with microwave 1 You heat the apple 1 using the microwave 1. >think: Now I heat an apple (1). Next, I need to put it in/on fridge 1. OK. >go to fridge 1 The fridge 1 is open. In it, you see a cup 1, and a egg 1. >put apple 1 in/on fridge 1 You put the apple 1 in/on the fridge 1. // You are in the middle of a room. Looking quickly around you, you see a cabinet 10, a cabinet 9, a cabinet 8, a cabinet 7, a cabinet 6, a cabinet 5, a cabinet 4, a cabinet 3, a cabinet 2, a cabinet 1, a coffeemachine 1, a countertop 3, a countertop 2, a countertop 1, a diningtable 1, a drawer 6, a drawer 5, a drawer 4, a drawer 3, a drawer 2, a drawer 1, a fridge 1, a garbagecan 1, a microwave 1, a sinkbasin 1, a stoveburner 4, a stoveburner 3, a stoveburner 2, a stoveburner 1, and a toaster 1. Your task is to: heat some egg and put it in diningtable. >think: To solve the task, I need to find and take an egg, then heat it with microwave, then put it in diningtable. OK. >think: First I need to find an egg. An egg is more likely to appear in fridge (1), countertop (1-3), diningtable (1), stoveburner (1-4), toaster (1), garbagecan (1), cabinet (1-10). I can check one by one, starting with fridge 1. OK. >open fridge 1 You open the fridge 1. The fridge 1 is open. In it, you see a lettuce 2, a mug 2, and a potato 3. >go to countertop 1 On the countertop 1, you see a bread 1, a fork 1, and a saltshaker 1. >go to countertop 2 On the countertop 2, you see nothing. >go to countertop 3 On the countertop 3, you see a bowl 1, a butterknife 1, a egg 2, a kettle 2, a plate 1, a sink 1, and a spatula 2. >think: Now I find an egg (2). Next, I need to take it. OK. >take egg 2 from countertop 3 You pick up the egg 2 from the countertop 3. >think: Now I take an egg (2). Next, I need go to a microwave (1) and heat it. OK. >go to microwave 1 The microwave 1 is closed. >heat egg 2 with microwave 1 You heat the egg 2 using the microwave 1. >think: Now I heat an egg (2). Next, I need to put it in/on diningtable 1. OK. >go to diningtable 1 On the diningtable 1, you see a apple 2, a bread 3, a egg 1, a kettle 1, a knife 1, a mug 1, a papertowelroll 1, a peppershaker 2, a potato 1, a soapbottle 1, and a spatula 1. >put egg 2 in/on diningtable 1 You put the egg 2 in/on the diningtable 1.
8.2 Example of ReAct’s decision-making
| Task: You are in the middle of a room. Looking quickly around you, you see a cabinet 6, a cabinet 5, a cabinet 4, a cabinet 3, a cabinet 2, a cabinet 1, a coffeemachine 1, a countertop 3, a countertop 2, a countertop 1, a drawer 3, a drawer 2, a drawer 1, a fridge 1, a garbagecan 1, a microwave 1, a shelf 3, a shelf 2, a shelf 1, a sinkbasin 1, a stoveburner 4, a stoveburner 3, a stoveburner 2, a stoveburner 1, and a toaster 1.Your task is to: put a hot tomato in garbagecan. |
| --- |
| ReAct’s trajectory: ReAct successfully identifies and picks a tomato. However, it encounters difficulties when attempting to heat it. The agent repetitively navigates to each of the stove burners, resulting in a continuous loop. |
| Conclusion: The trajectory ends with the agent trapped in a repetitive sequence of actions, unable to adjust its approach or adapt to the task of heating the tomato. |
>action: think: To solve the task, I need to find and take a tomato, then heat it with stoveburner, then put it in garbagecan. observation: OK. >action: think: First I need to find a tomato. A tomato is more likely to appear in fridge (1), countertop (1-3), cabinet (1-6), garbagecan (1), drawer (1-3). I can check one by one, starting with fridge 1. observation: OK. >action: open fridge 1 observation: Nothing happens. >action: go to countertop 1 observation: On the countertop 1, you see a dishsponge 1, and a tomato 1. >action: think: Now I find a tomato (1). Next, I need to take it. observation: OK. >action: take tomato 1 from countertop 1 observation: You pick up the tomato 1 from the countertop 1. >action: think: Now I take a tomato (1). Next, I need to go to a stoveburner (1-4) and heat it. observation: OK. >action: go to stoveburner 1 observation: On the stoveburner 1, you see nothing. >action: go to stoveburner 2 observation: On the stoveburner 2, you see nothing. >action: go to stoveburner 3 observation: On the stoveburner 3, you see nothing. >action: go to stoveburner 4 observation: On the stoveburner 4, you see nothing. >action: think: Now I need to find a stoveburner with a hot surface. I can check stoveburners 1-4. observation: OK. >action: go to stoveburner 1 observation: On the stoveburner 1, you see nothing. >action: go to stoveburner 2 observation: On the stoveburner 2, you see nothing. >action: go to stoveburner 3 observation: On the stoveburner 3, you see nothing. >action: go to stoveburner 4 observation: On the stoveburner 4, you see nothing. >action: think: I need to turn on a stoveburner and wait for it to heat up. I can check stoveburners 1-4. observation: OK. >action: turn on stoveburner 1 observation: Nothing happens. >action: turn on stoveburner 2 observation: Nothing happens. >action: turn on stoveburner 3 observation: Nothing happens. >action: turn on stoveburner 4 observation: Nothing happens. >action: think: I need to find a way to heat up a stoveburner. I can check the stove, the microwave, or the oven. observation: OK. >action: check stove observation: Nothing happens. >action: check microwave observation: Nothing happens. >action: check oven observation: Nothing happens. >action: think: I need to find a source of heat. I can check the stove, the microwave, or the oven. observation: OK. >action: check stove observation: Nothing happens. >action: check microwave observation: Nothing happens. >action: check oven observation: Nothing happens. >action: think: I need to find a way to heat up a tomato. I can check the stove, the microwave, or the oven. observation: OK. >action: check stove observation: Nothing happens. >action: check microwave observation: Nothing happens. >action: check oven observation: Nothing happens. >action: think: I need to find a way to heat up a tomato. I can check the stove, the microwave, or the oven. observation: OK. >action: check stove observation: Nothing happens. >action: check microwave observation: Nothing happens. >action: check oven observation: Nothing happens. >action: think: I need to find a way to heat up a tomato. I can check the stove, the microwave, or the oven. observation: OK. >action: check stove observation: Nothing happens. >action: check microwave observation: Nothing happens. >action: check oven observation: Nothing happens. >action: think: I need to find a way to heat up a tomato. I can check the stove, the microwave, or the oven. observation: OK. >action: check stove observation: Nothing happens. >action: check microwave observation: Nothing happens. >action: check oven observation: Nothing happens. >action: think: I need to find a way to heat up a tomato. I can check the stove, the microwave, or the oven. observation: OK. >action: check stove observation: Nothing happens. >action: check microwave observation: Nothing happens. >action: check oven observation: Nothing happens.
8.3 Example of Reflexion’s decision-making, demonstrating improvements over ReAct
| Task: You are in the middle of a room. Looking quickly around you, you see a cabinet 6, a cabinet 5, a cabinet 4, a cabinet 3, a cabinet 2, a cabinet 1, a coffeemachine 1, a countertop 3, a countertop 2, a countertop 1, a drawer 3, a drawer 2, a drawer 1, a fridge 1, a garbagecan 1, a microwave 1, a shelf 3, a shelf 2, a shelf 1, a sinkbasin 1, a stoveburner 4, a stoveburner 3, a stoveburner 2, a stoveburner 1, and a toaster 1.Your task is to: put a hot tomato in garbagecan. |
| --- |
| Reflexive feedback from first episode: “In this environment, my plan was to find a tomato, heat it on a stoveburner, and put it in the garbage can. However, I was unable to find a stoveburner with a hot surface. I should have checked the oven or microwave for alternative methods of heating the tomato. I will try to heat the tomato in the oven or microwave in the next trial.” |
| Reflexion’s trajectory: The Reflexion agent reflects on its initial failure to heat the tomato using the stove burners and identifies the potential to utilize alternative heating methods. In subsequent episodes, it successfully uses the microwave to heat the tomato. |
| Conclusion: This trajectory demonstrates the agent’s ability to learn from past mistakes and adapt its strategy, ultimately completing the task successfully by heating the tomato in the microwave and placing it in the garbage can. |
>action: think: To solve the task, I need to find and take a tomato, then heat it, and put it in garbagecan. observation: OK. >action: think: First I need to find a tomato. A tomato is more likely to appear in fridge (1), countertop (1-3), cabinet (1-6), garbagecan (1). I can check one by one, starting with fridge 1. observation: OK. >action: open fridge 1 observation: Nothing happens. >action: go to countertop 1 observation: On the countertop 1, you see a dishsponge 1, and a tomato 1. >action: think: Now I find a tomato (1). Next, I need to take it. observation: OK. >action: take tomato 1 from countertop 1 observation: You pick up the tomato 1 from the countertop 1. >action: think: Now I take a tomato (1). Next, I need to heat it. observation: OK. >action: think: I can heat a tomato in the microwave (1), oven, or on a stoveburner (1-4). I will try the microwave first. observation: OK. >action: go to microwave 1 observation: The microwave 1 is closed. >action: heat tomato 1 with microwave 1 observation: You heat the tomato 1 using the microwave 1. >action: think: Now I heat a tomato (1). Next, I need to put it in garbagecan 1. observation: OK. >action: go to garbagecan 1 observation: On the garbagecan 1, you see a egg 3, and a papertowelroll 1. >action: put tomato 1 in/on garbagecan 1 observation: You put the tomato 1 in/on the garbagecan 1.
8.4 Limitations of Reflexion compared to MUSE in strategic exploration and task execution
| Col1 |
| --- |
| Task: You are in the middle of a room. Looking quickly around you, you see a armchair 1, a cabinet 4, a cabinet 3, a cabinet 2, a cabinet 1, a drawer 5, a drawer 4, a drawer 3, a drawer 2, a drawer 1, a dresser 1, a garbagecan 1, a safe 1, a shelf 12, a shelf 11, a shelf 10, a shelf 9, a shelf 8, a shelf 7, a shelf 6, a shelf 5, a shelf 4, a shelf 3, a shelf 2, a shelf 1, a sidetable 1, and a sofa 1.Your task is to: put some watch on safe. |
| Reflexion’s trajectory: Reflexion initially plans to find a watch but begins its search in less likely locations instead of the dresser, the most probable spot. After inefficient exploration, it eventually locates the watch on the dresser. However, at the safe, it prematurely closes it without placing the watch inside, leading to a loop from which it cannot recover. |
| Conclusion: The trajectory ends with the agent stuck in a repetitive cycle, unable to adapt its strategy or correct its mistake in handling the watch and the safe. |
>action: think: To solve the task, I need to find and take a watch, then put it in the safe. observation: OK. >action: think: First I need to find a watch. A watch is more likely to appear in drawers (1-5), cabinet (1-4), dresser (1), and shelves (1-12). I can check one by one, starting with drawer 1. observation: OK. >action: go to drawer 1 observation: The drawer 1 is closed. >action: open drawer 1 observation: You open the drawer 1. The drawer 1 is open. In it, you see nothing. >action: go to drawer 2 observation: The drawer 2 is closed. >action: open drawer 2 observation: You open the drawer 2. The drawer 2 is open. In it, you see nothing. >action: go to drawer 3 observation: The drawer 3 is closed. >action: open drawer 3 observation: You open the drawer 3. The drawer 3 is open. In it, you see a creditcard 2. >action: go to drawer 4 observation: The drawer 4 is closed. >action: open drawer 4 observation: You open the drawer 4. The drawer 4 is open. In it, you see nothing. >action: go to drawer 5 observation: The drawer 5 is closed. >action: open drawer 5 observation: You open the drawer 5. The drawer 5 is open. In it, you see nothing. >action: go to cabinet 1 observation: The cabinet 1 is closed. >action: open cabinet 1 observation: You open the cabinet 1. The cabinet 1 is open. In it, you see a vase 1. >action: go to cabinet 2 observation: Nothing happens. >action: go to cabinet 3 observation: The cabinet 3 is closed. >action: open cabinet 3 observation: You open the cabinet 3. The cabinet 3 is open. In it, you see a tissuebox 2. >action: go to cabinet 4 observation: Nothing happens. >action: go to dresser 1 observation: On the dresser 1, you see a laptop 1, a remotecontrol 1, a tissuebox 1, a vase 3, a vase 2, and a watch 1. >action: think: Now I find a watch (1). Next, I need to take it. observation: OK. >action: take watch 1 from dresser 1 observation: You pick up the watch 1 from the dresser 1. >action: think: Now I take a watch (1). Next, I need to put it in/on safe 1. observation: OK. >action: go to safe 1 observation: The safe 1 is closed. >action: open safe 1 observation: You open the safe 1. The safe 1 is open. In it, you see a cellphone 3, and a cellphone 2. >action: think: The safe is not big enough for the watch and the cellphones. I should have put the watch in the safe, then closed the safe. I will try this new plan in the next trial. observation: OK. >action: close safe 1 observation: You close the safe 1. >action: put watch 1 in/on safe 1 observation: Nothing happens. >action: think: I need to put the watch in the safe, then close the safe. observation: OK. >action: put watch 1 in/on safe 1 observation: Nothing happens. >action: think: I need to put the watch in the safe, then close the safe. observation: OK. >action: put watch 1 in safe 1 observation: Nothing happens. >action: think: I need to put the watch in safe 1, then close the safe. observation: OK. >action: put watch 1 in safe 1 observation: Nothing happens. >action: think: I need to put the watch in safe 1, then close the safe. observation: OK. >action: put watch 1 in safe 1 observation: Nothing happens. >action: think: I need to put the watch in safe 1, then close the safe. observation: OK. >action: put watch 1 in safe 1 observation: Nothing happens. >action: think: I need to put the watch in safe 1, then close the safe. observation: OK. >action: put watch 1 in safe 1 observation: Nothing happens. >action: think: I need to put the watch in safe 1, then close the safe. observation: OK. >action: put watch 1 in safe 1 observation: Nothing happens. >action: think: I need to put the watch in safe 1, then close the safe. observation: OK. >action: put watch 1 in safe 1 observation: Nothing happens. >action: think: I need to put the watch in safe 1, then close the safe. observation: OK. >action: put watch 1 in safe 1 observation: Nothing happens. >action: think: I need to put the watch in safe 1, then close the safe. observation: OK. >action: put watch 1 in safe 1 observation: Nothing happens. >action: think: I need to put the watch in safe 1, then close the safe. observation: OK. >action: put watch 1 in safe 1 observation: Nothing happens.
| MUSE’s trajectory: MUSE begins with an intelligent search strategy, prioritizing the dresser as the most likely location for the watch. After efficiently locating the watch on the dresser, MUSE proceeds directly to the safe, opens it, places the watch inside, and completes the task without error. |
| --- |
| Conclusion: MUSE successfully completes the task through efficient exploration and precise execution, demonstrating effective problem-solving capabilities. |
>action: think: To solve the task, I need to find and take a watch, then put it in the safe. observation: OK. >action: think: First I need to find a watch. A watch is more likely to appear in dresser (1), cabinet (1-4), shelf (1-12), drawer (1-5). I can check one by one, starting with dresser 1. observation: OK. >action: go to dresser 1 observation: On the dresser 1, you see a laptop 1, a remotecontrol 1, a tissuebox 1, a vase 3, a vase 2, and a watch 1. >action: take watch 1 from dresser 1 observation: You pick up the watch 1 from the dresser 1. >action: think: Now I find a watch (1). Next, I need to put it in/on safe 1. observation: OK. >action: go to safe 1 observation: The safe 1 is closed. >action: open safe 1 observation: You open the safe 1. The safe 1 is open. In it, you see a cellphone 3, and a cellphone 2. >action: put watch 1 in/on safe 1 observation: You put the watch 1 in/on the safe 1.
8.5 Competence-aware action selection: A key advantage of MUSE over Reflexion
>action: think: To solve the task, I need to find and take a bowl, then clean it with sinkbasin, then put it in cabinet. observation: OK. >action: think: First I need to find a bowl. A bowl is more likely to appear in cabinet (1-6), countertop (1-3), sinkbasin (1), stoveburner (1-4), fridge (1). I can check one by one, starting with cabinet 1. observation: OK. >action: go to cabinet 1 observation: On the cabinet 1, you see a bowl 1. >action: take bowl 1 from cabinet 1 observation: You pick up the bowl 1 from the cabinet 1. >action: think: Now I find a bowl (1). Next, I need to take it. observation: OK. >action: take bowl 1 from cabinet 1 observation: Nothing happens. >action: think: I need to go to countertop 1 observation: OK. >action: go to countertop 1 observation: On the countertop 1, you see a creditcard 1, a egg 3, and a glassbottle 1. >action: think: Now I find a bowl (3). Next, I need to go to countertop 3 and find it. observation: OK. >action: go to countertop 3 observation: On the countertop 3, you see a bread 3, a cellphone 1, a glassbottle 3, a houseplant 1, a knife 3, a knife 2, a potato 3, a spatula 2, a spatula 1, a spoon 1, a statue 2, and a tomato 1. >action: take bowl 3 from countertop 3 observation: Nothing happens. >action: think: I can’t find bowl 3 in countertop 3. Maybe it’s in drawer (1-3). observation: OK. >action: go to drawer 3 observation: The drawer 3 is closed. >action: open drawer 3 observation: You open the drawer 3. The drawer 3 is open. In it, you see a fork 2, and a saltshaker 2. >action: think: Now I find a bowl (3). Next, I need to take it. observation: OK. >action: take bowl 3 from drawer 3 observation: Nothing happens. >action: think: I can’t find a bowl (3) in drawer (3). Maybe it’s in countertop (1-3) or cabinet (1-6). observation: OK. >action: go to countertop 1 observation: On the countertop 1, you see a creditcard 1, a egg 3, and a glassbottle 1. >action: take bowl 3 from countertop 1 observation: Nothing happens. >action: think: I can’t find a bowl (3) in countertop (1-3). Maybe it’s in drawer (1-3). observation: OK. >action: go to drawer 2 observation: The drawer 2 is closed. >action: open drawer 2 observation: You open the drawer 2. The drawer 2 is open. In it, you see a fork 1. >action: take bowl 3 from drawer 2 observation: Nothing happens. >action: think: I can’t find a bowl (3) in drawer (2). Maybe it’s in countertop (1-3) or cabinet (1-6). observation: OK. >action: go to countertop 1 observation: On the countertop 1, you see a creditcard 1, a egg 3, and a glassbottle 1. >action: take bowl 3 from countertop 1 observation: Nothing happens. >action: think: I can’t find a bowl (3) in countertop (1-3). Maybe it’s in cabinet (1-6). observation: OK. >action: go to cabinet 1 observation: On the cabinet 1, you see nothing. >action: go to cabinet 2 observation: The cabinet 2 is closed. >action: open cabinet 2 observation: You open the cabinet 2. The cabinet 2 is open. In it, you see a vase 1. >action: go to cabinet 3 observation: On the cabinet 3, you see a plate 1. >action: take bowl 3 from cabinet 3 observation: Nothing happens. >action: think: I can’t find a bowl (3) in cabinet (3-1). Maybe it’s in countertop (1-3) or drawer (1-3). observation: OK. >action: go to countertop 1 observation: On the countertop 1, you see a creditcard 1, a egg 3, and a glassbottle 1. >action: take bowl 3 from countertop 1 observation: Nothing happens. >action: think: I can’t find a bowl (3) in countertop (1-3). Maybe it’s in drawer (1-3). observation: OK. >action: go to drawer 1 observation: The drawer 1 is closed. >action: open drawer 1 observation: You open the drawer 1. The drawer 1 is open. In it, you see a peppershaker 1, and a saltshaker 1. >action: think: Now I find a bowl (3). It’s a potato 1. observation: OK. >action: take potato 1 from drawer 1 observation: Nothing happens. >action: think: I can’t find a bowl (3) in drawer (1). Maybe it’s in countertop (1-3) or cabinet (1-13). observation: OK. >action: go to countertop 1 observation: On the countertop 1, you see a creditcard 1, a egg 3, and a glassbottle 1. >action: think: Now I find a bowl (3). It’s a potato 1. observation: OK. >action: think: Now I find a bowl (3). It’s a potato 1. Next, I need to take it. observation: OK. >action: take potato 1 from countertop 1 observation: Nothing happens. >action: think: I can’t take a bowl (3) from countertop (1-3). Maybe it’s in cabinet (1-13). observation: OK. >action: go to cabinet 1 observation: On the cabinet 1, you see nothing. >action: go to cabinet 2 observation: The cabinet 2 is open. In it, you see a vase 1. >action: take bowl 3 from cabinet 2 observation: Nothing happens.
>action selected: think: To solve the task, I need to find and take a bowl, then clean it with sinkbasin, then put it in cabinet. observation: OK. >action selected: think: First I need to find a bowl. A bowl is more likely to appear in cabinet (1-6), countertop (1-3), sinkbasin (1), or garbagecan (1). I can check one by one, starting with cabinet 1. observation: OK. >action selected: go to cabinet 1 observation: On the cabinet 1, you see a bowl 1. >action selected: take bowl 1 from cabinet 1 observation: You pick up the bowl 1 from the cabinet 1. >action selected: think: Now I take a bowl (1). Next, I need to go to sinkbasin (1) and clean it. observation: OK. >action selected: go to sinkbasin 1 observation: On the sinkbasin 1, you see nothing. >action selected: clean bowl 1 with sinkbasin 1 observation: You clean the bowl 1 using the sinkbasin 1. >action selected: think: Now I clean a bowl (1). Next, I need to put it in/on cabinet 1. observation: OK. >action selected: go to cabinet 1 observation: On the cabinet 1, you see nothing. >action selected: put bowl 1 in/on cabinet 1 observation: You put the bowl 1 in/on the cabinet 1.
Detailed trajectory of the MUSE agent, which highlights the benefits of competence awareness in strategic planning and action selection >action selected: think: To solve the task, I need to find and take a bowl, then clean it with sinkbasin, then put it in cabinet. observation: OK. >action selected: think: First I need to find a bowl. A bowl is more likely to appear in cabinet (1-6), countertop (1-3), sinkbasin (1), or garbagecan (1). I can check one by one, starting with cabinet 1. observation: OK. Imagine Trajectory 0: go to cabinet 1.The cabinet 1 is closed..> open cabinet 1.You open the cabinet 1. The cabinet 1 is open. In it, you see a glassbottle 1..> go to cabinet 2.The cabinet 2 is closed..> open cabinet 2.You open the cabinet 2 Imagine Trajectory 1: go to cabinet 1.The cabinet 1 is closed..> open cabinet 1.You open the cabinet 1. The cabinet 1 is open. In it, you see a saltshaker 1..> go to cabinet 2.The cabinet 2 is closed..> open cabinet 2.You open the cabinet 2. Imagine Trajectory 2: go to cabinet 1.The cabinet 1 is closed..> open cabinet 1.You open the cabinet 1. The cabinet 1 is open. In it, you see a bowl 2..> go to cabinet 2.The cabinet 2 is closed..> open cabinet 2.You open the cabinet 2. Imagine Trajectory Score 0 : 0.6981 Imagine Trajectory Score 1 : 0.6585 Imagine Trajectory Score 2 : 0.6284 >action selected: go to cabinet 1 observation: On the cabinet 1, you see a bowl 1. Imagine Trajectory 0: take bowl 1 from cabinet 1.You pick up the bowl 1 from the cabinet 1..> think: Now I find a bowl (1). Next, I need to take it..OK..> take bowl 1 from cabinet 1.You pick up the bowl 1 from the cabinet 1. Imagine Trajectory 1: take bowl 1 from cabinet 1.You pick up the bowl 1 from the cabinet 1..> think: Now I take a bowl (1). Next, I need to go to sinkbasin 1 and clean it..OK..> go to sinkbasin 1.On the sinkbasin 1, you see nothing. Imagine Trajectory 2: take bowl 1 from cabinet 1.You pick up the bowl 1 from the cabinet 1..> think: Now I take a bowl (1). Next, I need to go to sinkbasin 1 and clean it..OK..> go to sinkbasin 1.On the sinkbasin 1, you see nothing. Imagine Trajectory Score 0 : 0.6284 Imagine Trajectory Score 1 : 0.8689 Imagine Trajectory Score 2 : 0.6417 >action selected: take bowl 1 from cabinet 1 observation: You pick up the bowl 1 from the cabinet 1. Imagine Trajectory 0: think: Now I find a bowl (1). Next, I need to take it..OK..> take bowl 1 from cabinet 1.You pick up the bowl 1 from the cabinet 1..> think: Now I take a bowl (1). Next, I need to go to sinkbasin (1) and clean it.. Imagine Trajectory 1: think: Now I take a bowl (1). Next, I need to go to sinkbasin (1) and clean it..OK..> go to sinkbasin 1.On the sinkbasin 1, you see nothing..> clean bowl 1 with sinkbasin 1.You clean the bowl 1 using the sinkbasin Imagine Trajectory 2: think: Now I find a bowl (1). Next, I need to take it..OK..> take bowl 1 from cabinet 1.Nothing happens..> think: I need to wait a while before I can find a bowl (1)..OK..> go to countertop 2.On the countertop 2, you Imagine Trajectory Score 0 : 0.1265 Imagine Trajectory Score 1 : 0.7831 Imagine Trajectory Score 2 : 0.0126 >action selected: think: Now I take a bowl (1). Next, I need to go to sinkbasin (1) and clean it. observation: OK. Imagine Trajectory 0: go to sinkbasin 1.On the sinkbasin 1, you see nothing..> clean bowl 1 with sinkbasin 1.You clean the bowl 1 using the sinkbasin 1..> think: Now I clean the bowl 1 with sinkbasin 1. Next, I need to put it in/on Imagine Trajectory 1: go to sinkbasin 1.On the sinkbasin 1, you see nothing..> clean bowl 1 with sinkbasin 1.You clean the bowl 1 using the sinkbasin 1..> think: Now I clean a bowl (1). Next, I need to put it in/on cabinet 1..OK Imagine Trajectory 2: go to sinkbasin 1.On the sinkbasin 1, you see nothing..> clean bowl 1 with sinkbasin 1.You clean the bowl 1 using the sinkbasin 1..> think: Now I clean the bowl 1 with sinkbasin 1. Next, I need to put it in/on Imagine Trajectory Score 0 : 0.6139 Imagine Trajectory Score 1 : 0.8206 Imagine Trajectory Score 2 : 0.5012 >action selected: go to sinkbasin 1 observation: On the sinkbasin 1, you see nothing. Imagine Trajectory 0: clean bowl 1 with sinkbasin 1.You clean the bowl 1 using the sinkbasin 1..> think: Now I clean the bowl 1 with sinkbasin 1. Next, I need to put it in/on cabinet 1..OK..> go to cabinet 1.The cabinet 1 is closed. Imagine Trajectory 1: clean bowl 1 with sinkbasin 1.You clean the bowl 1 using the sinkbasin 1..> think: Now I clean a bowl (1). Next, I need to put it in/on cabinet (1-6)..OK..> go to cabinet 6.The cabinet 6 is closed..> open cabinet Imagine Trajectory 2: clean bowl 1 with sinkbasin 1.You clean the bowl 1 using the sinkbasin 1..> think: Now I clean a bowl (1). Next, I need to put it in/on cabinet 1..OK..> go to cabinet 1.The cabinet 1 is closed..> open cabinet 1 Imagine Trajectory Score 0 : 0.7847 Imagine Trajectory Score 1 : 0.5952 Imagine Trajectory Score 2 : 0.7003 >action selected: clean bowl 1 with sinkbasin 1 observation: You clean the bowl 1 using the sinkbasin 1. Imagine Trajectory 0: think: Now I clean a bowl (1). Next, I need to put it in/on cabinet 1..OK..> go to cabinet 1.The cabinet 1 is closed..> open cabinet 1.You open the cabinet 1. The cabinet 1 is open. In it, you see a dishsponge 1 Imagine Trajectory 1: think: Now I clean a bowl (1). Next, I need to put it in/on cabinet 1..OK..> go to cabinet 1.The cabinet 1 is closed..> open cabinet 1.You open the cabinet 1. The cabinet 1 is open. In it, you see a bowl 1..> Imagine Trajectory 2: think: Now I clean the bowl 1 with sinkbasin 1. Next, I need to put it in/on cabinet 1..OK..> go to cabinet 1.The cabinet 1 is closed..> open cabinet 1.You open the cabinet 1. The cabinet 1 is open. In it, you see a Imagine Trajectory Score 0 : 0.7106 Imagine Trajectory Score 1 : 0.8489 Imagine Trajectory Score 2 : 0.8093 >action selected: think: Now I clean a bowl (1). Next, I need to put it in/on cabinet 1. observation: OK. Imagine Trajectory 0: go to cabinet 1.The cabinet 1 is closed..> open cabinet 1.You open the cabinet 1. The cabinet 1 is open. In it, you see a bowl 1..> put bowl 1 in/on cabinet 1.You put the bowl 1 in/on the cabinet 1..You are in Imagine Trajectory 1: go to cabinet 1.The cabinet 1 is closed..> open cabinet 1.You open the cabinet 1. The cabinet 1 is open. In it, you see a bowl 1..> think: Now I find a bowl (1). Next, I need to take it..OK..> take bowl 1 from cabinet 1 Imagine Trajectory 2: go to cabinet 1.On the cabinet 1, you see a bowl 1..> put bowl 1 in/on cabinet 1.You put the bowl 1 in/on the cabinet 1..Make sure you put items “in/on” instead of “in”. Make sure you interact with and refer to items by name and number Imagine Trajectory Score 0 : 0.7794 Imagine Trajectory Score 1 : 0.7131 Imagine Trajectory Score 2 : 0.5139 >action selected: go to cabinet 1 observation: On the cabinet 1, you see nothing. Imagine Trajectory 0: put bowl 1 in/on cabinet 1.You put the bowl 1 in cabinet 1..> think: Now I put bowl 1 in cabinet 1..OK..> go to cabinet 1.The cabinet 1 is closed..> open cabinet 1 Imagine Trajectory 1: open cabinet 1.You open the cabinet 1. The cabinet 1 is open. In it, you see a bowl 1..> take bowl 1 from cabinet 1.You pick up the bowl 1 from the cabinet 1..> think: Now I find a bowl (1). Next, I need to clean it with sinkbasin 1 Imagine Trajectory 2: put bowl 1 in/on cabinet 1.Nothing happens..> think: I need to wait a few seconds before putting it in cabinet..OK..> think: Now I put bowl 1 in/on cabinet 1..OK..> go to cabinet 1.The cabinet 1 is closed..> open cabinet 1 Imagine Trajectory Score 0 : 0.8193 Imagine Trajectory Score 1 : 0.0106 Imagine Trajectory Score 2 : 0.6214 >action selected: put bowl 1 in/on cabinet 1 observation: You put the bowl 1 in/on the cabinet 1.
References
- Asai et al. (2023) Akari Asai, Zeqiu Wu, Yizhong Wang, Avirup Sil, and Hannaneh Hajishirzi. Self-RAG: Learning to retrieve, generate, and critique through self-reflection. arXiv preprint arXiv:2310.11511, 2023.
- Brohan et al. (2023) Anthony Brohan, Noah Brown, Justice Carbajal, Yevgen Chebotar, Xi Chen, Krzysztof Choromanski, Tianli Ding, Danny Driess, Avinava Dubey, Chelsea Finn, Pete Florence, Chuyuan Fu, Montse Gonzalez Arenas, Keerthana Gopalakrishnan, Kehang Han, Karol Hausman, Alexander Herzog, Jasmine Hsu, Brian Ichter, Alex Irpan, Nikhil Joshi, Ryan Julian, Dmitry Kalashnikov, Yuheng Kuang, Isabel Leal, Lisa Lee, Tsang-Wei Edward Lee, Sergey Levine, Yao Lu, Henryk Michalewski, Igor Mordatch, Karl Pertsch, Kanishka Rao, Krista Reymann, Michael Ryoo, Grecia Salazar, Pannag Sanketi, Pierre Sermanet, Jaspiar Singh, Anikait Singh, Radu Soricut, Huong Tran, Vincent Vanhoucke, Quan Vuong, Ayzaan Wahid, Stefan Welker, Paul Wohlhart, Jialin Wu, Fei Xia, Ted Xiao, Peng Xu, Sichun Xu, Tianhe Yu, and Brianna Zitkovich. RT-2: Vision-language-action models transfer web knowledge to robotic control. arXiv preprint arXiv:2307.15818, 2023.
- Chatzipanteli et al. (2014) Athanasia Chatzipanteli, Vasilis Grammatikopoulos, and Athanasios Gregoriadis. Development and evaluation of metacognition in early childhood education. Early Child Development and Care, 184(8):1223–1232, 2014.
- Chen et al. (2017) Patricia Chen, Omar Chavez, Desmond C Ong, and Brenda Gunderson. Strategic resource use for learning: A self-administered intervention that guides self-reflection on effective resource use enhances academic performance. Psychological Science, 28(6):774–785, 2017.
- Chen et al. (2022) Wenhu Chen, Xueguang Ma, Xinyi Wang, and William W Cohen. Program of thoughts prompting: Disentangling computation from reasoning for numerical reasoning tasks. arXiv preprint arXiv:2211.12588, 2022.
- Cohen (2012) Marisa Cohen. The importance of self-regulation for college student learning. College Student Journal, 46(4):892–902, 2012.
- Collaboration et al. (2023) Open X-Embodiment Collaboration, Abby O’Neill, Abdul Rehman, Abhinav Gupta, et al. Open X-embodiment: Robotic learning datasets and RT-X models. arXiv preprint arXiv:2310.08864, 2023.
- Corbiere et al. (2019) Charles Corbière, Nicolas Thome, Avner Bar-Hen, Matthieu Cord, and Patrick Pérez. Addressing failure prediction by learning model confidence. Advances in Neural Information Processing Systems, 32, 2019.
- Dunlosky and Bjork (2013) John Dunlosky and Robert A Bjork. Handbook of Metamemory and Memory. Psychology Press, 2013.
- Dunlosky and Metcalfe (2008) John Dunlosky and Janet Metcalfe. Metacognition. Sage Publications, 2008.
- Dunning (2011) David Dunning. The Dunning–Kruger effect: On being ignorant of one’s own ignorance. Advances in Experimental Social Psychology, 44:247–296, 2011.
- Flavell (1979) John Flavell. Metacognition and cognitive monitoring: A new area of cognitive–developmental inquiry. American Psychologist, 34(10):906, 1979.
- Fleming (2024) Stephen M Fleming. Metacognition and confidence: A review and synthesis. Annual Review of Psychology, 75(1):241–268, 2024.
- Fleming and Lau (2014) Stephen M Fleming and Hakwan C Lau. How to measure metacognition. Frontiers in Human Neuroscience, 8, 443, 2014.
- Gou et al. (2023) Zhibin Gou, Zhihong Shao, Yeyun Gong, Yelong Shen, Yujiu Yang, Nan Duan, and Weizhu Chen. Critic: Large language models can self-correct with tool-interactive critiquing. arXiv preprint arXiv:2305.11738, 2023.
- Grossberg (1980) Stephen Grossberg. How does a brain build a cognitive code? Psychological Review, 87:1–51, 1980.
- Ha and Schmidhuber (2018) David Ha and Jürgen Schmidhuber. World Models. arXiv preprint arXiv:1803.10122, 2018.
- Hafner et al. (2023) Danijar Hafner, Jurgis Pasukonis, Jimmy Ba, and Timothy Lillicrap. Mastering diverse domains through World Models. arXiv preprint arXiv:2301.04104, 2023.
- Hansen et al. (2022) Nicklas Hansen, Yixin Lin, Hao Su, Xiaolong Wang, Vikash Kumar, and Aravind Rajeswaran. MoDem: Accelerating visual model-based reinforcement learning with demonstrations. arXiv preprint arXiv:2212.05698, 2022.
- Hansen et al. (2023) Nicklas Hansen, Hao Su, and Xiaolong Wang. TD-MPC2: Scalable, robust world models for continuous control. arXiv preprint arXiv:2310.16828, 2023.
- Hu et al. (2021) Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. LoRA: Low-rank adaptation of large language models. arXiv preprint arXiv:2106.09685, 2021.
- Hu et al. (2023) Xinyu Hu, Pengfei Tang, Simiao Zuo, Zihan Wang, Bowen Song, Qiang Lou, Jian Jiao, and Denis Charles. Evoke: Evoking critical thinking abilities in LLMs via reviewer-author prompt editing. arXiv preprint arXiv:2310.13855, 2023.
- Huang et al. (2023) Jie Huang, Xinyun Chen, Swaroop Mishra, Huaixiu Steven Zheng, Adams Wei Yu, Xinying Song, and Denny Zhou. Large language models cannot self-correct reasoning yet. arXiv preprint arXiv:2310.01798, 2023.
- Isaacson and Fujita (2006) Randy Isaacson and Frank Fujita. Metacognitive knowledge monitoring and self-regulated learning. Journal of the Scholarship of Teaching and Learning, 6(1): 39–55, 2006.
- Jiang et al. (2023) Albert Q Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lucile Saulnier, et al. Mistral 7B. arXiv preprint arXiv:2310.06825, 2023.
- Ketz and Pilly (2022) Nicholas A Ketz and Praveen K Pilly. Concept-modulated model-based offline reinforcement learning for rapid generalization. arXiv preprint arXiv:2209.03207, 2022.
- Kolouri et al. (2020) Soheil Kolouri, Nicholas Ketz, Andrea Soltoggio, and Praveen Pilly. Sliced Cramer synaptic consolidation for preserving deeply learned representations. International Conference on Learning Representations, 2020.
- Koriat (1997) Asher Koriat. Monitoring one’s own knowledge during study: A cue-utilization approach to judgments of learning. Journal of Experimental Psychology: General, 126(4):349, 1997.
- Koul et al. (2020) Anurag Koul, Varun V. Kumar, Alan Fern, and Somdeb Majumdar. Dream and search to control: Latent space planning for continuous control. arXiv preprint arXiv:2010.09832, 2020.
- Kramarski and Mevarech (2003) Bracha Kramarski and Zemira Mevarech. Enhancing mathematical reasoning in the classroom: Effects of cooperative learning and metacognitive training. American Educational Research Journal, 40, 281–310, 2003.
- Kruger and Dunning (1999) Justin Kruger and David Dunning. Unskilled and unaware of it: How difficulties in recognizing one’s own incompetence lead to inflated self-assessments. Journal of Personality and Social Psychology, 77(6):1121, 1999.
- Kudithipudi et al. (2023) Dhireesha Kudithipudi, Mario Aguilar-Simon, Jonathan Babb, et al. Biological underpinnings for lifelong learning machines. Nature Machine Intelligence, 4(3):196–210, 2023.
- Lu et al. (2025) Xiaping Lu, Carsten Murawski, Peter Bossaerts, and Shinsuke Suzuki. Estimating self-performance when making complex decisions. Scientific Reports, 15(1), 3203, 2025.
- Madaan et al. (2023) Aman Madaan, Niket Tandon, Prakhar Gupta, Skyler Hallinan, Luyu Gao, Sarah Wiegreffe, Uri Alon, Nouha Dziri, Shrimai Prabhumoye, Yiming Yang, et al. Self-Refine: Iterative refinement with self-feedback. arXiv preprint arXiv:2303.17651, 2023.
- Mandi et al. (2023) Zhao Mandi, Homanga Bharadhwaj, Vincent Moens, Shuran Song, Aravind Rajeswaran, and Vikash Kumar. CACTI: A framework for scalable multi-task multi-scene visual imitation learning. arXiv preprint arXiv:2212.05711, 2023.
- Maniscalco and Lau (2012) Brian Maniscalco and Hakwan Lau. A signal detection theoretic approach for estimating metacognitive sensitivity from confidence ratings. Consciousness and Cognition, 21(1), 422–430, 2025.
- Mehta et al. (2024) Sachin Mehta, Mohammad Hossein Sekhavat, Qingqing Cao, Maxwell Horton, Yanzi Jin, Chenfan Sun, Iman Mirzadeh, Mahyar Najibi, Dmitry Belenko, Peter Zatloukal, et al. OpenELM: An efficient language model family with open-source training and inference framework. arXiv preprint arXiv:2404.14619, 2024.
- Metcalfe et al. (1993) Janet Metcalfe, Bennett L Schwartz, and Scott G Joaquim. The cue-familiarity heuristic in metacognition. Journal of Experimental Psychology: Learning, Memory, and Cognition, 19(4):851, 1993.
- Micheli et al. (2023) Vincent Micheli, Eloi Alonso, and François Fleuret. Transformers are sample-efficient World Models. arXiv preprint arXiv:2209.00588, 2023.
- Middlebrooks et al. (2012) Paul Middlebrooks and Marc Sommer. Neuronal correlates of metacognition in primate frontal cortex. Neuron, 75(3):517–530, 2012.
- Miyamoto et al. (2017) Kentaro Miyamoto, Takahiro Osada, Rieko Setsuie, Masaki Takeda, Keita Tamura, Yusuke Adachi, and Yasushi Miyashita. Causal neural network of metamemory for retrospection in primates. Science, 355(6321):188–193, 2017.
- Moerland et al. (2023) Thomas Moerland, Joost Broekens, Aske Plaat, and Catholijn Jonker. Model-based reinforcement learning: A survey. Foundations and Trends® in Machine Learning, 16(1):1–118, 2023.
- Mukherjee et al. (2023) Subhabrata Mukherjee, Arindam Mitra, Ganesh Jawahar, Sahaj Agarwal, Hamid Palangi, and Ahmed Awadallah. Orca: Progressive learning from complex explanation traces of GPT-4. arXiv preprint arXiv:2306.02707, 2023.
- Nelson and Narens (1990) Thomas O Nelson and Louis Narens. Metamemory: A theoretical framework and new findings. Academic Press, 1990.
- Open-Orca (2024) Open-Orca. Mistral-7B-OpenOrca. https://huggingface.co/Open-Orca/Mistral-7B-OpenOrca, 2024.
- Paul et al. (2023) Debjit Paul, Mete Ismayilzada, Maxime Peyrard, Beatriz Borges, Antoine Bosselut, Robert West, and Boi Faltings. Refiner: Reasoning feedback on intermediate representations. arXiv preprint arXiv:2304.01904, 2023.
- Rafailov et al. (2024) Rafael Rafailov, Archit Sharma, Eric Mitchell, Christopher D. Manning, Stefano Ermon, and Chelsea Finn. Direct Preference Optimization: Your language model is secretly a reward model. Advances in Neural Information Processing Systems, 36, 2024.
- Robine et al. (2023) Jan Robine, Marc Höftmann, Tobias Uelwer, and Stefan Harmeling. Transformer-based World Models are happy with 100K interactions. arXiv preprint arXiv:2303.07109, 2023.
- Rostami et al. (2019) Mohammad Rostami, Soheil Kolouri, and Praveen Pilly. Complementary learning for overcoming catastrophic forgetting using experience replay. arXiv preprint arXiv:1903.04566, 2019.
- Schraw (1998) Gregory Schraw. Promoting general metacognitive awareness. Instructional Science, 26:113–125, 1998.
- Schraw et al. (2006) Gregory Schraw, Kent Crippen, and Kendall Hartley. Promoting self-regulation in science education: Metacognition as part of a broader perspective on learning. Research in Science Education, 36, 111–139, 2006.
- SentenceTransformers (2024) SentenceTransformers. all-MiniLM-L6-v2. https://huggingface.co/sentence-transformers/all-MiniLM-L6-v2, 2024.
- Shinn et al. (2023) Noah Shinn, Federico Cassano, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. Reflexion: Language agents with verbal reinforcement learning. Advances in Neural Information Processing Systems, 36:8634–8652, 2023.
- Shridhar et al. (2020) Mohit Shridhar, Xingdi Yuan, Marc-Alexandre Côté, Yonatan Bisk, Adam Trischler, and Matthew Hausknecht. ALFWorld: Aligning text and embodied environments for interactive learning. arXiv preprint arXiv:2010.03768, 2020.
- Silver et al. (2016) David Silver, Aja Huang, Chris J Maddison, Arthur Guez, Laurent Sifre, George Van Den Driessche, Julian Schrittwieser, Ioannis Antonoglou, Veda Panneershelvam, Marc Lanctot, et al. Mastering the game of Go with deep neural networks and tree search. Nature, 529(7587):484–489, 2016.
- Silver et al. (2017) David Silver, Julian Schrittwieser, Karen Simonyan, et al. Mastering the game of Go without human knowledge. Nature, 550(7676):354–359, 2017.
- Silver et al. (2018) David Silver, Thomas Hubert, Julian Schrittwieser, et al. A general reinforcement learning algorithm that masters chess, shogi, and Go through self-play. Science, 362(6419):1140–1144, 2018.
- Sutton (1991) Richard S. Sutton. Dyna, an integrated architecture for learning, planning, and reacting. SIGART Bulletin, 2(4):160–163, 1991.
- Team et al. (2023) Adaptive Agent Team, Jakob Bauer, Kate Baumli, Satinder Baveja, Feryal Behbahani, Avishkar Bhoopchand, Nathalie Bradley-Schmieg, Michael Chang, Natalie Clay, Adrian Collister, Vibhavari Dasagi, Lucy Gonzalez, Karol Gregor, Edward Hughes, Sheleem Kashem, Maria Loks-Thompson, Hannah Openshaw, Jack Parker-Holder, Shreya Pathak, Nicolas Perez-Nieves, Nemanja Rakicevic, Tim Rocktäschel, Yannick Schroecker, Jakub Sygnowski, Karl Tuyls, Sarah York, Alexander Zacherl, and Lei Zhang. Human-timescale adaptation in an open-ended task space. arXiv preprint arXiv:2301.07608, 2023.
- Team et al. (2021) Open Ended Learning Team, Adam Stooke, Anuj Mahajan, Catarina Barros, Charlie Deck, Jakob Bauer, Jakub Sygnowski, Maja Trebacz, Max Jaderberg, Michael Mathieu, Nat McAleese, Nathalie Bradley-Schmieg, Nathaniel Wong, Nicolas Porcel, Roberta Raileanu, Steph Hughes-Fitt, Valentin Dalibard, and Wojciech Marian Czarnecki. Open-ended learning leads to generally capable agents. arXiv preprint arXiv:2107.12808, 2021.
- Wang et al. (2021) Haoxiang Wang, Han Zhao, and Bo Li. Bridging multi-task learning and meta-learning: Towards efficient training and effective adaptation. International Conference on Machine Learning, 10991–11002, 2021.
- Wang et al. (2022) Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc Le, Ed Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. Self-consistency improves chain of thought reasoning in language models. arXiv preprint arXiv:2203.11171, 2022.
- Webb et al. (2023) Taylor Webb, Kiyofumi Miyoshi, Tsz Yan So, Sivananda Rajananda, and Hakwan Lau. Natural statistics support a rational account of confidence biases. Nature Communications, 14(1), 10991–11002, 2023.
- Wei et al. (2022) Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Ed Chi, Quoc Le, and Denny Zhou. Chain-of-thought prompting elicits reasoning in large language models. arXiv preprint arXiv:2201.11903, 2022.
- Xie et al. (2023) Yuxi Xie, Kenji Kawaguchi, Yiran Zhao, Xu Zhao, Min-Yen Kan, Junxian He, and Qizhe Xie. Decomposition enhances reasoning via self-evaluation guided decoding. arXiv preprint arXiv:2305.00633, 2023.
- Yao et al. (2022) Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. ReAct: Synergizing reasoning and acting in language models. arXiv preprint arXiv:2210.03629, 2022.
- Yao et al. (2024) Shunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Shafran, Tom Griffiths, Yuan Cao, and Karthik Narasimhan. Tree of thoughts: Deliberate problem solving with large language models. Advances in Neural Information Processing Systems, 36, 2024.
- Young and Fry (2008) Andria Young and Jane D Fry. Metacognitive awareness and academic achievement in college students. Journal of the Scholarship of Teaching and Learning, 8(2):1–10, 2008.
- Yu et al. (2020) Tianhe Yu, Deirdre Quillen, Zhanpeng He, Ryan Julian, Karol Hausman, Chelsea Finn, and Sergey Levine. Meta-World: A benchmark and evaluation for multi-task and meta reinforcement learning. Conference on Robot Learning, 1094–1100, 2020.
- Zhou et al. (2022) Denny Zhou, Nathanael Schärli, Le Hou, Jason Wei, Nathan Scales, Xuezhi Wang, Dale Schuurmans, Olivier Bousquet, Quoc Le, and Ed Chi. Least-to-most prompting enables complex reasoning in large language models. arXiv preprint arXiv:2205.10625, 2022.